
1. はじめに
この Codelab では、架空の Froyo 会社で「Midnight Swirl」という新製品のフレーバーを発売するデータ サイエンティストの役割を担います。グローバル リリースを成功させるには、成分、市場の需要、投資収益率(ROI)に関する重要な質問に答える必要があります。このエンドツーエンドのワークフローでは、Google Cloud の Knowledge Catalog(旧称 Dataplex)と Lakehouse for Apache Iceberg(旧称 BigLake)が、統合されたガバナンス レイヤを介して IDE(VS Code)で Gemini を使用し、「ダーク」な非構造化データと実用的なビジネス インテリジェンスのギャップを埋める方法を示します。
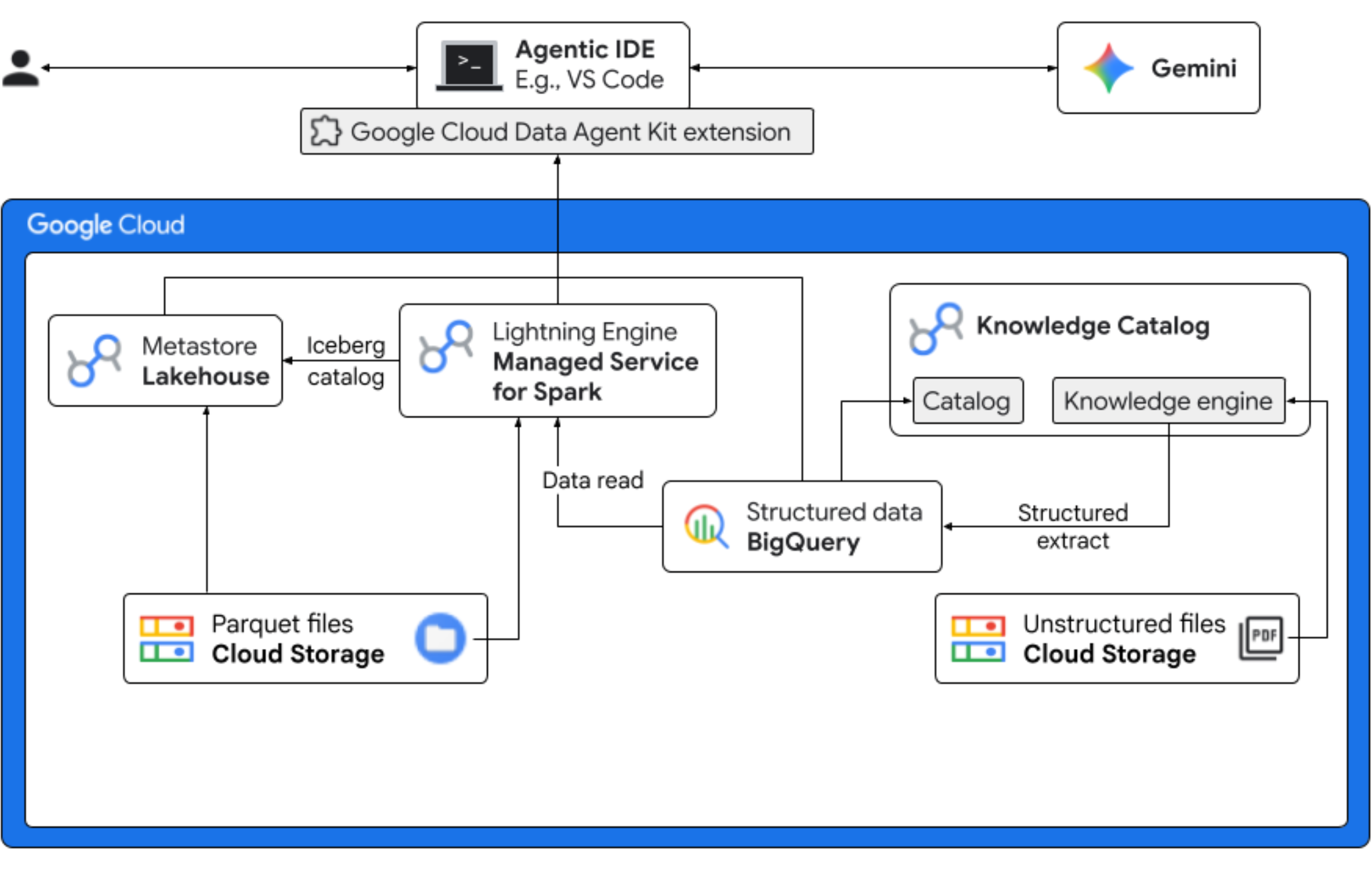
演習内容
- 非構造化検出: Cloud Storage に保存されている PDF レシピは、Knowledge Catalog DataScan によってクロールされます。スキャンした PDF の BigQuery にオブジェクト テーブルを作成します。Vertex AI Semantic Inference を使用して、システムは PDF を「読み取り」、商品、アレルゲン、成分、関連する属性の構造化された情報を抽出します。次に、PDF に保存されているデータのスキーマをインテリジェントに生成します。
- 統合メタデータ: PDF ファイルから抽出されたデータは、ネイティブのワイド テーブルとして BigQuery に直接保存され、一般的なクエリを支援するためにビューが作成されます。過去の販売データを含む独立した入力データセットが、Google Cloud Storage の Apache Iceberg テーブルに保存されています。この Iceberg テーブルは、後続のステップで BigQuery の抽出データと結合されます。
- クロスエンジン分析: Managed Service for Apache Spark(旧称 Dataproc)と Iceberg REST Catalog を使用して、この新しい PDF メタデータと推論された構造化セマンティック データ(BigQuery テーブルとビューから)を、Google Cloud Storage の Apache Iceberg テーブルに保存されている構造化された販売データと結合します。これは、Jupyter Notebook カーネルとして使用される Managed Apache Spark インタラクティブ セッション テンプレートによって制御され、Spark ジョブの一貫したセキュリティ設定とコンピューティング設定が保証されます。
- セマンティック分析情報: 推論された商品データを顧客データや販売データ(BigQuery 内)と結合することで、アレルゲン データの特定や収益予測などの分析情報を抽出できます。
- 自律型ガバナンス: 検出スキャンから Spark 実行まで、ライフサイクル全体が Gemini 対応のテンプレート、手順、ルール、エージェント駆動の自動化によってオーケストレートされ、AI が分析を支えるインフラストラクチャを管理できることが証明されています。
必要なもの
この Codelab を完了すると、費用が発生する可能性があります。一般的な使用量の場合、費用は $5 未満と推定されます。予想使用量または現在の料金に基づいて詳細な費用の見積もりを取得するには、Google Cloud 料金計算ツールを使用します。
この Codelab を完了するには、次の前提条件を満たしていることを確認してください。
- Chrome ウェブブラウザ。
- 「始める前に」セクションで提供されているトライアル クレジットを使用している場合は、個人の Gmail アカウント。
- Visual Studio(VS)Code をダウンロードしてインストールします。
2. 始める前に
Google Cloud プロジェクトの作成
- Google Cloud コンソールのプロジェクト セレクタ ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
Cloud Shell の起動
Cloud Shell は、必要なツールがプリロードされた Google Cloud で動作するコマンドライン環境です。
- Google Cloud コンソールの上部にある [Cloud Shell をアクティブにする] をクリックします。
- Cloud Shell に接続したら、認証を確認します。
gcloud auth list - プロジェクトが構成されていることを確認します。
gcloud config get project - プロジェクトが想定どおりに設定されていない場合は、設定します。
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
必要な API の有効化
次のコマンドを実行して、必要な API をすべて有効にします。
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
biglake.googleapis.com \
dataproc.googleapis.com \
metastore.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
secretmanager.googleapis.com \
storage.googleapis.com
Codelab のアセットをダウンロードする
このリポジトリには、この Codelab で使用する Parquet、レシピ、サプライヤー、copilot-instructions.md、template.yaml、quickstart.py ファイルが含まれています。これらのファイルをダウンロードしてください。
ファイルをダウンロードする手順は次のとおりです。
- Cloud Shell で、次のコマンドを実行します。
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git - 新しく作成したフォルダに移動します。
cd next-26-keynotes data-cloud-demoフォルダを pull するgit sparse-checkout set genkey/data-cloud-demo- チェックアウトが完了したら、
data-cloud-demoフォルダに移動して ZIP ファイルを解凍し、コードラボのアセットにアクセスします。
3. Froyo の顧客データ用に Lakehouse をセットアップ
このセクションでは、ワークフローで Lakehouse メタストアを使用するために、Lakehouse にカタログを作成します。すべての Iceberg データに関して単一の信頼できる情報源を提供することで、クエリエンジン間の相互運用性を実現します。これにより、Apache Spark などのクエリエンジンは、Iceberg テーブルを検出してメタデータを読み取り、一貫した方法で管理できます。
必要なロール
次の Identity and Access Management(IAM)ロールがあることを確認します。
roles/biglake.viewerroles/bigquery.userroles/bigquery.dataEditorroles/biglake.editorroles/biglake.metadataViewerroles/bigquery.connectionUserroles/storage.objectUserroles/storage.objectViewerroles/storage.objectCreatorroles/storage.admin
IAM ロールの付与の詳細については、IAM ロールを付与するをご覧ください。
バケットを使用して Lakehouse カタログを作成する
Iceberg テーブルのメタデータを管理する Lakehouse カタログを作成します。Spark ジョブでこのカタログに接続して、Iceberg テーブルを作成してクエリを実行します。
- Google Cloud コンソールで、[Lakehouse] に移動します。
- [カタログを作成] をクリックします。[カタログの作成] ページが開きます。
- [カタログタイプ] で、[Iceberg Rest カタログ] を選択します。
- [Lakehouse カタログ バケットのオプションを選択する] で、[単一バケット カタログ] を選択します。
- [デフォルトのカタログ Cloud Storage バケット] で、[参照]、[新しいバケットを作成] の順にクリックします。
- [バケットの作成] ページで、次の操作を行います。
- [始める] セクションで、バケット名の要件を満たすグローバルに一意の名前を入力します。
- [データの保存場所の選択] セクションで、[ロケーション タイプ] として [リージョン] を選択し、リージョンを入力します。例:
us-west1 - [オブジェクトへのアクセスを制御する方法を選択する] セクションで、[このバケットに対する公開アクセス禁止を適用する] チェックボックスをオフにします。
これにより、公開ウェブ コンテンツや共有データ リポジトリのホスティングなどの実際のシナリオをシミュレートできます。この変更がないと、バケットは厳格な「非公開のみ」ポリシーを適用します。ファイルに一般公開権限を付与しても、アセットにアクセスしようとすると403権限なしエラーが発生します。 - [続行] > [作成] > [選択] > [続行] をクリックします。
- [認証方法] で、[認証情報ベンダーモード] を選択します。
- [作成] をクリックします。カタログが作成され、[カタログの詳細] ページが開きます。
- [認証方法] で、[バケットの権限を設定] をクリックします。
- ダイアログで [確認] をクリックします。これにより、カタログのサービス アカウントにストレージ バケットに対する
Storage Object Userロールがあることが確認されます。 - [カタログの詳細] ページで、REST カタログの URI パスをコピーします。このパスは、Spark ジョブの実行タスクで使用します。
Parquet ファイルをバケットにアップロードする
Parquet ファイルをバケットのルートにアップロードする手順は次のとおりです。
- Google Cloud コンソールで、[Cloud Storage バケット] ページに移動します。
- バケットのリストで、バケット名をクリックします。例:
acai_demo - バケットの [オブジェクト] タブで、[アップロード] > [ファイルをアップロード] をクリックします。
