
1. Introduction
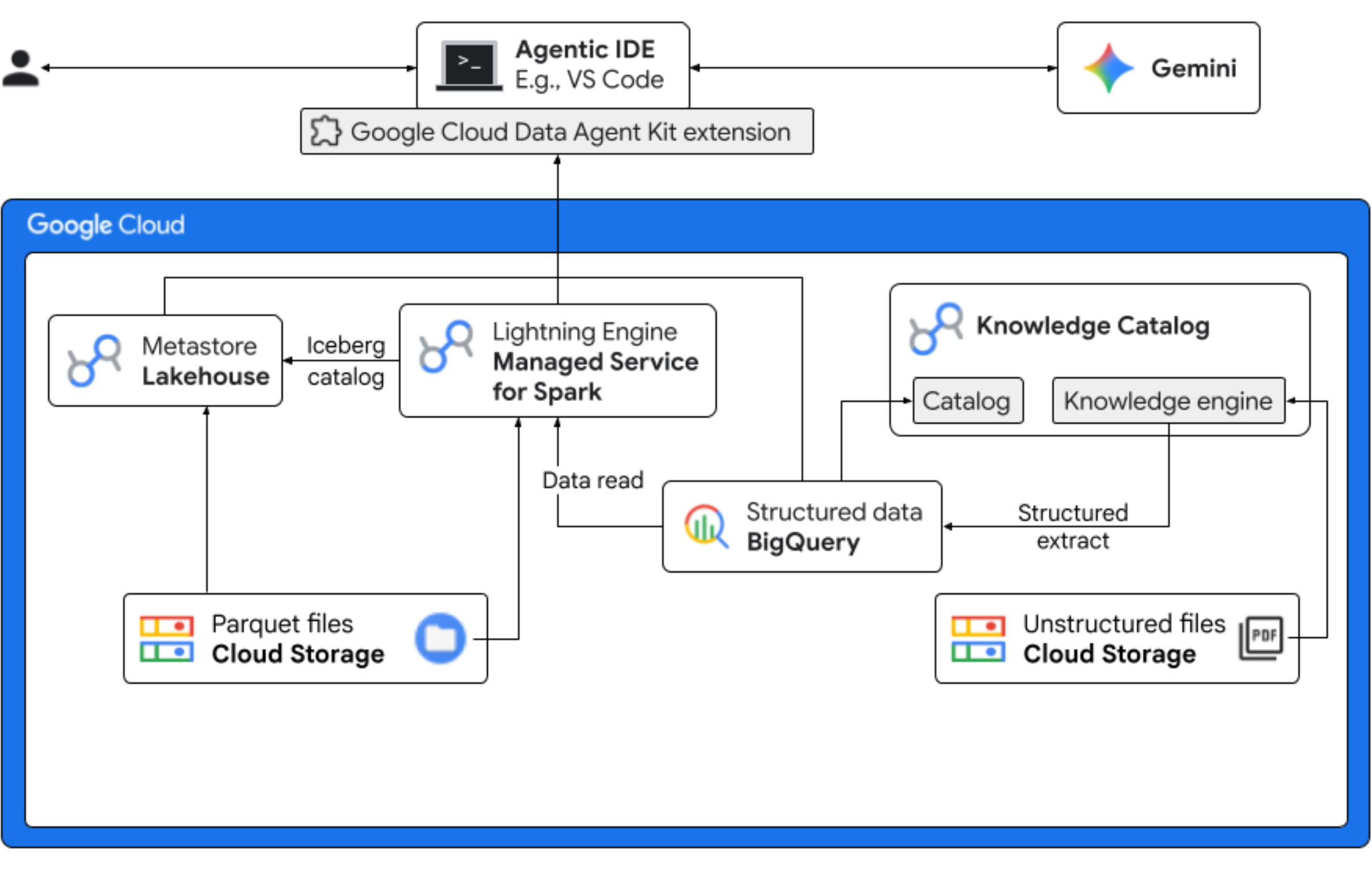
Dans cet atelier de programmation, vous allez jouer le rôle d'un data scientist pour une entreprise fictive de yaourts glacés qui lance une nouvelle saveur, "Midnight Swirl". Pour assurer le succès d'un lancement mondial, l'entreprise doit répondre à des questions essentielles concernant les ingrédients, la demande du marché et le retour sur investissement (ROI). Ce workflow de bout en bout montre comment le catalogue de connaissances de Google Cloud (anciennement Dataplex) et Lakehouse pour Apache Iceberg (anciennement BigLake) comblent le fossé entre les données non structurées "sombres" et fournissent des informations exploitables sur l'activité à l'aide de Gemini dans votre IDE (VS Code) via une couche de gouvernance unifiée.
Objectifs de l'atelier
- Découverte non structurée : les recettes PDF stockées dans Cloud Storage sont explorées par Knowledge Catalog DataScan. Créez des tables d'objets dans BigQuery pour les PDF analysés. À l'aide de l'inférence sémantique Vertex AI, le système "lit" les PDF pour extraire des informations structurées sur les produits, les allergènes, les ingrédients et les attributs associés. Il génère ensuite intelligemment un schéma pour les données stockées dans les PDF.
- Métadonnées unifiées : les données extraites des fichiers PDF sont stockées directement dans BigQuery sous forme de table large native. Des vues sont créées pour faciliter les requêtes courantes. Un ensemble de données d'entrée indépendant contenant des données de ventes historiques est stocké dans des tables Apache Iceberg sur Google Cloud Storage. Cette table Iceberg sera jointe aux données extraites dans BigQuery lors d'une étape ultérieure.
- Analyses inter-moteurs : en utilisant Managed Service pour Apache Spark (anciennement Dataproc) avec un catalogue REST Iceberg, vous allez joindre ces métadonnées PDF récentes et les données sémantiques structurées inférées (à partir des tables et vues BigQuery) avec les données de vente structurées stockées dans les tables Apache Iceberg sur Google Cloud Storage. Cela est régi par un modèle de session interactive Managed Apache Spark utilisé comme noyau de notebook Jupyter, qui garantit des paramètres de sécurité et de calcul cohérents pour le job Spark.
- Insights sémantiques : en associant les données produit inférées aux données client et de vente (dans BigQuery), la démo est en mesure d'extraire des insights tels que l'identification des données sur les allergènes et les prévisions de revenus.
- Gouvernance autonome : l'ensemble du cycle de vie, des analyses de découverte à l'exécution Spark, est orchestré à l'aide de modèles, d'instructions, de règles et d'une automatisation basée sur des agents compatibles avec Gemini. Cela prouve que l'IA peut gérer l'infrastructure qui alimente l'analyse.
Prérequis
La participation à cet atelier de programmation peut entraîner des coûts, estimés à moins de 5 $ pour une utilisation typique. Pour obtenir des estimations détaillées des coûts en fonction de votre utilisation prévue ou des tarifs actuels, utilisez le simulateur de coût Google Cloud.
Assurez-vous de remplir les conditions préalables suivantes pour effectuer l'atelier de programmation.
- Navigateur Web Chrome.
- Un compte Gmail personnel si vous utilisez les crédits d'essai fournis dans la section "Avant de commencer".
- Téléchargez et installez Visual Studio (VS) Code.
2. Avant de commencer
Créer un projet Google Cloud
- Dans la console Google Cloud, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
Démarrer Cloud Shell
Cloud Shell est un environnement de ligne de commande exécuté dans Google Cloud et fourni avec les outils nécessaires.
- Cliquez sur Activer Cloud Shell en haut de la console Google Cloud.
- Une fois connecté à Cloud Shell, vérifiez votre authentification :
gcloud auth list - Vérifiez que votre projet est configuré :
gcloud config get project - Si votre projet n'est pas défini comme prévu, définissez-le :
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Activer les API requises
Exécutez la commande suivante pour activer toutes les API requises :
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
biglake.googleapis.com \
dataproc.googleapis.com \
metastore.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
secretmanager.googleapis.com \
storage.googleapis.com
Télécharger les ressources de l'atelier de programmation
Ce dépôt contient les fichiers Parquet, recipes, suppliers, copilot-instructions.md, template.yaml et quickstart.py à utiliser dans cet atelier de programmation. Assurez-vous de télécharger ces fichiers.
Pour télécharger les fichiers, procédez comme suit :
- Dans Cloud Shell, exécutez la commande suivante :
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git - Accédez au dossier que vous venez de créer :
cd next-26-keynotes - Extrayez le dossier
data-cloud-demo.git sparse-checkout set genkey/data-cloud-demo - Une fois le paiement effectué, accédez au dossier
data-cloud-demoet extrayez les fichiers ZIP pour accéder aux ressources de l'atelier de programmation.
3. Configurer Lakehouse pour les données client Froyo
Dans cette section, vous allez créer un catalogue dans Lakehouse pour utiliser le metastore Lakehouse pour vos workflows. Il crée une interopérabilité entre vos moteurs de requête en offrant une source unique de vérité pour toutes vos données Iceberg. Il permet aux moteurs de requête, tels qu'Apache Spark, de découvrir, de lire les métadonnées et de gérer les tables Iceberg de manière cohérente.
Rôles requis
Assurez-vous de disposer des rôles Identity and Access Management (IAM) suivants :
roles/biglake.viewerroles/bigquery.userroles/bigquery.dataEditorroles/biglake.editorroles/biglake.metadataViewerroles/bigquery.connectionUserroles/storage.objectUserroles/storage.objectViewerroles/storage.objectCreatorroles/storage.admin
Pour en savoir plus sur l'attribution de rôles IAM, consultez Attribuer un rôle IAM.
Créer un catalogue Lakehouse avec un bucket
Créez un catalogue Lakehouse pour gérer les métadonnées de vos tables Iceberg. Vous vous connectez à ce catalogue dans votre job Spark pour créer et interroger des tables Iceberg.
- Dans la console Google Cloud, accédez à Lakehouse.
- Cliquez sur Créer un catalogue. La page Créer un catalogue s'ouvre.
- Pour Type de catalogue, sélectionnez Catalogue Iceberg REST.
- Pour Sélectionnez les options de bucket de votre catalogue Lakehouse, sélectionnez Catalogue de bucket unique.
- Pour Bucket Cloud Storage du catalogue par défaut, cliquez sur Parcourir, puis sur Créer un bucket.
- Sur la page Créer un bucket, procédez comme suit :
- Dans la section Premiers pas, saisissez un nom unique qui répond aux exigences de dénomination des buckets.
- Dans la section Choisissez où stocker vos données, sélectionnez Région pour Type d'emplacement, puis saisissez votre région. Par exemple,
us-west1. - Dans la section Choisir comment contrôler l'accès aux objets, décochez la case Appliquer la protection contre l'accès public sur ce bucket.
Cela vous permet de simuler des scénarios réels, comme l'hébergement de contenu Web public ou de dépôts de données partagés. Sans ce changement, le bucket appliquerait une règle stricte "privée uniquement". Toute tentative d'accès à vos composants entraînerait une erreur403(accès refusé), même si vous avez accordé des autorisations publiques aux fichiers. - Cliquez sur Continuer > Créer > Sélectionner > Continuer.
- Dans le champ Authentication method (Méthode d'authentification), sélectionnez Credential vending mode (Mode de distribution d'identifiants).
- Cliquez sur Créer.Votre catalogue est créé et la page Informations sur le catalogue s'ouvre.
- Sous Méthode d'authentification, cliquez sur Définir les autorisations du bucket.
- Dans la boîte de dialogue, cliquez sur Confirmer.Vous vérifiez ainsi que le compte de service de votre catalogue dispose du rôle
Storage Object Usersur votre bucket de stockage. - Sur la page Détails du catalogue, copiez le chemin d'URI du catalogue REST. Utilisez ce chemin d'accès lors de l'exécution du job Spark.
Importer les fichiers Parquet dans le bucket
Pour importer vos fichiers Parquet à la racine de votre bucket, procédez comme suit :
- Dans la console Google Cloud, accédez à la page Buckets Cloud Storage.
- Dans la liste des buckets, cliquez sur le nom du bucket. Par exemple :
acai_demo. - Dans l'onglet Objets du bucket, cliquez sur Importer > Importer des fichiers.
- Sélectionnez les fichiers du dossier Parquet que vous avez cloné dans la section Avant de commencer de cet atelier de programmation.
- Cliquez sur Open (Ouvrir).
4. Configurer le réseau VPC
Créez un réseau de cloud privé virtuel (VPC) et un sous-réseau qui permettent aux ressources de communiquer avec les API Google sans passer par l'Internet public, ainsi qu'un pare-feu qui permet au trafic interne de circuler librement entre vos nœuds de traitement des données.
- Dans la console Google Cloud, accédez à la page Réseaux VPC.
- Cliquez sur Créer un réseau VPC.
- Saisissez un Nom pour le réseau. Exemple :
acai-network - Pour configurer l'unité de transmission maximale (MTU) du réseau, cochez la case Définir automatiquement la MTU.
- Dans Mode de création du sous-réseau, sélectionnez Automatique.
- Dans la section Règles de pare-feu, cochez toutes les cases pour les règles de pare-feu IPv4.
