
1. Introduction
Présentation
Dans cet atelier, vous allez apprendre à créer et à déployer un agent de génération de code sécurisé sur Google Kubernetes Engine (GKE). Les agents de génération de code doivent exécuter du code qui peut ne pas être fiable, ce qui nécessite un environnement de bac à sable sécurisé. Vous apprendrez également à configurer l'agent avec une stratégie de modèle hybride, ce qui lui permettra de passer d'un modèle ouvert auto-hébergé sur GKE au service Gemini géré de Vertex AI pour une fiabilité accrue. Vous apprendrez également à optimiser le service d'inférence à l'aide de GKE Inference Gateway et de l'allocation dynamique des ressources (DRA). Enfin, vous apprendrez à exploiter Google Cloud Observability pour surveiller votre pile d'inférence à l'aide de Managed Prometheus.
Architecture
Voici l'architecture du système que vous allez créer :
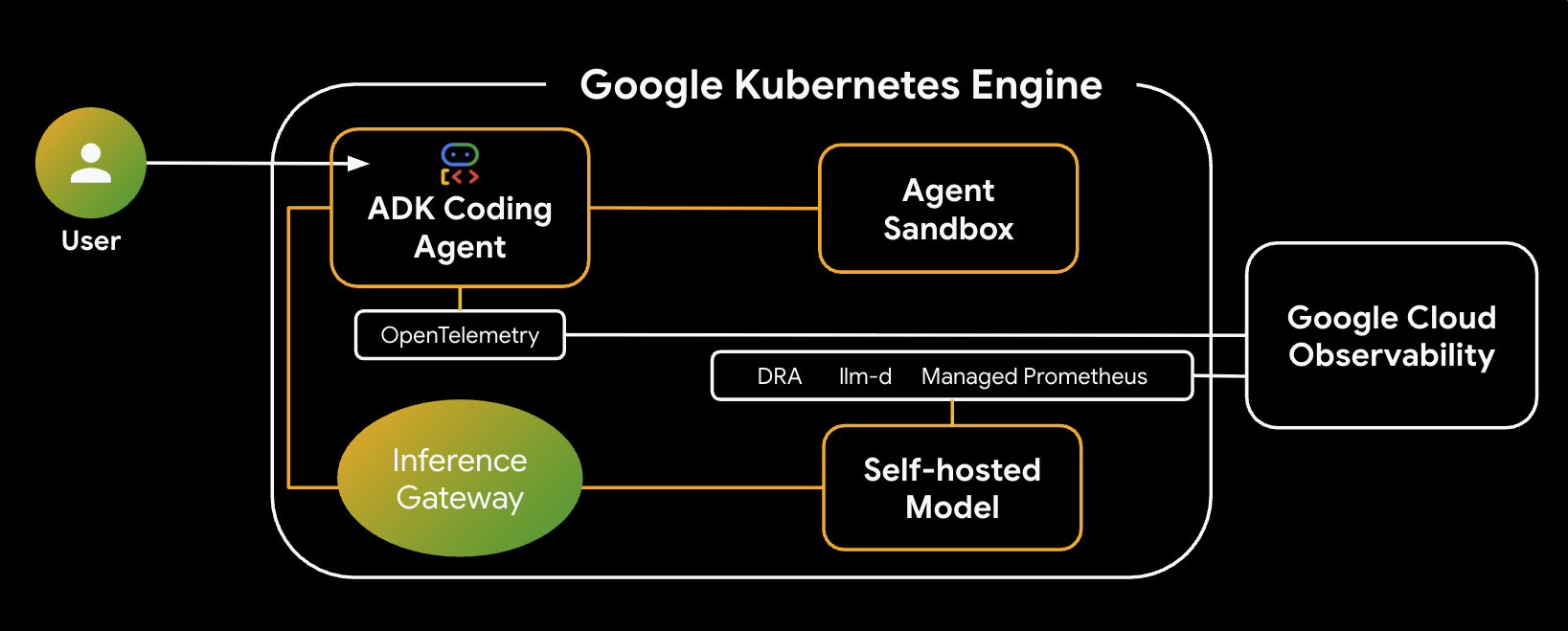
Composants et avantages clés
- Allocation dynamique des ressources (DRA) : utilisée dans cet atelier pour revendiquer et allouer dynamiquement des ressources GPU spécifiques (NVIDIA L4) aux pods du serveur de modèle, ce qui garantit un ciblage matériel précis pour notre charge de travail d'inférence. En savoir plus sur DRA sur GKE
- llm-d et vLLM : fournit le framework de mise en service de modèle et les graphiques Helm pour déployer le modèle Qwen. Dans cet atelier, il gère les requêtes d'inférence et s'intègre à DRA pour la gestion des ressources (le service désagrégé n'est pas activé dans cet atelier). Lisez le guide llm-d et consultez le dépôt GitHub llm-d.
- GKE Inference Gateway : déplace la logique de routage basée sur l'IA directement dans l'équilibreur de charge. Dans cet atelier, les requêtes sont acheminées pour maximiser les correspondances du préfixe de cache, ce qui réduit la latence du délai d'émission du premier jeton (TTFT). Découvrez les concepts d'Inference Gateway.
- Bac à sable de l'agent (gVisor) : fournit une isolation sécurisée pour l'exécution du code généré par l'agent d'IA. Il utilise gVisor pour fournir une isolation du noyau en profondeur, protégeant ainsi le nœud hôte contre les charges de travail non approuvées. En savoir plus sur Agent Sandbox sur GKE et les pods GKE Sandbox
Objectifs de l'atelier
- Provisionner l'infrastructure : configurez un cluster GKE avec l'allocation dynamique de ressources (DRA) pour la gestion des GPU.
- Déployer la pile d'inférence : déployez
llm-det vLLM avec une planification intelligente des inférences. - Configurer le routage intelligent : utilisez la passerelle d'inférence GKE pour le routage prenant en compte le préfixe du cache.
- Exécution de code sécurisée : déployez Agent Sandbox (gVisor) pour exécuter du code généré par l'IA de manière sécurisée.
- Observer et valider : utilisez Google Cloud Monitoring et Managed Prometheus pour afficher les métriques de diffusion du modèle.
Points abordés
- Découvrez comment configurer et utiliser l'allocation dynamique de ressources (DRA) dans GKE.
- Utiliser GKE Inference Gateway pour optimiser les performances de diffusion des LLM
- Découvrez comment utiliser Agent Sandbox pour exécuter du code non approuvé de manière sécurisée sur GKE.
- Découvrez comment utiliser Google Cloud Managed Service pour Prometheus afin de surveiller les performances de vLLM.
2. Préparation
Configuration du projet
Créer un projet Google Cloud
- Dans la console Google Cloud, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
Démarrer Cloud Shell
Cloud Shell est un environnement de ligne de commande exécuté dans Google Cloud et fourni avec les outils nécessaires.
- Cliquez sur Activer Cloud Shell en haut de la console Google Cloud.
- Une fois connecté à Cloud Shell, vérifiez votre authentification :
gcloud auth list - Vérifiez que votre projet est configuré :
gcloud config get project - Si votre projet n'est pas défini comme prévu, définissez-le :
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
3. Provisionner l'infrastructure et l'allocation dynamique des ressources (DRA)
Dans cette première étape, vous allez configurer votre cluster GKE pour qu'il utilise l'allocation d'accélérateurs moderne (DRA) au lieu des anciens plug-ins de périphériques. Cela vous permet de partager et d'allouer de manière flexible des GPU ou des TPU pour vos charges de travail de génération de code.
