
1. Giriş
Bu codelab'de, yeni bir ürün aroması olan "Midnight Swirl"ü piyasaya süren kurgusal bir Froyo şirketinde veri bilimci rolünü üstleneceksiniz. Başarılı bir global lansman için işletmenin içerikler, pazar talebi ve yatırım getirisi (YG) ile ilgili önemli soruları yanıtlaması gerekir. Bu uçtan uca iş akışı, Google Cloud'un Knowledge Catalog (eski adıyla Dataplex) ve Lakehouse for Apache Iceberg'in (eski adıyla BigLake) "karanlık" yapılandırılmamış veriler arasındaki boşluğu nasıl doldurduğunu ve IDE'nizde (VS Code) Gemini'ı kullanarak birleşik bir yönetim katmanı aracılığıyla uygulanabilir iş zekası sağladığını gösterir.
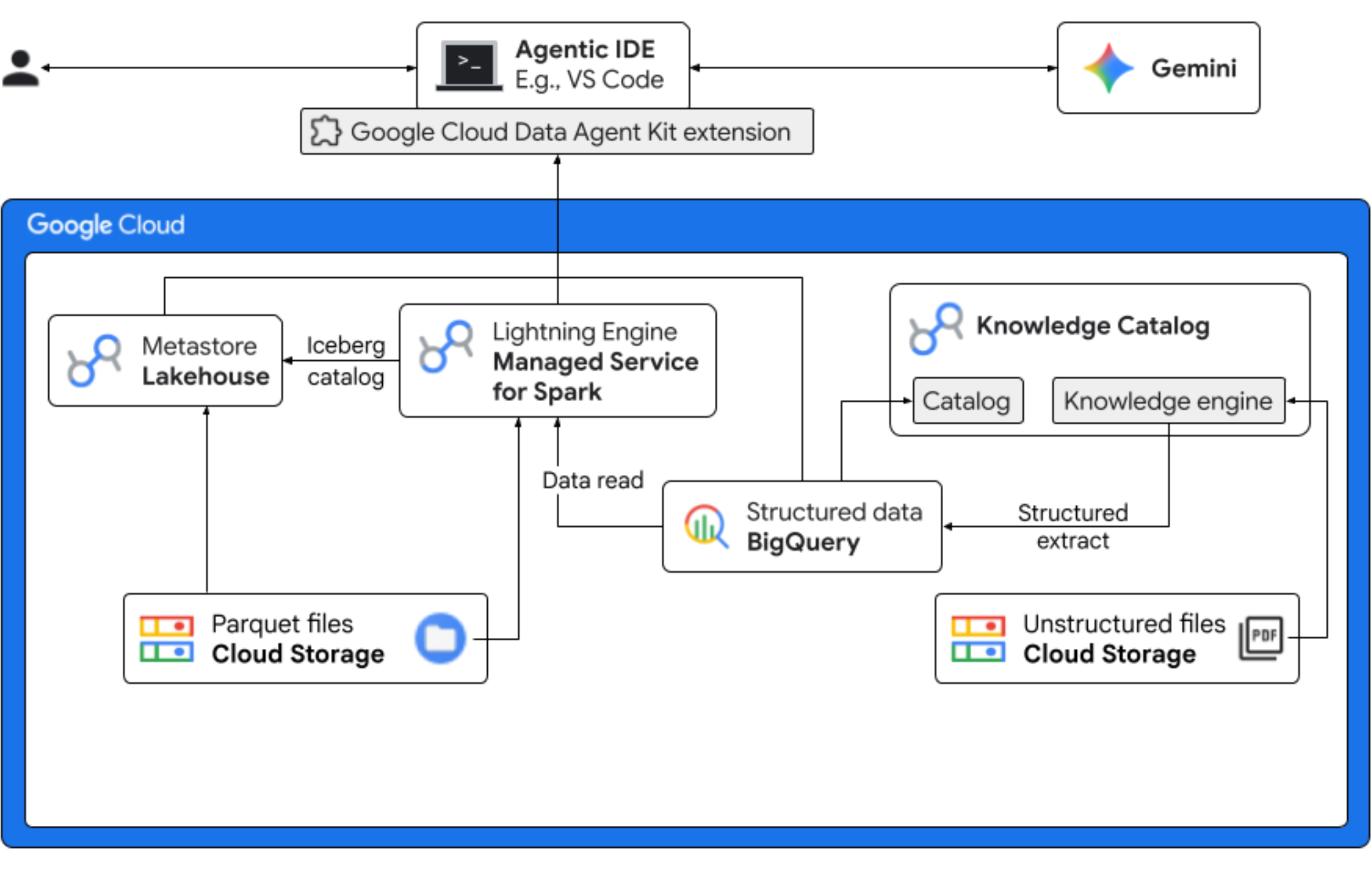
Yapacaklarınız
- Yapılandırılmamış keşif: Cloud Storage'da depolanan PDF tarifleri, Knowledge Catalog DataScan tarafından taranır. Taranan PDF'ler için BigQuery'de Nesne tabloları oluşturun. Vertex AI Semantic Inference'ı kullanan sistem, ürünler, alerjenler, malzemeler ve ilgili özellikler için yapılandırılmış bilgileri ayıklamak üzere PDF'leri "okur". Ardından, PDF'lerde depolanan veriler için akıllıca bir şema oluşturur.
- Birleştirilmiş meta veriler: PDF dosyalarından ayıklanan veriler, doğrudan BigQuery'de yerel bir geniş tablo olarak depolanır ve yaygın sorgulara yardımcı olmak için görünümler oluşturulur. Geçmiş satış verilerini içeren bağımsız bir giriş veri kümesi, Google Cloud Storage'daki Apache Iceberg tablolarında depolanır. Bu Iceberg tablosu, sonraki bir adımda BigQuery'deki çıkarılan verilerle birleştirilir.
- Motorlar arası analizler: Iceberg REST Kataloğu ile Apache Spark için Yönetilen Hizmet'i (eski adıyla Dataproc) kullanarak bu yeni PDF meta verilerini ve çıkarılmış yapılandırılmış anlamsal verileri (BigQuery tablolarından ve görünümlerinden) Google Cloud Storage'daki Apache Iceberg tablolarında depolanan yapılandırılmış satış verileriyle birleştirirsiniz. Bu, Jupyter Notebook çekirdeği olarak kullanılan ve Spark işi için tutarlı güvenlik ve işlem ayarları sağlayan yönetilen Apache Spark etkileşimli oturum şablonu tarafından yönetilir.
- Semantik analizler: Tahmin edilen ürün verileri, müşteri ve satış verileriyle (BigQuery'de) birleştirilerek alerjen verilerini belirleme ve gelir tahmini gibi analizler elde edilebilir.
- Özerk yönetim: Keşif taramalarından Spark yürütmeye kadar tüm yaşam döngüsü, Gemini'a hazır şablonlar, talimatlar, kurallar ve aracı odaklı otomasyon aracılığıyla düzenlenir. Bu sayede yapay zekanın, analitiklere güç veren altyapıyı yönetebileceği kanıtlanır.
İhtiyacınız olanlar
Bu codelab'i tamamlamak, normal kullanım için 5 ABD dolarından daha az olduğu tahmin edilen maliyetlere neden olabilir. Tahmini kullanımınıza veya mevcut fiyatlandırmaya göre ayrıntılı maliyet tahminleri almak için Google Cloud Fiyat Hesaplayıcı'yı kullanın.
Codelab'i tamamlamak için aşağıdaki ön koşulları karşıladığınızdan emin olun.
- Chrome web tarayıcısı
- Başlamadan önce bölümünde belirtilen deneme kredilerini kullanıyorsanız kişisel bir Gmail hesabı.
- Visual Studio (VS) Code'u indirip yükleyin.
2. Başlamadan önce
Google Cloud projesi oluşturma
- Google Cloud Console'daki proje seçici sayfasında bir Google Cloud projesi seçin veya oluşturun.
- Cloud projeniz için faturalandırmanın etkinleştirildiğinden emin olun. Bir projede faturalandırmanın etkin olup olmadığını kontrol etmeyi öğrenin.
Cloud Shell'i Başlatma
Cloud Shell, Google Cloud'da çalışan ve gerekli araçların önceden yüklendiği bir komut satırı ortamıdır.
- Google Cloud Console'un üst kısmından Cloud Shell'i etkinleştir'i tıklayın.
- Cloud Shell'e bağlandıktan sonra kimlik doğrulamanızı onaylayın:
gcloud auth list - Projenizin yapılandırıldığını onaylayın:
gcloud config get project - Projeniz beklendiği gibi ayarlanmamışsa şu şekilde ayarlayın:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Gerekli API'leri etkinleştirme
Gerekli tüm API'leri etkinleştirmek için bu komutu çalıştırın:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
biglake.googleapis.com \
dataproc.googleapis.com \
metastore.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
secretmanager.googleapis.com \
storage.googleapis.com
Codelab öğelerini indirme
Bu depo, bu codelab ile kullanılmak üzere Parquet, tarifler, tedarikçiler, copilot-instructions.md, template.yaml ve quickstart.py dosyalarını içerir. Bu dosyaları indirdiğinizden emin olun.
Dosyaları indirmek için aşağıdakileri yapın:
- Cloud Shell'de aşağıdaki komutu çalıştırın:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git - Yeni oluşturulan klasöre gidin:
cd next-26-keynotes data-cloud-demoklasörünü çekingit sparse-checkout set genkey/data-cloud-demo- Ödeme işlemi tamamlandıktan sonra
data-cloud-demoklasörüne gidin ve codelab öğelerine erişmek için ZIP dosyalarını çıkarın.
3. Froyo müşteri verileri için Lakehouse'u ayarlama
Bu bölümde, iş akışlarınızda Lakehouse metastore'u kullanmak için Lakehouse'da bir katalog oluşturacaksınız. Tüm Iceberg verileriniz için tek bir doğruluk kaynağı sunarak sorgu motorlarınız arasında birlikte çalışabilirlik oluşturur. Apache Spark gibi sorgu motorlarının Iceberg tablolarını tutarlı bir şekilde keşfetmesine, meta verileri okumasına ve yönetmesine olanak tanır.
Gerekli roller
Aşağıdaki Identity and Access Management (IAM) rollerine sahip olduğunuzdan emin olun:
roles/biglake.viewerroles/bigquery.userroles/bigquery.dataEditorroles/biglake.editorroles/biglake.metadataViewerroles/bigquery.connectionUserroles/storage.objectUserroles/storage.objectViewerroles/storage.objectCreatorroles/storage.admin
IAM rolleri verme hakkında daha fazla bilgi için IAM rolü verme başlıklı makaleyi inceleyin.
Paketle Lakehouse kataloğu oluşturma
Iceberg tablolarınızın meta verilerini yönetmek için bir veri gölü ambarı kataloğu oluşturun. Iceberg tabloları oluşturmak ve sorgulamak için Spark işinizde bu kataloğa bağlanırsınız.
- Google Cloud Console'da Lakehouse'a gidin.
- Katalog oluştur'u tıklayın. Katalog oluştur sayfası açılır.
- Katalog türü için Iceberg Rest kataloğu'nu seçin.
- Select your Lakehouse catalog bucket options (Lakehouse katalog paketi seçeneklerinizi belirleyin) bölümünde Single bucket catalog'u (Tek paketli katalog) seçin.
- Varsayılan katalog Cloud Storage paketi için Göz at'ı, ardından Yeni paket oluştur'u tıklayın.
- Paket oluştur sayfasında aşağıdakileri yapın:
- Başlayın bölümünde, paket adı şartlarını karşılayan, genel olarak benzersiz bir ad girin.
- Verilerinizi nerede saklayacağınızı seçin bölümünde, Konum türü için Bölge'yi seçin ve bölgenizi girin. Örneğin,
us-west1. - Nesnelere erişimi nasıl denetleyeceğinizi seçin bölümünde, Bu pakette herkese açık erişim engeli uygula onay kutusunun işaretini kaldırın.
Bu sayede, herkese açık web içeriği veya paylaşılan veri depoları barındırma gibi gerçek dünya senaryolarını simüle edebilirsiniz. Bu değişiklik yapılmadığı takdirde pakette katı bir "yalnızca özel" politikası uygulanır. Dosyalara herkese açık izinler vermeyi başarmış olsanız bile, öğelerinize erişmeye yönelik her girişim403yasak hatasıyla sonuçlanır. - Devam > Oluştur > Seç > Devam'ı tıklayın.
- Authentication method (Kimlik doğrulama yöntemi) için Credential vending mode'u (Kimlik bilgisi dağıtma modu) seçin.
- Oluştur'u tıklayın.Kataloğunuz oluşturulur ve Katalog ayrıntıları sayfası açılır.
- Kimlik doğrulama yöntemi bölümünde �Paket izinlerini ayarla'yı tıklayın.
- İletişim kutusunda Onayla'yı tıklayın.Bu işlem, kataloğunuzun hizmet hesabının depolama paketinize
Storage Object Userrolüyle erişebildiğini doğrular. - Katalog ayrıntıları sayfasında REST katalog URI yolunu kopyalayın. Bu yolu, Spark işini çalıştırma görevi sırasında kullanın.
Parquet dosyalarını pakete yükleyin.
Parquet dosyalarınızı paketinize yüklemek için aşağıdakileri yapın:
- Google Cloud Console'da Cloud Storage Paketleri sayfasına gidin.
- Paketler listesinde paket adını tıklayın. Örneğin,
acai_demo. - Paketin Nesneler sekmesinde Yükle > Dosyaları yükle'yi tıklayın.
