
1. บทนำ
ในโค้ดแล็บนี้ คุณจะสวมบทบาทเป็นนักวิทยาศาสตร์ข้อมูลของบริษัท Froyo สมมติที่กำลังจะเปิดตัวรสชาติใหม่ของผลิตภัณฑ์ "Midnight Swirl" เพื่อให้การเปิดตัวทั่วโลกประสบความสำเร็จ ธุรกิจต้องตอบคำถามสำคัญเกี่ยวกับส่วนผสม ความต้องการของตลาด และผลตอบแทนจากการลงทุน (ROI) เวิร์กโฟลว์แบบครบวงจรนี้แสดงให้เห็นว่าแคตตาล็อกความรู้ของ Google Cloud (เดิมชื่อ Dataplex) และ Lakehouse สำหรับ Apache Iceberg (เดิมชื่อ BigLake) ช่วยลดช่องว่างระหว่างข้อมูลที่ไม่มีโครงสร้าง "มืด" และส่งมอบ Business Intelligence ที่นำไปใช้ได้จริงโดยใช้ Gemini ใน IDE (VS Code) ผ่านเลเยอร์การกำกับดูแลแบบรวม
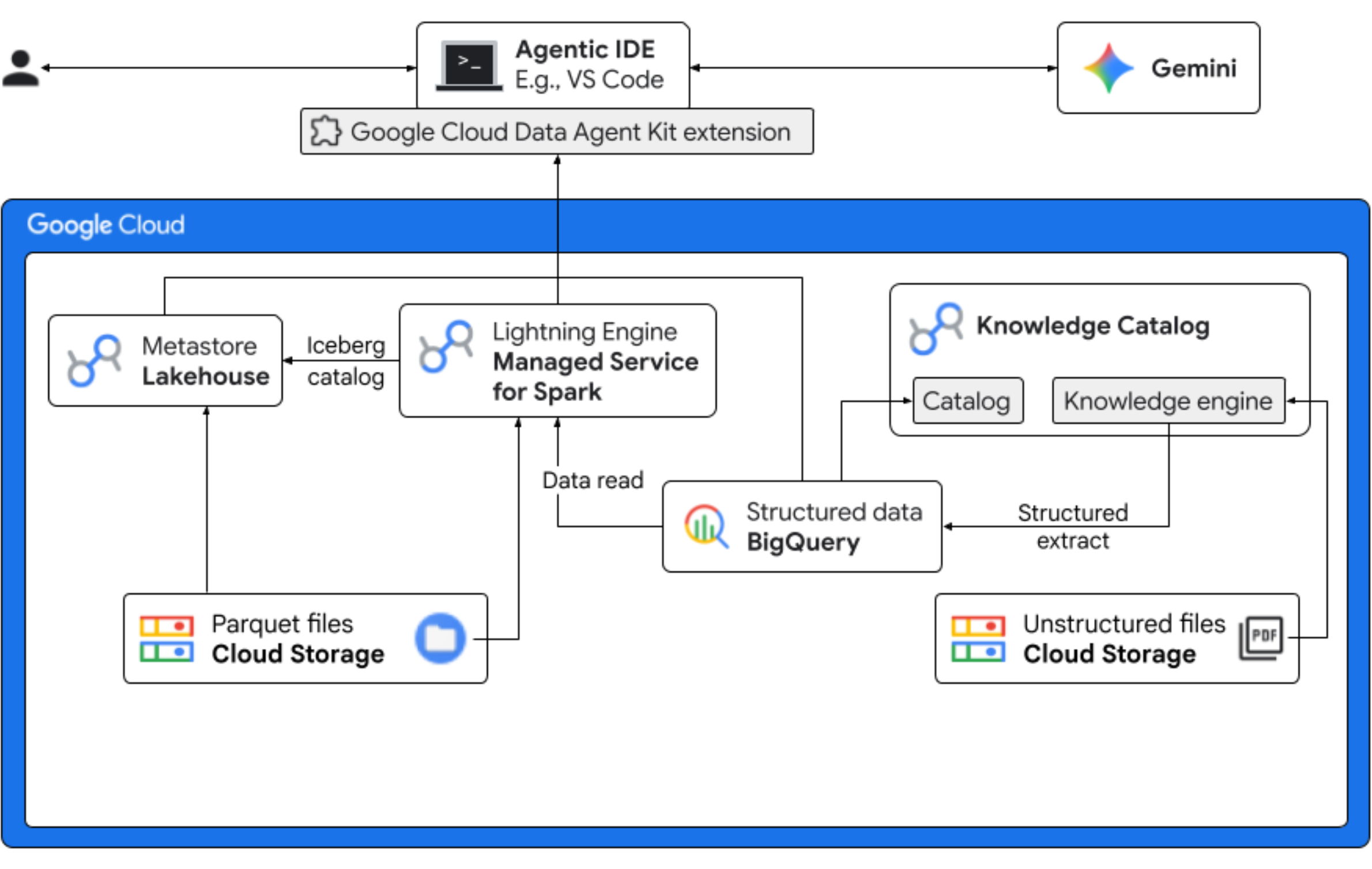
สิ่งที่คุณต้องดำเนินการ
- การค้นพบที่ไม่มีโครงสร้าง: Knowledge Catalog DataScan จะทำการ Crawl สูตรอาหารในรูปแบบ PDF ที่จัดเก็บไว้ใน Cloud Storage สร้างตารางออบเจ็กต์ใน BigQuery สำหรับ PDF ที่สแกน ระบบจะ "อ่าน" ไฟล์ PDF โดยใช้การอนุมานเชิงความหมายของ Vertex AI เพื่อดึงข้อมูลที่มีโครงสร้างสำหรับผลิตภัณฑ์ สารก่อภูมิแพ้ ส่วนผสม และแอตทริบิวต์ที่เกี่ยวข้อง จากนั้นจะสร้างสคีมาสำหรับข้อมูลที่จัดเก็บไว้ใน PDF อย่างชาญฉลาด
- ข้อมูลเมตาแบบรวม: ระบบจะจัดเก็บข้อมูลที่แยกจากไฟล์ PDF ลงใน BigQuery โดยตรงเป็นตารางแบบกว้างดั้งเดิม และสร้างมุมมองเพื่อช่วยในการค้นหาทั่วไป ระบบจะจัดเก็บชุดข้อมูลอินพุตอิสระที่มีข้อมูลการขายในอดีตไว้ในตาราง Apache Iceberg บน Google Cloud Storage ระบบจะรวมตาราง Iceberg นี้กับข้อมูลที่แยกออกมาใน BigQuery ในขั้นตอนถัดไป
- การวิเคราะห์ข้ามเครื่องมือ: การใช้ Managed Service สำหรับ Apache Spark (เดิมชื่อ Dataproc) กับแคตตาล็อก REST ของ Iceberg จะช่วยให้คุณรวมข้อมูลเมตา PDF ใหม่นี้และข้อมูลเชิงความหมายที่มีโครงสร้างที่อนุมาน (จากตารางและมุมมอง BigQuery) กับข้อมูลการขายที่มีโครงสร้างซึ่งจัดเก็บไว้ในตาราง Apache Iceberg ใน Google Cloud Storage ได้ ซึ่งควบคุมโดยเทมเพลตเซสชันแบบอินเทอร์แอกทีฟของ Apache Spark ที่มีการจัดการซึ่งใช้เป็นเคอร์เนล Jupyter Notebook เพื่อให้มั่นใจว่าการตั้งค่าความปลอดภัยและการตั้งค่าการคำนวณสำหรับงาน Spark จะสอดคล้องกัน
- ข้อมูลเชิงลึกเชิงความหมาย: การรวมข้อมูลผลิตภัณฑ์ที่อนุมานกับข้อมูลลูกค้าและการขาย (ใน BigQuery) ช่วยให้การสาธิตสามารถดึงข้อมูลเชิงลึก เช่น การระบุข้อมูลสารก่อภูมิแพ้และการคาดการณ์รายได้
- การกำกับดูแลแบบอัตโนมัติ: วงจรทั้งหมดตั้งแต่การสแกนการค้นพบไปจนถึงการดำเนินการ Spark จะได้รับการประสานงานผ่านเทมเพลต คำสั่ง กฎ และการทำงานอัตโนมัติที่ขับเคลื่อนด้วยเอเจนต์ที่พร้อมใช้งาน Gemini ซึ่งพิสูจน์ให้เห็นว่า AI สามารถจัดการโครงสร้างพื้นฐานที่ขับเคลื่อนการวิเคราะห์ได้
สิ่งที่คุณต้องมี
การทำ Codelab นี้อาจมีค่าใช้จ่าย ซึ่งคาดว่าจะไม่เกิน $5 สำหรับการใช้งานทั่วไป หากต้องการดูการประมาณค่าใช้จ่ายโดยละเอียดตามการใช้งานที่คาดการณ์ไว้หรือราคาปัจจุบัน ให้ใช้เครื่องคำนวณราคาของ Google Cloud
ตรวจสอบว่าคุณมีข้อกำหนดเบื้องต้นต่อไปนี้เพื่อทำ Codelab ให้เสร็จสมบูรณ์
- เว็บเบราว์เซอร์ Chrome
- บัญชี Gmail ส่วนตัวหากคุณใช้เครดิตทดลองที่ระบุไว้ในส่วน "ก่อนที่จะเริ่ม"
- ดาวน์โหลดและติดตั้ง Visual Studio (VS) Code
2. ก่อนเริ่มต้น
สร้างโปรเจ็กต์ Google Cloud
- ในคอนโซล Google Cloud ในหน้าตัวเลือกโปรเจ็กต์ ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud
- ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ที่อยู่ในระบบคลาวด์แล้ว ดูวิธีตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินในโปรเจ็กต์แล้วหรือไม่
เริ่มต้น Cloud Shell
Cloud Shell คือสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานใน Google Cloud ซึ่งโหลดเครื่องมือที่จำเป็นไว้ล่วงหน้า
- คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud
- เมื่อเชื่อมต่อกับ Cloud Shell แล้ว ให้ยืนยันการตรวจสอบสิทธิ์โดยทำดังนี้
gcloud auth list - ตรวจสอบว่าได้กำหนดค่าโปรเจ็กต์แล้ว
gcloud config get project - หากไม่ได้ตั้งค่าโปรเจ็กต์ตามที่คาดไว้ ให้ตั้งค่าดังนี้
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
เปิดใช้ API ที่จำเป็น
เรียกใช้คำสั่งนี้เพื่อเปิดใช้ API ที่จำเป็นทั้งหมด
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
biglake.googleapis.com \
dataproc.googleapis.com \
metastore.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
secretmanager.googleapis.com \
storage.googleapis.com
ดาวน์โหลดชิ้นงาน Codelab
ที่เก็บนี้มีไฟล์ Parquet, สูตร, ซัพพลายเออร์, copilot-instructions.md, template.yaml และ quickstart.py สำหรับใช้กับ Codelab นี้ โปรดตรวจสอบว่าคุณได้ดาวน์โหลดไฟล์เหล่านี้แล้ว
หากต้องการดาวน์โหลดไฟล์ ให้ทำดังนี้
- เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git - ไปที่โฟลเดอร์ที่สร้างขึ้นใหม่โดยทำดังนี้
cd next-26-keynotes - ดึงโฟลเดอร์
data-cloud-demogit sparse-checkout set genkey/data-cloud-demo - หลังจากชำระเงินเสร็จแล้ว ให้ไปที่โฟลเดอร์
data-cloud-demoแล้วแตกไฟล์ ZIP เพื่อเข้าถึงชิ้นงานของ Codelab
3. ตั้งค่า Lakehouse สำหรับข้อมูลลูกค้า Froyo
ในส่วนนี้ คุณจะได้สร้างแคตตาล็อกใน Lakehouse เพื่อใช้ที่เก็บข้อมูลเมตาของ Lakehouse สำหรับเวิร์กโฟลว์ โดยจะสร้างความสามารถในการทำงานร่วมกันระหว่างเครื่องมือค้นหาของคุณด้วยการเสนอแหล่งข้อมูลที่เชื่อถือได้เพียงแหล่งเดียว (SSOT) สำหรับข้อมูล Iceberg ทั้งหมด ซึ่งช่วยให้เครื่องมือค้นหา เช่น Apache Spark สามารถค้นหา อ่านข้อมูลเมตา และจัดการตาราง Iceberg ได้อย่างสอดคล้องกัน
บทบาทที่จำเป็น
ตรวจสอบว่าคุณมีบทบาท Identity and Access Management (IAM) ต่อไปนี้
roles/biglake.viewerroles/bigquery.userroles/bigquery.dataEditorroles/biglake.editorroles/biglake.metadataViewerroles/bigquery.connectionUserroles/storage.objectUserroles/storage.objectViewerroles/storage.objectCreatorroles/storage.admin
ดูข้อมูลเพิ่มเติมเกี่ยวกับการให้บทบาท IAM ได้ที่ให้บทบาท IAM
สร้างแคตตาล็อก Lakehouse ด้วยที่เก็บข้อมูล
สร้างแคตตาล็อก Lakehouse เพื่อจัดการข้อมูลเมตาสำหรับตาราง Iceberg คุณเชื่อมต่อกับแคตตาล็อกนี้ในงาน Spark เพื่อสร้างและค้นหาตาราง Iceberg
- ในคอนโซล Google Cloud ให้ไปที่ Lakehouse
- คลิกสร้างแคตตาล็อก หน้าสร้างแคตตาล็อกจะเปิดขึ้น
- สำหรับประเภทแคตตาล็อก ให้เลือกแคตตาล็อก Iceberg Rest
- สำหรับเลือกตัวเลือก Bucket แคตตาล็อก Lakehouse ให้เลือกแคตตาล็อก Bucket เดียว
- สำหรับBucket ของ Cloud Storage ในแคตตาล็อกเริ่มต้น ให้คลิกเรียกดู แล้วคลิกสร้าง Bucket ใหม่
- ในหน้าสร้าง Bucket ให้ทำดังนี้
- ในส่วนเริ่มต้นใช้งาน ให้ป้อนชื่อที่ไม่ซ้ำกันทั่วโลกซึ่งเป็นไปตามข้อกำหนดของชื่อที่เก็บข้อมูล
- ในส่วนเลือกที่จัดเก็บข้อมูล ให้เลือกภูมิภาคสำหรับประเภทสถานที่ตั้ง แล้วป้อนภูมิภาค ตัวอย่างเช่น
us-west1 - ในส่วนเลือกวิธีควบคุมการเข้าถึงออบเจ็กต์ ให้ยกเลิกการเลือกช่องทำเครื่องหมายบังคับใช้การป้องกันการเข้าถึงแบบสาธารณะใน Bucket นี้
ซึ่งช่วยให้คุณจำลองสถานการณ์ในโลกแห่งความเป็นจริงได้ เช่น การโฮสต์เนื้อหาเว็บสาธารณะหรือที่เก็บข้อมูลที่แชร์ หากไม่มีการเปลี่ยนแปลงนี้ Bucket จะบังคับใช้นโยบาย "ส่วนตัวเท่านั้น" อย่างเข้มงวด การพยายามเข้าถึงชิ้นงานจะส่งผลให้เกิดข้อผิดพลาด403ที่ถูกปฏิเสธ แม้ว่าคุณจะให้สิทธิ์สาธารณะแก่ไฟล์ได้สำเร็จก็ตาม - คลิกต่อไป > สร้าง > เลือก > ต่อไป
