
1. Введение
Обзор
В этой лабораторной работе вы научитесь создавать и развертывать безопасный агент генерации кода в Google Kubernetes Engine (GKE). Агенты генерации кода должны выполнять код, который может быть ненадежным, что требует защищенной песочницы. Вы также узнаете, как настроить агента с использованием гибридной стратегии модели, позволяющей ему переключаться с самостоятельно размещенной открытой модели в GKE на управляемый сервис Gemini от Vertex AI для повышения надежности. Кроме того, вы узнаете, как оптимизировать предоставление результатов инференции с помощью GKE Inference Gateway и динамического распределения ресурсов (DRA). Наконец, вы узнаете, как использовать Google Cloud Observability для мониторинга вашего стека инференции с помощью управляемого Prometheus.
Архитектура
Вот архитектура системы, которую вы будете создавать:
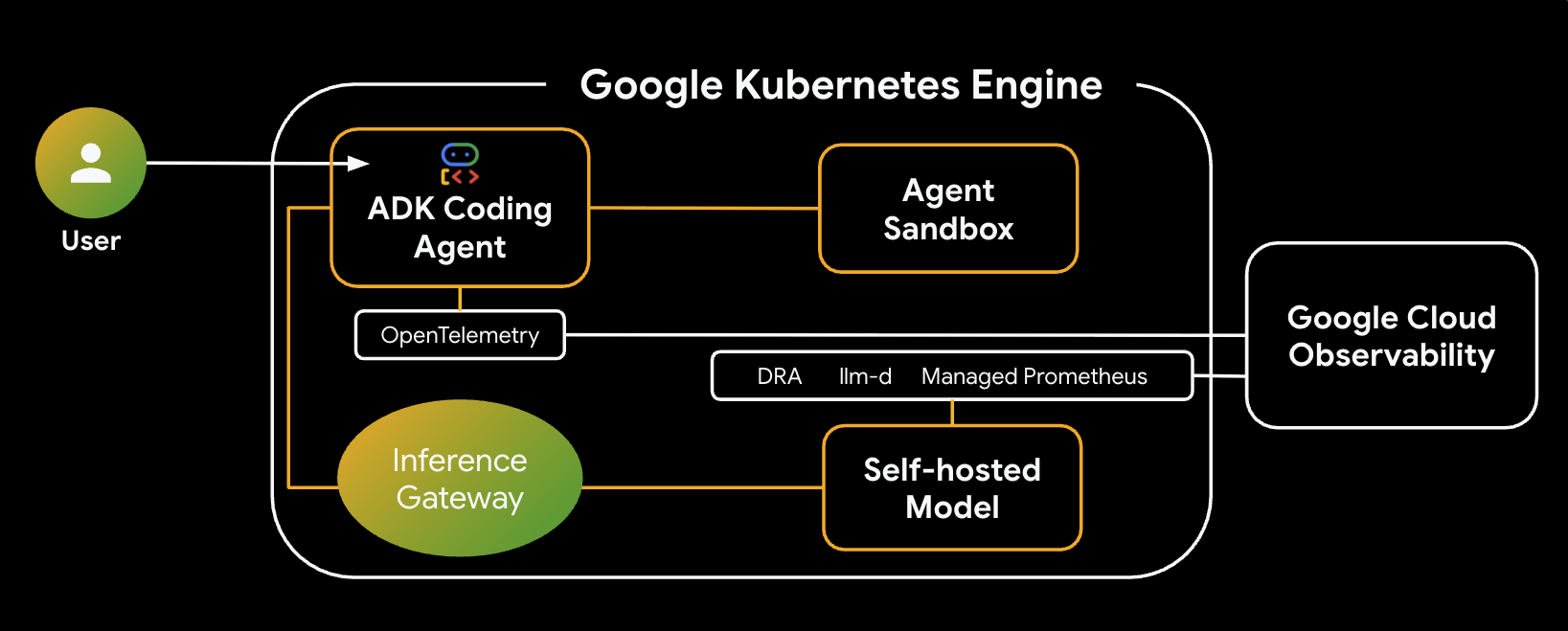
Основные компоненты и преимущества
- Динамическое распределение ресурсов (DRA) : используется в этой лабораторной работе для динамического выделения и распределения конкретных ресурсов графического процессора (NVIDIA L4) для Pod-ов сервера моделей, обеспечивая точное аппаратное обеспечение для нашей рабочей нагрузки вывода. Подробнее о DRA можно узнать в GKE .
- llm-d и vLLM : Предоставляют фреймворк для развертывания модели и Helm-диаграммы для развертывания модели Qwen. В этой лабораторной работе они обрабатывают запросы на вывод результатов и интегрируются с DRA для управления ресурсами (раздельное развертывание в этой лабораторной работе не включено). Ознакомьтесь с руководством по llm-d и репозиторием llm-d на GitHub .
- GKE Inference Gateway : Переносит логику маршрутизации с учетом особенностей ИИ непосредственно в балансировщик нагрузки. В этой лабораторной работе он маршрутизирует запросы для максимизации попаданий в кэш префиксов, сокращая задержку «Время до первого токена» (TTFT). Изучите концепции Inference Gateway .
- Agent Sandbox (gVisor) : Обеспечивает надежную изоляцию для выполнения кода, сгенерированного агентом ИИ. Он использует gVisor для обеспечения глубокой изоляции ядра, защищая хост-узел от ненадежных рабочих нагрузок. Узнайте больше об Agent Sandbox в GKE и GKE Sandbox Pods .
Что вы будете делать
- Подготовка инфраструктуры : Настройте кластер GKE с динамическим распределением ресурсов (DRA) для управления графическими процессорами.
- Развертывание стека вывода : Разверните
llm-dи vLLM с интеллектуальным планированием вывода. - Настройка интеллектуальной маршрутизации : используйте GKE Inference Gateway для маршрутизации с учетом кэша префиксов.
- Безопасное выполнение кода : разверните агентскую песочницу (gVisor) для безопасного запуска кода, сгенерированного ИИ.
- Наблюдение и проверка : используйте Google Cloud Monitoring и Managed Prometheus для просмотра метрик обслуживания моделей.
Что вы узнаете
- Как настроить и использовать динамическое распределение ресурсов (DRA) в GKE.
- Как использовать GKE Inference Gateway для оптимизации производительности обслуживания LLM.
- Как использовать Agent Sandbox для безопасного выполнения ненадежного кода в GKE.
- Как использовать Google Cloud Managed Service for Prometheus для мониторинга производительности vLLM.
2. Настройка и требования
Настройка проекта
Создайте проект в Google Cloud.
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud .
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
Запустить Cloud Shell
Cloud Shell — это среда командной строки, работающая в Google Cloud и поставляемая с предустановленными необходимыми инструментами.
- В верхней части консоли Google Cloud нажмите кнопку «Активировать Cloud Shell» .