- Cliquez sur Créer.
Activer l'accès privé à Google
Les nœuds Dataproc Serverless n'ont pas d'adresses IP publiques. Pour communiquer avec le catalogue Lakehouse et Cloud Storage, l'accès privé à Google doit être activé sur le sous-réseau.
- Dans la console Google Cloud, accédez à la page Réseaux VPC.
- Cliquez sur le nom du réseau contenant le sous-réseau pour lequel vous devez activer l'accès privé à Google. Par exemple :
us-west1. - Cliquez sur le nom du sous-réseau. La page d'informations Sous-réseau s'affiche.
- Cliquez sur Modifier.
- Dans la section Accès privé à Google, sélectionnez Activé.
- Cliquez sur Enregistrer.
5. Créer et exécuter un job Spark
Pour créer une table Iceberg et l'interroger, importez le job PySpark avec les instructions Spark SQL nécessaires. Exécutez ensuite le job avec Managed Service pour Spark.
Importer quickstart.py dans votre bucket Cloud Storage
Après avoir cloné les ressources de l'atelier de programmation, mettez à jour le script quickstart.py avec les informations de votre projet et importez-le dans le bucket Cloud Storage.
- Ouvrez le script
quickstart.pydans un éditeur de texte. - Remplacez l'espace réservé
BUCKET_NAMEdans le script par le nom de votre bucket Cloud Storage, puis enregistrez-le. - Dans la console Google Cloud, accédez à Buckets Cloud Storage.
- Cliquez sur le nom de votre bucket. Par exemple :
acai_demo. - Dans l'onglet Objets, cliquez sur Importer > Importer des fichiers.
- Dans l'explorateur de fichiers, sélectionnez le fichier
quickstart.pymis à jour, puis cliquez sur Ouvrir.
Exécuter le job Spark
Une fois le script quickstart.py importé, exécutez-le en tant que job par lot Managed Service pour Spark.
- Pour configurer les variables, exécutez la commande suivante dans Cloud Shell.
# Configuration Variables export PROJECT_ID="<PROJECT_ID>" export REGION="<REGION>" export BUCKET_NAME="<BUCKET_NAME>" export SUBNET="<SUBNET>" export LAKEHOUSE_CATALOG_ID="<LAKEHOUSE_CATALOG_ID>" export CATALOG_URI_ID="<CATALOG_URI_ID>"- LAKEHOUSE_CATALOG_ID : nom de la ressource de catalogue Lakehouse contenant votre fichier d'application PySpark. Par exemple,
acai_demo. - PROJECT_ID : ID de votre projet Google Cloud.
- REGION : région dans laquelle exécuter la charge de travail par lot Managed Service pour Spark. Exemple :
us-west1 - BUCKET_NAME : nom de votre bucket Cloud Storage. Exemple :
acai_demo - SUBNET : nom de votre sous-réseau VPC. Exemple :
acai-network - CATALOG_URI_ID : ID URI du catalogue Lakehouse que vous avez copié lors de la création d'un catalogue Lakehouse avec un bucket. Exemple :
https://biglake.googleapis.com/iceberg/v1/restcatalog
- LAKEHOUSE_CATALOG_ID : nom de la ressource de catalogue Lakehouse contenant votre fichier d'application PySpark. Par exemple,
- Dans Cloud Shell, exécutez le job par lot Managed Service for Spark suivant à l'aide du script
quickstart.py.gcloud dataproc batches submit pyspark gs://${BUCKET_NAME}/quickstart.py \ --project=${PROJECT_ID} \ --region=${REGION} \ --subnet=${SUBNET} \ --version=2.2 \ --properties="\ spark.sql.defaultCatalog=${LAKEHOUSE_CATALOG_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}=org.apache.iceberg.spark.SparkCatalog,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.type=rest,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.uri=${CATALOG_URI_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.warehouse=gs://${BUCKET_NAME},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.io-impl=org.apache.iceberg.gcp.gcs.GCSFileIO,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.x-goog-user-project=${PROJECT_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\ spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest-metrics-reporting-enabled=false,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.X-Iceberg-Access-Delegation=vended-credentials,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token"All tables registered successfully! Batch [126fa2226a904d2e944c8eecbe0b1840] finished. metadata: '@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata batch: projects/PROJECT_ID/locations/REGION/batches/126fa2226a904d2e944c8eecbe0b1840 batchUuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff createTime: '2026-04-09T13:17:26.222727Z' description: Batch labels: goog-dataproc-batch-id: 126fa2226a904d2e944c8eecbe0b1840 goog-dataproc-batch-uuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-drz-resource-uuid: batch-3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-location: REGION operationType: BATCH name: projects/PROJECT_ID/regions/REGION/operations/47bc59e8-5082-3af9-89a0-22289aa5f4b9
6. Interroger la table depuis BigQuery
En exécutant correctement le job par lot Spark, vous avez utilisé Managed Service pour Spark Serverless comme moteur de calcul distribué pour enregistrer plusieurs tables, une par fichier Parquet dans le metastore Lakehouse. Cette inscription permet à Google Cloud de traiter vos fichiers bruts dans Cloud Storage comme des tables structurées et hautes performances.
Les étapes suivantes vous guident pour vérifier que les métadonnées ont été correctement synchronisées. Vous vous assurez ainsi que vos données sont non seulement stockées de manière sécurisée, mais qu'elles sont également entièrement détectables et interrogeables via l'interface BigQuery.
- Dans la console Google Cloud, accédez à BigQuery.
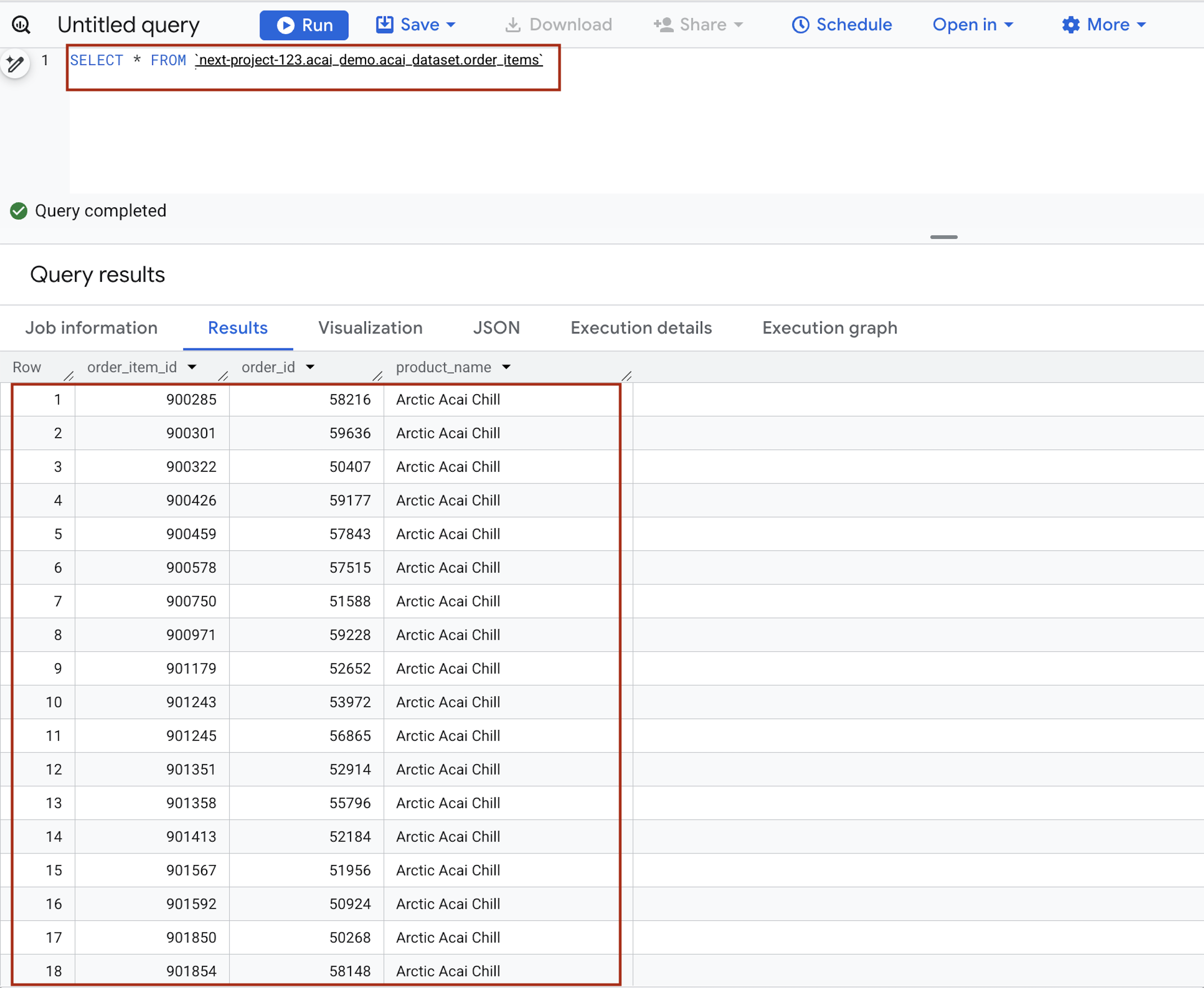
- Dans l'éditeur de requête, saisissez l'instruction suivante. La requête utilise la syntaxe
project.namespace.dataset.table.SELECT * FROM `<PROJECT_ID>.<NAMESPACE>.<ICEBERG_DATASET>.<ICEBERG_TABLE>`PROJECT_ID.acai_demo.acai_dataset.order_items.
Remplacez les éléments suivants :- PROJECT_ID : ID de votre projet Google Cloud.
- NAMESPACE : espace de noms créé à l'étape précédente à la suite de la tâche Spark. Vous le trouverez sur la page de l'explorateur d'objets BigQuery. Exemple :
acai_demo - ICEBERG_DATASET : nom de l'ensemble de données dans le catalogue Iceberg (par exemple,
acai_dataset). - ICEBERG_TABLE : nom de la table dans l'ensemble de données Iceberg, par exemple
order_items.
- Cliquez sur Exécuter. Les résultats de la requête affichent les données que vous avez insérées avec le job Spark.
7. Configurer des fichiers de données produit non structurées
Dans cette section, vous allez créer une structure organisationnelle dans BigQuery pour stocker les données sur les recettes et les fournisseurs de yaourts glacés, en particulier les informations sur les produits. Il établit également une connexion aux ressources cloud, qui sert de "pont" sécurisé permettant à BigQuery de lire les fichiers provenant de sources externes telles que Cloud Storage.
Créer un bucket et importer les fichiers de détails Froyo
Créez et importez les fichiers de fournisseurs et de recettes dans le bucket Cloud Storage.
- Dans la console Google Cloud, accédez à la page Buckets Cloud Storage.
- Cliquez sur Créer.
- Sur la page Créer un bucket, saisissez les informations concernant votre bucket. Après chacune des étapes suivantes, cliquez sur Continuer pour passer à la suivante :
- Dans la section Premiers pas, saisissez le nom du bucket. Exemple :
acai_pdfs - Dans la section Choisir où stocker vos données, sélectionnez Région, puis saisissez votre région. Par exemple,
us-west1. - Dans la section Choisir comment contrôler l'accès aux objets, décochez la case Appliquer la protection contre l'accès public sur ce bucket.
- Cliquez sur Créer.
- Dans la liste des buckets, cliquez sur celui que vous avez créé. Par exemple :
acai_pdfs. - Dans l'onglet Objets du bucket, cliquez sur Importer > Importer des dossiers.
- Sélectionnez le dossier
recipesque vous avez extrait dans la section Avant de commencer de cet atelier de programmation. - Cliquez sur Importer.
- Répétez la procédure d'importation pour le dossier
suppliers.
Créer une connexion
Créez une connexion aux ressources Cloud. Cela génère un compte de service unique qui sert de "carte d'identité" à BigQuery pour accéder aux fichiers externes.
- Accédez à la page BigQuery.
- Dans le volet de gauche, cliquez sur Explorateur. Si le volet de gauche ne s'affiche pas, cliquez sur Développer le volet de gauche pour l'ouvrir.
- Dans le volet Explorateur, développez le nom de votre projet, puis cliquez sur Connexions.
- Sur la page Connexions, cliquez sur Créer une connexion.
- Pour le champ Type de connexion, sélectionnez Modèles distants Vertex AI, fonctions distantes, BigLake et Spanner (Ressource cloud).
- Dans le champ ID de connexion, saisissez le nom de l'ID de connexion. Exemple :
acai_pdf_connectionVeillez à noter cet ID, car vous en aurez besoin lorsque vous configurerez l'analyse des données plus loin dans cet atelier de programmation. - Définissez Type d'emplacement sur Région, puis sélectionnez une région. Par exemple,
us-west1. La connexion doit être colocalisée avec vos autres ressources, comme les ensembles de données. - Cliquez sur Créer une connexion.
- Cliquez sur Accéder à la connexion.
