
1. Introdução
Neste codelab, você vai assumir o papel de um cientista de dados de uma empresa fictícia de sorvetes que está lançando uma nova variação de produto, o "Midnight Swirl". Para garantir um lançamento global bem-sucedido, a empresa precisa responder a perguntas importantes sobre ingredientes, demanda do mercado e retorno do investimento (ROI). Este fluxo de trabalho de ponta a ponta demonstra como o Knowledge Catalog do Google Cloud (antigo Dataplex) e o Lakehouse para Apache Iceberg (antigo BigLake) preenchem a lacuna entre dados não estruturados "ocultos" e oferecem Business Intelligence útil usando o Gemini no seu IDE (VS Code) por uma camada de governança unificada.
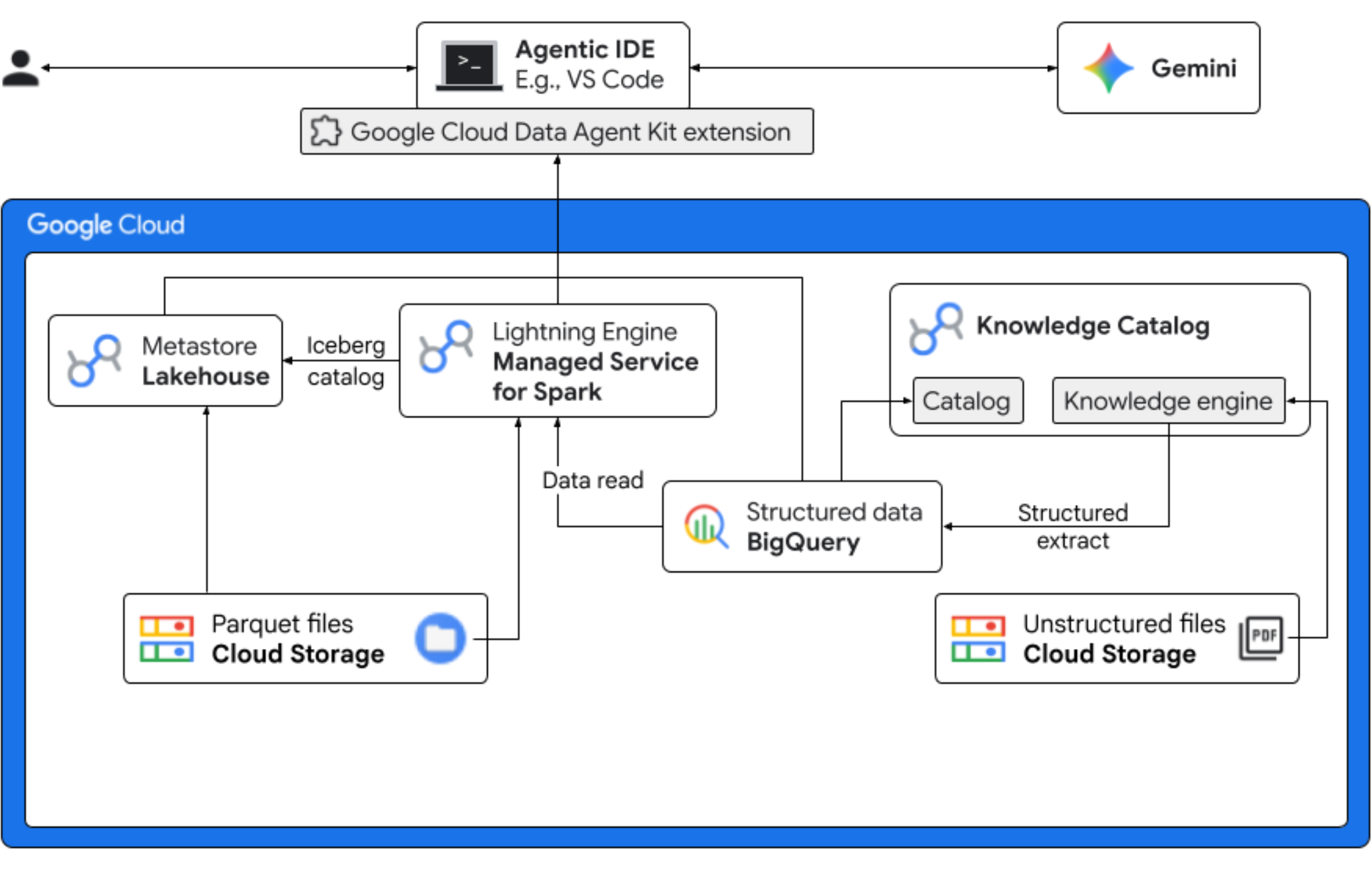
Atividades deste laboratório
- Descoberta não estruturada: as receitas em PDF armazenadas no Cloud Storage são rastreadas pelo DataScan do Knowledge Catalog. Crie tabelas de objetos no BigQuery para os PDFs digitalizados. Usando a inferência semântica da Vertex AI, o sistema "lê" os PDFs para extrair informações estruturadas sobre produtos, alérgenos, ingredientes e atributos relacionados. Em seguida, ele gera de forma inteligente um esquema para os dados armazenados nos PDFs.
- Metadados unificados: os dados extraídos de arquivos PDF são armazenados diretamente no BigQuery como uma tabela nativa ampla, e as visualizações são criadas para ajudar em consultas comuns. Um conjunto de dados de entrada independente com dados históricos de vendas é armazenado em tabelas do Apache Iceberg no Google Cloud Storage. Essa tabela do Iceberg será unida aos dados extraídos no BigQuery em uma etapa posterior.
- Análise entre mecanismos: usando o Serviço gerenciado para Apache Spark (antigo Dataproc) com um catálogo REST do Iceberg, você vai combinar esses metadados de PDF atualizados e dados semânticos estruturados inferidos (de tabelas e visualizações do BigQuery) com dados de vendas estruturados armazenados em tabelas do Apache Iceberg no Google Cloud Storage. Isso é regido por um modelo de sessão interativa do Apache Spark gerenciado usado como kernel do notebook Jupyter, que garante configurações consistentes de segurança e computação para o job do Spark.
- Insights semânticos: ao combinar os dados de produtos inferidos com dados de clientes e vendas (no BigQuery), a demonstração consegue extrair insights, como identificar dados de alérgenos e previsão de receita.
- Governança autônoma: todo o ciclo de vida, desde verificações de descoberta até a execução do Spark, é orquestrado por modelos, instruções, regras e automação baseada em agentes prontos para o Gemini. Isso prova que a IA pode gerenciar a infraestrutura que alimenta a análise.
O que é necessário
A conclusão deste codelab pode gerar custos, estimados em menos de US $5 para uso típico. Para receber estimativas de custo detalhadas com base no uso projetado ou nos preços atuais, use a calculadora de preços do Google Cloud.
Verifique se você atende aos seguintes pré-requisitos para concluir o codelab.
- Navegador da Web Chrome.
- Uma conta pessoal do Gmail se você estiver usando os créditos de teste fornecidos na seção "Antes de começar".
- Faça o download e instale o Visual Studio (VS) Code.
2. Antes de começar
Criar um projeto do Google Cloud
- No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto na nuvem do Google Cloud.
- Verifique se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto.
Iniciar o Cloud Shell
O Cloud Shell é um ambiente de linha de comando executado no Google Cloud que vem pré-carregado com as ferramentas necessárias.
- Clique em Ativar o Cloud Shell na parte de cima do console do Google Cloud.
- Depois de se conectar ao Cloud Shell, verifique sua autenticação:
gcloud auth list - Confirme se o projeto está configurado:
gcloud config get project - Se o projeto não estiver definido como esperado, faça o seguinte:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Ativar APIs obrigatórias
Execute este comando para ativar todas as APIs necessárias:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
biglake.googleapis.com \
dataproc.googleapis.com \
metastore.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
secretmanager.googleapis.com \
storage.googleapis.com
Baixar recursos do codelab
Este repositório contém arquivos Parquet, receitas, fornecedores, copilot-instructions.md, template.yaml e quickstart.py para uso com este codelab. Faça o download desses arquivos.
Para fazer o download dos arquivos, siga estas etapas:
- No Cloud Shell, execute este comando:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git - Acesse a pasta recém-criada:
cd next-26-keynotes - Extraia a pasta
data-cloud-demo.git sparse-checkout set genkey/data-cloud-demo - Depois que o pagamento for concluído, navegue até a pasta
data-cloud-demoe extraia os arquivos ZIP para acessar os recursos do codelab.
3. Configurar o Lakehouse para dados do cliente do Froyo
Nesta seção, você cria um catálogo no Lakehouse para usar o metastore do Lakehouse nos seus fluxos de trabalho. Ele cria interoperabilidade entre os mecanismos de consulta ao oferecer uma única fonte de informações para todos os dados do Iceberg. Ele permite que mecanismos de consulta, como o Apache Spark, descubram, leiam metadados e gerenciem tabelas do Iceberg de maneira consistente.
Funções exigidas
Verifique se você tem os seguintes papéis do Identity and Access Management (IAM):
roles/biglake.viewerroles/bigquery.userroles/bigquery.dataEditorroles/biglake.editorroles/biglake.metadataViewerroles/bigquery.connectionUserroles/storage.objectUserroles/storage.objectViewerroles/storage.objectCreatorroles/storage.admin
Para mais informações sobre como conceder papéis do IAM, consulte Conceder um papel do IAM.
Criar um catálogo de lakehouse com um bucket
Crie um catálogo do Lakehouse para gerenciar metadados das tabelas do Iceberg. Você se conecta a esse catálogo no seu job do Spark para criar e consultar tabelas do Iceberg.
- No console do Google Cloud, acesse Lakehouse.
- Clique em Criar catálogo. A página Criar catálogo é aberta.
- Em Tipo de catálogo, selecione Catálogo REST do Iceberg.
- Em Selecione as opções de bucket do catálogo do Lakehouse, escolha Catálogo de bucket único.
- Em bucket do Cloud Storage padrão do catálogo, clique em Procurar e em Criar novo bucket.
- Na página Criar um bucket, faça o seguinte:
- Na seção Começar, insira um nome globalmente exclusivo que atenda aos requisitos de nome de bucket.
- Na seção Escolha onde armazenar seus dados, selecione Região para Tipo de local e insira sua região. Por exemplo,
us-west1. - Na seção Escolha como controlar o acesso a objetos, desmarque a caixa de seleção Aplicar a prevenção do acesso público neste bucket.
Isso permite simular cenários do mundo real, como hospedagem de conteúdo da Web público ou repositórios de dados compartilhados. Sem essa mudança, o bucket aplicaria uma política estrita de "somente privado". Qualquer tentativa de acessar seus recursos resultaria em um erro403proibido, mesmo que você tenha concedido permissões públicas aos arquivos. - Clique em Continuar > Criar > Selecionar > Continuar.
- Em Método de autenticação, selecione Modo de fornecimento de credenciais.
- Clique em Criar.Seu catálogo será criado e a página Detalhes do catálogo será aberta.
- Em Método de autenticação, clique em Definir permissões do bucket.
- Na caixa de diálogo, clique em Confirmar.Isso verifica se a conta de serviço do seu catálogo tem o papel
Storage Object Userno bucket de armazenamento. - Na página Detalhes do catálogo, copie o caminho do URI do catálogo REST. Use esse caminho durante a tarefa "Executar job do Spark".
Faça upload dos arquivos Parquet para o bucket
Para fazer upload dos arquivos Parquet para a raiz do bucket, faça o seguinte:
- No console do Google Cloud, acesse a página Buckets do Cloud Storage.
- Na lista de buckets, clique no nome do bucket. Por exemplo,
acai_demo. - Na guia Objetos do bucket, clique em Fazer upload > Fazer upload de arquivos.
- Selecione os arquivos da pasta Parquet que você clonou na seção Antes de começar deste codelab.
- Clique em Abrir.
4. Configurar a rede VPC
Crie uma rede de nuvem privada virtual (VPC) e uma sub-rede que permita que os recursos se comuniquem com as APIs do Google sem sair para a Internet pública, além de um firewall que permita que o tráfego interno flua livremente entre os nós de processamento de dados.