- После подключения к Cloud Shell подтвердите свою аутентификацию:
gcloud auth list - Убедитесь, что ваш проект настроен:
gcloud config get project - Если параметры вашего проекта заданы не так, как ожидалось, настройте их следующим образом:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
3. Предоставление инфраструктуры и динамическое распределение ресурсов (DRA)
На первом этапе вы настроите свой кластер GKE для использования современного механизма распределения ресурсов ускорителей (DRA) вместо устаревших плагинов устройств. Это позволит вам гибко распределять и выделять графические процессоры или тензорные процессоры для рабочих нагрузок генерации кода.
Предварительные условия: Для поддержки DRA ваш кластер GKE Standard должен работать под управлением версии 1.34 или более поздней.
Включите API Google Cloud
Включите необходимые для этого практического занятия API Google Cloud, а именно API Compute Engine и Kubernetes Engine.
gcloud services enable compute.googleapis.com container.googleapis.com networkservices.googleapis.com cloudbuild.googleapis.com artifactregistry.googleapis.com telemetry.googleapis.com cloudtrace.googleapis.com aiplatform.googleapis.com
Установка переменных среды
Для упрощения настройки определите переменные среды. При необходимости вы можете скорректировать регион или правила именования.
export PROJECT_ID=$(gcloud config get-value project)
export ZONE=us-central1-a
export CLUSTER_NAME=ai-agent-cluster
export NODEPOOL_NAME=dra-accelerator-pool
gcloud config set project $PROJECT_ID
gcloud config set compute/region $ZONE
Создать рабочий каталог
Создайте для этой лабораторной работы отдельную рабочую директорию и перейдите в неё, чтобы ваши файлы оставались упорядоченными:
mkdir -p ~/gke-ai-agent-lab
cd ~/gke-ai-agent-lab
Настройка прав доступа (необязательно)
Если вы работаете в проекте с ограниченными правами или в общей среде, убедитесь, что ваша учетная запись имеет необходимые разрешения для создания кластеров и выполнения сборок:
export MY_ACCOUNT=$(gcloud config get-value account)
# Grant Container Admin to create clusters and manage nodes if needed
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/container.admin"
# Grant Cloud Build Builder to run builds
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/cloudbuild.builds.builder"
Создайте кластер GKE.
Для поддержки DRA ваш кластер GKE Standard должен работать под управлением версии 1.34 или более поздней. Также необходимо включить контроллеры Gateway API для поддержки интеллектуального планирования вычислений.
Для этой лабораторной работы вам предстоит создать новую сеть VPC и подсети.
Сначала создайте сеть VPC:
gcloud compute networks create ai-agent-network --subnet-mode=custom
Далее создайте подсеть для ваших узлов GKE:
gcloud compute networks subnets create ai-agent-subnet \
--network=ai-agent-network \
--range=10.0.0.0/20 \
--region=us-central1
Для работы API шлюза ( gke-l7-regional-internal-managed ) также требуется выделенная подсеть для размещения прокси-серверов Envoy. Создайте эту подсеть только для прокси в вашей новой сети:
gcloud compute networks subnets create proxy-only-subnet \
--purpose=REGIONAL_MANAGED_PROXY \
--role=ACTIVE \
--region=us-central1 \
--network=ai-agent-network \
--range=192.168.10.0/24
Теперь создайте кластер, используя новую сеть и подсеть:
gcloud beta container clusters create $CLUSTER_NAME \
--zone $ZONE \
--num-nodes 1 \
--machine-type n2-standard-4 \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--gateway-api=standard \
--managed-otel-scope=COLLECTION_AND_INSTRUMENTATION_COMPONENTS \
--network=ai-agent-network \
--subnetwork=ai-agent-subnet
Создайте пул узлов с отключенными плагинами по умолчанию.
Для передачи управления устройствами в DRA необходимо создать пул узлов, который явно отключает установку драйвера графического процессора по умолчанию и стандартный плагин устройства.
Выполните следующую команду gcloud , чтобы выделить пул узлов GPU (например, используя уровни L4 NVIDIA) с необходимыми метками DRA:
gcloud container node-pools create $NODEPOOL_NAME \
--cluster=$CLUSTER_NAME \
--location=$ZONE \
--machine-type=g2-standard-24 \
--accelerator=type=nvidia-l4,count=2,gpu-driver-version=disabled \
--node-labels=gke-no-default-nvidia-gpu-device-plugin=true,nvidia.com/gpu.present=true \
--num-nodes 3
Установите драйверы NVIDIA через DaemonSet.
Установите необходимые базовые драйверы устройств NVIDIA вручную на ваши узлы, используя предварительно настроенный Google Cloud DaemonSet:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
Установите драйвер DRA.
Далее установите необходимый драйвер DRA в свой кластер. Для графических процессоров NVIDIA его можно развернуть с помощью Helm:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
helm install nvidia-dra-driver-gpu nvidia/nvidia-dra-driver-gpu \
--version="25.3.2" --create-namespace --namespace=nvidia-dra-driver-gpu \
--set nvidiaDriverRoot="/home/kubernetes/bin/nvidia/" \
--set gpuResourcesEnabledOverride=true \
--set resources.computeDomains.enabled=false \
--set kubeletPlugin.priorityClassName="" \
--set 'kubeletPlugin.tolerations[0].key=nvidia.com/gpu' \
--set 'kubeletPlugin.tolerations[0].operator=Exists' \
--set 'kubeletPlugin.tolerations[0].effect=NoSchedule'
Понимание классов устройств
Вам не нужно вручную писать или применять YAML-файл DeviceClass . При настройке инфраструктуры GKE для DRA и установке драйвера драйверы DRA, работающие на ваших узлах, автоматически создают объекты DeviceClass в кластере.
Настройте шаблон ResourceClaimTemplate
Чтобы ваши Pod-ы llm-d могли динамически запрашивать эти ускорители, вам потребуется создать ResourceClaimTemplate . Этот шаблон определяет запрашиваемую конфигурацию устройства и указывает Kubernetes автоматически создавать уникальный ResourceClaim для каждого Pod-а и его рабочих нагрузок.
Выполните следующую команду, чтобы создать claim-template.yaml :
cat > claim-template.yaml <<EOF
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: gpu-claim-template
spec:
spec:
devices:
requests:
- name: single-gpu
exactly:
deviceClassName: gpu.nvidia.com
allocationMode: ExactCount
count: 1
EOF
Примените шаблон к своему кластеру:
kubectl apply -f claim-template.yaml
4. Внедрение интеллектуального планирования на основе логического вывода с использованием llm-d и DRA.
На этом этапе вы развернете свою большую языковую модель за интеллектуальным балансировщиком нагрузки Envoy, дополненным планировщиком вывода. Эта конфигурация оптимизирует обслуживание модели за счет применения маршрутизации с учетом префиксного кэша. GKE Inference Gateway распознает общий контекст в микросервисах и интеллектуально направляет запросы к одной и той же реплике модели, максимизируя попадания в кэш, сокращая время до получения первого токена и обеспечивая превосходную производительность на вложенные средства.
Подготовка окружающей среды
Настройте целевое пространство имен.
export NAMESPACE=ai-agents
kubectl create namespace $NAMESPACE
Надежно сохраните свой токен Hugging Face, необходимый для перемещения весов модели.
