
1. Pengantar
Dalam codelab ini, Anda akan berperan sebagai ilmuwan data untuk perusahaan Froyo fiktif yang meluncurkan rasa produk baru, "Midnight Swirl". Untuk memastikan peluncuran global yang sukses, bisnis harus menjawab pertanyaan penting terkait bahan, permintaan pasar, dan laba atas investasi (ROI). Alur kerja end-to-end ini menunjukkan cara Knowledge Catalog Google Cloud (sebelumnya dikenal sebagai Dataplex) dan Lakehouse untuk Apache Iceberg (sebelumnya dikenal sebagai BigLake) menjembatani kesenjangan antara data tidak terstruktur "gelap" dan memberikan business intelligence yang dapat ditindaklanjuti menggunakan Gemini di IDE Anda (VS Code) melalui lapisan tata kelola terpadu.
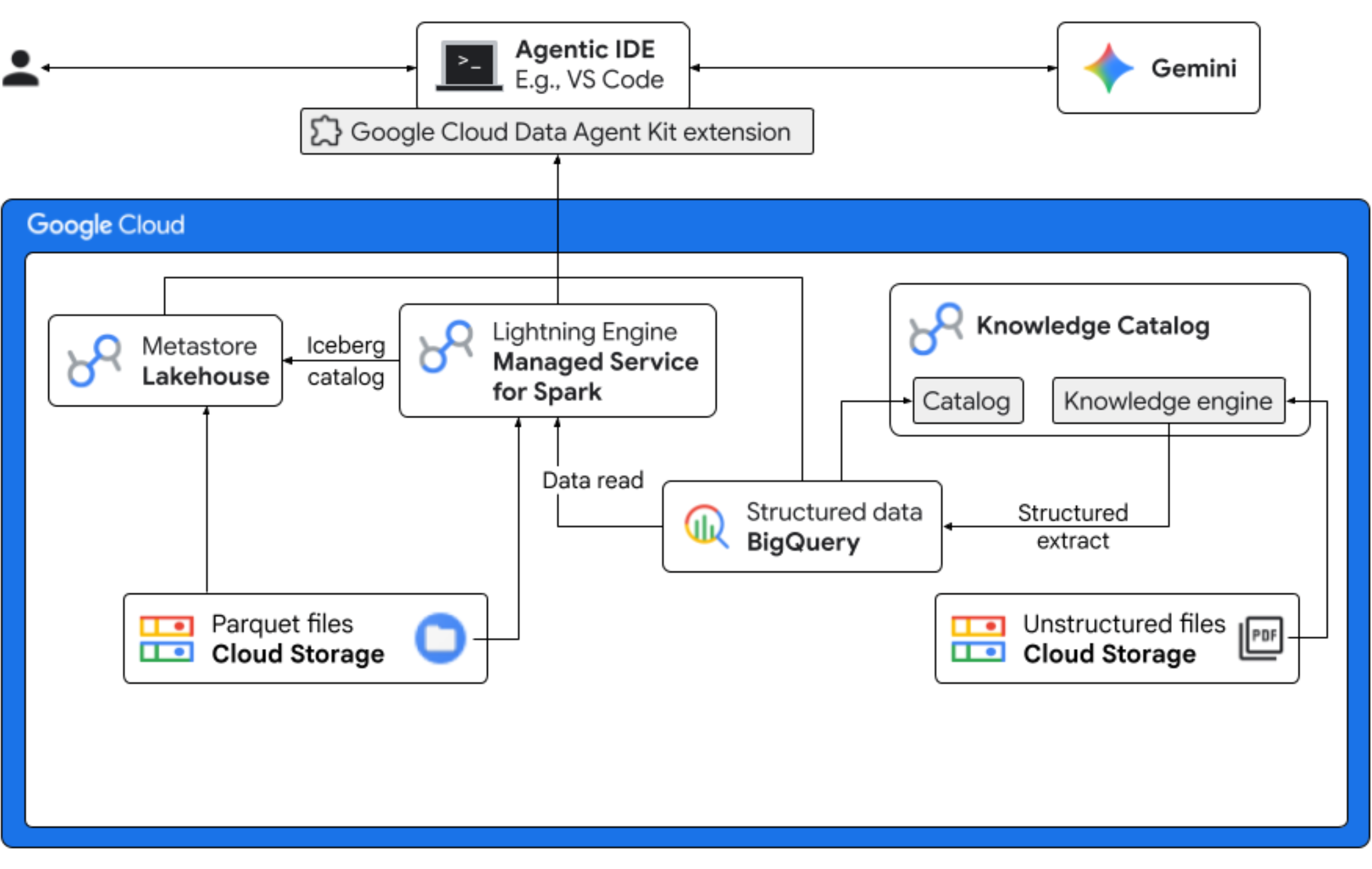
Yang akan Anda lakukan
- Penemuan tidak terstruktur: Resep PDF yang disimpan di Cloud Storage di-crawl oleh Knowledge Catalog DataScan. Buat Tabel objek di BigQuery untuk PDF yang dipindai. Dengan menggunakan Inferensi Semantik Vertex AI, sistem "membaca" PDF untuk mengekstrak informasi terstruktur tentang produk, alergen, bahan, dan atribut terkait. Kemudian, secara cerdas membuat skema untuk data yang disimpan dalam PDF.
- Metadata terpadu: Data yang diekstrak dari file PDF disimpan langsung ke BigQuery sebagai tabel lebar native, dan tampilan dibuat untuk membantu kueri umum. Set data input independen yang berisi data penjualan historis disimpan di Tabel Apache Iceberg di Google Cloud Storage. Tabel Iceberg ini akan digabungkan dengan data yang diekstrak di BigQuery pada langkah berikutnya.
- Analisis lintas mesin: Dengan menggunakan Managed Service untuk Apache Spark (sebelumnya dikenal sebagai Dataproc) dengan Katalog REST Iceberg, Anda akan menggabungkan metadata PDF baru ini dan data semantik terstruktur yang disimpulkan (dari tabel dan tampilan BigQuery) dengan data penjualan terstruktur yang disimpan dalam Tabel Apache Iceberg di Google Cloud Storage. Hal ini diatur oleh template sesi interaktif Managed Apache Spark yang digunakan sebagai kernel Jupyter Notebook yang memastikan setelan keamanan dan komputasi yang konsisten untuk tugas Spark.
- Insight semantik: Dengan menggabungkan data produk yang disimpulkan dengan data pelanggan dan penjualan (di BigQuery), demo ini dapat mengekstrak insight seperti mengidentifikasi data alergen dan perkiraan pendapatan.
- Tata kelola otonom: Seluruh siklus proses—mulai dari pemindaian penemuan hingga eksekusi Spark—diatur melalui template, petunjuk, aturan, dan otomatisasi yang didukung agen yang siap digunakan Gemini, sehingga membuktikan bahwa AI dapat mengelola infrastruktur yang mendukung analisis.
Yang Anda butuhkan
Menyelesaikan codelab ini dapat menimbulkan biaya, yang diperkirakan kurang dari $5 untuk penggunaan umum. Untuk mendapatkan perkiraan biaya mendetail berdasarkan proyeksi penggunaan atau harga saat ini, gunakan Kalkulator Harga Google Cloud.
Pastikan Anda memiliki prasyarat berikut untuk menyelesaikan codelab.
- Browser web Chrome.
- Akun Gmail pribadi jika Anda menggunakan kredit uji coba yang disediakan di bagian Sebelum Anda memulai.
- Download dan instal Visual Studio (VS) Code.
2. Sebelum memulai
Buat Project Google Cloud
- Di Konsol Google Cloud, di halaman pemilih project, pilih atau buat project Google Cloud.
- Pastikan penagihan diaktifkan untuk project Cloud Anda. Pelajari cara memeriksa apakah penagihan telah diaktifkan pada suatu project.
Mulai Cloud Shell
Cloud Shell adalah lingkungan command line yang berjalan di Google Cloud yang telah dilengkapi dengan alat yang diperlukan.
- Klik Activate Cloud Shell di bagian atas konsol Google Cloud.
- Setelah terhubung ke Cloud Shell, verifikasi autentikasi Anda:
gcloud auth list - Pastikan project Anda dikonfigurasi:
gcloud config get project - Jika project Anda tidak ditetapkan seperti yang diharapkan, tetapkan project:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Aktifkan API yang diperlukan
Jalankan perintah ini untuk mengaktifkan semua API yang diperlukan:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
biglake.googleapis.com \
dataproc.googleapis.com \
metastore.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
secretmanager.googleapis.com \
storage.googleapis.com
Mendownload aset codelab
Repositori ini berisi file Parquet, resep, pemasok, copilot-instructions.md, template.yaml, dan quickstart.py untuk digunakan dengan codelab ini. Pastikan Anda mendownload file ini.
Untuk mendownload file, lakukan hal berikut:
- Di Cloud Shell, jalankan perintah berikut:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git - Buka folder yang baru dibuat:
cd next-26-keynotes - Tarik folder
data-cloud-demogit sparse-checkout set genkey/data-cloud-demo - Setelah checkout selesai, buka folder
data-cloud-demodan ekstrak file ZIP untuk mengakses aset codelab.
3. Menyiapkan Lakehouse untuk data pelanggan Froyo
Di bagian ini, Anda akan membuat katalog di Lakehouse untuk menggunakan metastore Lakehouse bagi alur kerja Anda. BigLake menciptakan interoperabilitas antara mesin kueri Anda dengan menawarkan satu sumber tepercaya untuk semua data Iceberg Anda. Hal ini memungkinkan mesin kueri, seperti Apache Spark, menemukan, membaca metadata, dan mengelola tabel Iceberg secara konsisten.
Peran yang diperlukan
Pastikan Anda memiliki peran Identity and Access Management (IAM) berikut:
roles/biglake.viewerroles/bigquery.userroles/bigquery.dataEditorroles/biglake.editorroles/biglake.metadataViewerroles/bigquery.connectionUserroles/storage.objectUserroles/storage.objectViewerroles/storage.objectCreatorroles/storage.admin
Untuk mengetahui informasi selengkapnya tentang cara memberikan peran IAM, lihat Memberikan peran IAM.
Membuat katalog Lakehouse dengan bucket
Buat katalog Lakehouse untuk mengelola metadata tabel Iceberg Anda. Anda terhubung ke katalog ini di tugas Spark untuk membuat dan mengkueri tabel Iceberg.
- Di konsol Google Cloud, buka Lakehouse.
- Klik Buat katalog. Halaman Buat katalog akan terbuka.
- Untuk Catalog type, pilih Iceberg Rest catalog.
- Untuk Select your Lakehouse catalog bucket options, pilih Single bucket catalog.
- Untuk Default catalog bucket Cloud Storage, klik Browse, lalu klik Create new bucket.
- Di halaman Buat bucket, lakukan hal berikut:
- Di bagian Mulai, masukkan nama unik global yang memenuhi persyaratan nama bucket.
- Di bagian Pilih tempat untuk menyimpan data Anda, pilih Region untuk Location type, lalu masukkan region Anda. Contoh,
us-west1. - Di bagian Choose how to control access to objects, hapus centang pada kotak Enforce public access prevention on this bucket.
Dengan cara ini, Anda dapat menyimulasikan skenario dunia nyata seperti menghosting konten web publik atau repositori data yang dibagikan. Tanpa perubahan ini, bucket akan menerapkan kebijakan "khusus pribadi" yang ketat; setiap upaya untuk mengakses aset Anda akan menghasilkan error403terlarang, meskipun Anda berhasil memberikan izin publik ke file. - Klik Lanjutkan > Buat > Pilih > Lanjutkan.
- Untuk Authentication method, pilih Credential vending mode.
- Klik Buat.Katalog Anda akan dibuat dan halaman Detail katalog akan terbuka.
- Di bagian Metode autentikasi, klik Setel izin bucket.
- Di dialog, klik Konfirmasi.Tindakan ini akan memverifikasi bahwa akun layanan katalog Anda memiliki peran
Storage Object Userdi bucket penyimpanan Anda. - Dari halaman Detail katalog, salin jalur URI katalog REST. Gunakan jalur ini selama tugas Menjalankan tugas Spark.
Upload file Parquet ke bucket
Untuk mengupload file Parquet ke root bucket Anda, lakukan hal berikut:
- Di konsol Google Cloud, buka halaman Bucket Cloud Storage.
- Dalam daftar bucket, klik nama bucket. Misalnya,
acai_demo. - Di tab Objects untuk bucket, klik Upload > Upload files.
- Pilih file dari folder Parquet yang Anda clone di bagian Sebelum memulai codelab ini.
- Klik Buka.
