
1. 소개
이 Codelab에서는 새로운 제품 버전인 'Midnight Swirl'을 출시하는 가상의 Froyo 회사의 데이터 과학자 역할을 맡게 됩니다. 글로벌 출시를 성공적으로 진행하려면 비즈니스에서 성분, 시장 수요, 투자수익 (ROI)과 관련된 중요한 질문에 답해야 합니다. 이 엔드 투 엔드 워크플로는 Google Cloud의 Knowledge Catalog (이전 명칭: Dataplex)과 Lakehouse for Apache Iceberg (이전 명칭: BigLake)가 '어두운' 비구조화 데이터 간의 격차를 해소하고 통합 거버넌스 레이어를 통해 IDE (VS Code)에서 Gemini를 사용하여 실행 가능한 비즈니스 인텔리전스를 제공하는 방법을 보여줍니다.
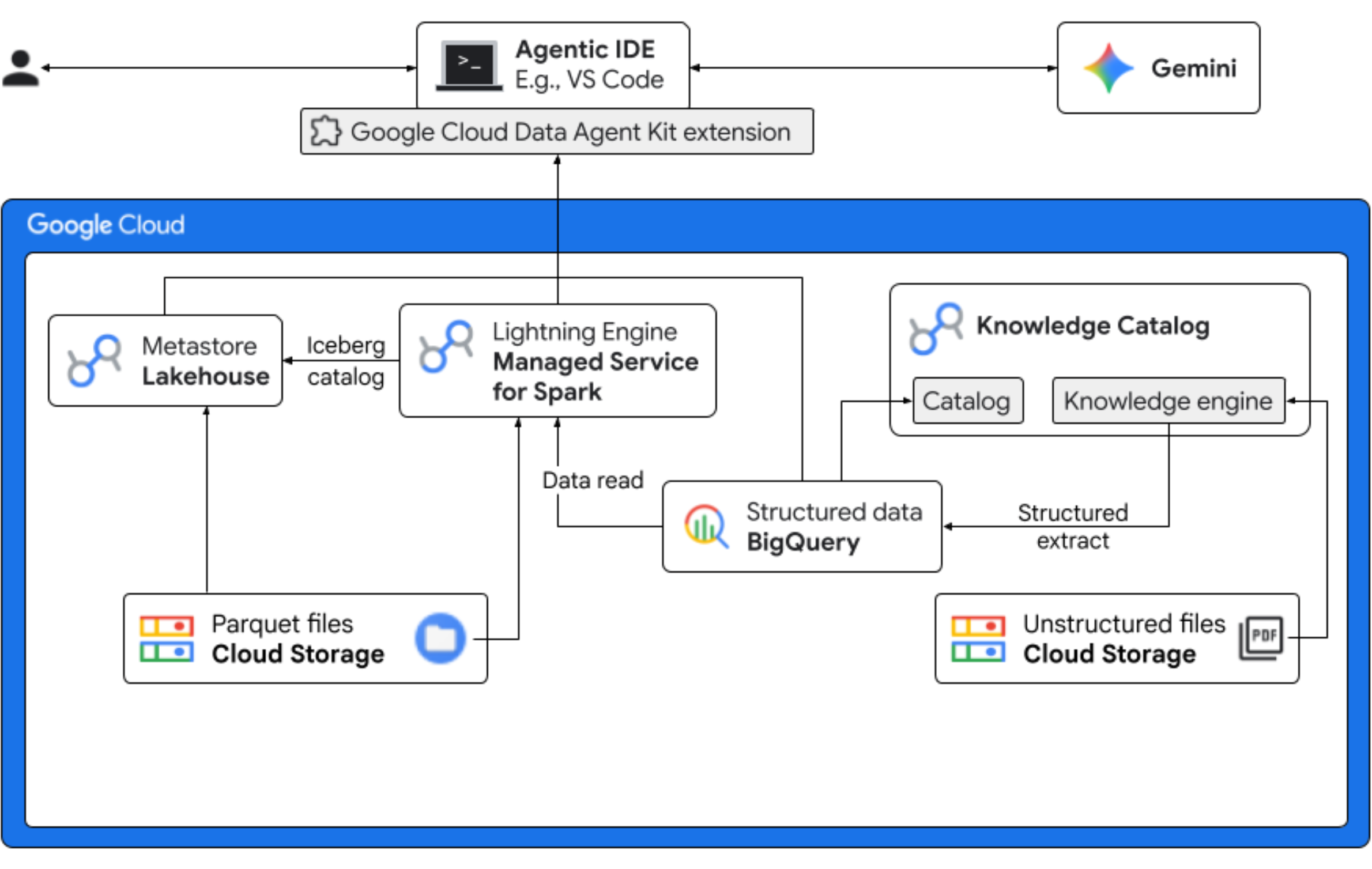
실습할 내용
- 구조화되지 않은 검색: Cloud Storage에 저장된 PDF 레시피는 Knowledge Catalog DataScan에 의해 크롤링됩니다. 스캔한 PDF에 대해 BigQuery에서 객체 테이블을 만듭니다. Vertex AI Semantic Inference를 사용하여 시스템은 PDF를 '읽어' 제품, 알레르기 유발 물질, 성분, 관련 속성에 관한 구조화된 정보를 추출합니다. 그런 다음 PDF에 저장된 데이터의 스키마를 지능적으로 생성합니다.
- 통합 메타데이터: PDF 파일에서 추출된 데이터는 BigQuery에 기본 와이드 테이블로 직접 저장되고 일반적인 쿼리를 지원하기 위해 뷰가 생성됩니다. 과거 판매 데이터가 포함된 독립적인 입력 데이터 세트는 Google Cloud Storage의 Apache Iceberg 테이블에 저장됩니다. 이 Iceberg 테이블은 후속 단계에서 BigQuery의 추출된 데이터와 조인됩니다.
- 크로스 엔진 분석: Iceberg REST 카탈로그와 함께 Managed Service for Apache Spark (이전의 Dataproc)를 사용하여 이 최신 PDF 메타데이터와 추론된 구조화된 시맨틱 데이터 (BigQuery 테이블 및 뷰에서 가져옴)를 Google Cloud Storage의 Apache Iceberg 테이블에 저장된 구조화된 판매 데이터와 결합합니다. 이는 Jupyter Notebook 커널로 사용되는 관리형 Apache Spark 대화형 세션 템플릿에 의해 관리되며, Spark 작업의 일관된 보안 및 컴퓨팅 설정을 보장합니다.
- 의미론적 통계: 추론된 제품 데이터를 고객 및 판매 데이터 (BigQuery)와 결합하여 데모에서 알레르기 유발 물질 데이터 식별 및 수익 예측과 같은 통계를 추출할 수 있습니다.
- 자율 거버넌스: 검색 스캔부터 Spark 실행에 이르기까지 전체 수명 주기가 Gemini 지원 템플릿, 안내, 규칙, 에이전트 기반 자동화를 통해 오케스트레이션되어 AI가 분석을 지원하는 인프라를 관리할 수 있음을 증명합니다.
필요한 항목
이 Codelab을 완료하는 데 비용이 발생할 수 있으며, 일반적인 사용량의 경우 5달러 미만으로 예상됩니다. 예상 사용량 또는 현재 가격을 기준으로 자세한 예상 비용을 확인하려면 Google Cloud 가격 계산기를 사용하세요.
Codelab을 완료하려면 다음 기본 요건이 충족되어야 합니다.
- Chrome 웹브라우저
- '시작하기 전' 섹션에 제공된 무료 크레딧을 사용하는 경우 개인 Gmail 계정
- Visual Studio (VS) Code를 다운로드하여 설치합니다.
2. 시작하기 전에
Google Cloud 프로젝트 만들기
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다. 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
Cloud Shell 시작
Cloud Shell은 Google Cloud에서 실행되는 명령줄 환경으로, 필요한 도구가 미리 로드되어 제공됩니다.
- Google Cloud 콘솔 상단에서 Cloud Shell 활성화를 클릭합니다.
- Cloud Shell에 연결되면 인증을 확인합니다.
gcloud auth list - 프로젝트가 구성되었는지 확인합니다.
gcloud config get project - 프로젝트가 예상대로 설정되지 않은 경우 설정합니다.
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
필요한 API 사용 설정
다음 명령어를 실행하여 필요한 모든 API를 사용 설정합니다.
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
biglake.googleapis.com \
dataproc.googleapis.com \
metastore.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
secretmanager.googleapis.com \
storage.googleapis.com
Codelab 애셋 다운로드
이 저장소에는 이 Codelab에서 사용할 Parquet, 레시피, 공급업체, copilot-instructions.md, template.yaml, quickstart.py 파일이 포함되어 있습니다. 이 파일을 다운로드해야 합니다.
파일을 다운로드하려면 다음 단계를 따르세요.
- Cloud Shell에서 다음 명령어를 실행합니다.
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git - 새로 만든 폴더로 이동합니다.
cd next-26-keynotes data-cloud-demo폴더 가져오기git sparse-checkout set genkey/data-cloud-demo- 결제가 완료되면
data-cloud-demo폴더로 이동하여 ZIP 파일을 추출하여 Codelab 애셋에 액세스합니다.
3. Froyo 고객 데이터용 레이크하우스 설정
이 섹션에서는 워크플로에 Lakehouse metastore를 사용하기 위해 Lakehouse에서 카탈로그를 만듭니다. 모든 Iceberg 데이터에 단일 소스를 제공하여 쿼리 엔진 간의 상호 운용성을 지원합니다. 이를 통해 Apache Spark와 같은 쿼리 엔진이 일관된 방식으로 Iceberg 테이블을 검색하고, 메타데이터를 읽고, 관리할 수 있습니다.
필요한 역할
다음 Identity and Access Management (IAM) 역할이 있는지 확인합니다.
roles/biglake.viewerroles/bigquery.userroles/bigquery.dataEditorroles/biglake.editorroles/biglake.metadataViewerroles/bigquery.connectionUserroles/storage.objectUserroles/storage.objectViewerroles/storage.objectCreatorroles/storage.admin
IAM 역할 부여에 대한 자세한 내용은 IAM 역할 부여를 참고하세요.
버킷으로 레이크하우스 카탈로그 만들기
Iceberg 테이블의 메타데이터를 관리할 Lakehouse 카탈로그를 만듭니다. Spark 작업에서 이 카탈로그에 연결하여 Iceberg 테이블을 만들고 쿼리합니다.
- Google Cloud 콘솔에서 Lakehouse로 이동합니다.
- 카탈로그 만들기를 클릭합니다. 카탈로그 만들기 페이지가 열립니다.
- 카탈로그 유형에서 Iceberg Rest 카탈로그를 선택합니다.
- 레이크하우스 카탈로그 버킷 옵션 선택에서 단일 버킷 카탈로그를 선택합니다.
- 기본 카탈로그 Cloud Storage 버킷에서 찾아보기를 클릭한 다음 새 버킷 만들기를 클릭합니다.
- 버킷 만들기 페이지에서 다음을 수행합니다.
- 시작하기 섹션에서 버킷 이름 요구사항을 충족하는 전역적으로 고유한 이름을 입력합니다.
- 데이터 저장 위치 선택 섹션에서 위치 유형으로 리전을 선택하고 리전을 입력합니다. 예를 들면
us-west1입니다. - 객체 액세스를 제어하는 방식 선택 섹션에서 이 버킷에 공개 액세스 방지 적용 체크박스를 선택 해제합니다.
이를 통해 공개 웹 콘텐츠 또는 공유 데이터 저장소를 호스팅하는 것과 같은 실제 시나리오를 시뮬레이션할 수 있습니다. 이 변경사항이 없으면 버킷에서 엄격한 '비공개 전용' 정책을 시행합니다. 파일에 공개 권한을 부여했더라도 애셋에 액세스하려고 하면403금지 오류가 발생합니다. - 계속 > 만들기 > 선택 > 계속을 클릭합니다.
- 인증 방법에서 사용자 인증 정보 벤더 제공 모드를 선택합니다.
- 만들기를 클릭합니다.카탈로그가 생성되고 카탈로그 세부정보 페이지가 열립니다.
- 인증 방법에서 버킷 권한 설정을 클릭합니다.
- 대화상자에서 확인을 클릭합니다.이렇게 하면 카탈로그의 서비스 계정에 스토리지 버킷에 대한
Storage Object User역할이 있는지 확인됩니다. - 카탈로그 세부정보 페이지에서 REST 카탈로그 URI 경로를 복사합니다. 'Spark 작업 실행' 작업 중에 이 경로를 사용합니다.
Parquet 파일을 버킷에 업로드합니다.
Parquet 파일을 버킷의 루트에 업로드하려면 다음 단계를 따르세요.
- Google Cloud 콘솔에서 Cloud Storage 버킷 페이지로 이동합니다.
- 버킷 목록에서 버킷 이름을 클릭합니다. 예를 들면
acai_demo입니다. - 버킷의 객체 탭에서 업로드 > 파일 업로드를 클릭합니다.
- 이 Codelab의 시작하기 전에 섹션에서 클론한 Parquet 폴더의 파일을 선택합니다.
