
1. מבוא
בשיעור ה-Lab הזה תלמדו איך ליצור מערכת מרובת סוכנים (MAS) מבוזרת, ולא רק צ'אטבוטים פשוטים.
מודל LLM יחיד יכול לענות על שאלות, אבל המורכבות של העולם האמיתי דורשת לעיתים קרובות תפקידים מיוחדים. אתם לא מבקשים ממהנדס ה-Backend לעצב את ממשק המשתמש, ואתם לא מבקשים מהמעצב לבצע אופטימיזציה של שאילתות במסד הנתונים. באופן דומה, אנחנו יכולים ליצור סוכני AI ייעודיים שמתמקדים במשימה אחת ומתואמים ביניהם כדי לפתור בעיות מורכבות.
תבנו מערכת ליצירת קורסים שתכלול:
- סוכן מחקר: שימוש ב-google_search כדי למצוא מידע עדכני.
- סוכן שופט: מבקר את המחקר כדי לבדוק את האיכות והשלמות שלו.
- סוכן ליצירת תוכן: הופך את המחקר לקורס מובנה.
- סוכן Orchestrator: ניהול תהליך העבודה והתקשורת בין המומחים האלה.
מה תלמדו
- הגדרת סוכן (חוקר) שיכול להשתמש בכלי לחיפוש באינטרנט.
- הטמעה של פלט מובנה באמצעות Pydantic בשביל השופט.
- התחברות לסוכנים מרוחקים באמצעות פרוטוקול Agent-to-Agent (A2A).
- כדאי ליצור LoopAgent כדי ליצור לולאת משוב בין החוקר לבין השופט.
- מריצים את המערכת המבוזרת באופן מקומי באמצעות ADK.
- פורסים את המערכת מרובת הסוכנים ב-Google Cloud Run.
- שימוש במודל Gemma ב-GPU של Cloud Run עבור סוכן ליצירת תוכן.
הדרישות
- דפדפן אינטרנט כמו Chrome
- פרויקט ב-Google Cloud שהחיוב בו מופעל
2. עקרונות של ארכיטקטורה ותזמור
קודם כל, נסביר איך הסוכנים האלה עובדים יחד. אנחנו מפתחים צינור ליצירת קורסים.
עיצוב המערכת
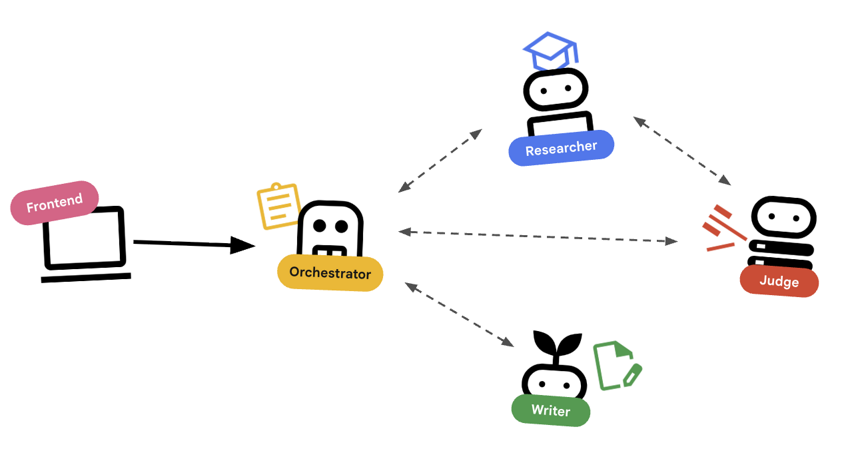
תזמור באמצעות סוכנים
סוכנים רגילים (כמו חוקר) מבצעים עבודה. סוכני תזמור (כמו LoopAgent או SequentialAgent) מנהלים סוכנים אחרים. אין להם כלים משלהם, והכלי שלהם הוא העברת הרשאה.
-
LoopAgent: הפעולה הזו דומה ללולאתwhileבקוד. הוא מריץ רצף של סוכנים שוב ושוב עד שתנאי מסוים מתקיים (או עד שמגיעים למספר המקסימלי של איטרציות). אנחנו משתמשים בזה בשביל לולאת המחקר:- חוקר מוצא מידע.
- שופט נותן ביקורת על התשובה.
- אם Judge אומר 'Fail', EscalationChecker מאפשר להמשיך את הלולאה.
- אם Judge אומר 'Pass', EscalationChecker יוצא מהלולאה.
-
SequentialAgent: הפעולה הזו דומה להרצת סקריפט רגילה. הוא מריץ סוכנים אחד אחרי השני. אנחנו משתמשים בזה בצינור עיבוד הנתונים ברמה גבוהה:- קודם מריצים את Research Loop (עד שהוא מסתיים עם נתונים טובים).
