
1. परिचय
खास जानकारी
इस लैब में, आपको Google Kubernetes Engine (GKE) पर सुरक्षित कोड जनरेट करने वाला एजेंट बनाने और उसे डिप्लॉय करने का तरीका बताया जाएगा. कोड जनरेट करने वाले एजेंट को ऐसे कोड को लागू करना होता है जिस पर भरोसा नहीं किया जा सकता. इसके लिए, सुरक्षित सैंडबॉक्स एनवायरमेंट की ज़रूरत होती है. आपको यह भी पता चलेगा कि हाइब्रिड मॉडल की रणनीति का इस्तेमाल करके, एजेंट को कैसे कॉन्फ़िगर किया जाता है. इससे एजेंट, ज़्यादा भरोसेमंद तरीके से काम कर पाएगा. इसके लिए, वह GKE पर सेल्फ़-होस्ट किए गए ओपन मॉडल से, Vertex AI की मैनेज की गई Gemini सेवा पर फ़ॉलबैक कर पाएगा. इसके अलावा, आपको GKE Inference Gateway और डाइनैमिक रिसॉर्स ऐलोकेशन (डीआरए) का इस्तेमाल करके, अनुमानित नतीजे दिखाने की प्रोसेस को ऑप्टिमाइज़ करने का तरीका भी बताया जाएगा. आखिर में, आपको यह पता चलेगा कि मैनेज किए गए Prometheus का इस्तेमाल करके, अपने अनुमान लगाने वाले स्टैक की निगरानी करने के लिए, Google Cloud Observability का फ़ायदा कैसे उठाया जा सकता है.
आर्किटेक्चर
यहां उस सिस्टम का आर्किटेक्चर दिया गया है जिसे आपको बनाना है:
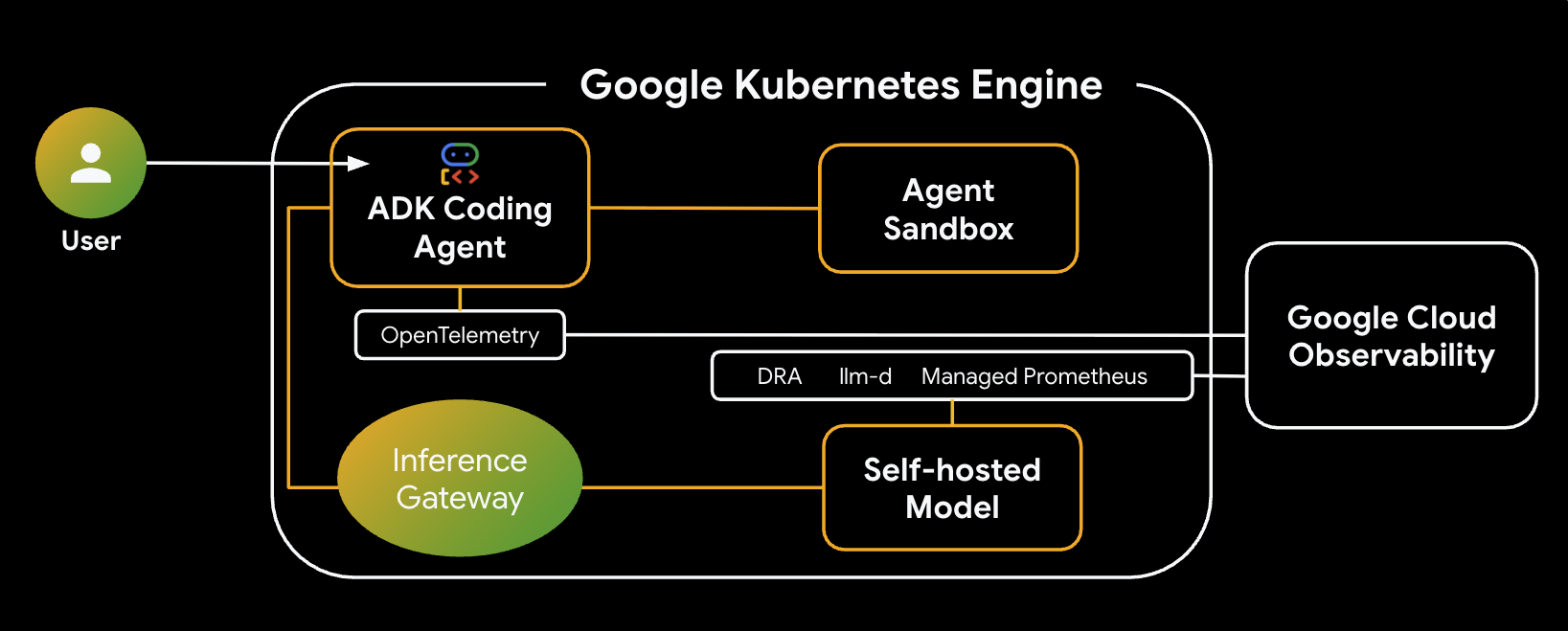
मुख्य कॉम्पोनेंट और फ़ायदे
- डाइनैमिक रिसोर्स ऐलोकेशन (डीआरए): इस लैब में, मॉडल सर्वर पॉड के लिए खास जीपीयू संसाधनों (NVIDIA L4s) को डाइनैमिक तरीके से ऐक्सेस करने और असाइन करने के लिए इसका इस्तेमाल किया जाता है. इससे यह पक्का किया जाता है कि हमारे अनुमान लगाने के वर्कलोड के लिए, सटीक हार्डवेयर टारगेटिंग हो. GKE पर DRA के बारे में जानें.
- llm-d और vLLM: Qwen मॉडल को डिप्लॉय करने के लिए, मॉडल सर्विंग फ़्रेमवर्क और Helm चार्ट उपलब्ध कराता है. इस लैब में, अनुमान लगाने के अनुरोधों को मैनेज किया जाता है. साथ ही, संसाधन मैनेजमेंट के लिए DRA के साथ इंटिग्रेट किया जाता है. इस लैब में, डिसऐग्रिगेटेड सर्विंग की सुविधा चालू नहीं है. llm-d गाइड पढ़ें और llm-d GitHub रिपॉज़िटरी देखें.
- GKE Inference Gateway: यह एआई के बारे में जानकारी रखने वाले राउटिंग लॉजिक को सीधे तौर पर लोड बैलेंसर में ले जाता है. इस लैब में, अनुरोधों को इस तरह से रूट किया जाता है कि प्रीफ़िक्स-कैश हिट को ज़्यादा से ज़्यादा किया जा सके. इससे, पहले टोकन के लिए लगने वाला समय (टीटीएफ़टी) कम हो जाता है. Inference Gateway के कॉन्सेप्ट के बारे में जानें.
- एजेंट सैंडबॉक्स (gVisor): यह एआई एजेंट से जनरेट किए गए कोड को एक्ज़ीक्यूट करने के लिए, सुरक्षित आइसोलेशन उपलब्ध कराता है. यह डीप कर्नल आइसोलेशन के लिए gVisor का इस्तेमाल करता है. इससे होस्ट नोड को गैर-भरोसेमंद वर्कलोड से सुरक्षित रखने में मदद मिलती है. GKE पर एजेंट सैंडबॉक्स और GKE सैंडबॉक्स पॉड के बारे में जानें.
आपको क्या करना होगा
- बुनियादी ढांचा उपलब्ध कराना: जीपीयू को मैनेज करने के लिए, डाइनैमिक रिसोर्स ऐलोकेशन (डीआरए) के साथ GKE क्लस्टर सेट अप करें.
- इन्फ़रेंस स्टैक डिप्लॉय करना:
llm-dऔर vLLM को, बेहतर इन्फ़रेंस शेड्यूलिंग के साथ डिप्लॉय करें. - इंटेलिजेंट रूटिंग कॉन्फ़िगर करना: प्रीफ़िक्स-कैश के बारे में जानकारी रखने वाली रूटिंग के लिए, GKE Inference Gateway का इस्तेमाल करें.
- सुरक्षित कोड एक्ज़ीक्यूशन: एआई से जनरेट किए गए कोड को सुरक्षित तरीके से चलाने के लिए, एजेंट सैंडबॉक्स (gVisor) डिप्लॉय करें.
- निगरानी करना और पुष्टि करना: मॉडल की परफ़ॉर्मेंस से जुड़ी मेट्रिक देखने के लिए, Google Cloud Monitoring और Managed Prometheus का इस्तेमाल करें.
आपको क्या सीखने को मिलेगा
- GKE में डाइनैमिक रिसॉर्स असाइन करने की सुविधा (डीआरए) को कॉन्फ़िगर करने और इस्तेमाल करने का तरीका.
- एलएलएम की परफ़ॉर्मेंस को ऑप्टिमाइज़ करने के लिए, GKE Inference Gateway का इस्तेमाल कैसे करें.
- GKE पर, भरोसेमंद न होने वाले कोड को सुरक्षित तरीके से एक्ज़ीक्यूट करने के लिए, एजेंट सैंडबॉक्स का इस्तेमाल कैसे करें.
- vLLM की परफ़ॉर्मेंस को मॉनिटर करने के लिए, Google Cloud Managed Service for Prometheus का इस्तेमाल कैसे करें.
2. सेटअप और ज़रूरी शर्तें
प्रोजेक्ट सेटअप करना
Google Cloud प्रोजेक्ट बनाना
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग चालू हो. किसी प्रोजेक्ट के लिए बिलिंग चालू है या नहीं, यह देखने का तरीका जानें.
Cloud Shell शुरू करना
Cloud Shell, Google Cloud में चलने वाला एक कमांड-लाइन एनवायरमेंट है. इसमें ज़रूरी टूल पहले से लोड होते हैं.
- Google Cloud कंसोल में सबसे ऊपर मौजूद, Cloud Shell चालू करें पर क्लिक करें.