- 열기를 클릭합니다.
4. VPC 네트워크 설정
리소스를 공개 인터넷에 연결하지 않고 Google API와 통신할 수 있는 가상 프라이빗 클라우드 (VPC) 네트워크 및 서브넷과 데이터 처리 노드 간에 내부 트래픽이 자유롭게 흐르도록 허용하는 방화벽을 만듭니다.
- Google Cloud 콘솔에서 VPC 네트워크 페이지로 이동합니다.
- VPC 네트워크 만들기를 클릭합니다.
- 네트워크의 이름을 입력합니다. 예를 들면 다음과 같습니다.
acai-network - 네트워크의 최대 전송 단위 (MTU)를 구성하려면 MTU 자동 설정 체크박스를 선택합니다.
- 서브넷 생성 모드에서 자동을 선택합니다.
- 방화벽 규칙 섹션에서 IPv4 방화벽 규칙의 체크박스를 모두 선택합니다.
- 만들기를 클릭합니다.
비공개 Google 액세스 사용 설정
Dataproc 서버리스 노드에는 공개 IP 주소가 없습니다. Lakehouse Catalog 및 Cloud Storage와 통신하려면 서브넷에 비공개 Google 액세스가 사용 설정되어 있어야 합니다.
- Google Cloud 콘솔에서 VPC 네트워크 페이지로 이동합니다.
- 비공개 Google 액세스를 사용 설정해야 하는 서브넷이 포함된 네트워크의 이름을 클릭합니다. 예를 들면
us-west1입니다. - 서브넷 이름을 클릭합니다. 서브넷 세부정보 페이지가 표시됩니다.
- 수정을 클릭합니다.
- 비공개 Google 액세스 섹션에서 사용을 선택합니다.
- 저장을 클릭합니다.
5. Spark 작업 만들기 및 실행
Iceberg 테이블을 만들고 쿼리하려면 필요한 Spark SQL 문이 포함된 PySpark 작업을 업로드합니다. 그런 다음 Managed Service for Spark로 작업을 실행합니다.
quickstart.py를 Cloud Storage 버킷에 업로드합니다.
코드랩 애셋을 클론한 후 프로젝트 세부정보로 quickstart.py 스크립트를 업데이트하고 Cloud Storage 버킷에 업로드합니다.
- 텍스트 편집기에서
quickstart.py스크립트를 엽니다. - 스크립트의
BUCKET_NAME자리표시자를 Cloud Storage 버킷 이름으로 바꾸고 저장합니다. - Google Cloud 콘솔에서 Cloud Storage 버킷으로 이동합니다.
- 버킷 이름을 클릭합니다. 예를 들면
acai_demo입니다. - 객체 탭에서 업로드 > 파일 업로드를 클릭합니다.
- 파일 브라우저에서 업데이트된
quickstart.py파일을 선택한 다음 열기를 클릭합니다.
Spark 작업 실행
quickstart.py 스크립트를 업로드한 후 Managed Service for Spark 일괄 작업으로 실행합니다.
- 변수를 구성하려면 Cloud Shell에서 다음 명령어를 실행합니다.
# Configuration Variables export PROJECT_ID="<PROJECT_ID>" export REGION="<REGION>" export BUCKET_NAME="<BUCKET_NAME>" export SUBNET="<SUBNET>" export LAKEHOUSE_CATALOG_ID="<LAKEHOUSE_CATALOG_ID>" export CATALOG_URI_ID="<CATALOG_URI_ID>"- LAKEHOUSE_CATALOG_ID: PySpark 애플리케이션 파일이 포함된 Lakehouse 카탈로그 리소스의 이름입니다. 예를 들면
acai_demo입니다. - PROJECT_ID: Google Cloud 프로젝트 ID입니다.
- REGION: Managed Service for Spark 일괄 워크로드를 실행할 리전입니다. 예를 들면 다음과 같습니다.
us-west1 - BUCKET_NAME: Cloud Storage 버킷 이름입니다. 예를 들면 다음과 같습니다.
acai_demo - SUBNET: VPC 서브넷 이름 예를 들면 다음과 같습니다.
acai-network - CATALOG_URI_ID: 버킷으로 레이크하우스 카탈로그를 만들 때 복사한 레이크하우스 카탈로그의 URI ID입니다. 예를 들면 다음과 같습니다.
https://biglake.googleapis.com/iceberg/v1/restcatalog
- LAKEHOUSE_CATALOG_ID: PySpark 애플리케이션 파일이 포함된 Lakehouse 카탈로그 리소스의 이름입니다. 예를 들면
- Cloud Shell에서
quickstart.py스크립트를 사용하여 다음 Managed Service for Spark 일괄 작업을 실행합니다.gcloud dataproc batches submit pyspark gs://${BUCKET_NAME}/quickstart.py \ --project=${PROJECT_ID} \ --region=${REGION} \ --subnet=${SUBNET} \ --version=2.2 \ --properties="\ spark.sql.defaultCatalog=${LAKEHOUSE_CATALOG_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}=org.apache.iceberg.spark.SparkCatalog,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.type=rest,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.uri=${CATALOG_URI_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.warehouse=gs://${BUCKET_NAME},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.io-impl=org.apache.iceberg.gcp.gcs.GCSFileIO,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.x-goog-user-project=${PROJECT_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\ spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest-metrics-reporting-enabled=false,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.X-Iceberg-Access-Delegation=vended-credentials,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token"All tables registered successfully! Batch [126fa2226a904d2e944c8eecbe0b1840] finished. metadata: '@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata batch: projects/PROJECT_ID/locations/REGION/batches/126fa2226a904d2e944c8eecbe0b1840 batchUuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff createTime: '2026-04-09T13:17:26.222727Z' description: Batch labels: goog-dataproc-batch-id: 126fa2226a904d2e944c8eecbe0b1840 goog-dataproc-batch-uuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-drz-resource-uuid: batch-3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-location: REGION operationType: BATCH name: projects/PROJECT_ID/regions/REGION/operations/47bc59e8-5082-3af9-89a0-22289aa5f4b9
6. BigQuery에서 테이블 쿼리
Spark 일괄 작업을 성공적으로 실행하여 관리형 Spark 서버리스 서비스를 분산 컴퓨팅 엔진으로 사용하여 Lakehouse Metastore 내에서 Parquet 파일당 하나의 테이블을 여러 개 등록했습니다. 이 등록을 통해 Google Cloud는 Cloud Storage의 원시 파일을 구조화된 고성능 테이블로 취급할 수 있습니다.
다음 단계에서는 메타데이터가 올바르게 동기화되었는지 확인하여 데이터가 안전하게 저장될 뿐만 아니라 BigQuery 인터페이스를 통해 완전히 검색 가능하고 쿼리 가능하도록 하는 방법을 안내합니다.
- Google Cloud 콘솔에서 BigQuery로 이동합니다.
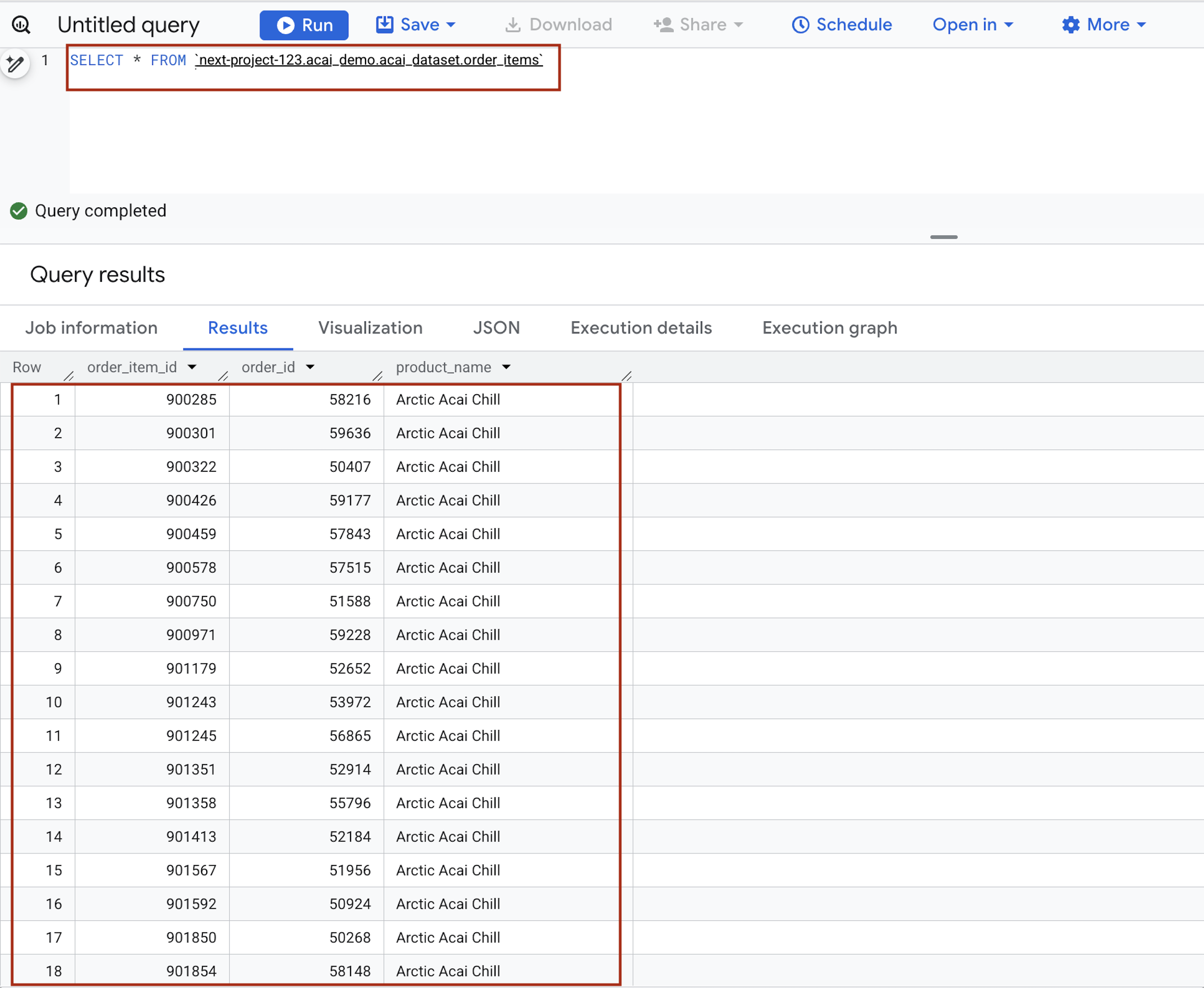
- 쿼리 편집기에서 다음 문을 입력합니다. 쿼리는
project.namespace.dataset.table문법을 사용합니다.SELECT * FROM `<PROJECT_ID>.<NAMESPACE>.<ICEBERG_DATASET>.<ICEBERG_TABLE>`PROJECT_ID.acai_demo.acai_dataset.order_items.
입니다. 다음을 바꿉니다.- PROJECT_ID: Google Cloud 프로젝트 ID입니다.
- NAMESPACE: 이전 단계에서 Spark 작업의 결과로 생성된 네임스페이스입니다. BigQuery 객체 탐색기 페이지에서 확인할 수 있습니다. 예를 들면 다음과 같습니다.
acai_demo - ICEBERG_DATASET: Iceberg 카탈로그 내의 데이터 세트 이름입니다(예:
acai_dataset). - ICEBERG_TABLE: Iceberg 데이터 세트 내의 테이블 이름입니다(예:
order_items).
- 실행을 클릭합니다. 쿼리 결과에 Spark 작업으로 삽입한 데이터가 표시됩니다.
7. 구조화되지 않은 제품 데이터 파일 설정
이 섹션에서는 Froyo 제품 세부정보를 위해 BigQuery 내에 조직 구조를 만들어 Froyo 레시피와 공급업체 데이터를 저장합니다. 또한 BigQuery가 Cloud Storage와 같은 외부 소스에서 파일을 읽을 수 있도록 하는 보안 '브리지' 역할을 하는 Cloud 리소스 연결을 설정합니다.
버킷을 만들고 Froyo 세부정보 파일을 업로드합니다.
공급업체 및 레시피 파일을 만들어 Cloud Storage 버킷에 업로드합니다.
- Google Cloud 콘솔에서 Cloud Storage 버킷 페이지로 이동합니다.
- 만들기를 클릭합니다.
- 버킷 만들기 페이지에서 버킷 정보를 입력합니다. 다음 각 단계를 완료한 후 계속을 클릭하여 다음 단계로 진행합니다.
- 시작하기 섹션에 버킷 이름을 입력합니다. 예를 들면 다음과 같습니다.
acai_pdfs - 데이터 저장 위치 선택 섹션에서 리전을 선택한 후 리전을 입력합니다. 예를 들면
us-west1입니다. - 객체 액세스를 제어하는 방식 선택 섹션에서 이 버킷에 공개 액세스 방지 적용 체크박스를 선택 해제합니다.
- 만들기를 클릭합니다.
