
১. ভূমিকা
সংক্ষিপ্ত বিবরণ
এই ল্যাবে, আপনি গুগল কুবারনেটিস ইঞ্জিন (GKE)-এ একটি সুরক্ষিত কোড জেনারেশন এজেন্ট তৈরি এবং স্থাপন করতে শিখবেন। কোড জেনারেশন এজেন্টদের এমন কোড চালাতে হয় যা অবিশ্বস্ত হতে পারে, যার জন্য একটি সুরক্ষিত স্যান্ডবক্স পরিবেশ প্রয়োজন। আপনি আরও শিখবেন কীভাবে একটি হাইব্রিড মডেল স্ট্র্যাটেজি দিয়ে এজেন্টটি কনফিগার করতে হয়, যা এটিকে বর্ধিত নির্ভরযোগ্যতার জন্য GKE-তে একটি সেলফ-হোস্টেড ওপেন মডেল থেকে ভার্টেক্স এআই-এর পরিচালিত জেমিনি পরিষেবাতে ফিরে যেতে সাহায্য করে। এছাড়াও, আপনি GKE ইনফারেন্স গেটওয়ে এবং ডাইনামিক রিসোর্স অ্যালোকেশন (DRA) ব্যবহার করে ইনফারেন্স সার্ভিং অপ্টিমাইজ করতে শিখবেন। সবশেষে, আপনি ম্যানেজড প্রোমিথিউস ব্যবহার করে আপনার ইনফারেন্স স্ট্যাক নিরীক্ষণের জন্য গুগল ক্লাউড অবজার্ভেবিলিটি কাজে লাগাতে শিখবেন।
স্থাপত্য
আপনি যে সিস্টেমটি তৈরি করবেন তার স্থাপত্যটি নিচে দেওয়া হলো:
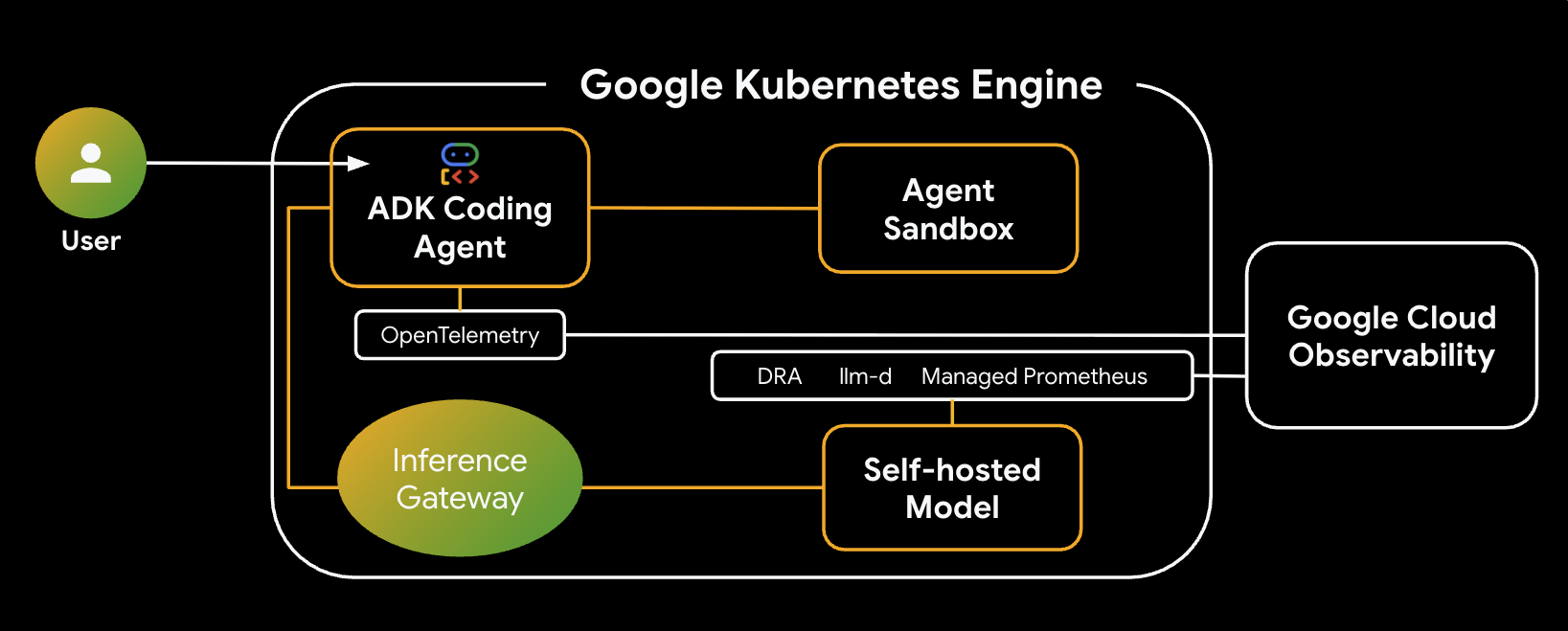
মূল উপাদান ও সুবিধাসমূহ
- ডাইনামিক রিসোর্স অ্যালোকেশন (DRA) : এই ল্যাবে মডেল সার্ভার পডগুলোর জন্য নির্দিষ্ট GPU রিসোর্স (NVIDIA L4s) ডাইনামিকভাবে দাবি ও বরাদ্দ করতে এটি ব্যবহৃত হয়, যা আমাদের ইনফারেন্স ওয়ার্কলোডের জন্য সুনির্দিষ্ট হার্ডওয়্যার টার্গেটিং নিশ্চিত করে। GKE-তে DRA সম্পর্কে জানুন।
- llm-d ও vLLM : Qwen মডেল ডেপ্লয় করার জন্য মডেল সার্ভিং ফ্রেমওয়ার্ক এবং Helm চার্ট প্রদান করে। এই ল্যাবে, এটি ইনফারেন্স রিকোয়েস্টগুলো পরিচালনা করে এবং রিসোর্স ম্যানেজমেন্টের জন্য DRA-এর সাথে ইন্টিগ্রেট করে (এই ল্যাবে ডিসঅ্যাগ্রিগেটেড সার্ভিং সক্রিয় করা নেই)। llm-d গাইডটি পড়ুন এবং llm-d গিটহাব রিপোজিটরিটি দেখুন।
- GKE ইনফারেন্স গেটওয়ে : এটি এআই-সচেতন রাউটিং লজিককে সরাসরি লোড ব্যালান্সারে নিয়ে আসে। এই ল্যাবে, এটি প্রিফিক্স-ক্যাশ হিট সর্বাধিক করার জন্য রিকোয়েস্ট রাউট করে, যার ফলে টাইম টু ফার্স্ট টোকেন (TTFT) ল্যাটেন্সি কমে আসে। ইনফারেন্স গেটওয়ের ধারণাগুলো সম্পর্কে জানুন।
- এজেন্ট স্যান্ডবক্স (gVisor) : এআই এজেন্ট দ্বারা জেনারেট করা কোড এক্সিকিউট করার জন্য নিরাপদ আইসোলেশন প্রদান করে। এটি ডিপ কার্নেল আইসোলেশন প্রদানের জন্য gVisor ব্যবহার করে, যা হোস্ট নোডকে অবিশ্বস্ত ওয়ার্কলোড থেকে রক্ষা করে। GKE-তে এজেন্ট স্যান্ডবক্স এবং GKE স্যান্ডবক্স পড সম্পর্কে জানুন।
আপনি যা করবেন
- পরিকাঠামো সংস্থান : GPU ব্যবস্থাপনার জন্য ডাইনামিক রিসোর্স অ্যালোকেশন (DRA) সহ একটি GKE ক্লাস্টার সেট আপ করুন।
- ইনফারেন্স স্ট্যাক স্থাপন করুন : ইন্টেলিজেন্ট ইনফারেন্স শিডিউলিং সহ
llm-dএবং vLLM স্থাপন করুন। - ইন্টেলিজেন্ট রাউটিং কনফিগার করুন : প্রিফিক্স-ক্যাশ সচেতন রাউটিংয়ের জন্য GKE ইনফারেন্স গেটওয়ে ব্যবহার করুন।
- নিরাপদ কোড নির্বাহ : এআই-নির্মিত কোড নিরাপদে চালানোর জন্য এজেন্ট স্যান্ডবক্স (gVisor) স্থাপন করুন।
- পর্যবেক্ষণ ও যাচাই করুন : মডেল সার্ভিং মেট্রিক্স দেখতে গুগল ক্লাউড মনিটরিং এবং ম্যানেজড প্রোমিথিউস ব্যবহার করুন।
আপনি যা শিখবেন
- GKE-তে ডাইনামিক রিসোর্স অ্যালোকেশন (DRA) কীভাবে কনফিগার এবং ব্যবহার করবেন।
- LLM সার্ভিং পারফরম্যান্স অপ্টিমাইজ করতে GKE ইনফারেন্স গেটওয়ে কীভাবে ব্যবহার করবেন
- GKE-তে এজেন্ট স্যান্ডবক্স ব্যবহার করে কীভাবে অবিশ্বস্ত কোড নিরাপদে চালানো যায়
- vLLM-এর পারফরম্যান্স নিরীক্ষণের জন্য কীভাবে Google Cloud Managed Service for Prometheus ব্যবহার করবেন।
২. সেটআপ এবং প্রয়োজনীয়তা
প্রজেক্ট সেটআপ
একটি গুগল ক্লাউড প্রজেক্ট তৈরি করুন
- গুগল ক্লাউড কনসোলের প্রজেক্ট সিলেক্টর পেজে, একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন ।
- আপনার ক্লাউড প্রোজেক্টের জন্য বিলিং চালু আছে কিনা তা নিশ্চিত করুন। কোনো প্রোজেক্টে বিলিং চালু আছে কিনা তা কীভাবে পরীক্ষা করবেন, তা জেনে নিন।
ক্লাউড শেল শুরু করুন
ক্লাউড শেল হলো গুগল ক্লাউডে চালিত একটি কমান্ড-লাইন পরিবেশ, যা প্রয়োজনীয় টুলস সহ আগে থেকেই লোড করা থাকে।
- Google Cloud কনসোলের শীর্ষে থাকা Activate Cloud Shell-এ ক্লিক করুন।
- ক্লাউড শেলে সংযুক্ত হওয়ার পর, আপনার প্রমাণীকরণ যাচাই করুন:
gcloud auth list - আপনার প্রজেক্টটি কনফিগার করা হয়েছে কিনা তা নিশ্চিত করুন:
gcloud config get project - আপনার প্রজেক্টটি প্রত্যাশা অনুযায়ী সেট করা না থাকলে, এটি সেট করুন:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
৩. পরিকাঠামো সরবরাহ এবং গতিশীল সম্পদ বরাদ্দ (ডিআরএ)
এই প্রথম ধাপে, আপনি লিগ্যাসি ডিভাইস প্লাগইনের পরিবর্তে মডার্ন অ্যাক্সিলারেটর অ্যালোকেশন (DRA) ব্যবহার করার জন্য আপনার GKE ক্লাস্টার কনফিগার করবেন। এর ফলে আপনি আপনার কোড জেনারেশন ওয়ার্কলোডের জন্য সুবিধাজনকভাবে GPU বা TPU শেয়ার ও বরাদ্দ করতে পারবেন।
পূর্বশর্ত: DRA সমর্থন করার জন্য আপনার GKE Standard ক্লাস্টারে অবশ্যই সংস্করণ 1.34 বা তার পরবর্তী সংস্করণ চলতে হবে।
গুগল ক্লাউড এপিআই সক্রিয় করুন
এই কোডল্যাবের জন্য প্রয়োজনীয় গুগল ক্লাউড এপিআইগুলো, বিশেষ করে কম্পিউট ইঞ্জিন এবং কুবারনেটিস ইঞ্জিন এপিআইগুলো সক্রিয় করুন।
gcloud services enable compute.googleapis.com container.googleapis.com networkservices.googleapis.com cloudbuild.googleapis.com artifactregistry.googleapis.com telemetry.googleapis.com cloudtrace.googleapis.com aiplatform.googleapis.com
পরিবেশ ভেরিয়েবল সেট করুন
সেটআপ সহজ করার জন্য, আপনার এনভায়রনমেন্ট ভেরিয়েবলগুলো নির্ধারণ করুন। প্রয়োজন অনুযায়ী আপনি অঞ্চল বা নামকরণের রীতি পরিবর্তন করতে পারেন।
export PROJECT_ID=$(gcloud config get-value project)
export ZONE=us-central1-a
export CLUSTER_NAME=ai-agent-cluster
export NODEPOOL_NAME=dra-accelerator-pool
gcloud config set project $PROJECT_ID
gcloud config set compute/region $ZONE
কার্যকরী ডিরেক্টরি তৈরি করুন
এই ল্যাবের জন্য একটি নির্দিষ্ট ওয়ার্কিং ডিরেক্টরি তৈরি করুন এবং সেটিতে প্রবেশ করুন, যাতে আপনার ফাইলগুলো সুসংগঠিত থাকে:
mkdir -p ~/gke-ai-agent-lab
cd ~/gke-ai-agent-lab
অনুমতি কনফিগার করুন (ঐচ্ছিক)
আপনি যদি কোনো সীমাবদ্ধ প্রজেক্ট বা শেয়ার্ড এনভায়রনমেন্টে কাজ করেন, তাহলে নিশ্চিত করুন যে ক্লাস্টার তৈরি করতে ও বিল্ড চালাতে আপনার অ্যাকাউন্টের প্রয়োজনীয় অনুমতি রয়েছে:
export MY_ACCOUNT=$(gcloud config get-value account)
# Grant Container Admin to create clusters and manage nodes if needed
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/container.admin"
# Grant Cloud Build Builder to run builds
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/cloudbuild.builds.builder"
GKE ক্লাস্টার তৈরি করুন
DRA সমর্থন করার জন্য আপনার GKE Standard ক্লাস্টারে অবশ্যই সংস্করণ 1.34 বা তার পরবর্তী সংস্করণ চলতে হবে। এছাড়াও, ইন্টেলিজেন্ট ইনফারেন্স শিডিউলিং সমর্থন করার জন্য আপনাকে Gateway API কন্ট্রোলারগুলো সক্রিয় করতে হবে।
এই ল্যাবের জন্য আপনি একটি নতুন ভিপিসি নেটওয়ার্ক ও সাবনেট তৈরি করবেন।
প্রথমে, VPC নেটওয়ার্কটি তৈরি করুন:
gcloud compute networks create ai-agent-network --subnet-mode=custom
এরপরে, আপনার GKE নোডগুলির জন্য একটি সাবনেট তৈরি করুন:
gcloud compute networks subnets create ai-agent-subnet \
--network=ai-agent-network \
--range=10.0.0.0/20 \
--region=us-central1
গেটওয়ে এপিআই ( gke-l7-regional-internal-managed )-এর জন্যও এনভয় প্রক্সিগুলো হোস্ট করার জন্য একটি ডেডিকেটেড সাবনেট প্রয়োজন। আপনার নতুন নেটওয়ার্কে এই প্রক্সি-অনলি সাবনেটটি তৈরি করুন:
gcloud compute networks subnets create proxy-only-subnet \
--purpose=REGIONAL_MANAGED_PROXY \
--role=ACTIVE \
