
1. Wprowadzenie
Przegląd
W tym module dowiesz się, jak utworzyć i wdrożyć bezpiecznego agenta do generowania kodu w Google Kubernetes Engine (GKE). Agenci generujący kod muszą wykonywać kod, który może być niezaufany, co wymaga bezpiecznego środowiska piaskownicy. Dowiesz się też, jak skonfigurować agenta za pomocą strategii modelu hybrydowego, która umożliwia mu przełączanie się z samodzielnie hostowanego otwartego modelu w GKE na zarządzaną usługę Gemini w Vertex AI, co zwiększa niezawodność. Dowiesz się też, jak zoptymalizować obsługę wnioskowania za pomocą bramy wnioskowania GKE i dynamicznej alokacji zasobów (DRA). Na koniec dowiesz się, jak korzystać z Google Cloud Observability do monitorowania stosu wnioskowania za pomocą usługi Managed Prometheus.
Architektura
Oto architektura systemu, który utworzysz:
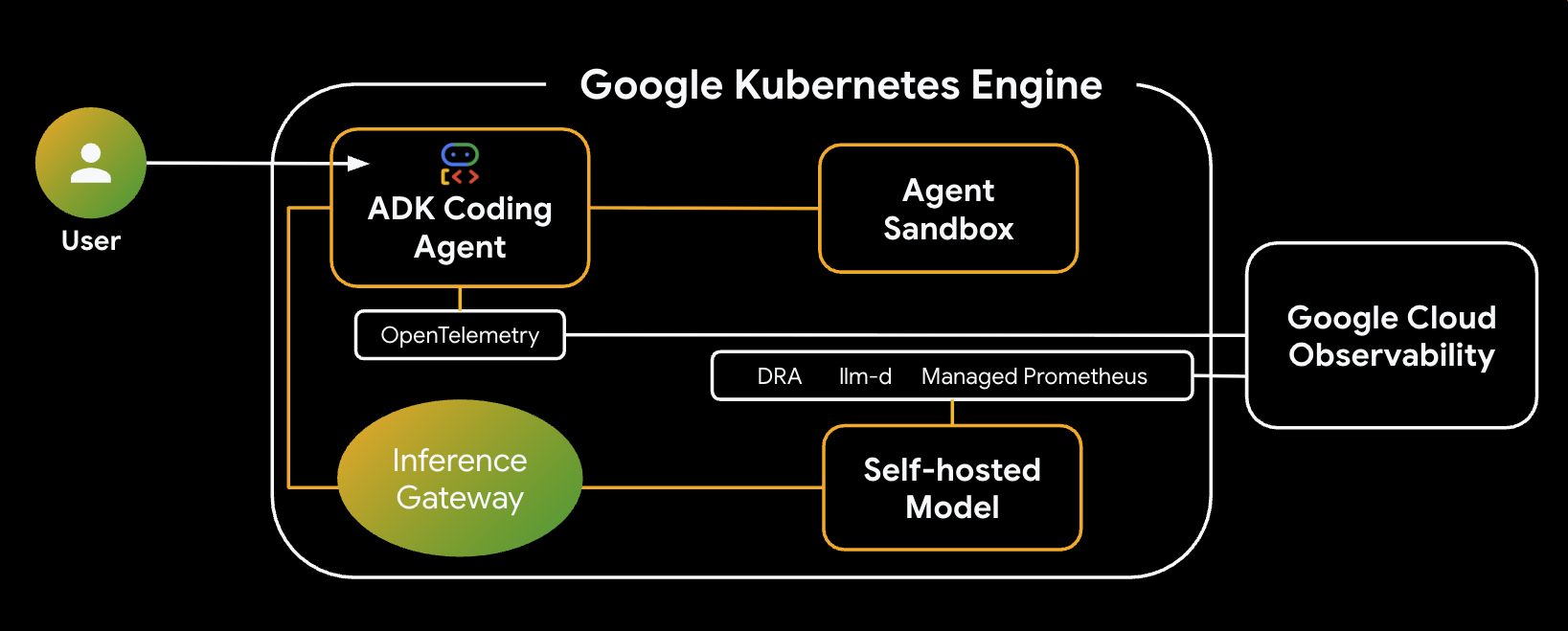
Najważniejsze komponenty i korzyści
- Dynamiczna alokacja zasobów (DRA): w tym laboratorium używana do dynamicznego zgłaszania i przydzielania określonych zasobów GPU (NVIDIA L4) do zasobników serwera modelu, co zapewnia precyzyjne kierowanie sprzętu do naszego zbioru zadań wymagających wnioskowania. Dowiedz się więcej o dynamicznym przydzielaniu zasobów w GKE.
- llm-d i vLLM: udostępnia platformę do udostępniania modeli i karty Helm do wdrażania modelu Qwen. W tym module obsługuje on żądania wnioskowania i integruje się z DRA w celu zarządzania zasobami (w tym module nie jest włączone rozproszone wyświetlanie). Przeczytaj przewodnik llm-d i zapoznaj się z repozytorium llm-d GitHub.
- GKE Inference Gateway: przenosi logikę routingu opartą na AI bezpośrednio do modułu równoważenia obciążenia. W tym module kieruje żądania w taki sposób, aby zmaksymalizować liczbę trafień w pamięci podręcznej prefiksów, co zmniejsza opóźnienie czasu do pierwszego tokena (TTFT). Poznaj koncepcje związane z bramą wnioskowania.
- Piaskownica agenta (gVisor): zapewnia bezpieczną izolację na potrzeby wykonywania kodu wygenerowanego przez agenta AI. Wykorzystuje gVisor do zapewnienia głębokiej izolacji jądra systemu operacyjnego, chroniąc węzeł hosta przed niezaufanymi zbiorami zadań. Dowiedz się więcej o Agent Sandbox w GKE i podach GKE Sandbox.
Jakie zadania wykonasz
- Provision Infrastructure (Provision Infrastructure): skonfiguruj klaster GKE z dynamiczną alokacją zasobów (DRA) do zarządzania procesorami GPU.
- Wdróż stos wnioskowania: wdróż
llm-di vLLM z inteligentnym harmonogramem wnioskowania. - Konfigurowanie inteligentnego routingu: używaj bramy wnioskowania GKE do routingu z uwzględnieniem pamięci podręcznej prefiksów.
- Bezpieczne wykonywanie kodu: wdróż piaskownicę agentów (gVisor), aby bezpiecznie uruchamiać kod wygenerowany przez AI.
- Obserwowanie i weryfikowanie: używaj Google Cloud Monitoring i Managed Prometheus do wyświetlania wskaźników obsługi modelu.
Czego się nauczysz
- Jak skonfigurować i używać dynamicznej alokacji zasobów (DRA) w GKE.
- Jak używać bramy wnioskowania GKE Inference Gateway do optymalizacji wydajności obsługi dużych modeli językowych.
- Jak używać piaskownicy agentów do bezpiecznego wykonywania niezaufanego kodu w GKE.
- Jak używać Google Cloud Managed Service for Prometheus do monitorowania wydajności vLLM.
2. Konfiguracja i wymagania
Konfiguracja projektu
Tworzenie projektu Google Cloud
- W konsoli Google Cloud na stronie selektora projektu wybierz lub utwórz projekt w chmurze Google.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności.
Uruchamianie Cloud Shell
Cloud Shell to środowisko wiersza poleceń działające w Google Cloud, które zawiera niezbędne narzędzia.
- Kliknij Aktywuj Cloud Shell u góry konsoli Google Cloud.
