
1. Einführung
In diesem Lab erstellen Sie ein verteiltes Multi-Agenten-System, das über einfache Chatbots hinausgeht.
Ein einzelnes LLM kann zwar Fragen beantworten, aber die Komplexität der realen Welt erfordert oft spezielle Rollen. Sie bitten Ihren Backend-Entwickler nicht, die Benutzeroberfläche zu gestalten, und Sie bitten Ihren Designer nicht, Datenbankabfragen zu optimieren. Ebenso können wir spezialisierte KI-Agenten erstellen, die sich auf eine Aufgabe konzentrieren und sich gegenseitig koordinieren, um komplexe Probleme zu lösen.
Sie erstellen ein System zur Kurserstellung, das aus Folgendem besteht:
- Recherche-Agent: Nutzt google_search, um aktuelle Informationen zu finden.
- Judge Agent: Er kritisiert die Recherche hinsichtlich Qualität und Vollständigkeit.
- Content Builder-Agent: Rechercheergebnisse in einen strukturierten Kurs umwandeln.
- Orchestrator-Agent: Er verwaltet den Workflow und die Kommunikation zwischen diesen Spezialisten.
Lerninhalte
- Definieren Sie einen Agenten, der Tools verwendet (Researcher), mit dem im Web gesucht werden kann.
- Implementieren Sie eine strukturierte Ausgabe mit Pydantic für den Judge.
- Mit dem Agent-zu-Agent-Protokoll (A2A) eine Verbindung zu Remote-Agenten herstellen.
- Erstellen Sie einen LoopAgent, um eine Feedback-Schleife zwischen dem Rechercheur und dem Richter zu erstellen.
- Führen Sie das verteilte System lokal mit dem ADK aus.
- Stellen Sie das Multi-Agenten-System in Google Cloud Run bereit.
- Verwenden Sie ein Gemma-Modell auf einer Cloud Run-GPU für den Content Builder-Agenten.
Voraussetzungen
- Ein Webbrowser wie Chrome
- Ein Google Cloud-Projekt mit aktivierter Abrechnungsfunktion
2. Prinzipien für Architektur und Orchestrierung
Sehen wir uns zuerst an, wie diese Agenten zusammenarbeiten. Wir entwickeln eine Pipeline zur Kurserstellung.
Systemdesign
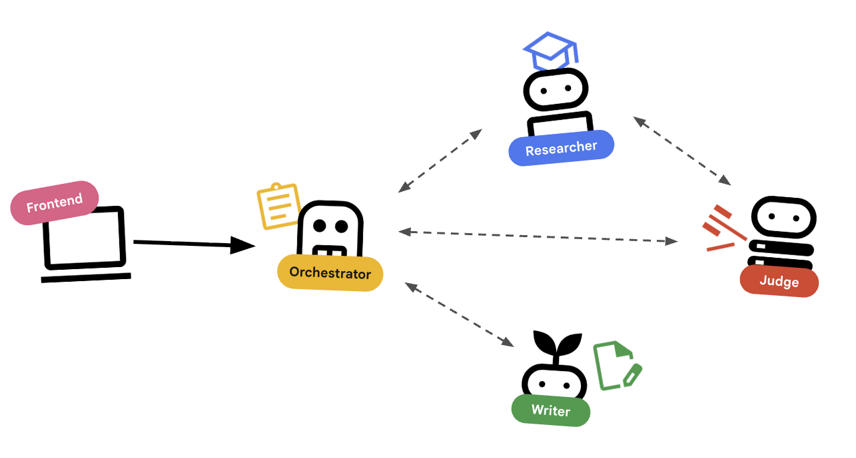
Orchestrierung mit Agents
Standard-Agents wie „Researcher“ funktionieren. Orchestrator-Agents (z. B. LoopAgent oder SequentialAgent) verwalten andere Agents. Sie haben keine eigenen Tools. Ihr „Tool“ ist die Delegation.
LoopAgent: Dies entspricht einerwhile-Schleife im Code. Es wird eine Sequenz von Agenten wiederholt ausgeführt, bis eine Bedingung erfüllt ist oder die maximale Anzahl von Iterationen erreicht wurde. Wir verwenden diese für den Recherchezyklus:- Researcher findet Informationen.
- Richter kritisieren sie.
- Wenn Judge „Fail“ zurückgibt, lässt EscalationChecker die Schleife weiterlaufen.
