
1. はじめに
このラボでは、単純な chatbot を超えて、分散型マルチエージェント システムを構築します。
1 つの LLM で質問に回答できますが、現実世界の複雑さには専門的な役割が必要になることがよくあります。バックエンド エンジニアに UI の設計を依頼したり、デザイナーにデータベース クエリの最適化を依頼したりすることはありません。同様に、1 つのタスクに焦点を当てた専門的な AI エージェントを作成し、それらを連携させて複雑な問題を解決することもできます。
次の要素で構成されるコース作成システムを構築します。
- リサーチャー エージェント: google_search を使用して最新情報を検索します。
- 評価担当エージェント: 調査の品質と完全性を評価します。
- コンテンツ ビルダー エージェント: 調査結果を構造化されたコースに変換します。
- オーケストレーター エージェント: これらのスペシャリスト間のワークフローとコミュニケーションを管理します。
学習内容
- ウェブを検索できるツール使用エージェント(研究者)を定義します。
- Pydantic を使用して、審査員の構造化出力を実装します。
- エージェント間(A2A)プロトコルを使用してリモート エージェントに接続します。
- LoopAgent を構築して、研究者と審査員の間にフィードバック ループを作成します。
- ADK を使用して分散システムをローカルで実行します。
- マルチエージェント システムを Google Cloud Run にデプロイします。
- コンテンツ ビルダー エージェントに Cloud Run GPU で Gemma モデルを使用する。
必要なもの
- ウェブブラウザ(Chrome など)
- 課金を有効にした Google Cloud プロジェクト
2. アーキテクチャとオーケストレーションの原則
まず、これらのエージェントがどのように連携して機能するかを理解しましょう。コース作成パイプラインを構築します。
システム設計
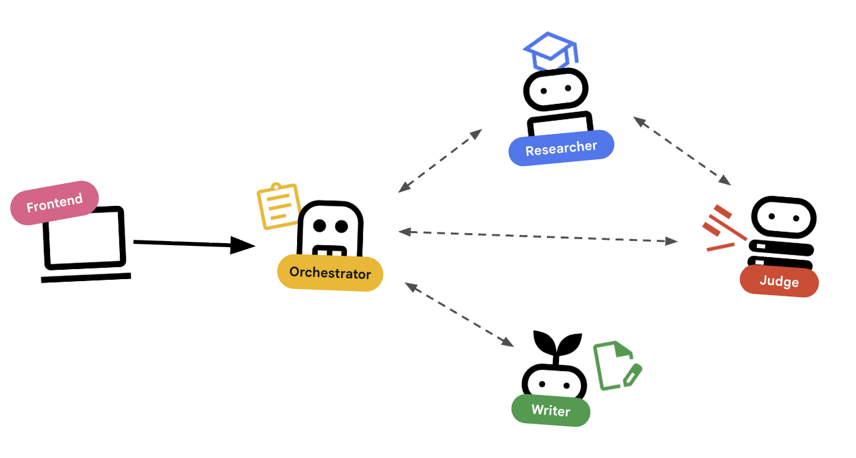
エージェントによるオーケストレーション
標準エージェント(Researcher など)は機能します。オーケストレーター エージェント(LoopAgent や SequentialAgent など)は、他のエージェントを管理します。独自のツールはありません。委任が「ツール」です。
LoopAgent: コード内のwhileループのように動作します。条件が満たされる(または最大イテレーション回数に達する)まで、エージェントのシーケンスを繰り返し実行します。これは、リサーチ ループで使用されます。- 調査担当が情報を見つけます。
- Judge が批判します。
- ジャッジが「不合格」と判断した場合、EscalationChecker はループを続行します。
- ジャッジが「合格」と判断した場合、EscalationChecker がループを抜けます。
SequentialAgent: 標準のスクリプト実行と同様に動作します。エージェントを 1 つずつ実行します。これは、高レベルのパイプラインに使用されます。- まず、Research Loop を実行します(適切なデータが得られるまで)。
- 次に、コンテンツ ビルダーを実行してコースを作成します。
これらを組み合わせることで、最終的な出力を生成する前に自己修正できる堅牢なシステムが作成されます。
3. セットアップ
プロジェクトの設定
Google Cloud プロジェクトの作成
- Google Cloud コンソールのプロジェクト セレクタ ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
Cloud Shell の起動
Cloud Shell は、必要なツールがプリロードされた Google Cloud で動作するコマンドライン環境です。
- Google Cloud コンソールの上部にある [Cloud Shell をアクティブにする] をクリックします。
- Cloud Shell に接続したら、認証を確認します。
gcloud auth list - プロジェクトが構成されていることを確認します。
gcloud config get project - プロジェクトが想定どおりに設定されていない場合は、設定します。
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
環境設定
- Cloud Shell を開く: Google Cloud コンソールの右上にある [Cloud Shell をアクティブにする] アイコンをクリックします。
スターター コードを取得する
- スターター リポジトリのクローンをホーム ディレクトリに作成します。ホーム ディレクトリに移動します。
cd ~git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git temp-repo && cd temp-repo && git sparse-checkout set agents/multi-agent-system && cd .. && mv temp-repo/agents/multi-agent-system . && rm -rf temp-repocd multi-agent-system - API を有効にする: 次のコマンドを実行して、必要な Google Cloud サービスを有効にします。
