
1. מבוא
סקירה כללית
בשיעור ה-Lab הזה תלמדו איך ליצור ולפרוס סוכן מאובטח ליצירת קוד ב-Google Kubernetes Engine (GKE). סוכני יצירת קוד צריכים להריץ קוד שאולי לא מהימן, ולכן נדרשת סביבת ארגז חול מאובטחת. תלמדו גם איך להגדיר את הסוכן באמצעות אסטרטגיית מודל היברידי, שתאפשר לו לחזור ממודל פתוח באירוח עצמי ב-GKE לשירות Gemini המנוהל של Vertex AI כדי לשפר את המהימנות. בנוסף, תלמדו איך לבצע אופטימיזציה של הסקת מסקנות באמצעות GKE Inference Gateway והקצאת משאבים דינמית (DRA). לבסוף, תלמדו איך להשתמש ב-Google Cloud Observability כדי לעקוב אחרי מחסנית ההסקה באמצעות Prometheus מנוהל.
ארכיטקטורה
זו הארכיטקטורה של המערכת שתבנו:
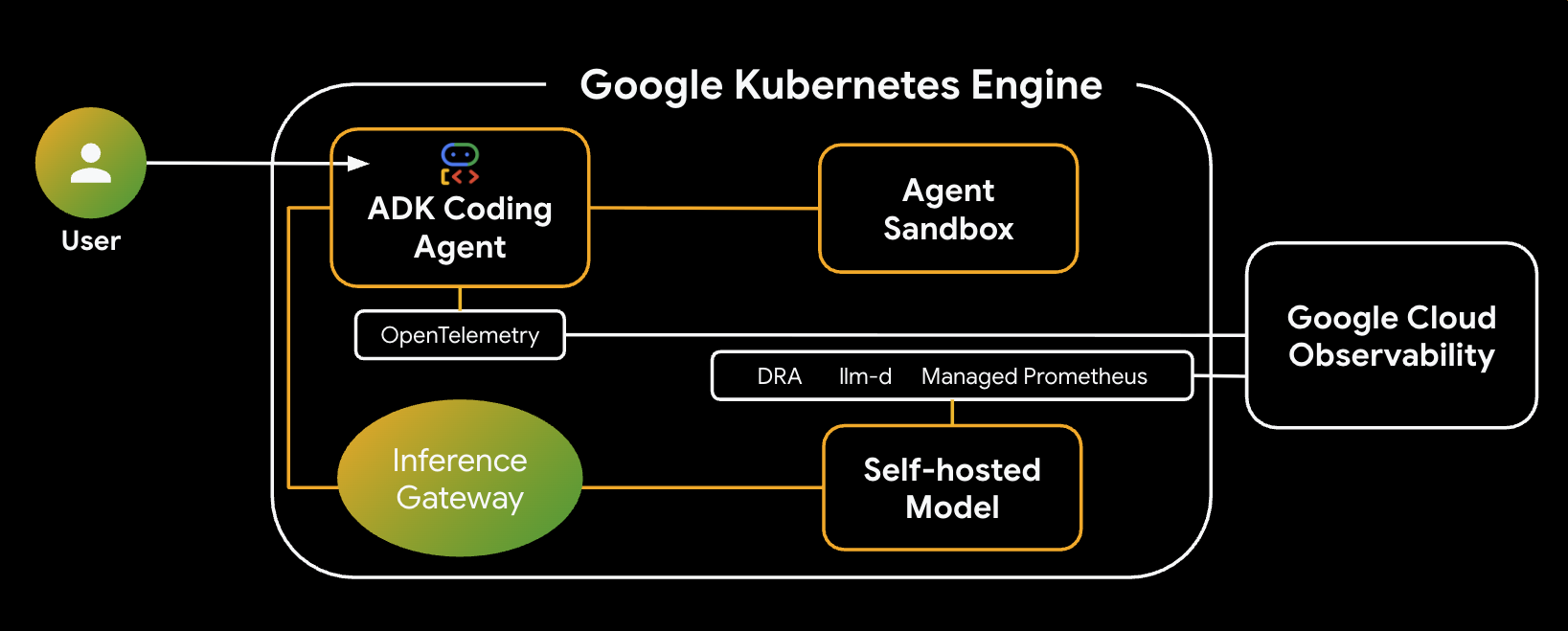
רכיבים עיקריים ויתרונות
- הקצאת משאבים דינמית (DRA): נעשה שימוש ב-DRA ב-Lab הזה כדי לתבוע ולהקצות באופן דינמי משאבי GPU ספציפיים (NVIDIA L4s) ל-Pods של שרת המודל, וכך להבטיח טירגוט מדויק של החומרה לעומס העבודה של ההיסק. מידע נוסף על DRA ב-GKE
- llm-d ו-vLLM: מספקים את מסגרת ההצגה של המודל ואת תרשימי Helm לפריסת מודל Qwen. בשיעור ה-Lab הזה, הוא מטפל בבקשות ההסקה ומשתלב עם DRA לניהול משאבים (הגשת מודעות מפוצלות לא מופעלת בשיעור ה-Lab הזה). מומלץ לקרוא את המדריך ל-llm-d ולעיין במאגר llm-d ב-GitHub.
- GKE Inference Gateway: מעביר את לוגיקת הניתוב שמודעת ל-AI ישירות למאזן העומסים. במעבדה הזו, הבקשות מנותבות כדי למקסם את הפגיעות במטמון של הקידומת, וכך לקצר את זמן האחזור של TTFT (הזמן עד לקבלת הטוקן הראשון). מושגים שקשורים ל-Inference Gateway
- ארגז חול לסוכנים (gVisor): מספק בידוד מאובטח להרצת הקוד שנוצר על ידי סוכן ה-AI. הוא משתמש ב-gVisor כדי לספק בידוד עמוק של הליבה, וכך להגן על צומת המארח מפני עומסי עבודה לא מהימנים. מידע על ארגז החול לסוכנים ב-GKE ועל GKE Sandbox Pods
הפעולות שתבצעו:
- הקצאת תשתית: הגדרת אשכול GKE עם הקצאת משאבים דינמית (DRA) לניהול GPU.
- פריסת Inference Stack: פריסת
llm-dו-vLLM עם תזמון חכם של הסקת מסקנות. - הגדרת ניתוב חכם: שימוש ב-GKE Inference Gateway לניתוב עם מודעות למטמון של קידומות.
- הרצת קוד מאובטחת: פורסים את ארגז החול לסוכנים (gVisor) כדי להריץ בבטחה קוד שנוצר על ידי AI.
- התבוננות ואימות: משתמשים ב-Google Cloud Monitoring וב-Managed Prometheus כדי להציג מדדים של מודלים שמוצגים.
מה תלמדו
- איך מגדירים את התכונה Dynamic Resource Allocation (הקצאת משאבים דינמית, DRA) ב-GKE ומשתמשים בה.
- איך משתמשים ב-GKE Inference Gateway כדי לשפר את הביצועים של מודלים גדולים של שפה (LLM).
- איך משתמשים בארגז החול לסוכנים כדי להריץ קוד לא מהימן בצורה מאובטחת ב-GKE.
- איך משתמשים בשירות המנוהל של Google Cloud ל-Prometheus כדי לעקוב אחרי הביצועים של vLLM.
2. הגדרה ודרישות
הגדרת הפרויקט
יצירת פרויקט ב-Google Cloud
- במסוף Google Cloud, בדף לבחירת הפרויקט, בוחרים פרויקט ב-Google Cloud או יוצרים פרויקט.
- הקפידו לוודא שהחיוב מופעל בפרויקט שלכם ב-Cloud. כך בודקים אם החיוב מופעל בפרויקט
הפעלת Cloud Shell
Cloud Shell היא סביבת שורת פקודה שפועלת ב-Google Cloud וכוללת מראש את הכלים הנדרשים.
- לוחצים על Activate Cloud Shell בחלק העליון של מסוף Google Cloud.
