
1. 简介
概览
在本实验中,您将学习如何在 Google Kubernetes Engine (GKE) 上构建和部署安全的代码生成代理。代码生成代理需要执行可能不受信任的代码,因此需要安全的沙盒环境。您还将学习如何配置采用混合模型策略的代理,使其能够从 GKE 上的自行托管开放模型回退到 Vertex AI 的托管式 Gemini 服务,从而提高可靠性。此外,您还将了解如何使用 GKE 推理网关和动态资源分配 (DRA) 来优化推理服务。最后,您将学习如何利用 Google Cloud Observability 使用 Managed Prometheus 监控推理堆栈。
架构
您将构建的系统架构如下:
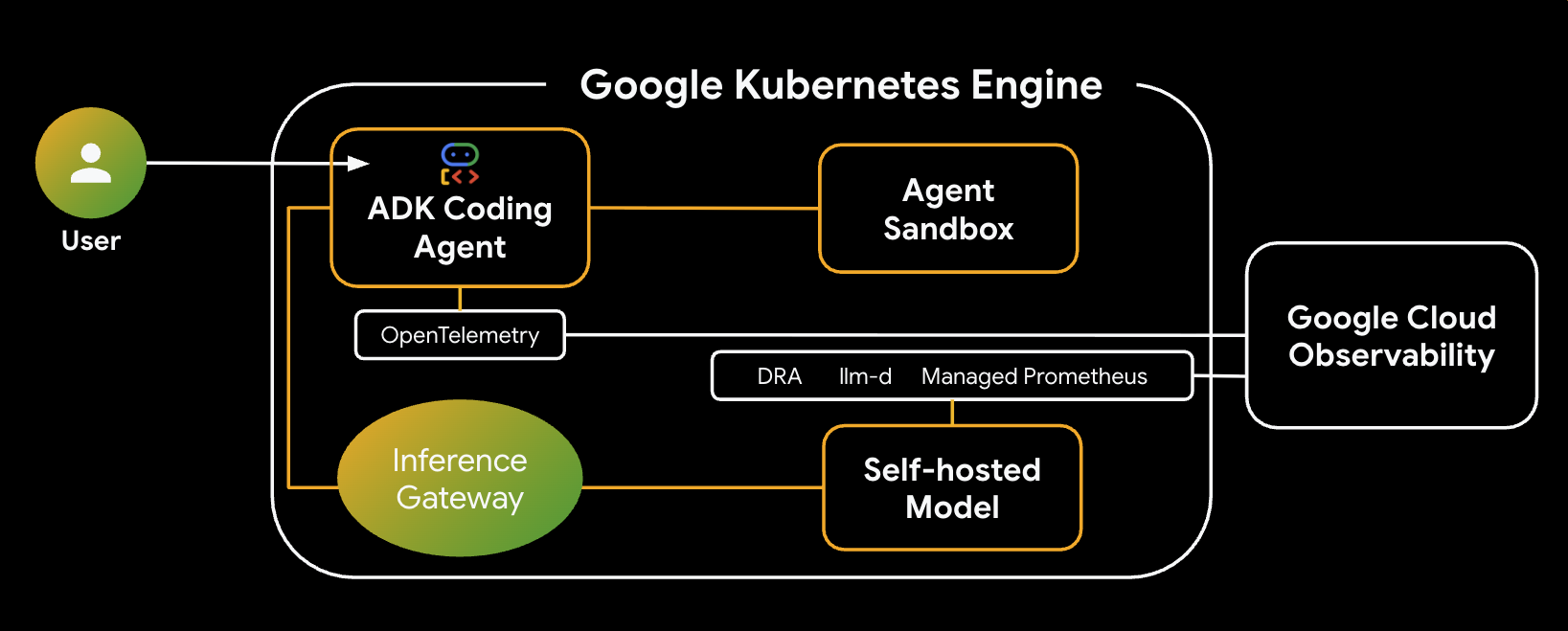
主要组件和优势
- 动态资源分配 (DRA):在本实验中用于为模型服务器 Pod 动态声明和分配特定的 GPU 资源 (NVIDIA L4),确保我们的推理工作负载能够精确地定位到硬件。了解 GKE 上的 DRA。
- llm-d 和 vLLM:提供模型部署框架和用于部署 Qwen 模型的 Helm 图表。在本实验中,它负责处理推理请求并与 DRA 集成以进行资源管理(在本实验中,分离式服务未启用)。阅读 llm-d 指南,并查看 llm-d GitHub 代码库。
- GKE 推理网关:将 AI 感知型路由逻辑直接移入负载平衡器。在此实验中,它会路由请求,以最大限度地提高前缀缓存命中率,从而缩短首 token 延迟 (TTFT)。探索推理网关概念。
- 智能体沙盒 (gVisor):为执行 AI 智能体生成的代码提供安全隔离。它使用 gVisor 提供深层内核隔离,保护宿主节点免受不受信任的工作负载的影响。了解 GKE 上的 Agent Sandbox 和 GKE Sandbox Pod。
您将执行的操作
- 预配基础架构:设置一个启用了动态资源分配 (DRA) 的 GKE 集群,以进行 GPU 管理。
- 部署推理堆栈:部署
llm-d和 vLLM,并进行智能推理调度。 - 配置智能路由:使用 GKE 推理网关进行前缀缓存感知路由。
- 安全的代码执行:部署 Agent Sandbox (gVisor) 以安全地运行 AI 生成的代码。
- 观察和验证:使用 Google Cloud Monitoring 和 Managed Prometheus 查看模型部署指标。
学习内容
- 如何在 GKE 中配置和使用动态资源分配 (DRA)。
- 如何使用 GKE Inference Gateway 优化 LLM 服务性能。
- 如何使用 Agent Sandbox 在 GKE 上安全地执行不受信任的代码。
- 如何使用 Google Cloud Managed Service for Prometheus 监控 vLLM 性能。
2. 设置和要求
项目设置
创建 Google Cloud 项目
- 在 Google Cloud 控制台的项目选择器页面上,选择或创建一个 Google Cloud 项目。
- 确保您的 Cloud 项目已启用结算功能。了解如何检查项目是否已启用结算功能。
启动 Cloud Shell
Cloud Shell 是在 Google Cloud 中运行的命令行环境,预加载了必要的工具。
- 点击 Google Cloud 控制台顶部的激活 Cloud Shell。
- 连接到 Cloud Shell 后,验证您的身份验证:
gcloud auth list - 确认您的项目已配置:
gcloud config get project - 如果项目未按预期设置,请进行设置:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
3. 预配基础设施和动态资源分配 (DRA)
在第一步中,您将配置 GKE 集群以使用现代加速器分配 (DRA) 而不是旧版设备插件。这样,您就可以灵活地共享和分配 GPU 或 TPU 来运行代码生成工作负载。
前提条件:您的 GKE Standard 集群必须运行 1.34 版或更高版本才能支持 DRA。
启用 Google Cloud API
启用此 Codelab 所需的 Google Cloud API,特别是 Compute Engine 和 Kubernetes Engine API。
gcloud services enable compute.googleapis.com container.googleapis.com networkservices.googleapis.com cloudbuild.googleapis.com artifactregistry.googleapis.com telemetry.googleapis.com cloudtrace.googleapis.com aiplatform.googleapis.com
设置环境变量
为简化设置,请定义环境变量。您可以根据需要调整地区或命名惯例。
export PROJECT_ID=$(gcloud config get-value project)
export ZONE=us-central1-a
export CLUSTER_NAME=ai-agent-cluster
export NODEPOOL_NAME=dra-accelerator-pool
gcloud config set project $PROJECT_ID
gcloud config set compute/region $ZONE
创建工作目录
为此实验创建一个专用工作目录,并导航到该目录,以便文件井井有条:
mkdir -p ~/gke-ai-agent-lab
cd ~/gke-ai-agent-lab
配置权限(可选)
如果您在受限项目或共享环境中运行,请确保您的账号拥有创建集群和运行 build 的必要权限:
export MY_ACCOUNT=$(gcloud config get-value account)
# Grant Container Admin to create clusters and manage nodes if needed
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/container.admin"
# Grant Cloud Build Builder to run builds
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="user:$MY_ACCOUNT" \
--role="roles/cloudbuild.builds.builder"
创建 GKE 集群
您的 GKE Standard 集群必须运行 1.34 版或更高版本才能支持 DRA。您还需要启用 Gateway API 控制器,以支持智能推理调度。
您将为此实验创建新的 VPC 网络和子网。
首先,创建 VPC 网络:
gcloud compute networks create ai-agent-network --subnet-mode=custom
接下来,为 GKE 节点创建子网:
gcloud compute networks subnets create ai-agent-subnet \
--network=ai-agent-network \
--range=10.0.0.0/20 \
--region=us-central1
Gateway API (gke-l7-regional-internal-managed) 还要求使用专用子网来托管 Envoy 代理。在新网络中创建此代理专用子网:
gcloud compute networks subnets create proxy-only-subnet \
--purpose=REGIONAL_MANAGED_PROXY \
--role=ACTIVE \
--region=us-central1 \
--network=ai-agent-network \
--range=192.168.10.0/24
现在,使用新网络和子网创建集群:
gcloud beta container clusters create $CLUSTER_NAME \
--zone $ZONE \
--num-nodes 1 \
--machine-type n2-standard-4 \
--workload-pool=${PROJECT_ID}.svc.id.goog \