gcloud services enable \ run.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - このフォルダをエディタで開きます。
cloudshell edit .
環境を設定する
- 環境変数を設定します。セッションが切断された場合に簡単に再読み込みできるように、これらの変数を格納する
.envファイルを作成します。cat <<EOF > .env export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) export GOOGLE_CLOUD_LOCATION=europe-west4 export GOOGLE_GENAI_USE_VERTEXAI=true EOF - 環境変数を取得します。
source .env
4. 🕵️ リサーチ エージェント
調査担当はスペシャリストです。その唯一の仕事は情報を見つけることです。そのためには、Google 検索というツールにアクセスする必要があります。
リサーチャーを分離する理由
詳細: 1 つのエージェントですべてを実行しないのはなぜですか?
小規模で集中的なエージェントは、評価とデバッグが容易です。調査が不十分な場合は、リサーチャーのプロンプトを繰り返し調整します。コースの書式設定が適切でない場合は、コンテンツ ビルダーを繰り返し使用します。モノリシックな「万能」プロンプトでは、1 つの修正が別の修正を壊すことがよくあります。
- Cloud Shell で作業している場合は、次のコマンドを実行して Cloud Shell エディタを開きます。
cloudshell workspace . agents/researcher/agent.pyを開きます。researcherエージェントを定義する次のコードを確認します。# ... existing imports ... # Define the Researcher Agent researcher = Agent( name="researcher", model=MODEL, description="Gathers information on a topic using Google Search.", instruction=""" You are an expert researcher. Your goal is to find comprehensive and accurate information on the user's topic. Use the `google_search` tool to find relevant information. Summarize your findings clearly. If you receive feedback that your research is insufficient, use the feedback to refine your next search. """, tools=[google_search], ) root_agent = researcher
重要なコンセプト: ツールの使用
tools=[google_search] を渡していることに注意してください。ADK は、このツールを LLM に説明する複雑さを処理します。モデルが必要な情報を判断すると、構造化されたツール呼び出しが生成され、ADK が Python 関数 google_search を実行し、結果をモデルにフィードバックします。
5. ⚖️ ジャッジ エージェント
研究者は熱心に作業しますが、LLM は怠け者になることがあります。作業をレビューするジャッジが必要です。ジャッジはリサーチを受け入れ、構造化された合格/不合格の評価を返します。
構造化出力
詳細: ワークフローを自動化するには、予測可能な出力が必要です。長文のテキスト レビューは、プログラムで解析するのが困難です。JSON スキーマ(Pydantic を使用)を適用することで、Judge がブール値 pass または fail を返し、コードが確実に動作するようにします。
agents/judge/agent.pyを開きます。JudgeFeedbackスキーマとjudgeエージェントを定義する次のコードを確認します。# 1. Define the Schema class JudgeFeedback(BaseModel): """Structured feedback from the Judge agent.""" status: Literal["pass", "fail"] = Field( description="Whether the research is sufficient ('pass') or needs more work ('fail')." ) feedback: str = Field( description="Detailed feedback on what is missing. If 'pass', a brief confirmation." ) # 2. Define the Agent judge = Agent( name="judge", model=MODEL, description="Evaluates research findings for completeness and accuracy.", instruction=""" You are a strict editor. Evaluate the 'research_findings' against the user's original request. If the findings are missing key info, return status='fail'. If they are comprehensive, return status='pass'. """, output_schema=JudgeFeedback, # Disallow delegation because it should only output the schema disallow_transfer_to_parent=True, disallow_transfer_to_peers=True, ) root_agent = judge
重要なコンセプト: エージェントの動作を制限する
disallow_transfer_to_parent=True と disallow_transfer_to_peers=True を設定します。これにより、Judge は構造化された JudgeFeedback のみを返すようになります。ユーザーと「チャット」したり、別のエージェントに委任したりすることはできません。これにより、ロジックフローの決定論的コンポーネントになります。
6. ✍️ コンテンツ ビルダー エージェント
コンテンツ ビルダーはクリエイティブ ライターです。承認された研究をコースに変換します。Cloud Run によってサービングされる Gemma モデルを使用します。
まず、モデルをホストする Cloud Run サービスを見てみましょう。
ollama_backend/Dockerfileを開く- ここでは、Dockerfile が Ollama イメージを使用し、ポート 8080 でリクエストをリッスンし、リクエストされたモデルを /model フォルダに保存する方法を確認できます。
FROM ollama/ollama:latest # Listen on all interfaces, port 8080 (Cloud Run default) ENV OLLAMA_HOST 0.0.0.0:8080 # Store model weight files in /models ENV OLLAMA_MODELS /models
⚙️ デプロイ時に、次の構成を設定します。
- GPU: 推論ワークロードの費用対効果に優れている NVIDIA L4 を選択。L4 は 24 GB の GPU メモリと最適化されたテンソル オペレーションを備えており、Gemma などの 2 億 7, 000 万のパラメータ モデルに最適です。
- メモリ: モデルの読み込み、CUDA オペレーション、Ollama のメモリ管理を処理するための 16 GB のシステム メモリ
- CPU: 最適な I/O 処理と前処理タスクのための 8 コア
- 同時実行数: インスタンスあたり 4 つのリクエストで、スループットと GPU メモリ使用量のバランスを取ります。
- タイムアウト: 600 秒は、モデルの初期読み込みとコンテナの起動に対応します。
次に、Gemma モデルを使用するコンテンツ ビルダー エージェントを見てみましょう。
agents/content_builder/agent.pyを開きます。content_builderエージェントを定義する次のコードを確認します。
# the `ollama-gemma-gpu` Cloud Run service URL which hosts the Gemma model
target_url = os.environ.get("OLLAMA_API_BASE")
# ... existing code ...
# (Note: We use 'ollama/gemma3:270m' to align with ADK's expected prefix)
gemma_model_name = os.environ.get("GEMMA_MODEL_NAME", "gemma3:270m")
model = LiteLlm(
model=f"ollama_chat/{gemma_model_name}",
api_base=target_url
)
# 5. Define the Agent
content_builder = Agent(
name="content_builder",
model=model,
description="Transforms research findings into a structured course.",
instruction="""
You are an expert course creator.
Take the approved 'research_findings' and transform them into a well-structured, engaging course module.
