
1. Introdução
Visão geral
Neste laboratório, você vai aprender a criar e implantar um agente de geração de código seguro no Google Kubernetes Engine (GKE). Os agentes de geração de código precisam executar códigos que podem não ser confiáveis, exigindo um ambiente de sandbox seguro. Você também vai aprender a configurar o agente com uma estratégia de modelo híbrido, permitindo que ele faça fallback de um modelo aberto autohospedado no GKE para o serviço gerenciado do Gemini da Vertex AI, aumentando a confiabilidade. Além disso, você vai aprender a otimizar a veiculação de inferências usando o GKE Inference Gateway e a alocação dinâmica de recursos (DRA, na sigla em inglês). Por fim, você vai aprender a usar o Google Cloud Observability para monitorar sua pilha de inferência usando o Prometheus gerenciado.
Arquitetura
Confira a arquitetura do sistema que você vai criar:
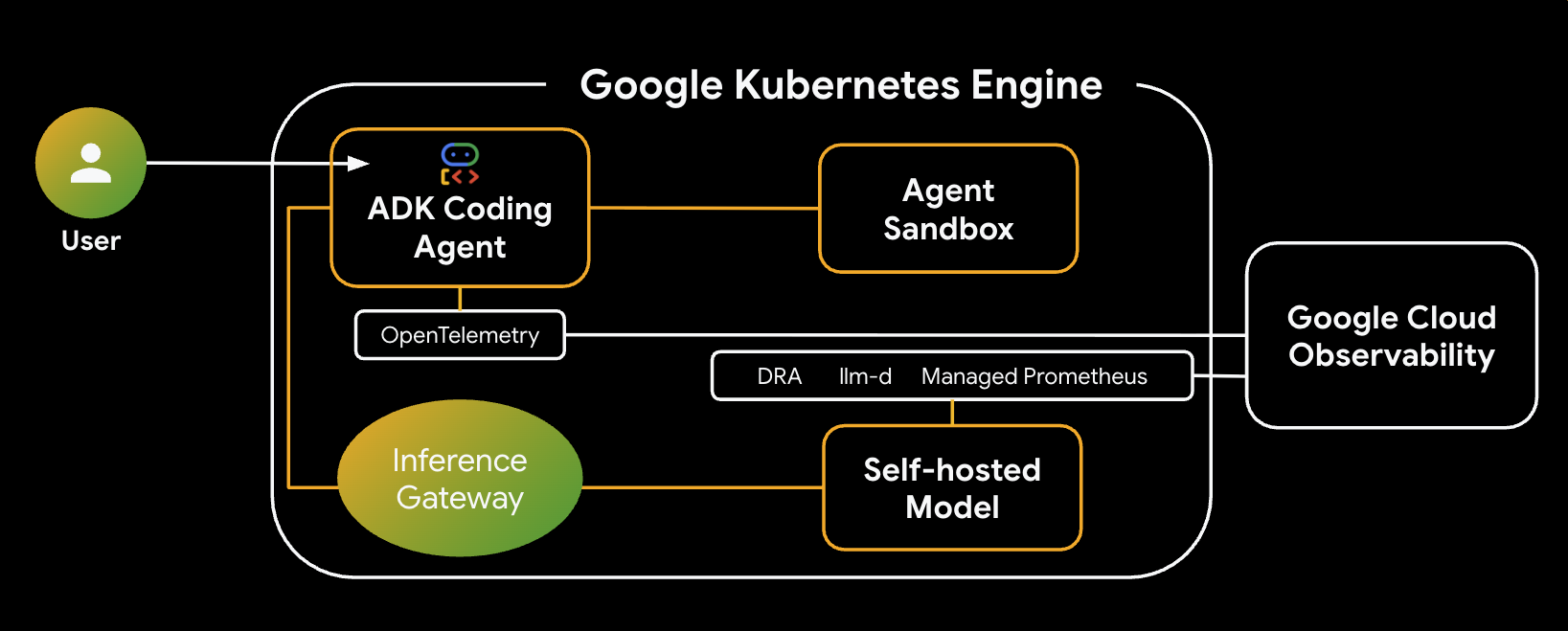
Principais componentes e benefícios
- Alocação dinâmica de recursos (DRA): usada neste laboratório para reivindicar e alocar dinamicamente recursos específicos de GPU (NVIDIA L4s) para os pods do servidor de modelo, garantindo o direcionamento preciso de hardware para nossa carga de trabalho de inferência. Saiba mais sobre a DRA no GKE.
- llm-d e vLLM: fornece a estrutura de disponibilização do modelo e os gráficos do Helm para implantar o modelo Qwen. Neste laboratório, ele processa as solicitações de inferência e se integra ao DRA para gerenciamento de recursos. O serviço desagregado não está ativado neste laboratório. Leia o guia llm-d e confira o repositório llm-d no GitHub.
- GKE Inference Gateway: move a lógica de roteamento com reconhecimento de IA diretamente para o balanceador de carga. Neste laboratório, ele encaminha solicitações para maximizar os acertos de cache de prefixo, reduzindo a latência do tempo até o primeiro token (TTFT). Conheça os conceitos do Inference Gateway.
- Sandbox do agente (gVisor): oferece isolamento seguro para executar o código gerado pelo agente de IA. Ele usa o gVisor para fornecer isolamento profundo do kernel, protegendo o nó host de cargas de trabalho não confiáveis. Saiba mais sobre o sandbox do agente no GKE e os pods do GKE Sandbox.
Atividades deste laboratório
- Provisionar infraestrutura: configure um cluster do GKE com alocação dinâmica de recursos (DRA, na sigla em inglês) para gerenciamento de GPU.
- Implantar a pilha de inferência: implante o
llm-de o vLLM com agendamento inteligente de inferência. - Configurar o encaminhamento inteligente: use o GKE Inference Gateway para o encaminhamento com reconhecimento de prefixo e cache.
- Execução segura de código: implante o Agent Sandbox (gVisor) para executar com segurança o código gerado por IA.
- Observar e validar: use o Google Cloud Monitoring e o Managed Prometheus para conferir métricas de disponibilização do modelo.
O que você vai aprender
- Como configurar e usar a alocação dinâmica de recursos (DRA, na sigla em inglês) no GKE.
- Como usar o GKE Inference Gateway para otimizar o desempenho da veiculação de LLMs.
- Como usar o Agent Sandbox para executar código não confiável com segurança no GKE.
- Como usar o Google Cloud Managed Service para Prometheus para monitorar a performance de vLLMs.
2. Configuração e requisitos
Configuração do projeto
Criar um projeto do Google Cloud
- No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto na nuvem do Google Cloud.
- Verifique se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto.
Iniciar o Cloud Shell
O Cloud Shell é um ambiente de linha de comando executado no Google Cloud que vem pré-carregado com as ferramentas necessárias.
- Clique em Ativar o Cloud Shell na parte de cima do console do Google Cloud.
