
1. 소개
개요
이 실습에서는 Google Kubernetes Engine (GKE)에서 보안 코드 생성 에이전트를 빌드하고 배포하는 방법을 알아봅니다. 코드 생성 에이전트는 신뢰할 수 없는 코드를 실행해야 하므로 안전한 샌드박스 환경이 필요합니다. 또한 하이브리드 모델 전략으로 에이전트를 구성하여 GKE의 자체 호스팅 개방형 모델에서 Vertex AI의 관리형 Gemini 서비스로 대체하여 안정성을 높이는 방법도 알아봅니다. 또한 GKE Inference Gateway 및 동적 리소스 할당 (DRA)을 사용하여 추론 서빙을 최적화하는 방법을 알아봅니다. 마지막으로 Google Cloud Observability를 활용하여 Managed Prometheus를 사용하여 추론 스택을 모니터링하는 방법을 알아봅니다.
아키텍처
빌드할 시스템의 아키텍처는 다음과 같습니다.
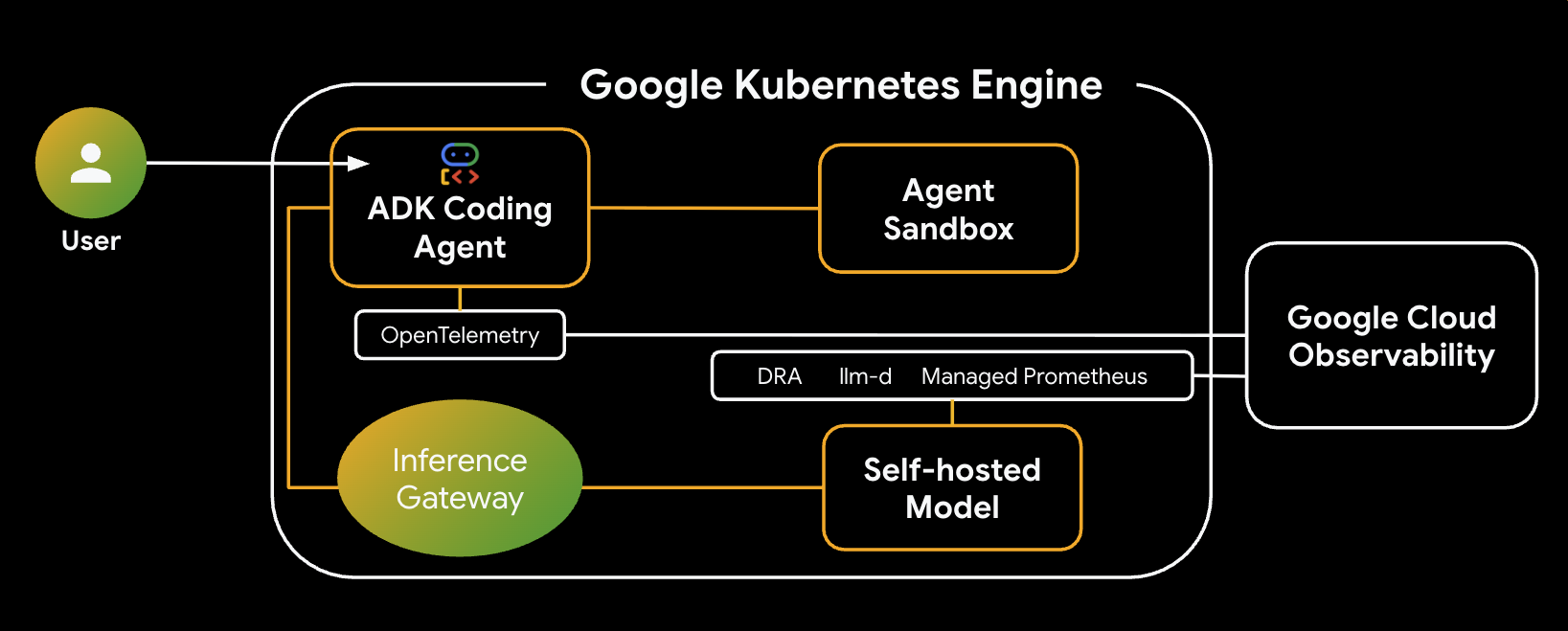
주요 구성요소 및 이점
- 동적 리소스 할당 (DRA): 이 실습에서 모델 서버 포드의 특정 GPU 리소스 (NVIDIA L4)를 동적으로 요청하고 할당하여 추론 워크로드의 정확한 하드웨어 타겟팅을 보장하는 데 사용됩니다. GKE의 DRA에 대해 알아봅니다.
- llm-d 및 vLLM: Qwen 모델을 배포하기 위한 모델 서빙 프레임워크와 Helm 차트를 제공합니다. 이 실습에서는 추론 요청을 처리하고 리소스 관리를 위해 DRA와 통합됩니다 (이 실습에서는 분리된 서빙이 사용 설정되지 않음). llm-d 가이드를 읽고 llm-d GitHub 저장소를 확인하세요.
- GKE Inference Gateway: AI 인식 라우팅 로직을 부하 분산기로 직접 이동합니다. 이 실습에서는 요청을 라우팅하여 접두사 캐시 적중을 최대화하고 첫 번째 토큰까지의 시간 (TTFT) 지연 시간을 줄입니다. 추론 게이트웨이 개념을 살펴봅니다.
- 에이전트 샌드박스 (gVisor): AI 에이전트가 생성한 코드를 실행하기 위한 안전한 격리를 제공합니다. gVisor를 사용하여 심층 커널 격리를 제공하고 신뢰할 수 없는 워크로드로부터 호스트 노드를 보호합니다. GKE의 에이전트 샌드박스 및 GKE Sandbox 포드에 대해 알아봅니다.
실습할 내용
- 인프라 프로비저닝: GPU 관리를 위해 동적 리소스 할당 (DRA)을 사용하여 GKE 클러스터를 설정합니다.
- 추론 스택 배포: 지능형 추론 스케줄링을 사용하여
llm-d및 vLLM을 배포합니다. - 지능형 라우팅 구성: GKE 추론 게이트웨이를 사용하여 접두사 캐시 인식 라우팅을 수행합니다.
- 안전한 코드 실행: 에이전트 샌드박스 (gVisor)를 배포하여 AI 생성 코드를 안전하게 실행합니다.
- 관찰 및 검증: Google Cloud Monitoring 및 Managed Prometheus를 사용하여 모델 서빙 측정항목을 확인합니다.
학습할 내용
- GKE에서 동적 리소스 할당 (DRA)을 구성하고 사용하는 방법
- GKE Inference Gateway를 사용하여 LLM 서빙 성능을 최적화하는 방법
- 에이전트 샌드박스를 사용하여 GKE에서 신뢰할 수 없는 코드를 안전하게 실행하는 방법
- Google Cloud Managed Service for Prometheus를 사용하여 vLLM 성능을 모니터링하는 방법
2. 설정 및 요구사항
프로젝트 설정
Google Cloud 프로젝트 만들기
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다. 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
Cloud Shell 시작
Cloud Shell은 Google Cloud에서 실행되는 명령줄 환경으로, 필요한 도구가 미리 로드되어 제공됩니다.
- Google Cloud 콘솔 상단에서 Cloud Shell 활성화를 클릭합니다.
- Cloud Shell에 연결되면 인증을 확인합니다.
gcloud auth list - 프로젝트가 구성되었는지 확인합니다.
gcloud config get project - 프로젝트가 예상대로 설정되지 않은 경우 설정합니다.
