
1. Einführung
Übersicht
In diesem Lab erfahren Sie, wie Sie einen sicheren Code-Generierungs-Agenten in Google Kubernetes Engine (GKE) erstellen und bereitstellen. Agents zur Codeerstellung müssen Code ausführen, der möglicherweise nicht vertrauenswürdig ist. Daher ist eine sichere Sandbox-Umgebung erforderlich. Außerdem erfahren Sie, wie Sie den Agent mit einer Hybridmodellstrategie konfigurieren, damit er zur Steigerung der Zuverlässigkeit von einem selbst gehosteten offenen Modell in GKE auf den verwalteten Gemini-Dienst von Vertex AI zurückgreifen kann. Außerdem erfahren Sie, wie Sie die Inferenzbereitstellung mit dem GKE Inference Gateway und der dynamischen Ressourcenzuweisung (Dynamic Resource Allocation, DRA) optimieren können. Schließlich erfahren Sie, wie Sie Google Cloud Observability nutzen, um Ihren Inferenz-Stack mit Managed Prometheus zu überwachen.
Architektur
Das ist die Architektur des Systems, das Sie erstellen werden:
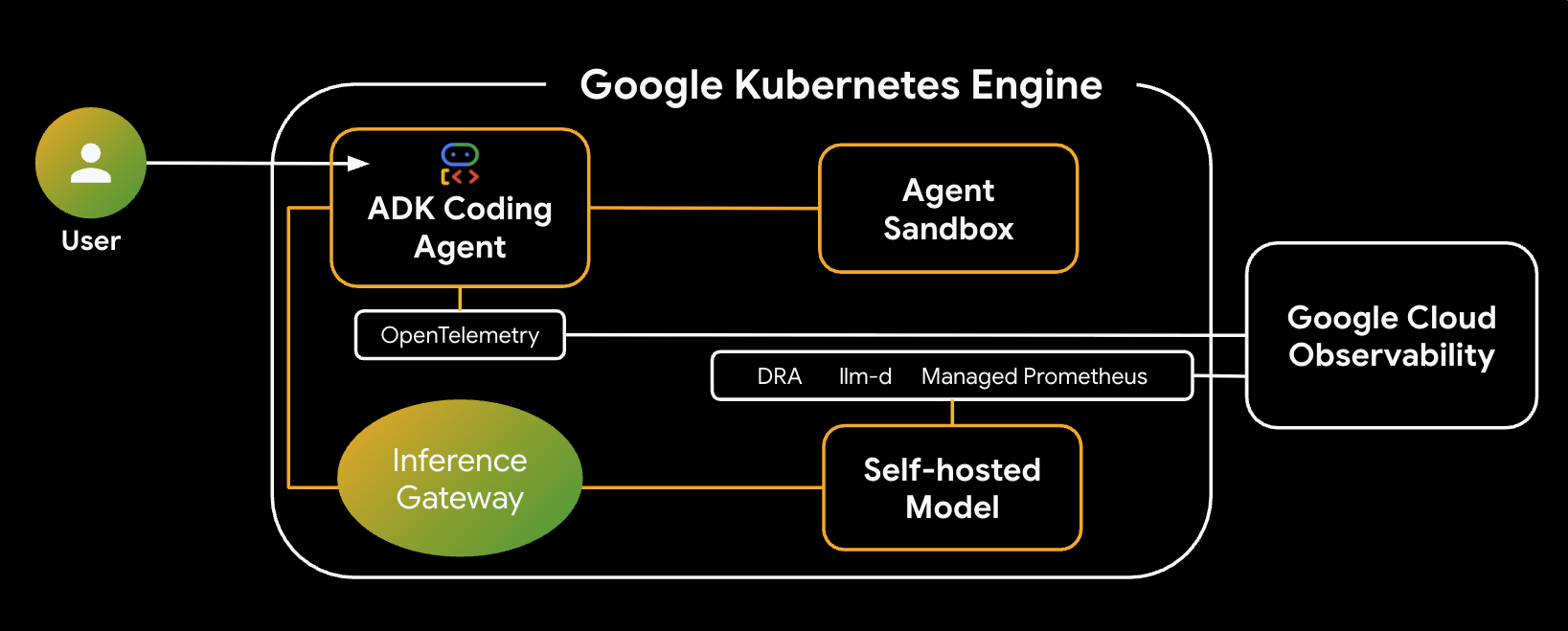
Wichtige Komponenten und Vorteile
- Dynamische Ressourcenzuweisung (Dynamic Resource Allocation, DRA): Wird in diesem Lab verwendet, um bestimmte GPU-Ressourcen (NVIDIA L4s) für die Modellserver-Pods dynamisch anzufordern und zuzuweisen. So wird eine präzise Hardwareausrichtung für unsere Inferenz-Arbeitslast erreicht. Weitere Informationen zu DRA in GKE
- llm-d & vLLM: Bietet das Framework für die Modellbereitstellung und Helm-Diagramme zum Bereitstellen des Qwen-Modells. In diesem Lab werden die Inferenzanfragen verarbeitet und die Integration mit DRA für die Ressourcenverwaltung erfolgt (disaggregated serving ist in diesem Lab nicht aktiviert). Lesen Sie den llm-d-Leitfaden und sehen Sie sich das llm-d-GitHub-Repository an.
- GKE Inference Gateway: Verschiebt die KI-bezogene Routinglogik direkt in den Load Balancer. In diesem Lab werden Anfragen so weitergeleitet, dass die Anzahl der Prefix-Cache-Treffer maximiert und die TTFT-Latenz (Time to First Token) reduziert wird. Inference Gateway-Konzepte
- Agent Sandbox (gVisor): Bietet eine sichere Isolation für die Ausführung des vom KI-Agenten generierten Codes. gVisor bietet eine umfassende Kernel-Isolation und schützt den Hostknoten vor nicht vertrauenswürdigen Arbeitslasten. Informationen zu Agent Sandbox in GKE und GKE Sandbox-Pods
Aufgaben
- Infrastruktur bereitstellen: Richten Sie einen GKE-Cluster mit Dynamic Resource Allocation (DRA) für die GPU-Verwaltung ein.
- Inference Stack bereitstellen: Stellen Sie
llm-dund vLLM mit intelligenter Inferenzplanung bereit. - Intelligent Routing konfigurieren: Verwenden Sie das GKE Inference Gateway für das präfixbasierte Routing mit Cache.
- Sichere Codeausführung: Stellen Sie die Agent Sandbox (gVisor) bereit, um KI-generierten Code sicher auszuführen.
- Beobachten und validieren: Verwenden Sie Google Cloud Monitoring und Managed Prometheus, um Messwerte für die Modellbereitstellung aufzurufen.
Lerninhalte
- Informationen zum Konfigurieren und Verwenden der dynamischen Ressourcenzuweisung (Dynamic Resource Allocation, DRA) in GKE.
- GKE Inference Gateway verwenden, um die Leistung beim Bereitstellen von LLMs zu optimieren
- So führen Sie nicht vertrauenswürdigen Code mit Agent Sandbox sicher in GKE aus.
- So verwenden Sie Google Cloud Managed Service for Prometheus, um die vLLM-Leistung zu überwachen.
2. Einrichtung und Anforderungen
Projekt einrichten
Google Cloud-Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
Cloud Shell starten
Cloud Shell ist eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird und mit den erforderlichen Tools vorinstalliert ist.
- Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren.
- Prüfen Sie nach der Verbindung mit Cloud Shell Ihre Authentifizierung:
gcloud auth list - Prüfen Sie, ob Ihr Projekt konfiguriert ist:
gcloud config get project - Wenn Ihr Projekt nicht wie erwartet festgelegt ist, legen Sie es fest:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
3. Infrastruktur bereitstellen und dynamische Ressourcenzuweisung (Dynamic Resource Allocation, DRA)
In diesem ersten Schritt konfigurieren Sie Ihren GKE-Cluster so, dass er die moderne Zuweisung von Beschleunigern (Device Resource Assignment, DRA) anstelle von Legacy-Geräte-Plug-ins verwendet. So können Sie GPUs oder TPUs flexibel für Ihre Arbeitslasten zur Codeerstellung freigeben und zuweisen.