- Bu codelab'in Başlamadan önce bölümünde klonladığınız Parquet klasöründeki dosyaları seçin.
- Aç'ı tıklayın.
4. VPC ağını ayarlama
Kaynakların genel internete çıkmadan Google API'leriyle iletişim kurmasına olanak tanıyan bir Sanal Özel Bulut (VPC) ağı ve alt ağı ile dahili trafiğin veri işleme düğümleriniz arasında serbestçe akmasına olanak tanıyan bir güvenlik duvarı oluşturun.
- Google Cloud Console'da VPC ağları sayfasına gidin.
- VPC ağı oluştur'u tıklayın.
- Ağ için bir Ad girin. Örneğin,
acai-network. - Ağın maksimum iletim birimini (MTU) yapılandırmak için MTU'yu otomatik olarak ayarla onay kutusunu işaretleyin.
- Alt ağ oluşturma modu için Otomatik'i seçin.
- Güvenlik duvarı kuralları bölümünde, IPv4 güvenlik duvarı kuralları için tüm onay kutularını seçin.
- Oluştur'u tıklayın.
Özel Google Erişimi'ni etkinleştirme
Dataproc Serverless düğümlerinin herkese açık IP adresleri yoktur. Lakehouse Catalog ve Cloud Storage ile iletişim kurmak için alt ağda Özel Google Erişimi etkinleştirilmelidir.
- Google Cloud Console'da VPC ağları sayfasına gidin.
- Özel Google Erişimini etkinleştirmeniz gereken alt ağı içeren ağın adını tıklayın. Örneğin,
us-west1. - Alt ağın adını tıklayın. Alt ağ ayrıntıları sayfası gösterilir.
- Düzenle'yi tıklayın.
- Özel Google Erişimi bölümünde Açık'ı seçin.
- Kaydet'i tıklayın.
5. Spark işi oluşturma ve çalıştırma
Iceberg tablosu oluşturmak ve sorgulamak için gerekli Spark SQL ifadelerini içeren PySpark işini yükleyin. Ardından, işi Managed Service for Spark ile çalıştırın.
quickstart.py dosyasını Cloud Storage paketinize yükleyin
Codelab öğelerini klonladıktan sonra quickstart.py komut dosyasını proje ayrıntılarınızla güncelleyin ve Cloud Storage paketine yükleyin.
quickstart.pykomut dosyasını bir metin düzenleyicide açın.- Komut dosyasındaki
BUCKET_NAMEyer tutucusunu Cloud Storage paketinizin adıyla değiştirip kaydedin. - Google Cloud Console'da Cloud Storage paketleri'ne gidin.
- Paketinizin adını tıklayın. Örneğin,
acai_demo. - Nesneler sekmesinde Yükle > Dosyaları yükle'yi tıklayın.
- Dosya tarayıcısında güncellenen
quickstart.pydosyasını seçip Aç'ı tıklayın.
Spark işini çalıştırma
quickstart.py komut dosyasını yükledikten sonra, Managed Service for Spark toplu işi olarak uygulayın.
- Değişkenleri yapılandırmak için Cloud Shell'de aşağıdaki komutu çalıştırın.
# Configuration Variables export PROJECT_ID="<PROJECT_ID>" export REGION="<REGION>" export BUCKET_NAME="<BUCKET_NAME>" export SUBNET="<SUBNET>" export LAKEHOUSE_CATALOG_ID="<LAKEHOUSE_CATALOG_ID>" export CATALOG_URI_ID="<CATALOG_URI_ID>"- LAKEHOUSE_CATALOG_ID: PySpark uygulama dosyanızı içeren Lakehouse katalog kaynağının adı. Örneğin,
acai_demo - PROJECT_ID: Google Cloud proje kimliğiniz.
- REGION: Spark için Yönetilen Hizmet toplu iş yükünün çalıştırılacağı bölge. Örneğin,
us-west1. - BUCKET_NAME: Cloud Storage paketinizin adı. Örneğin,
acai_demo. - SUBNET: VPC alt ağınızın adı. Örneğin,
acai-network. - CATALOG_URI_ID: Paket içeren bir Lakehouse kataloğu oluştururken kopyaladığınız Lakehouse kataloğunun URI kimliği. Örneğin,
https://biglake.googleapis.com/iceberg/v1/restcatalog.
- LAKEHOUSE_CATALOG_ID: PySpark uygulama dosyanızı içeren Lakehouse katalog kaynağının adı. Örneğin,
- Cloud Shell'de,
quickstart.pykomut dosyasını kullanarak aşağıdaki Managed Service for Spark toplu işini çalıştırın.gcloud dataproc batches submit pyspark gs://${BUCKET_NAME}/quickstart.py \ --project=${PROJECT_ID} \ --region=${REGION} \ --subnet=${SUBNET} \ --version=2.2 \ --properties="\ spark.sql.defaultCatalog=${LAKEHOUSE_CATALOG_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}=org.apache.iceberg.spark.SparkCatalog,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.type=rest,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.uri=${CATALOG_URI_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.warehouse=gs://${BUCKET_NAME},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.io-impl=org.apache.iceberg.gcp.gcs.GCSFileIO,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.x-goog-user-project=${PROJECT_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\ spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest-metrics-reporting-enabled=false,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.X-Iceberg-Access-Delegation=vended-credentials,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token"All tables registered successfully! Batch [126fa2226a904d2e944c8eecbe0b1840] finished. metadata: '@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata batch: projects/PROJECT_ID/locations/REGION/batches/126fa2226a904d2e944c8eecbe0b1840 batchUuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff createTime: '2026-04-09T13:17:26.222727Z' description: Batch labels: goog-dataproc-batch-id: 126fa2226a904d2e944c8eecbe0b1840 goog-dataproc-batch-uuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-drz-resource-uuid: batch-3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-location: REGION operationType: BATCH name: projects/PROJECT_ID/regions/REGION/operations/47bc59e8-5082-3af9-89a0-22289aa5f4b9
6. BigQuery'deki tabloyu sorgulama
Spark toplu işini başarıyla çalıştırarak, Lakehouse Metastore'da Parquet dosyası başına bir tane olmak üzere birden fazla tabloyu kaydetmek için Spark Sunucusuz için Yönetilen Hizmet'i dağıtılmış bir bilgi işlem motoru olarak kullandınız. Bu kayıt, Google Cloud'un Cloud Storage'daki ham dosyalarınızı yapılandırılmış, yüksek performanslı tablolar olarak işlemesine olanak tanır.
Aşağıdaki adımlar, meta verilerin doğru şekilde senkronize edildiğini doğrulama konusunda size yol gösterir. Bu sayede verilerinizin yalnızca güvenli bir şekilde depolanmasını değil, aynı zamanda BigQuery arayüzü üzerinden tamamen keşfedilebilir ve sorgulanabilir olmasını sağlayabilirsiniz.
- Google Cloud Console'da BigQuery'ye gidin.
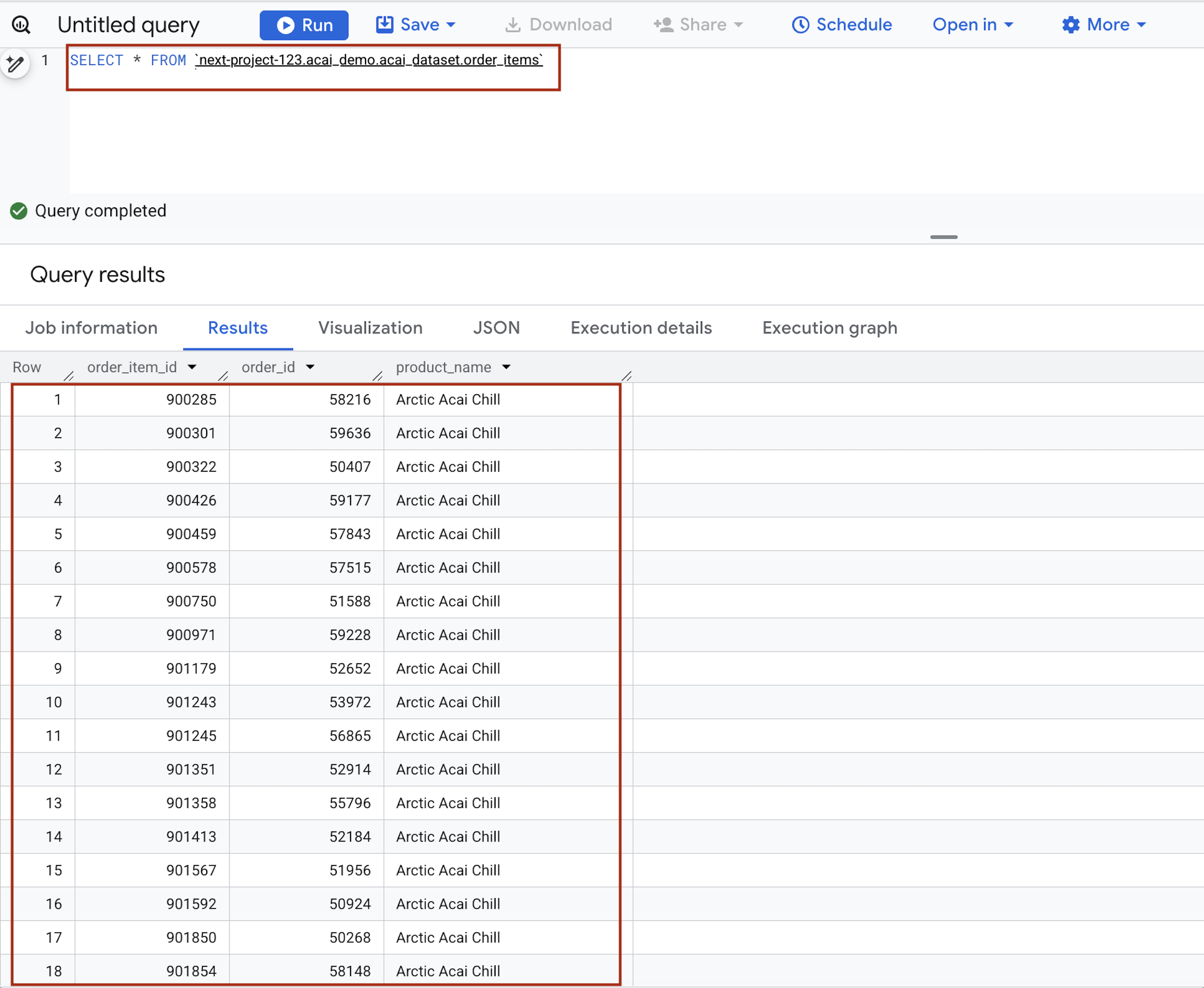
- Sorgu düzenleyicide aşağıdaki ifadeyi girin. Sorguda
project.namespace.dataset.tablesöz dizimi kullanılıyor.SELECT * FROM `<PROJECT_ID>.<NAMESPACE>.<ICEBERG_DATASET>.<ICEBERG_TABLE>`PROJECT_ID.acai_demo.acai_dataset.order_items.
Aşağıdakileri değiştirin:- PROJECT_ID: Google Cloud proje kimliğiniz.
- NAMESPACE: Önceki adımda Spark işi sonucunda oluşturulan ad alanı. Bu ad alanını BigQuery nesne gezgini sayfanızda bulabilirsiniz. Örneğin,
acai_demo. - ICEBERG_DATASET: Iceberg kataloğundaki veri kümesi adı (ör.
acai_dataset). - ICEBERG_TABLE: Iceberg veri kümesindeki tablo adı (ör.
order_items).
- Çalıştır'ı tıklayın. Sorgu sonuçlarında, Spark işiyle eklediğiniz veriler gösterilir.
7. Yapılandırılmamış ürün verileri dosyalarını ayarlama
Bu bölümde, özellikle Froyo ürün ayrıntıları için Froyo tarifi ve tedarikçi verilerini depolamak üzere BigQuery'de bir kuruluş yapısı oluşturacaksınız. Ayrıca, BigQuery'nin Cloud Storage gibi harici kaynaklardaki dosyaları okumasına olanak tanıyan güvenli bir "köprü" görevi gören bir Cloud Resource Connection (Bulut Kaynağı Bağlantısı) oluşturur.
Paket oluşturma ve Froyo ayrıntı dosyalarını yükleme
Tedarikçi ve tarif dosyalarını oluşturup Cloud Storage paketine yükleyin.
- Google Cloud Console'da Cloud Storage Paketleri sayfasına gidin.
- Oluştur'u tıklayın.
- Paket oluştur sayfasında paket bilgilerinizi girin. Aşağıdaki adımların her birinden sonra bir sonraki adıma geçmek için Devam et'i tıklayın:
- Başlayın bölümünde paket adını girin. Örneğin,
acai_pdfs. - Verilerinizi nerede depolayacağınızı seçin bölümünde Bölge'yi seçip bölgenizi girin. Örneğin,
us-west1. - Nesnelere erişimi nasıl denetleyeceğinizi seçin bölümünde, Bu pakette herkese açık erişim engeli uygula onay kutusunun işaretini kaldırın.
- Oluştur'u tıklayın.
- Paketler listesinde, oluşturduğunuz paketi tıklayın. Örneğin,
acai_pdfs. - Paketin Nesneler sekmesinde Yükle > Klasörleri yükle'yi tıklayın.
- Bu codelab'in Başlamadan önce bölümünde çıkardığınız
recipesklasörünü seçin. - Yükle'yi tıklayın.
suppliersklasörü için yükleme işlemini tekrarlayın.