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
3. 인프라 및 동적 리소스 할당 (DRA) 프로비저닝
이 첫 번째 단계에서는 기존 기기 플러그인이 아닌 최신 가속기 할당 (DRA)을 사용하도록 GKE 클러스터를 구성합니다. 이를 통해 코드 생성 워크로드에 GPU 또는 TPU를 유연하게 공유하고 할당할 수 있습니다.
기본 요건: GKE Standard 클러스터에서 DRA를 지원하려면 버전 1.34 이상을 실행해야 합니다.
Google Cloud API 사용 설정
이 Codelab에 필요한 Google Cloud API(특히 Compute Engine 및 Kubernetes Engine API)를 사용 설정합니다.
gcloud services enable compute.googleapis.com container.googleapis.com networkservices.googleapis.com cloudbuild.googleapis.com artifactregistry.googleapis.com telemetry.googleapis.com cloudtrace.googleapis.com aiplatform.googleapis.com
환경 변수 설정
설정을 더 쉽게 하려면 환경 변수를 정의하세요. 필요에 따라 리전 또는 명명 규칙을 조정할 수 있습니다.
export PROJECT_ID=$(gcloud config get-value project)
export ZONE=us-central1-a
export CLUSTER_NAME=ai-agent-cluster
export NODEPOOL_NAME=dra-accelerator-pool
gcloud config set project $PROJECT_ID
gcloud config set compute/region $ZONE
작업 디렉터리 만들기
이 실습을 위한 전용 작업 디렉터리를 만들고 디렉터리로 이동하여 파일을 정리합니다.
mkdir -p ~/gke-ai-agent-lab
cd ~/gke-ai-agent-lab
권한 구성 (선택사항)
제한된 프로젝트 또는 공유 환경에서 실행하는 경우 계정에 클러스터를 만들고 빌드를 실행하는 데 필요한 권한이 있는지 확인하세요.
export MY_ACCOUNT=$(gcloud config get-value account)
# Grant Container Admin to create clusters and manage nodes if needed
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/container.admin"
# Grant Cloud Build Builder to run builds
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/cloudbuild.builds.builder"
GKE 클러스터 만들기
GKE Standard 클러스터는 DRA를 지원하기 위해 버전 1.34 이상을 실행해야 합니다. 지능형 추론 일정 관리를 지원하려면 Gateway API 컨트롤러도 사용 설정해야 합니다.
이 실습에서는 새 VPC 네트워크와 서브넷을 만듭니다.
먼저 VPC 네트워크를 만듭니다.
gcloud compute networks create ai-agent-network --subnet-mode=custom
다음으로 GKE 노드용 서브넷을 만듭니다.
gcloud compute networks subnets create ai-agent-subnet \
--network=ai-agent-network \
--range=10.0.0.0/20 \
--region=us-central1
게이트웨이 API (gke-l7-regional-internal-managed)에도 Envoy 프록시를 호스팅할 전용 서브넷이 필요합니다. 새 네트워크에서 이 프록시 전용 서브넷을 만듭니다.
gcloud compute networks subnets create proxy-only-subnet \
--purpose=REGIONAL_MANAGED_PROXY \
--role=ACTIVE \
--region=us-central1 \
--network=ai-agent-network \
--range=192.168.10.0/24
이제 새 네트워크와 서브넷을 사용하여 클러스터를 만듭니다.
gcloud beta container clusters create $CLUSTER_NAME \
--zone $ZONE \
--num-nodes 1 \
--machine-type n2-standard-4 \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--gateway-api=standard \
--managed-otel-scope=COLLECTION_AND_INSTRUMENTATION_COMPONENTS \
--network=ai-agent-network \
--subnetwork=ai-agent-subnet
기본 플러그인이 사용 중지된 노드 풀 만들기
기기 관리를 DRA에 넘기려면 기본 GPU 드라이버 설치와 표준 기기 플러그인을 명시적으로 사용 중지하는 노드 풀을 만들어야 합니다.
다음 gcloud 명령어를 실행하여 필요한 DRA 라벨이 있는 GPU 노드 풀 (예: NVIDIA L4 사용)을 프로비저닝합니다.
gcloud container node-pools create $NODEPOOL_NAME \
--cluster=$CLUSTER_NAME \
--location=$ZONE \
--machine-type=g2-standard-24 \
--accelerator=type=nvidia-l4,count=2,gpu-driver-version=disabled \
--node-labels=gke-no-default-nvidia-gpu-device-plugin=true,nvidia.com/gpu.present=true \
--num-nodes 3
DaemonSet을 통해 NVIDIA 드라이버 설치
사전 구성된 Google Cloud DaemonSet을 사용하여 필요한 기본 NVIDIA 기기 드라이버를 노드에 수동으로 설치합니다.
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
DRA 드라이버 설치
그런 다음 특정 DRA 드라이버를 클러스터에 설치합니다. NVIDIA GPU의 경우 Helm을 통해 이를 배포할 수 있습니다.
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
helm install nvidia-dra-driver-gpu nvidia/nvidia-dra-driver-gpu \
--version="25.3.2" --create-namespace --namespace=nvidia-dra-driver-gpu \
--set nvidiaDriverRoot="/home/kubernetes/bin/nvidia/" \
--set gpuResourcesEnabledOverride=true \
--set resources.computeDomains.enabled=false \
--set kubeletPlugin.priorityClassName="" \
--set 'kubeletPlugin.tolerations[0].key=nvidia.com/gpu' \
--set 'kubeletPlugin.tolerations[0].operator=Exists' \
--set 'kubeletPlugin.tolerations[0].effect=NoSchedule'
DeviceClass 이해
DeviceClass YAML을 수동으로 작성하거나 적용할 필요가 없습니다. DRA용 GKE 인프라를 설정하고 드라이버를 설치하면 노드에서 실행되는 DRA 드라이버가 클러스터에 DeviceClass 객체를 자동으로 만듭니다.
ResourceClaimTemplate 구성
llm-d 포드가 이러한 액셀러레이터를 동적으로 요청할 수 있도록 ResourceClaimTemplate를 만듭니다. 이 템플릿은 요청된 기기 구성을 정의하고 Kubernetes에 워크로드의 고유한 포드별 ResourceClaim를 자동으로 만들도록 지시합니다.
다음 명령어를 실행하여 claim-template.yaml를 만듭니다.
cat > claim-template.yaml <<EOF
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: gpu-claim-template
spec:
spec:
devices:
requests:
- name: single-gpu
exactly:
deviceClassName: gpu.nvidia.com
allocationMode: ExactCount
count: 1
EOF
클러스터에 템플릿을 적용합니다.
kubectl apply -f claim-template.yaml
4. llm-d 및 DRA를 사용하여 지능형 추론 일정 관리 배포
이 단계에서는 추론 스케줄러로 강화된 스마트 Envoy 부하 분산기 뒤에 대규모 언어 모델을 배포합니다. 이 구성은 프리픽스-캐시 인식 라우팅을 적용하여 모델 서빙을 최적화합니다. GKE Inference Gateway는 마이크로서비스 전반에서 공유되는 컨텍스트를 인식하고 요청을 동일한 모델 복제본으로 지능적으로 라우팅하여 캐시 적중률을 극대화하고 첫 번째 토큰까지의 시간을 줄이며 우수한 성능 대비 비용을 제공합니다.
환경 준비
타겟 네임스페이스를 설정합니다.
export NAMESPACE=ai-agents
kubectl create namespace $NAMESPACE
모델 가중치를 가져오는 데 필요한 Hugging Face 토큰을 안전하게 저장합니다.
