
1. 소개
이 실습에서는 단순한 챗봇을 넘어 분산 멀티 에이전트 시스템을 빌드합니다.
단일 LLM이 질문에 답변할 수 있지만 실제로는 복잡한 경우가 많아 전문적인 역할이 필요합니다. 백엔드 엔지니어에게 UI를 설계해 달라고 요청하지 않고 디자이너에게 데이터베이스 쿼리를 최적화해 달라고 요청하지 않습니다. 마찬가지로 하나의 작업에 집중하고 서로 협력하여 복잡한 문제를 해결하는 전문 AI 에이전트를 만들 수 있습니다.
다음으로 구성된 강의 생성 시스템을 빌드합니다.
- 연구원 에이전트: google_search를 사용하여 최신 정보를 찾습니다.
- 심사원 에이전트: 품질과 완전성을 위해 연구를 비판합니다.
- 콘텐츠 빌더 에이전트: 조사 결과를 바탕으로 구조화된 과정을 만듭니다.
- 오케스트레이터 에이전트: 이러한 전문가 간의 워크플로와 커뮤니케이션을 관리합니다.
학습할 내용
- 웹을 검색할 수 있는 도구 사용 에이전트 (연구원)를 정의합니다.
- 심판을 위해 Pydantic으로 구조화된 출력을 구현합니다.
- 에이전트 간 (A2A) 프로토콜을 사용하여 원격 에이전트에 연결합니다.
- 연구원과 심사위원 간에 피드백 루프를 생성하는 LoopAgent를 구성합니다.
- ADK를 사용하여 로컬에서 분산 시스템을 실행합니다.
- 멀티 에이전트 시스템을 Google Cloud Run에 배포합니다.
- 콘텐츠 빌더 에이전트를 위해 Cloud Run GPU에서 Gemma 모델을 사용합니다.
필요한 항목
- 웹브라우저(예: Chrome)
- 결제가 사용 설정된 Google Cloud 프로젝트
2. 아키텍처 및 오케스트레이션 원칙
먼저 이러한 에이전트가 어떻게 함께 작동하는지 알아보겠습니다. 강의 제작 파이프라인을 구축하고 있습니다.
시스템 설계
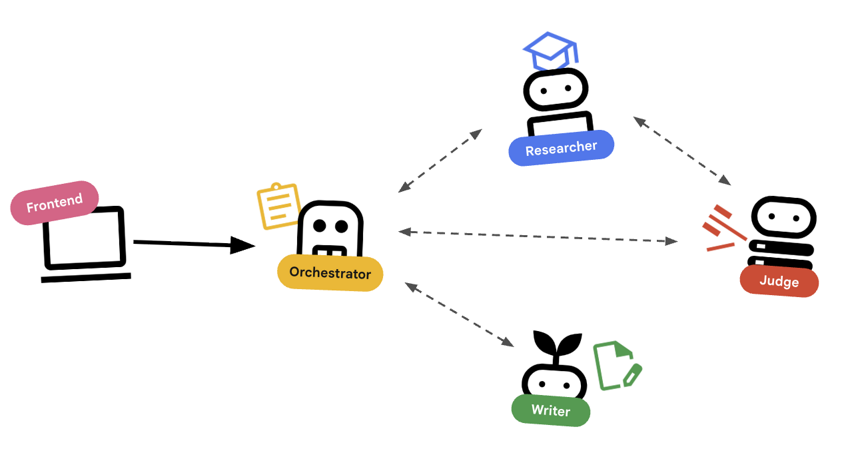
에이전트와 조정
표준 에이전트 (예: 연구원)는 작업을 수행합니다. 오케스트레이터 에이전트 (예: LoopAgent 또는 SequentialAgent)는 다른 에이전트를 관리합니다. 자체 도구가 없으며 '도구'는 위임입니다.
LoopAgent: 코드에서while루프와 같이 작동합니다. 조건이 충족되거나 최대 반복 횟수에 도달할 때까지 에이전트 시퀀스를 반복적으로 실행합니다. 이 데이터는 Research Loop에 사용됩니다.- 연구원이 정보를 찾습니다.
- 심사위원이 비판합니다.
- Judge가 'Fail'이라고 말하면 EscalationChecker가 루프를 계속 진행하도록 합니다.
- Judge가 'Pass'라고 말하면 EscalationChecker가 루프를 중단합니다.
SequentialAgent: 표준 스크립트 실행과 유사하게 작동합니다. 에이전트를 하나씩 차례로 실행합니다. 상위 수준 파이프라인에 사용됩니다.- 먼저 Research Loop를 실행합니다 (양질의 데이터로 완료될 때까지).