- אחרי שמתחברים ל-Cloud Shell, מאמתים את האימות:
gcloud auth list - מוודאים שהפרויקט מוגדר:
gcloud config get project - אם הפרויקט לא מוגדר כמו שציפיתם, מגדירים אותו:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
3. הקצאת תשתית והקצאה דינמית של משאבים (DRA)
בשלב הראשון הזה, תגדירו את אשכול GKE כך שישתמש בהקצאת מאיצים מודרנית (DRA) במקום בתוספי מכשירים מדור קודם. כך תוכלו לשתף ולהקצות מעבדי GPU או TPU לעומסי העבודה של יצירת הקוד.
דרישות מוקדמות: כדי לתמוך ב-DRA, אשכול GKE Standard צריך לפעול בגרסה 1.34 ואילך.
הפעלת Cloud APIs
מפעילים את ממשקי Google Cloud API שנדרשים ל-Codelab הזה, במיוחד את ממשקי Compute Engine ו-Kubernetes Engine.
gcloud services enable compute.googleapis.com container.googleapis.com networkservices.googleapis.com cloudbuild.googleapis.com artifactregistry.googleapis.com telemetry.googleapis.com cloudtrace.googleapis.com aiplatform.googleapis.com
הגדרה של משתני סביבה
כדי להקל על ההגדרה, מגדירים את משתני הסביבה. אפשר לשנות את האזור או את מוסכמות השמות לפי הצורך.
export PROJECT_ID=$(gcloud config get-value project)
export ZONE=us-central1-a
export CLUSTER_NAME=ai-agent-cluster
export NODEPOOL_NAME=dra-accelerator-pool
gcloud config set project $PROJECT_ID
gcloud config set compute/region $ZONE
יצירת ספריית עבודה
יוצרים ספריית עבודה ייעודית ל-Lab הזה ועוברים אליה כדי שהקבצים יישארו מסודרים:
mkdir -p ~/gke-ai-agent-lab
cd ~/gke-ai-agent-lab
הגדרת הרשאות (אופציונלי)
אם אתם מריצים את התהליך בפרויקט מוגבל או בסביבה משותפת, אתם צריכים לוודא שלחשבון שלכם יש את ההרשאות הנדרשות ליצירת אשכולות ולהרצת בנייה:
export MY_ACCOUNT=$(gcloud config get-value account)
# Grant Container Admin to create clusters and manage nodes if needed
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/container.admin"
# Grant Cloud Build Builder to run builds
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/cloudbuild.builds.builder"
יצירת אשכול GKE
כדי לתמוך ב-DRA, אשכול GKE Standard צריך לפעול בגרסה 1.34 ואילך. צריך גם להפעיל את בקרי Gateway API כדי לתמוך בתזמון חכם של הסקת מסקנות.
בשיעור ה-Lab הזה תיצרו רשת VPC חדשה ותת-רשתות.
קודם יוצרים את רשת ה-VPC:
gcloud compute networks create ai-agent-network --subnet-mode=custom
בשלב הבא, יוצרים רשת משנה לצמתי GKE:
gcloud compute networks subnets create ai-agent-subnet \
--network=ai-agent-network \
--range=10.0.0.0/20 \
--region=us-central1
בנוסף, Gateway API (gke-l7-regional-internal-managed) דורש תת-רשת ייעודית לאירוח של שרתי ה-proxy של Envoy. יוצרים את תת-הרשת הזו של שרת proxy בלבד ברשת החדשה:
gcloud compute networks subnets create proxy-only-subnet \
--purpose=REGIONAL_MANAGED_PROXY \
--role=ACTIVE \
--region=us-central1 \
--network=ai-agent-network \
--range=192.168.10.0/24
עכשיו יוצרים את האשכול באמצעות הרשת ורשת המשנה החדשות:
gcloud beta container clusters create $CLUSTER_NAME \
--zone $ZONE \
--num-nodes 1 \
--machine-type n2-standard-4 \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--gateway-api=standard \
--managed-otel-scope=COLLECTION_AND_INSTRUMENTATION_COMPONENTS \
--network=ai-agent-network \
--subnetwork=ai-agent-subnet
יצירת מאגר צמתים עם השבתה של פלאגינים שמופעלים כברירת מחדל
כדי להעביר את ניהול המכשיר ל-DRA, צריך ליצור מאגר צמתים שבו מושבתת באופן מפורש ההתקנה של מנהל התקן ברירת המחדל של ה-GPU ותוסף המכשיר הרגיל.
מריצים את הפקודה gcloud הבאה כדי להקצות מאגר צמתים של GPU (לדוגמה, באמצעות NVIDIA L4s) עם התוויות הנדרשות של DRA:
gcloud container node-pools create $NODEPOOL_NAME \
--cluster=$CLUSTER_NAME \
--location=$ZONE \
--machine-type=g2-standard-24 \
--accelerator=type=nvidia-l4,count=2,gpu-driver-version=disabled \
--node-labels=gke-no-default-nvidia-gpu-device-plugin=true,nvidia.com/gpu.present=true \
--num-nodes 3
התקנת דרייברים של NVIDIA באמצעות DaemonSet
מתקינים באופן ידני את מנהלי ההתקנים (דרייברים) של מכשיר NVIDIA הנדרשים בצמתים באמצעות Google Cloud DaemonSet שהוגדר מראש:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
התקנת מנהל ההתקן של DRA
בשלב הבא, מתקינים את מנהל ההתקן הספציפי של DRA באשכול. ב-GPU של NVIDIA, אפשר לפרוס את התוסף באמצעות Helm:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
helm install nvidia-dra-driver-gpu nvidia/nvidia-dra-driver-gpu \
--version="25.3.2" --create-namespace --namespace=nvidia-dra-driver-gpu \
--set nvidiaDriverRoot="/home/kubernetes/bin/nvidia/" \
--set gpuResourcesEnabledOverride=true \
--set resources.computeDomains.enabled=false \
--set kubeletPlugin.priorityClassName="" \
--set 'kubeletPlugin.tolerations[0].key=nvidia.com/gpu' \
--set 'kubeletPlugin.tolerations[0].operator=Exists' \
--set 'kubeletPlugin.tolerations[0].effect=NoSchedule'
הסבר על DeviceClasses
אתם לא צריכים לכתוב או להחיל קובץ DeviceClass YAML באופן ידני. כשמגדירים את התשתית של GKE ל-DRA ומתקינים את מנהל ההתקן, מנהלי ההתקן של DRA שפועלים בצמתים יוצרים באופן אוטומטי את אובייקטי DeviceClass באשכול.
הגדרת ResourceClaimTemplate
כדי לאפשר ל-Pods של llm-d לבקש באופן דינמי את המאיצים האלה, צריך ליצור ResourceClaimTemplate. התבנית הזו מגדירה את תצורת המכשיר המבוקשת, ומורה ל-Kubernetes ליצור באופן אוטומטי ResourceClaim ייחודי לכל Pod עבור עומסי העבודה.
מריצים את הפקודה הבאה כדי ליצור את claim-template.yaml:
cat > claim-template.yaml <<EOF
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: gpu-claim-template
spec:
spec:
devices:
requests:
- name: single-gpu
exactly:
deviceClassName: gpu.nvidia.com
allocationMode: ExactCount
count: 1
EOF
מחילים את התבנית על האשכול:
kubectl apply -f claim-template.yaml
4. פריסת תזמון חכם של היקשים באמצעות llm-d ו-DRA
בשלב הזה, תפרסו את מודל השפה הגדול מאחורי מאזן עומסים חכם של Envoy, שמשופר באמצעות מתזמן הסקה. ההגדרה הזו מבצעת אופטימיזציה לפרסום המודל באמצעות ניתוב עם מודעות למטמון של קידומות. שער ההסקה של GKE מזהה הקשר משותף בין מיקרו-שירותים ומנתב בקשות בצורה חכמה לאותו עותק של המודל, וכך ממקסם את הפגיעות במטמון, מקצר את הזמן עד לטוקן הראשון ומשפר את הביצועים ביחס לעלות.
הכנת הסביבה
מגדירים את מרחב השמות של היעד.
export NAMESPACE=ai-agents
kubectl create namespace $NAMESPACE
מאחסנים בצורה מאובטחת את האסימון של Hugging Face, שנדרש כדי לשלוף את משקלי המודל.