- Dans le volet Informations de connexion, copiez l'ID du compte de service à utiliser à l'étape suivante. Le compte de service ressemble à
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com.
Gérer l'accès aux comptes de service
Fournissez l'accès au compte de service afin que le Lakehouse puisse lire vos PDF.
- Accédez à la page IAM et administration.
- Cliquez sur Accorder l'accès. La boîte de dialogue "Ajouter des comptes principaux" s'ouvre.
- Dans le champ Nouveaux comptes principaux, saisissez l'ID de compte de service que vous avez copié précédemment.
- Dans le champ Sélectionner un rôle, ajoutez les rôles suivants :
roles/storage.objectUserroles/storage.objectViewerroles/bigquery.userroles/bigquery.dataEditorroles/aiplatform.userroles/storage.adminroles/dataproc.serviceAgent
- Cliquez sur Enregistrer.
Pour en savoir plus sur les rôles IAM dans BigQuery, consultez Rôles et autorisations prédéfinis.
8. Gérer les autorisations pour le job DataScan
Créez des comptes de service (identités) spécifiques pour Spark et Dataform, puis accordez-leur, ainsi qu'aux agents de service automatisés de Google, les autorisations précises nécessaires pour lire le stockage, exécuter des jobs BigQuery et utiliser Vertex AI pour la découverte.
Accès IAM pour Spark et Dataform
- Dans la console Google Cloud, accédez à la page Créer un compte de service.
- Si ce n'est pas le cas, sélectionnez votre projet Google Cloud.
- Cliquez sur Créer un compte de service.
- Saisissez un nom de compte de service. Par exemple :
sa-spark-stg1. La console Google Cloud génère un ID de compte de service basé sur ce nom. Modifiez l'ID si nécessaire. Vous ne pourrez pas le modifier par la suite. - Pour définir les contrôles des accès, cliquez sur Créer et continuer, puis passez à l'étape suivante.
- Choisissez les rôles IAM suivants à attribuer au compte de service du projet.
roles/dataproc.workerroles/storage.objectUserroles/bigquery.dataEditorroles/bigquery.jobUserroles/aiplatform.userroles/dataplex.discoveryPublishingServiceAgent
- Lorsque vous avez terminé d'ajouter des rôles, cliquez sur Continuer.
- Cliquez sur OK pour terminer la création du compte de service.
Autorisations de connexion BigQuery pour accéder à Knowledge Catalog
- Dans la console Google Cloud, accédez à la page Buckets Cloud Storage.
- Dans la liste des buckets, cliquez sur le nom du bucket que vous avez créé pour Froyo. Par exemple :
acai_pdfs. - Dans l'onglet Autorisations, cliquez sur Accorder l'accès. La boîte de dialogue "Ajouter des comptes principaux" s'affiche.
- Dans le champ Nouveaux comptes principaux, saisissez l'ID de votre compte de service BigQuery. Le compte de service ressemble à
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com. - Sélectionnez le ou les rôles suivants dans le menu déroulant Sélectionnez un rôle.
roles/storage.objectUserroles/dataplex.serviceAgentroles/dataplex.securityAdminroles/aiplatform.serviceAgentroles/dataplex.discoveryPublishingServiceAgent
- Cliquez sur "Enregistrer".
9. Configurer Knowledge Catalog
Créez un catalogue Knowledge Catalog pour unifier vos données liées à Froyo et automatiser la découverte de fichiers non structurés (comme les recettes et les fournisseurs au format PDF).
Créez DataScan via curl.
Dans cette section, vous allez créer des analyses pour votre bucket Cloud Storage (par exemple, acai_pdfs) en ajoutant datascan_ID et en le pointant vers vos ensembles de données BigQuery. Knowledge Catalog créera ensuite automatiquement des entrées pour vos PDF dans BigQuery.
- Pour analyser les PDF (fournisseurs et recettes), exécutez la commande suivante :
# 1. Set your variables PROJECT_ID="<PROJECT_ID>" REGION="<REGION>" ENV_SUFFIX="stg1" DATASCAN_ID="froyo-profile-${ENV_SUFFIX}" BUCKET_NAME="<BUCKET_NAME>" # 2. Set this to the Name of the connection you created in Step 7 CONNECTION_ID="<CONNECTION_ID_NAME>" # 3. Define the API Endpoint DATAPLEX_API="dataplex.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}" # 4. Create the DataScan via CURL echo "Creating Dataplex DataScan: ${DATASCAN_ID}..." curl -X POST "https://$DATAPLEX_API/dataScans?dataScanId=${DATASCAN_ID}" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d '{ "data": { "resource": "//storage.googleapis.com/projects/'"${PROJECT_ID}"'/buckets/'"${BUCKET_NAME}"'" }, "executionSpec": { "trigger": { "on_demand": {} } }, "dataDiscoverySpec": { "bigqueryPublishingConfig": { "tableType": "BIGLAKE", "connection": "projects/'"${PROJECT_ID}"'/locations/'"${REGION}"'/connections/'"${CONNECTION_ID}"'" }, "storageConfig": { "unstructuredDataOptions": { "entity_inference_enabled": true } } } }' - La commande
curlaffiche les résultats de l'analyse DataScan du Knowledge Catalog, comme illustré dans l'image suivante.
Exécuter le job
Exécutez la commande suivante :
gcloud dataplex datascans run $DATASCAN_ID --location=$REGION
Décrivez un job
Pour décrire le job, exécutez la commande suivante :
gcloud dataplex datascans describe $DATASCAN_ID --location=$REGION
Supprimer une tâche d'analyse de données
Si l'analyse s'exécute pendant plus de 10 minutes ou si l'état du job reste En attente pendant une longue période sans passer à En cours d'exécution, cela peut être dû à une indisponibilité temporaire des ressources dans la région. Dans ce cas, vous pouvez exécuter la commande suivante pour supprimer le job, puis essayer de le créer et de l'exécuter à nouveau. Il peut arriver qu'une première exécution échoue rapidement avec une erreur telle que unable to acquire necessary resources.
gcloud dataplex datascans delete $DATASCAN_ID --location=$REGION
Afficher l'état du job
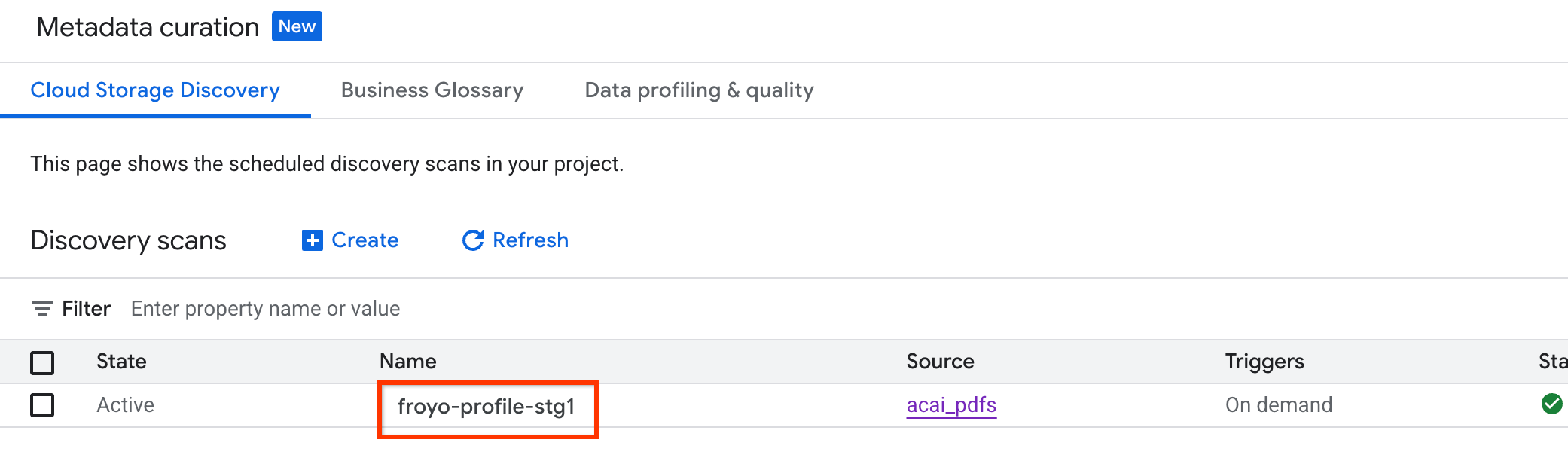
Pour vérifier l'état du job :
- Dans la console Google Cloud, accédez à la page Curation des métadonnées.
- Dans l'onglet Découverte Cloud Storage, cliquez sur le nom des analyses de découverte.
- Sur la page Détails de l'analyse, vous pouvez consulter l'état du job.
- Une fois le job terminé, vérifiez si l'ensemble de données publié (par exemple,
acai_pdfs_discovered_003) que vous avez créé à l'aide de la commandecurlest présent.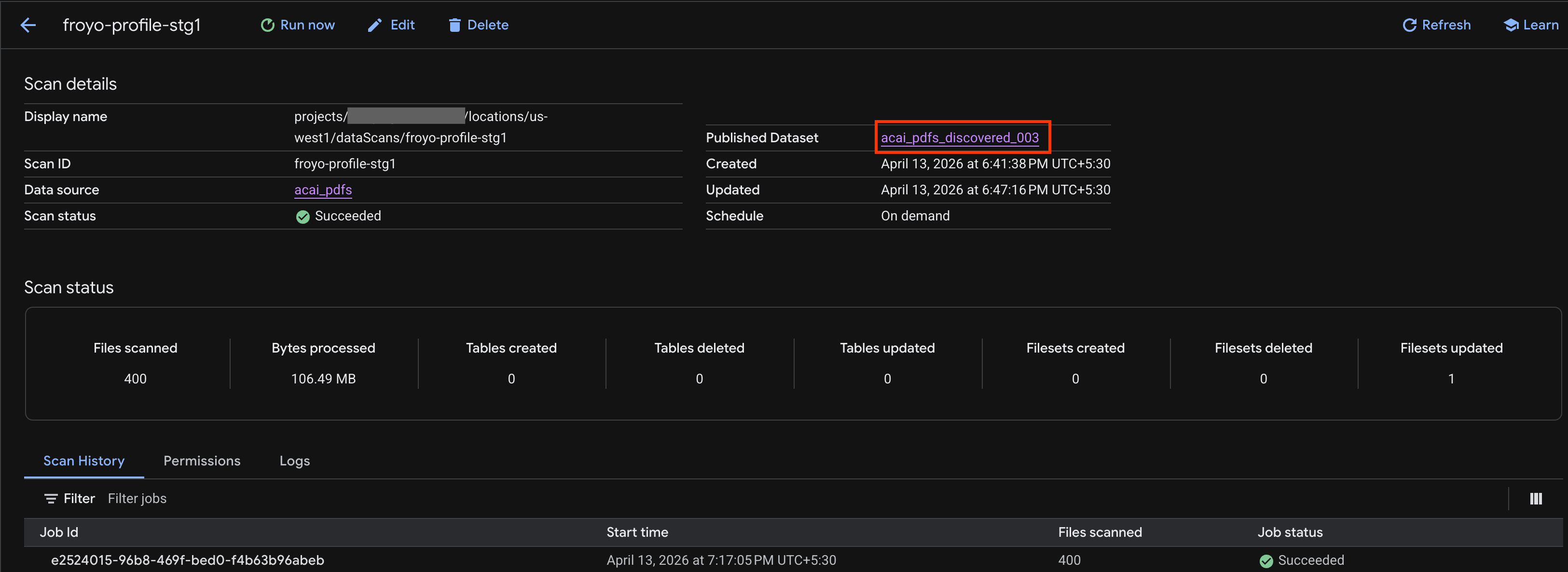
Afficher la table d'objets
Pour afficher la table d'objets créée après le job de découverte, procédez comme suit :
- Dans la console Google Cloud, accédez à BigQuery.
