
1. مقدمة
في هذا الدرس العملي، ستتولّى دور عالم بيانات في شركة Froyo الوهمية التي ستطلق نكهة منتج جديدة باسم "Midnight Swirl". لضمان إطلاق المنتج بنجاح على مستوى العالم، يجب أن يجيب النشاط التجاري عن أسئلة مهمة بشأن المكونات وطلب السوق وعائد الاستثمار. يوضّح سير العمل المتكامل هذا كيف يمكن لكتالوج المعرفة من Google Cloud (المعروف سابقًا باسم Dataplex) وLakehouse for Apache Iceberg (المعروف سابقًا باسم BigLake) سدّ الفجوة بين البيانات غير المنظَّمة "المخفية" وتقديم ذكاء الأعمال القابل للتنفيذ باستخدام Gemini في بيئة التطوير المتكاملة (VS Code) من خلال طبقة إدارة موحّدة.
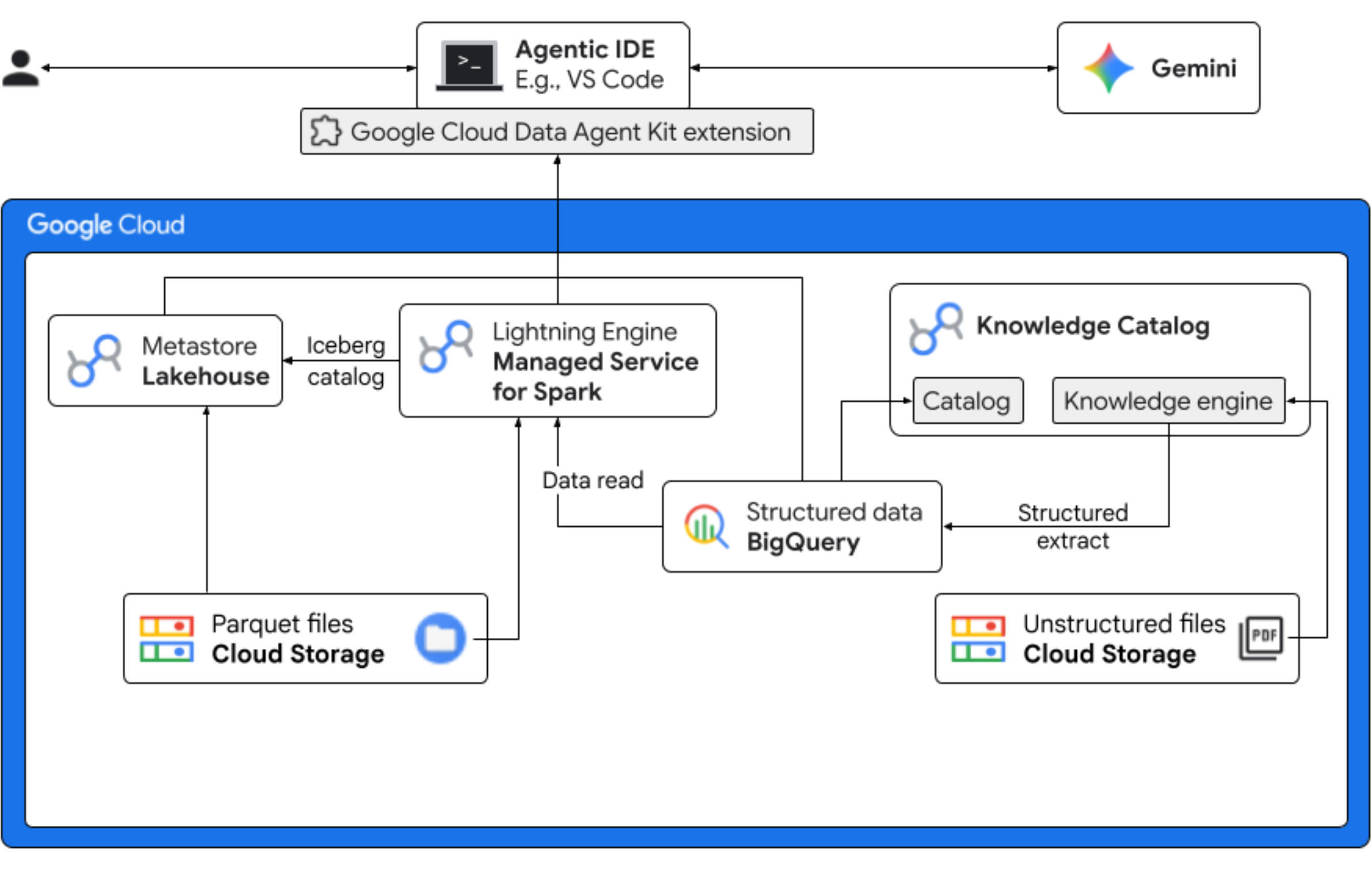
الإجراءات التي ستنفذّها
- الاستكشاف غير المنظَّم: يزحف Knowledge Catalog DataScan إلى وصفات PDF المخزَّنة في Cloud Storage. إنشاء جداول كائنات في BigQuery لملفات PDF التي تم فحصها باستخدام Vertex AI Semantic Inference، "يقرأ" النظام ملفات PDF لاستخراج معلومات منظَّمة حول المنتجات والمواد المسبّبة للحساسية والمكوّنات والسمات ذات الصلة. بعد ذلك، ينشئ مخططًا ذكيًا للبيانات المخزّنة في ملفات PDF.
- البيانات الوصفية الموحّدة: يتم تخزين البيانات المستخرَجة من ملفات PDF مباشرةً في BigQuery كجدول عريض أصلي، ويتم إنشاء طرق عرض للمساعدة في طلبات البحث الشائعة. يتم تخزين مجموعة بيانات إدخال مستقلة تحتوي على بيانات مبيعات سابقة في جداول Apache Iceberg على Google Cloud Storage. سيتم ربط جدول Iceberg هذا بالبيانات المستخرَجة في BigQuery في خطوة لاحقة.
- إحصاءات متعددة المحركات: باستخدام Managed Service for Apache Spark (المعروفة سابقًا باسم Dataproc) مع Iceberg REST Catalog، يمكنك دمج البيانات الوصفية الجديدة لملفات PDF والبيانات الدلالية المنظَّمة المستنتَجة (من جداول BigQuery وطرق العرض) مع بيانات المبيعات المنظَّمة المخزَّنة في جداول Apache Iceberg على Google Cloud Storage. ويتم تنظيم ذلك من خلال نموذج جلسة تفاعلية مُدارة من Apache Spark يُستخدَم كنواة Jupyter Notebook تضمن إعدادات أمان وحساب متسقة لمهمة Spark.
- الإحصاءات الدلالية: من خلال ربط بيانات المنتجات المستنتَجة ببيانات العملاء والمبيعات (في BigQuery)، يمكن للعرض التوضيحي استخراج إحصاءات، مثل تحديد بيانات مسبّبات الحساسية وتوقّع الأرباح.
- الإدارة الذاتية: يتم تنسيق دورة الحياة بأكملها، بدءًا من عمليات الفحص للاستكشاف ووصولاً إلى تنفيذ Spark، من خلال النماذج والتعليمات والقواعد والأتمتة المستندة إلى الوكيل المتوافقة مع Gemini، ما يثبت أنّ الذكاء الاصطناعي يمكنه إدارة البنية التحتية التي تشغّل الإحصاءات.
المتطلبات
قد يؤدي إكمال هذا الدرس التطبيقي حول الترميز إلى تكبّد تكاليف، ويُقدّر أنّها أقل من 5 دولار أمريكي للاستخدام العادي. للحصول على تقديرات تفصيلية للتكلفة استنادًا إلى الاستخدام المتوقّع أو الأسعار الحالية، استخدِم حاسبة الأسعار في Google Cloud.
تأكد من استيفاء المتطلبات الأساسية التالية لإكمال الدرس التطبيقي حول الترميز.
- متصفّح الويب Chrome
- حساب Gmail شخصي إذا كنت تستخدم رصيدًا تجريبيًا مقدَّمًا في قسم "قبل البدء"
- نزِّل محرِّر Visual Studio (VS) Code وثبِّته.
2. قبل البدء
إنشاء مشروع على Google Cloud
- في Google Cloud Console، في صفحة اختيار المشروع، اختَر مشروعًا على السحابة الإلكترونية أو أنشِئ مشروعًا على السحابة الإلكترونية.
- تأكَّد من تفعيل الفوترة لمشروعك على Cloud. كيفية التحقّق من تفعيل الفوترة في مشروع
بدء Cloud Shell
Cloud Shell هي بيئة سطر أوامر تعمل في Google Cloud ومحمّلة مسبقًا بالأدوات اللازمة.
- انقر على تفعيل Cloud Shell في أعلى "وحدة تحكّم Google Cloud".
- بعد الاتصال بـ Cloud Shell، تحقَّق من المصادقة باتّباع الخطوات التالية:
gcloud auth list - تأكَّد من إعداد مشروعك باتّباع الخطوات التالية:
gcloud config get project - إذا لم يتم ضبط مشروعك على النحو المتوقّع، اضبطه باتّباع الخطوات التالية:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
تفعيل واجهات برمجة التطبيقات المطلوبة
نفِّذ الأمر التالي لتفعيل جميع واجهات برمجة التطبيقات المطلوبة:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
biglake.googleapis.com \
dataproc.googleapis.com \
metastore.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
secretmanager.googleapis.com \
storage.googleapis.com
تنزيل مواد عرض الدرس التطبيقي حول الترميز
يحتوي هذا المستودع على ملفات Parquet والوصفات والمورّدين وcopilot-instructions.md وtemplate.yaml وquickstart.py لاستخدامها مع هذا الدرس التطبيقي حول الترميز. احرص على تنزيل هذه الملفات.
لتنزيل الملفات، اتّبِع الخطوات التالية:
- في Cloud Shell، نفِّذ الأمر التالي:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git - انتقِل إلى المجلد الذي تم إنشاؤه حديثًا:
cd next-26-keynotes - سحب المجلد
data-cloud-demogit sparse-checkout set genkey/data-cloud-demo - بعد إكمال عملية الدفع، انتقِل إلى المجلد
data-cloud-demoواستخرِج ملفات ZIP للوصول إلى مواد Codelab.
3- إعداد Lakehouse لبيانات عملاء Froyo
في هذا القسم، يمكنك إنشاء فهرس في Lakehouse لاستخدام مستودع البيانات الوصفية في Lakehouse لسير العمل. تتيح هذه الخدمة إمكانية التشغيل التفاعلي بين محركات طلبات البحث من خلال توفير مصدر واحد لجميع بيانات Iceberg. تتيح لمحركات طلب البحث، مثل Apache Spark، اكتشاف البيانات الوصفية وقراءتها وإدارة جداول Iceberg بطريقة متّسقة.
الأدوار المطلوبة
تأكَّد من توفّر أدوار "إدارة الهوية وإمكانية الوصول" (IAM) التالية لديك:
roles/biglake.viewerroles/bigquery.userroles/bigquery.dataEditorroles/biglake.editorroles/biglake.metadataViewerroles/bigquery.connectionUserroles/storage.objectUserroles/storage.objectViewerroles/storage.objectCreatorroles/storage.admin
لمزيد من المعلومات عن منح أدوار إدارة الهوية وإمكانية الوصول، يُرجى الاطّلاع على منح دور إدارة الهوية وإمكانية الوصول.
إنشاء كتالوج Lakehouse باستخدام حزمة
أنشِئ فهرس Lakehouse لإدارة البيانات الوصفية لجداول Iceberg. يمكنك الاتصال بهذا الكتالوج في مهمة Spark لإنشاء جداول Iceberg وتنفيذ طلبات بحث فيها.
- في Google Cloud Console، انتقِل إلى Lakehouse.
- انقر على إنشاء كتالوج. سيتم فتح صفحة إنشاء كتالوج.
- بالنسبة إلى نوع الكتالوج، اختَر كتالوج Iceberg Rest.
- بالنسبة إلى اختيار خيارات حزمة كتالوج Lakehouse، اختَر كتالوج حزمة واحدة.
- بالنسبة إلى حزمة Cloud Storage التلقائية للكتالوج، انقر على تصفّح، ثم انقر على إنشاء حزمة جديدة.
- في صفحة إنشاء مجموعة، اتّبِع الخطوات التالية:
- في قسم البدء، أدخِل اسمًا فريدًا على مستوى العالم يستوفي متطلبات اسم الحزمة.
- في قسم اختيار مكان تخزين بياناتك، اختَر المنطقة في نوع الموقع الجغرافي وأدخِل منطقتك. مثلاً:
us-west1. - في القسم اختيار طريقة التحكّم في الوصول إلى العناصر، أزِل العلامة من مربّع الاختيار فرض منع الوصول العلني إلى هذه الحزمة.
يتيح لك ذلك محاكاة سيناريوهات واقعية، مثل استضافة محتوى ويب عام أو مستودعات بيانات تمت مشاركتها. بدون هذا التغيير، سيفرض الحزمة سياسة "خاص فقط" صارمة، وسيؤدي أي محاولة للوصول إلى مواد العرض إلى ظهور خطأ403محظور، حتى إذا منحت أذونات عامة للملفات بنجاح. - انقر على متابعة > إنشاء > اختيار > متابعة.
- بالنسبة إلى طريقة المصادقة، اختَر وضع توفير بيانات الاعتماد.
- انقر على إنشاء.سيتم إنشاء الكتالوج وفتح صفحة تفاصيل الكتالوج.
- ضمن طريقة المصادقة، انقر على ضبط أذونات الحزمة.
- في مربّع الحوار، انقر على تأكيد.يؤكّد هذا الإجراء أنّ حساب خدمة الكتالوج لديه دور
Storage Object Userفي حزمة التخزين. - من صفحة تفاصيل قائمة المحتوى، انسخ مسار معرّف الموارد المنتظم (URI) الخاص بقائمة المحتوى REST. استخدِم هذا المسار أثناء تنفيذ مهمة Run Spark job.
