
۱. مقدمه
در این آزمایشگاه، شما فراتر از چتباتهای ساده خواهید رفت و یک سیستم چندعاملی توزیعشده خواهید ساخت.
در حالی که یک LLM به تنهایی میتواند به سوالات پاسخ دهد، پیچیدگیهای دنیای واقعی اغلب به نقشهای تخصصی نیاز دارند. شما از مهندس backend خود نمیخواهید که رابط کاربری را طراحی کند و از طراح خود نمیخواهید که پرسوجوهای پایگاه داده را بهینه کند. به طور مشابه، ما میتوانیم عوامل هوش مصنوعی تخصصی ایجاد کنیم که بر روی یک کار تمرکز میکنند و برای حل مشکلات پیچیده با یکدیگر هماهنگ میشوند.
شما یک سیستم ایجاد دوره آموزشی خواهید ساخت که شامل موارد زیر است:
- نماینده محقق : استفاده از google_search برای یافتن اطلاعات بهروز.
- قاضی نماینده : نقد تحقیق از نظر کیفیت و کامل بودن.
- عامل سازنده محتوا : تبدیل تحقیق به یک دوره آموزشی ساختارمند
- عامل هماهنگکننده : مدیریت گردش کار و ارتباط بین این متخصصان.
آنچه یاد خواهید گرفت
- یک عامل استفادهکننده از ابزار (محقق) تعریف کنید که بتواند وب را جستجو کند.
- پیادهسازی خروجی ساختاریافته با Pydantic برای قاضی.
- با استفاده از پروتکل Agent-to-Agent (A2A) به Agentهای راه دور متصل شوید.
- یک LoopAgent بسازید تا یک حلقه بازخورد بین محقق و قاضی ایجاد شود.
- سیستم توزیعشده را با استفاده از ADK به صورت محلی اجرا کنید.
- سیستم چندعاملی را در Google Cloud Run مستقر کنید.
- از یک مدل Gemma روی یک پردازنده گرافیکی Cloud Run برای عامل سازنده محتوا استفاده کنید.
آنچه نیاز دارید
- یک مرورگر وب مانند کروم
- یک پروژه گوگل کلود با قابلیت پرداخت صورتحساب
۲. اصول معماری و ارکستراسیون
اول، بیایید بفهمیم که این عاملها چگونه با هم کار میکنند. ما در حال ساخت یک خط تولید دوره (Course Creation Pipeline) هستیم.
طراحی سیستم
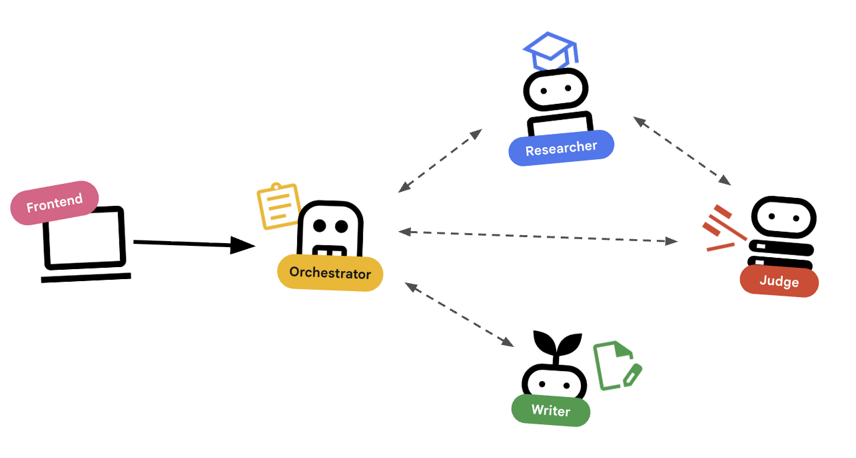
هماهنگی با نمایندگان
عاملهای استاندارد (مانند Researcher) کار میکنند. عاملهای هماهنگکننده (مانند LoopAgent یا SequentialAgent ) عاملهای دیگر را مدیریت میکنند. آنها ابزار مخصوص به خود را ندارند؛ «ابزار» آنها واگذاری اختیار است.
-
LoopAgent: این حلقه مانند یک حلقهwhileدر کد عمل میکند. این حلقه دنبالهای از عاملها را تا زمانی که یک شرط برقرار شود (یا به حداکثر تکرار برسد) به طور مکرر اجرا میکند. ما از این حلقه برای حلقه تحقیق استفاده میکنیم:- محقق اطلاعات را پیدا میکند.
- قاضی آن را نقد میکند.
- اگر Judge بگوید «ناموفق»، EscalationChecker اجازه میدهد حلقه ادامه یابد.
- اگر قاضی بگوید «قبول»، بررسیکنندهی تشدید، حلقه را میشکند.
