
1. บทนำ
ภาพรวม
ในแล็บนี้ คุณจะได้เรียนรู้วิธีสร้างและทำให้ Agent สร้างโค้ดที่ปลอดภัยใช้งานได้ใน Google Kubernetes Engine (GKE) เอเจนต์การสร้างโค้ดต้องเรียกใช้โค้ดที่อาจไม่น่าเชื่อถือ ซึ่งต้องใช้สภาพแวดล้อมแซนด์บ็อกซ์ที่ปลอดภัย นอกจากนี้ คุณยังจะได้เรียนรู้วิธีกำหนดค่า Agent ด้วยกลยุทธ์โมเดลแบบไฮบริด ซึ่งจะช่วยให้ Agent สามารถเปลี่ยนจากโมเดลโอเพนซอร์สที่โฮสต์ด้วยตนเองใน GKE ไปใช้บริการ Gemini ที่มีการจัดการของ Vertex AI เพื่อเพิ่มความน่าเชื่อถือได้ นอกจากนี้ คุณยังจะได้เรียนรู้วิธีเพิ่มประสิทธิภาพการแสดงผลการอนุมานโดยใช้ GKE Inference Gateway และการจัดสรรทรัพยากรแบบไดนามิก (DRA) สุดท้าย คุณจะได้เรียนรู้วิธีใช้ประโยชน์จาก Google Cloud Observability เพื่อตรวจสอบสแต็กการอนุมานโดยใช้ Prometheus ที่มีการจัดการ
สถาปัตยกรรม
สถาปัตยกรรมของระบบที่คุณจะสร้างมีดังนี้
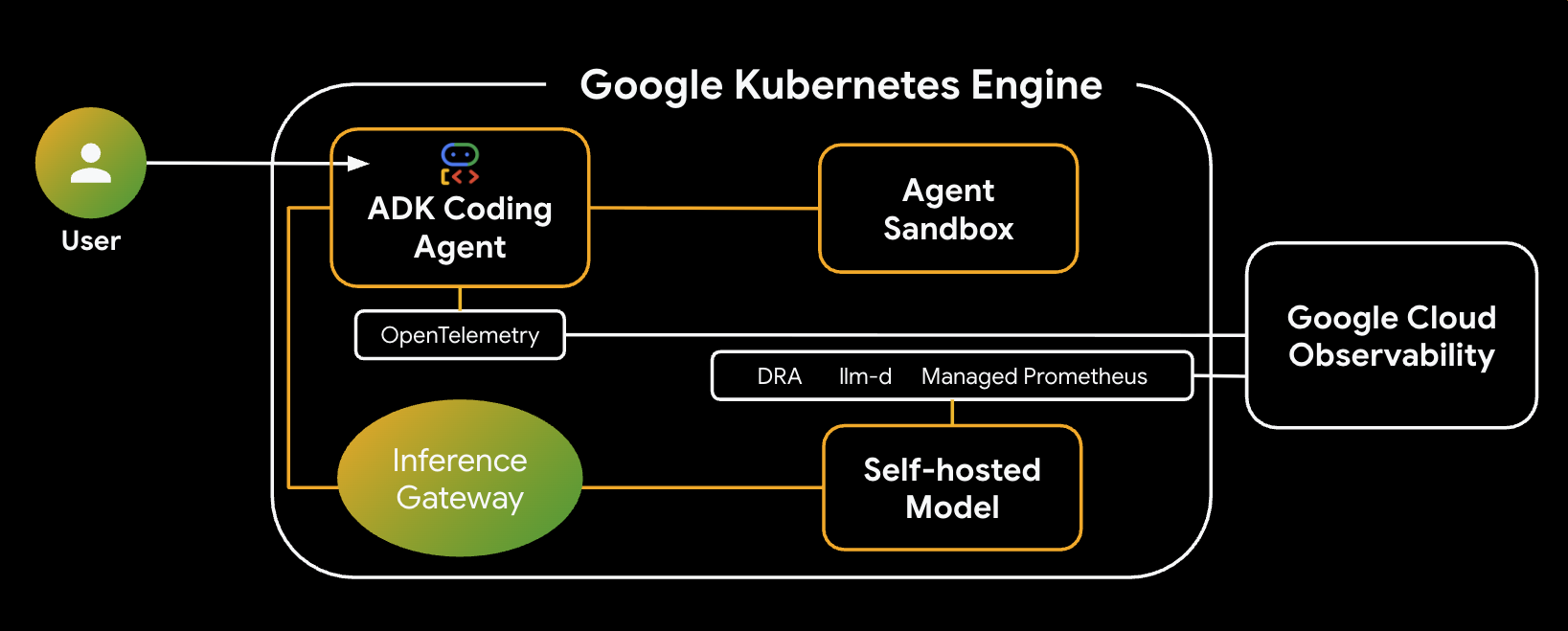
องค์ประกอบและประโยชน์หลัก
- การจัดสรรทรัพยากรแบบไดนามิก (DRA): ใช้ในแล็บนี้เพื่ออ้างสิทธิ์และจัดสรรทรัพยากร GPU ที่เฉพาะเจาะจง (NVIDIA L4) แบบไดนามิกสำหรับพ็อดเซิร์ฟเวอร์โมเดล เพื่อให้มั่นใจว่ามีการกำหนดเป้าหมายฮาร์ดแวร์ที่แม่นยำสำหรับภาระงานการอนุมานของเรา ดูข้อมูลเกี่ยวกับ DRA ใน GKE
- llm-d และ vLLM: มีเฟรมเวิร์กการแสดงโมเดลและแผนภูมิ Helm เพื่อใช้ในการติดตั้งใช้งานโมเดล Qwen ใน Lab นี้ จะจัดการคำขออนุมานและผสานรวมกับ DRA เพื่อการจัดการทรัพยากร (ไม่ได้เปิดใช้การแสดงผลแบบแยกส่วนใน Lab นี้) อ่านคู่มือ llm-d และดูที่เก็บ llm-d ใน GitHub
- GKE Inference Gateway: ย้ายตรรกะการกำหนดเส้นทางที่รับรู้ AI ไปยังตัวจัดสรรภาระงานโดยตรง ใน Lab นี้ ระบบจะกำหนดเส้นทางคำขอเพื่อเพิ่มจำนวนการเข้าถึงแคชคำนำหน้าให้ได้มากที่สุด ซึ่งจะช่วยลดเวลาในการตอบสนองของเวลาในการแสดงผลโทเค็นแรก (TTFT) สำรวจแนวคิดเกี่ยวกับ Inference Gateway
- Agent Sandbox (gVisor): ให้การแยกที่ปลอดภัยสําหรับการเรียกใช้โค้ดที่ AI Agent สร้างขึ้น โดยใช้ gVisor เพื่อให้การแยกเคอร์เนลอย่างละเอียด ซึ่งจะปกป้องโหนดโฮสต์จากภาระงานที่ไม่น่าเชื่อถือ ดูข้อมูลเกี่ยวกับ Agent Sandbox ใน GKE และ GKE Sandbox Pod
สิ่งที่คุณต้องดำเนินการ
- จัดสรรโครงสร้างพื้นฐาน: ตั้งค่าคลัสเตอร์ GKE ด้วยการจัดสรรทรัพยากรแบบไดนามิก (DRA) เพื่อการจัดการ GPU
- ติดตั้งใช้งาน Inference Stack: ติดตั้งใช้งาน
llm-dและ vLLM ด้วยการจัดกำหนดการอนุมานอัจฉริยะ - กำหนดค่าการกำหนดเส้นทางอัจฉริยะ: ใช้ GKE Inference Gateway สำหรับการกำหนดเส้นทางที่รับรู้แคชคำนำหน้า
- การเรียกใช้โค้ดอย่างปลอดภัย: ทำให้ใช้งานได้ Agent Sandbox (gVisor) เพื่อเรียกใช้โค้ดที่ AI สร้างขึ้นอย่างปลอดภัย
- สังเกตและตรวจสอบ: ใช้ Google Cloud Monitoring และ Prometheus ที่มีการจัดการเพื่อดูเมตริกการแสดงโมเดล
สิ่งที่คุณจะได้เรียนรู้
- วิธีกำหนดค่าและใช้การจัดสรรทรัพยากรแบบไดนามิก (DRA) ใน GKE
- วิธีใช้ GKE Inference Gateway เพื่อเพิ่มประสิทธิภาพการแสดงผล LLM
- วิธีใช้ Agent Sandbox เพื่อเรียกใช้โค้ดที่ไม่น่าเชื่อถืออย่างปลอดภัยใน GKE
- วิธีใช้บริการที่มีการจัดการของ Google Cloud สำหรับ Prometheus เพื่อตรวจสอบประสิทธิภาพของ vLLM
2. การตั้งค่าและข้อกำหนด
การตั้งค่าโปรเจ็กต์
สร้างโปรเจ็กต์ Google Cloud
- ในคอนโซล Google Cloud ในหน้าตัวเลือกโปรเจ็กต์ ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud
- ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ที่อยู่ในระบบคลาวด์แล้ว ดูวิธีตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินในโปรเจ็กต์แล้วหรือไม่
เริ่มต้น Cloud Shell
Cloud Shell คือสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานใน Google Cloud ซึ่งโหลดเครื่องมือที่จำเป็นไว้ล่วงหน้า
- คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud
- เมื่อเชื่อมต่อกับ Cloud Shell แล้ว ให้ยืนยันการตรวจสอบสิทธิ์โดยทำดังนี้
gcloud auth list - ตรวจสอบว่าได้กำหนดค่าโปรเจ็กต์แล้ว
gcloud config get project - หากไม่ได้ตั้งค่าโปรเจ็กต์ตามที่คาดไว้ ให้ตั้งค่าดังนี้
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
3. จัดสรรโครงสร้างพื้นฐานและการจัดสรรทรัพยากรแบบไดนามิก (DRA)
ในขั้นตอนแรกนี้ คุณจะกำหนดค่าคลัสเตอร์ GKE ให้ใช้การจัดสรรตัวเร่งความเร็วที่ทันสมัย (DRA) แทนปลั๊กอินอุปกรณ์เดิม ซึ่งช่วยให้คุณแชร์และจัดสรร GPU หรือ TPU สำหรับภาระงานการสร้างโค้ดได้อย่างยืดหยุ่น
ข้อกำหนดเบื้องต้น: คลัสเตอร์ GKE Standard ต้องใช้เวอร์ชัน 1.34 ขึ้นไปเพื่อรองรับ DRA
เปิดใช้ Google Cloud APIs
เปิดใช้ Google Cloud APIs ที่จำเป็นสำหรับ Codelab นี้ ซึ่งได้แก่ Compute Engine และ Kubernetes Engine APIs
gcloud services enable compute.googleapis.com container.googleapis.com networkservices.googleapis.com cloudbuild.googleapis.com artifactregistry.googleapis.com telemetry.googleapis.com cloudtrace.googleapis.com aiplatform.googleapis.com
ตั้งค่าตัวแปรสภาพแวดล้อม
กำหนดตัวแปรสภาพแวดล้อมเพื่อให้การตั้งค่าง่ายขึ้น คุณปรับภูมิภาคหรือรูปแบบการตั้งชื่อได้ตามต้องการ
export PROJECT_ID=$(gcloud config get-value project)
export ZONE=us-central1-a
export CLUSTER_NAME=ai-agent-cluster
export NODEPOOL_NAME=dra-accelerator-pool
gcloud config set project $PROJECT_ID
gcloud config set compute/region $ZONE
สร้างไดเรกทอรีการทำงาน
สร้างไดเรกทอรีการทำงานเฉพาะสำหรับ Lab นี้ แล้วไปที่ไดเรกทอรีดังกล่าวเพื่อให้ไฟล์เป็นระเบียบ
mkdir -p ~/gke-ai-agent-lab
cd ~/gke-ai-agent-lab
กำหนดค่าสิทธิ์ (ไม่บังคับ)
หากคุณใช้งานในโปรเจ็กต์ที่จำกัดหรือสภาพแวดล้อมที่ใช้ร่วมกัน โปรดตรวจสอบว่าบัญชีของคุณมีสิทธิ์ที่จำเป็นในการสร้างคลัสเตอร์และเรียกใช้บิลด์
export MY_ACCOUNT=$(gcloud config get-value account)
# Grant Container Admin to create clusters and manage nodes if needed
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/container.admin"
# Grant Cloud Build Builder to run builds
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/cloudbuild.builds.builder"
สร้างคลัสเตอร์ GKE
คลัสเตอร์ GKE Standard ต้องใช้เวอร์ชัน 1.34 ขึ้นไปจึงจะรองรับ DRA นอกจากนี้ คุณยังต้องเปิดใช้ตัวควบคุม Gateway API เพื่อรองรับการจัดกำหนดการอนุมานอัจฉริยะด้วย