--gateway-api=standard \
--managed-otel-scope=COLLECTION_AND_INSTRUMENTATION_COMPONENTS \
--network=ai-agent-network \
--subnetwork=ai-agent-subnet
创建停用了默认插件的节点池
如需将设备管理权交给 DRA,您必须创建一个明确停用默认 GPU 驱动程序安装和标准设备插件的节点池。
运行以下 gcloud 命令,以预配具有必要 DRA 标签的 GPU 节点池(例如,使用 NVIDIA L4):
gcloud container node-pools create $NODEPOOL_NAME \
--cluster=$CLUSTER_NAME \
--location=$ZONE \
--machine-type=g2-standard-24 \
--accelerator=type=nvidia-l4,count=2,gpu-driver-version=disabled \
--node-labels=gke-no-default-nvidia-gpu-device-plugin=true,nvidia.com/gpu.present=true \
--num-nodes 3
通过 DaemonSet 安装 NVIDIA 驱动程序
使用预配置的 Google Cloud DaemonSet 将所需的基础 NVIDIA 设备驱动程序手动安装到节点上:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
安装 DRA 驱动程序
接下来,将特定的 DRA 驱动程序安装到集群中。对于 NVIDIA GPU,您可以通过 Helm 部署此功能:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
helm install nvidia-dra-driver-gpu nvidia/nvidia-dra-driver-gpu \
--version="25.3.2" --create-namespace --namespace=nvidia-dra-driver-gpu \
--set nvidiaDriverRoot="/home/kubernetes/bin/nvidia/" \
--set gpuResourcesEnabledOverride=true \
--set resources.computeDomains.enabled=false \
--set kubeletPlugin.priorityClassName="" \
--set 'kubeletPlugin.tolerations[0].key=nvidia.com/gpu' \
--set 'kubeletPlugin.tolerations[0].operator=Exists' \
--set 'kubeletPlugin.tolerations[0].effect=NoSchedule'
了解 DeviceClass
您无需手动编写或应用 DeviceClass YAML。为 DRA 设置 GKE 基础设施并安装驱动程序后,节点上运行的 DRA 驱动程序会自动在集群中为您创建 DeviceClass 对象。
配置 ResourceClaimTemplate
为了让 llm-d Pod 能够动态请求这些加速器,您需要创建 ResourceClaimTemplate。此模板定义了所请求的设备配置,并告知 Kubernetes 为您的工作负载自动创建唯一的每个 Pod ResourceClaim。
运行以下命令以创建 claim-template.yaml:
cat > claim-template.yaml <<EOF
apiVersion: resource.k8s.io/v1
kind: ResourceClaimTemplate
metadata:
name: gpu-claim-template
spec:
spec:
devices:
requests:
- name: single-gpu
exactly:
deviceClassName: gpu.nvidia.com
allocationMode: ExactCount
count: 1
EOF
将模板应用于集群:
kubectl apply -f claim-template.yaml
4. 使用 llm-d 和 DRA 部署智能推理调度
在此步骤中,您将部署大语言模型,使其位于经过推理调度器增强的智能 Envoy 负载平衡器后面。此配置通过应用前缀缓存感知路由来优化模型部署。GKE Inference Gateway 可识别微服务之间的共享上下文,并将请求智能地路由到同一模型副本,从而最大限度地提高缓存命中率、缩短首 token 延迟时间,并实现出色的每美元性能。
准备环境
设置目标命名空间。
export NAMESPACE=ai-agents
kubectl create namespace $NAMESPACE
安全地存储您的 Hugging Face 令牌,这是提取模型权重所必需的。
# Replace with your actual Hugging Face token
kubectl create secret generic llm-d-hf-token \
--from-literal=HF_TOKEN="your_hugging_face_token" \
-n $NAMESPACE
创建 Helm 配置文件
模型服务和推理网关扩展程序的配置基于官方 llm-d 指南。
首先,为模型服务创建 ms-values.yaml 文件:
cat <<EOF > ms-values.yaml
multinode: false
modelArtifacts:
uri: "hf://Qwen/Qwen2.5-Coder-14B-Instruct"
name: "Qwen/Qwen2.5-Coder-14B-Instruct"
size: 50Gi # Slightly larger than the default to accommodate weights
authSecretName: "llm-d-hf-token"
labels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
llm-d.ai/accelerator-variant: "gpu"
llm-d.ai/accelerator-vendor: "nvidia"
llm-d.ai/model: "qwen-2-5-coder-14b"
routing:
proxy:
enabled: false # removes sidecar from deployment - no PD in inference scheduling
targetPort: 8000 # controls vLLM port to matchup with sidecar if deployed
accelerator:
dra: true
type: "nvidia"
resourceClaimTemplates:
nvidia:
class: "gpu.nvidia.com"
match: "exactly"
name: "gpu-claim-template"
decode:
create: true
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
parallelism:
tensor: 2
data: 1
replicas: 3
monitoring:
podmonitor:
enabled: true
portName: "vllm"
path: "/metrics"
interval: "30s"
containers:
- name: "vllm"
image: ghcr.io/llm-d/llm-d-cuda:v0.5.1
modelCommand: vllmServe
args:
- "--disable-uvicorn-access-log"
- "--gpu-memory-utilization=0.85"
- "--enable-auto-tool-choice"
- "--tool-call-parser"
- "hermes"
ports:
- containerPort: 8000