- 그런 다음 콘텐츠 빌더를 실행하여 과정을 작성합니다.
이러한 기능을 결합하여 최종 출력을 생성하기 전에 자체적으로 수정할 수 있는 강력한 시스템을 만듭니다.
3. 설정
프로젝트 설정
Google Cloud 프로젝트 만들기
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다. 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
Cloud Shell 시작
Cloud Shell은 Google Cloud에서 실행되는 명령줄 환경으로, 필요한 도구가 미리 로드되어 제공됩니다.
- Google Cloud 콘솔 상단에서 Cloud Shell 활성화를 클릭합니다.
- Cloud Shell에 연결되면 인증을 확인합니다.
gcloud auth list - 프로젝트가 구성되어 있는지 확인합니다.
gcloud config get project - 프로젝트가 예상대로 설정되지 않은 경우 설정합니다.
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
환경 설정
- Cloud Shell 열기: Google Cloud 콘솔의 오른쪽 상단에 있는 Cloud Shell 활성화 아이콘을 클릭합니다.
시작 코드 가져오기
- 시작 저장소를 홈 디렉터리에 클론합니다. 홈 디렉터리로 이동합니다.
cd ~git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git temp-repo && cd temp-repo && git sparse-checkout set agents/multi-agent-system && cd .. && mv temp-repo/agents/multi-agent-system . && rm -rf temp-repocd multi-agent-system - API 사용 설정: 다음 명령어를 실행하여 필요한 Google Cloud 서비스를 사용 설정합니다.
gcloud services enable \ run.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - 편집기에서 이 폴더를 엽니다.
cloudshell edit .
환경 설정
- 환경 변수를 설정합니다.세션 연결이 끊어질 경우 쉽게 다시 로드할 수 있도록 이러한 변수를 저장하는
.env파일을 만듭니다.cat <<EOF > .env export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) export GOOGLE_CLOUD_LOCATION=europe-west4 export GOOGLE_GENAI_USE_VERTEXAI=true EOF - 환경 변수를 소싱합니다.
source .env
4. 🕵️ 리서처 에이전트
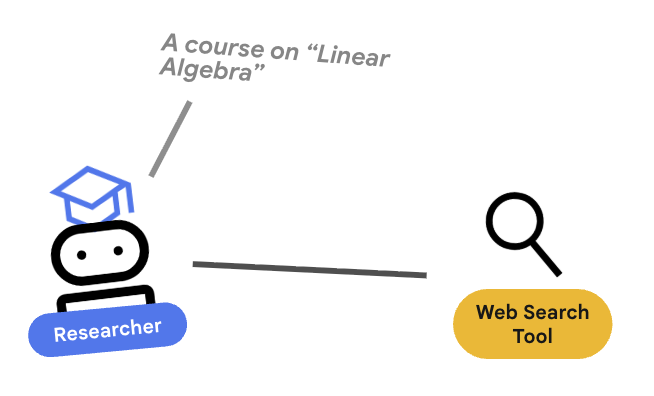
연구원은 전문가입니다. 정보를 찾는 것이 유일한 역할입니다. 이렇게 하려면 Google 검색이라는 도구에 액세스해야 합니다.
연구원을 분리하는 이유는 무엇인가요?
심층 분석: 하나의 에이전트가 모든 작업을 처리하면 안 되나요?
작고 집중된 에이전트는 평가하고 디버그하기가 더 쉽습니다. 리서치가 좋지 않으면 연구원의 프롬프트를 반복합니다. 과정 형식이 잘못된 경우 콘텐츠 빌더에서 반복합니다. 모놀리식 '만능' 프롬프트에서는 한 가지를 수정하면 다른 문제가 발생하는 경우가 많습니다.
- Cloud Shell에서 작업하는 경우 다음 명령어를 실행하여 Cloud Shell 편집기를 엽니다.
cloudshell workspace . agents/researcher/agent.py를 엽니다.researcher에이전트를 정의하는 다음 코드를 검토하세요.# ... existing imports ... # Define the Researcher Agent researcher = Agent( name="researcher", model=MODEL, description="Gathers information on a topic using Google Search.", instruction=""" You are an expert researcher. Your goal is to find comprehensive and accurate information on the user's topic. Use the `google_search` tool to find relevant information. Summarize your findings clearly. If you receive feedback that your research is insufficient, use the feedback to refine your next search. """, tools=[google_search], ) root_agent = researcher
핵심 개념: 도구 사용
tools=[google_search]를 전달합니다. ADK는 LLM에 이 도구를 설명하는 복잡성을 처리합니다. 모델이 정보가 필요하다고 판단하면 구조화된 도구 호출을 생성하고, ADK는 Python 함수 google_search를 실행하고, 결과를 모델에 다시 제공합니다.