- สำหรับ Authentication method ให้เลือก Credential vending mode
- คลิกสร้าง ระบบจะสร้างแคตตาล็อกและเปิดหน้ารายละเอียดแคตตาล็อก
- ในส่วนวิธีการตรวจสอบสิทธิ์ ให้คลิกตั้งค่าสิทธิ์ของที่เก็บข้อมูล
- ในกล่องโต้ตอบ ให้คลิกยืนยัน ซึ่งจะเป็นการยืนยันว่าบัญชีบริการของแคตตาล็อกมีบทบาท
Storage Object Userในที่เก็บข้อมูล - จากหน้ารายละเอียดแคตตาล็อก ให้คัดลอกเส้นทาง URI ของแคตตาล็อก REST ใช้เส้นทางนี้ในระหว่างงาน "เรียกใช้ Spark job"
อัปโหลดไฟล์ Parquet ไปยัง Bucket
หากต้องการอัปโหลดไฟล์ Parquet ไปยังรูทของที่เก็บข้อมูล ให้ทำดังนี้
- ในคอนโซล Google Cloud ให้ไปที่หน้าที่เก็บข้อมูล Cloud Storage
- คลิกชื่อที่เก็บข้อมูลในรายการที่เก็บข้อมูล เช่น
acai_demo - ในแท็บออบเจ็กต์ของ Bucket ให้คลิกอัปโหลด > อัปโหลดไฟล์
- เลือกไฟล์จากโฟลเดอร์ Parquet ที่คุณโคลนไว้ในส่วนก่อนที่จะเริ่มของ Codelab นี้
- คลิกเปิด
4. ตั้งค่าเครือข่าย VPC
สร้างเครือข่าย Virtual Private Cloud (VPC) และซับเน็ตที่อนุญาตให้ทรัพยากรสื่อสารกับ Google APIs ได้โดยไม่ต้องออกไปยังอินเทอร์เน็ตสาธารณะ รวมถึงไฟร์วอลล์ที่อนุญาตให้การเข้าชมภายในไหลเวียนได้อย่างอิสระระหว่างโหนดการประมวลผลข้อมูล
- ในคอนโซล Google Cloud ให้ไปที่หน้าเครือข่าย VPC
- คลิกสร้างเครือข่าย VPC
- ป้อนชื่อเครือข่าย เช่น
acai-network - หากต้องการกำหนดค่าหน่วยการส่งข้อมูลสูงสุด (MTU) ของเครือข่าย ให้เลือกช่องทำเครื่องหมายตั้งค่า MTU โดยอัตโนมัติ
- เลือกอัตโนมัติสำหรับโหมดการสร้างซับเน็ต
- ในส่วนกฎไฟร์วอลล์ ให้เลือกช่องทำเครื่องหมายทั้งหมดสำหรับกฎไฟร์วอลล์ IPv4
- คลิกสร้าง
เปิดใช้การเข้าถึง Google แบบส่วนตัว
โหนด Dataproc แบบไม่มีเซิร์ฟเวอร์ไม่มีที่อยู่ IP สาธารณะ หากต้องการสื่อสารกับแคตตาล็อก Lakehouse และ Cloud Storage ซับเน็ตต้องเปิดใช้การเข้าถึง Google แบบส่วนตัว
- ในคอนโซล Google Cloud ให้ไปที่หน้าเครือข่าย VPC
- คลิกชื่อเครือข่ายที่มีเครือข่ายย่อยที่คุณต้องเปิดใช้การเข้าถึง Google แบบส่วนตัว เช่น
us-west1 - คลิกชื่อของเครือข่ายย่อย หน้ารายละเอียดซับเน็ตจะปรากฏขึ้น
- คลิกแก้ไข
- เลือกเปิดในส่วนการเข้าถึง Google แบบส่วนตัว
- คลิกบันทึก
5. สร้างและเรียกใช้งาน Spark
หากต้องการสร้างและค้นหาตาราง Iceberg ให้อัปโหลดงาน PySpark พร้อมคำสั่ง Spark SQL ที่จำเป็น จากนั้นเรียกใช้งานด้วย Managed Service for Spark
อัปโหลด quickstart.py ไปยัง Bucket ของ Cloud Storage
หลังจากโคลนชิ้นงานของ Codelab แล้ว ให้อัปเดตสคริปต์ quickstart.py ด้วยรายละเอียดโปรเจ็กต์ของคุณ แล้วอัปโหลดไปยัง Bucket ของ Cloud Storage
- เปิด
quickstart.pyสคริปต์ในเครื่องมือแก้ไขข้อความ - แทนที่ตัวยึดตำแหน่ง
BUCKET_NAMEในสคริปต์ด้วยชื่อ Bucket ของ Cloud Storage แล้วบันทึก - ในคอนโซล Google Cloud ให้ไปที่ที่เก็บข้อมูล Cloud Storage
- คลิกชื่อที่เก็บข้อมูล เช่น
acai_demo - ในแท็บออบเจ็กต์ ให้คลิกอัปโหลด > อัปโหลดไฟล์
- ในโปรแกรมเรียกดูไฟล์ ให้เลือกไฟล์
quickstart.pyที่อัปเดต แล้วคลิกเปิด
เรียกใช้งาน Spark
หลังจากอัปโหลดquickstart.pyสคริปต์แล้ว ให้ดำเนินการเป็นงานแบบกลุ่มของ Managed Service สำหรับ Spark
- หากต้องการกำหนดค่าตัวแปร ให้เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell
# Configuration Variables export PROJECT_ID="<PROJECT_ID>" export REGION="<REGION>" export BUCKET_NAME="<BUCKET_NAME>" export SUBNET="<SUBNET>" export LAKEHOUSE_CATALOG_ID="<LAKEHOUSE_CATALOG_ID>" export CATALOG_URI_ID="<CATALOG_URI_ID>"- LAKEHOUSE_CATALOG_ID: ชื่อของทรัพยากรแคตตาล็อก Lakehouse ที่มีไฟล์แอปพลิเคชัน PySpark เช่น
acai_demo - PROJECT_ID: รหัสโปรเจ็กต์ Google Cloud
- REGION: ภูมิภาคที่จะเรียกใช้ภาระงานแบบกลุ่มของ Managed Service for Spark เช่น
us-west1 - BUCKET_NAME: ชื่อ Bucket ของ Cloud Storage เช่น
acai_demo - SUBNET: ชื่อซับเน็ต VPC เช่น
acai-network - CATALOG_URI_ID: รหัส URI ของแคตตาล็อก Lakehouse ที่คุณคัดลอกเมื่อสร้างแคตตาล็อก Lakehouse ด้วย Bucket เช่น
https://biglake.googleapis.com/iceberg/v1/restcatalog
- LAKEHOUSE_CATALOG_ID: ชื่อของทรัพยากรแคตตาล็อก Lakehouse ที่มีไฟล์แอปพลิเคชัน PySpark เช่น
- ใน Cloud Shell ให้เรียกใช้ชื่องานแบบกลุ่มของ Managed Service for Spark ต่อไปนี้โดยใช้สคริปต์
quickstart.pygcloud dataproc batches submit pyspark gs://${BUCKET_NAME}/quickstart.py \ --project=${PROJECT_ID} \ --region=${REGION} \ --subnet=${SUBNET} \ --version=2.2 \ --properties="\ spark.sql.defaultCatalog=${LAKEHOUSE_CATALOG_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}=org.apache.iceberg.spark.SparkCatalog,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.type=rest,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.uri=${CATALOG_URI_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.warehouse=gs://${BUCKET_NAME},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.io-impl=org.apache.iceberg.gcp.gcs.GCSFileIO,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.x-goog-user-project=${PROJECT_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\ spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest-metrics-reporting-enabled=false,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.X-Iceberg-Access-Delegation=vended-credentials,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token"All tables registered successfully! Batch [126fa2226a904d2e944c8eecbe0b1840] finished. metadata: '@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata batch: projects/PROJECT_ID/locations/REGION/batches/126fa2226a904d2e944c8eecbe0b1840 batchUuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff createTime: '2026-04-09T13:17:26.222727Z' description: Batch labels: goog-dataproc-batch-id: 126fa2226a904d2e944c8eecbe0b1840 goog-dataproc-batch-uuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-drz-resource-uuid: batch-3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-location: REGION operationType: BATCH name: projects/PROJECT_ID/regions/REGION/operations/47bc59e8-5082-3af9-89a0-22289aa5f4b9
6. สืบค้นตารางจาก BigQuery
การเรียกใช้งาน Spark Batch Job ได้สำเร็จหมายความว่าคุณได้ใช้ Managed Service สำหรับ Spark Serverless เป็นเครื่องมือประมวลผลแบบกระจายเพื่อลงทะเบียนหลายตาราง โดยแต่ละตารางจะอยู่ในไฟล์ Parquet ภายใน Lakehouse Metastore การลงทะเบียนนี้ช่วยให้ Google Cloud สามารถถือว่าไฟล์ดิบใน Cloud Storage เป็นตารางที่มีโครงสร้างและมีประสิทธิภาพสูง
ขั้นตอนต่อไปนี้จะแนะนําให้คุณยืนยันว่ามีการซิงค์ข้อมูลเมตาอย่างถูกต้อง เพื่อให้มั่นใจว่าข้อมูลของคุณจะไม่เพียงจัดเก็บอย่างปลอดภัย แต่ยังค้นหาและค้นหาผ่านอินเทอร์เฟซ BigQuery ได้อย่างเต็มที่
- ในคอนโซล Google Cloud ให้ไปที่ BigQuery
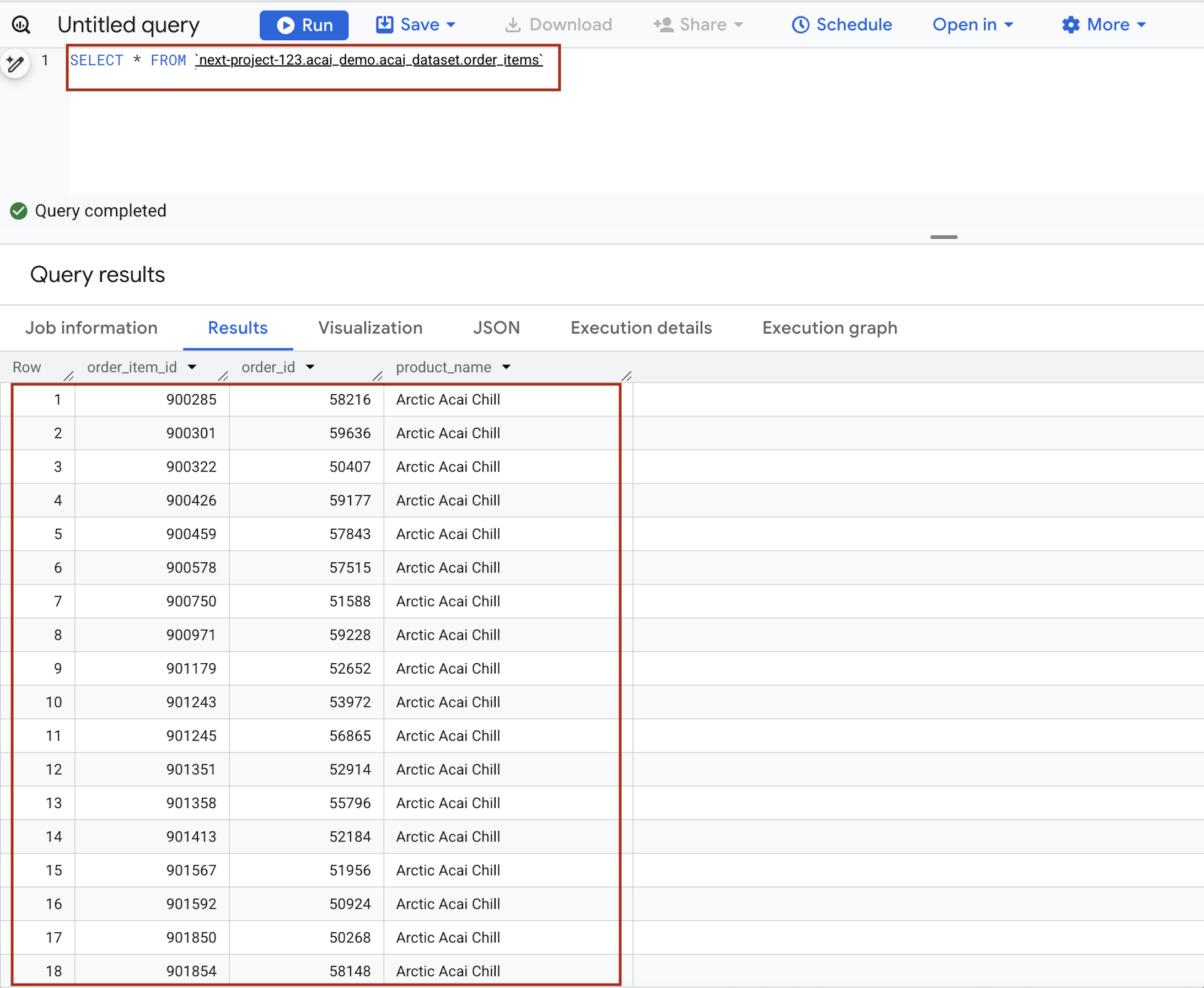
- ป้อนคำสั่งต่อไปนี้ในตัวแก้ไขคำค้นหา โดยคำค้นหาจะใช้ไวยากรณ์
project.namespace.dataset.tableSELECT * FROM `<PROJECT_ID>.<NAMESPACE>.<ICEBERG_DATASET>.<ICEBERG_TABLE>`PROJECT_ID.acai_demo.acai_dataset.order_items.
