
1. Giới thiệu
Tổng quan
Trong phòng thí nghiệm này, bạn sẽ tìm hiểu cách tạo và triển khai một tác nhân tạo mã an toàn trên Google Kubernetes Engine (GKE). Các tác nhân tạo mã cần thực thi mã có thể không đáng tin cậy, đòi hỏi một môi trường hộp cát an toàn. Bạn cũng sẽ tìm hiểu cách định cấu hình tác nhân bằng chiến lược mô hình kết hợp, cho phép tác nhân dự phòng từ một mô hình mở tự lưu trữ trên GKE sang dịch vụ Gemini được quản lý của Vertex AI để tăng độ tin cậy. Ngoài ra, bạn sẽ tìm hiểu cách tối ưu hoá việc phân phát suy luận bằng cách sử dụng Cổng suy luận GKE và Phân bổ tài nguyên động (DRA). Cuối cùng, bạn sẽ tìm hiểu cách tận dụng Google Cloud Observability để giám sát ngăn xếp suy luận bằng Managed Prometheus.
Kiến trúc
Sau đây là cấu trúc của hệ thống mà bạn sẽ xây dựng:
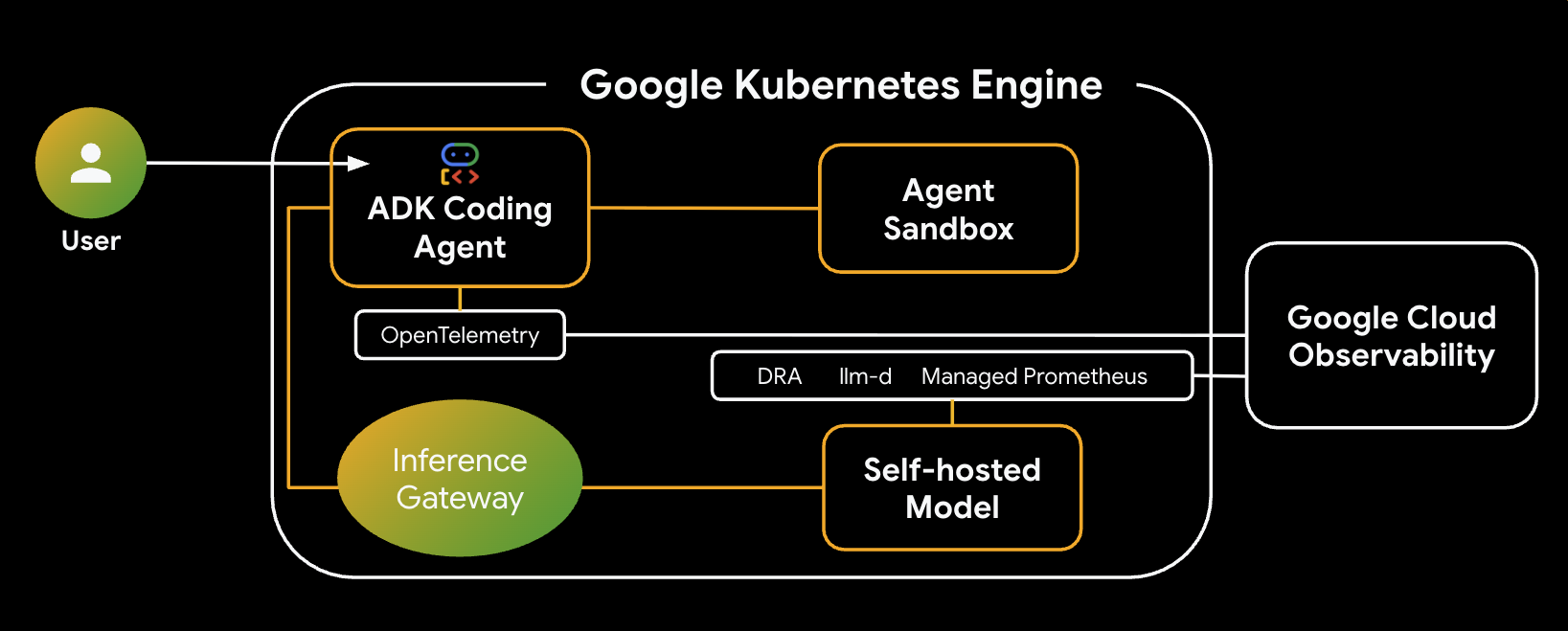
Các thành phần và lợi ích chính
- Phân bổ tài nguyên linh động (DRA): Được dùng trong phòng thí nghiệm này để yêu cầu và phân bổ linh động các tài nguyên GPU cụ thể (NVIDIA L4) cho các Pod máy chủ mô hình, đảm bảo nhắm đến phần cứng một cách chính xác cho tải công việc suy luận của chúng ta. Tìm hiểu về DRA trên GKE.
- llm-d và vLLM: Cung cấp khung phân phát mô hình và biểu đồ Helm để triển khai mô hình Qwen. Trong phòng thí nghiệm này, nó xử lý các yêu cầu suy luận và tích hợp với DRA để quản lý tài nguyên (không bật tính năng phân phát tách biệt trong phòng thí nghiệm này). Đọc Hướng dẫn về llm-d và xem Kho lưu trữ llm-d trên GitHub.
- Cổng suy luận GKE: Di chuyển logic định tuyến nhận biết AI trực tiếp vào trình cân bằng tải. Trong phòng thí nghiệm này, các yêu cầu sẽ được định tuyến để tối đa hoá số lượt truy cập vào bộ nhớ đệm tiền tố, giảm độ trễ Thời gian hiển thị mã thông báo đầu tiên (TTFT). Khám phá các khái niệm về Cổng suy luận.
- Hộp cát tác nhân (gVisor): Cung cấp khả năng cách ly an toàn để thực thi mã do tác nhân AI tạo. GKE Sandbox sử dụng gVisor để cung cấp khả năng tách biệt nhân hệ điều hành sâu, bảo vệ nút lưu trữ khỏi các khối lượng công việc không đáng tin cậy. Tìm hiểu về Agent Sandbox trên GKE và Pod GKE Sandbox.
Bạn sẽ thực hiện
- Cung cấp cơ sở hạ tầng: Thiết lập một cụm GKE có tính năng Phân bổ tài nguyên động (DRA) để quản lý GPU.
- Triển khai Inference Stack: Triển khai
llm-dvà vLLM bằng tính năng lập lịch suy luận thông minh. - Định cấu hình tính năng Định tuyến thông minh: Sử dụng Cổng suy luận GKE để định tuyến dựa trên bộ nhớ đệm tiền tố.
- Thực thi mã an toàn: Triển khai Hộp cát tác nhân (gVisor) để chạy mã do AI tạo một cách an toàn.
- Quan sát và xác thực: Sử dụng Google Cloud Monitoring và Prometheus được quản lý để xem các chỉ số phân phát mô hình.
Kiến thức bạn sẽ học được
- Cách định cấu hình và sử dụng tính năng Phân bổ tài nguyên động (DRA) trong GKE.
- Cách sử dụng GKE Inference Gateway để tối ưu hoá hiệu suất phân phát LLM.
- Cách sử dụng Hộp cát tác nhân để thực thi mã không đáng tin cậy một cách an toàn trên GKE.
- Cách sử dụng Dịch vụ được quản lý của Google Cloud cho Prometheus để theo dõi hiệu suất của vLLM.
2. Thiết lập và yêu cầu
Thiết lập dự án
Tạo một dự án trên Google Cloud
- Trong Google Cloud Console, trên trang chọn dự án, hãy chọn hoặc tạo một dự án trên Google Cloud.
- Đảm bảo rằng bạn đã bật tính năng thanh toán cho dự án trên Cloud. Tìm hiểu cách kiểm tra xem tính năng thanh toán có được bật trên một dự án hay không.
Khởi động Cloud Shell
Cloud Shell là một môi trường dòng lệnh chạy trong Google Cloud và được tải sẵn các công cụ cần thiết.
- Nhấp vào Kích hoạt Cloud Shell ở đầu bảng điều khiển Cloud.