# Replace with your actual Hugging Face token
kubectl create secret generic llm-d-hf-token \
--from-literal=HF_TOKEN="your_hugging_face_token" \
-n $NAMESPACE
יצירת קובצי ההגדרות של Helm
ההגדרות של שירות המודל ותוסף שער ההסקה מבוססות על מדריכי llm-d הרשמיים.
קודם יוצרים את קובץ ms-values.yaml של שירות המודל:
cat <<EOF > ms-values.yaml
multinode: false
modelArtifacts:
uri: "hf://Qwen/Qwen2.5-Coder-14B-Instruct"
name: "Qwen/Qwen2.5-Coder-14B-Instruct"
size: 50Gi # Slightly larger than the default to accommodate weights
authSecretName: "llm-d-hf-token"
labels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
llm-d.ai/accelerator-variant: "gpu"
llm-d.ai/accelerator-vendor: "nvidia"
llm-d.ai/model: "qwen-2-5-coder-14b"
routing:
proxy:
enabled: false # removes sidecar from deployment - no PD in inference scheduling
targetPort: 8000 # controls vLLM port to matchup with sidecar if deployed
accelerator:
dra: true
type: "nvidia"
resourceClaimTemplates:
nvidia:
class: "gpu.nvidia.com"
match: "exactly"
name: "gpu-claim-template"
decode:
create: true
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
parallelism:
tensor: 2
data: 1
replicas: 3
monitoring:
podmonitor:
enabled: true
portName: "vllm"
path: "/metrics"
interval: "30s"
containers:
- name: "vllm"
image: ghcr.io/llm-d/llm-d-cuda:v0.5.1
modelCommand: vllmServe
args:
- "--disable-uvicorn-access-log"
- "--gpu-memory-utilization=0.85"
- "--enable-auto-tool-choice"
- "--tool-call-parser"
- "hermes"
ports:
- containerPort: 8000
name: vllm
protocol: TCP
resources:
limits:
cpu: '16'
memory: 64Gi
requests:
cpu: '16'
memory: 64Gi
mountModelVolume: true
volumeMounts:
- name: metrics-volume
mountPath: /.config
- name: shm
mountPath: /dev/shm
- name: torch-compile-cache
mountPath: /.cache
startupProbe:
httpGet:
path: /v1/models
port: vllm
initialDelaySeconds: 15
periodSeconds: 30
timeoutSeconds: 5
failureThreshold: 120
livenessProbe:
httpGet:
path: /health
port: vllm
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /v1/models
port: vllm
periodSeconds: 5
timeoutSeconds: 2
failureThreshold: 3
volumes:
- name: metrics-volume
emptyDir: {}
- name: torch-compile-cache
emptyDir: {}
- name: shm
emptyDir:
medium: Memory
sizeLimit: 20Gi
prefill:
create: false
EOF
בשלב הבא, יוצרים את הקובץ gaie-values.yaml עבור התוסף GKE Inference Gateway:
cat <<EOF > gaie-values.yaml
inferenceExtension:
replicas: 1
image:
name: llm-d-inference-scheduler
hub: ghcr.io/llm-d
tag: v0.6.0
pullPolicy: Always
extProcPort: 9002
pluginsConfigFile: "default-plugins.yaml"
tracing:
enabled: false
monitoring:
interval: "10s"
prometheus:
enabled: true
auth:
secretName: inference-scheduling-gateway-sa-metrics-reader-secret
inferencePool:
targetPorts:
- number: 8000
modelServerType: vllm
modelServers:
matchLabels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
EOF
הסבר על ההגדרה
ההגדרה הזו יוצרת מחסנית הסקה עם ביצועים גבוהים, שכוללת את התכונות המרכזיות הבאות:
- בחירת מודל: הוא משתמש במודל Qwen 2.5 Coder 14B (
modelArtifacts), שעבר אופטימיזציה ליצירת קוד ולשימוש בכלי. - שילוב של DRA: בקטע
acceleratorמופעלת הקצאה דינמית של משאבים (dra: true), שמטרגטת את מחלקת המכשיריםgpu.nvidia.comואתgpu-claim-templateשיצרנו קודם. - אופטימיזציה של הביצועים:
-
parallelism.tensor: 2מגדיר מקביליות טנסור בין ה-GPU. -
argsfor vLLM כולל--enable-auto-tool-choiceכדי להבטיח שהסוכן שלנו ליצירת קוד יוכל להשתמש בכלים בצורה יעילה. - בקשות
cpuו-memoryמופחתות מתאימות לסוג המכונהg2-standard-24.
-
- ניתוב חכם: תוסף שער ההסקה (
gaie-values.yaml) מוגדר לעקוב אחרי שרתי המודלvllmולנתב בקשות כדי למקסם את ההתאמות במטמון KV.
פריסת חבילת התזמון של היקשים באמצעות Helm
עכשיו מוסיפים את מאגרי llm-d Helm ופורסים את התשתית, את תוסף השער ואת שירות המודל בנפרד.
קודם כול, מוסיפים את המאגרים הנדרשים:
helm repo add llm-d-infra https://llm-d-incubation.github.io/llm-d-infra/
helm repo add llm-d-modelservice https://llm-d-incubation.github.io/llm-d-modelservice/
helm repo update
פריסת הדרישות המוקדמות של התשתית
בתרשים הזה מותקנות ההגדרות הבסיסיות של שער הנתונים שנדרשות למערכת.
helm install infra-is llm-d-infra/llm-d-infra \
--namespace $NAMESPACE \
--set gateway.gatewayClassName=gke-l7-rilb \
--set gateway.gatewayParameters.enabled=false \
--set gateway.gatewayParameters.istio.accessLogging=false
פריסת התוסף GKE Inference Gateway
בשלב הזה מתבצע פריסה של InferencePool ו-Endpoint Picker, שמנטרים את מטמון KV של המודלים כדי לקבל החלטות חכמות לגבי ניתוב.
helm install gaie-is oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool \
--version v1.3.1 \
--namespace $NAMESPACE \
-f gaie-values.yaml \
--set provider.name=gke \
--set inferenceExtension.monitoring.prometheus.enabled=true
פריסת שירות המודלים
לבסוף, פורסים את שירות ה-LLM, שישתמש עכשיו ב-DRA כדי לתבוע בצורה מאובטחת את מעבדי ה-GPU מסוג L4.
helm install ms-is llm-d-modelservice/llm-d-modelservice \
--version v0.4.7 \
--namespace $NAMESPACE \
-f ms-values.yaml \
--set decode.monitoring.podmonitor.enabled=false
הפעלת Google Cloud Observability ל-vLLM
תרשימי Helm גנריים מנסים לעיתים קרובות לפרוס משאבי Prometheus Operator PodMonitor סטנדרטיים (monitoring.coreos.com/v1), מה שעלול לגרום לשגיאות אם לא התקנתם את ה-CRD האלה.
במקום להשתמש במתג המובנה של Helm למעקב, משאירים אותו במצב false ומחילים באופן ידני משאב של Google Cloud Managed Prometheus (GMP) PodMonitoring באמצעות קבוצת ה-API התואמת monitoring.googleapis.com/v1.
