
1. Pengantar
Ringkasan
Di lab ini, Anda akan mempelajari cara membangun dan men-deploy agen pembuatan kode yang aman di Google Kubernetes Engine (GKE). Agen pembuatan kode perlu menjalankan kode yang mungkin tidak tepercaya, sehingga memerlukan lingkungan sandbox yang aman. Anda juga akan mempelajari cara mengonfigurasi agen dengan strategi model hibrida, sehingga agen dapat melakukan penggantian dari model terbuka yang dihosting sendiri di GKE ke layanan Gemini terkelola Vertex AI untuk meningkatkan keandalan. Selain itu, Anda akan mempelajari cara mengoptimalkan inferensi menggunakan GKE Inference Gateway dan Alokasi Resource Dinamis (DRA). Terakhir, Anda akan mempelajari cara memanfaatkan Google Cloud Observability untuk memantau stack inferensi menggunakan Managed Prometheus.
Arsitektur
Berikut adalah arsitektur sistem yang akan Anda bangun:
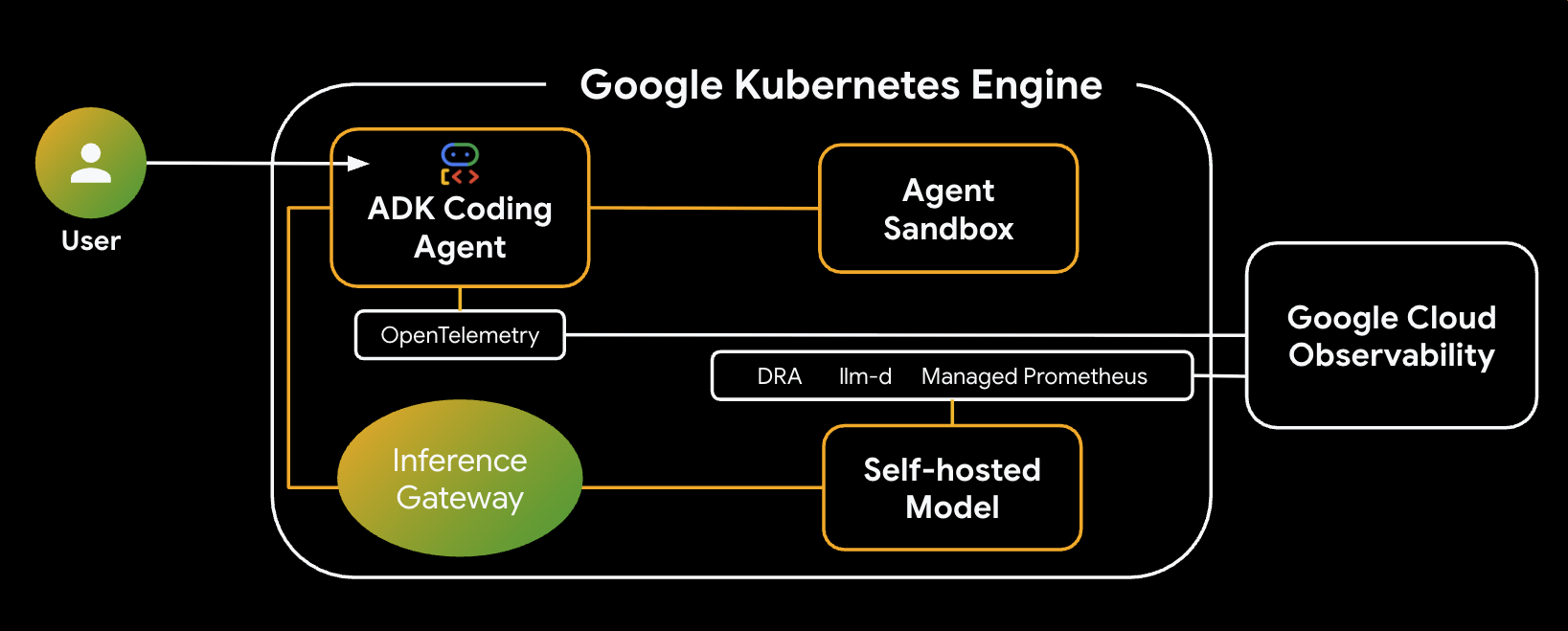
Komponen & Manfaat Utama
- Alokasi Resource Dinamis (DRA): Digunakan dalam lab ini untuk mengklaim dan mengalokasikan resource GPU tertentu (NVIDIA L4) secara dinamis untuk Pod server model, sehingga memastikan penargetan hardware yang tepat untuk workload inferensi kita. Pelajari DRA di GKE.
- llm-d & vLLM: Menyediakan framework penayangan model dan diagram Helm untuk men-deploy model Qwen. Di lab ini, server menangani permintaan inferensi dan terintegrasi dengan DRA untuk pengelolaan resource (penayangan yang dipisah-pisahkan tidak diaktifkan di lab ini). Baca Panduan llm-d dan lihat Repositori GitHub llm-d.
- GKE Inference Gateway: Memindahkan logika perutean yang mendukung AI langsung ke load balancer. Di lab ini, permintaan dirutekan untuk memaksimalkan hit cache awalan, sehingga mengurangi latensi Waktu hingga Token Pertama (TTFT). Pelajari konsep Inference Gateway.
- Sandbox Agen (gVisor): Memberikan isolasi yang aman untuk mengeksekusi kode yang dihasilkan oleh agen AI. Hal ini menggunakan gVisor untuk menyediakan isolasi kernel yang mendalam, sehingga melindungi node host dari workload yang tidak tepercaya. Pelajari Agent Sandbox di GKE dan Pod GKE Sandbox.
Yang akan Anda lakukan
- Menyediakan Infrastruktur: Siapkan cluster GKE dengan Alokasi Resource Dinamis (DRA) untuk pengelolaan GPU.
- Deploy Inference Stack: Deploy
llm-ddan vLLM dengan penjadwalan inferensi cerdas. - Mengonfigurasi Intelligent Routing: Gunakan GKE Inference Gateway untuk pemilihan rute yang peka terhadap cache awalan.
- Eksekusi Kode yang Aman: Deploy Agent Sandbox (gVisor) untuk menjalankan kode buatan AI dengan aman.
- Amati dan Validasi: Gunakan Google Cloud Monitoring dan Managed Prometheus untuk melihat metrik penayangan model.
Yang akan Anda pelajari
- Cara mengonfigurasi dan menggunakan Alokasi Resource Dinamis (DRA) di GKE.
- Cara menggunakan GKE Inference Gateway untuk mengoptimalkan performa penayangan LLM.
- Cara menggunakan Agent Sandbox untuk mengeksekusi kode yang tidak tepercaya secara aman di GKE.
- Cara menggunakan Google Cloud Managed Service for Prometheus untuk memantau performa vLLM.
2. Penyiapan dan Persyaratan
Penyiapan Project
Buat Project Google Cloud
- Di Konsol Google Cloud, di halaman pemilih project, pilih atau buat project Google Cloud.
- Pastikan penagihan diaktifkan untuk project Cloud Anda. Pelajari cara memeriksa apakah penagihan telah diaktifkan pada suatu project.
Mulai Cloud Shell
Cloud Shell adalah lingkungan command line yang berjalan di Google Cloud yang telah dilengkapi dengan alat yang diperlukan.
- Klik Activate Cloud Shell di bagian atas konsol Google Cloud.
