
1. Giriş
Genel Bakış
Bu laboratuvarda, Google Kubernetes Engine (GKE) üzerinde güvenli bir kod oluşturma aracısı oluşturmayı ve dağıtmayı öğreneceksiniz. Kod oluşturma aracıları, güvenilmeyen kodları çalıştırabilir. Bu nedenle güvenli bir sanal alan ortamı gerekir. Ayrıca, GKE'de kendi kendine barındırılan açık bir modelden Vertex AI'ın yönetilen Gemini hizmetine geri dönmesine olanak tanıyan hibrit model stratejisiyle aracıyı nasıl yapılandıracağınızı da öğreneceksiniz. Ayrıca, GKE Inference Gateway ve Dinamik Kaynak Ayırma (DRA) kullanarak çıkarım sunumunu nasıl optimize edeceğinizi de öğreneceksiniz. Son olarak, Managed Prometheus'u kullanarak çıkarım yığınınızı izlemek için Google Cloud Observability'den nasıl yararlanacağınızı öğreneceksiniz.
Mimari
Oluşturacağınız sistemin mimarisi:
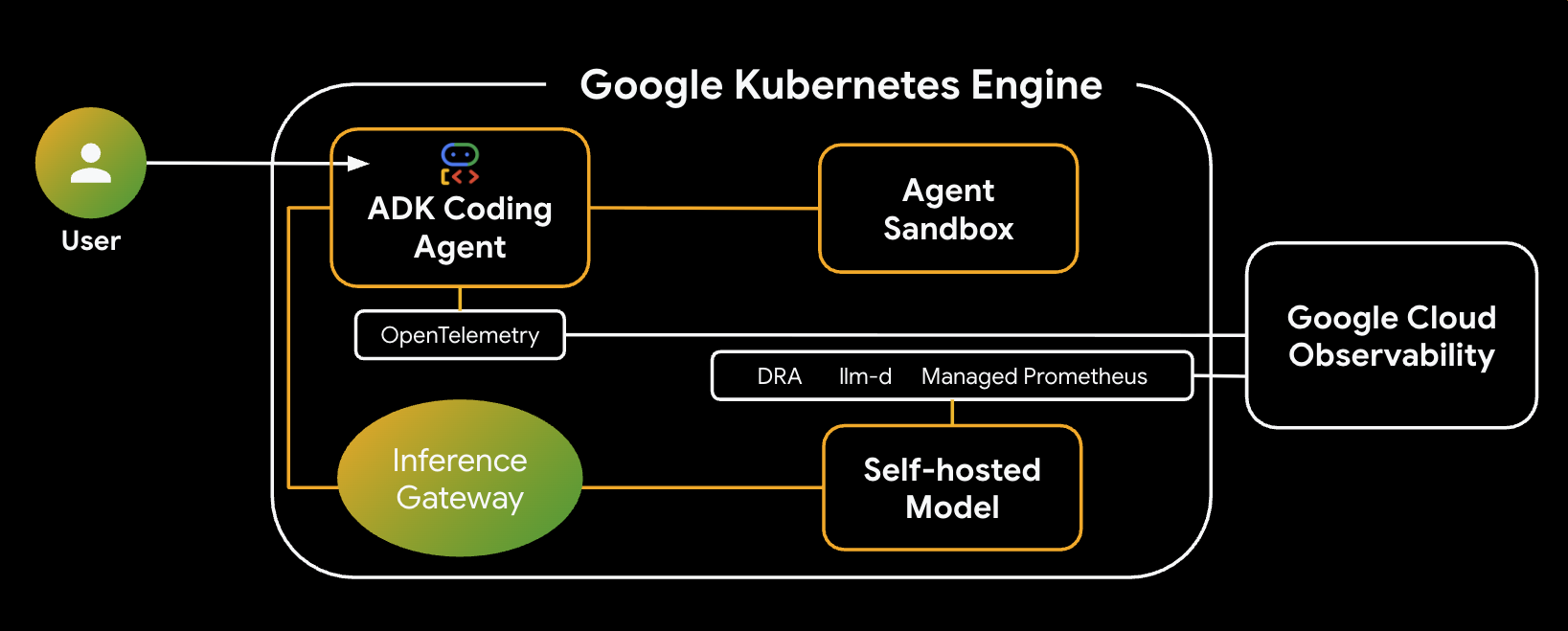
Temel Bileşenler ve Avantajlar
- Dinamik Kaynak Ayırma (DRA): Bu laboratuvarda, model sunucusu Pod'ları için belirli GPU kaynaklarını (NVIDIA L4'ler) dinamik olarak talep etmek ve ayırmak için kullanılır. Bu sayede çıkarım iş yükümüz için hassas donanım hedefleme sağlanır. GKE'de DRA hakkında bilgi edinin.
- llm-d ve vLLM: Qwen modelini dağıtmak için model sunma çerçevesini ve Helm grafiklerini sağlar. Bu laboratuvarda çıkarım isteklerini işler ve kaynak yönetimi için DRA ile entegre olur (bu laboratuvarda ayrıştırılmış sunum etkin değildir). llm-d Kılavuzu'nu okuyun ve llm-d GitHub deposuna göz atın.
- GKE Inference Gateway: Yapay zeka destekli yönlendirme mantığını doğrudan yük dengeleyiciye taşır. Bu laboratuvarda, istekler ön ek önbellek isabetlerini en üst düzeye çıkaracak şekilde yönlendirilir ve İlk Jeton Süresi (TTFT) gecikmesi azaltılır. Inference Gateway kavramlarını keşfedin.
- Agent Sandbox (gVisor): Yapay zeka ajanı tarafından oluşturulan kodu yürütmek için güvenli izolasyon sağlar. Derin çekirdek yalıtımı sağlamak için gVisor'u kullanarak ana makine düğümünü güvenilmeyen iş yüklerinden korur. GKE'de Agent Sandbox ve GKE Sandbox Pod'ları hakkında bilgi edinin.
Yapacaklarınız
- Altyapı sağlama: GPU yönetimi için dinamik kaynak ayırma (DRA) özelliğini kullanarak bir GKE kümesi oluşturun.
- Çıkarım Yığınını Dağıtma: Akıllı çıkarım planlamasıyla
llm-dve vLLM'yi dağıtın. - Akıllı Yönlendirmeyi Yapılandırma: Önek önbelleği kullanan yönlendirme için GKE Inference Gateway'i kullanın.
- Güvenli Kod Yürütme: Yapay zeka tarafından üretilen kodu güvenli bir şekilde çalıştırmak için Agent Sandbox'ı (gVisor) dağıtın.
- Gözlemleme ve Doğrulama: Model sunma metriklerini görüntülemek için Google Cloud Monitoring ve Managed Prometheus'u kullanın.
Neler öğreneceksiniz?
- GKE'de Dinamik Kaynak Ayırma'yı (DRA) yapılandırma ve kullanma
- LLM yayınlama performansını optimize etmek için GKE Inference Gateway'i kullanma
- GKE'de güvenilmeyen kodu güvenli bir şekilde yürütmek için Agent Sandbox'ı kullanma
- vLLM performansını izlemek için Google Cloud Managed Service for Prometheus'u kullanma
2. Kurulum ve Gereksinimler
Proje Ayarları
Google Cloud projesi oluşturma
- Google Cloud Console'daki proje seçici sayfasında bir Google Cloud projesi seçin veya oluşturun.
- Cloud projeniz için faturalandırmanın etkinleştirildiğinden emin olun. Bir projede faturalandırmanın etkin olup olmadığını kontrol etmeyi öğrenin.
Cloud Shell'i Başlatma
Cloud Shell, Google Cloud'da çalışan ve gerekli araçların önceden yüklendiği bir komut satırı ortamıdır.
- Google Cloud Console'un üst kısmından Cloud Shell'i etkinleştir'i tıklayın.
