
1. مقدمة
نظرة عامة
في هذا الدرس التطبيقي، ستتعلّم كيفية إنشاء وكيل آمن لإنشاء الرموز البرمجية ونشره على Google Kubernetes Engine (GKE). تحتاج وكالات إنشاء الرموز البرمجية إلى تنفيذ رموز برمجية قد تكون غير موثوق بها، ما يتطلّب توفير بيئة آمنة ومعزولة. ستتعرّف أيضًا على كيفية ضبط الوكيل باستخدام استراتيجية نموذج مختلط، ما يسمح له بالرجوع من نموذج مفتوح مستضاف ذاتيًا على GKE إلى خدمة Gemini المُدارة من Vertex AI لزيادة الموثوقية. بالإضافة إلى ذلك، ستتعرّف على كيفية تحسين عرض الاستنتاجات باستخدام GKE Inference Gateway وDynamic Resource Allocation (DRA). أخيرًا، ستتعرّف على كيفية الاستفادة من Google Cloud Observability لمراقبة حزمة الاستدلال باستخدام Managed Prometheus.
الهندسة المعمارية
في ما يلي بنية النظام الذي ستنشئه:
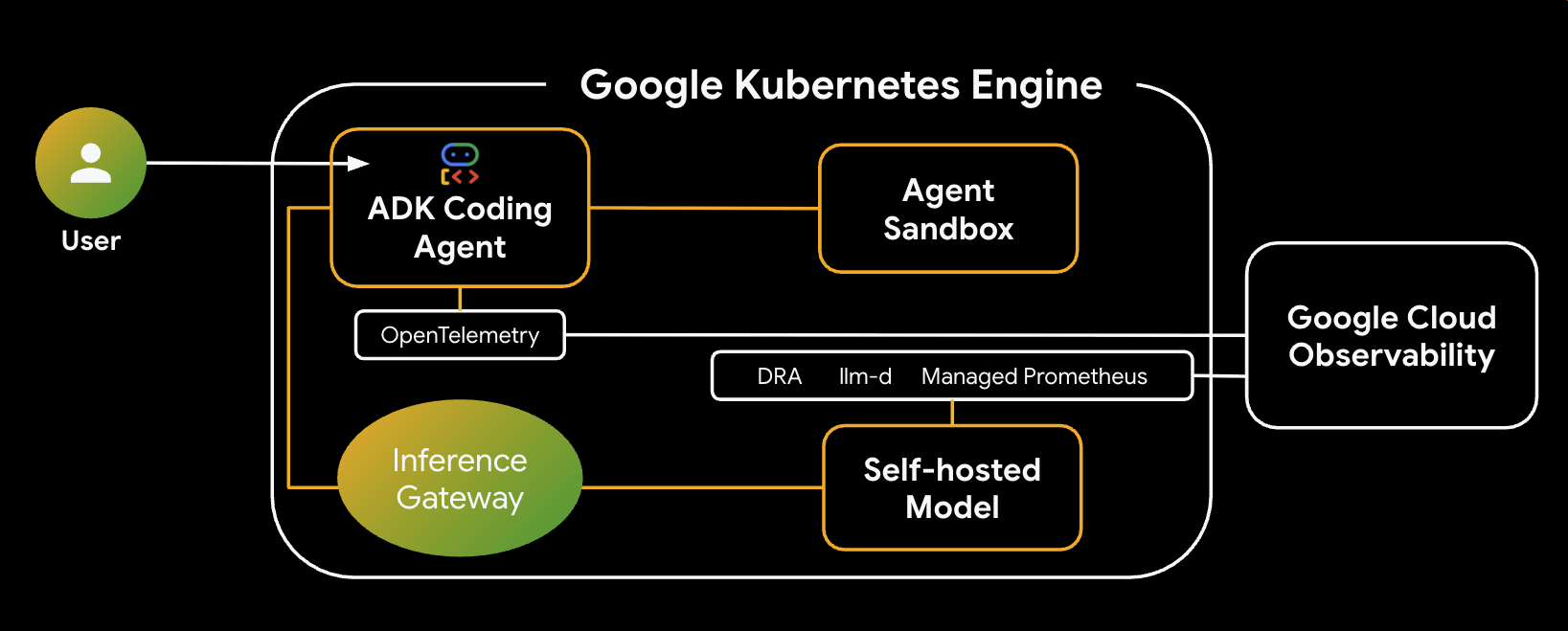
المكوّنات والمزايا الرئيسية
- تخصيص الموارد الديناميكي (DRA): يُستخدم في هذا الدرس التطبيقي لطلب موارد محدّدة من وحدة معالجة الرسومات (NVIDIA L4s) وتخصيصها بشكل ديناميكي لحاويات خادم النموذج، ما يضمن استهداف الأجهزة بدقة لحِمل عمل الاستدلال. مزيد من المعلومات عن "الوصول المقيّد بالبيانات" على GKE
- llm-d وvLLM: يوفّر إطار عمل عرض النموذج ومخططات Helm لتفعيل نموذج Qwen. في هذا التمرين العملي، يتم التعامل مع طلبات الاستنتاج والدمج مع DRA لإدارة الموارد (لا يتم تفعيل العرض المجزّأ في هذا التمرين العملي). يمكنك الاطّلاع على دليل llm-d ومستودع llm-d GitHub.
- بوابة الاستدلال في GKE: تنقل منطق التوجيه المتوافق مع الذكاء الاصطناعي مباشرةً إلى موازن التحميل. في هذا المختبر، يتم توجيه الطلبات لزيادة عدد مرات الوصول إلى ذاكرة التخزين المؤقت للبادئة إلى أقصى حد، ما يقلّل من وقت الاستجابة لأول رمز مميز (TTFT). استكشاف مفاهيم Inference Gateway
- Agent Sandbox (gVisor): توفّر عزلًا آمنًا لتنفيذ الرمز البرمجي الذي أنشأه وكيل الذكاء الاصطناعي. تستخدم هذه الميزة gVisor لتوفير عزل عميق للنواة، ما يحمي عقدة المضيف من أحجام العمل غير الموثوق بها. تعرَّف على Agent Sandbox على GKE وحِزم GKE Sandbox.
الإجراءات التي ستنفذّها
- توفير البنية الأساسية: يمكنك إعداد مجموعة GKE مع ميزة "تخصيص الموارد الديناميكي" (DRA) لإدارة وحدات معالجة الرسومات.
- نشر حزمة الاستدلال: يمكنك نشر
llm-dوvLLM باستخدام جدولة الاستدلال الذكي. - ضبط التوجيه الذكي: استخدِم GKE Inference Gateway للتوجيه المتوافق مع ذاكرة التخزين المؤقت للبادئة.
- تنفيذ الرمز البرمجي الآمن: يمكنك تفعيل Agent Sandbox (gVisor) لتشغيل الرمز البرمجي الذي تم إنشاؤه باستخدام الذكاء الاصطناعي بأمان.
- المراقبة والتحقّق من الصحة: استخدِم Google Cloud Monitoring وManaged Prometheus لعرض مقاييس عرض النموذج.
أهداف الدورة التعليمية
- كيفية ضبط ميزة "تخصيص الموارد الديناميكي" (DRA) واستخدامها في GKE
- كيفية استخدام GKE Inference Gateway لتحسين أداء عرض النماذج اللغوية الكبيرة
- كيفية استخدام Agent Sandbox لتنفيذ الرمز غير الموثوق به بأمان على GKE
- كيفية استخدام خدمة Google Cloud المُدارة لـ Prometheus من أجل مراقبة أداء vLLM
2. الإعداد والمتطلبات
إعداد المشروع
إنشاء مشروع على Google Cloud
- في Google Cloud Console، في صفحة اختيار المشروع، اختَر مشروعًا على Google Cloud أو أنشِئ مشروعًا.
- تأكَّد من تفعيل الفوترة لمشروعك على السحابة الإلكترونية. كيفية التحقّق مما إذا كانت الفوترة مفعَّلة في مشروع
بدء Cloud Shell
Cloud Shell هي بيئة سطر أوامر تعمل في Google Cloud ومحمّلة مسبقًا بالأدوات اللازمة.
- انقر على تفعيل Cloud Shell في أعلى "وحدة تحكّم Google Cloud".
