
1. はじめに
概要
このラボでは、Google Kubernetes Engine(GKE)で安全なコード生成エージェントを構築してデプロイする方法を学習します。コード生成エージェントは、信頼できない可能性のあるコードを実行する必要があるため、安全なサンドボックス環境が必要です。また、ハイブリッド モデル戦略を使用してエージェントを構成する方法も学習します。これにより、信頼性を高めるために、GKE のセルフホスト オープンモデルから Vertex AI のマネージド Gemini サービスにフォールバックできます。また、GKE Inference Gateway と動的リソース割り当て(DRA)を使用して推論サービングを最適化する方法についても学習します。最後に、Google Cloud Observability を活用して、マネージド Prometheus を使用して推論スタックをモニタリングする方法を学習します。
アーキテクチャ
構築するシステムのアーキテクチャは次のとおりです。
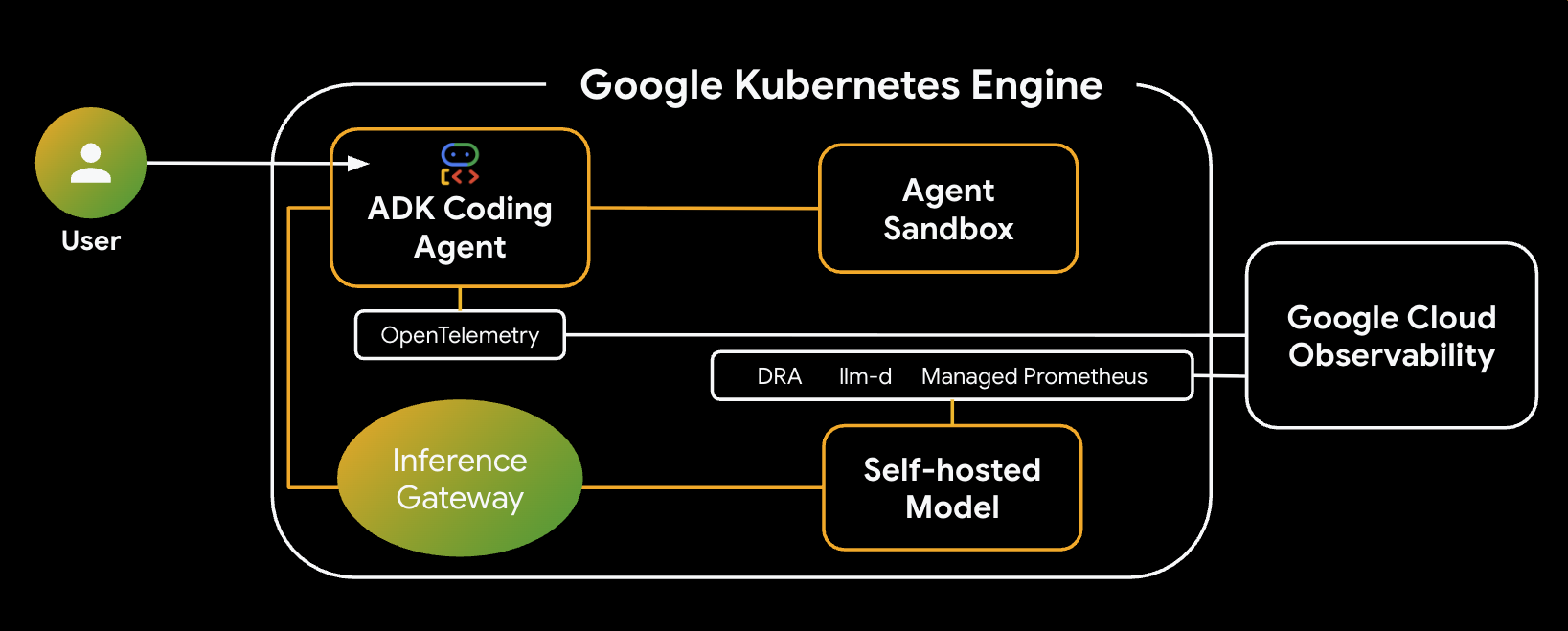
主なコンポーネントとメリット
- 動的リソース割り当て(DRA): このラボで使用され、モデルサーバー Pod の特定の GPU リソース(NVIDIA L4)を動的に要求して割り当て、推論ワークロードの正確なハードウェア ターゲティングを保証します。GKE の DRA について学習する。
- llm-d と vLLM: Qwen モデルをデプロイするためのモデル提供フレームワークと Helm チャートを提供します。このラボでは、推論リクエストを処理し、リソース管理のために DRA と統合します(このラボでは、分離型サービングは有効になっていません)。llm-d ガイドを読み、llm-d GitHub リポジトリを確認します。
- GKE Inference Gateway: AI 対応のルーティング ロジックをロードバランサに直接移動します。このラボでは、リクエストをルーティングしてプレフィックス キャッシュヒットを最大化し、最初のトークンまでの時間(TTFT)のレイテンシを短縮します。Inference Gateway のコンセプトを確認する。
- Agent Sandbox(gVisor): AI エージェントによって生成されたコードを実行するための安全な分離を提供します。gVisor を使用してカーネルを分離し、信頼できないワークロードからホストノードを保護します。GKE 上の Agent Sandbox と GKE Sandbox Pod について学習する。
演習内容
- インフラストラクチャをプロビジョニングする: GPU 管理用に動的リソース割り当て(DRA)を使用して GKE クラスタを設定します。
- 推論スタックをデプロイする: インテリジェントな推論スケジューリングを使用して
llm-dと vLLM をデプロイします。 - インテリジェント ルーティングを構成する: GKE Inference Gateway を使用して、プレフィックス キャッシュ対応のルーティングを行います。
- 安全なコード実行: Agent Sandbox(gVisor)をデプロイして、AI 生成コードを安全に実行します。
- モニタリングと検証: Google Cloud Monitoring と Managed Prometheus を使用して、モデル提供指標を表示します。
学習内容
- GKE で動的リソース割り当て(DRA)を構成して使用する方法。
- GKE Inference Gateway を使用して LLM サービングのパフォーマンスを最適化する方法。
- Agent Sandbox を使用して GKE で信頼できないコードを安全に実行する方法。
- Google Cloud Managed Service for Prometheus を使用して vLLM のパフォーマンスをモニタリングする方法。
2. 設定と要件
プロジェクトの設定
Google Cloud プロジェクトの作成
- Google Cloud コンソールのプロジェクト セレクタ ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
Cloud Shell の起動
Cloud Shell は、必要なツールがプリロードされた Google Cloud で動作するコマンドライン環境です。
- Google Cloud コンソールの上部にある [Cloud Shell をアクティブにする] をクリックします。
- Cloud Shell に接続したら、認証を確認します。
gcloud auth list - プロジェクトが構成されていることを確認します。
gcloud config get project - プロジェクトが想定どおりに設定されていない場合は、設定します。
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
3. インフラストラクチャと動的リソース割り当て(DRA)をプロビジョニングする
この最初のステップでは、以前のデバイス プラグインではなく最新のアクセラレータ割り当て(DRA)を使用するように GKE クラスタを構成します。これにより、コード生成ワークロードの GPU または TPU を柔軟に共有して割り当てることができます。
前提条件: DRA をサポートするには、GKE Standard クラスタでバージョン 1.34 以降を実行している必要があります。
Google Cloud API を有効にする
この Codelab に必要な Google Cloud APIs(Compute Engine API と Kubernetes Engine API)を有効にします。
gcloud services enable compute.googleapis.com container.googleapis.com networkservices.googleapis.com cloudbuild.googleapis.com artifactregistry.googleapis.com telemetry.googleapis.com cloudtrace.googleapis.com aiplatform.googleapis.com
環境変数の設定
設定を簡単にするために、環境変数を定義します。必要に応じて、リージョンまたは命名規則を調整できます。
export PROJECT_ID=$(gcloud config get-value project)
export ZONE=us-central1-a
export CLUSTER_NAME=ai-agent-cluster
export NODEPOOL_NAME=dra-accelerator-pool
gcloud config set project $PROJECT_ID
gcloud config set compute/region $ZONE
作業ディレクトリを作成する
このラボ専用の作業ディレクトリを作成し、そのディレクトリに移動して、ファイルを整理します。
mkdir -p ~/gke-ai-agent-lab
cd ~/gke-ai-agent-lab
権限を構成する(省略可)
制限付きプロジェクトまたは共有環境で実行している場合は、クラスタの作成とビルドの実行に必要な権限がアカウントに付与されていることを確認します。
export MY_ACCOUNT=$(gcloud config get-value account)
# Grant Container Admin to create clusters and manage nodes if needed
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/container.admin"
# Grant Cloud Build Builder to run builds
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/cloudbuild.builds.builder"
GKE クラスタを作成する
DRA をサポートするには、GKE Standard クラスタでバージョン 1.34 以降を実行している必要があります。インテリジェントな推論スケジューリングをサポートするには、Gateway API コントローラを有効にする必要もあります。
このラボでは、新しい VPC ネットワークとサブネットを作成します。
まず、VPC ネットワークを作成します。
gcloud compute networks create ai-agent-network --subnet-mode=custom
次に、GKE ノードのサブネットを作成します。
gcloud compute networks subnets create ai-agent-subnet \
--network=ai-agent-network \
--range=10.0.0.0/20 \
--region=us-central1
Gateway API(gke-l7-regional-internal-managed)では、Envoy プロキシをホストするための専用サブネットも必要です。新しいネットワークにこのプロキシ専用サブネットを作成します。
gcloud compute networks subnets create proxy-only-subnet \
--purpose=REGIONAL_MANAGED_PROXY \
--role=ACTIVE \
--region=us-central1 \
--network=ai-agent-network \
--range=192.168.10.0/24
新しいネットワークとサブネットを使用してクラスタを作成します。