4. Menyiapkan jaringan VPC
Buat jaringan Virtual Private Cloud (VPC) dan subnet yang memungkinkan resource berkomunikasi dengan Google API tanpa terhubung ke internet publik, serta firewall yang memungkinkan traffic internal mengalir bebas di antara node pemrosesan data Anda.
- Di konsol Google Cloud, buka halaman jaringan VPC.
- Klik Create VPC network.
- Masukkan Name untuk jaringan. Misalnya,
acai-network. - Untuk mengonfigurasi unit transmisi maksimum (MTU) jaringan, centang kotak Setel MTU secara otomatis.
- Pilih Automatic untuk Subnet creation mode.
- Di bagian Firewall rules, centang semua kotak untuk IPv4 firewall rules
- Klik Buat.
Mengaktifkan Akses Google Pribadi
Node Dataproc Serverless tidak memiliki alamat IP publik. Untuk berkomunikasi dengan Katalog Lakehouse dan Cloud Storage, subnet harus mengaktifkan Akses Google Pribadi.
- Di konsol Google Cloud, buka halaman jaringan VPC.
- Klik nama jaringan yang berisi subnet tempat Anda perlu mengaktifkan Akses Google Pribadi. Misalnya,
us-west1. - Klik nama subnet. Halaman detail Subnet akan ditampilkan.
- Klik Edit.
- Di bagian Akses Google Pribadi, pilih Aktif.
- Klik Simpan.
5. Membuat dan menjalankan tugas Spark
Untuk membuat dan membuat kueri tabel Iceberg, upload tugas PySpark dengan pernyataan Spark SQL yang diperlukan. Kemudian, jalankan tugas dengan Managed Service untuk Spark.
Upload quickstart.py ke bucket Cloud Storage Anda
Setelah meng-clone aset codelab, perbarui skrip quickstart.py dengan detail project Anda dan upload ke bucket Cloud Storage.
- Buka skrip
quickstart.pydi editor teks. - Ganti placeholder
BUCKET_NAMEdalam skrip dengan nama bucket Cloud Storage Anda dan simpan. - Di konsol Google Cloud, buka bucket Cloud Storage.
- Klik nama bucket Anda. Misalnya,
acai_demo. - Di tab Objects, klik Upload > Upload files.
- Di file browser, pilih file
quickstart.pyyang telah diupdate, lalu klik Open.
Jalankan tugas Spark
Setelah mengupload skrip quickstart.py, eksekusi sebagai tugas batch Managed Service for Spark.
- Untuk mengonfigurasi variabel, jalankan perintah berikut di Cloud Shell.
# Configuration Variables export PROJECT_ID="<PROJECT_ID>" export REGION="<REGION>" export BUCKET_NAME="<BUCKET_NAME>" export SUBNET="<SUBNET>" export LAKEHOUSE_CATALOG_ID="<LAKEHOUSE_CATALOG_ID>" export CATALOG_URI_ID="<CATALOG_URI_ID>"- LAKEHOUSE_CATALOG_ID: nama resource katalog Lakehouse yang berisi file aplikasi PySpark Anda. Misalnya,
acai_demo - PROJECT_ID: project ID Google Cloud Anda.
- REGION: region tempat menjalankan workload batch Managed Service for Spark. Misalnya,
us-west1. - BUCKET_NAME: nama bucket Cloud Storage Anda. Misalnya,
acai_demo. - SUBNET: nama subnet VPC Anda. Misalnya,
acai-network. - CATALOG_URI_ID: ID URI katalog Lakehouse yang Anda salin saat membuat katalog Lakehouse dengan bucket. Misalnya,
https://biglake.googleapis.com/iceberg/v1/restcatalog.
- LAKEHOUSE_CATALOG_ID: nama resource katalog Lakehouse yang berisi file aplikasi PySpark Anda. Misalnya,
- Di Cloud Shell, jalankan tugas batch Managed Service for Spark berikut menggunakan skrip
quickstart.py.gcloud dataproc batches submit pyspark gs://${BUCKET_NAME}/quickstart.py \ --project=${PROJECT_ID} \ --region=${REGION} \ --subnet=${SUBNET} \ --version=2.2 \ --properties="\ spark.sql.defaultCatalog=${LAKEHOUSE_CATALOG_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}=org.apache.iceberg.spark.SparkCatalog,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.type=rest,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.uri=${CATALOG_URI_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.warehouse=gs://${BUCKET_NAME},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.io-impl=org.apache.iceberg.gcp.gcs.GCSFileIO,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.x-goog-user-project=${PROJECT_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\ spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest-metrics-reporting-enabled=false,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.X-Iceberg-Access-Delegation=vended-credentials,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token"All tables registered successfully! Batch [126fa2226a904d2e944c8eecbe0b1840] finished. metadata: '@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata batch: projects/PROJECT_ID/locations/REGION/batches/126fa2226a904d2e944c8eecbe0b1840 batchUuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff createTime: '2026-04-09T13:17:26.222727Z' description: Batch labels: goog-dataproc-batch-id: 126fa2226a904d2e944c8eecbe0b1840 goog-dataproc-batch-uuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-drz-resource-uuid: batch-3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-location: REGION operationType: BATCH name: projects/PROJECT_ID/regions/REGION/operations/47bc59e8-5082-3af9-89a0-22289aa5f4b9
6. Menjalankan kueri pada tabel dari BigQuery
Dengan berhasil menjalankan tugas batch Spark, Anda telah menggunakan Managed Service for Spark Serverless sebagai mesin komputasi terdistribusi untuk mendaftarkan beberapa tabel, satu per file Parquet dalam Lakehouse Metastore. Pendaftaran ini memungkinkan Google Cloud memperlakukan file mentah Anda di Cloud Storage sebagai tabel berperforma tinggi yang terstruktur.
Langkah-langkah berikut akan memandu Anda mengonfirmasi bahwa metadata telah disinkronkan dengan benar, sehingga memastikan bahwa data Anda tidak hanya disimpan dengan aman, tetapi juga dapat ditemukan dan dikueri sepenuhnya melalui antarmuka BigQuery.
- Di konsol Google Cloud, buka BigQuery.
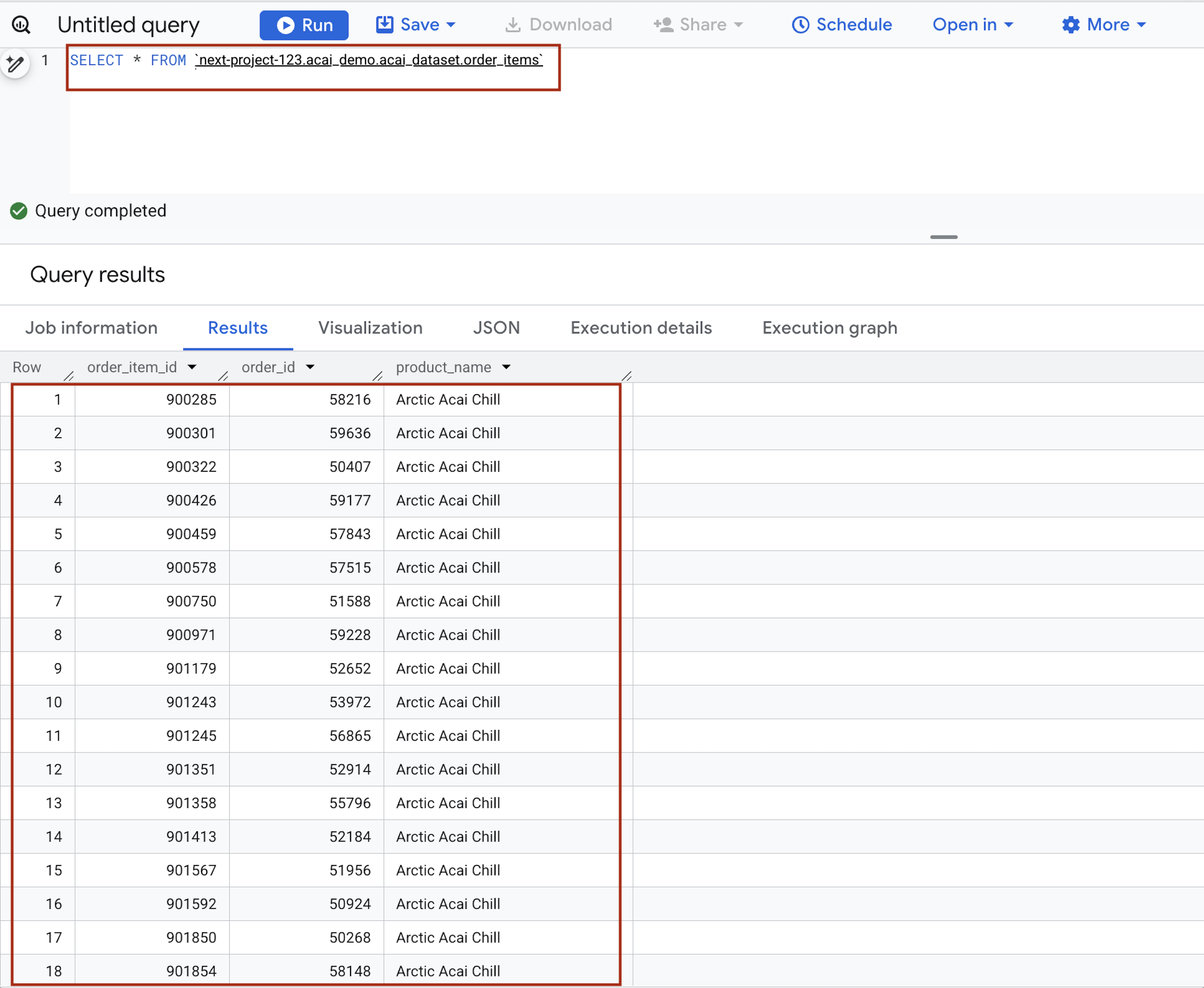
- Di editor kueri, masukkan pernyataan berikut. Kueri menggunakan sintaksis
project.namespace.dataset.table.SELECT * FROM `<PROJECT_ID>.<NAMESPACE>.<ICEBERG_DATASET>.<ICEBERG_TABLE>`PROJECT_ID.acai_demo.acai_dataset.order_items.
Ganti kode berikut:- PROJECT_ID: project ID Google Cloud Anda.
- NAMESPACE: namespace yang dibuat pada langkah sebelumnya sebagai hasil dari tugas Spark, yang dapat Anda temukan di halaman penjelajah objek BigQuery. Misalnya,
acai_demo. - ICEBERG_DATASET: nama set data dalam katalog Iceberg, misalnya,
acai_dataset. - ICEBERG_TABLE: nama tabel dalam set data Iceberg, misalnya,
order_items.
- Klik Run. Hasil kueri menampilkan data yang Anda masukkan dengan tugas Spark.
7. Menyiapkan file data produk tidak terstruktur
Di bagian ini, Anda akan membuat struktur organisasi dalam BigQuery untuk menyimpan data resep dan pemasok Froyo, khususnya untuk detail produk Froyo. Tindakan ini juga membuat Koneksi Resource Cloud, yang berfungsi sebagai "jembatan" aman yang memungkinkan BigQuery membaca file dari sumber eksternal seperti Cloud Storage.
Buat bucket dan upload file detail Froyo
Buat dan upload file pemasok dan resep ke bucket Cloud Storage.
- Di konsol Google Cloud, buka halaman Bucket Cloud Storage.
- Klik Buat.
- Di halaman Buat bucket, masukkan informasi bucket Anda. Setelah setiap langkah berikut, klik Lanjutkan untuk melanjutkan ke langkah berikutnya:
- Di bagian Mulai, masukkan nama bucket. Misalnya,
acai_pdfs. - Di bagian Pilih tempat untuk menyimpan data Anda, pilih Region, lalu masukkan region Anda. Misalnya,
us-west1. - Di bagian Choose how to control access to objects, hapus centang pada kotak Enforce public access prevention on this bucket.
- Klik Buat.
- Pada daftar bucket, klik bucket yang Anda buat. Misalnya,
acai_pdfs. - Di tab Objects untuk bucket, klik Upload > Upload folders.
- Pilih folder
recipesyang Anda ekstrak di bagian Sebelum memulai codelab ini. - Klik Upload.
- Ulangi proses upload untuk folder
suppliers.
Membuat koneksi
Buat Koneksi Resource Cloud. Tindakan ini akan menghasilkan Akun Layanan unik yang bertindak sebagai "kartu identitas" BigQuery untuk mengakses file eksternal.
- Buka halaman BigQuery.
- Di panel kiri, klik Explorer. Jika Anda tidak melihat panel kiri, klik Luaskan panel kiri untuk membuka panel.