- Sau khi kết nối với Cloud Shell, hãy xác minh thông tin xác thực của bạn:
gcloud auth list - Xác nhận rằng dự án của bạn đã được định cấu hình:
gcloud config get project - Nếu dự án của bạn không được thiết lập như mong đợi, hãy thiết lập dự án:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
3. Cung cấp cơ sở hạ tầng và Phân bổ tài nguyên linh hoạt (DRA)
Trong bước đầu tiên này, bạn sẽ định cấu hình cụm GKE để sử dụng tính năng phân bổ bộ tăng tốc hiện đại (DRA) thay vì trình bổ trợ thiết bị cũ. Nhờ đó, bạn có thể linh hoạt chia sẻ và phân bổ GPU hoặc TPU cho các khối lượng công việc tạo mã.
Điều kiện tiên quyết: Cụm GKE Standard phải chạy phiên bản 1.34 trở lên để hỗ trợ DRA.
Bật các API của Google Cloud
Bật các API của Google Cloud cần thiết cho lớp học lập trình này, cụ thể là API Compute Engine và Kubernetes Engine.
gcloud services enable compute.googleapis.com container.googleapis.com networkservices.googleapis.com cloudbuild.googleapis.com artifactregistry.googleapis.com telemetry.googleapis.com cloudtrace.googleapis.com aiplatform.googleapis.com
Đặt các biến môi trường
Để thiết lập dễ dàng hơn, hãy xác định các biến môi trường. Bạn có thể điều chỉnh khu vực hoặc quy ước đặt tên nếu cần.
export PROJECT_ID=$(gcloud config get-value project)
export ZONE=us-central1-a
export CLUSTER_NAME=ai-agent-cluster
export NODEPOOL_NAME=dra-accelerator-pool
gcloud config set project $PROJECT_ID
gcloud config set compute/region $ZONE
Tạo thư mục đang làm việc
Tạo một thư mục làm việc riêng cho lớp học này và chuyển đến thư mục đó để các tệp của bạn được sắp xếp gọn gàng:
mkdir -p ~/gke-ai-agent-lab
cd ~/gke-ai-agent-lab
Định cấu hình quyền (Không bắt buộc)
Nếu bạn đang chạy trong một dự án bị hạn chế hoặc môi trường dùng chung, hãy đảm bảo tài khoản của bạn có các quyền cần thiết để tạo cụm và chạy bản dựng:
export MY_ACCOUNT=$(gcloud config get-value account)
# Grant Container Admin to create clusters and manage nodes if needed
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/container.admin"
# Grant Cloud Build Builder to run builds
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/cloudbuild.builds.builder"
Tạo cụm GKE
Cụm GKE Standard phải chạy phiên bản 1.34 trở lên để hỗ trợ DRA. Bạn cũng cần bật các bộ điều khiển Gateway API để hỗ trợ lập lịch suy luận thông minh.
Bạn sẽ tạo một mạng VPC và mạng con mới cho phòng thí nghiệm này.
Trước tiên, hãy tạo mạng VPC:
gcloud compute networks create ai-agent-network --subnet-mode=custom
Tiếp theo, hãy tạo một mạng con cho các nút GKE:
gcloud compute networks subnets create ai-agent-subnet \
--network=ai-agent-network \
--range=10.0.0.0/20 \
--region=us-central1
Gateway API (gke-l7-regional-internal-managed) cũng yêu cầu một mạng con chuyên dụng để lưu trữ các proxy Envoy. Tạo mạng con chỉ dành cho proxy này trong mạng mới của bạn:
gcloud compute networks subnets create proxy-only-subnet \
--purpose=REGIONAL_MANAGED_PROXY \
--role=ACTIVE \
--region=us-central1 \
--network=ai-agent-network \
--range=192.168.10.0/24
Bây giờ, hãy tạo cụm bằng mạng và mạng con mới:
gcloud beta container clusters create $CLUSTER_NAME \
--zone $ZONE \
--num-nodes 1 \
--machine-type n2-standard-4 \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--gateway-api=standard \
--managed-otel-scope=COLLECTION_AND_INSTRUMENTATION_COMPONENTS \
--network=ai-agent-network \
--subnetwork=ai-agent-subnet
Tạo Nhóm nút khi Tắt các trình bổ trợ mặc định
Để chuyển giao quyền quản lý thiết bị cho DRA, bạn phải tạo một bộ nút vô hiệu hoá rõ ràng quá trình cài đặt trình điều khiển GPU mặc định và trình bổ trợ thiết bị tiêu chuẩn.
Chạy lệnh gcloud sau đây để cung cấp một bộ nút GPU (ví dụ: sử dụng NVIDIA L4) có các nhãn DRA cần thiết:
gcloud container node-pools create $NODEPOOL_NAME \
--cluster=$CLUSTER_NAME \
--location=$ZONE \
--machine-type=g2-standard-24 \
--accelerator=type=nvidia-l4,count=2,gpu-driver-version=disabled \
--node-labels=gke-no-default-nvidia-gpu-device-plugin=true,nvidia.com/gpu.present=true \
--num-nodes 3
Cài đặt trình điều khiển NVIDIA thông qua DaemonSet
Cài đặt trình điều khiển thiết bị cơ bản của NVIDIA theo cách thủ công vào các nút bằng cách sử dụng Google Cloud DaemonSet được định cấu hình sẵn:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
Cài đặt trình điều khiển DRA
Tiếp theo, hãy cài đặt trình điều khiển DRA cụ thể vào cụm của bạn. Đối với GPU NVIDIA, bạn có thể triển khai thông qua Helm:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
helm install nvidia-dra-driver-gpu nvidia/nvidia-dra-driver-gpu \
--version="25.3.2" --create-namespace --namespace=nvidia-dra-driver-gpu \
--set nvidiaDriverRoot="/home/kubernetes/bin/nvidia/" \
--set gpuResourcesEnabledOverride=true \
--set resources.computeDomains.enabled=false \
--set kubeletPlugin.priorityClassName="" \
--set 'kubeletPlugin.tolerations[0].key=nvidia.com/gpu' \
--set 'kubeletPlugin.tolerations[0].operator=Exists' \
--set 'kubeletPlugin.tolerations[0].effect=NoSchedule'
Tìm hiểu về DeviceClasses
Bạn không cần phải viết hoặc áp dụng DeviceClass YAML theo cách thủ công. Khi bạn thiết lập cơ sở hạ tầng GKE cho DRA và cài đặt trình điều khiển, các trình điều khiển DRA chạy trên các nút sẽ tự động tạo các đối tượng DeviceClass trong cụm cho bạn.
Định cấu hình ResourceClaimTemplate
Để cho phép các Pod llm-d của bạn yêu cầu động các bộ tăng tốc này, bạn sẽ tạo một ResourceClaimTemplate. Mẫu này xác định cấu hình thiết bị được yêu cầu và yêu cầu Kubernetes tự động tạo một ResourceClaim riêng biệt cho mỗi Pod cho các tải công việc của bạn.
Chạy lệnh sau để tạo claim-template.yaml:
cat > claim-template.yaml <<EOF
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: gpu-claim-template
spec:
spec:
devices:
requests:
- name: single-gpu
exactly:
deviceClassName: gpu.nvidia.com
allocationMode: ExactCount
count: 1
EOF
Áp dụng mẫu cho cụm của bạn:
kubectl apply -f claim-template.yaml
4. Triển khai tính năng Lập lịch suy luận thông minh bằng llm-d và DRA
Trong bước này, bạn sẽ triển khai Mô hình ngôn ngữ lớn sau một bộ cân bằng tải Envoy thông minh được tăng cường bằng một trình lập lịch suy luận. Cấu hình này tối ưu hoá việc phân phát mô hình bằng cách áp dụng tính năng Định tuyến nhận biết tiền tố. GKE Inference Gateway nhận ra ngữ cảnh chung trên các vi dịch vụ và định tuyến yêu cầu một cách thông minh đến cùng một bản sao mô hình, tối đa hoá số lượt truy cập bộ nhớ đệm, giảm Thời gian hiển thị mã thông báo đầu tiên và mang lại hiệu suất vượt trội trên mỗi đô la.
Chuẩn bị môi trường
Thiết lập không gian tên mục tiêu.
export NAMESPACE=ai-agents
kubectl create namespace $NAMESPACE
Lưu trữ mã thông báo Hugging Face một cách an toàn. Đây là mã thông báo bắt buộc để kéo trọng số mô hình.
# Replace with your actual Hugging Face token
kubectl create secret generic llm-d-hf-token \
--from-literal=HF_TOKEN="your_hugging_face_token" \
-n $NAMESPACE
Tạo tệp cấu hình Helm
Cấu hình cho dịch vụ mô hình và tiện ích cổng suy luận dựa trên các hướng dẫn chính thức về llm-d.