- Setelah terhubung ke Cloud Shell, verifikasi autentikasi Anda:
gcloud auth list - Pastikan project Anda dikonfigurasi:
gcloud config get project - Jika project Anda tidak ditetapkan seperti yang diharapkan, tetapkan project:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
3. Penyediaan Infrastruktur dan Alokasi Resource Dinamis (DRA)
Pada langkah pertama ini, Anda akan mengonfigurasi cluster GKE untuk menggunakan alokasi akselerator modern (DRA) dan bukan plugin perangkat lama. Dengan begitu, Anda dapat membagikan dan mengalokasikan GPU atau TPU secara fleksibel untuk workload pembuatan kode.
Prasyarat: Cluster GKE Standard Anda harus menjalankan versi 1.34 atau yang lebih baru untuk mendukung DRA.
Mengaktifkan Google Cloud API
Aktifkan Google Cloud API yang diperlukan untuk codelab ini, khususnya Compute Engine API dan Kubernetes Engine API.
gcloud services enable compute.googleapis.com container.googleapis.com networkservices.googleapis.com cloudbuild.googleapis.com artifactregistry.googleapis.com telemetry.googleapis.com cloudtrace.googleapis.com aiplatform.googleapis.com
Menetapkan Variabel Lingkungan
Untuk mempermudah penyiapan, tentukan variabel lingkungan Anda. Anda dapat menyesuaikan region atau konvensi penamaan sesuai kebutuhan.
export PROJECT_ID=$(gcloud config get-value project)
export ZONE=us-central1-a
export CLUSTER_NAME=ai-agent-cluster
export NODEPOOL_NAME=dra-accelerator-pool
gcloud config set project $PROJECT_ID
gcloud config set compute/region $ZONE
Buat Direktori Kerja
Buat direktori kerja khusus untuk lab ini dan buka direktori tersebut agar file Anda tetap teratur:
mkdir -p ~/gke-ai-agent-lab
cd ~/gke-ai-agent-lab
Mengonfigurasi Izin (Opsional)
Jika Anda menjalankan di project terbatas atau lingkungan bersama, pastikan akun Anda memiliki izin yang diperlukan untuk membuat cluster dan menjalankan build:
export MY_ACCOUNT=$(gcloud config get-value account)
# Grant Container Admin to create clusters and manage nodes if needed
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/container.admin"
# Grant Cloud Build Builder to run builds
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/cloudbuild.builds.builder"
Buat Cluster GKE
Cluster GKE Standard Anda harus menjalankan versi 1.34 atau yang lebih baru untuk mendukung DRA. Anda juga perlu mengaktifkan pengontrol Gateway API untuk mendukung penjadwalan inferensi cerdas.
Anda akan membuat jaringan dan subnet VPC baru untuk lab ini.
Pertama, buat jaringan VPC:
gcloud compute networks create ai-agent-network --subnet-mode=custom
Selanjutnya, buat subnet untuk node GKE Anda:
gcloud compute networks subnets create ai-agent-subnet \
--network=ai-agent-network \
--range=10.0.0.0/20 \
--region=us-central1
Gateway API (gke-l7-regional-internal-managed) juga memerlukan subnet khusus untuk menghosting proxy Envoy. Buat subnet khusus proxy ini di jaringan baru Anda:
gcloud compute networks subnets create proxy-only-subnet \
--purpose=REGIONAL_MANAGED_PROXY \
--role=ACTIVE \
--region=us-central1 \
--network=ai-agent-network \
--range=192.168.10.0/24
Sekarang, buat cluster menggunakan jaringan dan subnet baru:
gcloud beta container clusters create $CLUSTER_NAME \
--zone $ZONE \
--num-nodes 1 \
--machine-type n2-standard-4 \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--gateway-api=standard \
--managed-otel-scope=COLLECTION_AND_INSTRUMENTATION_COMPONENTS \
--network=ai-agent-network \
--subnetwork=ai-agent-subnet
Membuat Node Pool dengan Plugin Default yang Dinonaktifkan
Untuk menyerahkan pengelolaan perangkat ke DRA, Anda harus membuat node pool yang secara eksplisit menonaktifkan penginstalan driver GPU default dan plugin perangkat standar.
Jalankan perintah gcloud berikut untuk menyediakan node pool GPU (misalnya, menggunakan NVIDIA L4) dengan label DRA yang diperlukan:
gcloud container node-pools create $NODEPOOL_NAME \
--cluster=$CLUSTER_NAME \
--location=$ZONE \
--machine-type=g2-standard-24 \
--accelerator=type=nvidia-l4,count=2,gpu-driver-version=disabled \
--node-labels=gke-no-default-nvidia-gpu-device-plugin=true,nvidia.com/gpu.present=true \
--num-nodes 3
Menginstal Driver NVIDIA melalui DaemonSet
Instal driver perangkat NVIDIA dasar yang diperlukan secara manual ke node Anda menggunakan DaemonSet Google Cloud yang telah dikonfigurasi sebelumnya:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
Menginstal Driver DRA
Selanjutnya, instal driver DRA tertentu ke dalam cluster Anda. Untuk GPU NVIDIA, Anda dapat men-deploynya melalui Helm:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
helm install nvidia-dra-driver-gpu nvidia/nvidia-dra-driver-gpu \
--version="25.3.2" --create-namespace --namespace=nvidia-dra-driver-gpu \
--set nvidiaDriverRoot="/home/kubernetes/bin/nvidia/" \
--set gpuResourcesEnabledOverride=true \
--set resources.computeDomains.enabled=false \
--set kubeletPlugin.priorityClassName="" \
--set 'kubeletPlugin.tolerations[0].key=nvidia.com/gpu' \
--set 'kubeletPlugin.tolerations[0].operator=Exists' \
--set 'kubeletPlugin.tolerations[0].effect=NoSchedule'
Memahami DeviceClass
Anda tidak perlu menulis atau menerapkan YAML DeviceClass secara manual. Saat Anda menyiapkan infrastruktur GKE untuk DRA dan menginstal driver, driver DRA yang berjalan di node Anda akan otomatis membuat objek DeviceClass di cluster untuk Anda.
Konfigurasi ResourceClaimTemplate
Untuk mengizinkan Pod llm-d Anda meminta akselerator ini secara dinamis, Anda akan membuat ResourceClaimTemplate. Template ini menentukan konfigurasi perangkat yang diminta dan memberi tahu Kubernetes untuk membuat ResourceClaim per-Pod yang unik secara otomatis untuk workload Anda.
Jalankan perintah berikut untuk membuat claim-template.yaml:
cat > claim-template.yaml <<EOF
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: gpu-claim-template
spec:
spec:
devices:
requests:
- name: single-gpu
exactly:
deviceClassName: gpu.nvidia.com
allocationMode: ExactCount
count: 1
EOF
Terapkan template ke cluster Anda:
kubectl apply -f claim-template.yaml
4. Men-deploy Penjadwalan Inferensi Cerdas dengan llm-d dan DRA
Pada langkah ini, Anda akan men-deploy Model Bahasa Besar di belakang load balancer Envoy cerdas yang ditingkatkan dengan penjadwal inferensi. Konfigurasi ini mengoptimalkan penayangan model dengan menerapkan Perutean yang Mendukung Cache Awalan. GKE Inference Gateway mengenali konteks bersama di seluruh microservice dan secara cerdas merutekan permintaan ke replika model yang sama, sehingga memaksimalkan hit cache, mengurangi Waktu-hingga-Token-Pertama, dan mendorong performa per dolar yang lebih unggul.
