
۱. مقدمه
نمای کلی
در این آزمایشگاه، شما یاد خواهید گرفت که چگونه یک عامل تولید کد امن را در موتور گوگل کوبرنتیز (GKE) بسازید و مستقر کنید. عاملهای تولید کد باید کدی را اجرا کنند که ممکن است غیرقابل اعتماد باشد و به یک محیط سندباکس امن نیاز دارد. همچنین یاد خواهید گرفت که چگونه عامل را با یک استراتژی مدل ترکیبی پیکربندی کنید، که به آن اجازه میدهد از یک مدل باز خود-میزبان در GKE به سرویس Gemini مدیریتشدهی Vertex AI برای افزایش قابلیت اطمینان بازگردد. علاوه بر این، یاد خواهید گرفت که چگونه با استفاده از دروازه استنتاج GKE و تخصیص منابع پویا (DRA) سرویس استنتاج را بهینه کنید. در نهایت، یاد خواهید گرفت که چگونه از Google Cloud Observability برای نظارت بر پشته استنتاج خود با استفاده از پرومتئوس مدیریتشده استفاده کنید.
معماری
معماری سیستمی که خواهید ساخت به شرح زیر است:
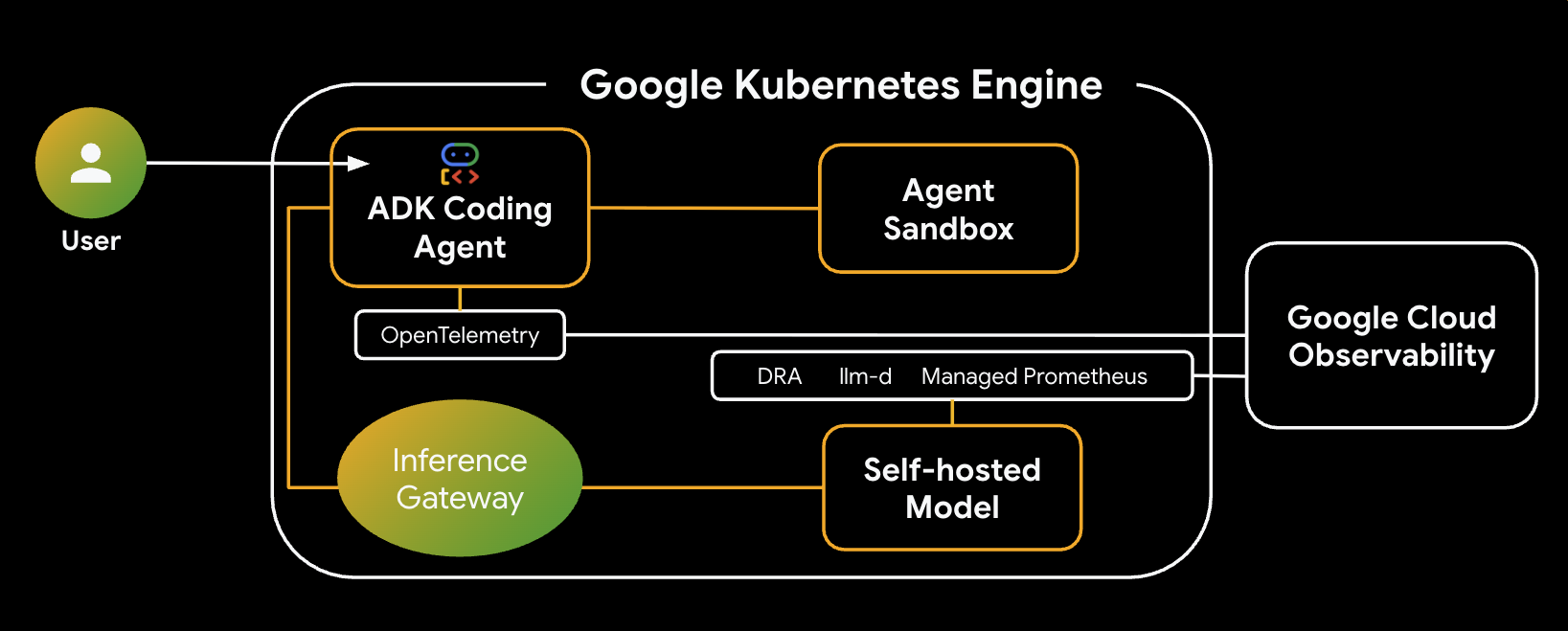
اجزای کلیدی و مزایا
- تخصیص پویای منابع (DRA) : در این آزمایشگاه برای تخصیص پویای منابع خاص GPU (NVIDIA L4s) برای Podهای سرور مدل استفاده میشود و هدفگیری دقیق سختافزار برای حجم کار استنتاج ما را تضمین میکند. در مورد DRA در GKE اطلاعات بیشتری کسب کنید.
- llm-d و vLLM : چارچوب سرویسدهی مدل و نمودارهای Helm را برای استقرار مدل Qwen فراهم میکند. در این آزمایش، درخواستهای استنتاج را مدیریت کرده و با DRA برای مدیریت منابع ادغام میشود (سرویسدهی تفکیکی در این آزمایش فعال نیست). راهنمای llm-d را مطالعه کنید و مخزن گیتهاب llm-d را بررسی کنید.
- GKE Inference Gateway : منطق مسیریابی آگاه از هوش مصنوعی را مستقیماً به متعادلکننده بار منتقل میکند. در این آزمایش، درخواستها را به گونهای مسیریابی میکند که تعداد بازدیدهای prefix-cache به حداکثر برسد و تأخیر زمان اولین توکن (TTFT) کاهش یابد. مفاهیم Inference Gateway را بررسی کنید.
- Agent Sandbox (gVisor) : جداسازی امنی را برای اجرای کد تولید شده توسط عامل هوش مصنوعی فراهم میکند. این ابزار از gVisor برای فراهم کردن جداسازی عمیق هسته استفاده میکند و از گره میزبان در برابر بارهای کاری غیرقابل اعتماد محافظت میکند. در مورد Agent Sandbox در GKE و GKE Sandbox Pods اطلاعات کسب کنید.
کاری که انجام خواهید داد
- زیرساخت تأمین : یک کلاستر GKE با تخصیص منابع پویا (DRA) برای مدیریت GPU راهاندازی کنید.
- استقرار پشته استنتاج : استقرار
llm-dو vLLM با زمانبندی استنتاج هوشمند. - پیکربندی مسیریابی هوشمند : از GKE Inference Gateway برای مسیریابی آگاه از حافظه پنهان پیشوند استفاده کنید.
- اجرای امن کد : برای اجرای ایمن کد تولید شده توسط هوش مصنوعی، Agent Sandbox (gVisor) را مستقر کنید.
- مشاهده و اعتبارسنجی : از Google Cloud Monitoring و Managed Prometheus برای مشاهده معیارهای ارائه مدل استفاده کنید.
آنچه یاد خواهید گرفت
- نحوه پیکربندی و استفاده از تخصیص منابع پویا (DRA) در GKE.
- نحوه استفاده از GKE Inference Gateway برای بهینه سازی عملکرد سرویس LLM.
- نحوه استفاده از Agent Sandbox برای اجرای امن کدهای نامطمئن در GKE.
- نحوه استفاده از سرویس مدیریتشدهی ابری گوگل برای پرومتئوس جهت نظارت بر عملکرد vLLM.
۲. تنظیمات و الزامات
راهاندازی پروژه
ایجاد یک پروژه ابری گوگل
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید .
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
شروع پوسته ابری
Cloud Shell یک محیط خط فرمان است که در Google Cloud اجرا میشود و ابزارهای لازم از قبل روی آن بارگذاری شدهاند.
- روی فعال کردن Cloud Shell در بالای کنسول Google Cloud کلیک کنید.
- پس از اتصال به Cloud Shell، احراز هویت خود را تأیید کنید:
gcloud auth list - تأیید کنید که پروژه شما پیکربندی شده است:
gcloud config get project - اگر پروژه شما مطابق انتظار تنظیم نشده است، آن را تنظیم کنید:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
۳. زیرساخت تأمین و تخصیص پویای منابع (DRA)
در این مرحله اول، شما خوشه GKE خود را طوری پیکربندی خواهید کرد که به جای افزونههای دستگاه قدیمی، از تخصیص شتابدهنده مدرن (DRA) استفاده کند. این به شما امکان میدهد تا GPUها یا TPUها را به صورت انعطافپذیر برای بارهای کاری تولید کد خود به اشتراک بگذارید و تخصیص دهید.
