
1. Introducción
Descripción general
En este lab, aprenderás a compilar e implementar un agente de generación de código seguro en Google Kubernetes Engine (GKE). Los agentes de generación de código deben ejecutar código que podría no ser de confianza, lo que requiere un entorno de zona de pruebas seguro. También aprenderás a configurar el agente con una estrategia de modelo híbrido, lo que le permitirá recurrir a un modelo abierto alojado por el usuario en GKE para el servicio administrado de Gemini de Vertex AI y, así, aumentar la confiabilidad. Además, aprenderás a optimizar la entrega de inferencias con GKE Inference Gateway y la asignación dinámica de recursos (DRA). Por último, aprenderás a aprovechar Google Cloud Observability para supervisar tu pila de inferencia con Managed Prometheus.
Arquitectura
Esta es la arquitectura del sistema que compilarás:
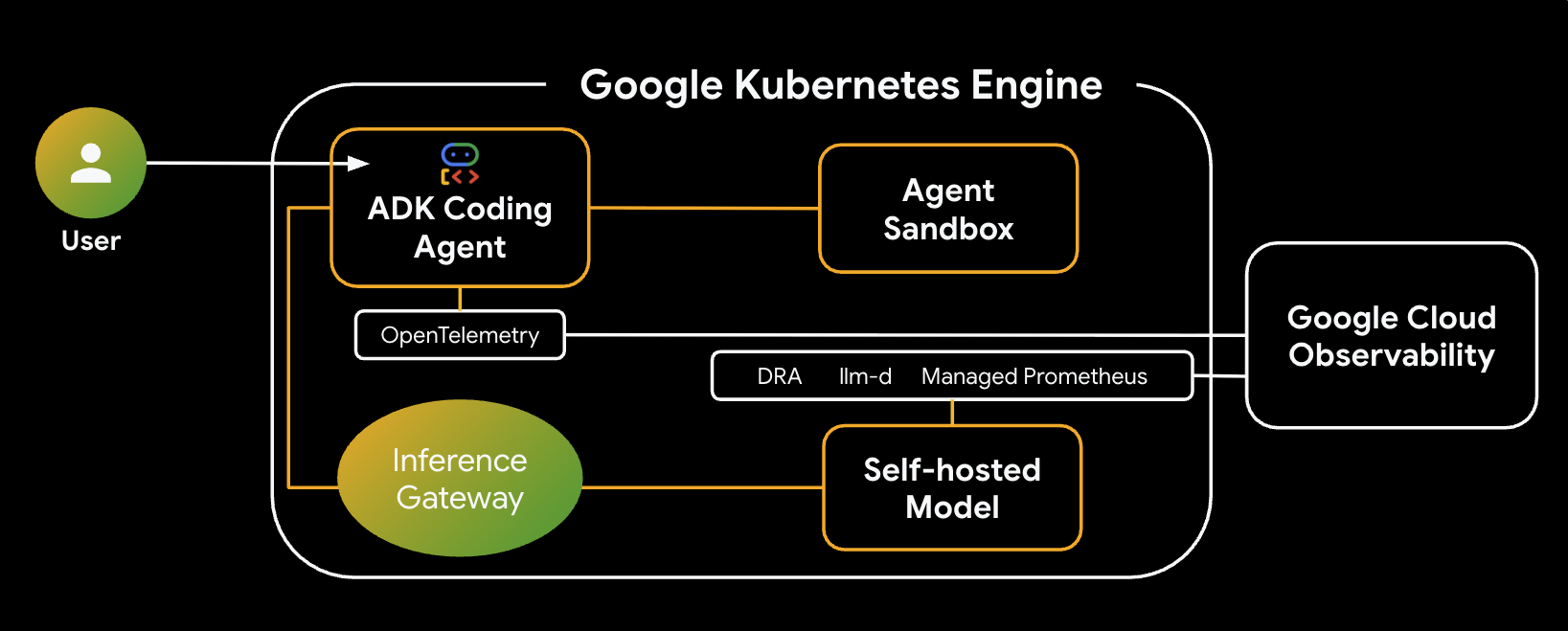
Componentes y beneficios clave
- Asignación dinámica de recursos (DRA): Se usa en este lab para reclamar y asignar de forma dinámica recursos específicos de GPU (NVIDIA L4) para los Pods del servidor de modelos, lo que garantiza una orientación de hardware precisa para nuestra carga de trabajo de inferencia. Obtén más información sobre la DRA en GKE.
- llm-d y vLLM: Proporciona el framework de entrega de modelos y los gráficos de Helm para implementar el modelo de Qwen. En este lab, se controlan las solicitudes de inferencia y se integra con DRA para la administración de recursos (la publicación desagregada no está habilitada en este lab). Lee la Guía de llm-d y consulta el repositorio de GitHub de llm-d.
- Puerta de enlace de inferencia de GKE: Traslada la lógica de enrutamiento con reconocimiento de IA directamente al balanceador de cargas. En este lab, se enrutan las solicitudes para maximizar los aciertos de la caché de prefijos, lo que reduce la latencia del tiempo hasta el primer token (TTFT). Explora los conceptos de Inference Gateway.
- Zona de pruebas del agente (gVisor): Proporciona aislamiento seguro para ejecutar el código generado por el agente de IA. Utiliza gVisor para proporcionar un aislamiento profundo del kernel, lo que protege el nodo host de cargas de trabajo no confiables. Obtén información sobre Agent Sandbox en GKE y los Pod de GKE Sandbox.
Actividades
- Aprovisiona la infraestructura: Configura un clúster de GKE con la asignación dinámica de recursos (DRA) para la administración de la GPU.
- Deploy Inference Stack: Implementa
llm-dy vLLM con una programación de inferencia inteligente. - Configura el enrutamiento inteligente: Usa GKE Inference Gateway para el enrutamiento basado en la caché de prefijos.
- Ejecución de código segura: Implementa Agent Sandbox (gVisor) para ejecutar de forma segura el código generado por IA.
- Observar y validar: Usa Google Cloud Monitoring y Managed Prometheus para ver las métricas de la entrega de modelos.
Qué aprenderás
- Cómo configurar y usar la asignación dinámica de recursos (DRA) en GKE
- Cómo usar GKE Inference Gateway para optimizar el rendimiento de la entrega de LLM
- Cómo usar Agent Sandbox para ejecutar código no confiable de forma segura en GKE
- Cómo usar Google Cloud Managed Service para Prometheus para supervisar el rendimiento de vLLM
2. Configuración y requisitos
Configuración del proyecto
Crea un proyecto de Google Cloud
- En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto.
Inicie Cloud Shell
Cloud Shell es un entorno de línea de comandos que se ejecuta en Google Cloud y que viene precargado con las herramientas necesarias.
- Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.
- Una vez que te conectes a Cloud Shell, verifica tu autenticación:
gcloud auth list - Confirma que tu proyecto esté configurado:
gcloud config get project - Si tu proyecto no está configurado como se esperaba, configúralo:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
3. Aprovisionamiento de infraestructura y asignación dinámica de recursos (DRA)
En este primer paso, configurarás tu clúster de GKE para que use la asignación de aceleradores moderna (DRA) en lugar de los complementos de dispositivos heredados. Esto te permite compartir y asignar de forma flexible GPU o TPU para tus cargas de trabajo de generación de código.
