
۱. مقدمه
در این آزمایشگاه کد، شما نقش یک دانشمند داده را برای یک شرکت خیالی Froyo که در حال عرضه محصول جدیدی به نام "Midnight Swirl" است، ایفا خواهید کرد. برای اطمینان از یک عرضه جهانی موفق، کسب و کار باید به سوالات حیاتی در مورد مواد تشکیل دهنده، تقاضای بازار و بازده سرمایه گذاری (ROI) پاسخ دهد. این گردش کار سرتاسری نشان میدهد که چگونه کاتالوگ دانش Google Cloud (که قبلاً با نام Dataplex شناخته میشد) و Lakehouse برای Apache Iceberg (که قبلاً با نام BigLake شناخته میشد) شکاف بین دادههای بدون ساختار "تاریک" را پر میکنند و هوش تجاری عملی را با استفاده از Gemini در IDE (VS Code) شما از طریق یک لایه مدیریت یکپارچه ارائه میدهند.
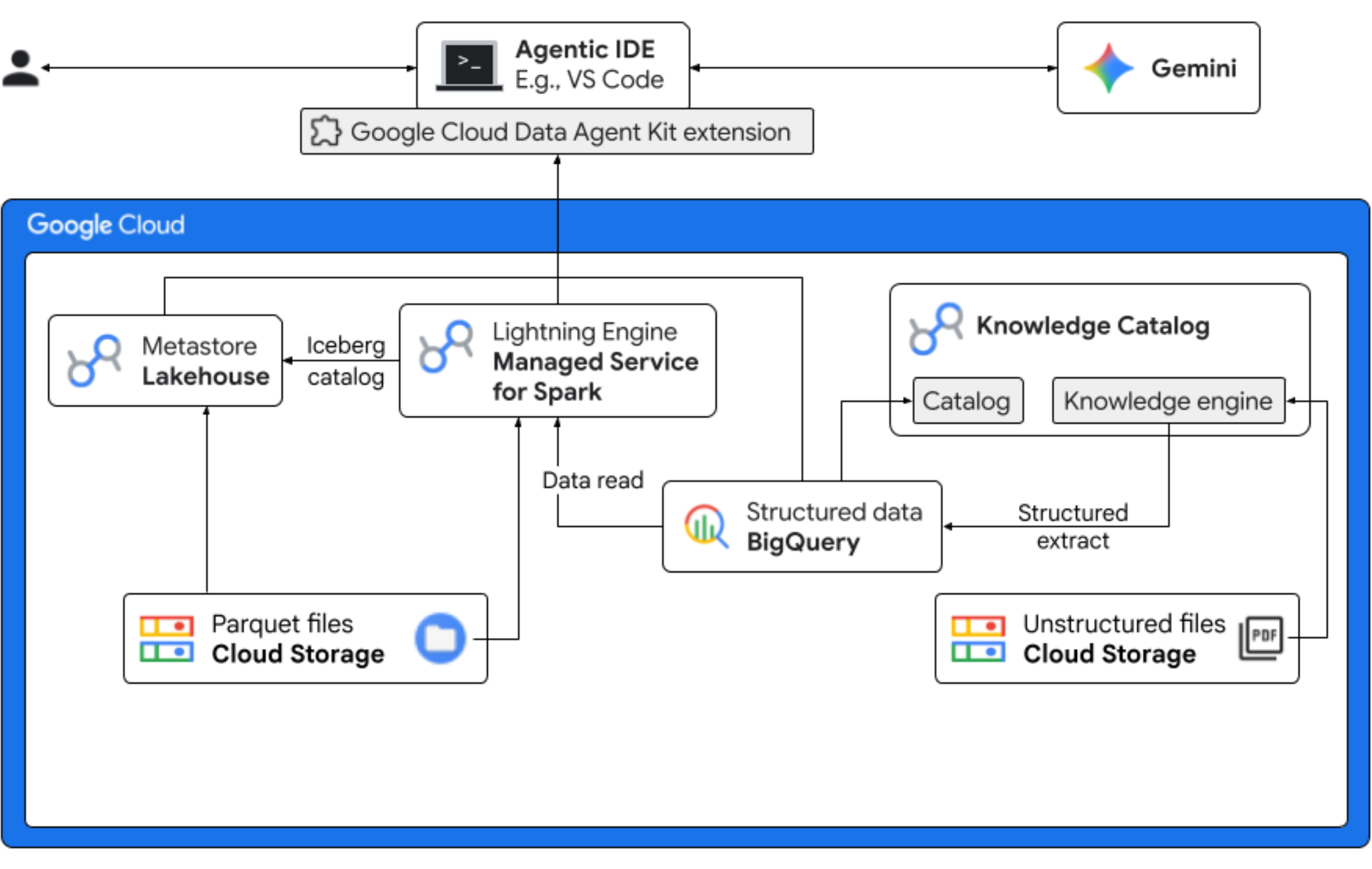
کاری که انجام خواهید داد
- کشف بدون ساختار : دستور العملهای PDF ذخیره شده در Cloud Storage توسط Knowledge Catalog DataScan خزش میشوند. برای PDFهای اسکن شده، جداول Object در BigQuery ایجاد کنید. با استفاده از استنتاج معنایی Vertex AI، سیستم PDFها را "میخواند" تا اطلاعات ساختار یافتهای را برای محصولات، آلرژنها، مواد تشکیل دهنده و ویژگیهای مرتبط استخراج کند. سپس به طور هوشمندانه یک طرحواره برای دادههای ذخیره شده در PDFها ایجاد میکند.
- فراداده یکپارچه : دادههای استخراجشده از فایلهای PDF مستقیماً در BigQuery به عنوان یک جدول بومی ذخیره میشوند و نماهایی برای کمک به پرسوجوهای رایج ایجاد میشوند. یک مجموعه داده ورودی مستقل حاوی دادههای فروش تاریخی در جداول آپاچی آیسبرگ در فضای ذخیرهسازی ابری گوگل ذخیره میشود. این جدول آیسبرگ در مرحله بعدی به دادههای استخراجشده در BigQuery متصل خواهد شد.
- تجزیه و تحلیل بین موتوری : با استفاده از سرویس مدیریتشده برای آپاچی اسپارک (که قبلاً با نام Dataproc شناخته میشد) به همراه کاتالوگ Iceberg REST، شما این متادیتای PDF جدید و دادههای معنایی ساختاریافته استنتاجشده (از جداول و نماهای BigQuery) را با دادههای فروش ساختاریافته ذخیرهشده در جداول آپاچی آیسبرگ در فضای ذخیرهسازی ابری گوگل ترکیب خواهید کرد. این امر توسط یک الگوی جلسه تعاملی مدیریتشده آپاچی اسپارک که به عنوان هسته Jupyter Notebook استفاده میشود، مدیریت میشود که امنیت و تنظیمات محاسباتی ثابتی را برای کار Spark تضمین میکند.
- بینشهای معنایی : با ترکیب دادههای استنباطشده محصول با دادههای مشتری و فروش (در BigQuery)، نسخه آزمایشی قادر به استخراج بینشهایی مانند شناسایی دادههای آلرژن و پیشبینی درآمد است.
- مدیریت خودکار : کل چرخه حیات - از اسکنهای اکتشافی گرفته تا اجرای Spark - از طریق قالبها، دستورالعملها، قوانین و اتوماسیون مبتنی بر عامل (agent-driven) آماده برای Gemini هماهنگ میشود و ثابت میکند که هوش مصنوعی میتواند زیرساختی را که به تجزیه و تحلیل قدرت میدهد، مدیریت کند.
آنچه نیاز دارید
تکمیل این آزمایشگاه کد ممکن است هزینههایی را در پی داشته باشد که برای استفاده معمولی کمتر از ۵ دلار تخمین زده میشود. برای دریافت برآوردهای دقیق هزینه بر اساس میزان استفاده پیشبینیشده یا قیمت فعلی خود، از ماشین حساب قیمتگذاری Google Cloud استفاده کنید.
برای تکمیل codelab مطمئن شوید که پیشنیازهای زیر را دارید.
- مرورگر وب کروم .
- یک حساب جیمیل شخصی در صورتی که از اعتبارهای آزمایشی ارائه شده در بخش «قبل از شروع» استفاده میکنید.
- ویژوال استودیو (VS) کد را دانلود و نصب کنید .
۲. قبل از شروع
ایجاد یک پروژه ابری گوگل
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید .
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
شروع پوسته ابری
Cloud Shell یک محیط خط فرمان است که در Google Cloud اجرا میشود و ابزارهای لازم از قبل روی آن بارگذاری شدهاند.
- روی فعال کردن Cloud Shell در بالای کنسول Google Cloud کلیک کنید.
- پس از اتصال به Cloud Shell، احراز هویت خود را تأیید کنید:
gcloud auth list - تأیید کنید که پروژه شما پیکربندی شده است:
gcloud config get project - اگر پروژه شما مطابق انتظار تنظیم نشده است، آن را تنظیم کنید:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
فعال کردن API های مورد نیاز
برای فعال کردن تمام API های مورد نیاز، این دستور را اجرا کنید:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
biglake.googleapis.com \
dataproc.googleapis.com \
metastore.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
secretmanager.googleapis.com \
storage.googleapis.com
دانلود فایلهای codelab
این مخزن شامل فایلهای Parquet، recipes، suppliers، copilot-instructions.md، template.yaml و quickstart.py برای استفاده در این codelab است. حتماً این فایلها را دانلود کنید.
برای دانلود فایلها، موارد زیر را انجام دهید:
- در Cloud Shell، دستور زیر را اجرا کنید:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git - به پوشه تازه ایجاد شده بروید:
cd next-26-keynotes - پوشه
data-cloud-demoرا استخراج کنیدgit sparse-checkout set genkey/data-cloud-demo - پس از اتمام پرداخت، به پوشه
data-cloud-demoبروید و فایلهای ZIP را استخراج کنید تا به فایلهای codelab دسترسی پیدا کنید.
۳. راهاندازی Lakehouse برای دادههای مشتری Froyo
در این بخش، شما یک کاتالوگ در Lakehouse ایجاد میکنید تا از متااستور Lakehouse برای گردشهای کاری خود استفاده کنید. این کار با ارائه یک منبع واحد برای تمام دادههای Iceberg شما، قابلیت همکاری بین موتورهای جستجوی شما را ایجاد میکند. این امر به موتورهای جستجو، مانند Apache Spark، اجازه میدهد تا جداول Iceberg را به روشی سازگار کشف، خواندن و مدیریت کنند.
نقشهای مورد نیاز
مطمئن شوید که نقشهای مدیریت هویت و دسترسی (IAM) زیر را دارید:
-
roles/biglake.viewer -
roles/bigquery.user -
roles/bigquery.dataEditor -
roles/biglake.editor -
roles/biglake.metadataViewer -
roles/bigquery.connectionUser -
roles/storage.objectUser -
roles/storage.objectViewer -
roles/storage.objectCreator -
roles/storage.admin
برای اطلاعات بیشتر در مورد اعطای نقشهای IAM، به اعطای نقش IAM مراجعه کنید.
با یک سطل، یک کاتالوگ Lakehouse ایجاد کنید
یک کاتالوگ Lakehouse برای مدیریت فرادادههای جداول Iceberg خود ایجاد کنید. شما در کار Spark خود به این کاتالوگ متصل میشوید تا جداول Iceberg را ایجاد و پرسوجو کنید.
- در کنسول گوگل کلود، به Lakehouse بروید.
- روی «ایجاد کاتالوگ» کلیک کنید. صفحه «ایجاد کاتالوگ» باز میشود.
- برای نوع کاتالوگ ، کاتالوگ Iceberg Rest را انتخاب کنید.
- برای انتخاب گزینههای سطلی کاتالوگ Lakehouse خود ، کاتالوگ تک سطلی را انتخاب کنید.
- برای سطل ذخیرهسازی ابری پیشفرض کاتالوگ ، روی مرور (Browse ) کلیک کنید و سپس روی ایجاد سطل جدید (Create new bucket) کلیک کنید.
- در صفحه ایجاد یک سطل ، موارد زیر را انجام دهید:
- در بخش شروع به کار ، یک نام منحصر به فرد جهانی که الزامات نام سطل را برآورده کند، وارد کنید.
- در بخش «انتخاب محل ذخیره دادههایتان» ، برای نوع مکان، منطقه را انتخاب کنید و منطقه خود را وارد کنید. برای مثال،
us-west1. - در بخش «انتخاب نحوه کنترل دسترسی به اشیاء» ، کادر انتخاب «اجرای پیشگیری از دسترسی عمومی در این بخش» را علامت بزنید.
این به شما اجازه میدهد سناریوهای دنیای واقعی مانند میزبانی محتوای وب عمومی یا مخازن داده مشترک را شبیهسازی کنید. بدون این تغییر، باکت یک سیاست سختگیرانه "فقط خصوصی" را اعمال میکند؛ هرگونه تلاشی برای دسترسی به داراییهای شما منجر به خطای403ممنوعه میشود، حتی اگر با موفقیت مجوزهای عمومی را به فایلها اعطا کرده باشید. - روی ادامه > ایجاد > انتخاب > ادامه کلیک کنید.
- برای روش احراز هویت ، حالت فروش اعتبارنامه را انتخاب کنید.
- روی ایجاد کلیک کنید. کاتالوگ شما ایجاد شده و صفحه جزئیات کاتالوگ باز میشود.
- در زیر روش احراز هویت ، روی تنظیم مجوزهای سطل کلیک کنید.
- در کادر محاورهای، روی تأیید کلیک کنید. این تأیید میکند که حساب سرویس کاتالوگ شما نقش
Storage Object Userرا در مخزن ذخیرهسازی شما دارد. - از صفحه جزئیات کاتالوگ ، مسیر URI کاتالوگ REST را کپی کنید. از این مسیر در طول اجرای وظیفه Spark استفاده کنید.