- بعد الاتصال بـ Cloud Shell، تحقَّق من مصادقتك باتّباع الخطوات التالية:
gcloud auth list - تأكَّد من إعداد مشروعك باتّباع الخطوات التالية:
gcloud config get project - إذا لم يتم ضبط مشروعك على النحو المتوقّع، اضبطه باتّباع الخطوات التالية:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
3- توفير البنية الأساسية وتخصيص الموارد الديناميكي (DRA)
في هذه الخطوة الأولى، عليك ضبط مجموعة GKE لاستخدام ميزة "تخصيص المسرّعات الحديثة" (DRA) بدلاً من المكوّنات الإضافية القديمة للأجهزة. يتيح لك ذلك مشاركة وحدات معالجة الرسومات (GPU) أو وحدات معالجة Tensor (TPU) وتخصيصها بشكل مرن لأحمال عمل إنشاء الرموز البرمجية.
المتطلبات الأساسية: يجب أن يعمل إصدار 1.34 أو إصدار أحدث من مجموعة GKE Standard لتوفير دعم DRA.
تفعيل واجهات برمجة التطبيقات في Google Cloud
فعِّل واجهات Google Cloud APIs المطلوبة لهذا الدرس التدريبي حول الترميز، وتحديدًا واجهتَي Compute Engine وKubernetes Engine APIs.
gcloud services enable compute.googleapis.com container.googleapis.com networkservices.googleapis.com cloudbuild.googleapis.com artifactregistry.googleapis.com telemetry.googleapis.com cloudtrace.googleapis.com aiplatform.googleapis.com
ضبط متغيرات البيئة
لتسهيل عملية الإعداد، حدِّد متغيّرات البيئة. يمكنك تعديل المنطقة أو اصطلاحات التسمية حسب الحاجة.
export PROJECT_ID=$(gcloud config get-value project)
export ZONE=us-central1-a
export CLUSTER_NAME=ai-agent-cluster
export NODEPOOL_NAME=dra-accelerator-pool
gcloud config set project $PROJECT_ID
gcloud config set compute/region $ZONE
إنشاء دليل عمل
أنشئ دليل عمل مخصّصًا لهذا الدرس التطبيقي وانتقِل إليه لتبقى ملفاتك منظَّمة:
mkdir -p ~/gke-ai-agent-lab
cd ~/gke-ai-agent-lab
ضبط الأذونات (اختياري)
إذا كنت تستخدم مشروعًا محظورًا أو بيئة مشتركة، تأكَّد من أنّ حسابك لديه الأذونات اللازمة لإنشاء المجموعات وتشغيل عمليات الإنشاء:
export MY_ACCOUNT=$(gcloud config get-value account)
# Grant Container Admin to create clusters and manage nodes if needed
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/container.admin"
# Grant Cloud Build Builder to run builds
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/cloudbuild.builds.builder"
إنشاء مجموعة GKE
يجب أن يعمل إصدار 1.34 أو إصدار أحدث من مجموعة GKE Standard لتوفير إمكانية استخدام DRA. يجب أيضًا تفعيل أدوات التحكّم في Gateway API لإتاحة جدولة الاستدلال الذكي.
ستنشئ شبكة VPC جديدة وشبكات فرعية لهذا الدرس التطبيقي.
أولاً، أنشئ شبكة VPC:
gcloud compute networks create ai-agent-network --subnet-mode=custom
بعد ذلك، أنشئ شبكة فرعية لعُقد GKE:
gcloud compute networks subnets create ai-agent-subnet \
--network=ai-agent-network \
--range=10.0.0.0/20 \
--region=us-central1
تتطلّب Gateway API (gke-l7-regional-internal-managed) أيضًا شبكة فرعية مخصّصة لاستضافة خوادم وكيل Envoy. أنشئ هذه الشبكة الفرعية التي تستخدم الخادم الوكيل فقط في شبكتك الجديدة:
gcloud compute networks subnets create proxy-only-subnet \
--purpose=REGIONAL_MANAGED_PROXY \
--role=ACTIVE \
--region=us-central1 \
--network=ai-agent-network \
--range=192.168.10.0/24
الآن، أنشِئ المجموعة باستخدام الشبكة والشبكة الفرعية الجديدتَين:
gcloud beta container clusters create $CLUSTER_NAME \
--zone $ZONE \
--num-nodes 1 \
--machine-type n2-standard-4 \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--gateway-api=standard \
--managed-otel-scope=COLLECTION_AND_INSTRUMENTATION_COMPONENTS \
--network=ai-agent-network \
--subnetwork=ai-agent-subnet
إنشاء مجموعة عقد مع إيقاف المكوّنات الإضافية التلقائية
لتسليم إدارة الجهاز إلى DRA، يجب إنشاء مجموعة أجهزة ذات التخصيص نفسه تعمل على إيقاف تثبيت برنامج تشغيل وحدة معالجة الرسومات التلقائي ومكوّن الجهاز الإضافي العادي بشكلٍ صريح.
نفِّذ الأمر gcloud التالي لتوفير مجموعة أجهزة ذات التخصيص نفسه لوحدة معالجة رسومات (مثل استخدام NVIDIA L4s) مع تصنيفات DRA اللازمة:
gcloud container node-pools create $NODEPOOL_NAME \
--cluster=$CLUSTER_NAME \
--location=$ZONE \
--machine-type=g2-standard-24 \
--accelerator=type=nvidia-l4,count=2,gpu-driver-version=disabled \
--node-labels=gke-no-default-nvidia-gpu-device-plugin=true,nvidia.com/gpu.present=true \
--num-nodes 3
تثبيت برامج تشغيل NVIDIA من خلال DaemonSet
ثبِّت يدويًا برامج تشغيل أجهزة NVIDIA الأساسية المطلوبة على العُقد باستخدام Google Cloud DaemonSet الذي تم إعداده مسبقًا:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
تثبيت برنامج تشغيل DRA
بعد ذلك، ثبِّت برنامج تشغيل DRA المحدّد في مجموعتك. بالنسبة إلى وحدات معالجة الرسومات من NVIDIA، يمكنك نشرها من خلال Helm:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
helm install nvidia-dra-driver-gpu nvidia/nvidia-dra-driver-gpu \
--version="25.3.2" --create-namespace --namespace=nvidia-dra-driver-gpu \
--set nvidiaDriverRoot="/home/kubernetes/bin/nvidia/" \
--set gpuResourcesEnabledOverride=true \
--set resources.computeDomains.enabled=false \
--set kubeletPlugin.priorityClassName="" \
--set 'kubeletPlugin.tolerations[0].key=nvidia.com/gpu' \
--set 'kubeletPlugin.tolerations[0].operator=Exists' \
--set 'kubeletPlugin.tolerations[0].effect=NoSchedule'
التعرّف على DeviceClasses
لست بحاجة إلى كتابة أو تطبيق ملف DeviceClass YAML يدويًا. عند إعداد البنية الأساسية لخدمة GKE من أجل DRA وتثبيت برنامج التشغيل، تنشئ برامج تشغيل DRA التي تعمل على العُقد تلقائيًا عناصر DeviceClass في المجموعة.
ضبط ResourceClaimTemplate
للسماح لـ llm-d Pods بطلب هذه أدوات التسريع بشكل ديناميكي، عليك إنشاء ResourceClaimTemplate. يحدّد هذا النموذج إعدادات الجهاز المطلوبة ويطلب من Kubernetes إنشاء ResourceClaim فريد لكلّ وحدة Pod تلقائيًا لأحمال العمل.
نفِّذ الأمر التالي لإنشاء claim-template.yaml:
cat > claim-template.yaml <<EOF
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: gpu-claim-template
spec:
spec:
devices:
requests:
- name: single-gpu
exactly:
deviceClassName: gpu.nvidia.com
allocationMode: ExactCount
count: 1
EOF
طبِّق النموذج على مجموعتك:
kubectl apply -f claim-template.yaml
4. تفعيل ميزة "جدولة الاستنتاج الذكي" باستخدام llm-d وDRA
في هذه الخطوة، ستنشر نموذج اللغة الكبير خلف موازن تحميل Envoy ذكي محسّن باستخدام أداة جدولة للاستدلال. يحسّن هذا الإعداد عملية عرض النماذج من خلال تطبيق ميزة "التوجيه المتوافق مع ذاكرة التخزين المؤقت للبادئة". تتعرّف GKE Inference Gateway على السياق المشترك بين الخدمات المصغّرة وتوجّه الطلبات بذكاء إلى نسخة طبق الأصل من النموذج نفسه، ما يزيد من عدد مرات الوصول إلى ذاكرة التخزين المؤقت ويقلّل من الوقت المستغرَق في عرض أول رمز مميّز ويحسّن الأداء لكل دولار.
إعداد البيئة
إعداد مساحة الاسم المستهدَفة
export NAMESPACE=ai-agents
kubectl create namespace $NAMESPACE
خزِّن رمز Hugging Face المميز بشكل آمن، وهو مطلوب لاسترداد أوزان النموذج.