-
SequentialAgent: این مانند اجرای یک اسکریپت استاندارد عمل میکند. عاملها را یکی پس از دیگری اجرا میکند. ما از این برای خط لوله سطح بالا استفاده میکنیم:- ابتدا، حلقه تحقیق را اجرا کنید (تا زمانی که با دادههای خوب به پایان برسد).
- سپس، سازنده محتوا را اجرا کنید (برای نوشتن دوره).
با ترکیب این موارد، ما یک سیستم قوی ایجاد میکنیم که میتواند قبل از تولید خروجی نهایی، خود را اصلاح کند.
۳. راهاندازی
راهاندازی پروژه
ایجاد یک پروژه ابری گوگل
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید .
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
شروع پوسته ابری
Cloud Shell یک محیط خط فرمان است که در Google Cloud اجرا میشود و ابزارهای لازم از قبل روی آن بارگذاری شدهاند.
- روی فعال کردن Cloud Shell در بالای کنسول Google Cloud کلیک کنید.
- پس از اتصال به Cloud Shell، احراز هویت خود را تأیید کنید:
gcloud auth list - تأیید کنید که پروژه شما پیکربندی شده است:
gcloud config get project - اگر پروژه شما مطابق انتظار تنظیم نشده است، آن را تنظیم کنید:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
تنظیمات محیط
- باز کردن Cloud Shell : روی آیکون Activate Cloud Shell در بالا سمت راست کنسول Google Cloud کلیک کنید.
کد شروع را دریافت کنید
- مخزن اولیه را در دایرکتوری خانگی خود کپی کنید: به دایرکتوری خانگی خود منتقل شوید
cd ~git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git temp-repo && cd temp-repo && git sparse-checkout set agents/multi-agent-system && cd .. && mv temp-repo/agents/multi-agent-system . && rm -rf temp-repocd multi-agent-system - فعال کردن APIها : دستور زیر را برای فعال کردن سرویسهای لازم Google Cloud اجرا کنید:
gcloud services enable \ run.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - این پوشه را در ویرایشگر خود باز کنید.
cloudshell edit .
محیط راهاندازی
- متغیرهای محیطی را تنظیم کنید. ما یک فایل
.envبرای ذخیره این متغیرها ایجاد خواهیم کرد تا در صورت قطع شدن جلسه، بتوانید به راحتی آنها را دوباره بارگذاری کنید.cat <<EOF > .env export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) export GOOGLE_CLOUD_LOCATION=europe-west4 export GOOGLE_GENAI_USE_VERTEXAI=true EOF - متغیرهای محیطی را منبعیابی کنید:
source .env
۴. 🕵️ نماینده محقق
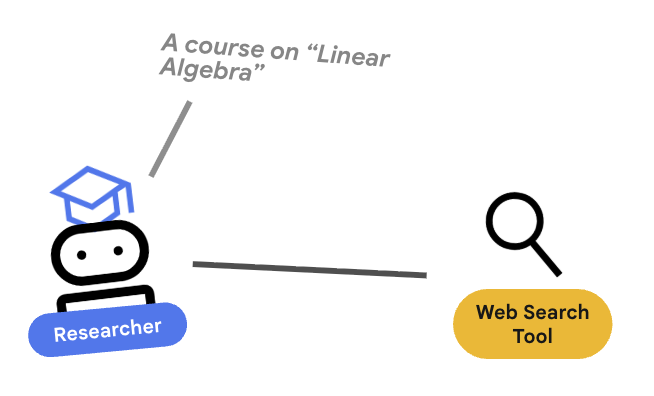
محقق یک متخصص است. تنها وظیفه او یافتن اطلاعات است. برای انجام این کار، به ابزاری نیاز دارد: جستجوی گوگل.
چرا محقق را جدا کنیم؟
بررسی عمیق: چرا فقط یک عامل همه کارها را انجام نمیدهد؟
ارزیابی و اشکالزدایی عاملهای کوچک و متمرکز آسانتر است. اگر تحقیق بد باشد، شما دستورالعمل محقق را تکرار میکنید. اگر قالببندی دوره بد باشد، شما دستورالعمل سازنده محتوا را تکرار میکنید. در یک دستورالعمل یکپارچه «همه کاره»، اصلاح یک چیز اغلب باعث خرابی چیز دیگر میشود.
- اگر در Cloud Shell کار میکنید، دستور زیر را برای باز کردن ویرایشگر Cloud Shell اجرا کنید:
cloudshell workspace . -
agents/researcher/agent.pyرا باز کنید. - کد زیر را که عامل
researcherرا تعریف میکند، بررسی کنید:# ... existing imports ... # Define the Researcher Agent researcher = Agent( name="researcher", model=MODEL, description="Gathers information on a topic using Google Search.", instruction=""" You are an expert researcher. Your goal is to find comprehensive and accurate information on the user's topic. Use the `google_search` tool to find relevant information. Summarize your findings clearly. If you receive feedback that your research is insufficient, use the feedback to refine your next search. """, tools=[google_search], ) root_agent = researcher
مفهوم کلیدی: استفاده از ابزار
توجه داشته باشید که ما tools=[google_search] را ارسال میکنیم. ADK پیچیدگی توصیف این ابزار را به LLM مدیریت میکند. وقتی مدل تصمیم میگیرد که به اطلاعات نیاز دارد، یک فراخوانی ساختاریافته ابزار ایجاد میکند، ADK تابع پایتون google_search اجرا میکند و نتیجه را به مدل بازمیگرداند.