แทนที่ข้อมูลต่อไปนี้- PROJECT_ID: รหัสโปรเจ็กต์ Google Cloud
- NAMESPACE: เนมสเปซที่สร้างในขั้นตอนก่อนหน้าเป็นผลมาจากงาน Spark ซึ่งคุณจะดูได้ในหน้าเครื่องมือสำรวจออบเจ็กต์ BigQuery เช่น
acai_demo - ICEBERG_DATASET: ชื่อชุดข้อมูลภายในแคตตาล็อก Iceberg เช่น
acai_dataset - ICEBERG_TABLE: ชื่อตารางภายในชุดข้อมูล Iceberg เช่น
order_items
- คลิกเรียกใช้ ผลการค้นหาจะแสดงข้อมูลที่คุณแทรกด้วยงาน Spark
7. ตั้งค่าไฟล์ข้อมูลสินค้าที่ไม่มีโครงสร้าง
ในส่วนนี้ คุณจะสร้างโครงสร้างองค์กรภายใน BigQuery เพื่อจัดเก็บข้อมูลสูตรและซัพพลายเออร์ของ Froyo โดยเฉพาะรายละเอียดสินค้า Froyo นอกจากนี้ยังสร้างการเชื่อมต่อทรัพยากรระบบคลาวด์ ซึ่งทำหน้าที่เป็น "บริดจ์" ที่ปลอดภัยเพื่อให้ BigQuery อ่านไฟล์จากแหล่งที่มาภายนอก เช่น Cloud Storage ได้
สร้าง Bucket และอัปโหลดไฟล์รายละเอียด Froyo
สร้างและอัปโหลดไฟล์ซัพพลายเออร์และสูตรอาหารไปยังBucket ใน Cloud Storage
- ในคอนโซล Google Cloud ให้ไปที่หน้าที่เก็บข้อมูล Cloud Storage
- คลิกสร้าง
- ในหน้าสร้าง Bucket ให้ป้อนข้อมูล Bucket หลังจากทำตามแต่ละขั้นตอนต่อไปนี้ ให้คลิกต่อไปเพื่อไปยังขั้นตอนถัดไป
- ป้อนชื่อที่เก็บข้อมูลในส่วนเริ่มต้นใช้งาน เช่น
acai_pdfs - ในส่วนเลือกตำแหน่งที่จะจัดเก็บข้อมูล ให้เลือกภูมิภาค แล้วป้อนภูมิภาค เช่น
us-west1 - ในส่วนเลือกวิธีควบคุมการเข้าถึงออบเจ็กต์ ให้ยกเลิกการเลือกช่องทำเครื่องหมายบังคับใช้การป้องกันการเข้าถึงแบบสาธารณะใน Bucket นี้
- คลิกสร้าง
- ในรายการ Bucket ให้คลิก Bucket ที่คุณสร้างขึ้น เช่น
acai_pdfs - ในแท็บออบเจ็กต์ของที่เก็บข้อมูล ให้คลิกอัปโหลด > อัปโหลดโฟลเดอร์
- เลือก
recipesโฟลเดอร์ที่คุณแตกไฟล์ในส่วนก่อนที่จะเริ่มของ Codelab นี้ - คลิกอัปโหลด
- ทำซ้ำขั้นตอนการอัปโหลดสำหรับโฟลเดอร์
suppliers
สร้างการเชื่อมต่อ
สร้างการเชื่อมต่อทรัพยากรระบบคลาวด์ ซึ่งจะสร้างบัญชีบริการที่ไม่ซ้ำกันซึ่งทำหน้าที่เป็น "บัตรประจำตัว" ของ BigQuery เพื่อเข้าถึงไฟล์ภายนอก
- ไปที่หน้า BigQuery
- คลิกExplorer ในแผงด้านซ้าย หากไม่เห็นแผงด้านซ้าย ให้คลิกขยายแผงด้านซ้ายเพื่อเปิดแผง
- ในบานหน้าต่าง Explorer ให้ขยายชื่อโปรเจ็กต์ แล้วคลิกการเชื่อมต่อ
- ในหน้าการเชื่อมต่อ ให้คลิกสร้างการเชื่อมต่อ
- สำหรับประเภทการเชื่อมต่อ ให้เลือก Vertex AI โมเดลระยะไกล ฟังก์ชันระยะไกล BigLake และ Spanner (ทรัพยากรระบบคลาวด์)
- ป้อนชื่อรหัสการเชื่อมต่อในช่องรหัสการเชื่อมต่อ เช่น
acai_pdf_connectionอย่าลืมจดรหัสดังกล่าวไว้เนื่องจากคุณจะต้องใช้เมื่อตั้งค่าการสแกนข้อมูลในภายหลังใน Codelab นี้ - ตั้งค่าประเภทสถานที่ตั้งเป็นภูมิภาค แล้วเลือกภูมิภาค เช่น
us-west1การเชื่อมต่อควรอยู่ร่วมกับทรัพยากรอื่นๆ เช่น ชุดข้อมูล - คลิกสร้างการเชื่อมต่อ
- คลิกไปที่การเชื่อมต่อ
- ในแผงข้อมูลการเชื่อมต่อ ให้คัดลอกรหัสบัญชีบริการเพื่อใช้ในขั้นตอนถัดไป บัญชีบริการมีลักษณะคล้ายกับ
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com
จัดการสิทธิ์เข้าถึงบัญชีบริการ
ให้สิทธิ์เข้าถึงบัญชีบริการเพื่อให้ Lakehouse อ่าน PDF ได้
- ไปที่หน้า IAM และผู้ดูแลระบบ
- คลิกให้สิทธิ์เข้าถึง กล่องโต้ตอบเพิ่มผู้รับสิทธิ์จะเปิดขึ้น
- ในช่องผู้ใช้หลักรายใหม่ ให้ป้อนรหัสบัญชีบริการที่คัดลอกไว้ก่อนหน้านี้
- ในช่องเลือกบทบาท ให้เพิ่มบทบาทต่อไปนี้
roles/storage.objectUserroles/storage.objectViewerroles/bigquery.userroles/bigquery.dataEditorroles/aiplatform.userroles/storage.adminroles/dataproc.serviceAgent
- คลิกบันทึก
ดูข้อมูลเพิ่มเติมเกี่ยวกับบทบาท IAM ใน BigQuery ได้ที่บทบาทและสิทธิ์ที่กำหนดไว้ล่วงหน้า
8. จัดการสิทธิ์สำหรับงาน DataScan
