
১. ভূমিকা
এই কোডল্যাবে, আপনি একটি কাল্পনিক ফ্রয়ো কোম্পানির ডেটা সায়েন্টিস্টের ভূমিকায় অবতীর্ণ হবেন, যারা "মিডনাইট সুইর্ল" নামে একটি নতুন ফ্লেভার বাজারে আনছে। বিশ্বব্যাপী সফলভাবে পণ্যটি চালু করার জন্য, ব্যবসাটিকে এর উপাদান, বাজারের চাহিদা এবং বিনিয়োগের উপর রিটার্ন (ROI) সম্পর্কিত গুরুত্বপূর্ণ প্রশ্নের উত্তর খুঁজে বের করতে হবে। এই এন্ড-টু-এন্ড ওয়ার্কফ্লোটি দেখায় কিভাবে গুগল ক্লাউডের নলেজ ক্যাটালগ (পূর্বে ডেটাপ্লেক্স নামে পরিচিত) এবং লেকহাউস ফর অ্যাপাচি আইসবার্গ (পূর্বে বিগলেক নামে পরিচিত) একটি সমন্বিত গভর্নেন্স লেয়ারের মাধ্যমে আপনার IDE (VS Code)-তে জেমিনি ব্যবহার করে "ডার্ক" বা অসংগঠিত ডেটার মধ্যেকার ব্যবধান পূরণ করে এবং কার্যকরী বিজনেস ইন্টেলিজেন্স সরবরাহ করে।
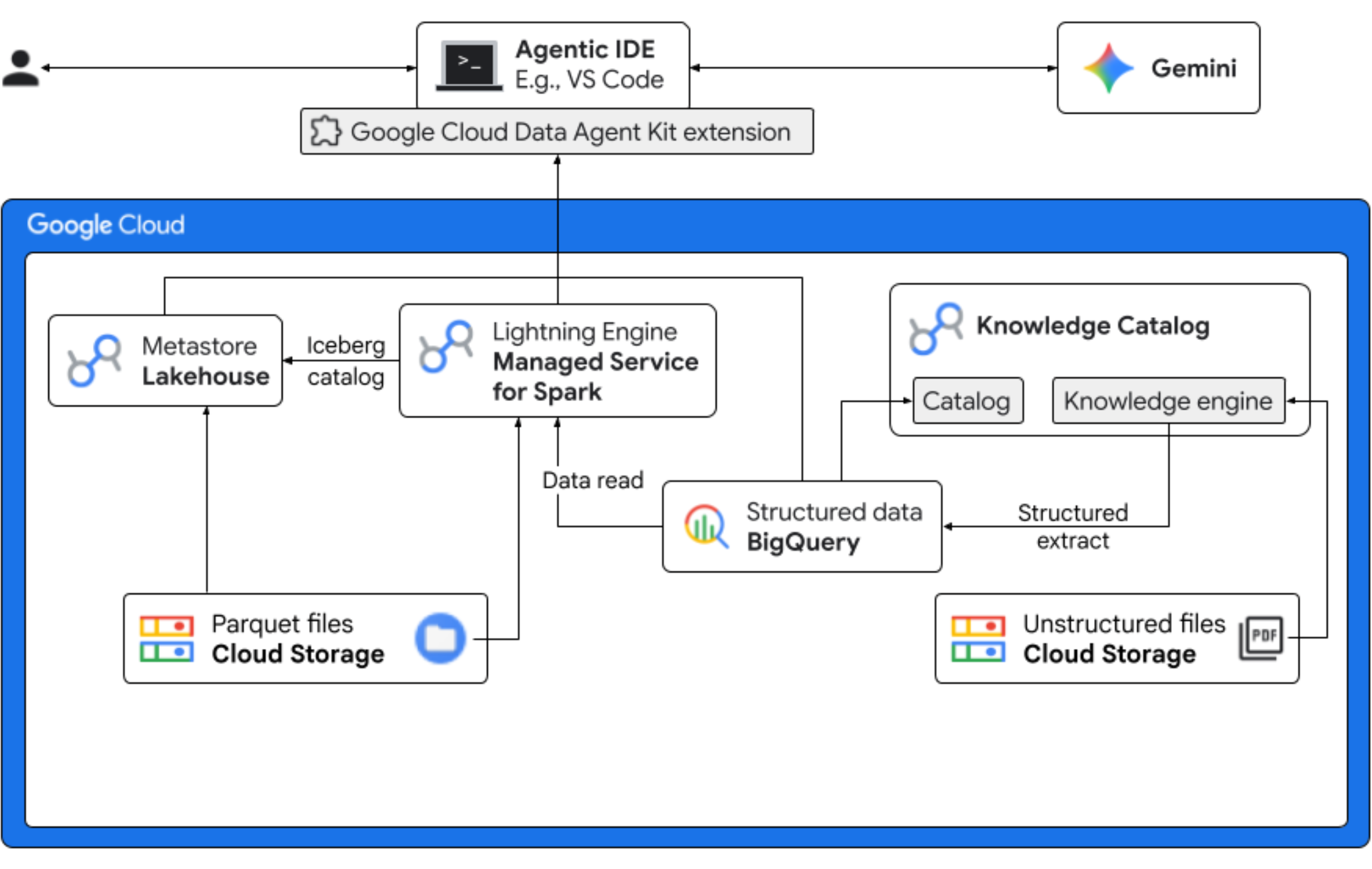
আপনি যা করবেন
- অসংগঠিত তথ্য অনুসন্ধান : ক্লাউড স্টোরেজে সংরক্ষিত পিডিএফ রেসিপিগুলো নলেজ ক্যাটালগ ডেটাস্ক্যান দ্বারা ক্রল করা হয়। স্ক্যান করা পিডিএফগুলোর জন্য বিগকোয়েরিতে অবজেক্ট টেবিল তৈরি করা হয়। ভার্টেক্স এআই সিমান্টিক ইনফারেন্স ব্যবহার করে, সিস্টেমটি পণ্য, অ্যালার্জেন, উপাদান এবং সম্পর্কিত অ্যাট্রিবিউটগুলোর জন্য কাঠামোগত তথ্য বের করতে পিডিএফগুলো "পড়ে"। এরপর এটি পিডিএফগুলোতে সংরক্ষিত ডেটার জন্য বুদ্ধিমত্তার সাথে একটি স্কিমা তৈরি করে।
- একীভূত মেটাডেটা : পিডিএফ ফাইল থেকে সংগৃহীত ডেটা সরাসরি BigQuery-তে একটি নেটিভ ওয়াইড টেবিল হিসেবে সংরক্ষণ করা হয় এবং সাধারণ কোয়েরিগুলোতে সহায়তার জন্য ভিউ তৈরি করা হয়। ঐতিহাসিক বিক্রয় ডেটা সম্বলিত একটি স্বতন্ত্র ইনপুট ডেটাসেট গুগল ক্লাউড স্টোরেজের অ্যাপাচি আইসবার্গ টেবিলে সংরক্ষণ করা হয়। পরবর্তী ধাপে এই আইসবার্গ টেবিলটি BigQuery-তে সংগৃহীত ডেটার সাথে যুক্ত করা হবে।
- ক্রস-ইঞ্জিন অ্যানালিটিক্স : একটি আইসবার্গ রেস্ট ক্যাটালগের সাথে অ্যাপাচি স্পার্কের জন্য ম্যানেজড সার্ভিস (পূর্বে ডেটাপ্রক নামে পরিচিত) ব্যবহার করে, আপনি এই নতুন পিডিএফ মেটাডেটা এবং অনুমানকৃত কাঠামোগত শব্দার্থিক ডেটা (বিগকোয়েরি টেবিল এবং ভিউ থেকে) গুগল ক্লাউড স্টোরেজে অ্যাপাচি আইসবার্গ টেবিলে সংরক্ষিত কাঠামোগত বিক্রয় ডেটার সাথে যুক্ত করবেন। এটি একটি ম্যানেজড অ্যাপাচি স্পার্ক ইন্টারেক্টিভ সেশন টেমপ্লেট দ্বারা পরিচালিত হয়, যা জুপিটার নোটবুক কার্নেল হিসাবে ব্যবহৃত হয় এবং স্পার্ক জবের জন্য সামঞ্জস্যপূর্ণ নিরাপত্তা ও কম্পিউট সেটিংস নিশ্চিত করে।
- অর্থগত অন্তর্দৃষ্টি : BigQuery-তে অনুমানকৃত পণ্যের ডেটার সাথে গ্রাহক এবং বিক্রয়ের ডেটা যুক্ত করার মাধ্যমে, এই ডেমোটি অ্যালার্জেন ডেটা শনাক্তকরণ এবং রাজস্ব পূর্বাভাসের মতো অন্তর্দৃষ্টি বের করতে সক্ষম।
- স্বায়ত্তশাসিত পরিচালনা : ডিসকভারি স্ক্যান থেকে শুরু করে স্পার্ক এক্সিকিউশন পর্যন্ত সম্পূর্ণ জীবনচক্রটি জেমিনি-রেডি টেমপ্লেট, নির্দেশাবলী, নিয়মাবলী এবং এজেন্ট-চালিত অটোমেশনের মাধ্যমে সমন্বিত করা হয়, যা প্রমাণ করে যে এআই অ্যানালিটিক্সকে চালিত করে এমন পরিকাঠামো পরিচালনা করতে পারে।
আপনার যা যা লাগবে
এই কোডল্যাবটি সম্পূর্ণ করতে খরচ হতে পারে, যা সাধারণ ব্যবহারের ক্ষেত্রে আনুমানিক $5-এর কম। আপনার প্রত্যাশিত ব্যবহার বা বর্তমান মূল্যের উপর ভিত্তি করে খরচের বিস্তারিত হিসাব পেতে, গুগল ক্লাউড প্রাইসিং ক্যালকুলেটর ব্যবহার করুন।
কোডল্যাবটি সম্পন্ন করার জন্য আপনার নিম্নলিখিত পূর্বশর্তগুলো থাকা নিশ্চিত করুন।
- ক্রোম ওয়েব ব্রাউজার।
- আপনি যদি 'শুরু করার আগে' বিভাগে দেওয়া ট্রায়াল ক্রেডিট ব্যবহার করেন, তাহলে একটি ব্যক্তিগত জিমেইল অ্যাকাউন্ট প্রয়োজন হবে।
- ভিজ্যুয়াল স্টুডিও (ভিএস) কোড ডাউনলোড এবং ইনস্টল করুন ।
২. শুরু করার আগে
একটি গুগল ক্লাউড প্রজেক্ট তৈরি করুন
- গুগল ক্লাউড কনসোলের প্রজেক্ট সিলেক্টর পেজে, একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন ।
- আপনার ক্লাউড প্রোজেক্টের জন্য বিলিং চালু আছে কিনা তা নিশ্চিত করুন। কোনো প্রোজেক্টে বিলিং চালু আছে কিনা তা কীভাবে পরীক্ষা করবেন, তা জেনে নিন।
ক্লাউড শেল শুরু করুন
ক্লাউড শেল হলো গুগল ক্লাউডে চালিত একটি কমান্ড-লাইন পরিবেশ, যা প্রয়োজনীয় টুলস সহ আগে থেকেই লোড করা থাকে।
- Google Cloud কনসোলের শীর্ষে থাকা Activate Cloud Shell-এ ক্লিক করুন।
- ক্লাউড শেলে সংযুক্ত হওয়ার পর, আপনার প্রমাণীকরণ যাচাই করুন:
gcloud auth list - আপনার প্রজেক্টটি কনফিগার করা হয়েছে কিনা তা নিশ্চিত করুন:
gcloud config get project - আপনার প্রজেক্টটি প্রত্যাশা অনুযায়ী সেট করা না থাকলে, এটি সেট করুন:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
প্রয়োজনীয় এপিআইগুলি সক্রিয় করুন
প্রয়োজনীয় সকল API সক্রিয় করতে এই কমান্ডটি চালান:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
biglake.googleapis.com \
dataproc.googleapis.com \
metastore.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
secretmanager.googleapis.com \
storage.googleapis.com
কোডল্যাব অ্যাসেট ডাউনলোড করুন
এই রিপোজিটরিতে এই কোডল্যাবে ব্যবহারের জন্য Parquet, recipes, suppliers, copilot-instructions.md, template.yaml, এবং quickstart.py ফাইলগুলো রয়েছে। এই ফাইলগুলো ডাউনলোড করে নিতে ভুলবেন না।
ফাইলগুলো ডাউনলোড করতে, নিম্নলিখিত পদক্ষেপগুলো অনুসরণ করুন:
- ক্লাউড শেলে, নিম্নলিখিত কমান্ডটি চালান:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git - নতুন তৈরি করা ফোল্ডারটিতে প্রবেশ করুন:
cd next-26-keynotes data-cloud-demoফোল্ডারটি পুল করুনgit sparse-checkout set genkey/data-cloud-demo- চেকআউট সম্পন্ন হওয়ার পর,
data-cloud-demoফোল্ডারে যান এবং কোডল্যাব অ্যাসেটগুলো অ্যাক্সেস করার জন্য ZIP ফাইলগুলো এক্সট্র্যাক্ট করুন।
৩. ফ্রয়ো গ্রাহকের ডেটার জন্য লেকহাউস সেটআপ করুন
এই বিভাগে, আপনি আপনার ওয়ার্কফ্লোর জন্য লেকহাউস মেটাস্টোর ব্যবহার করতে লেকহাউসে একটি ক্যাটালগ তৈরি করেন। এটি আপনার সমস্ত আইসবার্গ ডেটার জন্য একটি একক নির্ভরযোগ্য উৎস প্রদান করে আপনার কোয়েরি ইঞ্জিনগুলির মধ্যে আন্তঃকার্যক্ষমতা তৈরি করে। এটি অ্যাপাচি স্পার্কের মতো কোয়েরি ইঞ্জিনগুলিকে একটি সামঞ্জস্যপূর্ণ উপায়ে আইসবার্গ টেবিলগুলি আবিষ্কার করতে, মেটাডেটা পড়তে এবং পরিচালনা করতে দেয়।
প্রয়োজনীয় ভূমিকা
নিশ্চিত করুন যে আপনার নিম্নলিখিত আইডেন্টিটি অ্যান্ড অ্যাক্সেস ম্যানেজমেন্ট (IAM) রোলগুলো রয়েছে:
-
roles/biglake.viewer -
roles/bigquery.user -
roles/bigquery.dataEditor -
roles/biglake.editor -
roles/biglake.metadataViewer -
roles/bigquery.connectionUser -
roles/storage.objectUser -
roles/storage.objectViewer -
roles/storage.objectCreator -
roles/storage.admin
IAM রোল প্রদান করার বিষয়ে আরও তথ্যের জন্য, “Grant an IAM role” দেখুন।
একটি বালতি দিয়ে একটি লেকহাউস ক্যাটালগ তৈরি করুন
আপনার আইসবার্গ টেবিলগুলির মেটাডেটা পরিচালনা করার জন্য একটি লেকহাউস ক্যাটালগ তৈরি করুন। আইসবার্গ টেবিল তৈরি এবং কোয়েরি করার জন্য আপনি আপনার স্পার্ক জবে এই ক্যাটালগটির সাথে সংযোগ স্থাপন করেন।
- গুগল ক্লাউড কনসোলে, লেকহাউস- এ যান।
- 'ক্যাটালগ তৈরি করুন'- এ ক্লিক করুন। 'ক্যাটালগ তৈরি করুন' পৃষ্ঠাটি খুলবে।
- ক্যাটালগ প্রকারের জন্য, আইসবার্গ রেস্ট ক্যাটালগ নির্বাচন করুন।
- আপনার লেকহাউস ক্যাটালগ বাকেট অপশনগুলো বেছে নেওয়ার জন্য, সিঙ্গেল বাকেট ক্যাটালগ নির্বাচন করুন।
- ডিফল্ট ক্যাটালগ ক্লাউড স্টোরেজ বাকেটের জন্য, ব্রাউজ-এ ক্লিক করুন এবং তারপরে নতুন বাকেট তৈরি করুন-এ ক্লিক করুন।
- "Create a bucket" পেজে, নিম্নলিখিতগুলি করুন:
- 'Get started' বিভাগে, একটি বিশ্বব্যাপী অনন্য নাম লিখুন যা বাকেট নামের প্রয়োজনীয়তা পূরণ করে।
- 'আপনার ডেটা কোথায় সংরক্ষণ করবেন তা বেছে নিন' বিভাগে, 'অবস্থানের ধরন'-এর জন্য 'অঞ্চল ' নির্বাচন করুন এবং আপনার অঞ্চল লিখুন। উদাহরণস্বরূপ,
us-west1। - "Choose how to control access to objects" বিভাগে, "Enforce public access prevention on this bucket" চেকবক্সটি থেকে টিক চিহ্ন তুলে দিন।
এর মাধ্যমে আপনি পাবলিক ওয়েব কন্টেন্ট বা শেয়ার করা ডেটা রিপোজিটরি হোস্ট করার মতো বাস্তব পরিস্থিতিগুলো সিমুলেট করতে পারবেন। এই পরিবর্তনটি না করলে, বাকেটটি একটি কঠোর "শুধুমাত্র ব্যক্তিগত" নীতি প্রয়োগ করবে; আপনার অ্যাসেটগুলো অ্যাক্সেস করার যেকোনো চেষ্টার ফলে একটি403ফরবিডেন এরর দেখা দেবে, এমনকি যদি আপনি ফাইলগুলোতে সফলভাবে পাবলিক পারমিশন দিয়েও থাকেন। - চালিয়ে যান > তৈরি করুন > নির্বাচন করুন > চালিয়ে যান-এ ক্লিক করুন।