name: vllm
protocol: TCP
resources:
limits:
cpu: '16'
memory: 64Gi
requests:
cpu: '16'
memory: 64Gi
mountModelVolume: true
volumeMounts:
- name: metrics-volume
mountPath: /.config
- name: shm
mountPath: /dev/shm
- name: torch-compile-cache
mountPath: /.cache
startupProbe:
httpGet:
path: /v1/models
port: vllm
initialDelaySeconds: 15
periodSeconds: 30
timeoutSeconds: 5
failureThreshold: 120
livenessProbe:
httpGet:
path: /health
port: vllm
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /v1/models
port: vllm
periodSeconds: 5
timeoutSeconds: 2
failureThreshold: 3
volumes:
- name: metrics-volume
emptyDir: {}
- name: torch-compile-cache
emptyDir: {}
- name: shm
emptyDir:
medium: Memory
sizeLimit: 20Gi
prefill:
create: false
EOF
接下来,为 GKE 推理网关扩展程序创建 gaie-values.yaml 文件:
cat <<EOF > gaie-values.yaml
inferenceExtension:
replicas: 1
image:
name: llm-d-inference-scheduler
hub: ghcr.io/llm-d
tag: v0.6.0
pullPolicy: Always
extProcPort: 9002
pluginsConfigFile: "default-plugins.yaml"
tracing:
enabled: false
monitoring:
interval: "10s"
prometheus:
enabled: true
auth:
secretName: inference-scheduling-gateway-sa-metrics-reader-secret
inferencePool:
targetPorts:
- number: 8000
modelServerType: vllm
modelServers:
matchLabels:
llm-d.ai/inference-serving: "true"
llm-d.ai/guide: "inference-scheduling"
EOF
了解配置
此配置可设置高性能推理堆栈,并具有以下关键功能:
- 模型选择:它使用针对代码生成和工具使用进行了优化的 Qwen 2.5 Coder 14B 模型 (
modelArtifacts)。 - DRA 集成:
accelerator部分启用了动态资源分配 (DRA)dra: true,目标是gpu.nvidia.com设备类和我们之前创建的gpu-claim-template。 - 性能优化:
parallelism.tensor: 2用于配置 GPU 之间的张量并行处理。args的 vLLM 包含--enable-auto-tool-choice,以确保我们的编码代理可以有效地使用工具。- 减少后的
cpu和memory请求适合g2-standard-24机器类型。
- 智能路由:推理网关扩展程序 (
gaie-values.yaml) 配置为监控vllm模型服务器并路由请求,以最大限度地提高 KV 缓存命中率。
通过 Helm 部署推理调度堆栈
现在,添加 llm-d Helm 代码库,并单独部署基础架构、网关扩展服务和模型服务。
首先,添加所需的代码库:
helm repo add llm-d-infra https://llm-d-incubation.github.io/llm-d-infra/
helm repo add llm-d-modelservice https://llm-d-incubation.github.io/llm-d-modelservice/
helm repo update
部署基础架构前提条件
此图表会安装堆栈所需的基本网关配置。
helm install infra-is llm-d-infra/llm-d-infra \
--namespace $NAMESPACE \
--set gateway.gatewayClassName=gke-l7-rilb \
--set gateway.gatewayParameters.enabled=false \
--set gateway.gatewayParameters.istio.accessLogging=false
部署 GKE 推理网关扩展程序
此步骤会部署 InferencePool 和端点选择器,它们会监控模型的 KV 缓存,以做出智能的路由决策。
helm install gaie-is oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool \
--version v1.3.1 \
--namespace $NAMESPACE \
-f gaie-values.yaml \
--set provider.name=gke \
--set inferenceExtension.monitoring.prometheus.enabled=true
部署模型服务
最后,部署 LLM 服务,该服务现在将使用 DRA 安全地声明 L4 GPU。
helm install ms-is llm-d-modelservice/llm-d-modelservice \
--version v0.4.7 \
--namespace $NAMESPACE \
-f ms-values.yaml \
--set decode.monitoring.podmonitor.enabled=false
为 vLLM 启用 Google Cloud Observability
通用 Helm 图表通常会尝试部署标准 Prometheus Operator PodMonitor 资源 (monitoring.coreos.com/v1),如果您未安装这些 CRD,可能会导致错误。
请勿切换 Helm 的内置监控切换开关,而是将其保持为 false,并使用兼容的 monitoring.googleapis.com/v1 API 组手动应用 Google Cloud Managed Prometheus (GMP) PodMonitoring 资源。
运行以下命令以创建 podmonitoring.yaml:
cat > podmonitoring.yaml <<EOF
apiVersion: monitoring.googleapis.com/v1
kind: PodMonitoring
metadata:
name: ms-vllm-metrics
spec:
selector:
matchLabels:
llm-d.ai/model: "qwen-2-5-coder-14b" # Matches the label in values.yaml
endpoints:
- port: 8000 # vllm port
interval: 30s
path: /metrics
EOF
将 PodMonitoring 资源应用到您的集群:
kubectl apply -f podmonitoring.yaml -n $NAMESPACE
验证安装
验证组件是否已成功安装。您应该会看到命名空间中的所有三个 Helm 版本都处于活跃状态,并且相应的 pod 正在初始化。
helm ls -n $NAMESPACE
kubectl get pods -n $NAMESPACE
ms-is pod 可能需要大约 5-10 分钟才能启动。当用户执行此操作时,输出应如下所示:
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