- Wenn Judge „Bestanden“ zurückgibt, beendet EscalationChecker die Schleife.
SequentialAgent: Dies entspricht einer standardmäßigen Skriptausführung. KI-Agenten werden hierbei nacheinander ausgeführt. Wir verwenden diese für die Pipeline auf hoher Ebene:- Führen Sie zuerst den Research Loop aus, bis er mit guten Daten abgeschlossen ist.
- Führen Sie dann Content Builder aus, um den Kurs zu schreiben.
Durch die Kombination dieser beiden Ansätze entsteht ein robustes System, das sich selbst korrigieren kann, bevor die endgültige Ausgabe generiert wird.
3. Einrichtung
Projekt einrichten
Google Cloud-Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
Cloud Shell starten
Cloud Shell ist eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird und mit den erforderlichen Tools vorinstalliert ist.
- Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren.
- Prüfen Sie nach der Verbindung mit Cloud Shell Ihre Authentifizierung:
gcloud auth list - Prüfen Sie, ob Ihr Projekt konfiguriert ist:
gcloud config get project - Wenn Ihr Projekt nicht wie erwartet festgelegt ist, legen Sie es fest:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Umgebung einrichten
- Cloud Shell öffnen: Klicken Sie rechts oben in der Google Cloud Console auf das Symbol Cloud Shell aktivieren.
Starter-Code abrufen
- Klonen Sie das Starter-Repository in Ihr Basisverzeichnis:
cd ~git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git temp-repo && cd temp-repo && git sparse-checkout set agents/multi-agent-system && cd .. && mv temp-repo/agents/multi-agent-system . && rm -rf temp-repocd multi-agent-system - APIs aktivieren: Führen Sie den folgenden Befehl aus, um die erforderlichen Google Cloud-Dienste zu aktivieren:
gcloud services enable \ run.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - Öffnen Sie diesen Ordner in Ihrem Editor.
cloudshell edit .
Umgebung einrichten
- Umgebungsvariablen einrichten: Wir erstellen eine
.env-Datei zum Speichern dieser Variablen, damit Sie sie bei einer Trennung der Verbindung problemlos neu laden können.cat <<EOF > .env export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) export GOOGLE_CLOUD_LOCATION=europe-west4 export GOOGLE_GENAI_USE_VERTEXAI=true EOF - Quellen Sie die Umgebungsvariablen:
source .env
4. 🕵️ Der Recherche-Agent
Der Researcher ist ein Spezialist. Seine einzige Aufgabe ist es, Informationen zu finden. Dazu benötigt sie Zugriff auf ein Tool: die Google Suche.
Warum wird der Researcher separat angeboten?
Deep Dive:Warum gibt es nicht nur einen Agenten, der alles erledigt?
Kleine, fokussierte Agents lassen sich leichter bewerten und debuggen. Wenn die Recherche schlecht ist, wiederholen Sie den Prompt des Researchers. Wenn die Kursformatierung schlecht ist, können Sie den Content Builder verwenden, um sie zu verbessern. Bei einem monolithischen „All-in-One“-Prompt führt die Behebung eines Problems oft dazu, dass ein anderes Problem entsteht.
- Wenn Sie in Cloud Shell arbeiten, führen Sie den folgenden Befehl aus, um den Cloud Shell-Editor zu öffnen:
cloudshell workspace . - Öffnen Sie
agents/researcher/agent.py. - Sehen Sie sich den folgenden Code an, mit dem der
researcher-Agent definiert wird:# ... existing imports ... # Define the Researcher Agent researcher = Agent( name="researcher", model=MODEL, description="Gathers information on a topic using Google Search.", instruction=""" You are an expert researcher. Your goal is to find comprehensive and accurate information on the user's topic. Use the `google_search` tool to find relevant information. Summarize your findings clearly. If you receive feedback that your research is insufficient, use the feedback to refine your next search. """, tools=[google_search], ) root_agent = researcher
Schlüsselkonzept: Tool-Nutzung
Wir übergeben tools=[google_search]. Das ADK übernimmt die Komplexität der Beschreibung dieses Tools für das LLM. Wenn das Modell entscheidet, dass es Informationen benötigt, wird ein strukturierter Tool-Aufruf generiert. Das ADK führt die Python-Funktion google_search aus und gibt das Ergebnis an das Modell zurück.
