
1. परिचय
इस कोडलैब में, आपको एक काल्पनिक फ़्रोयो कंपनी के लिए डेटा साइंटिस्ट की भूमिका निभानी होगी. यह कंपनी, "मिडनाइट स्वर्ल" नाम का नया फ़्लेवर लॉन्च कर रही है. दुनिया भर में प्रॉडक्ट को लॉन्च करने से पहले, कारोबार को कुछ ज़रूरी सवालों के जवाब देने होंगे. जैसे, प्रॉडक्ट में इस्तेमाल किए गए कॉम्पोनेंट, बाज़ार में प्रॉडक्ट की मांग, और निवेश पर मिलने वाला रिटर्न (आरओआई). इस एंड-टू-एंड वर्कफ़्लो में बताया गया है कि Google Cloud का Knowledge Catalog (पहले इसे Dataplex के नाम से जाना जाता था) और Apache Iceberg के लिए Lakehouse (पहले इसे BigLake के नाम से जाना जाता था) किस तरह "डार्क" अनस्ट्रक्चर्ड डेटा और कार्रवाई की जा सकने वाली बिज़नेस इंटेलिजेंस के बीच के अंतर को कम करता है. साथ ही, एक यूनिफ़ाइड गवर्नेंस लेयर के ज़रिए, आपके आईडीई (वीएस कोड) में Gemini का इस्तेमाल करके, कार्रवाई की जा सकने वाली बिज़नेस इंटेलिजेंस उपलब्ध कराता है.
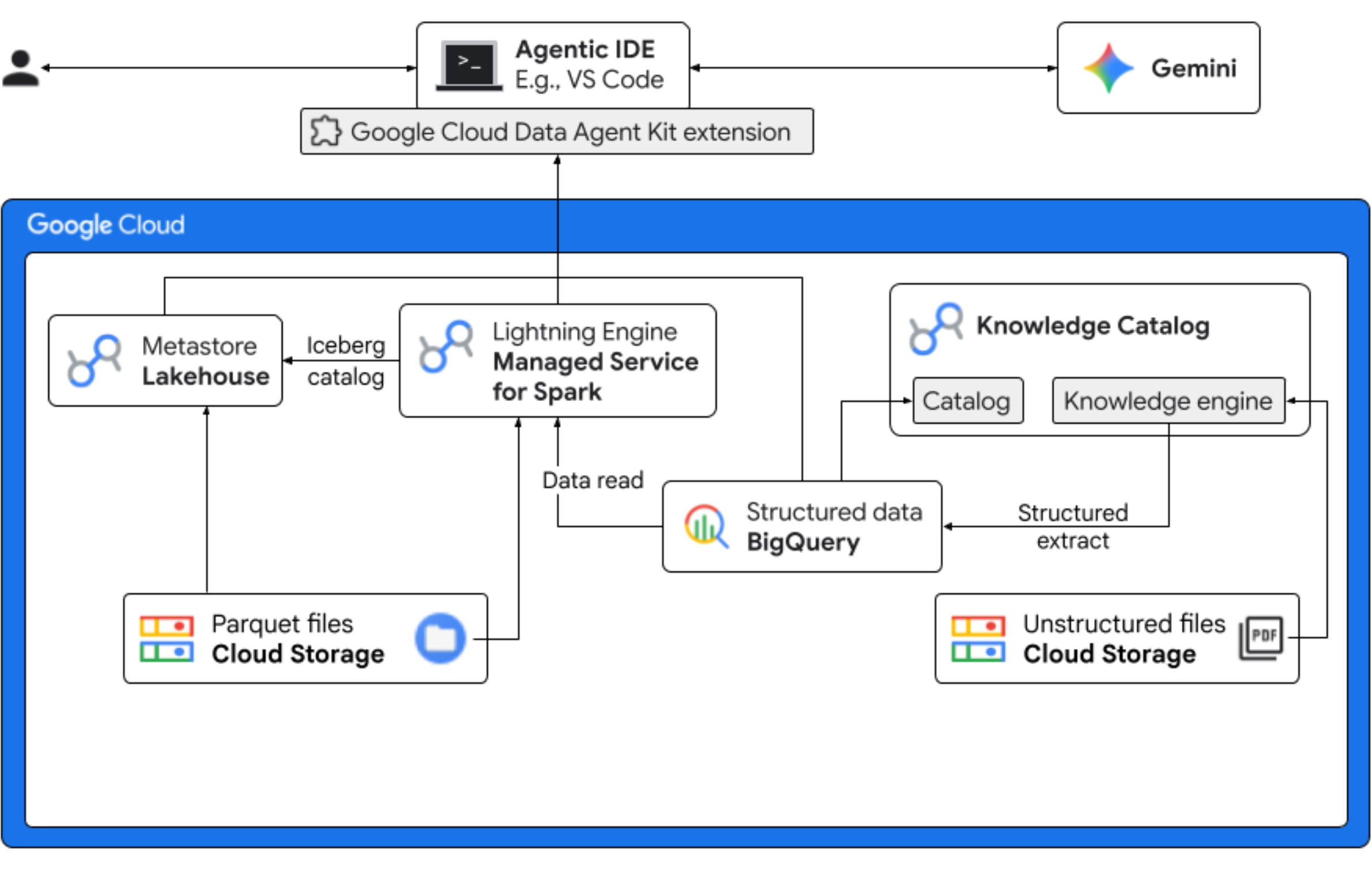
आपको क्या करना होगा
- अनस्ट्रक्चर्ड डेटा की पहचान करना: Knowledge Catalog DataScan, Cloud Storage में सेव की गई PDF फ़ाइलों को क्रॉल करता है. स्कैन किए गए PDF के लिए, BigQuery में ऑब्जेक्ट टेबल बनाएं. Vertex AI Semantic Inference का इस्तेमाल करके, सिस्टम PDF "पढ़ता" है. इससे प्रॉडक्ट, एलर्जी पैदा करने वाले कॉम्पोनेंट, सामग्री, और उनसे जुड़ी एट्रिब्यूट की स्ट्रक्चर्ड जानकारी निकाली जाती है. इसके बाद, यह PDF में सेव किए गए डेटा के लिए एक स्कीमा जनरेट करता है.
- यूनिफ़ाइड मेटाडेटा: PDF फ़ाइलों से निकाला गया डेटा, सीधे तौर पर BigQuery में नेटिव वाइड टेबल के तौर पर सेव किया जाता है. साथ ही, सामान्य क्वेरी में मदद करने के लिए व्यू बनाए जाते हैं. इंडिपेंडेंट इनपुट डेटासेट में, बिक्री का पुराना डेटा होता है. इसे Google Cloud Storage पर Apache Iceberg टेबल में सेव किया जाता है. इस Iceberg टेबल को, BigQuery में निकाले गए डेटा के साथ अगले चरण में जोड़ा जाएगा.
- क्रॉस-इंजन ऐनलिटिक्स: Iceberg REST Catalog के साथ Managed Service for Apache Spark (इसे पहले Dataproc कहा जाता था) का इस्तेमाल करके, इस नए PDF मेटाडेटा और अनुमानित स्ट्रक्चर्ड सिमैंटिक डेटा (BigQuery टेबल और व्यू से) को Google Cloud Storage पर Apache Iceberg टेबल में सेव किए गए स्ट्रक्चर्ड सेल्स डेटा के साथ जोड़ा जाएगा. इसे मैनेज किए गए Apache Spark इंटरैक्टिव सेशन के टेंप्लेट से नियंत्रित किया जाता है. इसका इस्तेमाल Jupyter Notebook कर्नल के तौर पर किया जाता है. इससे Spark जॉब के लिए, सुरक्षा और कंप्यूटिंग की सेटिंग एक जैसी रहती हैं.
- सिमेंटिक इनसाइट: अनुमानित प्रॉडक्ट डेटा को ग्राहक और बिक्री के डेटा (BigQuery में) के साथ जोड़कर, डेमो में इनसाइट निकाली जा सकती हैं. जैसे, एलर्जी पैदा करने वाले डेटा की पहचान करना और रेवेन्यू का अनुमान लगाना.
- ऑटोनॉमस गवर्नेंस: डिस्कवरी स्कैन से लेकर Spark को लागू करने तक, पूरे लाइफ़साइकल को Gemini-ready टेंप्लेट, निर्देशों, नियमों, और एजेंट की मदद से ऑटोमेशन के ज़रिए मैनेज किया जाता है. इससे यह साबित होता है कि एआई, उस इन्फ़्रास्ट्रक्चर को मैनेज कर सकता है जो आंकड़ों को प्रोसेस करता है.
आपको किन चीज़ों की ज़रूरत होगी
इस कोडलैब को पूरा करने पर, आपसे शुल्क लिया जा सकता है. सामान्य इस्तेमाल के लिए, यह शुल्क पांच डॉलर से कम हो सकता है. अपने अनुमानित इस्तेमाल या मौजूदा कीमत के आधार पर लागत का अनुमान लगाने के लिए, Google Cloud प्राइसिंग कैलकुलेटर का इस्तेमाल करें.
पक्का करें कि आपने इस कोडलैब को पूरा करने के लिए, इन ज़रूरी शर्तों को पूरा किया हो.
- Chrome वेब ब्राउज़र.
- अगर 'शुरू करने से पहले' सेक्शन में दिए गए ट्रायल क्रेडिट का इस्तेमाल किया जा रहा है, तो निजी Gmail खाता.
- Visual Studio (VS) Code को डाउनलोड और इंस्टॉल करें.
2. शुरू करने से पहले
Google Cloud प्रोजेक्ट बनाना
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग की सुविधा चालू हो. किसी प्रोजेक्ट के लिए बिलिंग चालू है या नहीं, यह देखने का तरीका जानें.
Cloud Shell शुरू करना
Cloud Shell, Google Cloud में चलने वाला एक कमांड-लाइन एनवायरमेंट है. इसमें ज़रूरी टूल पहले से लोड होते हैं.
- Google Cloud कंसोल में सबसे ऊपर मौजूद, Cloud Shell चालू करें पर क्लिक करें.
- Cloud Shell से कनेक्ट होने के बाद, अपने क्रेडेंशियल की पुष्टि करें:
gcloud auth list - पुष्टि करें कि आपका प्रोजेक्ट कॉन्फ़िगर किया गया है:
gcloud config get project - अगर आपका प्रोजेक्ट उम्मीद के मुताबिक सेट नहीं है, तो इसे सेट करें:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
ज़रूरी एपीआई चालू करना
सभी ज़रूरी एपीआई चालू करने के लिए, यह निर्देश चलाएं:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
biglake.googleapis.com \
dataproc.googleapis.com \
metastore.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
secretmanager.googleapis.com \
storage.googleapis.com
कोडलैब की ऐसेट डाउनलोड करना
इस रिपॉज़िटरी में, इस कोडलैब के साथ इस्तेमाल करने के लिए Parquet, recipes, suppliers, copilot-instructions.md, template.yaml, और quickstart.py फ़ाइलें शामिल हैं. पक्का करें कि आपने इन फ़ाइलों को डाउनलोड कर लिया हो.
फ़ाइलें डाउनलोड करने के लिए, यह तरीका अपनाएं:
- Cloud Shell में, यह कमांड चलाएं:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git - नए बनाए गए फ़ोल्डर में जाएं:
cd next-26-keynotes data-cloud-demoफ़ोल्डर को खींचेंgit sparse-checkout set genkey/data-cloud-demo- चेकआउट पूरा होने के बाद,
data-cloud-demoफ़ोल्डर पर जाएं और कोडलैब की ऐसेट ऐक्सेस करने के लिए, ZIP फ़ाइलों को एक्सट्रैक्ट करें.
3. Froyo के ग्राहक से जुड़े डेटा के लिए Lakehouse सेटअप करना
इस सेक्शन में, Lakehouse में एक कैटलॉग बनाया जाता है, ताकि अपने वर्कफ़्लो के लिए Lakehouse मेटास्टोर का इस्तेमाल किया जा सके. यह आपके सभी Iceberg डेटा के लिए, एक ही सोर्स उपलब्ध कराता है. इससे आपकी क्वेरी इंजन के बीच इंटरऑपरेबिलिटी बनती है. इससे Apache Spark जैसे क्वेरी इंजन, मेटाडेटा को खोज सकते हैं, पढ़ सकते हैं, और Iceberg टेबल को एक जैसे तरीके से मैनेज कर सकते हैं.
ज़रूरी भूमिकाएं
पक्का करें कि आपके पास पहचान और ऐक्सेस मैनेजमेंट (आईएएम) की ये भूमिकाएं हों:
roles/biglake.viewerroles/bigquery.userroles/bigquery.dataEditorroles/biglake.editorroles/biglake.metadataViewerroles/bigquery.connectionUserroles/storage.objectUserroles/storage.objectViewerroles/storage.objectCreatorroles/storage.admin
आईएएम की भूमिकाएं देने के बारे में ज़्यादा जानने के लिए, आईएएम की भूमिका असाइन करना लेख पढ़ें.
बकेट की मदद से लेकहाउस कैटलॉग बनाना
अपनी आइसबर्ग टेबल के मेटाडेटा को मैनेज करने के लिए, लेकहाउस कैटलॉग बनाएं. Iceberg टेबल बनाने और क्वेरी करने के लिए, अपने Spark जॉब में इस कैटलॉग से कनेक्ट करें.
- Google Cloud Console में, Lakehouse पर जाएं.
- कैटलॉग बनाएं पर क्लिक करें. ऐसा करने पर, कैटलॉग बनाएं पेज खुलता है.
- कैटलॉग टाइप के लिए, Iceberg का REST कैटलॉग चुनें.
- Select your Lakehouse catalog bucket options के लिए, Single bucket catalog को चुनें.
- डिफ़ॉल्ट कैटलॉग Cloud Storage बकेट के लिए, ब्राउज़ करें पर क्लिक करें. इसके बाद, नई बकेट बनाएं पर क्लिक करें.
- बकेट बनाएं पेज पर, यह तरीका अपनाएं:
- शुरू करें सेक्शन में, ऐसा नाम डालें जो दुनिया भर में यूनीक हो और बकेट के नाम से जुड़ी ज़रूरी शर्तों को पूरा करता हो.
- चुनें कि आपको अपना डेटा कहां सेव करना है सेक्शन में, जगह का टाइप के लिए क्षेत्र चुनें और अपना क्षेत्र डालें. उदाहरण के लिए,
us-west1. - ऑब्जेक्ट के ऐक्सेस को कंट्रोल करने का तरीका चुनें सेक्शन में जाकर, इस बकेट पर सार्वजनिक ऐक्सेस को रोकने की सुविधा लागू करें चेकबॉक्स से सही का निशान हटाएं.