คุณจะสร้างเครือข่าย VPC และซับเน็ตใหม่สำหรับ Lab นี้
ก่อนอื่น ให้สร้างเครือข่าย VPC โดยทำดังนี้
gcloud compute networks create ai-agent-network --subnet-mode=custom
จากนั้นสร้างเครือข่ายย่อยสำหรับโหนด GKE โดยทำดังนี้
gcloud compute networks subnets create ai-agent-subnet \
--network=ai-agent-network \
--range=10.0.0.0/20 \
--region=us-central1
นอกจากนี้ Gateway API (gke-l7-regional-internal-managed) ยังต้องใช้ซับเน็ตเฉพาะเพื่อโฮสต์พร็อกซี Envoy ด้วย สร้างซับเน็ตเฉพาะพร็อกซีนี้ในเครือข่ายใหม่
gcloud compute networks subnets create proxy-only-subnet \
--purpose=REGIONAL_MANAGED_PROXY \
--role=ACTIVE \
--region=us-central1 \
--network=ai-agent-network \
--range=192.168.10.0/24
ตอนนี้ให้สร้างคลัสเตอร์โดยใช้เครือข่ายและเครือข่ายย่อยใหม่
gcloud beta container clusters create $CLUSTER_NAME \
--zone $ZONE \
--num-nodes 1 \
--machine-type n2-standard-4 \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--gateway-api=standard \
--managed-otel-scope=COLLECTION_AND_INSTRUMENTATION_COMPONENTS \
--network=ai-agent-network \
--subnetwork=ai-agent-subnet
สร้าง Node Pool โดยปิดใช้ปลั๊กอินเริ่มต้น
หากต้องการส่งต่อการจัดการอุปกรณ์ไปยัง DRA คุณต้องสร้าง Node Pool ที่ปิดใช้การติดตั้งไดรเวอร์ GPU เริ่มต้นและปลั๊กอินอุปกรณ์มาตรฐานอย่างชัดเจน
เรียกใช้gcloudคำสั่งต่อไปนี้เพื่อจัดสรร Node Pool ของ GPU (เช่น ใช้ NVIDIA L4) ที่มีป้ายกำกับ DRA ที่จำเป็น
gcloud container node-pools create $NODEPOOL_NAME \
--cluster=$CLUSTER_NAME \
--location=$ZONE \
--machine-type=g2-standard-24 \
--accelerator=type=nvidia-l4,count=2,gpu-driver-version=disabled \
--node-labels=gke-no-default-nvidia-gpu-device-plugin=true,nvidia.com/gpu.present=true \
--num-nodes 3
ติดตั้งไดรเวอร์ NVIDIA ผ่าน DaemonSet
ติดตั้งไดรเวอร์อุปกรณ์พื้นฐานของ NVIDIA ที่จำเป็นลงในโหนดด้วยตนเองโดยใช้ Google Cloud DaemonSet ที่กำหนดค่าไว้ล่วงหน้า
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
ติดตั้งไดรเวอร์ DRA
จากนั้นติดตั้งไดรเวอร์ DRA ที่เฉพาะเจาะจงลงในคลัสเตอร์ สำหรับ GPU ของ NVIDIA คุณสามารถติดตั้งใช้งานผ่าน Helm ได้โดยทำดังนี้
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
helm install nvidia-dra-driver-gpu nvidia/nvidia-dra-driver-gpu \
--version="25.3.2" --create-namespace --namespace=nvidia-dra-driver-gpu \
--set nvidiaDriverRoot="/home/kubernetes/bin/nvidia/" \
--set gpuResourcesEnabledOverride=true \
--set resources.computeDomains.enabled=false \
--set kubeletPlugin.priorityClassName="" \
--set 'kubeletPlugin.tolerations[0].key=nvidia.com/gpu' \
--set 'kubeletPlugin.tolerations[0].operator=Exists' \
--set 'kubeletPlugin.tolerations[0].effect=NoSchedule'
ทำความเข้าใจ DeviceClasses
คุณไม่จำเป็นต้องเขียนหรือใช้ DeviceClass YAML ด้วยตนเอง เมื่อตั้งค่าโครงสร้างพื้นฐานของ GKE สำหรับ DRA และติดตั้งไดรเวอร์ ไดรเวอร์ DRA ที่ทำงานในโหนดจะสร้างออบเจ็กต์ DeviceClass ในคลัสเตอร์ให้คุณโดยอัตโนมัติ
กำหนดค่า ResourceClaimTemplate
หากต้องการอนุญาตให้ llm-d Pod ขอตัวเร่งเหล่านี้แบบไดนามิก คุณจะต้องสร้าง ResourceClaimTemplate เทมเพลตนี้กำหนดค่าอุปกรณ์ที่ขอและบอกให้ Kubernetes สร้าง ResourceClaim ที่ไม่ซ้ำกันต่อพ็อดสำหรับภาระงานโดยอัตโนมัติ
เรียกใช้คำสั่งต่อไปนี้เพื่อสร้าง claim-template.yaml
cat > claim-template.yaml <<EOF
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: gpu-claim-template
spec:
spec:
devices:
requests:
- name: single-gpu
exactly:
deviceClassName: gpu.nvidia.com
allocationMode: ExactCount
count: 1
EOF
ใช้เทมเพลตกับคลัสเตอร์โดยทำดังนี้
kubectl apply -f claim-template.yaml
4. ติดตั้งใช้งานการจัดกำหนดการอนุมานอัจฉริยะด้วย llm-d และ DRA
ในขั้นตอนนี้ คุณจะติดตั้งใช้งานโมเดลภาษาขนาดใหญ่ที่อยู่เบื้องหลังตัวจัดสรรภาระงาน Envoy อัจฉริยะที่ได้รับการปรับปรุงด้วยตัวกำหนดเวลาการอนุมาน การกำหนดค่านี้จะเพิ่มประสิทธิภาพการแสดงโมเดลโดยใช้การกำหนดเส้นทางที่คำนึงถึงแคชของคำนำหน้า GKE Inference Gateway จะจดจำบริบทที่แชร์ใน Microservice และกำหนดเส้นทางคำขออย่างชาญฉลาดไปยังแบบจำลองที่ซ้ำกัน ซึ่งจะเพิ่มจำนวนการเข้าชมแคช ลดเวลาในการแสดงผลโทเค็นแรก และเพิ่มประสิทธิภาพต่อดอลลาร์
เตรียมสภาพแวดล้อม
ตั้งค่าเนมสเปซเป้าหมาย
export NAMESPACE=ai-agents
kubectl create namespace $NAMESPACE
จัดเก็บโทเค็น Hugging Face อย่างปลอดภัย ซึ่งจำเป็นต้องใช้เพื่อดึงน้ำหนักของโมเดล
# Replace with your actual Hugging Face token
kubectl create secret generic llm-d-hf-token \
--from-literal=HF_TOKEN="your_hugging_face_token" \
-n $NAMESPACE
สร้างไฟล์การกำหนดค่า Helm
การกำหนดค่าสำหรับบริการโมเดลและส่วนขยายเกตเวย์การอนุมานจะอิงตามคำแนะนำ llm-d อย่างเป็นทางการ
ก่อนอื่น ให้สร้างไฟล์ ms-values.yaml สำหรับบริการโมเดล ดังนี้
cat <<EOF > ms-values.yaml
multinode: false
modelArtifacts:
uri: "hf://Qwen/Qwen2.5-Coder-14B-Instruct"
name: "Qwen/Qwen2.5-Coder-14B-Instruct"
size: 50Gi # Slightly larger than the default to accommodate weights
authSecretName: "llm-d-hf-token"
labels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
llm-d.ai/accelerator-variant: "gpu"
llm-d.ai/accelerator-vendor: "nvidia"
llm-d.ai/model: "qwen-2-5-coder-14b"
routing:
proxy:
enabled: false # removes sidecar from deployment - no PD in inference scheduling
targetPort: 8000 # controls vLLM port to matchup with sidecar if deployed
accelerator:
dra: true
type: "nvidia"
resourceClaimTemplates:
nvidia:
class: "gpu.nvidia.com"
match: "exactly"
name: "gpu-claim-template"
decode:
create: true
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
parallelism:
tensor: 2
data: 1
replicas: 3
monitoring:
podmonitor:
enabled: true
portName: "vllm"
path: "/metrics"
interval: "30s"
containers:
- name: "vllm"
image: ghcr.io/llm-d/llm-d-cuda:v0.5.1