- Cloud Shell'e bağlandıktan sonra kimlik doğrulamanızı onaylayın:
gcloud auth list - Projenizin yapılandırıldığını onaylayın:
gcloud config get project - Projeniz beklendiği gibi ayarlanmamışsa şu şekilde ayarlayın:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
3. Altyapı sağlama ve dinamik kaynak ayırma (DRA)
Bu ilk adımda, GKE kümenizi eski cihaz eklentileri yerine modern hızlandırıcı ayırma (DRA) kullanacak şekilde yapılandıracaksınız. Bu sayede, kod oluşturma iş yükleriniz için GPU'ları veya TPU'ları esnek bir şekilde paylaşabilir ve tahsis edebilirsiniz.
Ön koşullar: DRA'yı desteklemek için GKE Standard kümenizin 1.34 veya sonraki bir sürümde çalışması gerekir.
Google Cloud API'lerini etkinleştirin
Bu codelab için gerekli olan Google Cloud API'lerini (özellikle Compute Engine ve Kubernetes Engine API'leri) etkinleştirin.
gcloud services enable compute.googleapis.com container.googleapis.com networkservices.googleapis.com cloudbuild.googleapis.com artifactregistry.googleapis.com telemetry.googleapis.com cloudtrace.googleapis.com aiplatform.googleapis.com
Ortam değişkenlerini ayarlama
Kurulumu kolaylaştırmak için ortam değişkenlerinizi tanımlayın. Bölgeyi veya adlandırma kurallarını gerektiği gibi ayarlayabilirsiniz.
export PROJECT_ID=$(gcloud config get-value project)
export ZONE=us-central1-a
export CLUSTER_NAME=ai-agent-cluster
export NODEPOOL_NAME=dra-accelerator-pool
gcloud config set project $PROJECT_ID
gcloud config set compute/region $ZONE
Çalışma dizini oluşturma
Bu laboratuvar için özel bir çalışma dizini oluşturun ve dosyalarınızın düzenli kalması için bu dizine gidin:
mkdir -p ~/gke-ai-agent-lab
cd ~/gke-ai-agent-lab
İzinleri yapılandırma (isteğe bağlı)
Kısıtlanmış bir proje veya paylaşılan ortamda çalışıyorsanız hesabınızın küme oluşturmak ve derleme çalıştırmak için gerekli izinlere sahip olduğundan emin olun:
export MY_ACCOUNT=$(gcloud config get-value account)
# Grant Container Admin to create clusters and manage nodes if needed
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/container.admin"
# Grant Cloud Build Builder to run builds
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/cloudbuild.builds.builder"
GKE kümesini oluşturma
DRA'yı desteklemek için GKE Standard kümenizin 1.34 veya sonraki bir sürümde çalışması gerekir. Akıllı çıkarım planlamayı desteklemek için Gateway API denetleyicilerini de etkinleştirmeniz gerekir.
Bu laboratuvar için yeni bir VPC ağı ve alt ağlar oluşturacaksınız.
Öncelikle VPC ağını oluşturun:
gcloud compute networks create ai-agent-network --subnet-mode=custom
Ardından, GKE düğümleriniz için bir alt ağ oluşturun:
gcloud compute networks subnets create ai-agent-subnet \
--network=ai-agent-network \
--range=10.0.0.0/20 \
--region=us-central1
Gateway API (gke-l7-regional-internal-managed) için de Envoy proxy'lerini barındırmak üzere özel bir alt ağ gerekir. Yeni ağınızda şu yalnızca proxy alt ağını oluşturun:
gcloud compute networks subnets create proxy-only-subnet \
--purpose=REGIONAL_MANAGED_PROXY \
--role=ACTIVE \
--region=us-central1 \
--network=ai-agent-network \
--range=192.168.10.0/24
Şimdi yeni ağı ve alt ağı kullanarak kümeyi oluşturun:
gcloud beta container clusters create $CLUSTER_NAME \
--zone $ZONE \
--num-nodes 1 \
--machine-type n2-standard-4 \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--gateway-api=standard \
--managed-otel-scope=COLLECTION_AND_INSTRUMENTATION_COMPONENTS \
--network=ai-agent-network \
--subnetwork=ai-agent-subnet
Varsayılan Eklentilerin Devre Dışı Bırakıldığı Bir Düğüm Havuzu Oluşturma
Cihaz yönetimini DRA'ya devretmek için varsayılan GPU sürücüsü yüklemesini ve standart cihaz eklentisini açıkça devre dışı bırakan bir düğüm havuzu oluşturmanız gerekir.
Gerekli DRA etiketleriyle bir GPU düğüm havuzu (ör. NVIDIA L4'ler kullanılarak) sağlamak için aşağıdaki gcloud komutunu çalıştırın:
gcloud container node-pools create $NODEPOOL_NAME \
--cluster=$CLUSTER_NAME \
--location=$ZONE \
--machine-type=g2-standard-24 \
--accelerator=type=nvidia-l4,count=2,gpu-driver-version=disabled \
--node-labels=gke-no-default-nvidia-gpu-device-plugin=true,nvidia.com/gpu.present=true \
--num-nodes 3
NVIDIA sürücülerini DaemonSet aracılığıyla yükleme
Önceden yapılandırılmış bir Google Cloud DaemonSet kullanarak gerekli temel NVIDIA cihaz sürücülerini düğümlerinize manuel olarak yükleyin:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
DRA sürücüsünü yükleme
Ardından, kümenize özel DRA sürücüsünü yükleyin. NVIDIA GPU'lar için bunu Helm aracılığıyla dağıtabilirsiniz:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
helm install nvidia-dra-driver-gpu nvidia/nvidia-dra-driver-gpu \
--version="25.3.2" --create-namespace --namespace=nvidia-dra-driver-gpu \
--set nvidiaDriverRoot="/home/kubernetes/bin/nvidia/" \
--set gpuResourcesEnabledOverride=true \
--set resources.computeDomains.enabled=false \
--set kubeletPlugin.priorityClassName="" \
--set 'kubeletPlugin.tolerations[0].key=nvidia.com/gpu' \
--set 'kubeletPlugin.tolerations[0].operator=Exists' \
--set 'kubeletPlugin.tolerations[0].effect=NoSchedule'
DeviceClasses'ı anlama
DeviceClass YAML'yi manuel olarak yazmanız veya uygulamanız gerekmez. DRA için GKE altyapınızı ayarlayıp sürücüyü yüklediğinizde, düğümlerinizde çalışan DRA sürücüleri kümede sizin için otomatik olarak DeviceClass nesneleri oluşturur.
ResourceClaimTemplate'i yapılandırın
llm-d Pod'larınızın bu hızlandırıcıları dinamik olarak istemesine izin vermek için ResourceClaimTemplate oluşturursunuz. Bu şablon, istenen cihaz yapılandırmasını tanımlar ve Kubernetes'e iş yükleriniz için kapsül başına benzersiz bir ResourceClaim otomatik olarak oluşturmasını söyler.
claim-template.yaml oluşturmak için aşağıdaki komutu çalıştırın:
cat > claim-template.yaml <<EOF
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: gpu-claim-template
spec:
spec:
devices:
requests:
- name: single-gpu
exactly:
deviceClassName: gpu.nvidia.com
allocationMode: ExactCount
count: 1
EOF
Şablonu kümenize uygulayın:
kubectl apply -f claim-template.yaml
4. llm-d ve DRA ile Akıllı Çıkarım Planlaması'nı dağıtma
Bu adımda, büyük dil modelinizi çıkarım planlayıcıyla geliştirilmiş akıllı bir Envoy yük dengeleyicisinin arkasına dağıtacaksınız. Bu yapılandırma, önek önbelleği duyarlı yönlendirme uygulayarak model sunumunu optimize eder. GKE Inference Gateway, mikro hizmetler arasındaki paylaşılan bağlamı tanır ve istekleri aynı model replikasına akıllıca yönlendirerek önbellek isabetlerini en üst düzeye çıkarır, ilk jetona kadar geçen süreyi kısaltır ve dolar başına daha iyi performans sağlar.