۵. ⚖️ قاضی مامور
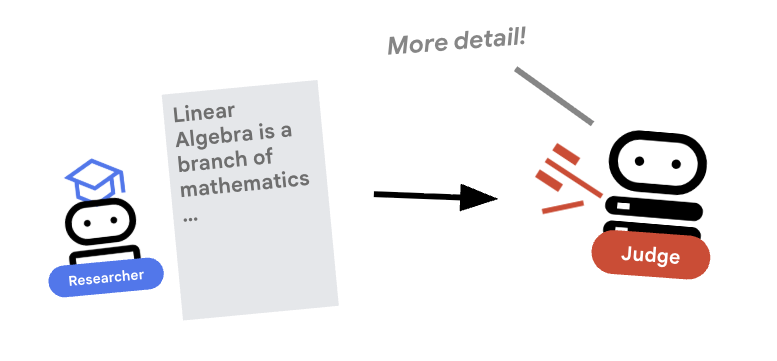
محقق سخت کار میکند، اما دانشجویان کارشناسی ارشد مدیریت بازرگانی میتوانند تنبل باشند. ما به یک داور برای بررسی کار نیاز داریم. داور تحقیق را میپذیرد و یک ارزیابی ساختارمند از قبول/رد ارائه میدهد.
خروجی ساختاریافته
بررسی عمیق: برای خودکارسازی گردشهای کاری، به خروجیهای قابل پیشبینی نیاز داریم. تجزیه و تحلیل یک متن درهم و برهم از طریق برنامهنویسی دشوار است. با اجرای یک طرحواره JSON (با استفاده از Pydantic)، اطمینان حاصل میکنیم که Judge یک pass بولیِ قبول یا fail را برمیگرداند که کد ما میتواند به طور قابل اعتمادی بر اساس آن عمل کند.
-
agents/judge/agent.pyرا باز کنید. - کد زیر را که طرحواره
JudgeFeedbackو عاملjudgeرا تعریف میکند، مرور کنید.# 1. Define the Schema class JudgeFeedback(BaseModel): """Structured feedback from the Judge agent.""" status: Literal["pass", "fail"] = Field( description="Whether the research is sufficient ('pass') or needs more work ('fail')." ) feedback: str = Field( description="Detailed feedback on what is missing. If 'pass', a brief confirmation." ) # 2. Define the Agent judge = Agent( name="judge", model=MODEL, description="Evaluates research findings for completeness and accuracy.", instruction=""" You are a strict editor. Evaluate the 'research_findings' against the user's original request. If the findings are missing key info, return status='fail'. If they are comprehensive, return status='pass'. """, output_schema=JudgeFeedback, # Disallow delegation because it should only output the schema disallow_transfer_to_parent=True, disallow_transfer_to_peers=True, ) root_agent = judge
مفهوم کلیدی: محدود کردن رفتار عامل
ما disallow_transfer_to_parent=True و disallow_transfer_to_peers=True را تنظیم میکنیم. این کار Judge را مجبور میکند که فقط JudgeFeedback ساختاریافته را برگرداند. نمیتواند تصمیم بگیرد که با کاربر "چت" کند یا به عامل دیگری محول کند. این امر آن را به یک جزء قطعی در جریان منطقی ما تبدیل میکند.
۶. ✍️ عامل سازنده محتوا
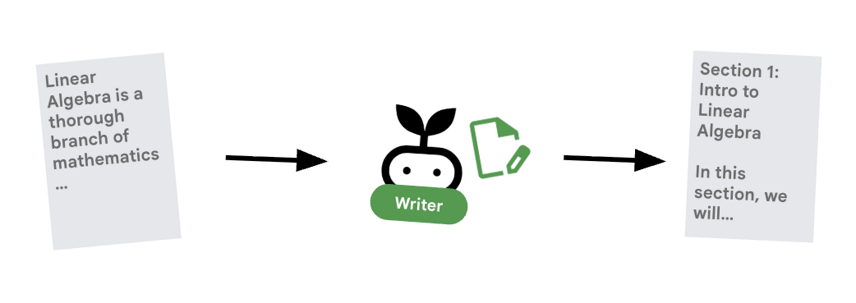
سازنده محتوا ، نویسنده خلاق است. او تحقیقات تایید شده را میگیرد و آن را به یک دوره تبدیل میکند. این نویسنده از مدل Gemma که توسط Cloud Run ارائه میشود، استفاده میکند.
بیایید ابتدا به سرویس Cloud Run که میزبان مدل است نگاهی بیندازیم.