# Replace with your actual Hugging Face token
kubectl create secret generic llm-d-hf-token \
--from-literal=HF_TOKEN="your_hugging_face_token" \
-n $NAMESPACE
إنشاء ملفات إعداد Helm
تستند إعدادات خدمة النموذج وإضافة بوابة الاستنتاج إلى أدلة llm-d الرسمية.
أولاً، أنشئ ملف ms-values.yaml لخدمة النموذج:
cat <<EOF > ms-values.yaml
multinode: false
modelArtifacts:
uri: "hf://Qwen/Qwen2.5-Coder-14B-Instruct"
name: "Qwen/Qwen2.5-Coder-14B-Instruct"
size: 50Gi # Slightly larger than the default to accommodate weights
authSecretName: "llm-d-hf-token"
labels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
llm-d.ai/accelerator-variant: "gpu"
llm-d.ai/accelerator-vendor: "nvidia"
llm-d.ai/model: "qwen-2-5-coder-14b"
routing:
proxy:
enabled: false # removes sidecar from deployment - no PD in inference scheduling
targetPort: 8000 # controls vLLM port to matchup with sidecar if deployed
accelerator:
dra: true
type: "nvidia"
resourceClaimTemplates:
nvidia:
class: "gpu.nvidia.com"
match: "exactly"
name: "gpu-claim-template"
decode:
create: true
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
parallelism:
tensor: 2
data: 1
replicas: 3
monitoring:
podmonitor:
enabled: true
portName: "vllm"
path: "/metrics"
interval: "30s"
containers:
- name: "vllm"
image: ghcr.io/llm-d/llm-d-cuda:v0.5.1
modelCommand: vllmServe
args:
- "--disable-uvicorn-access-log"
- "--gpu-memory-utilization=0.85"
- "--enable-auto-tool-choice"
- "--tool-call-parser"
- "hermes"
ports:
- containerPort: 8000
name: vllm
protocol: TCP
resources:
limits:
cpu: '16'
memory: 64Gi
requests:
cpu: '16'
memory: 64Gi
mountModelVolume: true
volumeMounts:
- name: metrics-volume
mountPath: /.config
- name: shm
mountPath: /dev/shm
- name: torch-compile-cache
mountPath: /.cache
startupProbe:
httpGet:
path: /v1/models
port: vllm
initialDelaySeconds: 15
periodSeconds: 30
timeoutSeconds: 5
failureThreshold: 120
livenessProbe:
httpGet:
path: /health
port: vllm
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /v1/models
port: vllm
periodSeconds: 5
timeoutSeconds: 2
failureThreshold: 3
volumes:
- name: metrics-volume
emptyDir: {}
- name: torch-compile-cache
emptyDir: {}
- name: shm
emptyDir:
medium: Memory
sizeLimit: 20Gi
prefill:
create: false
EOF
بعد ذلك، أنشِئ ملف gaie-values.yaml لإضافة GKE Inference Gateway:
cat <<EOF > gaie-values.yaml
inferenceExtension:
replicas: 1
image:
name: llm-d-inference-scheduler
hub: ghcr.io/llm-d
tag: v0.6.0
pullPolicy: Always
extProcPort: 9002
pluginsConfigFile: "default-plugins.yaml"
tracing:
enabled: false
monitoring:
interval: "10s"
prometheus:
enabled: true
auth:
secretName: inference-scheduling-gateway-sa-metrics-reader-secret
inferencePool:
targetPorts:
- number: 8000
modelServerType: vllm
modelServers:
matchLabels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
EOF
فهم الإعدادات
يُعدّ هذا الإعداد مجموعة استنتاج عالية الأداء تتضمّن الميزات الأساسية التالية:
- اختيار النموذج: يستخدم النموذج Qwen 2.5 Coder 14B (
modelArtifacts) المحسَّن لإنشاء الرموز البرمجية واستخدام الأدوات. - دمج DRA: يتيح القسم
acceleratorميزة "تخصيص الموارد الديناميكي" (dra: true)، مع استهداف فئة الجهازgpu.nvidia.comوgpu-claim-templateالذي أنشأناه سابقًا. - تحسين الأداء:
- تضبط
parallelism.tensor: 2التوازي بين الموترات على مستوى وحدات معالجة الرسومات. - يتضمّن
argsلنموذج vLLM--enable-auto-tool-choiceلضمان قدرة وكيل الترميز على استخدام الأدوات بفعالية. - تتلاءم طلبات
cpuوmemoryالمخفَّضة مع نوع الجهازg2-standard-24.
- تضبط
- التوجيه الذكي: تم إعداد إضافة Inference Gateway (
gaie-values.yaml) لمراقبة خوادم نموذجvllmوتوجيه الطلبات لزيادة عدد مرات الوصول إلى ذاكرة التخزين المؤقت KV إلى أقصى حد.
نشر حزمة جدولة الاستنتاج من خلال Helm
الآن، أضِف مستودعات llm-d Helm ونفِّذ البنية الأساسية وامتداد البوابة وخدمة النموذج بشكل منفصل.
أولاً، أضِف المستودعات المطلوبة:
helm repo add llm-d-infra https://llm-d-incubation.github.io/llm-d-infra/
helm repo add llm-d-modelservice https://llm-d-incubation.github.io/llm-d-modelservice/
helm repo update
تفعيل المتطلبات الأساسية للبنية التحتية
يُثبِّت هذا الرسم البياني إعدادات Gateway الأساسية المطلوبة للحزمة.
helm install infra-is llm-d-infra/llm-d-infra \
--namespace $NAMESPACE \
--set gateway.gatewayClassName=gke-l7-rilb \
--set gateway.gatewayParameters.enabled=false \
--set gateway.gatewayParameters.istio.accessLogging=false
نشر إضافة GKE Inference Gateway
تؤدي هذه الخطوة إلى نشر InferencePool وEndpoint Picker، اللذين يراقبان ذاكرة التخزين المؤقت لمفتاح القيمة (KV-cache) لنماذجك لاتخاذ قرارات توجيه ذكية.
helm install gaie-is oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool \
--version v1.3.1 \
--namespace $NAMESPACE \
-f gaie-values.yaml \
--set provider.name=gke \
--set inferenceExtension.monitoring.prometheus.enabled=true
نشر خدمة النموذج
أخيرًا، يمكنك نشر خدمة النموذج اللغوي الكبير، والتي ستستخدم الآن ميزة "تخصيص الموارد الديناميكي" للمطالبة بشكل آمن بوحدات معالجة الرسومات من المستوى 4.
helm install ms-is llm-d-modelservice/llm-d-modelservice \
--version v0.4.7 \
--namespace $NAMESPACE \
-f ms-values.yaml \
--set decode.monitoring.podmonitor.enabled=false
تفعيل Google Cloud Observability لـ vLLM
غالبًا ما تحاول مخططات Helm العامة نشر موارد PodMonitor القياسية الخاصة بمشغّل Prometheus (monitoring.coreos.com/v1)، ما قد يؤدي إلى حدوث أخطاء إذا لم تكن قد ثبّت وحدات CRD هذه.
بدلاً من تبديل خيار المراقبة المضمّن في Helm، اتركه false وطبِّق يدويًا مورد PodMonitoring Google Cloud Managed Prometheus (GMP) باستخدام مجموعة monitoring.googleapis.com/v1 API المتوافقة.
نفِّذ الأمر التالي لإنشاء podmonitoring.yaml:
cat > podmonitoring.yaml <<EOF
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: ms-vllm-metrics
spec:
selector:
matchLabels:
llm-d.ai/model: "qwen-2-5-coder-14b" # Matches the label in values.yaml
endpoints:
- port: 8000 # vllm port
interval: 30s
path: /metrics
EOF
طبِّق مرجع PodMonitoring على مجموعتك:
kubectl apply -f podmonitoring.yaml -n $NAMESPACE
التحقّق من عملية التثبيت
تأكَّد من تثبيت المكوّنات بنجاح. من المفترض أن ترى جميع إصدارات Helm الثلاث نشطة في مساحة الاسم وأن يتم تهيئة وحدات pod المقابلة.
helm ls -n $NAMESPACE
kubectl get pods -n $NAMESPACE
قد يستغرق ظهور وحدات ms-is من 5 إلى 10 دقائق. وعندما يحدث ذلك، يجب أن تبدو المخرجات على النحو التالي:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
gaie-is ai-agents 1 2026-03-28 16:51:41.055881618 +0000 UTC deployed inferencepool-v1.3.1 v1.3.1
infra-is ai-agents 1 2026-03-28 16:51:03.71042542 +0000 UTC deployed llm-d-infra-v1.4.0 v0.4.0
ms-is ai-agents 1 2026-03-28 17:30:00.341918958 +0000 UTC deployed llm-d-modelservice-v0.4.7 v0.4.0
NAME READY STATUS RESTARTS AGE
gaie-is-epp-848965cb4-78ktp 1/1 Running 0 10m
ms-is-llm-d-modelservice-decode-67548d5f8c-f25f4 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-rblvs 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-w6fcd 1/1 Running 0 6m2s
5- ضبط التوجيه الذكي باستخدام GKE Inference Gateway
في الخطوة 4، يؤدي نشر مخططات llm-d Helm إلى توفير كائنَي InferencePool وGateway تلقائيًا. تجمع InferencePool مجموعات vllm التي تعرض النموذج والتي تتشارك النموذج الأساسي نفسه وإعدادات الحوسبة نفسها.
