
1. 簡介
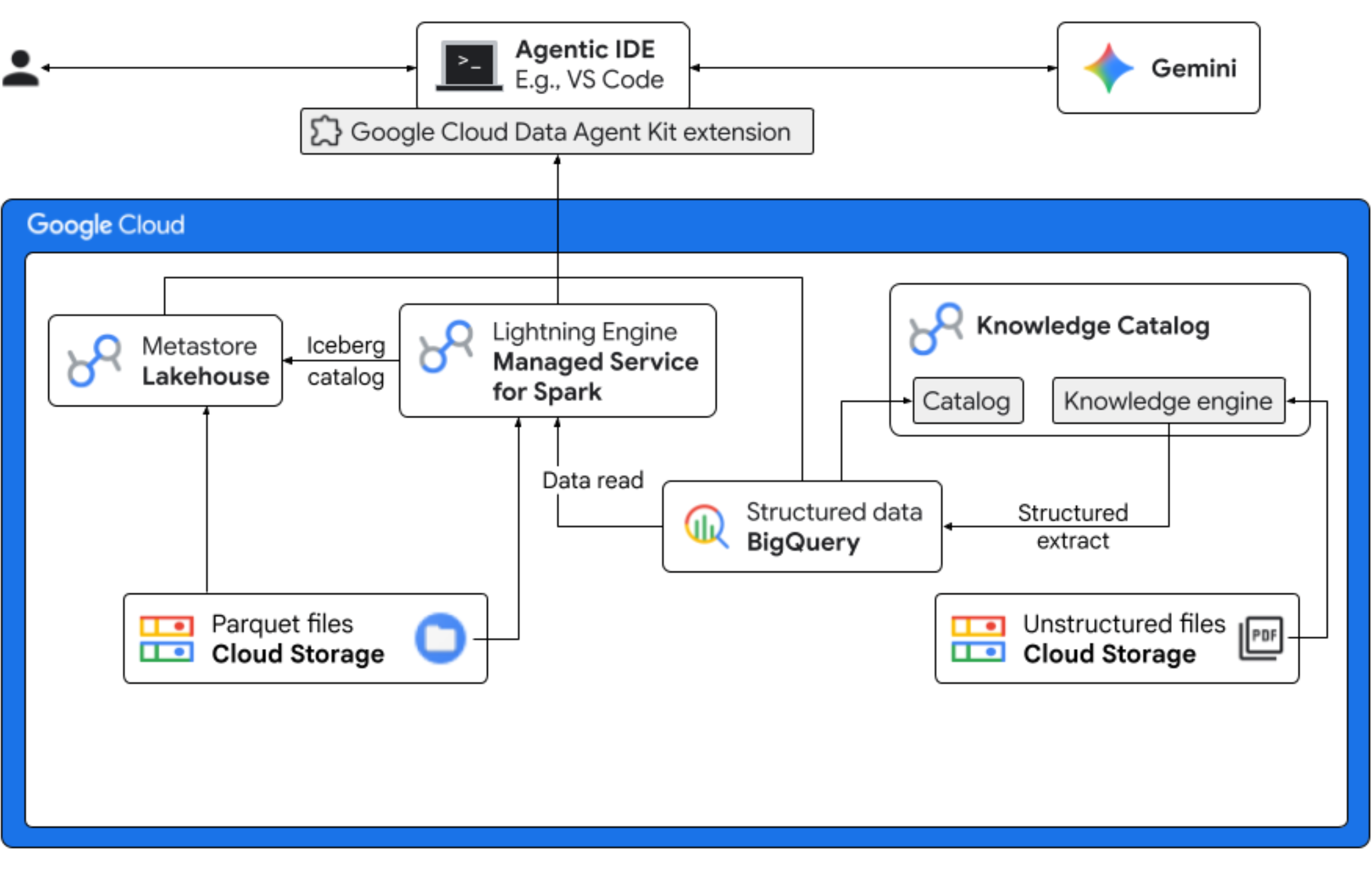
在本程式碼研究室中,您將扮演虛構 Froyo 公司的資料科學家,為新產品口味「午夜漩渦」進行行銷活動。為確保全球發布成功,企業必須回答有關成分、市場需求和投資報酬率 (ROI) 的重要問題。這個端對端工作流程會示範如何使用 Google Cloud 的 Knowledge Catalog (舊稱 Dataplex) 和 Lakehouse for Apache Iceberg (舊稱 BigLake),透過統一管理層,在 IDE (VS Code) 中使用 Gemini,彌合「暗」非結構化資料的差距,並提供可執行的商業智慧。
學習內容
- 非結構化探索:儲存在 Cloud Storage 中的 PDF 食譜會由 Knowledge Catalog DataScan 檢索。在 BigQuery 中為掃描的 PDF 建立物件資料表。系統會使用 Vertex AI 語意推論技術「讀取」PDF,擷取產品、過敏原、成分和相關屬性的結構化資訊。然後智慧地為 PDF 中儲存的資料產生結構定義。
- 統一中繼資料:從 PDF 檔案擷取的資料會直接儲存到 BigQuery 中,做為原生寬資料表,並建立檢視區塊來輔助常見查詢。含有歷來銷售資料的獨立輸入資料集,儲存在 Google Cloud Storage 的 Apache Iceberg 資料表中。後續步驟會將這個 Iceberg 資料表與 BigQuery 中擷取的資料彙整。
- 跨引擎分析:使用 Managed Service for Apache Spark (舊稱 Dataproc) 和 Iceberg REST 目錄,您將結合這個最新的 PDF 中繼資料和推論的結構化語意資料 (來自 BigQuery 表格和檢視區塊),以及儲存在 Google Cloud Storage 上 Apache Iceberg 表格中的結構化銷售資料。這項作業由做為 Jupyter Notebook 核心的 Managed Apache Spark 互動式工作階段範本控管,可確保 Spark 工作的一致安全性和運算設定。
- 語意洞察:將推斷的產品資料與客戶和銷售資料 (在 BigQuery 中) 合併後,這個試用版就能擷取洞察資料,例如識別過敏原資料和收益預測。
- 自主式控管:從探索掃描到 Spark 執行,整個生命週期都透過 Gemini 適用範本、指令、規則和代理驅動自動化功能進行協調,證明 AI 可以管理支援分析的基礎架構。
軟硬體需求
完成本程式碼研究室可能會產生費用,一般使用情況下預估費用不到 $5 美元。如要根據預測用量或目前價格取得詳細的預估費用,請使用 Google Cloud Pricing Calculator。
請確認您已具備下列必要條件,可完成程式碼研究室。
- Chrome 網路瀏覽器。
- 如果您使用「開始前」一節中提供的試用金,請使用個人 Gmail 帳戶。
- 下載並安裝 Visual Studio (VS) Code。
2. 事前準備
建立 Google Cloud 專案
- 在 Google Cloud 控制台的專案選取器頁面中,選取或建立 Google Cloud 專案。
- 確認 Cloud 專案已啟用計費功能。瞭解如何檢查專案是否已啟用計費功能。
啟動 Cloud Shell
Cloud Shell 是在 Google Cloud 中運作的指令列環境,已預先載入必要工具。
- 按一下 Google Cloud 控制台頂端的「啟用 Cloud Shell」。
- 連至 Cloud Shell 後,請驗證您的驗證:
gcloud auth list - 確認專案已設定完成:
gcloud config get project - 如果專案未如預期設定,請設定專案:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
啟用必要的 API
執行下列指令,啟用所有必要的 API:
gcloud services enable \
dataplex.googleapis.com \
datacatalog.googleapis.com \
discoveryengine.googleapis.com \
bigqueryconnection.googleapis.com \
bigquery.googleapis.com \
biglake.googleapis.com \
dataproc.googleapis.com \
metastore.googleapis.com \
dataform.googleapis.com \
notebooks.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
serviceusage.googleapis.com \
secretmanager.googleapis.com \
storage.googleapis.com
下載程式碼實驗室素材資源
這個存放區包含 Parquet、食譜、供應商、copilot-instructions.md、template.yaml 和 quickstart.py 檔案,可用於本程式碼研究室。請務必下載這些檔案。
如要下載檔案,請按照下列步驟操作:
- 在 Cloud Shell 中執行下列指令:
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/next-26-keynotes.git - 前往新建立的資料夾:
cd next-26-keynotes - 拉出「
data-cloud-demo」資料夾git sparse-checkout set genkey/data-cloud-demo - 結帳完成後,請前往
data-cloud-demo資料夾並解壓縮 ZIP 檔案,存取程式碼研究室資產。
3. 為 Froyo 客戶資料設定 Lakehouse
在本節中,您會在 Lakehouse 中建立目錄,以便在工作流程中使用 Lakehouse 中繼存放區。這個存放區是所有 Iceberg 資料的單一事實來源,可讓查詢引擎互通。讓 Apache Spark 等查詢引擎以一致的方式探索、讀取中繼資料及管理 Iceberg 資料表。
必要的角色