# Replace with your actual Hugging Face token
kubectl create secret generic llm-d-hf-token \
--from-literal=HF_TOKEN="your_hugging_face_token" \
-n $NAMESPACE
Helm 구성 파일 만들기
모델 서비스 및 추론 게이트웨이 확장 프로그램의 구성은 공식 llm-d 가이드를 기반으로 합니다.
먼저 모델 서비스의 ms-values.yaml 파일을 만듭니다.
cat <<EOF > ms-values.yaml
multinode: false
modelArtifacts:
uri: "hf://Qwen/Qwen2.5-Coder-14B-Instruct"
name: "Qwen/Qwen2.5-Coder-14B-Instruct"
size: 50Gi # Slightly larger than the default to accommodate weights
authSecretName: "llm-d-hf-token"
labels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
llm-d.ai/accelerator-variant: "gpu"
llm-d.ai/accelerator-vendor: "nvidia"
llm-d.ai/model: "qwen-2-5-coder-14b"
routing:
proxy:
enabled: false # removes sidecar from deployment - no PD in inference scheduling
targetPort: 8000 # controls vLLM port to matchup with sidecar if deployed
accelerator:
dra: true
type: "nvidia"
resourceClaimTemplates:
nvidia:
class: "gpu.nvidia.com"
match: "exactly"
name: "gpu-claim-template"
decode:
create: true
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
parallelism:
tensor: 2
data: 1
replicas: 3
monitoring:
podmonitor:
enabled: true
portName: "vllm"
path: "/metrics"
interval: "30s"
containers:
- name: "vllm"
image: ghcr.io/llm-d/llm-d-cuda:v0.5.1
modelCommand: vllmServe
args:
- "--disable-uvicorn-access-log"
- "--gpu-memory-utilization=0.85"
- "--enable-auto-tool-choice"
- "--tool-call-parser"
- "hermes"
ports:
- containerPort: 8000
name: vllm
protocol: TCP
resources:
limits:
cpu: '16'
memory: 64Gi
requests:
cpu: '16'
memory: 64Gi
mountModelVolume: true
volumeMounts:
- name: metrics-volume
mountPath: /.config
- name: shm
mountPath: /dev/shm
- name: torch-compile-cache
mountPath: /.cache
startupProbe:
httpGet:
path: /v1/models
port: vllm
initialDelaySeconds: 15
periodSeconds: 30
timeoutSeconds: 5
failureThreshold: 120
livenessProbe:
httpGet:
path: /health
port: vllm
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /v1/models
port: vllm
periodSeconds: 5
timeoutSeconds: 2
failureThreshold: 3
volumes:
- name: metrics-volume
emptyDir: {}
- name: torch-compile-cache
emptyDir: {}
- name: shm
emptyDir:
medium: Memory
sizeLimit: 20Gi
prefill:
create: false
EOF
다음으로 GKE 추론 게이트웨이 확장 프로그램의 gaie-values.yaml 파일을 만듭니다.
cat <<EOF > gaie-values.yaml
inferenceExtension:
replicas: 1
image:
name: llm-d-inference-scheduler
hub: ghcr.io/llm-d
tag: v0.6.0
pullPolicy: Always
extProcPort: 9002
pluginsConfigFile: "default-plugins.yaml"
tracing:
enabled: false
monitoring:
interval: "10s"
prometheus:
enabled: true
auth:
secretName: inference-scheduling-gateway-sa-metrics-reader-secret
inferencePool:
targetPorts:
- number: 8000
modelServerType: vllm
modelServers:
matchLabels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
EOF
구성 이해
이 구성은 다음과 같은 주요 기능을 갖춘 고성능 추론 스택을 설정합니다.
- 모델 선택: 코드 생성 및 도구 사용에 최적화된 Qwen 2.5 Coder 14B 모델 (
modelArtifacts)을 사용합니다. - DRA 통합:
accelerator섹션은gpu.nvidia.com기기 클래스와 이전에 생성한gpu-claim-template을 타겟팅하여 동적 리소스 할당 (dra: true)을 사용 설정합니다. - 성능 최적화:
parallelism.tensor: 2는 GPU 간 텐서 동시 로드를 구성합니다.- vLLM용
args에는 코딩 에이전트가 도구를 효과적으로 사용할 수 있도록--enable-auto-tool-choice가 포함되어 있습니다. cpu및memory요청이 감소하여g2-standard-24머신 유형에 적합합니다.
- 지능형 라우팅: 추론 게이트웨이 확장 프로그램 (
gaie-values.yaml)은vllm모델 서버를 모니터링하고 KV 캐시 적중을 최대화하도록 요청을 라우팅하도록 구성됩니다.
Helm을 통해 추론 스케줄링 스택 배포
이제 llm-d Helm 저장소를 추가하고 인프라, 게이트웨이 확장 프로그램, 모델 서비스를 개별적으로 배포합니다.
먼저 필요한 저장소를 추가합니다.
helm repo add llm-d-infra https://llm-d-incubation.github.io/llm-d-infra/
helm repo add llm-d-modelservice https://llm-d-incubation.github.io/llm-d-modelservice/
helm repo update
인프라 기본 요건 배포
이 차트는 스택에 필요한 기준 게이트웨이 구성을 설치합니다.
helm install infra-is llm-d-infra/llm-d-infra \
--namespace $NAMESPACE \
--set gateway.gatewayClassName=gke-l7-rilb \
--set gateway.gatewayParameters.enabled=false \
--set gateway.gatewayParameters.istio.accessLogging=false
GKE Inference Gateway 확장 프로그램 배포
이 단계에서는 모델의 KV 캐시를 모니터링하여 지능형 라우팅 결정을 내리는 InferencePool 및 Endpoint Picker를 배포합니다.
helm install gaie-is oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool \
--version v1.3.1 \
--namespace $NAMESPACE \
-f gaie-values.yaml \
--set provider.name=gke \
--set inferenceExtension.monitoring.prometheus.enabled=true
모델 서비스 배포
마지막으로 LLM 서비스를 배포합니다. 이제 DRA를 사용하여 L4 GPU를 안전하게 요청합니다.
helm install ms-is llm-d-modelservice/llm-d-modelservice \
--version v0.4.7 \
--namespace $NAMESPACE \
-f ms-values.yaml \
--set decode.monitoring.podmonitor.enabled=false
vLLM용 Google Cloud Observability 사용 설정
일반 Helm 차트는 종종 표준 Prometheus Operator PodMonitor 리소스 (monitoring.coreos.com/v1)를 배포하려고 시도하며, 이러한 CRD가 설치되어 있지 않으면 오류가 발생할 수 있습니다.
Helm의 기본 제공 모니터링 전환 버튼을 전환하는 대신 false로 유지하고 호환되는 monitoring.googleapis.com/v1 API 그룹을 사용하여 Google Cloud Managed Prometheus (GMP) PodMonitoring 리소스를 수동으로 적용합니다.
다음 명령어를 실행하여 podmonitoring.yaml를 만듭니다.
cat > podmonitoring.yaml <<EOF
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: ms-vllm-metrics
spec:
selector:
matchLabels:
llm-d.ai/model: "qwen-2-5-coder-14b" # Matches the label in values.yaml
endpoints:
- port: 8000 # vllm port
interval: 30s
path: /metrics
EOF
PodMonitoring 리소스를 클러스터에 적용합니다.
kubectl apply -f podmonitoring.yaml -n $NAMESPACE
설치 확인
구성요소가 성공적으로 설치되었는지 확인합니다. 네임스페이스에서 3개의 Helm 출시가 모두 활성 상태이고 해당 포드가 초기화되는 것을 확인할 수 있습니다.
helm ls -n $NAMESPACE
kubectl get pods -n $NAMESPACE
ms-is 포드가 실행되는 데 약 5~10분이 걸릴 수 있습니다. 이 경우 출력은 다음과 같이 표시됩니다.