Bağlantı oluştur
Cloud Resource Connection oluşturun. Bu işlem, harici dosyalara erişmek için BigQuery'nin "kimlik kartı" olarak işlev gören benzersiz bir hizmet hesabı oluşturur.
- BigQuery sayfasına gidin.
- Sol bölmede Explorer'ı tıklayın. Sol bölmeyi görmüyorsanız bölmeyi açmak için Sol bölmeyi genişlet'i tıklayın.
- Gezgin bölmesinde proje adınızı genişletin ve Bağlantılar'ı tıklayın.
- Bağlantılar sayfasında Bağlantı oluştur'u tıklayın.
- Bağlantı türü için Vertex AI uzak modelleri, uzak işlevler, BigLake ve Spanner (Cloud Kaynağı)'ı seçin.
- Bağlantı kimliği alanına bağlantı kimliği adını girin. Örneğin,
acai_pdf_connection. Bu kimliği not edin. Bu codelab'in ilerleyen bölümlerinde veri taraması ayarlarken bu kimliğe ihtiyacınız olacak. - Konum türü'nü Bölge olarak ayarlayın ve bir bölge seçin. Örneğin,
us-west1. Bağlantı, veri kümeleri gibi diğer kaynaklarınızla aynı konumda olmalıdır. - Bağlantı oluştur'u tıklayın.
- Bağlantıya git'i tıklayın.
- Bağlantı bilgileri bölmesinde, sonraki bir adımda kullanmak üzere hizmet hesabı kimliğini kopyalayın. Hizmet hesabı,
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.comhesabına benziyor.
Hizmet hesaplarına erişimi yönetme
Lakehouse'un PDF'lerinizi okuyabilmesi için hizmet hesabına erişim izni verin.
- IAM ve Yönetici sayfasına gidin.
- Grant access'i (Erişim izni ver) tıklayın. Asıl kullanıcı ekle iletişim kutusu açılır.
- New principals (Yeni ana hesaplar) alanına, daha önce kopyaladığınız hizmet hesabı kimliğini girin.
- Bir rol seçin alanında aşağıdaki rolleri ekleyin:
roles/storage.objectUserroles/storage.objectViewerroles/bigquery.userroles/bigquery.dataEditorroles/aiplatform.userroles/storage.adminroles/dataproc.serviceAgent
- Kaydet'i tıklayın.
BigQuery'deki IAM rolleri hakkında daha fazla bilgi için Önceden tanımlanmış roller ve izinler başlıklı makaleyi inceleyin.
8. DataScan işi için izinleri yönetme
Spark ve Dataform için belirli hizmet hesapları (kimlikler) oluşturun, ardından depolama alanını okumak, BigQuery işlerini çalıştırmak ve keşif için Vertex AI'ı kullanmak üzere gereken izinleri Google'ın otomatik hizmet aracılarıyla birlikte bu hesaplara verin.
Spark ve Dataform için IAM erişimi
- Google Cloud Console'da Hizmet hesabı oluştur sayfasına gidin.
- Seçilmemişse Google Cloud projenizi seçin.
- Hizmet hesabı oluştur'u tıklayın.
- Bir hizmet hesabı adı girin. Örneğin,
sa-spark-stg1. Google Cloud Console, bu ada göre bir hizmet hesabı kimliği oluşturur. Gerekirse kimliği düzenleyin. Kimliği daha sonra değiştiremezsiniz. - Erişim kontrollerini ayarlamak için Oluştur ve devam et'i tıklayın ve sonraki adıma geçin.
- Projedeki hizmet hesabına vermek için aşağıdaki IAM rollerini seçin.
roles/dataproc.workerroles/storage.objectUserroles/bigquery.dataEditorroles/bigquery.jobUserroles/aiplatform.userroles/dataplex.discoveryPublishingServiceAgent
- Rol ekleme işlemini tamamladığınızda Devam'ı tıklayın.
- Hizmet hesabını oluşturmayı tamamlamak için Bitti'yi tıklayın.
Bilgi Kataloğu'na erişmek için BigQuery bağlantı izinleri
- Google Cloud Console'da Cloud Storage Paketleri sayfasına gidin.
- Paketler listesinde, Froyo için oluşturduğunuz paket adını tıklayın. Örneğin,
acai_pdfs. - İzinler sekmesinde Erişim izni ver'i tıklayın. Asıl üyeleri ekle iletişim kutusu gösterilir.
- Yeni ana hesaplar alanına BigQuery hizmet hesabı kimliğinizi girin. Hizmet hesabı,
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.comhesabına benziyor. - Bir rol seçin açılır menüsünden aşağıdaki rolleri seçin.
roles/storage.objectUserroles/dataplex.serviceAgentroles/dataplex.securityAdminroles/aiplatform.serviceAgentroles/dataplex.discoveryPublishingServiceAgent
- Kaydet'i tıklayın.
9. Bilgi Kataloğu'nu ayarlama
Froyo ile ilgili verilerinizi birleştirmek ve yapılandırılmamış dosyaların (ör. PDF tarifleri ve PDF tedarikçileri) keşfedilmesini otomatikleştirmek için bir Bilgi Kataloğu oluşturun.
curl üzerinden DataScan oluşturma
Bu bölümde, datascan_ID öğesini ekleyip BigQuery veri kümelerinize yönlendirerek Cloud Storage paketinize (ör. acai_pdfs) yönelik taramalar oluşturursunuz. Ardından Knowledge Catalog, BigQuery'de PDF'leriniz için otomatik olarak girişler oluşturur.
- PDF'leri (tedarikçiler ve tarifler) taramak için aşağıdaki komutu çalıştırın:
# 1. Set your variables PROJECT_ID="<PROJECT_ID>" REGION="<REGION>" ENV_SUFFIX="stg1" DATASCAN_ID="froyo-profile-${ENV_SUFFIX}" BUCKET_NAME="<BUCKET_NAME>" # 2. Set this to the Name of the connection you created in Step 7 CONNECTION_ID="<CONNECTION_ID_NAME>" # 3. Define the API Endpoint DATAPLEX_API="dataplex.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}" # 4. Create the DataScan via CURL echo "Creating Dataplex DataScan: ${DATASCAN_ID}..." curl -X POST "https://$DATAPLEX_API/dataScans?dataScanId=${DATASCAN_ID}" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d '{ "data": { "resource": "//storage.googleapis.com/projects/'"${PROJECT_ID}"'/buckets/'"${BUCKET_NAME}"'" }, "executionSpec": { "trigger": { "on_demand": {} } }, "dataDiscoverySpec": { "bigqueryPublishingConfig": { "tableType": "BIGLAKE", "connection": "projects/'"${PROJECT_ID}"'/locations/'"${REGION}"'/connections/'"${CONNECTION_ID}"'" }, "storageConfig": { "unstructuredDataOptions": { "entity_inference_enabled": true } } } }' curlkomutu, aşağıdaki resimde gösterildiği gibi Knowledge Catalog DataScan sonuçlarını gösterir.
İşi çalıştırma
Aşağıdaki komutu çalıştırın:
gcloud dataplex datascans run $DATASCAN_ID --location=$REGION
İş tanımlama
İşi tanımlamak için aşağıdaki komutu çalıştırın:
gcloud dataplex datascans describe $DATASCAN_ID --location=$REGION
Veri tarama işini silme
Tarama 10 dakikadan uzun sürerse veya iş durumu Çalışıyor'a geçmeden uzun süre Beklemede kalırsa bunun nedeni bölgedeki kaynakların geçici olarak kullanılamaması olabilir. Bu durumda, işi silmek için aşağıdaki komutu çalıştırabilir, ardından işi tekrar oluşturup çalıştırmayı deneyebilirsiniz. Bazen ilk çalıştırma, unable to acquire necessary resources gibi bir hatayla hızlıca başarısız olabilir.
gcloud dataplex datascans delete $DATASCAN_ID --location=$REGION
İşin durumunu görüntüleme
İş durumunu kontrol etmek için aşağıdakileri yapın:
- Google Cloud Console'da Metadata curation (Meta veri düzenleme) sayfasına gidin.
- Cloud Storage keşfi sekmesinde, keşif taramalarının adını tıklayın.
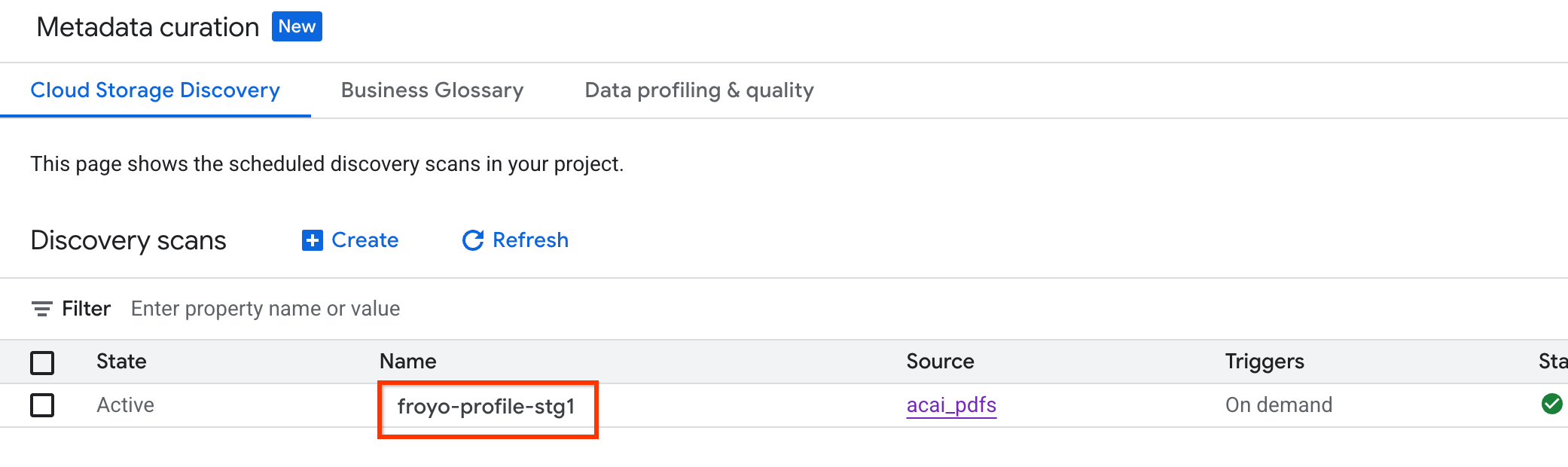
- Tarama ayrıntıları sayfasında iş durumunu görebilirsiniz.
- İşlem tamamlandıktan sonra,
curlkomutunu kullanarak oluşturduğunuz Published dataset (Yayınlanmış veri kümesi) öğesinin (ör.acai_pdfs_discovered_003) mevcut olup olmadığını kontrol edin.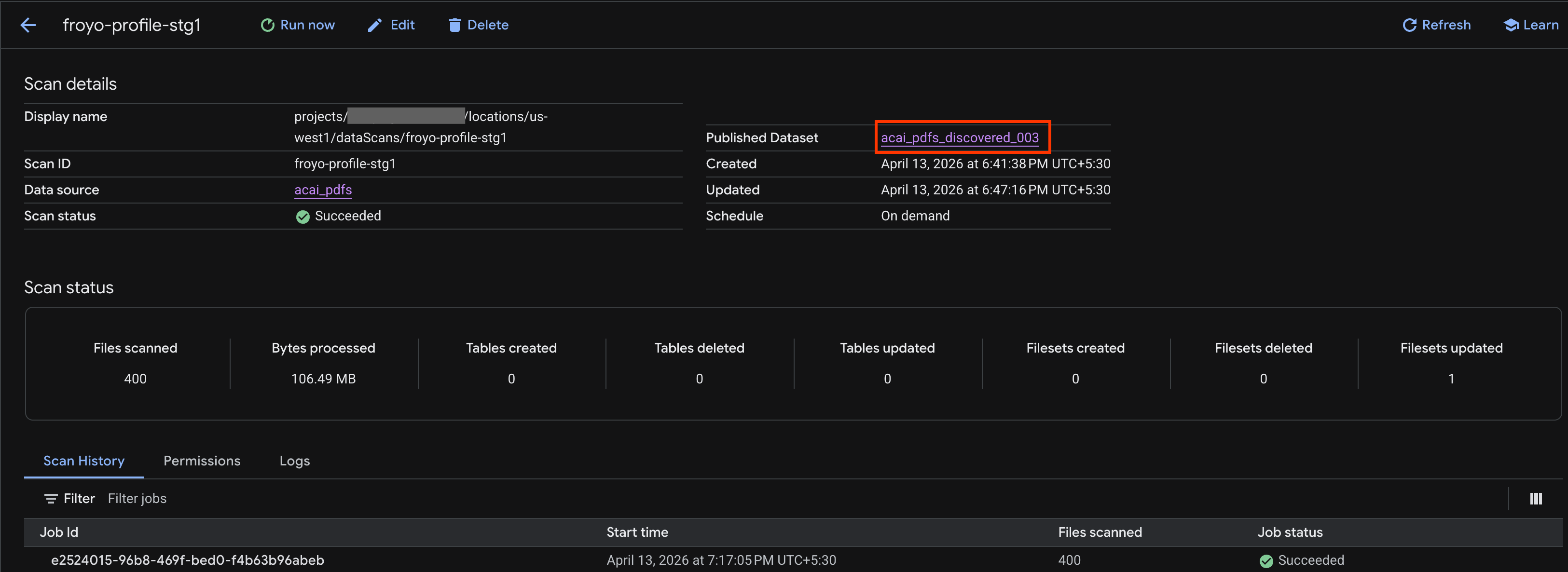
Nesne tablosunu görüntüleme
Bulma işinden sonra oluşturulan nesne tablosunu görüntülemek için aşağıdakileri yapın:
- Google Cloud Console'da BigQuery'ye gidin.