- باز کردن
ollama_backend/Dockerfile - در اینجا میتوانید ببینید که چگونه Dockerfile از یک تصویر Ollama استفاده میکند، به درخواستها روی پورت ۸۰۸۰ گوش میدهد و مدل درخواستی را در پوشه /model ذخیره میکند.
FROM ollama/ollama:latest # Listen on all interfaces, port 8080 (Cloud Run default) ENV OLLAMA_HOST 0.0.0.0:8080 # Store model weight files in /models ENV OLLAMA_MODELS /models
⚙️ هنگام استقرار، تنظیمات زیر را انجام خواهید داد:
- پردازنده گرافیکی : NVIDIA L4 به دلیل نسبت عالی قیمت به عملکرد برای بارهای کاری استنتاج انتخاب شده است. L4 حافظه پردازنده گرافیکی 24 گیگابایتی و عملیات تانسور بهینه شده را فراهم میکند و آن را برای مدلهای پارامتری 270M مانند Gemma ایدهآل میسازد.
- حافظه : ۱۶ گیگابایت حافظه سیستم برای مدیریت بارگذاری مدل، عملیات CUDA و مدیریت حافظه Ollama
- پردازنده : ۸ هسته برای مدیریت بهینه ورودی/خروجی و وظایف پیشپردازش
- همزمانی : ۴ درخواست در هر نمونه، توان عملیاتی را با استفاده از حافظه GPU متعادل میکند.
- زمان انتظار : ۶۰۰ ثانیه برای بارگذاری اولیه مدل و راهاندازی کانتینر
حالا بیایید نگاهی به عامل سازنده محتوا که از مدل Gemma استفاده میکند، بیندازیم.
-
agents/content_builder/agent.pyرا باز کنید. - کد زیر را که عامل
content_builderتعریف میکند، بررسی کنید.
# the `ollama-gemma-gpu` Cloud Run service URL which hosts the Gemma model
target_url = os.environ.get("OLLAMA_API_BASE")
# ... existing code ...
# (Note: We use 'ollama/gemma3:270m' to align with ADK's expected prefix)
gemma_model_name = os.environ.get("GEMMA_MODEL_NAME", "gemma3:270m")
model = LiteLlm(
model=f"ollama_chat/{gemma_model_name}",
api_base=target_url
)
# 5. Define the Agent
content_builder = Agent(
name="content_builder",
model=model,
description="Transforms research findings into a structured course.",
instruction="""
You are an expert course creator.
Take the approved 'research_findings' and transform them into a well-structured, engaging course module.
**Formatting Rules:**
1. Start with a main title using a single `#` (H1).
2. Use `##` (H2) for main section headings. These will be used for the Table of Contents.
3. Use `###` (H3) for sub-sections within main sections.
4. Use bullet points and clear paragraphs.
5. Maintain a professional but engaging tone.
**Structure Requirements:**
- Begin with a brief Introduction section explaining what the learner will gain.
- Organize content into 3-5 main sections with clear headings.
- Include Key Takeaways at the end as a bulleted summary.
- Keep each section focused and concise.
Ensure the content directly addresses the user's original request.
Do not include any preamble or explanation outside the course content itself.
""",
)
root_agent = content_builder
مفهوم کلیدی: انتشار زمینه
ممکن است از خود بپرسید: «سازنده محتوا چگونه میداند که محقق چه چیزی پیدا کرده است؟» در ADK، عوامل در یک خط لوله، session.state را به اشتراک میگذارند. بعداً، در Orchestrator، محقق و قاضی را پیکربندی میکنیم تا خروجیهای خود را در این وضعیت مشترک ذخیره کنند. اعلان سازنده محتوا عملاً به این تاریخچه دسترسی دارد.
۷. 🎻 رهبر ارکستر
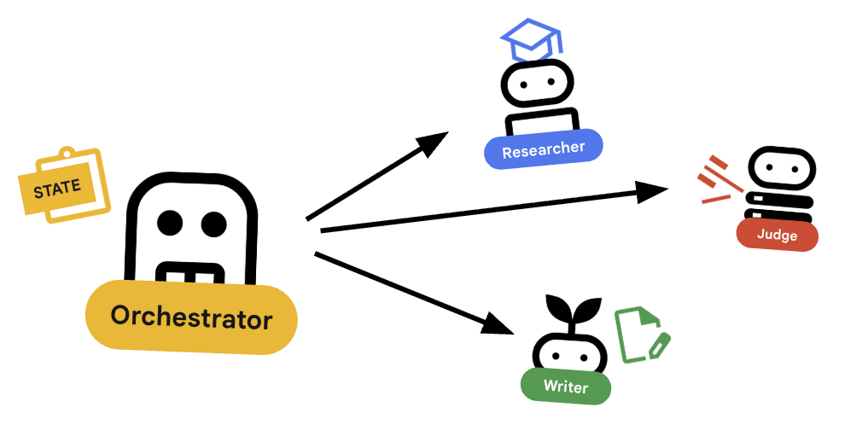
هماهنگکننده، مدیر تیم چندعاملی ما است. برخلاف عوامل متخصص (محقق، قاضی، سازنده محتوا) که وظایف خاصی را انجام میدهند، وظیفه هماهنگکننده، هماهنگی گردش کار و اطمینان از جریان صحیح اطلاعات بین آنها است.
