
1. Einführung
In diesem Codelab schlüpfen Sie in die Rolle eines Data Scientists für ein fiktives Froyo-Unternehmen, das eine neue Geschmacksrichtung namens „Midnight Swirl“ auf den Markt bringt. Für eine erfolgreiche globale Einführung muss das Unternehmen wichtige Fragen zu Inhaltsstoffen, Marktnachfrage und Return on Investment (ROI) beantworten. Dieser End-to-End-Workflow zeigt, wie Google Cloud Knowledge Catalog (früher Dataplex) und Lakehouse für Apache Iceberg (früher BigLake) die Lücke zwischen „dunklen“ unstrukturierten Daten schließen und über eine einheitliche Governance-Ebene mithilfe von Gemini in Ihrer IDE (VS Code) umsetzbare Business Intelligence liefern.
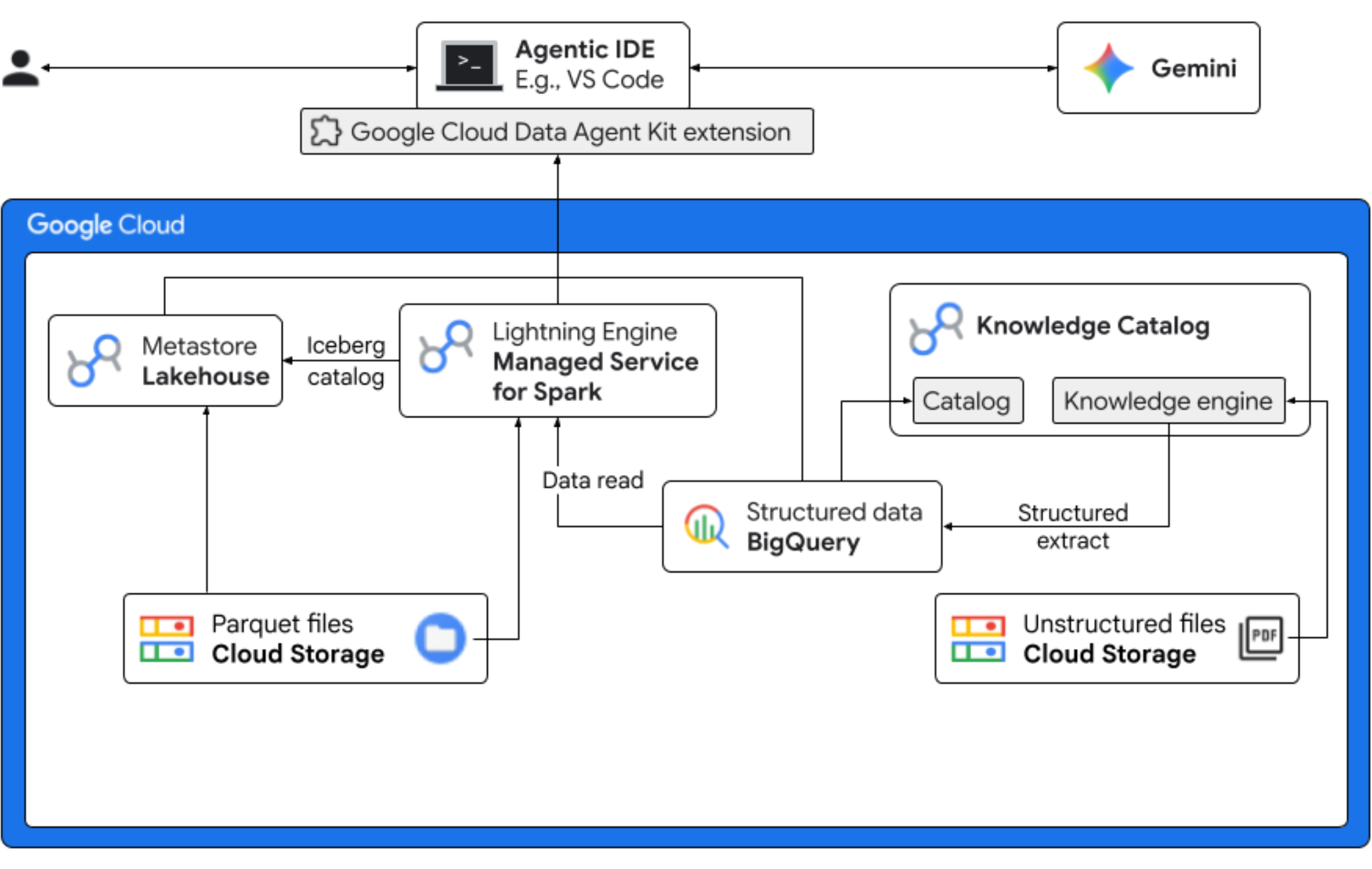
Aufgaben
- Unstrukturierte Ermittlung: PDF-Rezepte, die in Cloud Storage gespeichert sind, werden von Knowledge Catalog DataScan gecrawlt. Objekttabellen in BigQuery für die gescannten PDFs erstellen. Mit Vertex AI Semantic Inference „liest“ das System die PDFs, um strukturierte Informationen zu Produkten, Allergenen, Inhaltsstoffen und zugehörigen Attributen zu extrahieren. Anschließend wird auf intelligente Weise ein Schema für die in den PDFs gespeicherten Daten generiert.
- Einheitliche Metadaten: Die aus PDF-Dateien extrahierten Daten werden direkt als native breite Tabelle in BigQuery gespeichert. Ansichten werden erstellt, um gängige Abfragen zu unterstützen. Ein unabhängiges Eingabedataset mit historischen Verkaufsdaten wird in Apache Iceberg-Tabellen in Google Cloud Storage gespeichert. Diese Iceberg-Tabelle wird in einem späteren Schritt in BigQuery mit den extrahierten Daten verknüpft.
- Engine-übergreifende Analysen: Mit dem Managed Service for Apache Spark (früher Dataproc) mit einem Iceberg-REST-Katalog können Sie diese neuen PDF-Metadaten und abgeleiteten strukturierten semantischen Daten (aus BigQuery-Tabellen und -Ansichten) mit strukturierten Verkaufsdaten verknüpfen, die in Apache Iceberg-Tabellen in Google Cloud Storage gespeichert sind. Dies wird durch eine Vorlage für verwaltete interaktive Apache Spark-Sitzungen gesteuert, die als Jupyter-Notebook-Kernel verwendet wird und für konsistente Sicherheits- und Recheneinstellungen für den Spark-Job sorgt.
- Semantische Statistiken: Durch die Verknüpfung der abgeleiteten Produktdaten mit Kunden- und Verkaufsdaten (in BigQuery) können in der Demo Statistiken wie die Identifizierung von Allergendaten und die Umsatzprognose extrahiert werden.
- Autonome Governance: Der gesamte Lebenszyklus – von Discovery-Scans bis zur Spark-Ausführung – wird durch Gemini-kompatible Vorlagen, Anleitungen, Regeln und agentengesteuerte Automatisierung orchestriert. Das zeigt, dass KI die Infrastruktur verwalten kann, die die Analysen ermöglicht.
Voraussetzungen
Für dieses Codelab können Kosten anfallen, die bei normaler Nutzung auf weniger als 5 $geschätzt werden. Detaillierte Kostenschätzungen basierend auf Ihrer voraussichtlichen Nutzung oder den aktuellen Preisen erhalten Sie mit dem Google Cloud-Preisrechner.
Prüfen Sie, ob die folgenden Voraussetzungen erfüllt sind, bevor Sie mit dem Codelab beginnen.
- Chrome
- Ein privates Gmail-Konto, wenn Sie die im Abschnitt „Vorbereitung“ angegebenen Testguthaben verwenden.
- Laden Sie Visual Studio (VS) Code herunter und installieren Sie es.
2. Hinweis
Google Cloud-Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
Cloud Shell starten
Cloud Shell ist eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird und mit den erforderlichen Tools vorinstalliert ist.
- Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren.
- Prüfen Sie nach der Verbindung mit Cloud Shell Ihre Authentifizierung:
gcloud auth list - Prüfen Sie, ob Ihr Projekt konfiguriert ist:
gcloud config get project - Wenn Ihr Projekt nicht wie erwartet festgelegt ist, legen Sie es fest:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Erforderliche APIs aktivieren
Führen Sie diesen Befehl aus, um alle erforderlichen APIs zu aktivieren:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
biglake.googleapis.com \
dataproc.googleapis.com \
metastore.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
secretmanager.googleapis.com \
storage.googleapis.com
Codelab-Assets herunterladen
Dieses Repository enthält die Dateien „Parquet“, „recipes“, „suppliers“, „copilot-instructions.md“, „template.yaml“ und „quickstart.py“, die in diesem Codelab verwendet werden. Laden Sie diese Dateien herunter.
So laden Sie die Dateien herunter:
- Führen Sie in Cloud Shell den folgenden Befehl aus:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git - Wechseln Sie zum neu erstellten Ordner:
cd next-26-keynotes data-cloud-demo-Ordner abrufengit sparse-checkout set genkey/data-cloud-demo- Wechseln Sie nach Abschluss des Check-outs zum Ordner
data-cloud-demound entpacken Sie die ZIP-Dateien, um auf die Codelab-Assets zuzugreifen.
3. Lakehouse für Froyo-Kundendaten einrichten
In diesem Abschnitt erstellen Sie einen Katalog in Lakehouse, um den Lakehouse-Metastore für Ihre Workflows zu verwenden. Es sorgt für Interoperabilität zwischen Ihren Abfragemodulen, indem es eine einzige verlässliche Quelle für alle Ihre Iceberg-Daten bietet. Damit können Abfrage-Engines wie Apache Spark Iceberg-Tabellen auf konsistente Weise erkennen, Metadaten lesen und Tabellen verwalten.
Erforderliche Rollen
Sie benötigen die folgenden IAM-Rollen (Identity and Access Management):
roles/biglake.viewerroles/bigquery.userroles/bigquery.dataEditorroles/biglake.editorroles/biglake.metadataViewerroles/bigquery.connectionUserroles/storage.objectUserroles/storage.objectViewerroles/storage.objectCreatorroles/storage.admin
Weitere Informationen zum Zuweisen von IAM-Rollen finden Sie unter IAM-Rolle zuweisen.
Lakehouse-Katalog mit einem Bucket erstellen
Erstellen Sie einen Lakehouse-Katalog, um Metadaten für Ihre Iceberg-Tabellen zu verwalten. Sie stellen in Ihrem Spark-Job eine Verbindung zu diesem Katalog her, um Iceberg-Tabellen zu erstellen und abzufragen.
- Rufen Sie in der Google Cloud Console Lakehouse auf.
- Klicken Sie auf Katalog erstellen. Die Seite Katalog erstellen wird geöffnet.
- Wählen Sie für Katalogtyp die Option Iceberg-REST-Katalog aus.
- Wählen Sie unter Optionen für den Lakehouse-Katalog-Bucket auswählen die Option Katalog mit einem Bucket aus.
- Klicken Sie für Standard-Cloud Storage-Bucket für Katalog auf Durchsuchen und dann auf Neuen Bucket erstellen.
- Führen Sie auf der Seite Bucket erstellen folgende Schritte aus:
- Geben Sie im Bereich Einstieg einen global eindeutigen Namen ein, der den Anforderungen für Bucket-Namen entspricht.
- Wählen Sie im Abschnitt Speicherort für Daten auswählen für Standorttyp die Option Region aus und geben Sie Ihre Region ein. Beispiel:
us-west1 - Entfernen Sie im Abschnitt Zugriff auf Objekte steuern das Häkchen bei Verhinderung des öffentlichen Zugriffs für diesen Bucket erzwingen.
So können Sie reale Szenarien wie das Hosten öffentlicher Webinhalte oder gemeinsamer Datenrepositories simulieren. Ohne diese Änderung würde für den Bucket eine strenge „Nur privat“-Richtlinie gelten. Jeder Versuch, auf Ihre Assets zuzugreifen, würde zu einem403-Fehler führen, auch wenn Sie den Dateien öffentliche Berechtigungen erteilt haben. - Klicken Sie auf Weiter > Erstellen > Auswählen > Weiter.
- Wählen Sie unter Authentication method (Authentifizierungsmethode) die Option Credential vending mode (Modus für Bereitstellung von Anmeldedaten) aus.
- Klicken Sie auf Erstellen.Ihr Katalog wird erstellt und die Seite Katalogdetails wird geöffnet.
- Klicken Sie unter Authentifizierungsmethode auf Bucket-Berechtigungen festlegen.
- Klicken Sie im Dialogfeld auf Bestätigen.Dadurch wird bestätigt, dass das Dienstkonto Ihres Katalogs die Rolle
Storage Object Userfür Ihren Storage-Bucket hat. - Kopieren Sie auf der Seite Katalogdetails den REST-Katalog-URI-Pfad. Verwenden Sie diesen Pfad während der Aufgabe „Spark-Job ausführen“.
Parquet-Dateien in den Bucket hochladen
So laden Sie Ihre Parquet-Dateien in das Stammverzeichnis Ihres Buckets hoch:
- Wechseln Sie in der Cloud Console zur Seite Cloud Storage-Buckets.
- Klicken Sie in der Bucket-Liste auf den Bucket-Namen. Beispiel:
acai_demo. - Klicken Sie auf dem Tab Objekte für den Bucket auf Hochladen > Dateien hochladen.
- Wählen Sie die Dateien aus dem Parquet-Ordner aus, den Sie im Abschnitt Vorbereitung dieses Codelabs geklont haben.
- Klicken Sie auf Öffnen.
4. VPC-Netzwerk einrichten
Erstellen Sie ein VPC-Netzwerk (Virtual Private Cloud) und ein Subnetz, über das Ressourcen mit Google APIs kommunizieren können, ohne das öffentliche Internet zu nutzen. Außerdem benötigen Sie eine Firewall, die den internen Traffic zwischen Ihren Datenverarbeitungsknoten ermöglicht.