Trước tiên, hãy tạo tệp ms-values.yaml cho dịch vụ mô hình:
cat <<EOF > ms-values.yaml
multinode: false
modelArtifacts:
uri: "hf://Qwen/Qwen2.5-Coder-14B-Instruct"
name: "Qwen/Qwen2.5-Coder-14B-Instruct"
size: 50Gi # Slightly larger than the default to accommodate weights
authSecretName: "llm-d-hf-token"
labels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
llm-d.ai/accelerator-variant: "gpu"
llm-d.ai/accelerator-vendor: "nvidia"
llm-d.ai/model: "qwen-2-5-coder-14b"
routing:
proxy:
enabled: false # removes sidecar from deployment - no PD in inference scheduling
targetPort: 8000 # controls vLLM port to matchup with sidecar if deployed
accelerator:
dra: true
type: "nvidia"
resourceClaimTemplates:
nvidia:
class: "gpu.nvidia.com"
match: "exactly"
name: "gpu-claim-template"
decode:
create: true
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
parallelism:
tensor: 2
data: 1
replicas: 3
monitoring:
podmonitor:
enabled: true
portName: "vllm"
path: "/metrics"
interval: "30s"
containers:
- name: "vllm"
image: ghcr.io/llm-d/llm-d-cuda:v0.5.1
modelCommand: vllmServe
args:
- "--disable-uvicorn-access-log"
- "--gpu-memory-utilization=0.85"
- "--enable-auto-tool-choice"
- "--tool-call-parser"
- "hermes"
ports:
- containerPort: 8000
name: vllm
protocol: TCP
resources:
limits:
cpu: '16'
memory: 64Gi
requests:
cpu: '16'
memory: 64Gi
mountModelVolume: true
volumeMounts:
- name: metrics-volume
mountPath: /.config
- name: shm
mountPath: /dev/shm
- name: torch-compile-cache
mountPath: /.cache
startupProbe:
httpGet:
path: /v1/models
port: vllm
initialDelaySeconds: 15
periodSeconds: 30
timeoutSeconds: 5
failureThreshold: 120
livenessProbe:
httpGet:
path: /health
port: vllm
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /v1/models
port: vllm
periodSeconds: 5
timeoutSeconds: 2
failureThreshold: 3
volumes:
- name: metrics-volume
emptyDir: {}
- name: torch-compile-cache
emptyDir: {}
- name: shm
emptyDir:
medium: Memory
sizeLimit: 20Gi
prefill:
create: false
EOF
Tiếp theo, hãy tạo tệp gaie-values.yaml cho Tiện ích Cổng suy luận GKE:
cat <<EOF > gaie-values.yaml
inferenceExtension:
replicas: 1
image:
name: llm-d-inference-scheduler
hub: ghcr.io/llm-d
tag: v0.6.0
pullPolicy: Always
extProcPort: 9002
pluginsConfigFile: "default-plugins.yaml"
tracing:
enabled: false
monitoring:
interval: "10s"
prometheus:
enabled: true
auth:
secretName: inference-scheduling-gateway-sa-metrics-reader-secret
inferencePool:
targetPorts:
- number: 8000
modelServerType: vllm
modelServers:
matchLabels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
EOF
Tìm hiểu về cấu hình
Cấu hình này thiết lập một ngăn xếp suy luận hiệu suất cao với các tính năng chính sau:
- Lựa chọn mô hình: Sử dụng mô hình Qwen 2.5 Coder 14B (
modelArtifacts) được tối ưu hoá để tạo mã và sử dụng công cụ. - Tích hợp DRA: Phần
acceleratorcho phép Phân bổ tài nguyên động (dra: true), nhắm đến lớp thiết bịgpu.nvidia.comvàgpu-claim-templatemà chúng ta đã tạo trước đó. - Tối ưu hoá hiệu suất:
parallelism.tensor: 2định cấu hình tính song song của tensor trên các GPU.argscho vLLM bao gồm--enable-auto-tool-choiceđể đảm bảo tác nhân lập trình của chúng tôi có thể sử dụng các công cụ một cách hiệu quả.- Các yêu cầu
cpuvàmemoryđã giảm phù hợp với loại máyg2-standard-24.
- Định tuyến thông minh: Tiện ích Cổng suy luận (
gaie-values.yaml) được định cấu hình để giám sát các máy chủ mô hìnhvllmvà định tuyến các yêu cầu nhằm tối đa hoá số lượt truy cập vào bộ nhớ đệm KV.
Triển khai ngăn xếp Lập lịch suy luận thông qua Helm
Giờ đây, hãy thêm các kho lưu trữ Helm llm-d và triển khai riêng lẻ cơ sở hạ tầng, tiện ích cổng và dịch vụ mô hình.
Trước tiên, hãy thêm các kho lưu trữ bắt buộc:
helm repo add llm-d-infra https://llm-d-incubation.github.io/llm-d-infra/
helm repo add llm-d-modelservice https://llm-d-incubation.github.io/llm-d-modelservice/
helm repo update
Triển khai các điều kiện tiên quyết về cơ sở hạ tầng
Biểu đồ này cài đặt các cấu hình Gateway cơ bản cần thiết cho ngăn xếp.
helm install infra-is llm-d-infra/llm-d-infra \
--namespace $NAMESPACE \
--set gateway.gatewayClassName=gke-l7-rilb \
--set gateway.gatewayParameters.enabled=false \
--set gateway.gatewayParameters.istio.accessLogging=false
Triển khai Tiện ích Cổng suy luận GKE
Bước này triển khai InferencePool và Endpoint Picker, giúp theo dõi bộ nhớ đệm khoá-giá trị của các mô hình để đưa ra quyết định định tuyến thông minh.
helm install gaie-is oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool \
--version v1.3.1 \
--namespace $NAMESPACE \
-f gaie-values.yaml \
--set provider.name=gke \
--set inferenceExtension.monitoring.prometheus.enabled=true
Triển khai Dịch vụ mô hình
Cuối cùng, hãy triển khai dịch vụ LLM của bạn. Dịch vụ này hiện sẽ sử dụng DRA để xác nhận quyền sở hữu GPU L4 một cách an toàn.
helm install ms-is llm-d-modelservice/llm-d-modelservice \
--version v0.4.7 \
--namespace $NAMESPACE \
-f ms-values.yaml \
--set decode.monitoring.podmonitor.enabled=false
Bật Google Cloud Observability cho vLLM
Các biểu đồ Helm chung thường cố gắng triển khai các tài nguyên Prometheus Operator tiêu chuẩn (monitoring.coreos.com/v1). Điều này có thể gây ra lỗi nếu bạn chưa cài đặt các CRD đó.PodMonitor
Thay vì bật/tắt chế độ giám sát tích hợp của Helm, hãy giữ chế độ này ở trạng thái false và áp dụng tài nguyên PodMonitoring Google Cloud Managed Prometheus (GMP) theo cách thủ công bằng cách sử dụng nhóm API monitoring.googleapis.com/v1 tương thích.
Chạy lệnh sau để tạo podmonitoring.yaml:
cat > podmonitoring.yaml <<EOF
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: ms-vllm-metrics
spec:
selector:
matchLabels:
llm-d.ai/model: "qwen-2-5-coder-14b" # Matches the label in values.yaml
endpoints:
- port: 8000 # vllm port
interval: 30s
path: /metrics
EOF
Áp dụng tài nguyên PodMonitoring cho cụm của bạn:
kubectl apply -f podmonitoring.yaml -n $NAMESPACE
Xác minh quá trình cài đặt
Xác minh rằng các thành phần đã được cài đặt thành công. Bạn sẽ thấy cả 3 bản phát hành Helm đang hoạt động trong không gian tên của mình và các nhóm tương ứng đang khởi tạo.
helm ls -n $NAMESPACE
kubectl get pods -n $NAMESPACE
Các pod ms-is có thể mất khoảng 5 đến 10 phút để khởi động. Khi đó, đầu ra sẽ có dạng như sau:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
gaie-is ai-agents 1 2026-03-28 16:51:41.055881618 +0000 UTC deployed inferencepool-v1.3.1 v1.3.1
infra-is ai-agents 1 2026-03-28 16:51:03.71042542 +0000 UTC deployed llm-d-infra-v1.4.0 v0.4.0
ms-is ai-agents 1 2026-03-28 17:30:00.341918958 +0000 UTC deployed llm-d-modelservice-v0.4.7 v0.4.0
NAME READY STATUS RESTARTS AGE
gaie-is-epp-848965cb4-78ktp 1/1 Running 0 10m
ms-is-llm-d-modelservice-decode-67548d5f8c-f25f4 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-rblvs 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-w6fcd 1/1 Running 0 6m2s
5. Định cấu hình tính năng Định tuyến thông minh bằng GKE Inference Gateway
Ở Bước 4, việc triển khai biểu đồ Helm llm-d sẽ tự động cung cấp các đối tượng Cổng và InferencePool. InferencePool sẽ nhóm các Pod phân phát mô hình vllm dùng chung cùng một mô hình cơ sở và cấu hình điện toán.
