
1. Introducción
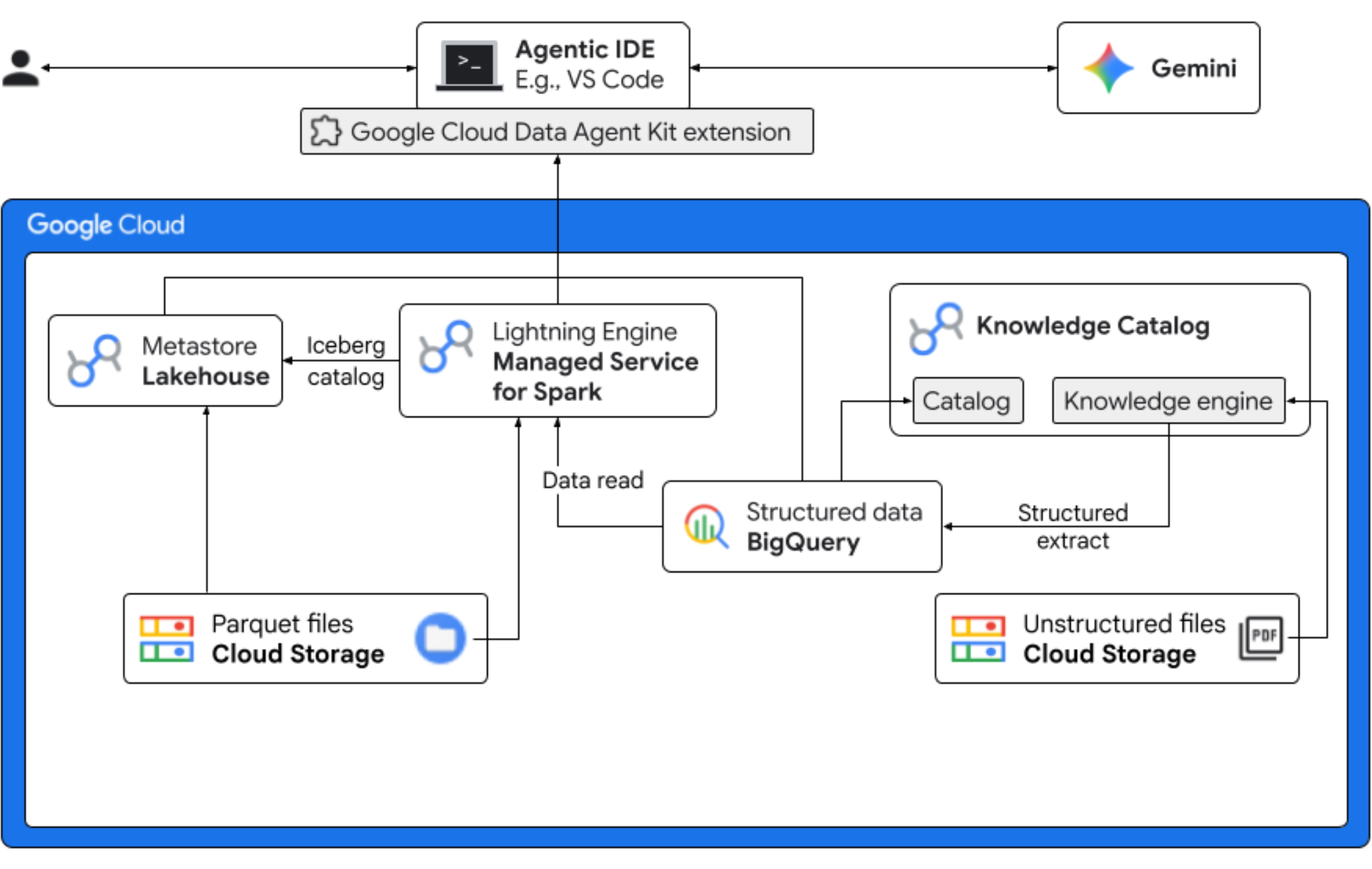
En este codelab, asumirás el rol de científico de datos de una empresa ficticia de froyo que lanzará una nueva variante de producto, "Midnight Swirl". Para garantizar un lanzamiento global exitoso, la empresa debe responder preguntas críticas sobre los ingredientes, la demanda del mercado y el retorno de la inversión (ROI). Este flujo de trabajo integral muestra cómo el Catálogo de conocimiento de Google Cloud (anteriormente conocido como Dataplex) y el Lakehouse para Apache Iceberg (anteriormente conocido como BigLake) cierran la brecha entre los datos no estructurados "oscuros" y proporcionan inteligencia empresarial práctica con Gemini en tu IDE (VS Code) a través de una capa de administración unificada.
Actividades
- Descubrimiento no estructurado: Knowledge Catalog DataScan rastrea las recetas en PDF almacenadas en Cloud Storage. Crea tablas de objetos en BigQuery para los PDFs analizados. Con la inferencia semántica de Vertex AI, el sistema "lee" los PDFs para extraer información estructurada sobre productos, alérgenos, ingredientes y atributos relacionados. Luego, genera de forma inteligente un esquema para los datos almacenados en los PDFs.
- Metadatos unificados: Los datos extraídos de los archivos PDF se almacenan directamente en BigQuery como una tabla ancha nativa, y se crean vistas para ayudar con las consultas comunes. Un conjunto de datos de entrada independiente que contiene datos históricos de ventas se almacena en tablas de Apache Iceberg en Google Cloud Storage. Esta tabla de Iceberg se unirá a los datos extraídos en BigQuery en un paso posterior.
- Análisis entre motores: Con Managed Service for Apache Spark (antes conocido como Dataproc) y un catálogo de Iceberg REST, unirás estos metadatos de PDF nuevos y los datos semánticos estructurados inferidos (de tablas y vistas de BigQuery) con los datos de ventas estructurados almacenados en tablas de Apache Iceberg en Google Cloud Storage. Esto se rige por una plantilla de sesión interactiva de Apache Spark administrada que se usa como kernel de Jupyter Notebook y garantiza una configuración coherente de seguridad y procesamiento para el trabajo de Spark.
- Estadísticas semánticas: Al unir los datos de productos inferidos con los datos de clientes y ventas (en BigQuery), la demostración puede extraer estadísticas, como la identificación de datos de alérgenos y la previsión de ingresos.
- Administración autónoma: Todo el ciclo de vida, desde los análisis de detección hasta la ejecución de Spark, se coordina a través de plantillas, instrucciones, reglas y automatización impulsada por agentes listos para Gemini, lo que demuestra que la IA puede administrar la infraestructura que impulsa las estadísticas.
Requisitos
Completar este codelab puede generar costos, que se estiman en menos de USD 5 para el uso típico. Para obtener estimaciones de costos detalladas según el uso previsto o los precios actuales, usa la calculadora de precios de Google Cloud.
Asegúrate de cumplir con los siguientes requisitos previos para completar el codelab.
- Navegador web Chrome
- Una cuenta personal de Gmail si usas los créditos de prueba que se proporcionan en la sección Antes de comenzar
- Descarga e instala Visual Studio (VS) Code.
2. Antes de comenzar
Crea un proyecto de Google Cloud
- En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto.
Inicie Cloud Shell
Cloud Shell es un entorno de línea de comandos que se ejecuta en Google Cloud y que viene precargado con las herramientas necesarias.
- Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.
- Una vez que te conectes a Cloud Shell, verifica tu autenticación:
gcloud auth list - Confirma que tu proyecto esté configurado:
gcloud config get project - Si tu proyecto no está configurado como se esperaba, configúralo:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Habilita las API obligatorias
Ejecuta este comando para habilitar todas las APIs requeridas:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
biglake.googleapis.com \
dataproc.googleapis.com \
metastore.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
secretmanager.googleapis.com \
storage.googleapis.com
Descarga los recursos del codelab
Este repositorio contiene archivos Parquet, recetas, proveedores, copilot-instructions.md, template.yaml y quickstart.py para usar con este codelab. Asegúrate de descargar estos archivos.
Para descargar los archivos, haz lo siguiente:
- En Cloud Shell, ejecuta el siguiente comando:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git - Navega a la carpeta recién creada:
cd next-26-keynotes - Extrae la carpeta
data-cloud-demo.git sparse-checkout set genkey/data-cloud-demo - Una vez que se complete la confirmación de compra, navega a la carpeta
data-cloud-demoy extrae los archivos ZIP para acceder a los recursos del codelab.
3. Configura Lakehouse para los datos de clientes de Froyo
En esta sección, crearás un catálogo en Lakehouse para usar el metastore de Lakehouse en tus flujos de trabajo. Ofrece una sola fuente confiable para todos tus datos de Iceberg, lo que crea interoperabilidad entre tus motores de consultas. Permite que los motores de consultas, como Apache Spark, descubran, lean metadatos y administren tablas de Iceberg de manera coherente.
Roles obligatorios
Asegúrate de tener los siguientes roles de Identity and Access Management (IAM):
roles/biglake.viewerroles/bigquery.userroles/bigquery.dataEditorroles/biglake.editorroles/biglake.metadataViewerroles/bigquery.connectionUserroles/storage.objectUserroles/storage.objectViewerroles/storage.objectCreatorroles/storage.admin
Para obtener más información sobre cómo otorgar roles de IAM, consulta Otorga un rol de IAM.
Crea un catálogo de Lakehouse con un bucket
Crea un catálogo de Lakehouse para administrar los metadatos de tus tablas de Iceberg. Te conectas a este catálogo en tu trabajo de Spark para crear y consultar tablas de Iceberg.
- En la consola de Google Cloud, ve a Lakehouse.
- Haz clic en Crear catálogo. Se abrirá la página Crear catálogo.
- En Catalog type, selecciona Iceberg Rest catalog.
- En Selecciona tus opciones de bucket para el catálogo de Lakehouse, elige Catálogo de bucket único.
- En Bucket de Cloud Storage del catálogo predeterminado, haz clic en Explorar y, luego, en Crear bucket nuevo.
- En la página Crear un bucket, haz lo siguiente:
- En la sección Comenzar, ingresa un nombre único a nivel global que cumpla con los requisitos de nombres de buckets.
- En la sección Elige dónde almacenar tus datos, selecciona Región para Tipo de ubicación y, luego, ingresa tu región. Por ejemplo,
us-west1. - En la sección Elige cómo controlar el acceso a los objetos, desmarca la casilla de verificación Aplicar la prevención de acceso público a este bucket.
Esto te permite simular situaciones del mundo real, como alojar contenido web público o repositorios de datos compartidos. Sin este cambio, el bucket aplicaría una política estricta de "solo privado"; cualquier intento de acceder a tus recursos generaría un error prohibido403, incluso si otorgaste permisos públicos a los archivos. - Haz clic en Continuar > Crear > Seleccionar > Continuar.
- En Método de autenticación, selecciona Modo de venta de credenciales.
- Haz clic en Crear.Se creará tu catálogo y se abrirá la página Detalles del catálogo.
- En Método de autenticación, haz clic en Establecer permisos del bucket.
- En el diálogo, haz clic en Confirmar.Esto verifica que la cuenta de servicio de tu catálogo tenga el rol de
Storage Object Useren tu bucket de almacenamiento. - En la página Detalles del catálogo, copia la ruta de URI del catálogo de REST. Usa esta ruta de acceso durante la tarea Ejecutar trabajo de Spark.
Sube los archivos Parquet al bucket
Para subir tus archivos Parquet a la raíz de tu bucket, haz lo siguiente:
- En la consola de Google Cloud, ve a la página Buckets de Cloud Storage.
- En la lista de buckets, haz clic en el nombre del bucket. Por ejemplo,
acai_demo. - En la pestaña Objetos del bucket, haz clic en Subir > Subir archivos.
- Selecciona los archivos de la carpeta Parquet que clonaste en la sección Antes de comenzar de este codelab.
- Haz clic en Abrir.
4. Configura la red de VPC
Crea una red de nube privada virtual (VPC) y una subred que permita que los recursos se comuniquen con las APIs de Google sin salir a Internet pública, y un firewall que permita que el tráfico interno fluya libremente entre tus nodos de procesamiento de datos.
- En la consola de Google Cloud, ve a la página Redes de VPC.
- Haz clic en Crear red de VPC.
- Ingresa un Nombre para la red. Por ejemplo,
acai-network - Para configurar la unidad de transmisión máxima (MTU) de la red, selecciona la casilla de verificación Establecer la MTU automáticamente.
- Elige Automático para el Modo de creación de subred.
- En la sección Reglas de firewall, selecciona todas las casillas de verificación de Reglas de firewall de IPv4.
- Haz clic en Crear.