--region=us-central1 \
--network=ai-agent-network \
--range=192.168.10.0/24
এখন, নতুন নেটওয়ার্ক ও সাবনেট ব্যবহার করে ক্লাস্টারটি তৈরি করুন:
gcloud beta container clusters create $CLUSTER_NAME \
--zone $ZONE \
--num-nodes 1 \
--machine-type n2-standard-4 \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--gateway-api=standard \
--managed-otel-scope=COLLECTION_AND_INSTRUMENTATION_COMPONENTS \
--network=ai-agent-network \
--subnetwork=ai-agent-subnet
ডিফল্ট প্লাগইনগুলি নিষ্ক্রিয় করে একটি নোড পুল তৈরি করুন
DRA-এর কাছে ডিভাইস ম্যানেজমেন্ট হস্তান্তর করতে হলে, আপনাকে এমন একটি নোড পুল তৈরি করতে হবে যা ডিফল্ট GPU ড্রাইভার ইনস্টলেশন এবং স্ট্যান্ডার্ড ডিভাইস প্লাগইনকে স্পষ্টভাবে নিষ্ক্রিয় করে রাখে।
প্রয়োজনীয় DRA লেবেল সহ একটি GPU নোড পুল (যেমন, NVIDIA L4s ব্যবহার করে) প্রোভিশন করতে নিম্নলিখিত gcloud কমান্ডটি চালান:
gcloud container node-pools create $NODEPOOL_NAME \
--cluster=$CLUSTER_NAME \
--location=$ZONE \
--machine-type=g2-standard-24 \
--accelerator=type=nvidia-l4,count=2,gpu-driver-version=disabled \
--node-labels=gke-no-default-nvidia-gpu-device-plugin=true,nvidia.com/gpu.present=true \
--num-nodes 3
DaemonSet-এর মাধ্যমে NVIDIA ড্রাইভার ইনস্টল করুন
আগে থেকে কনফিগার করা গুগল ক্লাউড ডেমনসেট ব্যবহার করে আপনার নোডগুলিতে প্রয়োজনীয় বেস এনভিডিয়া ডিভাইস ড্রাইভারগুলি ম্যানুয়ালি ইনস্টল করুন:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
ডিআরএ ড্রাইভার ইনস্টল করুন
এরপরে, আপনার ক্লাস্টারে নির্দিষ্ট DRA ড্রাইভারটি ইনস্টল করুন। NVIDIA GPU-এর জন্য, আপনি এটি Helm-এর মাধ্যমে স্থাপন করতে পারেন:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
helm install nvidia-dra-driver-gpu nvidia/nvidia-dra-driver-gpu \
--version="25.3.2" --create-namespace --namespace=nvidia-dra-driver-gpu \
--set nvidiaDriverRoot="/home/kubernetes/bin/nvidia/" \
--set gpuResourcesEnabledOverride=true \
--set resources.computeDomains.enabled=false \
--set kubeletPlugin.priorityClassName="" \
--set 'kubeletPlugin.tolerations[0].key=nvidia.com/gpu' \
--set 'kubeletPlugin.tolerations[0].operator=Exists' \
--set 'kubeletPlugin.tolerations[0].effect=NoSchedule'
ডিভাইসক্লাস বোঝা
আপনাকে ম্যানুয়ালি কোনো DeviceClass YAML লিখতে বা প্রয়োগ করতে হবে না। যখন আপনি DRA-এর জন্য আপনার GKE পরিকাঠামো সেট আপ করেন এবং ড্রাইভার ইনস্টল করেন, তখন আপনার নোডগুলিতে চলমান DRA ড্রাইভারগুলি স্বয়ংক্রিয়ভাবে আপনার জন্য ক্লাস্টারে DeviceClass অবজেক্টগুলি তৈরি করে দেয়।
ResourceClaimTemplate কনফিগার করুন
আপনার llm-d পডগুলিকে এই অ্যাক্সিলারেটরগুলির জন্য ডায়নামিকভাবে অনুরোধ করার অনুমতি দিতে, আপনাকে একটি ResourceClaimTemplate তৈরি করতে হবে। এই টেমপ্লেটটি অনুরোধ করা ডিভাইস কনফিগারেশন নির্ধারণ করে এবং Kubernetes-কে আপনার ওয়ার্কলোডগুলির জন্য স্বয়ংক্রিয়ভাবে প্রতিটি পডের জন্য একটি অনন্য ResourceClaim তৈরি করতে নির্দেশ দেয়।
claim-template.yaml তৈরি করতে নিম্নলিখিত কমান্ডটি চালান:
cat > claim-template.yaml <<EOF
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: gpu-claim-template
spec:
spec:
devices:
requests:
- name: single-gpu
exactly:
deviceClassName: gpu.nvidia.com
allocationMode: ExactCount
count: 1
EOF
আপনার ক্লাস্টারে টেমপ্লেটটি প্রয়োগ করুন:
kubectl apply -f claim-template.yaml
৪. llm-d এবং DRA ব্যবহার করে ইন্টেলিজেন্ট ইনফারেন্স শিডিউলিং স্থাপন করুন
এই ধাপে, আপনি আপনার বৃহৎ ল্যাঙ্গুয়েজ মডেলটিকে একটি ইনফারেন্স শিডিউলার দ্বারা উন্নত স্মার্ট এনভয় লোড ব্যালান্সারের পেছনে স্থাপন করবেন। এই কনফিগারেশনটি প্রিফিক্স-ক্যাশ অ্যাওয়্যার রাউটিং প্রয়োগের মাধ্যমে মডেল সার্ভিংকে অপ্টিমাইজ করে। GKE ইনফারেন্স গেটওয়ে মাইক্রোসার্ভিসগুলোর মধ্যে শেয়ার্ড কনটেক্সট শনাক্ত করে এবং বুদ্ধিমত্তার সাথে অনুরোধগুলোকে একই মডেল রেপ্লিকাতে রাউট করে, যার ফলে ক্যাশ হিট সর্বাধিক হয়, টাইম-টু-ফার্স্ট-টোকেন কমে আসে এবং প্রতি ডলারে সেরা পারফরম্যান্স নিশ্চিত হয়।
পরিবেশ প্রস্তুত করুন
আপনার টার্গেট নেমস্পেস সেট আপ করুন।
export NAMESPACE=ai-agents
kubectl create namespace $NAMESPACE
আপনার হাগিং ফেস টোকেনটি নিরাপদে সংরক্ষণ করুন, যা মডেলের ওজনগুলো টানতে প্রয়োজন।
# Replace with your actual Hugging Face token
kubectl create secret generic llm-d-hf-token \
--from-literal=HF_TOKEN="your_hugging_face_token" \
-n $NAMESPACE
হেলম কনফিগারেশন ফাইলগুলি তৈরি করুন
মডেল সার্ভিস এবং ইনফারেন্স গেটওয়ে এক্সটেনশনের কনফিগারেশনগুলো অফিসিয়াল llm-d গাইডের উপর ভিত্তি করে তৈরি করা হয়েছে।
প্রথমে, মডেল সার্ভিসের জন্য ms-values.yaml ফাইলটি তৈরি করুন:
cat <<EOF > ms-values.yaml
multinode: false
modelArtifacts:
uri: "hf://Qwen/Qwen2.5-Coder-14B-Instruct"
name: "Qwen/Qwen2.5-Coder-14B-Instruct"
size: 50Gi # Slightly larger than the default to accommodate weights
authSecretName: "llm-d-hf-token"
labels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
llm-d.ai/accelerator-variant: "gpu"
llm-d.ai/accelerator-vendor: "nvidia"
llm-d.ai/model: "qwen-2-5-coder-14b"
routing:
proxy:
enabled: false # removes sidecar from deployment - no PD in inference scheduling
targetPort: 8000 # controls vLLM port to matchup with sidecar if deployed
accelerator:
dra: true
type: "nvidia"
resourceClaimTemplates:
nvidia:
class: "gpu.nvidia.com"
match: "exactly"
name: "gpu-claim-template"
decode:
create: true
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
parallelism:
tensor: 2
data: 1
replicas: 3
monitoring:
podmonitor:
enabled: true
portName: "vllm"
path: "/metrics"
interval: "30s"
containers:
- name: "vllm"
image: ghcr.io/llm-d/llm-d-cuda:v0.5.1
modelCommand: vllmServe
args:
- "--disable-uvicorn-access-log"
- "--gpu-memory-utilization=0.85"
- "--enable-auto-tool-choice"
- "--tool-call-parser"
- "hermes"
ports:
- containerPort: 8000
name: vllm
protocol: TCP
resources:
limits:
cpu: '16'
memory: 64Gi
requests:
cpu: '16'
memory: 64Gi
mountModelVolume: true
volumeMounts:
- name: metrics-volume
mountPath: /.config
- name: shm
mountPath: /dev/shm
- name: torch-compile-cache
mountPath: /.cache
startupProbe:
httpGet:
path: /v1/models
port: vllm
initialDelaySeconds: 15
periodSeconds: 30
timeoutSeconds: 5
failureThreshold: 120
livenessProbe:
httpGet:
path: /health
port: vllm
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /v1/models
port: vllm
periodSeconds: 5
timeoutSeconds: 2
failureThreshold: 3
volumes:
- name: metrics-volume
emptyDir: {}
- name: torch-compile-cache
emptyDir: {}
- name: shm
emptyDir:
medium: Memory
sizeLimit: 20Gi
prefill:
create: false
EOF
এরপরে, GKE ইনফারেন্স গেটওয়ে এক্সটেনশনের জন্য gaie-values.yaml ফাইলটি তৈরি করুন:
cat <<EOF > gaie-values.yaml
inferenceExtension:
replicas: 1
image:
name: llm-d-inference-scheduler
hub: ghcr.io/llm-d
tag: v0.6.0
pullPolicy: Always
extProcPort: 9002
pluginsConfigFile: "default-plugins.yaml"
tracing:
enabled: false
monitoring:
interval: "10s"
prometheus:
enabled: true
auth:
secretName: inference-scheduling-gateway-sa-metrics-reader-secret