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
gaie-is ai-agents 1 2026-03-28 16:51:41.055881618 +0000 UTC deployed inferencepool-v1.3.1 v1.3.1
infra-is ai-agents 1 2026-03-28 16:51:03.71042542 +0000 UTC deployed llm-d-infra-v1.4.0 v0.4.0
ms-is ai-agents 1 2026-03-28 17:30:00.341918958 +0000 UTC deployed llm-d-modelservice-v0.4.7 v0.4.0
NAME READY STATUS RESTARTS AGE
gaie-is-epp-848965cb4-78ktp 1/1 Running 0 10m
ms-is-llm-d-modelservice-decode-67548d5f8c-f25f4 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-rblvs 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-w6fcd 1/1 Running 0 6m2s
5. GKE Inference Gateway로 지능형 라우팅 구성
4단계에서 llm-d Helm 차트를 배포하면 게이트웨이 및 InferencePool 객체가 자동으로 프로비저닝되었습니다. InferencePool는 동일한 기본 모델과 컴퓨팅 구성을 공유하는 vllm 모델 서빙 포드를 그룹화합니다.
이제 InferenceObjective를 구성하여 코딩 에이전트 요청의 우선순위를 설정하고 HTTPRoute를 구성하여 엔드포인트 선택기를 활용하여 KV 캐시 적중률을 최대화하는 방식으로 수신 트래픽을 라우팅하는 방법을 게이트웨이에 안내해야 합니다.
자동 생성된 리소스 확인
먼저 llm-d Helm 차트가 게이트웨이 및 InferencePool 리소스를 성공적으로 생성했는지 확인합니다.
kubectl get gateway,inferencepool -n $NAMESPACE
infra-is-inference-gateway라는 게이트웨이와 gaie-is라는 InferencePool이 표시됩니다. 다음과 유사합니다.
NAME CLASS ADDRESS PROGRAMMED AGE
gateway.gateway.networking.k8s.io/infra-is-inference-gateway gke-l7-regional-internal-managed 10.128.0.5 True 13m
NAME AGE
inferencepool.inference.networking.k8s.io/gaie-is 12m
HTTPRoute 만들기
HTTPRoute 리소스는 게이트웨이를 백엔드 InferencePool에 매핑합니다. 이렇게 하면 GKE Inference Gateway가 수신 요청 본문을 분석하고 공유 컨텍스트에 따라 프리픽스-캐시 적중률을 극대화하도록 동적으로 라우팅합니다.
다음 명령어를 실행하여 httproute.yaml를 만듭니다.
cat > httproute.yaml <<EOF
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: agent-route
spec:
parentRefs:
- group: gateway.networking.k8s.io
kind: Gateway
name: infra-is-inference-gateway
rules:
- backendRefs:
- group: inference.networking.k8s.io
kind: InferencePool
name: gaie-is
weight: 1
matches:
- path:
type: PathPrefix
value: /
EOF
클러스터에 경로를 적용합니다.
kubectl apply -f httproute.yaml -n $NAMESPACE
6. 에이전트 샌드박스를 사용한 안전한 코드 실행
이제 고성능 추론 백엔드가 실행되고 있으므로 에이전트 샌드박스를 사용하여 AI 생성 코드가 클러스터에서 안전하게 격리되어 실제로 실행될 보안 환경을 준비해 보겠습니다.
에이전트 샌드박스 컨트롤러 배포
AI 에이전트가 코드를 생성하고 실행하면 기본적으로 인프라에서 신뢰할 수 없는 워크로드를 실행하는 것입니다. 에이전트가 악성 코드를 생성하는 경우 내부 네트워크를 스캔하거나 기본 호스트 노드를 악용하려고 시도할 수 있습니다.
GKE 에이전트 샌드박스는 각 컨테이너에 특화된 게스트 커널을 제공하는 오픈소스 컨테이너 런타임인 gVisor를 활용합니다. 이렇게 하면 신뢰할 수 없는 코드가 호스트 노드에 직접 시스템 호출을 하지 못합니다.
공식 출시 매니페스트를 적용하여 에이전트 샌드박스 컨트롤러와 필수 구성요소를 배포합니다.
kubectl apply \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/manifest.yaml \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/extensions.yaml
샌드박스 템플릿 및 워밍 풀 구성
다음으로 Python 분석 환경의 재사용 가능한 청사진 역할을 하는 SandboxTemplate를 설정하여 gvisor 런타임 클래스를 명시적으로 타겟팅합니다. Standard 클러스터에서 수동 노드 풀을 관리하지 않고 배포를 간소화하려면 표준 autopilot을 활용하면 됩니다.
ComputeClass를 사용하여 gVisor 워크로드를 기본적으로 지원하는 관리형 컴퓨팅 노드를 필요에 따라 동적으로 프로비저닝할 수 있습니다.
보안 커널을 초기화하면 지연 시간이 추가될 수 있으므로 SandboxWarmPool도 배포합니다. 이렇게 하면 지정된 수의 사전 초기화된 샌드박스가 준비된 상태로 유지되므로 코드 생성 에이전트가 이를 요청하고 1초 이내에 코드 실행을 시작할 수 있습니다.
먼저 에이전트 샌드박스 런타임의 새 네임스페이스를 만듭니다.
kubectl create namespace agent-sandbox
다음을 sandbox-template-and-pool.yaml로 저장합니다.
cat > sandbox-template-and-pool.yaml <<EOF
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxTemplate
metadata:
name: python-runtime-template
namespace: agent-sandbox
spec:
podTemplate:
metadata:
labels:
sandbox: python-sandbox-example
spec:
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: python-runtime
image: registry.k8s.io/agent-sandbox/python-runtime-sandbox:v0.1.0
ports:
- containerPort: 8888
readinessProbe:
httpGet:
path: "/"
port: 8888
initialDelaySeconds: 0
periodSeconds: 1
resources:
requests:
cpu: "250m"
memory: "512Mi"
ephemeral-storage: "512Mi"
restartPolicy: "OnFailure"
---
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxWarmPool
metadata:
name: python-sandbox-warmpool
namespace: agent-sandbox
spec:
replicas: 2
sandboxTemplateRef:
name: python-runtime-template
EOF
구성을 적용합니다.
kubectl apply -f sandbox-template-and-pool.yaml
웜풀 포드가 초기화될 때까지 2~3분 정도 기다립니다. 다음 명령어를 사용하여 기본 컴퓨팅이 확장되는 동안 Pending에서 Running로 성공적으로 전환되는지 확인할 수 있습니다.
kubectl get pods -n agent-sandbox -w
python-sandbox-warmpool-*** 포드 두 개가 Running 및 1/1 Ready로 표시되면 안전한 실행 환경이 사전 워밍되었으며 클레임할 준비가 된 것입니다.
샌드박스 라우터 배포
Google의 코드 생성 에이전트는 샌드박스 라우터를 사용하여 실행 명령어를 격리된 포드로 안전하게 디스패치합니다.