สร้างบัญชีบริการ (ข้อมูลประจำตัว) ที่เฉพาะเจาะจงสำหรับ Spark และ Dataform จากนั้นให้สิทธิ์แก่บัญชีเหล่านั้นพร้อมกับตัวแทนบริการอัตโนมัติของ Google ซึ่งเป็นสิทธิ์ที่จำเป็นในการอ่านที่เก็บข้อมูล เรียกใช้งาน BigQuery และใช้ Vertex AI เพื่อการค้นพบ
สิทธิ์เข้าถึง IAM สำหรับ Spark และ Dataform
- ในคอนโซล Google Cloud ให้ไปที่หน้าสร้างบัญชีบริการ
- หากไม่ได้เลือก ให้เลือกโปรเจ็กต์ Google Cloud
- คลิกสร้างบัญชีบริการ
- ป้อนชื่อบัญชีบริการ เช่น
sa-spark-stg1คอนโซล Google Cloud จะสร้างรหัสบัญชีบริการตามชื่อนี้ แก้ไขรหัสหากจำเป็น คุณจะเปลี่ยนรหัสในภายหลังไม่ได้ - หากต้องการตั้งค่าการควบคุมการเข้าถึง ให้คลิกสร้างและดำเนินการต่อ แล้วทำตามขั้นตอนถัดไป
- เลือกบทบาท IAM ต่อไปนี้เพื่อมอบให้กับบัญชีบริการในโปรเจ็กต์
roles/dataproc.workerroles/storage.objectUserroles/bigquery.dataEditorroles/bigquery.jobUserroles/aiplatform.userroles/dataplex.discoveryPublishingServiceAgent
- เมื่อเพิ่มบทบาทเสร็จแล้ว ให้คลิกต่อไป
- คลิกเสร็จสิ้นเพื่อสร้างบัญชีบริการให้เสร็จสมบูรณ์
สิทธิ์การเชื่อมต่อ BigQuery สำหรับการเข้าถึงแคตตาล็อกความรู้
- ในคอนโซล Google Cloud ให้ไปที่หน้าที่เก็บข้อมูล Cloud Storage
- ในรายการ Bucket ให้คลิกชื่อ Bucket ที่คุณสร้างขึ้นสำหรับ Froyo เช่น
acai_pdfs - ในแท็บสิทธิ์ ให้คลิกให้สิทธิ์เข้าถึง กล่องโต้ตอบ "เพิ่มหลักการ" จะปรากฏขึ้น
- ในช่องผู้ใช้หลักรายใหม่ ให้ป้อนรหัสบัญชีบริการ BigQuery บัญชีบริการมีลักษณะคล้ายกับ
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com - เลือกบทบาทต่อไปนี้จากเมนูแบบเลื่อนลงเลือกบทบาท
roles/storage.objectUserroles/dataplex.serviceAgentroles/dataplex.securityAdminroles/aiplatform.serviceAgentroles/dataplex.discoveryPublishingServiceAgent
- คลิกบันทึก
9. ตั้งค่า Knowledge Catalog
สร้างแคตตาล็อกความรู้เพื่อรวมข้อมูลที่เกี่ยวข้องกับ Froyo และทำให้การค้นหาไฟล์ที่ไม่มีโครงสร้าง (เช่น สูตรอาหารและซัพพลายเออร์ในรูปแบบ PDF) เป็นแบบอัตโนมัติ
สร้าง DataScan ผ่าน curl
ในส่วนนี้ คุณจะสร้างการสแกนสำหรับ Bucket ของ Cloud Storage (เช่น acai_pdfs) โดยการเพิ่ม datascan_ID และชี้ไปยังชุดข้อมูล BigQuery หลังจากนั้นแคตตาล็อกความรู้จะสร้างรายการสำหรับไฟล์ PDF ใน BigQuery โดยอัตโนมัติ
- หากต้องการสแกน PDF (ซัพพลายเออร์และสูตรอาหาร) ให้เรียกใช้คำสั่งต่อไปนี้
# 1. Set your variables PROJECT_ID="<PROJECT_ID>" REGION="<REGION>" ENV_SUFFIX="stg1" DATASCAN_ID="froyo-profile-${ENV_SUFFIX}" BUCKET_NAME="<BUCKET_NAME>" # 2. Set this to the Name of the connection you created in Step 7 CONNECTION_ID="<CONNECTION_ID_NAME>" # 3. Define the API Endpoint DATAPLEX_API="dataplex.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}" # 4. Create the DataScan via CURL echo "Creating Dataplex DataScan: ${DATASCAN_ID}..." curl -X POST "https://$DATAPLEX_API/dataScans?dataScanId=${DATASCAN_ID}" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d '{ "data": { "resource": "//storage.googleapis.com/projects/'"${PROJECT_ID}"'/buckets/'"${BUCKET_NAME}"'" }, "executionSpec": { "trigger": { "on_demand": {} } }, "dataDiscoverySpec": { "bigqueryPublishingConfig": { "tableType": "BIGLAKE", "connection": "projects/'"${PROJECT_ID}"'/locations/'"${REGION}"'/connections/'"${CONNECTION_ID}"'" }, "storageConfig": { "unstructuredDataOptions": { "entity_inference_enabled": true } } } }' - คำสั่ง
curlจะแสดงผลการสแกนข้อมูลแคตตาล็อกความรู้ ซึ่งคล้ายกับรูปภาพต่อไปนี้
เรียกใช้งาน
เรียกใช้คำสั่งต่อไปนี้