تحميل ملفات Parquet إلى الحزمة
لتحميل ملفات Parquet إلى جذر الحزمة، اتّبِع الخطوات التالية:
- في Google Cloud Console، انتقِل إلى صفحة حِزم Cloud Storage.
- في قائمة الحِزم، انقر على اسم الحزمة. مثلاً:
acai_demo - في علامة التبويب الكائنات الخاصة بالحزمة، انقر على تحميل > تحميل الملفات.
- اختَر الملفات من مجلد Parquet الذي استنسخته في قسم قبل البدء من هذا الدرس العملي.
- انقر على فتح.
4. إعداد شبكة السحابة VPC
أنشئ شبكة سحابة إلكترونية خاصة افتراضية (VPC) وشبكة فرعية تتيح للموارد التواصل مع واجهات Google API بدون الخروج إلى الإنترنت العام، بالإضافة إلى جدار حماية يتيح نقل الزيارات الداخلية بحرية بين عُقد معالجة البيانات.
- في وحدة تحكّم Google Cloud، انتقِل إلى صفحة شبكات السحابة الإلكترونية الخاصة الافتراضية.
- انقر على إنشاء شبكة VPC.
- أدخِل اسمًا للشبكة. مثلاً:
acai-network - لضبط الحد الأقصى لوحدة الإرسال (MTU) للشبكة، ضَع علامة في مربّع الاختيار ضبط الحد الأقصى لوحدة الإرسال تلقائيًا.
- اختَر تلقائي وضع إنشاء الشبكة الفرعية.
- في قسم قواعد جدار الحماية، ضَع علامة في جميع مربّعات الاختيار لقواعد جدار حماية الإصدار الرابع من بروتوكول الإنترنت.
- انقر على إنشاء.
تفعيل ميزة "الوصول الخاص إلى Google"
لا تحتوي عقد Dataproc Serverless على عناوين IP عامة. للتواصل مع Lakehouse Catalog وCloud Storage، يجب تفعيل Private Google Access على الشبكة الفرعية.
- في وحدة تحكّم Google Cloud، انتقِل إلى صفحة شبكات السحابة الإلكترونية الخاصة الافتراضية.
- انقر على اسم الشبكة التي تحتوي على الشبكة الفرعية التي تحتاج إلى تفعيل ميزة "الوصول الخاص إلى Google" لها. مثلاً:
us-west1 - انقر على اسم الشبكة الفرعية. يتم عرض صفحة تفاصيل الشبكة الفرعية.
- انقر على تعديل.
- في قسم الوصول الخاص إلى Google، اختَر تفعيل.
- انقر على حفظ.
5- إنشاء مهمة Spark وتشغيلها
لإنشاء جدول Iceberg وتنفيذ طلب بحث فيه، حمِّل مهمة PySpark مع عبارات Spark SQL اللازمة. بعد ذلك، شغِّل المهمة باستخدام Managed Service for Spark.
حمِّل quickstart.py إلى حزمة Cloud Storage
بعد استنساخ مواد عرض Codelab، عدِّل النص البرمجي quickstart.py باستخدام تفاصيل مشروعك وحمِّله إلى حزمة Cloud Storage.
- افتح النص البرمجي
quickstart.pyفي محرِّر نصوص. - استبدِل العنصر النائب
BUCKET_NAMEفي النص البرمجي باسم حزمة Cloud Storage واحفظه. - في Google Cloud Console، انتقِل إلى حِزم Cloud Storage.
- انقر على اسم الحزمة. مثلاً:
acai_demo - في علامة التبويب الكائنات، انقر على تحميل > تحميل الملفات.
- في مستعرض الملفات، اختَر ملف
quickstart.pyالمعدَّل، ثم انقر على فتح.
تنفيذ مهمة Spark
بعد تحميل النص البرمجي quickstart.py، شغِّله كعملية دفعية في Managed Service for Spark.
- لضبط المتغيرات، نفِّذ الأمر التالي في Cloud Shell.
# Configuration Variables export PROJECT_ID="<PROJECT_ID>" export REGION="<REGION>" export BUCKET_NAME="<BUCKET_NAME>" export SUBNET="<SUBNET>" export LAKEHOUSE_CATALOG_ID="<LAKEHOUSE_CATALOG_ID>" export CATALOG_URI_ID="<CATALOG_URI_ID>"- استبدِل LAKEHOUSE_CATALOG_ID باسم مورد كتالوج Lakehouse الذي يحتوي على ملف تطبيق PySpark. على سبيل المثال،
acai_demo - PROJECT_ID: معرّف مشروعك على Google Cloud
- استبدِل REGION بالمنطقة التي سيتم فيها تشغيل وحدة عمل الدفعات في Managed Service for Spark. مثلاً:
us-west1 - استبدِل BUCKET_NAME باسم حزمة Cloud Storage. مثلاً:
acai_demo - SUBNET: اسم الشبكة الفرعية لشبكة VPC. مثلاً:
acai-network - CATALOG_URI_ID: معرّف الموارد المنتظم (URI) الخاص بكتالوج Lakehouse الذي نسخته عند إنشاء كتالوج Lakehouse باستخدام حزمة. مثلاً:
https://biglake.googleapis.com/iceberg/v1/restcatalog
- استبدِل LAKEHOUSE_CATALOG_ID باسم مورد كتالوج Lakehouse الذي يحتوي على ملف تطبيق PySpark. على سبيل المثال،
- في Cloud Shell، شغِّل مهمة الدفعات التالية في "الخدمة المُدارة لـ Spark" باستخدام النص البرمجي
quickstart.py.gcloud dataproc batches submit pyspark gs://${BUCKET_NAME}/quickstart.py \ --project=${PROJECT_ID} \ --region=${REGION} \ --subnet=${SUBNET} \ --version=2.2 \ --properties="\ spark.sql.defaultCatalog=${LAKEHOUSE_CATALOG_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}=org.apache.iceberg.spark.SparkCatalog,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.type=rest,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.uri=${CATALOG_URI_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.warehouse=gs://${BUCKET_NAME},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.io-impl=org.apache.iceberg.gcp.gcs.GCSFileIO,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.x-goog-user-project=${PROJECT_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\ spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest-metrics-reporting-enabled=false,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.X-Iceberg-Access-Delegation=vended-credentials,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token"All tables registered successfully! Batch [126fa2226a904d2e944c8eecbe0b1840] finished. metadata: '@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata batch: projects/PROJECT_ID/locations/REGION/batches/126fa2226a904d2e944c8eecbe0b1840 batchUuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff createTime: '2026-04-09T13:17:26.222727Z' description: Batch labels: goog-dataproc-batch-id: 126fa2226a904d2e944c8eecbe0b1840 goog-dataproc-batch-uuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-drz-resource-uuid: batch-3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-location: REGION operationType: BATCH name: projects/PROJECT_ID/regions/REGION/operations/47bc59e8-5082-3af9-89a0-22289aa5f4b9
6. إجراء طلب بحث في الجدول من BigQuery
من خلال تنفيذ مهمة الدفعات في Spark بنجاح، تكون قد استخدمت Managed Service for Spark Serverless كمحرّك حوسبة موزّع لتسجيل جداول متعددة، جدول واحد لكل ملف Parquet ضمن Lakehouse Metastore. يتيح هذا التسجيل لخدمة Google Cloud التعامل مع ملفاتك الأولية في Cloud Storage كجداول منظَّمة وعالية الأداء.
ترشدك الخطوات التالية إلى كيفية التأكّد من مزامنة البيانات الوصفية بشكل صحيح، ما يضمن تخزين بياناتك بأمان وإمكانية العثور عليها والاستعلام عنها بالكامل من خلال واجهة BigQuery.
- في Google Cloud Console، انتقِل إلى BigQuery.
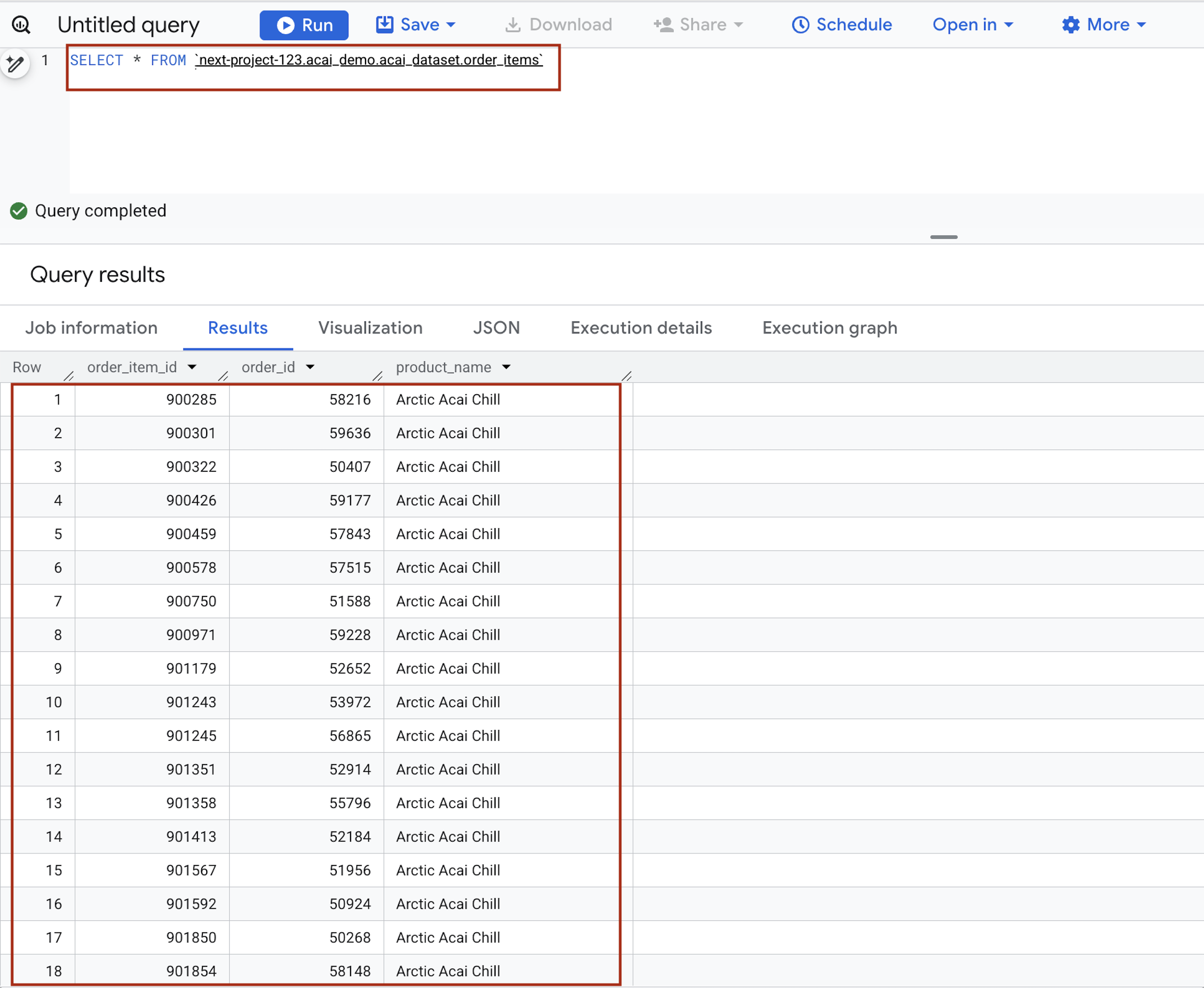
- في محرّر طلب البحث، أدخِل العبارة التالية. يستخدم طلب البحث بنية
project.namespace.dataset.table.SELECT * FROM `<PROJECT_ID>.<NAMESPACE>.<ICEBERG_DATASET>.<ICEBERG_TABLE>`PROJECT_ID.acai_demo.acai_dataset.order_items.
استبدِل ما يلي:- PROJECT_ID: معرّف مشروعك على Google Cloud
- NAMESPACE: مساحة الاسم التي تم إنشاؤها في الخطوة السابقة نتيجةً لمهمة Spark، ويمكنك العثور عليها في صفحة مستكشف عناصر BigQuery. مثلاً:
acai_demo - ICEBERG_DATASET: اسم مجموعة البيانات ضِمن كتالوج Iceberg، مثل
acai_dataset. - استبدِل ICEBERG_TABLE باسم الجدول ضمن مجموعة بيانات Iceberg، مثلاً
order_items.
- انقر على تشغيل. تعرض نتائج طلب البحث البيانات التي أدرجتها باستخدام مهمة Spark.
7. إعداد ملفات بيانات المنتجات غير المهيكلة
في هذا القسم، ستنشئ بنية تنظيمية ضمن BigQuery لتخزين بيانات وصفة Froyo وبيانات المورّدين، وتحديدًا لتفاصيل منتج Froyo. ويُنشئ أيضًا "عملية ربط بمورد على السحابة الإلكترونية" تعمل كـ "جسر" آمن يتيح لـ BigQuery قراءة الملفات من مصادر خارجية، مثل Cloud Storage.
إنشاء حزمة وتحميل ملفات تفاصيل Froyo
أنشئ ملفات المورّدين والوصفات وحمِّلها إلى حزمة Cloud Storage.
- في Google Cloud Console، انتقِل إلى صفحة حِزم Cloud Storage.
- انقر على إنشاء.
- في صفحة إنشاء حزمة، أدخِل معلومات الحزمة. بعد كل خطوة من الخطوات التالية، انقر على متابعة للانتقال إلى الخطوة التالية:
- في قسم البدء، أدخِل اسم المجموعة. مثلاً:
acai_pdfs - في قسم اختيار مكان تخزين البيانات، انقر على المنطقة ثم أدخِل منطقتك. على سبيل المثال،
us-west1. - في القسم اختيار طريقة التحكّم في الوصول إلى العناصر، أزِل العلامة من مربّع الاختيار فرض منع الوصول العلني إلى هذه الحزمة.