پیشنیازها: کلاستر استاندارد GKE شما باید نسخه ۱.۳۴ یا بالاتر را اجرا کند تا از DRA پشتیبانی کند.
فعال کردن APIهای گوگل کلود
APIهای Google Cloud مورد نیاز برای این آزمایشگاه کد، به ویژه APIهای Compute Engine و Kubernetes Engine را فعال کنید.
gcloud services enable compute.googleapis.com container.googleapis.com networkservices.googleapis.com cloudbuild.googleapis.com artifactregistry.googleapis.com telemetry.googleapis.com cloudtrace.googleapis.com aiplatform.googleapis.com
تنظیم متغیرهای محیطی
برای آسانتر کردن تنظیمات، متغیرهای محیطی خود را تعریف کنید. میتوانید در صورت نیاز، منطقه یا قراردادهای نامگذاری را تنظیم کنید.
export PROJECT_ID=$(gcloud config get-value project)
export ZONE=us-central1-a
export CLUSTER_NAME=ai-agent-cluster
export NODEPOOL_NAME=dra-accelerator-pool
gcloud config set project $PROJECT_ID
gcloud config set compute/region $ZONE
ایجاد دایرکتوری کاری
یک دایرکتوری کاری اختصاصی برای این آزمایشگاه ایجاد کنید و به آن بروید تا فایلهای شما سازماندهی شده باقی بمانند:
mkdir -p ~/gke-ai-agent-lab
cd ~/gke-ai-agent-lab
پیکربندی مجوزها (اختیاری)
اگر در یک پروژه محدود یا محیط اشتراکی کار میکنید، مطمئن شوید که حساب کاربری شما مجوزهای لازم برای ایجاد خوشهها و اجرای نسخههای ساختهشده را دارد:
export MY_ACCOUNT=$(gcloud config get-value account)
# Grant Container Admin to create clusters and manage nodes if needed
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/container.admin"
# Grant Cloud Build Builder to run builds
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/cloudbuild.builds.builder"
ایجاد خوشه GKE
برای پشتیبانی از DRA، کلاستر استاندارد GKE شما باید نسخه ۱.۳۴ یا بالاتر را اجرا کند. همچنین باید کنترلرهای Gateway API را برای پشتیبانی از زمانبندی استنتاج هوشمند فعال کنید.
شما برای این آزمایش یک شبکه VPC جدید و زیرشبکههای آن ایجاد خواهید کرد.
ابتدا، شبکه VPC را ایجاد کنید:
gcloud compute networks create ai-agent-network --subnet-mode=custom
سپس، یک زیرشبکه برای گرههای GKE خود ایجاد کنید:
gcloud compute networks subnets create ai-agent-subnet \
--network=ai-agent-network \
--range=10.0.0.0/20 \
--region=us-central1
رابط برنامهنویسی کاربردی گیتوی ( gke-l7-regional-internal-managed ) همچنین به یک زیرشبکه اختصاصی برای میزبانی پروکسیهای Envoy نیاز دارد. این زیرشبکه فقط پروکسی را در شبکه جدید خود ایجاد کنید:
gcloud compute networks subnets create proxy-only-subnet \
--purpose=REGIONAL_MANAGED_PROXY \
--role=ACTIVE \
--region=us-central1 \
--network=ai-agent-network \
--range=192.168.10.0/24
اکنون، با استفاده از شبکه و زیرشبکه جدید، خوشه را ایجاد کنید:
gcloud beta container clusters create $CLUSTER_NAME \
--zone $ZONE \
--num-nodes 1 \
--machine-type n2-standard-4 \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--gateway-api=standard \
--managed-otel-scope=COLLECTION_AND_INSTRUMENTATION_COMPONENTS \
--network=ai-agent-network \
--subnetwork=ai-agent-subnet
ایجاد یک Node Pool با غیرفعال کردن افزونههای پیشفرض
برای واگذاری مدیریت دستگاه به DRA، باید یک مجموعه گره ایجاد کنید که صراحتاً نصب درایور GPU پیشفرض و افزونه استاندارد دستگاه را غیرفعال کند.
دستور gcloud زیر را برای آمادهسازی یک استخر گره GPU (مثلاً با استفاده از NVIDIA L4s) با برچسبهای DRA لازم اجرا کنید:
gcloud container node-pools create $NODEPOOL_NAME \
--cluster=$CLUSTER_NAME \
--location=$ZONE \
--machine-type=g2-standard-24 \
--accelerator=type=nvidia-l4,count=2,gpu-driver-version=disabled \
--node-labels=gke-no-default-nvidia-gpu-device-plugin=true,nvidia.com/gpu.present=true \
--num-nodes 3
نصب درایورهای NVIDIA از طریق DaemonSet
درایورهای دستگاه NVIDIA پایه مورد نیاز را با استفاده از Google Cloud DaemonSet از پیش تنظیم شده، به صورت دستی روی گرههای خود نصب کنید:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
درایور DRA را نصب کنید
در مرحله بعد، درایور DRA مخصوص را در کلاستر خود نصب کنید. برای پردازندههای گرافیکی NVIDIA، میتوانید این درایور را از طریق Helm نصب کنید:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
helm install nvidia-dra-driver-gpu nvidia/nvidia-dra-driver-gpu \
--version="25.3.2" --create-namespace --namespace=nvidia-dra-driver-gpu \
--set nvidiaDriverRoot="/home/kubernetes/bin/nvidia/" \
--set gpuResourcesEnabledOverride=true \
--set resources.computeDomains.enabled=false \
--set kubeletPlugin.priorityClassName="" \
--set 'kubeletPlugin.tolerations[0].key=nvidia.com/gpu' \
--set 'kubeletPlugin.tolerations[0].operator=Exists' \
--set 'kubeletPlugin.tolerations[0].effect=NoSchedule'
درک کلاسهای دستگاه
نیازی نیست که به صورت دستی یک DeviceClass YAML بنویسید یا اعمال کنید. وقتی زیرساخت GKE خود را برای DRA تنظیم میکنید و درایور را نصب میکنید، درایورهای DRA که روی گرههای شما اجرا میشوند، به طور خودکار اشیاء DeviceClass را در خوشه برای شما ایجاد میکنند.
پیکربندی ResourceClaimTemplate
برای اینکه پادهای llm-d شما بتوانند به صورت پویا از این شتابدهندهها درخواست کنند، یک ResourceClaimTemplate ایجاد خواهید کرد. این الگو پیکربندی دستگاه درخواستی را تعریف میکند و به Kubernetes میگوید که به طور خودکار یک ResourceClaim منحصر به فرد برای هر پاد برای بارهای کاری شما ایجاد کند.
دستور زیر را برای ایجاد claim-template.yaml اجرا کنید:
cat > claim-template.yaml <<EOF
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: gpu-claim-template
spec:
spec:
devices:
requests:
- name: single-gpu
exactly:
deviceClassName: gpu.nvidia.com
allocationMode: ExactCount
count: 1
EOF
الگو را روی خوشه خود اعمال کنید:
kubectl apply -f claim-template.yaml
۴. پیادهسازی زمانبندی استنتاج هوشمند با llm-d و DRA
در این مرحله، شما مدل زبان بزرگ خود را پشت یک متعادلکننده بار هوشمند Envoy که با یک زمانبند استنتاج بهبود یافته است، مستقر خواهید کرد. این پیکربندی، سرویسدهی مدل را با اعمال مسیریابی Prefix-Cache Aware بهینه میکند. GKE Inference Gateway زمینه مشترک را در بین میکروسرویسها تشخیص میدهد و به طور هوشمندانه درخواستها را به همان مدل کپی هدایت میکند، بازدیدهای حافظه پنهان را به حداکثر میرساند، زمان رسیدن به اولین توکن را کاهش میدهد و عملکرد برتر را به ازای هر دلار هدایت میکند.