इससे आपको असल दुनिया के उदाहरणों को सिम्युलेट करने में मदद मिलती है. जैसे, सार्वजनिक वेब कॉन्टेंट होस्ट करना या शेयर किया गया डेटा रिपॉज़िटरी. इस बदलाव के बिना, बकेट में "सिर्फ़ निजी" नीति लागू होगी. आपकी ऐसेट को ऐक्सेस करने की किसी भी कोशिश के बाद,403का इस्तेमाल करने पर पाबंदी से जुड़ी गड़बड़ी का मैसेज दिखेगा. भले ही, आपने फ़ाइलों को सार्वजनिक तौर पर ऐक्सेस करने की अनुमति दी हो. - जारी रखें > बनाएं > चुनें > जारी रखें पर क्लिक करें.
- पुष्टि करने का तरीका के लिए, क्रेडेंशियल वेंडिंग मोड चुनें.
- बनाएं पर क्लिक करें.इससे आपका कैटलॉग बन जाएगा और कैटलॉग की जानकारी पेज खुल जाएगा.
- पुष्टि करने का तरीका में जाकर, बकेट की अनुमतियां सेट करें पर क्लिक करें.
- डायलॉग बॉक्स में, पुष्टि करें पर क्लिक करें.इससे यह पुष्टि होती है कि आपके कैटलॉग के सेवा खाते के पास, आपके स्टोरेज बकेट पर
Storage Object Userकी भूमिका है. - कैटलॉग की जानकारी पेज पर जाकर, REST कैटलॉग के यूआरआई पाथ को कॉपी करें. 'स्पार्क जॉब चलाएं' टास्क के दौरान इस पाथ का इस्तेमाल करें.
Parquet फ़ाइलों को बकेट में अपलोड करें
अपनी Parquet फ़ाइलों को बकेट के रूट में अपलोड करने के लिए, यह तरीका अपनाएं:
- Google Cloud Console में, Cloud Storage बकेट पेज पर जाएं.
- बकेट की सूची में, बकेट के नाम पर क्लिक करें. उदाहरण के लिए,
acai_demo. - बकेट के ऑब्जेक्ट टैब में, अपलोड करें > फ़ाइलें अपलोड करें पर क्लिक करें.
- Parquet फ़ोल्डर से वे फ़ाइलें चुनें जिन्हें आपने इस कोडलैब के शुरू करने से पहले सेक्शन में क्लोन किया था.
- खोलें पर क्लिक करें.
4. वीपीसी नेटवर्क सेट अप करना
एक वर्चुअल प्राइवेट क्लाउड (वीपीसी) नेटवर्क और एक सबनेट बनाएं. इससे संसाधन, सार्वजनिक इंटरनेट पर जाए बिना Google API से कम्यूनिकेट कर सकेंगे. साथ ही, एक फ़ायरवॉल बनाएं. इससे इंटरनल ट्रैफ़िक, डेटा प्रोसेसिंग नोड के बीच बिना किसी रुकावट के ट्रांसफ़र हो सकेगा.
- Google Cloud Console में, वीपीसी नेटवर्क पेज पर जाएं.
- वीपीसी नेटवर्क बनाएं पर क्लिक करें.
- नेटवर्क के लिए नाम डालें. उदाहरण के लिए,
acai-network. - नेटवर्क के ज़्यादा से ज़्यादा ट्रांसमिशन यूनिट (एमटीयू) को कॉन्फ़िगर करने के लिए, एमटीयू अपने-आप सेट हो जाए चेकबॉक्स को चुनें.
- सबनेट बनाने के मोड के लिए, अपने-आप चुनें.
- फ़ायरवॉल के नियम सेक्शन में, IPv4 फ़ायरवॉल के नियमों के लिए सभी चेकबॉक्स चुनें
- बनाएं पर क्लिक करें.
निजी Google ऐक्सेस की सुविधा चालू करना
Dataproc Serverless नोड के पास सार्वजनिक आईपी पते नहीं होते. लेकहाउस कैटलॉग और Cloud Storage से कम्यूनिकेट करने के लिए, सबनेट में निजी Google ऐक्सेस चालू होना चाहिए.
- Google Cloud Console में, वीपीसी नेटवर्क पेज पर जाएं.
- उस नेटवर्क के नाम पर क्लिक करें जिसमें वह सबनेट मौजूद है जिसके लिए आपको निजी Google ऐक्सेस की सुविधा चालू करनी है. उदाहरण के लिए,
us-west1. - सबनेट के नाम पर क्लिक करें. इसके बाद, सबनेट की जानकारी वाला पेज दिखेगा.
- बदलाव करें पर क्लिक करें.
- निजी Google ऐक्सेस सेक्शन में जाकर, On को चुनें.
- सेव करें पर क्लिक करें.
5. Spark जॉब बनाना और उसे चलाना
Iceberg टेबल बनाने और उससे क्वेरी करने के लिए, ज़रूरी Spark SQL स्टेटमेंट के साथ PySpark जॉब अपलोड करें. इसके बाद, Managed Service for Spark की मदद से जॉब चलाएँ.
quickstart.py को अपने Cloud Storage बकेट में अपलोड करें
कोड लैब की ऐसेट क्लोन करने के बाद, quickstart.py स्क्रिप्ट को अपने प्रोजेक्ट की जानकारी के साथ अपडेट करें. इसके बाद, इसे Cloud Storage बकेट में अपलोड करें.
quickstart.pyस्क्रिप्ट को किसी टेक्स्ट एडिटर में खोलें.- स्क्रिप्ट में मौजूद
BUCKET_NAMEप्लेसहोल्डर को Cloud Storage बकेट के नाम से बदलें और इसे सेव करें. - Google Cloud Console में, Cloud Storage बकेट पर जाएं.
- अपने बकेट के नाम पर क्लिक करें. उदाहरण के लिए,
acai_demo. - ऑब्जेक्ट टैब में, अपलोड करें > फ़ाइलें अपलोड करें पर क्लिक करें.
- फ़ाइल ब्राउज़र में, अपडेट की गई
quickstart.pyफ़ाइल चुनें. इसके बाद, खोलें पर क्लिक करें.
Spark जॉब को रन करना
quickstart.py स्क्रिप्ट अपलोड करने के बाद, इसे Spark के बैच जॉब के लिए मैनेज की गई सेवा के तौर पर चलाएं.
- वैरिएबल कॉन्फ़िगर करने के लिए, Cloud Shell में यह कमांड चलाएं.
# Configuration Variables export PROJECT_ID="<PROJECT_ID>" export REGION="<REGION>" export BUCKET_NAME="<BUCKET_NAME>" export SUBNET="<SUBNET>" export LAKEHOUSE_CATALOG_ID="<LAKEHOUSE_CATALOG_ID>" export CATALOG_URI_ID="<CATALOG_URI_ID>"- LAKEHOUSE_CATALOG_ID: यह Lakehouse कैटलॉग रिसॉर्स का नाम है. इसमें आपकी PySpark ऐप्लिकेशन फ़ाइल मौजूद होती है. उदाहरण के लिए,
acai_demo - PROJECT_ID: यह आपके Google Cloud प्रोजेक्ट का आईडी है.
- REGION: वह क्षेत्र जहां Managed Service for Spark के बैच वर्कलोड को चलाया जाना है. उदाहरण के लिए,
us-west1. - BUCKET_NAME: यह आपके Cloud Storage बकेट का नाम है. उदाहरण के लिए,
acai_demo. - SUBNET: आपके वीपीसी सबनेट का नाम. उदाहरण के लिए,
acai-network. - CATALOG_URI_ID: यह Lakehouse कैटलॉग का यूआरआई आईडी होता है. इसे बकेट के साथ Lakehouse कैटलॉग बनाते समय कॉपी किया जाता है. उदाहरण के लिए,
https://biglake.googleapis.com/iceberg/v1/restcatalog.
- LAKEHOUSE_CATALOG_ID: यह Lakehouse कैटलॉग रिसॉर्स का नाम है. इसमें आपकी PySpark ऐप्लिकेशन फ़ाइल मौजूद होती है. उदाहरण के लिए,
- Cloud Shell में,
quickstart.pyस्क्रिप्ट का इस्तेमाल करके, Managed Service for Spark का यह बैच जॉब चलाएं.gcloud dataproc batches submit pyspark gs://${BUCKET_NAME}/quickstart.py \ --project=${PROJECT_ID} \ --region=${REGION} \ --subnet=${SUBNET} \ --version=2.2 \ --properties="\ spark.sql.defaultCatalog=${LAKEHOUSE_CATALOG_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}=org.apache.iceberg.spark.SparkCatalog,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.type=rest,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.uri=${CATALOG_URI_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.warehouse=gs://${BUCKET_NAME},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.io-impl=org.apache.iceberg.gcp.gcs.GCSFileIO,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.x-goog-user-project=${PROJECT_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\ spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest-metrics-reporting-enabled=false,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.X-Iceberg-Access-Delegation=vended-credentials,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token"All tables registered successfully! Batch [126fa2226a904d2e944c8eecbe0b1840] finished. metadata: '@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata batch: projects/PROJECT_ID/locations/REGION/batches/126fa2226a904d2e944c8eecbe0b1840 batchUuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff createTime: '2026-04-09T13:17:26.222727Z' description: Batch labels: goog-dataproc-batch-id: 126fa2226a904d2e944c8eecbe0b1840 goog-dataproc-batch-uuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-drz-resource-uuid: batch-3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-location: REGION operationType: BATCH name: projects/PROJECT_ID/regions/REGION/operations/47bc59e8-5082-3af9-89a0-22289aa5f4b9
6. BigQuery से टेबल को क्वेरी करना
Spark बैच जॉब को सफलतापूर्वक चलाने के बाद, आपने Managed Service for Spark Serverless का इस्तेमाल, डिस्ट्रिब्यूटेड कंप्यूट इंजन के तौर पर किया है. इससे, Lakehouse Metastore में मौजूद हर Parquet फ़ाइल के लिए एक टेबल रजिस्टर की जा सकती है. इस रजिस्ट्रेशन की मदद से, Google Cloud, Cloud Storage में मौजूद आपकी रॉ फ़ाइलों को स्ट्रक्चर्ड और हाई-परफ़ॉर्मेंस टेबल के तौर पर इस्तेमाल कर सकता है.
यहां दिए गए चरणों से, यह पुष्टि करने में मदद मिलती है कि मेटाडेटा सही तरीके से सिंक हो गया है. इससे यह पक्का किया जा सकता है कि आपका डेटा न सिर्फ़ सुरक्षित तरीके से सेव किया गया है, बल्कि BigQuery इंटरफ़ेस के ज़रिए इसे पूरी तरह से खोजा और क्वेरी किया जा सकता है.
- Google Cloud Console में, BigQuery पर जाएं.
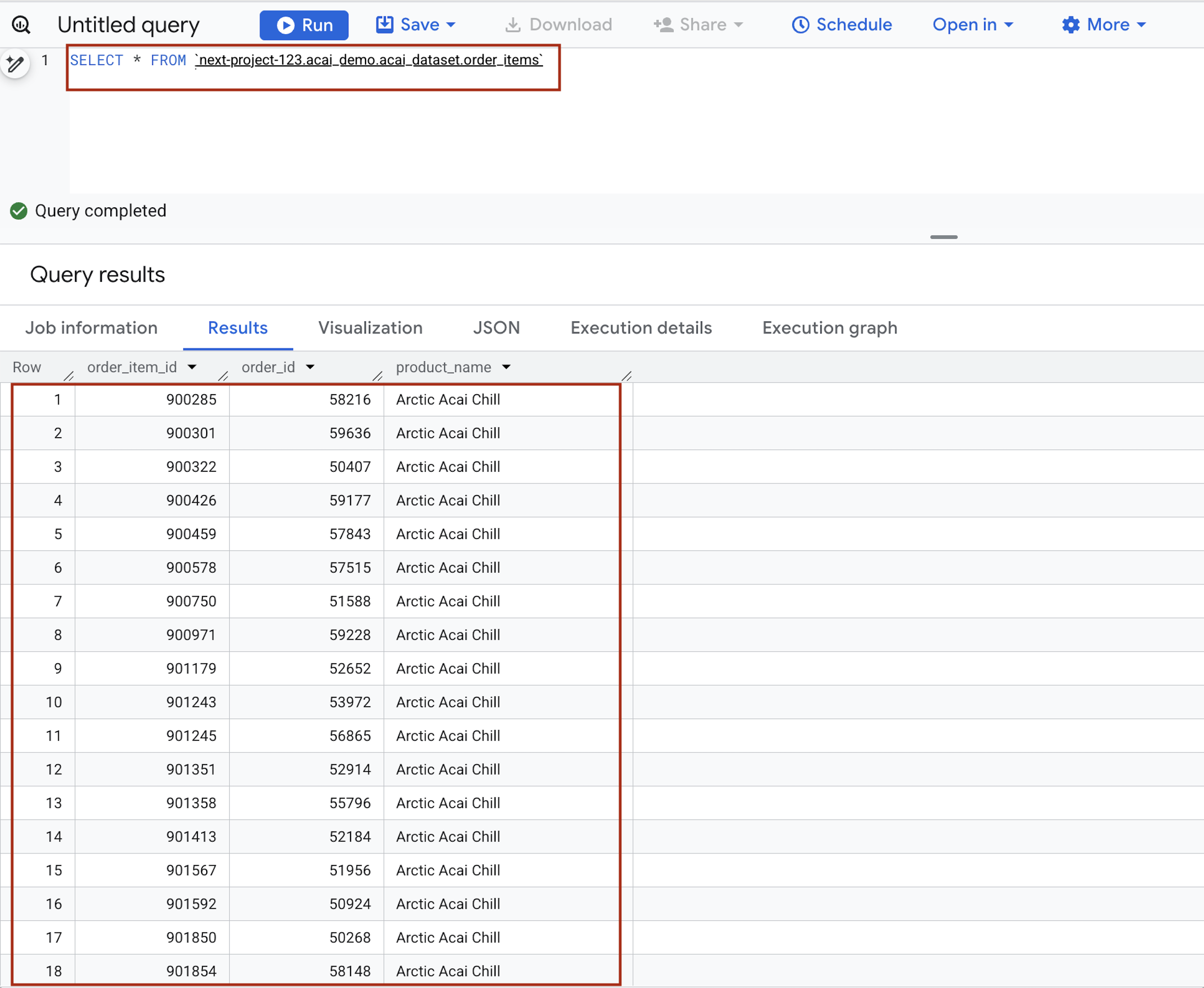
- क्वेरी एडिटर में, यह स्टेटमेंट डालें. क्वेरी में
project.namespace.dataset.tableसिंटैक्स का इस्तेमाल किया गया है.SELECT * FROM `<PROJECT_ID>.<NAMESPACE>.<ICEBERG_DATASET>.<ICEBERG_TABLE>`PROJECT_ID.acai_demo.acai_dataset.order_items.
इनकी जगह पर ये डालें:- PROJECT_ID: यह आपके Google Cloud प्रोजेक्ट का आईडी है.