- Depois de se conectar ao Cloud Shell, verifique sua autenticação:
gcloud auth list - Confirme se o projeto está configurado:
gcloud config get project - Se o projeto não estiver definido como esperado, faça o seguinte:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
3. Provisionar infraestrutura e alocação dinâmica de recursos (DRA)
Nesta primeira etapa, você vai configurar seu cluster do GKE para usar a alocação moderna de aceleradores (DRA, na sigla em inglês) em vez de plug-ins de dispositivos legados. Isso permite compartilhar e alocar GPUs ou TPUs de maneira flexível para suas cargas de trabalho de geração de código.
Pré-requisitos:seu cluster do GKE Standard precisa estar executando a versão 1.34 ou mais recente para oferecer suporte ao DRA.
ativar APIs do Google Cloud
Ative as APIs do Cloud necessárias para este codelab, especificamente as APIs Compute Engine e Kubernetes Engine.
gcloud services enable compute.googleapis.com container.googleapis.com networkservices.googleapis.com cloudbuild.googleapis.com artifactregistry.googleapis.com telemetry.googleapis.com cloudtrace.googleapis.com aiplatform.googleapis.com
Definir variáveis de ambiente
Para facilitar a configuração, defina as variáveis de ambiente. Você pode ajustar a região ou as convenções de nomenclatura conforme necessário.
export PROJECT_ID=$(gcloud config get-value project)
export ZONE=us-central1-a
export CLUSTER_NAME=ai-agent-cluster
export NODEPOOL_NAME=dra-accelerator-pool
gcloud config set project $PROJECT_ID
gcloud config set compute/region $ZONE
Criar diretório de trabalho
Crie um diretório de trabalho dedicado para este laboratório e navegue até ele para que seus arquivos fiquem organizados:
mkdir -p ~/gke-ai-agent-lab
cd ~/gke-ai-agent-lab
Configurar permissões (opcional)
Se você estiver executando em um projeto restrito ou ambiente compartilhado, verifique se sua conta tem as permissões necessárias para criar clusters e executar builds:
export MY_ACCOUNT=$(gcloud config get-value account)
# Grant Container Admin to create clusters and manage nodes if needed
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/container.admin"
# Grant Cloud Build Builder to run builds
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/cloudbuild.builds.builder"
Criar o cluster do GKE
Seu cluster do GKE Standard precisa estar executando a versão 1.34 ou posterior para oferecer suporte ao DRA. Você também precisa ativar os controladores da API Gateway para oferecer suporte ao agendamento inteligente de inferências.
Você vai criar uma rede e sub-redes VPC para este laboratório.
Primeiro, crie a rede VPC:
gcloud compute networks create ai-agent-network --subnet-mode=custom
Em seguida, crie uma sub-rede para os nós do GKE:
gcloud compute networks subnets create ai-agent-subnet \
--network=ai-agent-network \
--range=10.0.0.0/20 \
--region=us-central1
A API Gateway (gke-l7-regional-internal-managed) também exige uma sub-rede dedicada para hospedar os proxies Envoy. Crie esta sub-rede somente proxy na sua nova rede:
gcloud compute networks subnets create proxy-only-subnet \
--purpose=REGIONAL_MANAGED_PROXY \
--role=ACTIVE \
--region=us-central1 \
--network=ai-agent-network \
--range=192.168.10.0/24
Agora, crie o cluster usando a nova rede e sub-rede:
gcloud beta container clusters create $CLUSTER_NAME \
--zone $ZONE \
--num-nodes 1 \
--machine-type n2-standard-4 \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--gateway-api=standard \
--managed-otel-scope=COLLECTION_AND_INSTRUMENTATION_COMPONENTS \
--network=ai-agent-network \
--subnetwork=ai-agent-subnet
Criar um pool de nós com plug-ins padrão desativados
Para transferir o gerenciamento de dispositivos para o DRA, crie um pool de nós que desative explicitamente a instalação padrão do driver de GPU e o plug-in de dispositivo padrão.
Execute o seguinte comando gcloud para provisionar um pool de nós de GPU (por exemplo, usando NVIDIA L4s) com os rótulos DRA necessários:
gcloud container node-pools create $NODEPOOL_NAME \
--cluster=$CLUSTER_NAME \
--location=$ZONE \
--machine-type=g2-standard-24 \
--accelerator=type=nvidia-l4,count=2,gpu-driver-version=disabled \
--node-labels=gke-no-default-nvidia-gpu-device-plugin=true,nvidia.com/gpu.present=true \
--num-nodes 3
Instalar drivers da NVIDIA via DaemonSet
Instale manualmente os drivers de dispositivo NVIDIA básicos necessários nos nós usando um DaemonSet do Google Cloud pré-configurado:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
Instalar o driver DRA
Em seguida, instale o driver DRA específico no cluster. Para GPUs NVIDIA, é possível implantar isso usando o Helm:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
helm install nvidia-dra-driver-gpu nvidia/nvidia-dra-driver-gpu \
--version="25.3.2" --create-namespace --namespace=nvidia-dra-driver-gpu \
--set nvidiaDriverRoot="/home/kubernetes/bin/nvidia/" \
--set gpuResourcesEnabledOverride=true \
--set resources.computeDomains.enabled=false \
--set kubeletPlugin.priorityClassName="" \
--set 'kubeletPlugin.tolerations[0].key=nvidia.com/gpu' \
--set 'kubeletPlugin.tolerations[0].operator=Exists' \
--set 'kubeletPlugin.tolerations[0].effect=NoSchedule'
Noções básicas sobre DeviceClasses
Não é necessário escrever ou aplicar manualmente um YAML DeviceClass. Quando você configura a infraestrutura do GKE para DRA e instala o driver, os drivers de DRA em execução nos nós criam automaticamente os objetos DeviceClass no cluster.
Configurar o ResourceClaimTemplate
Para permitir que seus pods llm-d solicitem esses aceleradores de forma dinâmica, crie um ResourceClaimTemplate. Esse modelo define a configuração de dispositivo solicitada e informa ao Kubernetes para criar automaticamente um ResourceClaim exclusivo por pod para suas cargas de trabalho.
Execute o seguinte comando para criar claim-template.yaml:
cat > claim-template.yaml <<EOF
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: gpu-claim-template
spec:
spec:
devices:
requests:
- name: single-gpu
exactly:
deviceClassName: gpu.nvidia.com
allocationMode: ExactCount
count: 1
EOF
Aplique o modelo ao cluster:
kubectl apply -f claim-template.yaml
4. Implantar o agendamento inteligente de inferência com llm-d e DRA
Nesta etapa, você vai implantar seu modelo de linguagem grande por trás de um balanceador de carga Envoy inteligente aprimorado com um programador de inferência. Essa configuração otimiza a disponibilização do modelo aplicando o roteamento com reconhecimento de prefixo e cache. O GKE Inference Gateway reconhece o contexto compartilhado entre microsserviços e roteia solicitações de forma inteligente para a mesma réplica de modelo, maximizando os acertos de cache, reduzindo o tempo até o primeiro token e impulsionando uma performance superior por dólar.