- Po połączeniu z Cloud Shell sprawdź uwierzytelnianie:
gcloud auth list - Sprawdź, czy projekt jest skonfigurowany:
gcloud config get project - Jeśli projekt nie jest ustawiony zgodnie z oczekiwaniami, ustaw go:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
3. Udostępnianie infrastruktury i dynamiczna alokacja zasobów (DRA)
W tym pierwszym kroku skonfigurujesz klaster GKE tak, aby korzystał z nowoczesnego przydzielania akceleratorów (DRA) zamiast starszych wtyczek urządzeń. Umożliwia to elastyczne udostępnianie i przydzielanie GPU lub TPU do zbiorów zadań generowania kodu.
Wymagania wstępne: klaster GKE Standard musi działać w wersji 1.34 lub nowszej, aby obsługiwać DRA.
Włącz interfejsy Google Cloud API
Włącz interfejsy Cloud API Google Cloud wymagane w tym ćwiczeniu, a w szczególności interfejsy Compute Engine i Kubernetes Engine.
gcloud services enable compute.googleapis.com container.googleapis.com networkservices.googleapis.com cloudbuild.googleapis.com artifactregistry.googleapis.com telemetry.googleapis.com cloudtrace.googleapis.com aiplatform.googleapis.com
Ustawianie zmiennych środowiskowych
Aby ułatwić konfigurację, zdefiniuj zmienne środowiskowe. W razie potrzeby możesz dostosować region lub konwencje nazewnictwa.
export PROJECT_ID=$(gcloud config get-value project)
export ZONE=us-central1-a
export CLUSTER_NAME=ai-agent-cluster
export NODEPOOL_NAME=dra-accelerator-pool
gcloud config set project $PROJECT_ID
gcloud config set compute/region $ZONE
Tworzenie katalogu roboczego
Utwórz dedykowany katalog roboczy na potrzeby tego modułu i przejdź do niego, aby uporządkować pliki:
mkdir -p ~/gke-ai-agent-lab
cd ~/gke-ai-agent-lab
Konfigurowanie uprawnień (opcjonalnie)
Jeśli korzystasz z projektu z ograniczeniami lub środowiska współdzielonego, sprawdź, czy Twoje konto ma uprawnienia do tworzenia klastrów i uruchamiania kompilacji:
export MY_ACCOUNT=$(gcloud config get-value account)
# Grant Container Admin to create clusters and manage nodes if needed
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/container.admin"
# Grant Cloud Build Builder to run builds
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/cloudbuild.builds.builder"
Tworzenie klastra GKE
Aby obsługiwać DRA, klaster GKE Standard musi działać w wersji 1.34 lub nowszej. Aby obsługiwać inteligentne planowanie wnioskowania, musisz też włączyć kontrolery interfejsu Gateway API.
W tym module utworzysz nową sieć VPC i podsieci.
Najpierw utwórz sieć VPC:
gcloud compute networks create ai-agent-network --subnet-mode=custom
Następnie utwórz podsieć dla węzłów GKE:
gcloud compute networks subnets create ai-agent-subnet \
--network=ai-agent-network \
--range=10.0.0.0/20 \
--region=us-central1
Interfejs Gateway API (gke-l7-regional-internal-managed) wymaga też dedykowanej podsieci do hostowania serwerów proxy Envoy. Utwórz w nowej sieci tę podsieć tylko-proxy:
gcloud compute networks subnets create proxy-only-subnet \
--purpose=REGIONAL_MANAGED_PROXY \
--role=ACTIVE \
--region=us-central1 \
--network=ai-agent-network \
--range=192.168.10.0/24
Teraz utwórz klaster, korzystając z nowej sieci i podsieci:
gcloud beta container clusters create $CLUSTER_NAME \
--zone $ZONE \
--num-nodes 1 \
--machine-type n2-standard-4 \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--gateway-api=standard \
--managed-otel-scope=COLLECTION_AND_INSTRUMENTATION_COMPONENTS \
--network=ai-agent-network \
--subnetwork=ai-agent-subnet
Tworzenie puli węzłów z wyłączonymi domyślnymi wtyczkami
Aby przekazać zarządzanie urządzeniami do DRA, musisz utworzyć pulę węzłów, w której domyślna instalacja sterownika GPU i standardowa wtyczka urządzenia są wyraźnie wyłączone.
Aby udostępnić pulę węzłów GPU (np. z procesorami NVIDIA L4) z niezbędnymi etykietami DRA, uruchom to polecenie gcloud:
gcloud container node-pools create $NODEPOOL_NAME \
--cluster=$CLUSTER_NAME \
--location=$ZONE \
--machine-type=g2-standard-24 \
--accelerator=type=nvidia-l4,count=2,gpu-driver-version=disabled \
--node-labels=gke-no-default-nvidia-gpu-device-plugin=true,nvidia.com/gpu.present=true \
--num-nodes 3
Instalowanie sterowników NVIDIA za pomocą DaemonSet
Ręcznie zainstaluj wymagane podstawowe sterowniki urządzeń NVIDIA w węzłach za pomocą wstępnie skonfigurowanego narzędzia DaemonSet Google Cloud:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
Instalowanie sterownika DRA
Następnie zainstaluj w klastrze konkretny sterownik DRA. W przypadku procesorów GPU NVIDIA możesz wdrożyć to narzędzie za pomocą Helm:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
helm install nvidia-dra-driver-gpu nvidia/nvidia-dra-driver-gpu \
--version="25.3.2" --create-namespace --namespace=nvidia-dra-driver-gpu \
--set nvidiaDriverRoot="/home/kubernetes/bin/nvidia/" \
--set gpuResourcesEnabledOverride=true \
--set resources.computeDomains.enabled=false \
--set kubeletPlugin.priorityClassName="" \
--set 'kubeletPlugin.tolerations[0].key=nvidia.com/gpu' \
--set 'kubeletPlugin.tolerations[0].operator=Exists' \
--set 'kubeletPlugin.tolerations[0].effect=NoSchedule'
Informacje o klasach urządzeń
Nie musisz ręcznie pisać ani stosować pliku DeviceClass YAML. Gdy skonfigurujesz infrastrukturę GKE pod kątem DRA i zainstalujesz sterownik, sterowniki DRA działające w węzłach automatycznie utworzą w klastrze obiekty DeviceClass.
Skonfiguruj ResourceClaimTemplate
Aby umożliwić zasobnikom llm-d dynamiczne żądanie tych akceleratorów, musisz utworzyć ResourceClaimTemplate. Ten szablon określa żądaną konfigurację urządzenia i informuje Kubernetes, aby automatycznie tworzył unikalny element ResourceClaim dla każdego poda w Twoich zadaniach.
Aby utworzyć claim-template.yaml, uruchom to polecenie:
cat > claim-template.yaml <<EOF
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: gpu-claim-template
spec:
spec:
devices:
requests:
- name: single-gpu
exactly:
deviceClassName: gpu.nvidia.com
allocationMode: ExactCount
count: 1
EOF
Zastosuj szablon do klastra:
kubectl apply -f claim-template.yaml
4. Wdrażanie inteligentnego harmonogramu wnioskowania za pomocą llm-d i DRA
W tym kroku wdrożysz duży model językowy za inteligentnym systemem równoważenia obciążenia Envoy z harmonogramem wnioskowania. Ta konfiguracja optymalizuje udostępnianie modelu przez zastosowanie routingu z uwzględnieniem pamięci podręcznej prefiksów. GKE Inference Gateway rozpoznaje wspólny kontekst w mikrousługach i inteligentnie kieruje żądania do tej samej repliki modelu, co maksymalizuje liczbę trafień w pamięci podręcznej, skraca czas do pierwszego tokena i zapewnia lepszą wydajność w przeliczeniu na dolara.
Przygotowywanie środowiska
Skonfiguruj docelową przestrzeń nazw.
export NAMESPACE=ai-agents
kubectl create namespace $NAMESPACE
Bezpiecznie przechowuj token Hugging Face, który jest wymagany do pobrania wag modelu.