- NAMESPACE: यह वह नेमस्पेस है जो पिछले चरण में Spark जॉब के नतीजे के तौर पर बनाया गया था. इसे BigQuery ऑब्जेक्ट एक्सप्लोरर पेज पर देखा जा सकता है. उदाहरण के लिए,
acai_demo. - ICEBERG_DATASET: Iceberg कैटलॉग में मौजूद डेटासेट का नाम. उदाहरण के लिए,
acai_dataset. - ICEBERG_TABLE: Iceberg डेटासेट में मौजूद टेबल का नाम. उदाहरण के लिए,
order_items.
- चलाएं पर क्लिक करें. क्वेरी के नतीजों में, वह डेटा दिखता है जिसे आपने स्पार्क जॉब की मदद से डाला था.
7. बिना स्ट्रक्चर वाली प्रॉडक्ट डेटा फ़ाइलें सेट अप करना
इस सेक्शन में, BigQuery में एक संगठन का स्ट्रक्चर बनाया जाता है. इसमें Froyo की रेसिपी और सप्लायर का डेटा सेव किया जाता है. यह डेटा, खास तौर पर Froyo प्रॉडक्ट की जानकारी के लिए होता है. यह Cloud Resource Connection भी बनाता है. यह एक सुरक्षित "ब्रिज" के तौर पर काम करता है. इससे BigQuery, Cloud Storage जैसे बाहरी सोर्स से फ़ाइलें पढ़ पाता है.
बकेट बनाएं और Froyo की जानकारी वाली फ़ाइलें अपलोड करें
Cloud Storage बकेट में, सप्लायर और रेसिपी की फ़ाइलें बनाएं और अपलोड करें.
- Google Cloud Console में, Cloud Storage बकेट पेज पर जाएं.
- बनाएं पर क्लिक करें.
- बकेट बनाएं पेज पर, बकेट की जानकारी डालें. यहां दिए गए हर चरण को पूरा करने के बाद, अगले चरण पर जाने के लिए जारी रखें पर क्लिक करें:
- शुरू करें सेक्शन में, बकेट का नाम डालें. उदाहरण के लिए,
acai_pdfs. - चुनें कि आपको अपना डेटा कहां सेव करना है सेक्शन में जाकर, क्षेत्र को चुनें. इसके बाद, अपने क्षेत्र का नाम डालें. उदाहरण के लिए,
us-west1. - ऑब्जेक्ट के ऐक्सेस को कंट्रोल करने का तरीका चुनें सेक्शन में जाकर, इस बकेट पर सार्वजनिक ऐक्सेस को रोकने की सुविधा लागू करें चेकबॉक्स से सही का निशान हटाएं.
- बनाएं पर क्लिक करें.
- बकेट की सूची में, बनाई गई बकेट पर क्लिक करें. उदाहरण के लिए,
acai_pdfs. - बकेट के ऑब्जेक्ट टैब में, अपलोड करें > फ़ोल्डर अपलोड करें पर क्लिक करें.
- इस कोडलैब के शुरू करने से पहले सेक्शन में, एक्सट्रैक्ट किया गया
recipesफ़ोल्डर चुनें. - अपलोड करें पर क्लिक करें.
suppliersफ़ोल्डर के लिए, अपलोड करने की प्रोसेस दोहराएं.
कनेक्शन बनाना
Cloud Resource Connection बनाएं. इससे एक यूनीक सेवा खाता जनरेट होता है. यह बाहरी फ़ाइलों को ऐक्सेस करने के लिए, BigQuery के "आईडी कार्ड" के तौर पर काम करता है.
- BigQuery पेज पर जाएं.
- बाएं पैनल में, एक्सप्लोरर पर क्लिक करें. अगर आपको बायां पैनल नहीं दिखता है, तो पैनल खोलने के लिए बाएं पैनल को बड़ा करें पर क्लिक करें.
- एक्सप्लोरर पैनल में, अपने प्रोजेक्ट के नाम को बड़ा करें. इसके बाद, कनेक्शन पर क्लिक करें.
- कनेक्शन पेज पर, कनेक्शन बनाएं पर क्लिक करें.
- कनेक्शन टाइप के लिए, Vertex AI रिमोट मॉडल, रिमोट फ़ंक्शन, BigLake, और Spanner (क्लाउड रिसोर्स) चुनें.
- कनेक्शन आईडी फ़ील्ड में, कनेक्शन आईडी का नाम डालें. उदाहरण के लिए,
acai_pdf_connection. इस आईडी को नोट करना न भूलें. आपको इसकी ज़रूरत तब पड़ेगी, जब इस कोडलैब में बाद में डेटा स्कैन करने की सुविधा सेट अप की जाएगी. - जगह का टाइप को क्षेत्र पर सेट करें. इसके बाद, कोई क्षेत्र चुनें. उदाहरण के लिए,
us-west1. कनेक्शन को आपके अन्य संसाधनों, जैसे कि डेटासेट के साथ रखा जाना चाहिए. - कनेक्शन बनाएं पर क्लिक करें.
- कनेक्शन पर जाएं पर क्लिक करें.
- कनेक्शन की जानकारी वाले पैनल में, सेवा खाता आईडी को कॉपी करें, ताकि इसका इस्तेमाल बाद में किया जा सके. सेवा खाता,
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.comसे मिलता-जुलता है.
सेवा खातों का ऐक्सेस मैनेज करना
सेवा खाते को ऐक्सेस दें, ताकि Lakehouse आपके PDF पढ़ सके.
- IAM और एडमिन पेज पर जाएं.
- ऐक्सेस दें पर क्लिक करें. इससे, मुख्य उपयोगकर्ता जोड़ने का डायलॉग बॉक्स खुलता है.
- नए प्रिंसिपल फ़ील्ड में, सेवा खाते का वह आईडी डालें जिसे आपने पहले कॉपी किया था.
- भूमिका चुनें फ़ील्ड में जाकर, ये भूमिकाएं जोड़ें:
roles/storage.objectUserroles/storage.objectViewerroles/bigquery.userroles/bigquery.dataEditorroles/aiplatform.userroles/storage.adminroles/dataproc.serviceAgent
- सेव करें पर क्लिक करें.
BigQuery में IAM की भूमिकाओं के बारे में ज़्यादा जानने के लिए, पहले से तय की गई भूमिकाएं और अनुमतियां लेख पढ़ें.
8. DataScan जॉब के लिए अनुमतियां मैनेज करना
Spark और Dataform के लिए खास सेवा खाते (पहचान) बनाएं. इसके बाद, उन्हें और Google के ऑटोमेटेड सेवा एजेंटों को, स्टोरेज को पढ़ने, BigQuery जॉब चलाने, और डिस्कवरी के लिए Vertex AI का इस्तेमाल करने के लिए ज़रूरी अनुमतियां दें.
Spark और Dataform के लिए IAM ऐक्सेस
- Google Cloud Console में, सेवा खाता बनाएं पेज पर जाएं.
- अगर आपने Google Cloud प्रोजेक्ट नहीं चुना है, तो उसे चुनें.
- सेवा खाता बनाएं पर क्लिक करें.
- सेवा खाते का नाम डालें. उदाहरण के लिए,
sa-spark-stg1. Google Cloud Console, इस नाम के आधार पर सेवा खाते का आईडी जनरेट करता है. अगर ज़रूरी हो, तो आईडी में बदलाव करें. इसे बाद में नहीं बदला जा सकता. - ऐक्सेस कंट्रोल सेट करने के लिए, बनाएं और जारी रखें पर क्लिक करें. इसके बाद, अगले चरण पर जाएं.
- प्रोजेक्ट पर सेवा खाते को ये IAM भूमिकाएं असाइन करें.
roles/dataproc.workerroles/storage.objectUserroles/bigquery.dataEditorroles/bigquery.jobUserroles/aiplatform.userroles/dataplex.discoveryPublishingServiceAgent
- भूमिकाएं जोड़ने के बाद, जारी रखें पर क्लिक करें.
- सेवा खाता बनाने की प्रोसेस पूरी करने के लिए, हो गया पर क्लिक करें.
Knowledge Catalog को ऐक्सेस करने के लिए, BigQuery कनेक्शन की अनुमतियां
- Google Cloud Console में, Cloud Storage बकेट पेज पर जाएं.
- बकेट की सूची में, Froyo के लिए बनाई गई बकेट के नाम पर क्लिक करें. उदाहरण के लिए,
acai_pdfs. - अनुमतियां टैब में, ऐक्सेस दें पर क्लिक करें. 'मुख्य उपयोगकर्ता जोड़ें' डायलॉग बॉक्स दिखता है.
- नए प्रिंसिपल फ़ील्ड में, BigQuery के सेवा खाते का आईडी डालें. सेवा खाता,
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.comसे मिलता-जुलता है. - कोई भूमिका चुनें ड्रॉप-डाउन मेन्यू से, यहां दी गई भूमिका (या भूमिकाएं) चुनें.
roles/storage.objectUserroles/dataplex.serviceAgentroles/dataplex.securityAdminroles/aiplatform.serviceAgentroles/dataplex.discoveryPublishingServiceAgent
- 'सेव करें' पर क्लिक करें.
9. नॉलेज कैटलॉग सेट अप करना
Froyo से जुड़े डेटा को एक जगह इकट्ठा करने के लिए, नॉलेज कैटलॉग बनाएं. साथ ही, बिना स्ट्रक्चर वाली फ़ाइलों (जैसे, PDF फ़ॉर्मैट में रेसिपी और PDF फ़ॉर्मैट में सप्लायर) को अपने-आप ढूंढने की सुविधा चालू करें.
curl की मदद से DataScan बनाना
इस सेक्शन में, datascan_ID को जोड़कर और उसे अपने BigQuery डेटासेट पर ले जाकर, अपने Cloud Storage बकेट (उदाहरण के लिए, acai_pdfs) के लिए स्कैन बनाए जाते हैं. इसके बाद, Knowledge Catalog आपके PDF के लिए BigQuery में अपने-आप एंट्री बना देगा.
- पीडीएफ़ (सप्लायर और रेसिपी) को स्कैन करने के लिए, यह कमांड चलाएं:
# 1. Set your variables PROJECT_ID="<PROJECT_ID>" REGION="<REGION>" ENV_SUFFIX="stg1" DATASCAN_ID="froyo-profile-${ENV_SUFFIX}" BUCKET_NAME="<BUCKET_NAME>" # 2. Set this to the Name of the connection you created in Step 7 CONNECTION_ID="<CONNECTION_ID_NAME>" # 3. Define the API Endpoint DATAPLEX_API="dataplex.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}" # 4. Create the DataScan via CURL echo "Creating Dataplex DataScan: ${DATASCAN_ID}..." curl -X POST "https://$DATAPLEX_API/dataScans?dataScanId=${DATASCAN_ID}" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d '{ "data": { "resource": "//storage.googleapis.com/projects/'"${PROJECT_ID}"'/buckets/'"${BUCKET_NAME}"'" }, "executionSpec": { "trigger": { "on_demand": {} } }, "dataDiscoverySpec": { "bigqueryPublishingConfig": { "tableType": "BIGLAKE", "connection": "projects/'"${PROJECT_ID}"'/locations/'"${REGION}"'/connections/'"${CONNECTION_ID}"'" }, "storageConfig": { "unstructuredDataOptions": { "entity_inference_enabled": true } } } }' curlकमांड, नॉलेज कैटलॉग के डेटास्कैन के नतीजे दिखाती है. ये नतीजे, यहां दी गई इमेज की तरह दिखते हैं.
जॉब चलाना
यह कमांड चलाएं:
gcloud dataplex datascans run $DATASCAN_ID --location=$REGION
किसी नौकरी के बारे में जानकारी देना
नौकरी के बारे में जानकारी देने के लिए, यह कमांड चलाएं:
gcloud dataplex datascans describe $DATASCAN_ID --location=$REGION
डेटा स्कैन करने वाले किसी जॉब को मिटाना
अगर स्कैन 10 मिनट से ज़्यादा समय तक चलता है या अगर जॉब की स्थिति लंबे समय तक लंबित है और चल रहा है में नहीं बदलती है, तो ऐसा हो सकता है कि उस क्षेत्र में कुछ समय के लिए संसाधन उपलब्ध न हों. अगर ऐसा होता है, तो इस कमांड को चलाकर जॉब को मिटाया जा सकता है. इसके बाद, इसे फिर से बनाया और चलाया जा सकता है. कभी-कभी, शुरुआती रन में unable to acquire necessary resources जैसी गड़बड़ी की वजह से, तुरंत समस्या आ सकती है.
gcloud dataplex datascans delete $DATASCAN_ID --location=$REGION
जॉब का स्टेटस देखना
जॉब का स्टेटस देखने के लिए, यह तरीका अपनाएं:
- Google Cloud Console में, मेटाडेटा क्यूरेशन पेज पर जाएं.
- Cloud Storage की पहचान टैब में, पहचान के लिए स्कैन किए गए डेटा के नाम पर क्लिक करें.
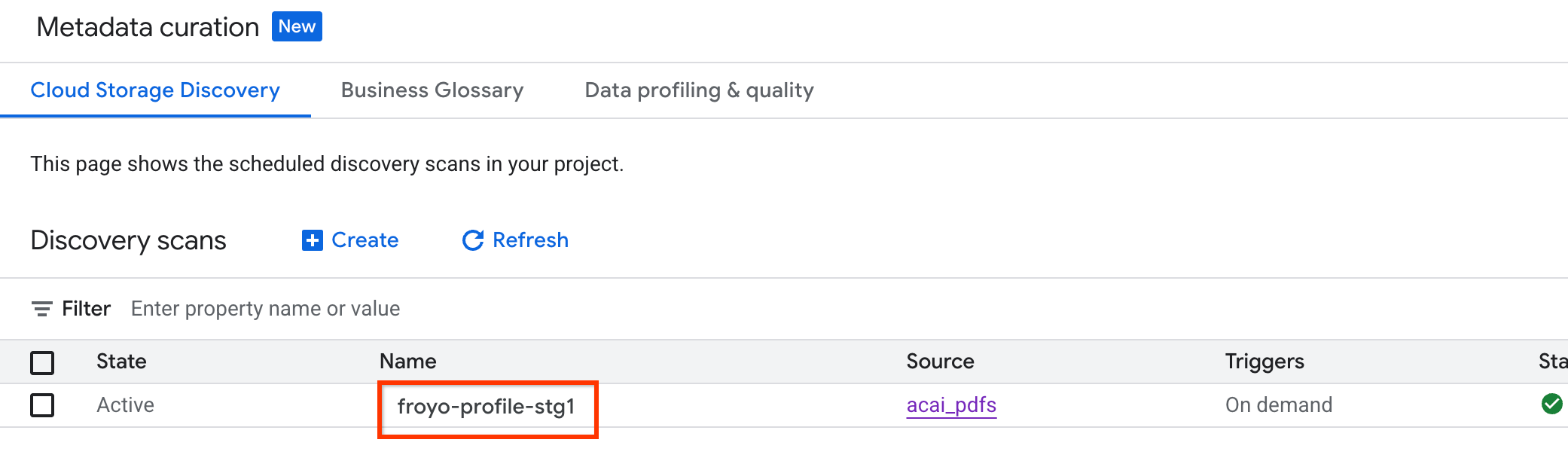
- स्कैन की जानकारी पेज पर, आपको जॉब का स्टेटस दिखेगा.