Requisitos previos: Tu clúster de GKE Standard debe ejecutar la versión 1.34 o una posterior para admitir la DRA.
Habilita las APIs de Google Cloud
Habilita las APIs de Google Cloud necesarias para este codelab, específicamente las APIs de Compute Engine y Kubernetes Engine.
gcloud services enable compute.googleapis.com container.googleapis.com networkservices.googleapis.com cloudbuild.googleapis.com artifactregistry.googleapis.com telemetry.googleapis.com cloudtrace.googleapis.com aiplatform.googleapis.com
Configura variables de entorno
Para facilitar la configuración, define tus variables de entorno. Puedes ajustar la región o las convenciones de nomenclatura según sea necesario.
export PROJECT_ID=$(gcloud config get-value project)
export ZONE=us-central1-a
export CLUSTER_NAME=ai-agent-cluster
export NODEPOOL_NAME=dra-accelerator-pool
gcloud config set project $PROJECT_ID
gcloud config set compute/region $ZONE
Crea un directorio de trabajo
Crea un directorio de trabajo exclusivo para este lab y navega a él para que tus archivos se mantengan organizados:
mkdir -p ~/gke-ai-agent-lab
cd ~/gke-ai-agent-lab
Configura permisos (opcional)
Si ejecutas el proceso en un proyecto restringido o en un entorno compartido, asegúrate de que tu cuenta tenga los permisos necesarios para crear clústeres y ejecutar compilaciones:
export MY_ACCOUNT=$(gcloud config get-value account)
# Grant Container Admin to create clusters and manage nodes if needed
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/container.admin"
# Grant Cloud Build Builder to run builds
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/cloudbuild.builds.builder"
Crea el clúster de GKE
Tu clúster de GKE Standard debe ejecutar la versión 1.34 o una posterior para admitir la DRA. También debes habilitar los controladores de la API de Gateway para admitir la programación de inferencias inteligentes.
En este lab, crearás una nueva red de VPC y subredes.
Primero, crea la red de VPC:
gcloud compute networks create ai-agent-network --subnet-mode=custom
A continuación, crea una subred para tus nodos de GKE:
gcloud compute networks subnets create ai-agent-subnet \
--network=ai-agent-network \
--range=10.0.0.0/20 \
--region=us-central1
La API de Gateway (gke-l7-regional-internal-managed) también requiere una subred dedicada para alojar los proxies de Envoy. Crea esta subred de solo proxy en tu red nueva:
gcloud compute networks subnets create proxy-only-subnet \
--purpose=REGIONAL_MANAGED_PROXY \
--role=ACTIVE \
--region=us-central1 \
--network=ai-agent-network \
--range=192.168.10.0/24
Ahora, crea el clúster con la nueva red y subred:
gcloud beta container clusters create $CLUSTER_NAME \
--zone $ZONE \
--num-nodes 1 \
--machine-type n2-standard-4 \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--gateway-api=standard \
--managed-otel-scope=COLLECTION_AND_INSTRUMENTATION_COMPONENTS \
--network=ai-agent-network \
--subnetwork=ai-agent-subnet
Crea un grupo de nodos con los complementos predeterminados inhabilitados
Para transferir la administración de dispositivos a la DRA, debes crear un grupo de nodos que inhabilite de forma explícita la instalación predeterminada del controlador de GPU y el complemento de dispositivo estándar.
Ejecuta el siguiente comando gcloud para aprovisionar un grupo de nodos de GPU (p.ej., con NVIDIA L4) con las etiquetas de DRA necesarias:
gcloud container node-pools create $NODEPOOL_NAME \
--cluster=$CLUSTER_NAME \
--location=$ZONE \
--machine-type=g2-standard-24 \
--accelerator=type=nvidia-l4,count=2,gpu-driver-version=disabled \
--node-labels=gke-no-default-nvidia-gpu-device-plugin=true,nvidia.com/gpu.present=true \
--num-nodes 3
Instala controladores de NVIDIA a través de DaemonSet
Instala de forma manual los controladores de dispositivos NVIDIA base necesarios en tus nodos con un DaemonSet de Google Cloud preconfigurado:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
Instala el controlador de DRA
A continuación, instala el controlador de DRA específico en tu clúster. En el caso de las GPU de NVIDIA, puedes implementar esto a través de Helm:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
helm install nvidia-dra-driver-gpu nvidia/nvidia-dra-driver-gpu \
--version="25.3.2" --create-namespace --namespace=nvidia-dra-driver-gpu \
--set nvidiaDriverRoot="/home/kubernetes/bin/nvidia/" \
--set gpuResourcesEnabledOverride=true \
--set resources.computeDomains.enabled=false \
--set kubeletPlugin.priorityClassName="" \
--set 'kubeletPlugin.tolerations[0].key=nvidia.com/gpu' \
--set 'kubeletPlugin.tolerations[0].operator=Exists' \
--set 'kubeletPlugin.tolerations[0].effect=NoSchedule'
Información sobre DeviceClasses
No es necesario que escribas o apliques manualmente un archivo YAML de DeviceClass. Cuando configuras tu infraestructura de GKE para DRA y, luego, instalas el controlador, los controladores de DRA que se ejecutan en tus nodos crean automáticamente los objetos DeviceClass en el clúster por ti.
Configura el ResourceClaimTemplate
Para permitir que tus Pods de llm-d soliciten dinámicamente estos aceleradores, crearás un ResourceClaimTemplate. Esta plantilla define la configuración del dispositivo solicitada y le indica a Kubernetes que cree automáticamente un ResourceClaim único por Pod para tus cargas de trabajo.
Ejecuta el siguiente comando para crear claim-template.yaml:
cat > claim-template.yaml <<EOF
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: gpu-claim-template
spec:
spec:
devices:
requests:
- name: single-gpu
exactly:
deviceClassName: gpu.nvidia.com
allocationMode: ExactCount
count: 1
EOF
Aplica la plantilla a tu clúster:
kubectl apply -f claim-template.yaml
4. Implementa la programación de inferencias inteligente con llm-d y DRA
En este paso, implementarás tu modelo de lenguaje grande detrás de un balanceador de cargas inteligente de Envoy mejorado con un programador de inferencias. Esta configuración optimiza la entrega de modelos aplicando el enrutamiento con reconocimiento de caché de prefijos. GKE Inference Gateway reconoce el contexto compartido en los microservicios y enruta de forma inteligente las solicitudes a la misma réplica del modelo, lo que maximiza los aciertos de caché, reduce el tiempo hasta el primer token y genera un rendimiento superior por dólar.
Prepare el entorno
Configura tu espacio de nombres objetivo.
export NAMESPACE=ai-agents
kubectl create namespace $NAMESPACE
Almacena de forma segura tu token de Hugging Face, que se requiere para extraer los pesos del modelo.