- انقر على إنشاء.
- في قائمة الحِزم، انقر على الحزمة التي أنشأتها. مثلاً:
acai_pdfs - في علامة التبويب العناصر الخاصة بالحزمة، انقر على تحميل > تحميل المجلدات.
- اختَر المجلد
recipesالذي استخرجته في قسم قبل البدء من هذا الدرس العملي. - انقر على تحميل.
- كرِّر عملية التحميل للمجلد
suppliers.
إنشاء اتصال
أنشئ Cloud Resource Connection. يؤدي ذلك إلى إنشاء حساب خدمة فريد يعمل كـ "بطاقة تعريف" لـ BigQuery للوصول إلى الملفات الخارجية.
- انتقِل إلى صفحة BigQuery.
- في اللوحة اليمنى، انقر على المستكشف. إذا لم يظهر الجزء الأيمن، انقر على توسيع الجزء الأيمن لفتحه.
- في جزء المستكشف، وسِّع اسم مشروعك، ثم انقر على عمليات الربط.
- في صفحة عمليات الربط، انقر على إنشاء عملية ربط.
- بالنسبة إلى نوع الاتصال، اختَر نماذج ودوال بعيدة في Vertex AI وBigLake وSpanner (مورد على السحابة الإلكترونية).
- في حقل معرّف الربط، أدخِل اسم معرّف الربط. مثلاً:
acai_pdf_connectionاحرص على تدوين رقم التعريف هذا لأنّك ستحتاج إليه عند إعداد عملية فحص البيانات لاحقًا في هذا الدرس التطبيقي حول الترميز. - اضبط نوع الموقع الجغرافي على منطقة، ثم اختَر منطقة. على سبيل المثال،
us-west1. يجب أن يكون الاتصال في الموقع الجغرافي نفسه الذي تتوفّر فيه مواردك الأخرى، مثل مجموعات البيانات. - انقر على إنشاء ربط.
- انقر على الانتقال إلى الاتصال.
- في لوحة معلومات الربط، انسخ رقم تعريف حساب الخدمة لاستخدامه في خطوة لاحقة. يبدو حساب الخدمة مشابهًا لـ
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com.
إدارة إذن الوصول إلى حسابات الخدمة
امنح إذن الوصول إلى حساب الخدمة ليتمكّن Lakehouse من قراءة ملفات PDF.
- انتقِل إلى صفحة إدارة الهوية وإمكانية الوصول.
- انقر على منح إذن الوصول. يفتح مربّع الحوار "إضافة جهات أصلية".
- في حقل المشرفون الجدد، أدخِل رقم تعريف حساب الخدمة الذي نسخته سابقًا.
- في الحقل اختيار دور، أضِف الأدوار التالية:
roles/storage.objectUserroles/storage.objectViewerroles/bigquery.userroles/bigquery.dataEditorroles/aiplatform.userroles/storage.adminroles/dataproc.serviceAgent
- انقر على حفظ.
لمزيد من المعلومات عن أدوار إدارة الهوية وإمكانية الوصول في BigQuery، يُرجى الاطّلاع على الأدوار والأذونات المحدّدة مسبقًا.
8. إدارة أذونات مهمة DataScan
أنشئ حسابات خدمة (هويات) محدّدة لكل من Spark وDataform، ثم امنحها، إلى جانب وكلاء الخدمة الآلية من Google، الأذونات الدقيقة اللازمة لقراءة مساحة التخزين وتشغيل مهام BigQuery واستخدام Vertex AI للاستكشاف.
أذونات الوصول إلى Spark وDataform في "إدارة الهوية والوصول"
- في Google Cloud Console، انتقِل إلى صفحة إنشاء حساب خدمة.
- إذا لم يتم اختياره، اختَر مشروعك على Google Cloud.
- انقر على إنشاء حساب خدمة.
- أدخِل اسم حساب الخدمة. مثلاً:
sa-spark-stg1تنشئ وحدة تحكّم Google Cloud معرّف حساب خدمة استنادًا إلى هذا الاسم. عدِّل المعرّف إذا لزم الأمر. لا يمكنك تغيير المعرّف لاحقًا. - لضبط عناصر التحكّم في الوصول، انقر على إنشاء ومتابعة وتابِع إلى الخطوة التالية.
- اختَر أدوار إدارة الهوية وإمكانية الوصول التالية لمنحها لحساب الخدمة في المشروع.
roles/dataproc.workerroles/storage.objectUserroles/bigquery.dataEditorroles/bigquery.jobUserroles/aiplatform.userroles/dataplex.discoveryPublishingServiceAgent
- عند الانتهاء من إضافة الأدوار، انقر على متابعة.
- انقر على تم للانتهاء من إنشاء حساب الخدمة.
أذونات ربط BigQuery للوصول إلى "كتالوج المعرفة"
- في Google Cloud Console، انتقِل إلى صفحة حِزم Cloud Storage.
- في قائمة الحِزم، انقر على اسم الحزمة التي أنشأتها لإصدار Froyo. مثلاً:
acai_pdfs - في علامة التبويب الأذونات، انقر على منح الوصول. يظهر مربّع الحوار "إضافة جهات أصلية".
- في الحقل الأعضاء الجُدد، أدخِل معرّف حساب خدمة BigQuery. يبدو حساب الخدمة مشابهًا لـ
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com. - اختَر الدور (أو الأدوار) التالية من القائمة المنسدلة اختيار دور.
roles/storage.objectUserroles/dataplex.serviceAgentroles/dataplex.securityAdminroles/aiplatform.serviceAgentroles/dataplex.discoveryPublishingServiceAgent
- انقر على "حفظ".
9. إعداد "كتالوج المعارف"
يمكنك إنشاء "كتالوج معرفة" لتوحيد البيانات ذات الصلة بـ Froyo وأتمتة عملية اكتشاف الملفات غير المهيكلة (مثل وصفات PDF والمورّدين الذين يستخدمون PDF).
إنشاء DataScan من خلال curl
في هذا القسم، يمكنك إنشاء عمليات فحص لحزمة Cloud Storage (على سبيل المثال، acai_pdfs) من خلال إضافة datascan_ID وتوجيهه إلى مجموعات بيانات BigQuery. بعد ذلك، سينشئ "كتالوج المعرفة" تلقائيًا إدخالات لملفات PDF في BigQuery.
- لفحص ملفات PDF (المورّدون والوصفات)، نفِّذ الأمر التالي:
# 1. Set your variables PROJECT_ID="<PROJECT_ID>" REGION="<REGION>" ENV_SUFFIX="stg1" DATASCAN_ID="froyo-profile-${ENV_SUFFIX}" BUCKET_NAME="<BUCKET_NAME>" # 2. Set this to the Name of the connection you created in Step 7 CONNECTION_ID="<CONNECTION_ID_NAME>" # 3. Define the API Endpoint DATAPLEX_API="dataplex.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}" # 4. Create the DataScan via CURL echo "Creating Dataplex DataScan: ${DATASCAN_ID}..." curl -X POST "https://$DATAPLEX_API/dataScans?dataScanId=${DATASCAN_ID}" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d '{ "data": { "resource": "//storage.googleapis.com/projects/'"${PROJECT_ID}"'/buckets/'"${BUCKET_NAME}"'" }, "executionSpec": { "trigger": { "on_demand": {} } }, "dataDiscoverySpec": { "bigqueryPublishingConfig": { "tableType": "BIGLAKE", "connection": "projects/'"${PROJECT_ID}"'/locations/'"${REGION}"'/connections/'"${CONNECTION_ID}"'" }, "storageConfig": { "unstructuredDataOptions": { "entity_inference_enabled": true } } } }' - يعرض الأمر
curlنتائج DataScan في "كتالوج المعرفة"، كما هو موضّح في الصورة التالية.
تشغيل المهمة
نفِّذ الأمر التالي:
gcloud dataplex datascans run $DATASCAN_ID --location=$REGION
وصف وظيفة
لوصف المهمة، شغِّل الأمر التالي:
gcloud dataplex datascans describe $DATASCAN_ID --location=$REGION
حذف مهمة فحص البيانات
إذا استغرقت عملية الفحص أكثر من 10 دقائق، أو إذا بقيت حالة المهمة في انتظار المراجعة لفترة طويلة بدون الانتقال إلى قيد التشغيل، قد يكون ذلك بسبب عدم توفّر الموارد مؤقتًا في المنطقة. في حال حدوث ذلك، يمكنك تنفيذ الأمر التالي لحذف المهمة، ثم محاولة إنشائها وتشغيلها مرة أخرى. في بعض الأحيان، قد يتعذّر تنفيذ عملية أولية بسرعة بسبب ظهور خطأ مثل unable to acquire necessary resources.
gcloud dataplex datascans delete $DATASCAN_ID --location=$REGION
عرض حالة المهمة
للاطّلاع على حالة المهمة، اتّبِع الخطوات التالية:
- في Google Cloud Console، انتقِل إلى صفحة تنظيم البيانات الوصفية.
- في علامة التبويب اكتشاف Cloud Storage، انقر على اسم عمليات الفحص الخاصة بالاكتشاف.
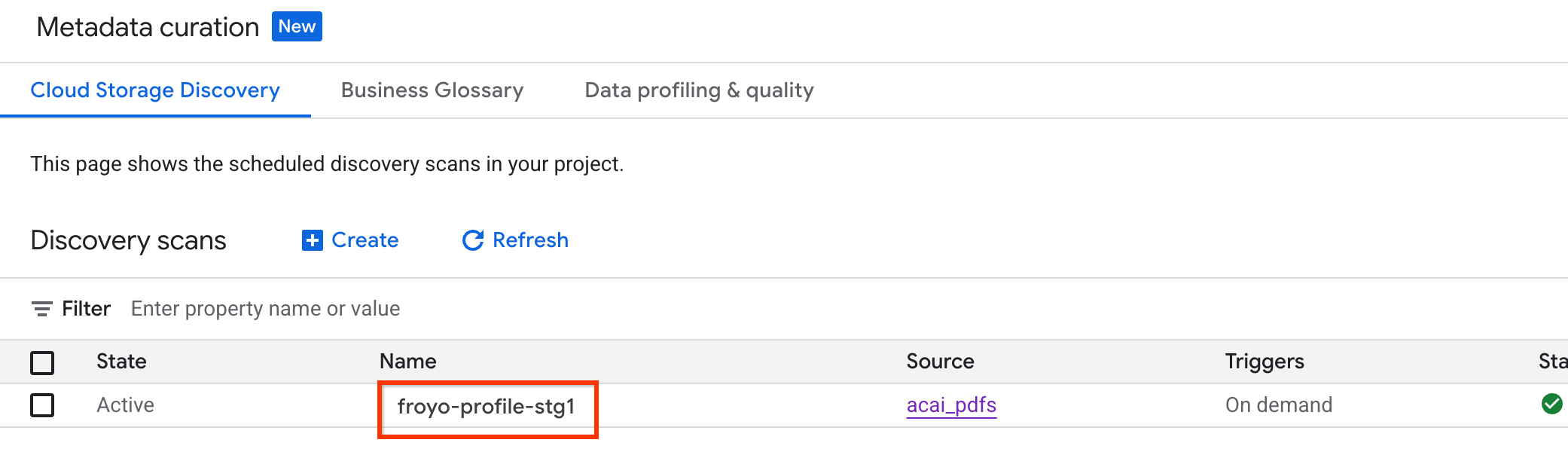
- في صفحة تفاصيل الفحص، يمكنك الاطّلاع على حالة المهمة.
- بعد انتهاء المهمة، تحقَّق مما إذا كانت مجموعة البيانات المنشورة (على سبيل المثال،
acai_pdfs_discovered_003) التي أنشأتها باستخدام الأمرcurlمتوفّرة.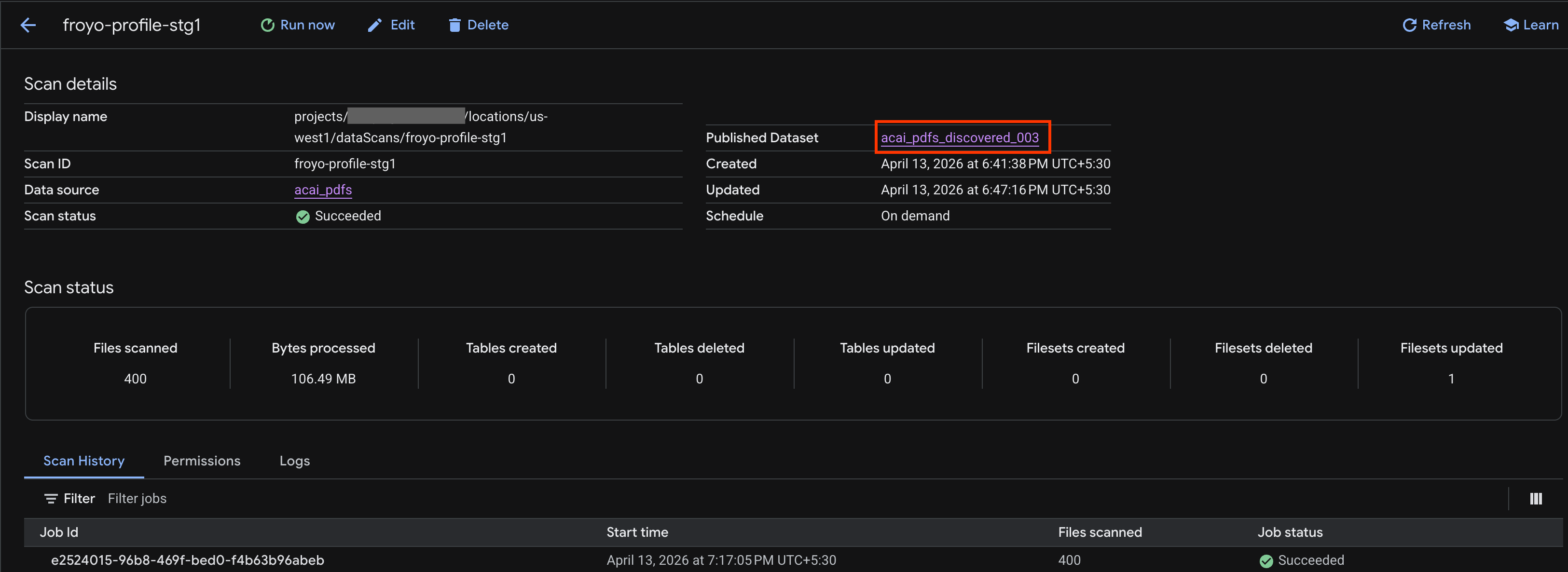
عرض جدول العناصر
للاطّلاع على جدول العناصر الذي تم إنشاؤه بعد مهمة الاكتشاف، اتّبِع الخطوات التالية:
- في Google Cloud Console، انتقِل إلى BigQuery.