確認您具備下列 Identity and Access Management (IAM) 角色:
roles/biglake.viewerroles/bigquery.userroles/bigquery.dataEditorroles/biglake.editorroles/biglake.metadataViewerroles/bigquery.connectionUserroles/storage.objectUserroles/storage.objectViewerroles/storage.objectCreatorroles/storage.admin
如要進一步瞭解如何授予 IAM 角色,請參閱「授予 IAM 角色」。
使用 bucket 建立 Lakehouse 目錄
建立 Lakehouse 目錄,管理 Iceberg 資料表的中繼資料。您可以在 Spark 工作中連線至這個目錄,建立及查詢 Iceberg 資料表。
- 前往 Google Cloud 控制台中的「Lakehouse」Lakehouse。
- 按一下「建立目錄」。「建立目錄」頁面隨即開啟。
- 在「目錄類型」部分,選取「Iceberg Rest 目錄」。
- 在「選取 Lakehouse 目錄 bucket 選項」中,選取「單一 bucket 目錄」。
- 在「Default catalog Cloud Storage bucket」(預設目錄 Cloud Storage bucket) 中,按一下「Browse」(瀏覽),然後按一下「Create new bucket」(建立新 bucket)。
- 在「Create a bucket」(建立 bucket) 頁面中執行下列操作:
- 在「開始使用」部分,輸入符合值區名稱規定的全域不重複名稱。
- 在「Choose where to store your data」(選擇資料的儲存位置) 專區中,選取「Region」(區域) 做為「Location type」(位置類型),然後輸入區域。例如:
us-west1。 - 在「選取如何控制物件的存取權」部分,取消勾選「強制禁止公開存取這個 bucket」核取方塊。
這項功能可讓您模擬真實世界情境,例如代管公開網頁內容或共用資料存放區。如果沒有這項變更,bucket 會強制執行嚴格的「僅限私人」政策;即使您已成功授予檔案公開權限,任何存取資產的嘗試都會導致403禁止錯誤。 - 依序點選「繼續」 >「建立」 >「選取」 >「繼續」。
- 在「Authentication method」部分,選取「Credential vending mode」。
- 按一下「建立」。系統會建立目錄,並開啟「目錄詳細資料」頁面。
- 在「驗證方式」下方,按一下「設定 bucket 權限」。
- 在對話方塊中,按一下「確認」。這會驗證目錄的服務帳戶是否在儲存空間 bucket 中具有
Storage Object User角色。 - 在「目錄詳細資料」頁面中,複製 REST 目錄 URI 路徑。在「執行 Spark 工作」工作期間使用這個路徑。
將 Parquet 檔案上傳至 bucket
如要將 Parquet 檔案上傳至 bucket 的根目錄,請按照下列步驟操作:
4. 設定虛擬私有雲網路
建立虛擬私有雲 (VPC) 網路和子網路,讓資源與 Google API 通訊時不必連上公開網際網路,並建立防火牆,允許內部流量在資料處理節點之間自由流動。
- 在 Google Cloud 控制台中,前往「VPC networks」(虛擬私有雲網路) 頁面。
- 按一下「建立虛擬私有雲網路」。
- 輸入網路的「Name」(名稱)。例如:
acai-network。 - 如要設定網路的最大傳輸單位 (MTU),請選取「自動設定 MTU」核取方塊。
- 在「Subnet creation mode」(建立子網路模式) 選擇 [Aotomatic] (自動)。
- 在「防火牆規則」部分,選取「IPv4 防火牆規則」的所有核取方塊。
- 點選「建立」。
啟用 Private Google Access
Dataproc Serverless 節點沒有公開 IP 位址。如要與 Lakehouse Catalog 和 Cloud Storage 通訊,子網路必須啟用 Private Google Access。
5. 建立及執行 Spark 工作
如要建立及查詢 Iceberg 資料表,請上傳包含必要 Spark SQL 陳述式的 PySpark 工作。然後使用 Managed Service for Spark 執行工作。
將 quickstart.py 上傳至 Cloud Storage bucket
複製 Codelab 資產後,請使用專案詳細資料更新 quickstart.py 指令碼,然後上傳至 Cloud Storage bucket。
- 在文字編輯器中開啟
quickstart.py指令碼。 - 將指令碼中的預留位置
BUCKET_NAME替換為 Cloud Storage 值區名稱,然後儲存。 - 前往 Google Cloud 控制台中的「Cloud Storage buckets」(Cloud Storage 值區)。
- 按一下 bucket 名稱,例如
acai_demo。 - 在「物件」分頁,依序點選「上傳」 >「上傳檔案」。
- 在檔案瀏覽器中選取更新後的
quickstart.py檔案,然後按一下「開啟」。
執行 Spark 工作
上傳 quickstart.py 指令碼後,請以 Managed Service for Spark 批次工作形式運作執行。
- 如要設定變數,請在 Cloud Shell 中執行下列指令。
# Configuration Variables export PROJECT_ID="<PROJECT_ID>" export REGION="<REGION>" export BUCKET_NAME="<BUCKET_NAME>" export SUBNET="<SUBNET>" export LAKEHOUSE_CATALOG_ID="<LAKEHOUSE_CATALOG_ID>" export CATALOG_URI_ID="<CATALOG_URI_ID>"- LAKEHOUSE_CATALOG_ID:包含 PySpark 應用程式檔案的 Lakehouse 目錄資源名稱。例如:
acai_demo - PROJECT_ID:您的 Google Cloud 專案 ID。
