
1. Wprowadzenie
W tym module wcielisz się w rolę analityka danych w fikcyjnej firmie Froyo, która wprowadza na rynek nowy smak produktu o nazwie „Midnight Swirl”. Aby wprowadzenie produktu na rynek globalny zakończyło się sukcesem, firma musi odpowiedzieć na kluczowe pytania dotyczące składników, popytu na rynku i zwrotu z inwestycji (ROI). Ten kompleksowy przepływ pracy pokazuje, jak Katalog wiedzy Google Cloud (wcześniej Dataplex) i Lakehouse for Apache Iceberg (wcześniej BigLake) wypełniają lukę między „ciemnymi” danymi nieustrukturyzowanymi i dostarczają przydatne informacje biznesowe przy użyciu Gemini w IDE (VS Code) za pomocą ujednoliconej warstwy zarządzania.
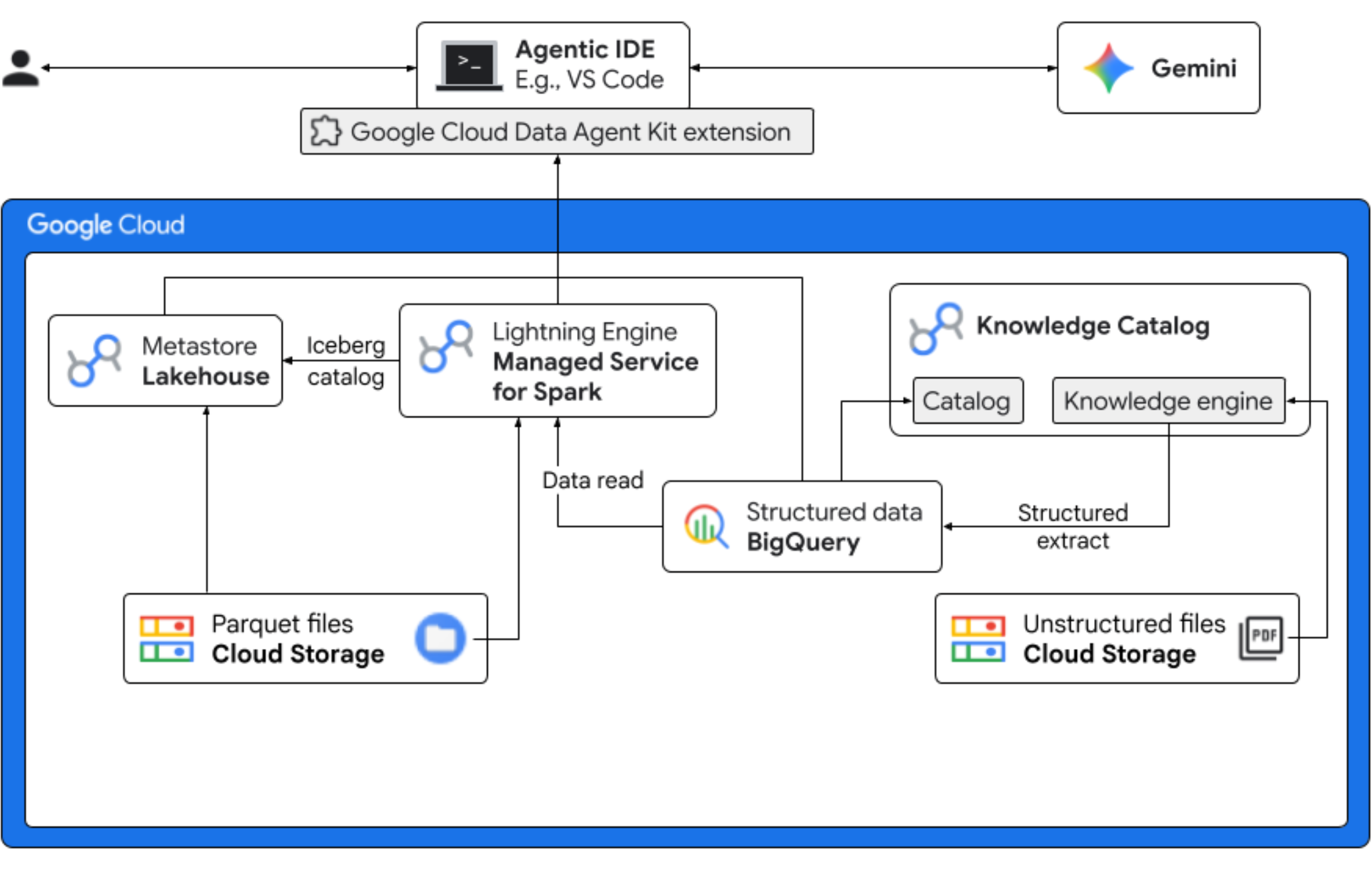
Jakie zadania wykonasz
- Odkrywanie danych nieuporządkowanych: skanowanie danych Knowledge Catalog przeszukuje przepisy w formacie PDF przechowywane w Cloud Storage. Utwórz w BigQuery tabele obiektów dla zeskanowanych plików PDF. Korzystając z Vertex AI Semantic Inference, system „odczytuje” pliki PDF, aby wyodrębnić strukturalne informacje o produktach, alergenach, składnikach i powiązanych atrybutach. Następnie inteligentnie generuje schemat danych przechowywanych w plikach PDF.
- Ujednolicone metadane: wyodrębnione dane z plików PDF są przechowywane bezpośrednio w BigQuery jako natywna szeroka tabela, a widoki są tworzone w celu ułatwienia wykonywania typowych zapytań. Niezależny zbiór danych wejściowych zawierający historyczne dane o sprzedaży jest przechowywany w tabelach Apache Iceberg w Google Cloud Storage. Ta tabela Iceberg zostanie w kolejnym kroku połączona z wyodrębnionymi danymi w BigQuery.
- Analiza w wielu silnikach: korzystając z usługi zarządzanej dla Apache Spark (wcześniej Dataproc) z katalogiem Iceberg REST, połączysz te nowe metadane PDF i wywnioskowane strukturalne dane semantyczne (z tabel i widoków BigQuery) ze strukturalnymi danymi o sprzedaży przechowywanymi w tabelach Apache Iceberg w Google Cloud Storage. Jest to regulowane przez szablon interaktywnej sesji zarządzanej Apache Spark używany jako jądro notatnika Jupyter, który zapewnia spójne ustawienia zabezpieczeń i obliczeń dla zadania Spark.
- Informacje semantyczne: dzięki połączeniu wywnioskowanych danych o produktach z danymi o klientach i sprzedaży (w BigQuery) wersja demonstracyjna może wyodrębniać informacje, takie jak dane o alergenach i prognozy przychodów.
- Autonomiczne zarządzanie: cały cykl życia – od skanowania wykrywającego po wykonywanie Sparka – jest koordynowany za pomocą szablonów, instrukcji, reguł i automatyzacji opartej na agentach, które są gotowe do użycia z Gemini. Udowadnia to, że AI może zarządzać infrastrukturą, która zasila analitykę.
Czego potrzebujesz
Wykonanie tego ćwiczenia może wiązać się z kosztami, które przy typowym wykorzystaniu szacuje się na mniej niż 5 USD. Aby uzyskać szczegółowe oszacowanie kosztów na podstawie przewidywanego wykorzystania lub aktualnych cen, skorzystaj z Kalkulatora cen Google Cloud.
Aby ukończyć ten kurs, musisz spełniać te wymagania wstępne.
- przeglądarki Chrome;
- osobiste konto Gmail, jeśli korzystasz z kredytów próbnych podanych w sekcji Zanim zaczniesz.
- Pobierz i zainstaluj Visual Studio (VS) Code.
2. Zanim zaczniesz
Tworzenie projektu Google Cloud
- W konsoli Google Cloud na stronie selektora projektu wybierz lub utwórz projekt w chmurze Google.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności.
Uruchamianie Cloud Shell
Cloud Shell to środowisko wiersza poleceń działające w Google Cloud, które zawiera niezbędne narzędzia.
- Kliknij Aktywuj Cloud Shell u góry konsoli Google Cloud.
- Po połączeniu z Cloud Shell sprawdź uwierzytelnianie:
gcloud auth list - Sprawdź, czy projekt jest skonfigurowany:
gcloud config get project - Jeśli projekt nie jest ustawiony zgodnie z oczekiwaniami, ustaw go:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Włącz wymagane interfejsy API
Aby włączyć wszystkie wymagane interfejsy API, uruchom to polecenie:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
biglake.googleapis.com \
dataproc.googleapis.com \
metastore.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
secretmanager.googleapis.com \
storage.googleapis.com
Pobieranie zasobów do ćwiczeń z programowania
To repozytorium zawiera pliki Parquet, przepisy, dostawców, copilot-instructions.md, template.yaml i quickstart.py, które można wykorzystać w tym laboratorium. Pobierz te pliki.
Aby pobrać pliki:
- W Cloud Shell uruchom to polecenie:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git - Otwórz nowo utworzony folder:
cd next-26-keynotes - Pobierz folder
data-cloud-demogit sparse-checkout set genkey/data-cloud-demo - Po zakończeniu płatności otwórz folder
data-cloud-demoi wyodrębnij pliki ZIP, aby uzyskać dostęp do zasobów codelabu.
3. Konfigurowanie Lakehouse na potrzeby danych klientów Froyo
W tej sekcji utworzysz katalog w Lakehouse, aby używać metastore Lakehouse w swoich przepływach pracy. Zapewnia interoperacyjność między silnikami zapytań, oferując jedno źródło informacji o wszystkich danych Iceberg. Umożliwia silnikom zapytań, takim jak Apache Spark, wykrywanie, odczytywanie metadanych i zarządzanie tabelami Iceberg w spójny sposób.
Wymagane role
Sprawdź, czy masz te role Identity and Access Management (IAM):
roles/biglake.viewerroles/bigquery.userroles/bigquery.dataEditorroles/biglake.editorroles/biglake.metadataViewerroles/bigquery.connectionUserroles/storage.objectUserroles/storage.objectViewerroles/storage.objectCreatorroles/storage.admin
Więcej informacji o przyznawaniu ról uprawnień znajdziesz w artykule Przyznawanie roli uprawnień.
Tworzenie katalogu Lakehouse z zasobnikiem
Utwórz katalog Lakehouse, aby zarządzać metadanymi tabel Iceberg. Łączysz się z tym katalogiem w zadaniu Spark, aby tworzyć tabele Iceberg i wysyłać do nich zapytania.
- W konsoli Google Cloud wybierz Lakehouse.
- Kliknij Utwórz katalog. Otworzy się strona Tworzenie katalogu.
- Jako Typ katalogu wybierz Katalog Iceberg REST.
- W sekcji Wybierz opcje zasobnika katalogu Lakehouse kliknij Katalog z jednym zasobnikiem.
- W polu Domyślny zasobnik Cloud Storage katalogu kliknij Przeglądaj, a następnie Utwórz nowy zasobnik.
- Na stronie Utwórz zasobnik wykonaj te czynności:
- W sekcji Rozpocznij wpisz globalnie niepowtarzalną nazwę, która spełnia wymagania dotyczące nazwy zasobnika.
- W sekcji Wybierz, gdzie chcesz zapisywać dane wybierz Region jako Typ lokalizacji i wpisz swój region. Na przykład:
us-west1. - W sekcji Wybierz sposób kontrolowania dostępu do obiektów odznacz pole wyboru Wyegzekwuj blokadę dostępu publicznego do tego zasobnika.