- この Codelab の「始める前に」セクションでクローンを作成した Parquet フォルダからファイルを選択します。
- [開く] をクリックします。
4. VPC ネットワークを設定する
リソースがパブリック インターネットにアクセスせずに Google API と通信できる Virtual Private Cloud(VPC)ネットワークとサブネット、およびデータ処理ノード間で内部トラフィックが自由に流れるようにするファイアウォールを作成します。
- Google Cloud コンソールの [VPC ネットワーク] ページに移動します。
- [VPC ネットワークを作成] をクリックします。
- ネットワークの名前を入力します。例:
acai-network - ネットワークの最大伝送単位(MTU)を構成するには、[MTU を自動的に設定] チェックボックスをオンにします。
- [サブネット作成モード] で [自動] を選択します。
- [ファイアウォール ルール] セクションで、[IPv4 ファイアウォール ルール] のチェックボックスをすべてオンにします。
- [作成] をクリックします。
限定公開の Google アクセスを有効にする
Dataproc Serverless ノードにはパブリック IP アドレスがありません。Lakehouse Catalog と Cloud Storage と通信するには、サブネットでプライベート Google アクセスを有効にする必要があります。
- Google Cloud コンソールの [VPC ネットワーク] ページに移動します。
- プライベート Google アクセスを有効にするサブネットが含まれるネットワークの名前をクリックします。例:
us-west1 - サブネットの名前をクリックします。[サブネット] の詳細ページが表示されます。
- [編集] をクリックします。
- [限定公開の Google アクセス] セクションで、[オン] を選択します。
- [保存] をクリックします。
5. Spark ジョブを作成して実行する
Iceberg テーブルを作成してクエリを実行するには、必要な Spark SQL ステートメントを含む PySpark ジョブをアップロードします。次に、Managed Service for Spark でジョブを実行します。
quickstart.py を Cloud Storage バケットにアップロードする
codelab アセットをクローンしたら、プロジェクトの詳細で quickstart.py スクリプトを更新し、Cloud Storage バケットにアップロードします。
- テキスト エディタで
quickstart.pyスクリプトを開きます。 - スクリプト内のプレースホルダ
BUCKET_NAMEを Cloud Storage バケット名に置き換えて保存します。 - Google Cloud コンソールで、[Cloud Storage バケット] に移動します。
- バケットの名前をクリックします。例:
acai_demo - [オブジェクト] タブで、[アップロード] > [ファイルをアップロード] をクリックします。
- ファイル ブラウザで、更新された
quickstart.pyファイルを選択し、[開く] をクリックします。
Spark ジョブを実行する
quickstart.py スクリプトをアップロードしたら、Managed Service for Spark バッチジョブとして実行します。
- 変数を構成するには、Cloud Shell で次のコマンドを実行します。
# Configuration Variables export PROJECT_ID="<PROJECT_ID>" export REGION="<REGION>" export BUCKET_NAME="<BUCKET_NAME>" export SUBNET="<SUBNET>" export LAKEHOUSE_CATALOG_ID="<LAKEHOUSE_CATALOG_ID>" export CATALOG_URI_ID="<CATALOG_URI_ID>"- LAKEHOUSE_CATALOG_ID: PySpark アプリケーション ファイルを含む Lakehouse カタログ リソースの名前。例:
acai_demo - PROJECT_ID: Google Cloud プロジェクト ID。
- REGION: Managed Service for Spark バッチ ワークロードを実行するリージョン。例:
us-west1 - BUCKET_NAME: Cloud Storage バケットの名前。例:
acai_demo - SUBNET: VPC サブネット名。例:
acai-network - CATALOG_URI_ID: バケットを使用して Lakehouse カタログを作成したときにコピーした Lakehouse カタログの URI ID。例:
https://biglake.googleapis.com/iceberg/v1/restcatalog
- LAKEHOUSE_CATALOG_ID: PySpark アプリケーション ファイルを含む Lakehouse カタログ リソースの名前。例:
- Cloud Shell で、
quickstart.pyスクリプトを使用して次の Managed Service for Spark バッチジョブを実行します。gcloud dataproc batches submit pyspark gs://${BUCKET_NAME}/quickstart.py \ --project=${PROJECT_ID} \ --region=${REGION} \ --subnet=${SUBNET} \ --version=2.2 \ --properties="\ spark.sql.defaultCatalog=${LAKEHOUSE_CATALOG_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}=org.apache.iceberg.spark.SparkCatalog,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.type=rest,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.uri=${CATALOG_URI_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.warehouse=gs://${BUCKET_NAME},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.io-impl=org.apache.iceberg.gcp.gcs.GCSFileIO,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.x-goog-user-project=${PROJECT_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\ spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest-metrics-reporting-enabled=false,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.X-Iceberg-Access-Delegation=vended-credentials,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token"All tables registered successfully! Batch [126fa2226a904d2e944c8eecbe0b1840] finished. metadata: '@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata batch: projects/PROJECT_ID/locations/REGION/batches/126fa2226a904d2e944c8eecbe0b1840 batchUuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff createTime: '2026-04-09T13:17:26.222727Z' description: Batch labels: goog-dataproc-batch-id: 126fa2226a904d2e944c8eecbe0b1840 goog-dataproc-batch-uuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-drz-resource-uuid: batch-3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-location: REGION operationType: BATCH name: projects/PROJECT_ID/regions/REGION/operations/47bc59e8-5082-3af9-89a0-22289aa5f4b9
6. BigQuery からテーブルに対してクエリを実行する
Spark バッチジョブを正常に実行することで、Managed Service for Spark Serverless を分散コンピューティング エンジンとして使用し、Lakehouse Metastore 内の Parquet ファイルごとに複数のテーブルを登録しました。この登録により、Google Cloud は Cloud Storage の未加工ファイルを構造化された高性能テーブルとして扱うことができます。
次の手順では、メタデータが正しく同期されていることを確認し、データが安全に保存されるだけでなく、BigQuery インターフェースを通じて完全に検出可能でクエリ可能であることを確認します。
- Google Cloud コンソールで [BigQuery] に移動します。
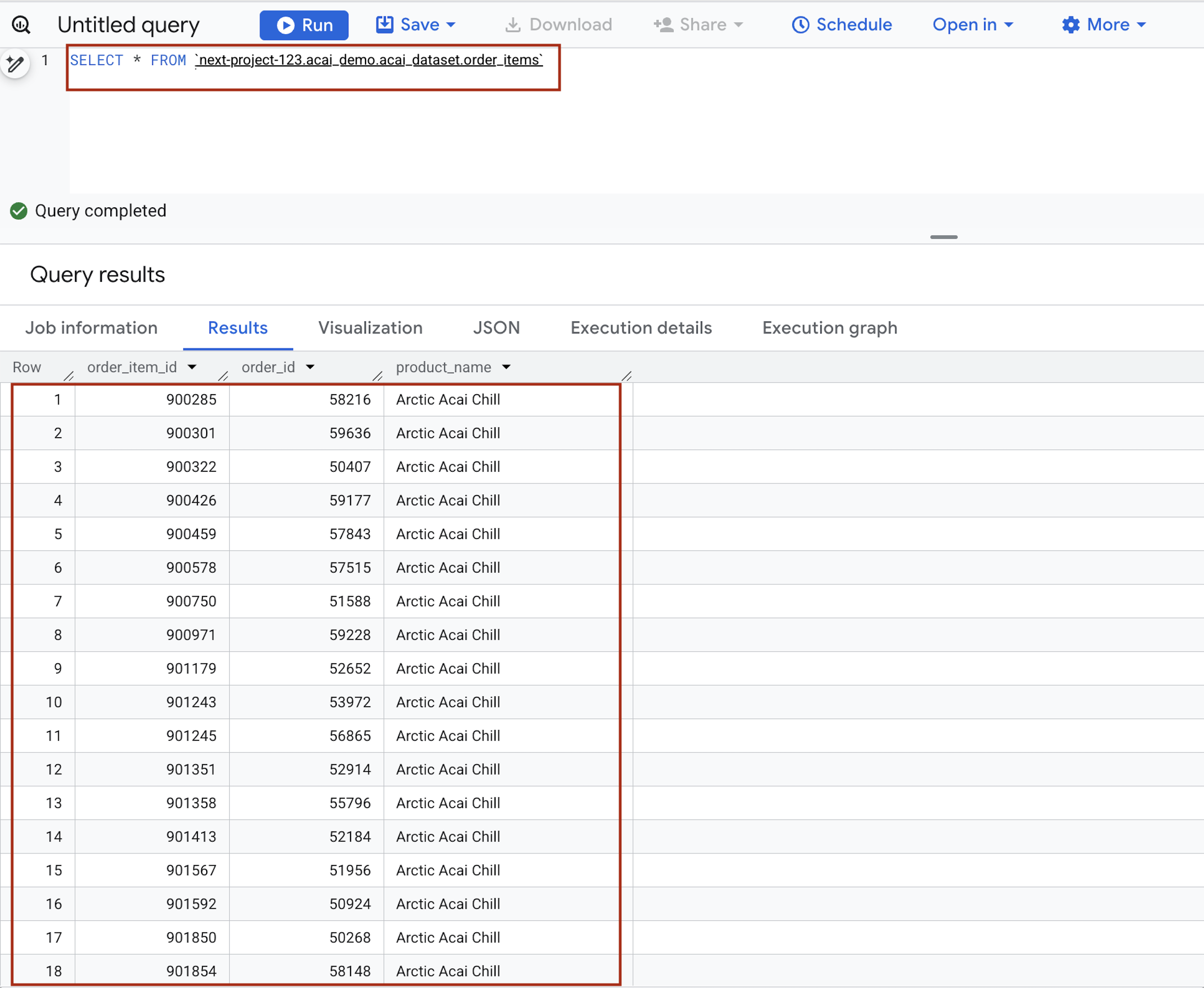
- クエリエディタで次のステートメントを入力します。このクエリでは
project.namespace.dataset.table構文を使用します。SELECT * FROM `<PROJECT_ID>.<NAMESPACE>.<ICEBERG_DATASET>.<ICEBERG_TABLE>`PROJECT_ID.acai_demo.acai_dataset.order_items.
