
1. Введение
В этом практическом занятии вы примерите на себя роль специалиста по анализу данных в вымышленной компании по производству замороженного йогурта, запускающей новый вкус продукта — «Полуночный вихрь». Для обеспечения успешного глобального запуска компания должна ответить на важные вопросы, касающиеся ингредиентов, рыночного спроса и рентабельности инвестиций (ROI). Этот комплексный рабочий процесс демонстрирует, как каталог знаний Google Cloud (ранее известный как Dataplex) и Lakehouse для Apache Iceberg (ранее известный как BigLake) преодолевают разрыв между «темными» неструктурированными данными и предоставляют полезную бизнес-аналитику с помощью Gemini в вашей IDE (VS Code) через единый уровень управления.
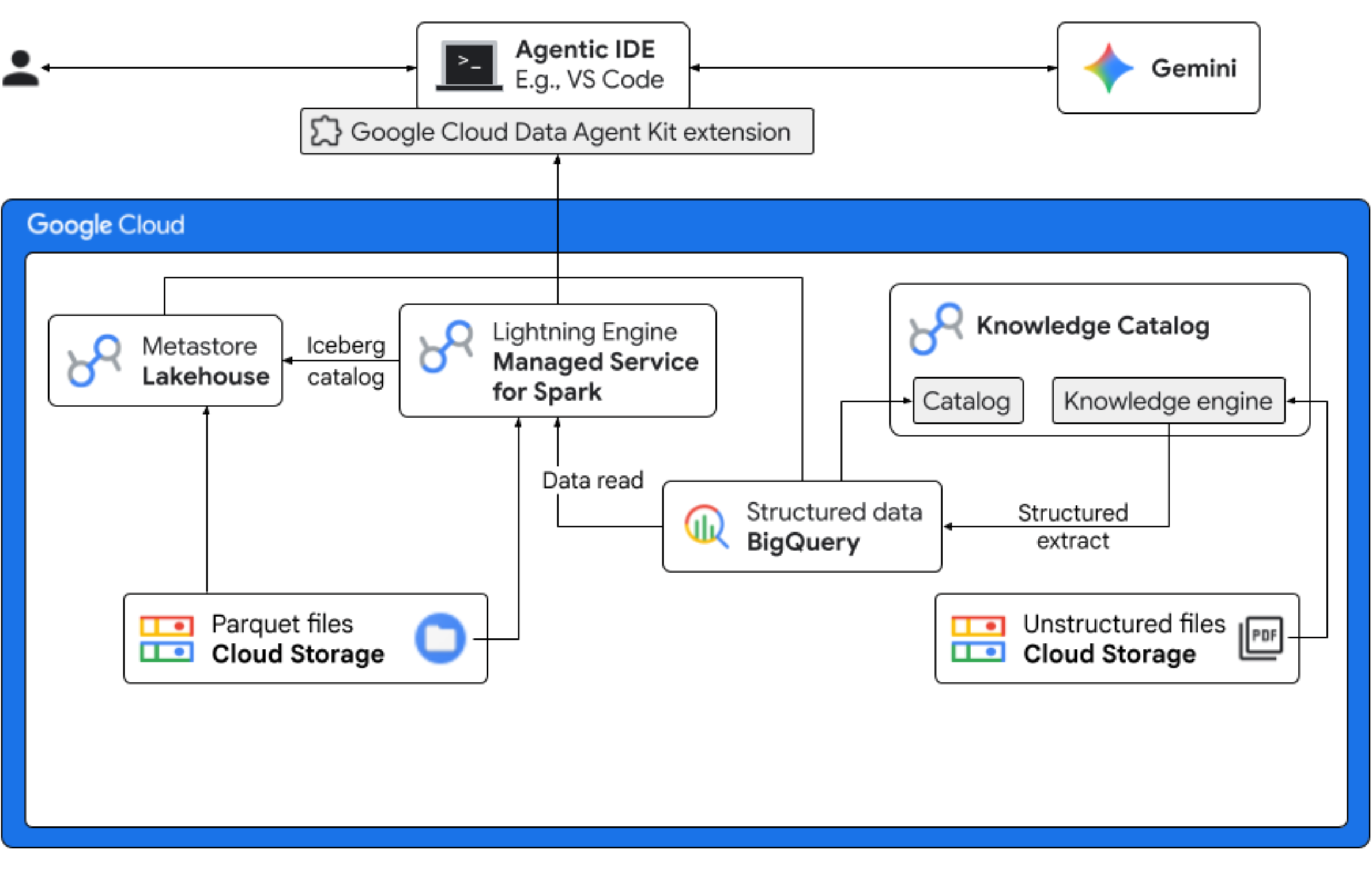
Что вы будете делать
- Поиск неструктурированной информации : PDF-рецепты, хранящиеся в облачном хранилище, обрабатываются системой Knowledge Catalog DataScan. Для отсканированных PDF-файлов создаются объектные таблицы в BigQuery. Используя семантический вывод Vertex AI, система «читает» PDF-файлы, извлекая структурированную информацию о продуктах, аллергенах, ингредиентах и связанных атрибутах. Затем она интеллектуально генерирует схему для данных, хранящихся в PDF-файлах.
- Унифицированные метаданные : извлеченные из PDF-файлов данные сохраняются непосредственно в BigQuery в виде собственной широкой таблицы, и создаются представления для упрощения стандартных запросов. Независимый входной набор данных, содержащий исторические данные о продажах, хранится в Apache Iceberg Tables в Google Cloud Storage. Эта таблица Iceberg будет объединена с извлеченными данными в BigQuery на последующем этапе.
- Кросс-движковая аналитика : Используя управляемый сервис для Apache Spark (ранее известный как Dataproc) с REST-каталогом Iceberg, вы объедините эти свежие метаданные PDF-файлов и полученные структурированные семантические данные (из таблиц и представлений BigQuery) со структурированными данными о продажах, хранящимися в таблицах Apache Iceberg в Google Cloud Storage. Это управляется интерактивным шаблоном сеанса управляемого Apache Spark, используемым в качестве ядра Jupyter Notebook, который обеспечивает согласованные настройки безопасности и вычислительных ресурсов для задания Spark.
- Семантические выводы : Объединяя полученные данные о продуктах с данными о клиентах и продажах (в BigQuery), демонстрационная версия позволяет извлекать такие аналитические данные, как информация об аллергенах и прогноз доходов.
- Автономное управление : весь жизненный цикл — от сканирования для обнаружения до выполнения Spark — координируется с помощью готовых к использованию в Gemini шаблонов, инструкций, правил и автоматизации на основе агентов, что доказывает способность ИИ управлять инфраструктурой, обеспечивающей работу аналитики.
Что вам понадобится
Выполнение этого практического задания может повлечь за собой расходы, которые, по оценкам, составят менее 5 долларов при типичном использовании. Для получения подробных оценок стоимости, основанных на вашем предполагаемом использовании или текущих ценах, воспользуйтесь калькулятором цен Google Cloud .
Убедитесь, что у вас есть следующие необходимые условия для выполнения практического задания.
- Веб-браузер Chrome .
- Если вы используете пробные кредиты, предоставленные в разделе «Перед началом работы», вам потребуется личный аккаунт Gmail.
- Загрузите и установите Visual Studio (VS) Code .
2. Прежде чем начать
Создайте проект в Google Cloud.
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud .
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
Запустить Cloud Shell
Cloud Shell — это среда командной строки, работающая в Google Cloud и поставляемая с предустановленными необходимыми инструментами.
- В верхней части консоли Google Cloud нажмите кнопку «Активировать Cloud Shell» .
- После подключения к Cloud Shell подтвердите свою аутентификацию:
gcloud auth list - Убедитесь, что ваш проект настроен:
gcloud config get project - Если параметры вашего проекта заданы не так, как ожидалось, настройте их следующим образом:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Включите необходимые API.
Выполните эту команду, чтобы включить все необходимые API:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
biglake.googleapis.com \
dataproc.googleapis.com \
metastore.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
secretmanager.googleapis.com \
storage.googleapis.com
Скачать материалы для CodeLab
В этом репозитории содержатся файлы Parquet, recipes, suppliers, copilot-instructions.md, template.yaml и quickstart.py, предназначенные для использования в этом практическом занятии. Обязательно скачайте эти файлы.
Для загрузки файлов выполните следующие действия:
- В оболочке Cloud Shell выполните следующую команду:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git - Перейдите в только что созданную папку:
cd next-26-keynotes - Загрузите папку
data-cloud-demogit sparse-checkout set genkey/data-cloud-demo - После завершения оформления заказа перейдите в папку
data-cloud-demoи распакуйте ZIP-файлы, чтобы получить доступ к ресурсам Codelab.
3. Настройка Lakehouse для работы с данными клиентов Froyo.
В этом разделе вы создадите каталог в Lakehouse для использования метаданных Lakehouse в ваших рабочих процессах. Это обеспечит совместимость между вашими механизмами запросов, предоставляя единый источник достоверной информации для всех ваших данных Iceberg. Это позволит механизмам запросов, таким как Apache Spark, обнаруживать, считывать метаданные и управлять таблицами Iceberg согласованным образом.
Требуемые роли
Убедитесь, что у вас есть следующие роли управления идентификацией и доступом (IAM):
-
roles/biglake.viewer -
roles/bigquery.user -
roles/bigquery.dataEditor -
roles/biglake.editor -
roles/biglake.metadataViewer -
roles/bigquery.connectionUser -
roles/storage.objectUser -
roles/storage.objectViewer -
roles/storage.objectCreator -
roles/storage.admin
Для получения дополнительной информации о предоставлении ролей IAM см. раздел «Предоставление роли IAM» .
Создайте каталог Lakehouse с помощью корзины.
Создайте каталог Lakehouse для управления метаданными для ваших таблиц Iceberg. Вы подключаетесь к этому каталогу в своем задании Spark для создания и выполнения запросов к таблицам Iceberg.
- В консоли Google Cloud перейдите в раздел Lakehouse .
- Нажмите «Создать каталог» . Откроется страница «Создать каталог» .
- В поле «Тип каталога» выберите каталог Iceberg Rest .
- В разделе «Выберите варианты ведер из каталога Lakehouse» выберите «Каталог с одним ведром» .
- Для выбора корзины Cloud Storage по умолчанию нажмите кнопку «Обзор» , а затем кнопку «Создать новую корзину» .
- На странице «Создать корзину» выполните следующие действия:
- В разделе «Начало работы» введите глобально уникальное имя, соответствующее требованиям к имени хранилища .
- В разделе «Выберите место для хранения данных» выберите «Регион» в качестве типа местоположения и введите свой регион. Например,
us-west1. - В разделе «Выберите способ управления доступом к объектам» снимите флажок « Применять публичную защиту доступа к этому сегменту» .
Это позволяет моделировать реальные сценарии, такие как размещение общедоступного веб-контента или общих хранилищ данных. Без этого изменения хранилище будет применять строгую политику «только для частного доступа»; любая попытка доступа к вашим ресурсам приведет к ошибке403Forbidden, даже если вы успешно предоставили публичные права доступа к файлам. - Нажмите «Продолжить» > «Создать» > «Выбрать» > «Продолжить» .
- В качестве метода аутентификации выберите режим предоставления учетных данных .
- Нажмите «Создать» . Ваш каталог будет создан, и откроется страница с подробными сведениями о каталоге .
- В разделе «Метод аутентификации» нажмите «Установить разрешения для корзины» .
- В диалоговом окне нажмите «Подтвердить ». Это подтвердит, что учетная запись службы вашего каталога имеет роль «
Storage Object Userв вашем сегменте хранилища. - На странице сведений о каталоге скопируйте путь REST-каталога. Используйте этот путь при выполнении задачи «Запуск задания Spark».