فایلهای پارکت را در سطل بارگذاری کنید
برای آپلود فایلهای پارکت خود در ریشهی باکت، مراحل زیر را انجام دهید:
- در کنسول گوگل کلود، به صفحه Cloud Storage Buckets بروید.
- در لیست سطلها، روی نام سطل کلیک کنید. برای مثال،
acai_demo. - در تب اشیاء مربوط به سطل، روی بارگذاری > بارگذاری فایلها کلیک کنید.
- فایلهای پوشهی Parquet را که در بخش « قبل از شروع» این codelab کپی کردهاید، انتخاب کنید.
- روی باز کردن کلیک کنید.
۴. شبکه VPC را راهاندازی کنید
یک شبکه ابر خصوصی مجازی (VPC) و یک زیرشبکه ایجاد کنید که به منابع اجازه میدهد بدون رفتن به اینترنت عمومی با APIهای گوگل ارتباط برقرار کنند، و یک فایروال که به ترافیک داخلی اجازه میدهد آزادانه بین گرههای پردازش داده شما جریان یابد.
- در کنسول گوگل کلود، به صفحه شبکههای VPC بروید.
- روی ایجاد شبکه VPC کلیک کنید.
- یک نام برای شبکه وارد کنید. برای مثال،
acai-network. - برای پیکربندی حداکثر واحد انتقال (MTU) شبکه، کادر انتخاب تنظیم خودکار MTU را علامت بزنید.
- برای حالت ایجاد زیرشبکه، حالت خودکار (Automatic) را انتخاب کنید.
- در بخش قوانین فایروال ، تمام کادرهای مربوط به قوانین فایروال IPv4 را علامت بزنید.
- روی ایجاد کلیک کنید.
فعال کردن دسترسی خصوصی گوگل
گرههای Dataproc Serverless آدرس IP عمومی ندارند. برای ارتباط با Lakehouse Catalog و Cloud Storage، زیرشبکه باید Private Google Access را فعال کند.
- در کنسول گوگل کلود، به صفحه شبکههای VPC بروید.
- روی نام شبکهای که شامل زیرشبکهای است که میخواهید دسترسی خصوصی گوگل را برای آن فعال کنید، کلیک کنید. برای مثال،
us-west1. - روی نام زیرشبکه کلیک کنید. صفحه جزئیات زیرشبکه نمایش داده میشود.
- روی ویرایش کلیک کنید.
- در بخش «دسترسی خصوصی به گوگل» ، «روشن» را انتخاب کنید.
- روی ذخیره کلیک کنید.
۵. یک کار Spark ایجاد و اجرا کنید
برای ایجاد و پرسوجو از جدول Iceberg، کار PySpark را به همراه دستورات لازم Spark SQL آپلود کنید. سپس کار را با Managed Service for Spark اجرا کنید.
quickstart.py را در فضای ذخیرهسازی ابری خود آپلود کنید
بعد از اینکه فایلهای codelab را کپی کردید ، اسکریپت quickstart.py را با جزئیات پروژه خود بهروزرسانی کنید و آن را در فضای ذخیرهسازی ابری آپلود کنید.
- اسکریپت
quickstart.pyرا در یک ویرایشگر متن باز کنید. - عبارت
BUCKET_NAMEرا در اسکریپت با نام مخزن ذخیرهسازی ابری خود جایگزین کنید و آن را ذخیره کنید. - در کنسول گوگل کلود، به بخش Cloud Storage buckets بروید.
- روی نام سطل خود کلیک کنید. برای مثال،
acai_demo. - در برگه اشیاء ، روی بارگذاری > بارگذاری فایلها کلیک کنید.
- در مرورگر فایل، فایل بهروزرسانیشدهی
quickstart.pyرا انتخاب کنید و سپس روی «باز کردن» کلیک کنید.
اجرای کار اسپارک
پس از آپلود اسکریپت quickstart.py ، آن را به عنوان یک سرویس مدیریتشده برای کار دستهای Spark اجرا کنید.
- برای پیکربندی متغیرها، دستور زیر را در Cloud Shell اجرا کنید.
# Configuration Variables export PROJECT_ID="<PROJECT_ID>" export REGION="<REGION>" export BUCKET_NAME="<BUCKET_NAME>" export SUBNET="<SUBNET>" export LAKEHOUSE_CATALOG_ID="<LAKEHOUSE_CATALOG_ID>" export CATALOG_URI_ID="<CATALOG_URI_ID>"- LAKEHOUSE_CATALOG_ID : نام منبع کاتالوگ Lakehouse که شامل فایل برنامه PySpark شما است. برای مثال،
acai_demo - PROJECT_ID : شناسه پروژه گوگل کلود شما.
- REGION : منطقهای که قرار است سرویس مدیریتشده برای حجم کار دستهای Spark در آن اجرا شود. برای مثال،
us-west1. - BUCKET_NAME : نام باکت فضای ذخیرهسازی ابری شما. برای مثال،
acai_demo. - SUBNET : نام زیرشبکه VPC شما. برای مثال،
acai-network. - CATALOG_URI_ID : شناسهی URL کاتالوگ Lakehouse که هنگام ایجاد کاتالوگ Lakehouse با یک سطل کپی کردهاید. برای مثال،
https://biglake.googleapis.com/iceberg/v1/restcatalog.
- LAKEHOUSE_CATALOG_ID : نام منبع کاتالوگ Lakehouse که شامل فایل برنامه PySpark شما است. برای مثال،
- در Cloud Shell، با استفاده از اسکریپت
quickstart.pyکار دستهای Managed Service for Spark زیر را اجرا کنید.gcloud dataproc batches submit pyspark gs://${BUCKET_NAME}/quickstart.py \ --project=${PROJECT_ID} \ --region=${REGION} \ --subnet=${SUBNET} \ --version=2.2 \ --properties="\ spark.sql.defaultCatalog=${LAKEHOUSE_CATALOG_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}=org.apache.iceberg.spark.SparkCatalog,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.type=rest,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.uri=${CATALOG_URI_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.warehouse=gs://${BUCKET_NAME},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.io-impl=org.apache.iceberg.gcp.gcs.GCSFileIO,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.x-goog-user-project=${PROJECT_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\ spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest-metrics-reporting-enabled=false,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.X-Iceberg-Access-Delegation=vended-credentials,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token"All tables registered successfully! Batch [126fa2226a904d2e944c8eecbe0b1840] finished. metadata: '@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata batch: projects/PROJECT_ID/locations/REGION/batches/126fa2226a904d2e944c8eecbe0b1840 batchUuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff createTime: '2026-04-09T13:17:26.222727Z' description: Batch labels: goog-dataproc-batch-id: 126fa2226a904d2e944c8eecbe0b1840 goog-dataproc-batch-uuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-drz-resource-uuid: batch-3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-location: REGION operationType: BATCH name: projects/PROJECT_ID/regions/REGION/operations/47bc59e8-5082-3af9-89a0-22289aa5f4b9
۶. پرس و جو از جدول از BigQuery
با اجرای موفقیتآمیز کار دستهای Spark، شما از سرویس مدیریتشده برای Spark Serverless به عنوان یک موتور محاسباتی توزیعشده برای ثبت چندین جدول، یکی به ازای هر فایل Parquet در Lakehouse Metastore، استفاده کردهاید. این ثبت به Google Cloud اجازه میدهد تا با فایلهای خام شما در Cloud Storage به عنوان جداول ساختاریافته و با کارایی بالا رفتار کند.
مراحل زیر شما را در تأیید همگامسازی صحیح فراداده راهنمایی میکند و تضمین میکند که دادههای شما نه تنها به طور ایمن ذخیره میشوند، بلکه از طریق رابط BigQuery نیز کاملاً قابل کشف و پرسوجو هستند.
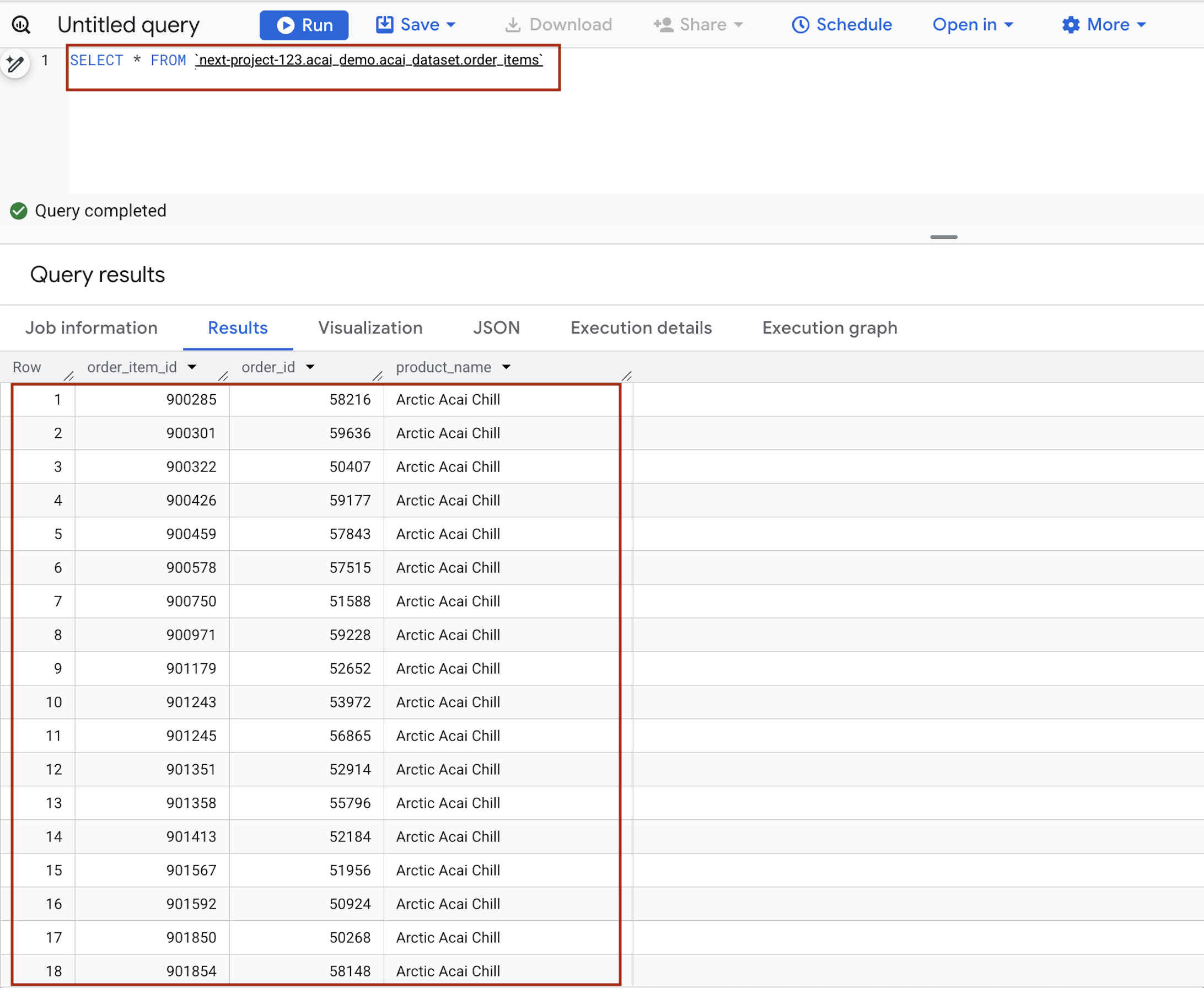
- در کنسول گوگل کلود، به BigQuery بروید.
- در ویرایشگر کوئری، عبارت زیر را وارد کنید. کوئری از سینتکس
project.namespace.dataset.tableاستفاده میکند.SELECT * FROM `<PROJECT_ID>.<NAMESPACE>.<ICEBERG_DATASET>.<ICEBERG_TABLE>`PROJECT_ID.acai_demo.acai_dataset.order_items.
موارد زیر را جایگزین کنید:- PROJECT_ID : شناسه پروژه گوگل کلود شما.
- NAMESPACE : فضای نامی که در مرحله قبل به عنوان نتیجه کار Spark ایجاد شده است، که میتوانید آن را در صفحه کاوشگر شیء BigQuery خود پیدا کنید. به عنوان مثال،
acai_demo. - ICEBERG_DATASET : نام مجموعه داده در کاتالوگ Iceberg، برای مثال،
acai_dataset. - ICEBERG_TABLE : نام جدول درون مجموعه داده Iceberg، برای مثال،
order_items.
- روی Run کلیک کنید. نتایج پرس و جو، دادههایی را که با کار Spark وارد کردهاید، نشان میدهد.
۷. فایلهای داده محصول بدون ساختار را تنظیم کنید
در این بخش، شما یک ساختار سازمانی در BigQuery ایجاد میکنید تا دادههای دستور پخت و تأمینکننده Froyo، به ویژه برای جزئیات محصول Froyo، را ذخیره کند. همچنین یک اتصال منابع ابری ایجاد میکند که به عنوان یک "پل" امن عمل میکند و به BigQuery اجازه میدهد فایلها را از منابع خارجی مانند Cloud Storage بخواند.
یک باکت ایجاد کنید و فایلهای جزئیات Froyo را آپلود کنید
فایلهای تامینکننده و دستور پخت را ایجاد و در فضای ذخیرهسازی ابری آپلود کنید.
- در کنسول گوگل کلود، به صفحه Cloud Storage Buckets بروید.
- روی ایجاد کلیک کنید.
- در صفحه ایجاد یک سطل ، اطلاعات سطل خود را وارد کنید. پس از هر یک از مراحل زیر، برای رفتن به مرحله بعدی، روی ادامه کلیک کنید:
- در بخش « شروع به کار» ، نام باکت را وارد کنید. برای مثال،
acai_pdfs. - در بخش «انتخاب محل ذخیره دادههایتان» ، منطقه را انتخاب کنید و سپس منطقه خود را وارد کنید. برای مثال،
us-west1. - در بخش «انتخاب نحوه کنترل دسترسی به اشیاء» ، کادر انتخاب «اجرای پیشگیری از دسترسی عمومی در این بخش» را علامت بزنید.