Conditions préalables : votre cluster GKE Standard doit exécuter la version 1.34 ou ultérieure pour être compatible avec DRA.
Activer les API Google Cloud
Activez les API Google Cloud requises pour cet atelier de programmation, en particulier les API Compute Engine et Kubernetes Engine.
gcloud services enable compute.googleapis.com container.googleapis.com networkservices.googleapis.com cloudbuild.googleapis.com artifactregistry.googleapis.com telemetry.googleapis.com cloudtrace.googleapis.com aiplatform.googleapis.com
Définir des variables d'environnement
Pour faciliter la configuration, définissez vos variables d'environnement. Vous pouvez ajuster la région ou les conventions de dénomination selon vos besoins.
export PROJECT_ID=$(gcloud config get-value project)
export ZONE=us-central1-a
export CLUSTER_NAME=ai-agent-cluster
export NODEPOOL_NAME=dra-accelerator-pool
gcloud config set project $PROJECT_ID
gcloud config set compute/region $ZONE
Créer un répertoire de travail
Créez un répertoire de travail dédié pour cet atelier et accédez-y afin d'organiser vos fichiers :
mkdir -p ~/gke-ai-agent-lab
cd ~/gke-ai-agent-lab
Configurer les autorisations (facultatif)
Si vous exécutez des builds dans un projet restreint ou un environnement partagé, assurez-vous que votre compte dispose des autorisations nécessaires pour créer des clusters et exécuter des builds :
export MY_ACCOUNT=$(gcloud config get-value account)
# Grant Container Admin to create clusters and manage nodes if needed
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/container.admin"
# Grant Cloud Build Builder to run builds
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/cloudbuild.builds.builder"
Créer le cluster GKE
Votre cluster GKE Standard doit exécuter la version 1.34 ou ultérieure pour être compatible avec DRA. Vous devez également activer les contrôleurs de l'API Gateway pour prendre en charge la planification intelligente des inférences.
Dans cet atelier, vous allez créer un réseau et des sous-réseaux VPC.
Commencez par créer le réseau VPC :
gcloud compute networks create ai-agent-network --subnet-mode=custom
Créez ensuite un sous-réseau pour vos nœuds GKE :
gcloud compute networks subnets create ai-agent-subnet \
--network=ai-agent-network \
--range=10.0.0.0/20 \
--region=us-central1
L'API Gateway (gke-l7-regional-internal-managed) nécessite également un sous-réseau dédié pour héberger les proxys Envoy. Créez ce sous-réseau proxy réservé dans votre nouveau réseau :
gcloud compute networks subnets create proxy-only-subnet \
--purpose=REGIONAL_MANAGED_PROXY \
--role=ACTIVE \
--region=us-central1 \
--network=ai-agent-network \
--range=192.168.10.0/24
Créez maintenant le cluster à l'aide du nouveau réseau et du nouveau sous-réseau :
gcloud beta container clusters create $CLUSTER_NAME \
--zone $ZONE \
--num-nodes 1 \
--machine-type n2-standard-4 \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--gateway-api=standard \
--managed-otel-scope=COLLECTION_AND_INSTRUMENTATION_COMPONENTS \
--network=ai-agent-network \
--subnetwork=ai-agent-subnet
Créer un pool de nœuds avec les plug-ins par défaut désactivés
Pour confier la gestion des appareils à DRA, vous devez créer un pool de nœuds qui désactive explicitement l'installation du pilote de GPU par défaut et le plug-in d'appareil standard.
Exécutez la commande gcloud suivante pour provisionner un pool de nœuds GPU (par exemple, à l'aide de NVIDIA L4) avec les libellés DRA nécessaires :
gcloud container node-pools create $NODEPOOL_NAME \
--cluster=$CLUSTER_NAME \
--location=$ZONE \
--machine-type=g2-standard-24 \
--accelerator=type=nvidia-l4,count=2,gpu-driver-version=disabled \
--node-labels=gke-no-default-nvidia-gpu-device-plugin=true,nvidia.com/gpu.present=true \
--num-nodes 3
Installer des pilotes NVIDIA via DaemonSet
Installez manuellement les pilotes d'appareils NVIDIA de base requis sur vos nœuds à l'aide d'un DaemonSet Google Cloud préconfiguré :
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
Installer le pilote DRA
Installez ensuite le pilote DRA spécifique dans votre cluster. Pour les GPU NVIDIA, vous pouvez déployer ce pilote via Helm :
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
helm install nvidia-dra-driver-gpu nvidia/nvidia-dra-driver-gpu \
--version="25.3.2" --create-namespace --namespace=nvidia-dra-driver-gpu \
--set nvidiaDriverRoot="/home/kubernetes/bin/nvidia/" \
--set gpuResourcesEnabledOverride=true \
--set resources.computeDomains.enabled=false \
--set kubeletPlugin.priorityClassName="" \
--set 'kubeletPlugin.tolerations[0].key=nvidia.com/gpu' \
--set 'kubeletPlugin.tolerations[0].operator=Exists' \
--set 'kubeletPlugin.tolerations[0].effect=NoSchedule'
Comprendre les DeviceClasses
Vous n'avez pas besoin d'écrire ni d'appliquer manuellement un fichier YAML DeviceClass. Lorsque vous configurez votre infrastructure GKE pour DRA et que vous installez le pilote, les pilotes DRA exécutés sur vos nœuds créent automatiquement les objets DeviceClass dans le cluster pour vous.
Configurer le ResourceClaimTemplate
Pour permettre à vos pods llm-d de demander dynamiquement ces accélérateurs, vous allez créer un ResourceClaimTemplate. Ce modèle définit la configuration de l'appareil demandée et indique à Kubernetes de créer automatiquement un ResourceClaim unique par pod pour vos charges de travail.
Exécutez la commande suivante pour créer claim-template.yaml :
cat > claim-template.yaml <<EOF
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: gpu-claim-template
spec:
spec:
devices:
requests:
- name: single-gpu
exactly:
deviceClassName: gpu.nvidia.com
allocationMode: ExactCount
count: 1
EOF
Appliquez le modèle à votre cluster :
kubectl apply -f claim-template.yaml
4. Déployer la planification intelligente des inférences avec llm-d et DRA
Dans cette étape, vous allez déployer votre grand modèle de langage derrière un équilibreur de charge Envoy intelligent amélioré avec un planificateur d'inférence. Cette configuration optimise la diffusion de modèles en appliquant le routage compatible avec la mise en cache des préfixes. GKE Inference Gateway reconnaît le contexte partagé entre les microservices et achemine intelligemment les requêtes vers la même réplique de modèle. Cela permet de maximiser les accès au cache, de réduire le délai d'émission du premier jeton et d'améliorer le rapport performances/prix.
Préparer l'environnement
Configurez votre espace de noms cible.
export NAMESPACE=ai-agents
kubectl create namespace $NAMESPACE
Stockez de manière sécurisée votre jeton Hugging Face, qui est nécessaire pour extraire les pondérations du modèle.