- Rufen Sie in der Google Cloud Console die Seite VPC-Netzwerke auf.
- Klicken Sie auf VPC-Netzwerk erstellen.
- Geben Sie einen Namen für das Netzwerk ein. Beispiel:
acai-network. - Wenn Sie die maximale Übertragungseinheit (Maximum Transmission Unit, MTU) des Netzwerks konfigurieren möchten, aktivieren Sie das Kästchen MTU automatisch festlegen.
- Wählen Sie unter Modus für Subnetzerstellung die Option Automatisch aus.
- Wählen Sie im Abschnitt Firewallregeln alle Kästchen für IPv4-Firewallregeln aus.
- Klicken Sie auf Erstellen.
Privaten Google-Zugriff aktivieren
Dataproc Serverless-Knoten haben keine öffentlichen IP-Adressen. Damit das Subnetz mit dem Lakehouse-Katalog und Cloud Storage kommunizieren kann, muss der private Google-Zugriff aktiviert sein.
- Rufen Sie in der Google Cloud Console die Seite VPC-Netzwerke auf.
- Klicken Sie auf den Namen des Netzwerks mit dem Subnetz, für das Sie den privaten Google-Zugriff aktivieren müssen. Beispiel:
us-west1. - Klicken Sie auf den Namen des Subnetzes. Die Subnetz-Detailseite wird angezeigt.
- Klicken Sie auf Bearbeiten.
- Wählen Sie im Abschnitt Privater Google-Zugriff die Option Ein aus.
- Klicken Sie auf Speichern.
5. Spark-Job erstellen und ausführen
Wenn Sie eine Iceberg-Tabelle erstellen und abfragen möchten, laden Sie den PySpark-Job mit den erforderlichen Spark SQL-Anweisungen hoch. Führen Sie den Job dann mit Managed Service for Spark aus.
„quickstart.py“ in Ihren Cloud Storage-Bucket hochladen
Nachdem Sie die Codelab-Assets geklont haben, aktualisieren Sie das quickstart.py-Skript mit Ihren Projektdetails und laden Sie es in den Cloud Storage-Bucket hoch.
- Öffnen Sie das
quickstart.py-Skript in einem Texteditor. - Ersetzen Sie den Platzhalter
BUCKET_NAMEim Skript durch den Namen Ihres Cloud Storage-Buckets und speichern Sie das Skript. - Wechseln Sie in der Google Cloud Console zu Cloud Storage-Buckets.
- Klicken Sie auf den Namen Ihres Buckets. Beispiel:
acai_demo. - Klicken Sie auf dem Tab Objekte auf Hochladen > Dateien hochladen.
- Wählen Sie im Dateibrowser die aktualisierte Datei
quickstart.pyaus und klicken Sie dann auf Öffnen.
Spark-Job ausführen
Nachdem Sie das quickstart.py-Skript hochgeladen haben, führen Sie es als Managed Service for Spark-Batchjob aus.
- Führen Sie den folgenden Befehl in Cloud Shell aus, um die Variablen zu konfigurieren.
# Configuration Variables export PROJECT_ID="<PROJECT_ID>" export REGION="<REGION>" export BUCKET_NAME="<BUCKET_NAME>" export SUBNET="<SUBNET>" export LAKEHOUSE_CATALOG_ID="<LAKEHOUSE_CATALOG_ID>" export CATALOG_URI_ID="<CATALOG_URI_ID>"- LAKEHOUSE_CATALOG_ID: Der Name der Lakehouse-Katalogressource, die Ihre PySpark-Anwendungsdatei enthält. z. B.
acai_demo. - PROJECT_ID: Ihre Google Cloud-Projekt-ID.
- REGION: Die Region, in der die Batcharbeitslast für Managed Service for Spark ausgeführt werden soll. Beispiel:
us-west1. - BUCKET_NAME: Der Name Ihres Cloud Storage-Buckets. Beispiel:
acai_demo. - SUBNET: der Name Ihres VPC-Subnetzes. Beispiel:
acai-network. - CATALOG_URI_ID: Die URI-ID des Lakehouse-Katalogs, die Sie beim Erstellen eines Lakehouse-Katalogs mit einem Bucket kopiert haben. Beispiel:
https://biglake.googleapis.com/iceberg/v1/restcatalog.
- LAKEHOUSE_CATALOG_ID: Der Name der Lakehouse-Katalogressource, die Ihre PySpark-Anwendungsdatei enthält. z. B.
- Führen Sie in Cloud Shell den folgenden Managed Service for Spark-Batchjob mit dem Skript
quickstart.pyaus.gcloud dataproc batches submit pyspark gs://${BUCKET_NAME}/quickstart.py \ --project=${PROJECT_ID} \ --region=${REGION} \ --subnet=${SUBNET} \ --version=2.2 \ --properties="\ spark.sql.defaultCatalog=${LAKEHOUSE_CATALOG_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}=org.apache.iceberg.spark.SparkCatalog,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.type=rest,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.uri=${CATALOG_URI_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.warehouse=gs://${BUCKET_NAME},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.io-impl=org.apache.iceberg.gcp.gcs.GCSFileIO,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.x-goog-user-project=${PROJECT_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\ spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest-metrics-reporting-enabled=false,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.X-Iceberg-Access-Delegation=vended-credentials,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token"All tables registered successfully! Batch [126fa2226a904d2e944c8eecbe0b1840] finished. metadata: '@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata batch: projects/PROJECT_ID/locations/REGION/batches/126fa2226a904d2e944c8eecbe0b1840 batchUuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff createTime: '2026-04-09T13:17:26.222727Z' description: Batch labels: goog-dataproc-batch-id: 126fa2226a904d2e944c8eecbe0b1840 goog-dataproc-batch-uuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-drz-resource-uuid: batch-3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-location: REGION operationType: BATCH name: projects/PROJECT_ID/regions/REGION/operations/47bc59e8-5082-3af9-89a0-22289aa5f4b9
6. Tabelle über BigQuery abfragen
Durch die erfolgreiche Ausführung des Spark-Batchjobs haben Sie Managed Service for Spark Serverless als verteilte Compute-Engine verwendet, um mehrere Tabellen zu registrieren, eine pro Parquet-Datei im Lakehouse Metastore. Durch diese Registrierung kann Google Cloud Ihre Rohdateien in Cloud Storage als strukturierte, leistungsstarke Tabellen behandeln.
In den folgenden Schritten wird beschrieben, wie Sie bestätigen, dass die Metadaten richtig synchronisiert wurden. So können Sie sicher sein, dass Ihre Daten nicht nur sicher gespeichert, sondern auch über die BigQuery-Benutzeroberfläche vollständig auffindbar und abfragbar sind.
- Wechseln Sie in der Google Cloud Console zu BigQuery.
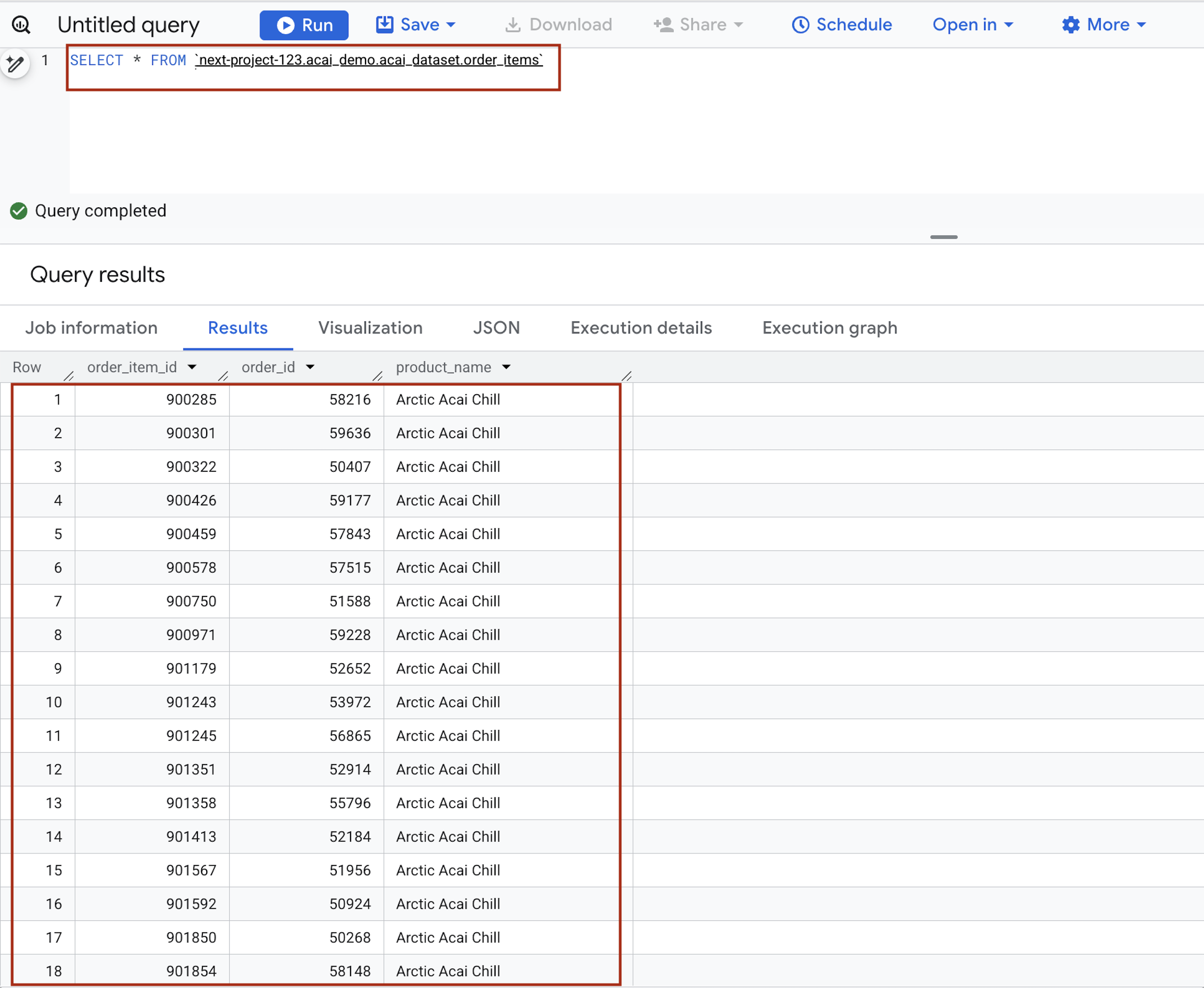
- Geben Sie im Abfrageeditor die folgende Anweisung ein. Die Abfrage verwendet die
project.namespace.dataset.table-Syntax.SELECT * FROM `<PROJECT_ID>.<NAMESPACE>.<ICEBERG_DATASET>.<ICEBERG_TABLE>`PROJECT_ID.acai_demo.acai_dataset.order_items.
Ersetzen Sie Folgendes:- PROJECT_ID: Ihre Google Cloud-Projekt-ID.
- NAMESPACE: Der Namespace, der im vorherigen Schritt als Ergebnis des Spark-Jobs erstellt wurde. Sie finden ihn auf der Seite „BigQuery-Objekt-Explorer“. Beispiel:
acai_demo. - ICEBERG_DATASET: Der Dataset-Name im Iceberg-Katalog, z. B.
acai_dataset. - ICEBERG_TABLE: Der Tabellenname im Iceberg-Dataset, z. B.
order_items.
- Klicken Sie auf Ausführen. In den Abfrageergebnissen sehen Sie die Daten, die Sie mit dem Spark-Job eingefügt haben.
7. Unstrukturierte Produktdatendateien einrichten
In diesem Abschnitt erstellen Sie eine Organisationsstruktur in BigQuery, um Froyo-Rezept- und ‑Lieferantendaten speziell für Froyo-Produktdetails zu speichern. Außerdem wird eine Cloud-Ressourcenverbindung eingerichtet, die als sichere „Brücke“ fungiert, über die BigQuery Dateien aus externen Quellen wie Cloud Storage lesen kann.
Bucket erstellen und Froyo-Detaildateien hochladen
Erstellen Sie die Lieferanten- und Rezeptdateien und laden Sie sie in den Cloud Storage-Bucket hoch.
- Wechseln Sie in der Cloud Console zur Seite Cloud Storage-Buckets.
- Klicken Sie auf Erstellen.
- Geben Sie auf der Seite Bucket erstellen die Bucket-Informationen ein. Klicken Sie nach jedem der folgenden Schritte auf Weiter, um mit dem nächsten Schritt fortzufahren:
- Geben Sie im Abschnitt Einstieg den Bucket-Namen ein. Beispiel:
acai_pdfs. - Wählen Sie im Abschnitt Speicherort für Daten auswählen die Option Region aus und geben Sie dann Ihre Region ein. Beispiel:
us-west1 - Entfernen Sie im Abschnitt Zugriff auf Objekte steuern das Häkchen bei Verhinderung des öffentlichen Zugriffs für diesen Bucket erzwingen.
- Klicken Sie auf Erstellen.
- Klicken Sie in der Liste der Buckets auf den Bucket, den Sie erstellt haben. Beispiel:
acai_pdfs. - Klicken Sie auf dem Tab Objekte für den Bucket auf Hochladen > Ordner hochladen.
- Wählen Sie den Ordner
recipesaus, den Sie im Abschnitt Vorbereitung dieses Codelabs extrahiert haben. - Klicken Sie auf Hochladen.
- Wiederholen Sie den Uploadvorgang für den Ordner
suppliers.