- REGION:執行 Managed Service for Spark 批次工作負載的區域。例如:
us-west1。 - BUCKET_NAME:您的 Cloud Storage bucket 名稱。例如:
acai_demo。 - SUBNET:虛擬私有雲子網路名稱。例如:
acai-network。 - CATALOG_URI_ID:建立含有 bucket 的 Lakehouse 目錄時複製的 Lakehouse 目錄 URI ID。例如:
https://biglake.googleapis.com/iceberg/v1/restcatalog。
- LAKEHOUSE_CATALOG_ID:包含 PySpark 應用程式檔案的 Lakehouse 目錄資源名稱。例如:
- 在 Cloud Shell 中,使用
quickstart.py指令碼執行下列 Managed Service for Spark 批次工作。gcloud dataproc batches submit pyspark gs://${BUCKET_NAME}/quickstart.py \ --project=${PROJECT_ID} \ --region=${REGION} \ --subnet=${SUBNET} \ --version=2.2 \ --properties="\ spark.sql.defaultCatalog=${LAKEHOUSE_CATALOG_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}=org.apache.iceberg.spark.SparkCatalog,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.type=rest,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.uri=${CATALOG_URI_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.warehouse=gs://${BUCKET_NAME},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.io-impl=org.apache.iceberg.gcp.gcs.GCSFileIO,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.x-goog-user-project=${PROJECT_ID},\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest.auth.type=org.apache.iceberg.gcp.auth.GoogleAuthManager,\ spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.rest-metrics-reporting-enabled=false,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.header.X-Iceberg-Access-Delegation=vended-credentials,\ spark.sql.catalog.${LAKEHOUSE_CATALOG_ID}.gcs.oauth2.refresh-credentials-endpoint=https://oauth2.googleapis.com/token"All tables registered successfully! Batch [126fa2226a904d2e944c8eecbe0b1840] finished. metadata: '@type': type.googleapis.com/google.cloud.dataproc.v1.BatchOperationMetadata batch: projects/PROJECT_ID/locations/REGION/batches/126fa2226a904d2e944c8eecbe0b1840 batchUuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff createTime: '2026-04-09T13:17:26.222727Z' description: Batch labels: goog-dataproc-batch-id: 126fa2226a904d2e944c8eecbe0b1840 goog-dataproc-batch-uuid: 3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-drz-resource-uuid: batch-3bff88ca-64d6-4c16-b9ad-2a47ae93ebff goog-dataproc-location: REGION operationType: BATCH name: projects/PROJECT_ID/regions/REGION/operations/47bc59e8-5082-3af9-89a0-22289aa5f4b9
6. 從 BigQuery 查詢資料表
成功執行 Spark 批次工作後,您已使用 Managed Service for Spark Serverless 做為分散式運算引擎,在 Lakehouse Metastore 中為每個 Parquet 檔案註冊一個資料表。完成註冊後,Google Cloud 就能將 Cloud Storage 中的原始檔案視為結構化的高效能表格。
請按照下列步驟確認中繼資料已正確同步,確保資料不僅安全儲存,還能透過 BigQuery 介面完整探索及查詢。
- 前往 Google Cloud 控制台中的「BigQuery」頁面。
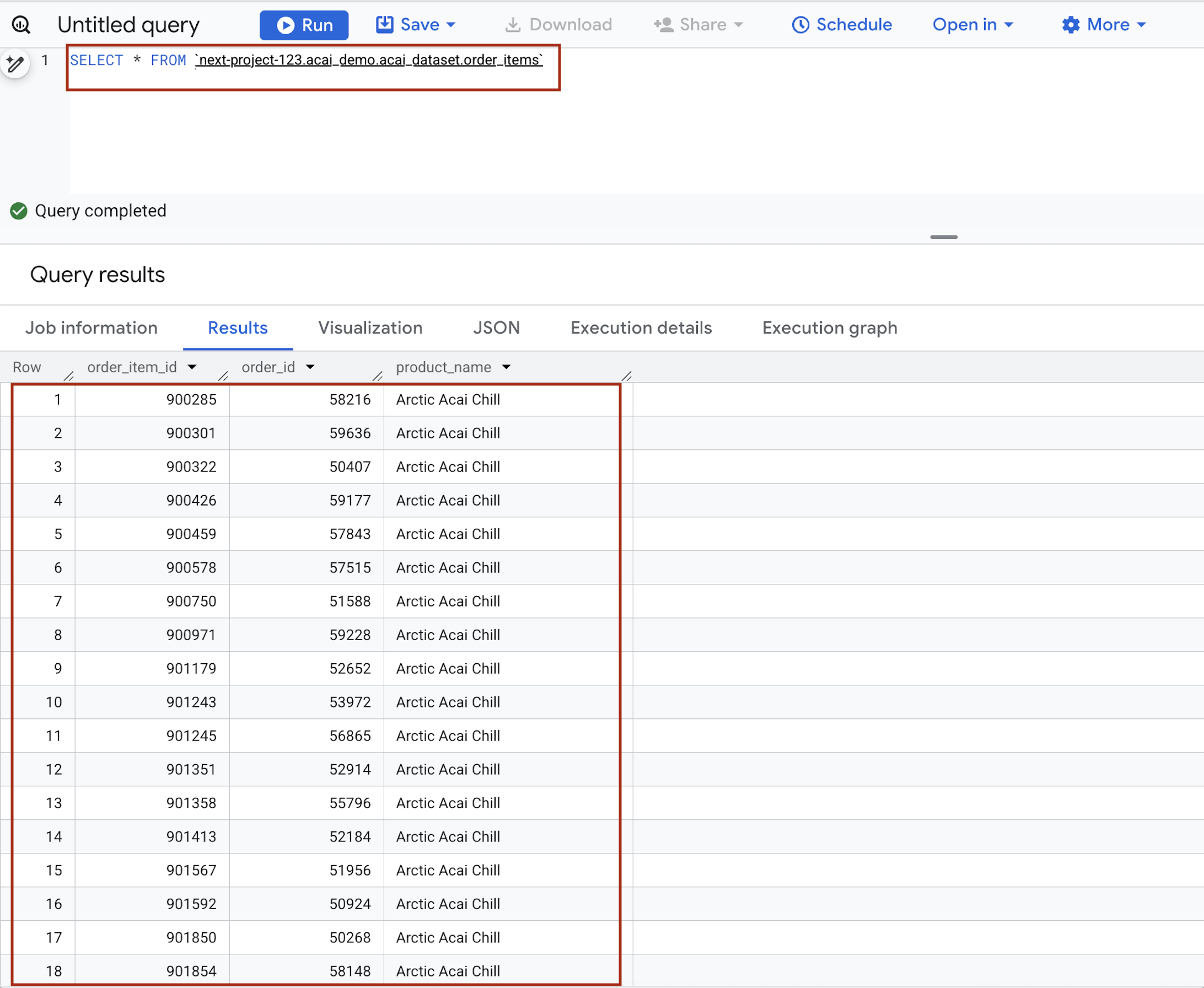
- 在查詢編輯器中輸入下列陳述式,查詢使用