Prepare o ambiente
Configure o namespace de destino.
export NAMESPACE=ai-agents
kubectl create namespace $NAMESPACE
Armazene com segurança seu token do Hugging Face, que é necessário para extrair os pesos do modelo.
# Replace with your actual Hugging Face token
kubectl create secret generic llm-d-hf-token \
--from-literal=HF_TOKEN="your_hugging_face_token" \
-n $NAMESPACE
Criar os arquivos de configuração do Helm
As configurações do serviço de modelo e da extensão do gateway de inferência são baseadas nos guias oficiais do llm-d.
Primeiro, crie o arquivo ms-values.yaml para o serviço de modelo:
cat <<EOF > ms-values.yaml
multinode: false
modelArtifacts:
uri: "hf://Qwen/Qwen2.5-Coder-14B-Instruct"
name: "Qwen/Qwen2.5-Coder-14B-Instruct"
size: 50Gi # Slightly larger than the default to accommodate weights
authSecretName: "llm-d-hf-token"
labels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
llm-d.ai/accelerator-variant: "gpu"
llm-d.ai/accelerator-vendor: "nvidia"
llm-d.ai/model: "qwen-2-5-coder-14b"
routing:
proxy:
enabled: false # removes sidecar from deployment - no PD in inference scheduling
targetPort: 8000 # controls vLLM port to matchup with sidecar if deployed
accelerator:
dra: true
type: "nvidia"
resourceClaimTemplates:
nvidia:
class: "gpu.nvidia.com"
match: "exactly"
name: "gpu-claim-template"
decode:
create: true
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
parallelism:
tensor: 2
data: 1
replicas: 3
monitoring:
podmonitor:
enabled: true
portName: "vllm"
path: "/metrics"
interval: "30s"
containers:
- name: "vllm"
image: ghcr.io/llm-d/llm-d-cuda:v0.5.1
modelCommand: vllmServe
args:
- "--disable-uvicorn-access-log"
- "--gpu-memory-utilization=0.85"
- "--enable-auto-tool-choice"
- "--tool-call-parser"
- "hermes"
ports:
- containerPort: 8000
name: vllm
protocol: TCP
resources:
limits:
cpu: '16'
memory: 64Gi
requests:
cpu: '16'
memory: 64Gi
mountModelVolume: true
volumeMounts:
- name: metrics-volume
mountPath: /.config
- name: shm
mountPath: /dev/shm
- name: torch-compile-cache
mountPath: /.cache
startupProbe:
httpGet:
path: /v1/models
port: vllm
initialDelaySeconds: 15
periodSeconds: 30
timeoutSeconds: 5
failureThreshold: 120
livenessProbe:
httpGet:
path: /health
port: vllm
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /v1/models
port: vllm
periodSeconds: 5
timeoutSeconds: 2
failureThreshold: 3
volumes:
- name: metrics-volume
emptyDir: {}
- name: torch-compile-cache
emptyDir: {}
- name: shm
emptyDir:
medium: Memory
sizeLimit: 20Gi
prefill:
create: false
EOF
Em seguida, crie o arquivo gaie-values.yaml para a extensão do GKE Inference Gateway:
cat <<EOF > gaie-values.yaml
inferenceExtension:
replicas: 1
image:
name: llm-d-inference-scheduler
hub: ghcr.io/llm-d
tag: v0.6.0
pullPolicy: Always
extProcPort: 9002
pluginsConfigFile: "default-plugins.yaml"
tracing:
enabled: false
monitoring:
interval: "10s"
prometheus:
enabled: true
auth:
secretName: inference-scheduling-gateway-sa-metrics-reader-secret
inferencePool:
targetPorts:
- number: 8000
modelServerType: vllm
modelServers:
matchLabels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
EOF
Como entender a configuração
Essa configuração cria uma pilha de inferência de alta performance com os seguintes recursos principais:
- Seleção de modelo: usa o modelo Qwen 2.5 Coder 14B (
modelArtifacts), que é otimizado para geração de código e uso de ferramentas. - Integração do DRA: a seção
acceleratorativa a alocação dinâmica de recursos (dra: true), segmentando a classe de dispositivogpu.nvidia.come ogpu-claim-templatecriado anteriormente. - Otimização da performance:
parallelism.tensor: 2configura o paralelismo de tensor nas GPUs.- O
argspara vLLM inclui--enable-auto-tool-choicepara garantir que nosso agente de programação possa usar ferramentas de maneira eficaz. - As solicitações reduzidas de
cpuememoryse ajustam ao tipo de máquinag2-standard-24.
- Roteamento inteligente: a extensão Inference Gateway (
gaie-values.yaml) é configurada para monitorar os servidores de modelovllme rotear solicitações para maximizar os acertos de cache KV.
Implantar a pilha de programação de inferência com o Helm
Agora, adicione os repositórios do Helm llm-d e implante a infraestrutura, a extensão do gateway e o serviço de modelo individualmente.
Primeiro, adicione os repositórios necessários:
helm repo add llm-d-infra https://llm-d-incubation.github.io/llm-d-infra/
helm repo add llm-d-modelservice https://llm-d-incubation.github.io/llm-d-modelservice/
helm repo update
Implantar os pré-requisitos de infraestrutura
Esse gráfico instala as configurações básicas do gateway necessárias para a pilha.
helm install infra-is llm-d-infra/llm-d-infra \
--namespace $NAMESPACE \
--set gateway.gatewayClassName=gke-l7-rilb \
--set gateway.gatewayParameters.enabled=false \
--set gateway.gatewayParameters.istio.accessLogging=false
Implante a extensão do GKE Inference Gateway
Esta etapa implanta o InferencePool e o Endpoint Picker, que monitora o cache de KV dos seus modelos para tomar decisões de roteamento inteligentes.
helm install gaie-is oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool \
--version v1.3.1 \
--namespace $NAMESPACE \
-f gaie-values.yaml \
--set provider.name=gke \
--set inferenceExtension.monitoring.prometheus.enabled=true
Implantar o serviço de modelo
Por fim, implante o serviço de LLM, que agora vai usar o DRA para reivindicar com segurança suas GPUs L4.
helm install ms-is llm-d-modelservice/llm-d-modelservice \
--version v0.4.7 \
--namespace $NAMESPACE \
-f ms-values.yaml \
--set decode.monitoring.podmonitor.enabled=false
Ativar o Google Cloud Observability para vLLM
Os gráficos do Helm genéricos geralmente tentam implantar recursos padrão do Prometheus Operator PodMonitor (monitoring.coreos.com/v1), o que pode causar erros se você não tiver esses CRDs instalados.