- Cloud Shell से कनेक्ट होने के बाद, अपने क्रेडेंशियल की पुष्टि करें:
gcloud auth list - पुष्टि करें कि आपका प्रोजेक्ट कॉन्फ़िगर किया गया है:
gcloud config get project - अगर आपका प्रोजेक्ट उम्मीद के मुताबिक सेट नहीं है, तो इसे सेट करें:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
3. इंफ़्रास्ट्रक्चर और डाइनैमिक रिसॉर्स ऐलोकेशन (डीआरए) की सुविधा उपलब्ध कराना
पहले चरण में, आपको अपने GKE क्लस्टर को कॉन्फ़िगर करना होगा, ताकि वह लेगसी डिवाइस प्लगिन के बजाय मॉडर्न ऐक्सलरेटर एलोकेशन (डीआरए) का इस्तेमाल कर सके. इससे, कोड जनरेट करने से जुड़े वर्कलोड के लिए, जीपीयू या टीपीयू को आसानी से शेयर और असाइन किया जा सकता है.
ज़रूरी शर्तें: DRA की सुविधा का इस्तेमाल करने के लिए, आपके GKE Standard क्लस्टर में 1.34 या इसके बाद का वर्शन होना चाहिए.
Google Cloud API चालू करना
इस कोडलैब के लिए ज़रूरी Google Cloud API चालू करें. खास तौर पर, Compute Engine और Kubernetes Engine API.
gcloud services enable compute.googleapis.com container.googleapis.com networkservices.googleapis.com cloudbuild.googleapis.com artifactregistry.googleapis.com telemetry.googleapis.com cloudtrace.googleapis.com aiplatform.googleapis.com
एनवायरमेंट वैरिएबल सेट करना
सेटअप को आसान बनाने के लिए, अपने एनवायरमेंट वैरिएबल तय करें. ज़रूरत के हिसाब से, देश/इलाके या नाम रखने के नियमों में बदलाव किया जा सकता है.
export PROJECT_ID=$(gcloud config get-value project)
export ZONE=us-central1-a
export CLUSTER_NAME=ai-agent-cluster
export NODEPOOL_NAME=dra-accelerator-pool
gcloud config set project $PROJECT_ID
gcloud config set compute/region $ZONE
वर्किंग डायरेक्ट्री बनाना
इस लैब के लिए एक वर्किंग डायरेक्ट्री बनाएं और उसमें जाएं, ताकि आपकी फ़ाइलें व्यवस्थित रहें:
mkdir -p ~/gke-ai-agent-lab
cd ~/gke-ai-agent-lab
अनुमतियां कॉन्फ़िगर करना (ज़रूरी नहीं)
अगर आपको किसी प्रतिबंधित प्रोजेक्ट या शेयर किए गए एनवायरमेंट में काम करना है, तो पक्का करें कि आपके खाते के पास क्लस्टर बनाने और बिल्ड चलाने की ज़रूरी अनुमतियां हों:
export MY_ACCOUNT=$(gcloud config get-value account)
# Grant Container Admin to create clusters and manage nodes if needed
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/container.admin"
# Grant Cloud Build Builder to run builds
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/cloudbuild.builds.builder"
GKE क्लस्टर बनाना
DRA की सुविधा इस्तेमाल करने के लिए, यह ज़रूरी है कि आपका GKE स्टैंडर्ड क्लस्टर, वर्शन 1.34 या उसके बाद वाले वर्शन पर काम करता हो. इंटेलिजेंट इन्फ़रेंस शेड्यूलिंग की सुविधा इस्तेमाल करने के लिए, आपको Gateway API कंट्रोलर भी चालू करने होंगे.
इस लैब के लिए, आपको एक नया वीपीसी नेटवर्क और सबनेट बनाने होंगे.
सबसे पहले, वीपीसी नेटवर्क बनाएं:
gcloud compute networks create ai-agent-network --subnet-mode=custom
इसके बाद, अपने GKE नोड के लिए एक सबनेट बनाएं:
gcloud compute networks subnets create ai-agent-subnet \
--network=ai-agent-network \
--range=10.0.0.0/20 \
--region=us-central1
Gateway API (gke-l7-regional-internal-managed) को भी Envoy प्रॉक्सी को होस्ट करने के लिए, एक खास सबनेट की ज़रूरत होती है. अपने नए नेटवर्क में, सिर्फ़ इस प्रॉक्सी वाला सबनेट बनाएं:
gcloud compute networks subnets create proxy-only-subnet \
--purpose=REGIONAL_MANAGED_PROXY \
--role=ACTIVE \
--region=us-central1 \
--network=ai-agent-network \
--range=192.168.10.0/24
अब नए नेटवर्क और सबनेट का इस्तेमाल करके क्लस्टर बनाएं:
gcloud beta container clusters create $CLUSTER_NAME \
--zone $ZONE \
--num-nodes 1 \
--machine-type n2-standard-4 \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--gateway-api=standard \
--managed-otel-scope=COLLECTION_AND_INSTRUMENTATION_COMPONENTS \
--network=ai-agent-network \
--subnetwork=ai-agent-subnet
डिफ़ॉल्ट रूप से प्लगिन बंद करके नोड पूल बनाना
डिवाइस मैनेजमेंट का ऐक्सेस DRA को देने के लिए, आपको एक नोड पूल बनाना होगा. इसमें डिफ़ॉल्ट जीपीयू ड्राइवर इंस्टॉलेशन और स्टैंडर्ड डिवाइस प्लगिन को साफ़ तौर पर बंद किया गया हो.
ज़रूरी DRA लेबल के साथ जीपीयू नोड पूल (जैसे, NVIDIA L4s का इस्तेमाल करके) उपलब्ध कराने के लिए, यह gcloud कमांड चलाएं:
gcloud container node-pools create $NODEPOOL_NAME \
--cluster=$CLUSTER_NAME \
--location=$ZONE \
--machine-type=g2-standard-24 \
--accelerator=type=nvidia-l4,count=2,gpu-driver-version=disabled \
--node-labels=gke-no-default-nvidia-gpu-device-plugin=true,nvidia.com/gpu.present=true \
--num-nodes 3
DaemonSet के ज़रिए NVIDIA ड्राइवर इंस्टॉल करना
पहले से कॉन्फ़िगर किए गए Google Cloud DaemonSet का इस्तेमाल करके, अपने नोड पर NVIDIA डिवाइस के ज़रूरी ड्राइवर मैन्युअल तरीके से इंस्टॉल करें:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
DRA ड्राइवर इंस्टॉल करना
इसके बाद, अपने क्लस्टर में खास DRA ड्राइवर इंस्टॉल करें. NVIDIA जीपीयू के लिए, इसे Helm के ज़रिए डिप्लॉय किया जा सकता है:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
helm install nvidia-dra-driver-gpu nvidia/nvidia-dra-driver-gpu \
--version="25.3.2" --create-namespace --namespace=nvidia-dra-driver-gpu \
--set nvidiaDriverRoot="/home/kubernetes/bin/nvidia/" \
--set gpuResourcesEnabledOverride=true \
--set resources.computeDomains.enabled=false \
--set kubeletPlugin.priorityClassName="" \
--set 'kubeletPlugin.tolerations[0].key=nvidia.com/gpu' \
--set 'kubeletPlugin.tolerations[0].operator=Exists' \
--set 'kubeletPlugin.tolerations[0].effect=NoSchedule'
DeviceClasses के बारे में जानकारी
आपको मैन्युअल तरीके से DeviceClass YAML लिखने या लागू करने की ज़रूरत नहीं है. DRA के लिए GKE इंफ़्रास्ट्रक्चर सेट अप करने और ड्राइवर इंस्टॉल करने पर, आपके नोड पर चल रहे DRA ड्राइवर, क्लस्टर में आपके लिए DeviceClass ऑब्जेक्ट अपने-आप बना देते हैं.
ResourceClaimTemplate को कॉन्फ़िगर करना
अपने llm-d पॉड को इन ऐक्सलरेटर के लिए डाइनैमिक तौर पर अनुरोध करने की अनुमति देने के लिए, आपको ResourceClaimTemplate बनाना होगा. इस टेंप्लेट में, अनुरोध किए गए डिवाइस कॉन्फ़िगरेशन के बारे में बताया गया है. साथ ही, Kubernetes को यह निर्देश दिया गया है कि वह आपके वर्कलोड के लिए, हर पॉड के हिसाब से एक यूनीक ResourceClaim अपने-आप बनाए.
claim-template.yaml बनाने के लिए, यह कमांड चलाएं:
cat > claim-template.yaml <<EOF
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: gpu-claim-template
spec:
spec:
devices:
requests:
- name: single-gpu
exactly:
deviceClassName: gpu.nvidia.com
allocationMode: ExactCount
count: 1
EOF
अपने क्लस्टर पर टेंप्लेट लागू करें:
kubectl apply -f claim-template.yaml
4. llm-d और DRA की मदद से, इंटेलिजेंट इन्फ़रेंस शेड्यूलिंग को डिप्लॉय करना
इस चरण में, आपको अपने लार्ज लैंग्वेज मॉडल को, स्मार्ट Envoy लोड बैलेंसर के पीछे डिप्लॉय करना होगा. इसे अनुमान लगाने वाले शेड्यूलर के साथ बेहतर बनाया गया है. यह कॉन्फ़िगरेशन, प्रीफ़िक्स-कैश अवेयर राउटिंग लागू करके मॉडल सर्विंग को ऑप्टिमाइज़ करता है. GKE Inference Gateway, माइक्रोसेवाओं के बीच शेयर किए गए कॉन्टेक्स्ट को पहचानता है. साथ ही, अनुरोधों को एक ही मॉडल रेप्लिका पर समझदारी से रूट करता है. इससे कैश मेमोरी हिट होने की संख्या बढ़ती है, टाइम-टू-फ़र्स्ट-टोकन कम होता है, और परफ़ॉर्मेंस-पर-डॉलर बेहतर होती है.
एनवायरमेंट तैयार करना
अपना टारगेट नेमस्पेस सेट अप करें.
export NAMESPACE=ai-agents
kubectl create namespace $NAMESPACE
अपने Hugging Face टोकन को सुरक्षित तरीके से सेव करें. मॉडल के वेट को पुल करने के लिए, इसकी ज़रूरत होती है.