Ortamı hazırlama
Hedef ad alanınızı ayarlayın.
export NAMESPACE=ai-agents
kubectl create namespace $NAMESPACE
Model ağırlıklarını çekmek için gereken Hugging Face jetonunuzu güvenli bir şekilde saklayın.
# Replace with your actual Hugging Face token
kubectl create secret generic llm-d-hf-token \
--from-literal=HF_TOKEN="your_hugging_face_token" \
-n $NAMESPACE
Helm yapılandırma dosyalarını oluşturma
Model hizmeti ve çıkarım ağ geçidi uzantısının yapılandırmaları, resmi llm-d kılavuzlarına dayanmaktadır.
İlk olarak, model hizmeti için ms-values.yaml dosyasını oluşturun:
cat <<EOF > ms-values.yaml
multinode: false
modelArtifacts:
uri: "hf://Qwen/Qwen2.5-Coder-14B-Instruct"
name: "Qwen/Qwen2.5-Coder-14B-Instruct"
size: 50Gi # Slightly larger than the default to accommodate weights
authSecretName: "llm-d-hf-token"
labels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
llm-d.ai/accelerator-variant: "gpu"
llm-d.ai/accelerator-vendor: "nvidia"
llm-d.ai/model: "qwen-2-5-coder-14b"
routing:
proxy:
enabled: false # removes sidecar from deployment - no PD in inference scheduling
targetPort: 8000 # controls vLLM port to matchup with sidecar if deployed
accelerator:
dra: true
type: "nvidia"
resourceClaimTemplates:
nvidia:
class: "gpu.nvidia.com"
match: "exactly"
name: "gpu-claim-template"
decode:
create: true
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
parallelism:
tensor: 2
data: 1
replicas: 3
monitoring:
podmonitor:
enabled: true
portName: "vllm"
path: "/metrics"
interval: "30s"
containers:
- name: "vllm"
image: ghcr.io/llm-d/llm-d-cuda:v0.5.1
modelCommand: vllmServe
args:
- "--disable-uvicorn-access-log"
- "--gpu-memory-utilization=0.85"
- "--enable-auto-tool-choice"
- "--tool-call-parser"
- "hermes"
ports:
- containerPort: 8000
name: vllm
protocol: TCP
resources:
limits:
cpu: '16'
memory: 64Gi
requests:
cpu: '16'
memory: 64Gi
mountModelVolume: true
volumeMounts:
- name: metrics-volume
mountPath: /.config
- name: shm
mountPath: /dev/shm
- name: torch-compile-cache
mountPath: /.cache
startupProbe:
httpGet:
path: /v1/models
port: vllm
initialDelaySeconds: 15
periodSeconds: 30
timeoutSeconds: 5
failureThreshold: 120
livenessProbe:
httpGet:
path: /health
port: vllm
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /v1/models
port: vllm
periodSeconds: 5
timeoutSeconds: 2
failureThreshold: 3
volumes:
- name: metrics-volume
emptyDir: {}
- name: torch-compile-cache
emptyDir: {}
- name: shm
emptyDir:
medium: Memory
sizeLimit: 20Gi
prefill:
create: false
EOF
Ardından, GKE Inference Gateway uzantısı için gaie-values.yaml dosyasını oluşturun:
cat <<EOF > gaie-values.yaml
inferenceExtension:
replicas: 1
image:
name: llm-d-inference-scheduler
hub: ghcr.io/llm-d
tag: v0.6.0
pullPolicy: Always
extProcPort: 9002
pluginsConfigFile: "default-plugins.yaml"
tracing:
enabled: false
monitoring:
interval: "10s"
prometheus:
enabled: true
auth:
secretName: inference-scheduling-gateway-sa-metrics-reader-secret
inferencePool:
targetPorts:
- number: 8000
modelServerType: vllm
modelServers:
matchLabels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
EOF
Yapılandırmayı Anlama
Bu yapılandırma, aşağıdaki temel özelliklere sahip yüksek performanslı bir çıkarım yığını oluşturur:
- Model Seçimi: Kod oluşturma ve araç kullanımı için optimize edilmiş Qwen 2.5 Coder 14B modelini (
modelArtifacts) kullanır. - DRA entegrasyonu:
acceleratorbölümü,gpu.nvidia.comcihaz sınıfını ve daha önce oluşturduğumuzgpu-claim-template'ı hedefleyerek dinamik kaynak ayırmayı (dra: true) etkinleştirir. - Performans Optimizasyonu:
parallelism.tensor: 2, GPU'lar arasında tensör paralelliğini yapılandırır.argsfor vLLM, kodlama aracımızın araçları etkili bir şekilde kullanabilmesini sağlamak için--enable-auto-tool-choiceiçerir.- Azaltılmış
cpuvememoryistekleri,g2-standard-24makine türüne uygundur.
- Akıllı yönlendirme: Inference Gateway uzantısı (
gaie-values.yaml),vllmmodel sunucularını izleyecek ve KV önbellek isabetlerini en üst düzeye çıkarmak için istekleri yönlendirecek şekilde yapılandırılır.
Helm aracılığıyla çıkarım planlama yığınını dağıtma
Şimdi llm-d Helm depolarını ekleyin ve altyapıyı, ağ geçidi uzantısını ve model hizmetini ayrı ayrı dağıtın.
Öncelikle gerekli depoları ekleyin:
helm repo add llm-d-infra https://llm-d-incubation.github.io/llm-d-infra/
helm repo add llm-d-modelservice https://llm-d-incubation.github.io/llm-d-modelservice/
helm repo update
Altyapı Ön Koşullarını Dağıtma
Bu grafik, yığın için gereken temel ağ geçidi yapılandırmalarını yükler.
helm install infra-is llm-d-infra/llm-d-infra \
--namespace $NAMESPACE \
--set gateway.gatewayClassName=gke-l7-rilb \
--set gateway.gatewayParameters.enabled=false \
--set gateway.gatewayParameters.istio.accessLogging=false
GKE Inference Gateway uzantısını dağıtma
Bu adımda, akıllı yönlendirme kararları vermek için modellerinizin KV önbelleğini izleyen InferencePool ve Endpoint Picker dağıtılır.
helm install gaie-is oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool \
--version v1.3.1 \
--namespace $NAMESPACE \
-f gaie-values.yaml \
--set provider.name=gke \
--set inferenceExtension.monitoring.prometheus.enabled=true
Model hizmetini dağıtma
Son olarak, artık L4 GPU'larınızı güvenli bir şekilde talep etmek için DRA'yı kullanacak olan LLM hizmetinizi dağıtın.
helm install ms-is llm-d-modelservice/llm-d-modelservice \
--version v0.4.7 \
--namespace $NAMESPACE \
-f ms-values.yaml \
--set decode.monitoring.podmonitor.enabled=false
vLLM için Google Cloud Gözlemlenebilirliği'ni etkinleştirme
Genel Helm grafikleri genellikle standart Prometheus Operator PodMonitor kaynaklarını (monitoring.coreos.com/v1) dağıtmaya çalışır. Bu da söz konusu CRD'ler yüklü değilse hatalara neden olabilir.