- No Console do Google Cloud, acesse a página Redes VPC.
- Clique em Criar rede VPC.
- Digite um Nome para a rede. Por exemplo,
acai-network. - Para configurar a unidade de transmissão máxima (MTU) da rede, marque a caixa de seleção Definir MTU automaticamente.
- Escolha Automático para o Modo de criação da sub-rede.
- Na seção Regras de firewall, marque todas as caixas de seleção em Regras de firewall IPv4.
- Clique em Criar.
Ativar o Acesso privado do Google
Os nós do Dataproc sem servidor não têm endereços IP públicos. Para se comunicar com o catálogo do Lakehouse e o Cloud Storage, a sub-rede precisa ter o Acesso privado do Google ativado.
- No Console do Google Cloud, acesse a página Redes VPC.
- Clique no nome da rede que contém a sub-rede para que você precisa ativar o Acesso privado do Google. Por exemplo,
us-west1. - Clique no nome da sub-rede. A página de detalhes da sub-rede é exibida.
- Clique em Editar.
- Na seção Acesso privado do Google, selecione Ativado.
- Clique em Salvar.
5. Criar e executar um job do Spark
Para criar e consultar uma tabela do Iceberg, faça upload do job PySpark com as instruções SQL do Spark necessárias. Em seguida, execute o job com o Serviço Gerenciado para Spark.
Faça upload de quickstart.py para o bucket do Cloud Storage.
Depois de clonar os recursos do codelab, atualize o script quickstart.py com os detalhes do projeto e faça upload dele para o bucket do Cloud Storage.
- Abra o script
quickstart.pyem um editor de texto. - Substitua o marcador de posição
BUCKET_NAMEno script pelo nome do bucket do Cloud Storage e salve. - No console do Google Cloud, acesse Buckets do Cloud Storage.
- Clique no nome do bucket. Por exemplo,
acai_demo. - Na guia Objetos, clique em Fazer upload > Fazer upload de arquivos.
- No navegador de arquivos, selecione o arquivo
quickstart.pyatualizado e clique em Abrir.
Executar o job do Spark
Depois de fazer upload do script quickstart.py, execute-o como um job em lote do Serviço Gerenciado para Spark.
- Para configurar as variáveis, execute o seguinte comando no Cloud Shell.
# Configuration Variables export PROJECT_ID="<PROJECT_ID>" export REGION="<REGION>" export BUCKET_NAME="<BUCKET_NAME>" export SUBNET="<SUBNET>" export LAKEHOUSE_CATALOG_ID="<LAKEHOUSE_CATALOG_ID>" export CATALOG_URI_ID="<CATALOG_URI_ID>"- LAKEHOUSE_CATALOG_ID: o nome do recurso de catálogo do Lakehouse que contém o arquivo do aplicativo PySpark. Por exemplo,
acai_demo - PROJECT_ID: o ID do projeto na nuvem do Google Cloud.
- REGION: a região em que executar a carga de trabalho em lote do Serviço Gerenciado para Spark. Por exemplo,
us-west1. - BUCKET_NAME: o nome do seu bucket do Cloud Storage. Por exemplo,
acai_demo. - SUBNET: o nome da sub-rede VPC. Por exemplo,
acai-network. - CATALOG_URI_ID: o ID do URI do catálogo do Lakehouse que você copiou ao criar um catálogo do Lakehouse com um bucket. Por exemplo,
https://biglake.googleapis.com/iceberg/v1/restcatalog.
- LAKEHOUSE_CATALOG_ID: o nome do recurso de catálogo do Lakehouse que contém o arquivo do aplicativo PySpark. Por exemplo,
- No Cloud Shell, execute o seguinte job em lote do Managed Service for Spark usando o script
quickstart.py.gcloud dataproc batches submit pyspark gs://${BUCKET_NAME}/quickstart.py \ --project=${PROJECT_ID} \ --region=${REGION} \ --subnet=${SUBNET} \ --version=2.2 \ --properties="\ spark.sql.defaultCatalog=${LAKEHOUSE_CATALOG_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}=org.apache.iceberg.spark.SparkCatalog,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.type=rest,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.uri=${CATALOG_URI_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.warehouse=gs://${BUCKET_NAME},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.io-impl=org.apache.iceberg.gcp.gcs.GCSFileIO,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.x-goog-user-project=${PROJECT_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\ spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest-metrics-reporting-enabled=false,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.X-Iceberg-Access-Delegation=vended-credentials,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token"All tables registered successfully! Batch [126fa2226a904d2e944c8eecbe0b1840] finished. metadata: '@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata batch: projects/PROJECT_ID/locations/REGION/batches/126fa2226a904d2e944c8eecbe0b1840 batchUuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff createTime: '2026-04-09T13:17:26.222727Z' description: Batch labels: goog-dataproc-batch-id: 126fa2226a904d2e944c8eecbe0b1840 goog-dataproc-batch-uuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-drz-resource-uuid: batch-3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-location: REGION operationType: BATCH name: projects/PROJECT_ID/regions/REGION/operations/47bc59e8-5082-3af9-89a0-22289aa5f4b9
6. Consultar a tabela no BigQuery
Ao executar o job em lote do Spark, você usou o Serviço gerenciado para Spark sem servidor como um mecanismo de computação distribuída para registrar várias tabelas, uma por arquivo Parquet, no metastore do Lakehouse. Com esse registro, o Google Cloud pode tratar seus arquivos brutos no Cloud Storage como tabelas estruturadas de alta performance.
As etapas a seguir orientam você a confirmar se os metadados foram sincronizados corretamente, garantindo que seus dados não apenas sejam armazenados com segurança, mas também sejam totalmente detectáveis e consultáveis pela interface do BigQuery.
- No console do Google Cloud, acesse o BigQuery.
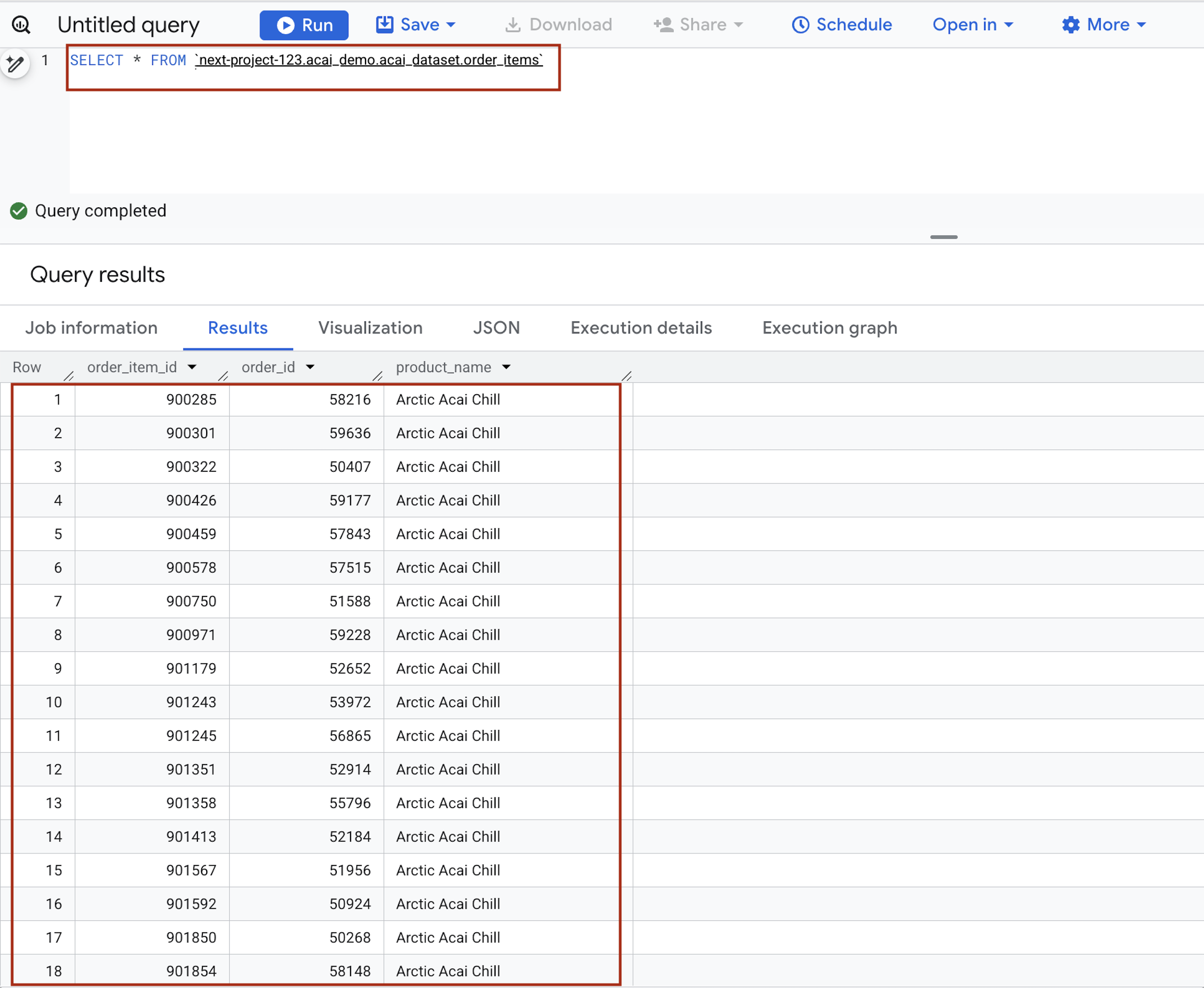
- No editor de consultas, insira a seguinte instrução: A consulta usa a sintaxe
project.namespace.dataset.table.SELECT * FROM `<PROJECT_ID>.<NAMESPACE>.<ICEBERG_DATASET>.<ICEBERG_TABLE>`PROJECT_ID.acai_demo.acai_dataset.order_items.
Substitua o seguinte:- PROJECT_ID: o ID do projeto na nuvem do Google Cloud.
- NAMESPACE: o namespace criado na etapa anterior como resultado do job do Spark, que pode ser encontrado na página do explorador de objetos do BigQuery. Por exemplo,
acai_demo. - ICEBERG_DATASET: o nome do conjunto de dados no catálogo do Iceberg, por exemplo,
acai_dataset. - ICEBERG_TABLE: o nome da tabela no conjunto de dados do Iceberg, por exemplo,
order_items.
- Clique em Executar. Os resultados da consulta mostram os dados que você inseriu com o job do Spark.
7. Configurar arquivos de dados de produtos não estruturados
Nesta seção, você vai criar uma estrutura organizacional no BigQuery para armazenar dados de receitas e fornecedores do Froyo, especificamente para detalhes do produto Froyo. Ele também estabelece uma conexão a recursos do Cloud, que atua como uma "ponte" segura, permitindo que o BigQuery leia arquivos de fontes externas, como o Cloud Storage.
Criar um bucket e fazer upload dos arquivos de detalhes do Froyo
Crie e faça upload dos arquivos de fornecedor e receita para o bucket do Cloud Storage.
- No console do Google Cloud, acesse a página Buckets do Cloud Storage.
- Clique em Criar.
- Na página Criar um bucket, insira as informações do seu bucket. Após cada uma das etapas a seguir, clique em Continuar para prosseguir para a próxima etapa:
- Na seção Começar, insira o nome do bucket. Por exemplo,
acai_pdfs. - Na seção Escolha onde armazenar seus dados, selecione Região e insira sua região. Por exemplo,
us-west1. - Na seção Escolha como controlar o acesso a objetos, desmarque a caixa de seleção Aplicar a prevenção do acesso público neste bucket.
- Clique em Criar.
- Na lista de buckets, clique no bucket que você criou. Por exemplo,
acai_pdfs. - Na guia Objetos do bucket, clique em Fazer upload > Fazer upload de pastas.
- Selecione a pasta
recipesextraída na seção Antes de começar deste codelab. - Clique em Fazer upload.
- Repita o processo de upload para a pasta
suppliers.
Crie uma conexão
Crie uma conexão a recursos do Cloud. Isso gera uma conta de serviço exclusiva que funciona como o "documento de identidade" do BigQuery para acessar arquivos externos.
- Acessar a página do BigQuery.