מריצים את הפקודה הבאה כדי ליצור את podmonitoring.yaml:
cat > podmonitoring.yaml <<EOF
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: ms-vllm-metrics
spec:
selector:
matchLabels:
llm-d.ai/model: "qwen-2-5-coder-14b" # Matches the label in values.yaml
endpoints:
- port: 8000 # vllm port
interval: 30s
path: /metrics
EOF
מחילים את משאב PodMonitoring על האשכול:
kubectl apply -f podmonitoring.yaml -n $NAMESPACE
אימות ההתקנה
מוודאים שהרכיבים הותקנו בהצלחה. אמורים לראות את כל שלושת הגרסאות של Helm פעילות במרחב השמות, ואת הפודים המתאימים מתחילים אתחול.
helm ls -n $NAMESPACE
kubectl get pods -n $NAMESPACE
יכול להיות שיחלפו 5 עד 10 דקות עד שה-pods של ms-is יפעלו. הפלט אמור להיראות כך:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
gaie-is ai-agents 1 2026-03-28 16:51:41.055881618 +0000 UTC deployed inferencepool-v1.3.1 v1.3.1
infra-is ai-agents 1 2026-03-28 16:51:03.71042542 +0000 UTC deployed llm-d-infra-v1.4.0 v0.4.0
ms-is ai-agents 1 2026-03-28 17:30:00.341918958 +0000 UTC deployed llm-d-modelservice-v0.4.7 v0.4.0
NAME READY STATUS RESTARTS AGE
gaie-is-epp-848965cb4-78ktp 1/1 Running 0 10m
ms-is-llm-d-modelservice-decode-67548d5f8c-f25f4 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-rblvs 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-w6fcd 1/1 Running 0 6m2s
5. הגדרת ניתוב חכם באמצעות GKE Inference Gateway
בשלב 4, פריסת תרשימי llm-d Helm הקצתה אוטומטית את האובייקטים של Gateway ו-InferencePool. הקבוצה InferencePool את תאי ה-Pod של פרסום המודל vllm שמשתפים את אותו מודל בסיסי ואת אותה הגדרת מחשוב.
עכשיו צריך להגדיר InferenceObjective כדי להגדיר את העדיפות של הבקשות של סוכן הקידוד, וHTTPRoute כדי להנחות את שער הגישה איך לנתב תנועה נכנסת, תוך שימוש ב-Endpoint Picker כדי למקסם את הפגיעות במטמון KV.
אימות משאבים שנוצרו אוטומטית
קודם כל, מוודאים שתרשימי ה-Helm יצרו בהצלחה את משאבי ה-Gateway ו-InferencePool.llm-d
kubectl get gateway,inferencepool -n $NAMESPACE
אמורים לראות שער בשם infra-is-inference-gateway ומאגר מסקנות בשם gaie-is. בדומה לזה:
NAME CLASS ADDRESS PROGRAMMED AGE
gateway.gateway.networking.k8s.io/infra-is-inference-gateway gke-l7-regional-internal-managed 10.128.0.5 True 13m
NAME AGE
inferencepool.inference.networking.k8s.io/gaie-is 12m
יצירת HTTPRoute
מקור המידע HTTPRoute ממפה את שער הגישה אל ה-backend InferencePool. ההגדרה הזו אומרת ל-GKE Inference Gateway לנתח את גופי הבקשות הנכנסות ולנתב אותן באופן דינמי כדי למקסם את ההתאמות של Prefix-Cache על סמך הקשר המשותף.
מריצים את הפקודה הבאה כדי ליצור את httproute.yaml:
cat > httproute.yaml <<EOF
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: agent-route
spec:
parentRefs:
- group: gateway.networking.k8s.io
kind: Gateway
name: infra-is-inference-gateway
rules:
- backendRefs:
- group: inference.networking.k8s.io
kind: InferencePool
name: gaie-is
weight: 1
matches:
- path:
type: PathPrefix
value: /
EOF
מחילים את המסלול על האשכול:
kubectl apply -f httproute.yaml -n $NAMESPACE
6. הפעלה מאובטחת של קוד באמצעות ארגז חול של סוכנים
עכשיו, כשהקצה העורפי של ההסקה עם הביצועים הגבוהים פועל, נכין את הסביבה המאובטחת שבה הקוד שנוצר על ידי AI יפעל בבידוד בטוח מהאשכול שלנו באמצעות ארגז חול לסוכנים.
פריסת Agent Sandbox Controller
כשסוכן AI יוצר ומריץ קוד, הוא בעצם מריץ עומס עבודה לא מהימן בתשתית שלכם. אם הסוכן יוצר קוד זדוני, הוא עלול לנסות לסרוק את הרשת הפנימית שלכם או לנצל את צומת המארח הבסיסי.
ארגז החול לסוכנים ב-GKE משתמש ב-gVisor, זמן ריצה של קונטיינר בקוד פתוח שמספק ליבת אורח מיוחדת לכל קונטיינר. כך קוד לא מהימן לא יכול לבצע קריאות מערכת ישירות לצומת המארח.
פורסים את בקר Agent Sandbox ואת הרכיבים הנדרשים שלו על ידי החלת מניפסטים של הגרסה הרשמית:
kubectl apply \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/manifest.yaml \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/extensions.yaml
הגדרת תבנית ארגז החול ומאגר השרתים המוכנים
בשלב הבא, אנחנו יוצרים SandboxTemplate שמשמש כתוכנית בסיס לשימוש חוזר עבור סביבות הניתוח של Python, ומכוון באופן מפורש למחלקת זמן הריצה gvisor. כדי לפשט את הפריסה בלי לנהל מאגרי צמתים ידניים באשכולות רגילים, אפשר להשתמש בכל autopilot רגיל
ComputeClass כדי להקצות באופן דינמי צמתים מנוהלים של מחשוב שתומכים באופן מובנה בעומסי עבודה של gVisor על פי דרישה.
מכיוון שאיתחול של ליבת מאובטחת עלול להוסיף זמן אחזור, אנחנו גם פורסים SandboxWarmPool. כך מובטח שמספר מסוים של ארגזי חול שכבר אותחלו יהיו מוכנים, כדי שהסוכן ליצירת קוד יוכל להשתמש בהם ולהתחיל להריץ קוד תוך פחות משנייה.
קודם יוצרים מרחב שמות חדש לסביבות זמן הריצה של ארגז החול של הסוכן:
kubectl create namespace agent-sandbox
שומרים את הקובץ הבא בשם sandbox-template-and-pool.yaml:
cat > sandbox-template-and-pool.yaml <<EOF
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxTemplate
metadata:
name: python-runtime-template
namespace: agent-sandbox
spec:
podTemplate:
metadata:
labels:
sandbox: python-sandbox-example
spec:
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: python-runtime
image: registry.k8s.io/agent-sandbox/python-runtime-sandbox:v0.1.0
ports:
- containerPort: 8888
readinessProbe:
httpGet:
path: "/"
port: 8888
initialDelaySeconds: 0
periodSeconds: 1
resources:
requests:
cpu: "250m"
memory: "512Mi"
ephemeral-storage: "512Mi"
restartPolicy: "OnFailure"
---
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxWarmPool
metadata:
name: python-sandbox-warmpool
namespace: agent-sandbox
spec:
replicas: 2
sandboxTemplateRef:
name: python-runtime-template
EOF
מחילים את ההגדרה:
kubectl apply -f sandbox-template-and-pool.yaml
ממתינים 2-3 דקות עד שה-pods של מאגר ה-IP יאותחלו. כדי לוודא שהמעבר מ-Pending (בזמן שהמשאבים הבסיסיים של המחשוב גדלים) ל-Running בוצע בהצלחה, אפשר להשתמש בפקודה:
kubectl get pods -n agent-sandbox -w
אחרי ששני תרמילים python-sandbox-warmpool-*** מופיעים כRunning ו1/1 Ready, סביבות ההפעלה הבטוחות שלכם מחוממות מראש ומוכנות לשימוש.
פריסת נתב ארגז החול
הסוכן שלנו ליצירת קוד מסתמך על נתב ארגז חול כדי לשלוח בצורה מאובטחת פקודות הפעלה ל-pods מבודדים.