gaie-is ai-agents 1 2026-03-28 16:51:41.055881618 +0000 UTC deployed inferencepool-v1.3.1 v1.3.1
infra-is ai-agents 1 2026-03-28 16:51:03.71042542 +0000 UTC deployed llm-d-infra-v1.4.0 v0.4.0
ms-is ai-agents 1 2026-03-28 17:30:00.341918958 +0000 UTC deployed llm-d-modelservice-v0.4.7 v0.4.0
NAME READY STATUS RESTARTS AGE
gaie-is-epp-848965cb4-78ktp 1/1 Running 0 10m
ms-is-llm-d-modelservice-decode-67548d5f8c-f25f4 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-rblvs 1/1 Running 0 6m2s
ms-is-llm-d-modelservice-decode-67548d5f8c-w6fcd 1/1 Running 0 6m2s
5. 使用 GKE 推理网关配置智能路由
在第 4 步中,部署 llm-d Helm 图表会自动预配网关和 InferencePool 对象。InferencePool 用于对共享相同基础模型和计算配置的 vllm 模型部署 Pod 进行分组。
现在,您需要配置 InferenceObjective 以设置编码代理请求的优先级,并配置 HTTPRoute 以指示网关如何路由传入流量,从而利用端点选择器最大限度地提高 KV 缓存命中率。
验证自动生成的资源
首先,验证 llm-d Helm 图表是否已成功创建网关和 InferencePool 资源。
kubectl get gateway,inferencepool -n $NAMESPACE
您应该会看到一个名为 infra-is-inference-gateway 的网关和一个名为 gaie-is 的 InferencePool。类似于以下内容:
NAME CLASS ADDRESS PROGRAMMED AGE
gateway.gateway.networking.k8s.io/infra-is-inference-gateway gke-l7-regional-internal-managed 10.128.0.5 True 13m
NAME AGE
inferencepool.inference.networking.k8s.io/gaie-is 12m
创建 HTTPRoute
HTTPRoute 资源会将您的网关映射到后端 InferencePool。这会告知 GKE 推理网关分析传入的请求正文,并根据共享上下文动态路由这些请求,以最大限度地提高前缀缓存命中率。
运行以下命令以创建 httproute.yaml:
cat > httproute.yaml <<EOF
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: agent-route
spec:
parentRefs:
- group: gateway.networking.k8s.io
kind: Gateway
name: infra-is-inference-gateway
rules:
- backendRefs:
- group: inference.networking.k8s.io
kind: InferencePool
name: gaie-is
weight: 1
matches:
- path:
type: PathPrefix
value: /
EOF
将路由应用到您的集群:
kubectl apply -f httproute.yaml -n $NAMESPACE
6. 使用智能体沙盒安全地执行代码
现在,高性能推理后端已在运行,接下来我们来准备安全环境,让 AI 生成的代码在其中实际执行,并使用 Agent Sandbox 安全地与集群隔离。
部署 Agent Sandbox 控制器
当 AI 智能体生成并执行代码时,它实际上是在您的基础设施上运行不受信任的工作负载。如果智能体生成恶意代码,则可能会尝试扫描您的内部网络或利用底层宿主节点。
GKE 代理沙盒利用 gVisor(一种开源容器运行时),为每个容器提供专门的 guest 内核。这样可以防止不可信的代码直接向宿主节点发出系统调用。
应用正式版清单,以部署 Agent Sandbox 控制器及其所需的组件:
kubectl apply \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/manifest.yaml \
-f https://github.com/kubernetes-sigs/agent-sandbox/releases/download/v0.1.0/extensions.yaml
配置沙盒模板和暖池
接下来,我们建立一个 SandboxTemplate,作为 Python 分析环境的可重用蓝图,明确以 gvisor 运行时类为目标。为了简化部署,而无需在 Standard 集群上管理手动节点池,我们可以利用任何标准 autopilot
ComputeClass 可用于动态预配托管式计算节点,以按需原生支持 gVisor 工作负载!
由于初始化安全内核可能会增加延迟时间,因此我们还部署了 SandboxWarmPool。这可确保系统始终保持指定数量的预初始化沙盒处于就绪状态,以便代码生成代理可以声明这些沙盒,并在不到一秒的时间内开始执行代码。
首先,为代理沙盒运行时创建一个新的命名空间:
kubectl create namespace agent-sandbox
将以下内容保存为 sandbox-template-and-pool.yaml:
cat > sandbox-template-and-pool.yaml <<EOF
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxTemplate
metadata:
name: python-runtime-template
namespace: agent-sandbox
spec:
podTemplate:
metadata:
labels:
sandbox: python-sandbox-example
spec:
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: python-runtime
image: registry.k8s.io/agent-sandbox/python-runtime-sandbox:v0.1.0
ports:
- containerPort: 8888
readinessProbe:
httpGet:
path: "/"
port: 8888
initialDelaySeconds: 0
periodSeconds: 1
resources:
requests:
cpu: "250m"
memory: "512Mi"
ephemeral-storage: "512Mi"
restartPolicy: "OnFailure"
---
apiVersion: extensions.agents.x-k8s.io/v1alpha1
kind: SandboxWarmPool
metadata:
name: python-sandbox-warmpool
namespace: agent-sandbox
spec:
replicas: 2
sandboxTemplateRef:
name: python-runtime-template
EOF
应用配置:
kubectl apply -f sandbox-template-and-pool.yaml
等待暖池 Pod 初始化,最多需要 2-3 分钟。您可以使用以下命令检查它们是否成功从 Pending(在底层计算扩容时)过渡到 Running:
kubectl get pods -n agent-sandbox -w
当您看到两个 python-sandbox-warmpool-*** pod 列为 Running 和 1/1 Ready 时,您的安全执行环境已预热完毕,可以声明了!