# Replace with your actual Hugging Face token
kubectl create secret generic llm-d-hf-token \
--from-literal=HF_TOKEN="your_hugging_face_token" \
-n $NAMESPACE
Создайте файлы конфигурации Helm.
Настройки службы моделей и расширения шлюза вывода основаны на официальных руководствах llm-d .
Сначала создайте файл ms-values.yaml для службы моделей:
cat <<EOF > ms-values.yaml
multinode: false
modelArtifacts:
uri: "hf://Qwen/Qwen2.5-Coder-14B-Instruct"
name: "Qwen/Qwen2.5-Coder-14B-Instruct"
size: 50Gi # Slightly larger than the default to accommodate weights
authSecretName: "llm-d-hf-token"
labels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
llm-d.ai/accelerator-variant: "gpu"
llm-d.ai/accelerator-vendor: "nvidia"
llm-d.ai/model: "qwen-2-5-coder-14b"
routing:
proxy:
enabled: false # removes sidecar from deployment - no PD in inference scheduling
targetPort: 8000 # controls vLLM port to matchup with sidecar if deployed
accelerator:
dra: true
type: "nvidia"
resourceClaimTemplates:
nvidia:
class: "gpu.nvidia.com"
match: "exactly"
name: "gpu-claim-template"
decode:
create: true
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
parallelism:
tensor: 2
data: 1
replicas: 3
monitoring:
podmonitor:
enabled: true
portName: "vllm"
path: "/metrics"
interval: "30s"
containers:
- name: "vllm"
image: ghcr.io/llm-d/llm-d-cuda:v0.5.1
modelCommand: vllmServe
args:
- "--disable-uvicorn-access-log"
- "--gpu-memory-utilization=0.85"
- "--enable-auto-tool-choice"
- "--tool-call-parser"
- "hermes"
ports:
- containerPort: 8000
name: vllm
protocol: TCP
resources:
limits:
cpu: '16'
memory: 64Gi
requests:
cpu: '16'
memory: 64Gi
mountModelVolume: true
volumeMounts:
- name: metrics-volume
mountPath: /.config
- name: shm
mountPath: /dev/shm
- name: torch-compile-cache
mountPath: /.cache
startupProbe:
httpGet:
path: /v1/models
port: vllm
initialDelaySeconds: 15
periodSeconds: 30
timeoutSeconds: 5
failureThreshold: 120
livenessProbe:
httpGet:
path: /health
port: vllm
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /v1/models
port: vllm
periodSeconds: 5
timeoutSeconds: 2
failureThreshold: 3
volumes:
- name: metrics-volume
emptyDir: {}
- name: torch-compile-cache
emptyDir: {}
- name: shm
emptyDir:
medium: Memory
sizeLimit: 20Gi
prefill:
create: false
EOF
Далее создайте файл gaie-values.yaml для расширения GKE Inference Gateway Extension:
cat <<EOF > gaie-values.yaml
inferenceExtension:
replicas: 1
image:
name: llm-d-inference-scheduler
hub: ghcr.io/llm-d
tag: v0.6.0
pullPolicy: Always
extProcPort: 9002
pluginsConfigFile: "default-plugins.yaml"
tracing:
enabled: false
monitoring:
interval: "10s"
prometheus:
enabled: true
auth:
secretName: inference-scheduling-gateway-sa-metrics-reader-secret
inferencePool:
targetPorts:
- number: 8000
modelServerType: vllm
modelServers:
matchLabels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
EOF
Понимание конфигурации
Данная конфигурация создает высокопроизводительный стек для выполнения инференции со следующими ключевыми функциями:
- Выбор модели : Используется модель Qwen 2.5 Coder 14B (
modelArtifacts), оптимизированная для генерации кода и использования инструментов. - Интеграция DRA : Раздел
acceleratorвключает динамическое распределение ресурсов (dra: true), ориентированное на класс устройствgpu.nvidia.comи наш ранее созданныйgpu-claim-template. - Оптимизация производительности :
-
parallelism.tensor: 2настраивает параллельную обработку тензоров на всех графических процессорах. - В
argsvLLM включен--enable-auto-tool-choiceчтобы гарантировать, что наш агент кодирования сможет эффективно использовать инструменты. - Сниженные требования
cpuиmemoryсоответствуют типу машиныg2-standard-24.
-
- Интеллектуальная маршрутизация : расширение Inference Gateway (
gaie-values.yaml) настроено на мониторинг серверов моделиvllmи маршрутизацию запросов для максимизации попаданий в KV-кэш.
Разверните стек планирования вывода с помощью Helm.
Теперь добавьте репозитории Helm llm-d и разверните инфраструктуру, расширение шлюза и службу модели по отдельности.
Сначала добавьте необходимые репозитории:
helm repo add llm-d-infra https://llm-d-incubation.github.io/llm-d-infra/
helm repo add llm-d-modelservice https://llm-d-incubation.github.io/llm-d-modelservice/
helm repo update
Разверните необходимые инфраструктурные компоненты.
Данная диаграмма устанавливает базовые конфигурации шлюза, необходимые для работы стека.
helm install infra-is llm-d-infra/llm-d-infra \
--namespace $NAMESPACE \
--set gateway.gatewayClassName=gke-l7-rilb \
--set gateway.gatewayParameters.enabled=false \
--set gateway.gatewayParameters.istio.accessLogging=false
Разверните расширение GKE Inference Gateway.
На этом этапе развертываются InferencePool и Endpoint Picker, которые отслеживают KV-кэш ваших моделей для принятия интеллектуальных решений по маршрутизации.
helm install gaie-is oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool \
--version v1.3.1 \
--namespace $NAMESPACE \
-f gaie-values.yaml \
--set provider.name=gke \
--set inferenceExtension.monitoring.prometheus.enabled=true
Разверните службу модели.
Наконец, разверните свою службу LLM, которая теперь будет использовать DRA для безопасного выделения ваших графических процессоров L4.
helm install ms-is llm-d-modelservice/llm-d-modelservice \
--version v0.4.7 \
--namespace $NAMESPACE \
-f ms-values.yaml \
--set decode.monitoring.podmonitor.enabled=false
Включите Google Cloud Observability для vLLM
Стандартные Helm-диаграммы часто пытаются развернуть стандартные ресурсы PodMonitor оператора Prometheus ( monitoring.coreos.com/v1 ), что может привести к ошибкам, если у вас не установлены соответствующие CRD.
Вместо того чтобы переключать встроенный в Helm параметр мониторинга, оставьте его false и вручную примените ресурс PodMonitoring в Google Cloud Managed Prometheus (GMP), используя совместимую группу API monitoring.googleapis.com/v1 .
Выполните следующую команду для создания podmonitoring.yaml :
cat > podmonitoring.yaml <<EOF
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: ms-vllm-metrics
spec:
selector:
matchLabels:
llm-d.ai/model: "qwen-2-5-coder-14b" # Matches the label in values.yaml
endpoints:
- port: 8000 # vllm port
interval: 30s
path: /metrics
EOF
Примените ресурс PodMonitoring к своему кластеру:
kubectl apply -f podmonitoring.yaml -n $NAMESPACE
Проверьте установку.