# Replace with your actual Hugging Face token
kubectl create secret generic llm-d-hf-token \
--from-literal=HF_TOKEN="your_hugging_face_token" \
-n $NAMESPACE
Tworzenie plików konfiguracji Helm
Konfiguracje usługi modelu i rozszerzenia bramy wnioskowania są oparte na oficjalnych przewodnikach llm-d.
Najpierw utwórz plik ms-values.yaml dla usługi modelu:
cat <<EOF > ms-values.yaml
multinode: false
modelArtifacts:
uri: "hf://Qwen/Qwen2.5-Coder-14B-Instruct"
name: "Qwen/Qwen2.5-Coder-14B-Instruct"
size: 50Gi # Slightly larger than the default to accommodate weights
authSecretName: "llm-d-hf-token"
labels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
llm-d.ai/accelerator-variant: "gpu"
llm-d.ai/accelerator-vendor: "nvidia"
llm-d.ai/model: "qwen-2-5-coder-14b"
routing:
proxy:
enabled: false # removes sidecar from deployment - no PD in inference scheduling
targetPort: 8000 # controls vLLM port to matchup with sidecar if deployed
accelerator:
dra: true
type: "nvidia"
resourceClaimTemplates:
nvidia:
class: "gpu.nvidia.com"
match: "exactly"
name: "gpu-claim-template"
decode:
create: true
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
parallelism:
tensor: 2
data: 1
replicas: 3
monitoring:
podmonitor:
enabled: true
portName: "vllm"
path: "/metrics"
interval: "30s"
containers:
- name: "vllm"
image: ghcr.io/llm-d/llm-d-cuda:v0.5.1
modelCommand: vllmServe
args:
- "--disable-uvicorn-access-log"
- "--gpu-memory-utilization=0.85"
- "--enable-auto-tool-choice"
- "--tool-call-parser"
- "hermes"
ports:
- containerPort: 8000
name: vllm
protocol: TCP
resources:
limits:
cpu: '16'
memory: 64Gi
requests:
cpu: '16'
memory: 64Gi
mountModelVolume: true
volumeMounts:
- name: metrics-volume
mountPath: /.config
- name: shm
mountPath: /dev/shm
- name: torch-compile-cache
mountPath: /.cache
startupProbe:
httpGet:
path: /v1/models
port: vllm
initialDelaySeconds: 15
periodSeconds: 30
timeoutSeconds: 5
failureThreshold: 120
livenessProbe:
httpGet:
path: /health
port: vllm
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /v1/models
port: vllm
periodSeconds: 5
timeoutSeconds: 2
failureThreshold: 3
volumes:
- name: metrics-volume
emptyDir: {}
- name: torch-compile-cache
emptyDir: {}
- name: shm
emptyDir:
medium: Memory
sizeLimit: 20Gi
prefill:
create: false
EOF
Następnie utwórz plik gaie-values.yaml dla rozszerzenia GKE Inference Gateway:
cat <<EOF > gaie-values.yaml
inferenceExtension:
replicas: 1
image:
name: llm-d-inference-scheduler
hub: ghcr.io/llm-d
tag: v0.6.0
pullPolicy: Always
extProcPort: 9002
pluginsConfigFile: "default-plugins.yaml"
tracing:
enabled: false
monitoring:
interval: "10s"
prometheus:
enabled: true
auth:
secretName: inference-scheduling-gateway-sa-metrics-reader-secret
inferencePool:
targetPorts:
- number: 8000
modelServerType: vllm
modelServers:
matchLabels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
EOF
Omówienie konfiguracji
Ta konfiguracja tworzy stos wnioskowania o wysokiej wydajności z tymi kluczowymi funkcjami:
- Wybór modelu: korzysta z modelu Qwen 2.5 Coder 14B (
modelArtifacts), który jest zoptymalizowany pod kątem generowania kodu i korzystania z narzędzi. - Integracja DRA: sekcja
acceleratorumożliwia dynamiczną alokację zasobów (dra: true) z kierowaniem na klasę urządzeniagpu.nvidia.comi utworzony wcześniejgpu-claim-template. - Optymalizacja wydajności:
parallelism.tensor: 2konfiguruje równoległość tensorów na wszystkich procesorach GPU.argsw przypadku vLLM obejmuje--enable-auto-tool-choice, aby nasz agent kodujący mógł skutecznie korzystać z narzędzi.- Zmniejszone żądania
cpuimemorypasują do typu maszynyg2-standard-24.
- Inteligentne kierowanie: rozszerzenie Inference Gateway (
gaie-values.yaml) jest skonfigurowane tak, aby monitorować serwery modelivllmi kierować żądania w sposób maksymalizujący liczbę trafień w pamięci podręcznej KV.
Wdrażanie stosu planowania wnioskowania za pomocą narzędzia Helm
Teraz dodaj repozytoria Helm llm-d i wdroż infrastrukturę, rozszerzenie bramy i usługę modelu osobno.
Najpierw dodaj wymagane repozytoria:
helm repo add llm-d-infra https://llm-d-incubation.github.io/llm-d-infra/
helm repo add llm-d-modelservice https://llm-d-incubation.github.io/llm-d-modelservice/
helm repo update
Wdrażanie wymagań wstępnych dotyczących infrastruktury
Ten wykres instaluje podstawowe konfiguracje bramy wymagane dla stosu.
helm install infra-is llm-d-infra/llm-d-infra \
--namespace $NAMESPACE \
--set gateway.gatewayClassName=gke-l7-rilb \
--set gateway.gatewayParameters.enabled=false \
--set gateway.gatewayParameters.istio.accessLogging=false
Wdrażanie rozszerzenia GKE Inference Gateway
Ten krok wdraża pulę wnioskowania i selektor punktów końcowych, który monitoruje pamięć podręczną klucz-wartość modeli, aby podejmować inteligentne decyzje dotyczące routingu.
helm install gaie-is oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool \
--version v1.3.1 \
--namespace $NAMESPACE \
-f gaie-values.yaml \
--set provider.name=gke \
--set inferenceExtension.monitoring.prometheus.enabled=true
Wdrażanie usługi modelu
Na koniec wdróż usługę LLM, która będzie teraz bezpiecznie korzystać z GPU L4 za pomocą DRA.
helm install ms-is llm-d-modelservice/llm-d-modelservice \
--version v0.4.7 \
--namespace $NAMESPACE \
-f ms-values.yaml \
--set decode.monitoring.podmonitor.enabled=false
Włączanie Google Cloud Observability dla vLLM
Ogólne wykresy Helm często próbują wdrożyć standardowe zasoby operatora Prometheusa PodMonitor (monitoring.coreos.com/v1), co może powodować błędy, jeśli nie masz zainstalowanych tych definicji CRD.
Zamiast przełączać wbudowany przełącznik monitorowania Helm, pozostaw go w stanie false i ręcznie zastosuj zasób PodMonitoring Google Cloud Managed Prometheus (GMP) za pomocą zgodnej grupy interfejsów API monitoring.googleapis.com/v1.