- Di panel Explorer, luaskan nama project Anda, lalu klik Connections.
- Di halaman Koneksi, klik Buat koneksi.
- Untuk jenis Connection, pilih Vertex AI remote models, fungsi jarak jauh, BigLake dan Spanner (Cloud Resource).
- Di kolom Connection ID, masukkan nama ID koneksi. Misalnya,
acai_pdf_connection. Pastikan untuk mencatat ID ini karena Anda akan memerlukannya saat menyiapkan pemindaian data nanti dalam codelab ini. - Tetapkan Location type ke Region, lalu pilih region. Misalnya,
us-west1. Koneksi harus ditempatkan bersama resource Anda yang lain seperti set data. - Klik Create connection.
- Klik Go to connection.
- Di panel Connection info, salin ID akun layanan untuk digunakan pada langkah berikutnya. Akun layanan akan terlihat seperti
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com.
Mengelola akses ke akun layanan
Beri akses ke akun layanan agar Lakehouse dapat membaca PDF Anda.
- Buka halaman IAM & Admin.
- Klik Grant access. Dialog Tambahkan akun utama akan terbuka.
- Di kolom New principals, masukkan ID akun layanan yang Anda salin sebelumnya.
- Di kolom Pilih peran, tambahkan peran berikut:
roles/storage.objectUserroles/storage.objectViewerroles/bigquery.userroles/bigquery.dataEditorroles/aiplatform.userroles/storage.adminroles/dataproc.serviceAgent
- Klik Simpan.
Untuk mengetahui informasi selengkapnya tentang peran IAM di BigQuery, lihat Peran dan izin bawaan.
8. Mengelola izin untuk tugas DataScan
Buat akun layanan (identitas) khusus untuk Spark dan Dataform, lalu berikan izin yang tepat kepada akun layanan tersebut—bersama dengan agen layanan otomatis Google—yang diperlukan untuk membaca penyimpanan, menjalankan tugas BigQuery, dan menggunakan Vertex AI untuk penemuan.
Akses IAM untuk Spark dan Dataform
- Di konsol Google Cloud, buka halaman Create service account.
- Jika belum dipilih, pilih project Google Cloud Anda.
- Klik Create service account.
- Masukkan nama akun layanan. Misalnya,
sa-spark-stg1. Konsol Google Cloud membuat ID akun layanan berdasarkan nama ini. Edit ID jika diperlukan. Anda tidak dapat mengubah ID nanti. - Untuk menetapkan kontrol akses, klik Buat dan lanjutkan, lalu lanjutkan ke langkah berikutnya.
- Pilih peran IAM berikut untuk diberikan ke akun layanan pada project.
roles/dataproc.workerroles/storage.objectUserroles/bigquery.dataEditorroles/bigquery.jobUserroles/aiplatform.userroles/dataplex.discoveryPublishingServiceAgent
- Setelah selesai menambahkan peran, klik Lanjutkan.
- Klik Selesai untuk menyelesaikan pembuatan akun layanan.
Izin koneksi BigQuery untuk mengakses Knowledge Catalog
- Di konsol Google Cloud, buka halaman Bucket Cloud Storage.
- Dalam daftar bucket, klik nama bucket yang Anda buat untuk Froyo. Misalnya,
acai_pdfs. - Di tab Permissions, klik Grant access. Dialog Tambahkan akun utama akan muncul.
- Di kolom New principals, masukkan ID akun Layanan BigQuery Anda. Akun layanan akan terlihat seperti
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com. - Pilih satu (atau beberapa) peran berikut dari menu drop-down Select a role.
roles/storage.objectUserroles/dataplex.serviceAgentroles/dataplex.securityAdminroles/aiplatform.serviceAgentroles/dataplex.discoveryPublishingServiceAgent
- Klik Simpan.
9. Menyiapkan Knowledge Catalog
Buat Knowledge Catalog untuk menyatukan data terkait Froyo dan mengotomatiskan penemuan file tidak terstruktur (seperti resep PDF dan pemasok PDF).
Membuat DataScan melalui curl
Di bagian ini, Anda akan membuat pemindaian untuk bucket Cloud Storage (misalnya, acai_pdfs) dengan menambahkan datascan_ID dan mengarahkannya ke set data BigQuery Anda. Setelah itu, Knowledge Catalog akan otomatis membuat entri untuk PDF Anda di BigQuery.
- Untuk memindai PDF (pemasok dan resep), jalankan perintah berikut:
# 1. Set your variables PROJECT_ID="<PROJECT_ID>" REGION="<REGION>" ENV_SUFFIX="stg1" DATASCAN_ID="froyo-profile-${ENV_SUFFIX}" BUCKET_NAME="<BUCKET_NAME>" # 2. Set this to the Name of the connection you created in Step 7 CONNECTION_ID="<CONNECTION_ID_NAME>" # 3. Define the API Endpoint DATAPLEX_API="dataplex.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}" # 4. Create the DataScan via CURL echo "Creating Dataplex DataScan: ${DATASCAN_ID}..." curl -X POST "https://$DATAPLEX_API/dataScans?dataScanId=${DATASCAN_ID}" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d '{ "data": { "resource": "//storage.googleapis.com/projects/'"${PROJECT_ID}"'/buckets/'"${BUCKET_NAME}"'" }, "executionSpec": { "trigger": { "on_demand": {} } }, "dataDiscoverySpec": { "bigqueryPublishingConfig": { "tableType": "BIGLAKE", "connection": "projects/'"${PROJECT_ID}"'/locations/'"${REGION}"'/connections/'"${CONNECTION_ID}"'" }, "storageConfig": { "unstructuredDataOptions": { "entity_inference_enabled": true } } } }' - Perintah
curlmenampilkan hasil Knowledge Catalog DataScan, seperti pada gambar berikut.
Menjalankan tugas
Jalankan perintah berikut:
gcloud dataplex datascans run $DATASCAN_ID --location=$REGION
Mendeskripsikan tugas
Untuk mendeskripsikan tugas, jalankan perintah berikut:
gcloud dataplex datascans describe $DATASCAN_ID --location=$REGION
Menghapus tugas pemindaian data
Jika pemindaian berjalan lebih dari 10 menit, atau jika status tugas tetap Tertunda untuk waktu yang lama tanpa beralih ke Berjalan, hal ini mungkin disebabkan oleh tidak tersedianya resource sementara di region. Jika hal ini terjadi, Anda dapat menjalankan perintah berikut untuk menghapus tugas, lalu mencoba membuat dan menjalankannya lagi. Terkadang, proses awal dapat gagal dengan cepat karena error seperti unable to acquire necessary resources.
gcloud dataplex datascans delete $DATASCAN_ID --location=$REGION
Melihat status tugas
Untuk memeriksa status tugas, lakukan hal berikut:
- Di konsol Google Cloud, buka halaman Kurasi metadata.
- Di tab Cloud Storage discovery, klik nama pemindaian penemuan.
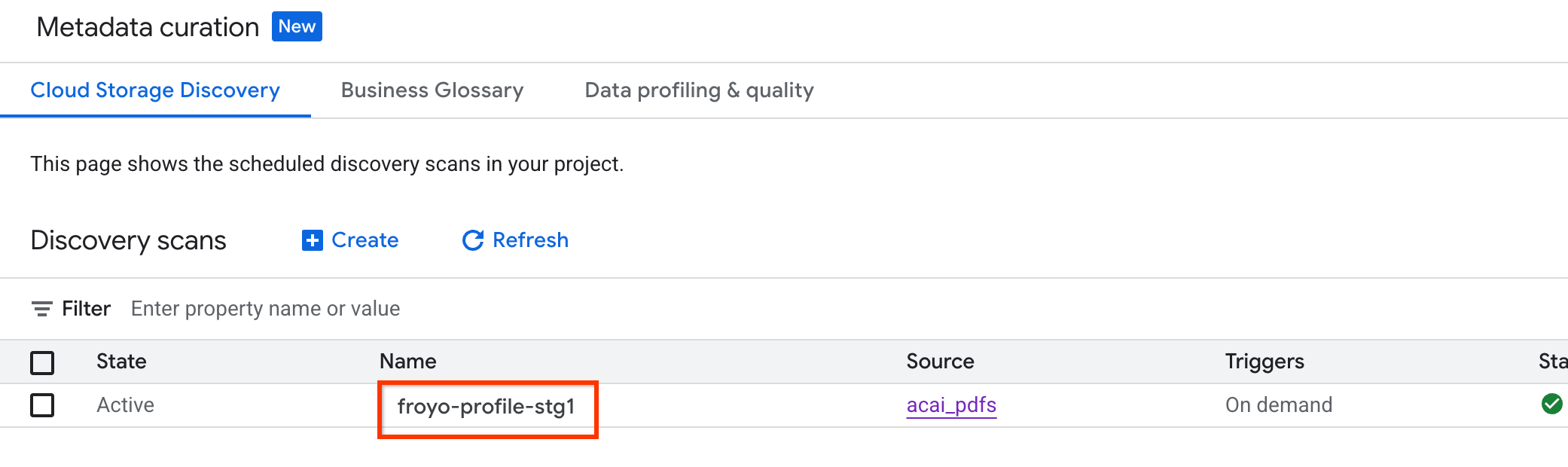
- Di halaman Detail pemindaian, Anda dapat melihat status tugas.
- Setelah tugas selesai, periksa apakah Set data yang dipublikasikan (misalnya,
acai_pdfs_discovered_003) yang Anda buat menggunakan perintahcurlada.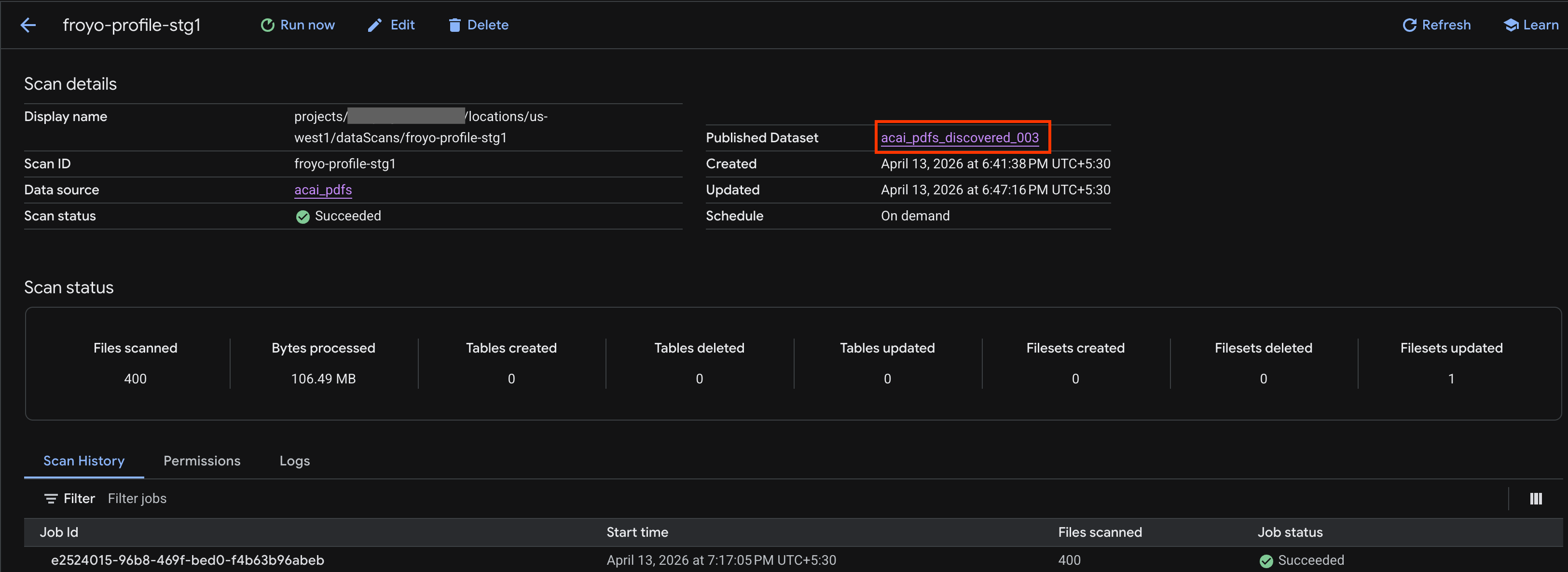
Melihat tabel objek
Untuk melihat tabel objek yang dibuat setelah tugas penemuan, lakukan hal berikut:
- Di konsol Google Cloud, buka BigQuery.