# Replace with your actual Hugging Face token
kubectl create secret generic llm-d-hf-token \
--from-literal=HF_TOKEN="your_hugging_face_token" \
-n $NAMESPACE
Crea los archivos de configuración de Helm
Los parámetros de configuración del servicio de modelos y la extensión de la puerta de enlace de inferencia se basan en las guías oficiales de llm-d.
Primero, crea el archivo ms-values.yaml para el servicio del modelo:
cat <<EOF > ms-values.yaml
multinode: false
modelArtifacts:
uri: "hf://Qwen/Qwen2.5-Coder-14B-Instruct"
name: "Qwen/Qwen2.5-Coder-14B-Instruct"
size: 50Gi # Slightly larger than the default to accommodate weights
authSecretName: "llm-d-hf-token"
labels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
llm-d.ai/accelerator-variant: "gpu"
llm-d.ai/accelerator-vendor: "nvidia"
llm-d.ai/model: "qwen-2-5-coder-14b"
routing:
proxy:
enabled: false # removes sidecar from deployment - no PD in inference scheduling
targetPort: 8000 # controls vLLM port to matchup with sidecar if deployed
accelerator:
dra: true
type: "nvidia"
resourceClaimTemplates:
nvidia:
class: "gpu.nvidia.com"
match: "exactly"
name: "gpu-claim-template"
decode:
create: true
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
parallelism:
tensor: 2
data: 1
replicas: 3
monitoring:
podmonitor:
enabled: true
portName: "vllm"
path: "/metrics"
interval: "30s"
containers:
- name: "vllm"
image: ghcr.io/llm-d/llm-d-cuda:v0.5.1
modelCommand: vllmServe
args:
- "--disable-uvicorn-access-log"
- "--gpu-memory-utilization=0.85"
- "--enable-auto-tool-choice"
- "--tool-call-parser"
- "hermes"
ports:
- containerPort: 8000
name: vllm
protocol: TCP
resources:
limits:
cpu: '16'
memory: 64Gi
requests:
cpu: '16'
memory: 64Gi
mountModelVolume: true
volumeMounts:
- name: metrics-volume
mountPath: /.config
- name: shm
mountPath: /dev/shm
- name: torch-compile-cache
mountPath: /.cache
startupProbe:
httpGet:
path: /v1/models
port: vllm
initialDelaySeconds: 15
periodSeconds: 30
timeoutSeconds: 5
failureThreshold: 120
livenessProbe:
httpGet:
path: /health
port: vllm
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /v1/models
port: vllm
periodSeconds: 5
timeoutSeconds: 2
failureThreshold: 3
volumes:
- name: metrics-volume
emptyDir: {}
- name: torch-compile-cache
emptyDir: {}
- name: shm
emptyDir:
medium: Memory
sizeLimit: 20Gi
prefill:
create: false
EOF
A continuación, crea el archivo gaie-values.yaml para la extensión de GKE Inference Gateway:
cat <<EOF > gaie-values.yaml
inferenceExtension:
replicas: 1
image:
name: llm-d-inference-scheduler
hub: ghcr.io/llm-d
tag: v0.6.0
pullPolicy: Always
extProcPort: 9002
pluginsConfigFile: "default-plugins.yaml"
tracing:
enabled: false
monitoring:
interval: "10s"
prometheus:
enabled: true
auth:
secretName: inference-scheduling-gateway-sa-metrics-reader-secret
inferencePool:
targetPorts:
- number: 8000
modelServerType: vllm
modelServers:
matchLabels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
EOF
Comprende la configuración
Esta configuración establece una pila de inferencia de alto rendimiento con las siguientes funciones clave:
- Selección de modelos: Usa el modelo Qwen 2.5 Coder 14B (
modelArtifacts), que está optimizado para la generación de código y el uso de herramientas. - Integración de DRA: La sección
acceleratorhabilita la asignación dinámica de recursos (dra: true), segmentando para la clase de dispositivogpu.nvidia.comy nuestrogpu-claim-templatecreado anteriormente. - Optimización del rendimiento:
parallelism.tensor: 2configura el paralelismo de tensor en las GPUs.argspara vLLM incluye--enable-auto-tool-choicepara garantizar que nuestro agente de codificación pueda usar herramientas de manera eficaz.- Las solicitudes
cpuymemoryreducidas se ajustan al tipo de máquinag2-standard-24.
- Enrutamiento inteligente: La extensión de Inference Gateway (
gaie-values.yaml) está configurada para supervisar los servidores de modelosvllmy enrutar las solicitudes para maximizar los aciertos de la caché de KV.
Implementa la pila de Inference Scheduling a través de Helm
Ahora, agrega los repositorios de Helm de llm-d y, luego, implementa la infraestructura, la extensión de puerta de enlace y el servicio de modelos de forma individual.
Primero, agrega los repositorios necesarios:
helm repo add llm-d-infra https://llm-d-incubation.github.io/llm-d-infra/
helm repo add llm-d-modelservice https://llm-d-incubation.github.io/llm-d-modelservice/
helm repo update
Implementa los requisitos previos de infraestructura
En este gráfico, se instalan los parámetros de configuración de puerta de enlace de referencia necesarios para la pila.
helm install infra-is llm-d-infra/llm-d-infra \
--namespace $NAMESPACE \
--set gateway.gatewayClassName=gke-l7-rilb \
--set gateway.gatewayParameters.enabled=false \
--set gateway.gatewayParameters.istio.accessLogging=false
Implementa la extensión de GKE Inference Gateway
En este paso, se implementan InferencePool y Endpoint Picker, que supervisan la caché de KV de tus modelos para tomar decisiones de enrutamiento inteligentes.
helm install gaie-is oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool \
--version v1.3.1 \
--namespace $NAMESPACE \
-f gaie-values.yaml \
--set provider.name=gke \
--set inferenceExtension.monitoring.prometheus.enabled=true
Implementa el servicio de modelos
Por último, implementa tu servicio de LLM, que ahora usará DRA para reclamar de forma segura tus GPUs L4.
helm install ms-is llm-d-modelservice/llm-d-modelservice \
--version v0.4.7 \
--namespace $NAMESPACE \
-f ms-values.yaml \
--set decode.monitoring.podmonitor.enabled=false
Habilita Google Cloud Observability para vLLM
Los gráficos de Helm genéricos suelen intentar implementar recursos PodMonitor estándar de Prometheus Operator (monitoring.coreos.com/v1), lo que puede causar errores si no tienes instaladas esas CRD.
En lugar de activar o desactivar el botón de activación de supervisión integrado de Helm, mantenlo false y aplica manualmente un recurso PodMonitoring de Google Cloud Managed Prometheus (GMP) con el grupo de la API monitoring.googleapis.com/v1 compatible.