Helm'in yerleşik izleme açma/kapatma düğmesini kullanmak yerine düğmeyi false konumunda tutun ve uyumlu monitoring.googleapis.com/v1 API grubunu kullanarak Google Cloud Managed Prometheus (GMP) PodMonitoring kaynağını manuel olarak uygulayın.
podmonitoring.yaml oluşturmak için aşağıdaki komutu çalıştırın:
cat > podmonitoring.yaml <<EOF
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: ms-vllm-metrics
spec:
selector:
matchLabels:
llm-d.ai/model: "qwen-2-5-coder-14b" # Matches the label in values.yaml
endpoints:
- port: 8000 # vllm port
interval: 30s
path: /metrics
EOF
PodMonitoring kaynağını kümenize uygulayın:
kubectl apply -f podmonitoring.yaml -n $NAMESPACE
Kurulumu doğrulama
Bileşenlerin başarıyla yüklendiğini doğrulayın. Ad alanınızda etkin olan üç Helm sürümünü ve başlatılan ilgili kapsülleri görmeniz gerekir.
helm ls -n $NAMESPACE
kubectl get pods -n $NAMESPACE
ms-is pod'larının başlatılması yaklaşık 5-10 dakika sürebilir. Bu durumda çıkış şöyle görünür:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
gaie-is ai-agents 1 2026-03-28 16:51:41.055881618 +0000 UTC deployed inferencepool-v1.3.1 v1.3.1
infra-is ai-agents 1 2026-03-28 16:51:03.71042542 +0000 UTC deployed llm-d-infra-v1.4.0 v0.4.0
ms-is ai-agents 1 2026-03-28 17:30:00.341918958 +0000 UTC deployed llm-d-modelservice-v0.4.7 v0.4.0
NAME READY STATUS RESTARTS AGE
gaie-is-epp-848965cb4-78ktp 1/1 Running 0 10m
ms-is-llm-d-modelservice-decode-67548d5f8c-f25f4 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-rblvs 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-w6fcd 1/1 Running 0 6m2s
5. GKE Inference Gateway ile Akıllı Yönlendirme'yi yapılandırma
4. adımda, llm-d Helm grafikleri dağıtıldığında Gateway ve InferencePool nesneleriniz otomatik olarak sağlanmıştı. InferencePool, aynı temel modeli ve işlem yapılandırmasını paylaşan vllm model sunma pod'larınızı gruplandırır.
Artık kodlama aracısı isteklerinizin önceliğini ayarlamak için bir InferenceObjective ve gelen trafiği nasıl yönlendireceği konusunda Ağ Geçidi'ne talimat vermek için bir HTTPRoute yapılandırmanız gerekir. Bu işlemde, KV önbellek isabetlerini en üst düzeye çıkarmak için Uç Nokta Seçici kullanılır.
Otomatik olarak oluşturulmuş kaynakları doğrulama
Öncelikle, llm-d Helm grafiklerinin Gateway ve InferencePool kaynaklarını başarıyla oluşturduğunu doğrulayın.
kubectl get gateway,inferencepool -n $NAMESPACE
infra-is-inference-gateway adlı bir ağ geçidi ve gaie-is adlı bir çıkarım havuzu görmeniz gerekir. Şuna benzer:
NAME CLASS ADDRESS PROGRAMMED AGE
gateway.gateway.networking.k8s.io/infra-is-inference-gateway gke-l7-regional-internal-managed 10.128.0.5 True 13m
NAME AGE
inferencepool.inference.networking.k8s.io/gaie-is 12m
HTTPRoute'u oluşturma
HTTPRoute kaynağı, ağ geçidinizi arka uca eşler InferencePool. Bu, GKE Çıkarım Ağ Geçidi'ne gelen istek gövdelerini analiz etmesini ve bunları dinamik olarak yönlendirerek paylaşılan bağlama göre Önek-Önbellek isabetlerini en üst düzeye çıkarmasını söyler.
httproute.yaml oluşturmak için aşağıdaki komutu çalıştırın:
cat > httproute.yaml <<EOF
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: agent-route
spec:
parentRefs:
- group: gateway.networking.k8s.io
kind: Gateway
name: infra-is-inference-gateway
rules:
- backendRefs:
- group: inference.networking.k8s.io
kind: InferencePool
name: gaie-is
weight: 1
matches:
- path:
type: PathPrefix
value: /
EOF
Rotayı kümenize uygulayın:
kubectl apply -f httproute.yaml -n $NAMESPACE
6. Agent Sandbox ile güvenli kod yürütme
Yüksek performanslı çıkarım arka ucumuz çalıştığına göre, yapay zeka tarafından üretilen kodun bir Agent Sandbox kullanarak kümemizden güvenli bir şekilde yalıtılmış olarak yürütüleceği güvenli ortamı hazırlayalım.
Aracı Korumalı Alan Denetleyicisini dağıtma
Bir yapay zeka aracısı kod oluşturup yürüttüğünde, altyapınızda güvenilmeyen bir iş yükü çalıştırıyor demektir. Aracı kötü amaçlı kod oluşturursa dahili ağınızı taramaya veya temel alınan ana makine düğümünden yararlanmaya çalışabilir.
GKE Agent Sandbox, her container için özel bir konuk çekirdeği sağlayan açık kaynaklı bir container çalışma zamanı olan gVisor'u kullanır. Bu, güvenilmeyen kodun ana makine düğümüne doğrudan sistem çağrıları yapmasını engeller.
Resmi yayın manifestlerini uygulayarak Agent Sandbox denetleyicisini ve gerekli bileşenlerini dağıtın:
kubectl apply \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/manifest.yaml \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/extensions.yaml
Sandbox şablonunu ve Warm Pool'u yapılandırma
Ardından, Python analiz ortamlarımız için yeniden kullanılabilir bir plan görevi gören bir SandboxTemplate oluşturuyoruz. Bu SandboxTemplate, gvisor çalışma zamanı sınıfını açıkça hedefliyor. Standart kümelerde manuel düğüm havuzlarını yönetmeden dağıtımı basitleştirmek için herhangi bir standart autopilot kullanabiliriz.
İsteğe bağlı olarak gVisor iş yüklerini yerel olarak destekleyen yönetilen işlem düğümlerini dinamik olarak sağlayan ComputeClass
Güvenli bir çekirdeğin başlatılması gecikmeye neden olabileceğinden SandboxWarmPool da kullanırız. Bu sayede, önceden başlatılmış belirli sayıda sanal alan hazır tutulur. Böylece Kod Oluşturma Temsilcisi bu alanları talep edebilir ve bir saniyeden kısa bir süre içinde kod yürütmeye başlayabilir.
İlk olarak, aracı sandbox çalışma zamanları için yeni bir ad alanı oluşturun:
kubectl create namespace agent-sandbox
Aşağıdakileri sandbox-template-and-pool.yaml olarak kaydedin:
cat > sandbox-template-and-pool.yaml <<EOF
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxTemplate
metadata:
name: python-runtime-template
namespace: agent-sandbox
spec:
podTemplate:
metadata:
labels:
sandbox: python-sandbox-example
spec:
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: python-runtime
image: registry.k8s.io/agent-sandbox/python-runtime-sandbox:v0.1.0
ports:
- containerPort: 8888
readinessProbe:
httpGet:
path: "/"
port: 8888
initialDelaySeconds: 0
periodSeconds: 1
resources:
requests:
cpu: "250m"
memory: "512Mi"
ephemeral-storage: "512Mi"
restartPolicy: "OnFailure"
---
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxWarmPool
metadata:
name: python-sandbox-warmpool
namespace: agent-sandbox
spec:
replicas: 2
sandboxTemplateRef:
name: python-runtime-template
EOF
Yapılandırmayı uygulayın:
kubectl apply -f sandbox-template-and-pool.yaml
Warmpool kapsüllerinin başlatılması için 2-3 dakika kadar bekleyin. Temel işlem ölçeği artırılırken Pending'dan Running'ye başarılı bir şekilde geçiş yapıldığını kontrol etmek için şunları kullanabilirsiniz:
kubectl get pods -n agent-sandbox -w
python-sandbox-warmpool-*** kapsülün Running ve 1/1 Hazır olarak listelendiğini gördüğünüzde güvenli yürütme ortamlarınız önceden ısıtılmış ve talep edilmeye hazır demektir.