- לאחר מכן, מפעילים את כלי יצירת התוכן (כדי לכתוב את הקורס).
השילוב של כל אלה מאפשר לנו ליצור מערכת חזקה שיכולה לתקן את עצמה לפני יצירת הפלט הסופי.
3. הגדרה
הגדרת הפרויקט
יצירת פרויקט ב-Google Cloud
- במסוף Google Cloud, בדף לבחירת הפרויקט, בוחרים פרויקט ב-Google Cloud או יוצרים פרויקט.
- הקפידו לוודא שהחיוב מופעל בפרויקט שלכם ב-Cloud. כך בודקים אם החיוב מופעל בפרויקט
הפעלת Cloud Shell
Cloud Shell היא סביבת שורת פקודה שפועלת ב-Google Cloud וכוללת מראש את הכלים הנדרשים.
- לוחצים על Activate Cloud Shell בחלק העליון של מסוף Google Cloud.
- אחרי שמתחברים ל-Cloud Shell, מאמתים את האימות:
gcloud auth list - מוודאים שהפרויקט מוגדר:
gcloud config get project - אם הפרויקט לא מוגדר כמו שציפיתם, מגדירים אותו:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
הגדרת הסביבה
- פותחים את Cloud Shell: לוחצים על הסמל Activate Cloud Shell (הפעלת Cloud Shell) בפינה הימנית העליונה של מסוף Google Cloud.
קבלת קוד לתחילת הדרך
- משכפלים את מאגר המתחילים לספריית הבית:עוברים לספריית הבית
cd ~git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git temp-repo && cd temp-repo && git sparse-checkout set agents/multi-agent-system && cd .. && mv temp-repo/agents/multi-agent-system . && rm -rf temp-repocd multi-agent-system - מפעילים ממשקי API: מריצים את הפקודה הבאה כדי להפעיל את שירותי Google Cloud הנדרשים:
gcloud services enable \ run.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - פותחים את התיקייה הזו בכלי העריכה.
cloudshell edit .
הגדרת הסביבה
- מגדירים משתני סביבה.ניצור קובץ
.envלאחסון המשתנים האלה, כדי שתוכלו לטעון אותם מחדש בקלות אם הסשן יתנתק.cat <<EOF > .env export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) export GOOGLE_CLOUD_LOCATION=europe-west4 export GOOGLE_GENAI_USE_VERTEXAI=true EOF - מקור משתני הסביבה:
source .env
4. 🕵️ סוכן המחקר
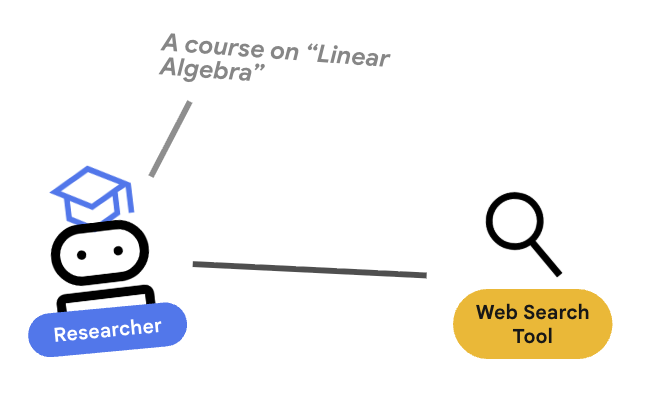
החוקר הוא מומחה. התפקיד היחיד שלו הוא למצוא מידע. כדי לעשות את זה, היא צריכה גישה לכלי: חיפוש Google.
למה כדאי להפריד את הכלי 'מחקר'?
ניתוח מעמיק: למה לא להשתמש רק בסוכן אחד שיעשה הכול?
קל יותר להעריך ולנפות באגים בסוכנים קטנים וממוקדים. אם המחקר לא טוב, משפרים את ההנחיה לחוקר. אם הפורמט של הקורס לא טוב, אפשר לחזור על התהליך ב-Content Builder. בהנחיה מונוליטית שכוללת את כל הפעולות, תיקון של דבר אחד גורם לעיתים קרובות לבעיה בדבר אחר.
- אם אתם עובדים ב-Cloud Shell, מריצים את הפקודה הבאה כדי לפתוח את Cloud Shell Editor:
cloudshell workspace . - פתיחת
agents/researcher/agent.py. - בודקים את הקוד הבא שמגדיר את הסוכן
researcher:# ... existing imports ... # Define the Researcher Agent researcher = Agent( name="researcher", model=MODEL, description="Gathers information on a topic using Google Search.", instruction=""" You are an expert researcher. Your goal is to find comprehensive and accurate information on the user's topic. Use the `google_search` tool to find relevant information. Summarize your findings clearly. If you receive feedback that your research is insufficient, use the feedback to refine your next search. """, tools=[google_search], ) root_agent = researcher
מושג מפתח: שימוש בכלי
שימו לב שאנחנו מעבירים את tools=[google_search]. ערכת ה-ADK מטפלת במורכבות של תיאור הכלי הזה ל-LLM. כשהמודל מחליט שהוא צריך מידע, הוא יוצר קריאה מובנית לכלי, ה-ADK מפעיל את פונקציית Python google_search ומחזיר את התוצאה למודל.