- روی ایجاد کلیک کنید.
- در لیست سطلها، روی سطلی که ایجاد کردهاید کلیک کنید. برای مثال،
acai_pdfs. - در تب اشیاء مربوط به سطل، روی بارگذاری > بارگذاری پوشهها کلیک کنید.
- پوشه
recipesکه در بخش « قبل از شروع » این آزمایشگاه کد، استخراج کردهاید را انتخاب کنید. - روی آپلود کلیک کنید.
- فرآیند آپلود را برای پوشه
suppliersتکرار کنید.
ایجاد یک اتصال
یک اتصال به منابع ابری ایجاد کنید. این یک حساب کاربری سرویس منحصر به فرد ایجاد میکند که به عنوان "کارت شناسایی" BigQuery برای دسترسی به فایلهای خارجی عمل میکند.
- به صفحه BigQuery بروید.
- در پنل سمت چپ، روی Explorer کلیک کنید. اگر پنل سمت چپ را نمیبینید، روی Expand left pane کلیک کنید تا پنل باز شود.
- در پنجره اکسپلورر ، نام پروژه خود را باز کنید و سپس روی Connections کلیک کنید.
- در صفحه اتصالات ، روی ایجاد اتصال کلیک کنید.
- برای نوع اتصال ، مدلهای از راه دور Vertex AI، توابع از راه دور، BigLake و Spanner (Cloud Resource) را انتخاب کنید.
- در فیلد شناسه اتصال ، نام شناسه اتصال را وارد کنید. برای مثال،
acai_pdf_connection. حتماً این شناسه را یادداشت کنید زیرا هنگام تنظیم اسکن دادهها در ادامه این codelab به آن نیاز خواهید داشت. - نوع مکان را روی منطقه تنظیم کنید و سپس یک منطقه را انتخاب کنید. برای مثال،
us-west1. اتصال باید با منابع دیگر شما مانند مجموعه دادهها در یک مکان قرار گیرد. - روی ایجاد اتصال کلیک کنید.
- روی رفتن به اتصال کلیک کنید.
- در پنجره اطلاعات اتصال ، شناسه حساب سرویس را برای استفاده در مرحله بعد کپی کنید. حساب سرویس شبیه به
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.comاست.
مدیریت دسترسی به حسابهای سرویس
دسترسی به حساب سرویس را فراهم کنید تا Lakehouse بتواند فایلهای PDF شما را بخواند.
- به صفحه مدیریت و دسترسی به حساب کاربری (IAM & Admin) بروید.
- روی اعطای دسترسی کلیک کنید. پنجرهی «افزودن مدیران» باز میشود.
- در فیلد New principals ، شناسه حساب سرویس را که قبلاً کپی کردهاید، وارد کنید.
- در فیلد «انتخاب نقش» ، نقشهای زیر را اضافه کنید:
-
roles/storage.objectUser -
roles/storage.objectViewer -
roles/bigquery.user -
roles/bigquery.dataEditor -
roles/aiplatform.user -
roles/storage.admin -
roles/dataproc.serviceAgent
-
- روی ذخیره کلیک کنید.
برای اطلاعات بیشتر در مورد نقشهای IAM در BigQuery، به نقشها و مجوزهای از پیش تعریف شده مراجعه کنید.
۸. مدیریت مجوزها برای کار DataScan
حسابهای کاربری سرویس (هویتهای) خاصی برای Spark و Dataform ایجاد کنید و سپس به آنها - به همراه نمایندگان سرویس خودکار گوگل - مجوزهای دقیق مورد نیاز برای خواندن فضای ذخیرهسازی، اجرای وظایف BigQuery و استفاده از Vertex AI برای کشف را اعطا کنید.
دسترسی IAM برای Spark و Dataform
- در کنسول گوگل کلود، به صفحه ایجاد حساب کاربری سرویس بروید.
- اگر انتخاب نشده است، پروژه Google Cloud خود را انتخاب کنید.
- روی ایجاد حساب سرویس کلیک کنید.
- نام حساب سرویس را وارد کنید. برای مثال،
sa-spark-stg1. کنسول Google Cloud بر اساس این نام، یک شناسه حساب سرویس ایجاد میکند. در صورت لزوم، شناسه را ویرایش کنید. نمیتوانید بعداً شناسه را تغییر دهید. - برای تنظیم کنترلهای دسترسی، روی ایجاد و ادامه کلیک کنید و به مرحله بعدی بروید.
- نقشهای IAM زیر را برای اعطای به حساب سرویس در پروژه انتخاب کنید.
-
roles/dataproc.worker -
roles/storage.objectUser -
roles/bigquery.dataEditor -
roles/bigquery.jobUser -
roles/aiplatform.user -
roles/dataplex.discoveryPublishingServiceAgent
-
- وقتی اضافه کردن نقشها تمام شد، روی ادامه کلیک کنید.
- برای پایان ایجاد حساب کاربری سرویس، روی «انجام شد» کلیک کنید.
مجوزهای اتصال BigQuery برای دسترسی به کاتالوگ دانش
- در کنسول گوگل کلود، به صفحه Cloud Storage Buckets بروید.
- در لیست سطلها، روی نام سطلی که برای Froyo ایجاد کردهاید کلیک کنید. برای مثال،
acai_pdfs. - در برگه مجوزها ، روی اعطای دسترسی کلیک کنید. کادر محاورهای افزودن مدیران اصلی ظاهر میشود.
- در فیلد New principals ، شناسه حساب کاربری سرویس BigQuery خود را وارد کنید. حساب کاربری سرویس شبیه به
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.comاست. - نقش (یا نقشهای) زیر را از منوی کشویی «انتخاب یک نقش» انتخاب کنید.
-
roles/storage.objectUser -
roles/dataplex.serviceAgent -
roles/dataplex.securityAdmin -
roles/aiplatform.serviceAgent -
roles/dataplex.discoveryPublishingServiceAgent
-
- روی ذخیره کلیک کنید.
۹. ایجاد کاتالوگ دانش
یک کاتالوگ دانش بسازید تا دادههای مربوط به Froyo خود را یکپارچه کنید و کشف فایلهای بدون ساختار (مانند دستور العملهای PDF و تامینکنندگان PDF) را خودکار کنید.
ایجاد DataScan از طریق curl
در این بخش، شما با اضافه کردن datascan_ID و اشاره به مجموعه دادههای BigQuery خود، اسکنهایی برای مخزن ذخیرهسازی ابری خود (برای مثال، acai_pdfs ) ایجاد میکنید. پس از آن، Knowledge Catalog به طور خودکار ورودیهایی برای PDF های شما در BigQuery ایجاد میکند.
- برای اسکن فایلهای PDF (تامینکنندگان و دستور پختها)، دستور زیر را اجرا کنید:
# 1. Set your variables PROJECT_ID="<PROJECT_ID>" REGION="<REGION>" ENV_SUFFIX="stg1" DATASCAN_ID="froyo-profile-${ENV_SUFFIX}" BUCKET_NAME="<BUCKET_NAME>" # 2. Set this to the Name of the connection you created in Step 7 CONNECTION_ID="<CONNECTION_ID_NAME>" # 3. Define the API Endpoint DATAPLEX_API="dataplex.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}" # 4. Create the DataScan via CURL echo "Creating Dataplex DataScan: ${DATASCAN_ID}..." curl -X POST "https://$DATAPLEX_API/dataScans?dataScanId=${DATASCAN_ID}" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d '{ "data": { "resource": "//storage.googleapis.com/projects/'"${PROJECT_ID}"'/buckets/'"${BUCKET_NAME}"'" }, "executionSpec": { "trigger": { "on_demand": {} } }, "dataDiscoverySpec": { "bigqueryPublishingConfig": { "tableType": "BIGLAKE", "connection": "projects/'"${PROJECT_ID}"'/locations/'"${REGION}"'/connections/'"${CONNECTION_ID}"'" }, "storageConfig": { "unstructuredDataOptions": { "entity_inference_enabled": true } } } }' - دستور
curlنتایج DataScan کاتالوگ دانش را مشابه تصویر زیر نمایش میدهد.
کار را اجرا کنید
دستور زیر را اجرا کنید:
gcloud dataplex datascans run $DATASCAN_ID --location=$REGION
یک شغل را توصیف کنید
برای توصیف کار، دستور زیر را اجرا کنید:
gcloud dataplex datascans describe $DATASCAN_ID --location=$REGION
حذف یک کار اسکن داده
اگر اسکن بیش از 10 دقیقه طول بکشد، یا اگر وضعیت کار برای مدت طولانی بدون انتقال به حالت در حال اجرا ، در حالت انتظار (Pending) باقی بماند، ممکن است به دلیل عدم دسترسی موقت به منابع در منطقه باشد. در این صورت، میتوانید دستور زیر را برای حذف کار اجرا کنید و سپس دوباره آن را ایجاد و اجرا کنید. گاهی اوقات، اجرای اولیه ممکن است به سرعت با خطایی مانند unable to acquire necessary resources با شکست مواجه شود.
gcloud dataplex datascans delete $DATASCAN_ID --location=$REGION
مشاهده وضعیت کار
برای بررسی وضعیت کار، موارد زیر را انجام دهید:
- در کنسول گوگل کلود، به صفحهی «گزینش متادیتا» (Metadata curation ) بروید.
- در برگه کشف فضای ابری ، روی نام اسکنهای کشفشده کلیک کنید.
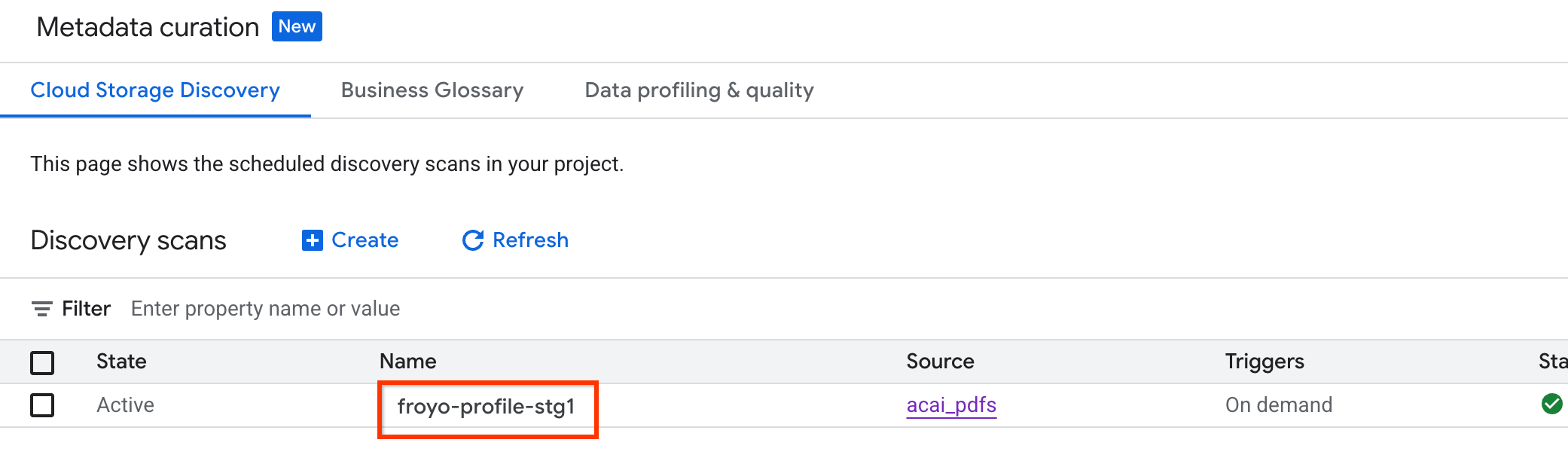
- در صفحه جزئیات اسکن ، میتوانید وضعیت کار را مشاهده کنید.