- প্রমাণীকরণ পদ্ধতির জন্য, ক্রেডেনশিয়াল ভেন্ডিং মোড নির্বাচন করুন।
- তৈরি করুন- এ ক্লিক করুন। আপনার ক্যাটালগ তৈরি হয়ে যাবে এবং ক্যাটালগের বিস্তারিত পৃষ্ঠাটি খুলে যাবে।
- প্রমাণীকরণ পদ্ধতির অধীনে, বাকেট অনুমতি সেট করুন-এ ক্লিক করুন।
- ডায়ালগ বক্সে, ' নিশ্চিত করুন ' (Confirm) বোতামে ক্লিক করুন। এর মাধ্যমে যাচাই করা হয় যে, আপনার ক্যাটালগের সার্ভিস অ্যাকাউন্টের আপনার স্টোরেজ বাকেটে '
Storage Object Userভূমিকাটি রয়েছে। - ক্যাটালগ বিবরণ পৃষ্ঠা থেকে REST ক্যাটালগ URI পাথটি কপি করুন। রান স্পার্ক জব টাস্কের সময় এই পাথটি ব্যবহার করুন।
পার্কেট ফাইলগুলো বাকেটে আপলোড করুন
আপনার Parquet ফাইলগুলো বাকেটের রুটে আপলোড করতে, নিম্নলিখিত পদক্ষেপগুলো অনুসরণ করুন:
- গুগল ক্লাউড কনসোলে, ক্লাউড স্টোরেজ বাকেটস পৃষ্ঠায় যান।
- বাকেটগুলোর তালিকা থেকে বাকেটের নামে ক্লিক করুন। যেমন,
acai_demo। - বাকেটটির অবজেক্টস ট্যাবে, আপলোড > ফাইল আপলোড-এ ক্লিক করুন।
- এই কোডল্যাবের 'শুরু করার আগে' অংশে আপনি যে Parquet ফোল্ডারটি ক্লোন করেছিলেন, সেখান থেকে ফাইলগুলো নির্বাচন করুন।
- খুলুন- এ ক্লিক করুন।
৪. ভিপিসি নেটওয়ার্ক স্থাপন করুন
একটি ভার্চুয়াল প্রাইভেট ক্লাউড (VPC) নেটওয়ার্ক ও সাবনেট তৈরি করুন যা রিসোর্সগুলোকে পাবলিক ইন্টারনেটে না গিয়েই গুগল এপিআই (Google APIs)-এর সাথে যোগাযোগ করতে দেয়, এবং একটি ফায়ারওয়াল তৈরি করুন যা আপনার ডেটা প্রসেসিং নোডগুলোর মধ্যে অভ্যন্তরীণ ট্র্যাফিককে অবাধে চলাচল করতে দেয়।
- গুগল ক্লাউড কনসোলে, VPC নেটওয়ার্ক পেজে যান।
- VPC নেটওয়ার্ক তৈরি করুন -এ ক্লিক করুন।
- নেটওয়ার্কটির জন্য একটি নাম লিখুন। উদাহরণস্বরূপ,
acai-network। - নেটওয়ার্কের সর্বোচ্চ ট্রান্সমিশন ইউনিট (MTU) কনফিগার করতে, ‘Set MTU automatically’ চেকবক্সটি নির্বাচন করুন।
- সাবনেট তৈরির মোডের জন্য স্বয়ংক্রিয় (Automatic) নির্বাচন করুন।
- ফায়ারওয়াল নিয়ম বিভাগে, IPv4 ফায়ারওয়াল নিয়মগুলির জন্য সমস্ত চেকবক্স নির্বাচন করুন।
- তৈরি করুন- এ ক্লিক করুন।
ব্যক্তিগত গুগল অ্যাক্সেস সক্ষম করুন
ডেটাপ্রোক সার্ভারলেস নোডগুলোর কোনো পাবলিক আইপি অ্যাড্রেস নেই। লেকহাউস ক্যাটালগ এবং ক্লাউড স্টোরেজের সাথে সংযোগ স্থাপনের জন্য সাবনেটটিতে অবশ্যই প্রাইভেট গুগল অ্যাক্সেস সক্রিয় থাকতে হবে।
- গুগল ক্লাউড কনসোলে, VPC নেটওয়ার্ক পেজে যান।
- যে সাবনেটটির জন্য আপনাকে প্রাইভেট গুগল অ্যাক্সেস চালু করতে হবে, সেই সাবনেটটি যে নেটওয়ার্কে রয়েছে, তার নামের উপর ক্লিক করুন। উদাহরণস্বরূপ,
us-west1। - সাবনেটের নামে ক্লিক করুন। সাবনেটের বিস্তারিত পৃষ্ঠাটি প্রদর্শিত হবে।
- সম্পাদনা-তে ক্লিক করুন।
- প্রাইভেট গুগল অ্যাক্সেস বিভাগে, অন নির্বাচন করুন।
- সংরক্ষণ করুন- এ ক্লিক করুন।
৫. একটি স্পার্ক জব তৈরি করুন এবং চালান
একটি আইসবার্গ টেবিল তৈরি ও কোয়েরি করার জন্য, প্রয়োজনীয় স্পার্ক SQL স্টেটমেন্টসহ পাইস্পার্ক জবটি আপলোড করুন। তারপর ম্যানেজড সার্ভিস ফর স্পার্ক ব্যবহার করে জবটি রান করুন।
quickstart.py ফাইলটি আপনার ক্লাউড স্টোরেজ বাকেটে আপলোড করুন।
কোডল্যাব অ্যাসেটগুলো ক্লোন করার পর, আপনার প্রোজেক্টের বিবরণ দিয়ে quickstart.py স্ক্রিপ্টটি আপডেট করুন এবং ক্লাউড স্টোরেজ বাকেটে আপলোড করুন।
- একটি টেক্সট এডিটরে
quickstart.pyস্ক্রিপ্টটি খুলুন। - স্ক্রিপ্টে থাকা
BUCKET_NAMEপ্লেসহোল্ডারটি আপনার ক্লাউড স্টোরেজ বাকেটের নাম দিয়ে প্রতিস্থাপন করুন এবং এটি সংরক্ষণ করুন। - গুগল ক্লাউড কনসোলে, ক্লাউড স্টোরেজ বাকেট- এ যান।
- আপনার বাকেটের নামে ক্লিক করুন। উদাহরণস্বরূপ,
acai_demo। - অবজেক্টস ট্যাবে, আপলোড > ফাইল আপলোড- এ ক্লিক করুন।
- ফাইল ব্রাউজারে, আপডেট করা
quickstart.pyফাইলটি নির্বাচন করুন এবং তারপরে ওপেন-এ ক্লিক করুন।
স্পার্ক জবটি চালান
quickstart.py স্ক্রিপ্টটি আপলোড করার পর, এটিকে একটি ম্যানেজড সার্ভিস ফর স্পার্ক ব্যাচ জব হিসেবে চালান।
- ভেরিয়েবলগুলো কনফিগার করতে, ক্লাউড শেলে নিম্নলিখিত কমান্ডটি চালান।
# Configuration Variables export PROJECT_ID="<PROJECT_ID>" export REGION="<REGION>" export BUCKET_NAME="<BUCKET_NAME>" export SUBNET="<SUBNET>" export LAKEHOUSE_CATALOG_ID="<LAKEHOUSE_CATALOG_ID>" export CATALOG_URI_ID="<CATALOG_URI_ID>"- LAKEHOUSE_CATALOG_ID : লেকহাউস ক্যাটালগ রিসোর্সের নাম, যেখানে আপনার পাইস্পার্ক অ্যাপ্লিকেশন ফাইলটি রয়েছে। উদাহরণস্বরূপ,
acai_demo - PROJECT_ID : আপনার গুগল ক্লাউড প্রজেক্ট আইডি।
- অঞ্চল : যে অঞ্চলে ম্যানেজড সার্ভিস ফর স্পার্ক ব্যাচ ওয়ার্কলোডটি চালানো হবে। উদাহরণস্বরূপ,
us-west1। - BUCKET_NAME : আপনার ক্লাউড স্টোরেজ বাকেটের নাম। উদাহরণস্বরূপ,
acai_demo। - সাবনেট : আপনার ভিপিসি সাবনেটের নাম। উদাহরণস্বরূপ,
acai-network। - CATALOG_URI_ID : এটি হলো সেই লেকহাউস ক্যাটালগের URI ID, যা আপনি একটি বাকেট সহ লেকহাউস ক্যাটালগ তৈরি করার সময় কপি করেছিলেন। উদাহরণস্বরূপ,
https://biglake.googleapis.com/iceberg/v1/restcatalog।
- LAKEHOUSE_CATALOG_ID : লেকহাউস ক্যাটালগ রিসোর্সের নাম, যেখানে আপনার পাইস্পার্ক অ্যাপ্লিকেশন ফাইলটি রয়েছে। উদাহরণস্বরূপ,
- ক্লাউড শেলে,
quickstart.pyস্ক্রিপ্টটি ব্যবহার করে নিম্নলিখিত ম্যানেজড সার্ভিস ফর স্পার্ক ব্যাচ জবটি চালান।gcloud dataproc batches submit pyspark gs://${BUCKET_NAME}/quickstart.py \ --project=${PROJECT_ID} \ --region=${REGION} \ --subnet=${SUBNET} \ --version=2.2 \ --properties="\ spark.sql.defaultCatalog=${LAKEHOUSE_CATALOG_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}=org.apache.iceberg.spark.SparkCatalog,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.type=rest,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.uri=${CATALOG_URI_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.warehouse=gs://${BUCKET_NAME},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.io-impl=org.apache.iceberg.gcp.gcs.GCSFileIO,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.x-goog-user-project=${PROJECT_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\ spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest-metrics-reporting-enabled=false,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.X-Iceberg-Access-Delegation=vended-credentials,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token"All tables registered successfully! Batch [126fa2226a904d2e944c8eecbe0b1840] finished. metadata: '@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata batch: projects/PROJECT_ID/locations/REGION/batches/126fa2226a904d2e944c8eecbe0b1840 batchUuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff createTime: '2026-04-09T13:17:26.222727Z' description: Batch labels: goog-dataproc-batch-id: 126fa2226a904d2e944c8eecbe0b1840 goog-dataproc-batch-uuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-drz-resource-uuid: batch-3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-location: REGION operationType: BATCH name: projects/PROJECT_ID/regions/REGION/operations/47bc59e8-5082-3af9-89a0-22289aa5f4b9
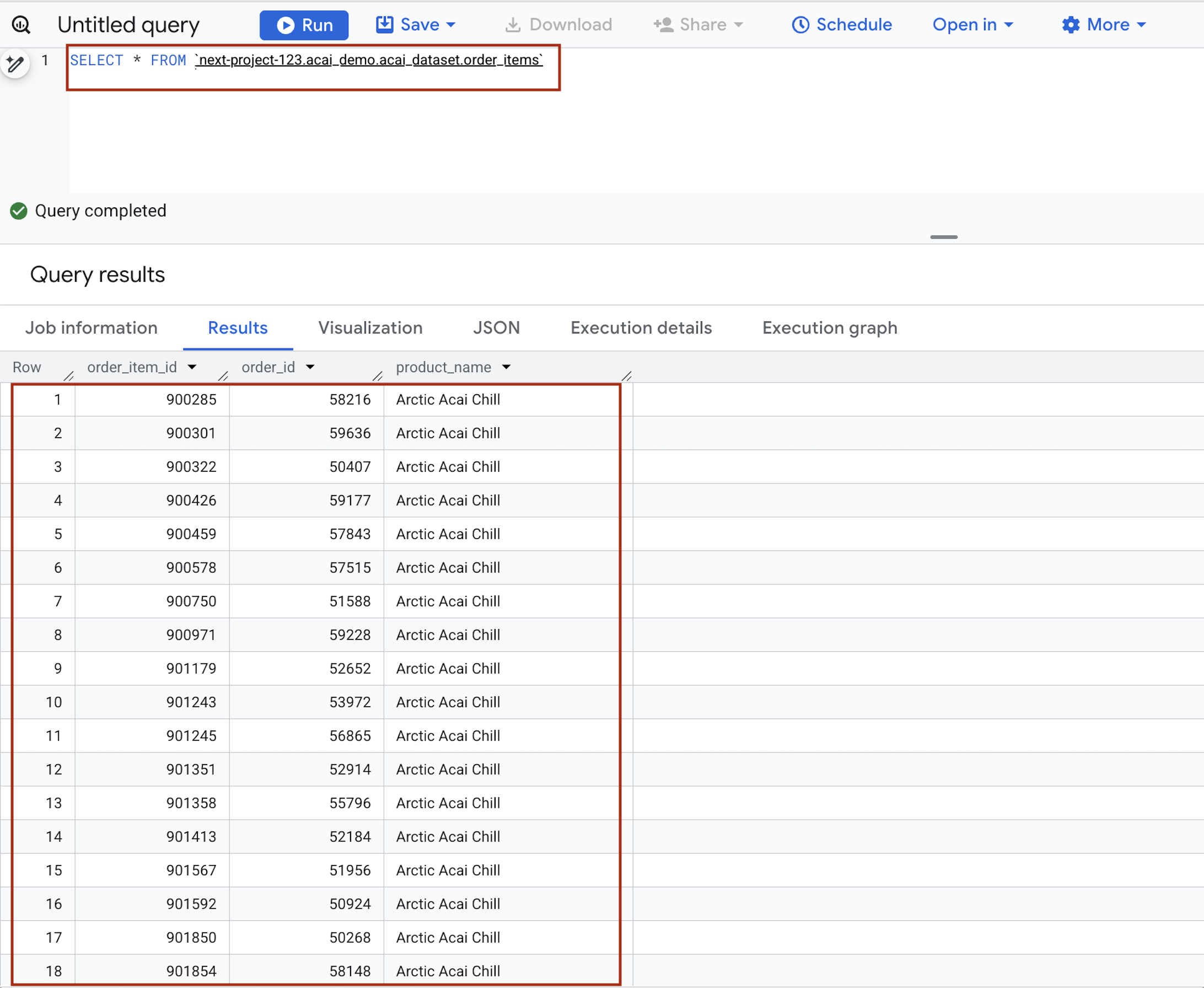
৬. BigQuery থেকে টেবিলটি কোয়েরি করুন।
স্পার্ক ব্যাচ জবটি সফলভাবে চালানোর মাধ্যমে, আপনি লেকহাউস মেটাস্টোরের মধ্যে প্রতিটি পার্কেট ফাইলের জন্য একটি করে একাধিক টেবিল রেজিস্টার করতে একটি ডিস্ট্রিবিউটেড কম্পিউট ইঞ্জিন হিসেবে ম্যানেজড সার্ভিস ফর স্পার্ক সার্ভারলেস ব্যবহার করেছেন। এই রেজিস্ট্রেশন গুগল ক্লাউডকে ক্লাউড স্টোরেজে থাকা আপনার র ফাইলগুলোকে স্ট্রাকচার্ড ও উচ্চ-পারফরম্যান্সের টেবিল হিসেবে বিবেচনা করার সুযোগ দেয়।
নিম্নলিখিত ধাপগুলো আপনাকে মেটাডেটা সঠিকভাবে সিঙ্ক্রোনাইজ হয়েছে কিনা তা নিশ্চিত করতে সাহায্য করবে, যা আপনার ডেটাকে কেবল নিরাপদে সংরক্ষিতই রাখে না, বরং BigQuery ইন্টারফেসের মাধ্যমে তা সম্পূর্ণরূপে খুঁজে পাওয়া এবং কোয়েরি করাও নিশ্চিত করে।
- Google Cloud কনসোলে, BigQuery- তে যান।
- কোয়েরি এডিটরে নিম্নলিখিত স্টেটমেন্টটি লিখুন। কোয়েরিটিতে
project.namespace.dataset.tableসিনট্যাক্স ব্যবহার করা হয়েছে।SELECT * FROM `<PROJECT_ID>.<NAMESPACE>.<ICEBERG_DATASET>.<ICEBERG_TABLE>`PROJECT_ID.acai_demo.acai_dataset.order_items.