# Replace with your actual Hugging Face token
kubectl create secret generic llm-d-hf-token \
--from-literal=HF_TOKEN="your_hugging_face_token" \
-n $NAMESPACE
Créer les fichiers de configuration Helm
Les configurations du service de modèle et de l'extension de passerelle d'inférence sont basées sur les guides llm-d officiels.
Commencez par créer le fichier ms-values.yaml pour le service de modèle :
cat <<EOF > ms-values.yaml
multinode: false
modelArtifacts:
uri: "hf://Qwen/Qwen2.5-Coder-14B-Instruct"
name: "Qwen/Qwen2.5-Coder-14B-Instruct"
size: 50Gi # Slightly larger than the default to accommodate weights
authSecretName: "llm-d-hf-token"
labels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
llm-d.ai/accelerator-variant: "gpu"
llm-d.ai/accelerator-vendor: "nvidia"
llm-d.ai/model: "qwen-2-5-coder-14b"
routing:
proxy:
enabled: false # removes sidecar from deployment - no PD in inference scheduling
targetPort: 8000 # controls vLLM port to matchup with sidecar if deployed
accelerator:
dra: true
type: "nvidia"
resourceClaimTemplates:
nvidia:
class: "gpu.nvidia.com"
match: "exactly"
name: "gpu-claim-template"
decode:
create: true
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
parallelism:
tensor: 2
data: 1
replicas: 3
monitoring:
podmonitor:
enabled: true
portName: "vllm"
path: "/metrics"
interval: "30s"
containers:
- name: "vllm"
image: ghcr.io/llm-d/llm-d-cuda:v0.5.1
modelCommand: vllmServe
args:
- "--disable-uvicorn-access-log"
- "--gpu-memory-utilization=0.85"
- "--enable-auto-tool-choice"
- "--tool-call-parser"
- "hermes"
ports:
- containerPort: 8000
name: vllm
protocol: TCP
resources:
limits:
cpu: '16'
memory: 64Gi
requests:
cpu: '16'
memory: 64Gi
mountModelVolume: true
volumeMounts:
- name: metrics-volume
mountPath: /.config
- name: shm
mountPath: /dev/shm
- name: torch-compile-cache
mountPath: /.cache
startupProbe:
httpGet:
path: /v1/models
port: vllm
initialDelaySeconds: 15
periodSeconds: 30
timeoutSeconds: 5
failureThreshold: 120
livenessProbe:
httpGet:
path: /health
port: vllm
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /v1/models
port: vllm
periodSeconds: 5
timeoutSeconds: 2
failureThreshold: 3
volumes:
- name: metrics-volume
emptyDir: {}
- name: torch-compile-cache
emptyDir: {}
- name: shm
emptyDir:
medium: Memory
sizeLimit: 20Gi
prefill:
create: false
EOF
Ensuite, créez le fichier gaie-values.yaml pour l'extension GKE Inference Gateway :
cat <<EOF > gaie-values.yaml
inferenceExtension:
replicas: 1
image:
name: llm-d-inference-scheduler
hub: ghcr.io/llm-d
tag: v0.6.0
pullPolicy: Always
extProcPort: 9002
pluginsConfigFile: "default-plugins.yaml"
tracing:
enabled: false
monitoring:
interval: "10s"
prometheus:
enabled: true
auth:
secretName: inference-scheduling-gateway-sa-metrics-reader-secret
inferencePool:
targetPorts:
- number: 8000
modelServerType: vllm
modelServers:
matchLabels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
EOF
Comprendre la configuration
Cette configuration permet de configurer une pile d'inférence hautes performances avec les principales fonctionnalités suivantes :
- Sélection du modèle : il utilise le modèle Qwen 2.5 Coder 14B (
modelArtifacts), qui est optimisé pour la génération de code et l'utilisation d'outils. - Intégration DRA : la section
acceleratorpermet l'allocation dynamique des ressources (dra: true), en ciblant la classe d'appareilsgpu.nvidia.comet notregpu-claim-templatecréé précédemment. - Optimisation des performances :
parallelism.tensor: 2configure le parallélisme Tensor sur les GPU.argspour vLLM inclut--enable-auto-tool-choicepour s'assurer que notre agent de codage peut utiliser les outils efficacement.- Les requêtes
cpuetmemoryréduites sont compatibles avec le type de machineg2-standard-24.
- Routage intelligent : l'extension Inference Gateway (
gaie-values.yaml) est configurée pour surveiller les serveurs de modèlesvllmet acheminer les requêtes afin de maximiser les accès au cache KV.
Déployer la pile de planification de l'inférence à l'aide de Helm
Ajoutez maintenant les dépôts Helm llm-d et déployez l'infrastructure, l'extension de passerelle et le service de modèle individuellement.
Commencez par ajouter les dépôts requis :
helm repo add llm-d-infra https://llm-d-incubation.github.io/llm-d-infra/
helm repo add llm-d-modelservice https://llm-d-incubation.github.io/llm-d-modelservice/
helm repo update
Déployer les prérequis de l'infrastructure
Ce graphique installe les configurations de passerelle de base requises pour la pile.
helm install infra-is llm-d-infra/llm-d-infra \
--namespace $NAMESPACE \
--set gateway.gatewayClassName=gke-l7-rilb \
--set gateway.gatewayParameters.enabled=false \
--set gateway.gatewayParameters.istio.accessLogging=false
Déployer l'extension GKE Inference Gateway
Cette étape déploie InferencePool et Endpoint Picker, qui surveillent le cache KV de vos modèles pour prendre des décisions de routage intelligentes.
helm install gaie-is oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool \
--version v1.3.1 \
--namespace $NAMESPACE \
-f gaie-values.yaml \
--set provider.name=gke \
--set inferenceExtension.monitoring.prometheus.enabled=true
Déployer le service de modèle
Enfin, déployez votre service LLM, qui utilisera désormais DRA pour revendiquer vos GPU L4 de manière sécurisée.
helm install ms-is llm-d-modelservice/llm-d-modelservice \
--version v0.4.7 \
--namespace $NAMESPACE \
-f ms-values.yaml \
--set decode.monitoring.podmonitor.enabled=false
Activer Google Cloud Observability pour vLLM
Les graphiques Helm génériques tentent souvent de déployer des ressources PodMonitor standard de l'opérateur Prometheus (monitoring.coreos.com/v1), ce qui peut entraîner des erreurs si vous n'avez pas installé ces CRD.
Au lieu d'activer ou de désactiver la surveillance intégrée de Helm, laissez-la sur false et appliquez manuellement une ressource PodMonitoring Google Cloud Managed Prometheus (GMP) à l'aide du groupe d'API monitoring.googleapis.com/v1 compatible.