Voraussetzungen:Ihr GKE-Standardcluster muss Version 1.34 oder höher ausführen, um DRA zu unterstützen.
Google Cloud APIs aktivieren
Aktivieren Sie die für dieses Codelab erforderlichen Google Cloud APIs, insbesondere die Compute Engine API und die Kubernetes Engine API.
gcloud services enable compute.googleapis.com container.googleapis.com networkservices.googleapis.com cloudbuild.googleapis.com artifactregistry.googleapis.com telemetry.googleapis.com cloudtrace.googleapis.com aiplatform.googleapis.com
Umgebungsvariablen festlegen
Definieren Sie Umgebungsvariablen, um die Einrichtung zu vereinfachen. Sie können die Region oder die Namenskonventionen nach Bedarf anpassen.
export PROJECT_ID=$(gcloud config get-value project)
export ZONE=us-central1-a
export CLUSTER_NAME=ai-agent-cluster
export NODEPOOL_NAME=dra-accelerator-pool
gcloud config set project $PROJECT_ID
gcloud config set compute/region $ZONE
Arbeitsverzeichnis erstellen
Erstellen Sie ein eigenes Arbeitsverzeichnis für dieses Lab und wechseln Sie in dieses Verzeichnis, damit Ihre Dateien organisiert bleiben:
mkdir -p ~/gke-ai-agent-lab
cd ~/gke-ai-agent-lab
Berechtigungen konfigurieren (optional)
Wenn Sie ein eingeschränktes Projekt oder eine freigegebene Umgebung verwenden, muss Ihr Konto die erforderlichen Berechtigungen zum Erstellen von Clustern und zum Ausführen von Builds haben:
export MY_ACCOUNT=$(gcloud config get-value account)
# Grant Container Admin to create clusters and manage nodes if needed
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/container.admin"
# Grant Cloud Build Builder to run builds
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/cloudbuild.builds.builder"
GKE-Cluster erstellen
Auf Ihrem GKE-Standardcluster muss Version 1.34 oder höher ausgeführt werden, um DRA zu unterstützen. Außerdem müssen Sie die Gateway API-Controller aktivieren, um die intelligente Planung von Inferenzen zu unterstützen.
In diesem Lab erstellen Sie ein neues VPC-Netzwerk und neue Subnetze.
Erstellen Sie zuerst das VPC-Netzwerk:
gcloud compute networks create ai-agent-network --subnet-mode=custom
Erstellen Sie als Nächstes ein Subnetz für Ihre GKE-Knoten:
gcloud compute networks subnets create ai-agent-subnet \
--network=ai-agent-network \
--range=10.0.0.0/20 \
--region=us-central1
Für die Gateway API (gke-l7-regional-internal-managed) ist auch ein dediziertes Subnetz zum Hosten der Envoy-Proxys erforderlich. Erstellen Sie dieses Nur-Proxy-Subnetz in Ihrem neuen Netzwerk:
gcloud compute networks subnets create proxy-only-subnet \
--purpose=REGIONAL_MANAGED_PROXY \
--role=ACTIVE \
--region=us-central1 \
--network=ai-agent-network \
--range=192.168.10.0/24
Erstellen Sie jetzt den Cluster mit dem neuen Netzwerk und Subnetz:
gcloud beta container clusters create $CLUSTER_NAME \
--zone $ZONE \
--num-nodes 1 \
--machine-type n2-standard-4 \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--gateway-api=standard \
--managed-otel-scope=COLLECTION_AND_INSTRUMENTATION_COMPONENTS \
--network=ai-agent-network \
--subnetwork=ai-agent-subnet
Knotenpool erstellen, in dem Standard-Plug-ins deaktiviert sind
Wenn Sie die Geräteverwaltung an DRA übergeben möchten, müssen Sie einen Knotenpool erstellen, in dem die standardmäßige GPU-Treiberinstallation und das Standardgeräte-Plug-in explizit deaktiviert sind.
Führen Sie den folgenden gcloud-Befehl aus, um einen GPU-Knotenpool (z.B. mit NVIDIA L4-GPUs) mit den erforderlichen DRA-Labels bereitzustellen:
gcloud container node-pools create $NODEPOOL_NAME \
--cluster=$CLUSTER_NAME \
--location=$ZONE \
--machine-type=g2-standard-24 \
--accelerator=type=nvidia-l4,count=2,gpu-driver-version=disabled \
--node-labels=gke-no-default-nvidia-gpu-device-plugin=true,nvidia.com/gpu.present=true \
--num-nodes 3
NVIDIA-Treiber über DaemonSet installieren
Installieren Sie die erforderlichen NVIDIA-Gerätetreiber manuell auf Ihren Knoten. Verwenden Sie dazu ein vorkonfiguriertes Google Cloud-DaemonSet:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
DRA-Treiber installieren
Installieren Sie als Nächstes den spezifischen DRA-Treiber in Ihrem Cluster. Für NVIDIA-GPUs können Sie dies über Helm bereitstellen:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
helm install nvidia-dra-driver-gpu nvidia/nvidia-dra-driver-gpu \
--version="25.3.2" --create-namespace --namespace=nvidia-dra-driver-gpu \
--set nvidiaDriverRoot="/home/kubernetes/bin/nvidia/" \
--set gpuResourcesEnabledOverride=true \
--set resources.computeDomains.enabled=false \
--set kubeletPlugin.priorityClassName="" \
--set 'kubeletPlugin.tolerations[0].key=nvidia.com/gpu' \
--set 'kubeletPlugin.tolerations[0].operator=Exists' \
--set 'kubeletPlugin.tolerations[0].effect=NoSchedule'
DeviceClasses
Sie müssen keine DeviceClass-YAML-Datei manuell schreiben oder anwenden. Wenn Sie Ihre GKE-Infrastruktur für DRA einrichten und den Treiber installieren, werden die DeviceClass-Objekte im Cluster automatisch von den DRA-Treibern erstellt, die auf Ihren Knoten ausgeführt werden.
ResourceClaimTemplate konfigurieren
Damit Ihre llm-d-Pods diese Beschleuniger dynamisch anfordern können, erstellen Sie eine ResourceClaimTemplate. In dieser Vorlage wird die angeforderte Gerätekonfiguration definiert und Kubernetes wird angewiesen, automatisch ein eindeutiges ResourceClaim pro Pod für Ihre Arbeitslasten zu erstellen.
Führen Sie den folgenden Befehl aus, um claim-template.yaml zu erstellen:
cat > claim-template.yaml <<EOF
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: gpu-claim-template
spec:
spec:
devices:
requests:
- name: single-gpu
exactly:
deviceClassName: gpu.nvidia.com
allocationMode: ExactCount
count: 1
EOF
Wenden Sie die Vorlage auf Ihren Cluster an:
kubectl apply -f claim-template.yaml
4. Intelligent Inference Scheduling mit llm-d und DRA bereitstellen
In diesem Schritt stellen Sie Ihr Large Language Model hinter einem intelligenten Envoy-Load-Balancer bereit, der mit einem Inferenz-Scheduler erweitert wurde. Diese Konfiguration optimiert die Modellbereitstellung durch Anwendung von Prefix-Cache Aware Routing. Das GKE Inference Gateway erkennt den gemeinsamen Kontext über Mikrodienste hinweg und leitet Anfragen intelligent an dasselbe Modellreplikat weiter. So werden Cache-Treffer maximiert, die Time-to-First-Token verkürzt und eine bessere Leistung pro Dollar erzielt.
Umgebung vorbereiten
Richten Sie den Ziel-Namespace ein.
export NAMESPACE=ai-agents
kubectl create namespace $NAMESPACE
Speichern Sie Ihr Hugging Face-Token, das zum Abrufen der Modellgewichte erforderlich ist, sicher.
