
1. Introduzione
In questo codelab, assumerai il ruolo di data scientist per una società fittizia di yogurt ghiacciato che lancia un nuovo gusto, "Midnight Swirl". Per garantire un lancio globale di successo, l'azienda deve rispondere a domande fondamentali su ingredienti, domanda di mercato e ritorno sull'investimento (ROI). Questo flusso di lavoro end-to-end mostra come il Knowledge Catalog di Google Cloud (precedentemente noto come Dataplex) e Lakehouse per Apache Iceberg (precedentemente noto come BigLake) colmano il divario tra i dati non strutturati "dark" e forniscono business intelligence azionabile utilizzando Gemini nel tuo IDE (VS Code) tramite un livello di governance unificato.
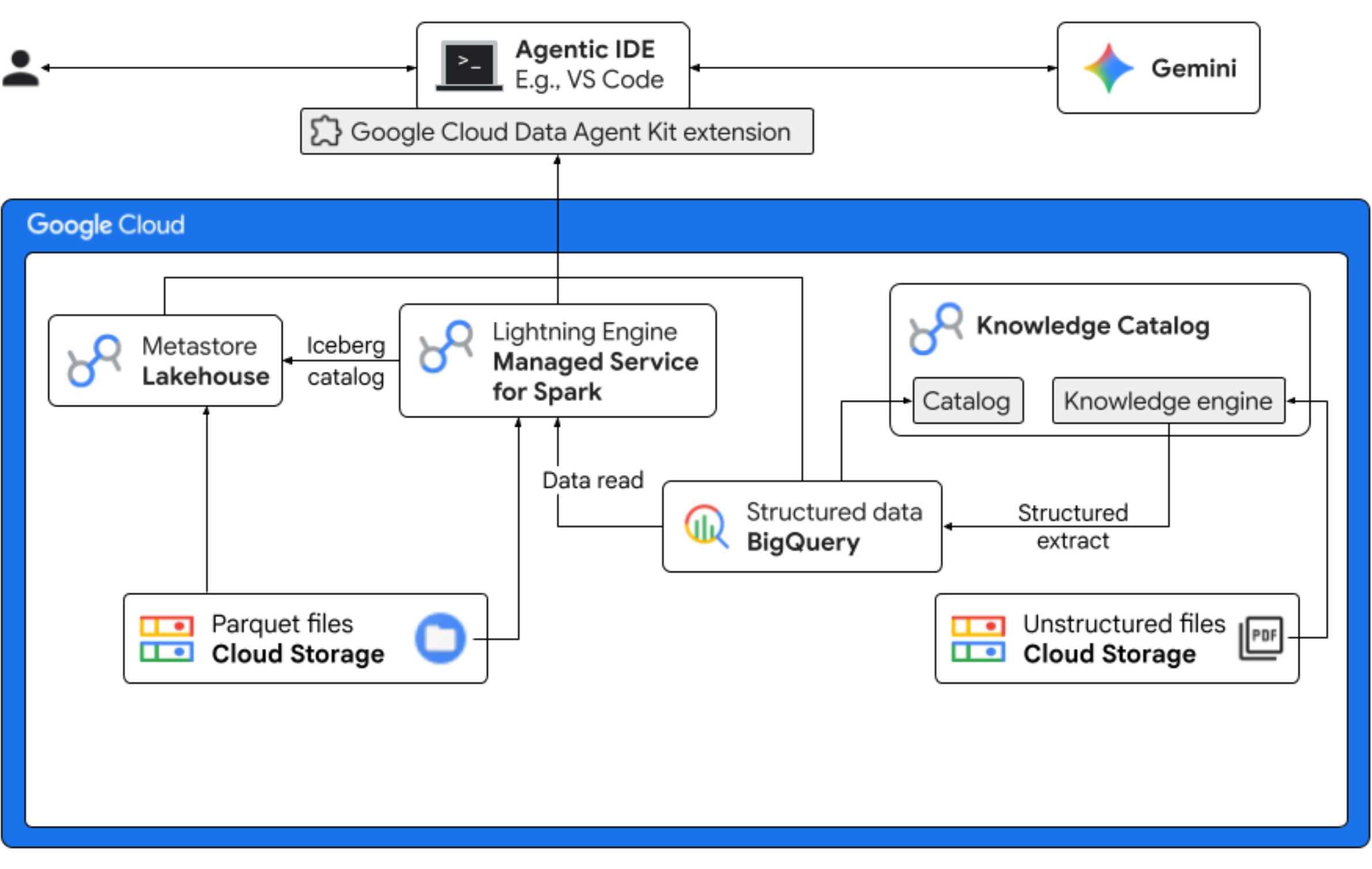
In questo lab proverai a:
- Individuazione non strutturata: le ricette in formato PDF archiviate in Cloud Storage vengono sottoposte a scansione da Knowledge Catalog DataScan. Crea tabelle di oggetti in BigQuery per i PDF scansionati. Utilizzando Vertex AI Semantic Inference, il sistema "legge" i PDF per estrarre informazioni strutturate su prodotti, allergeni, ingredienti e attributi correlati. Poi genera in modo intelligente uno schema per i dati archiviati nei PDF.
- Metadati unificati: i dati estratti dai file PDF vengono archiviati direttamente in BigQuery come tabella ampia nativa e vengono create viste per facilitare le query comuni. Un set di dati di input indipendente contenente dati storici sulle vendite è archiviato nelle tabelle Apache Iceberg su Google Cloud Storage. Questa tabella Iceberg verrà unita ai dati estratti in BigQuery in un passaggio successivo.
- Analisi cross-engine: utilizzando Managed Service for Apache Spark (precedentemente noto come Dataproc) con un catalogo REST di Iceberg, unirai questi metadati PDF aggiornati e i dati semantici strutturati inferiti (da tabelle e viste BigQuery) con i dati di vendita strutturati archiviati nelle tabelle Apache Iceberg su Google Cloud Storage. Questa operazione è regolata da un modello di sessione interattiva Managed Apache Spark utilizzato come kernel Jupyter Notebook che garantisce impostazioni di sicurezza e di calcolo coerenti per il job Spark.
- Approfondimenti semantici: unendo i dati di prodotto dedotti con i dati di clienti e vendite (in BigQuery), la demo è in grado di estrarre approfondimenti come l'identificazione dei dati sugli allergeni e la previsione delle entrate.
- Governance autonoma: l'intero ciclo di vita, dalle scansioni di rilevamento all'esecuzione di Spark, è orchestrato tramite modelli, istruzioni, regole e automazione basata su agenti pronti per Gemini, dimostrando che l'AI può gestire l'infrastruttura che alimenta l'analisi.
Che cosa ti serve
Il completamento di questo codelab potrebbe comportare costi stimati inferiori a 5 $per l'utilizzo tipico. Per ottenere stime dettagliate dei costi in base all'utilizzo previsto o ai prezzi attuali, utilizza il Calcolatore prezzi di Google Cloud.
Per completare il codelab, assicurati di disporre dei seguenti prerequisiti.
- Browser web Chrome.
- Un account Gmail personale se utilizzi i crediti di prova forniti nella sezione Prima di iniziare.
- Scarica e installa Visual Studio (VS) Code.
2. Prima di iniziare
Crea un progetto Google Cloud
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto.
Avvia Cloud Shell
Cloud Shell è un ambiente a riga di comando in esecuzione in Google Cloud che viene precaricato con gli strumenti necessari.
- Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud.
- Una volta connesso a Cloud Shell, verifica l'autenticazione:
gcloud auth list - Verifica che il progetto sia configurato:
gcloud config get project - Se il progetto non è impostato come previsto, impostalo:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Abilita le API richieste
Esegui questo comando per abilitare tutte le API richieste:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
biglake.googleapis.com \
dataproc.googleapis.com \
metastore.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
secretmanager.googleapis.com \
storage.googleapis.com
Scarica gli asset del codelab
Questo repository contiene i file Parquet, ricette, fornitori, copilot-instructions.md, template.yaml e quickstart.py da utilizzare con questo codelab. Assicurati di scaricare questi file.
Per scaricare i file:
- In Cloud Shell, esegui questo comando:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git - Vai alla cartella appena creata:
cd next-26-keynotes - Estrai la cartella
data-cloud-demogit sparse-checkout set genkey/data-cloud-demo - Al termine del pagamento, vai alla cartella
data-cloud-demoed estrai i file ZIP per accedere agli asset del codelab.
3. Configurare Lakehouse per i dati dei clienti Froyo
In questa sezione, creerai un catalogo in Lakehouse per utilizzare il metastore Lakehouse per i tuoi flussi di lavoro. Crea interoperabilità tra i motori di query offrendo un'unica fonte attendibile per tutti i dati Iceberg. Consente ai motori di query, come Apache Spark, di rilevare, leggere i metadati e gestire le tabelle Iceberg in modo coerente.
Ruoli obbligatori
Assicurati di disporre dei seguenti ruoli Identity and Access Management (IAM):
roles/biglake.viewerroles/bigquery.userroles/bigquery.dataEditorroles/biglake.editorroles/biglake.metadataViewerroles/bigquery.connectionUserroles/storage.objectUserroles/storage.objectViewerroles/storage.objectCreatorroles/storage.admin
Per saperne di più sulla concessione dei ruoli IAM, consulta Concedere un ruolo IAM.
Crea un catalogo Lakehouse con un bucket
Crea un catalogo Lakehouse per gestire i metadati delle tabelle Iceberg. Ti connetti a questo catalogo nel tuo job Spark per creare ed eseguire query sulle tabelle Iceberg.
- Nella console Google Cloud, vai a Lakehouse.
- Fai clic su Crea catalogo. Viene visualizzata la pagina Crea catalogo.
- Per Tipo di catalogo, seleziona Catalogo REST Iceberg.
- In Seleziona le opzioni del bucket del catalogo Lakehouse, seleziona Catalogo con un solo bucket.
- Per Bucket Cloud Storage del catalogo predefinito, fai clic su Sfoglia e poi su Crea nuovo bucket.
- Nella pagina Crea un bucket, segui questi passaggi:
- Nella sezione Inizia, inserisci un nome univoco globale che soddisfi i requisiti per il nome del bucket.
- Nella sezione Scegli dove archiviare i tuoi dati, seleziona Regione per Tipo di località e inserisci la tua regione. Ad esempio:
us-west1. - Nella sezione Scegli come controllare l'accesso agli oggetti, deseleziona la casella di controllo Applica la prevenzione dell'accesso pubblico in questo bucket.
In questo modo puoi simulare scenari reali come l'hosting di contenuti web pubblici o repository di dati condivisi. Senza questa modifica, il bucket applicherebbe un criterio "solo privato" rigoroso; qualsiasi tentativo di accedere ai tuoi asset genererebbe un errore403vietato, anche se hai concesso correttamente le autorizzazioni pubbliche ai file. - Fai clic su Continua > Crea > Seleziona > Continua.
- In Authentication method (Metodo di autenticazione), seleziona Credential vending mode (Modalità di distribuzione delle credenziali).
- Fai clic su Crea.Il catalogo viene creato e si apre la pagina Dettagli catalogo.
- Nella sezione Metodo di autenticazione, fai clic su Imposta autorizzazioni bucket.
- Nella finestra di dialogo, fai clic su Conferma.In questo modo, viene verificato che l'account di servizio del catalogo disponga del ruolo
Storage Object Usernel bucket di archiviazione. - Nella pagina Dettagli catalogo, copia il percorso dell'URI del catalogo REST. Utilizza questo percorso durante l'attività Esegui job Spark.
Carica i file Parquet nel bucket
Per caricare i file Parquet nella radice del bucket:
- Nella console Google Cloud, vai alla pagina Bucket Cloud Storage.
- Nell'elenco dei bucket, fai clic sul nome del bucket. Ad esempio,
acai_demo. - Nella scheda Oggetti del bucket, fai clic su Carica > Carica file.
- Seleziona i file dalla cartella Parquet che hai clonato nella sezione Prima di iniziare di questo codelab.
- Fai clic su Apri.
4. Configura la rete VPC
Crea una rete Virtual Private Cloud (VPC) e una subnet che consenta alle risorse di comunicare con le API di Google senza uscire su internet pubblico e un firewall che consenta al traffico interno di fluire liberamente tra i nodi di elaborazione dei dati.
- Nella console Google Cloud, vai alla pagina Reti VPC.
- Fai clic su Crea rete VPC.
- Inserisci un Nome per la rete. Ad esempio,
acai-network. - Per configurare l'unità massima di trasmissione (MTU) della rete, seleziona la casella di controllo Imposta MTU automaticamente.
- Scegli Automatica per la Modalità di creazione subnet.