Exécutez la commande suivante pour créer podmonitoring.yaml :
cat > podmonitoring.yaml <<EOF
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: ms-vllm-metrics
spec:
selector:
matchLabels:
llm-d.ai/model: "qwen-2-5-coder-14b" # Matches the label in values.yaml
endpoints:
- port: 8000 # vllm port
interval: 30s
path: /metrics
EOF
Appliquez la ressource PodMonitoring à votre cluster :
kubectl apply -f podmonitoring.yaml -n $NAMESPACE
Vérifier l'installation
Vérifiez que les composants ont bien été installés. Vous devriez voir les trois versions Helm actives dans votre espace de noms et les pods correspondants en cours d'initialisation.
helm ls -n $NAMESPACE
kubectl get pods -n $NAMESPACE
Le démarrage des pods ms-is peut prendre entre 5 et 10 minutes. Dans ce cas, le résultat devrait ressembler à ceci :
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
gaie-is ai-agents 1 2026-03-28 16:51:41.055881618 +0000 UTC deployed inferencepool-v1.3.1 v1.3.1
infra-is ai-agents 1 2026-03-28 16:51:03.71042542 +0000 UTC deployed llm-d-infra-v1.4.0 v0.4.0
ms-is ai-agents 1 2026-03-28 17:30:00.341918958 +0000 UTC deployed llm-d-modelservice-v0.4.7 v0.4.0
NAME READY STATUS RESTARTS AGE
gaie-is-epp-848965cb4-78ktp 1/1 Running 0 10m
ms-is-llm-d-modelservice-decode-67548d5f8c-f25f4 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-rblvs 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-w6fcd 1/1 Running 0 6m2s
5. Configurer le routage intelligent avec GKE Inference Gateway
À l'étape 4, le déploiement des charts Helm llm-d a automatiquement provisionné vos objets Gateway et InferencePool. InferencePool regroupe vos pods de diffusion de modèle vllm qui partagent le même modèle de base et la même configuration de calcul.
Vous devez maintenant configurer un InferenceObjective pour définir la priorité de vos requêtes d'agent de codage et un HTTPRoute pour indiquer à la passerelle comment acheminer le trafic entrant, en tirant parti du sélecteur de points de terminaison pour maximiser les accès au cache KV.
Vérifier les ressources générées automatiquement
Tout d'abord, vérifiez que les charts Helm llm-d ont bien créé les ressources Gateway et InferencePool.
kubectl get gateway,inferencepool -n $NAMESPACE
Une passerelle nommée infra-is-inference-gateway et un pool d'inférence nommé gaie-is doivent s'afficher. comme ceci :
NAME CLASS ADDRESS PROGRAMMED AGE
gateway.gateway.networking.k8s.io/infra-is-inference-gateway gke-l7-regional-internal-managed 10.128.0.5 True 13m
NAME AGE
inferencepool.inference.networking.k8s.io/gaie-is 12m
Créer la ressource HTTPRoute
La ressource HTTPRoute mappe votre passerelle au backend InferencePool. Cela indique à GKE Inference Gateway d'analyser les corps des requêtes entrantes et de les acheminer de manière dynamique pour maximiser les correspondances du cache de préfixes en fonction du contexte partagé.
Exécutez la commande suivante pour créer httproute.yaml :
cat > httproute.yaml <<EOF
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: agent-route
spec:
parentRefs:
- group: gateway.networking.k8s.io
kind: Gateway
name: infra-is-inference-gateway
rules:
- backendRefs:
- group: inference.networking.k8s.io
kind: InferencePool
name: gaie-is
weight: 1
matches:
- path:
type: PathPrefix
value: /
EOF
Appliquez la route à votre cluster :
kubectl apply -f httproute.yaml -n $NAMESPACE
6. Exécution de code sécurisée avec le bac à sable de l'agent
Maintenant que notre backend d'inférence hautes performances est en cours d'exécution, préparons l'environnement sécurisé dans lequel le code généré par l'IA sera réellement exécuté de manière isolée et sécurisée de notre cluster à l'aide d'un bac à sable d'agent.
Déployer le contrôleur du bac à sable de l'agent
Lorsqu'un agent d'IA génère et exécute du code, il exécute essentiellement une charge de travail non approuvée sur votre infrastructure. Si l'agent génère du code malveillant, il peut tenter d'analyser votre réseau interne ou d'exploiter le nœud hôte sous-jacent.
GKE Agent Sandbox utilise gVisor, un environnement d'exécution de conteneur Open Source qui fournit un noyau invité spécialisé pour chaque conteneur. Cela empêche le code non approuvé d'effectuer des appels système directs au nœud hôte.
Déployez le contrôleur Agent Sandbox et ses composants requis en appliquant les fichiers manifestes de la version officielle :
kubectl apply \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/manifest.yaml \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/extensions.yaml
Configurer le modèle de bac à sable et le pool de préchauffage
Nous allons ensuite établir un SandboxTemplate qui servira de plan réutilisable pour nos environnements d'analyse Python, en ciblant explicitement la classe d'exécution gvisor. Pour simplifier le déploiement sans gérer manuellement les pools de nœuds sur les clusters Standard, nous pouvons utiliser n'importe quel autopilot standard.
ComputeClass pour provisionner de manière dynamique des nœuds de calcul gérés qui prennent en charge nativement les charges de travail gVisor à la demande.
Étant donné que l'initialisation d'un noyau sécurisé peut ajouter de la latence, nous déployons également un SandboxWarmPool. Cela garantit qu'un nombre spécifié de bacs à sable pré-initialisés sont prêts à l'emploi afin que l'agent de génération de code puisse les revendiquer et commencer à exécuter du code en moins d'une seconde.
Commencez par créer un espace de noms pour les runtimes du bac à sable de l'agent :
kubectl create namespace agent-sandbox
Enregistrez le fichier suivant sous le nom sandbox-template-and-pool.yaml :
cat > sandbox-template-and-pool.yaml <<EOF
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxTemplate
metadata:
name: python-runtime-template
namespace: agent-sandbox
spec:
podTemplate:
metadata:
labels:
sandbox: python-sandbox-example
spec:
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: python-runtime
image: registry.k8s.io/agent-sandbox/python-runtime-sandbox:v0.1.0
ports:
- containerPort: 8888
readinessProbe:
httpGet:
path: "/"
port: 8888
initialDelaySeconds: 0
periodSeconds: 1
resources:
requests:
cpu: "250m"
memory: "512Mi"
ephemeral-storage: "512Mi"
restartPolicy: "OnFailure"
---
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxWarmPool
metadata:
name: python-sandbox-warmpool
namespace: agent-sandbox
spec:
replicas: 2
sandboxTemplateRef:
name: python-runtime-template
EOF
Appliquez la configuration :
kubectl apply -f sandbox-template-and-pool.yaml
Attendez deux à trois minutes que les pods du pool de préchauffage s'initialisent. Vous pouvez vérifier que la transition de Pending (pendant la mise à l'échelle du calcul sous-jacent) à Running s'est bien déroulée à l'aide de la commande suivante :
kubectl get pods -n agent-sandbox -w
Une fois que vous voyez deux pods python-sandbox-warmpool-*** listés comme Running et 1/1 prêt, vos environnements d'exécution sécurisés sont préchauffés et prêts à être revendiqués.
Déployer le routeur de bac à sable
Notre agent de génération de code s'appuie sur un routeur Sandbox pour envoyer de manière sécurisée les commandes d'exécution aux pods isolés.
