
1. Introduzione
Panoramica
In questo lab imparerai a creare ed eseguire il deployment di un agente di generazione di codice sicuro su Google Kubernetes Engine (GKE). Gli agenti di generazione del codice devono eseguire codice che potrebbe non essere attendibile, richiedendo un ambiente sandbox sicuro. Imparerai anche a configurare l'agente con una strategia di modello ibrido, che gli consente di eseguire il failover da un modello open source autogestito su GKE al servizio Gemini gestito di Vertex AI per una maggiore affidabilità. Inoltre, imparerai a ottimizzare la pubblicazione dell'inferenza utilizzando GKE Inference Gateway e l'allocazione dinamica delle risorse (DRA). Infine, imparerai a sfruttare Google Cloud Observability per monitorare lo stack di inferenza utilizzando Managed Prometheus.
Architettura
Ecco l'architettura del sistema che creerai:
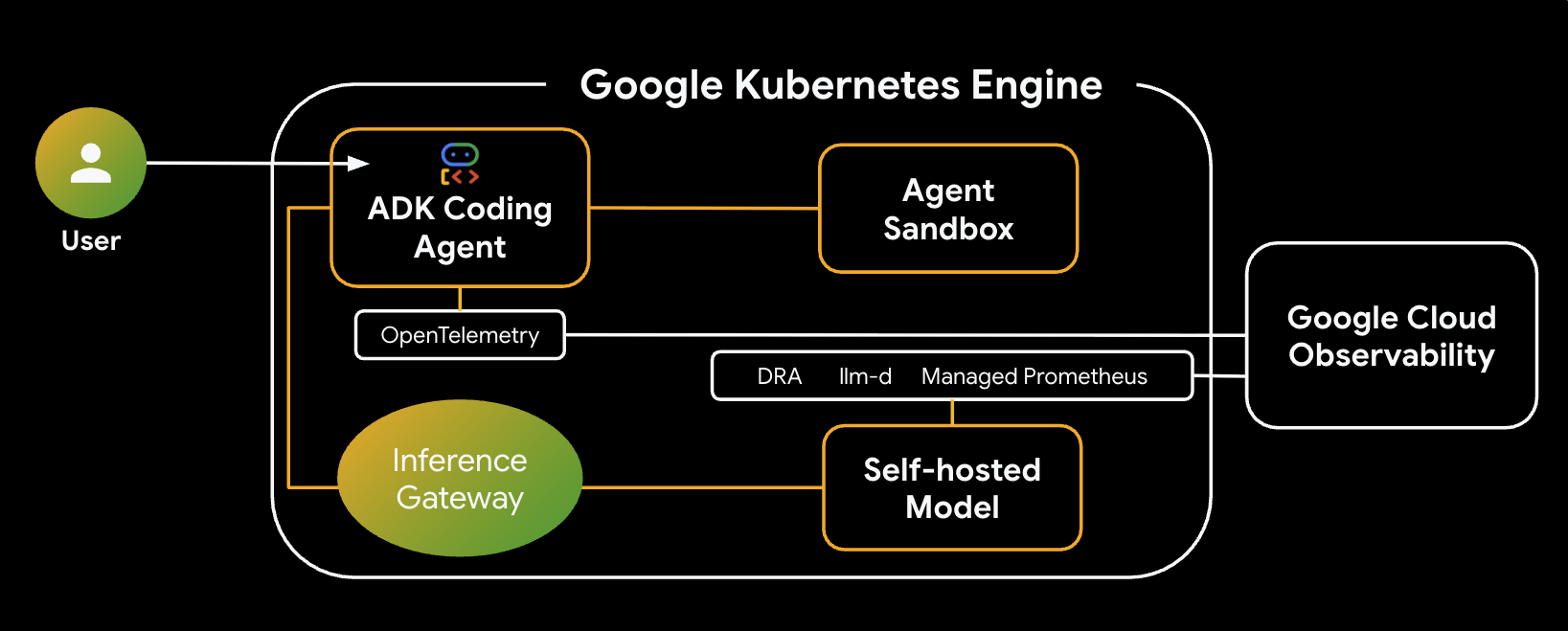
Componenti e vantaggi principali
- Allocazione dinamica delle risorse (DRA): utilizzata in questo lab per richiedere e allocare dinamicamente risorse GPU specifiche (NVIDIA L4) per i pod del server di modelli, garantendo un targeting hardware preciso per il nostro carico di lavoro di inferenza. Scopri di più su DRA su GKE.
- llm-d e vLLM: fornisce il framework di erogazione del modello e i grafici Helm per il deployment del modello Qwen. In questo lab, gestisce le richieste di inferenza e si integra con DRA per la gestione delle risorse (il servizio disaggregato non è abilitato in questo lab). Leggi la guida llm-d e consulta il repository GitHub llm-d.
- GKE Inference Gateway: sposta la logica di routing basata sull'AI direttamente nel bilanciatore del carico. In questo lab, le richieste vengono indirizzate in modo da massimizzare gli hit della cache dei prefissi, riducendo la latenza del Time to First Token (TTFT). Esplora i concetti di Inference Gateway.
- Sandbox dell'agente (gVisor): fornisce un isolamento sicuro per l'esecuzione del codice generato dall'agente AI. Utilizza gVisor per fornire un isolamento profondo del kernel, proteggendo il nodo host da carichi di lavoro non attendibili. Scopri di più su Agent Sandbox su GKE e sui pod GKE Sandbox.
In questo lab proverai a:
- Provisioning dell'infrastruttura: configura un cluster GKE con l'allocazione dinamica delle risorse (DRA) per la gestione delle GPU.
- Esegui il deployment di Inference Stack: esegui il deployment di
llm-de vLLM con la pianificazione intelligente dell'inferenza. - Configura il routing intelligente: utilizza GKE Inference Gateway per il routing con riconoscimento della cache dei prefissi.
- Esecuzione sicura del codice: esegui il deployment di Agent Sandbox (gVisor) per eseguire in modo sicuro il codice generato con l'AI.
- Osserva e convalida: utilizza Google Cloud Monitoring e Managed Prometheus per visualizzare le metriche di erogazione del modello.
Obiettivi didattici
- Come configurare e utilizzare l'allocazione dinamica delle risorse (DRA) in GKE.
- Come utilizzare GKE Inference Gateway per ottimizzare il rendimento della pubblicazione di LLM.
- Come utilizzare Agent Sandbox per eseguire codice non attendibile in modo sicuro su GKE.
- Come utilizzare Google Cloud Managed Service per Prometheus per monitorare le prestazioni di vLLM.
2. Configurazione e requisiti
Configurazione del progetto
Crea un progetto Google Cloud
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto.
Avvia Cloud Shell
Cloud Shell è un ambiente a riga di comando in esecuzione in Google Cloud che viene precaricato con gli strumenti necessari.
- Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud.