inferencePool:
targetPorts:
- number: 8000
modelServerType: vllm
modelServers:
matchLabels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
EOF
কনফিগারেশন বোঝা
এই কনফিগারেশনটি নিম্নলিখিত মূল বৈশিষ্ট্যসহ একটি উচ্চ-পারফরম্যান্স ইনফারেন্স স্ট্যাক তৈরি করে:
- মডেল নির্বাচন : এটি Qwen 2.5 Coder 14B মডেল (
modelArtifacts) ব্যবহার করে, যা কোড জেনারেশন এবং টুল ব্যবহারের জন্য অপ্টিমাইজ করা হয়েছে। - ডিআরএ ইন্টিগ্রেশন :
acceleratorসেকশনটি ডাইনামিক রিসোর্স অ্যালোকেশন (dra: true) সক্ষম করে, যাgpu.nvidia.comডিভাইস ক্লাস এবং আমাদের পূর্বে তৈরি করাgpu-claim-templateটার্গেট করে। - কর্মক্ষমতা অপ্টিমাইজেশন :
-
parallelism.tensor: 2জিপিইউগুলোর মধ্যে টেনসর প্যারালালিজম কনফিগার করে। - vLLM-এর
argsমধ্যে--enable-auto-tool-choiceঅন্তর্ভুক্ত রয়েছে, যা আমাদের কোডিং এজেন্টকে টুলগুলো কার্যকরভাবে ব্যবহার করতে সক্ষম করে। - হ্রাসকৃত
cpuএবংmemoryচাহিদাg2-standard-24মেশিন টাইপের জন্য উপযুক্ত।
-
- ইন্টেলিজেন্ট রাউটিং : ইনফারেন্স গেটওয়ে এক্সটেনশন (
gaie-values.yaml)vllmমডেল সার্ভারগুলোকে মনিটর করতে এবং KV-ক্যাশ হিট সর্বাধিক করার জন্য রিকোয়েস্ট রাউট করতে কনফিগার করা হয়েছে।
Helm-এর মাধ্যমে ইনফারেন্স শিডিউলিং স্ট্যাকটি স্থাপন করুন।
এখন, llm-d Helm রিপোজিটরিগুলো যোগ করুন এবং ইনফ্রাস্ট্রাকচার, গেটওয়ে এক্সটেনশন ও মডেল সার্ভিস আলাদাভাবে ডিপ্লয় করুন।
প্রথমে, প্রয়োজনীয় রিপোজিটরিগুলো যোগ করুন:
helm repo add llm-d-infra https://llm-d-incubation.github.io/llm-d-infra/
helm repo add llm-d-modelservice https://llm-d-incubation.github.io/llm-d-modelservice/
helm repo update
অবকাঠামোগত পূর্বশর্তগুলো স্থাপন করুন
এই চার্টটি স্ট্যাকের জন্য প্রয়োজনীয় বেসলাইন গেটওয়ে কনফিগারেশনগুলো ইনস্টল করে।
helm install infra-is llm-d-infra/llm-d-infra \
--namespace $NAMESPACE \
--set gateway.gatewayClassName=gke-l7-rilb \
--set gateway.gatewayParameters.enabled=false \
--set gateway.gatewayParameters.istio.accessLogging=false
GKE ইনফারেন্স গেটওয়ে এক্সটেনশন স্থাপন করুন
এই ধাপে ইনফারেন্সপুল এবং এন্ডপয়েন্ট পিকার স্থাপন করা হয়, যা বুদ্ধিদীপ্ত রাউটিং সিদ্ধান্ত নেওয়ার জন্য আপনার মডেলগুলোর কেভি-ক্যাশ পর্যবেক্ষণ করে।
helm install gaie-is oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool \
--version v1.3.1 \
--namespace $NAMESPACE \
-f gaie-values.yaml \
--set provider.name=gke \
--set inferenceExtension.monitoring.prometheus.enabled=true
মডেল পরিষেবাটি স্থাপন করুন
অবশেষে, আপনার LLM পরিষেবাটি স্থাপন করুন, যা এখন আপনার L4 GPU-গুলি নিরাপদে দাবি করার জন্য DRA ব্যবহার করবে।
helm install ms-is llm-d-modelservice/llm-d-modelservice \
--version v0.4.7 \
--namespace $NAMESPACE \
-f ms-values.yaml \
--set decode.monitoring.podmonitor.enabled=false
vLLM-এর জন্য Google Cloud Observability সক্রিয় করুন
জেনেরিক হেলম চার্টগুলো প্রায়শই স্ট্যান্ডার্ড প্রোমিথিউস অপারেটর PodMonitor রিসোর্স ( monitoring.coreos.com/v1 ) ডিপ্লয় করার চেষ্টা করে, যা আপনার সিস্টেমে এই CRD-গুলো ইনস্টল করা না থাকলে ত্রুটির কারণ হতে পারে।
Helm-এর বিল্ট-ইন মনিটরিং টগলটি চালু বা বন্ধ করার পরিবর্তে, এটিকে false রাখুন এবং সামঞ্জস্যপূর্ণ monitoring.googleapis.com/v1 API গ্রুপ ব্যবহার করে ম্যানুয়ালি একটি Google Cloud Managed Prometheus (GMP) PodMonitoring রিসোর্স প্রয়োগ করুন।
podmonitoring.yaml তৈরি করতে নিম্নলিখিত কমান্ডটি চালান:
cat > podmonitoring.yaml <<EOF
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: ms-vllm-metrics
spec:
selector:
matchLabels:
llm-d.ai/model: "qwen-2-5-coder-14b" # Matches the label in values.yaml
endpoints:
- port: 8000 # vllm port
interval: 30s
path: /metrics
EOF
আপনার ক্লাস্টারে PodMonitoring রিসোর্সটি প্রয়োগ করুন:
kubectl apply -f podmonitoring.yaml -n $NAMESPACE
ইনস্টলেশন যাচাই করুন
কম্পোনেন্টগুলো সফলভাবে ইনস্টল হয়েছে কিনা তা যাচাই করুন। আপনার নেমস্পেসে তিনটি Helm রিলিজই সক্রিয় দেখতে পাবেন এবং সংশ্লিষ্ট পডগুলো ইনিশিয়ালাইজ হতে দেখবেন।
helm ls -n $NAMESPACE
kubectl get pods -n $NAMESPACE
ms-is পডগুলো চালু হতে প্রায় ৫-১০ মিনিট সময় লাগতে পারে। চালু হয়ে গেলে, আউটপুটটি দেখতে অনেকটা এইরকম হবে:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
gaie-is ai-agents 1 2026-03-28 16:51:41.055881618 +0000 UTC deployed inferencepool-v1.3.1 v1.3.1
infra-is ai-agents 1 2026-03-28 16:51:03.71042542 +0000 UTC deployed llm-d-infra-v1.4.0 v0.4.0
ms-is ai-agents 1 2026-03-28 17:30:00.341918958 +0000 UTC deployed llm-d-modelservice-v0.4.7 v0.4.0
NAME READY STATUS RESTARTS AGE
gaie-is-epp-848965cb4-78ktp 1/1 Running 0 10m
ms-is-llm-d-modelservice-decode-67548d5f8c-f25f4 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-rblvs 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-w6fcd 1/1 Running 0 6m2s
৫. GKE ইনফারেন্স গেটওয়ের সাথে ইন্টেলিজেন্ট রাউটিং কনফিগার করুন
ধাপ ৪-এ, llm-d Helm চার্টগুলো ডিপ্লয় করার ফলে আপনার Gateway এবং InferencePool অবজেক্টগুলো স্বয়ংক্রিয়ভাবে প্রোভিশন করা হয়েছে। InferencePool আপনার vllm মডেল সার্ভিং Pod-গুলোকে একত্রিত করে, যেগুলো একই বেস মডেল এবং কম্পিউট কনফিগারেশন শেয়ার করে।
এখন, আপনার কোডিং এজেন্ট রিকোয়েস্টগুলোর অগ্রাধিকার নির্ধারণ করতে একটি InferenceObjective এবং ইনকামিং ট্র্যাফিক কীভাবে রাউট করতে হবে সে বিষয়ে গেটওয়েকে নির্দেশ দিতে একটি HTTPRoute কনফিগার করতে হবে, আর এর জন্য Endpoint Picker ব্যবহার করে KV-cache হিটের সংখ্যা সর্বাধিক করতে হবে।
স্বয়ংক্রিয়ভাবে তৈরি সম্পদ যাচাই করুন
প্রথমে, যাচাই করুন যে llm-d Helm চার্টগুলো Gateway এবং InferencePool রিসোর্সগুলো সফলভাবে তৈরি করেছে।
kubectl get gateway,inferencepool -n $NAMESPACE
আপনি infra-is-inference-gateway নামের একটি Gateway এবং gaie-is নামের একটি InferencePool দেখতে পাবেন। অনেকটা এইরকম:
NAME CLASS ADDRESS PROGRAMMED AGE
gateway.gateway.networking.k8s.io/infra-is-inference-gateway gke-l7-regional-internal-managed 10.128.0.5 True 13m
NAME AGE
inferencepool.inference.networking.k8s.io/gaie-is 12m
HTTPRoute তৈরি করুন
HTTPRoute রিসোর্সটি আপনার গেটওয়েকে ব্যাকএন্ড InferencePool সাথে ম্যাপ করে। এটি GKE ইনফারেন্স গেটওয়েকে নির্দেশ দেয় যেন সে আগত রিকোয়েস্ট বডিগুলো বিশ্লেষণ করে এবং শেয়ার্ড কনটেক্সটের উপর ভিত্তি করে প্রিফিক্স-ক্যাশ হিট সর্বাধিক করার জন্য সেগুলোকে ডায়নামিকভাবে রাউট করে।
httproute.yaml তৈরি করতে নিম্নলিখিত কমান্ডটি চালান:
cat > httproute.yaml <<EOF
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: agent-route
spec:
parentRefs:
- group: gateway.networking.k8s.io
kind: Gateway
name: infra-is-inference-gateway
rules:
- backendRefs:
- group: inference.networking.k8s.io
kind: InferencePool
name: gaie-is
weight: 1
matches:
- path:
type: PathPrefix
value: /
EOF
আপনার ক্লাস্টারে রুটটি প্রয়োগ করুন:
kubectl apply -f httproute.yaml -n $NAMESPACE
৬. এজেন্ট স্যান্ডবক্সের মাধ্যমে সুরক্ষিত কোড এক্সিকিউশন
এখন যেহেতু আমাদের উচ্চ-ক্ষমতাসম্পন্ন ইনফারেন্স ব্যাকএন্ডটি চালু হয়ে গেছে, চলুন একটি এজেন্ট স্যান্ডবক্স ব্যবহার করে সেই সুরক্ষিত পরিবেশটি প্রস্তুত করি যেখানে এআই-দ্বারা তৈরি কোডটি আমাদের ক্লাস্টার থেকে বিচ্ছিন্ন থেকে নিরাপদে নির্বাহ হবে।