Exécutez la commande suivante pour créer sandbox-router.yaml :
cat > sandbox-router.yaml <<EOF
apiVersion: v1
kind: Service
metadata:
name: sandbox-router-svc
namespace: agent-sandbox
spec:
type: ClusterIP
selector:
app: sandbox-router
ports:
- name: http
protocol: TCP
port: 8080
targetPort: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sandbox-router-deployment
namespace: agent-sandbox
spec:
replicas: 2
selector:
matchLabels:
app: sandbox-router
template:
metadata:
labels:
app: sandbox-router
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: sandbox-router
containers:
- name: router
image: us-central1-docker.pkg.dev/k8s-staging-images/agent-sandbox/sandbox-router:v20260225-v0.1.1.post3-10-ga5bcb57
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 10
resources:
requests:
cpu: "250m"
memory: "512Mi"
limits:
cpu: "1000m"
memory: "1Gi"
securityContext:
runAsUser: 1000
runAsGroup: 1000
EOF
Appliquez la configuration :
kubectl apply -f sandbox-router.yaml
Mettre en œuvre l'isolation du réseau
Pour renforcer la sécurité de l'environnement d'exécution et empêcher tout mouvement latéral non autorisé, appliquez une règle de réseau. Cela permet de "séparer" le bac à sable afin qu'il ne puisse pas atteindre le serveur de métadonnées Google Cloud ni d'autres réseaux internes sensibles.
Enregistrez le fichier suivant sous le nom sandbox-policy.yaml :
cat > sandbox-policy.yaml <<EOF
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: restrict-sandbox-egress
namespace: agent-sandbox
spec:
podSelector:
matchLabels:
sandbox: python-sandbox-example
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 0.0.0.0/0
except:
- 169.254.169.254/32 # Block metadata server
EOF
Appliquez la règle :
kubectl apply -f sandbox-policy.yaml
Valider les composants
Pour vous assurer que le niveau de cluster de bac à sable de code isolé est entièrement configuré, exécutez les commandes de validation d'état suivantes :
Tout d'abord, vérifiez que les pods et les routeurs du bac à sable sont en cours d'exécution et prêts.
kubectl get pods -n agent-sandbox
Le résultat devrait ressembler à ceci :
NAME READY STATUS RESTARTS AGE
python-sandbox-warmpool-7zlkv 1/1 Running 0 3m25s
python-sandbox-warmpool-cxln2 1/1 Running 0 3m25s
sandbox-router-deployment-668dfbbbb6-g9mpd 1/1 Running 0 42s
sandbox-router-deployment-668dfbbbb6-ppllz 1/1 Running 0 42s
Vérifier l'équilibreur de charge / l'exposition de l'adresse IP du routeur Sandbox
kubectl get service sandbox-router-svc -n agent-sandbox
Le résultat doit se présenter comme suit :
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
sandbox-router-svc ClusterIP 34.118.237.244 <none> 8080/TCP 114s
Vérifier que la règle de stratégie de réseau de sortie existe
kubectl get networkpolicy restrict-sandbox-egress -n agent-sandbox
Le résultat doit se présenter comme suit :
NAME POD-SELECTOR AGE
restrict-sandbox-egress sandbox=python-sandbox-example 113s
Faites les vérifications suivantes :
- Les pods
python-sandbox-warmpool-***sont prêts (Runninget1/1). - Les répliques
sandbox-router-deployment-***sontRunninget1/1prêtes. - Le
sandbox-router-svcest accessible et la règlerestrict-sandbox-egressprotège correctement les libellés de bac à sable correspondants.
Maintenant que notre environnement d'exécution sécurisé est initialisé, nous sommes prêts à déployer le véritable cerveau de notre opération : l'agent de génération de code.
7. Créer et déployer l'agent de génération de code (ADK)
Maintenant que notre bac à sable d'exécution sécurisé et notre backend LLM hautes performances sont configurés, nous pouvons créer le "cerveau" de notre système : un agent de génération de code à l'aide de l'Agent Development Kit (ADK).
Cet agent est conçu pour agir en tant que développeur Python expert. Contrairement à un chatbot standard qui ne produit que du texte, cet agent est équipé d'un outil d'exécution de code qui lui permet de résoudre des problèmes de manière interactive. Il suit une boucle de :
- Écrire du code Python en fonction de vos demandes.
- Exécuter le code de manière sécurisée dans le bac à sable de l'agent GKE que nous avons configuré à l'étape 6.
- Vérifiez la sortie ou lisez les erreurs qui se produisent lors de l'exécution.
- Fournir une solution testée et fonctionnelle en toute confiance.
En donnant à l'agent l'accès à un environnement d'exécution de bac à sable sécurisé, nous lui permettons de vérifier sa propre logique et de déboguer automatiquement les échecs, ce qui le rend beaucoup plus apte à effectuer des tâches de développement logiciel.
Développer l'agent de raisonnement ADK
Tout d'abord, nous écrivons la logique Python qui définit le comportement de l'agent et l'équipe de l'outil Sandbox que nous avons créé à l'étape 6. Dans cette section, nous allons également configurer une stratégie de modèle hybride : l'agent donnera la priorité à un modèle Qwen auto-hébergé s'exécutant sur votre cluster GKE, mais reviendra automatiquement à Gemini 2.5 Flash sur Vertex AI si le modèle local est lent ou indisponible, ce qui garantit une fiabilité élevée.
Créez un répertoire pour le code de l'agent :
mkdir -p ~/gke-ai-agent-lab/root_agent
cd ~/gke-ai-agent-lab
Créez un fichier nommé root_agent/agent.py avec le contenu suivant :
cat <<'EOF' > root_agent/agent.py
import os
from google.adk.agents import Agent
from google.adk.models.lite_llm import LiteLlm
from k8s_agent_sandbox import SandboxClient
import requests
# Instantiate the client globally to track sandboxes
sandbox_client = SandboxClient()
def run_python_code(code: str) -> str:
"""
Executes Python code safely in the GKE Agent Sandbox.
Use this tool whenever you need to execute code to solve a problem.
"""
sandbox = sandbox_client.create_sandbox(template="python-runtime-template", namespace="agent-sandbox")
try:
command = f"python3 -c \"{code}\""
result = sandbox.commands.run(command)
if result.stderr:
return f"Error: {result.stderr}"
return result.stdout
finally:
# Ensure the sandbox is deleted after use to avoid leaking resources
sandbox_client.delete_sandbox(sandbox.claim_name, namespace="agent-sandbox")
# Define the ADK Agent with a fallback mechanism.
# It prioritizes the Qwen 2.5 Coder model running on our Inference Gateway.
# If the local model is unavailable, it falls back to Gemini 2.5 Flash on Vertex AI.
root_agent = Agent(
name="CodeGenerationAgent",
model=LiteLlm(
model="openai/Qwen/Qwen2.5-Coder-14B-Instruct",
fallbacks=["vertex_ai/gemini-2.5-flash"],
timeout=10
),
instruction="""
You are an expert Python developer.