🌐 معماری: عامل به عامل (A2A)
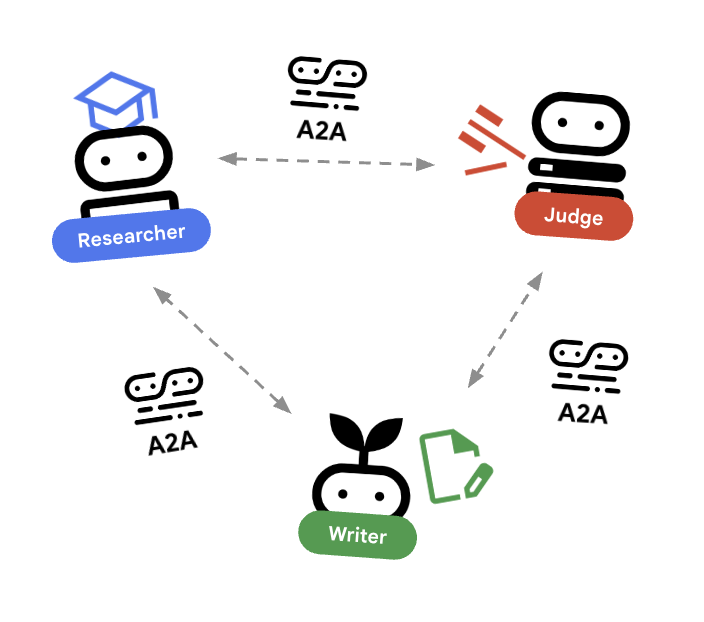
در این آزمایشگاه، ما در حال ساخت یک سیستم توزیعشده هستیم. به جای اجرای همه عاملها در یک فرآیند پایتون واحد، آنها را به عنوان میکروسرویسهای مستقل مستقر میکنیم. این به هر عامل اجازه میدهد تا به طور مستقل مقیاسبندی شود و بدون از کار افتادن کل سیستم، از کار بیفتد.
برای امکانپذیر کردن این امر، ما از پروتکل عامل به عامل (A2A) استفاده میکنیم.
پروتکل A2A
بررسی عمیق: در یک سیستم عملیاتی، عاملها روی سرورهای مختلف (یا حتی ابرهای مختلف) اجرا میشوند. پروتکل A2A یک روش استاندارد برای آنها ایجاد میکند تا یکدیگر را از طریق HTTP کشف و با هم صحبت کنند. RemoteA2aAgent کلاینت ADK برای این پروتکل است.
-
agents/orchestrator/agent.pyرا باز کنید. - کد زیر که اتصالات را تعریف میکند، نحوهی عملکرد آن را بررسی کنید.
# ... existing code ... # Connect to the Researcher (Localhost port 8001) researcher_url = os.environ.get("RESEARCHER_AGENT_CARD_URL", "http://localhost:8001/a2a/agent/.well-known/agent-card.json") researcher = RemoteA2aAgent( name="researcher", agent_card=researcher_url, description="Gathers information using Google Search.", # IMPORTANT: Save the output to state for the Judge to see after_agent_callback=create_save_output_callback("research_findings"), # IMPORTANT: Use authenticated client for communication httpx_client=create_authenticated_client(researcher_url) ) # Connect to the Judge (Localhost port 8002) judge_url = os.environ.get("JUDGE_AGENT_CARD_URL", "http://localhost:8002/a2a/agent/.well-known/agent-card.json") judge = RemoteA2aAgent( name="judge", agent_card=judge_url, description="Evaluates research.", after_agent_callback=create_save_output_callback("judge_feedback"), httpx_client=create_authenticated_client(judge_url) ) # Content Builder (Localhost port 8003) content_builder_url = os.environ.get("CONTENT_BUILDER_AGENT_CARD_URL", "http://localhost:8003/a2a/agent/.well-known/agent-card.json") content_builder = RemoteA2aAgent( name="content_builder", agent_card=content_builder_url, description="Builds the course.", httpx_client=create_authenticated_client(content_builder_url) )
۸. 🛑 بررسیکنندهی افزایش سطح
یک حلقه به راهی برای متوقف شدن نیاز دارد. اگر قاضی بگوید «قبول»، میخواهیم فوراً از حلقه خارج شویم و به سازنده محتوا برویم.
منطق سفارشی با BaseAgent
بررسی عمیق: همه عاملها از LLM استفاده نمیکنند. گاهی اوقات به منطق ساده پایتون نیاز دارید. BaseAgent به شما امکان میدهد عاملی را تعریف کنید که فقط کد را اجرا کند. در این حالت، وضعیت جلسه را بررسی میکنیم و EventActions(escalate=True) برای ارسال سیگنال توقف به LoopAgent استفاده میکنیم.