です。次のように置き換えます。- PROJECT_ID: Google Cloud プロジェクト ID。
- NAMESPACE: 前の手順で Spark ジョブの結果として作成された Namespace。BigQuery オブジェクト エクスプローラ ページで確認できます。例:
acai_demo - ICEBERG_DATASET: Iceberg カタログ内のデータセット名(
acai_datasetなど)。 - ICEBERG_TABLE: Iceberg データセット内のテーブル名(例:
order_items)。
- [実行] をクリックします。クエリ結果には、Spark ジョブで挿入したデータが表示されます。
7. 非構造化商品データファイルを設定する
このセクションでは、BigQuery 内に組織構造を作成して、Froyo のレシピとサプライヤーのデータ(特に Froyo 製品の詳細)を保存します。また、Cloud リソース接続も確立します。これは、BigQuery が Cloud Storage などの外部ソースからファイルを読み取ることができる安全な「ブリッジ」として機能します。
バケットを作成して Froyo の詳細ファイルをアップロードする
サプライヤー ファイルとレシピ ファイルを作成して、Cloud Storage バケットにアップロードします。
- Google Cloud コンソールで、[Cloud Storage バケット] ページに移動します。
- [作成] をクリックします。
- [バケットの作成] ページでユーザーのバケット情報を入力します。以下のステップでは、操作を完了した後に [続行] をクリックして、次のステップに進みます。
- [始める] セクションで、バケット名を入力します。例:
acai_pdfs - [データの保存場所の選択] セクションで、[リージョン] を選択し、リージョンを入力します。例:
us-west1 - [オブジェクトへのアクセスを制御する方法を選択する] セクションで、[このバケットに対する公開アクセス禁止を適用する] チェックボックスをオフにします。
- [作成] をクリックします。
- バケットのリストで、作成したバケットをクリックします。例:
acai_pdfs - バケットの [オブジェクト] タブで、[アップロード] > [フォルダをアップロード] をクリックします。
- この Codelab の「始める前に」セクションで抽出した
recipesフォルダを選択します。 - [アップロード] をクリックします。
suppliersフォルダについてもアップロードの手順を繰り返します。
接続を作成する
Cloud リソース接続を作成します。これにより、外部ファイルにアクセスするための BigQuery の「ID カード」として機能する一意のサービス アカウントが生成されます。
- [BigQuery] ページに移動します。
- 左側のペインで、[エクスプローラ] をクリックします。左側のペインが表示されていない場合は、[左ペインを開く] をクリックしてペインを開きます。
- [エクスプローラ] ペインで、プロジェクト名を開き、[接続] をクリックします。
- [接続] ページで、[接続を作成] をクリックします。
- [接続] タイプで、[Vertex AI リモートモデル、リモート関数、BigLake、Spanner(Cloud リソース)] を選択します。
- [接続 ID] フィールドに、接続 ID の名前を入力します。例:
acai_pdf_connectionこの ID は、この Codelab の後半でデータスキャンを設定する際に必要になるため、メモしておいてください。 - [ロケーション タイプ] を [リージョン] に設定し、リージョンを選択します。例:
us-west1。この接続は、データセットなどの他のリソースと同じロケーションに配置する必要があります。 - [接続を作成] をクリックします。
- [接続へ移動] をクリックします。
- [接続情報] ペインで、以降の手順で使用するサービス アカウント ID をコピーします。サービス アカウントは
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.comのようになります。
サービス アカウントに対するアクセス権の管理
Lakehouse が PDF を読み取れるように、サービス アカウントへのアクセス権を付与します。
- [IAM と管理] ページに移動します。
- [アクセス権を付与] をクリックします。[プリンシパルを追加] ダイアログが開きます。
- [新しいプリンシパル] フィールドに、前の手順でコピーしたサービス アカウント ID を入力します。
- [ロールを選択] フィールドで、次のロールを追加します。
roles/storage.objectUserroles/storage.objectViewerroles/bigquery.userroles/bigquery.dataEditorroles/aiplatform.userroles/storage.adminroles/dataproc.serviceAgent
- [保存] をクリックします。
BigQuery での IAM のロールの詳細については、事前定義ロールと権限をご覧ください。
8. DataScan ジョブの権限を管理する
Spark と Dataform 用に特定のサービス アカウント(ID)を作成し、それらのアカウントと Google の自動サービス エージェントに、ストレージの読み取り、BigQuery ジョブの実行、検出のための Vertex AI の使用に必要な正確な権限を付与します。
Spark と Dataform の IAM アクセス
- Google Cloud コンソールで [サービス アカウントの作成] ページに移動します。