# Replace with your actual Hugging Face token
kubectl create secret generic llm-d-hf-token \
--from-literal=HF_TOKEN="your_hugging_face_token" \
-n $NAMESPACE
Helm कॉन्फ़िगरेशन फ़ाइलें बनाना
मॉडल सेवा और अनुमान गेटवे एक्सटेंशन के कॉन्फ़िगरेशन, आधिकारिक llm-d गाइड पर आधारित हैं.
सबसे पहले, मॉडल सेवा के लिए ms-values.yaml फ़ाइल बनाएं:
cat <<EOF > ms-values.yaml
multinode: false
modelArtifacts:
uri: "hf://Qwen/Qwen2.5-Coder-14B-Instruct"
name: "Qwen/Qwen2.5-Coder-14B-Instruct"
size: 50Gi # Slightly larger than the default to accommodate weights
authSecretName: "llm-d-hf-token"
labels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
llm-d.ai/accelerator-variant: "gpu"
llm-d.ai/accelerator-vendor: "nvidia"
llm-d.ai/model: "qwen-2-5-coder-14b"
routing:
proxy:
enabled: false # removes sidecar from deployment - no PD in inference scheduling
targetPort: 8000 # controls vLLM port to matchup with sidecar if deployed
accelerator:
dra: true
type: "nvidia"
resourceClaimTemplates:
nvidia:
class: "gpu.nvidia.com"
match: "exactly"
name: "gpu-claim-template"
decode:
create: true
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
parallelism:
tensor: 2
data: 1
replicas: 3
monitoring:
podmonitor:
enabled: true
portName: "vllm"
path: "/metrics"
interval: "30s"
containers:
- name: "vllm"
image: ghcr.io/llm-d/llm-d-cuda:v0.5.1
modelCommand: vllmServe
args:
- "--disable-uvicorn-access-log"
- "--gpu-memory-utilization=0.85"
- "--enable-auto-tool-choice"
- "--tool-call-parser"
- "hermes"
ports:
- containerPort: 8000
name: vllm
protocol: TCP
resources:
limits:
cpu: '16'
memory: 64Gi
requests:
cpu: '16'
memory: 64Gi
mountModelVolume: true
volumeMounts:
- name: metrics-volume
mountPath: /.config
- name: shm
mountPath: /dev/shm
- name: torch-compile-cache
mountPath: /.cache
startupProbe:
httpGet:
path: /v1/models
port: vllm
initialDelaySeconds: 15
periodSeconds: 30
timeoutSeconds: 5
failureThreshold: 120
livenessProbe:
httpGet:
path: /health
port: vllm
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /v1/models
port: vllm
periodSeconds: 5
timeoutSeconds: 2
failureThreshold: 3
volumes:
- name: metrics-volume
emptyDir: {}
- name: torch-compile-cache
emptyDir: {}
- name: shm
emptyDir:
medium: Memory
sizeLimit: 20Gi
prefill:
create: false
EOF
इसके बाद, GKE Inference Gateway Extension के लिए gaie-values.yaml फ़ाइल बनाएं:
cat <<EOF > gaie-values.yaml
inferenceExtension:
replicas: 1
image:
name: llm-d-inference-scheduler
hub: ghcr.io/llm-d
tag: v0.6.0
pullPolicy: Always
extProcPort: 9002
pluginsConfigFile: "default-plugins.yaml"
tracing:
enabled: false
monitoring:
interval: "10s"
prometheus:
enabled: true
auth:
secretName: inference-scheduling-gateway-sa-metrics-reader-secret
inferencePool:
targetPorts:
- number: 8000
modelServerType: vllm
modelServers:
matchLabels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
EOF
कॉन्फ़िगरेशन के बारे में जानकारी
इस कॉन्फ़िगरेशन से, बेहतर परफ़ॉर्मेंस वाला इन्फ़्रेंस स्टैक सेट अप किया जाता है. इसमें ये मुख्य सुविधाएं होती हैं:
- मॉडल का चुनाव: यह Qwen 2.5 Coder 14B मॉडल (
modelArtifacts) का इस्तेमाल करता है. इसे कोड जनरेट करने और टूल इस्तेमाल करने के लिए ऑप्टिमाइज़ किया गया है. - डीआरए इंटिग्रेशन:
acceleratorसेक्शन, डाइनैमिक रिसोर्स ऐलोकेशन (dra: true) को चालू करता है. यहgpu.nvidia.comडिवाइस क्लास और हमारे पहले से बनाए गएgpu-claim-templateको टारगेट करता है. - परफ़ॉर्मेंस ऑप्टिमाइज़ेशन:
parallelism.tensor: 2, सभी जीपीयू के बीच टेंसर पैरललिज़्म को कॉन्फ़िगर करता है.- vLLM के लिए
argsमें--enable-auto-tool-choiceशामिल है, ताकि हमारा कोडिंग एजेंट टूल का असरदार तरीके से इस्तेमाल कर सके. cpuऔरmemoryके कम किए गए अनुरोध,g2-standard-24मशीन टाइप के लिए सही हैं.
- इंटेलिजेंट रूटिंग: Inference Gateway एक्सटेंशन (
gaie-values.yaml) कोvllmमॉडल सर्वर को मॉनिटर करने के लिए कॉन्फ़िगर किया जाता है. साथ ही, यह अनुरोधों को इस तरह से रूट करता है कि KV-कैश हिट ज़्यादा से ज़्यादा हो सकें.
Helm की मदद से, अनुमान लगाने की प्रोसेस को शेड्यूल करने वाले स्टैक को डिप्लॉय करना
अब llm-d Helm रिपॉज़िटरी जोड़ें. साथ ही, इन्फ़्रास्ट्रक्चर, गेटवे एक्सटेंशन, और मॉडल सेवा को अलग-अलग डिप्लॉय करें.
सबसे पहले, ज़रूरी रिपॉज़िटरी जोड़ें:
helm repo add llm-d-infra https://llm-d-incubation.github.io/llm-d-infra/
helm repo add llm-d-modelservice https://llm-d-incubation.github.io/llm-d-modelservice/
helm repo update
इन्फ़्रास्ट्रक्चर से जुड़ी ज़रूरी शर्तें पूरी करना
यह चार्ट, स्टैक के लिए ज़रूरी बुनियादी गेटवे कॉन्फ़िगरेशन इंस्टॉल करता है.
helm install infra-is llm-d-infra/llm-d-infra \
--namespace $NAMESPACE \
--set gateway.gatewayClassName=gke-l7-rilb \
--set gateway.gatewayParameters.enabled=false \
--set gateway.gatewayParameters.istio.accessLogging=false
GKE Inference Gateway एक्सटेंशन डिप्लॉय करना
इस चरण में, InferencePool और Endpoint Picker को डिप्लॉय किया जाता है. यह आपके मॉडल के KV-cache की निगरानी करता है, ताकि राउटिंग के बारे में बेहतर फ़ैसले लिए जा सकें.
helm install gaie-is oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool \
--version v1.3.1 \
--namespace $NAMESPACE \
-f gaie-values.yaml \
--set provider.name=gke \
--set inferenceExtension.monitoring.prometheus.enabled=true
मॉडल सेवा डिप्लॉय करना
आखिर में, अपनी एलएलएम सेवा को डिप्लॉय करें. अब यह सेवा, सुरक्षित तरीके से आपके L4 GPU का दावा करने के लिए, DRA का इस्तेमाल करेगी.
helm install ms-is llm-d-modelservice/llm-d-modelservice \
--version v0.4.7 \
--namespace $NAMESPACE \
-f ms-values.yaml \
--set decode.monitoring.podmonitor.enabled=false
vLLM के लिए Google Cloud Observability चालू करना
सामान्य Helm चार्ट, अक्सर स्टैंडर्ड Prometheus Operator PodMonitor रिसॉर्स (monitoring.coreos.com/v1) को डिप्लॉय करने की कोशिश करते हैं. अगर आपने उन CRD को इंस्टॉल नहीं किया है, तो इससे गड़बड़ियां हो सकती हैं.
Helm के बिल्ट-इन मॉनिटरिंग टॉगल को टॉगल करने के बजाय, इसे false पर सेट रखें. साथ ही, monitoring.googleapis.com/v1 API ग्रुप के साथ काम करने वाले PodMonitoring संसाधन का इस्तेमाल करके, Google Cloud Managed Prometheus (GMP) को मैन्युअल तरीके से लागू करें.
podmonitoring.yaml बनाने के लिए, यह कमांड चलाएं:
cat > podmonitoring.yaml <<EOF
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: ms-vllm-metrics
spec:
selector:
matchLabels:
llm-d.ai/model: "qwen-2-5-coder-14b" # Matches the label in values.yaml
endpoints:
- port: 8000 # vllm port
interval: 30s
path: /metrics
EOF
अपने क्लस्टर पर PodMonitoring संसाधन लागू करें:
kubectl apply -f podmonitoring.yaml -n $NAMESPACE
इंस्टॉलेशन की पुष्टि करना
पुष्टि करें कि कॉम्पोनेंट सही तरीके से इंस्टॉल हो गए हैं. आपको अपने नेमस्पेस में, तीनों Helm रिलीज़ चालू दिखनी चाहिए. साथ ही, उनसे जुड़े पॉड शुरू होने चाहिए.
helm ls -n $NAMESPACE
kubectl get pods -n $NAMESPACE
ms-is पॉड को चालू होने में करीब 5 से 10 मिनट लग सकते हैं. ऐसा होने पर, आउटपुट कुछ इस तरह दिखना चाहिए:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
gaie-is ai-agents 1 2026-03-28 16:51:41.055881618 +0000 UTC deployed inferencepool-v1.3.1 v1.3.1
infra-is ai-agents 1 2026-03-28 16:51:03.71042542 +0000 UTC deployed llm-d-infra-v1.4.0 v0.4.0
ms-is ai-agents 1 2026-03-28 17:30:00.341918958 +0000 UTC deployed llm-d-modelservice-v0.4.7 v0.4.0
NAME READY STATUS RESTARTS AGE
gaie-is-epp-848965cb4-78ktp 1/1 Running 0 10m
ms-is-llm-d-modelservice-decode-67548d5f8c-f25f4 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-rblvs 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-w6fcd 1/1 Running 0 6m2s
5. GKE Inference Gateway की मदद से, इंटेलिजेंट रूटिंग को कॉन्फ़िगर करना
चौथे चरण में, llm-d हेल्म चार्ट डिप्लॉय करने पर, आपके गेटवे और InferencePool ऑब्जेक्ट अपने-आप उपलब्ध हो गए थे. InferencePool, एक ही बेस मॉडल और कंप्यूट कॉन्फ़िगरेशन का इस्तेमाल करने वाले vllm मॉडल सर्विंग पॉड को ग्रुप करता है.
