
1. Introducción
En este lab, irás más allá de los chatbots simples y crearás un sistema multiagente distribuido.
Si bien un solo LLM puede responder preguntas, la complejidad del mundo real a menudo requiere roles especializados. No le pides a tu ingeniero de backend que diseñe la IU, ni le pides a tu diseñador que optimice las consultas de la base de datos. Del mismo modo, podemos crear agentes de IA especializados que se enfoquen en una tarea y se coordinen entre sí para resolver problemas complejos.
Compilarás un sistema de creación de cursos que constará de lo siguiente:
- Agente de investigación: Usa google_search para encontrar información actualizada.
- Agente de evaluación: Critica la investigación por su calidad y completitud.
- Agente de Content Builder: Convierte la investigación en un curso estructurado.
- Agente de Orchestrator: Administra el flujo de trabajo y la comunicación entre estos especialistas.
Qué aprenderás
- Define un agente que usa herramientas (investigador) y que puede buscar en la Web.
- Implementa resultados estructurados con Pydantic para el juez.
- Conéctate a agentes remotos con el protocolo Agent-to-Agent (A2A).
- Construye un LoopAgent para crear un ciclo de reacción entre el investigador y el juez.
- Ejecuta el sistema distribuido de forma local con el ADK.
- Implementa el sistema multiagente en Google Cloud Run.
- Usar un modelo de Gemma en una GPU de Cloud Run para el agente de creación de contenido
Requisitos
- Un navegador web, como Chrome
- Un proyecto de Google Cloud con la facturación habilitada.
2. Principios de arquitectura y organización
Primero, veamos cómo trabajan juntos estos agentes. Estamos creando una canalización de creación de cursos.
El diseño del sistema
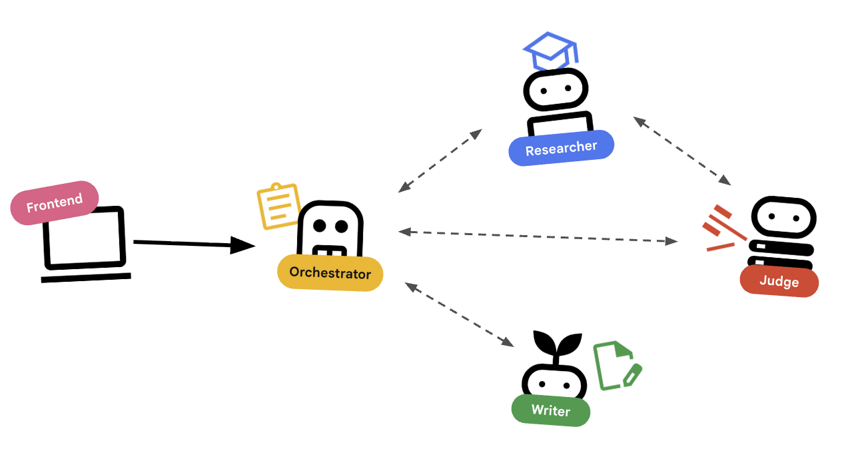
Organización con agentes
Los agentes estándar (como el Investigador) sí funcionan. Los agentes organizadores (como LoopAgent o SequentialAgent) administran otros agentes. No tienen sus propias herramientas; su "herramienta" es la delegación.
LoopAgent: Actúa como un buclewhileen el código. Ejecuta una secuencia de agentes de forma repetida hasta que se cumple una condición (o se alcanza la cantidad máxima de iteraciones). Usamos esta información para la Investigación con Loop:- El investigador encuentra información.
- El juez la critica.
- Si Judge dice "Fail", EscalationChecker permite que continúe el bucle.
- Si Judge dice "Pass", EscalationChecker interrumpe el bucle.
SequentialAgent: Actúa como una ejecución de secuencia de comandos estándar. Ejecuta los agentes uno tras otro. Usamos esto para la canalización de alto nivel:- Primero, ejecuta el Circuito de investigación (hasta que finalice con datos adecuados).
- Luego, ejecuta Content Builder (para escribir el curso).
Si combinamos estos elementos, creamos un sistema sólido que puede autocorregirse antes de generar el resultado final.
3. Configuración
Configura el proyecto
Crea un proyecto de Google Cloud
- En la consola de Google Cloud, en la página del selector de proyectos, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto.