آماده سازی محیط
فضای نام هدف خود را تنظیم کنید.
export NAMESPACE=ai-agents
kubectl create namespace $NAMESPACE
توکن چهره در آغوش گرفته خود را که برای کشیدن وزنههای مدل لازم است، به طور ایمن ذخیره کنید.
# Replace with your actual Hugging Face token
kubectl create secret generic llm-d-hf-token \
--from-literal=HF_TOKEN="your_hugging_face_token" \
-n $NAMESPACE
ایجاد فایلهای پیکربندی Helm
پیکربندیهای سرویس مدل و افزونهی دروازهی استنتاج بر اساس راهنماهای رسمی llm-d هستند.
ابتدا، فایل ms-values.yaml را برای سرویس مدل ایجاد کنید:
cat <<EOF > ms-values.yaml
multinode: false
modelArtifacts:
uri: "hf://Qwen/Qwen2.5-Coder-14B-Instruct"
name: "Qwen/Qwen2.5-Coder-14B-Instruct"
size: 50Gi # Slightly larger than the default to accommodate weights
authSecretName: "llm-d-hf-token"
labels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
llm-d.ai/accelerator-variant: "gpu"
llm-d.ai/accelerator-vendor: "nvidia"
llm-d.ai/model: "qwen-2-5-coder-14b"
routing:
proxy:
enabled: false # removes sidecar from deployment - no PD in inference scheduling
targetPort: 8000 # controls vLLM port to matchup with sidecar if deployed
accelerator:
dra: true
type: "nvidia"
resourceClaimTemplates:
nvidia:
class: "gpu.nvidia.com"
match: "exactly"
name: "gpu-claim-template"
decode:
create: true
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
parallelism:
tensor: 2
data: 1
replicas: 3
monitoring:
podmonitor:
enabled: true
portName: "vllm"
path: "/metrics"
interval: "30s"
containers:
- name: "vllm"
image: ghcr.io/llm-d/llm-d-cuda:v0.5.1
modelCommand: vllmServe
args:
- "--disable-uvicorn-access-log"
- "--gpu-memory-utilization=0.85"
- "--enable-auto-tool-choice"
- "--tool-call-parser"
- "hermes"
ports:
- containerPort: 8000
name: vllm
protocol: TCP
resources:
limits:
cpu: '16'
memory: 64Gi
requests:
cpu: '16'
memory: 64Gi
mountModelVolume: true
volumeMounts:
- name: metrics-volume
mountPath: /.config
- name: shm
mountPath: /dev/shm
- name: torch-compile-cache
mountPath: /.cache
startupProbe:
httpGet:
path: /v1/models
port: vllm
initialDelaySeconds: 15
periodSeconds: 30
timeoutSeconds: 5
failureThreshold: 120
livenessProbe:
httpGet:
path: /health
port: vllm
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /v1/models
port: vllm
periodSeconds: 5
timeoutSeconds: 2
failureThreshold: 3
volumes:
- name: metrics-volume
emptyDir: {}
- name: torch-compile-cache
emptyDir: {}
- name: shm
emptyDir:
medium: Memory
sizeLimit: 20Gi
prefill:
create: false
EOF
در مرحله بعد، فایل gaie-values.yaml را برای افزونه GKE Inference Gateway ایجاد کنید:
cat <<EOF > gaie-values.yaml
inferenceExtension:
replicas: 1
image:
name: llm-d-inference-scheduler
hub: ghcr.io/llm-d
tag: v0.6.0
pullPolicy: Always
extProcPort: 9002
pluginsConfigFile: "default-plugins.yaml"
tracing:
enabled: false
monitoring:
interval: "10s"
prometheus:
enabled: true
auth:
secretName: inference-scheduling-gateway-sa-metrics-reader-secret
inferencePool:
targetPorts:
- number: 8000
modelServerType: vllm
modelServers:
matchLabels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
EOF
درک پیکربندی
این پیکربندی، یک پشته استنتاج با عملکرد بالا با ویژگیهای کلیدی زیر ایجاد میکند:
- انتخاب مدل : از مدل Qwen 2.5 Coder 14B (
modelArtifacts) استفاده میکند که برای تولید کد و استفاده از ابزار بهینه شده است. - یکپارچهسازی DRA : بخش
acceleratorتخصیص پویای منابع (dra: true) را فعال میکند و کلاس دستگاهgpu.nvidia.comو الگویgpu-claim-templateکه قبلاً ایجاد کردهایم را هدف قرار میدهد. - بهینهسازی عملکرد :
-
parallelism.tensor: 2موازیسازی تانسور را در سراسر پردازندههای گرافیکی پیکربندی میکند. -
argsبرای vLLM شامل--enable-auto-tool-choiceاست تا اطمینان حاصل شود که عامل کدنویسی ما میتواند به طور مؤثر از ابزارها استفاده کند. - کاهش درخواستهای
cpuوmemoryمتناسب با نوع ماشینg2-standard-24.
-
- مسیریابی هوشمند : افزونهی Inference Gateway (
gaie-values.yaml) طوری پیکربندی شده است که سرورهای مدلvllmرا رصد کند و درخواستها را برای به حداکثر رساندن تعداد بازدیدهای KV-cache مسیریابی کند.
استقرار پشته زمانبندی استنتاج از طریق Helm
اکنون، مخازن llm-d Helm را اضافه کنید و زیرساخت، افزونه دروازه و سرویس مدل را به صورت جداگانه مستقر کنید.
ابتدا مخازن مورد نیاز را اضافه کنید:
helm repo add llm-d-infra https://llm-d-incubation.github.io/llm-d-infra/
helm repo add llm-d-modelservice https://llm-d-incubation.github.io/llm-d-modelservice/
helm repo update
استقرار پیشنیازهای زیرساختی
این نمودار، پیکربندیهای پایهی Gateway مورد نیاز برای استک را نصب میکند.
helm install infra-is llm-d-infra/llm-d-infra \
--namespace $NAMESPACE \
--set gateway.gatewayClassName=gke-l7-rilb \
--set gateway.gatewayParameters.enabled=false \
--set gateway.gatewayParameters.istio.accessLogging=false
افزونهی GKE Inference Gateway را مستقر کنید
این مرحله InferencePool و Endpoint Picker را مستقر میکند که KV-cache مدلهای شما را رصد میکند تا تصمیمات مسیریابی هوشمندی اتخاذ کند.
helm install gaie-is oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool \
--version v1.3.1 \
--namespace $NAMESPACE \
-f gaie-values.yaml \
--set provider.name=gke \
--set inferenceExtension.monitoring.prometheus.enabled=true
سرویس مدل را مستقر کنید
در نهایت، سرویس LLM خود را مستقر کنید، که اکنون از DRA برای ادعای ایمن GPU های L4 شما استفاده خواهد کرد.
helm install ms-is llm-d-modelservice/llm-d-modelservice \
--version v0.4.7 \
--namespace $NAMESPACE \
-f ms-values.yaml \
--set decode.monitoring.podmonitor.enabled=false
فعال کردن قابلیت مشاهده گوگل کلود برای vLLM
نمودارهای عمومی Helm اغلب سعی در استقرار منابع استاندارد Prometheus Operator PodMonitor ( monitoring.coreos.com/v1 ) دارند، که در صورت نصب نبودن آن CRDها میتواند باعث بروز خطا شود.
به جای فعال کردن گزینه مانیتورینگ داخلی Helm، آن را false نگه دارید و به صورت دستی یک منبع Google Cloud Managed Prometheus (GMP) PodMonitoring را با استفاده از گروه API سازگار monitoring.googleapis.com/v1 اعمال کنید.