5. ⚖️ 심판 에이전트
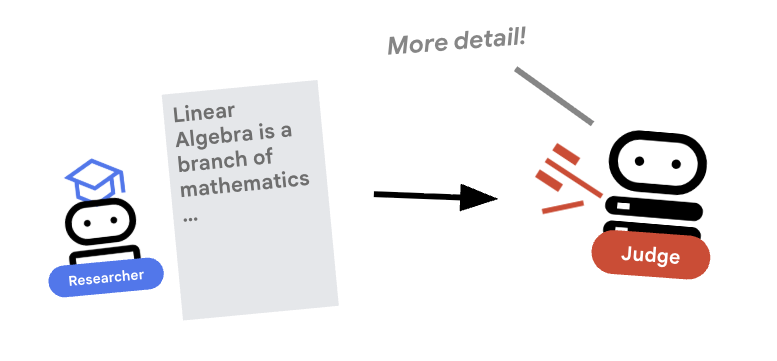
연구자는 열심히 일하지만 LLM은 게으를 수 있습니다. 작업을 검토할 심사위원이 필요합니다. 심사위원이 연구를 수락하고 구조화된 통과/실패 평가를 반환합니다.
구조화된 출력
자세히 알아보기: 워크플로를 자동화하려면 예측 가능한 출력이 필요합니다. 장황한 텍스트 리뷰는 프로그래매틱 방식으로 파싱하기 어렵습니다. JSON 스키마 (Pydantic 사용)를 적용하면 Judge가 코드에서 안정적으로 작동할 수 있는 불리언 pass 또는 fail을 반환합니다.
agents/judge/agent.py를 엽니다.JudgeFeedback스키마와judge에이전트를 정의하는 다음 코드를 검토하세요.# 1. Define the Schema class JudgeFeedback(BaseModel): """Structured feedback from the Judge agent.""" status: Literal["pass", "fail"] = Field( description="Whether the research is sufficient ('pass') or needs more work ('fail')." ) feedback: str = Field( description="Detailed feedback on what is missing. If 'pass', a brief confirmation." ) # 2. Define the Agent judge = Agent( name="judge", model=MODEL, description="Evaluates research findings for completeness and accuracy.", instruction=""" You are a strict editor. Evaluate the 'research_findings' against the user's original request. If the findings are missing key info, return status='fail'. If they are comprehensive, return status='pass'. """, output_schema=JudgeFeedback, # Disallow delegation because it should only output the schema disallow_transfer_to_parent=True, disallow_transfer_to_peers=True, ) root_agent = judge
핵심 개념: 에이전트 동작 제한
disallow_transfer_to_parent=True 및 disallow_transfer_to_peers=True을 설정합니다. 이렇게 하면 Judge가 구조화된 JudgeFeedback만 반환하도록 강제됩니다. 사용자와 '채팅'하거나 다른 상담사에게 위임할 수 없습니다. 따라서 로직 흐름에서 결정론적 구성요소가 됩니다.
6. ✍️ 콘텐츠 빌더 에이전트
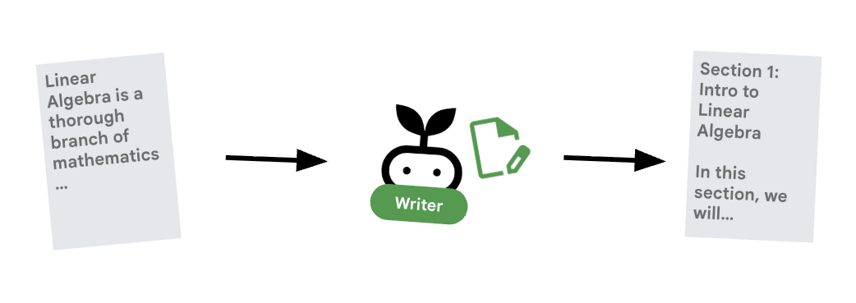
콘텐츠 빌더는 창의적인 작가입니다. 승인된 연구를 가져와 과정으로 전환합니다. Cloud Run에서 제공하는 Gemma 모델을 사용합니다.
먼저 모델을 호스팅하는 Cloud Run 서비스를 살펴보겠습니다.
ollama_backend/Dockerfile열기- 여기에서 Dockerfile이 Ollama 이미지를 사용하고, 포트 8080에서 요청을 수신 대기하고, 요청된 모델을 /model 폴더에 저장하는 방법을 확인할 수 있습니다.