Em vez de alternar a opção de monitoramento integrada do Helm, mantenha-a false e aplique manualmente um recurso PodMonitoring do Google Cloud Managed Prometheus (GMP) usando o grupo de APIs monitoring.googleapis.com/v1 compatível.
Execute o seguinte comando para criar podmonitoring.yaml:
cat > podmonitoring.yaml <<EOF
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: ms-vllm-metrics
spec:
selector:
matchLabels:
llm-d.ai/model: "qwen-2-5-coder-14b" # Matches the label in values.yaml
endpoints:
- port: 8000 # vllm port
interval: 30s
path: /metrics
EOF
Aplique o recurso PodMonitoring ao cluster:
kubectl apply -f podmonitoring.yaml -n $NAMESPACE
Verificar a instalação
Verifique se os componentes foram instalados corretamente. As três versões do Helm vão aparecer ativas no namespace, e os pods correspondentes serão inicializados.
helm ls -n $NAMESPACE
kubectl get pods -n $NAMESPACE
Os pods ms-is podem levar de 5 a 10 minutos para aparecer. Quando isso acontecer, a saída será semelhante a esta:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
gaie-is ai-agents 1 2026-03-28 16:51:41.055881618 +0000 UTC deployed inferencepool-v1.3.1 v1.3.1
infra-is ai-agents 1 2026-03-28 16:51:03.71042542 +0000 UTC deployed llm-d-infra-v1.4.0 v0.4.0
ms-is ai-agents 1 2026-03-28 17:30:00.341918958 +0000 UTC deployed llm-d-modelservice-v0.4.7 v0.4.0
NAME READY STATUS RESTARTS AGE
gaie-is-epp-848965cb4-78ktp 1/1 Running 0 10m
ms-is-llm-d-modelservice-decode-67548d5f8c-f25f4 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-rblvs 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-w6fcd 1/1 Running 0 6m2s
5. Configurar o roteamento inteligente com o GKE Inference Gateway
Na etapa 4, a implantação dos gráficos Helm llm-d provisionou automaticamente os objetos Gateway e InferencePool. O InferencePool agrupa os pods de disponibilização do modelo vllm que compartilham o mesmo modelo de base e configuração de computação.
Agora, você precisa configurar um InferenceObjective para definir a prioridade das solicitações do agente de programação e um HTTPRoute para instruir o gateway sobre como rotear o tráfego de entrada, aproveitando o seletor de endpoints para maximizar os acertos de cache de valor-chave.
Verificar recursos gerados automaticamente
Primeiro, verifique se os gráficos do Helm llm-d criaram os recursos do gateway e do InferencePool.
kubectl get gateway,inferencepool -n $NAMESPACE
Você vai encontrar um gateway chamado infra-is-inference-gateway e um InferencePool chamado gaie-is. Assim:
NAME CLASS ADDRESS PROGRAMMED AGE
gateway.gateway.networking.k8s.io/infra-is-inference-gateway gke-l7-regional-internal-managed 10.128.0.5 True 13m
NAME AGE
inferencepool.inference.networking.k8s.io/gaie-is 12m
Criar o HTTPRoute
O recurso HTTPRoute mapeia seu gateway para o back-end InferencePool. Isso informa ao GKE Inference Gateway para analisar os corpos de solicitação recebidos e encaminhá-los dinamicamente para maximizar os acertos do cache de prefixo com base no contexto compartilhado.
Execute o seguinte comando para criar httproute.yaml:
cat > httproute.yaml <<EOF
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: agent-route
spec:
parentRefs:
- group: gateway.networking.k8s.io
kind: Gateway
name: infra-is-inference-gateway
rules:
- backendRefs:
- group: inference.networking.k8s.io
kind: InferencePool
name: gaie-is
weight: 1
matches:
- path:
type: PathPrefix
value: /
EOF
Aplique a rota ao cluster:
kubectl apply -f httproute.yaml -n $NAMESPACE
6. Execução segura de código com o sandbox do agente
Agora que nosso back-end de inferência de alta performance está em execução, vamos preparar o ambiente seguro em que o código gerado por IA será executado com segurança e isolado do nosso cluster usando um sandbox de agente.
Implantar o controlador do sandbox do agente
Quando um agente de IA gera e executa código, ele está essencialmente executando uma carga de trabalho não confiável na sua infraestrutura. Se o agente gerar código malicioso, ele poderá tentar verificar sua rede interna ou explorar o nó host subjacente.
O GKE Agent Sandbox usa o gVisor, um ambiente de execução de contêiner de código aberto que fornece um kernel convidado especializado para cada contêiner. Isso impede que códigos não confiáveis façam chamadas diretas do sistema para o nó host.
Implante o controlador do sandbox do agente e os componentes necessários aplicando os manifestos de lançamento oficiais:
kubectl apply \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/manifest.yaml \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/extensions.yaml
Configurar o modelo de sandbox e o pool quente
Em seguida, estabelecemos um SandboxTemplate que atua como um esquema reutilizável para nossos ambientes de análise do Python, segmentando explicitamente a classe de tempo de execução gvisor. Para simplificar a implantação sem gerenciar pools de nós manuais em clusters Standard, podemos usar qualquer autopilot padrão.
ComputeClass para provisionar dinamicamente nós de computação gerenciados que oferecem suporte nativo a cargas de trabalho do gVisor sob demanda.
Como a inicialização de um kernel seguro pode adicionar latência, também implantamos um SandboxWarmPool. Isso garante que um número especificado de sandboxes pré-inicializados seja mantido pronto para que o agente de geração de código possa reivindicá-los e começar a executar o código em menos de um segundo.
Primeiro, crie um namespace para os ambientes de execução da sandbox do agente:
kubectl create namespace agent-sandbox
Salve o seguinte como sandbox-template-and-pool.yaml:
cat > sandbox-template-and-pool.yaml <<EOF
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxTemplate
metadata:
name: python-runtime-template
namespace: agent-sandbox
spec:
podTemplate:
metadata:
labels:
sandbox: python-sandbox-example
spec:
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: python-runtime
image: registry.k8s.io/agent-sandbox/python-runtime-sandbox:v0.1.0
ports:
- containerPort: 8888
readinessProbe:
httpGet:
path: "/"
port: 8888
initialDelaySeconds: 0
periodSeconds: 1
resources:
requests:
cpu: "250m"
memory: "512Mi"
ephemeral-storage: "512Mi"
restartPolicy: "OnFailure"
---
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxWarmPool
metadata:
name: python-sandbox-warmpool
namespace: agent-sandbox
spec:
replicas: 2
sandboxTemplateRef:
name: python-runtime-template
EOF
Aplique a configuração:
kubectl apply -f sandbox-template-and-pool.yaml
Aguarde de 2 a 3 minutos para que os pods do warmpool sejam inicializados. Você pode verificar se eles fazem a transição de Pending (enquanto a computação subjacente aumenta a escala) para Running usando:
kubectl get pods -n agent-sandbox -w
Quando dois pods python-sandbox-warmpool-*** forem listados como Running e 1/1 Ready, seus ambientes de execução seguros estarão pré-aquecidos e prontos para serem reivindicados.