modelCommand: vllmServe
args:
- "--disable-uvicorn-access-log"
- "--gpu-memory-utilization=0.85"
- "--enable-auto-tool-choice"
- "--tool-call-parser"
- "hermes"
ports:
- containerPort: 8000
name: vllm
protocol: TCP
resources:
limits:
cpu: '16'
memory: 64Gi
requests:
cpu: '16'
memory: 64Gi
mountModelVolume: true
volumeMounts:
- name: metrics-volume
mountPath: /.config
- name: shm
mountPath: /dev/shm
- name: torch-compile-cache
mountPath: /.cache
startupProbe:
httpGet:
path: /v1/models
port: vllm
initialDelaySeconds: 15
periodSeconds: 30
timeoutSeconds: 5
failureThreshold: 120
livenessProbe:
httpGet:
path: /health
port: vllm
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /v1/models
port: vllm
periodSeconds: 5
timeoutSeconds: 2
failureThreshold: 3
volumes:
- name: metrics-volume
emptyDir: {}
- name: torch-compile-cache
emptyDir: {}
- name: shm
emptyDir:
medium: Memory
sizeLimit: 20Gi
prefill:
create: false
EOF
จากนั้นสร้างไฟล์ gaie-values.yaml สำหรับส่วนขยาย GKE Inference Gateway ดังนี้
cat <<EOF > gaie-values.yaml
inferenceExtension:
replicas: 1
image:
name: llm-d-inference-scheduler
hub: ghcr.io/llm-d
tag: v0.6.0
pullPolicy: Always
extProcPort: 9002
pluginsConfigFile: "default-plugins.yaml"
tracing:
enabled: false
monitoring:
interval: "10s"
prometheus:
enabled: true
auth:
secretName: inference-scheduling-gateway-sa-metrics-reader-secret
inferencePool:
targetPorts:
- number: 8000
modelServerType: vllm
modelServers:
matchLabels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
EOF
ทำความเข้าใจการกำหนดค่า
การกำหนดค่านี้จะตั้งค่าสแต็กการอนุมานที่มีประสิทธิภาพสูงพร้อมฟีเจอร์หลักต่อไปนี้
- การเลือกโมเดล: ใช้โมเดล Qwen 2.5 Coder 14B (
modelArtifacts) ซึ่งได้รับการเพิ่มประสิทธิภาพสำหรับการสร้างโค้ดและการใช้เครื่องมือ - การผสานรวม DRA: ส่วน
acceleratorจะเปิดใช้การจัดสรรทรัพยากรแบบไดนามิก (dra: true) โดยกำหนดเป้าหมายไปยังคลาสอุปกรณ์gpu.nvidia.comและgpu-claim-templateที่เราสร้างไว้ก่อนหน้านี้ - การเพิ่มประสิทธิภาพ:
parallelism.tensor: 2กำหนดค่าการทำงานแบบขนานของเทนเซอร์ใน GPUargsสำหรับ vLLM มี--enable-auto-tool-choiceเพื่อให้มั่นใจว่าเอเจนต์การเขียนโค้ดของเราจะใช้เครื่องมือได้อย่างมีประสิทธิภาพ- คำขอ
cpuและmemoryที่ลดลงเหมาะกับประเภทเครื่องg2-standard-24
- การกำหนดเส้นทางอัจฉริยะ: ส่วนขยาย Inference Gateway (
gaie-values.yaml) ได้รับการกำหนดค่าให้ตรวจสอบเซิร์ฟเวอร์โมเดลvllmและกำหนดเส้นทางคำขอเพื่อเพิ่มการเข้าชมแคช KV ให้ได้สูงสุด
ติดตั้งใช้งานสแต็กการจัดกำหนดการอนุมานผ่าน Helm
ตอนนี้ให้เพิ่มที่เก็บ Helm ของ llm-d และติดตั้งใช้งานโครงสร้างพื้นฐาน ส่วนขยายเกตเวย์ และบริการโมเดลแยกกัน
ก่อนอื่น ให้เพิ่มที่เก็บที่จำเป็น
helm repo add llm-d-infra https://llm-d-incubation.github.io/llm-d-infra/
helm repo add llm-d-modelservice https://llm-d-incubation.github.io/llm-d-modelservice/
helm repo update
ติดตั้งข้อกำหนดเบื้องต้นของโครงสร้างพื้นฐาน
แผนภูมินี้จะติดตั้งการกำหนดค่าเกตเวย์พื้นฐานที่จำเป็นสำหรับสแต็ก
helm install infra-is llm-d-infra/llm-d-infra \
--namespace $NAMESPACE \
--set gateway.gatewayClassName=gke-l7-rilb \
--set gateway.gatewayParameters.enabled=false \
--set gateway.gatewayParameters.istio.accessLogging=false
ติดตั้งใช้งานส่วนขยาย GKE Inference Gateway
ขั้นตอนนี้จะติดตั้งใช้งาน InferencePool และ Endpoint Picker ซึ่งจะตรวจสอบ KV-cache ของโมเดลเพื่อทำการตัดสินใจในการกำหนดเส้นทางอย่างชาญฉลาด
helm install gaie-is oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool \
--version v1.3.1 \
--namespace $NAMESPACE \
-f gaie-values.yaml \
--set provider.name=gke \
--set inferenceExtension.monitoring.prometheus.enabled=true
ทำให้บริการโมเดลใช้งานได้
สุดท้าย ให้ติดตั้งใช้งานบริการ LLM ซึ่งตอนนี้จะใช้ DRA เพื่ออ้างสิทธิ์ GPU L4 อย่างปลอดภัย
helm install ms-is llm-d-modelservice/llm-d-modelservice \
--version v0.4.7 \
--namespace $NAMESPACE \
-f ms-values.yaml \
--set decode.monitoring.podmonitor.enabled=false
เปิดใช้ Google Cloud Observability สำหรับ vLLM
แผนภูมิ Helm ทั่วไปมักพยายามที่จะติดตั้งใช้งานทรัพยากร PodMonitor ตัวดำเนินการ Prometheus มาตรฐาน (monitoring.coreos.com/v1) ซึ่งอาจทำให้เกิดข้อผิดพลาดหากคุณไม่ได้ติดตั้ง CRD เหล่านั้น
แทนที่จะสลับการเปิด/ปิดการตรวจสอบในตัวของ Helm ให้falseเปิดไว้ แล้วใช้ทรัพยากร Google Cloud Managed Prometheus (GMP) PodMonitoring ด้วยตนเองโดยใช้กลุ่ม API monitoring.googleapis.com/v1 ที่เข้ากันได้
เรียกใช้คำสั่งต่อไปนี้เพื่อสร้าง podmonitoring.yaml
cat > podmonitoring.yaml <<EOF
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: ms-vllm-metrics
spec:
selector:
matchLabels:
llm-d.ai/model: "qwen-2-5-coder-14b" # Matches the label in values.yaml
endpoints:
- port: 8000 # vllm port
interval: 30s
path: /metrics
EOF
ใช้ทรัพยากร PodMonitoring กับคลัสเตอร์
kubectl apply -f podmonitoring.yaml -n $NAMESPACE
ยืนยันการติดตั้ง
ยืนยันว่าติดตั้งคอมโพเนนต์เรียบร้อยแล้ว คุณควรเห็น Helm ทั้ง 3 รุ่นที่ใช้งานอยู่ในเนมสเปซและพ็อดที่เกี่ยวข้องกำลังเริ่มต้น
helm ls -n $NAMESPACE
kubectl get pods -n $NAMESPACE
พ็อด ms-is อาจใช้เวลาประมาณ 5-10 นาทีในการเริ่มต้น เมื่อดำเนินการแล้ว เอาต์พุตควรมีลักษณะดังนี้
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
gaie-is ai-agents 1 2026-03-28 16:51:41.055881618 +0000 UTC deployed inferencepool-v1.3.1 v1.3.1
infra-is ai-agents 1 2026-03-28 16:51:03.71042542 +0000 UTC deployed llm-d-infra-v1.4.0 v0.4.0
ms-is ai-agents 1 2026-03-28 17:30:00.341918958 +0000 UTC deployed llm-d-modelservice-v0.4.7 v0.4.0
NAME READY STATUS RESTARTS AGE
gaie-is-epp-848965cb4-78ktp 1/1 Running 0 10m