- Veri kümeleri'ni tıklayın ve önceki adımda oluşturulan yayınlanmış veri kümesini seçin. Örneğin,
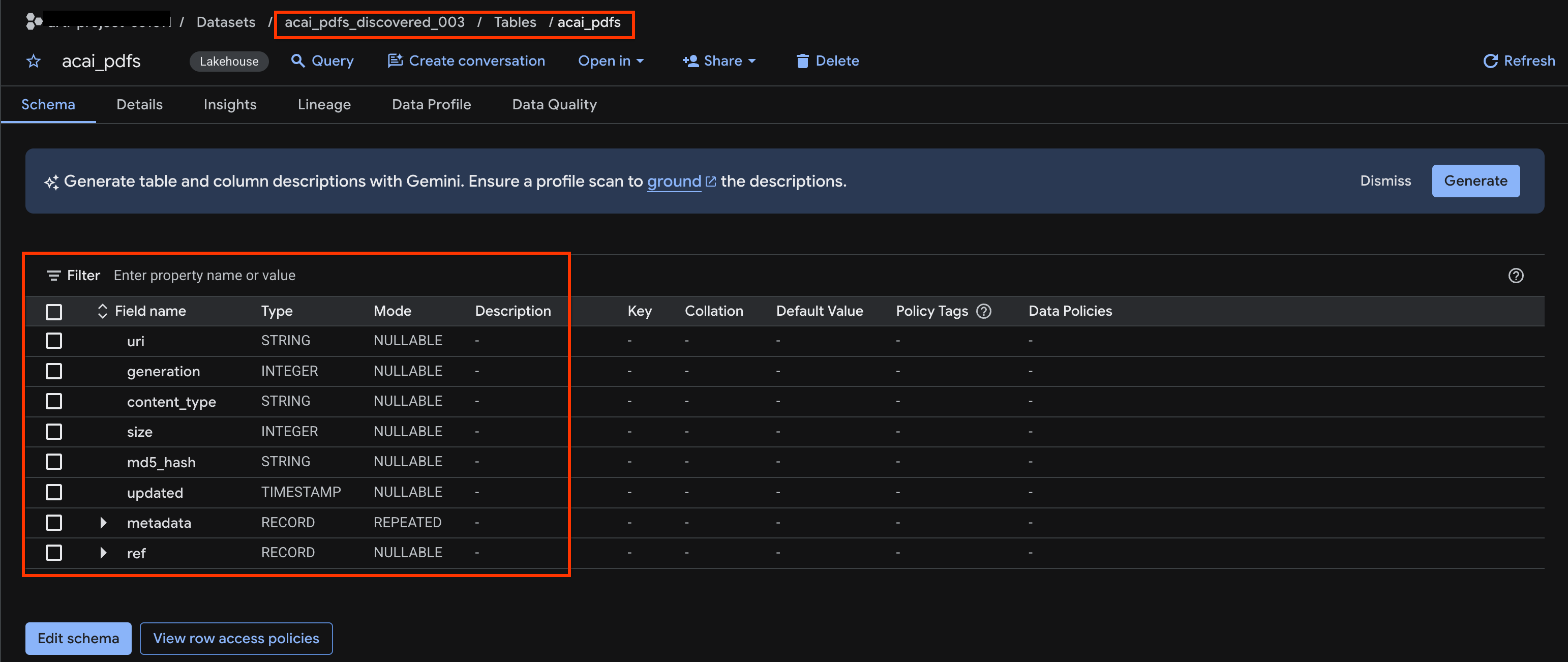
acai_pdfs_discovered_003. - Nesne tablosunu görüntülemek için tablo kimliğini tıklayın. Örneğin,
acai_pdfs. - Elde edilen nesne tablosu aşağıdaki resimdeki gibi görünür:
10. Semantik ayıklama
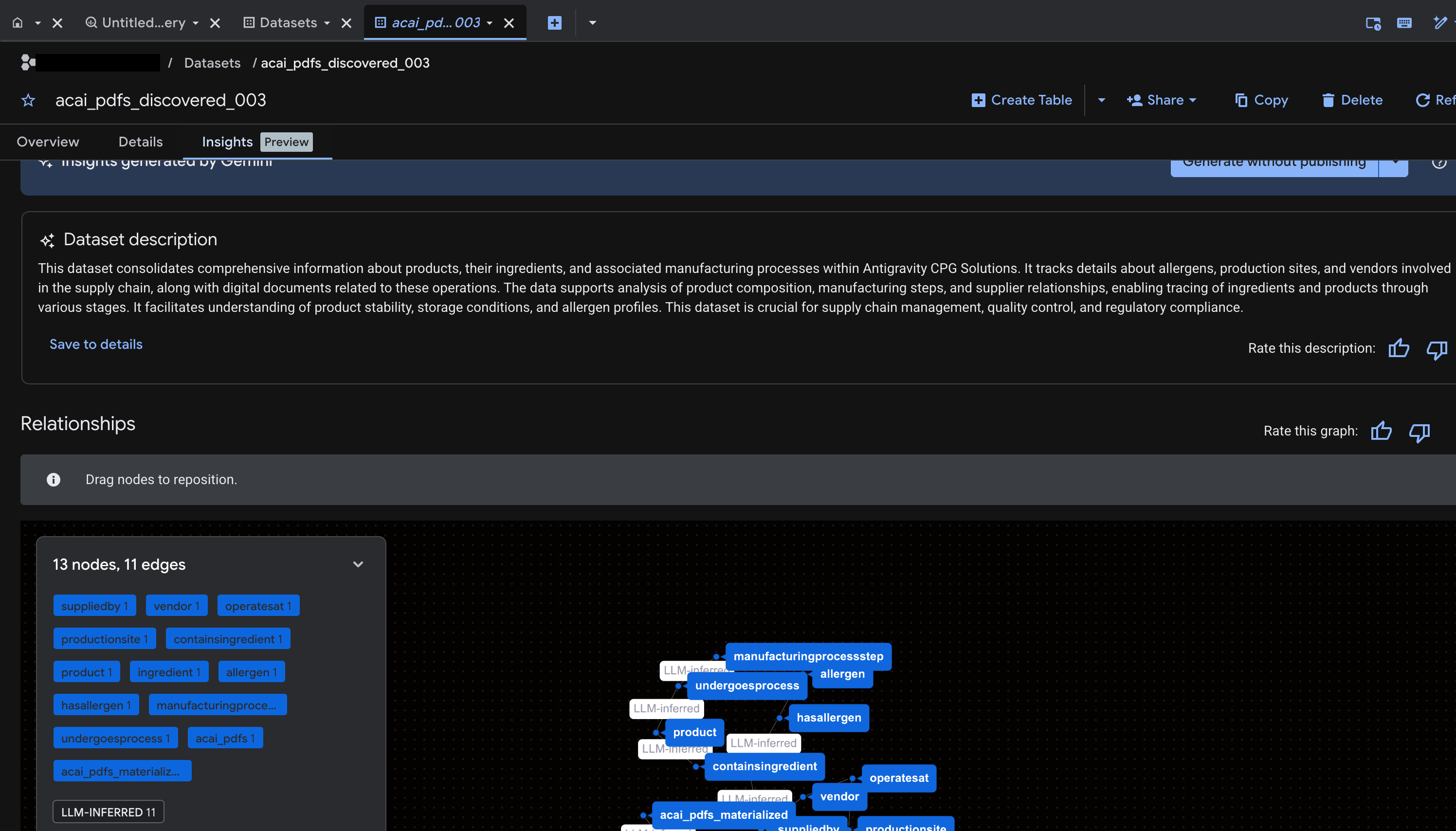
Önceki adımda oluşturduğunuz bu yapılandırılmamış nesne tablosu için yapılandırılmış tabloları, diğer veritabanı nesnelerini ve ilişkileri çıkarıp tahmin edeceksiniz. Bunun için, yapılandırılmamış tablodan yapılandırılmış verileri ayıklamak üzere SQL ifadeleri oluşturmak için Knowledge Catalog Insights özelliğini kullanacaksınız.
- Google Cloud Console'da Knowledge Catalog Search sayfasına gidin.
- Analizlerini görüntülemek istediğiniz veri kümesi tablosunu arayın. Örneğin,
acai_pdfs_discovered_003.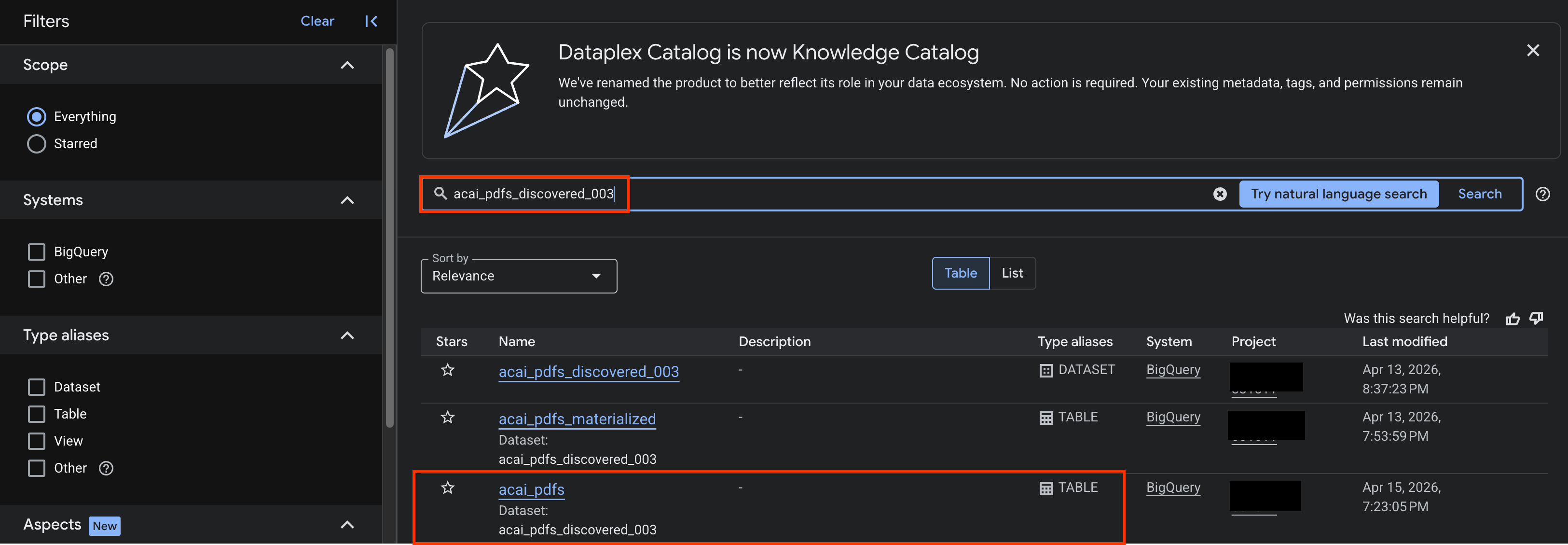
- Arama sonuçlarında, tablonun giriş sayfasını açmak için tabloyu tıklayın.
- Analizler sekmesini tıklayın. Sekme boşsa bu tabloyla ilgili analizler henüz oluşturulmamıştır. Analiz oluşturma işlemi 15-25 dakika sürebilir.
- Analizleri gördüğünüzde Ayıkla > SQL ile ayıkla'yı tıklayın.