अब आपको InferenceObjective को कॉन्फ़िगर करना होगा, ताकि कोडिंग एजेंट के अनुरोधों की प्राथमिकता सेट की जा सके. साथ ही, HTTPRoute को कॉन्फ़िगर करना होगा, ताकि Gateway को यह निर्देश दिया जा सके कि आने वाले ट्रैफ़िक को कैसे रूट किया जाए. इसके लिए, Endpoint Picker का इस्तेमाल करके KV-cache हिट को ज़्यादा से ज़्यादा किया जा सकता है.
अपने-आप जनरेट हुए संसाधनों की पुष्टि करना
सबसे पहले, पुष्टि करें कि llm-d हेल्म चार्ट ने गेटवे और InferencePool संसाधन बना लिए हैं.
kubectl get gateway,inferencepool -n $NAMESPACE
आपको infra-is-inference-gateway नाम का एक गेटवे और gaie-is नाम का एक InferencePool दिखेगा. इस तरह:
NAME CLASS ADDRESS PROGRAMMED AGE
gateway.gateway.networking.k8s.io/infra-is-inference-gateway gke-l7-regional-internal-managed 10.128.0.5 True 13m
NAME AGE
inferencepool.inference.networking.k8s.io/gaie-is 12m
HTTPRoute बनाना
HTTPRoute रिसॉर्स, आपके गेटवे को बैकएंड InferencePool पर मैप करता है. इससे GKE Inference Gateway को, आने वाले अनुरोधों के मुख्य हिस्से का विश्लेषण करने और उन्हें डाइनैमिक तरीके से रूट करने के लिए कहा जाता है. इससे, शेयर किए गए कॉन्टेक्स्ट के आधार पर, प्रीफ़िक्स-कैश हिट को ज़्यादा से ज़्यादा किया जा सकता है.
httproute.yaml बनाने के लिए, यह कमांड चलाएं:
cat > httproute.yaml <<EOF
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: agent-route
spec:
parentRefs:
- group: gateway.networking.k8s.io
kind: Gateway
name: infra-is-inference-gateway
rules:
- backendRefs:
- group: inference.networking.k8s.io
kind: InferencePool
name: gaie-is
weight: 1
matches:
- path:
type: PathPrefix
value: /
EOF
अपने क्लस्टर पर रूट लागू करें:
kubectl apply -f httproute.yaml -n $NAMESPACE
6. एजेंट सैंडबॉक्स की मदद से कोड को सुरक्षित तरीके से चलाना
अब हमारा हाई-परफ़ॉर्मेंस इन्फ़रेंस बैकएंड चल रहा है. चलिए, अब हम एक सुरक्षित एनवायरमेंट तैयार करते हैं. इसमें एआई से जनरेट किया गया कोड, एजेंट सैंडबॉक्स का इस्तेमाल करके हमारे क्लस्टर से अलग किया जाएगा.
Agent Sandbox Controller को डिप्लॉय करना
जब कोई एआई एजेंट कोड जनरेट और एक्ज़ीक्यूट करता है, तो वह आपके इंफ़्रास्ट्रक्चर पर एक ऐसा वर्कलोड चला रहा होता है जिस पर भरोसा नहीं किया जा सकता. अगर एजेंट नुकसान पहुंचाने वाला कोड जनरेट करता है, तो वह आपके इंटरनल नेटवर्क को स्कैन करने या होस्ट नोड का गलत इस्तेमाल करने की कोशिश कर सकता है.
GKE एजेंट सैंडबॉक्स, gVisor का इस्तेमाल करता है. यह एक ओपन-सोर्स कंटेनर रनटाइम है. यह हर कंटेनर के लिए, खास गेस्ट कर्नल उपलब्ध कराता है. इससे, भरोसेमंद न होने वाले कोड को होस्ट नोड पर सीधे सिस्टम कॉल करने से रोका जाता है.
आधिकारिक रिलीज़ मेनिफ़ेस्ट लागू करके, एजेंट सैंडबॉक्स कंट्रोलर और उसके ज़रूरी कॉम्पोनेंट डिप्लॉय करें:
kubectl apply \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/manifest.yaml \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/extensions.yaml
सैंडबॉक्स टेंप्लेट और वार्म पूल को कॉन्फ़िगर करना
इसके बाद, हम एक SandboxTemplate बनाते हैं. यह Python के विश्लेषण वाले एनवायरमेंट के लिए, फिर से इस्तेमाल किया जा सकने वाला ब्लूप्रिंट होता है. यह खास तौर पर gvisor रनटाइम क्लास को टारगेट करता है. स्टैंडर्ड क्लस्टर पर मैन्युअल नोड पूल को मैनेज किए बिना डिप्लॉयमेंट को आसान बनाने के लिए, हम किसी भी स्टैंडर्ड autopilot का इस्तेमाल कर सकते हैं
ComputeClass की मदद से, मैनेज किए गए कंप्यूट नोड को डाइनैमिक तरीके से उपलब्ध कराया जा सकता है. ये नोड, gVisor वर्कलोड को ज़रूरत के हिसाब से मूल रूप से सपोर्ट करते हैं!
सुरक्षित कर्नल को शुरू करने में समय लग सकता है. इसलिए, हम SandboxWarmPool को भी डिप्लॉय करते हैं. इससे यह पक्का किया जाता है कि तय की गई संख्या में पहले से शुरू किए गए सैंडबॉक्स तैयार रखे जाएं, ताकि कोड जनरेशन एजेंट उन्हें इस्तेमाल कर सके और एक सेकंड से भी कम समय में कोड को लागू करना शुरू कर सके.
सबसे पहले, एजेंट सैंडबॉक्स रनटाइम के लिए एक नया नेमस्पेस बनाएं:
kubectl create namespace agent-sandbox
इन्हें sandbox-template-and-pool.yaml के तौर पर सेव करें:
cat > sandbox-template-and-pool.yaml <<EOF
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxTemplate
metadata:
name: python-runtime-template
namespace: agent-sandbox
spec:
podTemplate:
metadata:
labels:
sandbox: python-sandbox-example
spec:
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: python-runtime
image: registry.k8s.io/agent-sandbox/python-runtime-sandbox:v0.1.0
ports:
- containerPort: 8888
readinessProbe:
httpGet:
path: "/"
port: 8888
initialDelaySeconds: 0
periodSeconds: 1
resources:
requests:
cpu: "250m"
memory: "512Mi"
ephemeral-storage: "512Mi"
restartPolicy: "OnFailure"
---
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxWarmPool
metadata:
name: python-sandbox-warmpool
namespace: agent-sandbox
spec:
replicas: 2
sandboxTemplateRef:
name: python-runtime-template
EOF
कॉन्फ़िगरेशन लागू करें:
kubectl apply -f sandbox-template-and-pool.yaml
वार्मपूल पॉड के शुरू होने में दो से तीन मिनट लग सकते हैं. यह देखने के लिए कि वे Pending से Running पर सही तरीके से माइग्रेट हुए हैं या नहीं, इन तरीकों का इस्तेमाल करें. इस दौरान, कंप्यूट की क्षमता बढ़ती है:
kubectl get pods -n agent-sandbox -w
जब आपको दो python-sandbox-warmpool-*** पॉड, Running और 1/1 के तौर पर दिखें, तब समझें कि आपके सुरक्षित एक्ज़ीक्यूशन एनवायरमेंट पहले से ही तैयार हैं और इन्हें इस्तेमाल किया जा सकता है!
सैंडबॉक्स राउटर को डिप्लॉय करना
हमारा कोड जनरेशन एजेंट, सैंडबॉक्स राउटर पर भरोसा करता है. यह राउटर, एक्ज़ीक्यूशन कमांड को अलग-अलग पॉड में सुरक्षित तरीके से भेजता है.
sandbox-router.yaml बनाने के लिए, यह कमांड चलाएं:
cat > sandbox-router.yaml <<EOF
apiVersion: v1
kind: Service
metadata:
name: sandbox-router-svc
namespace: agent-sandbox
spec:
type: ClusterIP
selector:
app: sandbox-router
ports:
- name: http
protocol: TCP
port: 8080
targetPort: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sandbox-router-deployment
namespace: agent-sandbox
spec:
replicas: 2
selector:
matchLabels:
app: sandbox-router
template:
metadata:
labels:
app: sandbox-router
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: sandbox-router
containers:
- name: router
image: us-central1-docker.pkg.dev/k8s-staging-images/agent-sandbox/sandbox-router:v20260225-v0.1.1.post3-10-ga5bcb57
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 10
resources:
requests:
cpu: "250m"
memory: "512Mi"
limits:
cpu: "1000m"
memory: "1Gi"
securityContext:
runAsUser: 1000
runAsGroup: 1000
EOF
कॉन्फ़िगरेशन लागू करें:
kubectl apply -f sandbox-router.yaml
नेटवर्क आइसोलेशन लागू करना
एक्ज़ीक्यूशन एनवायरमेंट को और ज़्यादा सुरक्षित करने और बिना अनुमति के किसी भी तरह की गतिविधि को रोकने के लिए, नेटवर्क नीति लागू करें. इससे सैंडबॉक्स में "एयर-गैप" बन जाता है. इसलिए, यह Google Cloud Metadata Server या अन्य संवेदनशील इंटरनल नेटवर्क तक नहीं पहुंच सकता.