Korumalı alan yönlendiricisini dağıtma
Kod oluşturma aracımız, yürütme komutlarını yalıtılmış pod'lara güvenli bir şekilde göndermek için bir Sandbox Router'a dayanır.
sandbox-router.yaml oluşturmak için aşağıdaki komutu çalıştırın:
cat > sandbox-router.yaml <<EOF
apiVersion: v1
kind: Service
metadata:
name: sandbox-router-svc
namespace: agent-sandbox
spec:
type: ClusterIP
selector:
app: sandbox-router
ports:
- name: http
protocol: TCP
port: 8080
targetPort: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sandbox-router-deployment
namespace: agent-sandbox
spec:
replicas: 2
selector:
matchLabels:
app: sandbox-router
template:
metadata:
labels:
app: sandbox-router
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: sandbox-router
containers:
- name: router
image: us-central1-docker.pkg.dev/k8s-staging-images/agent-sandbox/sandbox-router:v20260225-v0.1.1.post3-10-ga5bcb57
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 10
resources:
requests:
cpu: "250m"
memory: "512Mi"
limits:
cpu: "1000m"
memory: "1Gi"
securityContext:
runAsUser: 1000
runAsGroup: 1000
EOF
Yapılandırmayı uygulayın:
kubectl apply -f sandbox-router.yaml
Ağ izolasyonunu uygulama
Yürütme ortamını daha da güvenli hale getirmek ve yetkisiz yatay hareketleri önlemek için bir ağ politikası uygulayın. Bu işlem, korumalı alanı "hava boşluğu" ile ayırarak Google Cloud meta veri sunucusuna veya diğer hassas dahili ağlara ulaşmasını engeller.
Aşağıdakileri sandbox-policy.yaml olarak kaydedin:
cat > sandbox-policy.yaml <<EOF
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: restrict-sandbox-egress
namespace: agent-sandbox
spec:
podSelector:
matchLabels:
sandbox: python-sandbox-example
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 0.0.0.0/0
except:
- 169.254.169.254/32 # Block metadata server
EOF
Politikayı uygulayın:
kubectl apply -f sandbox-policy.yaml
Bileşenleri Doğrulama
İzole edilmiş kod sandbox'ı küme katmanınızın tamamen yapılandırıldığından emin olmak için aşağıdaki durum doğrulama komutlarını yürütün:
Öncelikle, korumalı alan kapsüllerinin ve yönlendiricilerinin Çalışıyor ve Hazır durumunda olduğunu doğrulayın.
kubectl get pods -n agent-sandbox
Çıkış şu şekilde görünmelidir:
NAME READY STATUS RESTARTS AGE
python-sandbox-warmpool-7zlkv 1/1 Running 0 3m25s
python-sandbox-warmpool-cxln2 1/1 Running 0 3m25s
sandbox-router-deployment-668dfbbbb6-g9mpd 1/1 Running 0 42s
sandbox-router-deployment-668dfbbbb6-ppllz 1/1 Running 0 42s
Sandbox Router yük dengeleyici / IP'ye maruz kalma durumunu doğrulama
kubectl get service sandbox-router-svc -n agent-sandbox
Çıkış şu şekilde görünmelidir:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
sandbox-router-svc ClusterIP 34.118.237.244 <none> 8080/TCP 114s
Çıkış ağı politikası kuralının mevcut olduğunu doğrulayın
kubectl get networkpolicy restrict-sandbox-egress -n agent-sandbox
Çıkış şu şekilde görünmelidir:
NAME POD-SELECTOR AGE
restrict-sandbox-egress sandbox=python-sandbox-example 113s
Aşağıdakilerden emin olun:
python-sandbox-warmpool-***kapsülleriRunningve1/1hazır.sandbox-router-deployment-***replikalarıRunningve1/1için hazır.sandbox-router-svcerişilebilir durumda verestrict-sandbox-egresspolitikası, eşleşen tüm korumalı alan etiketlerini başarıyla koruyor.
Güvenli yürütme ortamımız güvenli hale getirilip başlatıldıktan sonra operasyonumuzun asıl beynini, yani Kod Oluşturma Aracısı'nı dağıtmaya hazırız.
7. Kod oluşturma aracısını (ADK) oluşturma ve dağıtma
Güvenli yürütme sandbox'ımız ve yüksek performanslı LLM arka ucumuz yapılandırıldığına göre artık sistemimizin "beynini" oluşturabiliriz: Agent Development Kit (ADK)'yı kullanarak Kod Oluşturma Aracısı.
Bu ajan, uzman bir Python geliştirici gibi davranmak üzere tasarlanmıştır. Yalnızca metin üreten standart bir chatbot'un aksine bu aracıda, sorunları etkileşimli olarak çözmesini sağlayan bir kod yürütme aracı bulunur. Şu döngü izlenir:
- İsteklerinize göre Python kodu yazma
- 6. adımda kurduğumuz GKE Agent Sandbox'ta kodu güvenli bir şekilde yürütme.
- Çıkışı doğrulama veya yürütme sırasında ortaya çıkan hataları okuma
- Test edilmiş ve çalışan bir çözümü güvenle sunma
Aracıya güvenli bir korumalı alan yürütme ortamına erişim izni vererek kendi mantığını doğrulamasını ve hataları otomatik olarak ayıklamasını sağlıyoruz. Bu sayede, yazılım geliştirme görevlerinde çok daha yetenekli hale geliyor.
ADK Reasoning Agent'ı geliştirme
İlk olarak, aracının davranışını tanımlayan ve 6. adımda oluşturduğumuz Sandbox aracıyla donatan Python mantığını yazarız. Bu bölümde, hibrit model stratejisi de yapılandırıyoruz: Aracı, GKE kümenizde çalışan kendi kendine barındırılan bir Qwen modeline öncelik verecek ancak yerel model yavaşsa veya kullanılamıyorsa otomatik olarak Vertex AI'daki Gemini 2.5 Flash'a geri dönecek ve böylece yüksek güvenilirlik sağlayacak.
Aracı kodu için yeni bir dizin oluşturun:
mkdir -p ~/gke-ai-agent-lab/root_agent
cd ~/gke-ai-agent-lab
Aşağıdaki içeriğe sahip root_agent/agent.py adlı bir dosya oluşturun:
cat <<'EOF' > root_agent/agent.py
import os
from google.adk.agents import Agent
from google.adk.models.lite_llm import LiteLlm
from k8s_agent_sandbox import SandboxClient
import requests
# Instantiate the client globally to track sandboxes
sandbox_client = SandboxClient()
def run_python_code(code: str) -> str:
"""
Executes Python code safely in the GKE Agent Sandbox.
Use this tool whenever you need to execute code to solve a problem.
"""
sandbox = sandbox_client.create_sandbox(template="python-runtime-template", namespace="agent-sandbox")
try:
command = f"python3 -c \"{code}\""
result = sandbox.commands.run(command)
if result.stderr:
return f"Error: {result.stderr}"
return result.stdout
finally:
# Ensure the sandbox is deleted after use to avoid leaking resources
sandbox_client.delete_sandbox(sandbox.claim_name, namespace="agent-sandbox")
# Define the ADK Agent with a fallback mechanism.
# It prioritizes the Qwen 2.5 Coder model running on our Inference Gateway.
# If the local model is unavailable, it falls back to Gemini 2.5 Flash on Vertex AI.
root_agent = Agent(
name="CodeGenerationAgent",
model=LiteLlm(
model="openai/Qwen/Qwen2.5-Coder-14B-Instruct",
fallbacks=["vertex_ai/gemini-2.5-flash"],
timeout=10
),
instruction="""
You are an expert Python developer.
1. Write Python code to solve the user's problem.
2. Execute the code using the `run_python_code` tool to verify it works.
3. Return the exact output and a brief explanation of the code.
""",
tools=[run_python_code]
)
EOF
ADK'nın modülü tanıması için bir __init__.py dosyası oluşturun:
echo "from . import agent" > ~/gke-ai-agent-lab/root_agent/__init__.py
Ortam değişkenlerini ayarlayın. ADK uygulamasının, LLM isteklerini başarıyla yönlendirmek için Ağ Geçidinizin IP adresine ihtiyacı vardır. ADK, standart Open-AI uyumlu uç noktaları desteklediğinden (vLLM, ağ geçidimiz aracılığıyla sağlar) varsayılan API temel URL'sini geçersiz kılabiliriz.
export GATEWAY_IP=$(kubectl get gateway infra-is-inference-gateway -n $NAMESPACE -o jsonpath='{.status.addresses[0].value}')
cat <<EOF > ~/gke-ai-agent-lab/root_agent/.env
OPENAI_API_BASE=http://${GATEWAY_IP}/v1
OPENAI_API_KEY=no-key-required
# Vertex AI settings for fallback (Authentication is handled by Workload Identity)
VERTEXAI_PROJECT=$PROJECT_ID
VERTEXAI_LOCATION=${ZONE%-[a-z]}
EOF
Aracı Uygulamasını Kapsayıcıya Alma
Aracıyı GKE'de güvenli bir şekilde çalıştırılabilecek şekilde paketlememiz gerekir.