Habilita el Acceso privado a Google
Los nodos de Dataproc sin servidores no tienen direcciones IP públicas. Para comunicarse con Lakehouse Catalog y Cloud Storage, la subred debe tener habilitado el Acceso privado a Google.
- En la consola de Google Cloud, ve a la página Redes de VPC.
- Haz clic en el nombre de la red que contiene la subred en la que necesitas habilitar el Acceso privado a Google. Por ejemplo,
us-west1. - Haz clic en el nombre de la subred. Se mostrará la página de detalles de la subred.
- Haz clic en Editar.
- En la sección Acceso privado a Google selecciona Habilitar.
- Haz clic en Guardar.
5. Crea y ejecuta un trabajo de Spark
Para crear una tabla de Iceberg y consultarla, sube el trabajo de PySpark con las instrucciones de Spark SQL necesarias. Luego, ejecuta el trabajo con Managed Service para Spark.
Sube quickstart.py a tu bucket de Cloud Storage
Después de clonar los recursos del codelab, actualiza la secuencia de comandos quickstart.py con los detalles de tu proyecto y súbela al bucket de Cloud Storage.
- Abre la secuencia de comandos
quickstart.pyen un editor de texto. - Reemplaza el marcador de posición
BUCKET_NAMEen la secuencia de comandos por el nombre de tu bucket de Cloud Storage y guárdalo. - En la consola de Google Cloud, ve a Buckets de Cloud Storage.
- Haz clic en el nombre de tu bucket. Por ejemplo,
acai_demo. - En la pestaña Objetos, haz clic en Subir > Subir archivos.
- En el navegador de archivos, selecciona el archivo
quickstart.pyactualizado y, luego, haz clic en Abrir.
Ejecuta el trabajo de Spark
Después de subir la secuencia de comandos quickstart.py, ejecútala como un trabajo por lotes de Managed Service para Spark.
- Para configurar las variables, ejecuta el siguiente comando en Cloud Shell.
# Configuration Variables export PROJECT_ID="<PROJECT_ID>" export REGION="<REGION>" export BUCKET_NAME="<BUCKET_NAME>" export SUBNET="<SUBNET>" export LAKEHOUSE_CATALOG_ID="<LAKEHOUSE_CATALOG_ID>" export CATALOG_URI_ID="<CATALOG_URI_ID>"- LAKEHOUSE_CATALOG_ID: Es el nombre del recurso de catálogo de Lakehouse que contiene el archivo de tu aplicación de PySpark. Por ejemplo,
acai_demo - PROJECT_ID: Es el ID de tu proyecto de Google Cloud.
- REGION: Es la región en la que se ejecutará la carga de trabajo por lotes de Managed Service para Spark. Por ejemplo,
us-west1 - BUCKET_NAME: Es el nombre de tu bucket de Cloud Storage. Por ejemplo,
acai_demo - SUBNET: Es el nombre de tu subred de VPC. Por ejemplo,
acai-network - CATALOG_URI_ID: Es el ID de URI del catálogo de Lakehouse que copiaste cuando creaste un catálogo de Lakehouse con un bucket. Por ejemplo,
https://biglake.googleapis.com/iceberg/v1/restcatalog
- LAKEHOUSE_CATALOG_ID: Es el nombre del recurso de catálogo de Lakehouse que contiene el archivo de tu aplicación de PySpark. Por ejemplo,
- En Cloud Shell, ejecuta el siguiente trabajo por lotes de Managed Service for Spark con la secuencia de comandos
quickstart.py.gcloud dataproc batches submit pyspark gs://${BUCKET_NAME}/quickstart.py \ --project=${PROJECT_ID} \ --region=${REGION} \ --subnet=${SUBNET} \ --version=2.2 \ --properties="\ spark.sql.defaultCatalog=${LAKEHOUSE_CATALOG_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}=org.apache.iceberg.spark.SparkCatalog,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.type=rest,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.uri=${CATALOG_URI_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.warehouse=gs://${BUCKET_NAME},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.io-impl=org.apache.iceberg.gcp.gcs.GCSFileIO,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.x-goog-user-project=${PROJECT_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\ spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest-metrics-reporting-enabled=false,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.X-Iceberg-Access-Delegation=vended-credentials,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token"All tables registered successfully! Batch [126fa2226a904d2e944c8eecbe0b1840] finished. metadata: '@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata batch: projects/PROJECT_ID/locations/REGION/batches/126fa2226a904d2e944c8eecbe0b1840 batchUuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff createTime: '2026-04-09T13:17:26.222727Z' description: Batch labels: goog-dataproc-batch-id: 126fa2226a904d2e944c8eecbe0b1840 goog-dataproc-batch-uuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-drz-resource-uuid: batch-3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-location: REGION operationType: BATCH name: projects/PROJECT_ID/regions/REGION/operations/47bc59e8-5082-3af9-89a0-22289aa5f4b9
6. Consulta la tabla desde BigQuery
Si ejecutaste correctamente el trabajo por lotes de Spark, usaste Managed Service for Spark Serverless como un motor de procesamiento distribuido para registrar varias tablas, una por cada archivo Parquet dentro del almacén de metadatos de Lakehouse. Este registro permite que Google Cloud trate tus archivos sin procesar en Cloud Storage como tablas estructuradas de alto rendimiento.
En los siguientes pasos, se explica cómo confirmar que los metadatos se sincronizaron correctamente, lo que garantiza que tus datos no solo se almacenen de forma segura, sino que también se puedan detectar y consultar por completo a través de la interfaz de BigQuery.
- En la consola de Google Cloud, ve a BigQuery.
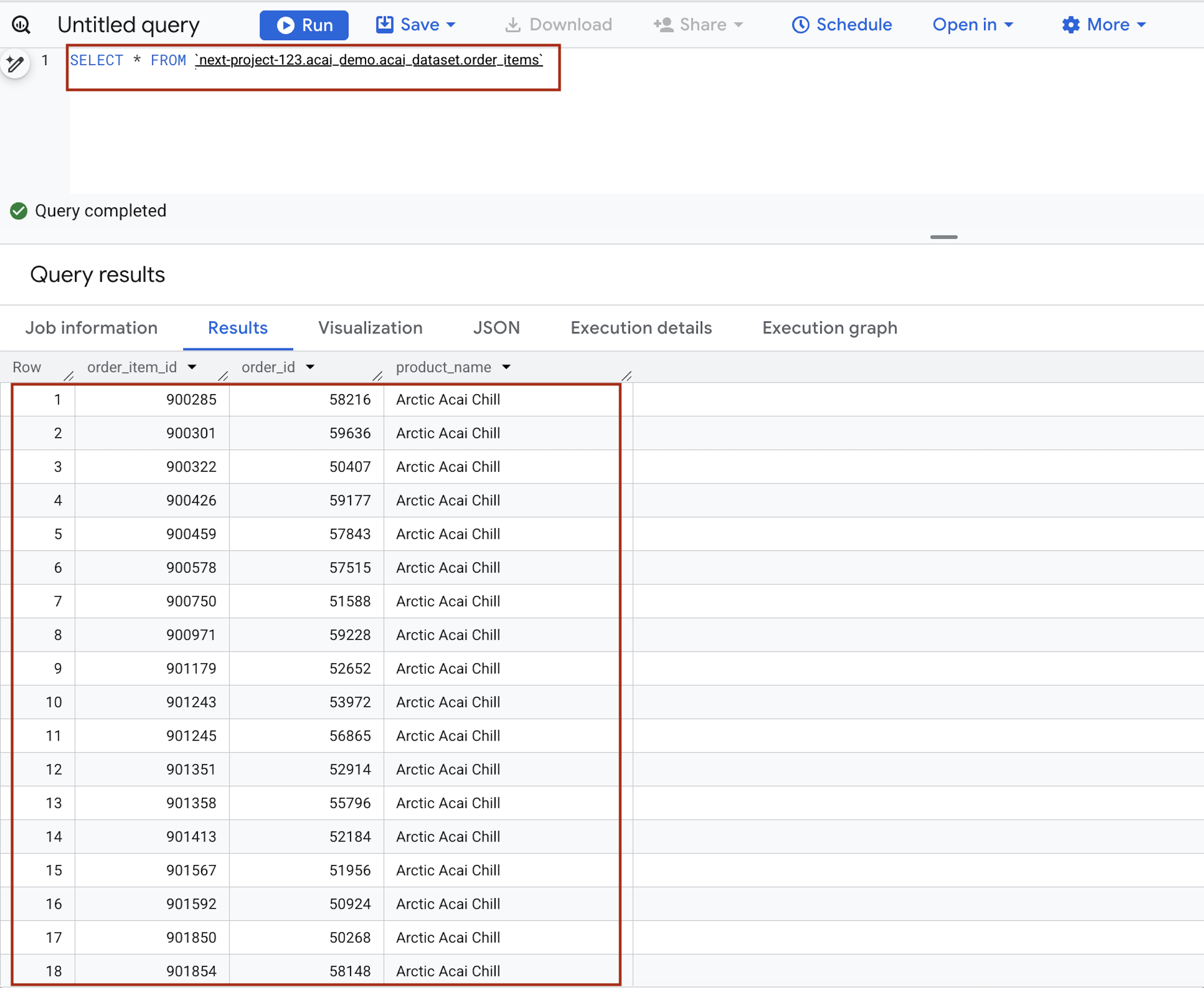
- En el editor de consultas, ingresa la siguiente instrucción. La consulta usa la sintaxis
project.namespace.dataset.table.SELECT * FROM `<PROJECT_ID>.<NAMESPACE>.<ICEBERG_DATASET>.<ICEBERG_TABLE>`PROJECT_ID.acai_demo.acai_dataset.order_items.
Reemplaza lo siguiente:- PROJECT_ID: Es el ID de tu proyecto de Google Cloud.
- NAMESPACE: Es el espacio de nombres que se crea en el paso anterior como resultado del trabajo de Spark, que puedes encontrar en la página del explorador de objetos de BigQuery. Por ejemplo,
acai_demo - ICEBERG_DATASET: Es el nombre del conjunto de datos dentro del catálogo de Iceberg, por ejemplo,
acai_dataset. - ICEBERG_TABLE: Es el nombre de la tabla dentro del conjunto de datos de Iceberg, por ejemplo,
order_items.
- Haz clic en Ejecutar. Los resultados de la consulta muestran los datos que insertaste con el trabajo de Spark.
7. Configura archivos de datos de productos no estructurados
En esta sección, crearás una estructura organizativa dentro de BigQuery para almacenar datos de recetas y proveedores de Froyo, específicamente para los detalles del producto Froyo. También establece una conexión de recursos de Cloud, que actúa como un "puente" seguro que permite a BigQuery leer archivos de fuentes externas, como Cloud Storage.
Crea un bucket y sube los archivos de detalles de Froyo
Crea y sube los archivos de proveedores y recetas al bucket de Cloud Storage.
- En la consola de Google Cloud, ve a la página Buckets de Cloud Storage.
- Haz clic en Crear.
- En la página Crear un bucket, ingresa la información de tu bucket. Después de cada uno de los siguientes pasos, haz clic en Continuar para avanzar al siguiente paso:
- En la sección Primeros pasos, ingresa el nombre del bucket. Por ejemplo,
acai_pdfs - En la sección Elige dónde almacenar tus datos, selecciona Región y, luego, ingresa tu región. Por ejemplo,
us-west1. - En la sección Elige cómo controlar el acceso a los objetos, desmarca la casilla de verificación Aplicar la prevención de acceso público a este bucket.
- Haz clic en Crear.
- En la lista de buckets, haz clic en el que creaste. Por ejemplo,
acai_pdfs. - En la pestaña Objetos del bucket, haz clic en Subir > Subir carpetas.
- Selecciona la carpeta
recipesque extrajiste en la sección Antes de comenzar de este codelab. - Haz clic en Subir.
- Repite el proceso de carga para la carpeta
suppliers.
Crear una conexión
Crea una conexión de recursos de Cloud. Esto genera una cuenta de servicio única que actúa como la "tarjeta de identificación" de BigQuery para acceder a archivos externos.
- Ve a la página de BigQuery.
- En el panel de la izquierda, haz clic en Explorar. Si no ves el panel izquierdo, haz clic en Expandir panel izquierdo para abrirlo.
- En el panel Explorador, expande el nombre de tu proyecto y, luego, haz clic en Conexiones.
- En la página Connections, haz clic en Create connection.
- En Tipo de conexión, elige Modelos remotos de Vertex AI, funciones remotas, BigLake y Spanner (Cloud Resource).