Pozwala to symulować rzeczywiste scenariusze, takie jak hostowanie publicznych treści internetowych lub repozytoriów udostępnionych danych. Bez tej zmiany zasobnik będzie egzekwować ścisłą zasadę „tylko prywatne”. Każda próba uzyskania dostępu do Twoich zasobów spowoduje błąd403, nawet jeśli przyznasz plikom uprawnienia publiczne. - Kliknij Dalej > Utwórz > Wybierz > Dalej.
- W sekcji Authentication method (Metoda uwierzytelniania) wybierz Credential vending mode (Tryb wystawiania tymczasowych danych uwierzytelniających).
- Kliknij Utwórz.Katalog zostanie utworzony i otworzy się strona Szczegóły katalogu.
- W sekcji Metoda uwierzytelniania kliknij Ustaw uprawnienia do zasobnika.
- W oknie dialogowym kliknij Potwierdź.Sprawdzisz w ten sposób, czy konto usługi katalogu ma w zasobniku pamięci rolę
Storage Object User. - Na stronie Szczegóły katalogu skopiuj ścieżkę identyfikatora URI katalogu REST. Użyj tej ścieżki podczas wykonywania zadania Uruchom zadanie Spark.
Prześlij pliki Parquet do zasobnika.
Aby przesłać pliki Parquet do katalogu głównego zasobnika:
- W konsoli Google Cloud otwórz stronę Zasobniki Cloud Storage.
- Na liście zasobników kliknij nazwę zasobnika. Na przykład:
acai_demo. - Na karcie Obiekty zasobnika kliknij Prześlij > Prześlij pliki.
- Wybierz pliki z folderu Parquet, który został sklonowany w sekcji Zanim zaczniesz tego laboratorium.
- Kliknij Otwórz.
4. Konfigurowanie sieci VPC
Utwórz sieć VPC i podsieć, które umożliwiają zasobom komunikowanie się z interfejsami API Google bez wychodzenia do publicznego internetu, oraz zaporę sieciową, która umożliwia swobodny przepływ ruchu wewnętrznego między węzłami przetwarzania danych.
- W konsoli Google Cloud otwórz stronę Sieci VPC.
- Kliknij Utwórz sieć VPC.
- Wpisz nazwę sieci. Na przykład:
acai-network. - Aby skonfigurować maksymalną jednostkę przesyłania (MTU) sieci, zaznacz pole wyboru Ustaw MTU automatycznie.
- W polu Tryb tworzenia podsieci wybierz Automatyczny.
- W sekcji Reguły zapory sieciowej zaznacz wszystkie pola wyboru Reguły zapory sieciowej IPv4.
- Kliknij Utwórz.
Włączanie prywatnego dostępu do Google
Węzły Dataproc Serverless nie mają publicznych adresów IP. Aby komunikować się z katalogiem Lakehouse i Cloud Storage, podsieć musi mieć włączony prywatny dostęp do Google.
- W konsoli Google Cloud otwórz stronę Sieci VPC.
- Kliknij nazwę sieci, która zawiera podsieć, w której musisz włączyć prywatny dostęp do Google. Na przykład:
us-west1. - Kliknij nazwę podsieci. Wyświetli się strona z informacjami o podsieci.
- Kliknij Edytuj.
- W sekcji Prywatny dostęp do Google wybierz Włącz.
- Kliknij Zapisz.
5. Tworzenie i uruchamianie zadania Spark
Aby utworzyć tabelę Iceberg i wysłać do niej zapytanie, prześlij zadanie PySpark z niezbędnymi instrukcjami Spark SQL. Następnie uruchom zadanie za pomocą usługi zarządzanej dla Spark.
Prześlij plik quickstart.py do zasobnika Cloud Storage
Po sklonowaniu zasobów codelabu zaktualizuj skrypt quickstart.py, podając szczegóły projektu, i prześlij go do zasobnika Cloud Storage.
- Otwórz skrypt
quickstart.pyw edytorze tekstu. - Zastąp w skrypcie symbol zastępczy
BUCKET_NAMEnazwą zasobnika Cloud Storage i zapisz skrypt. - W konsoli Google Cloud otwórz zasobniki Cloud Storage.
- Kliknij nazwę zasobnika. Na przykład:
acai_demo. - Na karcie Obiekty kliknij Prześlij > Prześlij pliki.
- W przeglądarce plików wybierz zaktualizowany plik
quickstart.py, a następnie kliknij Otwórz.
Uruchamianie zadania Spark
Po przesłaniu skryptu quickstart.py uruchom go jako zadanie wsadowe usługi zarządzanej dla Spark.
- Aby skonfigurować zmienne, uruchom to polecenie w Cloud Shell.
# Configuration Variables export PROJECT_ID="<PROJECT_ID>" export REGION="<REGION>" export BUCKET_NAME="<BUCKET_NAME>" export SUBNET="<SUBNET>" export LAKEHOUSE_CATALOG_ID="<LAKEHOUSE_CATALOG_ID>" export CATALOG_URI_ID="<CATALOG_URI_ID>"- LAKEHOUSE_CATALOG_ID: nazwa zasobu katalogu Lakehouse, który zawiera plik aplikacji PySpark. Na przykład
acai_demo - PROJECT_ID: identyfikator Twojego projektu Google Cloud.
- REGION: region, w którym będzie uruchamiany zbiór zadań wsadowych usługi zarządzanej dla Spark. Na przykład:
us-west1. - BUCKET_NAME: nazwa zasobnika Cloud Storage. Na przykład:
acai_demo. - SUBNET: nazwa podsieci VPC. Na przykład:
acai-network. - CATALOG_URI_ID: identyfikator URI katalogu Lakehouse, który został skopiowany podczas tworzenia katalogu Lakehouse z zasobnikiem. Na przykład:
https://biglake.googleapis.com/iceberg/v1/restcatalog.
- LAKEHOUSE_CATALOG_ID: nazwa zasobu katalogu Lakehouse, który zawiera plik aplikacji PySpark. Na przykład
- W Cloud Shell uruchom to zadanie wsadowe usługi zarządzanej dla Sparka, korzystając ze skryptu
quickstart.py.gcloud dataproc batches submit pyspark gs://${BUCKET_NAME}/quickstart.py \ --project=${PROJECT_ID} \ --region=${REGION} \ --subnet=${SUBNET} \ --version=2.2 \ --properties="\ spark.sql.defaultCatalog=${LAKEHOUSE_CATALOG_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}=org.apache.iceberg.spark.SparkCatalog,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.type=rest,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.uri=${CATALOG_URI_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.warehouse=gs://${BUCKET_NAME},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.io-impl=org.apache.iceberg.gcp.gcs.GCSFileIO,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.x-goog-user-project=${PROJECT_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\ spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest-metrics-reporting-enabled=false,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.X-Iceberg-Access-Delegation=vended-credentials,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token"All tables registered successfully! Batch [126fa2226a904d2e944c8eecbe0b1840] finished. metadata: '@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata batch: projects/PROJECT_ID/locations/REGION/batches/126fa2226a904d2e944c8eecbe0b1840 batchUuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff createTime: '2026-04-09T13:17:26.222727Z' description: Batch labels: goog-dataproc-batch-id: 126fa2226a904d2e944c8eecbe0b1840 goog-dataproc-batch-uuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-drz-resource-uuid: batch-3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-location: REGION operationType: BATCH name: projects/PROJECT_ID/regions/REGION/operations/47bc59e8-5082-3af9-89a0-22289aa5f4b9
6. Wykonywanie zapytań w tabeli z BigQuery
Uruchamiając zadanie wsadowe Spark, używasz usługi zarządzanej dla Spark Serverless jako rozproszonego silnika obliczeniowego do rejestrowania wielu tabel, po jednej na plik Parquet w metastore Lakehouse. Ta rejestracja umożliwia Google Cloud traktowanie nieprzetworzonych plików w Cloud Storage jako uporządkowanych tabel o wysokiej wydajności.
Poniższe kroki pomogą Ci sprawdzić, czy metadane zostały prawidłowo zsynchronizowane. Dzięki temu będziesz mieć pewność, że dane są nie tylko bezpiecznie przechowywane, ale też w pełni wykrywalne i można do nich wysyłać zapytania za pomocą interfejsu BigQuery.
- W konsoli Google Cloud otwórz BigQuery.
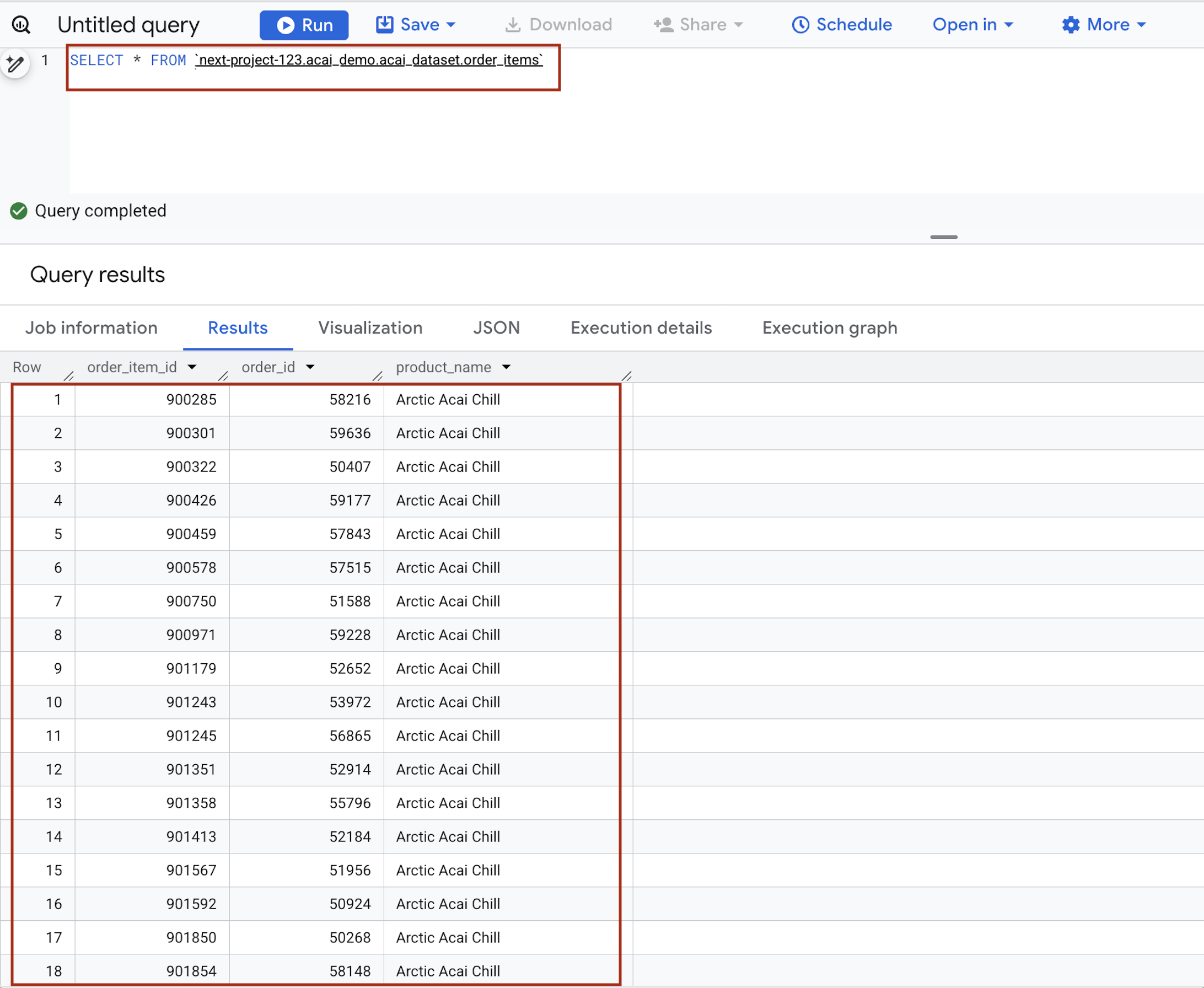
- W edytorze zapytań wpisz to stwierdzenie. Zapytanie korzysta ze składni
project.namespace.dataset.table.SELECT * FROM `<PROJECT_ID>.<NAMESPACE>.<ICEBERG_DATASET>.<ICEBERG_TABLE>`PROJECT_ID.acai_demo.acai_dataset.order_items.