- هنوز در
agents/orchestrator/agent.py. - کد زیر را بررسی کنید تا بازخورد داور را بررسی کند و در صورت آماده بودن به مرحله بعدی بروید.
class EscalationChecker(BaseAgent): """Checks the judge's feedback and escalates (breaks the loop) if it passed.""" async def _run_async_impl( self, ctx: InvocationContext ) -> AsyncGenerator[Event, None]: # Retrieve the feedback saved by the Judge feedback = ctx.session.state.get("judge_feedback") print(f"[EscalationChecker] Feedback: {feedback}") # Check for 'pass' status is_pass = False if isinstance(feedback, dict) and feedback.get("status") == "pass": is_pass = True # Handle string fallback if JSON parsing failed elif isinstance(feedback, str) and '"status": "pass"' in feedback: is_pass = True if is_pass: # 'escalate=True' tells the parent LoopAgent to stop looping yield Event(author=self.name, actions=EventActions(escalate=True)) else: # Continue the loop yield Event(author=self.name) escalation_checker = EscalationChecker(name="escalation_checker")
مفهوم کلیدی: کنترل جریان از طریق رویدادها
عاملها نه تنها با متن، بلکه با رویدادها نیز ارتباط برقرار میکنند. با ارائه یک رویداد با escalate=True )، این عامل سیگنالی را به والد خود ( LoopAgent ) ارسال میکند. LoopAgent طوری برنامهریزی شده است که این سیگنال را دریافت کرده و حلقه را خاتمه دهد.
۹. 🔁 حلقه تحقیق
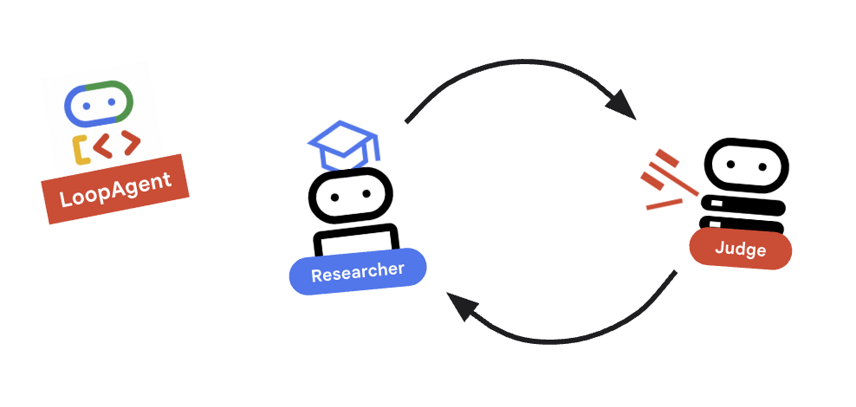
ما به یک حلقه بازخورد نیاز داریم: تحقیق -> قضاوت -> (شکست) -> تحقیق -> ...
- در
agents/orchestrator/agent.py. - بررسی کنید که کد زیر چگونه تعریف
research_loopرا تعریف میکند.research_loop = LoopAgent( name="research_loop", description="Iteratively researches and judges until quality standards are met.", sub_agents=[researcher, judge, escalation_checker], max_iterations=3, )
مفهوم کلیدی: LoopAgent
LoopAgent به ترتیب در میان sub_agents خود میچرخد.
-
researcher: دادهها را پیدا میکند. -
judge: دادهها را ارزیابی میکند. -
escalation_checker: تصمیم میگیرد که آیاyield Event(escalate=True)یا خیر. اگرescalate=Trueرخ دهد، حلقه زودتر متوقف میشود. در غیر این صورت، در محقق (تاmax_iterations) دوباره شروع میشود.
۱۰. 🔗 خط لوله نهایی
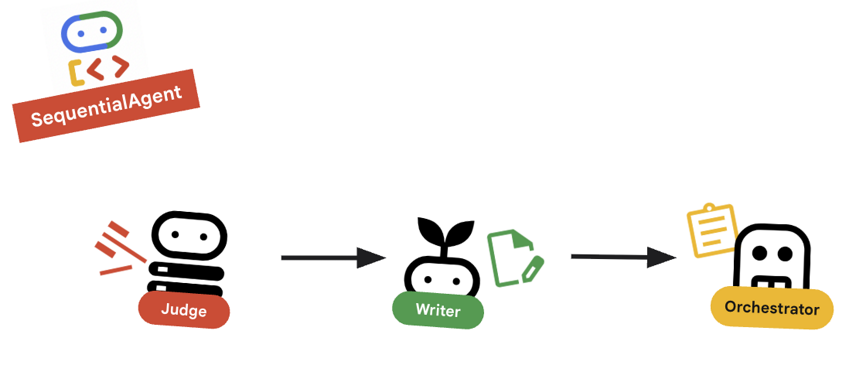
همه رو یه جا جمع کردن....