gcloud beta container clusters create $CLUSTER_NAME \
--zone $ZONE \
--num-nodes 1 \
--machine-type n2-standard-4 \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--gateway-api=standard \
--managed-otel-scope=COLLECTION_AND_INSTRUMENTATION_COMPONENTS \
--network=ai-agent-network \
--subnetwork=ai-agent-subnet
デフォルトのプラグインを無効にしてノードプールを作成する
デバイス管理を DRA に引き渡すには、デフォルトの GPU ドライバのインストールと標準のデバイス プラグインを明示的に無効にするノードプールを作成する必要があります。
次の gcloud コマンドを実行して、必要な DRA ラベルを使用して GPU ノードプール(NVIDIA L4 などを使用)をプロビジョニングします。
gcloud container node-pools create $NODEPOOL_NAME \
--cluster=$CLUSTER_NAME \
--location=$ZONE \
--machine-type=g2-standard-24 \
--accelerator=type=nvidia-l4,count=2,gpu-driver-version=disabled \
--node-labels=gke-no-default-nvidia-gpu-device-plugin=true,nvidia.com/gpu.present=true \
--num-nodes 3
DaemonSet を使用して NVIDIA ドライバをインストールする
事前構成された Google Cloud DaemonSet を使用して、必要なベース NVIDIA デバイス ドライバをノードに手動でインストールします。
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
DRA ドライバをインストールする
次に、特定の DRA ドライバをクラスタにインストールします。NVIDIA GPU の場合は、Helm を使用してデプロイできます。
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
helm install nvidia-dra-driver-gpu nvidia/nvidia-dra-driver-gpu \
--version="25.3.2" --create-namespace --namespace=nvidia-dra-driver-gpu \
--set nvidiaDriverRoot="/home/kubernetes/bin/nvidia/" \
--set gpuResourcesEnabledOverride=true \
--set resources.computeDomains.enabled=false \
--set kubeletPlugin.priorityClassName="" \
--set 'kubeletPlugin.tolerations[0].key=nvidia.com/gpu' \
--set 'kubeletPlugin.tolerations[0].operator=Exists' \
--set 'kubeletPlugin.tolerations[0].effect=NoSchedule'
DeviceClass を理解する
DeviceClass YAML を手動で記述または適用する必要はありません。DRA 用に GKE インフラストラクチャを設定してドライバをインストールすると、ノードで実行されている DRA ドライバが、クラスタ内に DeviceClass オブジェクトを自動的に作成します。
ResourceClaimTemplate を構成する
llm-d Pod がこれらのアクセラレータを動的にリクエストできるようにするには、ResourceClaimTemplate を作成します。このテンプレートは、リクエストされたデバイス構成を定義し、ワークロード用に Pod ごとに一意の ResourceClaim を自動的に作成するように Kubernetes に指示します。
次のコマンドを実行して claim-template.yaml を作成します。
cat > claim-template.yaml <<EOF
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: gpu-claim-template
spec:
spec:
devices:
requests:
- name: single-gpu
exactly:
deviceClassName: gpu.nvidia.com
allocationMode: ExactCount
count: 1
EOF
テンプレートをクラスタに適用します。
kubectl apply -f claim-template.yaml
4. llm-d と DRA を使用してインテリジェント推論スケジューリングをデプロイする
このステップでは、推論スケジューラで強化されたスマート Envoy ロードバランサの背後に大規模言語モデルをデプロイします。この構成は、プレフィックス キャッシュ対応ルーティングを適用してモデル提供を最適化します。GKE Inference Gateway は、マイクロサービス間の共有コンテキストを認識し、リクエストを同じモデル レプリカにインテリジェントにルーティングすることで、キャッシュ ヒットを最大化し、最初のトークンまでの時間を短縮し、費用対効果を向上させます。
環境を準備する
ターゲット Namespace を設定します。
export NAMESPACE=ai-agents
kubectl create namespace $NAMESPACE
モデルの重みを pull するために必要な Hugging Face トークンを安全に保存します。
# Replace with your actual Hugging Face token
kubectl create secret generic llm-d-hf-token \
--from-literal=HF_TOKEN="your_hugging_face_token" \
-n $NAMESPACE
Helm 構成ファイルを作成する
モデルサービスと推論ゲートウェイ拡張機能の構成は、公式の llm-d ガイドに基づいています。
まず、モデルサービス用の ms-values.yaml ファイルを作成します。
cat <<EOF > ms-values.yaml
multinode: false
modelArtifacts:
uri: "hf://Qwen/Qwen2.5-Coder-14B-Instruct"
name: "Qwen/Qwen2.5-Coder-14B-Instruct"
size: 50Gi # Slightly larger than the default to accommodate weights
authSecretName: "llm-d-hf-token"
labels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
llm-d.ai/accelerator-variant: "gpu"
llm-d.ai/accelerator-vendor: "nvidia"
llm-d.ai/model: "qwen-2-5-coder-14b"
routing:
proxy:
enabled: false # removes sidecar from deployment - no PD in inference scheduling
targetPort: 8000 # controls vLLM port to matchup with sidecar if deployed
accelerator:
dra: true
type: "nvidia"
resourceClaimTemplates:
nvidia:
class: "gpu.nvidia.com"
match: "exactly"
name: "gpu-claim-template"
decode:
create: true
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
parallelism:
tensor: 2
data: 1
replicas: 3
monitoring:
podmonitor:
enabled: true
portName: "vllm"
path: "/metrics"
interval: "30s"
containers:
- name: "vllm"
image: ghcr.io/llm-d/llm-d-cuda:v0.5.1
modelCommand: vllmServe
args:
- "--disable-uvicorn-access-log"
- "--gpu-memory-utilization=0.85"
- "--enable-auto-tool-choice"
- "--tool-call-parser"
- "hermes"
ports:
- containerPort: 8000
name: vllm
protocol: TCP
resources:
limits:
cpu: '16'
memory: 64Gi
requests:
cpu: '16'
memory: 64Gi
mountModelVolume: true
volumeMounts:
- name: metrics-volume
mountPath: /.config