- 버킷 목록에서 만든 버킷을 클릭합니다. 예를 들면
acai_pdfs입니다. - 버킷의 객체 탭에서 업로드 > 폴더 업로드를 클릭합니다.
- 이 Codelab의 시작하기 전에 섹션에서 추출한
recipes폴더를 선택합니다. - 업로드를 클릭합니다.
suppliers폴더에 대해 업로드 프로세스를 반복합니다.
연결 만들기
Cloud 리소스 연결을 만듭니다. 이렇게 하면 외부 파일에 액세스하는 BigQuery의 'ID 카드' 역할을 하는 고유한 서비스 계정이 생성됩니다.
- BigQuery 페이지로 이동합니다.
- 왼쪽 창에서 탐색기를 클릭합니다. 왼쪽 창이 표시되지 않으면 왼쪽 창 펼치기를 클릭하여 창을 엽니다.
- 탐색기 창에서 프로젝트 이름을 펼친 후 연결을 클릭합니다.
- 연결 페이지에서 연결 만들기를 클릭합니다.
- 연결 유형으로 Vertex AI 원격 모델, 원격 함수, BigLake, Spanner (Cloud 리소스)를 선택합니다.
- 연결 ID 필드에 연결 ID 이름을 입력합니다. 예를 들면 다음과 같습니다.
acai_pdf_connection이 ID는 이 Codelab의 후반부에서 데이터 스캔을 설정할 때 필요하므로 기록해 두세요. - 위치 유형을 리전으로 설정한 다음 리전을 선택합니다. 예를 들면
us-west1입니다. 연결은 데이터 세트와 같이 다른 리소스와 함께 배치해야 합니다. - 연결 만들기를 클릭합니다.
- 연결로 이동을 클릭합니다.
- 연결 정보 창에서 나중의 단계에 사용할 서비스 계정 ID를 복사합니다. 서비스 계정은
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com와 유사합니다.
서비스 계정에 대한 액세스 관리
Lakehouse가 PDF를 읽을 수 있도록 서비스 계정에 액세스 권한을 제공합니다.
- IAM 및 관리자 페이지로 이동합니다.
- 액세스 권한 부여를 클릭합니다. 주 구성원 추가 대화상자가 열립니다.
- 앞에서 복사한 서비스 계정 ID를 새 주 구성원 필드에 입력합니다.
- 역할 선택 필드에서 다음 역할을 추가합니다.
roles/storage.objectUserroles/storage.objectViewerroles/bigquery.userroles/bigquery.dataEditorroles/aiplatform.userroles/storage.adminroles/dataproc.serviceAgent
- 저장을 클릭합니다.
BigQuery의 IAM 역할에 대한 자세한 내용은 사전 정의된 역할 및 권한을 참고하세요.
8. DataScan 작업 권한 관리
Spark 및 Dataform용 특정 서비스 계정 (ID)을 만든 다음 Google의 자동 서비스 에이전트와 함께 스토리지 읽기, BigQuery 작업 실행, 검색을 위한 Vertex AI 사용에 필요한 정확한 권한을 부여합니다.
Spark 및 Dataform의 IAM 액세스
- Google Cloud 콘솔에서 서비스 계정 만들기 페이지로 이동합니다.
- 선택하지 않은 경우 Google Cloud 프로젝트를 선택합니다.
- 서비스 계정 만들기를 클릭합니다.
- 서비스 계정 이름을 예를 들면
sa-spark-stg1입니다. Google Cloud 콘솔에서 이 이름을 기반으로 서비스 계정 ID가 생성됩니다. 필요한 경우 ID를 수정합니다. 나중에 이 ID를 변경할 수 없습니다. - 액세스 제어를 설정하려면 만들고 계속하기를 클릭하고 다음 단계로 진행합니다.
- 프로젝트의 서비스 계정에 부여할 다음 IAM 역할을 선택합니다.
roles/dataproc.workerroles/storage.objectUserroles/bigquery.dataEditorroles/bigquery.jobUserroles/aiplatform.userroles/dataplex.discoveryPublishingServiceAgent
- 역할을 추가했으면 계속을 클릭합니다.
- 완료를 클릭하여 서비스 계정 만들기를 마칩니다.
Knowledge Catalog 액세스를 위한 BigQuery 연결 권한
- Google Cloud 콘솔에서 Cloud Storage 버킷 페이지로 이동합니다.
- 버킷 목록에서 Froyo용으로 만든 버킷 이름을 클릭합니다. 예를 들면
acai_pdfs입니다. - 권한 탭에서 액세스 권한 부여를 클릭합니다. 주 구성원 추가 대화상자가 표시됩니다.
- 새 주 구성원 필드에 BigQuery 서비스 계정 ID를 입력합니다. 서비스 계정은
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com와 유사합니다. - 역할 선택 드롭다운 메뉴에서 다음 역할을 선택합니다.
roles/storage.objectUserroles/dataplex.serviceAgentroles/dataplex.securityAdminroles/aiplatform.serviceAgentroles/dataplex.discoveryPublishingServiceAgent
- 저장을 클릭합니다.
9. Knowledge Catalog 설정
Knowledge Catalog를 빌드하여 Froyo 관련 데이터를 통합하고 비정형 파일 (예: PDF 레시피 및 PDF 공급업체)의 검색을 자동화합니다.
curl를 통해 DataScan 만들기
이 섹션에서는 datascan_ID를 추가하고 BigQuery 데이터 세트를 가리켜 Cloud Storage 버킷 (예: acai_pdfs)의 스캔을 만듭니다. 그러면 Knowledge Catalog가 BigQuery에 PDF 항목을 자동으로 만듭니다.
- PDF (공급업체 및 레시피)를 스캔하려면 다음 명령어를 실행합니다.
# 1. Set your variables PROJECT_ID="<PROJECT_ID>" REGION="<REGION>" ENV_SUFFIX="stg1" DATASCAN_ID="froyo-profile-${ENV_SUFFIX}" BUCKET_NAME="<BUCKET_NAME>" # 2. Set this to the Name of the connection you created in Step 7 CONNECTION_ID="<CONNECTION_ID_NAME>" # 3. Define the API Endpoint DATAPLEX_API="dataplex.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}" # 4. Create the DataScan via CURL echo "Creating Dataplex DataScan: ${DATASCAN_ID}..." curl -X POST "https://$DATAPLEX_API/dataScans?dataScanId=${DATASCAN_ID}" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d '{ "data": { "resource": "//storage.googleapis.com/projects/'"${PROJECT_ID}"'/buckets/'"${BUCKET_NAME}"'" }, "executionSpec": { "trigger": { "on_demand": {} } }, "dataDiscoverySpec": { "bigqueryPublishingConfig": { "tableType": "BIGLAKE", "connection": "projects/'"${PROJECT_ID}"'/locations/'"${REGION}"'/connections/'"${CONNECTION_ID}"'" }, "storageConfig": { "unstructuredDataOptions": { "entity_inference_enabled": true } } } }' curl명령어를 사용하면 다음 이미지와 같이 Knowledge Catalog DataScan 결과가 표시됩니다.
작업 실행
다음 명령어를 실행합니다.
gcloud dataplex datascans run $DATASCAN_ID --location=$REGION
작업 설명
작업을 설명하려면 다음 명령어를 실행합니다.
gcloud dataplex datascans describe $DATASCAN_ID --location=$REGION
데이터 스캔 작업 삭제
스캔이 10분 이상 실행되거나 작업 상태가 실행 중으로 전환되지 않고 장시간 대기 중으로 유지되는 경우 해당 리전에서 리소스를 일시적으로 사용할 수 없기 때문일 수 있습니다. 이 경우 다음 명령어를 실행하여 작업을 삭제한 후 다시 만들고 실행해 볼 수 있습니다. 경우에 따라 초기 실행이 unable to acquire necessary resources와 같은 오류로 빠르게 실패할 수 있습니다.
gcloud dataplex datascans delete $DATASCAN_ID --location=$REGION
작업 상태 보기
작업 상태를 확인하려면 다음 단계를 따르세요.
- Google Cloud 콘솔에서 메타데이터 선별 페이지로 이동합니다.
- Cloud Storage 탐색 탭에서 탐색 스캔의 이름을 클릭합니다.
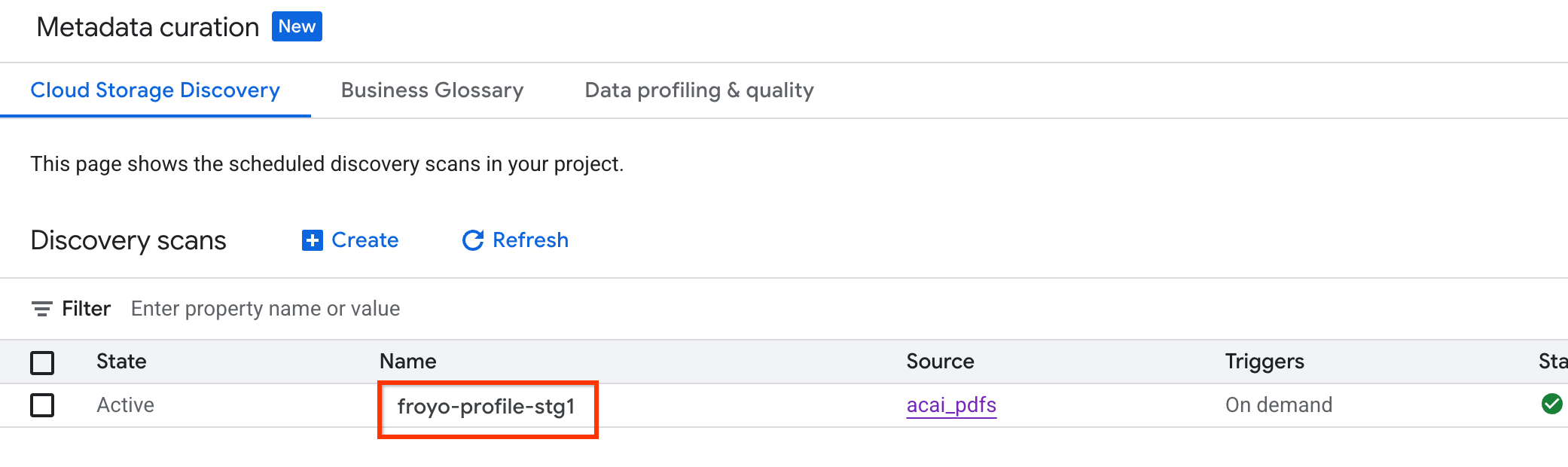
- 스캔 세부정보 페이지에서 작업 상태를 확인할 수 있습니다.
- 작업이 완료되면
curl명령어를 사용하여 만든 게시된 데이터 세트 (예:acai_pdfs_discovered_003)가 있는지 확인합니다.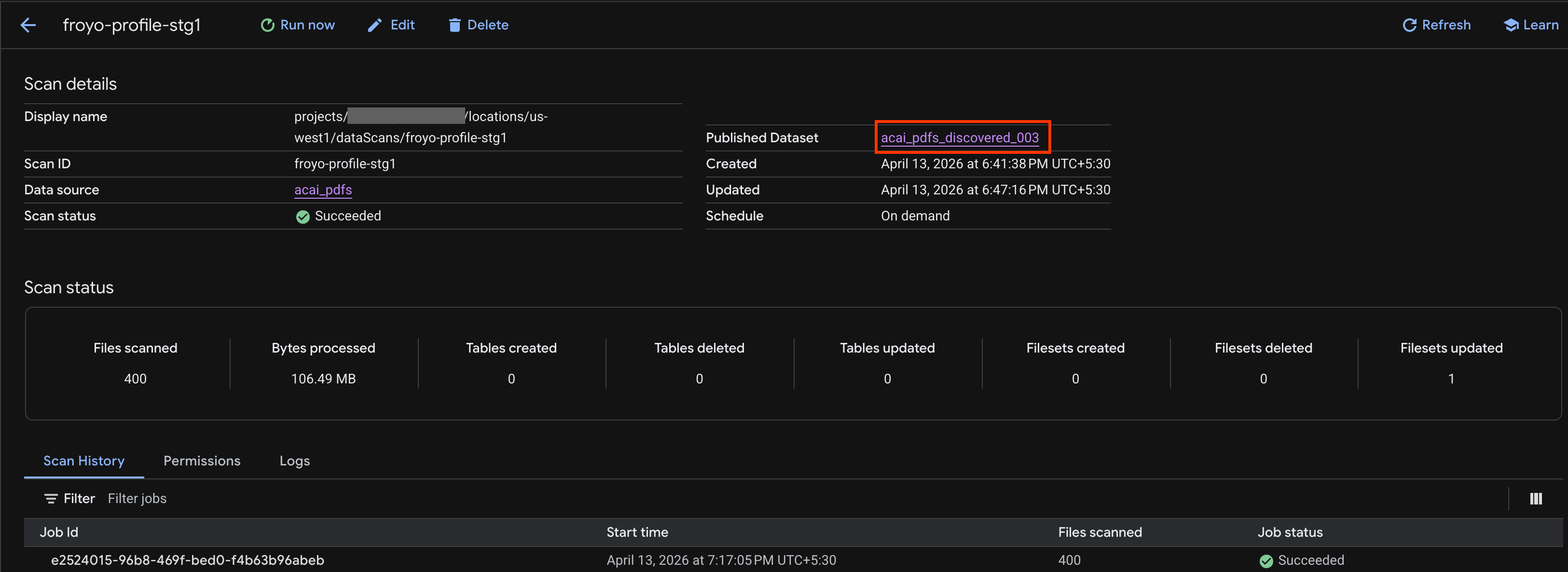
객체 테이블 보기
검색 작업 후에 생성된 객체 테이블을 보려면 다음 단계를 따르세요.