- 選択されていない場合は、Google Cloud プロジェクトを選択します。
- [サービス アカウントを作成] をクリックします。
- サービス アカウント名を入力します。(例:
sa-spark-stg1)。この名前に基づいてサービス アカウント ID が生成され、Google Cloud コンソールに表示されます。必要に応じて ID を編集します。後で ID を変更することはできません。 - アクセス制御を設定するには、[作成して続行] をクリックして次の手順に進みます。
- プロジェクトのサービス アカウントに付与する次の IAM ロールを選択します。
roles/dataproc.workerroles/storage.objectUserroles/bigquery.dataEditorroles/bigquery.jobUserroles/aiplatform.userroles/dataplex.discoveryPublishingServiceAgent
- ロールの追加が完了したら、[続行] をクリックします。
- [完了] をクリックして、サービス アカウントの作成を完了します。
Knowledge Catalog にアクセスするための BigQuery 接続権限
- Google Cloud コンソールで、[Cloud Storage バケット] ページに移動します。
- バケットのリストで、Froyo 用に作成したバケット名をクリックします。例:
acai_pdfs - [権限] タブで、[アクセス権を付与] をクリックします。[プリンシパルを追加] ダイアログが表示されます。
- [新しいプリンシパル] フィールドに、BigQuery サービス アカウント ID を入力します。サービス アカウントは
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.comのようになります。 - [ロールを選択] プルダウン メニューから、次のロールを選択します。
roles/storage.objectUserroles/dataplex.serviceAgentroles/dataplex.securityAdminroles/aiplatform.serviceAgentroles/dataplex.discoveryPublishingServiceAgent
- [保存] をクリックします。
9. Knowledge Catalog を設定する
Knowledge Catalog を構築して、Froyo 関連データを統合し、非構造化ファイル(PDF レシピや PDF サプライヤーなど)の検出を自動化します。
curl を使用して DataScan を作成する
このセクションでは、datascan_ID を追加して BigQuery データセットを指すようにすることで、Cloud Storage バケット(acai_pdfs など)のスキャンを作成します。その後、Knowledge Catalog は BigQuery で PDF のエントリを自動的に作成します。
- PDF(サプライヤーとレシピ)をスキャンするには、次のコマンドを実行します。
# 1. Set your variables PROJECT_ID="<PROJECT_ID>" REGION="<REGION>" ENV_SUFFIX="stg1" DATASCAN_ID="froyo-profile-${ENV_SUFFIX}" BUCKET_NAME="<BUCKET_NAME>" # 2. Set this to the Name of the connection you created in Step 7 CONNECTION_ID="<CONNECTION_ID_NAME>" # 3. Define the API Endpoint DATAPLEX_API="dataplex.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}" # 4. Create the DataScan via CURL echo "Creating Dataplex DataScan: ${DATASCAN_ID}..." curl -X POST "https://$DATAPLEX_API/dataScans?dataScanId=${DATASCAN_ID}" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d '{ "data": { "resource": "//storage.googleapis.com/projects/'"${PROJECT_ID}"'/buckets/'"${BUCKET_NAME}"'" }, "executionSpec": { "trigger": { "on_demand": {} } }, "dataDiscoverySpec": { "bigqueryPublishingConfig": { "tableType": "BIGLAKE", "connection": "projects/'"${PROJECT_ID}"'/locations/'"${REGION}"'/connections/'"${CONNECTION_ID}"'" }, "storageConfig": { "unstructuredDataOptions": { "entity_inference_enabled": true } } } }' curlコマンドは、次の図のような Knowledge Catalog DataScan の結果を表示します。
ジョブを実行する
次のコマンドを実行します。
gcloud dataplex datascans run $DATASCAN_ID --location=$REGION
ジョブの説明
ジョブの説明を取得するには、次のコマンドを実行します。