# Replace with your actual Hugging Face token
kubectl create secret generic llm-d-hf-token \
--from-literal=HF_TOKEN="your_hugging_face_token" \
-n $NAMESPACE
Helm-Konfigurationsdateien erstellen
Die Konfigurationen für den Modelldienst und die Inference Gateway-Erweiterung basieren auf den offiziellen llm-d-Anleitungen.
Erstellen Sie zuerst die ms-values.yaml-Datei für den Modelldienst:
cat <<EOF > ms-values.yaml
multinode: false
modelArtifacts:
uri: "hf://Qwen/Qwen2.5-Coder-14B-Instruct"
name: "Qwen/Qwen2.5-Coder-14B-Instruct"
size: 50Gi # Slightly larger than the default to accommodate weights
authSecretName: "llm-d-hf-token"
labels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
llm-d.ai/accelerator-variant: "gpu"
llm-d.ai/accelerator-vendor: "nvidia"
llm-d.ai/model: "qwen-2-5-coder-14b"
routing:
proxy:
enabled: false # removes sidecar from deployment - no PD in inference scheduling
targetPort: 8000 # controls vLLM port to matchup with sidecar if deployed
accelerator:
dra: true
type: "nvidia"
resourceClaimTemplates:
nvidia:
class: "gpu.nvidia.com"
match: "exactly"
name: "gpu-claim-template"
decode:
create: true
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
parallelism:
tensor: 2
data: 1
replicas: 3
monitoring:
podmonitor:
enabled: true
portName: "vllm"
path: "/metrics"
interval: "30s"
containers:
- name: "vllm"
image: ghcr.io/llm-d/llm-d-cuda:v0.5.1
modelCommand: vllmServe
args:
- "--disable-uvicorn-access-log"
- "--gpu-memory-utilization=0.85"
- "--enable-auto-tool-choice"
- "--tool-call-parser"
- "hermes"
ports:
- containerPort: 8000
name: vllm
protocol: TCP
resources:
limits:
cpu: '16'
memory: 64Gi
requests:
cpu: '16'
memory: 64Gi
mountModelVolume: true
volumeMounts:
- name: metrics-volume
mountPath: /.config
- name: shm
mountPath: /dev/shm
- name: torch-compile-cache
mountPath: /.cache
startupProbe:
httpGet:
path: /v1/models
port: vllm
initialDelaySeconds: 15
periodSeconds: 30
timeoutSeconds: 5
failureThreshold: 120
livenessProbe:
httpGet:
path: /health
port: vllm
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /v1/models
port: vllm
periodSeconds: 5
timeoutSeconds: 2
failureThreshold: 3
volumes:
- name: metrics-volume
emptyDir: {}
- name: torch-compile-cache
emptyDir: {}
- name: shm
emptyDir:
medium: Memory
sizeLimit: 20Gi
prefill:
create: false
EOF
Erstellen Sie als Nächstes die Datei gaie-values.yaml für die GKE Inference Gateway-Erweiterung:
cat <<EOF > gaie-values.yaml
inferenceExtension:
replicas: 1
image:
name: llm-d-inference-scheduler
hub: ghcr.io/llm-d
tag: v0.6.0
pullPolicy: Always
extProcPort: 9002
pluginsConfigFile: "default-plugins.yaml"
tracing:
enabled: false
monitoring:
interval: "10s"
prometheus:
enabled: true
auth:
secretName: inference-scheduling-gateway-sa-metrics-reader-secret
inferencePool:
targetPorts:
- number: 8000
modelServerType: vllm
modelServers:
matchLabels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
EOF
Konfiguration verstehen
Diese Konfiguration richtet einen leistungsstarken Inferenz-Stack mit den folgenden wichtigen Funktionen ein:
- Modellauswahl: Es wird das Modell Qwen 2.5 Coder 14B (
modelArtifacts) verwendet, das für die Codegenerierung und die Verwendung von Tools optimiert ist. - DRA-Integration: Im Abschnitt
acceleratorwird die dynamische Ressourcenzuweisung (Dynamic Resource Allocation,dra: true) für die Geräteklassegpu.nvidia.comund die zuvor erstelltegpu-claim-templateaktiviert. - Leistungsoptimierung:
- Mit
parallelism.tensor: 2wird die Tensor-Parallelität über die GPUs hinweg konfiguriert. argsfür vLLM enthält--enable-auto-tool-choice, damit unser Coding-Agent Tools effektiv nutzen kann.- Die reduzierten
cpu- undmemory-Anfragen passen zum Maschinentypg2-standard-24.
- Mit
- Intelligentes Routing: Die Inference Gateway-Erweiterung (
gaie-values.yaml) ist so konfiguriert, dass dievllm-Modellserver überwacht und Anfragen so weitergeleitet werden, dass die KV-Cache-Treffer maximiert werden.
Inference Scheduling Stack über Helm bereitstellen
Fügen Sie nun die Helm-Repositories für llm-d hinzu und stellen Sie die Infrastruktur, die Gateway-Erweiterung und den Model-Dienst einzeln bereit.
Fügen Sie zuerst die erforderlichen Repositories hinzu:
helm repo add llm-d-infra https://llm-d-incubation.github.io/llm-d-infra/
helm repo add llm-d-modelservice https://llm-d-incubation.github.io/llm-d-modelservice/
helm repo update
Infrastrukturvoraussetzungen bereitstellen
Mit diesem Diagramm werden die für den Stack erforderlichen Gateway-Basiskonfigurationen installiert.
helm install infra-is llm-d-infra/llm-d-infra \
--namespace $NAMESPACE \
--set gateway.gatewayClassName=gke-l7-rilb \
--set gateway.gatewayParameters.enabled=false \
--set gateway.gatewayParameters.istio.accessLogging=false
GKE Inference Gateway-Erweiterung bereitstellen
In diesem Schritt werden der InferencePool und der Endpoint Picker bereitgestellt. Der Endpoint Picker überwacht den KV-Cache Ihrer Modelle, um intelligente Routingentscheidungen zu treffen.
helm install gaie-is oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool \
--version v1.3.1 \
--namespace $NAMESPACE \
-f gaie-values.yaml \
--set provider.name=gke \
--set inferenceExtension.monitoring.prometheus.enabled=true
Modelldienst bereitstellen
Stellen Sie schließlich Ihren LLM-Dienst bereit. Er verwendet jetzt DRA, um Ihre L4-GPUs sicher zu beanspruchen.
helm install ms-is llm-d-modelservice/llm-d-modelservice \
--version v0.4.7 \
--namespace $NAMESPACE \
-f ms-values.yaml \
--set decode.monitoring.podmonitor.enabled=false
Google Cloud Observability für vLLM aktivieren
Mit generischen Helm-Diagrammen wird oft versucht, Standardressourcen des Prometheus-Operators PodMonitor (monitoring.coreos.com/v1) bereitzustellen. Das kann zu Fehlern führen, wenn diese CRDs nicht installiert sind.
Anstatt den integrierten Monitoring-Schalter von Helm zu aktivieren, lassen Sie ihn auf false und wenden Sie manuell eine GMP-Ressource (Google Cloud Managed Prometheus) PodMonitoring mit der kompatiblen API-Gruppe monitoring.googleapis.com/v1 an.