Verbindung herstellen
Cloud-Ressourcenverbindung erstellen Dadurch wird ein eindeutiges Dienstkonto erstellt, das als „Ausweis“ von BigQuery für den Zugriff auf externe Dateien dient.
- Rufen Sie die Seite BigQuery auf.
- Klicken Sie im linken Bereich auf Explorer. Wenn das linke Steuerfeld nicht angezeigt wird, klicken Sie auf Linkes Steuerfeld maximieren, um es zu öffnen.
- Maximieren Sie im Bereich Explorer den Namen Ihres Projekts und klicken Sie dann auf Verbindungen.
- Klicken Sie auf der Seite Verbindungen auf Verbindung erstellen.
- Wählen Sie als Verbindungstyp die Option Vertex AI-Remote-Modelle, Remote-Funktionen, BigLake und Cloud Spanner (Cloud-Ressource) aus.
- Geben Sie im Feld Verbindungs-ID den Namen der Verbindungs-ID ein. Beispiel:
acai_pdf_connection. Notieren Sie sich diese ID, da Sie sie später in diesem Codelab benötigen, wenn Sie den Daten-Scan einrichten. - Legen Sie Standorttyp auf Region fest und wählen Sie dann eine Region aus. Beispiel:
us-west1Die Verbindung sollte sich am selben Standort wie Ihre anderen Ressourcen, z. B. Datasets, befinden. - Klicken Sie auf Verbindung erstellen.
- Klicken Sie auf Zur Verbindung.
- Kopieren Sie im Bereich Verbindungsinformationen die Dienstkonto-ID zur Verwendung in einem späteren Schritt. Das Dienstkonto sieht in etwa so aus:
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com.
Zugriff auf Dienstkonten verwalten
Gewähren Sie dem Dienstkonto Zugriff, damit das Lakehouse Ihre PDFs lesen kann.
- Zur Seite IAM & Verwaltung.
- Klicken Sie auf Zugriff erlauben. Das Dialogfeld „Principals hinzufügen“ wird geöffnet.
- Geben Sie im Feld Neue Hauptkonten die Dienstkonto-ID ein, die Sie zuvor kopiert haben.
- Wählen Sie im Feld Rolle auswählen die folgenden Rollen aus:
roles/storage.objectUserroles/storage.objectViewerroles/bigquery.userroles/bigquery.dataEditorroles/aiplatform.userroles/storage.adminroles/dataproc.serviceAgent
- Klicken Sie auf Speichern.
Weitere Informationen zu IAM-Rollen in BigQuery finden Sie unter Vordefinierte Rollen und Berechtigungen.
8. Berechtigungen für DataScan-Jobs verwalten
Erstellen Sie spezifische Dienstkonten (Identitäten) für Spark und Dataform und erteilen Sie ihnen sowie den automatisierten Dienst-Agents von Google die genauen Berechtigungen, die zum Lesen von Speicher, zum Ausführen von BigQuery-Jobs und zur Verwendung von Vertex AI für die Suche erforderlich sind.
IAM-Zugriff für Spark und Dataform
- Wechseln Sie in der Google Cloud Console zur Seite Dienstkonto erstellen.
- Wählen Sie Ihr Google Cloud-Projekt aus, falls es nicht ausgewählt ist.
- Klicken Sie auf Dienstkonto erstellen.
- Geben Sie einen Namen für das Dienstkonto ein. Beispiel:
sa-spark-stg1. Die Google Cloud Console generiert anhand dieses Namens eine Dienstkonto-ID. Bearbeiten Sie gegebenenfalls die ID. Sie können die ID später nicht mehr ändern. - Wenn Sie die Zugriffssteuerungen festlegen möchten, klicken Sie auf Erstellen und fortfahren und fahren Sie mit dem nächsten Schritt fort.
- Wählen Sie die folgenden IAM-Rollen aus, die dem Dienstkonto für das Projekt zugewiesen werden sollen.
roles/dataproc.workerroles/storage.objectUserroles/bigquery.dataEditorroles/bigquery.jobUserroles/aiplatform.userroles/dataplex.discoveryPublishingServiceAgent
- Klicken Sie auf Weiter, wenn Sie alle Rollen hinzugefügt haben.
- Klicken Sie auf Fertig, um das Erstellen des Dienstkontos abzuschließen.
Berechtigungen für BigQuery-Verbindungen für den Zugriff auf Knowledge Catalog
- Wechseln Sie in der Cloud Console zur Seite Cloud Storage-Buckets.
- Klicken Sie in der Liste der Buckets auf den Namen des Buckets, den Sie für Froyo erstellt haben. Beispiel:
acai_pdfs. - Klicken Sie im Tab Berechtigungen auf Zugriff erlauben. Das Dialogfeld „Principals hinzufügen“ wird angezeigt.
- Geben Sie im Feld Neue Prinzipale die Konto-ID Ihres BigQuery-Dienstkontos ein. Das Dienstkonto sieht in etwa so aus:
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com. - Wählen Sie im Drop-down-Menü Rolle auswählen die folgende(n) Rolle(n) aus.
roles/storage.objectUserroles/dataplex.serviceAgentroles/dataplex.securityAdminroles/aiplatform.serviceAgentroles/dataplex.discoveryPublishingServiceAgent
- Klicken Sie auf „Speichern“.
9. Knowledge Catalog einrichten
Erstellen Sie einen Knowledge Catalog, um Ihre Froyo-bezogenen Daten zu vereinheitlichen und die Suche nach unstrukturierten Dateien (z. B. PDF-Rezepten und PDF-Lieferanten) zu automatisieren.
Datenscan über curl erstellen
In diesem Abschnitt erstellen Sie Scans für Ihren Cloud Storage-Bucket (z. B. acai_pdfs), indem Sie datascan_ID hinzufügen und auf Ihre BigQuery-Datasets verweisen. Danach werden automatisch Einträge für Ihre PDFs in BigQuery erstellt.
- Führen Sie den folgenden Befehl aus, um die PDFs (Lieferanten und Rezepte) zu scannen:
# 1. Set your variables PROJECT_ID="<PROJECT_ID>" REGION="<REGION>" ENV_SUFFIX="stg1" DATASCAN_ID="froyo-profile-${ENV_SUFFIX}" BUCKET_NAME="<BUCKET_NAME>" # 2. Set this to the Name of the connection you created in Step 7 CONNECTION_ID="<CONNECTION_ID_NAME>" # 3. Define the API Endpoint DATAPLEX_API="dataplex.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}" # 4. Create the DataScan via CURL echo "Creating Dataplex DataScan: ${DATASCAN_ID}..." curl -X POST "https://$DATAPLEX_API/dataScans?dataScanId=${DATASCAN_ID}" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d '{ "data": { "resource": "//storage.googleapis.com/projects/'"${PROJECT_ID}"'/buckets/'"${BUCKET_NAME}"'" }, "executionSpec": { "trigger": { "on_demand": {} } }, "dataDiscoverySpec": { "bigqueryPublishingConfig": { "tableType": "BIGLAKE", "connection": "projects/'"${PROJECT_ID}"'/locations/'"${REGION}"'/connections/'"${CONNECTION_ID}"'" }, "storageConfig": { "unstructuredDataOptions": { "entity_inference_enabled": true } } } }' - Mit dem Befehl
curlwerden die DataScan-Ergebnisse des Wissenskatalogs angezeigt, wie in der folgenden Abbildung zu sehen ist.
Job ausführen
Führen Sie dazu diesen Befehl aus:
gcloud dataplex datascans run $DATASCAN_ID --location=$REGION
Job beschreiben
Führen Sie den folgenden Befehl aus, um den Job zu beschreiben:
gcloud dataplex datascans describe $DATASCAN_ID --location=$REGION
Datascan-Job löschen
Wenn der Scan länger als 10 Minuten dauert oder der Jobstatus über einen längeren Zeitraum Ausstehend bleibt, ohne in Wird ausgeführt überzugehen, kann dies an einer vorübergehenden Nichtverfügbarkeit von Ressourcen in der Region liegen. In diesem Fall können Sie den folgenden Befehl ausführen, um den Job zu löschen, und dann versuchen, ihn noch einmal zu erstellen und auszuführen. Manchmal schlägt ein erster Lauf schnell mit einem Fehler wie unable to acquire necessary resources fehl.
gcloud dataplex datascans delete $DATASCAN_ID --location=$REGION
Jobstatus ansehen
So prüfen Sie den Jobstatus:
- Rufen Sie in der Google Cloud Console die Seite Metadaten-Kuration auf.
- Klicken Sie auf dem Tab Cloud Storage-Erkennung auf den Namen der Erkennungsscans.
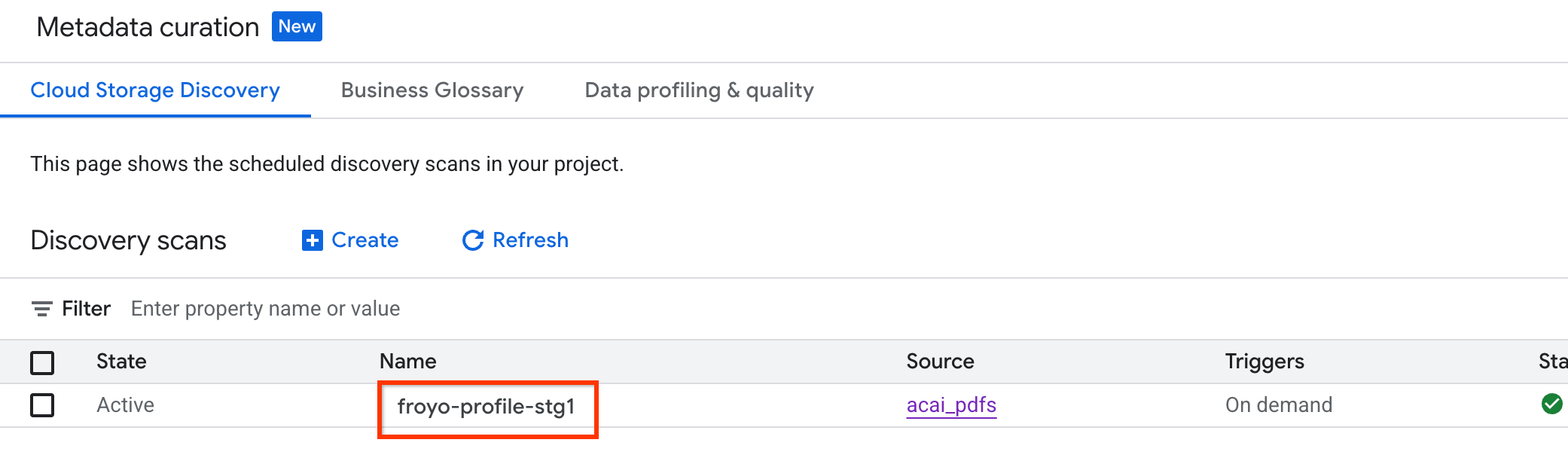
- Auf der Seite Scandetails sehen Sie den Jobstatus.
- Prüfen Sie nach Abschluss des Jobs, ob das veröffentlichte Dataset (z. B.
acai_pdfs_discovered_003), das Sie mit dem Befehlcurlerstellt haben, vorhanden ist.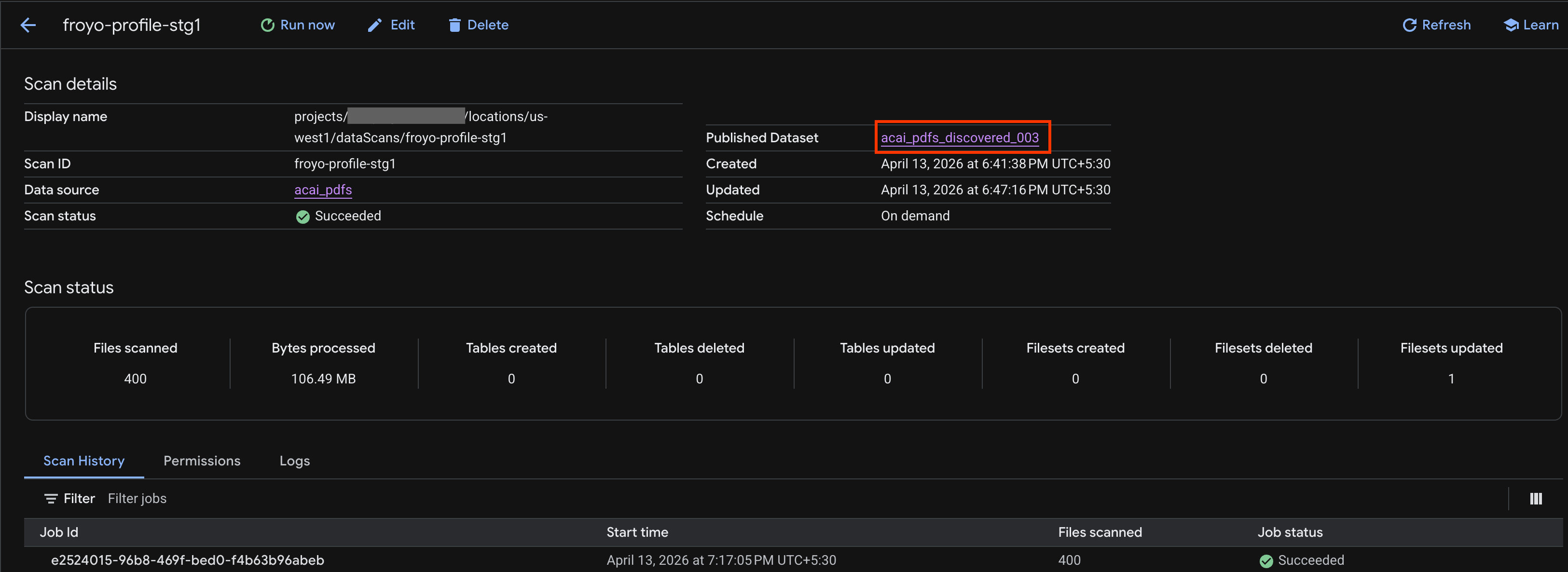
Objekttabelle ansehen
So rufen Sie die Objekttabelle auf, die nach dem Discovery-Job erstellt wurde:
- Wechseln Sie in der Google Cloud Console zu BigQuery.