gcloud dataplex datascans describe $DATASCAN_ID --location=$REGION
データスキャン ジョブを削除する
スキャンが 10 分以上実行される場合や、ジョブのステータスが 実行中に移行せずに 保留中のまま長時間経過する場合は、リージョンでリソースが一時的に利用できなくなっている可能性があります。この場合は、次のコマンドを実行してジョブを削除し、もう一度作成して実行してみてください。初回実行が unable to acquire necessary resources などのエラーで直ちに失敗することがあります。
gcloud dataplex datascans delete $DATASCAN_ID --location=$REGION
ジョブのステータスを表示する
ジョブのステータスを確認する手順は次のとおりです。
- Google Cloud コンソールで、[メタデータのキュレーション] ページに移動します。
- [Cloud Storage 検出] タブで、検出スキャンの名前をクリックします。
- [スキャンの詳細] ページで、ジョブのステータスを確認できます。
- ジョブが完了したら、
curlコマンドを使用して作成した公開データセット(acai_pdfs_discovered_003など)が存在するかどうかを確認します。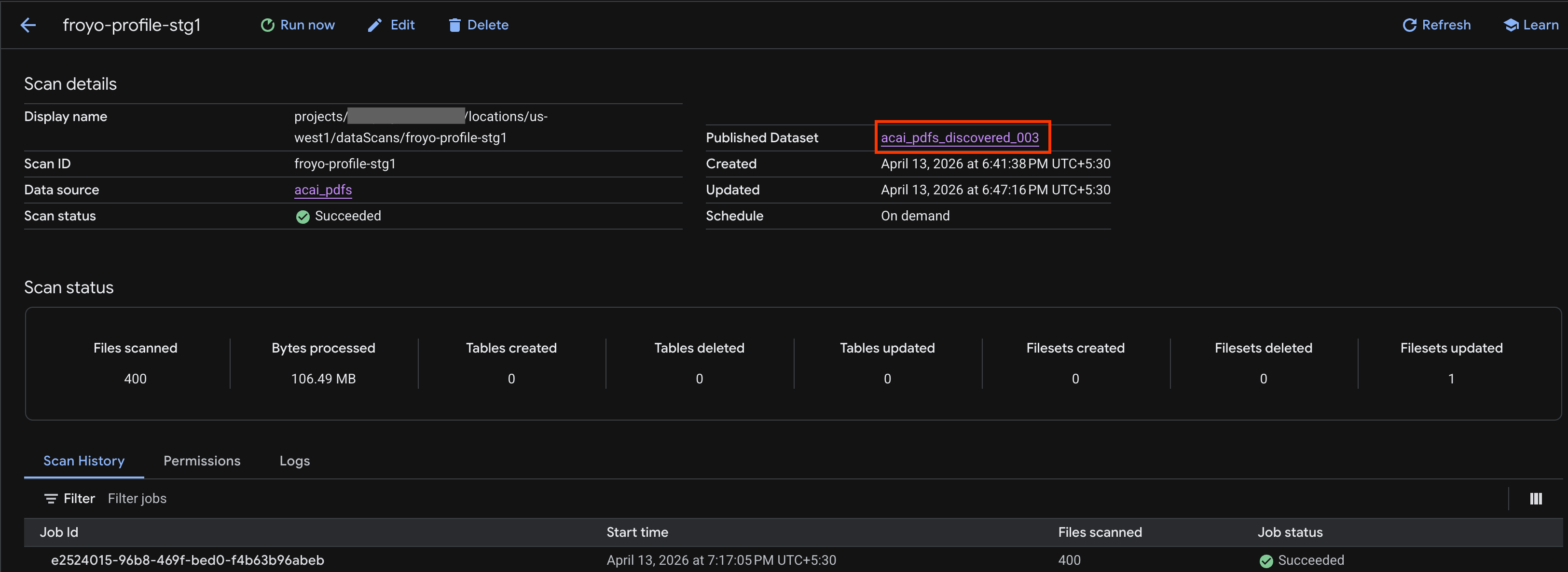
オブジェクト テーブルを表示する
検出ジョブの後に作成されたオブジェクト テーブルを表示する手順は次のとおりです。
- Google Cloud コンソールで [BigQuery] に移動します。
- [データセット] をクリックし、前の手順で作成した公開済みデータセットを選択します。例:
acai_pdfs_discovered_003 - オブジェクト テーブルを表示するには、テーブル ID をクリックします。例:
acai_pdfs - 作成されたオブジェクト テーブルは次のようになります。
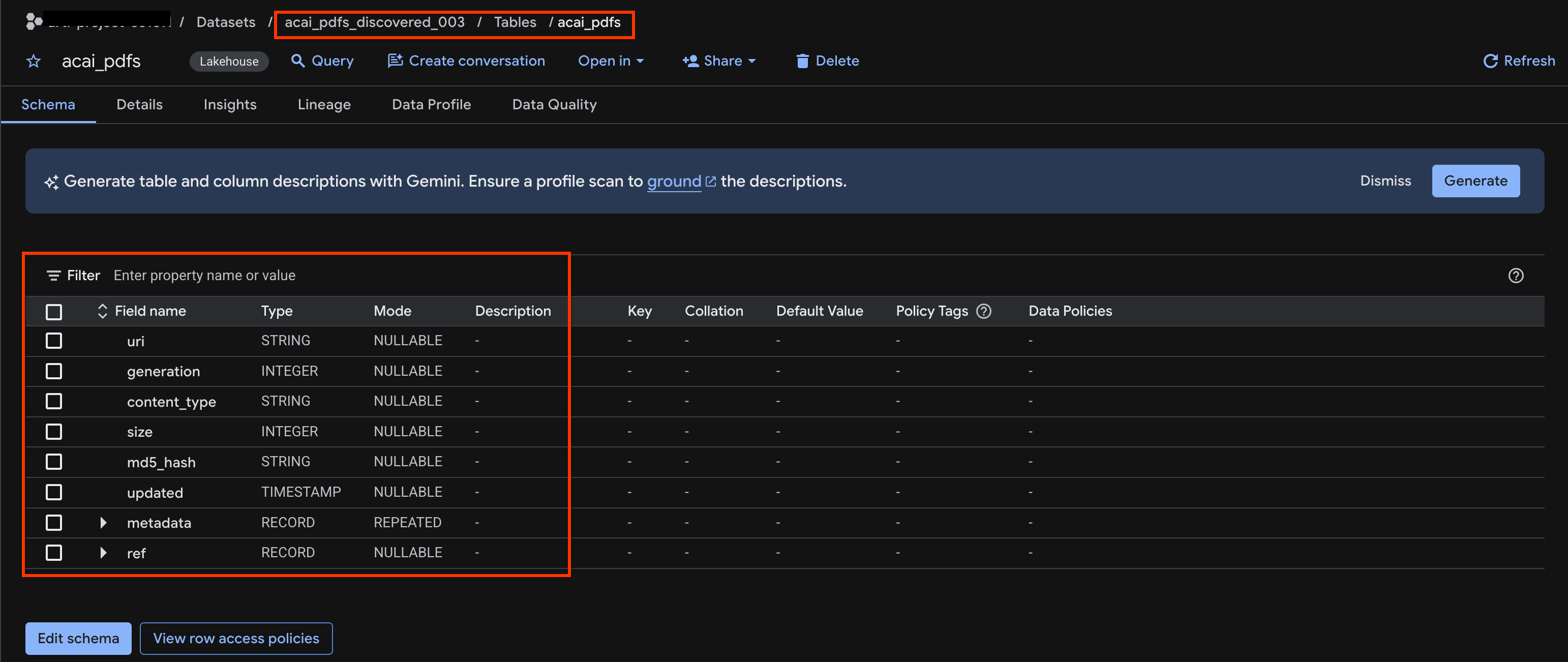
10. セマンティックの抽出
前の手順で作成した非構造化オブジェクト テーブルの構造化テーブル、他のデータベース オブジェクト、リレーションを推論して抽出します。そのため、Knowledge Catalog Insights 機能を使用して、非構造化テーブルから構造化データを抽出する SQL ステートメントを生成します。
- Google Cloud コンソールで、[Knowledge Catalog 検索] ページに移動します。
- 分析情報を表示するデータセット テーブルを検索します。例:
acai_pdfs_discovered_003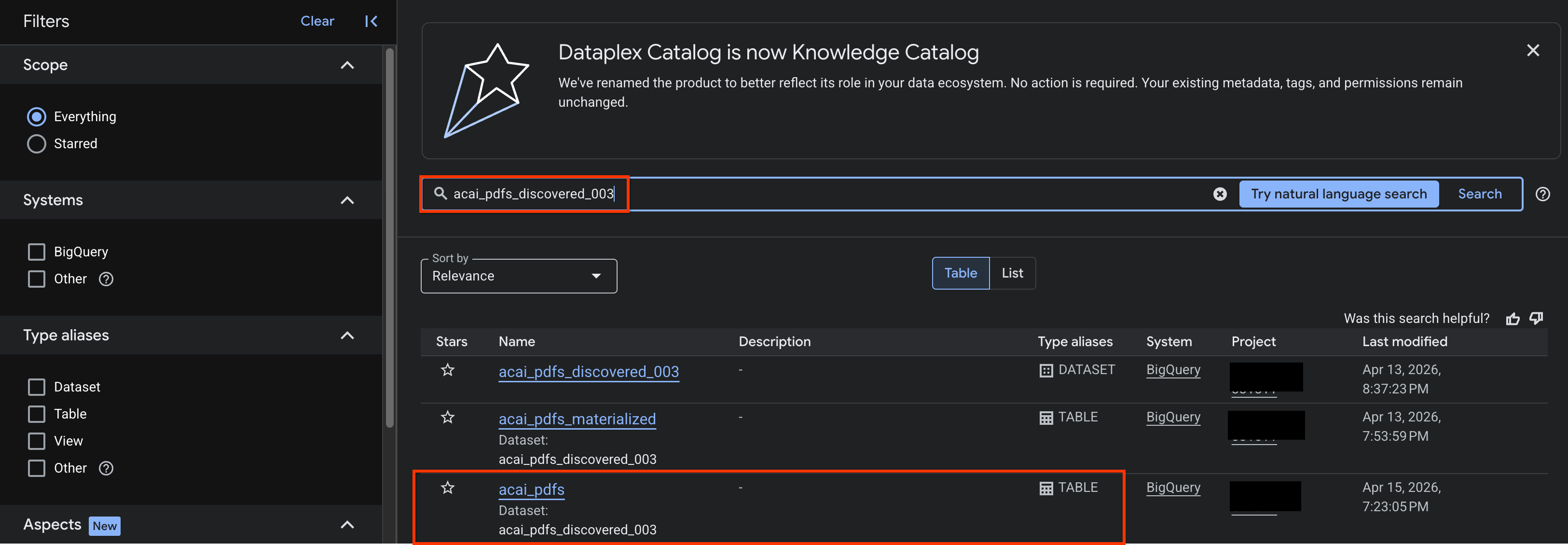
- 検索結果で、表をクリックしてエントリページを開きます。
- [分析情報] タブをクリックします。タブが空の場合、このテーブルの分析情報はまだ生成されていません。分析情報の生成には 15 ~ 25 分ほどかかることがあります。
- インサイトが表示されたら、[抽出] > [SQL で抽出] をクリックします。
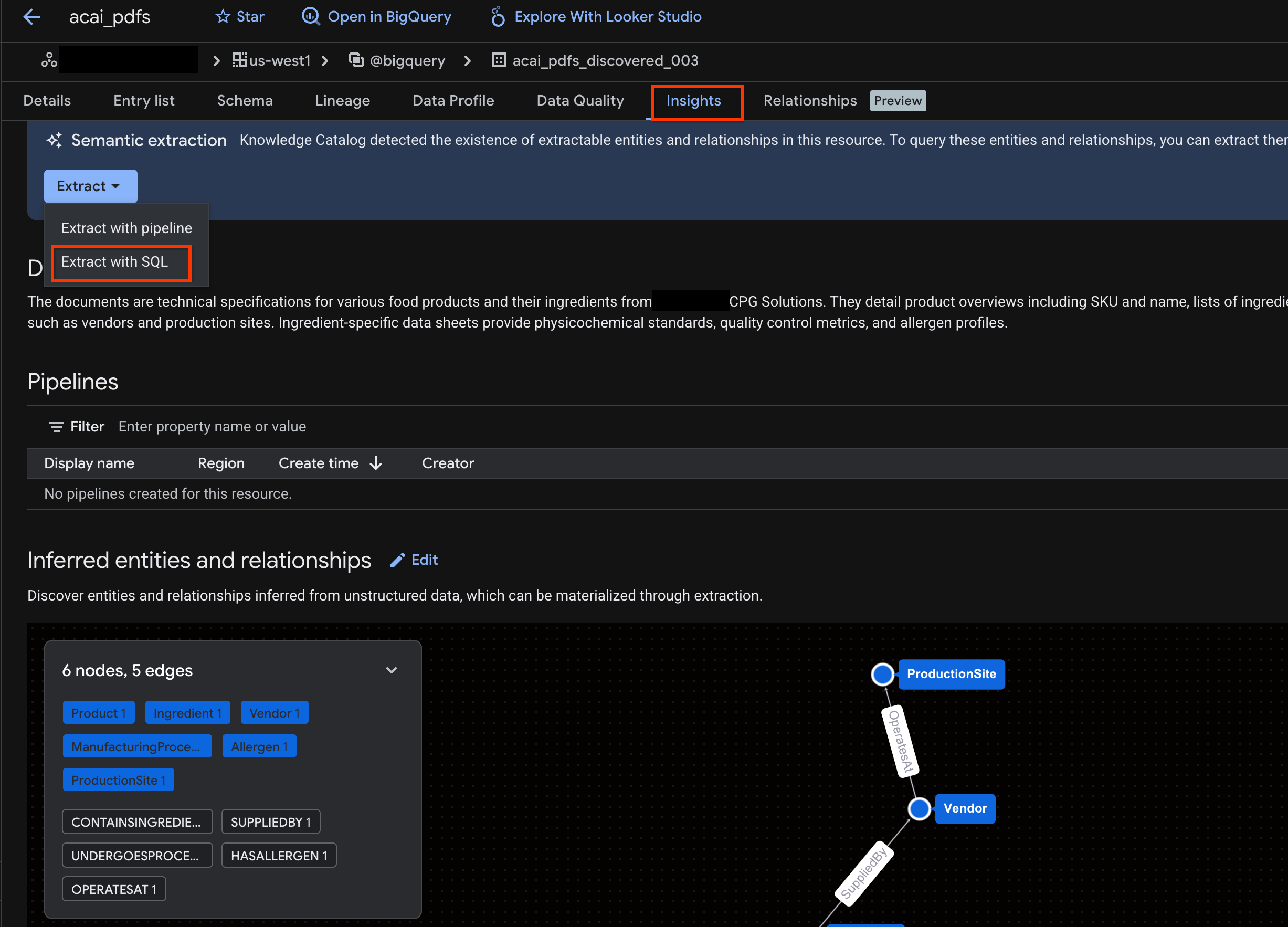
- [SQL で抽出] ページの [宛先] に、データセットを入力します。例:
acai_pdfs_discovered_003 - [抽出] をクリックします。BigQuery エディタが開き、クエリが読み込まれます。
- [実行] をクリックします。このステップでは一連のステートメントが生成されます。実行が完了するまでに数分かかることがあります。
- クエリが完了すると、次の結果が表示されます。
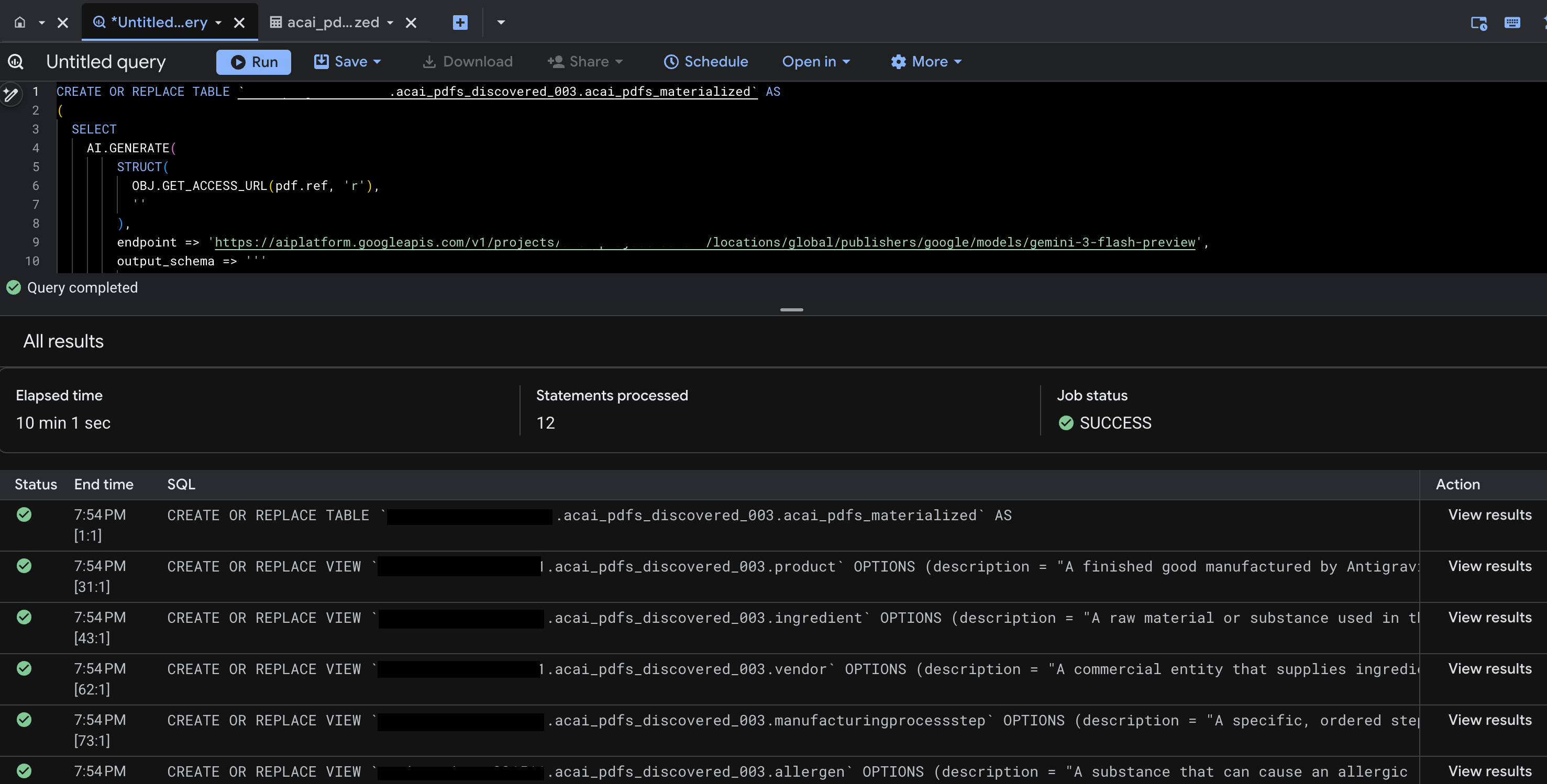
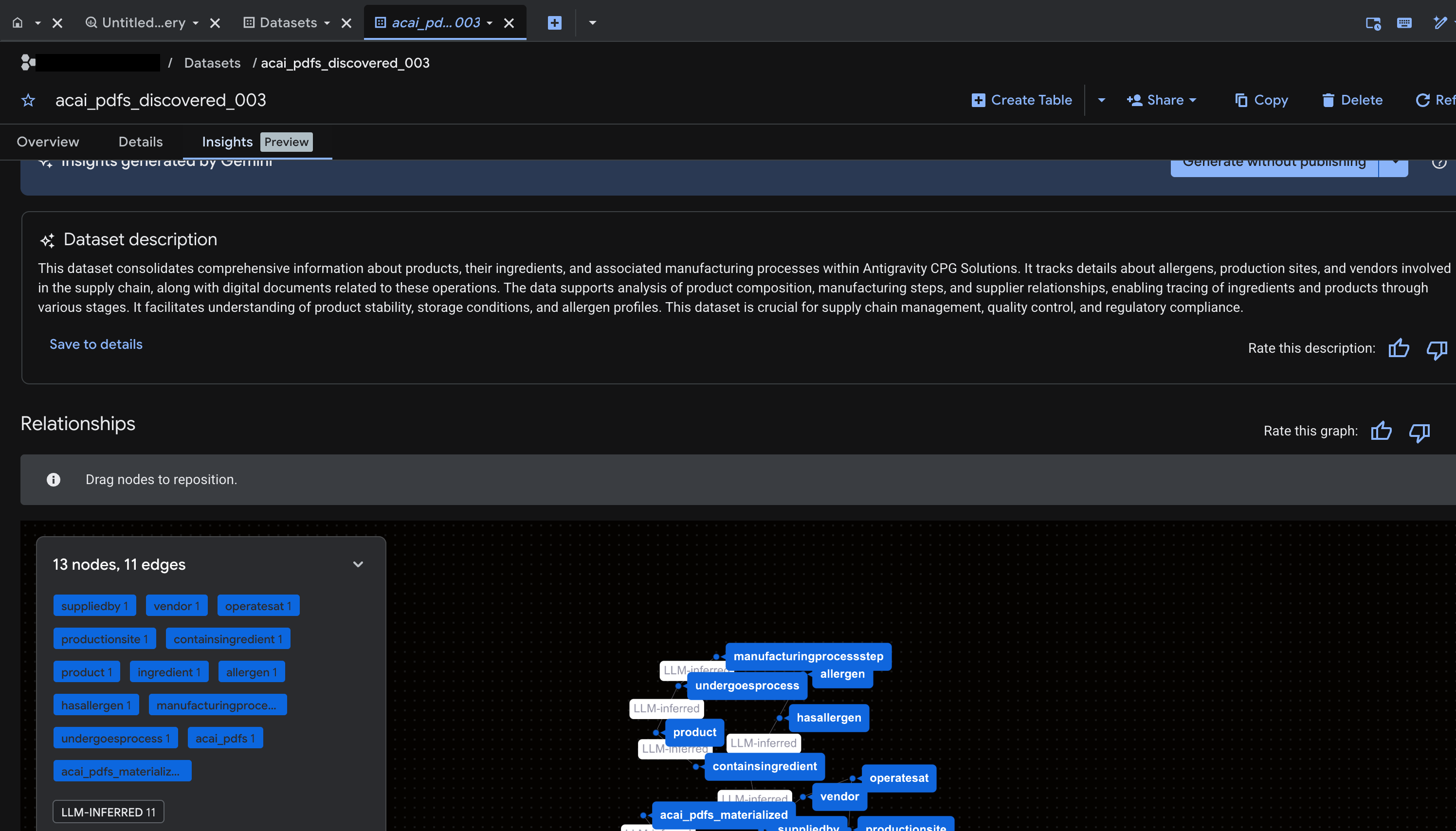
- BigQuery に移動し、[データセット](
acai_pdfs_discovered_003など)をクリックします。手順 6 で選択したデータセットに、新しい構造化データベース オブジェクトのセットが作成されます。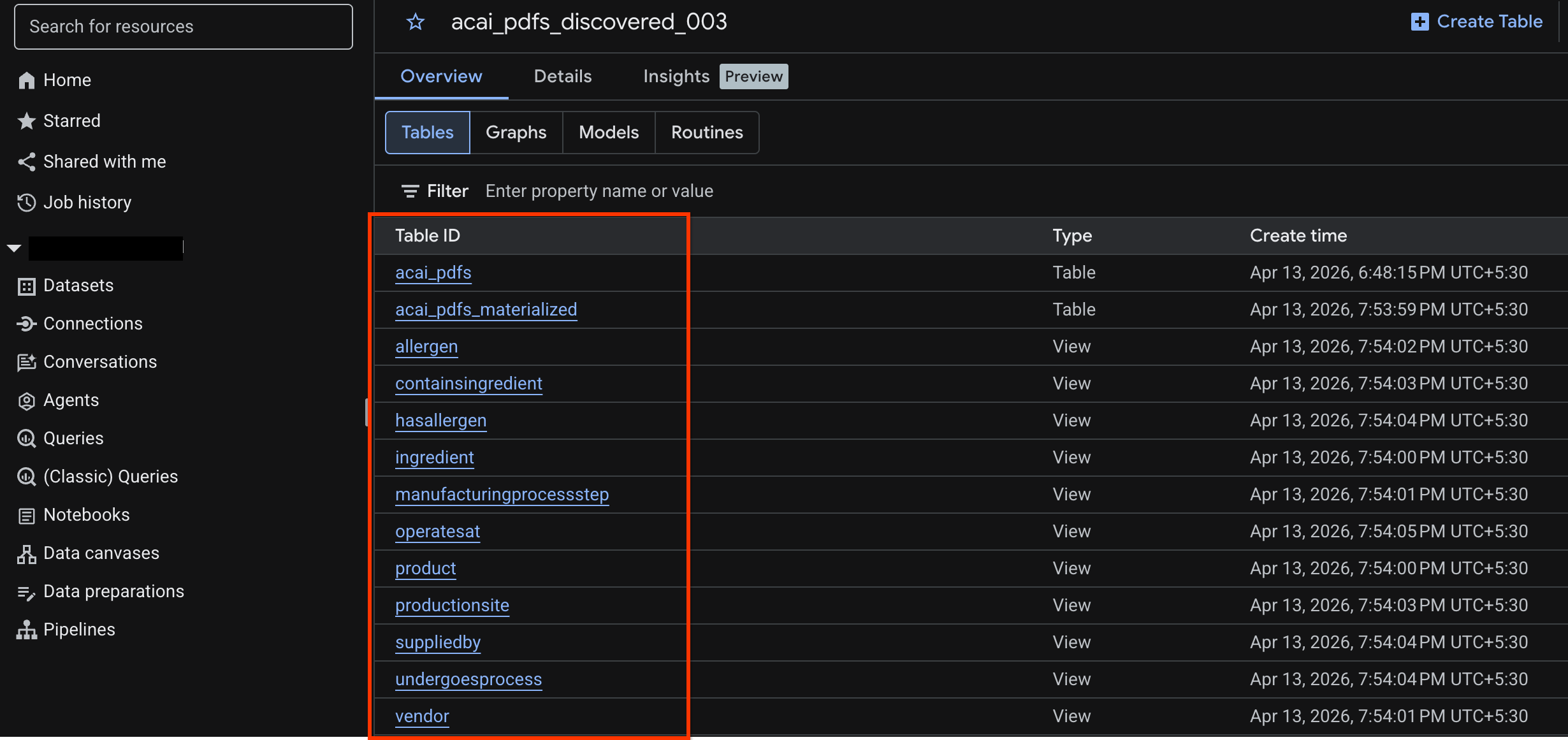
BigQuery でオブジェクトの分析情報を生成する
BigQuery データセットの分析情報を生成するには、BigQuery Studio を使用して BigQuery のデータセットにアクセスする必要があります。
- Google Cloud コンソールで、[BigQuery Studio] に移動します。
- [エクスプローラ] ペインで、プロジェクトを選択し、分析情報を生成するデータセットに移動します。
- [分析情報] タブをクリックします。
- [API を有効にする] ボタンが表示されている場合は、それをクリックして Gemini for Google Cloud を有効にします。[コア機能を有効にする] ウィンドウが開きます。
- [コア機能 API] セクションで、[Gemini for Google Cloud API] と [BigQuery Unified API] の [有効にする] をクリックし、[次へ] をクリックします。
- [権限(省略可)] セクションで、必要に応じてプリンシパルに IAM ロールを付与し、[次へ] をクリックします。
- 分析情報を生成して Knowledge Catalog に公開するには、[生成して公開] をクリックします。
- 公開すると、このタブで分析情報を確認できるようになります。
11. エージェント型データ分析用に IDE を設定する