Führen Sie den folgenden Befehl aus, um podmonitoring.yaml zu erstellen:
cat > podmonitoring.yaml <<EOF
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: ms-vllm-metrics
spec:
selector:
matchLabels:
llm-d.ai/model: "qwen-2-5-coder-14b" # Matches the label in values.yaml
endpoints:
- port: 8000 # vllm port
interval: 30s
path: /metrics
EOF
Wenden Sie die PodMonitoring-Ressource auf Ihren Cluster an:
kubectl apply -f podmonitoring.yaml -n $NAMESPACE
Installation prüfen
Prüfen Sie, ob die Komponenten erfolgreich installiert wurden. Alle drei Helm-Releases sollten in Ihrem Namespace aktiv sein und die entsprechenden Pods sollten initialisiert werden.
helm ls -n $NAMESPACE
kubectl get pods -n $NAMESPACE
Es kann etwa 5–10 Minuten dauern, bis die ms-is-Pods hochgefahren sind. In diesem Fall sollte die Ausgabe in etwa so aussehen:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
gaie-is ai-agents 1 2026-03-28 16:51:41.055881618 +0000 UTC deployed inferencepool-v1.3.1 v1.3.1
infra-is ai-agents 1 2026-03-28 16:51:03.71042542 +0000 UTC deployed llm-d-infra-v1.4.0 v0.4.0
ms-is ai-agents 1 2026-03-28 17:30:00.341918958 +0000 UTC deployed llm-d-modelservice-v0.4.7 v0.4.0
NAME READY STATUS RESTARTS AGE
gaie-is-epp-848965cb4-78ktp 1/1 Running 0 10m
ms-is-llm-d-modelservice-decode-67548d5f8c-f25f4 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-rblvs 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-w6fcd 1/1 Running 0 6m2s
5. Intelligent Routing mit GKE Inference Gateway konfigurieren
In Schritt 4 wurden beim Bereitstellen der llm-d-Helm-Diagramme automatisch Ihre Gateway- und InferencePool-Objekte bereitgestellt. In der InferencePool werden Ihre vllm-Modellbereitstellungs-Pods gruppiert, die dasselbe Basismodell und dieselbe Compute-Konfiguration verwenden.
Jetzt müssen Sie eine InferenceObjective konfigurieren, um die Priorität Ihrer Coding-Agent-Anfragen festzulegen, und eine HTTPRoute, um das Gateway anzuweisen, wie eingehender Traffic weitergeleitet werden soll. Dabei wird der Endpoint Picker verwendet, um die Anzahl der KV-Cache-Treffer zu maximieren.
Automatisch generierte Ressourcen überprüfen
Prüfen Sie zuerst, ob die llm-d-Helm-Charts das Gateway und die InferencePool-Ressourcen erfolgreich erstellt haben.
kubectl get gateway,inferencepool -n $NAMESPACE
Sie sollten ein Gateway mit dem Namen infra-is-inference-gateway und einen InferencePool mit dem Namen gaie-is sehen. Ähnlich wie hier:
NAME CLASS ADDRESS PROGRAMMED AGE
gateway.gateway.networking.k8s.io/infra-is-inference-gateway gke-l7-regional-internal-managed 10.128.0.5 True 13m
NAME AGE
inferencepool.inference.networking.k8s.io/gaie-is 12m
HTTPRoute erstellen
Die HTTPRoute-Ressource ordnet Ihr Gateway dem Backend InferencePool zu. Dadurch wird das GKE Inference Gateway angewiesen, eingehende Anfragetextkörper zu analysieren und sie dynamisch weiterzuleiten, um Prefix-Cache-Treffer basierend auf dem freigegebenen Kontext zu maximieren.
Führen Sie den folgenden Befehl aus, um httproute.yaml zu erstellen:
cat > httproute.yaml <<EOF
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: agent-route
spec:
parentRefs:
- group: gateway.networking.k8s.io
kind: Gateway
name: infra-is-inference-gateway
rules:
- backendRefs:
- group: inference.networking.k8s.io
kind: InferencePool
name: gaie-is
weight: 1
matches:
- path:
type: PathPrefix
value: /
EOF
Wenden Sie die Route auf Ihren Cluster an:
kubectl apply -f httproute.yaml -n $NAMESPACE
6. Sichere Codeausführung mit der Agent-Sandbox
Nachdem unser leistungsstarkes Inferenz-Backend ausgeführt wird, bereiten wir die sichere Umgebung vor, in der der KI-generierte Code mithilfe einer Agent Sandbox sicher isoliert von unserem Cluster ausgeführt wird.
Agent Sandbox Controller bereitstellen
Wenn ein KI-Agent Code generiert und ausführt, wird im Grunde eine nicht vertrauenswürdige Arbeitslast auf Ihrer Infrastruktur ausgeführt. Wenn der Agent schädlichen Code generiert, kann er versuchen, Ihr internes Netzwerk zu scannen oder den zugrunde liegenden Hostknoten auszunutzen.
GKE Agent Sandbox verwendet gVisor, eine Open-Source-Containerlaufzeit, die für jeden Container einen speziellen Gastkernel bereitstellt. Dadurch wird verhindert, dass nicht vertrauenswürdiger Code direkte Systemaufrufe an den Hostknoten ausführt.
Stellen Sie den Agent Sandbox-Controller und die erforderlichen Komponenten bereit, indem Sie die offiziellen Release-Manifeste anwenden:
kubectl apply \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/manifest.yaml \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/extensions.yaml
Sandbox-Vorlage und Warm Pool konfigurieren
Als Nächstes erstellen wir eine SandboxTemplate, die als wiederverwendbare Vorlage für unsere Python-Analyseumgebungen dient und explizit auf die Laufzeitklasse gvisor ausgerichtet ist. Um die Bereitstellung zu vereinfachen, ohne manuelle Knotenpools in Standardclustern verwalten zu müssen, können wir einen beliebigen Standard-autopilot verwenden.
Mit der ComputeClass können verwaltete Compute-Knoten dynamisch bereitgestellt werden, die gVisor-Arbeitslasten nativ unterstützen.
Da die Initialisierung eines sicheren Kernels zu Latenz führen kann, stellen wir auch einen SandboxWarmPool bereit. So wird dafür gesorgt, dass eine bestimmte Anzahl vorinitialisierter Sandboxes bereitgehalten wird, damit der Code Generation Agent sie in weniger als einer Sekunde in Anspruch nehmen und mit der Ausführung von Code beginnen kann.
Erstellen Sie zuerst einen neuen Namespace für die Agent-Sandbox-Runtimes:
kubectl create namespace agent-sandbox
Speichern Sie Folgendes als sandbox-template-and-pool.yaml:
cat > sandbox-template-and-pool.yaml <<EOF
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxTemplate
metadata:
name: python-runtime-template
namespace: agent-sandbox
spec:
podTemplate:
metadata:
labels:
sandbox: python-sandbox-example
spec:
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: python-runtime
image: registry.k8s.io/agent-sandbox/python-runtime-sandbox:v0.1.0
ports:
- containerPort: 8888
readinessProbe:
httpGet:
path: "/"
port: 8888
initialDelaySeconds: 0
periodSeconds: 1
resources:
requests:
cpu: "250m"
memory: "512Mi"
ephemeral-storage: "512Mi"
restartPolicy: "OnFailure"
---
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxWarmPool
metadata:
name: python-sandbox-warmpool
namespace: agent-sandbox
spec:
replicas: 2
sandboxTemplateRef:
name: python-runtime-template
EOF
Wenden Sie die Konfiguration an:
kubectl apply -f sandbox-template-and-pool.yaml
Warten Sie bis zu 2–3 Minuten, bis die Warmpool-Pods initialisiert sind. Mit dem folgenden Befehl können Sie prüfen, ob der Übergang von Pending (während die zugrunde liegende Rechenleistung skaliert wird) zu Running erfolgreich war:
kubectl get pods -n agent-sandbox -w
Sobald zwei python-sandbox-warmpool-***-Pods als Running und 1/1 „Bereit“ aufgeführt werden, sind Ihre sicheren Ausführungsumgebungen vorab aufgewärmt und können in Anspruch genommen werden.
Sandbox-Router bereitstellen
Unser Code Generation Agent verwendet einen Sandbox-Router, um Ausführungsbefehle sicher an die isolierten Pods zu senden.