5. ⚖️ Der Judge-Agent
Der Researcher arbeitet hart, aber LLMs können faul sein. Wir benötigen einen Judge, der die Arbeit prüft. Der Judge akzeptiert die Recherche und gibt eine strukturierte Bewertung mit „Bestanden“ oder „Nicht bestanden“ zurück.
Strukturierte Ausgabe
Weitere Informationen:Um Workflows zu automatisieren, benötigen wir vorhersehbare Ausgaben. Ein unstrukturierter Rezensionstext lässt sich programmatisch nur schwer parsen. Durch die Erzwingung eines JSON-Schemas (mit Pydantic) wird sichergestellt, dass der Judge einen booleschen Wert pass oder fail zurückgibt, auf den unser Code zuverlässig reagieren kann.
- Öffnen Sie
agents/judge/agent.py. - Sehen Sie sich den folgenden Code an, der das
JudgeFeedback-Schema und denjudge-Agenten definiert.# 1. Define the Schema class JudgeFeedback(BaseModel): """Structured feedback from the Judge agent.""" status: Literal["pass", "fail"] = Field( description="Whether the research is sufficient ('pass') or needs more work ('fail')." ) feedback: str = Field( description="Detailed feedback on what is missing. If 'pass', a brief confirmation." ) # 2. Define the Agent judge = Agent( name="judge", model=MODEL, description="Evaluates research findings for completeness and accuracy.", instruction=""" You are a strict editor. Evaluate the 'research_findings' against the user's original request. If the findings are missing key info, return status='fail'. If they are comprehensive, return status='pass'. """, output_schema=JudgeFeedback, # Disallow delegation because it should only output the schema disallow_transfer_to_parent=True, disallow_transfer_to_peers=True, ) root_agent = judge
Schlüsselkonzept: Verhalten von Agents einschränken
Wir legen disallow_transfer_to_parent=True und disallow_transfer_to_peers=True fest. Dadurch wird der Richter gezwungen, nur die strukturierte JudgeFeedback zurückzugeben. Sie kann nicht entscheiden, mit dem Nutzer zu chatten oder an einen anderen Agenten zu delegieren. Dadurch ist sie eine deterministische Komponente in unserem Logikfluss.
6. ✍️ Der Content Builder-Agent
Der Content Builder ist der kreative Autor. Es nimmt die genehmigte Recherche und wandelt sie in einen Kurs um. Dazu wird ein Gemma-Modell verwendet, das von Cloud Run bereitgestellt wird.
Sehen wir uns zuerst den Cloud Run-Dienst an, in dem das Modell gehostet wird.
ollama_backend/Dockerfileöffnen- Hier sehen Sie, wie das Dockerfile ein Ollama-Image verwendet, auf Port 8080 auf Anfragen wartet und das angeforderte Modell in einem Ordner „/model“ speichert.
FROM ollama/ollama:latest # Listen on all interfaces, port 8080 (Cloud Run default) ENV OLLAMA_HOST 0.0.0.0:8080 # Store model weight files in /models ENV OLLAMA_MODELS /models
⚙️ Bei der Bereitstellung legen Sie die folgenden Konfigurationen fest:
- GPU: NVIDIA L4 wurde aufgrund des hervorragenden Preis-Leistungs-Verhältnisses für Inferenzarbeitslasten ausgewählt. Die L4 bietet 24 GB GPU-Speicher und optimierte Tensor-Operationen und eignet sich daher ideal für Modelle mit 270 Millionen Parametern wie Gemma.
- Arbeitsspeicher: 16 GB Arbeitsspeicher für das Laden von Modellen, CUDA-Vorgänge und die Arbeitsspeicherverwaltung von Ollama
- CPU: 8 Kerne für die optimale Verarbeitung von E/A und Vorverarbeitungsaufgaben
- Gleichzeitigkeit: 4 Anfragen pro Instanz sorgen für ein ausgewogenes Verhältnis zwischen Durchsatz und GPU-Arbeitsspeichernutzung.
- Zeitlimit: 600 Sekunden für das anfängliche Laden des Modells und den Containerstart
Sehen wir uns nun den Content Builder-Agenten an, der das Gemma-Modell verwendet.
- Öffnen Sie
agents/content_builder/agent.py. - Sehen Sie sich den folgenden Code an, mit dem der
content_builder-Agent definiert wird.