ms-is-llm-d-modelservice-decode-67548d5f8c-f25f4 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-rblvs 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-w6fcd 1/1 Running 0 6m2s
5. กำหนดค่าการกำหนดเส้นทางอัจฉริยะด้วย GKE Inference Gateway
ในขั้นตอนที่ 4 การติดตั้งใช้งานllm-dแผนภูมิ Helm จะจัดสรรออบเจ็กต์ Gateway และ InferencePool โดยอัตโนมัติ ซึ่งInferencePoolจะจัดกลุ่มพ็อดที่ให้บริการโมเดล vllm ที่ใช้โมเดลพื้นฐานและการกำหนดค่าการประมวลผลเดียวกัน
ตอนนี้คุณต้องกำหนดค่า InferenceObjective เพื่อกำหนดลำดับความสำคัญของคำขอจากเอเจนต์การเขียนโค้ด และ HTTPRoute เพื่อสั่งให้เกตเวย์กำหนดเส้นทางการรับส่งข้อมูลขาเข้า โดยใช้เครื่องมือเลือกปลายทางเพื่อเพิ่มการเข้าชมแคช KV ให้ได้สูงสุด
ยืนยันแหล่งข้อมูลที่สร้างขึ้นอัตโนมัติ
ก่อนอื่น ให้ตรวจสอบว่าllm-dแผนภูมิ Helm สร้างทรัพยากร Gateway และ InferencePool ได้สำเร็จ
kubectl get gateway,inferencepool -n $NAMESPACE
คุณควรเห็นเกตเวย์ชื่อ infra-is-inference-gateway และ InferencePool ชื่อ gaie-is คล้ายกับตัวอย่างต่อไปนี้
NAME CLASS ADDRESS PROGRAMMED AGE
gateway.gateway.networking.k8s.io/infra-is-inference-gateway gke-l7-regional-internal-managed 10.128.0.5 True 13m
NAME AGE
inferencepool.inference.networking.k8s.io/gaie-is 12m
สร้าง HTTPRoute
HTTPRoute แหล่งข้อมูลจะแมปเกตเวย์กับแบ็กเอนด์InferencePool ซึ่งจะบอกให้ GKE Inference Gateway วิเคราะห์เนื้อหาคำขอขาเข้าและกำหนดเส้นทางแบบไดนามิกเพื่อเพิ่ม Hit ของแคชคำนำหน้าให้ได้สูงสุดตามบริบทที่แชร์
เรียกใช้คำสั่งต่อไปนี้เพื่อสร้าง httproute.yaml
cat > httproute.yaml <<EOF
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: agent-route
spec:
parentRefs:
- group: gateway.networking.k8s.io
kind: Gateway
name: infra-is-inference-gateway
rules:
- backendRefs:
- group: inference.networking.k8s.io
kind: InferencePool
name: gaie-is
weight: 1
matches:
- path:
type: PathPrefix
value: /
EOF
ใช้เส้นทางกับคลัสเตอร์โดยทำดังนี้
kubectl apply -f httproute.yaml -n $NAMESPACE
6. การรันโค้ดอย่างปลอดภัยด้วยแซนด์บ็อกซ์ของ Agent
ตอนนี้เรามีแบ็กเอนด์การอนุมานที่มีประสิทธิภาพสูงแล้ว มาเตรียมสภาพแวดล้อมที่ปลอดภัยซึ่งโค้ดที่ AI สร้างขึ้นจะทำงานจริงโดยแยกออกจากคลัสเตอร์ของเราอย่างปลอดภัยโดยใช้ Agent Sandbox
ติดตั้งใช้งานตัวควบคุมแซนด์บ็อกซ์ของตัวแทน
เมื่อ AI Agent สร้างและเรียกใช้โค้ด ก็เท่ากับว่ากำลังเรียกใช้ภาระงานที่ไม่น่าเชื่อถือในโครงสร้างพื้นฐานของคุณ หากเอเจนต์สร้างโค้ดที่เป็นอันตราย ก็อาจพยายามสแกนเครือข่ายภายในหรือใช้ประโยชน์จากโหนดโฮสต์พื้นฐาน
GKE Agent Sandbox ใช้ gVisor ซึ่งเป็นรันไทม์ของคอนเทนเนอร์แบบโอเพนซอร์สที่ให้เคอร์เนลของแขกรับเชิญที่เชี่ยวชาญสำหรับแต่ละคอนเทนเนอร์ ซึ่งจะป้องกันไม่ให้โค้ดที่ไม่น่าเชื่อถือทำการเรียกใช้ระบบโดยตรงไปยังโหนดโฮสต์
ทำให้ตัวควบคุมแซนด์บ็อกซ์ของเอเจนต์และคอมโพเนนต์ที่จำเป็นใช้งานได้โดยใช้ไฟล์ Manifest ของรุ่นอย่างเป็นทางการ
kubectl apply \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/manifest.yaml \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/extensions.yaml
กำหนดค่าเทมเพลต Sandbox และพูลอุ่น
จากนั้นเราจะสร้าง SandboxTemplate ซึ่งทำหน้าที่เป็นพิมพ์เขียวที่นำกลับมาใช้ใหม่ได้สำหรับสภาพแวดล้อมการวิเคราะห์ Python โดยกำหนดเป้าหมายไปยังคลาสรันไทม์ gvisor โดยเฉพาะ หากต้องการลดความซับซ้อนในการติดตั้งใช้งานโดยไม่ต้องจัดการ Node Pool ด้วยตนเองในคลัสเตอร์มาตรฐาน เราสามารถใช้ประโยชน์จาก autopilot มาตรฐานได้
ComputeClass เพื่อจัดสรรโหนดการประมวลผลที่มีการจัดการแบบไดนามิกซึ่งรองรับภาระงาน gVisor โดยกำเนิดตามความต้องการ
เนื่องจากการเริ่มต้นเคอร์เนลที่ปลอดภัยอาจทำให้เกิดเวลาในการตอบสนอง เราจึงใช้ SandboxWarmPool ด้วย ซึ่งจะช่วยให้มั่นใจได้ว่าระบบจะเตรียมแซนด์บ็อกซ์ที่เริ่มต้นไว้ล่วงหน้าตามจำนวนที่ระบุให้พร้อมใช้งานอยู่เสมอ เพื่อให้ Code Generation Agent สามารถอ้างสิทธิ์และเริ่มเรียกใช้โค้ดได้ภายในไม่ถึง 1 วินาที
ก่อนอื่น ให้สร้างเนมสเปซใหม่สำหรับรันไทม์แซนด์บ็อกซ์ของเอเจนต์
kubectl create namespace agent-sandbox
บันทึกรายการต่อไปนี้เป็น sandbox-template-and-pool.yaml
cat > sandbox-template-and-pool.yaml <<EOF
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxTemplate
metadata:
name: python-runtime-template
namespace: agent-sandbox
spec:
podTemplate:
metadata:
labels:
sandbox: python-sandbox-example
spec:
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: python-runtime
image: registry.k8s.io/agent-sandbox/python-runtime-sandbox:v0.1.0
ports:
- containerPort: 8888
readinessProbe:
httpGet:
path: "/"
port: 8888
initialDelaySeconds: 0
periodSeconds: 1
resources:
requests:
cpu: "250m"
memory: "512Mi"
ephemeral-storage: "512Mi"
restartPolicy: "OnFailure"
---
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxWarmPool
metadata:
name: python-sandbox-warmpool
namespace: agent-sandbox
spec:
replicas: 2
sandboxTemplateRef:
name: python-runtime-template
EOF
ใช้การกำหนดค่า
kubectl apply -f sandbox-template-and-pool.yaml
รอประมาณ 2-3 นาทีเพื่อให้พ็อด Warm Pool เริ่มต้น คุณสามารถตรวจสอบว่าผู้ใช้เปลี่ยนจาก Pending (ในขณะที่การประมวลผลพื้นฐานเพิ่มขึ้น) เป็น Running ได้สำเร็จหรือไม่โดยใช้สิ่งต่อไปนี้
kubectl get pods -n agent-sandbox -w
เมื่อเห็นพ็อด 2 พ็อดแสดงเป็น Running และ 1/1 พร้อมแล้ว แสดงว่าสภาพแวดล้อมการดำเนินการที่ปลอดภัยของคุณพร้อมใช้งานและรับได้แล้วpython-sandbox-warmpool-***
ติดตั้งใช้งานเราเตอร์แซนด์บ็อกซ์
Agent การสร้างโค้ดของเราใช้เราเตอร์ Sandbox เพื่อส่งคำสั่งการดำเนินการไปยังพ็อดที่แยกต่างหากอย่างปลอดภัย
เรียกใช้คำสั่งต่อไปนี้เพื่อสร้าง sandbox-router.yaml
cat > sandbox-router.yaml <<EOF
apiVersion: v1
kind: Service
metadata:
name: sandbox-router-svc
namespace: agent-sandbox
spec:
type: ClusterIP
selector:
app: sandbox-router
ports:
- name: http
protocol: TCP
port: 8080
targetPort: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sandbox-router-deployment
namespace: agent-sandbox
spec:
replicas: 2
selector:
matchLabels:
app: sandbox-router
template:
metadata:
labels:
app: sandbox-router
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: sandbox-router
containers:
- name: router
image: us-central1-docker.pkg.dev/k8s-staging-images/agent-sandbox/sandbox-router:v20260225-v0.1.1.post3-10-ga5bcb57
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 10
resources:
requests:
cpu: "250m"
memory: "512Mi"
limits:
cpu: "1000m"
memory: "1Gi"
securityContext:
runAsUser: 1000
runAsGroup: 1000
EOF
ใช้การกำหนดค่า
kubectl apply -f sandbox-router.yaml
ใช้การแยกเครือข่าย
หากต้องการล็อกสภาพแวดล้อมการดำเนินการเพิ่มเติมและป้องกันการเคลื่อนที่ด้านข้างที่ไม่ได้รับอนุญาต ให้ใช้นโยบายเครือข่าย ซึ่งจะ "แยก" แซนด์บ็อกซ์เพื่อไม่ให้เข้าถึงเซิร์ฟเวอร์ข้อมูลเมตาของ Google Cloud หรือเครือข่ายภายในที่ละเอียดอ่อนอื่นๆ ได้
บันทึกรายการต่อไปนี้เป็น sandbox-policy.yaml
cat > sandbox-policy.yaml <<EOF
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: restrict-sandbox-egress
namespace: agent-sandbox
spec:
podSelector:
matchLabels:
sandbox: python-sandbox-example
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 0.0.0.0/0
except:
- 169.254.169.254/32 # Block metadata server
EOF
ใช้นโยบาย
kubectl apply -f sandbox-policy.yaml
ยืนยันคอมโพเนนต์
หากต้องการให้มั่นใจว่าเลเยอร์คลัสเตอร์แซนด์บ็อกซ์โค้ดที่แยกต่างหากได้รับการกำหนดค่าอย่างสมบูรณ์ ให้เรียกใช้คำสั่งตรวจสอบสถานะต่อไปนี้
ก่อนอื่น ให้ตรวจสอบว่าพ็อดและเราเตอร์แซนด์บ็อกซ์ทำงานและพร้อมใช้งาน
kubectl get pods -n agent-sandbox
เอาต์พุตควรมีลักษณะดังนี้
NAME READY STATUS RESTARTS AGE
python-sandbox-warmpool-7zlkv 1/1 Running 0 3m25s
python-sandbox-warmpool-cxln2 1/1 Running 0 3m25s
sandbox-router-deployment-668dfbbbb6-g9mpd 1/1 Running 0 42s
sandbox-router-deployment-668dfbbbb6-ppllz 1/1 Running 0 42s
ยืนยันตัวจัดสรรภาระงาน / การเปิดเผย IP ของเราเตอร์ Sandbox
kubectl get service sandbox-router-svc -n agent-sandbox
เอาต์พุตควรมีลักษณะดังนี้
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
sandbox-router-svc ClusterIP 34.118.237.244 <none> 8080/TCP 114s
ตรวจสอบว่ามีกฎนโยบายเครือข่ายขาออก
kubectl get networkpolicy restrict-sandbox-egress -n agent-sandbox
เอาต์พุตควรมีลักษณะดังนี้
NAME POD-SELECTOR AGE
restrict-sandbox-egress sandbox=python-sandbox-example 113s
โปรดตรวจสอบว่า
python-sandbox-warmpool-***พ็อดRunningและ1/1พร้อมใช้งานแล้วsandbox-router-deployment-***แบบจำลองพร้อมใช้งานRunningและ1/1sandbox-router-svcเข้าถึงได้ และนโยบายrestrict-sandbox-egressปกป้องป้ายกำกับแซนด์บ็อกซ์ที่ตรงกันได้สำเร็จ
เมื่อสภาพแวดล้อมการดำเนินการที่ปลอดภัยของเราได้รับการรักษาความปลอดภัยและเริ่มต้นใช้งานแล้ว เราก็พร้อมที่จะติดตั้งใช้งานส่วนสำคัญของการดำเนินการ นั่นก็คือเอเจนต์การสร้างโค้ด
7. สร้างและติดตั้งใช้งาน Agent การสร้างโค้ด (ADK)
เมื่อกำหนดค่าแซนด์บ็อกซ์การดำเนินการที่ปลอดภัยและแบ็กเอนด์ LLM ประสิทธิภาพสูงแล้ว ตอนนี้เราก็สามารถสร้าง "สมอง" ของระบบได้แล้ว นั่นคือ Code Generation Agent โดยใช้ Agent Development Kit (ADK)
ตัวแทนนี้ออกแบบมาให้ทำหน้าที่เป็นนักพัฒนา Python ผู้เชี่ยวชาญ เอเจนต์นี้มีเครื่องมือการดำเนินการโค้ดที่ช่วยให้แก้ปัญหาแบบอินเทอร์แอกทีฟได้ ซึ่งแตกต่างจากแชทบ็อตมาตรฐานที่สร้างได้เฉพาะข้อความ โดยมีวงจรดังนี้
- เขียนโค้ด Python ตามคำขอของคุณ
- เรียกใช้โค้ดอย่างปลอดภัยภายใน GKE Agent Sandbox ที่เราตั้งค่าไว้ในขั้นตอนที่ 6
- การยืนยันเอาต์พุตหรืออ่านข้อผิดพลาดที่เกิดขึ้นระหว่างการดำเนินการ
- ส่งมอบโซลูชันที่ผ่านการทดสอบและใช้งานได้จริงด้วยความมั่นใจ
การให้สิทธิ์เข้าถึงสภาพแวดล้อมการดำเนินการแซนด์บ็อกซ์ที่ปลอดภัยแก่เอเจนต์จะช่วยให้เอเจนต์ยืนยันตรรกะของตนเองและแก้ไขข้อบกพร่องโดยอัตโนมัติได้ ซึ่งจะช่วยให้เอเจนต์มีความสามารถในการทำงานด้านการพัฒนาซอฟต์แวร์มากขึ้นอย่างมาก
พัฒนา Reasoning Agent ของ ADK
ก่อนอื่น เราจะเขียนตรรกะ Python ที่กำหนดลักษณะการทำงานของ Agent และติดตั้งเครื่องมือ Sandbox ที่เราสร้างขึ้นในขั้นตอนที่ 6 ในส่วนนี้ เรายังกำหนดค่ากลยุทธ์โมเดลแบบไฮบริดด้วย โดยเอเจนต์จะจัดลำดับความสำคัญของโมเดล Qwen ที่โฮสต์ด้วยตนเองซึ่งทำงานบนคลัสเตอร์ GKE แต่จะเปลี่ยนไปใช้ Gemini 2.5 Flash ใน Vertex AI โดยอัตโนมัติหากโมเดลในเครื่องทำงานช้าหรือไม่พร้อมใช้งาน เพื่อให้มั่นใจถึงความน่าเชื่อถือสูง
สร้างไดเรกทอรีใหม่สำหรับโค้ดของเอเจนต์
mkdir -p ~/gke-ai-agent-lab/root_agent
cd ~/gke-ai-agent-lab
สร้างไฟล์ชื่อ root_agent/agent.py ที่มีเนื้อหาต่อไปนี้
cat <<'EOF' > root_agent/agent.py
import os
from google.adk.agents import Agent
from google.adk.models.lite_llm import LiteLlm
from k8s_agent_sandbox import SandboxClient
import requests
# Instantiate the client globally to track sandboxes
sandbox_client = SandboxClient()
def run_python_code(code: str) -> str:
"""
Executes Python code safely in the GKE Agent Sandbox.
Use this tool whenever you need to execute code to solve a problem.
"""
sandbox = sandbox_client.create_sandbox(template="python-runtime-template", namespace="agent-sandbox")
try:
command = f"python3 -c \"{code}\""
result = sandbox.commands.run(command)
if result.stderr:
return f"Error: {result.stderr}"
return result.stdout
finally:
# Ensure the sandbox is deleted after use to avoid leaking resources
sandbox_client.delete_sandbox(sandbox.claim_name, namespace="agent-sandbox")
# Define the ADK Agent with a fallback mechanism.
# It prioritizes the Qwen 2.5 Coder model running on our Inference Gateway.
# If the local model is unavailable, it falls back to Gemini 2.5 Flash on Vertex AI.
root_agent = Agent(
name="CodeGenerationAgent",
model=LiteLlm(
model="openai/Qwen/Qwen2.5-Coder-14B-Instruct",
fallbacks=["vertex_ai/gemini-2.5-flash"],
timeout=10
),
instruction="""
You are an expert Python developer.