Führen Sie den folgenden Befehl aus, um sandbox-router.yaml zu erstellen:
cat > sandbox-router.yaml <<EOF
apiVersion: v1
kind: Service
metadata:
name: sandbox-router-svc
namespace: agent-sandbox
spec:
type: ClusterIP
selector:
app: sandbox-router
ports:
- name: http
protocol: TCP
port: 8080
targetPort: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sandbox-router-deployment
namespace: agent-sandbox
spec:
replicas: 2
selector:
matchLabels:
app: sandbox-router
template:
metadata:
labels:
app: sandbox-router
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: sandbox-router
containers:
- name: router
image: us-central1-docker.pkg.dev/k8s-staging-images/agent-sandbox/sandbox-router:v20260225-v0.1.1.post3-10-ga5bcb57
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 10
resources:
requests:
cpu: "250m"
memory: "512Mi"
limits:
cpu: "1000m"
memory: "1Gi"
securityContext:
runAsUser: 1000
runAsGroup: 1000
EOF
Wenden Sie die Konfiguration an:
kubectl apply -f sandbox-router.yaml
Netzwerkisolation implementieren
Um die Ausführungsumgebung weiter zu schützen und unbefugte laterale Bewegungen zu verhindern, wenden Sie eine Netzwerkrichtlinie an. Dadurch wird die Sandbox „luftdicht“ abgeschlossen, sodass sie nicht auf den Google Cloud-Metadatenserver oder andere vertrauliche interne Netzwerke zugreifen kann.
Speichern Sie Folgendes als sandbox-policy.yaml:
cat > sandbox-policy.yaml <<EOF
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: restrict-sandbox-egress
namespace: agent-sandbox
spec:
podSelector:
matchLabels:
sandbox: python-sandbox-example
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 0.0.0.0/0
except:
- 169.254.169.254/32 # Block metadata server
EOF
Wenden Sie die Richtlinie an:
kubectl apply -f sandbox-policy.yaml
Komponenten überprüfen
Führen Sie die folgenden Befehle zur Statusvalidierung aus, um sicherzustellen, dass die isolierte Code-Sandbox-Clusterebene vollständig konfiguriert ist:
Prüfen Sie zuerst, ob Sandbox-Pods und ‑Router ausgeführt werden und bereit sind.
kubectl get pods -n agent-sandbox
Die Ausgabe sollte in etwa so aussehen:
NAME READY STATUS RESTARTS AGE
python-sandbox-warmpool-7zlkv 1/1 Running 0 3m25s
python-sandbox-warmpool-cxln2 1/1 Running 0 3m25s
sandbox-router-deployment-668dfbbbb6-g9mpd 1/1 Running 0 42s
sandbox-router-deployment-668dfbbbb6-ppllz 1/1 Running 0 42s
Load Balancer / IP-Offenlegung des Sandbox-Routers prüfen
kubectl get service sandbox-router-svc -n agent-sandbox
Die Ausgabe sollte so aussehen:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
sandbox-router-svc ClusterIP 34.118.237.244 <none> 8080/TCP 114s
Prüfen, ob die Egress-Netzwerkrichtlinienregel vorhanden ist
kubectl get networkpolicy restrict-sandbox-egress -n agent-sandbox
Die Ausgabe sollte so aussehen:
NAME POD-SELECTOR AGE
restrict-sandbox-egress sandbox=python-sandbox-example 113s
Prüfe Folgendes:
- Die
python-sandbox-warmpool-***-Pods sindRunningund1/1bereit. - Die
sandbox-router-deployment-***Replikate sindRunningund1/1bereit. - Auf die
sandbox-router-svckann zugegriffen werden und dierestrict-sandbox-egress-Richtlinie schützt alle übereinstimmenden Sandbox-Labels.
Nachdem unsere sichere Ausführungsumgebung eingerichtet und initialisiert wurde, können wir das eigentliche Herzstück unseres Betriebs bereitstellen: den Code-Generierungs-Agenten.
7. Code-Generierungs-Agent (ADK) erstellen und bereitstellen
Nachdem wir unsere Sandbox für die sichere Ausführung und unser leistungsstarkes LLM-Backend konfiguriert haben, können wir nun das „Gehirn“ unseres Systems erstellen: einen Code Generation Agent (Agent zur Code-Generierung) mit dem Agent Development Kit (ADK).
Dieser Agent ist als Experte für Python-Entwicklung konzipiert. Im Gegensatz zu einem Standard-Chatbot, der nur Text generiert, ist dieser Agent mit einem Tool zur Codeausführung ausgestattet, mit dem er Probleme interaktiv lösen kann. Der Prozess läuft in einer Schleife ab:
- Python-Code auf Grundlage Ihrer Anfragen schreiben.
- Der Code wird sicher ausgeführt in der GKE Agent Sandbox, die wir in Schritt 6 eingerichtet haben.
- Ausgabe prüfen oder Fehler lesen, die während der Ausführung auftreten.
- Bereitstellung einer getesteten, funktionierenden Lösung.
Indem wir dem Agent Zugriff auf eine sichere Sandbox-Ausführungsumgebung gewähren, kann er seine eigene Logik überprüfen und Fehler automatisch beheben. Dadurch ist er wesentlich besser für Softwareentwicklungsaufgaben geeignet.
ADK-Reasoning-Agent entwickeln
Zuerst schreiben wir die Python-Logik, die das Verhalten des KI-Agents definiert und ihn mit dem Sandbox-Tool ausstattet, das wir in Schritt 6 erstellt haben. In diesem Abschnitt konfigurieren wir auch eine Hybridmodellstrategie: Der Agent priorisiert ein selbst gehostetes Qwen-Modell, das in Ihrem GKE-Cluster ausgeführt wird, greift aber automatisch auf Gemini 2.5 Flash in Vertex AI zurück, wenn das lokale Modell langsam oder nicht verfügbar ist. So wird eine hohe Zuverlässigkeit gewährleistet.
Erstellen Sie ein neues Verzeichnis für den Agent-Code:
mkdir -p ~/gke-ai-agent-lab/root_agent
cd ~/gke-ai-agent-lab
Erstellen Sie eine Datei mit dem Namen root_agent/agent.py und dem folgendem Inhalt:
cat <<'EOF' > root_agent/agent.py
import os
from google.adk.agents import Agent
from google.adk.models.lite_llm import LiteLlm
from k8s_agent_sandbox import SandboxClient
import requests
# Instantiate the client globally to track sandboxes
sandbox_client = SandboxClient()
def run_python_code(code: str) -> str:
"""
Executes Python code safely in the GKE Agent Sandbox.
Use this tool whenever you need to execute code to solve a problem.
"""
sandbox = sandbox_client.create_sandbox(template="python-runtime-template", namespace="agent-sandbox")
try:
command = f"python3 -c \"{code}\""
result = sandbox.commands.run(command)
if result.stderr:
return f"Error: {result.stderr}"
return result.stdout
finally:
# Ensure the sandbox is deleted after use to avoid leaking resources
sandbox_client.delete_sandbox(sandbox.claim_name, namespace="agent-sandbox")
# Define the ADK Agent with a fallback mechanism.
# It prioritizes the Qwen 2.5 Coder model running on our Inference Gateway.
# If the local model is unavailable, it falls back to Gemini 2.5 Flash on Vertex AI.
root_agent = Agent(
name="CodeGenerationAgent",
model=LiteLlm(
model="openai/Qwen/Qwen2.5-Coder-14B-Instruct",
fallbacks=["vertex_ai/gemini-2.5-flash"],
timeout=10
),
instruction="""
You are an expert Python developer.
1. Write Python code to solve the user's problem.
2. Execute the code using the `run_python_code` tool to verify it works.
3. Return the exact output and a brief explanation of the code.
""",
tools=[run_python_code]
)
EOF
Erstellen Sie eine __init__.py-Datei, damit das Modul vom ADK erkannt wird:
echo "from . import agent" > ~/gke-ai-agent-lab/root_agent/__init__.py
Legen Sie die Umgebungsvariablen fest. Die ADK-Anwendung benötigt die IP-Adresse Ihres Gateways, um die LLM-Anfragen erfolgreich weiterzuleiten. Da ADK standardmäßige Open-AI-kompatible Endpunkte unterstützt (die vLLM über unser Gateway bereitstellt), können wir die standardmäßige API-Basis-URL überschreiben.
export GATEWAY_IP=$(kubectl get gateway infra-is-inference-gateway -n $NAMESPACE -o jsonpath='{.status.addresses[0].value}')
cat <<EOF > ~/gke-ai-agent-lab/root_agent/.env
OPENAI_API_BASE=http://${GATEWAY_IP}/v1
OPENAI_API_KEY=no-key-required
# Vertex AI settings for fallback (Authentication is handled by Workload Identity)
VERTEXAI_PROJECT=$PROJECT_ID
VERTEXAI_LOCATION=${ZONE%-[a-z]}
EOF
Agent-Anwendung containerisieren
Wir müssen den Agent so verpacken, dass er sicher in GKE ausgeführt werden kann.