Убедитесь, что компоненты успешно установлены. Вы должны увидеть все три активных релиза Helm в вашем пространстве имен и соответствующие инициализирующиеся поды.
helm ls -n $NAMESPACE
kubectl get pods -n $NAMESPACE
Запуск модулей ms-is может занять от 5 до 10 минут. После запуска вывод должен выглядеть примерно так:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
gaie-is ai-agents 1 2026-03-28 16:51:41.055881618 +0000 UTC deployed inferencepool-v1.3.1 v1.3.1
infra-is ai-agents 1 2026-03-28 16:51:03.71042542 +0000 UTC deployed llm-d-infra-v1.4.0 v0.4.0
ms-is ai-agents 1 2026-03-28 17:30:00.341918958 +0000 UTC deployed llm-d-modelservice-v0.4.7 v0.4.0
NAME READY STATUS RESTARTS AGE
gaie-is-epp-848965cb4-78ktp 1/1 Running 0 10m
ms-is-llm-d-modelservice-decode-67548d5f8c-f25f4 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-rblvs 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-w6fcd 1/1 Running 0 6m2s
5. Настройка интеллектуальной маршрутизации с помощью шлюза вывода GKE.
На шаге 4 развертывание Helm-диаграмм llm-d автоматически создало объекты Gateway и InferencePool . InferencePool объединяет ваши поды vllm обслуживающие модели, которые используют одну и ту же базовую модель и вычислительную конфигурацию.
Теперь вам нужно настроить InferenceObjective , чтобы задать приоритет запросов к вашему агенту кодирования, и HTTPRoute , чтобы указать шлюзу, как маршрутизировать входящий трафик, используя Endpoint Picker для максимизации попаданий в KV-кэш.
Проверьте автоматически сгенерированные ресурсы
Во-первых, убедитесь, что Helm-диаграммы llm-d успешно создали ресурсы Gateway и InferencePool .
kubectl get gateway,inferencepool -n $NAMESPACE
Вы должны увидеть шлюз с именем infra-is-inference-gateway и пул вывода с именем gaie-is . Примерно так:
NAME CLASS ADDRESS PROGRAMMED AGE
gateway.gateway.networking.k8s.io/infra-is-inference-gateway gke-l7-regional-internal-managed 10.128.0.5 True 13m
NAME AGE
inferencepool.inference.networking.k8s.io/gaie-is 12m
Создайте HTTP-маршрут
Ресурс HTTPRoute сопоставляет ваш шлюз с InferencePool бэкэнда. Это указывает шлюзу вывода GKE анализировать тела входящих запросов и динамически маршрутизировать их для максимизации попаданий в Prefix-Cache на основе общего контекста.
Выполните следующую команду для создания файла httproute.yaml :
cat > httproute.yaml <<EOF
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: agent-route
spec:
parentRefs:
- group: gateway.networking.k8s.io
kind: Gateway
name: infra-is-inference-gateway
rules:
- backendRefs:
- group: inference.networking.k8s.io
kind: InferencePool
name: gaie-is
weight: 1
matches:
- path:
type: PathPrefix
value: /
EOF
Примените маршрут к вашему кластеру:
kubectl apply -f httproute.yaml -n $NAMESPACE
6. Безопасное выполнение кода с помощью агентской песочницы.
Теперь, когда наша высокопроизводительная система обработки данных запущена, давайте подготовим безопасную среду, в которой сгенерированный ИИ код будет безопасно выполняться в изоляции от нашего кластера с помощью агентской песочницы.
Разверните контроллер песочницы агента.
Когда агент ИИ генерирует и выполняет код, он, по сути, запускает ненадежную рабочую нагрузку на вашей инфраструктуре. Если агент генерирует вредоносный код, он может попытаться просканировать вашу внутреннюю сеть или использовать уязвимость на базовом узле хоста.
В GKE Agent Sandbox используется gVisor — среда выполнения контейнеров с открытым исходным кодом, которая предоставляет специализированное гостевое ядро для каждого контейнера. Это предотвращает прямые системные вызовы к хост-узлу со стороны ненадежного кода.
Разверните контроллер Agent Sandbox и необходимые для него компоненты, применив официальные манифесты релиза:
kubectl apply \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/manifest.yaml \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/extensions.yaml
Настройте шаблон песочницы и пул «теплых» процессов.
Далее мы создаём SandboxTemplate выступающий в качестве многократно используемого шаблона для наших сред анализа Python, явно ориентированного на класс среды выполнения gvisor . Чтобы упростить развертывание без ручного управления пулами узлов в кластерах Standard, мы можем использовать любой стандартный autopilot
ComputeClass позволяет динамически выделять управляемые вычислительные узлы, изначально поддерживающие рабочие нагрузки gVisor, по запросу!
Поскольку инициализация защищенного ядра может увеличить задержку, мы также используем пул SandboxWarmPool . Это гарантирует наличие определенного количества предварительно инициализированных песочниц, готовых к использованию агентом генерации кода, который сможет занять их и начать выполнение кода менее чем за секунду.
Сначала создайте новое пространство имен для сред выполнения песочницы агента:
kubectl create namespace agent-sandbox
Сохраните следующий код как sandbox-template-and-pool.yaml :
cat > sandbox-template-and-pool.yaml <<EOF
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxTemplate
metadata:
name: python-runtime-template
namespace: agent-sandbox
spec:
podTemplate:
metadata:
labels:
sandbox: python-sandbox-example
spec:
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: python-runtime
image: registry.k8s.io/agent-sandbox/python-runtime-sandbox:v0.1.0
ports:
- containerPort: 8888
readinessProbe:
httpGet:
path: "/"
port: 8888
initialDelaySeconds: 0
periodSeconds: 1
resources:
requests:
cpu: "250m"
memory: "512Mi"
ephemeral-storage: "512Mi"
restartPolicy: "OnFailure"
---
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxWarmPool
metadata:
name: python-sandbox-warmpool
namespace: agent-sandbox
spec:
replicas: 2
sandboxTemplateRef:
name: python-runtime-template
EOF
Примените конфигурацию:
kubectl apply -f sandbox-template-and-pool.yaml
Подождите 2-3 минуты, пока поды warmpool инициализируются. Вы можете убедиться, что они успешно перешли из Pending (пока происходит масштабирование вычислительных ресурсов) в Running , используя следующую команду:
kubectl get pods -n agent-sandbox -w
Как только вы увидите два пода python-sandbox-warmpool-*** отмеченных как Running и 1/1 Ready, ваши безопасные среды выполнения будут предварительно подготовлены и готовы к использованию!
Разверните маршрутизатор в песочнице.
Наш агент генерации кода использует маршрутизатор в изолированной среде (Sandbox Router) для безопасной отправки команд выполнения изолированным подам.