- Una volta connesso a Cloud Shell, verifica l'autenticazione:
gcloud auth list - Verifica che il progetto sia configurato:
gcloud config get project - Se il progetto non è impostato come previsto, impostalo:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
3. Provisioning dell'infrastruttura e allocazione dinamica delle risorse (DRA)
In questo primo passaggio, configurerai il cluster GKE in modo che utilizzi l'allocazione dinamica delle risorse (DRA) moderna anziché i plug-in per dispositivi legacy. In questo modo, puoi condividere e allocare in modo flessibile GPU o TPU per i tuoi carichi di lavoro di generazione di codice.
Prerequisiti:il cluster GKE Standard deve eseguire la versione 1.34 o successive per supportare DRA.
Abilita API Google Cloud
Abilita le API Google Cloud richieste per questo codelab, in particolare le API Compute Engine e Kubernetes Engine.
gcloud services enable compute.googleapis.com container.googleapis.com networkservices.googleapis.com cloudbuild.googleapis.com artifactregistry.googleapis.com telemetry.googleapis.com cloudtrace.googleapis.com aiplatform.googleapis.com
Imposta le variabili di ambiente
Per semplificare la configurazione, definisci le variabili di ambiente. Puoi modificare la regione o le convenzioni di denominazione in base alle tue esigenze.
export PROJECT_ID=$(gcloud config get-value project)
export ZONE=us-central1-a
export CLUSTER_NAME=ai-agent-cluster
export NODEPOOL_NAME=dra-accelerator-pool
gcloud config set project $PROJECT_ID
gcloud config set compute/region $ZONE
Crea directory di lavoro
Crea una directory di lavoro dedicata per questo lab e passa al suo interno per organizzare i file:
mkdir -p ~/gke-ai-agent-lab
cd ~/gke-ai-agent-lab
Configurare le autorizzazioni (facoltativo)
Se l'esecuzione avviene in un progetto con limitazioni o in un ambiente condiviso, assicurati che il tuo account disponga delle autorizzazioni necessarie per creare cluster ed eseguire build:
export MY_ACCOUNT=$(gcloud config get-value account)
# Grant Container Admin to create clusters and manage nodes if needed
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/container.admin"
# Grant Cloud Build Builder to run builds
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/cloudbuild.builds.builder"
Crea il cluster GKE
Per supportare DRA, il cluster GKE Standard deve eseguire la versione 1.34 o successive. Devi anche abilitare i controller dell'API Gateway per supportare la pianificazione dell'inferenza intelligente.
In questo lab creerai una nuova rete VPC e le relative subnet.
Innanzitutto, crea la rete VPC:
gcloud compute networks create ai-agent-network --subnet-mode=custom
Successivamente, crea una subnet per i nodi GKE:
gcloud compute networks subnets create ai-agent-subnet \
--network=ai-agent-network \
--range=10.0.0.0/20 \
--region=us-central1
L'API Gateway (gke-l7-regional-internal-managed) richiede anche una subnet dedicata per ospitare i proxy Envoy. Crea questa subnet solo proxy nella tua nuova rete:
gcloud compute networks subnets create proxy-only-subnet \
--purpose=REGIONAL_MANAGED_PROXY \
--role=ACTIVE \
--region=us-central1 \
--network=ai-agent-network \
--range=192.168.10.0/24
Ora crea il cluster utilizzando la nuova rete e la nuova subnet:
gcloud beta container clusters create $CLUSTER_NAME \
--zone $ZONE \
--num-nodes 1 \
--machine-type n2-standard-4 \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--gateway-api=standard \
--managed-otel-scope=COLLECTION_AND_INSTRUMENTATION_COMPONENTS \
--network=ai-agent-network \
--subnetwork=ai-agent-subnet
Crea un node pool con i plug-in predefiniti disattivati
Per trasferire la gestione dei dispositivi a DRA, devi creare un node pool che disattivi esplicitamente l'installazione del driver GPU predefinito e il plug-in del dispositivo standard.
Esegui il seguente comando gcloud per eseguire il provisioning di un node pool GPU (ad esempio utilizzando NVIDIA L4) con le etichette DRA necessarie:
gcloud container node-pools create $NODEPOOL_NAME \
--cluster=$CLUSTER_NAME \
--location=$ZONE \
--machine-type=g2-standard-24 \
--accelerator=type=nvidia-l4,count=2,gpu-driver-version=disabled \
--node-labels=gke-no-default-nvidia-gpu-device-plugin=true,nvidia.com/gpu.present=true \
--num-nodes 3
Installare i driver NVIDIA tramite DaemonSet
Installa manualmente i driver di base NVIDIA richiesti sui nodi utilizzando un DaemonSet Google Cloud preconfigurato:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
Installare il driver DRA
Successivamente, installa il driver DRA specifico nel cluster. Per le GPU NVIDIA, puoi eseguire il deployment tramite Helm:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
helm install nvidia-dra-driver-gpu nvidia/nvidia-dra-driver-gpu \
--version="25.3.2" --create-namespace --namespace=nvidia-dra-driver-gpu \
--set nvidiaDriverRoot="/home/kubernetes/bin/nvidia/" \
--set gpuResourcesEnabledOverride=true \
--set resources.computeDomains.enabled=false \
--set kubeletPlugin.priorityClassName="" \
--set 'kubeletPlugin.tolerations[0].key=nvidia.com/gpu' \
--set 'kubeletPlugin.tolerations[0].operator=Exists' \
--set 'kubeletPlugin.tolerations[0].effect=NoSchedule'
Informazioni su DeviceClasses
Non è necessario scrivere o applicare manualmente un file DeviceClass YAML. Quando configuri l'infrastruttura GKE per DRA e installi il driver, i driver DRA in esecuzione sui nodi creano automaticamente gli oggetti DeviceClass nel cluster.
Configura ResourceClaimTemplate
Per consentire ai tuoi pod llm-d di richiedere dinamicamente questi acceleratori, creerai un ResourceClaimTemplate. Questo modello definisce la configurazione del dispositivo richiesta e indica a Kubernetes di creare automaticamente un ResourceClaim univoco per pod per i tuoi workload.
Esegui questo comando per creare claim-template.yaml:
cat > claim-template.yaml <<EOF
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: gpu-claim-template
spec:
spec:
devices:
requests:
- name: single-gpu
exactly:
deviceClassName: gpu.nvidia.com
allocationMode: ExactCount
count: 1
EOF
Applica il modello al tuo cluster:
kubectl apply -f claim-template.yaml
4. Esegui il deployment della pianificazione dell'inferenza intelligente con llm-d e DRA
In questo passaggio, eseguirai il deployment del modello linguistico di grandi dimensioni dietro un bilanciatore del carico Envoy intelligente migliorato con uno scheduler di inferenza. Questa configurazione ottimizza l'erogazione del modello applicando il routing sensibile alla cache dei prefissi. GKE Inference Gateway riconosce il contesto condiviso tra i microservizi e indirizza in modo intelligente le richieste alla stessa replica del modello, massimizzando gli hit della cache, riducendo il tempo al primo token e migliorando il rendimento per dollaro.
Prepara l'ambiente
Configura lo spazio dei nomi di destinazione.
export NAMESPACE=ai-agents
kubectl create namespace $NAMESPACE
Archivia in modo sicuro il token Hugging Face, necessario per estrarre i pesi del modello.
