
1. Giới thiệu
Trong lớp học lập trình này, bạn sẽ đóng vai một nhà khoa học dữ liệu cho một công ty Froyo hư cấu đang ra mắt một hương vị sản phẩm mới, "Midnight Swirl". Để đảm bảo việc ra mắt trên toàn cầu thành công, doanh nghiệp phải trả lời các câu hỏi quan trọng liên quan đến thành phần, nhu cầu thị trường và lợi tức đầu tư (ROI). Quy trình làm việc toàn diện này minh hoạ cách Danh mục kiến thức của Google Cloud (trước đây gọi là Dataplex) và Lakehouse cho Apache Iceberg (trước đây gọi là BigLake) thu hẹp khoảng cách giữa dữ liệu không có cấu trúc "tối" và cung cấp thông tin kinh doanh hữu ích bằng Gemini trong IDE (VS Code) thông qua một lớp quản trị hợp nhất.
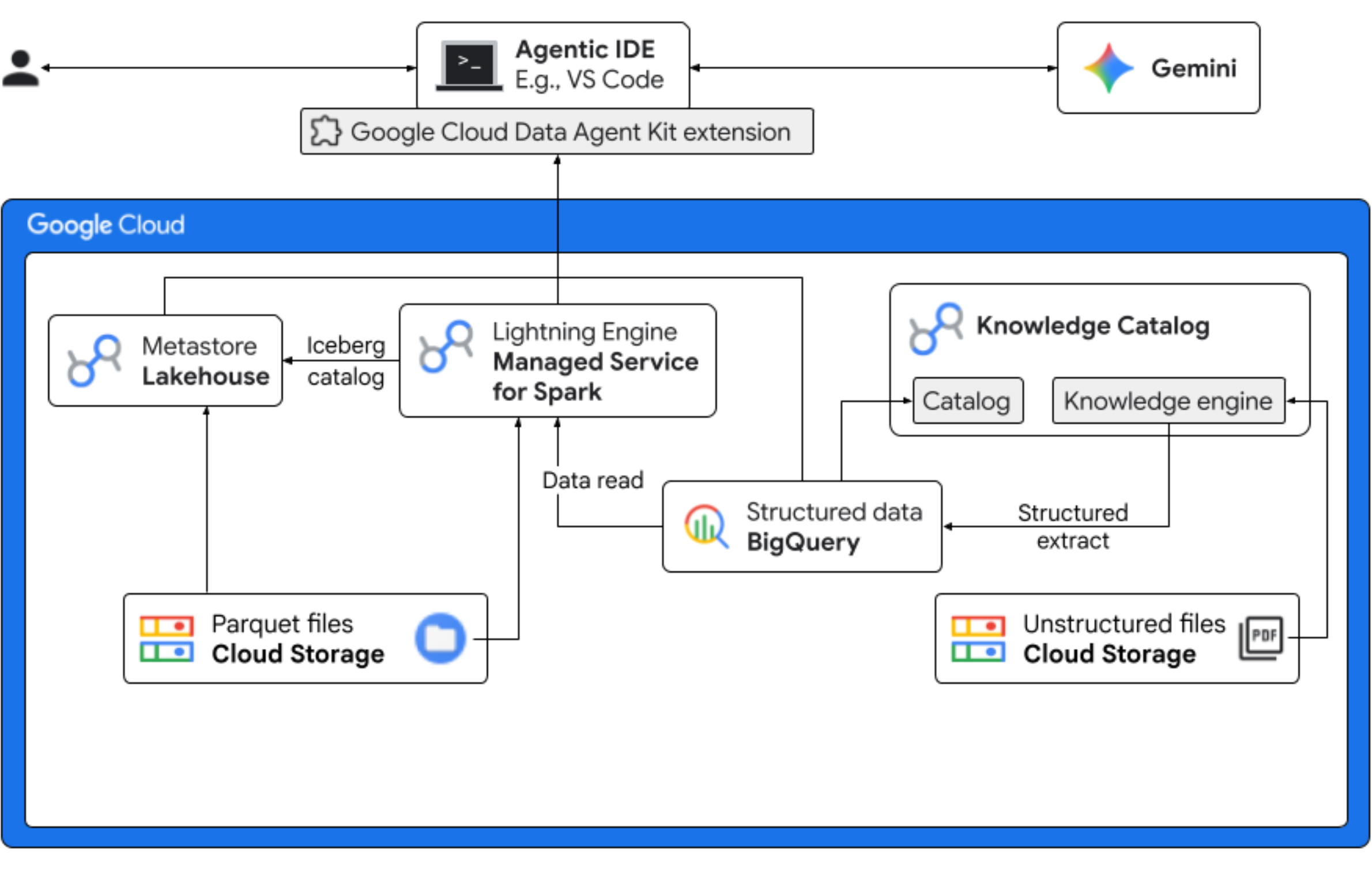
Bạn sẽ thực hiện
- Khám phá dữ liệu không có cấu trúc: Các công thức nấu ăn ở dạng PDF được lưu trữ trong Cloud Storage sẽ được Knowledge Catalog DataScan thu thập thông tin. Tạo bảng Đối tượng trong BigQuery cho các tệp PDF được quét. Bằng cách sử dụng Vertex AI Semantic Inference, hệ thống sẽ "đọc" các tệp PDF để trích xuất thông tin có cấu trúc về sản phẩm, chất gây dị ứng, thành phần và các thuộc tính liên quan. Sau đó, công cụ này sẽ tạo một lược đồ thông minh cho dữ liệu được lưu trữ trong tệp PDF.
- Siêu dữ liệu hợp nhất: Dữ liệu được trích xuất từ các tệp PDF sẽ được lưu trữ trực tiếp vào BigQuery dưới dạng một bảng rộng gốc và các chế độ xem sẽ được tạo để hỗ trợ các truy vấn phổ biến. Một tập dữ liệu đầu vào độc lập chứa dữ liệu bán hàng trước đây được lưu trữ trong Bảng Apache Iceberg trên Google Cloud Storage. Bảng Iceberg này sẽ được kết hợp với dữ liệu đã trích xuất trong BigQuery ở bước tiếp theo.
- Phân tích trên nhiều công cụ: Khi sử dụng Dịch vụ được quản lý cho Apache Spark (trước đây gọi là Dataproc) với Danh mục REST của Iceberg, bạn sẽ kết hợp siêu dữ liệu PDF mới và dữ liệu ngữ nghĩa có cấu trúc được suy luận (từ các bảng và khung hiển thị BigQuery) với dữ liệu bán hàng có cấu trúc được lưu trữ trong Bảng Apache Iceberg trên Google Cloud Storage. Điều này chịu sự điều chỉnh của một mẫu phiên tương tác Apache Spark được quản lý, được dùng làm nhân Jupyter Notebook, đảm bảo các chế độ cài đặt bảo mật và điện toán nhất quán cho công việc Spark.
- Thông tin chi tiết ngữ nghĩa: Bằng cách kết hợp dữ liệu sản phẩm được suy luận với dữ liệu khách hàng và dữ liệu bán hàng (trong BigQuery), bản minh hoạ có thể trích xuất thông tin chi tiết, chẳng hạn như xác định dữ liệu về chất gây dị ứng và dự báo doanh thu.
- Hoạt động quản trị tự động: Toàn bộ vòng đời (từ các lần quét khám phá đến quá trình thực thi Spark) được điều phối thông qua các mẫu, hướng dẫn, quy tắc và hoạt động tự động hoá dựa trên tác nhân tương thích với Gemini, chứng minh rằng AI có thể quản lý cơ sở hạ tầng hỗ trợ hoạt động phân tích.
Bạn cần có
Việc hoàn thành lớp học lập trình này có thể phát sinh chi phí, ước tính dưới 5 đô la cho mức sử dụng thông thường. Để biết thông tin chi tiết về chi phí ước tính dựa trên mức sử dụng dự kiến hoặc mức giá hiện tại, hãy sử dụng Công cụ tính giá của Google Cloud.
Đảm bảo bạn đáp ứng các điều kiện tiên quyết sau để hoàn thành lớp học lập trình.
- Trình duyệt web Chrome.
- Tài khoản Gmail cá nhân nếu bạn đang sử dụng tín dụng dùng thử được cung cấp trong phần Trước khi bắt đầu.
- Tải và cài đặt Visual Studio (VS) Code.
2. Trước khi bắt đầu
Tạo một dự án trên Google Cloud
- Trong Google Cloud Console, trên trang chọn dự án, hãy chọn hoặc tạo một dự án trên đám mây của Google Cloud.
- Đảm bảo bạn đã bật tính năng thanh toán cho dự án trên Cloud. Tìm hiểu cách kiểm tra xem tính năng thanh toán có được bật trong một dự án hay không.
Khởi động Cloud Shell
Cloud Shell là một môi trường dòng lệnh chạy trong Google Cloud và được tải sẵn các công cụ cần thiết.
- Nhấp vào Kích hoạt Cloud Shell ở đầu Cloud Console.
- Sau khi kết nối với Cloud Shell, hãy xác minh thông tin xác thực của bạn:
gcloud auth list - Xác nhận rằng dự án của bạn đã được định cấu hình:
gcloud config get project - Nếu dự án của bạn không được thiết lập như mong đợi, hãy thiết lập dự án:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Bật các API bắt buộc
Chạy lệnh này để bật tất cả các API bắt buộc:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
biglake.googleapis.com \
dataproc.googleapis.com \
metastore.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
secretmanager.googleapis.com \
storage.googleapis.com
Tải các thành phần của lớp học lập trình xuống
Kho lưu trữ này chứa các tệp Parquet, recipes, suppliers, copilot-instructions.md, template.yaml và quickstart.py để sử dụng với lớp học lập trình này. Hãy nhớ tải các tệp này xuống.
Để tải các tệp xuống, hãy làm như sau:
- Trong Cloud Shell, hãy chạy lệnh sau:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git - Chuyển đến thư mục mới tạo:
cd next-26-keynotes - Kéo thư mục
data-cloud-demogit sparse-checkout set genkey/data-cloud-demo - Sau khi hoàn tất quy trình thanh toán, hãy chuyển đến thư mục
data-cloud-demorồi giải nén các tệp ZIP để truy cập vào các thành phần của lớp học lập trình.
3. Thiết lập Lakehouse cho dữ liệu khách hàng của Froyo
Trong phần này, bạn sẽ tạo một danh mục trong Lakehouse để sử dụng kho siêu dữ liệu Lakehouse cho các quy trình công việc của mình. Công cụ này tạo khả năng tương tác giữa các công cụ truy vấn của bạn bằng cách cung cấp một nguồn đáng tin cậy duy nhất cho tất cả dữ liệu Iceberg. Điều này giúp các công cụ truy vấn (chẳng hạn như Apache Spark) khám phá, đọc siêu dữ liệu và quản lý các bảng Iceberg một cách nhất quán.
Vai trò bắt buộc
Đảm bảo rằng bạn có các vai trò Quản lý danh tính và quyền truy cập (IAM) sau đây:
roles/biglake.viewerroles/bigquery.userroles/bigquery.dataEditorroles/biglake.editorroles/biglake.metadataViewerroles/bigquery.connectionUserroles/storage.objectUserroles/storage.objectViewerroles/storage.objectCreatorroles/storage.admin
Để biết thêm thông tin về cách cấp vai trò IAM, hãy xem bài viết Cấp vai trò IAM.
Tạo danh mục Lakehouse bằng một vùng chứa
Tạo danh mục Lakehouse để quản lý siêu dữ liệu cho các bảng Iceberg. Bạn kết nối với danh mục này trong tác vụ Spark để tạo và truy vấn các bảng Iceberg.
- Trong Cloud Console, hãy chuyển đến Lakehouse.
- Nhấp vào Tạo danh mục. Trang Tạo danh mục sẽ mở ra.
- Đối với Loại danh mục, hãy chọn Danh mục Iceberg Rest.
- Đối với Chọn các lựa chọn về vùng chứa danh mục Lakehouse, hãy chọn Danh mục vùng chứa đơn.
- Đối với Bộ chứa mặc định của danh mục trong Cloud Storage, hãy nhấp vào Duyệt qua, rồi nhấp vào Tạo bộ chứa mới.
- Trên trang Tạo vùng chứa, hãy làm như sau:
- Trong phần Bắt đầu, hãy nhập một tên riêng biệt trên toàn cầu đáp ứng các yêu cầu về tên vùng lưu trữ.
- Trong phần Chọn nơi lưu trữ dữ liệu của bạn, hãy chọn Khu vực cho Loại vị trí rồi nhập khu vực của bạn. Ví dụ:
us-west1. - Trong phần Chọn cách kiểm soát quyền truy cập vào các đối tượng, hãy bỏ chọn hộp đánh dấu Thực thi biện pháp phòng tránh truy cập công khai trên bộ chứa này.
Điều này cho phép bạn mô phỏng các tình huống trong thế giới thực, chẳng hạn như lưu trữ nội dung web công khai hoặc kho lưu trữ dữ liệu được chia sẻ. Nếu không có thay đổi này, vùng lưu trữ sẽ thực thi chính sách "chỉ riêng tư" nghiêm ngặt; mọi nỗ lực truy cập vào tài sản của bạn sẽ dẫn đến lỗi403bị cấm, ngay cả khi bạn đã cấp quyền công khai cho các tệp. - Nhấp vào Tiếp tục > Tạo > Chọn > Tiếp tục.