এজেন্ট স্যান্ডবক্স কন্ট্রোলার স্থাপন করুন
যখন কোনো এআই এজেন্ট কোড তৈরি ও কার্যকর করে, তখন এটি মূলত আপনার পরিকাঠামোতে একটি অবিশ্বস্ত ওয়ার্কলোড চালায়। এজেন্টটি যদি ক্ষতিকারক কোড তৈরি করে, তবে এটি আপনার অভ্যন্তরীণ নেটওয়ার্ক স্ক্যান করার বা অন্তর্নিহিত হোস্ট নোডকে কাজে লাগানোর চেষ্টা করতে পারে।
GKE এজেন্ট স্যান্ডবক্স gVisor ব্যবহার করে, যা একটি ওপেন-সোর্স কন্টেইনার রানটাইম এবং এটি প্রতিটি কন্টেইনারের জন্য একটি বিশেষায়িত গেস্ট কার্নেল প্রদান করে। এর ফলে অবিশ্বস্ত কোড হোস্ট নোডে সরাসরি সিস্টেম কল করতে পারে না।
অফিসিয়াল রিলিজ ম্যানিফেস্টগুলো প্রয়োগ করে এজেন্ট স্যান্ডবক্স কন্ট্রোলার এবং এর প্রয়োজনীয় উপাদানগুলো স্থাপন করুন:
kubectl apply \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/manifest.yaml \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/extensions.yaml
স্যান্ডবক্স টেমপ্লেট এবং ওয়ার্ম পুল কনফিগার করুন
এরপরে, আমরা আমাদের পাইথন বিশ্লেষণ পরিবেশের জন্য একটি পুনঃব্যবহারযোগ্য ব্লুপ্রিন্ট হিসেবে একটি SandboxTemplate তৈরি করি, যা সুনির্দিষ্টভাবে gvisor রানটাইম ক্লাসকে লক্ষ্য করে। স্ট্যান্ডার্ড ক্লাস্টারে ম্যানুয়াল নোড পুল পরিচালনা না করে ডেপ্লয়মেন্ট সহজ করার জন্য, আমরা যেকোনো স্ট্যান্ডার্ড autopilot ব্যবহার করতে পারি।
ComputeClass চাহিদা অনুযায়ী গতিশীলভাবে পরিচালিত কম্পিউট নোড সরবরাহ করে, যা gVisor ওয়ার্কলোডকে স্বাভাবিকভাবেই সমর্থন করে!
যেহেতু একটি সুরক্ষিত কার্নেল ইনিশিয়ালাইজ করতে ল্যাটেন্সি বা বিলম্ব হতে পারে, তাই আমরা একটি SandboxWarmPool স্থাপন করি। এটি নিশ্চিত করে যে নির্দিষ্ট সংখ্যক আগে থেকে ইনিশিয়ালাইজ করা স্যান্ডবক্স প্রস্তুত থাকে, যাতে কোড জেনারেশন এজেন্ট সেগুলোকে গ্রহণ করে এক সেকেন্ডেরও কম সময়ে কোড চালানো শুরু করতে পারে।
প্রথমে, এজেন্ট স্যান্ডবক্স রানটাইমগুলির জন্য একটি নতুন নেমস্পেস তৈরি করুন:
kubectl create namespace agent-sandbox
নিম্নলিখিতটি sandbox-template-and-pool.yaml হিসাবে সংরক্ষণ করুন:
cat > sandbox-template-and-pool.yaml <<EOF
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxTemplate
metadata:
name: python-runtime-template
namespace: agent-sandbox
spec:
podTemplate:
metadata:
labels:
sandbox: python-sandbox-example
spec:
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: python-runtime
image: registry.k8s.io/agent-sandbox/python-runtime-sandbox:v0.1.0
ports:
- containerPort: 8888
readinessProbe:
httpGet:
path: "/"
port: 8888
initialDelaySeconds: 0
periodSeconds: 1
resources:
requests:
cpu: "250m"
memory: "512Mi"
ephemeral-storage: "512Mi"
restartPolicy: "OnFailure"
---
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxWarmPool
metadata:
name: python-sandbox-warmpool
namespace: agent-sandbox
spec:
replicas: 2
sandboxTemplateRef:
name: python-runtime-template
EOF
কনফিগারেশনটি প্রয়োগ করুন:
kubectl apply -f sandbox-template-and-pool.yaml
ওয়ার্মপুল পডগুলো ইনিশিয়ালাইজ হওয়ার জন্য ২-৩ মিনিট পর্যন্ত অপেক্ষা করুন। অন্তর্নিহিত কম্পিউট স্কেল আপ হওয়ার সময়কার Pending থেকে সেগুলো সফলভাবে Running রূপান্তরিত হয়েছে কিনা, তা আপনি নিম্নলিখিত কমান্ড ব্যবহার করে পরীক্ষা করতে পারেন:
kubectl get pods -n agent-sandbox -w
যখন আপনি দুটি python-sandbox-warmpool-*** পডকে Running এবং 1/1 Ready হিসেবে তালিকাভুক্ত দেখবেন, তার মানে আপনার নিরাপদ এক্সিকিউশন এনভায়রনমেন্টগুলো প্রি-ওয়ার্মড হয়ে গেছে এবং ক্লেইম করার জন্য প্রস্তুত!
স্যান্ডবক্স রাউটার স্থাপন করুন
আমাদের কোড জেনারেশন এজেন্ট বিচ্ছিন্ন পডগুলিতে নিরাপদে এক্সিকিউশন কমান্ড প্রেরণ করতে একটি স্যান্ডবক্স রাউটারের উপর নির্ভর করে।
sandbox-router.yaml তৈরি করতে নিম্নলিখিত কমান্ডটি চালান:
cat > sandbox-router.yaml <<EOF
apiVersion: v1
kind: Service
metadata:
name: sandbox-router-svc
namespace: agent-sandbox
spec:
type: ClusterIP
selector:
app: sandbox-router
ports:
- name: http
protocol: TCP
port: 8080
targetPort: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sandbox-router-deployment
namespace: agent-sandbox
spec:
replicas: 2
selector:
matchLabels:
app: sandbox-router
template:
metadata:
labels:
app: sandbox-router
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: sandbox-router
containers:
- name: router
image: us-central1-docker.pkg.dev/k8s-staging-images/agent-sandbox/sandbox-router:v20260225-v0.1.1.post3-10-ga5bcb57
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 10
resources:
requests:
cpu: "250m"
memory: "512Mi"
limits:
cpu: "1000m"
memory: "1Gi"
securityContext:
runAsUser: 1000
runAsGroup: 1000
EOF
কনফিগারেশনটি প্রয়োগ করুন:
kubectl apply -f sandbox-router.yaml
নেটওয়ার্ক আইসোলেশন বাস্তবায়ন করুন
এক্সিকিউশন এনভায়রনমেন্টকে আরও সুরক্ষিত করতে এবং যেকোনো অননুমোদিত পার্শ্বীয় চলাচল রোধ করতে, একটি নেটওয়ার্ক পলিসি প্রয়োগ করুন। এটি স্যান্ডবক্সকে 'এয়ার-গ্যাপ' করে, ফলে এটি গুগল ক্লাউড মেটাডেটা সার্ভার বা অন্যান্য সংবেদনশীল অভ্যন্তরীণ নেটওয়ার্কে পৌঁছাতে পারে না।
নিম্নলিখিতটি sandbox-policy.yaml হিসাবে সংরক্ষণ করুন:
cat > sandbox-policy.yaml <<EOF
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: restrict-sandbox-egress
namespace: agent-sandbox
spec:
podSelector:
matchLabels:
sandbox: python-sandbox-example
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 0.0.0.0/0
except:
- 169.254.169.254/32 # Block metadata server
EOF
নীতিমালা প্রয়োগ করুন:
kubectl apply -f sandbox-policy.yaml
উপাদানগুলি যাচাই করুন
আপনার আইসোলেটেড কোড স্যান্ডবক্স ক্লাস্টার লেয়ারটি সম্পূর্ণরূপে কনফিগার করা হয়েছে কিনা তা নিশ্চিত করতে, নিম্নলিখিত স্টেট ভ্যালিডেশন কমান্ডগুলো চালান:
প্রথমে, স্যান্ডবক্স পড এবং রাউটারগুলো চালু ও প্রস্তুত আছে কিনা তা যাচাই করুন।
kubectl get pods -n agent-sandbox
আউটপুটটি দেখতে অনেকটা এইরকম হবে:
NAME READY STATUS RESTARTS AGE
python-sandbox-warmpool-7zlkv 1/1 Running 0 3m25s
python-sandbox-warmpool-cxln2 1/1 Running 0 3m25s
sandbox-router-deployment-668dfbbbb6-g9mpd 1/1 Running 0 42s
sandbox-router-deployment-668dfbbbb6-ppllz 1/1 Running 0 42s
স্যান্ডবক্স রাউটার লোড ব্যালেন্সার / আইপি এক্সপোজার যাচাই করুন
kubectl get service sandbox-router-svc -n agent-sandbox
আউটপুটটি দেখতে এইরকম হওয়া উচিত:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
sandbox-router-svc ClusterIP 34.118.237.244 <none> 8080/TCP 114s
বহির্গমন নেটওয়ার্ক নীতি নিয়মটি বিদ্যমান আছে কিনা তা যাচাই করুন।
kubectl get networkpolicy restrict-sandbox-egress -n agent-sandbox
আউটপুটটি দেখতে এইরকম হওয়া উচিত:
NAME POD-SELECTOR AGE
restrict-sandbox-egress sandbox=python-sandbox-example 113s
নিশ্চিত করুন যে:
-
python-sandbox-warmpool-***পডগুলোRunningএবং1/1প্রস্তুত। -
sandbox-router-deployment-***রেপ্লিকাগুলোRunningএবং1/1Ready অবস্থায় আছে। -
sandbox-router-svcঅ্যাক্সেসযোগ্য, এবংrestrict-sandbox-egressপলিসিটি সফলভাবে যেকোনো মিলে যাওয়া স্যান্ডবক্স লেবেলকে সুরক্ষিত করছে।
আমাদের নিরাপদ এক্সিকিউশন এনভায়রনমেন্ট সুরক্ষিত ও ইনিশিয়ালাইজ করা হয়ে গেলে, আমরা এখন আমাদের অপারেশনের আসল মস্তিষ্ক, অর্থাৎ কোড জেনারেশন এজেন্টটি, ডেপ্লয় করার জন্য প্রস্তুত!