מריצים את הפקודה הבאה כדי ליצור את sandbox-router.yaml:
cat > sandbox-router.yaml <<EOF
apiVersion: v1
kind: Service
metadata:
name: sandbox-router-svc
namespace: agent-sandbox
spec:
type: ClusterIP
selector:
app: sandbox-router
ports:
- name: http
protocol: TCP
port: 8080
targetPort: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sandbox-router-deployment
namespace: agent-sandbox
spec:
replicas: 2
selector:
matchLabels:
app: sandbox-router
template:
metadata:
labels:
app: sandbox-router
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: sandbox-router
containers:
- name: router
image: us-central1-docker.pkg.dev/k8s-staging-images/agent-sandbox/sandbox-router:v20260225-v0.1.1.post3-10-ga5bcb57
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 10
resources:
requests:
cpu: "250m"
memory: "512Mi"
limits:
cpu: "1000m"
memory: "1Gi"
securityContext:
runAsUser: 1000
runAsGroup: 1000
EOF
מחילים את ההגדרה:
kubectl apply -f sandbox-router.yaml
הטמעה של בידוד רשת
כדי להגביל עוד יותר את סביבת ההפעלה ולמנוע תנועה לרוחב לא מורשית, צריך להחיל מדיניות רשת. כך נוצר 'פער אוויר' בארגז החול, והוא לא יכול להגיע לשרת המטא-נתונים של Google Cloud או לרשתות פנימיות רגישות אחרות.
שומרים את הקובץ הבא בשם sandbox-policy.yaml:
cat > sandbox-policy.yaml <<EOF
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: restrict-sandbox-egress
namespace: agent-sandbox
spec:
podSelector:
matchLabels:
sandbox: python-sandbox-example
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 0.0.0.0/0
except:
- 169.254.169.254/32 # Block metadata server
EOF
החלת המדיניות:
kubectl apply -f sandbox-policy.yaml
אימות הרכיבים
כדי לוודא ששכבת האשכול של ארגז החול המבודד מוגדרת במלואה, מריצים את פקודות האימות הבאות של המצב:
קודם כל, מוודאים שרכיבי ה-pod והנתבים של ארגז החול פועלים ומוכנים
kubectl get pods -n agent-sandbox
הפלט אמור להיראות כך:
NAME READY STATUS RESTARTS AGE
python-sandbox-warmpool-7zlkv 1/1 Running 0 3m25s
python-sandbox-warmpool-cxln2 1/1 Running 0 3m25s
sandbox-router-deployment-668dfbbbb6-g9mpd 1/1 Running 0 42s
sandbox-router-deployment-668dfbbbb6-ppllz 1/1 Running 0 42s
אימות של מאזן עומסים של נתב ארגז חול או חשיפה של כתובת IP
kubectl get service sandbox-router-svc -n agent-sandbox
הפלט אמור להיראות כך:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
sandbox-router-svc ClusterIP 34.118.237.244 <none> 8080/TCP 114s
מוודאים שקיים כלל במדיניות היציאה מהרשת
kubectl get networkpolicy restrict-sandbox-egress -n agent-sandbox
הפלט אמור להיראות כך:
NAME POD-SELECTOR AGE
restrict-sandbox-egress sandbox=python-sandbox-example 113s
ודא ש:
- הפודים
python-sandbox-warmpool-***הםRunningו-1/1Ready. - העותקים של
sandbox-router-deployment-***הםRunningו-1/1Ready. - אפשר לגשת אל
sandbox-router-svc, ומדיניותrestrict-sandbox-egressמגנה בהצלחה על כל תוויות ה-Sandbox התואמות.
אחרי שסיימנו להגדיר את סביבת ההרצה המאובטחת שלנו, אנחנו מוכנים לפרוס את המוח האמיתי של הפעולה שלנו: סוכן יצירת הקוד!
7. פיתוח ופריסה של סוכן ליצירת קוד (ADK)
אחרי שמגדירים את ארגז החול להרצה בטוחה ואת העורף של מודל שפה גדול (LLM) עם ביצועים גבוהים, אפשר ליצור את ה "מוח" של המערכת: סוכן ליצירת קוד באמצעות הערכה לפיתוח סוכנים (ADK).
הסוכן הזה נועד לפעול כמפתח Python מומחה. בניגוד לצ'אטבוט רגיל שמפיק רק טקסט, לסוכן הזה יש כלי להרצת קוד שמאפשר לו לפתור בעיות באופן אינטראקטיבי. הוא פועל בלולאה של:
- כתיבת קוד Python על סמך הבקשות שלכם.
- הרצה של הקוד בצורה מאובטחת בתוך ארגז החול לסוכנים ב-GKE שהגדרנו בשלב 6.
- אימות הפלט או קריאת השגיאות שמתרחשות במהלך הביצוע.
- מספקים פתרון שעבר בדיקות ופועל בצורה תקינה.
אנחנו נותנים לסוכן גישה לסביבת הפעלה מאובטחת של ארגז חול, וכך הוא יכול לאמת את הלוגיקה שלו ולנפות באגים באופן אוטומטי. זה משפר משמעותית את היכולת שלו לבצע משימות של פיתוח תוכנה.
פיתוח סוכן ADK Reasoning
קודם כל, אנחנו כותבים את הלוגיקה של Python שמגדירה את ההתנהגות של הסוכן ומציידת אותו בכלי ארגז החול שיצרנו בשלב 6. בקטע הזה אנחנו גם מגדירים אסטרטגיית מודל היברידי: הסוכן ייתן עדיפות למודל Qwen שמתארח באופן עצמאי ופועל באשכול GKE, אבל יעבור אוטומטית ל-Gemini 2.5 Flash ב-Vertex AI אם המודל המקומי איטי או לא זמין, כדי להבטיח מהימנות גבוהה.
יוצרים ספרייה חדשה לקוד הסוכן:
mkdir -p ~/gke-ai-agent-lab/root_agent
cd ~/gke-ai-agent-lab
יוצרים קובץ בשם root_agent/agent.py עם התוכן הבא:
cat <<'EOF' > root_agent/agent.py
import os
from google.adk.agents import Agent
from google.adk.models.lite_llm import LiteLlm
from k8s_agent_sandbox import SandboxClient
import requests
# Instantiate the client globally to track sandboxes
sandbox_client = SandboxClient()
def run_python_code(code: str) -> str:
"""
Executes Python code safely in the GKE Agent Sandbox.
Use this tool whenever you need to execute code to solve a problem.
"""
sandbox = sandbox_client.create_sandbox(template="python-runtime-template", namespace="agent-sandbox")
try:
command = f"python3 -c \"{code}\""
result = sandbox.commands.run(command)
if result.stderr:
return f"Error: {result.stderr}"
return result.stdout
finally:
# Ensure the sandbox is deleted after use to avoid leaking resources
sandbox_client.delete_sandbox(sandbox.claim_name, namespace="agent-sandbox")
# Define the ADK Agent with a fallback mechanism.
# It prioritizes the Qwen 2.5 Coder model running on our Inference Gateway.
# If the local model is unavailable, it falls back to Gemini 2.5 Flash on Vertex AI.
root_agent = Agent(
name="CodeGenerationAgent",
model=LiteLlm(
model="openai/Qwen/Qwen2.5-Coder-14B-Instruct",
fallbacks=["vertex_ai/gemini-2.5-flash"],
timeout=10
),
instruction="""
You are an expert Python developer.
1. Write Python code to solve the user's problem.
2. Execute the code using the `run_python_code` tool to verify it works.
3. Return the exact output and a brief explanation of the code.
""",
tools=[run_python_code]
)
EOF
יוצרים קובץ __init__.py כדי ש-ADK יזהה את המודול:
echo "from . import agent" > ~/gke-ai-agent-lab/root_agent/__init__.py
מגדירים את משתני הסביבה. אפליקציית ה-ADK צריכה את כתובת ה-IP של השער כדי לנתב את הבקשות למודל שפה גדול (LLM) בהצלחה. מכיוון ש-ADK תומך בנקודות קצה סטנדרטיות שתואמות ל-Open-AI (ש-vLLM מספק דרך ה-Gateway שלנו), אנחנו יכולים לבטל את כתובת ה-URL הבסיסית של ה-API שמוגדרת כברירת מחדל.
export GATEWAY_IP=$(kubectl get gateway infra-is-inference-gateway -n $NAMESPACE -o jsonpath='{.status.addresses[0].value}')
cat <<EOF > ~/gke-ai-agent-lab/root_agent/.env
OPENAI_API_BASE=http://${GATEWAY_IP}/v1
OPENAI_API_KEY=no-key-required
# Vertex AI settings for fallback (Authentication is handled by Workload Identity)
VERTEXAI_PROJECT=$PROJECT_ID
VERTEXAI_LOCATION=${ZONE%-[a-z]}
EOF
העברת אפליקציית הסוכן לקונטיינר
אנחנו צריכים לארוז את הסוכן כדי שהוא יוכל לפעול בצורה מאובטחת בתוך GKE.