- Nella sezione Regole firewall, seleziona tutte le caselle di controllo per Regole firewall IPv4.
- Fai clic su Crea.
Abilita l'accesso privato Google
I nodi Dataproc Serverless non hanno indirizzi IP pubblici. Per comunicare con Lakehouse Catalog e Cloud Storage, la subnet deve avere l'accesso privato Google abilitato.
- Nella console Google Cloud, vai alla pagina Reti VPC.
- Fai clic sul nome della rete che contiene la subnet per la quale devi attivare l'accesso privato Google. Ad esempio,
us-west1. - Fai clic sul nome della subnet. Viene visualizzata la pagina dei dettagli Subnet.
- Fai clic su Modifica.
- Nella sezione Accesso privato Google, seleziona On.
- Fai clic su Salva.
5. Crea ed esegui un job Spark
Per creare ed eseguire query su una tabella Iceberg, carica il job PySpark con le istruzioni Spark SQL necessarie. Poi esegui il job con Managed Service for Spark.
Carica quickstart.py nel bucket Cloud Storage
Dopo aver clonato gli asset del codelab, aggiorna lo script quickstart.py con i dettagli del progetto e caricalo nel bucket Cloud Storage.
- Apri lo script
quickstart.pyin un editor di testo. - Sostituisci il segnaposto
BUCKET_NAMEnello script con il nome del tuo bucket Cloud Storage e salvalo. - Nella console Google Cloud, vai a Bucket Cloud Storage.
- Fai clic sul nome del bucket. Ad esempio,
acai_demo. - Nella scheda Oggetti, fai clic su Carica > Carica file.
- Nel browser di file, seleziona il file
quickstart.pyaggiornato e poi fai clic su Apri.
Esegui il job Spark
Dopo aver caricato lo script quickstart.py, eseguilo come job batch Managed Service for Spark.
- Per configurare le variabili, esegui questo comando in Cloud Shell.
# Configuration Variables export PROJECT_ID="<PROJECT_ID>" export REGION="<REGION>" export BUCKET_NAME="<BUCKET_NAME>" export SUBNET="<SUBNET>" export LAKEHOUSE_CATALOG_ID="<LAKEHOUSE_CATALOG_ID>" export CATALOG_URI_ID="<CATALOG_URI_ID>"- LAKEHOUSE_CATALOG_ID: il nome della risorsa del catalogo Lakehouse che contiene il file dell'applicazione PySpark. Ad esempio,
acai_demo - PROJECT_ID: l'ID del tuo progetto Google Cloud.
- REGION: la regione in cui eseguire il workload batch Managed Service for Spark. Ad esempio,
us-west1. - BUCKET_NAME: il nome del tuo bucket Cloud Storage. Ad esempio,
acai_demo. - SUBNET: il nome della tua subnet VPC. Ad esempio,
acai-network. - CATALOG_URI_ID: l'ID URI del catalogo Lakehouse che hai copiato durante la creazione di un catalogo Lakehouse con un bucket. Ad esempio,
https://biglake.googleapis.com/iceberg/v1/restcatalog.
- LAKEHOUSE_CATALOG_ID: il nome della risorsa del catalogo Lakehouse che contiene il file dell'applicazione PySpark. Ad esempio,
- In Cloud Shell, esegui il seguente job batch Managed Service for Spark utilizzando lo script
quickstart.py.gcloud dataproc batches submit pyspark gs://${BUCKET_NAME}/quickstart.py \ --project=${PROJECT_ID} \ --region=${REGION} \ --subnet=${SUBNET} \ --version=2.2 \ --properties="\ spark.sql.defaultCatalog=${LAKEHOUSE_CATALOG_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}=org.apache.iceberg.spark.SparkCatalog,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.type=rest,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.uri=${CATALOG_URI_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.warehouse=gs://${BUCKET_NAME},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.io-impl=org.apache.iceberg.gcp.gcs.GCSFileIO,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.x-goog-user-project=${PROJECT_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\ spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest-metrics-reporting-enabled=false,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.X-Iceberg-Access-Delegation=vended-credentials,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token"All tables registered successfully! Batch [126fa2226a904d2e944c8eecbe0b1840] finished. metadata: '@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata batch: projects/PROJECT_ID/locations/REGION/batches/126fa2226a904d2e944c8eecbe0b1840 batchUuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff createTime: '2026-04-09T13:17:26.222727Z' description: Batch labels: goog-dataproc-batch-id: 126fa2226a904d2e944c8eecbe0b1840 goog-dataproc-batch-uuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-drz-resource-uuid: batch-3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-location: REGION operationType: BATCH name: projects/PROJECT_ID/regions/REGION/operations/47bc59e8-5082-3af9-89a0-22289aa5f4b9
6. Esegui query sulla tabella da BigQuery
Eseguendo correttamente il job batch Spark, hai utilizzato Managed Service for Spark Serverless come motore di calcolo distribuito per registrare più tabelle, una per ogni file Parquet all'interno di Lakehouse Metastore. Questa registrazione consente a Google Cloud di trattare i tuoi file non elaborati in Cloud Storage come tabelle strutturate ad alte prestazioni.
I seguenti passaggi ti guidano nella verifica della corretta sincronizzazione dei metadati, assicurando che i tuoi dati non solo siano archiviati in modo sicuro, ma siano anche completamente rilevabili e interrogabili tramite l'interfaccia BigQuery.
- Nella console Google Cloud, vai a BigQuery.
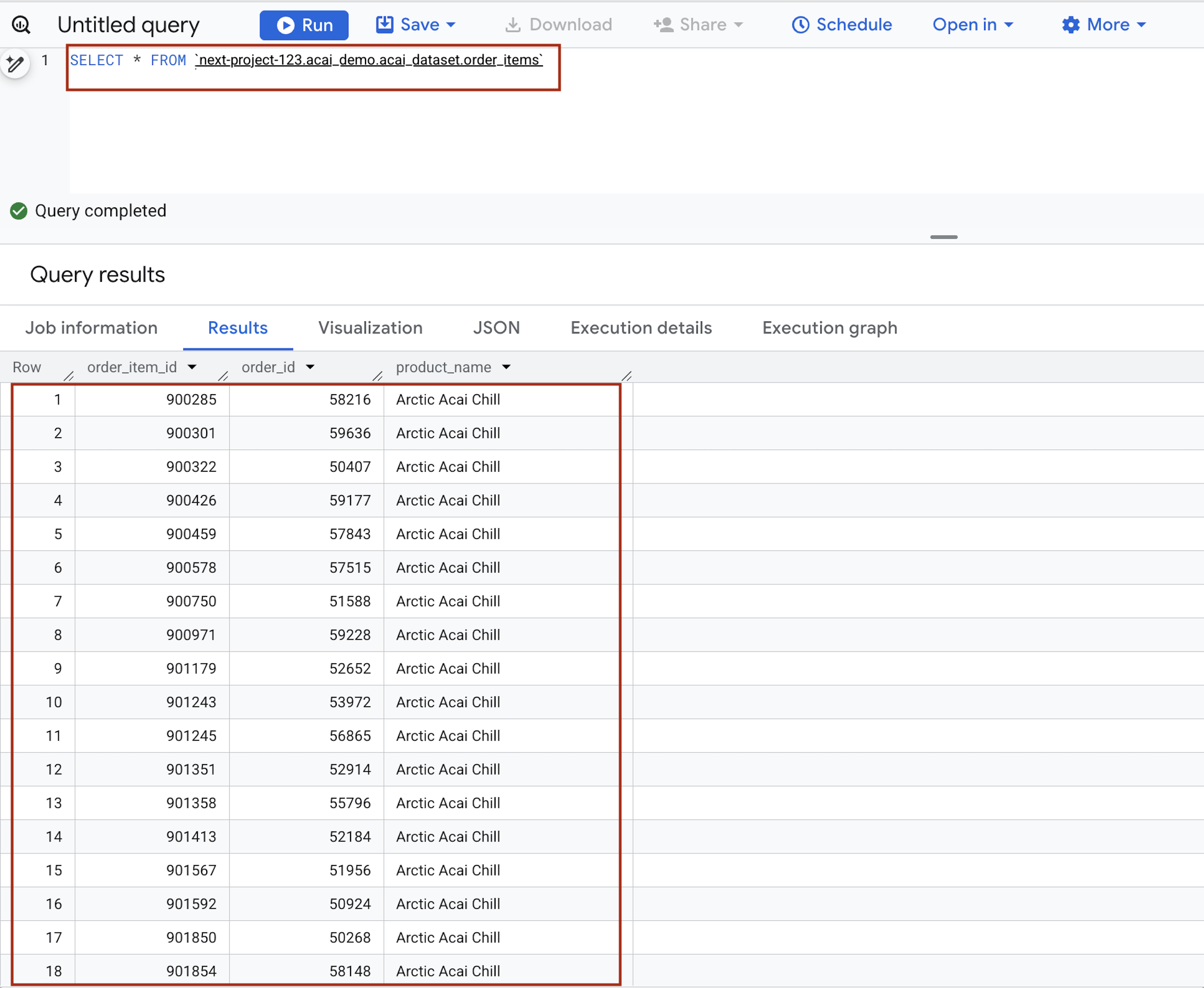
- Nell'editor di query, inserisci la seguente istruzione. La query utilizza la sintassi
project.namespace.dataset.table.SELECT * FROM `<PROJECT_ID>.<NAMESPACE>.<ICEBERG_DATASET>.<ICEBERG_TABLE>`PROJECT_ID.acai_demo.acai_dataset.order_items.
Sostituisci quanto segue:- PROJECT_ID: l'ID del tuo progetto Google Cloud.
- NAMESPACE: lo spazio dei nomi creato nel passaggio precedente come risultato del job Spark, che puoi trovare nella pagina dell'Explorer oggetti BigQuery. Ad esempio,
acai_demo. - ICEBERG_DATASET: il nome del set di dati all'interno del catalogo Iceberg, ad esempio
acai_dataset. - ICEBERG_TABLE: il nome della tabella all'interno del set di dati Iceberg, ad esempio
order_items.
- Fai clic su Esegui. I risultati della query mostrano i dati che hai inserito con il job Spark.
7. Configurare i file di dati di prodotto non strutturati
In questa sezione, crei una struttura organizzativa in BigQuery per archiviare i dati di fornitori e ricette di Froyo, in particolare per i dettagli del prodotto Froyo. Stabilisce anche una connessione alle risorse cloud, che funge da "ponte" sicuro che consente a BigQuery di leggere i file da origini esterne come Cloud Storage.
Crea il bucket e carica i file di dettagli di Froyo
Crea e carica i file del fornitore e della ricetta nel bucket Cloud Storage.
- Nella console Google Cloud, vai alla pagina Bucket Cloud Storage.
- Fai clic su Crea.
- Nella pagina Crea un bucket, inserisci le informazioni del bucket. Dopo ogni passaggio riportato di seguito, fai clic su Continua per passare al passaggio successivo:
- Nella sezione Inizia, inserisci il nome del bucket. Ad esempio,
acai_pdfs. - Nella sezione Scegli dove archiviare i tuoi dati, seleziona Regione e poi inserisci la tua regione. Ad esempio:
us-west1. - Nella sezione Scegli come controllare l'accesso agli oggetti, deseleziona la casella di controllo Applica la prevenzione dell'accesso pubblico in questo bucket.
- Fai clic su Crea.
- Nell'elenco dei bucket, fai clic su quello che hai creato. Ad esempio,
acai_pdfs. - Nella scheda Oggetti del bucket, fai clic su Carica > Carica cartelle.
- Seleziona la cartella
recipesche hai estratto nella sezione Prima di iniziare di questo codelab. - Fai clic su Carica.
- Ripeti la procedura di caricamento per la cartella
suppliers.
Crea una connessione
Crea una connessione alle risorse Cloud. In questo modo viene generato un service account univoco che funge da "documento di identità" di BigQuery per accedere ai file esterni.
- Vai alla pagina BigQuery.
- Nel riquadro a sinistra, fai clic su Explorer. Se non vedi il riquadro a sinistra, fai clic su Espandi riquadro a sinistra per aprirlo.
- Nel riquadro Explorer, espandi il nome del progetto e fai clic su Connessioni.
- Nella pagina Connessioni, fai clic su Crea connessione.
- Per il tipo Connessione, scegli Modelli remoti di Vertex AI, funzioni remote, BigLake e Spanner (risorsa Cloud).