# the `ollama-gemma-gpu` Cloud Run service URL which hosts the Gemma model
target_url = os.environ.get("OLLAMA_API_BASE")
# ... existing code ...
# (Note: We use 'ollama/gemma3:270m' to align with ADK's expected prefix)
gemma_model_name = os.environ.get("GEMMA_MODEL_NAME", "gemma3:270m")
model = LiteLlm(
model=f"ollama_chat/{gemma_model_name}",
api_base=target_url
)
# 5. Define the Agent
content_builder = Agent(
name="content_builder",
model=model,
description="Transforms research findings into a structured course.",
instruction="""
You are an expert course creator.
Take the approved 'research_findings' and transform them into a well-structured, engaging course module.
**Formatting Rules:**
1. Start with a main title using a single `#` (H1).
2. Use `##` (H2) for main section headings. These will be used for the Table of Contents.
3. Use `###` (H3) for sub-sections within main sections.
4. Use bullet points and clear paragraphs.
5. Maintain a professional but engaging tone.
**Structure Requirements:**
- Begin with a brief Introduction section explaining what the learner will gain.
- Organize content into 3-5 main sections with clear headings.
- Include Key Takeaways at the end as a bulleted summary.
- Keep each section focused and concise.
Ensure the content directly addresses the user's original request.
Do not include any preamble or explanation outside the course content itself.
""",
)
root_agent = content_builder
Wichtiges Konzept: Weitergabe von Kontext
Sie fragen sich vielleicht: „Woher weiß Content Builder, was Researcher gefunden hat?“ Im ADK teilen sich Agenten in einer Pipeline ein session.state. Später konfigurieren wir im Orchestrator den Researcher und den Judge so, dass sie ihre Ausgaben in diesem gemeinsamen Status speichern. Der Prompt des Content Builders hat effektiv Zugriff auf diesen Verlauf.
7. 🎻 Der Orchestrator
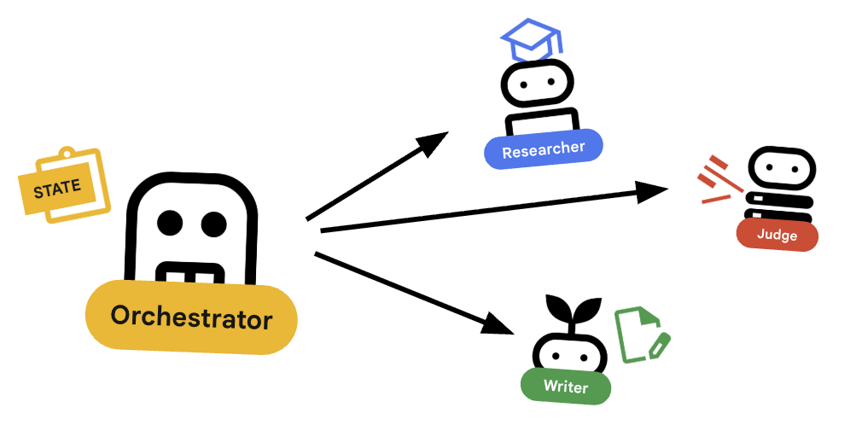
Der Orchestrator ist der Manager unseres Multi-Agenten-Teams. Im Gegensatz zu den spezialisierten Agents (Researcher, Judge, Content Builder), die bestimmte Aufgaben ausführen, koordiniert der Orchestrator den Workflow und sorgt dafür, dass Informationen richtig zwischen ihnen fließen.
🌐 Die Architektur: Agent-to-Agent (A2A)
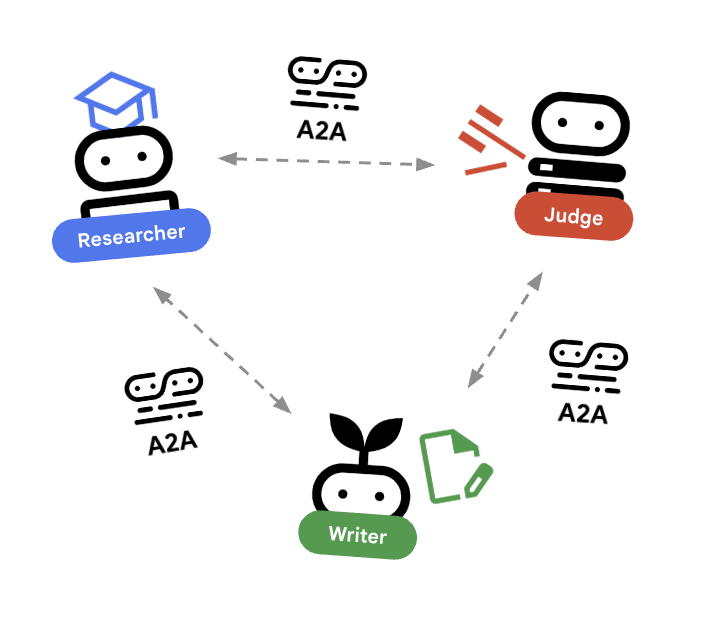
In diesem Lab erstellen wir ein verteiltes System. Anstatt alle Agents in einem einzigen Python-Prozess auszuführen, stellen wir sie als unabhängige Microservices bereit. So kann jeder Agent unabhängig skaliert werden und ausfallen, ohne dass das gesamte System abstürzt.