- Klik Set Data, lalu pilih set data yang dipublikasikan dan dibuat di langkah sebelumnya. Misalnya,
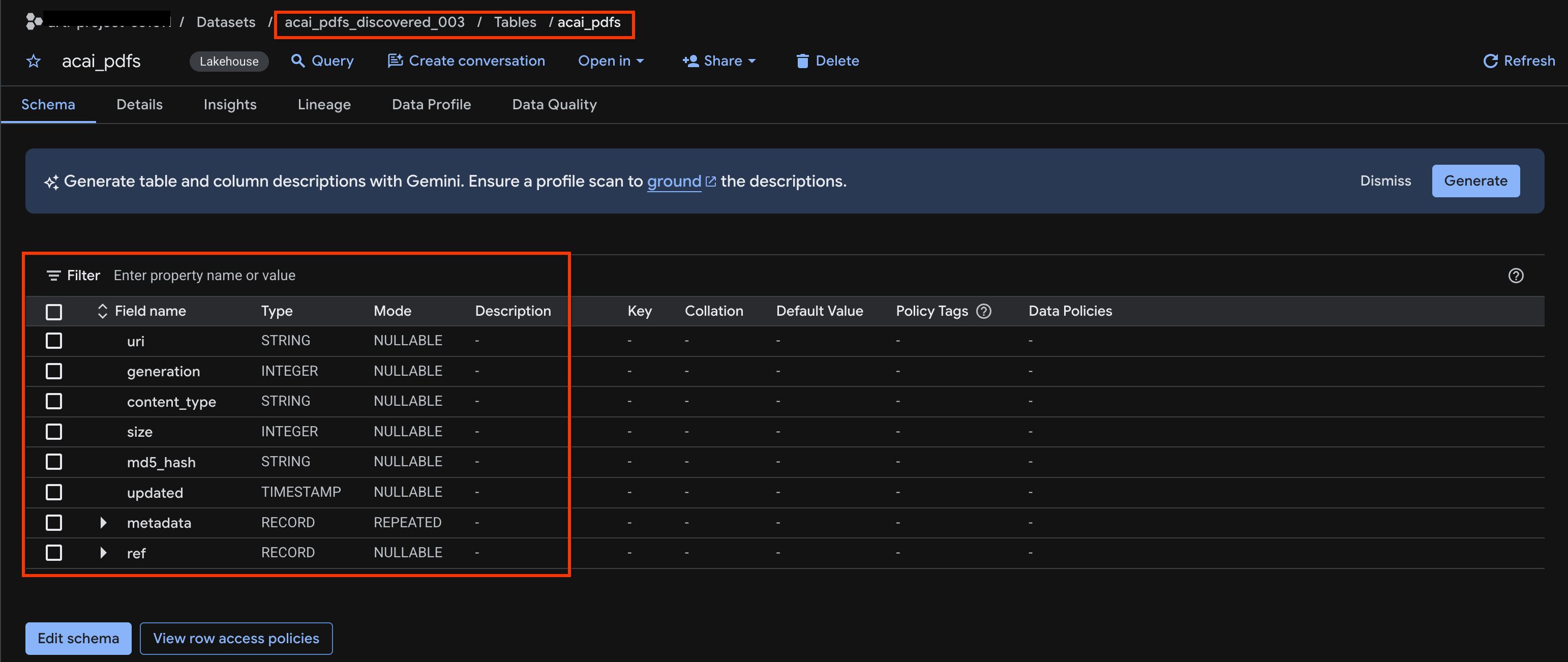
acai_pdfs_discovered_003. - Untuk melihat tabel objek, klik ID tabel. Misalnya,
acai_pdfs. - Tabel objek yang dihasilkan akan terlihat seperti gambar berikut:
10. Ekstraksi semantik
Anda akan menyimpulkan dan mengekstrak tabel terstruktur, objek database lain, dan hubungan untuk tabel objek tidak terstruktur yang Anda buat pada langkah sebelumnya. Untuk itu, Anda akan menggunakan fitur Insight Knowledge Catalog untuk membuat Pernyataan SQL guna mengekstrak data terstruktur dari tabel tidak terstruktur
- Di konsol Google Cloud, buka halaman Penelusuran Knowledge Catalog.
- Telusuri tabel set data yang ingin Anda lihat insight-nya. Misalnya,
acai_pdfs_discovered_003.
- Di hasil penelusuran, klik tabel untuk membuka halaman entri.
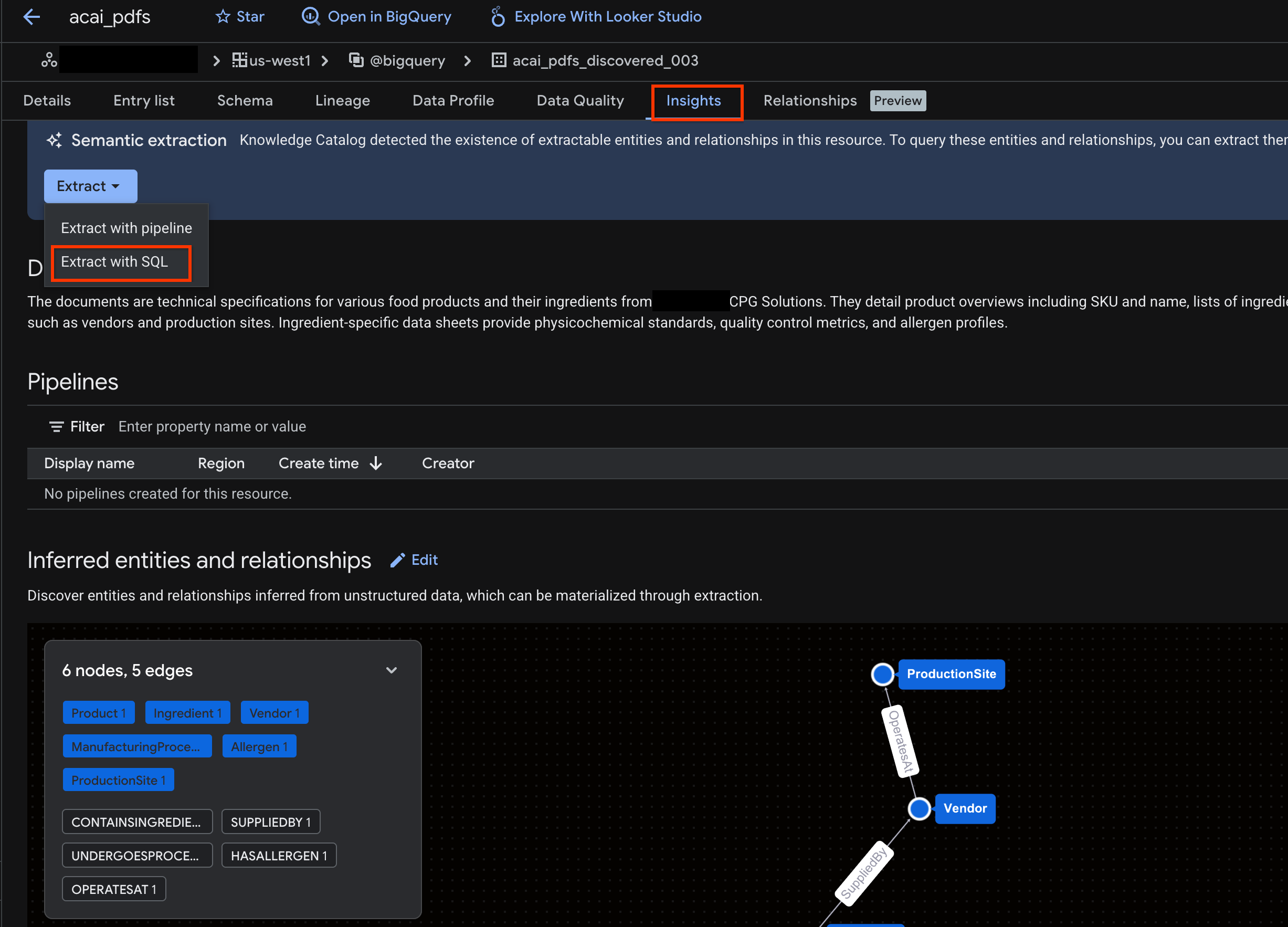
- Klik tab Insights. Jika tab kosong, berarti insight untuk tabel ini belum dibuat. Pembuatan insight mungkin memerlukan waktu 15 hingga 25 menit.
- Setelah Anda melihat insight, klik Ekstrak > Ekstrak dengan SQL.
- Di halaman Ekstrak dengan SQL, untuk Tujuan, masukkan set data Anda. Misalnya,
acai_pdfs_discovered_003. - Klik Ekstrak. Tindakan ini akan membuka Editor BigQuery dengan Kueri yang dimuat.
- Klik Run. Langkah ini menghasilkan serangkaian pernyataan dan mungkin memerlukan waktu beberapa menit untuk menyelesaikan prosesnya.
- Setelah kueri selesai, Anda akan melihat hasil berikut:
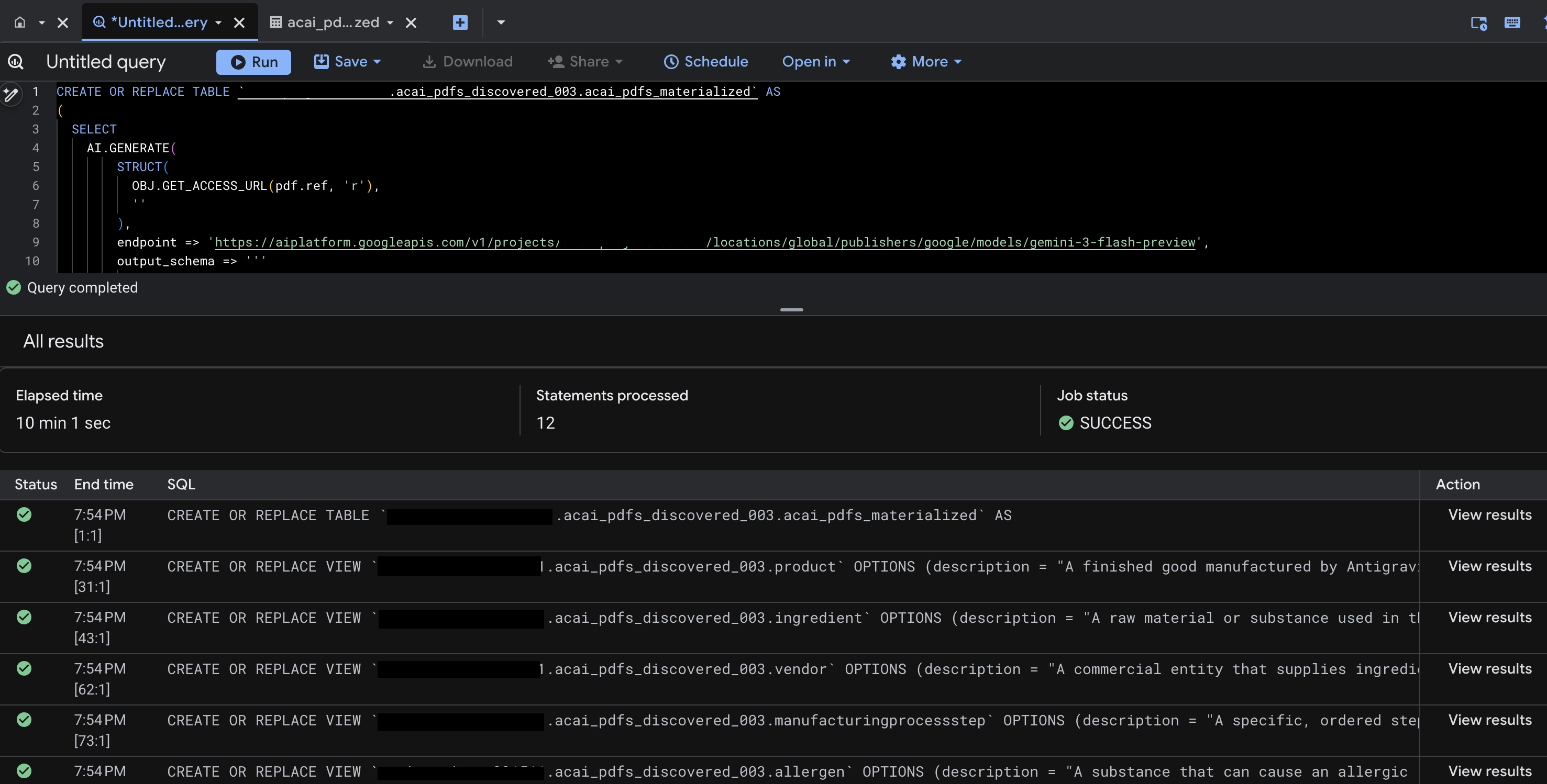
- Buka BigQuery, lalu klik Set Data (misalnya,
acai_pdfs_discovered_003). Serangkaian objek database terstruktur baru dibuat di set data yang Anda pilih pada langkah nomor 6.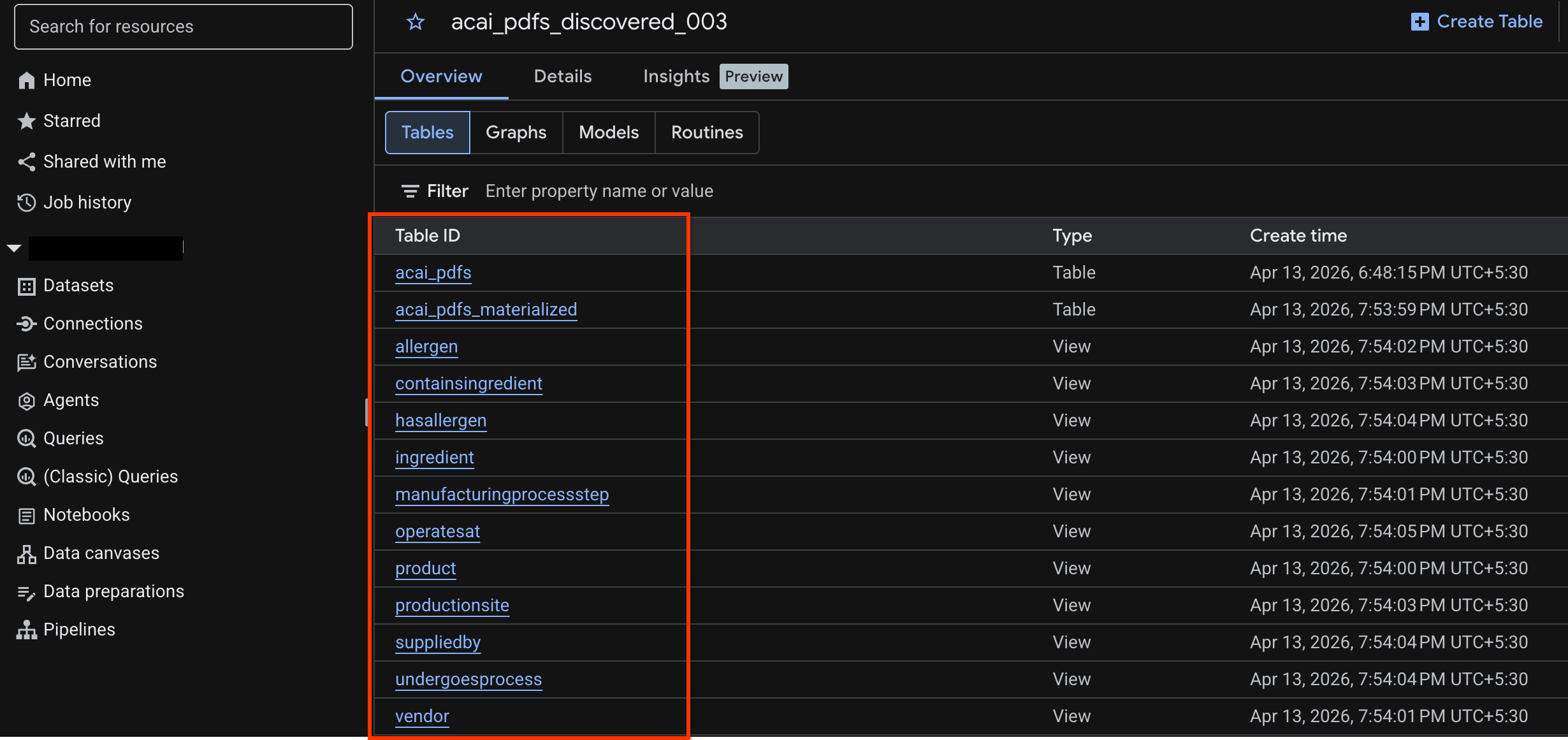
Menghasilkan insight untuk objek di BigQuery
Untuk membuat insight untuk set data BigQuery, Anda harus mengakses set data di BigQuery menggunakan BigQuery Studio.
- Di konsol Google Cloud, buka BigQuery Studio.
- Di panel Explorer, pilih project, lalu buka set data yang ingin Anda buat insight-nya.
- Klik tab Insights.
- Jika Anda melihat tombol Enable API, klik tombol tersebut untuk mengaktifkan Gemini for Google Cloud. Tindakan ini akan membuka jendela Aktifkan fitur inti.
- Di bagian Core feature APIs, klik Enable untuk Gemini for Google Cloud API dan BigQuery Unified API, lalu klik Next.
- Di bagian Permissions (optional), berikan peran IAM kepada principal jika diperlukan, lalu klik Next.
- Untuk membuat insight dan memublikasikannya ke Knowledge Catalog, klik Buat dan publikasikan.
- Setelah dipublikasikan, Anda dapat melihat insight di tab tersebut.
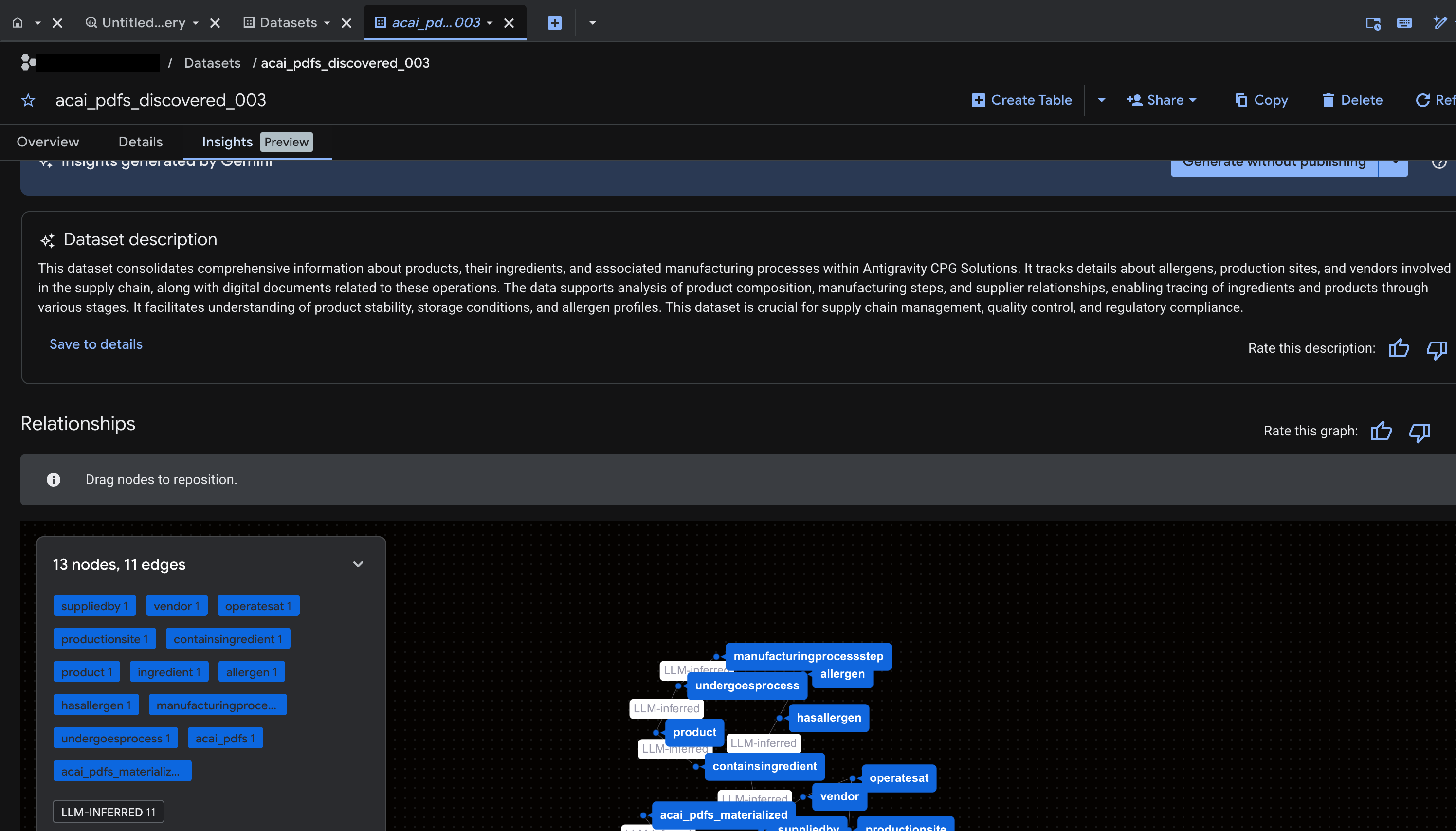
11. Menyiapkan IDE untuk analisis data agentic
Ekstensi Google Cloud Data Agent Kit untuk Visual Studio Code adalah ekstensi IDE untuk data scientist dan data engineer. Dengan fitur ini, Anda dapat terhubung ke dan menggunakan resource dan data Google Data Cloud langsung dari IDE. Untuk mengetahui informasi selengkapnya, lihat Ringkasan ekstensi Data Agent Kit untuk VS Code
Ekstensi Data Agent Kit untuk VS Code berguna saat Anda ingin melakukan hal berikut:
- Buat, uji, tinjau, dan deploy pipeline data yang siap produksi, seperti Spark ETL atau BigQuery ETL, langsung dari VS Code.
- Jelajahi data, bangun pipeline pelatihan, identifikasi model ML yang optimal, dan deploy ke endpoint produksi menggunakan bantuan AI.
- Hubungkan ke sumber data tepercaya, buat model data berperforma tinggi, dan publikasikan dasbor interaktif untuk pemangku kepentingan bisnis.
Menginstal ekstensi Data Agent Kit untuk VS Code
- Buka VS Code.
- Instal Google Cloud CLI. Untuk mengetahui informasi selengkapnya, lihat Menginstal Google Cloud CLI.
- Instal ekstensi Data Agent Kit untuk VS Code.
- Selesaikan proses aktivasi ekstensi, yang mengharuskan Anda untuk:
- Login ke ekstensi