5. ⚖️ סוכן השופט
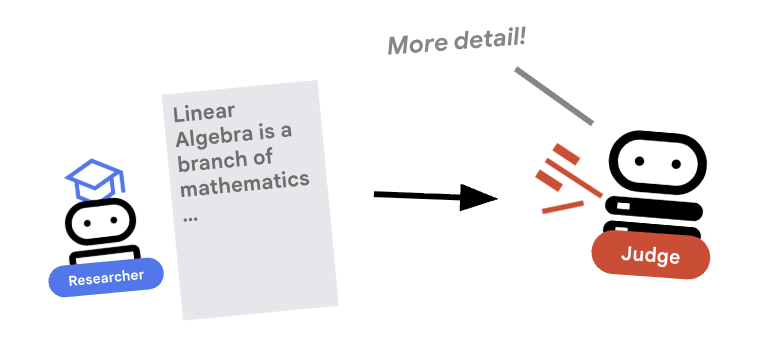
החוקר עובד קשה, אבל מודלים גדולים של שפה יכולים להיות עצלנים. אנחנו צריכים ששופט יבדוק את העבודה. השופט מקבל את המחקר ומחזיר הערכה מובנית של עובר/נכשל.
פלט מובנה
מידע נוסף: כדי להפוך תהליכי עבודה לאוטומטיים, אנחנו צריכים פלט צפוי. קשה לנתח ביקורת טקסט ארוכה ומבולבלת באופן אוטומטי. על ידי אכיפה של סכימת JSON (באמצעות Pydantic), אנחנו מוודאים שהשופט מחזיר ערך בוליאני pass או fail שהקוד שלנו יכול לפעול על פיו בצורה מהימנה.
- פתיחת
agents/judge/agent.py. - בודקים את הקוד הבא שמגדיר את סכימת
JudgeFeedbackואת סוכןjudge.# 1. Define the Schema class JudgeFeedback(BaseModel): """Structured feedback from the Judge agent.""" status: Literal["pass", "fail"] = Field( description="Whether the research is sufficient ('pass') or needs more work ('fail')." ) feedback: str = Field( description="Detailed feedback on what is missing. If 'pass', a brief confirmation." ) # 2. Define the Agent judge = Agent( name="judge", model=MODEL, description="Evaluates research findings for completeness and accuracy.", instruction=""" You are a strict editor. Evaluate the 'research_findings' against the user's original request. If the findings are missing key info, return status='fail'. If they are comprehensive, return status='pass'. """, output_schema=JudgeFeedback, # Disallow delegation because it should only output the schema disallow_transfer_to_parent=True, disallow_transfer_to_peers=True, ) root_agent = judge
מושג מפתח: הגבלת התנהגות של סוכנים
הגדרנו את disallow_transfer_to_parent=True ואת disallow_transfer_to_peers=True. הפעולה הזו גורמת ל-Judge להחזיר רק את הנתונים המובנים JudgeFeedback. הוא לא יכול להחליט להתכתב בצ'אט עם המשתמש או להעביר את הטיפול לסוכן אחר. כך הוא הופך לרכיב דטרמיניסטי בתהליך הלוגי שלנו.
6. ✍️ סוכן ליצירת תוכן
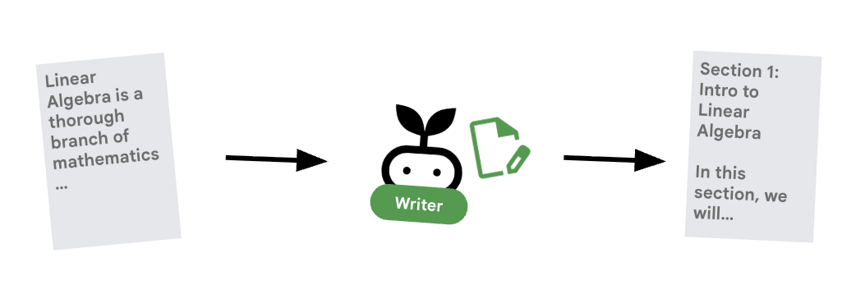
כלי יצירת התוכן הוא הכותב היצירתי. הוא לוקח את המחקר שאושר והופך אותו לקורס. הוא משתמש במודל Gemma שמופעל על ידי Cloud Run.