gcloud dataplex datascans run $DATASCAN_ID --location=$REGION
อธิบายงาน
หากต้องการอธิบายงาน ให้เรียกใช้คำสั่งต่อไปนี้
gcloud dataplex datascans describe $DATASCAN_ID --location=$REGION
ลบงาน Datascan
หากการสแกนทำงานนานกว่า 10 นาที หรือหากสถานะของงานยังคงเป็นรอดำเนินการเป็นเวลานานโดยไม่เปลี่ยนเป็นกำลังทำงาน อาจเป็นเพราะทรัพยากรในภูมิภาคไม่พร้อมใช้งานชั่วคราว หากเกิดกรณีนี้ คุณสามารถเรียกใช้คำสั่งต่อไปนี้เพื่อลบงาน แล้วลองสร้างและเรียกใช้อีกครั้ง บางครั้งการเรียกใช้ครั้งแรกอาจล้มเหลวอย่างรวดเร็วพร้อมข้อผิดพลาด เช่น unable to acquire necessary resources
gcloud dataplex datascans delete $DATASCAN_ID --location=$REGION
ดูสถานะของงาน
หากต้องการตรวจสอบสถานะของงาน ให้ทำดังนี้
- ในคอนโซล Google Cloud ให้ไปที่หน้าการดูแลจัดการข้อมูลเมตา
- ในแท็บการค้นพบ Cloud Storage ให้คลิกชื่อการสแกนการค้นพบ
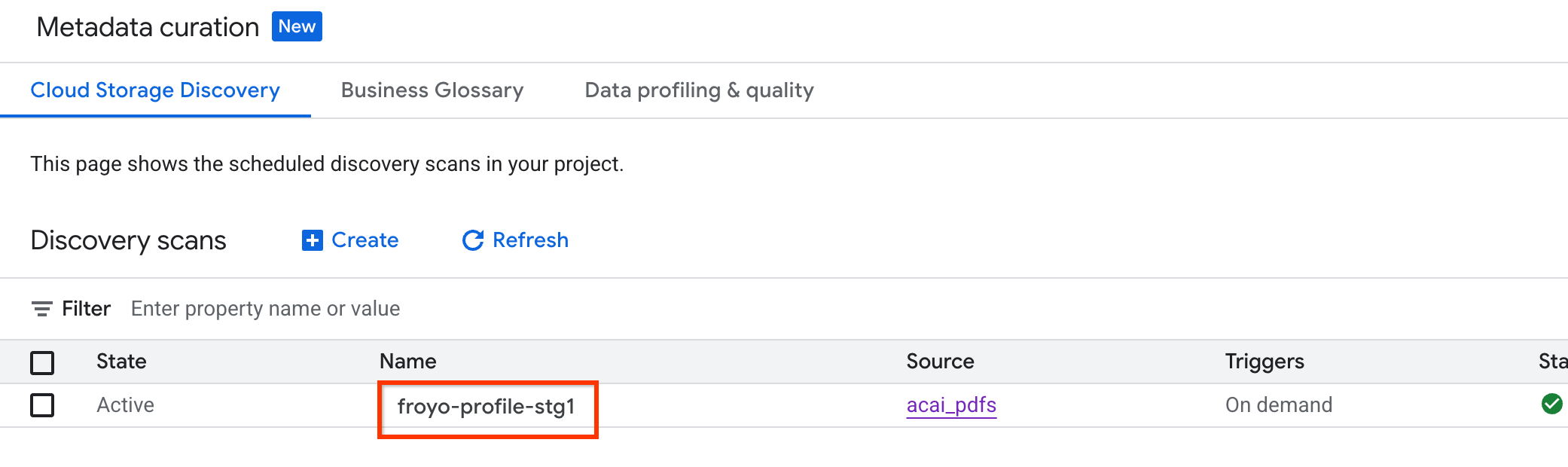
- ในหน้ารายละเอียดการสแกน คุณจะดูสถานะของงานได้
- เมื่อการดำเนินการเสร็จสิ้น ให้ตรวจสอบว่ามีชุดข้อมูลที่เผยแพร่ (เช่น
acai_pdfs_discovered_003) ที่คุณสร้างขึ้นโดยใช้คำสั่งcurlหรือไม่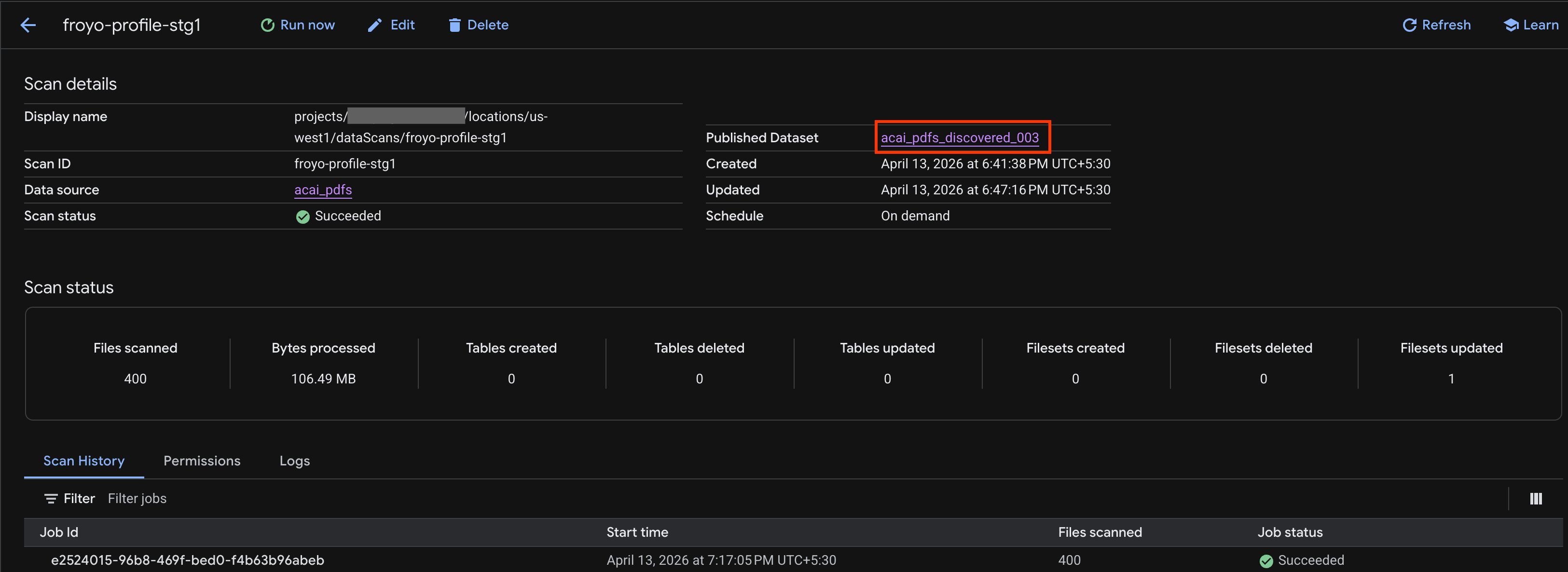
ดูตารางออบเจ็กต์
หากต้องการดูตารางออบเจ็กต์ที่สร้างขึ้นหลังจากงานการค้นพบ ให้ทำดังนี้
- ในคอนโซล Google Cloud ให้ไปที่ BigQuery
- คลิกชุดข้อมูล แล้วเลือกชุดข้อมูลที่เผยแพร่ซึ่งสร้างไว้ในขั้นตอนก่อนหน้า เช่น
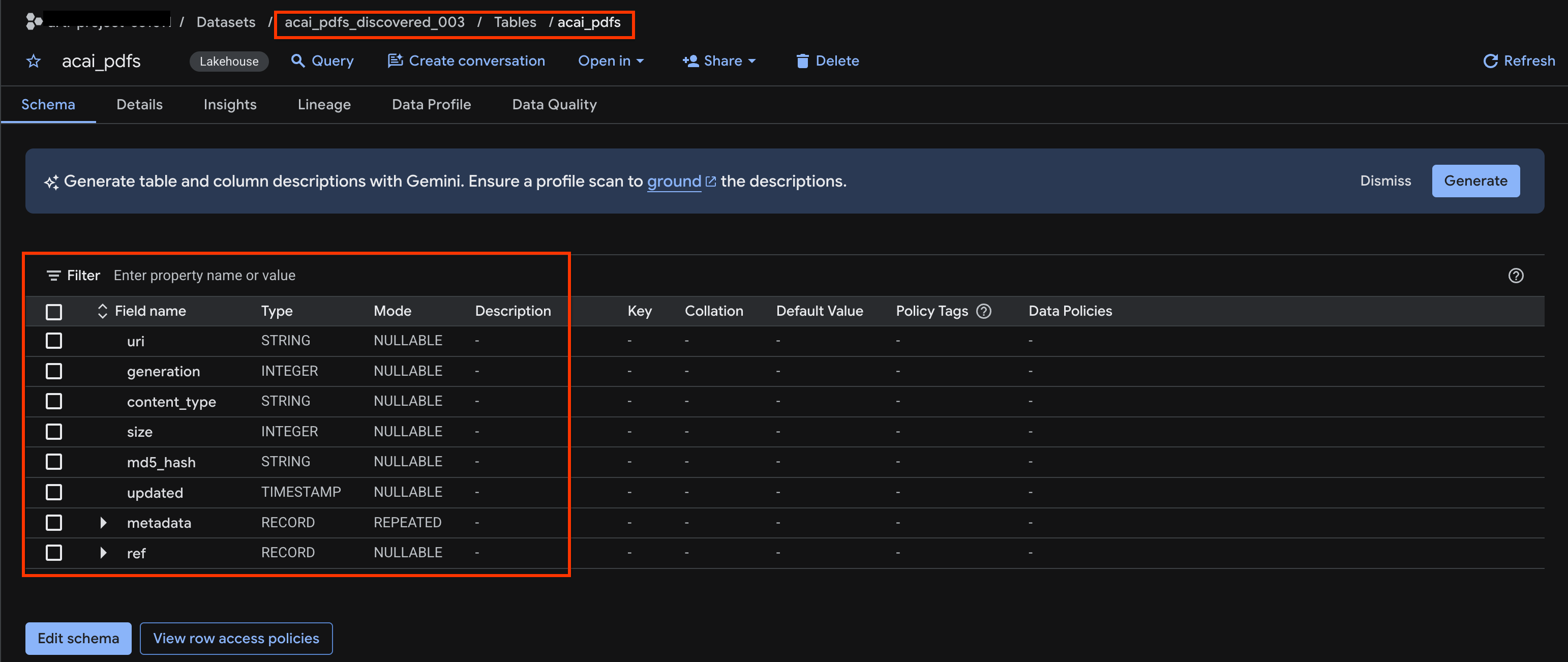
acai_pdfs_discovered_003 - หากต้องการดูตารางออบเจ็กต์ ให้คลิกรหัสตาราง เช่น
acai_pdfs - ตารางออบเจ็กต์ที่ได้จะมีลักษณะดังรูปภาพต่อไปนี้
10. การแยกความหมาย
คุณจะอนุมานและแยกตารางที่มีโครงสร้าง ออบเจ็กต์ฐานข้อมูลอื่นๆ และความสัมพันธ์สำหรับตารางออบเจ็กต์ที่ไม่มีโครงสร้างนี้ที่คุณสร้างขึ้นในขั้นตอนก่อนหน้า โดยคุณจะต้องใช้ฟีเจอร์ข้อมูลเชิงลึกของแคตตาล็อกความรู้เพื่อสร้างคำสั่ง SQL สำหรับดึง Structured Data จากตารางที่ไม่มีโครงสร้าง
- ในคอนโซล Google Cloud ให้ไปที่หน้าการค้นหาแคตตาล็อกความรู้
- ค้นหาตารางชุดข้อมูลที่ต้องการดูข้อมูลเชิงลึก เช่น
acai_pdfs_discovered_003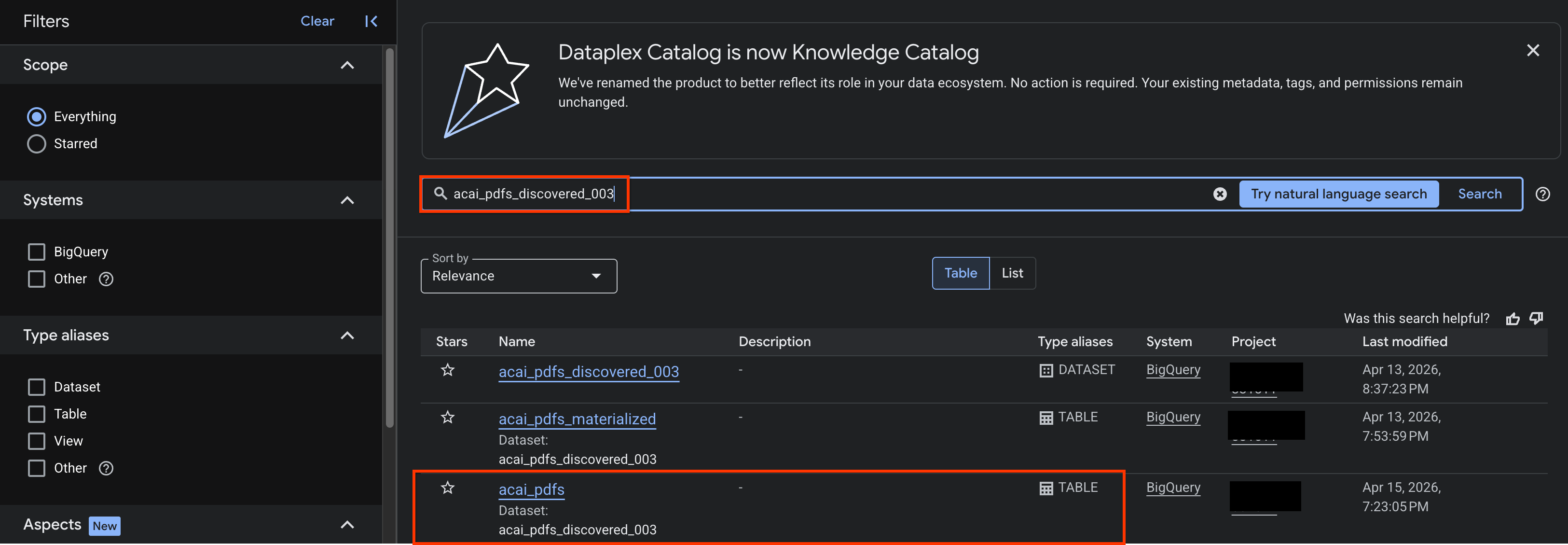
- ในผลการค้นหา ให้คลิกตารางเพื่อเปิดหน้าข้อมูล
- คลิกแท็บข้อมูลเชิงลึก หากแท็บว่างเปล่า แสดงว่าระบบยังไม่ได้สร้างข้อมูลเชิงลึกสำหรับตารางนี้ การสร้างข้อมูลเชิงลึกอาจใช้เวลา 15-25 นาที
- เมื่อเห็นข้อมูลเชิงลึกแล้ว ให้คลิกดึงข้อมูล > ดึงข้อมูลด้วย SQL
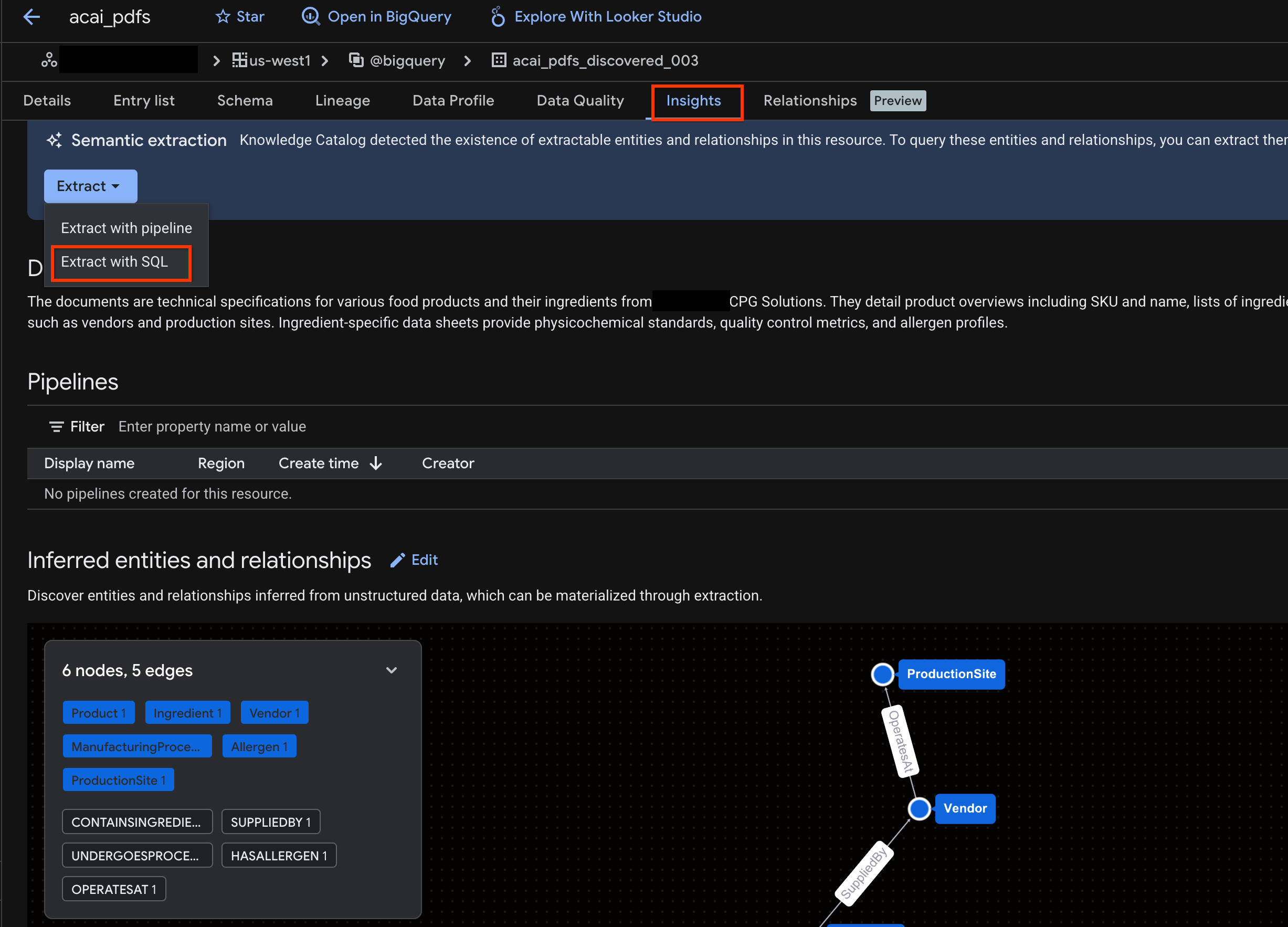
- ในหน้าดึงข้อมูลด้วย SQL ให้ป้อนชุดข้อมูลสำหรับปลายทาง เช่น
acai_pdfs_discovered_003 - คลิกแยก ซึ่งจะเปิดเครื่องมือแก้ไข BigQuery พร้อมกับการค้นหาที่โหลดไว้
- คลิกเรียกใช้ ขั้นตอนนี้จะสร้างชุดคำสั่งและอาจใช้เวลาสักครู่ในการเรียกใช้ให้เสร็จสมบูรณ์
- เมื่อการค้นหาเสร็จสมบูรณ์ คุณจะเห็นผลลัพธ์ต่อไปนี้
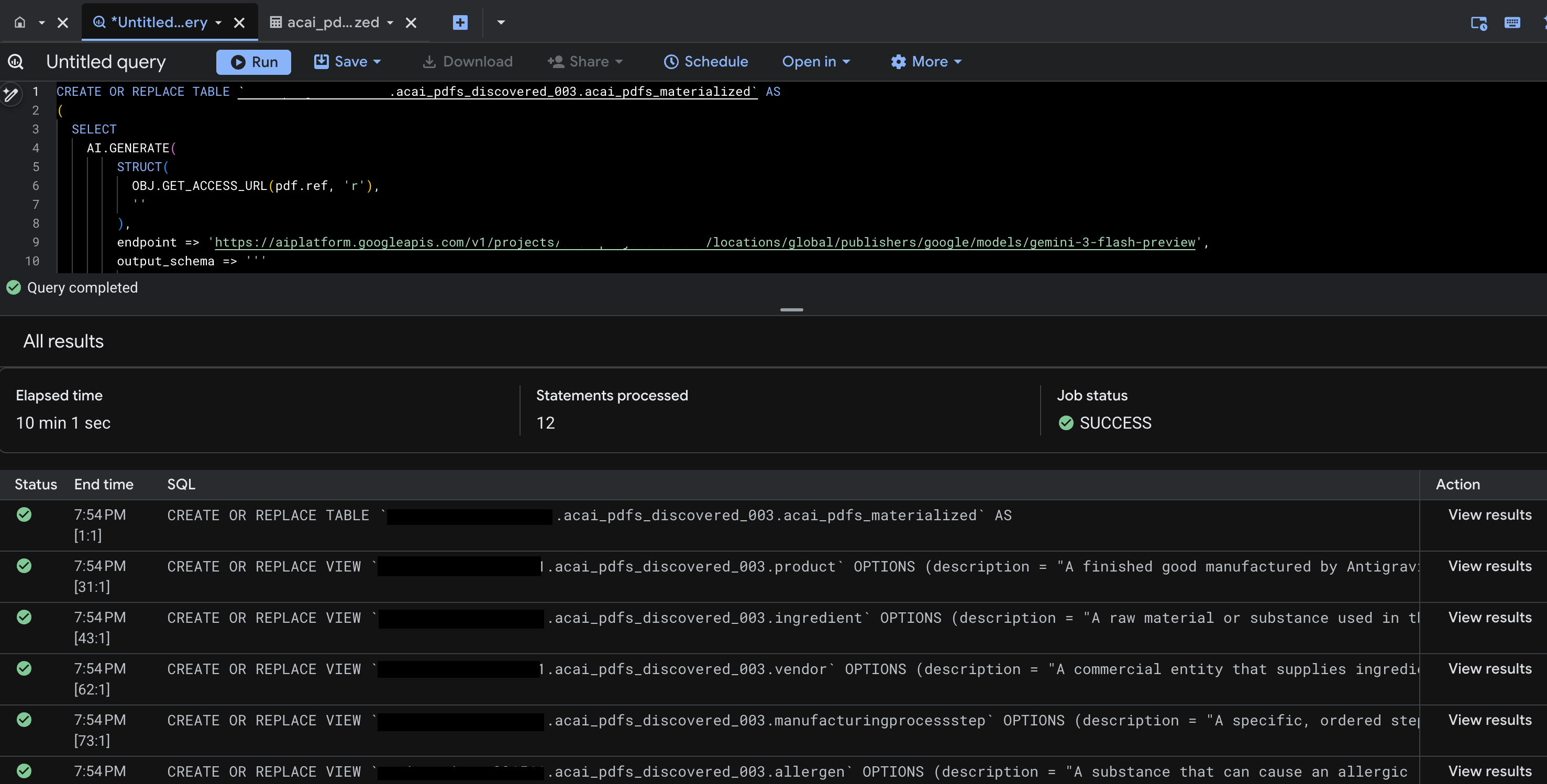
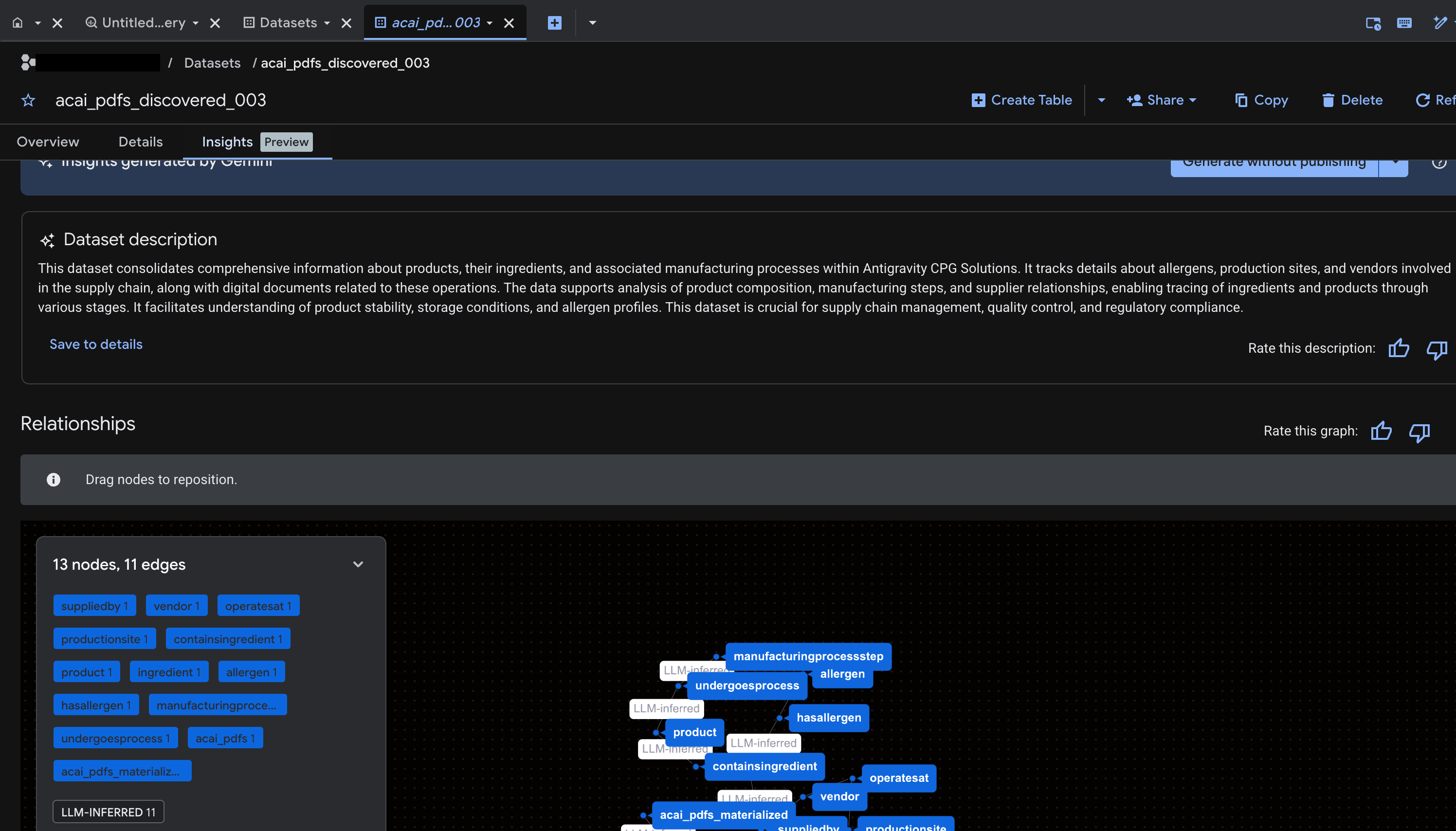
- ไปที่ BigQuery แล้วคลิกชุดข้อมูล (เช่น
acai_pdfs_discovered_003) ระบบจะสร้างออบเจ็กต์ฐานข้อมูลที่มีโครงสร้างชุดใหม่ในชุดข้อมูลที่คุณเลือกในขั้นตอนที่ 6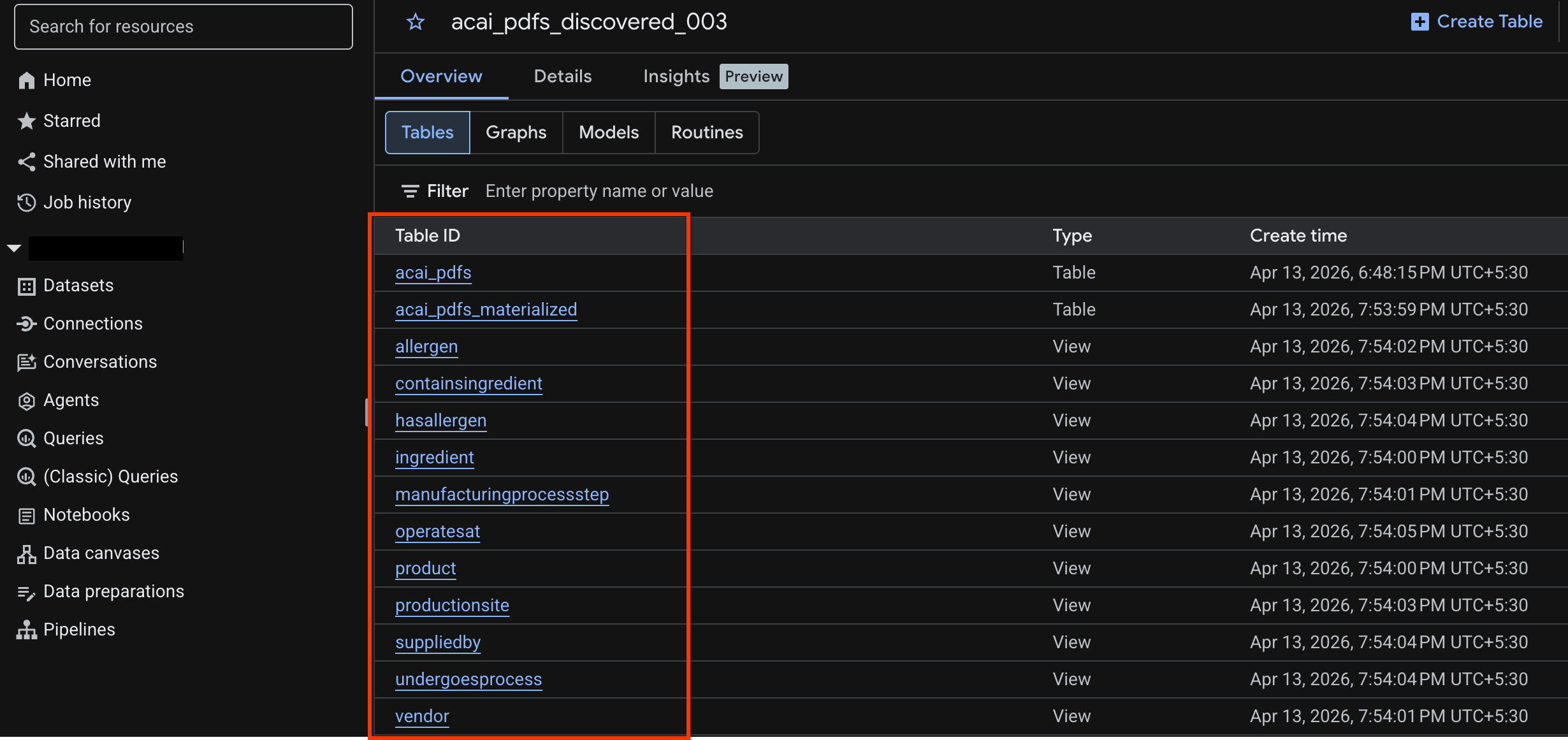
สร้างข้อมูลเชิงลึกสำหรับออบเจ็กต์ใน BigQuery
หากต้องการสร้างข้อมูลเชิงลึกสำหรับชุดข้อมูล BigQuery คุณต้องเข้าถึงชุดข้อมูลใน BigQuery โดยใช้ BigQuery Studio
- ในคอนโซล Google Cloud ให้ไปที่ BigQuery Studio
- ในแผง Explorer ให้เลือกโปรเจ็กต์ แล้วไปที่ชุดข้อมูลที่ต้องการสร้างข้อมูลเชิงลึก
- คลิกแท็บข้อมูลเชิงลึก
- หากเห็นปุ่มเปิดใช้ API ให้คลิกเพื่อเปิดใช้ Gemini สำหรับ Google Cloud ซึ่งจะเปิดหน้าต่างเปิดใช้ฟีเจอร์หลัก