יוצרים Dockerfile ב-~/gke-ai-agent-lab שמתקין את kubectl, את ספריית ה-ADK ואת לקוח Agent Sandbox:
cat <<'EOF' > ~/gke-ai-agent-lab/Dockerfile
FROM python:3.11-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
RUN apt-get update && apt-get install -y git curl \
&& curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl" \
&& install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl \
&& rm kubectl && apt-get clean && rm -rf /var/lib/apt/lists/*
RUN pip install --no-cache-dir "google-adk[extensions,otel-gcp]>=1.27.4" litellm pandas "git+https://github.com/kubernetes-sigs/agent-sandbox.git@main#subdirectory=clients/python/agentic-sandbox-client" \
"opentelemetry-instrumentation-google-genai>=0.4b0" \
"opentelemetry-exporter-otlp" \
"opentelemetry-instrumentation-vertexai>=2.0b0"
COPY ./root_agent /app/root_agent
EXPOSE 8080
ENTRYPOINT ["adk", "web", "--host", "0.0.0.0", "--port", "8080", "--otel_to_cloud"]
EOF
יוצרים מאגר Artifact Registry לאחסון קובץ האימג' של הקונטיינר.
gcloud artifacts repositories create agent-repo \
--repository-format=docker \
--location=us-central1
משתמשים ב-Cloud Build כדי ליצור את קובץ האימג' של הקונטיינר ולהעביר אותו בדחיפה.
gcloud builds submit --tag us-central1-docker.pkg.dev/$PROJECT_ID/agent-repo/code-agent:v1 ~/gke-ai-agent-lab/
פריסה ב-GKE עם RBAC
לבסוף, פורסים את הסוכן באשכול. הפריסה כוללת Role ו-RoleBinding שמעניקים לסוכן הרשאה לתבוע מופעים מ-SandboxWarmPool.
בפריסה הזו נעשה שימוש ב-Kubernetes ServiceAccount כדי לאפשר לסוכן שלכם לתקשר עם Sandbox claim API. היא לא דורשת ServiceAccount של Google IAM כי היא ניגשת למשאבי אשכול מקומי ולנקודת קצה (endpoint) מקומית של vLLM gateway.
למה כדאי להשתמש בפריסה רגילה ב-gVisor?
בשלב 6, השתמשנו בממשקי ה-API SandboxTemplate ו-SandboxClaim כדי ליצור ארגזי חול זמניים וחד-פעמיים עבור קוד ה-Python שנוצר (הפעלת הכלי).
עבור ממשק האינטרנט של הסוכן (המוח) עצמו, אנחנו משתמשים במפרטים רגילים של Kubernetes Deployment עם runtimeClassName: gvisor.
- ההבדל:
SandboxClaimsרגילים הם זמניים ומוגבלים לערך אחד (אידיאליים לסקריפטים לא מהימנים).Deploymentרגיל פועל לאורך זמן ומתמיד – הוא מושלם לממשקי משתמש באינטרנט שזקוקים לServiceיציב של Kubernetes ולמאזן עומסים. כשמשתמשים ב-runtimeClassName: gvisorישירות בפריסה רגילה, מקבלים את הבידוד של ליבת gVisor תוך שמירה על התכונות הרגילות שלDeployment.
שומרים את הקובץ הבא בשם deployment.yaml:
cat <<EOF > ~/gke-ai-agent-lab/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: code-agent
labels:
app: code-agent
spec:
replicas: 1
selector:
matchLabels:
app: code-agent
template:
metadata:
labels:
app: code-agent
spec:
serviceAccount: adk-agent-sa
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: code-agent
image: us-central1-docker.pkg.dev/YOUR_PROJECT_ID/agent-repo/code-agent:v1
imagePullPolicy: Always
env:
- name: OPENAI_API_KEY
value: "no-key-required"
- name: OPENAI_API_BASE
value: "http://YOUR_GATEWAY_IP/v1"
- name: VERTEXAI_PROJECT
value: "YOUR_PROJECT_ID"
- name: VERTEXAI_LOCATION
value: "YOUR_REGION"
- name: OTEL_SERVICE_NAME
value: "code-agent"
- name: GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY
value: "true"
- name: OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT
value: "true"
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: code-agent-service
spec:
selector:
app: code-agent
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: agent-sandbox
name: sandbox-creator-role
rules:
- apiGroups: [""]
resources: ["services", "pods", "pods/portforward"]
verbs: ["get", "list", "watch", "create"]
- apiGroups: ["extensions.agents.x-k8s.io"]
resources: ["sandboxclaims"]
verbs: ["create", "get", "list", "watch", "delete"]
- apiGroups: ["agents.x-k8s.io"]
resources: ["sandboxes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: adk-agent-binding
namespace: agent-sandbox
subjects:
- kind: ServiceAccount
name: adk-agent-sa
namespace: default
roleRef:
kind: Role
name: sandbox-creator-role
apiGroup: rbac.authorization.k8s.io
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: adk-agent-sa
EOF
מתן הרשאות IAM לניטור
כדי לאפשר לסוכן לשלוח נתוני טלמטריה (יומנים ועקבות) אל Google Cloud, צריך להעניק את ההרשאות הנדרשות לחשבון השירות של Kubernetes adk-agent-sa באמצעות Workload Identity.
מריצים את הפקודות הבאות ב-Cloud Shell:
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# Grant permission to write logs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/logging.logWriter \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to write traces
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/cloudtrace.agent \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to use Vertex AI
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/aiplatform.user \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
מריצים את הפקודה הבאה כדי להחליף אוטומטית את YOUR_PROJECT_ID במזהה הפרויקט בפועל ולהחיל את ההגדרה.
sed -i "s/YOUR_PROJECT_ID/$PROJECT_ID/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_GATEWAY_IP/$GATEWAY_IP/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_REGION/$ZONE/g" ~/gke-ai-agent-lab/deployment.yaml
kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml
8. התבוננות ואימות
הגיע הזמן לבדוק את המערכת המשולבת במלואה.
בדיקת סוכן ליצירת קוד בממשק המשתמש
מאתרים את כתובת ה-IP החיצונית של ממשק האינטרנט של ADK:
kubectl get services code-agent-service
הפלט אמור להיראות כך:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
code-agent-service LoadBalancer 34.118.230.182 34.31.250.60 80:32471/TCP 2m14s
- פותחים דפדפן ועוברים אל
http://[EXTERNAL-IP]. - בממשק האינטרנט של ADK, מוודאים שהאפשרות root_agent נבחרה מהתפריט הנפתח בפינה השמאלית העליונה. לאחר מכן, נותנים לסוכן הנחיה:
Write a python script that prints 'Hello from the isolated sandbox'.
כדי לראות איך הסוכן משתמש בעורף להסקת מסקנות ובארגז החול, עוברים לקטעים בדיקת סטטיסטיקות של המודל באמצעות Cloud Observability ובדיקת יכולת הצפייה בסוכן באמצעות ממשק המשתמש של GKE שבהמשך כדי לראות את לוחות הבקרה.
איך בודקים את יכולת הצפייה בסוכנים באמצעות ממשק המשתמש של GKE
אחרי שהרצתם כמה הנחיות, נבדוק את נתוני הטלמטריה. כך תוכלו להבין את הביצועים של הכלי לתזמון מסקנות ושל vLLM.
גישה למרכזי הבקרה של הסוכנים
- עוברים לדף Kubernetes Engine > Workloads.
- לוחצים על הפריסה של code-agent כדי לפתוח את הדף פרטי הפריסה.
- לוחצים על הכרטיסייה Observability (יכולת תצפית).
- בחלונית הניווט הימנית של מרכז הבקרה של יכולת התצפית, יופיע קטע חדש בשם Agent עם כרטיסיות משנה.