- name: shm
mountPath: /dev/shm
- name: torch-compile-cache
mountPath: /.cache
startupProbe:
httpGet:
path: /v1/models
port: vllm
initialDelaySeconds: 15
periodSeconds: 30
timeoutSeconds: 5
failureThreshold: 120
livenessProbe:
httpGet:
path: /health
port: vllm
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /v1/models
port: vllm
periodSeconds: 5
timeoutSeconds: 2
failureThreshold: 3
volumes:
- name: metrics-volume
emptyDir: {}
- name: torch-compile-cache
emptyDir: {}
- name: shm
emptyDir:
medium: Memory
sizeLimit: 20Gi
prefill:
create: false
EOF
次に、GKE Inference Gateway 拡張機能の gaie-values.yaml ファイルを作成します。
cat <<EOF > gaie-values.yaml
inferenceExtension:
replicas: 1
image:
name: llm-d-inference-scheduler
hub: ghcr.io/llm-d
tag: v0.6.0
pullPolicy: Always
extProcPort: 9002
pluginsConfigFile: "default-plugins.yaml"
tracing:
enabled: false
monitoring:
interval: "10s"
prometheus:
enabled: true
auth:
secretName: inference-scheduling-gateway-sa-metrics-reader-secret
inferencePool:
targetPorts:
- number: 8000
modelServerType: vllm
modelServers:
matchLabels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
EOF
構成について
この構成では、次の主な機能を備えたハイパフォーマンス推論スタックが設定されます。
- モデルの選択: コード生成とツールの使用に最適化された Qwen 2.5 Coder 14B モデル(
modelArtifacts)を使用します。 - DRA 統合:
acceleratorセクションでは、gpu.nvidia.comデバイスクラスと以前に作成したgpu-claim-templateを対象に、動的リソース割り当て(dra: true)を有効にします。 - パフォーマンスの最適化:
parallelism.tensor: 2は、GPU 間のテンソル並列処理を構成します。- vLLM の
argsには--enable-auto-tool-choiceが含まれており、コーディング エージェントがツールを効果的に使用できるようになっています。 - 削減された
cpuリクエストとmemoryリクエストはg2-standard-24マシンタイプに適合します。
- インテリジェント ルーティング: Inference Gateway 拡張機能(
gaie-values.yaml)は、vllmモデルサーバーをモニタリングし、KV キャッシュヒットを最大化するようにリクエストをルーティングするように構成されています。
Helm を使用して推論スケジューリング スタックをデプロイする
次に、llm-d Helm リポジトリを追加し、インフラストラクチャ、ゲートウェイ拡張機能、モデルサービスを個別にデプロイします。
まず、必要なリポジトリを追加します。
helm repo add llm-d-infra https://llm-d-incubation.github.io/llm-d-infra/
helm repo add llm-d-modelservice https://llm-d-incubation.github.io/llm-d-modelservice/
helm repo update
インフラストラクチャの前提条件をデプロイする
このグラフは、スタックに必要なベースライン Gateway 構成をインストールします。
helm install infra-is llm-d-infra/llm-d-infra \
--namespace $NAMESPACE \
--set gateway.gatewayClassName=gke-l7-rilb \
--set gateway.gatewayParameters.enabled=false \
--set gateway.gatewayParameters.istio.accessLogging=false
GKE Inference Gateway 拡張機能をデプロイする
このステップでは、モデルの KV キャッシュをモニタリングしてインテリジェントなルーティングの決定を行う InferencePool と Endpoint Picker をデプロイします。
helm install gaie-is oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool \
--version v1.3.1 \
--namespace $NAMESPACE \
-f gaie-values.yaml \
--set provider.name=gke \
--set inferenceExtension.monitoring.prometheus.enabled=true
モデルサービスをデプロイする
最後に、LLM サービスをデプロイします。このサービスは、DRA を使用して L4 GPU を安全に要求します。
helm install ms-is llm-d-modelservice/llm-d-modelservice \
--version v0.4.7 \
--namespace $NAMESPACE \
-f ms-values.yaml \
--set decode.monitoring.podmonitor.enabled=false
vLLM 用の Google Cloud Observability を有効にする
汎用 Helm チャートは、標準の Prometheus Operator PodMonitor リソース(monitoring.coreos.com/v1)のデプロイを試みることがよくあります。これらの CRD がインストールされていない場合、エラーが発生する可能性があります。
Helm の組み込みモニタリング トグルを切り替える代わりに、false のままにして、互換性のある monitoring.googleapis.com/v1 API グループを使用して Google Cloud Managed Prometheus(GMP)PodMonitoring リソースを手動で適用します。
次のコマンドを実行して podmonitoring.yaml を作成します。
cat > podmonitoring.yaml <<EOF
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: ms-vllm-metrics
spec:
selector:
matchLabels:
llm-d.ai/model: "qwen-2-5-coder-14b" # Matches the label in values.yaml
endpoints:
- port: 8000 # vllm port
interval: 30s
path: /metrics
EOF
PodMonitoring リソースをクラスタに適用します。
kubectl apply -f podmonitoring.yaml -n $NAMESPACE
インストールを確認する
コンポーネントが正常にインストールされたことを確認します。Namespace で 3 つの Helm リリースがすべてアクティブになり、対応する Pod が初期化されていることを確認します。
helm ls -n $NAMESPACE
kubectl get pods -n $NAMESPACE
ms-is Pod の起動には 5 ~ 10 分ほどかかることがあります。出力は次のようになります。
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
gaie-is ai-agents 1 2026-03-28 16:51:41.055881618 +0000 UTC deployed inferencepool-v1.3.1 v1.3.1
infra-is ai-agents 1 2026-03-28 16:51:03.71042542 +0000 UTC deployed llm-d-infra-v1.4.0 v0.4.0
ms-is ai-agents 1 2026-03-28 17:30:00.341918958 +0000 UTC deployed llm-d-modelservice-v0.4.7 v0.4.0
NAME READY STATUS RESTARTS AGE
gaie-is-epp-848965cb4-78ktp 1/1 Running 0 10m