- No painel à esquerda, clique em Explorer. Se o painel esquerdo não aparecer, clique em Expandir painel esquerdo para abrir.
- No painel Explorer, expanda o nome do projeto e clique em Conexões.
- Na página Conexões, clique em Criar conexão.
- Em Tipo de conexão, escolha Modelos remotos da Vertex AI, funções remotas, BigLake e Spanner (recurso do Cloud).
- No campo ID da conexão, insira o nome do ID da conexão. Por exemplo,
acai_pdf_connection. Anote esse ID, porque você vai precisar dele ao configurar a verificação de dados mais tarde neste codelab. - Defina Tipo de local como Região e selecione uma opção. Por exemplo,
us-west1. A conexão precisa estar localizada com seus outros recursos, como conjuntos de dados. - Clique em Criar conexão.
- Clique em Ir para conexão.
- No painel Informações da conexão, copie o ID da conta de serviço para usar em uma etapa posterior. A conta de serviço é semelhante a
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com.
Gerenciar o acesso às contas de serviço
Conceda acesso à conta de serviço para que o Lakehouse possa ler seus PDFs.
- Acessar a página AM e administrador
- Clique em Conceder acesso. A caixa de diálogo "Adicionar principais" é aberta.
- No campo Novos principais, digite o ID da conta de serviço que você copiou.
- No campo Selecionar um papel, adicione os seguintes papéis:
roles/storage.objectUserroles/storage.objectViewerroles/bigquery.userroles/bigquery.dataEditorroles/aiplatform.userroles/storage.adminroles/dataproc.serviceAgent
- Clique em Salvar.
Para mais informações sobre os papéis do IAM no BigQuery, consulte Papéis e permissões predefinidos.
8. Gerenciar permissões para o job DataScan
Crie contas de serviço (identidades) específicas para o Spark e o Dataform e conceda a elas, junto com os agentes de serviço automatizados do Google, as permissões exatas necessárias para ler o armazenamento, executar jobs do BigQuery e usar a Vertex AI para descoberta.
Acesso do IAM para Spark e Dataform
- No Console do Google Cloud, acesse a página Criar conta de serviço.
- Se não estiver selecionado, escolha seu projeto na nuvem do Google.
- Clique em Criar conta de serviço.
- Insira o nome da conta de serviço. Por exemplo,
sa-spark-stg1. O console do Google Cloud gera um ID de conta de serviço com base nesse nome. Edite o ID se for necessário. Não será possível alterar o ID depois. - Para definir os controles de acesso, clique em Criar e continuar e avance para a próxima etapa.
- Escolha os seguintes papéis do IAM para conceder à conta de serviço no projeto.
roles/dataproc.workerroles/storage.objectUserroles/bigquery.dataEditorroles/bigquery.jobUserroles/aiplatform.userroles/dataplex.discoveryPublishingServiceAgent
- Quando você terminar de adicionar papéis, clique em Continuar.
- Clique em Concluído para terminar a criação da conta de serviço.
Permissões de conexão do BigQuery para acessar o Knowledge Catalog
- No console do Google Cloud, acesse a página Buckets do Cloud Storage.
- Na lista de buckets, clique no nome do bucket que você criou para o Froyo. Por exemplo,
acai_pdfs. - Na guia Permissões, clique em Conceder acesso. A caixa de diálogo "Adicionar principais" aparece.
- No campo Novos principais, insira o ID da conta de serviço do BigQuery. A conta de serviço é semelhante a
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com. - Selecione os seguintes papéis no menu suspenso Selecionar um papel.
roles/storage.objectUserroles/dataplex.serviceAgentroles/dataplex.securityAdminroles/aiplatform.serviceAgentroles/dataplex.discoveryPublishingServiceAgent
- Clique em "Salvar".
9. Configurar o Knowledge Catalog
Crie um Knowledge Catalog para unificar seus dados relacionados ao Froyo e automatizar a descoberta de arquivos não estruturados (como receitas e fornecedores em PDF).
Crie o DataScan usando curl.
Nesta seção, você cria verificações para seu bucket do Cloud Storage (por exemplo, acai_pdfs) adicionando o datascan_ID e apontando-o para seus conjuntos de dados do BigQuery. Depois disso, o Knowledge Catalog vai criar automaticamente entradas para seus PDFs no BigQuery.
- Para verificar os PDFs (fornecedores e receitas), execute o seguinte comando:
# 1. Set your variables PROJECT_ID="<PROJECT_ID>" REGION="<REGION>" ENV_SUFFIX="stg1" DATASCAN_ID="froyo-profile-${ENV_SUFFIX}" BUCKET_NAME="<BUCKET_NAME>" # 2. Set this to the Name of the connection you created in Step 7 CONNECTION_ID="<CONNECTION_ID_NAME>" # 3. Define the API Endpoint DATAPLEX_API="dataplex.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}" # 4. Create the DataScan via CURL echo "Creating Dataplex DataScan: ${DATASCAN_ID}..." curl -X POST "https://$DATAPLEX_API/dataScans?dataScanId=${DATASCAN_ID}" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d '{ "data": { "resource": "//storage.googleapis.com/projects/'"${PROJECT_ID}"'/buckets/'"${BUCKET_NAME}"'" }, "executionSpec": { "trigger": { "on_demand": {} } }, "dataDiscoverySpec": { "bigqueryPublishingConfig": { "tableType": "BIGLAKE", "connection": "projects/'"${PROJECT_ID}"'/locations/'"${REGION}"'/connections/'"${CONNECTION_ID}"'" }, "storageConfig": { "unstructuredDataOptions": { "entity_inference_enabled": true } } } }' - O comando
curlmostra os resultados da DataScan do Knowledge Catalog, semelhante à imagem a seguir.
Execute o job
Execute este comando:
gcloud dataplex datascans run $DATASCAN_ID --location=$REGION
Descrever um job
Para descrever o job, execute o seguinte comando:
gcloud dataplex datascans describe $DATASCAN_ID --location=$REGION
Excluir um job de verificação de dados
Se a verificação for executada por mais de 10 minutos ou se o status do job permanecer Pendente por um longo período sem transição para Em execução, isso pode ser devido à indisponibilidade temporária de recursos na região. Se isso acontecer, execute o comando a seguir para excluir o job e tente criar e executar novamente. Às vezes, uma execução inicial pode falhar rapidamente com um erro como unable to acquire necessary resources.
gcloud dataplex datascans delete $DATASCAN_ID --location=$REGION
Ver o status do job
Para verificar o status do job, faça o seguinte:
- No console do Google Cloud, acesse a página Criação de metadados.
- Na guia Descoberta do Cloud Storage, clique no nome das verificações de descoberta.
- Na página Detalhes da verificação, confira o status do job.
- Quando o job terminar, verifique se o conjunto de dados publicado (por exemplo,
acai_pdfs_discovered_003) que você criou usando o comandocurlestá presente.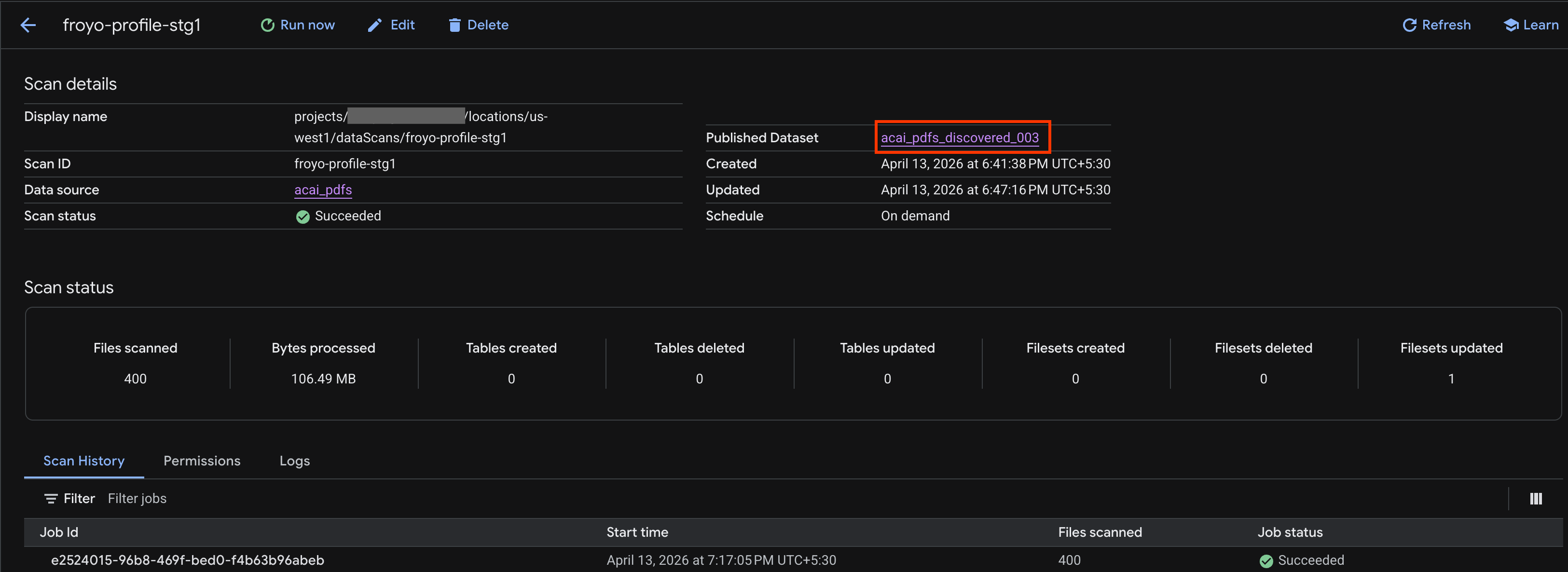
Ver a tabela de objetos
Para conferir a tabela de objetos criada após o job de descoberta, faça o seguinte:
- No console do Google Cloud, acesse o BigQuery.
- Clique em Conjuntos de dados e selecione o conjunto publicado criado na etapa anterior. Por exemplo,
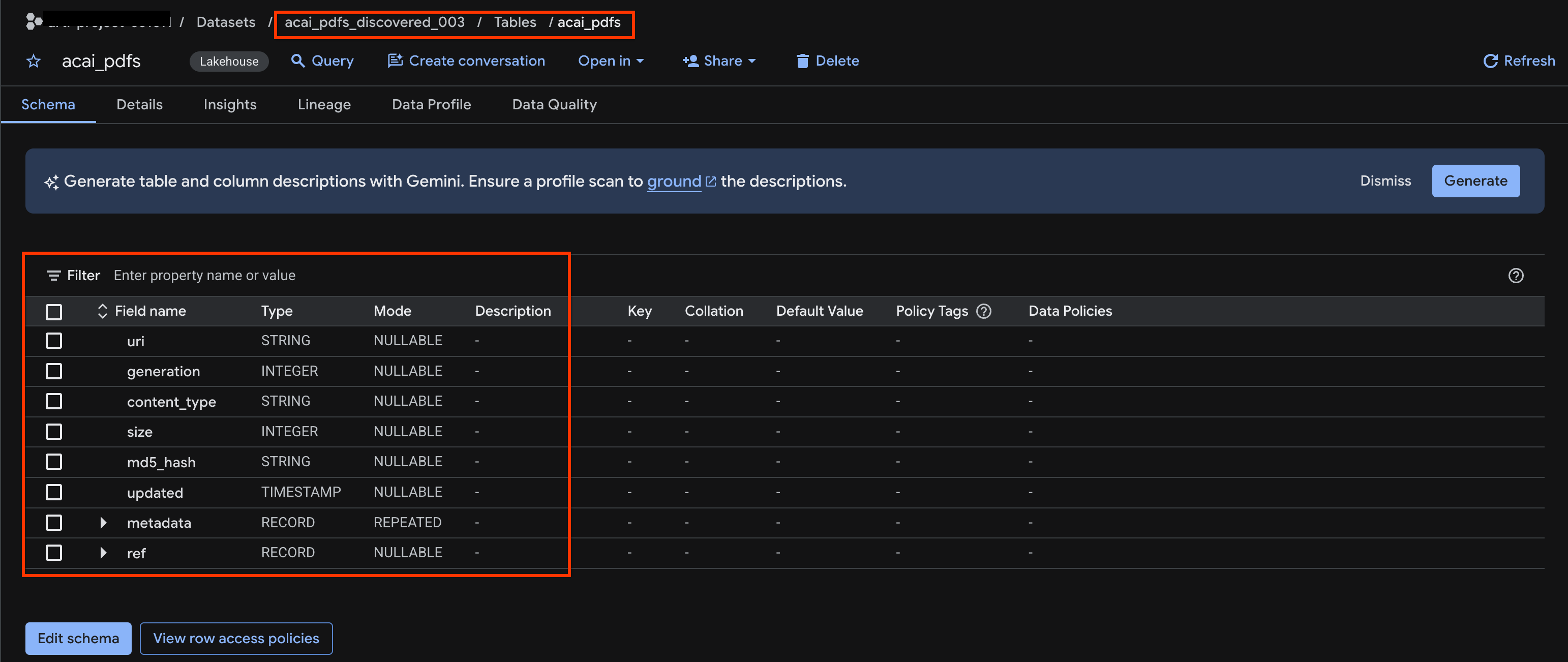
acai_pdfs_discovered_003. - Para acessar a tabela de objetos, clique no ID dela. Por exemplo,
acai_pdfs. - A tabela de objetos resultante é semelhante à imagem a seguir:
10. Extração semântica
Você vai inferir e extrair tabelas estruturadas, outros objetos de banco de dados e relações para essa tabela de objetos não estruturada criada na etapa anterior. Para isso, use o recurso Insights do Knowledge Catalog para gerar instruções SQL e extrair dados estruturados da tabela não estruturada.