Erstellen Sie in ~/gke-ai-agent-lab ein Dockerfile, mit dem kubectl, die ADK-Bibliothek und der Agent Sandbox-Client installiert werden:
cat <<'EOF' > ~/gke-ai-agent-lab/Dockerfile
FROM python:3.11-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
RUN apt-get update && apt-get install -y git curl \
&& curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl" \
&& install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl \
&& rm kubectl && apt-get clean && rm -rf /var/lib/apt/lists/*
RUN pip install --no-cache-dir "google-adk[extensions,otel-gcp]>=1.27.4" litellm pandas "git+https://github.com/kubernetes-sigs/agent-sandbox.git@main#subdirectory=clients/python/agentic-sandbox-client" \
"opentelemetry-instrumentation-google-genai>=0.4b0" \
"opentelemetry-exporter-otlp" \
"opentelemetry-instrumentation-vertexai>=2.0b0"
COPY ./root_agent /app/root_agent
EXPOSE 8080
ENTRYPOINT ["adk", "web", "--host", "0.0.0.0", "--port", "8080", "--otel_to_cloud"]
EOF
Erstellen Sie ein Artifact Registry-Repository zum Speichern des Container-Images.
gcloud artifacts repositories create agent-repo \
--repository-format=docker \
--location=us-central1
Mit Cloud Build das Container-Image erstellen und per Push übertragen.
gcloud builds submit --tag us-central1-docker.pkg.dev/$PROJECT_ID/agent-repo/code-agent:v1 ~/gke-ai-agent-lab/
In GKE mit RBAC bereitstellen
Stellen Sie den Agent schließlich in Ihrem Cluster bereit. Die Bereitstellung umfasst Role und RoleBinding, wodurch der Agent die Berechtigung erhält, Instanzen aus SandboxWarmPool zu beanspruchen.
Bei dieser Bereitstellung wird ein Kubernetes-Dienstkonto verwendet, damit Ihr Agent mit der Sandbox-Anspruchs-API kommunizieren kann. Es ist kein Google IAM-Dienstkonto erforderlich, da auf lokale Clusterressourcen und einen lokalen vLLM-Gateway-Endpunkt zugegriffen wird.
Warum eine Standardbereitstellung in gVisor?
In Schritt 6 haben wir die APIs SandboxTemplate und SandboxClaim verwendet, um temporäre, kurzlebige Sandboxes für den generierten Python-Code (die Tool-Ausführung) zu erstellen.
Für die Agent-Web-UI (das Brain) selbst verwenden wir Standard-Kubernetes-Deployment-Spezifikationen mit runtimeClassName: gvisor.
- Der Unterschied: Standard-
SandboxClaimssind kurzlebig und haben einen Wert zwischen 0 und 1. Sie eignen sich ideal für nicht vertrauenswürdige Skripts. Ein Standard-Deploymentist langlebig und persistent – ideal für Web-UIs, die einen stabilen Kubernetes-Serviceund Load Balancer benötigen. Wenn SieruntimeClassName: gvisordirekt für eine Standardbereitstellung verwenden, erhalten Sie die Isolation des gVisor-Kernels und behalten gleichzeitig die Standardfunktionen vonDeploymentbei.
Speichern Sie Folgendes als deployment.yaml:
cat <<EOF > ~/gke-ai-agent-lab/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: code-agent
labels:
app: code-agent
spec:
replicas: 1
selector:
matchLabels:
app: code-agent
template:
metadata:
labels:
app: code-agent
spec:
serviceAccount: adk-agent-sa
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: code-agent
image: us-central1-docker.pkg.dev/YOUR_PROJECT_ID/agent-repo/code-agent:v1
imagePullPolicy: Always
env:
- name: OPENAI_API_KEY
value: "no-key-required"
- name: OPENAI_API_BASE
value: "http://YOUR_GATEWAY_IP/v1"
- name: VERTEXAI_PROJECT
value: "YOUR_PROJECT_ID"
- name: VERTEXAI_LOCATION
value: "YOUR_REGION"
- name: OTEL_SERVICE_NAME
value: "code-agent"
- name: GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY
value: "true"
- name: OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT
value: "true"
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: code-agent-service
spec:
selector:
app: code-agent
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: agent-sandbox
name: sandbox-creator-role
rules:
- apiGroups: [""]
resources: ["services", "pods", "pods/portforward"]
verbs: ["get", "list", "watch", "create"]
- apiGroups: ["extensions.agents.x-k8s.io"]
resources: ["sandboxclaims"]
verbs: ["create", "get", "list", "watch", "delete"]
- apiGroups: ["agents.x-k8s.io"]
resources: ["sandboxes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: adk-agent-binding
namespace: agent-sandbox
subjects:
- kind: ServiceAccount
name: adk-agent-sa
namespace: default
roleRef:
kind: Role
name: sandbox-creator-role
apiGroup: rbac.authorization.k8s.io
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: adk-agent-sa
EOF
IAM-Berechtigungen für Observability gewähren
Damit der Agent Telemetriedaten (Logs und Traces) an Google Cloud senden kann, müssen Sie dem Kubernetes-Dienstkonto adk-agent-sa mit Workload Identity die erforderlichen Berechtigungen erteilen.
Führen Sie die folgenden Befehle in Ihrer Cloud Shell aus:
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# Grant permission to write logs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/logging.logWriter \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to write traces
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/cloudtrace.agent \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to use Vertex AI
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/aiplatform.user \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
Führen Sie den folgenden Befehl aus, um YOUR_PROJECT_ID automatisch durch Ihre tatsächliche Projekt-ID zu ersetzen und die Konfiguration anzuwenden.
sed -i "s/YOUR_PROJECT_ID/$PROJECT_ID/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_GATEWAY_IP/$GATEWAY_IP/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_REGION/$ZONE/g" ~/gke-ai-agent-lab/deployment.yaml
kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml
8. Beobachten und validieren
Jetzt ist es an der Zeit, das vollständig integrierte System zu testen.
Code-Generierungs-Agent in der Benutzeroberfläche testen
So finden Sie die externe IP-Adresse der ADK-Web-UI:
kubectl get services code-agent-service
Die Ausgabe sollte in etwa so aussehen:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
code-agent-service LoadBalancer 34.118.230.182 34.31.250.60 80:32471/TCP 2m14s
- Öffnen Sie einen Browser und rufen Sie
http://[EXTERNAL-IP]auf. - Achten Sie in der ADK-Weboberfläche darauf, dass im Drop-down-Menü rechts oben „root_agent“ ausgewählt ist. Senden Sie dann den folgenden Prompt an den Agenten:
Write a python script that prints 'Hello from the isolated sandbox'.
Um zu sehen, wie der Agent das Inferenz-Backend und die Sandbox nutzt, rufen Sie die Dashboards in den Abschnitten Modellstatistiken über Cloud Observability ansehen und Agent-Beobachtbarkeit über die GKE-UI ansehen unten auf.
Agent-Beobachtbarkeit über die GKE-Benutzeroberfläche untersuchen
Nachdem Sie einige Prompts ausgeführt haben, sehen wir uns die Telemetriedaten an. So können Sie die Leistung von Inference Scheduler und vLLM besser nachvollziehen.
Auf die Agent-Dashboards zugreifen
- Rufen Sie die Seite Kubernetes Engine > Arbeitslasten auf.
- Klicken Sie auf die code-agent-Bereitstellung, um die Seite Bereitstellungsdetails zu öffnen.
- Klicken Sie auf den Tab Beobachtbarkeit.
- Im linken Navigationsbereich des Observability-Dashboards sehen Sie einen neuen Bereich Agent mit untergeordneten Tabs.