ms-is-llm-d-modelservice-decode-67548d5f8c-f25f4 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-rblvs 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-w6fcd 1/1 Running 0 6m2s
5. GKE Inference Gateway を使用してインテリジェント ルーティングを構成する
ステップ 4 で llm-d Helm チャートをデプロイすると、Gateway オブジェクトと InferencePool オブジェクトが自動的にプロビジョニングされました。InferencePool は、同じベースモデルとコンピューティング構成を共有する vllm モデル提供 Pod をグループ化します。
次に、InferenceObjective を構成してコーディング エージェント リクエストの優先度を設定し、HTTPRoute を構成して、エンドポイント ピッカーを活用して KV キャッシュ ヒットを最大化する方法で受信トラフィックをルーティングするよう Gateway に指示する必要があります。
自動生成されたリソースを確認する
まず、llm-d Helm チャートが Gateway リソースと InferencePool リソースを正常に作成したことを確認します。
kubectl get gateway,inferencepool -n $NAMESPACE
infra-is-inference-gateway という名前の Gateway と、gaie-is という名前の InferencePool が表示されます。次のようなものです。
NAME CLASS ADDRESS PROGRAMMED AGE
gateway.gateway.networking.k8s.io/infra-is-inference-gateway gke-l7-regional-internal-managed 10.128.0.5 True 13m
NAME AGE
inferencepool.inference.networking.k8s.io/gaie-is 12m
HTTPRoute を作成する
HTTPRoute リソースは、Gateway をバックエンド InferencePool にマッピングします。これにより、GKE Inference Gateway は、受信リクエスト本文を分析し、共有コンテキストに基づいてプレフィックス キャッシュ ヒットを最大化するように動的にルーティングします。
次のコマンドを実行して httproute.yaml を作成します。
cat > httproute.yaml <<EOF
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: agent-route
spec:
parentRefs:
- group: gateway.networking.k8s.io
kind: Gateway
name: infra-is-inference-gateway
rules:
- backendRefs:
- group: inference.networking.k8s.io
kind: InferencePool
name: gaie-is
weight: 1
matches:
- path:
type: PathPrefix
value: /
EOF
ルートをクラスタに適用します。
kubectl apply -f httproute.yaml -n $NAMESPACE
6. Agent Sandbox による安全なコード実行
高性能の推論バックエンドが実行されているので、Agent Sandbox を使用して、AI 生成コードがクラスタから安全に分離されて実際に実行される安全な環境を準備しましょう。
Agent Sandbox コントローラをデプロイする
AI エージェントがコードを生成して実行する場合、インフラストラクチャで信頼できないワークロードが実行されます。エージェントが悪意のあるコードを生成した場合、内部ネットワークのスキャンや基盤となるホストノードの不正使用を試みる可能性があります。
GKE Agent Sandbox は、各コンテナに専用のゲスト カーネルを提供するオープンソースのコンテナ ランタイムである gVisor を利用します。これにより、信頼できないコードがホストノードに直接システムコールを行うことができなくなります。
公式リリース マニフェストを適用して、Agent Sandbox コントローラとその必須コンポーネントをデプロイします。
kubectl apply \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/manifest.yaml \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/extensions.yaml
サンドボックス テンプレートとウォーム プールを構成する
次に、Python 分析環境の再利用可能なブループリントとして機能する SandboxTemplate を確立し、gvisor ランタイム クラスを明示的にターゲットにします。Standard クラスタで手動ノードプールを管理せずにデプロイを簡素化するには、標準の autopilot を利用できます。
ComputeClass を使用して、gVisor ワークロードをネイティブでサポートするマネージド コンピューティング ノードをオンデマンドで動的にプロビジョニングします。
セキュア カーネルの初期化によってレイテンシが増加する可能性があるため、SandboxWarmPool もデプロイします。これにより、指定された数の事前初期化されたサンドボックスが準備され、コード生成エージェントがそれらを要求して 1 秒以内にコードの実行を開始できるようになります。
まず、エージェント サンドボックス ランタイム用の新しい Namespace を作成します。
kubectl create namespace agent-sandbox
次の行を sandbox-template-and-pool.yaml として保存します。
cat > sandbox-template-and-pool.yaml <<EOF
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxTemplate
metadata:
name: python-runtime-template
namespace: agent-sandbox
spec:
podTemplate:
metadata:
labels:
sandbox: python-sandbox-example
spec:
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: python-runtime
image: registry.k8s.io/agent-sandbox/python-runtime-sandbox:v0.1.0
ports:
- containerPort: 8888
readinessProbe:
httpGet:
path: "/"
port: 8888
initialDelaySeconds: 0
periodSeconds: 1
resources:
requests:
cpu: "250m"
memory: "512Mi"
ephemeral-storage: "512Mi"
restartPolicy: "OnFailure"
---
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxWarmPool
metadata:
name: python-sandbox-warmpool
namespace: agent-sandbox
spec:
replicas: 2
sandboxTemplateRef:
name: python-runtime-template
EOF
構成を適用します。
kubectl apply -f sandbox-template-and-pool.yaml
warmpool Pod が初期化されるまで 2 ~ 3 分ほど待ちます。次のコマンドを使用して、基盤となるコンピューティングがスケールアップしている間に Pending から Running に正常に移行したことを確認できます。
kubectl get pods -n agent-sandbox -w
2 つの python-sandbox-warmpool-*** Pod が Running と 1/1 の Ready としてリストされていることを確認したら、安全な実行環境が事前準備され、要求できるようになります。
サンドボックス ルーターをデプロイする
コード生成エージェントは、サンドボックス ルーターを使用して、実行コマンドを分離された Pod に安全にディスパッチします。
次のコマンドを実行して sandbox-router.yaml を作成します。
cat > sandbox-router.yaml <<EOF
apiVersion: v1
kind: Service
metadata:
name: sandbox-router-svc
namespace: agent-sandbox
spec:
type: ClusterIP
selector:
app: sandbox-router
ports:
- name: http
protocol: TCP
port: 8080
targetPort: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sandbox-router-deployment
namespace: agent-sandbox
spec:
replicas: 2
selector:
matchLabels:
app: sandbox-router
template:
metadata:
labels:
app: sandbox-router
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: sandbox-router
containers:
- name: router
image: us-central1-docker.pkg.dev/k8s-staging-images/agent-sandbox/sandbox-router:v20260225-v0.1.1.post3-10-ga5bcb57
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 10
resources:
requests:
cpu: "250m"
memory: "512Mi"
limits:
cpu: "1000m"
memory: "1Gi"
securityContext:
runAsUser: 1000
runAsGroup: 1000
EOF
構成を適用します。
kubectl apply -f sandbox-router.yaml
ネットワーク分離を実装する
実行環境をさらにロックダウンして、不正なラテラル ムーブメントを防ぐには、ネットワーク ポリシーを適用します。これにより、サンドボックスが「エアギャップ」され、Google Cloud メタデータ サーバーや他の機密性の高い内部ネットワークにアクセスできなくなります。
次の行を sandbox-policy.yaml として保存します。
cat > sandbox-policy.yaml <<EOF
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: restrict-sandbox-egress
namespace: agent-sandbox
spec:
podSelector:
matchLabels:
sandbox: python-sandbox-example
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 0.0.0.0/0
except:
- 169.254.169.254/32 # Block metadata server
EOF
ポリシーを適用します。
kubectl apply -f sandbox-policy.yaml
コンポーネントを確認する
分離されたコード サンドボックス クラスタレイヤが完全に構成されていることを確認するには、次の状態検証コマンドを実行します。
まず、サンドボックス Pod とルーターが実行中で準備完了であることを確認します。
kubectl get pods -n agent-sandbox
出力は次のようになります。
NAME READY STATUS RESTARTS AGE
python-sandbox-warmpool-7zlkv 1/1 Running 0 3m25s
python-sandbox-warmpool-cxln2 1/1 Running 0 3m25s
sandbox-router-deployment-668dfbbbb6-g9mpd 1/1 Running 0 42s
sandbox-router-deployment-668dfbbbb6-ppllz 1/1 Running 0 42s
サンドボックス ルーターのロードバランサ / IP の公開を確認する
kubectl get service sandbox-router-svc -n agent-sandbox
出力は次のようになります。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
sandbox-router-svc ClusterIP 34.118.237.244 <none> 8080/TCP 114s
下り(外向き)ネットワーク ポリシー ルールが存在することを確認する
kubectl get networkpolicy restrict-sandbox-egress -n agent-sandbox
出力は次のようになります。
NAME POD-SELECTOR AGE
restrict-sandbox-egress sandbox=python-sandbox-example 113s
次の点をご確認ください。
python-sandbox-warmpool-***Pod がRunningと1/1の Ready 状態です。sandbox-router-deployment-***レプリカはRunningと1/1の準備ができています。sandbox-router-svcにアクセスでき、restrict-sandbox-egressポリシーが一致するサンドボックス ラベルを正常に保護しています。
安全な実行環境が確保され、初期化されたので、オペレーションの実際の頭脳であるコード生成エージェントをデプロイする準備が整いました。
7. コード生成エージェント(ADK)をビルドしてデプロイする
安全な実行サンドボックスと高性能 LLM バックエンドの両方が構成されたので、システムの「頭脳」である Agent Development Kit(ADK)を使用したコード生成エージェントを構築できます。
このエージェントは、Python の専門家として機能するように設計されています。テキストのみを生成する標準的な chatbot とは異なり、このエージェントには、インタラクティブに問題を解決できるコード実行ツールが搭載されています。次のループに従います。
- リクエストに基づいて Python コードを作成します。
- ステップ 6 で設定した GKE Agent Sandbox 内でコードを安全に実行します。
- 出力を検証する、または実行中に発生したエラーを読み取る。
- テスト済みの動作するソリューションを自信を持って提供します。
エージェントに安全なサンドボックス実行環境へのアクセス権を付与することで、エージェントは独自のロジックを検証し、障害を自動的にデバッグできるようになり、ソフトウェア開発タスクの実行能力が大幅に向上します。
ADK Reasoning エージェントを開発する
まず、エージェントの動作を定義し、ステップ 6 で作成した Sandbox ツールを装備する Python ロジックを記述します。このセクションでは、ハイブリッド モデル戦略も構成します。エージェントは、GKE クラスタで実行されているセルフホストの Qwen モデルを優先しますが、ローカルモデルが遅い場合や使用できない場合は、Vertex AI の Gemini 2.5 Flash に自動的にフォールバックして、高い信頼性を確保します。
エージェント コード用の新しいディレクトリを作成します。
mkdir -p ~/gke-ai-agent-lab/root_agent
cd ~/gke-ai-agent-lab
次の内容で root_agent/agent.py という名前のファイルを作成します。
cat <<'EOF' > root_agent/agent.py
import os
from google.adk.agents import Agent
from google.adk.models.lite_llm import LiteLlm
from k8s_agent_sandbox import SandboxClient
import requests
# Instantiate the client globally to track sandboxes
sandbox_client = SandboxClient()
def run_python_code(code: str) -> str:
"""
Executes Python code safely in the GKE Agent Sandbox.
Use this tool whenever you need to execute code to solve a problem.
"""
sandbox = sandbox_client.create_sandbox(template="python-runtime-template", namespace="agent-sandbox")
try:
command = f"python3 -c \"{code}\""
result = sandbox.commands.run(command)
if result.stderr:
return f"Error: {result.stderr}"
return result.stdout
finally:
# Ensure the sandbox is deleted after use to avoid leaking resources
sandbox_client.delete_sandbox(sandbox.claim_name, namespace="agent-sandbox")
# Define the ADK Agent with a fallback mechanism.
# It prioritizes the Qwen 2.5 Coder model running on our Inference Gateway.
# If the local model is unavailable, it falls back to Gemini 2.5 Flash on Vertex AI.
root_agent = Agent(
name="CodeGenerationAgent",
model=LiteLlm(
model="openai/Qwen/Qwen2.5-Coder-14B-Instruct",
fallbacks=["vertex_ai/gemini-2.5-flash"],
timeout=10
),
instruction="""
You are an expert Python developer.
