
১. ভূমিকা
এই ল্যাবে, আপনি সাধারণ চ্যাটবটের গণ্ডি পেরিয়ে একটি ডিস্ট্রিবিউটেড মাল্টি-এজেন্ট সিস্টেম তৈরি করবেন।
যদিও একটিমাত্র এলএলএম ডিগ্রি দিয়ে বিভিন্ন প্রশ্নের উত্তর দেওয়া সম্ভব, বাস্তব জগতের জটিলতার জন্য প্রায়শই বিশেষায়িত ভূমিকার প্রয়োজন হয়। আপনি আপনার ব্যাকএন্ড ইঞ্জিনিয়ারকে ইউআই (UI) ডিজাইন করতে বলেন না, এবং আপনার ডিজাইনারকে ডাটাবেস কোয়েরি অপটিমাইজ করতেও বলেন না। একইভাবে, আমরা এমন বিশেষায়িত এআই এজেন্ট তৈরি করতে পারি, যারা একটি নির্দিষ্ট কাজে মনোনিবেশ করবে এবং জটিল সমস্যা সমাধানের জন্য একে অপরের সাথে সমন্বয় করবে।
আপনি একটি কোর্স তৈরির সিস্টেম তৈরি করবেন, যার মধ্যে থাকবে:
- গবেষক প্রতিনিধি : হালনাগাদ তথ্য খোঁজার জন্য গুগল সার্চ ব্যবহার করছেন।
- বিচারক প্রতিনিধি : গবেষণার গুণমান ও সম্পূর্ণতা যাচাই করা।
- কন্টেন্ট বিল্ডার এজেন্ট : গবেষণাকে একটি কাঠামোগত কোর্সে রূপান্তর করা।
- অর্কেস্ট্রেটর এজেন্ট : এই বিশেষজ্ঞদের মধ্যে কর্মপ্রবাহ এবং যোগাযোগ পরিচালনা করা।
আপনি যা শিখবেন
- এমন একটি টুল-ব্যবহারকারী এজেন্ট (গবেষক) সংজ্ঞায়িত করুন যা ওয়েবে অনুসন্ধান করতে পারে।
- বিচারকের জন্য পাইড্যান্টিক (Pydantic) ব্যবহার করে কাঠামোগত আউটপুট বাস্তবায়ন করুন।
- এজেন্ট-টু-এজেন্ট (A2A) প্রোটোকল ব্যবহার করে রিমোট এজেন্টদের সাথে সংযোগ স্থাপন করুন।
- গবেষক ও বিচারকের মধ্যে একটি ফিডব্যাক লুপ তৈরি করতে একটি LoopAgent নির্মাণ করুন।
- ADK ব্যবহার করে ডিস্ট্রিবিউটেড সিস্টেমটি স্থানীয়ভাবে চালান।
- মাল্টি-এজেন্ট সিস্টেমটি গুগল ক্লাউড রান-এ ডেপ্লয় করুন।
- কন্টেন্ট বিল্ডার এজেন্টের জন্য ক্লাউড রান জিপিইউ-তে একটি জেমা মডেল ব্যবহার করুন।
আপনার যা যা লাগবে
- ক্রোমের মতো একটি ওয়েব ব্রাউজার
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট
২. স্থাপত্য ও অর্কেস্ট্রেশন নীতিমালা
প্রথমে, চলুন বুঝে নিই এই এজেন্টগুলো কীভাবে একসাথে কাজ করে। আমরা একটি কোর্স তৈরির পাইপলাইন তৈরি করছি।
সিস্টেম ডিজাইন
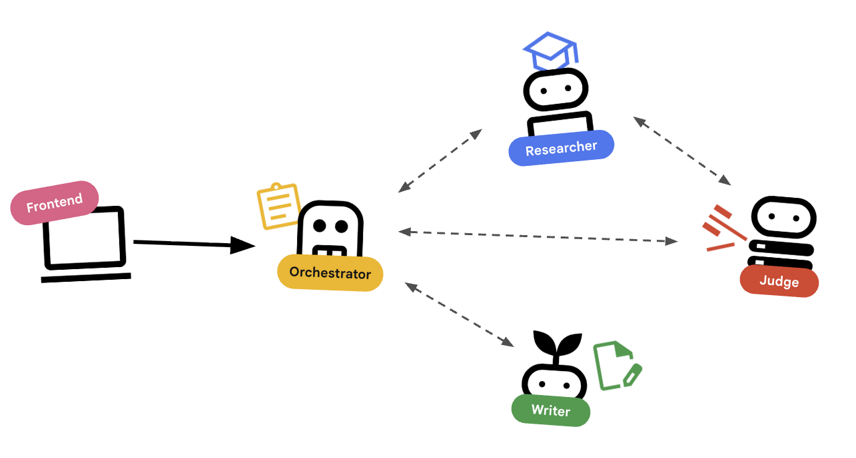
এজেন্টদের সাথে সমন্বয় সাধন
সাধারণ এজেন্টরা (যেমন রিসার্চার) কাজ করে। অর্কেস্ট্রেটর এজেন্টরা (যেমন LoopAgent বা SequentialAgent ) অন্যান্য এজেন্টদের পরিচালনা করে। তাদের নিজস্ব কোনো টুল নেই; তাদের 'টুল' হলো দায়িত্ব অর্পণ।
-
LoopAgent: এটি কোডেরwhileলুপের মতো কাজ করে। এটি একটি শর্ত পূরণ না হওয়া পর্যন্ত (বা সর্বোচ্চ পুনরাবৃত্তি না হওয়া পর্যন্ত) ধারাবাহিকভাবে এজেন্টগুলোকে বারবার চালায়। আমরা এটি রিসার্চ লুপের জন্য ব্যবহার করি।- গবেষক তথ্য খুঁজে পান।
- বিচারক এর সমালোচনা করেন।
- Judge যদি "Fail" বলে, তাহলে EscalationChecker লুপটিকে চলতে দেয়।
- যদি Judge "Pass" বলেন, তাহলে EscalationChecker লুপটি ভেঙে দেয়।
-