# Replace with your actual Hugging Face token
kubectl create secret generic llm-d-hf-token \
--from-literal=HF_TOKEN="your_hugging_face_token" \
-n $NAMESPACE
Crea i file di configurazione Helm
Le configurazioni per il servizio di modello e l'estensione del gateway di inferenza si basano sulle guide llm-d ufficiali.
Innanzitutto, crea il file ms-values.yaml per il servizio del modello:
cat <<EOF > ms-values.yaml
multinode: false
modelArtifacts:
uri: "hf://Qwen/Qwen2.5-Coder-14B-Instruct"
name: "Qwen/Qwen2.5-Coder-14B-Instruct"
size: 50Gi # Slightly larger than the default to accommodate weights
authSecretName: "llm-d-hf-token"
labels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
llm-d.ai/accelerator-variant: "gpu"
llm-d.ai/accelerator-vendor: "nvidia"
llm-d.ai/model: "qwen-2-5-coder-14b"
routing:
proxy:
enabled: false # removes sidecar from deployment - no PD in inference scheduling
targetPort: 8000 # controls vLLM port to matchup with sidecar if deployed
accelerator:
dra: true
type: "nvidia"
resourceClaimTemplates:
nvidia:
class: "gpu.nvidia.com"
match: "exactly"
name: "gpu-claim-template"
decode:
create: true
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
parallelism:
tensor: 2
data: 1
replicas: 3
monitoring:
podmonitor:
enabled: true
portName: "vllm"
path: "/metrics"
interval: "30s"
containers:
- name: "vllm"
image: ghcr.io/llm-d/llm-d-cuda:v0.5.1
modelCommand: vllmServe
args:
- "--disable-uvicorn-access-log"
- "--gpu-memory-utilization=0.85"
- "--enable-auto-tool-choice"
- "--tool-call-parser"
- "hermes"
ports:
- containerPort: 8000
name: vllm
protocol: TCP
resources:
limits:
cpu: '16'
memory: 64Gi
requests:
cpu: '16'
memory: 64Gi
mountModelVolume: true
volumeMounts:
- name: metrics-volume
mountPath: /.config
- name: shm
mountPath: /dev/shm
- name: torch-compile-cache
mountPath: /.cache
startupProbe:
httpGet:
path: /v1/models
port: vllm
initialDelaySeconds: 15
periodSeconds: 30
timeoutSeconds: 5
failureThreshold: 120
livenessProbe:
httpGet:
path: /health
port: vllm
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /v1/models
port: vllm
periodSeconds: 5
timeoutSeconds: 2
failureThreshold: 3
volumes:
- name: metrics-volume
emptyDir: {}
- name: torch-compile-cache
emptyDir: {}
- name: shm
emptyDir:
medium: Memory
sizeLimit: 20Gi
prefill:
create: false
EOF
Successivamente, crea il file gaie-values.yaml per l'estensione GKE Inference Gateway:
cat <<EOF > gaie-values.yaml
inferenceExtension:
replicas: 1
image:
name: llm-d-inference-scheduler
hub: ghcr.io/llm-d
tag: v0.6.0
pullPolicy: Always
extProcPort: 9002
pluginsConfigFile: "default-plugins.yaml"
tracing:
enabled: false
monitoring:
interval: "10s"
prometheus:
enabled: true
auth:
secretName: inference-scheduling-gateway-sa-metrics-reader-secret
inferencePool:
targetPorts:
- number: 8000
modelServerType: vllm
modelServers:
matchLabels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
EOF
Informazioni sulla configurazione
Questa configurazione configura uno stack di inferenza ad alte prestazioni con le seguenti funzionalità chiave:
- Selezione del modello: utilizza il modello Qwen 2.5 Coder 14B (
modelArtifacts), ottimizzato per la generazione di codice e l'utilizzo di strumenti. - Integrazione DRA: la sezione
acceleratorattiva l'allocazione dinamica delle risorse (dra: true), scegliendo come target la classe di dispositivigpu.nvidia.come ilgpu-claim-templatecreato in precedenza. - Ottimizzazione del rendimento:
parallelism.tensor: 2configura il parallelismo dei tensori tra le GPU.argsper vLLM include--enable-auto-tool-choiceper garantire che il nostro agente di programmazione possa utilizzare gli strumenti in modo efficace.- Le richieste
cpuememoryridotte si adattano al tipo di macchinag2-standard-24.
- Routing intelligente: l'estensione Inference Gateway (
gaie-values.yaml) è configurata per monitorare i server del modellovllme instradare le richieste per massimizzare gli hit della cache KV.
Esegui il deployment dello stack di pianificazione dell'inferenza tramite Helm
Ora aggiungi i repository Helm llm-d ed esegui il deployment dell'infrastruttura, dell'estensione del gateway e del servizio di modello singolarmente.
Innanzitutto, aggiungi i repository richiesti:
helm repo add llm-d-infra https://llm-d-incubation.github.io/llm-d-infra/
helm repo add llm-d-modelservice https://llm-d-incubation.github.io/llm-d-modelservice/
helm repo update
Esegui il deployment dei prerequisiti dell'infrastruttura
Questo grafico installa le configurazioni di base del gateway richieste per lo stack.
helm install infra-is llm-d-infra/llm-d-infra \
--namespace $NAMESPACE \
--set gateway.gatewayClassName=gke-l7-rilb \
--set gateway.gatewayParameters.enabled=false \
--set gateway.gatewayParameters.istio.accessLogging=false
Esegui il deployment dell'estensione GKE Inference Gateway
Questo passaggio esegue il deployment di InferencePool e Endpoint Picker, che monitorano la cache KV dei tuoi modelli per prendere decisioni di routing intelligenti.
helm install gaie-is oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool \
--version v1.3.1 \
--namespace $NAMESPACE \
-f gaie-values.yaml \
--set provider.name=gke \
--set inferenceExtension.monitoring.prometheus.enabled=true
Esegui il deployment del servizio di modello
Infine, esegui il deployment del servizio LLM, che ora utilizzerà DRA per richiedere in modo sicuro le GPU L4.
helm install ms-is llm-d-modelservice/llm-d-modelservice \
--version v0.4.7 \
--namespace $NAMESPACE \
-f ms-values.yaml \
--set decode.monitoring.podmonitor.enabled=false
Abilita Google Cloud Observability per vLLM
I grafici Helm generici spesso tentano di eseguire il deployment delle risorse standard di Prometheus Operator PodMonitor (monitoring.coreos.com/v1), il che può causare errori se non sono installate queste CRD.
Anziché attivare/disattivare l'opzione di monitoraggio integrata di Helm, mantienila false e applica manualmente una risorsa PodMonitoring Google Cloud Managed Prometheus (GMP) utilizzando il gruppo API monitoring.googleapis.com/v1 compatibile.