- En el campo ID de conexión, ingresa el nombre del ID de conexión. Por ejemplo,
acai_pdf_connectionAsegúrate de anotar este ID, ya que lo necesitarás cuando configures el análisis de datos más adelante en este codelab. - Configura Tipo de ubicación como Región y, luego, selecciona una región. Por ejemplo,
us-west1. La conexión debe estar ubicada junto con tus otros recursos, como los conjuntos de datos. - Haz clic en Crear conexión.
- Haz clic en Ir a la conexión.
- En el panel Información de conexión, copia el ID de la cuenta de servicio para usarlo en un paso posterior. La cuenta de servicio se verá de la siguiente manera:
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com.
Administra el acceso a las cuentas de servicio
Proporciona acceso a la cuenta de servicio para que Lakehouse pueda leer tus archivos PDF.
- Ir a la página IAM y administración
- Haz clic en Otorgar acceso. Se abrirá el diálogo Agregar principales.
- En el campo Principales nuevas, ingresa el ID de cuenta de servicio que copiaste antes.
- En el campo Seleccionar un rol, agrega los siguientes roles:
roles/storage.objectUserroles/storage.objectViewerroles/bigquery.userroles/bigquery.dataEditorroles/aiplatform.userroles/storage.adminroles/dataproc.serviceAgent
- Haz clic en Guardar.
Para obtener más información sobre los roles de IAM en BigQuery, consulta Funciones y permisos predefinidos.
8. Administra los permisos del trabajo de DataScan
Crea cuentas de servicio (identidades) específicas para Spark y Dataform, y luego otórgales a ellas, junto con los agentes de servicio automatizados de Google, los permisos precisos necesarios para leer el almacenamiento, ejecutar trabajos de BigQuery y usar Vertex AI para el descubrimiento.
Acceso a IAM para Spark y Dataform
- En la consola de Google Cloud, ve a la página Crear cuenta de servicio.
- Si no está seleccionado, elige tu proyecto de Google Cloud.
- Haga clic en Crear cuenta de servicio.
- Ingresa un nombre de cuenta de servicio. Por ejemplo,
sa-spark-stg1. La consola de Google Cloud genera un ID de cuenta de servicio a partir de este nombre. Si es necesario, edita el ID. No podrás cambiar el ID más adelante. - Para establecer controles de acceso, haz clic en Crear y continuar y continúa con el siguiente paso.
- Elige los siguientes roles de IAM para otorgar a la cuenta de servicio en el proyecto.
roles/dataproc.workerroles/storage.objectUserroles/bigquery.dataEditorroles/bigquery.jobUserroles/aiplatform.userroles/dataplex.discoveryPublishingServiceAgent
- Cuando hayas terminado de agregar roles, haz clic en Continuar.
- Haz clic en Listo para terminar de crear la cuenta de servicio.
Permisos de conexión de BigQuery para acceder a Knowledge Catalog
- En la consola de Google Cloud, ve a la página Buckets de Cloud Storage.
- En la lista de buckets, haz clic en el nombre del bucket que creaste para Froyo. Por ejemplo,
acai_pdfs. - En la pestaña Permisos, haz clic en Otorgar acceso. Aparecerá el cuadro de diálogo Agregar principales.
- En el campo Principales nuevas, ingresa el ID de tu cuenta de servicio de BigQuery. La cuenta de servicio se verá de la siguiente manera:
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com. - Selecciona los siguientes roles en el menú desplegable Selecciona un rol.
roles/storage.objectUserroles/dataplex.serviceAgentroles/dataplex.securityAdminroles/aiplatform.serviceAgentroles/dataplex.discoveryPublishingServiceAgent
- Haz clic en Guardar.
9. Configura Knowledge Catalog
Crea un Knowledge Catalog para unificar tus datos relacionados con Froyo y automatizar el descubrimiento de archivos no estructurados (como recetas y proveedores en formato PDF).
Crea el DataScan a través de curl
En esta sección, crearás análisis para tu bucket de Cloud Storage (por ejemplo, acai_pdfs) agregando el datascan_ID y apuntándolo a tus conjuntos de datos de BigQuery. Después de eso, el Catálogo de conocimiento creará automáticamente entradas para tus archivos PDF en BigQuery.
- Para analizar los PDFs (proveedores y recetas), ejecuta el siguiente comando:
# 1. Set your variables PROJECT_ID="<PROJECT_ID>" REGION="<REGION>" ENV_SUFFIX="stg1" DATASCAN_ID="froyo-profile-${ENV_SUFFIX}" BUCKET_NAME="<BUCKET_NAME>" # 2. Set this to the Name of the connection you created in Step 7 CONNECTION_ID="<CONNECTION_ID_NAME>" # 3. Define the API Endpoint DATAPLEX_API="dataplex.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}" # 4. Create the DataScan via CURL echo "Creating Dataplex DataScan: ${DATASCAN_ID}..." curl -X POST "https://$DATAPLEX_API/dataScans?dataScanId=${DATASCAN_ID}" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d '{ "data": { "resource": "//storage.googleapis.com/projects/'"${PROJECT_ID}"'/buckets/'"${BUCKET_NAME}"'" }, "executionSpec": { "trigger": { "on_demand": {} } }, "dataDiscoverySpec": { "bigqueryPublishingConfig": { "tableType": "BIGLAKE", "connection": "projects/'"${PROJECT_ID}"'/locations/'"${REGION}"'/connections/'"${CONNECTION_ID}"'" }, "storageConfig": { "unstructuredDataOptions": { "entity_inference_enabled": true } } } }' - El comando
curlmuestra los resultados de Knowledge Catalog DataScan, de forma similar a la siguiente imagen.
Ejecuta el trabajo
Ejecuta el siguiente comando:
gcloud dataplex datascans run $DATASCAN_ID --location=$REGION
Describe un trabajo
Para describir el trabajo, ejecuta el siguiente comando:
gcloud dataplex datascans describe $DATASCAN_ID --location=$REGION
Borra un trabajo de análisis de datos
Si la exploración se ejecuta durante más de 10 minutos o si el estado del trabajo permanece como Pendiente durante un tiempo prolongado sin cambiar a En ejecución, es posible que se deba a la falta de disponibilidad temporal de recursos en la región. Si esto sucede, puedes ejecutar el siguiente comando para borrar el trabajo y, luego, intentar crearlo y ejecutarlo de nuevo. A veces, una ejecución inicial puede fallar rápidamente con un error como unable to acquire necessary resources.
gcloud dataplex datascans delete $DATASCAN_ID --location=$REGION
Cómo ver el estado del trabajo
Para verificar el estado del trabajo, haz lo siguiente:
- En la consola de Google Cloud, ve a la página Curación de metadatos.
- En la pestaña Descubrimiento de Cloud Storage, haz clic en el nombre de los análisis de descubrimiento.
- En la página Detalles del análisis, puedes ver el estado del trabajo.
- Una vez que finalice el trabajo, verifica si está presente el conjunto de datos publicado (por ejemplo,
acai_pdfs_discovered_003) que creaste con el comandocurl.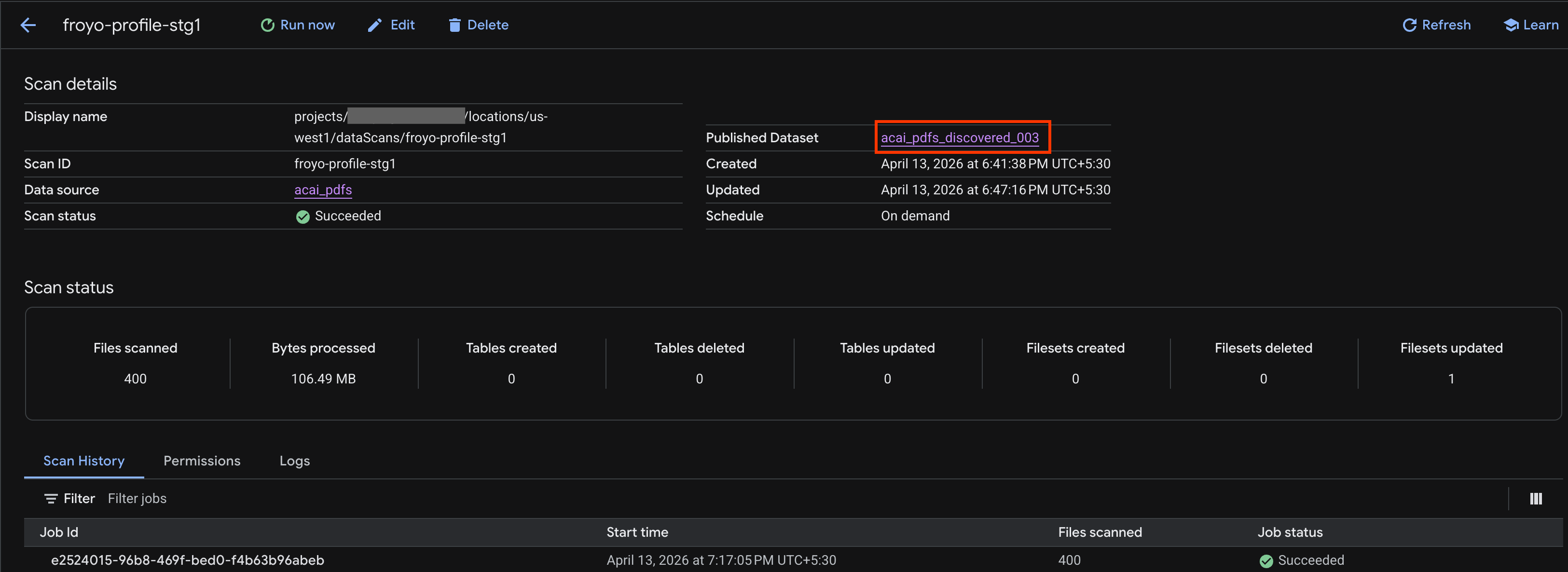
Cómo ver la tabla de objetos
Para ver la tabla de objetos creada después del trabajo de descubrimiento, haz lo siguiente:
- En la consola de Google Cloud, ve a BigQuery.
- Haz clic en Conjuntos de datos y selecciona el conjunto de datos publicado que se creó en el paso anterior. Por ejemplo,
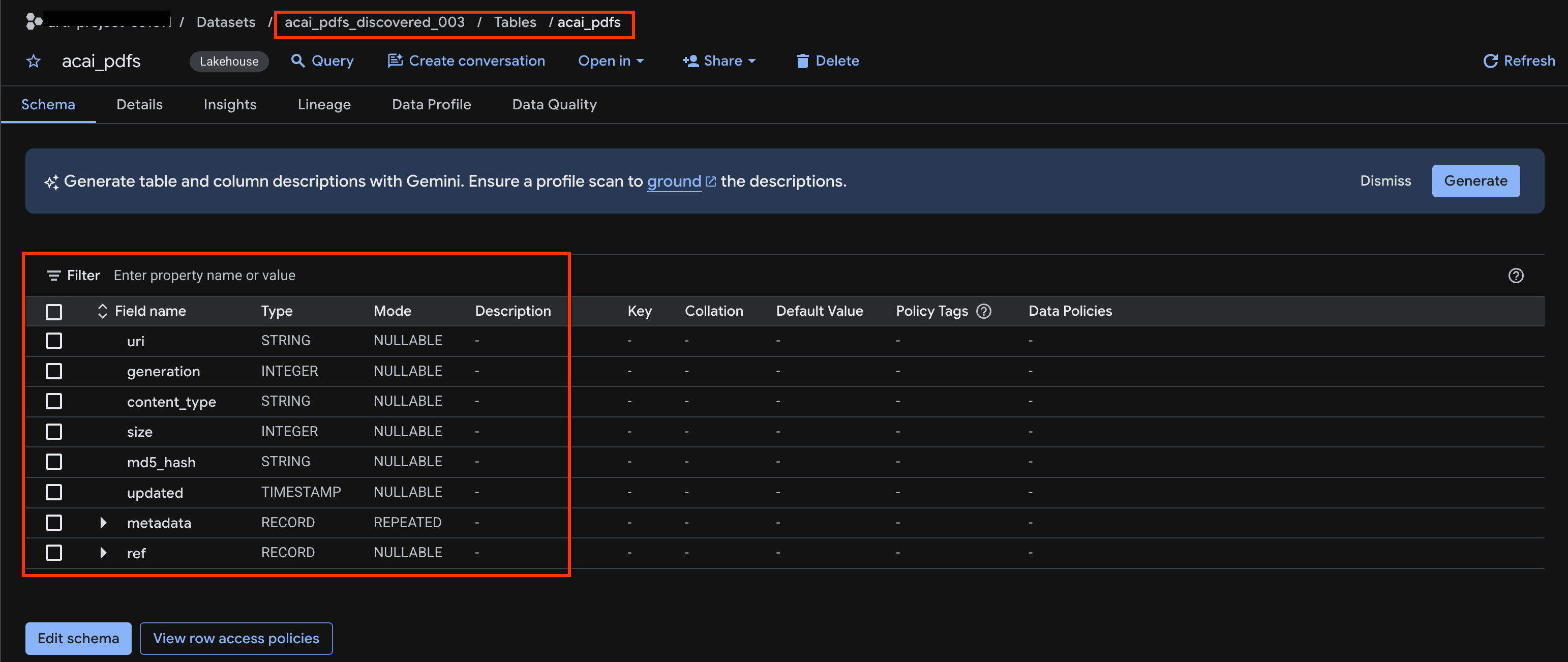
acai_pdfs_discovered_003 - Para ver la tabla de objetos, haz clic en su ID. Por ejemplo,
acai_pdfs. - La tabla de objetos resultante se ve como la siguiente imagen:
10. Extracción semántica
Inferirás y extraerás tablas estructuradas, otros objetos de bases de datos y relaciones para esta tabla de objetos no estructurada que creaste en el paso anterior. Para ello, usarás la función Knowledge Catalog Insights para generar sentencias SQL que permitan extraer datos estructurados de la tabla no estructurada.