FROM ollama/ollama:latest # Listen on all interfaces, port 8080 (Cloud Run default) ENV OLLAMA_HOST 0.0.0.0:8080 # Store model weight files in /models ENV OLLAMA_MODELS /models
⚙️ 배포할 때 다음 구성을 설정합니다.
- GPU: 추론 워크로드에 대한 뛰어난 가격 대비 성능을 제공하는 NVIDIA L4를 선택했습니다. L4는 24GB GPU 메모리와 최적화된 텐서 작업을 제공하므로 Gemma와 같은 2억 7천만 개의 매개변수 모델에 적합합니다.
- 메모리: 모델 로드, CUDA 작업, Ollama의 메모리 관리를 처리하기 위한 16GB 시스템 메모리
- CPU: 최적의 I/O 처리 및 전처리 작업을 위한 8코어
- 동시성: 인스턴스당 4개의 요청은 처리량과 GPU 메모리 사용량의 균형을 유지합니다.
- 제한 시간: 초기 모델 로드 및 컨테이너 시작을 고려하여 600초로 설정
이제 Gemma 모델을 사용하는 콘텐츠 빌더 에이전트를 살펴보겠습니다.
agents/content_builder/agent.py를 엽니다.content_builder에이전트를 정의하는 다음 코드를 검토합니다.
# the `ollama-gemma-gpu` Cloud Run service URL which hosts the Gemma model
target_url = os.environ.get("OLLAMA_API_BASE")
# ... existing code ...
# (Note: We use 'ollama/gemma3:270m' to align with ADK's expected prefix)
gemma_model_name = os.environ.get("GEMMA_MODEL_NAME", "gemma3:270m")
model = LiteLlm(
model=f"ollama_chat/{gemma_model_name}",
api_base=target_url
)
# 5. Define the Agent
content_builder = Agent(
name="content_builder",
model=model,
description="Transforms research findings into a structured course.",
instruction="""
You are an expert course creator.
Take the approved 'research_findings' and transform them into a well-structured, engaging course module.
**Formatting Rules:**
1. Start with a main title using a single `#` (H1).
2. Use `##` (H2) for main section headings. These will be used for the Table of Contents.
3. Use `###` (H3) for sub-sections within main sections.
4. Use bullet points and clear paragraphs.
5. Maintain a professional but engaging tone.
**Structure Requirements:**
- Begin with a brief Introduction section explaining what the learner will gain.
- Organize content into 3-5 main sections with clear headings.
- Include Key Takeaways at the end as a bulleted summary.
- Keep each section focused and concise.
Ensure the content directly addresses the user's original request.
Do not include any preamble or explanation outside the course content itself.
""",
)
root_agent = content_builder
주요 개념: 컨텍스트 전파
'콘텐츠 빌더는 연구원이 찾은 내용을 어떻게 알 수 있나요?'라고 궁금해하실 수 있습니다. ADK에서 파이프라인의 에이전트는 session.state를 공유합니다. 나중에 오케스트레이터에서 연구원과 심사위원이 이 공유 상태에 출력을 저장하도록 구성합니다. 콘텐츠 빌더의 프롬프트는 이 기록에 효과적으로 액세스할 수 있습니다.
7. 🎻 조정자
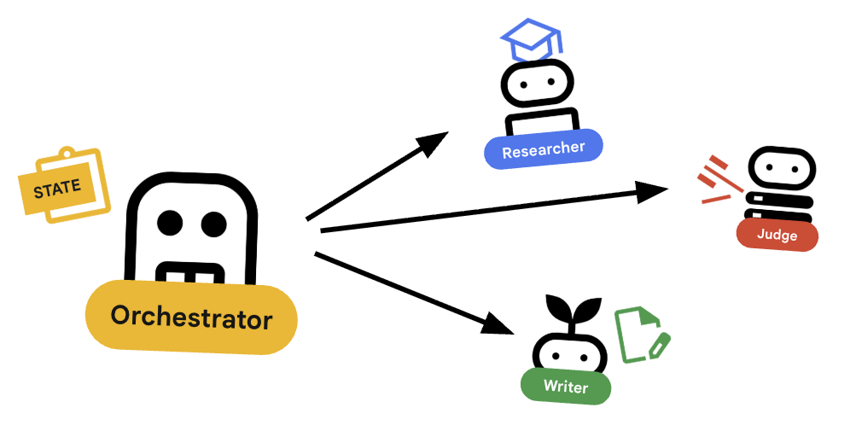
오케스트레이터는 멀티 에이전트 팀의 관리자입니다. 특정 작업을 수행하는 전문가 에이전트 (연구원, 심사관, 콘텐츠 작성자)와 달리 오케스트레이터의 역할은 워크플로를 조정하고 에이전트 간에 정보가 올바르게 흐르도록 하는 것입니다.