Zastąp te elementy:- PROJECT_ID: identyfikator Twojego projektu Google Cloud.
- NAMESPACE: przestrzeń nazw utworzona w poprzednim kroku w wyniku zadania Spark. Możesz ją znaleźć na stronie eksploratora obiektów BigQuery. Na przykład:
acai_demo. - ICEBERG_DATASET: nazwa zbioru danych w katalogu Iceberg, np.
acai_dataset. - ICEBERG_TABLE: nazwa tabeli w zbiorze danych Iceberg, np.
order_items.
- Kliknij Wykonaj. Wyniki zapytania pokazują dane wstawione za pomocą zadania Spark.
7. Konfigurowanie plików danych o produktach bez struktury
W tej sekcji utworzysz w BigQuery strukturę organizacyjną do przechowywania danych o przepisach i dostawcach Froyo, w szczególności szczegółów produktu Froyo. Ustanawia też połączenie z zasobem Cloud, które działa jak bezpieczny „most” umożliwiający BigQuery odczytywanie plików ze źródeł zewnętrznych, takich jak Cloud Storage.
Tworzenie zasobnika i przesyłanie plików szczegółowych Froyo
Utwórz pliki dostawcy i przepisu i prześlij je do zasobnika Cloud Storage.
- W konsoli Google Cloud otwórz stronę Zasobniki Cloud Storage.
- Kliknij Utwórz.
- Na stronie Utwórz zasobnik wpisz informacje o zasobniku. Po wykonaniu każdego z tych kroków kliknij Dalej, aby przejść do następnego:
- W sekcji Rozpocznij wpisz nazwę zasobnika. Na przykład:
acai_pdfs. - W sekcji Wybierz, gdzie chcesz zapisywać dane wybierz Region, a następnie wpisz region. Na przykład:
us-west1. - W sekcji Wybierz sposób kontrolowania dostępu do obiektów odznacz pole wyboru Wyegzekwuj blokadę dostępu publicznego do tego zasobnika.
- Kliknij Utwórz.
- Na liście zasobników kliknij utworzony zasobnik. Na przykład:
acai_pdfs. - Na karcie Obiekty w zasobniku kliknij Prześlij > Prześlij foldery.
- Wybierz folder
recipes, który został wyodrębniony w sekcji Zanim zaczniesz tego laboratorium. - Kliknij Prześlij.
- Powtórz proces przesyłania w przypadku folderu
suppliers.
Tworzenie połączenia
Utwórz połączenie z zasobem Cloud. Spowoduje to wygenerowanie unikalnego konta usługi, które będzie pełnić rolę „karty identyfikacyjnej” BigQuery umożliwiającej dostęp do plików zewnętrznych.
- Otwórz stronę BigQuery.
- W panelu po lewej stronie kliknij Eksplorator. Jeśli nie widzisz lewego panelu, kliknij Rozwiń lewy panel, aby go otworzyć.
- W panelu Eksplorator rozwiń nazwę projektu, a następnie kliknij Połączenia.
- Na stronie Połączenia kliknij Utwórz połączenie.
- W sekcji Połączenie wybierz Modele zdalne Vertex AI, funkcje zdalne, BigLake i Spanner (zasób Cloud).
- W polu Identyfikator połączenia wpisz nazwę identyfikatora połączenia. Na przykład:
acai_pdf_connection. Zanotuj ten identyfikator, ponieważ będzie on potrzebny podczas konfigurowania skanowania danych w dalszej części tego ćwiczenia. - Ustaw Typ lokalizacji na Region, a następnie wybierz region. Na przykład:
us-west1. Połączenie powinno być kolokowane z innymi zasobami, takimi jak zbiory danych. - Kliknij Utwórz połączenie.
- Kliknij Przejdź do połączenia.
- W panelu Informacje o połączeniu skopiuj identyfikator konta usługi, aby użyć go w kolejnym kroku. Konto usługi wygląda podobnie do
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com.
Zarządzanie dostępem do kont usługi
Przyznaj dostęp do konta usługi, aby Lakehouse mogło odczytywać pliki PDF.
- Otwórz stronę Administracja.
- Kliknij Przyznaj dostęp. Otworzy się okno Dodaj podmioty zabezpieczeń.
- W polu Nowe podmioty zabezpieczeń wpisz skopiowany wcześniej identyfikator konta usługi.
- W polu Wybierz rolę dodaj te role:
roles/storage.objectUserroles/storage.objectViewerroles/bigquery.userroles/bigquery.dataEditorroles/aiplatform.userroles/storage.adminroles/dataproc.serviceAgent
- Kliknij Zapisz.
Więcej informacji o rolach IAM w BigQuery znajdziesz w artykule Wstępnie zdefiniowane role i uprawnienia.
8. Zarządzanie uprawnieniami do zadania DataScan
Utwórz konkretne konta usługi (tożsamości) dla Sparka i Dataform, a następnie przyznaj im – wraz z automatycznymi agentami usługi Google – dokładne uprawnienia potrzebne do odczytywania pamięci masowej, uruchamiania zadań BigQuery i korzystania z Vertex AI na potrzeby wykrywania.
Dostęp IAM do Sparka i Dataform
- W konsoli Google Cloud otwórz stronę Utwórz konto usługi.
- Jeśli nie jest wybrany, wybierz projekt Google Cloud.
- Kliknij Utwórz konto usługi.
- Wpisz nazwę konta usługi. Na przykład:
sa-spark-stg1. Konsola Google Cloud wygeneruje na podstawie tej nazwy identyfikator konta usługi. W razie potrzeby zmodyfikuj identyfikator. Później nie będzie już można go zmienić. - Aby skonfigurować kontrolę dostępu, kliknij Utwórz i kontynuuj, a potem przejdź do następnego kroku.
- Wybierz te role uprawnień, które chcesz przypisać do konta usługi w projekcie.
roles/dataproc.workerroles/storage.objectUserroles/bigquery.dataEditorroles/bigquery.jobUserroles/aiplatform.userroles/dataplex.discoveryPublishingServiceAgent
- Gdy skończysz dodawać role, kliknij Dalej.
- Aby zakończyć tworzenie konta usługi, kliknij Gotowe.
Uprawnienia do połączenia z BigQuery umożliwiające dostęp do Knowledge Catalog
- W konsoli Google Cloud otwórz stronę Zasobniki Cloud Storage.
- Na liście zasobników kliknij nazwę zasobnika utworzonego dla Froyo. Na przykład:
acai_pdfs. - Na karcie Uprawnienia kliknij Przyznaj dostęp. Pojawi się okno Dodaj podmioty zabezpieczeń.
- W polu Nowe podmioty zabezpieczeń wpisz identyfikator konta usługi BigQuery. Konto usługi wygląda podobnie do
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com. - Wybierz z menu Wybierz rolę te role:
roles/storage.objectUserroles/dataplex.serviceAgentroles/dataplex.securityAdminroles/aiplatform.serviceAgentroles/dataplex.discoveryPublishingServiceAgent
- Kliknij Zapisz.
9. Konfigurowanie usługi Knowledge Catalog
Utwórz Knowledge Catalog, aby ujednolicić dane związane z mrożonym jogurtem i zautomatyzować wykrywanie nieuporządkowanych plików (takich jak przepisy w formacie PDF i dostawcy w formacie PDF).
Utwórz skanowanie danych za pomocą curl.
W tej sekcji utworzysz skanowania zasobnika Cloud Storage (np. acai_pdfs), dodając datascan_ID i kierując go do zbiorów danych BigQuery. Następnie usługa Knowledge Catalog automatycznie utworzy wpisy dotyczące plików PDF w BigQuery.
- Aby przeskanować pliki PDF (dostawców i przepisy), uruchom to polecenie:
# 1. Set your variables PROJECT_ID="<PROJECT_ID>" REGION="<REGION>" ENV_SUFFIX="stg1" DATASCAN_ID="froyo-profile-${ENV_SUFFIX}" BUCKET_NAME="<BUCKET_NAME>" # 2. Set this to the Name of the connection you created in Step 7 CONNECTION_ID="<CONNECTION_ID_NAME>" # 3. Define the API Endpoint DATAPLEX_API="dataplex.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}" # 4. Create the DataScan via CURL echo "Creating Dataplex DataScan: ${DATASCAN_ID}..." curl -X POST "https://$DATAPLEX_API/dataScans?dataScanId=${DATASCAN_ID}" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d '{ "data": { "resource": "//storage.googleapis.com/projects/'"${PROJECT_ID}"'/buckets/'"${BUCKET_NAME}"'" }, "executionSpec": { "trigger": { "on_demand": {} } }, "dataDiscoverySpec": { "bigqueryPublishingConfig": { "tableType": "BIGLAKE", "connection": "projects/'"${PROJECT_ID}"'/locations/'"${REGION}"'/connections/'"${CONNECTION_ID}"'" }, "storageConfig": { "unstructuredDataOptions": { "entity_inference_enabled": true } } } }' - Polecenie
curlwyświetla wyniki skanowania danych Knowledge Catalog, podobnie jak na tym obrazie.
Uruchamianie zadania
Uruchom to polecenie:
gcloud dataplex datascans run $DATASCAN_ID --location=$REGION
Opisywanie zadania
Aby opisać zadanie, uruchom to polecenie:
gcloud dataplex datascans describe $DATASCAN_ID --location=$REGION
Usuwanie zadania skanowania danych
Jeśli skanowanie trwa dłużej niż 10 minut lub stan zadania pozostaje Oczekujące przez dłuższy czas bez przejścia do stanu Wykonywanie, może to być spowodowane tymczasową niedostępnością zasobów w regionie. W takim przypadku możesz uruchomić to polecenie, aby usunąć zadanie, a następnie spróbować utworzyć i uruchomić je ponownie. Czasami pierwsze uruchomienie może szybko zakończyć się niepowodzeniem z błędem, np. unable to acquire necessary resources.
gcloud dataplex datascans delete $DATASCAN_ID --location=$REGION
Wyświetlanie stanu zadania
Aby sprawdzić stan zadania:
- W konsoli Google Cloud otwórz stronę Tworzenie metadanych.
- Na karcie Wykrywanie w Cloud Storage kliknij nazwę skanów wykrywania.
- Na stronie Szczegóły skanowania możesz sprawdzić stan zadania.