**Formatting Rules:**
1. Start with a main title using a single `#` (H1).
2. Use `##` (H2) for main section headings. These will be used for the Table of Contents.
3. Use `###` (H3) for sub-sections within main sections.
4. Use bullet points and clear paragraphs.
5. Maintain a professional but engaging tone.
**Structure Requirements:**
- Begin with a brief Introduction section explaining what the learner will gain.
- Organize content into 3-5 main sections with clear headings.
- Include Key Takeaways at the end as a bulleted summary.
- Keep each section focused and concise.
Ensure the content directly addresses the user's original request.
Do not include any preamble or explanation outside the course content itself.
""",
)
root_agent = content_builder
主なコンセプト: コンテキストの伝播
「コンテンツ ビルダーは、リサーチャーが見つけたものをどのようにして知るのですか?」という疑問が生じるかもしれません。ADK では、パイプライン内のエージェントは session.state を共有します。後で、Orchestrator で、この共有状態に出力を保存するように Researcher と Judge を構成します。コンテンツ ビルダーのプロンプトは、この履歴に効果的にアクセスできます。
7. 🎻 オーケストレーター
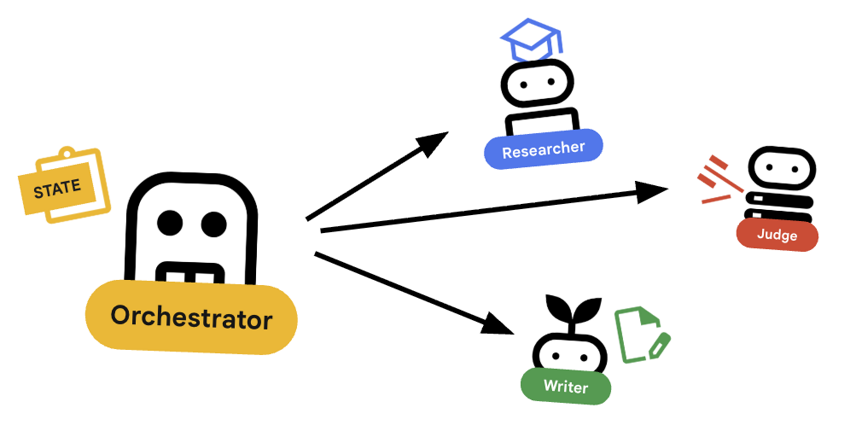
オーケストレーターは、マルチエージェント チームのマネージャーです。特定のタスクを実行するスペシャリスト エージェント(リサーチャー、ジャッジ、コンテンツ ビルダー)とは異なり、オーケストレーターの仕事はワークフローを調整し、エージェント間で情報が正しく流れるようにすることです。
🌐 アーキテクチャ: Agent-to-Agent(A2A)
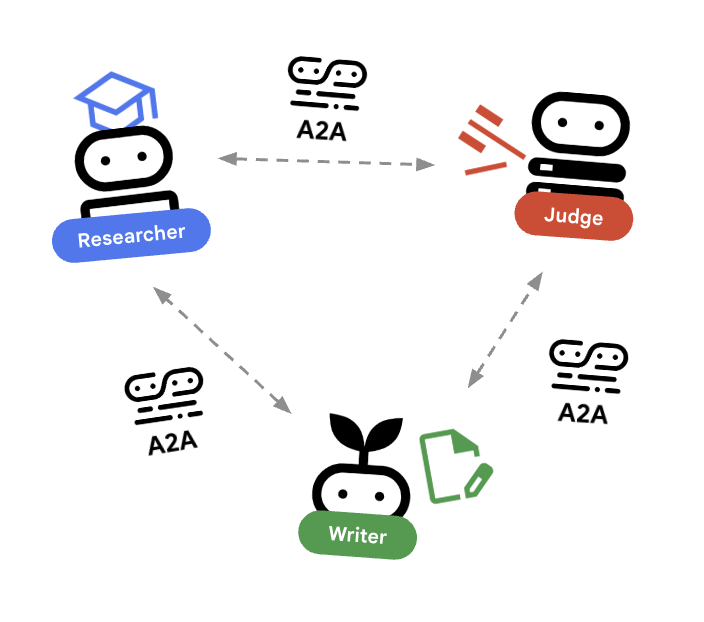
このラボでは、分散システムを構築します。すべてのエージェントを単一の Python プロセスで実行するのではなく、独立したマイクロサービスとしてデプロイします。これにより、各エージェントは個別にスケーリングでき、システム全体をクラッシュさせることなく障害が発生します。
これを実現するために、Agent-to-Agent(A2A)プロトコルを使用します。
A2A プロトコル
詳細: 本番環境システムでは、エージェントは異なるサーバー(または異なるクラウド)で実行されます。A2A プロトコルは、HTTP 経由で互いを検出し、通信するための標準的な方法を確立します。RemoteA2aAgent は、このプロトコルの ADK クライアントです。