Visual Studio Code 用の Google Cloud Data Agent Kit 拡張機能は、データ サイエンティストとデータ エンジニア向けの IDE 拡張機能です。これにより、IDE から Google Data Cloud のリソースとデータに直接接続して操作できます。詳細については、VS Code 用 Data Agent Kit 拡張機能の概要をご覧ください。
VS Code 用の Data Agent Kit 拡張機能は、次のような場合に役立ちます。
- VS Code から直接、Spark ETL や BigQuery ETL などの本番環境対応のデータ パイプラインを構築、テスト、レビュー、デプロイします。
- AI アシスタンスを使用して、データの探索、トレーニング パイプラインの構築、最適な ML モデルの特定を行い、本番環境のエンドポイントにデプロイします。
- 信頼できるデータソースに接続し、高性能のデータモデルを構築して、ビジネス関係者向けのインタラクティブなダッシュボードを公開します。
VS Code 用 Data Agent Kit 拡張機能をインストールする
- VS Code を開きます。
- Google Cloud CLI をインストールします。詳細については、Google Cloud CLI をインストールするをご覧ください。
- VS Code 用 Data Agent Kit 拡張機能をインストールします。
- 拡張機能のオンボーディング プロセスを完了します。これには、次の操作が必要です。
- 拡張機能にログインする
- スキル、MCP サーバーをインストールする
- オンボーディングが完了したら、ウィンドウを再読み込みするか、再起動します。詳細については、VS Code 用の Data Agent Kit 拡張機能を設定して構成するをご覧ください。
- IDE が再読み込みされたら、ナビゲーション パネルの Google データクラウド アイコンをクリックし、設定に移動して、共通設定でプロジェクト ID とリージョン(
us-west1)が正しく設定されていることを確認します。
VS Code でワークスペースを設定する
- VS Code を開き、[File] > [Open folder] > [New folder] を選択します。
acai_testという名前の新しいフォルダを作成し、[開く] をクリックします。これで、開いたフォルダがワークスペースとして認識されます。- [ワークスペースの信頼] ダイアログで、[はい、この作成者を信用します] を選択して、ワークスペースのすべての機能を有効にします。
acai_testワークスペースに.githubフォルダを作成します。.githubフォルダに新しいファイルcopilot-instructions.mdを作成し、次のルールを入力します。## 1. Project Context - **Project ID**: <PROJECT_ID> - **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors. - **Documentation**: Raw PDF documents detailing flavors and ingredients are stored in Google Cloud Storage at `gs://<BUCKET_NAME>`. ## 2. Execution & Data Processing Rules - **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `<BQ_DATASET_NAME>` (referred to as the Knowledge Catalog). - **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the dataset `<DATASET_ID>`. When you are referencing a dataset, ensure you are using it with the project ID (`<PROJECT_ID>`) and namespace prefix `<NAMESPACE_NAME>`. For example, to query order table in this dataset you should use `<PROJECT_ID>.<NAMESPACE>.<DATASET_ID>.orders`. - **CRITICAL RULE - Data Joins between BigQuery dataset and Iceberg dataset**: ANY task requiring a join or integration between the BigQuery datasets `<DATASET_ID>` of the PDF data and the `<DATASET_ID>` of the customer data MUST be executed using **Spark Notebooks**. - **CRITICAL RULE - Notebook Kernel**: Every Spark notebook utilized MUST exclusively be configured to run on the Serverless Session template `iceberg-federation-template` as its kernel. - **CRITICAL RULE - Data Science**: ANY data science, machine learning, or advanced analytical task MUST be performed strictly within **Spark Notebooks** using the aforementioned setup.acai_testワークスペースに別の新しいファイルtemplate.yamlを作成し、ファイルに次の情報を入力します。