Menyiapkan Lingkungan
Siapkan namespace target Anda.
export NAMESPACE=ai-agents
kubectl create namespace $NAMESPACE
Simpan token Hugging Face Anda dengan aman, yang diperlukan untuk menarik bobot model.
# Replace with your actual Hugging Face token
kubectl create secret generic llm-d-hf-token \
--from-literal=HF_TOKEN="your_hugging_face_token" \
-n $NAMESPACE
Membuat File Konfigurasi Helm
Konfigurasi untuk layanan model dan ekstensi gateway inferensi didasarkan pada panduan llm-d resmi.
Pertama, buat file ms-values.yaml untuk layanan model:
cat <<EOF > ms-values.yaml
multinode: false
modelArtifacts:
uri: "hf://Qwen/Qwen2.5-Coder-14B-Instruct"
name: "Qwen/Qwen2.5-Coder-14B-Instruct"
size: 50Gi # Slightly larger than the default to accommodate weights
authSecretName: "llm-d-hf-token"
labels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
llm-d.ai/accelerator-variant: "gpu"
llm-d.ai/accelerator-vendor: "nvidia"
llm-d.ai/model: "qwen-2-5-coder-14b"
routing:
proxy:
enabled: false # removes sidecar from deployment - no PD in inference scheduling
targetPort: 8000 # controls vLLM port to matchup with sidecar if deployed
accelerator:
dra: true
type: "nvidia"
resourceClaimTemplates:
nvidia:
class: "gpu.nvidia.com"
match: "exactly"
name: "gpu-claim-template"
decode:
create: true
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
parallelism:
tensor: 2
data: 1
replicas: 3
monitoring:
podmonitor:
enabled: true
portName: "vllm"
path: "/metrics"
interval: "30s"
containers:
- name: "vllm"
image: ghcr.io/llm-d/llm-d-cuda:v0.5.1
modelCommand: vllmServe
args:
- "--disable-uvicorn-access-log"
- "--gpu-memory-utilization=0.85"
- "--enable-auto-tool-choice"
- "--tool-call-parser"
- "hermes"
ports:
- containerPort: 8000
name: vllm
protocol: TCP
resources:
limits:
cpu: '16'
memory: 64Gi
requests:
cpu: '16'
memory: 64Gi
mountModelVolume: true
volumeMounts:
- name: metrics-volume
mountPath: /.config
- name: shm
mountPath: /dev/shm
- name: torch-compile-cache
mountPath: /.cache
startupProbe:
httpGet:
path: /v1/models
port: vllm
initialDelaySeconds: 15
periodSeconds: 30
timeoutSeconds: 5
failureThreshold: 120
livenessProbe:
httpGet:
path: /health
port: vllm
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /v1/models
port: vllm
periodSeconds: 5
timeoutSeconds: 2
failureThreshold: 3
volumes:
- name: metrics-volume
emptyDir: {}
- name: torch-compile-cache
emptyDir: {}
- name: shm
emptyDir:
medium: Memory
sizeLimit: 20Gi
prefill:
create: false
EOF
Selanjutnya, buat file gaie-values.yaml untuk Ekstensi GKE Inference Gateway:
cat <<EOF > gaie-values.yaml
inferenceExtension:
replicas: 1
image:
name: llm-d-inference-scheduler
hub: ghcr.io/llm-d
tag: v0.6.0
pullPolicy: Always
extProcPort: 9002
pluginsConfigFile: "default-plugins.yaml"
tracing:
enabled: false
monitoring:
interval: "10s"
prometheus:
enabled: true
auth:
secretName: inference-scheduling-gateway-sa-metrics-reader-secret
inferencePool:
targetPorts:
- number: 8000
modelServerType: vllm
modelServers:
matchLabels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
EOF
Memahami Konfigurasi
Konfigurasi ini menyiapkan stack inferensi berperforma tinggi dengan fitur utama berikut:
- Pemilihan Model: Model ini menggunakan model Qwen 2.5 Coder 14B (
modelArtifacts), yang dioptimalkan untuk pembuatan kode dan penggunaan alat. - Integrasi DRA: Bagian
acceleratormengaktifkan Alokasi Resource Dinamis (dra: true), yang menargetkan class perangkatgpu.nvidia.comdangpu-claim-templateyang dibuat sebelumnya. - Pengoptimalan Performa:
parallelism.tensor: 2mengonfigurasi paralelisme tensor di seluruh GPU.argsuntuk vLLM mencakup--enable-auto-tool-choiceuntuk memastikan agen pengodean kami dapat menggunakan alat secara efektif.- Permintaan
cpudanmemoryyang dikurangi sesuai dengan jenis mesing2-standard-24.
- Perutean Cerdas: Ekstensi Inference Gateway (
gaie-values.yaml) dikonfigurasi untuk memantau server modelvllmdan merutekan permintaan untuk memaksimalkan hit KV-cache.
Men-deploy Stack Penjadwalan Inferensi melalui Helm
Sekarang, tambahkan repositori Helm llm-d dan deploy infrastruktur, ekstensi gateway, dan layanan model secara terpisah.
Pertama, tambahkan repositori yang diperlukan:
helm repo add llm-d-infra https://llm-d-incubation.github.io/llm-d-infra/
helm repo add llm-d-modelservice https://llm-d-incubation.github.io/llm-d-modelservice/
helm repo update
Men-deploy Prasyarat Infrastruktur
Diagram ini menginstal konfigurasi Gateway dasar yang diperlukan untuk stack.
helm install infra-is llm-d-infra/llm-d-infra \
--namespace $NAMESPACE \
--set gateway.gatewayClassName=gke-l7-rilb \
--set gateway.gatewayParameters.enabled=false \
--set gateway.gatewayParameters.istio.accessLogging=false
Men-deploy Ekstensi GKE Inference Gateway
Langkah ini men-deploy InferencePool dan Endpoint Picker, yang memantau cache KV model Anda untuk membuat keputusan perutean yang cerdas.
helm install gaie-is oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool \
--version v1.3.1 \
--namespace $NAMESPACE \
-f gaie-values.yaml \
--set provider.name=gke \
--set inferenceExtension.monitoring.prometheus.enabled=true
Men-deploy Layanan Model
Terakhir, deploy layanan LLM Anda, yang kini akan menggunakan DRA untuk mengklaim GPU L4 Anda dengan aman.
helm install ms-is llm-d-modelservice/llm-d-modelservice \
--version v0.4.7 \
--namespace $NAMESPACE \
-f ms-values.yaml \
--set decode.monitoring.podmonitor.enabled=false
Mengaktifkan Google Cloud Observability untuk vLLM
Helm chart generik sering kali mencoba men-deploy resource PodMonitor Prometheus Operator standar (monitoring.coreos.com/v1), yang dapat menyebabkan error jika Anda tidak menginstal CRD tersebut.
Daripada mengaktifkan/menonaktifkan tombol pemantauan bawaan Helm, biarkan tombol tersebut false dan terapkan resource PodMonitoring Google Cloud Managed Prometheus (GMP) secara manual menggunakan grup API monitoring.googleapis.com/v1 yang kompatibel.