다음 명령어를 실행하여 sandbox-router.yaml를 만듭니다.
cat > sandbox-router.yaml <<EOF
apiVersion: v1
kind: Service
metadata:
name: sandbox-router-svc
namespace: agent-sandbox
spec:
type: ClusterIP
selector:
app: sandbox-router
ports:
- name: http
protocol: TCP
port: 8080
targetPort: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sandbox-router-deployment
namespace: agent-sandbox
spec:
replicas: 2
selector:
matchLabels:
app: sandbox-router
template:
metadata:
labels:
app: sandbox-router
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: sandbox-router
containers:
- name: router
image: us-central1-docker.pkg.dev/k8s-staging-images/agent-sandbox/sandbox-router:v20260225-v0.1.1.post3-10-ga5bcb57
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 10
resources:
requests:
cpu: "250m"
memory: "512Mi"
limits:
cpu: "1000m"
memory: "1Gi"
securityContext:
runAsUser: 1000
runAsGroup: 1000
EOF
구성을 적용합니다.
kubectl apply -f sandbox-router.yaml
네트워크 격리 구현
실행 환경을 더욱 잠그고 무단 측면 이동을 방지하려면 네트워크 정책을 적용하세요. 이렇게 하면 샌드박스가 Google Cloud 메타데이터 서버나 기타 민감한 내부 네트워크에 연결할 수 없도록 '에어 갭'이 생성됩니다.
다음을 sandbox-policy.yaml로 저장합니다.
cat > sandbox-policy.yaml <<EOF
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: restrict-sandbox-egress
namespace: agent-sandbox
spec:
podSelector:
matchLabels:
sandbox: python-sandbox-example
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 0.0.0.0/0
except:
- 169.254.169.254/32 # Block metadata server
EOF
정책을 적용합니다.
kubectl apply -f sandbox-policy.yaml
구성요소 확인
격리된 코드 샌드박스 클러스터 레이어가 완전히 구성되었는지 확인하려면 다음 상태 유효성 검사 명령어를 실행하세요.
먼저 샌드박스 포드와 라우터가 실행 중이고 준비되었는지 확인합니다.
kubectl get pods -n agent-sandbox
출력은 다음과 같이 표시됩니다.
NAME READY STATUS RESTARTS AGE
python-sandbox-warmpool-7zlkv 1/1 Running 0 3m25s
python-sandbox-warmpool-cxln2 1/1 Running 0 3m25s
sandbox-router-deployment-668dfbbbb6-g9mpd 1/1 Running 0 42s
sandbox-router-deployment-668dfbbbb6-ppllz 1/1 Running 0 42s
샌드박스 라우터 부하 분산기 / IP 노출 확인
kubectl get service sandbox-router-svc -n agent-sandbox
출력은 다음과 같이 표시됩니다.
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
sandbox-router-svc ClusterIP 34.118.237.244 <none> 8080/TCP 114s
이그레스 네트워크 정책 규칙이 있는지 확인
kubectl get networkpolicy restrict-sandbox-egress -n agent-sandbox
출력은 다음과 같이 표시됩니다.
NAME POD-SELECTOR AGE
restrict-sandbox-egress sandbox=python-sandbox-example 113s
다음 사항을 확인하세요.
python-sandbox-warmpool-***포드가Running및1/1준비 상태입니다.sandbox-router-deployment-***복제본은Running및1/1Ready입니다.sandbox-router-svc에 액세스할 수 있으며restrict-sandbox-egress정책이 일치하는 샌드박스 라벨을 성공적으로 보호하고 있습니다.
안전한 실행 환경이 확보되고 초기화되었으므로 이제 작업의 실제 브레인인 코드 생성 에이전트를 배포할 준비가 되었습니다.
7. 코드 생성 에이전트 (ADK) 빌드 및 배포
안전한 실행 샌드박스와 고성능 LLM 백엔드가 모두 구성되었으므로 이제 에이전트 개발 키트 (ADK)를 사용하여 시스템의 '브레인'인 코드 생성 에이전트를 빌드할 수 있습니다.
이 에이전트는 전문 Python 개발자 역할을 하도록 설계되었습니다. 텍스트만 생성하는 표준 챗봇과 달리 이 에이전트에는 대화형으로 문제를 해결할 수 있는 코드 실행 도구가 탑재되어 있습니다. 다음과 같은 루프를 따릅니다.
- 요청에 따라 Python 코드를 작성합니다.
- 6단계에서 설정한 GKE 에이전트 샌드박스 내에서 코드를 안전하게 실행합니다.
- 실행 중에 발생하는 오류를 확인하거나 읽습니다.
- 테스트를 거친 작동 가능한 솔루션을 제공합니다.
안전한 샌드박스 실행 환경에 에이전트가 액세스할 수 있도록 함으로써 에이전트가 자체 로직을 검증하고 실패를 자동으로 디버깅할 수 있으므로 소프트웨어 개발 작업을 훨씬 더 잘 수행할 수 있습니다.
ADK 추론 에이전트 개발
먼저 에이전트의 동작을 정의하고 6단계에서 만든 샌드박스 도구를 장착하는 Python 로직을 작성합니다. 이 섹션에서는 하이브리드 모델 전략도 구성합니다. 에이전트는 GKE 클러스터에서 실행되는 자체 호스팅 Qwen 모델을 우선시하지만 로컬 모델이 느리거나 사용할 수 없는 경우 Vertex AI의 Gemini 2.5 Flash로 자동 대체되어 높은 안정성을 보장합니다.
에이전트 코드의 새 디렉터리를 만듭니다.
mkdir -p ~/gke-ai-agent-lab/root_agent
cd ~/gke-ai-agent-lab
다음 콘텐츠로 root_agent/agent.py라는 파일을 만듭니다.
cat <<'EOF' > root_agent/agent.py
import os
from google.adk.agents import Agent
from google.adk.models.lite_llm import LiteLlm
from k8s_agent_sandbox import SandboxClient
import requests
# Instantiate the client globally to track sandboxes
sandbox_client = SandboxClient()
def run_python_code(code: str) -> str:
"""
Executes Python code safely in the GKE Agent Sandbox.
Use this tool whenever you need to execute code to solve a problem.
"""
sandbox = sandbox_client.create_sandbox(template="python-runtime-template", namespace="agent-sandbox")
try:
command = f"python3 -c \"{code}\""
result = sandbox.commands.run(command)
if result.stderr:
return f"Error: {result.stderr}"
return result.stdout
finally:
# Ensure the sandbox is deleted after use to avoid leaking resources
sandbox_client.delete_sandbox(sandbox.claim_name, namespace="agent-sandbox")
# Define the ADK Agent with a fallback mechanism.
# It prioritizes the Qwen 2.5 Coder model running on our Inference Gateway.
# If the local model is unavailable, it falls back to Gemini 2.5 Flash on Vertex AI.
root_agent = Agent(
name="CodeGenerationAgent",
model=LiteLlm(
model="openai/Qwen/Qwen2.5-Coder-14B-Instruct",
fallbacks=["vertex_ai/gemini-2.5-flash"],
timeout=10
),
instruction="""
You are an expert Python developer.