- Klicken Sie auf Datasets und wählen Sie das veröffentlichte Dataset aus, das Sie im vorherigen Schritt erstellt haben. Beispiel:
acai_pdfs_discovered_003. - Klicken Sie auf die Tabellen-ID, um die Objekttabelle aufzurufen. Beispiel:
acai_pdfs. - Die resultierende Objekttabelle sieht so aus:
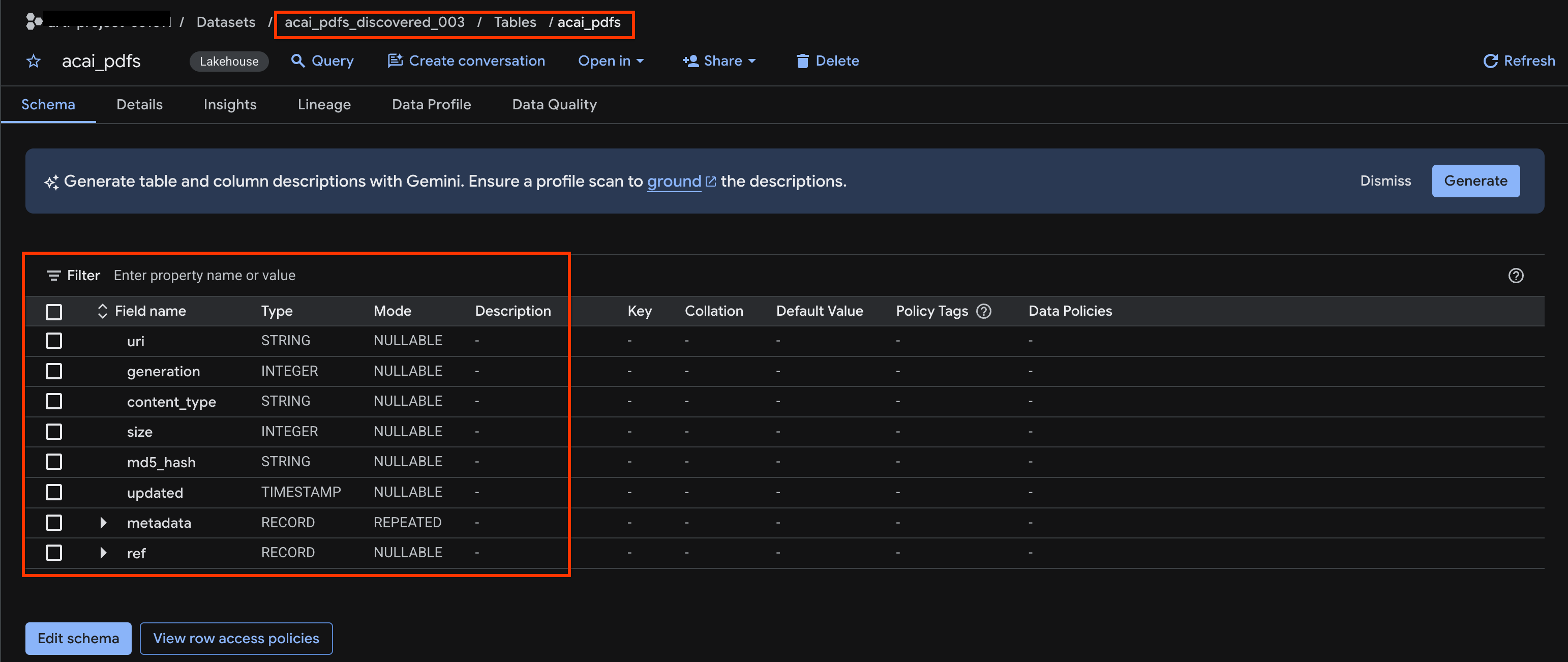
10. Semantische Extraktion
Sie werden strukturierte Tabellen, andere Datenbankobjekte und Beziehungen für diese unstrukturierte Objekttabelle ableiten und extrahieren, die Sie im vorherigen Schritt erstellt haben. Dazu verwenden Sie die Funktion „Knowledge Catalog Insights“, um SQL-Anweisungen zum Extrahieren strukturierter Daten aus der unstrukturierten Tabelle zu generieren.
- Rufen Sie in der Google Cloud Console die Seite Knowledge Catalog Search auf.
- Suchen Sie nach der Dataset-Tabelle, für die Sie Statistiken aufrufen möchten. Beispiel:
acai_pdfs_discovered_003.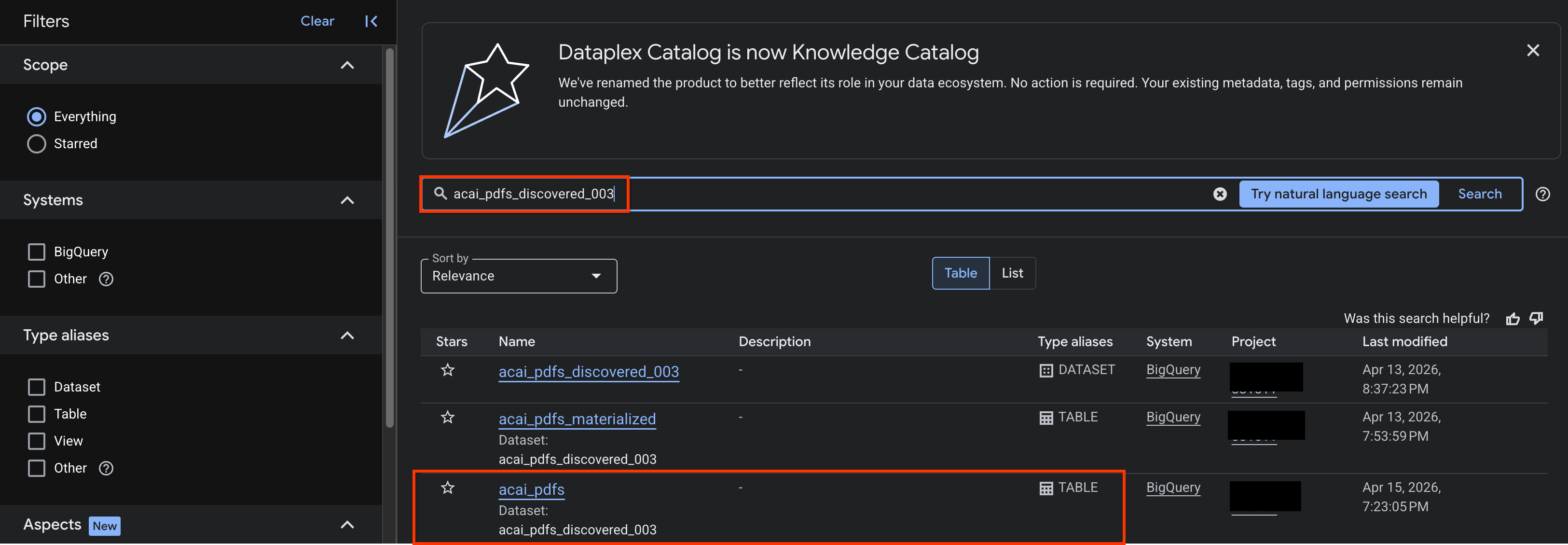
- Klicken Sie in den Suchergebnissen auf die Tabelle, um die zugehörige Eintragsseite zu öffnen.
- Klicken Sie auf den Tab Statistiken. Wenn der Tab leer ist, wurden die Statistiken für diese Tabelle noch nicht generiert. Das Generieren von Statistiken kann 15 bis 25 Minuten dauern.
- Wenn Sie die Statistiken sehen, klicken Sie auf Extrahieren > Mit SQL extrahieren.
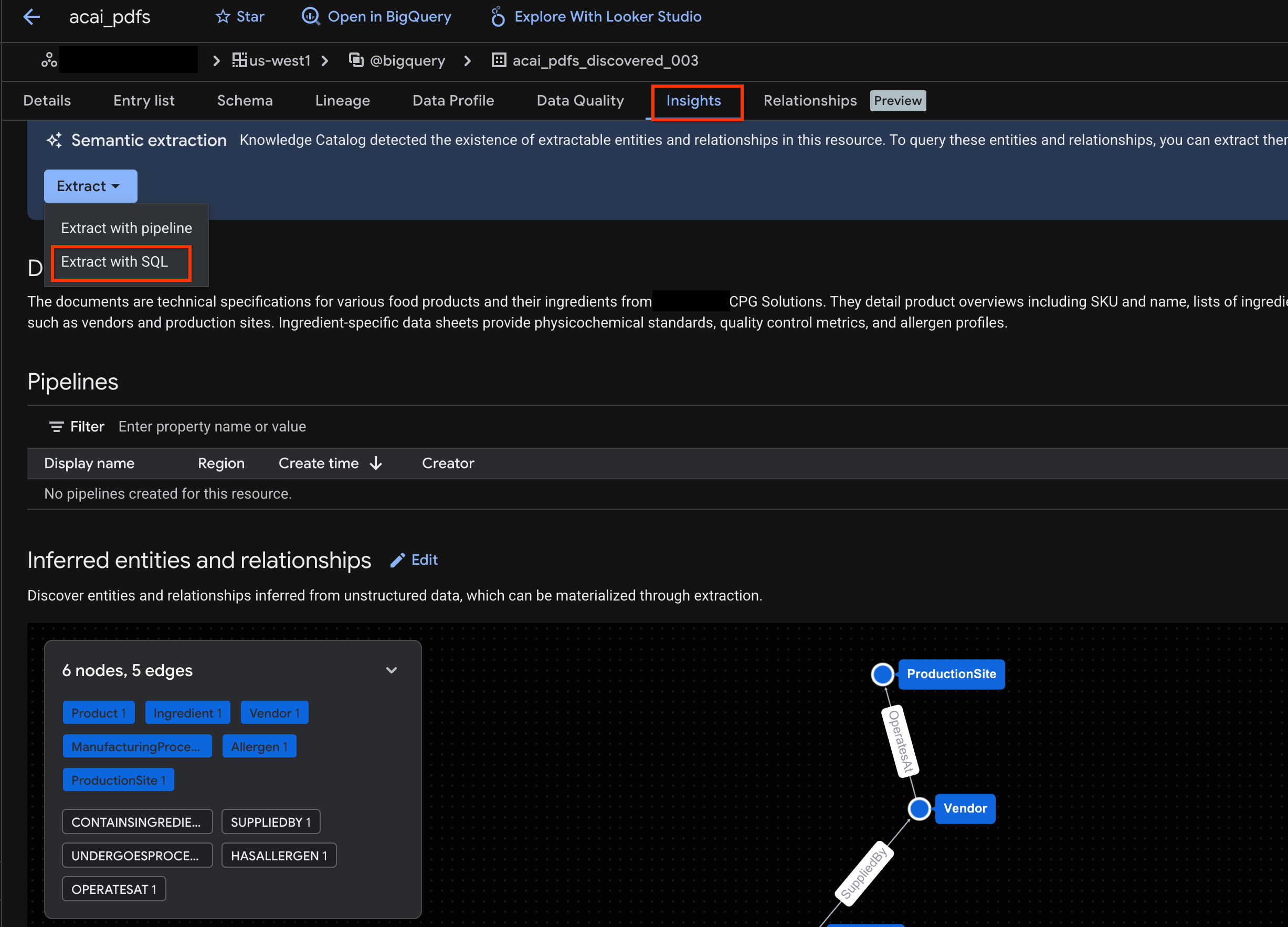
- Geben Sie auf der Seite Mit SQL extrahieren unter Ziel Ihr Dataset ein. Beispiel:
acai_pdfs_discovered_003 - Klicken Sie auf Extract. Dadurch wird der BigQuery-Editor mit der geladenen Abfrage geöffnet.
- Klicken Sie auf Ausführen. Bei diesem Schritt wird eine Reihe von Anweisungen generiert. Es kann einige Minuten dauern, bis der Vorgang abgeschlossen ist.