- जॉब पूरा होने के बाद, देखें कि
curlकमांड का इस्तेमाल करके बनाया गया पब्लिश किया गया डेटासेट (उदाहरण के लिए,acai_pdfs_discovered_003) मौजूद है या नहीं.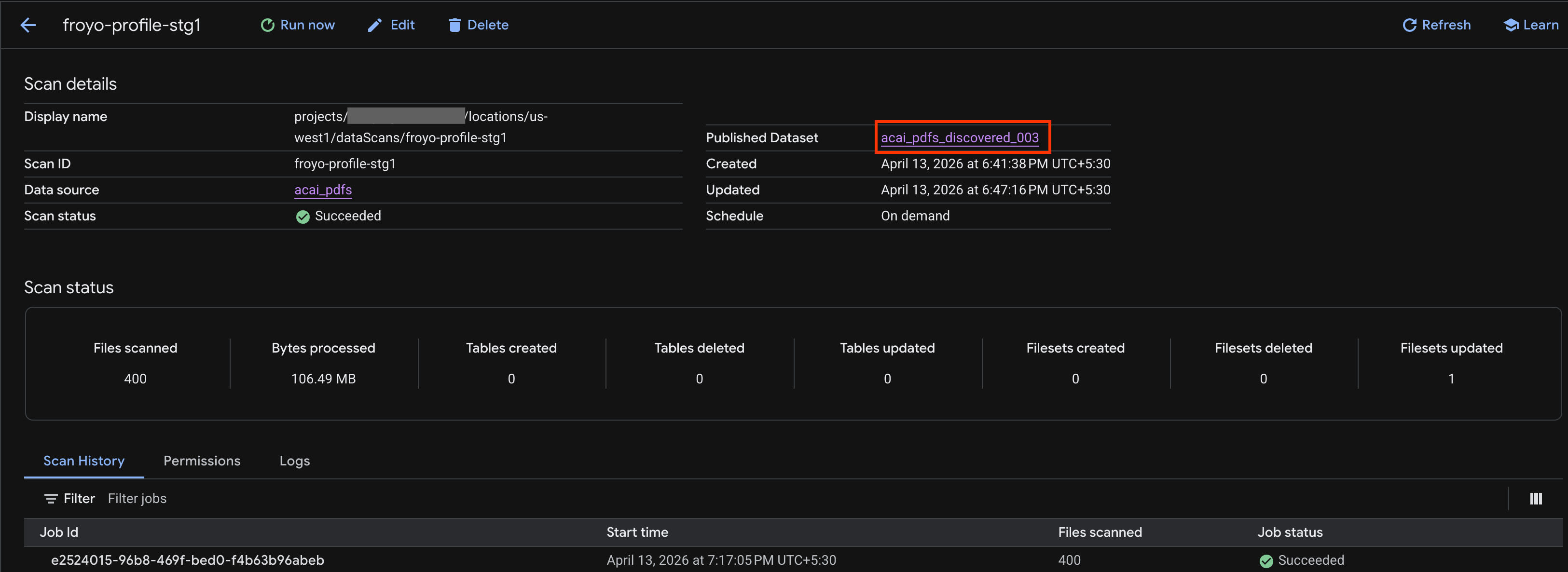
ऑब्जेक्ट टेबल देखना
डिस्कवरी जॉब के बाद बनाई गई ऑब्जेक्ट टेबल देखने के लिए, यह तरीका अपनाएं:
- Google Cloud Console में, BigQuery पर जाएं.
- डेटासेट पर क्लिक करें. इसके बाद, पिछले चरण में बनाया गया पब्लिश किया गया डेटासेट चुनें. उदाहरण के लिए,
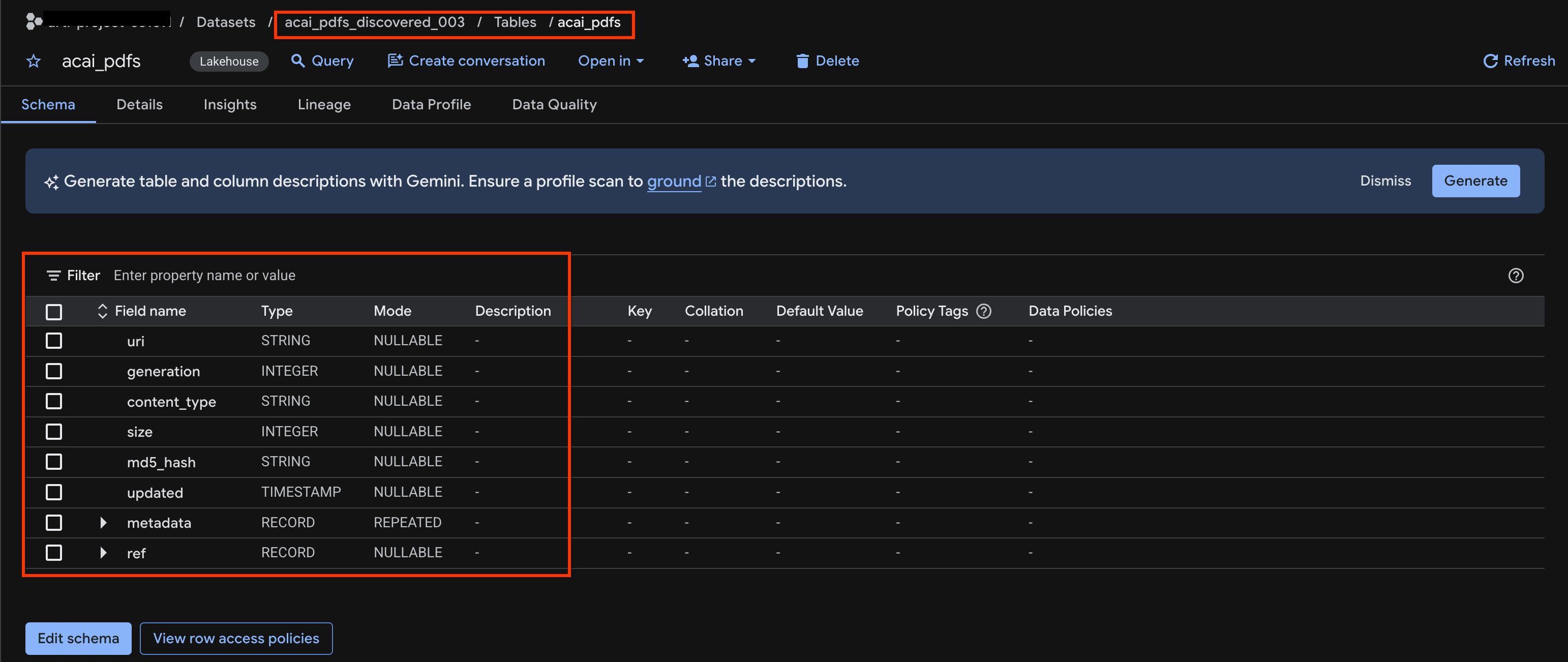
acai_pdfs_discovered_003. - ऑब्जेक्ट टेबल देखने के लिए, टेबल आईडी पर क्लिक करें. उदाहरण के लिए,
acai_pdfs. - इसके बाद, ऑब्जेक्ट टेबल इस इमेज की तरह दिखेगी:
10. सिमैंटिक एक्सट्रैक्शन
आपको पिछले चरण में बनाई गई इस अनस्ट्रक्चर्ड ऑब्जेक्ट टेबल के लिए, स्ट्रक्चर्ड टेबल, अन्य डेटाबेस ऑब्जेक्ट, और संबंध निकालने हैं. इसके लिए, आपको Knowledge Catalog Insights सुविधा का इस्तेमाल करके एसक्यूएल स्टेटमेंट जनरेट करने होंगे, ताकि बिना स्ट्रक्चर वाली टेबल से स्ट्रक्चर्ड डेटा निकाला जा सके
- Google Cloud Console में, नॉलेज कैटलॉग खोजें पेज पर जाएं.
- उस डेटासेट टेबल को खोजें जिसके लिए आपको अहम जानकारी देखनी है. उदाहरण के लिए,
acai_pdfs_discovered_003.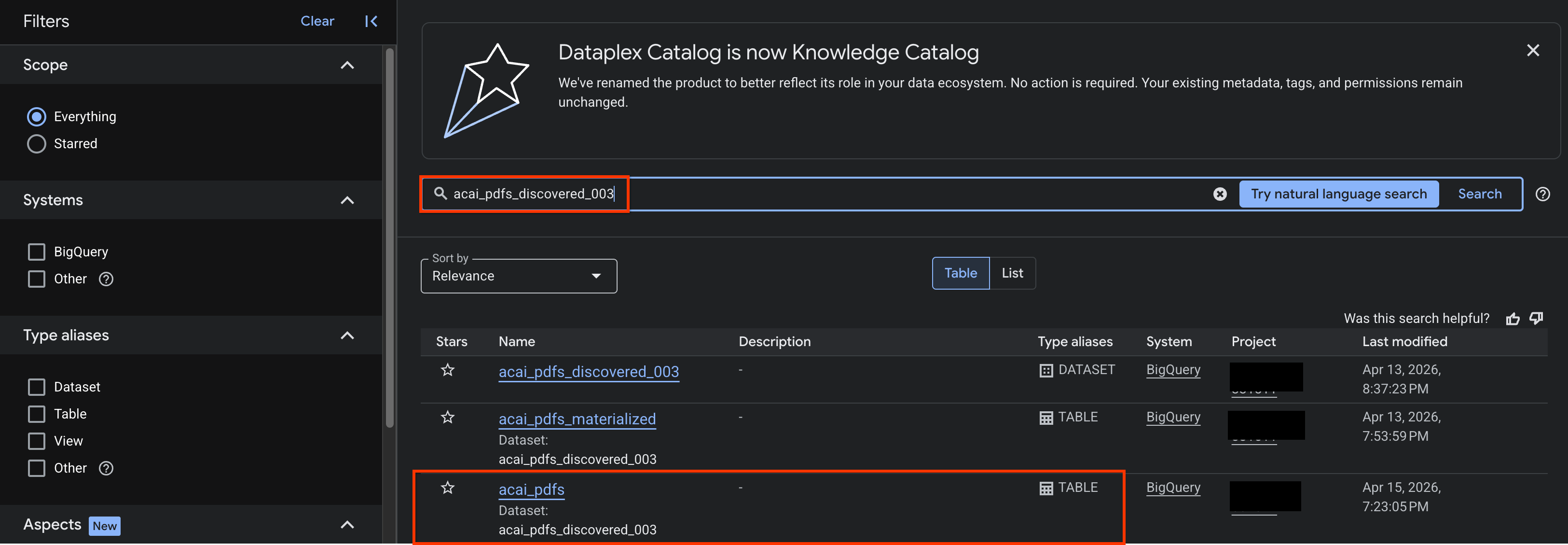
- खोज के नतीजों में, टेबल पर क्लिक करके उसका एंट्री पेज खोलें.
- अहम जानकारी टैब पर क्लिक करें. अगर टैब खाली है, तो इसका मतलब है कि इस टेबल के लिए अब तक अहम जानकारी जनरेट नहीं की गई है. इनसाइट जनरेट होने में 15 से 25 मिनट लग सकते हैं.
- इनसाइट दिखने के बाद, डेटा निकालें > SQL की मदद से डेटा निकालें पर क्लिक करें.
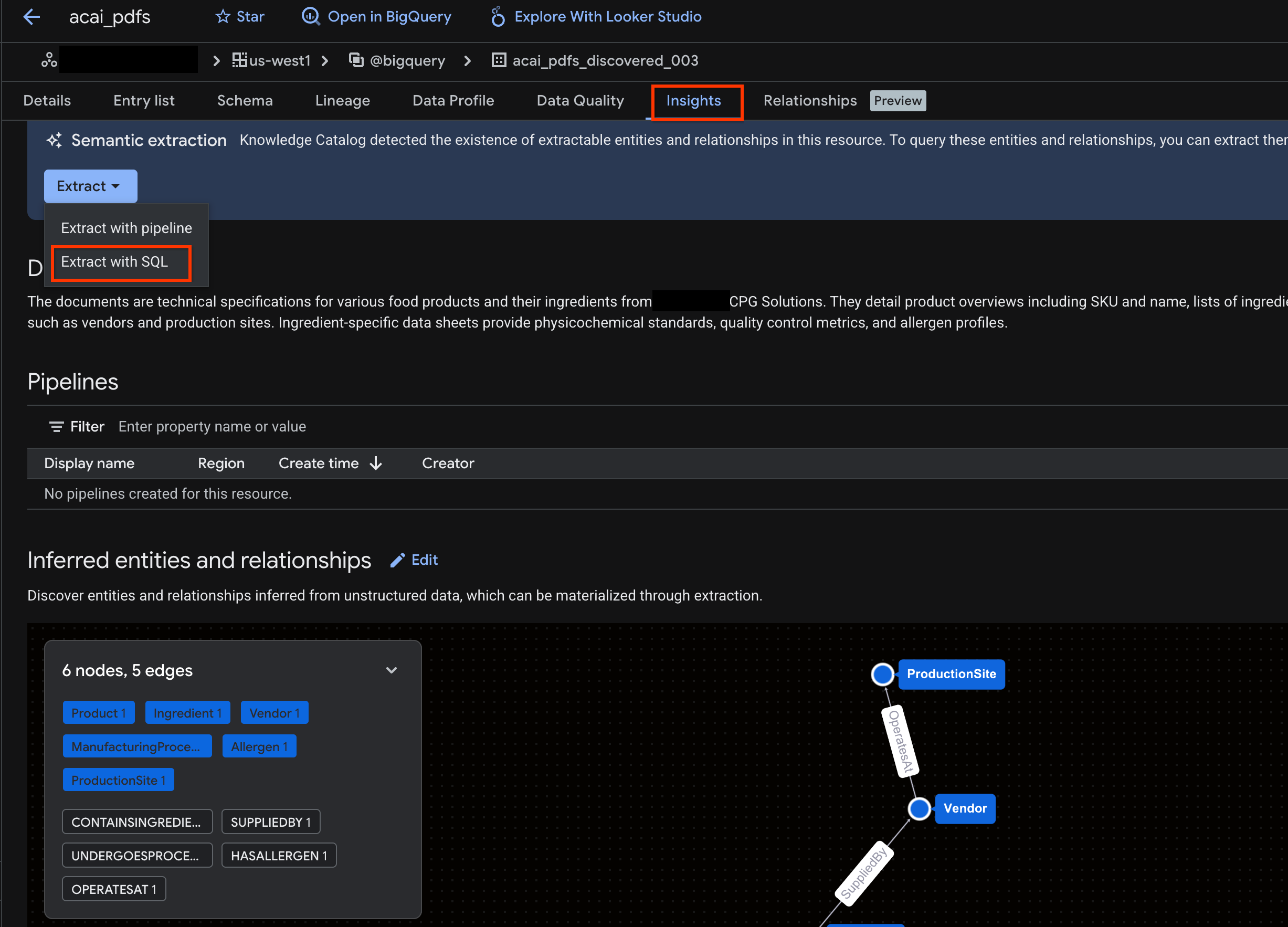
- SQL की मदद से डेटा निकालें पेज पर, डेस्टिनेशन के लिए अपना डेटासेट डालें. उदाहरण के लिए,
acai_pdfs_discovered_003. - निकालें पर क्लिक करें. इससे BigQuery एडिटर खुलता है और क्वेरी लोड हो जाती है.