इन्हें sandbox-policy.yaml के तौर पर सेव करें:
cat > sandbox-policy.yaml <<EOF
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: restrict-sandbox-egress
namespace: agent-sandbox
spec:
podSelector:
matchLabels:
sandbox: python-sandbox-example
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 0.0.0.0/0
except:
- 169.254.169.254/32 # Block metadata server
EOF
नीति लागू करें:
kubectl apply -f sandbox-policy.yaml
कॉम्पोनेंट की पुष्टि करना
यह पक्का करने के लिए कि आपका आइसोलेटेड कोड सैंडबॉक्स क्लस्टर लेयर पूरी तरह से कॉन्फ़िगर हो गया है, राज्य के हिसाब से पुष्टि करने वाले इन कमांड को लागू करें:
सबसे पहले, पुष्टि करें कि सैंडबॉक्स पॉड और राऊटर चालू हैं और इस्तेमाल के लिए तैयार हैं
kubectl get pods -n agent-sandbox
आउटपुट कुछ ऐसा दिखना चाहिए:
NAME READY STATUS RESTARTS AGE
python-sandbox-warmpool-7zlkv 1/1 Running 0 3m25s
python-sandbox-warmpool-cxln2 1/1 Running 0 3m25s
sandbox-router-deployment-668dfbbbb6-g9mpd 1/1 Running 0 42s
sandbox-router-deployment-668dfbbbb6-ppllz 1/1 Running 0 42s
सैंडबॉक्स राऊटर लोड बैलेंसर / आईपी पते के दिखने की पुष्टि करना
kubectl get service sandbox-router-svc -n agent-sandbox
आउटपुट ऐसा दिखना चाहिए:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
sandbox-router-svc ClusterIP 34.118.237.244 <none> 8080/TCP 114s
पुष्टि करें कि इग्रेस नेटवर्क नीति का नियम मौजूद है
kubectl get networkpolicy restrict-sandbox-egress -n agent-sandbox
आउटपुट ऐसा दिखना चाहिए:
NAME POD-SELECTOR AGE
restrict-sandbox-egress sandbox=python-sandbox-example 113s
सुनिश्चित करें कि:
python-sandbox-warmpool-***पॉडRunningऔर1/1के लिए तैयार हैं.sandbox-router-deployment-***की रेप्लिका,Runningऔर1/1के लिए तैयार हैं.sandbox-router-svcको ऐक्सेस किया जा सकता है. साथ ही,restrict-sandbox-egressनीति, मैच करने वाले सभी सैंडबॉक्स लेबल की सुरक्षा कर रही है.
सुरक्षित एक्ज़ीक्यूशन एनवायरमेंट को सुरक्षित और शुरू करने के बाद, हम अपने ऑपरेशन के मुख्य हिस्से को डिप्लॉय करने के लिए तैयार हैं: कोड जनरेशन एजेंट!
7. कोड जनरेशन एजेंट (ADK) बनाना और डिप्लॉय करना
सुरक्षित एक्ज़ीक्यूशन सैंडबॉक्स और हाई-परफ़ॉर्मेंस एलएलएम बैकएंड, दोनों को कॉन्फ़िगर करने के बाद, अब हम अपने सिस्टम का "दिमाग़" बना सकते हैं: Agent Development Kit (ADK) का इस्तेमाल करके, कोड जनरेशन एजेंट.
इस एजेंट को एक विशेषज्ञ Python डेवलपर के तौर पर काम करने के लिए डिज़ाइन किया गया है. आम तौर पर, चैटबॉट सिर्फ़ टेक्स्ट जनरेट करते हैं. हालांकि, इस एजेंट में कोड एक्ज़ीक्यूशन टूल होता है. इसकी मदद से, यह इंटरैक्टिव तरीके से समस्याओं को हल कर सकता है. यह इस तरह काम करता है:
- आपके अनुरोधों के आधार पर Python कोड लिखना.
- छठे चरण में सेट अप किए गए GKE एजेंट सैंडबॉक्स में, कोड को सुरक्षित तरीके से एक्ज़ीक्यूट करना.
- आउटपुट की पुष्टि करना या स्क्रिप्ट चलाने के दौरान होने वाली गड़बड़ियों को पढ़ना.
- टेस्ट किए गए और काम करने वाले समाधान को भरोसे के साथ डिलीवर करना.
एजेंट को सुरक्षित सैंडबॉक्स एक्ज़ीक्यूशन एनवायरमेंट का ऐक्सेस देकर, हम उसे अपने लॉजिक की पुष्टि करने और अपने-आप डीबग करने की सुविधा देते हैं. इससे, वह सॉफ़्टवेयर डेवलपमेंट के टास्क को ज़्यादा बेहतर तरीके से पूरा कर पाता है!
ADK रीज़निंग एजेंट को डेवलप करना
सबसे पहले, हम Python लॉजिक लिखते हैं. यह लॉजिक, एजेंट के व्यवहार को तय करता है. साथ ही, इसमें छठे चरण में बनाया गया सैंडबॉक्स टूल भी शामिल होता है. इस सेक्शन में, हम हाइब्रिड मॉडल की रणनीति भी कॉन्फ़िगर करते हैं: एजेंट, आपके GKE क्लस्टर पर चल रहे, खुद होस्ट किए गए Qwen मॉडल को प्राथमिकता देगा. हालांकि, अगर लोकल मॉडल धीमा है या उपलब्ध नहीं है, तो यह अपने-आप Vertex AI पर Gemini 2.5 Flash पर वापस आ जाएगा. इससे यह पक्का किया जा सकेगा कि एजेंट भरोसेमंद है.
एजेंट कोड के लिए नई डायरेक्ट्री बनाएं:
mkdir -p ~/gke-ai-agent-lab/root_agent
cd ~/gke-ai-agent-lab
यहां दिए गए कॉन्टेंट के साथ root_agent/agent.py नाम की फ़ाइल बनाएं:
cat <<'EOF' > root_agent/agent.py
import os
from google.adk.agents import Agent
from google.adk.models.lite_llm import LiteLlm
from k8s_agent_sandbox import SandboxClient
import requests
# Instantiate the client globally to track sandboxes
sandbox_client = SandboxClient()
def run_python_code(code: str) -> str:
"""
Executes Python code safely in the GKE Agent Sandbox.
Use this tool whenever you need to execute code to solve a problem.
"""
sandbox = sandbox_client.create_sandbox(template="python-runtime-template", namespace="agent-sandbox")
try:
command = f"python3 -c \"{code}\""
result = sandbox.commands.run(command)
if result.stderr:
return f"Error: {result.stderr}"
return result.stdout
finally:
# Ensure the sandbox is deleted after use to avoid leaking resources
sandbox_client.delete_sandbox(sandbox.claim_name, namespace="agent-sandbox")
# Define the ADK Agent with a fallback mechanism.
# It prioritizes the Qwen 2.5 Coder model running on our Inference Gateway.
# If the local model is unavailable, it falls back to Gemini 2.5 Flash on Vertex AI.
root_agent = Agent(
name="CodeGenerationAgent",
model=LiteLlm(
model="openai/Qwen/Qwen2.5-Coder-14B-Instruct",
fallbacks=["vertex_ai/gemini-2.5-flash"],
timeout=10
),
instruction="""
You are an expert Python developer.
1. Write Python code to solve the user's problem.
2. Execute the code using the `run_python_code` tool to verify it works.
3. Return the exact output and a brief explanation of the code.
""",
tools=[run_python_code]
)
EOF
__init__.py फ़ाइल बनाएं, ताकि ADK मॉड्यूल को पहचान सके:
echo "from . import agent" > ~/gke-ai-agent-lab/root_agent/__init__.py
एनवायरमेंट वैरिएबल सेट करें. एलएलएम के अनुरोधों को सही तरीके से रूट करने के लिए, ADK ऐप्लिकेशन को आपके गेटवे के आईपी पते की ज़रूरत होती है. ADK, Open-AI के साथ काम करने वाले स्टैंडर्ड एंडपॉइंट के साथ काम करता है. ये एंडपॉइंट, vLLM हमारे गेटवे के ज़रिए उपलब्ध कराता है. इसलिए, हम एपीआई के डिफ़ॉल्ट बेस यूआरएल को बदल सकते हैं!
export GATEWAY_IP=$(kubectl get gateway infra-is-inference-gateway -n $NAMESPACE -o jsonpath='{.status.addresses[0].value}')
cat <<EOF > ~/gke-ai-agent-lab/root_agent/.env
OPENAI_API_BASE=http://${GATEWAY_IP}/v1
OPENAI_API_KEY=no-key-required
# Vertex AI settings for fallback (Authentication is handled by Workload Identity)
VERTEXAI_PROJECT=$PROJECT_ID
VERTEXAI_LOCATION=${ZONE%-[a-z]}
EOF
एजेंट ऐप्लिकेशन को कंटेनर में बदलना
हमें एजेंट को पैकेज करना होगा, ताकि वह GKE में सुरक्षित तरीके से चल सके.
~/gke-ai-agent-lab में एक Dockerfile बनाएं. इससे kubectl, ADK लाइब्रेरी, और एजेंट सैंडबॉक्स क्लाइंट इंस्टॉल हो जाता है:
cat <<'EOF' > ~/gke-ai-agent-lab/Dockerfile
FROM python:3.11-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
RUN apt-get update && apt-get install -y git curl \
&& curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl" \
&& install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl \
&& rm kubectl && apt-get clean && rm -rf /var/lib/apt/lists/*
RUN pip install --no-cache-dir "google-adk[extensions,otel-gcp]>=1.27.4" litellm pandas "git+https://github.com/kubernetes-sigs/agent-sandbox.git@main#subdirectory=clients/python/agentic-sandbox-client" \
"opentelemetry-instrumentation-google-genai>=0.4b0" \
"opentelemetry-exporter-otlp" \
"opentelemetry-instrumentation-vertexai>=2.0b0"
COPY ./root_agent /app/root_agent
EXPOSE 8080
ENTRYPOINT ["adk", "web", "--host", "0.0.0.0", "--port", "8080", "--otel_to_cloud"]
EOF
कंटेनर इमेज को सेव करने के लिए, Artifact Registry में एक डेटाबेस बनाएं.
gcloud artifacts repositories create agent-repo \
--repository-format=docker \
--location=us-central1
कंटेनर इमेज बनाने और उसे पुश करने के लिए, Cloud Build का इस्तेमाल करें.
gcloud builds submit --tag us-central1-docker.pkg.dev/$PROJECT_ID/agent-repo/code-agent:v1 ~/gke-ai-agent-lab/
RBAC की मदद से GKE पर डिप्लॉय करना
आखिर में, एजेंट को अपने क्लस्टर पर डिप्लॉय करें. डिप्लॉयमेंट में Role और RoleBinding शामिल हैं. ये एजेंट को SandboxWarmPool से इंस्टेंस का दावा करने की अनुमति देते हैं.