🌐 아키텍처: 에이전트 간 (A2A)
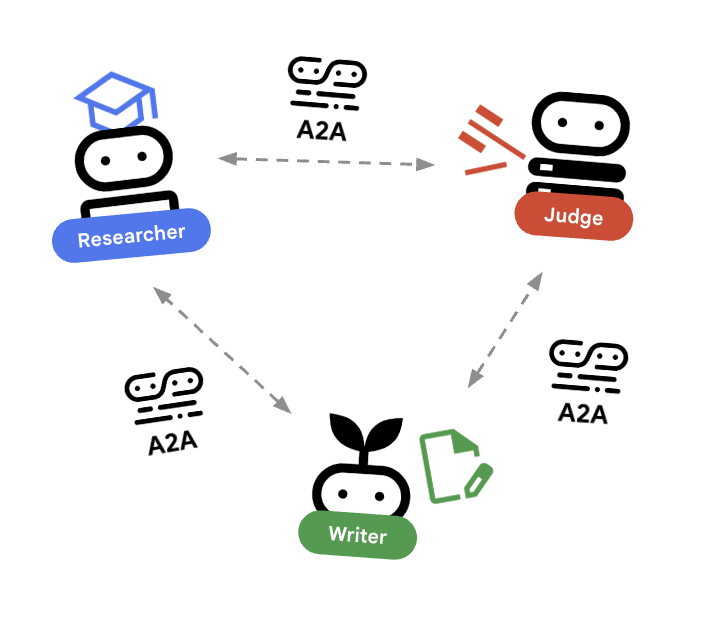
이 실습에서는 분산 시스템을 빌드합니다. 모든 에이전트를 단일 Python 프로세스에서 실행하는 대신 독립적인 마이크로서비스로 배포합니다. 이를 통해 각 에이전트는 독립적으로 확장할 수 있으며 전체 시스템이 비정상 종료되지 않고 실패할 수 있습니다.
이를 위해 에이전트 간 (A2A) 프로토콜을 사용합니다.
A2A 프로토콜
심층 분석: 프로덕션 시스템에서 에이전트는 서로 다른 서버 (또는 서로 다른 클라우드)에서 실행됩니다. A2A 프로토콜은 HTTP를 통해 서로를 검색하고 대화할 수 있는 표준 방법을 만듭니다. RemoteA2aAgent은 이 프로토콜의 ADK 클라이언트입니다.
agents/orchestrator/agent.py를 엽니다.- 연결을 정의하는 다음 코드를 검토합니다.
# ... existing code ... # Connect to the Researcher (Localhost port 8001) researcher_url = os.environ.get("RESEARCHER_AGENT_CARD_URL", "http://localhost:8001/a2a/agent/.well-known/agent-card.json") researcher = RemoteA2aAgent( name="researcher", agent_card=researcher_url, description="Gathers information using Google Search.", # IMPORTANT: Save the output to state for the Judge to see after_agent_callback=create_save_output_callback("research_findings"), # IMPORTANT: Use authenticated client for communication httpx_client=create_authenticated_client(researcher_url) ) # Connect to the Judge (Localhost port 8002) judge_url = os.environ.get("JUDGE_AGENT_CARD_URL", "http://localhost:8002/a2a/agent/.well-known/agent-card.json") judge = RemoteA2aAgent( name="judge", agent_card=judge_url, description="Evaluates research.", after_agent_callback=create_save_output_callback("judge_feedback"), httpx_client=create_authenticated_client(judge_url) ) # Content Builder (Localhost port 8003) content_builder_url = os.environ.get("CONTENT_BUILDER_AGENT_CARD_URL", "http://localhost:8003/a2a/agent/.well-known/agent-card.json") content_builder = RemoteA2aAgent( name="content_builder", agent_card=content_builder_url, description="Builds the course.", httpx_client=create_authenticated_client(content_builder_url) )
8. 🛑 에스컬레이션 검사기
루프에는 중지하는 방법이 필요합니다. 심판이 '통과'라고 말하면 루프를 즉시 종료하고 콘텐츠 빌더로 이동해야 합니다.
BaseAgent를 사용한 맞춤 로직
심층 분석: 일부 에이전트는 LLM을 사용하지 않습니다. 간단한 Python 로직이 필요한 경우도 있습니다. BaseAgent를 사용하면 코드를 실행하는 에이전트를 정의할 수 있습니다. 이 경우 세션 상태를 확인하고 EventActions(escalate=True)을 사용하여 LoopAgent에 중지 신호를 보냅니다.