1. Write Python code to solve the user's problem.
2. Execute the code using the `run_python_code` tool to verify it works.
3. Return the exact output and a brief explanation of the code.
""",
tools=[run_python_code]
)
EOF
ADK가 모듈을 인식할 수 있도록 __init__.py 파일을 만듭니다.
echo "from . import agent" > ~/gke-ai-agent-lab/root_agent/__init__.py
환경 변수를 설정하고, ADK 애플리케이션은 LLM 요청을 성공적으로 라우팅하기 위해 게이트웨이의 IP 주소가 필요합니다. ADK는 표준 Open-AI 호환 엔드포인트 (vLLM이 게이트웨이를 통해 제공)를 지원하므로 기본 API 기본 URL을 재정의할 수 있습니다.
export GATEWAY_IP=$(kubectl get gateway infra-is-inference-gateway -n $NAMESPACE -o jsonpath='{.status.addresses[0].value}')
cat <<EOF > ~/gke-ai-agent-lab/root_agent/.env
OPENAI_API_BASE=http://${GATEWAY_IP}/v1
OPENAI_API_KEY=no-key-required
# Vertex AI settings for fallback (Authentication is handled by Workload Identity)
VERTEXAI_PROJECT=$PROJECT_ID
VERTEXAI_LOCATION=${ZONE%-[a-z]}
EOF
에이전트 애플리케이션 컨테이너화
GKE 내에서 안전하게 실행할 수 있도록 에이전트를 패키징해야 합니다.
kubectl, ADK 라이브러리, 에이전트 샌드박스 클라이언트를 설치하는 ~/gke-ai-agent-lab에서 Dockerfile를 만듭니다.
cat <<'EOF' > ~/gke-ai-agent-lab/Dockerfile
FROM python:3.11-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
RUN apt-get update && apt-get install -y git curl \
&& curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl" \
&& install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl \
&& rm kubectl && apt-get clean && rm -rf /var/lib/apt/lists/*
RUN pip install --no-cache-dir "google-adk[extensions,otel-gcp]>=1.27.4" litellm pandas "git+https://github.com/kubernetes-sigs/agent-sandbox.git@main#subdirectory=clients/python/agentic-sandbox-client" \
"opentelemetry-instrumentation-google-genai>=0.4b0" \
"opentelemetry-exporter-otlp" \
"opentelemetry-instrumentation-vertexai>=2.0b0"
COPY ./root_agent /app/root_agent
EXPOSE 8080
ENTRYPOINT ["adk", "web", "--host", "0.0.0.0", "--port", "8080", "--otel_to_cloud"]
EOF
컨테이너 이미지를 저장할 Artifact Registry 저장소를 만듭니다.
gcloud artifacts repositories create agent-repo \
--repository-format=docker \
--location=us-central1
Cloud Build를 사용하여 컨테이너 이미지를 빌드하고 푸시합니다.
gcloud builds submit --tag us-central1-docker.pkg.dev/$PROJECT_ID/agent-repo/code-agent:v1 ~/gke-ai-agent-lab/
RBAC를 사용하여 GKE에 배포
마지막으로 에이전트를 클러스터에 배포합니다. 배포에는 에이전트가 SandboxWarmPool에서 인스턴스를 요청할 수 있는 권한을 부여하는 Role 및 RoleBinding이 포함됩니다.
이 배포는 Kubernetes ServiceAccount를 사용하여 에이전트가 샌드박스 클레임 API와 통신할 수 있도록 합니다. 로컬 클러스터 리소스와 로컬 vLLM 게이트웨이 엔드포인트에 액세스하므로 Google IAM ServiceAccount가 필요하지 않습니다.
gVisor에서 표준 배포를 사용하는 이유
6단계에서는 SandboxTemplate 및 SandboxClaim API를 사용하여 생성된 Python 코드 (도구 실행)를 위한 일시적인 일회용 샌드박스를 만들었습니다.
에이전트 웹 UI (브레인) 자체의 경우 runtimeClassName: gvisor와 함께 표준 Kubernetes Deployment 사양을 사용합니다.
- 차이점: 표준
SandboxClaims는 일시적이며 0~1입니다 (신뢰할 수 없는 스크립트에 적합). 표준Deployment는 장기 실행되고 지속되므로 안정적인 KubernetesService및 부하 분산기가 필요한 웹 UI에 적합합니다. 표준 배포에서runtimeClassName: gvisor를 직접 사용하면 표준Deployment기능을 유지하면서 gVisor 커널을 격리할 수 있습니다.
다음을 deployment.yaml로 저장합니다.
cat <<EOF > ~/gke-ai-agent-lab/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: code-agent
labels:
app: code-agent
spec:
replicas: 1
selector:
matchLabels:
app: code-agent
template:
metadata:
labels:
app: code-agent
spec:
serviceAccount: adk-agent-sa
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: code-agent
image: us-central1-docker.pkg.dev/YOUR_PROJECT_ID/agent-repo/code-agent:v1
imagePullPolicy: Always
env:
- name: OPENAI_API_KEY
value: "no-key-required"
- name: OPENAI_API_BASE
value: "http://YOUR_GATEWAY_IP/v1"
- name: VERTEXAI_PROJECT
value: "YOUR_PROJECT_ID"
- name: VERTEXAI_LOCATION
value: "YOUR_REGION"
- name: OTEL_SERVICE_NAME
value: "code-agent"
- name: GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY
value: "true"
- name: OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT
value: "true"
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: code-agent-service
spec:
selector:
app: code-agent
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: agent-sandbox
name: sandbox-creator-role
rules:
- apiGroups: [""]
resources: ["services", "pods", "pods/portforward"]
verbs: ["get", "list", "watch", "create"]
- apiGroups: ["extensions.agents.x-k8s.io"]
resources: ["sandboxclaims"]
verbs: ["create", "get", "list", "watch", "delete"]
- apiGroups: ["agents.x-k8s.io"]
resources: ["sandboxes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: adk-agent-binding
namespace: agent-sandbox
subjects:
- kind: ServiceAccount
name: adk-agent-sa
namespace: default
roleRef:
kind: Role
name: sandbox-creator-role
apiGroup: rbac.authorization.k8s.io
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: adk-agent-sa
EOF
관측 가능성에 대한 IAM 권한 부여
에이전트가 Google Cloud에 원격 분석 데이터 (로그 및 트레이스)를 전송하도록 하려면 워크로드 아이덴티티를 사용하여 Kubernetes 서비스 계정 adk-agent-sa에 필요한 권한을 부여해야 합니다.
Cloud Shell에서 다음 명령어를 실행합니다.
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# Grant permission to write logs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/logging.logWriter \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to write traces
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/cloudtrace.agent \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to use Vertex AI
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/aiplatform.user \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
다음 명령어를 실행하여 YOUR_PROJECT_ID를 실제 프로젝트 ID로 자동 교체하고 구성을 적용합니다.
sed -i "s/YOUR_PROJECT_ID/$PROJECT_ID/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_GATEWAY_IP/$GATEWAY_IP/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_REGION/$ZONE/g" ~/gke-ai-agent-lab/deployment.yaml
kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml
8. 관찰 및 검증
이제 완전히 통합된 시스템을 테스트할 차례입니다.
UI에서 코드 생성 에이전트 테스트
ADK 웹 UI의 외부 IP를 찾습니다.
kubectl get services code-agent-service
출력은 다음과 같이 표시됩니다.
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
code-agent-service LoadBalancer 34.118.230.182 34.31.250.60 80:32471/TCP 2m14s
- 브라우저를 열고
http://[EXTERNAL-IP]로 이동합니다. - ADK 웹 인터페이스에서 오른쪽 상단의 드롭다운 메뉴에서 'root_agent'가 선택되어 있는지 확인합니다. 그런 다음 에이전트에게 다음과 같이 프롬프트를 표시합니다.
Write a python script that prints 'Hello from the isolated sandbox'.
에이전트가 추론 백엔드와 샌드박스를 활용하는 방식을 관찰하려면 아래의 Cloud Observability를 통해 모델 통계 탐색 및 GKE UI를 통해 에이전트 관측 가능성 탐색 섹션으로 이동하여 대시보드를 확인하세요.
GKE UI를 통한 에이전트 관측 가능성 살펴보기
이제 프롬프트를 실행했으므로 원격 분석 데이터를 살펴보겠습니다. 이를 통해 추론 스케줄러와 vLLM의 성능을 파악할 수 있습니다.
상담사 대시보드 액세스
- Kubernetes Engine > 워크로드 페이지로 이동합니다.