部署沙盒路由器
我们的代码生成代理依赖于沙盒路由器,以安全地将执行命令分派给隔离的 pod。
运行以下命令以创建 sandbox-router.yaml:
cat > sandbox-router.yaml <<EOF
apiVersion: v1
kind: Service
metadata:
name: sandbox-router-svc
namespace: agent-sandbox
spec:
type: ClusterIP
selector:
app: sandbox-router
ports:
- name: http
protocol: TCP
port: 8080
targetPort: 8080
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sandbox-router-deployment
namespace: agent-sandbox
spec:
replicas: 2
selector:
matchLabels:
app: sandbox-router
template:
metadata:
labels:
app: sandbox-router
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: sandbox-router
containers:
- name: router
image: us-central1-docker.pkg.dev/k8s-staging-images/agent-sandbox/sandbox-router:v20260225-v0.1.1.post3-10-ga5bcb57
ports:
- containerPort: 8080
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 10
resources:
requests:
cpu: "250m"
memory: "512Mi"
limits:
cpu: "1000m"
memory: "1Gi"
securityContext:
runAsUser: 1000
runAsGroup: 1000
EOF
应用配置:
kubectl apply -f sandbox-router.yaml
实现网络隔离
为了进一步锁定执行环境并防止任何未经授权的横向移动,请应用网络政策。这样可以“隔离”沙盒,使其无法访问 Google Cloud 元数据服务器或其他敏感的内部网络。
将以下内容保存为 sandbox-policy.yaml:
cat > sandbox-policy.yaml <<EOF
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: restrict-sandbox-egress
namespace: agent-sandbox
spec:
podSelector:
matchLabels:
sandbox: python-sandbox-example
policyTypes:
- Egress
egress:
- to:
- ipBlock:
cidr: 0.0.0.0/0
except:
- 169.254.169.254/32 # Block metadata server
EOF
应用政策:
kubectl apply -f sandbox-policy.yaml
验证组件
为确保您的隔离代码沙盒集群层已完全配置,请执行以下状态验证命令:
首先,验证沙盒 pod 和路由器是否正在运行且已准备就绪
kubectl get pods -n agent-sandbox
输出应如下所示:
NAME READY STATUS RESTARTS AGE
python-sandbox-warmpool-7zlkv 1/1 Running 0 3m25s
python-sandbox-warmpool-cxln2 1/1 Running 0 3m25s
sandbox-router-deployment-668dfbbbb6-g9mpd 1/1 Running 0 42s
sandbox-router-deployment-668dfbbbb6-ppllz 1/1 Running 0 42s
验证沙盒路由器负载平衡器 / IP 地址暴露
kubectl get service sandbox-router-svc -n agent-sandbox
输出应如下所示:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
sandbox-router-svc ClusterIP 34.118.237.244 <none> 8080/TCP 114s
验证出站网络政策规则是否存在
kubectl get networkpolicy restrict-sandbox-egress -n agent-sandbox
输出应如下所示:
NAME POD-SELECTOR AGE
restrict-sandbox-egress sandbox=python-sandbox-example 113s
请确保:
python-sandbox-warmpool-***Pod 处于Running和1/1“就绪”状态。sandbox-router-deployment-***个副本中有Running个和1/1个已准备就绪。sandbox-router-svc可访问,并且restrict-sandbox-egress政策成功保护了任何匹配的沙盒标签。
在安全执行环境得到保护并完成初始化后,我们就可以部署实际的运营大脑:代码生成智能体!
7. 构建和部署代码生成代理 (ADK)
在配置好安全执行沙盒和高性能 LLM 后端后,我们现在可以使用智能体开发套件 (ADK) 构建系统的“大脑”:代码生成智能体。
此代理旨在充当专业的 Python 开发者。与仅生成文本的标准聊天机器人不同,此代理配备了代码执行工具,可用于以交互方式解决问题。它遵循以下循环:
- 根据您的要求编写 Python 代码。
- 在我们在第 6 步中设置的 GKE Agent Sandbox 中安全地执行代码。
- 验证输出或读取执行期间出现的任何错误。
- 交付经过测试且可正常运行的解决方案,让您信心十足。
通过授予代理对安全沙盒执行环境的访问权限,我们使其能够验证自己的逻辑并自动调试故障,从而大幅提升其执行软件开发任务的能力!
开发 ADK 推理智能体
首先,我们编写 Python 逻辑来定义代理的行为,并为其配备我们在第 6 步中创建的 Sandbox 工具。在此部分中,我们还配置了混合模型策略:智能体将优先使用在 GKE 集群上运行的自行托管的 Qwen 模型,但如果本地模型运行缓慢或不可用,则会自动回退到 Vertex AI 上的 Gemini 2.5 Flash,从而确保高可靠性。
为代理代码创建新目录:
mkdir -p ~/gke-ai-agent-lab/root_agent
cd ~/gke-ai-agent-lab
创建一个名为 root_agent/agent.py 的文件,其中包含以下内容:
cat <<'EOF' > root_agent/agent.py
import os
from google.adk.agents import Agent
from google.adk.models.lite_llm import LiteLlm
from k8s_agent_sandbox import SandboxClient
import requests
# Instantiate the client globally to track sandboxes
sandbox_client = SandboxClient()
def run_python_code(code: str) -> str:
"""
Executes Python code safely in the GKE Agent Sandbox.
Use this tool whenever you need to execute code to solve a problem.
"""
sandbox = sandbox_client.create_sandbox(template="python-runtime-template", namespace="agent-sandbox")
try:
command = f"python3 -c \"{code}\""
result = sandbox.commands.run(command)
if result.stderr:
return f"Error: {result.stderr}"
return result.stdout
finally:
# Ensure the sandbox is deleted after use to avoid leaking resources
sandbox_client.delete_sandbox(sandbox.claim_name, namespace="agent-sandbox")
# Define the ADK Agent with a fallback mechanism.
# It prioritizes the Qwen 2.5 Coder model running on our Inference Gateway.
# If the local model is unavailable, it falls back to Gemini 2.5 Flash on Vertex AI.
root_agent = Agent(
name="CodeGenerationAgent",
model=LiteLlm(
model="openai/Qwen/Qwen2.5-Coder-14B-Instruct",
fallbacks=["vertex_ai/gemini-2.5-flash"],
timeout=10
),
instruction="""
You are an expert Python developer.