৭. কোড জেনারেশন এজেন্ট (ADK) তৈরি এবং স্থাপন করুন
আমাদের নিরাপদ এক্সিকিউশন স্যান্ডবক্স এবং উচ্চ-পারফরম্যান্স সম্পন্ন এলএলএম ব্যাকএন্ড উভয়ই কনফিগার করা হয়ে গেলে, আমরা এখন এজেন্ট ডেভেলপমেন্ট কিট (ADK) ব্যবহার করে আমাদের সিস্টেমের 'মস্তিষ্ক' অর্থাৎ একটি কোড জেনারেশন এজেন্ট তৈরি করতে পারি।
এই এজেন্টটিকে একজন বিশেষজ্ঞ পাইথন ডেভেলপারের মতো কাজ করার জন্য ডিজাইন করা হয়েছে। সাধারণ চ্যাটবটের মতো নয়, যা কেবল টেক্সট তৈরি করে, এই এজেন্টটি একটি কোড এক্সিকিউশন টুল দিয়ে সজ্জিত, যা এটিকে ইন্টারেক্টিভভাবে সমস্যা সমাধান করতে সক্ষম করে। এটি একটি লুপ অনুসরণ করে:
- আপনার অনুরোধের ভিত্তিতে পাইথন কোড লেখা ।
- ধাপ ৬-এ আমাদের সেট আপ করা GKE এজেন্ট স্যান্ডবক্সের ভিতরে কোডটি নিরাপদে চালানো হচ্ছে ।
- আউটপুট যাচাই করা অথবা কার্য সম্পাদনের সময় উদ্ভূত যেকোনো ত্রুটি পড়া।
- আত্মবিশ্বাসের সাথে একটি পরীক্ষিত ও কার্যকর সমাধান প্রদান করা ।
এজেন্টকে একটি সুরক্ষিত স্যান্ডবক্স এক্সিকিউশন এনভায়রনমেন্টে অ্যাক্সেস দেওয়ার মাধ্যমে, আমরা এটিকে এর নিজস্ব লজিক যাচাই করতে এবং স্বয়ংক্রিয়ভাবে ব্যর্থতা ডিবাগ করতে সক্ষম করি, যা এটিকে সফটওয়্যার ডেভেলপমেন্টের কাজকর্মে যথেষ্ট বেশি পারদর্শী করে তোলে!
ADK রিজনিং এজেন্ট তৈরি করুন
প্রথমে, আমরা পাইথন লজিক লিখি যা এজেন্টের আচরণ নির্ধারণ করে এবং এটিকে ধাপ ৬-এ তৈরি করা স্যান্ডবক্স টুলটি দিয়ে সজ্জিত করে। এই অংশে, আমরা একটি হাইব্রিড মডেল স্ট্র্যাটেজিও কনফিগার করি: এজেন্টটি আপনার GKE ক্লাস্টারে চলমান একটি সেলফ-হোস্টেড Qwen মডেলকে অগ্রাধিকার দেবে, কিন্তু স্থানীয় মডেলটি ধীর বা অনুপলব্ধ হলে স্বয়ংক্রিয়ভাবে Vertex AI-তে থাকা Gemini 2.5 Flash-এ ফিরে যাবে, যা উচ্চ নির্ভরযোগ্যতা নিশ্চিত করে।
এজেন্ট কোডের জন্য একটি নতুন ডিরেক্টরি তৈরি করুন:
mkdir -p ~/gke-ai-agent-lab/root_agent
cd ~/gke-ai-agent-lab
root_agent/agent.py নামে একটি ফাইল তৈরি করুন এবং তাতে নিম্নলিখিত বিষয়বস্তু যোগ করুন:
cat <<'EOF' > root_agent/agent.py
import os
from google.adk.agents import Agent
from google.adk.models.lite_llm import LiteLlm
from k8s_agent_sandbox import SandboxClient
import requests
# Instantiate the client globally to track sandboxes
sandbox_client = SandboxClient()
def run_python_code(code: str) -> str:
"""
Executes Python code safely in the GKE Agent Sandbox.
Use this tool whenever you need to execute code to solve a problem.
"""
sandbox = sandbox_client.create_sandbox(template="python-runtime-template", namespace="agent-sandbox")
try:
command = f"python3 -c \"{code}\""
result = sandbox.commands.run(command)
if result.stderr:
return f"Error: {result.stderr}"
return result.stdout
finally:
# Ensure the sandbox is deleted after use to avoid leaking resources
sandbox_client.delete_sandbox(sandbox.claim_name, namespace="agent-sandbox")
# Define the ADK Agent with a fallback mechanism.
# It prioritizes the Qwen 2.5 Coder model running on our Inference Gateway.
# If the local model is unavailable, it falls back to Gemini 2.5 Flash on Vertex AI.
root_agent = Agent(
name="CodeGenerationAgent",
model=LiteLlm(
model="openai/Qwen/Qwen2.5-Coder-14B-Instruct",
fallbacks=["vertex_ai/gemini-2.5-flash"],
timeout=10
),
instruction="""
You are an expert Python developer.
1. Write Python code to solve the user's problem.
2. Execute the code using the `run_python_code` tool to verify it works.
3. Return the exact output and a brief explanation of the code.
""",
tools=[run_python_code]
)
EOF
একটি __init__.py ফাইল তৈরি করুন যাতে ADK মডিউলটি চিনতে পারে:
echo "from . import agent" > ~/gke-ai-agent-lab/root_agent/__init__.py
এনভায়রনমেন্ট ভেরিয়েবলগুলো সেট করুন। LLM রিকোয়েস্টগুলো সফলভাবে রাউট করার জন্য ADK অ্যাপ্লিকেশনটির আপনার গেটওয়ের আইপি অ্যাড্রেস প্রয়োজন। যেহেতু ADK স্ট্যান্ডার্ড ওপেন-এআই কম্প্যাটিবল এন্ডপয়েন্টগুলো সাপোর্ট করে (যা vLLM আমাদের গেটওয়ের মাধ্যমে সরবরাহ করে), তাই আমরা ডিফল্ট API বেস URL-টি ওভাররাইড করতে পারি!
export GATEWAY_IP=$(kubectl get gateway infra-is-inference-gateway -n $NAMESPACE -o jsonpath='{.status.addresses[0].value}')
cat <<EOF > ~/gke-ai-agent-lab/root_agent/.env
OPENAI_API_BASE=http://${GATEWAY_IP}/v1
OPENAI_API_KEY=no-key-required
# Vertex AI settings for fallback (Authentication is handled by Workload Identity)
VERTEXAI_PROJECT=$PROJECT_ID
VERTEXAI_LOCATION=${ZONE%-[a-z]}
EOF
এজেন্ট অ্যাপ্লিকেশনটিকে কন্টেইনারাইজ করুন
আমাদের এজেন্টটিকে এমনভাবে প্যাকেজ করতে হবে যাতে এটি GKE-এর ভেতরে নিরাপদে চলতে পারে।
~/gke-ai-agent-lab এ একটি Dockerfile তৈরি করুন যা kubectl , ADK লাইব্রেরি এবং এজেন্ট স্যান্ডবক্স ক্লায়েন্ট ইনস্টল করবে:
cat <<'EOF' > ~/gke-ai-agent-lab/Dockerfile
FROM python:3.11-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
RUN apt-get update && apt-get install -y git curl \
&& curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl" \
&& install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl \
&& rm kubectl && apt-get clean && rm -rf /var/lib/apt/lists/*
RUN pip install --no-cache-dir "google-adk[extensions,otel-gcp]>=1.27.4" litellm pandas "git+https://github.com/kubernetes-sigs/agent-sandbox.git@main#subdirectory=clients/python/agentic-sandbox-client" \
"opentelemetry-instrumentation-google-genai>=0.4b0" \
"opentelemetry-exporter-otlp" \
"opentelemetry-instrumentation-vertexai>=2.0b0"
COPY ./root_agent /app/root_agent
EXPOSE 8080
ENTRYPOINT ["adk", "web", "--host", "0.0.0.0", "--port", "8080", "--otel_to_cloud"]
EOF
কন্টেইনার ইমেজটি সংরক্ষণের জন্য একটি আর্টিফ্যাক্ট রেজিস্ট্রি রিপোজিটরি তৈরি করুন।
gcloud artifacts repositories create agent-repo \
--repository-format=docker \
--location=us-central1
কন্টেইনার ইমেজটি বিল্ড ও পুশ করতে ক্লাউড বিল্ড ব্যবহার করুন।
gcloud builds submit --tag us-central1-docker.pkg.dev/$PROJECT_ID/agent-repo/code-agent:v1 ~/gke-ai-agent-lab/
RBAC ব্যবহার করে GKE-তে স্থাপন করুন
অবশেষে, আপনার ক্লাস্টারে এজেন্টটি ডেপ্লয় করুন। এই ডেপ্লয়মেন্টে একটি Role এবং RoleBinding অন্তর্ভুক্ত থাকে, যা এজেন্টকে SandboxWarmPool থেকে ইনস্ট্যান্স ক্লেইম করার অনুমতি দেয়।
এই ডেপ্লয়মেন্টটি আপনার এজেন্টকে স্যান্ডবক্স ক্লেইম এপিআই (Sandbox claim API)-এর সাথে যোগাযোগ করতে সক্ষম করার জন্য একটি কুবারনেটিস সার্ভিসঅ্যাকাউন্ট (Kubernetes ServiceAccount) ব্যবহার করবে। এর জন্য কোনো গুগল আইএএম সার্ভিসঅ্যাকাউন্ট (Google IAM ServiceAccount)-এর প্রয়োজন নেই, কারণ এটি স্থানীয় ক্লাস্টার রিসোর্স এবং একটি স্থানীয় ভিএলএলএম গেটওয়ে এন্ডপয়েন্ট (vLLM gateway endpoint) অ্যাক্সেস করছে।
gVisor-এ স্ট্যান্ডার্ড ডেপ্লয়মেন্ট কেন প্রয়োজন?