Ejecuta el siguiente comando para crear podmonitoring.yaml:
cat > podmonitoring.yaml <<EOF
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: ms-vllm-metrics
spec:
selector:
matchLabels:
llm-d.ai/model: "qwen-2-5-coder-14b" # Matches the label in values.yaml
endpoints:
- port: 8000 # vllm port
interval: 30s
path: /metrics
EOF
Aplica el recurso PodMonitoring a tu clúster:
kubectl apply -f podmonitoring.yaml -n $NAMESPACE
Verifica la instalación
Verifica que los componentes se hayan instalado correctamente. Deberías ver las tres versiones de Helm activas en tu espacio de nombres y los Pods correspondientes inicializándose.
helm ls -n $NAMESPACE
kubectl get pods -n $NAMESPACE
Los pods de ms-is pueden tardar entre 5 y 10 minutos en iniciarse. Cuando lo hagan, el resultado debería ser similar al siguiente:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
gaie-is ai-agents 1 2026-03-28 16:51:41.055881618 +0000 UTC deployed inferencepool-v1.3.1 v1.3.1
infra-is ai-agents 1 2026-03-28 16:51:03.71042542 +0000 UTC deployed llm-d-infra-v1.4.0 v0.4.0
ms-is ai-agents 1 2026-03-28 17:30:00.341918958 +0000 UTC deployed llm-d-modelservice-v0.4.7 v0.4.0
NAME READY STATUS RESTARTS AGE
gaie-is-epp-848965cb4-78ktp 1/1 Running 0 10m
ms-is-llm-d-modelservice-decode-67548d5f8c-f25f4 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-rblvs 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-w6fcd 1/1 Running 0 6m2s
5. Configura el enrutamiento inteligente con GKE Inference Gateway
En el paso 4, la implementación de los gráficos de Helm de llm-d aprovisionó automáticamente tus objetos Gateway y InferencePool. El objeto InferencePool agrupa los Pods de entrega del modelo vllm que comparten el mismo modelo base y la misma configuración de procesamiento.
Ahora, debes configurar un InferenceObjective para establecer la prioridad de las solicitudes de tu agente de codificación y un HTTPRoute para indicarle a la puerta de enlace cómo enrutar el tráfico entrante, aprovechando el selector de extremos para maximizar los aciertos de la caché de KV.
Verifica los recursos generados automáticamente
Primero, verifica que los gráficos de Helm de llm-d hayan creado correctamente los recursos de la puerta de enlace y de InferencePool.
kubectl get gateway,inferencepool -n $NAMESPACE
Deberías ver una puerta de enlace llamada infra-is-inference-gateway y un InferencePool llamado gaie-is. Similar a lo siguiente:
NAME CLASS ADDRESS PROGRAMMED AGE
gateway.gateway.networking.k8s.io/infra-is-inference-gateway gke-l7-regional-internal-managed 10.128.0.5 True 13m
NAME AGE
inferencepool.inference.networking.k8s.io/gaie-is 12m
Crea la HTTPRoute
El recurso HTTPRoute asigna tu puerta de enlace al backend InferencePool. Esto le indica a GKE Inference Gateway que analice los cuerpos de las solicitudes entrantes y los enrute de forma dinámica para maximizar los aciertos de la caché de prefijos según el contexto compartido.
Ejecuta el siguiente comando para crear httproute.yaml:
cat > httproute.yaml <<EOF
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: agent-route
spec:
parentRefs:
- group: gateway.networking.k8s.io
kind: Gateway
name: infra-is-inference-gateway
rules:
- backendRefs:
- group: inference.networking.k8s.io
kind: InferencePool
name: gaie-is
weight: 1
matches:
- path:
type: PathPrefix
value: /
EOF
Aplica la ruta a tu clúster:
kubectl apply -f httproute.yaml -n $NAMESPACE
6. Ejecución de código segura con Agent Sandbox
Ahora que nuestro backend de inferencia de alto rendimiento está en funcionamiento, preparemos el entorno seguro en el que el código generado por IA se ejecutará de forma segura y aislado de nuestro clúster con un Agent Sandbox.
Implementa el controlador de la zona de pruebas del agente
Cuando un agente de IA genera y ejecuta código, básicamente ejecuta una carga de trabajo no confiable en tu infraestructura. Si el agente genera código malicioso, podría intentar analizar tu red interna o aprovechar el nodo host subyacente.
GKE Agent Sandbox utiliza gVisor, un entorno de ejecución de contenedores de código abierto que proporciona un kernel invitado especializado para cada contenedor. Esto evita que el código no confiable realice llamadas directas al sistema del nodo host.
Para implementar el controlador de Agent Sandbox y sus componentes requeridos, aplica los manifiestos de la versión oficial:
kubectl apply \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/manifest.yaml \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/extensions.yaml
Configura la plantilla de zona de pruebas y el grupo de instancias en espera
A continuación, establecemos un SandboxTemplate que actúa como un plano reutilizable para nuestros entornos de análisis de Python, y que se orienta de forma explícita a la clase de tiempo de ejecución gvisor. Para simplificar la implementación sin administrar grupos de nodos manuales en clústeres de Standard, podemos aprovechar cualquier autopilot estándar.
ComputeClass para aprovisionar de forma dinámica nodos de procesamiento administrados que admitan de forma nativa cargas de trabajo de gVisor a pedido
Como inicializar un kernel seguro puede agregar latencia, también implementamos un SandboxWarmPool. Esto garantiza que se mantenga lista una cantidad especificada de zonas de pruebas preinicializadas para que el agente de generación de código pueda reclamarlas y comenzar a ejecutar código en menos de un segundo.
Primero, crea un espacio de nombres nuevo para los tiempos de ejecución de la zona de pruebas del agente:
kubectl create namespace agent-sandbox
Guarda el siguiente código como sandbox-template-and-pool.yaml:
cat > sandbox-template-and-pool.yaml <<EOF
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxTemplate
metadata:
name: python-runtime-template
namespace: agent-sandbox
spec:
podTemplate:
metadata:
labels:
sandbox: python-sandbox-example
spec:
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: python-runtime
image: registry.k8s.io/agent-sandbox/python-runtime-sandbox:v0.1.0
ports:
- containerPort: 8888
readinessProbe:
httpGet:
path: "/"
port: 8888
initialDelaySeconds: 0
periodSeconds: 1
resources:
requests:
cpu: "250m"
memory: "512Mi"
ephemeral-storage: "512Mi"
restartPolicy: "OnFailure"
---
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxWarmPool
metadata:
name: python-sandbox-warmpool
namespace: agent-sandbox
spec:
replicas: 2
sandboxTemplateRef:
name: python-runtime-template
EOF
Aplica la configuración:
kubectl apply -f sandbox-template-and-pool.yaml
Espera de 2 a 3 minutos para que se inicialicen los pods de warmpool. Puedes verificar que la transición de Pending (mientras se amplía la capacidad de procesamiento subyacente) a Running se realice correctamente con el siguiente comando:
kubectl get pods -n agent-sandbox -w
Una vez que veas dos pods python-sandbox-warmpool-*** que aparecen como Running y 1/1 Ready, tus entornos de ejecución seguros estarán precalentados y listos para reclamarse.
Implementa el router de zona de pruebas
Nuestro agente de generación de código se basa en un enrutador de zona de pruebas para enviar de forma segura comandos de ejecución a los pods aislados.