agents/orchestrator/agent.pyを開きます。- 次のコードで接続がどのように定義されているかを確認します。
# ... existing code ... # Connect to the Researcher (Localhost port 8001) researcher_url = os.environ.get("RESEARCHER_AGENT_CARD_URL", "http://localhost:8001/a2a/agent/.well-known/agent-card.json") researcher = RemoteA2aAgent( name="researcher", agent_card=researcher_url, description="Gathers information using Google Search.", # IMPORTANT: Save the output to state for the Judge to see after_agent_callback=create_save_output_callback("research_findings"), # IMPORTANT: Use authenticated client for communication httpx_client=create_authenticated_client(researcher_url) ) # Connect to the Judge (Localhost port 8002) judge_url = os.environ.get("JUDGE_AGENT_CARD_URL", "http://localhost:8002/a2a/agent/.well-known/agent-card.json") judge = RemoteA2aAgent( name="judge", agent_card=judge_url, description="Evaluates research.", after_agent_callback=create_save_output_callback("judge_feedback"), httpx_client=create_authenticated_client(judge_url) ) # Content Builder (Localhost port 8003) content_builder_url = os.environ.get("CONTENT_BUILDER_AGENT_CARD_URL", "http://localhost:8003/a2a/agent/.well-known/agent-card.json") content_builder = RemoteA2aAgent( name="content_builder", agent_card=content_builder_url, description="Builds the course.", httpx_client=create_authenticated_client(content_builder_url) )
8. 🛑 エスカレーション チェッカー
ループには停止する方法が必要です。ジャッジが「合格」と判断した場合は、すぐにループを抜けてコンテンツ ビルダーに移動します。
BaseAgent を使用したカスタム ロジック