নিম্নলিখিতগুলি প্রতিস্থাপন করুন:- PROJECT_ID : আপনার গুগল ক্লাউড প্রজেক্ট আইডি।
- নেমস্পেস : পূর্ববর্তী ধাপে স্পার্ক জবের ফলে যে নেমস্পেসটি তৈরি হয়, যা আপনি আপনার BigQuery অবজেক্ট এক্সপ্লোরার পেজে খুঁজে পাবেন। উদাহরণস্বরূপ,
acai_demo। - ICEBERG_DATASET : আইসবার্গ ক্যাটালগের মধ্যে ডেটাসেটের নাম, উদাহরণস্বরূপ,
acai_dataset। - ICEBERG_TABLE : আইসবার্গ ডেটাসেটের অন্তর্গত টেবিলের নাম, উদাহরণস্বরূপ,
order_items।
- রান-এ ক্লিক করুন। কোয়েরির ফলাফলে সেই ডেটাগুলো দেখানো হবে যা আপনি স্পার্ক জব দিয়ে প্রবেশ করিয়েছেন।
৭. অসংগঠিত পণ্য ডেটা ফাইল তৈরি করুন
এই অংশে, আপনি BigQuery-এর মধ্যে Froyo রেসিপি এবং সরবরাহকারীর ডেটা, বিশেষ করে Froyo পণ্যের বিবরণ সংরক্ষণের জন্য একটি সাংগঠনিক কাঠামো তৈরি করেন। এটি একটি ক্লাউড রিসোর্স কানেকশনও স্থাপন করে, যা একটি সুরক্ষিত 'সেতু' হিসেবে কাজ করে এবং BigQuery-কে ক্লাউড স্টোরেজের মতো বাহ্যিক উৎস থেকে ফাইল পড়তে সাহায্য করে।
বাকেট তৈরি করুন এবং ফ্রোয়ো ডিটেইল ফাইলগুলো আপলোড করুন
সরবরাহকারী এবং রেসিপি ফাইলগুলো তৈরি করে ক্লাউড স্টোরেজ বাকেটে আপলোড করুন।
- গুগল ক্লাউড কনসোলে, ক্লাউড স্টোরেজ বাকেটস পৃষ্ঠায় যান।
- তৈরি করুন- এ ক্লিক করুন।
- 'Create a bucket ' পেজে আপনার বাকেটের তথ্য লিখুন। নিচের প্রতিটি ধাপের পর, পরবর্তী ধাপে যাওয়ার জন্য 'Continue'-তে ক্লিক করুন:
- 'Get started' বিভাগে বাকেটের নামটি লিখুন। উদাহরণস্বরূপ,
acai_pdfs। - 'আপনার ডেটা কোথায় সংরক্ষণ করবেন তা বেছে নিন' বিভাগে, 'অঞ্চল' নির্বাচন করুন এবং তারপরে আপনার অঞ্চলটি লিখুন। উদাহরণস্বরূপ,
us-west1। - "Choose how to control access to objects" বিভাগে, "Enforce public access prevention on this bucket" চেকবক্সটি থেকে টিক চিহ্ন তুলে দিন।
- তৈরি করুন- এ ক্লিক করুন।
- বাকেটগুলোর তালিকা থেকে আপনার তৈরি করা বাকেটটিতে ক্লিক করুন। উদাহরণস্বরূপ,
acai_pdfs। - বাকেটের অবজেক্টস ট্যাবে, আপলোড > আপলোড ফোল্ডারস- এ ক্লিক করুন।
- এই কোডল্যাবের 'শুরু করার আগে' অংশে আপনি যে
recipesফোল্ডারটি এক্সট্র্যাক্ট করেছিলেন, সেটি নির্বাচন করুন। - আপলোড-এ ক্লিক করুন।
-
suppliersফোল্ডারটির জন্য আপলোড প্রক্রিয়াটি পুনরাবৃত্তি করুন।
একটি সংযোগ তৈরি করুন
একটি ক্লাউড রিসোর্স কানেকশন তৈরি করুন। এটি একটি অনন্য সার্ভিস অ্যাকাউন্ট তৈরি করে যা বাইরের ফাইল অ্যাক্সেস করার জন্য BigQuery-এর "আইডি কার্ড" হিসেবে কাজ করে।
- BigQuery পৃষ্ঠায় যান।
- বাম প্যানে, Explorer-এ ক্লিক করুন। যদি আপনি বাম প্যানেটি দেখতে না পান, তাহলে প্যানেটি খোলার জন্য Expand left pane-এ ক্লিক করুন।
- এক্সপ্লোরার প্যানে, আপনার প্রজেক্টের নামটি এক্সপ্যান্ড করুন এবং তারপরে কানেকশনস-এ ক্লিক করুন।
- কানেকশন পেজে, ক্রিয়েট কানেকশন-এ ক্লিক করুন।
- কানেকশন টাইপের জন্য, ভার্টেক্স এআই রিমোট মডেল, রিমোট ফাংশন, বিগলেক এবং স্প্যানার (ক্লাউড রিসোর্স) বেছে নিন।
- কানেকশন আইডি ফিল্ডে কানেকশন আইডি নামটি লিখুন। উদাহরণস্বরূপ,
acai_pdf_connection। এই আইডিটি অবশ্যই লিখে রাখুন, কারণ এই কোডল্যাবের পরবর্তী অংশে ডেটা স্ক্যান সেট আপ করার সময় আপনার এটি প্রয়োজন হবে। - লোকেশন টাইপ ‘ রিজিওন’ -এ সেট করুন এবং তারপর একটি অঞ্চল নির্বাচন করুন। উদাহরণস্বরূপ,
us-west1। সংযোগটি আপনার অন্যান্য রিসোর্স, যেমন ডেটাসেট-এর সাথে একই স্থানে থাকা উচিত। - সংযোগ তৈরি করুন -এ ক্লিক করুন।
- সংযোগে যান-এ ক্লিক করুন।
- কানেকশন ইনফো প্যানে, পরবর্তী ধাপে ব্যবহারের জন্য সার্ভিস অ্যাকাউন্ট আইডিটি কপি করুন। সার্ভিস অ্যাকাউন্টটি দেখতে
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.comএর মতো।
পরিষেবা অ্যাকাউন্টগুলিতে অ্যাক্সেস পরিচালনা করুন
সার্ভিস অ্যাকাউন্টে অ্যাক্সেস দিন যাতে লেকহাউস আপনার পিডিএফগুলো পড়তে পারে।
- IAM ও অ্যাডমিন পেজে যান।
- অ্যাক্সেস দিন-এ ক্লিক করুন। প্রিন্সিপাল যোগ করুন ডায়ালগ বক্সটি খুলবে।
- 'New principals' ফিল্ডে, পূর্বে কপি করা সার্ভিস অ্যাকাউন্ট আইডিটি প্রবেশ করান।
- 'ভূমিকা নির্বাচন করুন' ফিল্ডে, নিম্নলিখিত ভূমিকাগুলি যোগ করুন:
-
roles/storage.objectUser -
roles/storage.objectViewer -
roles/bigquery.user -
roles/bigquery.dataEditor -
roles/aiplatform.user -
roles/storage.admin -