Dazu verwenden wir das Agent-to-Agent-Protokoll (A2A).
Das A2A-Protokoll
Weitere Informationen:In einem Produktionssystem werden Agents auf verschiedenen Servern oder sogar in verschiedenen Clouds ausgeführt. Das A2A-Protokoll bietet eine Standardmethode, mit der sie sich gegenseitig über HTTP erkennen und miteinander kommunizieren können. RemoteA2aAgent ist der ADK-Client für dieses Protokoll.
- Öffnen Sie
agents/orchestrator/agent.py. - Sehen Sie sich an, wie die Verbindungen im folgenden Code definiert werden.
# ... existing code ... # Connect to the Researcher (Localhost port 8001) researcher_url = os.environ.get("RESEARCHER_AGENT_CARD_URL", "http://localhost:8001/a2a/agent/.well-known/agent-card.json") researcher = RemoteA2aAgent( name="researcher", agent_card=researcher_url, description="Gathers information using Google Search.", # IMPORTANT: Save the output to state for the Judge to see after_agent_callback=create_save_output_callback("research_findings"), # IMPORTANT: Use authenticated client for communication httpx_client=create_authenticated_client(researcher_url) ) # Connect to the Judge (Localhost port 8002) judge_url = os.environ.get("JUDGE_AGENT_CARD_URL", "http://localhost:8002/a2a/agent/.well-known/agent-card.json") judge = RemoteA2aAgent( name="judge", agent_card=judge_url, description="Evaluates research.", after_agent_callback=create_save_output_callback("judge_feedback"), httpx_client=create_authenticated_client(judge_url) ) # Content Builder (Localhost port 8003) content_builder_url = os.environ.get("CONTENT_BUILDER_AGENT_CARD_URL", "http://localhost:8003/a2a/agent/.well-known/agent-card.json") content_builder = RemoteA2aAgent( name="content_builder", agent_card=content_builder_url, description="Builds the course.", httpx_client=create_authenticated_client(content_builder_url) )
8. 🛑 Eskalationsprüfung
Eine Schleife muss beendet werden können. Wenn der Judge „Pass“ sagt, möchten wir die Schleife sofort verlassen und zum Content Builder wechseln.
Benutzerdefinierte Logik mit BaseAgent
Detaillierte Informationen:Nicht alle KI-Agenten verwenden LLMs. Manchmal benötigen Sie nur eine einfache Python-Logik. Mit BaseAgent können Sie einen KI-Agenten definieren, der nur Code ausführt. In diesem Fall prüfen wir den Sitzungsstatus und verwenden EventActions(escalate=True), um LoopAgent zu signalisieren, dass sie beendet werden soll.
- Noch in
agents/orchestrator/agent.py. - Im folgenden Code wird das Feedback des Prüfers berücksichtigt und mit dem nächsten Schritt fortgefahren, wenn alles bereit ist.
class EscalationChecker(BaseAgent): """Checks the judge's feedback and escalates (breaks the loop) if it passed.""" async def _run_async_impl( self, ctx: InvocationContext ) -> AsyncGenerator[Event, None]: # Retrieve the feedback saved by the Judge feedback = ctx.session.state.get("judge_feedback") print(f"[EscalationChecker] Feedback: {feedback}") # Check for 'pass' status is_pass = False if isinstance(feedback, dict) and feedback.get("status") == "pass": is_pass = True # Handle string fallback if JSON parsing failed elif isinstance(feedback, str) and '"status": "pass"' in feedback: is_pass = True if is_pass: # 'escalate=True' tells the parent LoopAgent to stop looping yield Event(author=self.name, actions=EventActions(escalate=True)) else: # Continue the loop yield Event(author=self.name) escalation_checker = EscalationChecker(name="escalation_checker")
Wichtiges Konzept: Steuerung des Ablaufs über Ereignisse
KI-Agents kommunizieren nicht nur über Text, sondern auch über Ereignisse. Durch das Ausgeben eines Ereignisses mit escalate=True sendet dieser Agent ein Signal an seinen übergeordneten Agenten (LoopAgent). Der LoopAgent ist so programmiert, dass er dieses Signal abfängt und die Schleife beendet.