1. Write Python code to solve the user's problem.
2. Execute the code using the `run_python_code` tool to verify it works.
3. Return the exact output and a brief explanation of the code.
""",
tools=[run_python_code]
)
EOF
สร้างไฟล์ __init__.py เพื่อให้ ADK รู้จักโมดูล
echo "from . import agent" > ~/gke-ai-agent-lab/root_agent/__init__.py
ตั้งค่าตัวแปรสภาพแวดล้อม แอปพลิเคชัน ADK ต้องใช้ที่อยู่ IP ของเกตเวย์เพื่อกำหนดเส้นทางคำขอ LLM ให้สำเร็จ เนื่องจาก ADK รองรับปลายทางมาตรฐานที่เข้ากันได้กับ Open-AI (ซึ่ง vLLM มีให้ผ่านเกตเวย์ของเรา) เราจึงสามารถลบล้าง URL ฐานของ API เริ่มต้นได้
export GATEWAY_IP=$(kubectl get gateway infra-is-inference-gateway -n $NAMESPACE -o jsonpath='{.status.addresses[0].value}')
cat <<EOF > ~/gke-ai-agent-lab/root_agent/.env
OPENAI_API_BASE=http://${GATEWAY_IP}/v1
OPENAI_API_KEY=no-key-required
# Vertex AI settings for fallback (Authentication is handled by Workload Identity)
VERTEXAI_PROJECT=$PROJECT_ID
VERTEXAI_LOCATION=${ZONE%-[a-z]}
EOF
สร้างคอนเทนเนอร์ให้แอปพลิเคชัน Agent
เราต้องจัดแพ็กเกจเอเจนต์เพื่อให้ทำงานได้อย่างปลอดภัยภายใน GKE
สร้าง Dockerfile ใน ~/gke-ai-agent-lab ที่ติดตั้ง kubectl, ไลบรารี ADK และไคลเอ็นต์ Agent Sandbox
cat <<'EOF' > ~/gke-ai-agent-lab/Dockerfile
FROM python:3.11-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
RUN apt-get update && apt-get install -y git curl \
&& curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl" \
&& install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl \
&& rm kubectl && apt-get clean && rm -rf /var/lib/apt/lists/*
RUN pip install --no-cache-dir "google-adk[extensions,otel-gcp]>=1.27.4" litellm pandas "git+https://github.com/kubernetes-sigs/agent-sandbox.git@main#subdirectory=clients/python/agentic-sandbox-client" \
"opentelemetry-instrumentation-google-genai>=0.4b0" \
"opentelemetry-exporter-otlp" \
"opentelemetry-instrumentation-vertexai>=2.0b0"
COPY ./root_agent /app/root_agent
EXPOSE 8080
ENTRYPOINT ["adk", "web", "--host", "0.0.0.0", "--port", "8080", "--otel_to_cloud"]
EOF
สร้างที่เก็บ Artifact Registry เพื่อจัดเก็บอิมเมจคอนเทนเนอร์
gcloud artifacts repositories create agent-repo \
--repository-format=docker \
--location=us-central1
ใช้ Cloud Build เพื่อสร้างและพุชอิมเมจคอนเทนเนอร์
gcloud builds submit --tag us-central1-docker.pkg.dev/$PROJECT_ID/agent-repo/code-agent:v1 ~/gke-ai-agent-lab/
ทำให้ใช้งานได้ใน GKE ด้วย RBAC
สุดท้าย ให้ติดตั้งใช้งานเอเจนต์ในคลัสเตอร์ การติดตั้งใช้งานประกอบด้วย Role และ RoleBinding ที่ให้สิทธิ์แก่ตัวแทนในการอ้างสิทธิ์อินสแตนซ์จาก SandboxWarmPool
การติดตั้งใช้งานนี้จะใช้ ServiceAccount ของ Kubernetes เพื่อให้ Agent สื่อสารกับ Sandbox Claim API ได้ ไม่จำเป็นต้องใช้ Google IAM ServiceAccount เนื่องจากเข้าถึงทรัพยากรคลัสเตอร์ในเครื่องและปลายทางเกตเวย์ vLLM ในเครื่อง
เหตุผลที่ควรใช้การติดตั้งใช้งานมาตรฐานใน gVisor
ในขั้นตอนที่ 6 เราใช้ API SandboxTemplate และ SandboxClaim เพื่อสร้างแซนด์บ็อกซ์แบบใช้ครั้งเดียวสำหรับโค้ด Python ที่สร้างขึ้น (การดำเนินการเครื่องมือ)
สำหรับ Agent Web UI (สมอง) เอง เราใช้ข้อกำหนด Deployment ของ Kubernetes มาตรฐานกับ runtimeClassName: gvisor
- ความแตกต่าง:
SandboxClaimsมาตรฐานมีอายุสั้นและมีค่าตั้งแต่ 0 ถึง 1 (เหมาะสำหรับสคริปต์ที่ไม่น่าเชื่อถือ)Deploymentมาตรฐานจะทำงานเป็นเวลานานและคงอยู่ถาวร ซึ่งเหมาะอย่างยิ่งสำหรับ UI ทางเว็บที่ต้องการServiceและตัวจัดสรรภาระงานของ Kubernetes ที่เสถียร การใช้runtimeClassName: gvisorในการทำให้ใช้งานได้มาตรฐานโดยตรงจะช่วยให้คุณแยกเคอร์เนล gVisor ออกจากกันได้ในขณะที่ยังคงใช้ฟีเจอร์มาตรฐานของDeploymentได้
บันทึกรายการต่อไปนี้เป็น deployment.yaml
cat <<EOF > ~/gke-ai-agent-lab/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: code-agent
labels:
app: code-agent
spec:
replicas: 1
selector:
matchLabels:
app: code-agent
template:
metadata:
labels:
app: code-agent
spec:
serviceAccount: adk-agent-sa
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: code-agent
image: us-central1-docker.pkg.dev/YOUR_PROJECT_ID/agent-repo/code-agent:v1
imagePullPolicy: Always
env:
- name: OPENAI_API_KEY
value: "no-key-required"
- name: OPENAI_API_BASE
value: "http://YOUR_GATEWAY_IP/v1"
- name: VERTEXAI_PROJECT
value: "YOUR_PROJECT_ID"
- name: VERTEXAI_LOCATION
value: "YOUR_REGION"
- name: OTEL_SERVICE_NAME
value: "code-agent"
- name: GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY
value: "true"
- name: OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT
value: "true"
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: code-agent-service
spec:
selector:
app: code-agent
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: agent-sandbox
name: sandbox-creator-role
rules:
- apiGroups: [""]
resources: ["services", "pods", "pods/portforward"]
verbs: ["get", "list", "watch", "create"]
- apiGroups: ["extensions.agents.x-k8s.io"]
resources: ["sandboxclaims"]
verbs: ["create", "get", "list", "watch", "delete"]
- apiGroups: ["agents.x-k8s.io"]
resources: ["sandboxes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: adk-agent-binding
namespace: agent-sandbox
subjects:
- kind: ServiceAccount
name: adk-agent-sa
namespace: default
roleRef:
kind: Role
name: sandbox-creator-role
apiGroup: rbac.authorization.k8s.io
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: adk-agent-sa
EOF
ให้สิทธิ์ IAM สำหรับการสังเกตการณ์
หากต้องการให้ตัวแทนส่งข้อมูลการวัดและส่งข้อมูล (บันทึกและร่องรอย) ไปยัง Google Cloud คุณต้องให้สิทธิ์ที่จำเป็นแก่บัญชีบริการ Kubernetes adk-agent-sa โดยใช้ Workload Identity
เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# Grant permission to write logs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/logging.logWriter \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to write traces
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/cloudtrace.agent \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to use Vertex AI
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/aiplatform.user \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
เรียกใช้คำสั่งต่อไปนี้เพื่อแทนที่ YOUR_PROJECT_ID ด้วยรหัสโปรเจ็กต์จริงของคุณโดยอัตโนมัติและใช้การกำหนดค่า
sed -i "s/YOUR_PROJECT_ID/$PROJECT_ID/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_GATEWAY_IP/$GATEWAY_IP/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_REGION/$ZONE/g" ~/gke-ai-agent-lab/deployment.yaml
kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml
8. สังเกตและตรวจสอบ
ถึงเวลาทดสอบระบบที่ผสานรวมอย่างเต็มรูปแบบแล้ว
ทดสอบเอเจนต์การสร้างโค้ดใน UI
ค้นหา IP ภายนอกของเว็บ UI ของ ADK โดยทำดังนี้
kubectl get services code-agent-service
เอาต์พุตควรมีลักษณะดังนี้
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
code-agent-service LoadBalancer 34.118.230.182 34.31.250.60 80:32471/TCP 2m14s
- เปิดเบราว์เซอร์แล้วไปที่
http://[EXTERNAL-IP] - ในเว็บอินเทอร์เฟซของ ADK ให้ตรวจสอบว่าได้เลือก "root_agent" จากเมนูแบบเลื่อนลงที่ด้านขวาบน จากนั้นแจ้งตัวแทนดังนี้
Write a python script that prints 'Hello from the isolated sandbox'.
หากต้องการดูว่าเอเจนต์ใช้แบ็กเอนด์การอนุมานและแซนด์บ็อกซ์อย่างไร ให้ไปที่ส่วนสำรวจสถิติโมเดลผ่าน Cloud Observability และสำรวจการสังเกตการณ์เอเจนต์ผ่าน UI ของ GKE ด้านล่างเพื่อดูแดชบอร์ด
สำรวจการสังเกตการณ์ Agent ผ่าน UI ของ GKE
ตอนนี้คุณได้เรียกใช้พรอมต์บางส่วนแล้ว มาดูข้อมูลการวัดและส่งข้อมูลทางไกลกัน ซึ่งจะช่วยให้คุณเข้าใจประสิทธิภาพของตัวจัดตารางเวลาการอนุมานและ vLLM
เข้าถึงแดชบอร์ดของตัวแทน
- ไปที่หน้า Kubernetes Engine > ภาระงาน
- คลิกการติดตั้งใช้งาน code-agent เพื่อเปิดหน้ารายละเอียดการติดตั้งใช้งาน
- คลิกแท็บการสังเกตการณ์
- ในแผงการนำทางด้านซ้ายของแดชบอร์ดการสังเกตการณ์ คุณจะเห็นส่วนAgentใหม่พร้อมแท็บย่อย
สำรวจอะไรได้บ้าง
สำรวจแท็บย่อยต่อไปนี้เพื่อดูลักษณะการทำงานของแอปพลิเคชันตัวแทน
- ภาพรวม: ดูตารางสรุปสถิติสำหรับเซสชัน เทิร์นเฉลี่ย และการเรียกใช้
- โมเดล: ดูจำนวนการเรียกใช้โมเดล อัตราข้อผิดพลาด และเวลาในการตอบสนองที่จัดหมวดหมู่ตามโมเดลที่เอเจนต์ใช้
- เครื่องมือ: ตรวจสอบการเรียกใช้เครื่องมือและระยะเวลาการดำเนินการเพื่อดูว่าเอเจนต์ใช้เครื่องมือการดำเนินการในแซนด์บ็อกซ์ได้อย่างมีประสิทธิภาพเพียงใด
- การใช้งาน: ติดตามการใช้โทเค็นและการจัดสรรทรัพยากรคอนเทนเนอร์มาตรฐาน (CPU และหน่วยความจำ)
- การติดตาม Agent: เปลี่ยนไปที่แท็บนี้เพื่อดูรายการเซสชันการดำเนินการหรือช่วงการติดตามดิบ เมื่อคลิกแถว ฟลายเอาต์ที่มีรายละเอียดของการติดตามที่เลือกจะเปิดขึ้น
การรวมเมตริกระดับโมเดลจาก vLLM เข้ากับการวัดระยะระดับแอปจาก ADK ทำให้ตอนนี้คุณมีเครื่องมือสังเกตการณ์แบบ Full Stack สำหรับ AI Agent Generative AI ใน GKE แล้ว
สำรวจสถิติโมเดล vLLM ผ่าน Cloud Observability
ตอนนี้คุณได้เรียกใช้พรอมต์บางส่วนแล้ว มาดูข้อมูลการวัดและส่งข้อมูลทางไกลกัน ซึ่งจะช่วยให้คุณเข้าใจประสิทธิภาพของตัวจัดตารางเวลาการอนุมานและ vLLM
เข้าถึงแดชบอร์ด
- ไปที่ คอนโซล Google Cloud
- ไปที่การตรวจสอบ > แดชบอร์ด
- ค้นหาและเลือกแดชบอร์ดภาพรวม Prometheus ของ vLLM
เมตริกที่น่าสนใจที่ควรสังเกต
ขณะดูแดชบอร์ด ให้พิจารณาเมตริกหลักต่อไปนี้เพื่อดูผลกระทบของ GKE Inference Gateway และการแคชคำนำหน้า
- การใช้แคช KV (
vllm:gpu_cache_usage):- เหตุใดจึงสำคัญ: ข้อมูลนี้แสดงปริมาณหน่วยความจำ GPU ที่ใช้แคชบริบท หากค่านี้สูง แสดงว่าระบบกำลังเก็บบริบทไว้เพื่อเร่งคำขอในอนาคต หากคุณเรียกใช้พรอมต์เดียวกันหลายครั้ง คุณควรเห็นการใช้งานนี้เพิ่มขึ้นแล้วจึงคงที่
- คำขอที่กำลังทำงานเทียบกับคำขอที่รอ (
vllm:num_requests_runningเทียบกับvllm:num_requests_waiting):- ความสำคัญ: แสดงถึงการโหลด หากคำขอที่รออยู่มีจำนวนมาก แสดงว่าโหนดทำงานหนักเกินไป
- อัตราการส่งข้อมูลของโทเค็น (
vllm:request_prompt_tokens_totและvllm:request_generation_tokens_tot):- ความสำคัญ: ติดตามปริมาณโทเค็นอินพุตและเอาต์พุตที่คลัสเตอร์ประมวลผล
- Time To First Token (TTFT):
- เหตุผลที่มีความสำคัญ: เมตริกนี้เป็นเมตริกที่สำคัญสำหรับเอเจนต์แบบอินเทอร์แอกทีฟ การใช้ GKE Inference Gateway กับการกำหนดเส้นทางที่รับรู้แคชคำนำหน้าจะทำให้คำขอที่แชร์บริบททั่วไป (เช่น พรอมต์ของระบบหรือหน้าต่างบริบทขนาดใหญ่) ได้รับการกำหนดเส้นทางไปยังรีพลิก้าเดียวกัน ซึ่งจะช่วยลด TTFT โดยการนำแคชที่มีอยู่มาใช้ซ้ำ
การทดสอบที่ควรลอง
ลองใช้สถานการณ์ต่อไปนี้เพื่อดูการเปลี่ยนแปลงของเมตริกแบบเรียลไทม์และตรวจสอบการจัดตารางเวลาที่เหมาะสม
การทดลองที่ 1: "ความเร็วในการทำซ้ำ" (การเข้าถึงแคชของคำนำหน้า)
- ส่งพรอมต์ที่ซับซ้อนไปยังเอเจนต์ (เช่น "เขียนสคริปต์ Python เพื่อแยกวิเคราะห์ไฟล์ CSV ขนาด 100 MB และคำนวณสถิติ")
- เมื่อได้รับคำตอบแล้ว ให้ส่งพรอมต์เดียวกันอีกครั้งทันที
- สังเกตอัตราการเข้าถึงแคชของคำนำหน้าและเวลาจนกว่าจะได้รับโทเค็นแรก (TTFT)
- สิ่งที่คุณควรเห็น: อัตราการเข้าชมแคชของคำนำหน้าควรเพิ่มขึ้นเป็น 100% และ TTFT ควรลดลงอย่างมาก
- ความหมาย: GKE Inference Gateway รู้จักบริบทที่แชร์และกำหนดเส้นทางไปยังรีพลิก้าเดียวกัน ซึ่งใช้แคชบริบทที่ประเมินแล้วซ้ำ
การทดลองที่ 2: กลับไปใช้ระบบคลาวด์ (ความน่าเชื่อถือของโมเดล)
- หากต้องการจำลองความล้มเหลวของโมเดล Qwen ในเครื่อง คุณสามารถหยุดบริการอนุมานหรือเพียงแค่ระบุ
OPENAI_API_BASEที่ไม่ถูกต้องในการติดตั้งใช้งาน - อัปเดต
OPENAI_API_BASEในdeployment.yamlเป็น IP หรือพอร์ตที่ไม่มีอยู่จริง แล้วใช้การเปลี่ยนแปลงโดยทำดังนี้sed -i "s|value: \"http://$GATEWAY_IP/v1\"|value: \"http://10.0.0.1:8080/v1\"|g" ~/gke-ai-agent-lab/deployment.yaml kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml - รอให้พ็อดรีสตาร์ท แล้วส่งพรอมต์ไปยังตัวแทนใน UI
- สิ่งที่คุณควรเห็น: ตัวแทนยังคงตอบกลับได้สำเร็จ
- ความหมาย: เนื่องจาก
fallbacksการกำหนดค่า ADK จึงรับรู้ถึงความล้มเหลวของอุปกรณ์ปลายทาง Qwen ในเครื่อง และกำหนดเส้นทางคำขอไปยัง Gemini 2.5 Flash ใน Vertex AI ได้อย่างราบรื่น โปรดทราบว่าเนื่องจากการเรียกใช้สำรองเหล่านี้ไปยัง Vertex AI จะข้ามผ่านเกตเวย์การอนุมาน vLLM ในเครื่อง จึงจะไม่ปรากฏในแดชบอร์ดการสังเกตการณ์เอเจนต์ > โมเดล ซึ่งจะติดตามเฉพาะการรับส่งข้อมูลที่ผ่าน vLLM
ทำความเข้าใจประสิทธิภาพของการจัดสรรทรัพยากรแบบไดนามิก (DRA)
แม้ว่า vLLM และ Inference Gateway จะเพิ่มประสิทธิภาพวิธีกำหนดเส้นทางและให้บริการคำขอ แต่การจัดสรรทรัพยากรแบบไดนามิก (DRA) คือสิ่งที่ทำให้สามารถแนบฮาร์ดแวร์ที่เหมาะสมกับภาระงานของคุณได้อย่างแม่นยำตั้งแต่แรก
DRA ช่วยเพิ่มความสามารถในการจัดการฮาร์ดแวร์แบบละเอียดในคลัสเตอร์โดยให้คุณกำหนดทรัพยากรฮาร์ดแวร์ที่ยืดหยุ่นได้โดยใช้ ResourceClaimTemplate และ DeviceClasses
เหตุผลที่ DRA เป็นตัวเปลี่ยนเกมสำหรับภาระงาน AI
- คำขอฮาร์ดแวร์แบบละเอียด: DRA ไม่ได้เพียงแค่ช่วยให้มั่นใจว่าระบบจะจัดกำหนดการภาระงานในเครื่องที่มีตัวเร่งที่เหมาะสมเท่านั้น แต่ยังช่วยให้คุณอ้างสิทธิ์ในทรัพยากรเหล่านั้นเพื่อให้ภาระงานที่เชื่อมโยงกับ ResourceClaim ใช้ทรัพยากรดังกล่าวได้แต่เพียงผู้เดียว
- วงจรการใช้งานที่แยกจากกัน: ระบบจะจัดการการอ้างสิทธิ์อุปกรณ์โดยไม่ขึ้นกับวงจรการใช้งานของพ็อด หากพ็อดขัดข้อง การอ้างสิทธิ์ GPU จะยังคงอยู่เพื่อให้การติดตั้งใช้งานที่ครอบคลุมหรือออบเจ็กต์ภาระงานอื่นๆ สามารถรีสตาร์ทได้โดยไม่ต้องรอให้ระบบปล่อย GPU และรับ GPU อีกครั้ง