1. Write Python code to solve the user's problem.
2. Execute the code using the `run_python_code` tool to verify it works.
3. Return the exact output and a brief explanation of the code.
""",
tools=[run_python_code]
)
EOF
创建 __init__.py 文件,以便 ADK 识别模块:
echo "from . import agent" > ~/gke-ai-agent-lab/root_agent/__init__.py
设置环境变量。ADK 应用需要网关的 IP 地址才能成功路由 LLM 请求。由于 ADK 支持标准 Open-AI 兼容端点(vLLM 通过我们的网关提供),我们可以替换默认 API 基本网址!
export GATEWAY_IP=$(kubectl get gateway infra-is-inference-gateway -n $NAMESPACE -o jsonpath='{.status.addresses[0].value}')
cat <<EOF > ~/gke-ai-agent-lab/root_agent/.env
OPENAI_API_BASE=http://${GATEWAY_IP}/v1
OPENAI_API_KEY=no-key-required
# Vertex AI settings for fallback (Authentication is handled by Workload Identity)
VERTEXAI_PROJECT=$PROJECT_ID
VERTEXAI_LOCATION=${ZONE%-[a-z]}
EOF
将代理应用容器化
我们需要打包代理,以便它可以在 GKE 中安全运行。
在 ~/gke-ai-agent-lab 中创建一个 Dockerfile,用于安装 kubectl、ADK 库和 Agent Sandbox 客户端:
cat <<'EOF' > ~/gke-ai-agent-lab/Dockerfile
FROM python:3.11-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
WORKDIR /app
RUN apt-get update && apt-get install -y git curl \
&& curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl" \
&& install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl \
&& rm kubectl && apt-get clean && rm -rf /var/lib/apt/lists/*
RUN pip install --no-cache-dir "google-adk[extensions,otel-gcp]>=1.27.4" litellm pandas "git+https://github.com/kubernetes-sigs/agent-sandbox.git@main#subdirectory=clients/python/agentic-sandbox-client" \
"opentelemetry-instrumentation-google-genai>=0.4b0" \
"opentelemetry-exporter-otlp" \
"opentelemetry-instrumentation-vertexai>=2.0b0"
COPY ./root_agent /app/root_agent
EXPOSE 8080
ENTRYPOINT ["adk", "web", "--host", "0.0.0.0", "--port", "8080", "--otel_to_cloud"]
EOF
创建 Artifact Registry 制品库以存储容器映像。
gcloud artifacts repositories create agent-repo \
--repository-format=docker \
--location=us-central1
使用 Cloud Build 构建并推送容器映像。
gcloud builds submit --tag us-central1-docker.pkg.dev/$PROJECT_ID/agent-repo/code-agent:v1 ~/gke-ai-agent-lab/
使用 RBAC 部署到 GKE
最后,将代理部署到集群。部署包含 Role 和 RoleBinding,用于授予代理从 SandboxWarmPool 声明实例的权限。
此部署将使用 Kubernetes ServiceAccount 来使您的代理能够与 Sandbox 声明 API 通信。由于它访问的是本地集群资源和本地 vLLM 网关端点,因此不需要 Google IAM 服务账号。
为何要在 gVisor 中使用标准 Deployment?
在第 6 步中,我们使用 SandboxTemplate 和 SandboxClaim API 为生成的 Python 代码(工具执行)创建了临时性的一次性沙盒。
对于 Agent Web 界面(大脑)本身,我们使用带有 runtimeClassName: gvisor 的标准 Kubernetes Deployment 规范。
- 区别:标准
SandboxClaims是临时性的,取值为 0 或 1(非常适合不受信任的脚本)。标准Deployment持久运行,非常适合需要稳定的 KubernetesService和负载平衡器的 Web 界面!通过直接在标准 Deployment 上使用runtimeClassName: gvisor,您可以在保留标准Deployment功能的同时获得 gVisor 内核的隔离。
将以下内容保存为 deployment.yaml:
cat <<EOF > ~/gke-ai-agent-lab/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: code-agent
labels:
app: code-agent
spec:
replicas: 1
selector:
matchLabels:
app: code-agent
template:
metadata:
labels:
app: code-agent
spec:
serviceAccount: adk-agent-sa
runtimeClassName: gvisor
nodeSelector:
cloud.google.com/compute-class: autopilot
containers:
- name: code-agent
image: us-central1-docker.pkg.dev/YOUR_PROJECT_ID/agent-repo/code-agent:v1
imagePullPolicy: Always
env:
- name: OPENAI_API_KEY
value: "no-key-required"
- name: OPENAI_API_BASE
value: "http://YOUR_GATEWAY_IP/v1"
- name: VERTEXAI_PROJECT
value: "YOUR_PROJECT_ID"
- name: VERTEXAI_LOCATION
value: "YOUR_REGION"
- name: OTEL_SERVICE_NAME
value: "code-agent"
- name: GOOGLE_CLOUD_AGENT_ENGINE_ENABLE_TELEMETRY
value: "true"
- name: OTEL_INSTRUMENTATION_GENAI_CAPTURE_MESSAGE_CONTENT
value: "true"
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: code-agent-service
spec:
selector:
app: code-agent
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: agent-sandbox
name: sandbox-creator-role
rules:
- apiGroups: [""]
resources: ["services", "pods", "pods/portforward"]
verbs: ["get", "list", "watch", "create"]
- apiGroups: ["extensions.agents.x-k8s.io"]
resources: ["sandboxclaims"]
verbs: ["create", "get", "list", "watch", "delete"]
- apiGroups: ["agents.x-k8s.io"]
resources: ["sandboxes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: adk-agent-binding
namespace: agent-sandbox
subjects:
- kind: ServiceAccount
name: adk-agent-sa
namespace: default
roleRef:
kind: Role
name: sandbox-creator-role
apiGroup: rbac.authorization.k8s.io
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: adk-agent-sa
EOF
授予可观测性的 IAM 权限
如需让代理向 Google Cloud 发送遥测数据(日志和跟踪记录),您需要使用 Workload Identity 向 Kubernetes 服务账号 adk-agent-sa 授予所需权限。
在 Cloud Shell 中运行以下命令:
PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
# Grant permission to write logs
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/logging.logWriter \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to write traces
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/cloudtrace.agent \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
# Grant permission to use Vertex AI
gcloud projects add-iam-policy-binding $PROJECT_ID \
--role=roles/aiplatform.user \
--member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/default/sa/adk-agent-sa
运行以下命令,以自动将 YOUR_PROJECT_ID 替换为您的实际项目 ID 并应用配置!