詳細: すべてのエージェントが LLM を使用するわけではありません。シンプルな Python ロジックが必要になることがあります。BaseAgent を使用すると、コードを実行するだけのエージェントを定義できます。この場合、セッションの状態を確認し、EventActions(escalate=True) を使用して LoopAgent に停止を通知します。
- 引き続き
agents/orchestrator/agent.pyで、 - 次のコードは、審査員のフィードバックを確認し、準備ができたら次のステップに進みます。
class EscalationChecker(BaseAgent): """Checks the judge's feedback and escalates (breaks the loop) if it passed.""" async def _run_async_impl( self, ctx: InvocationContext ) -> AsyncGenerator[Event, None]: # Retrieve the feedback saved by the Judge feedback = ctx.session.state.get("judge_feedback") print(f"[EscalationChecker] Feedback: {feedback}") # Check for 'pass' status is_pass = False if isinstance(feedback, dict) and feedback.get("status") == "pass": is_pass = True # Handle string fallback if JSON parsing failed elif isinstance(feedback, str) and '"status": "pass"' in feedback: is_pass = True if is_pass: # 'escalate=True' tells the parent LoopAgent to stop looping yield Event(author=self.name, actions=EventActions(escalate=True)) else: # Continue the loop yield Event(author=self.name) escalation_checker = EscalationChecker(name="escalation_checker")
重要なコンセプト: イベントによる制御フロー
エージェントは、テキストだけでなくイベントでも通信します。escalate=True でイベントを生成することで、このエージェントは親(LoopAgent)にシグナルを送信します。LoopAgent は、このシグナルをキャッチしてループを終了するようにプログラムされています。
9. 🔁 リサーチ ループ
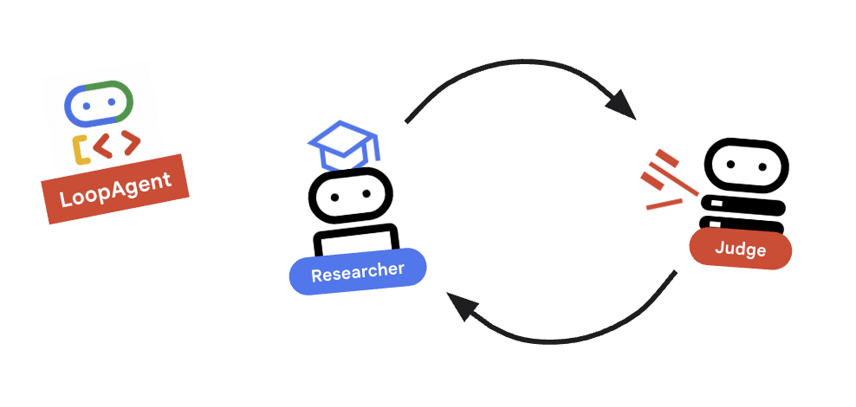
フィードバック ループが必要です。調査 -> 判断 -> (失敗) -> 調査 -> ...
agents/orchestrator/agent.py内。- 次のコードで
research_loopの定義がどのように行われているかを確認します。research_loop = LoopAgent( name="research_loop", description="Iteratively researches and judges until quality standards are met.", sub_agents=[researcher, judge, escalation_checker], max_iterations=3, )