Giờ đây, bạn cần định cấu hình một InferenceObjective để đặt mức độ ưu tiên cho các yêu cầu của tác nhân mã hoá và một HTTPRoute để hướng dẫn Cổng cách định tuyến lưu lượng truy cập đến, tận dụng Trình chọn điểm cuối để tối đa hoá số lượt truy cập vào bộ nhớ đệm KV.
Xác minh tài nguyên được tạo tự động
Trước tiên, hãy xác minh rằng biểu đồ Helm llm-d đã tạo thành công các tài nguyên Gateway và InferencePool.
kubectl get gateway,inferencepool -n $NAMESPACE
Bạn sẽ thấy một Cổng có tên là infra-is-inference-gateway và một InferencePool có tên là gaie-is. Tương tự như sau:
NAME CLASS ADDRESS PROGRAMMED AGE
gateway.gateway.networking.k8s.io/infra-is-inference-gateway gke-l7-regional-internal-managed 10.128.0.5 True 13m
NAME AGE
inferencepool.inference.networking.k8s.io/gaie-is 12m
Tạo HTTPRoute
Tài nguyên HTTPRoute sẽ liên kết Cổng của bạn với InferencePool phụ trợ. Điều này cho phép GKE Inference Gateway phân tích các phần nội dung yêu cầu đến và định tuyến chúng một cách linh hoạt để tối đa hoá số lượt truy cập vào Prefix-Cache dựa trên ngữ cảnh được chia sẻ.
Chạy lệnh sau để tạo httproute.yaml:
cat > httproute.yaml <<EOF
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: agent-route
spec:
parentRefs:
- group: gateway.networking.k8s.io
kind: Gateway
name: infra-is-inference-gateway
rules:
- backendRefs:
- group: inference.networking.k8s.io
kind: InferencePool
name: gaie-is
weight: 1
matches:
- path:
type: PathPrefix
value: /
EOF
Áp dụng tuyến đường cho cụm của bạn:
kubectl apply -f httproute.yaml -n $NAMESPACE
6. Thực thi mã an toàn bằng hộp cát tác nhân
Giờ đây, khi phần phụ trợ suy luận hiệu suất cao của chúng ta đang chạy, hãy chuẩn bị môi trường an toàn nơi mã do AI tạo sẽ thực sự thực thi một cách an toàn, tách biệt với cụm của chúng ta bằng Hộp cát tác nhân.
Triển khai Trình điều khiển hộp cát của tác nhân
Khi một tác nhân AI tạo và thực thi mã, về cơ bản, tác nhân đó đang chạy một khối lượng công việc không đáng tin cậy trên cơ sở hạ tầng của bạn. Nếu tác nhân tạo mã độc hại, thì tác nhân đó có thể cố gắng quét mạng nội bộ của bạn hoặc khai thác nút máy chủ lưu trữ cơ bản.
GKE Agent Sandbox sử dụng gVisor, một thời gian chạy vùng chứa nguồn mở cung cấp nhân khách chuyên biệt cho từng vùng chứa. Điều này ngăn mã không đáng tin cậy thực hiện các lệnh gọi hệ thống trực tiếp đến nút máy chủ.
Triển khai bộ điều khiển Hộp cát tác nhân và các thành phần bắt buộc của bộ điều khiển này bằng cách áp dụng tệp kê khai phát hành chính thức:
kubectl apply \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/manifest.yaml \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/extensions.yaml
Định cấu hình Mẫu hộp cát và Nhóm dự phòng
Tiếp theo, chúng ta thiết lập một SandboxTemplate đóng vai trò là bản thiết kế có thể dùng lại cho các môi trường phân tích Python, nhắm đến một cách rõ ràng lớp thời gian chạy gvisor. Để đơn giản hoá việc triển khai mà không cần quản lý các nhóm nút thủ công trên các cụm Chuẩn, chúng ta có thể tận dụng mọi autopilot chuẩn
ComputeClass để cung cấp linh hoạt các nút điện toán được quản lý, hỗ trợ sẵn tải công việc gVisor theo yêu cầu!
Vì việc khởi động một nhân bảo mật có thể làm tăng độ trễ, nên chúng tôi cũng triển khai một SandboxWarmPool. Điều này đảm bảo một số lượng hộp cát được khởi chạy trước theo chỉ định luôn sẵn sàng để Code Generation Agent có thể nhận và bắt đầu thực thi mã trong vòng chưa đầy một giây.
Trước tiên, hãy tạo một không gian tên mới cho các thời gian chạy hộp cát của tác nhân:
kubectl create namespace agent-sandbox
Lưu những nội dung sau dưới dạng sandbox-template-and-pool.yaml:
cat > sandbox-template-and-pool.yaml <<EOF
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxTemplate
metadata:
name: python-runtime-template
namespace: agent-sandbox
spec:
podTemplate:
metadata:
labels:
sandbox: python-sandbox-example
spec:
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: python-runtime
image: registry.k8s.io/agent-sandbox/python-runtime-sandbox:v0.1.0
ports:
- containerPort: 8888
readinessProbe:
httpGet:
path: "/"
port: 8888
initialDelaySeconds: 0
periodSeconds: 1
resources:
requests:
cpu: "250m"
memory: "512Mi"
ephemeral-storage: "512Mi"
restartPolicy: "OnFailure"
---
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxWarmPool
metadata:
name: python-sandbox-warmpool
namespace: agent-sandbox
spec:
replicas: 2
sandboxTemplateRef:
name: python-runtime-template
EOF
Áp dụng cấu hình:
kubectl apply -f sandbox-template-and-pool.yaml
Chờ tối đa 2 đến 3 phút để các nhóm warmpool khởi động. Bạn có thể kiểm tra xem chúng có chuyển đổi thành công từ Pending (trong khi quá trình tính toán cơ bản tăng lên) sang Running hay không bằng cách sử dụng:
kubectl get pods -n agent-sandbox -w
Khi bạn thấy 2 nhóm python-sandbox-warmpool-*** được liệt kê là Running và 1/1 Ready, các môi trường thực thi an toàn của bạn đã được khởi động trước và sẵn sàng để yêu cầu!
Triển khai Bộ định tuyến hộp cát
Tác nhân tạo mã của chúng tôi dựa vào một Bộ định tuyến hộp cát để gửi các lệnh thực thi một cách an toàn đến các nhóm riêng biệt.
Chạy lệnh sau để tạo sandbox-router.yaml:
cat > sandbox-router.yaml <<EOF
apiVersion: v1
kind: Service
metadata:
name: sandbox-router-svc
namespace: agent-sandbox
spec:
type: ClusterIP
selector:
app: sandbox-router
ports:
- name: http
protocol: TCP
port: 8080
targetPort: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sandbox-router-deployment
namespace: agent-sandbox
spec:
replicas: 2
selector:
matchLabels:
app: sandbox-router
template:
metadata:
labels:
app: sandbox-router
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: sandbox-router
containers:
- name: router
image: us-central1-docker.pkg.dev/k8s-staging-images/agent-sandbox/sandbox-router:v20260225-v0.1.1.post3-10-ga5bcb57
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 10
resources:
requests:
cpu: "250m"
memory: "512Mi"
limits:
cpu: "1000m"
memory: "1Gi"
securityContext:
runAsUser: 1000
runAsGroup: 1000
EOF
Áp dụng cấu hình:
kubectl apply -f sandbox-router.yaml
Triển khai tính năng Phân tách mạng
Để khoá chặt hơn nữa môi trường thực thi và ngăn chặn mọi hành vi di chuyển ngang trái phép, hãy áp dụng Chính sách mạng. Điều này sẽ "tạo khoảng trống" cho hộp cát để hộp cát không thể kết nối với Máy chủ siêu dữ liệu Google Cloud hoặc các mạng nội bộ nhạy cảm khác.