Aby utworzyć podmonitoring.yaml, uruchom to polecenie:
cat > podmonitoring.yaml <<EOF
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: ms-vllm-metrics
spec:
selector:
matchLabels:
llm-d.ai/model: "qwen-2-5-coder-14b" # Matches the label in values.yaml
endpoints:
- port: 8000 # vllm port
interval: 30s
path: /metrics
EOF
Zastosuj zasób PodMonitoring do klastra:
kubectl apply -f podmonitoring.yaml -n $NAMESPACE
Sprawdzanie instalacji
Sprawdź, czy komponenty zostały zainstalowane. W przestrzeni nazw powinny być widoczne wszystkie 3 aktywne wersje Helm i odpowiednie pody, które się inicjują.
helm ls -n $NAMESPACE
kubectl get pods -n $NAMESPACE
Uruchomienie podów ms-is może potrwać około 5–10 minut. Dane wyjściowe powinny wyglądać mniej więcej tak:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
gaie-is ai-agents 1 2026-03-28 16:51:41.055881618 +0000 UTC deployed inferencepool-v1.3.1 v1.3.1
infra-is ai-agents 1 2026-03-28 16:51:03.71042542 +0000 UTC deployed llm-d-infra-v1.4.0 v0.4.0
ms-is ai-agents 1 2026-03-28 17:30:00.341918958 +0000 UTC deployed llm-d-modelservice-v0.4.7 v0.4.0
NAME READY STATUS RESTARTS AGE
gaie-is-epp-848965cb4-78ktp 1/1 Running 0 10m
ms-is-llm-d-modelservice-decode-67548d5f8c-f25f4 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-rblvs 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-w6fcd 1/1 Running 0 6m2s
5. Konfigurowanie inteligentnego routingu za pomocą bramy wnioskowania GKE Inference Gateway
W kroku 4 wdrożenie wykresów Helm llm-d automatycznie udostępniło obiekty Gateway i InferencePool. InferencePool grupuje pody obsługujące model vllm, które mają ten sam model podstawowy i konfigurację obliczeniową.
Teraz musisz skonfigurować InferenceObjective, aby ustawić priorytet żądań agenta kodującego, oraz HTTPRoute, aby poinstruować bramę, jak kierować ruch przychodzący, korzystając z wybierania punktu końcowego w celu maksymalizacji trafień w pamięci podręcznej klucz-wartość.
Weryfikowanie zasobów wygenerowanych automatycznie
Najpierw sprawdź, czy wykresy Helm llm-d utworzyły bramę i zasoby InferencePool.
kubectl get gateway,inferencepool -n $NAMESPACE
Powinny się wyświetlić brama o nazwie infra-is-inference-gateway i pula wnioskowania o nazwie gaie-is. Podobnie jak w tym przykładzie:
NAME CLASS ADDRESS PROGRAMMED AGE
gateway.gateway.networking.k8s.io/infra-is-inference-gateway gke-l7-regional-internal-managed 10.128.0.5 True 13m
NAME AGE
inferencepool.inference.networking.k8s.io/gaie-is 12m
Tworzenie HTTPRoute
Zasób HTTPRoute mapuje bramę na backend InferencePool. To ustawienie nakazuje bramie wnioskowania GKE analizować treści żądań przychodzących i dynamicznie kierować je w celu maksymalizacji liczby trafień w pamięci podręcznej prefiksów na podstawie kontekstu udostępnionego.
Aby utworzyć httproute.yaml, uruchom to polecenie:
cat > httproute.yaml <<EOF
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: agent-route
spec:
parentRefs:
- group: gateway.networking.k8s.io
kind: Gateway
name: infra-is-inference-gateway
rules:
- backendRefs:
- group: inference.networking.k8s.io
kind: InferencePool
name: gaie-is
weight: 1
matches:
- path:
type: PathPrefix
value: /
EOF
Zastosuj trasę do klastra:
kubectl apply -f httproute.yaml -n $NAMESPACE
6. Bezpieczne wykonywanie kodu w piaskownicy agenta
Gdy nasz backend wnioskowania o wysokiej wydajności jest już uruchomiony, przygotujmy bezpieczne środowisko, w którym kod wygenerowany przez AI będzie wykonywany w bezpiecznej izolacji od naszego klastra przy użyciu piaskownicy agentów.
Wdrażanie kontrolera piaskownicy agenta
Gdy agent AI generuje i wykonuje kod, w zasadzie uruchamia w Twojej infrastrukturze niezaufane zadanie. Jeśli agent wygeneruje złośliwy kod, może spróbować przeskanować Twoją sieć wewnętrzną lub wykorzystać bazowy węzeł hosta.
Piaskownica agenta GKE korzysta z gVisor, środowiska wykonawczego kontenerów typu open source, które udostępnia specjalne jądro gościa dla każdego kontenera. Zapobiega to wykonywaniu przez niezaufany kod bezpośrednich wywołań systemowych do węzła hosta.
Wdróż kontroler piaskownicy agenta i jego wymagane komponenty, stosując oficjalne manifesty wersji:
kubectl apply \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/manifest.yaml \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/extensions.yaml
Konfigurowanie szablonu piaskownicy i puli wstępnej
Następnie tworzymy SandboxTemplate, który będzie służyć jako szablon wielokrotnego użytku dla naszych środowisk analitycznych w Pythonie, wyraźnie wskazując klasę środowiska wykonawczego gvisor. Aby uprościć wdrażanie bez zarządzania ręcznymi pulami węzłów w klastrach standardowych, możemy użyć dowolnego standardowego autopilot
ComputeClass, aby dynamicznie udostępniać zarządzane węzły obliczeniowe, które natywnie obsługują zadania gVisor na żądanie.
Inicjowanie bezpiecznego jądra może powodować opóźnienia, dlatego wdrażamy też SandboxWarmPool. Dzięki temu określona liczba wstępnie zainicjowanych piaskownic jest zawsze gotowa, aby agent generujący kod mógł je przejąć i rozpocząć wykonywanie kodu w mniej niż sekundę.
Najpierw utwórz nową przestrzeń nazw dla środowisk wykonawczych piaskownicy agenta:
kubectl create namespace agent-sandbox
Zapisz te informacje jako sandbox-template-and-pool.yaml:
cat > sandbox-template-and-pool.yaml <<EOF
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxTemplate
metadata:
name: python-runtime-template
namespace: agent-sandbox
spec:
podTemplate:
metadata:
labels:
sandbox: python-sandbox-example
spec:
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: python-runtime
image: registry.k8s.io/agent-sandbox/python-runtime-sandbox:v0.1.0
ports:
- containerPort: 8888
readinessProbe:
httpGet:
path: "/"
port: 8888
initialDelaySeconds: 0
periodSeconds: 1
resources:
requests:
cpu: "250m"
memory: "512Mi"
ephemeral-storage: "512Mi"
restartPolicy: "OnFailure"
---
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxWarmPool
metadata:
name: python-sandbox-warmpool
namespace: agent-sandbox
spec:
replicas: 2
sandboxTemplateRef:
name: python-runtime-template
EOF
Zastosuj konfigurację:
kubectl apply -f sandbox-template-and-pool.yaml
Poczekaj 2–3 minuty, aż pody puli wstępnej zostaną zainicjowane. Aby sprawdzić, czy udało się przejść z Pending (podczas skalowania w górę podstawowej mocy obliczeniowej) na Running, użyj tego polecenia:
kubectl get pods -n agent-sandbox -w
Gdy zobaczysz 2 pody oznaczone jako Running i 1/1 Gotowe, Twoje bezpieczne środowiska wykonawcze będą wstępnie rozgrzane i gotowe do przejęcia.python-sandbox-warmpool-***
Wdrażanie routera piaskownicy
Nasz agent generowania kodu korzysta z routera piaskownicy, aby bezpiecznie wysyłać polecenia wykonania do odizolowanych zasobników.