Esegui questo comando per creare podmonitoring.yaml:
cat > podmonitoring.yaml <<EOF
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: ms-vllm-metrics
spec:
selector:
matchLabels:
llm-d.ai/model: "qwen-2-5-coder-14b" # Matches the label in values.yaml
endpoints:
- port: 8000 # vllm port
interval: 30s
path: /metrics
EOF
Applica la risorsa PodMonitoring al tuo cluster:
kubectl apply -f podmonitoring.yaml -n $NAMESPACE
Verifica l'installazione
Verifica che i componenti siano stati installati correttamente. Dovresti vedere tutte e tre le release di Helm attive nel tuo spazio dei nomi e i pod corrispondenti in fase di inizializzazione.
helm ls -n $NAMESPACE
kubectl get pods -n $NAMESPACE
L'attivazione dei pod ms-is può richiedere circa 5-10 minuti. In questo caso, l'output dovrebbe essere simile al seguente:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
gaie-is ai-agents 1 2026-03-28 16:51:41.055881618 +0000 UTC deployed inferencepool-v1.3.1 v1.3.1
infra-is ai-agents 1 2026-03-28 16:51:03.71042542 +0000 UTC deployed llm-d-infra-v1.4.0 v0.4.0
ms-is ai-agents 1 2026-03-28 17:30:00.341918958 +0000 UTC deployed llm-d-modelservice-v0.4.7 v0.4.0
NAME READY STATUS RESTARTS AGE
gaie-is-epp-848965cb4-78ktp 1/1 Running 0 10m
ms-is-llm-d-modelservice-decode-67548d5f8c-f25f4 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-rblvs 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-w6fcd 1/1 Running 0 6m2s
5. Configura il routing intelligente con GKE Inference Gateway
Nel passaggio 4, l'implementazione dei grafici Helm llm-d ha eseguito il provisioning automatico degli oggetti Gateway e InferencePool. Il InferencePool raggruppa i pod di erogazione del modello vllm che condividono lo stesso modello di base e la stessa configurazione di calcolo.
Ora devi configurare un InferenceObjective per impostare la priorità delle richieste dell'agente di codifica e un HTTPRoute per indicare al gateway come instradare il traffico in entrata, sfruttando lo strumento di selezione degli endpoint per massimizzare gli hit della cache KV.
Verificare le risorse generate automaticamente
Innanzitutto, verifica che i grafici Helm llm-d abbiano creato correttamente le risorse Gateway e InferencePool.
kubectl get gateway,inferencepool -n $NAMESPACE
Dovresti vedere un gateway denominato infra-is-inference-gateway e un InferencePool denominato gaie-is. Simile a questo:
NAME CLASS ADDRESS PROGRAMMED AGE
gateway.gateway.networking.k8s.io/infra-is-inference-gateway gke-l7-regional-internal-managed 10.128.0.5 True 13m
NAME AGE
inferencepool.inference.networking.k8s.io/gaie-is 12m
Crea HTTPRoute
La risorsa HTTPRoute mappa il gateway al backend InferencePool. In questo modo, GKE Inference Gateway analizza i corpi delle richieste in entrata e li indirizza in modo dinamico per massimizzare gli hit della cache dei prefissi in base al contesto condiviso.
Esegui questo comando per creare httproute.yaml:
cat > httproute.yaml <<EOF
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: agent-route
spec:
parentRefs:
- group: gateway.networking.k8s.io
kind: Gateway
name: infra-is-inference-gateway
rules:
- backendRefs:
- group: inference.networking.k8s.io
kind: InferencePool
name: gaie-is
weight: 1
matches:
- path:
type: PathPrefix
value: /
EOF
Applica la route al cluster:
kubectl apply -f httproute.yaml -n $NAMESPACE
6. Esecuzione sicura del codice con la sandbox dell'agente
Ora che il backend di inferenza ad alte prestazioni è in esecuzione, prepariamo l'ambiente sicuro in cui il codice generato con l'AI verrà eseguito in modo sicuro e isolato dal nostro cluster utilizzando una sandbox dell'agente.
Esegui il deployment del controller della sandbox dell'agente
Quando un agente AI genera ed esegue codice, esegue essenzialmente un workload non attendibile sulla tua infrastruttura. Se l'agente genera codice dannoso, potrebbe tentare di eseguire la scansione della tua rete interna o sfruttare il nodo host sottostante.
GKE Agent Sandbox utilizza gVisor, un runtime dei container open source che fornisce un kernel guest specializzato per ogni container. In questo modo, il codice non attendibile non può effettuare chiamate di sistema dirette al nodo host.
Esegui il deployment del controller Agent Sandbox e dei relativi componenti richiesti applicando i manifest di rilascio ufficiali:
kubectl apply \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/manifest.yaml \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/extensions.yaml
Configura il modello di sandbox e il pool caldo
Successivamente, creiamo un SandboxTemplate che funge da progetto riutilizzabile per i nostri ambienti di analisi Python, prendendo di mira in modo esplicito la classe di runtime gvisor. Per semplificare il deployment senza gestire i node pool manuali sui cluster Standard, possiamo sfruttare qualsiasi autopilot standard
ComputeClass per eseguire il provisioning dinamico dei nodi di calcolo gestiti che supportano in modo nativo i workload gVisor on demand.
Poiché l'inizializzazione di un kernel sicuro può aggiungere latenza, implementiamo anche un SandboxWarmPool. In questo modo, un numero specificato di sandbox preinizializzate viene mantenuto pronto, in modo che l'agente di generazione del codice possa rivendicarle e iniziare a eseguire il codice in meno di un secondo.
Innanzitutto, crea un nuovo spazio dei nomi per i runtime della sandbox dell'agente:
kubectl create namespace agent-sandbox
Salva quanto segue come sandbox-template-and-pool.yaml:
cat > sandbox-template-and-pool.yaml <<EOF
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxTemplate
metadata:
name: python-runtime-template
namespace: agent-sandbox
spec:
podTemplate:
metadata:
labels:
sandbox: python-sandbox-example
spec:
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: python-runtime
image: registry.k8s.io/agent-sandbox/python-runtime-sandbox:v0.1.0
ports:
- containerPort: 8888
readinessProbe:
httpGet:
path: "/"
port: 8888
initialDelaySeconds: 0
periodSeconds: 1
resources:
requests:
cpu: "250m"
memory: "512Mi"
ephemeral-storage: "512Mi"
restartPolicy: "OnFailure"
---
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxWarmPool
metadata:
name: python-sandbox-warmpool
namespace: agent-sandbox
spec:
replicas: 2
sandboxTemplateRef:
name: python-runtime-template
EOF
Applica la configurazione:
kubectl apply -f sandbox-template-and-pool.yaml
Attendi fino a 2-3 minuti per l'inizializzazione dei pod warm pool. Puoi verificare che la transizione da Pending (mentre la risorsa di calcolo sottostante aumenta) a Running sia avvenuta correttamente utilizzando:
kubectl get pods -n agent-sandbox -w
Quando vedi due pod python-sandbox-warmpool-*** elencati come Running e 1/1 Pronti, gli ambienti di esecuzione sicuri sono pre-riscaldati e pronti per essere rivendicati.
Esegui il deployment del router sandbox
Il nostro agente di generazione di codice si basa su un router sandbox per inviare in modo sicuro i comandi di esecuzione ai pod isolati.