Inicie Cloud Shell
Cloud Shell es un entorno de línea de comandos que se ejecuta en Google Cloud y que viene precargado con las herramientas necesarias.
- Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.
- Una vez que te conectes a Cloud Shell, verifica tu autenticación:
gcloud auth list - Confirma que tu proyecto esté configurado:
gcloud config get project - Si tu proyecto no está configurado como se esperaba, configúralo:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Configuración del entorno
- Abre Cloud Shell: Haz clic en el ícono de Activar Cloud Shell en la parte superior derecha de la consola de Google Cloud.
Obtén el código de partida
- Clona el repositorio de inicio en tu directorio principal:Ve a tu directorio principal
cd ~git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git temp-repo && cd temp-repo && git sparse-checkout set agents/multi-agent-system && cd .. && mv temp-repo/agents/multi-agent-system . && rm -rf temp-repocd multi-agent-system - Habilita las APIs: Ejecuta el siguiente comando para habilitar los servicios de Google Cloud necesarios:
gcloud services enable \ run.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - Abre esta carpeta en tu editor.
cloudshell edit .
Configura el entorno
- Configura las variables de entorno.Crearemos un archivo
.envpara almacenar estas variables, de modo que puedas volver a cargarlas fácilmente si se desconecta tu sesión.cat <<EOF > .env export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) export GOOGLE_CLOUD_LOCATION=europe-west4 export GOOGLE_GENAI_USE_VERTEXAI=true EOF - Obtén las variables de entorno:
source .env
4. 🕵️ El agente de investigación
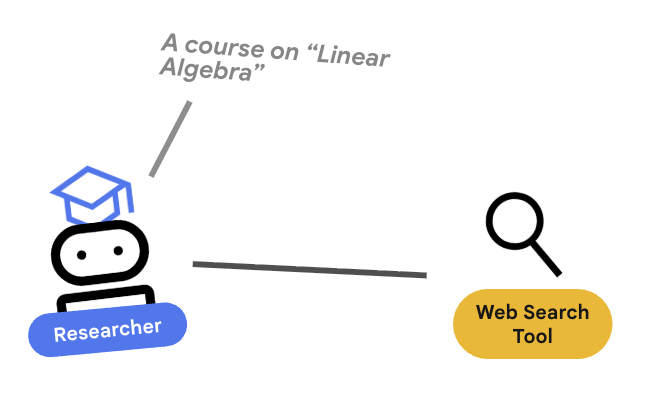
El Investigador es un especialista. Su único trabajo es encontrar información. Para ello, necesita acceder a una herramienta: la Búsqueda de Google.
¿Por qué separar al investigador?
Análisis detallado: ¿Por qué no tener solo un agente que haga todo?
Los agentes pequeños y enfocados son más fáciles de evaluar y depurar. Si la investigación es deficiente, itera sobre la instrucción del investigador. Si el formato del curso es incorrecto, debes iterar en el Creador de contenido. En una instrucción monolítica que "lo hace todo", corregir una cosa a menudo rompe otra.
- Si trabajas en Cloud Shell, ejecuta el siguiente comando para abrir el editor de Cloud Shell:
cloudshell workspace . - Abre
agents/researcher/agent.py. - Revisa el siguiente código que define el agente
researcher:# ... existing imports ... # Define the Researcher Agent researcher = Agent( name="researcher", model=MODEL, description="Gathers information on a topic using Google Search.", instruction=""" You are an expert researcher. Your goal is to find comprehensive and accurate information on the user's topic. Use the `google_search` tool to find relevant information. Summarize your findings clearly. If you receive feedback that your research is insufficient, use the feedback to refine your next search. """, tools=[google_search], ) root_agent = researcher
Concepto clave: Uso de herramientas
Observa que pasamos tools=[google_search]. El ADK controla la complejidad de describir esta herramienta al LLM. Cuando el modelo decide que necesita información, genera una llamada a herramienta estructurada, el ADK ejecuta la función de Python google_search y devuelve el resultado al modelo.