Aby utworzyć sandbox-router.yaml, uruchom to polecenie:
cat > sandbox-router.yaml <<EOF
apiVersion: v1
kind: Service
metadata:
name: sandbox-router-svc
namespace: agent-sandbox
spec:
type: ClusterIP
selector:
app: sandbox-router
ports:
- name: http
protocol: TCP
port: 8080
targetPort: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sandbox-router-deployment
namespace: agent-sandbox
spec:
replicas: 2
selector:
matchLabels:
app: sandbox-router
template:
metadata:
labels:
app: sandbox-router
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: sandbox-router
containers:
- name: router
image: us-central1-docker.pkg.dev/k8s-staging-images/agent-sandbox/sandbox-router:v20260225-v0.1.1.post3-10-ga5bcb57
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 10
resources:
requests:
cpu: "250m"
memory: "512Mi"
limits:
cpu: "1000m"
memory: "1Gi"
securityContext:
runAsUser: 1000
runAsGroup: 1000
EOF
Zastosuj konfigurację:
kubectl apply -f sandbox-router.yaml
Wdrażanie izolacji sieci
Aby jeszcze bardziej zabezpieczyć środowisko wykonawcze i zapobiec nieautoryzowanemu ruchowi bocznemu (lateral movement), zastosuj zasadę sieciową. W ten sposób tworzy się „przerwę” w piaskownicy, która uniemożliwia jej dostęp do serwera metadanych Google Cloud lub innych wrażliwych sieci wewnętrznych.
Zapisz te informacje jako sandbox-policy.yaml:
cat > sandbox-policy.yaml <<EOF
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: restrict-sandbox-egress
namespace: agent-sandbox
spec:
podSelector:
matchLabels:
sandbox: python-sandbox-example
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 0.0.0.0/0
except:
- 169.254.169.254/32 # Block metadata server
EOF
Zastosuj zasadę:
kubectl apply -f sandbox-policy.yaml
Weryfikowanie komponentów
Aby mieć pewność, że warstwa klastra odizolowanego piaskownicy kodu jest w pełni skonfigurowana, wykonaj te polecenia weryfikacji stanu:
Najpierw sprawdź, czy pody i routery piaskownicy są uruchomione i gotowe.
kubectl get pods -n agent-sandbox
Dane wyjściowe powinny wyglądać mniej więcej tak:
NAME READY STATUS RESTARTS AGE
python-sandbox-warmpool-7zlkv 1/1 Running 0 3m25s
python-sandbox-warmpool-cxln2 1/1 Running 0 3m25s
sandbox-router-deployment-668dfbbbb6-g9mpd 1/1 Running 0 42s
sandbox-router-deployment-668dfbbbb6-ppllz 1/1 Running 0 42s
Sprawdzanie systemu równoważenia obciążenia / ujawnienia adresu IP routera w piaskownicy
kubectl get service sandbox-router-svc -n agent-sandbox
Dane wyjściowe powinny wyglądać tak:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
sandbox-router-svc ClusterIP 34.118.237.244 <none> 8080/TCP 114s
Sprawdzanie, czy istnieje reguła zasad sieci wychodzącej
kubectl get networkpolicy restrict-sandbox-egress -n agent-sandbox
Dane wyjściowe powinny wyglądać tak:
NAME POD-SELECTOR AGE
restrict-sandbox-egress sandbox=python-sandbox-example 113s
Sprawdź, czy:
- Pody
python-sandbox-warmpool-***są gotowe do pracy w trybachRunningi1/1. - Repliki
sandbox-router-deployment-***sąRunningi1/1Ready. sandbox-router-svcjest dostępny, a zasadarestrict-sandbox-egressskutecznie chroni wszystkie pasujące etykiety piaskownicy.
Po zabezpieczeniu i zainicjowaniu bezpiecznego środowiska wykonawczego możemy wdrożyć prawdziwy mózg naszej operacji: agenta generowania kodu.
7. Kompilowanie i wdrażanie agenta generującego kod (ADK)
Po skonfigurowaniu bezpiecznej piaskownicy wykonawczej i wydajnego backendu LLM możemy teraz zbudować „mózg” naszego systemu: agenta generującego kod przy użyciu pakietu Agent Development Kit (ADK).
Ten agent został zaprojektowany tak, aby działać jak doświadczony programista Pythona. W przeciwieństwie do standardowego czatbota, który generuje tylko tekst, ten agent jest wyposażony w narzędzie do wykonywania kodu, które umożliwia interaktywne rozwiązywanie problemów. Przebiega ona w pętli:
- pisanie kodu w Pythonie na podstawie Twoich próśb,
- Bezpieczne wykonywanie kodu w piaskownicy agentów GKE skonfigurowanej w kroku 6.
- Weryfikowanie danych wyjściowych lub odczytywanie błędów, które pojawiają się podczas wykonywania.
- Dostarczanie sprawdzonego, działającego rozwiązania.
Dzięki dostępowi do bezpiecznego środowiska wykonawczego w piaskownicy agent może weryfikować własną logikę i automatycznie debugować błędy, co znacznie zwiększa jego możliwości w zakresie tworzenia oprogramowania.
Tworzenie agenta rozumowania ADK
Najpierw piszemy logikę Pythona, która definiuje zachowanie agenta i wyposaża go w narzędzie Sandbox utworzone w kroku 6. W tej sekcji skonfigurujemy też strategię modelu hybrydowego: agent będzie traktować priorytetowo model Qwen hostowany samodzielnie i działający w klastrze GKE, ale w przypadku, gdy lokalny model będzie działać wolno lub będzie niedostępny, automatycznie przełączy się na Gemini 2.5 Flash w Vertex AI, co zapewni wysoką niezawodność.
Utwórz nowy katalog na kod agenta:
mkdir -p ~/gke-ai-agent-lab/root_agent
cd ~/gke-ai-agent-lab
Utwórz plik o nazwie root_agent/agent.py z tą zawartością:
cat <<'EOF' > root_agent/agent.py
import os
from google.adk.agents import Agent
from google.adk.models.lite_llm import LiteLlm
from k8s_agent_sandbox import SandboxClient
import requests
# Instantiate the client globally to track sandboxes
sandbox_client = SandboxClient()
def run_python_code(code: str) -> str:
"""
Executes Python code safely in the GKE Agent Sandbox.
Use this tool whenever you need to execute code to solve a problem.
"""
sandbox = sandbox_client.create_sandbox(template="python-runtime-template", namespace="agent-sandbox")
try:
command = f"python3 -c \"{code}\""
result = sandbox.commands.run(command)
if result.stderr:
return f"Error: {result.stderr}"
return result.stdout
finally:
# Ensure the sandbox is deleted after use to avoid leaking resources
sandbox_client.delete_sandbox(sandbox.claim_name, namespace="agent-sandbox")
# Define the ADK Agent with a fallback mechanism.
# It prioritizes the Qwen 2.5 Coder model running on our Inference Gateway.
# If the local model is unavailable, it falls back to Gemini 2.5 Flash on Vertex AI.
root_agent = Agent(
name="CodeGenerationAgent",
model=LiteLlm(
model="openai/Qwen/Qwen2.5-Coder-14B-Instruct",
fallbacks=["vertex_ai/gemini-2.5-flash"],
timeout=10
),
instruction="""
You are an expert Python developer.
1. Write Python code to solve the user's problem.
2. Execute the code using the `run_python_code` tool to verify it works.
3. Return the exact output and a brief explanation of the code.
""",
tools=[run_python_code]
)
EOF
Utwórz plik __init__.py, aby ADK rozpoznawał moduł:
echo "from . import agent" > ~/gke-ai-agent-lab/root_agent/__init__.py
Ustaw zmienne środowiskowe. Aby aplikacja ADK mogła prawidłowo kierować żądania LLM, potrzebuje adresu IP bramy. ADK obsługuje standardowe punkty końcowe zgodne z Open AI (które vLLM udostępnia za pomocą naszej bramy), więc możemy zastąpić domyślny podstawowy adres URL interfejsu API.
export GATEWAY_IP=$(kubectl get gateway infra-is-inference-gateway -n $NAMESPACE -o jsonpath='{.status.addresses[0].value}')
cat <<EOF > ~/gke-ai-agent-lab/root_agent/.env
OPENAI_API_BASE=http://${GATEWAY_IP}/v1
OPENAI_API_KEY=no-key-required
# Vertex AI settings for fallback (Authentication is handled by Workload Identity)
VERTEXAI_PROJECT=$PROJECT_ID
VERTEXAI_LOCATION=${ZONE%-[a-z]}
EOF
Konteneryzacja aplikacji agenta
Musimy spakować agenta, aby można go było bezpiecznie uruchomić w GKE.