- Cliquez sur Ensembles de données, puis sélectionnez l'ensemble de données publié créé à l'étape précédente. Exemple :
acai_pdfs_discovered_003 - Pour afficher la table d'objets, cliquez sur son ID. Par exemple :
acai_pdfs. - La table d'objets obtenue ressemble à l'image suivante :
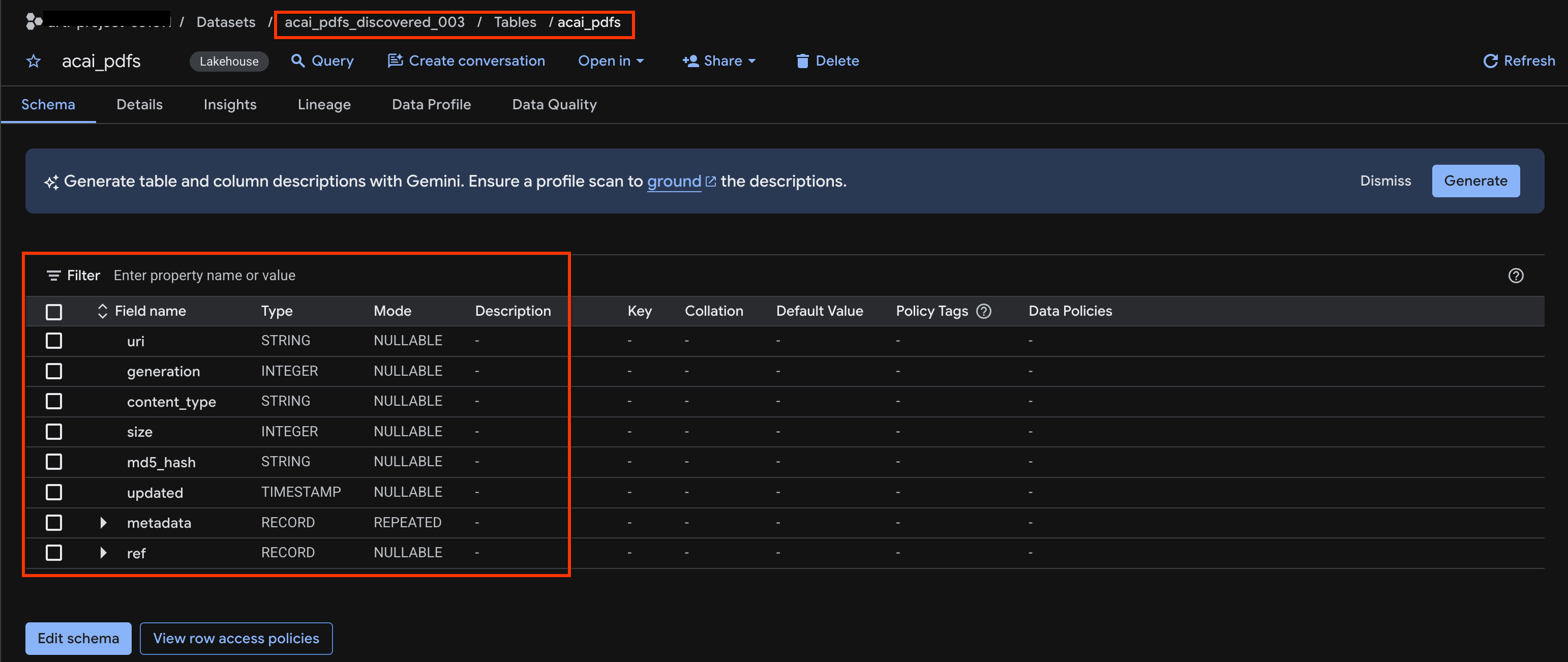
10. Extraction sémantique
Vous allez inférer et extraire des tables structurées, d'autres objets de base de données et des relations pour cette table d'objets non structurée que vous avez créée à l'étape précédente. Pour ce faire, vous utiliserez la fonctionnalité Insights du Knowledge Catalog afin de générer des instructions SQL permettant d'extraire des données structurées de la table non structurée.
- Dans la console Google Cloud, accédez à la page Recherche Knowledge Catalog.
- Recherchez la table de l'ensemble de données pour laquelle vous souhaitez afficher des insights. Par exemple :
acai_pdfs_discovered_003.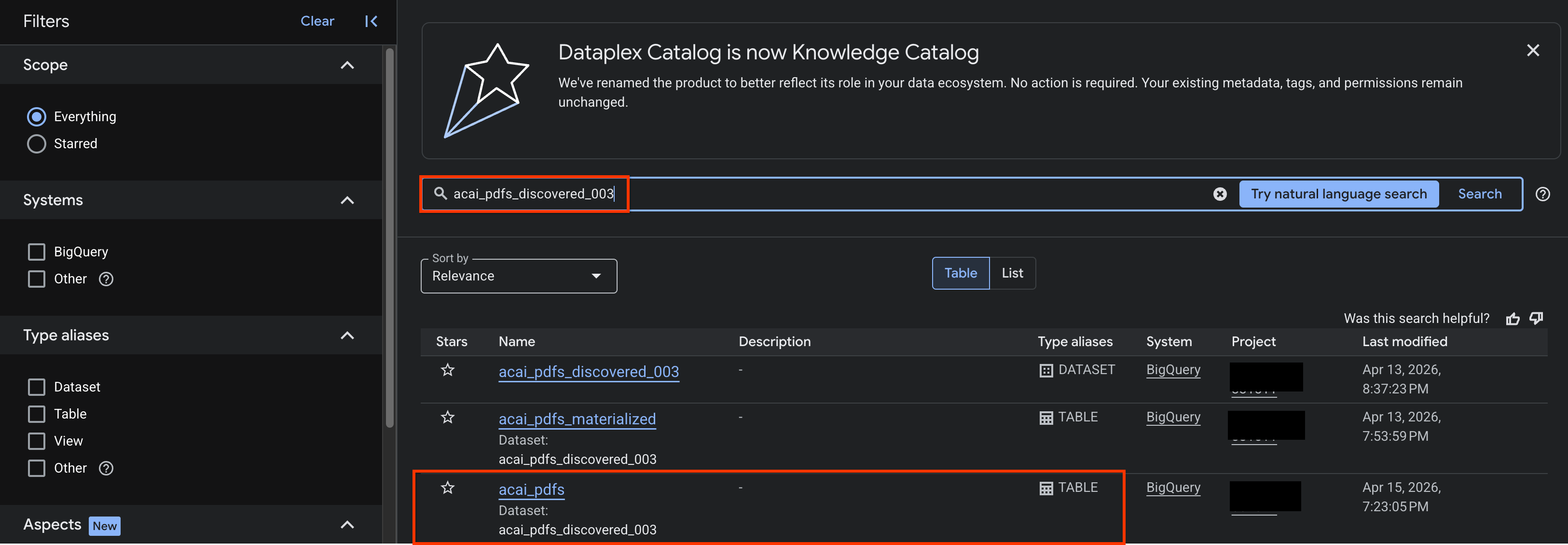
- Dans les résultats de recherche, cliquez sur le tableau pour ouvrir la page d'entrée correspondante.
- Cliquez sur l'onglet Insights. Si l'onglet est vide, cela signifie que les insights de cette table n'ont pas encore été générés. La génération d'insights peut prendre entre 15 et 25 minutes.
- Une fois les insights affichés, cliquez sur Extraire > Extraire avec SQL.
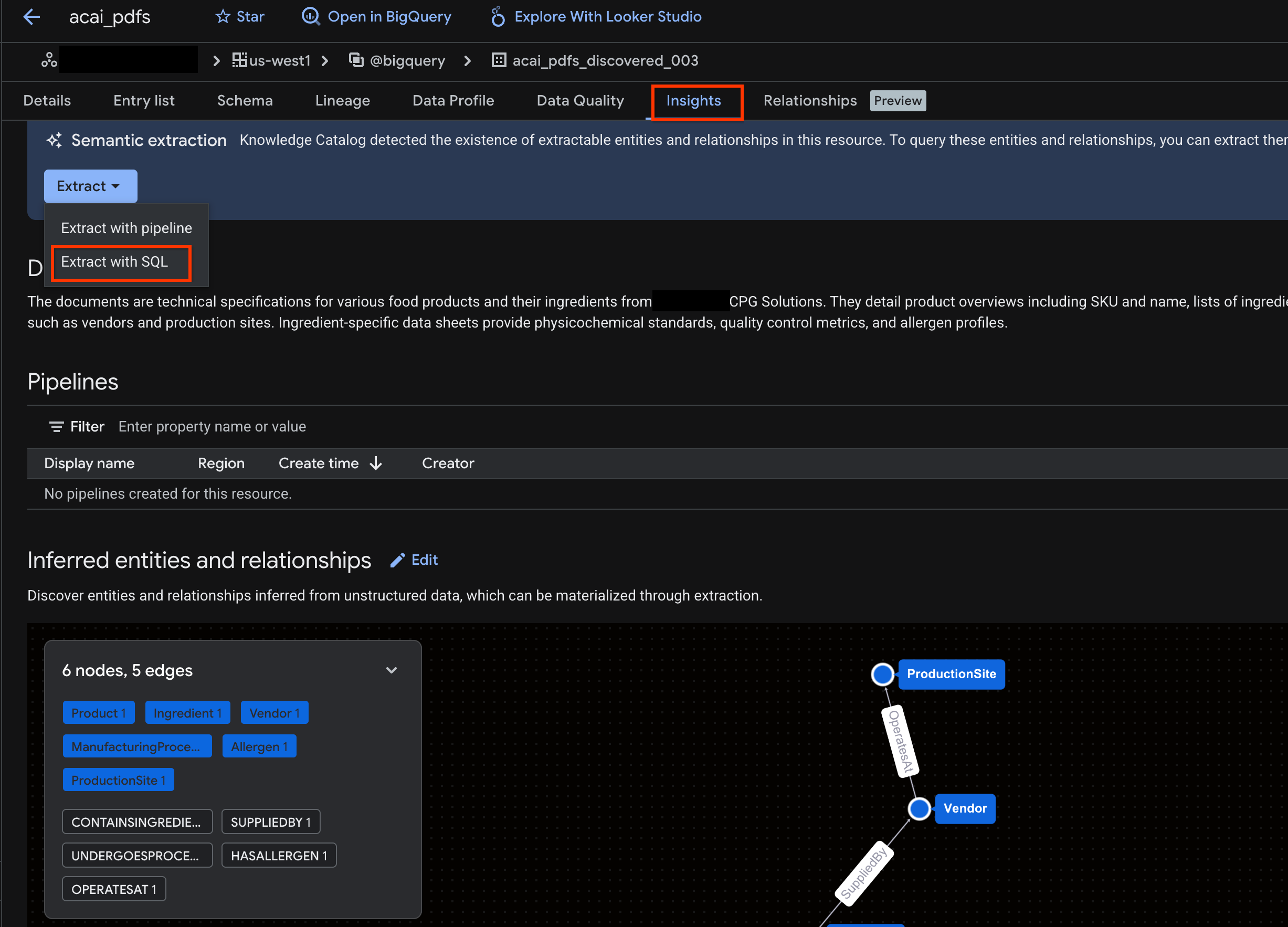
- Sur la page Extraire avec SQL, saisissez votre ensemble de données dans Destination. Par exemple,
acai_pdfs_discovered_003. - Cliquez sur Extraire. L'éditeur BigQuery s'ouvre et la requête est chargée.
- Cliquez sur Exécuter. Cette étape génère un ensemble d'instructions et peut prendre quelques minutes.