- Đối với Phương thức xác thực, hãy chọn Chế độ bán thông tin đăng nhập.
- Nhấp vào Tạo.Danh mục của bạn sẽ được tạo và trang Thông tin chi tiết về danh mục sẽ mở ra.
- Trong phần Phương thức xác thực, hãy nhấp vào Đặt quyền cho nhóm.
- Trong hộp thoại, hãy nhấp vào Xác nhận.Thao tác này sẽ xác minh rằng tài khoản dịch vụ của danh mục có vai trò
Storage Object Usertrên vùng lưu trữ của bạn. - Trên trang Chi tiết danh mục, hãy sao chép đường dẫn URI danh mục REST. Sử dụng đường dẫn này trong quá trình thực hiện tác vụ Chạy lệnh Spark.
Tải tệp Parquet lên bộ chứa
Để tải tệp Parquet lên thư mục gốc của nhóm, hãy làm như sau:
- Trong bảng điều khiển Google Cloud, hãy chuyển đến trang Cloud Storage Buckets (Bộ chứa Cloud Storage).
- Trong danh sách các nhóm, hãy nhấp vào tên nhóm. Ví dụ:
acai_demo. - Trong thẻ Objects (Đối tượng) của nhóm, hãy nhấp vào Upload (Tải lên) > Upload files (Tải tệp lên).
- Chọn các tệp trong thư mục Parquet mà bạn đã sao chép trong phần Trước khi bắt đầu của lớp học lập trình này.
- Nhấp vào Mở.
4. Thiết lập mạng VPC
Tạo một mạng Virtual Private Cloud (VPC) và một mạng con cho phép các tài nguyên giao tiếp với API của Google mà không cần truy cập vào Internet công cộng, đồng thời tạo một tường lửa cho phép lưu lượng truy cập nội bộ lưu chuyển tự do giữa các nút xử lý dữ liệu.
- Trong bảng điều khiển Google Cloud, hãy chuyển đến trang Mạng VPC.
- Nhấp vào Tạo mạng VPC.
- Nhập Tên cho mạng. Ví dụ:
acai-network. - Để định cấu hình đơn vị truyền tải tối đa (MTU) của mạng, hãy chọn hộp đánh dấu Đặt MTU tự động.
- Chọn Tự động cho Chế độ tạo mạng con.
- Trong phần Firewall rules (Quy tắc tường lửa), hãy chọn tất cả hộp đánh dấu cho IPv4 firewall rules (Quy tắc tường lửa IPv4)
- Nhấp vào Tạo.
Bật tính năng Truy cập riêng tư vào Google
Các nút Dataproc Serverless không có địa chỉ IP công khai. Để giao tiếp với Lakehouse Catalog và Cloud Storage, mạng con phải bật tính năng Private Google Access.
- Trong bảng điều khiển Google Cloud, hãy chuyển đến trang Mạng VPC.
- Nhấp vào tên của mạng chứa mạng con mà bạn cần bật tính năng Private Google Access. Ví dụ:
us-west1. - Nhấp vào tên của mạng con. Trang thông tin chi tiết Mạng con sẽ xuất hiện.
- Nhấp vào Chỉnh sửa.
- Trong phần Private Google Access (Quyền truy cập riêng tư vào Google), hãy chọn Bật.
- Nhấp vào Lưu.
5. Tạo và chạy một công việc Spark
Để tạo và truy vấn một bảng Iceberg, hãy tải công việc PySpark lên bằng các câu lệnh Spark SQL cần thiết. Sau đó, hãy chạy công việc bằng Managed Service for Spark.
Tải quickstart.py lên bộ chứa Cloud Storage
Sau khi bạn sao chép các tài sản của lớp học lập trình, hãy cập nhật tập lệnh quickstart.py bằng thông tin chi tiết về dự án của bạn rồi tải tập lệnh đó lên vùng lưu trữ Cloud Storage.
- Mở tập lệnh
quickstart.pytrong trình chỉnh sửa văn bản. - Thay thế phần giữ chỗ
BUCKET_NAMEtrong tập lệnh bằng tên bộ chứa Cloud Storage rồi lưu tập lệnh. - Trong Cloud Console của Google Cloud, hãy chuyển đến Bộ chứa Cloud Storage.
- Nhấp vào tên của nhóm. Ví dụ:
acai_demo. - Trên thẻ Đối tượng, hãy nhấp vào Tải lên > Tải tệp lên.
- Trong trình duyệt tệp, hãy chọn tệp
quickstart.pyđã cập nhật rồi nhấp vào Mở.
Chạy lệnh Spark
Sau khi tải tập lệnh quickstart.py lên, hãy kích hoạt tập lệnh đó dưới dạng một công việc hàng loạt Managed Service for Spark.
- Để định cấu hình các biến, hãy chạy lệnh sau trong Cloud Shell.
# Configuration Variables export PROJECT_ID="<PROJECT_ID>" export REGION="<REGION>" export BUCKET_NAME="<BUCKET_NAME>" export SUBNET="<SUBNET>" export LAKEHOUSE_CATALOG_ID="<LAKEHOUSE_CATALOG_ID>" export CATALOG_URI_ID="<CATALOG_URI_ID>"- LAKEHOUSE_CATALOG_ID: tên của tài nguyên danh mục Lakehouse chứa tệp ứng dụng PySpark. Ví dụ:
acai_demo - PROJECT_ID: mã dự án trên đám mây của bạn trên Google Cloud.
- REGION: khu vực để chạy tải công việc hàng loạt Managed Service for Spark. Ví dụ:
us-west1. - BUCKET_NAME: tên bộ chứa Cloud Storage của bạn. Ví dụ:
acai_demo. - SUBNET: tên mạng con VPC của bạn. Ví dụ:
acai-network. - CATALOG_URI_ID: mã nhận dạng URI của danh mục Lakehouse mà bạn đã sao chép khi tạo danh mục Lakehouse bằng một bộ chứa. Ví dụ:
https://biglake.googleapis.com/iceberg/v1/restcatalog.
- LAKEHOUSE_CATALOG_ID: tên của tài nguyên danh mục Lakehouse chứa tệp ứng dụng PySpark. Ví dụ:
- Trong Cloud Shell, hãy chạy công việc hàng loạt Managed Service for Spark sau đây bằng tập lệnh
quickstart.py.gcloud dataproc batches submit pyspark gs://${BUCKET_NAME}/quickstart.py \ --project=${PROJECT_ID} \ --region=${REGION} \ --subnet=${SUBNET} \ --version=2.2 \ --properties="\ spark.sql.defaultCatalog=${LAKEHOUSE_CATALOG_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}=org.apache.iceberg.spark.SparkCatalog,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.type=rest,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.uri=${CATALOG_URI_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.warehouse=gs://${BUCKET_NAME},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.io-impl=org.apache.iceberg.gcp.gcs.GCSFileIO,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.x-goog-user-project=${PROJECT_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\ spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest-metrics-reporting-enabled=false,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.X-Iceberg-Access-Delegation=vended-credentials,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token"All tables registered successfully! Batch [126fa2226a904d2e944c8eecbe0b1840] finished. metadata: '@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata batch: projects/PROJECT_ID/locations/REGION/batches/126fa2226a904d2e944c8eecbe0b1840 batchUuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff createTime: '2026-04-09T13:17:26.222727Z' description: Batch labels: goog-dataproc-batch-id: 126fa2226a904d2e944c8eecbe0b1840 goog-dataproc-batch-uuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-drz-resource-uuid: batch-3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-location: REGION operationType: BATCH name: projects/PROJECT_ID/regions/REGION/operations/47bc59e8-5082-3af9-89a0-22289aa5f4b9
6. Truy vấn bảng từ BigQuery
Bằng cách chạy thành công công việc hàng loạt Spark, bạn đã sử dụng Dịch vụ được quản lý cho Spark không máy chủ làm công cụ điện toán phân tán để đăng ký nhiều bảng, mỗi bảng một tệp Parquet trong Lakehouse Metastore. Việc đăng ký này cho phép Google Cloud coi các tệp thô của bạn trong Cloud Storage là các bảng có cấu trúc và hiệu suất cao.
Các bước sau đây sẽ hướng dẫn bạn xác nhận rằng siêu dữ liệu đã được đồng bộ hoá chính xác, đảm bảo rằng dữ liệu của bạn không chỉ được lưu trữ an toàn mà còn có thể được phát hiện và truy vấn đầy đủ thông qua giao diện BigQuery.
- Trong bảng điều khiển Google Cloud, hãy chuyển đến BigQuery.
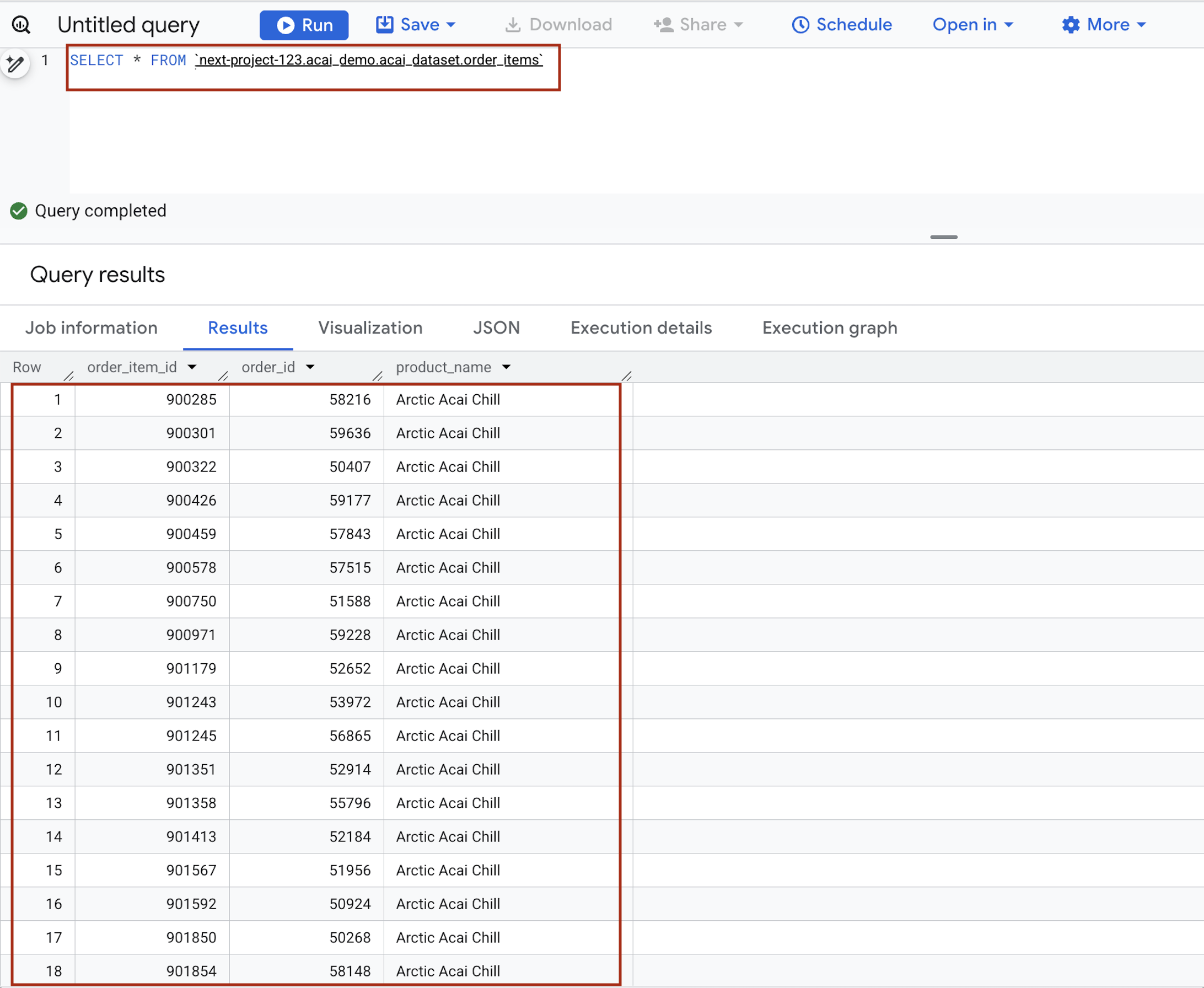
- Trong trình chỉnh sửa truy vấn, hãy nhập câu lệnh sau. Truy vấn này sử dụng cú pháp
project.namespace.dataset.table.SELECT * FROM `<PROJECT_ID>.<NAMESPACE>.<ICEBERG_DATASET>.<ICEBERG_TABLE>`PROJECT_ID.acai_demo.acai_dataset.order_items.
Thay thế những nội dung sau:- PROJECT_ID: mã dự án trên đám mây của bạn trên Google Cloud.