- پس از اتمام کار، بررسی کنید که آیا مجموعه داده منتشر شده (برای مثال،
acai_pdfs_discovered_003) که با استفاده از دستورcurlایجاد کردهاید، وجود دارد یا خیر.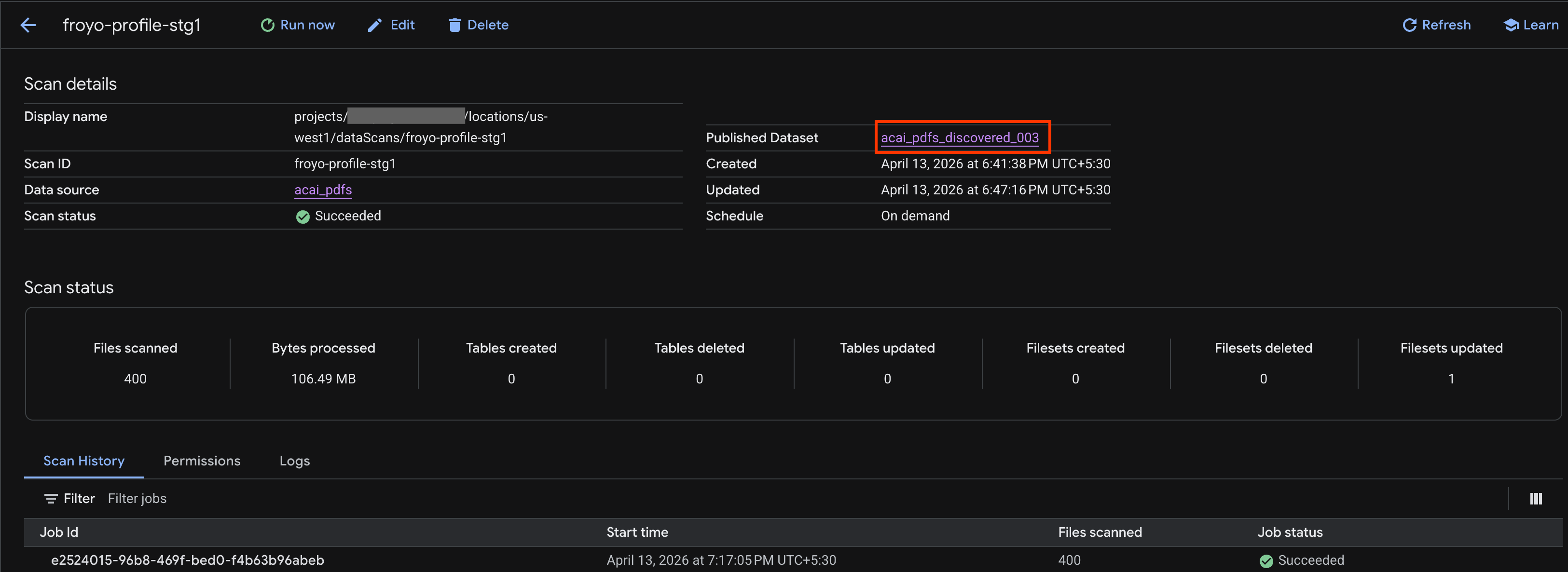
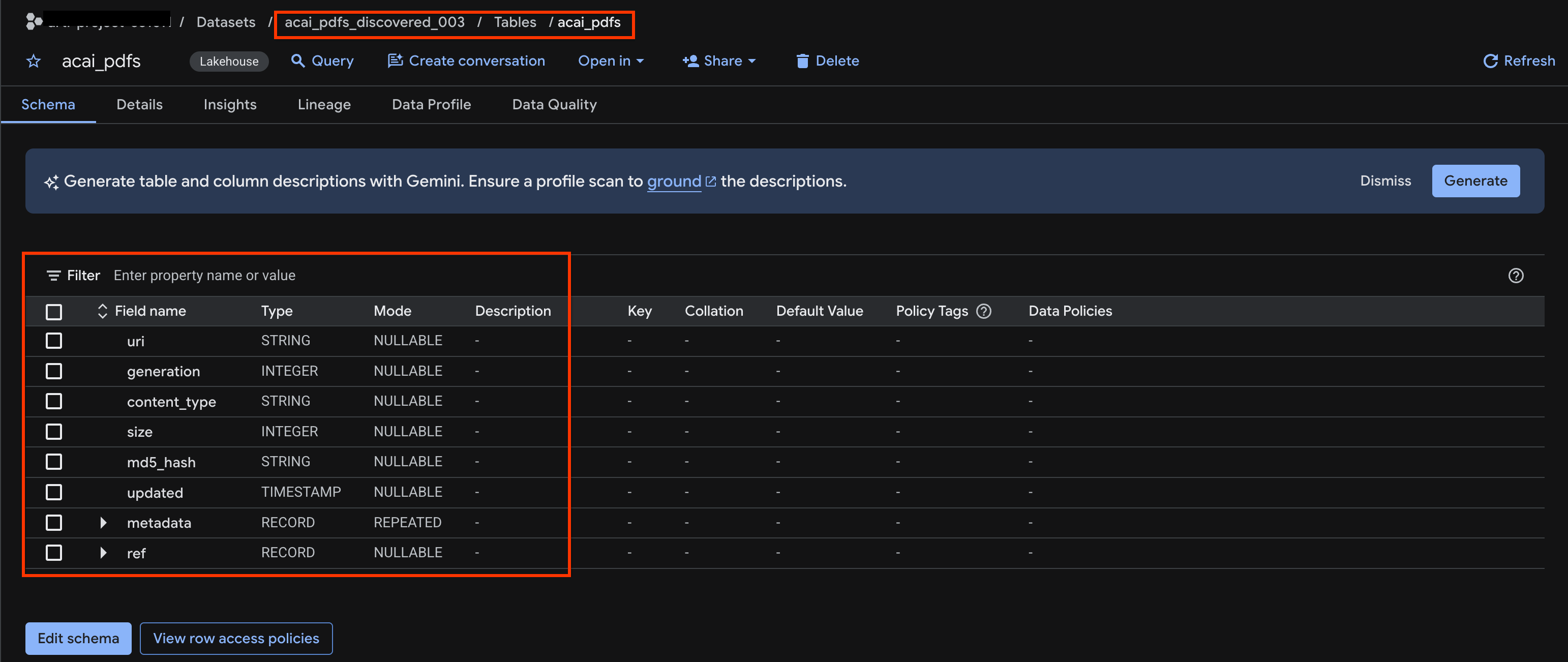
جدول اشیاء را مشاهده کنید
برای مشاهده جدول اشیاء ایجاد شده پس از عملیات کشف، مراحل زیر را انجام دهید:
- در کنسول گوگل کلود، به BigQuery بروید.
- روی Datasets کلیک کنید و مجموعه داده منتشر شدهای که در مرحله قبل ایجاد شده است را انتخاب کنید. برای مثال،
acai_pdfs_discovered_003. - برای مشاهده جدول شیء، روی شناسه جدول کلیک کنید. برای مثال،
acai_pdfs. - جدول اشیاء حاصل مانند تصویر زیر خواهد بود:
۱۰. استخراج معنایی
شما قرار است جداول ساختاریافته، سایر اشیاء پایگاه داده و روابط را برای این جدول شیء بدون ساختار که در مرحله قبل ایجاد کردهاید، استنباط و استخراج کنید. برای این کار از ویژگی Knowledge Catalog Insights برای تولید دستورات SQL جهت استخراج دادههای ساختاریافته از جدول بدون ساختار استفاده خواهید کرد.
- در کنسول گوگل کلود، به صفحه جستجوی کاتالوگ دانش بروید.
- جدول مجموعه دادهای را که میخواهید اطلاعات مربوط به آن را مشاهده کنید، جستجو کنید. برای مثال،
acai_pdfs_discovered_003.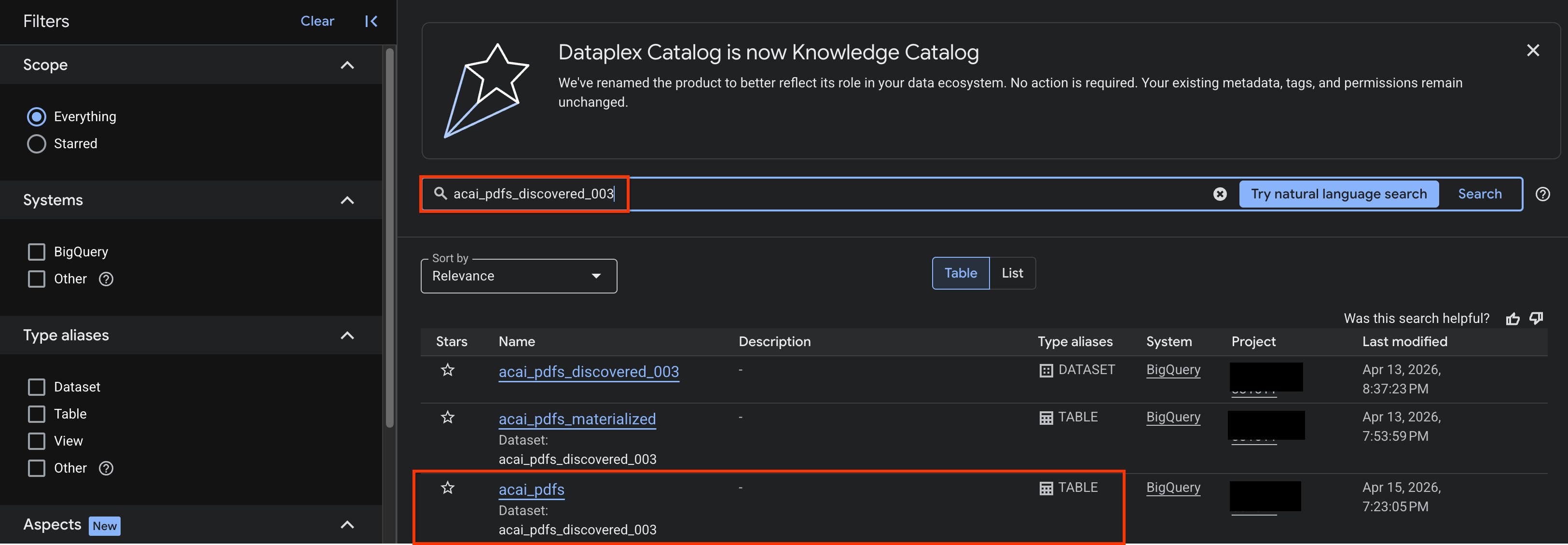
- در نتایج جستجو، روی جدول کلیک کنید تا صفحه ورودی آن باز شود.
- روی برگه Insights کلیک کنید. اگر برگه خالی باشد، به این معنی است که Insights برای این جدول هنوز ایجاد نشده است. ایجاد Insight ممکن است ۱۵ تا ۲۵ دقیقه طول بکشد.
- وقتی اطلاعات را مشاهده کردید، روی Extract > Extract with SQL کلیک کنید.
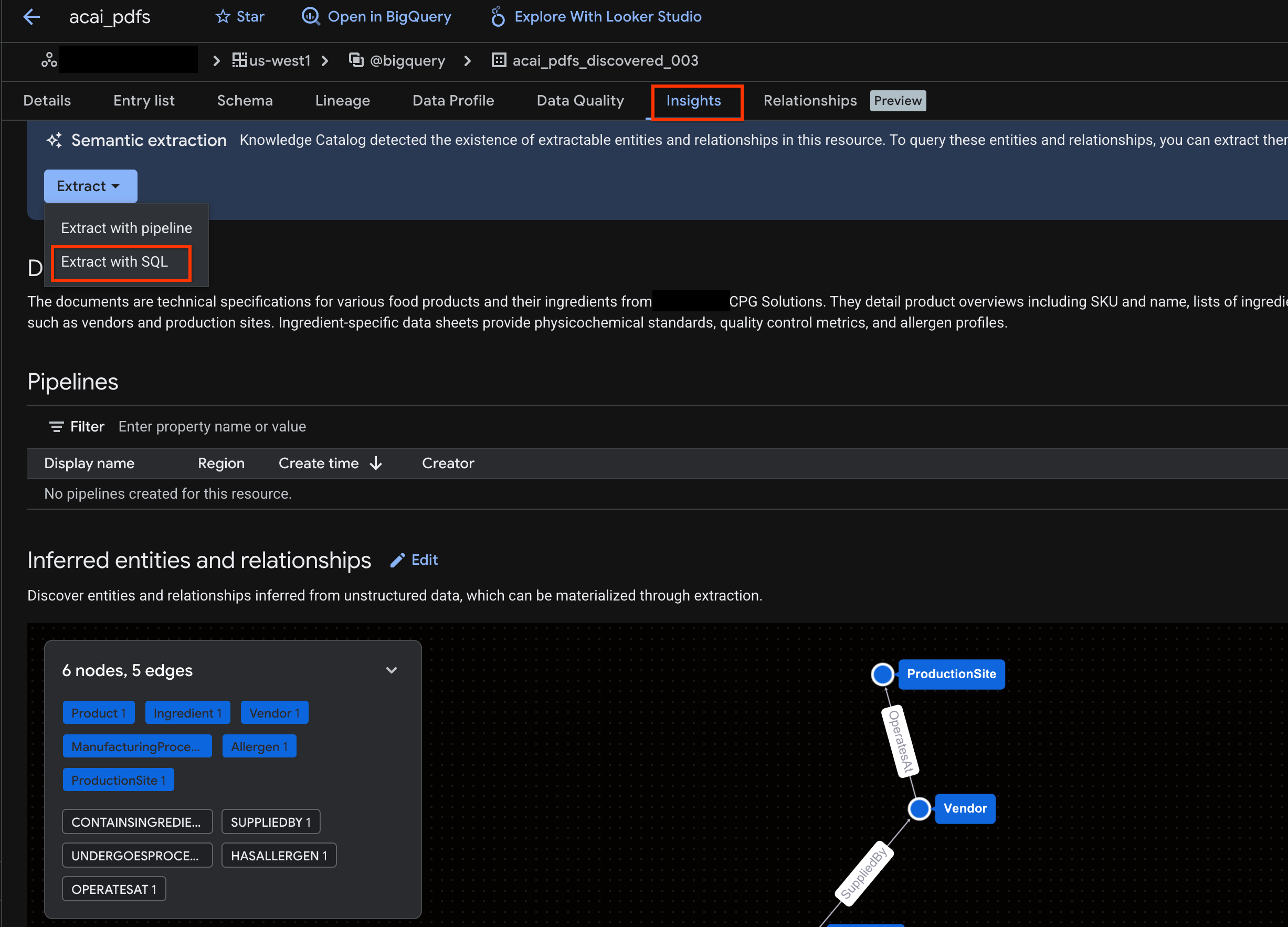
- در صفحه Extract with SQL ، برای Destination ، مجموعه داده خود را وارد کنید. برای مثال،
acai_pdfs_discovered_003. - روی Extract کلیک کنید. این کار ویرایشگر BigQuery را با کوئری بارگذاری شده باز میکند.
- روی اجرا کلیک کنید. این مرحله مجموعهای از دستورات را تولید میکند و ممکن است چند دقیقه طول بکشد تا اجرا شود.