برای ایجاد podmonitoring.yaml دستور زیر را اجرا کنید:
cat > podmonitoring.yaml <<EOF
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: ms-vllm-metrics
spec:
selector:
matchLabels:
llm-d.ai/model: "qwen-2-5-coder-14b" # Matches the label in values.yaml
endpoints:
- port: 8000 # vllm port
interval: 30s
path: /metrics
EOF
منبع PodMonitoring را روی کلاستر خود اعمال کنید:
kubectl apply -f podmonitoring.yaml -n $NAMESPACE
نصب را تأیید کنید
تأیید کنید که اجزا با موفقیت نصب شدهاند. باید هر سه نسخه Helm را در فضای نام خود فعال و پادهای مربوطه را در حال راهاندازی اولیه ببینید.
helm ls -n $NAMESPACE
kubectl get pods -n $NAMESPACE
بالا آمدن پادهای ms-is میتواند حدود ۵ تا ۱۰ دقیقه طول بکشد. وقتی این اتفاق میافتد، خروجی باید چیزی شبیه به این باشد:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
gaie-is ai-agents 1 2026-03-28 16:51:41.055881618 +0000 UTC deployed inferencepool-v1.3.1 v1.3.1
infra-is ai-agents 1 2026-03-28 16:51:03.71042542 +0000 UTC deployed llm-d-infra-v1.4.0 v0.4.0
ms-is ai-agents 1 2026-03-28 17:30:00.341918958 +0000 UTC deployed llm-d-modelservice-v0.4.7 v0.4.0
NAME READY STATUS RESTARTS AGE
gaie-is-epp-848965cb4-78ktp 1/1 Running 0 10m
ms-is-llm-d-modelservice-decode-67548d5f8c-f25f4 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-rblvs 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-w6fcd 1/1 Running 0 6m2s
۵. پیکربندی مسیریابی هوشمند با GKE Inference Gateway
در مرحله ۴، با استقرار نمودارهای llm-d Helm، اشیاء Gateway و InferencePool شما به طور خودکار آمادهسازی شدند. InferencePool مدل vllm شما را که به Podهایی که مدل پایه و پیکربندی محاسباتی یکسانی دارند، ارائه میدهد، گروهبندی میکند.
اکنون، باید یک InferenceObjective برای تعیین اولویت درخواستهای عامل کدنویسی خود و یک HTTPRoute را برای آموزش نحوه مسیریابی ترافیک ورودی به Gateway پیکربندی کنید و از Endpoint Picker برای به حداکثر رساندن بازدیدهای KV-cache استفاده کنید.
منابع تولید شده خودکار را تأیید کنید
ابتدا، تأیید کنید که نمودارهای llm-d Helm با موفقیت منابع Gateway و InferencePool را ایجاد کردهاند.
kubectl get gateway,inferencepool -n $NAMESPACE
شما باید یک Gateway با نام infra-is-inference-gateway و یک InferencePool با نام gaie-is ببینید. مشابه این:
NAME CLASS ADDRESS PROGRAMMED AGE
gateway.gateway.networking.k8s.io/infra-is-inference-gateway gke-l7-regional-internal-managed 10.128.0.5 True 13m
NAME AGE
inferencepool.inference.networking.k8s.io/gaie-is 12m
ایجاد HTTPRoute
منبع HTTPRoute Gateway شما را به InferencePool بکاند نگاشت میکند. این به GKE Inference Gateway میگوید که بدنههای درخواست ورودی را تجزیه و تحلیل کند و آنها را به صورت پویا مسیریابی کند تا بر اساس زمینه مشترک، تعداد بازدیدهای Prefix-Cache را به حداکثر برساند.
برای ایجاد httproute.yaml دستور زیر را اجرا کنید:
cat > httproute.yaml <<EOF
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: agent-route
spec:
parentRefs:
- group: gateway.networking.k8s.io
kind: Gateway
name: infra-is-inference-gateway
rules:
- backendRefs:
- group: inference.networking.k8s.io
kind: InferencePool
name: gaie-is
weight: 1
matches:
- path:
type: PathPrefix
value: /
EOF
مسیر را به خوشه خود اعمال کنید:
kubectl apply -f httproute.yaml -n $NAMESPACE
۶. اجرای امن کد با Agent Sandbox
اکنون که بخش استنتاج با عملکرد بالای ما در حال اجرا است، بیایید محیط امنی را آماده کنیم که در آن کد تولید شده توسط هوش مصنوعی با استفاده از یک Agent Sandbox به صورت ایمن و جدا از کلاستر ما اجرا شود.
کنترلر Agent Sandbox را مستقر کنید
وقتی یک عامل هوش مصنوعی کدی را تولید و اجرا میکند، اساساً یک بار کاری غیرقابل اعتماد را روی زیرساخت شما اجرا میکند. اگر این عامل کد مخرب تولید کند، میتواند تلاش کند شبکه داخلی شما را اسکن کند یا از گره میزبان اصلی سوءاستفاده کند.
GKE Agent Sandbox از gVisor ، یک محیط اجرای کانتینر متنباز که یک هسته مهمان اختصاصی برای هر کانتینر فراهم میکند، استفاده میکند. این امر از فراخوانی مستقیم سیستم توسط کدهای غیرقابل اعتماد به گره میزبان جلوگیری میکند.
با اعمال مانیفستهای رسمی انتشار، کنترلر Agent Sandbox و اجزای مورد نیاز آن را مستقر کنید:
kubectl apply \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/manifest.yaml \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/extensions.yaml
پیکربندی قالب Sandbox و Warm Pool
در مرحله بعد، ما یک SandboxTemplate ایجاد میکنیم که به عنوان یک طرح اولیه قابل استفاده مجدد برای محیطهای تحلیل پایتون ما عمل میکند و به صراحت کلاس زمان اجرای gvisor را هدف قرار میدهد. برای سادهسازی استقرار بدون مدیریت دستی گرههای کلاسترهای استاندارد، میتوانیم از هر autopilot استانداردی استفاده کنیم.
ComputeClass برای ارائه پویای گرههای محاسباتی مدیریتشده که به صورت بومی از حجم کاری gVisor در صورت تقاضا پشتیبانی میکنند!
از آنجا که مقداردهی اولیه یک هسته امن میتواند باعث افزایش تأخیر شود، ما همچنین یک SandboxWarmPool راهاندازی میکنیم. این امر تضمین میکند که تعداد مشخصی از جعبههای شنی از پیش مقداردهی شده آماده نگه داشته میشوند تا عامل تولید کد بتواند آنها را تصاحب کرده و اجرای کد را در کمتر از یک ثانیه آغاز کند.
ابتدا، یک فضای نام جدید برای زمانهای اجرای جعبه شنی عامل ایجاد کنید:
kubectl create namespace agent-sandbox
موارد زیر را با نام sandbox-template-and-pool.yaml ذخیره کنید:
cat > sandbox-template-and-pool.yaml <<EOF
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxTemplate
metadata:
name: python-runtime-template
namespace: agent-sandbox
spec:
podTemplate:
metadata:
labels:
sandbox: python-sandbox-example
spec:
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: python-runtime
image: registry.k8s.io/agent-sandbox/python-runtime-sandbox:v0.1.0
ports:
- containerPort: 8888
readinessProbe:
httpGet:
path: "/"
port: 8888
initialDelaySeconds: 0
periodSeconds: 1
resources:
requests:
cpu: "250m"
memory: "512Mi"
ephemeral-storage: "512Mi"
restartPolicy: "OnFailure"
---
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxWarmPool
metadata:
name: python-sandbox-warmpool
namespace: agent-sandbox
spec:
replicas: 2
sandboxTemplateRef:
name: python-runtime-template
EOF
پیکربندی را اعمال کنید:
kubectl apply -f sandbox-template-and-pool.yaml
۲ تا ۳ دقیقه صبر کنید تا پادهای warmpool راهاندازی شوند. میتوانید با استفاده از دستور زیر بررسی کنید که آیا با موفقیت از Pending (در حالی که محاسبات زیربنایی افزایش مییابد) به Running ) منتقل میشوند یا خیر:
kubectl get pods -n agent-sandbox -w
به محض اینکه دو پاد python-sandbox-warmpool-*** را به عنوان Running و 1/1 آماده مشاهده کردید، محیطهای اجرای امن شما از قبل گرم شده و آمادهی استفاده هستند!
روتر Sandbox را مستقر کنید
عامل تولید کد ما برای ارسال ایمن دستورات اجرایی به پادهای ایزوله، به یک روتر Sandbox متکی است.