- Po zakończeniu zadania sprawdź, czy istnieje opublikowany zbiór danych (np.
acai_pdfs_discovered_003) utworzony za pomocą poleceniacurl.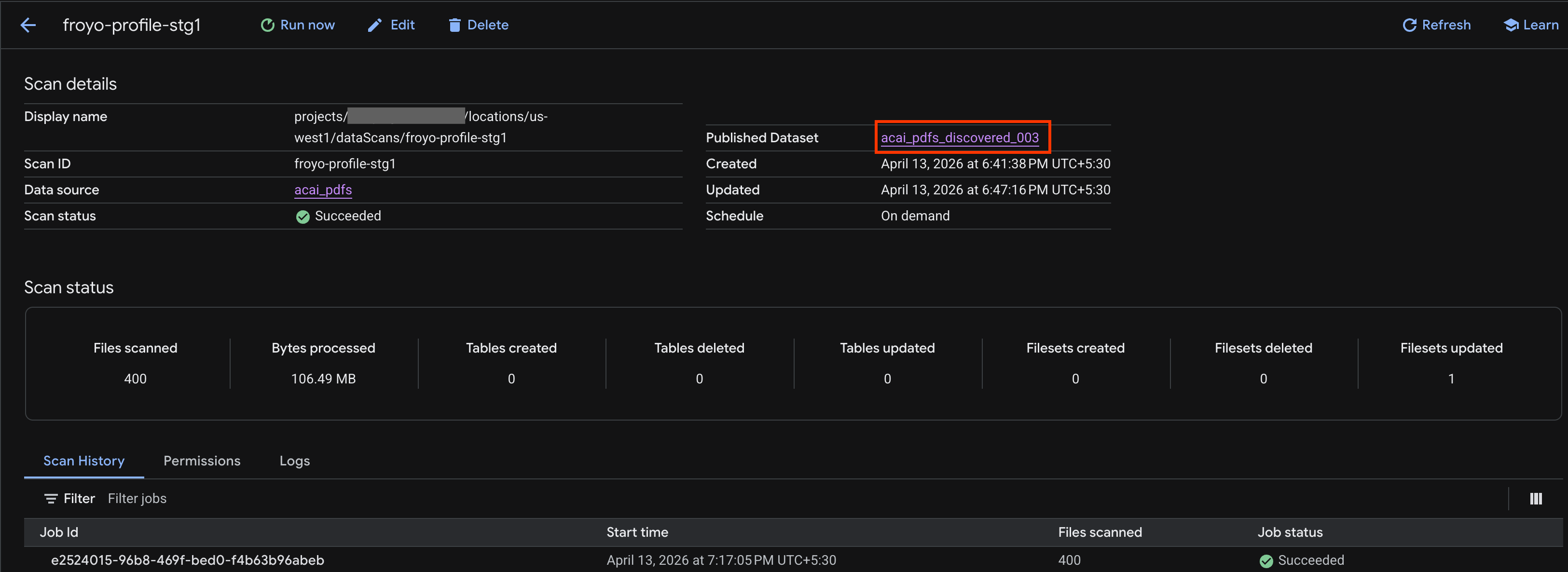
Wyświetlanie tabeli obiektów
Aby wyświetlić tabelę obiektów utworzoną po zakończeniu zadania wykrywania:
- W konsoli Google Cloud otwórz BigQuery.
- Kliknij Zbiory danych i wybierz opublikowany zbiór danych utworzony w poprzednim kroku. Na przykład:
acai_pdfs_discovered_003. - Aby wyświetlić tabelę obiektów, kliknij identyfikator tabeli. Na przykład:
acai_pdfs. - Wynikowa tabela obiektów wygląda tak:
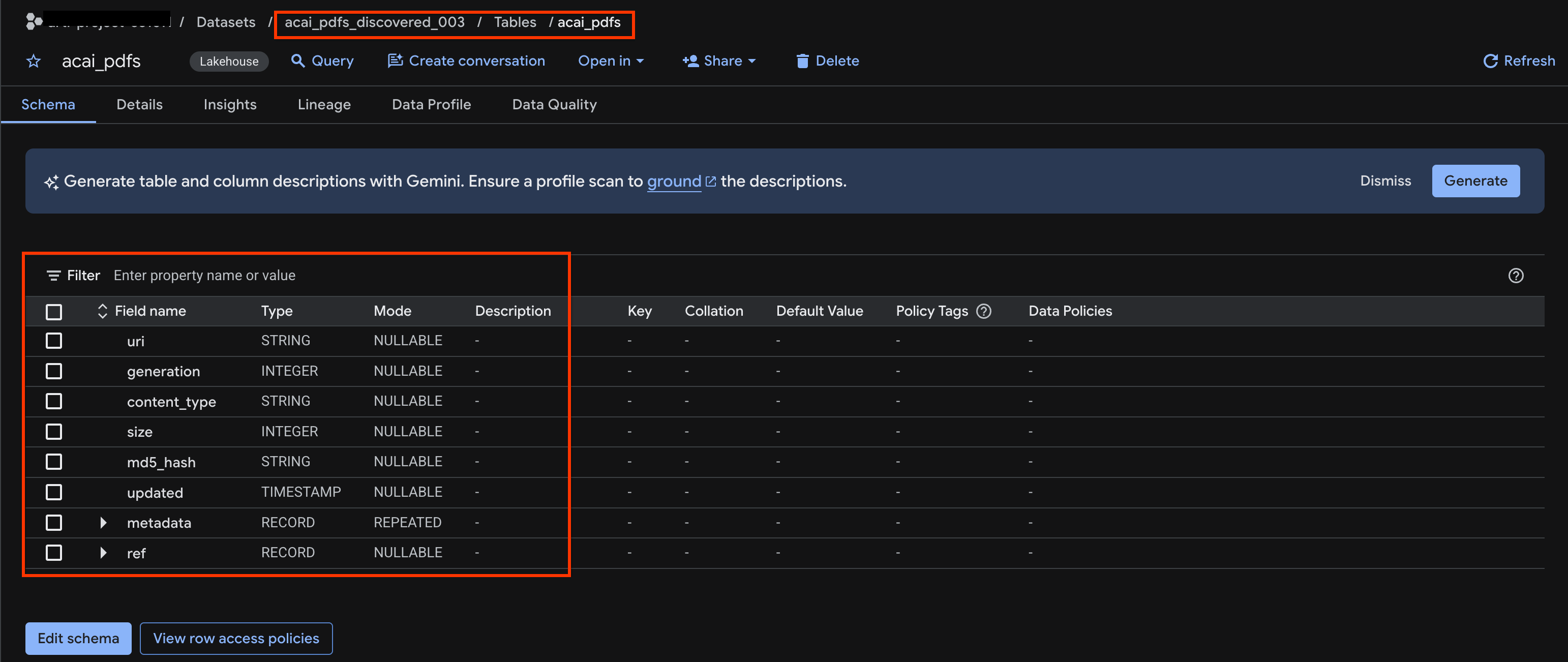
10. Wyodrębnianie semantyczne
Wywnioskujesz i wyodrębnisz uporządkowane tabele, inne obiekty bazy danych i relacje dla utworzonej w poprzednim kroku nieuporządkowanej tabeli obiektów. W tym celu użyjesz funkcji statystyk Knowledge Catalog, aby wygenerować instrukcje SQL do wyodrębniania danych strukturalnych z nieustrukturyzowanej tabeli.
- W konsoli Google Cloud otwórz stronę Wyszukiwanie w Knowledge Catalog.
- Wyszukaj tabelę zbioru danych, dla której chcesz wyświetlić statystyki. Na przykład:
acai_pdfs_discovered_003.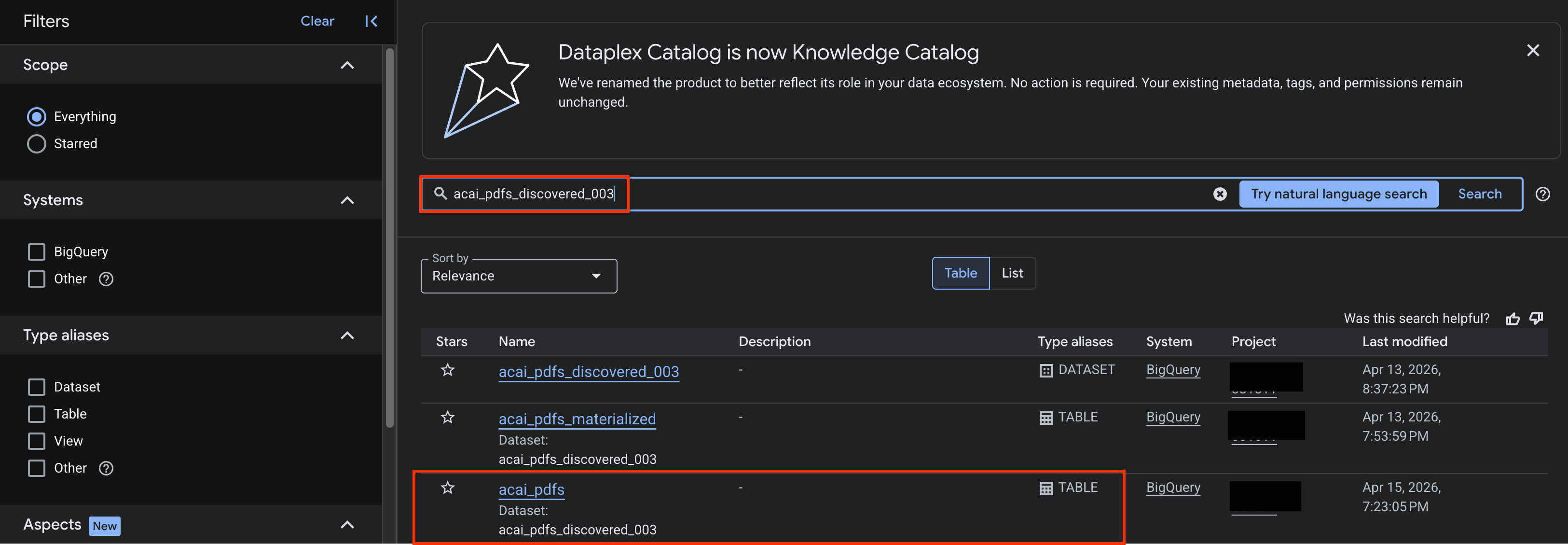
- W wynikach wyszukiwania kliknij tabelę, aby otworzyć jej stronę.
- Kliknij kartę Statystyki. Jeśli karta jest pusta, oznacza to, że statystyki dotyczące tej tabeli nie zostały jeszcze wygenerowane. Wygenerowanie statystyk może potrwać od 15 do 25 minut.
- Gdy zobaczysz statystyki, kliknij Wyodrębnij > Wyodrębnij za pomocą SQL.