5. ⚖️ El agente juez
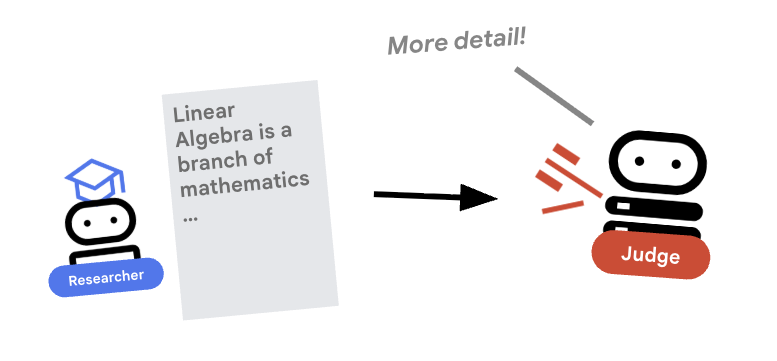
El Investigador trabaja mucho, pero los LLM pueden ser perezosos. Necesitamos un juez para que revise el trabajo. El juez acepta la investigación y devuelve una evaluación estructurada de aprobado o rechazado.
Resultado estructurado
Análisis detallado: Para automatizar los flujos de trabajo, necesitamos resultados predecibles. Una opinión de texto divagante es difícil de analizar de forma programática. Al aplicar un esquema JSON (con Pydantic), nos aseguramos de que Judge devuelva un valor booleano pass o fail sobre el que nuestro código pueda actuar de manera confiable.
- Abre
agents/judge/agent.py. - Revisa el siguiente código que define el esquema
JudgeFeedbacky el agentejudge.# 1. Define the Schema class JudgeFeedback(BaseModel): """Structured feedback from the Judge agent.""" status: Literal["pass", "fail"] = Field( description="Whether the research is sufficient ('pass') or needs more work ('fail')." ) feedback: str = Field( description="Detailed feedback on what is missing. If 'pass', a brief confirmation." ) # 2. Define the Agent judge = Agent( name="judge", model=MODEL, description="Evaluates research findings for completeness and accuracy.", instruction=""" You are a strict editor. Evaluate the 'research_findings' against the user's original request. If the findings are missing key info, return status='fail'. If they are comprehensive, return status='pass'. """, output_schema=JudgeFeedback, # Disallow delegation because it should only output the schema disallow_transfer_to_parent=True, disallow_transfer_to_peers=True, ) root_agent = judge
Concepto clave: Restricción del comportamiento del agente
Establecemos disallow_transfer_to_parent=True y disallow_transfer_to_peers=True. Esto obliga al juez a solo devolver el JudgeFeedback estructurado. No puede decidir "chatear" con el usuario ni delegar la tarea a otro agente. Esto lo convierte en un componente determinístico en nuestro flujo de lógica.
6. ✍️ El agente de Content Builder
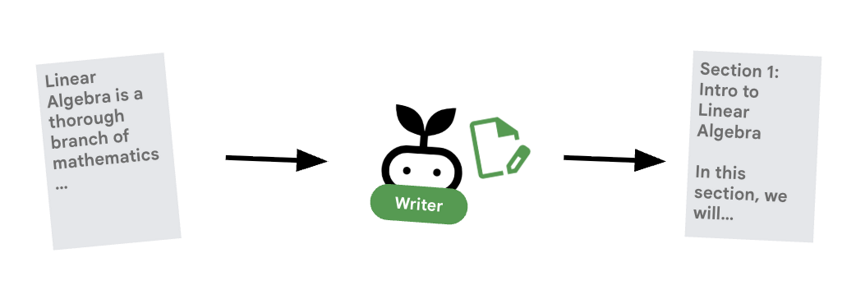
El Creador de contenido es el escritor creativo. Toma la investigación aprobada y la convierte en un curso. Utiliza un modelo de Gemma que entrega Cloud Run.
Primero, veamos el servicio de Cloud Run que aloja el modelo.
- Abrir
ollama_backend/Dockerfile - Aquí puedes ver cómo el Dockerfile usa una imagen de Ollama, escucha solicitudes en el puerto 8080 y almacena el modelo solicitado en una carpeta /model.
FROM ollama/ollama:latest # Listen on all interfaces, port 8080 (Cloud Run default) ENV OLLAMA_HOST 0.0.0.0:8080 # Store model weight files in /models ENV OLLAMA_MODELS /models
⚙️ Cuando realices la implementación, establecerás los siguientes parámetros de configuración:
- GPU: Se eligió la NVIDIA L4 por su excelente relación precio-rendimiento para las cargas de trabajo de inferencia. La L4 proporciona 24 GB de memoria de GPU y operaciones de tensor optimizadas, lo que la hace ideal para modelos de 270 millones de parámetros, como Gemma.