- وقتی پرس و جو کامل شد، نتایج زیر را مشاهده میکنید:
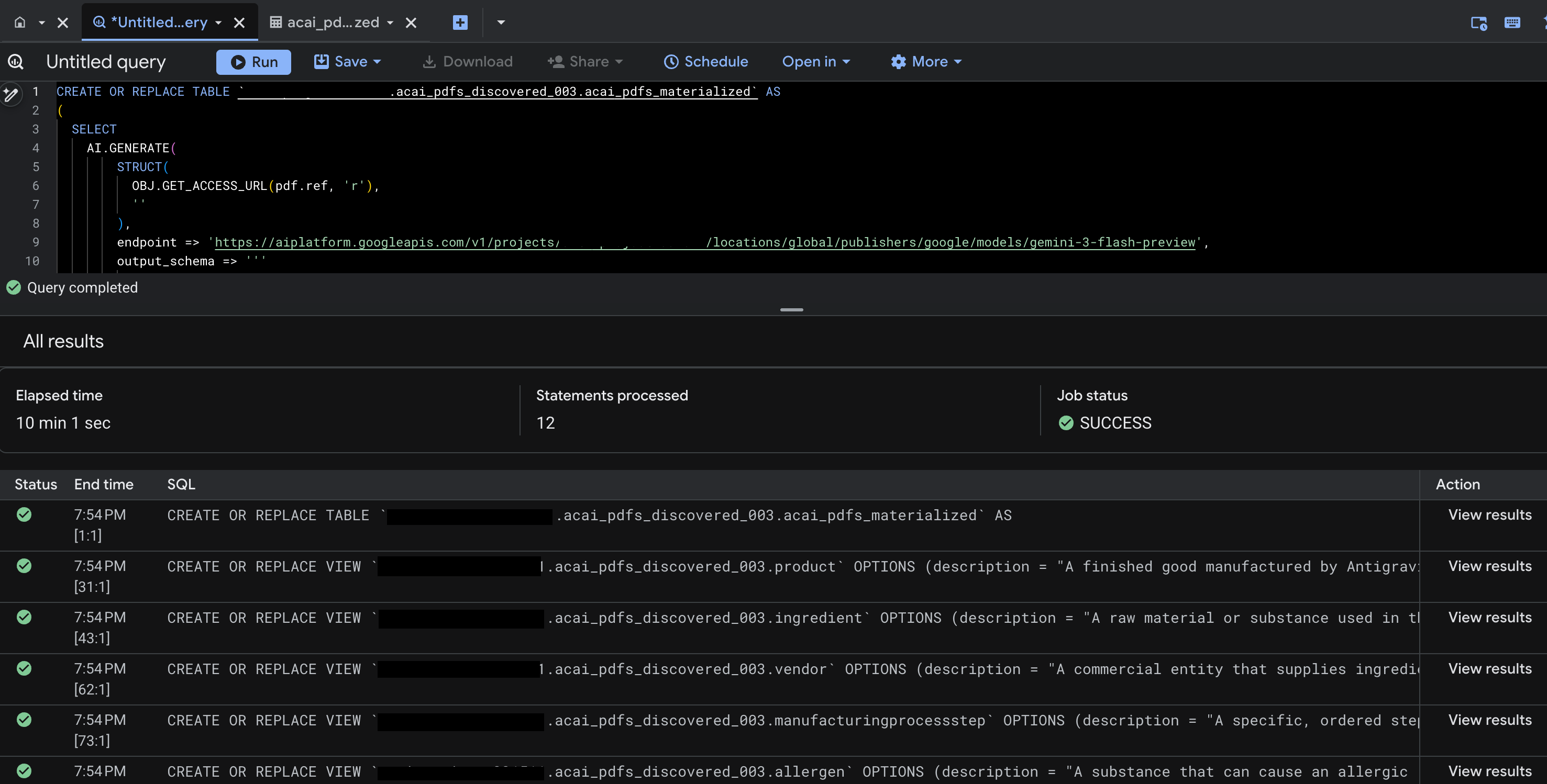
- به BigQuery بروید و روی Datasets کلیک کنید (برای مثال،
acai_pdfs_discovered_003). مجموعهای جدید از اشیاء پایگاه داده ساختاریافته در مجموعه دادهای که در مرحله ۶ انتخاب کردهاید، ایجاد میشوند.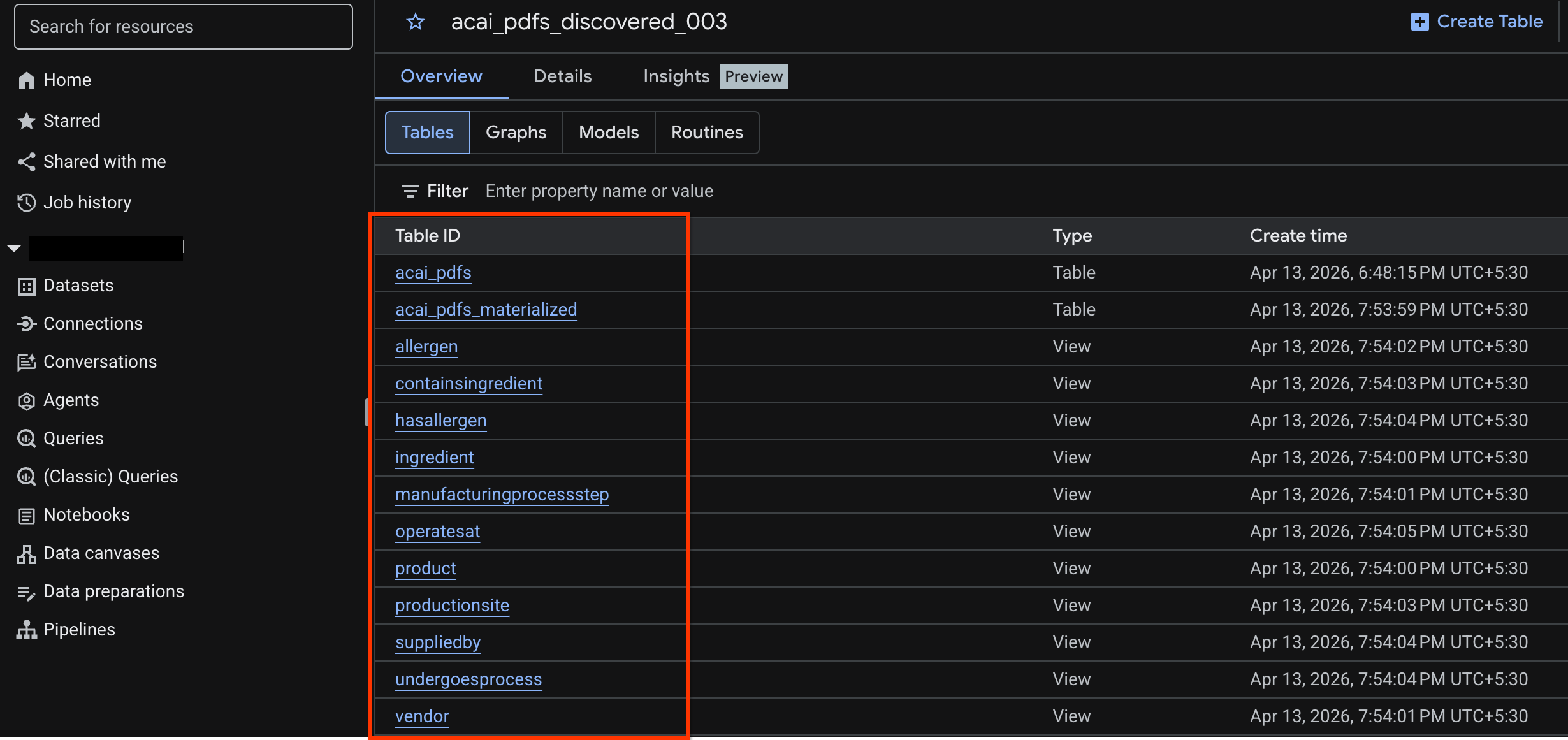
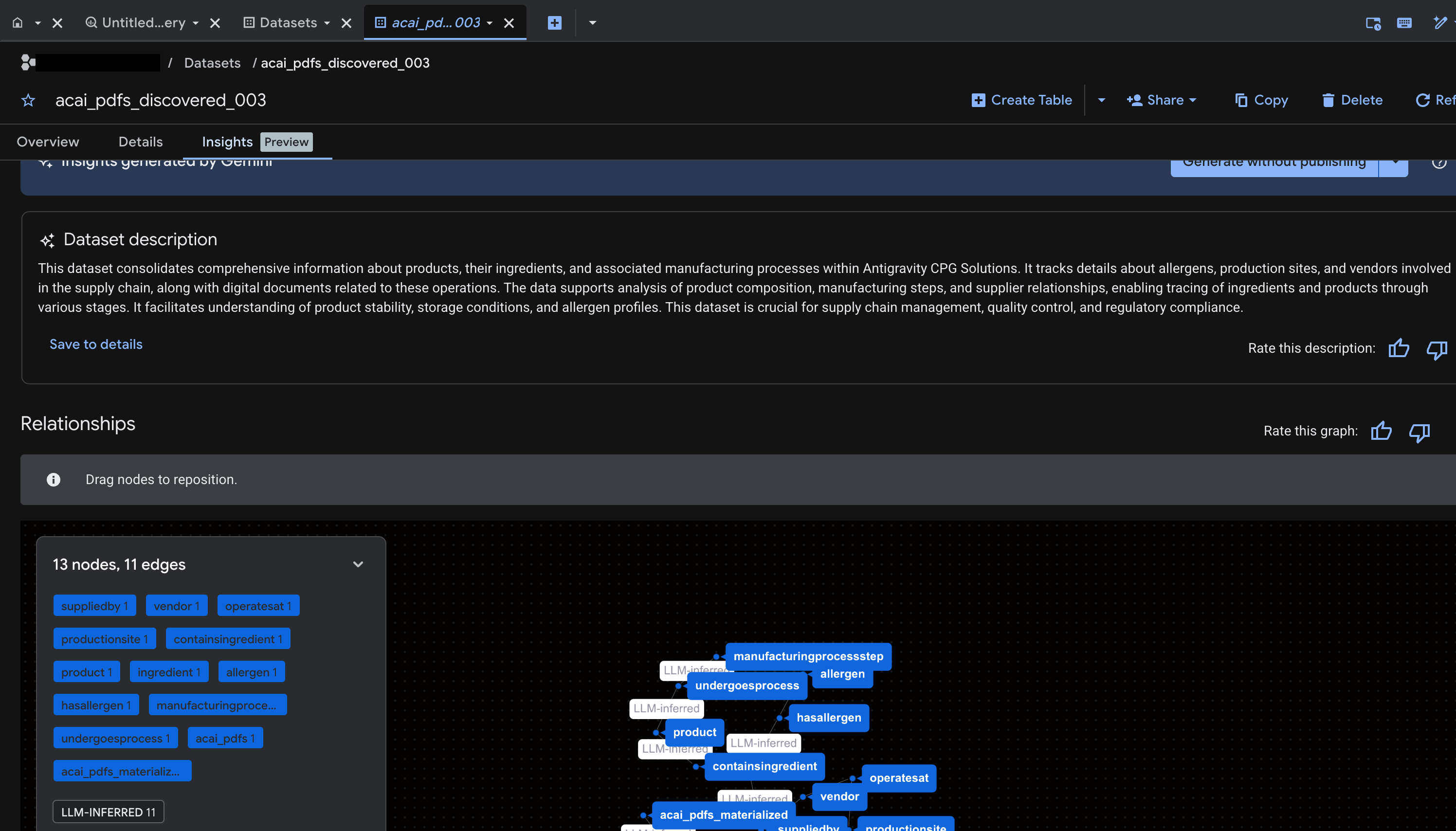
ایجاد بینش برای شیء در BigQuery
برای ایجاد بینش برای مجموعه دادههای BigQuery، باید با استفاده از BigQuery Studio به مجموعه دادهها در BigQuery دسترسی پیدا کنید.
- در کنسول گوگل کلود، به BigQuery Studio بروید.
- در پنل اکسپلورر ، پروژه را انتخاب کنید، به مجموعه دادهای که میخواهید برای آن بینش ایجاد کنید، بروید.
- روی برگه بینشها کلیک کنید.
- اگر دکمهی «فعال کردن API» را مشاهده کردید، روی آن کلیک کنید تا Gemini برای Google Cloud فعال شود. این کار پنجرهی «فعال کردن ویژگیهای اصلی» را باز میکند.
- در بخش Core feature APIs ، روی Enable for Gemini for Google Cloud API و BigQuery Unified API کلیک کنید و سپس روی Next کلیک کنید.
- در بخش مجوزها (اختیاری) ، در صورت نیاز، نقشهای IAM را به مدیران اعطا کنید و سپس روی Next کلیک کنید.
- برای تولید بینش و انتشار آنها در کاتالوگ دانش، روی «تولید و انتشار» کلیک کنید.
- پس از انتشار، میتوانید اطلاعات آماری را در برگه مشاهده کنید.
۱۱. محیط توسعه یکپارچه (IDE) خود را برای تجزیه و تحلیل دادههای عاملمحور تنظیم کنید
افزونه Google Cloud Data Agent Kit برای Visual Studio Code یک افزونه IDE برای دانشمندان داده و مهندسان داده است. این افزونه به شما امکان میدهد مستقیماً از طریق IDE به منابع و دادههای Google Data Cloud خود متصل شده و با آنها کار کنید. برای اطلاعات بیشتر، به نمای کلی افزونه Data Agent Kit برای VS Code مراجعه کنید.
افزونه Data Agent Kit برای VS Code زمانی مفید است که بخواهید موارد زیر را انجام دهید:
- ساخت، آزمایش، بررسی و استقرار یک خط لوله داده آماده برای تولید، مانند Spark ETL یا BigQuery ETL، مستقیماً از VS Code.
- دادهها را کاوش کنید، یک خط لوله آموزشی بسازید، مدلهای بهینه یادگیری ماشین را شناسایی کنید و آنها را با استفاده از کمک هوش مصنوعی به یک نقطه پایانی تولید مستقر کنید.
- به منابع دادهی قابل اعتماد متصل شوید، یک مدل داده با کارایی بالا بسازید و یک داشبورد تعاملی برای ذینفعان کسبوکار منتشر کنید.
افزونه Data Agent Kit را برای VS Code نصب کنید
- کد VS را باز کنید.
- رابط خط فرمان گوگل کلود (Google Cloud CLI) را نصب کنید. برای اطلاعات بیشتر، به «نصب رابط خط فرمان گوگل کلود» مراجعه کنید.
- افزونه Data Agent Kit را برای VS Code نصب کنید .