- Google Cloud 콘솔에서 BigQuery로 이동합니다.
- 데이터 세트를 클릭하고 이전 단계에서 만든 게시된 데이터 세트를 선택합니다. 예를 들면 다음과 같습니다.
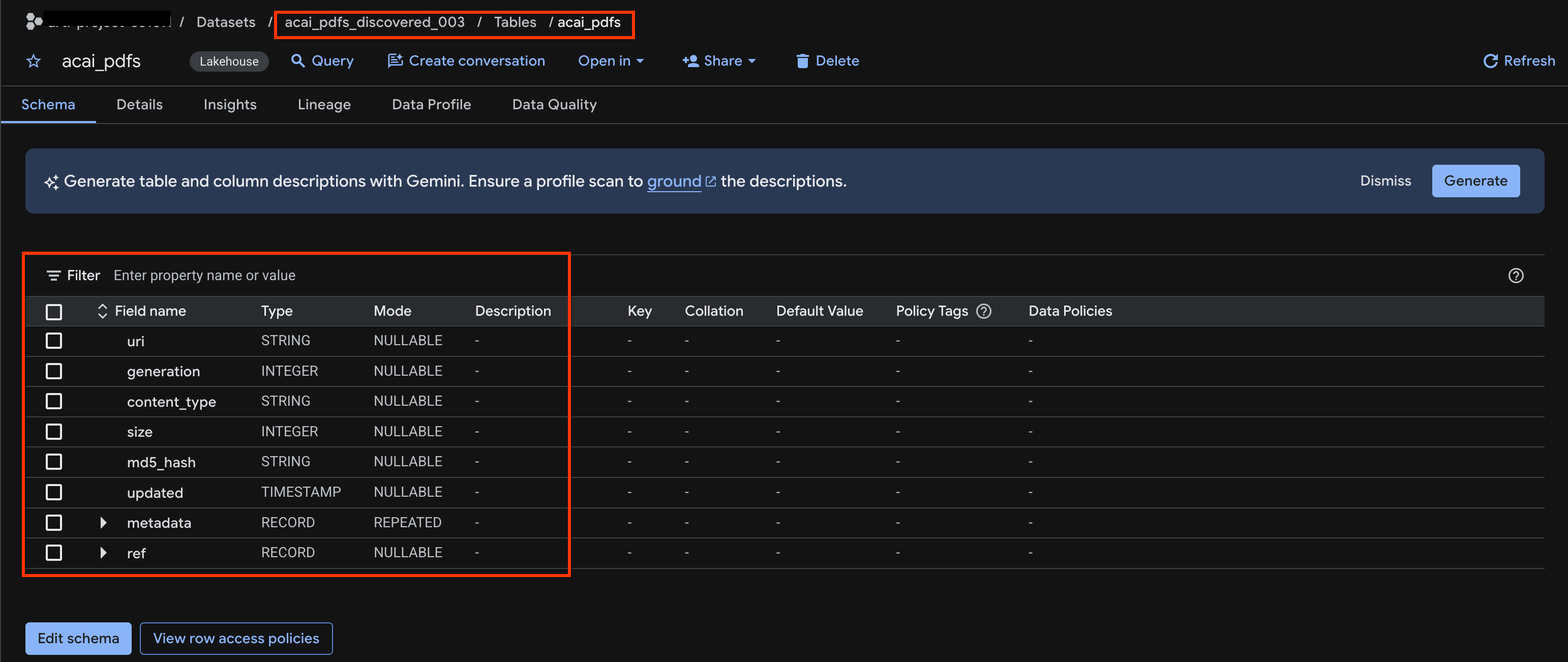
acai_pdfs_discovered_003 - 객체 테이블을 보려면 테이블 ID를 클릭합니다. 예를 들면
acai_pdfs입니다. - 결과 객체 테이블은 다음 이미지와 같습니다.
10. 시맨틱 추출
이전 단계에서 만든 비정형 객체 테이블의 구조화된 테이블, 기타 데이터베이스 객체, 관계를 추론하고 추출합니다. 이를 위해 Knowledge Catalog 인사이트 기능을 사용하여 비정형 테이블에서 구조화된 데이터를 추출하는 SQL 문을 생성합니다.
- Google Cloud 콘솔에서 Knowledge Catalog 검색 페이지로 이동합니다.
- 인사이트를 보려는 데이터 세트 테이블을 검색합니다. 예를 들면
acai_pdfs_discovered_003입니다.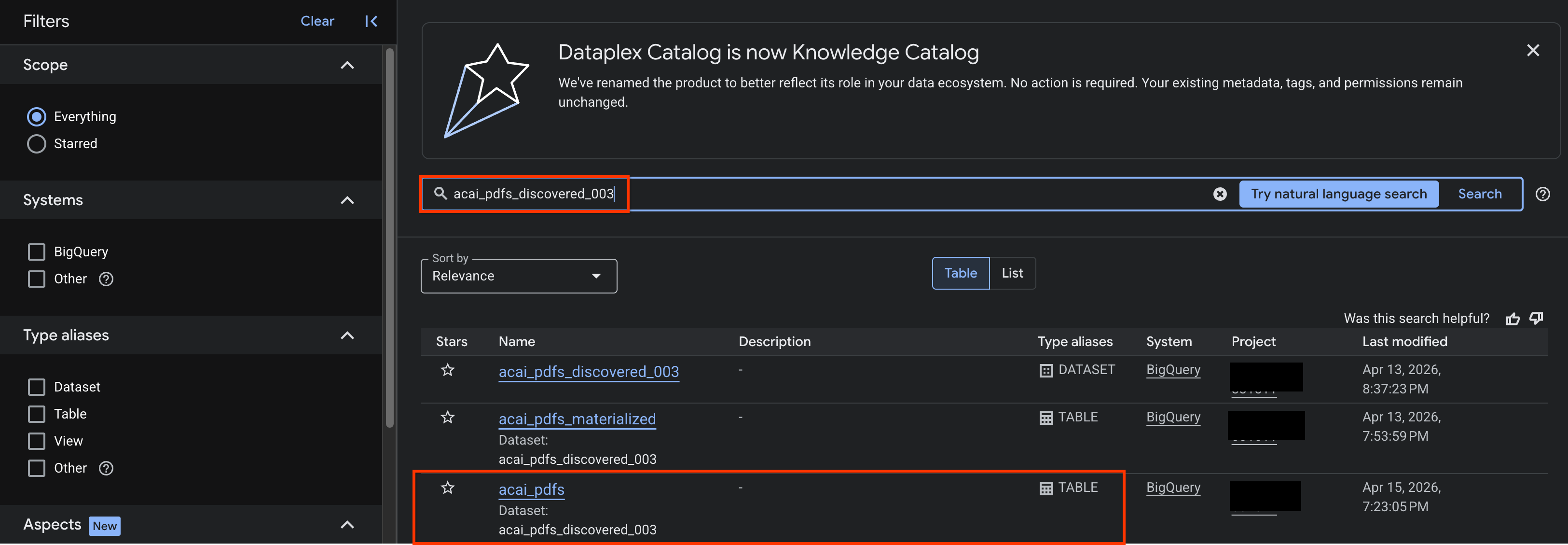
- 검색 결과에서 테이블을 클릭하여 항목 페이지를 엽니다.
- 통계 탭을 클릭합니다. 탭이 비어 있는 경우 이는 이 테이블의 인사이트가 아직 생성되지 않았음을 의미합니다. 인사이트 생성에는 15~25분이 걸릴 수 있습니다.
- 통계가 표시되면 추출 > SQL로 추출을 클릭합니다.
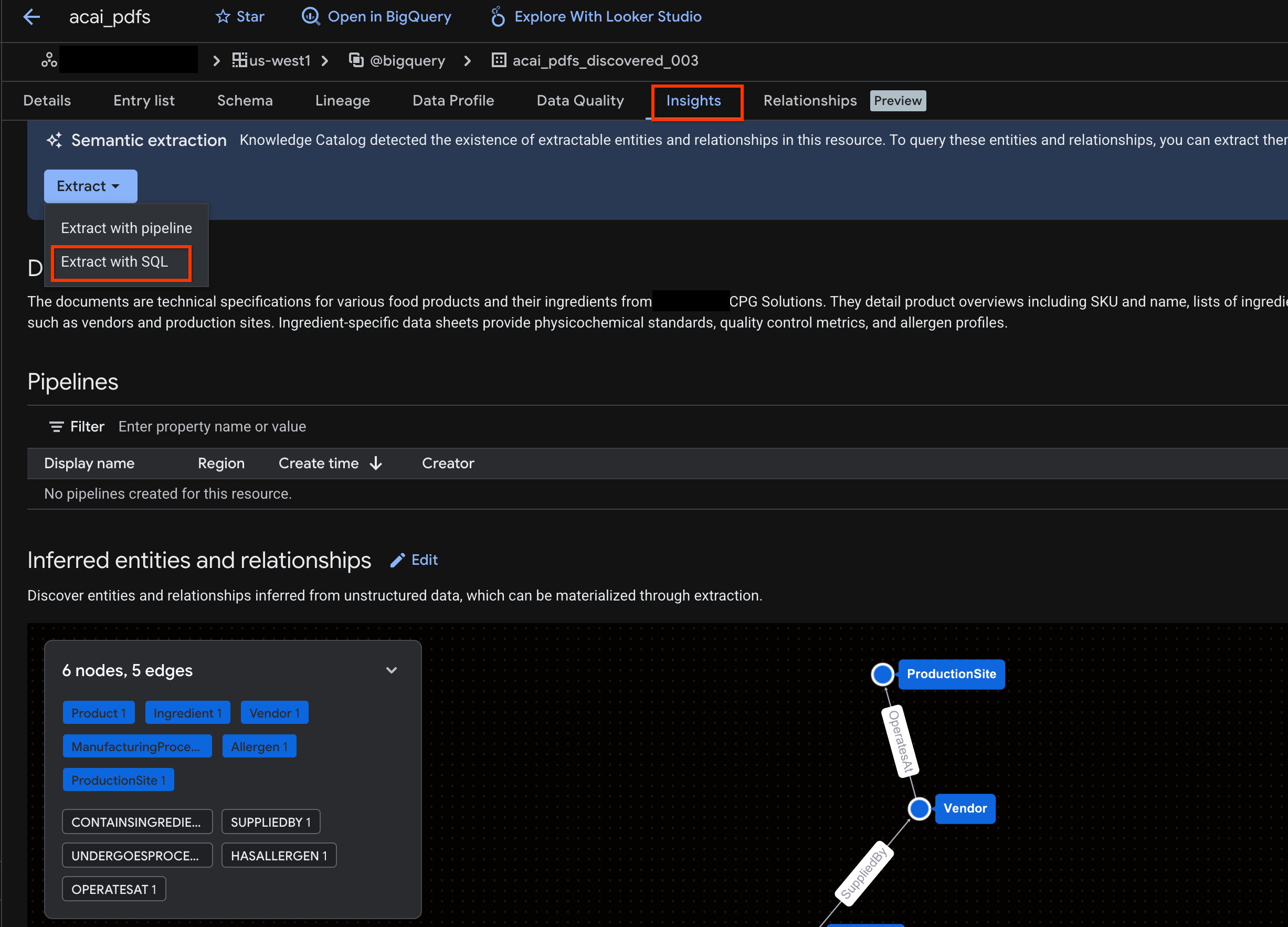
- SQL로 추출 페이지의 대상에 데이터 세트를 입력합니다. 예를 들면
acai_pdfs_discovered_003입니다. - 추출을 클릭합니다. 그러면 쿼리가 로드된 BigQuery 편집기가 열립니다.
- 실행을 클릭합니다. 이 단계에서는 일련의 문을 생성하며 실행을 완료하는 데 몇 분 정도 걸릴 수 있습니다.