מה אפשר לחפש
כדי לראות את ההתנהגות של אפליקציית הסוכן, עוברים לכרטיסיות המשנה הבאות:
- סקירה כללית: צפייה בכרטיסי מידע של סשנים, פניות ממוצעות והפעלות.
- מודלים: מספר הקריאות למודל, שיעורי השגיאות וזמן הטעינה, לפי המודלים שבהם השתמש הסוכן.
- כלים: אפשר לעקוב אחרי הקריאות לכלי ומשך ההרצה כדי לראות עד כמה הסוכן משתמש ביעילות בכלי ההרצה של ארגז החול.
- שימוש: מעקב אחרי השימוש בטוקן והקצאת משאבים רגילה של מאגר התגים (מעבד וזיכרון).
- מעקב אחר סוכנים: בכרטיסייה הזו מוצגת רשימה של סשנים של ביצוע או של טווחים של מעקב גולמי. לחיצה על שורה פותחת חלונית צדדית עם פרטים על העקבות שנבחרו.
שילוב של מדדים ברמת המודל מ-vLLM עם טלמטריה ברמת האפליקציה מ-ADK מאפשר לכם ליהנות מניטור מלא של סוכן ה-AI הגנרטיבי שלכם ב-GKE.
עיון בנתונים הסטטיסטיים של מודל vLLM באמצעות Cloud Observability
אחרי שהרצתם כמה הנחיות, נבדוק את נתוני הטלמטריה. כך תוכלו להבין את הביצועים של הכלי לתזמון מסקנות ושל vLLM.
גישה למרכזי הבקרה
- עוברים אל מסוף Google Cloud.
- עוברים אל מעקב > מרכזי בקרה.
- מחפשים את מרכז הבקרה vLLM Prometheus Overview ובוחרים בו.
מדדים מעניינים שכדאי לעקוב אחריהם
כשצופים בלוח הבקרה, כדאי לשים לב למדדי המפתח האלה כדי לראות את ההשפעה של GKE Inference Gateway ושל שמירת נתונים במטמון לפי קידומת:
- ניצול של מטמון KV (
vllm:gpu_cache_usage):- למה זה חשוב: בעמודה הזו אפשר לראות כמה מזיכרון ה-GPU מנוצל לשמירת ההקשר במטמון. אם הערך גבוה, המשמעות היא שהמערכת שומרת על ההקשר כדי להאיץ בקשות עתידיות. אם מריצים את אותה הנחיה כמה פעמים, השימוש הזה אמור לעלות ואז להתייצב.
- בקשות שמופעלות לעומת בקשות בהמתנה (
vllm:num_requests_runningלעומתvllm:num_requests_waiting):- למה זה חשוב: הערך הזה מציין את העומס. אם יש הרבה בקשות בהמתנה, המשמעות היא שהצמתים שלכם עמוסים מדי.
- קצב העברת נתונים של טוקנים (
vllm:request_prompt_tokens_totו-vllm:request_generation_tokens_tot):- למה זה חשוב: מעקב אחרי נפח הטוקנים של הקלט והפלט שעברו עיבוד באשכול.
- הזמן עד לקבלת הטוקן הראשון (TTFT):
- למה זה חשוב: זהו המדד הקריטי לסוכנים אינטראקטיביים. כשמשתמשים ב-GKE Inference Gateway עם ניתוב שמודע למטמון של קידומות, בקשות שמשתפות הקשרים משותפים (כמו הנחיות מערכת או חלונות הקשר גדולים) מנותבות לאותה רפליקה, וכך מצמצמים את זמן התגובה הראשוני על ידי שימוש חוזר בתוצאות חיפוש במטמון.
ניסויים שכדאי לנסות
כדאי לנסות את התרחישים האלה כדי לראות את השינוי במדדים בזמן אמת ולוודא שהתזמון תקין.
ניסוי 1: 'מהירות החזרה' (פגיעה במטמון של הקידומת)
- שולחים לסוכן הנחיות מורכבות (לדוגמה, "תכתוב סקריפט Python לניתוח קובץ CSV בגודל 100MB ולחישוב נתונים סטטיסטיים").
- אחרי שהמודל מגיב, שולחים שוב את אותה הנחיה בדיוק באופן מיידי.
- בודקים את שיעור הפגיעה במטמון של הקידומת ואת הזמן עד לטוקן הראשון (TTFT).
- מה אמור להופיע: הערך של Prefix Cache Hit Rate אמור לעלות ל-100% והערך של TTFT אמור לרדת באופן משמעותי.
- מה זה אומר: שער ההסקה של GKE זיהה את ההקשר המשותף והעביר אותו לאותו עותק משוכפל בדיוק, שנעשה בו שימוש חוזר במטמון ההקשר המוערך שלו.
ניסוי 2: חזרה ל-Cloud (מהימנות המודל)
- כדי לדמות כשל במודל Qwen המקומי, אפשר להפסיק את שירות ההיסקים או פשוט לספק ערך פיקטיבי
OPENAI_API_BASEבפריסה. - מעדכנים את
OPENAI_API_BASEב-deployment.yamlלכתובת IP או ליציאה שלא קיימות ומחילים את השינויים:sed -i "s|value: \"http://$GATEWAY_IP/v1\"|value: \"http://10.0.0.1:8080/v1\"|g" ~/gke-ai-agent-lab/deployment.yaml kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml - ממתינים עד שה-pod יופעל מחדש, ואז שולחים הנחיה לסוכן בממשק המשתמש.
- מה אמור לקרות: הסוכן עדיין מגיב בהצלחה.
- מה זה אומר: בגלל ההגדרה של
fallbacks, ADK זיהה את הכשל בנקודת הקצה המקומית של Qwen והעביר את הבקשה בצורה חלקה אל Gemini 2.5 Flash ב-Vertex AI. שימו לב: מכיוון שהקריאות האלה ל-Vertex AI עוקפות את שער ההסקה המקומי של vLLM, הן לא יופיעו בלוח הבקרה Agent Observability > Models, שבו מתבצע מעקב רק אחרי תנועה שעוברת דרך vLLM.
הסבר על היתרונות של הקצאת משאבים דינמית (DRA)
הספרייה vLLM ו-Inference Gateway מייעלות את הניתוב והטיפול בבקשות, אבל הקצאת משאבים דינמית (DRA) היא מה שמאפשר לצרף את החומרה המתאימה בדיוק לעומס העבודה שלכם.
התכונה DRA משפרת את היכולת שלכם לנהל חומרה באשכול באופן מפורט, ומאפשרת לכם להגדיר משאבי חומרה גמישים באמצעות ResourceClaimTemplate ו-DeviceClasses.
למה DRA הוא פתרון פורץ דרך לעומסי עבודה של AI:
- בקשות מפורטות לחומרה: באמצעות DRA, אתם לא רק מוודאים שעומסי העבודה מתוזמנים במכונות עם המאיץ המתאים, אלא גם יכולים להגיש בקשה למשאבים האלה כדי לוודא שהם ישמשו באופן בלעדי את עומס העבודה שמשויך ל-ResourceClaim.
- מחזור חיים מנותק: תביעות בעלות על מכשירים מנוהלות בנפרד ממחזורי החיים של ה-Pod. אם Pod קורס, תביעת הבעלות על ה-GPU יכולה להימשך, כך שאפשר להפעיל מחדש את הפריסה הכוללת או אובייקט אחר של עומס עבודה בלי לחכות לשחרור ה-GPU ולרכישה מחדש שלו.
- תקנון של כמה ספקים: DRA מספק API מאוחד של Kubernetes גם למעבדים גרפיים של NVIDIA וגם ל-TPU של Google. אתם משתמשים באותה סכימה בדיוק כשאתם פורסים את אחד מהם, כך שקובצי ה-YAML של עומסי העבודה ניידים מאוד.
ב-codelab הזה ראיתם את זה בפעולה כשקבעתם את ערכי Helm כדי לבצע קישור ל-gpu-claim-template בצורה חלקה, בלי שהגדרות של תוסף מכשיר תלויות יחסמו את ההשקות.