Esegui questo comando per creare sandbox-router.yaml:
cat > sandbox-router.yaml <<EOF
apiVersion: v1
kind: Service
metadata:
name: sandbox-router-svc
namespace: agent-sandbox
spec:
type: ClusterIP
selector:
app: sandbox-router
ports:
- name: http
protocol: TCP
port: 8080
targetPort: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sandbox-router-deployment
namespace: agent-sandbox
spec:
replicas: 2
selector:
matchLabels:
app: sandbox-router
template:
metadata:
labels:
app: sandbox-router
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: sandbox-router
containers:
- name: router
image: us-central1-docker.pkg.dev/k8s-staging-images/agent-sandbox/sandbox-router:v20260225-v0.1.1.post3-10-ga5bcb57
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 10
resources:
requests:
cpu: "250m"
memory: "512Mi"
limits:
cpu: "1000m"
memory: "1Gi"
securityContext:
runAsUser: 1000
runAsGroup: 1000
EOF
Applica la configurazione:
kubectl apply -f sandbox-router.yaml
Implementare l'isolamento di rete
Per proteggere ulteriormente l'ambiente di esecuzione e impedire qualsiasi movimento laterale non autorizzato, applica un criterio di rete. In questo modo, la sandbox viene isolata in modo che non possa raggiungere il server di metadati Google Cloud o altre reti interne sensibili.
Salva quanto segue come sandbox-policy.yaml:
cat > sandbox-policy.yaml <<EOF
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: restrict-sandbox-egress
namespace: agent-sandbox
spec:
podSelector:
matchLabels:
sandbox: python-sandbox-example
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 0.0.0.0/0
except:
- 169.254.169.254/32 # Block metadata server
EOF
Applica la policy:
kubectl apply -f sandbox-policy.yaml
Verifica dei componenti
Per assicurarti che il livello del cluster sandbox di codice isolato sia completamente configurato, esegui i seguenti comandi di convalida dello stato:
Innanzitutto, verifica che i pod e i router sandbox siano in esecuzione e pronti
kubectl get pods -n agent-sandbox
L'output dovrebbe essere simile al seguente:
NAME READY STATUS RESTARTS AGE
python-sandbox-warmpool-7zlkv 1/1 Running 0 3m25s
python-sandbox-warmpool-cxln2 1/1 Running 0 3m25s
sandbox-router-deployment-668dfbbbb6-g9mpd 1/1 Running 0 42s
sandbox-router-deployment-668dfbbbb6-ppllz 1/1 Running 0 42s
Verifica il bilanciatore del carico / l'esposizione IP del router sandbox
kubectl get service sandbox-router-svc -n agent-sandbox
L'output dovrebbe essere simile al seguente:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
sandbox-router-svc ClusterIP 34.118.237.244 <none> 8080/TCP 114s
Verifica che esista la regola del criterio di rete in uscita
kubectl get networkpolicy restrict-sandbox-egress -n agent-sandbox
L'output dovrebbe essere simile al seguente:
NAME POD-SELECTOR AGE
restrict-sandbox-egress sandbox=python-sandbox-example 113s
Verifica quanto segue:
- I pod
python-sandbox-warmpool-***sonoRunninge1/1Ready. - Le repliche di
sandbox-router-deployment-***sonoRunninge1/1pronte. sandbox-router-svcè accessibile e il criteriorestrict-sandbox-egressprotegge correttamente tutte le etichette sandbox corrispondenti.
Con il nostro ambiente di esecuzione sicuro protetto e inizializzato, siamo pronti a eseguire il deployment del vero e proprio cervello della nostra operazione: l'agente di generazione del codice.
7. Crea ed esegui il deployment dell'agente di generazione del codice (ADK)
Ora che sono configurati sia la sandbox di esecuzione sicura sia il backend LLM ad alte prestazioni, possiamo creare il "cervello" del nostro sistema: un agente di generazione di codice utilizzando l'Agent Development Kit (ADK).
Questo agente è progettato per agire come uno sviluppatore Python esperto. A differenza di un chatbot standard che produce solo testo, questo agente è dotato di uno strumento di esecuzione del codice che gli consente di risolvere i problemi in modo interattivo. Segue un ciclo di:
- Scrittura di codice Python in base alle tue richieste.
- Esecuzione del codice in modo sicuro all'interno di GKE Agent Sandbox che abbiamo configurato nel passaggio 6.
- Verifica l'output o leggi gli eventuali errori che si verificano durante l'esecuzione.
- Fornire una soluzione testata e funzionante con sicurezza.
Fornendo all'agente l'accesso a un ambiente di esecuzione sandbox sicuro, gli consentiamo di verificare la propria logica e di eseguire il debug automatico degli errori, rendendolo notevolmente più capace di svolgere attività di sviluppo software.
Sviluppa l'agente di ragionamento ADK
Innanzitutto, scriviamo la logica Python che definisce il comportamento dell'agente e lo dota dello strumento Sandbox che abbiamo creato nel passaggio 6. In questa sezione configuriamo anche una strategia di modello ibrido: l'agente darà la priorità a un modello Qwen autogestito in esecuzione sul cluster GKE, ma tornerà automaticamente a Gemini 2.5 Flash su Vertex AI se il modello locale è lento o non disponibile, garantendo un'affidabilità elevata.
Crea una nuova directory per il codice dell'agente:
mkdir -p ~/gke-ai-agent-lab/root_agent
cd ~/gke-ai-agent-lab
Crea un file denominato root_agent/agent.py con i seguenti contenuti:
cat <<'EOF' > root_agent/agent.py
import os
from google.adk.agents import Agent
from google.adk.models.lite_llm import LiteLlm
from k8s_agent_sandbox import SandboxClient
import requests
# Instantiate the client globally to track sandboxes
sandbox_client = SandboxClient()
def run_python_code(code: str) -> str:
"""
Executes Python code safely in the GKE Agent Sandbox.
Use this tool whenever you need to execute code to solve a problem.
"""
sandbox = sandbox_client.create_sandbox(template="python-runtime-template", namespace="agent-sandbox")
try:
command = f"python3 -c \"{code}\""
result = sandbox.commands.run(command)
if result.stderr:
return f"Error: {result.stderr}"
return result.stdout
finally:
# Ensure the sandbox is deleted after use to avoid leaking resources
sandbox_client.delete_sandbox(sandbox.claim_name, namespace="agent-sandbox")
# Define the ADK Agent with a fallback mechanism.
# It prioritizes the Qwen 2.5 Coder model running on our Inference Gateway.
# If the local model is unavailable, it falls back to Gemini 2.5 Flash on Vertex AI.
root_agent = Agent(
name="CodeGenerationAgent",
model=LiteLlm(
model="openai/Qwen/Qwen2.5-Coder-14B-Instruct",
fallbacks=["vertex_ai/gemini-2.5-flash"],
timeout=10
),
instruction="""
You are an expert Python developer.