roles/dataproc.serviceAgent
-
- সংরক্ষণ করুন- এ ক্লিক করুন।
BigQuery-তে IAM রোল সম্পর্কে আরও তথ্যের জন্য, পূর্বনির্ধারিত রোল এবং অনুমতিসমূহ দেখুন।
৮. ডেটাস্ক্যান জবের জন্য অনুমতি পরিচালনা করুন
Spark এবং Dataform-এর জন্য নির্দিষ্ট সার্ভিস অ্যাকাউন্ট (আইডেন্টিটি) তৈরি করুন, এবং তারপর সেগুলোকে—Google-এর স্বয়ংক্রিয় সার্ভিস এজেন্টদের সাথে—স্টোরেজ পড়া, BigQuery জব চালানো, এবং ডিসকভারির জন্য Vertex AI ব্যবহার করার জন্য প্রয়োজনীয় সুনির্দিষ্ট অনুমতি প্রদান করুন।
স্পার্ক এবং ডেটাফর্মের জন্য IAM অ্যাক্সেস
- গুগল ক্লাউড কনসোলে, 'Create service account' পেজে যান।
- নির্বাচিত না থাকলে, আপনার গুগল ক্লাউড প্রজেক্টটি নির্বাচন করুন।
- সার্ভিস অ্যাকাউন্ট তৈরি করুন -এ ক্লিক করুন।
- একটি সার্ভিস অ্যাকাউন্ট নাম লিখুন। উদাহরণস্বরূপ,
sa-spark-stg1। গুগল ক্লাউড কনসোল এই নামের উপর ভিত্তি করে একটি সার্ভিস অ্যাকাউন্ট আইডি তৈরি করবে। প্রয়োজনে আইডিটি সম্পাদনা করুন। আপনি পরে আইডিটি পরিবর্তন করতে পারবেন না। - অ্যাক্সেস নিয়ন্ত্রণ সেট করতে, 'তৈরি করুন এবং চালিয়ে যান'- এ ক্লিক করুন এবং পরবর্তী ধাপে এগিয়ে যান।
- প্রজেক্টে সার্ভিস অ্যাকাউন্টকে প্রদান করার জন্য নিম্নলিখিত IAM রোলগুলো নির্বাচন করুন।
-
roles/dataproc.worker -
roles/storage.objectUser -
roles/bigquery.dataEditor -
roles/bigquery.jobUser -
roles/aiplatform.user -
roles/dataplex.discoveryPublishingServiceAgent
-
- ভূমিকা যোগ করা হয়ে গেলে, 'চালিয়ে যান'-এ ক্লিক করুন।
- সার্ভিস অ্যাকাউন্ট তৈরি সম্পন্ন করতে 'সম্পন্ন' বাটনে ক্লিক করুন।
নলেজ ক্যাটালগ অ্যাক্সেস করার জন্য BigQuery সংযোগের অনুমতি
- গুগল ক্লাউড কনসোলে, ক্লাউড স্টোরেজ বাকেটস পৃষ্ঠায় যান।
- বাকেটগুলির তালিকায়, Froyo-এর জন্য আপনার তৈরি করা বাকেটের নামে ক্লিক করুন। উদাহরণস্বরূপ,
acai_pdfs। - পারমিশন ট্যাবে, ‘Grant access’- এ ক্লিক করুন। ‘Add principals’ ডায়ালগ বক্সটি প্রদর্শিত হবে।
- 'New principals' ফিল্ডে আপনার BigQuery সার্ভিস অ্যাকাউন্ট আইডি লিখুন। সার্ভিস অ্যাকাউন্টটি দেখতে
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.comএর মতো। - 'ভূমিকা নির্বাচন করুন ' ড্রপ-ডাউন মেনু থেকে নিম্নলিখিত ভূমিকা (বা ভূমিকাগুলি) নির্বাচন করুন।
-
roles/storage.objectUser -
roles/dataplex.serviceAgent -
roles/dataplex.securityAdmin -
roles/aiplatform.serviceAgent -
roles/dataplex.discoveryPublishingServiceAgent
-
- সংরক্ষণ করুন-এ ক্লিক করুন।
৯. নলেজ ক্যাটালগ তৈরি করুন
আপনার ফ্রয়ো-সম্পর্কিত ডেটা একত্রিত করতে এবং অসংগঠিত ফাইল (যেমন পিডিএফ রেসিপি ও পিডিএফ সরবরাহকারী) স্বয়ংক্রিয়ভাবে খুঁজে বের করার জন্য একটি নলেজ ক্যাটালগ তৈরি করুন।
curl এর মাধ্যমে DataScan তৈরি করুন
এই অংশে, আপনি datascan_ID যোগ করে এবং সেটিকে আপনার BigQuery ডেটাসেটের দিকে নির্দেশ করে আপনার ক্লাউড স্টোরেজ বাকেটের (উদাহরণস্বরূপ, acai_pdfs ) জন্য স্ক্যান তৈরি করেন। এরপর নলেজ ক্যাটালগ স্বয়ংক্রিয়ভাবে BigQuery-তে আপনার পিডিএফগুলোর জন্য এন্ট্রি তৈরি করে দেবে।
- পিডিএফগুলো (সরবরাহকারী এবং রেসিপি) স্ক্যান করতে, নিম্নলিখিত কমান্ডটি চালান:
# 1. Set your variables PROJECT_ID="<PROJECT_ID>" REGION="<REGION>" ENV_SUFFIX="stg1" DATASCAN_ID="froyo-profile-${ENV_SUFFIX}" BUCKET_NAME="<BUCKET_NAME>" # 2. Set this to the Name of the connection you created in Step 7 CONNECTION_ID="<CONNECTION_ID_NAME>" # 3. Define the API Endpoint DATAPLEX_API="dataplex.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}" # 4. Create the DataScan via CURL echo "Creating Dataplex DataScan: ${DATASCAN_ID}..." curl -X POST "https://$DATAPLEX_API/dataScans?dataScanId=${DATASCAN_ID}" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d '{ "data": { "resource": "//storage.googleapis.com/projects/'"${PROJECT_ID}"'/buckets/'"${BUCKET_NAME}"'" }, "executionSpec": { "trigger": { "on_demand": {} } }, "dataDiscoverySpec": { "bigqueryPublishingConfig": { "tableType": "BIGLAKE", "connection": "projects/'"${PROJECT_ID}"'/locations/'"${REGION}"'/connections/'"${CONNECTION_ID}"'" }, "storageConfig": { "unstructuredDataOptions": { "entity_inference_enabled": true } } } }' -
curlকমান্ডটি নিচের ছবির মতো নলেজ ক্যাটালগ ডেটাস্ক্যান-এর ফলাফল প্রদর্শন করে।