קודם נסתכל על שירות Cloud Run שמארח את המודל
- פתיחה של
ollama_backend/Dockerfile - כאן אפשר לראות איך קובץ ה-Dockerfile משתמש בקובץ אימג' של Ollama, מקשיב לבקשות ביציאה 8080 ומאחסן את המודל המבוקש בתיקייה /model.
FROM ollama/ollama:latest # Listen on all interfaces, port 8080 (Cloud Run default) ENV OLLAMA_HOST 0.0.0.0:8080 # Store model weight files in /models ENV OLLAMA_MODELS /models
⚙️ כשפורסים את האפליקציה, מגדירים את ההגדרות הבאות:
- GPU: נבחר NVIDIA L4 בגלל יחס המחיר-ביצועים המצוין שלו לעומסי עבודה של הסקת מסקנות. ה-L4 מספק זיכרון GPU של 24GB ופעולות טנסור מותאמות, ולכן הוא אידיאלי למודלים עם 270 מיליון פרמטרים כמו Gemma
- זיכרון: זיכרון מערכת בנפח 16GB לטיפול בטעינת המודל, בפעולות CUDA ובניהול הזיכרון של Ollama
- מעבד (CPU): 8 ליבות לטיפול אופטימלי בקלט/פלט ובמשימות של עיבוד מקדים
- בו-זמניות (concurrency): 4 בקשות לכל מכונה מאזנות את התפוקה עם השימוש בזיכרון ה-GPU
- Timeout: 600 שניות, כדי לאפשר טעינה ראשונית של המודל והפעלה של הקונטיינר
עכשיו נסתכל על סוכן ליצירת תוכן שמשתמש במודל Gemma.
- פתיחת
agents/content_builder/agent.py. - בודקים את הקוד הבא שמגדיר את סוכן
content_builder.
# the `ollama-gemma-gpu` Cloud Run service URL which hosts the Gemma model
target_url = os.environ.get("OLLAMA_API_BASE")
# ... existing code ...
# (Note: We use 'ollama/gemma3:270m' to align with ADK's expected prefix)
gemma_model_name = os.environ.get("GEMMA_MODEL_NAME", "gemma3:270m")
model = LiteLlm(
model=f"ollama_chat/{gemma_model_name}",
api_base=target_url
)
# 5. Define the Agent
content_builder = Agent(
name="content_builder",
model=model,
description="Transforms research findings into a structured course.",
instruction="""
You are an expert course creator.
Take the approved 'research_findings' and transform them into a well-structured, engaging course module.
**Formatting Rules:**
1. Start with a main title using a single `#` (H1).
2. Use `##` (H2) for main section headings. These will be used for the Table of Contents.
3. Use `###` (H3) for sub-sections within main sections.
4. Use bullet points and clear paragraphs.
5. Maintain a professional but engaging tone.
**Structure Requirements:**
- Begin with a brief Introduction section explaining what the learner will gain.
- Organize content into 3-5 main sections with clear headings.
- Include Key Takeaways at the end as a bulleted summary.
- Keep each section focused and concise.
Ensure the content directly addresses the user's original request.
Do not include any preamble or explanation outside the course content itself.
""",
)
root_agent = content_builder
מושג מרכזי: העברת הקשר
יכול להיות שתשאלו: "איך כלי יצירת התוכן יודע מה כלי המחקר מצא?" ב-ADK, סוכנים בצינור משתפים session.state. בהמשך, ב-Orchestrator, נגדיר את Researcher ואת Judge כך שהפלט שלהם יישמר במצב המשותף הזה. ההיסטוריה הזו נגישה להנחיה של הכלי ליצירת תוכן.
7. 🎻 כלי התזמור
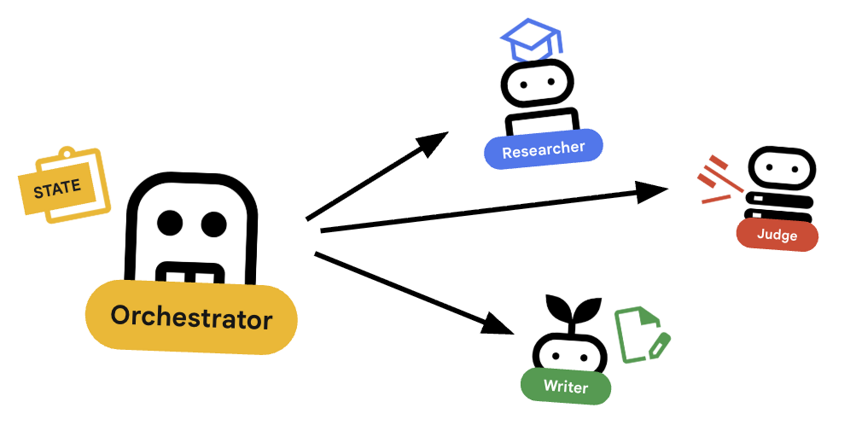
המתזמר הוא המנהל של צוות המולטי-אייג'נט שלנו. בניגוד לסוכנים המומחים (חוקר, שופט, יוצר תוכן) שמבצעים משימות ספציפיות, התפקיד של המנהל הוא לתאם את תהליך העבודה ולוודא שהמידע זורם ביניהם בצורה נכונה.