- 여전히
agents/orchestrator/agent.py에 있습니다. - 다음 코드는 심사위원의 의견을 검토하고 준비가 되면 다음 단계로 진행합니다.
class EscalationChecker(BaseAgent): """Checks the judge's feedback and escalates (breaks the loop) if it passed.""" async def _run_async_impl( self, ctx: InvocationContext ) -> AsyncGenerator[Event, None]: # Retrieve the feedback saved by the Judge feedback = ctx.session.state.get("judge_feedback") print(f"[EscalationChecker] Feedback: {feedback}") # Check for 'pass' status is_pass = False if isinstance(feedback, dict) and feedback.get("status") == "pass": is_pass = True # Handle string fallback if JSON parsing failed elif isinstance(feedback, str) and '"status": "pass"' in feedback: is_pass = True if is_pass: # 'escalate=True' tells the parent LoopAgent to stop looping yield Event(author=self.name, actions=EventActions(escalate=True)) else: # Continue the loop yield Event(author=self.name) escalation_checker = EscalationChecker(name="escalation_checker")
주요 개념: 이벤트를 통한 흐름 제어
에이전트는 텍스트뿐만 아니라 이벤트를 통해 소통합니다. escalate=True로 이벤트를 생성하여 이 에이전트는 상위 요소 (LoopAgent)에 신호를 전송합니다. LoopAgent는 이 신호를 포착하고 루프를 종료하도록 프로그래밍되어 있습니다.
9. 🔁 연구 루프
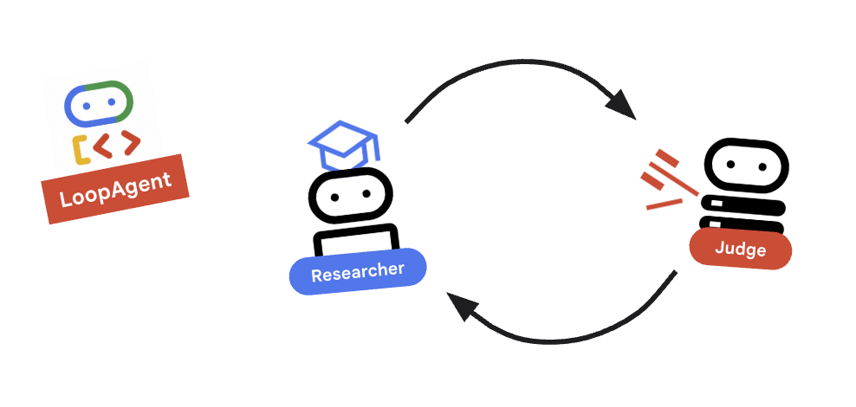
피드백 루프가 필요합니다. 조사 -> 판단 -> (실패) -> 조사 -> ...
agents/orchestrator/agent.py에서- 다음 코드가
research_loop정의를 정의하는 방법을 검토하세요.research_loop = LoopAgent( name="research_loop", description="Iteratively researches and judges until quality standards are met.", sub_agents=[researcher, judge, escalation_checker], max_iterations=3, )
주요 개념: LoopAgent
LoopAgent는 sub_agents을 순서대로 순환합니다.
researcher: 데이터를 찾습니다.judge: 데이터를 평가합니다.escalation_checker:yield Event(escalate=True)여부를 결정합니다.escalate=True가 발생하면 루프가 일찍 중단됩니다. 그렇지 않으면 연구자 (최대max_iterations)에서 다시 시작됩니다.
10. 🔗 최종 파이프라인
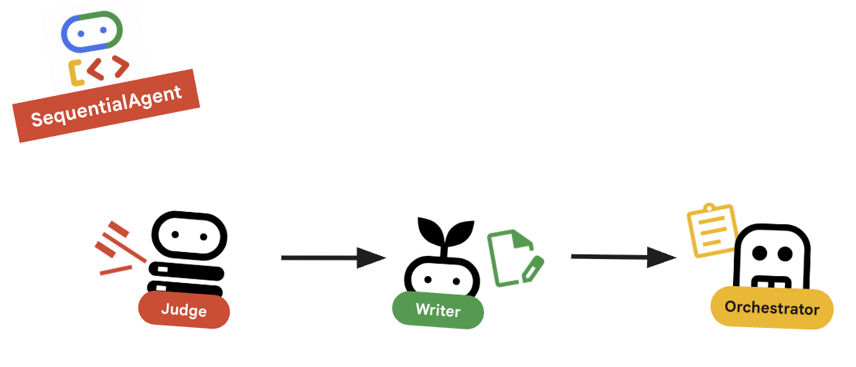
모든 것을 한곳에 모으기
agents/orchestrator/agent.py에서- 파일 하단에서
root_agent가 정의된 방식을 검토합니다.root_agent = SequentialAgent( name="course_creation_pipeline", description="A pipeline that researches a topic and then builds a course from it.", sub_agents=[research_loop, content_builder], )
핵심 개념: 계층적 컴포지션
research_loop는 에이전트 (LoopAgent)입니다. SequentialAgent의 다른 하위 에이전트와 마찬가지로 취급합니다. 이러한 구성 가능성을 통해 간단한 패턴 (시퀀스 내 루프, 라우터 내 시퀀스 등)을 중첩하여 복잡한 로직을 빌드할 수 있습니다.