- Memoria: 16 GB de memoria del sistema para controlar la carga del modelo, las operaciones de CUDA y la administración de memoria de Ollama
- CPU: 8 núcleos para un manejo óptimo de las tareas de E/S y de preprocesamiento
- Simultaneidad: 4 solicitudes por instancia equilibran la capacidad de procesamiento con el uso de memoria de la GPU
- Tiempo de espera: 600 segundos para la carga inicial del modelo y el inicio del contenedor
Ahora veamos el agente Creador de contenido que usa el modelo de Gemma.
- Abre
agents/content_builder/agent.py. - Revisa el siguiente código que define el agente
content_builder.
# the `ollama-gemma-gpu` Cloud Run service URL which hosts the Gemma model
target_url = os.environ.get("OLLAMA_API_BASE")
# ... existing code ...
# (Note: We use 'ollama/gemma3:270m' to align with ADK's expected prefix)
gemma_model_name = os.environ.get("GEMMA_MODEL_NAME", "gemma3:270m")
model = LiteLlm(
model=f"ollama_chat/{gemma_model_name}",
api_base=target_url
)
# 5. Define the Agent
content_builder = Agent(
name="content_builder",
model=model,
description="Transforms research findings into a structured course.",
instruction="""
You are an expert course creator.
Take the approved 'research_findings' and transform them into a well-structured, engaging course module.
**Formatting Rules:**
1. Start with a main title using a single `#` (H1).
2. Use `##` (H2) for main section headings. These will be used for the Table of Contents.
3. Use `###` (H3) for sub-sections within main sections.
4. Use bullet points and clear paragraphs.
5. Maintain a professional but engaging tone.
**Structure Requirements:**
- Begin with a brief Introduction section explaining what the learner will gain.
- Organize content into 3-5 main sections with clear headings.
- Include Key Takeaways at the end as a bulleted summary.
- Keep each section focused and concise.
Ensure the content directly addresses the user's original request.
Do not include any preamble or explanation outside the course content itself.
""",
)
root_agent = content_builder
Concepto clave: Propagación del contexto
Quizás te preguntes: "¿Cómo sabe el Creador de contenido lo que encontró el Investigador?". En el ADK, los agentes de una canalización comparten un session.state. Más adelante, en el orquestador, configuraremos el investigador y el juez para que guarden sus resultados en este estado compartido. La instrucción de Content Builder tiene acceso efectivo a este historial.
7. 🎻 El organizador
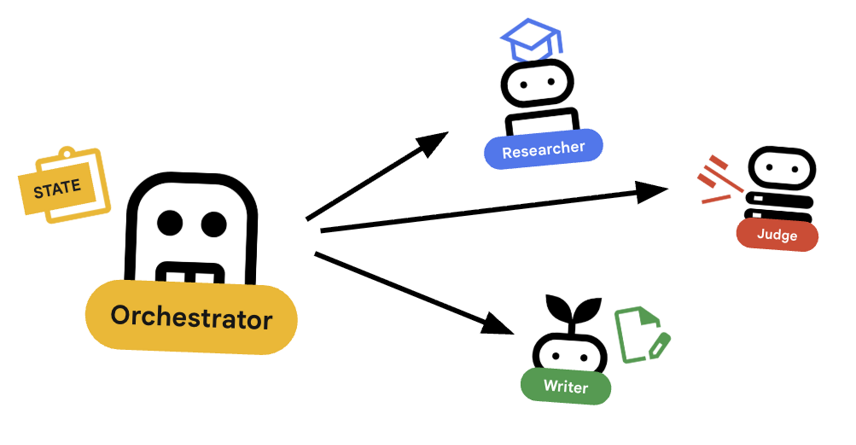
El organizador es el administrador de nuestro equipo multiagente. A diferencia de los agentes especializados (Investigador, Juez y Creador de contenido) que realizan tareas específicas, el trabajo del Organizador es coordinar el flujo de trabajo y garantizar que la información fluya correctamente entre ellos.