🌐 הארכיטקטורה: סוכן לסוכן (A2A)
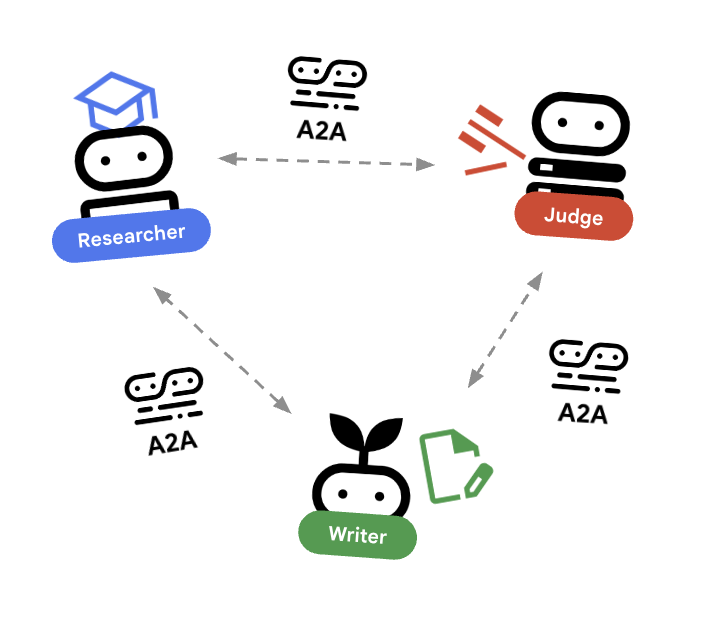
בשיעור ה-Lab הזה נבנה מערכת מבוזרת. במקום להפעיל את כל הסוכנים בתהליך Python יחיד, אנחנו פורסים אותם כמיקרו-שירותים עצמאיים. כך כל סוכן יכול להתרחב באופן עצמאי ולהיכשל בלי לגרום לקריסה של המערכת כולה.
כדי לאפשר את זה, אנחנו משתמשים בפרוטוקול Agent-to-Agent (A2A).
פרוטוקול A2A
הסבר מפורט: במערכת ייצור, סוכנים פועלים בשרתים שונים (או אפילו בעננים שונים). פרוטוקול A2A יוצר דרך סטנדרטית לחיפוש ולתקשורת ביניהם באמצעות HTTP. RemoteA2aAgent הוא לקוח ה-ADK של הפרוטוקול הזה.
- פתיחת
agents/orchestrator/agent.py. - כדאי לעיין בקוד הבא שמגדיר את החיבורים.
# ... existing code ... # Connect to the Researcher (Localhost port 8001) researcher_url = os.environ.get("RESEARCHER_AGENT_CARD_URL", "http://localhost:8001/a2a/agent/.well-known/agent-card.json") researcher = RemoteA2aAgent( name="researcher", agent_card=researcher_url, description="Gathers information using Google Search.", # IMPORTANT: Save the output to state for the Judge to see after_agent_callback=create_save_output_callback("research_findings"), # IMPORTANT: Use authenticated client for communication httpx_client=create_authenticated_client(researcher_url) ) # Connect to the Judge (Localhost port 8002) judge_url = os.environ.get("JUDGE_AGENT_CARD_URL", "http://localhost:8002/a2a/agent/.well-known/agent-card.json") judge = RemoteA2aAgent( name="judge", agent_card=judge_url, description="Evaluates research.", after_agent_callback=create_save_output_callback("judge_feedback"), httpx_client=create_authenticated_client(judge_url) ) # Content Builder (Localhost port 8003) content_builder_url = os.environ.get("CONTENT_BUILDER_AGENT_CARD_URL", "http://localhost:8003/a2a/agent/.well-known/agent-card.json") content_builder = RemoteA2aAgent( name="content_builder", agent_card=content_builder_url, description="Builds the course.", httpx_client=create_authenticated_client(content_builder_url) )
8. 🛑 הכלי לבדיקת העברה לטיפול ברמה גבוהה יותר
צריך שתהיה דרך לעצור לולאה. אם השופט אומר 'עבר', אנחנו רוצים לצאת מהלולאה באופן מיידי ולעבור לכלי ליצירת תוכן.