- فرآیند پذیرش افزونه را که مستلزم موارد زیر است، به پایان برسانید:
- وارد افزونه شوید
- مهارتهای نصب، سرورهای MCP
- پس از اتمام فرآیند آنبوردینگ، پنجره را مجدداً بارگذاری یا ریاستارت کنید. برای اطلاعات بیشتر، به بخش راهاندازی و پیکربندی افزونه Data Agent Kit برای VS Code مراجعه کنید.
- پس از بارگذاری مجدد IDE، روی آیکون Google Data Cloud در پنل ناوبری کلیک کنید، به تنظیمات بروید و مطمئن شوید که شناسه پروژه و منطقه (
us-west1) خود را در تنظیمات عمومی به درستی تنظیم کردهاید.
تنظیم فضای کاری در VS Code
- VS Code را باز کنید و File > Open folder > New folder را انتخاب کنید.
- یک پوشه جدید با نام
acai_testایجاد کنید و سپس روی Open کلیک کنید. VS Code اکنون پوشهای را که باز کردهاید، یک فضای کاری در نظر میگیرد. - در پنجرهی اعتماد به فضای کاری ، گزینهی «بله، من به نویسندگان اعتماد دارم» را انتخاب کنید تا تمام ویژگیها در فضای کاری فعال شوند.
- یک پوشه
.githubدر فضای کاریacai_testایجاد کنید. - یک فایل جدید
copilot-instructions.mdدر پوشه.githubایجاد کنید و قوانین زیر را در آن وارد کنید.## 1. Project Context - **Project ID**: <PROJECT_ID> - **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors. - **Documentation**: Raw PDF documents detailing flavors and ingredients are stored in Google Cloud Storage at `gs://<BUCKET_NAME>`. ## 2. Execution & Data Processing Rules - **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `<BQ_DATASET_NAME>` (referred to as the Knowledge Catalog). - **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the dataset `<DATASET_ID>`. When you are referencing a dataset, ensure you are using it with the project ID (`<PROJECT_ID>`) and namespace prefix `<NAMESPACE_NAME>`. For example, to query order table in this dataset you should use `<PROJECT_ID>.<NAMESPACE>.<DATASET_ID>.orders`. - **CRITICAL RULE - Data Joins between BigQuery dataset and Iceberg dataset**: ANY task requiring a join or integration between the BigQuery datasets `<DATASET_ID>` of the PDF data and the `<DATASET_ID>` of the customer data MUST be executed using **Spark Notebooks**. - **CRITICAL RULE - Notebook Kernel**: Every Spark notebook utilized MUST exclusively be configured to run on the Serverless Session template `iceberg-federation-template` as its kernel. - **CRITICAL RULE - Data Science**: ANY data science, machine learning, or advanced analytical task MUST be performed strictly within **Spark Notebooks** using the aforementioned setup. - یک فایل جدید دیگر
template.yamlدر فضای کاریacai_testایجاد کنید و اطلاعات زیر را در آن وارد کنید.labels: client: "vscode" jupyterSession: displayName: "iceberg-federation-template" kernel: "PYTHON" environmentConfig: executionConfig: serviceAccount: "sa-spark-dev1@<PROJECT_ID>.iam.gserviceaccount.com" subnetworkUri: "projects/<PROJECT_ID>/regions/<REGION>/subnetworks/<SUBNET_NAME>" runtimeConfig: version: "2.3" properties: # This enables the secure proxy URL you were looking for dataproc.tier: "premium" spark.dataproc.engine: "lightningEngine" spark.dataproc.lightningEngine.runtime: "native" spark.memory.offHeap.enabled: "true" spark.memory.offHeap.size: "1g" spark.executor.memory: "4g" "dataproc.component.gateway.enabled": "true" "dataproc.jupyter.listen.all.interfaces": "true" "spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" "spark.sql.defaultCatalog": "<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>": "org.apache.iceberg.spark.SparkCatalog" "spark.sql.catalog.<CATALOG_NAME>.type": "rest" "spark.sql.catalog.<CATALOG_NAME>.uri": "<CATALOG_URI_ID>" "spark.sql.catalog.<CATALOG_NAME>.warehouse": "bl://projects/<PROJECT_ID>/catalogs/<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>.rest.auth.type": "org.apache.iceberg.gcp.auth.GoogleAuthManager" - در VS Code، روی ترمینال کلیک کنید و دستور زیر را برای وارد کردن فایل
template.yamlبه عنوان الگوی جلسه اجرا کنید. این الگو بعداً توسط عامل برای ایجاد جلسه Spark استفاده میشود.gcloud beta dataproc session-templates import iceberg-federation-template \ --source=template.yaml \ --location=<REGION>REGIONمنطقهی خودتان را بنویسید.
۱۲. انجام تحلیل عاملی دادهها
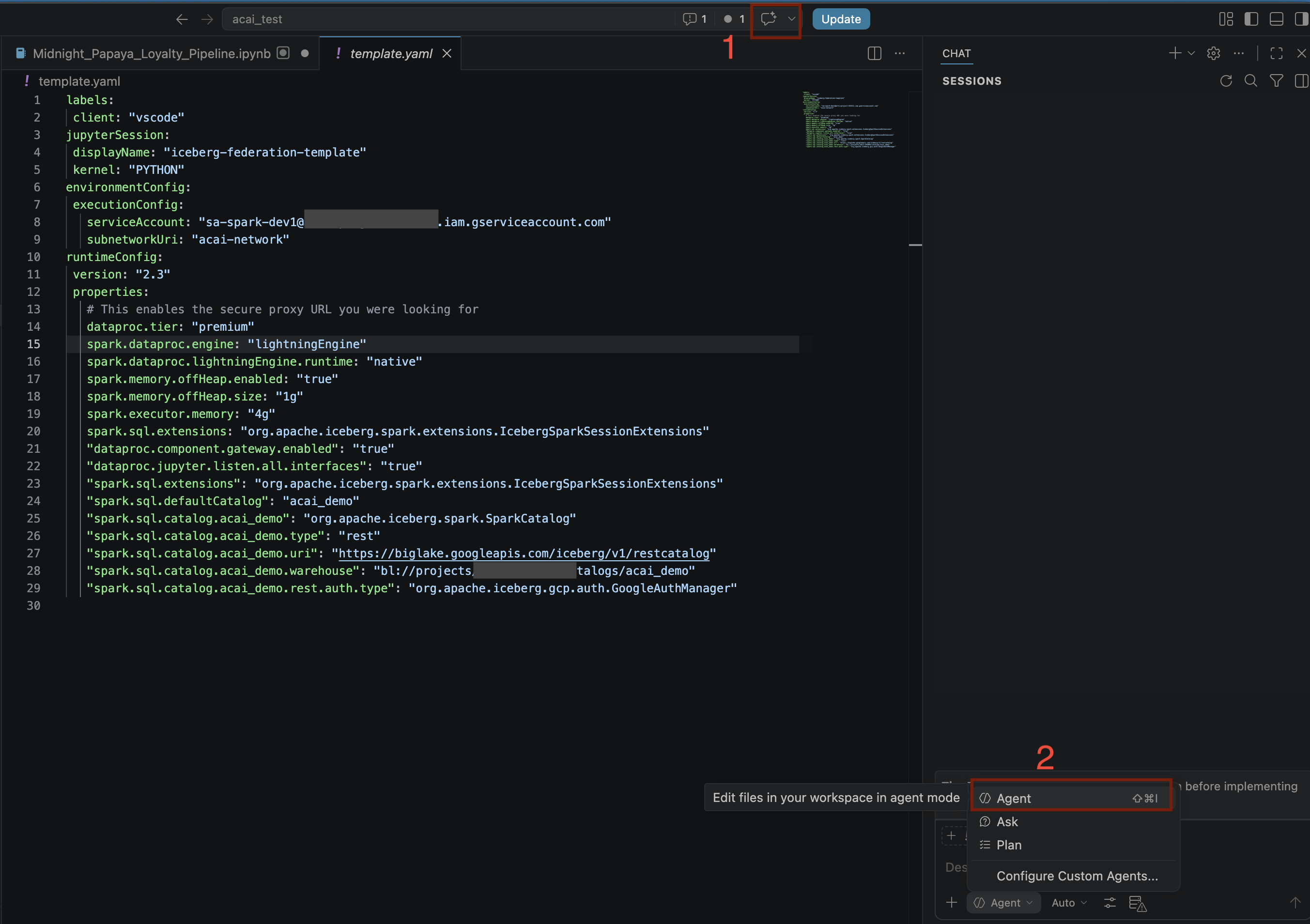
- در ویرایشگر VS Code، روی گزینهی «Toggle chat» کلیک کنید.
- برای پیکربندی عاملهای سفارشی ، عامل را انتخاب کنید.
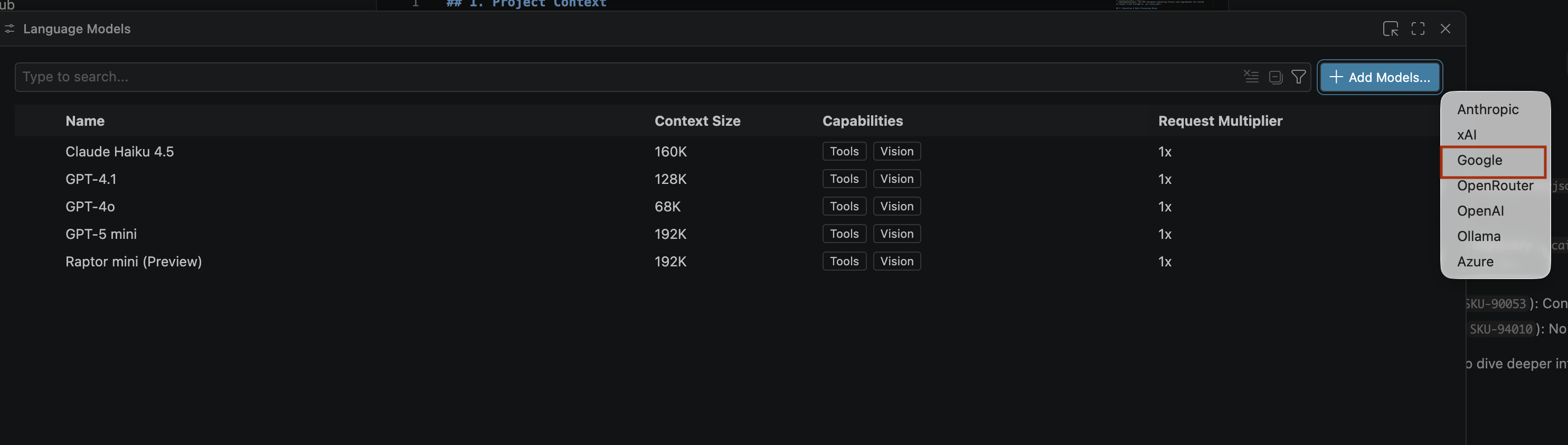
- در صفحه «جستجوی مدلها» ، روی «مدیریت مدلهای زبان» کلیک کنید.
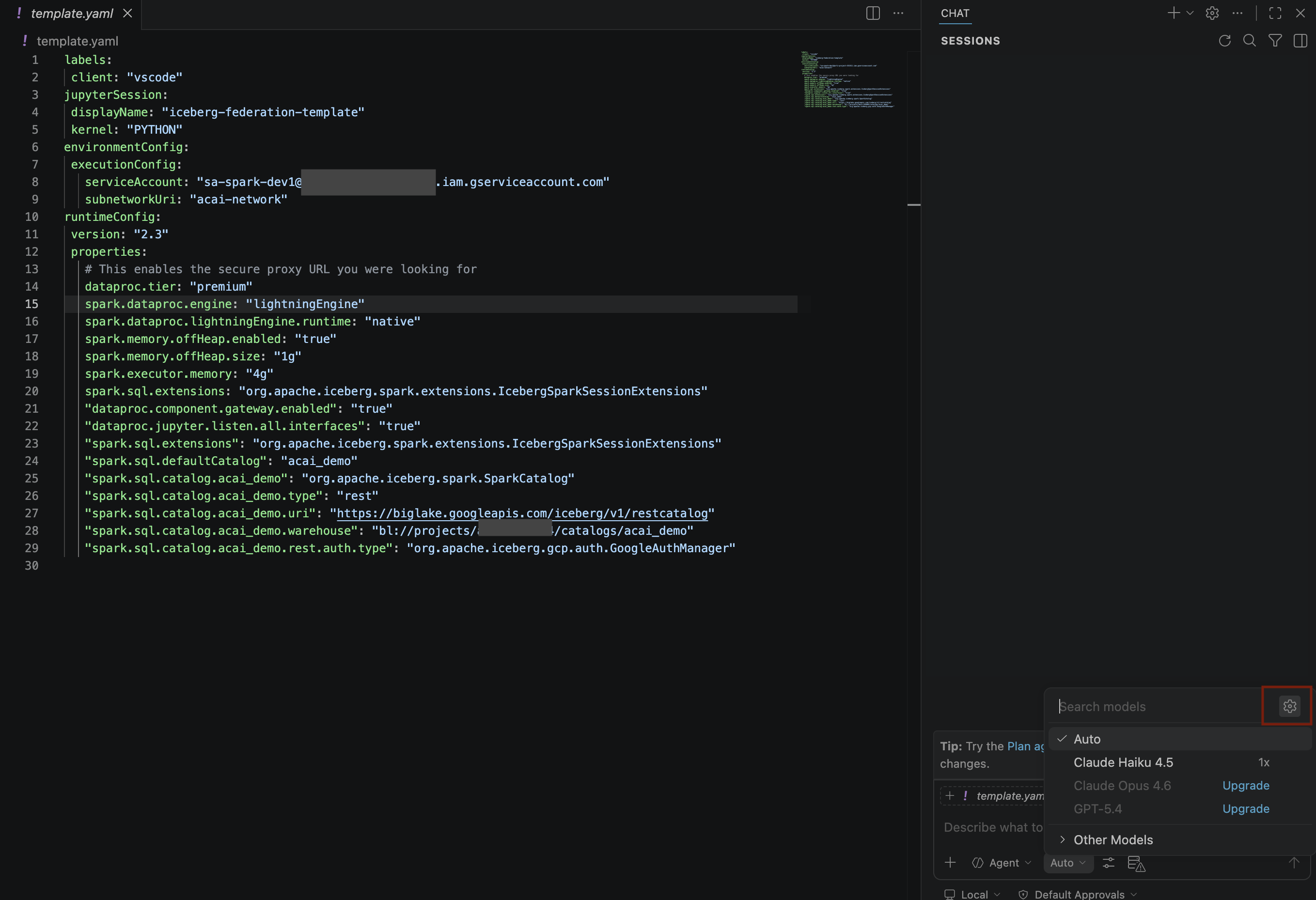
- در صفحه مدلهای زبان ، روی افزودن مدلها کلیک کنید.