الآن، عليك ضبط InferenceObjective لتحديد أولوية طلبات وكيل الترميز وHTTPRoute لإرشاد البوابة حول كيفية توجيه الزيارات الواردة، والاستفادة من أداة اختيار نقطة النهاية لتحقيق أقصى عدد من النتائج في ذاكرة التخزين المؤقت لمفاتيح القيمة.
التحقّق من صحة المراجع التي يتم إنشاؤها تلقائيًا
أولاً، تأكَّد من أنّ مخططات llm-d Helm أنشأت موارد Gateway وInferencePool بنجاح.
kubectl get gateway,inferencepool -n $NAMESPACE
سيظهر لك بوابة باسم infra-is-inference-gateway ومجموعة استنتاج باسم gaie-is. على النحو التالي:
NAME CLASS ADDRESS PROGRAMMED AGE
gateway.gateway.networking.k8s.io/infra-is-inference-gateway gke-l7-regional-internal-managed 10.128.0.5 True 13m
NAME AGE
inferencepool.inference.networking.k8s.io/gaie-is 12m
إنشاء HTTPRoute
تربط HTTPRoute الموارد بين البوابة وInferencePool الواجهة الخلفية. يطلب هذا الخيار من GKE Inference Gateway تحليل نص الطلبات الواردة وتوجيهها بشكل ديناميكي لتحقيق أقصى عدد من النتائج المطابقة في Prefix-Cache استنادًا إلى السياق المشترك.
نفِّذ الأمر التالي لإنشاء httproute.yaml:
cat > httproute.yaml <<EOF
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: agent-route
spec:
parentRefs:
- group: gateway.networking.k8s.io
kind: Gateway
name: infra-is-inference-gateway
rules:
- backendRefs:
- group: inference.networking.k8s.io
kind: InferencePool
name: gaie-is
weight: 1
matches:
- path:
type: PathPrefix
value: /
EOF
طبِّق المسار على مجموعتك:
kubectl apply -f httproute.yaml -n $NAMESPACE
6. تنفيذ الرمز البرمجي بشكل آمن باستخدام "وضع الحماية للوكيل"
بعد تشغيل الخلفية عالية الأداء للاستدلال، لنستعد الآن لإنشاء بيئة آمنة يتم فيها تنفيذ الرمز الذي تم إنشاؤه باستخدام الذكاء الاصطناعي بشكل آمن ومعزول عن مجموعتنا باستخدام Agent Sandbox.
نشر "وحدة التحكّم في وضع الحماية للوكيل"
عندما ينشئ وكيل الذكاء الاصطناعي رمزًا برمجيًا وينفّذه، يكون في الأساس بصدد تشغيل عبء عمل غير موثوق به على بنيتك التحتية. إذا أنشأ العميل رمزًا برمجيًا ضارًا، قد يحاول إجراء مسح ضوئي لشبكتك الداخلية أو استغلال عقدة المضيف الأساسية.
يستخدم GKE Agent Sandbox gVisor، وهو وقت تشغيل حاوية مفتوح المصدر يوفّر نواة ضيف متخصّصة لكل حاوية. يمنع ذلك الرمز غير الموثوق به من إجراء طلبات نظام مباشرة إلى عقدة المضيف.
يمكنك نشر وحدة التحكّم في "وضع الحماية للوكيل" والمكوّنات المطلوبة من خلال تطبيق بيانات الإصدار الرسمية:
kubectl apply \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/manifest.yaml \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/extensions.yaml
ضبط نموذج Sandbox ومجموعة Warm Pool
بعد ذلك، ننشئ SandboxTemplate يعمل كمخطط أولي قابل لإعادة الاستخدام لبيئات تحليل Python، مع استهداف فئة وقت التشغيل gvisor بشكل صريح. لتبسيط عملية النشر بدون إدارة مجموعات العُقد اليدوية في مجموعات Standard، يمكننا الاستفادة من أي autopilot عادي.
ComputeClass لتوفير عُقد حوسبة مُدارة بشكل ديناميكي تتوافق أصلاً مع أحمال عمل gVisor عند الطلب
بما أنّ بدء تشغيل نواة آمنة يمكن أن يؤدي إلى زيادة وقت الاستجابة، فإنّنا نستخدم أيضًا SandboxWarmPool. يضمن ذلك الاحتفاظ بعدد محدّد من البيئات التجريبية التي تمّت تهيئتها مسبقًا لتكون جاهزة كي يتمكّن "وكيل إنشاء الرموز البرمجية" من المطالبة بها وبدء تنفيذ الرمز البرمجي في أقل من ثانية.
أولاً، أنشئ مساحة اسم جديدة لوقت تشغيل البيئة التجريبية للوكيل:
kubectl create namespace agent-sandbox
احفظ ما يلي باسم sandbox-template-and-pool.yaml:
cat > sandbox-template-and-pool.yaml <<EOF
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxTemplate
metadata:
name: python-runtime-template
namespace: agent-sandbox
spec:
podTemplate:
metadata:
labels:
sandbox: python-sandbox-example
spec:
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: python-runtime
image: registry.k8s.io/agent-sandbox/python-runtime-sandbox:v0.1.0
ports:
- containerPort: 8888
readinessProbe:
httpGet:
path: "/"
port: 8888
initialDelaySeconds: 0
periodSeconds: 1
resources:
requests:
cpu: "250m"
memory: "512Mi"
ephemeral-storage: "512Mi"
restartPolicy: "OnFailure"
---
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxWarmPool
metadata:
name: python-sandbox-warmpool
namespace: agent-sandbox
spec:
replicas: 2
sandboxTemplateRef:
name: python-runtime-template
EOF
طبِّق الإعدادات:
kubectl apply -f sandbox-template-and-pool.yaml
انتظِر لمدة تتراوح بين دقيقتَين و3 دقائق حتى يتم تهيئة وحدات warmpool. يمكنك التأكّد من أنّ عملية الانتقال من Pending (أثناء زيادة حجم الحوسبة الأساسية) إلى Running تمت بنجاح باستخدام:
kubectl get pods -n agent-sandbox -w
بعد ظهور وحدتَي python-sandbox-warmpool-*** مدرَجتَين على أنّهما Running و1/1 جاهزتَين، تكون بيئات التنفيذ الآمنة قد تمّت تهيئتها مسبقًا وأصبحت جاهزة للمطالبة بها.
تفعيل Sandbox Router
يعتمد "وكيل إنشاء الرموز البرمجية" على "موجّه وضع الحماية" لإرسال أوامر التنفيذ بشكل آمن إلى وحدات Pods المعزولة.
نفِّذ الأمر التالي لإنشاء sandbox-router.yaml:
cat > sandbox-router.yaml <<EOF
apiVersion: v1
kind: Service
metadata:
name: sandbox-router-svc
namespace: agent-sandbox
spec:
type: ClusterIP
selector:
app: sandbox-router
ports:
- name: http
protocol: TCP
port: 8080
targetPort: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sandbox-router-deployment
namespace: agent-sandbox
spec:
replicas: 2
selector:
matchLabels:
app: sandbox-router
template:
metadata:
labels:
app: sandbox-router
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: sandbox-router
containers:
- name: router
image: us-central1-docker.pkg.dev/k8s-staging-images/agent-sandbox/sandbox-router:v20260225-v0.1.1.post3-10-ga5bcb57
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 10
resources:
requests:
cpu: "250m"
memory: "512Mi"
limits:
cpu: "1000m"
memory: "1Gi"
securityContext:
runAsUser: 1000
runAsGroup: 1000
EOF
طبِّق الإعدادات:
kubectl apply -f sandbox-router.yaml
تنفيذ عزل الشبكة
لزيادة تأمين بيئة التنفيذ ومنع أي تنقّل جانبي غير مصرّح به، طبِّق "سياسة شبكة". يؤدي ذلك إلى "عزل" وضع الحماية عن الشبكات الأخرى، ما يمنعه من الوصول إلى خادم البيانات الوصفية في Google Cloud أو الشبكات الداخلية الحساسة الأخرى.