1. Write Python code to solve the user's problem.
2. Execute the code using the `run_python_code` tool to verify it works.
3. Return the exact output and a brief explanation of the code.
""",
tools=[run_python_code]
)
EOF
Crea un file __init__.py in modo che ADK riconosca il modulo:
echo "from . import agent" > ~/gke-ai-agent-lab/root_agent/__init__.py
Imposta le variabili di ambiente. L'applicazione ADK ha bisogno dell'indirizzo IP del gateway per instradare correttamente le richieste LLM. Poiché ADK supporta gli endpoint standard compatibili con Open AI (che vLLM fornisce tramite il nostro gateway), possiamo sostituire l'URL di base dell'API predefinito.
export GATEWAY_IP=$(kubectl get gateway infra-is-inference-gateway -n $NAMESPACE -o jsonpath='{.status.addresses[0].value}')
cat <<EOF > ~/gke-ai-agent-lab/root_agent/.env
OPENAI_API_BASE=http://${GATEWAY_IP}/v1
OPENAI_API_KEY=no-key-required
# Vertex AI settings for fallback (Authentication is handled by Workload Identity)
VERTEXAI_PROJECT=$PROJECT_ID
VERTEXAI_LOCATION=${ZONE%-[a-z]}
EOF
Containerizza l'applicazione agente
Dobbiamo creare un pacchetto dell'agente in modo che possa essere eseguito in modo sicuro all'interno di GKE.
Crea un Dockerfile in ~/gke-ai-agent-lab che installa kubectl, la libreria ADK e il client Agent Sandbox:
cat <<'EOF' > ~/gke-ai-agent-lab/Dockerfile
FROM python:3.11-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
RUN apt-get update && apt-get install -y git curl \
&& curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl" \
&& install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl \
&& rm kubectl && apt-get clean && rm -rf /var/lib/apt/lists/*
RUN pip install --no-cache-dir "google-adk[extensions,otel-gcp]>=1.27.4" litellm pandas "git+https://github.com/kubernetes-sigs/agent-sandbox.git@main#subdirectory=clients/python/agentic-sandbox-client" \
"opentelemetry-instrumentation-google-genai>=0.4b0" \
"opentelemetry-exporter-otlp" \
"opentelemetry-instrumentation-vertexai>=2.0b0"
COPY ./root_agent /app/root_agent
EXPOSE 8080
ENTRYPOINT ["adk", "web", "--host", "0.0.0.0", "--port", "8080", "--otel_to_cloud"]
EOF
Crea un repository Artifact Registry per archiviare l'immagine container.
gcloud artifacts repositories create agent-repo \
--repository-format=docker \
--location=us-central1
Utilizza Cloud Build per creare ed eseguire il push dell'immagine container.
gcloud builds submit --tag us-central1-docker.pkg.dev/$PROJECT_ID/agent-repo/code-agent:v1 ~/gke-ai-agent-lab/
Esegui il deployment su GKE con RBAC
Infine, esegui il deployment dell'agente nel tuo cluster. Il deployment include un Role e un RoleBinding che concedono all'agente l'autorizzazione a rivendicare istanze da SandboxWarmPool.
Questo deployment utilizzerà un ServiceAccount Kubernetes per consentire all'agente di comunicare con l'API Sandbox claim. Non richiede un service account Google IAM, poiché accede alle risorse del cluster locale e a un endpoint gateway vLLM locale.
Perché un deployment standard in gVisor?
Nel passaggio 6, abbiamo utilizzato le API SandboxTemplate e SandboxClaim per creare sandbox effimere e temporanee per il codice Python generato (l'esecuzione dello strumento).
Per la GUI web dell'agente (il cervello), utilizziamo le specifiche Kubernetes standard Deployment con runtimeClassName: gvisor.
- La distinzione: i
SandboxClaimsstandard sono effimeri e zero-to-one (ideali per script non attendibili). UnDeploymentstandard è di lunga durata e persistente, perfetto per le UI web che richiedono unServicee un bilanciatore del carico Kubernetes stabili. UtilizzandoruntimeClassName: gvisordirettamente in un deployment standard, ottieni l'isolamento del kernel gVisor mantenendo le funzionalità standard diDeployment.
Salva quanto segue come deployment.yaml:
cat <<EOF > ~/gke-ai-agent-lab/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: code-agent
labels:
app: code-agent
spec:
replicas: 1
selector:
matchLabels:
app: code-agent
template:
metadata:
labels:
app: code-agent
spec:
serviceAccount: adk-agent-sa
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: code-agent
image: us-central1-docker.pkg.dev/YOUR_PROJECT_ID/agent-repo/code-agent:v1
imagePullPolicy: Always
env:
- name: OPENAI_API_KEY
value: "no-key-required"
- name: OPENAI_API_BASE
value: "http://YOUR_GATEWAY_IP/v1"
- name: VERTEXAI_PROJECT
value: "YOUR_PROJECT_ID"
- name: VERTEXAI_LOCATION
value: "YOUR_REGION"
- name: OTEL_SERVICE_NAME
value: "code-agent"
- name: GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY
value: "true"
- name: OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT
value: "true"
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: code-agent-service
spec:
selector:
app: code-agent
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: agent-sandbox
name: sandbox-creator-role
rules:
- apiGroups: [""]
resources: ["services", "pods", "pods/portforward"]
verbs: ["get", "list", "watch", "create"]
- apiGroups: ["extensions.agents.x-k8s.io"]
resources: ["sandboxclaims"]
verbs: ["create", "get", "list", "watch", "delete"]
- apiGroups: ["agents.x-k8s.io"]
resources: ["sandboxes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: adk-agent-binding
namespace: agent-sandbox
subjects:
- kind: ServiceAccount
name: adk-agent-sa
namespace: default
roleRef:
kind: Role
name: sandbox-creator-role
apiGroup: rbac.authorization.k8s.io
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: adk-agent-sa
EOF
Concedi autorizzazioni IAM per l'osservabilità
Per consentire all'agente di inviare dati di telemetria (log e tracce) a Google Cloud, devi concedere le autorizzazioni richieste all'account di servizio Kubernetes adk-agent-sa utilizzando Workload Identity.
Esegui questi comandi in Cloud Shell:
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# Grant permission to write logs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/logging.logWriter \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to write traces
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/cloudtrace.agent \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to use Vertex AI
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/aiplatform.user \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
Esegui questo comando per sostituire automaticamente YOUR_PROJECT_ID con il tuo ID progetto effettivo e applicare la configurazione.
sed -i "s/YOUR_PROJECT_ID/$PROJECT_ID/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_GATEWAY_IP/$GATEWAY_IP/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_REGION/$ZONE/g" ~/gke-ai-agent-lab/deployment.yaml
kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml
8. Osserva e convalida
È il momento di testare il sistema completamente integrato.
Testare l'agente di generazione di codice nell'interfaccia utente
Trova l'IP esterno della GUI web di ADK:
kubectl get services code-agent-service
L'output dovrebbe essere simile al seguente:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
code-agent-service LoadBalancer 34.118.230.182 34.31.250.60 80:32471/TCP 2m14s
- Apri un browser e vai all'indirizzo
http://[EXTERNAL-IP]. - Nell'interfaccia web dell'ADK, assicurati che "root_agent" sia selezionato dal menu a discesa in alto a destra. Quindi, chiedi all'agente:
Write a python script that prints 'Hello from the isolated sandbox'.