9. 🔁 Der Research-Loop
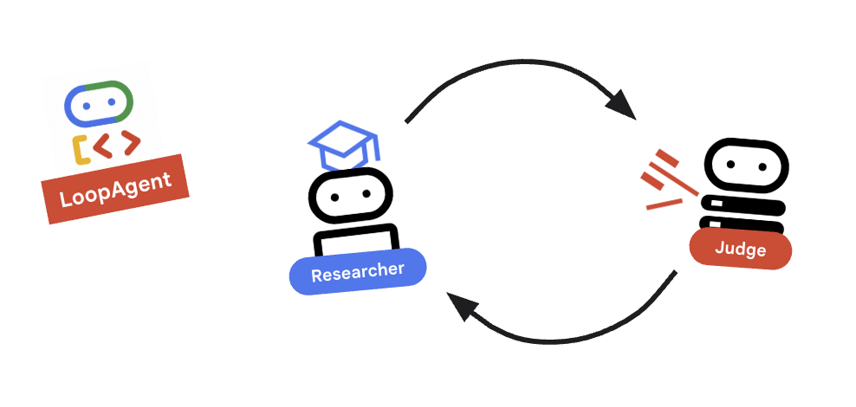
Wir benötigen einen Feedbackloop: Recherchieren –> Bewerten –> (Fehler) –> Recherchieren –> …
- In
agents/orchestrator/agent.py. - Sehen Sie sich an, wie die
research_loop-Definition im folgenden Code definiert wird.research_loop = LoopAgent( name="research_loop", description="Iteratively researches and judges until quality standards are met.", sub_agents=[researcher, judge, escalation_checker], max_iterations=3, )
Wichtiges Konzept: LoopAgent
Die LoopAgent durchläuft ihre sub_agents in der Reihenfolge.
researcher: Daten finden.judge: Daten werden ausgewertet.escalation_checker: Legt fest, obyield Event(escalate=True). Wennescalate=Trueeintritt, wird die Schleife vorzeitig beendet. Andernfalls beginnt der Prozess beim Researcher neu (bis zumax_iterations).
10. 🔗 Die endgültige Pipeline
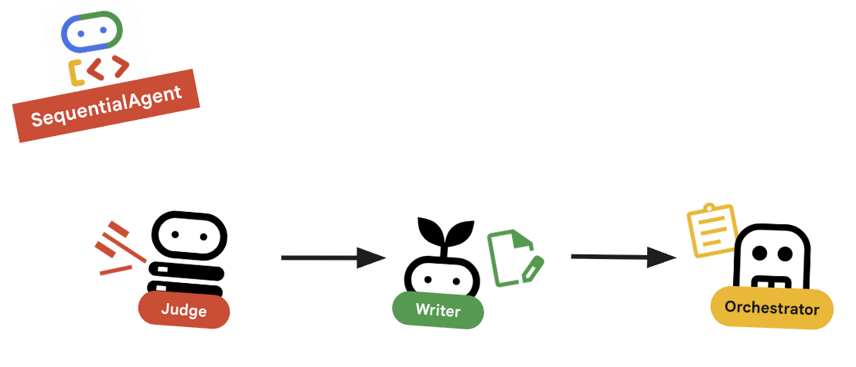
Alles wird zusammengefügt…
- In
agents/orchestrator/agent.py. - Sehen Sie sich an, wie
root_agentunten in der Datei definiert ist.root_agent = SequentialAgent( name="course_creation_pipeline", description="A pipeline that researches a topic and then builds a course from it.", sub_agents=[research_loop, content_builder], )
Wichtiges Konzept: Hierarchische Zusammensetzung
research_loop ist selbst ein Agent (ein LoopAgent). Er wird wie jeder andere Sub-Agent im SequentialAgent behandelt. Durch diese Zusammensetzbarkeit können Sie komplexe Logik erstellen, indem Sie einfache Muster verschachteln (Schleifen in Sequenzen, Sequenzen in Routern usw.).