- ในส่วน API ฟีเจอร์หลัก ให้คลิกเปิดใช้สำหรับ Gemini สำหรับ Google Cloud API และ BigQuery Unified API จากนั้นคลิกถัดไป
- ในส่วนสิทธิ์ (ไม่บังคับ) ให้มอบบทบาท IAM แก่ผู้ใช้หลักหากจำเป็น แล้วคลิกถัดไป
- หากต้องการสร้างข้อมูลเชิงลึกและเผยแพร่ไปยังแคตตาล็อกความรู้ ให้คลิกสร้างและเผยแพร่
- เมื่อเผยแพร่แล้ว คุณจะดูข้อมูลเชิงลึกในแท็บได้
11. ตั้งค่า IDE สำหรับการวิเคราะห์ข้อมูลแบบเอเจนต์
ส่วนขยายชุดเครื่องมือ Data Agent ของ Google Cloud สำหรับ Visual Studio Code เป็นส่วนขยาย IDE สำหรับนักวิทยาศาสตร์ข้อมูลและวิศวกรข้อมูล ซึ่งช่วยให้คุณเชื่อมต่อและทำงานกับทรัพยากรและข้อมูล Google Data Cloud ได้โดยตรงจาก IDE ดูข้อมูลเพิ่มเติมได้ที่ภาพรวมของส่วนขยาย Data Agent Kit สำหรับ VS Code
ส่วนขยาย Data Agent Kit สำหรับ VS Code มีประโยชน์เมื่อคุณต้องการทำสิ่งต่อไปนี้
- สร้าง ทดสอบ ตรวจสอบ และทำให้ใช้งานได้ไปป์ไลน์ข้อมูลที่พร้อมใช้งานจริง เช่น Spark ETL หรือ BigQuery ETL ได้โดยตรงจาก VS Code
- สํารวจข้อมูล สร้างไปป์ไลน์การฝึก ระบุโมเดล ML ที่ดีที่สุด และทำให้ใช้งานได้โมเดลไปยังปลายทางการผลิตโดยใช้ความช่วยเหลือจาก AI
- เชื่อมต่อกับแหล่งข้อมูลที่เชื่อถือได้ สร้างโมเดลข้อมูลที่มีประสิทธิภาพสูง และเผยแพร่แดชบอร์ดแบบอินเทอร์แอกทีฟสำหรับผู้มีส่วนเกี่ยวข้องทางธุรกิจ
ติดตั้งส่วนขยาย Data Agent Kit สำหรับ VS Code
- เปิด VS Code
- ติดตั้ง Google Cloud CLI ดูข้อมูลเพิ่มเติมได้ที่ติดตั้ง Google Cloud CLI
- ติดตั้งส่วนขยาย Data Agent Kit สำหรับ VS Code
- ทําตามกระบวนการเริ่มต้นใช้งานส่วนขยายให้เสร็จสมบูรณ์ ซึ่งคุณจะต้องทําสิ่งต่อไปนี้
- ลงชื่อเข้าใช้ส่วนขยาย
- ติดตั้งทักษะ เซิร์ฟเวอร์ MCP
- โหลดซ้ำหรือรีสตาร์ทหน้าต่างเมื่อคุณเริ่มต้นใช้งานเสร็จแล้ว ดูข้อมูลเพิ่มเติมได้ที่ตั้งค่าและกำหนดค่าส่วนขยาย Data Agent Kit สำหรับ VS Code
- หลังจาก IDE โหลดซ้ำแล้ว ให้คลิกไอคอน Google Data Cloud ในแผงการนำทาง ไปที่การตั้งค่า และตรวจสอบว่าคุณได้ตั้งค่ารหัสโปรเจ็กต์และภูมิภาค (
us-west1) อย่างถูกต้องในการตั้งค่าทั่วไป
ตั้งค่าพื้นที่ทำงานใน VS Code
- เปิด VS Code แล้วเลือกไฟล์ > เปิดโฟลเดอร์ > โฟลเดอร์ใหม่
- สร้างโฟลเดอร์ใหม่ชื่อ
acai_testแล้วคลิกเปิด ตอนนี้ VS Code จะถือว่าโฟลเดอร์ที่คุณเปิดเป็นพื้นที่ทำงาน - ในกล่องโต้ตอบความน่าเชื่อถือของ Workspace ให้เลือกใช่ ฉันเชื่อถือผู้เขียนเพื่อเปิดใช้ฟีเจอร์ทั้งหมดในพื้นที่ทำงาน
- สร้างโฟลเดอร์
.githubในพื้นที่ทำงานacai_test - สร้างไฟล์ใหม่
copilot-instructions.mdในโฟลเดอร์.githubแล้วป้อนกฎต่อไปนี้## 1. Project Context - **Project ID**: <PROJECT_ID> - **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors. - **Documentation**: Raw PDF documents detailing flavors and ingredients are stored in Google Cloud Storage at `gs://<BUCKET_NAME>`. ## 2. Execution & Data Processing Rules - **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `<BQ_DATASET_NAME>` (referred to as the Knowledge Catalog). - **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the dataset `<DATASET_ID>`. When you are referencing a dataset, ensure you are using it with the project ID (`<PROJECT_ID>`) and namespace prefix `<NAMESPACE_NAME>`. For example, to query order table in this dataset you should use `<PROJECT_ID>.<NAMESPACE>.<DATASET_ID>.orders`. - **CRITICAL RULE - Data Joins between BigQuery dataset and Iceberg dataset**: ANY task requiring a join or integration between the BigQuery datasets `<DATASET_ID>` of the PDF data and the `<DATASET_ID>` of the customer data MUST be executed using **Spark Notebooks**. - **CRITICAL RULE - Notebook Kernel**: Every Spark notebook utilized MUST exclusively be configured to run on the Serverless Session template `iceberg-federation-template` as its kernel. - **CRITICAL RULE - Data Science**: ANY data science, machine learning, or advanced analytical task MUST be performed strictly within **Spark Notebooks** using the aforementioned setup. - สร้างไฟล์ใหม่ขึ้นมาอีกไฟล์