Загрузите файлы Parquet в хранилище.
Чтобы загрузить файлы Parquet в корневой каталог вашего хранилища, выполните следующие действия:
- В консоли Google Cloud перейдите на страницу «Корзины облачного хранилища» .
- В списке корзин щелкните по названию корзины. Например,
acai_demo. - На вкладке «Объекты» для корзины нажмите «Загрузить» > «Загрузить файлы» .
- Выберите файлы из папки Parquet, которую вы клонировали в разделе «Перед началом работы » этого практического задания.
- Нажмите «Открыть» .
4. Настройка сети VPC
Создайте виртуальную частную сеть (VPC) и подсеть, которые позволят ресурсам взаимодействовать с API Google без выхода в общедоступный интернет, а также межсетевой экран, который обеспечит беспрепятственный поток внутреннего трафика между узлами обработки данных.
- В консоли Google Cloud перейдите на страницу сетей VPC .
- Нажмите «Создать сеть VPC» .
- Введите название для сети. Например,
acai-network. - Для настройки максимального размера передаваемого блока (MTU) сети установите флажок «Установить MTU автоматически» .
- Для режима создания подсети выберите «Автоматический» .
- В разделе «Правила брандмауэра» установите флажки напротив всех правил брандмауэра IPv4.
- Нажмите «Создать» .
Включить приватный доступ Google
Узлы Dataproc Serverless не имеют публичных IP-адресов. Для взаимодействия с каталогом Lakehouse и облачным хранилищем необходимо включить частный доступ Google в подсети.
- В консоли Google Cloud перейдите на страницу сетей VPC .
- Щелкните по названию сети, содержащей подсеть, для которой необходимо включить частный доступ Google. Например,
us-west1. - Щелкните по названию подсети. Отобразится страница с подробными сведениями о подсети .
- Нажмите «Редактировать» .
- В разделе «Частный доступ Google» выберите «Включено» .
- Нажмите « Сохранить ».
5. Создайте и запустите задание Spark.
Для создания и выполнения запросов к таблице Iceberg загрузите задание PySpark с необходимыми SQL-запросами Spark. Затем запустите задание с помощью Managed Service for Spark.
Загрузите файл quickstart.py в свой облачный накопитель (Cloud Storage).
После клонирования ресурсов codelab обновите скрипт quickstart.py , указав данные вашего проекта, и загрузите его в хранилище Cloud Storage.
- Откройте скрипт
quickstart.pyв текстовом редакторе. - Замените в скрипте заполнитель
BUCKET_NAMEна имя вашего сегмента Cloud Storage и сохраните изменения. - В консоли Google Cloud перейдите в раздел «Корзины Cloud Storage» .
- Щелкните по названию вашего бакета. Например,
acai_demo. - На вкладке «Объекты» нажмите «Загрузить» > «Загрузить файлы» .
- В файловом браузере выберите обновленный файл
quickstart.pyи нажмите « Открыть» .
Запустите задание Spark
После загрузки скрипта quickstart.py запустите его как управляемую службу для пакетного задания Spark.
- Для настройки переменных выполните следующую команду в Cloud Shell.
# Configuration Variables export PROJECT_ID="<PROJECT_ID>" export REGION="<REGION>" export BUCKET_NAME="<BUCKET_NAME>" export SUBNET="<SUBNET>" export LAKEHOUSE_CATALOG_ID="<LAKEHOUSE_CATALOG_ID>" export CATALOG_URI_ID="<CATALOG_URI_ID>"- LAKEHOUSE_CATALOG_ID : имя ресурса каталога Lakehouse, содержащего файл вашего приложения PySpark. Например,
acai_demo - PROJECT_ID : идентификатор вашего проекта в Google Cloud.
- РЕГИОН : регион, в котором будет запускаться пакетная рабочая нагрузка Managed Service for Spark. Например,
us-west1. - BUCKET_NAME : имя вашего сегмента Cloud Storage. Например,
acai_demo. - ПОДСЕТЬ : имя вашей подсети VPC. Например,
acai-network. - CATALOG_URI_ID : URI-идентификатор каталога Lakehouse, который вы скопировали при создании каталога Lakehouse с использованием хранилища данных. Например,
https://biglake.googleapis.com/iceberg/v1/restcatalog.
- LAKEHOUSE_CATALOG_ID : имя ресурса каталога Lakehouse, содержащего файл вашего приложения PySpark. Например,
- В Cloud Shell запустите следующее пакетное задание Managed Service for Spark, используя скрипт
quickstart.py.gcloud dataproc batches submit pyspark gs://${BUCKET_NAME}/quickstart.py \ --project=${PROJECT_ID} \ --region=${REGION} \ --subnet=${SUBNET} \ --version=2.2 \ --properties="\ spark.sql.defaultCatalog=${LAKEHOUSE_CATALOG_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}=org.apache.iceberg.spark.SparkCatalog,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.type=rest,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.uri=${CATALOG_URI_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.warehouse=gs://${BUCKET_NAME},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.io-impl=org.apache.iceberg.gcp.gcs.GCSFileIO,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.x-goog-user-project=${PROJECT_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\ spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest-metrics-reporting-enabled=false,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.X-Iceberg-Access-Delegation=vended-credentials,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token"All tables registered successfully! Batch [126fa2226a904d2e944c8eecbe0b1840] finished. metadata: '@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata batch: projects/PROJECT_ID/locations/REGION/batches/126fa2226a904d2e944c8eecbe0b1840 batchUuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff createTime: '2026-04-09T13:17:26.222727Z' description: Batch labels: goog-dataproc-batch-id: 126fa2226a904d2e944c8eecbe0b1840 goog-dataproc-batch-uuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-drz-resource-uuid: batch-3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-location: REGION operationType: BATCH name: projects/PROJECT_ID/regions/REGION/operations/47bc59e8-5082-3af9-89a0-22289aa5f4b9
6. Выполните запрос к таблице из BigQuery.
Успешно запустив пакетное задание Spark, вы использовали Managed Service for Spark Serverless в качестве распределенного вычислительного механизма для регистрации нескольких таблиц, по одной на каждый файл Parquet, в хранилище метаданных Lakehouse. Эта регистрация позволяет Google Cloud обрабатывать ваши необработанные файлы в Cloud Storage как структурированные высокопроизводительные таблицы.
Следующие шаги помогут вам убедиться в правильной синхронизации метаданных, гарантируя, что ваши данные не только безопасно хранятся, но и полностью доступны для поиска и выполнения запросов через интерфейс BigQuery.
- В консоли Google Cloud перейдите в раздел BigQuery .
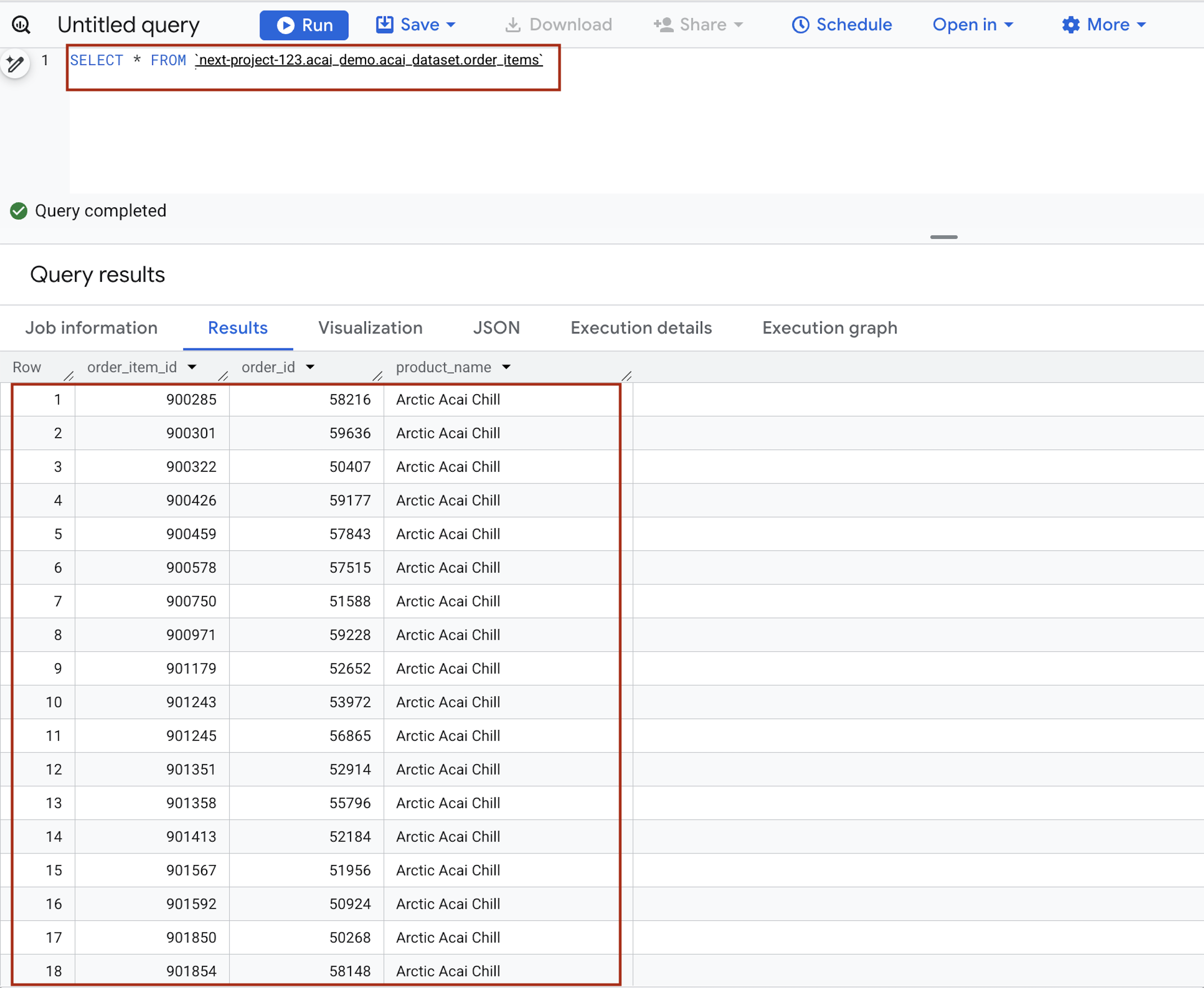
- В редакторе запросов введите следующее выражение. Запрос использует синтаксис
project.namespace.dataset.table.SELECT * FROM `<PROJECT_ID>.<NAMESPACE>.<ICEBERG_DATASET>.<ICEBERG_TABLE>`PROJECT_ID.acai_demo.acai_dataset.order_items.
Замените следующее:- PROJECT_ID : идентификатор вашего проекта в Google Cloud.
- ПРОСТРАНСТВО ИМЕН : пространство имен, созданное на предыдущем шаге в результате выполнения задания Spark, которое можно найти на странице обозревателя объектов BigQuery. Например,
acai_demo. - ICEBERG_DATASET : имя набора данных в каталоге Iceberg, например,
acai_dataset. - ICEBERG_TABLE : имя таблицы в наборе данных Iceberg, например,
order_items.
- Нажмите кнопку «Выполнить» . В результатах запроса отобразятся данные, которые вы вставили с помощью задания Spark.
7. Создайте неструктурированные файлы данных о продукции.
В этом разделе вы создаете организационную структуру в BigQuery для хранения данных о рецептах и поставщиках замороженного йогурта, в частности, подробной информации о продукте. Также устанавливается соединение с облачным ресурсом, которое выступает в качестве защищенного «моста», позволяющего BigQuery считывать файлы из внешних источников, таких как облачное хранилище.