11. 🚀 In Cloud Run bereitstellen
Wir stellen jeden Agent als separaten Dienst in Cloud Run bereit, einschließlich eines Cloud Run-Dienstes für die Benutzeroberfläche des Kurserstellers und eines Cloud Run-Dienstes mit GPUs für das Gemma-Modell.
Konfiguration der Bereitstellung
Wenn Sie Agents in Cloud Run bereitstellen, werden mehrere Umgebungsvariablen übergeben, um ihr Verhalten und ihre Konnektivität zu konfigurieren:
GOOGLE_CLOUD_PROJECT: Sorgt dafür, dass der Agent das richtige Google Cloud-Projekt für Logging und Vertex AI-Aufrufe verwendet.GOOGLE_GENAI_USE_VERTEXAI: Weist das Agent-Framework (ADK) an, Vertex AI für die Modellinferenz zu verwenden, anstatt Gemini APIs direkt aufzurufen.[AGENT]_AGENT_CARD_URL: Das ist entscheidend für den Orchestrator. Es teilt dem Orchestrator mit, wo sich die Remote-Agents befinden. Wenn Sie diese Einstellung auf die bereitgestellte Cloud Run-URL (insbesondere den Pfad der Agent-Karte) festlegen, kann der Orchestrator die Researcher-, Judge- und Content Builder-Agents über das Internet erkennen und mit ihnen kommunizieren.
Führen Sie das folgende Script aus, um alle Agents in Cloud Run-Diensten bereitzustellen.
Prüfen Sie zuerst, ob das Skript ausführbar ist.
chmod u+x ~/multi-agent-system/deploy.sh
Hinweis: Die Ausführung dieses Befehls kann mehrere Minuten dauern, da die einzelnen Dienste sequenziell bereitgestellt werden.
~/multi-agent-system/deploy.sh
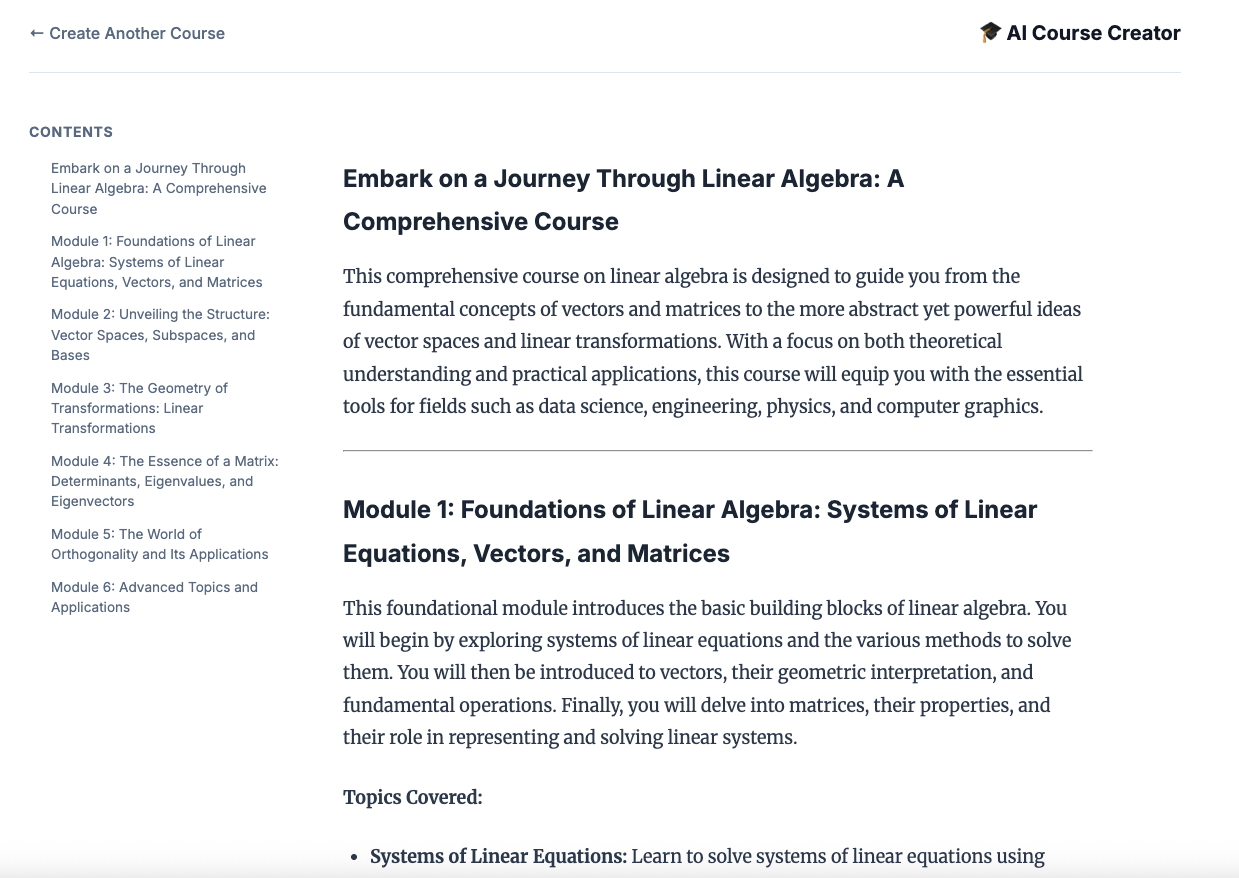
12. Kurs erstellen
Öffnen Sie die Course Creator-Website. Der Cloud Run-Dienst „Course Creator“ ist der letzte Dienst, der über das Skript bereitgestellt wird. Die URL zum Kursersteller ist https://course-creator-. Das sollte die letzte Ausgabezeile des Bereitstellungsskripts sein.
Geben Sie eine Kursidee ein, z.B. „Lineare Algebra“.
Ihre KI-Agents beginnen mit der Arbeit an Ihrem Kurs.
13. Bereinigen
Mit den folgenden Schritten vermeiden Sie, dass Ihrem Google Cloud-Konto die in diesem Codelab verwendeten Ressourcen in Rechnung gestellt werden.
1. Cloud Run-Dienste löschen
Am effizientesten bereinigen Sie, indem Sie die Dienste löschen, die Sie in Cloud Run bereitgestellt haben.