- En la consola de Google Cloud, ve a la página Búsqueda en Knowledge Catalog.
- Busca la tabla del conjunto de datos para la que deseas ver estadísticas. Por ejemplo,
acai_pdfs_discovered_003.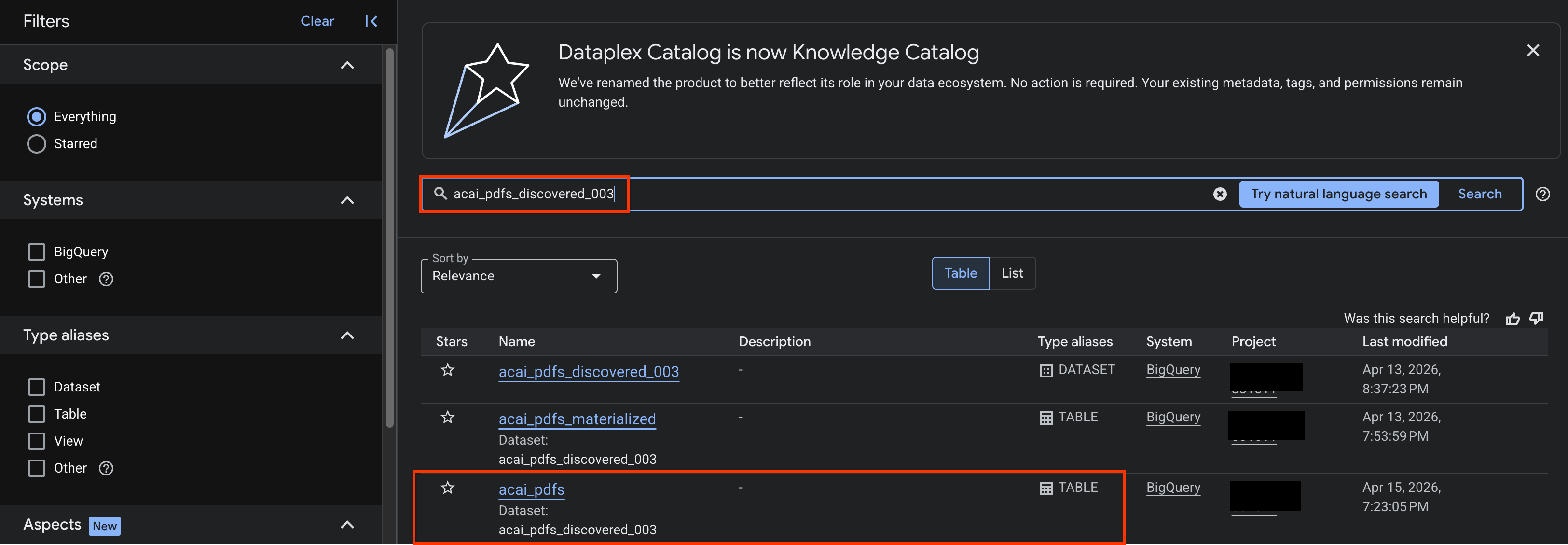
- En los resultados de la búsqueda, haz clic en la tabla para abrir su página de entrada.
- Haz clic en la pestaña Estadísticas. Si la pestaña está vacía, significa que las estadísticas de esta tabla aún no se generaron. La generación de estadísticas puede tardar entre 15 y 25 minutos.
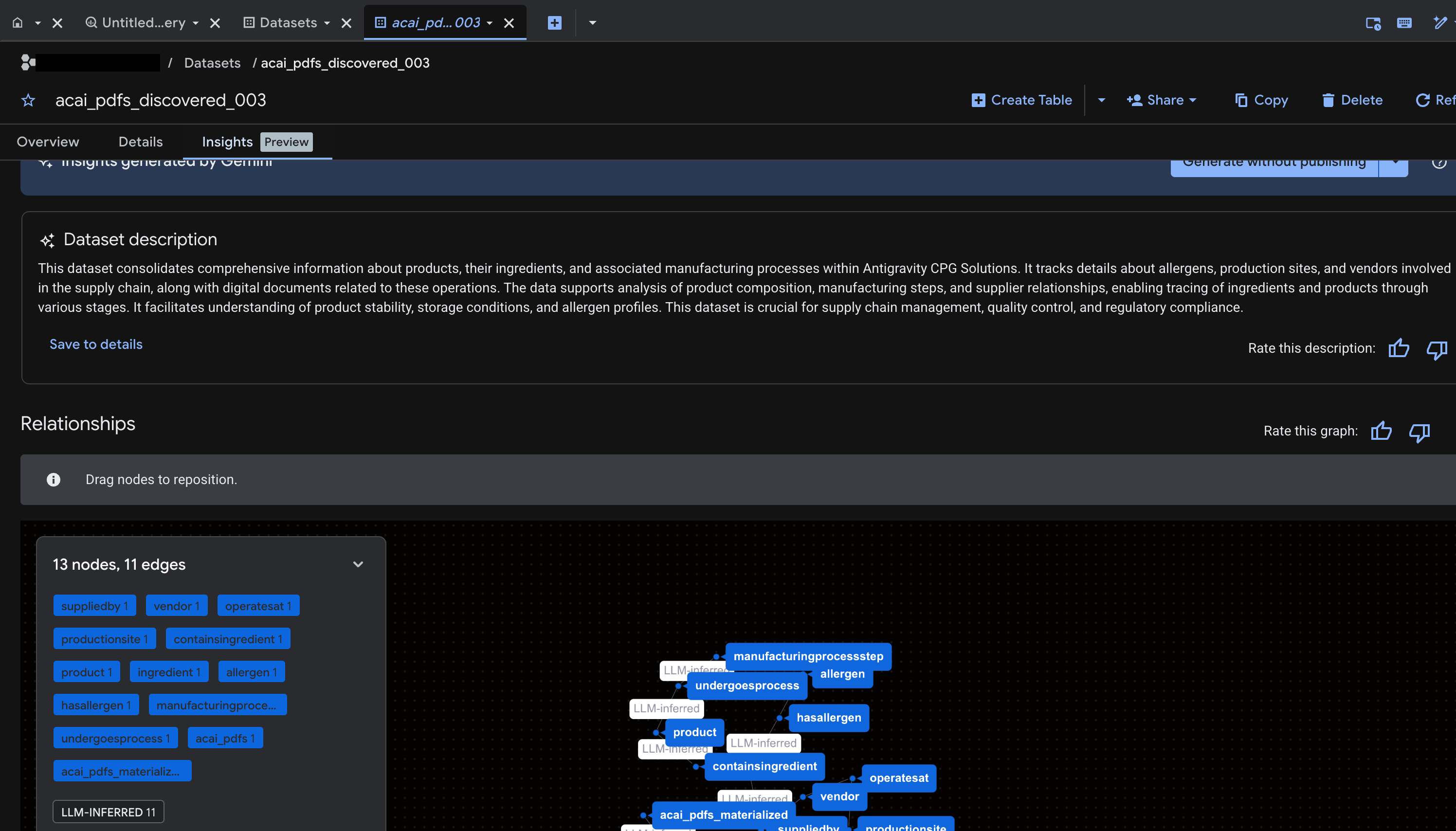
- Una vez que veas las estadísticas, haz clic en Extraer > Extraer con SQL.
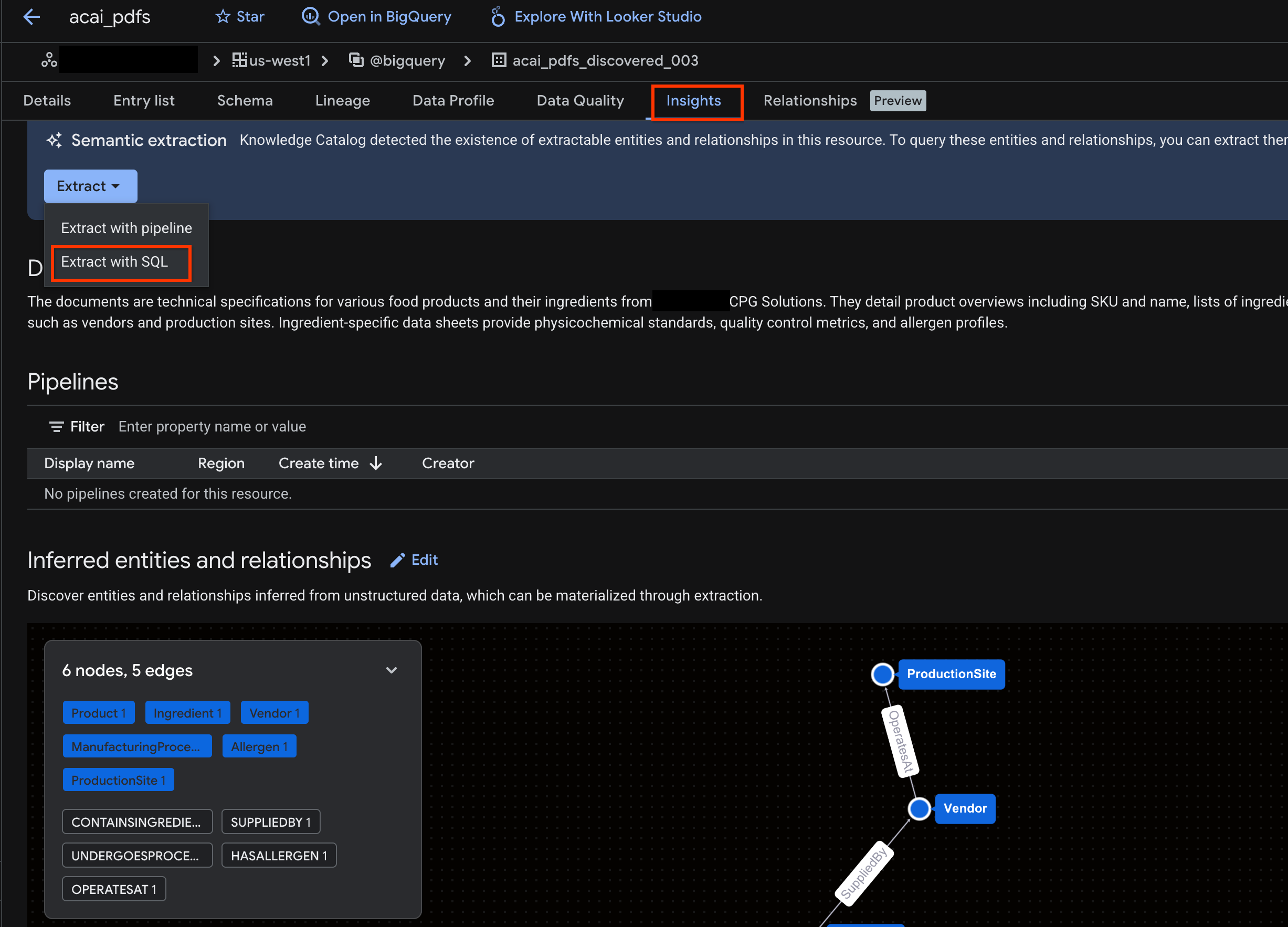
- En la página Extraer con SQL, en Destino, ingresa tu conjunto de datos. Por ejemplo,
acai_pdfs_discovered_003. - Haz clic en Extract. Se abrirá el editor de BigQuery con la consulta cargada.