Выполните следующую команду для создания файла sandbox-router.yaml :
cat > sandbox-router.yaml <<EOF
apiVersion: v1
kind: Service
metadata:
name: sandbox-router-svc
namespace: agent-sandbox
spec:
type: ClusterIP
selector:
app: sandbox-router
ports:
- name: http
protocol: TCP
port: 8080
targetPort: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sandbox-router-deployment
namespace: agent-sandbox
spec:
replicas: 2
selector:
matchLabels:
app: sandbox-router
template:
metadata:
labels:
app: sandbox-router
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: sandbox-router
containers:
- name: router
image: us-central1-docker.pkg.dev/k8s-staging-images/agent-sandbox/sandbox-router:v20260225-v0.1.1.post3-10-ga5bcb57
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 10
resources:
requests:
cpu: "250m"
memory: "512Mi"
limits:
cpu: "1000m"
memory: "1Gi"
securityContext:
runAsUser: 1000
runAsGroup: 1000
EOF
Примените конфигурацию:
kubectl apply -f sandbox-router.yaml
Внедрить сетевую изоляцию
Для дальнейшей защиты среды выполнения и предотвращения несанкционированного перемещения по сети примените сетевую политику. Это создаст «воздушный зазор» в песочнице, не позволяя ей получить доступ к серверу метаданных Google Cloud или другим конфиденциальным внутренним сетям.
Сохраните следующий код как sandbox-policy.yaml :
cat > sandbox-policy.yaml <<EOF
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: restrict-sandbox-egress
namespace: agent-sandbox
spec:
podSelector:
matchLabels:
sandbox: python-sandbox-example
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 0.0.0.0/0
except:
- 169.254.169.254/32 # Block metadata server
EOF
Примените данную политику:
kubectl apply -f sandbox-policy.yaml
Проверка компонентов
Чтобы убедиться в полной настройке изолированного кластера песочницы для кода, выполните следующие команды проверки состояния:
Во-первых, убедитесь, что изолированные модули и маршрутизаторы запущены и готовы к работе.
kubectl get pods -n agent-sandbox
Результат должен выглядеть примерно так:
NAME READY STATUS RESTARTS AGE
python-sandbox-warmpool-7zlkv 1/1 Running 0 3m25s
python-sandbox-warmpool-cxln2 1/1 Running 0 3m25s
sandbox-router-deployment-668dfbbbb6-g9mpd 1/1 Running 0 42s
sandbox-router-deployment-668dfbbbb6-ppllz 1/1 Running 0 42s
Проверьте доступность балансировщика нагрузки/IP-адреса на маршрутизаторе в песочнице.
kubectl get service sandbox-router-svc -n agent-sandbox
Результат должен выглядеть следующим образом:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
sandbox-router-svc ClusterIP 34.118.237.244 <none> 8080/TCP 114s
Убедитесь, что правило политики исходящей сети существует.
kubectl get networkpolicy restrict-sandbox-egress -n agent-sandbox
Результат должен выглядеть следующим образом:
NAME POD-SELECTOR AGE
restrict-sandbox-egress sandbox=python-sandbox-example 113s
Убедитесь, что:
- Поды
python-sandbox-warmpool-***Runningи готовы к работе1/1. - Реплики
sandbox-router-deployment-***находятсяRunningи1/1Ready. - Сервис
sandbox-router-svcдоступен, и политикаrestrict-sandbox-egressуспешно защищает все соответствующие метки песочницы.
После того, как наша безопасная среда выполнения была защищена и инициализирована, мы готовы развернуть настоящий мозг нашей системы: агент генерации кода!
7. Создайте и разверните агент генерации кода (ADK).
После настройки безопасной песочницы для выполнения кода и высокопроизводительного бэкэнда LLM мы можем создать «мозг» нашей системы: агент генерации кода, использующий комплект разработки агентов (ADK) .
Этот агент разработан как опытный разработчик на Python. В отличие от стандартного чат-бота, который только генерирует текст, этот агент оснащен инструментом выполнения кода , позволяющим ему интерактивно решать задачи. Он следует циклу:
- Написание кода на Python в соответствии с вашими запросами.
- Безопасное выполнение кода внутри песочницы агента GKE, которую мы настроили на шаге 6.
- Проверка выходных данных или чтение любых ошибок, возникающих во время выполнения.
- Мы предлагаем проверенное, работающее решение, в котором вы можете быть уверены.
Предоставляя агенту доступ к защищенной среде выполнения в виде песочницы, мы даем ему возможность проверять собственную логику и автоматически отлаживать ошибки, что значительно повышает его возможности в задачах разработки программного обеспечения!
Разработайте агент логического мышления ADK.
Сначала мы пишем логику на Python, определяющую поведение агента, и оснащаем его инструментом Sandbox, созданным на шаге 6. В этом разделе мы также настраиваем стратегию гибридной модели: агент будет отдавать приоритет самостоятельно размещенной модели Qwen, работающей на вашем кластере GKE, но автоматически переключится на Gemini 2.5 Flash на Vertex AI, если локальная модель работает медленно или недоступна, обеспечивая высокую надежность.
Создайте новую директорию для кода агента:
mkdir -p ~/gke-ai-agent-lab/root_agent
cd ~/gke-ai-agent-lab
Создайте файл с именем root_agent/agent.py со следующим содержимым:
cat <<'EOF' > root_agent/agent.py
import os
from google.adk.agents import Agent
from google.adk.models.lite_llm import LiteLlm
from k8s_agent_sandbox import SandboxClient
import requests
# Instantiate the client globally to track sandboxes
sandbox_client = SandboxClient()
def run_python_code(code: str) -> str:
"""
Executes Python code safely in the GKE Agent Sandbox.
Use this tool whenever you need to execute code to solve a problem.
"""
sandbox = sandbox_client.create_sandbox(template="python-runtime-template", namespace="agent-sandbox")
try:
command = f"python3 -c \"{code}\""
result = sandbox.commands.run(command)
if result.stderr:
return f"Error: {result.stderr}"
return result.stdout
finally:
# Ensure the sandbox is deleted after use to avoid leaking resources
sandbox_client.delete_sandbox(sandbox.claim_name, namespace="agent-sandbox")
# Define the ADK Agent with a fallback mechanism.
# It prioritizes the Qwen 2.5 Coder model running on our Inference Gateway.
# If the local model is unavailable, it falls back to Gemini 2.5 Flash on Vertex AI.
root_agent = Agent(
name="CodeGenerationAgent",
model=LiteLlm(
model="openai/Qwen/Qwen2.5-Coder-14B-Instruct",
fallbacks=["vertex_ai/gemini-2.5-flash"],
timeout=10
),
instruction="""
You are an expert Python developer.