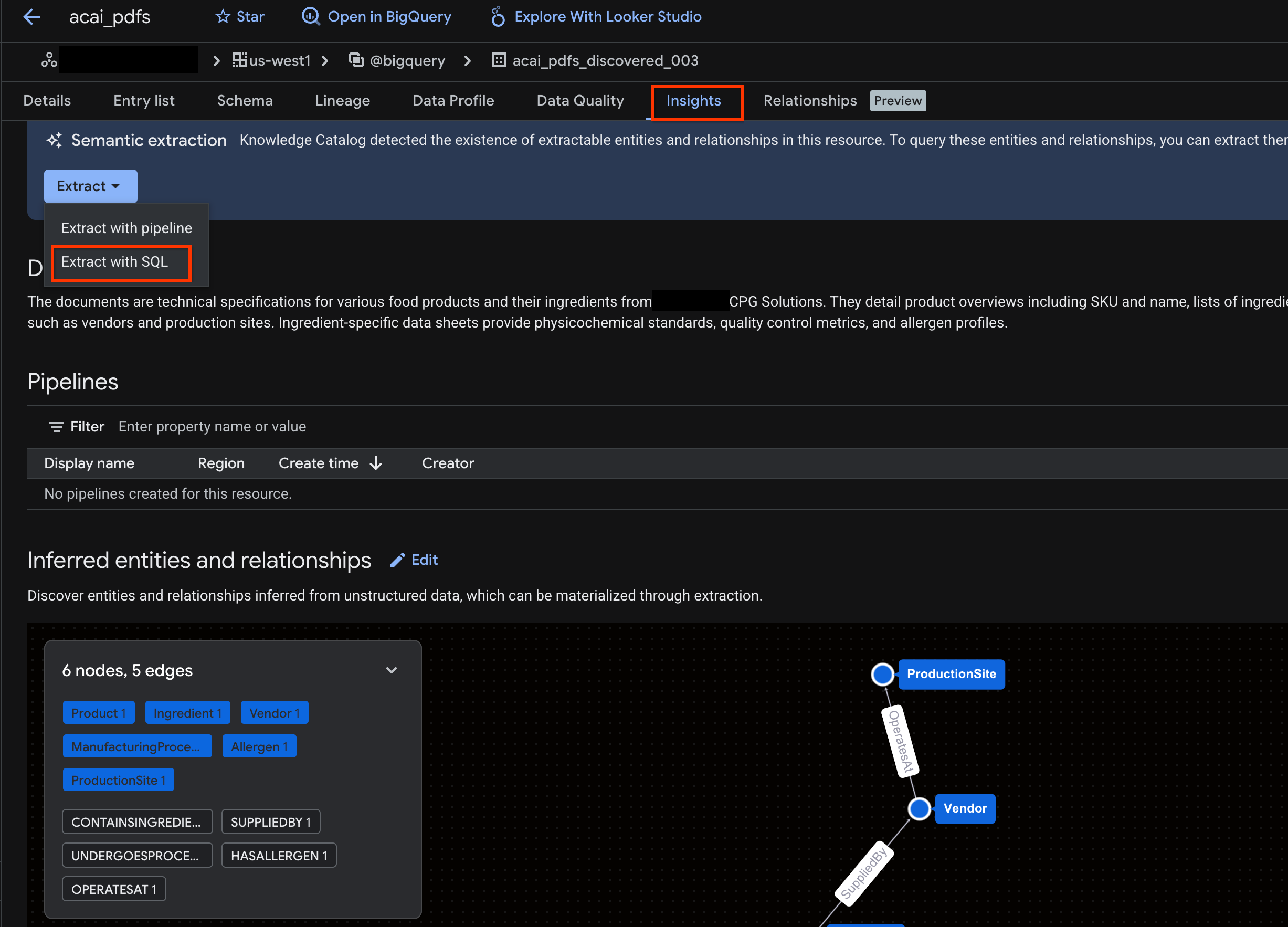
- Na stronie Wyodrębnij za pomocą SQL w polu Miejsce docelowe wpisz zbiór danych. Na przykład:
acai_pdfs_discovered_003. - Kliknij Wyodrębnij. Otworzy się edytor BigQuery z załadowanym zapytaniem.
- Kliknij Wykonaj. Ten krok generuje zestaw instrukcji i może potrwać kilka minut.
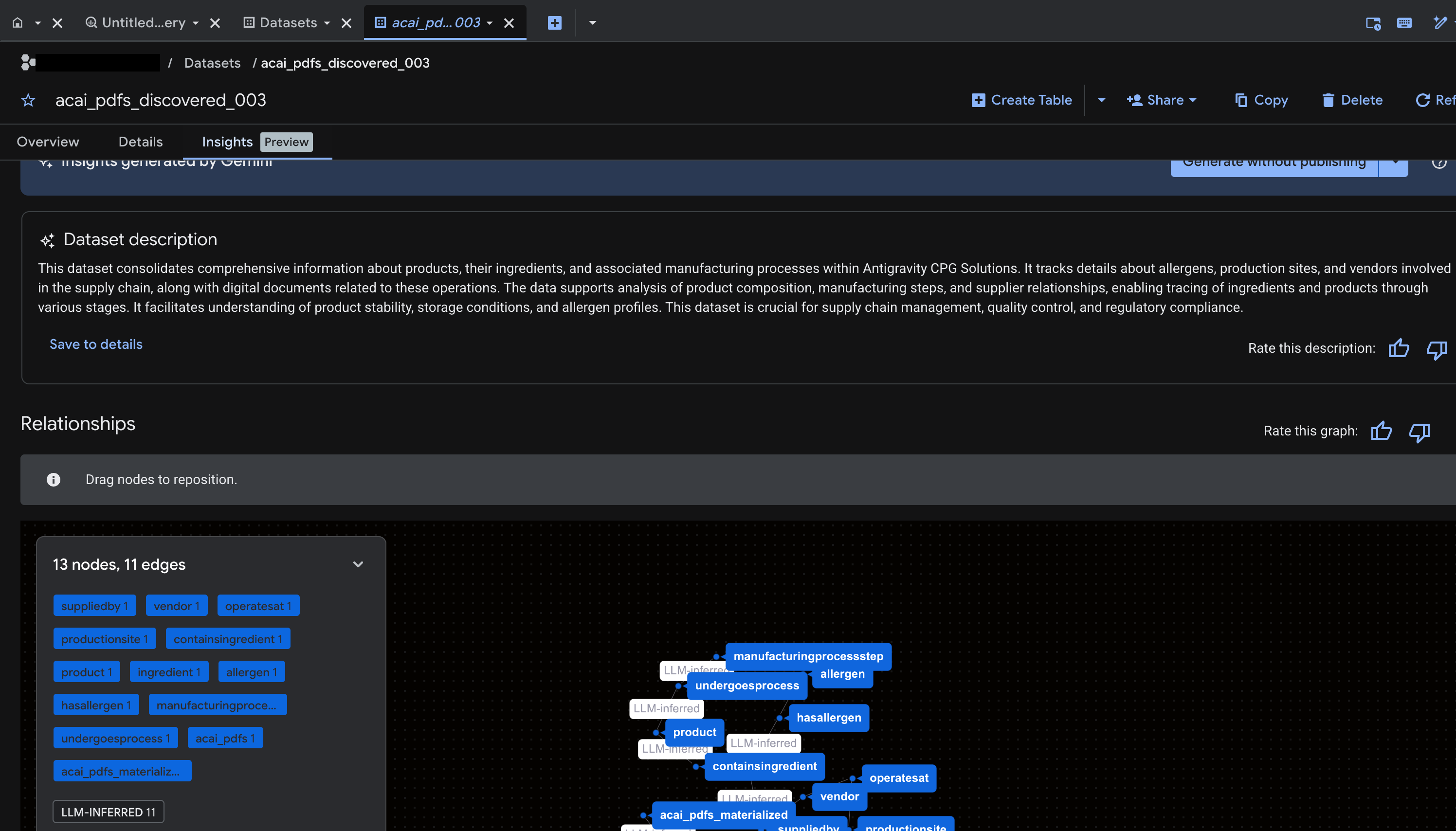
- Po zakończeniu zapytania zobaczysz te wyniki:
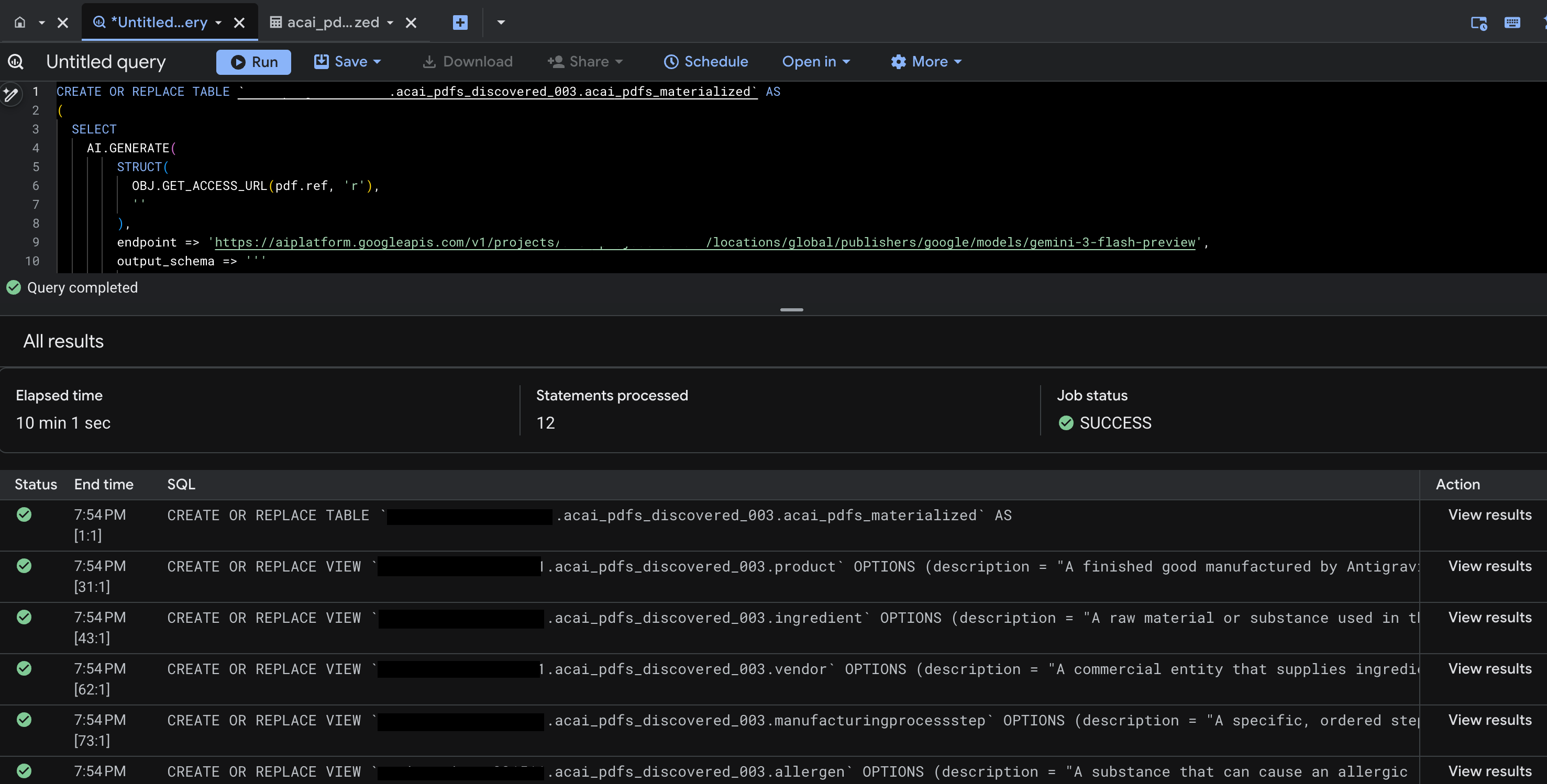
- Otwórz BigQuery i kliknij Zbiory danych (np.