- การสร้างมาตรฐานแบบหลายผู้ให้บริการ: DRA มี Kubernetes API แบบรวมสำหรับทั้ง GPU ของ NVIDIA และ TPU ของ Google คุณใช้สคีมาเดียวกันทุกประการไม่ว่าจะติดตั้งใช้งานสำหรับอย่างใดอย่างหนึ่ง ทำให้ไฟล์ Manifest YAML ของเวิร์กโหลดมีความสามารถในการพกพาสูง
ใน Codelab นี้ คุณได้เห็นการทำงานของฟีเจอร์นี้เมื่อกำหนดค่า Helm เพื่อผูกกับ gpu-claim-template ได้อย่างราบรื่น โดยไม่ต้องมีการกำหนดค่าปลั๊กอินอุปกรณ์ที่ค้างอยู่ซึ่งจะบล็อกการเปิดตัว
ทำความเข้าใจบทบาทของ llm-d
ขณะที่ vLLM ประเมินน้ำหนักของโครงข่ายประสาทและ GKE Gateway จะกำหนดเส้นทางการค้นหา llm-d จะทำหน้าที่เป็นเลเยอร์การกำหนดค่าและ "กาว" ที่เชื่อมโยงทุกอย่างเข้าด้วยกัน
หากไม่มี llm-d คุณจะต้องเขียนไฟล์ Manifest ของ Kubernetes ดิบเพื่อประกาศการทำให้ใช้งานได้ของ vLLM พอร์ตบริการ การติดตั้งโวลุ่ม และการอ้างสิทธิ์ทรัพยากร DRA ตั้งแต่ต้น
เหตุผลที่ควรใช้ llm-d ในการติดตั้งใช้งาน
- การกำหนดค่าแบบรวม (การลบล้างแบบบรรทัดเดียว):
llm-dแผนภูมิ Helm จะรวมทรัพยากร Kubernetes ที่ซับซ้อนระดับล่างไว้ในปุ่มเปิด/ปิดระดับสูงที่สะอาดตา (เช่น การตั้งค่าaccelerator.dra: true) - "เส้นทางที่สว่าง" ที่ผ่านการคัดกรองเบื้องต้น: ที่เก็บ
llm-dมีการกำหนดค่าที่ผู้เชี่ยวชาญได้เปรียบเทียบและทดสอบแล้ว เมื่อคุณติดตั้งใช้งานllm-d-modelserviceคุณจะได้รับการตั้งค่าเริ่มต้นที่เพิ่มประสิทธิภาพสำหรับการใช้หน่วยความจำ GPU, เวลาในการตรวจสอบที่แนะนำ (ความพร้อมใช้งาน/ความพร้อม) และการเปิดเผยที่ถูกต้องสำหรับการขูดเมตริก - การแมปความสามารถในการสังเกตที่ราบรื่น:
llm-dช่วยให้มั่นใจได้ว่าพอร์ตคอนเทนเนอร์มาตรฐานและเส้นทางการขูด (/metrics) จะแสดงอย่างถูกต้อง ทำให้เชื่อมต่อการทำให้ใช้งานได้กับ Google Cloud Monitoring ได้ง่ายโดยไม่ต้องแก้ไขข้อบกพร่องด้วยตนเอง
กล่าวโดยย่อคือ llm-d มีพิมพ์เขียวสถาปัตยกรรมที่นำกลับมาใช้ใหม่ได้ เพื่อให้นักพัฒนาไม่ต้องเริ่มทุกอย่างจากก้าวแรกทุกครั้งที่ติดตั้งใช้งานสแต็กการอนุมานใน GKE
เจาะลึก: เกตเวย์การอนุมานของ GKE
ตัวจัดสรรภาระงานเลเยอร์ 7 มาตรฐานจะทำงานโดยดูที่ส่วนหัว HTTP เช่น เส้นทาง (/v1/completions) หรือคุกกี้ GKE Inference Gateway มีความสามารถที่ลึกซึ้งกว่ามาก โดยออกแบบมาสําหรับการรับส่งข้อมูลของ Generative AI โดยเฉพาะ
วิธีกระตุ้นให้เกิดประสิทธิภาพและประสิทธิผล
- การกำหนดเส้นทางตามเนื้อหา (การแฮชพรอมต์): GKE Inference Gateway จะสกัดกั้นเนื้อหาคำขอ JSON โดยจะคำนวณแฮชของพรอมต์และติดตามว่ารีพลิกาแบ็กเอนด์ใดมีโทเค็นเหล่านั้นอยู่ในหน่วยความจำ GPU (แคช KV) อยู่แล้ว
- เพิ่มจำนวนการเข้าชมแคชสูงสุด: ในการทดสอบ เมื่อคุณป้อนพรอมต์ซ้ำ Gateway จะส่งพรอมต์ไปยังรีพลิก้าเดียวกัน การประเมินพรอมต์ต้องใช้การประมวลผลอย่างหนัก การใช้แคชซ้ำจะช่วยให้คุณไม่ต้อง "อ่าน" พรอมต์อีกครั้ง ซึ่งจะช่วยประหยัดเงินและเวลา GPU
- ลดเวลาในการแสดงผลไบต์แรก (TTFT): TTFT เป็นเมตริกความสามารถในการใช้งานที่สำคัญสำหรับตัวแทนที่ให้บริการแก่ผู้ใช้ การเข้าถึงแคชจะช่วยให้โมเดลเริ่มสร้างโทเค็นได้ในหน่วยมิลลิวินาทีแทนที่จะเป็นวินาที
- การกระจายโหลดอัจฉริยะ: หาก VRAM ของรีพลิคาหนึ่งเต็มไปด้วยแคชฮิตทั้งหมด เกตเวย์จะกำหนดเส้นทางพรอมต์ใหม่ไปยังรีพลิคาอื่นที่มีพื้นที่ว่างแบบไดนามิก เพื่อรักษาสมดุลระหว่างประสิทธิภาพและความพร้อมใช้งาน
วิธีที่ Agent Sandbox ช่วยลดความเสี่ยง
ในแล็บนี้ เราได้สาธิตวิธีที่Agent Sandboxปกป้องโครงสร้างพื้นฐานของคุณจากความเสี่ยงที่เกี่ยวข้องกับ AI Agent โดยการจัดเลเยอร์การแยก 2 ชั้น ดังนี้
- การแยกเครื่องมือเรียกใช้: เอเจนต์จะเรียกใช้โค้ดที่สร้างขึ้นในแซนด์บ็อกซ์ชั่วคราว วิธีนี้ช่วยให้มั่นใจได้ว่าโค้ดที่ไม่น่าเชื่อถือซึ่ง LLM สร้างขึ้นจะทำงานในสภาพแวดล้อมที่ปลอดภัยและแยกต่างหาก ซึ่งจะปกป้องเอเจนต์และคลัสเตอร์
- การเริ่มต้นอย่างรวดเร็ว: การใช้ WarmPool ทำให้แซนด์บ็อกซ์ใหม่เริ่มต้นได้ภายในไม่ถึง 1 วินาที พร้อมที่จะรันโค้ด
- การแยกเอเจนต์เอง: เรายังเรียกใช้แอปพลิเคชันเอเจนต์ในโหนดที่เปิดใช้ gVisor (ผ่าน
runtimeClassName: gvisor) เพื่อให้การป้องกันแบบหลายชั้นต่อช่องโหว่ในซัพพลายเชนในทรัพยากร Dependency ของเอเจนต์ด้วย
เหตุผลที่การดำเนินการนี้สร้างขอบเขตความปลอดภัยที่แข็งแกร่งมีดังนี้
- การดักจับการเรียกใช้ระบบ: gVisor จะดักจับการเรียกใช้ระบบก่อนที่จะไปถึงเคอร์เนล Linux ของโฮสต์ ซึ่งจะบล็อกการโจมตีที่พยายามหลุดออกจากคอนเทนเนอร์เพื่อเข้าถึงโหนดโฮสต์
- การเคลื่อนที่ด้านข้างที่จำกัด: เมื่อใช้ร่วมกับนโยบายเครือข่าย แม้ว่าสภาพแวดล้อมจะถูกบุกรุก แต่ก็จะไม่สามารถสแกนเซิร์ฟเวอร์ข้อมูลเมตาภายในหรือเปลี่ยนไปใช้บริการอื่นๆ ที่มีความละเอียดอ่อนในคลัสเตอร์ได้
การเรียกใช้ Agent แบบเต็มในแซนด์บ็อกซ์
ในแล็บนี้ เราใช้แซนด์บ็อกซ์เป็นเครื่องมือสำหรับแอปพลิเคชันตัวแทนแบบถาวร อย่างไรก็ตาม เพื่อความปลอดภัยสูงสุด โดยเฉพาะอย่างยิ่งเมื่อจัดการข้อมูลที่ละเอียดอ่อนหรือให้บริการผู้ใช้ที่ไม่น่าเชื่อถือหลายราย คุณสามารถเรียกใช้แอปพลิเคชันตัวแทนทั้งหมดภายในแซนด์บ็อกซ์เฉพาะสำหรับแต่ละเซสชันหรือผู้ใช้ ซึ่งจะช่วยให้มั่นใจได้ว่าหน่วยความจำ สถานะ และสภาพแวดล้อมการดำเนินการของเอเจนต์จะแยกออกจากกันอย่างสมบูรณ์ และระบบจะทำลายสภาพแวดล้อมดังกล่าวทันทีหลังจากเซสชันเสร็จสมบูรณ์
9. ล้างข้อมูล
โปรดทำตามขั้นตอนต่อไปนี้เพื่อลบทรัพยากรดังกล่าวเพื่อเลี่ยงไม่ให้เกิดการเรียกเก็บเงินกับบัญชี Google Cloud สำหรับทรัพยากรที่ใช้ในโค้ดแล็บนี้
ลบทรัพยากรแต่ละรายการ
- ลบคลัสเตอร์ GKE
gcloud container clusters delete $CLUSTER_NAME --zone $ZONE --quiet
- ลบที่เก็บ Artifact Registry
gcloud artifacts repositories delete agent-repo --location=us-central1 --quiet
- ลบเครือข่าย VPC
gcloud compute networks delete ai-agent-network --quiet
ลบโปรเจ็กต์
หากไม่ต้องการใช้โปรเจ็กต์อีกต่อไป คุณสามารถลบโปรเจ็กต์ได้หลังจากนำทรัพยากรออกแล้ว โดยทำดังนี้
gcloud projects delete $PROJECT_ID
10. สรุป
ยินดีด้วย คุณสร้างและติดตั้งใช้งานเอเจนต์การสร้างโค้ดที่มีประสิทธิภาพสูงและปลอดภัยใน GKE เรียบร้อยแล้ว
สิ่งที่คุณได้เรียนรู้
- วิธีกำหนดค่าและใช้การจัดสรรทรัพยากรแบบไดนามิก (DRA) ใน GKE เพื่อจัดการทรัพยากร GPU
- วิธีใช้ GKE Inference Gateway เพื่อเพิ่มประสิทธิภาพการแสดงผล LLM ผ่านการกำหนดเส้นทางที่รับรู้แคชคำนำหน้า
- วิธีใช้แซนด์บ็อกซ์ของ Agent (gVisor) เพื่อเรียกใช้โค้ดที่ไม่น่าเชื่อถืออย่างปลอดภัยใน GKE
- วิธีใช้ Google Cloud Managed Service for Prometheus เพื่อตรวจสอบประสิทธิภาพของ vLLM
- วิธีกำหนดค่าและดูAgent Observability โดยใช้ ADK และ OpenTelemetry ที่มีการจัดการของ GKE
ขั้นตอนถัดไปและข้อมูลอ้างอิง
- Agent Sandbox: ดูข้อมูลเกี่ยวกับ Agent Sandbox ใน GKE และ Pod ของ GKE Sandbox
- llm-d: อ่านคู่มือ llm-d และดูที่เก็บ llm-d ใน GitHub
- การจัดสรรทรัพยากรแบบไดนามิก: ดูข้อมูลเกี่ยวกับ DRA ใน GKE
- GKE Inference Gateway: ดูแนวคิดเกี่ยวกับ Inference Gateway
- Codelabs เพิ่มเติม: ดูบทแนะนำเพิ่มเติมได้ที่ Google Cloud Codelabs