- No console do Google Cloud, acesse a página Pesquisa do Knowledge Catalog.
- Pesquise a tabela do conjunto de dados para que você quer ver insights. Por exemplo,
acai_pdfs_discovered_003.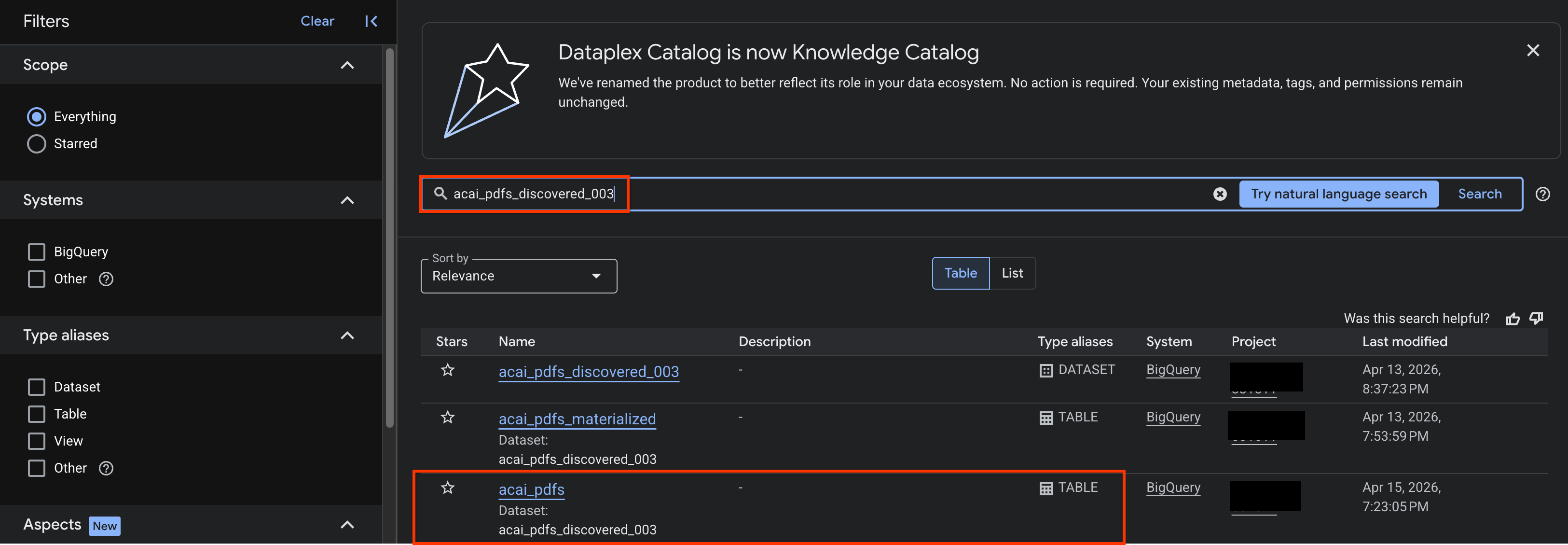
- Nos resultados da pesquisa, clique na tabela para abrir a página de entrada dela.
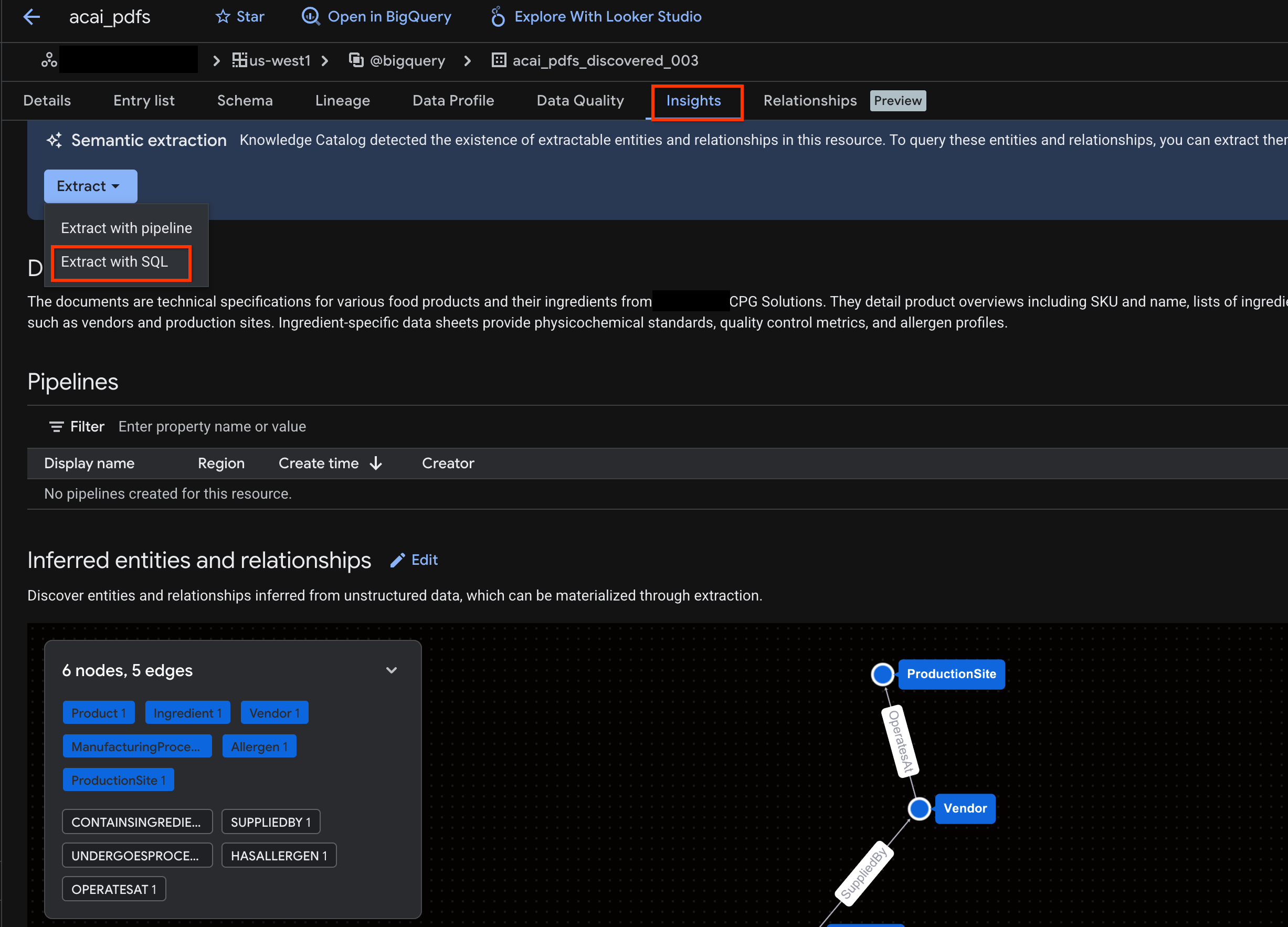
- Clique na guia Insights. Se a guia estiver vazia, isso significa que os insights da tabela ainda não foram gerados. A geração de insights pode levar de 15 a 25 minutos.
- Depois de ver os insights, clique em Extrair > Extrair com SQL.
- Na página Extrair com SQL, em Destino, insira seu conjunto de dados. Por exemplo,
acai_pdfs_discovered_003. - Clique em Extrair. Isso abre o editor do BigQuery com a consulta carregada.
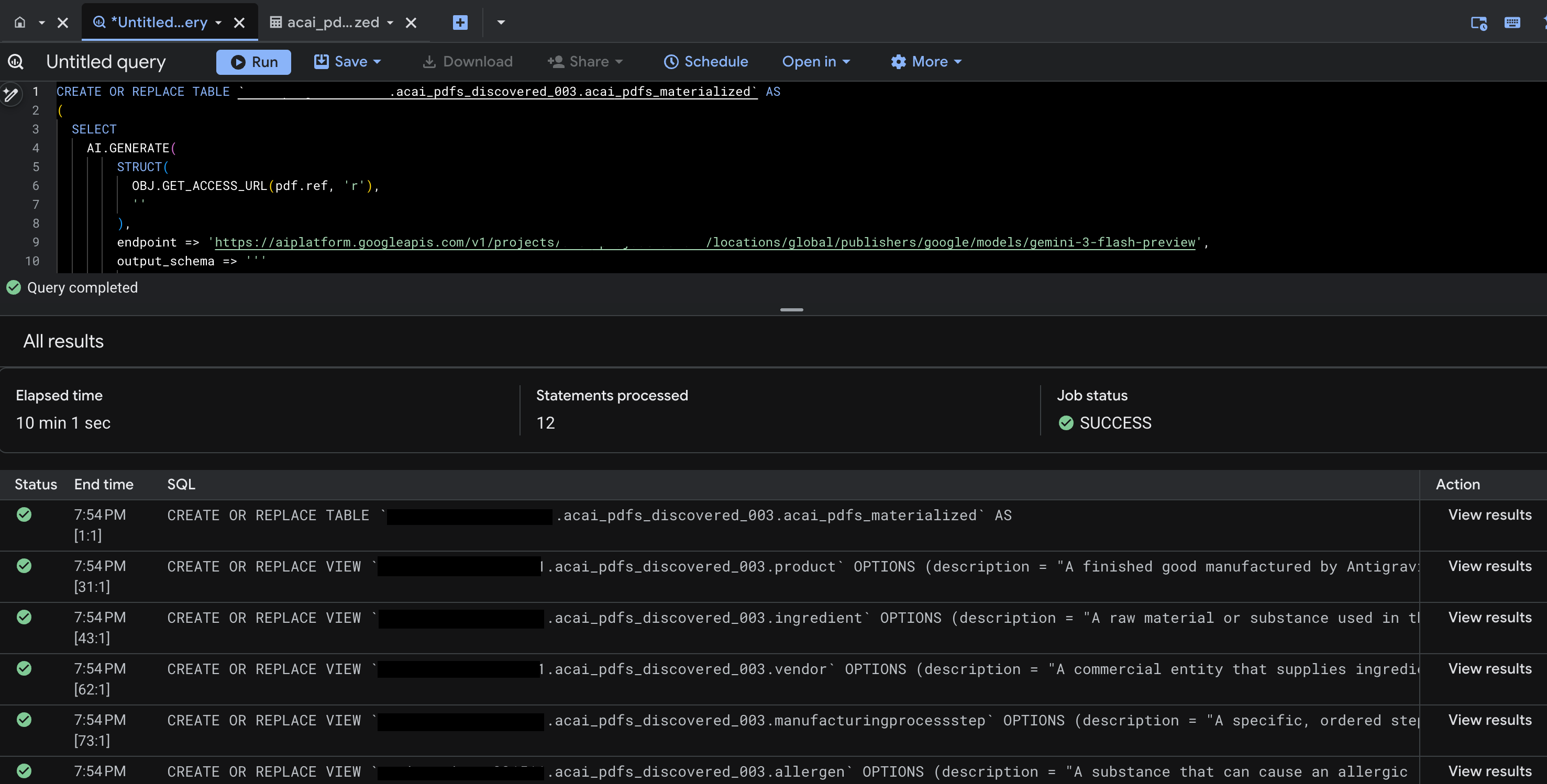
- Clique em Executar. Essa etapa gera um conjunto de instruções e pode levar alguns minutos para ser concluída.