重要なコンセプト: LoopAgent
LoopAgent は sub_agents を順番に切り替えます。
researcher: データを検索します。judge: データを評価します。escalation_checker:yield Event(escalate=True)するかどうかを決定します。escalate=Trueが発生すると、ループは早期に終了します。それ以外の場合は、研究者で再開されます(最大max_iterations)。
10. 🔗 最終的なパイプライン
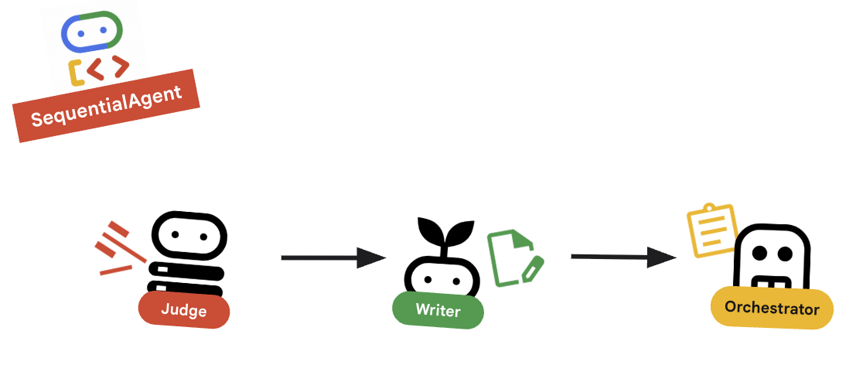
まとめ
agents/orchestrator/agent.py内。- ファイルの下部で
root_agentがどのように定義されているかを確認します。root_agent = SequentialAgent( name="course_creation_pipeline", description="A pipeline that researches a topic and then builds a course from it.", sub_agents=[research_loop, content_builder], )
重要なコンセプト: 階層構成
research_loop はエージェント(LoopAgent)です。SequentialAgent の他のサブエージェントと同じように扱われます。このコンポーザビリティにより、単純なパターン(シーケンス内のループ、ルーター内のシーケンスなど)をネストして複雑なロジックを構築できます。
11. 🚀 Cloud Run にデプロイする
各エージェントは、Cloud Run 上の個別のサービスとしてデプロイします。これには、コース作成者 UI 用の Cloud Run サービスと、Gemma モデル用の GPU を使用する Cloud Run サービスが含まれます。
デプロイ構成について
エージェントを Cloud Run にデプロイするときに、動作と接続を構成するためにいくつかの環境変数を渡します。
GOOGLE_CLOUD_PROJECT: エージェントがロギングと Vertex AI 呼び出しに正しい Google Cloud プロジェクトを使用するようにします。GOOGLE_GENAI_USE_VERTEXAI: Gemini API を直接呼び出すのではなく、モデル推論に Vertex AI を使用するようにエージェント フレームワーク(ADK)に指示します。[AGENT]_AGENT_CARD_URL: これは Orchestrator にとって重要です。Orchestrator に リモート エージェントの場所を伝えます。これをデプロイされた Cloud Run URL(具体的にはエージェント カードのパス)に設定することで、オーケストレーターはインターネット経由で Researcher、Judge、Content Builder を検出して通信できるようになります。
すべてのエージェントを Cloud Run サービスにデプロイするには、次のスクリプトを実行します。
まず、スクリプトが実行可能であることを確認します。
chmod u+x ~/multi-agent-system/deploy.sh
注 各サービスが順番にデプロイされるため、この処理には数分かかります。
~/multi-agent-system/deploy.sh
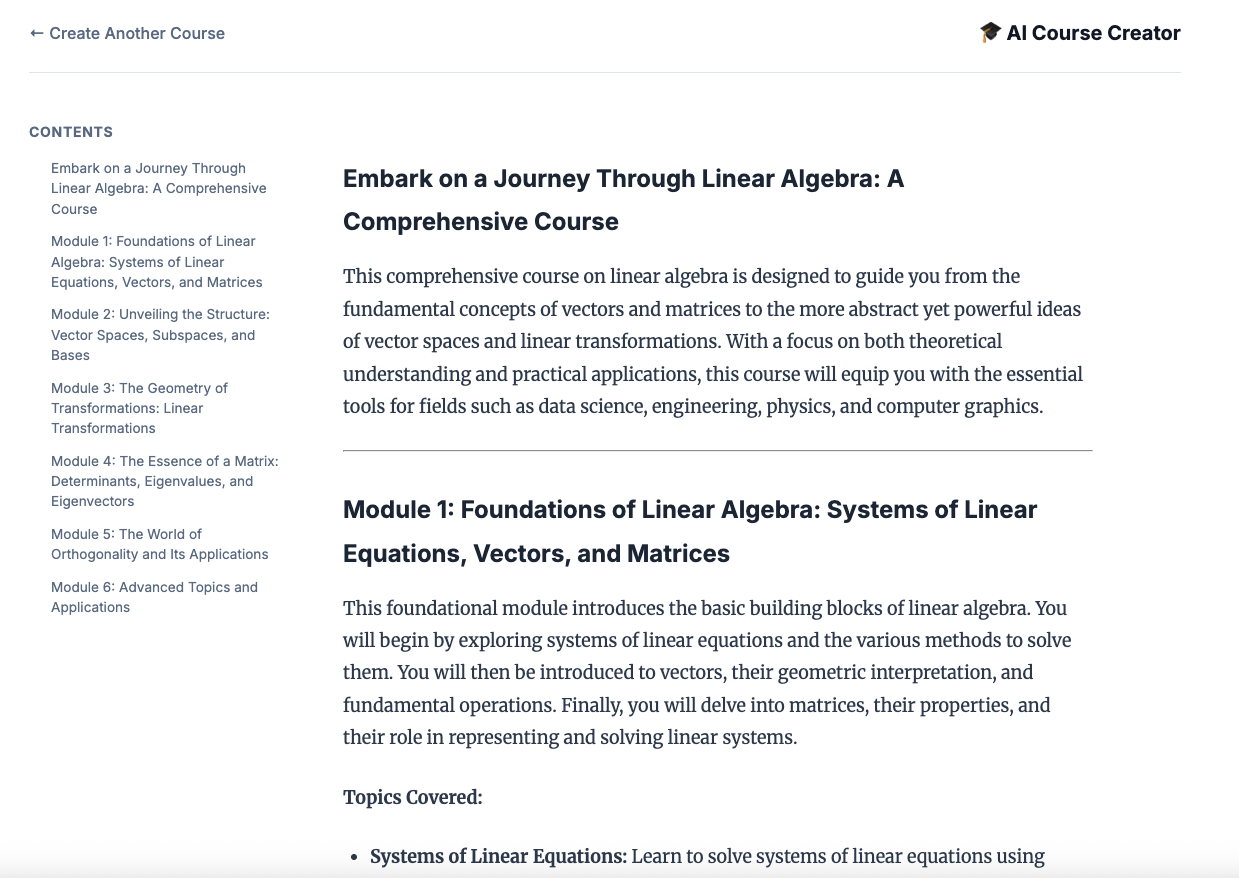