# Delete the main agent and app services
gcloud run services delete researcher content-builder judge orchestrator course-creator \
--region $REGION --quiet
# Delete the GPU backend (Ollama)
gcloud run services delete ollama-gemma-gpu \
--region $OLLAMA_REGION --quiet
2. Artifact Registry-Images löschen
Wenn Sie das Flag --source für die Bereitstellung verwendet haben, hat Google Cloud ein Repository in Artifact Registry erstellt, in dem Ihre Container-Images gespeichert werden. Wenn Sie diese entfernen und Speicherkosten sparen möchten, löschen Sie das Repository:
gcloud artifacts repositories delete cloud-run-source-deploy --location us-east4 --quiet
3. Lokale Dateien und Umgebung entfernen
Damit Ihre Cloud Shell-Umgebung sauber bleibt, entfernen Sie den Projektordner und alle lokalen Konfigurationen:
cd ~
rm -rf multi-agent-system
4. (Optional) Projekt löschen
Wenn Sie ein Projekt nur für dieses Codelab erstellt haben, können Sie weitere Abrechnungen vermeiden, indem Sie das Projekt selbst über die Seite „Ressourcen verwalten“ herunterfahren.
14. Das wars! Sie haben das Lab erfolgreich abgeschlossen.
Sie haben ein produktionsreifes, verteiltes Multi-Agenten-System erstellt und bereitgestellt.
Ihr Lernerfolg
- Komplexe Aufgabe zerlegt: Anstelle eines riesigen Prompts haben wir die Arbeit in spezialisierte Rollen aufgeteilt (Researcher, Judge, Content Builder).
- Implementierte Qualitätskontrolle: Wir haben einen
LoopAgentund einen strukturiertenJudgeverwendet, um sicherzustellen, dass nur hochwertige Informationen den letzten Schritt erreichen. - Für die Produktion entwickelt: Durch die Verwendung des Agent-to-Agent-Protokolls (A2A) und von Cloud Run haben wir ein System geschaffen, in dem jeder Agent ein unabhängiger, skalierbarer Microservice ist. Das ist viel robuster, als alles in einem einzigen Python-Skript auszuführen.
- Orchestrierung: Wir haben
SequentialAgentundLoopAgentverwendet, um klare Kontrollflussmuster zu definieren. *. Cloud Run-GPUs: Sie haben ein Gemma-Modell auf einer Cloud Run-GPU bereitgestellt.