Implante o roteador do sandbox
Nosso agente de geração de código depende de um roteador de sandbox para enviar comandos de execução com segurança aos pods isolados.
Execute o seguinte comando para criar sandbox-router.yaml:
cat > sandbox-router.yaml <<EOF
apiVersion: v1
kind: Service
metadata:
name: sandbox-router-svc
namespace: agent-sandbox
spec:
type: ClusterIP
selector:
app: sandbox-router
ports:
- name: http
protocol: TCP
port: 8080
targetPort: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sandbox-router-deployment
namespace: agent-sandbox
spec:
replicas: 2
selector:
matchLabels:
app: sandbox-router
template:
metadata:
labels:
app: sandbox-router
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: sandbox-router
containers:
- name: router
image: us-central1-docker.pkg.dev/k8s-staging-images/agent-sandbox/sandbox-router:v20260225-v0.1.1.post3-10-ga5bcb57
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 10
resources:
requests:
cpu: "250m"
memory: "512Mi"
limits:
cpu: "1000m"
memory: "1Gi"
securityContext:
runAsUser: 1000
runAsGroup: 1000
EOF
Aplique a configuração:
kubectl apply -f sandbox-router.yaml
Implementar o isolamento de rede
Para bloquear ainda mais o ambiente de execução e evitar movimentos laterais não autorizados, aplique uma política de rede. Isso "isola" o sandbox para que ele não alcance o servidor de metadados do Google Cloud ou outras redes internas sensíveis.
Salve o seguinte como sandbox-policy.yaml:
cat > sandbox-policy.yaml <<EOF
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: restrict-sandbox-egress
namespace: agent-sandbox
spec:
podSelector:
matchLabels:
sandbox: python-sandbox-example
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 0.0.0.0/0
except:
- 169.254.169.254/32 # Block metadata server
EOF
Aplique a política:
kubectl apply -f sandbox-policy.yaml
Verificar componentes
Para garantir que a camada de cluster da sandbox de código isolada esteja totalmente configurada, execute os seguintes comandos de validação de estado:
Primeiro, verifique se os pods e roteadores do sandbox estão em execução e prontos.
kubectl get pods -n agent-sandbox
A resposta será semelhante a esta:
NAME READY STATUS RESTARTS AGE
python-sandbox-warmpool-7zlkv 1/1 Running 0 3m25s
python-sandbox-warmpool-cxln2 1/1 Running 0 3m25s
sandbox-router-deployment-668dfbbbb6-g9mpd 1/1 Running 0 42s
sandbox-router-deployment-668dfbbbb6-ppllz 1/1 Running 0 42s
Verificar o balanceador de carga do roteador do Sandbox / exposição de IP
kubectl get service sandbox-router-svc -n agent-sandbox
A saída será semelhante a esta:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
sandbox-router-svc ClusterIP 34.118.237.244 <none> 8080/TCP 114s
Verificar se a regra da política de rede de saída existe
kubectl get networkpolicy restrict-sandbox-egress -n agent-sandbox
A saída será semelhante a esta:
NAME POD-SELECTOR AGE
restrict-sandbox-egress sandbox=python-sandbox-example 113s
Confira se:
- Os pods
python-sandbox-warmpool-***estãoRunninge1/1prontos. - As réplicas
sandbox-router-deployment-***estãoRunninge1/1prontas. - O
sandbox-router-svcestá acessível, e a políticarestrict-sandbox-egressprotege com sucesso todos os rótulos de sandbox correspondentes.
Com nosso ambiente de execução seguro protegido e inicializado, estamos prontos para implantar o cérebro da nossa operação: o agente de geração de código.
7. Criar e implantar o agente de geração de código (ADK)
Com nosso sandbox de execução segura e o back-end de LLM de alta performance configurados, agora podemos criar o "cérebro" do nosso sistema: um agente de geração de código usando o Kit de Desenvolvimento de Agente (ADK).
Ele foi projetado para agir como um desenvolvedor Python especialista. Ao contrário de um chatbot padrão que só produz texto, esse agente está equipado com uma ferramenta de execução de código que permite resolver problemas de forma interativa. Ele segue um loop de:
- Escrever código Python com base nas suas solicitações.
- Executar o código com segurança no sandbox do agente do GKE que configuramos na etapa 6.
- Verificar a saída ou ler os erros que surgem durante a execução.
- Entregar uma solução testada e funcional com confiança.
Ao dar ao agente acesso a um ambiente de execução de sandbox seguro, permitimos que ele verifique a própria lógica e depure falhas automaticamente, o que o torna muito mais capaz de realizar tarefas de desenvolvimento de software.
Desenvolver o agente de raciocínio do ADK
Primeiro, escrevemos a lógica do Python que define o comportamento do agente e o equipa com a ferramenta Sandbox criada na etapa 6. Nesta seção, também configuramos uma estratégia de modelo híbrido: o agente vai priorizar um modelo Qwen auto-hospedado em execução no cluster do GKE, mas vai fazer fallback automático para o Gemini 2.5 Flash na Vertex AI se o modelo local estiver lento ou indisponível, garantindo alta confiabilidade.
Crie um novo diretório para o código do agente:
mkdir -p ~/gke-ai-agent-lab/root_agent
cd ~/gke-ai-agent-lab
Crie um arquivo chamado root_agent/agent.py com o conteúdo a seguir:
cat <<'EOF' > root_agent/agent.py
import os
from google.adk.agents import Agent
from google.adk.models.lite_llm import LiteLlm
from k8s_agent_sandbox import SandboxClient
import requests
# Instantiate the client globally to track sandboxes
sandbox_client = SandboxClient()
def run_python_code(code: str) -> str:
"""
Executes Python code safely in the GKE Agent Sandbox.
Use this tool whenever you need to execute code to solve a problem.
"""
sandbox = sandbox_client.create_sandbox(template="python-runtime-template", namespace="agent-sandbox")
try:
command = f"python3 -c \"{code}\""
result = sandbox.commands.run(command)
if result.stderr:
return f"Error: {result.stderr}"
return result.stdout
finally:
# Ensure the sandbox is deleted after use to avoid leaking resources
sandbox_client.delete_sandbox(sandbox.claim_name, namespace="agent-sandbox")
# Define the ADK Agent with a fallback mechanism.
# It prioritizes the Qwen 2.5 Coder model running on our Inference Gateway.
# If the local model is unavailable, it falls back to Gemini 2.5 Flash on Vertex AI.
root_agent = Agent(
name="CodeGenerationAgent",
model=LiteLlm(
model="openai/Qwen/Qwen2.5-Coder-14B-Instruct",
fallbacks=["vertex_ai/gemini-2.5-flash"],
timeout=10
),
instruction="""
You are an expert Python developer.