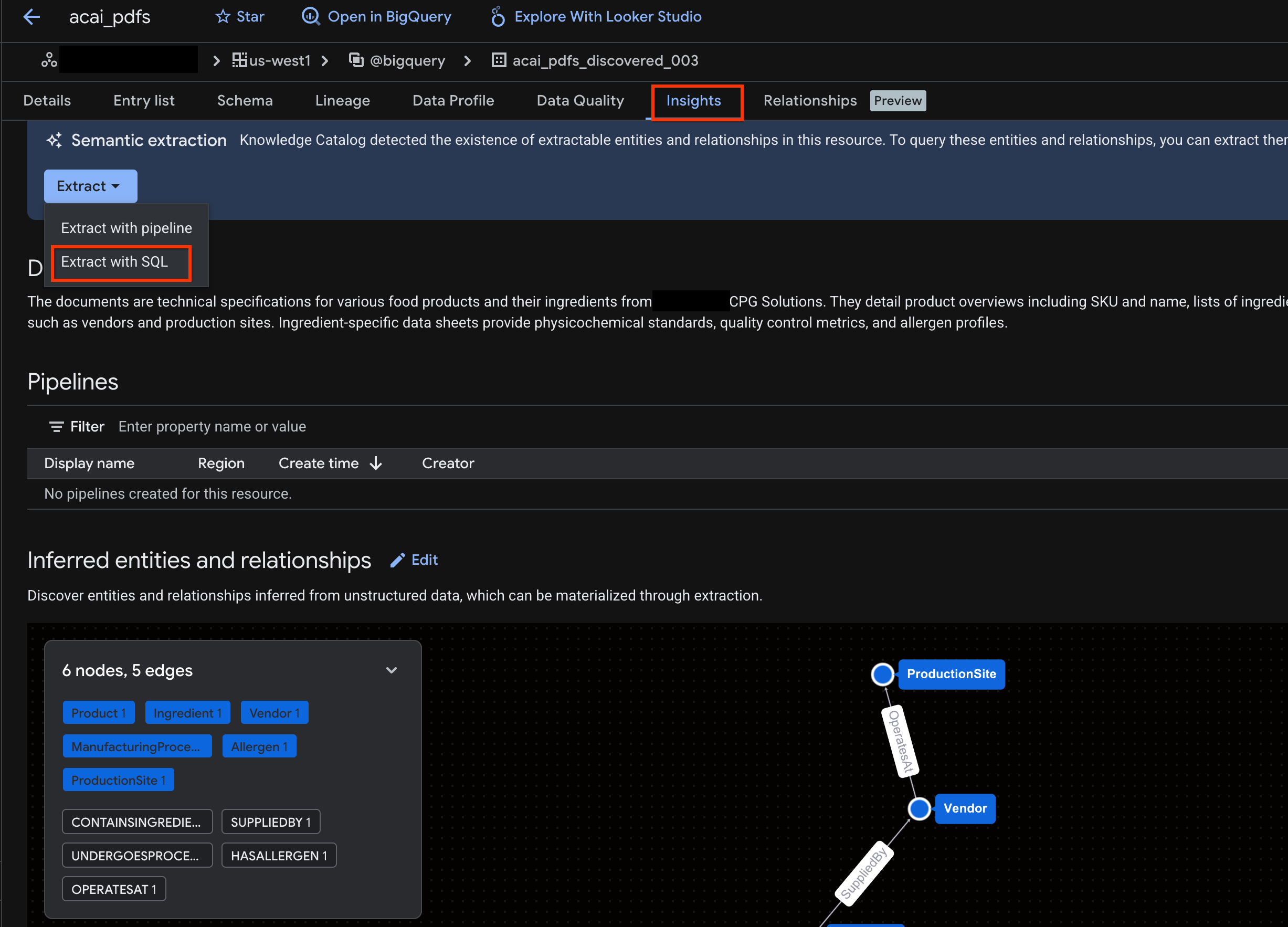
- SQL ile ayıklama sayfasında, Hedef için veri kümenizi girin. Örneğin,
acai_pdfs_discovered_003. - Çıkar'ı tıklayın. Bu işlem, sorgunun yüklendiği BigQuery Düzenleyici'yi açar.
- Çalıştır'ı tıklayın. Bu adımda bir dizi ifade oluşturulur ve çalıştırmanın tamamlanması birkaç dakika sürebilir.
- Sorgu tamamlandığında aşağıdaki sonuçları görürsünüz:
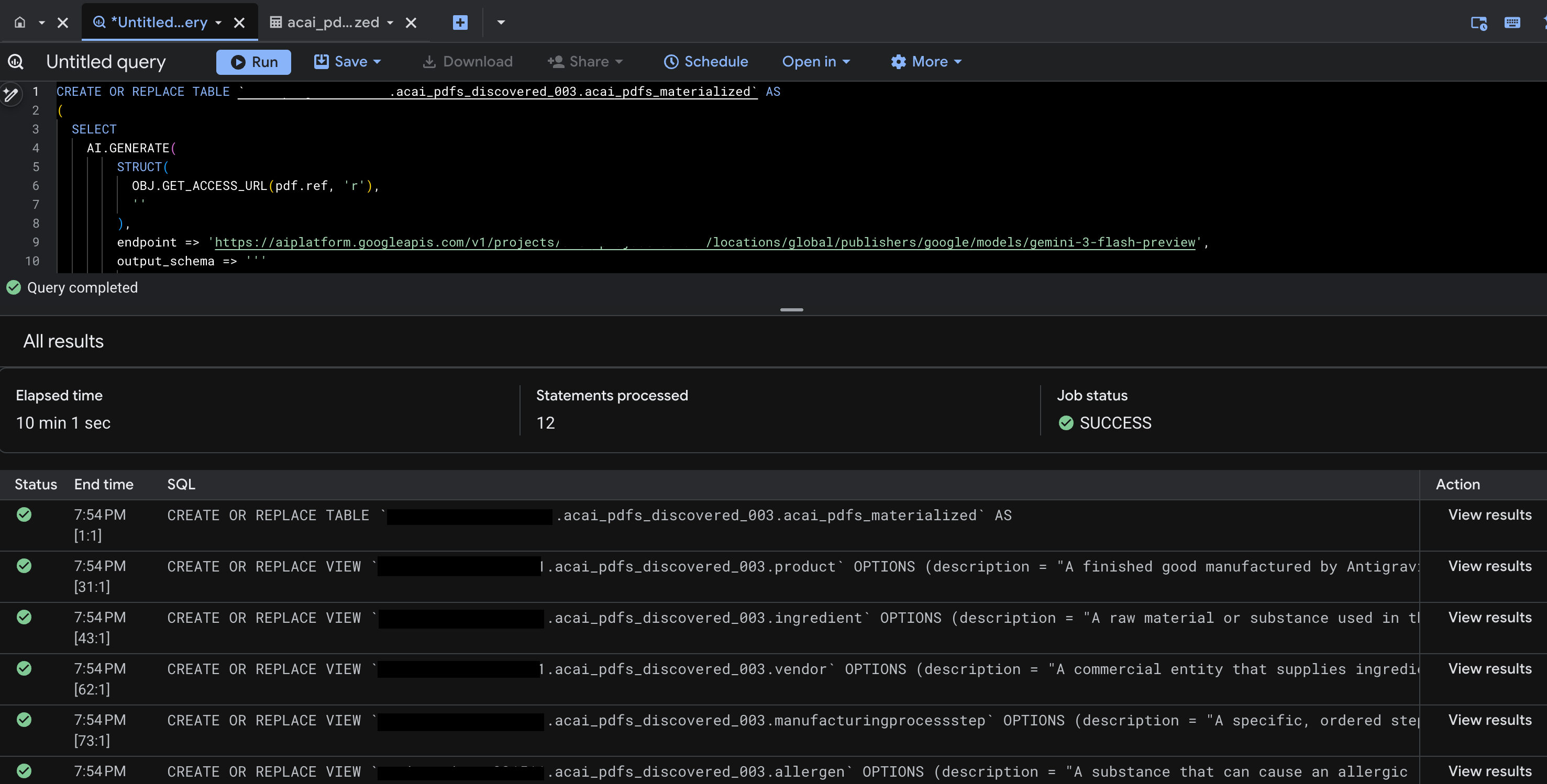
- BigQuery'ye gidin ve Veri Kümeleri'ni (örneğin,
acai_pdfs_discovered_003) tıklayın. 6. adımda seçtiğiniz veri kümesinde yeni bir yapılandırılmış veritabanı nesnesi grubu oluşturulur.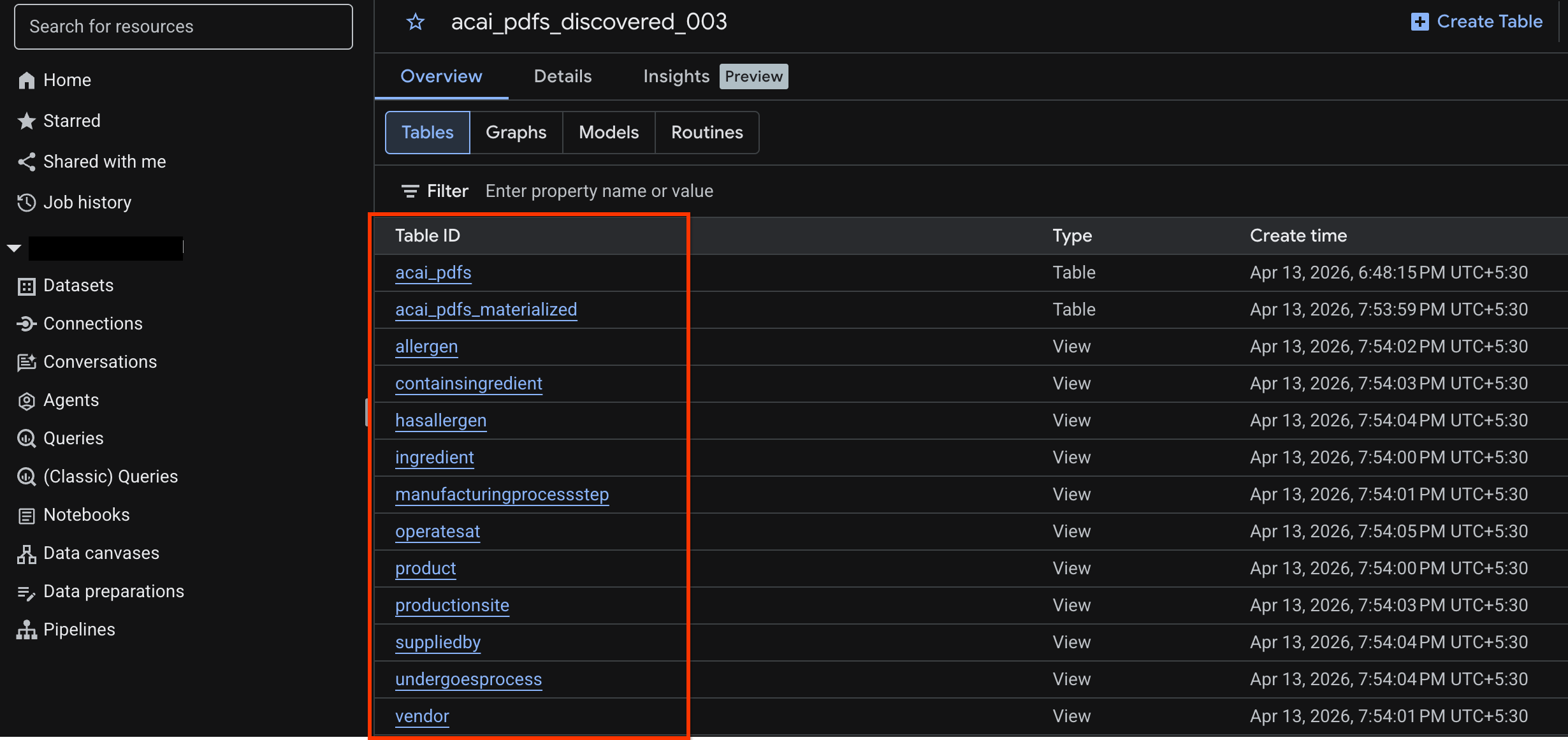
BigQuery'de nesne için analiz oluşturma
BigQuery veri kümesi için analiz oluşturmak üzere BigQuery Studio'yu kullanarak BigQuery'deki veri kümesine erişmeniz gerekir.
- Google Cloud Console'da BigQuery Studio'ya gidin.
- Gezgin bölmesinde projeyi seçin ve analiz oluşturmak istediğiniz veri kümesine gidin.
- Analizler sekmesini tıklayın.
- Enable API (API'yi etkinleştir) düğmesini görüyorsanız Google Cloud için Gemini'ı etkinleştirmek üzere bu düğmeyi tıklayın. Temel özellikleri etkinleştir penceresi açılır.
- Temel özellik API'leri bölümünde Google Cloud için Gemini API ve BigQuery Unified API için Etkinleştir'i, ardından Sonraki'yi tıklayın.
- İzinler (isteğe bağlı) bölümünde, gerekirse ana hesaplara IAM rolleri verin ve Sonraki'yi tıklayın.
- Analiz oluşturmak ve bunları Bilgi Kataloğu'nda yayınlamak için Oluştur ve yayınla'yı tıklayın.
- Yayınlandıktan sonra sekmede analizleri görüntüleyebilirsiniz.
11. IDE'nizi agent destekli veri analizi için ayarlama
Visual Studio Code için Google Cloud Data Agent Kit uzantısı, veri bilimciler ve veri mühendisleri için bir IDE uzantısıdır. Google Data Cloud kaynaklarınıza ve verilerinize doğrudan IDE'den bağlanıp bunları kullanmanıza olanak tanır. Daha fazla bilgi için VS Code için Data Agent Kit uzantısına genel bakış başlıklı makaleyi inceleyin.
VS Code için Data Agent Kit uzantısı, aşağıdakileri yapmak istediğinizde kullanışlıdır:
- Doğrudan VS Code'dan Spark ETL veya BigQuery ETL gibi üretime hazır bir veri ardışık düzeni oluşturun, test edin, inceleyin ve dağıtın.
- Verileri keşfedin, eğitim ardışık düzeni oluşturun, en uygun makine öğrenimi modellerini belirleyin ve bunları yapay zeka yardımını kullanarak bir üretim uç noktasına dağıtın.
- Güvenilir veri kaynaklarına bağlanın, yüksek performanslı bir veri modeli oluşturun ve iş paydaşları için etkileşimli bir kontrol paneli yayınlayın.
VS Code için Data Agent Kit uzantısını yükleme
- VS Code'u açın.
- Google Cloud CLI'yı yükleyin. Daha fazla bilgi için Google Cloud CLI'yı yükleme başlıklı makaleyi inceleyin.
- VS Code için Data Agent Kit uzantısını yükleyin.
- Uzantı ilk katılım sürecini tamamlayın. Bu süreçte şunları yapmanız gerekir:
- Uzantıda oturum açma
- Becerileri ve MCP sunucularını yükleme
- Oryantasyonu tamamladığınızda pencereyi yeniden yükleyin veya yeniden başlatın. Daha fazla bilgi için VS Code için Veri Aracısı Kiti uzantısını kurma ve yapılandırma başlıklı makaleyi inceleyin.
- IDE yeniden yüklendikten sonra gezinme bölmesinde Google Data Cloud simgesini tıklayın, ayarlara gidin ve ortak ayarlarda proje kimliğinizi ve bölgenizi doğru şekilde ayarladığınızdan emin olun (
us-west1).