Jalankan perintah berikut untuk membuat podmonitoring.yaml:
cat > podmonitoring.yaml <<EOF
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: ms-vllm-metrics
spec:
selector:
matchLabels:
llm-d.ai/model: "qwen-2-5-coder-14b" # Matches the label in values.yaml
endpoints:
- port: 8000 # vllm port
interval: 30s
path: /metrics
EOF
Terapkan resource PodMonitoring ke cluster Anda:
kubectl apply -f podmonitoring.yaml -n $NAMESPACE
Memverifikasi Penginstalan
Pastikan komponen telah berhasil diinstal. Anda akan melihat ketiga rilis Helm aktif di namespace Anda dan pod yang sesuai sedang diinisialisasi.
helm ls -n $NAMESPACE
kubectl get pods -n $NAMESPACE
Pod ms-is dapat memerlukan waktu sekitar 5-10 menit untuk muncul. Jika sudah, output akan terlihat seperti:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
gaie-is ai-agents 1 2026-03-28 16:51:41.055881618 +0000 UTC deployed inferencepool-v1.3.1 v1.3.1
infra-is ai-agents 1 2026-03-28 16:51:03.71042542 +0000 UTC deployed llm-d-infra-v1.4.0 v0.4.0
ms-is ai-agents 1 2026-03-28 17:30:00.341918958 +0000 UTC deployed llm-d-modelservice-v0.4.7 v0.4.0
NAME READY STATUS RESTARTS AGE
gaie-is-epp-848965cb4-78ktp 1/1 Running 0 10m
ms-is-llm-d-modelservice-decode-67548d5f8c-f25f4 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-rblvs 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-w6fcd 1/1 Running 0 6m2s
5. Mengonfigurasi Intelligent Routing dengan GKE Inference Gateway
Pada Langkah 4, men-deploy diagram Helm llm-d akan otomatis menyediakan objek Gateway dan InferencePool Anda. InferencePool mengelompokkan Pod penyajian model vllm yang memiliki model dasar dan konfigurasi komputasi yang sama.
Sekarang, Anda perlu mengonfigurasi InferenceObjective untuk menetapkan prioritas permintaan agen coding dan HTTPRoute untuk menginstruksikan Gateway tentang cara merutekan traffic masuk, dengan memanfaatkan Pemilih Endpoint untuk memaksimalkan hit cache KV.
Memverifikasi Resource yang Dibuat Otomatis
Pertama, pastikan bahwa diagram Helm llm-d berhasil membuat resource Gateway dan InferencePool.
kubectl get gateway,inferencepool -n $NAMESPACE
Anda akan melihat Gateway bernama infra-is-inference-gateway dan InferencePool bernama gaie-is. Mirip dengan ini:
NAME CLASS ADDRESS PROGRAMMED AGE
gateway.gateway.networking.k8s.io/infra-is-inference-gateway gke-l7-regional-internal-managed 10.128.0.5 True 13m
NAME AGE
inferencepool.inference.networking.k8s.io/gaie-is 12m
Membuat HTTPRoute
Resource HTTPRoute memetakan Gateway Anda ke backend InferencePool. Hal ini memberi tahu GKE Inference Gateway untuk menganalisis isi permintaan yang masuk dan merutekannya secara dinamis untuk memaksimalkan hit Prefix-Cache berdasarkan konteks bersama.
Jalankan perintah berikut untuk membuat httproute.yaml:
cat > httproute.yaml <<EOF
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: agent-route
spec:
parentRefs:
- group: gateway.networking.k8s.io
kind: Gateway
name: infra-is-inference-gateway
rules:
- backendRefs:
- group: inference.networking.k8s.io
kind: InferencePool
name: gaie-is
weight: 1
matches:
- path:
type: PathPrefix
value: /
EOF
Terapkan rute ke cluster Anda:
kubectl apply -f httproute.yaml -n $NAMESPACE
6. Eksekusi Kode yang Aman dengan Sandbox Agen
Setelah backend inferensi berperforma tinggi kita berjalan, mari siapkan lingkungan yang aman tempat kode buatan AI akan dieksekusi dengan aman dan terisolasi dari cluster kita menggunakan Sandbox Agen.
Men-deploy Pengontrol Sandbox Agen
Saat agen AI membuat dan mengeksekusi kode, pada dasarnya agen tersebut menjalankan workload yang tidak tepercaya di infrastruktur Anda. Jika agen membuat kode berbahaya, agen tersebut dapat mencoba memindai jaringan internal Anda atau mengeksploitasi node host yang mendasarinya.
GKE Agent Sandbox menggunakan gVisor, runtime container open source yang menyediakan kernel tamu khusus untuk setiap container. Tindakan ini mencegah kode yang tidak tepercaya melakukan panggilan sistem langsung ke node host.
Deploy pengontrol Agent Sandbox dan komponen yang diperlukan dengan menerapkan manifes rilis resmi:
kubectl apply \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/manifest.yaml \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/extensions.yaml
Mengonfigurasi Template Sandbox dan Warm Pool
Selanjutnya, kita membuat SandboxTemplate yang berfungsi sebagai cetak biru yang dapat digunakan kembali untuk lingkungan analisis Python, yang secara eksplisit menargetkan class runtime gvisor. Untuk menyederhanakan deployment tanpa mengelola node pool manual di cluster Standard, kita dapat memanfaatkan autopilot standar
ComputeClass untuk menyediakan node komputasi terkelola secara dinamis yang secara native mendukung workload gVisor sesuai permintaan.
Karena menginisialisasi kernel yang aman dapat menambah latensi, kami juga men-deploy SandboxWarmPool. Hal ini memastikan sejumlah sandbox yang telah diinisialisasi sebelumnya tetap siap sehingga Agen Pembuatan Kode dapat mengklaimnya dan mulai mengeksekusi kode dalam waktu kurang dari satu detik.
Pertama, buat namespace baru untuk runtime sandbox agen:
kubectl create namespace agent-sandbox
Simpan yang berikut sebagai sandbox-template-and-pool.yaml:
cat > sandbox-template-and-pool.yaml <<EOF
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxTemplate
metadata:
name: python-runtime-template
namespace: agent-sandbox
spec:
podTemplate:
metadata:
labels:
sandbox: python-sandbox-example
spec:
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: python-runtime
image: registry.k8s.io/agent-sandbox/python-runtime-sandbox:v0.1.0
ports:
- containerPort: 8888
readinessProbe:
httpGet:
path: "/"
port: 8888
initialDelaySeconds: 0
periodSeconds: 1
resources:
requests:
cpu: "250m"
memory: "512Mi"
ephemeral-storage: "512Mi"
restartPolicy: "OnFailure"
---
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxWarmPool
metadata:
name: python-sandbox-warmpool
namespace: agent-sandbox
spec:
replicas: 2
sandboxTemplateRef:
name: python-runtime-template
EOF
Terapkan konfigurasi:
kubectl apply -f sandbox-template-and-pool.yaml
Tunggu hingga 2-3 menit agar pod warmpool diinisialisasi. Anda dapat memeriksa apakah transisi dari Pending (saat komputasi yang mendasarinya di-scale up) ke Running berhasil menggunakan:
kubectl get pods -n agent-sandbox -w
Setelah Anda melihat dua pod python-sandbox-warmpool-*** yang tercantum sebagai Running dan 1/1 Siap, lingkungan eksekusi yang aman telah dipanaskan dan siap diklaim.
Men-deploy Sandbox Router
Agen Pembuatan Kode kami mengandalkan Sandbox Router untuk mengirimkan perintah eksekusi secara aman ke pod yang terisolasi.