Lưu những nội dung sau dưới dạng sandbox-policy.yaml:
cat > sandbox-policy.yaml <<EOF
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: restrict-sandbox-egress
namespace: agent-sandbox
spec:
podSelector:
matchLabels:
sandbox: python-sandbox-example
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 0.0.0.0/0
except:
- 169.254.169.254/32 # Block metadata server
EOF
Áp dụng chính sách:
kubectl apply -f sandbox-policy.yaml
Xác minh các thành phần
Để đảm bảo lớp cụm hộp cát mã biệt lập được định cấu hình đầy đủ, hãy thực thi các lệnh xác thực trạng thái sau:
Trước tiên, hãy xác minh rằng các nhóm và bộ định tuyến trong hộp cát đang chạy và sẵn sàng
kubectl get pods -n agent-sandbox
Kết quả đầu ra sẽ có dạng như sau:
NAME READY STATUS RESTARTS AGE
python-sandbox-warmpool-7zlkv 1/1 Running 0 3m25s
python-sandbox-warmpool-cxln2 1/1 Running 0 3m25s
sandbox-router-deployment-668dfbbbb6-g9mpd 1/1 Running 0 42s
sandbox-router-deployment-668dfbbbb6-ppllz 1/1 Running 0 42s
Xác minh bộ cân bằng tải / IP của Bộ định tuyến trong Hộp cát
kubectl get service sandbox-router-svc -n agent-sandbox
Kết quả đầu ra sẽ có dạng như sau:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
sandbox-router-svc ClusterIP 34.118.237.244 <none> 8080/TCP 114s
Xác minh rằng quy tắc chính sách mạng xuất hiện
kubectl get networkpolicy restrict-sandbox-egress -n agent-sandbox
Kết quả đầu ra sẽ có dạng như sau:
NAME POD-SELECTOR AGE
restrict-sandbox-egress sandbox=python-sandbox-example 113s
Hãy chắc chắn rằng:
- Các nhóm
python-sandbox-warmpool-***đã sẵn sàngRunningvà1/1. - Các bản sao
sandbox-router-deployment-***làRunningvà1/1Ready. - Có thể truy cập vào
sandbox-router-svcvà chính sáchrestrict-sandbox-egressđang bảo vệ thành công mọi nhãn hộp cát trùng khớp.
Sau khi môi trường thực thi an toàn của chúng ta được bảo mật và khởi tạo, chúng ta đã sẵn sàng triển khai bộ não thực sự của hoạt động: Tác nhân tạo mã!
7. Tạo và triển khai tác nhân tạo mã (ADK)
Sau khi thiết lập cả hộp cát thực thi an toàn và phần phụ trợ LLM hiệu suất cao, giờ đây, chúng ta có thể xây dựng "bộ não" của hệ thống: một Tác nhân tạo mã bằng Bộ công cụ phát triển tác nhân (ADK).
Tác nhân này được thiết kế để đóng vai trò là một nhà phát triển Python chuyên nghiệp. Không giống như một chatbot tiêu chuẩn chỉ tạo ra văn bản, tác nhân này được trang bị công cụ thực thi mã cho phép tác nhân giải quyết vấn đề một cách tương tác. Quy trình này tuân theo một vòng lặp:
- Viết mã Python dựa trên yêu cầu của bạn.
- Thực thi mã một cách an toàn trong Hộp cát tác nhân GKE mà chúng ta đã thiết lập ở Bước 6.
- Xác minh kết quả đầu ra hoặc đọc mọi lỗi phát sinh trong quá trình thực thi.
- Cung cấp một giải pháp đã được kiểm thử, hoạt động hiệu quả và đáng tin cậy.
Bằng cách cấp cho tác nhân quyền truy cập vào một môi trường thực thi hộp cát bảo mật, chúng tôi cho phép tác nhân xác minh logic của chính nó và tự động gỡ lỗi, giúp tác nhân có khả năng thực hiện các tác vụ phát triển phần mềm một cách đáng kể!
Phát triển Tác nhân suy luận ADK
Trước tiên, chúng ta viết logic Python xác định hành vi của tác nhân và trang bị cho tác nhân đó công cụ Hộp cát mà chúng ta đã tạo ở Bước 6. Trong phần này, chúng ta cũng sẽ định cấu hình một chiến lược mô hình kết hợp: tác nhân sẽ ưu tiên mô hình Qwen tự lưu trữ chạy trên cụm GKE của bạn, nhưng sẽ tự động chuyển về Gemini 2.5 Flash trên Vertex AI nếu mô hình cục bộ chạy chậm hoặc không hoạt động, đảm bảo độ tin cậy cao.
Tạo một thư mục mới cho mã tác nhân:
mkdir -p ~/gke-ai-agent-lab/root_agent
cd ~/gke-ai-agent-lab
Tạo một tệp có tên là root_agent/agent.py với nội dung sau:
cat <<'EOF' > root_agent/agent.py
import os
from google.adk.agents import Agent
from google.adk.models.lite_llm import LiteLlm
from k8s_agent_sandbox import SandboxClient
import requests
# Instantiate the client globally to track sandboxes
sandbox_client = SandboxClient()
def run_python_code(code: str) -> str:
"""
Executes Python code safely in the GKE Agent Sandbox.
Use this tool whenever you need to execute code to solve a problem.
"""
sandbox = sandbox_client.create_sandbox(template="python-runtime-template", namespace="agent-sandbox")
try:
command = f"python3 -c \"{code}\""
result = sandbox.commands.run(command)
if result.stderr:
return f"Error: {result.stderr}"
return result.stdout
finally:
# Ensure the sandbox is deleted after use to avoid leaking resources
sandbox_client.delete_sandbox(sandbox.claim_name, namespace="agent-sandbox")
# Define the ADK Agent with a fallback mechanism.
# It prioritizes the Qwen 2.5 Coder model running on our Inference Gateway.
# If the local model is unavailable, it falls back to Gemini 2.5 Flash on Vertex AI.
root_agent = Agent(
name="CodeGenerationAgent",
model=LiteLlm(
model="openai/Qwen/Qwen2.5-Coder-14B-Instruct",
fallbacks=["vertex_ai/gemini-2.5-flash"],
timeout=10
),
instruction="""
You are an expert Python developer.
1. Write Python code to solve the user's problem.
2. Execute the code using the `run_python_code` tool to verify it works.
3. Return the exact output and a brief explanation of the code.
""",
tools=[run_python_code]
)
EOF
Tạo tệp __init__.py để ADK nhận dạng mô-đun:
echo "from . import agent" > ~/gke-ai-agent-lab/root_agent/__init__.py
Thiết lập các biến môi trường. Ứng dụng ADK cần địa chỉ IP của Cổng để định tuyến thành công các yêu cầu LLM. Vì ADK hỗ trợ các điểm cuối tiêu chuẩn tương thích với Open-AI (vLLM cung cấp thông qua Cổng của chúng tôi), nên chúng tôi có thể ghi đè URL cơ sở API mặc định!
export GATEWAY_IP=$(kubectl get gateway infra-is-inference-gateway -n $NAMESPACE -o jsonpath='{.status.addresses[0].value}')
cat <<EOF > ~/gke-ai-agent-lab/root_agent/.env
OPENAI_API_BASE=http://${GATEWAY_IP}/v1
OPENAI_API_KEY=no-key-required
# Vertex AI settings for fallback (Authentication is handled by Workload Identity)
VERTEXAI_PROJECT=$PROJECT_ID
VERTEXAI_LOCATION=${ZONE%-[a-z]}
EOF
Đóng gói ứng dụng tác nhân vào vùng chứa
Chúng ta cần đóng gói tác nhân để tác nhân có thể chạy một cách an toàn trong GKE.