Создайте бакет и загрузите файлы с подробными данными о Froyo.
Создайте и загрузите файлы поставщика и рецепта в хранилище Cloud Storage.
- В консоли Google Cloud перейдите на страницу «Корзины облачного хранилища» .
- Нажмите «Создать» .
- На странице «Создать корзину» введите информацию о вашей корзине. После каждого из следующих шагов нажимайте «Продолжить» , чтобы перейти к следующему шагу:
- В разделе «Начало работы » введите имя хранилища. Например,
acai_pdfs. - В разделе «Выберите место для хранения данных» выберите «Регион» , а затем введите свой регион. Например,
us-west1. - В разделе «Выберите способ управления доступом к объектам» снимите флажок « Применять публичную защиту доступа к этому сегменту» .
- Нажмите «Создать» .
- В списке категорий щелкните по созданной вами категории. Например,
acai_pdfs. - На вкладке «Объекты» для корзины нажмите «Загрузить» > «Загрузить папки» .
- Выберите папку
recipes, которую вы распаковали в разделе « Перед началом работы » этого практического задания. - Нажмите «Загрузить» .
- Повторите процесс загрузки для папки
suppliers.
Создать соединение
Создайте подключение к облачным ресурсам. Это создаст уникальную учетную запись службы, которая будет выступать в качестве «идентификационной карты» BigQuery для доступа к внешним файлам.
- Перейдите на страницу BigQuery .
- В левой панели щелкните «Проводник» . Если левая панель не отображается, щелкните «Развернуть левую панель» , чтобы открыть ее.
- В панели «Проводник» разверните название проекта, а затем щелкните «Подключения» .
- На странице «Подключения» нажмите «Создать подключение» .
- В поле «Тип подключения» выберите модели удаленного доступа Vertex AI, функции удаленного доступа, BigLake и Spanner (облачный ресурс) .
- В поле «Идентификатор подключения» введите имя идентификатора подключения. Например,
acai_pdf_connection. Обязательно запишите этот идентификатор, так как он понадобится вам при настройке сканирования данных позже в этом практическом задании. - Установите тип местоположения на «Регион» , а затем выберите регион. Например,
us-west1. Соединение должно быть размещено совместно с другими вашими ресурсами, такими как наборы данных. - Нажмите «Создать соединение» .
- Нажмите « Перейти к подключению» .
- В панели информации о подключении скопируйте идентификатор учетной записи службы для использования на следующем шаге. Учетная запись службы выглядит примерно так:
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com.
Управление доступом к служебным учетным записям
Предоставьте доступ к учетной записи службы, чтобы Lakehouse мог читать ваши PDF-файлы.
- Перейдите на страницу IAM и администрирования .
- Нажмите «Предоставить доступ» . Откроется диалоговое окно «Добавить субъектов».
- В поле «Новые участники» введите идентификатор учетной записи службы, который вы скопировали ранее.
- В поле «Выберите роль» добавьте следующие роли:
-
roles/storage.objectUser -
roles/storage.objectViewer -
roles/bigquery.user -
roles/bigquery.dataEditor -
roles/aiplatform.user -
roles/storage.admin -
roles/dataproc.serviceAgent
-
- Нажмите « Сохранить ».
Для получения дополнительной информации о ролях IAM в BigQuery см. раздел «Предопределенные роли и разрешения» .
8. Управление правами доступа для задания DataScan.
Создайте отдельные учетные записи служб (идентификаторы) для Spark и Dataform, а затем предоставьте им — вместе с автоматизированными агентами служб Google — необходимые разрешения для чтения хранилища, запуска заданий BigQuery и использования Vertex AI для обнаружения.
Доступ IAM для Spark и Dataform
- В консоли Google Cloud перейдите на страницу создания учетной записи службы .
- Если ваш проект в Google Cloud не выбран, выберите его.
- Нажмите «Создать учетную запись службы» .
- Введите имя учетной записи службы. Например,
sa-spark-stg1. Консоль Google Cloud сгенерирует идентификатор учетной записи службы на основе этого имени. При необходимости отредактируйте идентификатор. Изменить идентификатор позже будет невозможно. - Чтобы настроить права доступа, нажмите «Создать и продолжить» и перейдите к следующему шагу.
- Выберите следующие роли IAM для предоставления учетной записи службы в проекте.
-
roles/dataproc.worker -
roles/storage.objectUser -
roles/bigquery.dataEditor -
roles/bigquery.jobUser -
roles/aiplatform.user -
roles/dataplex.discoveryPublishingServiceAgent
-
- После добавления всех ролей нажмите «Продолжить» .
- Нажмите «Готово» , чтобы завершить создание учетной записи службы.
Права доступа к каталогу знаний через подключение к BigQuery
- В консоли Google Cloud перейдите на страницу «Корзины облачного хранилища» .
- В списке корзин щелкните по названию корзины, которую вы создали для Froyo. Например,
acai_pdfs. - На вкладке «Разрешения» нажмите «Предоставить доступ» . Откроется диалоговое окно «Добавить субъектов».
- В поле «Новые участники» введите идентификатор вашей учетной записи службы BigQuery. Учетная запись службы будет выглядеть примерно так:
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com. - Выберите следующую роль (или роли) из выпадающего меню «Выберите роль» .
-
roles/storage.objectUser -
roles/dataplex.serviceAgent -
roles/dataplex.securityAdmin -
roles/aiplatform.serviceAgent -
roles/dataplex.discoveryPublishingServiceAgent
-
- Нажмите «Сохранить».
9. Создайте каталог знаний.
Создайте каталог знаний, чтобы объединить ваши данные, связанные с Froyo, и автоматизировать поиск неструктурированных файлов (таких как PDF-рецепты и поставщики PDF-файлов).
Создайте DataScan с помощью curl
В этом разделе вы создаете запросы на сканирование для вашего хранилища Cloud Storage (например, acai_pdfs ), добавляя datascan_ID и указывая на ваши наборы данных BigQuery. После этого Knowledge Catalog автоматически создаст записи для ваших PDF-файлов в BigQuery.
- Для сканирования PDF-файлов (с информацией о поставщиках и рецептами) выполните следующую команду:
# 1. Set your variables PROJECT_ID="<PROJECT_ID>" REGION="<REGION>" ENV_SUFFIX="stg1" DATASCAN_ID="froyo-profile-${ENV_SUFFIX}" BUCKET_NAME="<BUCKET_NAME>" # 2. Set this to the Name of the connection you created in Step 7 CONNECTION_ID="<CONNECTION_ID_NAME>" # 3. Define the API Endpoint DATAPLEX_API="dataplex.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}" # 4. Create the DataScan via CURL echo "Creating Dataplex DataScan: ${DATASCAN_ID}..." curl -X POST "https://$DATAPLEX_API/dataScans?dataScanId=${DATASCAN_ID}" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d '{ "data": { "resource": "//storage.googleapis.com/projects/'"${PROJECT_ID}"'/buckets/'"${BUCKET_NAME}"'" }, "executionSpec": { "trigger": { "on_demand": {} } }, "dataDiscoverySpec": { "bigqueryPublishingConfig": { "tableType": "BIGLAKE", "connection": "projects/'"${PROJECT_ID}"'/locations/'"${REGION}"'/connections/'"${CONNECTION_ID}"'" }, "storageConfig": { "unstructuredDataOptions": { "entity_inference_enabled": true } } } }' - Команда
curlотображает результаты сканирования данных из каталога знаний, аналогичные приведенному ниже изображению.
Запустите задание
Выполните следующую команду:
gcloud dataplex datascans run $DATASCAN_ID --location=$REGION
Опишите работу
Для описания задания выполните следующую команду:
gcloud dataplex datascans describe $DATASCAN_ID --location=$REGION
Удаление задания сканирования данных
Если сканирование длится более 10 минут или если статус задания остается «Ожидание» в течение длительного времени, не переходя в состояние «Выполняется» , это может быть связано с временной недоступностью ресурсов в регионе. В этом случае вы можете выполнить следующую команду для удаления задания, а затем попробовать создать и запустить его снова. Иногда первоначальный запуск может быстро завершиться ошибкой, например, unable to acquire necessary resources .
gcloud dataplex datascans delete $DATASCAN_ID --location=$REGION
Просмотрите статус задания.
Чтобы проверить статус задания, выполните следующие действия:
- В консоли Google Cloud перейдите на страницу управления метаданными .
- На вкладке «Обнаружение облачного хранилища» щелкните название сканирования для обнаружения.
- На странице с подробными сведениями о сканировании вы можете увидеть статус задания.
- После завершения задания проверьте, присутствует ли опубликованный набор данных (например,
acai_pdfs_discovered_003), созданный с помощью командыcurl.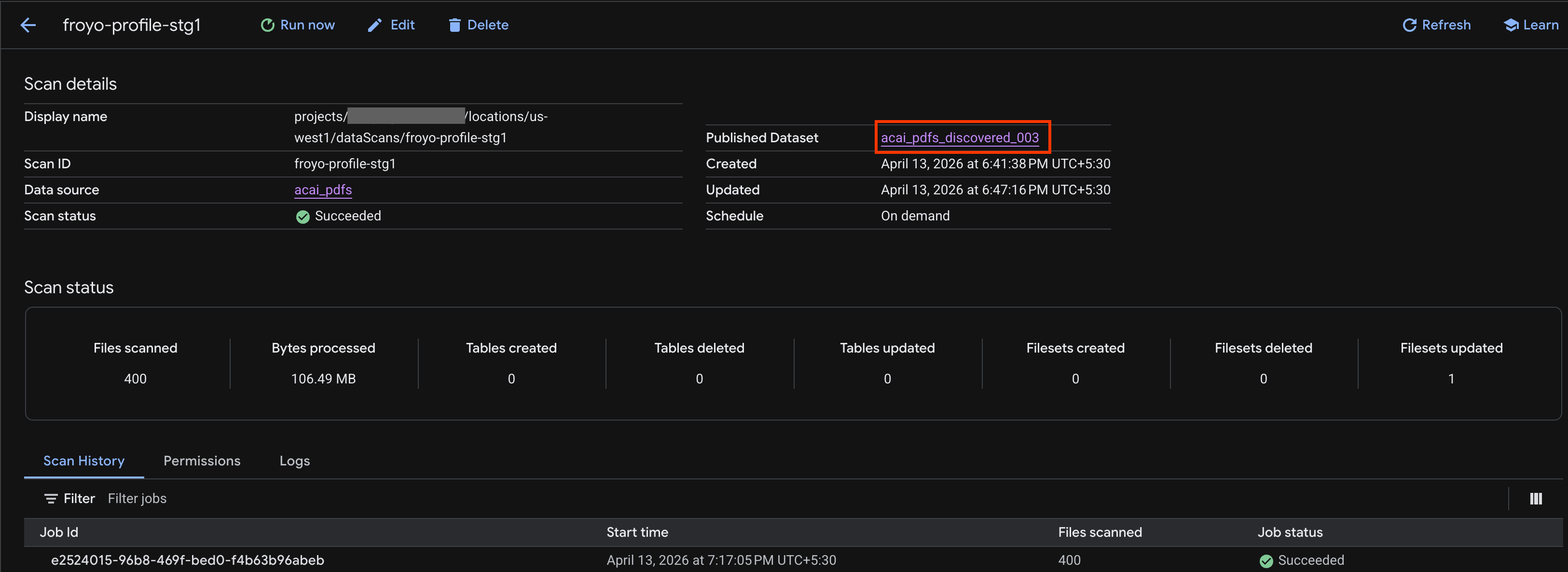
Просмотреть таблицу объектов
Чтобы просмотреть таблицу объектов, созданную после выполнения задания обнаружения, выполните следующие действия:
- В консоли Google Cloud перейдите в раздел BigQuery .