কাজটি চালান
নিম্নলিখিত কমান্ডটি চালান:
gcloud dataplex datascans run $DATASCAN_ID --location=$REGION
একটি কাজের বর্ণনা দিন
কাজটি বর্ণনা করতে, নিম্নলিখিত কমান্ডটি চালান:
gcloud dataplex datascans describe $DATASCAN_ID --location=$REGION
একটি ডেটাস্ক্যান জব মুছে ফেলুন
যদি স্ক্যানটি ১০ মিনিটের বেশি সময় ধরে চলে, অথবা যদি জবের স্ট্যাটাস দীর্ঘ সময় ধরে 'রানিং' -এ পরিবর্তিত না হয়ে 'পেন্ডিং ' থাকে, তবে এর কারণ হতে পারে ওই অঞ্চলে সাময়িক রিসোর্সের অপ্রাপ্যতা। এমনটা হলে, আপনি জবটি ডিলিট করার জন্য নিম্নলিখিত কমান্ডটি চালাতে পারেন এবং তারপর এটি আবার তৈরি ও চালানোর চেষ্টা করতে পারেন। কখনও কখনও, প্রাথমিক রানটি unable to acquire necessary resources -এর মতো ত্রুটির কারণে দ্রুত ব্যর্থ হয়ে যেতে পারে।
gcloud dataplex datascans delete $DATASCAN_ID --location=$REGION
চাকরির অবস্থা দেখুন
কাজের অবস্থা পরীক্ষা করতে, নিম্নলিখিতগুলি করুন:
- গুগল ক্লাউড কনসোলে, মেটাডেটা কিউরেশন পেজে যান।
- ক্লাউড স্টোরেজ ডিসকভারি ট্যাবে, ডিসকভারি স্ক্যানগুলোর নামে ক্লিক করুন।
- স্ক্যান বিবরণ পৃষ্ঠায় আপনি কাজের অবস্থা দেখতে পাবেন।
- কাজটি শেষ হয়ে গেলে,
curlকমান্ড ব্যবহার করে আপনার তৈরি করা প্রকাশিত ডেটাসেটটি (উদাহরণস্বরূপ,acai_pdfs_discovered_003) উপস্থিত আছে কিনা তা পরীক্ষা করুন।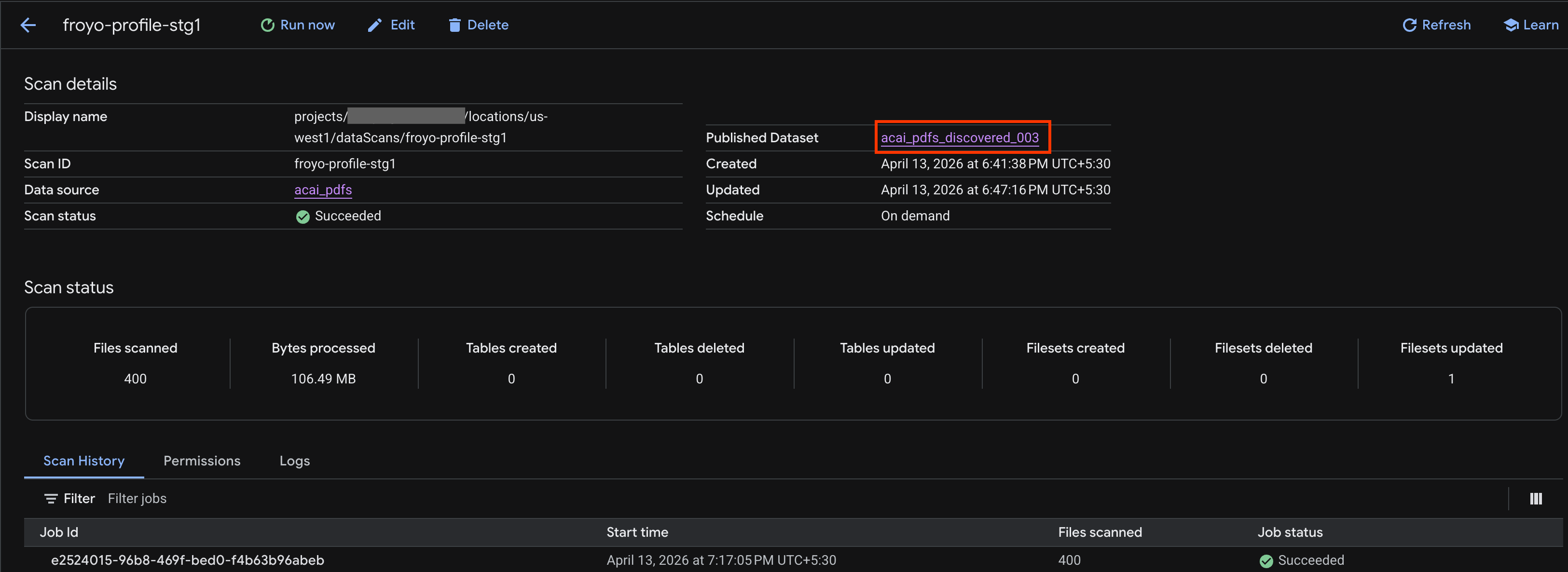
অবজেক্ট টেবিলটি দেখুন
ডিসকভারি জবের পরে তৈরি হওয়া অবজেক্ট টেবিলটি দেখতে, নিম্নলিখিতগুলি করুন:
- Google Cloud কনসোলে, BigQuery- তে যান।
- ডেটাসেট-এ ক্লিক করুন এবং পূর্ববর্তী ধাপে তৈরি করা প্রকাশিত ডেটাসেটটি নির্বাচন করুন। উদাহরণস্বরূপ,
acai_pdfs_discovered_003। - অবজেক্ট টেবিলটি দেখতে টেবিল আইডি-তে ক্লিক করুন। উদাহরণস্বরূপ,
acai_pdfs। - ফলাফলস্বরূপ অবজেক্ট টেবিলটি নিচের ছবির মতো দেখায়:
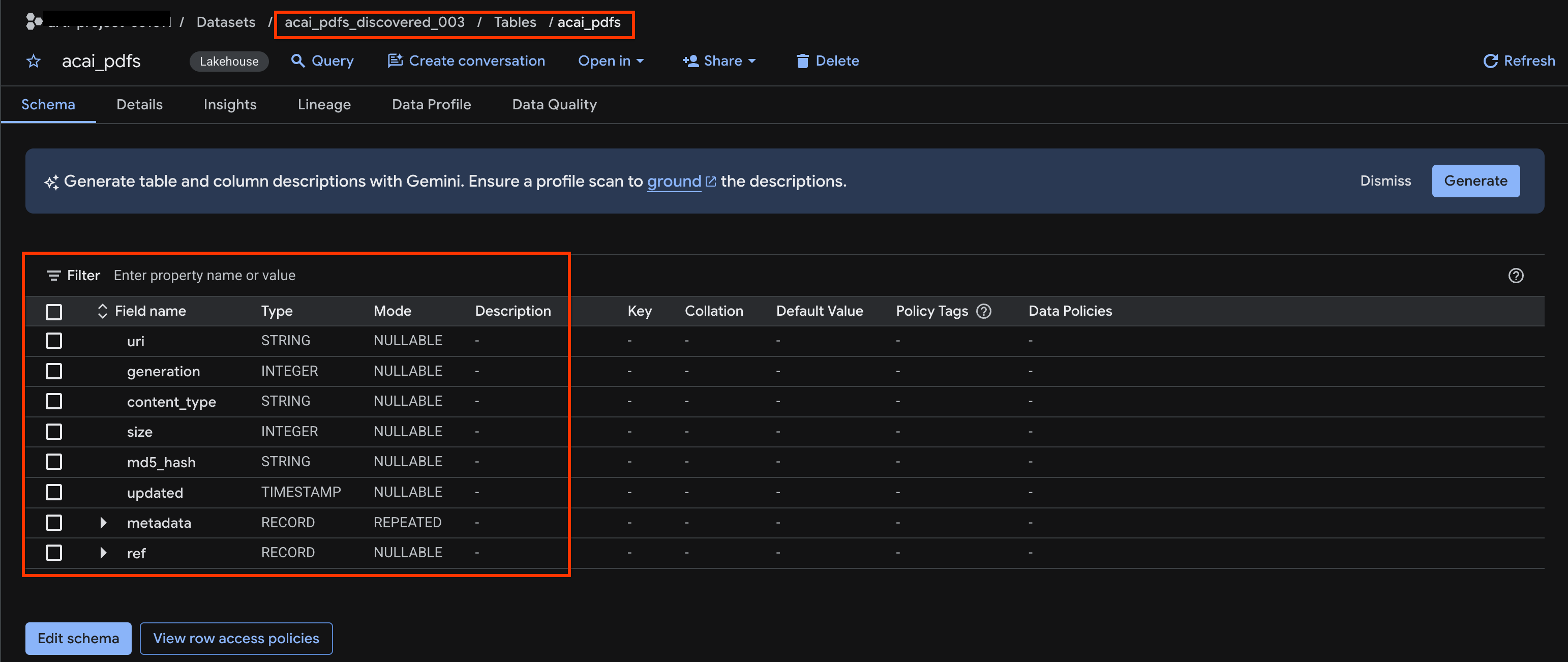
১০. শব্দার্থ নিষ্কাশন
আপনি পূর্ববর্তী ধাপে তৈরি করা এই অসংগঠিত অবজেক্ট টেবিলটি থেকে সংগঠিত টেবিল, অন্যান্য ডাটাবেস অবজেক্ট এবং সম্পর্কসমূহ অনুমান ও নিষ্কাশন করবেন। এর জন্য, আপনি অসংগঠিত টেবিল থেকে সংগঠিত ডেটা নিষ্কাশন করতে SQL স্টেটমেন্ট তৈরি করার জন্য নলেজ ক্যাটালগ ইনসাইটস (Knowledge Catalog Insights) ফিচারটি ব্যবহার করবেন।
- গুগল ক্লাউড কনসোলে, নলেজ ক্যাটালগ সার্চ পেজে যান।
- যে ডেটাসেট টেবিলের অন্তর্দৃষ্টি দেখতে চান, সেটি অনুসন্ধান করুন। উদাহরণস্বরূপ,
acai_pdfs_discovered_003।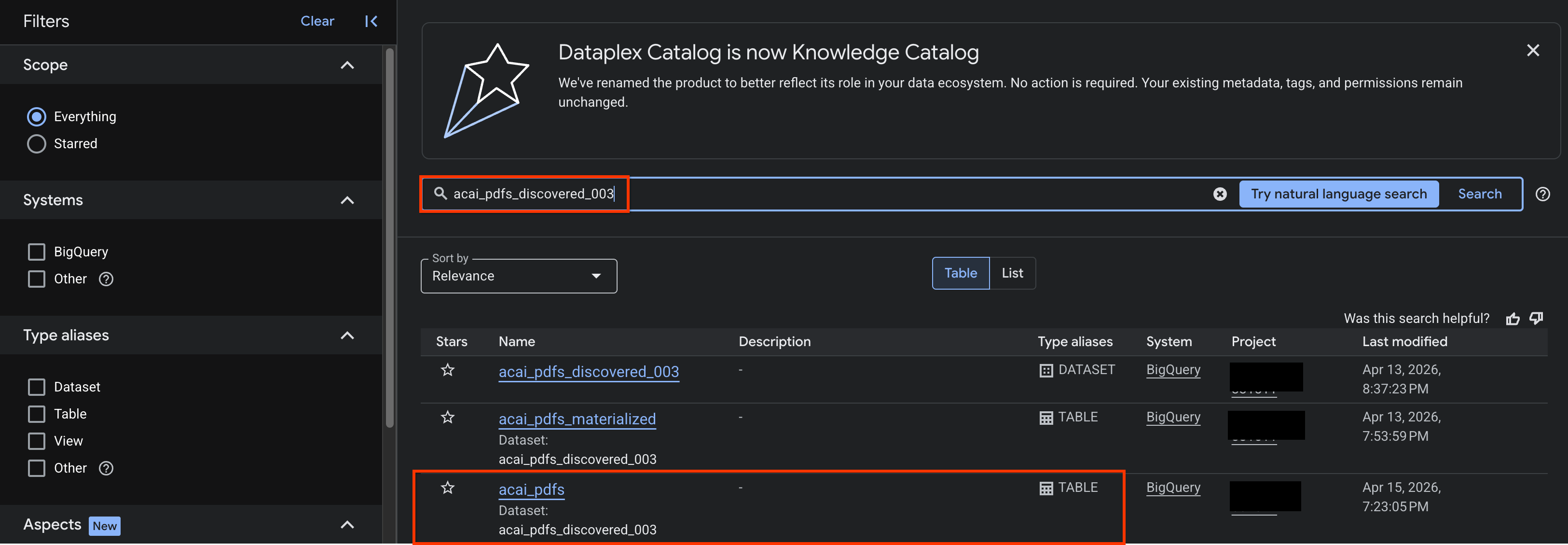
- অনুসন্ধানের ফলাফলে, টেবিলটির এন্ট্রি পেজ খুলতে সেটিতে ক্লিক করুন।
- ইনসাইটস ট্যাবে ক্লিক করুন। যদি ট্যাবটি খালি থাকে, তার মানে এই টেবিলের জন্য ইনসাইটস এখনও তৈরি হয়নি। ইনসাইট তৈরি হতে ১৫ থেকে ২৫ মিনিট সময় লাগতে পারে।
- একবার ইনসাইটগুলো দেখতে পেলে, Extract > Extract with SQL-এ ক্লিক করুন।
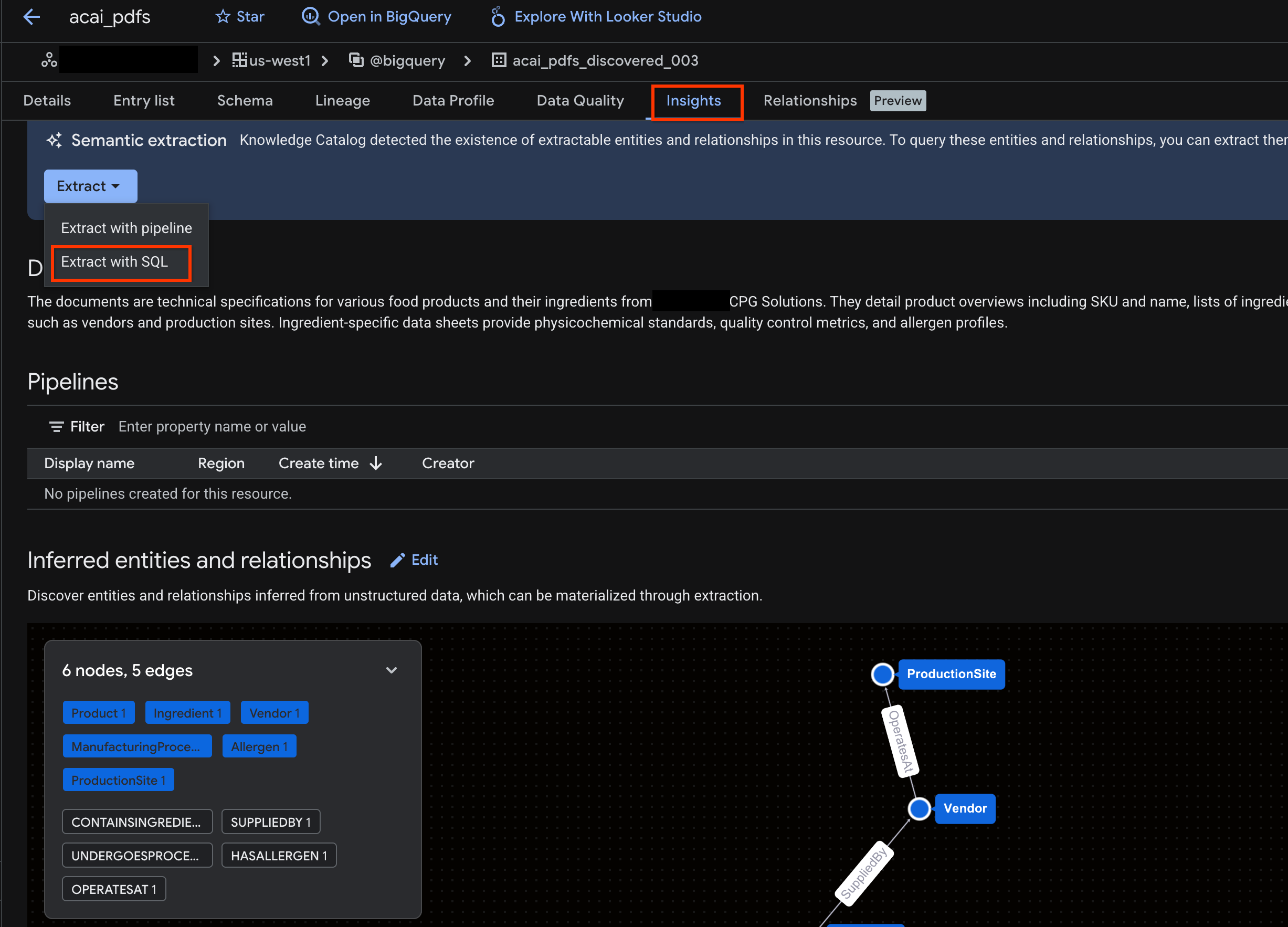
- "Extract with SQL" পৃষ্ঠায়, "Destination" -এর জায়গায় আপনার ডেটাসেটটি লিখুন। উদাহরণস্বরূপ,
acai_pdfs_discovered_003। - এক্সট্র্যাক্ট-এ ক্লিক করুন। এটি কোয়েরি লোড করা অবস্থায় বিগকোয়েরি এডিটর খুলে দেবে।
- রান-এ ক্লিক করুন। এই ধাপে কিছু স্টেটমেন্ট তৈরি হবে এবং রানটি সম্পন্ন হতে কয়েক মিনিট সময় লাগতে পারে।
- কোয়েরিটি সম্পন্ন হলে, আপনি নিম্নলিখিত ফলাফলগুলো দেখতে পাবেন:
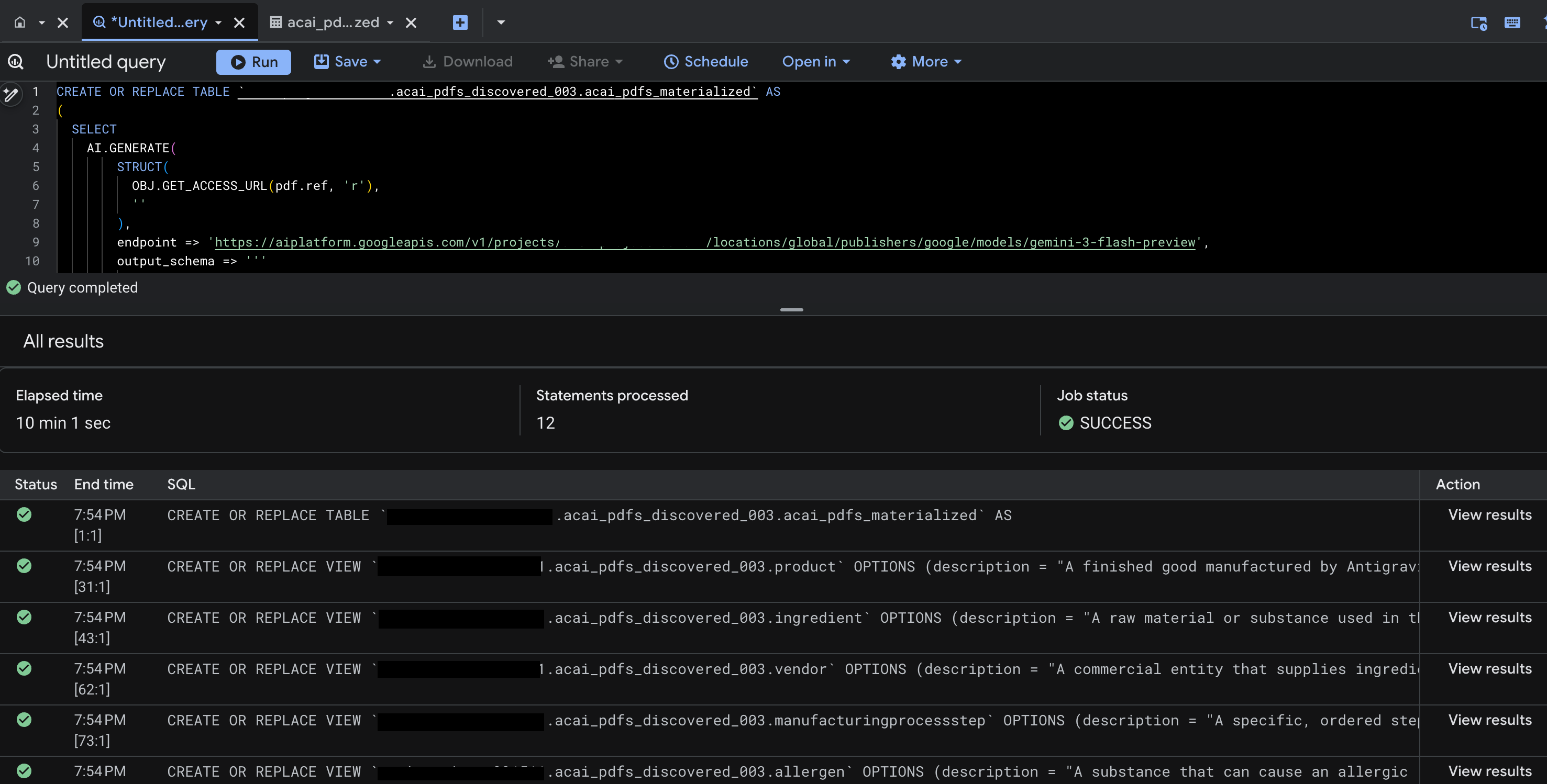
- BigQuery- তে যান এবং ডেটাসেট-এ ক্লিক করুন (উদাহরণস্বরূপ,
acai_pdfs_discovered_003)। ধাপ ৬-এ আপনার নির্বাচিত ডেটাসেটটিতে এক সেট নতুন স্ট্রাকচার্ড ডেটাবেস অবজেক্ট তৈরি হবে।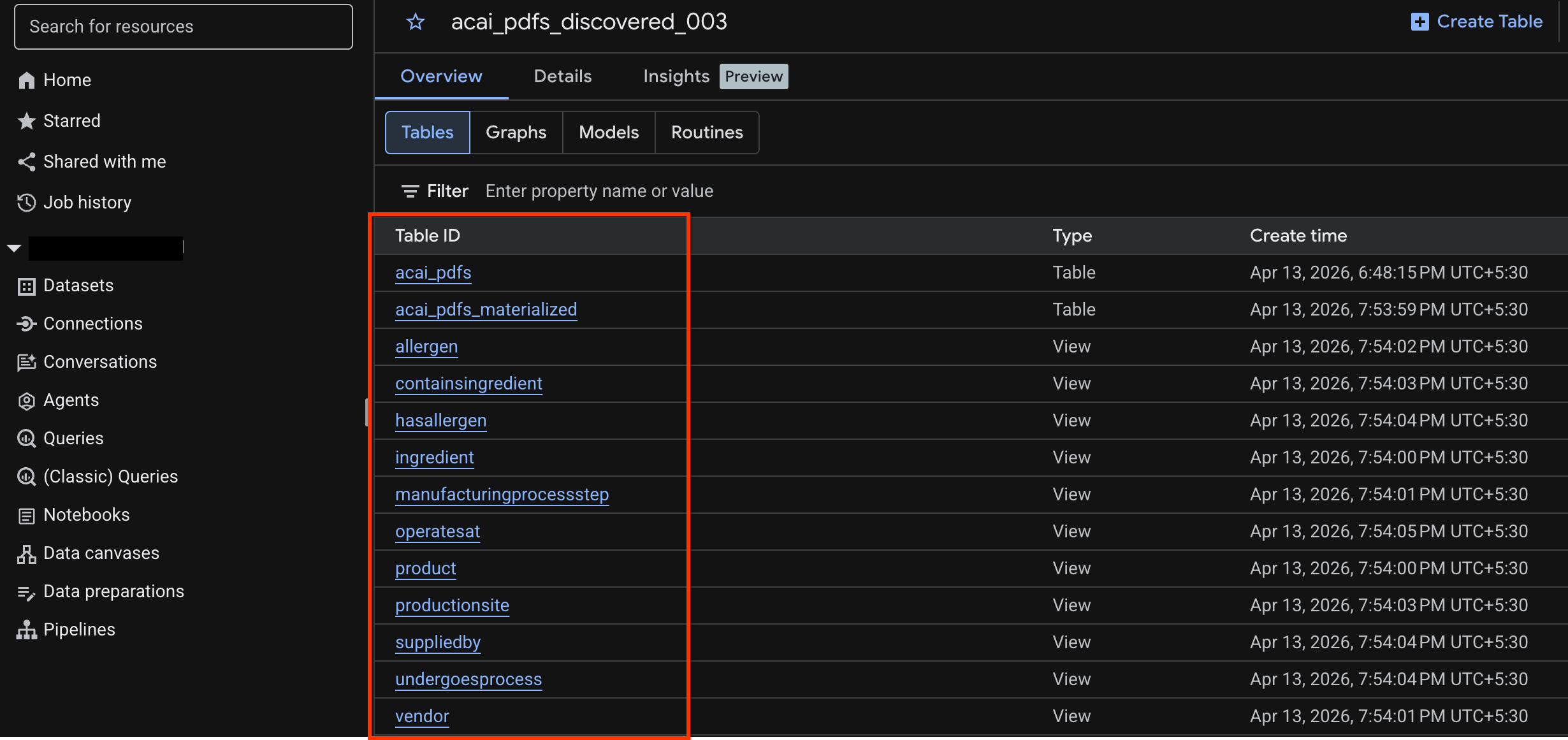
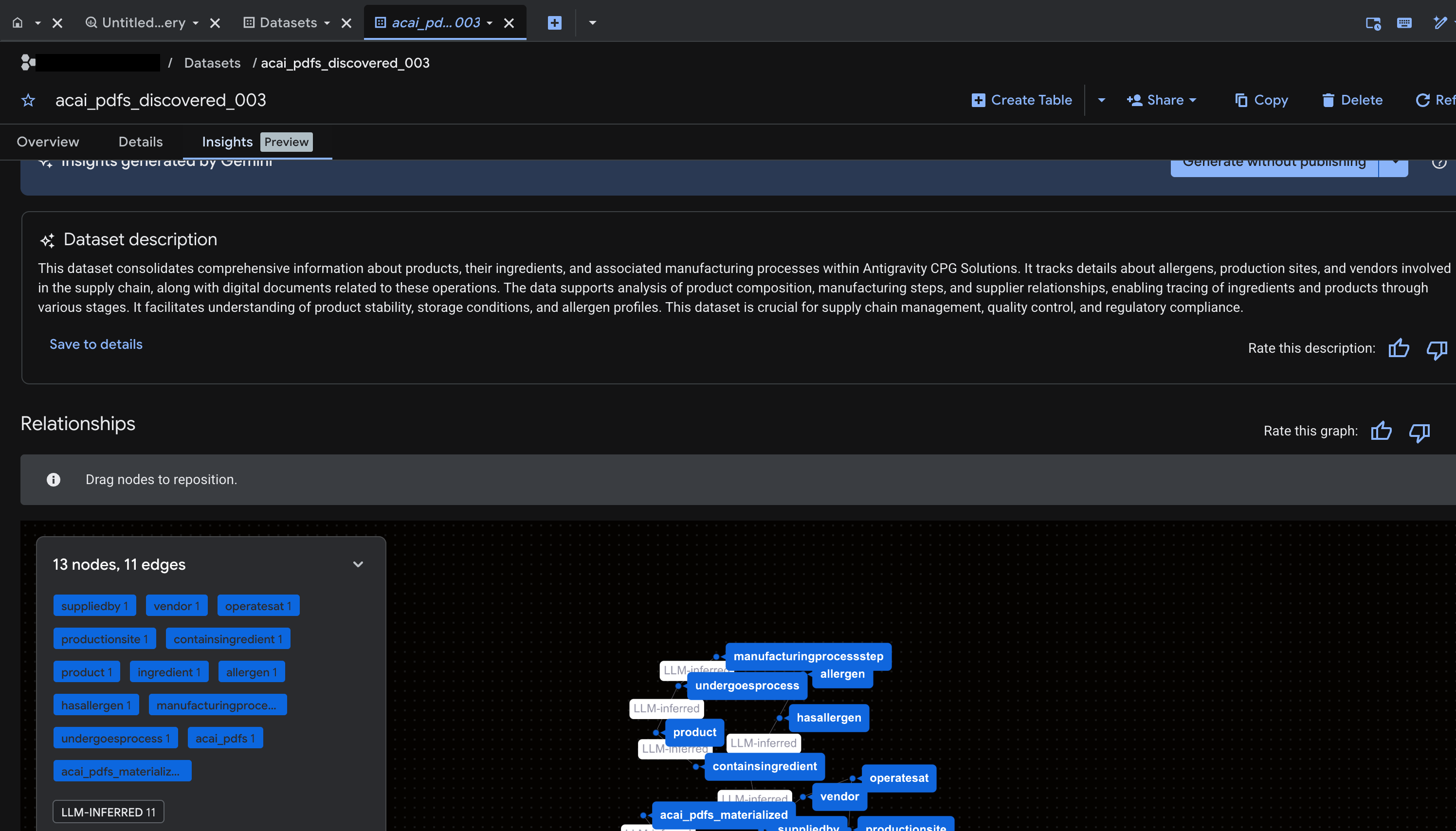
BigQuery-তে অবজেক্টের জন্য ইনসাইট তৈরি করুন
একটি BigQuery ডেটাসেটের জন্য ইনসাইটস তৈরি করতে, আপনাকে অবশ্যই BigQuery Studio ব্যবহার করে BigQuery-তে ডেটাসেটটি অ্যাক্সেস করতে হবে।
- Google Cloud কনসোলে, BigQuery Studio- তে যান।