acai_pdfs_discovered_003). W zbiorze danych wybranym w kroku 6 utworzy się nowy zestaw obiektów bazy danych o strukturze.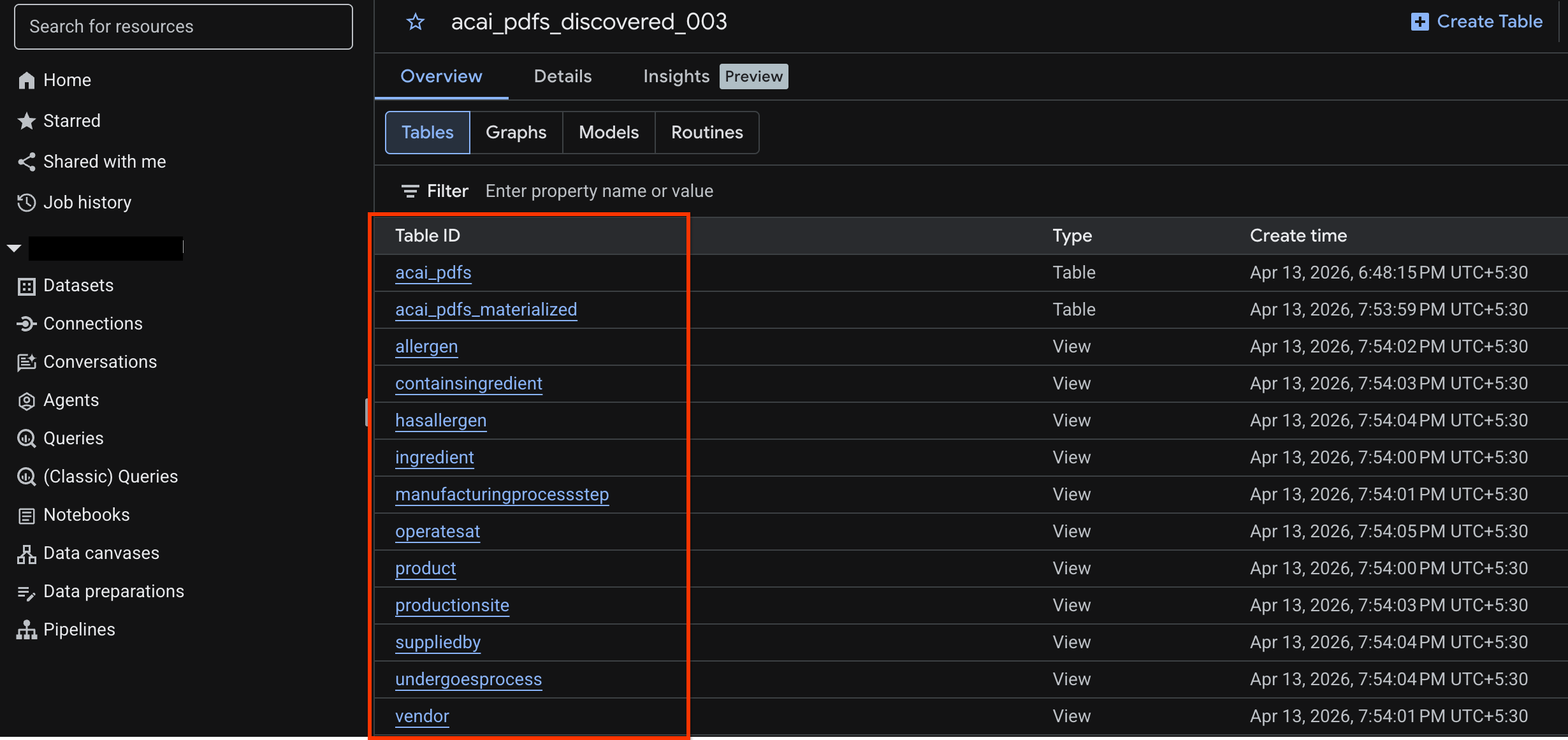
Generowanie statystyk dotyczących obiektu w BigQuery
Aby wygenerować statystyki dotyczące zbioru danych BigQuery, musisz uzyskać do niego dostęp w BigQuery za pomocą BigQuery Studio.
- W konsoli Google Cloud otwórz BigQuery Studio.
- W panelu Eksplorator wybierz projekt i przejdź do zbioru danych, dla którego chcesz wygenerować statystyki.
- Kliknij kartę Statystyki.
- Jeśli widzisz przycisk Włącz API, kliknij go, aby włączyć Gemini w Google Cloud. Otworzy się okno Włącz podstawowe funkcje.
- W sekcji Interfejsy API głównych funkcji kliknij Włącz w przypadku Gemini for Google Cloud API i BigQuery Unified API, a następnie kliknij Dalej.
- W sekcji Uprawnienia (opcjonalnie) w razie potrzeby przyznaj rolę uprawnień podmiotom, a potem kliknij Dalej.
- Aby wygenerować statystyki i opublikować je w Knowledge Catalog, kliknij Wygeneruj i opublikuj.
- Po opublikowaniu na karcie będą dostępne statystyki.
11. Konfigurowanie środowiska IDE pod kątem analityki danych opartej na agentach
Rozszerzenie Google Cloud Data Agent Kit dla Visual Studio Code to rozszerzenie IDE dla analityków i inżynierów danych. Umożliwia łączenie się z zasobami i danymi Google Data Cloud oraz pracę z nimi bezpośrednio w IDE. Więcej informacji znajdziesz w omówieniu rozszerzenia Data Agent Kit dla VS Code.
Rozszerzenie Data Agent Kit do VS Code przydaje się, gdy chcesz:
- Twórz, testuj, sprawdzaj i wdrażaj gotowe do produkcji potoki danych, takie jak Spark ETL lub BigQuery ETL, bezpośrednio z VS Code.
- Eksploruj dane, twórz potok trenowania, identyfikuj optymalne modele ML i wdrażaj je w punkcie końcowym produkcyjnym za pomocą pomocy AI.
- Łącz się z zaufanymi źródłami danych, twórz modele danych o wysokiej wydajności i publikuj interaktywne panele dla osób zainteresowanych wynikami biznesowymi.
Instalowanie rozszerzenia Data Agent Kit w VS Code
- Otwórz VS Code.
- Zainstaluj Google Cloud CLI. Więcej informacji znajdziesz w artykule Instalowanie Google Cloud CLI.
- Zainstaluj rozszerzenie Data Agent Kit dla VS Code.
- Dokończ proces rejestracji rozszerzenia. W tym celu:
- Zaloguj się w rozszerzeniu
- Instalowanie umiejętności, serwery MCP
- Po zakończeniu procesu wprowadzającego odśwież lub uruchom ponownie okno. Więcej informacji znajdziesz w artykule Konfigurowanie i instalowanie rozszerzenia Data Agent Kit w VS Code.
- Po ponownym wczytaniu środowiska IDE kliknij ikonę Google Data Cloud w panelu nawigacji, przejdź do ustawień i upewnij się, że w ustawieniach ogólnych prawidłowo skonfigurowano identyfikator projektu i region (
us-west1).
Konfigurowanie obszaru roboczego w VS Code
- Otwórz VS Code i wybierz Plik > Otwórz folder > Nowy folder.
- Utwórz nowy folder o nazwie
acai_test, a następnie kliknij Otwórz. VS Code uzna teraz otwarty folder za obszar roboczy. - W oknie dialogowym Zaufanie do Workspace wybierz Tak, ufam autorom, aby włączyć wszystkie funkcje w obszarze roboczym.
- Utwórz folder
.githubw obszarze roboczymacai_test. - Utwórz nowy plik
copilot-instructions.mdw folderze.githubi wpisz w nim te reguły.## 1. Project Context - **Project ID**: <PROJECT_ID> - **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors. - **Documentation**: Raw PDF documents detailing flavors and ingredients are stored in Google Cloud Storage at `gs://<BUCKET_NAME>`. ## 2. Execution & Data Processing Rules - **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `<BQ_DATASET_NAME>` (referred to as the Knowledge Catalog). - **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the dataset `<DATASET_ID>`. When you are referencing a dataset, ensure you are using it with the project ID (`<PROJECT_ID>`) and namespace prefix `<NAMESPACE_NAME>`. For example, to query order table in this dataset you should use `<PROJECT_ID>.<NAMESPACE>.<DATASET_ID>.orders`. - **CRITICAL RULE - Data Joins between BigQuery dataset and Iceberg dataset**: ANY task requiring a join or integration between the BigQuery datasets `<DATASET_ID>` of the PDF data and the `<DATASET_ID>` of the customer data MUST be executed using **Spark Notebooks**. - **CRITICAL RULE - Notebook Kernel**: Every Spark notebook utilized MUST exclusively be configured to run on the Serverless Session template `iceberg-federation-template` as its kernel. - **CRITICAL RULE - Data Science**: ANY data science, machine learning, or advanced analytical task MUST be performed strictly within **Spark Notebooks** using the aforementioned setup. - Utwórz kolejny nowy plik
template.yamlw obszarze roboczymacai_testi wpisz w nim te informacje:labels: client: "vscode" jupyterSession: displayName: "iceberg-federation-template" kernel: "PYTHON" environmentConfig: executionConfig: serviceAccount: "sa-spark-dev1@<PROJECT_ID>.iam.gserviceaccount.com" subnetworkUri: "projects/<PROJECT_ID>/regions/<REGION>/subnetworks/<SUBNET_NAME>" runtimeConfig: version: "2.3" properties: # This enables the secure proxy URL you were looking for dataproc.tier: "premium" spark.dataproc.engine: "lightningEngine" spark.dataproc.lightningEngine.runtime: "native" spark.memory.offHeap.enabled: "true" spark.memory.offHeap.size: "1g" spark.executor.memory: "4g" "dataproc.component.gateway.enabled": "true" "dataproc.jupyter.listen.all.interfaces": "true" "spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" "spark.sql.defaultCatalog": "<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>": "org.apache.iceberg.spark.SparkCatalog" "spark.sql.catalog.<CATALOG_NAME>.type": "rest" "spark.sql.catalog.<CATALOG_NAME>.uri": "<CATALOG_URI_ID>" "spark.sql.catalog.<CATALOG_NAME>.warehouse": "bl://projects/<PROJECT_ID>/catalogs/<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>.rest.auth.type": "org.apache.iceberg.gcp.auth.GoogleAuthManager" - W VS Code kliknij Terminal i uruchom to polecenie, aby zaimportować plik
template.yamljako szablon sesji. Ten szablon jest później używany przez agenta do utworzenia sesji Spark.gcloud beta dataproc session-templates import iceberg-federation-template \ --source=template.yaml \ --location=<REGION>REGIONswoim regionem.
12. Przeprowadzanie analizy danych przez agenta
- W edytorze kodu VS Code kliknij Przełącz czat.
- W sekcji Skonfiguruj agentów niestandardowych wybierz Agent.
- W panelu Modele wyszukiwania kliknij Zarządzaj modelami językowymi.
- Na stronie Modele językowe kliknij Dodaj modele.
- Wybierz z listy Google i naciśnij Enter, aby potwierdzić wybór.
- Aby wprowadzić klucz interfejsu API do Google Gemini, wykonaj te czynności:
- Otwórz stronę Google AI Studio.
- Zaloguj się na konto Google.
- Na pasku bocznym kliknij Uzyskaj klucz API.
- Kliknij Utwórz klucz interfejsu API. Otworzy się strona Utwórz nowy klucz.
- Na liście Wybierz projekt w chmurze kliknij Importuj projekt.
- Wpisz nazwę istniejącego projektu.
- Kliknij Utwórz klucz i skopiuj klucz interfejsu API. Klucz zapewnia dostęp do zasobów Gemini API na Twoim koncie.Więcej informacji znajdziesz w artykule Korzystanie z kluczy Gemini API.