इस डिप्लॉयमेंट में Kubernetes ServiceAccount का इस्तेमाल किया जाएगा, ताकि आपका एजेंट सैंडबॉक्स क्लेम एपीआई से कम्यूनिकेट कर सके. इसके लिए, Google IAM ServiceAccount की ज़रूरत नहीं होती, क्योंकि यह लोकल क्लस्टर रिसॉर्स और लोकल vLLM गेटवे एंडपॉइंट को ऐक्सेस करता है.
gVisor में स्टैंडर्ड डिप्लॉयमेंट क्यों?
छठे चरण में, हमने SandboxTemplate और SandboxClaim एपीआई का इस्तेमाल करके, जनरेट किए गए Python कोड (टूल को लागू करना) के लिए, कुछ समय के लिए उपलब्ध होने वाले सैंडबॉक्स बनाए.
हम एजेंट के वेब यूज़र इंटरफ़ेस (ब्रेन) के लिए, runtimeClassName: gvisor के साथ स्टैंडर्ड Kubernetes Deployment स्पेसिफ़िकेशन का इस्तेमाल कर रहे हैं.
- अंतर: स्टैंडर्ड
SandboxClaimsकुछ समय के लिए होते हैं और इनकी संख्या शून्य से एक होती है. ये ऐसे स्क्रिप्ट के लिए सबसे सही होते हैं जिन पर भरोसा नहीं किया जा सकता. स्टैंडर्डDeploymentलंबे समय तक चलता है और लगातार काम करता रहता है. यह उन वेब यूज़र इंटरफ़ेस (यूआई) के लिए सबसे सही है जिन्हें स्टेबल KubernetesServiceऔर लोड बैलेंसर की ज़रूरत होती है! स्टैंडर्ड डिप्लॉयमेंट पर सीधेruntimeClassName: gvisorका इस्तेमाल करने से, आपको gVisor कर्नल को अलग करने की सुविधा मिलती है. साथ ही,Deploymentकी स्टैंडर्ड सुविधाओं का इस्तेमाल जारी रखा जा सकता है.
इन्हें deployment.yaml के तौर पर सेव करें:
cat <<EOF > ~/gke-ai-agent-lab/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: code-agent
labels:
app: code-agent
spec:
replicas: 1
selector:
matchLabels:
app: code-agent
template:
metadata:
labels:
app: code-agent
spec:
serviceAccount: adk-agent-sa
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: code-agent
image: us-central1-docker.pkg.dev/YOUR_PROJECT_ID/agent-repo/code-agent:v1
imagePullPolicy: Always
env:
- name: OPENAI_API_KEY
value: "no-key-required"
- name: OPENAI_API_BASE
value: "http://YOUR_GATEWAY_IP/v1"
- name: VERTEXAI_PROJECT
value: "YOUR_PROJECT_ID"
- name: VERTEXAI_LOCATION
value: "YOUR_REGION"
- name: OTEL_SERVICE_NAME
value: "code-agent"
- name: GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY
value: "true"
- name: OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT
value: "true"
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: code-agent-service
spec:
selector:
app: code-agent
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: agent-sandbox
name: sandbox-creator-role
rules:
- apiGroups: [""]
resources: ["services", "pods", "pods/portforward"]
verbs: ["get", "list", "watch", "create"]
- apiGroups: ["extensions.agents.x-k8s.io"]
resources: ["sandboxclaims"]
verbs: ["create", "get", "list", "watch", "delete"]
- apiGroups: ["agents.x-k8s.io"]
resources: ["sandboxes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: adk-agent-binding
namespace: agent-sandbox
subjects:
- kind: ServiceAccount
name: adk-agent-sa
namespace: default
roleRef:
kind: Role
name: sandbox-creator-role
apiGroup: rbac.authorization.k8s.io
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: adk-agent-sa
EOF
ऑब्ज़र्वेबिलिटी के लिए IAM अनुमतियां देना
एजेंट को Google Cloud पर टेलीमेट्री डेटा (लॉग और ट्रेस) भेजने की अनुमति देने के लिए, आपको Workload Identity का इस्तेमाल करके, Kubernetes सेवा खाते adk-agent-sa को ज़रूरी अनुमतियां देनी होंगी.
अपने Cloud Shell में ये कमांड चलाएं:
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# Grant permission to write logs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/logging.logWriter \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to write traces
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/cloudtrace.agent \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to use Vertex AI
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/aiplatform.user \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
YOUR_PROJECT_ID को अपने प्रोजेक्ट आईडी से अपने-आप बदलने और कॉन्फ़िगरेशन लागू करने के लिए, यह कमांड चलाएं!
sed -i "s/YOUR_PROJECT_ID/$PROJECT_ID/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_GATEWAY_IP/$GATEWAY_IP/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_REGION/$ZONE/g" ~/gke-ai-agent-lab/deployment.yaml
kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml
8. देखना और पुष्टि करना
अब पूरी तरह से इंटिग्रेट किए गए सिस्टम को टेस्ट करने का समय है.
यूज़र इंटरफ़ेस में, कोड जनरेट करने वाले एजेंट को टेस्ट करना
ADK Web UI का एक्सटर्नल आईपी पता ढूंढने के लिए:
kubectl get services code-agent-service
आउटपुट कुछ ऐसा दिखना चाहिए:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
code-agent-service LoadBalancer 34.118.230.182 34.31.250.60 80:32471/TCP 2m14s
- कोई ब्राउज़र खोलें और
http://[EXTERNAL-IP]पर जाएं. - ADK के वेब इंटरफ़ेस में, पक्का करें कि सबसे ऊपर दाईं ओर मौजूद ड्रॉप-डाउन मेन्यू से "root_agent" चुना गया हो. इसके बाद, एजेंट को यह प्रॉम्प्ट दें:
Write a python script that prints 'Hello from the isolated sandbox'.
यह देखने के लिए कि एजेंट, अनुमान लगाने वाले बैकएंड और सैंडबॉक्स का इस्तेमाल कैसे करता है, नीचे दिए गए Cloud Observability की मदद से मॉडल के आंकड़े एक्सप्लोर करना और GKE के यूज़र इंटरफ़ेस (यूआई) की मदद से एजेंट की परफ़ॉर्मेंस एक्सप्लोर करना सेक्शन पर जाएं. यहां आपको डैशबोर्ड दिखेंगे.
GKE के यूज़र इंटरफ़ेस (यूआई) के ज़रिए एजेंट की परफ़ॉर्मेंस को मॉनिटर करने की सुविधा के बारे में जानकारी
अब जब आपने कुछ प्रॉम्प्ट चला लिए हैं, तो आइए टेलीमेट्री डेटा देखते हैं. इससे आपको यह समझने में मदद मिलती है कि Inference Scheduler और vLLM कैसा परफ़ॉर्म कर रहे हैं.
एजेंट डैशबोर्ड ऐक्सेस करना
- Kubernetes Engine > वर्कलोड पेज पर जाएं.
- कोड-एजेंट डिप्लॉयमेंट पर क्लिक करके, डिप्लॉयमेंट की जानकारी पेज खोलें.
- Observability टैब पर क्लिक करें.
- ऑब्ज़र्वेबिलिटी डैशबोर्ड के बाईं ओर मौजूद नेविगेशन पैनल में, आपको एजेंट सेक्शन दिखेगा. इसमें सब-टैब भी होंगे.
और भी देखें
अपने एजेंट ऐप्लिकेशन के व्यवहार को देखने के लिए, यहां दिए गए सब-टैब एक्सप्लोर करें:
- खास जानकारी: सेशन, औसत टर्न, और इनवोकेशन के लिए स्कोरकार्ड देखें.
- मॉडल: आपके एजेंट ने जिन मॉडल का इस्तेमाल किया है उनके हिसाब से, मॉडल कॉल की संख्या, गड़बड़ी की दरें, और लेटेन्सी देखें.
- टूल: टूल कॉल और एक्ज़ीक्यूशन की अवधि को मॉनिटर करें. इससे यह पता चलेगा कि आपका एजेंट, सैंडबॉक्स एक्ज़ीक्यूशन टूल का कितना असरदार तरीके से इस्तेमाल कर रहा है.
- इस्तेमाल: टोकन के इस्तेमाल और स्टैंडर्ड कंटेनर के लिए संसाधन के बंटवारे (सीपीयू और मेमोरी) को ट्रैक करता है.
- एजेंट ट्रेस: इस टैब पर स्विच करके, एक्ज़ीक्यूशन सेशन या रॉ ट्रेस स्पैन की सूची देखें. किसी लाइन पर क्लिक करने से, चुने गए ट्रेस की जानकारी वाला फ़्लायआउट खुलता है!
vLLM से मॉडल-लेवल की मेट्रिक और ADK से ऐप्लिकेशन-लेवल की टेलीमेट्री को मिलाकर, अब आपके पास GKE पर जनरेटिव एआई एजेंट के लिए फ़ुल-स्टैक ऑब्ज़र्वेबिलिटी है!
Cloud Observability की मदद से, vLLM मॉडल के आंकड़े देखना
अब जब आपने कुछ प्रॉम्प्ट चला लिए हैं, तो आइए टेलीमेट्री डेटा देखते हैं. इससे आपको यह समझने में मदद मिलती है कि Inference Scheduler और vLLM कैसा परफ़ॉर्म कर रहे हैं.
डैशबोर्ड ऐक्सेस करना
- Google Cloud Console पर जाएं.
- मॉनिटरिंग > डैशबोर्ड पर जाएं.