labels: client: "vscode" jupyterSession: displayName: "iceberg-federation-template" kernel: "PYTHON" environmentConfig: executionConfig: serviceAccount: "sa-spark-dev1@<PROJECT_ID>.iam.gserviceaccount.com" subnetworkUri: "projects/<PROJECT_ID>/regions/<REGION>/subnetworks/<SUBNET_NAME>" runtimeConfig: version: "2.3" properties: # This enables the secure proxy URL you were looking for dataproc.tier: "premium" spark.dataproc.engine: "lightningEngine" spark.dataproc.lightningEngine.runtime: "native" spark.memory.offHeap.enabled: "true" spark.memory.offHeap.size: "1g" spark.executor.memory: "4g" "dataproc.component.gateway.enabled": "true" "dataproc.jupyter.listen.all.interfaces": "true" "spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" "spark.sql.defaultCatalog": "<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>": "org.apache.iceberg.spark.SparkCatalog" "spark.sql.catalog.<CATALOG_NAME>.type": "rest" "spark.sql.catalog.<CATALOG_NAME>.uri": "<CATALOG_URI_ID>" "spark.sql.catalog.<CATALOG_NAME>.warehouse": "bl://projects/<PROJECT_ID>/catalogs/<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>.rest.auth.type": "org.apache.iceberg.gcp.auth.GoogleAuthManager"- VS Code で、[ターミナル] をクリックし、次のコマンドを実行して
template.yamlファイルをセッション テンプレートとしてインポートします。このテンプレートは、後でエージェントが Spark セッションを作成するために使用します。gcloud beta dataproc session-templates import iceberg-federation-template \ --source=template.yaml \ --location=<REGION>REGIONは、実際のリージョンに置き換えます。
12. エージェントによるデータ分析を行う
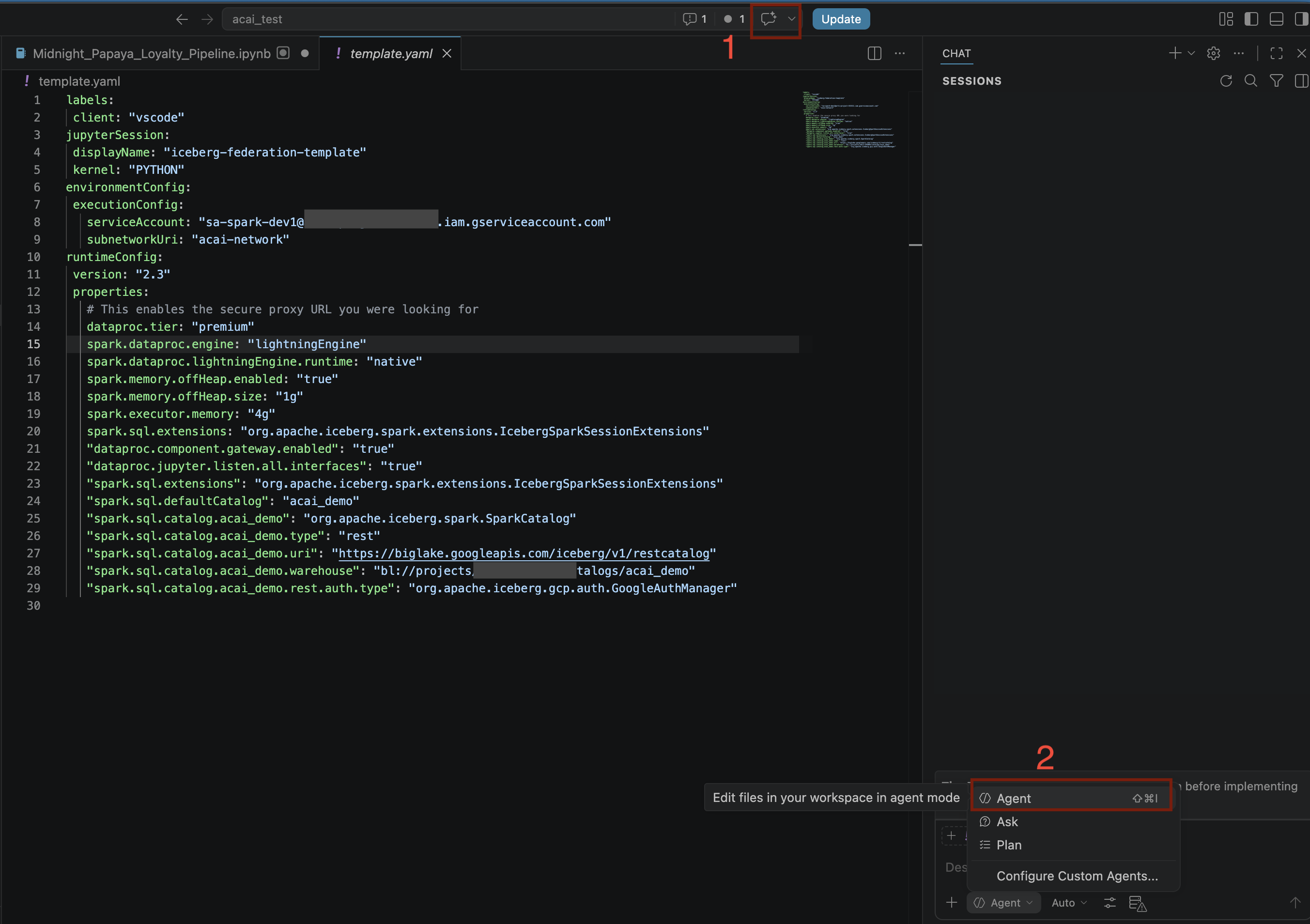
- VS Code エディタで、[チャットの切り替え] をクリックします。
- [カスタム エージェントを構成する] で [エージェント] を選択します。
- [検索モデル] ペインで、[言語モデルを管理] をクリックします。
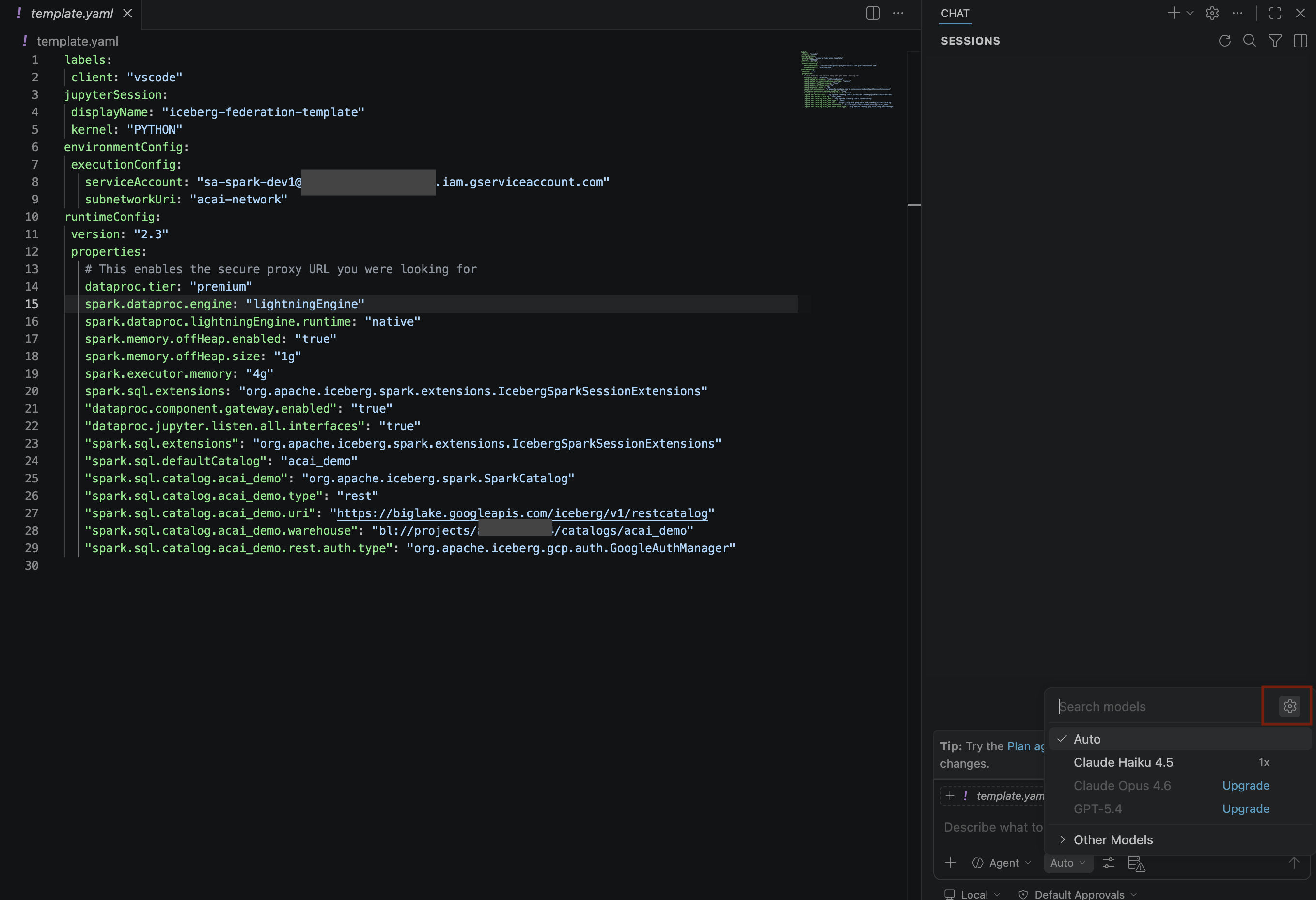
- [言語モデル] ページで、[モデルを追加] をクリックします。
- リストから [Google] を選択し、Enter キーを押して入力を確定します。
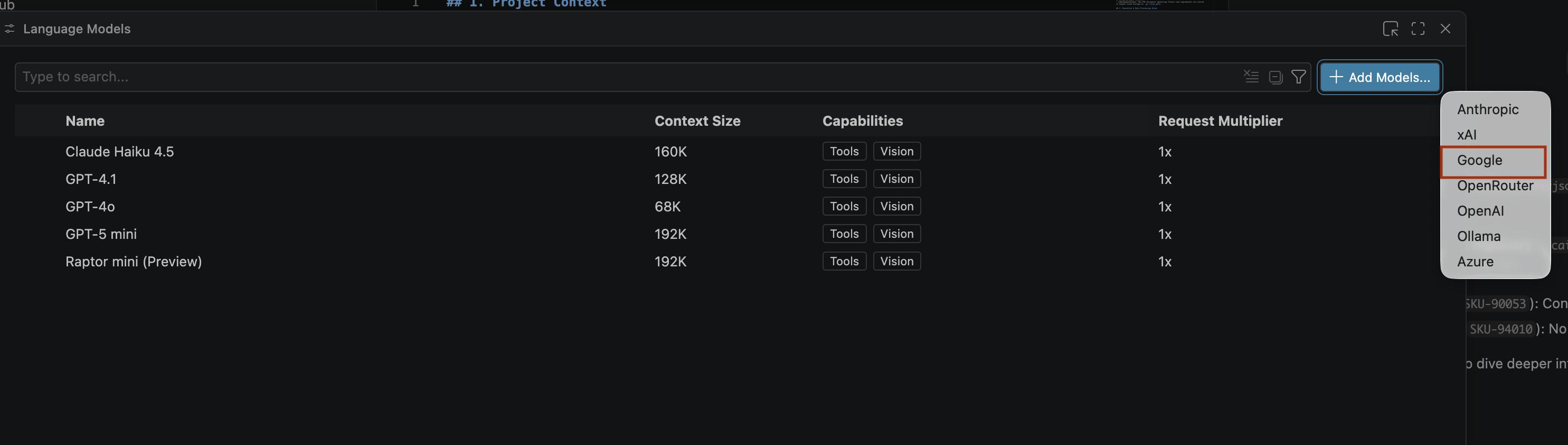
- Google Gemini の API キーを入力する手順は次のとおりです。
- Google AI Studio のウェブサイトにアクセスします。
- Google アカウントでログインします。
- サイドバーで [API キーを取得] をクリックします。
- [API キーを作成] をクリックします。[新しいキーを作成] ページが開きます。
- [クラウド プロジェクトを選択] リストから、[プロジェクトをインポート] を選択します。
- 既存のプロジェクトの名前を入力します。
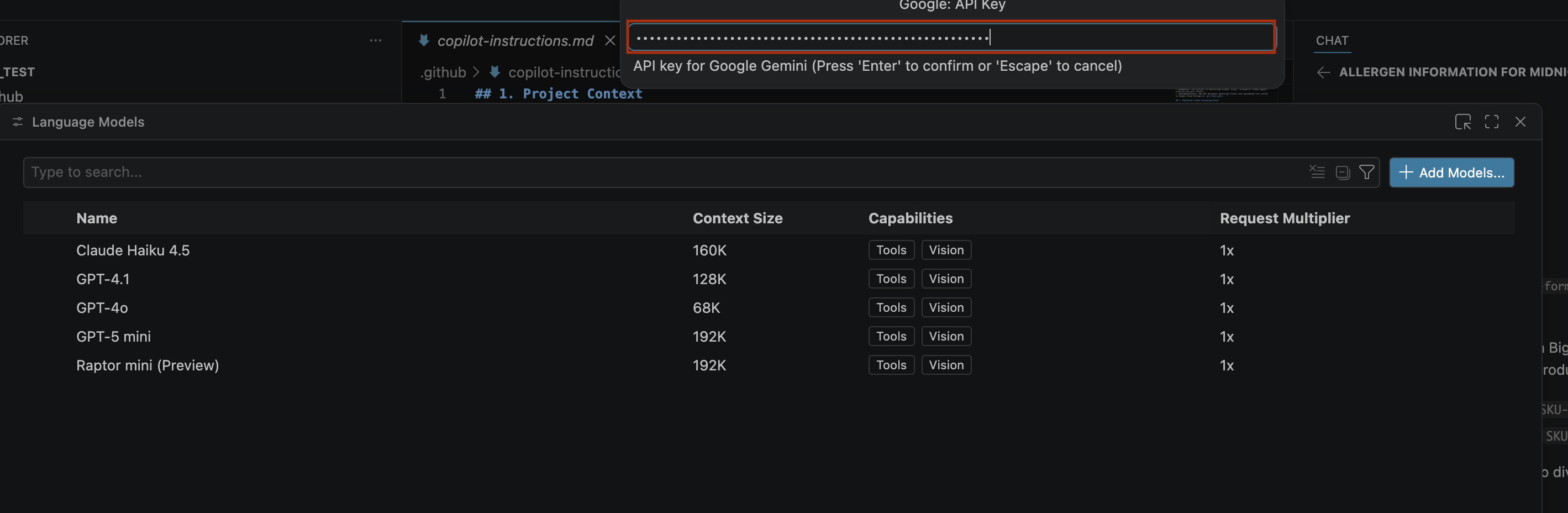
- [キーを作成] をクリックし、API キーをコピーします。このキーを使用すると、アカウントの Gemini API リソースにアクセスできます。詳細については、Gemini API キーを使用するをご覧ください。
- 生成した API キーを検索バーに貼り付け、Enter キーを押します。
- Gemini モデルが表示されない場合は、次の図に示すように、Gemini モデルの非表示を解除します。
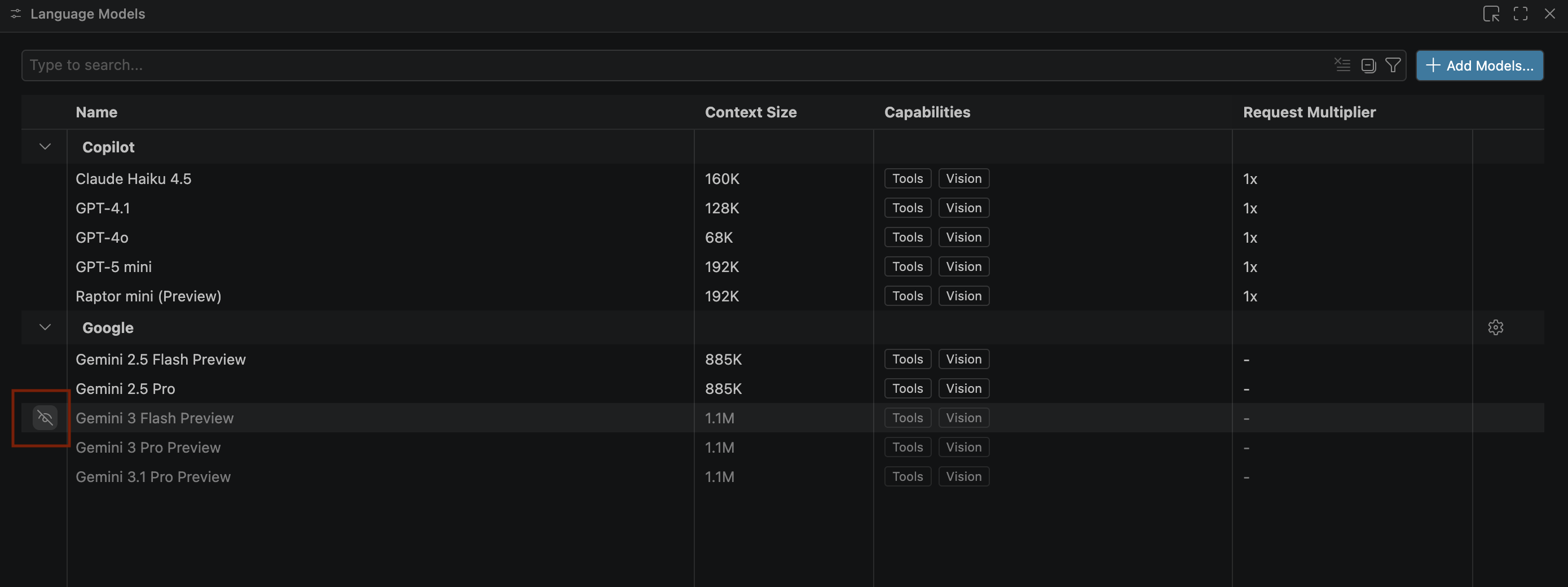
- Google Gemini モデルのリストから [Gemini 3.1 Pro プレビュー版] を選択し、[言語モデル] ウィンドウを閉じます。
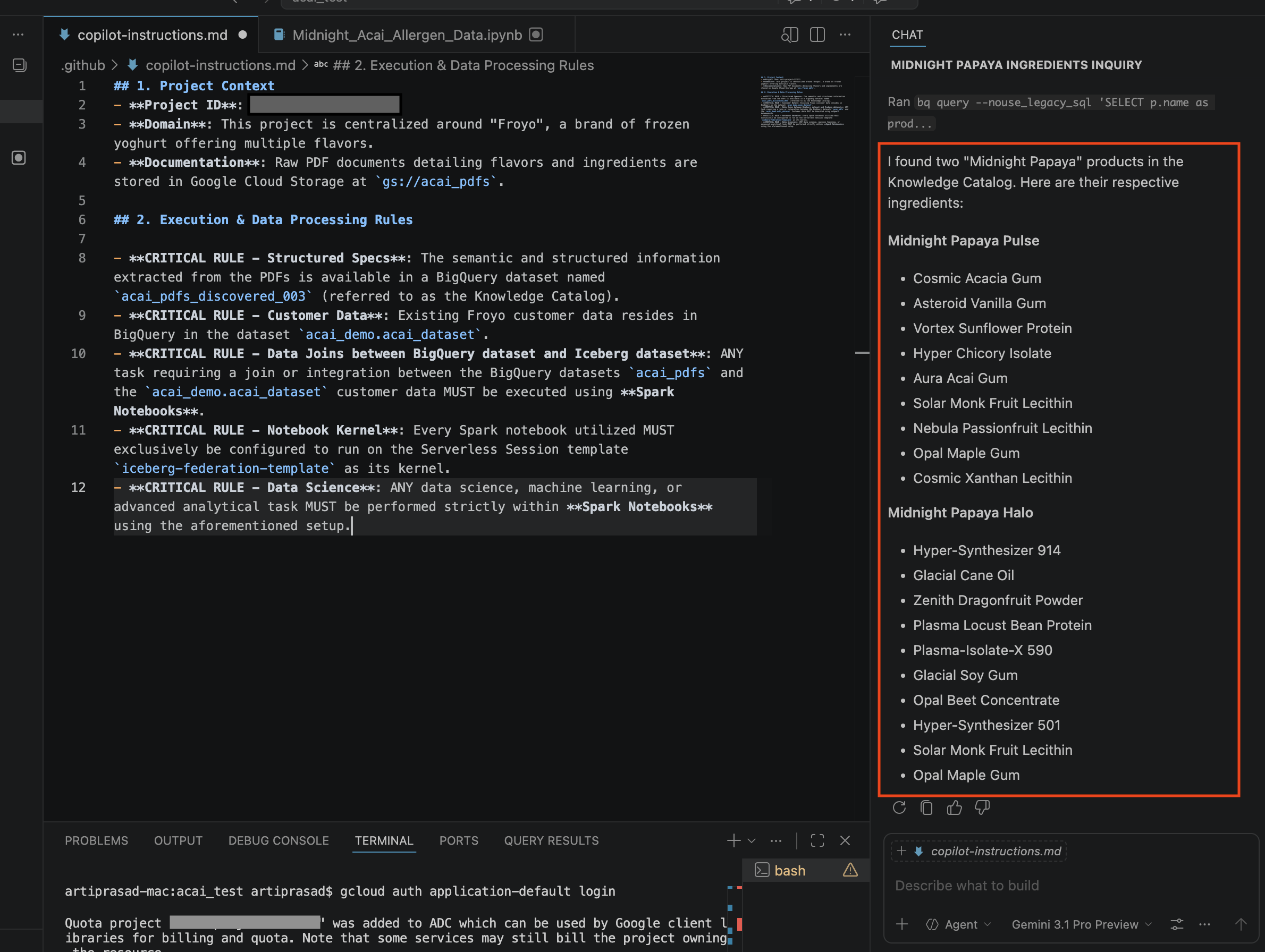
- チャット ウィンドウで、次の質問を入力します。
Search ingredients for Midnight papaya - 操作後、次のような結果が表示されます。