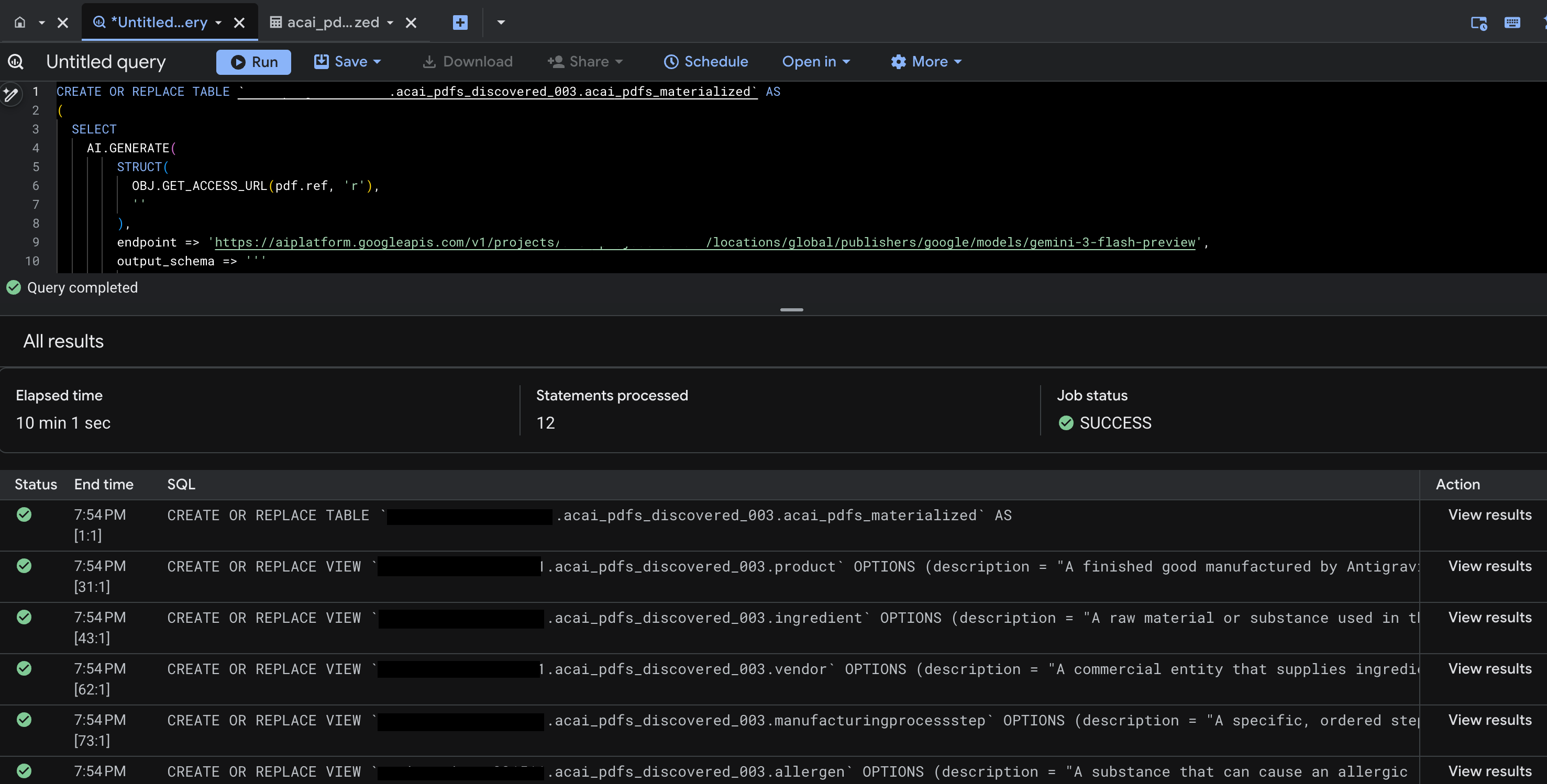
- Haz clic en Ejecutar. Este paso genera un conjunto de instrucciones y puede tardar unos minutos en completar la ejecución.
- Cuando se complete la consulta, verás los siguientes resultados:
- Ve a BigQuery y haz clic en Conjuntos de datos (por ejemplo,
acai_pdfs_discovered_003). Se creará un nuevo conjunto de objetos de base de datos estructurados en el conjunto de datos que seleccionaste en el paso 6.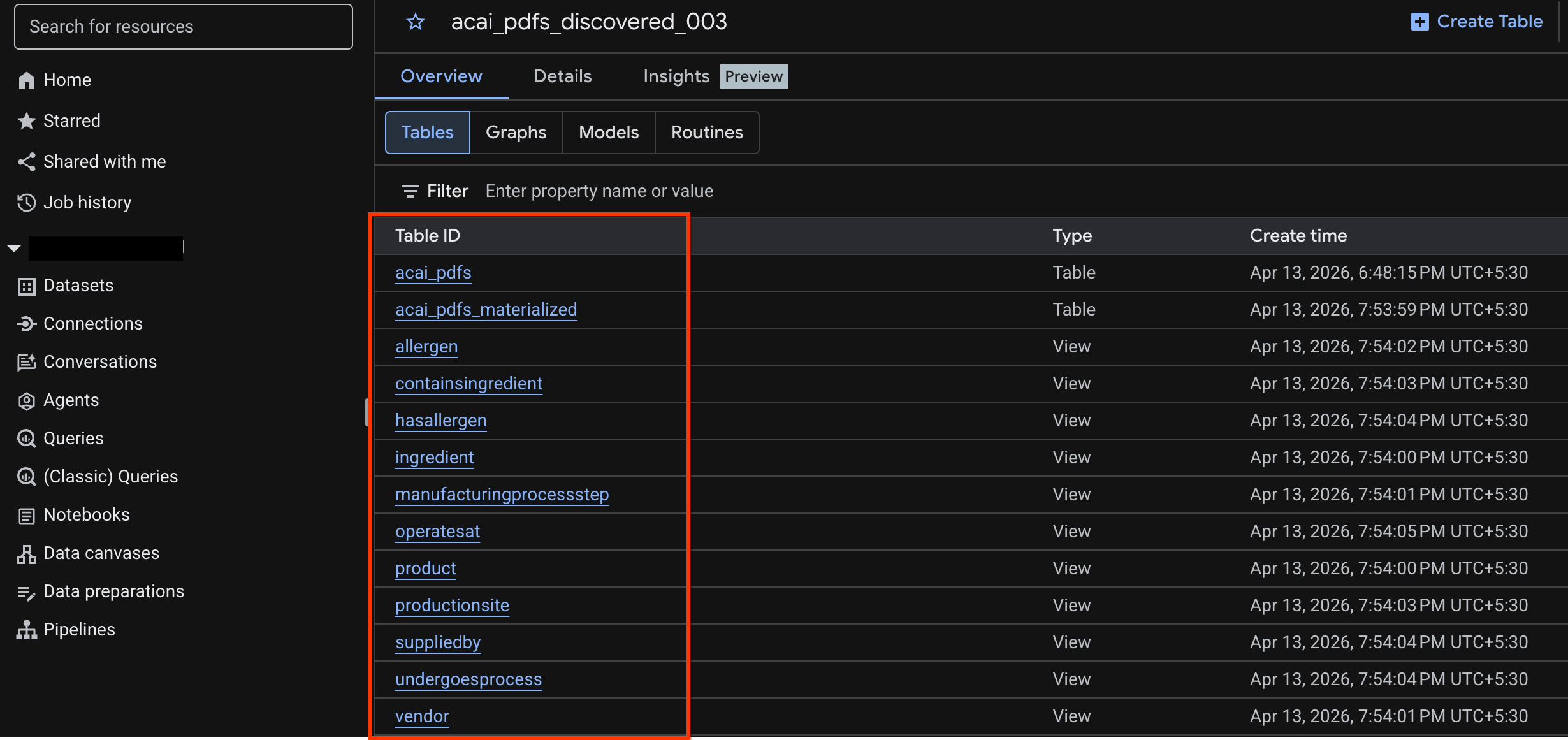
Genera estadísticas para un objeto en BigQuery
Para generar estadísticas para un conjunto de datos de BigQuery, debes acceder al conjunto de datos en BigQuery con BigQuery Studio.
- En la consola de Google Cloud, ve a BigQuery Studio.
- En el panel Explorador, selecciona el proyecto y ve al conjunto de datos para el que deseas generar estadísticas.
- Haz clic en la pestaña Estadísticas.
- Si ves un botón Habilitar API, haz clic en él para habilitar Gemini for Google Cloud. Se abrirá la ventana Habilitar funciones principales.
- En la sección APIs de funciones principales, haz clic en Habilitar para la API de Gemini for Google Cloud y la API de BigQuery Unified, y, luego, haz clic en Siguiente.
- En la sección Permisos (opcional), otorga roles de IAM a las entidades principales si es necesario y, luego, haz clic en Siguiente.
- Para generar estadísticas y publicarlas en Knowledge Catalog, haz clic en Generar y publicar.
- Una vez que se publique, podrás ver las estadísticas en la pestaña.
11. Configura tu IDE para el análisis de datos con agentes
La extensión Google Cloud Data Agent Kit para Visual Studio Code es una extensión de IDE para científicos e ingenieros de datos. Te permite conectarte a tus recursos y datos de Google Data Cloud, y trabajar con ellos directamente desde el IDE. Para obtener más información, consulta Descripción general de la extensión Data Agent Kit para VS Code.
La extensión Data Agent Kit para VS Code es útil cuando deseas hacer lo siguiente:
- Compila, prueba, revisa y, luego, implementa una canalización de datos lista para producción, como ETL de Spark o ETL de BigQuery, directamente desde VS Code.
- Explorar datos, compilar una canalización de entrenamiento, identificar modelos de AA óptimos y, luego, implementarlos en un extremo de producción con asistencia de IA
- Conéctate a fuentes de datos confiables, crea un modelo de datos de alto rendimiento y publica un panel interactivo para las partes interesadas de la empresa.
Instala la extensión Data Agent Kit para VS Code
- Abre VS Code.
- Instala Google Cloud CLI. Para obtener más información, consulta Instala Google Cloud CLI.
- Instala la extensión Data Agent Kit para VS Code.
- Finaliza el proceso de incorporación de la extensión, para lo que debes hacer lo siguiente:
- Accede a la extensión
- Instala habilidades y servidores de MCP
- Vuelve a cargar o reiniciar la ventana cuando termines la incorporación. Para obtener más información, consulta Configura y configura la extensión del Kit del agente de datos para VS Code.
- Después de que se vuelva a cargar el IDE, haz clic en el ícono de Google Data Cloud en el panel de navegación, ve a la configuración y asegúrate de configurar correctamente el ID del proyecto y la región (
us-west1) en la configuración común.
Configura el espacio de trabajo en VS Code
- Abre VS Code y selecciona File > Open folder > New folder.
- Crea una carpeta nueva llamada
acai_testy, luego, haz clic en Abrir. Ahora VS Code considera que la carpeta que abriste es un espacio de trabajo. - En el diálogo Confianza en el espacio de trabajo, selecciona Sí, confío en los autores para habilitar todas las funciones del espacio de trabajo.