Tạo một Dockerfile trong ~/gke-ai-agent-lab để cài đặt kubectl, thư viện ADK và ứng dụng Hộp cát cho tác nhân:
cat <<'EOF' > ~/gke-ai-agent-lab/Dockerfile
FROM python:3.11-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
RUN apt-get update && apt-get install -y git curl \
&& curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl" \
&& install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl \
&& rm kubectl && apt-get clean && rm -rf /var/lib/apt/lists/*
RUN pip install --no-cache-dir "google-adk[extensions,otel-gcp]>=1.27.4" litellm pandas "git+https://github.com/kubernetes-sigs/agent-sandbox.git@main#subdirectory=clients/python/agentic-sandbox-client" \
"opentelemetry-instrumentation-google-genai>=0.4b0" \
"opentelemetry-exporter-otlp" \
"opentelemetry-instrumentation-vertexai>=2.0b0"
COPY ./root_agent /app/root_agent
EXPOSE 8080
ENTRYPOINT ["adk", "web", "--host", "0.0.0.0", "--port", "8080", "--otel_to_cloud"]
EOF
Tạo một kho lưu trữ Artifact Registry để lưu trữ hình ảnh vùng chứa.
gcloud artifacts repositories create agent-repo \
--repository-format=docker \
--location=us-central1
Sử dụng Cloud Build để tạo và đẩy hình ảnh vùng chứa.
gcloud builds submit --tag us-central1-docker.pkg.dev/$PROJECT_ID/agent-repo/code-agent:v1 ~/gke-ai-agent-lab/
Triển khai vào GKE bằng RBAC
Cuối cùng, hãy triển khai tác nhân vào cụm của bạn. Quy trình triển khai bao gồm Role và RoleBinding cấp cho tác nhân quyền yêu cầu các thực thể từ SandboxWarmPool.
Quy trình triển khai này sẽ sử dụng Kubernetes ServiceAccount để cho phép tác nhân của bạn giao tiếp với API yêu cầu của Hộp cát. Thư viện này không yêu cầu Google IAM ServiceAccount vì đang truy cập vào các tài nguyên cụm cục bộ và một điểm cuối cổng vLLM cục bộ.
Tại sao nên triển khai tiêu chuẩn trong gVisor?
Ở Bước 6, chúng ta đã sử dụng các API SandboxTemplate và SandboxClaim để tạo các hộp cát tạm thời, dùng một lần cho mã Python được tạo (quá trình thực thi Công cụ).
Đối với chính Giao diện người dùng web của Agent (Brain), chúng tôi đang sử dụng các thông số kỹ thuật Deployment Kubernetes tiêu chuẩn với runtimeClassName: gvisor.
- Điểm khác biệt:
SandboxClaimstiêu chuẩn là tạm thời và có giá trị từ 0 đến 1 (lý tưởng cho các tập lệnh không đáng tin cậy).Deploymenttiêu chuẩn có thời gian chạy dài và liên tục – rất phù hợp với những giao diện người dùng web cần cóServicevà Bộ cân bằng tải Kubernetes ổn định! Bằng cách sử dụng trực tiếpruntimeClassName: gvisortrên một hoạt động triển khai tiêu chuẩn, bạn sẽ có được khả năng cô lập của nhân gVisor trong khi vẫn giữ được các tính năng tiêu chuẩn củaDeployment.
Lưu những nội dung sau dưới dạng deployment.yaml:
cat <<EOF > ~/gke-ai-agent-lab/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: code-agent
labels:
app: code-agent
spec:
replicas: 1
selector:
matchLabels:
app: code-agent
template:
metadata:
labels:
app: code-agent
spec:
serviceAccount: adk-agent-sa
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: code-agent
image: us-central1-docker.pkg.dev/YOUR_PROJECT_ID/agent-repo/code-agent:v1
imagePullPolicy: Always
env:
- name: OPENAI_API_KEY
value: "no-key-required"
- name: OPENAI_API_BASE
value: "http://YOUR_GATEWAY_IP/v1"
- name: VERTEXAI_PROJECT
value: "YOUR_PROJECT_ID"
- name: VERTEXAI_LOCATION
value: "YOUR_REGION"
- name: OTEL_SERVICE_NAME
value: "code-agent"
- name: GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY
value: "true"
- name: OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT
value: "true"
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: code-agent-service
spec:
selector:
app: code-agent
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: agent-sandbox
name: sandbox-creator-role
rules:
- apiGroups: [""]
resources: ["services", "pods", "pods/portforward"]
verbs: ["get", "list", "watch", "create"]
- apiGroups: ["extensions.agents.x-k8s.io"]
resources: ["sandboxclaims"]
verbs: ["create", "get", "list", "watch", "delete"]
- apiGroups: ["agents.x-k8s.io"]
resources: ["sandboxes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: adk-agent-binding
namespace: agent-sandbox
subjects:
- kind: ServiceAccount
name: adk-agent-sa
namespace: default
roleRef:
kind: Role
name: sandbox-creator-role
apiGroup: rbac.authorization.k8s.io
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: adk-agent-sa
EOF
Cấp quyền IAM cho tính năng quan sát
Để cho phép tác nhân gửi dữ liệu đo từ xa (nhật ký và dấu vết) đến Google Cloud, bạn cần cấp các quyền bắt buộc cho Tài khoản dịch vụ Kubernetes adk-agent-sa bằng cách sử dụng Workload Identity.
Chạy các lệnh sau trong Cloud Shell:
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# Grant permission to write logs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/logging.logWriter \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to write traces
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/cloudtrace.agent \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to use Vertex AI
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/aiplatform.user \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
Chạy lệnh sau để tự động thay thế YOUR_PROJECT_ID bằng mã dự án thực tế của bạn và áp dụng cấu hình!
sed -i "s/YOUR_PROJECT_ID/$PROJECT_ID/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_GATEWAY_IP/$GATEWAY_IP/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_REGION/$ZONE/g" ~/gke-ai-agent-lab/deployment.yaml
kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml
8. Quan sát và xác thực
Đã đến lúc kiểm thử hệ thống được tích hợp đầy đủ.
Kiểm thử Code Generation Agent trong giao diện người dùng
Tìm IP ngoài của giao diện người dùng web ADK:
kubectl get services code-agent-service
Kết quả đầu ra sẽ có dạng như sau:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
code-agent-service LoadBalancer 34.118.230.182 34.31.250.60 80:32471/TCP 2m14s
- Mở trình duyệt rồi chuyển đến
http://[EXTERNAL-IP]. - Trong giao diện web ADK, hãy đảm bảo rằng "root_agent" được chọn trong trình đơn thả xuống ở phía trên cùng bên phải. Sau đó, hãy đưa ra câu lệnh cho trợ lý ảo:
Write a python script that prints 'Hello from the isolated sandbox'.
Để quan sát cách tác nhân sử dụng phần phụ trợ suy luận và hộp cát, hãy chuyển đến các phần Khám phá số liệu thống kê về mô hình thông qua Cloud Observability và Khám phá khả năng quan sát tác nhân thông qua giao diện người dùng GKE bên dưới để xem trang tổng quan.
Khám phá khả năng quan sát tác nhân thông qua giao diện người dùng GKE
Bây giờ, bạn đã chạy một số câu lệnh, hãy xem dữ liệu đo từ xa. Điều này giúp bạn hiểu được hiệu suất của Trình lập lịch suy luận và vLLM.
Truy cập vào Trang tổng quan dành cho tác nhân
- Chuyển đến trang Kubernetes Engine > Workloads (Kubernetes Engine > Tải).
- Nhấp vào quá trình triển khai code-agent để mở trang Chi tiết triển khai.
- Nhấp vào thẻ Observability (Khả năng quan sát).
- Trong bảng điều hướng bên trái của trang tổng quan về khả năng ghi nhận, bạn sẽ thấy một mục Agent (Tác nhân) mới có các thẻ con.
Nội dung cần khám phá
Khám phá các thẻ phụ sau đây để xem hành vi của ứng dụng đại lý:
- Tổng quan: Xem thẻ điểm cho số phiên, số lượt tương tác trung bình và số lượt gọi.
- Mô hình: Xem số lượng lệnh gọi mô hình, tỷ lệ lỗi và độ trễ được phân loại theo các mô hình mà trợ lý của bạn đã sử dụng.
- Công cụ: Theo dõi các lệnh gọi công cụ và thời lượng thực thi để xem mức độ hiệu quả của tác nhân khi sử dụng công cụ thực thi hộp cát.
- Cách sử dụng: Theo dõi mức sử dụng mã thông báo và việc phân bổ tài nguyên vùng chứa tiêu chuẩn (CPU và bộ nhớ).
- Dấu vết của tác nhân: Chuyển sang thẻ này để xem danh sách các phiên thực thi hoặc khoảng thời gian theo dõi thô. Khi bạn nhấp vào một hàng, một bảng chọn sẽ mở ra kèm theo thông tin chi tiết về dấu vết đã chọn!