1. Write Python code to solve the user's problem.
2. Execute the code using the `run_python_code` tool to verify it works.
3. Return the exact output and a brief explanation of the code.
""",
tools=[run_python_code]
)
EOF
Créez un fichier __init__.py pour que l'ADK reconnaisse le module :
echo "from . import agent" > ~/gke-ai-agent-lab/root_agent/__init__.py
Définissez les variables d'environnement. L'application ADK a besoin de l'adresse IP de votre passerelle pour acheminer correctement les requêtes LLM. Étant donné qu'ADK est compatible avec les points de terminaison standards compatibles avec OpenAI (que vLLM fournit via notre passerelle), nous pouvons remplacer l'URL de base de l'API par défaut.
export GATEWAY_IP=$(kubectl get gateway infra-is-inference-gateway -n $NAMESPACE -o jsonpath='{.status.addresses[0].value}')
cat <<EOF > ~/gke-ai-agent-lab/root_agent/.env
OPENAI_API_BASE=http://${GATEWAY_IP}/v1
OPENAI_API_KEY=no-key-required
# Vertex AI settings for fallback (Authentication is handled by Workload Identity)
VERTEXAI_PROJECT=$PROJECT_ID
VERTEXAI_LOCATION=${ZONE%-[a-z]}
EOF
Conteneuriser l'application de l'agent
Nous devons empaqueter l'agent pour qu'il puisse s'exécuter de manière sécurisée dans GKE.
Créez un Dockerfile dans ~/gke-ai-agent-lab qui installe kubectl, la bibliothèque ADK et le client Agent Sandbox :
cat <<'EOF' > ~/gke-ai-agent-lab/Dockerfile
FROM python:3.11-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
RUN apt-get update && apt-get install -y git curl \
&& curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl" \
&& install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl \
&& rm kubectl && apt-get clean && rm -rf /var/lib/apt/lists/*
RUN pip install --no-cache-dir "google-adk[extensions,otel-gcp]>=1.27.4" litellm pandas "git+https://github.com/kubernetes-sigs/agent-sandbox.git@main#subdirectory=clients/python/agentic-sandbox-client" \
"opentelemetry-instrumentation-google-genai>=0.4b0" \
"opentelemetry-exporter-otlp" \
"opentelemetry-instrumentation-vertexai>=2.0b0"
COPY ./root_agent /app/root_agent
EXPOSE 8080
ENTRYPOINT ["adk", "web", "--host", "0.0.0.0", "--port", "8080", "--otel_to_cloud"]
EOF
Créez un dépôt Artifact Registry pour stocker l'image de conteneur.
gcloud artifacts repositories create agent-repo \
--repository-format=docker \
--location=us-central1
Utilisez Cloud Build pour compiler et transférer l'image de conteneur.
gcloud builds submit --tag us-central1-docker.pkg.dev/$PROJECT_ID/agent-repo/code-agent:v1 ~/gke-ai-agent-lab/
Déployer sur GKE avec RBAC
Enfin, déployez l'agent sur votre cluster. Le déploiement inclut un Role et un RoleBinding qui accordent à l'agent l'autorisation de revendiquer des instances à partir du SandboxWarmPool.
Ce déploiement utilisera un compte de service Kubernetes pour permettre à votre agent de communiquer avec l'API de revendication du bac à sable. Il ne nécessite pas de compte de service Google IAM, car il accède aux ressources du cluster local et à un point de terminaison de passerelle vLLM local.
Pourquoi un déploiement standard dans gVisor ?
À l'étape 6, nous avons utilisé les API SandboxTemplate et SandboxClaim pour créer des bacs à sable éphémères et jetables pour le code Python généré (l'exécution de l'outil).
Pour l'UI Web de l'agent (le cerveau), nous utilisons des spécifications Deployment Kubernetes standards avec runtimeClassName: gvisor.
- Distinction : les
SandboxClaimsstandards sont éphémères et de zéro à un (idéaux pour les scripts non fiables). UnDeploymentstandard est persistant et de longue durée. Il est idéal pour les UI Web qui ont besoin d'unServiceKubernetes et d'un équilibreur de charge stables. En utilisantruntimeClassName: gvisordirectement sur un déploiement standard, vous bénéficiez de l'isolation du noyau gVisor tout en conservant les fonctionnalitésDeploymentstandards.
Enregistrez le fichier suivant sous le nom deployment.yaml :
cat <<EOF > ~/gke-ai-agent-lab/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: code-agent
labels:
app: code-agent
spec:
replicas: 1
selector:
matchLabels:
app: code-agent
template:
metadata:
labels:
app: code-agent
spec:
serviceAccount: adk-agent-sa
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: code-agent
image: us-central1-docker.pkg.dev/YOUR_PROJECT_ID/agent-repo/code-agent:v1
imagePullPolicy: Always
env:
- name: OPENAI_API_KEY
value: "no-key-required"
- name: OPENAI_API_BASE
value: "http://YOUR_GATEWAY_IP/v1"
- name: VERTEXAI_PROJECT
value: "YOUR_PROJECT_ID"
- name: VERTEXAI_LOCATION
value: "YOUR_REGION"
- name: OTEL_SERVICE_NAME
value: "code-agent"
- name: GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY
value: "true"
- name: OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT
value: "true"
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: code-agent-service
spec:
selector:
app: code-agent
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: agent-sandbox
name: sandbox-creator-role
rules:
- apiGroups: [""]
resources: ["services", "pods", "pods/portforward"]
verbs: ["get", "list", "watch", "create"]
- apiGroups: ["extensions.agents.x-k8s.io"]
resources: ["sandboxclaims"]
verbs: ["create", "get", "list", "watch", "delete"]
- apiGroups: ["agents.x-k8s.io"]
resources: ["sandboxes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: adk-agent-binding
namespace: agent-sandbox
subjects:
- kind: ServiceAccount
name: adk-agent-sa
namespace: default
roleRef:
kind: Role
name: sandbox-creator-role
apiGroup: rbac.authorization.k8s.io
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: adk-agent-sa
EOF
Accorder des autorisations IAM pour l'observabilité
Pour permettre à l'agent d'envoyer des données de télémétrie (journaux et traces) à Google Cloud, vous devez accorder les autorisations requises au compte de service Kubernetes adk-agent-sa à l'aide de Workload Identity.
Exécutez les commandes suivantes dans Cloud Shell :
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# Grant permission to write logs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/logging.logWriter \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to write traces
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/cloudtrace.agent \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to use Vertex AI
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/aiplatform.user \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
Exécutez la commande suivante pour remplacer automatiquement YOUR_PROJECT_ID par l'ID de votre projet et appliquer la configuration :
sed -i "s/YOUR_PROJECT_ID/$PROJECT_ID/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_GATEWAY_IP/$GATEWAY_IP/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_REGION/$ZONE/g" ~/gke-ai-agent-lab/deployment.yaml
kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml
8. Observer et valider
Il est temps de tester le système entièrement intégré.
Tester l'agent de génération de code dans l'UI
Recherchez l'adresse IP externe de l'interface utilisateur Web de votre ADK :
kubectl get services code-agent-service
Le résultat devrait ressembler à ceci :
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
code-agent-service LoadBalancer 34.118.230.182 34.31.250.60 80:32471/TCP 2m14s
- Ouvrez un navigateur et accédez à
http://[EXTERNAL-IP]. - Dans l'interface Web de l'ADK, assurez-vous que "root_agent" est sélectionné dans le menu déroulant en haut à droite. Ensuite, envoyez la requête suivante à l'agent :
Write a python script that prints 'Hello from the isolated sandbox'.
Pour observer comment l'agent utilise le backend d'inférence et le bac à sable, consultez les sections Explorer les statistiques du modèle avec Cloud Observability et Explorer l'observabilité de l'agent avec l'interface utilisateur GKE ci-dessous pour afficher les tableaux de bord.