project.namespace.dataset.table語法。SELECT * FROM `<PROJECT_ID>.<NAMESPACE>.<ICEBERG_DATASET>.<ICEBERG_TABLE>`PROJECT_ID.acai_demo.acai_dataset.order_items。
請替換下列項目:- PROJECT_ID:您的 Google Cloud 專案 ID。
- NAMESPACE:上一個步驟中,Spark 工作建立的命名空間,您可以在 BigQuery 物件瀏覽器頁面中找到。例如:
acai_demo。 - ICEBERG_DATASET:Iceberg 目錄中的資料集名稱,例如
acai_dataset。 - ICEBERG_TABLE:Iceberg 資料集中的資料表名稱,例如
order_items。
- 按一下「執行」。查詢結果會顯示您透過 Spark 工作插入的資料。
7. 設定非結構化產品資料檔案
在本節中,您將在 BigQuery 中建立機構結構,專門儲存 Froyo 食譜和供應商資料,特別是 Froyo 產品詳細資料。此外,這項服務也會建立雲端資源連線,做為安全「橋樑」,讓 BigQuery 從 Cloud Storage 等外部來源讀取檔案。
建立 bucket 並上傳 Froyo 詳細資料檔案
建立供應商和食譜檔案,並上傳至 Cloud Storage bucket。
- 前往 Google Cloud 控制台中的「Cloud Storage Buckets」(Cloud Storage 值區) 頁面。
- 點選「建立」。
- 在「建立 bucket」頁面中,輸入 bucket 資訊。完成下列每個步驟後,請按一下「繼續」前往下一個步驟:
- 在「開始使用」部分,輸入 bucket 名稱。例如:
acai_pdfs。 - 在「Choose where to store your data」(選擇資料的儲存位置) 專區中,選取「Region」(區域),然後輸入區域。例如:
us-west1。 - 在「選取如何控制物件的存取權」部分,取消勾選「強制禁止公開存取這個 bucket」核取方塊。
- 點選「建立」。
- 在值區清單中,按一下您建立的值區。例如
acai_pdfs。 - 在 bucket 的「物件」分頁中,依序點選「上傳」 >「上傳資料夾」。
- 選取您在本程式碼研究室「開始前」一節中解壓縮的
recipes資料夾。 - 按一下「上傳」。
- 針對
suppliers資料夾重複上傳程序。
建立連線
建立 Cloud 資源連結。這會產生專屬服務帳戶,做為 BigQuery 存取外部檔案的「身分證」。
- 前往「BigQuery」頁面
- 點選左側窗格中的「Explorer」。如果沒有看到左側窗格,請按一下「Expand left pane」(展開左側窗格),開啟窗格。
- 在「Explorer」窗格中展開專案名稱,然後按一下「連線」。
- 在「Connections」(連線) 頁面中,按一下「Create connection」(建立連線)。
- 在「連線」類型中,選擇「Vertex AI 遠端模型、遠端函式、BigLake 和 Spanner (Cloud 資源)」。
- 在「連線 ID」欄位中,輸入連線 ID 名稱。例如,
acai_pdf_connection。請務必記下這個 ID,因為稍後在本程式碼研究室中設定資料掃描時,您會需要用到這個 ID。 - 將「位置類型」設為「區域」,然後選取區域。例如
us-west1。連線應與資料集等其他資源位於同一位置。 - 點選「建立連線」。
- 點選「前往連線」。
- 在「連線資訊」窗格中,複製服務帳戶 ID,以便在後續步驟中使用。服務帳戶類似於
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com。
管理服務帳戶的存取權
提供服務帳戶的存取權,讓 Lakehouse 可以讀取 PDF。
- 前往「IAM & Admin」(IAM 與管理) 頁面。
- 按一下「Grant access」(授予存取權)。系統會開啟「新增主體」對話方塊。
- 在「新主體」欄位,輸入先前複製的服務帳戶 ID。
- 在「請選取角色」欄位中,新增下列角色:
roles/storage.objectUserroles/storage.objectViewerroles/bigquery.userroles/bigquery.dataEditorroles/aiplatform.userroles/storage.adminroles/dataproc.serviceAgent
- 按一下 [儲存]。
如要進一步瞭解 BigQuery 中的 IAM 角色,請參閱預先定義的角色與權限一文。
8. 管理 DataScan 作業的權限
為 Spark 和 Dataform 建立專屬服務帳戶 (身分),然後授予這些帳戶和 Google 自動化服務代理程式精確的權限,以便讀取儲存空間、執行 BigQuery 工作,以及使用 Vertex AI 進行探索。
Spark 和 Dataform 的 IAM 存取權
- 前往 Google Cloud 控制台中的「Create service account」(建立服務帳戶) 頁面。
- 如果未選取,請選取 Google Cloud 專案。
- 按一下「建立服務帳戶」。
- 輸入服務帳戶名稱。例如:
sa-spark-stg1。Google Cloud 控制台會依據這個名稱產生服務帳戶 ID。請視需要編輯 ID,ID 設定後即無法變更。 - 如要設定存取權控管,請按一下「Create and continue」(建立並繼續),然後繼續進行下一個步驟。
- 選擇下列 IAM 角色,授予專案的服務帳戶。
roles/dataproc.workerroles/storage.objectUserroles/bigquery.dataEditorroles/bigquery.jobUserroles/aiplatform.userroles/dataplex.discoveryPublishingServiceAgent
- 新增角色之後,請按一下「Continue」(繼續)。
- 按一下「Done」(完成),即完成建立服務帳戶。
存取 Knowledge Catalog 的 BigQuery 連線權限