- Quando a consulta for concluída, você vai ver os seguintes resultados:
- Acesse o BigQuery e clique em Conjuntos de dados (por exemplo,
acai_pdfs_discovered_003). Um novo conjunto de objetos de banco de dados estruturados é criado no conjunto de dados selecionado na etapa 6.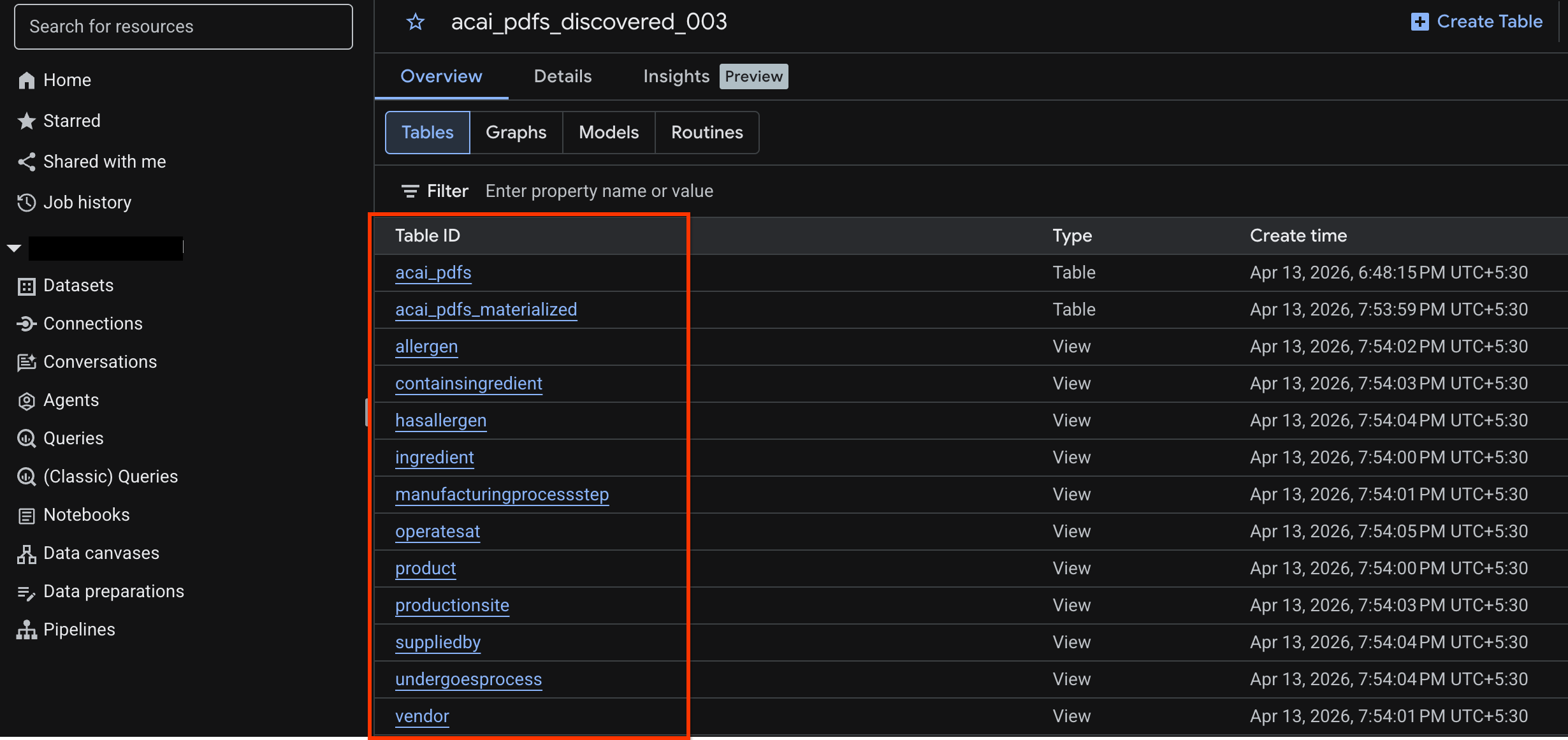
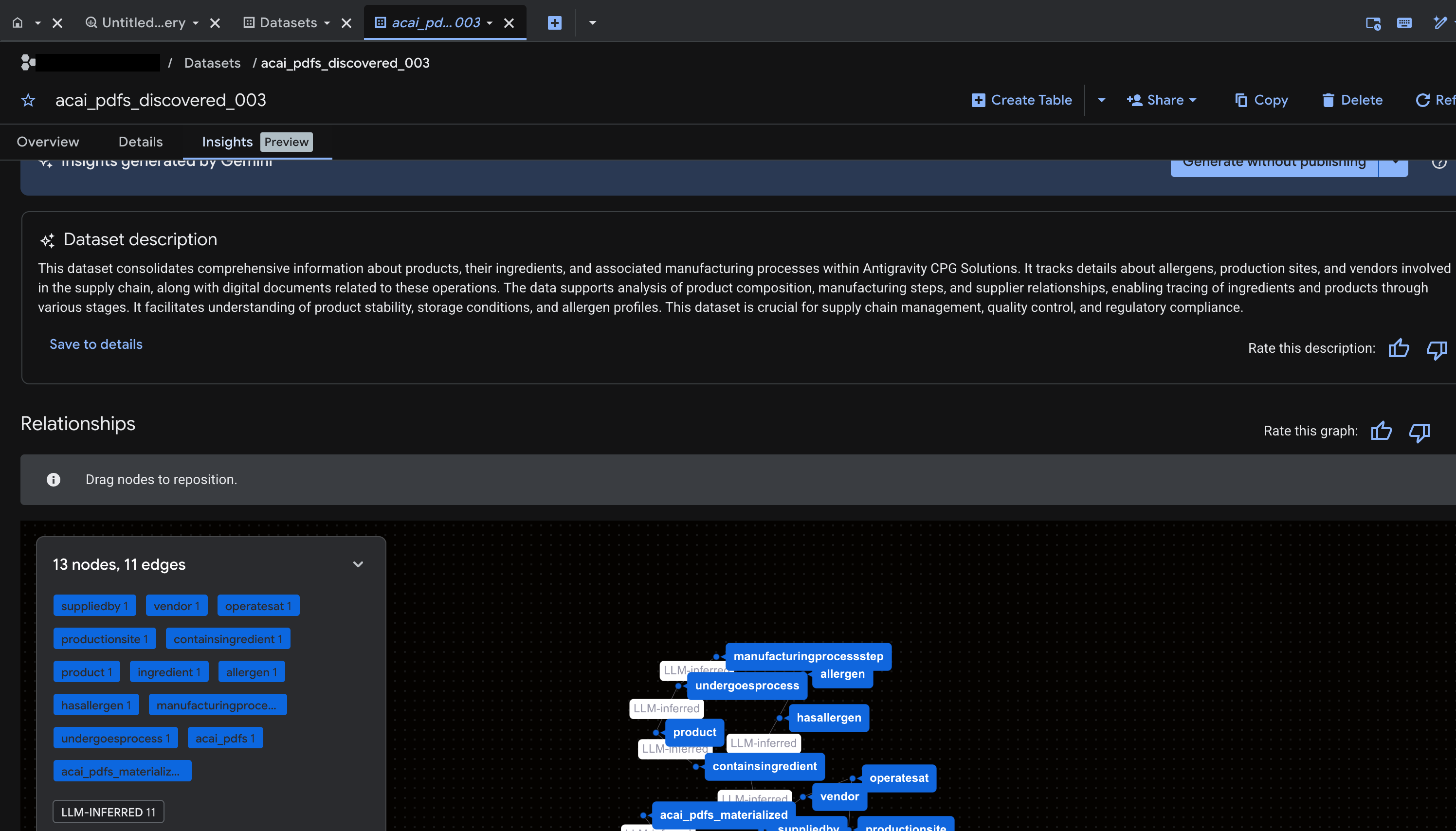
Gerar insights para objetos no BigQuery
Para gerar insights de um conjunto de dados do BigQuery, acesse o conjunto de dados no BigQuery usando o BigQuery Studio.
- No console do Google Cloud, acesse o BigQuery Studio.
- No painel Explorador, selecione o projeto e acesse o conjunto de dados para gerar insights.
- Clique na guia Insights.
- Se o botão Ativar API aparecer, clique nele para ativar o Gemini para Google Cloud. A janela Ativar recursos principais será aberta.
- Na seção APIs de recursos principais, clique em Ativar para API Gemini para Google Cloud e API unificada do BigQuery e clique em Próxima.
- Na seção Permissões (opcional), conceda papéis do IAM aos principais, se necessário, e clique em Próxima.
- Para gerar insights e publicá-los no Knowledge Catalog, clique em Gerar e publicar.
- Depois da publicação, você poderá conferir insights na guia.
11. Configurar o ambiente de desenvolvimento integrado para análise de dados com agentes
A extensão do Google Cloud Data Agent Kit para Visual Studio Code é uma extensão de ambiente de desenvolvimento integrado para cientistas e engenheiros de dados. Ele permite que você se conecte e trabalhe com seus recursos e dados do Google Data Cloud diretamente do ambiente de desenvolvimento integrado. Para mais informações, consulte Visão geral da extensão do Data Agent Kit para VS Code.
A extensão Data Agent Kit para VS Code é útil quando você quer fazer o seguinte:
- Crie, teste, revise e implante um pipeline de dados pronto para produção, como Spark ETL ou BigQuery ETL, diretamente do VS Code.
- Analise dados, crie um pipeline de treinamento, identifique modelos de ML ideais e implante-os em um endpoint de produção usando a assistência de IA.
- Conecte-se a fontes de dados confiáveis, crie um modelo de dados de alta performance e publique um painel interativo para as partes interessadas da empresa.
Instalar a extensão do Data Agent Kit para VS Code
- Abra o VS Code.
- Instale a Google Cloud CLI. Para mais informações, consulte Instalar a CLI do Google Cloud.
- Instale a extensão do Data Agent Kit para VS Code.
- Conclua o processo de integração da extensão, que exige que você:
- Fazer login na extensão
- Instalar habilidades e servidores MCP
- Atualize ou reinicie a janela depois de concluir a integração. Para mais informações, consulte Configurar e configurar a extensão do Data Agent Kit para VS Code.
- Depois que o IDE for recarregado, clique no ícone Google Data Cloud no painel de navegação, acesse as configurações e verifique se você definiu corretamente o ID do projeto e a região (
us-west1) nas configurações comuns.
Configurar o espaço de trabalho no VS Code
- Abra o VS Code e selecione Arquivo > Abrir pasta > Nova pasta.
- Crie uma pasta chamada
acai_teste clique em Abrir. Agora, o VS Code considera a pasta aberta como um espaço de trabalho. - Na caixa de diálogo Confiança do Workspace, selecione Sim, confio nos autores para ativar todos os recursos no espaço de trabalho.