Bằng cách kết hợp các chỉ số cấp mô hình từ vLLM với dữ liệu đo từ xa cấp ứng dụng từ ADK, giờ đây, bạn có thể quan sát toàn bộ ngăn xếp cho tác nhân AI tạo sinh của mình trên GKE!
Khám phá số liệu thống kê về mô hình vLLM thông qua Cloud Observability
Bây giờ, bạn đã chạy một số câu lệnh, hãy xem dữ liệu đo từ xa. Điều này giúp bạn hiểu được hiệu suất của Trình lập lịch suy luận và vLLM.
Truy cập vào Trang tổng quan
- Chuyển đến Google Cloud Console.
- Chuyển đến Giám sát > Trang tổng quan.
- Tìm kiếm và chọn trang tổng quan vLLM Prometheus Overview (Tổng quan về vLLM Prometheus).
Các chỉ số thú vị cần quan sát
Khi xem trang tổng quan, hãy chú ý đến những chỉ số chính sau để xem mức độ tác động của Cổng suy luận GKE và tính năng lưu vào bộ nhớ đệm theo tiền tố:
- Mức sử dụng bộ nhớ đệm KV (
vllm:gpu_cache_usage):- Tại sao lại quan trọng: Thông tin này cho biết lượng bộ nhớ GPU đang được dùng để lưu vào bộ nhớ đệm ngữ cảnh. Nếu giá trị này cao, tức là hệ thống đang giữ lại ngữ cảnh để tăng tốc các yêu cầu trong tương lai. Nếu chạy cùng một câu lệnh nhiều lần, bạn sẽ thấy mức sử dụng này tăng lên rồi ổn định.
- Yêu cầu đang chạy so với yêu cầu đang chờ (
vllm:num_requests_runningso vớivllm:num_requests_waiting):- Tại sao điều này lại quan trọng: Điều này cho biết mức tải. Nếu số lượng yêu cầu đang chờ xử lý cao, tức là các nút của bạn đang bị quá tải.
- Thông lượng token (
vllm:request_prompt_tokens_totvàvllm:request_generation_tokens_tot):- Tại sao chỉ số này lại quan trọng: Theo dõi số lượng mã thông báo đầu vào và đầu ra mà cụm đã xử lý.
- Thời gian hiển thị mã thông báo đầu tiên (TTFT):
- Lý do chỉ số này quan trọng: Đây là chỉ số quan trọng đối với các tác nhân tương tác. Bằng cách sử dụng GKE Inference Gateway với tính năng Định tuyến nhận biết tiền tố-bộ nhớ đệm, các yêu cầu chia sẻ ngữ cảnh chung (chẳng hạn như lời nhắc hệ thống hoặc cửa sổ ngữ cảnh lớn) sẽ được định tuyến đến cùng một bản sao, giảm thiểu TTFT bằng cách sử dụng lại các lượt truy cập bộ nhớ đệm hiện có!
Thử nghiệm nên thử
Hãy thử các trường hợp này để xem sự thay đổi của các chỉ số theo thời gian thực và xác thực việc lập lịch phù hợp!
Thử nghiệm 1: "Tốc độ lặp lại" (Lượt truy cập vào bộ nhớ đệm tiền tố)
- Gửi một câu lệnh phức tạp cho trợ lý (ví dụ: "Viết một tập lệnh Python để phân tích cú pháp một tệp CSV 100 MB và tính toán số liệu thống kê.").
- Sau khi nhận được câu trả lời, hãy gửi lại chính xác câu lệnh đó ngay lập tức.
- Theo dõi Tỷ lệ truy cập bộ nhớ đệm tiền tố và Thời gian xuất hiện mã thông báo đầu tiên (TTFT).
- Những gì bạn sẽ thấy: Tỷ lệ truy cập vào bộ nhớ đệm tiền tố sẽ tăng lên 100% và TTFT sẽ giảm đáng kể!
- Ý nghĩa: GKE Inference Gateway đã nhận ra bối cảnh được chia sẻ và định tuyến bối cảnh đó đến chính bản sao đã sử dụng lại bộ nhớ đệm bối cảnh được đánh giá!
Thử nghiệm 2: Chuyển về Đám mây (Độ tin cậy của mô hình)
- Để mô phỏng lỗi của mô hình Qwen cục bộ, bạn có thể dừng dịch vụ suy luận hoặc chỉ cần cung cấp một
OPENAI_API_BASEgiả trong quá trình triển khai. - Cập nhật
OPENAI_API_BASEtrongdeployment.yamlthành một IP hoặc cổng không tồn tại rồi áp dụng các thay đổi:sed -i "s|value: \"http://$GATEWAY_IP/v1\"|value: \"http://10.0.0.1:8080/v1\"|g" ~/gke-ai-agent-lab/deployment.yaml kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml - Đợi cho đến khi nhóm khởi động lại, sau đó gửi một câu lệnh cho tác nhân trong giao diện người dùng.
- Những gì bạn sẽ thấy: Tác nhân vẫn phản hồi thành công!
- Ý nghĩa: Do cấu hình
fallbacks, ADK nhận ra lỗi của điểm cuối Qwen cục bộ và chuyển yêu cầu một cách liền mạch đến Gemini 2.5 Flash trên Vertex AI. Xin lưu ý rằng vì các lệnh gọi dự phòng này đến Vertex AI sẽ bỏ qua Cổng suy luận vLLM cục bộ của bạn, nên chúng sẽ không xuất hiện trong trang tổng quan Khả năng ghi nhận của tác nhân > Mô hình. Trang tổng quan này chỉ theo dõi lưu lượng truy cập đi qua vLLM.
Tìm hiểu sức mạnh của tính năng Phân bổ tài nguyên linh động (DRA)
Mặc dù vLLM và Inference Gateway tối ưu hoá cách các yêu cầu được định tuyến và phân phát, nhưng Phân bổ tài nguyên linh hoạt (DRA) là yếu tố giúp bạn có thể gắn phần cứng phù hợp chính xác vào khối lượng công việc ngay từ đầu.
DRA nâng cao khả năng quản lý phần cứng một cách chi tiết trên toàn bộ cụm bằng cách cho phép bạn xác định các tài nguyên phần cứng linh hoạt bằng cách sử dụng ResourceClaimTemplate và DeviceClasses.
Tại sao DRA là một yếu tố đột phá cho các tải công việc AI:
- Yêu cầu phần cứng chi tiết: Với DRA, bạn không chỉ đảm bảo các khối lượng công việc được lên lịch trên những máy có bộ tăng tốc phù hợp, mà còn có thể yêu cầu các tài nguyên đó để đảm bảo rằng chúng chỉ được sử dụng bởi khối lượng công việc được liên kết với ResourceClaim.
- Vòng đời tách biệt: Yêu cầu về thiết bị được quản lý độc lập với vòng đời của Pod. Nếu một Pod gặp sự cố, yêu cầu GPU có thể vẫn tồn tại, để việc triển khai tổng thể hoặc đối tượng tải khác có thể được khởi động lại mà không cần phải đợi GPU được giải phóng và lấy lại.
- Tiêu chuẩn hoá nhiều nhà cung cấp: DRA cung cấp một API Kubernetes hợp nhất cho cả GPU NVIDIA và TPU của Google. Bạn sử dụng chính xác cùng một giản đồ cho dù đang triển khai cho giản đồ này hay giản đồ kia, giúp các tệp kê khai YAML của khối lượng công việc có tính di động cao!
Trong lớp học lập trình này, bạn đã thấy điều này trong thực tế khi định cấu hình các giá trị Helm để liên kết với gpu-claim-template một cách liền mạch, mà không cần có các cấu hình trình bổ trợ thiết bị đang chờ xử lý chặn quá trình triển khai của bạn.
Tìm hiểu vai trò của llm-d
Trong khi vLLM đánh giá trọng số nơ-ron và Cổng GKE định tuyến các truy vấn, llm-d đóng vai trò là lớp cấu hình và "Keo" liên kết tất cả các thành phần này với nhau.
Nếu không có llm-d, bạn sẽ phải viết các tệp kê khai Kubernetes thô để khai báo việc triển khai vLLM, các cổng dịch vụ, các điểm gắn kết ổ đĩa và các yêu cầu về tài nguyên DRA từ đầu.