🌐 La arquitectura: Agent-to-Agent (A2A)
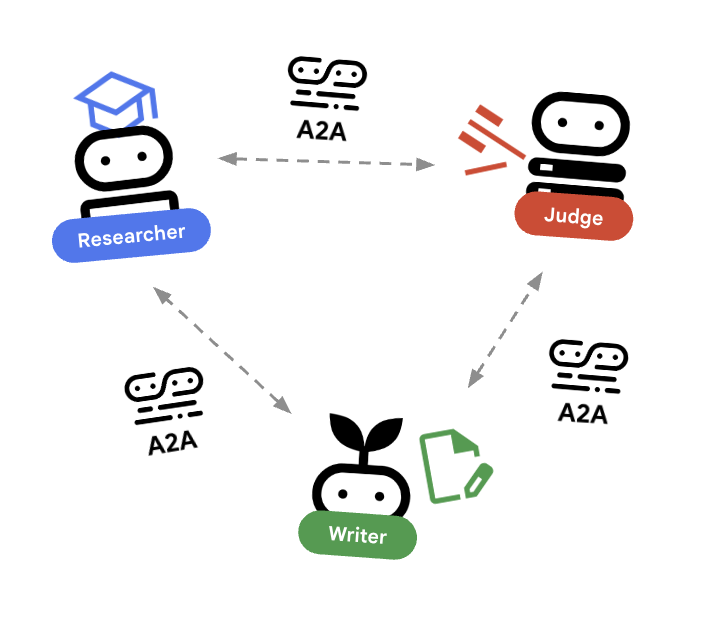
En este lab, crearemos un sistema distribuido. En lugar de ejecutar todos los agentes en un solo proceso de Python, los implementamos como microservicios independientes. Esto permite que cada agente se escale de forma independiente y falle sin que se bloquee todo el sistema.
Para que esto sea posible, usamos el protocolo Agent-to-Agent (A2A).
El protocolo A2A
Análisis detallado: En un sistema de producción, los agentes se ejecutan en diferentes servidores (o incluso en diferentes nubes). El protocolo A2A crea una forma estándar para que se descubran y se comuniquen entre sí a través de HTTP. RemoteA2aAgent es el cliente del ADK para este protocolo.
- Abre
agents/orchestrator/agent.py. - Revisa cómo el siguiente código define las conexiones.
# ... existing code ... # Connect to the Researcher (Localhost port 8001) researcher_url = os.environ.get("RESEARCHER_AGENT_CARD_URL", "http://localhost:8001/a2a/agent/.well-known/agent-card.json") researcher = RemoteA2aAgent( name="researcher", agent_card=researcher_url, description="Gathers information using Google Search.", # IMPORTANT: Save the output to state for the Judge to see after_agent_callback=create_save_output_callback("research_findings"), # IMPORTANT: Use authenticated client for communication httpx_client=create_authenticated_client(researcher_url) ) # Connect to the Judge (Localhost port 8002) judge_url = os.environ.get("JUDGE_AGENT_CARD_URL", "http://localhost:8002/a2a/agent/.well-known/agent-card.json") judge = RemoteA2aAgent( name="judge", agent_card=judge_url, description="Evaluates research.", after_agent_callback=create_save_output_callback("judge_feedback"), httpx_client=create_authenticated_client(judge_url) ) # Content Builder (Localhost port 8003) content_builder_url = os.environ.get("CONTENT_BUILDER_AGENT_CARD_URL", "http://localhost:8003/a2a/agent/.well-known/agent-card.json") content_builder = RemoteA2aAgent( name="content_builder", agent_card=content_builder_url, description="Builds the course.", httpx_client=create_authenticated_client(content_builder_url) )
8. 🛑 El verificador de derivaciones
Un bucle necesita una forma de detenerse. Si el juez dice "Aprobar", queremos salir del bucle de inmediato y pasar al Creador de contenido.
Lógica personalizada con BaseAgent
Análisis detallado: No todos los agentes usan LLMs. A veces, necesitas una lógica de Python simple. BaseAgent te permite definir un agente que solo ejecuta código. En este caso, verificamos el estado de la sesión y usamos EventActions(escalate=True) para indicarle a LoopAgent que se detenga.