- Une fois la requête terminée, les résultats suivants s'affichent :
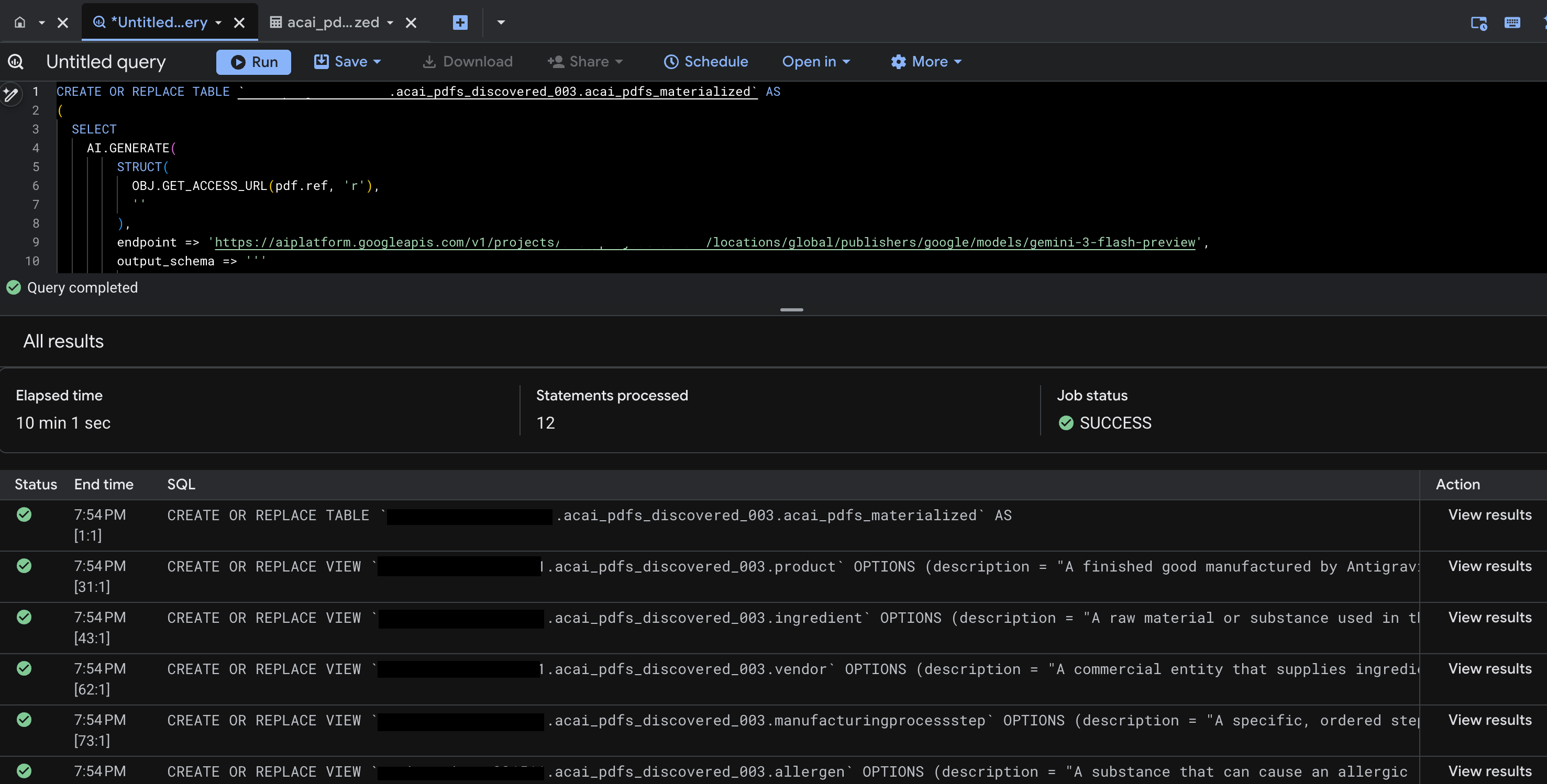
- Accédez à BigQuery, puis cliquez sur Ensembles de données (par exemple,
acai_pdfs_discovered_003). Un nouvel ensemble d'objets de base de données structurés est créé dans l'ensemble de données que vous avez sélectionné à l'étape 6.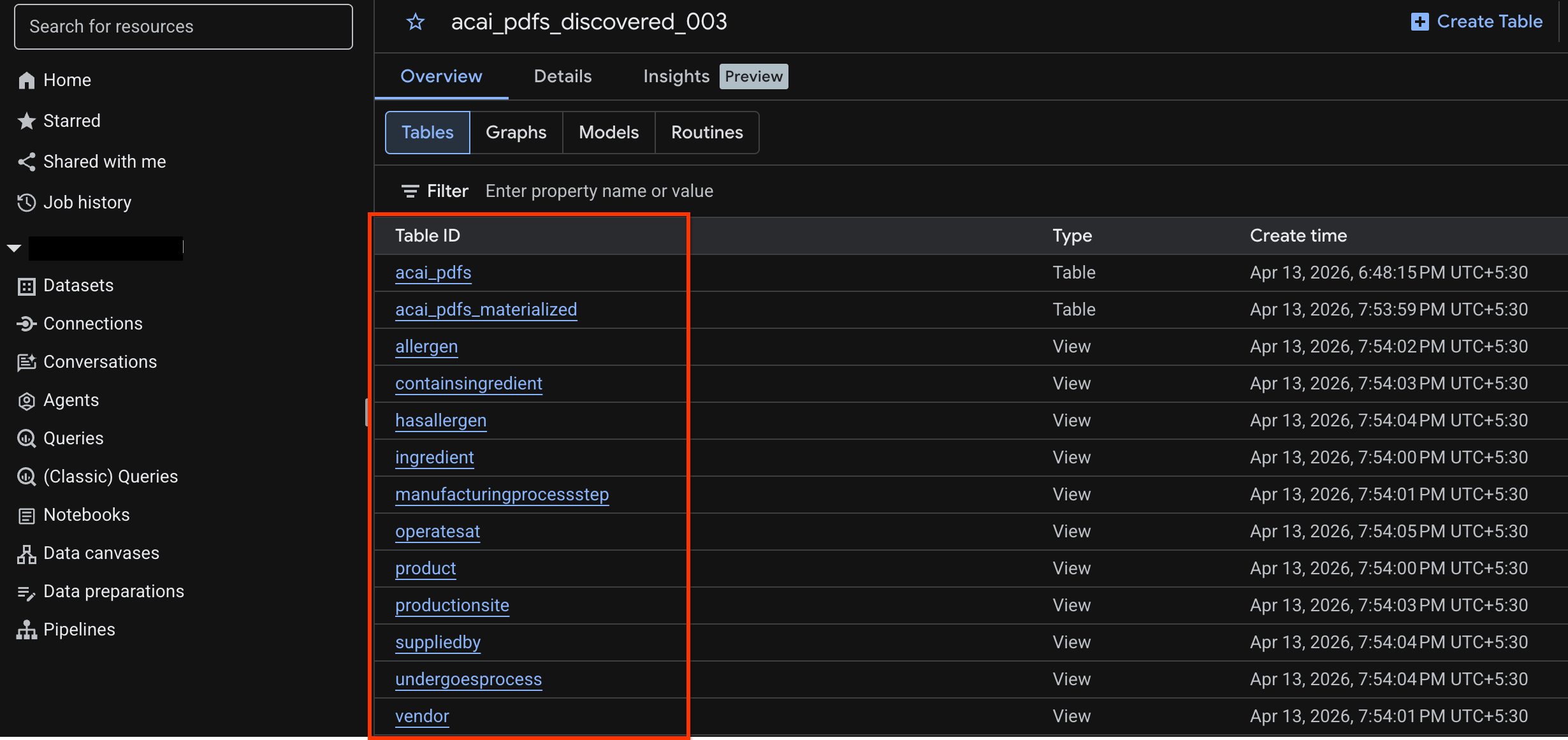
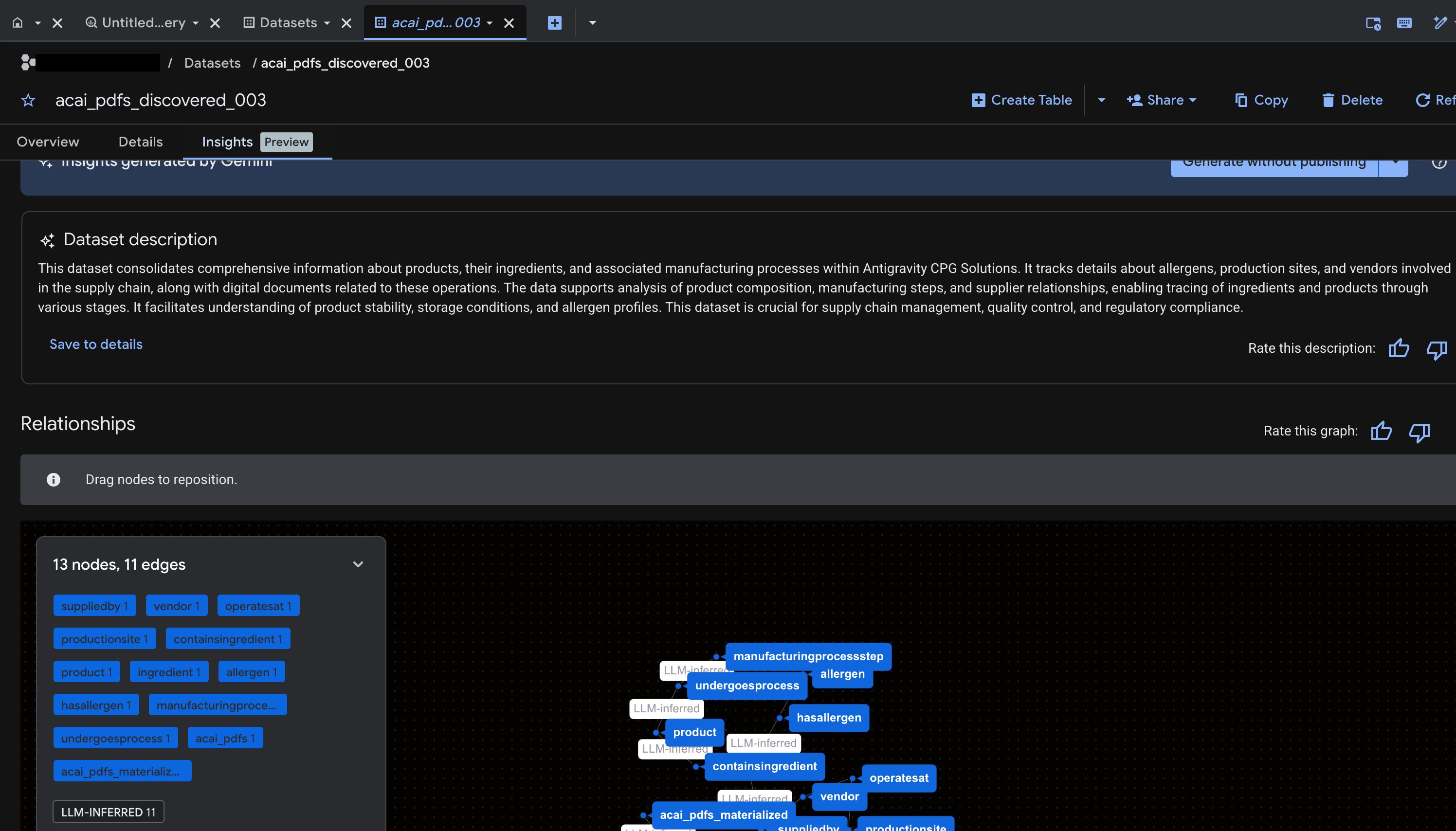
Générer des insights pour un objet dans BigQuery
Afin de générer des insights pour un ensemble de données BigQuery, vous devez accéder à l'ensemble de données dans BigQuery à l'aide de BigQuery Studio.
- Dans la console Google Cloud, accédez à BigQuery Studio.
- Dans le volet Explorateur, sélectionnez le projet, puis accédez à l'ensemble de données pour lequel vous souhaitez générer des insights.
- Cliquez sur l'onglet Insights.
- Si le bouton Activer l'API s'affiche, cliquez dessus pour activer Gemini pour Google Cloud. La fenêtre Activer les fonctionnalités essentielles s'ouvre.
- Dans la section API des fonctionnalités principales, cliquez sur Activer pour API Gemini pour Google Cloud et API unifiée BigQuery, puis cliquez sur Suivant.
- Dans la section Autorisations (facultatif), attribuez des rôles IAM aux principaux si nécessaire, puis cliquez sur Suivant.
- Pour générer des insights et les publier dans Knowledge Catalog, cliquez sur Générer et publier.
- Une fois la publication effectuée, vous pourrez consulter les insights dans l'onglet.
11. Configurer votre IDE pour l'analyse de données agentique
L'extension Google Cloud Data Agent Kit pour Visual Studio Code est une extension d'IDE destinée aux data scientists et aux ingénieurs de données. Il vous permet de vous connecter à vos ressources et données Google Data Cloud et de les utiliser directement depuis l'IDE. Pour en savoir plus, consultez Présentation de l'extension Data Agent Kit pour VS Code.
L'extension Data Agent Kit pour VS Code est utile lorsque vous souhaitez effectuer les opérations suivantes :
- Créez, testez, examinez et déployez un pipeline de données prêt pour la production, tel que Spark ETL ou BigQuery ETL, directement depuis VS Code.
- Explorez les données, créez un pipeline d'entraînement, identifiez les modèles de ML optimaux et déployez-les sur un point de terminaison de production à l'aide de l'assistance IA.
- Connectez-vous à des sources de données fiables, créez un modèle de données hautes performances et publiez un tableau de bord interactif pour les parties prenantes de l'entreprise.
Installer l'extension Data Agent Kit pour VS Code
- Ouvrez VS Code.
- Installez Google Cloud CLI. Pour en savoir plus, consultez Installer Google Cloud CLI.
- Installez l'extension Data Agent Kit pour VS Code.
- Terminez le processus d'intégration de l'extension. Pour cela, vous devez :
- Se connecter à l'extension
- Installer des compétences et des serveurs MCP
- Une fois l'intégration terminée, rechargez ou redémarrez la fenêtre. Pour en savoir plus, consultez Configurer et configurer l'extension Data Agent Kit pour VS Code.
- Une fois l'IDE rechargé, cliquez sur l'icône Google Data Cloud dans le volet de navigation, accédez aux paramètres et assurez-vous d'avoir correctement défini l'ID de votre projet et votre région (
us-west1) dans les paramètres communs.
Configurer l'espace de travail dans VS Code
- Ouvrez VS Code, puis sélectionnez File > Open folder > New folder (Fichier > Ouvrir le dossier > Nouveau dossier).
- Créez un dossier nommé
acai_test, puis cliquez sur Ouvrir. VS Code considère désormais le dossier que vous avez ouvert comme un espace de travail. - Dans la boîte de dialogue Approuver l'espace de travail, sélectionnez Oui, je fais confiance aux auteurs pour activer toutes les fonctionnalités de l'espace de travail.