1. Write Python code to solve the user's problem.
2. Execute the code using the `run_python_code` tool to verify it works.
3. Return the exact output and a brief explanation of the code.
""",
tools=[run_python_code]
)
EOF
ADK がモジュールを認識できるように __init__.py ファイルを作成します。
echo "from . import agent" > ~/gke-ai-agent-lab/root_agent/__init__.py
環境変数を設定します。ADK アプリケーションは、LLM リクエストを正常に転送するために、Gateway の IP アドレスを必要とします。ADK は標準の Open-AI 互換エンドポイント(vLLM が Gateway 経由で提供)をサポートしているため、デフォルトの API ベース URL をオーバーライドできます。
export GATEWAY_IP=$(kubectl get gateway infra-is-inference-gateway -n $NAMESPACE -o jsonpath='{.status.addresses[0].value}')
cat <<EOF > ~/gke-ai-agent-lab/root_agent/.env
OPENAI_API_BASE=http://${GATEWAY_IP}/v1
OPENAI_API_KEY=no-key-required
# Vertex AI settings for fallback (Authentication is handled by Workload Identity)
VERTEXAI_PROJECT=$PROJECT_ID
VERTEXAI_LOCATION=${ZONE%-[a-z]}
EOF
エージェント アプリケーションをコンテナ化する
エージェントをパッケージ化して、GKE 内で安全に実行できるようにする必要があります。
kubectl、ADK ライブラリ、エージェント サンドボックス クライアントをインストールする ~/gke-ai-agent-lab に Dockerfile を作成します。
cat <<'EOF' > ~/gke-ai-agent-lab/Dockerfile
FROM python:3.11-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
RUN apt-get update && apt-get install -y git curl \
&& curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl" \
&& install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl \
&& rm kubectl && apt-get clean && rm -rf /var/lib/apt/lists/*
RUN pip install --no-cache-dir "google-adk[extensions,otel-gcp]>=1.27.4" litellm pandas "git+https://github.com/kubernetes-sigs/agent-sandbox.git@main#subdirectory=clients/python/agentic-sandbox-client" \
"opentelemetry-instrumentation-google-genai>=0.4b0" \
"opentelemetry-exporter-otlp" \
"opentelemetry-instrumentation-vertexai>=2.0b0"
COPY ./root_agent /app/root_agent
EXPOSE 8080
ENTRYPOINT ["adk", "web", "--host", "0.0.0.0", "--port", "8080", "--otel_to_cloud"]
EOF
コンテナ イメージを保存する Artifact Registry リポジトリを作成します。
gcloud artifacts repositories create agent-repo \
--repository-format=docker \
--location=us-central1
Cloud Build を使用してコンテナ イメージをビルドし、push します。
gcloud builds submit --tag us-central1-docker.pkg.dev/$PROJECT_ID/agent-repo/code-agent:v1 ~/gke-ai-agent-lab/
RBAC を使用して GKE にデプロイする
最後に、エージェントをクラスタにデプロイします。このデプロイには、Role と RoleBinding が含まれており、エージェントに SandboxWarmPool からインスタンスを要求する権限が付与されます。
このデプロイでは、Kubernetes ServiceAccount を使用して、エージェントが Sandbox クレーム API と通信できるようにします。ローカル クラスタ リソースとローカル vLLM ゲートウェイ エンドポイントにアクセスするため、Google IAM ServiceAccount は必要ありません。
gVisor で標準の Deployment を使用する理由
ステップ 6 では、SandboxTemplate API と SandboxClaim API を使用して、生成された Python コード(ツールの実行)用の一時的な使い捨てサンドボックスを作成しました。
エージェント ウェブ UI(Brain)自体には、runtimeClassName: gvisor を使用した標準の Kubernetes Deployment 仕様を使用しています。
- 違い: 標準の
SandboxClaimsはエフェメラルで、ゼロから 1 までです(信頼できないスクリプトに最適)。標準のDeploymentは長時間実行され、永続的です。安定した KubernetesServiceとロードバランサが必要なウェブ UI に最適です。標準の Deployment でruntimeClassName: gvisorを直接使用すると、標準のDeployment機能を維持しながら、gVisor カーネルの分離を実現できます。
次の行を deployment.yaml として保存します。
cat <<EOF > ~/gke-ai-agent-lab/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: code-agent
labels:
app: code-agent
spec:
replicas: 1
selector:
matchLabels:
app: code-agent
template:
metadata:
labels:
app: code-agent
spec:
serviceAccount: adk-agent-sa
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: code-agent
image: us-central1-docker.pkg.dev/YOUR_PROJECT_ID/agent-repo/code-agent:v1
imagePullPolicy: Always
env:
- name: OPENAI_API_KEY
value: "no-key-required"
- name: OPENAI_API_BASE
value: "http://YOUR_GATEWAY_IP/v1"
- name: VERTEXAI_PROJECT
value: "YOUR_PROJECT_ID"
- name: VERTEXAI_LOCATION
value: "YOUR_REGION"
- name: OTEL_SERVICE_NAME
value: "code-agent"
- name: GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY
value: "true"
- name: OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT
value: "true"
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: code-agent-service
spec:
selector:
app: code-agent
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: agent-sandbox
name: sandbox-creator-role
rules:
- apiGroups: [""]
resources: ["services", "pods", "pods/portforward"]
verbs: ["get", "list", "watch", "create"]
- apiGroups: ["extensions.agents.x-k8s.io"]
resources: ["sandboxclaims"]
verbs: ["create", "get", "list", "watch", "delete"]
- apiGroups: ["agents.x-k8s.io"]
resources: ["sandboxes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: adk-agent-binding
namespace: agent-sandbox
subjects:
- kind: ServiceAccount
name: adk-agent-sa
namespace: default
roleRef:
kind: Role
name: sandbox-creator-role
apiGroup: rbac.authorization.k8s.io
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: adk-agent-sa
EOF
オブザーバビリティの IAM 権限を付与する
エージェントがテレメトリー データ(ログとトレース)を Google Cloud に送信できるようにするには、Workload Identity を使用して Kubernetes サービス アカウント adk-agent-sa に必要な権限を付与する必要があります。
Cloud Shell で次のコマンドを実行します。
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# Grant permission to write logs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/logging.logWriter \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to write traces
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/cloudtrace.agent \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to use Vertex AI
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/aiplatform.user \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
次のコマンドを実行して、YOUR_PROJECT_ID を実際のプロジェクト ID に自動的に置き換え、構成を適用します。
sed -i "s/YOUR_PROJECT_ID/$PROJECT_ID/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_GATEWAY_IP/$GATEWAY_IP/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_REGION/$ZONE/g" ~/gke-ai-agent-lab/deployment.yaml
kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml
8. 観察と検証
完全に統合されたシステムをテストします。
UI でコード生成エージェントをテストする
ADK ウェブ UI の外部 IP を確認します。
kubectl get services code-agent-service
出力は次のようになります。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
code-agent-service LoadBalancer 34.118.230.182 34.31.250.60 80:32471/TCP 2m14s
- ブラウザを開き、
http://[EXTERNAL-IP]に移動します。 - ADK ウェブ インターフェースで、右上にあるプルダウン メニューから [root_agent] が選択されていることを確認します。次に、エージェントに次のように入力します。
Write a python script that prints 'Hello from the isolated sandbox'.