Was Sie entdecken können
Auf den folgenden Untertabs können Sie das Verhalten Ihrer Agent-Anwendung ansehen:
- Übersicht:Hier finden Sie Kurzübersichten für Sitzungen, durchschnittliche Anzahl von Zügen und Aufrufe.
- Modelle:Hier sehen Sie die Anzahl der Modellaufrufe, Fehlerraten und Latenzzeiten, kategorisiert nach den Modellen, die von Ihrem KI-Agenten verwendet wurden.
- Tools:Hier können Sie Toolaufrufe und die Ausführungsdauer im Blick behalten, um zu sehen, wie effektiv Ihr Agent sein Sandbox-Ausführungstool nutzt.
- Nutzung:Hier können Sie die Tokennutzung und die Standardzuweisung von Containerressourcen (CPU und Arbeitsspeicher) nachverfolgen.
- Agent-Traces:Auf diesem Tab sehen Sie eine Liste der Ausführungssitzungen oder Roh-Trace-Spans. Wenn Sie auf eine Zeile klicken, wird ein Flyout mit Details zum ausgewählten Trace geöffnet.
Durch die Kombination von Messwerten auf Modellebene aus vLLM mit Telemetriedaten auf Anwendungsebene aus dem ADK erhalten Sie jetzt eine vollständige Observability für Ihren generativen KI-Agenten in GKE.
vLLM-Modellstatistiken über Cloud Observability ansehen
Nachdem Sie einige Prompts ausgeführt haben, sehen wir uns die Telemetriedaten an. So können Sie die Leistung von Inference Scheduler und vLLM besser nachvollziehen.
Auf Dashboards zugreifen
- Öffnen Sie die Google Cloud Console:
- Rufen Sie Monitoring > Dashboards auf.
- Suchen Sie nach dem Dashboard vLLM Prometheus Overview und wählen Sie es aus.
Interessante Messwerte
Achten Sie beim Aufrufen des Dashboards auf die folgenden wichtigen Messwerte, um die Auswirkungen von GKE Inference Gateway und Prefix-Caching zu sehen:
- KV-Cache-Auslastung (
vllm:gpu_cache_usage):- Bedeutung:Hier sehen Sie, wie viel GPU-Arbeitsspeicher zum Zwischenspeichern von Kontext verwendet wird. Wenn dieser Wert hoch ist, behält das System Kontext bei, um zukünftige Anfragen zu beschleunigen. Wenn Sie denselben Prompt mehrmals ausführen, sollte die Auslastung steigen und sich dann stabilisieren.
- Laufende Anfragen im Vergleich zu Anfragen im Wartestatus (
vllm:num_requests_runningim Vergleich zuvllm:num_requests_waiting):- Warum ist das wichtig? Dieser Wert gibt die Belastung an. Wenn viele Anfragen warten, sind Ihre Knoten überlastet.
- Token-Durchsatz (
vllm:request_prompt_tokens_totundvllm:request_generation_tokens_tot):- Relevanz:Sie können das Volumen der vom Cluster verarbeiteten Eingabe- und Ausgabetokens nachvollziehen.
- Time To First Token (TTFT):
- Warum ist das wichtig? Dies ist der wichtigste Messwert für interaktive Agents. Wenn Sie das GKE Inference Gateway mit Prefix-Cache Aware Routing verwenden, werden Anfragen mit gemeinsamen Kontexten (z. B. Systemprompts oder großen Kontextfenstern) an dasselbe Replikat weitergeleitet. So wird die TTFT minimiert, da vorhandene Cache-Treffer wiederverwendet werden.
Mögliche Tests
Sehen Sie sich die folgenden Szenarien an, um zu sehen, wie sich die Messwerte in Echtzeit ändern, und um die richtige Planung zu bestätigen.
Test 1: „Geschwindigkeit der Wiederholung“ (Prefix Cache Hit)
- Senden Sie einen komplexen Prompt an den Agenten, z.B. „Schreibe ein Python-Script, um eine 100 MB große CSV-Datei zu parsen und Statistiken zu berechnen.“.
- Sobald das Modell geantwortet hat, senden Sie sofort denselben Prompt noch einmal.
- Beobachten Sie die Cache-Trefferquote für Präfixe und die Zeit bis zum ersten Token (Time To First Token, TTFT).
- Das sollten Sie sehen:Die Trefferrate des Präfix-Cache sollte auf 100% steigen und die TTFT sollte drastisch sinken.
- Bedeutung:Das GKE Inference Gateway hat den freigegebenen Kontext erkannt und an dasselbe Replikat weitergeleitet, das seinen ausgewerteten Kontextcache wiederverwendet hat.
Test 2: Fallback auf die Cloud (Modellzuverlässigkeit)
- Um einen Fehler Ihres lokalen Qwen-Modells zu simulieren, können Sie entweder den Inferenzdienst beenden oder einfach eine gefälschte
OPENAI_API_BASEin der Bereitstellung angeben. - Aktualisieren Sie die
OPENAI_API_BASEin Ihrerdeployment.yamlauf eine nicht vorhandene IP-Adresse oder einen nicht vorhandenen Port und übernehmen Sie die Änderungen:sed -i "s|value: \"http://$GATEWAY_IP/v1\"|value: \"http://10.0.0.1:8080/v1\"|g" ~/gke-ai-agent-lab/deployment.yaml kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml - Warten Sie, bis der Pod neu gestartet wurde, und senden Sie dann einen Prompt an den Kundenservicemitarbeiter in der Benutzeroberfläche.
- Was Sie sehen sollten:Der Agent antwortet weiterhin erfolgreich.
- Bedeutung:Aufgrund der
fallbacks-Konfiguration hat das ADK den Fehler des lokalen Qwen-Endpunkts erkannt und die Anfrage nahtlos an Gemini 2.5 Flash in Vertex AI weitergeleitet. Da diese Fallback-Aufrufe an Vertex AI Ihr lokales vLLM Inference Gateway umgehen, werden sie nicht im Dashboard Agent Observability > Models angezeigt, in dem nur der Traffic über vLLM erfasst wird.
Die Leistungsfähigkeit der dynamischen Ressourcenzuweisung
Während vLLM und Inference Gateway die Weiterleitung und Verarbeitung von Anfragen optimieren, hat Dynamic Resource Allocation (DRA) es erst möglich gemacht, die genau richtige Hardware an Ihre Arbeitslast anzuhängen.
Mit DRA können Sie Hardware in Ihrem Cluster detaillierter verwalten, da Sie flexible Hardwareressourcen mit ResourceClaimTemplate und DeviceClasses definieren können.
Warum DRA ein Gamechanger für KI-Arbeitslasten ist:
- Feingranulare Hardwareanforderungen: Mit DRA sorgen Sie nicht nur dafür, dass Arbeitslasten auf Maschinen mit dem richtigen Beschleuniger geplant werden, sondern können auch einen Anspruch auf diese Ressourcen erheben, damit sie ausschließlich von der Arbeitslast verwendet werden, die mit dem ResourceClaim verknüpft ist.
- Entkoppelter Lebenszyklus: Geräteansprüche werden unabhängig von Pod-Lebenszyklen verwaltet. Wenn ein Pod abstürzt, kann der GPU-Anspruch bestehen bleiben, sodass das übergeordnete Deployment oder ein anderes Arbeitslastobjekt neu gestartet werden kann, ohne dass darauf gewartet werden muss, dass die GPU freigegeben und neu angefordert wird.
- Standardisierung für mehrere Anbieter: DRA bietet eine einheitliche Kubernetes API für NVIDIA-GPUs und Google-TPUs. Sie verwenden genau dasselbe Schema, unabhängig davon, ob Sie die Bereitstellung für das eine oder das andere vornehmen. Dadurch sind die YAML-Manifeste Ihrer Arbeitslasten sehr portabel.
In diesem Codelab haben Sie gesehen, wie das funktioniert, als Sie Ihre Helm-Werte so konfiguriert haben, dass sie nahtlos an gpu-claim-template gebunden werden, ohne dass ausstehende Geräte-Plug-in-Konfigurationen Ihre Rollouts blockieren.