- vLLM Prometheus की खास जानकारी डैशबोर्ड को खोजें और चुनें.
निगरानी के लिए दिलचस्प मेट्रिक
डैशबोर्ड देखते समय, इन मुख्य मेट्रिक पर ध्यान दें. इससे आपको GKE Inference Gateway और प्रीफ़िक्स-कैशिंग का असर दिखेगा:
- केवी कैश का इस्तेमाल (
vllm:gpu_cache_usage):- यह क्यों ज़रूरी है: इससे पता चलता है कि कॉन्टेक्स्ट को कैश मेमोरी में सेव करने के लिए, GPU मेमोरी का कितना हिस्सा इस्तेमाल किया जा रहा है. अगर यह ज़्यादा है, तो इसका मतलब है कि सिस्टम, आने वाले समय में किए जाने वाले अनुरोधों को तेज़ी से पूरा करने के लिए कॉन्टेक्स्ट को सेव कर रहा है. एक ही प्रॉम्प्ट को कई बार चलाने पर, आपको इस इस्तेमाल में बढ़ोतरी दिखेगी. इसके बाद, यह स्थिर हो जाएगा.
- चल रहे बनाम इंतज़ार में रखे गए अनुरोध (
vllm:num_requests_runningबनामvllm:num_requests_waiting):- यह ज़रूरी क्यों है: इससे लोड का पता चलता है. अगर इंतज़ार कर रहे अनुरोधों की संख्या ज़्यादा है, तो इसका मतलब है कि आपके नोड ओवरलोड हो गए हैं.
- टोकन थ्रूपुट (
vllm:request_prompt_tokens_totऔरvllm:request_generation_tokens_tot):- यह ज़रूरी क्यों है: इससे क्लस्टर में प्रोसेस किए गए इनपुट और आउटपुट टोकन की संख्या को ट्रैक किया जा सकता है.
- टाइम टू फ़र्स्ट टोकन (टीटीएफ़टी):
- यह क्यों ज़रूरी है: यह इंटरैक्टिव एजेंट के लिए सबसे अहम मेट्रिक है. प्रीफ़िक्स-कैश अवेयर राउटिंग के साथ GKE Inference Gateway का इस्तेमाल करने पर, एक जैसे कॉन्टेक्स्ट (जैसे कि सिस्टम प्रॉम्प्ट या लार्ज कॉन्टेक्स्ट विंडो) शेयर करने वाले अनुरोधों को एक ही रेप्लिका पर राउट किया जाता है. इससे, मौजूदा कैश हिट का फिर से इस्तेमाल करके टीटीएफ़टी को कम किया जा सकता है!
आज़माने के लिए एक्सपेरिमेंट
इन उदाहरणों को आज़माकर, मेट्रिक में रीयल-टाइम में होने वाले बदलाव देखें. साथ ही, यह पुष्टि करें कि शेड्यूल सही तरीके से काम कर रहा है!
पहला एक्सपेरिमेंट: "दोहराव की स्पीड" (प्रीफ़िक्स कैश हिट)
- एजेंट को कोई मुश्किल प्रॉम्प्ट भेजें. उदाहरण के लिए, "100 एमबी की CSV फ़ाइल को पार्स करने और आंकड़े कैलकुलेट करने के लिए, एक Python स्क्रिप्ट लिखो."
- जवाब मिलने के बाद, उसी प्रॉम्प्ट को तुरंत फिर से भेजें.
- प्रीफ़िक्स कैश हिट रेट और पहले टोकन के लिए समय (टीटीएफ़टी) देखें.
- आपको क्या दिखेगा: प्रीफ़िक्स कैश हिट रेट बढ़कर 100% हो जाना चाहिए और टीटीएफ़टी में काफ़ी गिरावट आनी चाहिए!
- इसका मतलब: GKE Inference Gateway ने शेयर किए गए कॉन्टेक्स्ट को पहचान लिया है. साथ ही, इसे उसी रेप्लिका पर भेज दिया है जिसने पहले से मौजूद कॉन्टेक्स्ट कैश का फिर से इस्तेमाल किया है!
दूसरा एक्सपेरिमेंट: क्लाउड पर वापस जाना (मॉडल की विश्वसनीयता)
- अपने लोकल Qwen मॉडल के काम न करने की स्थिति को सिम्युलेट करने के लिए, अनुमान लगाने की सेवा को बंद किया जा सकता है. इसके अलावा, डिप्लॉयमेंट में सिर्फ़ एक फ़र्ज़ी
OPENAI_API_BASEदिया जा सकता है. - अपने
deployment.yamlमें मौजूदOPENAI_API_BASEको ऐसे आईपी या पोर्ट पर अपडेट करें जो मौजूद नहीं है. इसके बाद, बदलाव लागू करें:sed -i "s|value: \"http://$GATEWAY_IP/v1\"|value: \"http://10.0.0.1:8080/v1\"|g" ~/gke-ai-agent-lab/deployment.yaml kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml - पॉड के फिर से शुरू होने का इंतज़ार करें. इसके बाद, यूज़र इंटरफ़ेस (यूआई) में एजेंट को कोई प्रॉम्प्ट भेजें.
- आपको क्या दिखेगा: एजेंट अब भी जवाब दे रहा है!
- इसका मतलब:
fallbacksकॉन्फ़िगरेशन की वजह से, ADK ने लोकल Qwen एंडपॉइंट के काम न करने की समस्या को पहचान लिया. साथ ही, अनुरोध को Vertex AI पर मौजूद Gemini 2.5 Flash पर भेज दिया. ध्यान दें कि Vertex AI को किए गए ये फ़ॉलबैक कॉल, आपके लोकल vLLM Inference Gateway को बायपास करते हैं. इसलिए, ये Agent Observability > Models डैशबोर्ड में नहीं दिखेंगे. यह डैशबोर्ड, सिर्फ़ vLLM से आने वाले ट्रैफ़िक को ट्रैक करता है.
डाइनैमिक रिसॉर्स असाइनमेंट (डीआरए) की सुविधा के बारे में जानकारी
vLLM और Inference Gateway, अनुरोधों को रूट करने और उन्हें पूरा करने के तरीके को ऑप्टिमाइज़ करते हैं. वहीं, डाइनैमिक रिसोर्स ऐलोकेशन (डीआरए) की वजह से, आपके वर्कलोड के लिए सही हार्डवेयर अटैच करना मुमकिन हो पाता है.
डीआरए की मदद से, अपने क्लस्टर में हार्डवेयर को बेहतर तरीके से मैनेज किया जा सकता है. इसके लिए, ResourceClaimTemplate और DeviceClasses का इस्तेमाल करके, हार्डवेयर के संसाधनों को अपनी ज़रूरत के हिसाब से तय किया जा सकता है.
एआई वर्कलोड के लिए, DRA एक गेम-चेंजर क्यों है:
- हार्डवेयर के लिए सटीक अनुरोध: DRA की मदद से, यह पक्का किया जा सकता है कि वर्कलोड को सही ऐक्सलरेटर वाली मशीनों पर शेड्यूल किया गया है. साथ ही, उन संसाधनों पर दावा भी किया जा सकता है, ताकि यह पक्का किया जा सके कि उनका इस्तेमाल सिर्फ़ ResourceClaim से जुड़े वर्कलोड के लिए किया जा रहा है.
- डिकपल्ड लाइफ़साइकल: डिवाइस के दावों को पॉड के लाइफ़साइकल से अलग मैनेज किया जाता है. अगर कोई पॉड क्रैश हो जाता है, तो जीपीयू का दावा बना रह सकता है. इससे पूरे डिप्लॉयमेंट या अन्य वर्कलोड ऑब्जेक्ट को फिर से शुरू किया जा सकता है. इसके लिए, जीपीयू के रिलीज़ होने और फिर से हासिल किए जाने का इंतज़ार नहीं करना पड़ता.
- एक से ज़्यादा वेंडर के लिए स्टैंडर्डाइज़ेशन: DRA, NVIDIA के जीपीयू और Google के टीपीयू, दोनों के लिए एक जैसा Kubernetes API उपलब्ध कराता है. दोनों के लिए एक ही स्कीमा का इस्तेमाल किया जाता है. इससे, आपके वर्कलोड की YAML मेनिफ़ेस्ट को आसानी से पोर्ट किया जा सकता है!
इस कोडलैब में, आपने इसे ऐक्शन में तब देखा, जब आपने gpu-claim-template से बाइंड करने के लिए, अपनी Helm वैल्यू कॉन्फ़िगर की थीं. इससे, डिवाइस प्लगिन के कॉन्फ़िगरेशन को निलंबित किए बिना, रोलआउट को आसानी से किया जा सका.
llm-d की भूमिका को समझना
vLLM न्यूरल वेट का आकलन करता है और GKE गेटवे क्वेरी को राउट करता है. वहीं, llm-d कॉन्फ़िगरेशन लेयर के तौर पर काम करता है और "Glue" के तौर पर काम करता है, जो इन सभी को एक साथ जोड़ता है.
llm-d के बिना, आपको vLLM डिप्लॉयमेंट, सेवा पोर्ट, वॉल्यूम माउंट, और DRA संसाधन के दावों के बारे में बताने के लिए, Kubernetes मेनिफ़ेस्ट को शुरू से लिखना होगा.
अपने डिप्लॉयमेंट में llm-d का इस्तेमाल क्यों करें?
- यूनिफ़ाइड कॉन्फ़िगरेशन (एक लाइन में बदलाव करना):
llm-dHelm चार्ट, जटिल और लो-लेवल के Kubernetes संसाधनों को साफ़-सुथरे और हाई-लेवल के टॉगल में बंडल करते हैं. जैसे,accelerator.dra: trueको सेट करना. - पहले से जांचे गए "वेल-लिट-पाथ":
llm-dरिपॉज़िटरी में ऐसे कॉन्फ़िगरेशन होते हैं जिनकी तुलना पहले से बेंचमार्क से की जा चुकी है और विशेषज्ञों ने उनकी जांच कर ली है.llm-d-modelserviceको डिप्लॉय करने पर, आपको ये सुविधाएं मिलती हैं: जीपीयू मेमोरी के इस्तेमाल के लिए ऑप्टिमाइज़ किए गए डिफ़ॉल्ट, सुझाई गई जांच की समयावधि (लाइवनेस/रेडीनेस), और मेट्रिक स्क्रैपिंग के लिए सही एक्सपोज़र. - आसानी से मॉनिटरिंग की सुविधा:
llm-dयह पक्का करता है कि स्टैंडर्ड कंटेनर पोर्ट और स्क्रैप पाथ (/metrics) सही तरीके से दिखाए जाएं. इससे, मैन्युअल तरीके से डीबग किए बिना, Google Cloud Monitoring में अपने डिप्लॉयमेंट को आसानी से कनेक्ट किया जा सकता है.