دستور زیر را برای ایجاد sandbox-router.yaml اجرا کنید:
cat > sandbox-router.yaml <<EOF
apiVersion: v1
kind: Service
metadata:
name: sandbox-router-svc
namespace: agent-sandbox
spec:
type: ClusterIP
selector:
app: sandbox-router
ports:
- name: http
protocol: TCP
port: 8080
targetPort: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sandbox-router-deployment
namespace: agent-sandbox
spec:
replicas: 2
selector:
matchLabels:
app: sandbox-router
template:
metadata:
labels:
app: sandbox-router
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: sandbox-router
containers:
- name: router
image: us-central1-docker.pkg.dev/k8s-staging-images/agent-sandbox/sandbox-router:v20260225-v0.1.1.post3-10-ga5bcb57
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 10
resources:
requests:
cpu: "250m"
memory: "512Mi"
limits:
cpu: "1000m"
memory: "1Gi"
securityContext:
runAsUser: 1000
runAsGroup: 1000
EOF
پیکربندی را اعمال کنید:
kubectl apply -f sandbox-router.yaml
پیادهسازی جداسازی شبکه
برای قفل کردن بیشتر محیط اجرا و جلوگیری از هرگونه حرکت جانبی غیرمجاز، یک خطمشی شبکه اعمال کنید. این کار باعث ایجاد «شکاف هوایی» در سندباکس میشود تا نتواند به سرور ابرداده گوگل یا سایر شبکههای داخلی حساس دسترسی پیدا کند.
موارد زیر را با نام sandbox-policy.yaml ذخیره کنید:
cat > sandbox-policy.yaml <<EOF
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: restrict-sandbox-egress
namespace: agent-sandbox
spec:
podSelector:
matchLabels:
sandbox: python-sandbox-example
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 0.0.0.0/0
except:
- 169.254.169.254/32 # Block metadata server
EOF
اعمال سیاست:
kubectl apply -f sandbox-policy.yaml
تأیید قطعات
برای اطمینان از پیکربندی کامل لایه کلاستر سندباکس کد ایزوله، دستورات اعتبارسنجی وضعیت زیر را اجرا کنید:
ابتدا، بررسی کنید که پادها و روترهای سندباکس در حال اجرا و آماده به کار هستند.
kubectl get pods -n agent-sandbox
خروجی باید چیزی شبیه به این باشد:
NAME READY STATUS RESTARTS AGE
python-sandbox-warmpool-7zlkv 1/1 Running 0 3m25s
python-sandbox-warmpool-cxln2 1/1 Running 0 3m25s
sandbox-router-deployment-668dfbbbb6-g9mpd 1/1 Running 0 42s
sandbox-router-deployment-668dfbbbb6-ppllz 1/1 Running 0 42s
بررسی متعادلکننده بار/معرضبودن IP در روتر سندباکس
kubectl get service sandbox-router-svc -n agent-sandbox
خروجی باید به شکل زیر باشد:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
sandbox-router-svc ClusterIP 34.118.237.244 <none> 8080/TCP 114s
تأیید کنید که قانون سیاست شبکه خروجی وجود دارد
kubectl get networkpolicy restrict-sandbox-egress -n agent-sandbox
خروجی باید به شکل زیر باشد:
NAME POD-SELECTOR AGE
restrict-sandbox-egress sandbox=python-sandbox-example 113s
مطمئن شوید که:
- پادهای
python-sandbox-warmpool-***Runningو1/1آماده هستند. - کپیهای
sandbox-router-deployment-***Runningو1/1آماده هستند. -
sandbox-router-svcقابل دسترسی است و سیاستrestrict-sandbox-egressبا موفقیت از هرگونه برچسب سندباکس منطبق محافظت میکند.
با ایمنسازی و مقداردهی اولیه محیط اجرای امن، آمادهایم تا مغز متفکر عملیات خود را مستقر کنیم: عامل تولید کد!
۷. ساخت و استقرار عامل تولید کد (ADK)
با پیکربندی هر دو سندباکس اجرای ایمن و بکاند LLM با عملکرد بالای خود، اکنون میتوانیم «مغز» سیستم خود را بسازیم: یک عامل تولید کد با استفاده از کیت توسعه عامل (ADK) .
این عامل به گونهای طراحی شده است که به عنوان یک توسعهدهنده متخصص پایتون عمل کند. برخلاف یک چتبات استاندارد که فقط متن تولید میکند، این عامل به یک ابزار اجرای کد مجهز است که به آن اجازه میدهد تا به صورت تعاملی مشکلات را حل کند. این عامل از یک حلقه پیروی میکند:
- نوشتن کد پایتون بر اساس درخواستهای شما.
- اجرای امن کد درون GKE Agent Sandbox که در مرحله 6 راهاندازی کردیم.
- تأیید خروجی یا خواندن هرگونه خطایی که هنگام اجرا رخ میدهد.
- ارائه یک راه حل آزمایش شده و کارآمد با اطمینان.
با دسترسی دادن به عامل (agent) به یک محیط اجرای امن سندباکس (sandbox)، ما آن را قادر میسازیم تا منطق خود را تأیید کند و خطاهای خود را به طور خودکار اشکالزدایی کند، که این امر آن را به طور قابل توجهی در انجام وظایف توسعه نرمافزار توانمندتر میکند!
توسعه عامل استدلال ADK
ابتدا، منطق پایتون را مینویسیم که رفتار عامل را تعریف میکند و آن را به ابزار Sandbox که در مرحله 6 ایجاد کردیم، مجهز میکنیم. در این بخش، یک استراتژی مدل ترکیبی را نیز پیکربندی میکنیم: عامل، یک مدل Qwen خود-میزبان را که روی خوشه GKE شما اجرا میشود، در اولویت قرار میدهد، اما اگر مدل محلی کند یا در دسترس نباشد، به طور خودکار به Gemini 2.5 Flash روی Vertex AI برمیگردد و قابلیت اطمینان بالایی را تضمین میکند.
یک دایرکتوری جدید برای کد عامل ایجاد کنید:
mkdir -p ~/gke-ai-agent-lab/root_agent
cd ~/gke-ai-agent-lab
فایلی با نام root_agent/agent.py با محتوای زیر ایجاد کنید:
cat <<'EOF' > root_agent/agent.py
import os
from google.adk.agents import Agent
from google.adk.models.lite_llm import LiteLlm
from k8s_agent_sandbox import SandboxClient
import requests
# Instantiate the client globally to track sandboxes
sandbox_client = SandboxClient()
def run_python_code(code: str) -> str:
"""
Executes Python code safely in the GKE Agent Sandbox.
Use this tool whenever you need to execute code to solve a problem.
"""
sandbox = sandbox_client.create_sandbox(template="python-runtime-template", namespace="agent-sandbox")
try:
command = f"python3 -c \"{code}\""
result = sandbox.commands.run(command)
if result.stderr:
return f"Error: {result.stderr}"
return result.stdout
finally:
# Ensure the sandbox is deleted after use to avoid leaking resources
sandbox_client.delete_sandbox(sandbox.claim_name, namespace="agent-sandbox")
# Define the ADK Agent with a fallback mechanism.
# It prioritizes the Qwen 2.5 Coder model running on our Inference Gateway.
# If the local model is unavailable, it falls back to Gemini 2.5 Flash on Vertex AI.
root_agent = Agent(
name="CodeGenerationAgent",
model=LiteLlm(
model="openai/Qwen/Qwen2.5-Coder-14B-Instruct",
fallbacks=["vertex_ai/gemini-2.5-flash"],
timeout=10
),
instruction="""
You are an expert Python developer.
1. Write Python code to solve the user's problem.
2. Execute the code using the `run_python_code` tool to verify it works.
3. Return the exact output and a brief explanation of the code.
""",
tools=[run_python_code]
)
EOF
یک فایل __init__.py ایجاد کنید تا ADK ماژول را تشخیص دهد:
echo "from . import agent" > ~/gke-ai-agent-lab/root_agent/__init__.py
متغیرهای محیطی را تنظیم کنید. برنامه ADK برای مسیریابی موفقیتآمیز درخواستهای LLM به آدرس IP دروازه شما نیاز دارد. از آنجا که ADK از نقاط پایانی استاندارد سازگار با Open-AI (که vLLM از طریق دروازه ما ارائه میدهد) پشتیبانی میکند، میتوانیم URL پایه API پیشفرض را نادیده بگیریم!
export GATEWAY_IP=$(kubectl get gateway infra-is-inference-gateway -n $NAMESPACE -o jsonpath='{.status.addresses[0].value}')
cat <<EOF > ~/gke-ai-agent-lab/root_agent/.env
OPENAI_API_BASE=http://${GATEWAY_IP}/v1
OPENAI_API_KEY=no-key-required
# Vertex AI settings for fallback (Authentication is handled by Workload Identity)
VERTEXAI_PROJECT=$PROJECT_ID
VERTEXAI_LOCATION=${ZONE%-[a-z]}
EOF
کانتینر کردن برنامه عامل
ما باید عامل را طوری بستهبندی کنیم که بتواند به طور ایمن درون GKE اجرا شود.