Jalankan perintah berikut untuk membuat sandbox-router.yaml:
cat > sandbox-router.yaml <<EOF
apiVersion: v1
kind: Service
metadata:
name: sandbox-router-svc
namespace: agent-sandbox
spec:
type: ClusterIP
selector:
app: sandbox-router
ports:
- name: http
protocol: TCP
port: 8080
targetPort: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sandbox-router-deployment
namespace: agent-sandbox
spec:
replicas: 2
selector:
matchLabels:
app: sandbox-router
template:
metadata:
labels:
app: sandbox-router
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: sandbox-router
containers:
- name: router
image: us-central1-docker.pkg.dev/k8s-staging-images/agent-sandbox/sandbox-router:v20260225-v0.1.1.post3-10-ga5bcb57
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 10
resources:
requests:
cpu: "250m"
memory: "512Mi"
limits:
cpu: "1000m"
memory: "1Gi"
securityContext:
runAsUser: 1000
runAsGroup: 1000
EOF
Terapkan konfigurasi:
kubectl apply -f sandbox-router.yaml
Menerapkan Isolasi Jaringan
Untuk lebih mengamankan lingkungan eksekusi dan mencegah penyebaran infeksi tanpa izin, terapkan Kebijakan Jaringan. Hal ini "mengisolasi" sandbox sehingga tidak dapat menjangkau Server Metadata Google Cloud atau jaringan internal sensitif lainnya.
Simpan yang berikut sebagai sandbox-policy.yaml:
cat > sandbox-policy.yaml <<EOF
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: restrict-sandbox-egress
namespace: agent-sandbox
spec:
podSelector:
matchLabels:
sandbox: python-sandbox-example
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 0.0.0.0/0
except:
- 169.254.169.254/32 # Block metadata server
EOF
Terapkan kebijakan:
kubectl apply -f sandbox-policy.yaml
Verifikasi Komponen
Untuk memastikan lapisan cluster sandbox kode terisolasi Anda telah dikonfigurasi sepenuhnya, jalankan perintah validasi status berikut:
Pertama, pastikan pod dan router sandbox Berjalan dan Siap
kubectl get pods -n agent-sandbox
Outputnya akan terlihat seperti ini:
NAME READY STATUS RESTARTS AGE
python-sandbox-warmpool-7zlkv 1/1 Running 0 3m25s
python-sandbox-warmpool-cxln2 1/1 Running 0 3m25s
sandbox-router-deployment-668dfbbbb6-g9mpd 1/1 Running 0 42s
sandbox-router-deployment-668dfbbbb6-ppllz 1/1 Running 0 42s
Memverifikasi Load balancer Router Sandbox / eksposur IP
kubectl get service sandbox-router-svc -n agent-sandbox
Output akan terlihat seperti:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
sandbox-router-svc ClusterIP 34.118.237.244 <none> 8080/TCP 114s
Memastikan aturan kebijakan jaringan keluar ada
kubectl get networkpolicy restrict-sandbox-egress -n agent-sandbox
Output akan terlihat seperti:
NAME POD-SELECTOR AGE
restrict-sandbox-egress sandbox=python-sandbox-example 113s
Pastikan:
- Pod
python-sandbox-warmpool-***sudahRunningdan1/1Siap. - Replika
sandbox-router-deployment-***sudahRunningdan1/1Siap. sandbox-router-svcdapat diakses, dan kebijakanrestrict-sandbox-egressberhasil melindungi semua label sandbox yang cocok.
Dengan lingkungan eksekusi yang aman dan diinisialisasi, kita siap men-deploy otak sebenarnya dari operasi kita: Agen Pembuatan Kode.
7. Membangun dan Men-deploy Agen Pembuatan Kode (ADK)
Dengan sandbox eksekusi yang aman dan backend LLM berperforma tinggi yang telah dikonfigurasi, kita kini dapat membangun "otak" sistem: Agen Pembuatan Kode menggunakan Agent Development Kit (ADK).
Agen ini dirancang untuk bertindak sebagai developer Python ahli. Tidak seperti chatbot standar yang hanya menghasilkan teks, agen ini dilengkapi dengan alat eksekusi kode yang memungkinkannya menyelesaikan masalah secara interaktif. Ini mengikuti loop:
- Menulis kode Python berdasarkan permintaan Anda.
- Menjalankan kode secara aman di dalam GKE Agent Sandbox yang kita siapkan di Langkah 6.
- Memverifikasi output atau membaca error yang muncul selama eksekusi.
- Menyampaikan solusi yang teruji dan berfungsi dengan baik secara percaya diri.
Dengan memberi agen akses ke lingkungan eksekusi sandbox yang aman, kami memungkinkannya memverifikasi logikanya sendiri dan melakukan debug kegagalan secara otomatis, sehingga agen tersebut jauh lebih mampu melakukan tugas pengembangan software.
Mengembangkan Agen Penalaran ADK
Pertama, kita menulis logika Python yang menentukan perilaku agen dan melengkapinya dengan alat Sandbox yang kita buat di Langkah 6. Di bagian ini, kita juga mengonfigurasi strategi model hybrid: agen akan memprioritaskan model Qwen yang dihosting sendiri dan berjalan di cluster GKE Anda, tetapi akan otomatis beralih ke Gemini 2.5 Flash di Vertex AI jika model lokal lambat atau tidak tersedia, sehingga memastikan keandalan yang tinggi.
Buat direktori baru untuk kode agen:
mkdir -p ~/gke-ai-agent-lab/root_agent
cd ~/gke-ai-agent-lab
Buat file bernama root_agent/agent.py dengan konten berikut:
cat <<'EOF' > root_agent/agent.py
import os
from google.adk.agents import Agent
from google.adk.models.lite_llm import LiteLlm
from k8s_agent_sandbox import SandboxClient
import requests
# Instantiate the client globally to track sandboxes
sandbox_client = SandboxClient()
def run_python_code(code: str) -> str:
"""
Executes Python code safely in the GKE Agent Sandbox.
Use this tool whenever you need to execute code to solve a problem.
"""
sandbox = sandbox_client.create_sandbox(template="python-runtime-template", namespace="agent-sandbox")
try:
command = f"python3 -c \"{code}\""
result = sandbox.commands.run(command)
if result.stderr:
return f"Error: {result.stderr}"
return result.stdout
finally:
# Ensure the sandbox is deleted after use to avoid leaking resources
sandbox_client.delete_sandbox(sandbox.claim_name, namespace="agent-sandbox")
# Define the ADK Agent with a fallback mechanism.
# It prioritizes the Qwen 2.5 Coder model running on our Inference Gateway.
# If the local model is unavailable, it falls back to Gemini 2.5 Flash on Vertex AI.
root_agent = Agent(
name="CodeGenerationAgent",
model=LiteLlm(
model="openai/Qwen/Qwen2.5-Coder-14B-Instruct",
fallbacks=["vertex_ai/gemini-2.5-flash"],
timeout=10
),
instruction="""
You are an expert Python developer.