sed -i "s/YOUR_PROJECT_ID/$PROJECT_ID/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_GATEWAY_IP/$GATEWAY_IP/g" ~/gke-ai-agent-lab/deployment.yaml
sed -i "s/YOUR_REGION/$ZONE/g" ~/gke-ai-agent-lab/deployment.yaml
kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml
8. 观察和验证
现在可以测试完全集成的系统了。
在界面中测试代码生成智能体
找到 ADK Web 界面对应的外部 IP:
kubectl get services code-agent-service
输出应如下所示:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
code-agent-service LoadBalancer 34.118.230.182 34.31.250.60 80:32471/TCP 2m14s
- 打开浏览器,然后前往
http://[EXTERNAL-IP]。 - 在 ADK Web 界面中,确保从右上角的下拉菜单中选择“root_agent”。然后,向智能体发出提示:
Write a python script that prints 'Hello from the isolated sandbox'.
如需观察代理如何利用推理后端和沙盒,请继续阅读下文中的通过 Cloud 可观测性探索模型统计信息和通过 GKE 界面探索代理可观测性部分,以查看信息中心。
通过 GKE 界面探索代理可观测性
现在您已经运行了一些提示,接下来我们来看看遥测数据。这有助于您了解推理调度程序和 vLLM 的性能。
访问代理信息中心
- 前往 Kubernetes Engine > 工作负载页面。
- 点击 code-agent 部署以打开部署详情页面。
- 点击可观测性标签页。
- 在可观测性信息中心的左侧导航面板中,您会看到一个包含多个子标签页的新代理部分。
探索内容
探索以下子标签页,了解代理应用的行为:
- 概览:查看会话数、平均回合数和调用次数的统计信息摘要。
- 模型:查看按智能体使用的模型分类的模型调用次数、错误率和延迟时间。
- 工具:监控工具调用和执行时长,了解代理使用沙盒执行工具的效率。
- 用量:跟踪令牌用量和标准容器资源分配(CPU 和内存)。
- 代理跟踪记录:切换到此标签页可查看执行会话或原始跟踪记录范围的列表。点击任意一行即可打开一个弹出式窗口,其中显示了所选跟踪记录的详细信息!
通过将 vLLM 中的模型级指标与 ADK 中的应用级遥测相结合,您现在可以对 GKE 上的生成式 AI 智能体实现全栈可观测性!
通过 Cloud Observability 探索 vLLM 模型统计信息
现在您已经运行了一些提示,接下来我们来看看遥测数据。这有助于您了解推理调度程序和 vLLM 的性能。
访问信息中心
- 导航到 Google Cloud Console。
- 前往 Monitoring > 信息中心。
- 搜索并选择 vLLM Prometheus 概览信息中心。
值得关注的指标
在查看信息中心时,请注意以下关键指标,以了解 GKE 推理网关和前缀缓存的影响:
- KV 缓存利用率 (
vllm:gpu_cache_usage):- 重要性:此指标显示了有多少 GPU 内存用于缓存上下文。如果此值较高,则表示系统正在保留上下文,以加快未来请求的处理速度。如果您多次运行同一提示,应该会看到此利用率上升,然后趋于稳定。
- 正在运行的请求与等待中的请求(
vllm:num_requests_running与vllm:num_requests_waiting):- 重要性:此指标表示负荷。如果等待请求数较高,则表示您的节点过载。
- token 吞吐量(
vllm:request_prompt_tokens_tot和vllm:request_generation_tokens_tot):- 重要性:跟踪集群处理的输入和输出令牌数量。
- 首次获取令牌的时间 (TTFT):
- 重要性:这是交互式代理的关键指标。通过将 GKE Inference Gateway 与前缀缓存感知路由搭配使用,共享常见上下文(例如系统提示或大型上下文窗口)的请求会被路由到同一副本,从而通过重用现有缓存命中来最大限度地缩短 TTFT!
可尝试的实验
尝试以下场景,实时查看指标变化并验证调度是否正确!
实验 1:“重复速度”(前缀缓存命中)
- 向代理发送复杂的提示(例如“编写一个 Python 脚本来解析 100MB 的 CSV 文件并计算统计信息”)。
- 在收到回答后,立即再次发送完全相同的提示。
- 观察前缀缓存命中率和首 token 延迟 (TTFT)。
- 您应该会看到:前缀缓存命中率应升至 100%,而 TTFT 应大幅下降!
- 这意味着:GKE 推理网关识别了共享上下文,并将其路由到完全相同的副本,该副本重用了其评估的上下文缓存!
实验 2:回退到云端(模型可靠性)
- 如需模拟本地 Qwen 模型发生故障,您可以停止推理服务,也可以在部署中提供虚假的
OPENAI_API_BASE。 - 将
deployment.yaml中的OPENAI_API_BASE更新为不存在的 IP 或端口,然后应用更改:sed -i "s|value: \"http://$GATEWAY_IP/v1\"|value: \"http://10.0.0.1:8080/v1\"|g" ~/gke-ai-agent-lab/deployment.yaml kubectl apply -f ~/gke-ai-agent-lab/deployment.yaml - 等待 pod 重启,然后在界面中向代理发送提示。
- 您应该会看到:代理仍然成功响应!
- 这意味着:由于
fallbacks配置,ADK 识别到本地 Qwen 端点出现故障,并将请求无缝路由到 Vertex AI 上的 Gemini 2.5 Flash。请注意,由于这些对 Vertex AI 的回退调用会绕过本地 vLLM 推理网关,因此不会显示在代理可观测性 > 模型信息中心内,该信息中心仅跟踪通过 vLLM 的流量。
了解动态资源分配 (DRA) 的强大功能
虽然 vLLM 和推理网关可优化请求的路由和处理方式,但动态资源分配 (DRA) 才是让您能够为工作负载附加精确合适的硬件的根本原因。
借助 DRA,您可以使用 ResourceClaimTemplate 和 DeviceClasses 定义灵活的硬件资源,从而更精细地管理集群中的硬件。
为何 DRA 能颠覆 AI 工作负载:
- 精细的硬件请求:借助 DRA,您不仅可以确保工作负载调度到具有合适加速器的机器上,还可以声明这些资源,以确保它们仅供与 ResourceClaim 关联的工作负载使用。
- 生命周期解耦:设备声明的生命周期与 Pod 的生命周期无关。如果 Pod 崩溃,GPU 声明可以保持不变,这样,即使无需等待 GPU 释放并重新获取,也可以重新启动总体部署或其他工作负载对象。
- 多供应商标准化:DRA 为 NVIDIA GPU 和 Google TPU 提供统一的 Kubernetes API。无论您是为其中一个平台部署,都使用完全相同的架构,这使得您的工作负载 YAML 清单具有高度的可移植性!