template.yamlในพื้นที่ทำงานacai_testแล้วป้อนข้อมูลต่อไปนี้ในไฟล์labels: client: "vscode" jupyterSession: displayName: "iceberg-federation-template" kernel: "PYTHON" environmentConfig: executionConfig: serviceAccount: "sa-spark-dev1@<PROJECT_ID>.iam.gserviceaccount.com" subnetworkUri: "projects/<PROJECT_ID>/regions/<REGION>/subnetworks/<SUBNET_NAME>" runtimeConfig: version: "2.3" properties: # This enables the secure proxy URL you were looking for dataproc.tier: "premium" spark.dataproc.engine: "lightningEngine" spark.dataproc.lightningEngine.runtime: "native" spark.memory.offHeap.enabled: "true" spark.memory.offHeap.size: "1g" spark.executor.memory: "4g" "dataproc.component.gateway.enabled": "true" "dataproc.jupyter.listen.all.interfaces": "true" "spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" "spark.sql.defaultCatalog": "<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>": "org.apache.iceberg.spark.SparkCatalog" "spark.sql.catalog.<CATALOG_NAME>.type": "rest" "spark.sql.catalog.<CATALOG_NAME>.uri": "<CATALOG_URI_ID>" "spark.sql.catalog.<CATALOG_NAME>.warehouse": "bl://projects/<PROJECT_ID>/catalogs/<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>.rest.auth.type": "org.apache.iceberg.gcp.auth.GoogleAuthManager" - ใน VS Code ให้คลิกเทอร์มินัล แล้วเรียกใช้คำสั่งต่อไปนี้เพื่อนำเข้าไฟล์
template.yamlเป็นเทมเพลตเซสชัน เอเจนต์จะใช้เทมเพลตนี้ในภายหลังเพื่อสร้างเซสชัน Sparkgcloud beta dataproc session-templates import iceberg-federation-template \ --source=template.yaml \ --location=<REGION>REGIONด้วยภูมิภาคของคุณ
12. ทำการวิเคราะห์ข้อมูลแบบเอเจนต์
- ในตัวแก้ไขโค้ด VS Code ให้คลิกสลับแชท
- สำหรับกำหนดค่าตัวแทนที่กำหนดเอง ให้เลือกตัวแทน
- ในแผงโมเดลการค้นหา ให้คลิกจัดการโมเดลภาษา
- ในหน้าโมเดลภาษา ให้คลิกเพิ่มโมเดล
- เลือก Google จากรายการ แล้วกด Enter เพื่อยืนยันข้อมูลที่ป้อน
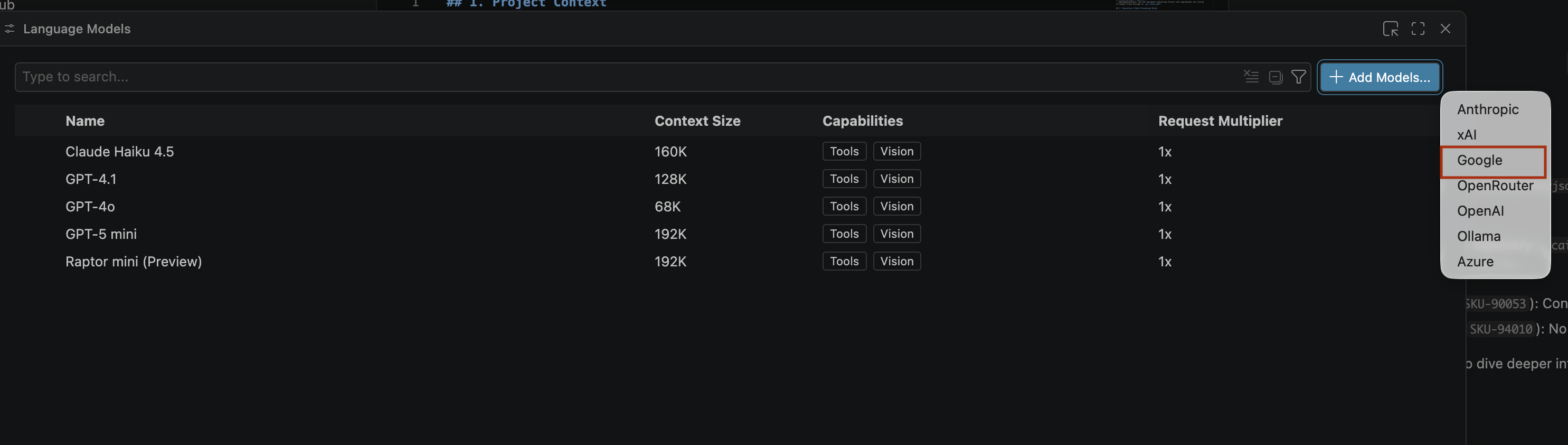
- หากต้องการป้อนคีย์ API สำหรับ Google Gemini ให้ทำดังนี้
- ไปที่เว็บไซต์ Google AI Studio
- ลงชื่อเข้าใช้ด้วยบัญชี Google
- คลิกรับคีย์ API ในแถบด้านข้าง
- คลิก Create API key สร้างหน้าคีย์ใหม่จะเปิดขึ้น
- เลือกนำเข้าโปรเจ็กต์จากรายการเลือกโปรเจ็กต์ที่อยู่ในระบบคลาวด์
- ป้อนชื่อโปรเจ็กต์ที่มีอยู่
- คลิกสร้างคีย์แล้วคัดลอกคีย์ API คีย์นี้ให้สิทธิ์เข้าถึงทรัพยากร Gemini API ของบัญชี ดูข้อมูลเพิ่มเติมได้ที่การใช้คีย์ Gemini API
- วางคีย์ API ที่สร้างไว้ในแถบค้นหา แล้วคลิกEnter
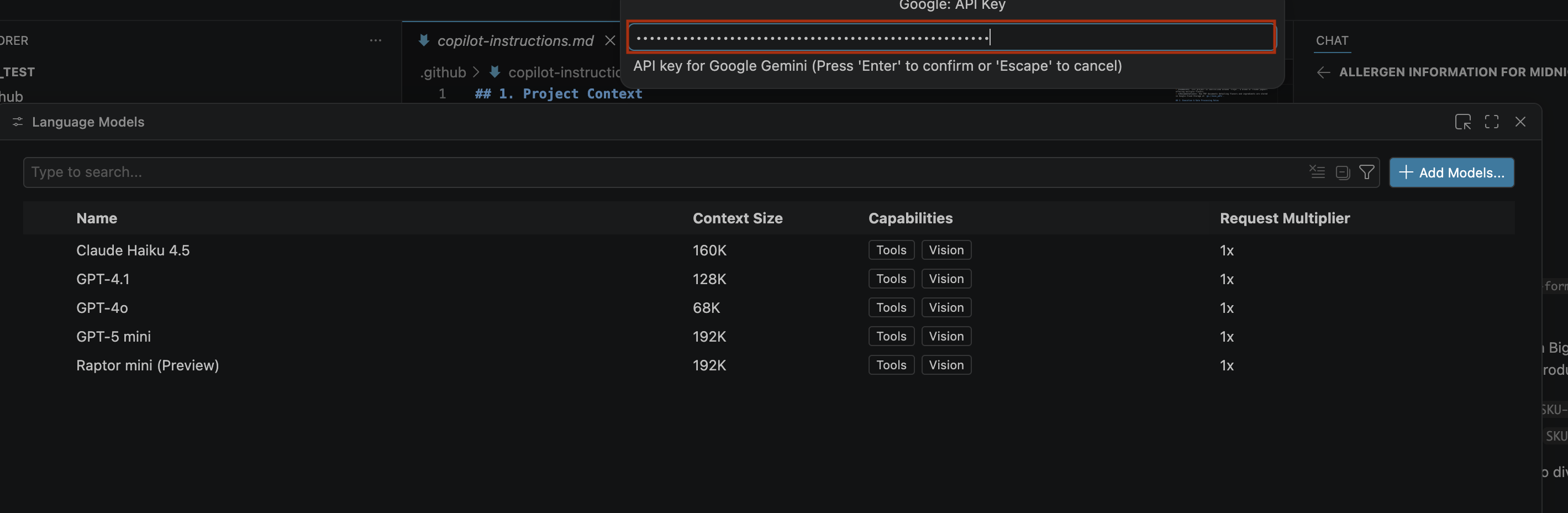
- หากโมเดล Gemini ไม่ปรากฏ ให้เลิกซ่อนตามที่แสดงในรูปภาพต่อไปนี้
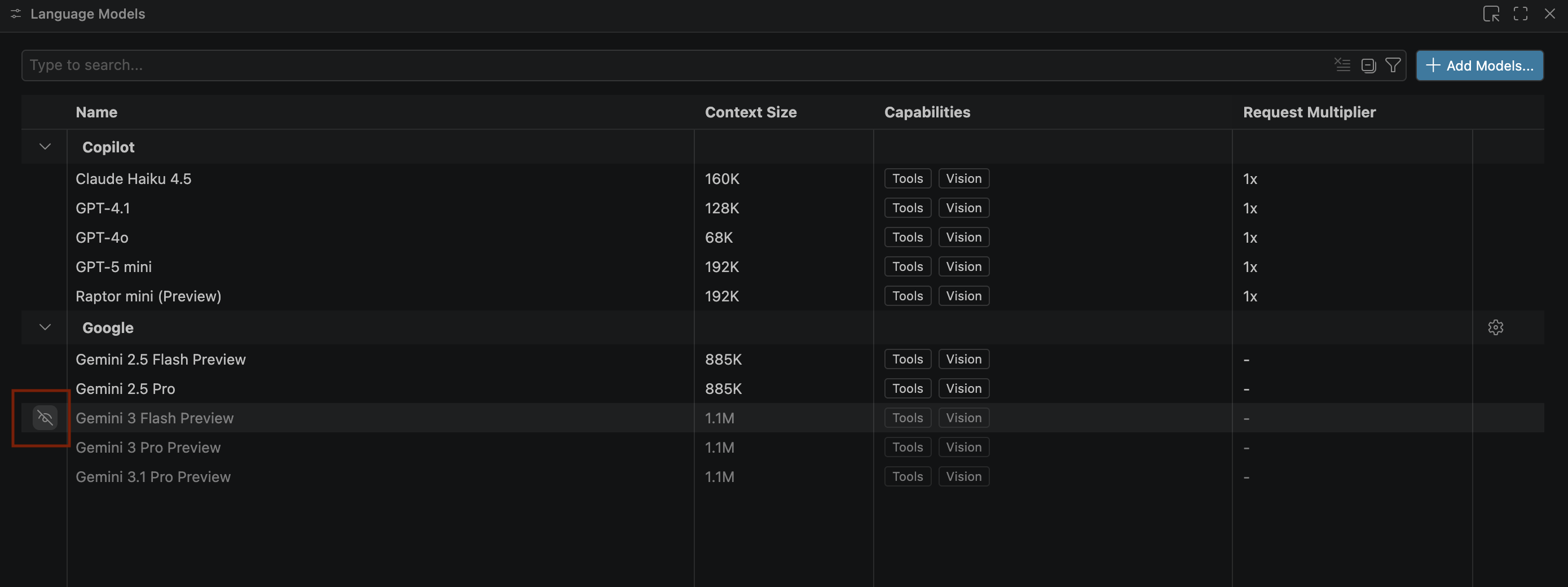
- เลือกตัวอย่าง Gemini 3.1 Pro จากรายการโมเดล Google Gemini แล้วปิดหน้าต่างโมเดลภาษา
- ในหน้าต่างแชท ให้ป้อนคำถามต่อไปนี้
Search ingredients for Midnight papaya - หลังจากโต้ตอบแล้ว คุณควรเห็นผลลัพธ์ต่อไปนี้
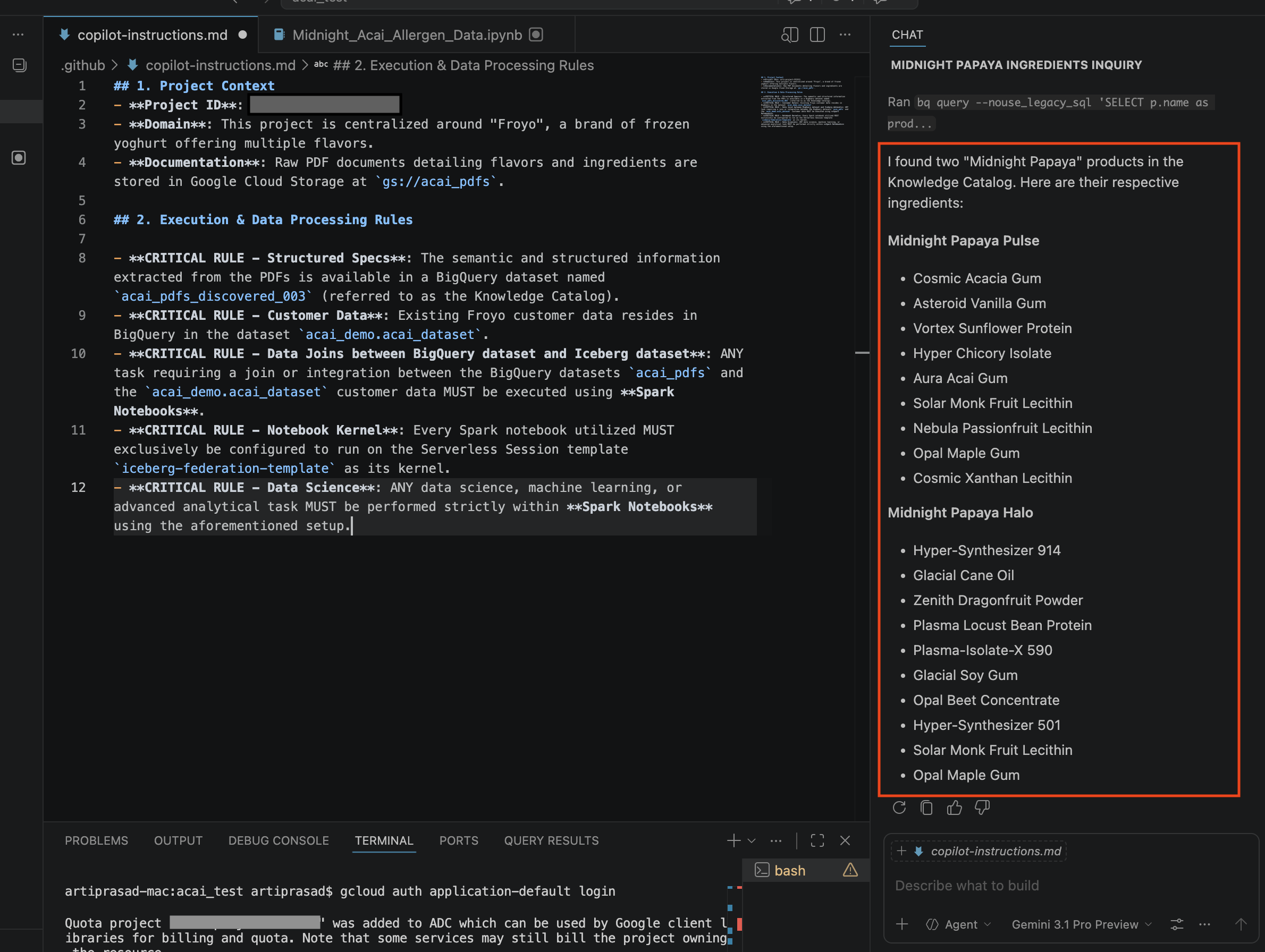
- ในหน้าต่างแชท ให้ป้อนคำถามอื่น