SequentialAgent: এটি একটি সাধারণ স্ক্রিপ্ট এক্সিকিউশনের মতো কাজ করে। এটি এজেন্টগুলোকে একের পর এক চালায়। আমরা এটি হাই-লেভেল পাইপলাইনের জন্য ব্যবহার করি।- প্রথমে, রিসার্চ লুপটি চালান (যতক্ষণ না এটি ভালো ডেটা দিয়ে শেষ হয়)।
- এরপর, কন্টেন্ট বিল্ডারটি চালান (কোর্সটি লেখার জন্য)।
এগুলোকে একত্রিত করে আমরা একটি শক্তিশালী সিস্টেম তৈরি করি যা চূড়ান্ত আউটপুট দেওয়ার আগে নিজেকে সংশোধন করতে পারে।
৩. সেটআপ
প্রজেক্ট সেটআপ
একটি গুগল ক্লাউড প্রজেক্ট তৈরি করুন
- গুগল ক্লাউড কনসোলের প্রজেক্ট সিলেক্টর পেজে, একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন ।
- আপনার ক্লাউড প্রোজেক্টের জন্য বিলিং চালু আছে কিনা তা নিশ্চিত করুন। কোনো প্রোজেক্টে বিলিং চালু আছে কিনা তা কীভাবে পরীক্ষা করবেন, তা জেনে নিন।
ক্লাউড শেল শুরু করুন
ক্লাউড শেল হলো গুগল ক্লাউডে চালিত একটি কমান্ড-লাইন পরিবেশ, যা প্রয়োজনীয় টুলস সহ আগে থেকেই লোড করা থাকে।
- Google Cloud কনসোলের শীর্ষে থাকা Activate Cloud Shell-এ ক্লিক করুন।
- ক্লাউড শেলে সংযুক্ত হওয়ার পর, আপনার প্রমাণীকরণ যাচাই করুন:
gcloud auth list - আপনার প্রজেক্টটি কনফিগার করা হয়েছে কিনা তা নিশ্চিত করুন:
gcloud config get project - আপনার প্রজেক্টটি প্রত্যাশা অনুযায়ী সেট করা না থাকলে, এটি সেট করুন:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
পরিবেশ সেটআপ
- ক্লাউড শেল খুলুন : গুগল ক্লাউড কনসোলের উপরের ডানদিকে থাকা ‘অ্যাক্টিভেট ক্লাউড শেল’ আইকনটিতে ক্লিক করুন।
স্টার্টার কোডটি নিন
- স্টার্টার রিপোজিটরিটি আপনার হোম ডিরেক্টরিতে ক্লোন করুন: আপনার হোম ডিরেক্টরিতে সরান
cd ~git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git temp-repo && cd temp-repo && git sparse-checkout set agents/multi-agent-system && cd .. && mv temp-repo/agents/multi-agent-system . && rm -rf temp-repocd multi-agent-system - এপিআই সক্রিয় করুন : প্রয়োজনীয় গুগল ক্লাউড পরিষেবাগুলি সক্রিয় করতে নিম্নলিখিত কমান্ডটি চালান:
gcloud services enable \ run.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - আপনার এডিটরে এই ফোল্ডারটি খুলুন।
cloudshell edit .
সেটআপ পরিবেশ
- এনভায়রনমেন্ট ভেরিয়েবল সেট আপ করুন। আমরা এই ভেরিয়েবলগুলো সংরক্ষণের জন্য একটি
.envফাইল তৈরি করব, যাতে আপনার সেশন সংযোগ বিচ্ছিন্ন হয়ে গেলে আপনি সহজেই সেগুলো পুনরায় লোড করতে পারেন।cat <<EOF > .env export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) export GOOGLE_CLOUD_LOCATION=europe-west4 export GOOGLE_GENAI_USE_VERTEXAI=true EOF - এনভায়রনমেন্ট ভেরিয়েবলগুলো সোর্স করুন:
source .env
৪. 🕵️ গবেষক প্রতিনিধি
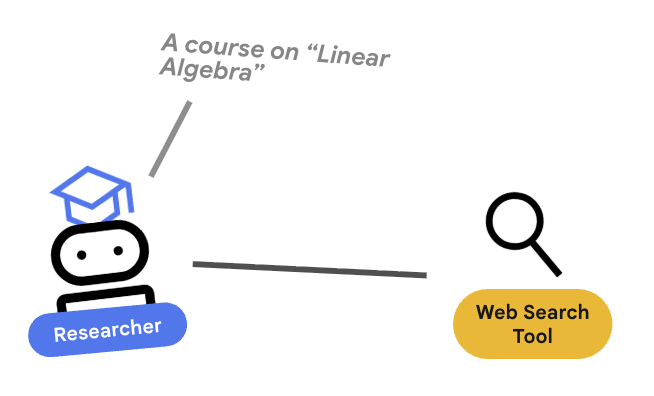
গবেষক একজন বিশেষজ্ঞ। তার একমাত্র কাজ হলো তথ্য খুঁজে বের করা। এই কাজটি করার জন্য তার একটি টুলের প্রয়োজন: গুগল সার্চ।
গবেষককে কেন আলাদা করা হয়?
গভীর বিশ্লেষণ: কেন একজন এজেন্টকেই সবকিছু করতে দেওয়া হয় না?