- Нажмите «Наборы данных» и выберите опубликованный набор данных, созданный на предыдущем шаге. Например,
acai_pdfs_discovered_003. - Чтобы просмотреть таблицу объектов, щелкните идентификатор таблицы. Например,
acai_pdfs. - Полученная таблица объектов выглядит следующим образом:
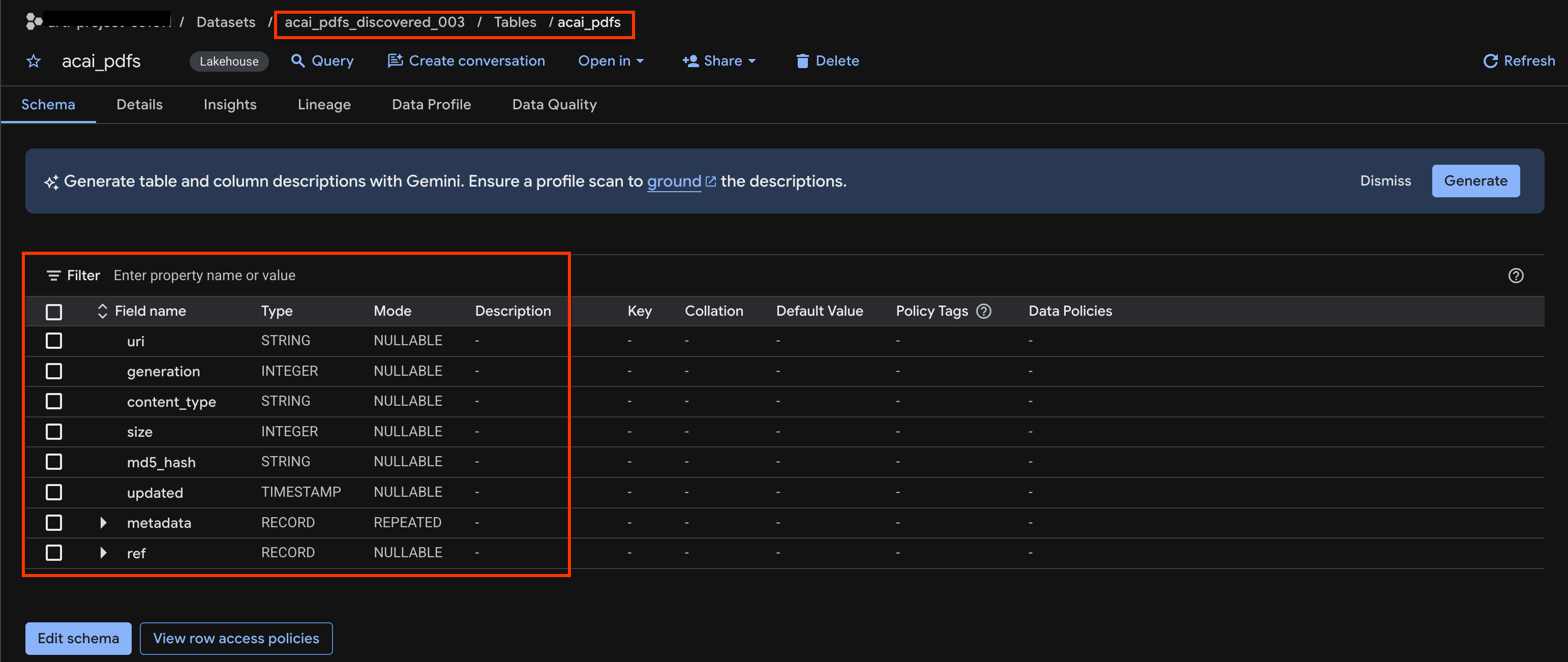
10. Семантическое извлечение
Вам предстоит определить и извлечь структурированные таблицы, другие объекты базы данных и связи для неструктурированной таблицы объектов, созданной на предыдущем шаге. Для этого вы будете использовать функцию Knowledge Catalog Insights для генерации SQL-запросов, позволяющих извлечь структурированные данные из неструктурированной таблицы.
- В консоли Google Cloud перейдите на страницу поиска по каталогу знаний .
- Найдите таблицу набора данных, для которой вы хотите просмотреть аналитические данные. Например,
acai_pdfs_discovered_003.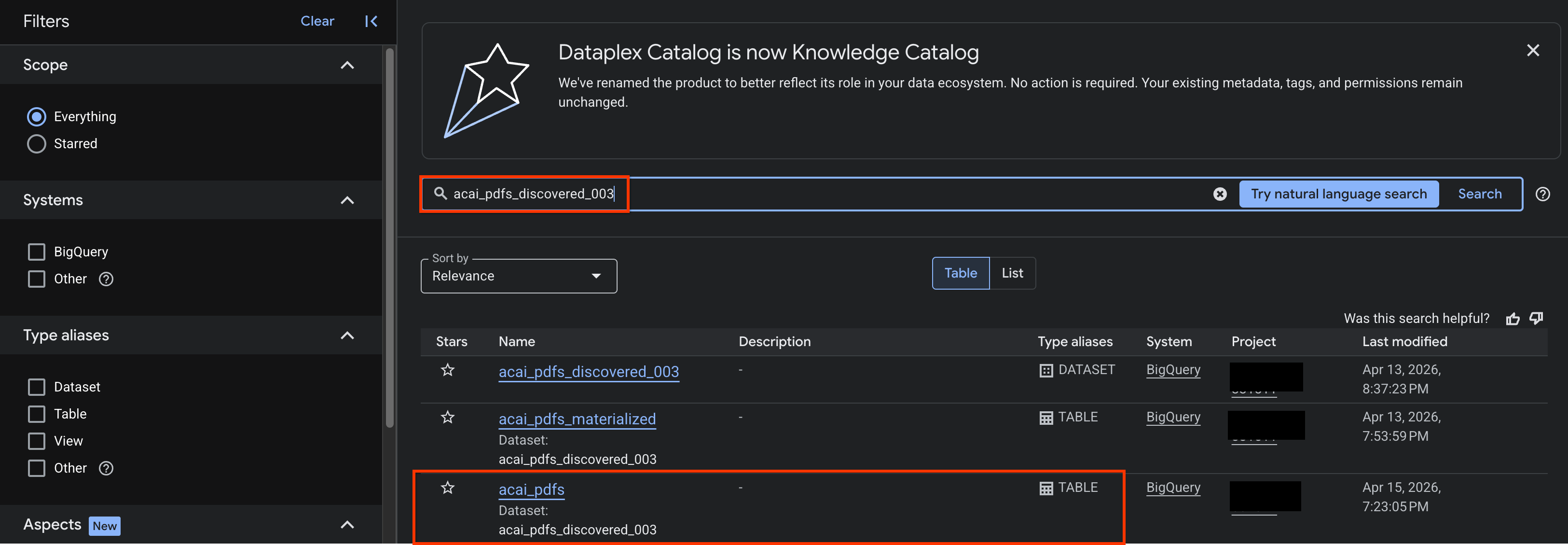
- В результатах поиска щелкните по таблице, чтобы открыть страницу с ее записью.
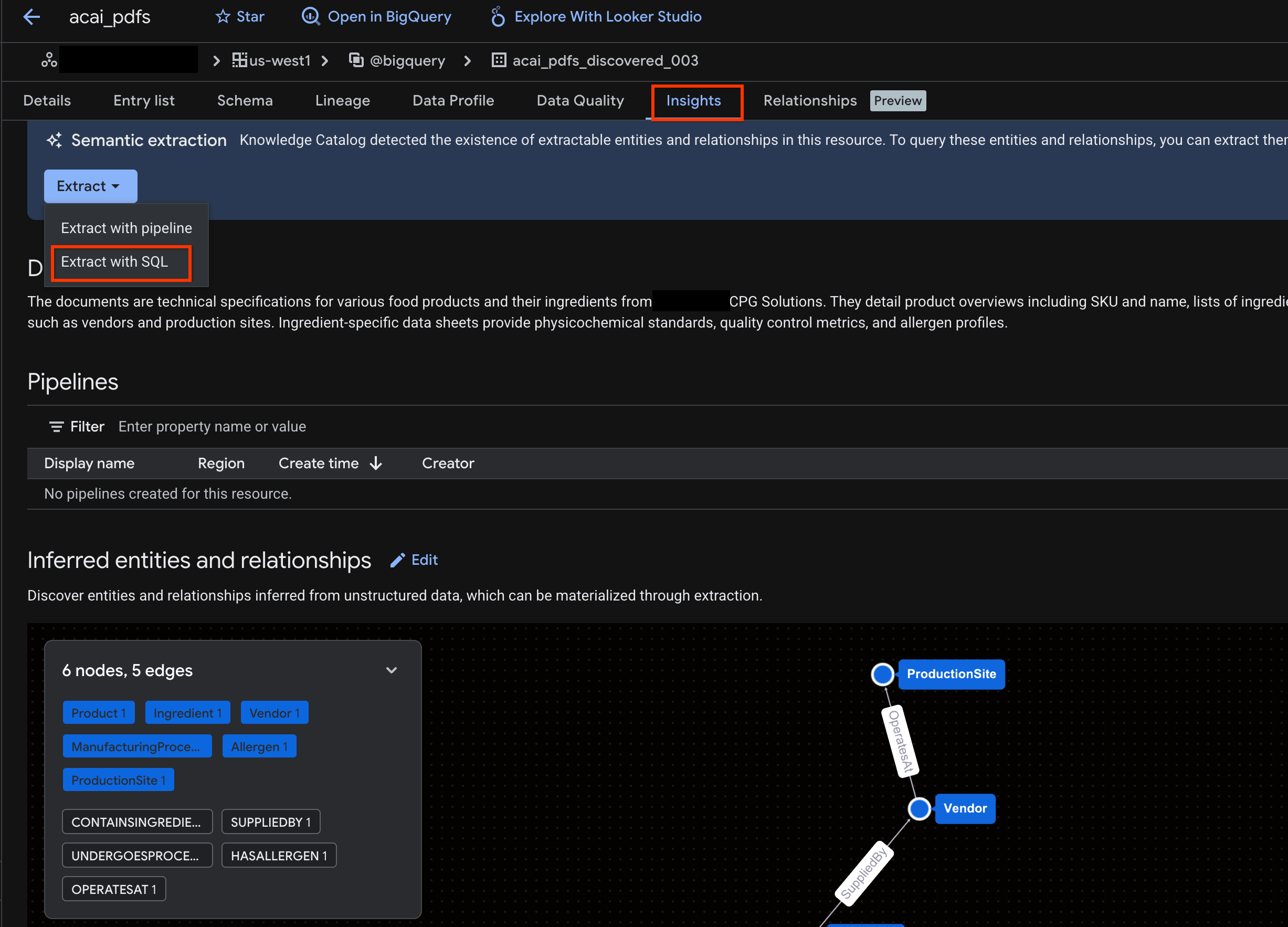
- Нажмите вкладку «Аналитика» . Если вкладка пуста, это означает, что аналитика для этой таблицы еще не сгенерирована. Генерация аналитики может занять от 15 до 25 минут.
- После просмотра полученных данных нажмите «Извлечь» > «Извлечь с помощью SQL» .
- На странице «Извлечение с помощью SQL» в поле «Назначение» введите свой набор данных. Например,
acai_pdfs_discovered_003. - Нажмите «Извлечь» . Откроется редактор BigQuery с загруженным запросом.
- Нажмите кнопку «Выполнить» . На этом этапе будет сгенерирован набор инструкций, и выполнение может занять несколько минут.