11. 🚀 Cloud Run에 배포
각 에이전트는 과정 제작자 UI용 Cloud Run 서비스와 Gemma 모델용 GPU를 사용하는 Cloud Run 서비스를 비롯하여 Cloud Run의 별도 서비스로 배포됩니다.
배포 구성 이해하기
Cloud Run에 에이전트를 배포할 때 동작과 연결을 구성하기 위해 여러 환경 변수를 전달합니다.
GOOGLE_CLOUD_PROJECT: 에이전트가 로깅 및 Vertex AI 호출에 올바른 Google Cloud 프로젝트를 사용하도록 합니다.GOOGLE_GENAI_USE_VERTEXAI: 에이전트 프레임워크 (ADK)에 Gemini API를 직접 호출하는 대신 모델 추론에 Vertex AI를 사용하도록 지시합니다.[AGENT]_AGENT_CARD_URL: 조정자에게는 이 부분이 중요합니다. 원격 에이전트를 찾을 위치를 오케스트레이터에 알려줍니다. 이를 배포된 Cloud Run URL (특히 에이전트 카드 경로)로 설정하면 오케스트레이터가 인터넷을 통해 연구원, 심사자, 콘텐츠 빌더를 검색하고 통신할 수 있습니다.
모든 에이전트를 Cloud Run 서비스에 배포하려면 다음 스크립트를 실행합니다.
먼저 스크립트가 실행 가능한지 확인합니다.
chmod u+x ~/multi-agent-system/deploy.sh
참고 각 서비스가 순차적으로 배포되므로 실행하는 데 몇 분 정도 걸립니다.
~/multi-agent-system/deploy.sh
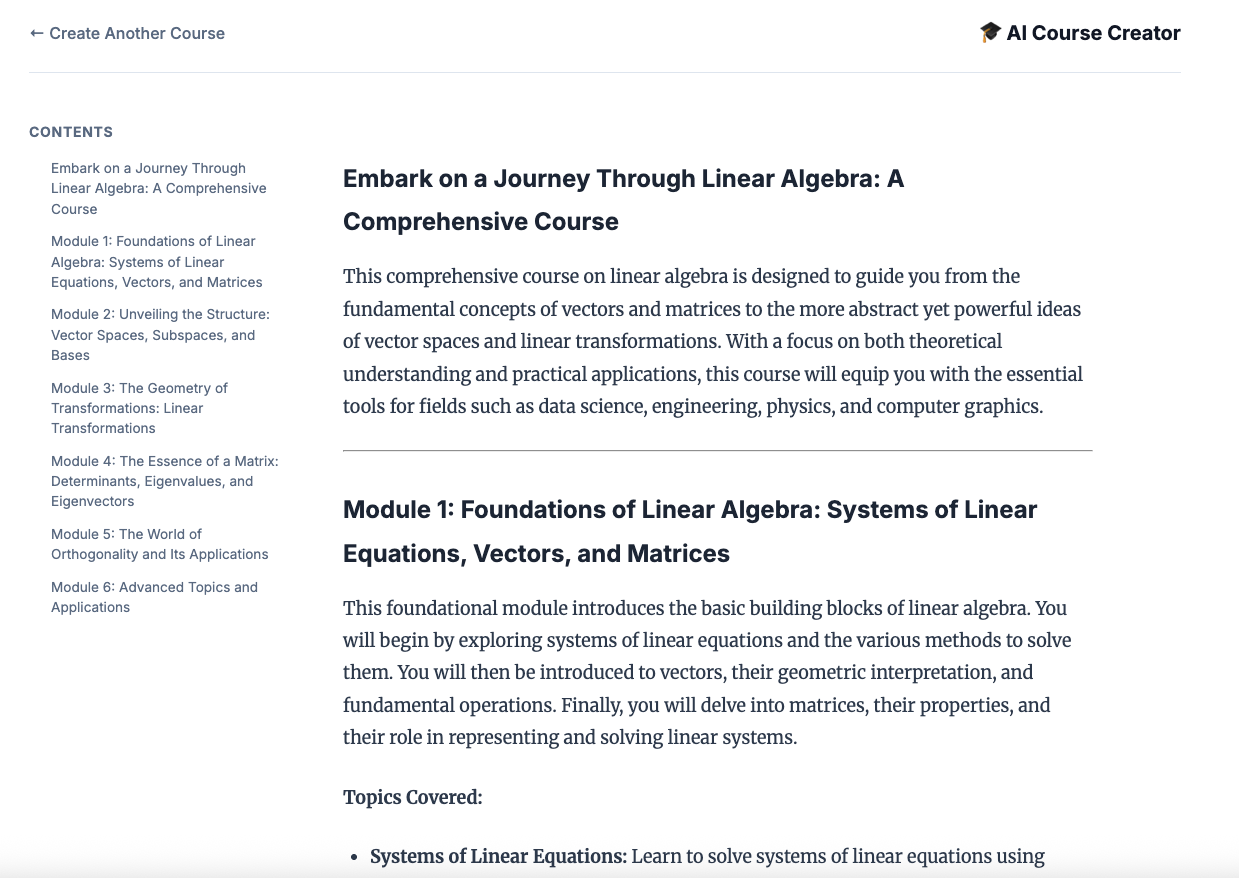
12. 강의를 만들어 보세요.
Course Creator 웹사이트를 엽니다. Course Creator Cloud Run 서비스는 스크립트에서 배포된 마지막 서비스입니다. 과정 생성자에게 제공할 URL은 https://course-creator-로 식별할 수 있으며, 이는 배포 스크립트의 최종 출력 줄이어야 합니다.
'선형대수'와 같은 강의 아이디어를 입력합니다.
에이전트가 강의 작업을 시작합니다.
13. 삭제
이 Codelab에서 사용한 리소스의 비용이 Google Cloud 계정에 청구되지 않도록 하려면 다음 단계에 따라 서비스와 컨테이너 이미지를 삭제하세요.
1. Cloud Run 서비스 삭제
정리하는 가장 효율적인 방법은 Cloud Run에 배포한 서비스를 삭제하는 것입니다.