ছোট ও সুনির্দিষ্ট এজেন্টগুলো মূল্যায়ন এবং ডিবাগ করা সহজ। গবেষণাটি খারাপ হলে, আপনি গবেষকের প্রম্পটটি নিয়ে কাজ করেন। কোর্সের ফরম্যাটিং খারাপ হলে, আপনি কন্টেন্ট বিল্ডারটি নিয়ে কাজ করেন। একটি একক, সবকিছু-করার প্রম্পটে, একটি জিনিস ঠিক করতে গেলে প্রায়শই অন্যটি ভেঙে যায়।
- আপনি যদি ক্লাউড শেলে কাজ করেন, তাহলে ক্লাউড শেল এডিটর খোলার জন্য নিম্নলিখিত কমান্ডটি চালান:
cloudshell workspace . -
agents/researcher/agent.pyখুলুন। -
researcherএজেন্টকে সংজ্ঞায়িত করে এমন নিম্নলিখিত কোডটি পর্যালোচনা করুন:# ... existing imports ... # Define the Researcher Agent researcher = Agent( name="researcher", model=MODEL, description="Gathers information on a topic using Google Search.", instruction=""" You are an expert researcher. Your goal is to find comprehensive and accurate information on the user's topic. Use the `google_search` tool to find relevant information. Summarize your findings clearly. If you receive feedback that your research is insufficient, use the feedback to refine your next search. """, tools=[google_search], ) root_agent = researcher
মূল ধারণা: সরঞ্জাম ব্যবহার
লক্ষ্য করুন, আমরা tools=[google_search] পাস করছি। ADK এই টুলটিকে LLM-এর কাছে বর্ণনা করার জটিলতা সামলে নেয়। যখন মডেলটি মনে করে যে তার তথ্যের প্রয়োজন, তখন এটি একটি স্ট্রাকচার্ড টুল কল তৈরি করে, ADK পাইথন ফাংশন google_search এক্সিকিউট করে এবং ফলাফলটি মডেলকে ফেরত পাঠায়।
৫. ⚖️ বিচারক এজেন্ট
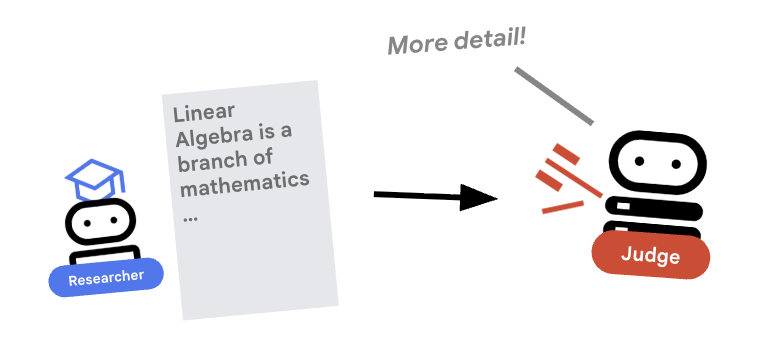
গবেষক কঠোর পরিশ্রম করেন, কিন্তু এলএলএম-রা অলস হতে পারে। কাজটি পর্যালোচনা করার জন্য আমাদের একজন বিচারক প্রয়োজন। বিচারক গবেষণাটি গ্রহণ করেন এবং একটি কাঠামোগত পাস/ফেল মূল্যায়নপত্র প্রদান করেন।
কাঠামোগত আউটপুট
গভীর বিশ্লেষণ: ওয়ার্কফ্লো স্বয়ংক্রিয় করতে আমাদের অনুমানযোগ্য আউটপুট প্রয়োজন। একটি অসংলগ্ন টেক্সট রিভিউ প্রোগ্রামগতভাবে বিশ্লেষণ করা কঠিন। পাইড্যান্টিক (Pydantic) ব্যবহার করে একটি JSON স্কিমা প্রয়োগের মাধ্যমে আমরা নিশ্চিত করি যে, জাজ (Judge) একটি বুলিয়ান pass বা fail রিটার্ন করবে, যার উপর ভিত্তি করে আমাদের কোড নির্ভরযোগ্যভাবে কাজ করতে পারবে।
-
agents/judge/agent.pyখুলুন। -
JudgeFeedbackস্কিমা এবংjudgeএজেন্টকে সংজ্ঞায়িত করে এমন নিম্নলিখিত কোডটি পর্যালোচনা করুন।# 1. Define the Schema class JudgeFeedback(BaseModel): """Structured feedback from the Judge agent.""" status: Literal["pass", "fail"] = Field( description="Whether the research is sufficient ('pass') or needs more work ('fail')." ) feedback: str = Field( description="Detailed feedback on what is missing. If 'pass', a brief confirmation." ) # 2. Define the Agent judge = Agent( name="judge", model=MODEL, description="Evaluates research findings for completeness and accuracy.", instruction=""" You are a strict editor. Evaluate the 'research_findings' against the user's original request. If the findings are missing key info, return status='fail'. If they are comprehensive, return status='pass'. """, output_schema=JudgeFeedback, # Disallow delegation because it should only output the schema disallow_transfer_to_parent=True, disallow_transfer_to_peers=True, ) root_agent = judge
মূল ধারণা: এজেন্টের আচরণ সীমাবদ্ধ করা