- Crie uma pasta
.githubno espaço de trabalhoacai_test. - Crie um arquivo
copilot-instructions.mdna pasta.githube insira as seguintes regras nele.## 1. Project Context - **Project ID**: <PROJECT_ID> - **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors. - **Documentation**: Raw PDF documents detailing flavors and ingredients are stored in Google Cloud Storage at `gs://<BUCKET_NAME>`. ## 2. Execution & Data Processing Rules - **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `<BQ_DATASET_NAME>` (referred to as the Knowledge Catalog). - **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the dataset `<DATASET_ID>`. When you are referencing a dataset, ensure you are using it with the project ID (`<PROJECT_ID>`) and namespace prefix `<NAMESPACE_NAME>`. For example, to query order table in this dataset you should use `<PROJECT_ID>.<NAMESPACE>.<DATASET_ID>.orders`. - **CRITICAL RULE - Data Joins between BigQuery dataset and Iceberg dataset**: ANY task requiring a join or integration between the BigQuery datasets `<DATASET_ID>` of the PDF data and the `<DATASET_ID>` of the customer data MUST be executed using **Spark Notebooks**. - **CRITICAL RULE - Notebook Kernel**: Every Spark notebook utilized MUST exclusively be configured to run on the Serverless Session template `iceberg-federation-template` as its kernel. - **CRITICAL RULE - Data Science**: ANY data science, machine learning, or advanced analytical task MUST be performed strictly within **Spark Notebooks** using the aforementioned setup. - Crie outro arquivo
template.yamlno espaço de trabalhoacai_teste insira as seguintes informações nele.labels: client: "vscode" jupyterSession: displayName: "iceberg-federation-template" kernel: "PYTHON" environmentConfig: executionConfig: serviceAccount: "sa-spark-dev1@<PROJECT_ID>.iam.gserviceaccount.com" subnetworkUri: "projects/<PROJECT_ID>/regions/<REGION>/subnetworks/<SUBNET_NAME>" runtimeConfig: version: "2.3" properties: # This enables the secure proxy URL you were looking for dataproc.tier: "premium" spark.dataproc.engine: "lightningEngine" spark.dataproc.lightningEngine.runtime: "native" spark.memory.offHeap.enabled: "true" spark.memory.offHeap.size: "1g" spark.executor.memory: "4g" "dataproc.component.gateway.enabled": "true" "dataproc.jupyter.listen.all.interfaces": "true" "spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" "spark.sql.defaultCatalog": "<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>": "org.apache.iceberg.spark.SparkCatalog" "spark.sql.catalog.<CATALOG_NAME>.type": "rest" "spark.sql.catalog.<CATALOG_NAME>.uri": "<CATALOG_URI_ID>" "spark.sql.catalog.<CATALOG_NAME>.warehouse": "bl://projects/<PROJECT_ID>/catalogs/<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>.rest.auth.type": "org.apache.iceberg.gcp.auth.GoogleAuthManager" - No VS Code, clique em Terminal e execute o comando a seguir para importar o arquivo
template.yamlcomo um modelo de sessão. Esse modelo é usado pelo agente mais tarde para criar uma sessão do Spark.gcloud beta dataproc session-templates import iceberg-federation-template \ --source=template.yaml \ --location=<REGION>REGIONpela sua região.
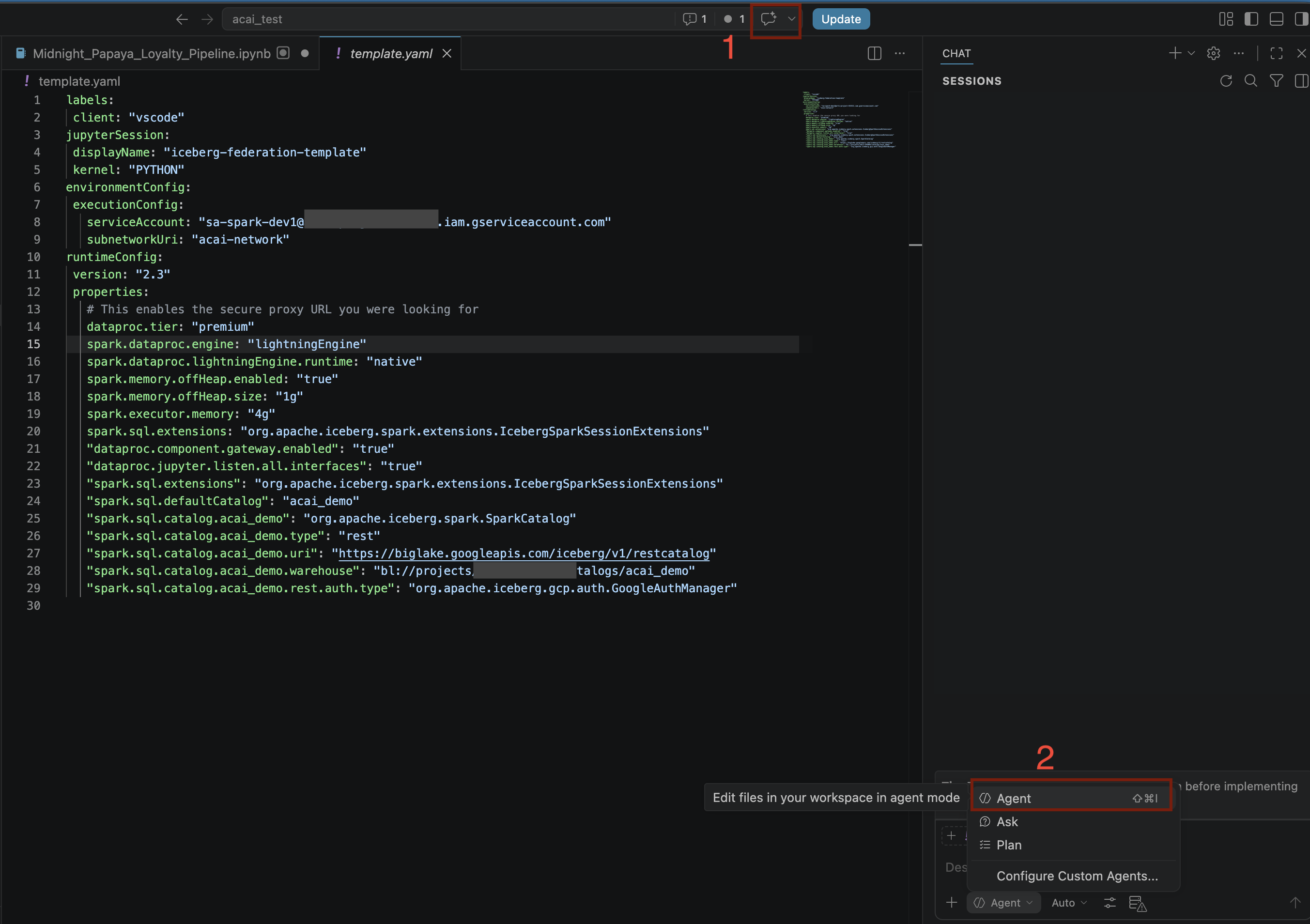
12. Fazer análise de dados com agentes
- No editor de código do VS Code, clique em Alternar chat.
- Em Configurar agentes personalizados, selecione Agente.
- No painel Modelos de pesquisa, clique em Gerenciar modelos de linguagem.
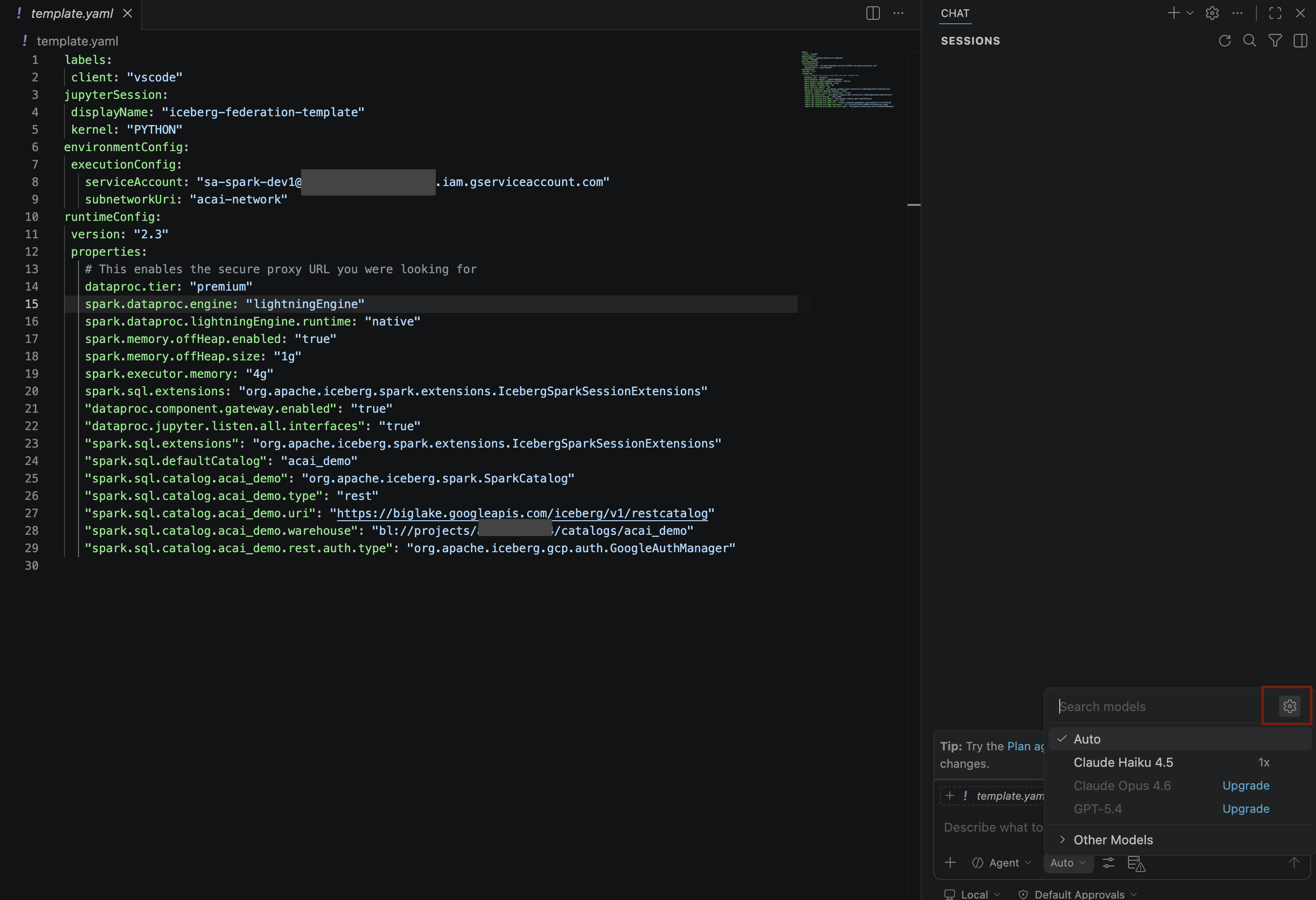
- Na página Modelos de linguagem, clique em Adicionar modelos.
- Selecione Google na lista e pressione Enter para confirmar sua entrada.
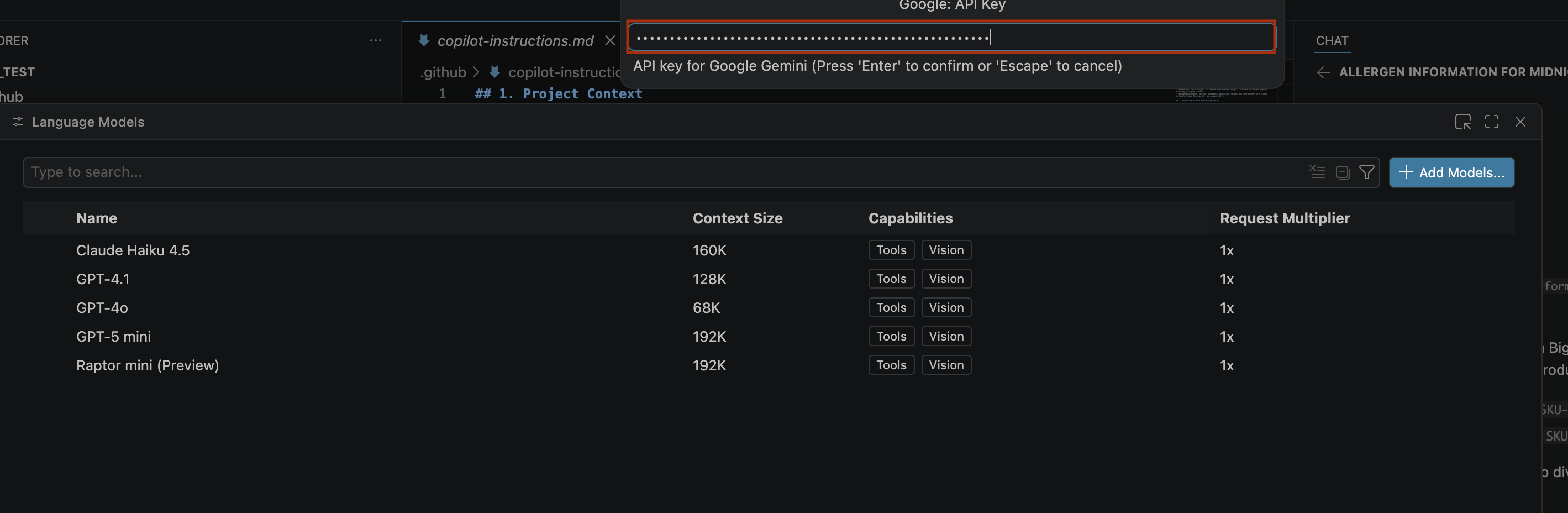
- Para inserir a chave de API do Google Gemini, faça o seguinte:
- Acesse o site do Google AI Studio.