Utwórz Dockerfile w ~/gke-ai-agent-lab, który instaluje kubectl, bibliotekę ADK i klienta piaskownicy agenta:
cat <<'EOF' > ~/gke-ai-agent-lab/Dockerfile
FROM python:3.11-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
RUN apt-get update && apt-get install -y git curl \
&& curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl" \
&& install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl \
&& rm kubectl && apt-get clean && rm -rf /var/lib/apt/lists/*
RUN pip install --no-cache-dir "google-adk[extensions,otel-gcp]>=1.27.4" litellm pandas "git+https://github.com/kubernetes-sigs/agent-sandbox.git@main#subdirectory=clients/python/agentic-sandbox-client" \
"opentelemetry-instrumentation-google-genai>=0.4b0" \
"opentelemetry-exporter-otlp" \
"opentelemetry-instrumentation-vertexai>=2.0b0"
COPY ./root_agent /app/root_agent
EXPOSE 8080
ENTRYPOINT ["adk", "web", "--host", "0.0.0.0", "--port", "8080", "--otel_to_cloud"]
EOF
Utwórz repozytorium Artifact Registry, w którym zapiszesz obraz kontenera.
gcloud artifacts repositories create agent-repo \
--repository-format=docker \
--location=us-central1
Dowiedz się, jak za pomocą Cloud Build utworzyć obraz kontenera i przenieść go do rejestru.
gcloud builds submit --tag us-central1-docker.pkg.dev/$PROJECT_ID/agent-repo/code-agent:v1 ~/gke-ai-agent-lab/
Wdrażanie w GKE z RBAC
Na koniec wdróż agenta w klastrze. Wdrożenie obejmuje Role i RoleBinding, które przyznają agentowi uprawnienia do zgłaszania instancji z SandboxWarmPool.
To wdrożenie będzie używać konta usługi Kubernetes, aby umożliwić agentowi komunikację z interfejsem Sandbox Claim API. Nie wymaga konta usługi Google IAM, ponieważ uzyskuje dostęp do lokalnych zasobów klastra i lokalnego punktu końcowego bramy vLLM.
Dlaczego standardowe wdrożenie w gVisor?
W kroku 6 użyliśmy interfejsów API SandboxTemplate i SandboxClaim, aby utworzyć tymczasowe, jednorazowe piaskownice dla wygenerowanego kodu Pythona (wykonanie narzędzia).
W przypadku samego interfejsu internetowego agenta (mózgu) używamy standardowych specyfikacji Kubernetes Deployment z runtimeClassName: gvisor.
- Różnica: standardowe
SandboxClaimssą tymczasowe i mają wartość od 0 do 1 (idealne w przypadku niezaufanych skryptów). StandardowyDeploymentdziała długo i jest trwały – idealny do interfejsów internetowych, które wymagają stabilnegoServiceKubernetes i systemu równoważenia obciążenia. Korzystając zruntimeClassName: gvisorbezpośrednio w standardowym wdrożeniu, uzyskujesz izolację jądra gVisor, zachowując standardowe funkcjeDeployment.
Zapisz te informacje jako deployment.yaml:
cat <<EOF > ~/gke-ai-agent-lab/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: code-agent
labels:
app: code-agent
spec:
replicas: 1
selector:
matchLabels:
app: code-agent
template:
metadata:
labels:
app: code-agent
spec:
serviceAccount: adk-agent-sa
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: code-agent
image: us-central1-docker.pkg.dev/YOUR_PROJECT_ID/agent-repo/code-agent:v1
imagePullPolicy: Always
env:
- name: OPENAI_API_KEY
value: "no-key-required"
- name: OPENAI_API_BASE
value: "http://YOUR_GATEWAY_IP/v1"
- name: VERTEXAI_PROJECT
value: "YOUR_PROJECT_ID"
- name: VERTEXAI_LOCATION
value: "YOUR_REGION"
- name: OTEL_SERVICE_NAME
value: "code-agent"
- name: GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY
value: "true"
- name: OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT
value: "true"
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: code-agent-service
spec:
selector:
app: code-agent
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: agent-sandbox
name: sandbox-creator-role
rules:
- apiGroups: [""]
resources: ["services", "pods", "pods/portforward"]
verbs: ["get", "list", "watch", "create"]
- apiGroups: ["extensions.agents.x-k8s.io"]
resources: ["sandboxclaims"]
verbs: ["create", "get", "list", "watch", "delete"]
- apiGroups: ["agents.x-k8s.io"]
resources: ["sandboxes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: adk-agent-binding
namespace: agent-sandbox
subjects:
- kind: ServiceAccount
name: adk-agent-sa
namespace: default
roleRef:
kind: Role
name: sandbox-creator-role
apiGroup: rbac.authorization.k8s.io
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: adk-agent-sa
EOF
Przyznawanie uprawnień do Observability
Aby umożliwić agentowi wysyłanie danych telemetrycznych (logów i śladów) do Google Cloud, musisz przyznać wymagane uprawnienia kontu usługi Kubernetes adk-agent-sa za pomocą Workload Identity.
W Cloud Shell uruchom te polecenia:
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# Grant permission to write logs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/logging.logWriter \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to write traces
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/cloudtrace.agent \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to use Vertex AI
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/aiplatform.user \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
Uruchom to polecenie, aby automatycznie zastąpić YOUR_PROJECT_ID rzeczywistym identyfikatorem projektu i zastosować konfigurację.
sed -i "s/YOUR_PROJECT_ID/$PROJECT_ID/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_GATEWAY_IP/$GATEWAY_IP/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_REGION/$ZONE/g" ~/gke-ai-agent-lab/deployment.yaml
kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml
8. Obserwowanie i weryfikowanie
Czas przetestować w pełni zintegrowany system.
Testowanie agenta generującego kod w interfejsie
Znajdź zewnętrzny adres IP interfejsu ADK Web UI:
kubectl get services code-agent-service
Dane wyjściowe powinny wyglądać mniej więcej tak:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
code-agent-service LoadBalancer 34.118.230.182 34.31.250.60 80:32471/TCP 2m14s
- Otwórz przeglądarkę i wejdź na stronę
http://[EXTERNAL-IP]. - W interfejsie internetowym ADK w menu w prawym górnym rogu wybierz „root_agent”. Następnie wpisz prompta:
Write a python script that prints 'Hello from the isolated sandbox'.
Aby sprawdzić, jak agent korzysta z backendu wnioskowania i piaskownicy, przejdź do sekcji Sprawdzanie statystyk modelu za pomocą Cloud Observability i Sprawdzanie dostrzegalności agenta za pomocą interfejsu GKE poniżej, aby wyświetlić panele.
Poznawanie dostrzegalności agenta w interfejsie GKE
Po uruchomieniu kilku promptów przyjrzyjmy się danym telemetrycznym. Dzięki temu możesz dowiedzieć się, jak działają harmonogram wnioskowania i vLLM.
Dostęp do paneli agenta
- Otwórz stronę Kubernetes Engine > Zadania.
- Kliknij wdrożenie code-agent, aby otworzyć stronę Szczegóły wdrożenia.
- Kliknij kartę Dostrzegalność.
- W panelu użytkownika po lewej stronie panelu obserwacji zobaczysz nową sekcję Agent z kartami podrzędnymi.