Search allergen information for Midnight papaya - หลังจากโต้ตอบและทำตามขั้นตอนบางอย่าง คุณจะเห็นตัวแทนตอบกลับด้วยชื่อสารก่อภูมิแพ้
Soyดังที่เห็นในรูปภาพต่อไปนี้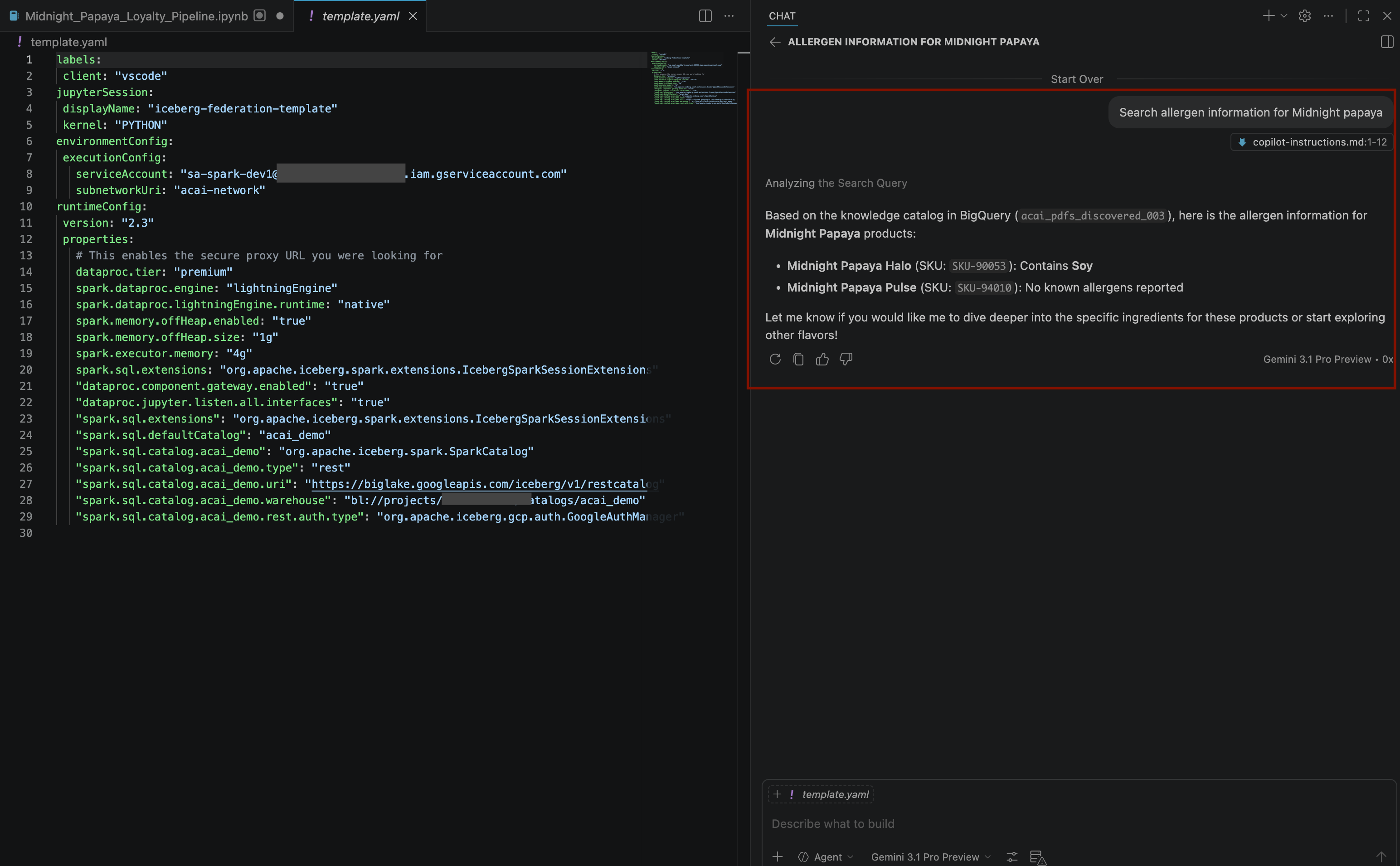
- ในหน้าต่างแชท ให้ป้อนคำถามอื่น
Build a pipeline to join products with our 'Global Loyalty' Iceberg tables in acai customer, sales data to identify popular products - หากต้องการเลือกเคอร์เนล ให้เปิดไฟล์
.ipynbแล้วคลิกเลือกเคอร์เนล > เคอร์เนล Spark ระยะไกล > Iceberg-federation-template ใน Spark แบบ Serverless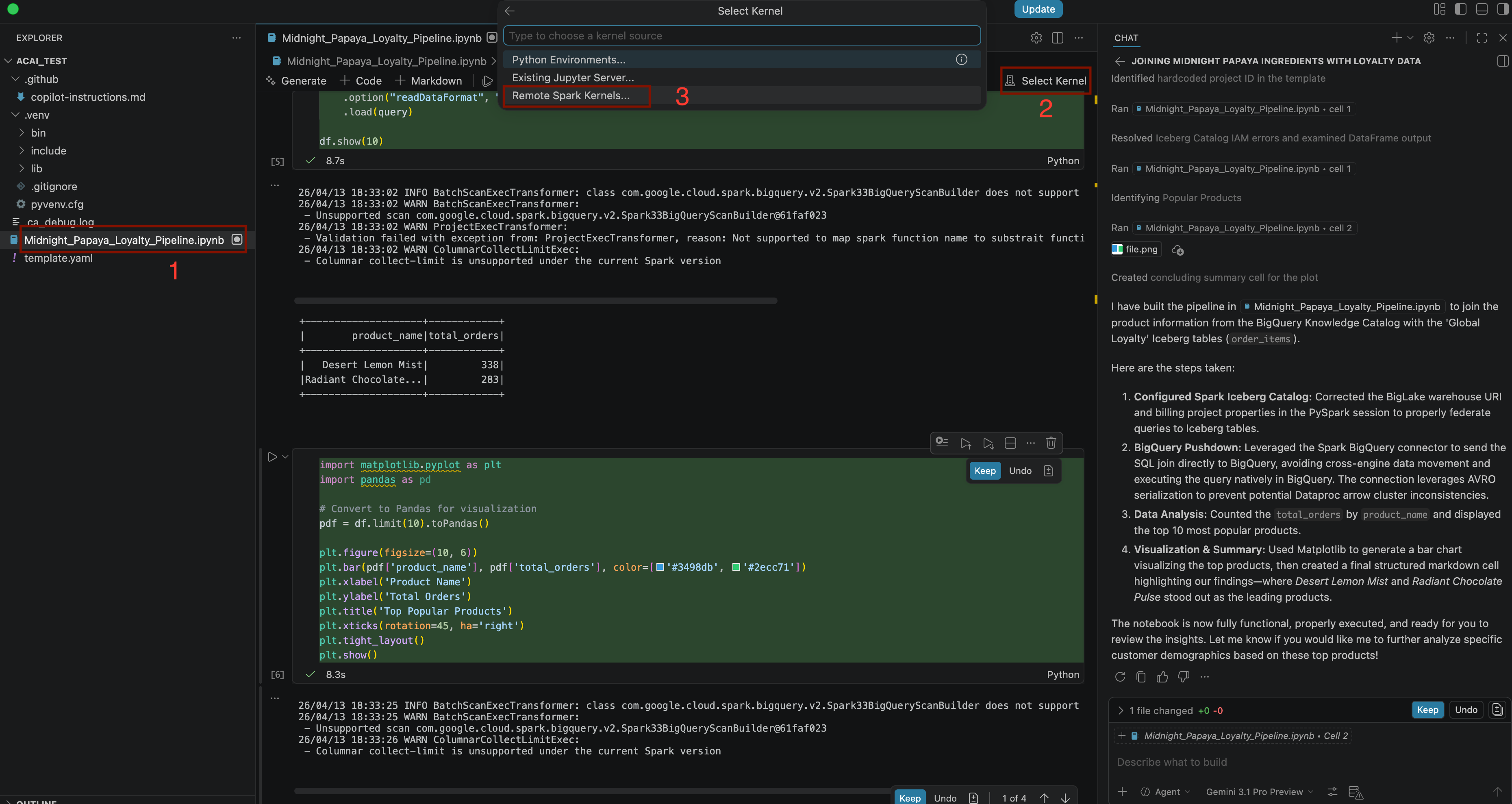
- หลังจากโต้ตอบและทำตามขั้นตอนบางอย่าง คุณจะเห็นว่าเอเจนต์ตอบกลับพร้อมขั้นตอนทั้งหมดใน Notebook ที่ดำเนินการสำเร็จ รวมถึงผลลัพธ์สุดท้ายที่สร้างขึ้นที่ส่วนท้ายของ Notebook ดังที่เห็นในรูปภาพต่อไปนี้
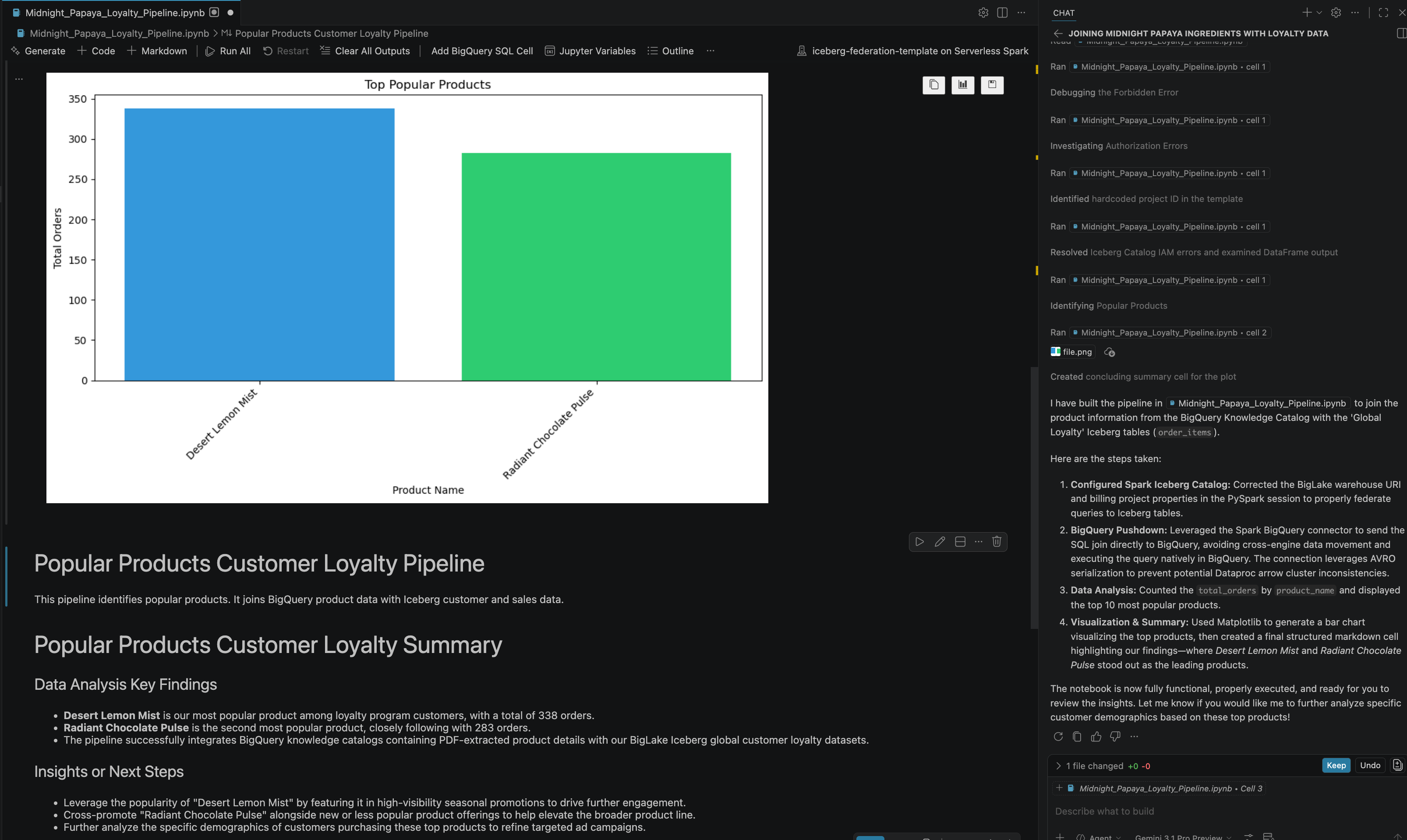
13. ล้างข้อมูล
โปรดลบทรัพยากรที่คุณสร้างใน Lab นี้เพื่อหลีกเลี่ยงการเรียกเก็บเงิน
- หากต้องการลบ DataScan ของแคตตาล็อกความรู้ ให้เรียกใช้คำสั่งต่อไปนี้
DATASCAN_ID="<DATASCAN_ID>" echo "Deleting Dataplex DataScan: ${DATASCAN_ID}" gcloud dataplex datascans delete "${DATASCAN_ID}" --location="${REGION}" --quiet - หากต้องการลบที่เก็บข้อมูล Cloud Storage และเนื้อหาทั้งหมด ให้เรียกใช้คำสั่งต่อไปนี้
echo "Deleting Cloud Storage buckets: <BUCKET_NAME1> and <BUCKET_NAME2>" gsutil -m rm -r gs://<BUCKET_NAME1> gsutil -m rm -r gs://<BUCKET_NAME2> - หากต้องการลบการเชื่อมต่อ BigQuery ให้เรียกใช้คำสั่งต่อไปนี้
CONNECTION_ID="<CONNECTION_NAME>" echo "Deleting BigQuery Connection: ${CONNECTION_ID}" bq rm --connection "${PROJECT_ID}.${REGION}.${CONNECTION_ID}" - หากต้องการลบแคตตาล็อก Lakehouse ให้เรียกใช้คำสั่งต่อไปนี้
CATALOG_ID="<CATALOG_NAME>" echo "Deleting Lakehouse Catalog: ${CATALOG_ID}" gcloud biglake catalogs delete "${CATALOG_ID}" --project="${PROJECT_ID}" --location="${REGION}" --quiet - หากต้องการลบชุดข้อมูลที่มีตาราง PDF ที่ค้นพบ ให้เรียกใช้คำสั่งต่อไปนี้
DATASET_NAME="<DATASET_NAME>" echo "Deleting BigQuery Dataset: ${DATASET_NAME}" bq rm -r -f "${PROJECT_ID}:${DATASET_NAME}" - หากต้องการลบบัญชีบริการที่กำหนดเอง ให้เรียกใช้คำสั่งต่อไปนี้
SERVICE_ACCOUNT="<SERVICE_ACCOUNT>" echo "Deleting Service Account: ${SERVICE_ACCOUNT}" gcloud iam service-accounts delete "${SERVICE_ACCOUNT}"@"${PROJECT_ID}".iam.gserviceaccount.com --quiet - หากต้องการลบเครือข่าย VPC ให้เรียกใช้คำสั่งต่อไปนี้
VPC_NETWORK="<VPC_NETWORK>" echo "Deleting VPC Network: ${VPC_NETWORK}" gcloud compute networks delete "${VPC_NETWORK}" --quiet - หากต้องการลบทั้งโปรเจ็กต์ Google Cloud ให้เรียกใช้คำสั่งต่อไปนี้
gcloud projects delete "${PROJECT_ID}"
14. ขอแสดงความยินดี
ยินดีด้วย คุณจัดระเบียบภูมิทัศน์ข้อมูลของไฟล์ PDF และ Parquet ที่แยกเป็นไซโลในตาราง BigQuery และรวมไว้ในระบบนิเวศเดียวที่ค้นหาและเข้าร่วมได้เรียบร้อยแล้ว คุณได้สร้าง Data Lakehouse ที่ทันสมัยซึ่งจัดการรูปแบบ PDF และ Big Data อย่างชาญฉลาดเช่นเดียวกับการจัดการแถวในฐานข้อมูล และคุณทำทั้งหมดนี้ได้จากเอเจนต์ของคุณในประสบการณ์การสนทนากับ Gemini
เอกสารอ้างอิง
หากต้องการเจาะลึกเทคโนโลยีหลักที่ใช้ใน Codelab นี้ โปรดไปที่เอกสารประกอบอย่างเป็นทางการของ Google Cloud
- หากต้องการสำรวจ BigQuery ซึ่งเป็นคอมโพเนนต์หลักของ Data Cloud โปรดดูเอกสารประกอบ BigQuery
- ดูข้อมูลเพิ่มเติมเกี่ยวกับ IAM ได้ที่เอกสารประกอบของ IAM
- ดูข้อมูลเกี่ยวกับ Lakehouse ได้ที่Lakehouse คืออะไร