یک Dockerfile در ~/gke-ai-agent-lab ایجاد کنید که kubectl ، کتابخانه ADK و کلاینت Agent Sandbox را نصب کند:
cat <<'EOF' > ~/gke-ai-agent-lab/Dockerfile
FROM python:3.11-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
RUN apt-get update && apt-get install -y git curl \
&& curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl" \
&& install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl \
&& rm kubectl && apt-get clean && rm -rf /var/lib/apt/lists/*
RUN pip install --no-cache-dir "google-adk[extensions,otel-gcp]>=1.27.4" litellm pandas "git+https://github.com/kubernetes-sigs/agent-sandbox.git@main#subdirectory=clients/python/agentic-sandbox-client" \
"opentelemetry-instrumentation-google-genai>=0.4b0" \
"opentelemetry-exporter-otlp" \
"opentelemetry-instrumentation-vertexai>=2.0b0"
COPY ./root_agent /app/root_agent
EXPOSE 8080
ENTRYPOINT ["adk", "web", "--host", "0.0.0.0", "--port", "8080", "--otel_to_cloud"]
EOF
یک مخزن Artifact Registry برای ذخیره تصویر کانتینر ایجاد کنید.
gcloud artifacts repositories create agent-repo \
--repository-format=docker \
--location=us-central1
از Cloud Build برای ساخت و انتشار ایمیج کانتینر استفاده کنید.
gcloud builds submit --tag us-central1-docker.pkg.dev/$PROJECT_ID/agent-repo/code-agent:v1 ~/gke-ai-agent-lab/
با RBAC به GKE مستقر شوید
در نهایت، عامل را در کلاستر خود مستقر کنید. این استقرار شامل یک Role و RoleBinding است که به عامل اجازه میدهد تا نمونههایی را از SandboxWarmPool مطالبه کند.
این استقرار از یک Kubernetes ServiceAccount استفاده میکند تا عامل شما بتواند با API مربوط به Sandbox Claim ارتباط برقرار کند. از آنجایی که به منابع خوشهای محلی و یک نقطه پایانی دروازه vLLM محلی دسترسی دارد، نیازی به Google IAM ServiceAccount ندارد.
چرا استقرار استاندارد در gVisor؟
در مرحله ۶، ما از APIهای SandboxTemplate و SandboxClaim برای ایجاد جعبههای شنی (sandbox) موقت و یکبار مصرف برای کد پایتون تولید شده (اجرای ابزار) استفاده کردیم.
برای رابط کاربری وب Agent (یا همان Brain) ، ما از مشخصات استاندارد Kubernetes Deployment با runtimeClassName: gvisor استفاده میکنیم.
- وجه تمایز : Standard
SandboxClaimsزودگذر و صفر به یک هستند (ایدهآل برای اسکریپتهای غیرقابل اعتماد). یک StandardDeploymentطولانیمدت و پایدار است - برای رابطهای کاربری وب که به یکServiceKubernetes پایدار و متعادلکننده بار نیاز دارند، ایدهآل است! با استفاده مستقیم ازruntimeClassName: gvisorدر یک Standard Deployment، شما جداسازی هسته gVisor را در عین حفظ ویژگیهای استانداردDeploymentدریافت میکنید.
موارد زیر را با نام deployment.yaml ذخیره کنید:
cat <<EOF > ~/gke-ai-agent-lab/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: code-agent
labels:
app: code-agent
spec:
replicas: 1
selector:
matchLabels:
app: code-agent
template:
metadata:
labels:
app: code-agent
spec:
serviceAccount: adk-agent-sa
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: code-agent
image: us-central1-docker.pkg.dev/YOUR_PROJECT_ID/agent-repo/code-agent:v1
imagePullPolicy: Always
env:
- name: OPENAI_API_KEY
value: "no-key-required"
- name: OPENAI_API_BASE
value: "http://YOUR_GATEWAY_IP/v1"
- name: VERTEXAI_PROJECT
value: "YOUR_PROJECT_ID"
- name: VERTEXAI_LOCATION
value: "YOUR_REGION"
- name: OTEL_SERVICE_NAME
value: "code-agent"
- name: GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY
value: "true"
- name: OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT
value: "true"
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: code-agent-service
spec:
selector:
app: code-agent
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: agent-sandbox
name: sandbox-creator-role
rules:
- apiGroups: [""]
resources: ["services", "pods", "pods/portforward"]
verbs: ["get", "list", "watch", "create"]
- apiGroups: ["extensions.agents.x-k8s.io"]
resources: ["sandboxclaims"]
verbs: ["create", "get", "list", "watch", "delete"]
- apiGroups: ["agents.x-k8s.io"]
resources: ["sandboxes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: adk-agent-binding
namespace: agent-sandbox
subjects:
- kind: ServiceAccount
name: adk-agent-sa
namespace: default
roleRef:
kind: Role
name: sandbox-creator-role
apiGroup: rbac.authorization.k8s.io
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: adk-agent-sa
EOF
مجوزهای IAM را برای مشاهدهپذیری اعطا کنید
برای اینکه agent بتواند دادههای تلهمتری (لاگها و ردیابیها) را به Google Cloud ارسال کند، باید مجوزهای لازم را با استفاده از Workload Identity به حساب سرویس Kubernetes، adk-agent-sa اعطا کنید.
دستورات زیر را در Cloud Shell خود اجرا کنید:
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# Grant permission to write logs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/logging.logWriter \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to write traces
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/cloudtrace.agent \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to use Vertex AI
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/aiplatform.user \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
دستور زیر را اجرا کنید تا YOUR_PROJECT_ID به طور خودکار با شناسه پروژه واقعی شما جایگزین شود و پیکربندی اعمال شود!
sed -i "s/YOUR_PROJECT_ID/$PROJECT_ID/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_GATEWAY_IP/$GATEWAY_IP/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_REGION/$ZONE/g" ~/gke-ai-agent-lab/deployment.yaml
kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml
۸. مشاهده و اعتبارسنجی
وقت آن رسیده که سیستم کاملاً یکپارچه را آزمایش کنیم.
عامل تولید کد را در رابط کاربری آزمایش کنید
IP خارجی رابط کاربری وب ADK خود را پیدا کنید:
kubectl get services code-agent-service
خروجی باید چیزی شبیه به این باشد:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
code-agent-service LoadBalancer 34.118.230.182 34.31.250.60 80:32471/TCP 2m14s
- یک مرورگر باز کنید و به
http://[EXTERNAL-IP]بروید. - در رابط وب ADK، مطمئن شوید که "root_agent" از منوی کشویی در بالا سمت راست انتخاب شده است. سپس، از agent درخواست کنید:
Write a python script that prints 'Hello from the isolated sandbox'.
برای مشاهده نحوه استفاده عامل از بخش استنتاج و سندباکس، برای مشاهده داشبوردها به بخشهای «کاوش آمار مدل از طریق مشاهده ابری» و «کاوش مشاهده عامل از طریق رابط کاربری GKE» در زیر مراجعه کنید.
مشاهدهپذیری عامل را از طریق رابط کاربری GKE بررسی کنید
حالا که چند دستور را اجرا کردهاید، بیایید نگاهی به دادههای تلهمتری بیندازیم. این به شما کمک میکند تا نحوه عملکرد زمانبندی استنتاج و vLLM را درک کنید.
دسترسی به داشبوردهای نمایندگان
- به صفحه Kubernetes Engine > Workloads بروید.
- برای باز کردن صفحه جزئیات استقرار ، روی استقرار کد-اِیجن کلیک کنید.
- روی برگه مشاهدهپذیری کلیک کنید.
- در پنل ناوبری سمت چپ داشبورد مشاهدهپذیری، بخش جدید Agent با زیربرگهها را مشاهده خواهید کرد.