エージェントが推論バックエンドとサンドボックスをどのように使用しているかを確認するには、以下のCloud Observability を使用してモデル統計情報を確認すると GKE UI を使用してエージェントのオブザーバビリティを確認するのセクションに進み、ダッシュボードを表示します。
GKE UI でエージェントのオブザーバビリティを確認する
プロンプトを実行したので、テレメトリー データを見てみましょう。これにより、推論スケジューラと vLLM のパフォーマンスを把握できます。
エージェント ダッシュボードにアクセスする
- [Kubernetes Engine] > [ワークロード] ページに移動します。
- [code-agent] デプロイをクリックして、[デプロイの詳細] ページを開きます。
- [オブザーバビリティ] タブをクリックします。
- オブザーバビリティ ダッシュボードの左側のナビゲーション パネルに、サブタブを含む新しい [エージェント] セクションが表示されます。
探索する内容
次のサブタブで、エージェント アプリケーションの動作を確認します。
- 概要: セッション、平均ターン数、呼び出しのスコアカードを表示します。
- モデル: エージェントが使用したモデル別に、モデル呼び出しの数、エラー率、レイテンシを確認できます。
- ツール: ツール呼び出しと実行時間をモニタリングして、エージェントがサンドボックス実行ツールをどの程度効果的に使用しているかを確認します。
- 使用量: トークンの使用量と標準コンテナ リソース割り当て(CPU とメモリ)を追跡します。
- エージェント トレース: このタブに切り替えると、実行セッションまたは未加工のトレース スパンのリストが表示されます。行をクリックすると、選択したトレースの詳細を含むフライアウトが開きます。
vLLM のモデルレベルの指標と ADK のアプリレベルのテレメトリーを組み合わせることで、GKE 上の生成 AI エージェントのフルスタックのオブザーバビリティを実現できます。
Cloud Observability で vLLM モデルの統計情報を確認する
プロンプトを実行したので、テレメトリー データを見てみましょう。これにより、推論スケジューラと vLLM のパフォーマンスを把握できます。
ダッシュボードにアクセスする
- Google Cloud Console に移動します。
- [モニタリング] > [ダッシュボード] に移動します。
- [vLLM Prometheus Overview] ダッシュボードを検索して選択します。
注目すべき指標
ダッシュボードを表示する際は、次の主要な指標に注目して、GKE Inference Gateway とプレフィックス キャッシュ保存の影響を確認します。
- KV キャッシュ使用率(
vllm:gpu_cache_usage):- 重要である理由: これは、コンテキストのキャッシュ保存に使用されている GPU メモリの量を示します。この値が高い場合は、システムがコンテキストを保持して、今後のリクエストを高速化していることを意味します。同じプロンプトを複数回実行すると、この使用率が上昇してから安定します。
- 実行中のリクエストと待機中のリクエスト(
vllm:num_requests_running対vllm:num_requests_waiting):- 重要である理由: これは負荷を示します。待機中のリクエストが多い場合は、ノードが過負荷になっていることを意味します。
- トークン スループット(
vllm:request_prompt_tokens_totとvllm:request_generation_tokens_tot):- 重要である理由: クラスタで処理された入力トークンと出力トークンの量を追跡します。
- 最初のトークンまでの時間(TTFT):
- 重要である理由: これは、インタラクティブ エージェントにとって重要な指標です。GKE Inference Gateway でプレフィックス キャッシュ対応ルーティングを使用すると、共通のコンテキスト(システム プロンプトや大きなコンテキスト ウィンドウなど)を共有するリクエストが同じレプリカに転送され、既存のキャッシュ ヒットを再利用することで TTFT が最小限に抑えられます。
試してみるテスト
これらのシナリオを試して、指標がリアルタイムで変化し、適切なスケジューリングが検証されることを確認してください。
実験 1: 「繰り返し速度」(プレフィックス キャッシュ ヒット)
- エージェントに複雑なプロンプトを送信します(例: 「100 MB の CSV ファイルを解析して統計情報を計算する Python スクリプトを作成してください。」)。
- 応答が返ってきたら、まったく同じプロンプトをすぐに再度送信します。
- プレフィックス キャッシュ ヒット率と最初のトークンまでの時間(TTFT)を確認します。
- 確認事項: プレフィックス キャッシュ ヒット率が 100% に上昇し、TTFT が大幅に低下します。
- 意味: GKE Inference Gateway が共有コンテキストを認識し、評価済みのコンテキスト キャッシュを再利用したまったく同じレプリカにルーティングしました。
テスト 2: クラウドへのフォールバック(モデルの信頼性)
- ローカルの Qwen モデルの障害をシミュレートするには、推論サービスを停止するか、デプロイに偽の
OPENAI_API_BASEを指定します。 deployment.yamlのOPENAI_API_BASEを存在しない IP またはポートに更新し、変更を適用します。sed -i "s|value: \"http://$GATEWAY_IP/v1\"|value: \"http://10.0.0.1:8080/v1\"|g" ~/gke-ai-agent-lab/deployment.yaml kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml- Pod が再起動するまで待ってから、UI でエージェントにプロンプトを送信します。
- 表示される内容: エージェントは引き続き正常に応答します。
- 意味:
fallbacks構成により、ADK はローカル Qwen エンドポイントの障害を認識し、リクエストを Vertex AI の Gemini 2.5 Flash にシームレスに転送しました。Vertex AI へのこれらのフォールバック呼び出しはローカル vLLM 推論ゲートウェイをバイパスするため、vLLM を通過するトラフィックのみを追跡する [エージェントのオブザーバビリティ > モデル] ダッシュボードには表示されません。
動的リソース割り当て(DRA)の機能について
vLLM と Inference Gateway はリクエストのルーティングと処理を最適化しますが、動的リソース割り当て(DRA)により、ワークロードに適切なハードウェアを正確に割り当てることが可能になります。
DRA を使用すると、ResourceClaimTemplate と DeviceClasses を使用して柔軟なハードウェア リソースを定義できるため、クラスタ全体でハードウェアをきめ細かく管理できます。
DRA が AI ワークロードに大きな変化をもたらす理由:
- きめ細かいハードウェア リクエスト: DRA を使用すると、ワークロードが適切なアクセラレータを備えたマシンでスケジュールされるようにするだけでなく、これらのリソースに対する要求を行うことで、ResourceClaim に関連付けられたワークロードによって排他的に使用されるようにすることもできます。
- ライフサイクルの分離: デバイスの所有権は Pod のライフサイクルとは別に管理されます。Pod がクラッシュしても GPU クレームは保持されるため、GPU が解放されて再取得されるのを待つことなく、包括的なデプロイや他のワークロード オブジェクトを再起動できます。
- マルチベンダーの標準化: DRA は、NVIDIA GPU と Google TPU の両方に統一された Kubernetes API を提供します。どちらにデプロイする場合でも同じスキーマを使用するため、ワークロード YAML マニフェストの移植性が高くなります。