- এক্সপ্লোরার প্যানে, প্রজেক্টটি নির্বাচন করুন, এরপর যে ডেটাসেটটির জন্য আপনি ইনসাইটস তৈরি করতে চান সেখানে যান।
- ইনসাইটস ট্যাবে ক্লিক করুন।
- আপনি যদি একটি ‘Enable API’ বাটন দেখতে পান, তাহলে Gemini for Google Cloud চালু করতে সেটিতে ক্লিক করুন। এতে ‘ Enable core features’ উইন্ডোটি খুলবে।
- Core feature APIs সেকশনে, Gemini for Google Cloud API এবং BigQuery Unified API-এর জন্য Enable-এ ক্লিক করুন, এবং তারপর Next-এ ক্লিক করুন।
- অনুমতি (ঐচ্ছিক) বিভাগে, প্রয়োজনে প্রিন্সিপালদের IAM রোল প্রদান করুন এবং তারপরে পরবর্তী ক্লিক করুন।
- ইনসাইট তৈরি করতে এবং সেগুলোকে নলেজ ক্যাটালগে প্রকাশ করতে, ‘জেনারেট অ্যান্ড পাবলিশ’- এ ক্লিক করুন।
- প্রকাশিত হয়ে গেলে আপনি ট্যাবটিতে ইনসাইটগুলো দেখতে পারবেন।
১১. এজেন্টিক ডেটা অ্যানালিটিক্সের জন্য আপনার IDE সেট আপ করুন।
ভিজ্যুয়াল স্টুডিও কোডের জন্য গুগল ক্লাউড ডেটা এজেন্ট কিট এক্সটেনশনটি হলো ডেটা সায়েন্টিস্ট এবং ডেটা ইঞ্জিনিয়ারদের জন্য একটি IDE এক্সটেনশন। এটি আপনাকে সরাসরি IDE থেকে আপনার গুগল ডেটা ক্লাউড রিসোর্স এবং ডেটার সাথে সংযোগ স্থাপন করতে ও কাজ করতে দেয়। আরও তথ্যের জন্য, ভিএস কোডের জন্য ডেটা এজেন্ট কিট এক্সটেনশনের ওভারভিউ দেখুন।
VS Code-এর জন্য ডেটা এজেন্ট কিট এক্সটেনশনটি নিম্নলিখিত কাজগুলো করার জন্য উপযোগী:
- সরাসরি ভিএস কোড থেকে Spark ETL বা BigQuery ETL-এর মতো একটি প্রোডাকশন-রেডি ডেটা পাইপলাইন তৈরি, পরীক্ষা, পর্যালোচনা এবং স্থাপন করুন।
- এআই-এর সহায়তায় ডেটা অন্বেষণ করুন, একটি প্রশিক্ষণ পাইপলাইন তৈরি করুন, সর্বোত্তম এমএল মডেল শনাক্ত করুন এবং সেগুলোকে একটি প্রোডাকশন এন্ডপয়েন্টে স্থাপন করুন।
- নির্ভরযোগ্য ডেটা উৎসের সাথে সংযোগ স্থাপন করুন, একটি উচ্চ-কর্মক্ষমতাসম্পন্ন ডেটা মডেল তৈরি করুন এবং ব্যবসায়িক অংশীদারদের জন্য একটি ইন্টারেক্টিভ ড্যাশবোর্ড প্রকাশ করুন।
VS Code-এর জন্য ডেটা এজেন্ট কিট এক্সটেনশনটি ইনস্টল করুন।
- ভিএস কোড খুলুন।
- Google Cloud CLI ইনস্টল করুন। আরও তথ্যের জন্য, Google Cloud CLI ইনস্টল করুন দেখুন।
- VS Code-এর জন্য ডেটা এজেন্ট কিট এক্সটেনশনটি ইনস্টল করুন ।
- এক্সটেনশন অনবোর্ডিং প্রক্রিয়াটি সম্পন্ন করুন, যার জন্য আপনাকে নিম্নলিখিত কাজগুলো করতে হবে:
- এক্সটেনশনে সাইন ইন করুন
- দক্ষতা ইনস্টল করুন, এমসিপি সার্ভার
- অনবোর্ডিং সম্পন্ন হয়ে গেলে উইন্ডোটি রিলোড বা রিস্টার্ট করুন। আরও তথ্যের জন্য, VS Code-এর জন্য ডেটা এজেন্ট কিট এক্সটেনশন সেটআপ এবং কনফিগার করুন দেখুন।
- IDE রিলোড হওয়ার পর, নেভিগেশন প্যানেলে থাকা Google Data Cloud আইকনে ক্লিক করুন, সেটিংসে যান এবং কমন সেটিংসে আপনার প্রজেক্ট আইডি ও অঞ্চল (
us-west1) সঠিকভাবে সেট করেছেন কিনা তা নিশ্চিত করুন।
VS Code-এ ওয়ার্কস্পেস সেট আপ করুন
- ভিএস কোড খুলুন এবং ফাইল > ওপেন ফোল্ডার > নিউ ফোল্ডার নির্বাচন করুন।
-
acai_testনামে একটি নতুন ফোল্ডার তৈরি করুন এবং তারপরে ওপেন-এ ক্লিক করুন। VS Code এখন আপনার খোলা ফোল্ডারটিকে একটি ওয়ার্কস্পেস হিসেবে বিবেচনা করবে। - ওয়ার্কস্পেস ট্রাস্ট ডায়ালগে, ‘হ্যাঁ, আমি লেখকদের ওয়ার্কস্পেসের সমস্ত ফিচার চালু করার জন্য বিশ্বাস করি’ বিকল্পটি নির্বাচন করুন।
-
acai_testওয়ার্কস্পেসে.githubনামে একটি ফোল্ডার তৈরি করুন। -
.githubফোল্ডারেcopilot-instructions.mdএকটি নতুন ফাইল তৈরি করুন এবং এতে নিম্নলিখিত নিয়মগুলো লিখুন।## 1. Project Context - **Project ID**: <PROJECT_ID> - **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors. - **Documentation**: Raw PDF documents detailing flavors and ingredients are stored in Google Cloud Storage at `gs://<BUCKET_NAME>`. ## 2. Execution & Data Processing Rules - **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `<BQ_DATASET_NAME>` (referred to as the Knowledge Catalog). - **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the dataset `<DATASET_ID>`. When you are referencing a dataset, ensure you are using it with the project ID (`<PROJECT_ID>`) and namespace prefix `<NAMESPACE_NAME>`. For example, to query order table in this dataset you should use `<PROJECT_ID>.<NAMESPACE>.