
1. מבוא
ב-codelab הזה, תגלמו תפקיד של מדעני נתונים בחברת Froyo פיקטיבית שמשיקה טעם חדש של מוצר, 'Midnight Swirl'. כדי להבטיח השקה מוצלחת בשוק הגלובלי, העסק צריך לענות על שאלות חשובות לגבי רכיבים, ביקוש בשוק והחזר על ההשקעה (ROI). תהליך העבודה מקצה לקצה הזה מדגים איך Knowledge Catalog של Google Cloud (לשעבר Dataplex) ו-Lakehouse for Apache Iceberg (לשעבר BigLake) מגשרים על הפער בין נתונים לא מובנים 'חשוכים' ומספקים תובנות עסקיות מעשיות באמצעות Gemini בסביבת הפיתוח המשולבת (IDE) שלכם (VS Code) דרך שכבת ניהול מאוחדת.
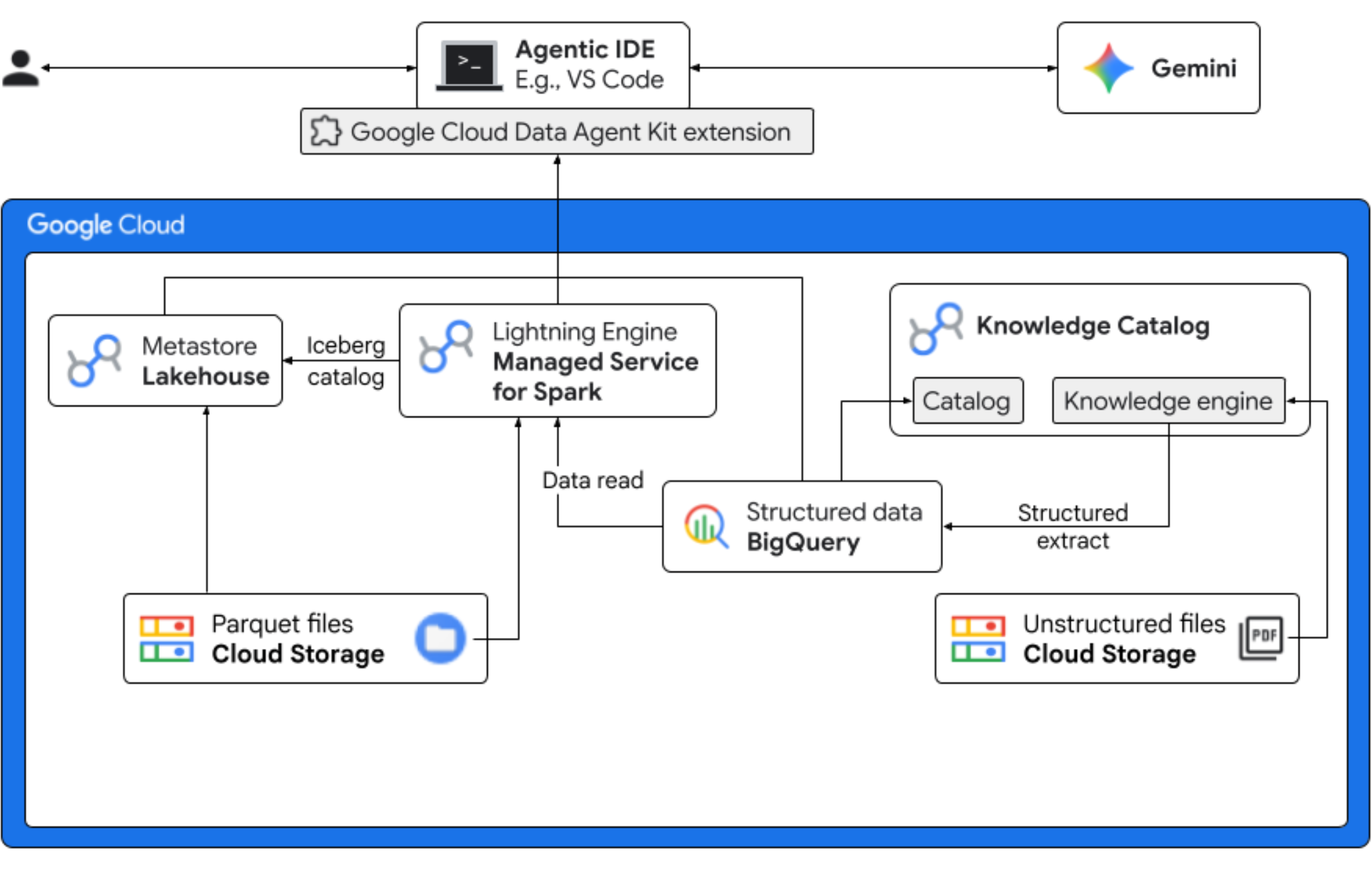
הפעולות שתבצעו:
- גילוי לא מובנה: מתכוני PDF שמאוחסנים ב-Cloud Storage נסרקים על ידי Knowledge Catalog DataScan. יצירת טבלאות אובייקטים ב-BigQuery עבור קובצי ה-PDF שנסרקו. באמצעות Vertex AI Semantic Inference, המערכת 'קוראת' את קובצי ה-PDF כדי לחלץ מידע מובנה על מוצרים, אלרגנים, רכיבים ומאפיינים קשורים. לאחר מכן, הוא יוצר באופן חכם סכמה לנתונים ששמורים בקובצי ה-PDF.
- מטא-נתונים מאוחדים: הנתונים שחולצו מקובצי PDF מאוחסנים ישירות ב-BigQuery כטבלה רחבה מקורית, ונוצרות תצוגות מפורטות כדי לעזור בהרצת שאילתות נפוצות. מערך נתונים עצמאי של נתוני מכירות היסטוריים מאוחסן בטבלאות Apache Iceberg ב-Google Cloud Storage. בשלב הבא, הטבלה הזו בפורמט Iceberg תצורף לנתונים שחולצו ב-BigQuery.
- ניתוח נתונים חוצה-מנועים: באמצעות Managed Service for Apache Spark (לשעבר Dataproc) עם קטלוג Iceberg REST, תוכלו לצרף את המטא-נתונים החדשים של ה-PDF ואת הנתונים הסמנטיים המובנים (מטבלאות ותצוגות של BigQuery) עם נתוני מכירות מובנים שמאוחסנים בטבלאות Apache Iceberg ב-Google Cloud Storage. הפעולה הזו מבוססת על תבנית של סשן אינטראקטיבי מנוהל של Apache Spark שמשמשת כליבת Jupyter Notebook, ומבטיחה הגדרות אחידות של אבטחה וחישוב למשימת Spark.
- תובנות סמנטיות: על ידי שילוב של נתוני המוצרים המשוערים עם נתוני הלקוחות והמכירות (ב-BigQuery), ההדגמה יכולה לחלץ תובנות כמו זיהוי נתוני אלרגנים ותחזית הכנסות.
- ניהול אוטונומי: כל מחזור החיים – מסריקות לגילוי ועד להרצת Spark – מתבצע באמצעות תבניות, הוראות, כללים ואוטומציה מבוססת-סוכן שמוכנים לשימוש ב-Gemini. כך מוכח ש-AI יכול לנהל את התשתית שמפעילה את הניתוח.
הדרישות
יכול להיות שיהיו עלויות על השלמת ה-Codelab הזה. העלות המשוערת לשימוש רגיל היא פחות מ-5$. כדי לקבל הערכות עלויות מפורטות על סמך השימוש החזוי או התמחור הנוכחי, אפשר להשתמש במחשבון התמחור של Google Cloud.
כדי להשלים את ה-codelab, צריך לוודא שמתקיימות הדרישות המוקדמות הבאות.
- דפדפן האינטרנט Chrome.
- חשבון Gmail אישי אם אתם משתמשים בקרדיטים לניסיון שמופיעים בקטע 'לפני שמתחילים'.
- מורידים ומתקינים את Visual Studio (VS) Code.
2. לפני שמתחילים
יצירת פרויקט ב-Google Cloud
- במסוף Google Cloud, בדף לבחירת הפרויקט, בוחרים פרויקט ב-Google Cloud או יוצרים פרויקט.
- הקפידו לוודא שהחיוב מופעל בפרויקט שלכם ב-Cloud. כך בודקים אם החיוב מופעל בפרויקט
הפעלת Cloud Shell
Cloud Shell היא סביבת שורת פקודה שפועלת ב-Google Cloud וכוללת מראש את הכלים הנדרשים.
- לוחצים על Activate Cloud Shell בחלק העליון של מסוף Google Cloud.
- אחרי שמתחברים ל-Cloud Shell, מאמתים את האימות:
gcloud auth list - מוודאים שהפרויקט מוגדר:
gcloud config get project - אם הפרויקט לא מוגדר כמו שציפיתם, מגדירים אותו:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
הפעלת ממשקי ה-API הנדרשים
מריצים את הפקודה הבאה כדי להפעיל את כל ממשקי ה-API הנדרשים:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
biglake.googleapis.com \
dataproc.googleapis.com \
metastore.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
secretmanager.googleapis.com \
storage.googleapis.com
הורדת נכסים דיגיטליים של Codelab
המאגר הזה מכיל קבצים של Parquet, מתכונים, ספקים, copilot-instructions.md, template.yaml ו-quickstart.py לשימוש בשיעור Codelab הזה. חשוב להוריד את הקבצים האלה.
כדי להוריד את הקבצים:
- ב-Cloud Shell, מריצים את הפקודה הבאה:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git - עוברים לתיקייה החדשה שנוצרה:
cd next-26-keynotes - מושכים את התיקייה
data-cloud-demogit sparse-checkout set genkey/data-cloud-demo - אחרי שמסיימים את התשלום, עוברים לתיקייה
data-cloud-demoומחלצים את קובצי ה-ZIP כדי לגשת לנכסי ה-codelab.
3. הגדרת Lakehouse לנתוני לקוחות של Froyo
בקטע הזה יוצרים קטלוג ב-Lakehouse כדי להשתמש במאגר המטא-נתונים של Lakehouse בתהליכי העבודה. הוא יוצר יכולת פעולה הדדית בין מנועי השאילתות שלכם על ידי הצעת מקור יחיד של אמת לכל נתוני Iceberg. הוא מאפשר למנועי שאילתות, כמו Apache Spark, לגלות ולקרוא מטא-נתונים ולנהל טבלאות Iceberg באופן עקבי.
התפקידים הנדרשים
מוודאים שיש לכם את התפקידים הבאים בניהול זהויות והרשאות גישה (IAM):
roles/biglake.viewerroles/bigquery.userroles/bigquery.dataEditorroles/biglake.editorroles/biglake.metadataViewerroles/bigquery.connectionUserroles/storage.objectUserroles/storage.objectViewerroles/storage.objectCreatorroles/storage.admin
מידע נוסף על מתן תפקידי IAM זמין במאמר הענקת תפקיד IAM.
יצירת קטלוג Lakehouse עם קטגוריה
יוצרים קטלוג Lakehouse כדי לנהל את המטא-נתונים של טבלאות Iceberg. מתחברים לקטלוג הזה בעבודת Spark כדי ליצור טבלאות Iceberg ולבצע עליהן שאילתות.
- במסוף Google Cloud, עוברים אל Lakehouse.
- לוחצים על יצירת קטלוג. ייפתח הדף Create catalog.
- בקטע Catalog type (סוג הקטלוג), בוחרים באפשרות Iceberg Rest catalog (קטלוג REST של Iceberg).
- בקטע Select your Lakehouse catalog bucket options (בחירת אפשרויות לקטלוג של קטגוריית Lakehouse), בוחרים באפשרות Single bucket catalog (קטלוג של קטגוריה יחידה).
- בשדה Default catalog Cloud Storage bucket (קטגוריית ברירת המחדל של Cloud Storage לקטלוג), לוחצים על Browse (עיון) ואז על Create new bucket (יצירת קטגוריה חדשה).
- בדף Create a bucket, מבצעים את הפעולות הבאות:
- בקטע Get started (תחילת העבודה), מזינים שם ייחודי גלובלית שעומד בקריטריונים לשמות של קטגוריות.
- בקטע Choose where to store your data, בוחרים באפשרות Region בשדה Location type ומזינים את האזור. לדוגמה,
us-west1. - בקטע Choose how to control access to objects, מבטלים את הסימון בתיבת הסימון Enforce public access prevention on this bucket.
האפשרות הזו מאפשרת לכם לדמות תרחישים מהעולם האמיתי, כמו אירוח תוכן אינטרנט ציבורי או מאגרי נתונים משותפים. בלי השינוי הזה, הקטגוריה תאכוף מדיניות מחמירה של 'פרטי בלבד'. כל ניסיון לגשת לנכסים שלכם יגרום לשגיאת403forbidden, גם אם הענקתם הרשאות ציבוריות לקבצים. - לוחצים על המשך > יצירה > בחירה > המשך.