Ejecuta el siguiente comando para crear sandbox-router.yaml:
cat > sandbox-router.yaml <<EOF
apiVersion: v1
kind: Service
metadata:
name: sandbox-router-svc
namespace: agent-sandbox
spec:
type: ClusterIP
selector:
app: sandbox-router
ports:
- name: http
protocol: TCP
port: 8080
targetPort: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sandbox-router-deployment
namespace: agent-sandbox
spec:
replicas: 2
selector:
matchLabels:
app: sandbox-router
template:
metadata:
labels:
app: sandbox-router
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: sandbox-router
containers:
- name: router
image: us-central1-docker.pkg.dev/k8s-staging-images/agent-sandbox/sandbox-router:v20260225-v0.1.1.post3-10-ga5bcb57
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 10
resources:
requests:
cpu: "250m"
memory: "512Mi"
limits:
cpu: "1000m"
memory: "1Gi"
securityContext:
runAsUser: 1000
runAsGroup: 1000
EOF
Aplica la configuración:
kubectl apply -f sandbox-router.yaml
Implementa el aislamiento de red
Para proteger aún más el entorno de ejecución y evitar cualquier movimiento lateral no autorizado, aplica una política de red. Esto "aísla" la zona de pruebas para que no pueda acceder al servidor de metadatos de Google Cloud ni a otras redes internas sensibles.
Guarda el siguiente código como sandbox-policy.yaml:
cat > sandbox-policy.yaml <<EOF
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: restrict-sandbox-egress
namespace: agent-sandbox
spec:
podSelector:
matchLabels:
sandbox: python-sandbox-example
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 0.0.0.0/0
except:
- 169.254.169.254/32 # Block metadata server
EOF
Aplica la política:
kubectl apply -f sandbox-policy.yaml
Verifica los componentes
Para asegurarte de que la capa del clúster de la zona de pruebas de código aislada esté completamente configurada, ejecuta los siguientes comandos de validación de estado:
Primero, verifica que los Pods y los routers de la zona de pruebas estén en ejecución y listos
kubectl get pods -n agent-sandbox
El resultado debería ser similar a lo siguiente:
NAME READY STATUS RESTARTS AGE
python-sandbox-warmpool-7zlkv 1/1 Running 0 3m25s
python-sandbox-warmpool-cxln2 1/1 Running 0 3m25s
sandbox-router-deployment-668dfbbbb6-g9mpd 1/1 Running 0 42s
sandbox-router-deployment-668dfbbbb6-ppllz 1/1 Running 0 42s
Verifica la exposición de la IP o el balanceador de cargas del enrutador de Sandbox
kubectl get service sandbox-router-svc -n agent-sandbox
El resultado debería verse así:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
sandbox-router-svc ClusterIP 34.118.237.244 <none> 8080/TCP 114s
Verifica que exista la regla de política de red de salida
kubectl get networkpolicy restrict-sandbox-egress -n agent-sandbox
El resultado debería verse así:
NAME POD-SELECTOR AGE
restrict-sandbox-egress sandbox=python-sandbox-example 113s
Asegúrate de lo siguiente:
- Los pods
python-sandbox-warmpool-***estánRunningy1/1listos. - Las réplicas
sandbox-router-deployment-***están listas (Runningy1/1). - Se puede acceder a
sandbox-router-svcy la política derestrict-sandbox-egressprotege correctamente las etiquetas de zona de pruebas coincidentes.
Ahora que nuestro entorno de ejecución seguro está protegido y se inicializó, podemos implementar el cerebro real de nuestra operación: el agente de generación de código.
7. Compila e implementa el agente de generación de código (ADK)
Con nuestro entorno de pruebas de ejecución segura y nuestro backend de LLM de alto rendimiento configurados, ahora podemos crear el "cerebro" de nuestro sistema: un agente de generación de código con el kit de desarrollo de agentes (ADK).
Este agente está diseñado para actuar como un desarrollador experto de Python. A diferencia de un chatbot estándar que solo produce texto, este agente está equipado con una herramienta de ejecución de código que le permite resolver problemas de forma interactiva. Sigue un bucle de los siguientes pasos:
- Escribir código de Python según tus solicitudes
- Ejecutar el código de forma segura dentro de la zona de pruebas del agente de GKE que configuramos en el paso 6
- Verificar el resultado o leer los errores que surjan durante la ejecución
- Entregar con confianza una solución probada y funcional
Al darle acceso a un entorno de ejecución de zona de pruebas seguro, permitimos que el agente verifique su propia lógica y depure errores automáticamente, lo que lo hace mucho más capaz para las tareas de desarrollo de software.
Desarrolla el agente de razonamiento del ADK
Primero, escribimos la lógica de Python que define el comportamiento del agente y lo equipa con la herramienta de Sandbox que creamos en el paso 6. En esta sección, también configuramos una estrategia de modelo híbrido: el agente priorizará un modelo de Qwen autoalojado que se ejecute en tu clúster de GKE, pero recurrirá automáticamente a Gemini 2.5 Flash en Vertex AI si el modelo local es lento o no está disponible, lo que garantiza una alta confiabilidad.
Crea un directorio nuevo para el código del agente:
mkdir -p ~/gke-ai-agent-lab/root_agent
cd ~/gke-ai-agent-lab
Crea un archivo llamado root_agent/agent.py con el siguiente contenido:
cat <<'EOF' > root_agent/agent.py
import os
from google.adk.agents import Agent
from google.adk.models.lite_llm import LiteLlm
from k8s_agent_sandbox import SandboxClient
import requests
# Instantiate the client globally to track sandboxes
sandbox_client = SandboxClient()
def run_python_code(code: str) -> str:
"""
Executes Python code safely in the GKE Agent Sandbox.
Use this tool whenever you need to execute code to solve a problem.
"""
sandbox = sandbox_client.create_sandbox(template="python-runtime-template", namespace="agent-sandbox")
try:
command = f"python3 -c \"{code}\""
result = sandbox.commands.run(command)
if result.stderr:
return f"Error: {result.stderr}"
return result.stdout
finally:
# Ensure the sandbox is deleted after use to avoid leaking resources
sandbox_client.delete_sandbox(sandbox.claim_name, namespace="agent-sandbox")
# Define the ADK Agent with a fallback mechanism.
# It prioritizes the Qwen 2.5 Coder model running on our Inference Gateway.
# If the local model is unavailable, it falls back to Gemini 2.5 Flash on Vertex AI.
root_agent = Agent(
name="CodeGenerationAgent",
model=LiteLlm(
model="openai/Qwen/Qwen2.5-Coder-14B-Instruct",
fallbacks=["vertex_ai/gemini-2.5-flash"],
timeout=10
),
instruction="""
You are an expert Python developer.