چه چیزی را باید بررسی کرد
برای مشاهده رفتار برنامه عامل خود، زیربرگههای زیر را بررسی کنید:
- مرور کلی: کارتهای امتیاز مربوط به جلسات، میانگین نوبتها و فراخوانها را مشاهده کنید.
- مدلها: تعداد فراخوانیهای مدل، نرخ خطا و تأخیر دستهبندیشده بر اساس مدلهایی که عامل شما استفاده کرده است را مشاهده کنید.
- ابزارها: فراخوانی ابزارها و مدت زمان اجرا را رصد کنید تا ببینید عامل شما چقدر مؤثر از ابزار اجرای sandbox خود استفاده میکند.
- میزان استفاده: میزان استفاده از توکن و تخصیص منابع استاندارد کانتینر (پردازنده و حافظه) را پیگیری کنید.
- ردیابی عامل: برای مشاهده لیستی از جلسات اجرا یا بازههای ردیابی خام، به این برگه بروید. کلیک روی یک ردیف، یک پنجره شناور با جزئیات ردیابی انتخاب شده باز میکند!
با ترکیب معیارهای سطح مدل از vLLM با تلهمتری سطح برنامه از ADK، اکنون قابلیت مشاهدهپذیری کامل برای عامل هوش مصنوعی مولد خود در GKE دارید!
بررسی آمار مدل vLLM از طریق قابلیت مشاهده ابری
حالا که چند دستور را اجرا کردهاید، بیایید نگاهی به دادههای تلهمتری بیندازیم. این به شما کمک میکند تا نحوه عملکرد زمانبندی استنتاج و vLLM را درک کنید.
دسترسی به داشبوردها
- به کنسول ابری گوگل بروید.
- به بخش نظارت > داشبوردها بروید.
- داشبورد vLLM Prometheus Overview را جستجو و انتخاب کنید.
معیارهای جالب برای مشاهده
هنگام مشاهده داشبورد، به این معیارهای کلیدی توجه کنید تا تأثیر GKE Inference Gateway و prefix-caching را مشاهده کنید:
- میزان استفاده از حافظه نهان KV (
vllm:gpu_cache_usage):- دلیل اهمیت: این نشان میدهد که چه مقدار از حافظه GPU برای ذخیره متن استفاده میشود. اگر این مقدار زیاد باشد، به این معنی است که سیستم برای سرعت بخشیدن به درخواستهای آینده، متن را نگه میدارد. اگر چندین بار یک اعلان را اجرا کنید، باید شاهد افزایش و سپس تثبیت این میزان استفاده باشید.
- درخواستهای در حال اجرا در مقابل درخواستهای در حال انتظار (
vllm:num_requests_runningدر مقابلvllm:num_requests_waiting):- دلیل اهمیت: این نشان دهنده بار است. اگر درخواستهای انتظار زیاد باشد، به این معنی است که گرههای شما بیش از حد بارگذاری شدهاند.
- توان عملیاتی توکن (
vllm:request_prompt_tokens_totوvllm:request_generation_tokens_tot):- دلیل اهمیت: حجم توکنهای ورودی و خروجی پردازششده توسط کلاستر را پیگیری کنید.
- زمان دریافت اولین توکن (TTFT) :
- دلیل اهمیت: این معیار حیاتی برای عاملهای تعاملی است. با استفاده از GKE Inference Gateway به همراه Prefix-Cache Aware Routing، درخواستهایی که زمینههای مشترکی (مانند اعلانهای سیستم یا پنجرههای زمینه بزرگ) را به اشتراک میگذارند، به یک کپی یکسان هدایت میشوند و با استفاده مجدد از بازدیدهای حافظه پنهان موجود، TTFT را به حداقل میرسانند!
آزمایشهایی برای امتحان کردن
این سناریوها را امتحان کنید تا تغییر معیارها را در لحظه ببینید و زمانبندی مناسب را تأیید کنید!
آزمایش ۱: «سرعت تکرار» (ضربه به حافظه پنهان پیشوند)
- یک درخواست پیچیده به عامل ارسال کنید (مثلاً «یک اسکریپت پایتون بنویسید تا یک فایل CSV با حجم ۱۰۰ مگابایت را تجزیه و تحلیل کرده و آمار آن را محاسبه کند.» ).
- به محض اینکه پاسخ داد، بلافاصله همان پیام را دوباره ارسال کنید.
- نرخ موفقیت در حافظه پنهان پیشوند (Prefix Cache Hit Rate) و زمان رسیدن به اولین توکن (TTFT) را مشاهده کنید.
- چیزی که باید ببینید: نرخ موفقیت در کش پیشوند باید به ۱۰۰٪ افزایش یابد و TTFT باید به طرز چشمگیری کاهش یابد!
- معنی آن: دروازه استنتاج GKE زمینه مشترک را تشخیص داد و آن را دقیقاً به همان کپی که از حافظه نهان زمینه ارزیابی شده خود استفاده مجدد میکرد، هدایت کرد!
آزمایش ۲: بازگشت به ابر (قابلیت اطمینان مدل)
- برای شبیهسازی خرابی مدل محلی Qwen خود، میتوانید سرویس استنتاج را متوقف کنید یا به سادگی یک
OPENAI_API_BASEجعلی در پیادهسازی ارائه دهید. -
OPENAI_API_BASEرا درdeployment.yamlخود به یک IP یا پورت ناموجود بهروزرسانی کنید و تغییرات را اعمال کنید:sed -i "s|value: \"http://$GATEWAY_IP/v1\"|value: \"http://10.0.0.1:8080/v1\"|g" ~/gke-ai-agent-lab/deployment.yaml kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml - صبر کنید تا پاد دوباره راهاندازی شود، سپس در رابط کاربری، پیامی به عامل ارسال کنید.
- آنچه باید ببینید: اپراتور همچنان با موفقیت پاسخ میدهد!
- معنی آن: به دلیل پیکربندی
fallbacks، ADK خرابی نقطه پایانی محلی Qwen را تشخیص داد و درخواست را به طور یکپارچه به Gemini 2.5 Flash روی Vertex AI هدایت کرد. توجه داشته باشید که از آنجا که این فراخوانیهای fallback به Vertex AI از vLLM Inference Gateway محلی شما عبور میکنند، در داشبورد Agent Observability > Models که فقط ترافیک عبوری از vLLM را ردیابی میکند، ظاهر نمیشوند.
درک قدرت تخصیص منابع پویا (DRA)
در حالی که vLLM و Inference Gateway نحوه مسیریابی و ارائه درخواستها را بهینه میکنند، تخصیص پویای منابع (DRA) همان چیزی است که از همان ابتدا امکان اتصال سختافزار دقیقاً مناسب به بار کاری شما را فراهم میکند.
DRA با فراهم کردن امکان تعریف منابع سختافزاری انعطافپذیر با استفاده از ResourceClaimTemplate و DeviceClasses ، توانایی شما را در مدیریت جزئیتر سختافزار در سراسر کلاسترتان افزایش میدهد.
چرا DRA برای بارهای کاری هوش مصنوعی انقلابی است؟
- درخواستهای سختافزاری دقیق : با DRA، شما نه تنها از زمانبندی بارهای کاری روی ماشینهایی با شتابدهنده مناسب اطمینان حاصل میکنید، بلکه میتوانید ادعایی بر روی آن منابع نیز داشته باشید تا مطمئن شوید که آنها منحصراً توسط بار کاری مرتبط با ResourceClaim استفاده میشوند.
- چرخه حیات جدا شده : ادعاهای مربوط به دستگاه مستقل از چرخه حیات Pod مدیریت میشوند. اگر یک Pod از کار بیفتد، ادعای مربوط به GPU میتواند پابرجا بماند، به طوری که استقرار کلی یا سایر اشیاء بار کاری بدون نیاز به انتظار برای آزادسازی و دریافت مجدد GPU، مجدداً راهاندازی شود.
- استانداردسازی چندفروشندهای : DRA یک API یکپارچه Kubernetes را برای GPUهای NVIDIA و TPUهای Google ارائه میدهد. شما چه برای یکی از آنها و چه برای دیگری مستقر شوید، از طرحواره دقیقاً یکسانی استفاده میکنید و این باعث میشود بار کاری شما به صورت YAML به شدت قابل حمل باشد!