- בקטע שיטת אימות, בוחרים באפשרות מצב מכירת אישורים.
- לוחצים על יצירה.הקטלוג נוצר ונפתח הדף פרטי הקטלוג.
- בקטע שיטת אימות, לוחצים על הגדרת הרשאות של דלי.
- בתיבת הדו-שיח, לוחצים על אישור.כך מאמתים שלחשבון השירות של הקטלוג יש את התפקיד
Storage Object Userבדליקת האחסון. - בדף פרטי הקטלוג, מעתיקים את נתיב ה-URI של קטלוג REST. משתמשים בנתיב הזה במהלך המשימה Run Spark job.
העלאת קובצי Parquet למאגר
כדי להעלות את קובצי Parquet לשורש של הקטגוריה:
- במסוף Google Cloud, נכנסים לדף Cloud Storage Buckets.
- ברשימת הקטגוריות, לוחצים על שם הקטגוריה. לדוגמה,
acai_demo. - בכרטיסייה Objects של הקטגוריה, לוחצים על Upload > Upload files.
- בוחרים את הקבצים מתיקיית Parquet ששיבטתם בקטע לפני שמתחילים של ה-codelab הזה.
- לוחצים על פתיחה.
4. הגדרת רשת ה-VPC
יוצרים רשת ענן וירטואלי פרטי (VPC) ותת-רשת שמאפשרות למשאבים לתקשר עם Google APIs בלי לצאת לאינטרנט הציבורי, וחומת אש שמאפשרת לתעבורה פנימית לזרום באופן חופשי בין צמתי עיבוד הנתונים.
- נכנסים לדף VPC networks במסוף Google Cloud.
- לוחצים על יצירת רשת VPC.
- מזינים שם לרשת. לדוגמה,
acai-network. - כדי להגדיר את יחידת השידור המקסימלית (MTU) של הרשת, מסמנים את תיבת הסימון הגדרת MTU באופן אוטומטי.
- בוחרים באפשרות אוטומטי בשביל מצב יצירת רשת משנה.
- בקטע Firewall rules (כללי חומת אש), מסמנים את כל תיבות הסימון של IPv4 firewall rules (כללי חומת אש של IPv4).
- לוחצים על יצירה.
הפעלת גישה פרטית ל-Google
לצמתים של Dataproc Serverless אין כתובות IP ציבוריות. כדי לתקשר עם קטלוג Lakehouse ועם Cloud Storage, צריך להפעיל בתת-הרשת גישה פרטית ל-Google.
- נכנסים לדף VPC networks במסוף Google Cloud.
- לוחצים על השם של הרשת שמכילה את רשת המשנה שרוצים להפעיל עבורה גישה פרטית ל-Google. לדוגמה,
us-west1. - לוחצים על שם רשת המשנה. יוצג דף הפרטים של Subnet.
- לוחצים על עריכה.
- בקטע Private Google Access (גישה פרטית ל-Google), בוחרים באפשרות On (מופעל).
- לוחצים על שמירה.
5. יצירה והרצה של משימת Spark
כדי ליצור טבלת Iceberg ולשאול עליה שאילתות, מעלים את משימת PySpark עם הצהרות Spark SQL הנדרשות. לאחר מכן מריצים את העבודה באמצעות Managed Service for Spark.
העלאת quickstart.py לקטגוריה של Cloud Storage
אחרי שיבוט של נכסי ה-codelab, מעדכנים את הסקריפט quickstart.py עם פרטי הפרויקט ומעלים אותו לקטגוריה של Cloud Storage.
- פותחים את הסקריפט
quickstart.pyבכלי לעריכת טקסט. - מחליפים את ה-placeholder
BUCKET_NAMEבסקריפט בשם הקטגוריה שלכם ב-Cloud Storage ושומרים אותו. - במסוף Google Cloud, נכנסים אל Cloud Storage buckets.
- לוחצים על שם הקטגוריה. לדוגמה,
acai_demo. - בכרטיסייה Objects, לוחצים על Upload > Upload files.
- בדפדפן הקבצים, בוחרים את הקובץ המעודכן
quickstart.pyולוחצים על פתיחה.
הפעלת משימת Spark
אחרי שמעלים את הסקריפט quickstart.py, מפעילים פתרונות חכמים כמשימה באצווה של Managed Service for Spark.
- כדי להגדיר את המשתנים, מריצים את הפקודה הבאה ב-Cloud Shell.
# Configuration Variables export PROJECT_ID="<PROJECT_ID>" export REGION="<REGION>" export BUCKET_NAME="<BUCKET_NAME>" export SUBNET="<SUBNET>" export LAKEHOUSE_CATALOG_ID="<LAKEHOUSE_CATALOG_ID>" export CATALOG_URI_ID="<CATALOG_URI_ID>"- LAKEHOUSE_CATALOG_ID: השם של משאב קטלוג Lakehouse שמכיל את קובץ האפליקציה של PySpark. לדוגמה,
acai_demo. - PROJECT_ID: מזהה הפרויקט ב-Google Cloud.
- REGION: האזור שבו יופעל עומס העבודה באצווה של Managed Service for Spark. לדוגמה,
us-west1. - BUCKET_NAME: שם הקטגוריה של Cloud Storage. לדוגמה,
acai_demo. - SUBNET: השם של תת-הרשת ב-VPC. לדוגמה,
acai-network. - CATALOG_URI_ID: מזהה ה-URI של קטלוג Lakehouse שהעתקתם כשיוצרים קטלוג Lakehouse עם bucket. לדוגמה,
https://biglake.googleapis.com/iceberg/v1/restcatalog.
- LAKEHOUSE_CATALOG_ID: השם של משאב קטלוג Lakehouse שמכיל את קובץ האפליקציה של PySpark. לדוגמה,
- ב-Cloud Shell, מריצים את משימת האצווה הבאה של Managed Service for Spark באמצעות הסקריפט
quickstart.py.gcloud dataproc batches submit pyspark gs://${BUCKET_NAME}/quickstart.py \ --project=${PROJECT_ID} \ --region=${REGION} \ --subnet=${SUBNET} \ --version=2.2 \ --properties="\ spark.sql.defaultCatalog=${LAKEHOUSE_CATALOG_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}=org.apache.iceberg.spark.SparkCatalog,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.type=rest,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.uri=${CATALOG_URI_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.warehouse=gs://${BUCKET_NAME},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.io-impl=org.apache.iceberg.gcp.gcs.GCSFileIO,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.x-goog-user-project=${PROJECT_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\ spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest-metrics-reporting-enabled=false,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.X-Iceberg-Access-Delegation=vended-credentials,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token"All tables registered successfully! Batch [126fa2226a904d2e944c8eecbe0b1840] finished. metadata: '@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata batch: projects/PROJECT_ID/locations/REGION/batches/126fa2226a904d2e944c8eecbe0b1840 batchUuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff createTime: '2026-04-09T13:17:26.222727Z' description: Batch labels: goog-dataproc-batch-id: 126fa2226a904d2e944c8eecbe0b1840 goog-dataproc-batch-uuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-drz-resource-uuid: batch-3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-location: REGION operationType: BATCH name: projects/PROJECT_ID/regions/REGION/operations/47bc59e8-5082-3af9-89a0-22289aa5f4b9
6. שליחת שאילתה לטבלה מ-BigQuery
הפעלתם בהצלחה את עבודת ה-batch של Spark, והשתמשתם ב-Managed Service for Spark Serverless כמנוע מחשוב מבוזר כדי לרשום כמה טבלאות, אחת לכל קובץ Parquet במאגר המטא-נתונים של Lakehouse. ההרשמה הזו מאפשרת ל-Google Cloud להתייחס לקבצים הגולמיים שלכם ב-Cloud Storage כאל טבלאות מובנות עם ביצועים גבוהים.
השלבים הבאים יעזרו לכם לוודא שהמטא-נתונים סונכרנו בצורה נכונה, כדי שהנתונים שלכם לא רק יישמרו בצורה בטוחה, אלא גם יהיו ניתנים לגילוי ולשאילת שאילתות דרך הממשק של BigQuery.
- במסוף Google Cloud, עוברים אל BigQuery.
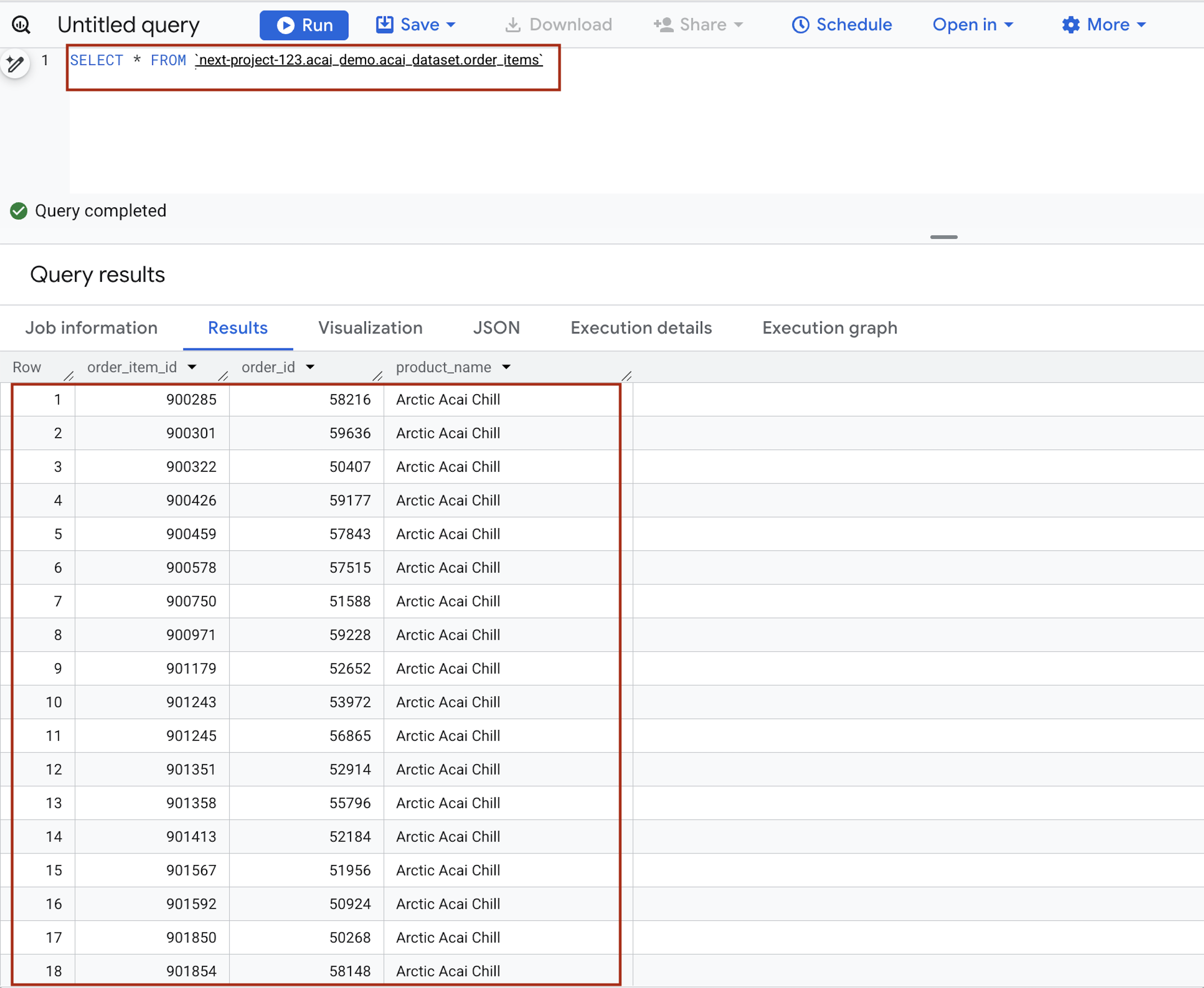
- מזינים את ההצהרה הבאה בעורך השאילתות. השאילתה משתמשת בתחביר
project.namespace.dataset.table.SELECT * FROM `<PROJECT_ID>.<NAMESPACE>.<ICEBERG_DATASET>.<ICEBERG_TABLE>`PROJECT_ID.acai_demo.acai_dataset.order_items.
מחליפים את מה שכתוב בשדות הבאים:- PROJECT_ID: מזהה הפרויקט ב-Google Cloud.
- NAMESPACE: מרחב השמות שנוצר בשלב הקודם כתוצאה מעבודת Spark. אפשר למצוא אותו בדף סייר האובייקטים ב-BigQuery. לדוגמה,
acai_demo. - ICEBERG_DATASET: שם מערך הנתונים בקטלוג Iceberg, למשל
acai_dataset. - ICEBERG_TABLE: שם הטבלה במערך הנתונים של Iceberg, לדוגמה,
order_items.