- Aún en
agents/orchestrator/agent.py. - Revisa el siguiente código, analiza los comentarios del juez y continúa con el siguiente paso cuando esté listo.
class EscalationChecker(BaseAgent): """Checks the judge's feedback and escalates (breaks the loop) if it passed.""" async def _run_async_impl( self, ctx: InvocationContext ) -> AsyncGenerator[Event, None]: # Retrieve the feedback saved by the Judge feedback = ctx.session.state.get("judge_feedback") print(f"[EscalationChecker] Feedback: {feedback}") # Check for 'pass' status is_pass = False if isinstance(feedback, dict) and feedback.get("status") == "pass": is_pass = True # Handle string fallback if JSON parsing failed elif isinstance(feedback, str) and '"status": "pass"' in feedback: is_pass = True if is_pass: # 'escalate=True' tells the parent LoopAgent to stop looping yield Event(author=self.name, actions=EventActions(escalate=True)) else: # Continue the loop yield Event(author=self.name) escalation_checker = EscalationChecker(name="escalation_checker")
Concepto clave: Flujo de control a través de eventos
Los agentes se comunican no solo con texto, sino también con eventos. Cuando se genera un evento con escalate=True, este agente envía un indicador a su elemento superior (el LoopAgent). El LoopAgent está programado para captar este indicador y finalizar el bucle.
9. 🔁 El ciclo de investigación
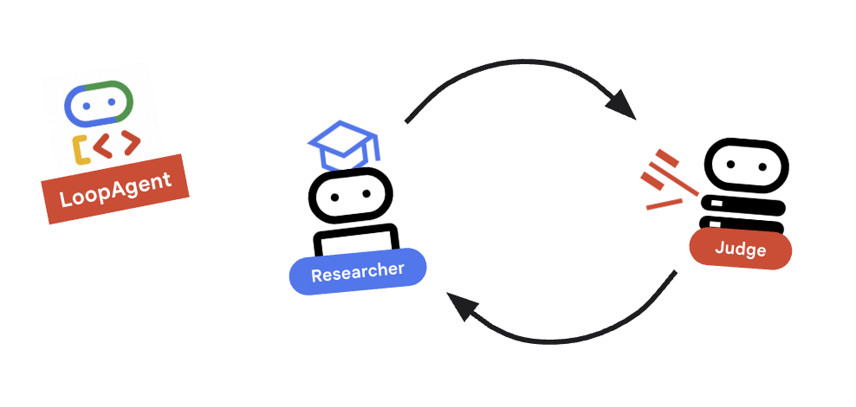
Necesitamos un ciclo de retroalimentación: Investigación -> Evaluación -> (Falla) -> Investigación -> …
- In
agents/orchestrator/agent.py, - Revisa cómo el siguiente código define la definición de
research_loop.research_loop = LoopAgent( name="research_loop", description="Iteratively researches and judges until quality standards are met.", sub_agents=[researcher, judge, escalation_checker], max_iterations=3, )
Concepto clave: LoopAgent
El LoopAgent recorre sus sub_agents en orden.
researcher: Busca datos.judge: Evalúa datos.escalation_checker: Decide si se debeyield Event(escalate=True). Si sucedeescalate=True, el bucle se interrumpe antes. De lo contrario, se reinicia en el investigador (hastamax_iterations).
10. 🔗 La canalización final
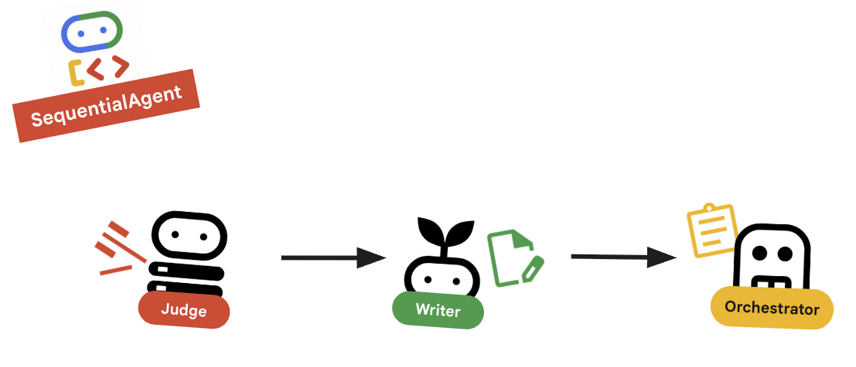
Reúne todo…
- In
agents/orchestrator/agent.py, - Revisa cómo se define
root_agenten la parte inferior del archivo.root_agent = SequentialAgent( name="course_creation_pipeline", description="A pipeline that researches a topic and then builds a course from it.", sub_agents=[research_loop, content_builder], )
Concepto clave: Composición jerárquica
Ten en cuenta que research_loop es en sí mismo un agente (un LoopAgent). Lo tratamos como cualquier otro agente secundario en SequentialAgent. Esta componibilidad te permite compilar lógica compleja anidando patrones simples (bucles dentro de secuencias, secuencias dentro de routers, etcétera).