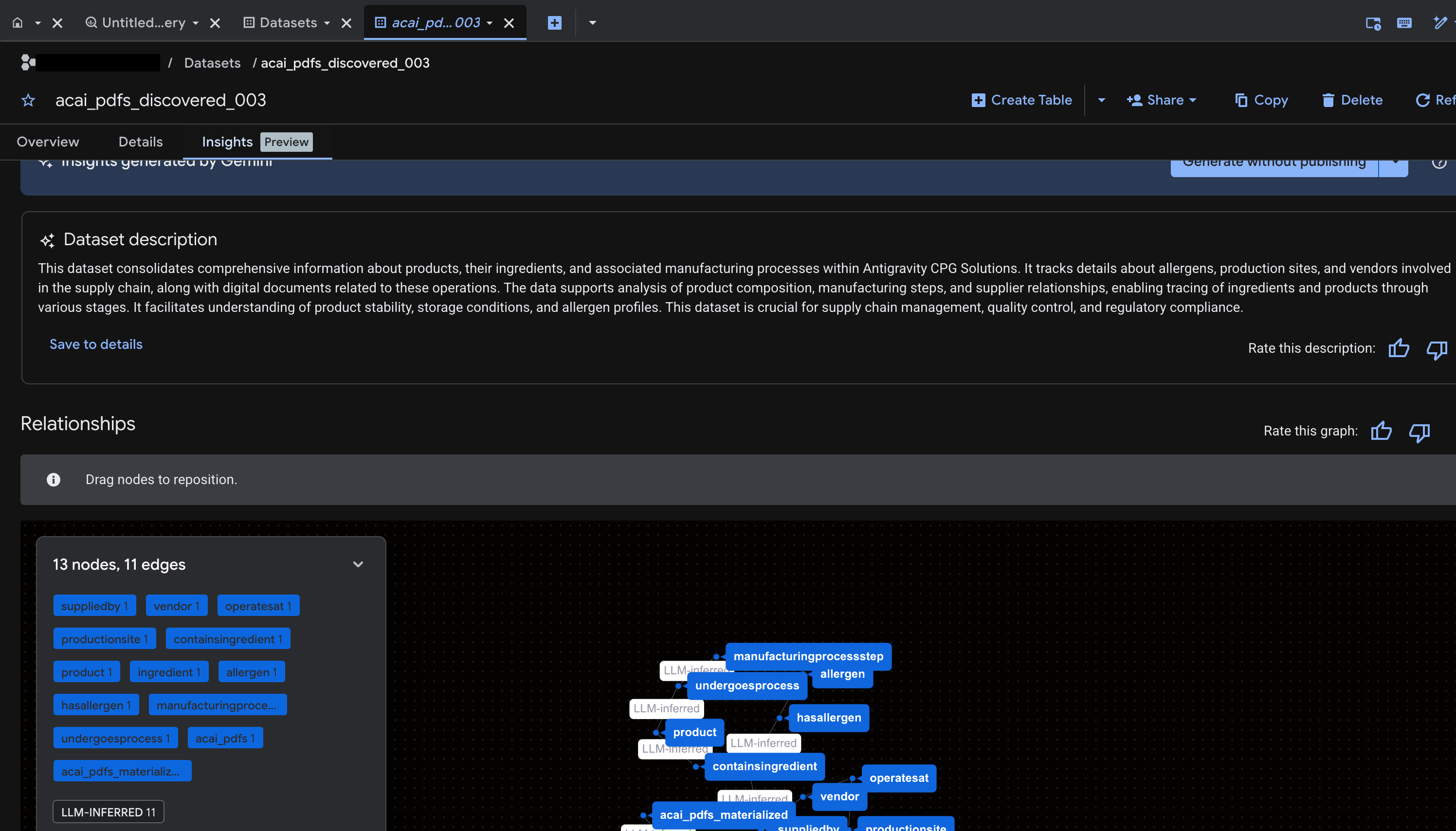
- 쿼리가 완료되면 다음과 같은 결과가 표시됩니다.
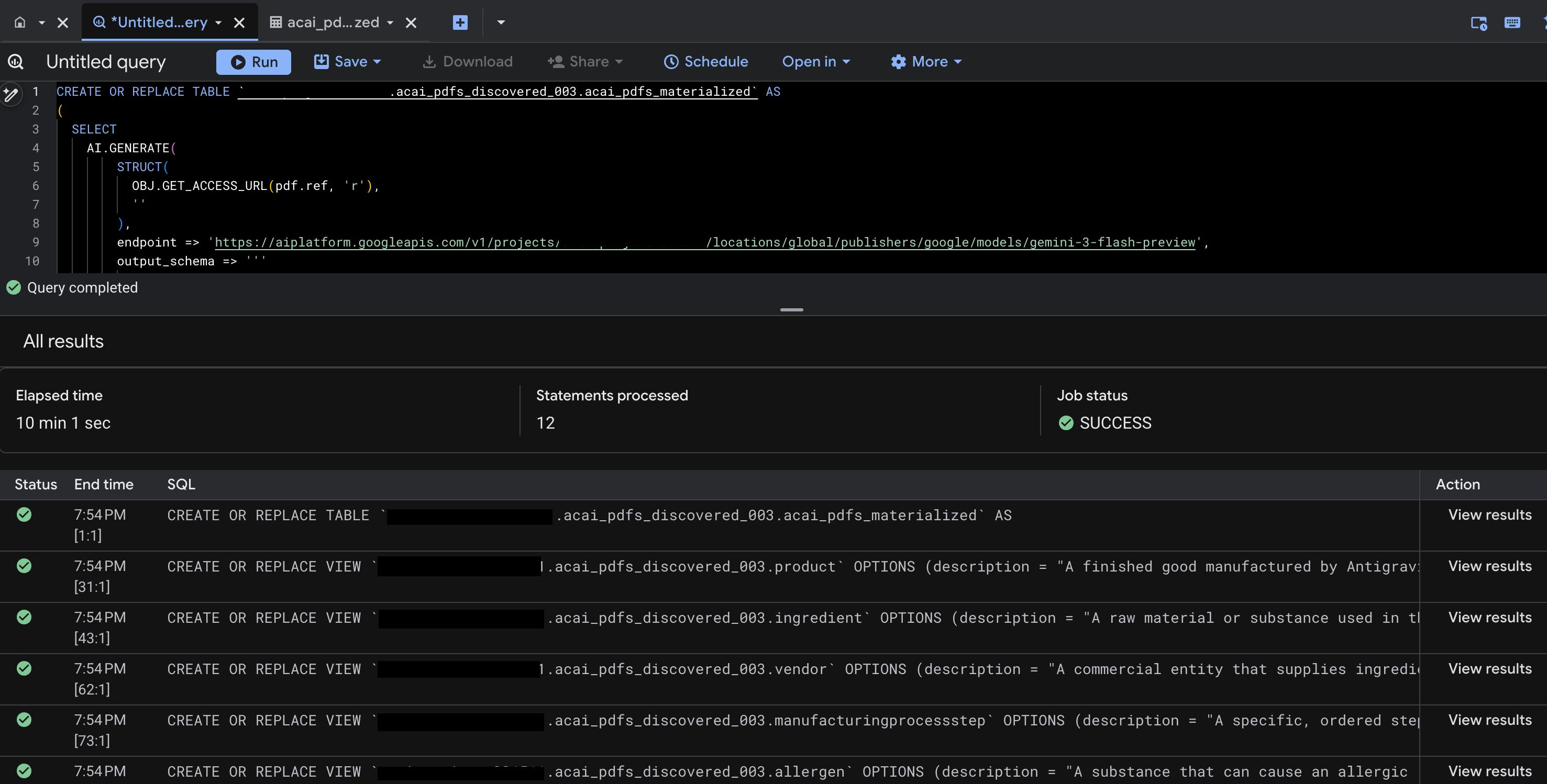
- BigQuery로 이동하여 데이터 세트 (예:
acai_pdfs_discovered_003)를 클릭합니다. 6단계에서 선택한 데이터 세트에 새로운 구조화된 데이터베이스 객체가 생성됩니다.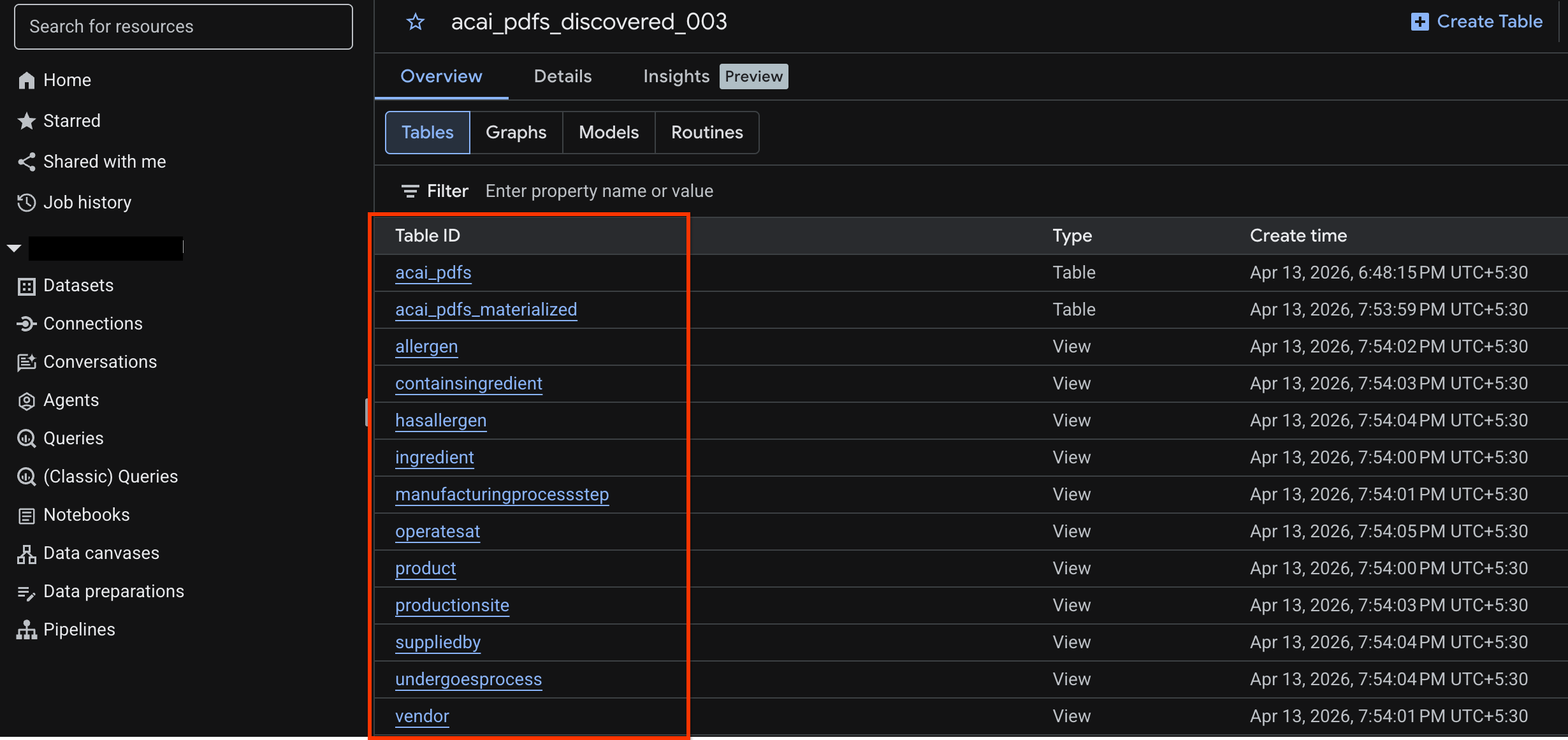
BigQuery에서 객체의 통계 생성
BigQuery 데이터 세트의 통계를 생성하려면 BigQuery Studio를 사용하여 BigQuery의 데이터 세트에 액세스해야 합니다.
- Google Cloud 콘솔에서 BigQuery Studio로 이동합니다.
- 탐색기 창에서 프로젝트를 선택하고 통계를 생성할 데이터 세트로 이동합니다.
- 통계 탭을 클릭합니다.
- API 사용 설정 버튼이 표시되면 클릭하여 Google Cloud를 위한 Gemini를 사용 설정합니다. 그러면 핵심 기능 사용 설정 창이 열립니다.
- 핵심 기능 API 섹션에서 Gemini for Google Cloud API 및 BigQuery Unified API에 대해 사용 설정을 클릭한 후 다음을 클릭합니다.
- 권한 (선택사항) 섹션에서 필요한 경우 보안 주체에게 IAM 역할을 부여한 다음 다음을 클릭합니다.
- 통계를 생성하고 Knowledge Catalog에 게시하려면 생성 및 게시를 클릭합니다.
- 게시되면 탭에서 유용한 정보를 확인할 수 있습니다.
11. 에이전트 기반 데이터 분석을 위한 IDE 설정
Visual Studio Code용 Google Cloud Data Agent Kit 확장 프로그램은 데이터 과학자 및 데이터 엔지니어를 위한 IDE 확장 프로그램입니다. IDE에서 직접 Google 데이터 클라우드 리소스 및 데이터에 연결하고 작업할 수 있습니다. 자세한 내용은 VS Code용 데이터 에이전트 키트 확장 프로그램 개요를 참고하세요.
VS Code용 데이터 에이전트 키트 확장 프로그램은 다음을 수행하려는 경우에 유용합니다.
- VS Code에서 직접 Spark ETL 또는 BigQuery ETL과 같은 프로덕션 지원 데이터 파이프라인을 빌드, 테스트, 검토, 배포합니다.