1. Write Python code to solve the user's problem.
2. Execute the code using the `run_python_code` tool to verify it works.
3. Return the exact output and a brief explanation of the code.
""",
tools=[run_python_code]
)
EOF
Buat file __init__.py agar ADK mengenali modul:
echo "from . import agent" > ~/gke-ai-agent-lab/root_agent/__init__.py
Tetapkan variabel lingkungan. Aplikasi ADK memerlukan alamat IP Gateway Anda untuk merutekan permintaan LLM dengan berhasil. Karena ADK mendukung endpoint yang kompatibel dengan Open-AI standar (yang disediakan vLLM melalui Gateway kami), kita dapat mengganti URL dasar API default.
export GATEWAY_IP=$(kubectl get gateway infra-is-inference-gateway -n $NAMESPACE -o jsonpath='{.status.addresses[0].value}')
cat <<EOF > ~/gke-ai-agent-lab/root_agent/.env
OPENAI_API_BASE=http://${GATEWAY_IP}/v1
OPENAI_API_KEY=no-key-required
# Vertex AI settings for fallback (Authentication is handled by Workload Identity)
VERTEXAI_PROJECT=$PROJECT_ID
VERTEXAI_LOCATION=${ZONE%-[a-z]}
EOF
Memasukkan Aplikasi Agen ke dalam Container
Kita perlu memaketkan agen agar dapat berjalan dengan aman di dalam GKE.
Buat Dockerfile di ~/gke-ai-agent-lab yang menginstal kubectl, library ADK, dan klien Agent Sandbox:
cat <<'EOF' > ~/gke-ai-agent-lab/Dockerfile
FROM python:3.11-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
RUN apt-get update && apt-get install -y git curl \
&& curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl" \
&& install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl \
&& rm kubectl && apt-get clean && rm -rf /var/lib/apt/lists/*
RUN pip install --no-cache-dir "google-adk[extensions,otel-gcp]>=1.27.4" litellm pandas "git+https://github.com/kubernetes-sigs/agent-sandbox.git@main#subdirectory=clients/python/agentic-sandbox-client" \
"opentelemetry-instrumentation-google-genai>=0.4b0" \
"opentelemetry-exporter-otlp" \
"opentelemetry-instrumentation-vertexai>=2.0b0"
COPY ./root_agent /app/root_agent
EXPOSE 8080
ENTRYPOINT ["adk", "web", "--host", "0.0.0.0", "--port", "8080", "--otel_to_cloud"]
EOF
Buat repositori Artifact Registry untuk menyimpan image container.
gcloud artifacts repositories create agent-repo \
--repository-format=docker \
--location=us-central1
Gunakan Cloud Build untuk membangun dan mengirim image container.
gcloud builds submit --tag us-central1-docker.pkg.dev/$PROJECT_ID/agent-repo/code-agent:v1 ~/gke-ai-agent-lab/
Men-deploy ke GKE dengan RBAC
Terakhir, deploy agen ke cluster Anda. Deployment mencakup Role dan RoleBinding yang memberikan izin kepada agen untuk mengklaim instance dari SandboxWarmPool.
Deployment ini akan menggunakan ServiceAccount Kubernetes untuk memungkinkan agen Anda berinteraksi dengan API klaim Sandbox. Tidak memerlukan ServiceAccount IAM Google karena mengakses resource cluster lokal dan endpoint gateway vLLM lokal.
Mengapa Deployment standar di gVisor?
Pada Langkah 6, kita menggunakan API SandboxTemplate dan SandboxClaim untuk membuat sandbox sementara yang dapat dibuang untuk kode python yang dihasilkan (eksekusi Alat).
Untuk UI Web Agen (Otak) itu sendiri, kami menggunakan spesifikasi Deployment Kubernetes standar dengan runtimeClassName: gvisor.
- Perbedaan:
SandboxClaimsstandar bersifat sementara dan nol-ke-satu (ideal untuk skrip yang tidak tepercaya).Deploymentstandar berjalan dalam waktu lama dan persisten—cocok untuk UI web yang memerlukanServiceKubernetes dan Load Balancer yang stabil. Dengan menggunakanruntimeClassName: gvisorsecara langsung pada Deployment standar, Anda akan mendapatkan isolasi kernel gVisor sambil mempertahankan fiturDeploymentstandar.
Simpan yang berikut sebagai deployment.yaml:
cat <<EOF > ~/gke-ai-agent-lab/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: code-agent
labels:
app: code-agent
spec:
replicas: 1
selector:
matchLabels:
app: code-agent
template:
metadata:
labels:
app: code-agent
spec:
serviceAccount: adk-agent-sa
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: code-agent
image: us-central1-docker.pkg.dev/YOUR_PROJECT_ID/agent-repo/code-agent:v1
imagePullPolicy: Always
env:
- name: OPENAI_API_KEY
value: "no-key-required"
- name: OPENAI_API_BASE
value: "http://YOUR_GATEWAY_IP/v1"
- name: VERTEXAI_PROJECT
value: "YOUR_PROJECT_ID"
- name: VERTEXAI_LOCATION
value: "YOUR_REGION"
- name: OTEL_SERVICE_NAME
value: "code-agent"
- name: GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY
value: "true"
- name: OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT
value: "true"
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: code-agent-service
spec:
selector:
app: code-agent
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: agent-sandbox
name: sandbox-creator-role
rules:
- apiGroups: [""]
resources: ["services", "pods", "pods/portforward"]
verbs: ["get", "list", "watch", "create"]
- apiGroups: ["extensions.agents.x-k8s.io"]
resources: ["sandboxclaims"]
verbs: ["create", "get", "list", "watch", "delete"]
- apiGroups: ["agents.x-k8s.io"]
resources: ["sandboxes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: adk-agent-binding
namespace: agent-sandbox
subjects:
- kind: ServiceAccount
name: adk-agent-sa
namespace: default
roleRef:
kind: Role
name: sandbox-creator-role
apiGroup: rbac.authorization.k8s.io
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: adk-agent-sa
EOF
Memberikan Izin IAM untuk Kemampuan Observasi
Agar agen dapat mengirim data telemetri (log dan rekaman aktivitas) ke Google Cloud, Anda harus memberikan izin yang diperlukan ke Akun Layanan Kubernetes adk-agent-sa menggunakan Workload Identity.
Jalankan perintah berikut di Cloud Shell:
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# Grant permission to write logs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/logging.logWriter \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to write traces
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/cloudtrace.agent \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to use Vertex AI
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/aiplatform.user \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
Jalankan perintah berikut untuk mengganti YOUR_PROJECT_ID secara otomatis dengan project ID Anda yang sebenarnya dan terapkan konfigurasi.
sed -i "s/YOUR_PROJECT_ID/$PROJECT_ID/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_GATEWAY_IP/$GATEWAY_IP/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_REGION/$ZONE/g" ~/gke-ai-agent-lab/deployment.yaml
kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml
8. Mengamati dan Memvalidasi
Sekarang saatnya menguji sistem yang terintegrasi sepenuhnya.
Menguji Agen Pembuatan Kode di UI
Temukan IP Eksternal UI Web ADK Anda:
kubectl get services code-agent-service
Outputnya akan terlihat seperti ini:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
code-agent-service LoadBalancer 34.118.230.182 34.31.250.60 80:32471/TCP 2m14s
- Buka browser, lalu buka
http://[EXTERNAL-IP]. - Di antarmuka web ADK, pastikan "root_agent" dipilih dari menu drop-down di kanan atas. Kemudian, berikan perintah kepada agen:
Write a python script that prints 'Hello from the isolated sandbox'.
Untuk mengamati cara agen menggunakan backend inferensi dan sandbox, lanjutkan ke bagian Menjelajahi Statistik Model melalui Cloud Observability dan Menjelajahi Observabilitas Agen melalui UI GKE di bawah untuk melihat dasbor.