Dockerfile, ~/gke-ai-agent-lab içinde kubectl, ADK kitaplığı ve Agent Sandbox istemcisini yükleyen bir Dockerfile oluşturun:
cat <<'EOF' > ~/gke-ai-agent-lab/Dockerfile
FROM python:3.11-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
RUN apt-get update && apt-get install -y git curl \
&& curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl" \
&& install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl \
&& rm kubectl && apt-get clean && rm -rf /var/lib/apt/lists/*
RUN pip install --no-cache-dir "google-adk[extensions,otel-gcp]>=1.27.4" litellm pandas "git+https://github.com/kubernetes-sigs/agent-sandbox.git@main#subdirectory=clients/python/agentic-sandbox-client" \
"opentelemetry-instrumentation-google-genai>=0.4b0" \
"opentelemetry-exporter-otlp" \
"opentelemetry-instrumentation-vertexai>=2.0b0"
COPY ./root_agent /app/root_agent
EXPOSE 8080
ENTRYPOINT ["adk", "web", "--host", "0.0.0.0", "--port", "8080", "--otel_to_cloud"]
EOF
Container görüntüsünü depolamak için bir Artifact Registry deposu oluşturun.
gcloud artifacts repositories create agent-repo \
--repository-format=docker \
--location=us-central1
Container görüntüsünü oluşturmak ve aktarmak için Cloud Build'i kullanın.
gcloud builds submit --tag us-central1-docker.pkg.dev/$PROJECT_ID/agent-repo/code-agent:v1 ~/gke-ai-agent-lab/
RBAC ile GKE'ye dağıtma
Son olarak, aracıyı kümenize dağıtın. Dağıtım, aracının SandboxWarmPool'den örnekler talep etmesine izin veren bir Role ve RoleBinding içerir.
Bu dağıtım, aracınızın Sandbox talebi API'si ile iletişim kurmasını sağlamak için bir Kubernetes ServiceAccount kullanır. Yerel küme kaynaklarına ve yerel bir vLLM ağ geçidi uç noktasına eriştiği için Google IAM ServiceAccount gerektirmez.
gVisor'da neden standart dağıtım?
6. adımda, oluşturulan Python kodu (aracın yürütülmesi) için geçici, tek kullanımlık sanal alanlar oluşturmak üzere SandboxTemplate ve SandboxClaim API'lerini kullandık.
Aracı Web Kullanıcı Arayüzü (Beyin) için runtimeClassName: gvisor ile birlikte standart Kubernetes Deployment spesifikasyonlarını kullanıyoruz.
- Fark: Standart
SandboxClaimsgeçicidir ve sıfırdan bire kadardır (güvenilmeyen komut dosyaları için idealdir). Standart birDeploymentuzun süreli ve kalıcıdır. Bu nedenle, kararlı bir KubernetesServiceve yük dengeleyiciye ihtiyaç duyan web kullanıcı arayüzleri için idealdir.runtimeClassName: gvisor'ı doğrudan standart bir dağıtımda kullanarak standartDeploymentözelliklerini korurken gVisor çekirdeğinin yalıtımını elde edersiniz.
Aşağıdakileri deployment.yaml olarak kaydedin:
cat <<EOF > ~/gke-ai-agent-lab/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: code-agent
labels:
app: code-agent
spec:
replicas: 1
selector:
matchLabels:
app: code-agent
template:
metadata:
labels:
app: code-agent
spec:
serviceAccount: adk-agent-sa
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: code-agent
image: us-central1-docker.pkg.dev/YOUR_PROJECT_ID/agent-repo/code-agent:v1
imagePullPolicy: Always
env:
- name: OPENAI_API_KEY
value: "no-key-required"
- name: OPENAI_API_BASE
value: "http://YOUR_GATEWAY_IP/v1"
- name: VERTEXAI_PROJECT
value: "YOUR_PROJECT_ID"
- name: VERTEXAI_LOCATION
value: "YOUR_REGION"
- name: OTEL_SERVICE_NAME
value: "code-agent"
- name: GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY
value: "true"
- name: OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT
value: "true"
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: code-agent-service
spec:
selector:
app: code-agent
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: agent-sandbox
name: sandbox-creator-role
rules:
- apiGroups: [""]
resources: ["services", "pods", "pods/portforward"]
verbs: ["get", "list", "watch", "create"]
- apiGroups: ["extensions.agents.x-k8s.io"]
resources: ["sandboxclaims"]
verbs: ["create", "get", "list", "watch", "delete"]
- apiGroups: ["agents.x-k8s.io"]
resources: ["sandboxes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: adk-agent-binding
namespace: agent-sandbox
subjects:
- kind: ServiceAccount
name: adk-agent-sa
namespace: default
roleRef:
kind: Role
name: sandbox-creator-role
apiGroup: rbac.authorization.k8s.io
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: adk-agent-sa
EOF
Gözlemlenebilirlik için IAM izinleri verme
Aracının telemetri verilerini (günlükler ve izlemeler) Google Cloud'a göndermesini sağlamak için Workload Identity'yi kullanarak Kubernetes hizmet hesabına adk-agent-sa gerekli izinleri vermeniz gerekir.
Cloud Shell'inizde aşağıdaki komutları çalıştırın:
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# Grant permission to write logs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/logging.logWriter \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to write traces
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/cloudtrace.agent \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to use Vertex AI
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/aiplatform.user \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
YOUR_PROJECT_ID öğesini gerçek proje kimliğinizle otomatik olarak değiştirmek ve yapılandırmayı uygulamak için aşağıdaki komutu çalıştırın.
sed -i "s/YOUR_PROJECT_ID/$PROJECT_ID/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_GATEWAY_IP/$GATEWAY_IP/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_REGION/$ZONE/g" ~/gke-ai-agent-lab/deployment.yaml
kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml
8. Gözlemleme ve Doğrulama
Tamamen entegre sistemi test etme zamanı.
Kullanıcı arayüzünde Kod Oluşturma Temsilcisi'ni test etme
ADK web kullanıcı arayüzünüzün harici IP'sini bulun:
kubectl get services code-agent-service
Çıkış şu şekilde görünmelidir:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
code-agent-service LoadBalancer 34.118.230.182 34.31.250.60 80:32471/TCP 2m14s
- Bir tarayıcı açın ve
http://[EXTERNAL-IP]adresine gidin. - ADK web arayüzünde, sağ üstteki açılır menüden "root_agent"ın seçildiğinden emin olun. Ardından, temsilciye şu istemi girin:
Write a python script that prints 'Hello from the isolated sandbox'.
Aracının çıkarım arka ucunu ve sanal alanı nasıl kullandığını gözlemlemek için aşağıdaki Cloud Observability ile Model İstatistiklerini Keşfetme ve GKE kullanıcı arayüzü ile Aracı Gözlemlenebilirliğini Keşfetme bölümlerine giderek kontrol panellerini görüntüleyin.
GKE kullanıcı arayüzü üzerinden aracı gözlemlenebilirliğini keşfetme
Bazı istemler çalıştırdığınıza göre şimdi telemetri verilerine göz atalım. Bu sayede, Inference Scheduler ve vLLM'nin nasıl performans gösterdiğini anlayabilirsiniz.
Temsilci kontrol panellerine erişme
- Kubernetes Engine > İş Yükleri sayfasına gidin.
- code-agent dağıtımını tıklayarak Dağıtım Ayrıntıları sayfasını açın.
- Gözlemlenebilirlik sekmesini tıklayın.
- Gözlemlenebilirlik kontrol panelinin sol gezinme panelinde, alt sekmeleri olan yeni bir Aracı bölümü görürsünüz.