- चलाएं पर क्लिक करें. इस चरण में, स्टेटमेंट का एक सेट जनरेट होता है. इसे पूरा होने में कुछ मिनट लग सकते हैं.
- क्वेरी पूरी होने पर, आपको ये नतीजे दिखते हैं:
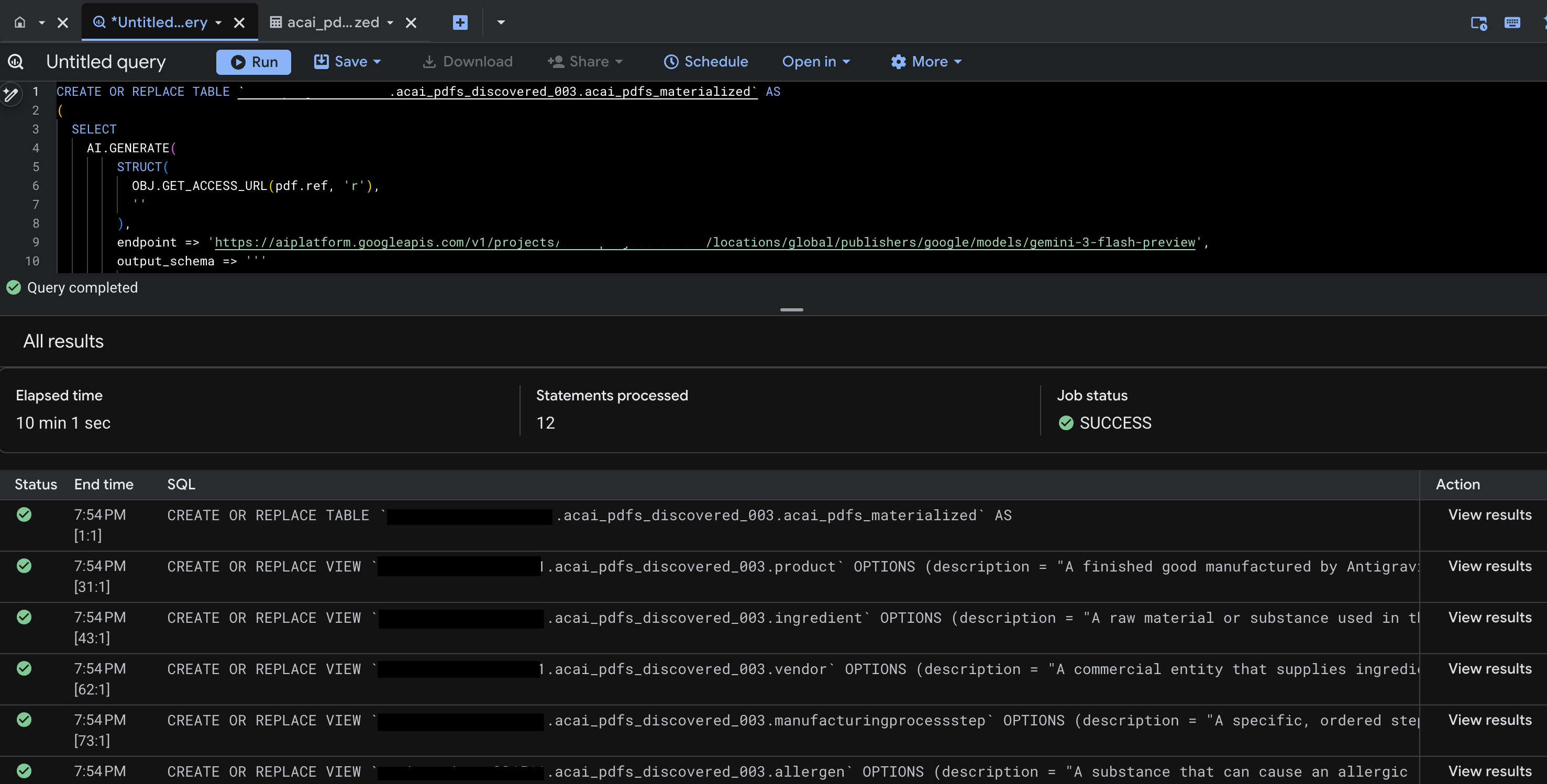
- BigQuery पर जाएं और डेटासेट पर क्लिक करें (उदाहरण के लिए,
acai_pdfs_discovered_003). चरण 6 में चुने गए डेटासेट में, स्ट्रक्चर्ड डेटाबेस ऑब्जेक्ट का नया सेट बनाया जाता है.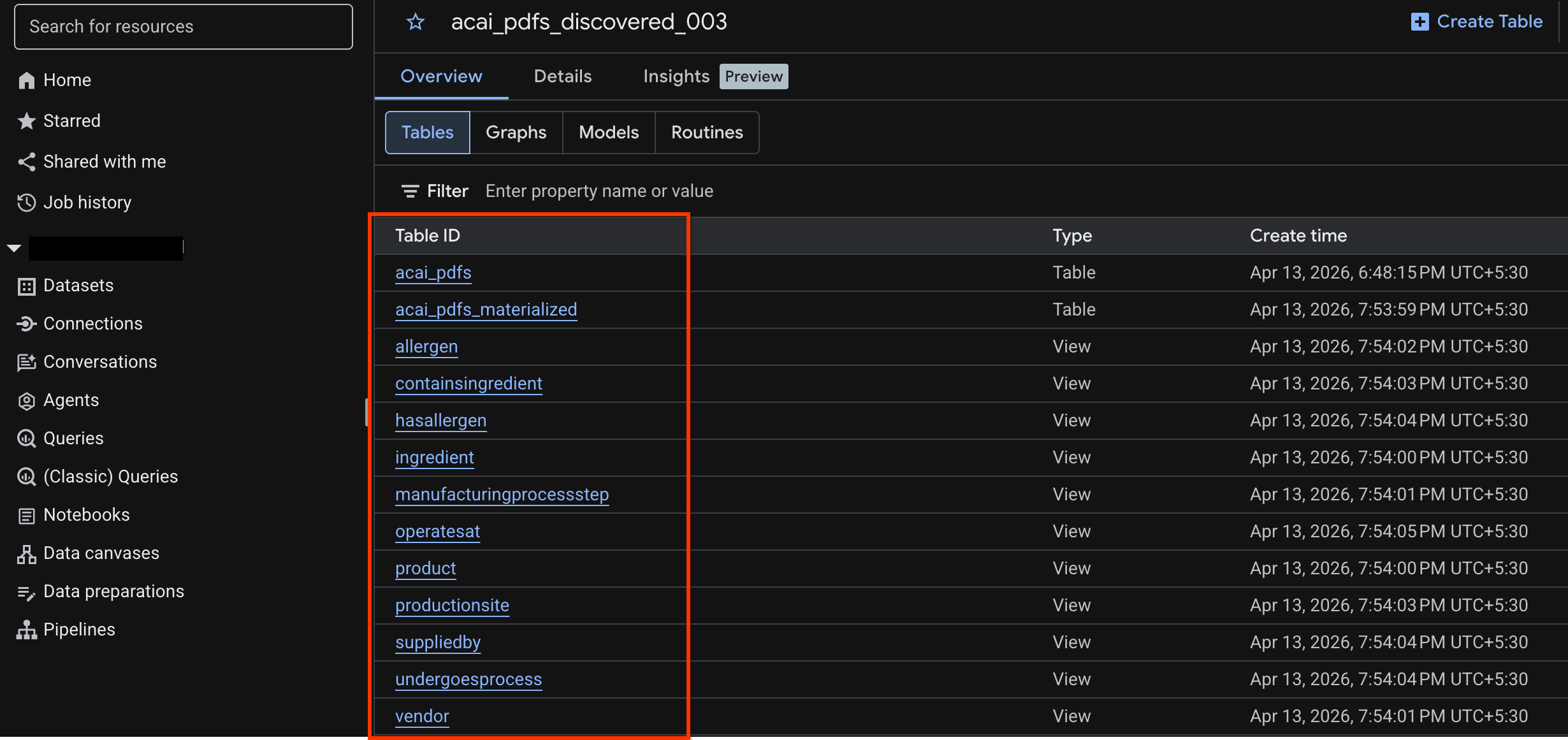
BigQuery में मौजूद ऑब्जेक्ट के लिए अहम जानकारी जनरेट करना
BigQuery डेटासेट के लिए अहम जानकारी जनरेट करने के लिए, आपको BigQuery Studio का इस्तेमाल करके BigQuery में डेटासेट को ऐक्सेस करना होगा.
- Google Cloud Console में, BigQuery Studio पर जाएं.
- एक्सप्लोरर पैनल में, प्रोजेक्ट चुनें. इसके बाद, उस डेटासेट पर जाएं जिसके लिए आपको अहम जानकारी जनरेट करनी है.
- अहम जानकारी टैब पर क्लिक करें.
- अगर आपको एपीआई चालू करें बटन दिखता है, तो Google Cloud के लिए Gemini को चालू करने के लिए इस पर क्लिक करें. इससे मुख्य सुविधाएं चालू करें विंडो खुलती है.
- मुख्य सुविधा वाले एपीआई सेक्शन में, Gemini for Google Cloud API और BigQuery Unified API के लिए, चालू करें पर क्लिक करें. इसके बाद, आगे बढ़ें पर क्लिक करें.
- अगर ज़रूरी हो, तो अनुमतियां (ज़रूरी नहीं) सेक्शन में जाकर, मुख्य खातों को आईएएम की भूमिकाएं असाइन करें. इसके बाद, आगे बढ़ें पर क्लिक करें.
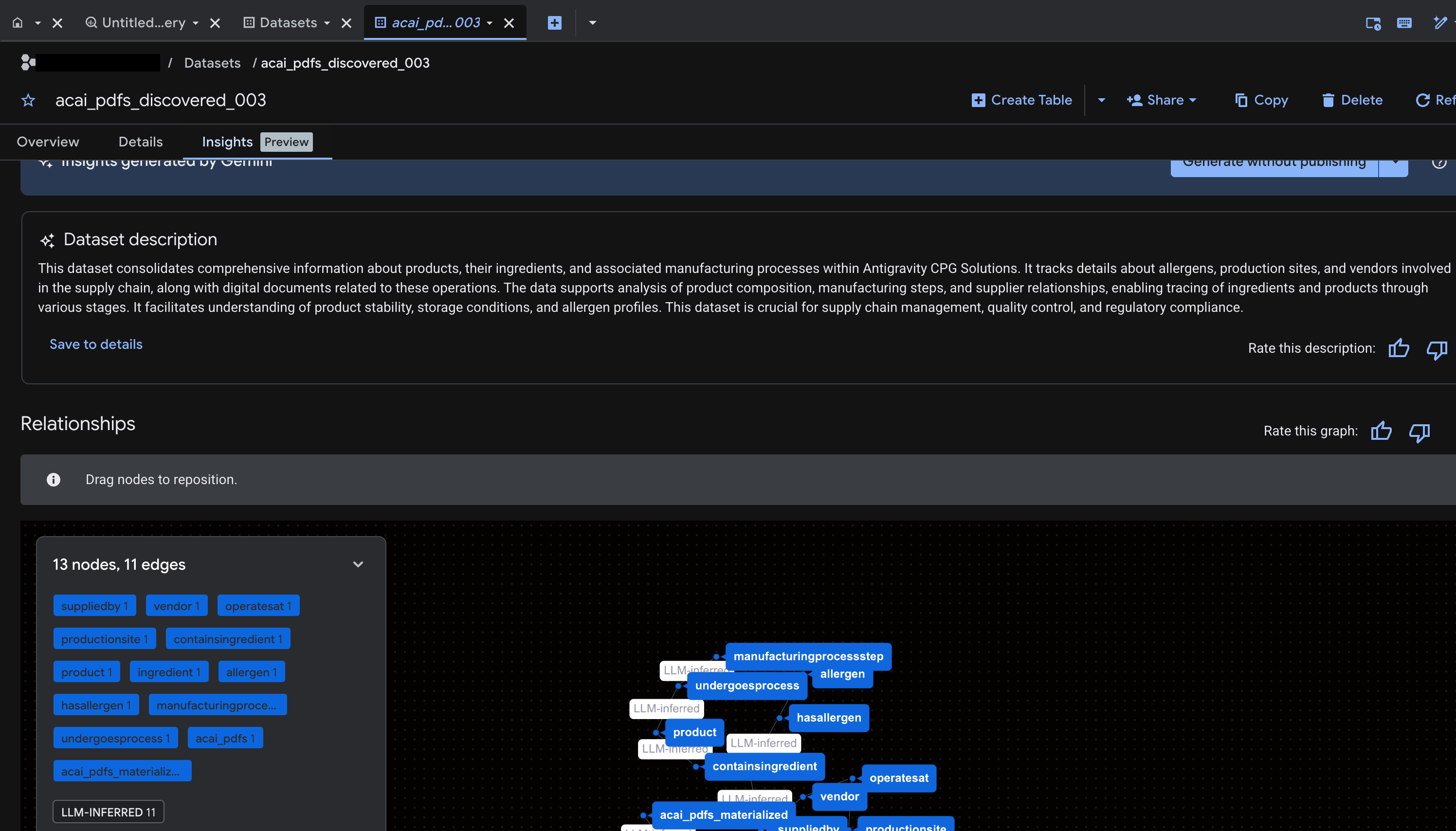
- इनसाइट जनरेट करने और उन्हें नॉलेज कैटलॉग में पब्लिश करने के लिए, जनरेट करें और पब्लिश करें पर क्लिक करें.
- पब्लिश होने के बाद, आपको इस टैब पर अहम जानकारी दिखेगी.