Co warto odkryć
Aby sprawdzić działanie aplikacji agenta, otwórz te karty:
- Omówienie: wyświetlaj podsumowania statystyk dotyczące sesji, średniej liczby tur i wywołań.
- Modele: wyświetl liczbę wywołań modelu, odsetek błędów i opóźnień w podziale na modele używane przez agenta.
- Narzędzia: monitoruj wywołania narzędzi i czas ich wykonywania, aby sprawdzić, jak skutecznie Twój agent korzysta z narzędzia do wykonywania w sandboxie.
- Wykorzystanie: śledź wykorzystanie tokenów i standardową alokację zasobów kontenera (procesora i pamięci).
- Logi czasu agenta: przełącz się na tę kartę, aby wyświetlić listę sesji wykonania lub surowych zakresów logów czasu. Kliknięcie wiersza powoduje otwarcie wysuwanego menu ze szczegółami wybranego logu czasu.
Łącząc wskaźniki na poziomie modelu z vLLM z telemetrią na poziomie aplikacji z pakietu ADK, uzyskasz pełną dostrzegalność stosu dla agenta AI generatywnej w GKE.
Sprawdzanie statystyk modelu vLLM za pomocą Cloud Observability
Po uruchomieniu kilku promptów przyjrzyjmy się danym telemetrycznym. Dzięki temu możesz dowiedzieć się, jak działają harmonogram wnioskowania i vLLM.
Dostęp do paneli
- Otwórz konsolę Google Cloud.
- Kliknij Monitorowanie > Panele.
- Wyszukaj i wybierz panel vLLM Prometheus Overview.
Ciekawe dane do obserwacji
Podczas przeglądania panelu zwróć uwagę na te kluczowe dane, aby zobaczyć wpływ bramy wnioskowania GKE i pamięci podręcznej z prefiksami:
- Wykorzystanie pamięci podręcznej KV (
vllm:gpu_cache_usage):- Dlaczego to ważne: pokazuje, ile pamięci GPU jest używane do buforowania kontekstu. Jeśli ta wartość jest wysoka, oznacza to, że system przechowuje kontekst, aby przyspieszyć przyszłe żądania. Jeśli uruchomisz ten sam prompt kilka razy, zobaczysz, że wykorzystanie wzrośnie, a potem się ustabilizuje.
- Trwające a oczekujące żądania (
vllm:num_requests_runningavllm:num_requests_waiting):- Dlaczego to jest ważne: wskazuje to obciążenie. Jeśli liczba oczekujących żądań jest wysoka, oznacza to, że węzły są przeciążone.
- Przepustowość tokenów (
vllm:request_prompt_tokens_totivllm:request_generation_tokens_tot):- Dlaczego to ważne: śledź liczbę tokenów wejściowych i wyjściowych przetwarzanych przez klaster.
- Czas do pierwszego tokena (TTFT):
- Dlaczego to jest ważne: to kluczowy wskaźnik w przypadku interaktywnych agentów. Dzięki używaniu bramy wnioskowania GKE z routingiem uwzględniającym pamięć podręczną prefiksów żądania, które mają wspólne konteksty (np. prompt systemowy lub duże okna kontekstowe), są kierowane do tej samej repliki, co minimalizuje czas do pierwszego tokena dzięki ponownemu wykorzystaniu istniejących trafień w pamięci podręcznej.
Eksperymenty do wypróbowania
Wypróbuj te scenariusze, aby zobaczyć zmiany w statystykach w czasie rzeczywistym i sprawdzić prawidłowość harmonogramu.
Eksperyment 1. „Szybkość powtarzania” (trafienie w pamięci podręcznej prefiksu)
- Wysyłaj do agenta złożone prompty (np. „Napisz skrypt w Pythonie, który przeanalizuje plik CSV o rozmiarze 100 MB i obliczy statystyki”).
- Gdy odpowie, natychmiast ponownie wyślij dokładnie ten sam prompt.
- Obserwuj odsetek trafień w pamięci podręcznej prefiksów i czas do pierwszego tokena (TTFT).
- Co powinno się wyświetlić: Współczynnik trafień w pamięci podręcznej prefiksów powinien wzrosnąć do 100%, a TTFT powinien znacznie się zmniejszyć.
- Co to oznacza: brama wnioskowania GKE rozpoznała wspólny kontekst i przekierowała go do tej samej repliki, która ponownie wykorzystała pamięć podręczną ocenionego kontekstu.
Eksperyment 2. Przełączanie się na chmurę (niezawodność modelu)
- Aby zasymulować awarię lokalnego modelu Qwen, możesz zatrzymać usługę wnioskowania lub po prostu podać fałszywy adres
OPENAI_API_BASEwe wdrożeniu. - Zaktualizuj
OPENAI_API_BASEwdeployment.yaml, wpisując nieistniejący adres IP lub port, i zastosuj zmiany:sed -i "s|value: \"http://$GATEWAY_IP/v1\"|value: \"http://10.0.0.1:8080/v1\"|g" ~/gke-ai-agent-lab/deployment.yaml kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml - Poczekaj, aż urządzenie ponownie się uruchomi, a potem wyślij prompta do agenta w interfejsie.
- Co powinno się wyświetlić: agent nadal odpowiada prawidłowo.
- Co to oznacza: dzięki konfiguracji
fallbackspakiet ADK rozpoznał awarię lokalnego punktu końcowego Qwen i bezproblemowo przekierował żądanie do modelu Gemini 2.5 Flash w Vertex AI. Pamiętaj, że te wywołania rezerwowe do Vertex AI omijają lokalną bramę wnioskowania vLLM, więc nie będą widoczne w panelu Obserwowanie agenta > Modele, który śledzi tylko ruch przechodzący przez vLLM.
Informacje o możliwościach dynamicznego przydzielania zasobów
vLLM i Inference Gateway optymalizują sposób kierowania i obsługi żądań, ale to dynamiczna alokacja zasobów (DRA) umożliwiła w pierwszej kolejności przypisanie do zbioru zadań odpowiedniego sprzętu.
DRA zwiększa możliwości szczegółowego zarządzania sprzętem w klastrze, ponieważ umożliwia definiowanie elastycznych zasobów sprzętowych za pomocą ResourceClaimTemplate i DeviceClasses.
Dlaczego DRA zmienia zasady gry w przypadku zadań AI:
- Szczegółowe żądania sprzętowe: dzięki DRA możesz nie tylko mieć pewność, że zbiory zadań są planowane na maszynach z odpowiednim akceleratorem, ale też możesz zgłosić roszczenie do tych zasobów, aby mieć pewność, że są one używane wyłącznie przez zbiór zadań powiązany z obiektem ResourceClaim.
- Oddzielny cykl życia: roszczenia dotyczące urządzeń są zarządzane niezależnie od cykli życia podów. Jeśli pod ulegnie awarii, roszczenie GPU może się utrzymać, dzięki czemu można ponownie uruchomić nadrzędne wdrożenie lub inny obiekt obciążenia bez konieczności czekania na zwolnienie i ponowne uzyskanie dostępu do GPU.
- Standaryzacja wielu dostawców: DRA udostępnia ujednolicony interfejs Kubernetes API zarówno dla procesorów GPU NVIDIA, jak i TPU Google. Niezależnie od tego, czy wdrażasz aplikację w jednym, czy w drugim środowisku, używasz tego samego schematu, dzięki czemu manifesty YAML obciążeń są bardzo przenośne.
W tym laboratorium zobaczysz to w praktyce, gdy skonfigurujesz wartości Helm, aby bezproblemowo powiązać je z gpu-claim-template, bez blokowania wdrożeń przez konfiguracje wtyczek urządzenia.