- NAMESPACE: không gian tên được tạo ở bước trước do công việc Spark, bạn có thể tìm thấy không gian tên này trên trang trình khám phá đối tượng BigQuery. Ví dụ:
acai_demo. - ICEBERG_DATASET: tên tập dữ liệu trong danh mục Iceberg, ví dụ:
acai_dataset. - ICEBERG_TABLE: tên bảng trong tập dữ liệu Iceberg, ví dụ:
order_items.
- Nhấp vào Chạy. Kết quả truy vấn cho thấy dữ liệu mà bạn đã chèn bằng lệnh Spark.
7. Thiết lập tệp dữ liệu sản phẩm không có cấu trúc
Trong phần này, bạn sẽ tạo một cấu trúc tổ chức trong BigQuery để lưu trữ dữ liệu về công thức và nhà cung cấp Froyo, đặc biệt là thông tin chi tiết về sản phẩm Froyo. Thao tác này cũng thiết lập một Cloud Resource Connection (Kết nối tài nguyên trên đám mây), đóng vai trò là "cầu nối" an toàn cho phép BigQuery đọc các tệp từ các nguồn bên ngoài như Cloud Storage.
Tạo vùng lưu trữ và tải các tệp chi tiết về Froyo lên
Tạo và tải tệp nhà cung cấp cũng như tệp công thức lên nhóm Cloud Storage.
- Trong bảng điều khiển Google Cloud, hãy chuyển đến trang Cloud Storage Buckets (Bộ chứa Cloud Storage).
- Nhấp vào Tạo.
- Trên trang Tạo vùng lưu trữ, hãy nhập thông tin về vùng lưu trữ của bạn. Sau mỗi bước sau đây, hãy nhấp vào Tiếp tục để chuyển sang bước tiếp theo:
- Trong phần Bắt đầu, hãy nhập tên nhóm. Ví dụ:
acai_pdfs. - Trong mục Chọn nơi lưu trữ dữ liệu của bạn, hãy chọn Khu vực rồi nhập khu vực của bạn. Ví dụ:
us-west1. - Trong phần Chọn cách kiểm soát quyền truy cập vào các đối tượng, hãy bỏ chọn hộp đánh dấu Thực thi biện pháp phòng tránh truy cập công khai trên bộ chứa này.
- Nhấp vào Tạo.
- Trong danh sách các nhóm, hãy nhấp vào nhóm mà bạn đã tạo. Ví dụ:
acai_pdfs. - Trong thẻ Objects (Đối tượng) của nhóm lưu trữ, hãy nhấp vào Upload (Tải lên) > Upload folders (Tải thư mục lên).
- Chọn thư mục
recipesmà bạn đã giải nén trong phần Trước khi bắt đầu của lớp học lập trình này. - Nhấp vào Tải lên.
- Lặp lại quy trình tải lên cho thư mục
suppliers.
Tạo mối kết nối
Tạo một Cloud Resource Connection. Thao tác này sẽ tạo một Tài khoản dịch vụ duy nhất đóng vai trò là "thẻ căn cước" của BigQuery để truy cập vào các tệp bên ngoài.
- Chuyển đến trang BigQuery.
- Trong ngăn bên trái, hãy nhấp vào Trình khám phá. Nếu bạn không thấy ngăn bên trái, hãy nhấp vào Mở rộng ngăn bên trái để mở ngăn này.
- Trong ngăn Explorer (Trình khám phá), hãy mở rộng tên dự án của bạn, rồi nhấp vào Connections (Kết nối).
- Trên trang Kết nối, hãy nhấp vào Tạo kết nối.
- Đối với loại Connection (Kết nối), hãy chọn Vertex AI remote models, remote functions, BigLake and Spanner (Cloud Resource) (Mô hình từ xa, hàm từ xa, BigLake và Spanner (Tài nguyên trên đám mây) của Vertex AI).
- Trong trường Connection ID (Mã nhận dạng mối kết nối), hãy nhập tên mã nhận dạng mối kết nối. Ví dụ:
acai_pdf_connection. Hãy nhớ ghi lại mã nhận dạng này vì bạn sẽ cần đến mã này khi thiết lập tính năng quét dữ liệu sau này trong lớp học lập trình này. - Đặt Loại vị trí thành Khu vực rồi chọn một khu vực. Ví dụ:
us-west1. Bạn nên đặt kết nối cùng với các tài nguyên khác, chẳng hạn như tập dữ liệu. - Nhấp vào Tạo mối kết nối.
- Nhấp vào Chuyển đến phần kết nối.
- Trong ngăn Thông tin kết nối, hãy sao chép mã nhận dạng tài khoản dịch vụ để sử dụng ở bước sau. Tài khoản dịch vụ có dạng như
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com.
Quản lý quyền truy cập vào tài khoản dịch vụ
Cấp quyền truy cập vào tài khoản dịch vụ để Lakehouse có thể đọc các tệp PDF của bạn.
- Chuyển đến trang IAM & Admin (Quản trị và quản lý danh tính và quyền truy cập).
- Nhấp vào Cấp quyền truy cập. Hộp thoại Thêm người dùng chính sẽ mở ra.
- Trong trường Bên giao đại lý mới, hãy nhập mã nhận dạng tài khoản dịch vụ mà bạn đã sao chép trước đó.
- Trong trường Chọn vai trò, hãy thêm các vai trò sau:
roles/storage.objectUserroles/storage.objectViewerroles/bigquery.userroles/bigquery.dataEditorroles/aiplatform.userroles/storage.adminroles/dataproc.serviceAgent
- Nhấp vào Lưu.
Để biết thêm thông tin về các vai trò IAM trong BigQuery, hãy xem phần Các vai trò và quyền được xác định trước.
8. Quản lý quyền đối với lệnh DataScan
Tạo các tài khoản dịch vụ (danh tính) cụ thể cho Spark và Dataform, sau đó cấp cho các tài khoản này (cùng với các tác nhân dịch vụ tự động của Google) những quyền chính xác cần thiết để đọc bộ nhớ, chạy các công việc BigQuery và sử dụng Vertex AI để khám phá.
Quyền truy cập IAM cho Spark và Dataform
- Trong bảng điều khiển Google Cloud, hãy chuyển đến trang Tạo tài khoản dịch vụ.
- Nếu chưa chọn, hãy chọn dự án trên đám mây của bạn.
- Nhấp vào Tạo tài khoản dịch vụ.
- Nhập tên tài khoản dịch vụ. Ví dụ:
sa-spark-stg1. Cloud Console sẽ tạo mã tài khoản dịch vụ dựa trên tên này. Chỉnh sửa mã nhận dạng nếu cần. Sau này bạn không thể thay đổi mã nhận dạng. - Để thiết lập chế độ kiểm soát quyền truy cập, hãy nhấp vào Tạo và tiếp tục rồi chuyển sang bước tiếp theo.
- Chọn các vai trò IAM sau đây để cấp cho tài khoản dịch vụ trên dự án.
roles/dataproc.workerroles/storage.objectUserroles/bigquery.dataEditorroles/bigquery.jobUserroles/aiplatform.userroles/dataplex.discoveryPublishingServiceAgent
- Khi bạn thêm xong các vai trò, hãy nhấp vào Tiếp tục.
- Nhấp vào Xong để hoàn tất quá trình tạo tài khoản dịch vụ.
Quyền kết nối BigQuery để truy cập vào Danh mục tri thức
- Trong bảng điều khiển Google Cloud, hãy chuyển đến trang Cloud Storage Buckets (Bộ chứa Cloud Storage).
- Trong danh sách các nhóm, hãy nhấp vào tên nhóm mà bạn đã tạo cho Froyo. Ví dụ:
acai_pdfs. - Trong thẻ Quyền, hãy nhấp vào Cấp quyền truy cập. Hộp thoại Add principals (Thêm đối tượng chính) sẽ xuất hiện.
- Trong trường Bên giao đại lý mới, hãy nhập mã tài khoản dịch vụ BigQuery. Tài khoản dịch vụ có dạng như
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com. - Chọn (các) vai trò sau đây trong trình đơn thả xuống Chọn vai trò.
roles/storage.objectUserroles/dataplex.serviceAgentroles/dataplex.securityAdminroles/aiplatform.serviceAgentroles/dataplex.discoveryPublishingServiceAgent
- Nhấp vào Lưu.
9. Thiết lập Knowledge Catalog
Xây dựng Danh mục kiến thức để hợp nhất dữ liệu liên quan đến Froyo và tự động hoá việc khám phá các tệp không có cấu trúc (chẳng hạn như công thức và nhà cung cấp dưới dạng tệp PDF).
Tạo DataScan thông qua curl
Trong phần này, bạn sẽ tạo các lượt quét cho bộ chứa Cloud Storage (ví dụ: acai_pdfs) bằng cách thêm datascan_ID và trỏ đến các tập dữ liệu BigQuery. Sau đó, Danh mục kiến thức sẽ tự động tạo các mục cho tệp PDF của bạn trong BigQuery.
- Để quét các tệp PDF (nhà cung cấp và công thức), hãy chạy lệnh sau:
# 1. Set your variables PROJECT_ID="<PROJECT_ID>" REGION="<REGION>" ENV_SUFFIX="stg1" DATASCAN_ID="froyo-profile-${ENV_SUFFIX}" BUCKET_NAME="<BUCKET_NAME>" # 2. Set this to the Name of the connection you created in Step 7 CONNECTION_ID="<CONNECTION_ID_NAME>" # 3. Define the API Endpoint DATAPLEX_API="dataplex.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}" # 4. Create the DataScan via CURL echo "Creating Dataplex DataScan: ${DATASCAN_ID}..." curl -X POST "https://$DATAPLEX_API/dataScans?dataScanId=${DATASCAN_ID}" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d '{ "data": { "resource": "//storage.googleapis.com/projects/'"${PROJECT_ID}"'/buckets/'"${BUCKET_NAME}"'" }, "executionSpec": { "trigger": { "on_demand": {} } }, "dataDiscoverySpec": { "bigqueryPublishingConfig": { "tableType": "BIGLAKE", "connection": "projects/'"${PROJECT_ID}"'/locations/'"${REGION}"'/connections/'"${CONNECTION_ID}"'" }, "storageConfig": { "unstructuredDataOptions": { "entity_inference_enabled": true } } } }' - Lệnh
curlhiển thị kết quả DataScan của Danh mục kiến thức, tương tự như hình ảnh sau.
Chạy lệnh
Chạy lệnh sau:
gcloud dataplex datascans run $DATASCAN_ID --location=$REGION
Mô tả công việc
Để mô tả công việc, hãy chạy lệnh sau:
gcloud dataplex datascans describe $DATASCAN_ID --location=$REGION
Xoá một công việc quét dữ liệu
Nếu quá trình quét diễn ra trong hơn 10 phút hoặc nếu trạng thái của tác vụ vẫn là Đang chờ xử lý trong một thời gian dài mà không chuyển sang trạng thái Đang chạy, thì có thể là do tài nguyên tạm thời không có sẵn trong khu vực. Nếu điều này xảy ra, bạn có thể chạy lệnh sau để xoá công việc, rồi thử tạo và chạy lại công việc đó. Đôi khi, lần chạy ban đầu có thể nhanh chóng thất bại với lỗi như unable to acquire necessary resources.
gcloud dataplex datascans delete $DATASCAN_ID --location=$REGION
Xem trạng thái của công việc
Để kiểm tra trạng thái của lệnh, hãy làm như sau:
- Trong Cloud Console của Google, hãy chuyển đến trang Tuyển chọn siêu dữ liệu.
- Trong thẻ Phát hiện Cloud Storage, hãy nhấp vào tên của các lượt quét phát hiện.
- Trên trang Chi tiết về hoạt động quét, bạn có thể xem trạng thái của công việc.