- AI 지원을 사용하여 데이터를 탐색하고, 학습 파이프라인을 빌드하고, 최적의 ML 모델을 식별하고, 프로덕션 엔드포인트에 배포합니다.
- 신뢰할 수 있는 데이터 소스에 연결하고, 고성능 데이터 모델을 빌드하고, 비즈니스 이해관계자를 위한 대화형 대시보드를 게시합니다.
VS Code용 데이터 에이전트 키트 확장 프로그램 설치
- VS Code를 엽니다.
- Google Cloud CLI 설치 자세한 내용은 Google Cloud CLI 설치를 참고하세요.
- VS Code용 데이터 에이전트 키트 확장 프로그램을 설치합니다.
- 확장 프로그램 온보딩 프로세스를 완료합니다. 이 프로세스에서는 다음이 필요합니다.
- 확장 프로그램에 로그인
- 스킬, MCP 서버 설치
- 온보딩을 완료한 후 창을 새로고침하거나 다시 시작합니다. 자세한 내용은 VS Code용 데이터 에이전트 키 확장 프로그램 설정 및 구성을 참고하세요.
- IDE가 다시 로드되면 탐색 창에서 Google 데이터 클라우드 아이콘을 클릭하고 설정으로 이동하여 공통 설정에서 프로젝트 ID와 리전 (
us-west1)을 올바르게 설정했는지 확인합니다.
VS Code에서 작업공간 설정
- VS Code를 열고 File > Open folder > New folder를 선택합니다.
acai_test라는 새 폴더를 만든 다음 열기를 클릭합니다. 이제 VS Code에서 열린 폴더를 워크스페이스로 간주합니다.- 워크스페이스 신뢰 대화상자에서 예, 작성자를 신뢰합니다를 선택하여 워크스페이스의 모든 기능을 사용 설정합니다.
acai_test작업공간에.github폴더를 만듭니다..github폴더에 새 파일copilot-instructions.md를 만들고 다음 규칙을 입력합니다.## 1. Project Context - **Project ID**: <PROJECT_ID> - **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors. - **Documentation**: Raw PDF documents detailing flavors and ingredients are stored in Google Cloud Storage at `gs://<BUCKET_NAME>`. ## 2. Execution & Data Processing Rules - **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `<BQ_DATASET_NAME>` (referred to as the Knowledge Catalog). - **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the dataset `<DATASET_ID>`. When you are referencing a dataset, ensure you are using it with the project ID (`<PROJECT_ID>`) and namespace prefix `<NAMESPACE_NAME>`. For example, to query order table in this dataset you should use `<PROJECT_ID>.<NAMESPACE>.<DATASET_ID>.orders`. - **CRITICAL RULE - Data Joins between BigQuery dataset and Iceberg dataset**: ANY task requiring a join or integration between the BigQuery datasets `<DATASET_ID>` of the PDF data and the `<DATASET_ID>` of the customer data MUST be executed using **Spark Notebooks**. - **CRITICAL RULE - Notebook Kernel**: Every Spark notebook utilized MUST exclusively be configured to run on the Serverless Session template `iceberg-federation-template` as its kernel. - **CRITICAL RULE - Data Science**: ANY data science, machine learning, or advanced analytical task MUST be performed strictly within **Spark Notebooks** using the aforementioned setup.acai_test작업공간에 새 파일template.yaml를 하나 더 만들고 파일에 다음 정보를 입력합니다.labels: client: "vscode" jupyterSession: displayName: "iceberg-federation-template" kernel: "PYTHON" environmentConfig: executionConfig: serviceAccount: "sa-spark-dev1@<PROJECT_ID>.iam.gserviceaccount.com" subnetworkUri: "projects/<PROJECT_ID>/regions/<REGION>/subnetworks/<SUBNET_NAME>" runtimeConfig: version: "2.3" properties: # This enables the secure proxy URL you were looking for dataproc.tier: "premium" spark.dataproc.engine: "lightningEngine" spark.dataproc.lightningEngine.runtime: "native" spark.memory.offHeap.enabled: "true" spark.memory.offHeap.size: "1g" spark.executor.memory: "4g" "dataproc.component.gateway.enabled": "true" "dataproc.jupyter.listen.all.interfaces": "true" "spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" "spark.sql.defaultCatalog": "<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>": "org.apache.iceberg.spark.SparkCatalog" "spark.sql.catalog.<CATALOG_NAME>.type": "rest" "spark.sql.catalog.<CATALOG_NAME>.uri": "<CATALOG_URI_ID>" "spark.sql.catalog.<CATALOG_NAME>.warehouse": "bl://projects/<PROJECT_ID>/catalogs/<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>.rest.auth.type": "org.apache.iceberg.gcp.auth.GoogleAuthManager"- VS Code에서 터미널을 클릭하고 다음 명령어를 실행하여
template.yaml파일을 세션 템플릿으로 가져옵니다. 이 템플릿은 나중에 에이전트가 Spark 세션을 만드는 데 사용됩니다.gcloud beta dataproc session-templates import iceberg-federation-template \ --source=template.yaml \ --location=<REGION>REGION을 현재 리전으로 바꿉니다.
12. 에이전트 기반 데이터 분석 수행
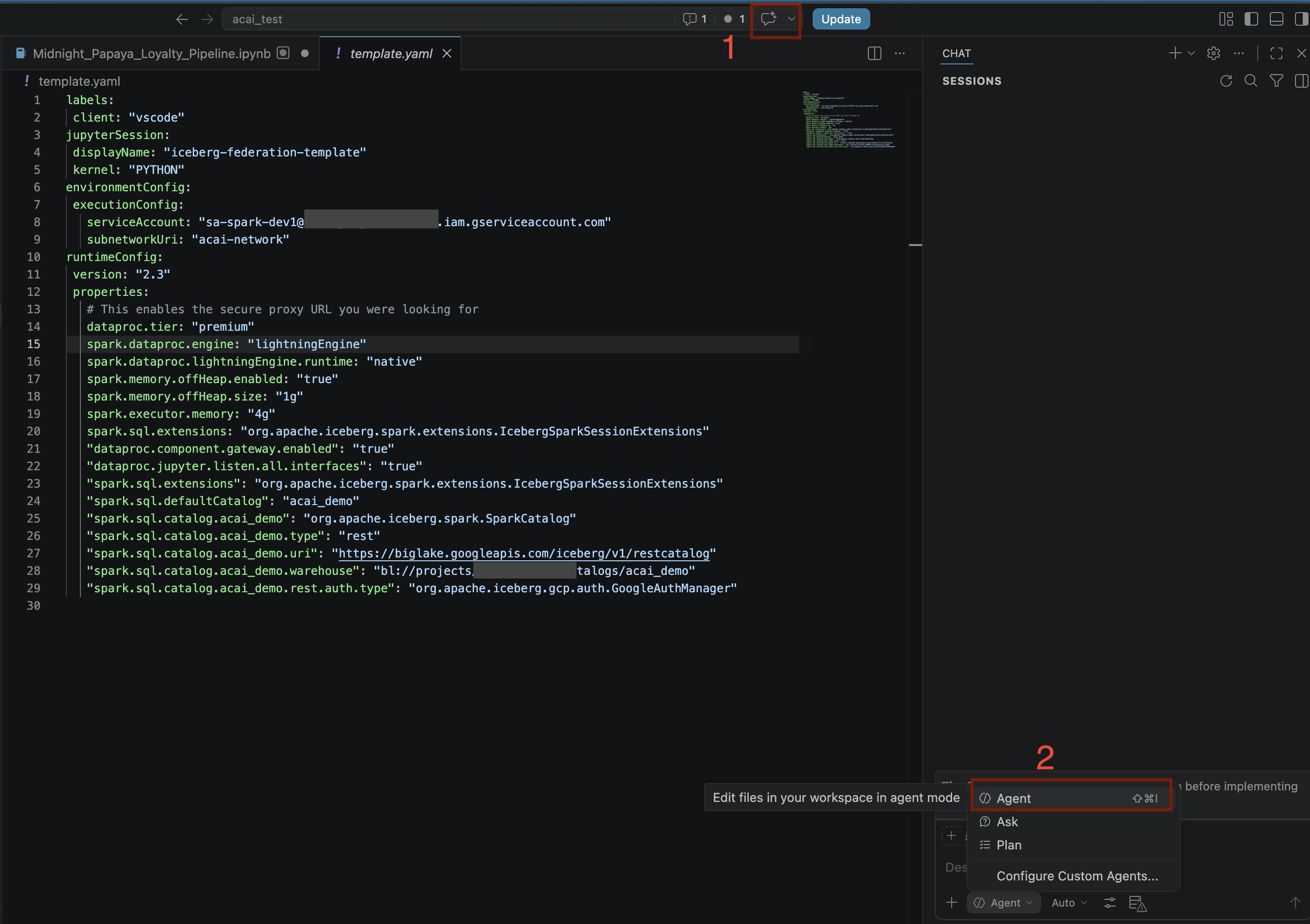
- VS Code 코드 편집기에서 채팅 전환을 클릭합니다.
- 맞춤 에이전트 구성에서 에이전트를 선택합니다.
- 검색 모델 창에서 언어 모델 관리를 클릭합니다.
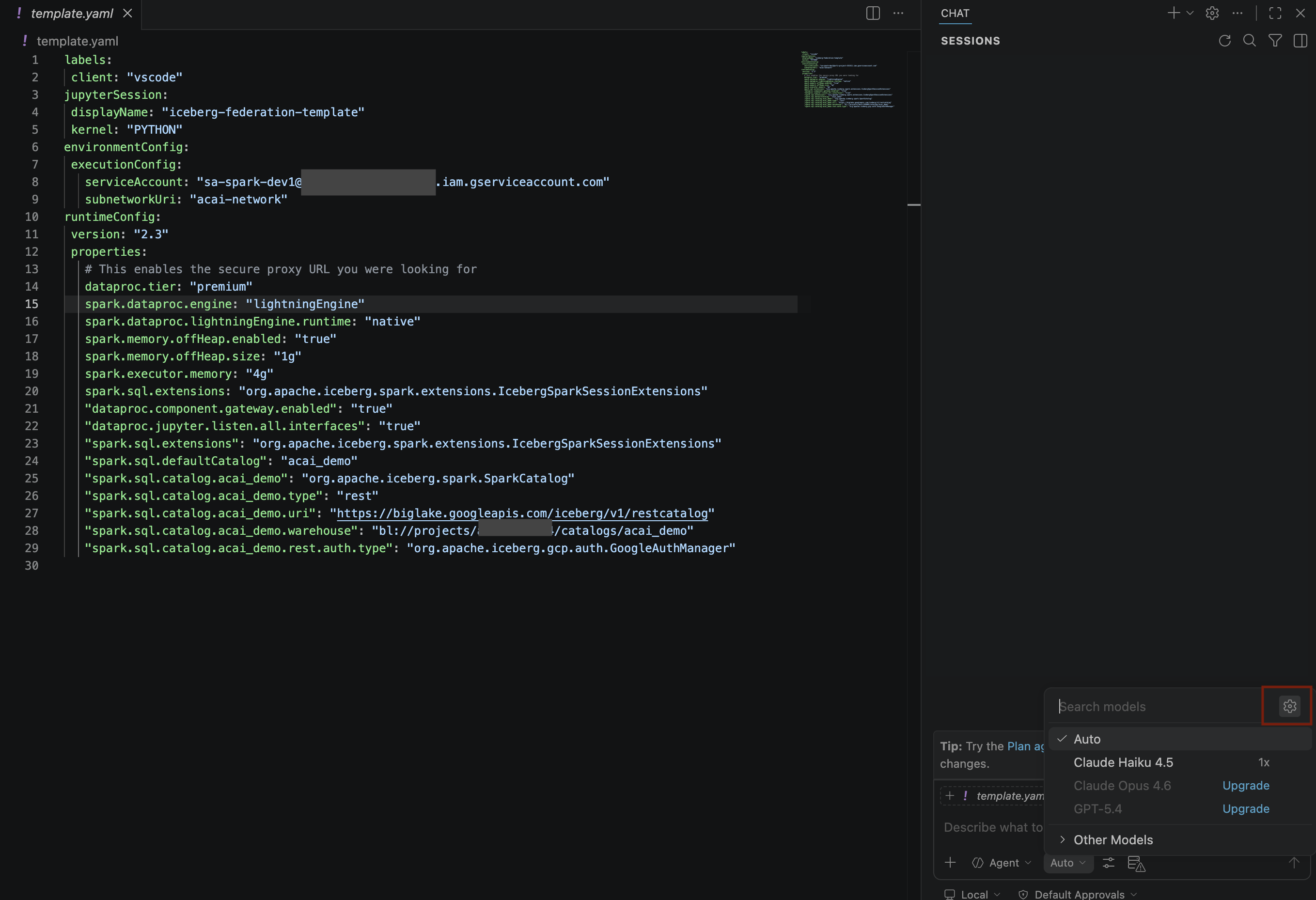
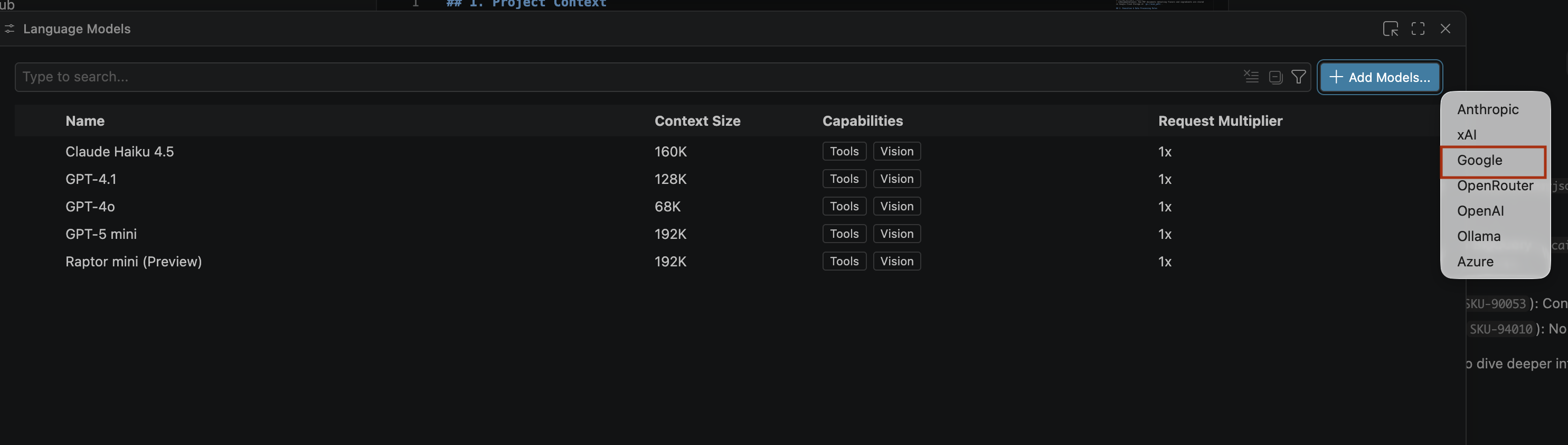
- 언어 모델 페이지에서 모델 추가를 클릭합니다.