در این آزمایشگاه کد، این را در عمل مشاهده کردید، زمانی که مقادیر Helm خود را طوری پیکربندی کردید که به طور یکپارچه به gpu-claim-template متصل شوند، بدون اینکه تنظیمات افزونه دستگاه هنگ کرده، مانع از اجرای برنامههای شما شود.
درک نقش llm-d
در حالی که vLLM وزنهای عصبی را ارزیابی میکند و GKE Gateway پرسوجوها را مسیریابی میکند، llm-d به عنوان لایه پیکربندی و "چسبی" که همه آنها را به هم متصل میکند، عمل میکند.
بدون llm-d ، شما مجبور بودید مانیفستهای خام Kubernetes را برای اعلام استقرار vLLM ، پورتهای سرویس، نصبهای Volume و ادعاهای منابع DRA خود از ابتدا بنویسید.
چرا از llm-d در استقرار خود استفاده کنیم؟
- پیکربندی یکپارچه (لغو دستورات تکخطی) : نمودارهای
llm-dHelm منابع پیچیده و سطح پایین Kubernetes را در گزینههای سطح بالا و واضح (مانند تنظیمaccelerator.dra: true) دستهبندی میکنند. - «مسیرهای با نور مناسب» از پیش بررسیشده : مخزن
llm-dشامل پیکربندیهایی است که از قبل توسط متخصصان محک زده و آزمایش شدهاند. وقتیllm-d-modelserviceرا مستقر میکنید، پیشفرضهای بهینهشده برای استفاده از حافظه GPU، زمانبندیهای پیشنهادی برای پروب (liveness/readiness) و نوردهیهای صحیح برای جمعآوری معیارها را دریافت میکنید. - نگاشت مشاهدهپذیری یکپارچه :
llm-dبه صورت پیشفرض تضمین میکند که پورتهای استاندارد کانتینر و مسیرهای scrape (/metrics) به درستی نمایش داده شوند و اتصال استقرار شما به Google Cloud Monitoring را بدون اشکالزدایی دستی آسان میکند.
به طور خلاصه، llm-d طرحهای معماری قابل استفاده مجدد را ارائه میدهد، بنابراین توسعهدهندگان مجبور نیستند هر بار که یک پشته استنتاج را در GKE مستقر میکنند، چرخ را از نو اختراع کنند.
بررسی عمیق: دروازه استنتاج GKE
متعادلکنندههای بار استاندارد لایه ۷ با نگاه کردن به هدرهای HTTP مانند مسیرها ( /v1/completions ) یا کوکیها عمل میکنند. دروازه استنتاج GKE بسیار عمیقتر عمل میکند - این دروازه به طور خاص برای ترافیک مولد هوش مصنوعی طراحی شده است.
چگونه عملکرد و کارایی را افزایش میدهد:
- مسیریابی آگاه از محتوا (هشینگ اعلان) : دروازه استنتاج GKE بدنه درخواست JSON را رهگیری میکند. هش اعلان را محاسبه کرده و ردیابی میکند که کدام کپی backend از قبل آن توکنها را در حافظه GPU خود (KV Cache) نگه داشته است.
- به حداکثر رساندن بازدیدهای حافظه پنهان : در آزمایش شما، وقتی یک اعلان را تکرار میکردید، Gateway آن را دقیقاً به همان نسخه مشابه ارسال میکرد. ارزیابی یک اعلان نیاز به محاسبات سنگین دارد. با استفاده مجدد از حافظه پنهان، از "خواندن مجدد" اعلان جلوگیری میکنید و در هزینه و زمان GPU صرفهجویی میکنید.
- کاهش زمان اولین توکن (TTFT) : TTFT معیار سنجش قابلیت استفاده حیاتی برای عوامل انسانی است. با فعال کردن حافظه پنهان، مدل میتواند به جای ثانیه، توکنها را در میلیثانیه تولید کند.
- توزیع هوشمند بار : اگر VRAM یک کپی کاملاً پر از دادههای کش باشد، Gateway میتواند به صورت پویا یک اعلان جدید را به کپی دیگری که فضای کافی دارد، هدایت کند و کارایی را با در دسترس بودن متعادل سازد.
چگونه Agent Sandbox ریسک را کاهش میدهد
در این آزمایشگاه، ما نشان دادیم که چگونه Agent Sandbox با ارائه دو لایه جداسازی، زیرساخت شما را از خطرات مرتبط با عوامل هوش مصنوعی محافظت میکند:
- ایزوله کردن ابزار اجرا : عامل، کدی را که تولید میکند در یک محیط موقت اجرا میکند. این امر تضمین میکند که کد غیرقابل اعتماد تولید شده توسط LLM در یک محیط امن و ایزوله اجرا میشود و از عامل و خوشه محافظت میکند.
- راهاندازی سریع : با استفاده از WarmPool، سندباکسهای جدید در کمتر از یک ثانیه راهاندازی میشوند و آماده اجرای کد هستند.
- ایزوله کردن خود عامل : ما همچنین خود برنامه عامل را در یک گره فعال شده با gVisor (از طریق
runtimeClassName: gvisor) اجرا کردیم تا دفاع عمیقی در برابر آسیبپذیریهای زنجیره تأمین در وابستگیهای عامل ارائه دهیم.
به همین دلیل است که این امر چنین مرز امنیتی مستحکمی ایجاد میکند:
- رهگیری فراخوانی سیستم : gVisor فراخوانیهای سیستم را قبل از رسیدن به هسته لینوکس میزبان رهگیری میکند. این کار، سوءاستفادههایی را که سعی در خروج از کانتینر برای دسترسی به گره میزبان دارند، مسدود میکند.
- حرکت جانبی محدود : در ترکیب با سیاستهای شبکه، حتی اگر یک محیط به خطر بیفتد، نمیتواند سرورهای فراداده داخلی شما را اسکن کند یا به سایر سرویسهای حساس در خوشه شما متصل شود.
اجرای Full Agentها در Sandboxها
در این آزمایش، ما از جعبههای شنی (sandboxes) به عنوان ابزاری برای یک برنامه عامل پایدار استفاده کردیم. با این حال، برای حداکثر امنیت - به خصوص هنگام مدیریت دادههای حساس یا سرویسدهی به چندین کاربر غیرقابل اعتماد - میتوانید کل برنامه عامل را در داخل یک جعبه شنی اختصاصی برای هر جلسه یا کاربر اجرا کنید. این امر جداسازی کامل حافظه، وضعیت و محیط اجرای عامل را تضمین میکند که بلافاصله پس از اتمام جلسه از بین میرود.
۹. پاکسازی
برای جلوگیری از تحمیل هزینه به حساب Google Cloud خود برای منابع استفاده شده در این codelab، این مراحل را برای حذف آنها دنبال کنید.
حذف منابع تکی
- خوشه GKE را حذف کنید:
gcloud container clusters delete $CLUSTER_NAME --zone $ZONE --quiet
- مخزن رجیستری Artifact را حذف کنید:
gcloud artifacts repositories delete agent-repo --location=us-central1 --quiet
- شبکه VPC را حذف کنید:
gcloud compute networks delete ai-agent-network --quiet
حذف پروژه
اگر دیگر به پروژه نیاز ندارید، میتوانید پس از حذف منابع، آن را حذف کنید:
gcloud projects delete $PROJECT_ID
۱۰. خلاصه
تبریک! شما با موفقیت یک عامل تولید کد امن و با کارایی بالا را در GKE ساختید و مستقر کردید.
آنچه آموختید
- نحوه پیکربندی و استفاده از تخصیص منابع پویا (DRA) در GKE برای مدیریت منابع GPU.
- How to use GKE Inference Gateway to optimize LLM serving performance via prefix-cache aware routing.
- How to use Agent Sandbox (gVisor) to execute untrusted code securely on GKE.
- How to use Google Cloud Managed Service for Prometheus to monitor vLLM performance.
- How to configure and view Agent Observability using ADK and GKE Managed OpenTelemetry.
Next Steps & References
- Agent Sandbox : Learn about Agent Sandbox on GKE and GKE Sandbox Pods .
- llm-d : Read the llm-d Guide and check out the llm-d GitHub Repository .
- Dynamic Resource Allocation : Learn about DRA on GKE .
- GKE Inference Gateway : Explore Inference Gateway concepts .
- More Codelabs : Find more tutorials at Google Cloud Codelabs .