- Menginstal keahlian, server MCP
- Muat ulang atau mulai ulang jendela setelah Anda selesai melakukan aktivasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan dan mengonfigurasi ekstensi Data Agent Kit untuk VS Code.
- Setelah IDE dimuat ulang, klik ikon Google Data Cloud di panel navigasi, buka setelan, dan pastikan Anda menyetel project ID dan region (
us-west1) dengan benar di setelan umum.
Menyiapkan ruang kerja di VS Code
- Buka VS Code, lalu pilih File > Open folder > New folder.
- Buat folder baru bernama
acai_test, lalu klik Open. VS Code kini menganggap folder yang Anda buka sebagai ruang kerja. - Pada dialog Kepercayaan ruang kerja, pilih Ya, saya memercayai penulis untuk mengaktifkan semua fitur di ruang kerja.
- Buat folder
.githubdi ruang kerjaacai_test. - Buat file baru
copilot-instructions.mddi folder.githubdan masukkan aturan berikut di dalamnya.## 1. Project Context - **Project ID**: <PROJECT_ID> - **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors. - **Documentation**: Raw PDF documents detailing flavors and ingredients are stored in Google Cloud Storage at `gs://<BUCKET_NAME>`. ## 2. Execution & Data Processing Rules - **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `<BQ_DATASET_NAME>` (referred to as the Knowledge Catalog). - **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the dataset `<DATASET_ID>`. When you are referencing a dataset, ensure you are using it with the project ID (`<PROJECT_ID>`) and namespace prefix `<NAMESPACE_NAME>`. For example, to query order table in this dataset you should use `<PROJECT_ID>.<NAMESPACE>.<DATASET_ID>.orders`. - **CRITICAL RULE - Data Joins between BigQuery dataset and Iceberg dataset**: ANY task requiring a join or integration between the BigQuery datasets `<DATASET_ID>` of the PDF data and the `<DATASET_ID>` of the customer data MUST be executed using **Spark Notebooks**. - **CRITICAL RULE - Notebook Kernel**: Every Spark notebook utilized MUST exclusively be configured to run on the Serverless Session template `iceberg-federation-template` as its kernel. - **CRITICAL RULE - Data Science**: ANY data science, machine learning, or advanced analytical task MUST be performed strictly within **Spark Notebooks** using the aforementioned setup. - Buat file baru lainnya
template.yamldi ruang kerjaacai_test, lalu masukkan informasi berikut dalam file.labels: client: "vscode" jupyterSession: displayName: "iceberg-federation-template" kernel: "PYTHON" environmentConfig: executionConfig: serviceAccount: "sa-spark-dev1@<PROJECT_ID>.iam.gserviceaccount.com" subnetworkUri: "projects/<PROJECT_ID>/regions/<REGION>/subnetworks/<SUBNET_NAME>" runtimeConfig: version: "2.3" properties: # This enables the secure proxy URL you were looking for dataproc.tier: "premium" spark.dataproc.engine: "lightningEngine" spark.dataproc.lightningEngine.runtime: "native" spark.memory.offHeap.enabled: "true" spark.memory.offHeap.size: "1g" spark.executor.memory: "4g" "dataproc.component.gateway.enabled": "true" "dataproc.jupyter.listen.all.interfaces": "true" "spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" "spark.sql.defaultCatalog": "<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>": "org.apache.iceberg.spark.SparkCatalog" "spark.sql.catalog.<CATALOG_NAME>.type": "rest" "spark.sql.catalog.<CATALOG_NAME>.uri": "<CATALOG_URI_ID>" "spark.sql.catalog.<CATALOG_NAME>.warehouse": "bl://projects/<PROJECT_ID>/catalogs/<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>.rest.auth.type": "org.apache.iceberg.gcp.auth.GoogleAuthManager" - Di VS Code, klik Terminal dan jalankan perintah berikut untuk mengimpor file
template.yamlsebagai template sesi. Template ini digunakan oleh agen nanti untuk membuat sesi Spark.gcloud beta dataproc session-templates import iceberg-federation-template \ --source=template.yaml \ --location=<REGION>REGIONdengan region Anda.