Explorer l'observabilité des agents via l'interface utilisateur GKE
Maintenant que vous avez exécuté des requêtes, examinons les données de télémétrie. Cela vous aide à comprendre les performances du planificateur d'inférence et de vLLM.
Accéder aux tableaux de bord des agents
- Accédez à la page Kubernetes Engine > Charges de travail.
- Cliquez sur le déploiement code-agent pour ouvrir la page Détails du déploiement.
- Cliquez sur l'onglet Observability (Observabilité).
- Dans le panneau de navigation de gauche du tableau de bord d'observabilité, une nouvelle section Agent s'affiche avec des sous-onglets.
À découvrir
Explorez les sous-onglets suivants pour observer le comportement de votre application d'agent :
- Vue d'ensemble : affichez les tableaux de données pour les sessions, le nombre moyen de tours et les invocations.
- Modèles : consultez le nombre d'appels de modèle, les taux d'erreur et la latence, classés par modèle utilisé par votre agent.
- Outils : surveillez les appels d'outils et la durée d'exécution pour voir dans quelle mesure votre agent utilise efficacement son outil d'exécution du bac à sable.
- Utilisation : suivez l'utilisation des jetons et l'allocation standard des ressources de conteneur (processeur et mémoire).
- Traces de l'agent : passez à cet onglet pour afficher la liste des sessions d'exécution ou des étendues de trace brutes. Cliquez sur une ligne pour ouvrir un menu volant contenant des informations sur la trace sélectionnée.
En combinant les métriques au niveau du modèle de vLLM avec la télémétrie au niveau de l'application de l'ADK, vous disposez désormais d'une observabilité complète pour votre agent d'IA générative sur GKE.
Explorer les statistiques du modèle vLLM avec Cloud Observability
Maintenant que vous avez exécuté des requêtes, examinons les données de télémétrie. Cela vous aide à comprendre les performances du planificateur d'inférence et de vLLM.
Accéder aux tableaux de bord
- Accédez à Google Cloud Console.
- Accédez à Monitoring > Tableaux de bord.
- Recherchez et sélectionnez le tableau de bord Présentation de vLLM-Prometheus.
Métriques intéressantes à observer
Lorsque vous consultez le tableau de bord, prêtez attention aux métriques clés suivantes pour évaluer l'impact de GKE Inference Gateway et de la mise en cache des préfixes :
- Utilisation du cache KV (
vllm:gpu_cache_usage) :- Utilité : indique la quantité de mémoire GPU utilisée pour mettre en cache le contexte. Si cette valeur est élevée, cela signifie que le système conserve le contexte pour accélérer les futures requêtes. Si vous exécutez la même requête plusieurs fois, vous devriez voir cette utilisation augmenter, puis se stabiliser.
- Requêtes en cours d'exécution par rapport aux requêtes en attente (
vllm:num_requests_runningcontrevllm:num_requests_waiting) :- Pourquoi c'est important : cela indique la charge. Si le nombre de requêtes en attente est élevé, cela signifie que vos nœuds sont surchargés.
- Débit en jetons (
vllm:request_prompt_tokens_totetvllm:request_generation_tokens_tot) :- Pourquoi est-ce important ? Suivez le volume de jetons d'entrée et de sortie traités par le cluster.
- Temps avant le premier jeton (TTFT) :
- Pourquoi c'est important : il s'agit de la métrique essentielle pour les agents interactifs. En utilisant la passerelle d'inférence GKE avec le routage tenant compte du cache de préfixes, les requêtes partageant des contextes communs (comme les invites système ou les grandes fenêtres de contexte) sont acheminées vers le même réplica, ce qui minimise le TTFT en réutilisant les accès au cache existants.
Tests à essayer
Essayez ces scénarios pour voir les métriques évoluer en temps réel et valider la planification appropriée.
Expérience 1 : "Vitesse de répétition" (succès du cache de préfixe)
- Envoyez une requête complexe à l'agent (par exemple, "Écris un script Python pour analyser un fichier CSV de 100 Mo et calculer des statistiques.").
- Une fois qu'il a répondu, renvoyez exactement la même requête immédiatement.
- Observez le taux de succès du cache de préfixes et le délai d'émission du premier jeton (TTFT).
- Ce que vous devriez voir : le taux de réussite du cache de préfixes devrait atteindre 100 % et le TTFT devrait chuter de manière spectaculaire.
- Ce que cela signifie : la passerelle d'inférence GKE a reconnu le contexte partagé et l'a acheminé vers la même réplique, qui a réutilisé son cache de contexte évalué.
Expérience 2 : Retour au cloud (fiabilité du modèle)
- Pour simuler une défaillance de votre modèle Qwen local, vous pouvez arrêter le service d'inférence ou simplement fournir un
OPENAI_API_BASEfactice dans le déploiement. - Mettez à jour le
OPENAI_API_BASEdans votredeployment.yamlen indiquant une adresse IP ou un port inexistants, puis appliquez les modifications :sed -i "s|value: \"http://$GATEWAY_IP/v1\"|value: \"http://10.0.0.1:8080/v1\"|g" ~/gke-ai-agent-lab/deployment.yaml kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml - Attendez que le pod redémarre, puis envoyez une requête à l'agent dans l'UI.
- Ce que vous devriez voir : l'agent répond toujours correctement.
- Explication : en raison de la configuration
fallbacks, ADK a détecté l'échec du point de terminaison Qwen local et a acheminé la requête de manière transparente vers Gemini 2.5 Flash sur Vertex AI. Notez que ces appels de secours à Vertex AI contournent votre passerelle d'inférence vLLM locale. Ils n'apparaîtront donc pas dans le tableau de bord Observabilité de l'agent > Modèles, qui ne suit que le trafic transitant par vLLM.
Comprendre la puissance de l'allocation dynamique des ressources
Alors que vLLM et Inference Gateway optimisent la façon dont les requêtes sont acheminées et traitées, c'l'allocation dynamique des ressources est ce qui a permis d'associer le matériel exactement adapté à votre charge de travail en premier lieu.
DRA vous permet de gérer de manière précise le matériel de votre cluster en vous permettant de définir des ressources matérielles flexibles à l'aide de ResourceClaimTemplate et DeviceClasses.
Pourquoi DRA change la donne pour les charges de travail d'IA :
- Demandes de matériel précises : avec DRA, vous ne vous contentez pas de vous assurer que les charges de travail sont planifiées sur des machines dotées du bon accélérateur. Vous pouvez également revendiquer ces ressources pour vous assurer qu'elles sont utilisées exclusivement par la charge de travail associée à ResourceClaim.
- Cycle de vie dissocié : les revendications d'appareils sont gérées indépendamment des cycles de vie des pods. Si un pod plante, la revendication de GPU peut persister, de sorte que le déploiement global ou un autre objet de charge de travail peut être redémarré sans avoir à attendre que le GPU soit libéré et récupéré.
- Normalisation multivendeur : DRA fournit une API Kubernetes unifiée pour les GPU NVIDIA et les TPU Google. Vous utilisez exactement le même schéma, que vous déployiez pour l'un ou l'autre. Vos fichiers manifestes YAML de charge de travail sont donc très portables.