- انقر على مجموعات البيانات واختَر مجموعة البيانات المنشورة التي تم إنشاؤها في الخطوة السابقة. مثلاً:
acai_pdfs_discovered_003 - لعرض جدول العناصر، انقر على رقم تعريف الجدول. مثلاً:
acai_pdfs - يبدو جدول العناصر الناتج على النحو التالي:
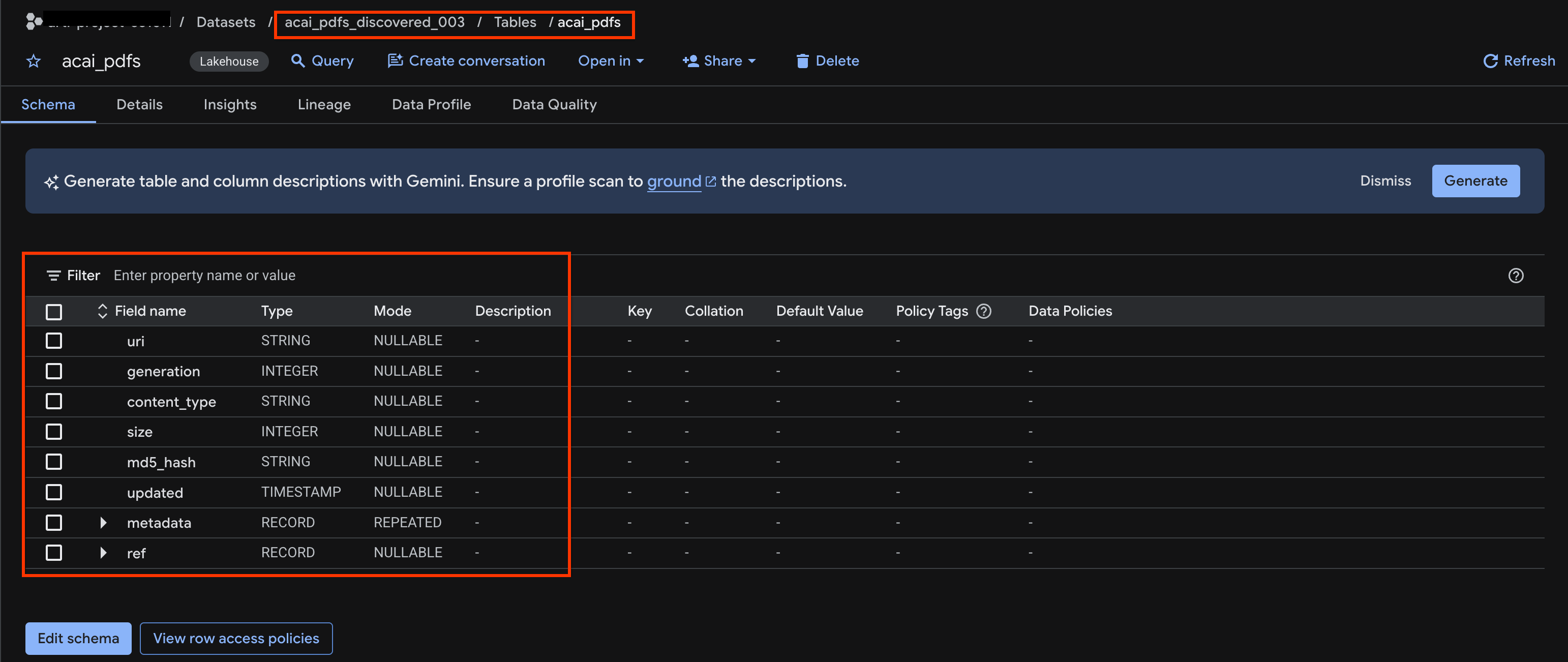
10. الاستخراج الدلالي
ستستنتج وتستخرج جداول منظَّمة وكائنات أخرى من قاعدة البيانات وعلاقات لجدول الكائنات غير المنظَّمة الذي أنشأته في الخطوة السابقة. لإجراء ذلك، ستستخدم ميزة "إحصاءات Knowledge Catalog" لإنشاء عبارات SQL لاستخراج البيانات المنظَّمة من الجدول غير المنظَّم.
- في Google Cloud Console، انتقِل إلى صفحة بحث Knowledge Catalog.
- ابحث عن جدول مجموعة البيانات الذي تريد الاطّلاع على الإحصاءات الخاصة به. مثلاً:
acai_pdfs_discovered_003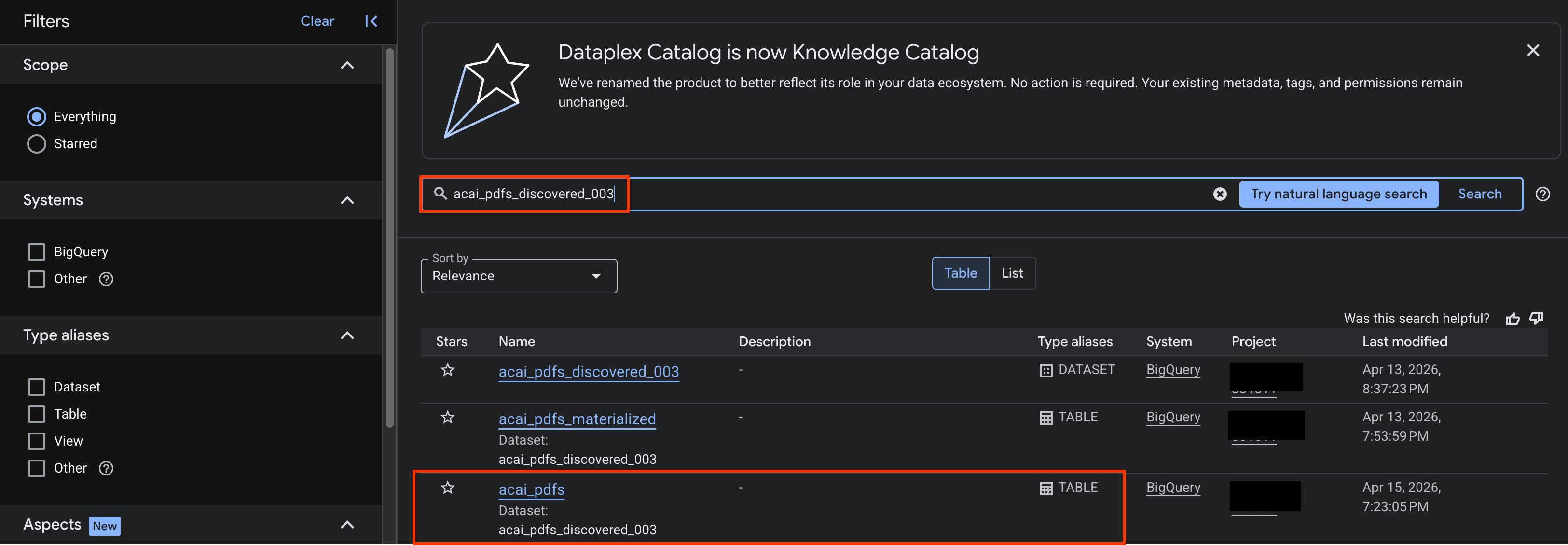
- في نتائج البحث، انقر على الجدول لفتح صفحة الإدخال.
- انقر على علامة التبويب الإحصاءات. إذا كانت علامة التبويب فارغة، يعني ذلك أنّه لم يتم إنشاء الإحصاءات لهذا الجدول بعد. قد يستغرق إنشاء الإحصاءات من 15 إلى 25 دقيقة.
- بعد ظهور الإحصاءات، انقر على استخراج > الاستخراج باستخدام SQL.
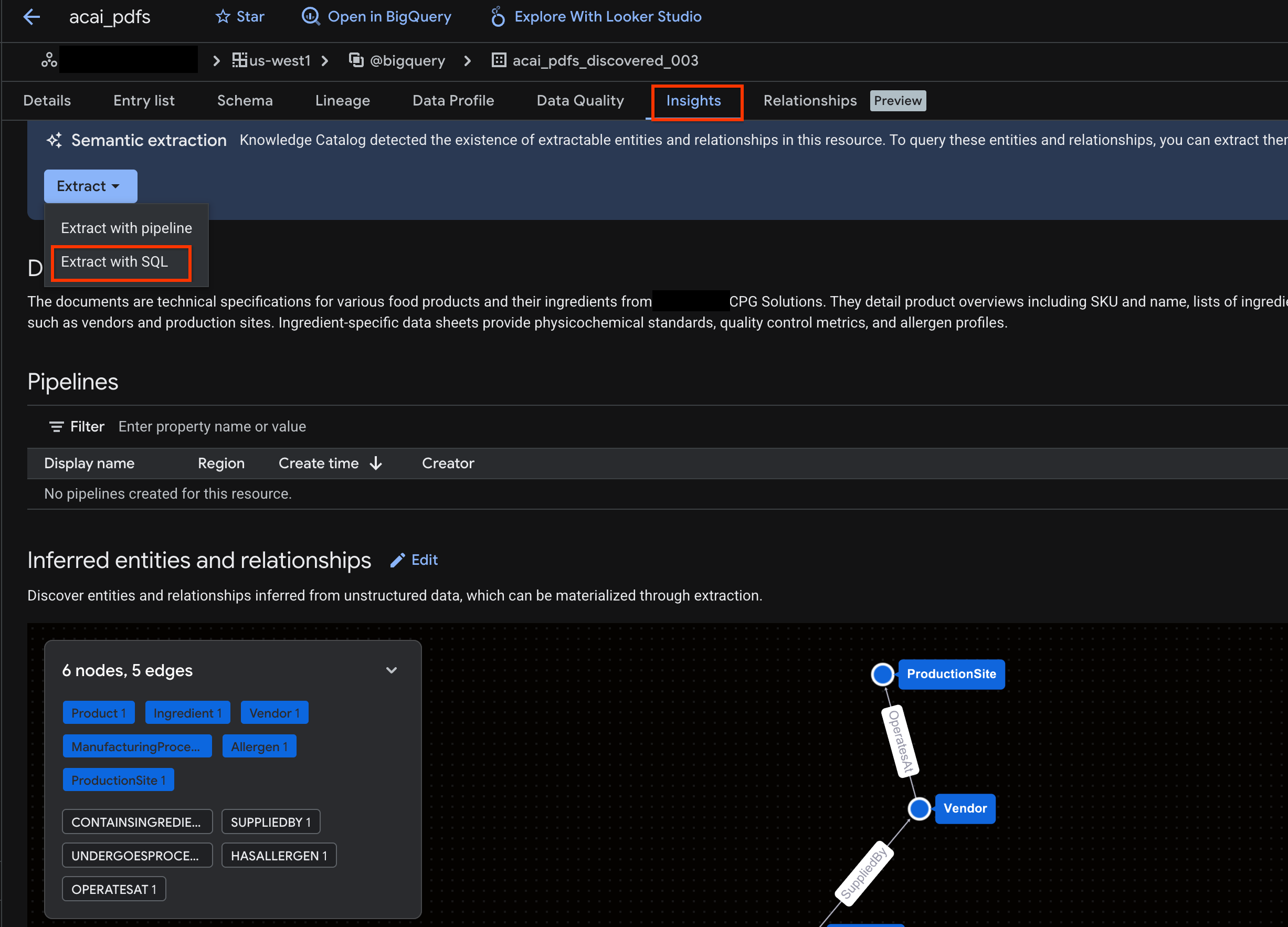
- في صفحة استخراج البيانات باستخدام SQL، أدخِل مجموعة البيانات في الوجهة. على سبيل المثال،
acai_pdfs_discovered_003. - انقر على استخراج. سيؤدي ذلك إلى فتح "محرِّر BigQuery" مع تحميل الطلب.
- انقر على تشغيل. تُنشئ هذه الخطوة مجموعة من العبارات وقد يستغرق إكمال عملية التشغيل بضع دقائق.