- در
agents/orchestrator/agent.py. - نحوه تعریف
root_agentرا در پایین فایل بررسی کنید.root_agent = SequentialAgent( name="course_creation_pipeline", description="A pipeline that researches a topic and then builds a course from it.", sub_agents=[research_loop, content_builder], )
مفهوم کلیدی: ترکیب سلسله مراتبی
توجه داشته باشید که research_loop خودش یک عامل (یک LoopAgent ) است. ما با آن درست مانند هر زیرعامل دیگری در SequentialAgent رفتار میکنیم. این قابلیت ترکیب به شما امکان میدهد با تودرتو کردن الگوهای ساده (حلقهها درون توالیها، توالیها درون روترها و غیره) منطق پیچیدهای بسازید.
۱۱. 🚀 استقرار در Cloud Run
ما هر عامل را به عنوان یک سرویس جداگانه در Cloud Run مستقر خواهیم کرد، از جمله یک سرویس Cloud Run برای رابط کاربری سازنده دوره و یک سرویس Cloud Run با استفاده از GPU برای مدل Gemma.
درک پیکربندی استقرار
هنگام استقرار عاملها در Cloud Run، چندین متغیر محیطی را برای پیکربندی رفتار و اتصال آنها ارسال میکنیم:
-
GOOGLE_CLOUD_PROJECT: تضمین میکند که عامل از پروژه صحیح Google Cloud برای ثبت وقایع و فراخوانیهای Vertex AI استفاده میکند. -
GOOGLE_GENAI_USE_VERTEXAI: به چارچوب عامل (ADK) میگوید که به جای فراخوانی مستقیم APIهای Gemini، از Vertex AI برای استنتاج مدل استفاده کند. -
[AGENT]_AGENT_CARD_URL: این برای Orchestrator بسیار مهم است. این به Orchestrator میگوید که کجا میتواند Agentهای از راه دور را پیدا کند. با تنظیم این مورد روی Cloud Run URL مستقر شده (به طور خاص مسیر کارت Agent)، Orchestrator را قادر میسازیم تا محقق، قاضی و سازنده محتوا را از طریق اینترنت کشف و با آنها ارتباط برقرار کند.
برای استقرار همه عاملها در سرویسهای Cloud Run، اسکریپت زیر را اجرا کنید.
ابتدا مطمئن شوید که اسکریپت قابل اجرا است.
chmod u+x ~/multi-agent-system/deploy.sh
توجه داشته باشید که اجرای این دستور چند دقیقه طول میکشد، زیرا هر سرویس به ترتیب مستقر میشود.
~/multi-agent-system/deploy.sh
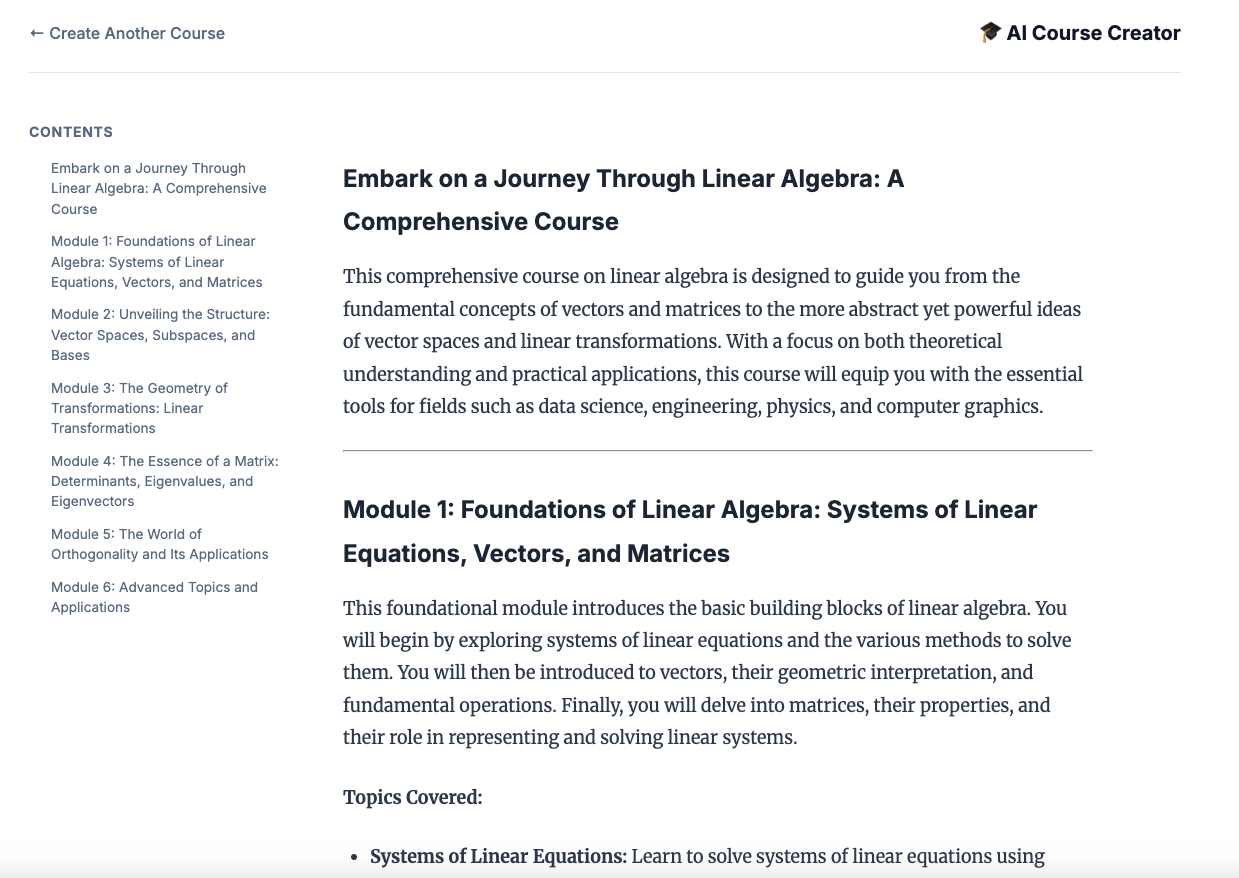
۱۲. یک دوره آموزشی ایجاد کنید!