আমরা disallow_transfer_to_parent=True এবং disallow_transfer_to_peers=True সেট করেছি। এটি Judge-কে শুধুমাত্র স্ট্রাকচার্ড JudgeFeedback ফেরত দিতে বাধ্য করে। এটি ব্যবহারকারীর সাথে "চ্যাট" করবে নাকি অন্য কোনো এজেন্টের কাছে দায়িত্ব অর্পণ করবে, সেই সিদ্ধান্ত নিতে পারে না। এটি আমাদের লজিক ফ্লো-তে এটিকে একটি ডিটারমিনিস্টিক কম্পোনেন্টে পরিণত করে।
৬. ✍️ কন্টেন্ট বিল্ডার এজেন্ট
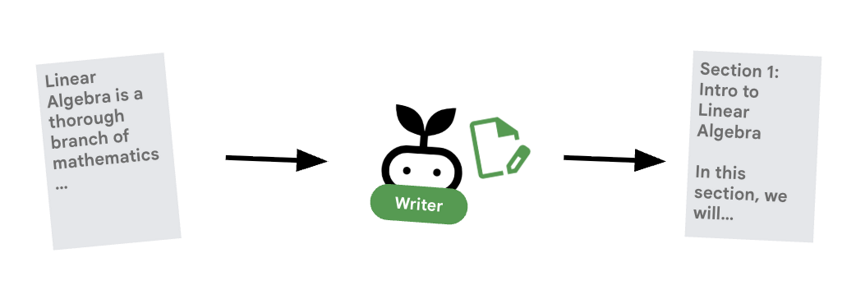
কন্টেন্ট বিল্ডার হলো সৃজনশীল লেখক। এটি অনুমোদিত গবেষণাকে একটি কোর্সে রূপান্তরিত করে। এটি ক্লাউড রান দ্বারা পরিচালিত একটি জেমা মডেল ব্যবহার করে।
চলুন প্রথমে ক্লাউড রান পরিষেবাটি দেখি যা মডেলটি হোস্ট করে।
-
ollama_backend/Dockerfileখুলুন - এখানে আপনি দেখতে পারেন কিভাবে Dockerfile-টি একটি Ollama ইমেজ ব্যবহার করে, পোর্ট 8080-এ অনুরোধ শোনে এবং অনুরোধ করা মডেলটিকে একটি /model ফোল্ডারে সংরক্ষণ করে।
FROM ollama/ollama:latest # Listen on all interfaces, port 8080 (Cloud Run default) ENV OLLAMA_HOST 0.0.0.0:8080 # Store model weight files in /models ENV OLLAMA_MODELS /models
⚙️ স্থাপন করার সময়, আপনাকে নিম্নলিখিত কনফিগারেশনগুলো সেট করতে হবে:
- জিপিইউ : ইনফারেন্স ওয়ার্কলোডের জন্য এর চমৎকার মূল্য-কর্মক্ষমতা অনুপাতের কারণে এনভিডিয়া এল৪ (NVIDIA L4) বেছে নেওয়া হয়েছে। এল৪ (L4) ২৪ জিবি জিপিইউ মেমরি এবং অপ্টিমাইজড টেনসর অপারেশন প্রদান করে, যা এটিকে জেমার (Gemma) মতো ২৭০ মিলিয়ন প্যারামিটার মডেলের জন্য আদর্শ করে তোলে।
- মেমরি : মডেল লোডিং, CUDA অপারেশন এবং Ollama-র মেমরি ম্যানেজমেন্ট পরিচালনার জন্য ১৬ জিবি সিস্টেম মেমরি।
- সিপিইউ : সর্বোত্তম আই/ও হ্যান্ডলিং এবং প্রিপ্রসেসিং কাজের জন্য ৮টি কোর
- কনকারেন্সি : প্রতি ইনস্ট্যান্সে ৪টি অনুরোধ জিপিইউ মেমরি ব্যবহারের সাথে থ্রুপুটের ভারসাম্য বজায় রাখে।
- টাইমআউট : ৬০০ সেকেন্ড, যা প্রাথমিক মডেল লোডিং এবং কন্টেইনার চালু করার জন্য ব্যবহৃত হয়।
এবার আমরা জেমা মডেল ব্যবহারকারী কন্টেন্ট বিল্ডার এজেন্টটি দেখব।
-
agents/content_builder/agent.pyখুলুন। -
content_builderএজেন্টকে সংজ্ঞায়িত করে এমন নিম্নলিখিত কোডটি পর্যালোচনা করুন।
# the `ollama-gemma-gpu` Cloud Run service URL which hosts the Gemma model
target_url = os.environ.get("OLLAMA_API_BASE")
# ... existing code ...
# (Note: We use 'ollama/gemma3:270m' to align with ADK's expected prefix)
gemma_model_name = os.environ.get("GEMMA_MODEL_NAME", "gemma3:270m")
model = LiteLlm(
model=f"ollama_chat/{gemma_model_name}",
api_base=target_url
)
# 5. Define the Agent
content_builder = Agent(
name="content_builder",
model=model,
description="Transforms research findings into a structured course.",
instruction="""
You are an expert course creator.
Take the approved 'research_findings' and transform them into a well-structured, engaging course module.
**Formatting Rules:**
1. Start with a main title using a single `#` (H1).
2. Use `##` (H2) for main section headings. These will be used for the Table of Contents.
3. Use `###` (H3) for sub-sections within main sections.
4. Use bullet points and clear paragraphs.
5. Maintain a professional but engaging tone.
**Structure Requirements:**
- Begin with a brief Introduction section explaining what the learner will gain.
- Organize content into 3-5 main sections with clear headings.
- Include Key Takeaways at the end as a bulleted summary.
- Keep each section focused and concise.
Ensure the content directly addresses the user's original request.
Do not include any preamble or explanation outside the course content itself.