- לוחצים על Run. בתוצאות השאילתה מוצגים הנתונים שהוספתם באמצעות עבודת Spark.
7. הגדרת קבצים של נתוני מוצרים לא מובנים
בקטע הזה, תיצרו מבנה ארגוני ב-BigQuery כדי לאחסן את המתכון של הפרוזן יוגורט ואת נתוני הספקים, במיוחד את פרטי המוצר של הפרוזן יוגורט. החיבור גם יוצר קישור למשאבים ב-Cloud, שמשמש כ'גשר' מאובטח שמאפשר ל-BigQuery לקרוא קבצים ממקורות חיצוניים כמו Cloud Storage.
יצירת קטגוריה והעלאת קובצי הפרטים של Froyo
יוצרים את קובצי הספקים והמתכונים ומעלים אותם לקטגוריה ב-Cloud Storage.
- במסוף Google Cloud, נכנסים לדף Cloud Storage Buckets.
- לוחצים על יצירה.
- ממלאים את פרטי הקטגוריה בדף Create a bucket. אחרי כל אחד מהשלבים הבאים, לוחצים על המשך כדי לעבור לשלב הבא:
- בקטע Get started (תחילת העבודה), מזינים את שם הקטגוריה. לדוגמה,
acai_pdfs. - בקטע Choose where to store your data, בוחרים באפשרות Region ומזינים את האזור. לדוגמה,
us-west1. - בקטע Choose how to control access to objects, מבטלים את הסימון בתיבת הסימון Enforce public access prevention on this bucket.
- לוחצים על יצירה.
- ברשימת הקטגוריות, לוחצים על הקטגוריה שיצרתם. לדוגמה,
acai_pdfs. - בכרטיסייה Objects של הקטגוריה, לוחצים על Upload > Upload folders.
- בוחרים את התיקייה
recipesשחולצה בקטע לפני שמתחילים ב-codelab הזה. - לוחצים על העלאה.
- חוזרים על תהליך ההעלאה של התיקייה
suppliers.
יצירת חיבור
יוצרים קישור למשאבים ב-Cloud. הפעולה הזו יוצרת חשבון שירות ייחודי שמשמש כ"תעודת הזהות" של BigQuery לצורך גישה לקבצים חיצוניים.
- עוברים לדף BigQuery.
- בחלונית הימנית, לוחצים על כלי הניתוחים. אם החלונית השמאלית לא מוצגת, לוחצים על הרחבת החלונית השמאלית כדי לפתוח אותה.
- בחלונית Explorer, מרחיבים את שם הפרויקט ואז לוחצים על Connections.
- בדף Connections (חיבורים), לוחצים על Create connection (יצירת חיבור).
- בקטע Connection (חיבור), בוחרים באפשרות Vertex AI remote models, remote functions, BigLake and Spanner (Cloud Resource) (מודלים מרוחקים, פונקציות מרוחקות, BigLake ו-Spanner של Vertex AI (משאב בענן)).
- בשדה מזהה החיבור, מזינים את שם מזהה החיבור. לדוגמה,
acai_pdf_connection. חשוב לרשום את המזהה הזה, כי תצטרכו אותו בהמשך כשתיצרו את סריקת הנתונים ב-codelab הזה. - בשדה Location type בוחרים באפשרות Region ואז בוחרים אזור. לדוגמה,
us-west1. החיבור צריך להיות ממוקם באותו מקום כמו שאר המשאבים, כמו קבוצות נתונים. - לוחצים על יצירת קישור.
- לוחצים על מעבר לחיבור.
- בחלונית פרטי החיבור, מעתיקים את מזהה חשבון השירות לשימוש בשלב מאוחר יותר. חשבון השירות נראה דומה ל-
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com.
ניהול הגישה לחשבונות שירות
נותנים גישה לחשבון השירות כדי שה-Lakehouse יוכל לקרוא את קובצי ה-PDF.
- עוברים לדף IAM & Admin.
- לוחצים על הענקת גישה. תיבת הדו-שיח Add principals נפתחת.
- בשדה New principals, מזינים את מזהה חשבון השירות שהעתקתם קודם.
- בשדה Select a role (בחירת תפקיד), מוסיפים את התפקידים הבאים:
roles/storage.objectUserroles/storage.objectViewerroles/bigquery.userroles/bigquery.dataEditorroles/aiplatform.userroles/storage.adminroles/dataproc.serviceAgent
- לוחצים על שמירה.
במאמר תפקידים והרשאות מוגדרים מראש יש מידע נוסף על תפקידי IAM ב-BigQuery.
8. ניהול הרשאות לעבודת DataScan
יוצרים חשבונות שירות ספציפיים (זהויות) ל-Spark ול-Dataform, ואז מעניקים להם – יחד עם סוכני השירות האוטומטיים של Google – את ההרשאות המדויקות שנדרשות לקריאת אחסון, להרצת משימות BigQuery ולשימוש ב-Vertex AI לצורך גילוי.
גישת IAM ל-Spark ול-Dataform
- במסוף Google Cloud, נכנסים לדף יצירת חשבון שירות.
- אם לא בחרתם פרויקט, בוחרים את הפרויקט ב-Google Cloud.
- לוחצים על יצירת חשבון שירות.
- מזינים שם לחשבון השירות. לדוגמה,
sa-spark-stg1. מסוף Google Cloud יפיק מזהה של חשבון שירות על סמך השם הזה. עורכים את המזהה לפי הצורך. אי אפשר יהיה לשנות את המזהה בשלב מאוחר יותר. - כדי להגדיר אמצעי בקרת גישה, לוחצים על יצירה והמשך וממשיכים לשלב הבא.
- בוחרים את תפקידי ה-IAM הבאים כדי להקצות לחשבון השירות בפרויקט.
roles/dataproc.workerroles/storage.objectUserroles/bigquery.dataEditorroles/bigquery.jobUserroles/aiplatform.userroles/dataplex.discoveryPublishingServiceAgent
- כשמסיימים להוסיף תפקידים, לוחצים על Continue.
- לוחצים על Done כדי לסיים ליצור את חשבון השירות.
הרשאות לחיבור BigQuery לגישה ל-Knowledge Catalog
- במסוף Google Cloud, נכנסים לדף Cloud Storage Buckets.
- ברשימת הקטגוריות, לוחצים על שם הקטגוריה שיצרתם בשביל Froyo. לדוגמה,
acai_pdfs. - בכרטיסייה Permissions, לוחצים על Grant access. מופיעה תיבת הדו-שיח Add principals.
- בשדה New principals, מזינים את מזהה חשבון השירות של BigQuery. חשבון השירות נראה דומה ל-
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com. - בוחרים את התפקיד (או התפקידים) הבא בתפריט הנפתח Select a role.
roles/storage.objectUserroles/dataplex.serviceAgentroles/dataplex.securityAdminroles/aiplatform.serviceAgentroles/dataplex.discoveryPublishingServiceAgent
- לוחצים על 'שמירה'.
9. הגדרת Knowledge Catalog
אפשר ליצור Knowledge Catalog כדי לאחד את הנתונים שקשורים ל-Froyo ולאתר באופן אוטומטי קבצים לא מובנים (כמו מתכוני PDF וספקי PDF).
יצירת DataScan דרך curl
בקטע הזה נסביר איך ליצור סריקות לקטגוריה של Cloud Storage (לדוגמה, acai_pdfs) על ידי הוספת datascan_ID והפניה שלו למערכי הנתונים ב-BigQuery. לאחר מכן, ב-Knowledge Catalog ייווצרו באופן אוטומטי רשומות עבור קובצי ה-PDF שלכם ב-BigQuery.
- כדי לסרוק את קובצי ה-PDF (ספקים ומתכונים), מריצים את הפקודה הבאה:
# 1. Set your variables PROJECT_ID="<PROJECT_ID>" REGION="<REGION>" ENV_SUFFIX="stg1" DATASCAN_ID="froyo-profile-${ENV_SUFFIX}" BUCKET_NAME="<BUCKET_NAME>" # 2. Set this to the Name of the connection you created in Step 7 CONNECTION_ID="<CONNECTION_ID_NAME>" # 3. Define the API Endpoint DATAPLEX_API="dataplex.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}" # 4. Create the DataScan via CURL echo "Creating Dataplex DataScan: ${DATASCAN_ID}..." curl -X POST "https://$DATAPLEX_API/dataScans?dataScanId=${DATASCAN_ID}" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d '{ "data": { "resource": "//storage.googleapis.com/projects/'"${PROJECT_ID}"'/buckets/'"${BUCKET_NAME}"'" }, "executionSpec": { "trigger": { "on_demand": {} } }, "dataDiscoverySpec": { "bigqueryPublishingConfig": { "tableType": "BIGLAKE", "connection": "projects/'"${PROJECT_ID}"'/locations/'"${REGION}"'/connections/'"${CONNECTION_ID}"'" }, "storageConfig": { "unstructuredDataOptions": { "entity_inference_enabled": true } } } }' - הפקודה
curlמציגה את תוצאות הסריקה של Knowledge Catalog, בדומה לתמונה הבאה.
הרצת המשימה
מריצים את הפקודה הבאה:
gcloud dataplex datascans run $DATASCAN_ID --location=$REGION
תארי את התפקיד
כדי לתאר את העבודה, מריצים את הפקודה הבאה:
gcloud dataplex datascans describe $DATASCAN_ID --location=$REGION
מחיקה של משימת סריקת נתונים
אם הסריקה נמשכת יותר מ-10 דקות, או אם סטטוס המשימה נשאר בהמתנה למשך זמן ממושך בלי לעבור לסטטוס פועל, יכול להיות שהסיבה לכך היא חוסר זמינות זמני של משאבים באזור. במקרה כזה, אפשר להריץ את הפקודה הבאה כדי למחוק את העבודה, ואז לנסות ליצור ולהריץ אותה שוב. לפעמים, הפעלה ראשונית עשויה להיכשל במהירות עם שגיאה כמו unable to acquire necessary resources.
gcloud dataplex datascans delete $DATASCAN_ID --location=$REGION
הצגת הסטטוס של העבודה
כדי לבדוק את סטטוס העבודה:
- במסוף Google Cloud, עוברים לדף Metadata curation.
- בכרטיסייה Cloud Storage discovery (גילוי ב-Cloud Storage), לוחצים על השם של סריקות הגילוי.
- בדף פרטי הסריקה אפשר לראות את סטטוס העבודה.