- Créez un dossier
.githubdans l'espace de travailacai_test. - Créez un fichier
copilot-instructions.mddans le dossier.githubet saisissez-y les règles suivantes.## 1. Project Context - **Project ID**: <PROJECT_ID> - **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors. - **Documentation**: Raw PDF documents detailing flavors and ingredients are stored in Google Cloud Storage at `gs://<BUCKET_NAME>`. ## 2. Execution & Data Processing Rules - **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `<BQ_DATASET_NAME>` (referred to as the Knowledge Catalog). - **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the dataset `<DATASET_ID>`. When you are referencing a dataset, ensure you are using it with the project ID (`<PROJECT_ID>`) and namespace prefix `<NAMESPACE_NAME>`. For example, to query order table in this dataset you should use `<PROJECT_ID>.<NAMESPACE>.<DATASET_ID>.orders`. - **CRITICAL RULE - Data Joins between BigQuery dataset and Iceberg dataset**: ANY task requiring a join or integration between the BigQuery datasets `<DATASET_ID>` of the PDF data and the `<DATASET_ID>` of the customer data MUST be executed using **Spark Notebooks**. - **CRITICAL RULE - Notebook Kernel**: Every Spark notebook utilized MUST exclusively be configured to run on the Serverless Session template `iceberg-federation-template` as its kernel. - **CRITICAL RULE - Data Science**: ANY data science, machine learning, or advanced analytical task MUST be performed strictly within **Spark Notebooks** using the aforementioned setup. - Créez un autre fichier
template.yamldans l'espace de travailacai_testet saisissez-y les informations suivantes.labels: client: "vscode" jupyterSession: displayName: "iceberg-federation-template" kernel: "PYTHON" environmentConfig: executionConfig: serviceAccount: "sa-spark-dev1@<PROJECT_ID>.iam.gserviceaccount.com" subnetworkUri: "projects/<PROJECT_ID>/regions/<REGION>/subnetworks/<SUBNET_NAME>" runtimeConfig: version: "2.3" properties: # This enables the secure proxy URL you were looking for dataproc.tier: "premium" spark.dataproc.engine: "lightningEngine" spark.dataproc.lightningEngine.runtime: "native" spark.memory.offHeap.enabled: "true" spark.memory.offHeap.size: "1g" spark.executor.memory: "4g" "dataproc.component.gateway.enabled": "true" "dataproc.jupyter.listen.all.interfaces": "true" "spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" "spark.sql.defaultCatalog": "<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>": "org.apache.iceberg.spark.SparkCatalog" "spark.sql.catalog.<CATALOG_NAME>.type": "rest" "spark.sql.catalog.<CATALOG_NAME>.uri": "<CATALOG_URI_ID>" "spark.sql.catalog.<CATALOG_NAME>.warehouse": "bl://projects/<PROJECT_ID>/catalogs/<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>.rest.auth.type": "org.apache.iceberg.gcp.auth.GoogleAuthManager" - Dans VS Code, cliquez sur Terminal et exécutez la commande suivante pour importer le fichier
template.yamlen tant que modèle de session. Ce modèle est utilisé ultérieurement par l'agent pour créer une session Spark.gcloud beta dataproc session-templates import iceberg-federation-template \ --source=template.yaml \ --location=<REGION>REGIONpar votre région.
12. Effectuer une analyse de données agentique
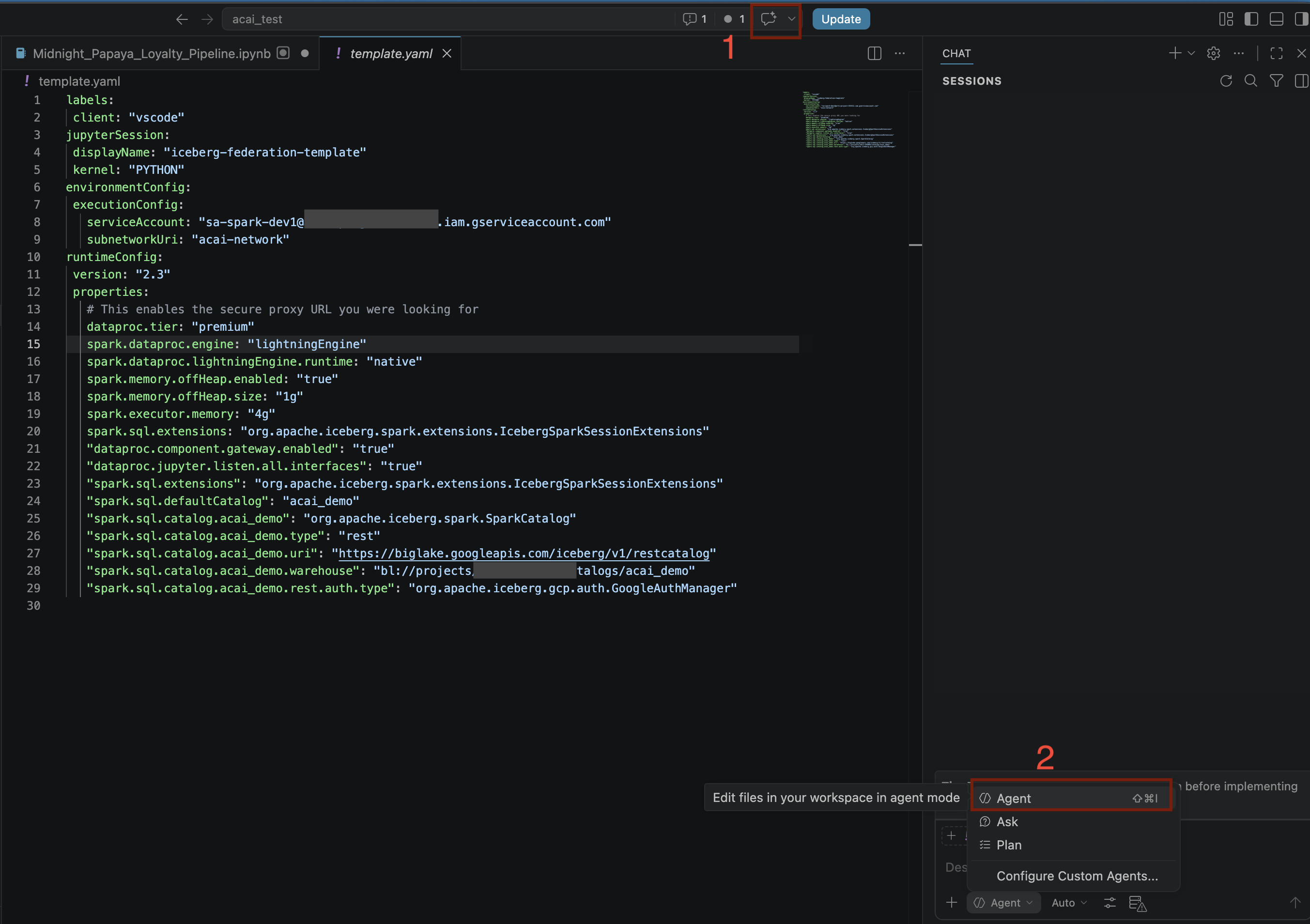
- Dans l'éditeur VS Code, cliquez sur Activer/Désactiver le chat.
- Pour Configurer des agents personnalisés, sélectionnez Agent.
- Dans le volet Modèles de recherche, cliquez sur Gérer les modèles de langage.
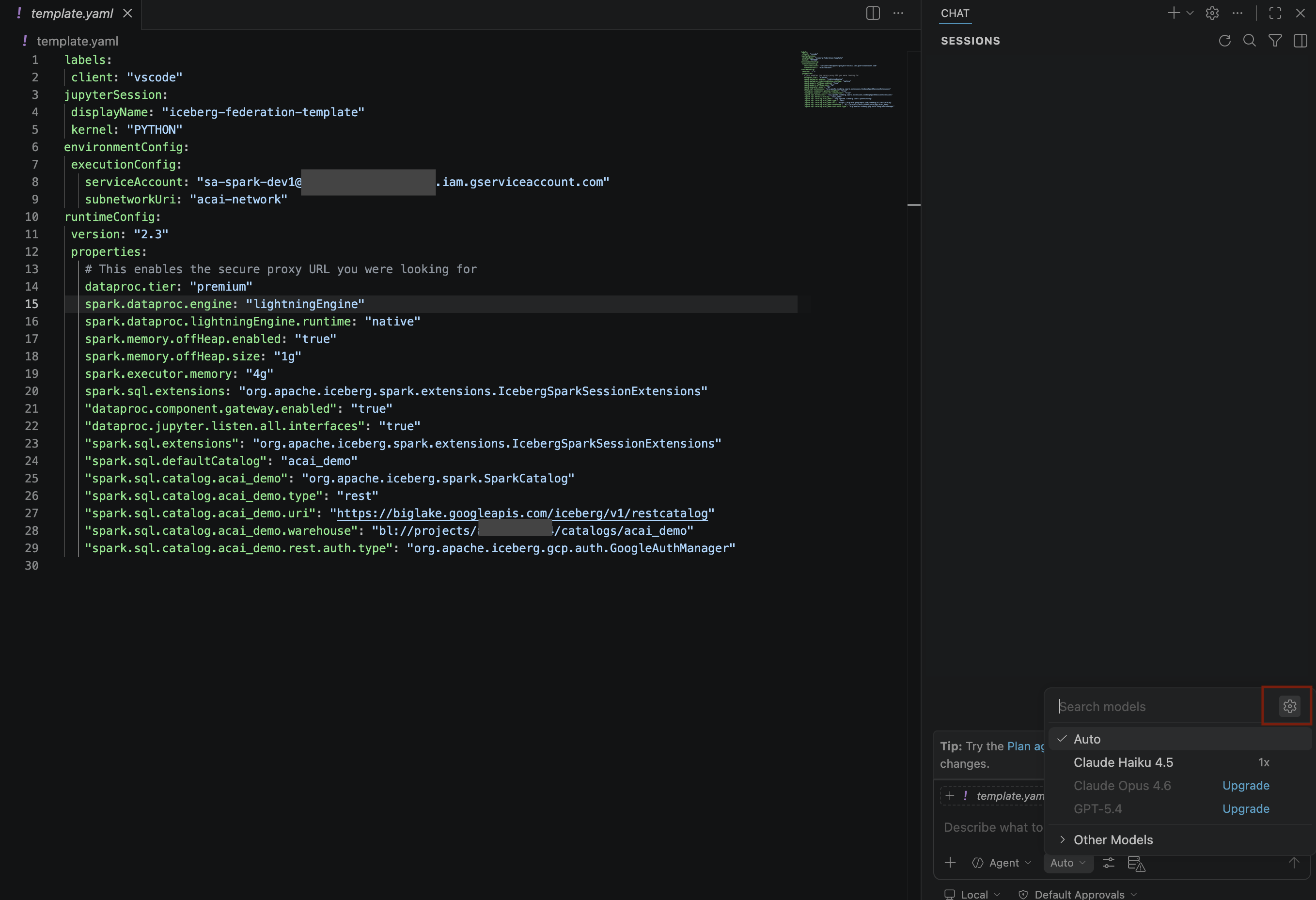
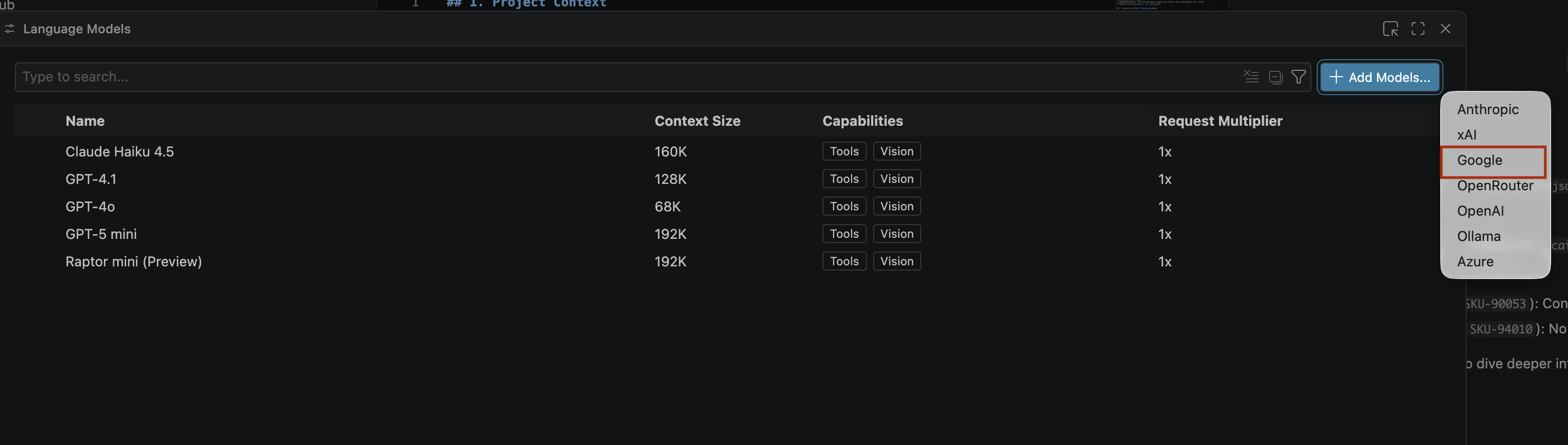
- Sur la page Modèles de langage, cliquez sur Ajouter des modèles.
- Sélectionnez Google dans la liste, puis appuyez sur Entrée pour confirmer votre saisie.
- Pour saisir la clé API de Google Gemini, procédez comme suit :
- Accédez au site Web Google AI Studio.