Rolle von llm-d
Während vLLM neuronale Gewichte auswertet und das GKE-Gateway Anfragen weiterleitet, fungiert llm-d als Konfigurationsschicht und als „Klebstoff“, der alles zusammenhält.
Ohne llm-d müssten Sie Kubernetes-Rohmanifeste schreiben, um Ihre vLLM-Bereitstellung, Ihre Dienstports, die Einbindung von Volumes und Ihre DRA-Ressourcenansprüche von Grund auf neu zu deklarieren.
Warum llm-d in Ihrer Bereitstellung verwenden?
- Einheitliche Konfiguration (einzeilige Überschreibungen):
llm-dHelm-Diagramme bündeln komplexe Kubernetes-Ressourcen auf niedriger Ebene in übersichtlichen Schaltern auf hoher Ebene (z. B. durch Festlegen vonaccelerator.dra: true). - Vorab geprüfte „Well-Lit-Paths“: Das Repository
llm-denthält Konfigurationen, die bereits von Experten getestet und mit Benchmarks versehen wurden. Wenn Siellm-d-modelservicebereitstellen, erhalten Sie optimierte Standardeinstellungen für die GPU-Arbeitsspeichernutzung, empfohlene Prüfungs-Timings (Aktivität/Bereitschaft) und korrekte Einstellungen für das Erfassen von Messwerten. - Nahtloses Observability-Mapping:
llm-dsorgt dafür, dass Standard-Containerports und Scrape-Pfade (/metrics) sofort richtig verfügbar gemacht werden. So lässt sich Ihre Bereitstellung ganz einfach in Google Cloud Monitoring einbinden, ohne dass manuelles Debugging erforderlich ist.
Kurz gesagt: llm-d bietet die wiederverwendbaren Architektur-Blueprints, sodass Entwickler nicht jedes Mal das Rad neu erfinden müssen, wenn sie einen Inferenz-Stack in GKE bereitstellen.
Im Detail: Das GKE Inference Gateway
Standard-Load-Balancer für Layer 7 funktionieren, indem sie sich HTTP-Header wie Pfade (/v1/completions) oder Cookies ansehen. Das GKE Inference Gateway geht viel weiter und wurde speziell für generativen KI-Traffic entwickelt.
So werden Leistung und Effizienz gesteigert:
- Inhaltsbasiertes Routing (Prompt-Hashing): Das GKE Inference Gateway fängt den JSON-Anfragetext ab. Es wird ein Hash des Prompts berechnet und nachverfolgt, welche Backend-Replica diese Tokens bereits im GPU-Arbeitsspeicher (KV-Cache) enthält.
- Maximizing Cache Hits (Maximierung von Cache-Treffern): Bei Ihren Tests wurde eine wiederholte Aufforderung vom Gateway an genau dasselbe Replikat gesendet. Die Auswertung eines Prompts erfordert viel Rechenleistung. Durch die Wiederverwendung des Cache wird das erneute Lesen des Prompts vermieden, wodurch Sie Geld und GPU-Zeit sparen.
- Verkürzung der Zeit bis zum ersten Token (Time-to-First-Token, TTFT): TTFT ist die entscheidende Usability-Messgröße für benutzerorientierte Kundenservicemitarbeiter. Durch den Zugriff auf den Cache kann das Modell Token in Millisekunden statt in Sekunden generieren.
- Intelligente Lastverteilung: Wenn der VRAM eines Replikats vollständig mit Cache-Treffern belegt ist, kann das Gateway einen neuen Prompt dynamisch an ein anderes Replikat weiterleiten, das noch Kapazität hat. So wird die Effizienz mit der Verfügbarkeit in Einklang gebracht.
So wird das Risiko durch die Agent Sandbox reduziert
In diesem Lab haben wir gezeigt, wie Agent Sandbox Ihre Infrastruktur vor den Risiken schützt, die mit KI-Agenten verbunden sind. Dazu werden zwei Isolationsebenen verwendet:
- Ausführungstool isolieren: Der KI-Agent führt den generierten Code in einer temporären Sandbox aus. So wird sichergestellt, dass nicht vertrauenswürdiger Code, der vom LLM generiert wird, in einer sicheren, isolierten Umgebung ausgeführt wird und der Agent und der Cluster geschützt sind.
- Schneller Start: Mit einem WarmPool werden neue Sandboxes in weniger als einer Sekunde gestartet und sind bereit für die Ausführung von Code.
- Isolierung des Agents selbst: Wir haben die Agent-Anwendung selbst auch auf einem gVisor-fähigen Knoten (über
runtimeClassName: gvisor) ausgeführt, um eine umfassende Abwehr gegen Schwachstellen in der Lieferkette in den Abhängigkeiten des Agents zu bieten.
Das sind die Gründe, warum dadurch eine so sichere Grenze entsteht:
- Abfangen von Systemaufrufen: gVisor fängt Systemaufrufe ab, bevor sie den Host-Linux-Kernel erreichen. Dadurch werden Exploits blockiert, die versuchen, aus dem Container auszubrechen, um auf den Hostknoten zuzugreifen.
- Eingeschränkte laterale Bewegung: In Kombination mit Netzwerkrichtlinien kann eine Umgebung, selbst wenn sie kompromittiert wird, Ihre internen Metadatenserver nicht scannen oder auf andere sensible Dienste in Ihrem Cluster umstellen.
Vollständige Agents in Sandboxes ausführen
In diesem Lab haben wir Sandboxes als Tools für eine persistente Agent-Anwendung verwendet. Für maximale Sicherheit – insbesondere bei der Verarbeitung sensibler Daten oder der Bereitstellung für mehrere nicht vertrauenswürdige Nutzer – können Sie die gesamte Agent-Anwendung in einer dedizierten Sandbox für jede Sitzung oder jeden Nutzer ausführen. So wird eine vollständige Isolation des Speichers, des Status und der Ausführungsumgebung des Agenten erreicht. Diese wird unmittelbar nach Abschluss der Sitzung zerstört.
9. Bereinigen
Mit den folgenden Schritten vermeiden Sie, dass Ihrem Google Cloud-Konto die in diesem Codelab verwendeten Ressourcen in Rechnung gestellt werden.
Einzelne Ressourcen löschen
- Löschen Sie den GKE-Cluster:
gcloud container clusters delete $CLUSTER_NAME --zone $ZONE --quiet
- Löschen Sie das Artifact Registry-Repository:
gcloud artifacts repositories delete agent-repo --location=us-central1 --quiet
- Löschen Sie das VPC-Netzwerk:
gcloud compute networks delete ai-agent-network --quiet
Projekt löschen
Wenn Sie das Projekt nicht mehr benötigen, können Sie es löschen, nachdem Sie die Ressourcen entfernt haben:
gcloud projects delete $PROJECT_ID
10. Zusammenfassung
Glückwunsch! Sie haben einen sicheren, leistungsstarken Code-Generierungs-Agent in GKE erstellt und bereitgestellt.
Das haben Sie gelernt
- Konfiguration und Verwendung von Dynamic Resource Allocation (DRA) in GKE zur Verwaltung von GPU-Ressourcen.
- GKE Inference Gateway verwenden, um die Leistung der LLM-Bereitstellung durch Routing mit Prefix-Cache zu optimieren.
- Agent Sandbox (gVisor) verwenden, um nicht vertrauenswürdigen Code sicher in GKE auszuführen.
- Google Cloud Managed Service for Prometheus verwenden, um die Leistung von vLLM zu überwachen.
- Agent Observability mit ADK und GKE Managed OpenTelemetry konfigurieren und ansehen
Nächste Schritte und Referenzen
- Agent Sandbox: Informationen zu Agent Sandbox in GKE und GKE Sandbox-Pods.
- llm-d: Lesen Sie den llm-d-Leitfaden und sehen Sie sich das llm-d-GitHub-Repository an.
- Dynamische Ressourcenzuweisung: Weitere Informationen zur dynamischen Ressourcenzuweisung in GKE
- GKE Inference Gateway: Konzepte für das Inference Gateway
- Weitere Codelabs: Weitere Tutorials finden Sie unter Google Cloud Codelabs.