Keşfedilecekler
Aracı uygulamanızın davranışını görmek için aşağıdaki alt sekmeleri inceleyin:
- Genel bakış: Oturumlar, ortalama dönüşler ve çağırmalar için puan kartlarını görüntüleyin.
- Modeller: Aracılarınızın kullandığı modellere göre sınıflandırılmış model çağrılarının sayısını, hata oranlarını ve gecikmeyi görün.
- Araçlar: Aracınızın sandbox yürütme aracını ne kadar etkili kullandığını görmek için araç çağrılarını ve yürütme süresini izleyin.
- Kullanım: Jeton kullanımını ve standart kapsayıcı kaynak ayırımını (CPU ve bellek) izleyin.
- Aracı izleri: Yürütme oturumlarının veya ham izleme aralıklarının listesini görmek için bu sekmeye geçin. Bir satırı tıkladığınızda, seçilen izle ilgili ayrıntıların yer aldığı bir pop-up açılır.
vLLM'den alınan model düzeyindeki metrikleri ADK'dan alınan uygulama düzeyindeki telemetriyle birleştirerek artık GKE'deki üretken yapay zeka aracınız için tam yığın gözlemlenebilirliğine sahip olabilirsiniz.
Cloud Gözlemlenebilirliği ile vLLM Model İstatistiklerini Keşfetme
Bazı istemler çalıştırdığınıza göre şimdi telemetri verilerine göz atalım. Bu sayede, Inference Scheduler ve vLLM'nin nasıl performans gösterdiğini anlayabilirsiniz.
Kontrol panellerine erişme
- Google Cloud Console'a gidin.
- İzleme > Kontrol panelleri'ne gidin.
- vLLM Prometheus Overview kontrol panelini arayıp seçin.
İzlenmesi gereken ilginç metrikler
Kontrol panelini görüntülerken GKE Inference Gateway ve ön ek önbelleğe almanın etkisini görmek için şu temel metriklere dikkat edin:
- KV Cache Utilization (
vllm:gpu_cache_usage):- Neden önemlidir? Bu metrik, GPU belleğinin ne kadarının bağlamı önbelleğe almak için kullanıldığını gösterir. Bu değer yüksekse sistem, gelecekteki istekleri hızlandırmak için bağlamı tutuyor demektir. Aynı istemi birden çok kez çalıştırırsanız bu kullanımın önce yükseldiğini, ardından dengelendiğini görürsünüz.
- Çalışan ve Bekleyen İstekler (
vllm:num_requests_runningvevllm:num_requests_waiting):- Neden önemli? Bu, yükü gösterir. Bekleyen istek sayısı yüksekse düğümleriniz aşırı yüklenmiş demektir.
- Jeton İşleme Hızı (
vllm:request_prompt_tokens_totvevllm:request_generation_tokens_tot):- Önemi: Küme tarafından işlenen giriş ve çıkış jetonlarının hacmini izleyin.
- İlk jetona kadar geçen süre (TTFT):
- Neden önemli? Bu, etkileşimli temsilciler için kritik bir metriktir. GKE Inference Gateway'i Prefix-Cache Aware Routing ile kullandığınızda, ortak bağlamları (ör. sistem istemleri veya büyük bağlam pencereleri) paylaşan istekler aynı replikaya yönlendirilir. Böylece, mevcut önbellek isabetleri yeniden kullanılarak TTFT en aza indirilir.
Denenecek Denemeler
Metriklerdeki değişiklikleri anlık olarak görmek ve uygun planlamayı doğrulamak için bu senaryoları deneyin.
Deneme 1: "Tekrar Hızı" (Önek Önbellek İsabeti)
- Aracıya karmaşık bir istem gönderin (ör. "100 MB'lık bir CSV dosyasını ayrıştırıp istatistikleri hesaplamak için bir Python komut dosyası yaz.").
- Yanıt verdikten sonra istemin aynısını hemen tekrar gönderin.
- Önek Önbellek Hit Oranı ve İlk Jeton Süresi (TTFT) değerlerini inceleyin.
- Görmeniz gerekenler: Önek önbellek isabet oranı% 100'e yükselmeli ve TTFT önemli ölçüde düşmelidir.
- Ne anlama geliyor? GKE Çıkarım Ağ Geçidi, paylaşılan bağlamı tanıdı ve değerlendirilen bağlam önbelleğini yeniden kullanan aynı replikaya yönlendirdi.
2. deneme: Buluta geri dönme (Model Güvenilirliği)
- Yerel Qwen modelinizde hata simülasyonu yapmak için çıkarım hizmetini durdurabilir veya dağıtımda sahte bir
OPENAI_API_BASEsağlayabilirsiniz. deployment.yamluygulamanızdakiOPENAI_API_BASEdeğerini mevcut olmayan bir IP veya bağlantı noktasıyla güncelleyin ve değişiklikleri uygulayın:sed -i "s|value: \"http://$GATEWAY_IP/v1\"|value: \"http://10.0.0.1:8080/v1\"|g" ~/gke-ai-agent-lab/deployment.yaml kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml- Pod'un yeniden başlatılmasını bekleyin, ardından kullanıcı arayüzünde aracıya bir istem gönderin.
- Görmeniz gereken: Ajan, başarılı bir şekilde yanıt vermeye devam eder.
- Ne anlama geliyor? ADK,
fallbacksyapılandırması nedeniyle yerel Qwen uç noktasının başarısız olduğunu algıladı ve isteği sorunsuz bir şekilde Vertex AI'daki Gemini 2.5 Flash'e yönlendirdi. Vertex AI'a yapılan bu yedek çağrıların yerel vLLM Çıkarım Ağ Geçidi'nizi atladığı için yalnızca vLLM üzerinden geçen trafiği izleyen Agent Observability > Models kontrol panelinde görünmeyeceğini unutmayın.
Dinamik kaynak ayırmanın (DRA) gücünü anlama
vLLM ve Inference Gateway, isteklerin nasıl yönlendirildiğini ve sunulduğunu optimize ederken Dinamik Kaynak Ayırma (DRA), iş yükünüze tam olarak doğru donanımı bağlamanızı mümkün kılan özelliktir.
DRA, ResourceClaimTemplate ve DeviceClasses kullanarak esnek donanım kaynakları tanımlamanıza olanak tanıyarak kümenizdeki donanımı ayrıntılı bir şekilde yönetme olanağınızı artırır.
DRA, yapay zeka iş yükleri için neden oyunun kurallarını değiştiriyor?
- Ayrıntılı Donanım İstekleri: DRA ile iş yüklerinin doğru hızlandırıcıya sahip makinelerde planlanmasını sağlamanın yanı sıra, bu kaynakların ResourceClaim ile ilişkili iş yükü tarafından özel olarak kullanılmasını sağlamak için bu kaynaklar üzerinde hak talebinde de bulunabilirsiniz.
- Ayrılmış Yaşam Döngüsü: Cihaz talepleri, kapsül yaşam döngülerinden bağımsız olarak yönetilir. Bir kapsül çökerse GPU talebi devam edebilir. Böylece, GPU'nun serbest bırakılmasını ve yeniden alınmasını beklemeden kapsamlı dağıtım veya diğer iş yükü nesnesi yeniden başlatılabilir.
- Çok tedarikçili standardizasyon: DRA, hem NVIDIA GPU'lar hem de Google TPU'lar için birleşik bir Kubernetes API'si sağlar. İster biri ister diğeri için dağıtım yapın, tam olarak aynı şemayı kullanırsınız. Bu sayede iş yükü YAML manifestleriniz son derece taşınabilir olur.
Bu codelab'de, Helm değerlerinizi gpu-claim-template ile sorunsuz bir şekilde bağlanacak şekilde yapılandırırken, dağıtımlarınızı engelleyen asılı cihaz eklentisi yapılandırmaları olmadan bunu uygulamada gördünüz.
llm-d'nin Rolünü Anlama
vLLM sinirsel ağırlıkları değerlendirirken ve GKE Gateway sorguları yönlendirirken llm-d yapılandırma katmanı ve hepsini birbirine bağlayan "yapıştırıcı" görevi görür.
llm-d olmadan, vLLM dağıtımınızı, hizmet bağlantı noktalarınızı, birim bağlamalarınızı ve DRA kaynak taleplerinizi sıfırdan bildirmek için ham Kubernetes manifestleri yazmanız gerekir.