- Wenn die Abfrage abgeschlossen ist, werden die folgenden Ergebnisse angezeigt:
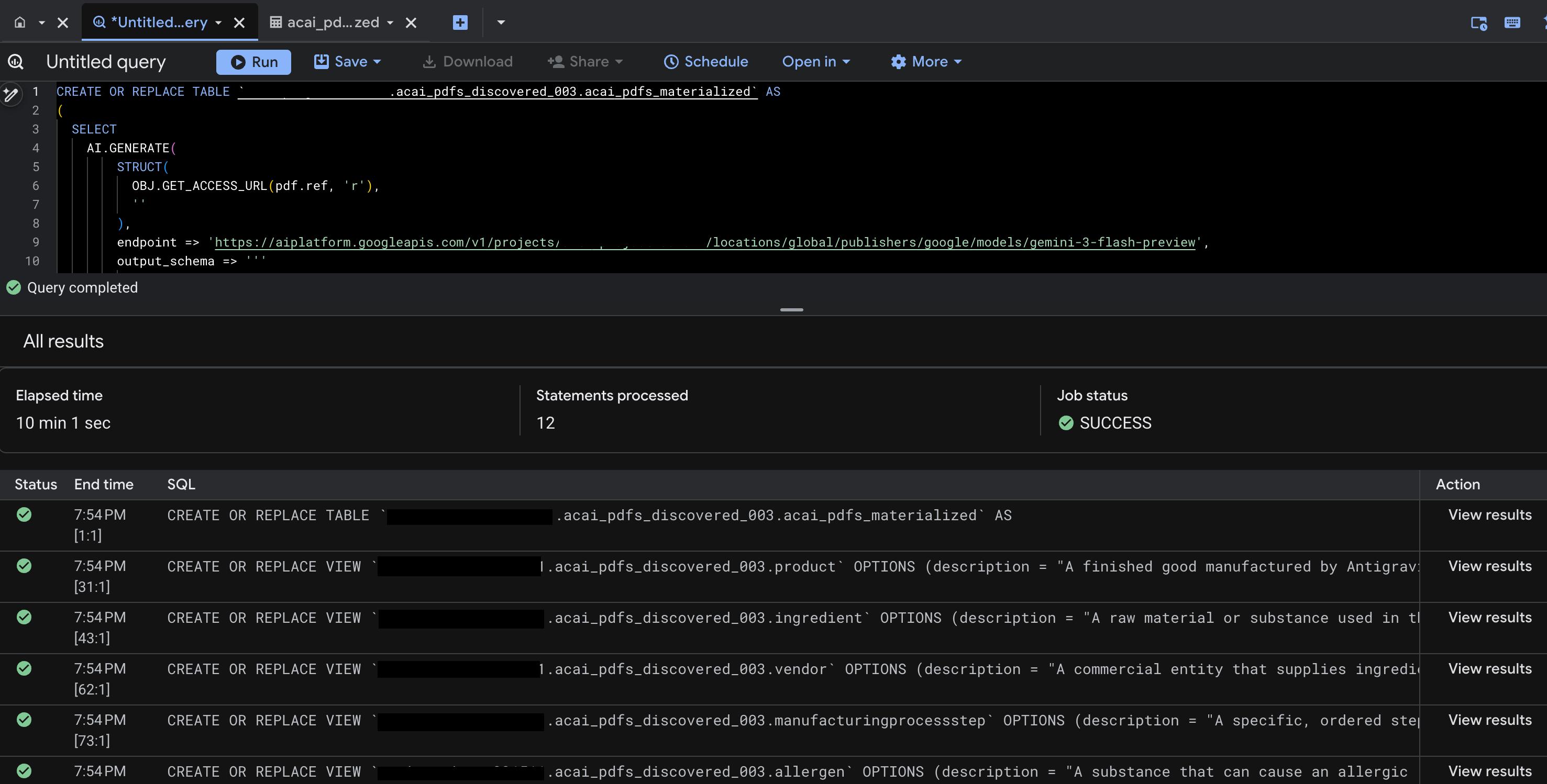
- Rufen Sie BigQuery auf und klicken Sie auf Datasets (z. B.
acai_pdfs_discovered_003). Im Dataset, das Sie in Schritt 6 ausgewählt haben, wird eine neue Gruppe strukturierter Datenbankobjekte erstellt.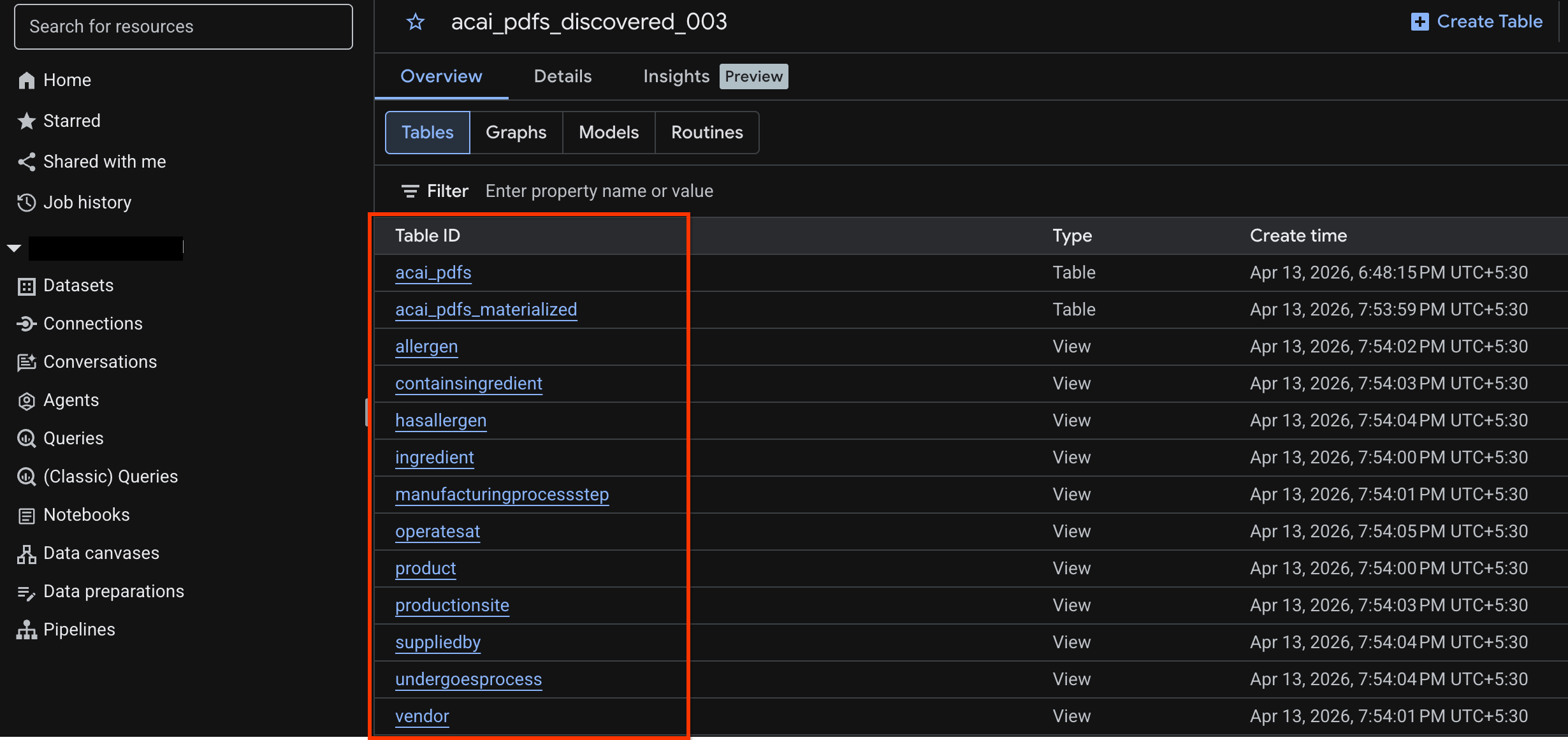
Statistiken für Objekte in BigQuery generieren
Um Statistiken für ein BigQuery-Dataset zu generieren, müssen Sie mit BigQuery Studio auf das Dataset in BigQuery zugreifen.
- Wechseln Sie in der Google Cloud Console zu BigQuery Studio.
- Wählen Sie im Bereich Explorer das Projekt aus und rufen Sie das Dataset auf, für das Sie Statistiken generieren möchten.
- Klicken Sie auf den Tab Statistiken.
- Wenn der Button API aktivieren angezeigt wird, klicken Sie darauf, um Gemini for Google Cloud zu aktivieren. Das Fenster Hauptfunktionen aktivieren wird geöffnet.
- Klicken Sie im Bereich Core feature APIs (APIs für Hauptfunktionen) für Gemini for Google Cloud API und BigQuery Unified API auf Aktivieren und dann auf Weiter.
- Weisen Sie im Abschnitt Berechtigungen (optional) den Prinzipalen bei Bedarf IAM-Rollen zu und klicken Sie dann auf Weiter.
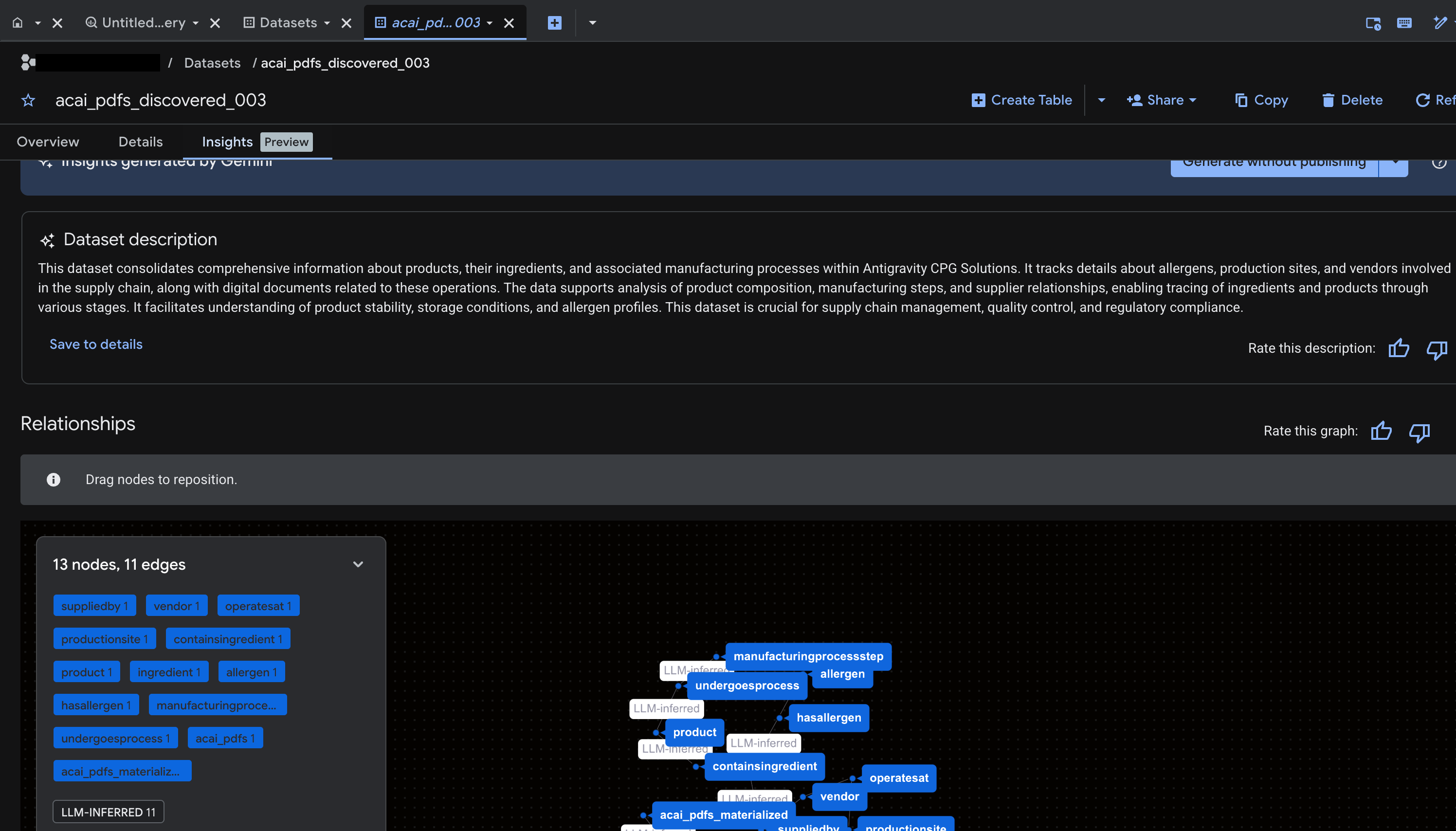
- Wenn Sie Statistiken generieren und in Knowledge Catalog veröffentlichen möchten, klicken Sie auf Generieren und veröffentlichen.
- Nach der Veröffentlichung können Sie sich auf dem Tab Statistiken ansehen.
11. IDE für agentenbasierte Datenanalyse einrichten
Die Google Cloud Data Agent Kit-Erweiterung für Visual Studio Code ist eine IDE-Erweiterung für Data Scientists und Data Engineers. Damit können Sie direkt über die IDE eine Verbindung zu Ihren Google Data Cloud-Ressourcen und -Daten herstellen und damit arbeiten. Weitere Informationen finden Sie unter Data Agent Kit-Erweiterung für VS Code – Übersicht.
Die Data Agent Kit-Erweiterung für VS Code ist nützlich, wenn Sie Folgendes tun möchten:
- Erstellen, testen, überprüfen und stellen Sie eine produktionsreife Datenpipeline wie Spark ETL oder BigQuery ETL direkt in VS Code bereit.
- Mithilfe von KI-Unterstützung können Sie Daten untersuchen, eine Trainingspipeline erstellen, optimale ML-Modelle ermitteln und sie auf einem Produktionsendpunkt bereitstellen.
- Verbinden Sie sich mit vertrauenswürdigen Datenquellen, erstellen Sie ein leistungsstarkes Datenmodell und veröffentlichen Sie ein interaktives Dashboard für Geschäftsverantwortliche.
Data Agent Kit-Erweiterung für VS Code installieren
- Öffnen Sie VS Code.
- Installieren Sie die Google Cloud CLI. Weitere Informationen finden Sie unter Google Cloud CLI installieren.
- Installieren Sie die Data Agent Kit-Erweiterung für VS Code.
- Schließen Sie das Onboarding für die Erweiterung ab. Dazu müssen Sie Folgendes tun:
- In der Erweiterung anmelden
- Skills und MCP-Server installieren
- Laden Sie das Fenster neu oder starten Sie es neu, wenn Sie mit dem Onboarding fertig sind. Weitere Informationen finden Sie unter Data Agent Kit-Erweiterung für VS Code einrichten und konfigurieren.
- Klicken Sie nach dem Neuladen der IDE im Navigationsbereich auf das Symbol Google Data Cloud, rufen Sie die Einstellungen auf und prüfen Sie, ob Sie Ihre Projekt-ID und Region (
us-west1) in den allgemeinen Einstellungen richtig festgelegt haben.