在此 Codelab 中,您配置了 Helm 值以无缝绑定到 gpu-claim-template,而不会因设备插件配置悬而未决而导致发布受阻,从而看到了此功能在实际应用中的效果。
了解 llm-d 的角色
在 vLLM 评估神经权重和 GKE 网关路由查询时,llm-d 充当配置层和将它们全部绑定在一起的“粘合剂”。
如果没有 llm-d,您必须从头开始编写原始 Kubernetes 清单,以声明 vLLM 部署、服务端口、卷挂载和 DRA 资源声明。
为何要在部署中使用 llm-d?
- 统一配置(单行替换):
llm-dHelm 图表将复杂的低级别 Kubernetes 资源捆绑到简洁的高级别切换开关中(例如设置accelerator.dra: true)。 - 经过预先审查的“照明充足的路径”:
llm-d代码库包含已经过专家基准测试和测试的配置。部署llm-d-modelservice时,您会获得针对 GPU 内存利用率的优化默认值、建议的探测时间(活跃度/就绪状态)以及用于指标抓取的正确公开设置。 - 无缝可观测性映射:
llm-d可确保标准容器端口和抓取路径 (/metrics) 正确公开,从而轻松将部署连接到 Google Cloud Monitoring,无需手动调试。
简而言之,llm-d 提供可重复使用的架构蓝图,因此开发者不必每次在 GKE 上部署推理堆栈时都从头开始。
深入探讨:GKE 推理网关
标准第 7 层负载平衡器通过查看路径 (/v1/completions) 或 Cookie 等 HTTP 标头来运行。GKE 推理网关则更深入,它是专门为生成式 AI 流量设计的。
如何提升效果和效率:
- 内容感知型路由(提示哈希):GKE 推理网关会拦截 JSON 请求正文。它会计算提示的哈希值,并跟踪哪个后端副本已在其 GPU 内存(即 KV 缓存)中保存这些令牌。
- 最大限度地提高缓存命中率:在测试中,当您重复提示时,网关会将其发送到完全相同的副本。评估提示需要大量计算资源。通过重复使用缓存,您可以避免“重新读取”提示,从而节省资金和 GPU 时间。
- 大幅缩短第一个 token 的时间 (TTFT):TTFT 是面向用户的代理的关键可用性指标。通过命中缓存,模型可以在毫秒内开始生成令牌,而不是需要等待数秒。
- 智能负载分配:如果某个副本的 VRAM 完全被缓存命中占据,网关可以将新的提示动态路由到有空间的另一个副本,从而在效率和可用性之间实现平衡。
代理沙盒如何降低风险
在本实验中,我们演示了 Agent Sandbox 如何通过提供两层隔离来保护您的基础架构免受与 AI 智能体相关的风险:
- 隔离执行工具:智能体会在临时沙盒中执行其生成的代码。这可确保 LLM 生成的不受信任的代码在安全、隔离的环境中运行,从而保护代理和集群。
- 快速启动:通过使用 WarmPool,新的沙盒可在不到一秒的时间内启动,随时可以执行代码。
- 隔离代理本身:我们还在启用 gVisor 的节点中(通过
runtimeClassName: gvisor)运行代理应用本身,以针对代理依赖项中的供应链漏洞提供纵深防御。
以下是这种方式之所以能创建如此坚固的安全边界的原因:
- 系统调用拦截:gVisor 会在系统调用到达宿主 Linux 内核之前将其拦截。这会阻止试图突破容器来访问宿主节点的漏洞利用。
- 限制横向移动:与网络政策结合使用,即使环境遭到入侵,也无法扫描内部元数据服务器或转向集群中的其他敏感服务。
在沙盒中运行完整版代理
在本实验中,我们使用沙盒作为持久代理应用的工具。不过,为了尽可能提高安全性(尤其是在处理敏感数据或为多个不受信任的用户提供服务时),您可以为每个会话或用户在专用沙盒中运行整个代理应用。这样可确保智能体的内存、状态和执行环境完全隔离,并在会话完成后立即销毁。
9. 清理
为避免系统因本 Codelab 中使用的资源向您的 Google Cloud 账号收取费用,请按照以下步骤删除这些资源。
删除单个资源
- 删除 GKE 集群:
gcloud container clusters delete $CLUSTER_NAME --zone $ZONE --quiet
- 删除 Artifact Registry 代码库:
gcloud artifacts repositories delete agent-repo --location=us-central1 --quiet
- 删除 VPC 网络:
gcloud compute networks delete ai-agent-network --quiet
删除项目
如果您不再需要该项目,可以在移除资源后将其删除:
gcloud projects delete $PROJECT_ID
10. 总结
恭喜!您已在 GKE 上成功构建并部署了安全、高性能的代码生成代理。
要点回顾
- 如何在 GKE 中配置和使用动态资源分配 (DRA) 来管理 GPU 资源。
- 如何使用 GKE Inference Gateway 通过前缀缓存感知路由优化 LLM 服务性能。
- 如何使用 Agent Sandbox (gVisor) 在 GKE 上安全地执行不受信任的代码。
- 如何使用 Google Cloud Managed Service for Prometheus 监控 vLLM 性能。
- 如何使用 ADK 和 GKE 托管的 OpenTelemetry 配置和查看代理可观测性。
后续步骤和参考资料
- Agent Sandbox:了解 GKE 上的 Agent Sandbox和 GKE Sandbox Pod。
- llm-d:阅读 llm-d 指南并查看 llm-d GitHub 代码库。
- 动态资源分配:了解 GKE 上的 DRA。
- GKE 推理网关:探索推理网关概念。
- 更多 Codelab:如需查找更多教程,请访问 Google Cloud Codelab。