Per osservare come l'agente utilizza il backend di inferenza e la sandbox, vai alle sezioni Esplora le statistiche del modello tramite Cloud Observability ed Esplora l'osservabilità dell'agente tramite la UI di GKE di seguito per visualizzare le dashboard.
Esplora l'osservabilità degli agenti tramite la UI di GKE
Ora che hai eseguito alcuni prompt, esaminiamo i dati di telemetria. In questo modo, puoi capire il rendimento di Inference Scheduler e vLLM.
Accedere alle dashboard degli agenti
- Vai alla pagina Kubernetes Engine > Workload.
- Fai clic sul deployment code-agent per aprire la pagina Dettagli deployment.
- Fai clic sulla scheda Osservabilità.
- Nel pannello di navigazione a sinistra della dashboard di osservabilità, vedrai una nuova sezione Agente con schede secondarie.
Cosa esplorare
Esplora le seguenti schede secondarie per visualizzare il comportamento della tua applicazione agente:
- Panoramica:visualizza i prospetti per sessioni, turni medi e invocazioni.
- Modelli:visualizza il numero di chiamate al modello, i tassi di errore e la latenza classificati in base ai modelli utilizzati dall'agente.
- Strumenti:monitora le chiamate e la durata di esecuzione degli strumenti per verificare l'efficacia con cui l'agente utilizza lo strumento di esecuzione sandbox.
- Utilizzo:monitora l'utilizzo dei token e l'allocazione delle risorse standard dei container (CPU e memoria).
- Tracce dell'agente:passa a questa scheda per visualizzare un elenco di sessioni di esecuzione o intervalli di traccia non elaborati. Se fai clic su una riga, si apre un riquadro a comparsa con i dettagli della traccia selezionata.
Combinando le metriche a livello di modello di vLLM con la telemetria a livello di app di ADK, ora hai l'osservabilità full-stack per il tuo agente AI generativa su GKE.
Esplora le statistiche del modello vLLM tramite Cloud Observability
Ora che hai eseguito alcuni prompt, esaminiamo i dati di telemetria. In questo modo, puoi capire il rendimento di Inference Scheduler e vLLM.
Accedere alle dashboard
- Vai alla console Google Cloud.
- Vai a Monitoraggio > Dashboard.
- Cerca e seleziona la dashboard Panoramica di vLLM Prometheus.
Metriche interessanti da osservare
Quando visualizzi la dashboard, presta attenzione a queste metriche chiave per vedere l'impatto di GKE Inference Gateway e della memorizzazione nella cache dei prefissi:
- Utilizzo della cache KV (
vllm:gpu_cache_usage):- Perché è importante: mostra la quantità di memoria della GPU utilizzata per memorizzare nella cache il contesto. Se questo valore è elevato, significa che il sistema mantiene il contesto per velocizzare le richieste future. Se esegui lo stesso prompt più volte, dovresti notare un aumento e poi una stabilizzazione dell'utilizzo.
- Running vs Waiting Requests (
vllm:num_requests_runningvsvllm:num_requests_waiting):- Perché è importante: indica il carico. Se le richieste in attesa sono elevate, significa che i nodi sono sovraccarichi.
- Throughput dei token (
vllm:request_prompt_tokens_totevllm:request_generation_tokens_tot):- Perché è importante: monitora il volume dei token di input e output elaborati dal cluster.
- Time To First Token (TTFT):
- Perché è importante:questa è la metrica fondamentale per gli agenti interattivi. Utilizzando GKE Inference Gateway con il routing basato sulla cache dei prefissi, le richieste che condividono contesti comuni (come prompt di sistema o finestre contestuali di grandi dimensioni) vengono indirizzate alla stessa replica, riducendo al minimo il TTFT riutilizzando i risultati della cache esistenti.
Esperimenti da provare
Prova questi scenari per vedere le metriche cambiare in tempo reale e convalidare la corretta pianificazione.
Esperimento 1: "Velocità di ripetizione" (riscontro cache prefisso)
- Invia un prompt complesso all'agente (ad es. "Scrivi uno script Python per analizzare un file CSV di 100 MB e calcolare le statistiche").
- Una volta che ha risposto, invia di nuovo esattamente lo stesso prompt.
- Osserva la percentuale di hit della cache dei prefissi e il Time to First Token (TTFT).
- Cosa dovresti vedere: la percentuale di hit della cache dei prefissi dovrebbe salire al 100% e il TTFT dovrebbe diminuire drasticamente.
- Che cosa significa: GKE Inference Gateway ha riconosciuto il contesto condiviso e lo ha indirizzato alla stessa replica che ha riutilizzato la cache del contesto valutato.
Esperimento 2: fallback al cloud (affidabilità del modello)
- Per simulare un errore del modello Qwen locale, puoi interrompere il servizio di inferenza o semplicemente fornire un
OPENAI_API_BASEfittizio nel deployment. - Aggiorna
OPENAI_API_BASEindeployment.yamlcon un IP o una porta inesistenti e applica le modifiche:sed -i "s|value: \"http://$GATEWAY_IP/v1\"|value: \"http://10.0.0.1:8080/v1\"|g" ~/gke-ai-agent-lab/deployment.yaml kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml - Attendi il riavvio del pod, quindi invia un prompt all'agente nella UI.
- Cosa dovresti vedere: l'agente risponde ancora correttamente.
- Che cosa significa:a causa della configurazione
fallbacks, l'ADK ha riconosciuto l'errore dell'endpoint Qwen locale e ha indirizzato senza problemi la richiesta a Gemini 2.5 Flash su Vertex AI. Tieni presente che, poiché queste chiamate di fallback a Vertex AI bypassano il gateway di inferenza vLLM locale, non verranno visualizzate nella dashboard Osservabilità degli agenti > Modelli, che monitora solo il traffico che passa attraverso vLLM.
Comprendere la potenza dell'allocazione dinamica delle risorse (DRA)
Mentre vLLM e Inference Gateway ottimizzano il modo in cui le richieste vengono instradate e gestite, l'allocazione dinamica delle risorse (DRA) ha reso possibile collegare l'hardware giusto al tuo workload.
DRA migliora la tua capacità di gestire in modo granulare l'hardware nel cluster consentendoti di definire risorse hardware flessibili utilizzando ResourceClaimTemplate e DeviceClasses.
Perché DRA è una svolta per i workload di AI:
- Richieste hardware granulari: con DRA, non solo ti assicuri che i carichi di lavoro vengano pianificati su macchine con l'acceleratore giusto, ma puoi anche rivendicare queste risorse per assicurarti che vengano utilizzate esclusivamente dal carico di lavoro associato a ResourceClaim.
- Ciclo di vita disaccoppiato: le rivendicazioni dei dispositivi vengono gestite indipendentemente dai cicli di vita dei pod. Se un pod si arresta in modo anomalo, la richiesta di GPU può persistere, in modo che il deployment generale o un altro oggetto workload possa essere riavviato senza dover attendere il rilascio e l'acquisizione della GPU.