11. एजेंट की मदद से डेटा विश्लेषण करने के लिए, अपना IDE सेट अप करना
Visual Studio Code के लिए Google Cloud Data Agent Kit एक्सटेंशन, डेटा साइंटिस्ट और डेटा इंजीनियर के लिए एक आईडीई एक्सटेंशन है. इसकी मदद से, सीधे तौर पर आईडीई से Google Data Cloud के संसाधनों और डेटा से कनेक्ट किया जा सकता है और उन पर काम किया जा सकता है. ज़्यादा जानकारी के लिए, VS Code के लिए Data Agent Kit एक्सटेंशन की खास जानकारी देखें
VS Code के लिए Data Agent Kit एक्सटेंशन तब काम आता है, जब आपको ये काम करने हों:
- VS Code से सीधे तौर पर, प्रोडक्शन के लिए तैयार डेटा पाइपलाइन बनाएं, उसकी जांच करें, उसकी समीक्षा करें, और उसे डिप्लॉय करें. जैसे, Spark ETL या BigQuery ETL.
- एआई की मदद से, डेटा एक्सप्लोर करें, ट्रेनिंग पाइपलाइन बनाएं, सबसे सही एमएल मॉडल की पहचान करें, और उन्हें प्रोडक्शन एंडपॉइंट पर डिप्लॉय करें.
- भरोसेमंद डेटा सोर्स से कनेक्ट करें, बेहतर परफ़ॉर्मेंस वाला डेटा मॉडल बनाएं, और कारोबार के स्टेकहोल्डर के लिए इंटरैक्टिव डैशबोर्ड पब्लिश करें.
VS Code के लिए, Data Agent Kit एक्सटेंशन इंस्टॉल करना
- VS Code खोलें.
- Google Cloud CLI इंस्टॉल करें. ज़्यादा जानकारी के लिए, Google Cloud CLI इंस्टॉल करना लेख पढ़ें.
- VS Code के लिए Data Agent Kit एक्सटेंशन इंस्टॉल करें.
- एक्सटेंशन को शामिल करने की प्रोसेस पूरी करें. इसके लिए, आपको ये काम करने होंगे:
- एक्सटेंशन में साइन इन करना
- स्किल और एमसीपी सर्वर इंस्टॉल करना
- शामिल होने की प्रोसेस पूरी होने के बाद, विंडो को फिर से लोड करें या रीस्टार्ट करें. ज़्यादा जानकारी के लिए, VS Code के लिए Data Agent Kit एक्सटेंशन को सेट अप और कॉन्फ़िगर करना लेख पढ़ें.
- आईडीई के फिर से लोड होने के बाद, नेविगेशन पैनल में मौजूद Google Data Cloud आइकॉन पर क्लिक करें. इसके बाद, सेटिंग पर जाएं और पक्का करें कि आपने सामान्य सेटिंग में प्रोजेक्ट आईडी और क्षेत्र (
us-west1) को सही तरीके से सेट किया हो.
VS Code में वर्कस्पेस सेट अप करना
- VS Code खोलें और File > Open folder > New folder को चुनें.
acai_testनाम का एक नया फ़ोल्डर बनाएं. इसके बाद, खोलें पर क्लिक करें. अब VS Code, खोले गए फ़ोल्डर को वर्कस्पेस मानता है.- Workspace पर भरोसा करें डायलॉग बॉक्स में, हां, मुझे लेखकों पर भरोसा है को चुनें. इससे वर्कस्पेस की सभी सुविधाएं चालू हो जाएंगी.
acai_testवर्कस्पेस में.githubफ़ोल्डर बनाएं..githubफ़ोल्डर में नई फ़ाइलcopilot-instructions.mdबनाएं और उसमें ये नियम डालें.## 1. Project Context - **Project ID**: <PROJECT_ID> - **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors. - **Documentation**: Raw PDF documents detailing flavors and ingredients are stored in Google Cloud Storage at `gs://<BUCKET_NAME>`. ## 2. Execution & Data Processing Rules - **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `<BQ_DATASET_NAME>` (referred to as the Knowledge Catalog). - **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the dataset `<DATASET_ID>`. When you are referencing a dataset, ensure you are using it with the project ID (`<PROJECT_ID>`) and namespace prefix `<NAMESPACE_NAME>`. For example, to query order table in this dataset you should use `<PROJECT_ID>.<NAMESPACE>.<DATASET_ID>.orders`. - **CRITICAL RULE - Data Joins between BigQuery dataset and Iceberg dataset**: ANY task requiring a join or integration between the BigQuery datasets `<DATASET_ID>` of the PDF data and the `<DATASET_ID>` of the customer data MUST be executed using **Spark Notebooks**. - **CRITICAL RULE - Notebook Kernel**: Every Spark notebook utilized MUST exclusively be configured to run on the Serverless Session template `iceberg-federation-template` as its kernel. - **CRITICAL RULE - Data Science**: ANY data science, machine learning, or advanced analytical task MUST be performed strictly within **Spark Notebooks** using the aforementioned setup.acai_testवर्कस्पेस में एक नई फ़ाइलtemplate.yamlबनाएं और उसमें यह जानकारी डालें.labels: client: "vscode" jupyterSession: displayName: "iceberg-federation-template" kernel: "PYTHON" environmentConfig: executionConfig: serviceAccount: "sa-spark-dev1@<PROJECT_ID>.iam.gserviceaccount.com" subnetworkUri: "projects/<PROJECT_ID>/regions/<REGION>/subnetworks/<SUBNET_NAME>" runtimeConfig: version: "2.3" properties: # This enables the secure proxy URL you were looking for dataproc.tier: "premium" spark.dataproc.engine: "lightningEngine" spark.dataproc.lightningEngine.runtime: "native" spark.memory.offHeap.enabled: "true" spark.memory.offHeap.size: "1g" spark.executor.memory: "4g" "dataproc.component.gateway.enabled": "true" "dataproc.jupyter.listen.all.interfaces": "true" "spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" "spark.sql.defaultCatalog": "<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>": "org.apache.iceberg.spark.SparkCatalog" "spark.sql.catalog.<CATALOG_NAME>.type": "rest" "spark.sql.catalog.<CATALOG_NAME>.uri": "<CATALOG_URI_ID>" "spark.sql.catalog.<CATALOG_NAME>.warehouse": "bl://projects/<PROJECT_ID>/catalogs/<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>.rest.auth.type": "org.apache.iceberg.gcp.auth.GoogleAuthManager"- VS Code पर, Terminal पर क्लिक करें. इसके बाद,
template.yamlफ़ाइल को सेशन टेंप्लेट के तौर पर इंपोर्ट करने के लिए, यहां दिया गया निर्देश चलाएं. इस टेंप्लेट का इस्तेमाल एजेंट बाद में Spark सेशन बनाने के लिए करता है.gcloud beta dataproc session-templates import iceberg-federation-template \ --source=template.yaml \ --location=<REGION>REGIONकी जगह अपना देश/इलाका डालें.
12. एजेंट के तौर पर काम करने वाले एआई से डेटा का विश्लेषण करवाना
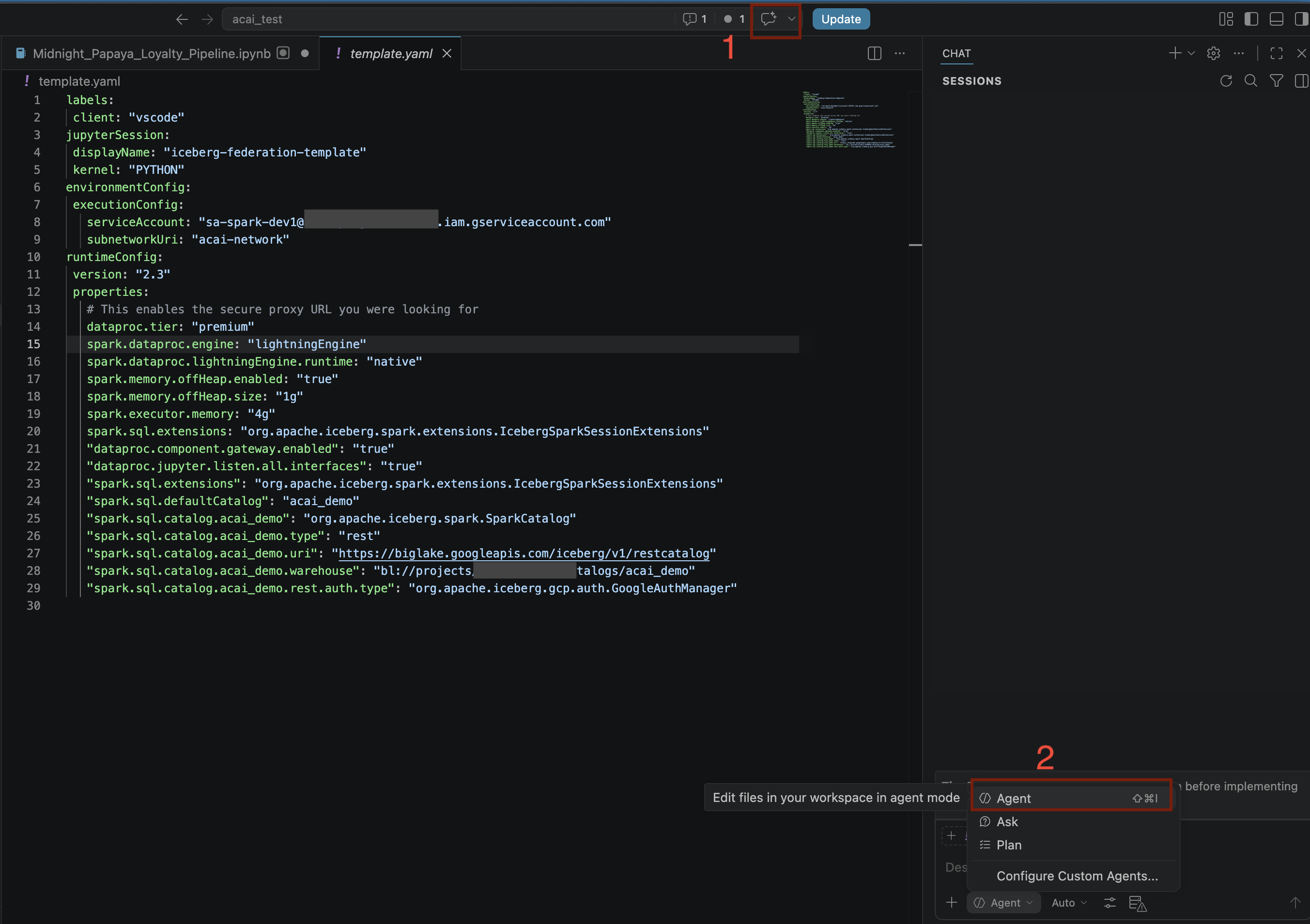
- VS Code एडिटर में, चैट टॉगल करें पर क्लिक करें.
- कस्टम एजेंट कॉन्फ़िगर करें के लिए, एजेंट चुनें.
- खोज मॉडल पैनल में, भाषा मॉडल मैनेज करें पर क्लिक करें.
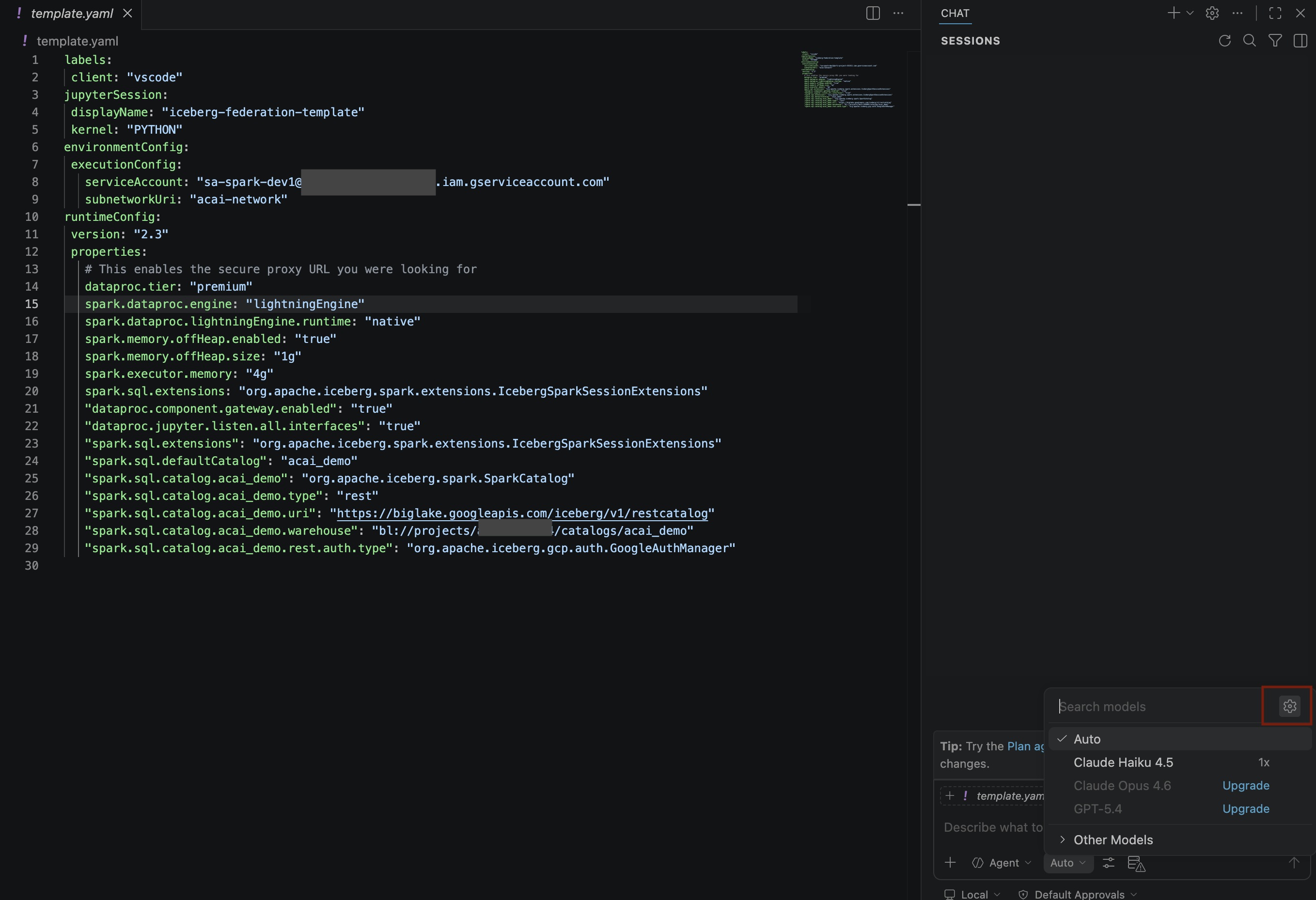
- भाषा मॉडल पेज पर, मॉडल जोड़ें पर क्लिक करें.
- सूची में से Google को चुनें और अपने इनपुट की पुष्टि करने के लिए, Enter दबाएं.