- 목록에서 Google을 선택하고 Enter 키를 눌러 입력을 확인합니다.
- Google Gemini의 API 키를 입력하려면 다음 단계를 따르세요.
- Google AI Studio 웹사이트로 이동합니다.
- Google 계정으로 로그인합니다.
- 사이드바에서 API 키 가져오기를 클릭합니다.
- API 키 만들기를 클릭합니다. 새 키 만들기 페이지가 열립니다.
- 클라우드 프로젝트 선택 목록에서 프로젝트 가져오기를 선택합니다.
- 기존 프로젝트의 이름을 입력합니다.
- 키 만들기를 클릭하고 API 키를 복사합니다. 이 키를 사용하면 계정의 Gemini API 리소스에 액세스할 수 있습니다.자세한 내용은 Gemini API 키 사용을 참고하세요.
- 생성한 API 키를 검색창에 붙여넣고 Enter를 클릭합니다.
- Gemini 모델이 표시되지 않으면 다음 이미지와 같이 숨김 해제합니다.
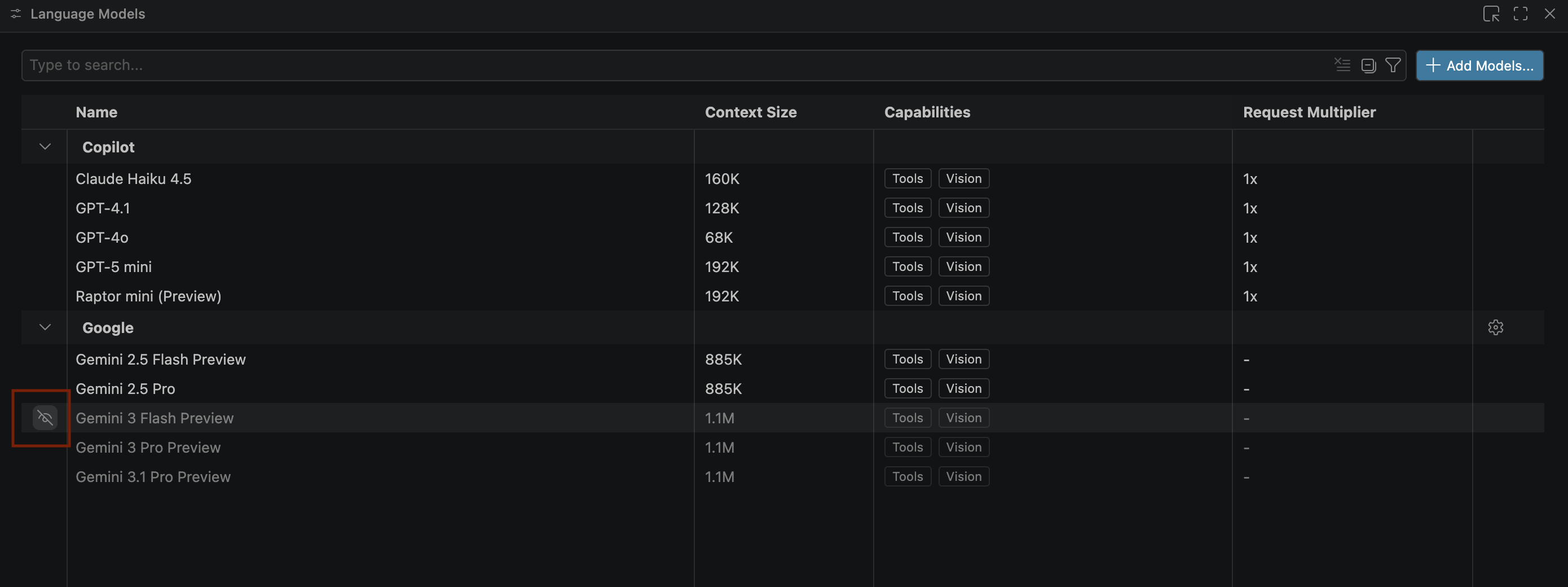
- Google Gemini 모델 목록에서 Gemini 3.1 Pro 프리뷰를 선택하고 언어 모델 창을 닫습니다.
- 채팅 창에 다음 질문을 입력합니다.
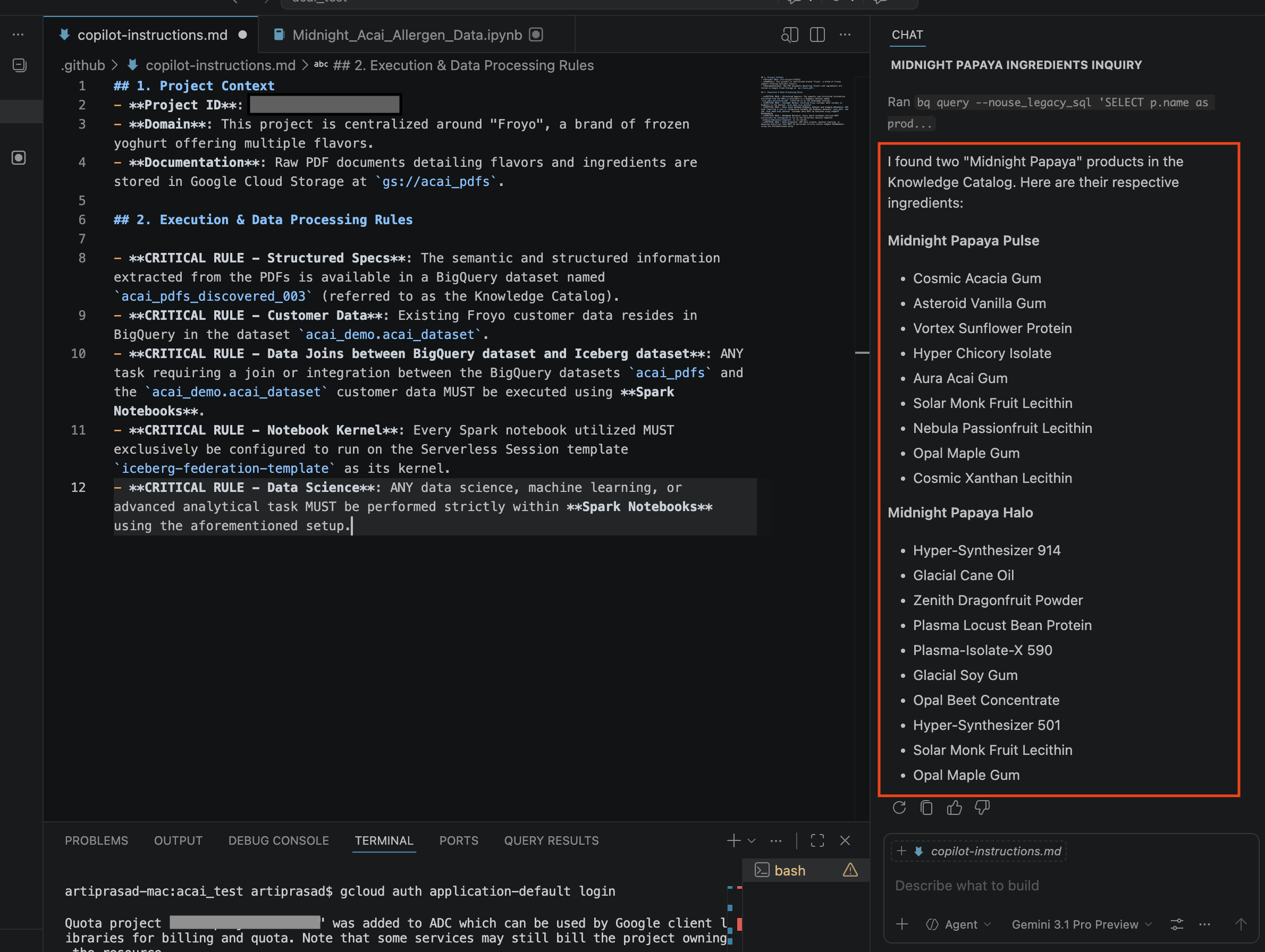
Search ingredients for Midnight papaya - 상호작용 후 다음과 같은 결과가 표시됩니다.
- 채팅 창에 다른 질문을 입력합니다.
Search allergen information for Midnight papaya - 몇 번의 상호작용과 단계를 거치면 다음 이미지와 같이 에이전트가 알레르기 유발 물질 이름
Soy으로 응답하는 것을 확인할 수 있습니다.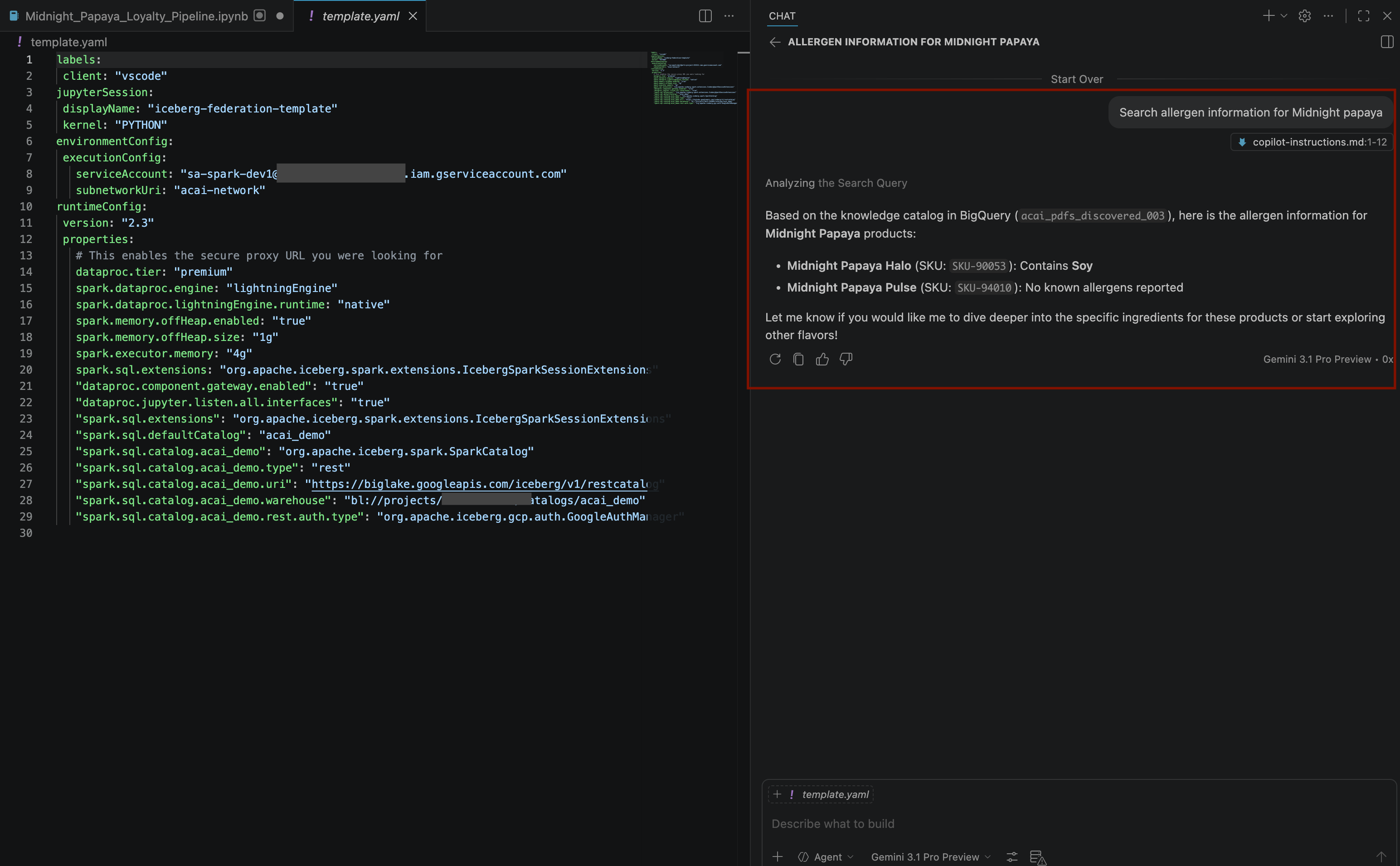
- 채팅 창에 다른 질문을 입력합니다.