- אחרי שהעבודה מסתיימת, בודקים אם מערך הנתונים שפורסם (לדוגמה,
acai_pdfs_discovered_003) שיצרתם באמצעות הפקודהcurlמופיע.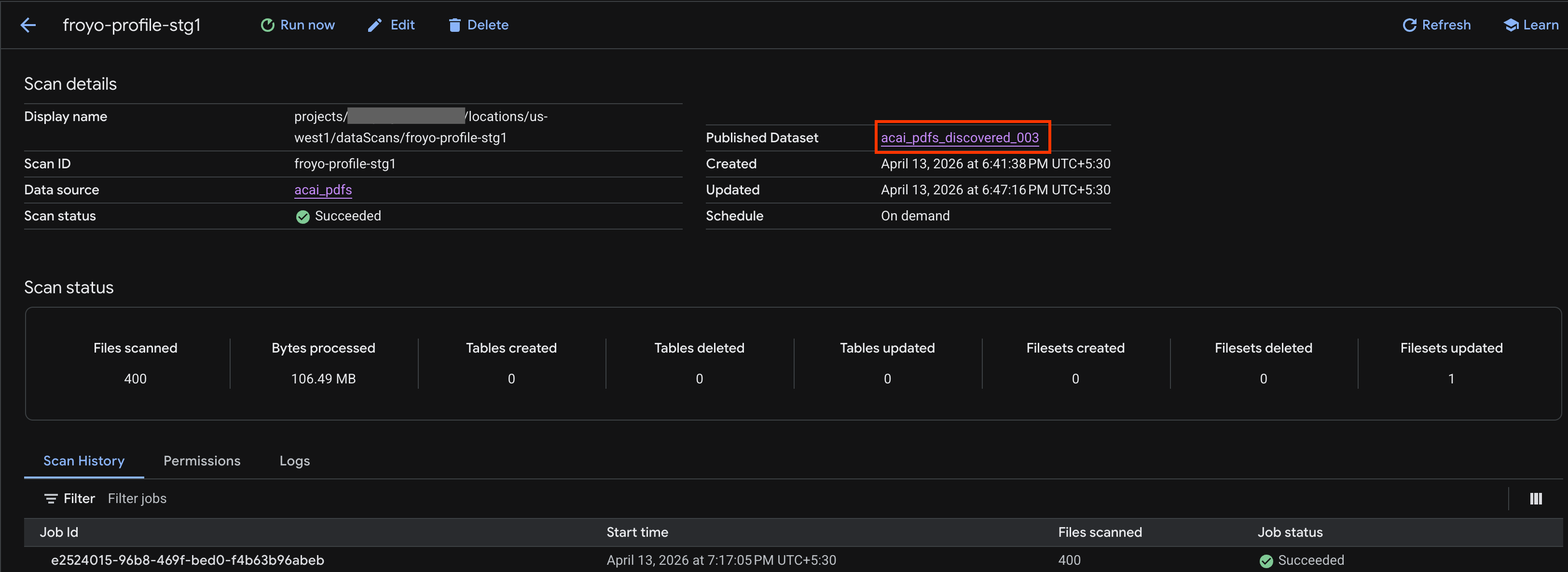
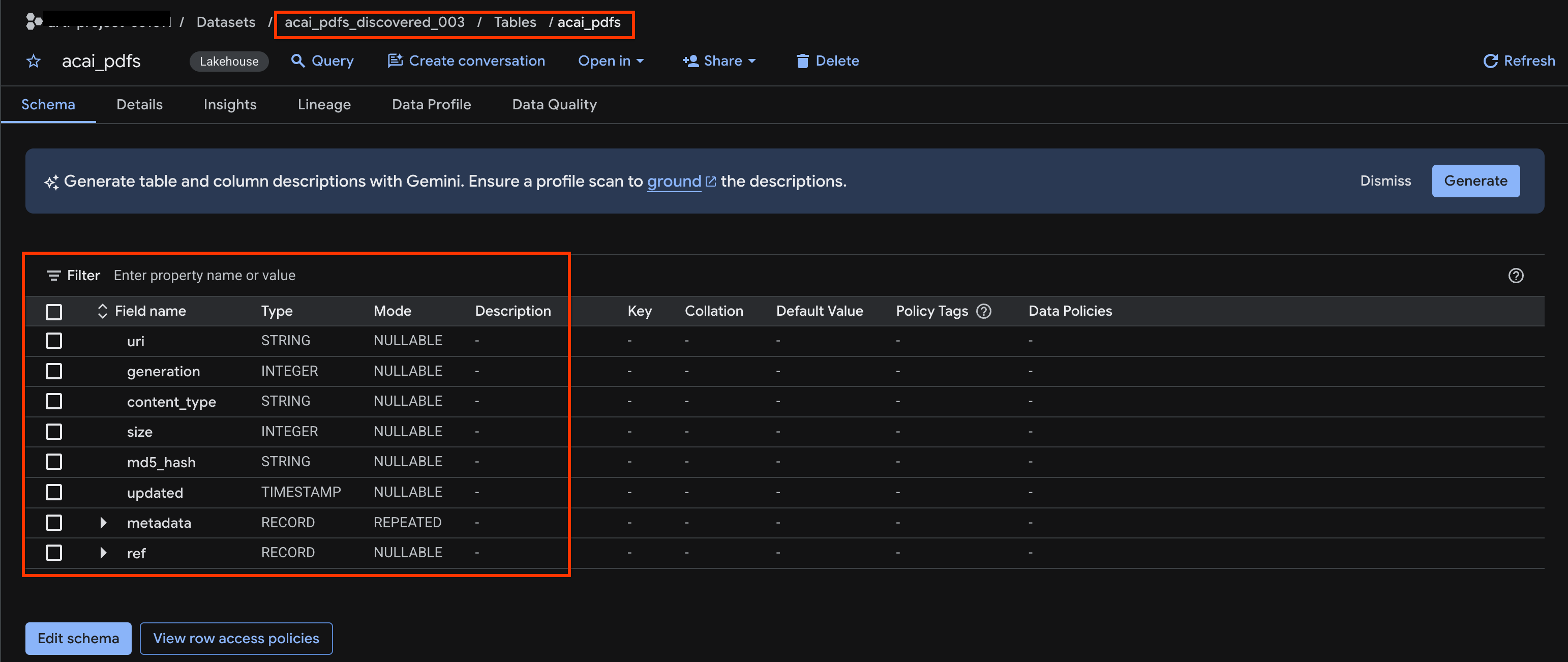
הצגת טבלת האובייקטים
כדי לראות את טבלת האובייקטים שנוצרה אחרי משימת הגילוי:
- במסוף Google Cloud, עוברים אל BigQuery.
- לוחצים על Datasets (מערכי נתונים) ובוחרים את מערך הנתונים שפורסם ונוצר בשלב הקודם. לדוגמה,
acai_pdfs_discovered_003. - כדי להציג את טבלת האובייקטים, לוחצים על מזהה הטבלה. לדוגמה,
acai_pdfs. - טבלת האובייקטים שמתקבלת נראית כמו בתמונה הבאה:
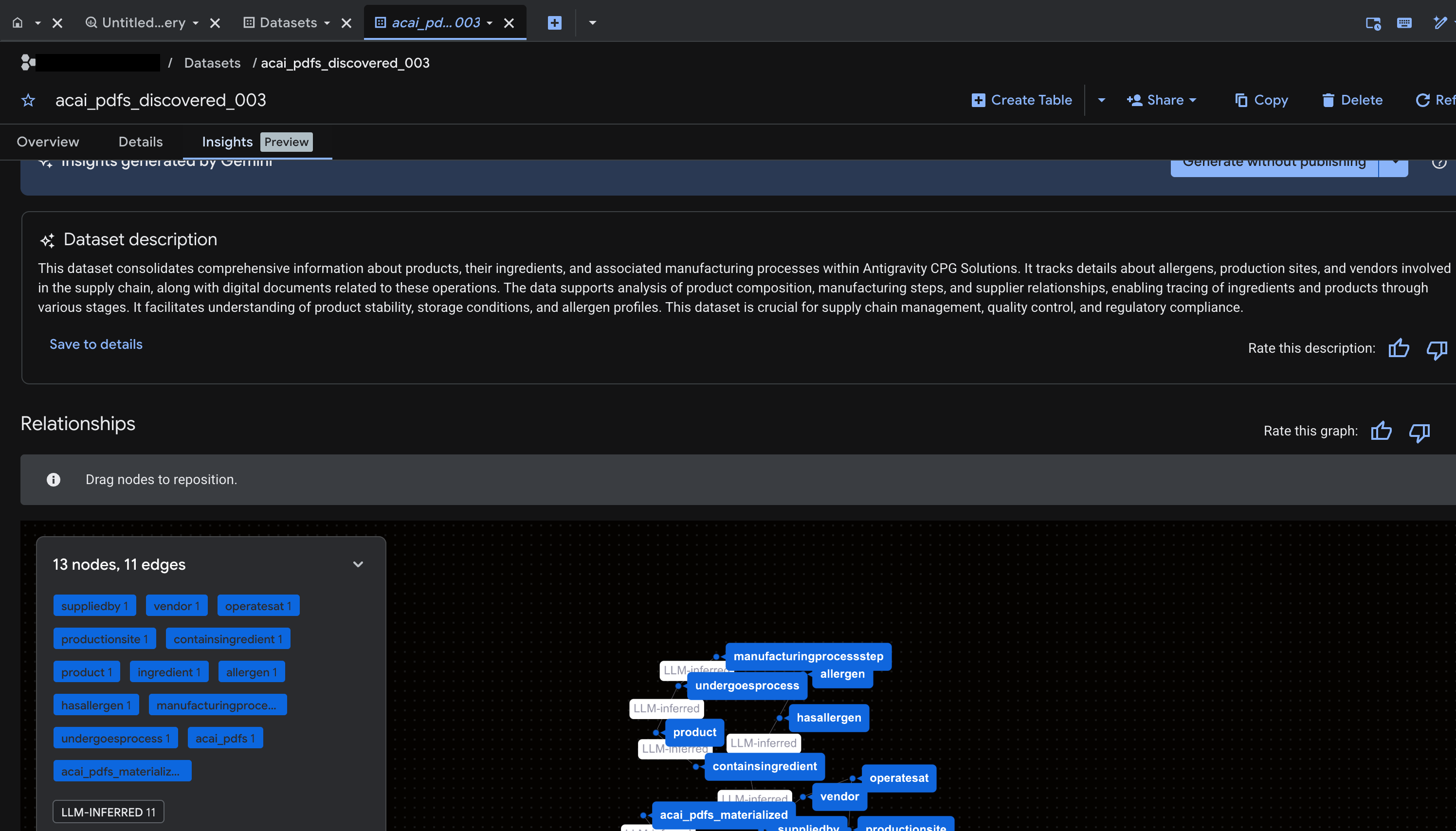
10. חילוץ סמנטי
תסיקו ותחלצו טבלאות מובנות, אובייקטים אחרים של מסד נתונים ויחסים עבור טבלת האובייקטים הלא מובנית הזו שיצרתם בשלב הקודם. לשם כך, תשתמשו בתכונה 'תובנות מתוך Knowledge Catalog' כדי ליצור הצהרות SQL לחילוץ נתונים מובְנים מהטבלה הלא מובְנית
- במסוף Google Cloud, עוברים לדף Knowledge Catalog Search.
- מחפשים את טבלת מערך הנתונים שרוצים לראות את התובנות לגביה. לדוגמה,
acai_pdfs_discovered_003.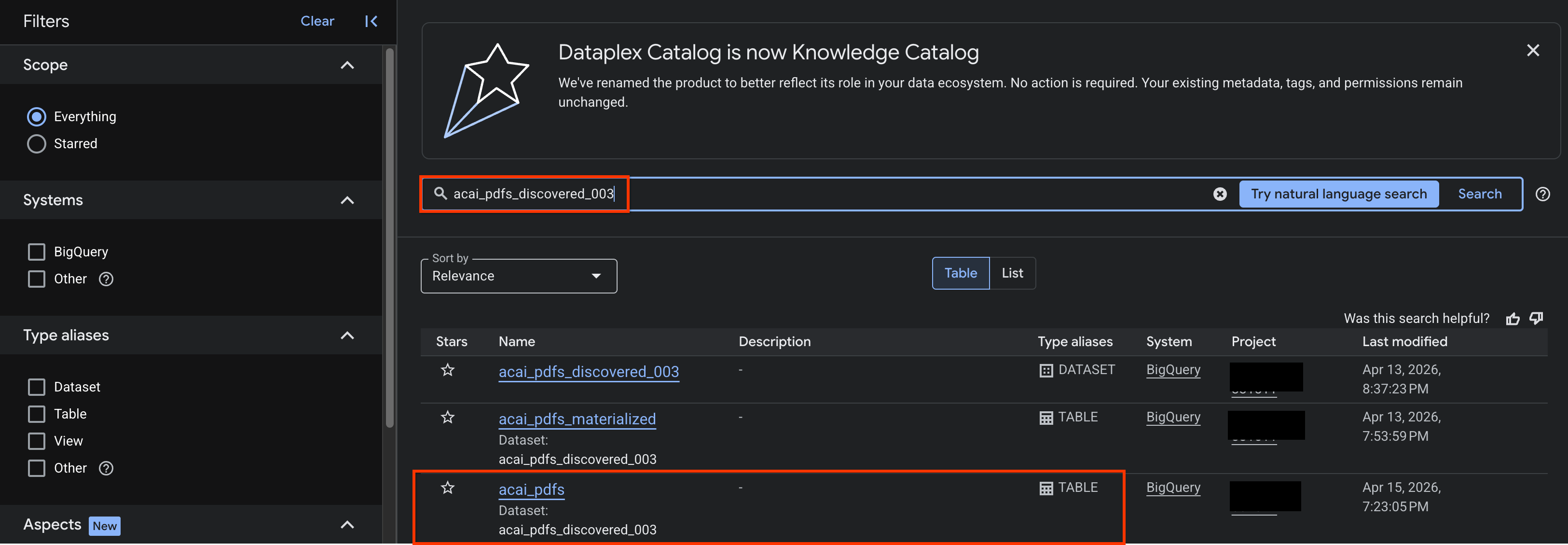
- בתוצאות החיפוש, לוחצים על הטבלה כדי לפתוח את דף הערך שלה.
- לוחצים על הכרטיסייה תובנות. אם הכרטיסייה ריקה, זה אומר שהתובנות לגבי הטבלה הזו עדיין לא נוצרו. יצירת התובנות עשויה להימשך 15 עד 25 דקות.
- אחרי שרואים את התובנות, לוחצים על חילוץ > חילוץ באמצעות SQL.