11. 🚀 Implementa en Cloud Run
Implementaremos cada agente como un servicio independiente en Cloud Run, incluido un servicio de Cloud Run para la IU del creador del curso y un servicio de Cloud Run que usa GPUs para el modelo de Gemma.
Información sobre la configuración de la implementación
Cuando implementamos agentes en Cloud Run, pasamos varias variables de entorno para configurar su comportamiento y conectividad:
GOOGLE_CLOUD_PROJECT: Garantiza que el agente use el proyecto de Google Cloud correcto para el registro y las llamadas a Vertex AI.GOOGLE_GENAI_USE_VERTEXAI: Indica al framework del agente (ADK) que use Vertex AI para la inferencia del modelo en lugar de llamar directamente a las APIs de Gemini.[AGENT]_AGENT_CARD_URL: Es fundamental para el orquestador. Le indica al orquestador dónde encontrar los agentes remotos. Si configuras este parámetro en la URL de Cloud Run implementada (específicamente, la ruta de acceso a la tarjeta del agente), permitimos que el orquestador descubra y se comunique con el investigador, el juez y el creador de contenido a través de Internet.
Para implementar todos los agentes en los servicios de Cloud Run, ejecuta la siguiente secuencia de comandos.
Primero, asegúrate de que la secuencia de comandos sea ejecutable.
chmod u+x ~/multi-agent-system/deploy.sh
Nota: La ejecución tardará varios minutos, ya que cada servicio se implementa de forma secuencial.
~/multi-agent-system/deploy.sh
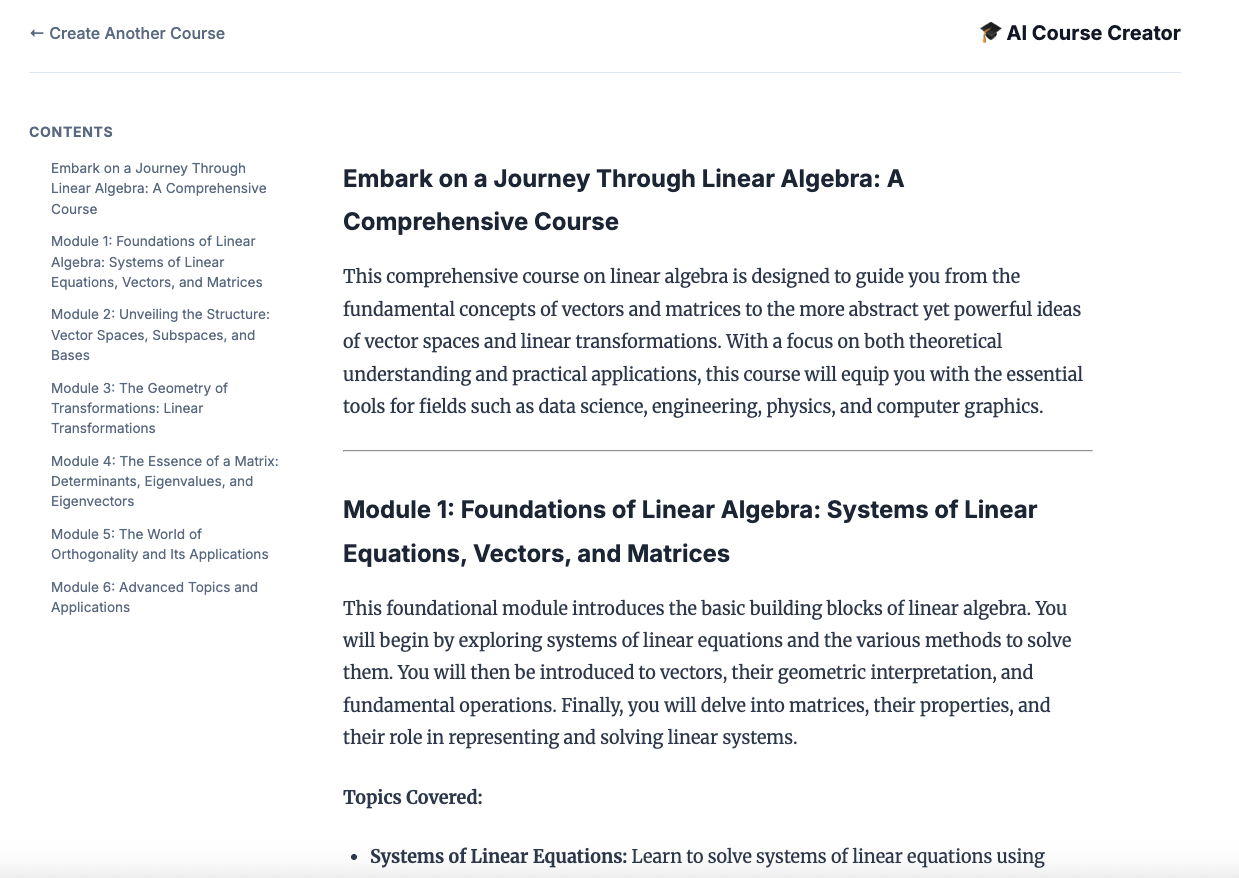
12. ¡Crea un curso!
Abre el sitio web de Course Creator. El servicio de Cloud Run de Course Creator es el último servicio que se implementa desde la secuencia de comandos. Puedes identificar la URL del creador del curso como https://course-creator-, que debería ser la línea de salida final de la secuencia de comandos de implementación.
Escribe una idea de curso, p.ej., "álgebra lineal".
Tus agentes comenzarán a trabajar en tu curso.
13. Limpieza
Sigue estos pasos para borrar tus servicios y las imágenes de contenedor y, así, evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos que usaste en este codelab.