संक्षेप में कहें, तो llm-d, फिर से इस्तेमाल किए जा सकने वाले आर्किटेक्चर ब्लूप्रिंट उपलब्ध कराता है. इससे डेवलपर को GKE पर इन्फ़रेंस स्टैक डिप्लॉय करते समय, हर बार एक ही काम को बार-बार नहीं करना पड़ता.
ज़्यादा जानकारी: GKE Inference Gateway
स्टैंडर्ड लेयर 7 लोड बैलेंसर, एचटीटीपी हेडर को देखकर काम करते हैं. जैसे, पाथ (/v1/completions) या कुकी. GKE इन्फ़रेंस गेटवे, इससे कहीं ज़्यादा बेहतर है. इसे खास तौर पर जनरेटिव एआई के ट्रैफ़िक के लिए डिज़ाइन किया गया है.
इससे परफ़ॉर्मेंस और बेहतर तरीके से काम करने में कैसे मदद मिलती है:
- कॉन्टेंट के हिसाब से राउटिंग (प्रॉम्प्ट हैशिंग): GKE Inference Gateway, JSON अनुरोध के मुख्य हिस्से को इंटरसेप्ट करता है. यह प्रॉम्प्ट का हैश कैलकुलेट करता है और यह ट्रैक करता है कि कौनसी बैकएंड रेप्लिका, उन टोकन को पहले से ही अपने GPU मेमोरी (KV कैश) में सेव करके रखती है.
- कैश हिट को ज़्यादा से ज़्यादा करना: टेस्टिंग के दौरान, जब आपने किसी प्रॉम्प्ट को दोहराया, तो Gateway ने उसे ठीक उसी रेप्लिका पर भेजा. किसी प्रॉम्प्ट का आकलन करने के लिए, ज़्यादा कंप्यूटिंग पावर की ज़रूरत होती है. कैश मेमोरी का दोबारा इस्तेमाल करने से, आपको प्रॉम्प्ट को "दोबारा पढ़ने" की ज़रूरत नहीं पड़ती. इससे आपके पैसे और GPU का समय बचता है.
- टाइम-टू-फ़र्स्ट-टोकन (टीटीएफ़टी) को कम करना: टीटीएफ़टी, लोगों से बातचीत करने वाले एजेंट के लिए इस्तेमाल की जा सकने वाली एक अहम मेट्रिक है. कैश मेमोरी का इस्तेमाल करके, मॉडल सेकंड के बजाय मिलीसेकंड में टोकन जनरेट कर सकता है.
- इंटेलिजेंट लोड डिस्ट्रिब्यूशन: अगर किसी रेप्लिका का वीआरएएम, कैश हिट से पूरी तरह भर जाता है, तो गेटवे, नए प्रॉम्प्ट को डाइनैमिक तरीके से किसी ऐसे रेप्लिका पर भेज सकता है जिसमें जगह हो. इससे, उपलब्धता के साथ-साथ परफ़ॉर्मेंस को भी बेहतर बनाया जा सकता है.
एजेंट सैंडबॉक्स, जोखिम को कैसे कम करता है
इस लैब में, हमने यह दिखाया है कि Agent Sandbox, एआई एजेंट से जुड़े जोखिमों से आपके इन्फ़्रास्ट्रक्चर की सुरक्षा कैसे करता है. इसके लिए, यह दो लेयर का आइसोलेशन उपलब्ध कराता है:
- एक्ज़ीक्यूशन टूल को अलग करना: एजेंट, जनरेट किए गए कोड को कुछ समय के लिए उपलब्ध सैंडबॉक्स में एक्ज़ीक्यूट करता है. इससे यह पक्का होता है कि एलएलएम से जनरेट किया गया, भरोसेमंद न होने वाला कोड एक अलग और सुरक्षित एनवायरमेंट में चलता है. इससे एजेंट और क्लस्टर सुरक्षित रहते हैं.
- तेज़ी से चालू होने की सुविधा: WarmPool का इस्तेमाल करने पर, नए सैंडबॉक्स एक सेकंड से भी कम समय में चालू हो जाते हैं और कोड को एक्ज़ीक्यूट करने के लिए तैयार हो जाते हैं.
- एजेंट को अलग करना: हमने एजेंट ऐप्लिकेशन को gVisor की सुविधा वाले नोड (
runtimeClassName: gvisorके ज़रिए) में भी चलाया, ताकि एजेंट की डिपेंडेंसी में सप्लाई चेन की कमज़ोरियों से पूरी तरह से सुरक्षा मिल सके.
इसकी वजह से, सुरक्षा से जुड़ी इतनी मज़बूत बाउंड्री क्यों बनती है, यहां इसकी जानकारी दी गई है:
- सिस्टम कॉल इंटरसेप्शन: gVisor, सिस्टम कॉल को होस्ट Linux कर्नल तक पहुंचने से पहले ही इंटरसेप्ट कर लेता है. इससे उन एक्सप्लॉइट को ब्लॉक किया जाता है जो कंटेनर से बाहर निकलकर होस्ट नोड को ऐक्सेस करने की कोशिश करते हैं.
- साइड में मौजूद अन्य सिस्टम से कम संपर्क: नेटवर्क की नीतियों के साथ मिलकर काम करने की वजह से, अगर कोई एनवायरमेंट हैक हो जाता है, तो भी वह आपके इंटरनल मेटाडेटा सर्वर को स्कैन नहीं कर सकता. साथ ही, आपके क्लस्टर में मौजूद अन्य संवेदनशील सेवाओं पर भी स्विच नहीं कर सकता.
सैंडबॉक्स में पूरे एजेंट चलाना
इस लैब में, हमने पर्सिस्टेंट एजेंट ऐप्लिकेशन के लिए, सैंडबॉक्स को टूल के तौर पर इस्तेमाल किया है. हालांकि, ज़्यादा सुरक्षा के लिए—खास तौर पर, संवेदनशील डेटा को मैनेज करते समय या कई ऐसे उपयोगकर्ताओं को सेवा देते समय जिन पर भरोसा नहीं किया जा सकता—हर सेशन या उपयोगकर्ता के लिए, पूरे एजेंट ऐप्लिकेशन को किसी खास सैंडबॉक्स में चलाया जा सकता है. इससे एजेंट की मेमोरी, स्थिति, और एक्ज़ीक्यूशन एनवायरमेंट पूरी तरह से अलग हो जाता है. सेशन पूरा होने के तुरंत बाद इसे मिटा दिया जाता है.
9. साफ़-सफ़ाई सेवा
इस कोडलैब में इस्तेमाल किए गए संसाधनों के लिए, अपने Google Cloud खाते से शुल्क लिए जाने से बचने के लिए, उन्हें मिटाने के लिए यह तरीका अपनाएं.
एक-एक करके संसाधन मिटाना
- GKE क्लस्टर मिटाएं:
gcloud container clusters delete $CLUSTER_NAME --zone $ZONE --quiet
- Artifact Registry रिपॉज़िटरी मिटाएं:
gcloud artifacts repositories delete agent-repo --location=us-central1 --quiet
- वीपीसी नेटवर्क मिटाने के लिए:
gcloud compute networks delete ai-agent-network --quiet
प्रोजेक्ट मिटाना
अगर आपको प्रोजेक्ट की ज़रूरत नहीं है, तो संसाधनों को हटाने के बाद इसे मिटाया जा सकता है:
gcloud projects delete $PROJECT_ID
10. खास जानकारी
बधाई हो! आपने GKE पर, सुरक्षित और बेहतर परफ़ॉर्मेंस वाला कोड जनरेट करने वाला एजेंट बना लिया है और उसे डिप्लॉय कर दिया है.
आपको क्या सीखने को मिला
- जीपीयू संसाधनों को मैनेज करने के लिए, GKE में डाइनैमिक रिसोर्स ऐलोकेशन (डीआरए) को कॉन्फ़िगर और इस्तेमाल करने का तरीका.
- प्रीफ़िक्स-कैश के बारे में जानकारी रखने वाली राउटिंग की मदद से, एलएलएम की परफ़ॉर्मेंस को ऑप्टिमाइज़ करने के लिए, GKE Inference Gateway का इस्तेमाल कैसे करें.
- GKE पर, भरोसेमंद न होने वाले कोड को सुरक्षित तरीके से एक्ज़ीक्यूट करने के लिए, एजेंट सैंडबॉक्स (gVisor) का इस्तेमाल कैसे करें.
- vLLM की परफ़ॉर्मेंस को मॉनिटर करने के लिए, Google Cloud Managed Service for Prometheus का इस्तेमाल कैसे करें.
- ADK और GKE Managed OpenTelemetry का इस्तेमाल करके, एजेंट की परफ़ॉर्मेंस पर नज़र रखने की सुविधा को कॉन्फ़िगर और देखने का तरीका.
अगले चरण और संदर्भ
- एजेंट सैंडबॉक्स: GKE पर एजेंट सैंडबॉक्स और GKE सैंडबॉक्स पॉड के बारे में जानें.
- llm-d: llm-d गाइड पढ़ें और llm-d GitHub रिपॉज़िटरी देखें.
- डाइनैमिक रिसोर्स ऐलोकेशन: GKE पर DRA के बारे में जानें.
- GKE Inference Gateway: Inference Gateway के कॉन्सेप्ट के बारे में जानें.
- ज़्यादा कोडलैब: Google Cloud Codelabs पर जाकर, ज़्यादा ट्यूटोरियल देखें.