ধাপ ৬-এ, আমরা তৈরি করা পাইথন কোডের (টুল এক্সিকিউশন) জন্য ক্ষণস্থায়ী ও বাতিলযোগ্য স্যান্ডবক্স তৈরি করতে SandboxTemplate এবং SandboxClaim API ব্যবহার করেছি।
এজেন্ট ওয়েব UI (মূল কাঠামো) -এর জন্য আমরা runtimeClassName: gvisor সহ স্ট্যান্ডার্ড Kubernetes Deployment স্পেকস ব্যবহার করছি।
- পার্থক্যটি হলো : স্ট্যান্ডার্ড
SandboxClaimsক্ষণস্থায়ী এবং জিরো-টু-ওয়ান (যা অবিশ্বস্ত স্ক্রিপ্টের জন্য আদর্শ)। একটি স্ট্যান্ডার্ডDeploymentদীর্ঘস্থায়ী এবং স্থায়ী—ওয়েব UI-এর জন্য নিখুঁত, যেগুলোর একটি স্থিতিশীল কুবারনেটিসServiceএবং লোড ব্যালেন্সার প্রয়োজন! একটি স্ট্যান্ডার্ড ডিপ্লয়মেন্টে সরাসরিruntimeClassName: gvisorব্যবহার করে, আপনি স্ট্যান্ডার্ডDeploymentবৈশিষ্ট্যগুলো বজায় রেখেই gVisor কার্নেলের আইসোলেশন লাভ করেন।
নিম্নলিখিতটি deployment.yaml হিসাবে সংরক্ষণ করুন:
cat <<EOF > ~/gke-ai-agent-lab/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: code-agent
labels:
app: code-agent
spec:
replicas: 1
selector:
matchLabels:
app: code-agent
template:
metadata:
labels:
app: code-agent
spec:
serviceAccount: adk-agent-sa
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: code-agent
image: us-central1-docker.pkg.dev/YOUR_PROJECT_ID/agent-repo/code-agent:v1
imagePullPolicy: Always
env:
- name: OPENAI_API_KEY
value: "no-key-required"
- name: OPENAI_API_BASE
value: "http://YOUR_GATEWAY_IP/v1"
- name: VERTEXAI_PROJECT
value: "YOUR_PROJECT_ID"
- name: VERTEXAI_LOCATION
value: "YOUR_REGION"
- name: OTEL_SERVICE_NAME
value: "code-agent"
- name: GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY
value: "true"
- name: OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT
value: "true"
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: code-agent-service
spec:
selector:
app: code-agent
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: agent-sandbox
name: sandbox-creator-role
rules:
- apiGroups: [""]
resources: ["services", "pods", "pods/portforward"]
verbs: ["get", "list", "watch", "create"]
- apiGroups: ["extensions.agents.x-k8s.io"]
resources: ["sandboxclaims"]
verbs: ["create", "get", "list", "watch", "delete"]
- apiGroups: ["agents.x-k8s.io"]
resources: ["sandboxes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: adk-agent-binding
namespace: agent-sandbox
subjects:
- kind: ServiceAccount
name: adk-agent-sa
namespace: default
roleRef:
kind: Role
name: sandbox-creator-role
apiGroup: rbac.authorization.k8s.io
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: adk-agent-sa
EOF
পর্যবেক্ষণযোগ্যতার জন্য IAM অনুমতি প্রদান করুন
এজেন্টকে গুগল ক্লাউডে টেলিমেট্রি ডেটা (লগ এবং ট্রেস) পাঠানোর সুযোগ দিতে, আপনাকে ওয়ার্কলোড আইডেন্টিটি ব্যবহার করে কুবারনেটিস সার্ভিস অ্যাকাউন্ট adk-agent-sa কে প্রয়োজনীয় অনুমতি প্রদান করতে হবে।
আপনার ক্লাউড শেলে নিম্নলিখিত কমান্ডগুলি চালান:
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# Grant permission to write logs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/logging.logWriter \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to write traces
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/cloudtrace.agent \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to use Vertex AI
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/aiplatform.user \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
YOUR_PROJECT_ID স্বয়ংক্রিয়ভাবে আপনার আসল প্রজেক্ট আইডি দিয়ে প্রতিস্থাপন করতে এবং কনফিগারেশনটি প্রয়োগ করতে নিম্নলিখিত কমান্ডটি চালান!
sed -i "s/YOUR_PROJECT_ID/$PROJECT_ID/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_GATEWAY_IP/$GATEWAY_IP/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_REGION/$ZONE/g" ~/gke-ai-agent-lab/deployment.yaml
kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml
৮. পর্যবেক্ষণ ও যাচাই করুন
সম্পূর্ণ সমন্বিত সিস্টেমটি পরীক্ষা করার সময় এসেছে।
UI-তে কোড জেনারেশন এজেন্টটি পরীক্ষা করুন
আপনার ADK ওয়েব UI-এর এক্সটার্নাল আইপি খুঁজুন:
kubectl get services code-agent-service
আউটপুটটি দেখতে অনেকটা এইরকম হবে:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
code-agent-service LoadBalancer 34.118.230.182 34.31.250.60 80:32471/TCP 2m14s
- একটি ব্রাউজার খুলুন এবং
http://[EXTERNAL-IP]-এ যান। - ADK ওয়েব ইন্টারফেসে, উপরের ডানদিকের ড্রপ-ডাউন মেনু থেকে 'root_agent' নির্বাচিত আছে কিনা তা নিশ্চিত করুন। তারপর, এজেন্টকে নির্দেশ দিন:
Write a python script that prints 'Hello from the isolated sandbox'.
এজেন্ট কীভাবে ইনফারেন্স ব্যাকএন্ড এবং স্যান্ডবক্স ব্যবহার করে তা পর্যবেক্ষণ করতে, ড্যাশবোর্ডগুলো দেখার জন্য নিচের 'ক্লাউড অবজার্ভেবিলিটির মাধ্যমে মডেলের পরিসংখ্যান অন্বেষণ করুন' এবং 'জিকেই ইউআই-এর মাধ্যমে এজেন্টের অবজার্ভেবিলিটি অন্বেষণ করুন' বিভাগগুলোতে যান।
GKE UI-এর মাধ্যমে এজেন্ট অবজার্ভেবিলিটি অন্বেষণ করুন
এখন যেহেতু আপনি কিছু প্রম্পট চালিয়েছেন, চলুন টেলিমেট্রি ডেটাগুলো দেখি। এটি আপনাকে বুঝতে সাহায্য করবে যে ইনফারেন্স শিডিউলার এবং ভিএলএলএম কেমন পারফর্ম করছে।
এজেন্ট ড্যাশবোর্ডগুলিতে প্রবেশ করুন
- Kubernetes Engine > Workloads পৃষ্ঠায় যান।
- ডিপ্লয়মেন্ট ডিটেইলস পেজটি খুলতে কোড-এজেন্ট ডিপ্লয়মেন্ট-এর উপর ক্লিক করুন।
- Observability ট্যাবে ক্লিক করুন।
- অবজার্ভেবিলিটি ড্যাশবোর্ডের বাম দিকের নেভিগেশন প্যানেলে আপনি সাব-ট্যাবসহ একটি নতুন এজেন্ট সেকশন দেখতে পাবেন।
কী অন্বেষণ করবেন
আপনার এজেন্ট অ্যাপ্লিকেশনের আচরণ দেখতে নিম্নলিখিত সাব-ট্যাবগুলি অন্বেষণ করুন:
- সারসংক্ষেপ: সেশন, গড় পালা এবং আহ্বানের স্কোরকার্ড দেখুন।
- মডেলসমূহ: আপনার এজেন্ট যে মডেলগুলো ব্যবহার করেছে, সে অনুযায়ী মডেল কলের সংখ্যা, ত্রুটির হার এবং লেটেন্সি দেখুন।
- টুল: আপনার এজেন্ট তার স্যান্ডবক্স এক্সিকিউশন টুলটি কতটা কার্যকরভাবে ব্যবহার করছে তা দেখতে টুল কল এবং এক্সিকিউশনের সময়কাল নিরীক্ষণ করুন।
- ব্যবহার: টোকেনের ব্যবহার এবং কন্টেইনারের সাধারণ রিসোর্স বরাদ্দ (সিপিইউ এবং মেমরি) ট্র্যাক করা।
- এজেন্ট ট্রেস: এক্সিকিউশন সেশন বা র ট্রেস স্প্যানের তালিকা দেখতে এই ট্যাবে যান। কোনো সারিতে ক্লিক করলে নির্বাচিত ট্রেসের বিস্তারিত বিবরণসহ একটি ফ্লাইআউট খুলে যায়!
vLLM থেকে মডেল-স্তরের মেট্রিক্স এবং ADK থেকে অ্যাপ-স্তরের টেলিমেট্রি একত্রিত করার মাধ্যমে, আপনি এখন GKE-তে আপনার জেনারেটিভ এআই এজেন্টের জন্য ফুল-স্ট্যাক পর্যবেক্ষণযোগ্যতা পাচ্ছেন!