1. Write Python code to solve the user's problem.
2. Execute the code using the `run_python_code` tool to verify it works.
3. Return the exact output and a brief explanation of the code.
""",
tools=[run_python_code]
)
EOF
Создайте файл __init__.py , чтобы ADK распознал модуль:
echo "from . import agent" > ~/gke-ai-agent-lab/root_agent/__init__.py
Установите переменные среды. Приложению ADK необходим IP-адрес вашего шлюза для успешной маршрутизации запросов LLM. Поскольку ADK поддерживает стандартные конечные точки, совместимые с Open-AI (которые vLLM предоставляет через наш шлюз), мы можем переопределить базовый URL-адрес API по умолчанию!
export GATEWAY_IP=$(kubectl get gateway infra-is-inference-gateway -n $NAMESPACE -o jsonpath='{.status.addresses[0].value}')
cat <<EOF > ~/gke-ai-agent-lab/root_agent/.env
OPENAI_API_BASE=http://${GATEWAY_IP}/v1
OPENAI_API_KEY=no-key-required
# Vertex AI settings for fallback (Authentication is handled by Workload Identity)
VERTEXAI_PROJECT=$PROJECT_ID
VERTEXAI_LOCATION=${ZONE%-[a-z]}
EOF
Контейнеризация приложения агента
Нам необходимо упаковать агент таким образом, чтобы он мог безопасно работать внутри GKE.
Создайте Dockerfile в ~/gke-ai-agent-lab , который установит kubectl , библиотеку ADK и клиент Agent Sandbox:
cat <<'EOF' > ~/gke-ai-agent-lab/Dockerfile
FROM python:3.11-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
RUN apt-get update && apt-get install -y git curl \
&& curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl" \
&& install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl \
&& rm kubectl && apt-get clean && rm -rf /var/lib/apt/lists/*
RUN pip install --no-cache-dir "google-adk[extensions,otel-gcp]>=1.27.4" litellm pandas "git+https://github.com/kubernetes-sigs/agent-sandbox.git@main#subdirectory=clients/python/agentic-sandbox-client" \
"opentelemetry-instrumentation-google-genai>=0.4b0" \
"opentelemetry-exporter-otlp" \
"opentelemetry-instrumentation-vertexai>=2.0b0"
COPY ./root_agent /app/root_agent
EXPOSE 8080
ENTRYPOINT ["adk", "web", "--host", "0.0.0.0", "--port", "8080", "--otel_to_cloud"]
EOF
Создайте репозиторий в реестре артефактов для хранения образа контейнера.
gcloud artifacts repositories create agent-repo \
--repository-format=docker \
--location=us-central1
Используйте Cloud Build для сборки и отправки образа контейнера.
gcloud builds submit --tag us-central1-docker.pkg.dev/$PROJECT_ID/agent-repo/code-agent:v1 ~/gke-ai-agent-lab/
Развертывание в GKE с использованием RBAC
Наконец, разверните агента в вашем кластере. Развертывание включает в себя Role и RoleBinding предоставляющие агенту разрешение на получение экземпляров из SandboxWarmPool .
В этом развертывании будет использоваться учетная запись службы Kubernetes, чтобы ваш агент мог взаимодействовать с API обработки утверждений в тестовой среде. Учетная запись службы Google IAM не требуется, поскольку она обращается к локальным ресурсам кластера и локальной конечной точке шлюза vLLM.
Почему в gVisor используется стандартное развертывание?
На шаге 6 мы использовали API SandboxTemplate и SandboxClaim для создания временных, одноразовых песочниц для сгенерированного кода Python (выполнения инструмента).
Для самого веб-интерфейса агента (мозга) мы используем стандартные спецификации Deployment Kubernetes с runtimeClassName: gvisor .
- Отличие : Стандартные
SandboxClaimsявляются временными и равны нулю к единице (идеально подходят для ненадежных скриптов). СтандартноеDeploymentявляется долговременным и постоянным — идеально подходит для веб-интерфейсов, которым требуется стабильныйServiceKubernetes и балансировщик нагрузки! ИспользуяruntimeClassName: gvisorнепосредственно в стандартном развертывании, вы получаете изоляцию ядра gVisor, сохраняя при этом стандартные функцииDeployment.
Сохраните следующий код как deployment.yaml :
cat <<EOF > ~/gke-ai-agent-lab/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: code-agent
labels:
app: code-agent
spec:
replicas: 1
selector:
matchLabels:
app: code-agent
template:
metadata:
labels:
app: code-agent
spec:
serviceAccount: adk-agent-sa
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: code-agent
image: us-central1-docker.pkg.dev/YOUR_PROJECT_ID/agent-repo/code-agent:v1
imagePullPolicy: Always
env:
- name: OPENAI_API_KEY
value: "no-key-required"
- name: OPENAI_API_BASE
value: "http://YOUR_GATEWAY_IP/v1"
- name: VERTEXAI_PROJECT
value: "YOUR_PROJECT_ID"
- name: VERTEXAI_LOCATION
value: "YOUR_REGION"
- name: OTEL_SERVICE_NAME
value: "code-agent"
- name: GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY
value: "true"
- name: OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT
value: "true"
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: code-agent-service
spec:
selector:
app: code-agent
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: agent-sandbox
name: sandbox-creator-role
rules:
- apiGroups: [""]
resources: ["services", "pods", "pods/portforward"]
verbs: ["get", "list", "watch", "create"]
- apiGroups: ["extensions.agents.x-k8s.io"]
resources: ["sandboxclaims"]
verbs: ["create", "get", "list", "watch", "delete"]
- apiGroups: ["agents.x-k8s.io"]
resources: ["sandboxes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: adk-agent-binding
namespace: agent-sandbox
subjects:
- kind: ServiceAccount
name: adk-agent-sa
namespace: default
roleRef:
kind: Role
name: sandbox-creator-role
apiGroup: rbac.authorization.k8s.io
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: adk-agent-sa
EOF
Предоставить разрешения IAM для обеспечения возможности наблюдения.
Чтобы агент мог отправлять телеметрические данные (журналы и трассировки) в Google Cloud, необходимо предоставить необходимые разрешения учетной записи службы Kubernetes adk-agent-sa с помощью Workload Identity.
Выполните следующие команды в Cloud Shell:
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# Grant permission to write logs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/logging.logWriter \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to write traces
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/cloudtrace.agent \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to use Vertex AI
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/aiplatform.user \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
Выполните следующую команду, чтобы автоматически заменить YOUR_PROJECT_ID на фактический идентификатор вашего проекта и применить конфигурацию!
sed -i "s/YOUR_PROJECT_ID/$PROJECT_ID/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_GATEWAY_IP/$GATEWAY_IP/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_REGION/$ZONE/g" ~/gke-ai-agent-lab/deployment.yaml
kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml
8. Наблюдайте и подтверждайте.
Пришло время протестировать полностью интегрированную систему.
Протестируйте агент генерации кода в пользовательском интерфейсе.
Найдите внешний IP-адрес вашего веб-интерфейса ADK:
kubectl get services code-agent-service
Результат должен выглядеть примерно так:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
code-agent-service LoadBalancer 34.118.230.182 34.31.250.60 80:32471/TCP 2m14s
- Откройте браузер и перейдите по адресу
http://[EXTERNAL-IP]. - В веб-интерфейсе ADK убедитесь, что в раскрывающемся меню в правом верхнем углу выбран параметр "root_agent". Затем отправьте запрос агенту:
Write a python script that prints 'Hello from the isolated sandbox'.