وبسایت Course Creator را باز کنید. سرویس Course Creator Cloud Run آخرین سرویسی است که از اسکریپت پیادهسازی شده است. میتوانید URL مربوط به سازنده دوره را به صورت https://course-creator- شناسایی کنید. https://course-creator- ، که باید آخرین خط خروجی از اسکریپت استقرار باشد.
و یک ایده درسی، مثلاً «جبر خطی» را تایپ کنید.
نمایندگان شما شروع به کار روی دوره شما خواهند کرد.
۱۳. تمیز کردن
برای جلوگیری از تحمیل هزینه به حساب Google Cloud خود برای منابع استفاده شده در این codelab، این مراحل را برای حذف سرویسها و تصاویر کانتینر خود دنبال کنید.
۱. سرویسهای Cloud Run را حذف کنید
کارآمدترین راه برای پاکسازی، حذف سرویسهایی است که در Cloud Run مستقر کردهاید.
# Delete the main agent and app services
gcloud run services delete researcher content-builder judge orchestrator course-creator \
--region $REGION --quiet
# Delete the GPU backend (Ollama)
gcloud run services delete ollama-gemma-gpu \
--region $OLLAMA_REGION --quiet
۲. تصاویر رجیستری مصنوعات را حذف کنید
وقتی از پرچم --source برای استقرار استفاده کردید، Google Cloud یک مخزن در رجیستری Artifact برای ذخیره تصاویر کانتینر شما ایجاد کرد. برای حذف این تصاویر و صرفهجویی در هزینههای ذخیرهسازی، مخزن را حذف کنید:
gcloud artifacts repositories delete cloud-run-source-deploy --location us-east4 --quiet
۳. حذف فایلهای محلی و محیط
برای تمیز نگه داشتن محیط Cloud Shell، پوشه پروژه و هرگونه پیکربندی محلی را حذف کنید:
cd ~
rm -rf multi-agent-system
۴. (اختیاری) حذف پروژه
اگر پروژهای را فقط برای این آزمایشگاه کد ایجاد کردهاید، میتوانید با بستن خود پروژه از طریق صفحه مدیریت منابع ، اطمینان حاصل کنید که هیچ هزینه دیگری پرداخت نخواهید کرد.
۱۴. تبریک میگویم!
شما با موفقیت یک سیستم چندعاملی توزیعشده و آماده برای تولید را ساخته و مستقر کردهاید.
آنچه شما به انجام رساندهاید
- تجزیه یک وظیفه پیچیده : به جای یک کار بسیار بزرگ، ما کار را به نقشهای تخصصی (محقق، داور، سازنده محتوا) تقسیم کردیم.
- کنترل کیفیت پیادهسازی شده : ما از یک
LoopAgentو یکJudgeساختاریافته استفاده کردیم تا اطمینان حاصل کنیم که فقط اطلاعات با کیفیت بالا به مرحله نهایی میرسند. - ساخته شده برای تولید : با استفاده از پروتکل عامل به عامل (A2A) و Cloud Run ، ما سیستمی ایجاد کردیم که در آن هر عامل یک میکروسرویس مستقل و مقیاسپذیر است. این بسیار قویتر از اجرای همه چیز در یک اسکریپت پایتون است.
- ارکستراسیون : ما از
SequentialAgentوLoopAgentبرای تعریف الگوهای جریان کنترل واضح استفاده کردیم. *. Cloud Run GPUs : یک مدل Gemma را روی یک Cloud Run GPU مستقر کردیم.