הסבר על התפקיד של llm-d
vLLM מעריך משקלים של רשתות עצביות ו-GKE Gateway מנתב שאילתות, אבל llm-d פועל כשכבת ההגדרה וכגורם המקשר בין כולם.
בלי llm-d, תצטרכו לכתוב מניפסטים גולמיים של Kubernetes כדי להצהיר על פריסת vLLM, על יציאות השירות, על טעינת נפח ועל תביעות המשאבים של DRA מאפס.
למה כדאי להשתמש ב-llm-d בפריסה?
- הגדרה מאוחדת (החלפת הגדרות בשורה אחת):
llm-dתרשימי Helm מאגדים משאבי Kubernetes מורכבים ברמה נמוכה למתגים ברמה גבוהה (כמו הגדרה שלaccelerator.dra: true). - נתיבים מוארים שעברו בדיקה מראש: במאגר
llm-dיש הגדרות שכבר נבדקו על ידי מומחים. כשפורסים אתllm-d-modelservice, מקבלים ערכי ברירת מחדל אופטימליים לניצול זיכרון ה-GPU, תזמונים מומלצים של בדיקות (מצב פעילות (liveness)/מוּכנוּת (readiness)) וחשיפות נכונות לגירוד מדדים. - מיפוי חלק של ניראות (observability):
llm-dמבטיח שפורטים סטנדרטיים של קונטיינרים ונתיבי גירוד (/metrics) ייחשפו בצורה נכונה, כך שקל לחבר את הפריסה ל-Google Cloud Monitoring בלי לבצע ניפוי באגים ידני.
בקיצור, llm-d מספק תוכניות אדריכליות לשימוש חוזר, כך שמפתחים לא צריכים להמציא את הגלגל כל פעם שהם פורסים מחסנית של הסקה ב-GKE.
התעמקות בנושא: GKE Inference Gateway
מאזני עומסים רגילים בשכבה 7 פועלים על ידי בדיקת כותרות HTTP כמו נתיבים (/v1/completions) או קובצי Cookie. המאמר GKE Inference Gateway מתעמק בנושא הרבה יותר, והוא מיועד במיוחד לתנועה של AI גנרטיבי.
איך זה משפר את הביצועים והיעילות:
- ניתוב מודע-תוכן (גיבוב הנחיות): שער ההסקה של GKE מיירט את תוכן בקשת ה-JSON. הוא מחשב גיבוב (hash) של ההנחיה ועוקב אחרי העותק המשוכפל של הקצה העורפי שכבר מחזיק את הטוקנים האלה בזיכרון ה-GPU שלו (המטמון של KV).
- הגדלת מספר הפעמים שבהן נשלף מידע מהמטמון: בבדיקה שלכם, כשחזרתם על הנחיה, שער הכניסה שלח אותה לאותו עותק בדיוק. הערכת הנחיה דורשת כוח מחשוב רב. שימוש חוזר במטמון מאפשר להימנע מ'קריאה חוזרת' של ההנחיה, וכך לחסוך כסף וזמן שימוש ב-GPU.
- קיצור הזמן עד לטוקן הראשון (TTFT): TTFT הוא מדד השימושיות הקריטי לסוכנים שפונים למשתמשים. אם המודל ניגש למטמון, הוא יכול להתחיל ליצור טוקנים במילישניות ולא בשניות.
- חלוקת עומס חכמה: אם זיכרון ה-VRAM של רפליקה מסוימת מלא לגמרי בלהיטי מטמון, שער הכניסה יכול להפנות באופן דינמי הנחיה חדשה לרפליקה אחרת שיש בה מקום, וכך לאזן בין יעילות לזמינות.
איך ארגז החול של הסוכן מצמצם את הסיכון
במעבדה הזו הדגמנו איך ארגז החול של הסוכן מגן על התשתית שלכם מפני הסיכונים שקשורים לסוכני AI, באמצעות שתי שכבות בידוד:
- בידוד כלי ההרצה: הסוכן מריץ את הקוד שהוא יוצר בארגז חול זמני. כך מובטח שקוד לא מהימן שנוצר על ידי מודל שפה גדול יפעל בסביבה מאובטחת ומבודדת, ויגן על הסוכן ועל האשכול.
- הפעלה מהירה: באמצעות WarmPool, ארגזי חול חדשים מופעלים תוך פחות משנייה, ומוכנים להרצת קוד.
- בידוד הסוכן עצמו: הפעלנו את אפליקציית הסוכן עצמה בצומת עם gVisor (באמצעות
runtimeClassName: gvisor) כדי לספק הגנה מקיפה מפני נקודות חולשה בשרשרת האספקה בתלות של הסוכן.
למה זה יוצר גבול אבטחה חזק כל כך:
- יירוט של קריאות למערכת: gVisor מיירט קריאות למערכת לפני שהן מגיעות לליבת Linux של המארח. החסימה הזו מונעת ניצול לרעה של פרצות אבטחה בניסיון לצאת מהקונטיינר כדי לגשת לצומת המארח.
- תנועה לרוחב מוגבלת: בשילוב עם מדיניות רשת, גם אם סביבה נפרצה, היא לא יכולה לסרוק את שרתי המטא-נתונים הפנימיים שלכם או לעבור לשירותים רגישים אחרים באשכול.
הפעלת נציגים מלאים בארגזי חול
בשיעור ה-Lab הזה השתמשנו בארגזי חול ככלים לאפליקציית סוכן קבועה. עם זאת, כדי להשיג אבטחה מקסימלית – במיוחד כשמטפלים בנתונים רגישים או כשמציגים מודעות למספר משתמשים לא מהימנים – אפשר להריץ את כל אפליקציית הסוכן בתוך ארגז חול ייעודי לכל סשן או משתמש. כך מובטח בידוד מלא של הזיכרון, המצב וסביבת ההרצה של הנציג, שנמחקים מיד אחרי שהסשן מסתיים.
9. הסרת המשאבים
כדי לא לצבור חיובים לחשבון Google Cloud על המשאבים שבהם השתמשתם ב-Codelab הזה, אתם צריכים למחוק אותם.
מחיקת משאבים בודדים
- מחיקת אשכול GKE:
gcloud container clusters delete $CLUSTER_NAME --zone $ZONE --quiet
- מחיקת מאגר Artifact Registry:
gcloud artifacts repositories delete agent-repo --location=us-central1 --quiet
- מחיקת רשת ה-VPC:
gcloud compute networks delete ai-agent-network --quiet
מחיקת הפרויקט
אם אין לכם יותר צורך בפרויקט, אתם יכולים למחוק אותו אחרי שתסירו את המשאבים:
gcloud projects delete $PROJECT_ID
10. סיכום
מעולה! הצלחתם ליצור ולפרוס סוכן מאובטח ליצירת קוד עם ביצועים גבוהים ב-GKE.
מה למדתם
- איך מגדירים ומשתמשים בהקצאת משאבים דינמית (DRA) ב-GKE כדי לנהל משאבי GPU.
- איך משתמשים ב-GKE Inference Gateway כדי לבצע אופטימיזציה של ביצועי ההצגה של LLM באמצעות ניתוב עם מודעות למטמון של קידומות.
- איך משתמשים ב-Agent Sandbox (gVisor) כדי להריץ קוד לא מהימן בצורה מאובטחת ב-GKE.
- איך משתמשים בשירות המנוהל של Google Cloud ל-Prometheus כדי לעקוב אחרי הביצועים של vLLM.
- איך מגדירים וצופים בניראות הסוכן באמצעות ADK ו-GKE Managed OpenTelemetry.
השלבים הבאים ומקורות מידע
- ארגז חול לסוכנים: מידע על ארגז חול לסוכנים ב-GKE ועל פודים של GKE Sandbox.
- llm-d: אפשר לקרוא את המדריך ל-llm-d ולעיין במאגר GitHub של llm-d.
- הקצאת משאבים דינמית: מידע נוסף על DRA ב-GKE
- GKE Inference Gateway: אפשר לעיין במושגים של Inference Gateway.
- עוד Codelabs: מדריכים נוספים זמינים ב-Google Cloud Codelabs.