Чтобы понаблюдать за тем, как агент использует бэкэнд для вывода результатов и песочницу, перейдите к разделам «Изучение статистики модели через облачную систему мониторинга» и «Изучение мониторинга агента через пользовательский интерфейс GKE» ниже, чтобы просмотреть панели мониторинга.
Изучите возможности мониторинга агентов через пользовательский интерфейс GKE.
Теперь, когда вы выполнили несколько запросов, давайте посмотрим на данные телеметрии. Это поможет вам понять, как работают планировщик вывода и vLLM.
Получите доступ к панелям управления агентов.
- Перейдите на страницу Kubernetes Engine > Workloads .
- Чтобы открыть страницу с подробными сведениями о развертывании, щелкните по развертыванию code-agent .
- Перейдите на вкладку «Наблюдаемость» .
- В левой панели навигации панели мониторинга вы увидите новый раздел «Агенты» с подвкладками.
Что посмотреть
Чтобы ознакомиться с поведением вашего агентского приложения, перейдите на следующие вкладки:
- Обзор: Просмотрите оценочные таблицы для сессий, среднего количества ходов и обращений.
- Модели: Посмотрите количество вызовов моделей, частоту ошибок и задержку, сгруппированные по моделям, которые использовал ваш агент.
- Инструменты: Отслеживайте вызовы инструментов и продолжительность их выполнения, чтобы оценить эффективность использования агентом инструмента выполнения в тестовой среде.
- Применение: Отслеживание использования токенов и стандартного распределения ресурсов контейнера (процессор и память).
- Трассировка агента: Перейдите на эту вкладку, чтобы просмотреть список сеансов выполнения или необработанных фрагментов трассировки. Щелчок по строке открывает всплывающее окно с подробной информацией о выбранной трассировке!
Благодаря объединению метрик уровня модели из vLLM с телеметрией уровня приложения из ADK, вы теперь получаете полную возможность мониторинга вашего генеративного ИИ-агента в GKE!
Изучите статистику модели vLLM с помощью облачной системы мониторинга.
Теперь, когда вы выполнили несколько запросов, давайте посмотрим на данные телеметрии. Это поможет вам понять, как работают планировщик вывода и vLLM.
Получите доступ к панелям мониторинга
- Перейдите в консоль Google Cloud .
- Перейдите в раздел «Мониторинг» > «Панели мониторинга» .
- Найдите и выберите панель мониторинга vLLM Prometheus Overview .
Интересные показатели для наблюдения
При просмотре панели мониторинга обратите внимание на следующие ключевые показатели, чтобы увидеть влияние GKE Inference Gateway и кэширования префиксов:
- Использование KV-кэша (
vllm:gpu_cache_usage):- Почему это важно: Это показывает, какой объем памяти графического процессора используется для кэширования контекста. Если этот показатель высок, это означает, что система сохраняет контекст для ускорения будущих запросов. Если вы запустите одну и ту же командную строку несколько раз, вы увидите, как этот показатель сначала возрастет, а затем стабилизируется.
- Выполняемые запросы и запросы, ожидающие ответа (
vllm:num_requests_runningvsvllm:num_requests_waiting):- Почему это важно: Это указывает на нагрузку. Если количество ожидающих запросов велико, это означает, что ваши узлы перегружены.
- Пропускная способность токенов (
vllm:request_prompt_tokens_totиvllm:request_generation_tokens_tot):- Почему это важно: Отслеживайте объем входных и выходных токенов, обрабатываемых кластером.
- Время до получения первого токена (TTFT) :
- Почему это важно: Это критически важный показатель для интерактивных агентов. Благодаря использованию GKE Inference Gateway с маршрутизацией, учитывающей префиксный кэш, запросы, имеющие общий контекст (например, системные подсказки или большие контекстные окна), направляются на одну и ту же реплику, минимизируя время отклика за счет повторного использования существующих попаданий в кэш!
Эксперименты, которые стоит попробовать
Попробуйте эти сценарии, чтобы увидеть изменения показателей в режиме реального времени и подтвердить правильность планирования!
Эксперимент 1: «Скорость повторения» (попадание в кэш префиксов)
- Отправьте агенту сложное сообщение (например, «Напишите скрипт на Python для анализа CSV-файла размером 100 МБ и расчета статистики» ).
- После получения ответа немедленно отправьте точно такое же сообщение еще раз.
- Обратите внимание на коэффициент попадания в кэш префиксов и время до получения первого токена (TTFT) .
- Что вы должны увидеть: Коэффициент попаданий в кэш префиксов должен подняться до 100%, а TTFT должен резко снизиться!
- Что это значит: Шлюз вывода GKE распознал общий контекст и направил его на ту же самую реплику, которая повторно использовала свой кэш оцененных контекстов!
Эксперимент 2: Переход на облачные технологии (надежность модели)
- Чтобы имитировать сбой вашей локальной модели Qwen, вы можете либо остановить службу вывода, либо просто указать фиктивный
OPENAI_API_BASEпри развертывании. - Обновите значение параметра
OPENAI_API_BASEв файлеdeployment.yaml, указав несуществующий IP-адрес или порт, и примените изменения:sed -i "s|value: \"http://$GATEWAY_IP/v1\"|value: \"http://10.0.0.1:8080/v1\"|g" ~/gke-ai-agent-lab/deployment.yaml kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml - Дождитесь перезапуска пода, затем отправьте запрос агенту через пользовательский интерфейс.
- Что вы должны увидеть: Агент по-прежнему успешно отвечает!
- Что это значит: Благодаря конфигурации
fallbacks, ADK распознал сбой локальной конечной точки Qwen и беспрепятственно перенаправил запрос на Gemini 2.5 Flash на Vertex AI. Обратите внимание, что поскольку эти резервные вызовы к Vertex AI обходят ваш локальный шлюз вывода vLLM, они не будут отображаться на панели мониторинга Agent Observability > Models , которая отслеживает только трафик, проходящий через vLLM.
Понимание преимуществ динамического распределения ресурсов (DRA)
В то время как vLLM и Inference Gateway оптимизируют маршрутизацию и обработку запросов, именно динамическое распределение ресурсов (DRA) позволило изначально подключить к рабочей нагрузке именно то оборудование, которое было необходимо.
DRA расширяет ваши возможности по детальному управлению оборудованием в кластере, позволяя определять гибкие аппаратные ресурсы с помощью ResourceClaimTemplate и DeviceClasses .
Почему DRA кардинально меняет ситуацию в задачах искусственного интеллекта:
- Детально настроенные запросы на оборудование : с помощью DRA вы не просто обеспечиваете планирование рабочих нагрузок на машинах с подходящим ускорителем, но и можете заявить права на эти ресурсы, чтобы гарантировать их использование исключительно рабочей нагрузкой, связанной с запросом на ресурсы.
- Разделенный жизненный цикл : Запросы на использование устройств управляются независимо от жизненного цикла Pod-ов. Если Pod-под аварийно завершает работу, запрос на использование графического процессора может сохраниться, так что развертывание или другой объект рабочей нагрузки может быть перезапущен без необходимости ждать освобождения и повторного получения графического процессора.