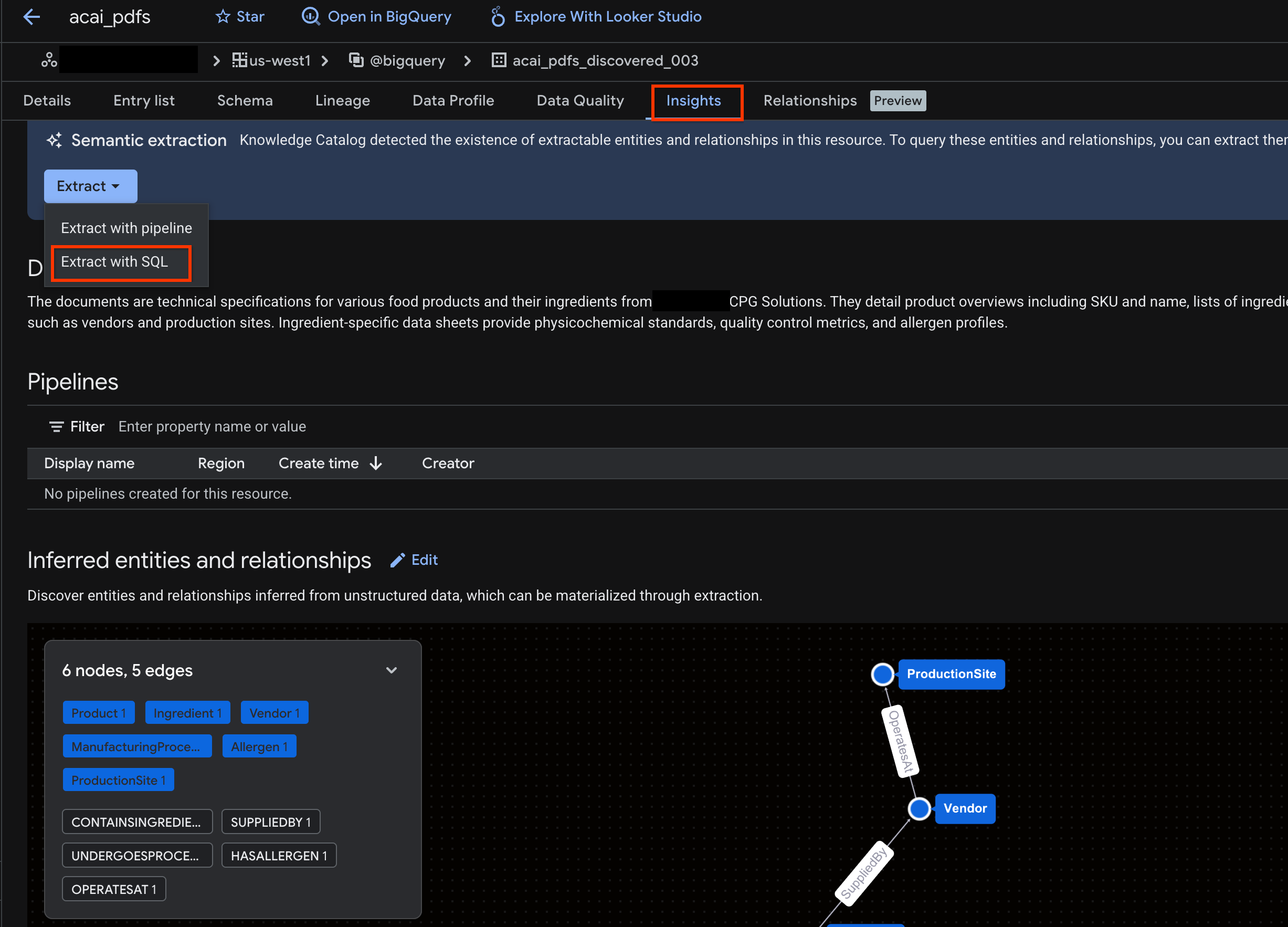
- בדף Extract with SQL (חילוץ באמצעות SQL), בשדה Destination (יעד), מזינים את מערך הנתונים. לדוגמה,
acai_pdfs_discovered_003. - לוחצים על חילוץ. עורך BigQuery ייפתח עם השאילתה שנטענה.
- לוחצים על Run. בשלב הזה נוצרת קבוצה של הצהרות, והוא עשוי להימשך כמה דקות.
- בסיום השאילתה, יוצגו התוצאות הבאות:
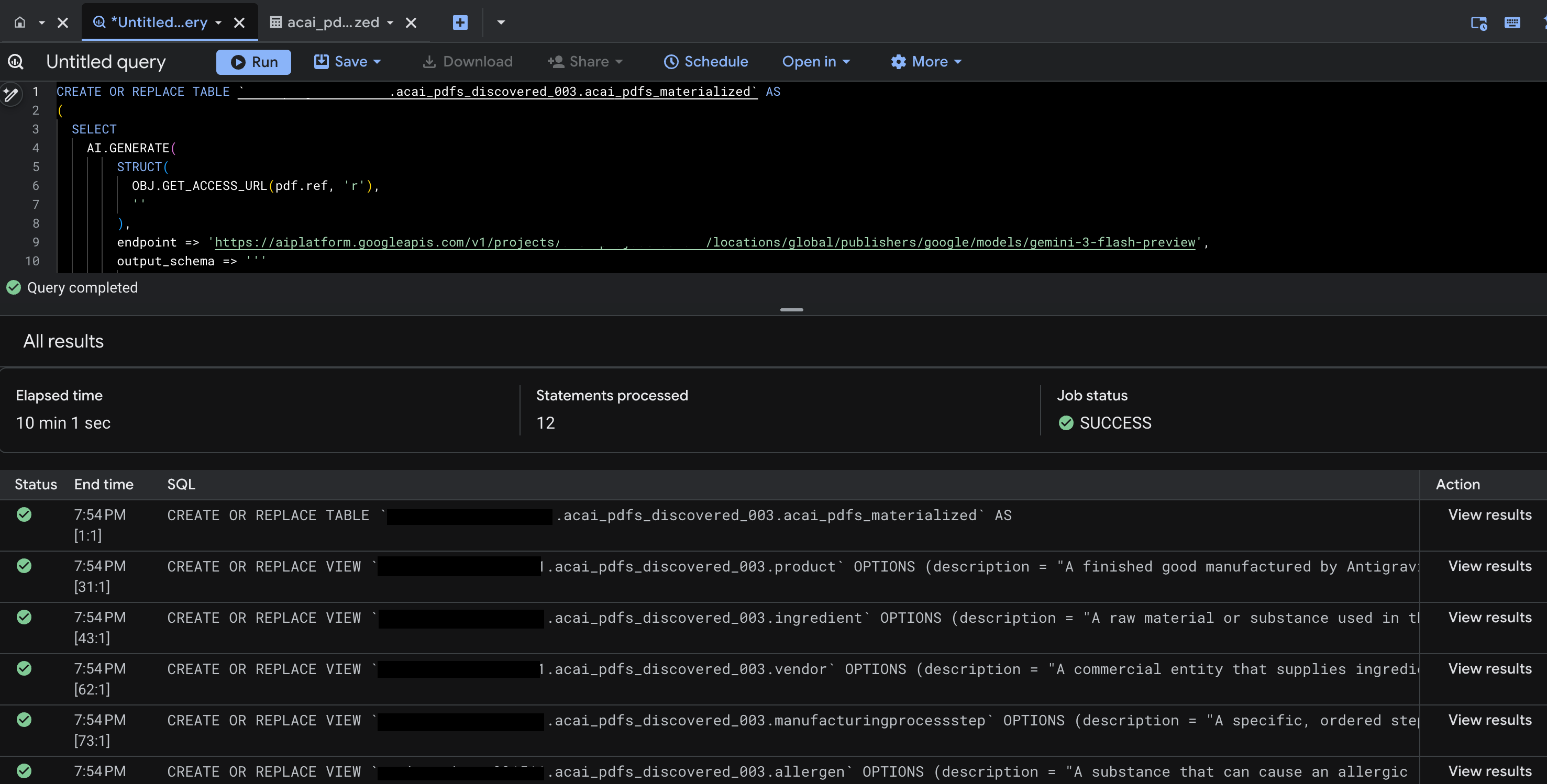
- עוברים אל BigQuery ולוחצים על Datasets (לדוגמה,
acai_pdfs_discovered_003). נוצרת קבוצה חדשה של אובייקטים מובנים של מסד נתונים במערך הנתונים שבחרתם בשלב 6.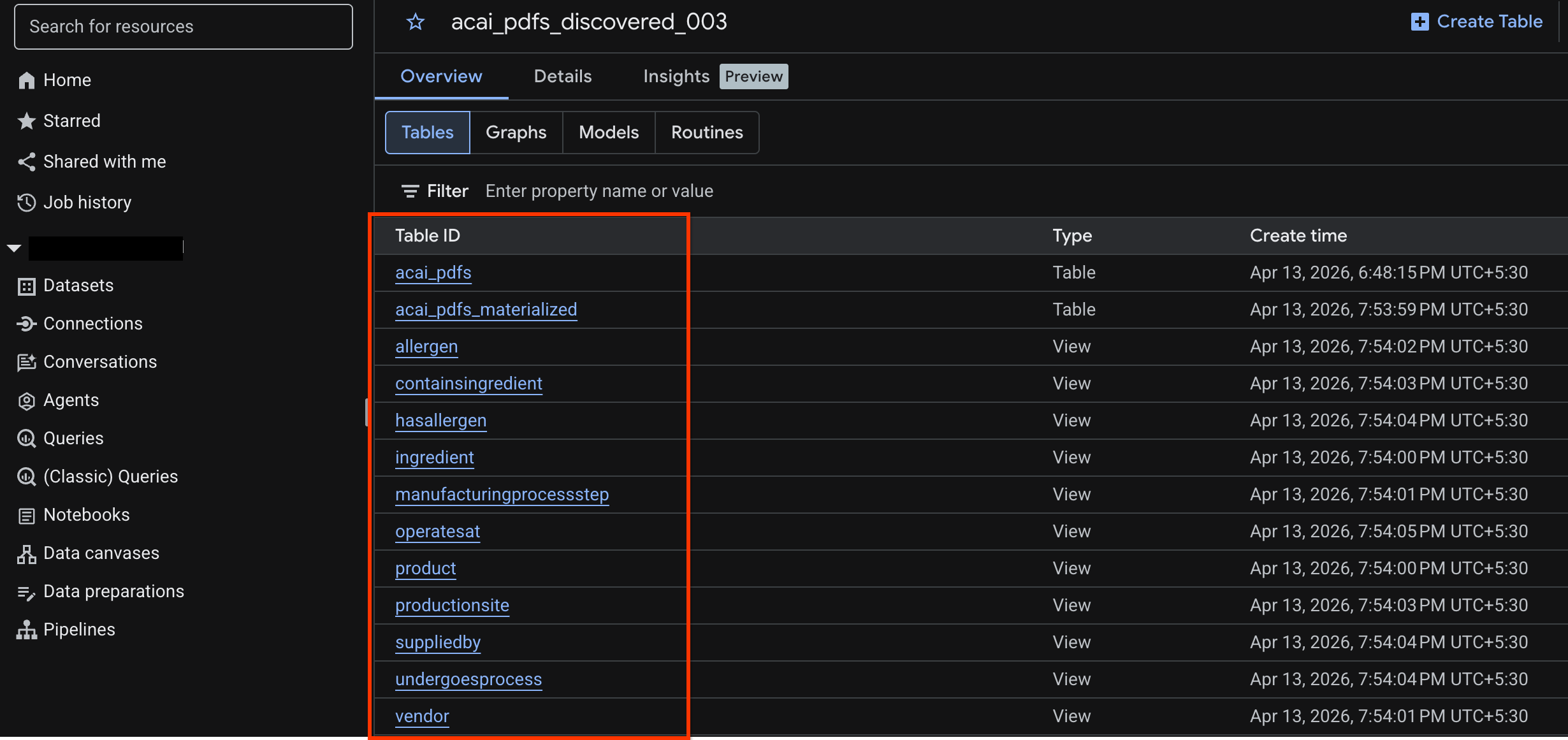
יצירת תובנות לגבי אובייקט ב-BigQuery
כדי ליצור תובנות לגבי מערך נתונים ב-BigQuery, צריך לגשת למערך הנתונים ב-BigQuery באמצעות BigQuery Studio.
- במסוף Google Cloud, עוברים אל BigQuery Studio.
- בחלונית Explorer, בוחרים את הפרויקט ועוברים למערך הנתונים שרוצים ליצור לגביו תובנות.
- לוחצים על הכרטיסייה תובנות.
- אם מופיע הלחצן Enable API, לוחצים עליו כדי להפעיל את Gemini for Google Cloud. ייפתח החלון הפעלת התכונות העיקריות.
- בקטע Core feature APIs, לוחצים על Enable ליד Gemini for Google Cloud API ו-BigQuery Unified API, ואז לוחצים על Next.
- בקטע Permissions (optional) (הרשאות (אופציונלי)), מקצים תפקידי IAM לחשבונות משתמשים אם צריך, ואז לוחצים על Next (הבא).
- כדי ליצור תובנות ולפרסם אותן ב-Knowledge Catalog, לוחצים על יצירה ופרסום.
- אחרי הפרסום, תוכלו לראות תובנות בכרטיסייה.