- code-agent 배포를 클릭하여 배포 세부정보 페이지를 엽니다.
- 관측 가능성 탭을 클릭합니다.
- 모니터링 가능성 대시보드의 왼쪽 탐색 패널에 하위 탭이 있는 새 에이전트 섹션이 표시됩니다.
둘러볼 만한 항목
다음 하위 탭을 탐색하여 에이전트 애플리케이션의 동작을 확인하세요.
- 개요: 세션, 평균 턴, 호출에 대한 스코어카드를 확인합니다.
- 모델: 에이전트가 사용한 모델별로 분류된 모델 호출 수, 오류율, 지연 시간을 확인할 수 있습니다.
- 도구: 도구 호출 및 실행 시간을 모니터링하여 에이전트가 샌드박스 실행 도구를 얼마나 효과적으로 사용하고 있는지 확인합니다.
- 사용량: 토큰 사용량과 표준 컨테이너 리소스 할당 (CPU 및 메모리)을 추적합니다.
- 에이전트 트레이스: 이 탭으로 전환하여 실행 세션 또는 원시 트레이스 스팬 목록을 확인합니다. 행을 클릭하면 선택한 trace의 세부정보가 포함된 플라이아웃이 열립니다.
이제 vLLM의 모델 수준 측정항목과 ADK의 앱 수준 원격 분석을 결합하여 GKE의 생성형 AI 에이전트에 대한 전체 스택 관측 가능성을 확보할 수 있습니다.
Cloud Observability를 통해 vLLM 모델 통계 살펴보기
이제 프롬프트를 실행했으므로 원격 분석 데이터를 살펴보겠습니다. 이를 통해 추론 스케줄러와 vLLM의 성능을 파악할 수 있습니다.
대시보드 액세스
- Google Cloud Console로 이동합니다.
- 모니터링 > 대시보드로 이동합니다.
- vLLM Prometheus 개요 대시보드를 검색하여 선택합니다.
관찰할 만한 측정항목
대시보드를 보는 동안 다음 주요 측정항목을 확인하여 GKE 추론 게이트웨이와 접두사 캐싱의 영향을 파악하세요.
- KV 캐시 사용률 (
vllm:gpu_cache_usage):- 중요한 이유: 컨텍스트를 캐시하는 데 사용되는 GPU 메모리의 양을 보여줍니다. 이 값이 높으면 시스템이 향후 요청의 속도를 높이기 위해 컨텍스트를 유지하고 있다는 의미입니다. 동일한 프롬프트를 여러 번 실행하면 이 사용률이 상승한 후 안정화됩니다.
- 실행 중인 요청과 대기 중인 요청 (
vllm:num_requests_running대vllm:num_requests_waiting):- 중요한 이유: 이는 부하를 나타냅니다. 대기 요청이 많으면 노드가 과부하 상태임을 의미합니다.
- 토큰 처리량 (
vllm:request_prompt_tokens_tot및vllm:request_generation_tokens_tot):- 중요한 이유: 클러스터에서 처리한 입력 및 출력 토큰의 양을 추적합니다.
- 첫 번째 토큰까지의 시간 (TTFT):
- 중요한 이유: 이는 대화형 에이전트에게 중요한 측정항목입니다. 프리픽스-캐시 인식 라우팅과 함께 GKE Inference Gateway를 사용하면 시스템 프롬프트나 대형 컨텍스트 창과 같은 공통 컨텍스트를 공유하는 요청이 동일한 복제본으로 라우팅되어 기존 캐시 적중을 재사용하여 TTFT를 최소화합니다.
실험해 볼 만한 항목
다음 시나리오를 통해 측정항목이 실시간으로 변경되는지 확인하고 적절한 일정을 검증해 보세요.
실험 1: '반복 속도' (접두사 캐시 적중)
- 에이전트에게 복잡한 프롬프트를 보냅니다 (예: '100MB CSV 파일을 파싱하고 통계를 계산하는 Python 스크립트를 작성해 줘.').
- 대답이 나오면 즉시 동일한 프롬프트를 다시 보냅니다.
- 접두사 캐시 적중률과 첫 번째 토큰까지의 시간 (TTFT)을 관찰합니다.
- 표시되는 내용: 접두사 캐시 적중률이 100% 로 상승하고 TTFT가 크게 감소합니다.
- 의미: GKE Inference Gateway가 공유 컨텍스트를 인식하고 평가된 컨텍스트 캐시를 재사용한 정확히 동일한 복제본으로 라우팅했습니다.
실험 2: 클라우드로 대체 (모델 신뢰성)
- 로컬 Qwen 모델의 장애를 시뮬레이션하려면 추론 서비스를 중지하거나 배포에 가짜
OPENAI_API_BASE를 제공하면 됩니다. deployment.yaml에서OPENAI_API_BASE를 존재하지 않는 IP 또는 포트로 업데이트하고 변경사항을 적용합니다.sed -i "s|value: \"http://$GATEWAY_IP/v1\"|value: \"http://10.0.0.1:8080/v1\"|g" ~/gke-ai-agent-lab/deployment.yaml kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml- 포드가 다시 시작될 때까지 기다린 후 UI에서 상담사에게 프롬프트를 보냅니다.
- 표시되는 내용: 에이전트가 여전히 성공적으로 응답합니다.
- 의미:
fallbacks구성으로 인해 ADK가 로컬 Qwen 엔드포인트의 실패를 인식하고 Vertex AI의 Gemini 2.5 Flash로 요청을 원활하게 라우팅했습니다. Vertex AI에 대한 이러한 대체 호출은 로컬 vLLM 추론 게이트웨이를 우회하므로 vLLM을 통과하는 트래픽만 추적하는 에이전트 관측 가능성 > 모델 대시보드에 표시되지 않습니다.
동적 리소스 할당 (DRA)의 강력한 기능 이해하기
vLLM과 추론 게이트웨이는 요청이 라우팅되고 처리되는 방식을 최적화하는 반면, 동적 리소스 할당 (DRA)은 처음부터 워크로드에 정확히 적합한 하드웨어를 연결할 수 있도록 지원합니다.
DRA를 사용하면 ResourceClaimTemplate 및 DeviceClasses를 사용하여 유연한 하드웨어 리소스를 정의할 수 있으므로 클러스터 전반에서 하드웨어를 세부적으로 관리할 수 있습니다.
DRA가 AI 워크로드에 획기적인 이유:
- 세부적인 하드웨어 요청: DRA를 사용하면 워크로드가 올바른 가속기가 있는 머신에 예약되도록 할 뿐만 아니라 이러한 리소스에 대한 클레임을 배치하여 ResourceClaim과 연결된 워크로드에서만 사용되도록 할 수 있습니다.
- 분리된 수명 주기: 기기 소유권 주장은 포드 수명 주기와 별개로 관리됩니다. 포드가 비정상 종료되면 GPU 클레임이 유지되므로 GPU가 해제되고 다시 획득될 때까지 기다리지 않고도 전반적인 배포 또는 기타 워크로드 객체를 다시 시작할 수 있습니다.
- 다중 공급업체 표준화: DRA는 NVIDIA GPU와 Google TPU 모두에 통합 Kubernetes API를 제공합니다. 어느 쪽으로 배포하든 정확히 동일한 스키마를 사용하므로 워크로드 YAML 매니페스트의 이식성이 매우 높습니다.