Arbeitsbereich in VS Code einrichten
- Öffnen Sie VS Code und wählen Sie Datei > Ordner öffnen > Neuer Ordner aus.
- Erstellen Sie einen neuen Ordner mit dem Namen
acai_testund klicken Sie dann auf Öffnen. VS Code betrachtet den geöffneten Ordner nun als Arbeitsbereich. - Wählen Sie im Dialogfeld Workspace-Vertrauen die Option Ja, ich vertraue den Erstellern aus, um alle Funktionen im Arbeitsbereich zu aktivieren.
- Erstellen Sie im Arbeitsbereich
acai_testeinen Ordner.github. - Erstellen Sie im Ordner
.githubeine neue Datei mit dem Namencopilot-instructions.mdund geben Sie die folgenden Regeln ein.## 1. Project Context - **Project ID**: <PROJECT_ID> - **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors. - **Documentation**: Raw PDF documents detailing flavors and ingredients are stored in Google Cloud Storage at `gs://<BUCKET_NAME>`. ## 2. Execution & Data Processing Rules - **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `<BQ_DATASET_NAME>` (referred to as the Knowledge Catalog). - **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the dataset `<DATASET_ID>`. When you are referencing a dataset, ensure you are using it with the project ID (`<PROJECT_ID>`) and namespace prefix `<NAMESPACE_NAME>`. For example, to query order table in this dataset you should use `<PROJECT_ID>.<NAMESPACE>.<DATASET_ID>.orders`. - **CRITICAL RULE - Data Joins between BigQuery dataset and Iceberg dataset**: ANY task requiring a join or integration between the BigQuery datasets `<DATASET_ID>` of the PDF data and the `<DATASET_ID>` of the customer data MUST be executed using **Spark Notebooks**. - **CRITICAL RULE - Notebook Kernel**: Every Spark notebook utilized MUST exclusively be configured to run on the Serverless Session template `iceberg-federation-template` as its kernel. - **CRITICAL RULE - Data Science**: ANY data science, machine learning, or advanced analytical task MUST be performed strictly within **Spark Notebooks** using the aforementioned setup. - Erstellen Sie eine weitere neue Datei
template.yamlim Arbeitsbereichacai_testund geben Sie die folgenden Informationen in die Datei ein.labels: client: "vscode" jupyterSession: displayName: "iceberg-federation-template" kernel: "PYTHON" environmentConfig: executionConfig: serviceAccount: "sa-spark-dev1@<PROJECT_ID>.iam.gserviceaccount.com" subnetworkUri: "projects/<PROJECT_ID>/regions/<REGION>/subnetworks/<SUBNET_NAME>" runtimeConfig: version: "2.3" properties: # This enables the secure proxy URL you were looking for dataproc.tier: "premium" spark.dataproc.engine: "lightningEngine" spark.dataproc.lightningEngine.runtime: "native" spark.memory.offHeap.enabled: "true" spark.memory.offHeap.size: "1g" spark.executor.memory: "4g" "dataproc.component.gateway.enabled": "true" "dataproc.jupyter.listen.all.interfaces": "true" "spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" "spark.sql.defaultCatalog": "<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>": "org.apache.iceberg.spark.SparkCatalog" "spark.sql.catalog.<CATALOG_NAME>.type": "rest" "spark.sql.catalog.<CATALOG_NAME>.uri": "<CATALOG_URI_ID>" "spark.sql.catalog.<CATALOG_NAME>.warehouse": "bl://projects/<PROJECT_ID>/catalogs/<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>.rest.auth.type": "org.apache.iceberg.gcp.auth.GoogleAuthManager" - Klicken Sie in VS Code auf Terminal und führen Sie den folgenden Befehl aus, um die Datei
template.yamlals Sitzungsvorlage zu importieren. Diese Vorlage wird später vom Agent verwendet, um eine Spark-Sitzung zu erstellen.gcloud beta dataproc session-templates import iceberg-federation-template \ --source=template.yaml \ --location=<REGION>REGIONdurch Ihre Region.
12. Agentenbasierte Datenanalyse durchführen
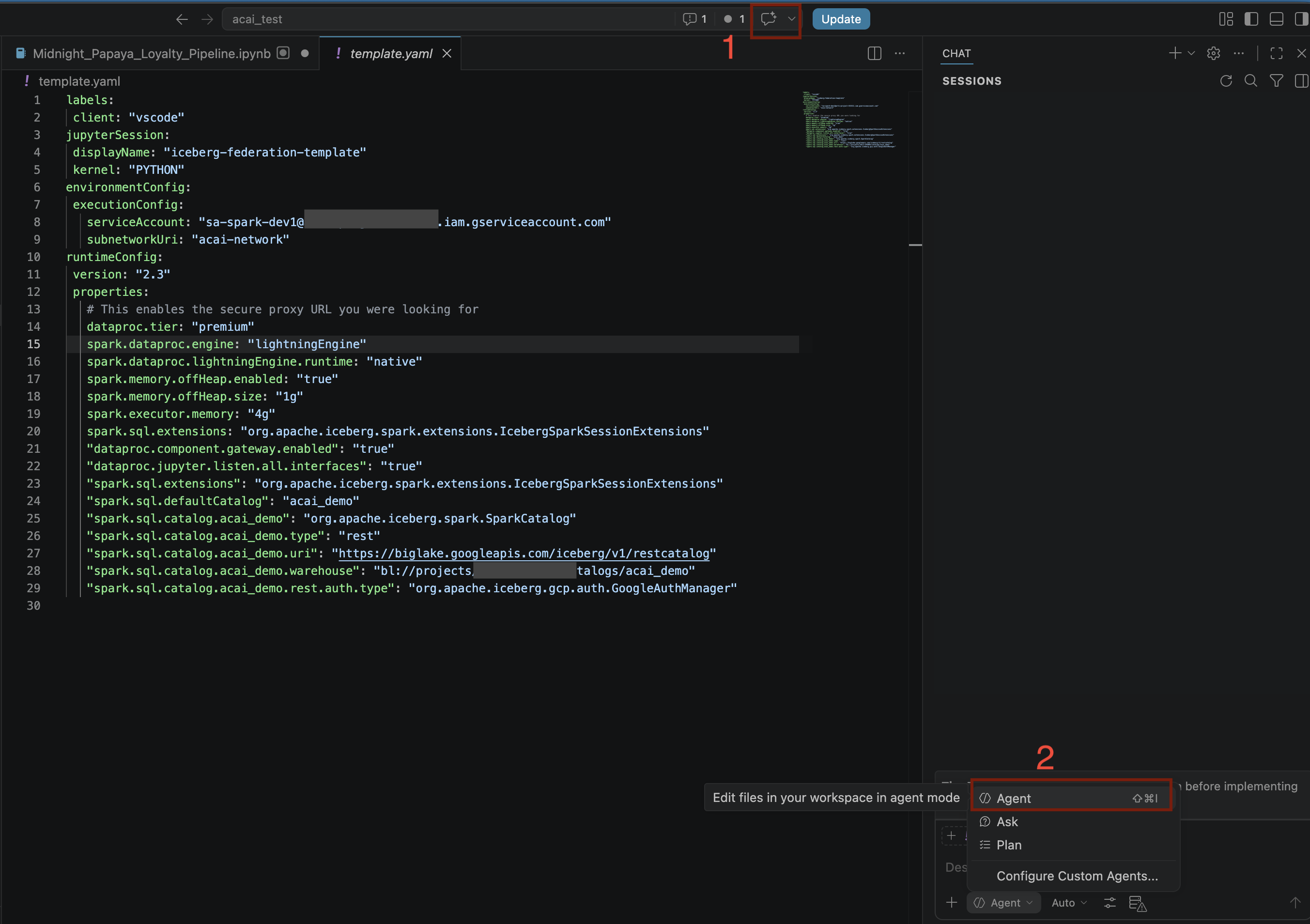
- Klicken Sie im VS Code-Editor auf Chat ein-/ausblenden.
- Wählen Sie unter Benutzerdefinierte Agents konfigurieren die Option Agent aus.
- Klicken Sie im Bereich Suchmodelle auf Sprachmodelle verwalten.
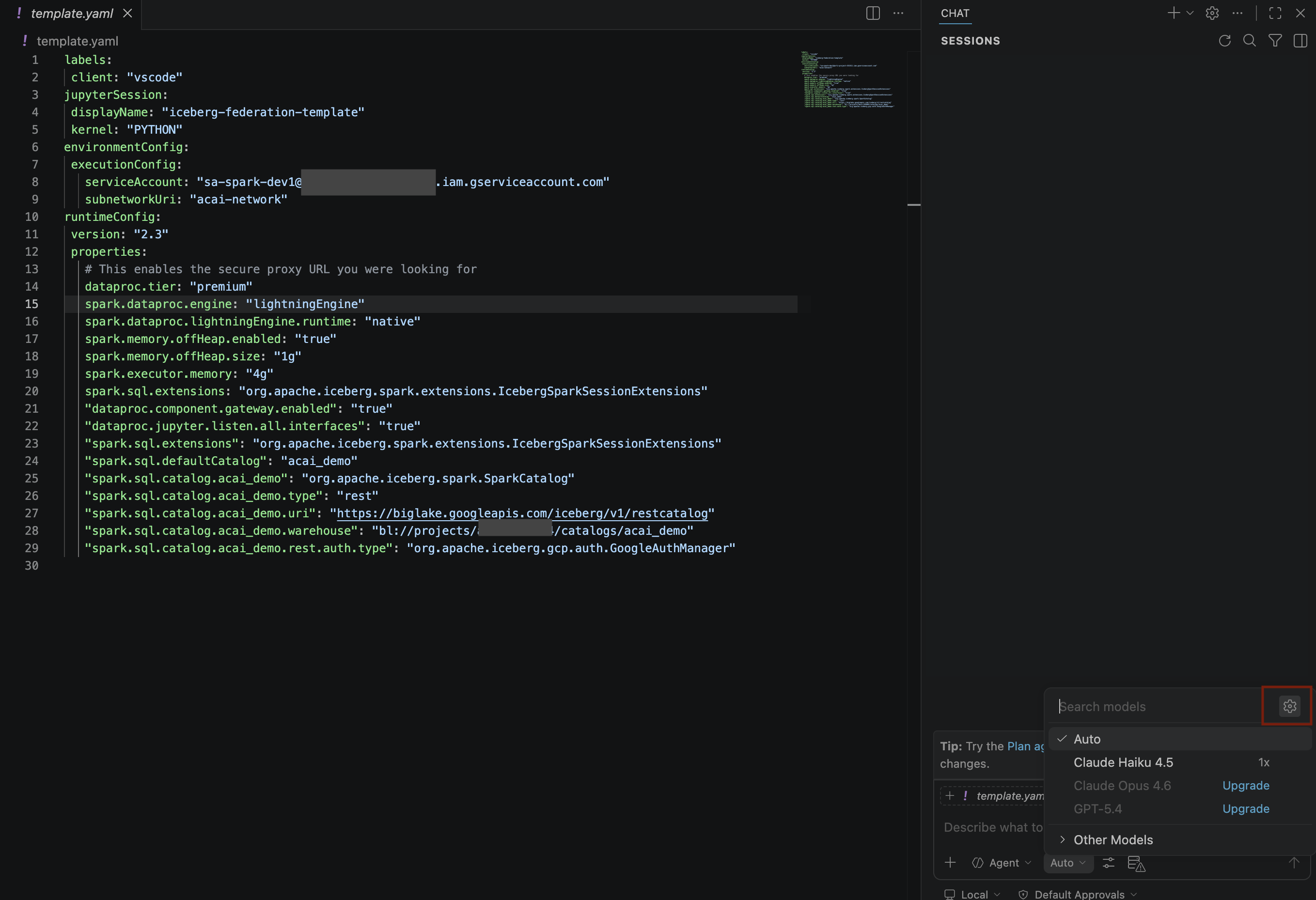
- Klicken Sie auf der Seite Sprachmodelle auf Modelle hinzufügen.
- Wählen Sie Google aus der Liste aus und drücken Sie die Eingabetaste, um Ihre Eingabe zu bestätigen.
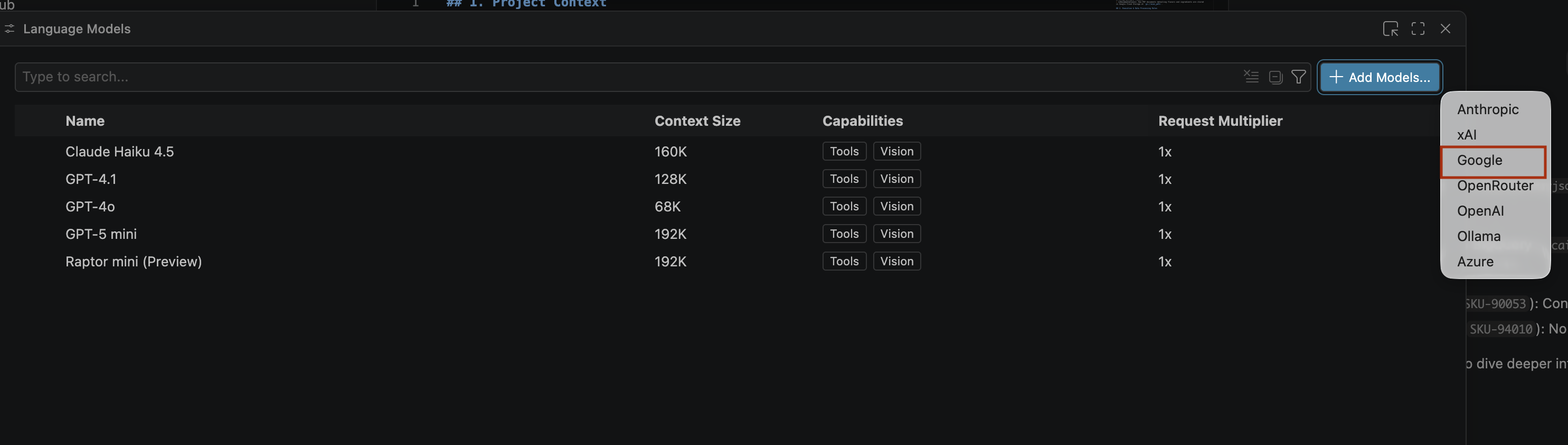
- So geben Sie den API-Schlüssel für Google Gemini ein:
- Rufen Sie die Google AI Studio-Website auf.