1. Write Python code to solve the user's problem.
2. Execute the code using the `run_python_code` tool to verify it works.
3. Return the exact output and a brief explanation of the code.
""",
tools=[run_python_code]
)
EOF
Crie um arquivo __init__.py para que o ADK reconheça o módulo:
echo "from . import agent" > ~/gke-ai-agent-lab/root_agent/__init__.py
Defina as variáveis de ambiente. O aplicativo ADK precisa do endereço IP do gateway para encaminhar as solicitações de LLM com sucesso. Como o ADK oferece suporte a endpoints padrão compatíveis com a OpenAI (que o vLLM fornece pelo nosso gateway), podemos substituir o URL de base da API padrão.
export GATEWAY_IP=$(kubectl get gateway infra-is-inference-gateway -n $NAMESPACE -o jsonpath='{.status.addresses[0].value}')
cat <<EOF > ~/gke-ai-agent-lab/root_agent/.env
OPENAI_API_BASE=http://${GATEWAY_IP}/v1
OPENAI_API_KEY=no-key-required
# Vertex AI settings for fallback (Authentication is handled by Workload Identity)
VERTEXAI_PROJECT=$PROJECT_ID
VERTEXAI_LOCATION=${ZONE%-[a-z]}
EOF
Colocar o aplicativo do agente em um contêiner
Precisamos empacotar o agente para que ele possa ser executado com segurança no GKE.
Crie um Dockerfile em ~/gke-ai-agent-lab que instale kubectl, a biblioteca do ADK e o cliente do Sandbox do agente:
cat <<'EOF' > ~/gke-ai-agent-lab/Dockerfile
FROM python:3.11-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
RUN apt-get update && apt-get install -y git curl \
&& curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl" \
&& install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl \
&& rm kubectl && apt-get clean && rm -rf /var/lib/apt/lists/*
RUN pip install --no-cache-dir "google-adk[extensions,otel-gcp]>=1.27.4" litellm pandas "git+https://github.com/kubernetes-sigs/agent-sandbox.git@main#subdirectory=clients/python/agentic-sandbox-client" \
"opentelemetry-instrumentation-google-genai>=0.4b0" \
"opentelemetry-exporter-otlp" \
"opentelemetry-instrumentation-vertexai>=2.0b0"
COPY ./root_agent /app/root_agent
EXPOSE 8080
ENTRYPOINT ["adk", "web", "--host", "0.0.0.0", "--port", "8080", "--otel_to_cloud"]
EOF
Crie um repositório do Artifact Registry para armazenar a imagem do contêiner.
gcloud artifacts repositories create agent-repo \
--repository-format=docker \
--location=us-central1
Use o Cloud Build para criar e enviar a imagem do contêiner.
gcloud builds submit --tag us-central1-docker.pkg.dev/$PROJECT_ID/agent-repo/code-agent:v1 ~/gke-ai-agent-lab/
Implantar no GKE com RBAC
Por fim, implante o agente no cluster. A implantação inclui um Role e um RoleBinding que concedem ao agente permissão para reivindicar instâncias do SandboxWarmPool.
Essa implantação vai usar uma ServiceAccount do Kubernetes para permitir que seu agente se comunique com a API de reivindicação da Sandbox. Não é necessário uma conta de serviço do IAM do Google, já que ela está acessando recursos de cluster local e um endpoint de gateway vLLM local.
Por que uma implantação padrão no gVisor?
Na etapa 6, usamos as APIs SandboxTemplate e SandboxClaim para criar sandbox descartáveis e efêmeras para o código Python gerado (a execução da ferramenta).
Para a interface da Web do agente (o Brain), usamos especificações padrão do Kubernetes Deployment com runtimeClassName: gvisor.
- A distinção: os
SandboxClaimspadrão são efêmeros e de zero a um (ideal para scripts não confiáveis). UmDeploymentpadrão é de longa duração e persistente, perfeito para interfaces de usuário da Web que precisam de umServicee um balanceador de carga do Kubernetes estáveis. Ao usarruntimeClassName: gvisordiretamente em uma implantação padrão, você tem o isolamento do kernel do gVisor e mantém os recursos padrão doDeployment.
Salve o seguinte como deployment.yaml:
cat <<EOF > ~/gke-ai-agent-lab/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: code-agent
labels:
app: code-agent
spec:
replicas: 1
selector:
matchLabels:
app: code-agent
template:
metadata:
labels:
app: code-agent
spec:
serviceAccount: adk-agent-sa
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: code-agent
image: us-central1-docker.pkg.dev/YOUR_PROJECT_ID/agent-repo/code-agent:v1
imagePullPolicy: Always
env:
- name: OPENAI_API_KEY
value: "no-key-required"
- name: OPENAI_API_BASE
value: "http://YOUR_GATEWAY_IP/v1"
- name: VERTEXAI_PROJECT
value: "YOUR_PROJECT_ID"
- name: VERTEXAI_LOCATION
value: "YOUR_REGION"
- name: OTEL_SERVICE_NAME
value: "code-agent"
- name: GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY
value: "true"
- name: OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT
value: "true"
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: code-agent-service
spec:
selector:
app: code-agent
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: agent-sandbox
name: sandbox-creator-role
rules:
- apiGroups: [""]
resources: ["services", "pods", "pods/portforward"]
verbs: ["get", "list", "watch", "create"]
- apiGroups: ["extensions.agents.x-k8s.io"]
resources: ["sandboxclaims"]
verbs: ["create", "get", "list", "watch", "delete"]
- apiGroups: ["agents.x-k8s.io"]
resources: ["sandboxes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: adk-agent-binding
namespace: agent-sandbox
subjects:
- kind: ServiceAccount
name: adk-agent-sa
namespace: default
roleRef:
kind: Role
name: sandbox-creator-role
apiGroup: rbac.authorization.k8s.io
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: adk-agent-sa
EOF
Conceder permissões do IAM para observabilidade
Para permitir que o agente envie dados de telemetria (registros e traces) ao Google Cloud, conceda as permissões necessárias à conta de serviço do Kubernetes adk-agent-sa usando a Identidade da carga de trabalho.
Execute os comandos a seguir no Cloud Shell:
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# Grant permission to write logs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/logging.logWriter \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to write traces
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/cloudtrace.agent \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to use Vertex AI
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/aiplatform.user \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
Execute o comando a seguir para substituir automaticamente YOUR_PROJECT_ID pelo ID do projeto real e aplicar a configuração.
sed -i "s/YOUR_PROJECT_ID/$PROJECT_ID/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_GATEWAY_IP/$GATEWAY_IP/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_REGION/$ZONE/g" ~/gke-ai-agent-lab/deployment.yaml
kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml
8. Observar e validar
Agora é hora de testar o sistema totalmente integrado.