Tại sao nên sử dụng llm-d trong quá trình triển khai?
- Cấu hình hợp nhất (Ghi đè một dòng):
llm-dCác biểu đồ Helm kết hợp các tài nguyên Kubernetes phức tạp, cấp thấp thành các nút bật/tắt cấp cao, gọn gàng (chẳng hạn như thiết lậpaccelerator.dra: true). - "Well-Lit-Paths" (Đường dẫn rõ ràng) đã được kiểm tra trước: Kho lưu trữ
llm-dchứa các cấu hình đã được chuyên gia đo điểm chuẩn và kiểm thử. Khi triển khaillm-d-modelservice, bạn sẽ nhận được các giá trị mặc định được tối ưu hoá cho mức sử dụng bộ nhớ GPU, thời gian thăm dò được đề xuất (trạng thái hoạt động/sẵn sàng) và mức độ hiển thị chính xác để thu thập chỉ số. - Ánh xạ khả năng ghi nhận liền mạch: Ngay từ đầu,
llm-dđảm bảo các cổng vùng chứa tiêu chuẩn và đường dẫn trích xuất (/metrics) được hiển thị chính xác, giúp bạn dễ dàng kết nối việc triển khai với Google Cloud Monitoring mà không cần gỡ lỗi theo cách thủ công.
Nói tóm lại, llm-d cung cấp bản thiết kế kiến trúc có thể sử dụng lại để nhà phát triển không phải sáng tạo lại từ đầu mỗi khi triển khai một ngăn xếp suy luận trên GKE.
Tìm hiểu chuyên sâu: Cổng suy luận GKE
Trình cân bằng tải tiêu chuẩn Lớp 7 hoạt động bằng cách xem xét các tiêu đề HTTP như đường dẫn (/v1/completions) hoặc cookie. Cổng suy luận GKE có phạm vi hoạt động rộng hơn nhiều, được thiết kế riêng cho lưu lượng truy cập AI tạo sinh.
Cách dữ liệu của bên thứ nhất thúc đẩy hiệu suất và hiệu quả:
- Định tuyến dựa trên nội dung (Băm câu lệnh): Cổng suy luận GKE chặn nội dung yêu cầu JSON. Thao tác này tính toán một hàm băm của câu lệnh và theo dõi bản sao phụ trợ nào đã giữ các mã thông báo đó trong bộ nhớ GPU (KV Cache).
- Tối đa hoá số lượt truy cập vào bộ nhớ đệm: Trong quá trình thử nghiệm, khi bạn lặp lại một câu lệnh, Cổng sẽ gửi câu lệnh đó đến bản sao chính xác. Việc đánh giá một câu lệnh cần nhiều tài nguyên tính toán. Bằng cách sử dụng lại bộ nhớ đệm, bạn sẽ tránh được việc "đọc lại" câu lệnh, tiết kiệm tiền và thời gian GPU.
- Giảm Thời gian xuất hiện mã thông báo đầu tiên (TTFT): TTFT là chỉ số quan trọng về khả năng sử dụng đối với các tác nhân tương tác với người dùng. Bằng cách truy cập vào bộ nhớ đệm, mô hình có thể bắt đầu tạo mã thông báo trong vài mili giây thay vì vài giây.
- Phân phối tải thông minh: Nếu VRAM của một bản sao chứa đầy các lượt truy cập bộ nhớ đệm, Cổng có thể định tuyến động một câu lệnh mới đến một bản sao khác có dung lượng, cân bằng hiệu quả với tính sẵn có.
Cách Hộp cát tác nhân giảm thiểu rủi ro
Trong phòng thí nghiệm này, chúng tôi đã minh hoạ cách Agent Sandbox bảo vệ cơ sở hạ tầng của bạn khỏi những rủi ro liên quan đến tác nhân AI bằng cách cung cấp 2 lớp cách ly:
- Cách ly công cụ thực thi: Agent thực thi mã mà nó tạo trong một hộp cát tạm thời. Điều này đảm bảo rằng mã không đáng tin cậy do LLM tạo ra sẽ chạy trong một môi trường an toàn, biệt lập, giúp bảo vệ tác nhân và cụm.
- Khởi động nhanh: Bằng cách sử dụng WarmPool, các hộp cát mới sẽ khởi động trong vòng chưa đầy một giây, sẵn sàng thực thi mã.
- Cách ly chính Agent: Chúng tôi cũng chạy chính ứng dụng tác nhân trong một nút có gVisor (thông qua
runtimeClassName: gvisor) để cung cấp khả năng bảo vệ chuyên sâu trước các lỗ hổng bảo mật trong chuỗi cung ứng trong các phần phụ thuộc của tác nhân.
Sau đây là lý do khiến quy trình này tạo ra một ranh giới bảo mật vững chắc như vậy:
- Chặn lệnh gọi hệ thống: gVisor chặn các lệnh gọi hệ thống trước khi chúng đến được nhân Linux của máy chủ. Điều này sẽ chặn các lỗ hổng bảo mật cố gắng thoát khỏi vùng chứa để truy cập vào nút máy chủ.
- Hạn chế di chuyển ngang: Kết hợp với Chính sách mạng, ngay cả khi môi trường bị xâm nhập, môi trường đó cũng không thể quét các máy chủ siêu dữ liệu nội bộ của bạn hoặc chuyển sang các dịch vụ nhạy cảm khác trong cụm.
Chạy các Tác nhân đầy đủ trong Hộp cát
Trong phòng thí nghiệm này, chúng ta đã sử dụng hộp cát làm công cụ cho một ứng dụng tác nhân liên tục. Tuy nhiên, để có độ bảo mật tối đa (đặc biệt là khi xử lý dữ liệu nhạy cảm hoặc phục vụ nhiều người dùng không đáng tin cậy), bạn có thể chạy toàn bộ ứng dụng tác nhân trong một hộp cát chuyên dụng cho mỗi phiên hoặc người dùng. Điều này đảm bảo sự cô lập hoàn toàn bộ nhớ, trạng thái và môi trường thực thi của tác nhân. Môi trường này sẽ bị hủy bỏ ngay sau khi phiên kết thúc.
9. Dọn dẹp
Để tránh phát sinh phí cho tài khoản Google Cloud của bạn đối với các tài nguyên được dùng trong lớp học lập trình này, hãy làm theo các bước sau để xoá các tài nguyên đó.
Xoá từng tài nguyên
- Xoá Cụm GKE:
gcloud container clusters delete $CLUSTER_NAME --zone $ZONE --quiet
- Xoá kho lưu trữ Artifact Registry:
gcloud artifacts repositories delete agent-repo --location=us-central1 --quiet
- Xoá mạng VPC:
gcloud compute networks delete ai-agent-network --quiet
Xoá dự án
Nếu không cần dự án nữa, bạn có thể xoá dự án sau khi xoá các tài nguyên:
gcloud projects delete $PROJECT_ID
10. Tóm tắt
Xin chúc mừng! Bạn đã tạo và triển khai thành công một tác nhân tạo mã an toàn, hiệu suất cao trên GKE.
Kiến thức bạn học được
- Cách định cấu hình và sử dụng Tính năng phân bổ tài nguyên động (DRA) trong GKE để quản lý tài nguyên GPU.
- Cách sử dụng Cổng suy luận GKE để tối ưu hoá hiệu suất phân phát LLM thông qua định tuyến có nhận biết bộ nhớ đệm tiền tố.
- Cách sử dụng Hộp cát tác nhân (gVisor) để thực thi mã không đáng tin cậy một cách an toàn trên GKE.
- Cách sử dụng Dịch vụ được quản lý của Google Cloud cho Prometheus để giám sát hiệu suất của vLLM.
- Cách định cấu hình và xem Khả năng ghi nhận tác nhân bằng ADK và OpenTelemetry được quản lý của GKE.
Các bước tiếp theo và tài liệu tham khảo
- Hộp cát tác nhân: Tìm hiểu về Hộp cát tác nhân trên GKE và Các nhóm hộp cát GKE.
- llm-d: Đọc Hướng dẫn về llm-d và xem Kho lưu trữ llm-d trên GitHub.
- Phân bổ tài nguyên linh động: Tìm hiểu về DRA trên GKE.
- GKE Inference Gateway: Khám phá các khái niệm về Inference Gateway.
- Các lớp học lập trình khác: Tìm thêm hướng dẫn tại Google Cloud Codelabs.