- 前往 Google Cloud 控制台中的「Cloud Storage Buckets」(Cloud Storage 值區) 頁面。
- 在 bucket 清單中,按一下您為 Froyo 建立的 bucket 名稱。例如
acai_pdfs。 - 在「Permissions」(權限) 分頁中,按一下「Grant access」(授予存取權限)。系統會顯示「新增主體」對話方塊。
- 在「新增主體」欄位中,輸入 BigQuery 服務帳戶 ID。服務帳戶類似於
bqcx-175930350285-qn3a@gcp-sa-bigquery-condel.iam.gserviceaccount.com。 - 從「Select a role」(選取角色) 下拉式選單中選取下列角色。
roles/storage.objectUserroles/dataplex.serviceAgentroles/dataplex.securityAdminroles/aiplatform.serviceAgentroles/dataplex.discoveryPublishingServiceAgent
- 按一下「儲存」。
9. 設定 Knowledge Catalog
建構 Knowledge Catalog,統一管理與 Froyo 相關的資料,並自動探索非結構化檔案 (例如 PDF 食譜和 PDF 供應商)。
透過 curl 建立 DataScan
在本節中,您將新增 datascan_ID 並指向 BigQuery 資料集,為 Cloud Storage bucket (例如 acai_pdfs) 建立掃描作業。之後,Knowledge Catalog 會自動在 BigQuery 中為 PDF 建立項目。
- 如要掃描 PDF (供應商和食譜),請執行下列指令:
# 1. Set your variables PROJECT_ID="<PROJECT_ID>" REGION="<REGION>" ENV_SUFFIX="stg1" DATASCAN_ID="froyo-profile-${ENV_SUFFIX}" BUCKET_NAME="<BUCKET_NAME>" # 2. Set this to the Name of the connection you created in Step 7 CONNECTION_ID="<CONNECTION_ID_NAME>" # 3. Define the API Endpoint DATAPLEX_API="dataplex.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}" # 4. Create the DataScan via CURL echo "Creating Dataplex DataScan: ${DATASCAN_ID}..." curl -X POST "https://$DATAPLEX_API/dataScans?dataScanId=${DATASCAN_ID}" \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ -d '{ "data": { "resource": "//storage.googleapis.com/projects/'"${PROJECT_ID}"'/buckets/'"${BUCKET_NAME}"'" }, "executionSpec": { "trigger": { "on_demand": {} } }, "dataDiscoverySpec": { "bigqueryPublishingConfig": { "tableType": "BIGLAKE", "connection": "projects/'"${PROJECT_ID}"'/locations/'"${REGION}"'/connections/'"${CONNECTION_ID}"'" }, "storageConfig": { "unstructuredDataOptions": { "entity_inference_enabled": true } } } }' curl指令會顯示 Knowledge Catalog DataScan 結果,如下圖所示。
執行工作
執行下列指令:
gcloud dataplex datascans run $DATASCAN_ID --location=$REGION
說明工作
如要說明這項工作,請執行下列指令:
gcloud dataplex datascans describe $DATASCAN_ID --location=$REGION
刪除資料掃描工作
如果掃描作業執行時間超過 10 分鐘,或工作狀態長時間維持「待處理」而未轉換為「執行中」,可能是因為該區域的資源暫時無法使用。如果發生這種情況,您可以執行下列指令刪除作業,然後嘗試再次建立及執行作業。有時,初始執行可能會快速失敗,並顯示類似 unable to acquire necessary resources 的錯誤。
gcloud dataplex datascans delete $DATASCAN_ID --location=$REGION
查看工作狀態
如要查看工作狀態,請按照下列步驟操作:
- 前往 Google Cloud 控制台的「中繼資料管理」頁面。
- 在「Cloud Storage 探索」分頁中,按一下探索掃描的名稱。
- 在「掃描詳細資料」頁面中,您可以查看工作狀態。
- 工作完成後,請檢查您使用
curl指令建立的已發布資料集 (例如acai_pdfs_discovered_003) 是否存在。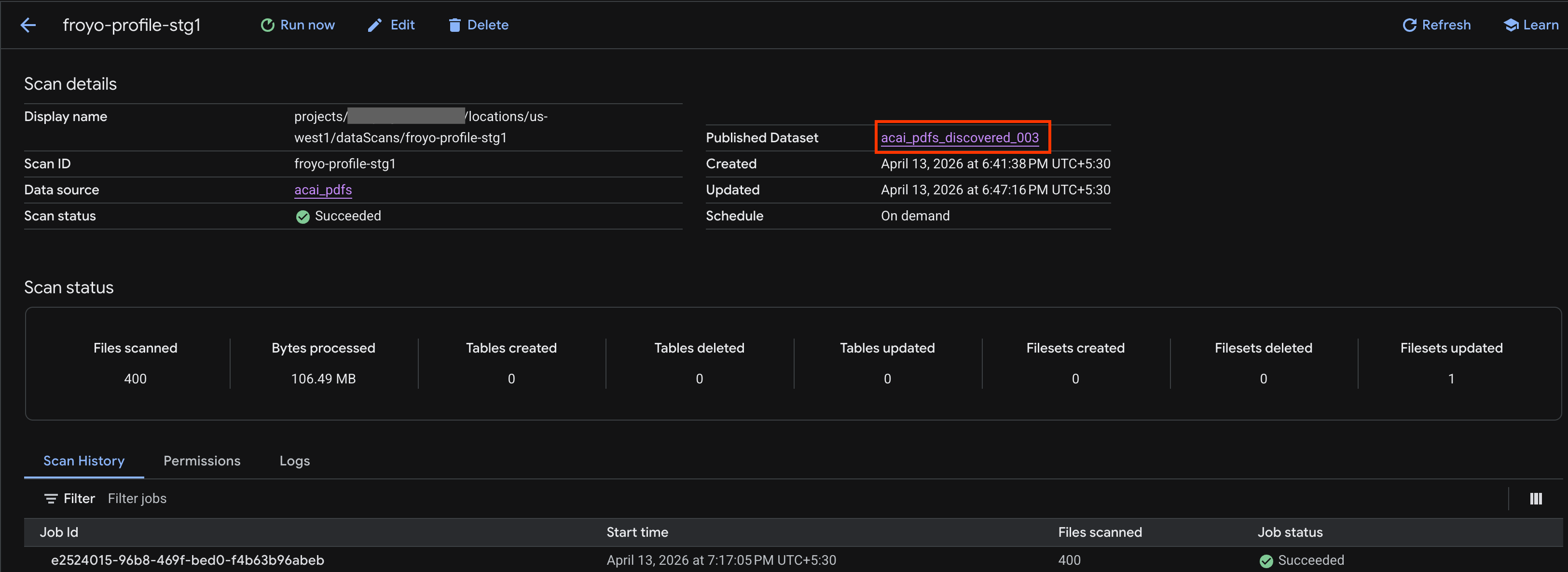
查看物件資料表
如要查看探索作業後建立的物件資料表,請按照下列步驟操作:
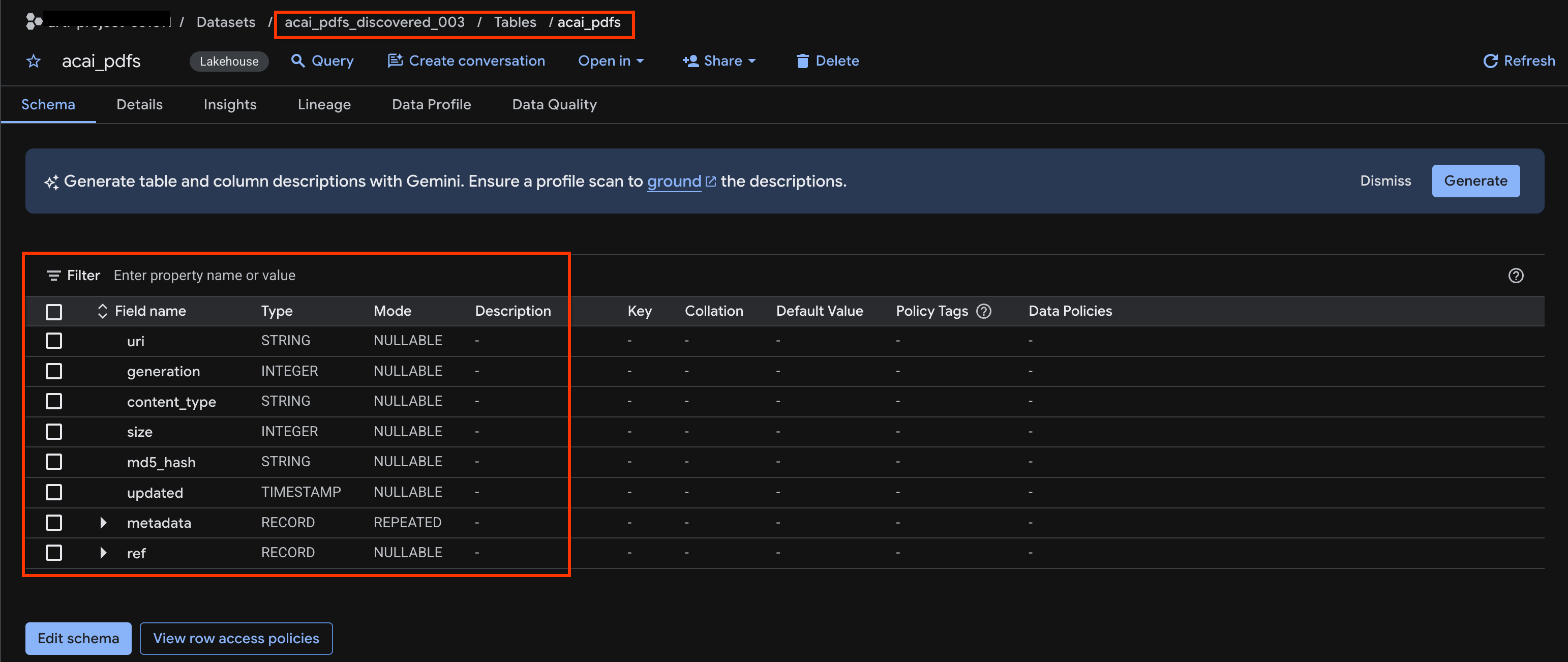
10. 語意擷取
您將為上一個步驟中建立的非結構化物件資料表,推論及擷取結構化資料表、其他資料庫物件和關係。為此,您可以使用 Knowledge Catalog Insights 功能生成 SQL 陳述式,從非結構化表格中擷取結構化資料
- 在 Google Cloud 控制台中,前往「Knowledge Catalog Search」(知識目錄搜尋) 頁面。