לוגיקה מותאמת אישית באמצעות BaseAgent
הסבר מפורט: לא כל הנציגים משתמשים ב-LLM. לפעמים צריך לוגיקה פשוטה של Python. BaseAgent מאפשרת להגדיר סוכן שמריץ רק קוד. במקרה כזה, אנחנו בודקים את מצב הסשן ומשתמשים ב-EventActions(escalate=True) כדי לסמן ל-LoopAgent להפסיק.
- עדיין ב-
agents/orchestrator/agent.py. - הקוד הבא בודק את המשוב של השופט ועובר לשלב הבא כשהוא מוכן
class EscalationChecker(BaseAgent): """Checks the judge's feedback and escalates (breaks the loop) if it passed.""" async def _run_async_impl( self, ctx: InvocationContext ) -> AsyncGenerator[Event, None]: # Retrieve the feedback saved by the Judge feedback = ctx.session.state.get("judge_feedback") print(f"[EscalationChecker] Feedback: {feedback}") # Check for 'pass' status is_pass = False if isinstance(feedback, dict) and feedback.get("status") == "pass": is_pass = True # Handle string fallback if JSON parsing failed elif isinstance(feedback, str) and '"status": "pass"' in feedback: is_pass = True if is_pass: # 'escalate=True' tells the parent LoopAgent to stop looping yield Event(author=self.name, actions=EventActions(escalate=True)) else: # Continue the loop yield Event(author=self.name) escalation_checker = EscalationChecker(name="escalation_checker")
מושג מרכזי: בקרה על זרימת נתונים באמצעות אירועים
הסוכנים מתקשרים לא רק באמצעות טקסט, אלא גם באמצעות אירועים. על ידי הפקת אירוע באמצעות escalate=True, הסוכן הזה שולח אות אל ההורה שלו (LoopAgent). ה-LoopAgent מתוכנת לזהות את האות הזה ולסיים את הלולאה.
9. 🔁 מחזור המחקר
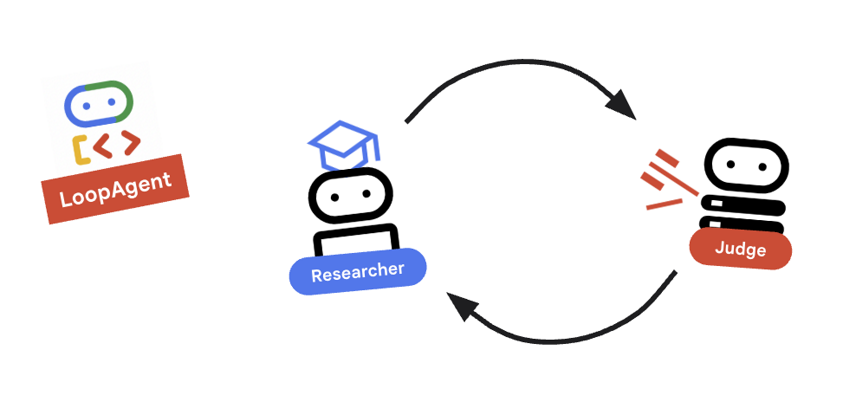
אנחנו צריכים לולאת משוב: מחקר -> שיפוט -> (כישלון) -> מחקר -> ...
- ב-
agents/orchestrator/agent.py. - כדאי לעיין בהגדרה של
research_loopבקוד הבא.research_loop = LoopAgent( name="research_loop", description="Iteratively researches and judges until quality standards are met.", sub_agents=[researcher, judge, escalation_checker], max_iterations=3, )
מושג מרכזי: LoopAgent
האפשרות LoopAgent עוברת בין sub_agents לפי הסדר.
-
researcher: חיפוש נתונים. -
judge: הערכת נתונים. escalation_checker: קובע אםyield Event(escalate=True). אם מתרחשescalate=True, הלולאה נשברת מוקדם. אחרת, הוא יופעל מחדש אצל החוקר (עדmax_iterations).
10. 🔗 צינור עיבוד הנתונים הסופי
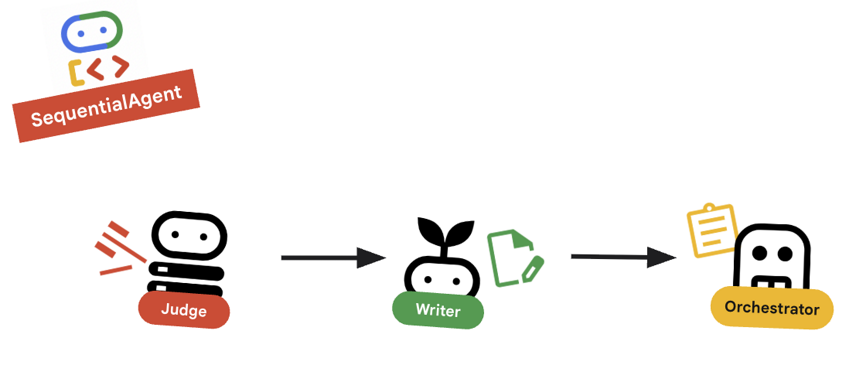
מסכמים בשבילך את כל המידע...