1. Write Python code to solve the user's problem.
2. Execute the code using the `run_python_code` tool to verify it works.
3. Return the exact output and a brief explanation of the code.
""",
tools=[run_python_code]
)
EOF
Crea un archivo __init__.py para que el ADK reconozca el módulo:
echo "from . import agent" > ~/gke-ai-agent-lab/root_agent/__init__.py
Configura las variables de entorno. La aplicación del ADK necesita la dirección IP de tu puerta de enlace para enrutar las solicitudes del LLM correctamente. Dado que ADK admite extremos estándares compatibles con Open-AI (que vLLM proporciona a través de nuestra puerta de enlace), podemos anular la URL base de la API predeterminada.
export GATEWAY_IP=$(kubectl get gateway infra-is-inference-gateway -n $NAMESPACE -o jsonpath='{.status.addresses[0].value}')
cat <<EOF > ~/gke-ai-agent-lab/root_agent/.env
OPENAI_API_BASE=http://${GATEWAY_IP}/v1
OPENAI_API_KEY=no-key-required
# Vertex AI settings for fallback (Authentication is handled by Workload Identity)
VERTEXAI_PROJECT=$PROJECT_ID
VERTEXAI_LOCATION=${ZONE%-[a-z]}
EOF
Crea un contenedor para la aplicación del agente
Necesitamos empaquetar el agente para que se pueda ejecutar de forma segura dentro de GKE.
Crea un Dockerfile en ~/gke-ai-agent-lab que instale kubectl, la biblioteca del ADK y el cliente de Agent Sandbox:
cat <<'EOF' > ~/gke-ai-agent-lab/Dockerfile
FROM python:3.11-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
RUN apt-get update && apt-get install -y git curl \
&& curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl" \
&& install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl \
&& rm kubectl && apt-get clean && rm -rf /var/lib/apt/lists/*
RUN pip install --no-cache-dir "google-adk[extensions,otel-gcp]>=1.27.4" litellm pandas "git+https://github.com/kubernetes-sigs/agent-sandbox.git@main#subdirectory=clients/python/agentic-sandbox-client" \
"opentelemetry-instrumentation-google-genai>=0.4b0" \
"opentelemetry-exporter-otlp" \
"opentelemetry-instrumentation-vertexai>=2.0b0"
COPY ./root_agent /app/root_agent
EXPOSE 8080
ENTRYPOINT ["adk", "web", "--host", "0.0.0.0", "--port", "8080", "--otel_to_cloud"]
EOF
Crea un repositorio de Artifact Registry para almacenar la imagen de contenedor.
gcloud artifacts repositories create agent-repo \
--repository-format=docker \
--location=us-central1
Usa Cloud Build para compilar y enviar la imagen del contenedor.
gcloud builds submit --tag us-central1-docker.pkg.dev/$PROJECT_ID/agent-repo/code-agent:v1 ~/gke-ai-agent-lab/
Implementa en GKE con RBAC
Por último, implementa el agente en tu clúster. La implementación incluye un Role y un RoleBinding que otorgan al agente permiso para reclamar instancias del SandboxWarmPool.
Esta implementación usará una ServiceAccount de Kubernetes para permitir que tu agente se comunique con la API de reclamos de Sandbox. No requiere una ServiceAccount de IAM de Google, ya que accede a recursos locales del clúster y a un extremo de puerta de enlace de vLLM local.
¿Por qué una implementación estándar en gVisor?
En el paso 6, usamos las APIs de SandboxTemplate y SandboxClaim para crear zonas de pruebas efímeras y desechables para el código de Python generado (la ejecución de la herramienta).
Para la IU web del agente (el cerebro), usamos especificaciones Deployment estándar de Kubernetes con runtimeClassName: gvisor.
- La distinción: Los objetos
SandboxClaimsestándar son efímeros y de cero a uno (ideales para secuencias de comandos no confiables). UnDeploymentestándar es de ejecución prolongada y persistente, perfecto para las IU web que necesitan unServicey un balanceador de cargas de Kubernetes estables. Si usasruntimeClassName: gvisordirectamente en una implementación estándar, obtendrás el aislamiento del kernel de gVisor y conservarás las funciones estándar deDeployment.
Guarda el siguiente código como deployment.yaml:
cat <<EOF > ~/gke-ai-agent-lab/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: code-agent
labels:
app: code-agent
spec:
replicas: 1
selector:
matchLabels:
app: code-agent
template:
metadata:
labels:
app: code-agent
spec:
serviceAccount: adk-agent-sa
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: code-agent
image: us-central1-docker.pkg.dev/YOUR_PROJECT_ID/agent-repo/code-agent:v1
imagePullPolicy: Always
env:
- name: OPENAI_API_KEY
value: "no-key-required"
- name: OPENAI_API_BASE
value: "http://YOUR_GATEWAY_IP/v1"
- name: VERTEXAI_PROJECT
value: "YOUR_PROJECT_ID"
- name: VERTEXAI_LOCATION
value: "YOUR_REGION"
- name: OTEL_SERVICE_NAME
value: "code-agent"
- name: GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY
value: "true"
- name: OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT
value: "true"
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: code-agent-service
spec:
selector:
app: code-agent
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: agent-sandbox
name: sandbox-creator-role
rules:
- apiGroups: [""]
resources: ["services", "pods", "pods/portforward"]
verbs: ["get", "list", "watch", "create"]
- apiGroups: ["extensions.agents.x-k8s.io"]
resources: ["sandboxclaims"]
verbs: ["create", "get", "list", "watch", "delete"]
- apiGroups: ["agents.x-k8s.io"]
resources: ["sandboxes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: adk-agent-binding
namespace: agent-sandbox
subjects:
- kind: ServiceAccount
name: adk-agent-sa
namespace: default
roleRef:
kind: Role
name: sandbox-creator-role
apiGroup: rbac.authorization.k8s.io
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: adk-agent-sa
EOF
Otorga permisos de IAM para la observabilidad
Para permitir que el agente envíe datos de telemetría (registros y seguimientos) a Google Cloud, debes otorgar los permisos necesarios a la cuenta de servicio de Kubernetes adk-agent-sa con Workload Identity.
Ejecuta los siguientes comandos en Cloud Shell:
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# Grant permission to write logs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/logging.logWriter \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to write traces
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/cloudtrace.agent \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to use Vertex AI
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/aiplatform.user \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
Ejecuta el siguiente comando para reemplazar automáticamente YOUR_PROJECT_ID por el ID del proyecto real y aplicar la configuración.
sed -i "s/YOUR_PROJECT_ID/$PROJECT_ID/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_GATEWAY_IP/$GATEWAY_IP/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_REGION/$ZONE/g" ~/gke-ai-agent-lab/deployment.yaml
kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml
8. Observa y valida
Es hora de probar el sistema completamente integrado.
Prueba el agente de generación de código en la IU
Busca la IP externa de la IU web del ADK:
kubectl get services code-agent-service
El resultado debería ser similar a lo siguiente:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
code-agent-service LoadBalancer 34.118.230.182 34.31.250.60 80:32471/TCP 2m14s
- Abre un navegador y navega a
http://[EXTERNAL-IP]. - En la interfaz web del ADK, asegúrate de que esté seleccionado "root_agent" en el menú desplegable de la parte superior derecha. Luego, pídele al agente lo siguiente:
Write a python script that prints 'Hello from the isolated sandbox'.