- Sau khi công việc hoàn tất, hãy kiểm tra xem Tập dữ liệu đã xuất bản (ví dụ:
acai_pdfs_discovered_003) mà bạn đã tạo bằng lệnhcurlcó xuất hiện hay không.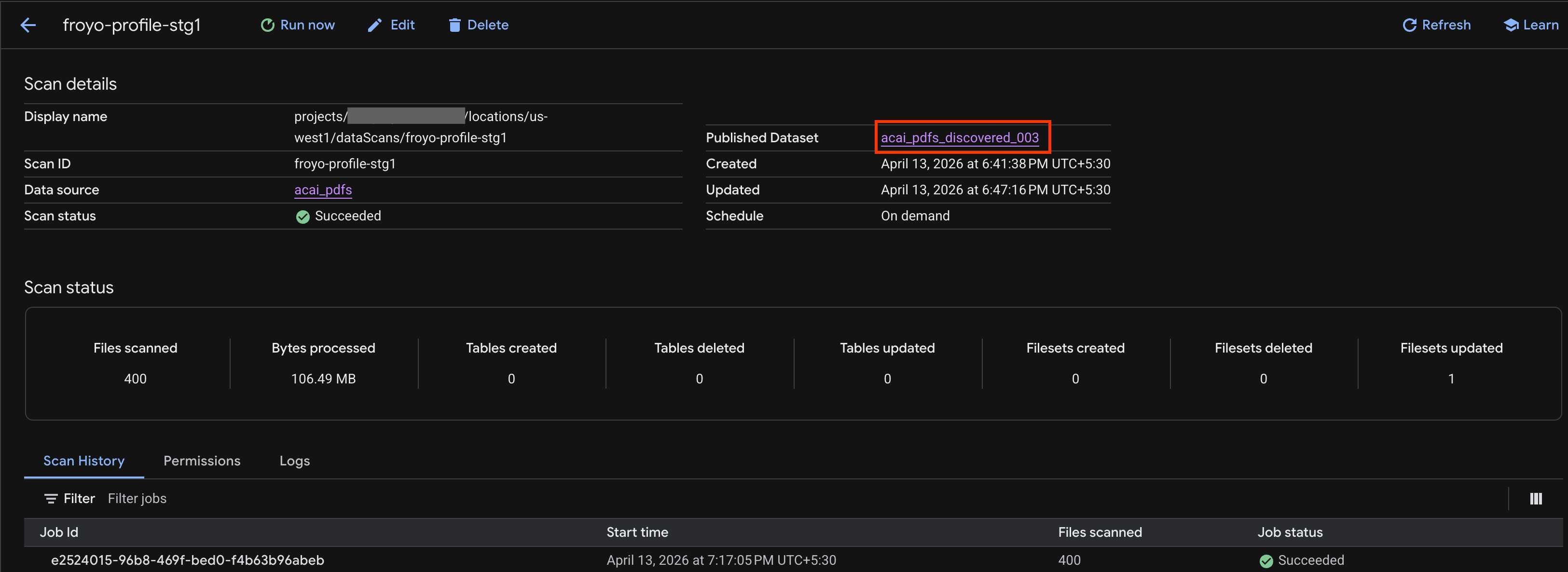
Xem bảng đối tượng
Để xem bảng đối tượng được tạo sau khi công việc khám phá hoàn tất, hãy làm như sau:
- Trong bảng điều khiển Google Cloud, hãy chuyển đến BigQuery.
- Nhấp vào Tập dữ liệu rồi chọn tập dữ liệu đã xuất bản được tạo ở bước trước. Ví dụ:
acai_pdfs_discovered_003. - Để xem bảng đối tượng, hãy nhấp vào mã nhận dạng bảng. Ví dụ:
acai_pdfs. - Bảng đối tượng kết quả sẽ có dạng như hình ảnh sau:
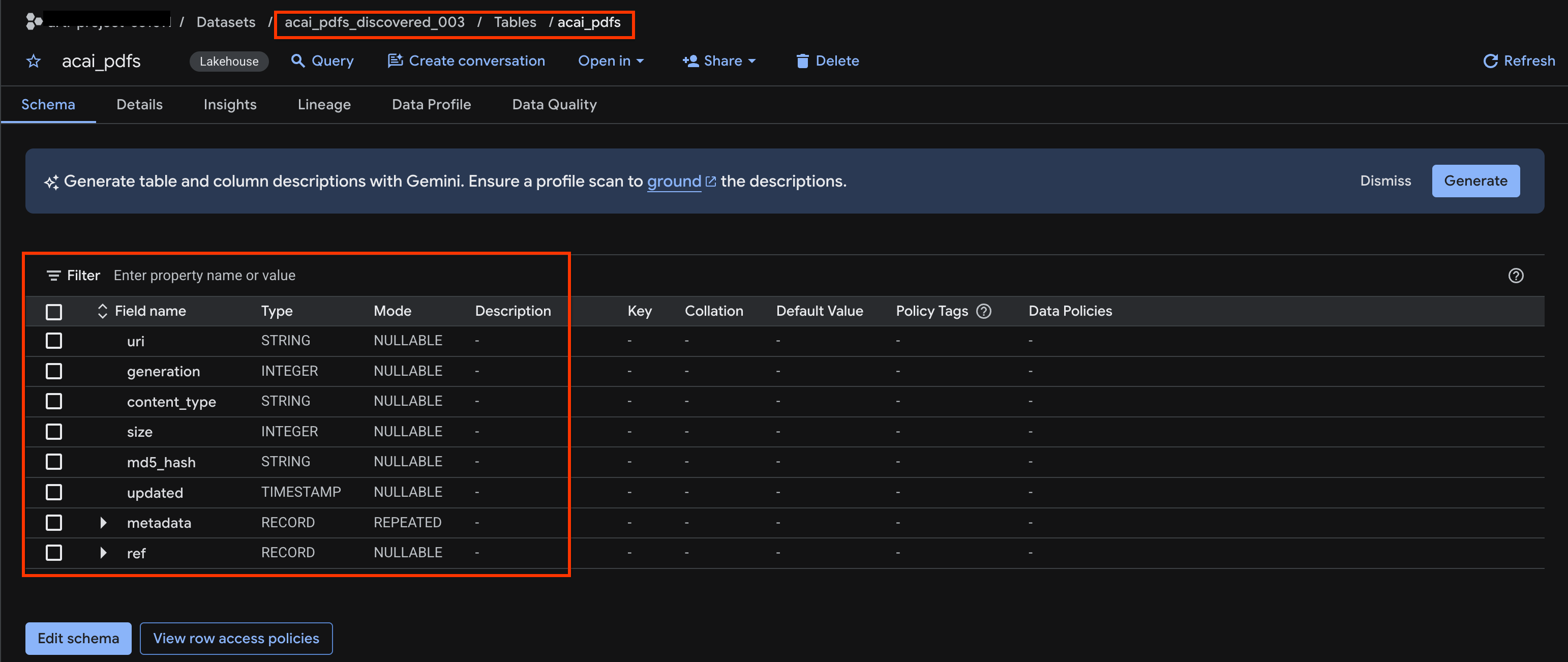
10. Trích xuất ngữ nghĩa
Bạn sẽ suy luận và trích xuất các bảng có cấu trúc, các đối tượng cơ sở dữ liệu khác và mối quan hệ cho bảng đối tượng không có cấu trúc mà bạn đã tạo ở bước trước. Để làm việc đó, bạn sẽ dùng tính năng Thông tin chi tiết về danh mục kiến thức để tạo câu lệnh SQL nhằm trích xuất dữ liệu có cấu trúc từ bảng không có cấu trúc
- Trong bảng điều khiển Cloud Console, hãy chuyển đến trang Knowledge Catalog Search (Tìm kiếm danh mục kiến thức).
- Tìm bảng tập dữ liệu mà bạn muốn xem thông tin chi tiết. Ví dụ:
acai_pdfs_discovered_003.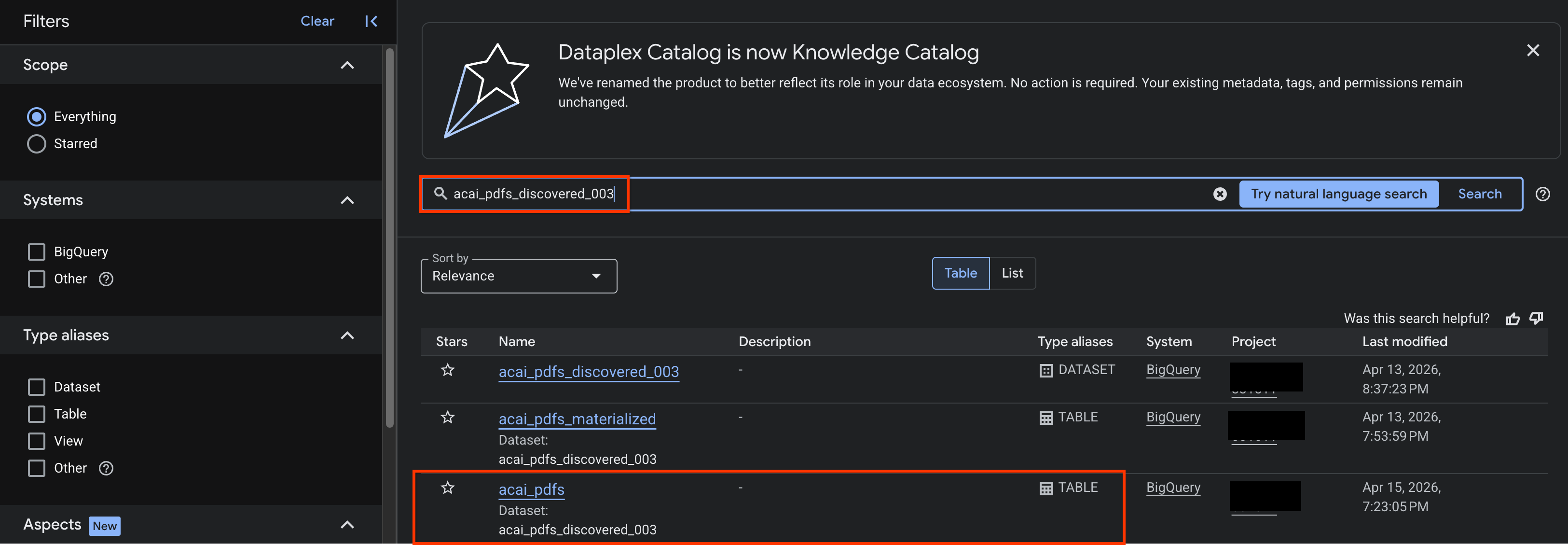
- Trong kết quả tìm kiếm, hãy nhấp vào bảng để mở trang mục nhập của bảng đó.
- Nhấp vào thẻ Thông tin chi tiết. Nếu thẻ này trống, tức là thông tin chi tiết cho bảng này chưa được tạo. Quá trình tạo thông tin chi tiết có thể mất từ 15 đến 25 phút.
- Sau khi bạn thấy thông tin chi tiết, hãy nhấp vào Trích xuất > Trích xuất bằng SQL.
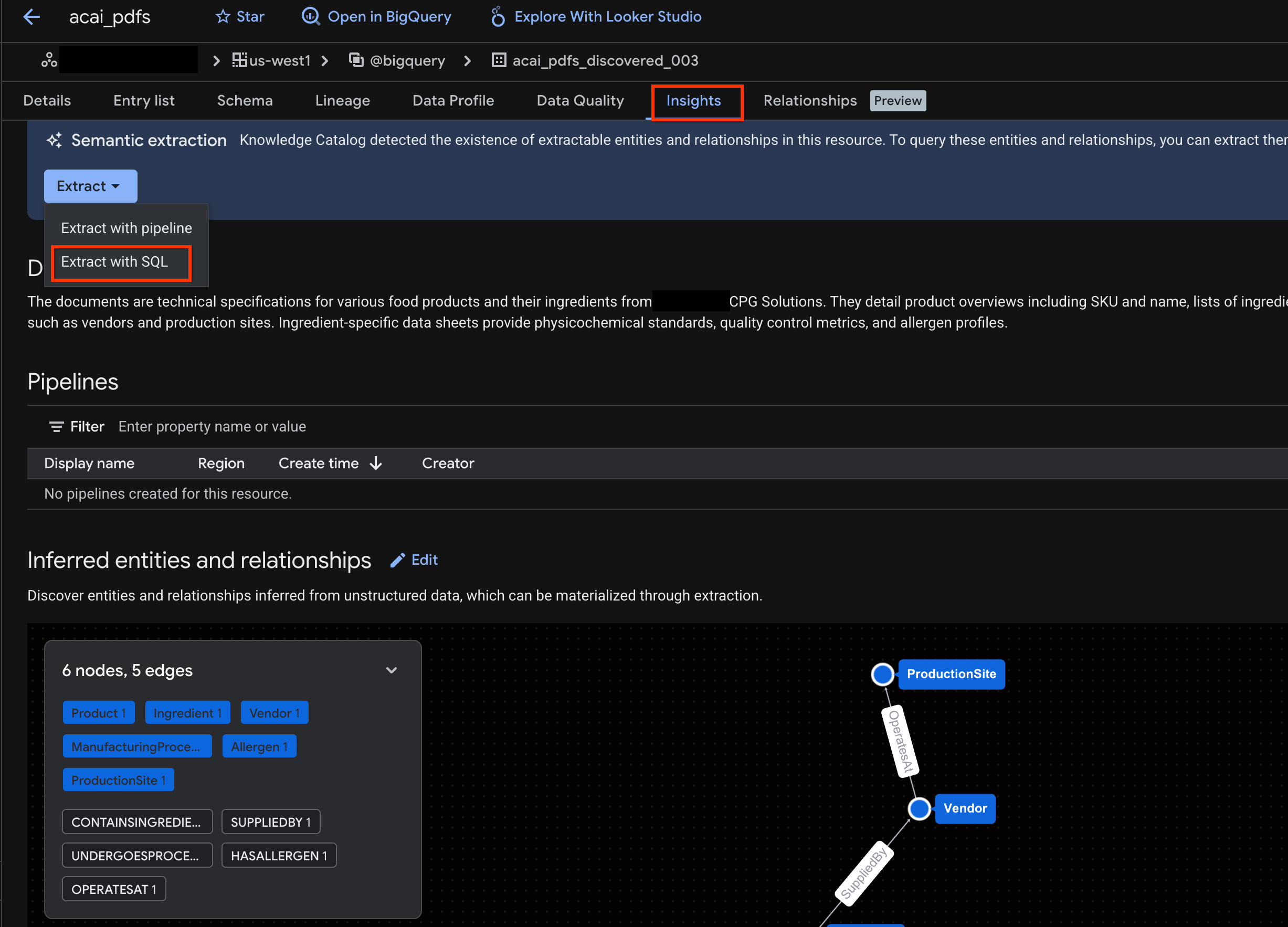
- Trong trang Trích xuất bằng SQL, đối với Đích đến, hãy nhập tập dữ liệu của bạn. Ví dụ:
acai_pdfs_discovered_003. - Nhấp vào Trích xuất. Thao tác này sẽ mở Trình chỉnh sửa BigQuery với Truy vấn đã tải.