- Nel campo ID connessione, inserisci il nome dell'ID connessione. Ad esempio,
acai_pdf_connection. Assicurati di annotare questo ID, perché ti servirà quando configurerai la scansione dei dati più avanti in questo codelab. - Imposta Tipo di località su Regione, quindi seleziona una regione. Ad esempio:
us-west1. La connessione deve essere collocata insieme alle altre risorse, ad esempio i set di dati. - Fai clic su Crea connessione.
- Fai clic su Vai alla connessione.
- Nel riquadro Informazioni sulla connessione, copia l'ID dell'account di servizio da utilizzare in un passaggio successivo. Il service account è simile a
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com.
Gestire l'accesso agli account di servizio
Fornisci l'accesso al service account in modo che Lakehouse possa leggere i tuoi PDF.
- Vai alla pagina IAM e amministrazione.
- Fai clic su Concedi l'accesso. Si apre la finestra di dialogo Aggiungi entità.
- Nel campo Nuove entità, inserisci l'ID account del service account che hai copiato in precedenza.
- Nel campo Seleziona un ruolo, aggiungi i seguenti ruoli:
roles/storage.objectUserroles/storage.objectViewerroles/bigquery.userroles/bigquery.dataEditorroles/aiplatform.userroles/storage.adminroles/dataproc.serviceAgent
- Fai clic su Salva.
Per saperne di più sui ruoli IAM in BigQuery, consulta Ruoli e autorizzazioni predefiniti.
8. Gestisci le autorizzazioni per il job DataScan
Crea account di servizio (identità) specifici per Spark e Dataform, quindi concedi a questi, insieme agli agenti di servizio automatizzati di Google, le autorizzazioni precise necessarie per leggere l'archiviazione, eseguire job BigQuery e utilizzare Vertex AI per l'individuazione.
Accesso IAM per Spark e Dataform
- Nella console Google Cloud, vai alla pagina Crea service account.
- Se non è selezionato, seleziona il tuo progetto Google Cloud.
- Fai clic su Crea account di servizio.
- Inserisci un nome per il service account. Ad esempio,
sa-spark-stg1. La console Google Cloud genera un ID service account in base a questo nome. Modifica l'ID, se necessario. Non potrai modificare l'ID in un secondo momento. - Per impostare i controlli dell'accesso, fai clic su Crea e continua e vai al passaggio successivo.
- Scegli i seguenti ruoli IAM da concedere al service account nel progetto.
roles/dataproc.workerroles/storage.objectUserroles/bigquery.dataEditorroles/bigquery.jobUserroles/aiplatform.userroles/dataplex.discoveryPublishingServiceAgent
- Quando hai finito di aggiungere i ruoli, fai clic su Continua.
- Fai clic su Fine per completare la creazione del service account.
Autorizzazioni di connessione BigQuery per l'accesso a Knowledge Catalog
- Nella console Google Cloud, vai alla pagina Bucket Cloud Storage.
- Nell'elenco dei bucket, fai clic sul nome del bucket che hai creato per Froyo. Ad esempio,
acai_pdfs. - Nella scheda Autorizzazioni, fai clic su Concedi l'accesso. Viene visualizzata la finestra di dialogo Aggiungi entità.
- Nel campo Nuove entità, inserisci l'ID del service account BigQuery. Il service account è simile a
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com. - Seleziona il seguente ruolo (o ruoli) dal menu a discesa Seleziona un ruolo.
roles/storage.objectUserroles/dataplex.serviceAgentroles/dataplex.securityAdminroles/aiplatform.serviceAgentroles/dataplex.discoveryPublishingServiceAgent
- Fai clic su Salva.
9. Configurare Knowledge Catalog
Crea un Knowledge Catalog per unificare i dati correlati a Froyo e automatizzare l'individuazione di file non strutturati (come ricette in PDF e fornitori in PDF).
Crea DataScan tramite curl
In questa sezione, crei scansioni per il tuo bucket Cloud Storage (ad esempio acai_pdfs) aggiungendo datascan_ID e indirizzandolo ai tuoi set di dati BigQuery. Dopodiché, Knowledge Catalog creerà automaticamente le voci per i tuoi PDF in BigQuery.
- Per eseguire la scansione dei PDF (fornitori e ricette), esegui il comando seguente:
# 1. Set your variables PROJECT_ID="<PROJECT_ID>" REGION="<REGION>" ENV_SUFFIX="stg1" DATASCAN_ID="froyo-profile-${ENV_SUFFIX}" BUCKET_NAME="<BUCKET_NAME>" # 2. Set this to the Name of the connection you created in Step 7 CONNECTION_ID="<CONNECTION_ID_NAME>" # 3. Define the API Endpoint DATAPLEX_API="dataplex.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}" # 4. Create the DataScan via CURL echo "Creating Dataplex DataScan: ${DATASCAN_ID}..." curl -X POST "https://$DATAPLEX_API/dataScans?dataScanId=${DATASCAN_ID}" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d '{ "data": { "resource": "//storage.googleapis.com/projects/'"${PROJECT_ID}"'/buckets/'"${BUCKET_NAME}"'" }, "executionSpec": { "trigger": { "on_demand": {} } }, "dataDiscoverySpec": { "bigqueryPublishingConfig": { "tableType": "BIGLAKE", "connection": "projects/'"${PROJECT_ID}"'/locations/'"${REGION}"'/connections/'"${CONNECTION_ID}"'" }, "storageConfig": { "unstructuredDataOptions": { "entity_inference_enabled": true } } } }' - Il comando
curlmostra i risultati di Knowledge Catalog DataScan, in modo simile all'immagine seguente.
Esegui il job
Esegui questo comando:
gcloud dataplex datascans run $DATASCAN_ID --location=$REGION
Descrivere un lavoro
Per descrivere il job, esegui questo comando:
gcloud dataplex datascans describe $DATASCAN_ID --location=$REGION
Eliminare un job di scansione dei dati
Se la scansione viene eseguita per più di 10 minuti o se lo stato del job rimane In attesa per un periodo di tempo prolungato senza passare a In esecuzione, il problema potrebbe essere dovuto alla mancata disponibilità temporanea delle risorse nella regione. In questo caso, puoi eseguire il comando seguente per eliminare il job, quindi provare a crearlo ed eseguirlo di nuovo. A volte, un'esecuzione iniziale potrebbe non riuscire rapidamente con un errore come unable to acquire necessary resources.
gcloud dataplex datascans delete $DATASCAN_ID --location=$REGION
Visualizzare lo stato del job
Per controllare lo stato del job:
- Nella console Google Cloud, vai alla pagina Curation dei metadati.
- Nella scheda Rilevamento Cloud Storage, fai clic sul nome delle scansioni di rilevamento.
- Nella pagina Dettagli scansione, puoi visualizzare lo stato del job.
- Al termine del job, controlla se è presente il set di dati pubblicato (ad esempio,
acai_pdfs_discovered_003) che hai creato utilizzando il comandocurl.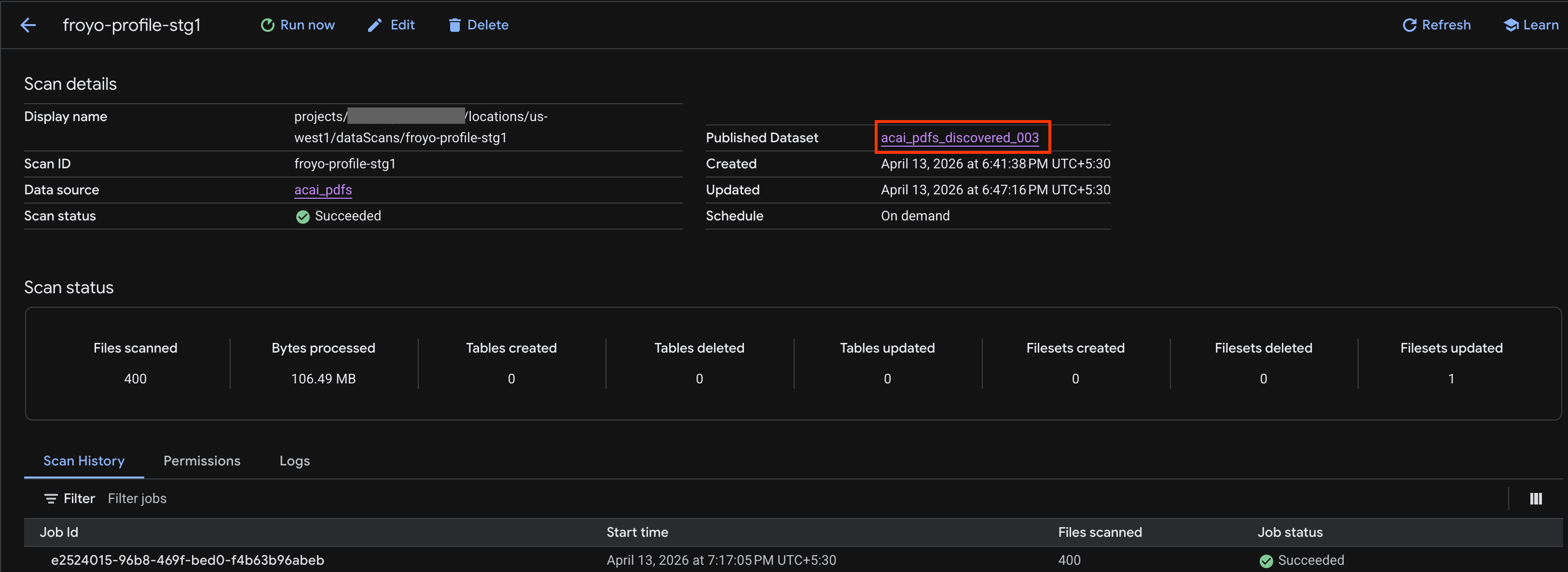
Visualizzare la tabella degli oggetti
Per visualizzare la tabella degli oggetti creata dopo il job di rilevamento:
- Nella console Google Cloud, vai a BigQuery.
- Fai clic su Set di dati e seleziona il set di dati pubblicato creato nel passaggio precedente. Ad esempio,
acai_pdfs_discovered_003. - Per visualizzare la tabella degli oggetti, fai clic sull'ID tabella. Ad esempio,
acai_pdfs. - La tabella degli oggetti risultante è simile all'immagine seguente:
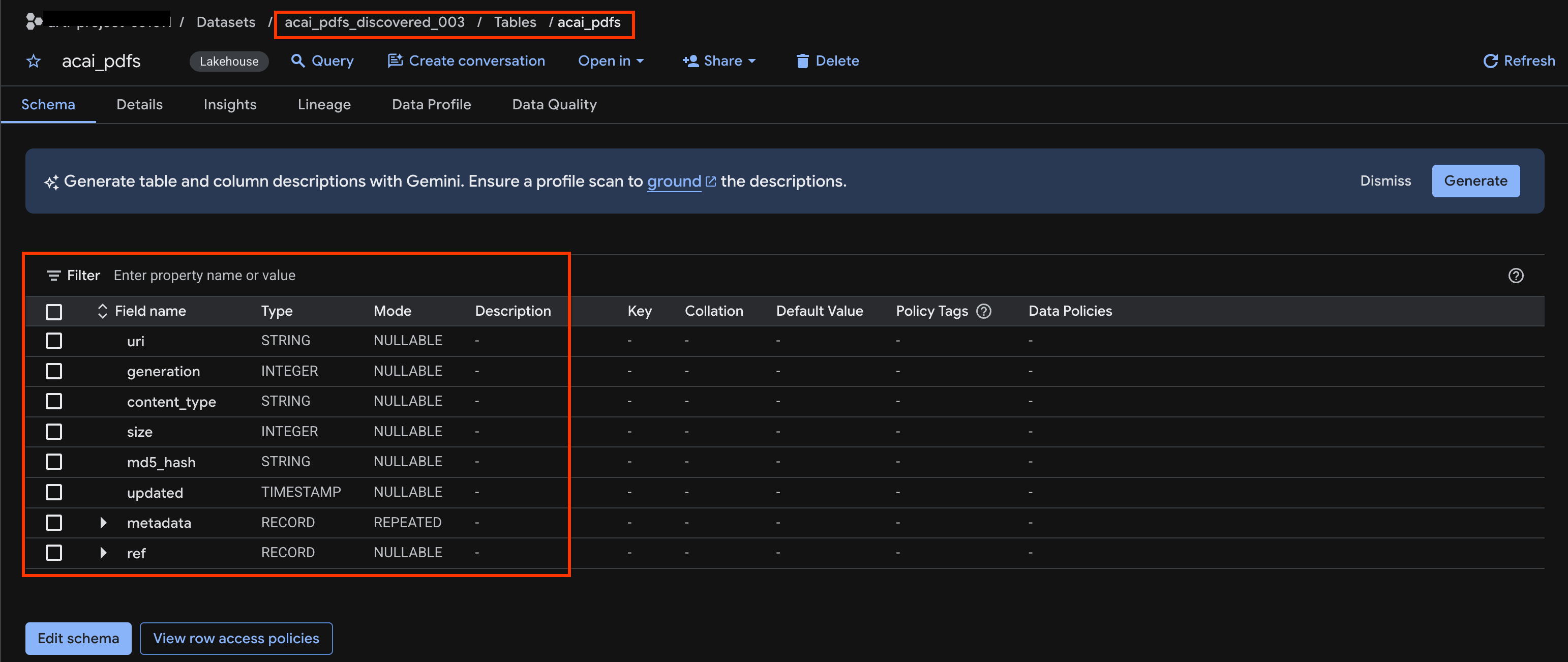
10. Estrazione semantica
Inferirai ed estrarrai tabelle strutturate, altri oggetti di database e relazioni per questa tabella di oggetti non strutturati che hai creato nel passaggio precedente. Per farlo, utilizzerai la funzionalità Knowledge Catalog Insights per generare istruzioni SQL per estrarre dati strutturati dalla tabella non strutturata.