- Faça login com sua Conta do Google.
- Na barra lateral, clique em Receber chave de API.
- Clique em Criar chave de API. A página "Criar uma nova chave" é aberta.
- Na lista Selecionar um projeto na nuvem, escolha Importar projeto.
- Insira o nome de um projeto.
- Clique em Criar chave e copie a chave de API. Ela dá acesso aos recursos da API Gemini da sua conta.Para mais informações, consulte Como usar chaves da API Gemini.
- Cole a chave de API gerada na barra de pesquisa e clique em Enter.
- Se os modelos do Gemini não aparecerem, mostre-os como na imagem a seguir:
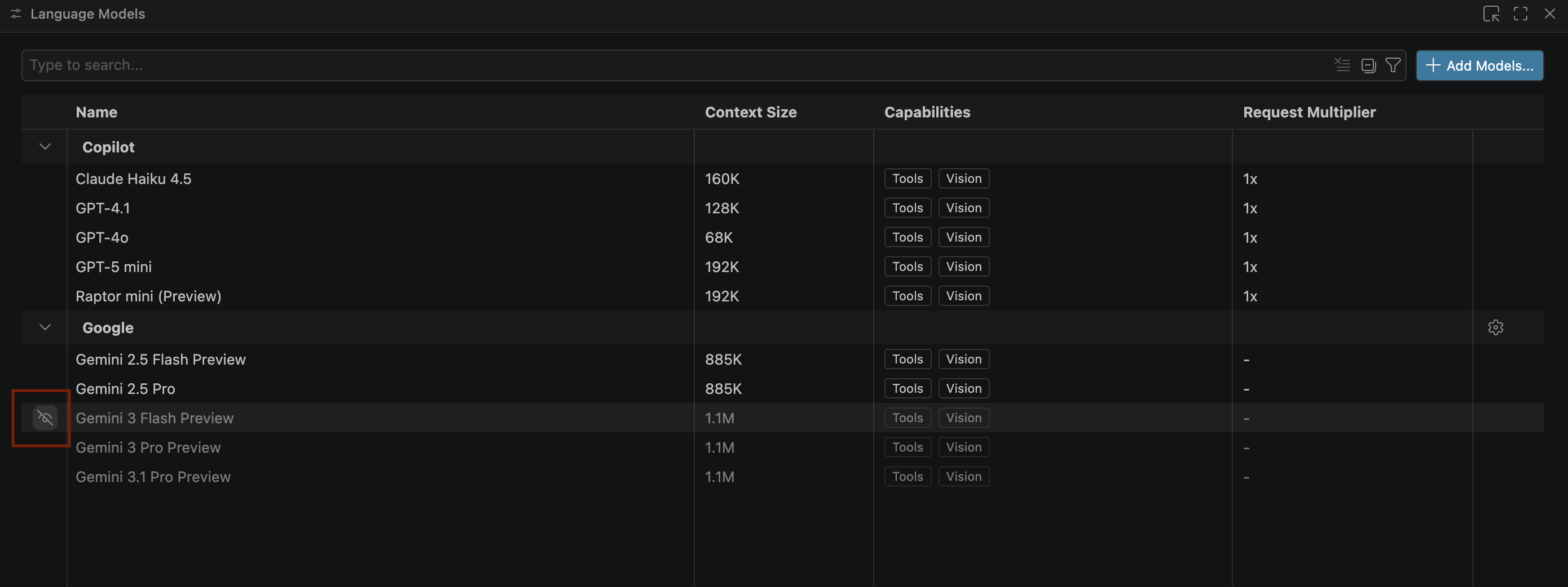
- Selecione Pré-lançamento do Gemini 3.1 Pro na lista de modelos do Google Gemini e feche a janela Modelos de linguagem.
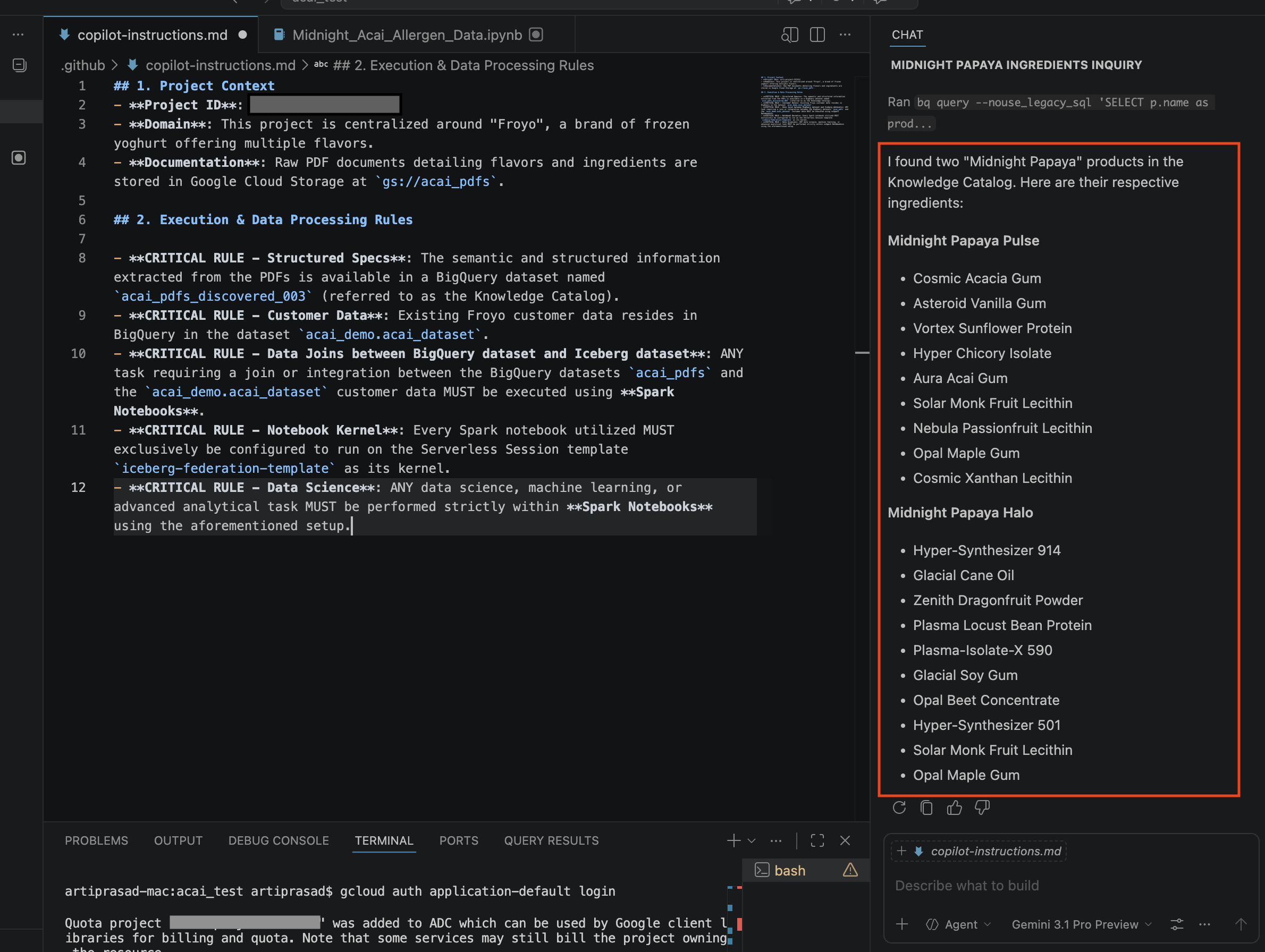
- Na janela de conversa, digite a seguinte pergunta:
Search ingredients for Midnight papaya - Depois de alguma interação, você vai ver o seguinte resultado:
- Na janela de conversa, digite outra pergunta:
Search allergen information for Midnight papaya - Depois de algumas interações e etapas, o agente vai responder com o nome do alérgeno
Soy, como você pode ver na imagem a seguir: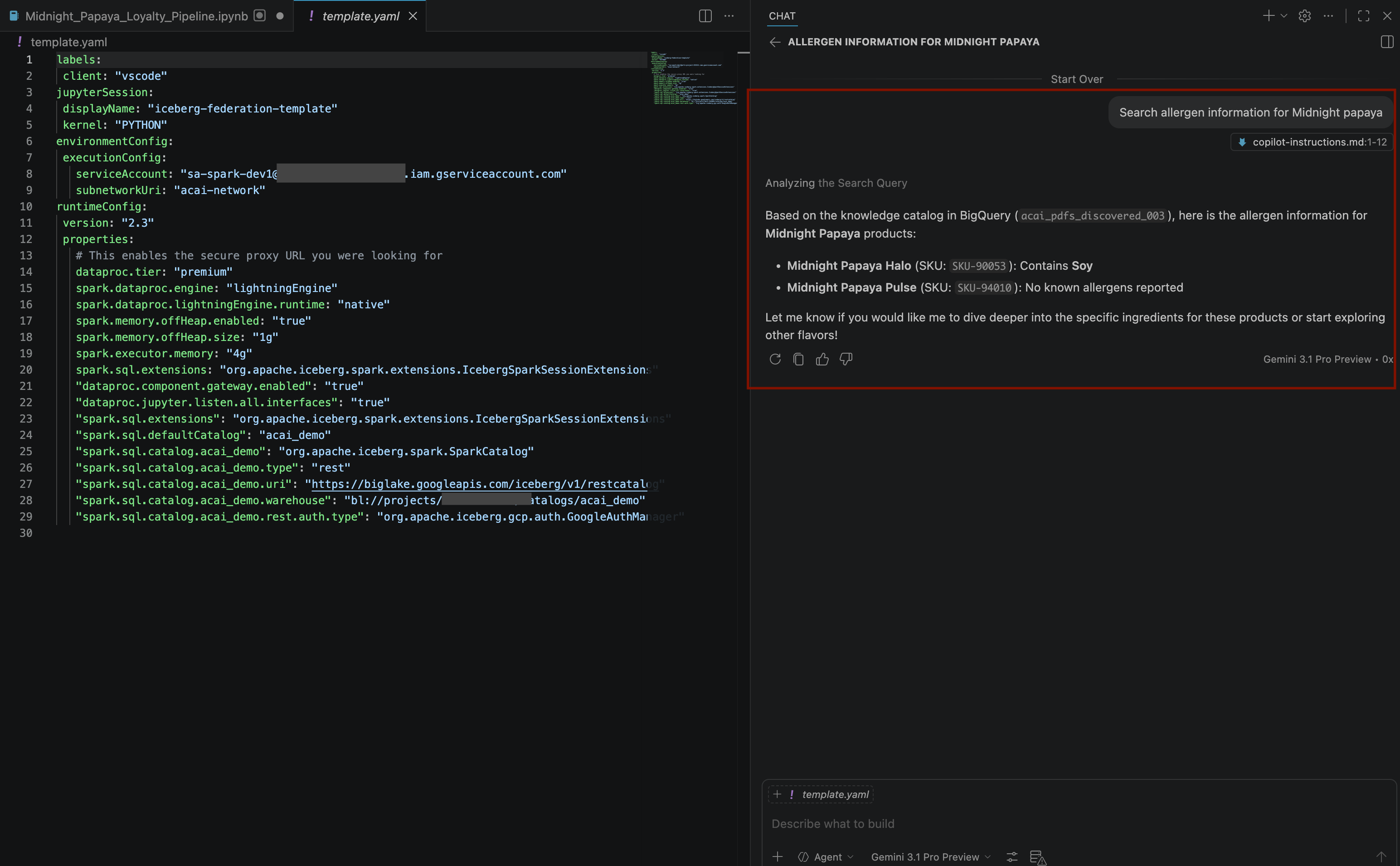
- Na janela de conversa, digite outra pergunta:
Build a pipeline to join products with our 'Global Loyalty' Iceberg tables in acai customer, sales data to identify popular products - Para selecionar o kernel, abra o arquivo
.ipynbe clique em Selecionar kernel > Kernels remotos do Spark > Iceberg-federation-template no Spark sem servidor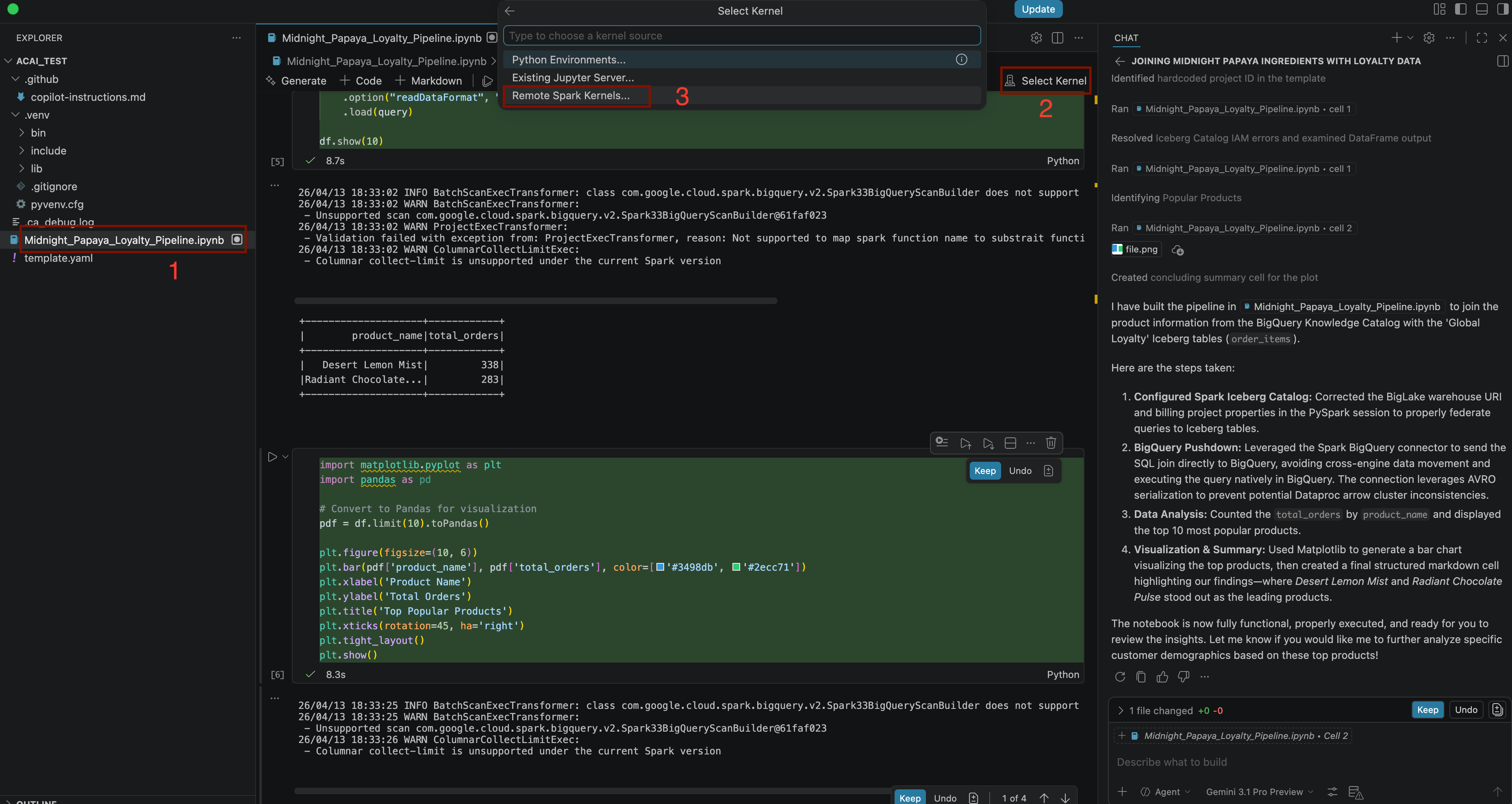
- Depois de algumas interações e etapas, o agente vai responder com todas as etapas do notebook executadas com sucesso, além do resultado final gerado no fim do notebook, como você pode ver na imagem a seguir:
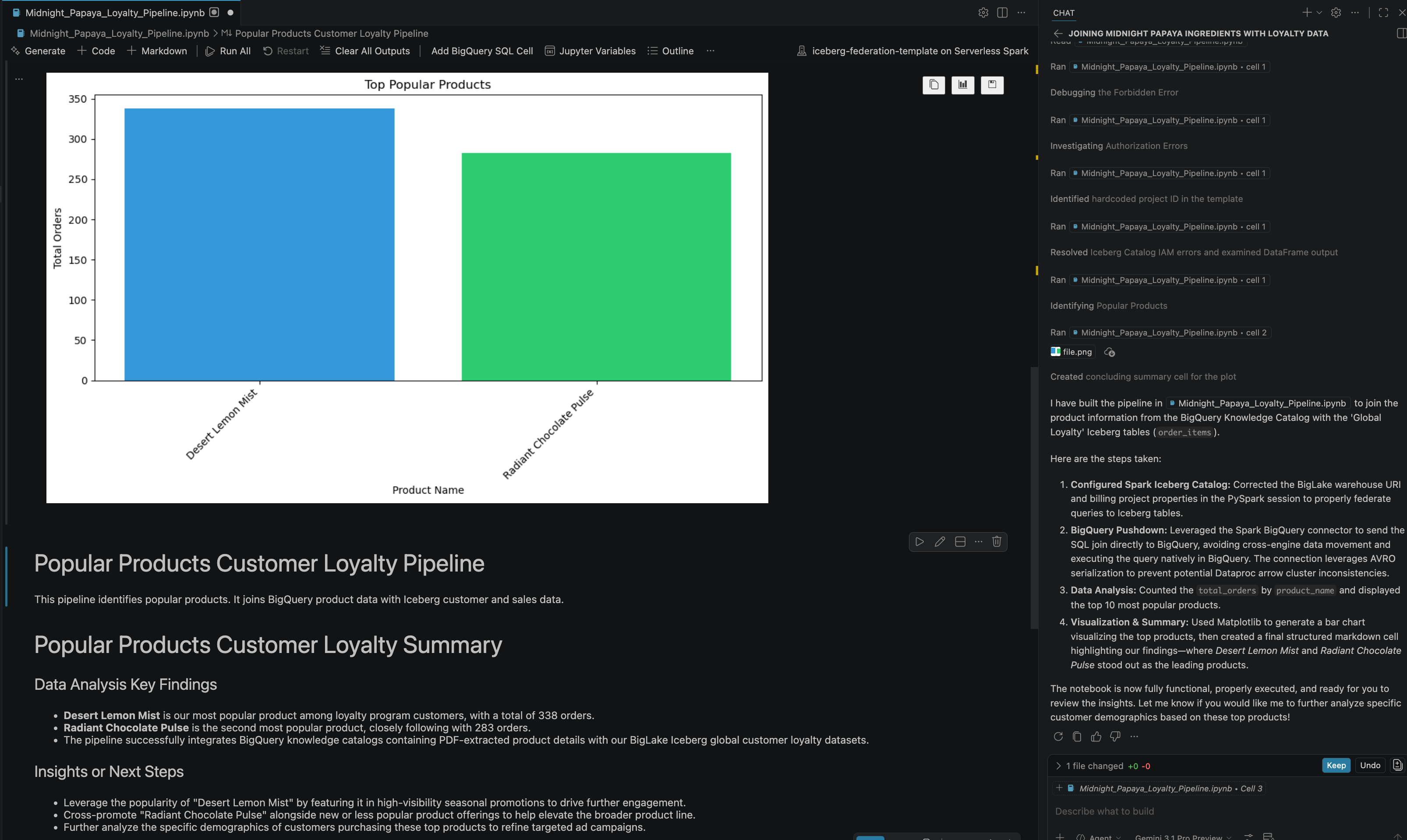
13. Limpar
Para evitar cobranças, exclua os recursos criados neste laboratório.
- Para excluir o DataScan do catálogo de dados do Knowledge Catalog, execute o seguinte comando:
DATASCAN_ID="<DATASCAN_ID>" echo "Deleting Dataplex DataScan: ${DATASCAN_ID}" gcloud dataplex datascans delete "${DATASCAN_ID}" --location="${REGION}" --quiet - Para excluir buckets do Cloud Storage e todo o conteúdo deles, execute o seguinte comando:
echo "Deleting Cloud Storage buckets: <BUCKET_NAME1> and <BUCKET_NAME2>" gsutil -m rm -r gs://<BUCKET_NAME1> gsutil -m rm -r gs://<BUCKET_NAME2> - Para excluir a conexão do BigQuery, execute o seguinte comando:
CONNECTION_ID="<CONNECTION_NAME>" echo "Deleting BigQuery Connection: ${CONNECTION_ID}" bq rm --connection "${PROJECT_ID}.${REGION}.${CONNECTION_ID}" - Para excluir o catálogo do Lakehouse, execute o seguinte comando:
CATALOG_ID="<CATALOG_NAME>" echo "Deleting Lakehouse Catalog: ${CATALOG_ID}" gcloud biglake catalogs delete "${CATALOG_ID}" --project="${PROJECT_ID}" --location="${REGION}" --quiet - Para excluir o conjunto de dados que contém as tabelas de PDF descobertas, execute o seguinte comando:
DATASET_NAME="<DATASET_NAME>" echo "Deleting BigQuery Dataset: ${DATASET_NAME}" bq rm -r -f "${PROJECT_ID}:${DATASET_NAME}" - Para excluir a conta de serviço personalizada, execute o seguinte comando:
SERVICE_ACCOUNT="<SERVICE_ACCOUNT>" echo "Deleting Service Account: ${SERVICE_ACCOUNT}" gcloud iam service-accounts delete "${SERVICE_ACCOUNT}"@"${PROJECT_ID}".iam.gserviceaccount.com --quiet - Para excluir a rede VPC, execute o seguinte comando:
VPC_NETWORK="<VPC_NETWORK>" echo "Deleting VPC Network: ${VPC_NETWORK}" gcloud compute networks delete "${VPC_NETWORK}" --quiet - Para excluir todo o projeto do Google Cloud, execute o seguinte comando:
gcloud projects delete "${PROJECT_ID}"
14. Parabéns
Parabéns! Você organizou o cenário de dados de PDFs e arquivos Parquet isolados em tabelas do BigQuery e o reduziu a um único ecossistema pesquisável e combinável. Você criou um data lakehouse moderno que trata PDFs e formatos de Big Data com a mesma inteligência que trata uma linha em um banco de dados. E você fez tudo isso direto do seu agente em uma experiência de conversa com o Gemini.
Documentos de referência
Para saber mais sobre as principais tecnologias usadas neste codelab, acesse a documentação oficial do Google Cloud:
- Para conhecer o BigQuery, um componente principal da Data Cloud, consulte a documentação do BigQuery.
- Para saber mais sobre o IAM, consulte a documentação do IAM.
- Para saber mais sobre o Lakehouse, consulte O que é o Lakehouse?