VS Code'da çalışma alanını ayarlama
- VS Code'u açıp File (Dosya) > Open folder (Klasör aç) > New folder'ı (Yeni klasör) seçin.
acai_testadlı yeni bir klasör oluşturun ve Aç'ı tıklayın. VS Code, açtığınız klasörü artık bir çalışma alanı olarak kabul eder.- Workspace güveni iletişim kutusunda, çalışma alanındaki tüm özellikleri etkinleştirmek için Evet, yazarlara güveniyorum'u seçin.
acai_testçalışma alanında.githubklasörü oluşturun..githubklasöründe yeni bir dosyacopilot-instructions.mdoluşturun ve aşağıdaki kuralları girin.## 1. Project Context - **Project ID**: <PROJECT_ID> - **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors. - **Documentation**: Raw PDF documents detailing flavors and ingredients are stored in Google Cloud Storage at `gs://<BUCKET_NAME>`. ## 2. Execution & Data Processing Rules - **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `<BQ_DATASET_NAME>` (referred to as the Knowledge Catalog). - **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the dataset `<DATASET_ID>`. When you are referencing a dataset, ensure you are using it with the project ID (`<PROJECT_ID>`) and namespace prefix `<NAMESPACE_NAME>`. For example, to query order table in this dataset you should use `<PROJECT_ID>.<NAMESPACE>.<DATASET_ID>.orders`. - **CRITICAL RULE - Data Joins between BigQuery dataset and Iceberg dataset**: ANY task requiring a join or integration between the BigQuery datasets `<DATASET_ID>` of the PDF data and the `<DATASET_ID>` of the customer data MUST be executed using **Spark Notebooks**. - **CRITICAL RULE - Notebook Kernel**: Every Spark notebook utilized MUST exclusively be configured to run on the Serverless Session template `iceberg-federation-template` as its kernel. - **CRITICAL RULE - Data Science**: ANY data science, machine learning, or advanced analytical task MUST be performed strictly within **Spark Notebooks** using the aforementioned setup.acai_testçalışma alanındatemplate.yamlbaşka bir yeni dosya oluşturun ve dosyaya aşağıdaki bilgileri girin.labels: client: "vscode" jupyterSession: displayName: "iceberg-federation-template" kernel: "PYTHON" environmentConfig: executionConfig: serviceAccount: "sa-spark-dev1@<PROJECT_ID>.iam.gserviceaccount.com" subnetworkUri: "projects/<PROJECT_ID>/regions/<REGION>/subnetworks/<SUBNET_NAME>" runtimeConfig: version: "2.3" properties: # This enables the secure proxy URL you were looking for dataproc.tier: "premium" spark.dataproc.engine: "lightningEngine" spark.dataproc.lightningEngine.runtime: "native" spark.memory.offHeap.enabled: "true" spark.memory.offHeap.size: "1g" spark.executor.memory: "4g" "dataproc.component.gateway.enabled": "true" "dataproc.jupyter.listen.all.interfaces": "true" "spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" "spark.sql.defaultCatalog": "<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>": "org.apache.iceberg.spark.SparkCatalog" "spark.sql.catalog.<CATALOG_NAME>.type": "rest" "spark.sql.catalog.<CATALOG_NAME>.uri": "<CATALOG_URI_ID>" "spark.sql.catalog.<CATALOG_NAME>.warehouse": "bl://projects/<PROJECT_ID>/catalogs/<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>.rest.auth.type": "org.apache.iceberg.gcp.auth.GoogleAuthManager"- VS Code'da Terminal'i tıklayın ve
template.yamldosyasını oturum şablonu olarak içe aktarmak için aşağıdaki komutu çalıştırın. Bu şablon, daha sonra aracı tarafından Spark oturumu oluşturmak için kullanılır.gcloud beta dataproc session-templates import iceberg-federation-template \ --source=template.yaml \ --location=<REGION>REGIONyerine bölgenizi yazın.
12. Ajan tabanlı veri analizi yapma
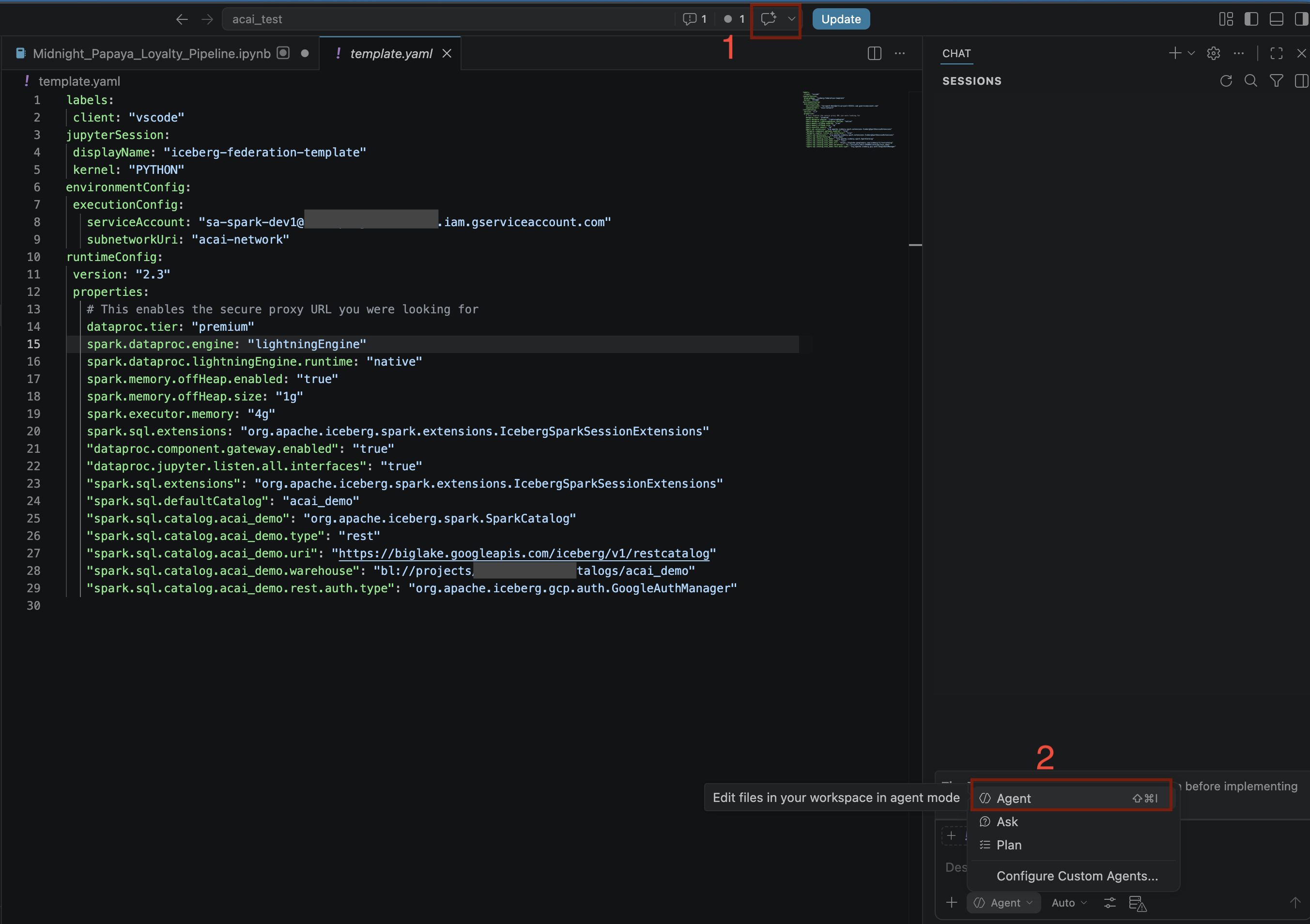
- VS Code düzenleyicide Toggle chat'i (Sohbeti aç/kapat) tıklayın.
- Özel aracıları yapılandırın bölümünde Aracı'yı seçin.
- Arama modelleri bölmesinde Dil modellerini yönet'i tıklayın.
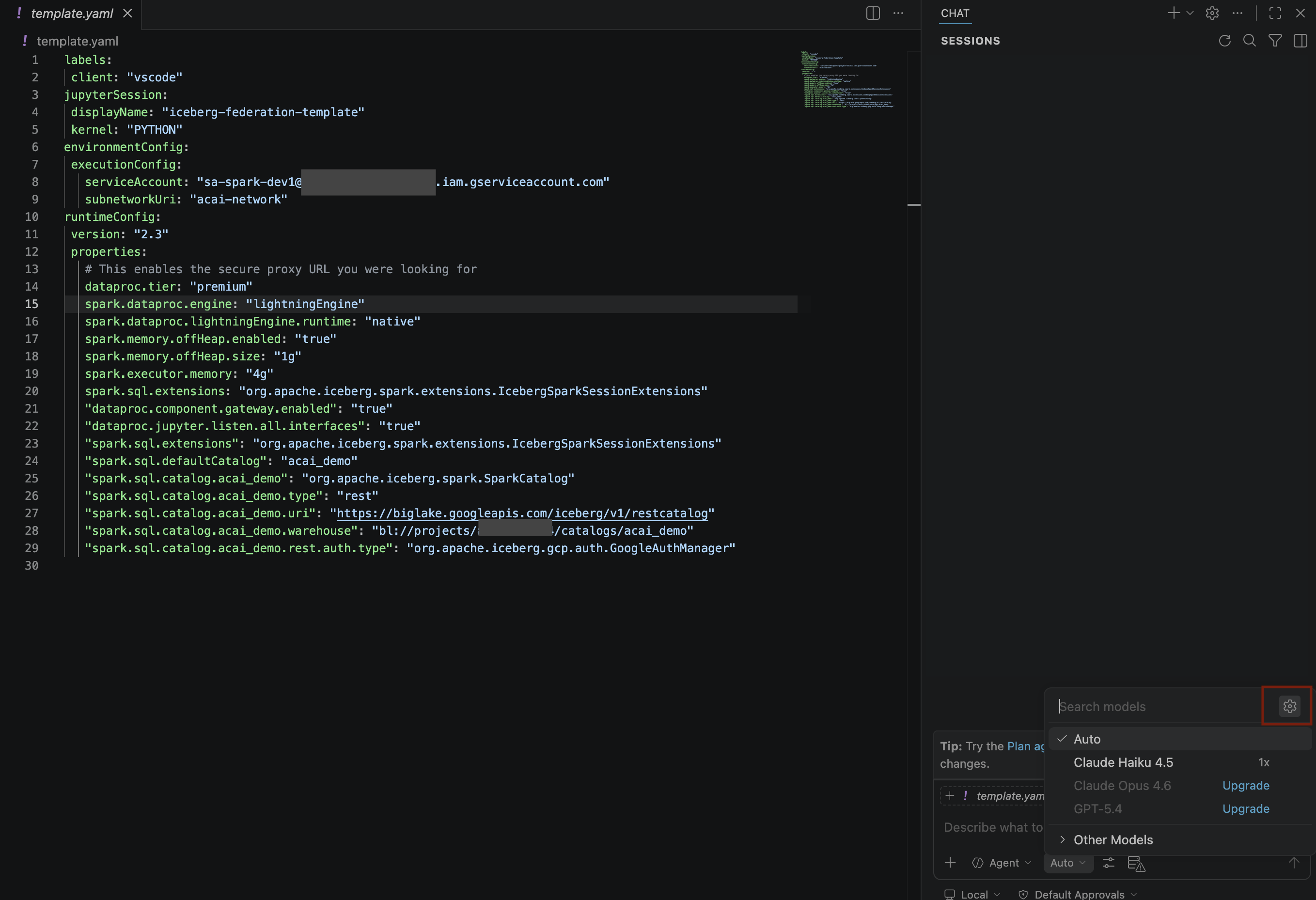
- Dil modelleri sayfasında Model ekle'yi tıklayın.
- Listeden Google'ı seçin ve girişinizi onaylamak için Enter tuşuna basın.
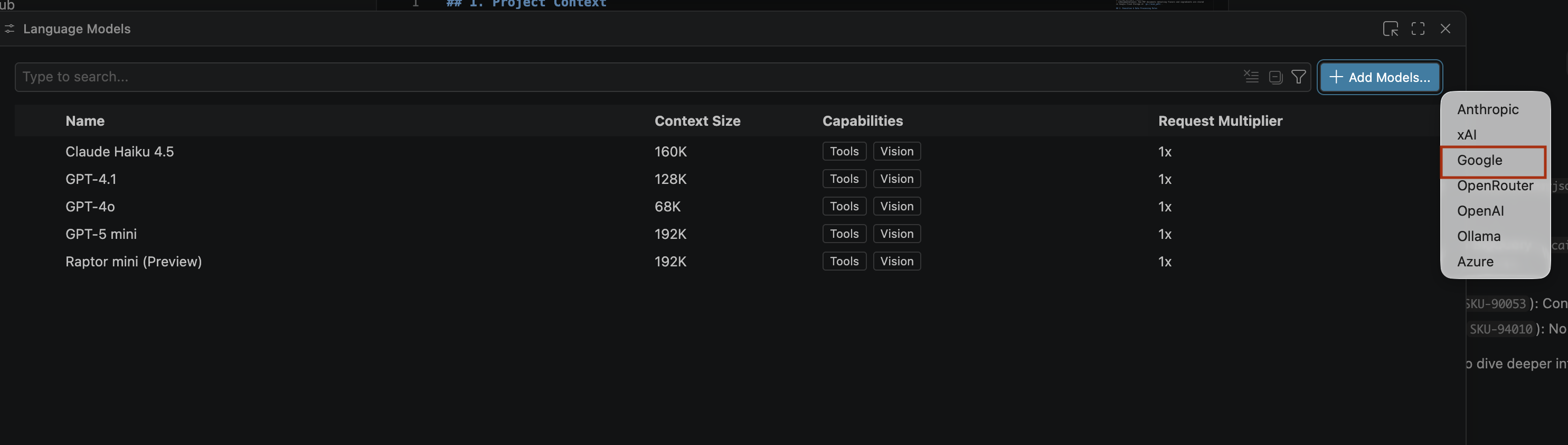
- Google Gemini'ın API anahtarını girmek için aşağıdakileri yapın:
- Google AI Studio web sitesine gidin.