- Nella console Google Cloud, vai alla pagina Ricerca nel catalogo delle conoscenze.
- Cerca la tabella del set di dati per cui vuoi visualizzare gli approfondimenti. Ad esempio,
acai_pdfs_discovered_003.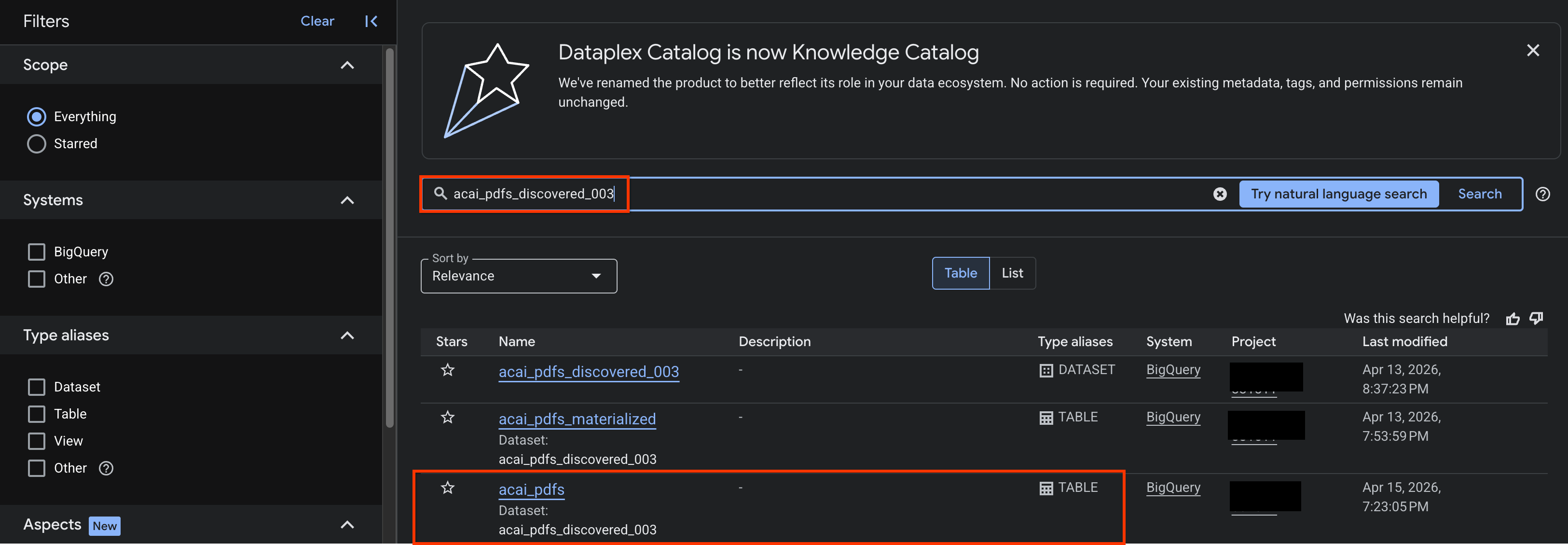
- Nei risultati di ricerca, fai clic sulla tabella per aprire la relativa pagina di inserimento.
- Fai clic sulla scheda Approfondimenti. Se la scheda è vuota, significa che gli approfondimenti per questa tabella non sono ancora stati generati. La generazione di insight potrebbe richiedere dai 15 ai 25 minuti.
- Una volta visualizzati gli approfondimenti, fai clic su Estrai > Estrai con SQL.
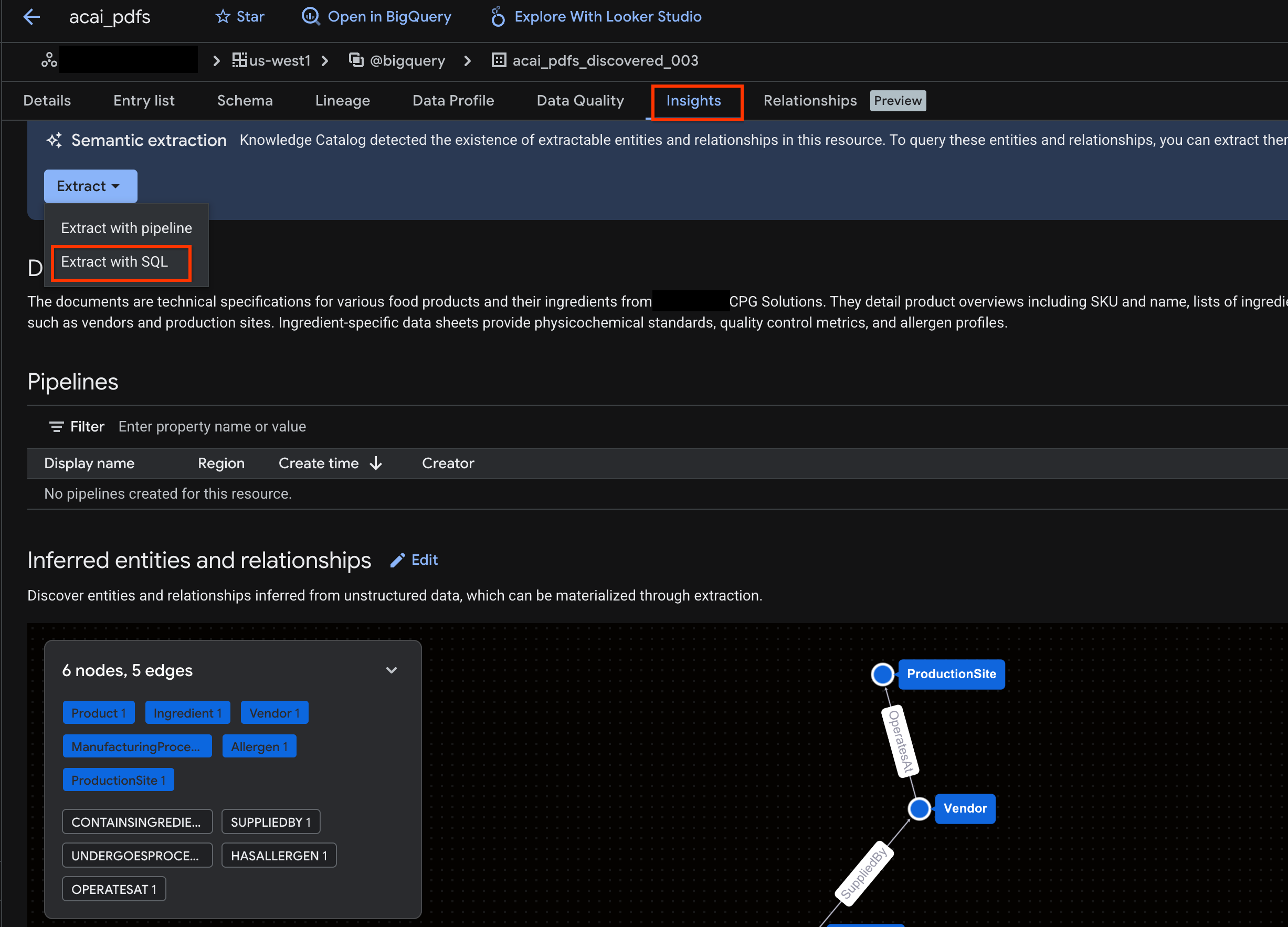
- Nella pagina Estrai con SQL, inserisci il set di dati in Destinazione. Ad esempio:
acai_pdfs_discovered_003. - Fai clic su Estrai. Si apre l'editor BigQuery con la query caricata.
- Fai clic su Esegui. Questo passaggio genera un insieme di istruzioni e potrebbe richiedere alcuni minuti per il completamento dell'esecuzione.
- Al termine della query, vengono visualizzati i seguenti risultati:
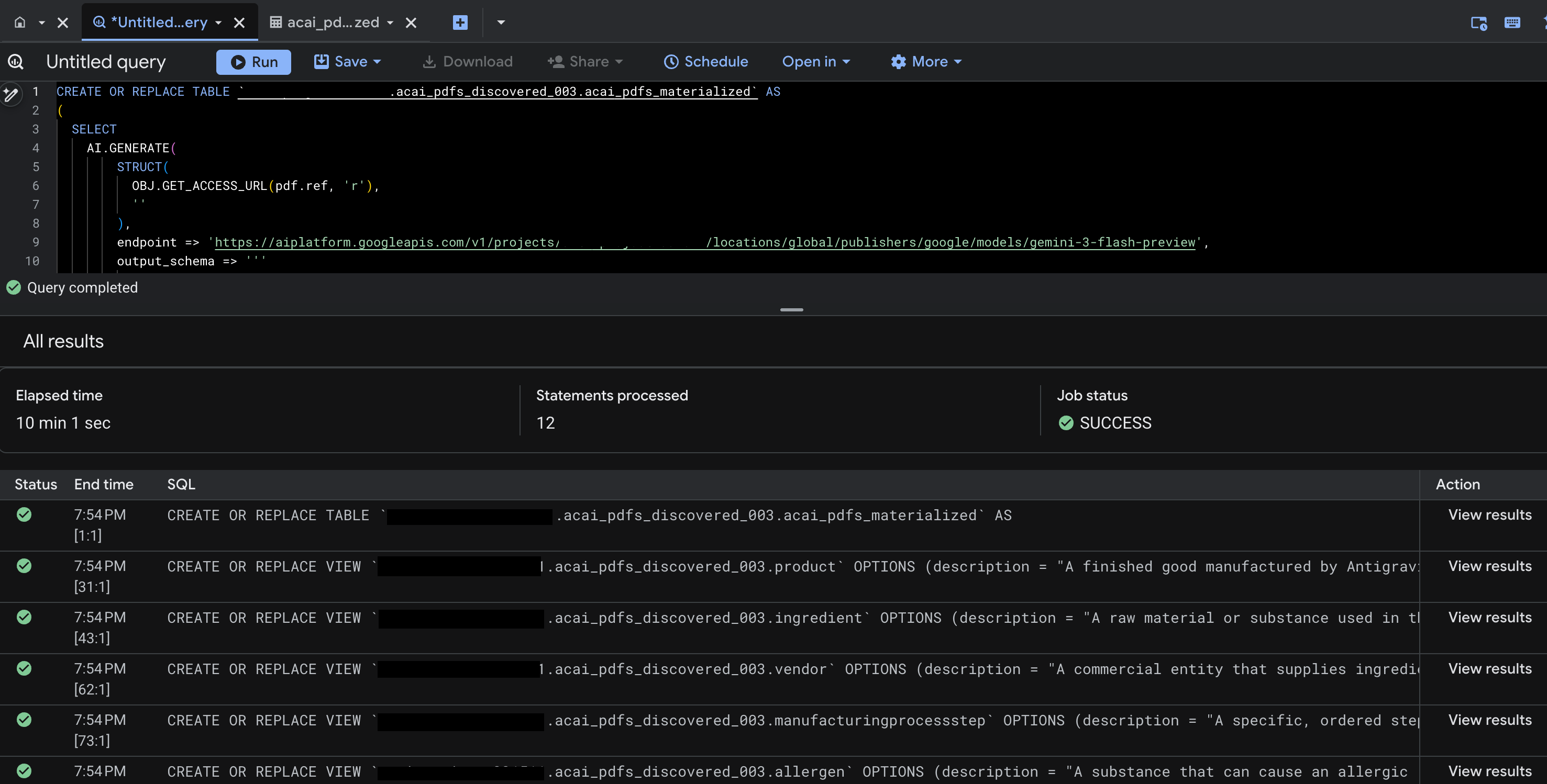
- Vai a BigQuery e fai clic su Set di dati (ad esempio
acai_pdfs_discovered_003). Nel set di dati selezionato al passaggio 6 viene creato un nuovo insieme di oggetti di database strutturati.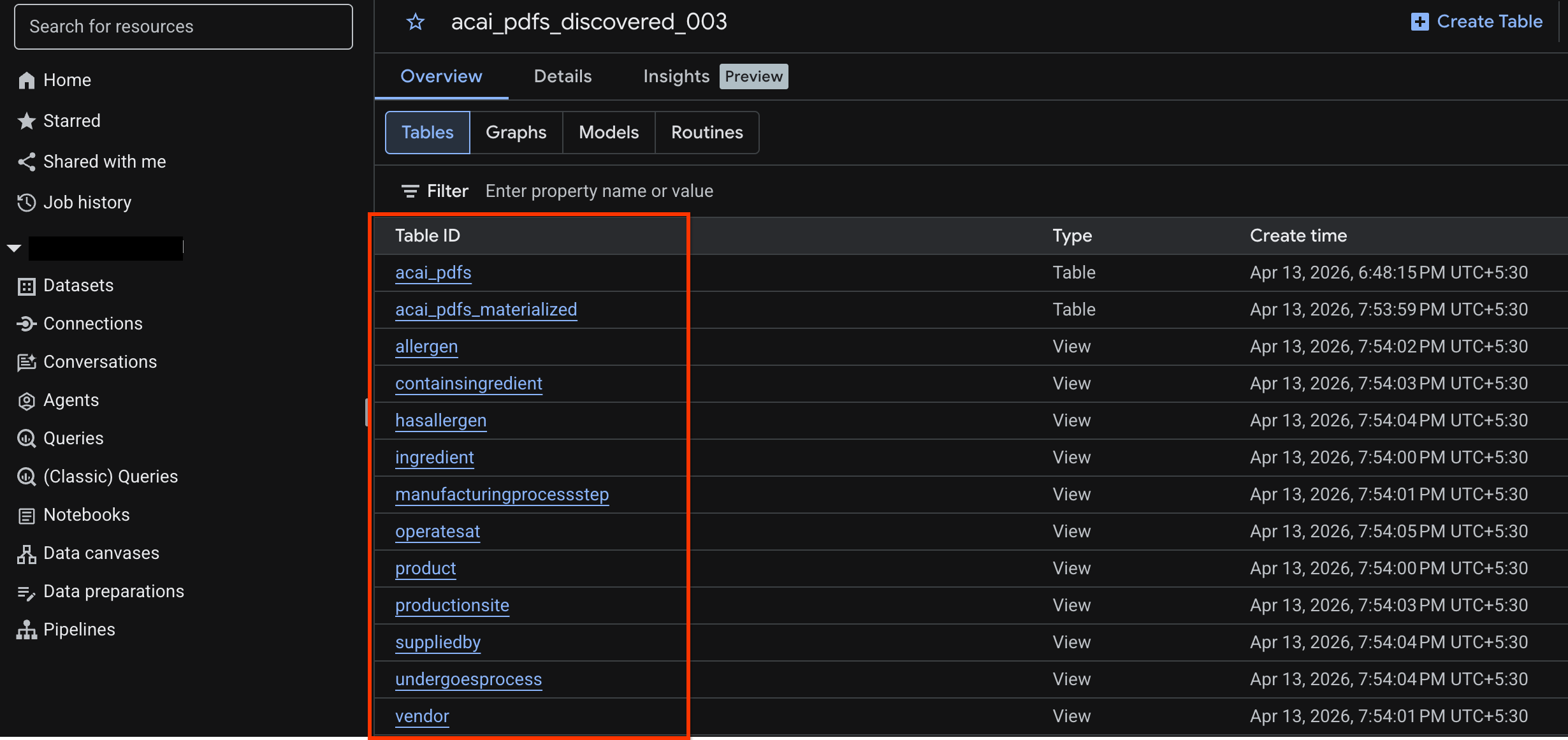
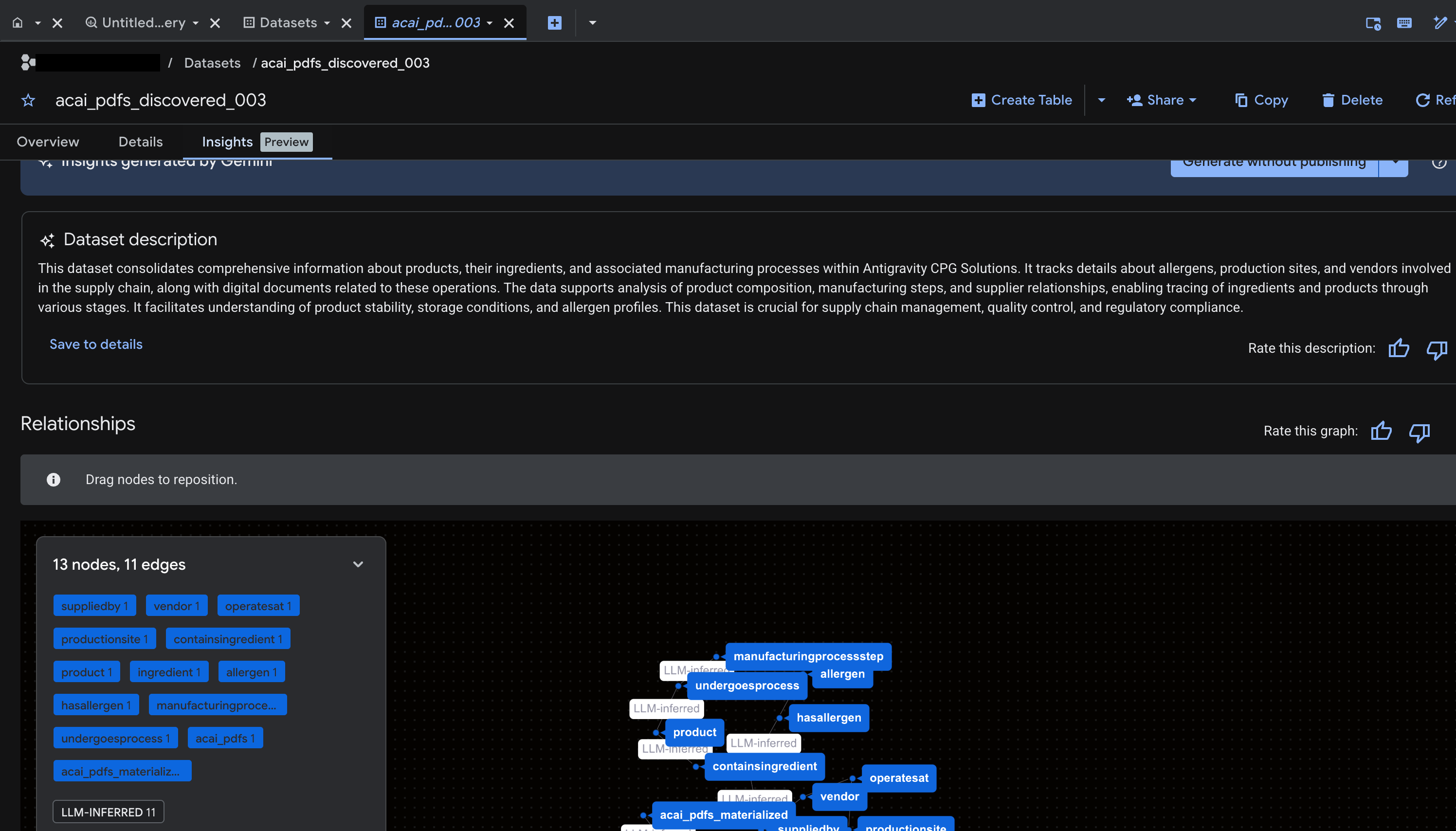
Genera insight per l'oggetto in BigQuery
Per generare approfondimenti per un set di dati BigQuery, devi accedere al set di dati in BigQuery utilizzando BigQuery Studio.
- Nella console Google Cloud, vai a BigQuery Studio.
- Nel riquadro Spazio di esplorazione, seleziona il progetto e vai al set di dati per cui vuoi generare approfondimenti.
- Fai clic sulla scheda Approfondimenti.
- Se vedi il pulsante Abilita API, fai clic per abilitare Gemini in Google Cloud. Si aprirà la finestra Abilita funzionalità principali.
- Nella sezione API delle funzionalità principali, fai clic su Attiva per API Gemini for Google Cloud e API BigQuery Unified, quindi fai clic su Avanti.
- Nella sezione Autorizzazioni (facoltativo), concedi i ruoli IAM alle entità se necessario, quindi fai clic su Avanti.