- Nhấp vào Chạy. Bước này tạo ra một tập hợp các câu lệnh và có thể mất vài phút để hoàn tất quá trình chạy.
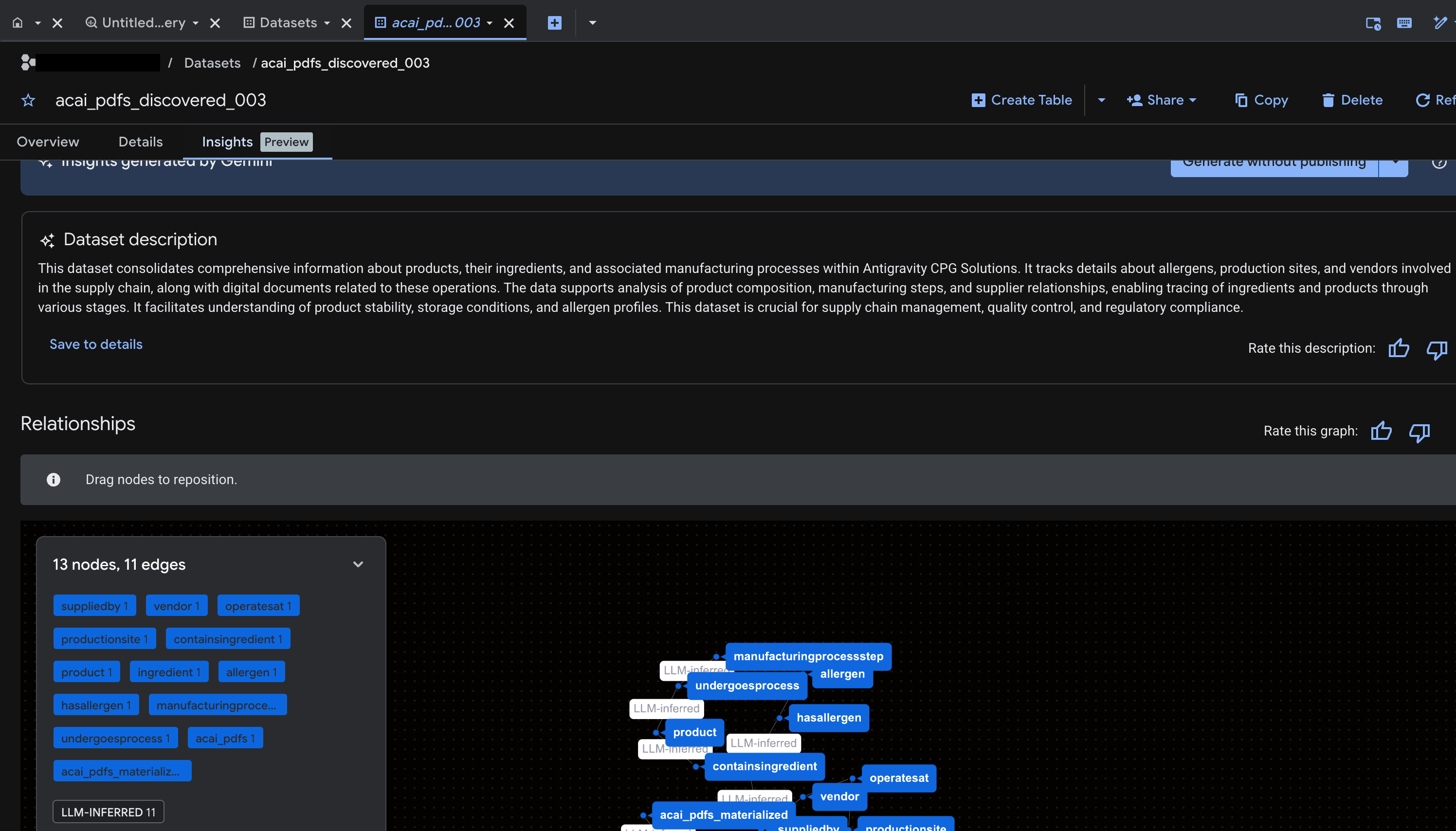
- Khi truy vấn hoàn tất, bạn sẽ thấy kết quả như sau:
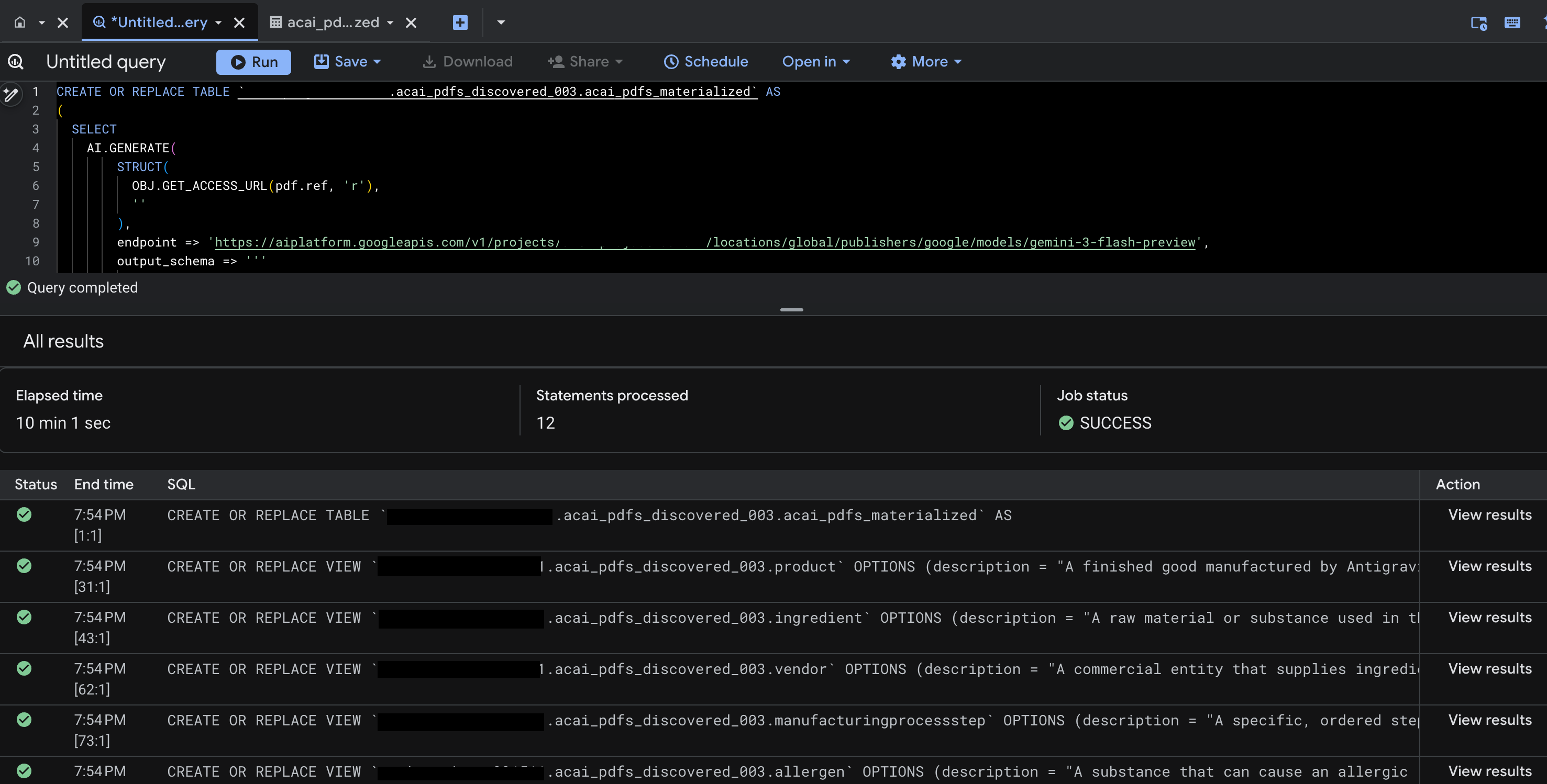
- Chuyển đến BigQuery rồi nhấp vào Tập dữ liệu (ví dụ:
acai_pdfs_discovered_003). Một nhóm đối tượng cơ sở dữ liệu có cấu trúc mới sẽ được tạo trong tập dữ liệu mà bạn đã chọn ở bước 6.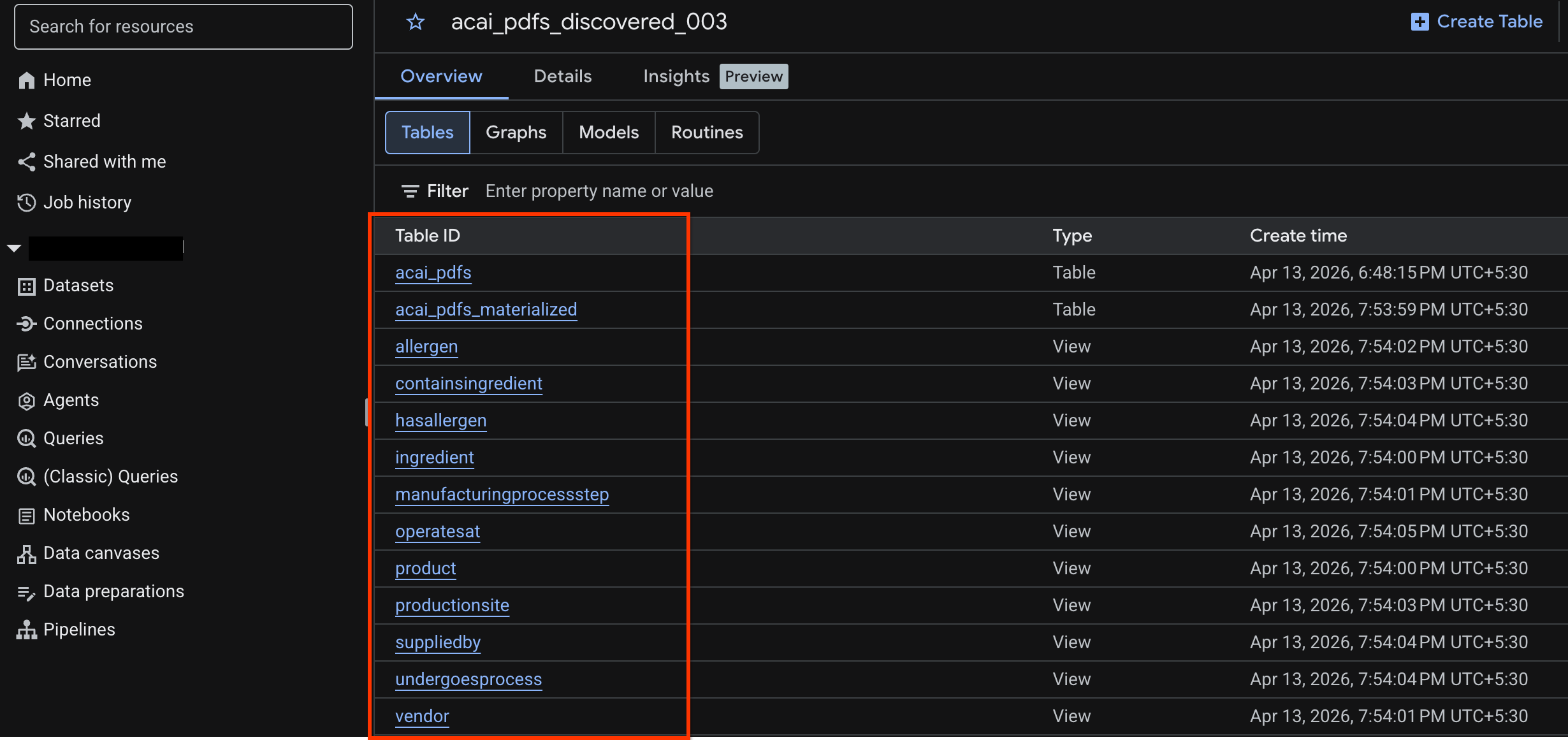
Tạo thông tin chi tiết cho đối tượng trong BigQuery
Để tạo thông tin chi tiết cho một tập dữ liệu BigQuery, bạn phải truy cập vào tập dữ liệu đó trong BigQuery bằng BigQuery Studio.
- Trong Cloud Console, hãy chuyển đến BigQuery Studio.
- Trong ngăn Trình khám phá, hãy chọn dự án, chuyển đến tập dữ liệu mà bạn muốn tạo thông tin chi tiết.