احفظ ما يلي باسم sandbox-policy.yaml:
cat > sandbox-policy.yaml <<EOF
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: restrict-sandbox-egress
namespace: agent-sandbox
spec:
podSelector:
matchLabels:
sandbox: python-sandbox-example
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 0.0.0.0/0
except:
- 169.254.169.254/32 # Block metadata server
EOF
طبِّق السياسة باتّباع الخطوات التالية:
kubectl apply -f sandbox-policy.yaml
التحقّق من المكوّنات
لضمان إعداد طبقة مجموعة أدوات اختبار الترميز المعزولة بالكامل، نفِّذ أوامر التحقّق من الحالة التالية:
أولاً، تأكَّد من أنّ وحدات Pod وموجّهات وضع "الحماية" تعمل وجاهزة.
kubectl get pods -n agent-sandbox
يجب أن تبدو النتيجة على النحو التالي:
NAME READY STATUS RESTARTS AGE
python-sandbox-warmpool-7zlkv 1/1 Running 0 3m25s
python-sandbox-warmpool-cxln2 1/1 Running 0 3m25s
sandbox-router-deployment-668dfbbbb6-g9mpd 1/1 Running 0 42s
sandbox-router-deployment-668dfbbbb6-ppllz 1/1 Running 0 42s
التحقّق من موازن التحميل / عرض عنوان IP في Sandbox Router
kubectl get service sandbox-router-svc -n agent-sandbox
يجب أن تبدو المخرجات على النحو التالي:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
sandbox-router-svc ClusterIP 34.118.237.244 <none> 8080/TCP 114s
التأكّد من توفّر قاعدة سياسة شبكة الخروج
kubectl get networkpolicy restrict-sandbox-egress -n agent-sandbox
يجب أن تبدو المخرجات على النحو التالي:
NAME POD-SELECTOR AGE
restrict-sandbox-egress sandbox=python-sandbox-example 113s
تأكَّد مما يلي:
- وحدات
python-sandbox-warmpool-***جاهزةRunningو1/1. - نسخ
sandbox-router-deployment-***المتماثلة هيRunningو1/1Ready. - يمكن الوصول إلى
sandbox-router-svc، وتعمل سياسةrestrict-sandbox-egressعلى حماية أي تصنيفات مطابقة في وضع الحماية بنجاح.
بعد تأمين بيئة التنفيذ الآمنة وتهيئتها، أصبحنا جاهزين لنشر الجزء الأساسي من عمليتنا، وهو "وكيل إنشاء الرموز البرمجية".
7. إنشاء وكيل إنشاء الرموز البرمجية ونشره (ADK)
بعد إعداد بيئة الاختبار المعزولة للتنفيذ الآمن وخادم الخلفية الخاص بنموذج اللغة الكبير عالي الأداء، يمكننا الآن إنشاء "عقل" نظامنا: وكيل إنشاء الرموز البرمجية باستخدام حزمة تطوير الوكلاء (ADK).
تم تصميم هذا الوكيل ليكون مطوّرًا خبيرًا في لغة Python. على عكس روبوت الدردشة العادي الذي ينتج نصًا فقط، تم تجهيز هذا الوكيل بأداة لتنفيذ الرموز البرمجية تتيح له حلّ المشاكل بشكل تفاعلي. تتّبع هذه العملية الخطوات التالية:
- كتابة رموز Python البرمجية استنادًا إلى طلباتك
- تنفيذ الرمز البرمجي بأمان داخل GKE Agent Sandbox الذي أعددناه في الخطوة 6
- التحقّق من الناتج أو قراءة أي أخطاء تظهر أثناء التنفيذ
- تقديم حلّ تم اختباره ويعمل بشكل جيد بثقة
من خلال منح الوكيل إذن الوصول إلى بيئة تنفيذ آمنة في وضع الحماية، نتيح له التحقّق من منطق عمله وتصحيح الأخطاء تلقائيًا، ما يجعله أكثر قدرة على تنفيذ مهام تطوير البرامج.
تطوير "وكيل الاستدلال" في حزمة تطوير الوكلاء (ADK)
أولاً، نكتب منطق Python الذي يحدّد سلوك الوكيل ويجهّزه بأداة Sandbox التي أنشأناها في الخطوة 6. في هذا القسم، نضبط أيضًا استراتيجية نموذج مختلط: سيعطي الوكيل الأولوية لنموذج Qwen مستضاف ذاتيًا يعمل على مجموعة GKE، ولكن سيتم تلقائيًا الرجوع إلى Gemini 2.5 Flash على Vertex AI إذا كان النموذج المحلي بطيئًا أو غير متوفّر، ما يضمن موثوقية عالية.
أنشئ دليلاً جديدًا لرمز الوكيل:
mkdir -p ~/gke-ai-agent-lab/root_agent
cd ~/gke-ai-agent-lab
أنشئ ملفًا باسم root_agent/agent.py يتضمّن المحتوى التالي:
cat <<'EOF' > root_agent/agent.py
import os
from google.adk.agents import Agent
from google.adk.models.lite_llm import LiteLlm
from k8s_agent_sandbox import SandboxClient
import requests
# Instantiate the client globally to track sandboxes
sandbox_client = SandboxClient()
def run_python_code(code: str) -> str:
"""
Executes Python code safely in the GKE Agent Sandbox.
Use this tool whenever you need to execute code to solve a problem.
"""
sandbox = sandbox_client.create_sandbox(template="python-runtime-template", namespace="agent-sandbox")
try:
command = f"python3 -c \"{code}\""
result = sandbox.commands.run(command)
if result.stderr:
return f"Error: {result.stderr}"
return result.stdout
finally:
# Ensure the sandbox is deleted after use to avoid leaking resources
sandbox_client.delete_sandbox(sandbox.claim_name, namespace="agent-sandbox")
# Define the ADK Agent with a fallback mechanism.
# It prioritizes the Qwen 2.5 Coder model running on our Inference Gateway.
# If the local model is unavailable, it falls back to Gemini 2.5 Flash on Vertex AI.
root_agent = Agent(
name="CodeGenerationAgent",
model=LiteLlm(
model="openai/Qwen/Qwen2.5-Coder-14B-Instruct",
fallbacks=["vertex_ai/gemini-2.5-flash"],
timeout=10
),
instruction="""
You are an expert Python developer.
1. Write Python code to solve the user's problem.
2. Execute the code using the `run_python_code` tool to verify it works.
3. Return the exact output and a brief explanation of the code.
""",
tools=[run_python_code]
)
EOF
أنشئ ملف __init__.py لكي يتعرّف "حزمة تطوير التطبيقات" (ADK) على الوحدة:
echo "from . import agent" > ~/gke-ai-agent-lab/root_agent/__init__.py
اضبط متغيّرات البيئة. يحتاج تطبيق ADK إلى عنوان IP الخاص ببوابة الدفع لتوجيه طلبات LLM بنجاح. بما أنّ ADK تتيح نقاط نهاية عادية متوافقة مع Open-AI (توفّرها vLLM من خلال البوابة)، يمكننا تجاهل عنوان URL الأساسي التلقائي لواجهة برمجة التطبيقات.
export GATEWAY_IP=$(kubectl get gateway infra-is-inference-gateway -n $NAMESPACE -o jsonpath='{.status.addresses[0].value}')
cat <<EOF > ~/gke-ai-agent-lab/root_agent/.env
OPENAI_API_BASE=http://${GATEWAY_IP}/v1
OPENAI_API_KEY=no-key-required
# Vertex AI settings for fallback (Authentication is handled by Workload Identity)
VERTEXAI_PROJECT=$PROJECT_ID
VERTEXAI_LOCATION=${ZONE%-[a-z]}
EOF
تضمين تطبيق الوكيل في حاوية
علينا تجميع الوكيل حتى يتمكّن من العمل بأمان داخل GKE.