- Per generare insight e pubblicarli in Knowledge Catalog, fai clic su Genera e pubblica.
- Una volta pubblicate, potrai visualizzare le statistiche nella scheda.
11. Configurare l'IDE per l'analisi dei dati con agenti
L'estensione Google Cloud Data Agent Kit per Visual Studio Code è un'estensione IDE per data scientist e data engineer. Consente di connettersi e lavorare con le risorse e i dati di Google Data Cloud direttamente dall'IDE. Per ulteriori informazioni, consulta la panoramica dell'estensione Data Agent Kit per VS Code.
L'estensione Data Agent Kit per VS Code è utile quando vuoi:
- Crea, testa, rivedi e implementa una pipeline di dati pronta per la produzione, come Spark ETL o BigQuery ETL, direttamente da VS Code.
- Esplora i dati, crea una pipeline di addestramento, identifica i modelli ML ottimali ed esegui il deployment in un endpoint di produzione utilizzando l'assistenza AI.
- Connettiti a origini dati attendibili, crea un modello di dati ad alte prestazioni e pubblica una dashboard interattiva per gli stakeholder aziendali.
Installa l'estensione Data Agent Kit per VS Code
- Apri VS Code.
- Installa Google Cloud CLI. Per saperne di più, consulta Installa Google Cloud CLI.
- Installa l'estensione Data Agent Kit per VS Code.
- Completa la procedura di onboarding dell'estensione, che richiede di:
- Accedere all'estensione
- Installare le skill, server MCP
- Ricarica o riavvia la finestra al termine dell'onboarding. Per saperne di più, vedi Configurare l'estensione Data Agent Kit per VS Code.
- Dopo il ricaricamento dell'IDE, fai clic sull'icona Google Data Cloud nel riquadro di navigazione, vai alle impostazioni e assicurati di aver impostato correttamente l'ID progetto e la regione (
us-west1) nelle impostazioni comuni.
Configurare lo spazio di lavoro in VS Code
- Apri VS Code e seleziona File > Apri cartella > Nuova cartella.
- Crea una nuova cartella denominata
acai_teste poi fai clic su Apri. VS Code ora considera la cartella che hai aperto come uno spazio di lavoro. - Nella finestra di dialogo Affidabilità dello spazio di lavoro, seleziona Sì, mi fido degli autori per attivare tutte le funzionalità dello spazio di lavoro.