- Wklej wygenerowany klucz interfejsu API w pasku wyszukiwania i kliknij Enter.
- Jeśli modele Gemini się nie wyświetlają, odkryj je, jak pokazano na tym obrazie:
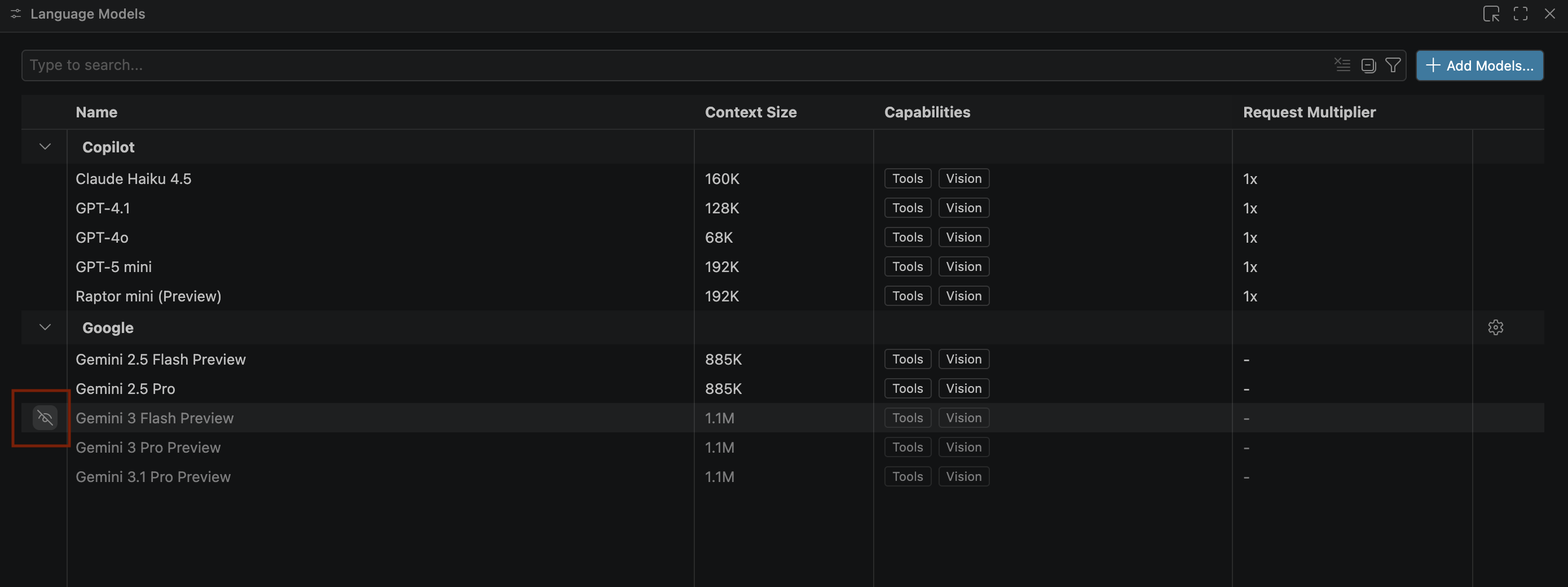
- Na liście modeli Google Gemini wybierz Gemini 3.1 Pro w wersji testowej i zamknij okno Modele językowe.
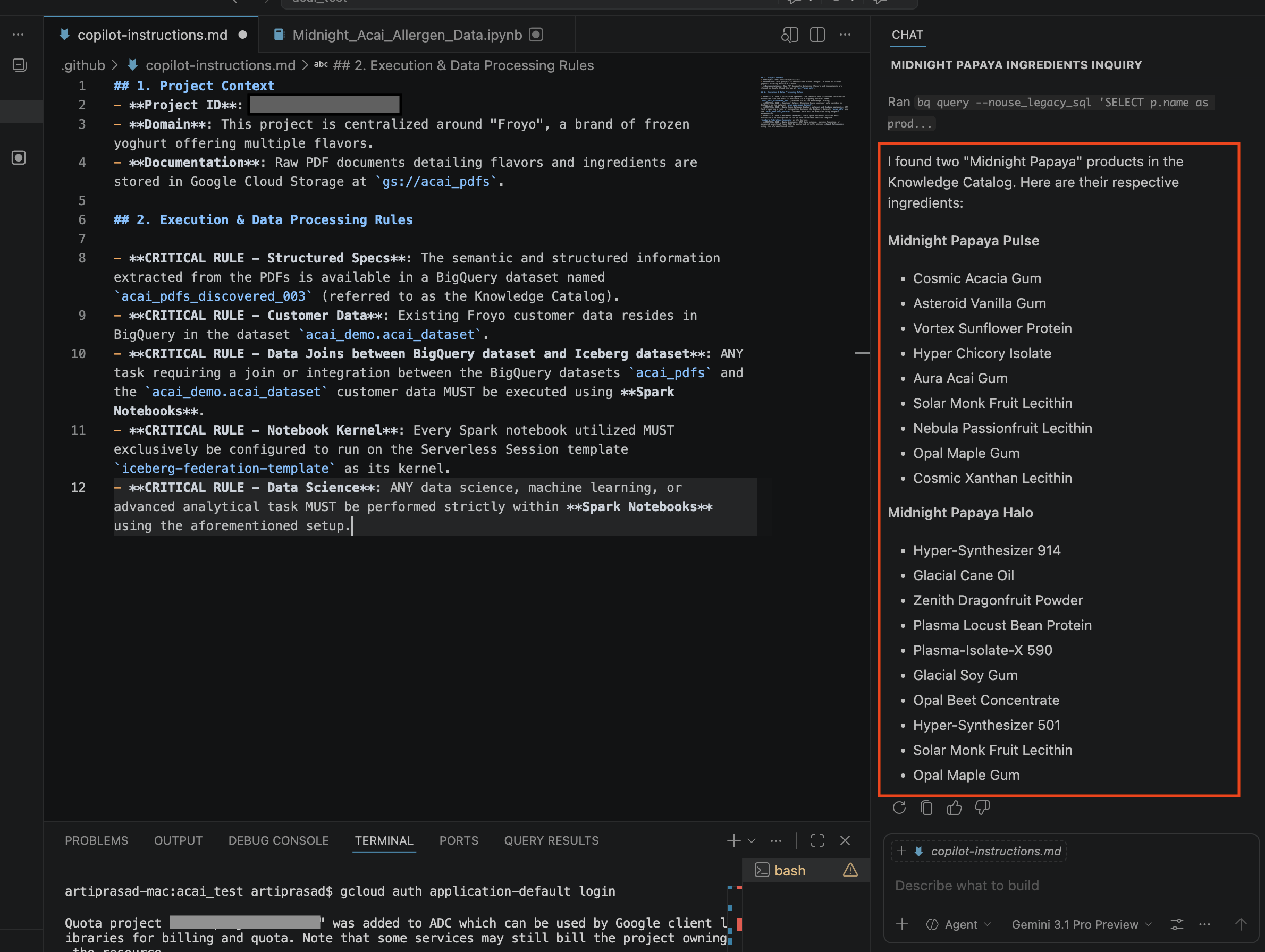
- W oknie czatu wpisz to pytanie:
Search ingredients for Midnight papaya - Po pewnym czasie powinny się wyświetlić te wyniki:
- W oknie czatu wpisz kolejne pytanie:
Search allergen information for Midnight papaya - Po kilku interakcjach i wykonaniu kilku czynności zobaczysz odpowiedź agenta z nazwą alergenu
Soy, jak widać na tym obrazie: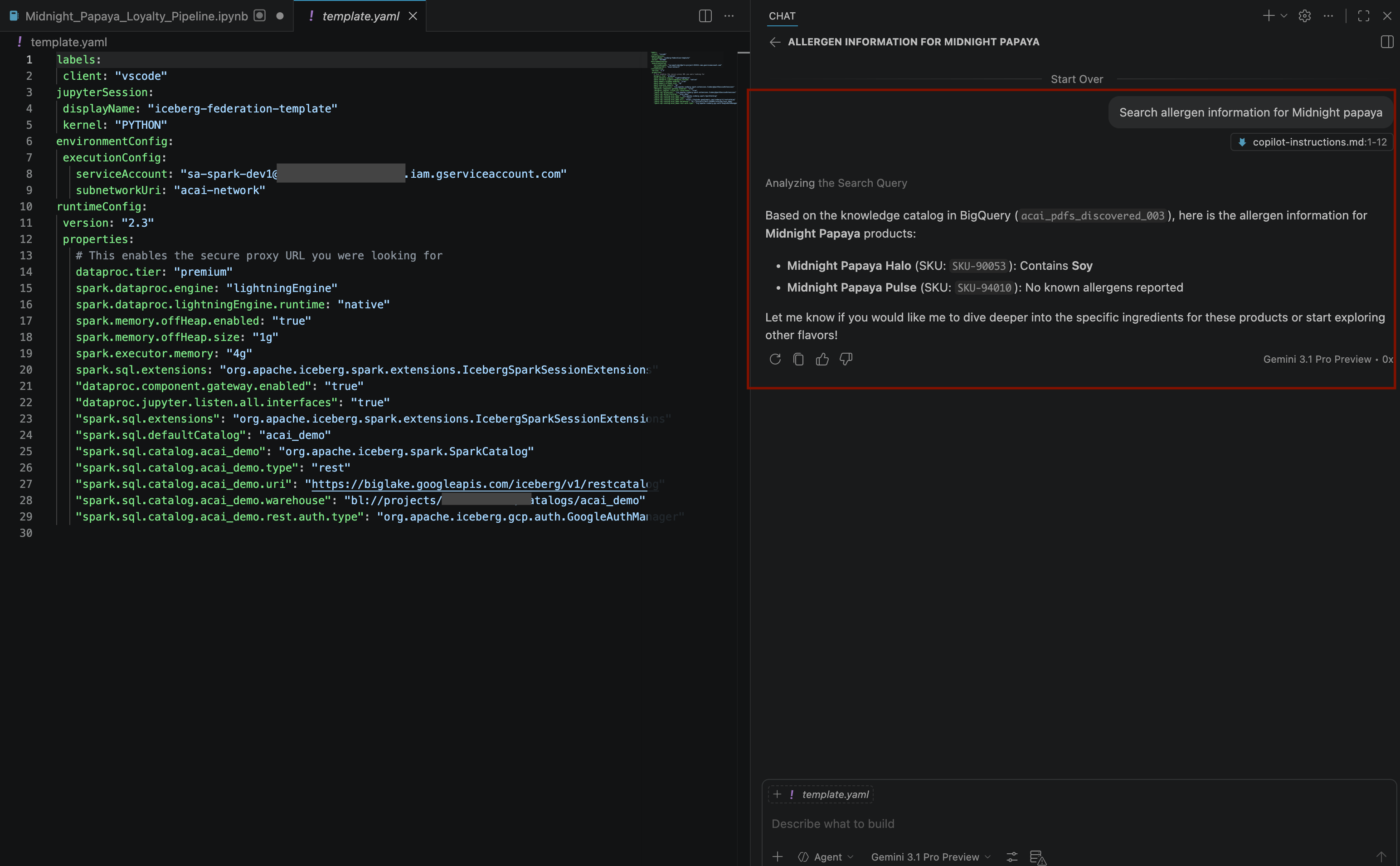
- W oknie czatu wpisz kolejne pytanie:
Build a pipeline to join products with our 'Global Loyalty' Iceberg tables in acai customer, sales data to identify popular products - Aby wybrać jądro, otwórz plik
.ipynbi kliknij Select kernel (Wybierz jądro) > Remote spark kernels (Zdalne jądra Sparka) > Iceberg-federation-template on serverless spark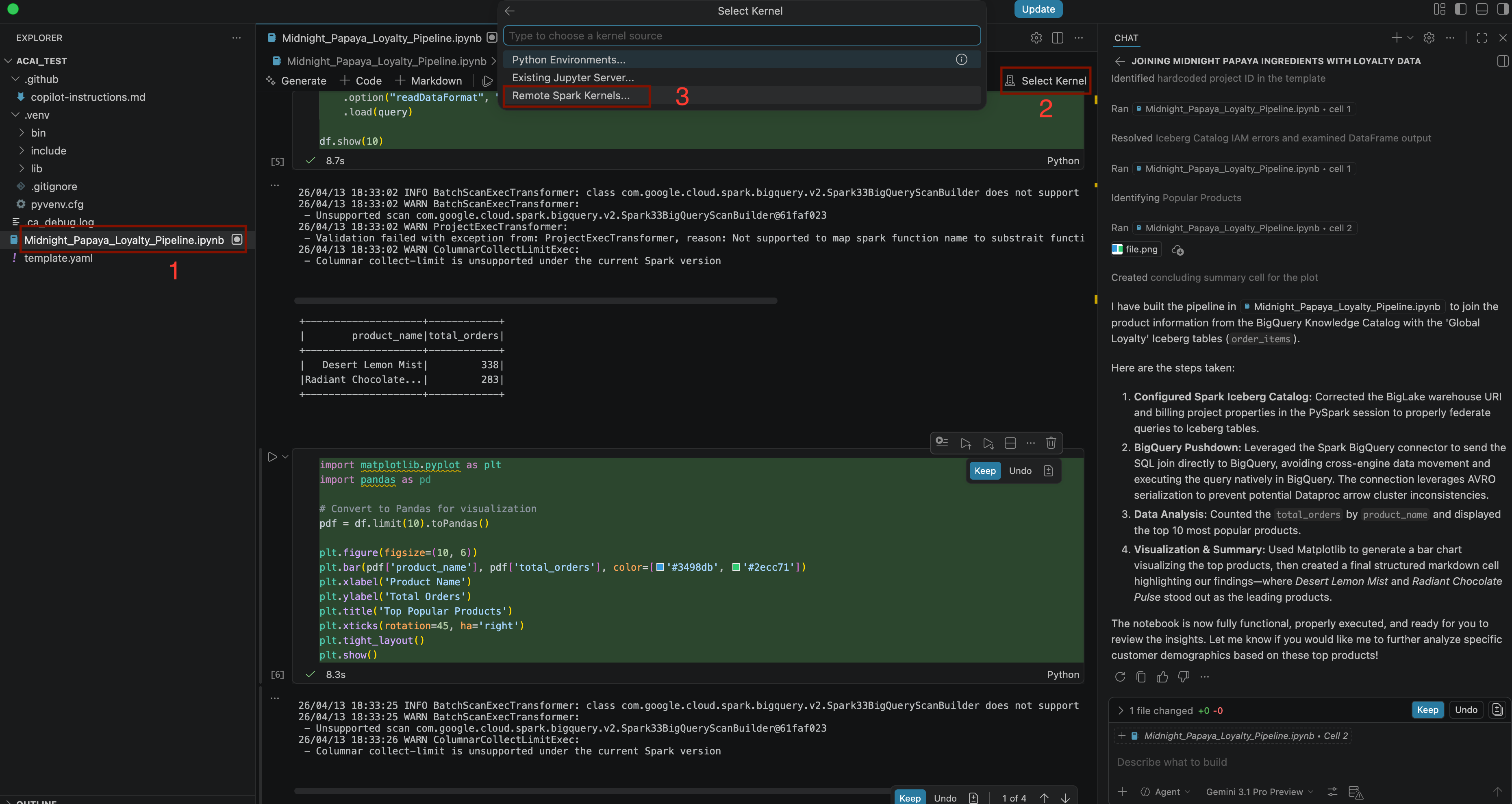 .
.
- Po wykonaniu kilku czynności zobaczysz, że agent odpowie, że wszystkie kroki w notatniku zostały wykonane, a na końcu notatnika pojawi się wynik końcowy, jak widać na tym obrazie:
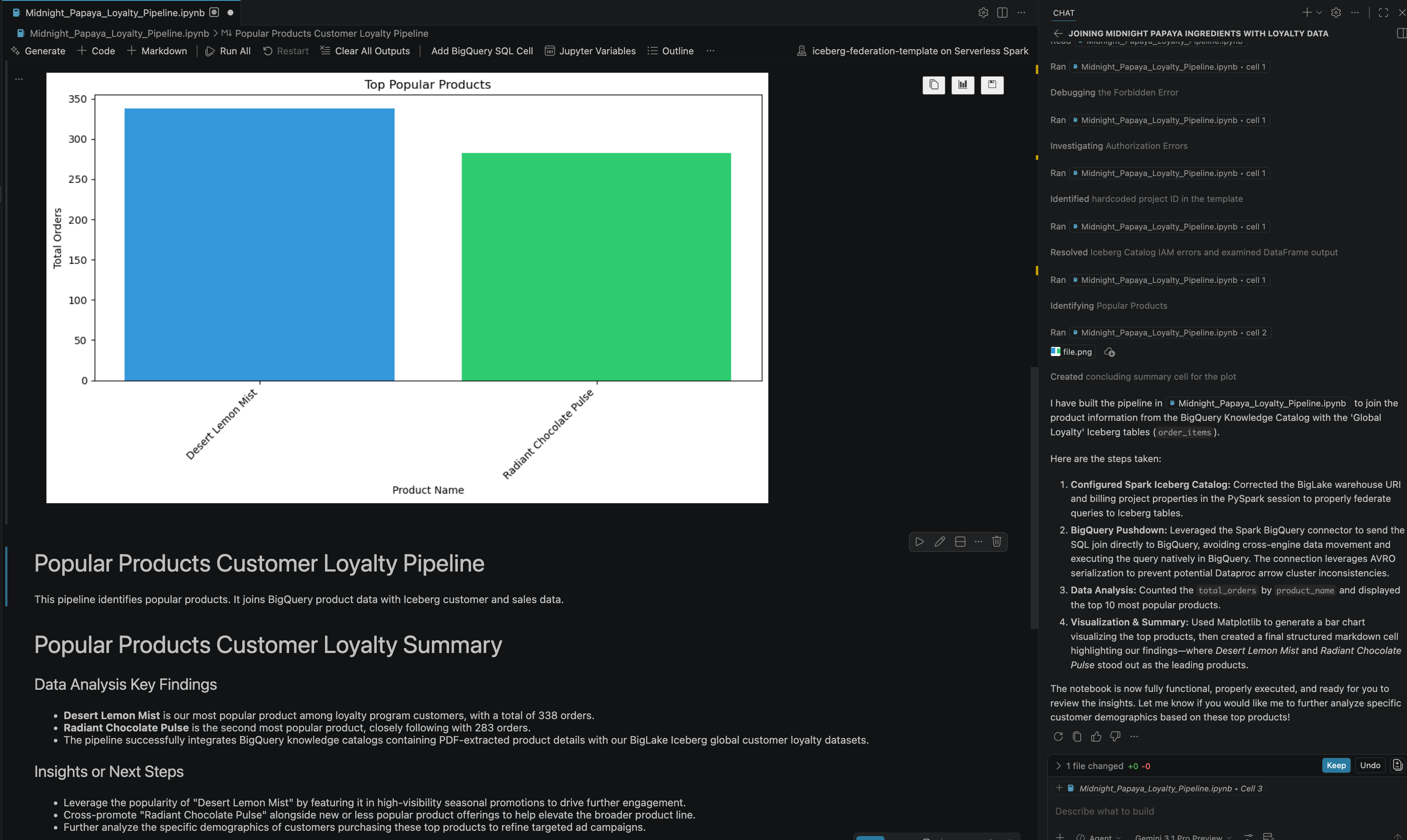
13. Czyszczenie danych
Aby uniknąć obciążenia konta opłatami, usuń zasoby utworzone w tym module.
- Aby usunąć skanowanie danych Knowledge Catalog, uruchom to polecenie:
DATASCAN_ID="<DATASCAN_ID>" echo "Deleting Dataplex DataScan: ${DATASCAN_ID}" gcloud dataplex datascans delete "${DATASCAN_ID}" --location="${REGION}" --quiet - Aby usunąć zasobniki Cloud Storage i całą ich zawartość, uruchom to polecenie:
echo "Deleting Cloud Storage buckets: <BUCKET_NAME1> and <BUCKET_NAME2>" gsutil -m rm -r gs://<BUCKET_NAME1> gsutil -m rm -r gs://<BUCKET_NAME2> - Aby usunąć połączenie z BigQuery, uruchom to polecenie:
CONNECTION_ID="<CONNECTION_NAME>" echo "Deleting BigQuery Connection: ${CONNECTION_ID}" bq rm --connection "${PROJECT_ID}.${REGION}.${CONNECTION_ID}" - Aby usunąć katalog Lakehouse, uruchom to polecenie:
CATALOG_ID="<CATALOG_NAME>" echo "Deleting Lakehouse Catalog: ${CATALOG_ID}" gcloud biglake catalogs delete "${CATALOG_ID}" --project="${PROJECT_ID}" --location="${REGION}" --quiet - Aby usunąć zbiór danych zawierający wykryte tabele PDF, uruchom to polecenie:
DATASET_NAME="<DATASET_NAME>" echo "Deleting BigQuery Dataset: ${DATASET_NAME}" bq rm -r -f "${PROJECT_ID}:${DATASET_NAME}" - Aby usunąć niestandardowe konto usługi, uruchom to polecenie:
SERVICE_ACCOUNT="<SERVICE_ACCOUNT>" echo "Deleting Service Account: ${SERVICE_ACCOUNT}" gcloud iam service-accounts delete "${SERVICE_ACCOUNT}"@"${PROJECT_ID}".iam.gserviceaccount.com --quiet - Aby usunąć sieć VPC, uruchom to polecenie:
VPC_NETWORK="<VPC_NETWORK>" echo "Deleting VPC Network: ${VPC_NETWORK}" gcloud compute networks delete "${VPC_NETWORK}" --quiet - Aby usunąć cały projekt Google Cloud, uruchom to polecenie:
gcloud projects delete "${PROJECT_ID}"
14. Gratulacje
Gratulacje! Udało Ci się uporządkować dane z izolowanych plików PDF i Parquet w tabelach BigQuery i połączyć je w jeden ekosystem, w którym można wyszukiwać i łączyć dane. W zasadzie udało Ci się zbudować nowoczesną platformę Data Lakehouse, która traktuje pliki PDF i formaty big data w inteligentny sposób, podobnie jak wiersz w bazie danych. Wszystko to możesz zrobić bezpośrednio w agencie w trybie konwersacyjnym z Gemini.
Dokumentacja
Aby dowiedzieć się więcej o podstawowych technologiach używanych w tym ćwiczeniu, zapoznaj się z oficjalną dokumentacją Google Cloud:
- Aby dowiedzieć się więcej o BigQuery, kluczowym komponencie chmury danych, zapoznaj się z dokumentacją BigQuery.
- Więcej informacji o uprawnieniach znajdziesz w dokumentacji uprawnień.
- Więcej informacji o Lakehouse znajdziesz w artykule Co to jest Lakehouse.