- Crea una carpeta
.githuben el espacio de trabajoacai_test. - Crea un archivo nuevo
copilot-instructions.mden la carpeta.githuby, luego, ingresa las siguientes reglas.## 1. Project Context - **Project ID**: <PROJECT_ID> - **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors. - **Documentation**: Raw PDF documents detailing flavors and ingredients are stored in Google Cloud Storage at `gs://<BUCKET_NAME>`. ## 2. Execution & Data Processing Rules - **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `<BQ_DATASET_NAME>` (referred to as the Knowledge Catalog). - **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the dataset `<DATASET_ID>`. When you are referencing a dataset, ensure you are using it with the project ID (`<PROJECT_ID>`) and namespace prefix `<NAMESPACE_NAME>`. For example, to query order table in this dataset you should use `<PROJECT_ID>.<NAMESPACE>.<DATASET_ID>.orders`. - **CRITICAL RULE - Data Joins between BigQuery dataset and Iceberg dataset**: ANY task requiring a join or integration between the BigQuery datasets `<DATASET_ID>` of the PDF data and the `<DATASET_ID>` of the customer data MUST be executed using **Spark Notebooks**. - **CRITICAL RULE - Notebook Kernel**: Every Spark notebook utilized MUST exclusively be configured to run on the Serverless Session template `iceberg-federation-template` as its kernel. - **CRITICAL RULE - Data Science**: ANY data science, machine learning, or advanced analytical task MUST be performed strictly within **Spark Notebooks** using the aforementioned setup. - Crea otro archivo nuevo
template.yamlen el espacio de trabajoacai_testy, luego, ingresa la siguiente información en él.labels: client: "vscode" jupyterSession: displayName: "iceberg-federation-template" kernel: "PYTHON" environmentConfig: executionConfig: serviceAccount: "sa-spark-dev1@<PROJECT_ID>.iam.gserviceaccount.com" subnetworkUri: "projects/<PROJECT_ID>/regions/<REGION>/subnetworks/<SUBNET_NAME>" runtimeConfig: version: "2.3" properties: # This enables the secure proxy URL you were looking for dataproc.tier: "premium" spark.dataproc.engine: "lightningEngine" spark.dataproc.lightningEngine.runtime: "native" spark.memory.offHeap.enabled: "true" spark.memory.offHeap.size: "1g" spark.executor.memory: "4g" "dataproc.component.gateway.enabled": "true" "dataproc.jupyter.listen.all.interfaces": "true" "spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" "spark.sql.defaultCatalog": "<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>": "org.apache.iceberg.spark.SparkCatalog" "spark.sql.catalog.<CATALOG_NAME>.type": "rest" "spark.sql.catalog.<CATALOG_NAME>.uri": "<CATALOG_URI_ID>" "spark.sql.catalog.<CATALOG_NAME>.warehouse": "bl://projects/<PROJECT_ID>/catalogs/<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>.rest.auth.type": "org.apache.iceberg.gcp.auth.GoogleAuthManager" - En VS Code, haz clic en Terminal y ejecuta el siguiente comando para importar el archivo
template.yamlcomo una plantilla de sesión. El agente usa esta plantilla más adelante para crear una sesión de Spark.gcloud beta dataproc session-templates import iceberg-federation-template \ --source=template.yaml \ --location=<REGION>REGIONpor tu región.
12. Realiza análisis de datos con agentes
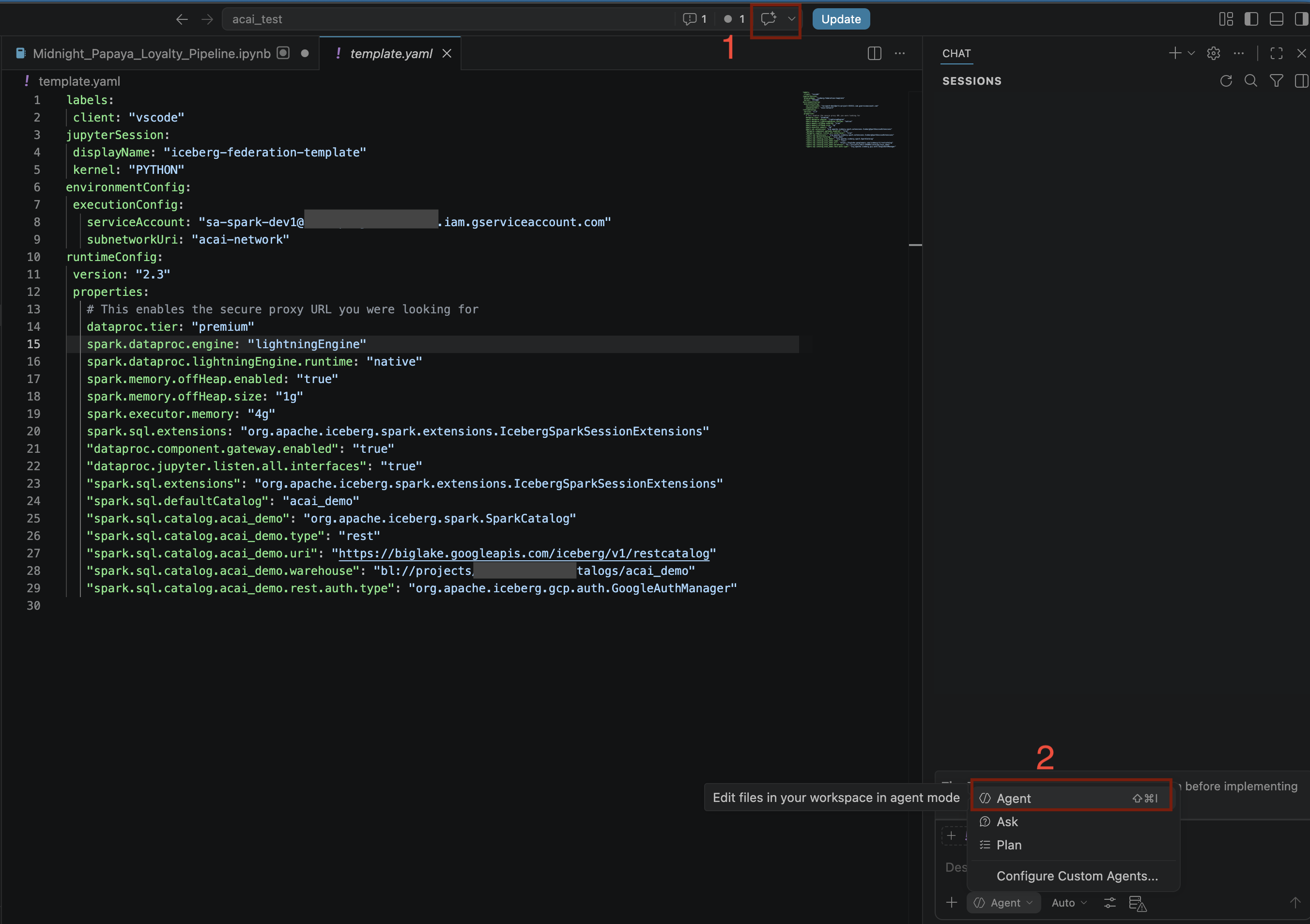
- En el editor de código de VS Code, haz clic en Alternar chat.
- En Configure custom agents, selecciona Agent.
- En el panel Modelos de búsqueda, haz clic en Administrar modelos de lenguaje.
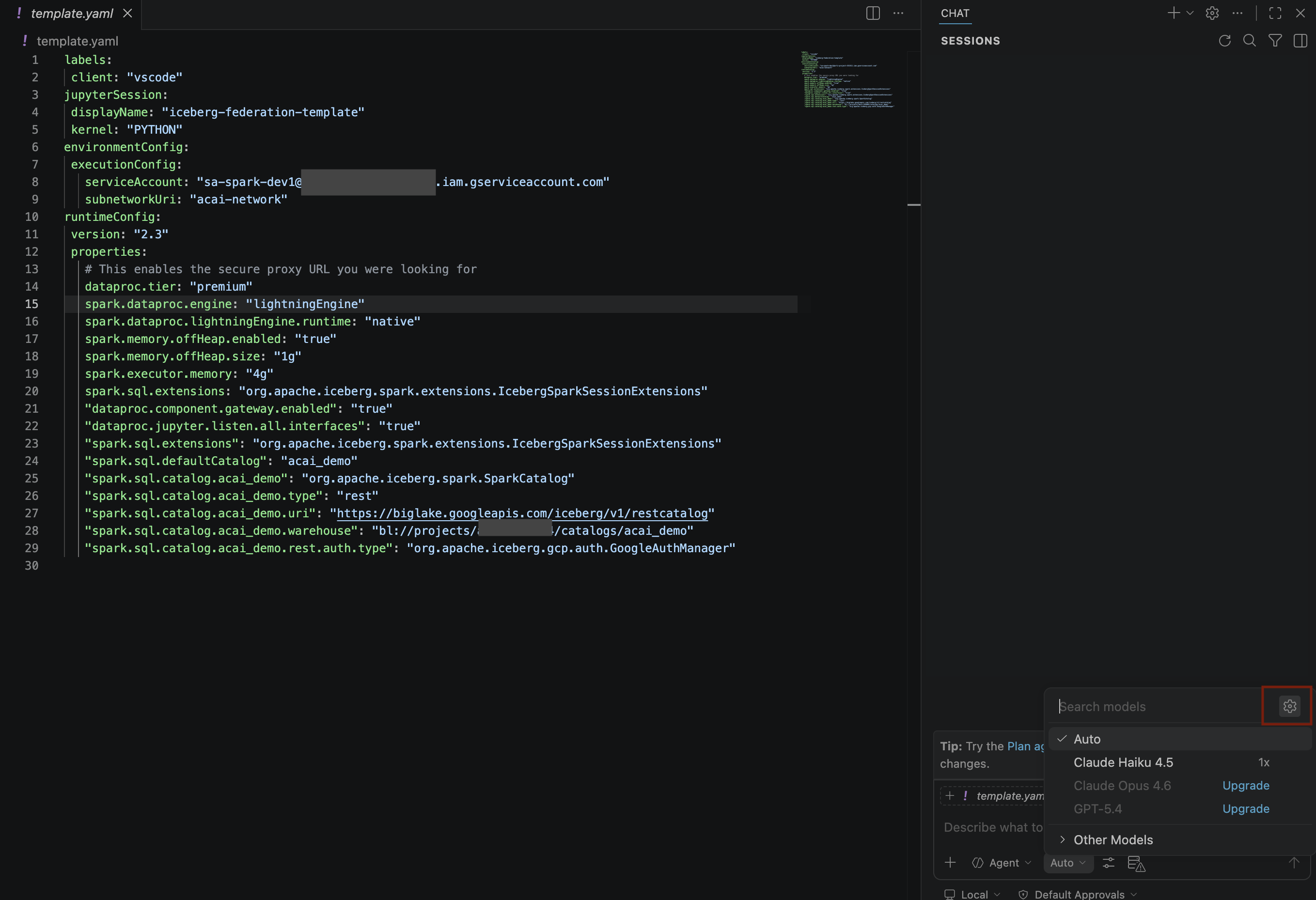
- En la página Modelos de lenguaje, haz clic en Agregar modelos.
- Selecciona Google en la lista y presiona Intro para confirmar tu entrada.
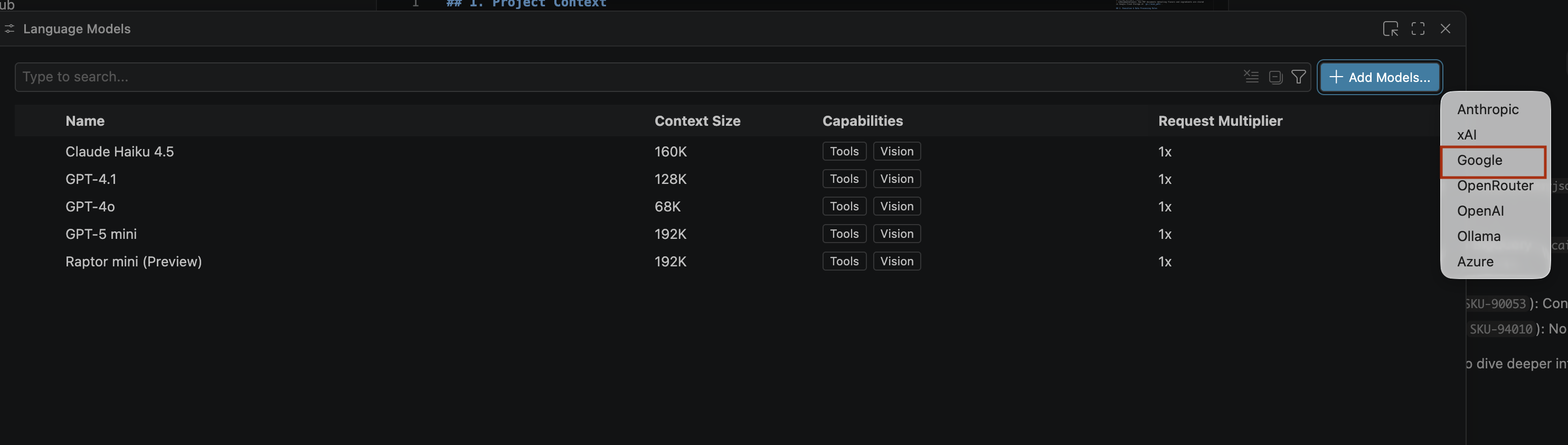
- Para ingresar la clave de API de Google Gemini, haz lo siguiente:
- Ve al sitio web de Google AI Studio.
- Accede con tu Cuenta de Google.
- En la barra lateral, haz clic en Obtener clave de API.
- Haz clic en Crear clave de API. Se abrirá la página para crear una clave nueva.
- En la lista Selecciona un proyecto de Cloud, selecciona Importar proyecto.
- Ingresa el nombre de un proyecto existente.