- Standardizzazione multifornitore: DRA fornisce un'API Kubernetes unificata per le GPU NVIDIA e le TPU Google. Utilizzi esattamente lo stesso schema indipendentemente dal deployment, il che rende i manifest YAML del carico di lavoro altamente portabili.
In questo codelab, hai visto questo in azione quando hai configurato i valori Helm per il binding a gpu-claim-template senza problemi, senza che le configurazioni dei plug-in del dispositivo in sospeso blocchino i tuoi rollout.
Informazioni sul ruolo di llm-d
Mentre vLLM valuta i pesi neurali e GKE Gateway indirizza le query, llm-d funge da strato di configurazione e da "collante" che li unisce tutti.
Senza llm-d, dovresti scrivere da zero i manifest Kubernetes non elaborati per dichiarare il deployment di vLLM, le porte di servizio, i montaggi dei volumi e le richieste di risorse DRA.
Perché utilizzare llm-d nel deployment?
- Configurazione unificata (override di una riga):
llm-di grafici Helm raggruppano risorse Kubernetes complesse e di basso livello in semplici opzioni di attivazione/disattivazione di alto livello (come l'impostazione diaccelerator.dra: true). - Percorsi ben illuminati pre-verificati: il repository
llm-dcontiene configurazioni già sottoposte a benchmark e testate da esperti. Quando esegui il deployment dillm-d-modelservice, ricevi valori predefiniti ottimizzati per l'utilizzo della memoria GPU, tempistiche di probe consigliate (attività/prontezza) ed esposizioni corrette per lo scraping delle metriche. - Mappatura dell'osservabilità senza interruzioni:
llm-dgarantisce che le porte e i percorsi di scraping standard dei container (/metrics) siano esposti correttamente, semplificando il collegamento del deployment a Google Cloud Monitoring senza il debug manuale.
In breve, llm-d fornisce i progetti di architettura riutilizzabili in modo che gli sviluppatori non debbano reinventare la ruota ogni volta che eseguono il deployment di uno stack di inferenza su GKE.
Approfondimento: GKE Inference Gateway
I bilanciatori del carico standard di livello 7 operano esaminando le intestazioni HTTP come i percorsi (/v1/completions) o i cookie. GKE Inference Gateway è molto più approfondito: è progettato specificamente per il traffico di AI generativa.
Come contribuiscono a un rendimento e un'efficienza migliori:
- Content-Aware Routing (hashing dei prompt): GKE Inference Gateway intercetta il corpo della richiesta JSON. Calcola un hash del prompt e monitora quale replica di backend contiene già questi token nella memoria GPU (la cache KV).
- Massimizzazione degli hit della cache: durante i test, quando hai ripetuto un prompt, il gateway lo ha inviato alla stessa replica. La valutazione di un prompt richiede una potenza di calcolo elevata. Riutilizzando la cache, eviti di "rileggere" il prompt, risparmiando denaro e tempo della GPU.
- Riduzione del Time-to-First-Token (TTFT): il TTFT è la metrica di usabilità fondamentale per gli agenti rivolti agli utenti. Se la cache viene raggiunta, il modello può iniziare a generare token in millisecondi anziché in secondi.
- Distribuzione intelligente del carico: se la VRAM di una replica è completamente piena di hit della cache, il gateway può indirizzare dinamicamente un nuovo prompt a una replica diversa che ha spazio, bilanciando efficienza e disponibilità.
In che modo Agent Sandbox riduce il rischio
In questo lab, abbiamo dimostrato come Agent Sandbox protegge la tua infrastruttura dai rischi associati agli agenti AI fornendo due livelli di isolamento:
- Isolamento dello strumento di esecuzione: l'agente esegue il codice che genera in una sandbox temporanea. In questo modo, il codice non attendibile generato dall'LLM viene eseguito in un ambiente sicuro e isolato, proteggendo l'agente e il cluster.
- Avvio rapido: utilizzando un WarmPool, le nuove sandbox si avviano in meno di un secondo, pronte per l'esecuzione del codice.
- Isolamento dell'agente stesso: abbiamo eseguito l'applicazione dell'agente in un nodo abilitato a gVisor (tramite
runtimeClassName: gvisor) per fornire una difesa in profondità contro le vulnerabilità della catena di fornitura nelle dipendenze dell'agente.
Ecco perché questo crea un confine di sicurezza così rigido:
- Intercettazione delle chiamate di sistema: gVisor intercetta le chiamate di sistema prima che raggiungano il kernel Linux host. In questo modo vengono bloccati gli exploit che tentano di uscire dal container per accedere al nodo host.
- Movimento laterale limitato: in combinazione con i criteri di rete, anche se un ambiente viene compromesso, non può eseguire la scansione dei server di metadati interni o passare ad altri servizi sensibili nel cluster.
Esecuzione di agenti completi nelle sandbox
In questo lab abbiamo utilizzato le sandbox come strumenti per un'applicazione di agente persistente. Tuttavia, per la massima sicurezza, soprattutto quando gestisci dati sensibili o servi più utenti non attendibili, puoi eseguire l'intera applicazione agente all'interno di una sandbox dedicata per ogni sessione o utente. In questo modo si garantisce l'isolamento completo della memoria, dello stato e dell'ambiente di esecuzione dell'agente, che viene distrutto immediatamente dopo il completamento della sessione.
9. Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo codelab, segui questi passaggi per eliminarle.
Eliminare singole risorse
- Elimina il cluster GKE:
gcloud container clusters delete $CLUSTER_NAME --zone $ZONE --quiet
- Elimina il repository Artifact Registry:
gcloud artifacts repositories delete agent-repo --location=us-central1 --quiet
- Elimina la rete VPC:
gcloud compute networks delete ai-agent-network --quiet
Elimina il progetto
Se non hai più bisogno del progetto, puoi eliminarlo dopo aver rimosso le risorse:
gcloud projects delete $PROJECT_ID
10. Riepilogo
Complimenti! Hai creato ed eseguito il deployment di un agente di generazione di codice sicuro e ad alte prestazioni su GKE.
Che cosa hai imparato
- Come configurare e utilizzare l'allocazione dinamica delle risorse (DRA) in GKE per gestire le risorse GPU.
- Come utilizzare GKE Inference Gateway per ottimizzare le prestazioni di serving LLM tramite il routing basato sulla cache dei prefissi.
- Come utilizzare Agent Sandbox (gVisor) per eseguire in modo sicuro codice non attendibile su GKE.
- Come utilizzare Google Cloud Managed Service per Prometheus per monitorare le prestazioni di vLLM.
- Come configurare e visualizzare l'osservabilità degli agenti utilizzando ADK e GKE Managed OpenTelemetry.
Passaggi successivi e riferimenti
- Agent Sandbox: scopri di più su Agent Sandbox su GKE e sui pod GKE Sandbox.
- llm-d: leggi la guida llm-d e dai un'occhiata al repository GitHub llm-d.
- Allocazione dinamica delle risorse: scopri di più sull'allocazione dinamica delle risorse su GKE.
- GKE Inference Gateway: scopri i concetti di Inference Gateway.
- Altri codelab: scopri altri tutorial su Google Cloud Codelabs.