Para observar cómo el agente utiliza el backend de inferencia y el entorno de pruebas, consulta las secciones Explora las estadísticas del modelo a través de Cloud Observability y Explora la observabilidad del agente a través de la IU de GKE a continuación para ver los paneles.
Explora la observabilidad del agente a través de la IU de GKE
Ahora que ejecutaste algunas instrucciones, veamos los datos de telemetría. Esto te ayuda a comprender el rendimiento del Inference Scheduler y de vLLM.
Accede a los paneles de agentes
- Navega a la página Kubernetes Engine > Cargas de trabajo.
- Haz clic en la implementación de code-agent para abrir la página Detalles de la implementación.
- Haz clic en la pestaña Observabilidad.
- En el panel de navegación de la izquierda del panel de observabilidad, verás una nueva sección Agent con pestañas secundarias.
Qué explorar
Explora las siguientes subpestañas para ver el comportamiento de la aplicación del agente:
- Resumen: Consulta los cuadros de evaluación de las sesiones, los turnos promedio y las invocaciones.
- Modelos: Consulta la cantidad de llamadas a modelos, las tasas de error y la latencia categorizadas por los modelos que usó tu agente.
- Herramientas: Supervisa las llamadas a herramientas y la duración de la ejecución para ver con qué eficacia tu agente usa su herramienta de ejecución de zona de pruebas.
- Uso: Realiza un seguimiento del uso de tokens y la asignación de recursos de contenedores estándar (CPU y memoria).
- Registros del agente: Cambia a esta pestaña para ver una lista de sesiones de ejecución o intervalos de registro sin procesar. Cuando haces clic en una fila, se abre un panel desplegable con detalles del registro seleccionado.
Si combinas las métricas a nivel del modelo de vLLM con la telemetría a nivel de la app del ADK, ahora tienes observabilidad de pila completa para tu agente de IA generativa en GKE.
Explora las estadísticas del modelo vLLM a través de Cloud Observability
Ahora que ejecutaste algunas instrucciones, veamos los datos de telemetría. Esto te ayuda a comprender el rendimiento del Inference Scheduler y de vLLM.
Accede a los paneles
- Navega a la consola de Google Cloud.
- Ve a Monitoring > Paneles.
- Busca y selecciona el panel vLLM Prometheus Overview.
Métricas interesantes para observar
Mientras ves el panel, presta atención a estas métricas clave para observar el impacto de GKE Inference Gateway y el almacenamiento en caché de prefijos:
- Utilización de la caché de KV (
vllm:gpu_cache_usage):- Por qué es importante: Muestra cuánta memoria de la GPU se usa para almacenar en caché el contexto. Si este valor es alto, significa que el sistema retiene el contexto para acelerar las solicitudes futuras. Si ejecutas la misma instrucción varias veces, deberías ver que este uso aumenta y, luego, se estabiliza.
- Solicitudes en ejecución vs. solicitudes en espera (
vllm:num_requests_runningvs.vllm:num_requests_waiting):- Por qué es importante: Esto indica la carga. Si la cantidad de solicitudes en espera es alta, significa que tus nodos están sobrecargados.
- Capacidad de procesamiento de tokens (
vllm:request_prompt_tokens_totyvllm:request_generation_tokens_tot):- Importancia: Realiza un seguimiento del volumen de tokens de entrada y salida que procesa el clúster.
- Tiempo hasta el primer token (TTFT):
- Por qué es importante: Esta es la métrica fundamental para los agentes interactivos. Si usas la puerta de enlace de inferencia de GKE con el enrutamiento con reconocimiento de caché de prefijos, las solicitudes que comparten contextos comunes (como instrucciones del sistema o ventanas de contexto grandes) se enrutan a la misma réplica, lo que minimiza el TTFT gracias a la reutilización de aciertos de caché existentes.
Experimentos para probar
Prueba estas situaciones para ver cómo cambian las métricas en tiempo real y validar la programación correcta.
Experimento 1: La “velocidad de repetición” (acierto de caché de prefijo)
- Envía una instrucción compleja al agente (p. ej., "Escribe un script de Python para analizar un archivo CSV de 100 MB y calcular estadísticas").
- Una vez que responda, vuelve a enviar la misma instrucción de inmediato.
- Observa el porcentaje de aciertos de la caché de prefijos y el tiempo hasta el primer token (TTFT).
- Qué deberías ver: El porcentaje de aciertos de la caché de prefijos debería aumentar hasta el 100% y el TTFT debería disminuir drásticamente.
- Qué significa: GKE Inference Gateway reconoció el contexto compartido y lo enrutó a la misma réplica que reutilizó su caché de contexto evaluado.
Experimento 2: Recurso a la nube (confiabilidad del modelo)
- Para simular una falla en tu modelo Qwen local, puedes detener el servicio de inferencia o simplemente proporcionar un
OPENAI_API_BASEfalso en la implementación. - Actualiza el
OPENAI_API_BASEen tudeployment.yamla una IP o un puerto inexistentes y aplica los cambios:sed -i "s|value: \"http://$GATEWAY_IP/v1\"|value: \"http://10.0.0.1:8080/v1\"|g" ~/gke-ai-agent-lab/deployment.yaml kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml - Espera a que se reinicie el pod y, luego, envía una instrucción al agente en la IU.
- Qué deberías ver: El agente sigue respondiendo correctamente.
- Qué significa: Debido a la configuración de
fallbacks, el ADK reconoció la falla del extremo local de Qwen y enrutó sin problemas la solicitud a Gemini 2.5 Flash en Vertex AI. Ten en cuenta que, debido a que estas llamadas de respaldo a Vertex AI omiten tu puerta de enlace de inferencia de vLLM local, no aparecerán en el panel de Agent Observability > Models, que solo hace un seguimiento del tráfico que pasa por vLLM.
Información sobre el poder de la asignación dinámica de recursos (DRA)
Si bien vLLM y Inference Gateway optimizan la forma en que se enrutan y se entregan las solicitudes, la asignación dinámica de recursos (DRA) es lo que hizo posible adjuntar el hardware adecuado con precisión a tu carga de trabajo en primer lugar.
La DRA mejora tu capacidad de administrar el hardware de forma detallada en todo el clúster, ya que te permite definir recursos de hardware flexibles con ResourceClaimTemplate y DeviceClasses.
Por qué la DRA cambia las reglas del juego para las cargas de trabajo de IA:
- Solicitudes de hardware detalladas: Con DRA, no solo te aseguras de que las cargas de trabajo se programen en máquinas con el acelerador adecuado, sino que también puedes reclamar esos recursos para garantizar que la carga de trabajo asociada con el ResourceClaim los use de forma exclusiva.
- Ciclo de vida desacoplado: Los reclamos de dispositivos se administran de forma independiente de los ciclos de vida de los Pods. Si un Pod falla, el reclamo de la GPU puede persistir, de modo que la implementación general o cualquier otro objeto de carga de trabajo se pueda reiniciar sin tener que esperar a que se libere y se vuelva a adquirir la GPU.
- Estandarización de varios proveedores: DRA proporciona una API de Kubernetes unificada para las GPU de NVIDIA y las TPU de Google. Usas exactamente el mismo esquema, ya sea que realices la implementación para uno u otro, lo que hace que tus manifiestos de YAML de carga de trabajo sean altamente portátiles.