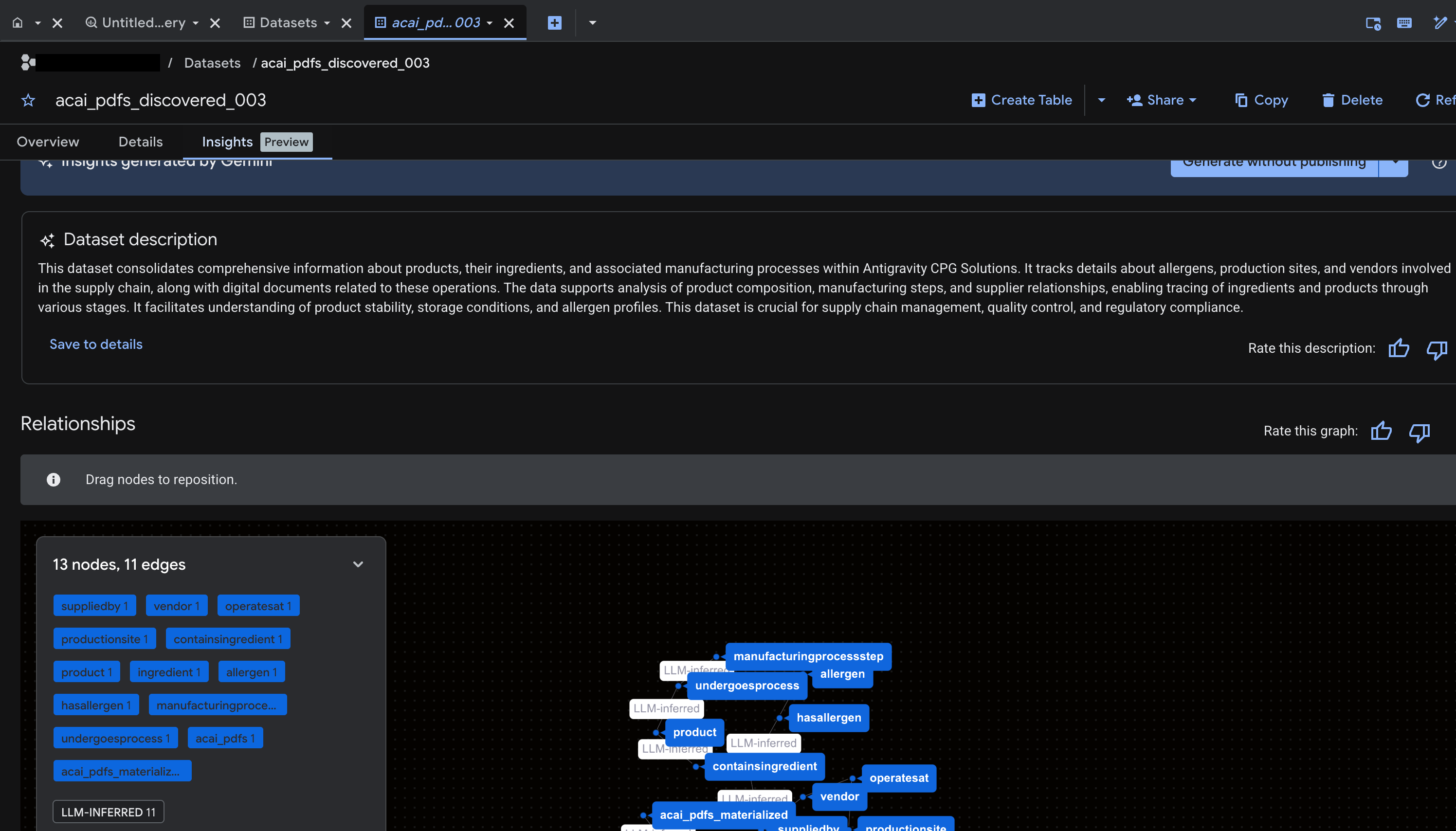
- عند اكتمال طلب البحث، ستظهر لك النتائج التالية:
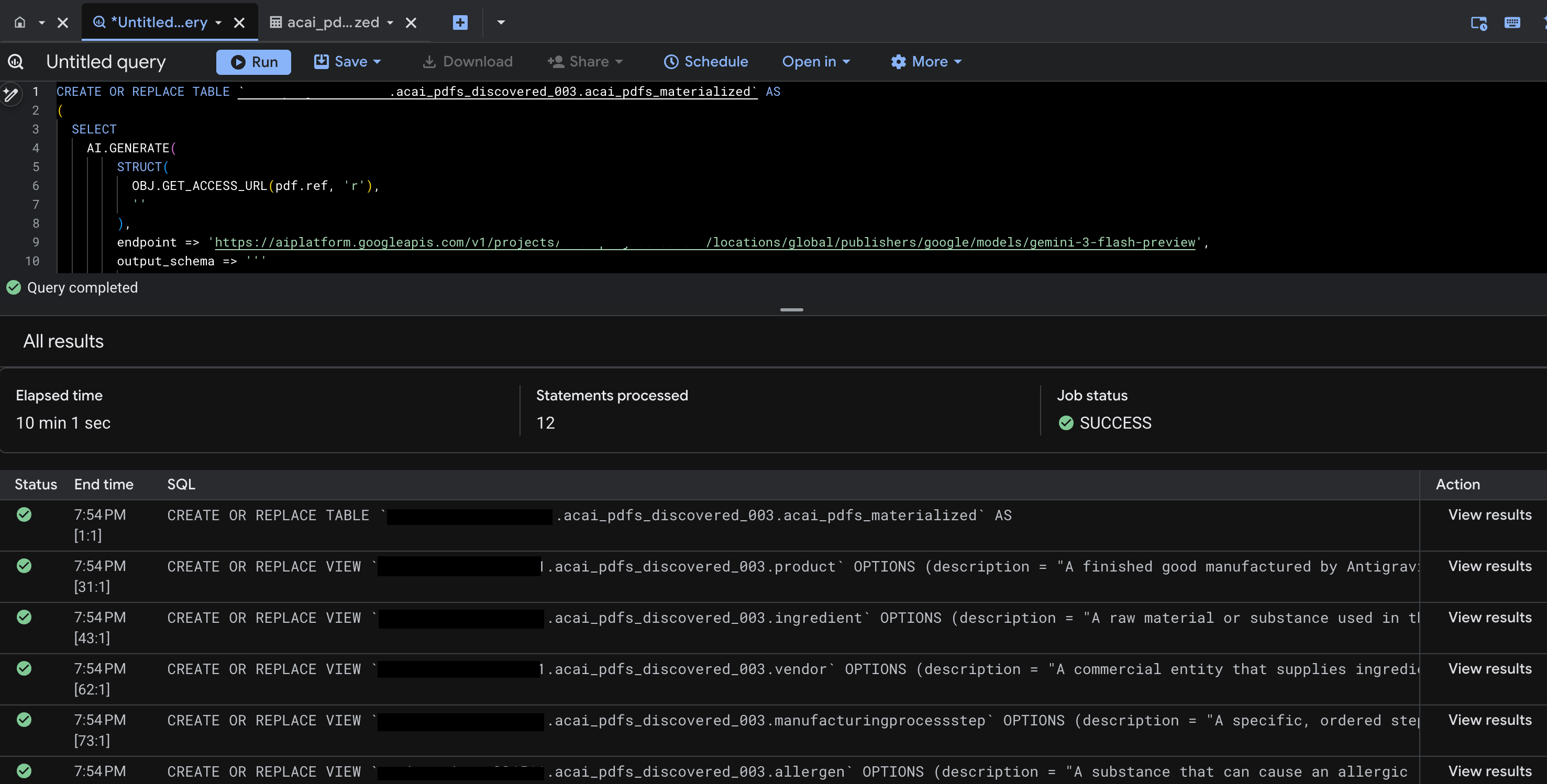
- انتقِل إلى BigQuery وانقر على مجموعات البيانات (على سبيل المثال،
acai_pdfs_discovered_003). يتم إنشاء مجموعة جديدة من عناصر قاعدة البيانات المنظَّمة في مجموعة البيانات التي اخترتها في الخطوة رقم 6.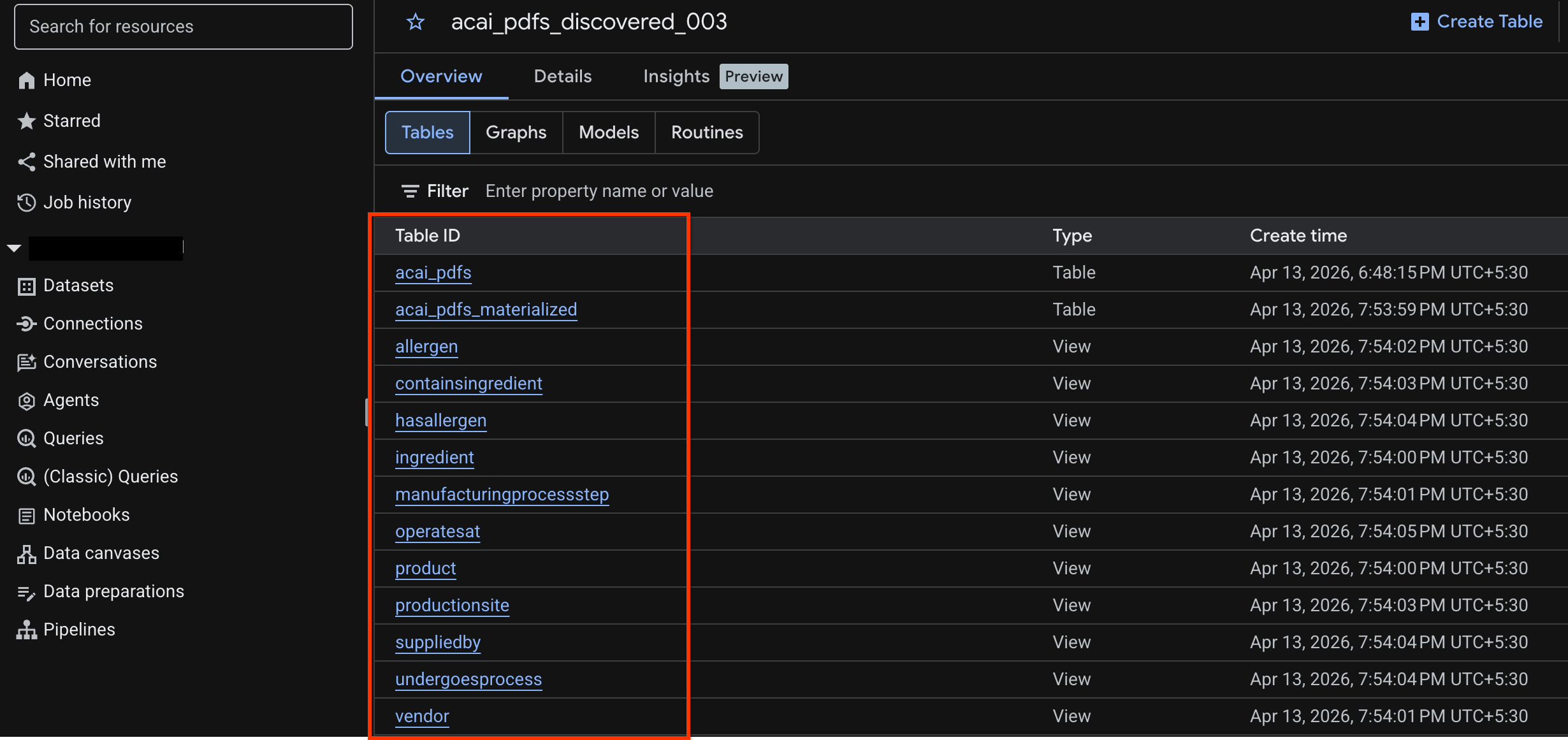
إنشاء إحصاءات حول عنصر في BigQuery
لإنشاء إحصاءات لمجموعة بيانات BigQuery، يجب الوصول إلى مجموعة البيانات في BigQuery باستخدام BigQuery Studio.
- في Google Cloud Console، انتقِل إلى BigQuery Studio.
- في لوحة المستكشف، اختَر المشروع، ثم انتقِل إلى مجموعة البيانات التي تريد إنشاء إحصاءات لها.
- انقر على علامة التبويب الإحصاءات.
- إذا ظهر لك الزر تفعيل واجهة برمجة التطبيقات، انقر عليه لتفعيل "Gemini في Google Cloud". سيؤدي ذلك إلى فتح نافذة تفعيل الميزات الأساسية.
- في قسم واجهات برمجة التطبيقات للميزات الأساسية، انقر على تفعيل لكل من Gemini for Google Cloud API وBigQuery Unified API، ثم انقر على التالي.
- في قسم الأذونات (اختياري)، امنح الجهات الرئيسية أدوار "إدارة الهوية وإمكانية الوصول" إذا لزم الأمر، ثم انقر على التالي.
- لإنشاء إحصاءات ونشرها في "كتالوج المعرفة"، انقر على إنشاء ونشر.
- بعد نشر المشاركة، ستتمكّن من الاطّلاع على الإحصاءات في علامة التبويب.
11. إعداد بيئة التطوير المتكاملة (IDE) لتحليل البيانات المستند إلى الوكلاء
إضافة Google Cloud Data Agent Kit لـ Visual Studio Code هي إضافة لبيئة تطوير متكاملة (IDE) مخصّصة لعلماء البيانات ومهندسي البيانات. تتيح لك هذه الأداة الربط بموارد وبيانات Google Data Cloud والعمل عليها مباشرةً من بيئة التطوير المتكاملة. لمزيد من المعلومات، يُرجى الاطّلاع على نظرة عامة على إضافة Data Agent Kit إلى VS Code.
تكون إضافة "حزمة أدوات وكيل البيانات" في VS Code مفيدة عندما تريد تنفيذ ما يلي:
- يمكنك إنشاء مسار بيانات جاهز للاستخدام واختباره ومراجعته ونشره، مثل Spark ETL أو BigQuery ETL، مباشرةً من VS Code.
- استكشاف البيانات وإنشاء مسار تدريب وتحديد نماذج تعلُّم الآلة المثالية وتفعيلها في نقطة نهاية إنتاج باستخدام مساعدة الذكاء الاصطناعي
- يمكنك الربط بمصادر بيانات موثوقة وإنشاء نموذج بيانات عالي الأداء ونشر لوحة بيانات تفاعلية للجهات المعنية في المؤسسة.
تثبيت إضافة "حزمة أدوات وكيل البيانات" في VS Code
- افتح VS Code.
- ثبِّت Google Cloud CLI. لمزيد من المعلومات، يُرجى الاطّلاع على تثبيت Google Cloud CLI.