11. הגדרת סביבת פיתוח משולבת (IDE) לניתוח נתונים באמצעות סוכנים
התוסף Google Cloud Data Agent Kit ל-Visual Studio Code הוא תוסף IDE למדעני נתונים ולמהנדסי נתונים. הוא מאפשר לכם להתחבר למשאבים ולנתונים של Google Data Cloud ולעבוד איתם ישירות מ-IDE. מידע נוסף זמין במאמר בנושא סקירה כללית של Data Agent Kit extension for VS Code
התוסף Data Agent Kit ל-VS Code שימושי כשרוצים לבצע את הפעולות הבאות:
- ליצור, לבדוק, לבדוק ולפרוס צינור נתונים מוכן לייצור, כמו Spark ETL או BigQuery ETL, ישירות מ-VS Code.
- בעזרת AI, תוכלו לחקור נתונים, ליצור צינור אימון, לזהות מודלים אופטימליים של למידת מכונה ולפרוס אותם לנקודת קצה של ייצור.
- חיבור למקורות נתונים מהימנים, בניית מודל נתונים עם ביצועים גבוהים ופרסום לוח בקרה אינטראקטיבי לבעלי עניין עסקיים.
התקנת התוסף Data Agent Kit ל-VS Code
- פותחים את VS Code.
- מתקינים את Google Cloud CLI. מידע נוסף זמין במאמר התקנת Google Cloud CLI.
- התקנת התוסף Data Agent Kit ל-VS Code
- משלימים את תהליך ההצטרפות לתוסף. לשם כך צריך:
- כניסה לתוסף
- התקנת מיומנויות, שרתי MCP
- אחרי שמסיימים את תהליך ההצטרפות, טוענים מחדש את החלון או מפעילים אותו מחדש. מידע נוסף זמין במאמר בנושא הגדרה וקביעת הגדרות של התוסף Data Agent Kit ל-VS Code.
- אחרי שה-IDE נטען מחדש, לוחצים על סמל Google Data Cloud בחלונית הניווט, עוברים להגדרות ומוודאים שהגדרתם נכון את מזהה הפרויקט והאזור (
us-west1) בהגדרות המשותפות.
הגדרת סביבת העבודה ב-VS Code
- פותחים את VS Code ובוחרים באפשרות File (קובץ) > Open folder (פתיחת תיקייה) > New folder (תיקייה חדשה).
- יוצרים תיקייה חדשה בשם
acai_testולוחצים על Open. עכשיו VS Code מתייחס לתיקייה שפתחתם כאל סביבת עבודה. - בתיבת הדו-שיח Workspace trust (מהימנות ב-Workspace), בוחרים באפשרות Yes, I trust the authors (כן, אני סומך על היוצרים) כדי להפעיל את כל התכונות בסביבת העבודה.
- יוצרים תיקייה
.githubבסביבת העבודהacai_test. - יוצרים קובץ חדש
copilot-instructions.mdבתיקייה.githubומזינים בו את הכללים הבאים.## 1. Project Context - **Project ID**: <PROJECT_ID> - **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors. - **Documentation**: Raw PDF documents detailing flavors and ingredients are stored in Google Cloud Storage at `gs://<BUCKET_NAME>`. ## 2. Execution & Data Processing Rules - **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `<BQ_DATASET_NAME>` (referred to as the Knowledge Catalog). - **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the dataset `<DATASET_ID>`. When you are referencing a dataset, ensure you are using it with the project ID (`<PROJECT_ID>`) and namespace prefix `<NAMESPACE_NAME>`. For example, to query order table in this dataset you should use `<PROJECT_ID>.<NAMESPACE>.<DATASET_ID>.orders`. - **CRITICAL RULE - Data Joins between BigQuery dataset and Iceberg dataset**: ANY task requiring a join or integration between the BigQuery datasets `<DATASET_ID>` of the PDF data and the `<DATASET_ID>` of the customer data MUST be executed using **Spark Notebooks**. - **CRITICAL RULE - Notebook Kernel**: Every Spark notebook utilized MUST exclusively be configured to run on the Serverless Session template `iceberg-federation-template` as its kernel. - **CRITICAL RULE - Data Science**: ANY data science, machine learning, or advanced analytical task MUST be performed strictly within **Spark Notebooks** using the aforementioned setup. - יוצרים עוד קובץ חדש
template.yamlבסביבת העבודהacai_testומזינים בו את הפרטים הבאים.labels: client: "vscode" jupyterSession: displayName: "iceberg-federation-template" kernel: "PYTHON" environmentConfig: executionConfig: serviceAccount: "sa-spark-dev1@<PROJECT_ID>.iam.gserviceaccount.com" subnetworkUri: "projects/<PROJECT_ID>/regions/<REGION>/subnetworks/<SUBNET_NAME>" runtimeConfig: version: "2.3" properties: # This enables the secure proxy URL you were looking for dataproc.tier: "premium" spark.dataproc.engine: "lightningEngine" spark.dataproc.lightningEngine.runtime: "native" spark.memory.offHeap.enabled: "true" spark.memory.offHeap.size: "1g" spark.executor.memory: "4g" "dataproc.component.gateway.enabled": "true" "dataproc.jupyter.listen.all.interfaces": "true" "spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" "spark.sql.defaultCatalog": "<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>": "org.apache.iceberg.spark.SparkCatalog" "spark.sql.catalog.<CATALOG_NAME>.type": "rest" "spark.sql.catalog.<CATALOG_NAME>.uri": "<CATALOG_URI_ID>" "spark.sql.catalog.<CATALOG_NAME>.warehouse": "bl://projects/<PROJECT_ID>/catalogs/<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>.rest.auth.type": "org.apache.iceberg.gcp.auth.GoogleAuthManager" - ב-VS Code, לוחצים על Terminal (טרמינל) ומריצים את הפקודה הבאה כדי לייבא את קובץ
template.yamlכתבנית סשן. הסוכן ישתמש בתבנית הזו בהמשך כדי ליצור סשן Spark.gcloud beta dataproc session-templates import iceberg-federation-template \ --source=template.yaml \ --location=<REGION>REGIONבאזור שלכם.
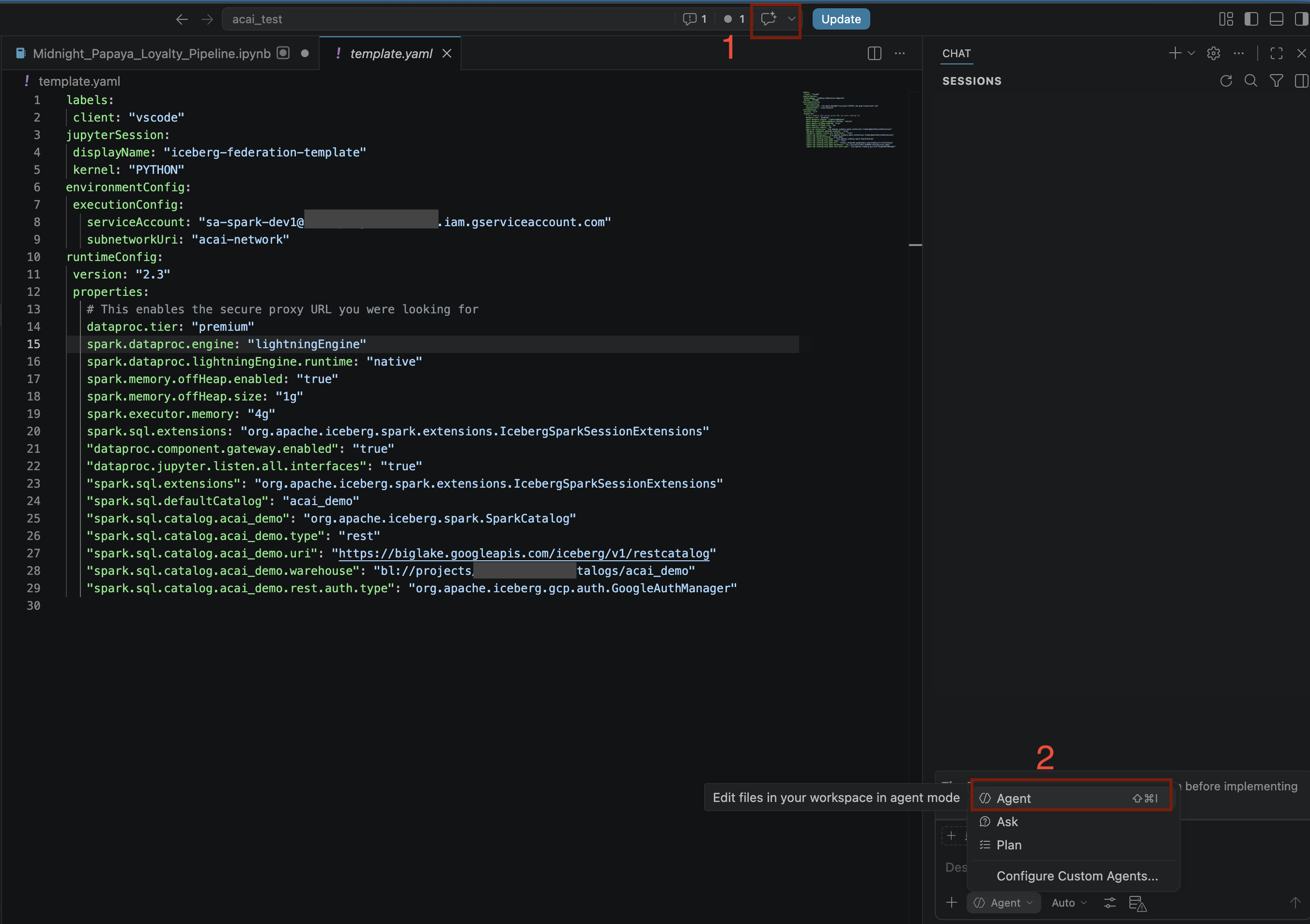
12. ביצוע ניתוח נתונים באמצעות סוכן
- בעורך VS Code, לוחצים על החלפת מצב הצ'אט.
- בקטע Configure custom agents (הגדרת סוכנים בהתאמה אישית), בוחרים באפשרות Agent (סוכן).
- בחלונית מודלים של חיפוש, לוחצים על ניהול מודלים של שפה.
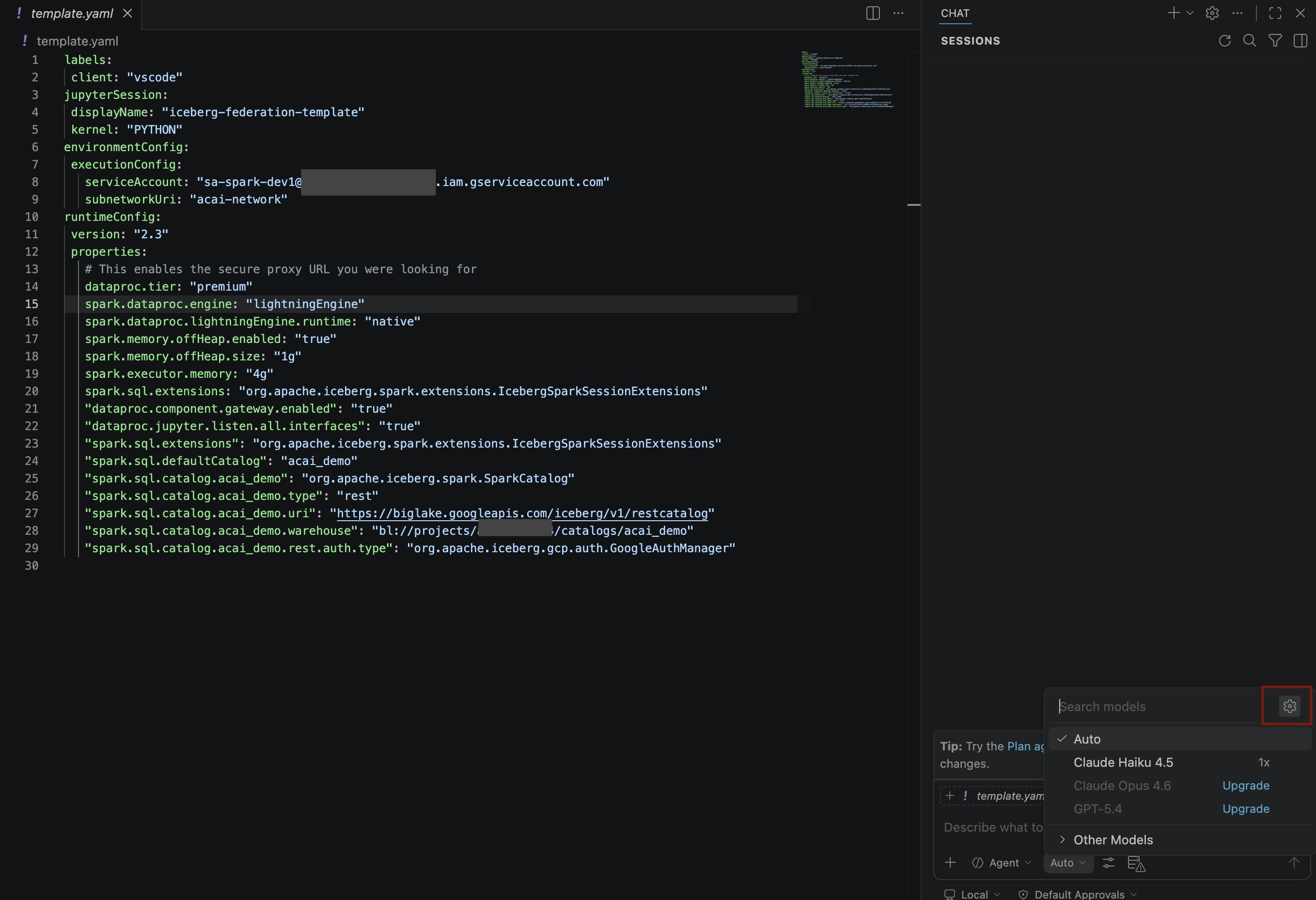
- בדף Language models (מודלים של שפה), לוחצים על Add models (הוספת מודלים).