Build a pipeline to join products with our 'Global Loyalty' Iceberg tables in acai customer, sales data to identify popular products - 커널을 선택하려면
.ipynb파일을 열고 커널 선택 > 원격 Spark 커널 > 서버리스 Spark의 Iceberg-federation-template을 클릭합니다.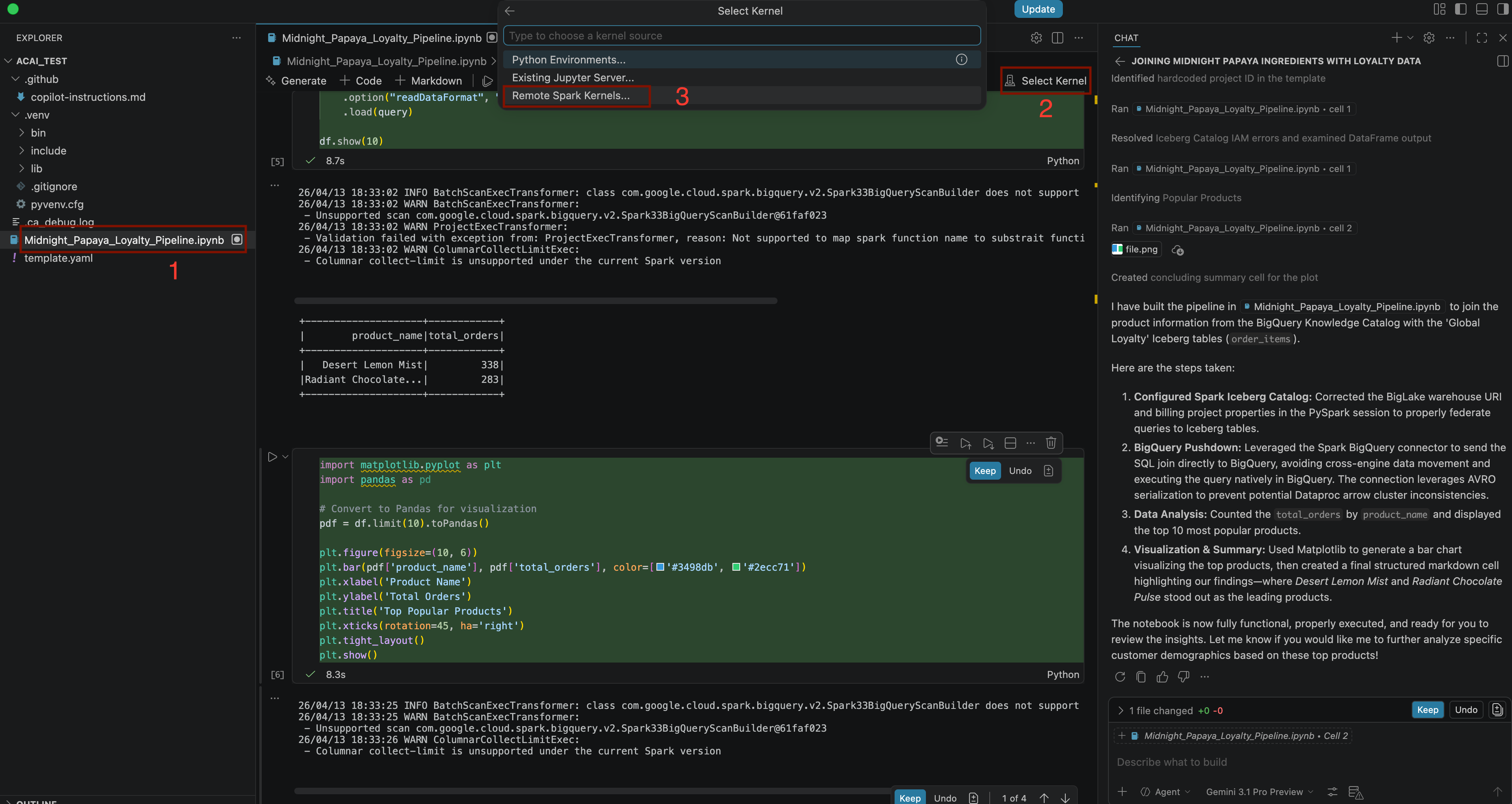
- 일부 상호작용과 단계를 거치면 다음 이미지와 같이 노트북의 모든 단계가 성공적으로 실행되고 노트북 끝에 최종 결과가 생성되어 에이전트가 응답하는 것을 확인할 수 있습니다.
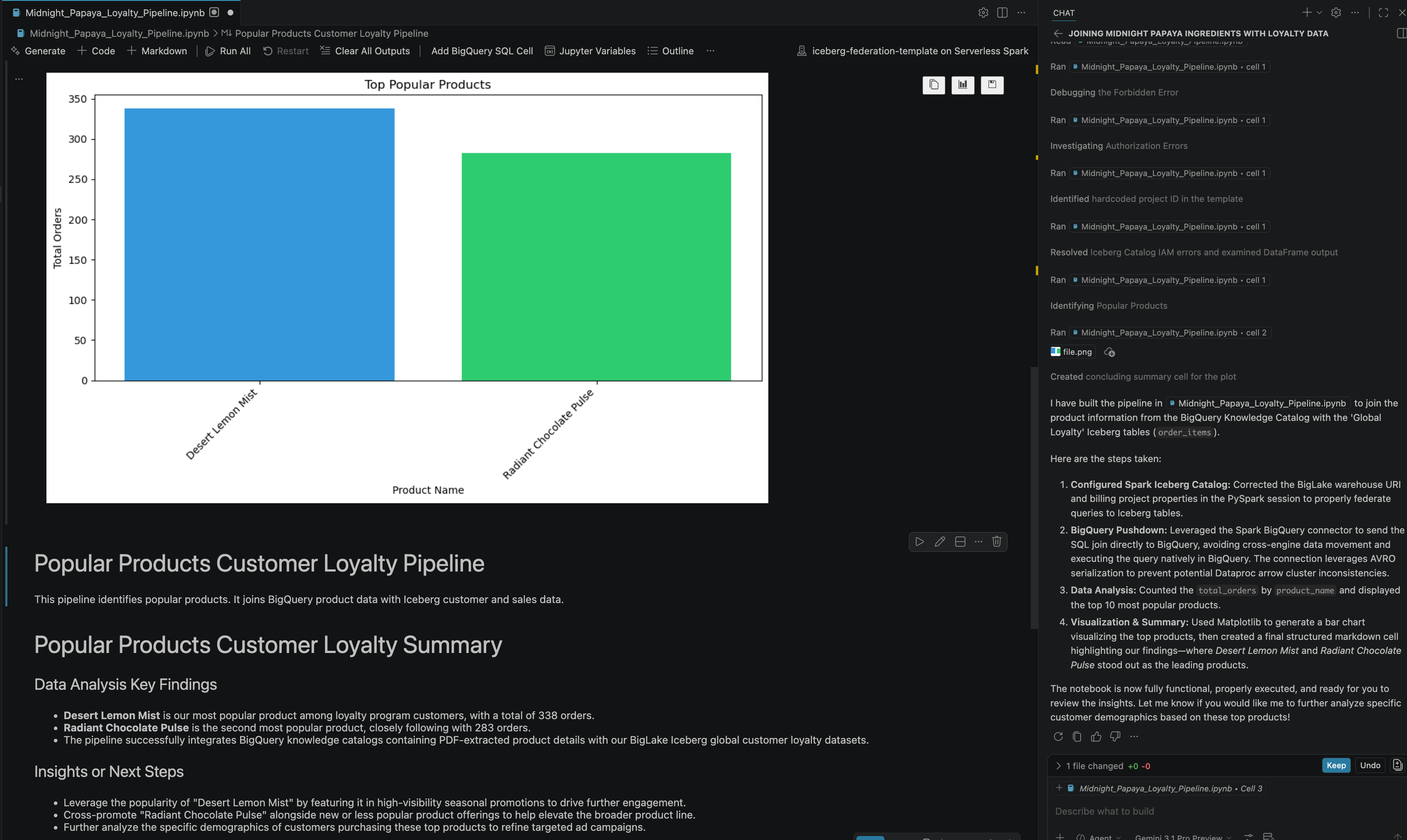
13. 삭제
요금이 발생하지 않도록 하려면 이 실습에서 만든 리소스를 삭제합니다.
- Knowledge Catalog DataScan을 삭제하려면 다음 명령어를 실행합니다.
DATASCAN_ID="<DATASCAN_ID>" echo "Deleting Dataplex DataScan: ${DATASCAN_ID}" gcloud dataplex datascans delete "${DATASCAN_ID}" --location="${REGION}" --quiet - Cloud Storage 버킷과 모든 콘텐츠를 삭제하려면 다음 명령어를 실행합니다.
echo "Deleting Cloud Storage buckets: <BUCKET_NAME1> and <BUCKET_NAME2>" gsutil -m rm -r gs://<BUCKET_NAME1> gsutil -m rm -r gs://<BUCKET_NAME2> - BigQuery 연결을 삭제하려면 다음 명령어를 실행합니다.
CONNECTION_ID="<CONNECTION_NAME>" echo "Deleting BigQuery Connection: ${CONNECTION_ID}" bq rm --connection "${PROJECT_ID}.${REGION}.${CONNECTION_ID}" - Lakehouse 카탈로그를 삭제하려면 다음 명령어를 실행합니다.
CATALOG_ID="<CATALOG_NAME>" echo "Deleting Lakehouse Catalog: ${CATALOG_ID}" gcloud biglake catalogs delete "${CATALOG_ID}" --project="${PROJECT_ID}" --location="${REGION}" --quiet - 검색된 PDF 테이블이 포함된 데이터 세트를 삭제하려면 다음 명령어를 실행합니다.
DATASET_NAME="<DATASET_NAME>" echo "Deleting BigQuery Dataset: ${DATASET_NAME}" bq rm -r -f "${PROJECT_ID}:${DATASET_NAME}" - 커스텀 서비스 계정을 삭제하려면 다음 명령어를 실행합니다.
SERVICE_ACCOUNT="<SERVICE_ACCOUNT>" echo "Deleting Service Account: ${SERVICE_ACCOUNT}" gcloud iam service-accounts delete "${SERVICE_ACCOUNT}"@"${PROJECT_ID}".iam.gserviceaccount.com --quiet - VPC 네트워크를 삭제하려면 다음 명령어를 실행합니다.
VPC_NETWORK="<VPC_NETWORK>" echo "Deleting VPC Network: ${VPC_NETWORK}" gcloud compute networks delete "${VPC_NETWORK}" --quiet - 전체 Google Cloud 프로젝트를 삭제하려면 다음 명령어를 실행합니다.
gcloud projects delete "${PROJECT_ID}"
14. 축하합니다
축하합니다. BigQuery 테이블에서 사일로화된 PDF 및 Parquet 파일의 데이터 환경을 구성하고 검색 가능하고 조인 가능한 단일 생태계로 축소했습니다. 기본적으로 PDF와 빅데이터 형식을 데이터베이스의 행처럼 지능적으로 처리하는 최신 데이터 레이크하우스를 빌드한 것입니다. 이 모든 작업은 Gemini와의 대화형 환경에서 에이전트를 통해 이루어졌습니다.
참조 문서
이 Codelab에서 사용된 핵심 기술을 자세히 알아보려면 공식 Google Cloud 문서를 참고하세요.
- 데이터 클라우드의 핵심 구성요소인 BigQuery를 살펴보려면 BigQuery 문서를 참고하세요.
- IAM에 대해 자세히 알아보려면 IAM 문서를 참고하세요.
- 레이크하우스에 대해 알아보려면 레이크하우스란 무엇인가요?를 참고하세요.