- 搜尋要查看洞察資料的資料集資料表。例如:
acai_pdfs_discovered_003。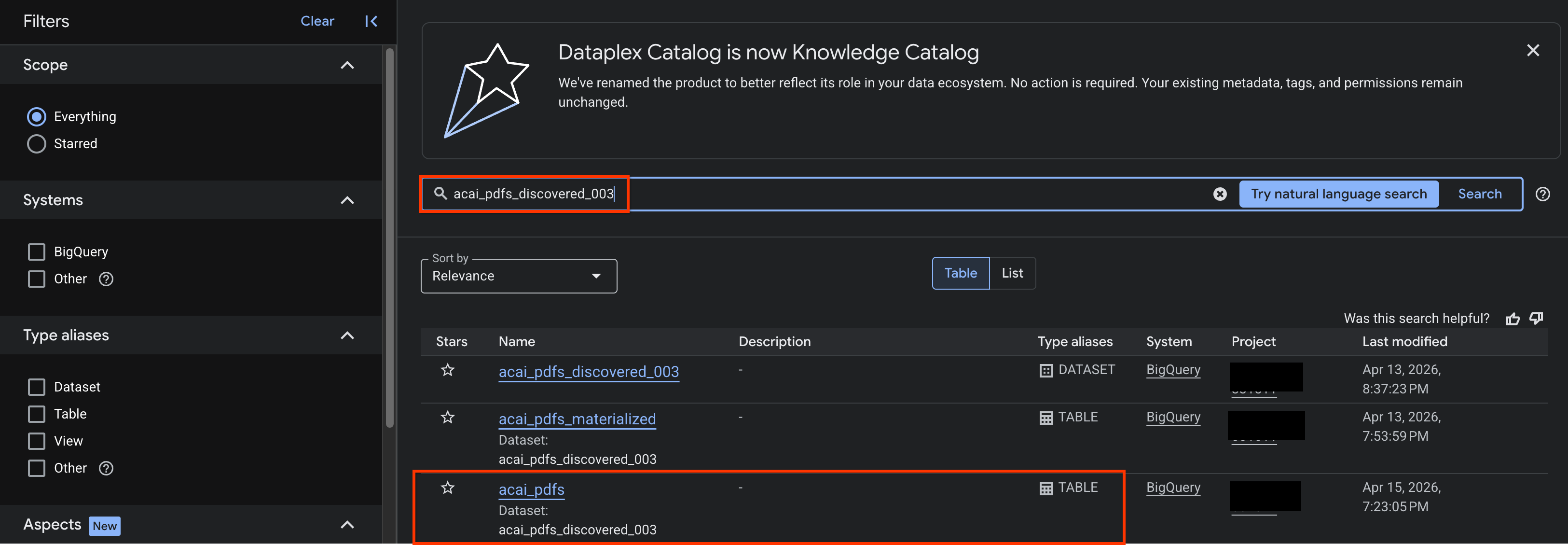
- 在搜尋結果中按一下表格,開啟表格的項目頁面。
- 點按「深入分析結果」分頁標籤,如果分頁空白,表示系統尚未產生這個資料表的洞察資料。生成洞察資訊可能需要 15 至 25 分鐘。
- 看到洞察資料後,依序點選「擷取」 >「透過 SQL 擷取」。
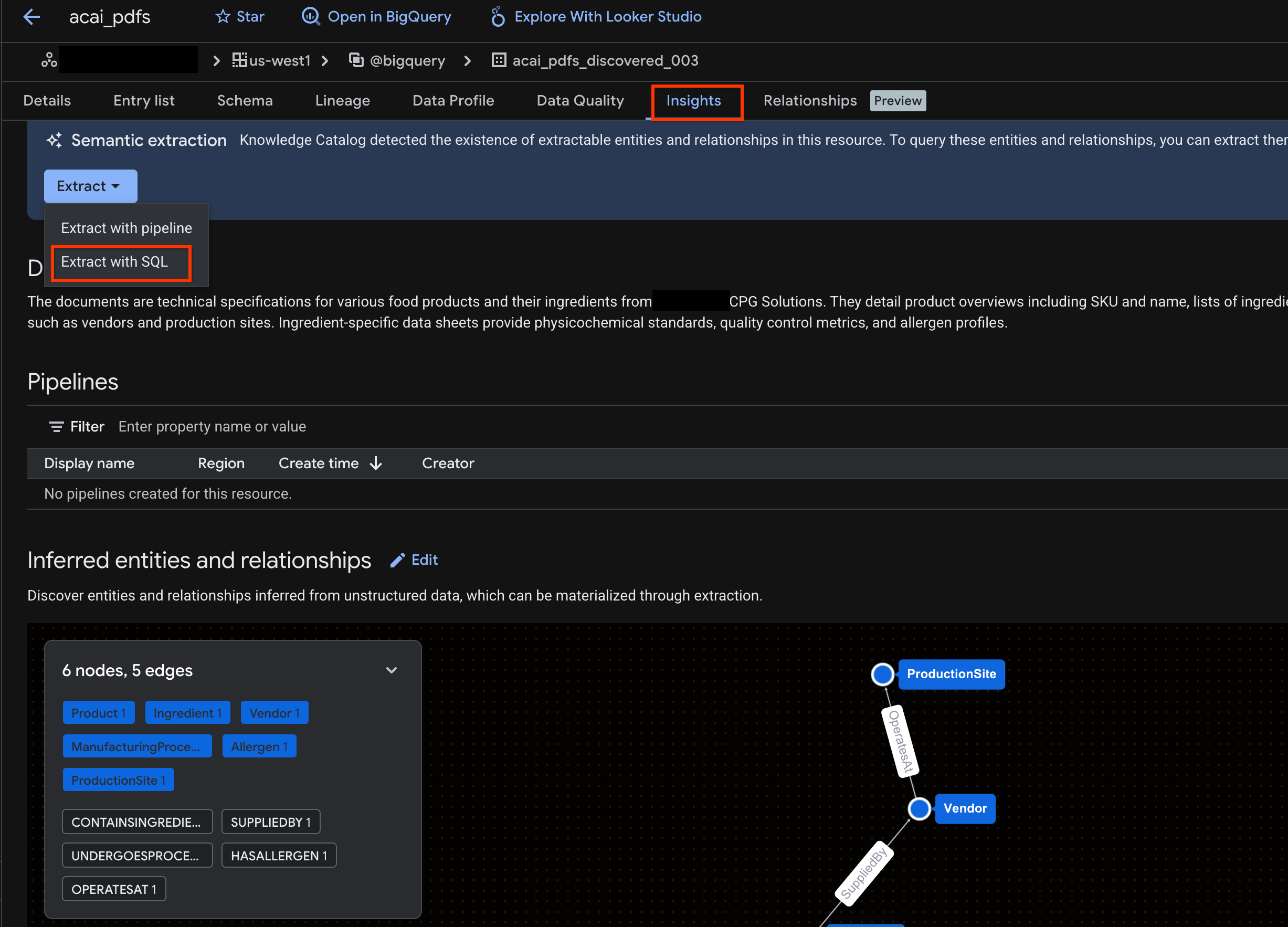
- 在「Extract with SQL」(使用 SQL 擷取) 頁面中,輸入「Destination」(目的地) 的資料集。例如:
acai_pdfs_discovered_003。 - 按一下「擷取」。系統會開啟 BigQuery 編輯器,並載入查詢。
- 按一下「執行」。這個步驟會產生一組陳述式,可能需要幾分鐘才能完成執行。
- 查詢完成後,您會看到下列結果:
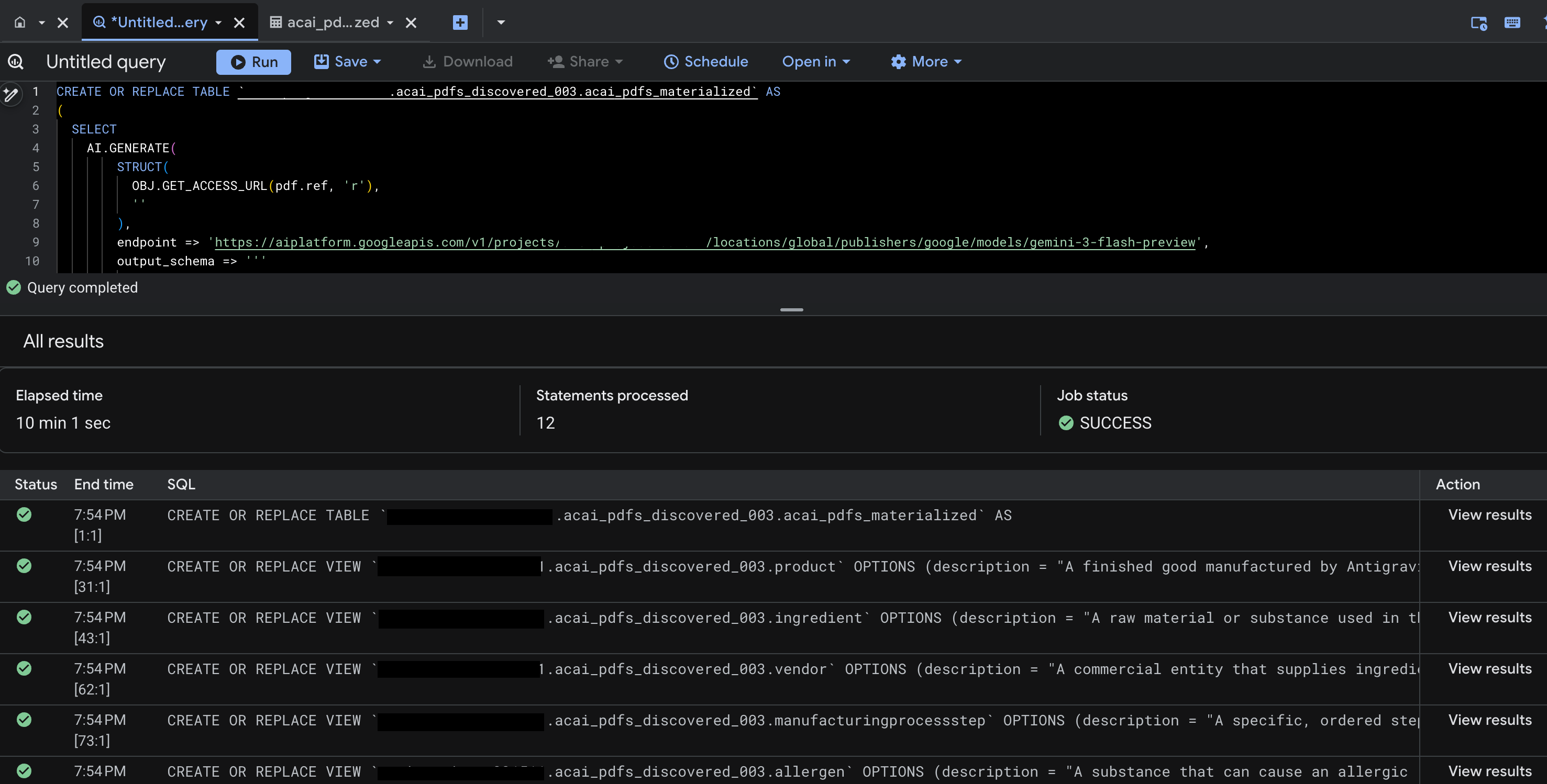
- 前往 BigQuery,然後按一下「資料集」 (例如
acai_pdfs_discovered_003)。系統會在步驟 6 中選取的資料集內,建立一組新的結構化資料庫物件。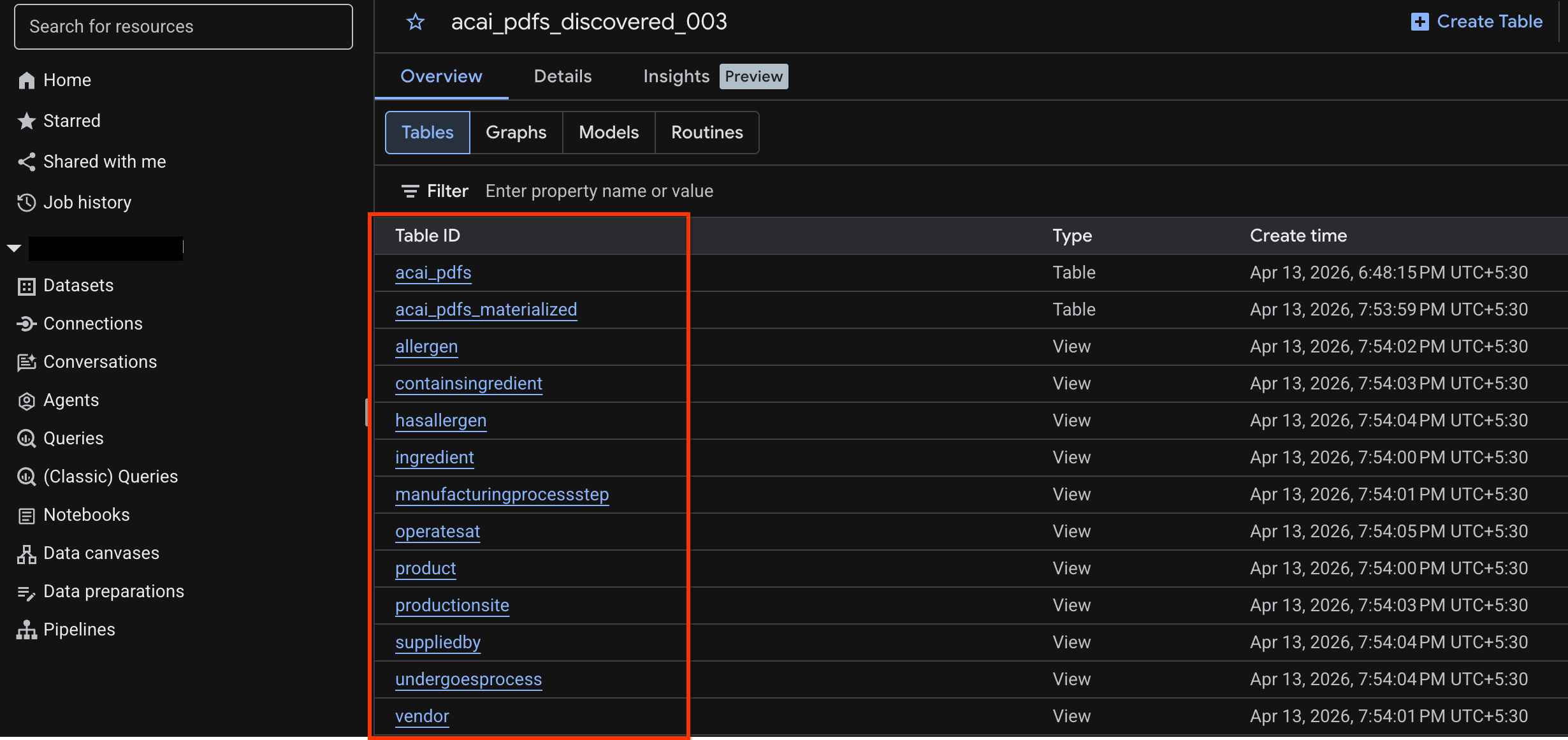
在 BigQuery 中產生物件的洞察資料
如要為 BigQuery 資料集產生洞察資訊,您必須使用 BigQuery Studio 存取 BigQuery 中的資料集。
- 前往 Google Cloud 控制台中的「BigQuery Studio」頁面。
- 在「Explorer」窗格中選取專案,然後前往要產生洞察資料的資料集。
- 按一下「洞察」分頁標籤。
- 如果看到「啟用 API」按鈕,請點選啟用 Gemini for Google Cloud。「啟用核心功能」視窗隨即開啟。
- 在「核心功能 API」部分,依序點選「Gemini for Google Cloud API」和「BigQuery Unified API」的「啟用」,然後按一下「下一步」。
- 在「權限 (選用)」部分,視需要將 IAM 角色授予主體,然後按一下「下一步」。
- 如要生成洞察資料並發布至 Knowledge Catalog,請按一下「生成並發布」。
- 發布後,您可以在該分頁中查看洞察資料。
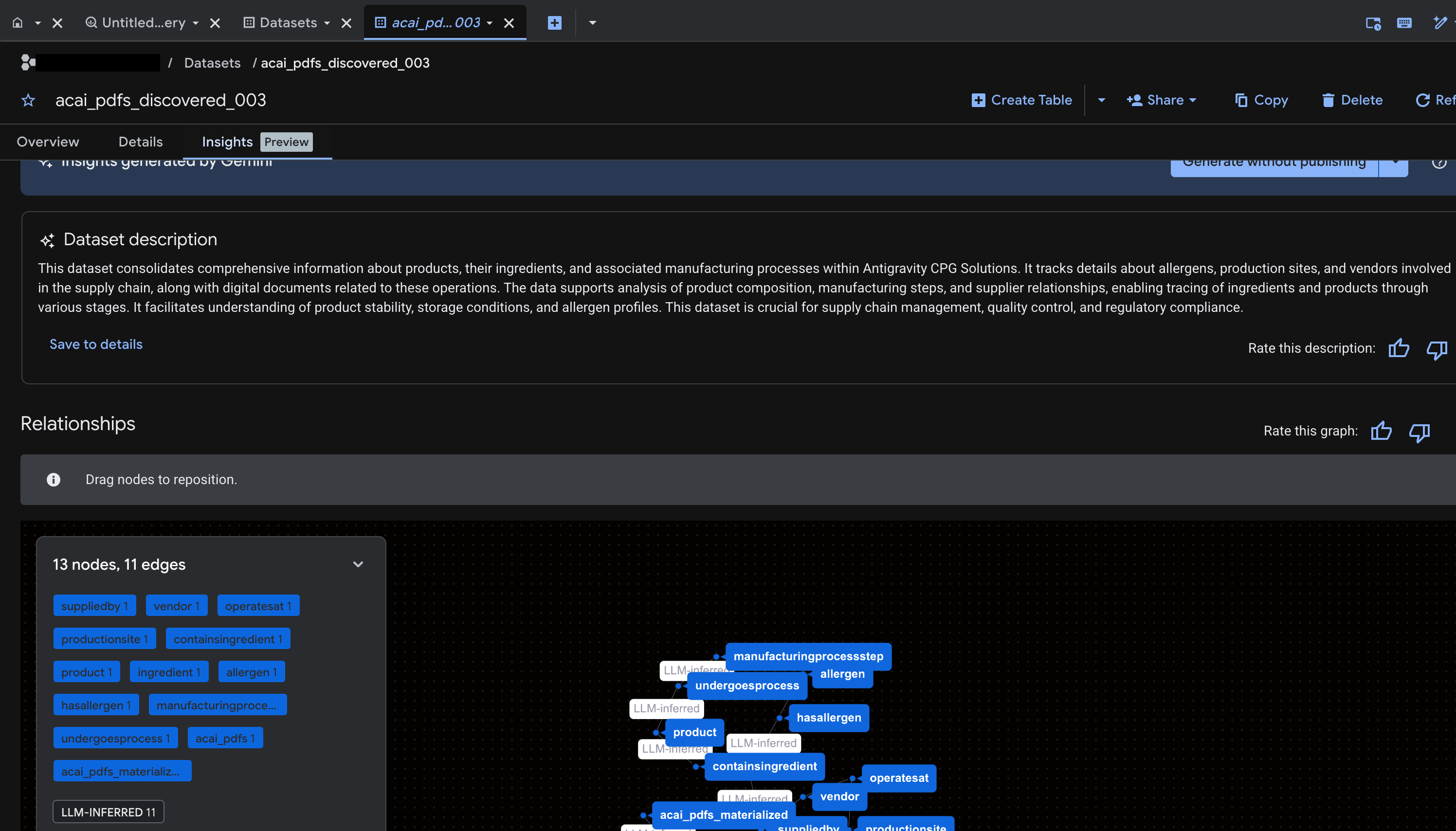
11. 設定 IDE,進行代理式資料分析
Visual Studio Code 適用的 Google Cloud Data Agent Kit 擴充功能是 IDE 擴充功能,適用於資料科學家和資料工程師。您可透過這項功能直接從 IDE 連結及使用 Google Data Cloud 資源和資料。詳情請參閱「VS Code 適用的 Data Agent Kit 擴充功能總覽」
如果您想執行下列操作,VS Code 的 Data Agent Kit 擴充功能就非常實用:
- 直接在 VS Code 中建構、測試、檢查及部署適用於正式環境的資料管道,例如 Spark ETL 或 BigQuery ETL。
- 運用 AI 輔助功能探索資料、建構訓練管道、找出最佳機器學習模型,並將模型部署至正式環境端點。
- 連結至可信的資料來源、建構高效能資料模型,並為業務利害關係人發布互動式資訊主頁。
安裝 VS Code 適用的 Data Agent Kit 擴充功能
- 開啟 VS Code。
- 安裝 Google Cloud CLI。詳情請參閱「安裝 Google Cloud CLI」。
- 安裝 VS Code 適用的 Data Agent Kit 擴充功能。
- 完成擴充功能新手上路程序,包括:
- 登入擴充功能
- 安裝技能、MCP 伺服器
- 完成新手上路程序後,請重新載入或重新啟動視窗。詳情請參閱「設定及配置 VS Code 的 Data Agent Kit 擴充功能」。
- IDE 重新載入後,按一下導覽窗格中的「Google Data Cloud」圖示,前往設定,並確認您在一般設定中正確設定專案 ID 和區域 (
us-west1)。
在 VS Code 中設定工作區
- 開啟 VS Code,然後依序選取「File」 >「Open folder」 >「New folder」。
- 建立名為
acai_test的新資料夾,然後按一下「開啟」。VS Code 現在會將您開啟的資料夾視為工作區。 - 在「Workspace trust」對話方塊中,選取「Yes, I trust the authors」,即可啟用工作區中的所有功能。
- 在
acai_test工作區中建立.github資料夾。 - 在
.github資料夾中建立新檔案copilot-instructions.md,並輸入下列規則。## 1. Project Context - **Project ID**: <PROJECT_ID> - **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors. - **Documentation**: Raw PDF documents detailing flavors and ingredients are stored in Google Cloud Storage at `gs://<BUCKET_NAME>`. ## 2. Execution & Data Processing Rules - **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `<BQ_DATASET_NAME>` (referred to as the Knowledge Catalog). - **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the dataset `<DATASET_ID>`. When you are referencing a dataset, ensure you are using it with the project ID (`<PROJECT_ID>`) and namespace prefix `<NAMESPACE_NAME>`. For example, to query order table in this dataset you should use `<PROJECT_ID>.