Testar o agente de geração de código na interface
Encontre o IP externo da interface da Web do ADK:
kubectl get services code-agent-service
A resposta será semelhante a esta:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
code-agent-service LoadBalancer 34.118.230.182 34.31.250.60 80:32471/TCP 2m14s
- Abra um navegador e acesse
http://[EXTERNAL-IP]. - Na interface da Web do ADK, verifique se "root_agent" está selecionado no menu suspenso no canto superior direito. Em seguida, peça ao agente:
Write a python script that prints 'Hello from the isolated sandbox'.
Para observar como o agente usa o back-end de inferência e o sandbox, acesse as seções Analisar estatísticas do modelo usando o Cloud Observability e Analisar a capacidade de observação do agente usando a interface do GKE abaixo para conferir os painéis.
Conhecer a observabilidade do agente na interface do GKE
Agora que você executou alguns comandos, vamos analisar os dados de telemetria. Isso ajuda você a entender a performance do Inference Scheduler e do vLLM.
Acessar os painéis de agentes
- Acesse a página Kubernetes Engine > Cargas de trabalho.
- Clique na implantação code-agent para abrir a página Detalhes da implantação.
- Clique na guia Observabilidade.
- No painel de navegação à esquerda do painel de observabilidade, você vai encontrar uma nova seção Agente com subguias.
O que explorar
Confira as seguintes subguias para ver o comportamento do aplicativo do agente:
- Visão geral:confira visões gerais de sessões, média de turnos e invocações.
- Modelos:confira o número de chamadas de modelo, as taxas de erro e a latência categorizadas pelos modelos usados pelo seu agente.
- Ferramentas:monitore as chamadas de ferramentas e a duração da execução para saber se o agente está usando a ferramenta de execução do sandbox de maneira eficaz.
- Uso:rastreie o uso de tokens e a alocação padrão de recursos de contêiner (CPU e memória).
- Traces do agente:mude para essa guia para ver uma lista de sessões de execução ou intervalos de trace brutos. Clique em uma linha para abrir um submenu com detalhes do trace selecionado.
Ao combinar métricas no nível do modelo do vLLM com telemetria no nível do app do ADK, você tem observabilidade de pilha completa para seu agente de IA generativa no GKE.
Conheça as estatísticas do modelo vLLM usando o Cloud Observability
Agora que você executou alguns comandos, vamos analisar os dados de telemetria. Isso ajuda você a entender a performance do Inference Scheduler e do vLLM.
Acessar os painéis
- Navegue até o Console do Google Cloud.
- Acesse Monitoring > Painéis.
- Procure e selecione o painel Visão geral do vLLM Prometheus.
Métricas interessantes para observar
Ao visualizar o painel, preste atenção a estas métricas principais para conferir o impacto do GKE Inference Gateway e do cache de prefixo:
- Utilização do cache de KV (
vllm:gpu_cache_usage):- Por que isso é importante:mostra quanta memória da GPU está sendo usada para armazenar contexto em cache. Se esse valor for alto, significa que o sistema está mantendo o contexto para acelerar solicitações futuras. Se você executar o mesmo comando várias vezes, vai notar que essa utilização aumenta e depois se estabiliza.
- Solicitações em execução x em espera (
vllm:num_requests_runningxvllm:num_requests_waiting):- Por que isso é importante:indica a cardio. Se as solicitações em espera forem altas, isso significa que os nós estão sobrecarregados.
- Capacidade de processamento de tokens (
vllm:request_prompt_tokens_totevllm:request_generation_tokens_tot):- Por que isso é importante:acompanhe o volume de tokens de entrada e saída processados pelo cluster.
- Tempo até o primeiro token (TTFT):
- Por que isso é importante:essa é a métrica essencial para agentes interativos. Ao usar o GKE Inference Gateway com o roteamento com reconhecimento de cache de prefixo, as solicitações que compartilham contextos comuns (como comandos do sistema ou grandes janelas de contexto) são encaminhadas para a mesma réplica, minimizando o TTFT ao reutilizar os acertos de cache atuais.
Experimentos para testar
Teste estes cenários para ver a mudança nas métricas em tempo real e validar o agendamento correto.
Experimento 1: a "velocidade de repetição" (acerto de cache de prefixo)
- Envie um comando complexo para o agente (por exemplo, "Escreva um script em Python para analisar um arquivo CSV de 100 MB e calcular estatísticas").
- Quando ele responder, envie o mesmo comando de novo imediatamente.
- Observe a taxa de acerto do cache de prefixo e o tempo até o primeiro token (TTFT).
- O que você vai ver:a taxa de acertos do cache de prefixo vai subir para 100%, e o TTFT vai cair drasticamente.
- O que isso significa:o GKE Inference Gateway reconheceu o contexto compartilhado e o encaminhou para a mesma réplica, que reutilizou o cache de contexto avaliado.
Experimento 2: voltar para a nuvem (confiabilidade do modelo)
- Para simular uma falha no seu modelo Qwen local, pare o serviço de inferência ou forneça um
OPENAI_API_BASEfalso na implantação. - Atualize o
OPENAI_API_BASEno seudeployment.yamlpara um IP ou porta inexistente e aplique as mudanças:sed -i "s|value: \"http://$GATEWAY_IP/v1\"|value: \"http://10.0.0.1:8080/v1\"|g" ~/gke-ai-agent-lab/deployment.yaml kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml - Aguarde a reinicialização do pod e envie um comando ao agente na interface.
- O que você vai ver:o agente ainda responde com sucesso.
- O que isso significa:devido à configuração
fallbacks, o ADK reconheceu a falha do endpoint local do Qwen e encaminhou a solicitação para o Gemini 2.5 Flash na Vertex AI. Como essas chamadas de substituição para a Vertex AI ignoram o gateway de inferência vLLM local, elas não aparecem no painel Observabilidade do agente > Modelos, que rastreia apenas o tráfego que passa pelo vLLM.
Entender o poder da alocação dinâmica de recursos (DRA)
Embora o vLLM e o Inference Gateway otimizem como as solicitações são encaminhadas e atendidas, a Alocação dinâmica de recursos (DRA) é o que possibilitou anexar o hardware certo à sua carga de trabalho.
Com o DRA, você pode gerenciar o hardware de maneira granular em todo o cluster, definindo recursos de hardware flexíveis usando ResourceClaimTemplate e DeviceClasses.
Por que o DRA é uma mudança radical para cargas de trabalho de IA:
- Solicitações de hardware refinadas: com o DRA, você não apenas garante que as cargas de trabalho sejam programadas em máquinas com o acelerador certo, mas também pode reivindicar esses recursos para garantir que eles sejam usados exclusivamente pela carga de trabalho associada ao ResourceClaim.
- Ciclo de vida dissociado: as reivindicações de dispositivos são gerenciadas de forma independente dos ciclos de vida do pod. Se um pod falhar, a reivindicação de GPU poderá persistir para que a implantação geral ou outro objeto de carga de trabalho possa ser reiniciado sem precisar esperar que a GPU seja liberada e adquirida novamente.