ক্লাউড অবজার্ভেবিলিটির মাধ্যমে vLLM মডেলের পরিসংখ্যান অন্বেষণ করুন
এখন যেহেতু আপনি কিছু প্রম্পট চালিয়েছেন, চলুন টেলিমেট্রি ডেটাগুলো দেখি। এটি আপনাকে বুঝতে সাহায্য করবে যে ইনফারেন্স শিডিউলার এবং ভিএলএলএম কেমন পারফর্ম করছে।
ড্যাশবোর্ডগুলিতে প্রবেশ করুন
- গুগল ক্লাউড কনসোলে যান।
- মনিটরিং > ড্যাশবোর্ড- এ যান।
- vLLM Prometheus Overview ড্যাশবোর্ডটি অনুসন্ধান করুন এবং নির্বাচন করুন।
পর্যবেক্ষণ করার মতো আকর্ষণীয় মেট্রিক
ড্যাশবোর্ড দেখার সময়, GKE ইনফারেন্স গেটওয়ে এবং প্রিফিক্স-ক্যাশিং-এর প্রভাব দেখতে এই মূল মেট্রিকগুলিতে মনোযোগ দিন:
- কেভি ক্যাশে ব্যবহার (
vllm:gpu_cache_usage):- কেন এটি গুরুত্বপূর্ণ: এটি দেখায় যে কনটেক্সট ক্যাশ করার জন্য জিপিইউ মেমরির কতটা অংশ ব্যবহৃত হচ্ছে। যদি এর পরিমাণ বেশি হয়, তার মানে হলো সিস্টেমটি ভবিষ্যতের অনুরোধগুলোকে দ্রুত করার জন্য কনটেক্সট ধরে রাখছে। আপনি যদি একই প্রম্পট একাধিকবার চালান, তাহলে দেখবেন এই ব্যবহার প্রথমে বাড়বে এবং তারপর স্থিতিশীল হবে।
- চলমান বনাম অপেক্ষারত অনুরোধ (
vllm:num_requests_runningবনামvllm:num_requests_waiting):- কেন এটি গুরুত্বপূর্ণ: এটি লোড নির্দেশ করে। যদি অপেক্ষারত অনুরোধের সংখ্যা বেশি হয়, তার মানে আপনার নোডগুলো ওভারলোডেড।
- টোকেন থ্রুপুট (
vllm:request_prompt_tokens_totএবংvllm:request_generation_tokens_tot):- কেন এটি গুরুত্বপূর্ণ: ক্লাস্টার দ্বারা প্রক্রিয়াকৃত ইনপুট এবং আউটপুট টোকেনের পরিমাণ ট্র্যাক করুন।
- প্রথম টোকেন পাওয়ার সময় (TTFT) :
- কেন এটি গুরুত্বপূর্ণ: এটি ইন্টারেক্টিভ এজেন্টদের জন্য একটি অত্যন্ত গুরুত্বপূর্ণ মেট্রিক। প্রিফিক্স-ক্যাশ অ্যাওয়্যার রাউটিং সহ GKE ইনফারেন্স গেটওয়ে ব্যবহার করে, একই কনটেক্সট শেয়ার করা রিকোয়েস্টগুলো (যেমন সিস্টেম প্রম্পট বা বড় কনটেক্সট উইন্ডো) একই রেপ্লিকাতে রাউট করা হয়, যা বিদ্যমান ক্যাশ হিটগুলো পুনঃব্যবহারের মাধ্যমে TTFT কমিয়ে আনে!
চেষ্টা করার মতো পরীক্ষা
রিয়েল-টাইমে মেট্রিকগুলোর পরিবর্তন দেখতে এবং সঠিক সময়সূচী যাচাই করতে এই সিনারিওগুলো চেষ্টা করে দেখুন!
পরীক্ষা ১: "পুনরাবৃত্তির গতি" (প্রিফিক্স ক্যাশে হিট)
- এজেন্টকে একটি জটিল নির্দেশ পাঠান (যেমন, "একটি ১০০ মেগাবাইটের CSV ফাইল পার্স করে পরিসংখ্যান গণনা করার জন্য একটি পাইথন স্ক্রিপ্ট লিখুন।" )।
- এটি সাড়া দিলে, সাথে সাথে হুবহু একই প্রম্পটটি আবার পাঠান।
- প্রিফিক্স ক্যাশ হিট রেট এবং টাইম টু ফার্স্ট টোকেন (TTFT) পর্যবেক্ষণ করুন।
- যা দেখতে পাবেন: প্রিফিক্স ক্যাশ হিট রেট বেড়ে ১০০% হয়ে যাবে এবং TTFT ব্যাপকভাবে কমে যাবে!
- এর মানে হলো: GKE ইনফারেন্স গেটওয়ে শেয়ার্ড কনটেক্সটটি শনাক্ত করেছে এবং এটিকে হুবহু সেই রেপ্লিকাতে রাউট করেছে, যেটি তার ইভ্যালুয়েটেড কনটেক্সট ক্যাশে পুনরায় ব্যবহার করেছে!
পরীক্ষা ২: ক্লাউডে প্রত্যাবর্তন (মডেলের নির্ভরযোগ্যতা)
- আপনার স্থানীয় Qwen মডেলের ব্যর্থতা অনুকরণ করতে, আপনি হয় ইনফারেন্স পরিষেবাটি বন্ধ করতে পারেন অথবা ডিপ্লয়মেন্টে একটি ভুয়া
OPENAI_API_BASEপ্রদান করতে পারেন। - আপনার
deployment.yamlফাইলেOPENAI_API_BASEএকটি অস্তিত্বহীন IP বা পোর্টে আপডেট করুন এবং পরিবর্তনগুলি প্রয়োগ করুন:sed -i "s|value: \"http://$GATEWAY_IP/v1\"|value: \"http://10.0.0.1:8080/v1\"|g" ~/gke-ai-agent-lab/deployment.yaml kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml - পডটি পুনরায় চালু হওয়ার জন্য অপেক্ষা করুন, তারপর UI-তে এজেন্টকে একটি প্রম্পট পাঠান।
- আপনি যা দেখতে পাবেন: এজেন্টটি এখনও সফলভাবে সাড়া দিচ্ছে!
- এর অর্থ হলো:
fallbacksকনফিগারেশনের কারণে, ADK স্থানীয় Qwen এন্ডপয়েন্টের ব্যর্থতা শনাক্ত করে অনুরোধটি নির্বিঘ্নে Vertex AI-তে থাকা Gemini 2.5 Flash-এ পাঠিয়ে দিয়েছে। উল্লেখ্য যে, যেহেতু Vertex AI-তে করা এই ফলব্যাক কলগুলো আপনার স্থানীয় vLLM ইনফারেন্স গেটওয়েকে বাইপাস করে, তাই এগুলো Agent Observability > Models ড্যাশবোর্ডে দেখা যাবে না, যেটি শুধুমাত্র vLLM-এর মধ্য দিয়ে যাওয়া ট্র্যাফিক ট্র্যাক করে।
গতিশীল সম্পদ বরাদ্দ (ডিআরএ)-এর শক্তি অনুধাবন করা
যদিও vLLM এবং ইনফারেন্স গেটওয়ে অনুরোধ রাউটিং এবং পরিষেবা প্রদানের পদ্ধতিকে অপ্টিমাইজ করে, কিন্তু ডাইনামিক রিসোর্স অ্যালোকেশন (DRA)- ই মূলত আপনার ওয়ার্কলোডের জন্য একেবারে সঠিক হার্ডওয়্যার সংযুক্ত করা সম্ভব করেছে।
DRA আপনাকে ResourceClaimTemplate এবং DeviceClasses ব্যবহার করে নমনীয় হার্ডওয়্যার রিসোর্স সংজ্ঞায়িত করার সুযোগ দিয়ে আপনার ক্লাস্টার জুড়ে হার্ডওয়্যারকে সূক্ষ্মভাবে পরিচালনা করার ক্ষমতাকে উন্নত করে।
এআই ওয়ার্কলোডের ক্ষেত্রে ডিআরএ কেন একটি যুগান্তকারী পরিবর্তন:
- সুনির্দিষ্ট হার্ডওয়্যার অনুরোধ : DRA-এর মাধ্যমে, আপনি শুধু সঠিক অ্যাক্সিলারেটরযুক্ত মেশিনে ওয়ার্কলোড শিডিউল করাই নিশ্চিত করেন না, বরং সেই রিসোর্সগুলোর উপর দাবিও করতে পারেন, যাতে সেগুলো শুধুমাত্র ResourceClaim-এর সাথে যুক্ত ওয়ার্কলোড দ্বারাই ব্যবহৃত হয়।
- বিচ্ছিন্ন জীবনচক্র : ডিভাইস ক্লেইমগুলো পড জীবনচক্র থেকে স্বাধীনভাবে পরিচালিত হয়। যদি কোনো পড ক্র্যাশ করে, তাহলে জিপিইউ ক্লেইমটি টিকে থাকতে পারে, ফলে জিপিইউ মুক্ত ও পুনরায় অধিগ্রহণের জন্য অপেক্ষা না করেই সামগ্রিক ডেপ্লয়মেন্ট বা অন্য ওয়ার্কলোড অবজেক্ট পুনরায় চালু করা যায়।
- মাল্টি-ভেন্ডর স্ট্যান্ডার্ডাইজেশন : DRA, NVIDIA GPU এবং Google TPU উভয়ের জন্য একটি সমন্বিত Kubernetes API প্রদান করে। আপনি যে কোনো একটির জন্য ডেপ্লয় করুন না কেন, হুবহু একই স্কিমা ব্যবহার করতে পারেন, যা আপনার ওয়ার্কলোড YAML ম্যানিফেস্টগুলোকে অত্যন্ত পোর্টেবল করে তোলে!
এই কোডল্যাবে আপনি এর বাস্তব প্রয়োগ দেখেছেন, যেখানে আপনি আপনার Helm ভ্যালুগুলোকে gpu-claim-template এর সাথে নির্বিঘ্নে বাইন্ড করার জন্য কনফিগার করেছেন, এবং এর ফলে কোনো হ্যাং হয়ে থাকা ডিভাইস প্লাগইন কনফিগারেশন আপনার রোলআউটগুলোকে বাধা দেয়নি।
llm-d এর ভূমিকা বোঝা
vLLM যখন নিউরাল ওয়েট মূল্যায়ন করে এবং GKE গেটওয়ে কোয়েরি রাউট করে, তখন llm-d কনফিগারেশন লেয়ার এবং এই সবগুলোকে একসাথে বেঁধে রাখার 'আঠা' হিসেবে কাজ করে।
llm-d ছাড়া, আপনাকে আপনার vLLM ডিপ্লয়মেন্ট, সার্ভিস পোর্ট, ভলিউম মাউন্ট এবং DRA রিসোর্স ক্লেইমগুলো একেবারে গোড়া থেকে ঘোষণা করার জন্য সরাসরি Kubernetes ম্যানিফেস্ট লিখতে হতো।
আপনার ডেপ্লয়মেন্টে কেন llm-d ব্যবহার করবেন?