أنشئ Dockerfile في ~/gke-ai-agent-lab لتثبيت kubectl ومكتبة ADK وبرنامج Agent Sandbox:
cat <<'EOF' > ~/gke-ai-agent-lab/Dockerfile
FROM python:3.11-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
RUN apt-get update && apt-get install -y git curl \
&& curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl" \
&& install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl \
&& rm kubectl && apt-get clean && rm -rf /var/lib/apt/lists/*
RUN pip install --no-cache-dir "google-adk[extensions,otel-gcp]>=1.27.4" litellm pandas "git+https://github.com/kubernetes-sigs/agent-sandbox.git@main#subdirectory=clients/python/agentic-sandbox-client" \
"opentelemetry-instrumentation-google-genai>=0.4b0" \
"opentelemetry-exporter-otlp" \
"opentelemetry-instrumentation-vertexai>=2.0b0"
COPY ./root_agent /app/root_agent
EXPOSE 8080
ENTRYPOINT ["adk", "web", "--host", "0.0.0.0", "--port", "8080", "--otel_to_cloud"]
EOF
أنشئ مستودع Artifact Registry لتخزين صورة الحاوية.
gcloud artifacts repositories create agent-repo \
--repository-format=docker \
--location=us-central1
استخدِم Cloud Build لإنشاء صورة الحاوية ونقلها.
gcloud builds submit --tag us-central1-docker.pkg.dev/$PROJECT_ID/agent-repo/code-agent:v1 ~/gke-ai-agent-lab/
النشر على GKE باستخدام ميزة "التحكّم المستند إلى الأدوار"
أخيرًا، يمكنك نشر الوكيل في مجموعتك. يتضمّن النشر Role وRoleBinding يمنح الوكيل الإذن بالمطالبة بالمثيلات من SandboxWarmPool.
سيستخدم هذا النشر ServiceAccount في Kubernetes للسماح للوكيل بالتواصل مع واجهة برمجة التطبيقات الخاصة بالمطالبة في Sandbox. لا يتطلّب ذلك حساب خدمة Google IAM ServiceAccount لأنّه يصل إلى موارد المجموعة المحلية ونقطة نهاية محلية لبوابة vLLM.
لماذا يجب استخدام عملية نشر عادية في gVisor؟
في الخطوة 6، استخدمنا واجهتَي برمجة التطبيقات SandboxTemplate وSandboxClaim لإنشاء بيئات اختبار مؤقتة يمكن التخلص منها لرمز Python الذي تم إنشاؤه (تنفيذ الأداة).
بالنسبة إلى واجهة مستخدم الويب الخاصة بالوكيل (الدماغ)، نستخدم مواصفات Kubernetes Deployment العادية مع runtimeClassName: gvisor.
- الفرق: تكون
SandboxClaimsالعادية مؤقتة وتتراوح قيمتها بين صفر وواحد (وهي مثالية للبرامج النصية غير الموثوق بها).Deploymentالعادي طويل الأمد وثابت، وهو مثالي لواجهات المستخدم على الويب التي تحتاج إلىServiceثابت في Kubernetes وموازن تحميل. باستخدامruntimeClassName: gvisorمباشرةً على عملية نشر عادية، يمكنك الاستفادة من عزل نواة gVisor مع الاحتفاظ بميزاتDeploymentالعادية.
احفظ ما يلي باسم deployment.yaml:
cat <<EOF > ~/gke-ai-agent-lab/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: code-agent
labels:
app: code-agent
spec:
replicas: 1
selector:
matchLabels:
app: code-agent
template:
metadata:
labels:
app: code-agent
spec:
serviceAccount: adk-agent-sa
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: code-agent
image: us-central1-docker.pkg.dev/YOUR_PROJECT_ID/agent-repo/code-agent:v1
imagePullPolicy: Always
env:
- name: OPENAI_API_KEY
value: "no-key-required"
- name: OPENAI_API_BASE
value: "http://YOUR_GATEWAY_IP/v1"
- name: VERTEXAI_PROJECT
value: "YOUR_PROJECT_ID"
- name: VERTEXAI_LOCATION
value: "YOUR_REGION"
- name: OTEL_SERVICE_NAME
value: "code-agent"
- name: GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY
value: "true"
- name: OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT
value: "true"
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: code-agent-service
spec:
selector:
app: code-agent
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: agent-sandbox
name: sandbox-creator-role
rules:
- apiGroups: [""]
resources: ["services", "pods", "pods/portforward"]
verbs: ["get", "list", "watch", "create"]
- apiGroups: ["extensions.agents.x-k8s.io"]
resources: ["sandboxclaims"]
verbs: ["create", "get", "list", "watch", "delete"]
- apiGroups: ["agents.x-k8s.io"]
resources: ["sandboxes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: adk-agent-binding
namespace: agent-sandbox
subjects:
- kind: ServiceAccount
name: adk-agent-sa
namespace: default
roleRef:
kind: Role
name: sandbox-creator-role
apiGroup: rbac.authorization.k8s.io
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: adk-agent-sa
EOF
منح أذونات "إدارة الهوية وإمكانية الوصول" لميزة "قابلية المراقبة"
للسماح للعامل بإرسال بيانات القياس عن بُعد (السجلات وعمليات التتبُّع) إلى Google Cloud، عليك منح الأذونات المطلوبة إلى حساب خدمة Kubernetes adk-agent-sa باستخدام Workload Identity.
نفِّذ الأوامر التالية في Cloud Shell:
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# Grant permission to write logs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/logging.logWriter \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to write traces
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/cloudtrace.agent \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to use Vertex AI
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/aiplatform.user \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
نفِّذ الأمر التالي لاستبدال YOUR_PROJECT_ID تلقائيًا برقم تعريف مشروعك الفعلي وتطبيق الإعدادات.
sed -i "s/YOUR_PROJECT_ID/$PROJECT_ID/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_GATEWAY_IP/$GATEWAY_IP/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_REGION/$ZONE/g" ~/gke-ai-agent-lab/deployment.yaml
kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml
8. المراقبة والتحقّق
حان الوقت لاختبار النظام المدمج بالكامل.
اختبار "وكيل إنشاء الرموز البرمجية" في واجهة المستخدم
ابحث عن عنوان IP الخارجي لواجهة مستخدم الويب الخاصة بـ ADK:
kubectl get services code-agent-service
يجب أن تبدو النتيجة على النحو التالي:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
code-agent-service LoadBalancer 34.118.230.182 34.31.250.60 80:32471/TCP 2m14s
- افتح متصفّحًا وانتقِل إلى
http://[EXTERNAL-IP]. - في واجهة ADK على الويب، تأكَّد من اختيار "root_agent" من القائمة المنسدلة في أعلى يسار الصفحة. بعد ذلك، وجِّه الطلب إلى الوكيل:
Write a python script that prints 'Hello from the isolated sandbox'.
لمراقبة كيفية استخدام الوكيل لخادم الخلفية والاستنتاج وبيئة الاختبار المعزولة، انتقِل إلى القسمَين استكشاف إحصاءات النموذج من خلال Cloud Observability واستكشاف إمكانية مراقبة الوكيل من خلال واجهة مستخدم GKE أدناه لعرض لوحات البيانات.
استكشاف إمكانية مراقبة الوكيل من خلال واجهة مستخدم GKE
بعد تنفيذ بعض الطلبات، لنلقِ نظرة على بيانات القياس عن بُعد. يساعدك ذلك في فهم مستوى أداء Inference Scheduler وvLLM.
الوصول إلى لوحات بيانات الوكلاء
- انتقِل إلى صفحة Kubernetes Engine > أحمال العمل.
- انقر على عملية نشر code-agent لفتح صفحة تفاصيل عملية النشر.
- انقر على علامة التبويب إمكانية المراقبة.
- في لوحة التنقّل اليمنى ضمن لوحة بيانات المراقبة، سيظهر قسم الوكيل جديد يتضمّن علامات تبويب فرعية.
محتوى مقترَح
استكشِف علامات التبويب الفرعية التالية للاطّلاع على سلوك تطبيق الوكيل:
- نظرة عامة: يمكنك الاطّلاع على بطاقات قياس الأداء للجلسات ومتوسط عدد الأدوار وعمليات الاستدعاء.
- النماذج: اطّلِع على عدد طلبات النماذج ونِسب الخطأ ووقت الاستجابة مصنّفة حسب النماذج التي استخدمها الوكيل.
- الأدوات: يمكنك تتبُّع عدد مرات استخدام الأدوات ومدة التنفيذ لمعرفة مدى فعالية استخدام وكيلك لأداة التنفيذ في البيئة التجريبية.