この Codelab では、デバイス プラグイン構成がロールアウトをブロックすることなく、gpu-claim-template にシームレスにバインドするように Helm 値を構成する際に、この動作を確認しました。
llm-d の役割について
vLLM がニューラル ネットワークの重みを評価し、GKE Gateway がクエリをルーティングするのに対し、llm-d は構成レイヤとして機能し、それらをすべて結び付ける「接着剤」として機能します。
llm-d がないと、vLLM Deployment、サービス ポート、ボリューム マウント、DRA リソース クレームを最初から宣言するために、生の Kubernetes マニフェストを作成する必要があります。
デプロイで llm-d を使用する理由
- 統合構成(1 行のオーバーライド):
llm-dHelm チャートは、複雑な低レベルの Kubernetes リソースを、簡潔な高レベルの切り替え(accelerator.dra: trueの設定など)にバンドルします。 - 事前審査済みの「Well-Lit-Paths」:
llm-dリポジトリには、エキスパートによってすでにベンチマークとテストが行われている構成が含まれています。llm-d-modelserviceをデプロイすると、GPU メモリ使用率の最適化されたデフォルト、推奨されるプローブ タイミング(ライブネス/準備状況)、指標スクレイピングの正しいエクスポージャーが提供されます。 - シームレスなオブザーバビリティ マッピング:
llm-dは、標準のコンテナポートとスクレイピング パス(/metrics)が正しく公開されるようにします。これにより、手動でデバッグすることなく、デプロイを Google Cloud Monitoring に簡単に接続できます。
つまり、llm-d は再利用可能なアーキテクチャ ブループリントを提供するため、デベロッパーは GKE に推論スタックをデプロイするたびに一から作り直す必要がありません。
詳細: GKE Inference Gateway
標準のレイヤ 7 ロードバランサは、パス(/v1/completions)や Cookie などの HTTP ヘッダーを調べて動作します。GKE Inference Gateway は、生成 AI トラフィック専用に設計されています。
パフォーマンスと効率の向上に貢献する仕組み:
- コンテンツ認識ルーティング(プロンプト ハッシュ): GKE Inference Gateway が JSON リクエスト本文をインターセプトします。プロンプトのハッシュを計算し、どのバックエンド レプリカが GPU メモリ(KV キャッシュ)にこれらのトークンを保持しているかを追跡します。
- キャッシュ ヒットの最大化: テストでプロンプトを繰り返すと、Gateway はまったく同じレプリカにプロンプトを送信しました。プロンプトの評価には大量のコンピューティングが必要です。キャッシュを再利用することで、プロンプトの「再読み取り」を回避し、費用と GPU 時間を節約できます。
- 最初のトークンまでの時間(TTFT)の短縮: TTFT は、ユーザー向けのエージェントにとって重要なユーザビリティ指標です。キャッシュにヒットすることで、モデルは秒単位ではなくミリ秒単位でトークンの生成を開始できます。
- インテリジェントなロード バランシング: 1 つのレプリカの VRAM がキャッシュ ヒットで完全に満たされている場合、Gateway は新しいプロンプトを空きのある別のレプリカに動的に転送し、効率と可用性のバランスを取ることができます。
エージェント サンドボックスがリスクを軽減する仕組み
このラボでは、エージェント サンドボックスが 2 つの分離レイヤを提供することで、AI エージェントに関連するリスクからインフラストラクチャを保護する方法を説明しました。
- 実行ツールを分離する: エージェントは、生成したコードをエフェメラル サンドボックスで実行します。これにより、LLM によって生成された信頼できないコードが安全な隔離環境で実行され、エージェントとクラスタが保護されます。
- 高速起動: WarmPool を使用すると、新しいサンドボックスが 1 秒以内に起動し、コードを実行できるようになります。
- エージェント自体の分離: エージェントの依存関係におけるサプライ チェーンの脆弱性に対する多層防御を提供するため、エージェント アプリケーション自体も gVisor 対応ノード(
runtimeClassName: gvisor経由)で実行しました。
この方法でセキュリティ境界を強化できる理由は次のとおりです。
- システム コール インターセプト: gVisor は、システム コールがホスト Linux カーネルに到達する前にインターセプトします。これにより、コンテナから抜け出してホストノードにアクセスしようとするエクスプロイトがブロックされます。
- 制限された横方向の移動: ネットワーク ポリシーと組み合わせることで、環境が侵害されても、内部メタデータ サーバーをスキャンしたり、クラスタ内の他の機密性の高いサービスにピボットしたりすることはできません。
サンドボックスでのフル エージェントの実行
このラボでは、永続エージェント アプリケーションのツールとしてサンドボックスを使用しました。ただし、センシティブ データを処理する場合や、信頼できない複数のユーザーにサービスを提供する場合など、セキュリティを最大限に高めるには、セッションまたはユーザーごとに専用のサンドボックス内でエージェント アプリケーション全体を実行できます。これにより、エージェントのメモリ、状態、実行環境が完全に分離され、セッションの完了直後に破棄されます。
9. クリーンアップ
この Codelab で使用したリソースについて、Google Cloud アカウントに課金されないようにするには、次の手順で削除します。
リソースを個別に削除する
- GKE クラスタを削除します。
gcloud container clusters delete $CLUSTER_NAME --zone $ZONE --quiet
- Artifact Registry リポジトリを削除します。
gcloud artifacts repositories delete agent-repo --location=us-central1 --quiet
- VPC ネットワークを削除します。
gcloud compute networks delete ai-agent-network --quiet
プロジェクトを削除する
プロジェクトが不要になった場合は、リソースを削除してからプロジェクトを削除できます。
gcloud projects delete $PROJECT_ID
10. まとめ
おめでとうございます!GKE に安全で高性能なコード生成エージェントを構築してデプロイできました。
学習した内容
- GKE で 動的リソース割り当て(DRA)を構成して使用し、GPU リソースを管理する方法。
- GKE Inference Gateway を使用して、プレフィックス キャッシュ対応ルーティングで LLM サービングのパフォーマンスを最適化する方法。
- Agent Sandbox(gVisor)を使用して、GKE で信頼できないコードを安全に実行する方法。
- Google Cloud Managed Service for Prometheus を使用して vLLM のパフォーマンスをモニタリングする方法。
- ADK と GKE マネージド OpenTelemetry を使用して Agent Observability を構成して表示する方法。
次のステップと参考資料
- Agent Sandbox: GKE 上の Agent Sandbox と GKE Sandbox Pod について学習します。
- llm-d: llm-d ガイドを読み、llm-d GitHub リポジトリを確認します。
- 動的リソース割り当て: GKE での DRA について学習します。
- GKE Inference Gateway: Inference Gateway のコンセプトを確認する。
- その他の Codelabs: その他のチュートリアルについては、Google Cloud Codelabs をご覧ください。