- Crea una cartella
.githubnello spazio di lavoroacai_test. - Crea un nuovo file
copilot-instructions.mdnella cartella.githube inserisci le seguenti regole.## 1. Project Context - **Project ID**: <PROJECT_ID> - **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors. - **Documentation**: Raw PDF documents detailing flavors and ingredients are stored in Google Cloud Storage at `gs://<BUCKET_NAME>`. ## 2. Execution & Data Processing Rules - **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `<BQ_DATASET_NAME>` (referred to as the Knowledge Catalog). - **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the dataset `<DATASET_ID>`. When you are referencing a dataset, ensure you are using it with the project ID (`<PROJECT_ID>`) and namespace prefix `<NAMESPACE_NAME>`. For example, to query order table in this dataset you should use `<PROJECT_ID>.<NAMESPACE>.<DATASET_ID>.orders`. - **CRITICAL RULE - Data Joins between BigQuery dataset and Iceberg dataset**: ANY task requiring a join or integration between the BigQuery datasets `<DATASET_ID>` of the PDF data and the `<DATASET_ID>` of the customer data MUST be executed using **Spark Notebooks**. - **CRITICAL RULE - Notebook Kernel**: Every Spark notebook utilized MUST exclusively be configured to run on the Serverless Session template `iceberg-federation-template` as its kernel. - **CRITICAL RULE - Data Science**: ANY data science, machine learning, or advanced analytical task MUST be performed strictly within **Spark Notebooks** using the aforementioned setup. - Crea un altro nuovo file
template.yamlnello spazio di lavoroacai_teste inserisci le seguenti informazioni nel file.labels: client: "vscode" jupyterSession: displayName: "iceberg-federation-template" kernel: "PYTHON" environmentConfig: executionConfig: serviceAccount: "sa-spark-dev1@<PROJECT_ID>.iam.gserviceaccount.com" subnetworkUri: "projects/<PROJECT_ID>/regions/<REGION>/subnetworks/<SUBNET_NAME>" runtimeConfig: version: "2.3" properties: # This enables the secure proxy URL you were looking for dataproc.tier: "premium" spark.dataproc.engine: "lightningEngine" spark.dataproc.lightningEngine.runtime: "native" spark.memory.offHeap.enabled: "true" spark.memory.offHeap.size: "1g" spark.executor.memory: "4g" "dataproc.component.gateway.enabled": "true" "dataproc.jupyter.listen.all.interfaces": "true" "spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" "spark.sql.defaultCatalog": "<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>": "org.apache.iceberg.spark.SparkCatalog" "spark.sql.catalog.<CATALOG_NAME>.type": "rest" "spark.sql.catalog.<CATALOG_NAME>.uri": "<CATALOG_URI_ID>" "spark.sql.catalog.<CATALOG_NAME>.warehouse": "bl://projects/<PROJECT_ID>/catalogs/<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>.rest.auth.type": "org.apache.iceberg.gcp.auth.GoogleAuthManager" - In VS Code, fai clic su Terminale ed esegui questo comando per importare il file
template.yamlcome modello di sessione. Questo modello viene utilizzato in un secondo momento dall'agente per creare una sessione Spark.gcloud beta dataproc session-templates import iceberg-federation-template \ --source=template.yaml \ --location=<REGION>REGIONcon la tua regione.
12. Eseguire l'analisi dei dati agentica
- Nell'editor di codice di VS Code, fai clic su Attiva/disattiva chat.
- In Configura agenti personalizzati, seleziona Agente.
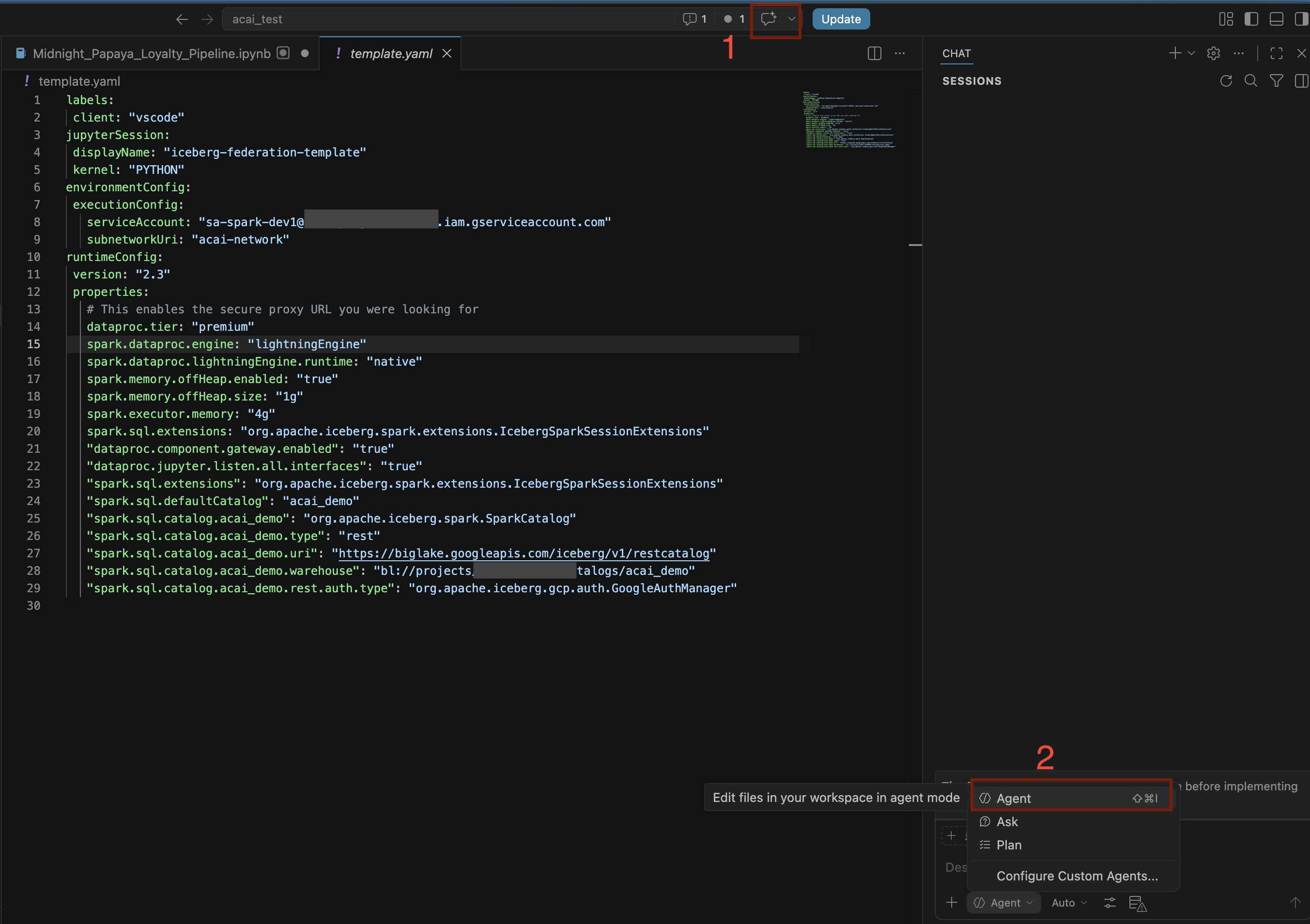
- Nel riquadro Modelli di ricerca, fai clic su Gestisci modelli linguistici.
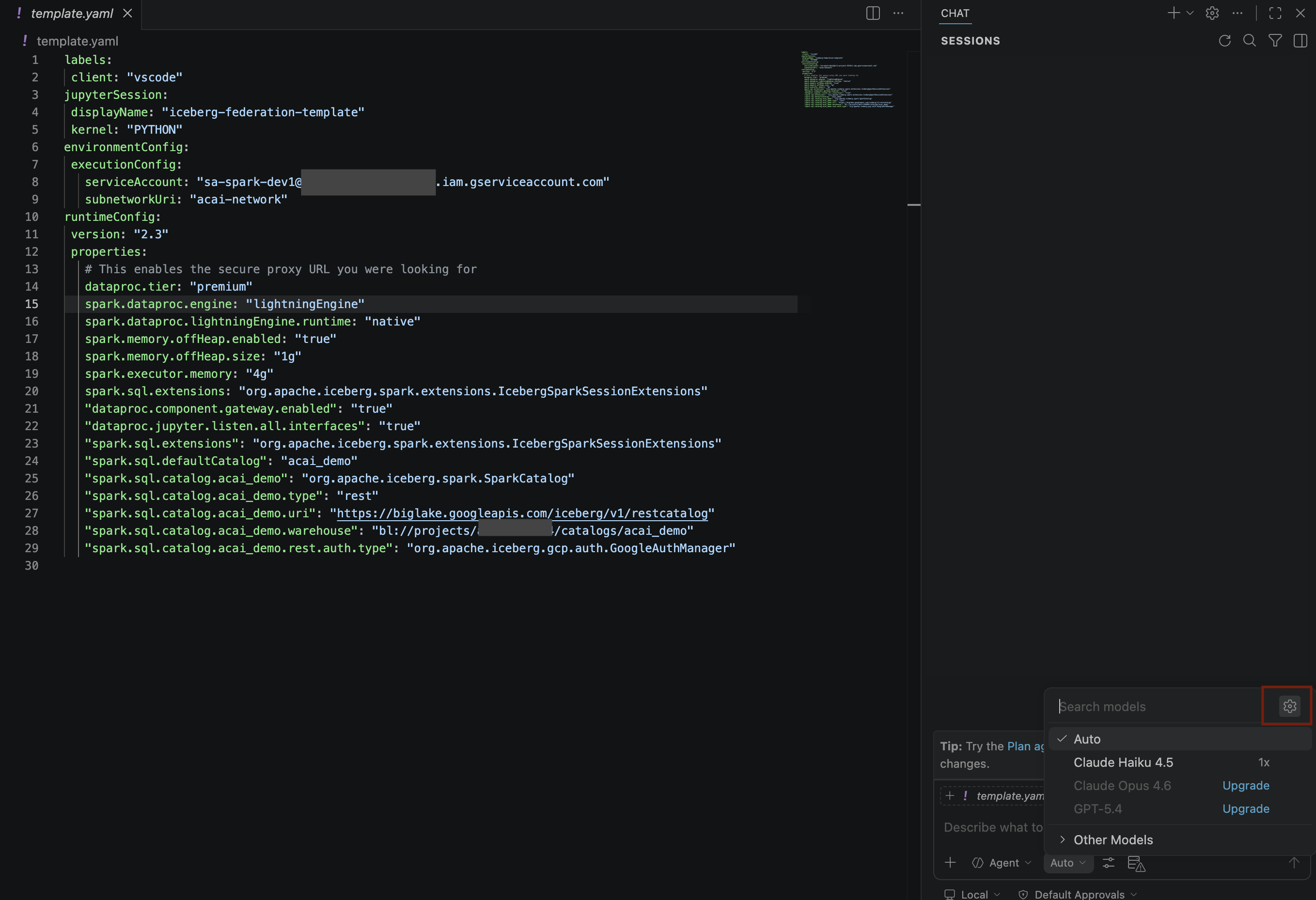
- Nella pagina Modelli linguistici, fai clic su Aggiungi modelli.
- Seleziona Google dall'elenco e premi Invio per confermare l'input.
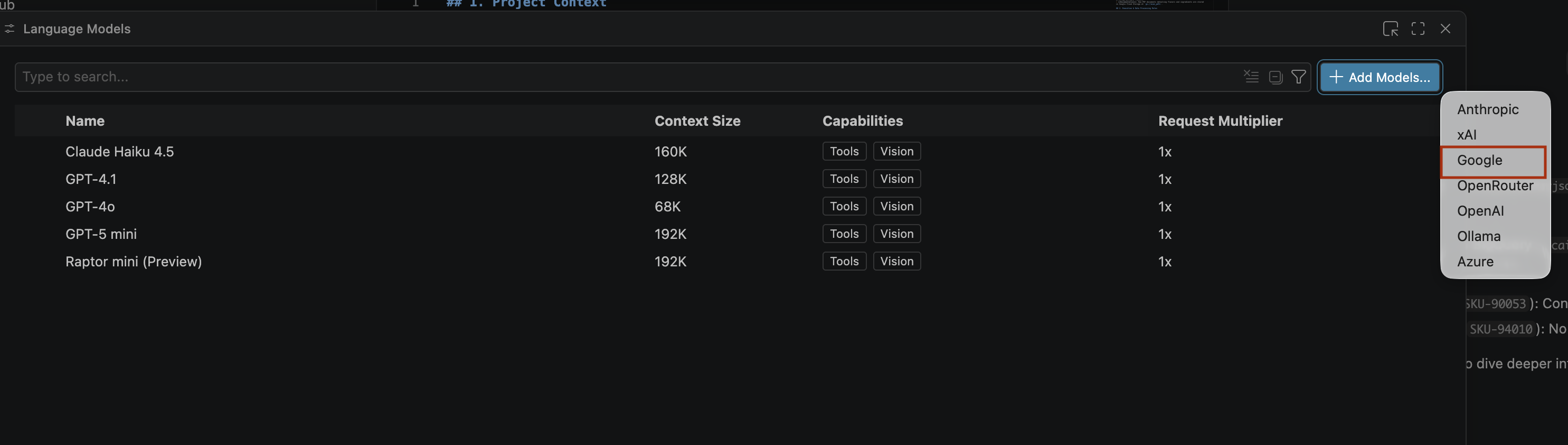
- Per inserire la chiave API per Google Gemini, procedi nel seguente modo:
- Vai al sito web di Google AI Studio.
- Accedi con il tuo Account Google.
- Nella barra laterale, fai clic su Ottieni chiave API.
- Fai clic su Crea chiave API. Si apre la pagina Crea una nuova chiave.
- Dall'elenco Seleziona un progetto cloud, seleziona Importa progetto.
- Inserisci il nome di un progetto esistente.