<NAMESPACE>.<DATASET_ID>.orders`. - **CRITICAL RULE - Data Joins between BigQuery dataset and Iceberg dataset**: ANY task requiring a join or integration between the BigQuery datasets `<DATASET_ID>` of the PDF data and the `<DATASET_ID>` of the customer data MUST be executed using **Spark Notebooks**. - **CRITICAL RULE - Notebook Kernel**: Every Spark notebook utilized MUST exclusively be configured to run on the Serverless Session template `iceberg-federation-template` as its kernel. - **CRITICAL RULE - Data Science**: ANY data science, machine learning, or advanced analytical task MUST be performed strictly within **Spark Notebooks** using the aforementioned setup. - 在
acai_test工作區中建立另一個新檔案template.yaml,並在檔案中輸入下列資訊。labels: client: "vscode" jupyterSession: displayName: "iceberg-federation-template" kernel: "PYTHON" environmentConfig: executionConfig: serviceAccount: "sa-spark-dev1@<PROJECT_ID>.iam.gserviceaccount.com" subnetworkUri: "projects/<PROJECT_ID>/regions/<REGION>/subnetworks/<SUBNET_NAME>" runtimeConfig: version: "2.3" properties: # This enables the secure proxy URL you were looking for dataproc.tier: "premium" spark.dataproc.engine: "lightningEngine" spark.dataproc.lightningEngine.runtime: "native" spark.memory.offHeap.enabled: "true" spark.memory.offHeap.size: "1g" spark.executor.memory: "4g" "dataproc.component.gateway.enabled": "true" "dataproc.jupyter.listen.all.interfaces": "true" "spark.sql.extensions": "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" "spark.sql.defaultCatalog": "<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>": "org.apache.iceberg.spark.SparkCatalog" "spark.sql.catalog.<CATALOG_NAME>.type": "rest" "spark.sql.catalog.<CATALOG_NAME>.uri": "<CATALOG_URI_ID>" "spark.sql.catalog.<CATALOG_NAME>.warehouse": "bl://projects/<PROJECT_ID>/catalogs/<CATALOG_NAME>" "spark.sql.catalog.<CATALOG_NAME>.rest.auth.type": "org.apache.iceberg.gcp.auth.GoogleAuthManager" - 在 VS Code 中,按一下「Terminal」(終端機),然後執行下列指令,將
template.yaml檔案匯入為工作階段範本。代理程式稍後會使用這個範本建立 Spark 工作階段。gcloud beta dataproc session-templates import iceberg-federation-template \ --source=template.yaml \ --location=<REGION>REGION替換為您的區域。
12. 執行代理式資料分析
- 在 VS Code 編輯器中,按一下「切換對話」。
- 在「設定自訂代理程式」部分中,選取「代理程式」。
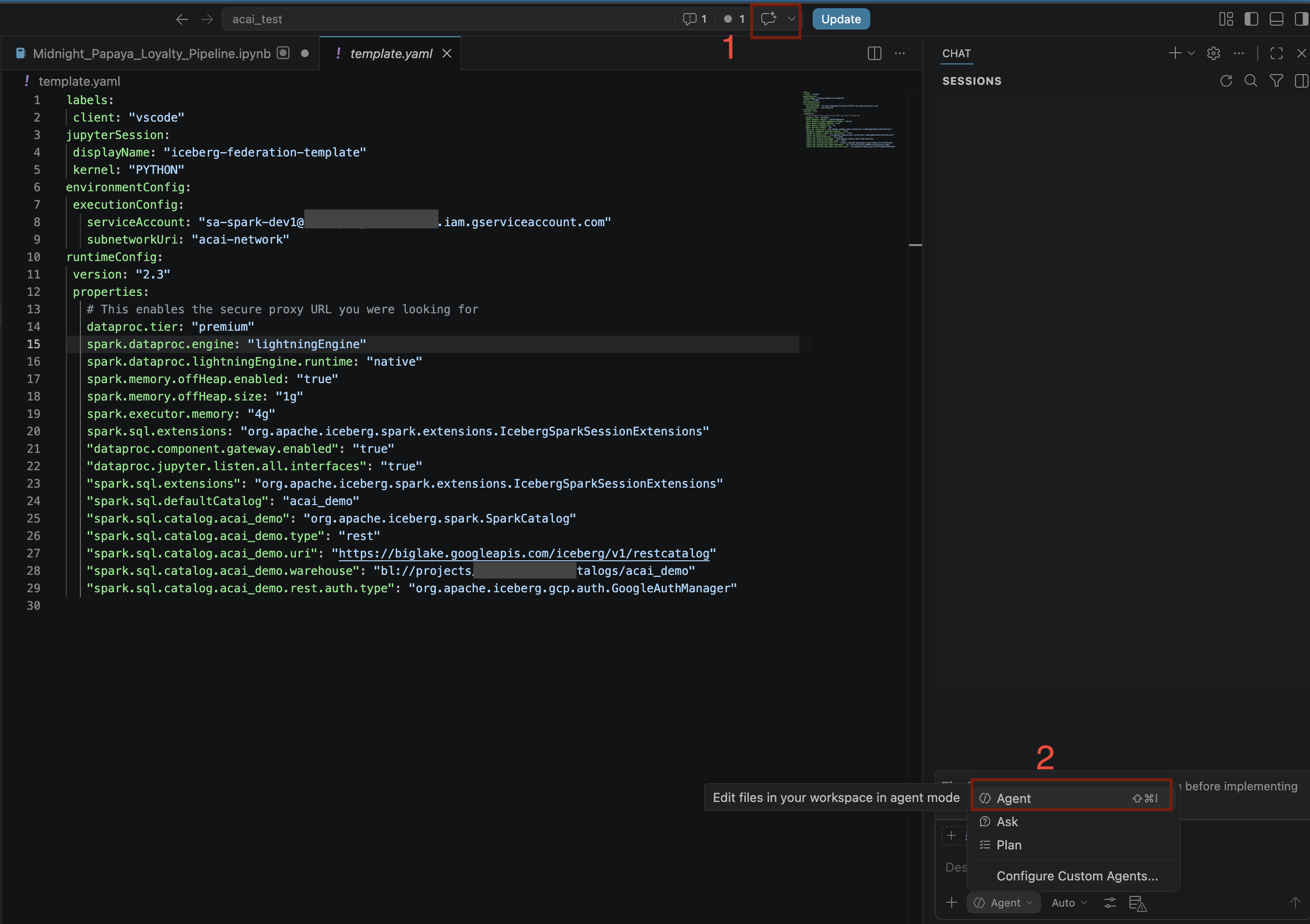
- 在「搜尋模型」窗格中,按一下「管理語言模型」。
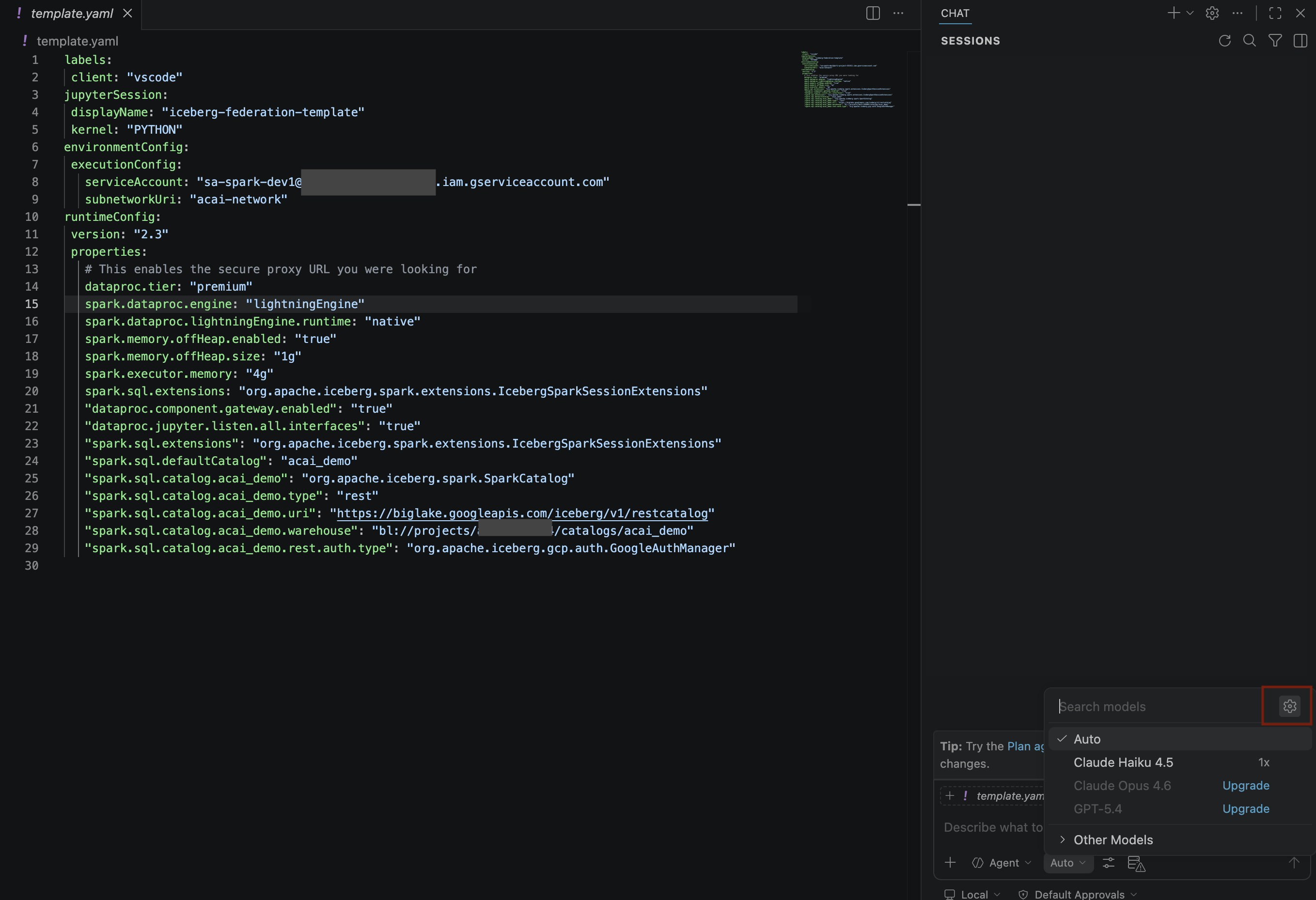
- 在「語言模型」頁面上,按一下「新增模型」。
- 從清單中選取「Google」,然後按下 Enter 鍵確認輸入。
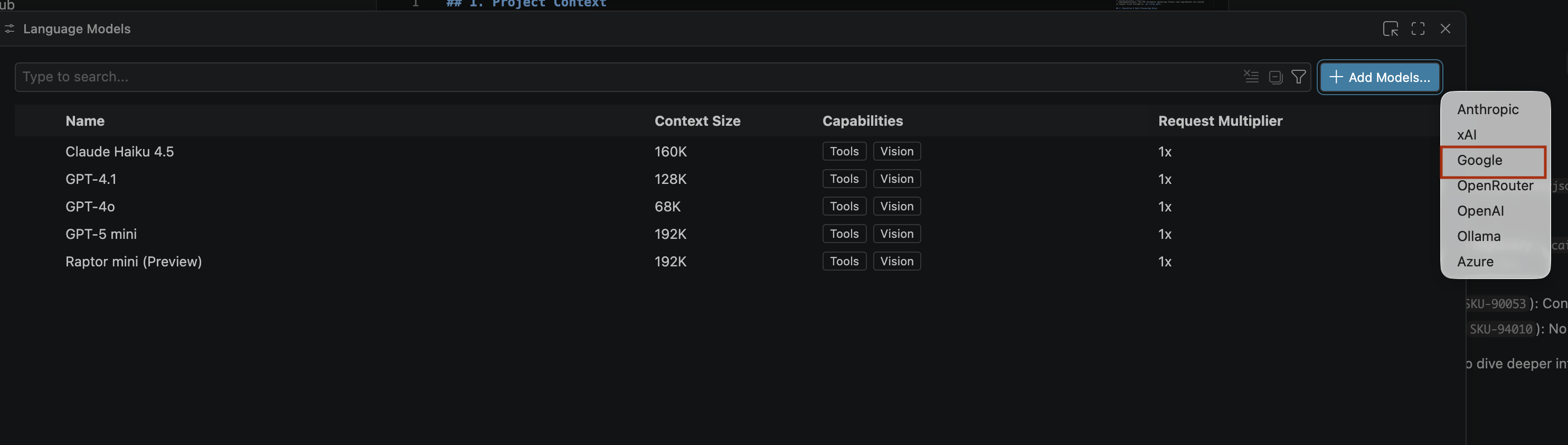
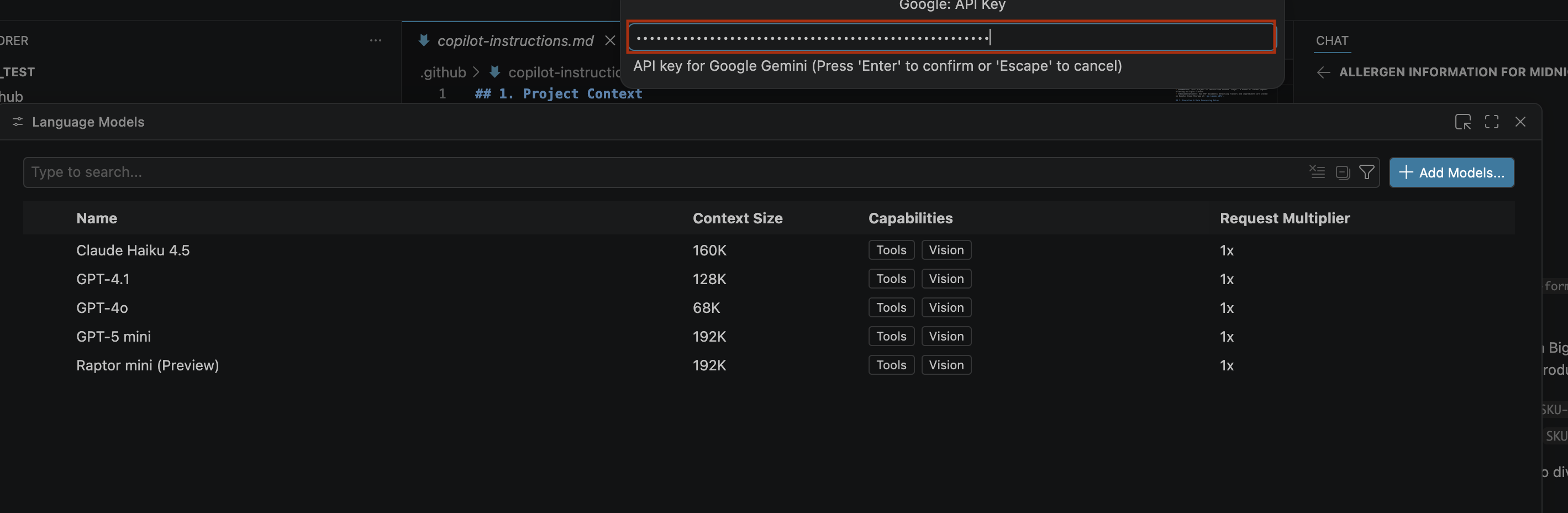
- 如要輸入 Google Gemini 的 API 金鑰,請按照下列步驟操作:
- 前往 Google AI Studio 網站。
- 使用你的 Google 帳戶登入。
- 按一下側欄中的「取得 API 金鑰」。
- 按一下「建立 API 金鑰」。系統會開啟「建立新金鑰」頁面。