- گوگل را از لیست انتخاب کنید و برای تأیید ورودی خود، Enter را فشار دهید.
- برای وارد کردن کلید API برای Google Gemini، مراحل زیر را انجام دهید:
- به وبسایت استودیوی هوش مصنوعی گوگل بروید.
- با حساب گوگل خود وارد شوید.
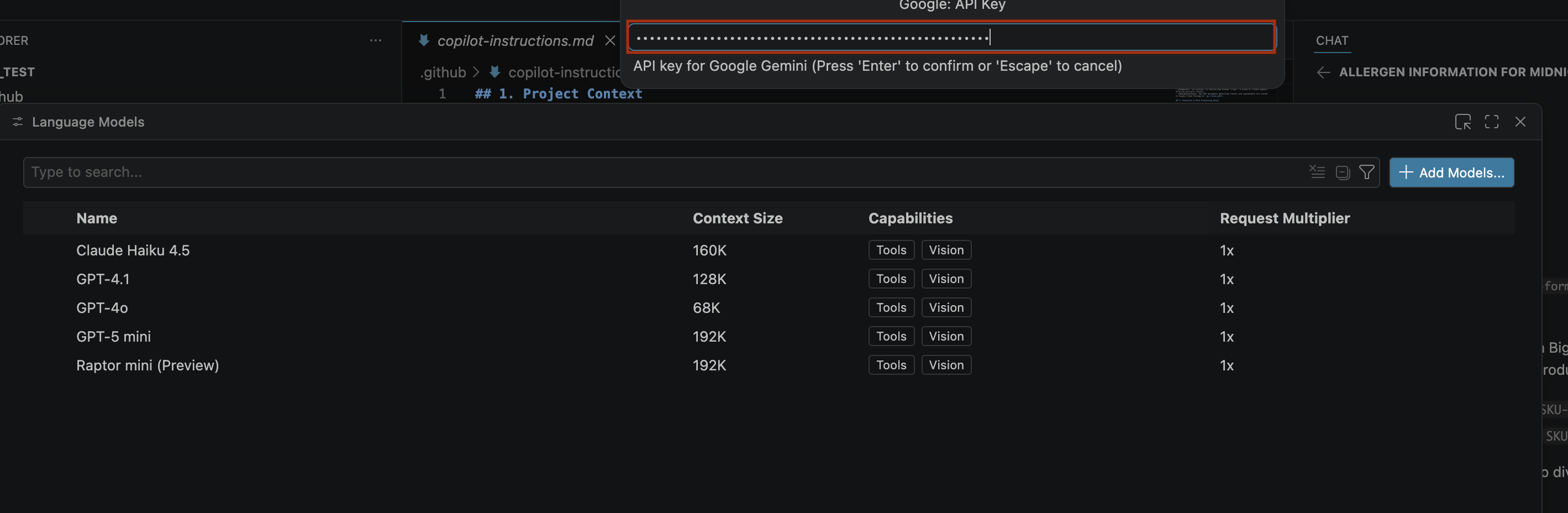
- در نوار کناری، روی دریافت کلید API کلیک کنید.
- روی «ایجاد کلید API» کلیک کنید. صفحه «ایجاد یک کلید جدید» باز میشود.
- از فهرست «انتخاب یک پروژه ابری» ، «وارد کردن پروژه» را انتخاب کنید.
- نام یک پروژه موجود را وارد کنید.
- روی ایجاد کلید کلیک کنید و کلید API را کپی کنید. این کلید دسترسی به منابع API حساب Gemini شما را فراهم میکند. برای اطلاعات بیشتر، به استفاده از کلیدهای API Gemini مراجعه کنید.
- کلید API که ایجاد کردهاید را در نوار جستجو جایگذاری کنید و روی Enter کلیک کنید.
- اگر مدلهای Gemini نمایش داده نمیشوند، آنها را مطابق تصویر زیر از حالت مخفی خارج کنید:
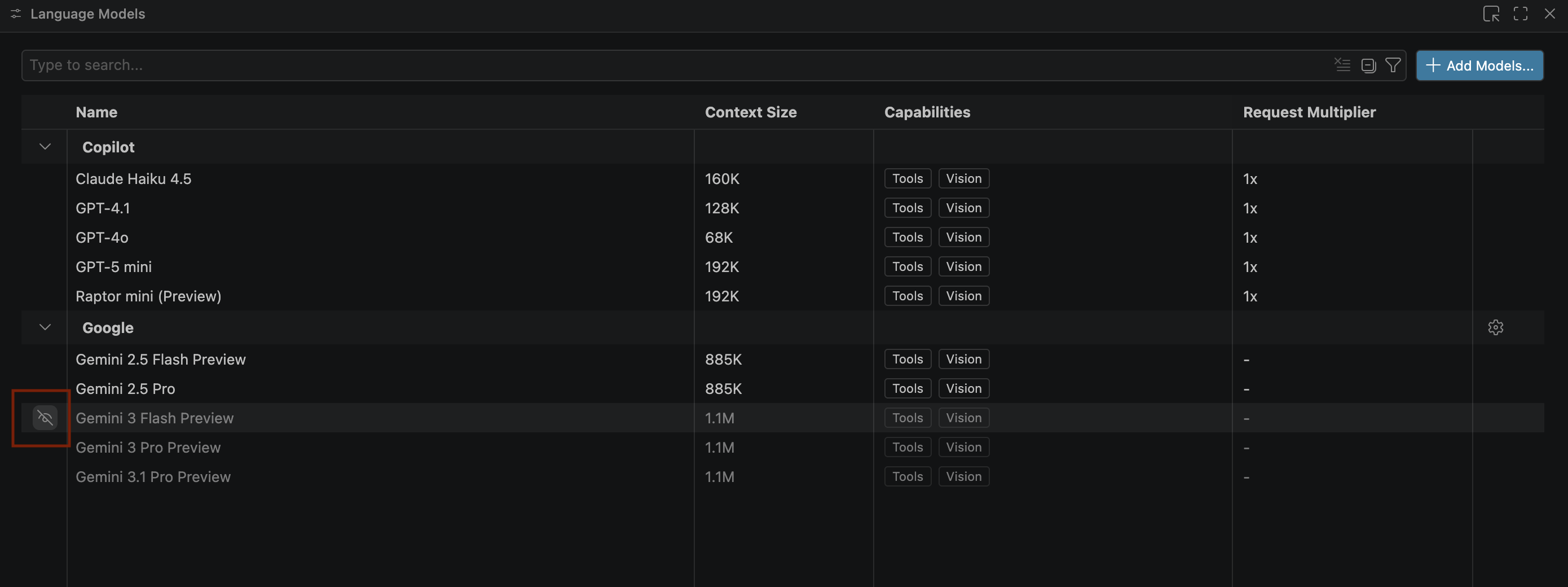
- پیشنمایش Gemini 3.1 Pro را از فهرست مدلهای Google Gemini انتخاب کنید و پنجره مدلهای زبان را ببندید.
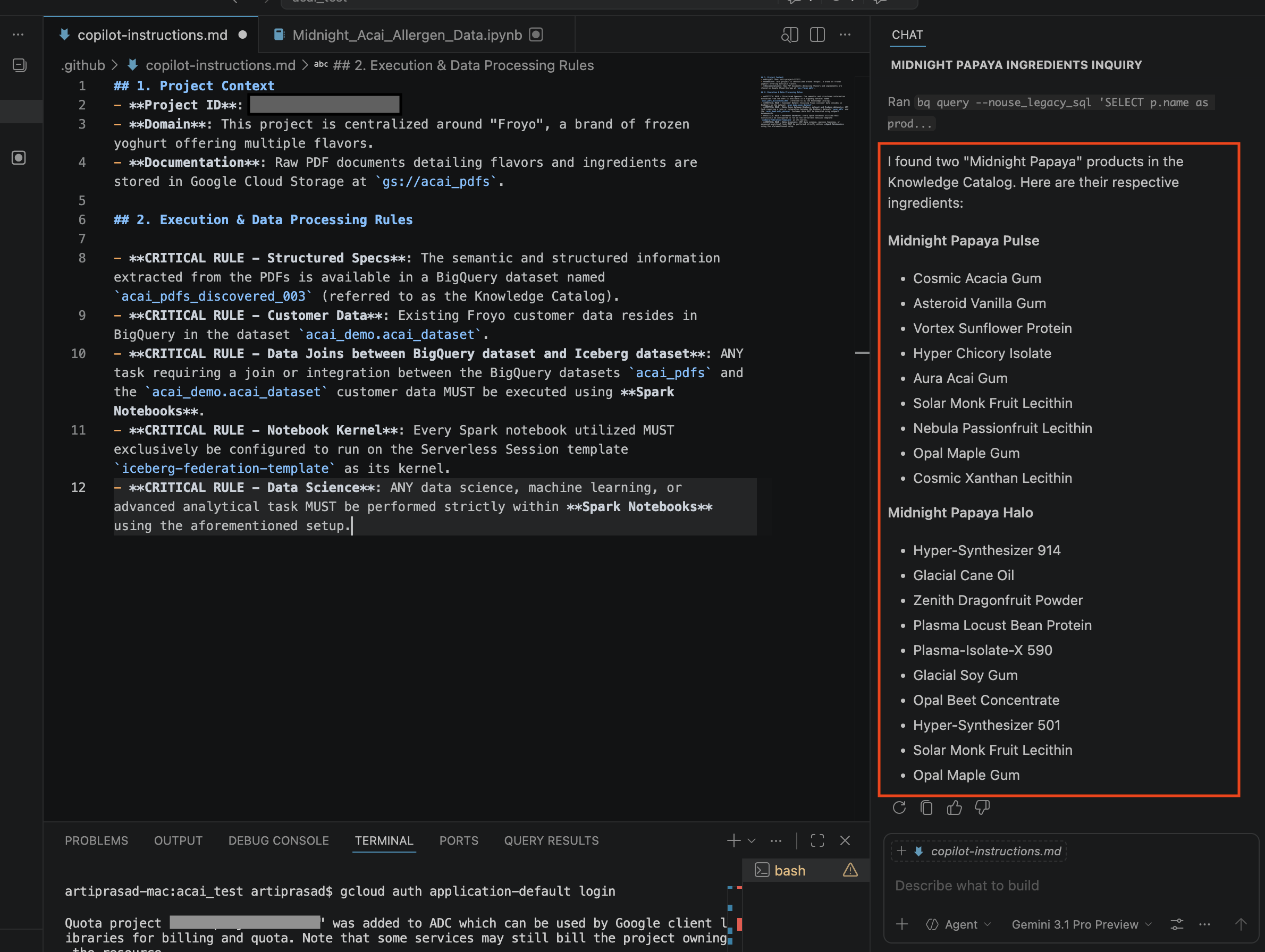
- در پنجره چت، سوال زیر را وارد کنید:
Search ingredients for Midnight papaya - پس از کمی تعامل، باید نتیجه زیر را مشاهده کنید:
- در پنجره چت، سوال دیگری را وارد کنید:
Search allergen information for Midnight papaya - پس از انجام برخی تعاملات و مراحل، همانطور که در تصویر زیر مشاهده میکنید، خواهید دید که عامل با نام آلرژن
Soyپاسخ میدهد: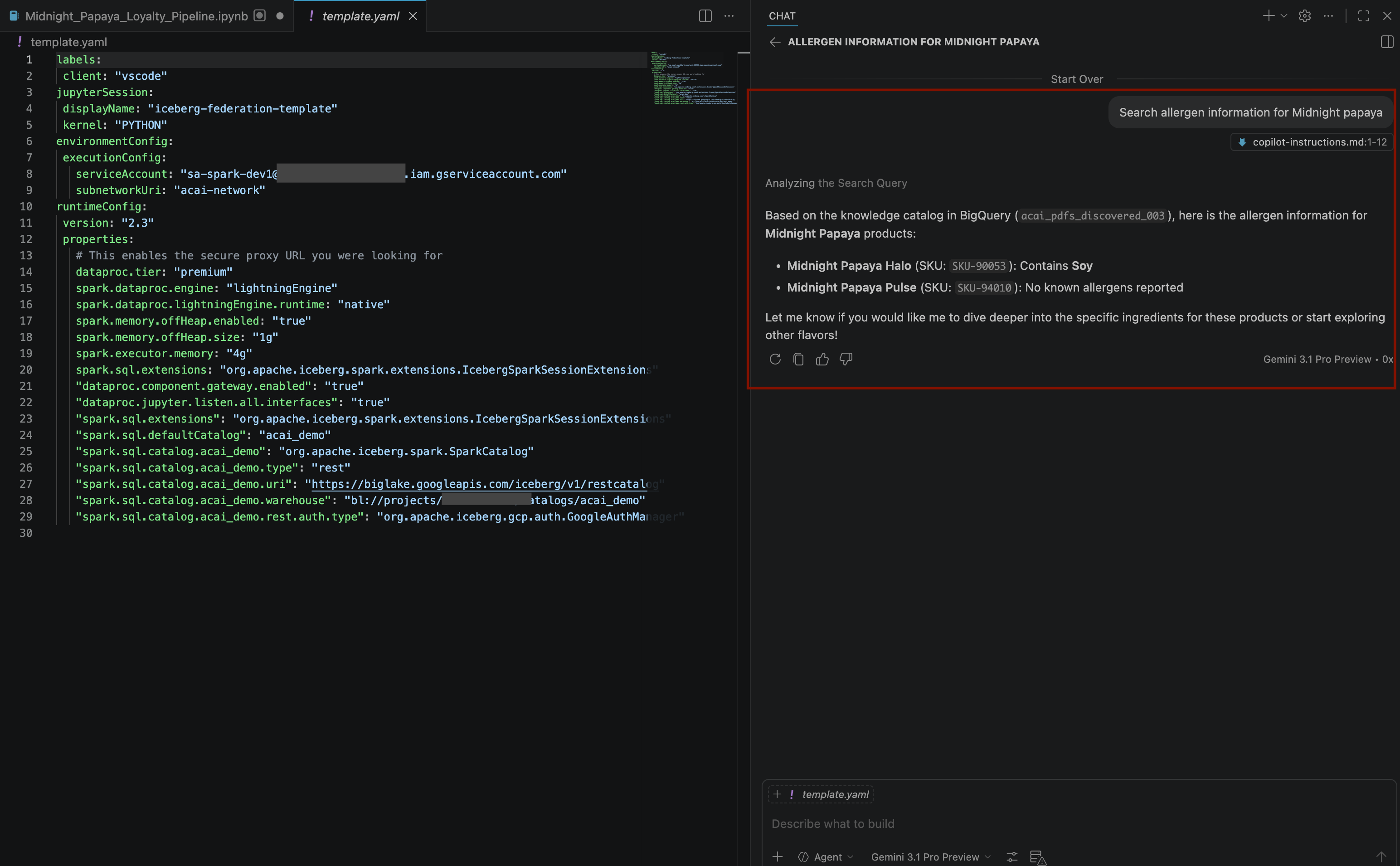
- در پنجره چت، سوال دیگری را وارد کنید:
Build a pipeline to join products with our 'Global Loyalty' Iceberg tables in acai customer, sales data to identify popular products - برای انتخاب کرنل، فایل
.ipynbرا باز کنید و روی Select kernel > Remote spark kernels > Iceberg-federation-template در serverless spark کلیک کنید.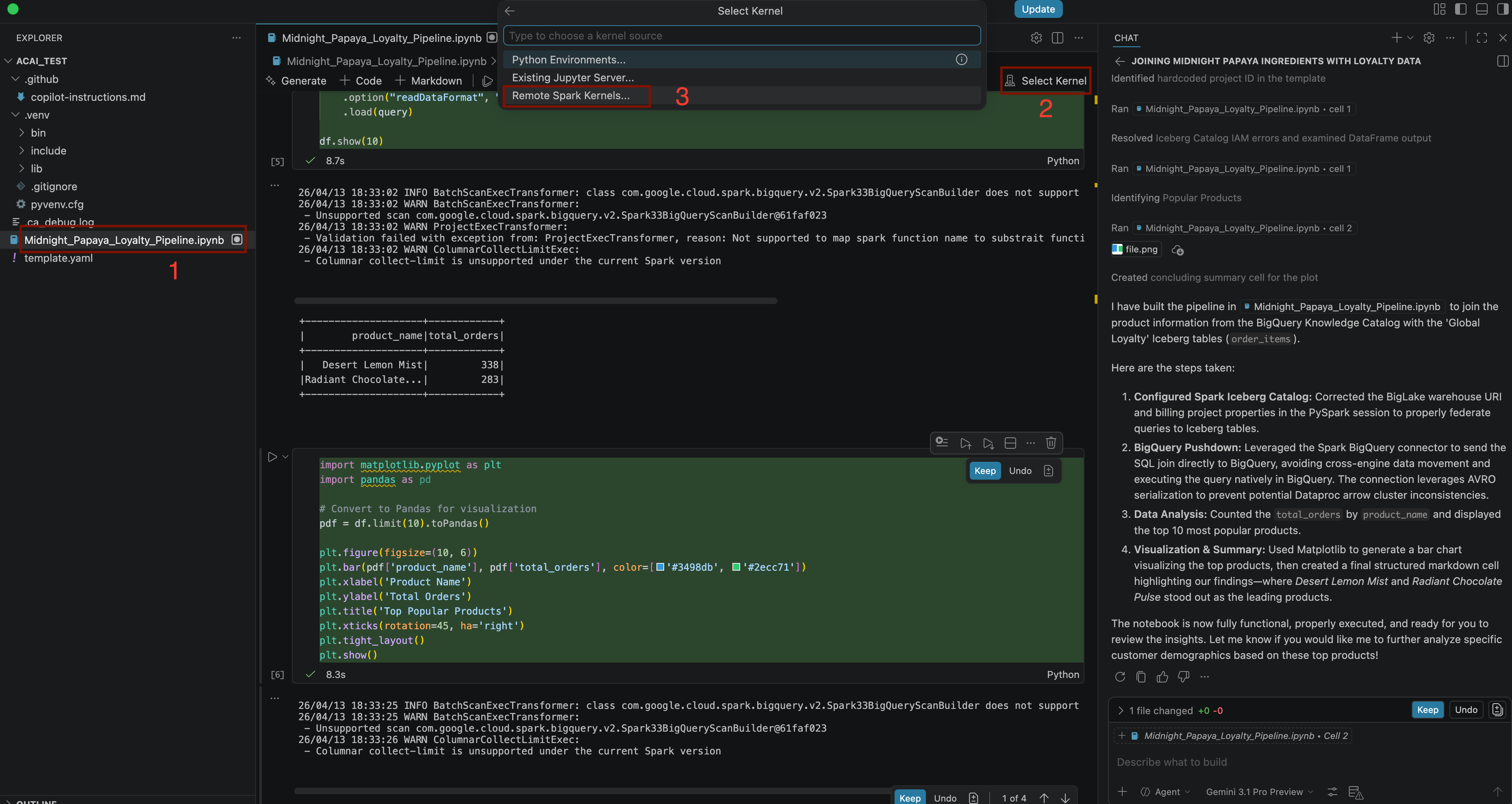
- پس از انجام برخی تعاملات و مراحل، خواهید دید که عامل با موفقیت تمام مراحل موجود در دفترچه یادداشت را به همراه نتیجه نهایی تولید شده در انتهای دفترچه یادداشت، همانطور که در تصویر زیر مشاهده میکنید، پاسخ میدهد:
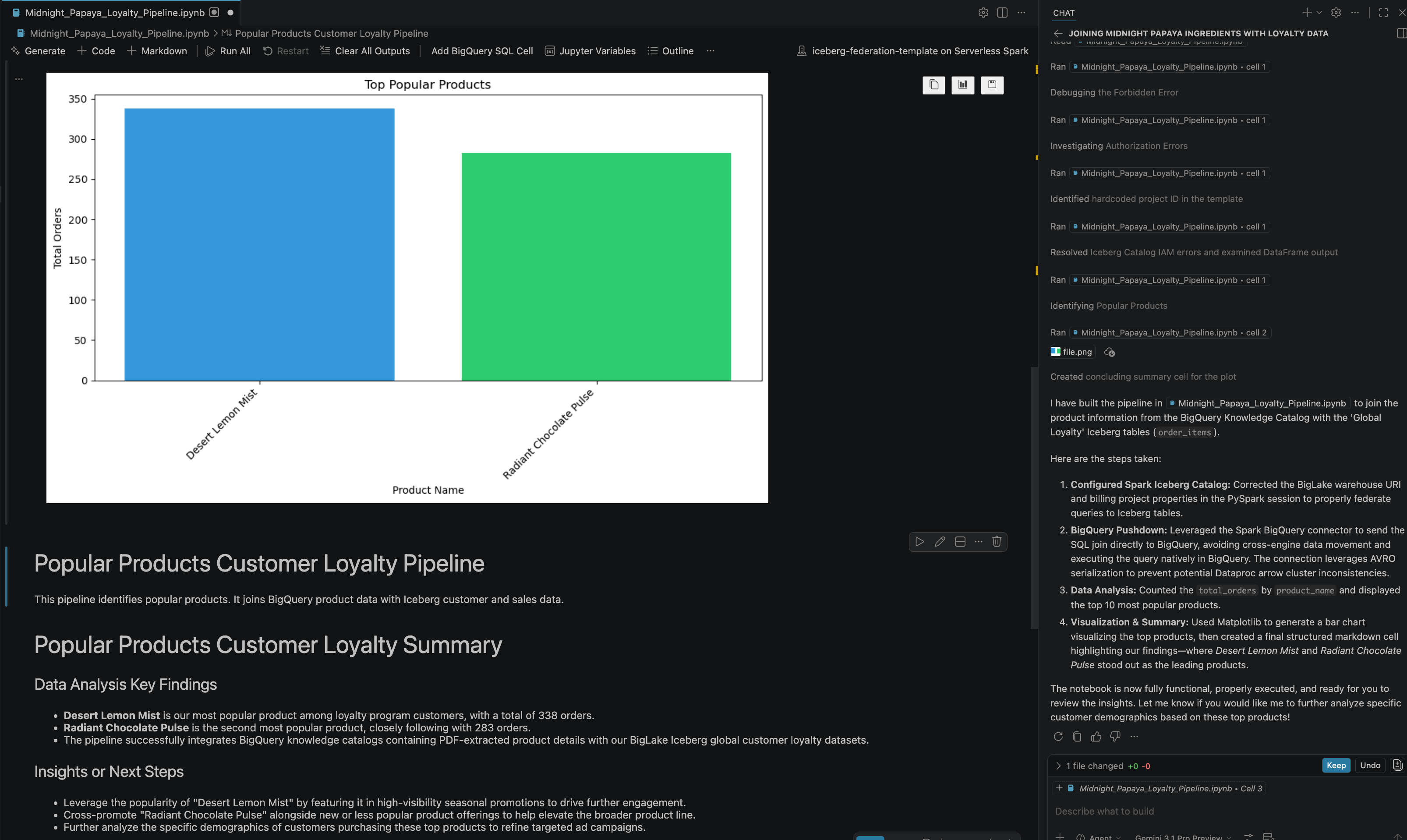
۱۳. تمیز کردن
برای جلوگیری از تحمیل هزینه، منابعی را که در این آزمایشگاه ایجاد کردهاید حذف کنید.
- برای حذف DataScan کاتالوگ دانش، دستور زیر را اجرا کنید:
DATASCAN_ID="<DATASCAN_ID>" echo "Deleting Dataplex DataScan: ${DATASCAN_ID}" gcloud dataplex datascans delete "${DATASCAN_ID}" --location="${REGION}" --quiet - برای حذف سطلهای ذخیرهسازی ابری و تمام محتویات آنها، دستور زیر را اجرا کنید:
echo "Deleting Cloud Storage buckets: <BUCKET_NAME1> and <BUCKET_NAME2>" gsutil -m rm -r gs://<BUCKET_NAME1> gsutil -m rm -r gs://<BUCKET_NAME2> - برای حذف BigQuery Connection، دستور زیر را اجرا کنید:
CONNECTION_ID="<CONNECTION_NAME>" echo "Deleting BigQuery Connection: ${CONNECTION_ID}" bq rm --connection "${PROJECT_ID}.${REGION}.${CONNECTION_ID}" - برای حذف کاتالوگ Lakehouse، دستور زیر را اجرا کنید:
CATALOG_ID="<CATALOG_NAME>" echo "Deleting Lakehouse Catalog: ${CATALOG_ID}" gcloud biglake catalogs delete "${CATALOG_ID}" --project="${PROJECT_ID}" --location="${REGION}" --quiet - برای حذف مجموعه داده حاوی جداول PDF کشف شده، دستور زیر را اجرا کنید:
DATASET_NAME="<DATASET_NAME>" echo "Deleting BigQuery Dataset: ${DATASET_NAME}" bq rm -r -f "${PROJECT_ID}:${DATASET_NAME}" - برای حذف حساب کاربری سرویس سفارشی، دستور زیر را اجرا کنید:
SERVICE_ACCOUNT="<SERVICE_ACCOUNT>" echo "Deleting Service Account: ${SERVICE_ACCOUNT}" gcloud iam service-accounts delete "${SERVICE_ACCOUNT}"@"${PROJECT_ID}".iam.gserviceaccount.com --quiet - برای حذف شبکه VPC، دستور زیر را اجرا کنید:
VPC_NETWORK="<VPC_NETWORK>" echo "Deleting VPC Network: ${VPC_NETWORK}" gcloud compute networks delete "${VPC_NETWORK}" --quiet - برای حذف کل پروژه Google Cloud، دستور زیر را اجرا کنید:
gcloud projects delete "${PROJECT_ID}"
۱۴. تبریک
تبریک! شما با موفقیت چشمانداز دادههای فایلهای PDF و Parquet را در جداول BigQuery سازماندهی کرده و آن را در یک اکوسیستم واحد، قابل جستجو و قابل اتصال قرار دادهاید. شما اساساً یک Data Lakehouse مدرن ساختهاید که با فایلهای PDF و فرمتهای کلان داده به همان اندازه هوشمندانه که با یک ردیف در پایگاه داده رفتار میکند، رفتار میکند. و شما همه این کارها را مستقیماً از طریق نماینده خود در یک تجربه مکالمه با Gemini انجام دادهاید.
اسناد مرجع
برای بررسی عمیقتر فناوریهای اصلی مورد استفاده در این آزمایشگاه کد، به مستندات رسمی Google Cloud مراجعه کنید:
- برای آشنایی با BigQuery، یکی از اجزای اصلی Data Cloud، به مستندات BigQuery مراجعه کنید.
- برای کسب اطلاعات بیشتر در مورد IAM، به مستندات IAM مراجعه کنید.
- برای آشنایی با لیکهاوس، به مقاله لیکهاوس چیست ؟ مراجعه کنید.