Menjelajahi Kemampuan Observasi Agen melalui UI GKE
Setelah Anda menjalankan beberapa perintah, mari kita lihat data telemetri. Hal ini membantu Anda memahami performa Penjadwal Inferensi dan vLLM.
Mengakses Dasbor Agen
- Buka halaman Kubernetes Engine > Workloads.
- Klik deployment code-agent untuk membuka halaman Deployment Details.
- Klik tab Observability.
- Di panel navigasi kiri dasbor observabilitas, Anda akan melihat bagian Agent baru dengan sub-tab.
Yang Dapat Dieksplorasi
Jelajahi subtab berikut untuk melihat perilaku aplikasi agen Anda:
- Ringkasan: Lihat kartu skor untuk sesi, rata-rata giliran, dan pemanggilan.
- Model: Lihat jumlah panggilan model, tingkat error, dan latensi yang dikategorikan menurut model yang digunakan agen Anda.
- Alat: Pantau panggilan alat dan durasi eksekusi untuk melihat seberapa efektif agen Anda menggunakan alat eksekusi sandbox-nya.
- Penggunaan: Lacak penggunaan token dan alokasi resource container standar (CPU dan Memori).
- Tracing agen: Beralihlah ke tab ini untuk melihat daftar sesi eksekusi atau rentang rekaman aktivitas mentah. Mengklik baris akan membuka flyout dengan detail rekaman aktivitas yang dipilih.
Dengan menggabungkan metrik tingkat model dari vLLM dengan telemetri tingkat aplikasi dari ADK, Anda kini memiliki kemampuan observasi full-stack untuk agen AI generatif di GKE.
Mempelajari Statistik Model vLLM melalui Cloud Observability
Setelah Anda menjalankan beberapa perintah, mari kita lihat data telemetri. Hal ini membantu Anda memahami performa Penjadwal Inferensi dan vLLM.
Mengakses Dasbor
- Buka Konsol Google Cloud.
- Buka Monitoring > Dashboards.
- Telusuri dan pilih dasbor vLLM Prometheus Overview.
Metrik Menarik untuk Diamati
Saat melihat dasbor, perhatikan metrik utama berikut untuk melihat dampak GKE Inference Gateway dan prefix-caching:
- Penggunaan Cache KV (
vllm:gpu_cache_usage):- Mengapa penting: Ini menunjukkan seberapa banyak memori GPU yang digunakan untuk meng-cache konteks. Jika nilainya tinggi, berarti sistem menyimpan konteks untuk mempercepat permintaan mendatang. Jika Anda menjalankan perintah yang sama beberapa kali, Anda akan melihat penggunaan ini meningkat lalu stabil.
- Permintaan yang Sedang Berjalan vs. Permintaan yang Menunggu (
vllm:num_requests_runningvsvllm:num_requests_waiting):- Mengapa hal ini penting: Hal ini menunjukkan beban. Jika permintaan yang menunggu tinggi, berarti node Anda kelebihan beban.
- Throughput Token (
vllm:request_prompt_tokens_totdanvllm:request_generation_tokens_tot):- Mengapa hal ini penting: Lacak volume token input dan output yang diproses oleh cluster.
- Time To First Token (TTFT):
- Mengapa ini penting: Ini adalah metrik penting untuk agen interaktif. Dengan menggunakan GKE Inference Gateway dengan Perutean yang Mendukung Cache Awalan, permintaan yang berbagi konteks umum (seperti perintah sistem atau jendela konteks besar) akan dirutekan ke replika yang sama, sehingga meminimalkan TTFT dengan menggunakan kembali hit cache yang ada.
Eksperimen yang Dapat Dicoba
Coba skenario ini untuk melihat perubahan metrik secara real-time dan memvalidasi penjadwalan yang tepat.
Eksperimen 1: "Kecepatan Pengulangan" (Hit Cache Awalan)
- Kirim perintah yang kompleks ke agen (misalnya, "Tulis skrip python untuk mengurai file CSV 100 MB dan menghitung statistik.").
- Setelah merespons, segera kirim prompt yang sama persis lagi.
- Amati Rasio Hit Cache Awalan dan Waktu hingga Token Pertama (TTFT).
- Yang akan Anda lihat: Rasio Hit Cache Awalan akan naik menjadi 100% dan TTFT akan turun secara drastis.
- Artinya: GKE Inference Gateway mengenali konteks bersama dan merutekannya ke replika yang sama persis yang menggunakan kembali cache konteks yang dievaluasi.
Eksperimen 2: Kembali ke Cloud (Keandalan Model)
- Untuk menyimulasikan kegagalan model Qwen lokal, Anda dapat menghentikan layanan inferensi atau cukup memberikan
OPENAI_API_BASEpalsu dalam deployment. - Perbarui
OPENAI_API_BASEdideployment.yamlAnda ke IP atau port yang tidak ada dan terapkan perubahan:sed -i "s|value: \"http://$GATEWAY_IP/v1\"|value: \"http://10.0.0.1:8080/v1\"|g" ~/gke-ai-agent-lab/deployment.yaml kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml - Tunggu hingga pod dimulai ulang, lalu kirim perintah ke agen di UI.
- Yang akan Anda lihat: Agen masih merespons dengan berhasil.
- Artinya: Karena konfigurasi
fallbacks, ADK mengenali kegagalan endpoint Qwen lokal dan mengarahkan permintaan secara lancar ke Gemini 2.5 Flash di Vertex AI. Perhatikan bahwa karena panggilan penggantian ini ke Vertex AI melewati vLLM Inference Gateway lokal Anda, panggilan tersebut tidak akan muncul di dasbor Agent Observability > Models, yang hanya melacak traffic yang melalui vLLM.
Memahami Keunggulan Alokasi Resource Dinamis (DRA)
Meskipun vLLM dan Inference Gateway mengoptimalkan cara permintaan dirutekan dan ditayangkan, Alokasi Resource Dinamis (DRA)-lah yang memungkinkan hardware yang tepat dipasang ke workload Anda sejak awal.
DRA meningkatkan kemampuan Anda untuk mengelola hardware secara terperinci di seluruh cluster dengan memungkinkan Anda menentukan resource hardware yang fleksibel menggunakan ResourceClaimTemplate dan DeviceClasses.
Alasan DRA adalah Terobosan Baru untuk Workload AI:
- Permintaan Hardware Terperinci: Dengan DRA, Anda tidak hanya memastikan workload dijadwalkan di mesin dengan akselerator yang tepat, Anda juga dapat mengklaim resource tersebut untuk memastikan resource tersebut digunakan secara eksklusif oleh workload yang terkait dengan ResourceClaim.
- Siklus Proses yang Tidak Terikat: Klaim perangkat dikelola secara independen dari siklus proses Pod. Jika Pod mengalami error, klaim GPU dapat tetap ada, sehingga deployment menyeluruh atau objek workload lainnya dapat dimulai ulang tanpa harus menunggu GPU dilepaskan dan diperoleh kembali.
- Standardisasi Multi-Vendor: DRA menyediakan API Kubernetes terpadu untuk GPU NVIDIA dan TPU Google. Anda menggunakan skema yang sama persis saat men-deploy untuk salah satu atau keduanya, sehingga manifes YAML workload Anda sangat portabel.
Dalam codelab ini, Anda melihat cara kerjanya saat mengonfigurasi nilai Helm untuk terikat ke gpu-claim-template dengan lancar, tanpa konfigurasi plugin perangkat yang tertunda menghalangi peluncuran Anda.