En este codelab, viste esto en acción cuando configuraste tus valores de Helm para que se vinculen a gpu-claim-template sin problemas, sin que las configuraciones pendientes del complemento del dispositivo bloqueen tus lanzamientos.
Información sobre el rol de llm-d
Mientras que vLLM evalúa los pesos neuronales y GKE Gateway enruta las consultas, llm-d actúa como la capa de configuración y el "pegamento" que une todo.
Sin llm-d, tendrías que escribir manifiestos de Kubernetes sin procesar para declarar tu implementación de vLLM, los puertos de servicio, las vinculaciones de volúmenes y las declaraciones de recursos de DRA desde cero.
¿Por qué usar llm-d en tu implementación?
- Configuración unificada (anulaciones de una sola línea): Los gráficos de Helm
llm-dagrupan recursos complejos de Kubernetes de nivel bajo en alternadores limpios de nivel alto (como estableceraccelerator.dra: true). - Rutas "bien iluminadas" previamente verificadas: El repositorio
llm-dcontiene configuraciones que ya se compararon y probaron por expertos. Cuando implementasllm-d-modelservice, recibes valores predeterminados optimizados para el uso de la memoria de la GPU, tiempos de sondeo recomendados (actividad/preparación) y exposiciones correctas para la extracción de métricas. - Asignación de observabilidad sin problemas: De forma predeterminada,
llm-dgarantiza que los puertos de contenedores y las rutas de extracción (/metrics) estándar se expongan correctamente, lo que facilita la conexión de tu implementación a Google Cloud Monitoring sin necesidad de depuración manual.
En resumen, llm-d proporciona los planos de arquitectura reutilizables para que los desarrolladores no tengan que reinventar la rueda cada vez que implementan una pila de inferencia en GKE.
Análisis detallado: GKE Inference Gateway
Los balanceadores de cargas estándar de capa 7 operan observando los encabezados HTTP, como las rutas (/v1/completions) o las cookies. La puerta de enlace de inferencia de GKE va mucho más allá, ya que está diseñada específicamente para el tráfico de IA generativa.
Cómo impulsa el rendimiento y la eficiencia:
- Enrutamiento según el contenido (hash de instrucciones): La puerta de enlace de inferencia de GKE intercepta el cuerpo de la solicitud JSON. Calcula un hash de la instrucción y hace un seguimiento de qué réplica de backend ya tiene esos tokens en su memoria de GPU (la caché de KV).
- Cómo maximizar los aciertos de caché: En las pruebas, cuando repetiste una instrucción, la puerta de enlace la envió a la misma réplica. Evaluar una instrucción requiere una gran capacidad de procesamiento. Al reutilizar la caché, evitas "releer" la instrucción, lo que ahorra dinero y tiempo de GPU.
- Reducción del tiempo hasta el primer token (TTFT): El TTFT es la métrica de usabilidad fundamental para los agentes orientados a los usuarios. Cuando se accede a la caché, el modelo puede comenzar a generar tokens en milisegundos en lugar de segundos.
- Distribución de carga inteligente: Si la VRAM de una réplica está completamente llena de aciertos de caché, la puerta de enlace puede enrutar de forma dinámica una instrucción nueva a otra réplica que tenga espacio, lo que equilibra la eficiencia con la disponibilidad.
Cómo Agent Sandbox reduce el riesgo
En este lab, demostramos cómo Agent Sandbox protege tu infraestructura de los riesgos asociados a los agentes de IA proporcionando dos capas de aislamiento:
- Aislamiento de la herramienta de ejecución: El agente ejecuta el código que genera en una zona de pruebas efímera. Esto garantiza que el código no confiable generado por el LLM se ejecute en un entorno seguro y aislado, lo que protege al agente y al clúster.
- Inicio rápido: Con WarmPool, las nuevas zonas de pruebas se inician en menos de un segundo y están listas para ejecutar código.
- Aislamiento del agente: También ejecutamos la aplicación del agente en un nodo habilitado para gVisor (a través de
runtimeClassName: gvisor) para proporcionar una defensa en profundidad contra las vulnerabilidades de la cadena de suministro en las dependencias del agente.
Estos son los motivos por los que se crea un límite de seguridad tan reforzado:
- Interceptación de llamadas al sistema: gVisor intercepta las llamadas al sistema antes de que lleguen al kernel de Linux del host. Esto bloquea los exploits que intentan salir del contenedor para acceder al nodo host.
- Movimiento lateral restringido: En combinación con las políticas de red, incluso si se vulnera un entorno, no se pueden analizar los servidores de metadatos internos ni pivotar a otros servicios sensibles en tu clúster.
Ejecución de agentes completos en zonas de pruebas
En este lab, usamos zonas de pruebas como herramientas para una aplicación de agente persistente. Sin embargo, para obtener la máxima seguridad, en especial cuando se manejan datos sensibles o se atiende a varios usuarios no confiables, puedes ejecutar la aplicación del agente completa dentro de un sandbox dedicado para cada sesión o usuario. Esto garantiza el aislamiento completo de la memoria, el estado y el entorno de ejecución del agente, que se destruyen inmediatamente después de que finaliza la sesión.
9. Limpieza
Sigue estos pasos para borrar los recursos y evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos que usaste en este codelab.
Borra recursos individuales
- Borra el clúster de GKE:
gcloud container clusters delete $CLUSTER_NAME --zone $ZONE --quiet
- Borra el repositorio de Artifact Registry:
gcloud artifacts repositories delete agent-repo --location=us-central1 --quiet
- Borra la red de VPC:
gcloud compute networks delete ai-agent-network --quiet
Borra el proyecto
Si ya no necesitas el proyecto, puedes borrarlo después de quitar los recursos:
gcloud projects delete $PROJECT_ID
10. Resumen
¡Felicitaciones! Creaste e implementaste correctamente un agente de generación de código seguro y de alto rendimiento en GKE.
Qué aprendiste
- Cómo configurar y usar la Asignación dinámica de recursos (DRA) en GKE para administrar los recursos de GPU
- Cómo usar GKE Inference Gateway para optimizar el rendimiento de la entrega de LLM a través del enrutamiento que tiene en cuenta la caché de prefijos
- Cómo usar Agent Sandbox (gVisor) para ejecutar código no confiable de forma segura en GKE
- Cómo usar Google Cloud Managed Service para Prometheus para supervisar el rendimiento de vLLM
- Cómo configurar y ver la observabilidad del agente con el ADK y OpenTelemetry administrado de GKE
Próximos pasos y referencias
- Agent Sandbox: Obtén información sobre Agent Sandbox en GKE y los Pods de GKE Sandbox.
- llm-d: Lee la Guía de llm-d y consulta el repositorio de GitHub de llm-d.
- Asignación dinámica de recursos: Obtén información sobre la DRA en GKE.
- GKE Inference Gateway: Explora los conceptos de Inference Gateway.
- Más codelabs: Encuentra más instructivos en Codelabs de Google Cloud.