- После завершения запроса вы увидите следующие результаты:
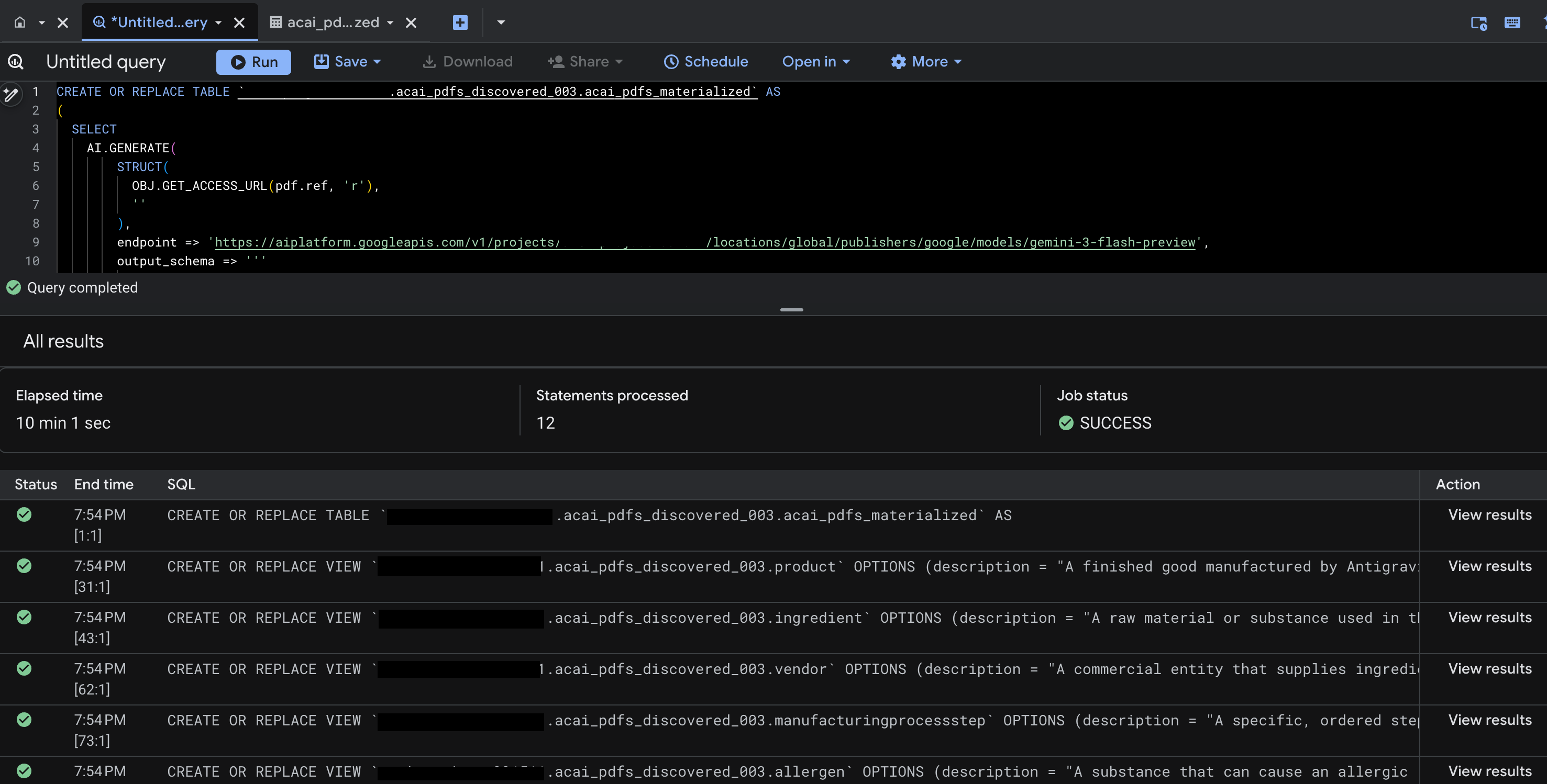
- Перейдите в BigQuery и нажмите «Наборы данных» (например,
acai_pdfs_discovered_003). В выбранном вами на шаге 6 наборе данных будет создан новый набор структурированных объектов базы данных.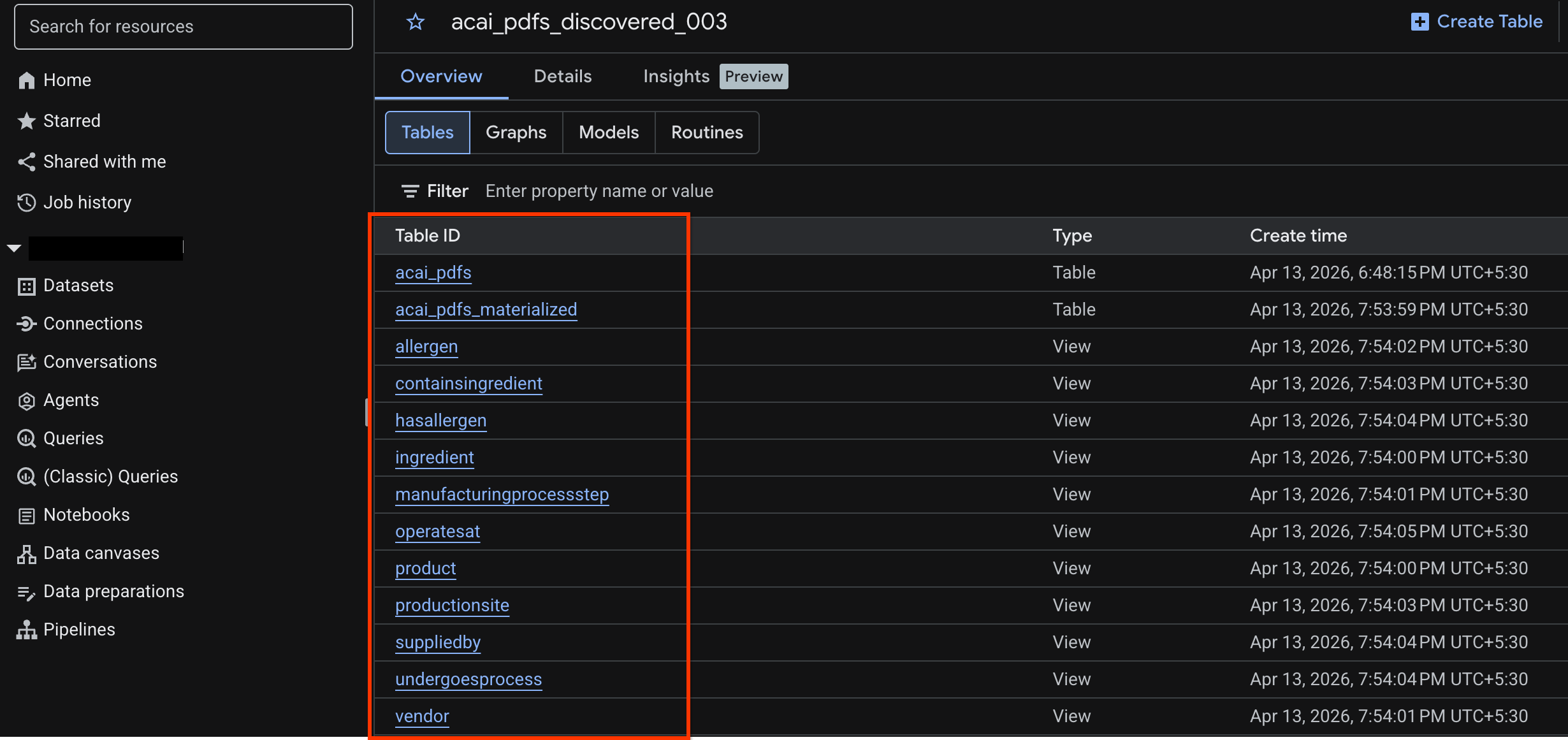
Получайте аналитические данные по объектам в BigQuery.
Для получения аналитических данных из набора данных BigQuery необходимо получить доступ к этому набору данных в BigQuery с помощью BigQuery Studio.
- В консоли Google Cloud перейдите в BigQuery Studio .
- В панели «Проводник» выберите проект, перейдите к набору данных, для которого хотите получить аналитические данные.
- Перейдите во вкладку «Аналитика» .
- Если вы видите кнопку «Включить API» , нажмите на нее, чтобы активировать Gemini для Google Cloud. Откроется окно «Включить основные функции» .
- В разделе «Основные функции API» нажмите «Включить» для Gemini for Google Cloud API и BigQuery Unified API , а затем нажмите «Далее» .
- В разделе «Разрешения (необязательно)» при необходимости предоставьте субъектам роли IAM, а затем нажмите «Далее» .
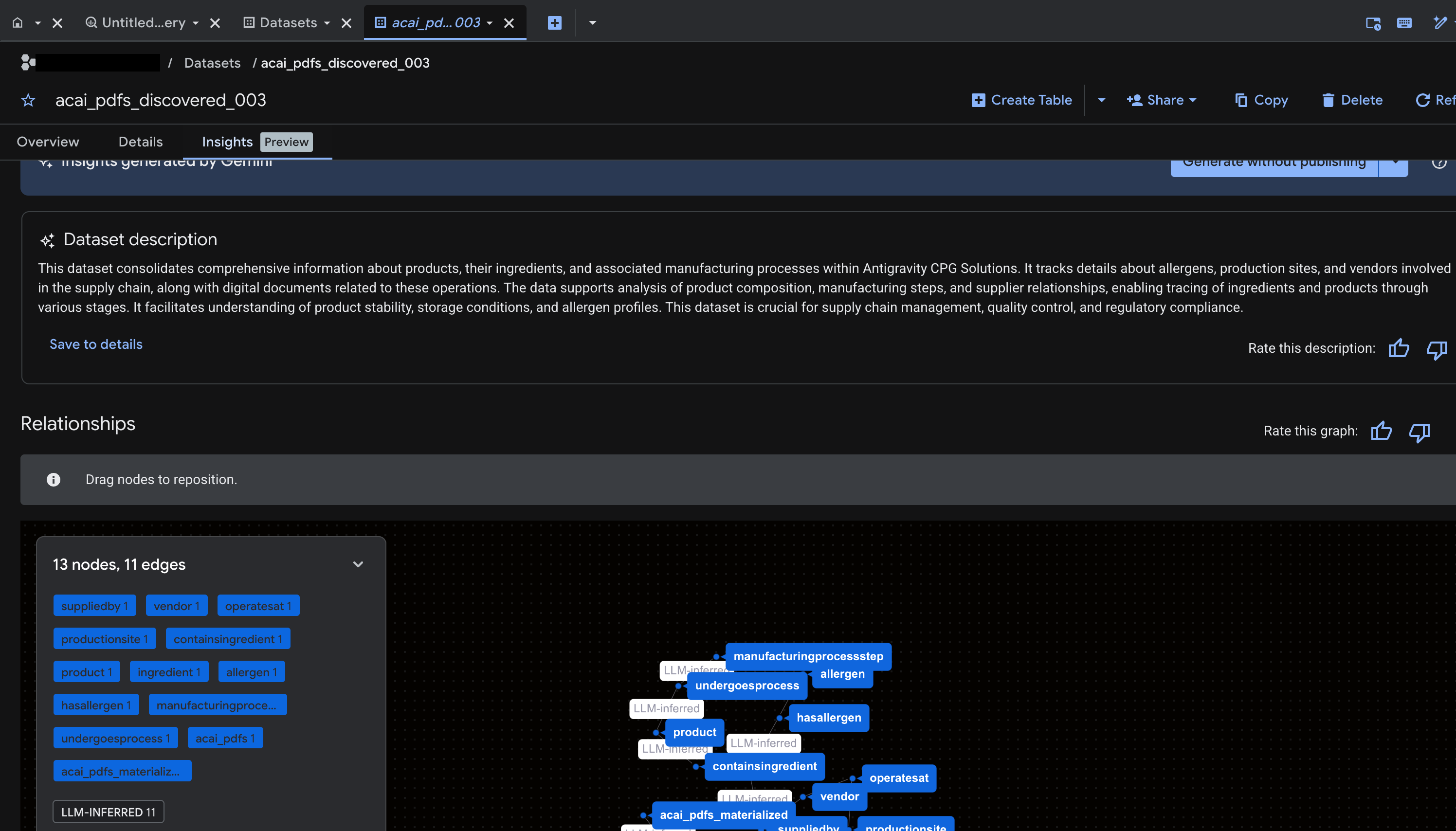
- Чтобы получить аналитические данные и опубликовать их в Каталоге знаний, нажмите «Сгенерировать и опубликовать» .