- Nhấp vào thẻ Thông tin chi tiết.
- Nếu bạn thấy nút Bật API, hãy nhấp vào nút đó để bật Gemini cho Google Cloud. Thao tác này sẽ mở cửa sổ Bật các tính năng cốt lõi.
- Trong phần API tính năng cốt lõi, hãy nhấp vào Bật cho Gemini cho Google Cloud API và BigQuery Unified API, rồi nhấp vào Tiếp theo.
- Trong mục Quyền (không bắt buộc), hãy cấp vai trò IAM cho các thực thể chính nếu cần, rồi nhấp vào Tiếp theo.
- Để tạo thông tin chi tiết và xuất bản thông tin đó lên Danh mục tri thức, hãy nhấp vào Tạo và xuất bản.
- Sau khi xuất bản, bạn có thể xem thông tin chi tiết trên thẻ này.
11. Thiết lập IDE cho hoạt động phân tích dữ liệu dựa trên tác nhân
Tiện ích Google Cloud Data Agent Kit cho Visual Studio Code là một tiện ích IDE dành cho nhà khoa học dữ liệu và kỹ sư dữ liệu. Tính năng này cho phép bạn kết nối và làm việc với các tài nguyên và dữ liệu trên Google Data Cloud ngay trong IDE. Để biết thêm thông tin, hãy xem bài viết Tổng quan về tiện ích Data Agent Kit cho VS Code
Tiện ích Data Agent Kit cho VS Code rất hữu ích khi bạn muốn làm những việc sau:
- Xây dựng, kiểm thử, xem xét và triển khai một quy trình dữ liệu sẵn sàng cho hoạt động sản xuất, chẳng hạn như Spark ETL hoặc BigQuery ETL, ngay trong VS Code.
- Khám phá dữ liệu, xây dựng quy trình huấn luyện, xác định các mô hình học máy tối ưu và triển khai các mô hình đó đến một điểm cuối sản xuất bằng cách sử dụng tính năng hỗ trợ AI.
- Kết nối với các nguồn dữ liệu đáng tin cậy, xây dựng mô hình dữ liệu hiệu suất cao và xuất bản trang tổng quan tương tác cho các bên liên quan trong doanh nghiệp.
Cài đặt tiện ích Data Agent Kit cho VS Code
- Mở VS Code.
- Cài đặt Google Cloud CLI. Để biết thêm thông tin, hãy xem bài viết Cài đặt Google Cloud CLI.
- Cài đặt tiện ích Data Agent Kit cho VS Code.
- Hoàn tất quy trình tham gia chương trình tiện ích. Quy trình này yêu cầu bạn phải:
- Đăng nhập vào tiện ích
- Cài đặt các kỹ năng, máy chủ MCP
- Tải lại hoặc khởi động lại cửa sổ sau khi bạn hoàn tất quá trình thiết lập ban đầu. Để biết thêm thông tin, hãy xem bài viết Thiết lập và định cấu hình tiện ích Data Agent Kit cho VS Code.
- Sau khi IDE tải lại, hãy nhấp vào biểu tượng Google Data Cloud trong ngăn điều hướng, chuyển đến phần cài đặt và đảm bảo bạn đã đặt đúng mã dự án và khu vực (
us-west1) trong phần cài đặt chung.
Thiết lập không gian làm việc trong VS Code
- Mở VS Code rồi chọn File (Tệp) > Open folder (Mở thư mục) > New folder (Thư mục mới).
- Tạo một thư mục mới có tên
acai_testrồi nhấp vào Open (Mở). Giờ đây, VS Code sẽ coi thư mục bạn đã mở là một không gian làm việc. - Trên hộp thoại Độ tin cậy của Workspace, hãy chọn Có, tôi tin tưởng những tác giả này để bật tất cả các tính năng trong không gian làm việc.
- Tạo một thư mục
.githubtrong không gian làm việcacai_test. - Tạo một tệp mới
copilot-instructions.mdtrong thư mục.githubrồi nhập các quy tắc sau vào tệp đó.## 1. Project Context - **Project ID**: <PROJECT_ID> - **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors. - **Documentation**: Raw PDF documents detailing flavors and ingredients are stored in Google Cloud Storage at `gs://<BUCKET_NAME>`. ## 2. Execution & Data Processing Rules - **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `<BQ_DATASET_NAME>` (referred to as the Knowledge Catalog). - **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the dataset `<DATASET_ID>`. When you are referencing a dataset, ensure you are using it with the project ID (`<PROJECT_ID>`) and namespace prefix `<NAMESPACE_NAME>`. For example, to query order table in this dataset you should use `<PROJECT_ID>.<NAMESPACE>.<DATASET_ID>.orders`. - **CRITICAL RULE - Data Joins between BigQuery dataset and Iceberg dataset**: ANY task requiring a join or integration between the BigQuery datasets `<DATASET_ID>` of the PDF data and the `<DATASET_ID>` of the customer data MUST be executed using **Spark Notebooks**. - **CRITICAL RULE - Notebook Kernel**: Every Spark notebook utilized MUST exclusively be configured to run on the Serverless Session template `iceberg-federation-template` as its kernel. - **CRITICAL RULE - Data Science**: ANY data science, machine learning, or advanced analytical task MUST be performed strictly within **Spark Notebooks** using the aforementioned setup. - Tạo một tệp mới khác
template.yamltrong không gian làm việcacai_testrồi nhập thông tin sau vào tệp.labels: client: "vscode" jupyterSession: displayName: "iceberg-federation-template" kernel: "PYTHON" environmentConfig: executionConfig: serviceAccount: "sa-spark-dev1@<PROJECT_ID>.iam.gserviceaccount.com" subnetworkUri: "projects/<PROJECT_ID>/regions/<REGION>/subnetworks/<SUBNET_NAME>" runtimeConfig: version: "2.3" properties: # This enables the secure proxy URL you were looking for dataproc.tier: "premium" spark.dataproc.engine: "lightningEngine" spark.dataproc.lightningEngine.runtime: "native" spark.memory.offHeap.enabled: "true" spark.memory.offHeap.size: "1g" spark.executor.memory: "4g" "dataproc.component.gateway.enabled": "true" "dataproc.jupyter.listen.all.interfaces": "true" "spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" "spark.sql.defaultCatalog": "<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>": "org.apache.iceberg.spark.SparkCatalog" "spark.sql.catalog.<CATALOG_NAME>.type": "rest" "spark.sql.catalog.<CATALOG_NAME>.uri": "<CATALOG_URI_ID>" "spark.sql.catalog.<CATALOG_NAME>.warehouse": "bl://projects/<PROJECT_ID>/catalogs/<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>.rest.auth.type": "org.apache.iceberg.gcp.auth.GoogleAuthManager" - Trên VS Code, hãy nhấp vào Terminal (Thiết bị đầu cuối) rồi chạy lệnh sau để nhập tệp
template.yamldưới dạng một mẫu phiên. Sau đó, tác nhân sẽ dùng mẫu này để tạo một phiên Spark.gcloud beta dataproc session-templates import iceberg-federation-template \ --source=template.yaml \ --location=<REGION>REGIONbằng khu vực của bạn.
12. Thực hiện phân tích dữ liệu dựa trên tác nhân
- Trong trình chỉnh sửa VS Code, hãy nhấp vào Toggle chat (Bật/tắt tính năng trò chuyện).
- Đối với Định cấu hình các tác nhân tuỳ chỉnh, hãy chọn Tác nhân.
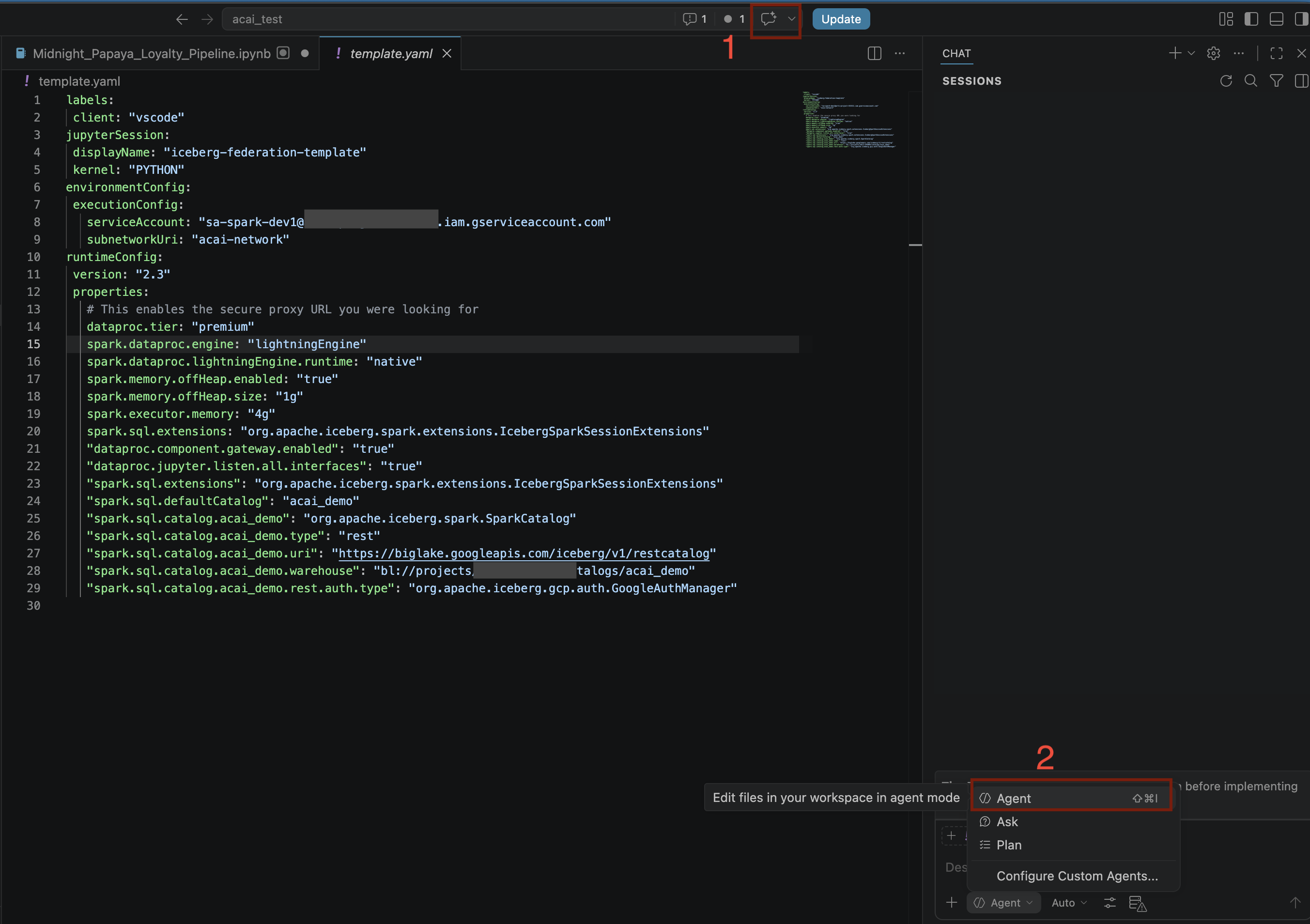
- Trên ngăn Mô hình tìm kiếm, hãy nhấp vào Quản lý mô hình ngôn ngữ.