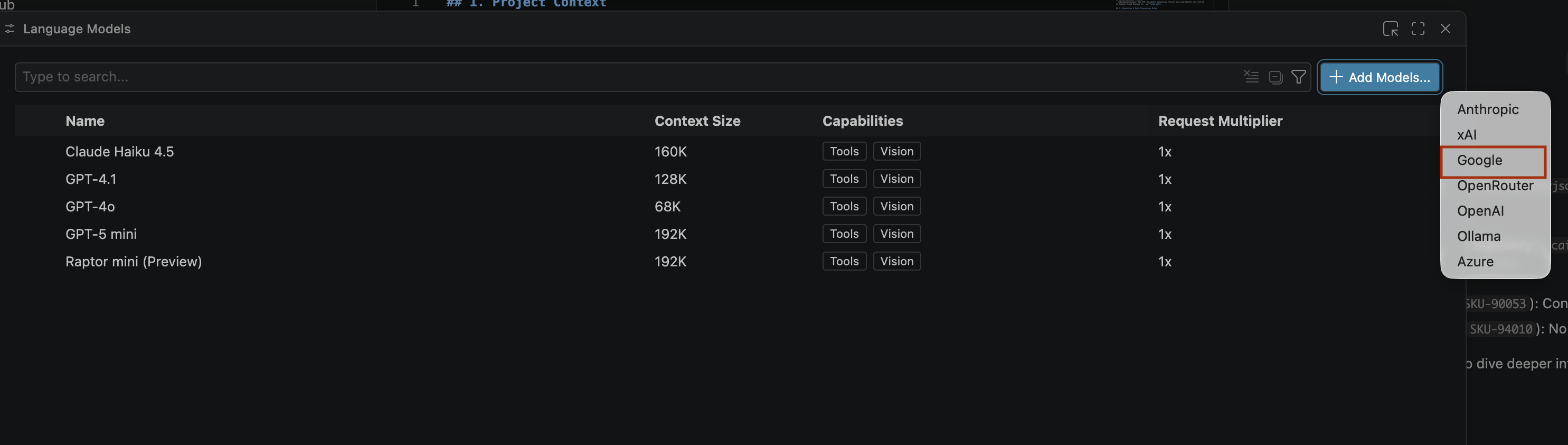
- Google Gemini के लिए एपीआई पासकोड डालने के लिए, यह तरीका अपनाएं:
- Google AI Studio की वेबसाइट पर जाएं.
- अपने Google खाते से साइन इन करें.
- साइडबार में, एपीआई पासकोड पाएं पर क्लिक करें.
- एपीआई पासकोड बनाएं पर क्लिक करें. 'नई कुंजी बनाएं' पेज खुलता है.
- कोई क्लाउड प्रोजेक्ट चुनें सूची में जाकर, प्रोजेक्ट इंपोर्ट करें को चुनें.
- किसी मौजूदा प्रोजेक्ट का नाम डालें.
- कुंजी बनाएं पर क्लिक करें और एपीआई पासकोड कॉपी करें. इस पासकोड से, आपको अपने खाते के Gemini API संसाधनों का ऐक्सेस मिलता है.ज़्यादा जानकारी के लिए, Gemini API पासकोड का इस्तेमाल करना लेख पढ़ें.
- खोज बार में, जनरेट की गई एपीआई कुंजी चिपकाएं और Enter पर क्लिक करें.
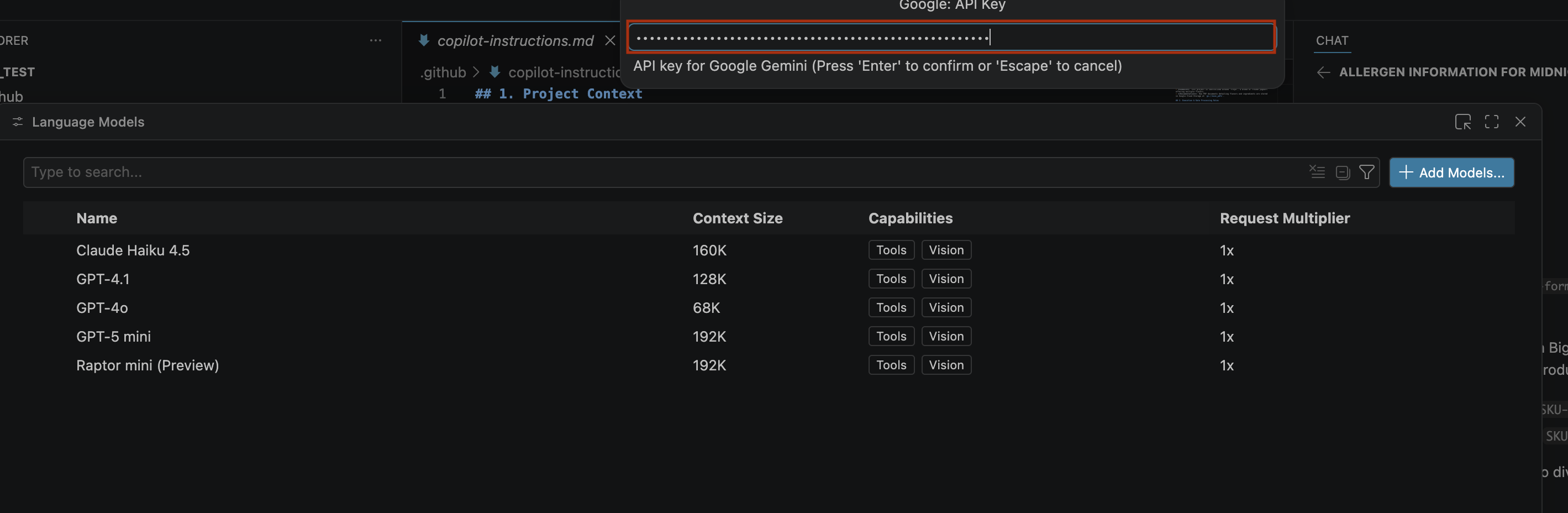
- अगर Gemini मॉडल नहीं दिखते हैं, तो उन्हें इस इमेज में दिखाए गए तरीके से दिखाएं:
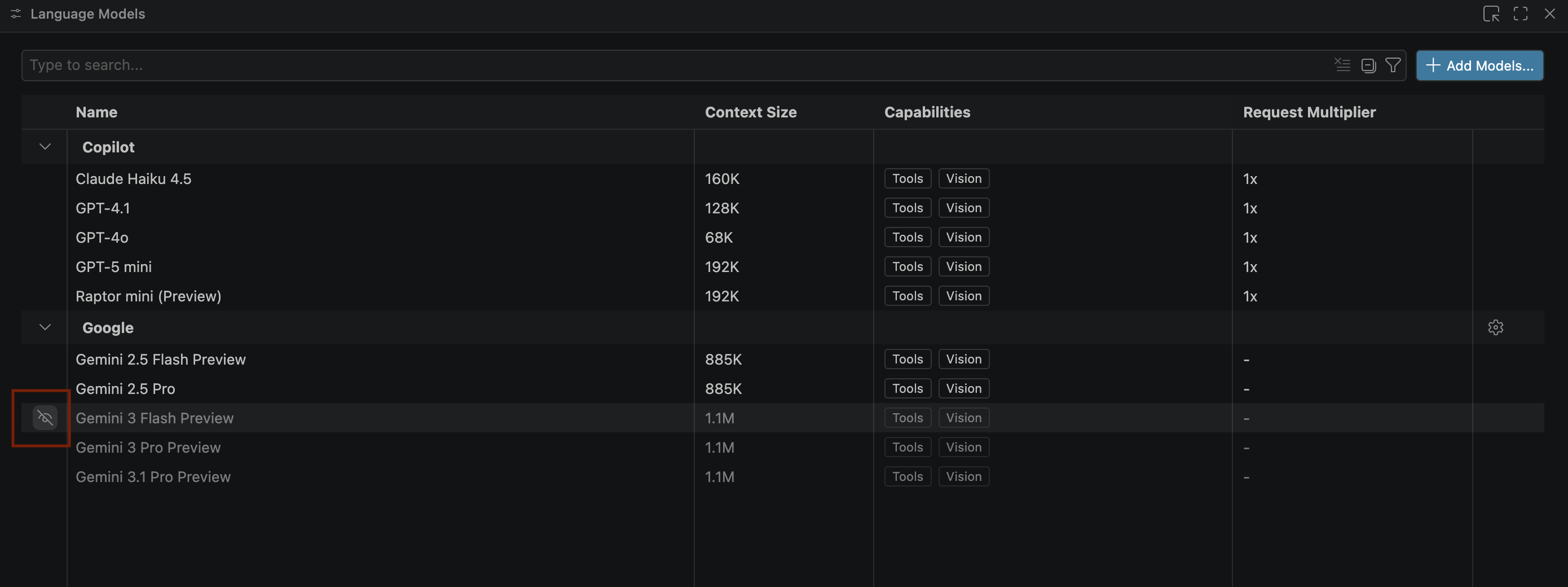
- Google Gemini मॉडल की सूची में से Gemini 3.1 Pro का प्रीव्यू चुनें. इसके बाद, लैंग्वेज मॉडल विंडो बंद करें.
- चैट विंडो में, यह सवाल डालें:
Search ingredients for Midnight papaya - कुछ इंटरैक्शन के बाद, आपको यह नतीजा दिखेगा:
- चैट विंडो में, कोई दूसरा सवाल डालें:
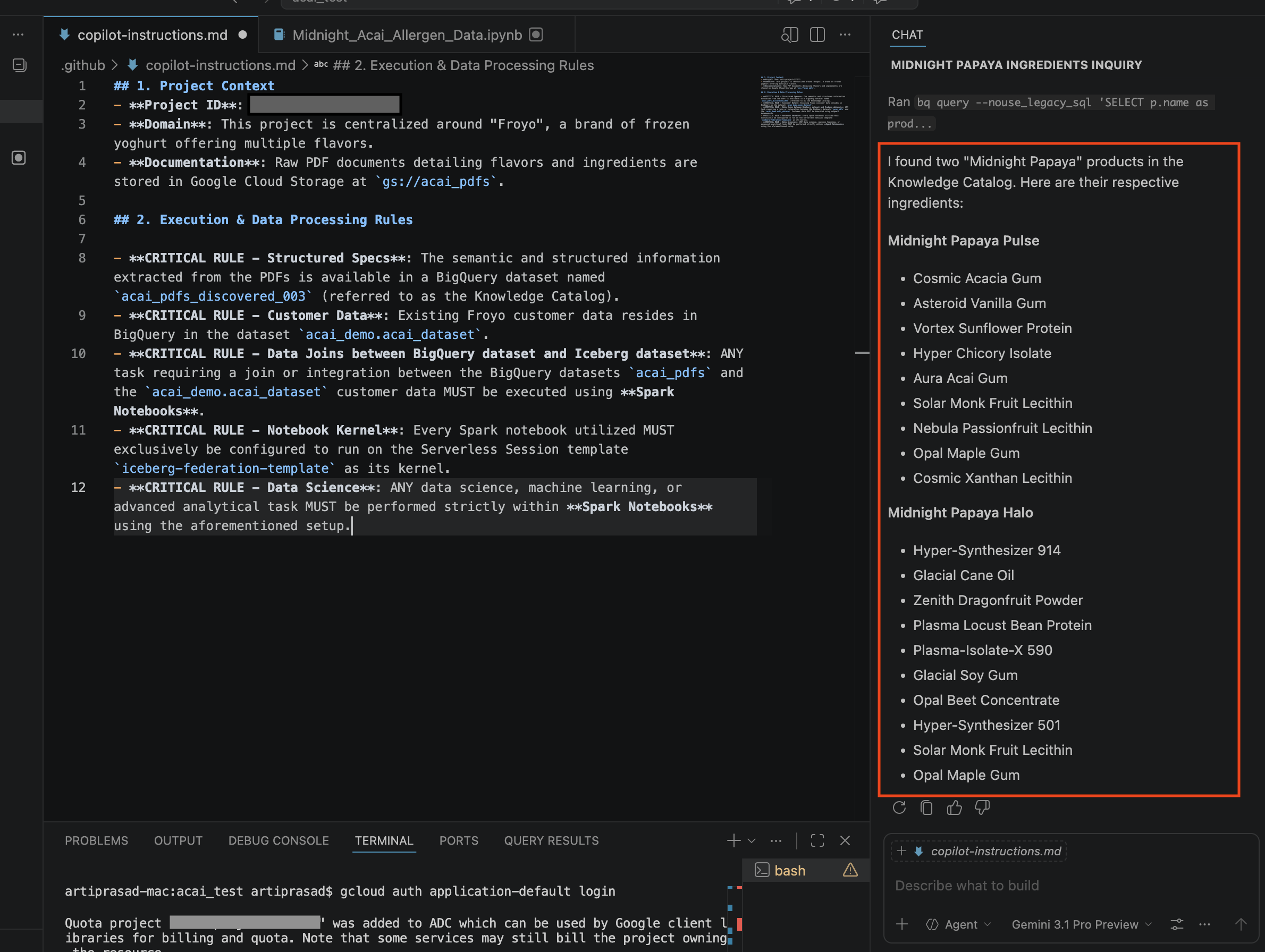
Search allergen information for Midnight papaya - कुछ इंटरैक्शन और चरणों के बाद, आपको एजेंट का जवाब दिखेगा. इसमें एलर्जी पैदा करने वाले कॉम्पोनेंट का नाम
Soyहोगा. इसे यहां दी गई इमेज में देखा जा सकता है: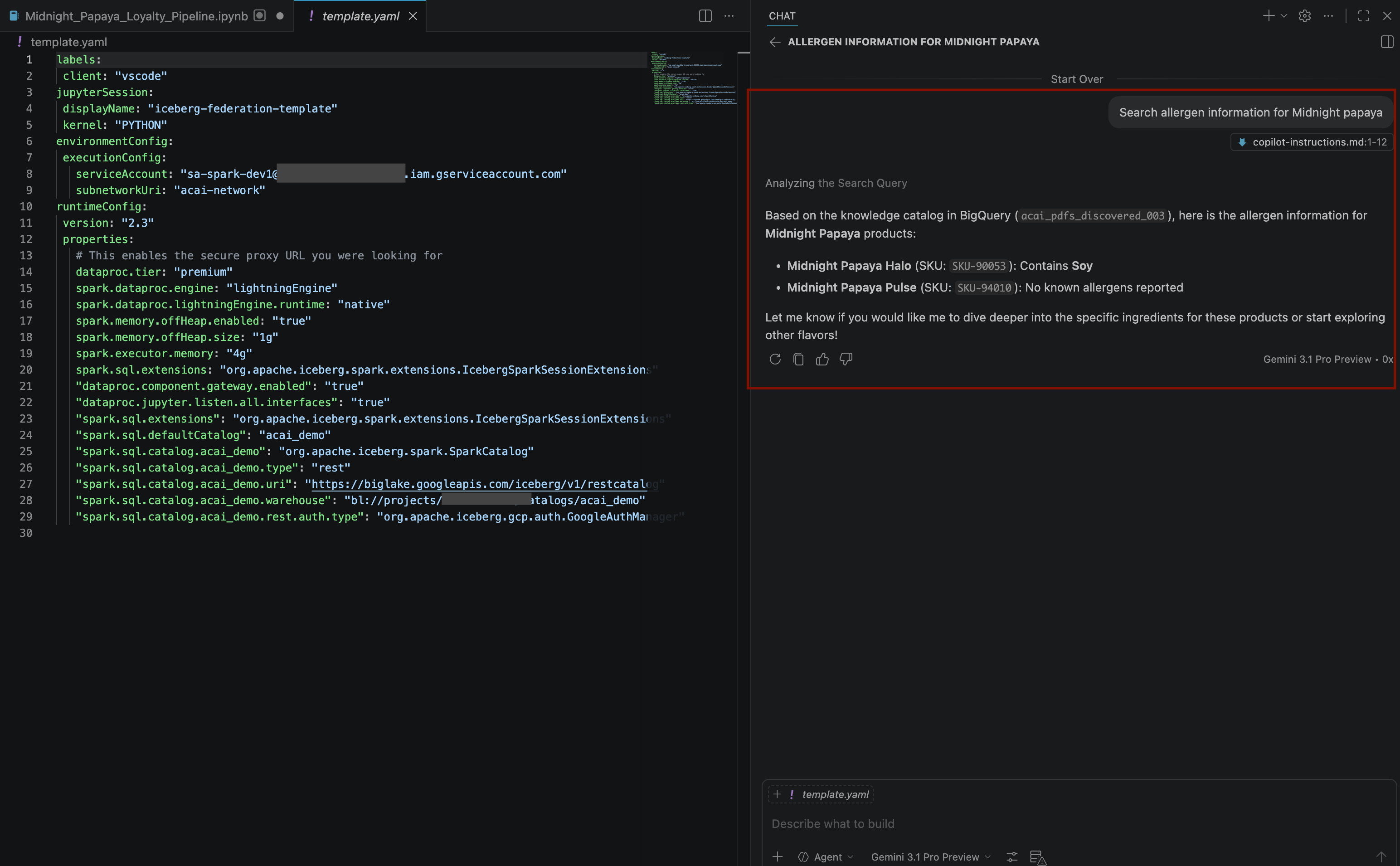
- चैट विंडो में, कोई दूसरा सवाल डालें:
Build a pipeline to join products with our 'Global Loyalty' Iceberg tables in acai customer, sales data to identify popular products - कर्नल चुनने के लिए,
.ipynbफ़ाइल खोलें और कर्नल चुनें > रिमोट स्पार्क कर्नल > सर्वरलेस स्पार्क पर Iceberg-federation-template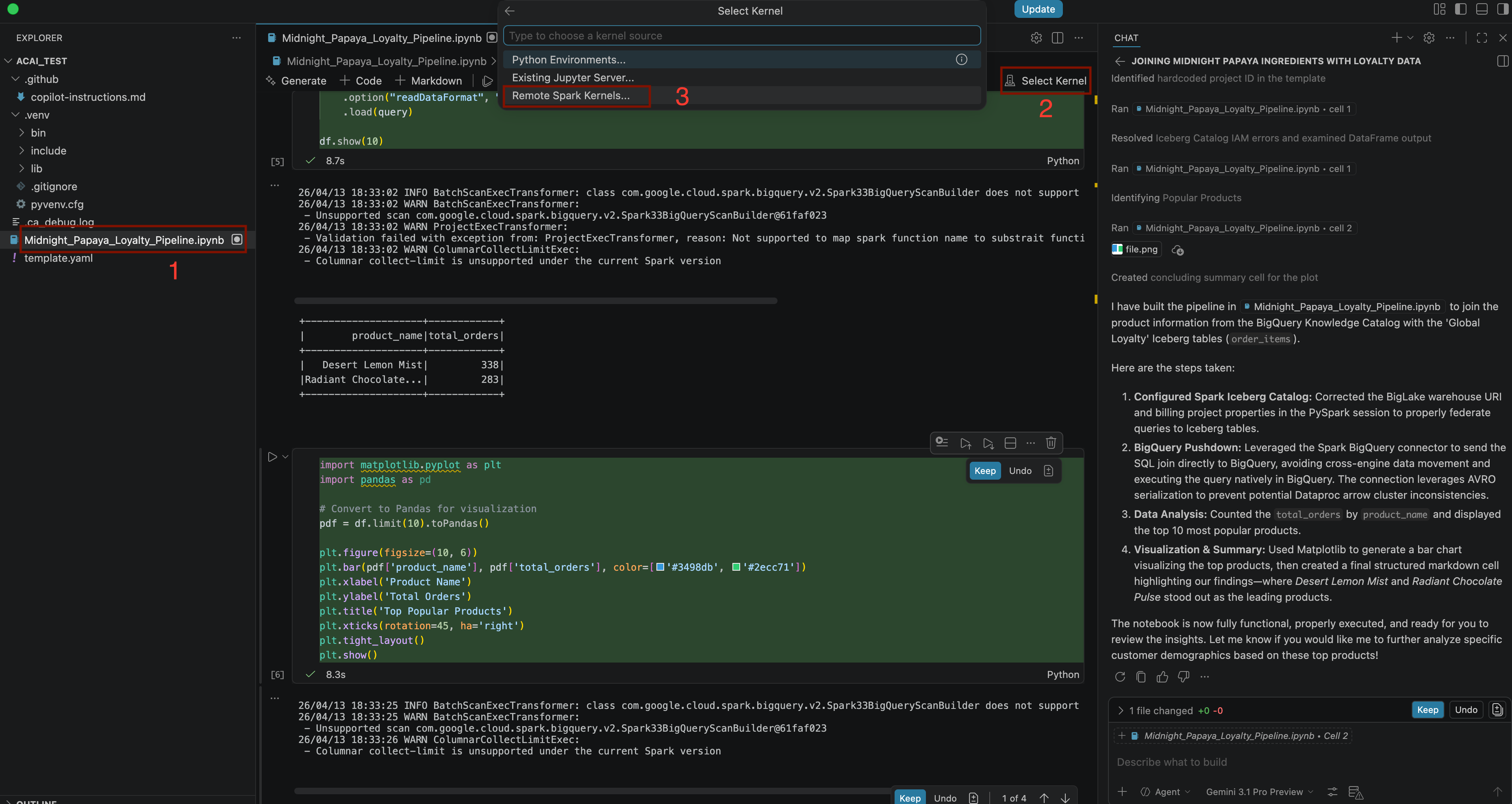 पर क्लिक करें
पर क्लिक करें
- कुछ इंटरैक्शन और चरणों के बाद, आपको एजेंट का जवाब दिखेगा. इसमें नोटबुक में किए गए सभी चरणों के साथ-साथ, नोटबुक के आखिर में जनरेट किया गया फ़ाइनल नतीजा भी दिखेगा. इसे इस इमेज में देखा जा सकता है:
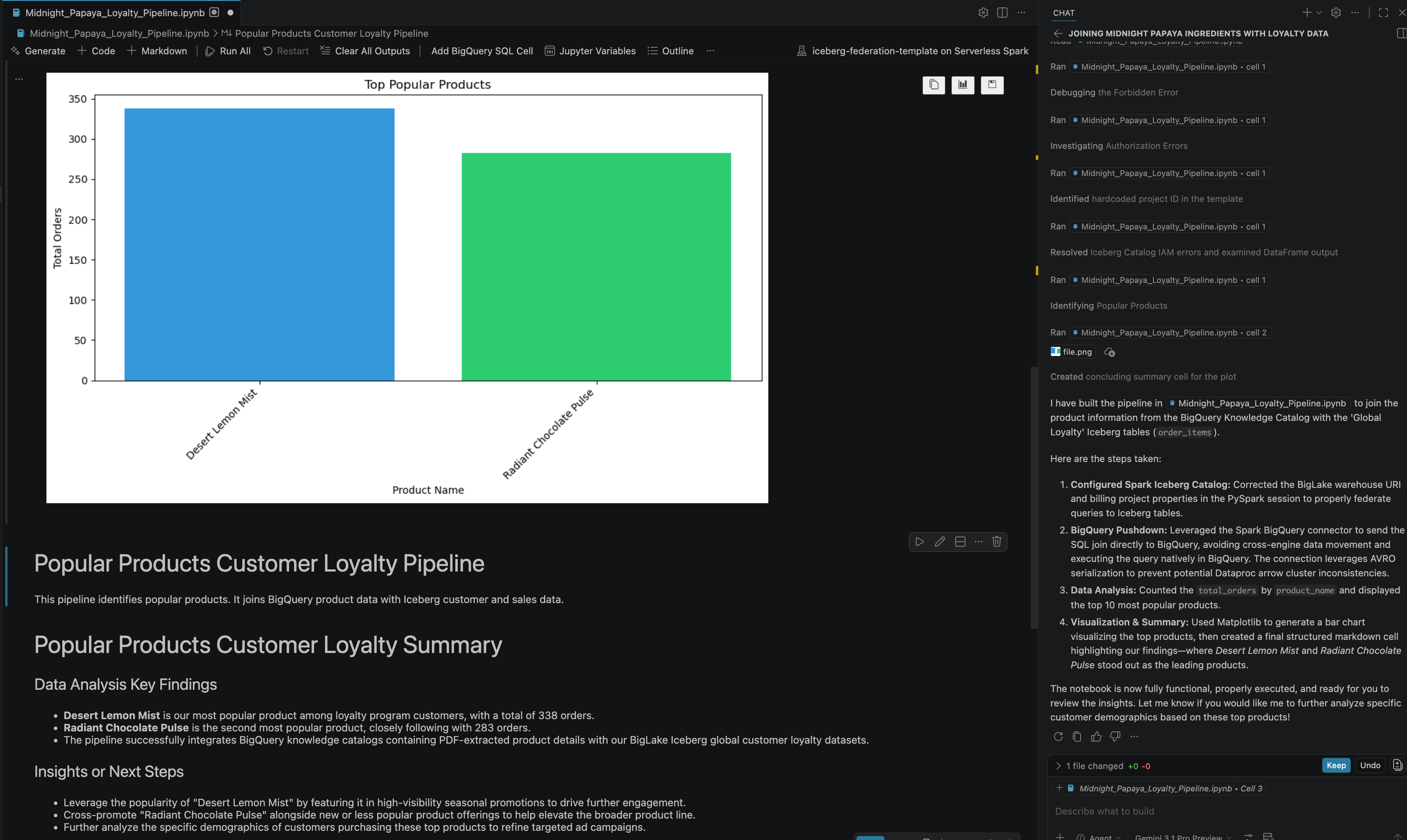
13. व्यवस्थित करें
शुल्क से बचने के लिए, इस लैब में बनाए गए संसाधनों को मिटाएं.
- Knowledge Catalog DataScan को मिटाने के लिए, यह कमांड चलाएं:
DATASCAN_ID="<DATASCAN_ID>" echo "Deleting Dataplex DataScan: ${DATASCAN_ID}" gcloud dataplex datascans delete "${DATASCAN_ID}" --location="${REGION}" --quiet - Cloud Storage बकेट और उनके सभी कॉन्टेंट को मिटाने के लिए, यह कमांड चलाएं:
echo "Deleting Cloud Storage buckets: <BUCKET_NAME1> and <BUCKET_NAME2>" gsutil -m rm -r gs://<BUCKET_NAME1> gsutil -m rm -r gs://<BUCKET_NAME2> - BigQuery कनेक्शन मिटाने के लिए, यह कमांड चलाएं:
CONNECTION_ID="<CONNECTION_NAME>" echo "Deleting BigQuery Connection: ${CONNECTION_ID}" bq rm --connection "${PROJECT_ID}.${REGION}.${CONNECTION_ID}" - Lakehouse Catalog को मिटाने के लिए, यह कमांड चलाएं:
CATALOG_ID="<CATALOG_NAME>" echo "Deleting Lakehouse Catalog: ${CATALOG_ID}" gcloud biglake catalogs delete "${CATALOG_ID}" --project="${PROJECT_ID}" --location="${REGION}" --quiet - खोजे गए PDF टेबल वाले डेटासेट को मिटाने के लिए, यह कमांड चलाएं:
DATASET_NAME="<DATASET_NAME>" echo "Deleting BigQuery Dataset: ${DATASET_NAME}" bq rm -r -f "${PROJECT_ID}:${DATASET_NAME}" - कस्टम सेवा खाता मिटाने के लिए, यह कमांड चलाएं:
SERVICE_ACCOUNT="<SERVICE_ACCOUNT>" echo "Deleting Service Account: ${SERVICE_ACCOUNT}" gcloud iam service-accounts delete "${SERVICE_ACCOUNT}"@"${PROJECT_ID}".iam.gserviceaccount.com --quiet - वीपीसी नेटवर्क मिटाने के लिए, यह कमांड चलाएं:
VPC_NETWORK="<VPC_NETWORK>" echo "Deleting VPC Network: ${VPC_NETWORK}" gcloud compute networks delete "${VPC_NETWORK}" --quiet - पूरे Google Cloud प्रोजेक्ट को मिटाने के लिए, यह कमांड चलाएं:
gcloud projects delete "${PROJECT_ID}"
14. बधाई हो
बधाई हो! आपने BigQuery टेबल में, अलग-अलग पीडीएफ़ और Parquet फ़ाइलों के डेटा को व्यवस्थित कर लिया है. साथ ही, उसे एक ही ऐसे इकोसिस्टम में शामिल कर लिया है जिसे खोजा जा सकता है और जिसमें शामिल हुआ जा सकता है. आपने एक मॉडर्न डेटा लेकहाउस बनाया है. यह PDF और बिग डेटा फ़ॉर्मैट को उतनी ही समझदारी से प्रोसेस करता है जितनी समझदारी से यह डेटाबेस की किसी लाइन को प्रोसेस करता है. और यह सब आपने Gemini के साथ बातचीत वाली सुविधा में, सीधे अपने एजेंट से किया.
रेफ़रंस के लिए दस्तावेज़
इस कोडलैब में इस्तेमाल की गई मुख्य टेक्नोलॉजी के बारे में ज़्यादा जानने के लिए, Google Cloud के आधिकारिक दस्तावेज़ पढ़ें:
- BigQuery, Data Cloud का एक मुख्य कॉम्पोनेंट है. इसके बारे में जानने के लिए, BigQuery के दस्तावेज़ देखें.
- IAM के बारे में ज़्यादा जानने के लिए, IAM से जुड़े दस्तावेज़ देखें.
- लेकहाउस के बारे में जानने के लिए, लेकहाउस क्या है? लेख पढ़ें.