- После публикации вы сможете просмотреть статистику на соответствующей вкладке.
11. Настройте свою IDE для агентного анализа данных.
Расширение Google Cloud Data Agent Kit для Visual Studio Code — это расширение для IDE, предназначенное для специалистов по анализу данных и инженеров данных. Оно позволяет подключаться к ресурсам и данным Google Data Cloud и работать с ними непосредственно из IDE. Для получения дополнительной информации см. обзор расширения Data Agent Kit для VS Code.
Расширение Data Agent Kit для VS Code полезно, когда вам нужно выполнить следующие действия:
- Создавайте, тестируйте, проверяйте и развертывайте готовый к использованию в производственной среде конвейер обработки данных, например, Spark ETL или BigQuery ETL, непосредственно из VS Code.
- Изучайте данные, создавайте конвейер обучения, определяйте оптимальные модели машинного обучения и развертывайте их на рабочей точке с помощью ИИ.
- Подключайтесь к надежным источникам данных, создавайте высокопроизводительную модель данных и публикуйте интерактивную панель мониторинга для заинтересованных сторон бизнеса.
Установите расширение Data Agent Kit для VS Code.
- Откройте VS Code.
- Установите Google Cloud CLI. Дополнительную информацию см. в разделе «Установка Google Cloud CLI» .
- Установите расширение Data Agent Kit для VS Code .
- Завершите процесс подключения расширения, для чего вам необходимо:
- Войдите в расширение
- Установка навыков, серверов MCP
- После завершения процесса адаптации обновите или перезапустите окно. Дополнительную информацию см. в разделе «Настройка и конфигурирование расширения Data Agent Kit для VS Code» .
- После перезагрузки IDE щелкните значок Google Data Cloud на панели навигации, перейдите в настройки и убедитесь, что вы правильно указали идентификатор проекта и регион (
us-west1) в общих настройках.
Настройте рабочее пространство в VS Code.
- Откройте VS Code и выберите Файл > Открыть папку > Создать папку .
- Создайте новую папку с именем
acai_test, а затем нажмите «Открыть». Теперь VS Code будет считать открытую папку рабочей областью. - В диалоговом окне «Доверие к рабочей области» выберите «Да, я доверяю авторам в вопросе включения всех функций в рабочей области».
- Создайте папку
.githubв рабочей областиacai_test. - Создайте новый файл
copilot-instructions.mdв папке.githubи введите в него следующие правила.## 1. Project Context - **Project ID**: <PROJECT_ID> - **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors. - **Documentation**: Raw PDF documents detailing flavors and ingredients are stored in Google Cloud Storage at `gs://<BUCKET_NAME>`. ## 2. Execution & Data Processing Rules - **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `<BQ_DATASET_NAME>` (referred to as the Knowledge Catalog). - **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the dataset `<DATASET_ID>`. When you are referencing a dataset, ensure you are using it with the project ID (`<PROJECT_ID>`) and namespace prefix `<NAMESPACE_NAME>`. For example, to query order table in this dataset you should use `<PROJECT_ID>.<NAMESPACE>.<DATASET_ID>.orders`. - **CRITICAL RULE - Data Joins between BigQuery dataset and Iceberg dataset**: ANY task requiring a join or integration between the BigQuery datasets `<DATASET_ID>` of the PDF data and the `<DATASET_ID>` of the customer data MUST be executed using **Spark Notebooks**. - **CRITICAL RULE - Notebook Kernel**: Every Spark notebook utilized MUST exclusively be configured to run on the Serverless Session template `iceberg-federation-template` as its kernel. - **CRITICAL RULE - Data Science**: ANY data science, machine learning, or advanced analytical task MUST be performed strictly within **Spark Notebooks** using the aforementioned setup. - Создайте еще один новый файл
template.yamlв рабочей областиacai_testи введите в него следующую информацию.labels: client: "vscode" jupyterSession: displayName: "iceberg-federation-template" kernel: "PYTHON" environmentConfig: executionConfig: serviceAccount: "sa-spark-dev1@<PROJECT_ID>.iam.gserviceaccount.com" subnetworkUri: "projects/<PROJECT_ID>/regions/<REGION>/subnetworks/<SUBNET_NAME>" runtimeConfig: version: "2.3" properties: # This enables the secure proxy URL you were looking for dataproc.tier: "premium" spark.dataproc.engine: "lightningEngine" spark.dataproc.lightningEngine.runtime: "native" spark.memory.offHeap.enabled: "true" spark.memory.offHeap.size: "1g" spark.executor.memory: "4g" "dataproc.component.gateway.enabled": "true" "dataproc.jupyter.listen.all.interfaces": "true" "spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" "spark.sql.defaultCatalog": "<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>": "org.apache.iceberg.spark.SparkCatalog" "spark.sql.catalog.<CATALOG_NAME>.type": "rest" "spark.sql.catalog.<CATALOG_NAME>.uri": "<CATALOG_URI_ID>" "spark.sql.catalog.<CATALOG_NAME>.warehouse": "bl://projects/<PROJECT_ID>/catalogs/<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>.rest.auth.type": "org.apache.iceberg.gcp.auth.GoogleAuthManager" - В VS Code нажмите «Терминал» и выполните следующую команду, чтобы импортировать файл
template.yamlв качестве шаблона сессии. Этот шаблон будет использоваться агентом позже для создания сессии Spark.gcloud beta dataproc session-templates import iceberg-federation-template \ --source=template.yaml \ --location=<REGION>REGIONна название вашего региона.
12. Провести анализ агентных данных.
- В редакторе VS Code нажмите кнопку «Включить/выключить чат» .
- Для настройки пользовательских агентов выберите «Агент» .
- В панели «Модели поиска» нажмите «Управление языковыми моделями» .
- На странице «Языковые модели» нажмите «Добавить модели» .
- Выберите Google из списка и нажмите Enter для подтверждения ввода.
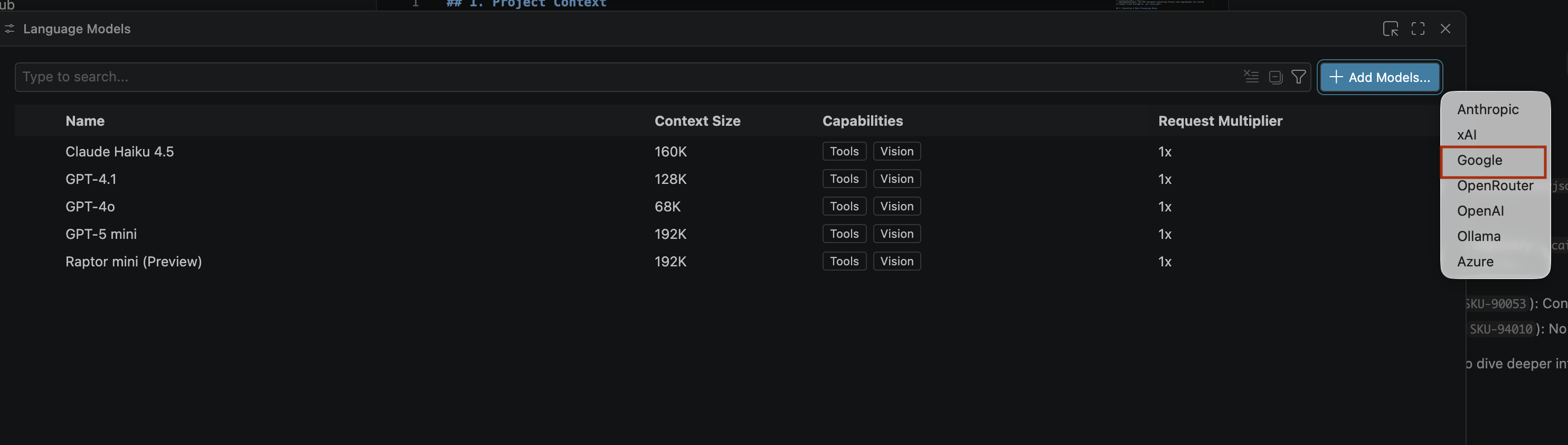
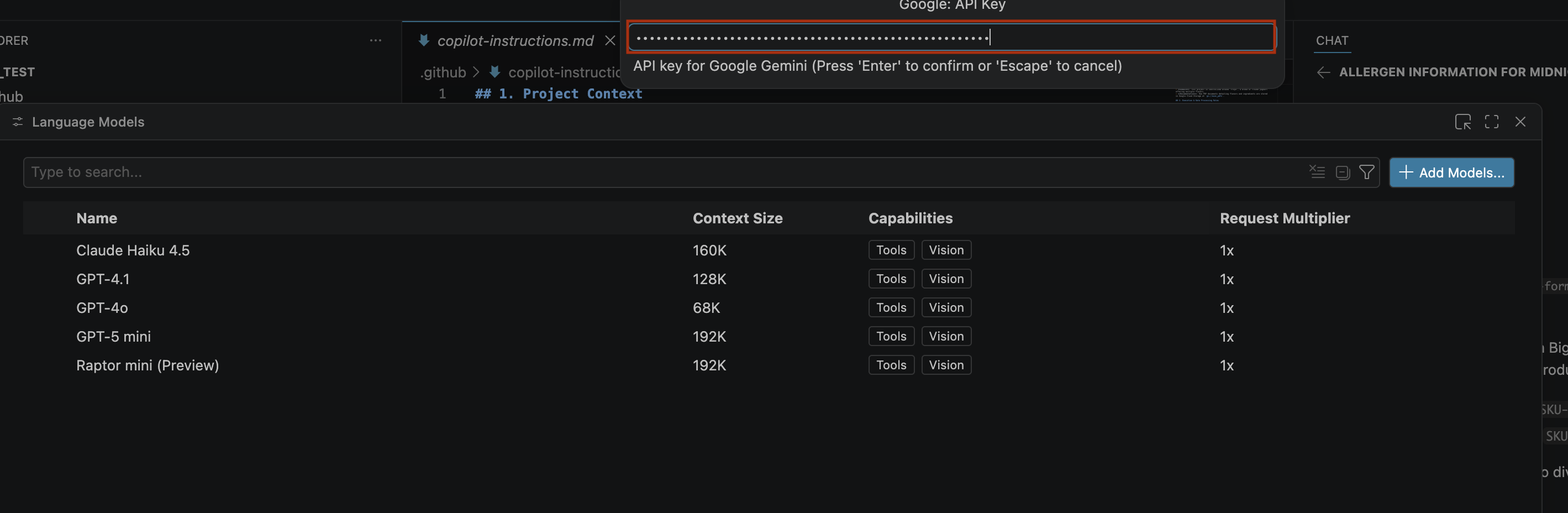
- Чтобы ввести ключ API для Google Gemini, выполните следующие действия:
- Перейдите на сайт Google AI Studio .