- الاستخدام: تتبُّع استخدام الرموز المميزة وتخصيص موارد الحاوية العادية (وحدة المعالجة المركزية والذاكرة)
- عمليات تتبُّع الوكيل: انتقِل إلى علامة التبويب هذه للاطّلاع على قائمة بجلسات التنفيذ أو فترات التتبُّع الأولية. يؤدي النقر على صف إلى فتح نافذة منبثقة تتضمّن تفاصيل التتبُّع المحدّد.
من خلال الجمع بين مقاييس على مستوى النموذج من vLLM وقياسات استخدام التطبيق على مستوى التطبيق من ADK، يمكنك الآن مراقبة جميع جوانب وكيل الذكاء الاصطناعي التوليدي على GKE.
استكشاف إحصاءات نموذج vLLM من خلال Cloud Observability
بعد تنفيذ بعض الطلبات، لنلقِ نظرة على بيانات القياس عن بُعد. يساعدك ذلك في فهم مستوى أداء Inference Scheduler وvLLM.
الوصول إلى لوحات البيانات
- انتقِل إلى Google Cloud Console.
- انتقِل إلى المراقبة > لوحات البيانات.
- ابحث عن لوحة بيانات نظرة عامة على Prometheus الخاص بنموذج اللغة الكبير جدًا واختَرها.
مقاييس مهمة يجب مراقبتها
أثناء الاطّلاع على لوحة البيانات، انتبه إلى المقاييس الرئيسية التالية لمعرفة تأثير GKE Inference Gateway والتخزين المؤقت للبادئة:
- استخدام ذاكرة التخزين المؤقت KV (
vllm:gpu_cache_usage):- سبب أهميته: يوضّح هذا المقياس مقدار ذاكرة وحدة معالجة الرسومات المستخدَمة لتخزين السياق مؤقتًا. إذا كانت هذه القيمة مرتفعة، يعني ذلك أنّ النظام يحتفظ بالسياق لتسريع الطلبات المستقبلية. إذا نفّذت الطلب نفسه عدّة مرات، من المفترض أن يرتفع معدّل الاستخدام هذا ثم يستقر.
- الطلبات الجارية مقابل الطلبات في انتظار المراجعة (
vllm:num_requests_runningمقابلvllm:num_requests_waiting):- سبب الأهمية: يشير ذلك إلى مستوى التحميل. إذا كان عدد الطلبات في انتظار المعالجة مرتفعًا، يعني ذلك أنّ العُقد محمّلة بشكل زائد.
- معدّل نقل الرموز المميزة (
vllm:request_prompt_tokens_totوvllm:request_generation_tokens_tot):- سبب الأهمية: تتبُّع حجم الرموز المميزة للإدخال والإخراج التي تتم معالجتها بواسطة المجموعة.
- الوقت اللازم للحصول على الرمز المميز الأول (TTFT):
- سبب الأهمية: هذا هو المقياس المهم للعوامل التفاعلية. باستخدام GKE Inference Gateway مع ميزة "التوجيه المتوافق مع ذاكرة التخزين المؤقت المستندة إلى البادئة"، يتم توجيه الطلبات التي تتشارك السياقات الشائعة (مثل طلبات النظام أو نوافذ السياق الكبيرة) إلى النسخة المتطابقة نفسها، ما يقلّل من وقت الاستجابة الأول من خلال إعادة استخدام عمليات البحث الناجحة في ذاكرة التخزين المؤقت الحالية.
تجارب مقترَحة
جرِّب هذه السيناريوهات للاطّلاع على تغيُّر المقاييس في الوقت الفعلي والتحقّق من صحة الجدولة.
التجربة 1: "سرعة التكرار" (مطابقة بادئة ذاكرة التخزين المؤقت)
- أرسِل طلبًا معقّدًا إلى الوكيل (مثلاً، "اكتب نصًا برمجيًا بلغة Python لتحليل ملف CSV بحجم 100 ميغابايت وحساب الإحصاءات").
- بعد أن يردّ، أرسِل الطلب نفسه تمامًا مرة أخرى على الفور.
- راقِب معدّل إصابة ذاكرة التخزين المؤقت للبادئة والوقت المستغرَق للحصول على الرمز المميز الأول (TTFT).
- ما يجب أن تراه: يجب أن ترتفع نسبة الوصول إلى ذاكرة التخزين المؤقت للبادئة إلى% 100 وأن ينخفض وقت استجابة أول بايت بشكل كبير.
- المعنى: تعرّفت "بوابة الاستدلال" في GKE على السياق المشترك وأحالته إلى النسخة المتطابقة نفسها التي أعادت استخدام ذاكرة التخزين المؤقت للسياق الذي تم تقييمه.
التجربة 2: الرجوع إلى السحابة الإلكترونية (موثوقية النموذج)
- لمحاكاة تعذُّر عمل نموذج Qwen المحلّي، يمكنك إيقاف خدمة الاستدلال أو تقديم
OPENAI_API_BASEمزيّف في عملية النشر. - عدِّل
OPENAI_API_BASEفيdeployment.yamlإلى عنوان IP أو منفذ غير متوفّر وطبِّق التغييرات:sed -i "s|value: \"http://$GATEWAY_IP/v1\"|value: \"http://10.0.0.1:8080/v1\"|g" ~/gke-ai-agent-lab/deployment.yaml kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml - انتظِر إلى أن تتم إعادة تشغيل الحاوية، ثم أرسِل طلبًا إلى الوكيل في واجهة المستخدم.
- ما يجب أن يظهر لك: سيظلّ الوكيل يستجيب بنجاح.
- المعنى: بسبب إعدادات
fallbacks، رصدت حزمة تطوير التطبيقات (ADK) تعذُّر الوصول إلى نقطة نهاية Qwen المحلية، ووجّهت الطلب بسلاسة إلى Gemini 2.5 Flash على Vertex AI. يُرجى العِلم أنّه بما أنّ عمليات الرجوع إلى Vertex AI هذه تتجاوز بوابة vLLM Inference Gateway المحلية، لن تظهر في لوحة بيانات مراقبة أداء الوكيل > النماذج التي تتتبّع فقط عدد الزيارات التي تمرّ عبر vLLM.
فهم مزايا ميزة "تخصيص الموارد الديناميكي" (DRA)
في حين أنّ vLLM وInference Gateway يحسّنان طريقة توجيه الطلبات وتقديمها، فإنّ تخصيص الموارد الديناميكي (DRA) هو ما أتاح إرفاق الأجهزة المناسبة تمامًا بعبء العمل في المقام الأول.
تعزّز ميزة "تخصيص الموارد الديناميكي" قدرتك على إدارة الأجهزة بدقة في جميع أنحاء مجموعتك من خلال السماح لك بتحديد موارد الأجهزة المرنة باستخدام ResourceClaimTemplate وDeviceClasses.
أهمية DRA في أحمال عمل الذكاء الاصطناعي:
- طلبات الأجهزة الدقيقة: باستخدام DRA، لا تضمن فقط جدولة أحمال العمل على الأجهزة التي تتضمّن أداة التسريع المناسبة، بل يمكنك أيضًا تقديم طلب للحصول على هذه الموارد لضمان استخدامها حصريًا من خلال حمل العمل المرتبط بـ ResourceClaim.
- دورة الحياة المنفصلة: تتم إدارة طلبات الأجهزة بشكل مستقل عن دورات حياة الحاويات. في حال تعذُّر تشغيل Pod، يمكن أن يظل طلب وحدة معالجة الرسومات ساريًا، ما يتيح إعادة تشغيل عملية النشر الشاملة أو عنصر عبء العمل الآخر بدون الحاجة إلى انتظار تحرير وحدة معالجة الرسومات وإعادة الحصول عليها.
- التوحيد بين عدة مورّدين: توفّر DRA واجهة Kubernetes API موحّدة لكلّ من وحدات معالجة الرسومات من NVIDIA ووحدات معالجة الموتّرات من Google. يمكنك استخدام المخطط نفسه تمامًا سواء كنت تنشر على أحدهما أو الآخر، ما يجعل بيانات YAML الخاصة بعبء العمل قابلة للنقل بدرجة كبيرة.
في هذا الدرس التطبيقي حول الترميز، رأيت ذلك عمليًا عند ضبط قيم Helm للربط بـ gpu-claim-template بسلاسة، بدون أن تحظر عمليات الطرح إعدادات المكوّن الإضافي للأجهزة المعلقة.
فهم دور llm-d
بينما يقيّم vLLM الأوزان العصبية ويوجه GKE Gateway طلبات البحث، يعمل llm-d كطبقة إعداد و "غراء" يربط كل هذه العناصر معًا.
بدون llm-d، عليك كتابة بيانات Kubernetes الأولية لتحديد عملية نشر vLLM ومنافذ الخدمة وعمليات ربط وحدات التخزين ومطالبات موارد DRA من البداية.