- تثبيت إضافة Data Agent Kit في VS Code
- أكمِل عملية إعداد الإضافة، والتي تتطلّب منك تنفيذ ما يلي:
- تسجيل الدخول إلى الإضافة
- تثبيت المهارات وخوادم MCP
- أعِد تحميل النافذة أو أعِد تشغيلها بعد الانتهاء من عملية الإعداد. لمزيد من المعلومات، يُرجى الاطّلاع على إعداد إضافة Data Agent Kit وتكوينها في VS Code.
- بعد إعادة تحميل بيئة التطوير المتكاملة، انقر على رمز Google Data Cloud في لوحة التنقّل، وانتقِل إلى الإعدادات، وتأكَّد من ضبط رقم تعريف مشروعك والمنطقة بشكلٍ صحيح (
us-west1) في الإعدادات العامة.
إعداد مساحة العمل في VS Code
- افتح VS Code وانقر على ملف (File) > فتح مجلد (Open folder) > مجلد جديد (New folder).
- أنشئ مجلدًا جديدًا باسم
acai_test، ثم انقر على فتح. سيعتبر VS Code الآن المجلد الذي فتحته مساحة عمل. - في مربّع الحوار الثقة في Workspace، انقر على نعم، أثق في المؤلّفين لتفعيل جميع الميزات في مساحة العمل.
- أنشئ مجلدًا
.githubفي مساحة العملacai_test. - أنشئ ملفًا جديدًا
copilot-instructions.mdفي المجلد.githubوأدخِل فيه القواعد التالية.## 1. Project Context - **Project ID**: <PROJECT_ID> - **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors. - **Documentation**: Raw PDF documents detailing flavors and ingredients are stored in Google Cloud Storage at `gs://<BUCKET_NAME>`. ## 2. Execution & Data Processing Rules - **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `<BQ_DATASET_NAME>` (referred to as the Knowledge Catalog). - **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the dataset `<DATASET_ID>`. When you are referencing a dataset, ensure you are using it with the project ID (`<PROJECT_ID>`) and namespace prefix `<NAMESPACE_NAME>`. For example, to query order table in this dataset you should use `<PROJECT_ID>.<NAMESPACE>.<DATASET_ID>.orders`. - **CRITICAL RULE - Data Joins between BigQuery dataset and Iceberg dataset**: ANY task requiring a join or integration between the BigQuery datasets `<DATASET_ID>` of the PDF data and the `<DATASET_ID>` of the customer data MUST be executed using **Spark Notebooks**. - **CRITICAL RULE - Notebook Kernel**: Every Spark notebook utilized MUST exclusively be configured to run on the Serverless Session template `iceberg-federation-template` as its kernel. - **CRITICAL RULE - Data Science**: ANY data science, machine learning, or advanced analytical task MUST be performed strictly within **Spark Notebooks** using the aforementioned setup. - أنشئ ملفًا جديدًا آخر
template.yamlفي مساحة العملacai_testوأدخِل المعلومات التالية في الملف.labels: client: "vscode" jupyterSession: displayName: "iceberg-federation-template" kernel: "PYTHON" environmentConfig: executionConfig: serviceAccount: "sa-spark-dev1@<PROJECT_ID>.iam.gserviceaccount.com" subnetworkUri: "projects/<PROJECT_ID>/regions/<REGION>/subnetworks/<SUBNET_NAME>" runtimeConfig: version: "2.3" properties: # This enables the secure proxy URL you were looking for dataproc.tier: "premium" spark.dataproc.engine: "lightningEngine" spark.dataproc.lightningEngine.runtime: "native" spark.memory.offHeap.enabled: "true" spark.memory.offHeap.size: "1g" spark.executor.memory: "4g" "dataproc.component.gateway.enabled": "true" "dataproc.jupyter.listen.all.interfaces": "true" "spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" "spark.sql.defaultCatalog": "<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>": "org.apache.iceberg.spark.SparkCatalog" "spark.sql.catalog.<CATALOG_NAME>.type": "rest" "spark.sql.catalog.<CATALOG_NAME>.uri": "<CATALOG_URI_ID>" "spark.sql.catalog.<CATALOG_NAME>.warehouse": "bl://projects/<PROJECT_ID>/catalogs/<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>.rest.auth.type": "org.apache.iceberg.gcp.auth.GoogleAuthManager" - في VS Code، انقر على الوحدة الطرفية (Terminal) وشغِّل الأمر التالي لاستيراد ملف
template.yamlكنموذج جلسة. يستخدم الوكيل هذا النموذج لاحقًا لإنشاء جلسة Spark.gcloud beta dataproc session-templates import iceberg-federation-template \ --source=template.yaml \ --location=<REGION>REGIONبمنطقتك.
12. إجراء تحليل البيانات المستند إلى الوكلاء
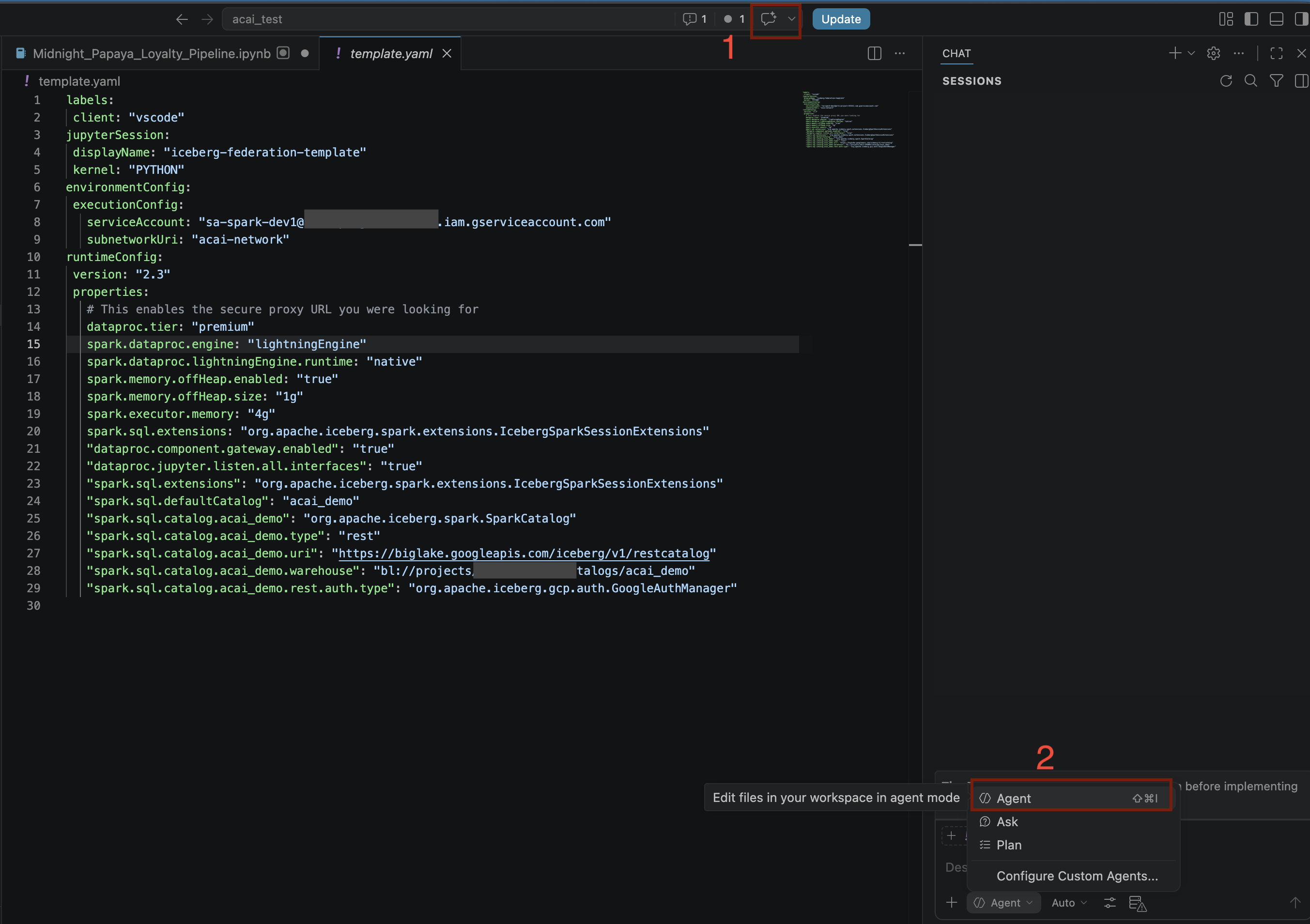
- في محرِّر VS Code، انقر على تبديل المحادثة.
- بالنسبة إلى ضبط الوكلاء المخصّصين، اختَر الوكيل.
- في لوحة نماذج البحث، انقر على إدارة نماذج اللغة.
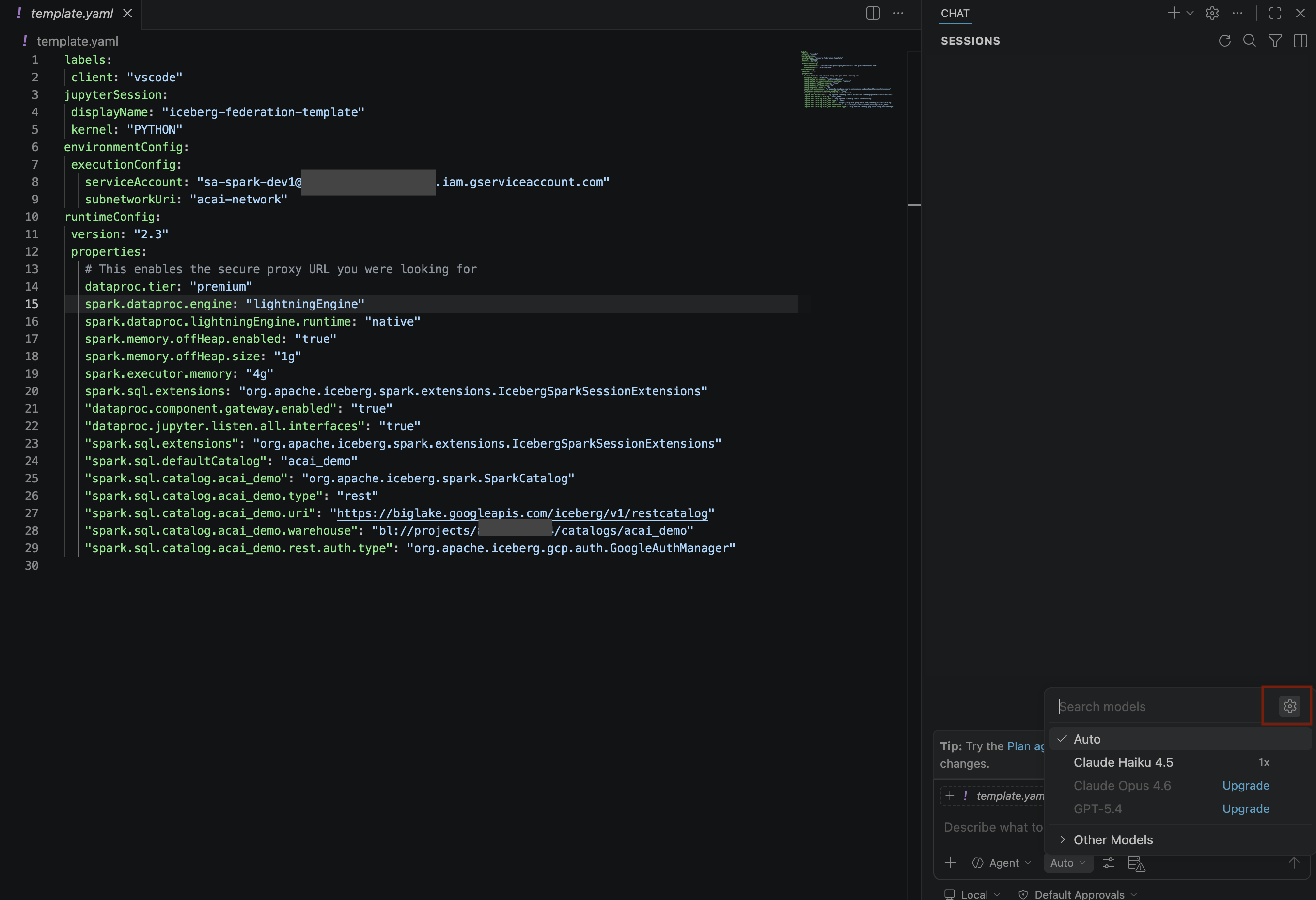
- في صفحة نماذج اللغة، انقر على إضافة نماذج.
- اختَر Google من القائمة واضغط على Enter لتأكيد إدخالك.
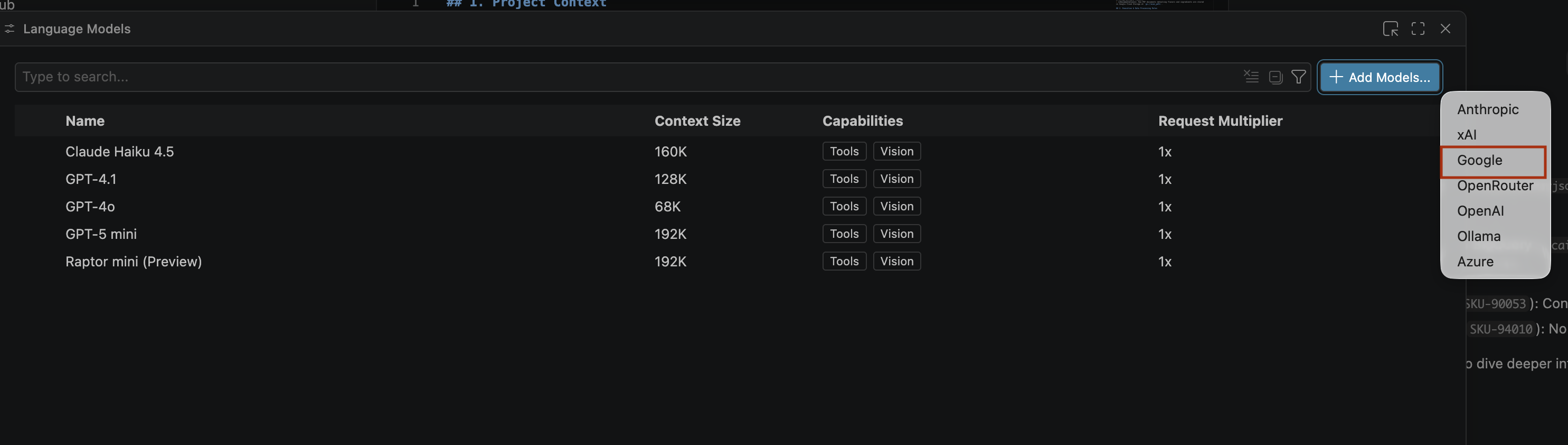
- لإدخال مفتاح واجهة برمجة التطبيقات في Google Gemini، اتّبِع الخطوات التالية:
- انتقِل إلى موقع Google AI Studio الإلكتروني.