12. コースを作成する
コース作成者のウェブサイトを開きます。Course Creator Cloud Run サービスは、スクリプトからデプロイされる最後のサービスです。コース作成者の URL は https://course-creator- として識別できます。これは、デプロイ スクリプトの最終出力行です。
コースのアイデア(「線形代数」など)を入力します。
エージェントがコースの作成を開始します。
13. クリーンアップ
この Codelab で使用したリソースについて、Google Cloud アカウントに課金されないようにするには、次の手順でサービスとコンテナ イメージを削除します。
1. Cloud Run サービスを削除する
最も効率的なクリーンアップ方法は、Cloud Run にデプロイしたサービスを削除することです。
# Delete the main agent and app services
gcloud run services delete researcher content-builder judge orchestrator course-creator \
--region $REGION --quiet
# Delete the GPU backend (Ollama)
gcloud run services delete ollama-gemma-gpu \
--region $OLLAMA_REGION --quiet
2. Artifact Registry イメージを削除する
--source フラグを使用してデプロイすると、Google Cloud は Artifact Registry にコンテナ イメージを保存するリポジトリを作成します。これらを削除してストレージ費用を節約するには、リポジトリを削除します。
gcloud artifacts repositories delete cloud-run-source-deploy --location us-east4 --quiet
3. ローカル ファイルと環境を削除する
Cloud Shell 環境をクリーンな状態に保つため、プロジェクト フォルダとローカル構成を削除します。
cd ~
rm -rf multi-agent-system
4. (省略可)プロジェクトを削除する
この Codelab 専用にプロジェクトを作成した場合は、リソースの管理ページからプロジェクト自体をシャットダウンすることで、それ以上の請求が発生しないようにできます。
14. 完了
プロダクション レディな分散型マルチエージェント システムを構築してデプロイしました。
達成したこと
- 複雑なタスクを分解した: 1 つの巨大なプロンプトではなく、作業を専門的な役割(研究者、審査員、コンテンツ ビルダー)に分割しました。
- 品質管理の実装:
LoopAgentと構造化されたJudgeを使用して、高品質の情報のみが最終ステップに到達するようにしました。 - 本番環境向けに構築: Agent-to-Agent(A2A)プロトコルと Cloud Run を使用して、各エージェントが独立したスケーラブルなマイクロサービスであるシステムを作成しました。これは、すべてを 1 つの Python スクリプトで実行するよりもはるかに堅牢です。
- オーケストレーション:
SequentialAgentとLoopAgentを使用して、明確な制御フロー パターンを定義しました。*. Cloud Run GPU: Gemma モデルを Cloud Run GPU にデプロイしました