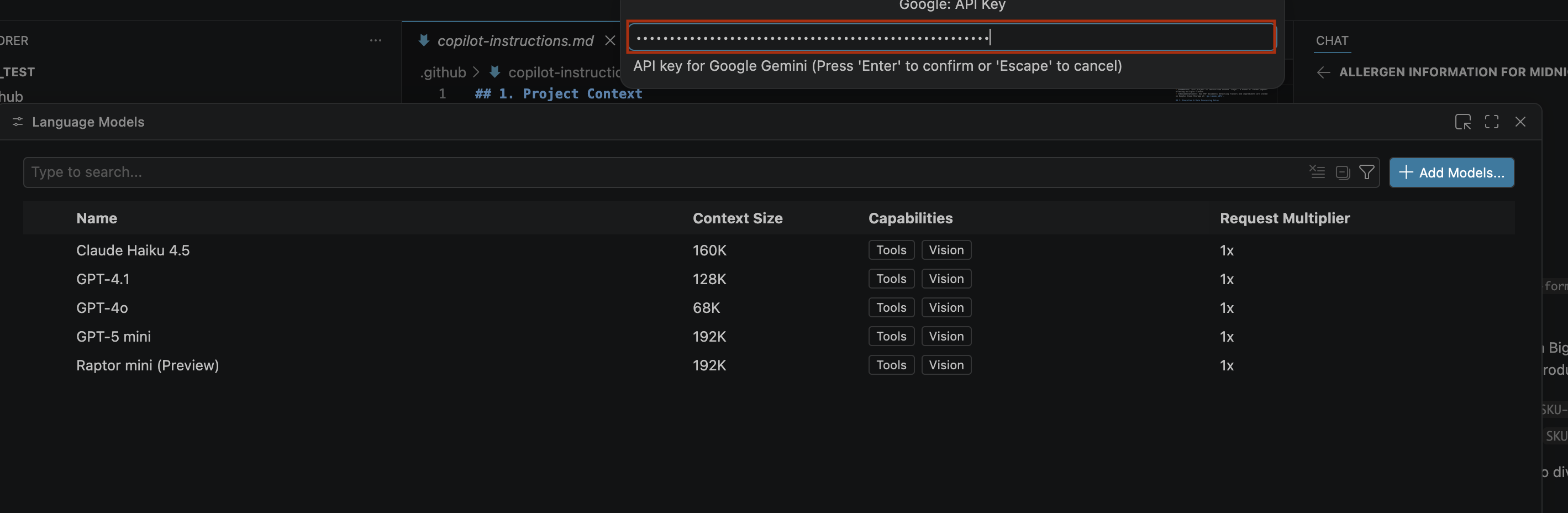
- Haz clic en Crear clave y copia la clave de API. La clave proporciona acceso a los recursos de la API de Gemini de tu cuenta.Para obtener más información, consulta Cómo usar claves de la API de Gemini.
- Pega la clave de API que generaste en la barra de búsqueda y haz clic en Intro.
- Si no aparecen los modelos de Gemini, muéstralos como se indica en la siguiente imagen:
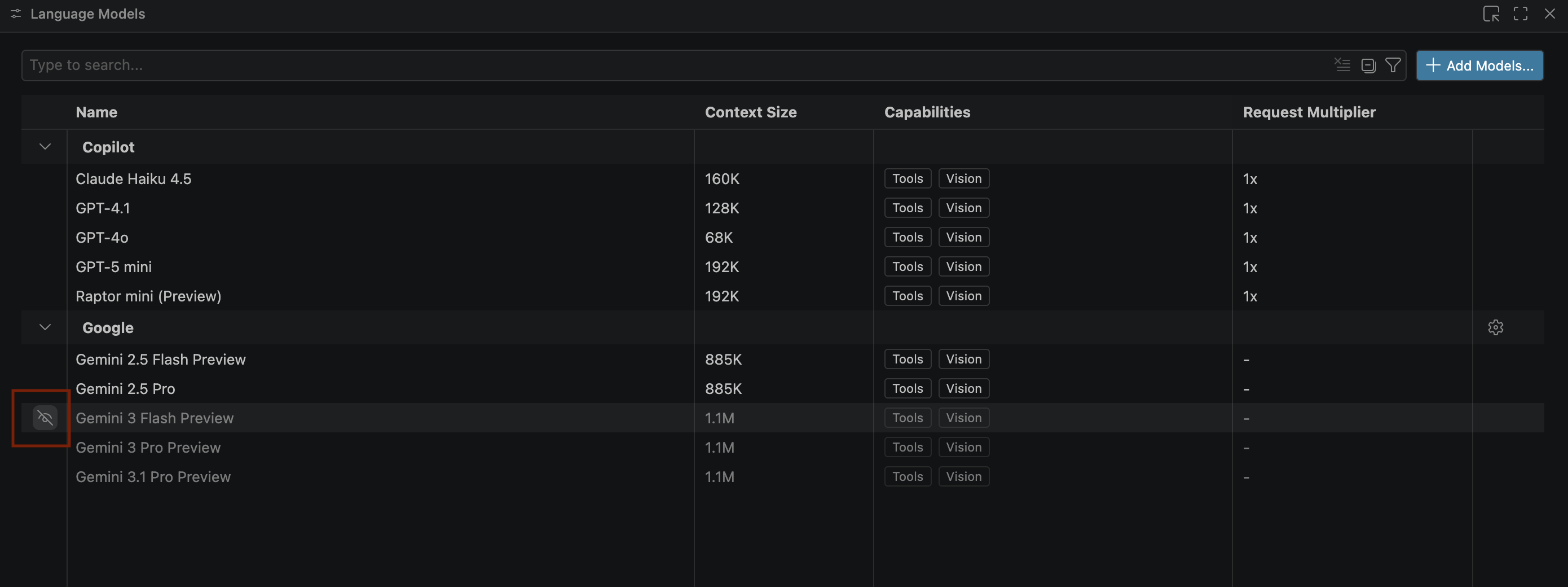
- Selecciona Gemini 3.1 Pro Preview en la lista de modelos de Google Gemini y cierra la ventana Modelos de lenguaje.
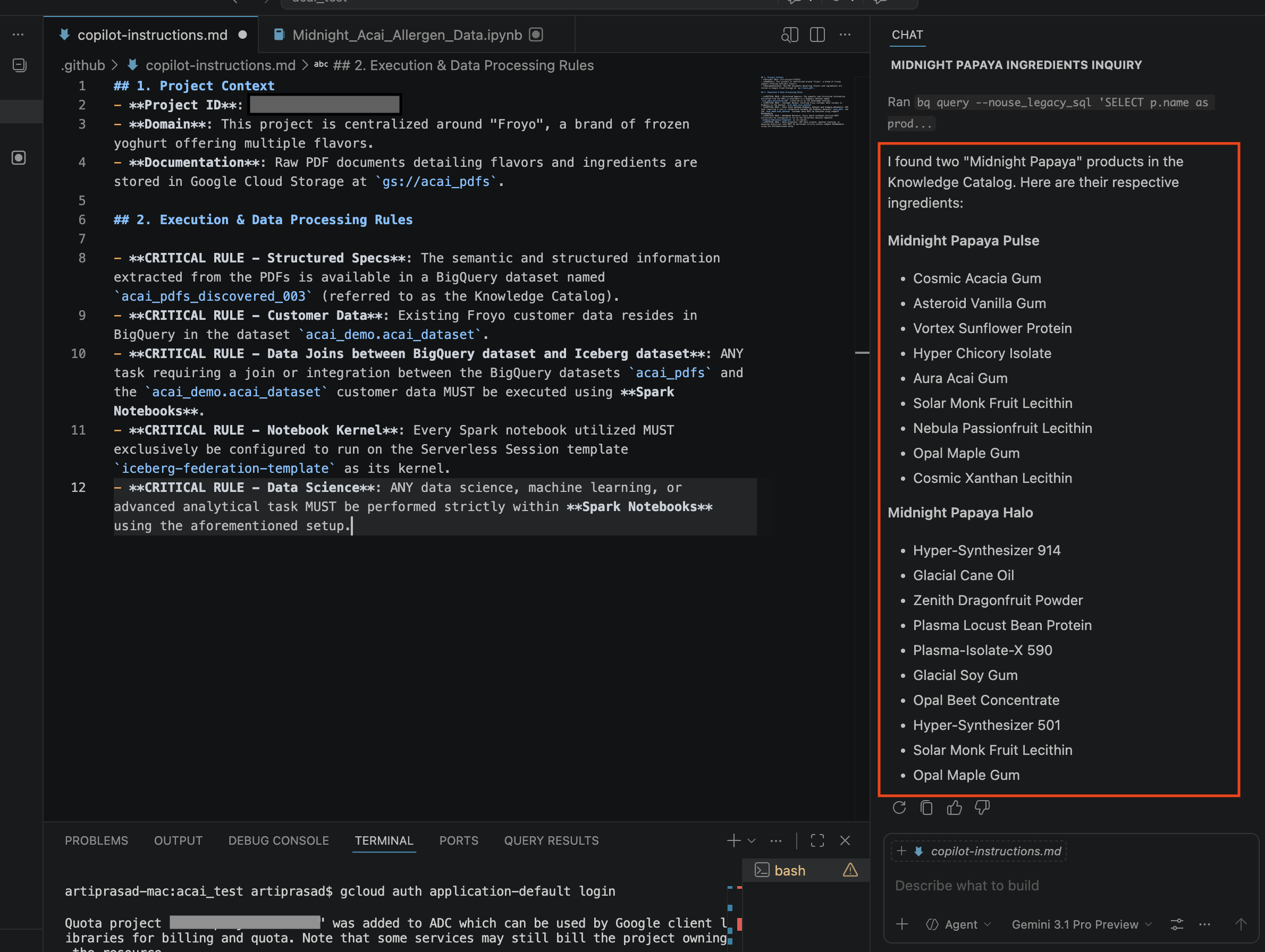
- En la ventana del chat, ingresa la siguiente pregunta:
Search ingredients for Midnight papaya - Después de interactuar un poco, deberías ver el siguiente resultado:
- En la ventana de chat, ingresa otra pregunta:
Search allergen information for Midnight papaya - Después de algunas interacciones y pasos, verás que el agente responde con el nombre del alérgeno
Soy, como se muestra en la siguiente imagen: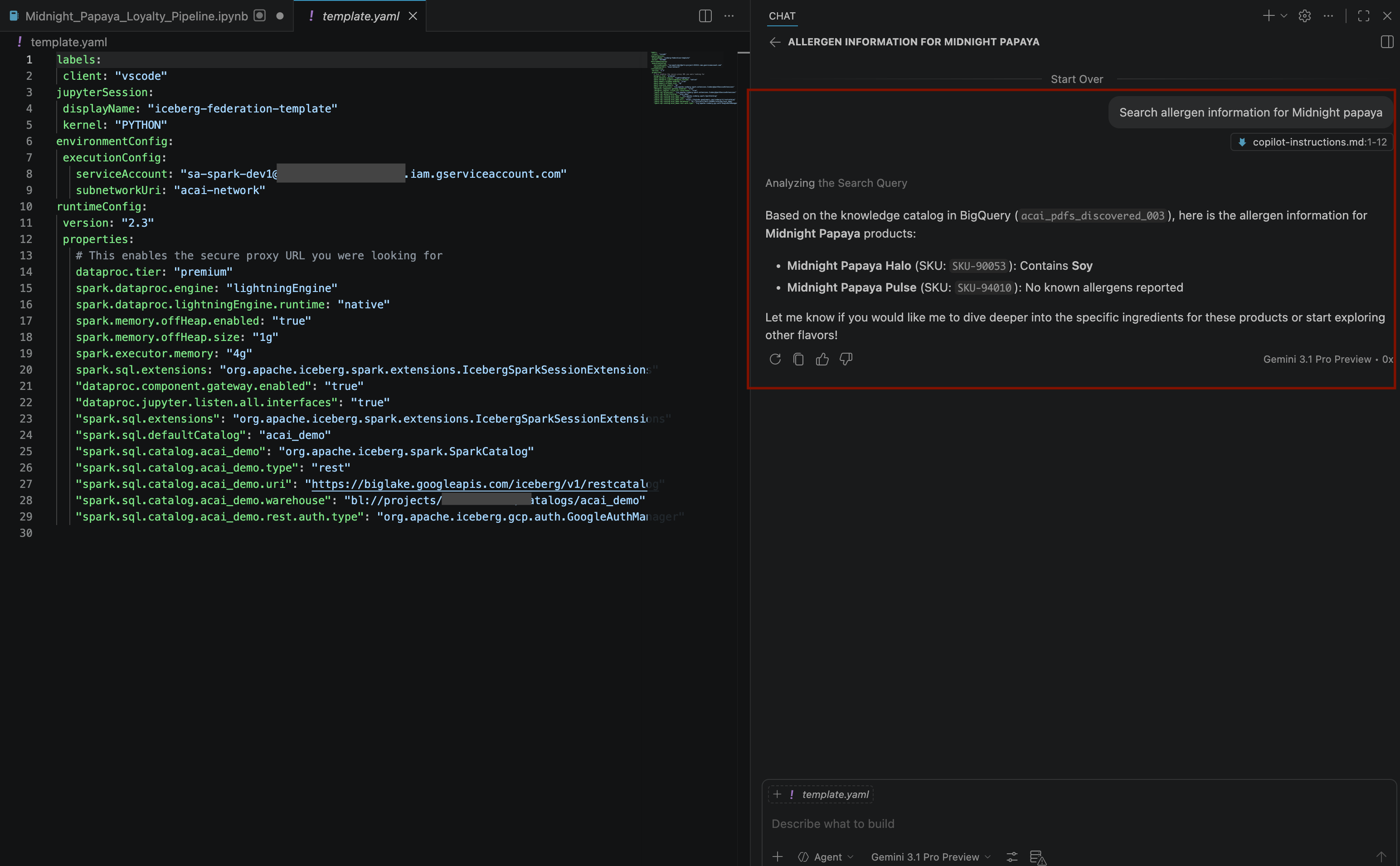
- En la ventana de chat, ingresa otra pregunta:
Build a pipeline to join products with our 'Global Loyalty' Iceberg tables in acai customer, sales data to identify popular products - Para seleccionar el kernel, abre el archivo
.ipynby haz clic en Select kernel > Remote spark kernels > Iceberg-federation-template on serverless spark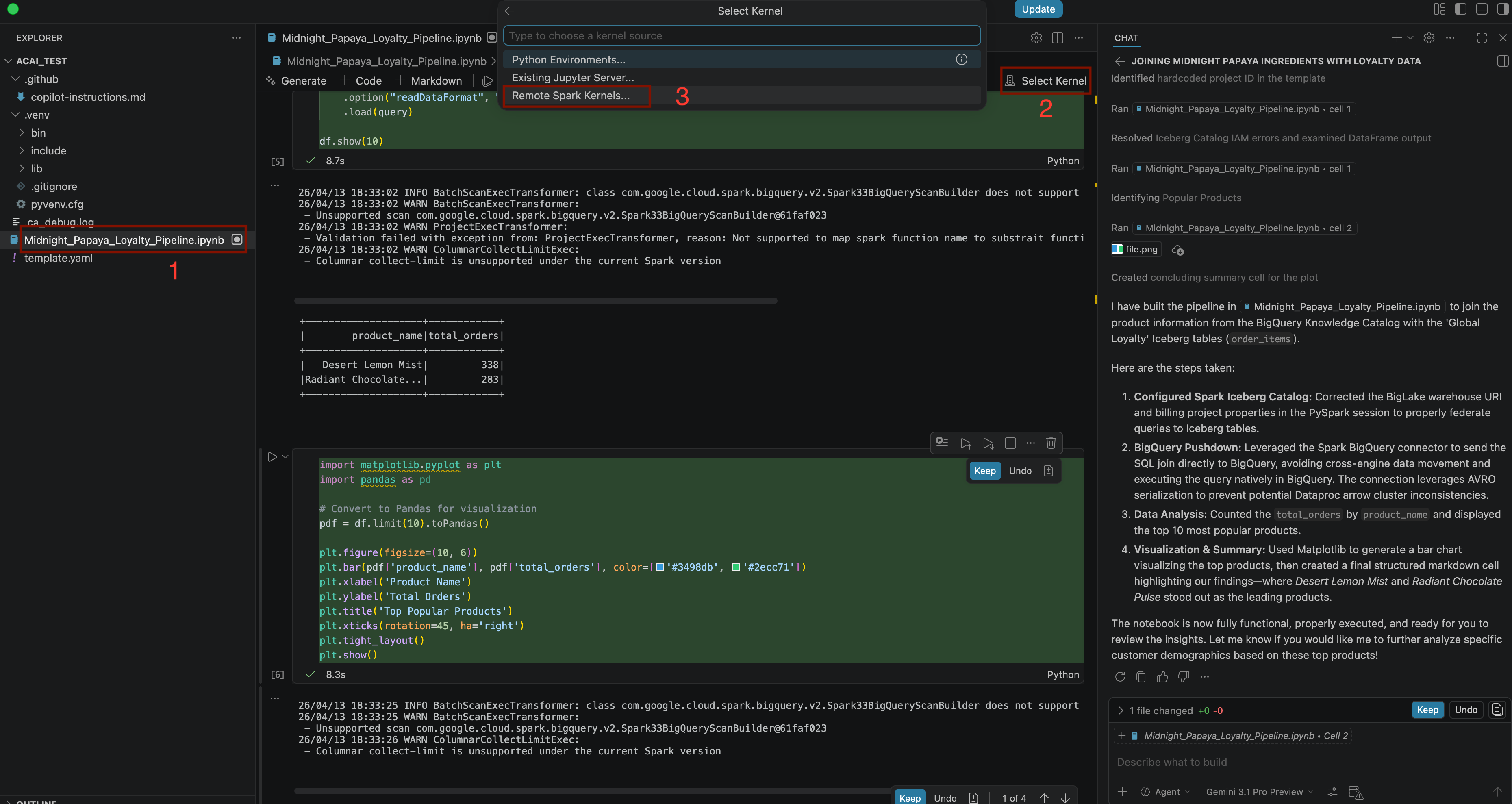 .
.
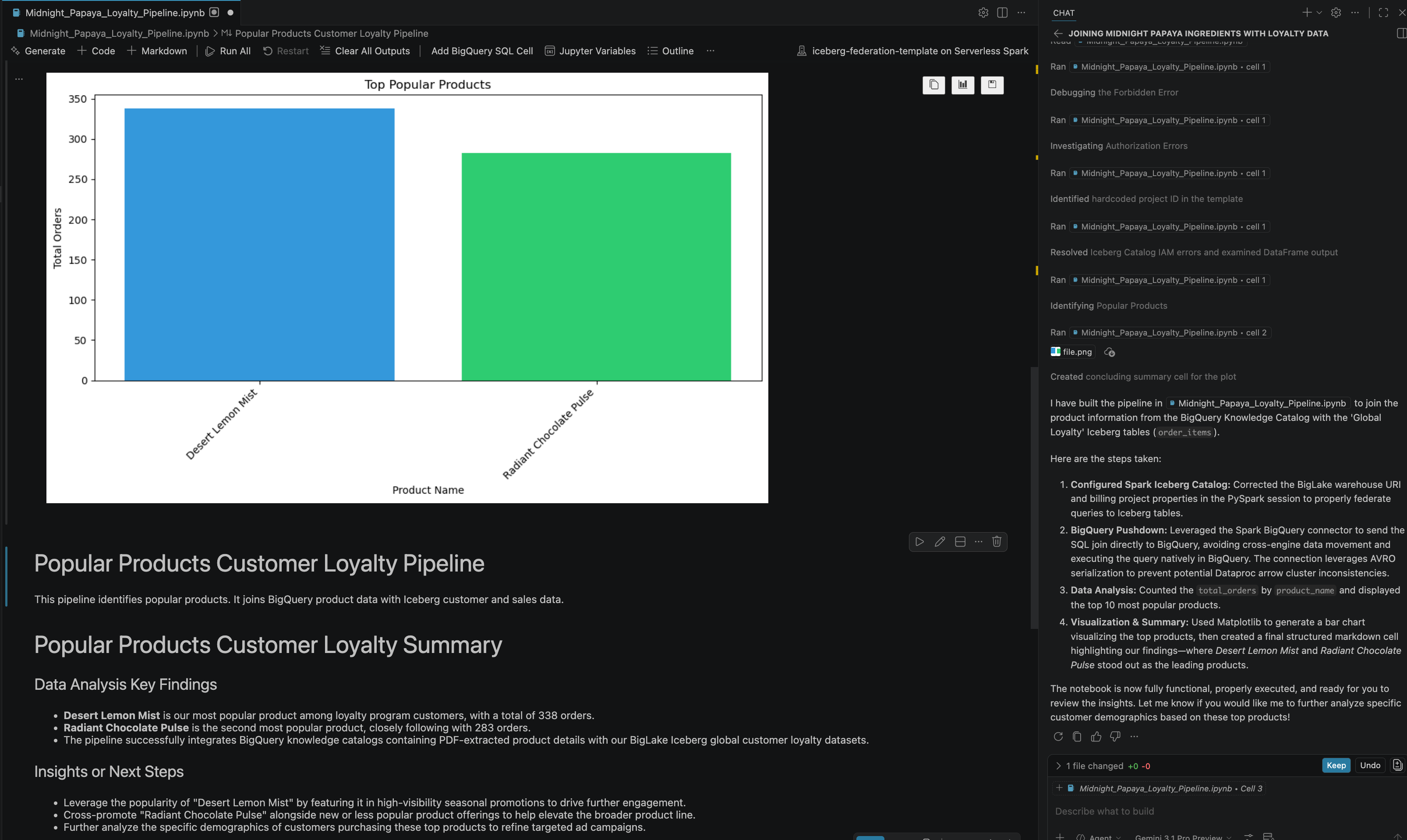
- Después de algunas interacciones y pasos, verás que el agente responde con todos los pasos del notebook ejecutados correctamente, junto con el resultado final generado al final del notebook, como se puede ver en la siguiente imagen:
13. Limpia
Para evitar que se generen cobros, borra los recursos que creaste en este lab.
- Para borrar el DataScan de Knowledge Catalog, ejecuta el siguiente comando:
DATASCAN_ID="<DATASCAN_ID>" echo "Deleting Dataplex DataScan: ${DATASCAN_ID}" gcloud dataplex datascans delete "${DATASCAN_ID}" --location="${REGION}" --quiet - Para borrar los buckets de Cloud Storage y todo su contenido, ejecuta el siguiente comando:
echo "Deleting Cloud Storage buckets: <BUCKET_NAME1> and <BUCKET_NAME2>" gsutil -m rm -r gs://<BUCKET_NAME1> gsutil -m rm -r gs://<BUCKET_NAME2> - Para borrar BigQuery Connection, ejecuta el siguiente comando:
CONNECTION_ID="<CONNECTION_NAME>" echo "Deleting BigQuery Connection: ${CONNECTION_ID}" bq rm --connection "${PROJECT_ID}.${REGION}.${CONNECTION_ID}" - Para borrar el catálogo de Lakehouse, ejecuta el siguiente comando:
CATALOG_ID="<CATALOG_NAME>" echo "Deleting Lakehouse Catalog: ${CATALOG_ID}" gcloud biglake catalogs delete "${CATALOG_ID}" --project="${PROJECT_ID}" --location="${REGION}" --quiet - Para borrar el conjunto de datos que contiene las tablas en PDF descubiertas, ejecuta el siguiente comando:
DATASET_NAME="<DATASET_NAME>" echo "Deleting BigQuery Dataset: ${DATASET_NAME}" bq rm -r -f "${PROJECT_ID}:${DATASET_NAME}" - Para borrar la cuenta de servicio personalizada, ejecuta el siguiente comando:
SERVICE_ACCOUNT="<SERVICE_ACCOUNT>" echo "Deleting Service Account: ${SERVICE_ACCOUNT}" gcloud iam service-accounts delete "${SERVICE_ACCOUNT}"@"${PROJECT_ID}".iam.gserviceaccount.com --quiet - Para borrar la red de VPC, ejecuta el siguiente comando:
VPC_NETWORK="<VPC_NETWORK>" echo "Deleting VPC Network: ${VPC_NETWORK}" gcloud compute networks delete "${VPC_NETWORK}" --quiet - Para borrar todo el proyecto de Google Cloud, ejecuta el siguiente comando:
gcloud projects delete "${PROJECT_ID}"
14. Felicitaciones
¡Felicitaciones! Organizaste correctamente el panorama de datos de los archivos PDF y Parquet aislados en tablas de BigQuery y lo condensaste en un ecosistema único, apto para búsquedas y combinaciones. Básicamente, creaste un data lakehouse moderno que trata los formatos de PDF y de macrodatos con la misma inteligencia con la que trata una fila en una base de datos. Y todo esto lo hiciste directamente desde tu agente en una experiencia de conversación con Gemini.
Documentos de referencia
Para profundizar en las tecnologías principales que se usan en este codelab, consulta la documentación oficial de Google Cloud:
- Para explorar BigQuery, un componente principal de Data Cloud, consulta la documentación de BigQuery.
- Para obtener más información sobre IAM, consulta la Documentación de IAM.
- Para obtener información sobre el lakehouse, consulta ¿Qué es un lakehouse?