12. Melakukan analisis data dengan agen
- Di editor VS Code, klik Toggle chat.
- Untuk Konfigurasi agen kustom, pilih Agen.
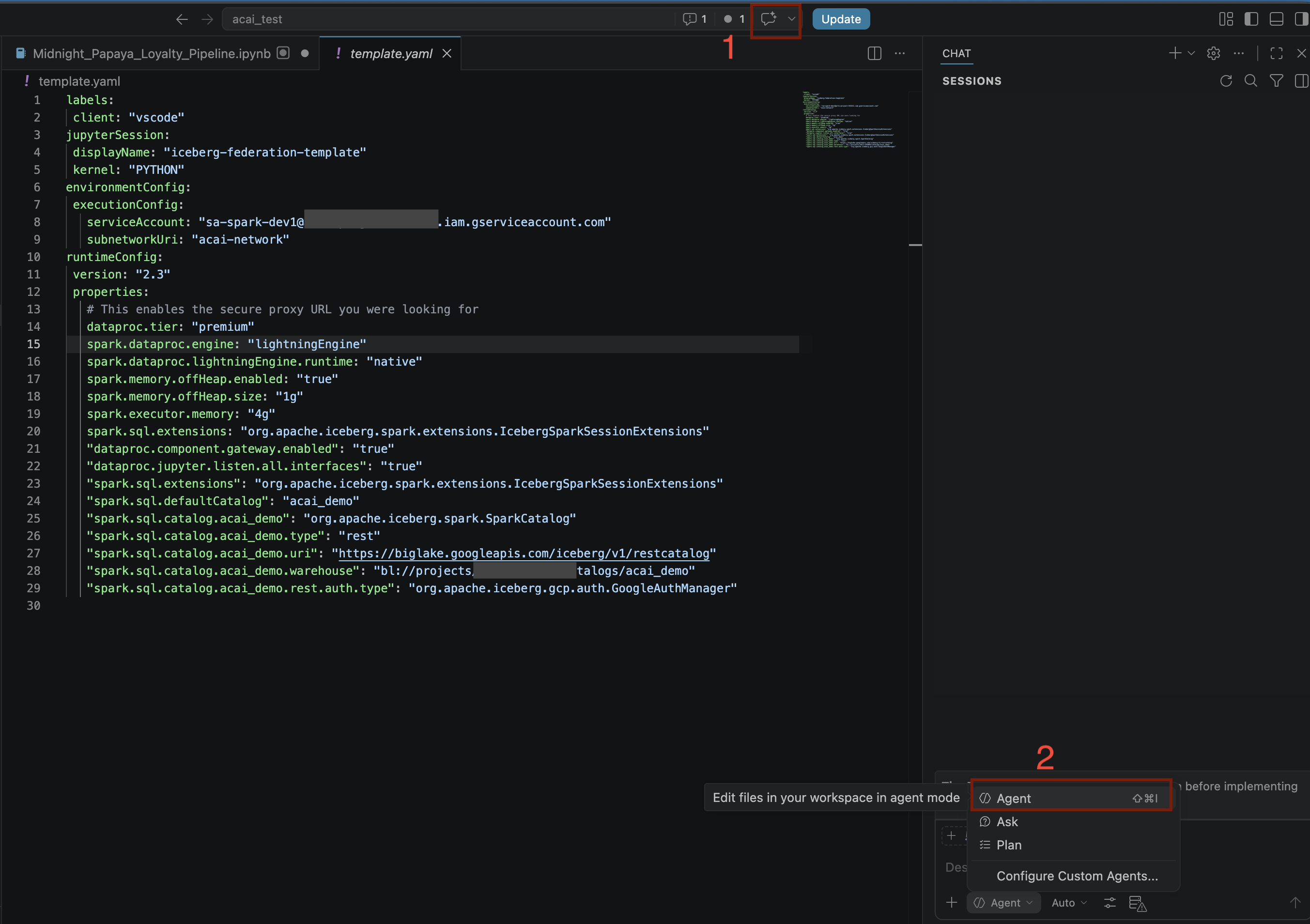
- Di panel Search models, klik Manage language models.
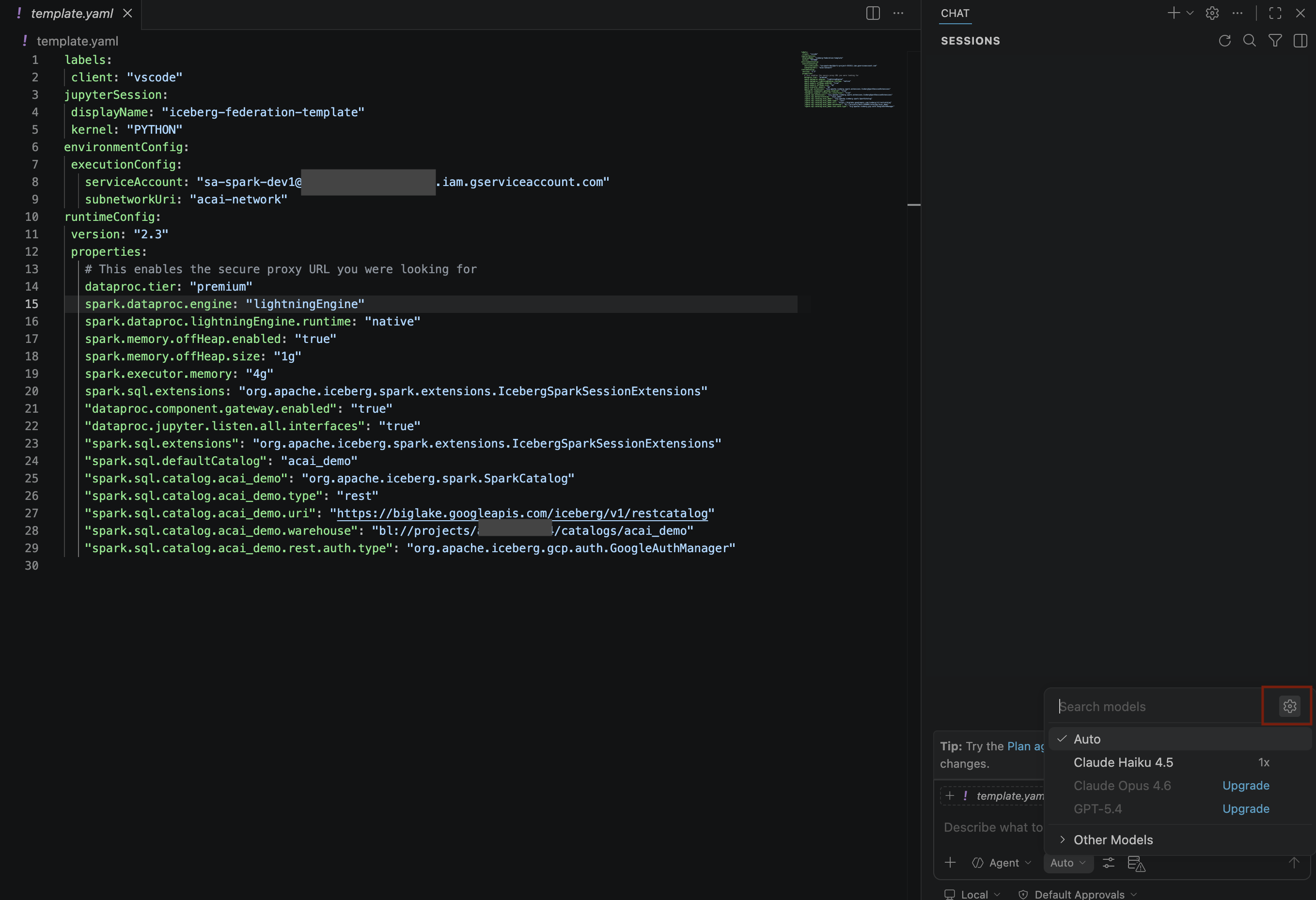
- Di halaman Language models, klik Add models.
- Pilih Google dari daftar, lalu tekan Enter untuk mengonfirmasi input Anda.
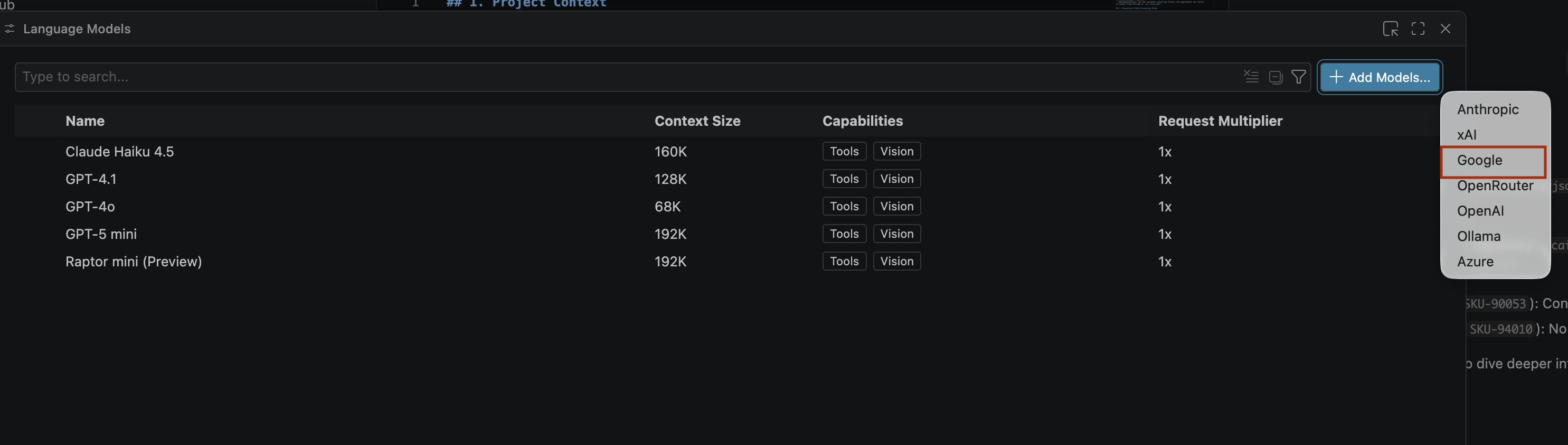
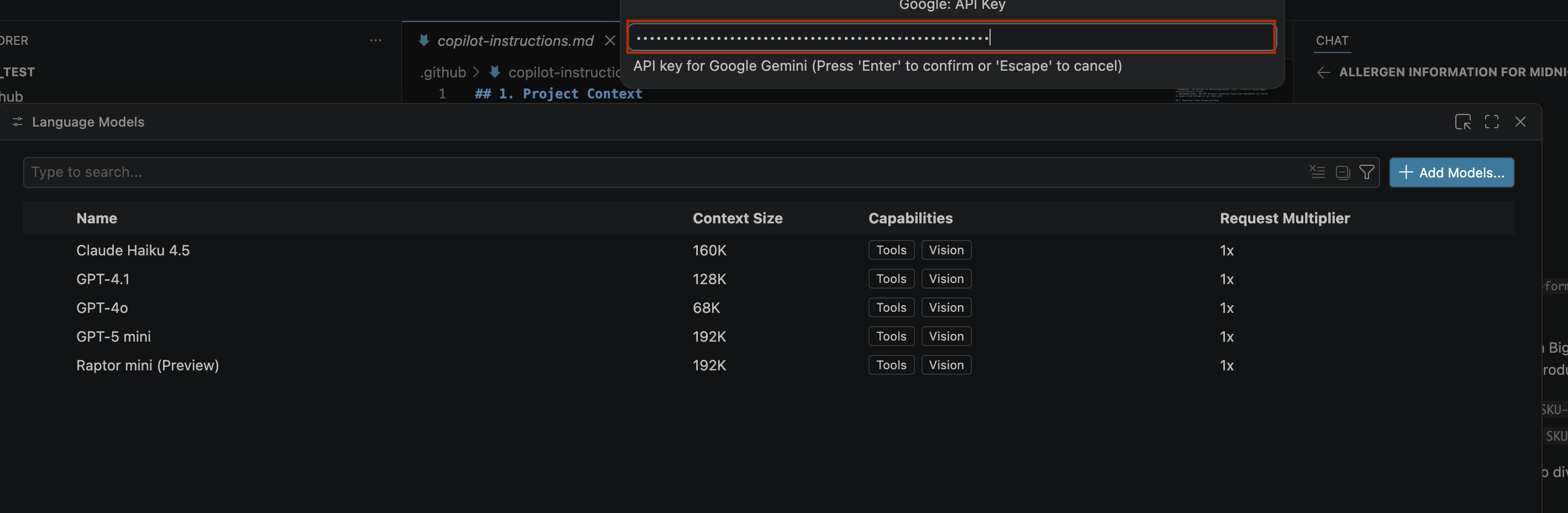
- Untuk memasukkan kunci API untuk Google Gemini, lakukan hal berikut:
- Buka situs Google AI Studio.