<DATASET_ID>.orders`. - **CRITICAL RULE - Data Joins between BigQuery dataset and Iceberg dataset**: ANY task requiring a join or integration between the BigQuery datasets `<DATASET_ID>` of the PDF data and the `<DATASET_ID>` of the customer data MUST be executed using **Spark Notebooks**. - **CRITICAL RULE - Notebook Kernel**: Every Spark notebook utilized MUST exclusively be configured to run on the Serverless Session template `iceberg-federation-template` as its kernel. - **CRITICAL RULE - Data Science**: ANY data science, machine learning, or advanced analytical task MUST be performed strictly within **Spark Notebooks** using the aforementioned setup. -
acai_testওয়ার্কস্পেসেtemplate.yamlআরেকটি নতুন ফাইল তৈরি করুন এবং ফাইলটিতে নিম্নলিখিত তথ্যগুলো প্রবেশ করান।labels: client: "vscode" jupyterSession: displayName: "iceberg-federation-template" kernel: "PYTHON" environmentConfig: executionConfig: serviceAccount: "sa-spark-dev1@<PROJECT_ID>.iam.gserviceaccount.com" subnetworkUri: "projects/<PROJECT_ID>/regions/<REGION>/subnetworks/<SUBNET_NAME>" runtimeConfig: version: "2.3" properties: # This enables the secure proxy URL you were looking for dataproc.tier: "premium" spark.dataproc.engine: "lightningEngine" spark.dataproc.lightningEngine.runtime: "native" spark.memory.offHeap.enabled: "true" spark.memory.offHeap.size: "1g" spark.executor.memory: "4g" "dataproc.component.gateway.enabled": "true" "dataproc.jupyter.listen.all.interfaces": "true" "spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" "spark.sql.defaultCatalog": "<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>": "org.apache.iceberg.spark.SparkCatalog" "spark.sql.catalog.<CATALOG_NAME>.type": "rest" "spark.sql.catalog.<CATALOG_NAME>.uri": "<CATALOG_URI_ID>" "spark.sql.catalog.<CATALOG_NAME>.warehouse": "bl://projects/<PROJECT_ID>/catalogs/<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>.rest.auth.type": "org.apache.iceberg.gcp.auth.GoogleAuthManager" - ভিএস কোডে, টার্মিনালে ক্লিক করুন এবং
template.yamlফাইলটিকে একটি সেশন টেমপ্লেট হিসেবে ইম্পোর্ট করতে নিম্নলিখিত কমান্ডটি চালান। এই টেমপ্লেটটি পরবর্তীতে এজেন্ট দ্বারা একটি স্পার্ক সেশন তৈরি করতে ব্যবহৃত হয়।gcloud beta dataproc session-templates import iceberg-federation-template \ --source=template.yaml \ --location=<REGION>REGIONজায়গায় আপনার অঞ্চল লিখুন।
১২. সক্রিয় তথ্য বিশ্লেষণ সম্পাদন করুন
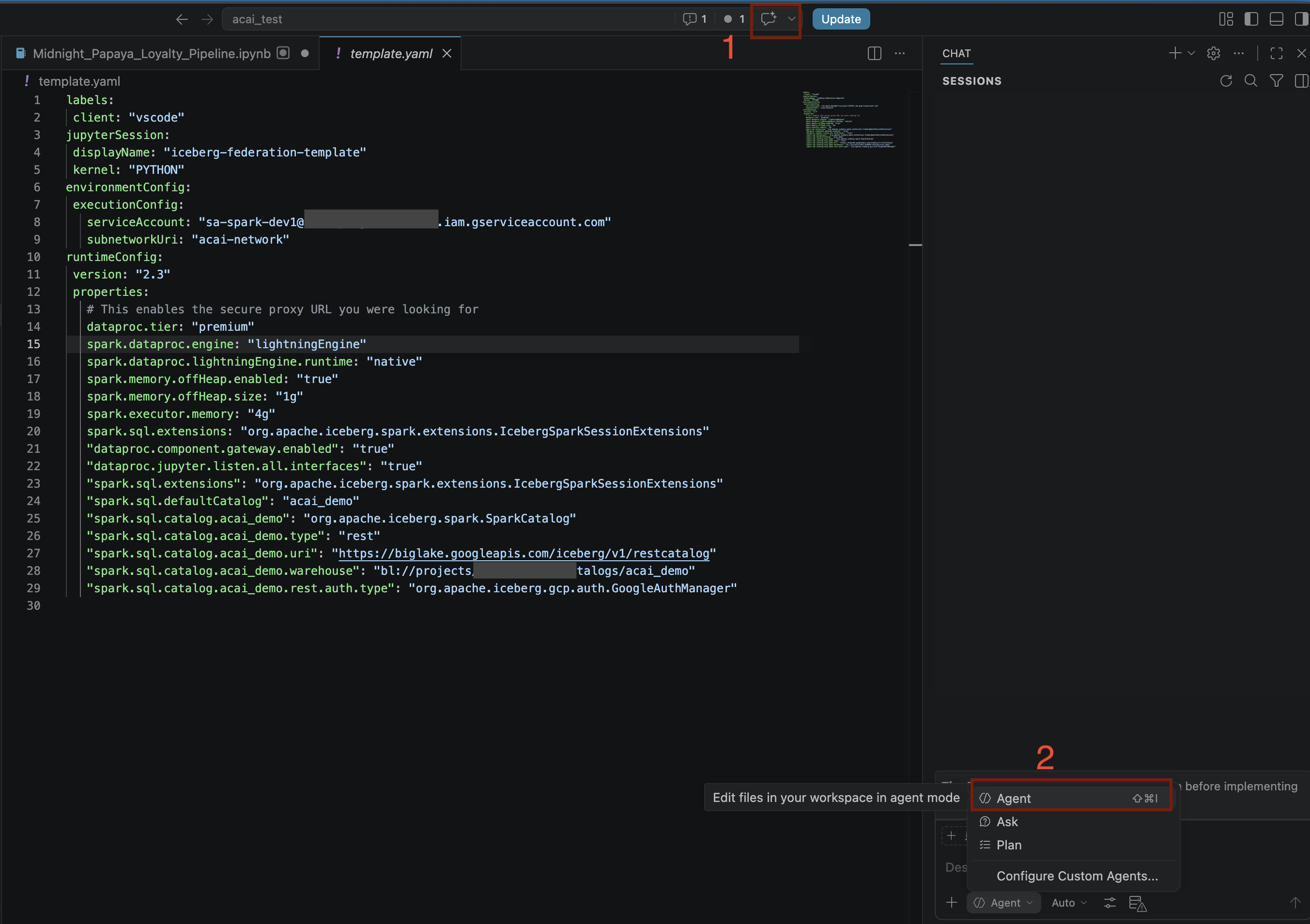
- VS Code এডিটরে, ‘Toggle chat’- এ ক্লিক করুন।
- কাস্টম এজেন্ট কনফিগার করার জন্য, এজেন্ট নির্বাচন করুন।
- সার্চ মডেলস প্যানে, ম্যানেজ ল্যাঙ্গুয়েজ মডেলস -এ ক্লিক করুন।
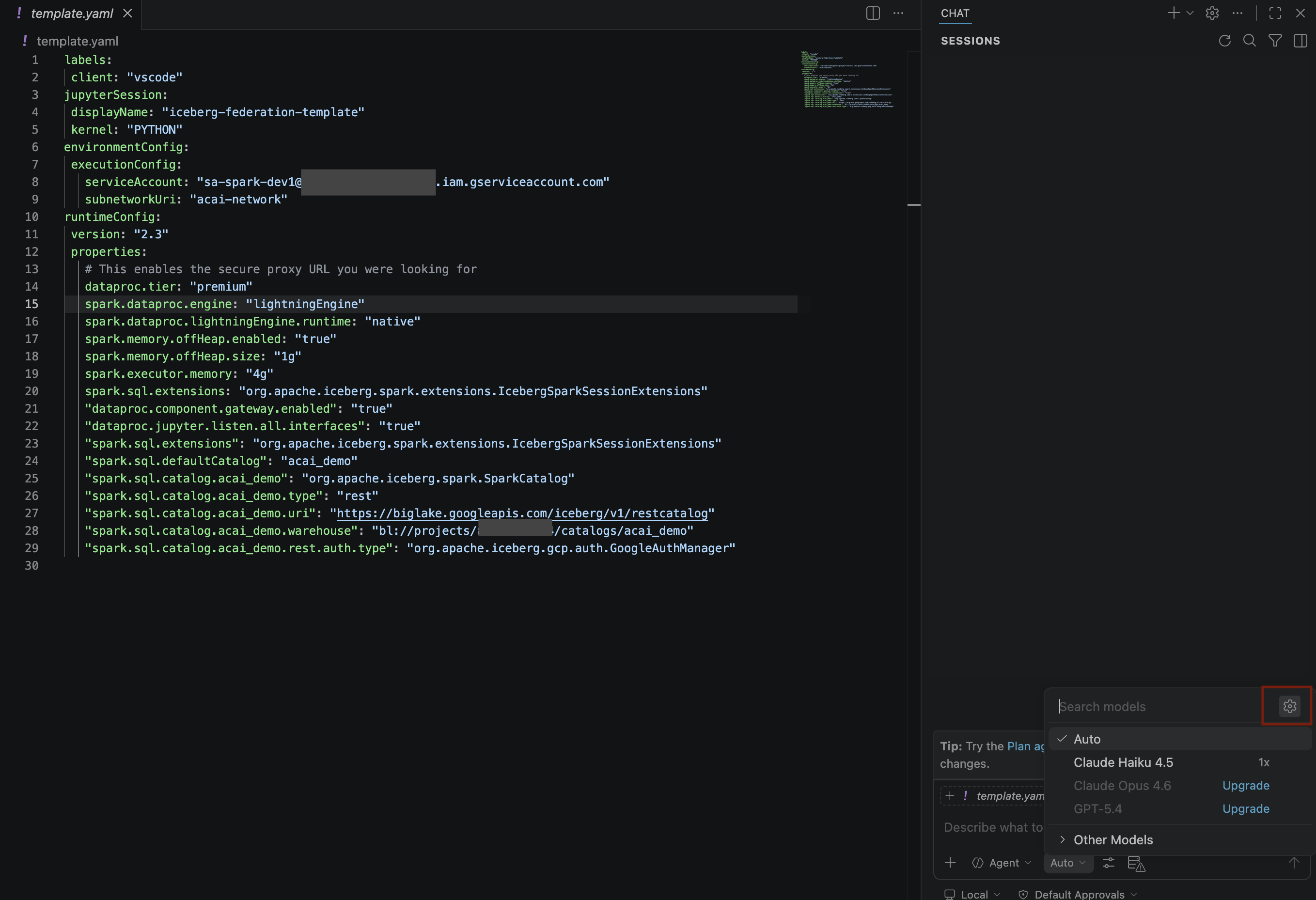
- ল্যাঙ্গুয়েজ মডেলস পেজে, অ্যাড মডেলস- এ ক্লিক করুন।
- তালিকা থেকে Google নির্বাচন করুন এবং আপনার ইনপুট নিশ্চিত করতে Enter চাপুন।
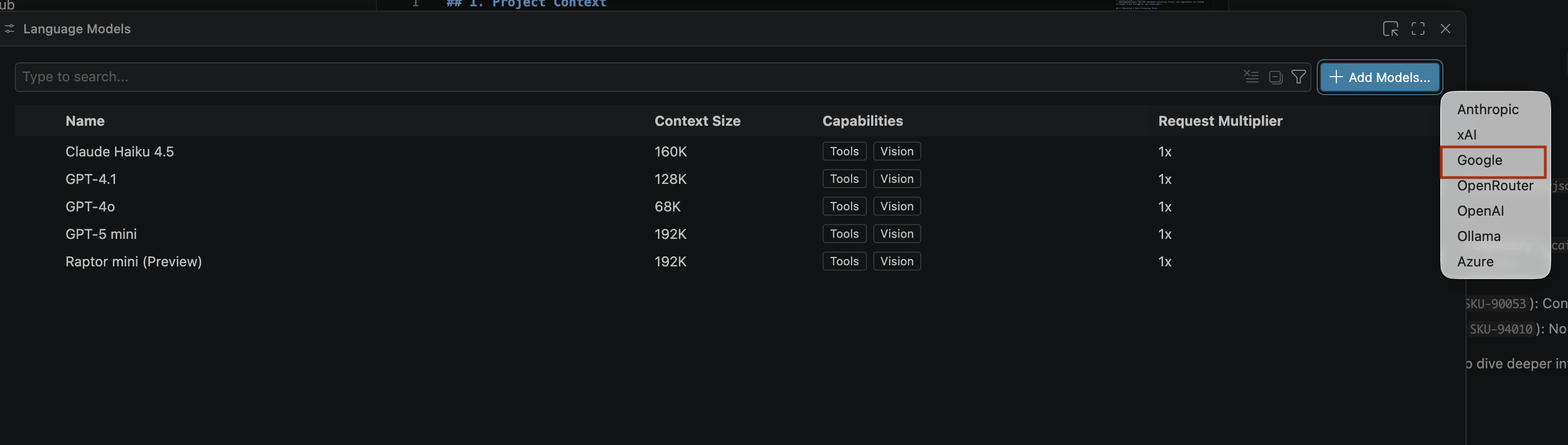
- Google Gemini-এর API কী প্রবেশ করাতে, নিম্নলিখিতগুলি করুন:
- গুগল এআই স্টুডিও ওয়েবসাইটে যান।
- আপনার গুগল অ্যাকাউন্ট দিয়ে সাইন ইন করুন।
- সাইডবারে, ‘Get API key’-তে ক্লিক করুন।
- Create API key-তে ক্লিক করুন। একটি নতুন কী তৈরি করার পেজ খুলবে।
- ক্লাউড প্রজেক্ট তালিকা থেকে ‘প্রজেক্ট ইম্পোর্ট করুন’ নির্বাচন করুন।
- একটি চলমান প্রকল্পের নাম লিখুন।
- Create key-তে ক্লিক করুন এবং API কী-টি কপি করুন। এই কী-টি আপনার অ্যাকাউন্টের Gemini API রিসোর্সগুলিতে অ্যাক্সেস প্রদান করে। আরও তথ্যের জন্য, Using Gemini API keys দেখুন।
- আপনার তৈরি করা API কী-টি সার্চ বারে পেস্ট করুন এবং এন্টার চাপুন।
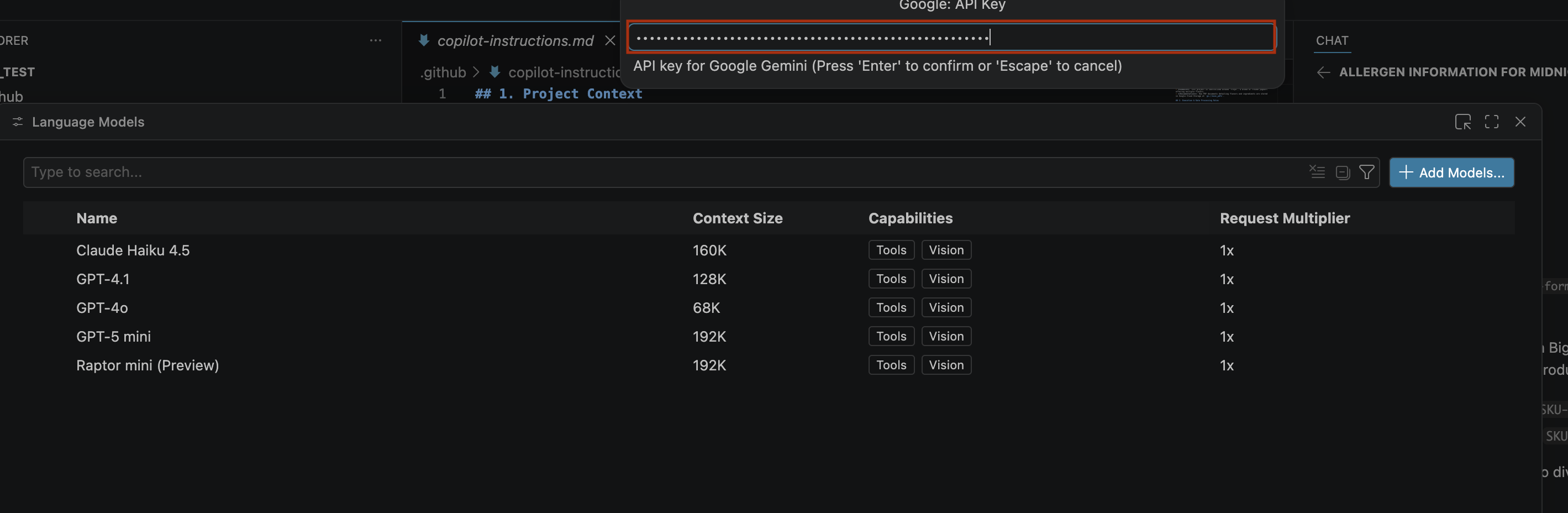
- যদি জেমিনি মডেলগুলো দেখা না যায়, তাহলে নিচের ছবিতে দেখানো অনুযায়ী সেগুলোকে আনহাইড করুন:
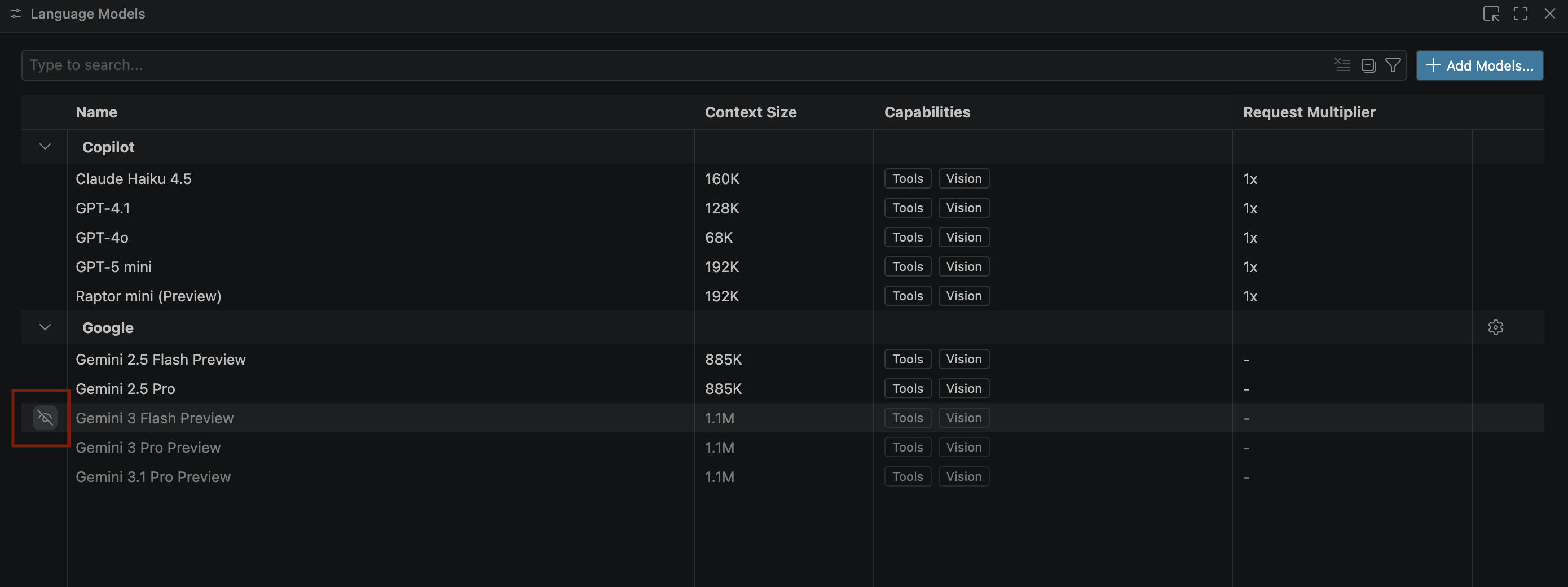
- গুগল জেমিনি মডেল তালিকা থেকে জেমিনি ৩.১ প্রো প্রিভিউ নির্বাচন করুন এবং ল্যাঙ্গুয়েজ মডেল উইন্ডোটি বন্ধ করুন।
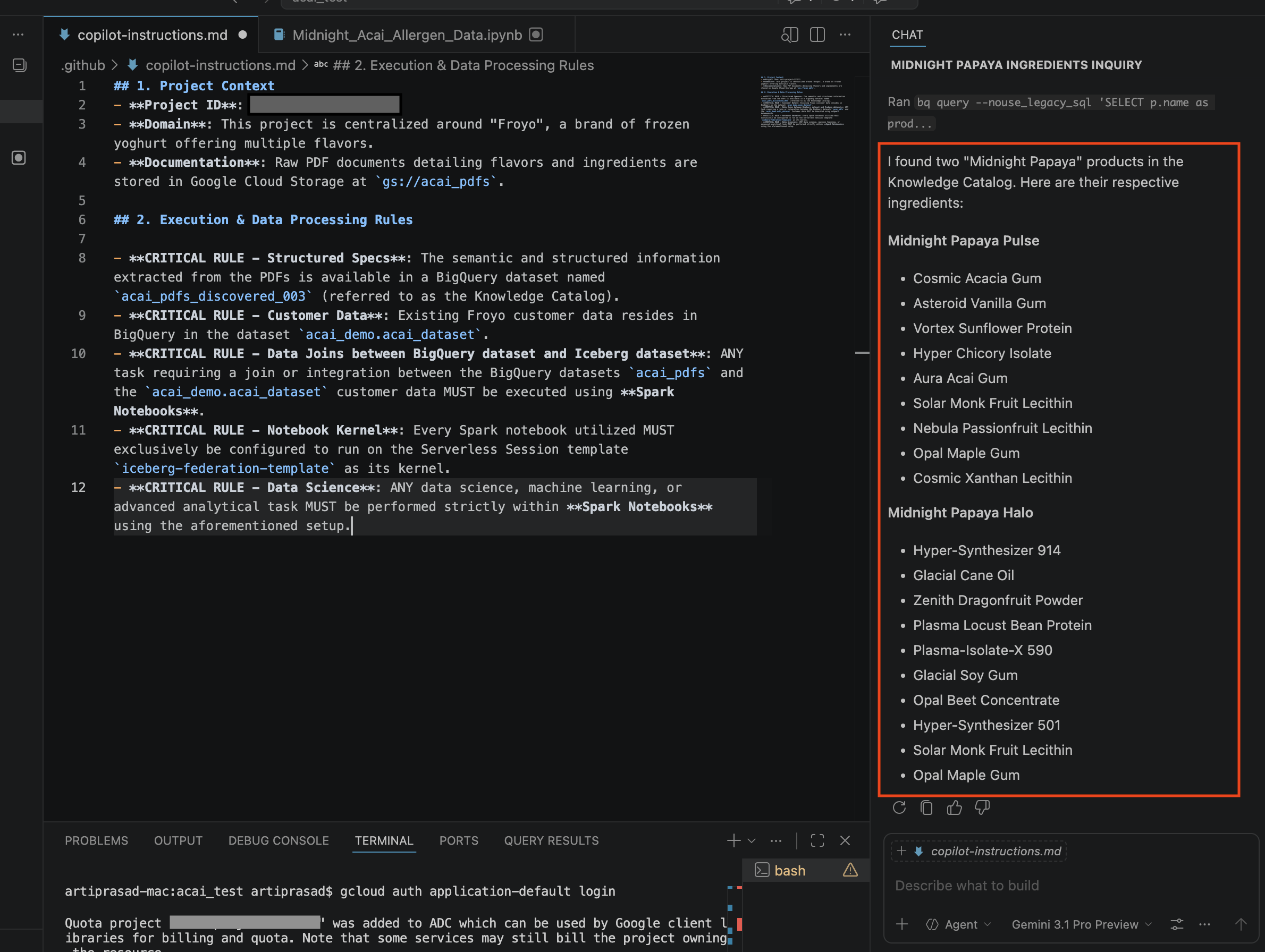