- 在「選取雲端專案」清單中,選取「匯入專案」。
- 輸入現有專案的名稱。
- 按一下「建立金鑰」,然後複製 API 金鑰。這個金鑰可存取帳戶的 Gemini API 資源。詳情請參閱「使用 Gemini API 金鑰」。
- 將您產生的 API 金鑰貼到搜尋列,然後按一下「Enter」。
- 如果沒有顯示 Gemini 模型,請按照下圖所示取消隱藏:
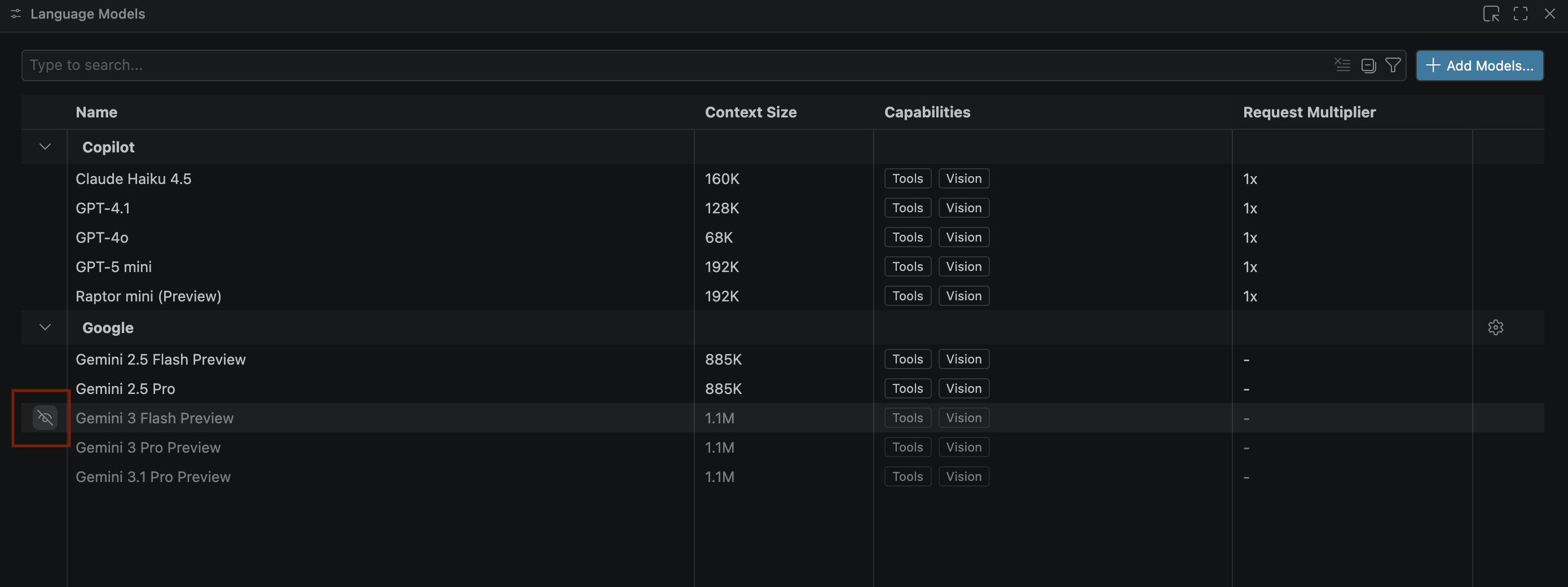
- 從 Google Gemini 模型清單中選取「Gemini 3.1 Pro 搶先版」,然後關閉「語言模型」視窗。
- 在對話視窗中輸入下列問題:
Search ingredients for Midnight papaya - 互動後,您應該會看到以下結果:
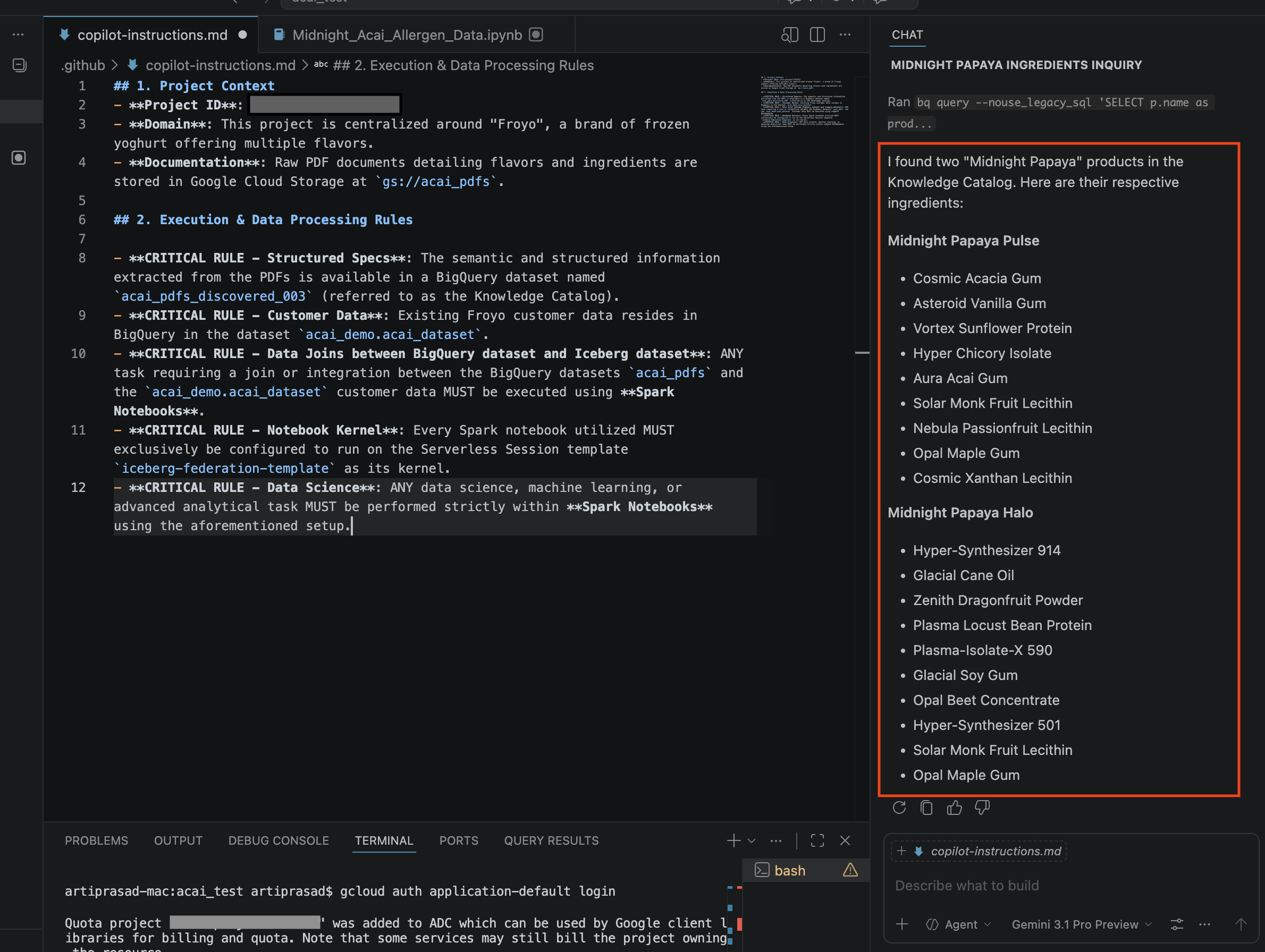
- 在對話視窗中輸入其他問題:
Search allergen information for Midnight papaya - 經過幾次互動和步驟後,你會看到代理回覆過敏原名稱
Soy,如下圖所示: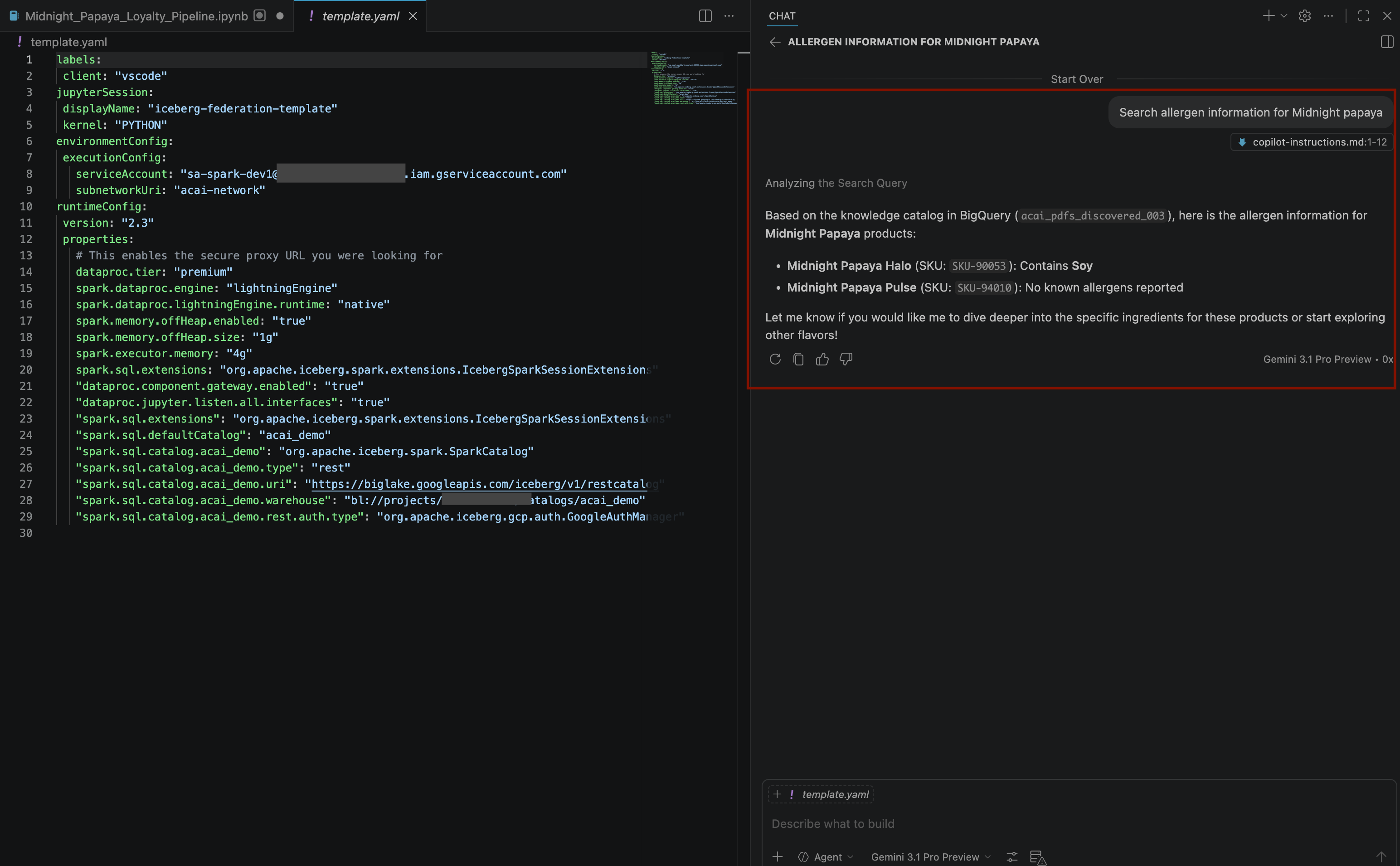
- 在對話視窗中輸入其他問題:
Build a pipeline to join products with our 'Global Loyalty' Iceberg tables in acai customer, sales data to identify popular products - 如要選取核心,請開啟
.ipynb檔案,然後依序點選「Select kernel」(選取核心) >「Remote spark kernels」(遠端 Spark 核心) >「Iceberg-federation-template on serverless spark」(無伺服器 Spark 上的 Iceberg 聯盟範本)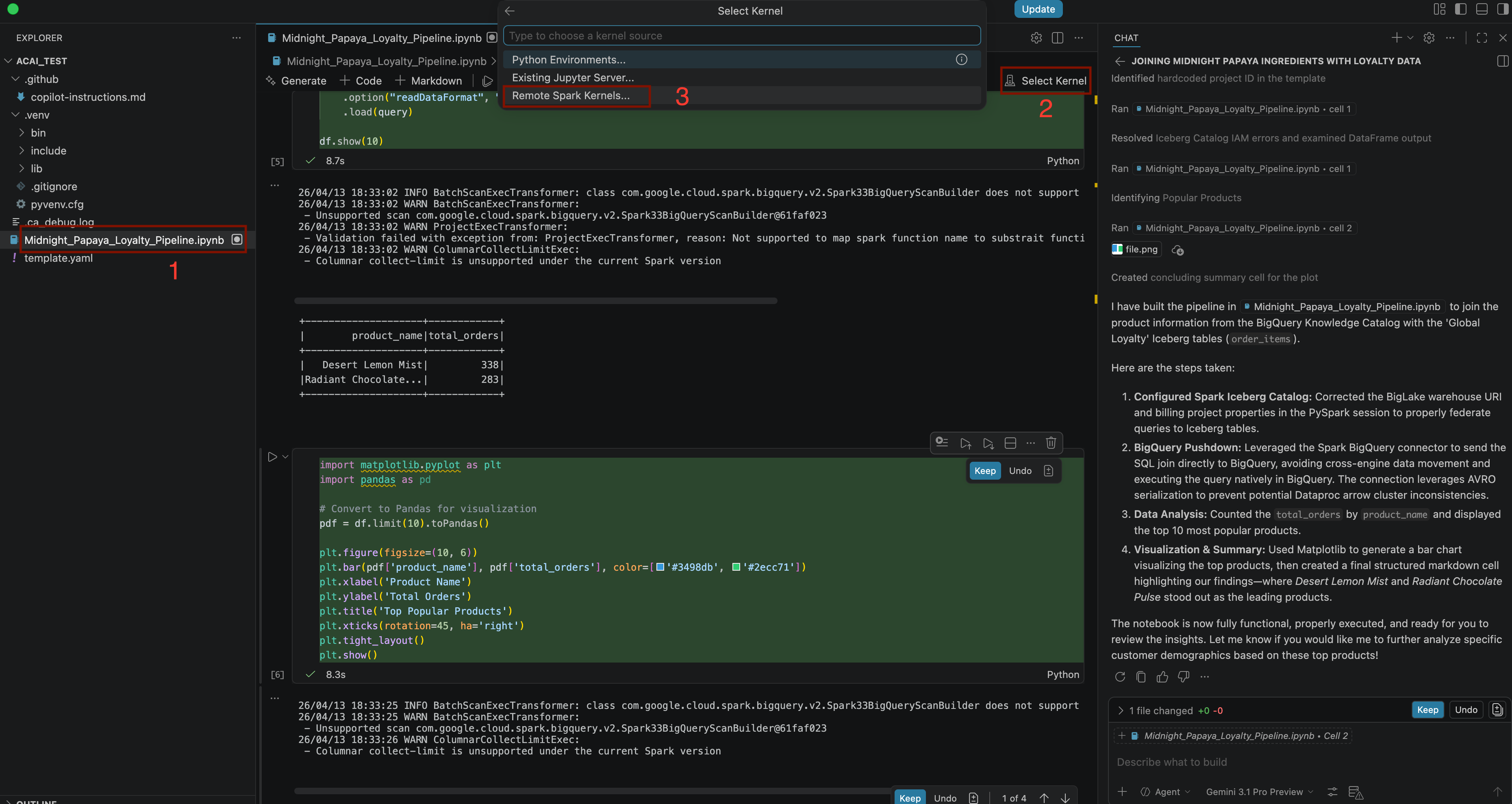
- 經過一些互動和步驟後,您會看到代理回覆筆記本中所有成功執行的步驟,以及筆記本結尾產生的最終結果,如下圖所示:
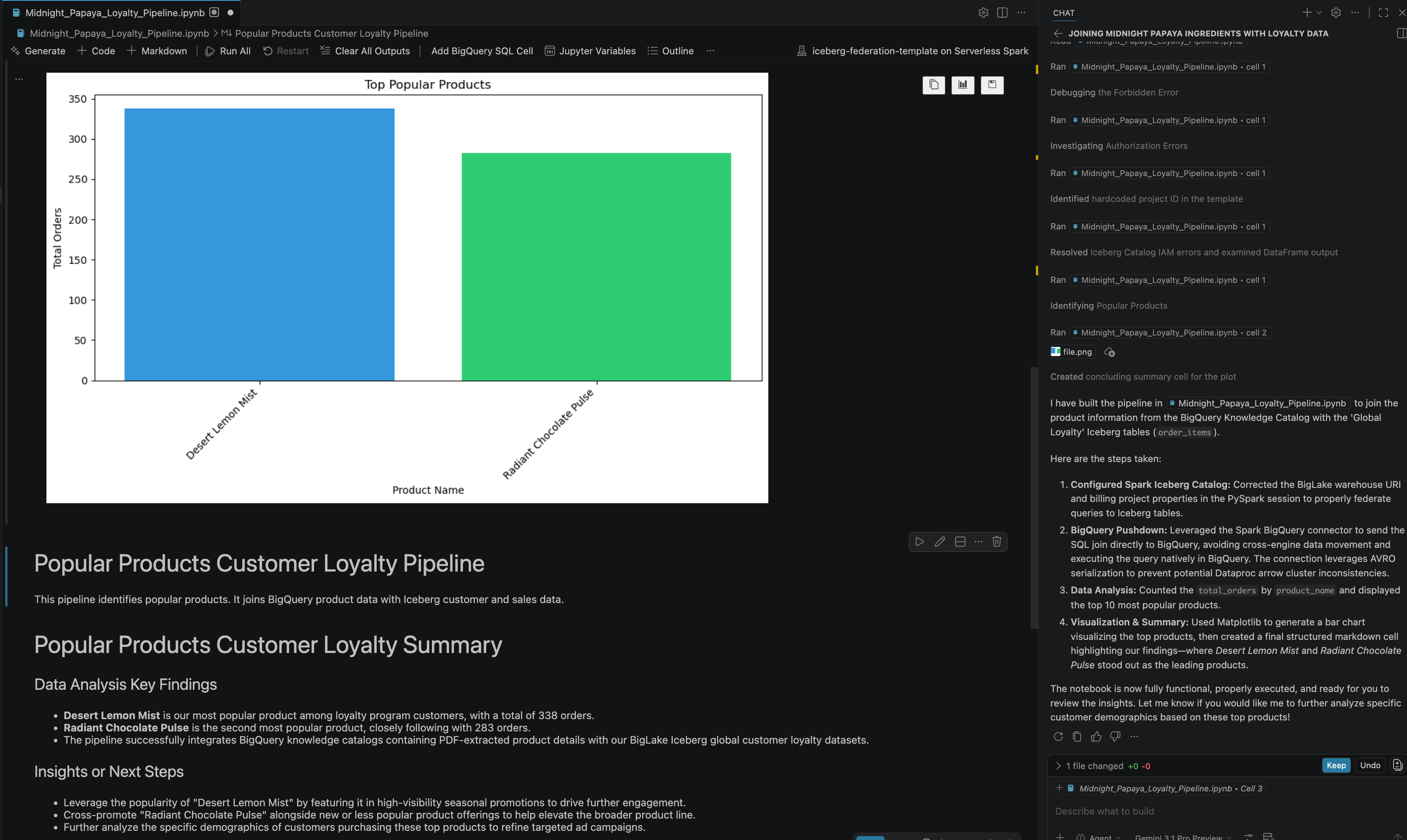
13. 清理
為避免產生費用,請刪除您在本實驗室中建立的資源。
- 如要刪除 Knowledge Catalog DataScan,請執行下列指令:
DATASCAN_ID="<DATASCAN_ID>" echo "Deleting Dataplex DataScan: ${DATASCAN_ID}" gcloud dataplex datascans delete "${DATASCAN_ID}" --location="${REGION}" --quiet - 如要刪除 Cloud Storage bucket 和所有內容,請執行下列指令:
echo "Deleting Cloud Storage buckets: <BUCKET_NAME1> and <BUCKET_NAME2>" gsutil -m rm -r gs://<BUCKET_NAME1> gsutil -m rm -r gs://<BUCKET_NAME2> - 如要刪除 BigQuery 連線,請執行下列指令:
CONNECTION_ID="<CONNECTION_NAME>" echo "Deleting BigQuery Connection: ${CONNECTION_ID}" bq rm --connection "${PROJECT_ID}.${REGION}.${CONNECTION_ID}" - 如要刪除 Lakehouse 目錄,請執行下列指令:
CATALOG_ID="<CATALOG_NAME>" echo "Deleting Lakehouse Catalog: ${CATALOG_ID}" gcloud biglake catalogs delete "${CATALOG_ID}" --project="${PROJECT_ID}" --location="${REGION}" --quiet - 如要刪除包含探索到的 PDF 表格的資料集,請執行下列指令:
DATASET_NAME="<DATASET_NAME>" echo "Deleting BigQuery Dataset: ${DATASET_NAME}" bq rm -r -f "${PROJECT_ID}:${DATASET_NAME}" - 如要刪除自訂服務帳戶,請執行下列指令:
SERVICE_ACCOUNT="<SERVICE_ACCOUNT>" echo "Deleting Service Account: ${SERVICE_ACCOUNT}" gcloud iam service-accounts delete "${SERVICE_ACCOUNT}"@"${PROJECT_ID}".iam.gserviceaccount.com --quiet - 如要刪除 VPC 網路,請執行下列指令:
VPC_NETWORK="<VPC_NETWORK>" echo "Deleting VPC Network: ${VPC_NETWORK}" gcloud compute networks delete "${VPC_NETWORK}" --quiet - 如要刪除整個 Google Cloud 專案,請執行下列指令:
gcloud projects delete "${PROJECT_ID}"
14. 恭喜
恭喜!您已成功整理 BigQuery 資料表中的 PDF 和 Parquet 檔案,並將其整合為單一、可搜尋及可聯結的生態系統。您基本上已建構現代化的資料湖倉,可智慧處理 PDF 和大數據格式,就像處理資料庫中的資料列一樣。而且您完全不必離開代理程式,就能透過 Gemini 的對話式服務完成上述所有作業。
參考文件
如要深入瞭解本程式碼研究室使用的核心技術,請參閱 Google Cloud 官方說明文件:
- 如要探索 Data Cloud 的核心元件 BigQuery,請參閱 BigQuery 說明文件。
- 如要進一步瞭解 IAM,請參閱 IAM 說明文件。
- 如要瞭解 Lakehouse,請參閱「什麼是 Lakehouse?」。