- Melden Sie sich mit Ihrem Google-Konto an.
- Klicken Sie in der Seitenleiste auf API-Schlüssel abrufen.
- Klicken Sie auf API-Schlüssel erstellen. Die Seite „Neuen Schlüssel erstellen“ wird geöffnet.
- Wählen Sie in der Liste Cloud-Projekt auswählen die Option Projekt importieren aus.
- Geben Sie den Namen eines vorhandenen Projekts ein.
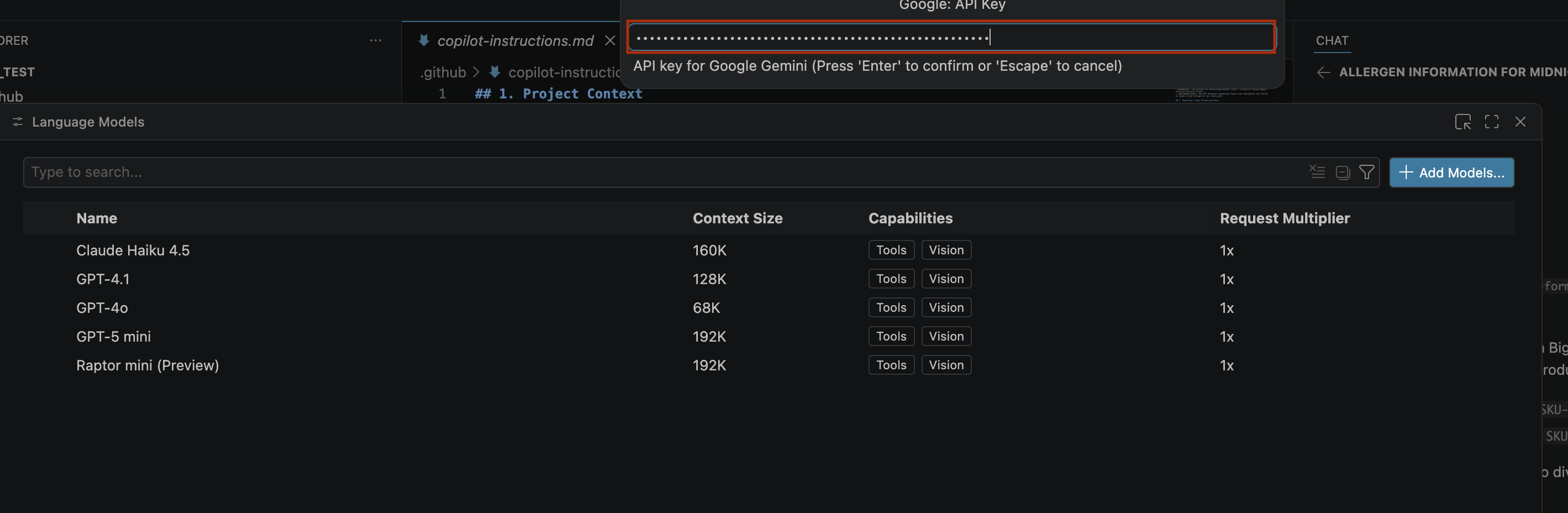
- Klicken Sie auf Schlüssel erstellen und kopieren Sie den API-Schlüssel. Der Schlüssel bietet Zugriff auf die Gemini API-Ressourcen Ihres Kontos.Weitere Informationen finden Sie unter Gemini API-Schlüssel verwenden.
- Fügen Sie den generierten API-Schlüssel in die Suchleiste ein und klicken Sie auf die Eingabetaste.
- Wenn die Gemini-Modelle nicht angezeigt werden, blenden Sie sie ein, wie in der folgenden Abbildung dargestellt:
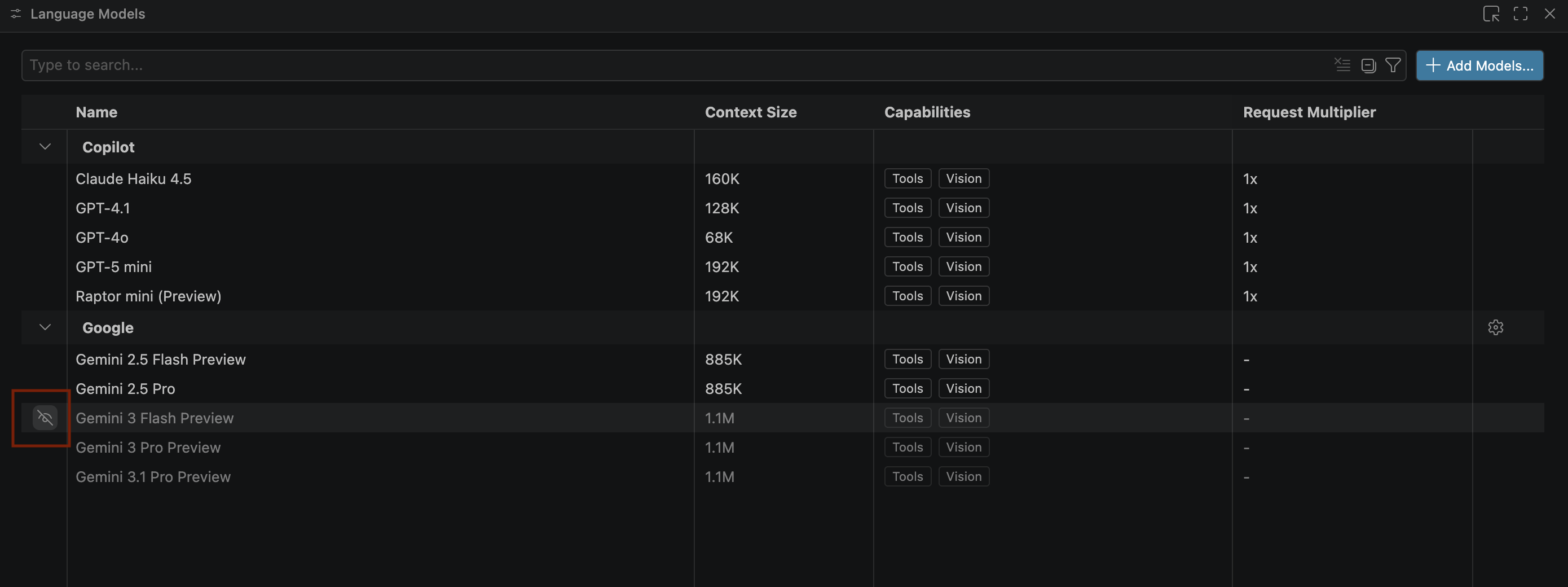
- Wählen Sie in der Liste der Google Gemini-Modelle Gemini 3.1 Pro Preview aus und schließen Sie das Fenster Sprachmodelle.
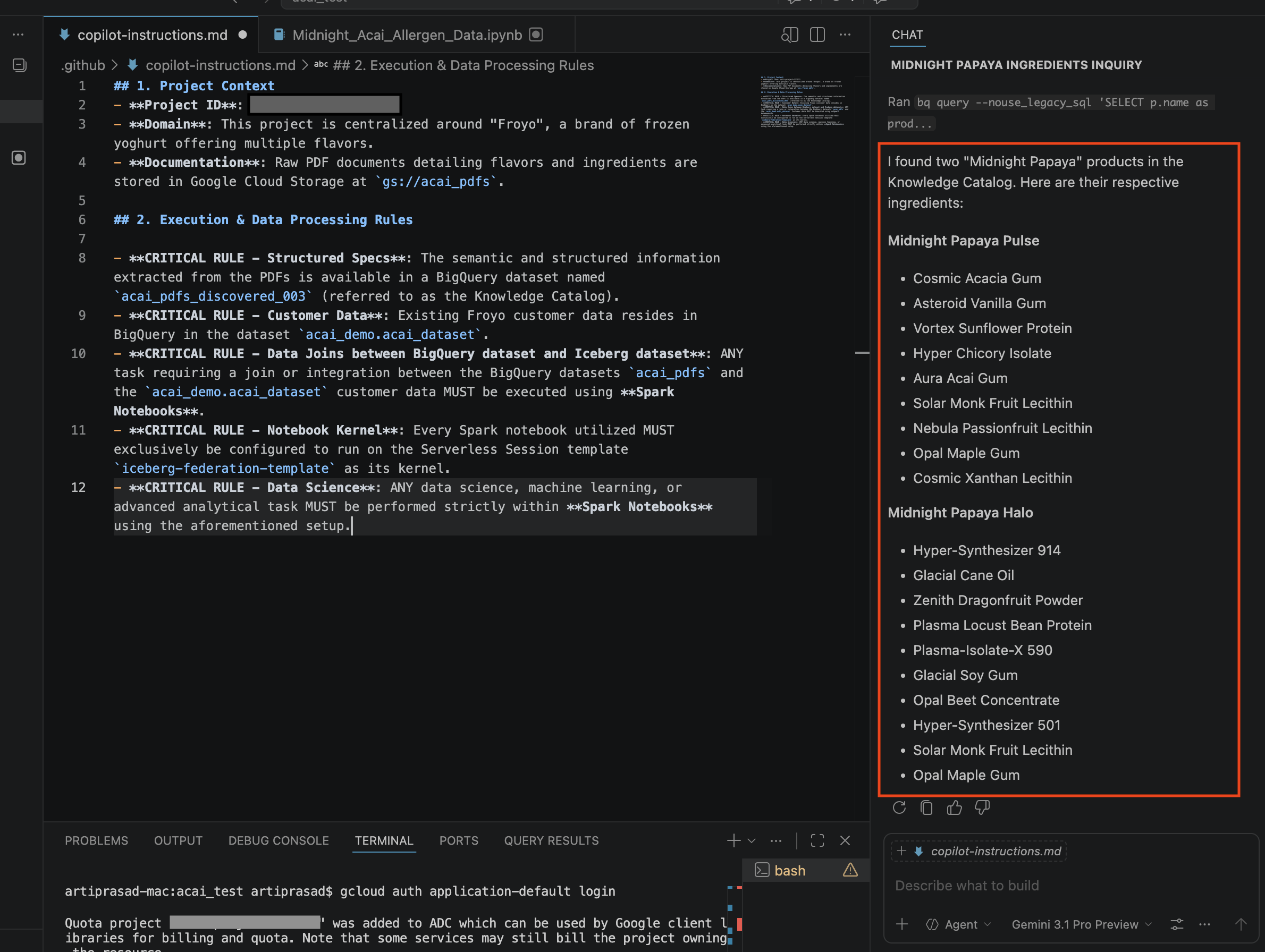
- Geben Sie im Chatfenster die folgende Frage ein:
Search ingredients for Midnight papaya - Nach einigen Interaktionen sollte das folgende Ergebnis angezeigt werden:
- Geben Sie im Chatfenster eine weitere Frage ein:
Search allergen information for Midnight papaya - Nach einigen Interaktionen und Schritten antwortet der Agent mit dem Namen des Allergens
Soy, wie im folgenden Bild zu sehen ist: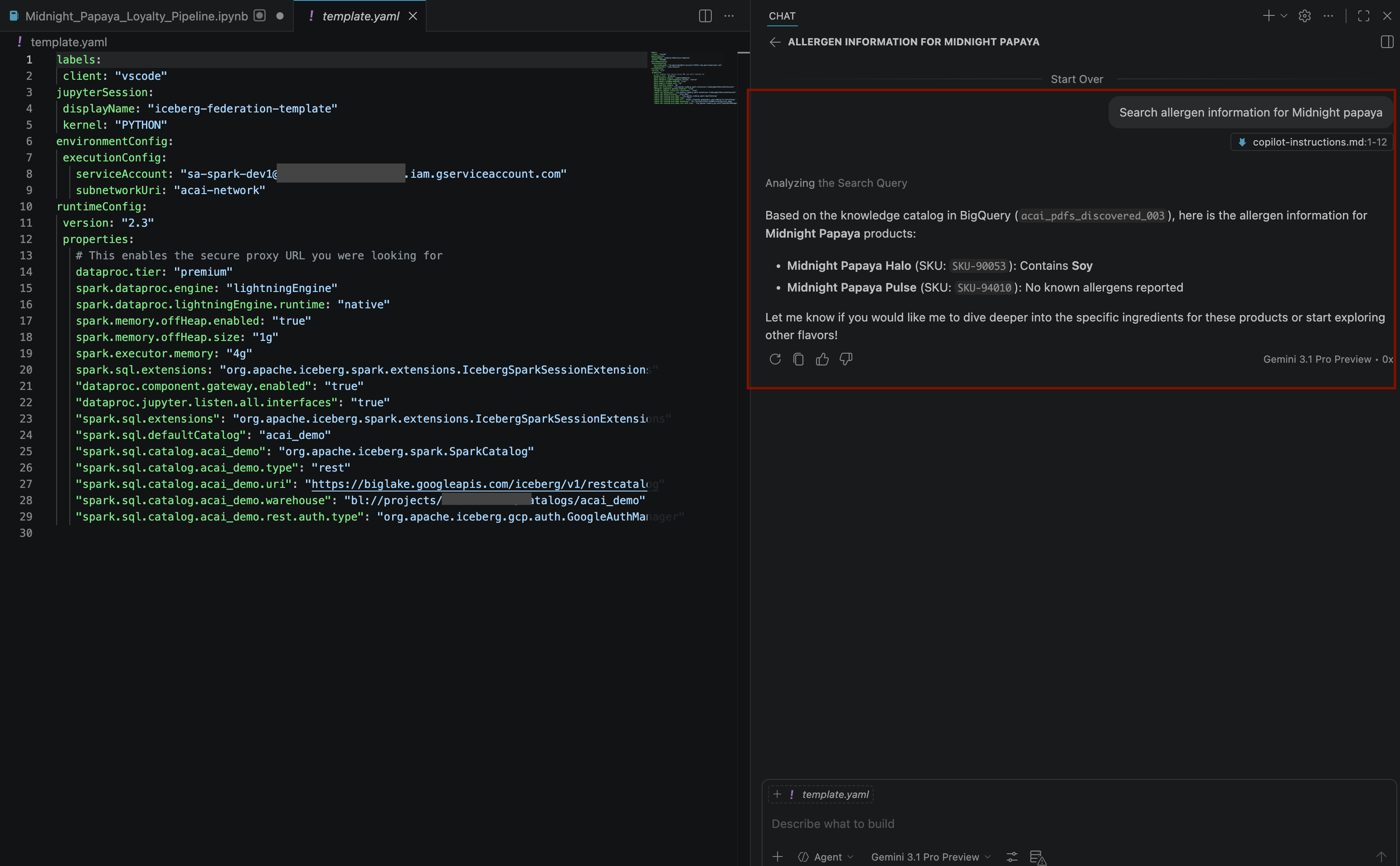
- Geben Sie im Chatfenster eine weitere Frage ein:
Build a pipeline to join products with our 'Global Loyalty' Iceberg tables in acai customer, sales data to identify popular products - Um den Kernel auszuwählen, öffnen Sie die Datei
.ipynbund klicken Sie auf Kernel auswählen > Remote Spark-Kernels > Iceberg-Federation-Vorlage auf Serverless Spark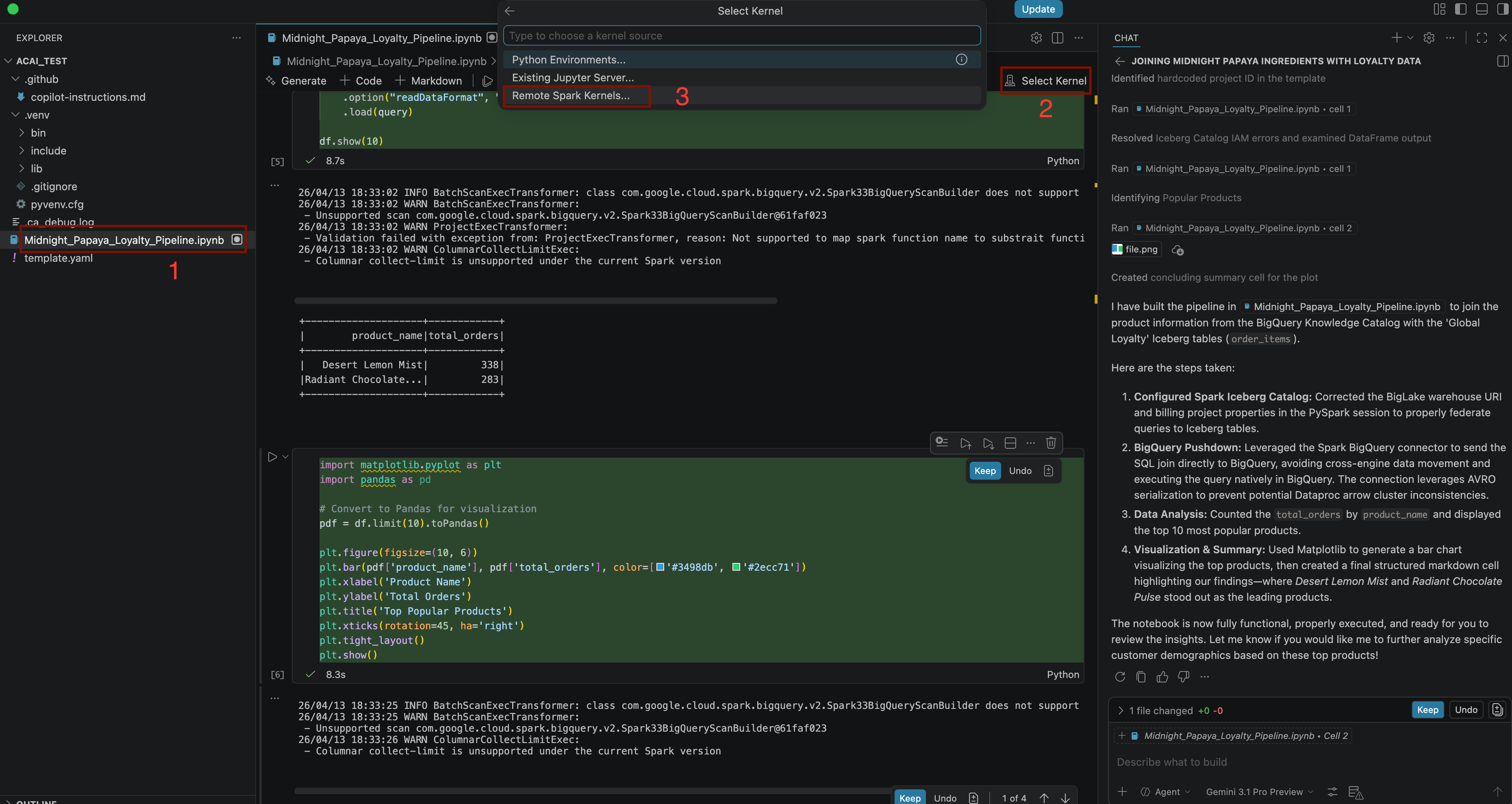 .
.
- Nach einigen Interaktionen und Schritten antwortet der Agent mit allen Schritten im Notebook, die erfolgreich ausgeführt wurden, sowie dem endgültigen Ergebnis, das am Ende des Notebooks generiert wurde, wie im folgenden Bild zu sehen ist:
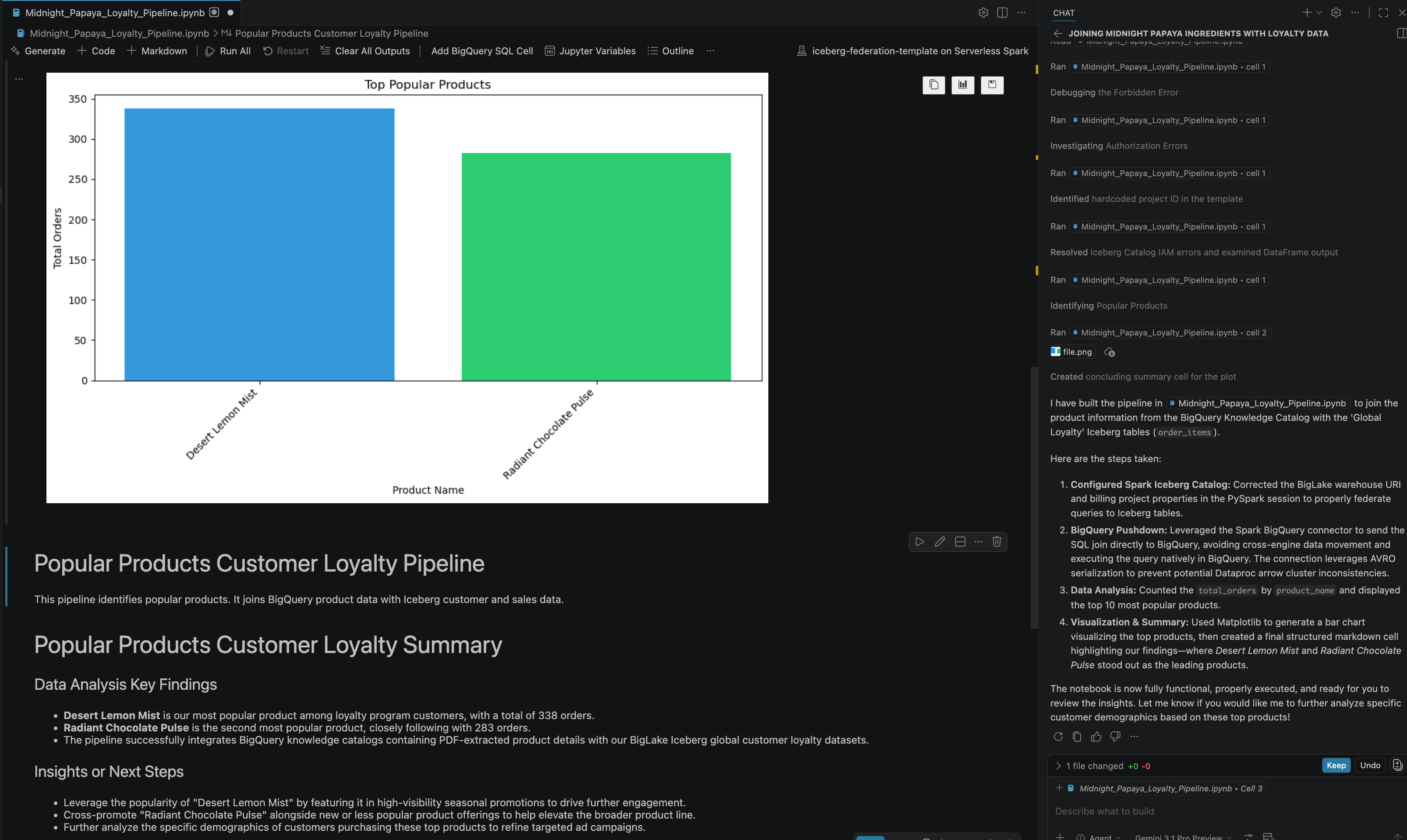
13. Bereinigen
Löschen Sie die in diesem Lab erstellten Ressourcen, um Gebühren zu vermeiden.
- Führen Sie den folgenden Befehl aus, um den Knowledge Catalog DataScan zu löschen:
DATASCAN_ID="<DATASCAN_ID>" echo "Deleting Dataplex DataScan: ${DATASCAN_ID}" gcloud dataplex datascans delete "${DATASCAN_ID}" --location="${REGION}" --quiet - Führen Sie den folgenden Befehl aus, um Cloud Storage-Buckets und alle zugehörigen Inhalte zu löschen:
echo "Deleting Cloud Storage buckets: <BUCKET_NAME1> and <BUCKET_NAME2>" gsutil -m rm -r gs://<BUCKET_NAME1> gsutil -m rm -r gs://<BUCKET_NAME2> - Führen Sie den folgenden Befehl aus, um die BigQuery-Verbindung zu löschen:
CONNECTION_ID="<CONNECTION_NAME>" echo "Deleting BigQuery Connection: ${CONNECTION_ID}" bq rm --connection "${PROJECT_ID}.${REGION}.${CONNECTION_ID}" - Führen Sie den folgenden Befehl aus, um den Lakehouse-Katalog zu löschen:
CATALOG_ID="<CATALOG_NAME>" echo "Deleting Lakehouse Catalog: ${CATALOG_ID}" gcloud biglake catalogs delete "${CATALOG_ID}" --project="${PROJECT_ID}" --location="${REGION}" --quiet - Führen Sie den folgenden Befehl aus, um das Dataset mit den erkannten PDF-Tabellen zu löschen:
DATASET_NAME="<DATASET_NAME>" echo "Deleting BigQuery Dataset: ${DATASET_NAME}" bq rm -r -f "${PROJECT_ID}:${DATASET_NAME}" - Führen Sie den folgenden Befehl aus, um das benutzerdefinierte Dienstkonto zu löschen:
SERVICE_ACCOUNT="<SERVICE_ACCOUNT>" echo "Deleting Service Account: ${SERVICE_ACCOUNT}" gcloud iam service-accounts delete "${SERVICE_ACCOUNT}"@"${PROJECT_ID}".iam.gserviceaccount.com --quiet - Führen Sie den folgenden Befehl aus, um das VPC-Netzwerk zu löschen:
VPC_NETWORK="<VPC_NETWORK>" echo "Deleting VPC Network: ${VPC_NETWORK}" gcloud compute networks delete "${VPC_NETWORK}" --quiet - Führen Sie den folgenden Befehl aus, um das gesamte Google Cloud-Projekt zu löschen:
gcloud projects delete "${PROJECT_ID}"
14. Glückwunsch
Glückwunsch! Sie haben die Datenlandschaft aus isolierten PDFs und Parquet-Dateien erfolgreich in BigQuery-Tabellen organisiert und in einem einzigen, durchsuchbaren und verknüpfbaren Ökosystem zusammengeführt. Sie haben im Grunde ein modernes Data Lakehouse erstellt, in dem PDFs und Big-Data-Formate genauso intelligent behandelt werden wie eine Zeile in einer Datenbank. Und das alles direkt über Ihren Agenten im Konversationsmodus mit Gemini.
Referenzdokumente
Weitere Informationen zu den in diesem Codelab verwendeten Kerntechnologien finden Sie in der offiziellen Google Cloud-Dokumentation:
- Weitere Informationen zu BigQuery, einer Kernkomponente der Data Cloud, finden Sie in der BigQuery-Dokumentation.
- Weitere Informationen zu IAM finden Sie in der IAM-Dokumentation.
- Weitere Informationen zum Lakehouse finden Sie unter Was ist ein Lakehouse?.