لماذا يجب استخدام llm-d في عملية النشر؟
- الإعداد الموحّد (عمليات الإلغاء بسطر واحد): تجمّع مخططات Helm موارد Kubernetes المعقّدة ذات المستوى المنخفض في مفاتيح تبديل واضحة ذات مستوى عالٍ (مثل ضبط
accelerator.dra: true).llm-d - "المسارات المضاءة جيدًا" التي تم التحقّق من صحتها مسبقًا: يحتوي مستودع
llm-dعلى إعدادات سبق أن قيّمها الخبراء واختبروها. عند نشرllm-d-modelservice، تتلقّى إعدادات تلقائية محسَّنة لاستخدام ذاكرة وحدة معالجة الرسومات، وتوقيتات الفحص المقترَحة (النشاط/الاستعداد)، وعمليات العرض الصحيحة لعملية استخراج المقاييس. - ربط سلس لإمكانية تتبّع البيانات: يضمن
llm-dإمكانية عرض منافذ الحاويات ومسارات جمع البيانات (/metrics) بشكل صحيح، ما يسهّل ربط عملية التفعيل بخدمة "رصد Google Cloud" بدون الحاجة إلى تصحيح الأخطاء يدويًا.
باختصار، يوفّر llm-d مخططات معمارية قابلة لإعادة الاستخدام كي لا يضطر المطوّرون إلى البدء من الصفر في كل مرة ينشرون فيها حزمة استدلال على GKE.
نظرة متعمّقة: بوابة GKE Inference
تعمل أجهزة موازنة الحمل العادية من الطبقة 7 من خلال فحص عناوين HTTP، مثل المسارات (/v1/completions) أو ملفات تعريف الارتباط. تتضمّن بوابة GKE Inference المزيد من التفاصيل، فهي مصمَّمة خصيصًا لزيارات الذكاء الاصطناعي التوليدي.
كيفية تحسين الأداء والكفاءة:
- التوجيه المستند إلى المحتوى (تجزئة الطلب): يعترض GKE Inference Gateway على نص طلب JSON. ويحسب تجزئة للطلب ويتتبّع نسخة الخلفية التي تحتوي على الرموز المميزة في ذاكرة وحدة معالجة الرسومات (ذاكرة التخزين المؤقت KV).
- زيادة عدد مرات الوصول إلى ذاكرة التخزين المؤقت: أثناء الاختبار، عندما كرّرت طلبًا، أرسلته البوابة إلى النسخة المتطابقة نفسها تمامًا. تتطلّب عملية تقييم الطلب قدرًا كبيرًا من الحوسبة. من خلال إعادة استخدام ذاكرة التخزين المؤقت، يمكنك تجنُّب "إعادة قراءة" الطلب، ما يوفّر لك المال ووقت وحدة معالجة الرسومات.
- تقليل وقت عرض أول رمز مميز (TTFT): وقت عرض أول رمز مميز هو مقياس قابلية الاستخدام المهم للوكلاء الذين يتعاملون مع المستخدمين. ومن خلال الاستفادة من ذاكرة التخزين المؤقت، يمكن للنموذج بدء إنشاء الرموز المميزة في غضون أجزاء من الثانية بدلاً من ثوانٍ.
- توزيع التحميل الذكي: إذا كانت ذاكرة الوصول العشوائي المرئية (VRAM) لإحدى النسخ المتماثلة ممتلئة تمامًا بطلبات البحث المخزّنة مؤقتًا، يمكن أن توجّه البوابة طلبًا جديدًا بشكل ديناميكي إلى نسخة متماثلة أخرى تتضمّن مساحة، ما يحقّق التوازن بين الكفاءة ومدى التوفّر.
كيف تقلّل "بيئة الاختبار الآمنة للوكلاء" من المخاطر؟
في هذا المختبر، أوضحنا كيف تحمي Agent Sandbox بنيتك الأساسية من المخاطر المرتبطة بوكلاء الذكاء الاصطناعي من خلال توفير طبقتَين من العزل:
- عزل أداة التنفيذ: ينفّذ الوكيل الرمز البرمجي الذي ينشئه في بيئة اختبار مؤقتة. يضمن ذلك تشغيل الرموز غير الموثوق بها التي تم إنشاؤها بواسطة نموذج اللغة الكبير في بيئة آمنة ومنفصلة، ما يحمي الوكيل والمجموعة.
- بدء التشغيل السريع: باستخدام WarmPool، تبدأ البيئات التجريبية الجديدة في أقل من ثانية، وتكون جاهزة لتنفيذ الرمز.
- عزل تطبيق الوكيل نفسه: شغّلنا أيضًا تطبيق الوكيل نفسه في عقدة مفعّلة باستخدام gVisor (عبر
runtimeClassName: gvisor) لتوفير الدفاع في العمق ضد الثغرات الأمنية في سلسلة الإمداد في التبعيات الخاصة بالوكيل.
إليك سبب إنشاء حدود أمان محصّنة:
- اعتراض طلبات النظام: يعترض gVisor طلبات النظام قبل وصولها إلى نواة Linux المضيفة. يؤدي ذلك إلى حظر الثغرات التي تحاول الخروج من الحاوية للوصول إلى عقدة المضيف.
- الحدّ من التنقّل الجانبي: عند الدمج مع "سياسات الشبكة"، حتى إذا تم اختراق بيئة ما، لا يمكنها إجراء مسح ضوئي لخوادم البيانات الوصفية الداخلية أو الانتقال إلى خدمات حساسة أخرى في مجموعتك.
تشغيل وكلاء كاملين في أوضاع الحماية
في هذا التمرين العملي، استخدمنا البيئات التجريبية كأدوات لتطبيق وكيل مستمر. ومع ذلك، لتحقيق أقصى قدر من الأمان، خاصةً عند التعامل مع بيانات حساسة أو تقديم الخدمة لعدة مستخدمين غير موثوق بهم، يمكنك تشغيل تطبيق الوكيل بأكمله داخل وضع حماية مخصّص لكل جلسة أو مستخدم. يضمن ذلك عزل ذاكرة الوكيل وحالته وبيئة التنفيذ بشكل كامل، ويتم إتلافها فور انتهاء الجلسة.
9- تنظيف
لتجنُّب تحمّل رسوم في حسابك على Google Cloud مقابل الموارد المستخدَمة في هذا الدرس التطبيقي حول الترميز، اتّبِع الخطوات التالية لحذفها.
حذف مراجع فردية
- احذف مجموعة GKE:
gcloud container clusters delete $CLUSTER_NAME --zone $ZONE --quiet
- احذف مستودع Artifact Registry:
gcloud artifacts repositories delete agent-repo --location=us-central1 --quiet
- احذف شبكة VPC باتّباع الخطوات التالية:
gcloud compute networks delete ai-agent-network --quiet
حذف المشروع
إذا لم تعُد بحاجة إلى المشروع، يمكنك حذفه بعد إزالة المراجع:
gcloud projects delete $PROJECT_ID
10. ملخّص
تهانينا! لقد أنشأت ونشرت بنجاح وكيلًا آمنًا وعالي الأداء لإنشاء الرموز البرمجية على GKE.
ما تعلّمته
- كيفية إعداد تخصيص الموارد الديناميكي (DRA) واستخدامه في GKE لإدارة موارد وحدة معالجة الرسومات
- كيفية استخدام GKE Inference Gateway لتحسين أداء عرض النماذج اللغوية الكبيرة من خلال التوجيه المتوافق مع ذاكرة التخزين المؤقت للبادئة
- كيفية استخدام Agent Sandbox (gVisor) لتنفيذ الرمز غير الموثوق به بأمان على GKE
- كيفية استخدام Google Cloud Managed Service for Prometheus لمراقبة أداء vLLM
- كيفية ضبط إعدادات إمكانية تتبّع بيانات الوكيل وعرضها باستخدام ADK وGKE Managed OpenTelemetry
الخطوات التالية والمراجع
- Agent Sandbox: تعرَّف على Agent Sandbox على GKE وحاويات GKE Sandbox.
- llm-d: يمكنك الاطّلاع على دليل llm-d ومستودع llm-d GitHub.
- تخصيص الموارد الديناميكي: تعرَّف على تخصيص الموارد الديناميكي على GKE.
- GKE Inference Gateway: يمكنك الاطّلاع على مفاهيم Inference Gateway.
- المزيد من دروس Codelabs: يمكنك العثور على المزيد من البرامج التعليمية في Google Cloud Codelabs.