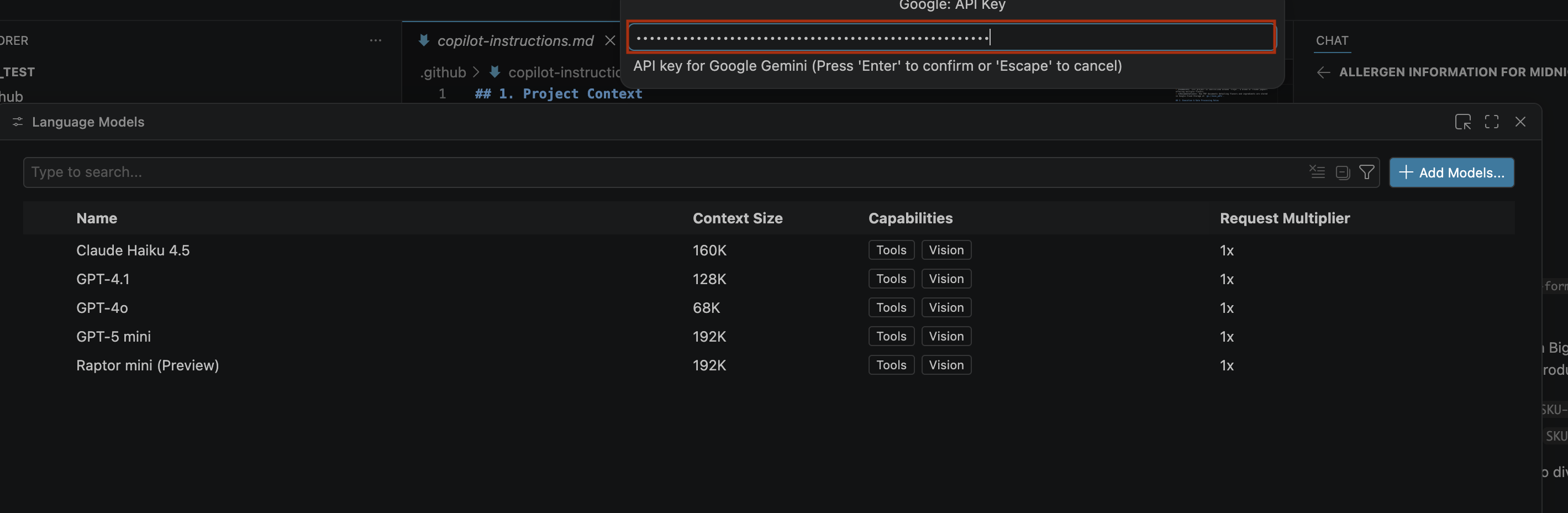
- Fai clic su Crea chiave e copia la chiave API. La chiave fornisce l'accesso alle risorse dell'API Gemini del tuo account.Per saperne di più, consulta Utilizzo delle chiavi API Gemini.
- Incolla la chiave API che hai generato nella barra di ricerca e fai clic su Invio.
- Se i modelli Gemini non vengono visualizzati, mostrali come illustrato nell'immagine seguente:
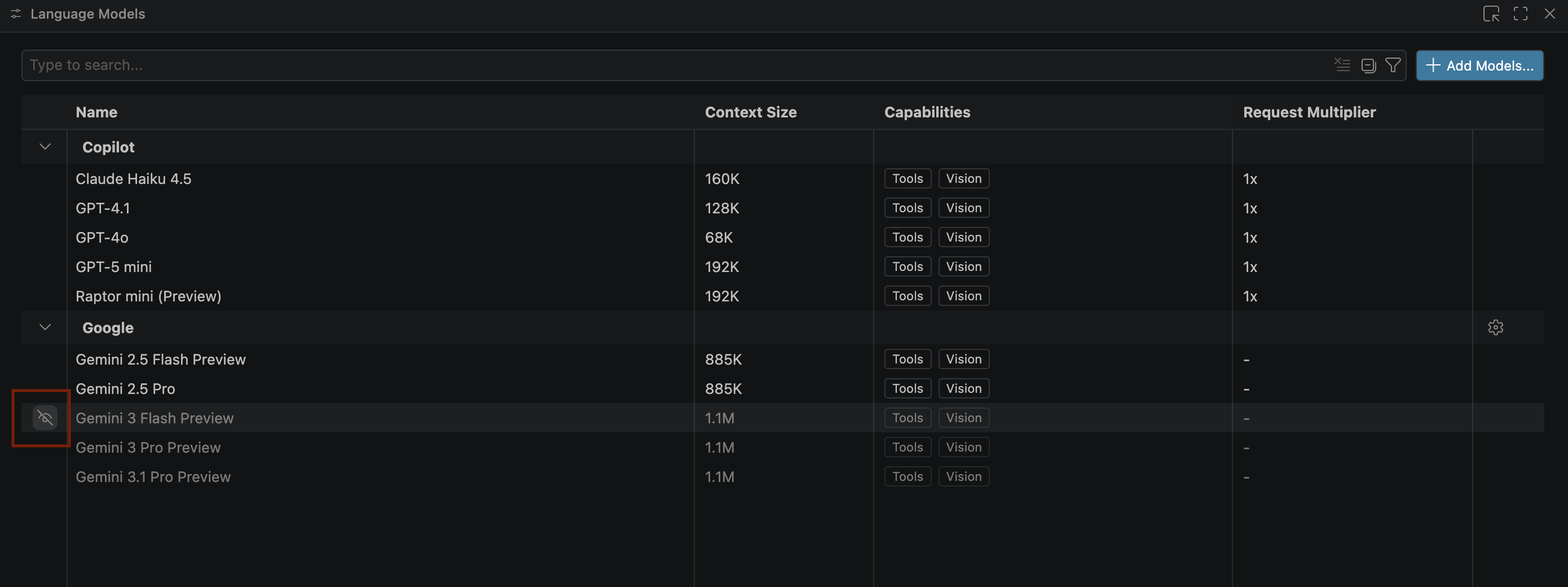
- Seleziona Anteprima di Gemini 3.1 Pro dall'elenco dei modelli Google Gemini e chiudi la finestra Modelli linguistici.
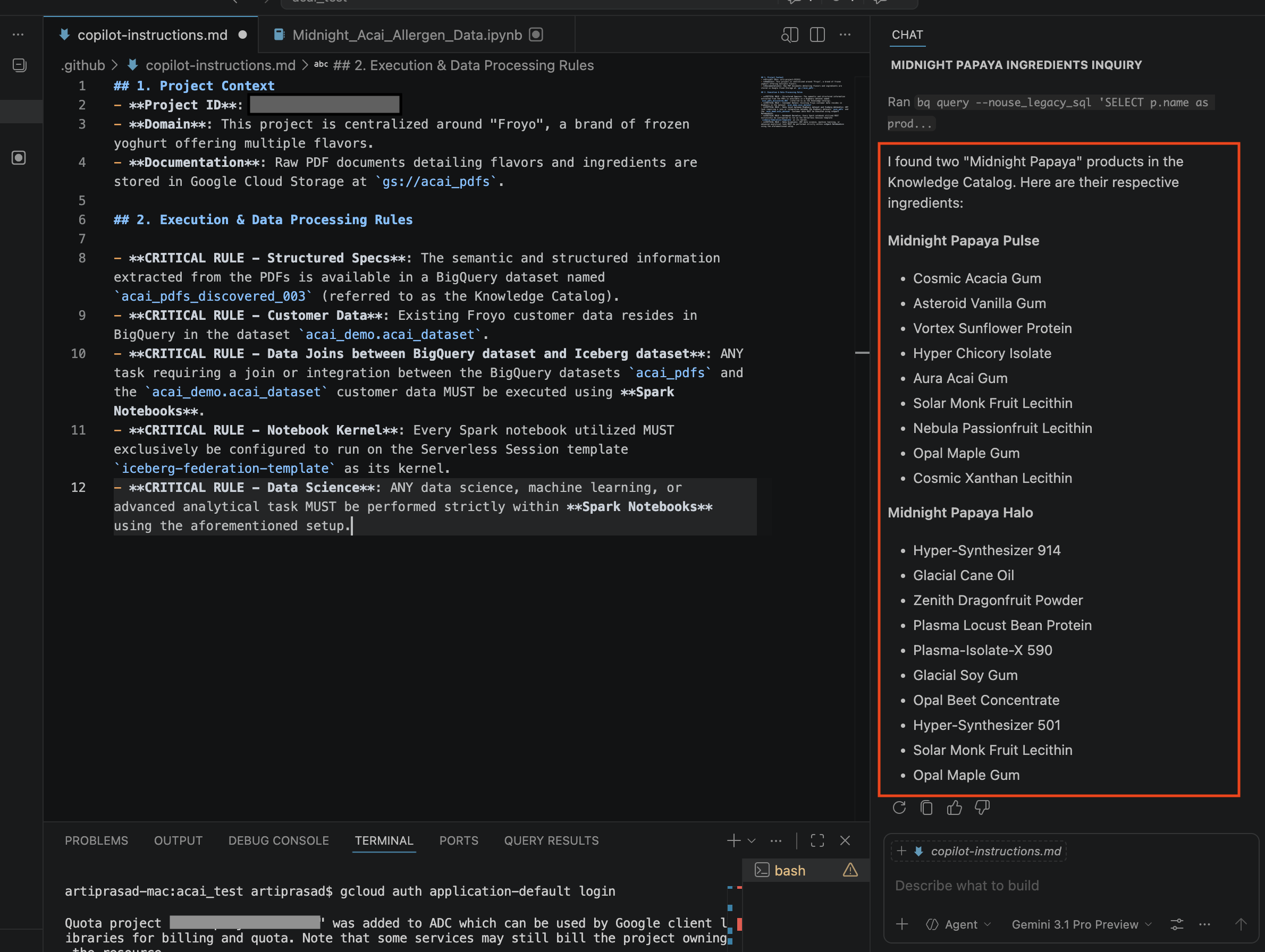
- Nella finestra della chat, inserisci la seguente domanda:
Search ingredients for Midnight papaya - Dopo alcune interazioni, dovresti vedere il seguente risultato:
- Nella finestra della chat, inserisci un'altra domanda:
Search allergen information for Midnight papaya - Dopo alcune interazioni e passaggi, l'agente risponderà con il nome dell'allergene
Soy, come puoi vedere nell'immagine seguente: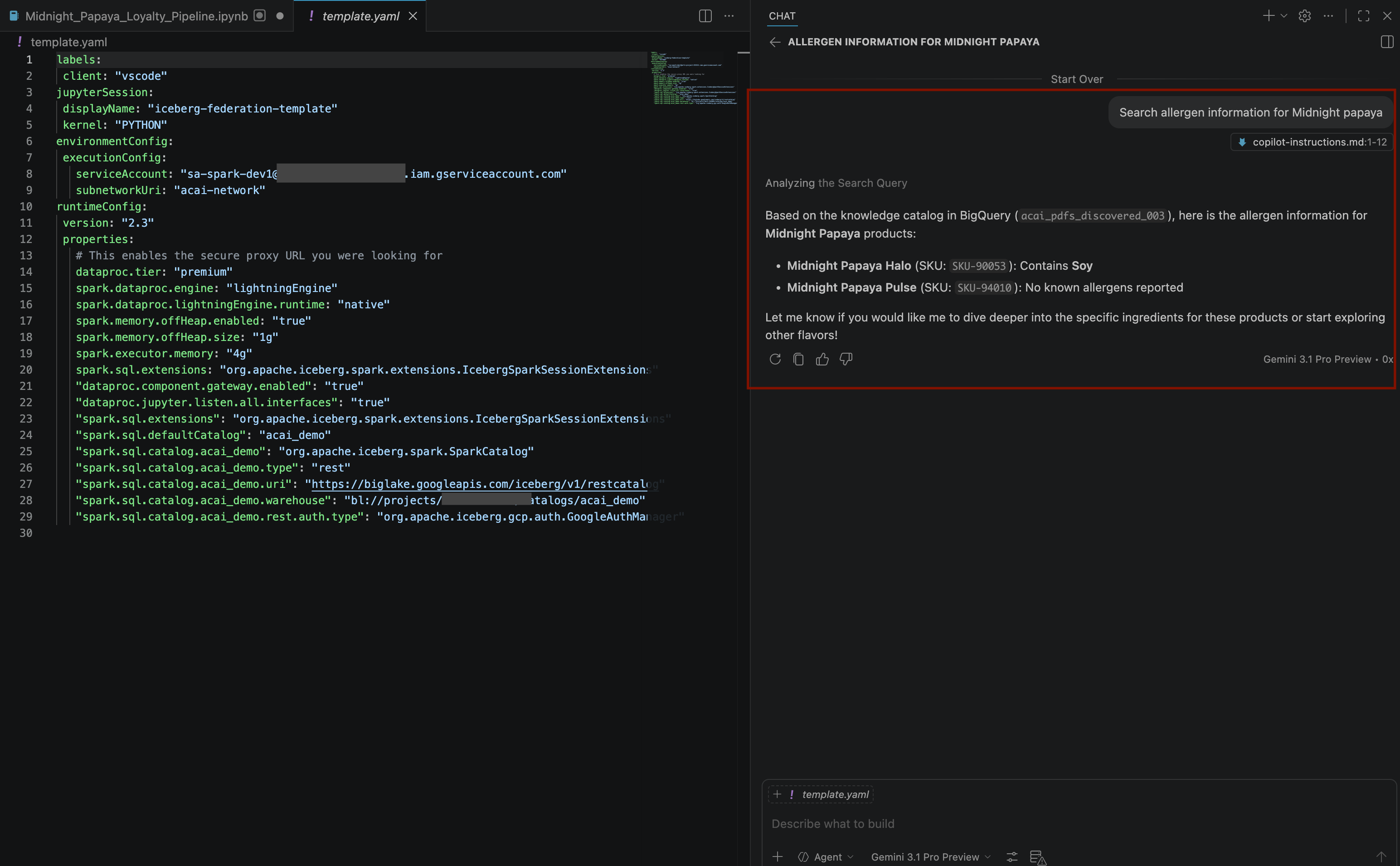
- Nella finestra della chat, inserisci un'altra domanda:
Build a pipeline to join products with our 'Global Loyalty' Iceberg tables in acai customer, sales data to identify popular products - Per selezionare il kernel, apri il file
.ipynbe fai clic su Seleziona kernel > Kernel Spark remoti > Iceberg-federation-template su Spark serverless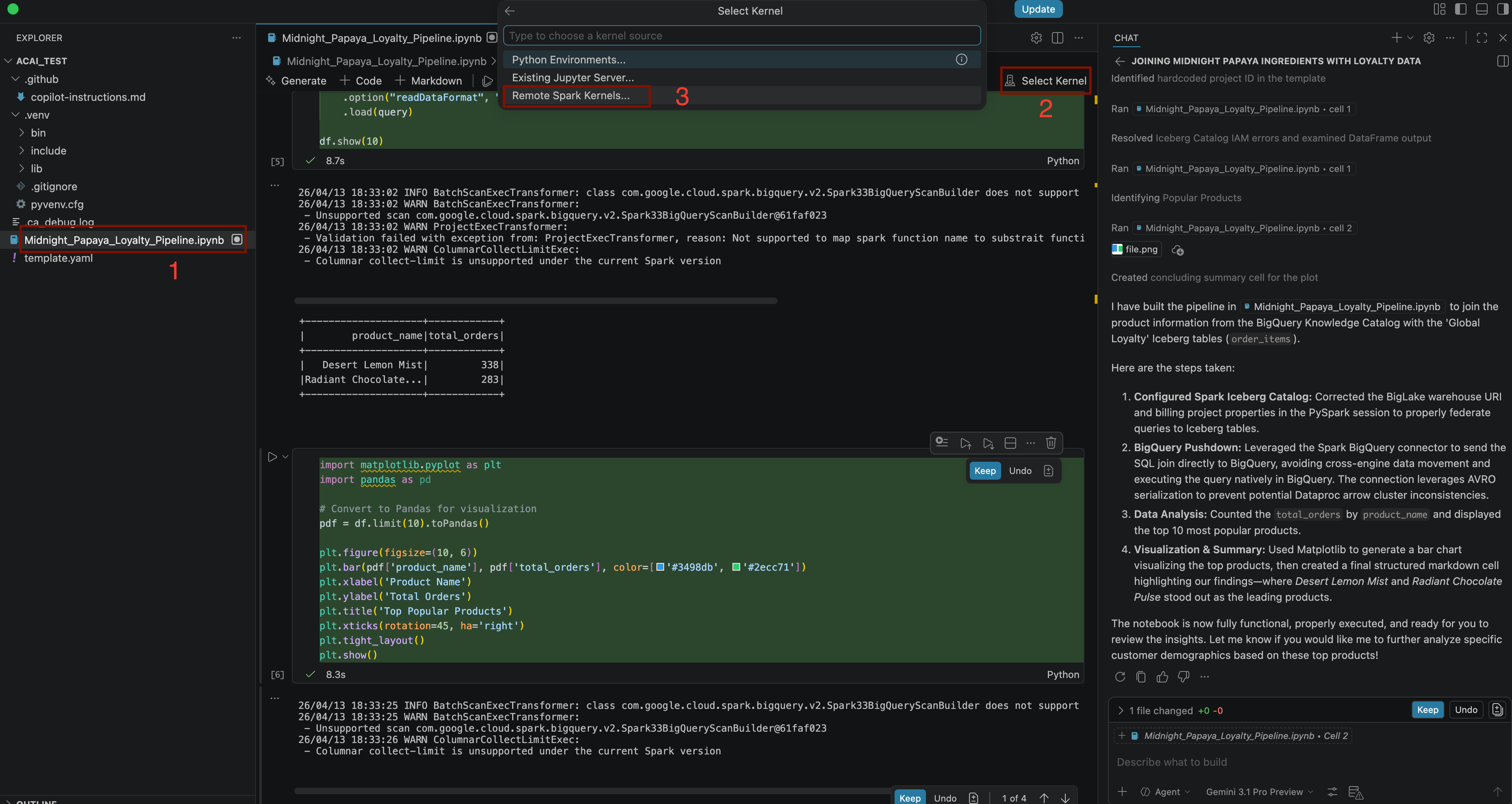
- Dopo alcune interazioni e passaggi, vedrai l'agente rispondere con tutti i passaggi del notebook eseguiti correttamente, insieme al risultato finale generato alla fine del notebook, come puoi vedere nell'immagine seguente:
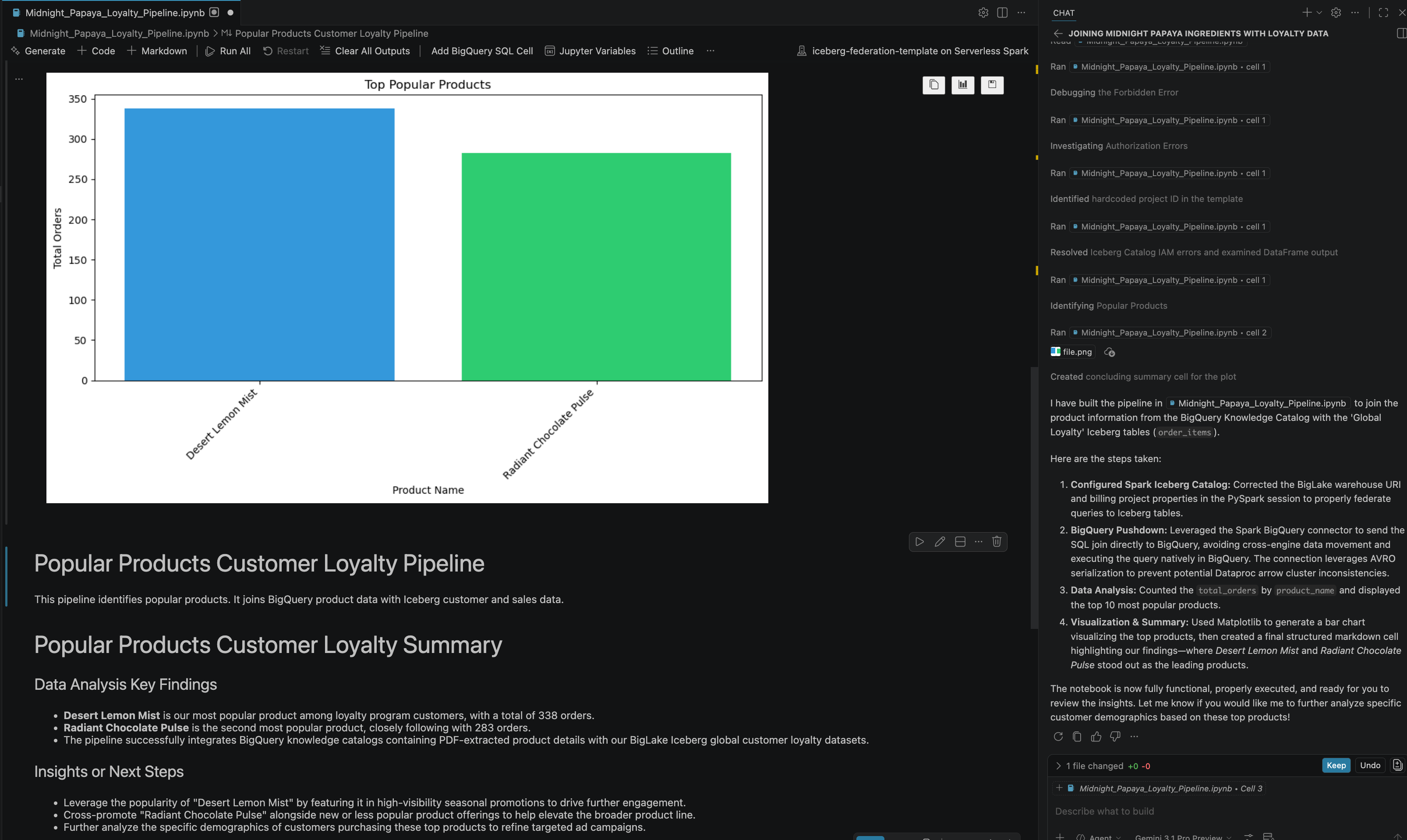
13. Esegui la pulizia
Per evitare che ti vengano addebitati dei costi, elimina le risorse che hai creato in questo lab.
- Per eliminare Knowledge Catalog DataScan, esegui questo comando:
DATASCAN_ID="<DATASCAN_ID>" echo "Deleting Dataplex DataScan: ${DATASCAN_ID}" gcloud dataplex datascans delete "${DATASCAN_ID}" --location="${REGION}" --quiet - Per eliminare i bucket Cloud Storage e tutti i relativi contenuti, esegui questo comando:
echo "Deleting Cloud Storage buckets: <BUCKET_NAME1> and <BUCKET_NAME2>" gsutil -m rm -r gs://<BUCKET_NAME1> gsutil -m rm -r gs://<BUCKET_NAME2> - Per eliminare la connessione BigQuery, esegui questo comando:
CONNECTION_ID="<CONNECTION_NAME>" echo "Deleting BigQuery Connection: ${CONNECTION_ID}" bq rm --connection "${PROJECT_ID}.${REGION}.${CONNECTION_ID}" - Per eliminare Lakehouse Catalog, esegui questo comando:
CATALOG_ID="<CATALOG_NAME>" echo "Deleting Lakehouse Catalog: ${CATALOG_ID}" gcloud biglake catalogs delete "${CATALOG_ID}" --project="${PROJECT_ID}" --location="${REGION}" --quiet - Per eliminare il set di dati contenente le tabelle PDF rilevate, esegui questo comando:
DATASET_NAME="<DATASET_NAME>" echo "Deleting BigQuery Dataset: ${DATASET_NAME}" bq rm -r -f "${PROJECT_ID}:${DATASET_NAME}" - Per eliminare il service account personalizzato, esegui questo comando:
SERVICE_ACCOUNT="<SERVICE_ACCOUNT>" echo "Deleting Service Account: ${SERVICE_ACCOUNT}" gcloud iam service-accounts delete "${SERVICE_ACCOUNT}"@"${PROJECT_ID}".iam.gserviceaccount.com --quiet - Per eliminare la rete VPC, esegui questo comando:
VPC_NETWORK="<VPC_NETWORK>" echo "Deleting VPC Network: ${VPC_NETWORK}" gcloud compute networks delete "${VPC_NETWORK}" --quiet - Per eliminare l'intero progetto Google Cloud, esegui questo comando:
gcloud projects delete "${PROJECT_ID}"
14. Complimenti
Complimenti! Hai organizzato correttamente il panorama dei dati di PDF e file Parquet isolati in tabelle BigQuery e li hai raggruppati in un unico ecosistema ricercabile e unibile. In sostanza, hai creato un moderno data lakehouse che tratta i PDF e i formati di big data in modo intelligente come tratta una riga di un database. E hai fatto tutto questo direttamente dal tuo agente in un'esperienza conversazionale con Gemini.
Documenti di riferimento
Per approfondire le tecnologie di base utilizzate in questo codelab, consulta la documentazione ufficiale di Google Cloud:
- Per esplorare BigQuery, un componente principale di Data Cloud, consulta la documentazione di BigQuery.
- Per saperne di più su IAM, consulta la documentazione di IAM.
- Per scoprire di più su Lakehouse, consulta Che cos'è Lakehouse?