- سجِّل الدخول باستخدام حسابك على Google.
- في الشريط الجانبي، انقر على الحصول على مفتاح واجهة برمجة التطبيقات.
- انقر على إنشاء مفتاح واجهة برمجة تطبيقات. سيتم فتح صفحة إنشاء مفتاح جديد.
- من قائمة اختيار مشروع على السحابة الإلكترونية، اختَر استيراد مشروع.
- أدخِل اسم مشروع حالي.
- انقر على إنشاء مفتاح وانسخ مفتاح واجهة برمجة التطبيقات. يوفّر المفتاح إمكانية الوصول إلى موارد Gemini API في حسابك.لمزيد من المعلومات، يُرجى الاطّلاع على استخدام مفاتيح Gemini API.
- الصِق مفتاح واجهة برمجة التطبيقات الذي أنشأته في شريط البحث وانقر على Enter.
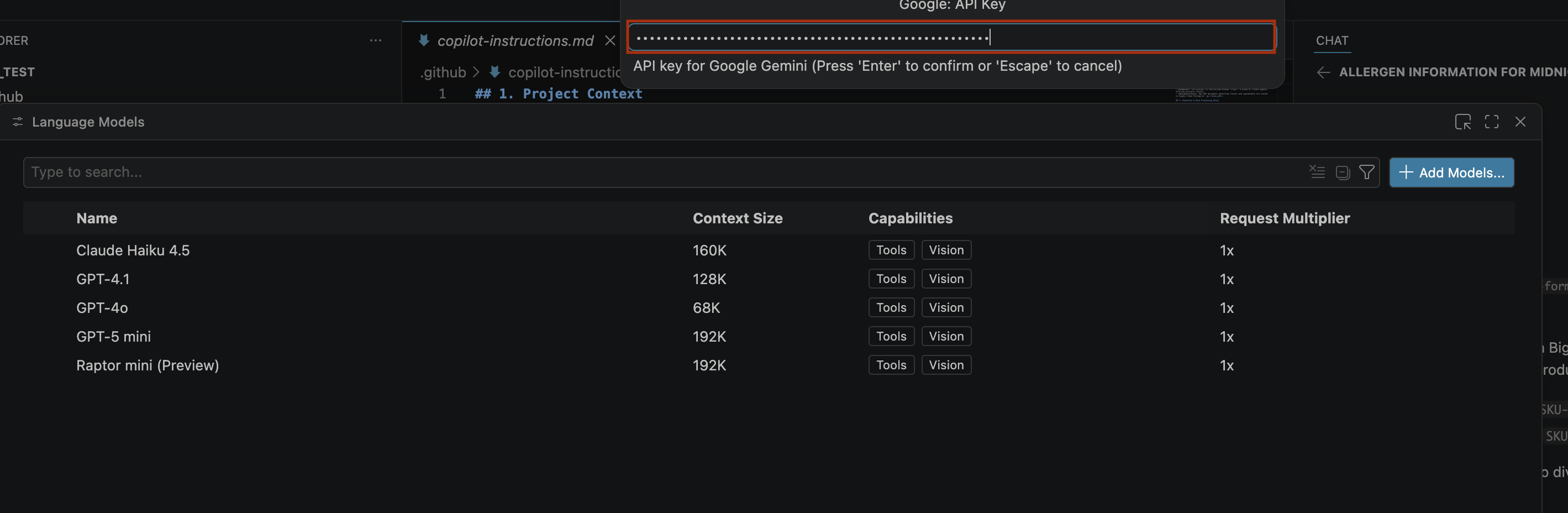
- إذا لم تظهر نماذج Gemini، أظهِرها كما هو موضّح في الصورة التالية:
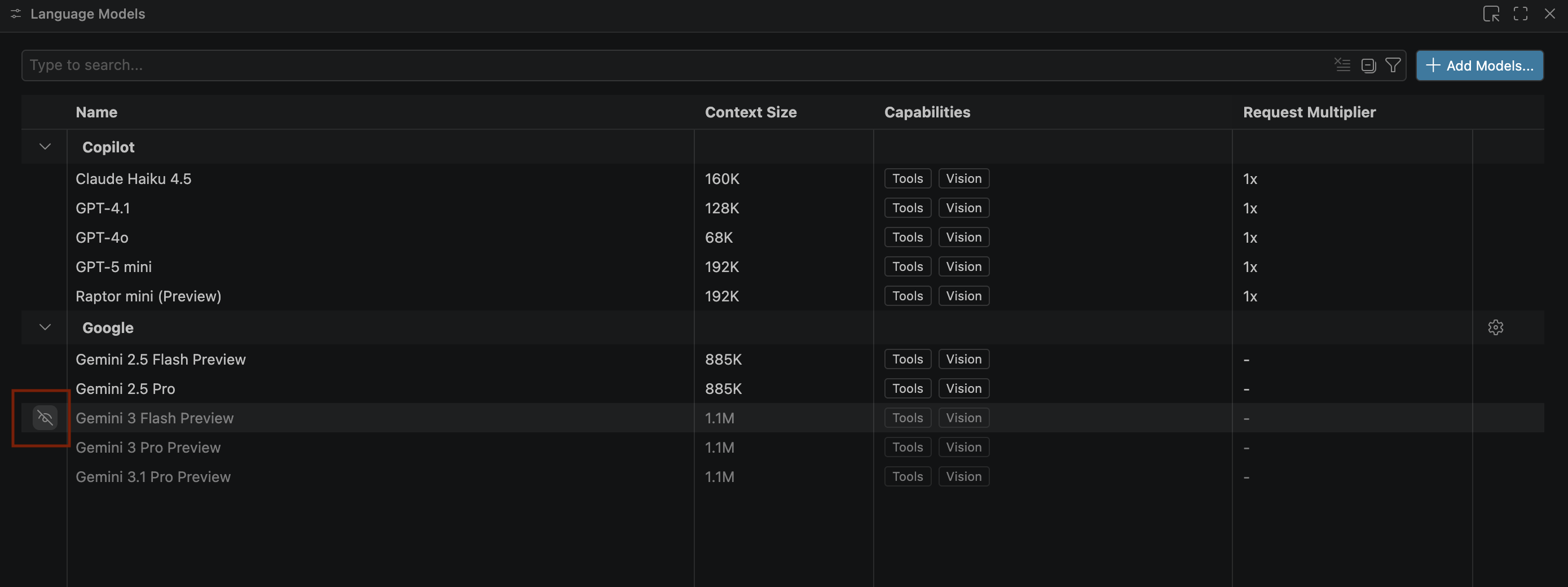
- اختَر معاينة Gemini 3.1 Pro من قائمة نماذج Google Gemini وأغلِق نافذة نماذج اللغة.
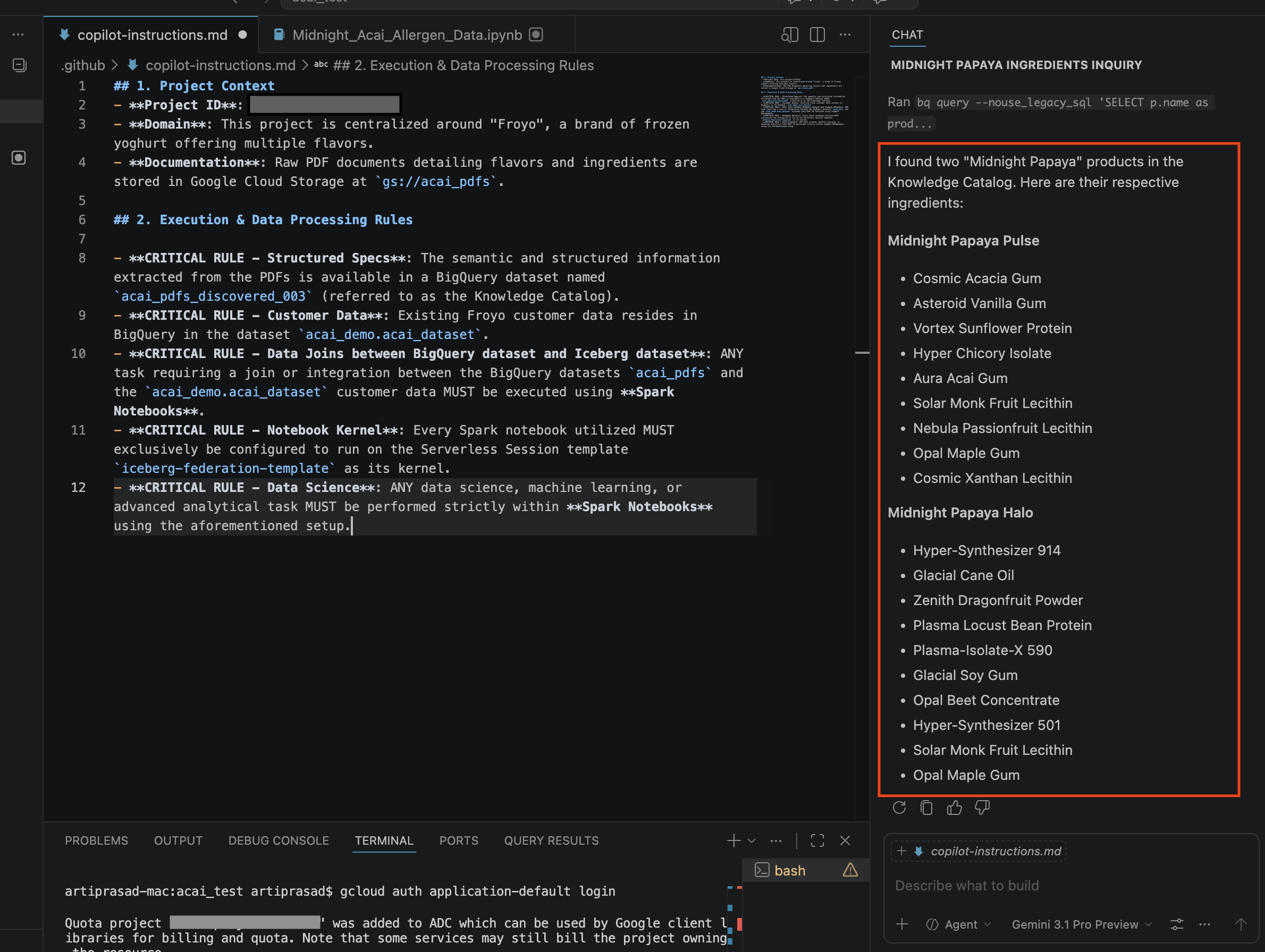
- في نافذة المحادثة، أدخِل السؤال التالي:
Search ingredients for Midnight papaya - بعد بعض التفاعل، من المفترض أن تظهر لك النتيجة التالية:
- في نافذة المحادثة، أدخِل سؤالاً آخر:
Search allergen information for Midnight papaya - بعد بعض التفاعل والخطوات، سترى الوكيل يردّ باسم مادة مسبّبة للحساسية
Soyكما هو موضّح في الصورة التالية: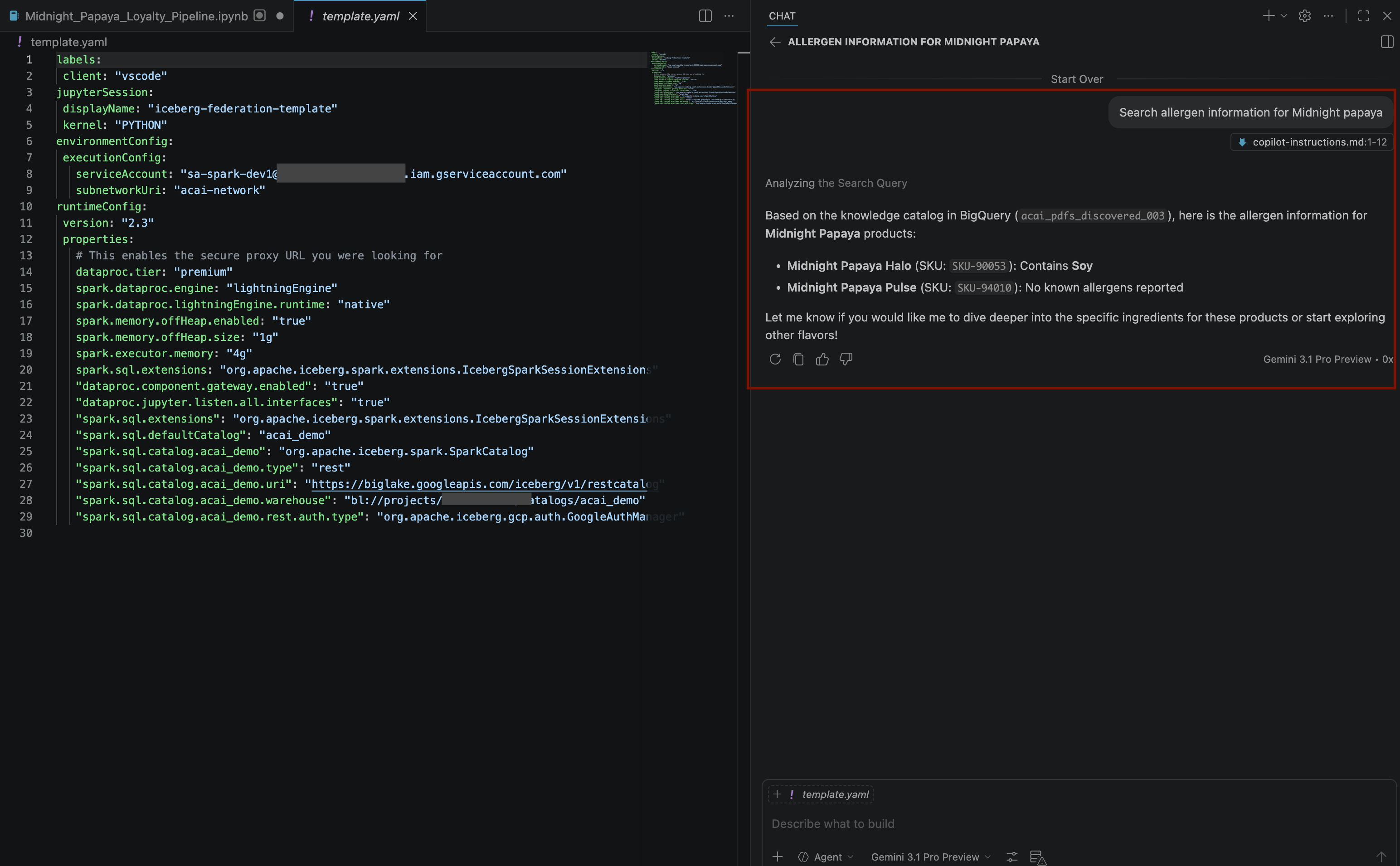
- في نافذة المحادثة، أدخِل سؤالاً آخر:
Build a pipeline to join products with our 'Global Loyalty' Iceberg tables in acai customer, sales data to identify popular products - لاختيار النواة، افتح الملف
.ipynbوانقر على اختيار النواة > نواة Spark البعيدة > نموذج Iceberg-federation على Spark بلا خادم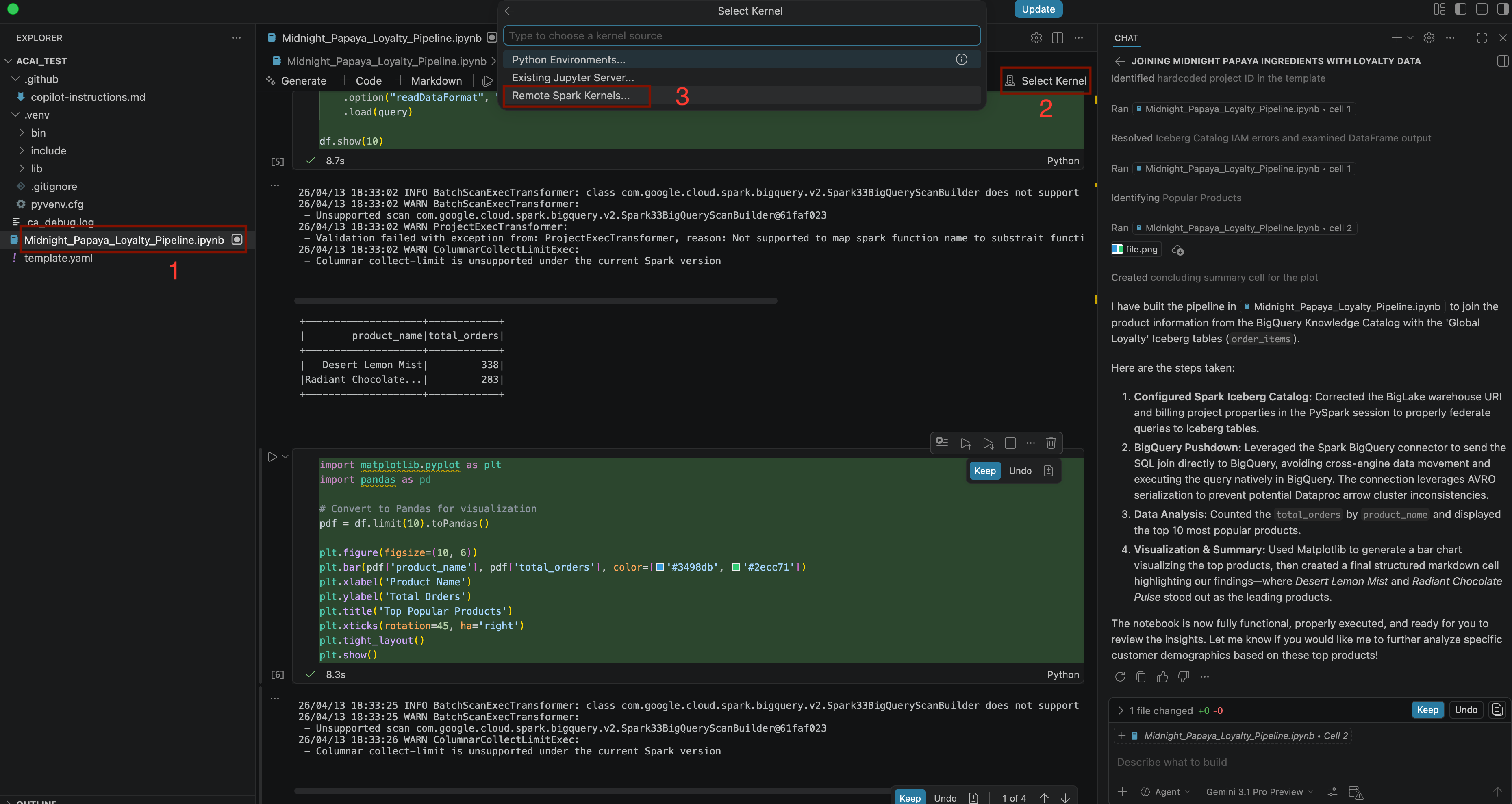
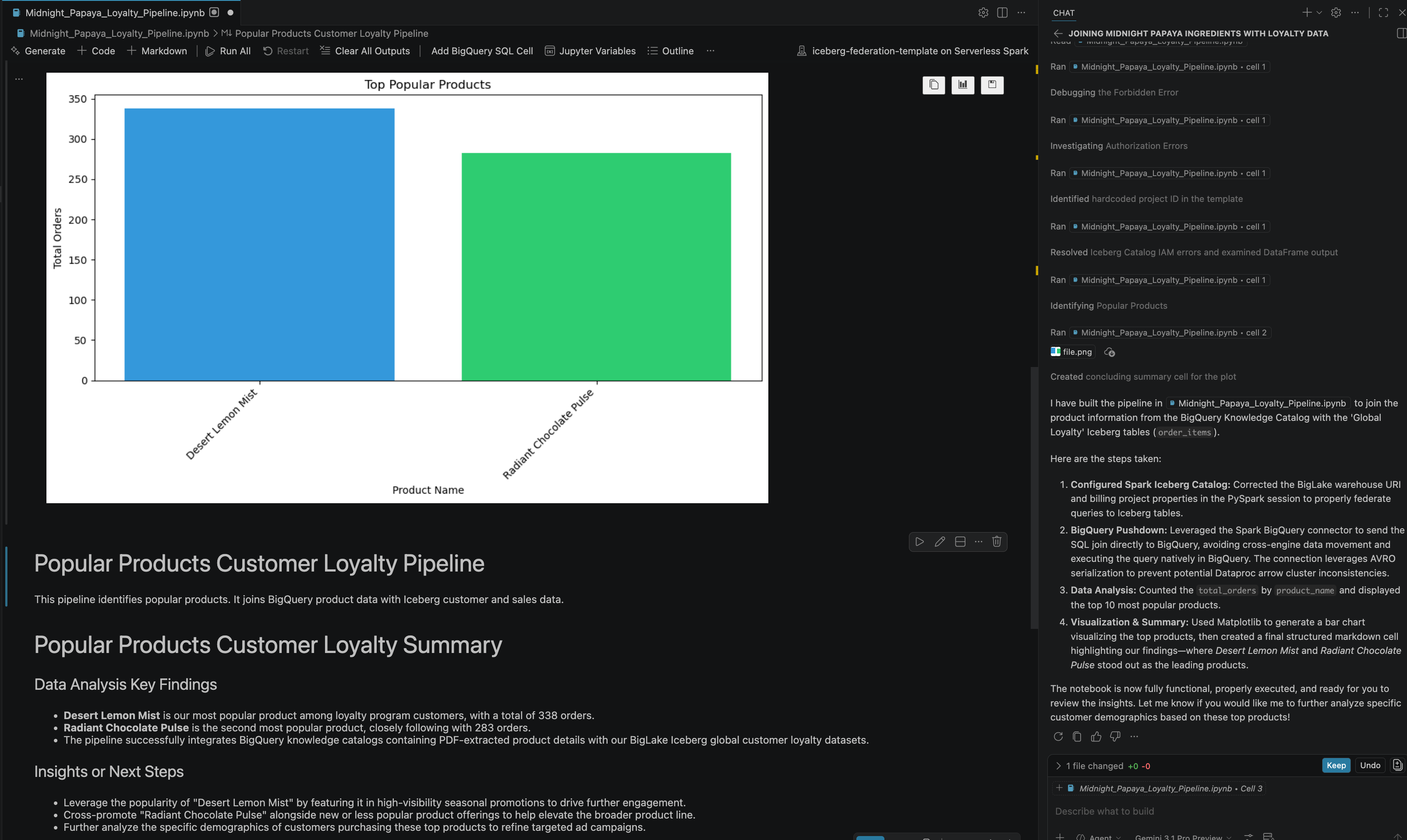
- بعد بعض التفاعلات والخطوات، سترى الردّ من الوكيل يتضمّن جميع الخطوات التي تم تنفيذها بنجاح في دفتر الملاحظات بالإضافة إلى النتيجة النهائية التي تم إنشاؤها في نهاية دفتر الملاحظات، كما هو موضّح في الصورة التالية:
13. تَنظيم
لتجنُّب تحمّل رسوم، احذف الموارد التي أنشأتها في هذا الدرس التطبيقي.
- لحذف Knowledge Catalog DataScan، نفِّذ الأمر التالي:
DATASCAN_ID="<DATASCAN_ID>" echo "Deleting Dataplex DataScan: ${DATASCAN_ID}" gcloud dataplex datascans delete "${DATASCAN_ID}" --location="${REGION}" --quiet - لحذف حِزم Cloud Storage وجميع محتوياتها، نفِّذ الأمر التالي:
echo "Deleting Cloud Storage buckets: <BUCKET_NAME1> and <BUCKET_NAME2>" gsutil -m rm -r gs://<BUCKET_NAME1> gsutil -m rm -r gs://<BUCKET_NAME2> - لحذف BigQuery Connection، نفِّذ الأمر التالي:
CONNECTION_ID="<CONNECTION_NAME>" echo "Deleting BigQuery Connection: ${CONNECTION_ID}" bq rm --connection "${PROJECT_ID}.${REGION}.${CONNECTION_ID}" - لحذف Lakehouse Catalog، شغِّل الأمر التالي:
CATALOG_ID="<CATALOG_NAME>" echo "Deleting Lakehouse Catalog: ${CATALOG_ID}" gcloud biglake catalogs delete "${CATALOG_ID}" --project="${PROJECT_ID}" --location="${REGION}" --quiet - لحذف مجموعة البيانات التي تحتوي على جداول PDF التي تم اكتشافها، نفِّذ الأمر التالي:
DATASET_NAME="<DATASET_NAME>" echo "Deleting BigQuery Dataset: ${DATASET_NAME}" bq rm -r -f "${PROJECT_ID}:${DATASET_NAME}" - لحذف حساب الخدمة المخصّص، نفِّذ الأمر التالي:
SERVICE_ACCOUNT="<SERVICE_ACCOUNT>" echo "Deleting Service Account: ${SERVICE_ACCOUNT}" gcloud iam service-accounts delete "${SERVICE_ACCOUNT}"@"${PROJECT_ID}".iam.gserviceaccount.com --quiet - لحذف شبكة VPC، نفِّذ الأمر التالي:
VPC_NETWORK="<VPC_NETWORK>" echo "Deleting VPC Network: ${VPC_NETWORK}" gcloud compute networks delete "${VPC_NETWORK}" --quiet - لحذف مشروع Google Cloud بأكمله، نفِّذ الأمر التالي:
gcloud projects delete "${PROJECT_ID}"
14. تهانينا
تهانينا! لقد تمكّنت بنجاح من تنظيم مشهد البيانات الخاص بملفات PDF وملفات Parquet المعزولة في جداول BigQuery ودمجها في نظام بيئي واحد قابل للبحث والربط. لقد أنشأت بشكل أساسي Data Lakehouse حديثًا يعامل ملفات PDF وتنسيقات البيانات الكبيرة بذكاء كما يعامل صفًا في قاعدة بيانات. وقد تمكّنت من إجراء كل ذلك مباشرةً من وكيلك في تجربة حوارية مع Gemini.
المستندات المرجعية
للتعمّق أكثر في التقنيات الأساسية المستخدَمة في هذا الدرس التطبيقي حول الترميز، يُرجى الانتقال إلى مستندات Google Cloud الرسمية:
- لاستكشاف BigQuery، وهو أحد المكوّنات الأساسية في Data Cloud، يمكنك الاطّلاع على مستندات BigQuery.
- لمزيد من المعلومات عن "إدارة الهوية وإمكانية الوصول"، يُرجى الاطّلاع على مستندات "إدارة الهوية وإمكانية الوصول".
- لمعرفة المزيد عن Lakehouse، يمكنك الاطّلاع على ما هو Lakehouse؟