- Google Hesabınızla oturum açın.
- Kenar çubuğunda API anahtarı al'ı tıklayın.
- Create API key'i (API anahtarı oluştur) tıklayın. Yeni anahtar oluşturma sayfası açılır.
- Bulut projesi seçin listesinden Projeyi içe aktar'ı seçin.
- Mevcut bir projenin adını girin.
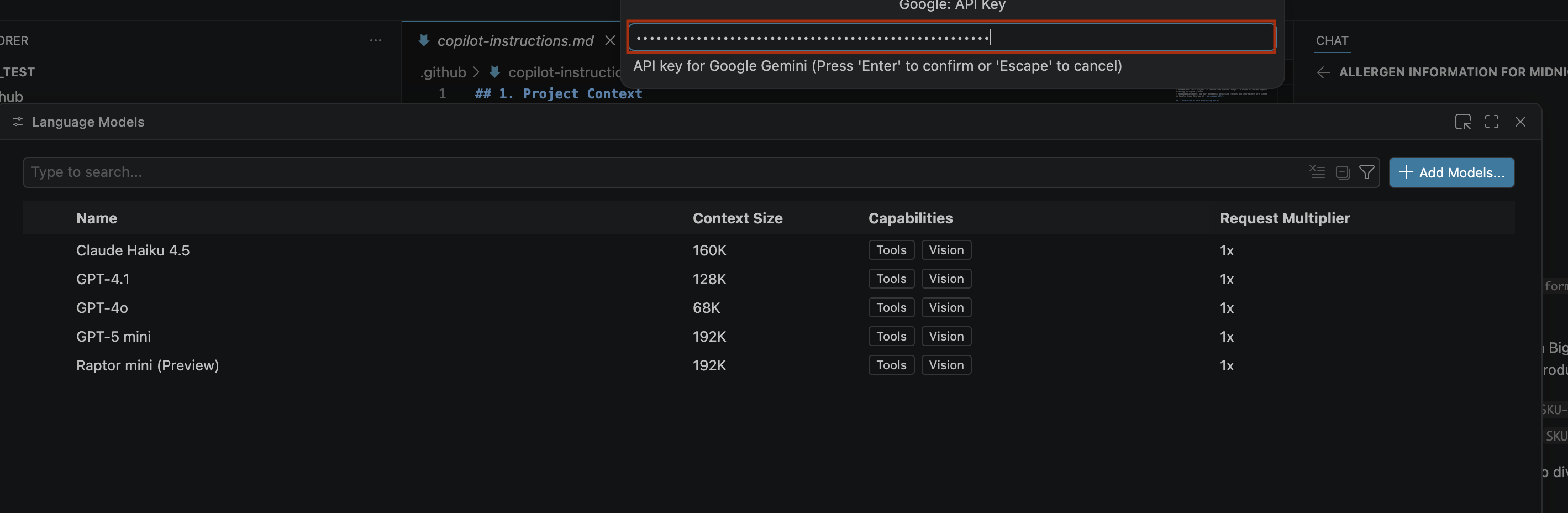
- Anahtar oluştur'u tıklayın ve API anahtarını kopyalayın. Anahtar, hesabınızın Gemini API kaynaklarına erişim sağlar.Daha fazla bilgi için Gemini API anahtarlarını kullanma başlıklı makaleyi inceleyin.
- Oluşturduğunuz API anahtarını arama çubuğuna yapıştırın ve Enter'ı tıklayın.
- Gemini modelleri görünmüyorsa aşağıdaki resimde gösterildiği gibi bunları görünür hale getirin:
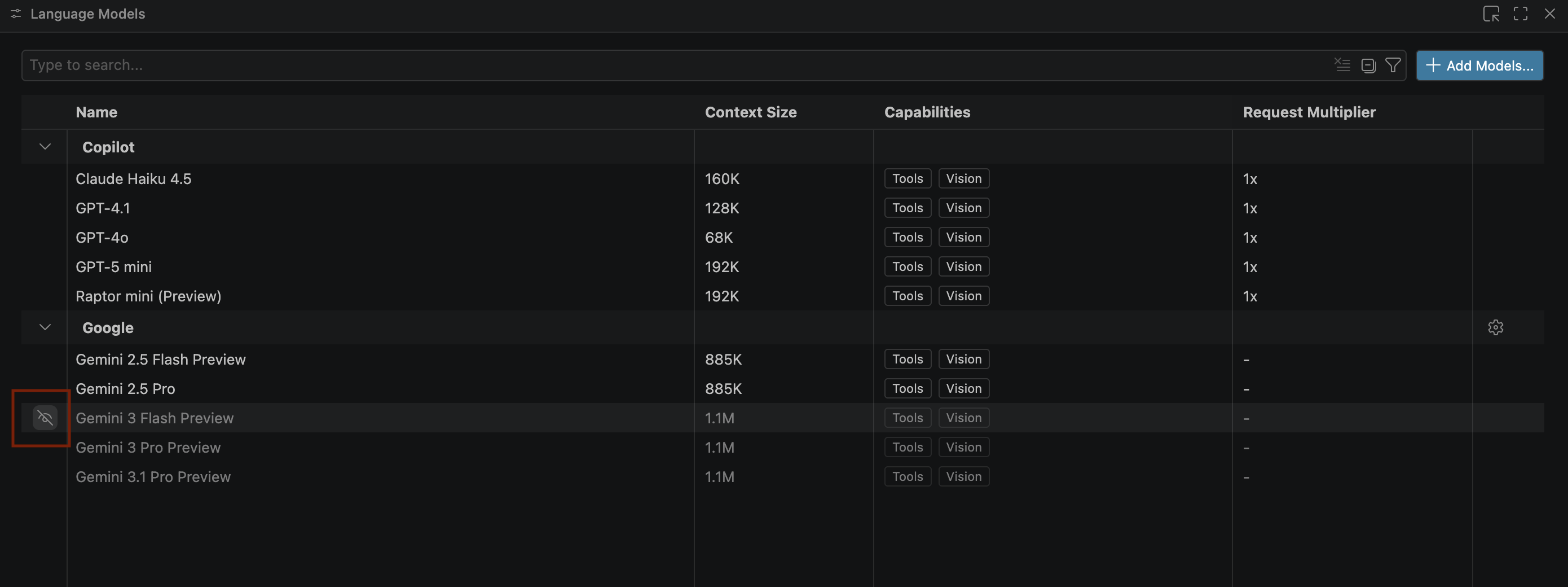
- Google Gemini model listesinden Gemini 3.1 Pro Önizlemesi'ni seçin ve Dil modelleri penceresini kapatın.
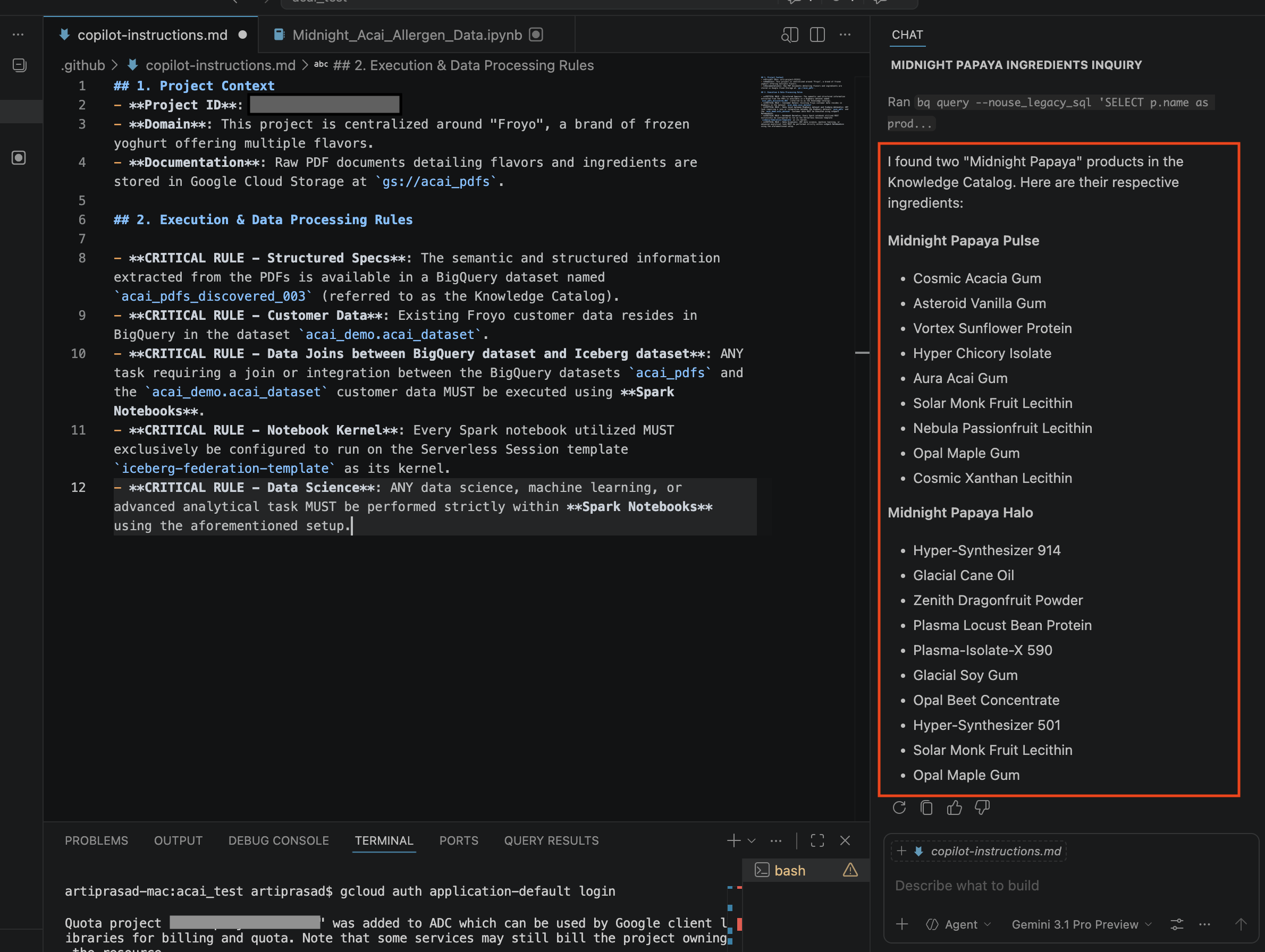
- Sohbet penceresine aşağıdaki soruyu girin:
Search ingredients for Midnight papaya - Biraz etkileşimden sonra aşağıdaki sonucu görmeniz gerekir:
- Sohbet penceresine başka bir soru girin:
Search allergen information for Midnight papaya - Birkaç etkileşim ve adımın ardından, aşağıdaki resimde görebileceğiniz gibi, temsilcinin alerjen adıyla
Soyyanıt verdiğini görürsünüz: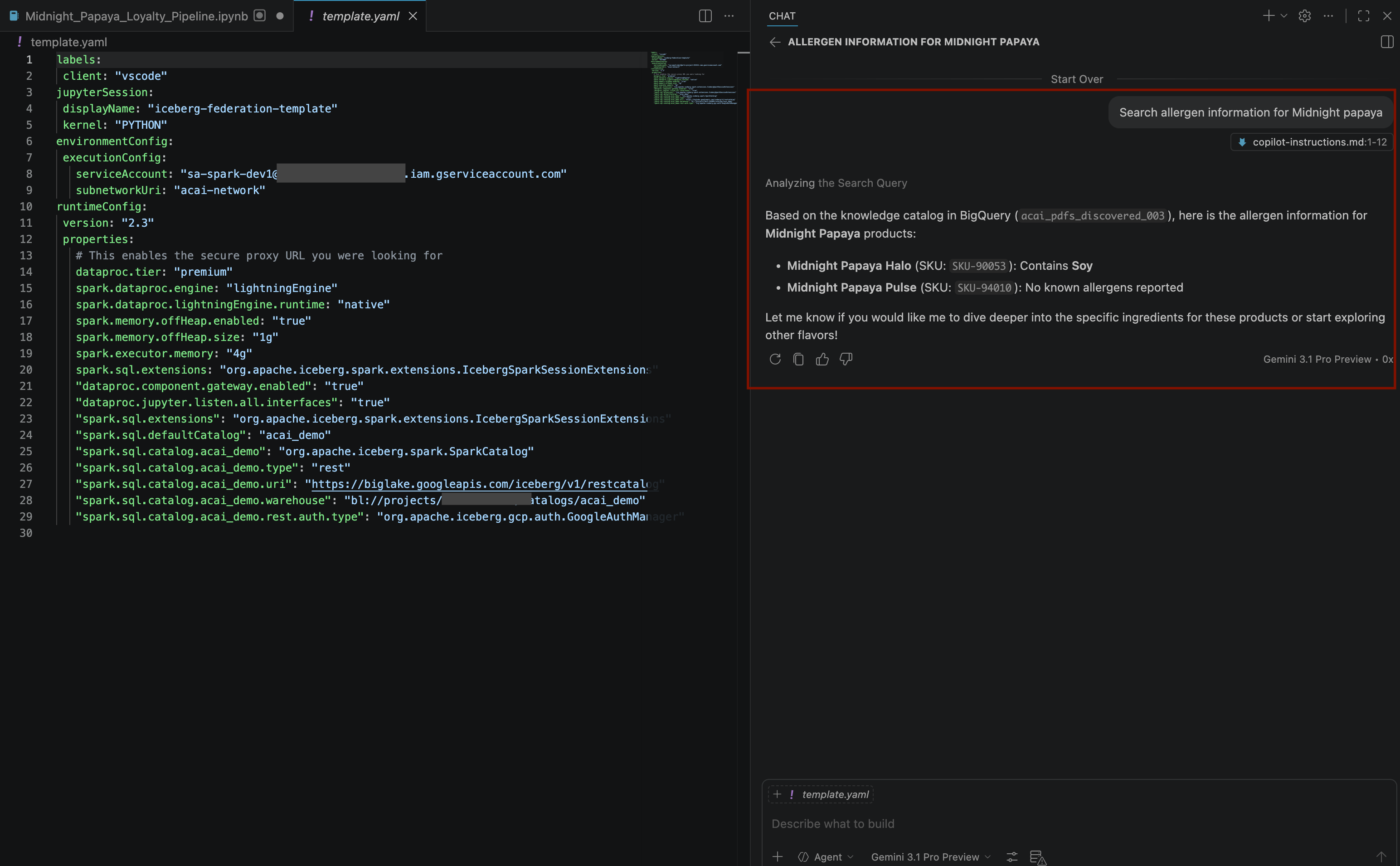
- Sohbet penceresine başka bir soru girin:
Build a pipeline to join products with our 'Global Loyalty' Iceberg tables in acai customer, sales data to identify popular products - Çekirdeği seçmek için
.ipynbdosyasını açın ve Çekirdek seç > Uzak Spark çekirdekleri > Sunucusuz Spark'ta Iceberg-federation-template'i tıklayın.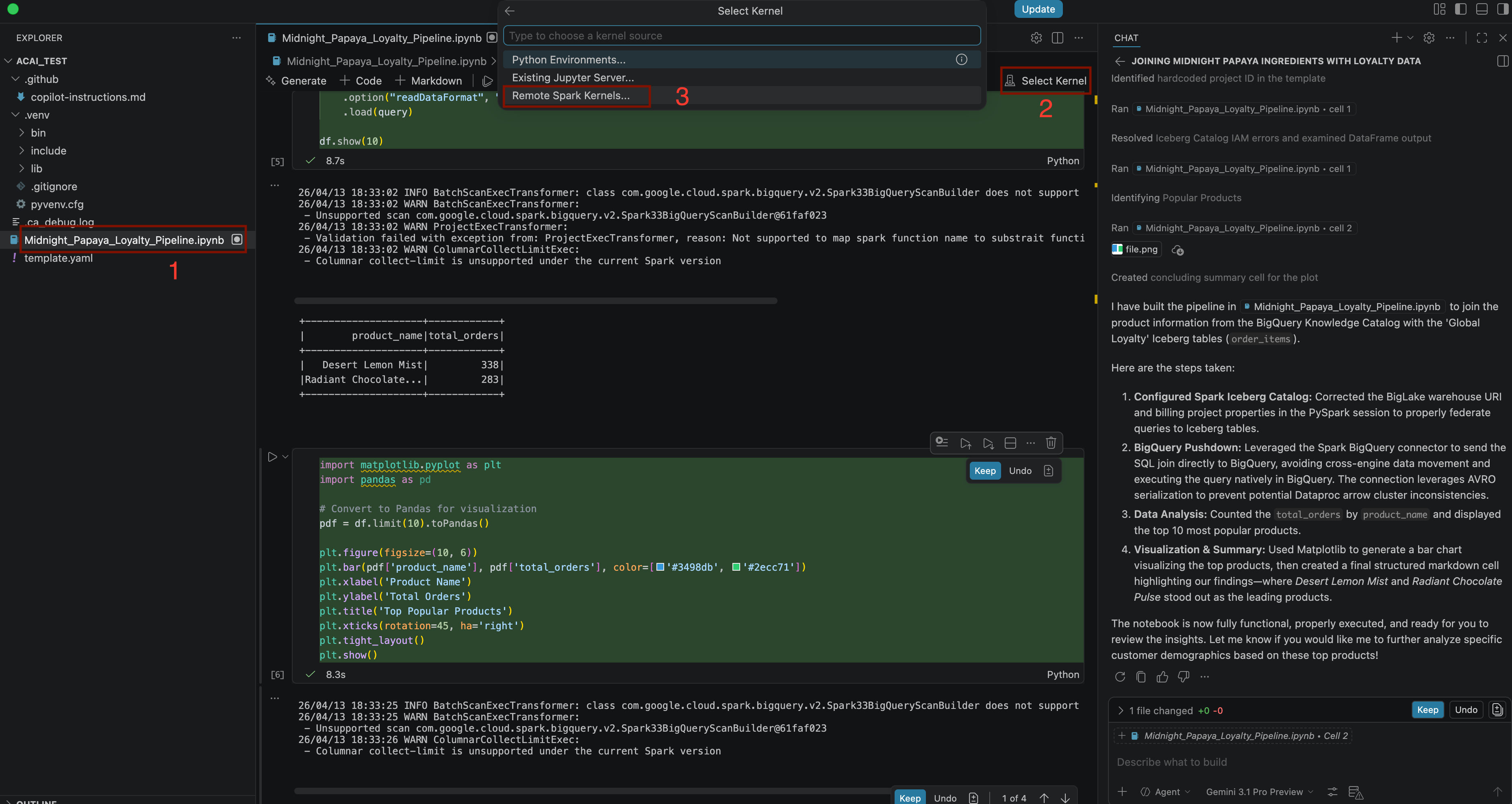
- Biraz etkileşim ve birkaç adımın ardından, aşağıdaki resimde görebileceğiniz gibi, not defterindeki tüm adımların başarıyla yürütüldüğü ve not defterinin sonunda oluşturulan nihai sonuçla birlikte yanıt veren bir aracı görürsünüz:
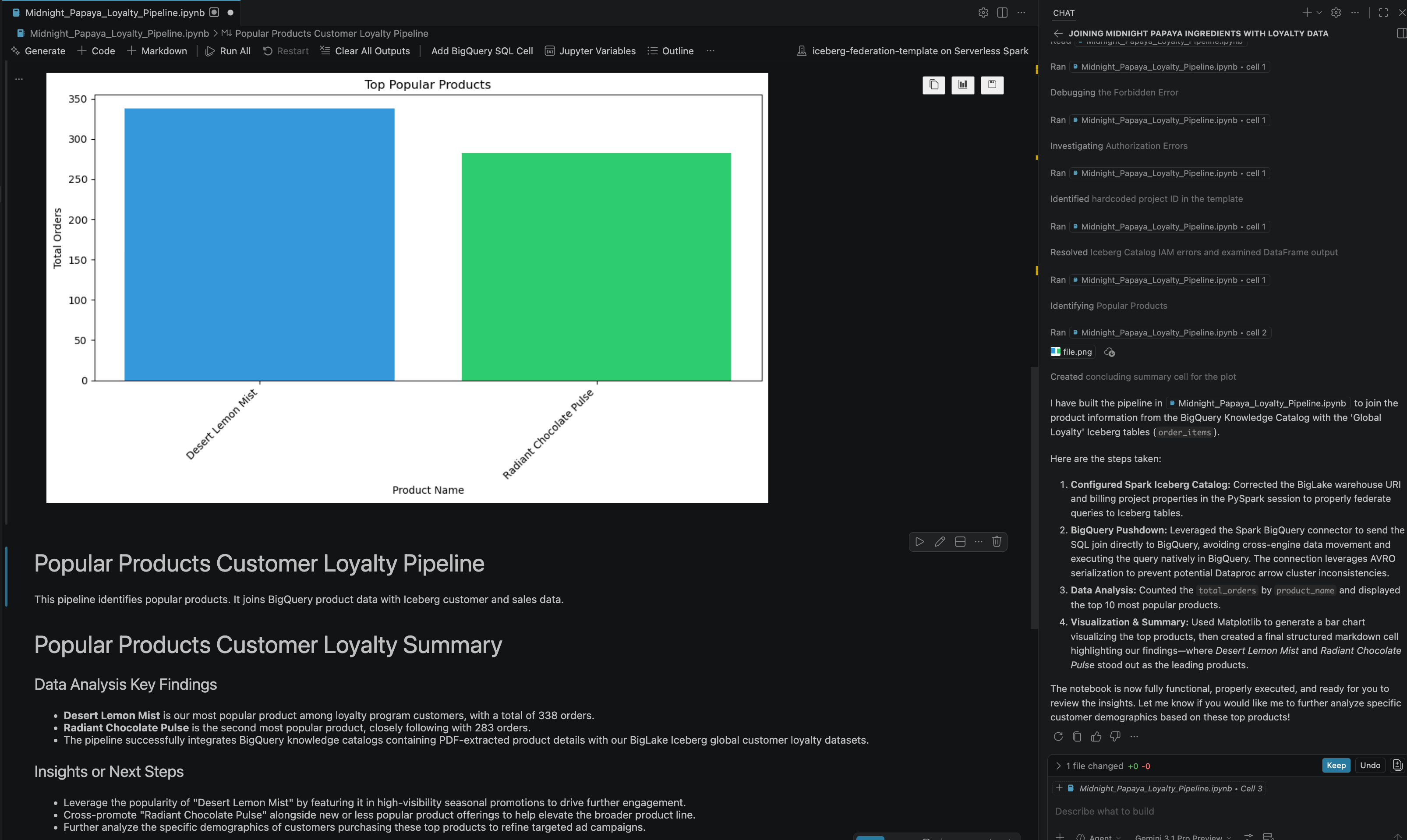
13. Temizleme
Ücretlendirilmemek için bu laboratuvarda oluşturduğunuz kaynakları silin.
- Bilgi Kataloğu DataScan'i silmek için aşağıdaki komutu çalıştırın:
DATASCAN_ID="<DATASCAN_ID>" echo "Deleting Dataplex DataScan: ${DATASCAN_ID}" gcloud dataplex datascans delete "${DATASCAN_ID}" --location="${REGION}" --quiet - Cloud Storage paketlerini ve tüm içeriklerini silmek için aşağıdaki komutu çalıştırın:
echo "Deleting Cloud Storage buckets: <BUCKET_NAME1> and <BUCKET_NAME2>" gsutil -m rm -r gs://<BUCKET_NAME1> gsutil -m rm -r gs://<BUCKET_NAME2> - BigQuery bağlantısını silmek için aşağıdaki komutu çalıştırın:
CONNECTION_ID="<CONNECTION_NAME>" echo "Deleting BigQuery Connection: ${CONNECTION_ID}" bq rm --connection "${PROJECT_ID}.${REGION}.${CONNECTION_ID}" - Lakehouse Kataloğu'nu silmek için aşağıdaki komutu çalıştırın:
CATALOG_ID="<CATALOG_NAME>" echo "Deleting Lakehouse Catalog: ${CATALOG_ID}" gcloud biglake catalogs delete "${CATALOG_ID}" --project="${PROJECT_ID}" --location="${REGION}" --quiet - Bulunan PDF tablolarını içeren veri kümesini silmek için aşağıdaki komutu çalıştırın:
DATASET_NAME="<DATASET_NAME>" echo "Deleting BigQuery Dataset: ${DATASET_NAME}" bq rm -r -f "${PROJECT_ID}:${DATASET_NAME}" - Özel hizmet hesabını silmek için aşağıdaki komutu çalıştırın:
SERVICE_ACCOUNT="<SERVICE_ACCOUNT>" echo "Deleting Service Account: ${SERVICE_ACCOUNT}" gcloud iam service-accounts delete "${SERVICE_ACCOUNT}"@"${PROJECT_ID}".iam.gserviceaccount.com --quiet - VPC ağını silmek için aşağıdaki komutu çalıştırın:
VPC_NETWORK="<VPC_NETWORK>" echo "Deleting VPC Network: ${VPC_NETWORK}" gcloud compute networks delete "${VPC_NETWORK}" --quiet - Google Cloud projesinin tamamını silmek için aşağıdaki komutu çalıştırın:
gcloud projects delete "${PROJECT_ID}"
14. Tebrikler
Tebrikler! BigQuery tablolarındaki ayrılmış PDF'lerin ve Parquet dosyalarının veri ortamını başarıyla düzenleyip tek bir aranabilir ve birleştirilebilir ekosisteme daralttınız. PDF'leri ve büyük veri biçimlerini bir veritabanındaki satır gibi akıllıca işleyen modern bir veri gölü evi oluşturmuş olursunuz. Tüm bunları, Gemini ile yapay zeka destekli kampanya oluşturma deneyimi sunan temsilcinizden yapabilirsiniz.
Referans belgeleri
Bu codelab'de kullanılan temel teknolojiler hakkında daha fazla bilgi edinmek için resmi Google Cloud belgelerini ziyaret edin:
- Veri Bulutu'nun temel bileşenlerinden biri olan BigQuery'yi keşfetmek için BigQuery Belgeleri'ne bakın.
- IAM hakkında daha fazla bilgi edinmek için IAM belgelerine bakın.
- Lakehouse hakkında bilgi edinmek için Lakehouse nedir? başlıklı makaleyi inceleyin.