- ב-
agents/orchestrator/agent.py. - בודקים איך
root_agentמוגדר בחלק התחתון של הקובץ.root_agent = SequentialAgent( name="course_creation_pipeline", description="A pipeline that researches a topic and then builds a course from it.", sub_agents=[research_loop, content_builder], )
מושג מרכזי: קומפוזיציה היררכית
שימו לב ש-research_loop הוא סוכן בעצמו (LoopAgent). אנחנו מתייחסים אליו כמו לכל סוכן משנה אחר ב-SequentialAgent. האפשרות הזו מאפשרת לכם לבנות לוגיקה מורכבת על ידי קינון של דפוסים פשוטים (לולאות בתוך רצפים, רצפים בתוך נתבים וכו').
11. 🚀 פריסה ב-Cloud Run
נפרוס כל סוכן כשירות נפרד ב-Cloud Run, כולל שירות Cloud Run לממשק המשתמש של יוצר הקורס ושירות Cloud Run שמשתמש ב-GPU למודל Gemma.
הסבר על הגדרת הפריסה
כשפורסים סוכנים ב-Cloud Run, אנחנו מעבירים כמה משתני סביבה כדי להגדיר את ההתנהגות והקישוריות שלהם:
-
GOOGLE_CLOUD_PROJECT: מוודא שהנציג משתמש בפרויקט הנכון ב-Google Cloud לרישום ביומן ולקריאות ל-Vertex AI. -
GOOGLE_GENAI_USE_VERTEXAI: מציין ל-Agent Development Kit (ADK) להשתמש ב-Vertex AI להסקת מסקנות ממודלים במקום להפעיל ישירות את Gemini API. -
[AGENT]_AGENT_CARD_URL: זהו נתון חיוני עבור כלי התזמור. הוא מציין ל-Orchestrator איפה נמצאים הסוכנים המרוחקים. הגדרת הערך הזה לכתובת ה-URL של Cloud Run שנפרסה (בספציפיות, הנתיב של כרטיס הסוכן) מאפשרת ל-Orchestrator לגלות את Researcher, Judge ו-Content Builder ולתקשר איתם באינטרנט.
כדי לפרוס את כל הסוכנים לשירותי Cloud Run, מריצים את הסקריפט הבא.
קודם כל, מוודאים שהסקריפט ניתן להרצה.
chmod u+x ~/multi-agent-system/deploy.sh
הערה התהליך יימשך כמה דקות כי כל שירות נפרס ברצף.
~/multi-agent-system/deploy.sh
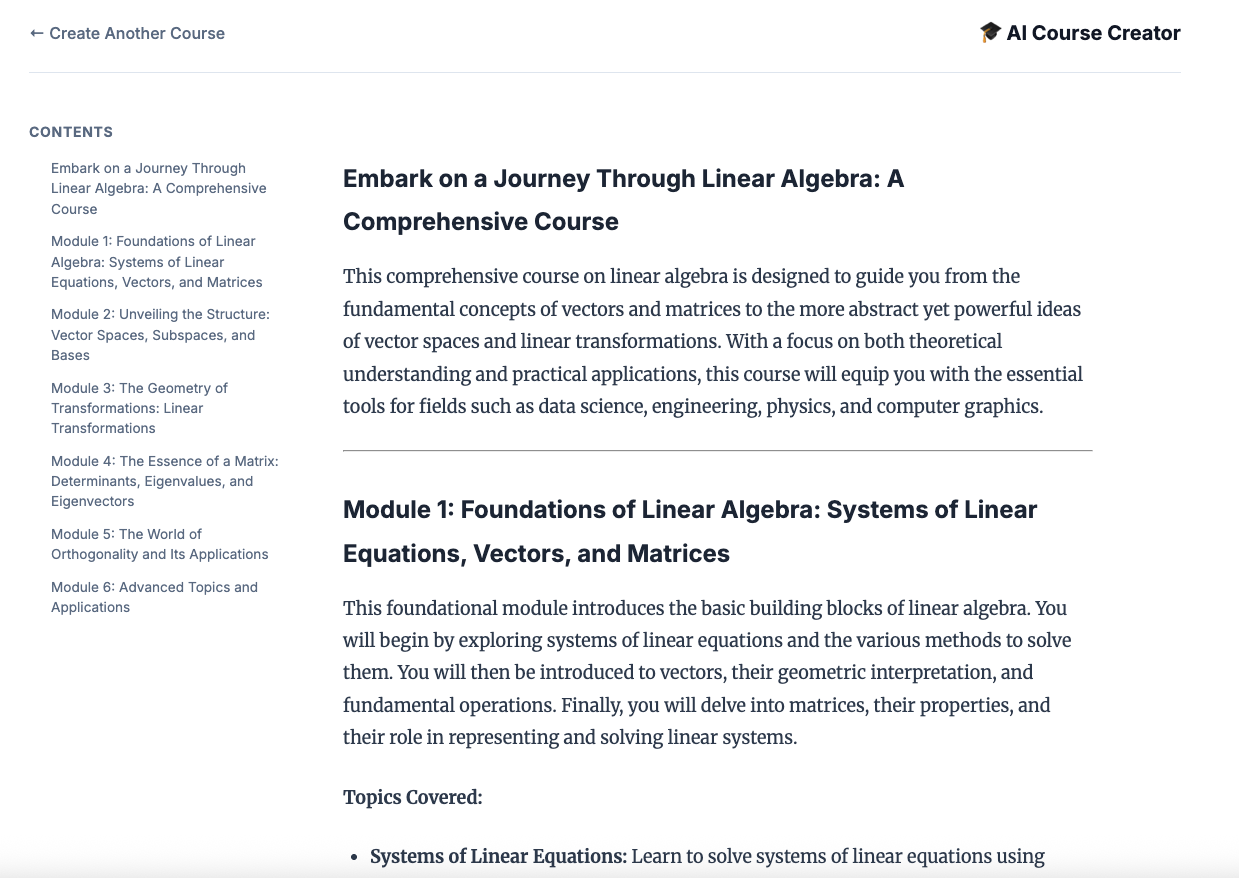
12. יוצרים קורס!
פותחים את האתר של הכלי ליצירת קורסים. שירות Cloud Run של כלי יצירת הקורסים הוא השירות האחרון שנפרס מהסקריפט. אפשר לזהות את כתובת ה-URL של יוצר הקורס כ-https://course-creator-, שצריכה להיות שורת הפלט הסופית מסקריפט הפריסה.