- Padronização de vários fornecedores: o DRA oferece uma API Kubernetes unificada para GPUs NVIDIA e TPUs do Google. Você usa exatamente o mesmo esquema, seja para um ou para outro, o que torna os manifestos YAML da sua carga de trabalho altamente portáteis.
Neste codelab, você viu isso em ação ao configurar os valores do Helm para vincular ao gpu-claim-template sem problemas, sem ter configurações de plug-in de dispositivo pendentes bloqueando seus rollouts.
Entender a função do llm-d
Enquanto o vLLM avalia pesos neurais e o Gateway do GKE encaminha consultas, o llm-d atua como a camada de configuração e a "cola" que une tudo.
Sem o llm-d, você precisaria escrever manifestos brutos do Kubernetes para declarar a implantação do vLLM, as portas de serviço, as montagens de volume e as reivindicações de recursos do DRA do zero.
Por que usar o llm-d na sua implantação?
- Configuração unificada (substituições de uma linha): os gráficos do Helm
llm-dagrupam recursos complexos e de baixo nível do Kubernetes em alternâncias limpas e de alto nível (como definiraccelerator.dra: true). - Caminhos bem iluminados pré-testados: o repositório
llm-dcontém configurações que já foram comparadas e testadas por especialistas. Ao implantar ollm-d-modelservice, você recebe padrões otimizados para utilização da memória da GPU, tempos de sondagem recomendados (atividade/prontidão) e exposições corretas para raspagem de métricas. - Mapeamento de observabilidade integrado: o
llm-dgarante que as portas de contêiner padrão e os caminhos de raspagem (/metrics) sejam expostos corretamente, facilitando a conexão da implantação ao Google Cloud Monitoring sem depuração manual.
Em resumo, o llm-d fornece os projetos de arquitetura reutilizáveis para que os desenvolvedores não precisem reinventar a roda toda vez que implantam uma pilha de inferência no GKE.
Detalhes: o GKE Inference Gateway
Os balanceadores de carga padrão da camada 7 operam analisando cabeçalhos HTTP, como caminhos (/v1/completions) ou cookies. O GKE Inference Gateway vai muito além: ele foi projetado especificamente para o tráfego de IA generativa.
Como isso impulsiona a performance e a eficiência:
- Roteamento sensível ao conteúdo (hash de comandos): o gateway de inferência do GKE intercepta o corpo da solicitação JSON. Ele calcula um hash do comando e rastreia qual réplica de back-end já está armazenando esses tokens na memória da GPU (o cache KV).
- Como maximizar os acertos de cache: nos seus testes, quando você repetia um comando, o Gateway o enviava para a mesma réplica. A avaliação de um comando exige muito poder de computação. Ao reutilizar o cache, você evita "reler" o comando, economizando dinheiro e tempo de GPU.
- Redução do tempo até o primeiro token (TTFT): o TTFT é a métrica de usabilidade essencial para agentes voltados ao usuário. Ao acessar o cache, o modelo pode começar a gerar tokens em milissegundos em vez de segundos.
- Distribuição inteligente de carga: se a VRAM de uma réplica estiver completamente cheia de acertos de cache, o gateway poderá encaminhar dinamicamente um novo comando para uma réplica diferente que tenha espaço, equilibrando eficiência e disponibilidade.
Como o Agent Sandbox reduz o risco
Neste laboratório, mostramos como o Sandbox do agente protege sua infraestrutura dos riscos associados aos agentes de IA, oferecendo duas camadas de isolamento:
- Isolamento da ferramenta de execução: o agente executa o código gerado em um sandbox efêmero. Isso garante que o código não confiável gerado pelo LLM seja executado em um ambiente seguro e isolado, protegendo o agente e o cluster.
- Inicialização rápida: ao usar um WarmPool, novos sandboxes são iniciados em menos de um segundo, prontos para executar o código.
- Isolamento do próprio agente: também executamos o aplicativo do agente em um nó ativado pelo gVisor (via
runtimeClassName: gvisor) para oferecer defesa em profundidade contra vulnerabilidades da cadeia de suprimentos nas dependências do agente.
Confira por que isso cria um limite de segurança tão reforçado:
- Interceptação de chamadas do sistema: o gVisor intercepta chamadas do sistema antes que elas cheguem ao kernel do Linux host. Isso bloqueia exploits que tentam sair do contêiner para acessar o nó do host.
- Movimentação lateral restrita: combinada com políticas de rede, mesmo que um ambiente seja comprometido, ele não pode verificar seus servidores de metadados internos nem migrar para outros serviços sensíveis no cluster.
Executar agentes completos em sandboxes
Neste laboratório, usamos sandboxes como ferramentas para um aplicativo de agente persistente. No entanto, para máxima segurança, principalmente ao lidar com dados sensíveis ou atender a vários usuários não confiáveis, é possível executar o aplicativo de agente inteiro em uma sandbox dedicada para cada sessão ou usuário. Isso garante o isolamento completo da memória, do estado e do ambiente de execução do agente, que são destruídos imediatamente após a conclusão da sessão.
9. Limpeza
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados neste codelab, siga estas etapas para excluí-los.
Excluir recursos individuais
- Exclua o cluster do GKE:
gcloud container clusters delete $CLUSTER_NAME --zone $ZONE --quiet
- Exclua o repositório do Artifact Registry:
gcloud artifacts repositories delete agent-repo --location=us-central1 --quiet
- Exclua a rede VPC:
gcloud compute networks delete ai-agent-network --quiet
Excluir o projeto
Se você não precisar mais do projeto, exclua-o depois de remover os recursos:
gcloud projects delete $PROJECT_ID
10. Resumo
Parabéns! Você criou e implantou um agente de geração de código seguro e de alta performance no GKE.
O que você aprendeu
- Como configurar e usar a alocação dinâmica de recursos (DRA) no GKE para gerenciar recursos de GPU.
- Como usar o GKE Inference Gateway para otimizar o desempenho da veiculação de LLMs usando o roteamento com reconhecimento de prefixo-cache.
- Como usar o Agent Sandbox (gVisor) para executar código não confiável com segurança no GKE.
- Como usar o Google Cloud Managed Service para Prometheus para monitorar a performance de vLLMs.
- Como configurar e visualizar a observabilidade do agente usando o ADK e o OpenTelemetry gerenciado do GKE.
Próximas etapas e referências
- Sandbox do agente: saiba mais sobre o Sandbox do agente no GKE e os pods do GKE Sandbox.
- llm-d: leia o guia do llm-d e confira o repositório do llm-d no GitHub.
- Alocação dinâmica de recursos: saiba mais sobre a DRA no GKE.
- GKE Inference Gateway: conheça os conceitos do Inference Gateway.
- Mais codelabs: encontre mais tutoriais em Codelabs do Google Cloud.