""",
)
root_agent = content_builder
মূল ধারণা: প্রসঙ্গ প্রচার
আপনার মনে প্রশ্ন জাগতে পারে: "কন্টেন্ট বিল্ডার কীভাবে জানে যে রিসার্চার কী খুঁজে পেয়েছে?" ADK-তে, একটি পাইপলাইনের এজেন্টরা একটি session.state শেয়ার করে। পরবর্তীতে, অর্কেস্ট্রেটরে, আমরা রিসার্চার এবং জাজকে তাদের আউটপুট এই শেয়ার করা স্টেটে সংরক্ষণ করার জন্য কনফিগার করব। কন্টেন্ট বিল্ডারের প্রম্পট কার্যকরভাবে এই হিস্টোরিতে অ্যাক্সেস পায়।
৭. 🎻 দ্য অর্কেস্ট্রেটর
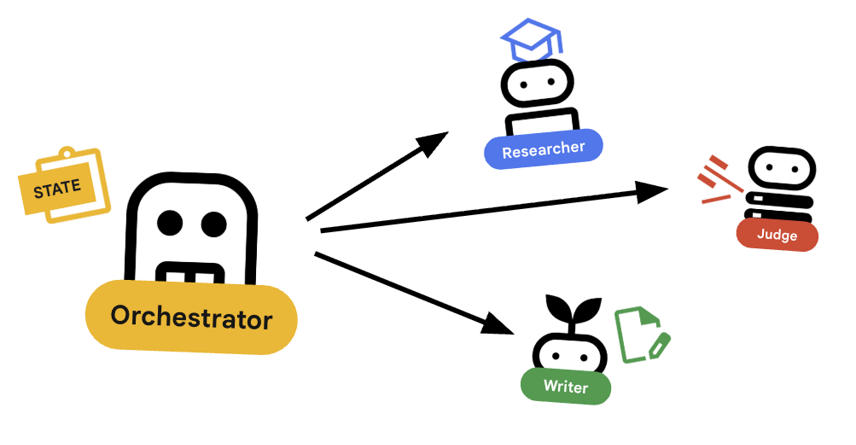
অর্কেস্ট্রেটর আমাদের একাধিক এজেন্টের দলের ব্যবস্থাপক। বিশেষজ্ঞ এজেন্টরা (গবেষক, বিচারক, কন্টেন্ট নির্মাতা) নির্দিষ্ট কাজ সম্পাদন করলেও, অর্কেস্ট্রেটরের কাজ হলো কর্মপ্রবাহের সমন্বয় সাধন করা এবং তাদের মধ্যে তথ্যের সঠিক প্রবাহ নিশ্চিত করা।
🌐 স্থাপত্য: এজেন্ট-টু-এজেন্ট (A2A)
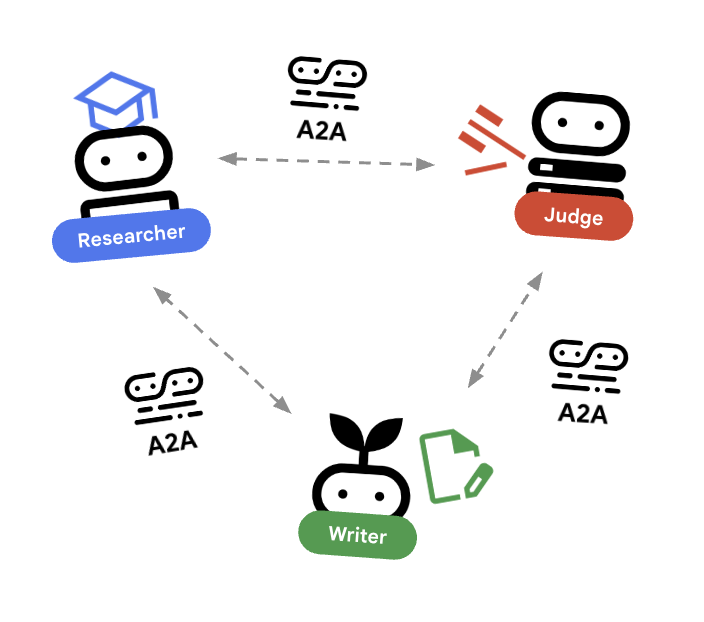
এই ল্যাবে আমরা একটি ডিস্ট্রিবিউটেড সিস্টেম তৈরি করছি। সমস্ত এজেন্টকে একটিমাত্র পাইথন প্রসেসে চালানোর পরিবর্তে, আমরা সেগুলোকে স্বাধীন মাইক্রোসার্ভিস হিসেবে ডেপ্লয় করি। এর ফলে প্রতিটি এজেন্ট স্বাধীনভাবে স্কেল করতে পারে এবং পুরো সিস্টেম ক্র্যাশ না করেই ব্যর্থ হতে পারে।
এটি সম্ভব করার জন্য, আমরা এজেন্ট-টু-এজেন্ট (A2A) প্রোটোকল ব্যবহার করি।
A2A প্রোটোকল
বিস্তারিত: একটি প্রোডাকশন সিস্টেমে, এজেন্টরা বিভিন্ন সার্ভারে (বা এমনকি বিভিন্ন ক্লাউডে) চলে। A2A প্রোটোকল তাদের জন্য HTTP-এর মাধ্যমে একে অপরকে খুঁজে বের করা এবং যোগাযোগ করার একটি আদর্শ উপায় তৈরি করে। RemoteA2aAgent হলো এই প্রোটোকলের জন্য ADK ক্লায়েন্ট।
-
agents/orchestrator/agent.pyখুলুন। - সংযোগগুলি সংজ্ঞায়িত করে এমন নিম্নলিখিত কোডটি পর্যালোচনা করুন।
# ... existing code ... # Connect to the Researcher (Localhost port 8001) researcher_url = os.environ.get("RESEARCHER_AGENT_CARD_URL", "http://localhost:8001/a2a/agent/.well-known/agent-card.json") researcher = RemoteA2aAgent( name="researcher", agent_card=researcher_url, description="Gathers information using Google Search.", # IMPORTANT: Save the output to state for the Judge to see after_agent_callback=create_save_output_callback("research_findings"), # IMPORTANT: Use authenticated client for communication httpx_client=create_authenticated_client(researcher_url) ) # Connect to the Judge (Localhost port 8002) judge_url = os.environ.get("JUDGE_AGENT_CARD_URL", "http://localhost:8002/a2a/agent/.well-known/agent-card.json") judge = RemoteA2aAgent( name="judge", agent_card=judge_url, description="Evaluates research.", after_agent_callback=create_save_output_callback("judge_feedback"), httpx_client=create_authenticated_client(judge_url) ) # Content Builder (Localhost port 8003) content_builder_url = os.environ.get("CONTENT_BUILDER_AGENT_CARD_URL", "http://localhost:8003/a2a/agent/.well-known/agent-card.json") content_builder = RemoteA2aAgent( name="content_builder", agent_card=content_builder_url, description="Builds the course.", httpx_client=create_authenticated_client(content_builder_url) )
৮. 🛑 এস্কেলেশন চেকার