- Login dengan Akun Google Anda.
- Di sidebar, klik Dapatkan kunci API.
- Klik Buat kunci API. Halaman Buat kunci baru akan terbuka.
- Dari daftar Select a cloud project, pilih Import project.
- Masukkan nama project yang ada.
- Klik Create key, lalu salin kunci API. Kunci ini memberikan akses ke resource Gemini API akun Anda.Untuk mengetahui informasi selengkapnya, lihat Menggunakan kunci Gemini API.
- Tempelkan kunci API yang Anda buat di kotak penelusuran, lalu klik Enter.
- Jika model Gemini tidak muncul, tampilkan model tersebut seperti yang ditunjukkan pada gambar berikut:
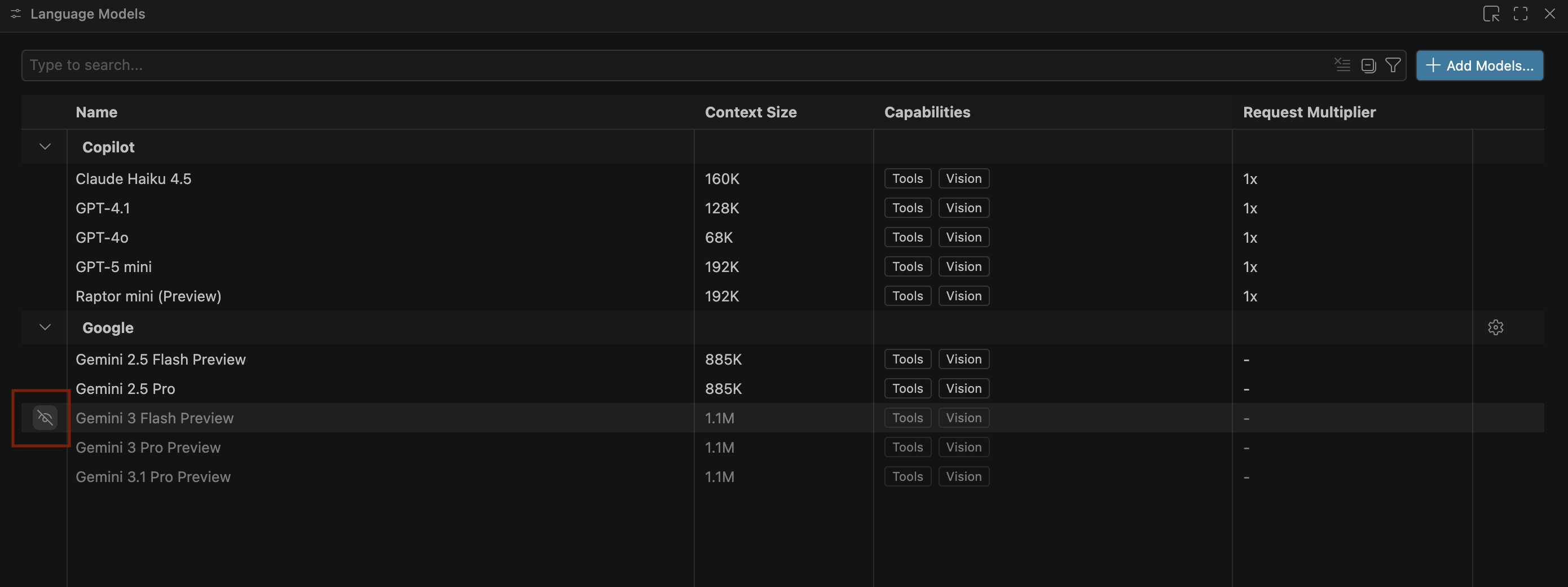
- Pilih Pratinjau Gemini 3.1 Pro dari daftar model Google Gemini, lalu tutup jendela Model bahasa.
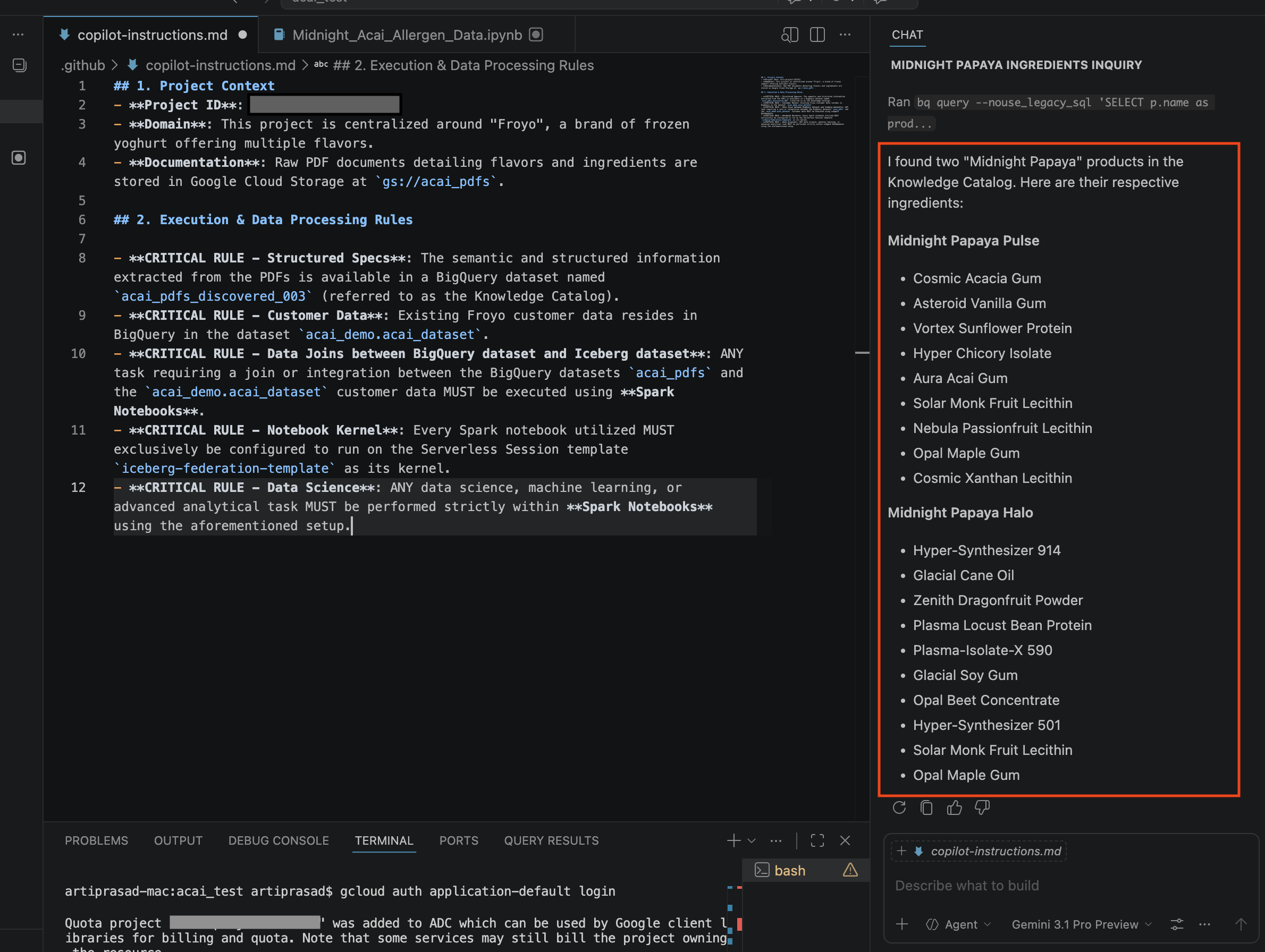
- Di jendela percakapan, masukkan pertanyaan berikut:
Search ingredients for Midnight papaya - Setelah beberapa interaksi, Anda akan melihat hasil berikut:
- Di jendela percakapan, masukkan pertanyaan lain:
Search allergen information for Midnight papaya - Setelah beberapa interaksi dan langkah, Anda akan melihat agen merespons dengan nama alergen
Soyseperti yang dapat Anda lihat pada gambar berikut: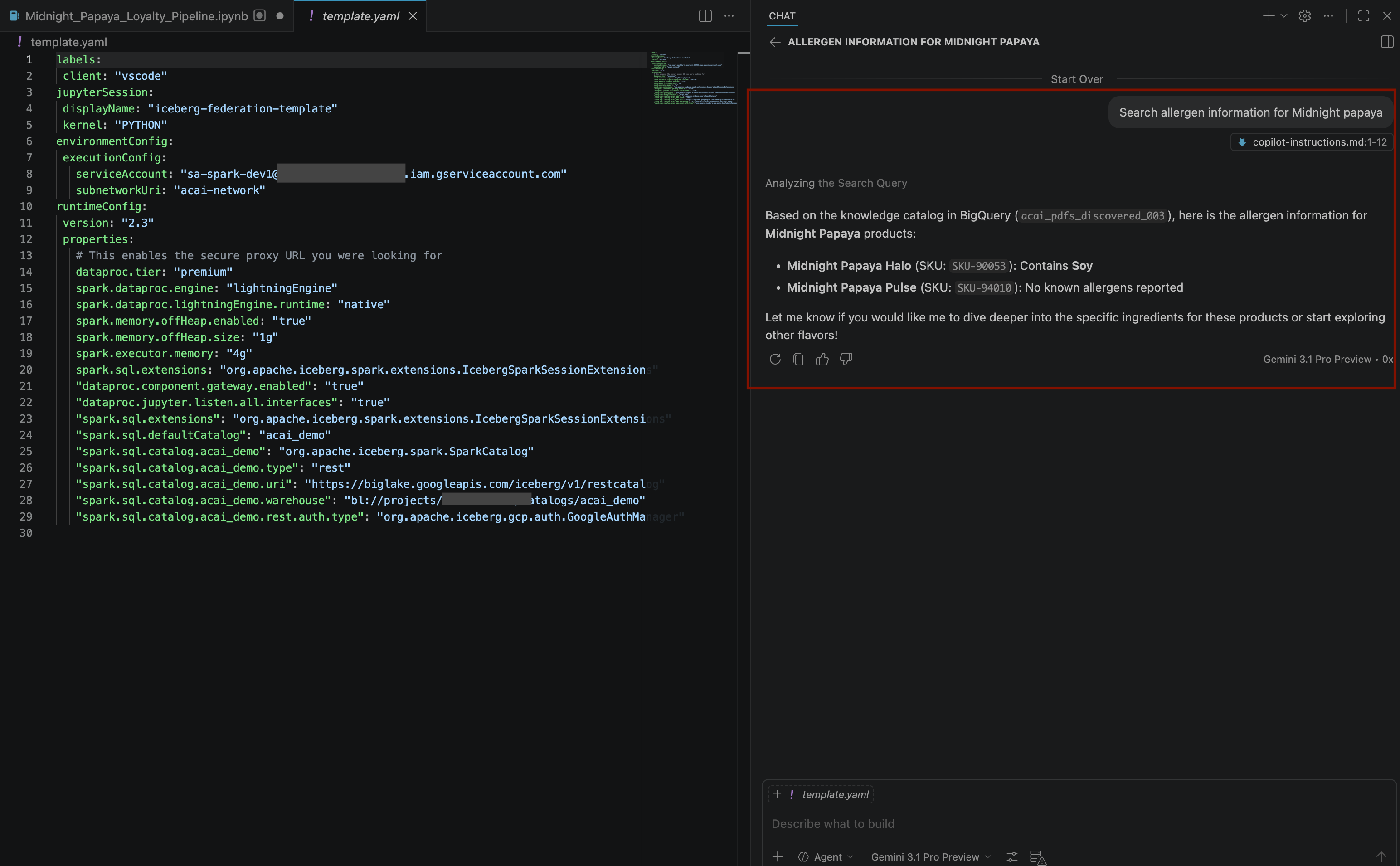
- Di jendela percakapan, masukkan pertanyaan lain:
Build a pipeline to join products with our 'Global Loyalty' Iceberg tables in acai customer, sales data to identify popular products - Untuk memilih kernel, buka file
.ipynb, lalu klik Select kernel > Remote spark kernels > Iceberg-federation-template on serverless spark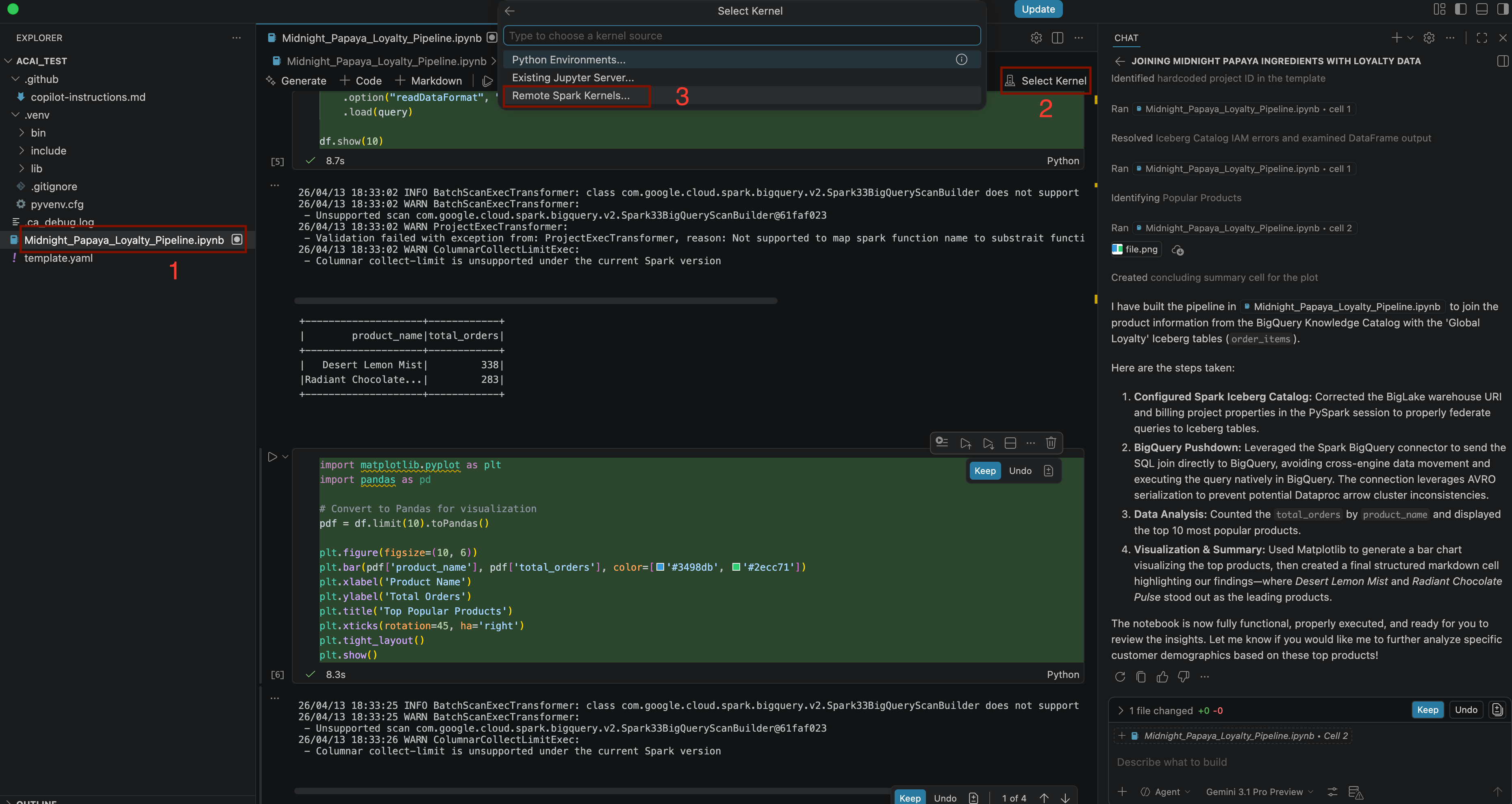
- Setelah beberapa interaksi dan langkah, Anda akan melihat agen merespons dengan semua langkah di notebook yang berhasil dieksekusi beserta hasil akhir yang dihasilkan di akhir notebook seperti yang dapat Anda lihat pada gambar berikut:
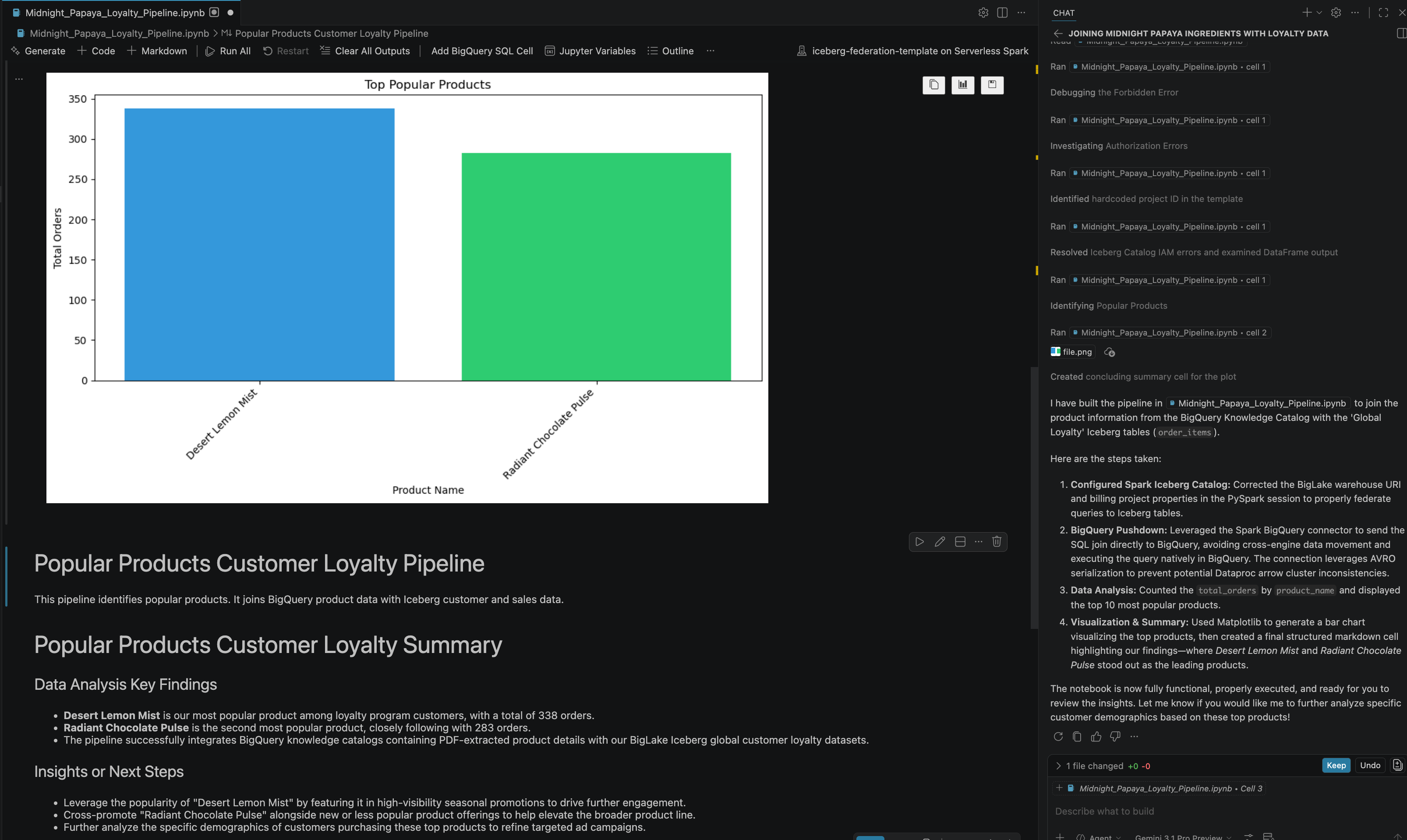
13. Pembersihan
Untuk menghindari biaya, hapus resource yang Anda buat di lab ini.
- Untuk menghapus Knowledge Catalog DataScan, jalankan perintah berikut:
DATASCAN_ID="<DATASCAN_ID>" echo "Deleting Dataplex DataScan: ${DATASCAN_ID}" gcloud dataplex datascans delete "${DATASCAN_ID}" --location="${REGION}" --quiet - Untuk menghapus bucket Cloud Storage dan semua isinya, jalankan perintah berikut:
echo "Deleting Cloud Storage buckets: <BUCKET_NAME1> and <BUCKET_NAME2>" gsutil -m rm -r gs://<BUCKET_NAME1> gsutil -m rm -r gs://<BUCKET_NAME2> - Untuk menghapus Koneksi BigQuery, jalankan perintah berikut:
CONNECTION_ID="<CONNECTION_NAME>" echo "Deleting BigQuery Connection: ${CONNECTION_ID}" bq rm --connection "${PROJECT_ID}.${REGION}.${CONNECTION_ID}" - Untuk menghapus Katalog Lakehouse, jalankan perintah berikut:
CATALOG_ID="<CATALOG_NAME>" echo "Deleting Lakehouse Catalog: ${CATALOG_ID}" gcloud biglake catalogs delete "${CATALOG_ID}" --project="${PROJECT_ID}" --location="${REGION}" --quiet - Untuk menghapus set data yang berisi tabel PDF yang ditemukan, jalankan perintah berikut:
DATASET_NAME="<DATASET_NAME>" echo "Deleting BigQuery Dataset: ${DATASET_NAME}" bq rm -r -f "${PROJECT_ID}:${DATASET_NAME}" - Untuk menghapus Akun Layanan Kustom, jalankan perintah berikut:
SERVICE_ACCOUNT="<SERVICE_ACCOUNT>" echo "Deleting Service Account: ${SERVICE_ACCOUNT}" gcloud iam service-accounts delete "${SERVICE_ACCOUNT}"@"${PROJECT_ID}".iam.gserviceaccount.com --quiet - Untuk menghapus Jaringan VPC, jalankan perintah berikut:
VPC_NETWORK="<VPC_NETWORK>" echo "Deleting VPC Network: ${VPC_NETWORK}" gcloud compute networks delete "${VPC_NETWORK}" --quiet - Untuk menghapus seluruh project Google Cloud, jalankan perintah berikut:
gcloud projects delete "${PROJECT_ID}"
14. Selamat
Selamat! Anda telah berhasil mengatur lanskap data file PDF dan Parquet yang terisolasi dalam tabel BigQuery dan menggabungkannya ke dalam satu ekosistem yang dapat ditelusuri dan digabungkan. Pada dasarnya, Anda telah membangun Lakehouse Data modern yang memperlakukan PDF dan format data besar dengan cerdas seperti halnya memperlakukan baris dalam database. Dan Anda melakukan semua ini langsung dari agen Anda dalam fitur percakapan AI dengan Gemini.
Dokumen referensi
Untuk mempelajari lebih lanjut teknologi inti yang digunakan dalam codelab ini, buka dokumentasi resmi Google Cloud:
- Untuk menjelajahi BigQuery, komponen inti Data Cloud, lihat Dokumentasi BigQuery.
- Untuk mempelajari IAM lebih lanjut, lihat Dokumentasi IAM.
- Untuk mempelajari Lakehouse, lihat Apa itu Lakehouse?