- Войдите в систему, используя свою учетную запись Google.
- В боковой панели нажмите «Получить ключ API» .
- Нажмите «Создать ключ API» . Откроется страница создания нового ключа.
- В списке «Выберите облачный проект» выберите «Импорт проекта» .
- Введите название существующего проекта.
- Нажмите «Создать ключ» и скопируйте ключ API. Этот ключ предоставляет доступ к ресурсам Gemini API вашей учетной записи. Для получения дополнительной информации см. раздел «Использование ключей Gemini API» .
- Вставьте сгенерированный вами API-ключ в строку поиска и нажмите Enter .
- Если модели Gemini не отображаются, отобразите их, как показано на следующем изображении:
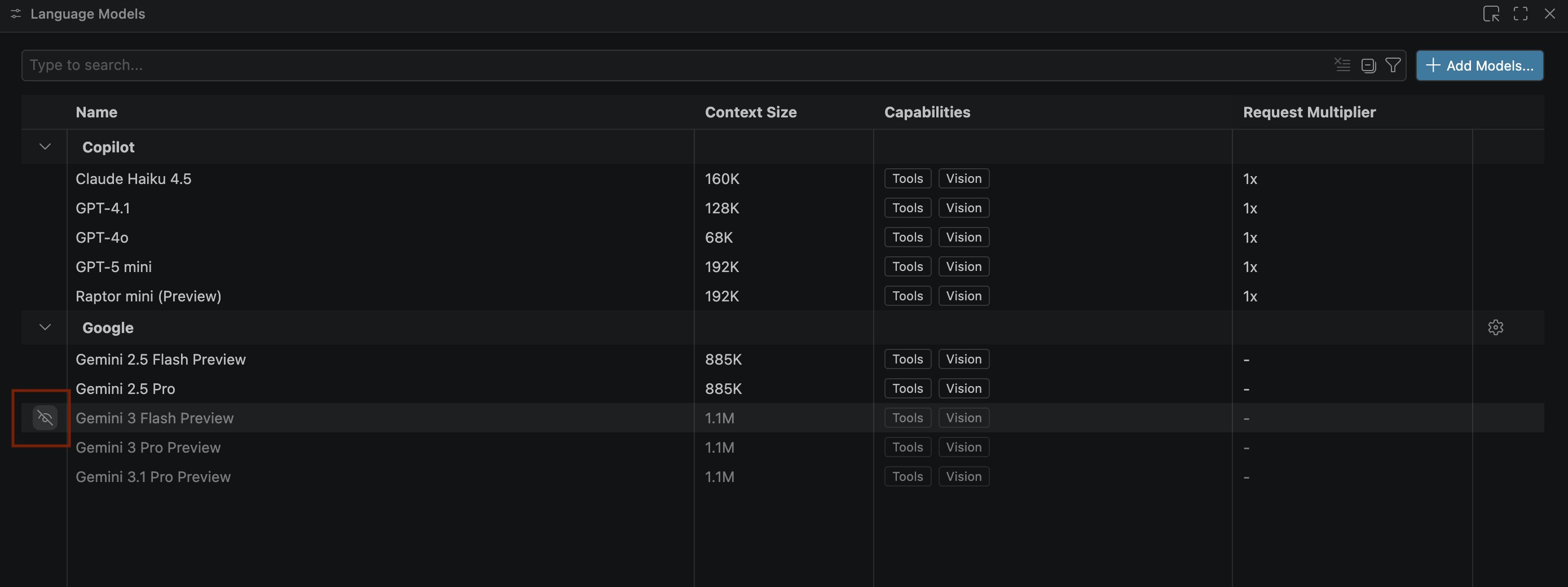
- Выберите Gemini 3.1 Pro Preview из списка языковых моделей Google Gemini и закройте окно языковых моделей .
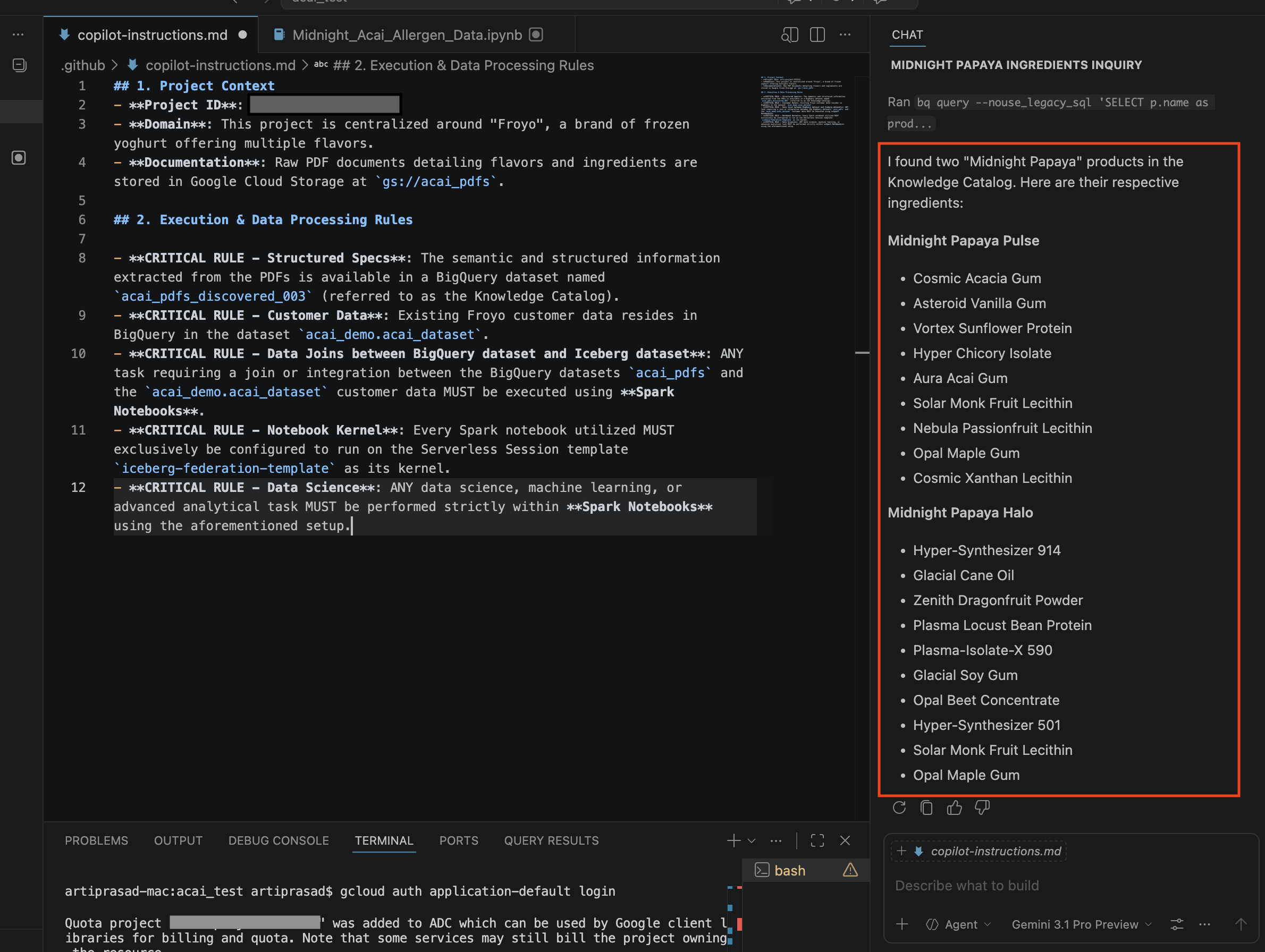
- В окне чата введите следующий вопрос:
Search ingredients for Midnight papaya - После некоторых действий вы должны увидеть следующий результат:
- В окне чата введите еще один вопрос:
Search allergen information for Midnight papaya - После выполнения ряда действий и процедур вы увидите, как агент выдаст название аллергена
Soyкак показано на следующем изображении: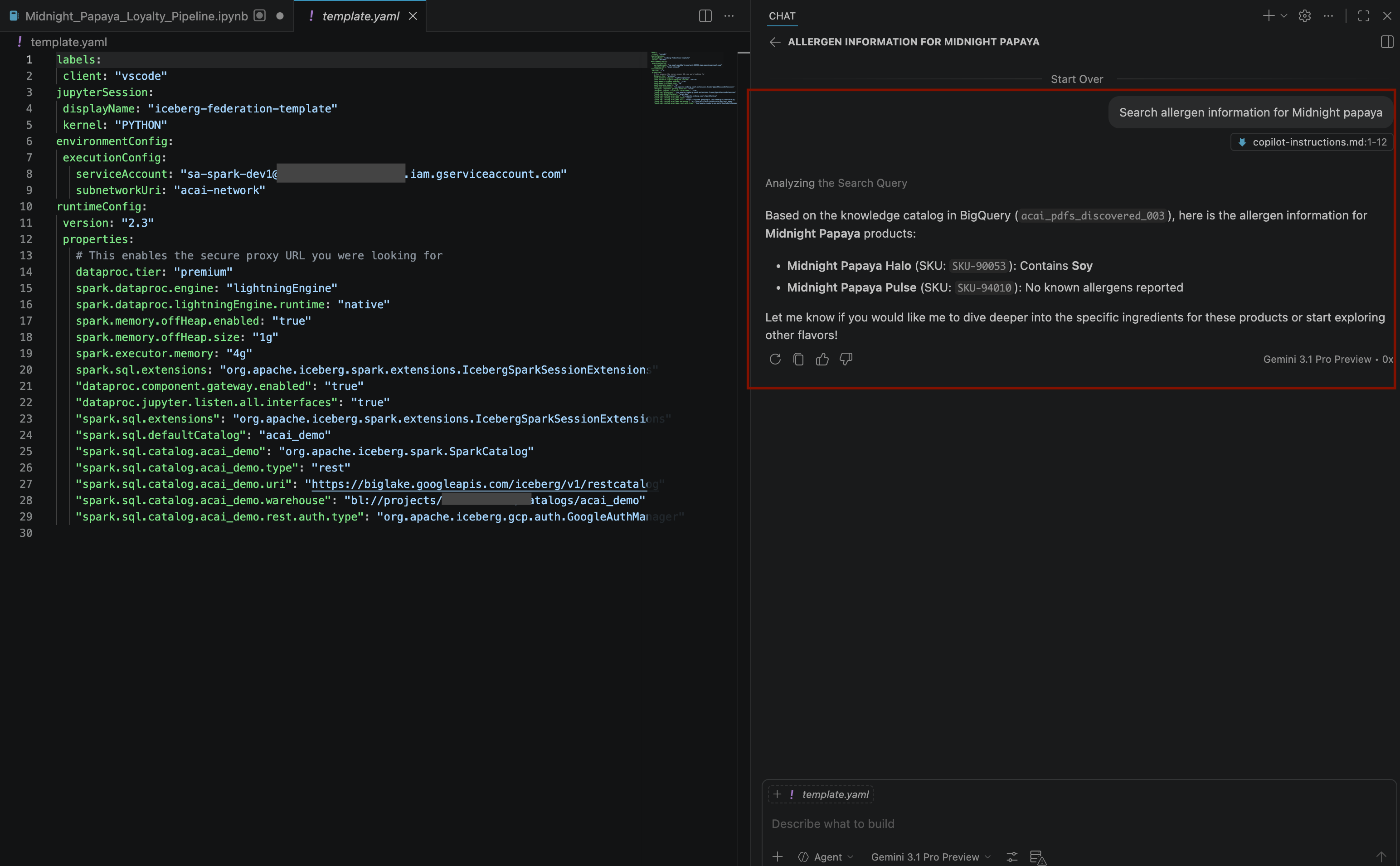
- В окне чата введите еще один вопрос:
Build a pipeline to join products with our 'Global Loyalty' Iceberg tables in acai customer, sales data to identify popular products - Чтобы выбрать ядро, откройте файл
.ipynbи нажмите «Выбрать ядро» > «Удаленные ядра Spark» > «Iceberg-federation-template на serverless spark».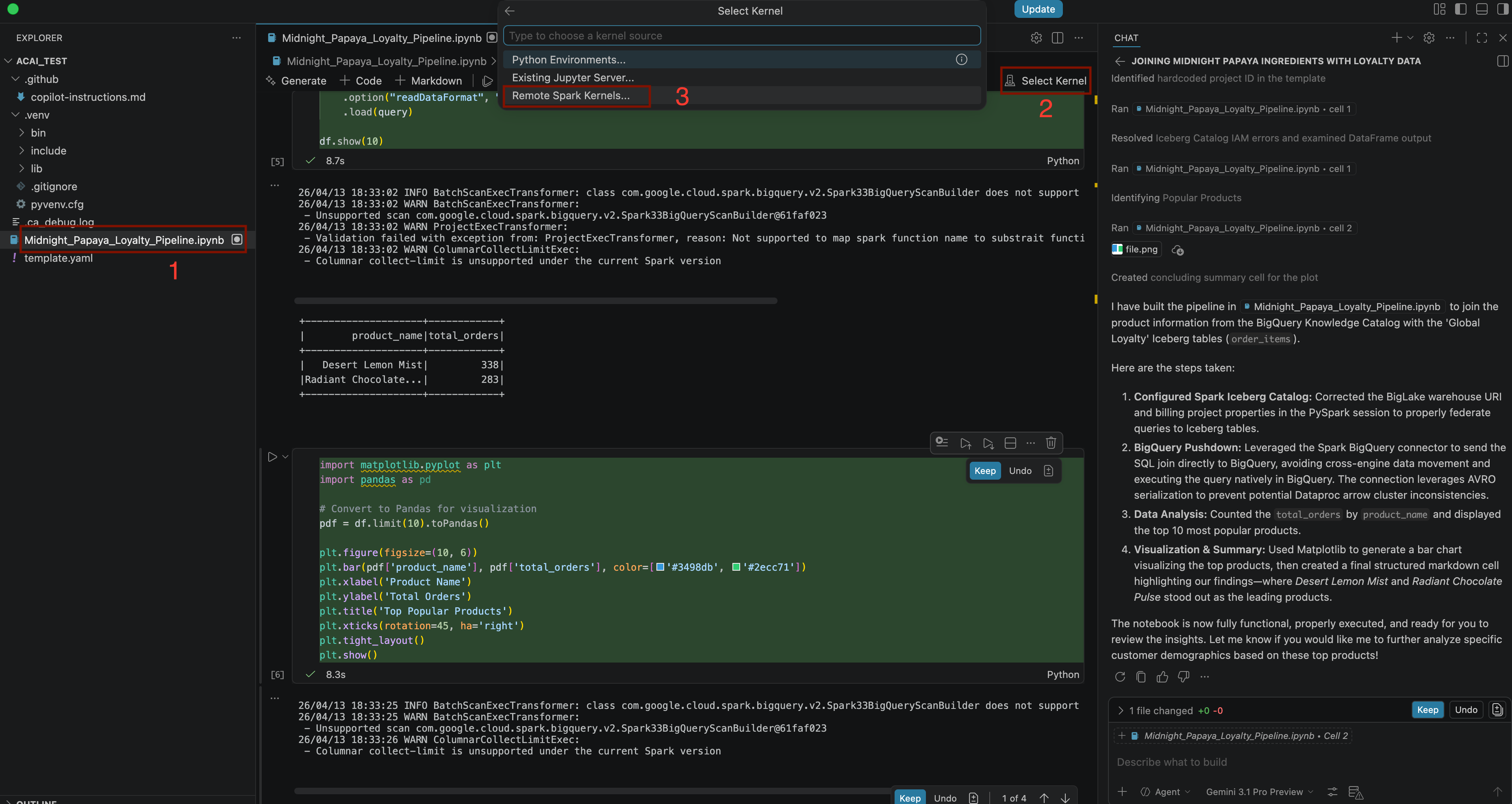
- После выполнения ряда действий и шагов вы увидите ответ агента, в котором все шаги в блокноте будут успешно выполнены, а также окончательный результат, сгенерированный в конце блокнота, как показано на следующем изображении:
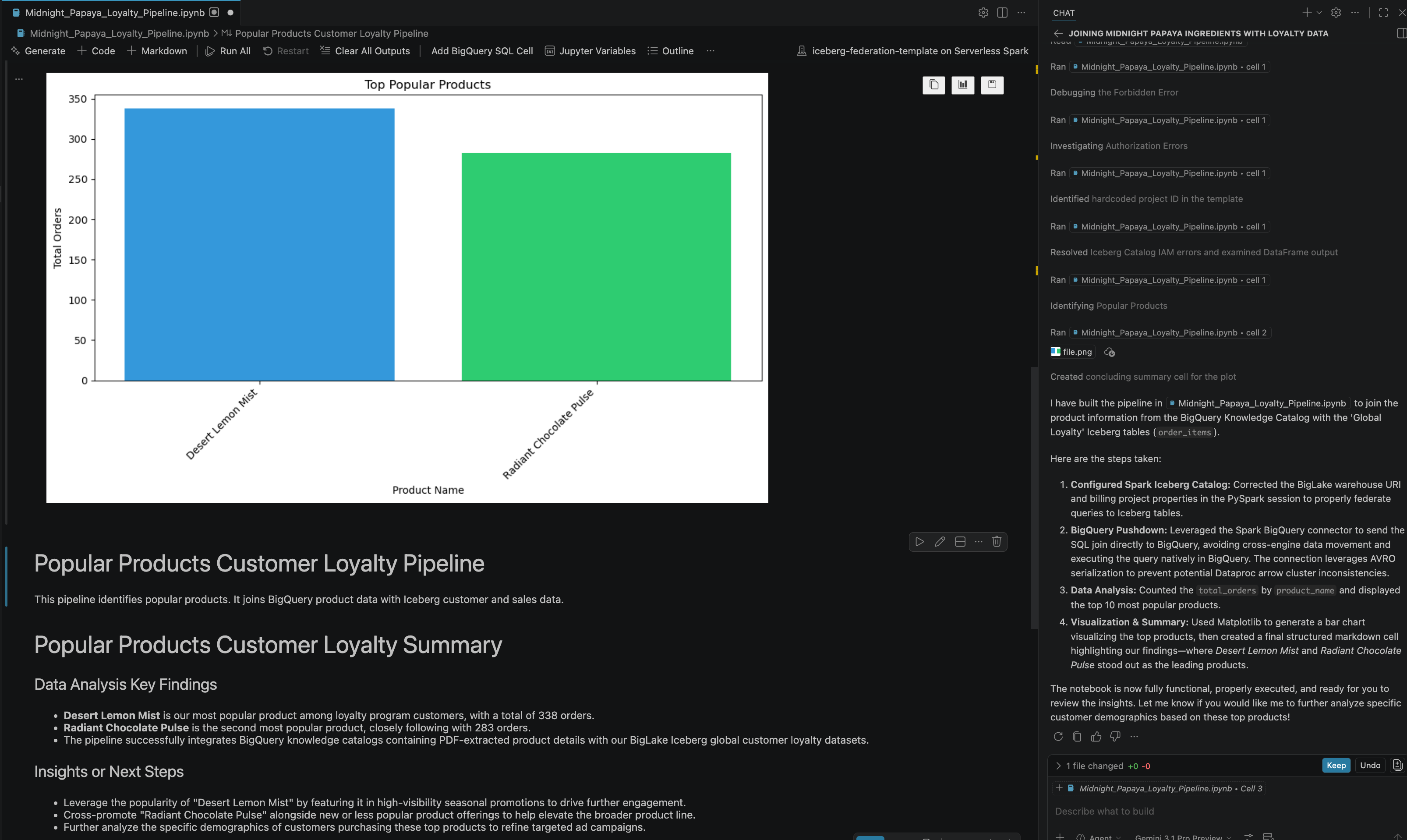
13. Уборка
Во избежание дополнительных расходов удалите ресурсы, созданные вами в этой лабораторной работе.
- Для удаления данных сканирования каталога знаний выполните следующую команду:
DATASCAN_ID="<DATASCAN_ID>" echo "Deleting Dataplex DataScan: ${DATASCAN_ID}" gcloud dataplex datascans delete "${DATASCAN_ID}" --location="${REGION}" --quiet - Чтобы удалить сегменты Cloud Storage и все их содержимое, выполните следующую команду:
echo "Deleting Cloud Storage buckets: <BUCKET_NAME1> and <BUCKET_NAME2>" gsutil -m rm -r gs://<BUCKET_NAME1> gsutil -m rm -r gs://<BUCKET_NAME2> - Чтобы удалить подключение к BigQuery, выполните следующую команду:
CONNECTION_ID="<CONNECTION_NAME>" echo "Deleting BigQuery Connection: ${CONNECTION_ID}" bq rm --connection "${PROJECT_ID}.${REGION}.${CONNECTION_ID}" - Чтобы удалить каталог Lakehouse, выполните следующую команду:
CATALOG_ID="<CATALOG_NAME>" echo "Deleting Lakehouse Catalog: ${CATALOG_ID}" gcloud biglake catalogs delete "${CATALOG_ID}" --project="${PROJECT_ID}" --location="${REGION}" --quiet - Чтобы удалить набор данных, содержащий обнаруженные таблицы PDF, выполните следующую команду:
DATASET_NAME="<DATASET_NAME>" echo "Deleting BigQuery Dataset: ${DATASET_NAME}" bq rm -r -f "${PROJECT_ID}:${DATASET_NAME}" - Для удаления пользовательской учетной записи службы выполните следующую команду:
SERVICE_ACCOUNT="<SERVICE_ACCOUNT>" echo "Deleting Service Account: ${SERVICE_ACCOUNT}" gcloud iam service-accounts delete "${SERVICE_ACCOUNT}"@"${PROJECT_ID}".iam.gserviceaccount.com --quiet - Для удаления сети VPC выполните следующую команду:
VPC_NETWORK="<VPC_NETWORK>" echo "Deleting VPC Network: ${VPC_NETWORK}" gcloud compute networks delete "${VPC_NETWORK}" --quiet - Чтобы удалить весь проект Google Cloud, выполните следующую команду:
gcloud projects delete "${PROJECT_ID}"
14. Поздравляем!
Поздравляем! Вы успешно организовали разрозненные данные PDF-файлов и файлов Parquet в таблицах BigQuery и объединили их в единую, доступную для поиска и объединения экосистему. По сути, вы создали современный Data Lakehouse, который обрабатывает PDF-файлы и большие объемы данных так же интеллектуально, как и строки в базе данных. И все это вы сделали прямо через своего агента в интерактивном режиме с Gemini.
Справочная документация
Чтобы подробнее ознакомиться с основными технологиями, используемыми в этом практическом занятии, посетите официальную документацию Google Cloud:
- Чтобы ознакомиться с BigQuery, ключевым компонентом Data Cloud, см. документацию BigQuery .
- Для получения дополнительной информации об IAM см. документацию по IAM .
- Чтобы узнать больше о Lakehouse, см. раздел «Что такое Lakehouse ?».