- בוחרים באפשרות Google מהרשימה ולוחצים על Enter כדי לאשר את הקלט.
- כדי להזין את מפתח ה-API של Google Gemini:
- נכנסים לאתר Google AI Studio.
- נכנסים באמצעות חשבון Google.
- בסרגל הצד, לוחצים על Get API key (קבלת מפתח API).
- לוחצים על Create API key (יצירת מפתח API). נפתח דף חדש ליצירת מפתח.
- ברשימה בחירת פרויקט בענן, בוחרים באפשרות ייבוא פרויקט.
- מזינים את השם של פרויקט קיים.
- לוחצים על Create key ומעתיקים את מפתח ה-API. המפתח מספק גישה למשאבי Gemini API בחשבון שלכם.למידע נוסף, תוכלו לקרוא את המאמר שימוש במפתחות Gemini API.
- מדביקים את מפתח ה-API שיצרתם בסרגל החיפוש ולוחצים על Enter.
- אם מודלי Gemini לא מופיעים, מבטלים את ההסתרה שלהם כמו שמוצג בתמונה הבאה:
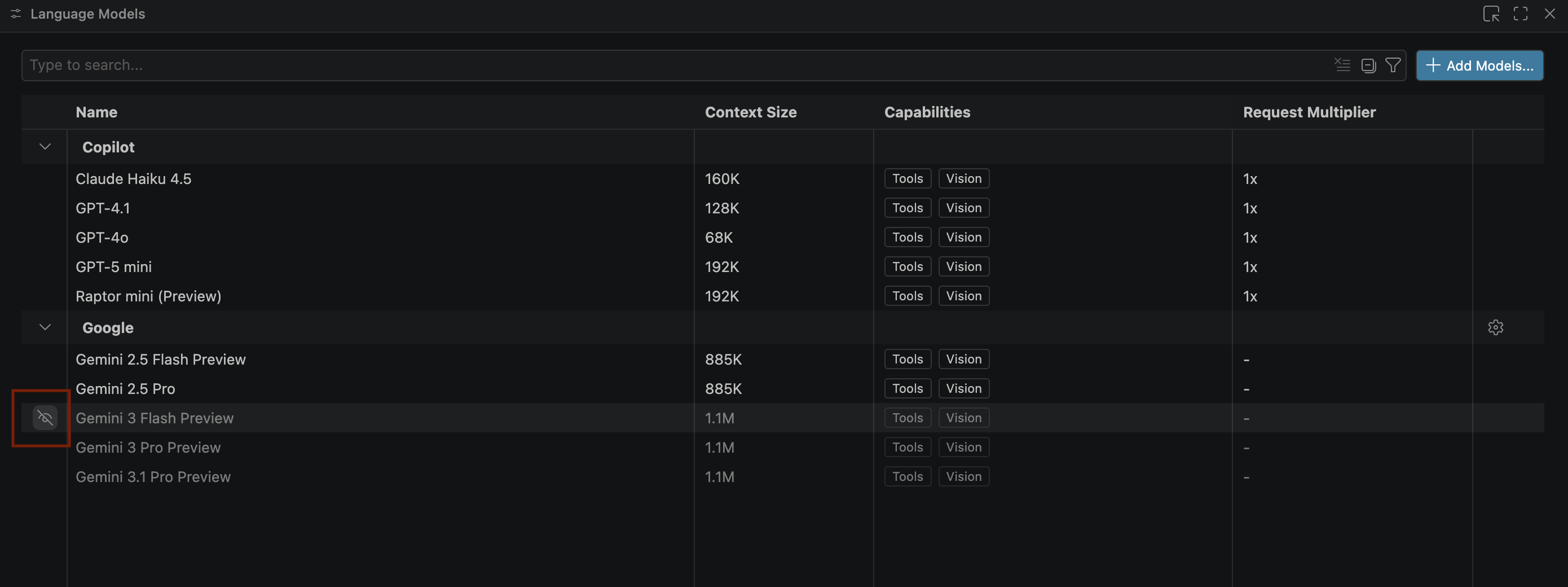
- בוחרים באפשרות Gemini 3.1 Pro Preview (תצוגה מקדימה של Gemini 3.1 Pro) מרשימת המודלים של Google Gemini וסוגרים את החלון Language models (מודלים של שפה).
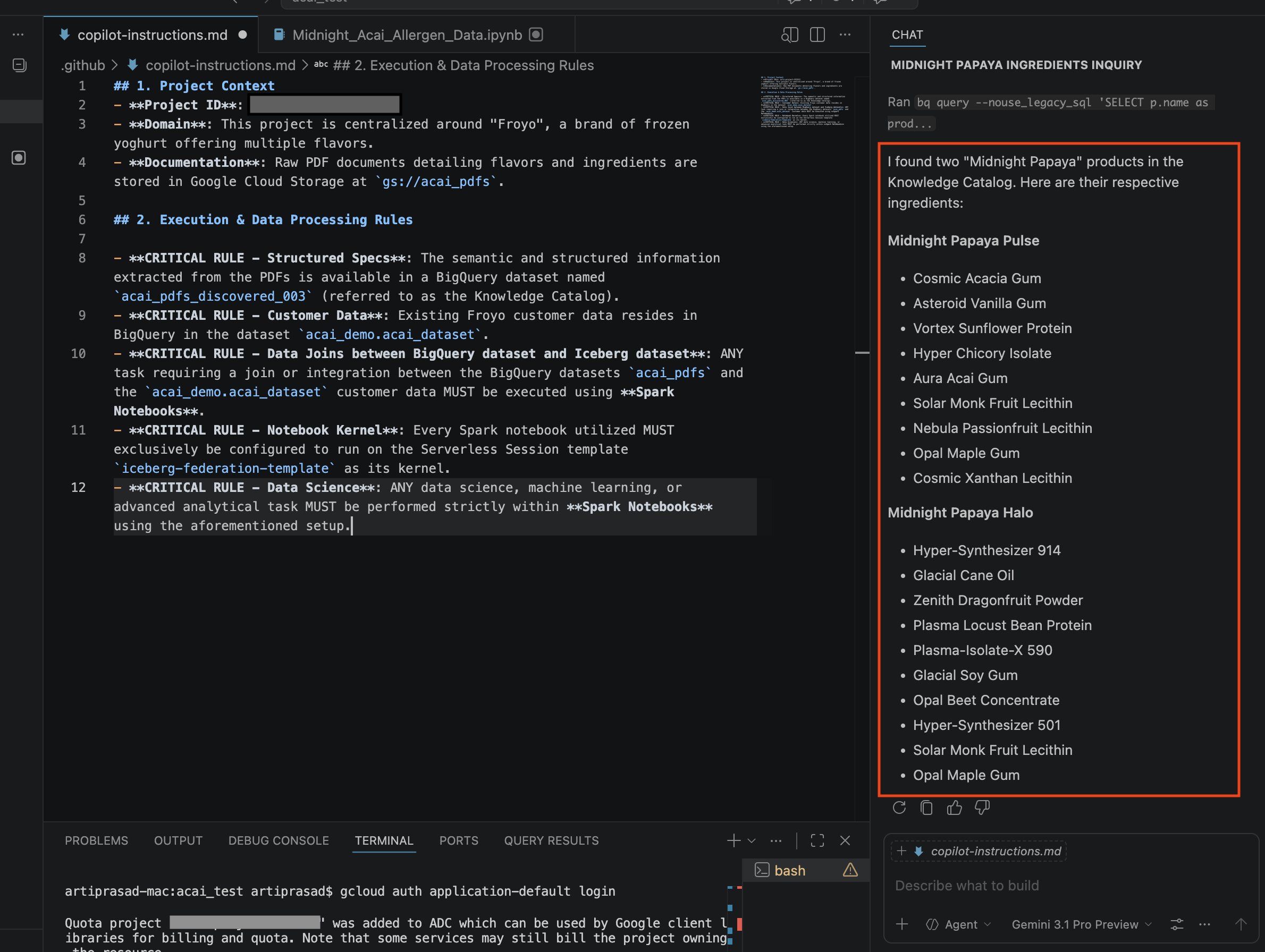
- בחלון הצ'אט, מזינים את השאלה הבאה:
Search ingredients for Midnight papaya - אחרי כמה אינטראקציות, אמורה להתקבל התוצאה הבאה:
- בחלון הצ'אט, מזינים שאלה נוספת:
Search allergen information for Midnight papaya - אחרי כמה אינטראקציות ושלבים, הסוכן יגיב עם שם האלרגן
Soyכמו שרואים בתמונה הבאה: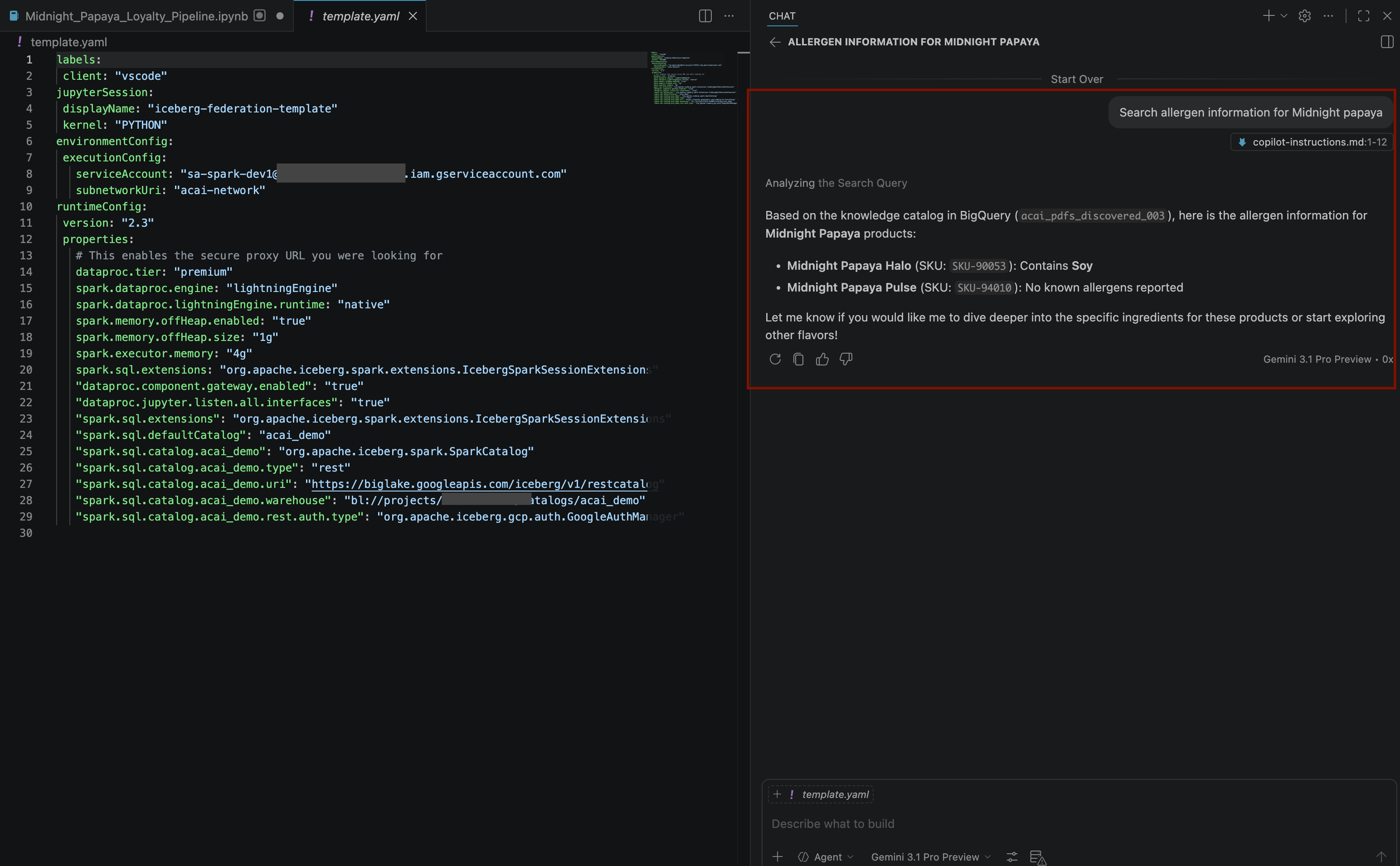
- בחלון הצ'אט, מזינים שאלה נוספת:
Build a pipeline to join products with our 'Global Loyalty' Iceberg tables in acai customer, sales data to identify popular products - כדי לבחור את ליבת המערכת, פותחים את הקובץ
.ipynbולוחצים על Select kernel (בחירת ליבת מערכת) > Remote spark kernels (ליבות מערכת מרוחקות של Spark) > Iceberg-federation-template on serverless spark (תבנית Iceberg-federation ב-Spark ללא שרת)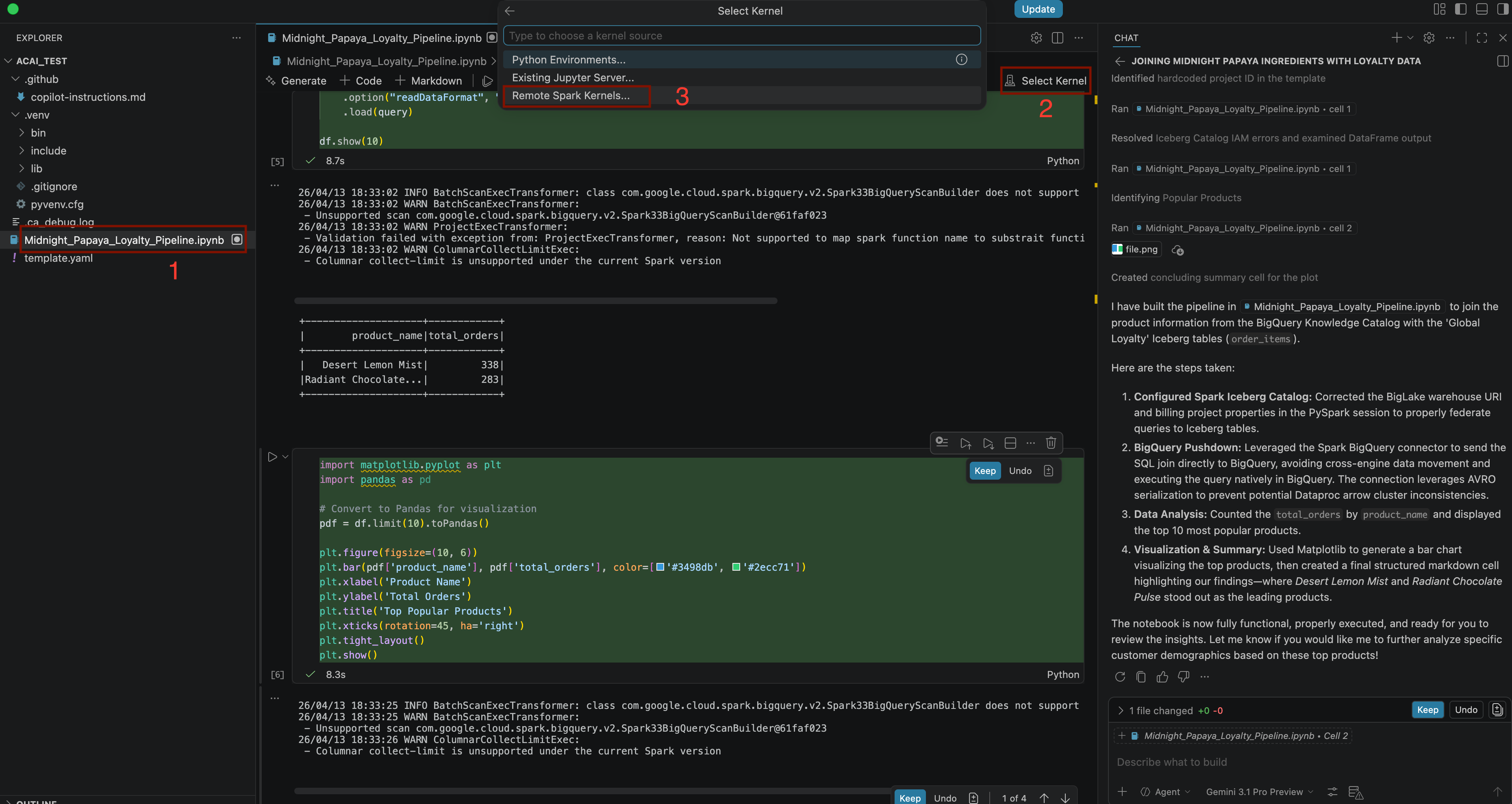
- אחרי כמה אינטראקציות ושלבים, תראו שהסוכן מגיב עם כל השלבים במחברת שהושלמו בהצלחה, יחד עם התוצאה הסופית שנוצרה בסוף המחברת, כמו שרואים בתמונה הבאה:
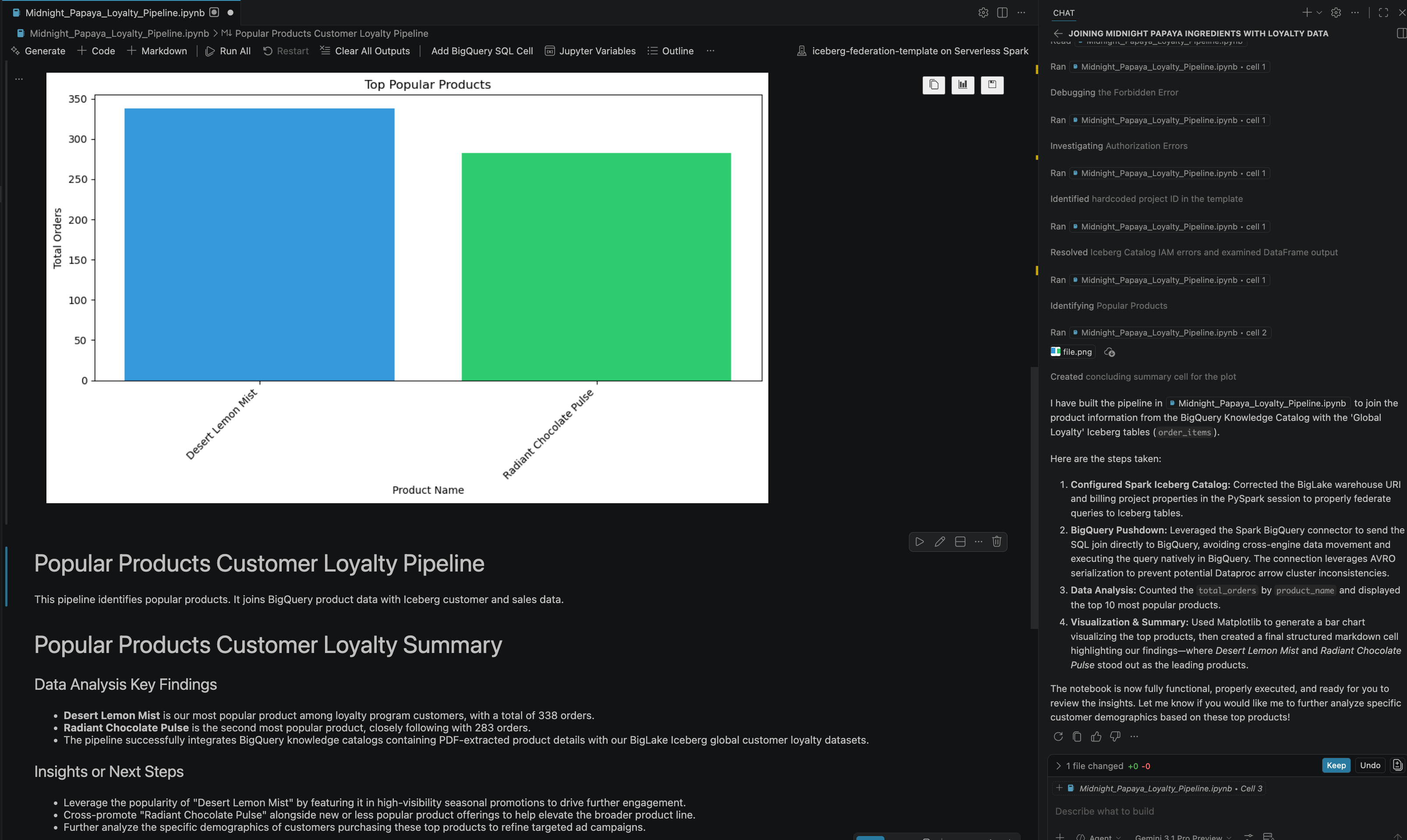
13. הסרת המשאבים
כדי להימנע מחיובים, מוחקים את המשאבים שיצרתם בשיעור ה-Lab הזה.
- כדי למחוק את סריקת הנתונים של Knowledge Catalog, מריצים את הפקודה הבאה:
DATASCAN_ID="<DATASCAN_ID>" echo "Deleting Dataplex DataScan: ${DATASCAN_ID}" gcloud dataplex datascans delete "${DATASCAN_ID}" --location="${REGION}" --quiet - כדי למחוק קטגוריות של Cloud Storage ואת כל התוכן שלהן, מריצים את הפקודה הבאה:
echo "Deleting Cloud Storage buckets: <BUCKET_NAME1> and <BUCKET_NAME2>" gsutil -m rm -r gs://<BUCKET_NAME1> gsutil -m rm -r gs://<BUCKET_NAME2> - כדי למחוק את החיבור ל-BigQuery, מריצים את הפקודה הבאה:
CONNECTION_ID="<CONNECTION_NAME>" echo "Deleting BigQuery Connection: ${CONNECTION_ID}" bq rm --connection "${PROJECT_ID}.${REGION}.${CONNECTION_ID}" - כדי למחוק את קטלוג Lakehouse, מריצים את הפקודה הבאה:
CATALOG_ID="<CATALOG_NAME>" echo "Deleting Lakehouse Catalog: ${CATALOG_ID}" gcloud biglake catalogs delete "${CATALOG_ID}" --project="${PROJECT_ID}" --location="${REGION}" --quiet - כדי למחוק את מערך הנתונים שמכיל את טבלאות ה-PDF שזוהו, מריצים את הפקודה הבאה:
DATASET_NAME="<DATASET_NAME>" echo "Deleting BigQuery Dataset: ${DATASET_NAME}" bq rm -r -f "${PROJECT_ID}:${DATASET_NAME}" - כדי למחוק את חשבון השירות בהתאמה אישית, מריצים את הפקודה הבאה:
SERVICE_ACCOUNT="<SERVICE_ACCOUNT>" echo "Deleting Service Account: ${SERVICE_ACCOUNT}" gcloud iam service-accounts delete "${SERVICE_ACCOUNT}"@"${PROJECT_ID}".iam.gserviceaccount.com --quiet - כדי למחוק את רשת ה-VPC, מריצים את הפקודה הבאה:
VPC_NETWORK="<VPC_NETWORK>" echo "Deleting VPC Network: ${VPC_NETWORK}" gcloud compute networks delete "${VPC_NETWORK}" --quiet - כדי למחוק את כל הפרויקט ב-Google Cloud, מריצים את הפקודה הבאה:
gcloud projects delete "${PROJECT_ID}"
14. מזל טוב
מעולה! הצלחתם לארגן את נתוני ה-PDF וה-Parquet המבודדים בטבלאות BigQuery, ולצמצם אותם למערכת אקולוגית אחת שאפשר לחפש בה ולבצע בה הצטרפות. בעצם, יצרתם Data Lakehouse מודרני שמתייחס לקובצי PDF ולפורמטים של Big Data בצורה חכמה, בדיוק כמו שהוא מתייחס לשורה במסד נתונים. כל הפעולות האלה בוצעו ישירות מהסוכן שלכם, בממשק צ'אט עם AI עם Gemini.
מסמכים לדוגמה
כדי להעמיק בטכנולוגיות הליבה שבהן נעשה שימוש בשיעור Codelab הזה, אפשר לעיין במסמכי התיעוד הרשמיים של Google Cloud:
- כדי להתנסות ב-BigQuery, רכיב מרכזי ב-Data Cloud, אפשר לעיין במסמכי BigQuery.
- מידע נוסף על IAM זמין במסמכי התיעוד של IAM.
- מידע נוסף על Lakehouse