- チャット ウィンドウに別の質問を入力します。
Search allergen information for Midnight papaya - いくつかのやり取りと手順を終えると、次の画像のように、エージェントがアレルゲン名
Soyを返します。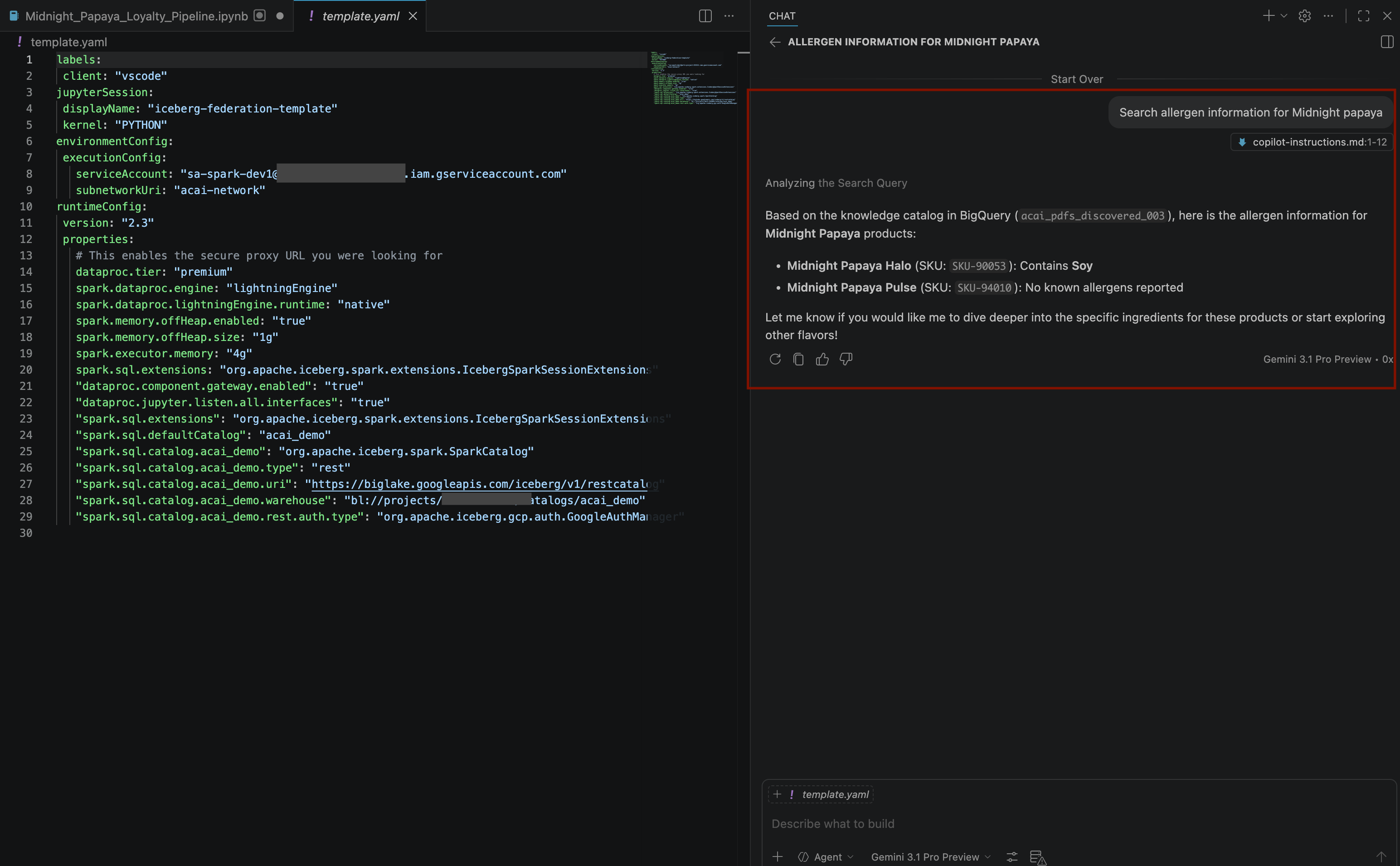
- チャット ウィンドウに別の質問を入力します。
Build a pipeline to join products with our 'Global Loyalty' Iceberg tables in acai customer, sales data to identify popular products - カーネルを選択するには、
.ipynbファイルを開き、[カーネルを選択] > [リモート Spark カーネル] > [サーバーレス Spark の Iceberg-federation-template] をクリックします。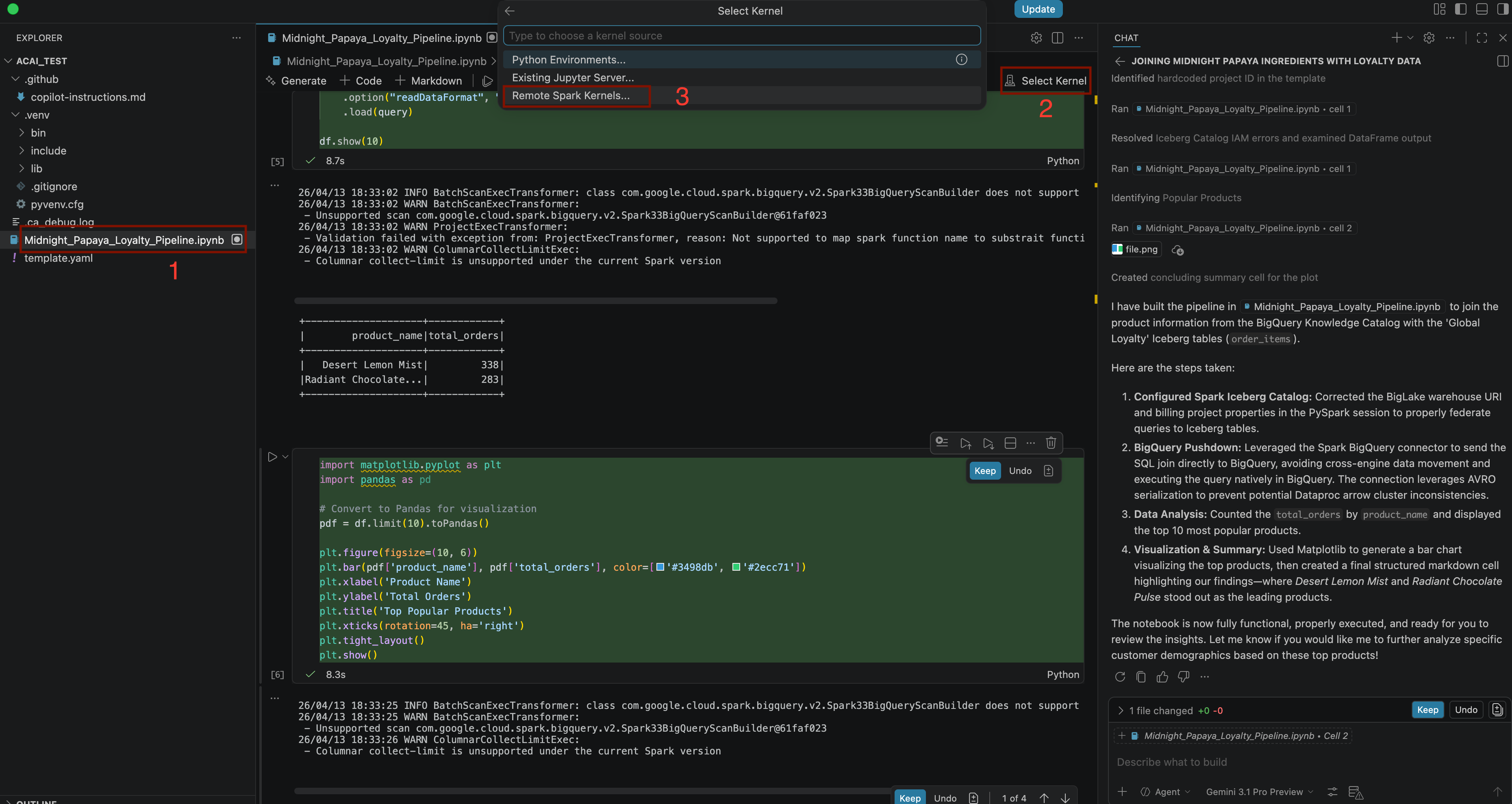
- いくつかの操作と手順を行うと、次の画像のように、ノートブックのすべての手順が正常に実行され、ノートブックの最後に最終結果が生成されたことがエージェントから返信されます。
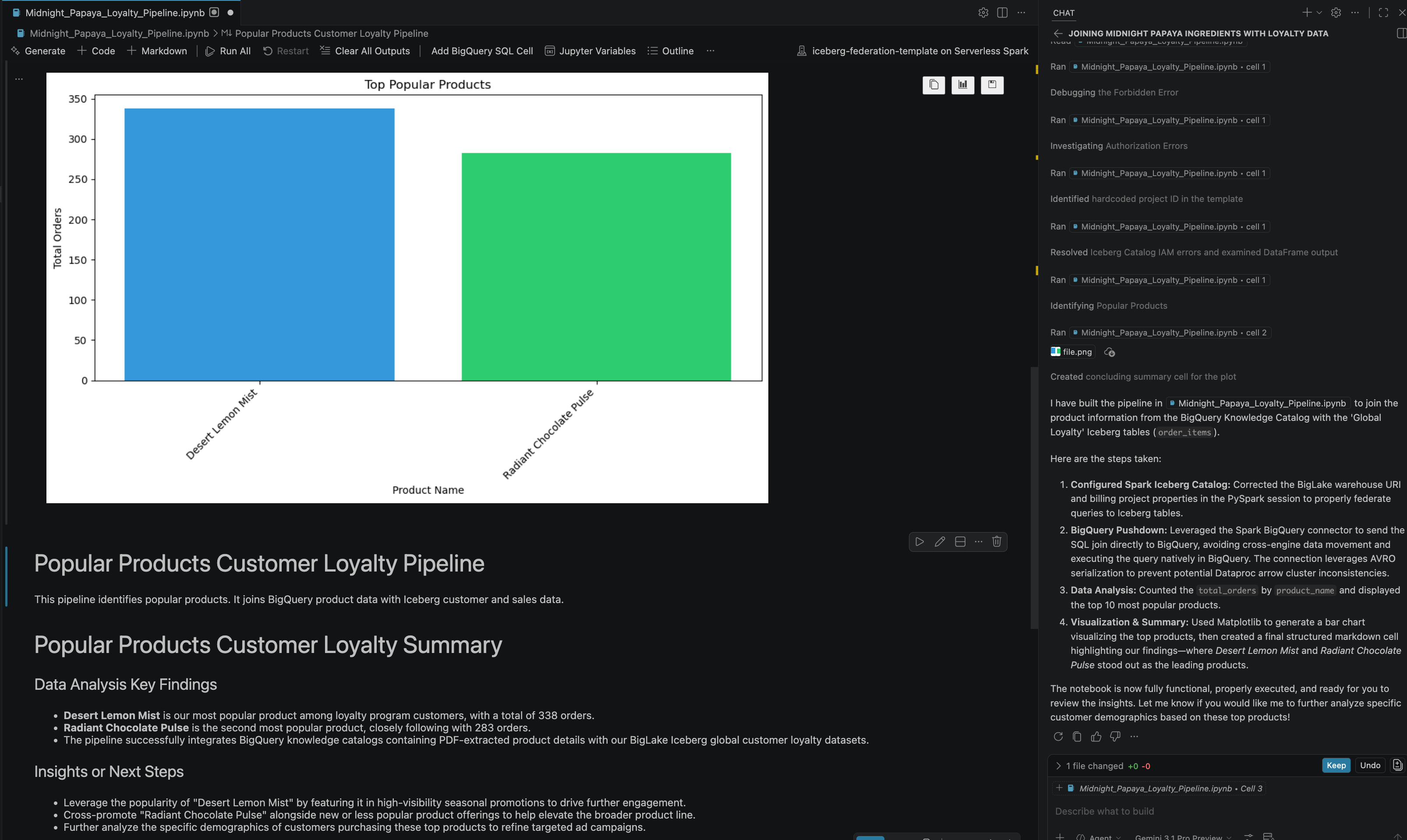
13. クリーンアップ
課金されないようにするには、このラボで作成したリソースを削除します。
- Knowledge Catalog DataScan を削除するには、次のコマンドを実行します。
DATASCAN_ID="<DATASCAN_ID>" echo "Deleting Dataplex DataScan: ${DATASCAN_ID}" gcloud dataplex datascans delete "${DATASCAN_ID}" --location="${REGION}" --quiet - Cloud Storage バケットとそのすべてのコンテンツを削除するには、次のコマンドを実行します。
echo "Deleting Cloud Storage buckets: <BUCKET_NAME1> and <BUCKET_NAME2>" gsutil -m rm -r gs://<BUCKET_NAME1> gsutil -m rm -r gs://<BUCKET_NAME2> - BigQuery 接続を削除するには、次のコマンドを実行します。
CONNECTION_ID="<CONNECTION_NAME>" echo "Deleting BigQuery Connection: ${CONNECTION_ID}" bq rm --connection "${PROJECT_ID}.${REGION}.${CONNECTION_ID}" - Lakehouse Catalog を削除するには、次のコマンドを実行します。
CATALOG_ID="<CATALOG_NAME>" echo "Deleting Lakehouse Catalog: ${CATALOG_ID}" gcloud biglake catalogs delete "${CATALOG_ID}" --project="${PROJECT_ID}" --location="${REGION}" --quiet - 検出された PDF テーブルを含むデータセットを削除するには、次のコマンドを実行します。
DATASET_NAME="<DATASET_NAME>" echo "Deleting BigQuery Dataset: ${DATASET_NAME}" bq rm -r -f "${PROJECT_ID}:${DATASET_NAME}" - カスタム サービス アカウントを削除するには、次のコマンドを実行します。
SERVICE_ACCOUNT="<SERVICE_ACCOUNT>" echo "Deleting Service Account: ${SERVICE_ACCOUNT}" gcloud iam service-accounts delete "${SERVICE_ACCOUNT}"@"${PROJECT_ID}".iam.gserviceaccount.com --quiet - VPC ネットワークを削除するには、次のコマンドを実行します。
VPC_NETWORK="<VPC_NETWORK>" echo "Deleting VPC Network: ${VPC_NETWORK}" gcloud compute networks delete "${VPC_NETWORK}" --quiet - Google Cloud プロジェクト全体を削除するには、次のコマンドを実行します。
gcloud projects delete "${PROJECT_ID}"
14. 完了
おめでとうございます!BigQuery テーブルでサイロ化された PDF ファイルと Parquet ファイルのデータランドスケープを整理し、検索可能で結合可能な単一のエコシステムに統合しました。これにより、PDF やビッグデータ形式をデータベースの行と同じようにインテリジェントに処理する最新のデータ レイクハウスが構築されました。これらの操作はすべて、Gemini との会話機能を通じてエージェントから直接行いました。
リファレンス ドキュメント
この Codelab で使用されているコアテクノロジーの詳細については、Google Cloud の公式ドキュメントをご覧ください。
- Data Cloud のコア コンポーネントである BigQuery の詳細については、BigQuery のドキュメントをご覧ください。
- IAM の詳細については、IAM のドキュメントをご覧ください。
- Lakehouse については、Lakehouse とはをご覧ください。