Rola modelu llm-d
vLLM ocenia wagi sieci neuronowych, a brama GKE kieruje zapytania. llm-d pełni funkcję warstwy konfiguracji i „kleju”, który łączy wszystkie te elementy.
Bez llm-d musisz od zera napisać surowe manifesty Kubernetes, aby zadeklarować wdrożenie vLLM, porty usługi, mocowania woluminów i roszczenia do zasobów DRA.
Dlaczego warto używać llm-d w swoim wdrożeniu?
- Ujednolicona konfiguracja (zastąpienia w 1 wierszu):
llm-dwykresy Helm łączą złożone zasoby Kubernetes niskiego poziomu w proste przełączniki wysokiego poziomu (np. ustawienieaccelerator.dra: true). - Wstępnie sprawdzone „dobrze oświetlone ścieżki”: repozytorium
llm-dzawiera konfiguracje, które zostały już przetestowane przez ekspertów i dla których przeprowadzono testy porównawcze. Podczas wdrażaniallm-d-modelserviceotrzymujesz zoptymalizowane wartości domyślne dotyczące wykorzystania pamięci GPU, zalecane czasy sondowania (aktywność/gotowość) i prawidłowe ekspozycje na potrzeby zbierania danych. - Bezproblemowe mapowanie dostrzegalności:
llm-dzapewnia prawidłowe udostępnianie standardowych portów kontenerów i ścieżek pobierania (/metrics), co ułatwia połączenie wdrożenia z Google Cloud Monitoring bez ręcznego debugowania.
Krótko mówiąc, llm-d udostępnia wielokrotnego użytku plany architektury, dzięki czemu deweloperzy nie muszą za każdym razem wymyślać koła na nowo, gdy wdrażają stos wnioskowania w GKE.
Szczegółowe omówienie: GKE Inference Gateway
Standardowe systemy równoważenia obciążenia warstwy 7 działają na podstawie nagłówków HTTP, takich jak ścieżki (/v1/completions) lub pliki cookie. Brama wnioskowania GKE jest znacznie bardziej zaawansowana – została zaprojektowana specjalnie pod kątem ruchu generatywnej AI.
Jak wpływa na skuteczność i wydajność:
- Routing z uwzględnieniem treści (haszowanie promptów): GKE Inference Gateway przechwytuje treść żądania w formacie JSON. Oblicza ona hash prompu i śledzi, która replika backendu przechowuje już te tokeny w pamięci GPU (pamięć podręczna KV).
- Maksymalizacja trafień w pamięci podręcznej: podczas testów, gdy powtarzano prompt, Gateway wysyłał go do tej samej repliki. Ocena prompta wymaga dużej mocy obliczeniowej. Ponowne użycie pamięci podręcznej pozwala uniknąć „ponownego odczytywania” prompta, co oszczędza pieniądze i czas procesora graficznego.
- Skrócenie czasu do pierwszego tokena (TTFT): TTFT to kluczowy wskaźnik użyteczności dla agentów, z którymi wchodzą w interakcję użytkownicy. Dzięki temu model może zacząć generować tokeny w milisekundach, a nie w sekundach.
- Inteligentne rozdzielanie obciążenia: jeśli pamięć VRAM jednej repliki jest całkowicie wypełniona trafieniami w pamięci podręcznej, brama może dynamicznie kierować nowe prompty do innej repliki, która ma wolne miejsce, równoważąc wydajność z dostępnością.
Jak Piaskownica agentów zmniejsza ryzyko
W tym laboratorium pokazaliśmy, jak bezpieczna piaskownica agentów chroni infrastrukturę przed zagrożeniami związanymi z agentami AI, zapewniając 2 warstwy izolacji:
- Izolowanie narzędzia do wykonywania kodu: agent wykonuje wygenerowany kod w tymczasowej piaskownicy. Dzięki temu niezaufany kod wygenerowany przez LLM jest uruchamiany w bezpiecznym, odizolowanym środowisku, co chroni agenta i klaster.
- Szybkie uruchamianie: dzięki użyciu puli WarmPool nowe piaskownice uruchamiają się w mniej niż sekundę i są gotowe do wykonania kodu.
- Izolacja samego agenta: uruchomiliśmy też samą aplikację agenta w węźle z włączoną funkcją gVisor (za pomocą
runtimeClassName: gvisor), aby zapewnić wielowarstwową ochronę przed lukami w zabezpieczeniach łańcucha dostaw w zależnościach agenta.
Oto dlaczego tworzy to tak silną granicę zabezpieczeń:
- Przechwytywanie wywołań systemowych: gVisor przechwytuje wywołania systemowe, zanim dotrą do jądra systemu Linux na hoście. Blokuje to exploity, które próbują wydostać się z kontenera, aby uzyskać dostęp do węzła hosta.
- Ograniczone przemieszczanie się w sieci: w połączeniu z zasadami sieci nawet w przypadku naruszenia bezpieczeństwa środowiska nie można skanować wewnętrznych serwerów metadanych ani przełączać się na inne wrażliwe usługi w klastrze.
Uruchamianie pełnych agentów w piaskownicach
W tym module użyliśmy piaskownic jako narzędzi dla aplikacji z trwałym agentem. Jednak w celu zapewnienia maksymalnego bezpieczeństwa – zwłaszcza podczas przetwarzania danych wrażliwych lub obsługi wielu niezaufanych użytkowników – możesz uruchomić całą aplikację agenta w dedykowanej piaskownicy dla każdej sesji lub każdego użytkownika. Zapewnia to pełną izolację pamięci, stanu i środowiska wykonawczego agenta, które są niszczone natychmiast po zakończeniu sesji.
9. Czyszczenie
Aby uniknąć obciążenia konta Google Cloud opłatami za zasoby zużyte w tym samouczku, wykonaj te czynności, aby je usunąć.
Usuwanie poszczególnych zasobów
- Usuń klaster GKE:
gcloud container clusters delete $CLUSTER_NAME --zone $ZONE --quiet
- Usuń repozytorium Artifact Registry:
gcloud artifacts repositories delete agent-repo --location=us-central1 --quiet
- Usuń sieć VPC:
gcloud compute networks delete ai-agent-network --quiet
Usuwanie projektu
Jeśli projekt nie jest już potrzebny, możesz go usunąć po usunięciu zasobów:
gcloud projects delete $PROJECT_ID
10. Podsumowanie
Gratulacje! Udało Ci się utworzyć i wdrożyć w GKE bezpiecznego agenta generowania kodu o wysokiej wydajności.
Czego się dowiedziałeś
- Jak skonfigurować i używać dynamicznej alokacji zasobów (DRA) w GKE do zarządzania zasobami GPU.
- Jak używać GKE Inference Gateway do optymalizacji wydajności udostępniania LLM za pomocą routingu uwzględniającego pamięć podręczną prefiksów.
- Jak używać piaskownicy agentów (gVisor) do bezpiecznego wykonywania niezaufanego kodu w GKE.
- Jak używać Google Cloud Managed Service for Prometheus do monitorowania wydajności vLLM.
- Jak skonfigurować i wyświetlić dostrzegalność agenta za pomocą ADK i zarządzanego OpenTelemetry w GKE.
Dalsze kroki i źródła
- Agent Sandbox: dowiedz się więcej o Agent Sandbox w GKE i podach GKE Sandbox.
- llm-d: przeczytaj przewodnik po llm-d i zapoznaj się z repozytorium llm-d w GitHubie.
- Dynamiczna alokacja zasobów: dowiedz się więcej o DRA w GKE.
- GKE Inference Gateway: zapoznaj się z koncepcjami dotyczącymi bramy wnioskowania.
- Więcej ćwiczeń: więcej samouczków znajdziesz na stronie Google Cloud Codelabs.