- Connectez-vous avec votre compte Google.
- Dans la barre latérale, cliquez sur Obtenir une clé API.
- Cliquez sur Créer une clé API. La page "Créer une clé" s'ouvre.
- Dans la liste Sélectionner un projet cloud, sélectionnez Importer un projet.
- Saisissez le nom d'un projet existant.
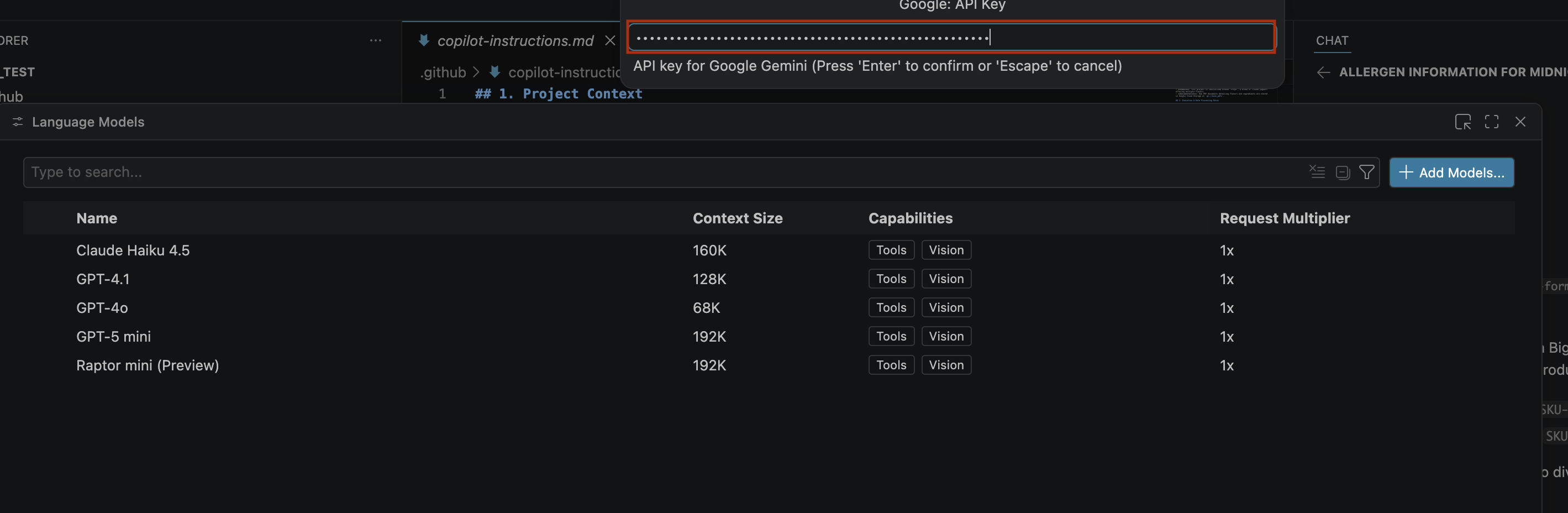
- Cliquez sur Créer une clé et copiez la clé API. Cette clé permet d'accéder aux ressources de l'API Gemini de votre compte.Pour en savoir plus, consultez Utiliser des clés API Gemini.
- Collez la clé API que vous avez générée dans la barre de recherche, puis cliquez sur Entrée.
- Si les modèles Gemini n'apparaissent pas, affichez-les comme indiqué dans l'image suivante :
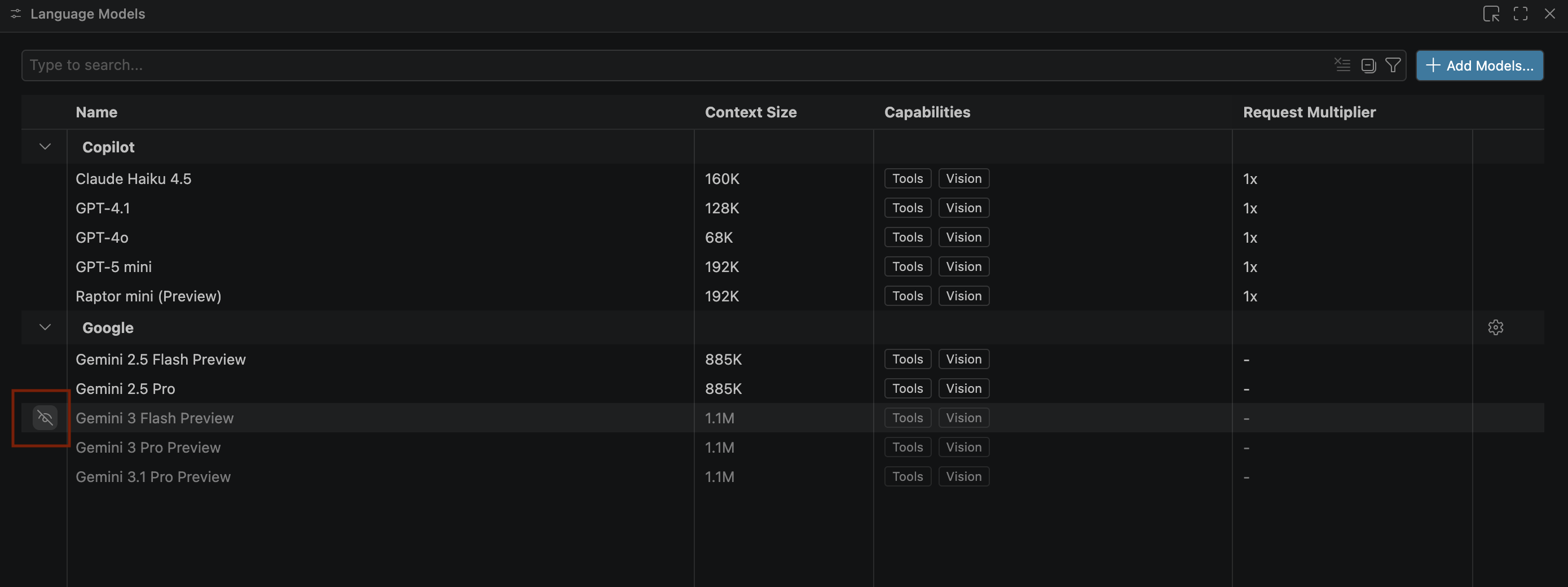
- Sélectionnez Aperçu de Gemini 3.1 Pro dans la liste des modèles Google Gemini, puis fermez la fenêtre Modèles de langage.
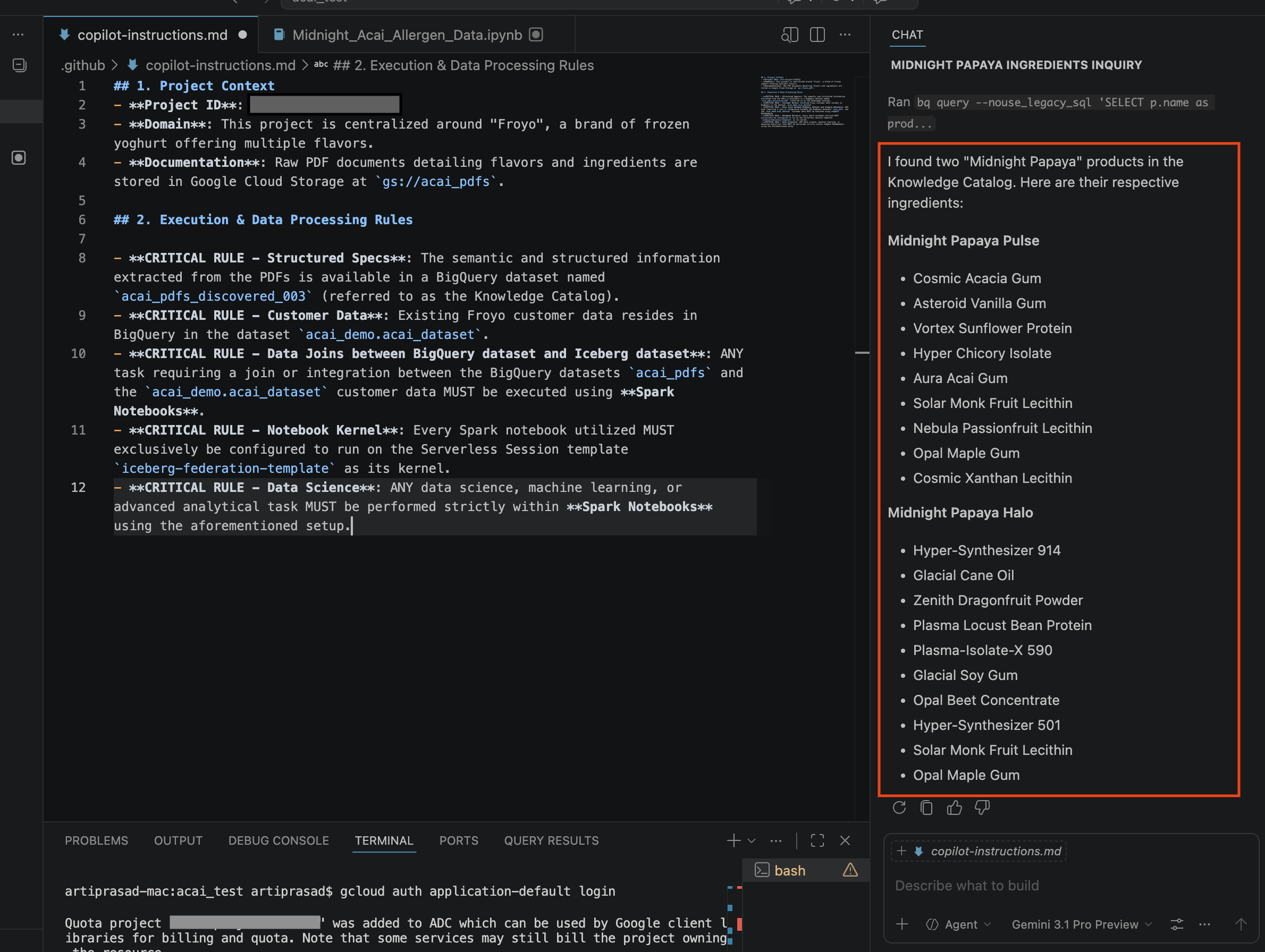
- Dans la fenêtre de chat, saisissez la question suivante :
Search ingredients for Midnight papaya - Après quelques interactions, le résultat suivant devrait s'afficher :
- Dans la fenêtre de chat, saisissez une autre question :
Search allergen information for Midnight papaya - Après quelques interactions et étapes, l'agent répondra en indiquant le nom de l'allergène
Soy, comme vous pouvez le voir sur l'image suivante :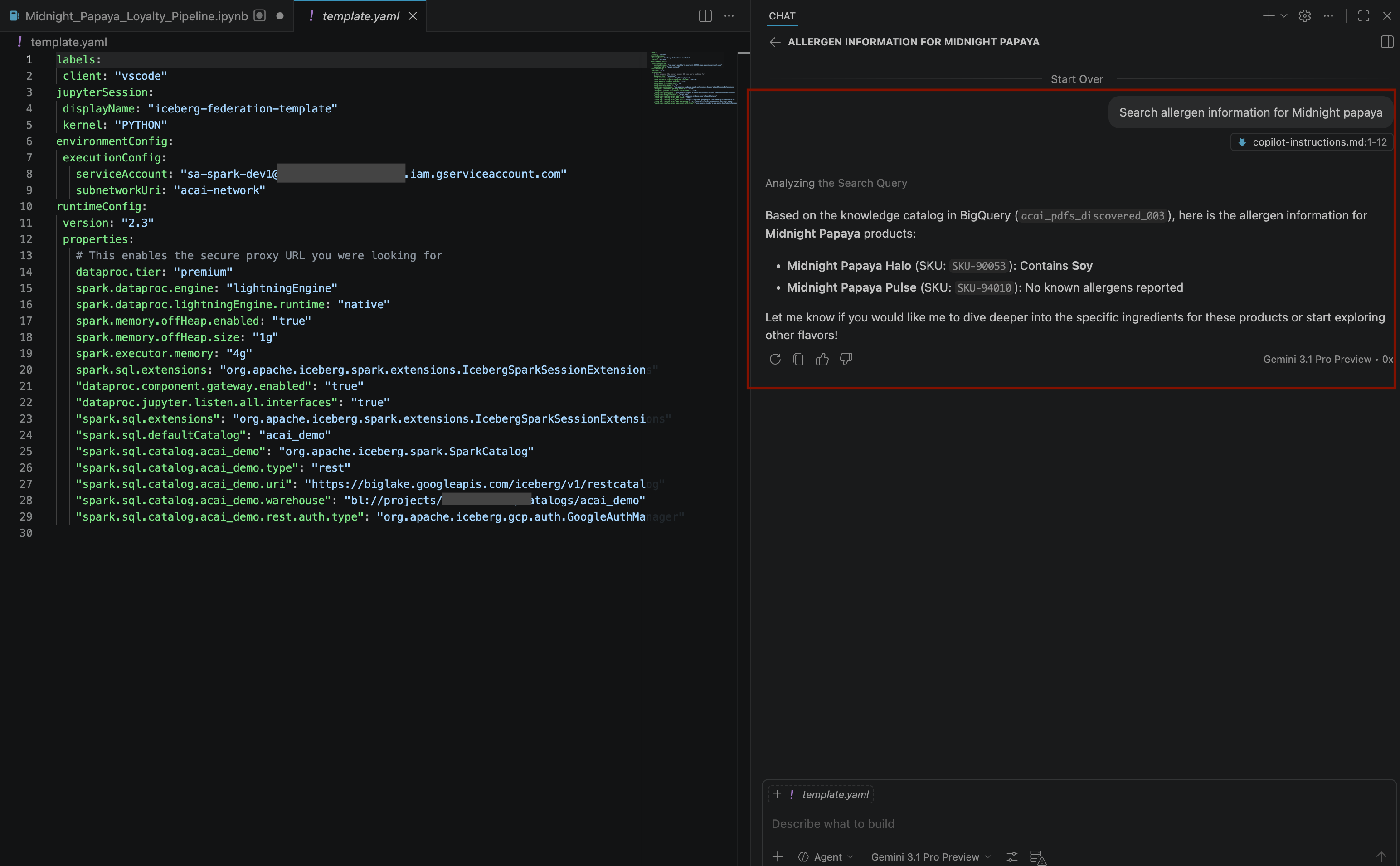
- Dans la fenêtre de chat, saisissez une autre question :
Build a pipeline to join products with our 'Global Loyalty' Iceberg tables in acai customer, sales data to identify popular products - Pour sélectionner le noyau, ouvrez le fichier
.ipynb, puis cliquez sur Sélectionner le noyau > Noyaux Spark à distance > Modèle Iceberg-federation sur Spark sans serveur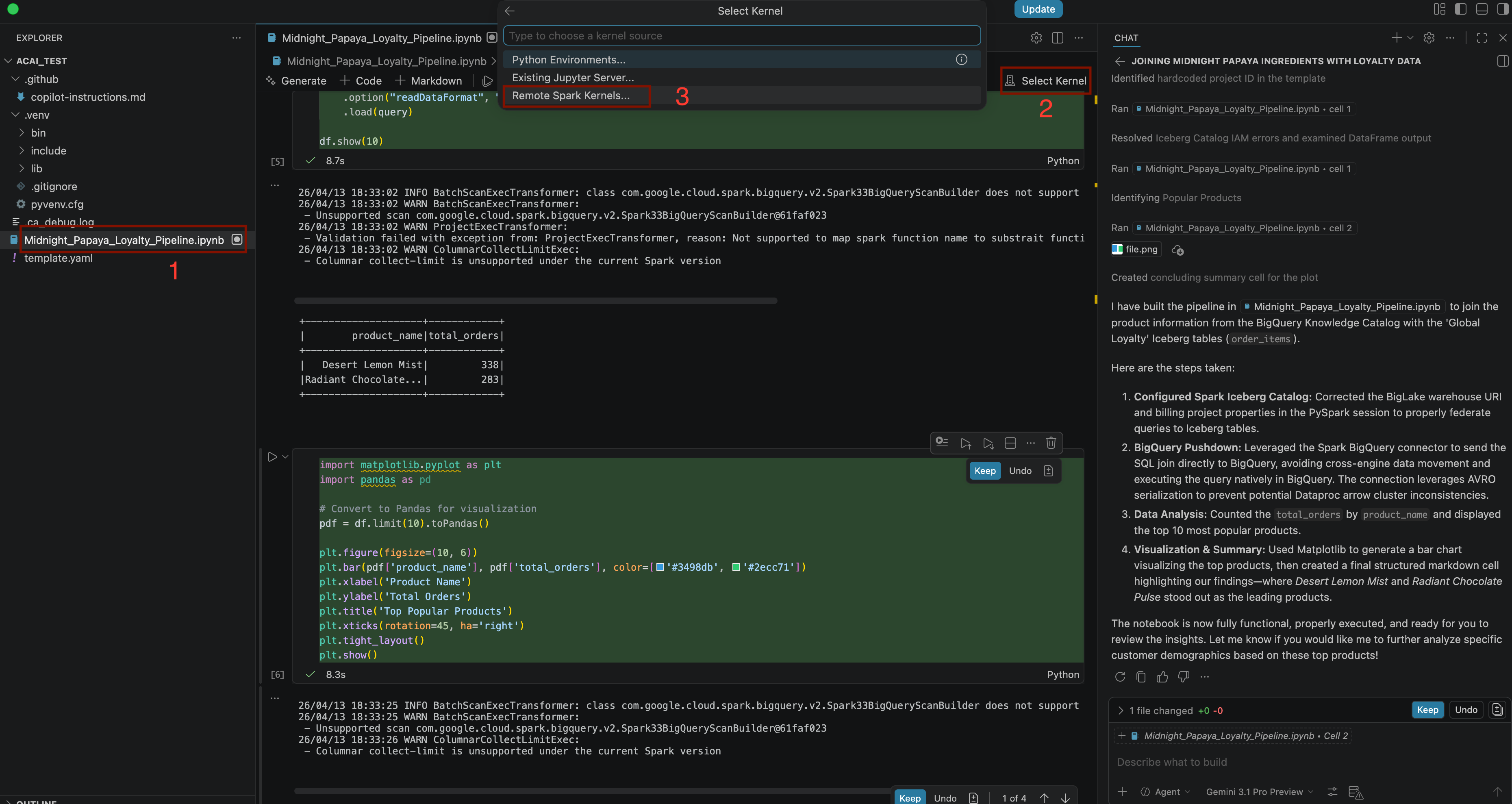 .
.
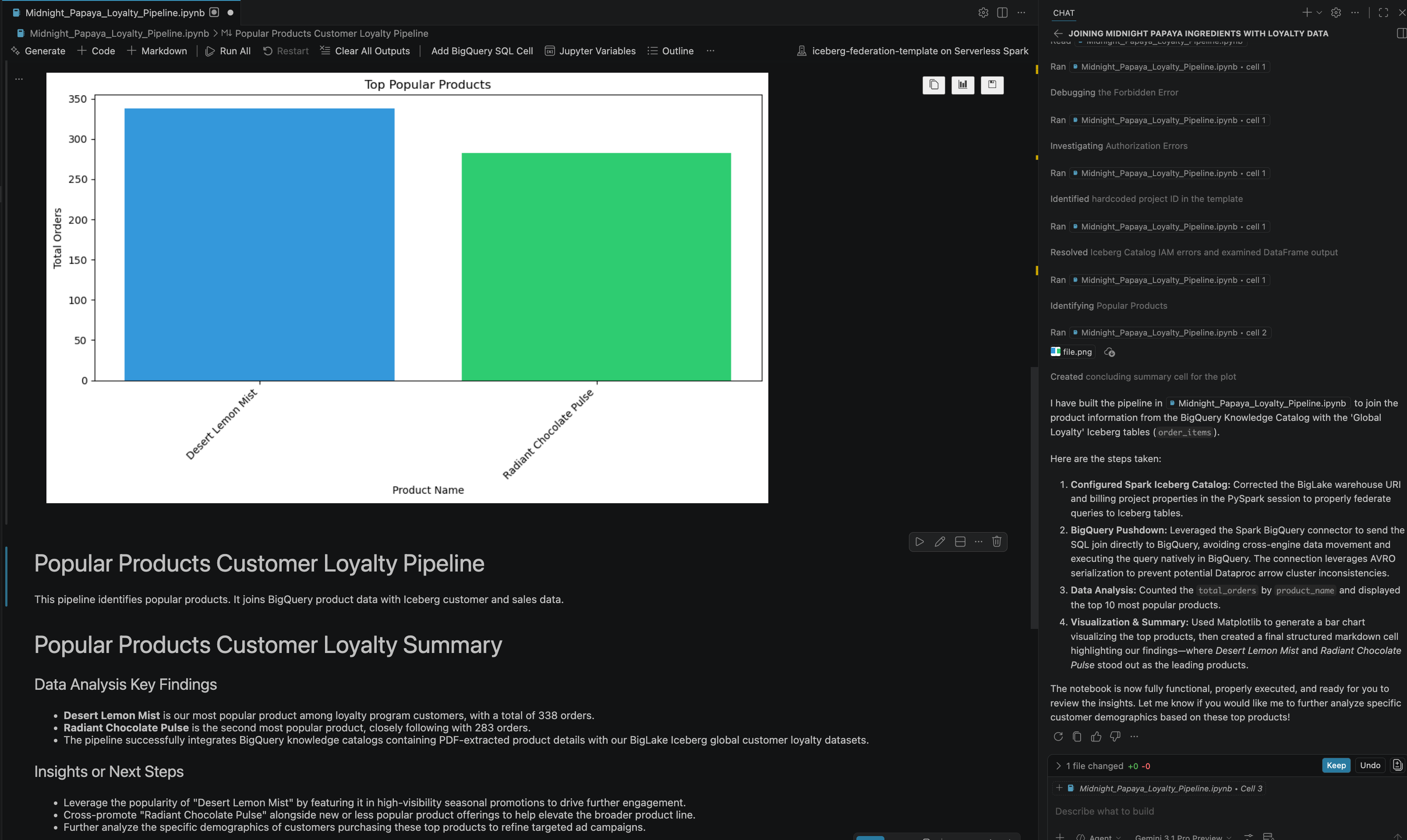
- Après quelques interactions et étapes, l'agent répond en indiquant que toutes les étapes du notebook ont été exécutées avec succès, ainsi que le résultat final généré à la fin du notebook, comme vous pouvez le voir sur l'image suivante :
13. Effectuer un nettoyage
Pour éviter que des frais ne vous soient facturés, supprimez les ressources que vous avez créées dans cet atelier.
- Pour supprimer le DataScan du Knowledge Catalog, exécutez la commande suivante :
DATASCAN_ID="<DATASCAN_ID>" echo "Deleting Dataplex DataScan: ${DATASCAN_ID}" gcloud dataplex datascans delete "${DATASCAN_ID}" --location="${REGION}" --quiet - Pour supprimer les buckets Cloud Storage et tout leur contenu, exécutez la commande suivante :