- একীভূত কনফিগারেশন (এক-লাইনের ওভাররাইড) :
llm-dHelm চার্টগুলো জটিল, নিম্ন-স্তরের Kubernetes রিসোর্সগুলোকে পরিচ্ছন্ন, উচ্চ-স্তরের টগলে একত্রিত করে (যেমনaccelerator.dra: trueসেট করা)। - পূর্ব-যাচাইকৃত "সুস্পষ্ট পথসমূহ" :
llm-dরিপোজিটরিতে এমন সব কনফিগারেশন রয়েছে যা বিশেষজ্ঞদের দ্বারা ইতোমধ্যেই বেঞ্চমার্ক ও পরীক্ষা করা হয়েছে। আপনি যখনllm-d-modelserviceডেপ্লয় করেন, তখন আপনি GPU মেমরি ব্যবহারের জন্য অপ্টিমাইজ করা ডিফল্ট, প্রস্তাবিত প্রোব টাইমিং (লাইভনেস/রেডিনেস), এবং মেট্রিক্স স্ক্র্যাপিংয়ের জন্য সঠিক এক্সপোজার পেয়ে থাকেন। - নির্বিঘ্ন পর্যবেক্ষণযোগ্যতা ম্যাপিং :
llm-dডিফল্টভাবেই স্ট্যান্ডার্ড কন্টেইনার পোর্ট এবং স্ক্র্যাপ পাথ (/metrics) সঠিকভাবে উন্মুক্ত করে, যার ফলে ম্যানুয়াল ডিবাগিং ছাড়াই আপনার ডেপ্লয়মেন্টকে গুগল ক্লাউড মনিটরিং-এর সাথে সংযুক্ত করা সহজ হয়।
সংক্ষেপে, llm-d পুনঃব্যবহারযোগ্য আর্কিটেকচার ব্লুপ্রিন্ট সরবরাহ করে, ফলে ডেভেলপারদের প্রতিবার GKE-তে একটি ইনফারেন্স স্ট্যাক ডেপ্লয় করার সময় নতুন করে সবকিছু তৈরি করতে হয় না।
গভীর বিশ্লেষণ: GKE ইনফারেন্স গেটওয়ে
সাধারণ লেয়ার ৭ লোড ব্যালেন্সারগুলো পাথ ( /v1/completions ) বা কুকির মতো HTTP হেডার দেখে কাজ করে। GKE ইনফারেন্স গেটওয়ে আরও গভীরে যায়—এটি বিশেষভাবে জেনারেটিভ এআই ট্র্যাফিকের জন্য ডিজাইন করা হয়েছে।
এটি কীভাবে কর্মক্ষমতা এবং দক্ষতা বৃদ্ধি করে:
- কন্টেন্ট-অ্যাওয়ার রাউটিং (প্রম্পট হ্যাশিং) : GKE ইনফারেন্স গেটওয়ে JSON রিকোয়েস্ট বডিটি গ্রহণ করে। এটি প্রম্পটটির একটি হ্যাশ গণনা করে এবং ট্র্যাক করে যে কোন ব্যাকএন্ড রেপ্লিকাটি ইতিমধ্যেই তার GPU মেমরিতে (KV ক্যাশে) সেই টোকেনগুলি ধারণ করে রেখেছে।
- ক্যাশে হিটের সর্বোচ্চ ব্যবহার : আপনার পরীক্ষায়, যখন আপনি একটি প্রম্পট পুনরাবৃত্তি করেছিলেন, গেটওয়ে সেটিকে হুবহু একই রেপ্লিকাতে পাঠিয়েছিল। একটি প্রম্পট মূল্যায়ন করতে প্রচুর কম্পিউট প্রয়োজন হয়। ক্যাশে পুনঃব্যবহারের মাধ্যমে, আপনি প্রম্পটটি "পুনরায় পড়া" এড়াতে পারেন, যা অর্থ এবং জিপিইউ সময় সাশ্রয় করে।
- টাইম-টু-ফার্স্ট-টোকেন (TTFT) কমানো : TTFT হলো মানুষের সাথে সরাসরি কাজ করে এমন এজেন্টদের জন্য একটি অত্যন্ত গুরুত্বপূর্ণ ব্যবহারযোগ্যতা মেট্রিক। ক্যাশে অ্যাক্সেস করার মাধ্যমে, মডেলটি সেকেন্ডের পরিবর্তে মিলিসেকেন্ডের মধ্যেই টোকেন তৈরি করা শুরু করতে পারে।
- বুদ্ধিমান লোড বন্টন : যদি কোনো একটি রেপ্লিকার VRAM ক্যাশ হিটে সম্পূর্ণরূপে পূর্ণ হয়ে যায়, তাহলে গেটওয়ে কার্যকারিতা এবং প্রাপ্যতার মধ্যে ভারসাম্য বজায় রেখে, একটি নতুন প্রম্পটকে গতিশীলভাবে অন্য একটি রেপ্লিকাতে পাঠিয়ে দিতে পারে যেখানে জায়গা আছে।
এজেন্ট স্যান্ডবক্স কীভাবে ঝুঁকি কমায়
এই ল্যাবে আমরা দেখিয়েছি, কীভাবে এজেন্ট স্যান্ডবক্স দুই স্তরের আইসোলেশন প্রদানের মাধ্যমে আপনার পরিকাঠামোকে এআই এজেন্ট-সম্পর্কিত ঝুঁকি থেকে সুরক্ষিত রাখে:
- এক্সিকিউশন টুলকে বিচ্ছিন্ন করা : এজেন্ট তার তৈরি করা কোড একটি ক্ষণস্থায়ী স্যান্ডবক্সে নির্বাহ করে। এটি নিশ্চিত করে যে LLM দ্বারা তৈরি অবিশ্বস্ত কোড একটি নিরাপদ ও বিচ্ছিন্ন পরিবেশে চলে, যা এজেন্ট এবং ক্লাস্টার উভয়কেই সুরক্ষিত রাখে।
- দ্রুত স্টার্টআপ : ওয়ার্মপুল ব্যবহারের মাধ্যমে নতুন স্যান্ডবক্সগুলো এক সেকেন্ডেরও কম সময়ে চালু হয়ে কোড চালানোর জন্য প্রস্তুত হয়ে যায়।
- এজেন্টটিকে স্বয়ং বিচ্ছিন্ন করা : এজেন্টের নির্ভরতাগুলিতে থাকা সাপ্লাই চেইন দুর্বলতার বিরুদ্ধে গভীরতর প্রতিরক্ষা প্রদানের জন্য, আমরা এজেন্ট অ্যাপ্লিকেশনটিকেও একটি gVisor-সক্ষম নোডে (
runtimeClassName: gvisorএর মাধ্যমে) রান করেছি।
এই কারণেই এটি এমন একটি কঠোর নিরাপত্তা বেষ্টনী তৈরি করে:
- সিস্টেম কল ইন্টারসেপশন : gVisor সিস্টেম কলগুলোকে হোস্ট লিনাক্স কার্নেলে পৌঁছানোর আগেই আটকে দেয়। এর ফলে, কন্টেইনার থেকে বেরিয়ে হোস্ট নোড অ্যাক্সেস করার চেষ্টাকারী এক্সপ্লয়েটগুলো প্রতিরোধ করা যায়।
- সীমাবদ্ধ পার্শ্বীয় চলাচল : নেটওয়ার্ক পলিসির সাথে মিলিতভাবে, কোনো পরিবেশ অরক্ষিত হয়ে পড়লেও, এটি আপনার অভ্যন্তরীণ মেটাডেটা সার্ভার স্ক্যান করতে বা আপনার ক্লাস্টারের অন্যান্য সংবেদনশীল পরিষেবাগুলিতে প্রবেশ করতে পারে না।
স্যান্ডবক্সে সম্পূর্ণ এজেন্ট চালানো
এই ল্যাবে, আমরা একটি পারসিস্টেন্ট এজেন্ট অ্যাপ্লিকেশনের টুল হিসেবে স্যান্ডবক্স ব্যবহার করেছি। তবে, সর্বোচ্চ নিরাপত্তার জন্য—বিশেষ করে সংবেদনশীল ডেটা পরিচালনা করার সময় বা একাধিক অবিশ্বস্ত ব্যবহারকারীকে পরিষেবা দেওয়ার ক্ষেত্রে—আপনি প্রতিটি সেশন বা ব্যবহারকারীর জন্য একটি ডেডিকেটেড স্যান্ডবক্সের ভিতরে সম্পূর্ণ এজেন্ট অ্যাপ্লিকেশনটি চালাতে পারেন। এটি এজেন্টের মেমরি, স্টেট এবং এক্সিকিউশন এনভায়রনমেন্টের সম্পূর্ণ বিচ্ছিন্নতা নিশ্চিত করে, যা সেশন শেষ হওয়ার সাথে সাথেই ধ্বংস হয়ে যায়।
৯. পরিচ্ছন্নতা
এই কোডল্যাবে ব্যবহৃত রিসোর্সগুলোর জন্য আপনার গুগল ক্লাউড অ্যাকাউন্টে চার্জ হওয়া এড়াতে, সেগুলোকে ডিলিট করার জন্য এই ধাপগুলো অনুসরণ করুন।
ব্যক্তিগত সম্পদ মুছে ফেলুন
- GKE ক্লাস্টারটি মুছে ফেলুন:
gcloud container clusters delete $CLUSTER_NAME --zone $ZONE --quiet
- আর্টিফ্যাক্ট রেজিস্ট্রি রিপোজিটরিটি মুছে ফেলুন:
gcloud artifacts repositories delete agent-repo --location=us-central1 --quiet
- VPC নেটওয়ার্কটি মুছে ফেলুন:
gcloud compute networks delete ai-agent-network --quiet
প্রকল্পটি মুছে ফেলুন
আপনার যদি প্রজেক্টটির আর প্রয়োজন না থাকে, তাহলে রিসোর্সগুলো সরিয়ে ফেলার পর এটি ডিলিট করে দিতে পারেন:
gcloud projects delete $PROJECT_ID
১০. সারসংক্ষেপ
অভিনন্দন! আপনি GKE-তে সফলভাবে একটি সুরক্ষিত ও উচ্চ-কর্মক্ষমতাসম্পন্ন কোড জেনারেশন এজেন্ট তৈরি এবং স্থাপন করেছেন।
আপনি যা শিখেছেন
- GPU রিসোর্স পরিচালনা করার জন্য GKE-তে ডাইনামিক রিসোর্স অ্যালোকেশন (DRA) কীভাবে কনফিগার ও ব্যবহার করবেন।
- প্রিফিক্স-ক্যাশ সচেতন রাউটিংয়ের মাধ্যমে LLM সার্ভিং পারফরম্যান্স অপ্টিমাইজ করতে GKE ইনফারেন্স গেটওয়ে কীভাবে ব্যবহার করবেন
- GKE-তে এজেন্ট স্যান্ডবক্স (gVisor) ব্যবহার করে কীভাবে অবিশ্বস্ত কোড নিরাপদে চালানো যায়
- vLLM-এর পারফরম্যান্স নিরীক্ষণের জন্য কীভাবে Google Cloud Managed Service for Prometheus ব্যবহার করবেন।
- How to configure and view Agent Observability using ADK and GKE Managed OpenTelemetry.
Next Steps & References
- Agent Sandbox : Learn about Agent Sandbox on GKE and GKE Sandbox Pods .
- llm-d : Read the llm-d Guide and check out the llm-d GitHub Repository .
- Dynamic Resource Allocation : Learn about DRA on GKE .
- GKE Inference Gateway : Explore Inference Gateway concepts .
- More Codelabs : Find more tutorials at Google Cloud Codelabs .