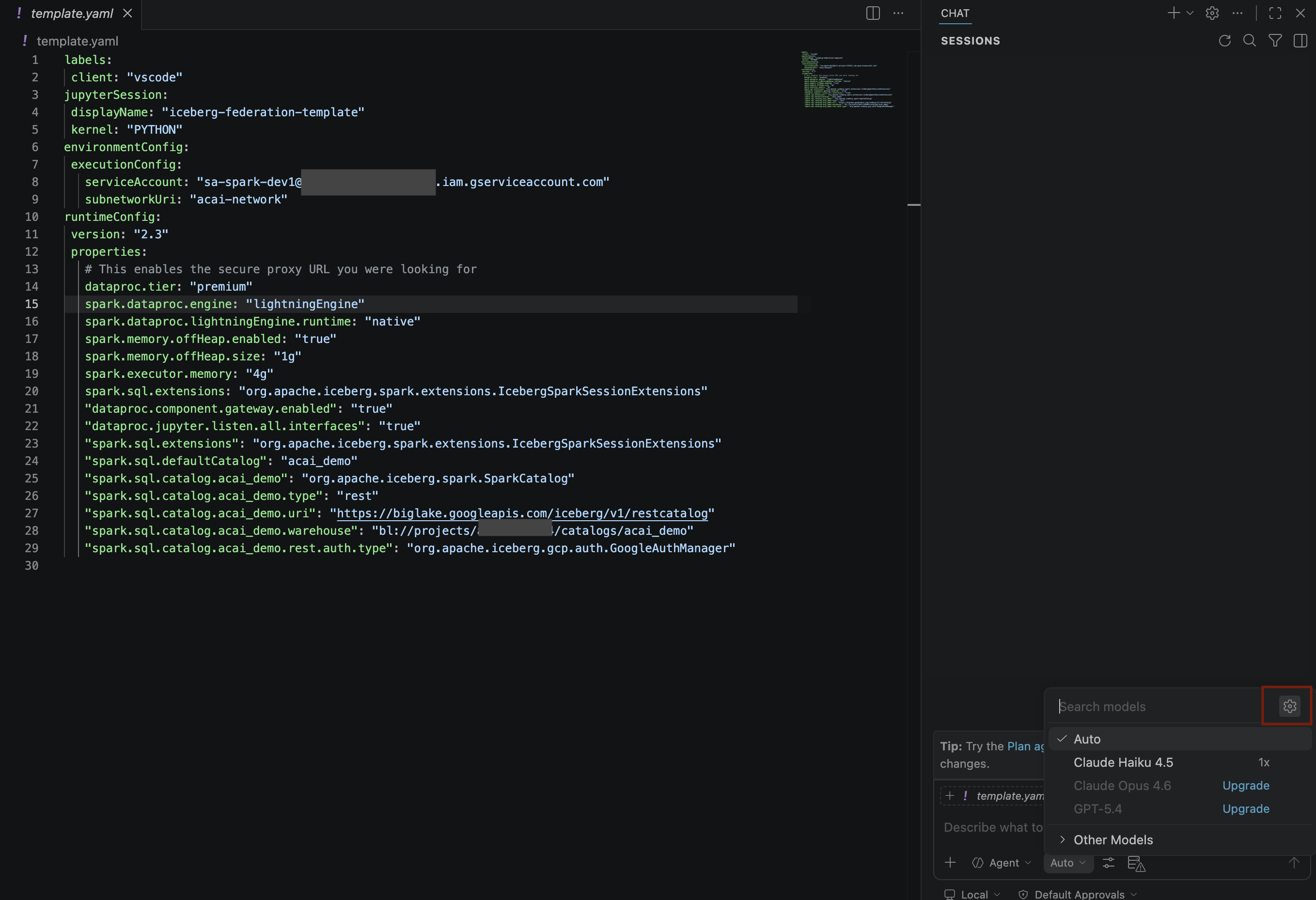
- Trên trang Mô hình ngôn ngữ, hãy nhấp vào Thêm mô hình.
- Chọn Google trong danh sách rồi nhấn phím Enter để xác nhận thông tin bạn nhập.
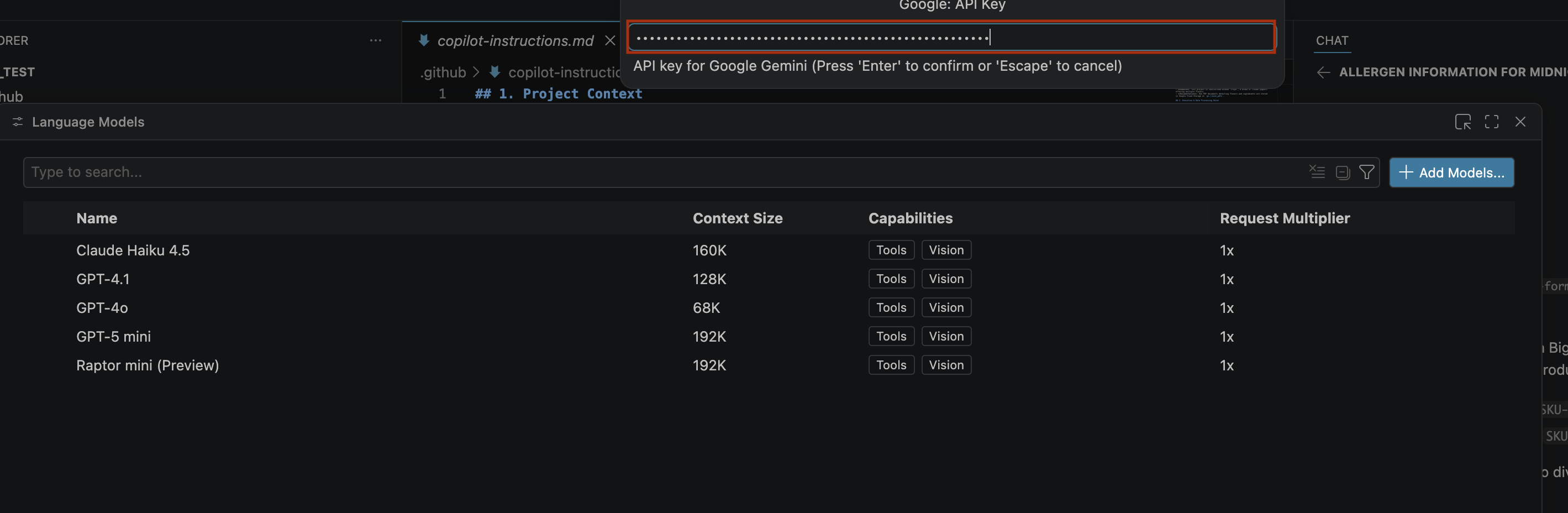
- Để nhập khoá API cho Google Gemini, hãy làm như sau:
- Truy cập vào trang web Google AI Studio.
- Đăng nhập bằng Tài khoản Google của bạn.
- Trong thanh bên, hãy nhấp vào Lấy khoá API.
- Nhấp vào Tạo khoá API. Một trang khoá mới sẽ mở ra.
- Trong danh sách Chọn một dự án trên đám mây, hãy chọn Nhập dự án.
- Nhập tên của một dự án hiện có.
- Nhấp vào Tạo khoá rồi sao chép khoá API. Khoá này cho phép bạn truy cập vào các tài nguyên Gemini API của tài khoản.Để biết thêm thông tin, hãy xem bài viết Sử dụng khoá Gemini API.
- Dán khoá API mà bạn đã tạo vào thanh tìm kiếm rồi nhấp vào Enter.
- Nếu các mô hình Gemini không xuất hiện, hãy bỏ ẩn chúng như trong hình sau:

- Chọn Gemini 3.1 Pro Preview trong danh sách mô hình Google Gemini rồi đóng cửa sổ Mô hình ngôn ngữ.
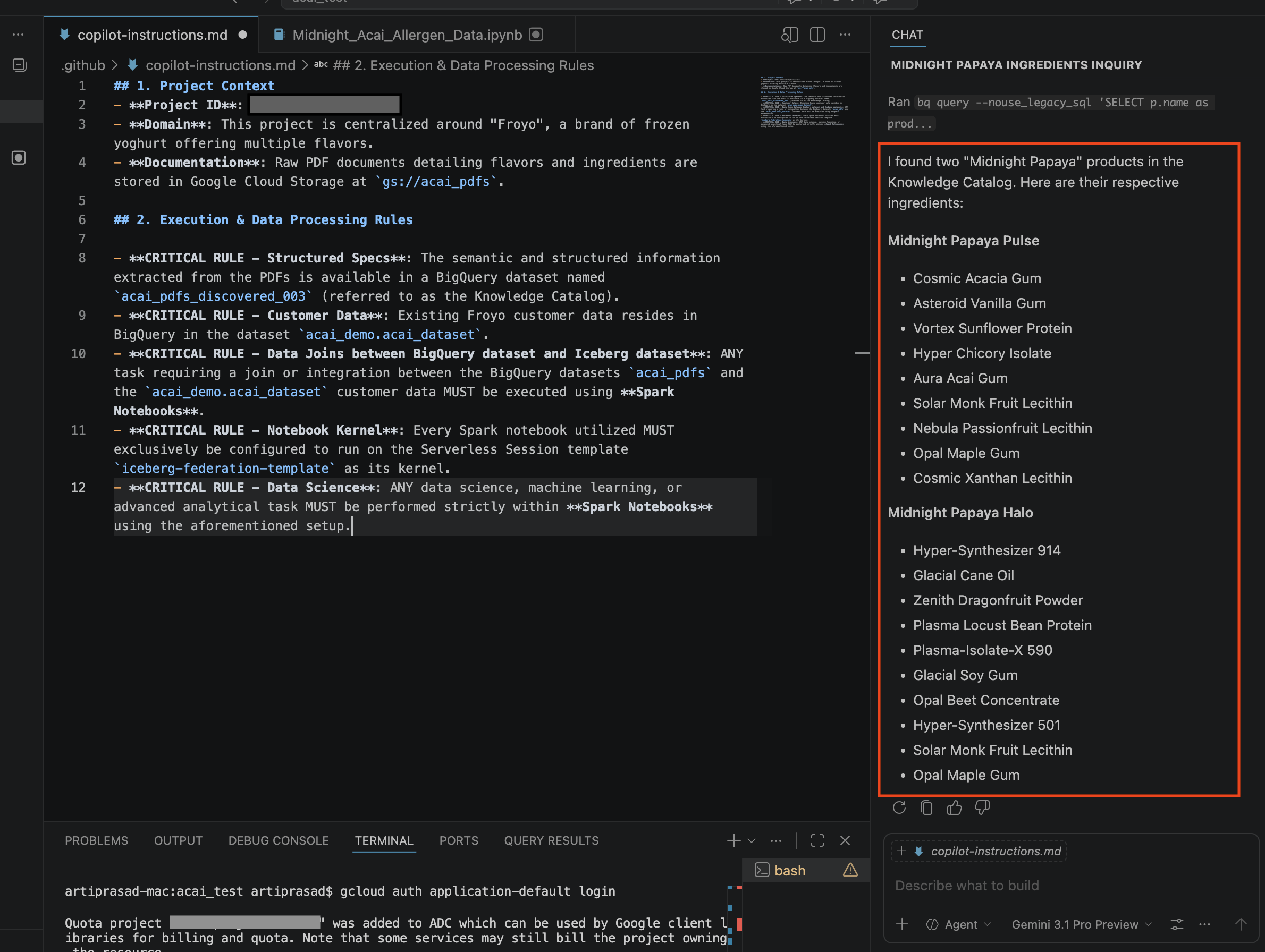
- Trong cửa sổ trò chuyện, hãy nhập câu hỏi sau:
Search ingredients for Midnight papaya - Sau khi tương tác, bạn sẽ thấy kết quả sau:
- Trong cửa sổ trò chuyện, hãy nhập một câu hỏi khác:
Search allergen information for Midnight papaya - Sau một số lượt tương tác và bước thực hiện, bạn sẽ thấy tác nhân phản hồi bằng tên chất gây dị ứng
Soynhư bạn có thể thấy trong hình ảnh sau: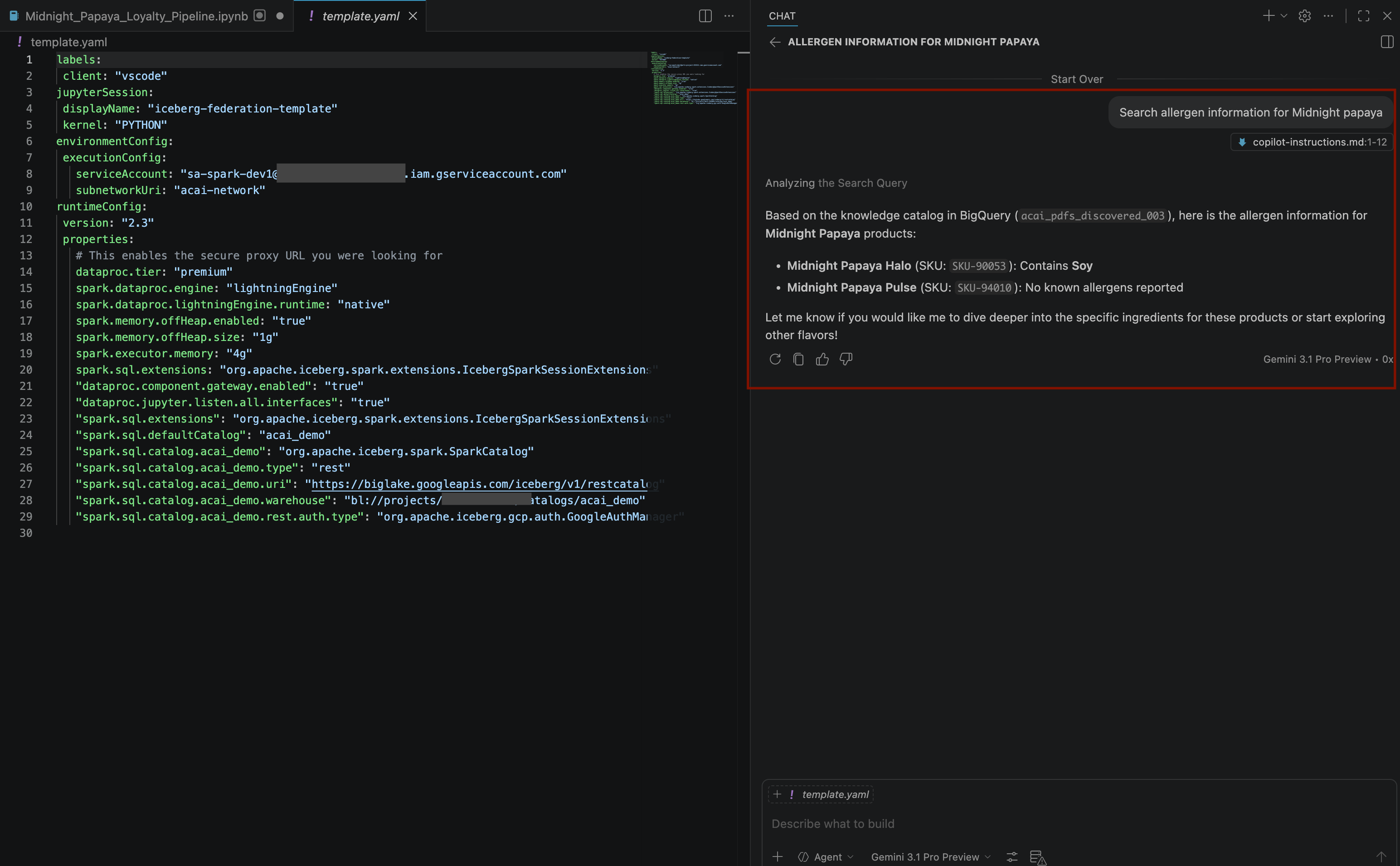
- Trong cửa sổ trò chuyện, hãy nhập một câu hỏi khác:
Build a pipeline to join products with our 'Global Loyalty' Iceberg tables in acai customer, sales data to identify popular products - Để chọn hạt nhân, hãy mở tệp
.ipynbrồi nhấp vào Select kernel (Chọn hạt nhân) > Remote spark kernels (Hạt nhân Spark từ xa) > Iceberg-federation-template on serverless spark (Mẫu liên kết Iceberg trên Spark không cần máy chủ)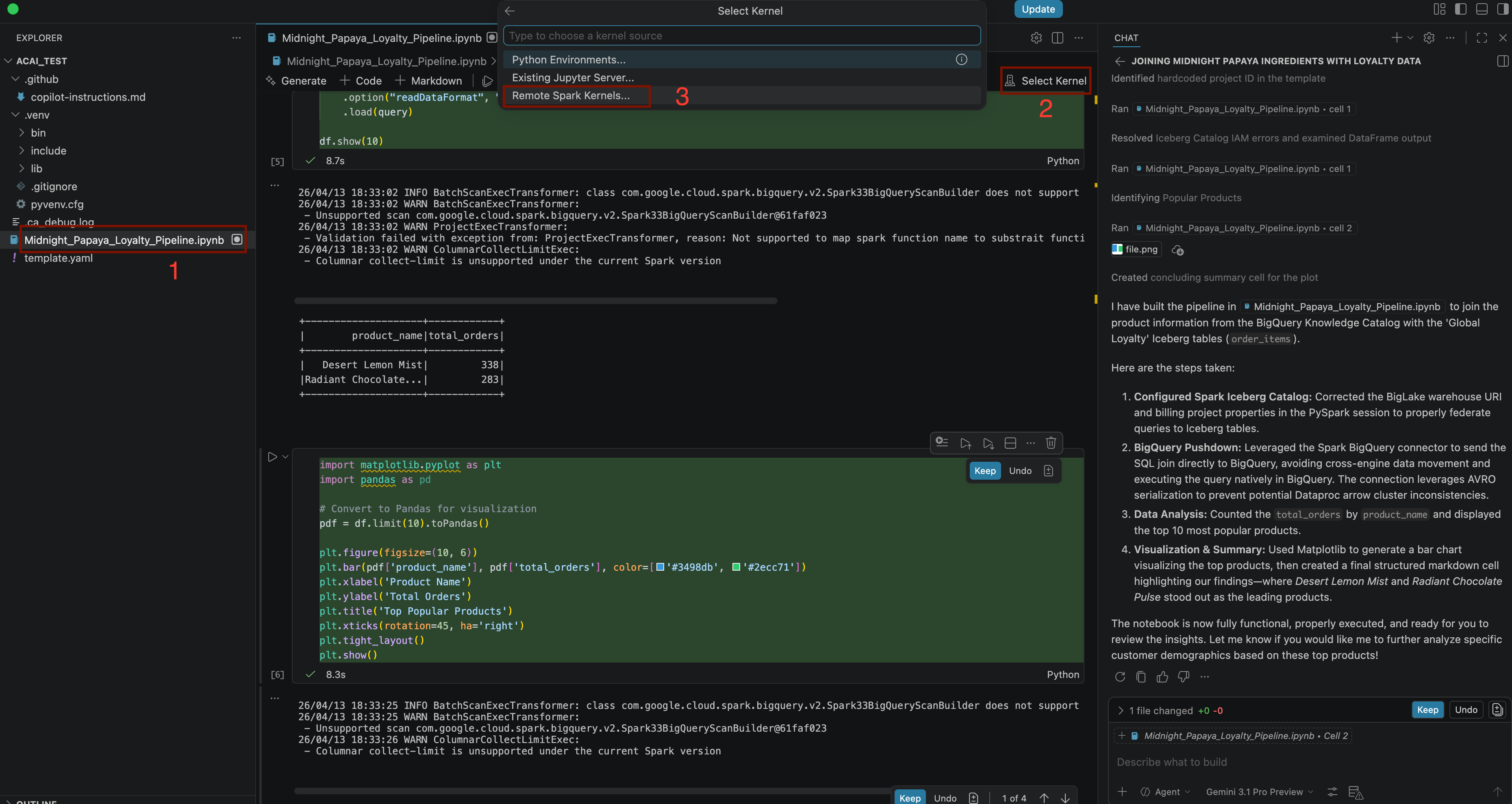
- Sau một số bước tương tác, bạn sẽ thấy tác nhân phản hồi bằng tất cả các bước đã thực hiện thành công trong sổ tay cùng với kết quả cuối cùng được tạo ở cuối sổ tay như bạn có thể thấy trong hình ảnh sau:
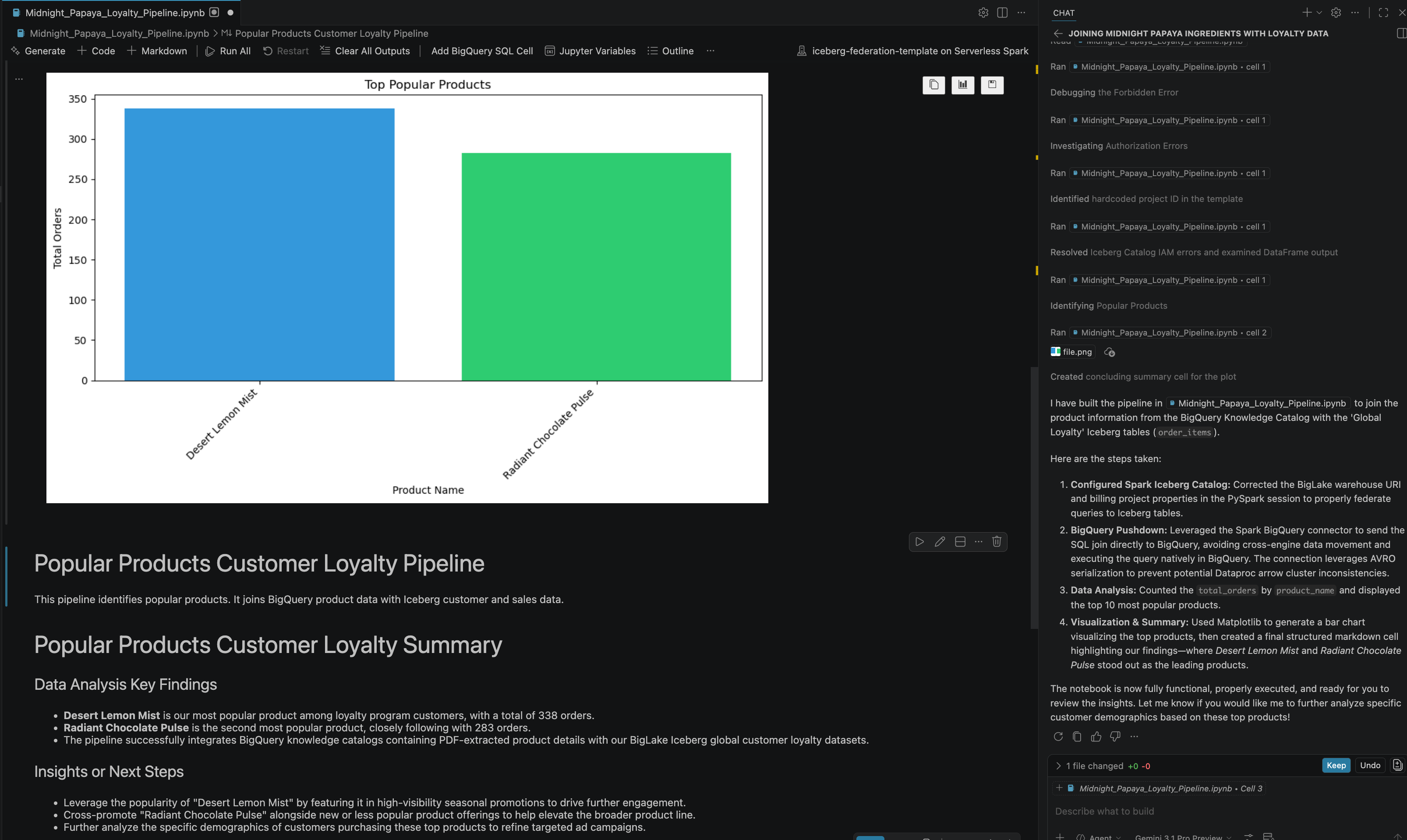
13. Dọn dẹp
Để tránh bị tính phí, hãy xoá các tài nguyên mà bạn đã tạo trong phòng thí nghiệm này.
- Để xoá Knowledge Catalog DataScan, hãy chạy lệnh sau:
DATASCAN_ID="<DATASCAN_ID>" echo "Deleting Dataplex DataScan: ${DATASCAN_ID}" gcloud dataplex datascans delete "${DATASCAN_ID}" --location="${REGION}" --quiet - Để xoá các vùng chứa Cloud Storage và toàn bộ nội dung trong đó, hãy chạy lệnh sau:
echo "Deleting Cloud Storage buckets: <BUCKET_NAME1> and <BUCKET_NAME2>" gsutil -m rm -r gs://<BUCKET_NAME1> gsutil -m rm -r gs://<BUCKET_NAME2> - Để xoá BigQuery Connection, hãy chạy lệnh sau:
CONNECTION_ID="<CONNECTION_NAME>" echo "Deleting BigQuery Connection: ${CONNECTION_ID}" bq rm --connection "${PROJECT_ID}.${REGION}.${CONNECTION_ID}" - Để xoá Danh mục Lakehouse, hãy chạy lệnh sau:
CATALOG_ID="<CATALOG_NAME>" echo "Deleting Lakehouse Catalog: ${CATALOG_ID}" gcloud biglake catalogs delete "${CATALOG_ID}" --project="${PROJECT_ID}" --location="${REGION}" --quiet - Để xoá tập dữ liệu chứa các bảng PDF đã phát hiện, hãy chạy lệnh sau:
DATASET_NAME="<DATASET_NAME>" echo "Deleting BigQuery Dataset: ${DATASET_NAME}" bq rm -r -f "${PROJECT_ID}:${DATASET_NAME}" - Để xoá Tài khoản dịch vụ tuỳ chỉnh, hãy chạy lệnh sau:
SERVICE_ACCOUNT="<SERVICE_ACCOUNT>" echo "Deleting Service Account: ${SERVICE_ACCOUNT}" gcloud iam service-accounts delete "${SERVICE_ACCOUNT}"@"${PROJECT_ID}".iam.gserviceaccount.com --quiet - Để xoá Mạng VPC, hãy chạy lệnh sau:
VPC_NETWORK="<VPC_NETWORK>" echo "Deleting VPC Network: ${VPC_NETWORK}" gcloud compute networks delete "${VPC_NETWORK}" --quiet - Để xoá toàn bộ dự án trên Google Cloud, hãy chạy lệnh sau:
gcloud projects delete "${PROJECT_ID}"
14. Xin chúc mừng
Xin chúc mừng! Bạn đã sắp xếp thành công bối cảnh dữ liệu của các tệp PDF và tệp Parquet riêng biệt trong các bảng BigQuery, đồng thời hợp nhất thành một hệ sinh thái duy nhất, có thể tìm kiếm và kết hợp. Về cơ bản, bạn đã xây dựng một Data Lakehouse hiện đại, xử lý các định dạng PDF và dữ liệu lớn một cách thông minh như cách xử lý một hàng trong cơ sở dữ liệu. Bạn đã thực hiện tất cả những việc này ngay trong tác nhân của mình trong một trải nghiệm đàm thoại với Gemini.
Tài liệu tham khảo
Để tìm hiểu sâu hơn về các công nghệ cốt lõi được dùng trong lớp học lập trình này, hãy truy cập vào tài liệu chính thức của Google Cloud:
- Để khám phá BigQuery (một thành phần cốt lõi của Data Cloud), hãy xem Tài liệu về BigQuery.
- Để tìm hiểu thêm về IAM, hãy xem Tài liệu về IAM.
- Để tìm hiểu về Lakehouse, hãy xem bài viết Lakehouse là gì?