Dağıtımınızda llm-d'yi Neden Kullanmalısınız?
- Birleştirilmiş Yapılandırma (Tek satırlık geçersiz kılmalar):
llm-dHelm grafikleri, karmaşık ve düşük düzeyli Kubernetes kaynaklarını temiz ve üst düzey açma/kapatma anahtarları (ör.accelerator.dra: trueayarı) halinde paketler. - Önceden incelenmiş "iyi aydınlatılmış yollar":
llm-ddeposunda, uzmanlar tarafından zaten karşılaştırması yapılmış ve test edilmiş yapılandırmalar bulunur.llm-d-modelservice'yı dağıttığınızda GPU bellek kullanımı, önerilen yoklama zamanlamaları (canlılık/hazırlık) ve metrikleri kazıma için doğru pozlamalarla ilgili optimize edilmiş varsayılan değerler alırsınız. - Sorunsuz Gözlemlenebilirlik Eşleme:
llm-d, standart kapsayıcı bağlantı noktalarının ve kazıma yollarının (/metrics) doğru şekilde kullanıma sunulmasını sağlar. Böylece, dağıtımınızı manuel hata ayıklama yapmadan Google Cloud Monitoring'e kolayca bağlayabilirsiniz.
Kısacası llm-d, yeniden kullanılabilir mimari planları sunar. Böylece geliştiricilerin GKE'de çıkarım yığını dağıtırken her seferinde Amerika'yı yeniden keşfetmesine gerek kalmaz.
Ayrıntılı İnceleme: GKE Inference Gateway
Standart Katman 7 yük dengeleyiciler, yollar (/v1/completions) veya çerezler gibi HTTP başlıklarına bakarak çalışır. GKE Inference Gateway ise çok daha kapsamlıdır ve özellikle üretken yapay zeka trafiği için tasarlanmıştır.
Performansı ve Verimliliği Nasıl Artırır?
- İçeriğe Duyarlı Yönlendirme (İstem Karma Oluşturma): GKE Inference Gateway, JSON istek gövdesini yakalar. İstem için bir karma hesaplar ve hangi arka uç replikasının bu jetonları GPU belleğinde (KV önbelleği) tuttuğunu izler.
- Önbellek isabetlerini en üst düzeye çıkarma: Testinizde bir istemi tekrarladığınızda Ağ Geçidi, istemi tam olarak aynı replikaya gönderdi. Bir istemi değerlendirmek için yoğun bilgi işlem gücü gerekir. Önbelleği yeniden kullanarak istemi "yeniden okumaktan" kaçınır, böylece paradan ve GPU süresinden tasarruf edersiniz.
- İlk jetona kadar geçen süreyi (TTFT) kısaltma: TTFT, kullanıcıya yönelik aracıların kullanılabilirliği açısından kritik bir metriktir. Model, önbelleğe erişerek saniyeler yerine milisaniyeler içinde jeton oluşturmaya başlayabilir.
- Akıllı Yük Dağıtımı: Bir replikanın VRAM'i tamamen önbellek isabetleriyle doluysa Gateway, yeni bir istemi dinamik olarak yer olan farklı bir replikaya yönlendirebilir ve verimliliği kullanılabilirlikle dengeleyebilir.
Temsilci Korumalı Alanı riski nasıl azaltır?
Bu laboratuvarda, Agent Sandbox'ın iki yalıtım katmanı sağlayarak altyapınızı yapay zeka temsilcileriyle ilişkili risklerden nasıl koruduğunu gösterdik:
- Yürütme aracını yalıtma: Temsilci, oluşturduğu kodu kısa ömürlü bir sanal alanda yürütür. Bu sayede, LLM tarafından oluşturulan güvenilmeyen kodun güvenli ve ayrı bir ortamda çalışması sağlanarak aracı ve küme korunur.
- Hızlı Başlatma: WarmPool kullanıldığında yeni sanal alanlar bir saniyeden kısa sürede başlatılır ve kod yürütmeye hazır hâle gelir.
- Aracıyı yalıtma: Ayrıca, aracının bağımlılıklarındaki tedarik zinciri güvenlik açıklarına karşı derinlemesine savunma sağlamak için aracı uygulamasını
runtimeClassName: gvisoraracılığıyla gVisor özellikli bir düğümde çalıştırdık.
Bu durumun neden bu kadar sıkı bir güvenlik sınırı oluşturduğunu aşağıda açıklıyoruz:
- Sistem çağrısı yakalama: gVisor, sistem çağrılarını ana makine Linux çekirdeğine ulaşmadan önce yakalar. Bu, ana makine düğümüne erişmek için kapsayıcının dışına çıkmaya çalışan saldırıları engeller.
- Sınırlı Yanlara Hareket: Ağ politikalarıyla birlikte kullanıldığında, bir ortam saldırıya uğrasa bile dahili meta veri sunucularınızı tarayamaz veya kümenizdeki diğer hassas hizmetlere geçiş yapamaz.
Korumalı alanlarda tam aracıları çalıştırma
Bu laboratuvarda, kalıcı bir aracı uygulaması için araç olarak sanal alanları kullandık. Ancak özellikle hassas verileri işlerken veya birden fazla güvenilmeyen kullanıcıya hizmet verirken maksimum güvenlik için tüm aracı uygulamasını her oturum veya kullanıcı için özel bir korumalı alanda çalıştırabilirsiniz. Bu, oturum tamamlandıktan hemen sonra yok edilen aracının belleğinin, durumunun ve yürütme ortamının tamamen izole edilmesini sağlar.
9. Temizleme
Bu codelab'de kullanılan kaynaklar için Google Cloud hesabınızın ücretlendirilmesini istemiyorsanız bunları silmek için aşağıdaki adımları uygulayın.
Tek tek kaynakları silme
- GKE kümesini silin:
gcloud container clusters delete $CLUSTER_NAME --zone $ZONE --quiet
- Artifact Registry deposunu silin:
gcloud artifacts repositories delete agent-repo --location=us-central1 --quiet
- VPC ağını silin:
gcloud compute networks delete ai-agent-network --quiet
Projeyi silme
Artık ihtiyacınız olmayan projeleri kaynakları kaldırdıktan sonra silebilirsiniz:
gcloud projects delete $PROJECT_ID
10. Özet
Tebrikler! GKE'de güvenli ve yüksek performanslı bir kod oluşturma aracısını başarıyla oluşturup dağıttınız.
Öğrendikleriniz
- GPU kaynaklarını yönetmek için GKE'de Dinamik Kaynak Tahsisi'ni (DRA) yapılandırma ve kullanma
- Önek önbelleği kullanan yönlendirme aracılığıyla LLM sunma performansını optimize etmek için GKE Inference Gateway'i kullanma
- GKE'de güvenilmeyen kodu güvenli bir şekilde yürütmek için Agent Sandbox (gVisor) nasıl kullanılır?
- vLLM performansını izlemek için Google Cloud Managed Service for Prometheus'u kullanma
- ADK ve GKE Managed OpenTelemetry kullanarak Agent Observability'yi yapılandırma ve görüntüleme
Sonraki Adımlar ve Referanslar
- Agent Sandbox: GKE'deki Agent Sandbox ve GKE Sandbox Pod'ları hakkında bilgi edinin.
- llm-d: llm-d Kılavuzu'nu okuyun ve llm-d GitHub deposunu inceleyin.
- Dinamik kaynak ayırma: GKE'de DRA hakkında bilgi edinin.
- GKE Inference Gateway: Inference Gateway kavramlarını inceleyin.
- Diğer Codelab'ler: Google Cloud Codelab'lerinde daha fazla eğiticiler bulabilirsiniz.