- চ্যাট উইন্ডোতে নিম্নলিখিত প্রশ্নটি লিখুন:
Search ingredients for Midnight papaya - কিছু ইন্টারঅ্যাকশনের পরে, আপনি নিম্নলিখিত ফলাফলটি দেখতে পাবেন:
- চ্যাট উইন্ডোতে আরেকটি প্রশ্ন লিখুন:
Search allergen information for Midnight papaya - কিছু মিথস্ক্রিয়া এবং ধাপ অতিক্রম করার পর, আপনি দেখবেন এজেন্টটি
Soyনামক অ্যালার্জেনটির নাম দিয়ে সাড়া দিচ্ছে, যেমনটি আপনি নিচের ছবিতে দেখতে পাচ্ছেন: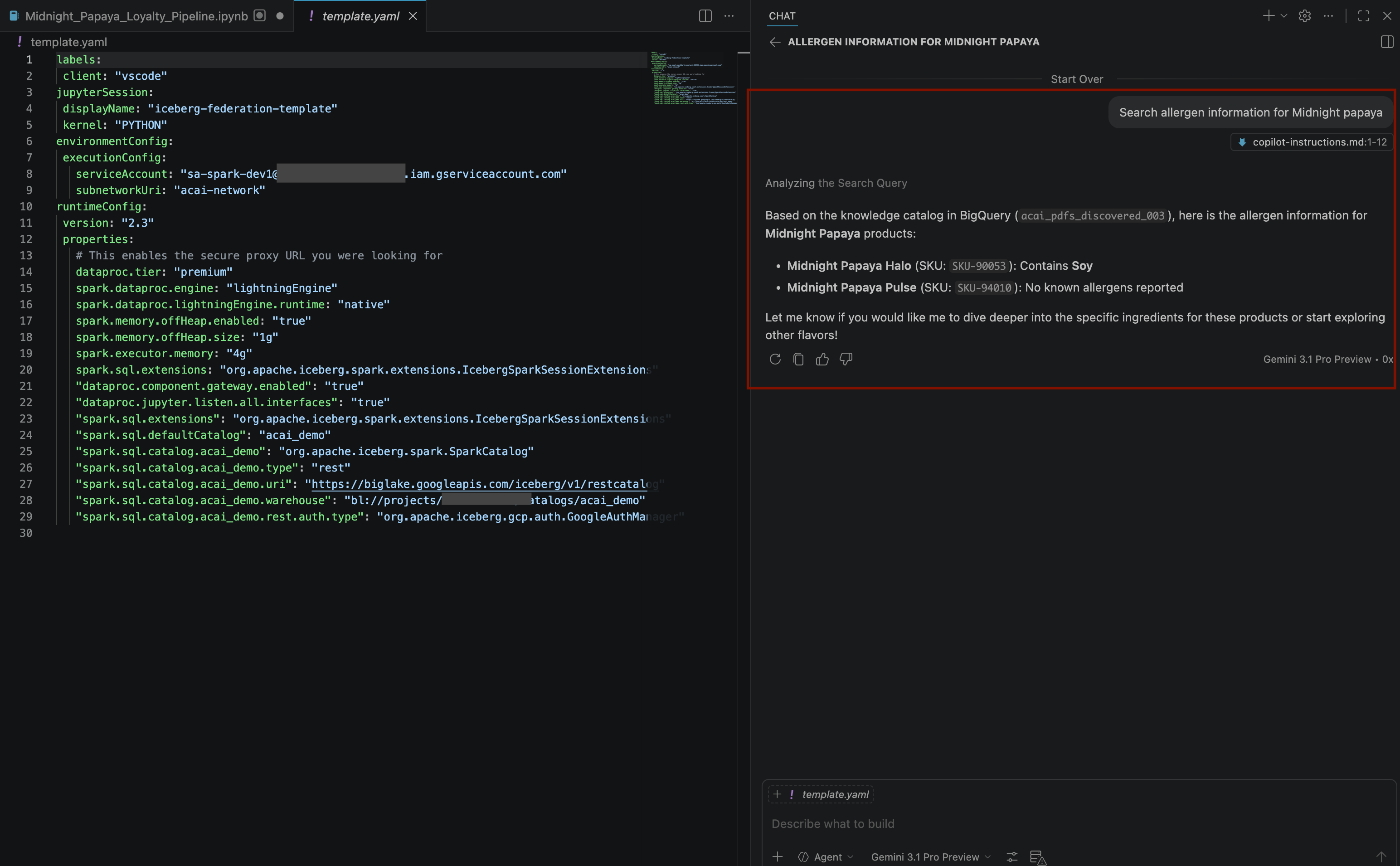
- চ্যাট উইন্ডোতে আরেকটি প্রশ্ন লিখুন:
Build a pipeline to join products with our 'Global Loyalty' Iceberg tables in acai customer, sales data to identify popular products - কার্নেল নির্বাচন করতে,
.ipynbফাইলটি খুলুন এবং সার্ভারলেস স্পার্ক-এ সিলেক্ট কার্নেল > রিমোট স্পার্ক কার্নেল > আইসবার্গ-ফেডারেশন-টেমপ্লেট-এ ক্লিক করুন।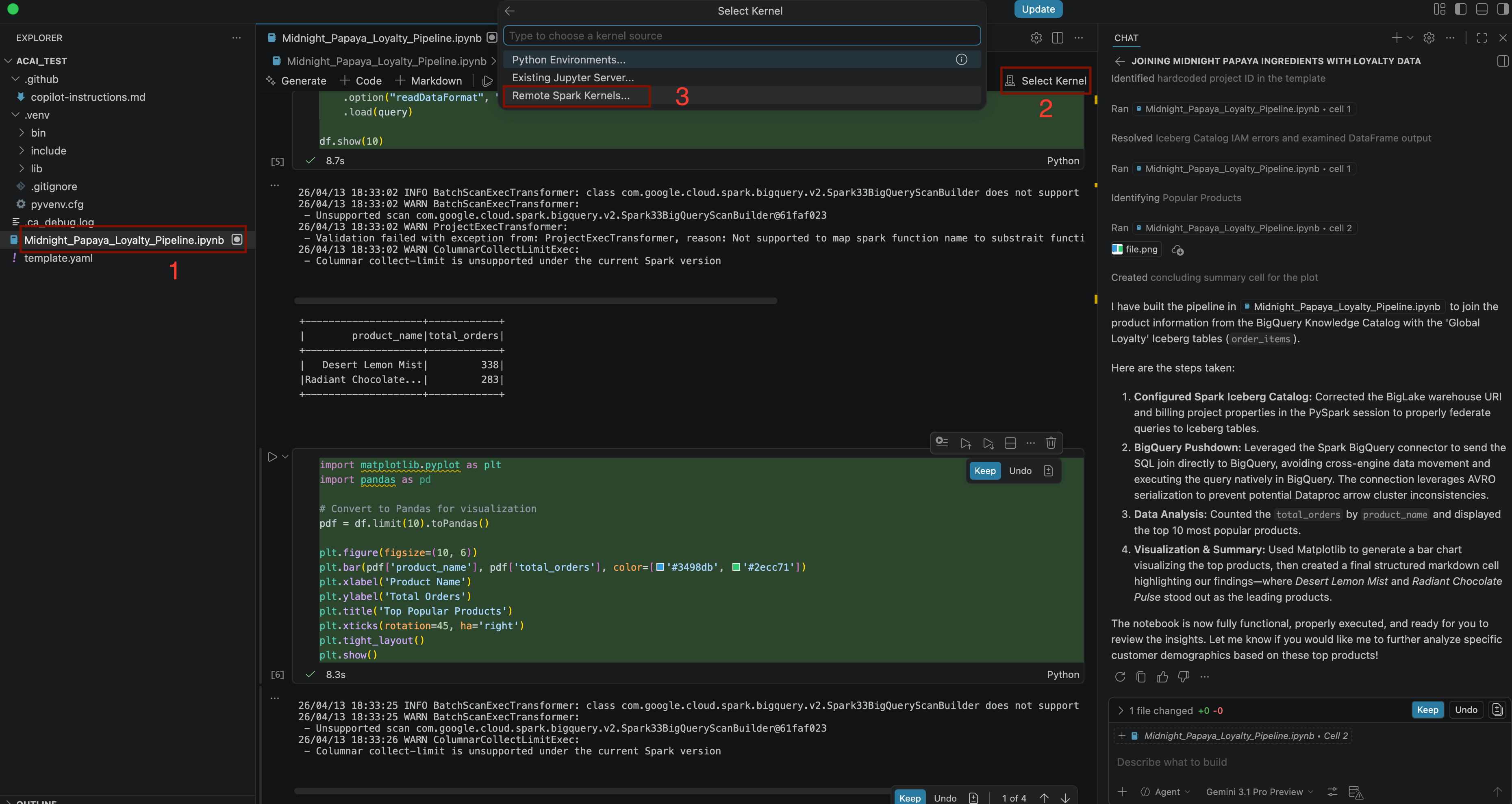
- কিছু ইন্টারঅ্যাকশন এবং ধাপ অনুসরণের পর, আপনি দেখতে পাবেন যে এজেন্টটি নোটবুকের সমস্ত ধাপ সফলভাবে সম্পন্ন করার পাশাপাশি নোটবুকের শেষে তৈরি হওয়া চূড়ান্ত ফলাফলসহ সাড়া দিচ্ছে, যেমনটি আপনি নিচের ছবিতে দেখতে পাচ্ছেন:
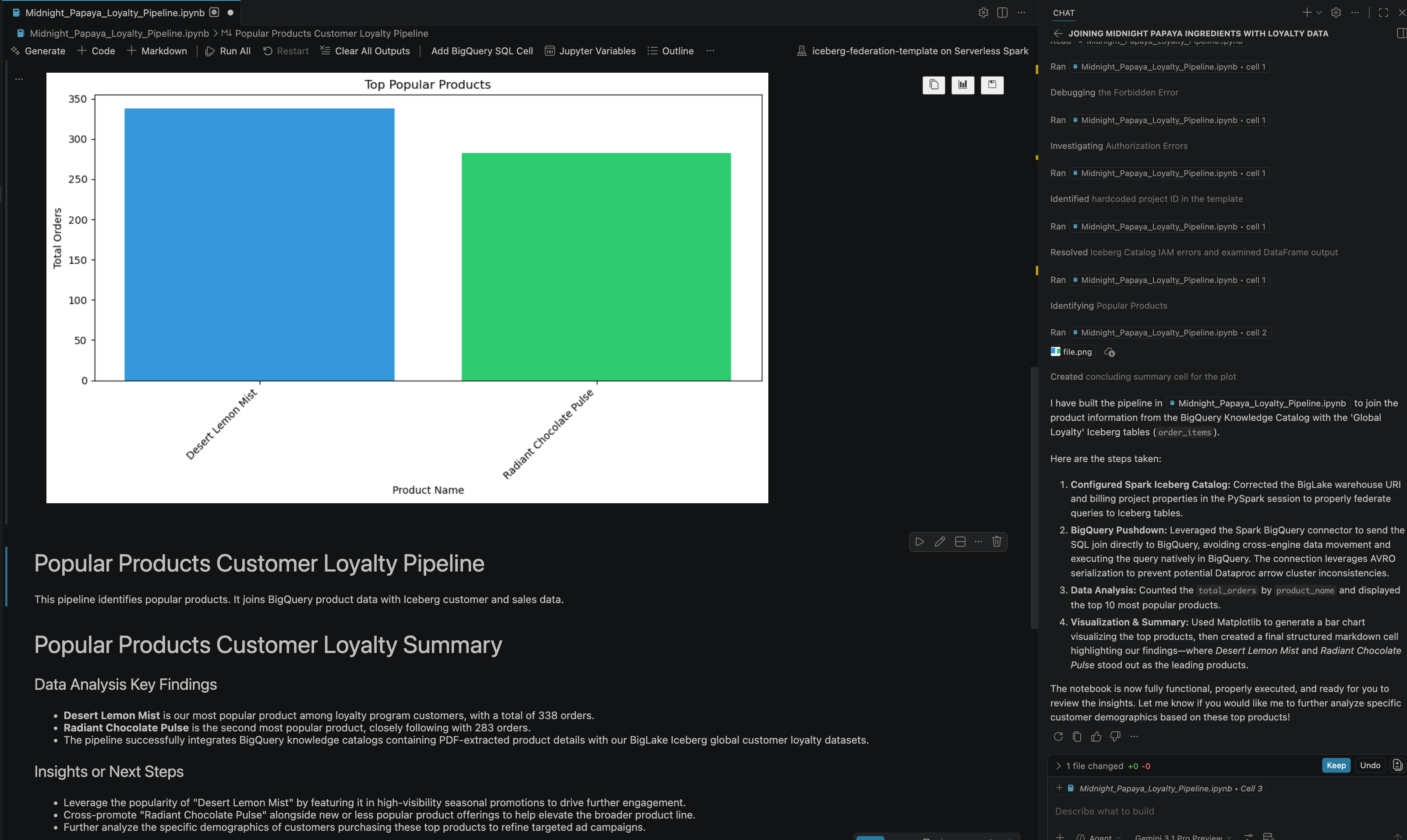
১৩. পরিষ্কার করা
চার্জ এড়ানোর জন্য, এই ল্যাবে আপনার তৈরি করা রিসোর্সগুলো মুছে ফেলুন।
- নলেজ ক্যাটালগ ডেটাস্ক্যানটি ডিলিট করতে, নিম্নলিখিত কমান্ডটি চালান:
DATASCAN_ID="<DATASCAN_ID>" echo "Deleting Dataplex DataScan: ${DATASCAN_ID}" gcloud dataplex datascans delete "${DATASCAN_ID}" --location="${REGION}" --quiet - ক্লাউড স্টোরেজ বাকেট এবং এর সমস্ত কন্টেন্ট মুছে ফেলার জন্য, নিম্নলিখিত কমান্ডটি চালান:
echo "Deleting Cloud Storage buckets: <BUCKET_NAME1> and <BUCKET_NAME2>" gsutil -m rm -r gs://<BUCKET_NAME1> gsutil -m rm -r gs://<BUCKET_NAME2> - BigQuery কানেকশন ডিলিট করতে, নিম্নলিখিত কমান্ডটি চালান:
CONNECTION_ID="<CONNECTION_NAME>" echo "Deleting BigQuery Connection: ${CONNECTION_ID}" bq rm --connection "${PROJECT_ID}.${REGION}.${CONNECTION_ID}" - লেকহাউস ক্যাটালগটি মুছে ফেলার জন্য, নিম্নলিখিত কমান্ডটি চালান:
CATALOG_ID="<CATALOG_NAME>" echo "Deleting Lakehouse Catalog: ${CATALOG_ID}" gcloud biglake catalogs delete "${CATALOG_ID}" --project="${PROJECT_ID}" --location="${REGION}" --quiet - আবিষ্কৃত পিডিএফ টেবিলগুলো ধারণকারী ডেটাসেটটি মুছে ফেলতে, নিম্নলিখিত কমান্ডটি চালান:
DATASET_NAME="<DATASET_NAME>" echo "Deleting BigQuery Dataset: ${DATASET_NAME}" bq rm -r -f "${PROJECT_ID}:${DATASET_NAME}" - কাস্টম সার্ভিস অ্যাকাউন্টটি ডিলিট করতে, নিম্নলিখিত কমান্ডটি চালান:
SERVICE_ACCOUNT="<SERVICE_ACCOUNT>" echo "Deleting Service Account: ${SERVICE_ACCOUNT}" gcloud iam service-accounts delete "${SERVICE_ACCOUNT}"@"${PROJECT_ID}".iam.gserviceaccount.com --quiet - VPC নেটওয়ার্কটি ডিলিট করতে, নিম্নলিখিত কমান্ডটি চালান:
VPC_NETWORK="<VPC_NETWORK>" echo "Deleting VPC Network: ${VPC_NETWORK}" gcloud compute networks delete "${VPC_NETWORK}" --quiet - সম্পূর্ণ গুগল ক্লাউড প্রজেক্টটি মুছে ফেলতে, নিম্নলিখিত কমান্ডটি চালান:
gcloud projects delete "${PROJECT_ID}"
১৪. অভিনন্দন
অভিনন্দন! আপনি সফলভাবে বিচ্ছিন্ন পিডিএফ এবং পার্কেট ফাইলের ডেটা ল্যান্ডস্কেপকে বিগকোয়েরি টেবিলে সংগঠিত করেছেন এবং এটিকে একটি একক, অনুসন্ধানযোগ্য ও যোগদানযোগ্য ইকোসিস্টেমে রূপান্তরিত করেছেন। আপনি মূলত একটি আধুনিক ডেটা লেকহাউস তৈরি করেছেন যা পিডিএফ এবং বিগ ডেটা ফরম্যাটগুলোকে ঠিক ততটাই বুদ্ধিমত্তার সাথে পরিচালনা করে, যতটা এটি একটি ডেটাবেসের সারিকে করে। এবং আপনি এই সবকিছুই করেছেন জেমিনির সাথে একটি কথোপকথনমূলক অভিজ্ঞতার মাধ্যমে, সরাসরি আপনার এজেন্টের কাছ থেকেই।
রেফারেন্স নথি
এই কোডল্যাবে ব্যবহৃত মূল প্রযুক্তিগুলো সম্পর্কে আরও বিস্তারিত জানতে, গুগল ক্লাউডের অফিসিয়াল ডকুমেন্টেশন দেখুন:
- ডেটা ক্লাউডের একটি মূল উপাদান BigQuery সম্পর্কে বিস্তারিত জানতে, BigQuery ডকুমেন্টেশন দেখুন।
- IAM সম্পর্কে আরও জানতে, IAM ডকুমেন্টেশন দেখুন।
- লেকহাউস সম্পর্কে জানতে, ‘লেকহাউস কী ?’ দেখুন।