Dans cet atelier de programmation, vous avez pu constater cela en action lorsque vous avez configuré vos valeurs Helm pour qu'elles se lient à gpu-claim-template de manière fluide, sans que des configurations de plug-in d'appareil en attente bloquent vos déploiements.
Comprendre le rôle de llm-d
Alors que vLLM évalue les pondérations neuronales et que GKE Gateway achemine les requêtes, llm-d sert de couche de configuration et de "colle" qui les relie toutes.
Sans llm-d, vous devriez écrire des fichiers manifestes Kubernetes bruts pour déclarer votre déploiement vLLM, vos ports de service, vos montages de volumes et vos revendications de ressources DRA à partir de zéro.
Pourquoi utiliser llm-d dans votre déploiement ?
- Configuration unifiée (remplacements sur une ligne) : les charts Helm regroupent des ressources Kubernetes complexes de bas niveau en bascules claires de haut niveau (comme la définition de
accelerator.dra: true).llm-d - Chemins bien éclairés prévalidés : le dépôt
llm-dcontient des configurations qui ont déjà été évaluées et testées par des experts. Lorsque vous déployezllm-d-modelservice, vous bénéficiez de valeurs par défaut optimisées pour l'utilisation de la mémoire GPU, de timings de sonde recommandés (vivacité/disponibilité) et d'expositions correctes pour le scraping des métriques. - Mappage d'observabilité fluide :
llm-dgarantit que les ports de conteneur et les chemins d'extraction standards (/metrics) sont correctement exposés, ce qui facilite l'intégration de votre déploiement à Google Cloud Monitoring sans débogage manuel.
En bref, llm-d fournit des plans d'architecture réutilisables afin que les développeurs n'aient pas à tout créer de A à Z chaque fois qu'ils déploient une pile d'inférence sur GKE.
Présentation détaillée : GKE Inference Gateway
Les équilibreurs de charge de niveau 7 standards fonctionnent en examinant les en-têtes HTTP tels que les chemins d'accès (/v1/completions) ou les cookies. GKE Inference Gateway va beaucoup plus loin : il est spécialement conçu pour le trafic d'IA générative.
Comment cela améliore-t-il les performances et l'efficacité ?
- Routage basé sur le contenu (hachage des requêtes) : la passerelle d'inférence GKE intercepte le corps de la requête JSON. Il calcule un hachage du prompt et suit la réplique de backend qui contient déjà ces jetons dans sa mémoire GPU (le cache KV).
- Maximiser les accès au cache : lors de vos tests, lorsque vous avez répété une requête, la passerelle l'a envoyée à la même réplique. L'évaluation d'un prompt nécessite une puissance de calcul importante. En réutilisant le cache, vous évitez de "relire" le prompt, ce qui vous permet d'économiser de l'argent et du temps de GPU.
- Réduire le délai avant le premier jeton (TTFT) : le TTFT est une métrique d'usabilité essentielle pour les agents destinés aux utilisateurs. En accédant au cache, le modèle peut commencer à générer des jetons en millisecondes plutôt qu'en secondes.
- Distribution intelligente de la charge : si la VRAM d'une réplique est complètement remplie de résultats mis en cache, la passerelle peut acheminer dynamiquement une nouvelle requête vers une autre réplique disposant d'espace, ce qui permet d'équilibrer l'efficacité et la disponibilité.
Comment l'agent sandbox réduit les risques
Dans cet atelier, nous avons montré comment Agent Sandbox protège votre infrastructure contre les risques associés aux agents d'IA en fournissant deux niveaux d'isolation :
- Isolation de l'outil d'exécution : l'agent exécute le code qu'il génère dans un bac à sable éphémère. Cela garantit que le code non fiable généré par le LLM s'exécute dans un environnement sécurisé et isolé, ce qui protège l'agent et le cluster.
- Démarrage rapide : en utilisant un WarmPool, les nouveaux bacs à sable démarrent en moins d'une seconde et sont prêts à exécuter du code.
- Isolation de l'agent lui-même : nous avons également exécuté l'application d'agent elle-même dans un nœud compatible avec gVisor (via
runtimeClassName: gvisor) pour fournir une défense en profondeur contre les failles de la chaîne d'approvisionnement dans les dépendances de l'agent.
Voici pourquoi cela crée une limite de sécurité renforcée :
- Interception des appels système : gVisor intercepte les appels système avant qu'ils n'atteignent le noyau Linux de l'hôte. Cela bloque les exploits qui tentent de sortir du conteneur pour accéder au nœud hôte.
- Mouvement latéral restreint : combiné aux règles de réseau, même si un environnement est compromis, il ne peut pas analyser vos serveurs de métadonnées internes ni pivoter vers d'autres services sensibles de votre cluster.
Exécuter des agents complets dans des bacs à sable
Dans cet atelier, nous avons utilisé des bacs à sable comme outils pour une application d'agent persistant. Toutefois, pour une sécurité maximale, en particulier lorsque vous traitez des données sensibles ou que vous servez plusieurs utilisateurs non fiables, vous pouvez exécuter l'application d'agent entière dans un bac à sable dédié pour chaque session ou utilisateur. Cela garantit l'isolation complète de la mémoire, de l'état et de l'environnement d'exécution de l'agent, qui sont détruits immédiatement après la fin de la session.
9. Nettoyage
Pour éviter que les ressources utilisées dans cet atelier de programmation soient facturées sur votre compte Google Cloud, supprimez-les en suivant ces étapes.
Supprimer des ressources individuelles
- Supprimez le cluster GKE :
gcloud container clusters delete $CLUSTER_NAME --zone $ZONE --quiet
- Supprimez le dépôt Artifact Registry :
gcloud artifacts repositories delete agent-repo --location=us-central1 --quiet
- Supprimez le réseau VPC :
gcloud compute networks delete ai-agent-network --quiet
Supprimer le projet
Si vous n'avez plus besoin du projet, vous pouvez le supprimer après avoir supprimé les ressources :
gcloud projects delete $PROJECT_ID
10. Résumé
Félicitations ! Vous avez créé et déployé un agent de génération de code sécurisé et performant sur GKE.
Ce que vous avez appris
- Découvrez comment configurer et utiliser l'allocation dynamique de ressources (DRA) dans GKE pour gérer les ressources GPU.
- Découvrez comment utiliser la passerelle d'inférence GKE pour optimiser les performances de mise en service des LLM grâce au routage tenant compte du cache de préfixes.
- Comment utiliser Agent Sandbox (gVisor) pour exécuter du code non approuvé de manière sécurisée sur GKE.
- Découvrez comment utiliser Google Cloud Managed Service pour Prometheus afin de surveiller les performances de vLLM.
- Découvrez comment configurer et afficher l'observabilité des agents à l'aide d'ADK et de GKE Managed OpenTelemetry.
Étapes suivantes et références
- Agent Sandbox : découvrez Agent Sandbox sur GKE et les pods GKE Sandbox.
- llm-d : lisez le guide llm-d et consultez le dépôt GitHub llm-d.
- Allocation dynamique des ressources : découvrez l'ADR sur GKE.
- GKE Inference Gateway : découvrez les concepts d'Inference Gateway.
- Autres ateliers de programmation : retrouvez d'autres tutoriels sur Google Cloud Codelabs.