# Delete the main agent and app services
gcloud run services delete researcher content-builder judge orchestrator course-creator \
--region $REGION --quiet
# Delete the GPU backend (Ollama)
gcloud run services delete ollama-gemma-gpu \
--region $OLLAMA_REGION --quiet
2. Artifact Registry 이미지 삭제
--source 플래그를 사용하여 배포하면 Google Cloud에서 Artifact Registry에 컨테이너 이미지를 저장할 저장소를 만듭니다. 이러한 파일을 삭제하고 스토리지 비용을 절약하려면 저장소를 삭제하세요.
gcloud artifacts repositories delete cloud-run-source-deploy --location us-east4 --quiet
3. 로컬 파일 및 환경 삭제
Cloud Shell 환경을 정리하려면 프로젝트 폴더와 로컬 구성을 삭제하세요.
cd ~
rm -rf multi-agent-system
4. (선택사항) 프로젝트 삭제
이 Codelab을 위해 프로젝트를 만든 경우 리소스 관리 페이지를 통해 프로젝트 자체를 종료하면 추가 요금이 청구되지 않습니다.
14. 수고하셨습니다
프로덕션에 즉시 사용 가능한 분산 멀티 에이전트 시스템을 빌드하고 배포했습니다.
학습한 내용
- 복잡한 작업 분해: 하나의 거대한 프롬프트 대신 작업을 전문 역할 (연구원, 심사관, 콘텐츠 빌더)로 분할했습니다.
- 품질 관리 구현: 고품질 정보만 최종 단계에 도달하도록
LoopAgent및 구조화된Judge를 사용했습니다. - 프로덕션용으로 빌드됨: 에이전트 간 (A2A) 프로토콜과 Cloud Run을 사용하여 각 에이전트가 독립적이고 확장 가능한 마이크로서비스인 시스템을 만들었습니다. 이는 단일 Python 스크립트에서 모든 것을 실행하는 것보다 훨씬 강력합니다.
- 조정:
SequentialAgent및LoopAgent를 사용하여 명확한 제어 흐름 패턴을 정의했습니다. *. Cloud Run GPU: Gemma 모델을 Cloud Run GPU에 배포함