echo "Deleting Cloud Storage buckets: <BUCKET_NAME1> and <BUCKET_NAME2>" gsutil -m rm -r gs://<BUCKET_NAME1> gsutil -m rm -r gs://<BUCKET_NAME2> - Pour supprimer la connexion BigQuery, exécutez la commande suivante :
CONNECTION_ID="<CONNECTION_NAME>" echo "Deleting BigQuery Connection: ${CONNECTION_ID}" bq rm --connection "${PROJECT_ID}.${REGION}.${CONNECTION_ID}" - Pour supprimer le catalogue Lakehouse, exécutez la commande suivante :
CATALOG_ID="<CATALOG_NAME>" echo "Deleting Lakehouse Catalog: ${CATALOG_ID}" gcloud biglake catalogs delete "${CATALOG_ID}" --project="${PROJECT_ID}" --location="${REGION}" --quiet - Pour supprimer l'ensemble de données contenant les tables PDF détectées, exécutez la commande suivante :
DATASET_NAME="<DATASET_NAME>" echo "Deleting BigQuery Dataset: ${DATASET_NAME}" bq rm -r -f "${PROJECT_ID}:${DATASET_NAME}" - Pour supprimer le compte de service personnalisé, exécutez la commande suivante :
SERVICE_ACCOUNT="<SERVICE_ACCOUNT>" echo "Deleting Service Account: ${SERVICE_ACCOUNT}" gcloud iam service-accounts delete "${SERVICE_ACCOUNT}"@"${PROJECT_ID}".iam.gserviceaccount.com --quiet - Pour supprimer le réseau VPC, exécutez la commande suivante :
VPC_NETWORK="<VPC_NETWORK>" echo "Deleting VPC Network: ${VPC_NETWORK}" gcloud compute networks delete "${VPC_NETWORK}" --quiet - Pour supprimer l'intégralité du projet Google Cloud, exécutez la commande suivante :
gcloud projects delete "${PROJECT_ID}"
14. Félicitations
Félicitations ! Vous avez réussi à organiser le paysage de données des fichiers PDF et Parquet cloisonnés dans des tables BigQuery, et à le regrouper dans un écosystème unique, interrogeable et joignable. Vous avez essentiellement créé un data lakehouse moderne qui traite les PDF et les formats de big data aussi intelligemment qu'une ligne dans une base de données. Et vous avez fait tout cela directement depuis votre agent, dans une expérience conversationnelle avec Gemini.
Documents de référence
Pour en savoir plus sur les technologies de base utilisées dans cet atelier de programmation, consultez la documentation officielle de Google Cloud :
- Pour explorer BigQuery, un composant essentiel de Data Cloud, consultez la documentation BigQuery.
- Pour en savoir plus sur IAM, consultez la documentation IAM.
- Pour en savoir plus sur le lakehouse, consultez Qu'est-ce qu'un lakehouse ?