একটি লুপ থামার জন্য একটি উপায় প্রয়োজন। যদি জাজ "পাস" বলেন, আমরা অবিলম্বে লুপ থেকে বেরিয়ে কন্টেন্ট বিল্ডারে যেতে চাই।
BaseAgent সহ কাস্টম লজিক
গভীর বিশ্লেষণ: সব এজেন্ট LLM ব্যবহার করে না। কখনও কখনও আপনার সাধারণ পাইথন লজিকের প্রয়োজন হয়। BaseAgent আপনাকে এমন একটি এজেন্ট সংজ্ঞায়িত করার সুযোগ দেয় যা শুধু কোড চালায়। এক্ষেত্রে, আমরা সেশনের অবস্থা পরীক্ষা করি এবং LoopAgent থামার সংকেত দিতে EventActions(escalate=True) ব্যবহার করি।
- এখনও
agents/orchestrator/agent.pyফাইলে আছে। - নিম্নলিখিত কোডটি বিচারকের মতামত পর্যালোচনা করে এবং প্রস্তুত হলে পরবর্তী ধাপে অগ্রসর হয়।
class EscalationChecker(BaseAgent): """Checks the judge's feedback and escalates (breaks the loop) if it passed.""" async def _run_async_impl( self, ctx: InvocationContext ) -> AsyncGenerator[Event, None]: # Retrieve the feedback saved by the Judge feedback = ctx.session.state.get("judge_feedback") print(f"[EscalationChecker] Feedback: {feedback}") # Check for 'pass' status is_pass = False if isinstance(feedback, dict) and feedback.get("status") == "pass": is_pass = True # Handle string fallback if JSON parsing failed elif isinstance(feedback, str) and '"status": "pass"' in feedback: is_pass = True if is_pass: # 'escalate=True' tells the parent LoopAgent to stop looping yield Event(author=self.name, actions=EventActions(escalate=True)) else: # Continue the loop yield Event(author=self.name) escalation_checker = EscalationChecker(name="escalation_checker")
মূল ধারণা: ইভেন্টের মাধ্যমে নিয়ন্ত্রণ প্রবাহ
এজেন্টরা শুধু টেক্সটের মাধ্যমেই নয়, ইভেন্টের মাধ্যমেও যোগাযোগ করে। escalate=True সহ একটি ইভেন্ট ইয়েল্ড করার মাধ্যমে, এই এজেন্ট তার প্যারেন্টের ( LoopAgent ) কাছে একটি সিগন্যাল পাঠায়। LoopAgent এই সিগন্যালটি গ্রহণ করে লুপটি বন্ধ করে দেওয়ার জন্য প্রোগ্রাম করা থাকে।
৯. 🔁 গবেষণা চক্র
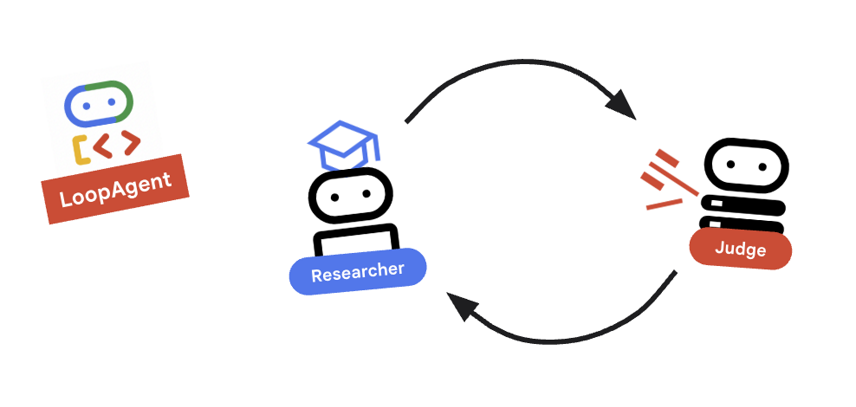
আমাদের একটি ফিডব্যাক লুপ প্রয়োজন: গবেষণা -> বিচার -> (ব্যর্থতা) -> গবেষণা -> ...
-
agents/orchestrator/agent.pyতে। - নিম্নলিখিত কোডটি কীভাবে
research_loopসংজ্ঞা নির্ধারণ করে তা পর্যালোচনা করুন।research_loop = LoopAgent( name="research_loop", description="Iteratively researches and judges until quality standards are met.", sub_agents=[researcher, judge, escalation_checker], max_iterations=3, )
মূল ধারণা: লুপএজেন্ট
LoopAgent তার sub_agents ক্রমানুসারে আবর্তন করে।
-
researcher: তথ্য খুঁজে বের করেন। -
judge: তথ্য মূল্যায়ন করেন। -
escalation_checker:yield Event(escalate=True)কিনা তা নির্ধারণ করে। যদিescalate=Trueঘটে, তাহলে লুপটি সময়ের আগেই থেমে যায়। অন্যথায়, এটি researcher থেকে পুনরায় শুরু হয় (max_iterationsপর্যন্ত)।
১০. 🔗 চূড়ান্ত পাইপলাইন
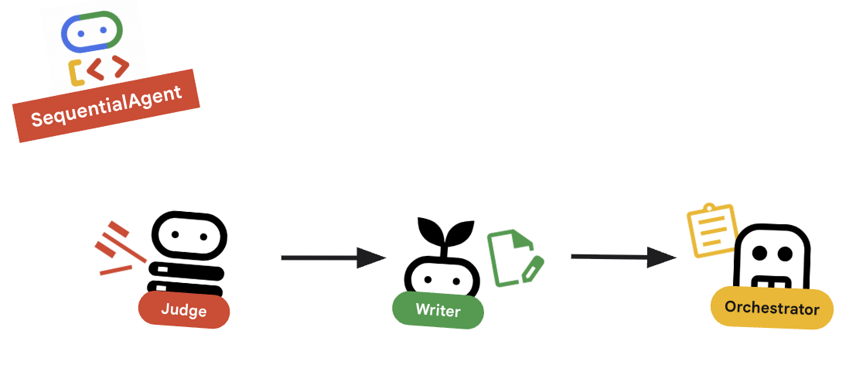
সবকিছু একসাথে মিলিয়ে...