- Стандартизация для разных производителей : DRA предоставляет унифицированный API Kubernetes как для графических процессоров NVIDIA, так и для TPU Google. Вы используете одну и ту же схему независимо от того, развертываете ли вы приложение для одного или другого, что делает ваши манифесты YAML для рабочих нагрузок очень переносимыми!
В этом практическом занятии вы увидели это в действии, когда настроили значения Helm для бесшовной привязки к gpu-claim-template , избежав при этом блокировки развертывания из-за зависших конфигураций плагинов устройств.
Понимание роли llm-d
В то время как vLLM вычисляет веса нейронных сетей, а шлюз GKE маршрутизирует запросы, llm-d выступает в качестве уровня конфигурации и «связующего звена», которое объединяет все эти компоненты.
Без llm-d вам пришлось бы с нуля писать манифесты Kubernetes для объявления развертывания vLLM , портов служб, точек монтирования томов и запросов на ресурсы DRA.
Зачем использовать llm-d при развертывании?
- Единая конфигурация (переопределения в одну строку) : Helm-диаграммы
llm-dобъединяют сложные низкоуровневые ресурсы Kubernetes в понятные высокоуровневые переключатели (например, установкаaccelerator.dra: true). - Предварительно проверенные "хорошо освещенные пути" : репозиторий
llm-dсодержит конфигурации, которые уже прошли тестирование и сравнительный анализ производительности экспертами. При развертыванииllm-d-modelserviceвы получаете оптимизированные значения по умолчанию для использования памяти GPU, рекомендуемые параметры времени проверки (готовность/активность) и корректные параметры для сбора метрик. - Бесшовное сопоставление показателей мониторинга :
llm-dпо умолчанию обеспечивает корректное отображение стандартных портов контейнеров и путей сбора метрик (/metrics), что упрощает интеграцию вашего развертывания с Google Cloud Monitoring без ручной отладки.
Вкратце, llm-d предоставляет многократно используемые архитектурные шаблоны , чтобы разработчикам не приходилось изобретать велосипед каждый раз при развертывании стека вывода на GKE.
Подробный анализ: Шлюз вывода GKE
Стандартные балансировщики нагрузки уровня 7 работают, анализируя HTTP-заголовки, такие как пути ( /v1/completions ) или cookie-файлы. GKE Inference Gateway работает гораздо эффективнее — он разработан специально для трафика, связанного с генеративным искусственным интеллектом.
Как это повышает производительность и эффективность:
- Маршрутизация с учетом содержимого (хеширование запроса) : Шлюз вывода GKE перехватывает тело JSON-запроса. Он вычисляет хеш запроса и отслеживает, какая реплика бэкэнда уже хранит эти токены в своей памяти GPU (кэш ключ-значение).
- Максимизация попаданий в кэш : В ходе тестирования, когда вы повторяли запрос, шлюз отправлял его на ту же самую копию. Оценка запроса требует значительных вычислительных ресурсов. Повторное использование кэша позволяет избежать «повторного чтения» запроса, экономя деньги и время работы графического процессора.
- Сокращение времени до получения первого токена (TTFT) : TTFT — это критически важный показатель удобства использования для агентов, взаимодействующих с пользователем. Благодаря обращению к кэшу модель может начать генерировать токены за миллисекунды, а не за секунды.
- Интеллектуальное распределение нагрузки : если видеопамять одной реплики полностью заполнена данными кэша, шлюз может динамически перенаправлять новый запрос на другую реплику, у которой есть свободное место, обеспечивая баланс между эффективностью и доступностью.
Как песочница агентов снижает риски
В этой лабораторной работе мы продемонстрировали, как Agent Sandbox защищает вашу инфраструктуру от рисков, связанных с агентами искусственного интеллекта, обеспечивая два уровня изоляции:
- Изоляция инструмента выполнения : Агент выполняет сгенерированный им код во временной песочнице. Это гарантирует, что ненадежный код, сгенерированный LLM, будет выполняться в безопасной, изолированной среде, защищая агента и кластер.
- Быстрый запуск : благодаря использованию WarmPool новые песочницы запускаются менее чем за секунду и готовы к выполнению кода.
- Изоляция самого агента : Мы также запустили само приложение агента на узле с поддержкой gVisor (через
runtimeClassName: gvisor), чтобы обеспечить многоуровневую защиту от уязвимостей цепочки поставок в зависимостях агента.
Вот почему это создает такой усиленный барьер безопасности:
- Перехват системных вызовов : gVisor перехватывает системные вызовы до того, как они достигнут ядра Linux хоста. Это блокирует попытки взлома, направленные на выход за пределы контейнера для доступа к хост-узлу.
- Ограниченное горизонтальное перемещение : в сочетании с сетевыми политиками, даже если среда скомпрометирована, система не сможет сканировать ваши внутренние серверы метаданных или перенаправлять трафик на другие конфиденциальные службы в вашем кластере.
Запуск полноценных агентов в песочницах
В этой лабораторной работе мы использовали песочницы в качестве инструментов для постоянного приложения агента. Однако для максимальной безопасности — особенно при работе с конфиденциальными данными или обслуживании нескольких ненадежных пользователей — можно запускать все приложение агента внутри отдельной песочницы для каждой сессии или пользователя. Это обеспечивает полную изоляцию памяти, состояния и среды выполнения агента, которая уничтожается сразу после завершения сессии.
9. Уборка
Чтобы избежать списания средств с вашего аккаунта Google Cloud за ресурсы, использованные в этом практическом задании, выполните следующие шаги для их удаления.
Удалить отдельные ресурсы
- Удалите кластер GKE:
gcloud container clusters delete $CLUSTER_NAME --zone $ZONE --quiet
- Удалите репозиторий реестра артефактов:
gcloud artifacts repositories delete agent-repo --location=us-central1 --quiet
- Удалите сеть VPC:
gcloud compute networks delete ai-agent-network --quiet
Удалить проект
Если проект вам больше не нужен, вы можете удалить его после удаления ресурсов:
gcloud projects delete $PROJECT_ID
10. Резюме
Поздравляем! Вы успешно создали и развернули безопасный, высокопроизводительный агент генерации кода в GKE.
Что вы узнали
- Как настроить и использовать динамическое распределение ресурсов (DRA) в GKE для управления ресурсами графического процессора.
- Как использовать GKE Inference Gateway для оптимизации производительности обслуживания LLM с помощью маршрутизации с учетом кэша префиксов.
- Как использовать Agent Sandbox (gVisor) для безопасного выполнения ненадежного кода в GKE.
- Как использовать Google Cloud Managed Service for Prometheus для мониторинга производительности vLLM.
- How to configure and view Agent Observability using ADK and GKE Managed OpenTelemetry.
Next Steps & References
- Agent Sandbox : Learn about Agent Sandbox on GKE and GKE Sandbox Pods .
- llm-d : Read the llm-d Guide and check out the llm-d GitHub Repository .
- Dynamic Resource Allocation : Learn about DRA on GKE .
- GKE Inference Gateway : Explore Inference Gateway concepts .
- More Codelabs : Find more tutorials at Google Cloud Codelabs .