מקלידים רעיון לקורס, למשל 'אלגברה לינארית'.
הסוכנים יתחילו לעבוד על הקורס.
13. מחיקה
כדי לא לצבור חיובים לחשבון Google Cloud על המשאבים שבהם השתמשתם ב-codelab הזה, צריך למחוק את השירותים ואת קובצי האימג' של הקונטיינרים.
1. מחיקת שירותי Cloud Run
הדרך הכי יעילה לנקות היא למחוק את השירותים שפרסתם ב-Cloud Run.
# Delete the main agent and app services
gcloud run services delete researcher content-builder judge orchestrator course-creator \
--region $REGION --quiet
# Delete the GPU backend (Ollama)
gcloud run services delete ollama-gemma-gpu \
--region $OLLAMA_REGION --quiet
2. מחיקת תמונות מ-Artifact Registry
כשמשתמשים בדגל --source לפריסה, Google Cloud יוצר מאגר ב-Artifact Registry כדי לאחסן את קובצי האימג' של הקונטיינרים. כדי להסיר את הנתונים האלה ולחסוך בעלויות אחסון, צריך למחוק את המאגר:
gcloud artifacts repositories delete cloud-run-source-deploy --location us-east4 --quiet
3. הסרת קבצים מקומיים וסביבה
כדי לשמור על סביבת Cloud Shell נקייה, מסירים את תיקיית הפרויקט ואת ההגדרות המקומיות:
cd ~
rm -rf multi-agent-system
4. (אופציונלי) מחיקת הפרויקט
אם יצרתם פרויקט רק בשביל ה-Codelab הזה, תוכלו להשבית את הפרויקט עצמו דרך הדף 'ניהול משאבים' כדי לוודא שלא יחויבו חיובים נוספים.
14. מעולה!
יצרתם ופרסתם בהצלחה מערכת מרובת סוכנים מבוזרת שמוכנה לייצור.
ההישגים שלכם
- פירוק משימה מורכבת: במקום הנחיה אחת גדולה, פיצלנו את העבודה לתפקידים מיוחדים (חוקר, שופט, יוצר תוכן).
- הטמענו בקרת איכות: השתמשנו ב
LoopAgentובJudgeמובנה כדי להבטיח שרק מידע באיכות גבוהה יגיע לשלב הסופי. - מיועד לשימוש בסביבת ייצור: באמצעות פרוטוקול Agent-to-Agent (A2A) ו-Cloud Run, יצרנו מערכת שבה כל סוכן הוא מיקרו-שירות עצמאי שניתן להתאמה. השיטה הזו אמינה הרבה יותר מאשר הפעלה של הכול בסקריפט Python יחיד.
- תזמור: השתמשנו ב-
SequentialAgentוב-LoopAgentכדי להגדיר דפוסי זרימת בקרה ברורים. *. Cloud Run GPUs: Deployed a Gemma model to a Cloud Run GPU