-
agents/orchestrator/agent.pyতে। - ফাইলের একদম নিচে
root_agentকীভাবে সংজ্ঞায়িত করা হয়েছে তা পর্যালোচনা করুন।root_agent = SequentialAgent( name="course_creation_pipeline", description="A pipeline that researches a topic and then builds a course from it.", sub_agents=[research_loop, content_builder], )
মূল ধারণা: স্তরক্রমিক গঠন
লক্ষ্য করুন যে research_loop নিজেই একটি এজেন্ট (একটি LoopAgent )। আমরা এটিকে SequentialAgent এর অন্য যেকোনো সাব-এজেন্টের মতোই বিবেচনা করি। এই কম্পোজেবিলিটি আপনাকে সাধারণ প্যাটার্নগুলোকে নেস্ট করার মাধ্যমে জটিল লজিক তৈরি করতে সাহায্য করে (যেমন সিকোয়েন্সের ভেতরে লুপ, রাউটারের ভেতরে সিকোয়েন্স ইত্যাদি)।
১১. 🚀 ক্লাউড রানে ডেপ্লয় করুন
আমরা ক্লাউড রান-এ প্রতিটি এজেন্টকে একটি পৃথক পরিষেবা হিসাবে স্থাপন করব, যার মধ্যে কোর্স ক্রিয়েটর UI-এর জন্য একটি ক্লাউড রান পরিষেবা এবং জেমা মডেলের জন্য GPU ব্যবহারকারী একটি ক্লাউড রান পরিষেবা অন্তর্ভুক্ত থাকবে।
ডেপ্লয়মেন্ট কনফিগারেশন বোঝা
ক্লাউড রান-এ এজেন্ট স্থাপন করার সময়, আমরা তাদের আচরণ ও সংযোগ কনফিগার করার জন্য বেশ কিছু এনভায়রনমেন্ট ভেরিয়েবল পাস করি:
-
GOOGLE_CLOUD_PROJECT: এটি নিশ্চিত করে যে এজেন্ট লগিং এবং ভার্টেক্স এআই কলের জন্য সঠিক গুগল ক্লাউড প্রজেক্ট ব্যবহার করছে। -
GOOGLE_GENAI_USE_VERTEXAI: এজেন্ট ফ্রেমওয়ার্ককে (ADK) নির্দেশ দেয় যেন এটি সরাসরি জেমিনি এপিআই (Gemini APIs) কল করার পরিবর্তে মডেল ইনফারেন্সের জন্য ভার্টেক্স এআই (Vertex AI) ব্যবহার করে। -
[AGENT]_AGENT_CARD_URL: এটি অর্কেস্ট্রেটরের জন্য অত্যন্ত গুরুত্বপূর্ণ। এটি অর্কেস্ট্রেটরকে বলে দেয় যে রিমোট এজেন্টদের কোথায় খুঁজে পাওয়া যাবে। এটিকে ডেপ্লয় করা ক্লাউড রান ইউআরএল-এ (বিশেষত এজেন্ট কার্ড পাথে) সেট করার মাধ্যমে, আমরা অর্কেস্ট্রেটরকে ইন্টারনেটের মাধ্যমে রিসার্চার, জাজ এবং কন্টেন্ট বিল্ডারকে খুঁজে বের করতে ও তাদের সাথে যোগাযোগ করতে সক্ষম করি।
ক্লাউড রান পরিষেবাগুলিতে সমস্ত এজেন্ট স্থাপন করতে, নিম্নলিখিত স্ক্রিপ্টটি চালান।
প্রথমে নিশ্চিত করুন যে স্ক্রিপ্টটি নির্বাহযোগ্য।
chmod u+x ~/multi-agent-system/deploy.sh
দ্রষ্টব্য: এটি চলতে কয়েক মিনিট সময় লাগবে, কারণ প্রতিটি পরিষেবা ক্রমানুসারে স্থাপন করা হয়।
~/multi-agent-system/deploy.sh
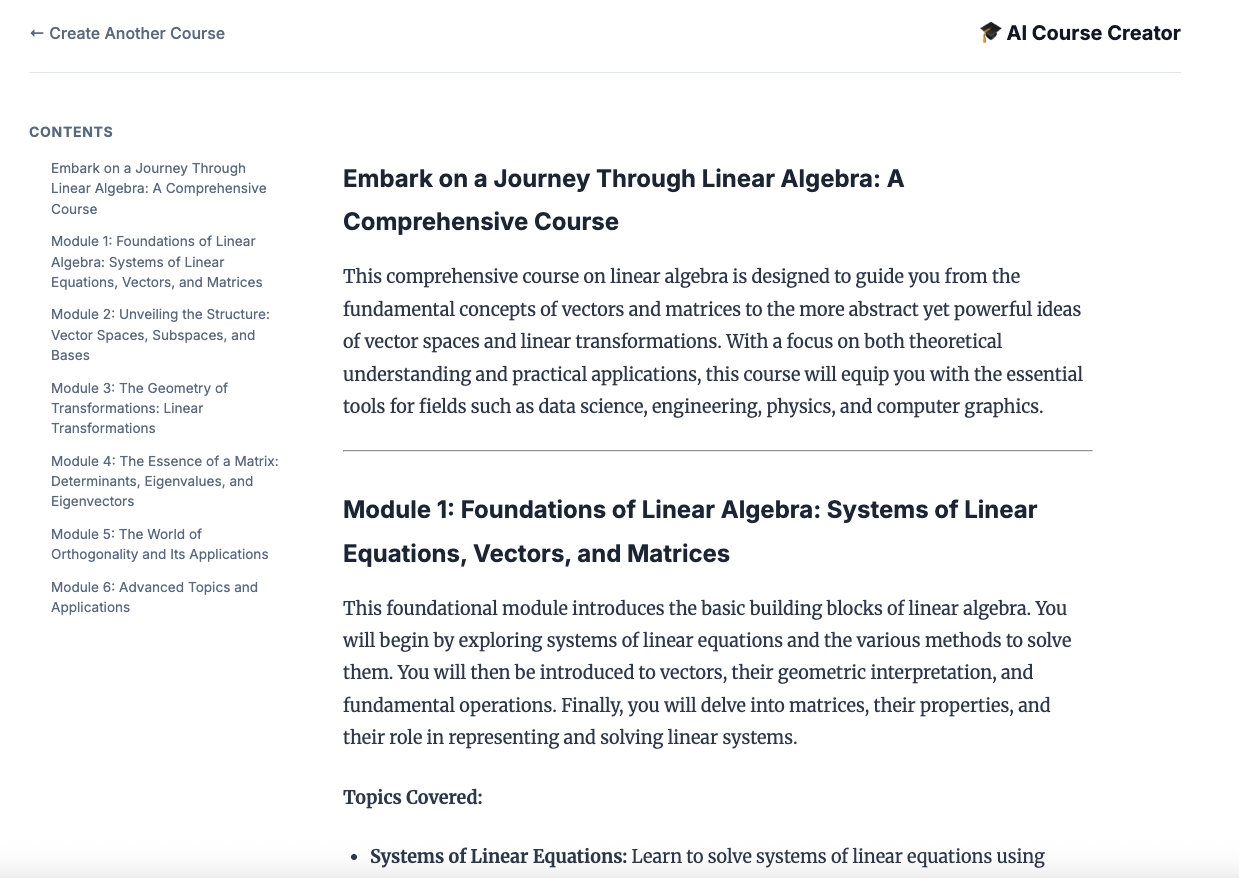
১২. একটি কোর্স তৈরি করুন!