1. Borra los servicios de Cloud Run
La forma más eficiente de limpiar es borrar los servicios que implementaste en Cloud Run.
# Delete the main agent and app services
gcloud run services delete researcher content-builder judge orchestrator course-creator \
--region $REGION --quiet
# Delete the GPU backend (Ollama)
gcloud run services delete ollama-gemma-gpu \
--region $OLLAMA_REGION --quiet
2. Borra imágenes de Artifact Registry
Cuando usaste la marca --source para realizar la implementación, Google Cloud creó un repositorio en Artifact Registry para almacenar tus imágenes de contenedor. Para quitar estos archivos y ahorrar en costos de almacenamiento, borra el repositorio:
gcloud artifacts repositories delete cloud-run-source-deploy --location us-east4 --quiet
3. Cómo quitar archivos locales y el entorno
Para mantener limpio tu entorno de Cloud Shell, quita la carpeta del proyecto y cualquier configuración local:
cd ~
rm -rf multi-agent-system
4. Borra el proyecto (opcional)
Si creaste un proyecto solo para este codelab, puedes asegurarte de que no se produzcan más cargos cerrando el proyecto en la página Administrar recursos.
14. ¡Felicitaciones!
Creaste e implementaste correctamente un sistema multiagente distribuido listo para producción.
Objetivos logrados
- Descomposición de una tarea compleja: En lugar de una instrucción gigante, dividimos el trabajo en roles especializados (investigador, juez y creador de contenido).
- Control de calidad implementado: Utilizamos un
LoopAgenty unJudgeestructurado para garantizar que solo la información de alta calidad llegue al paso final. - Creado para la producción: Con el protocolo Agent-to-Agent (A2A) y Cloud Run, creamos un sistema en el que cada agente es un microservicio independiente y escalable. Esto es mucho más sólido que ejecutar todo en una sola secuencia de comandos de Python.
- Orquestación: Usamos
SequentialAgentyLoopAgentpara definir patrones claros de flujo de control. *. GPUs de Cloud Run: Se implementó un modelo de Gemma en una GPU de Cloud Run.