이 Codelab에서는 기기 플러그인 구성이 롤아웃을 차단하지 않고 gpu-claim-template에 원활하게 바인딩되도록 Helm 값을 구성할 때 이 기능을 실제로 확인했습니다.
llm-d의 역할 이해
vLLM이 신경망 가중치를 평가하고 GKE Gateway가 쿼리를 라우팅하는 동안 llm-d는 구성 레이어이자 이 모든 것을 함께 묶는 '접착제' 역할을 합니다.
llm-d가 없으면 vLLM 배포, 서비스 포트, 볼륨 마운트, DRA 리소스 요청을 처음부터 선언하는 원시 Kubernetes 매니페스트를 작성해야 합니다.
배포에서 llm-d를 사용해야 하는 이유
- 통합 구성 (한 줄 재정의):
llm-dHelm 차트는 복잡한 하위 수준 Kubernetes 리소스를 깨끗한 상위 수준 전환 버튼 (예:accelerator.dra: true설정)으로 번들링합니다. - 사전 검증된 '잘 조명된 경로':
llm-d저장소에는 전문가가 이미 벤치마킹하고 테스트한 구성이 포함되어 있습니다.llm-d-modelservice를 배포하면 GPU 메모리 사용률, 권장 프로브 타이밍 (활성/준비성), 측정항목 스크래핑을 위한 올바른 노출에 최적화된 기본값이 제공됩니다. - 원활한 관측 가능성 매핑:
llm-d는 기본적으로 표준 컨테이너 포트와 스크랩 경로 (/metrics)가 올바르게 노출되도록 하므로 수동 디버깅 없이 배포를 Google Cloud Monitoring에 쉽게 연결할 수 있습니다.
간단히 말해 llm-d는 재사용 가능한 아키텍처 청사진을 제공하므로 개발자는 GKE에 추론 스택을 배포할 때마다 처음부터 다시 만들 필요가 없습니다.
심층 분석: GKE Inference Gateway
표준 레이어 7 부하 분산기는 경로 (/v1/completions) 또는 쿠키와 같은 HTTP 헤더를 확인하여 작동합니다. GKE Inference Gateway는 훨씬 더 심층적입니다. 생성형 AI 트래픽을 위해 특별히 설계되었기 때문입니다.
성능과 효율성을 높이는 방법:
- 콘텐츠 인식 라우팅 (프롬프트 해싱): GKE Inference Gateway가 JSON 요청 본문을 가로챕니다. 프롬프트의 해시를 계산하고 GPU 메모리 (KV 캐시)에 해당 토큰을 이미 보유하고 있는 백엔드 복제본을 추적합니다.
- 캐시 적중 최대화: 테스트에서 프롬프트를 반복하면 게이트웨이가 정확히 동일한 복제본으로 전송했습니다. 프롬프트를 평가하려면 많은 컴퓨팅 리소스가 필요합니다. 캐시를 재사용하면 프롬프트를 '다시 읽지' 않아도 되므로 비용과 GPU 시간을 절약할 수 있습니다.
- 첫 번째 토큰까지의 시간 (TTFT) 단축: TTFT는 사람을 응대하는 상담사에게 중요한 유용성 측정항목입니다. 캐시를 사용하면 모델이 초가 아닌 밀리초 단위로 토큰을 생성할 수 있습니다.
- 지능형 로드 분산: 하나의 복제본의 VRAM이 캐시 적중으로 완전히 채워진 경우 게이트웨이는 여유 공간이 있는 다른 복제본으로 새로운 프롬프트를 동적으로 라우팅하여 효율성과 가용성의 균형을 맞출 수 있습니다.
에이전트 샌드박스가 위험을 줄이는 방법
이 실습에서는 에이전트 샌드박스가 두 가지 격리 계층을 제공하여 AI 에이전트와 관련된 위험으로부터 인프라를 보호하는 방법을 보여드렸습니다.
- 실행 도구 격리: 에이전트는 생성된 코드를 일시적인 샌드박스에서 실행합니다. 이렇게 하면 LLM에서 생성된 신뢰할 수 없는 코드가 안전하고 격리된 환경에서 실행되어 에이전트와 클러스터를 보호할 수 있습니다.
- 빠른 시작: WarmPool을 사용하면 새 샌드박스가 1초 이내에 시작되어 코드를 실행할 준비가 됩니다.
- 에이전트 자체 격리: 또한 에이전트 종속성의 공급망 취약점에 대한 심층 방어를 제공하기 위해
runtimeClassName: gvisor를 통해 gVisor 지원 노드에서 에이전트 애플리케이션 자체를 실행했습니다.
이러한 방식으로 보안 경계를 강화하는 이유는 다음과 같습니다.
- 시스템 호출 가로채기: gVisor는 시스템 호출이 호스트 Linux 커널에 도달하기 전에 가로챕니다. 이렇게 하면 컨테이너에서 빠져나와 호스트 노드에 액세스하려는 익스플로잇이 차단됩니다.
- 제한된 측면 이동: 네트워크 정책과 결합하면 환경이 손상되더라도 내부 메타데이터 서버를 스캔하거나 클러스터의 다른 민감한 서비스로 피벗할 수 없습니다.
샌드박스에서 전체 에이전트 실행
이 실습에서는 샌드박스를 지속적인 에이전트 애플리케이션의 도구로 사용했습니다. 하지만 특히 민감한 정보를 처리하거나 신뢰할 수 없는 여러 사용자를 지원하는 경우 보안을 극대화하기 위해 각 세션 또는 사용자를 위한 전용 샌드박스 내에서 전체 에이전트 애플리케이션을 실행할 수 있습니다. 이렇게 하면 세션이 완료된 직후에 파기되는 에이전트의 메모리, 상태, 실행 환경이 완전히 격리됩니다.
9. 삭제
이 Codelab에서 사용한 리소스의 비용이 Google Cloud 계정에 청구되지 않도록 하려면 다음 단계에 따라 리소스를 삭제하세요.
개별 리소스 삭제
- GKE 클러스터를 삭제합니다.
gcloud container clusters delete $CLUSTER_NAME --zone $ZONE --quiet
- Artifact Registry 저장소를 삭제합니다.
gcloud artifacts repositories delete agent-repo --location=us-central1 --quiet
- VPC 네트워크를 삭제합니다.
gcloud compute networks delete ai-agent-network --quiet
프로젝트 삭제
프로젝트가 더 이상 필요하지 않으면 리소스를 삭제한 후 프로젝트를 삭제하면 됩니다.
gcloud projects delete $PROJECT_ID
10. 요약
축하합니다. GKE에서 안전하고 고성능의 코드 생성 에이전트를 빌드하고 배포했습니다.
학습한 내용
- GKE에서 동적 리소스 할당 (DRA)을 구성하고 사용하여 GPU 리소스를 관리하는 방법
- GKE 추론 게이트웨이를 사용하여 접두사 캐시 인식 라우팅을 통해 LLM 서빙 성능을 최적화하는 방법
- 에이전트 샌드박스 (gVisor)를 사용하여 GKE에서 신뢰할 수 없는 코드를 안전하게 실행하는 방법
- Google Cloud Managed Service for Prometheus를 사용하여 vLLM 성능을 모니터링하는 방법
- ADK 및 GKE 관리 OpenTelemetry를 사용하여 에이전트 관측 가능성을 구성하고 보는 방법
다음 단계 및 참고 자료
- 에이전트 샌드박스: GKE의 에이전트 샌드박스 및 GKE Sandbox 포드에 대해 알아봅니다.
- llm-d: llm-d 가이드를 읽고 llm-d GitHub 저장소를 확인하세요.
- 동적 리소스 할당: GKE의 DRA에 대해 알아봅니다.
- GKE Inference Gateway: Inference Gateway 개념을 살펴봅니다.
- 더 많은 Codelab: Google Cloud Codelabs에서 더 많은 튜토리얼을 확인하세요.