কোর্স ক্রিয়েটর ওয়েবসাইটটি খুলুন। কোর্স ক্রিয়েটর ক্লাউড রান সার্ভিসটি হলো স্ক্রিপ্ট থেকে ডেপ্লয় করা সর্বশেষ সার্ভিস। আপনি কোর্স ক্রিয়েটরের URL-টি https://course-creator- হিসেবে শনাক্ত করতে পারবেন। https://course-creator- , যেটি ডিপ্লয়মেন্ট স্ক্রিপ্টের চূড়ান্ত আউটপুট লাইন হওয়া উচিত।
এবং একটি কোর্সের ধারণা টাইপ করুন, যেমন "রৈখিক বীজগণিত"।
আপনার এজেন্টরা আপনার কোর্স নিয়ে কাজ শুরু করবে।
১৩. পরিষ্কার করা
এই কোডল্যাবে ব্যবহৃত রিসোর্সগুলির জন্য আপনার গুগল ক্লাউড অ্যাকাউন্টে চার্জ হওয়া এড়াতে, আপনার সার্ভিস এবং কন্টেইনার ইমেজগুলি ডিলিট করতে এই ধাপগুলি অনুসরণ করুন।
১. ক্লাউড রান পরিষেবাগুলি মুছে ফেলুন
পরিষ্কার করার সবচেয়ে কার্যকর উপায় হলো ক্লাউড রানে ডেপ্লয় করা সার্ভিসগুলো ডিলিট করে দেওয়া।
# Delete the main agent and app services
gcloud run services delete researcher content-builder judge orchestrator course-creator \
--region $REGION --quiet
# Delete the GPU backend (Ollama)
gcloud run services delete ollama-gemma-gpu \
--region $OLLAMA_REGION --quiet
২. আর্টিফ্যাক্ট রেজিস্ট্রি ইমেজগুলো মুছে ফেলুন
যখন আপনি ডিপ্লয় করার জন্য --source ফ্ল্যাগটি ব্যবহার করেছিলেন, তখন গুগল ক্লাউড আপনার কন্টেইনার ইমেজগুলো সংরক্ষণ করার জন্য আর্টিফ্যাক্ট রেজিস্ট্রি-তে একটি রিপোজিটরি তৈরি করেছিল। এগুলো অপসারণ করতে এবং স্টোরেজ খরচ বাঁচাতে, রিপোজিটরিটি ডিলিট করে দিন:
gcloud artifacts repositories delete cloud-run-source-deploy --location us-east4 --quiet
৩. স্থানীয় ফাইল এবং পরিবেশ মুছে ফেলুন
আপনার ক্লাউড শেল পরিবেশ পরিষ্কার রাখতে, প্রজেক্ট ফোল্ডার এবং যেকোনো স্থানীয় কনফিগারেশন মুছে ফেলুন:
cd ~
rm -rf multi-agent-system
৪. (ঐচ্ছিক) প্রজেক্টটি মুছে ফেলুন
আপনি যদি শুধুমাত্র এই কোডল্যাবের জন্য একটি প্রজেক্ট তৈরি করে থাকেন, তাহলে ম্যানেজ রিসোর্সেস পেজ- এর মাধ্যমে প্রজেক্টটি বন্ধ করে দিয়ে আর কোনো বিলিং হওয়া নিশ্চিত করতে পারেন।
১৪. অভিনন্দন!
আপনি সফলভাবে একটি প্রোডাকশন-রেডি, ডিস্ট্রিবিউটেড মাল্টি-এজেন্ট সিস্টেম তৈরি এবং স্থাপন করেছেন।
আপনি যা অর্জন করেছেন
- জটিল কাজকে খণ্ডিত করা : একটি বিশাল নির্দেশনার পরিবর্তে, আমরা কাজটিকে বিশেষায়িত ভূমিকায় (গবেষক, বিচারক, বিষয়বস্তু নির্মাতা) ভাগ করেছি।
- বাস্তবায়িত গুণমান নিয়ন্ত্রণ : শুধুমাত্র উচ্চ-মানের তথ্যই যেন চূড়ান্ত ধাপে পৌঁছায়, তা নিশ্চিত করতে আমরা একটি
LoopAgentএবং একটি কাঠামোগতJudgeব্যবহার করেছি। - প্রোডাকশনের জন্য নির্মিত : এজেন্ট-টু-এজেন্ট (A2A) প্রোটোকল এবং ক্লাউড রান ব্যবহার করে, আমরা এমন একটি সিস্টেম তৈরি করেছি যেখানে প্রতিটি এজেন্ট একটি স্বাধীন, স্কেলেবল মাইক্রোসার্ভিস। একটিমাত্র পাইথন স্ক্রিপ্টে সবকিছু চালানোর চেয়ে এটি অনেক বেশি শক্তিশালী।
- অর্কেস্ট্রেশন : আমরা সুস্পষ্ট নিয়ন্ত্রণ প্রবাহের ধরণ নির্ধারণ করতে
SequentialAgentএবংLoopAgentব্যবহার করেছি। ক্লাউড রান জিপিইউ : একটি জেমা মডেল ক্লাউড রান জিপিইউ-তে স্থাপন করা হয়েছে।