Memahami Peran llm-d
Saat vLLM mengevaluasi bobot neural dan GKE Gateway merutekan kueri, llm-d bertindak sebagai lapisan konfigurasi dan "Perekat" yang mengikat semuanya.
Tanpa llm-d, Anda harus menulis manifes Kubernetes mentah untuk mendeklarasikan deployment vLLM, port layanan, pemasangan volume, dan klaim resource DRA dari awal.
Mengapa Menggunakan llm-d dalam Deployment Anda?
- Konfigurasi Terpadu (Penggantian satu baris): Diagram Helm
llm-dmenggabungkan resource Kubernetes level rendah yang kompleks ke dalam tombol tingkat tinggi yang bersih (seperti menyetelaccelerator.dra: true). - "Jalur yang Terang" yang Sudah Diperiksa Awalnya: Repositori
llm-dberisi konfigurasi yang sudah diukur dan diuji oleh pakar. Saat men-deployllm-d-modelservice, Anda akan menerima default yang dioptimalkan untuk pemanfaatan memori GPU, pengaturan waktu probe yang direkomendasikan (keaktifan/kesiapan), dan eksposur yang benar untuk scraping metrik. - Pemetaan Observabilitas yang Lancar: Secara langsung,
llm-dmemastikan port container standar dan jalur pengambilan data (/metrics) diekspos dengan benar, sehingga memudahkan penyiapan deployment Anda ke Google Cloud Monitoring tanpa proses debug manual.
Singkatnya, llm-d menyediakan cetak biru arsitektur yang dapat digunakan kembali sehingga developer tidak perlu membuat semuanya dari nol setiap kali mereka men-deploy stack inferensi di GKE.
Mempelajari Lebih Dalam: GKE Inference Gateway
Load balancer Lapis 7 standar beroperasi dengan melihat header HTTP seperti jalur (/v1/completions) atau cookie. GKE Inference Gateway memiliki fungsi yang jauh lebih mendalam—dirancang khusus untuk traffic AI generatif.
Cara Mendorong Performa dan Efisiensi:
- Perutean yang Mendukung Konten (Hashing Perintah): GKE Inference Gateway mencegat isi permintaan JSON. Sistem ini menghitung hash perintah dan melacak replika backend mana yang sudah menyimpan token tersebut dalam memori GPU-nya (Cache KV).
- Memaksimalkan Hit Cache: Dalam pengujian Anda, saat Anda mengulangi perintah, Gateway mengirimkannya ke replika yang sama persis. Mengevaluasi perintah memerlukan komputasi yang berat. Dengan menggunakan kembali cache, Anda menghindari "membaca ulang" perintah, sehingga menghemat uang dan waktu GPU.
- Memangkas Waktu hingga Token Pertama (TTFT): TTFT adalah metrik kegunaan penting untuk agen yang berinteraksi dengan manusia. Dengan mengakses cache, model dapat mulai membuat token dalam milidetik, bukan detik.
- Distribusi Beban yang Cerdas: Jika VRAM salah satu replika penuh dengan hit cache, Gateway dapat secara dinamis merutekan perintah baru ke replika lain yang memiliki ruang, sehingga menyeimbangkan efisiensi dengan ketersediaan.
Cara Agent Sandbox Mengurangi Risiko
Di lab ini, kami mendemonstrasikan cara Sandbox Agen melindungi infrastruktur Anda dari risiko yang terkait dengan agen AI dengan menyediakan dua lapisan isolasi:
- Mengisolasi Alat Eksekusi: Agen mengeksekusi kode yang dibuatnya di sandbox sementara. Hal ini memastikan bahwa kode tidak tepercaya yang dihasilkan oleh LLM berjalan di lingkungan yang aman dan terisolasi, sehingga melindungi agen dan cluster.
- Startup Cepat: Dengan menggunakan WarmPool, sandbox baru dimulai dalam waktu kurang dari satu detik, siap untuk mengeksekusi kode.
- Mengisolasi Agen itu sendiri: Kami juga menjalankan aplikasi agen itu sendiri di node yang kompatibel dengan gVisor (melalui
runtimeClassName: gvisor) untuk memberikan pertahanan mendalam terhadap kerentanan supply chain dalam dependensi agen.
Berikut alasan hal ini menciptakan batas keamanan yang sangat kuat:
- Penyadapan Panggilan Sistem: gVisor menyadap panggilan sistem sebelum mencapai kernel Linux host. Hal ini memblokir eksploitasi yang mencoba keluar dari container untuk mengakses node host.
- Perpindahan Lateral yang Dibatasi: Jika dikombinasikan dengan Kebijakan Jaringan, meskipun lingkungan terganggu, lingkungan tersebut tidak dapat memindai server Metadata internal Anda atau melakukan pivot ke layanan sensitif lainnya di cluster Anda.
Menjalankan Agen Lengkap di Sandbox
Di lab ini, kita menggunakan sandbox sebagai alat untuk aplikasi agen persisten. Namun, untuk keamanan maksimum—terutama saat menangani data sensitif atau melayani beberapa pengguna yang tidak tepercaya—Anda dapat menjalankan seluruh aplikasi agen di dalam sandbox khusus untuk setiap sesi atau pengguna. Hal ini memastikan isolasi lengkap memori, status, dan lingkungan eksekusi agen, yang akan dihancurkan segera setelah sesi selesai.
9. Pembersihan
Agar tidak menimbulkan biaya pada akun Google Cloud Anda untuk resource yang digunakan dalam codelab ini, ikuti langkah-langkah berikut untuk menghapusnya.
Menghapus Resource Individual
- Hapus Cluster GKE:
gcloud container clusters delete $CLUSTER_NAME --zone $ZONE --quiet
- Hapus repositori Artifact Registry:
gcloud artifacts repositories delete agent-repo --location=us-central1 --quiet
- Hapus Jaringan VPC:
gcloud compute networks delete ai-agent-network --quiet
Menghapus Project
Jika tidak memerlukan project lagi, Anda dapat menghapusnya setelah menghapus resource:
gcloud projects delete $PROJECT_ID
10. Ringkasan
Selamat! Anda telah berhasil membangun dan men-deploy agen pembuatan kode berperforma tinggi yang aman di GKE.
Yang telah Anda pelajari
- Cara mengonfigurasi dan menggunakan Alokasi Resource Dinamis (DRA) di GKE untuk mengelola resource GPU.
- Cara menggunakan GKE Inference Gateway untuk mengoptimalkan performa penayangan LLM melalui perutean yang sadar akan cache awalan.
- Cara menggunakan Agent Sandbox (gVisor) untuk mengeksekusi kode yang tidak tepercaya secara aman di GKE.
- Cara menggunakan Google Cloud Managed Service for Prometheus untuk memantau performa vLLM.
- Cara mengonfigurasi dan melihat Kemampuan Observasi Agen menggunakan ADK dan OpenTelemetry Terkelola GKE.
Langkah Berikutnya & Referensi
- Agent Sandbox: Pelajari Agent Sandbox di GKE dan Pod GKE Sandbox.
- llm-d: Baca Panduan llm-d dan lihat Repositori GitHub llm-d.
- Alokasi Resource Dinamis: Pelajari DRA di GKE.
- GKE Inference Gateway: Jelajahi konsep Inference Gateway.
- Codelab Lainnya: Temukan tutorial lainnya di Codelab Google Cloud.