
1. Wprowadzenie
W tym laboratorium wyjdziesz poza proste czatboty i skonfigurujesz rozproszony system wieloagentowy.
Pojedynczy LLM może odpowiadać na pytania, ale złożoność rzeczywistego świata często wymaga specjalistycznych ról. Nie prosisz inżyniera backendu o zaprojektowanie interfejsu ani projektanta o optymalizację zapytań do bazy danych. Podobnie możemy tworzyć wyspecjalizowane agenty AI, które skupiają się na jednym zadaniu i współpracują ze sobą, aby rozwiązywać złożone problemy.
Zbudujesz system tworzenia kursów, który będzie się składać z:
- Agent badawczy: korzysta z wyszukiwarki Google, aby znajdować aktualne informacje.
- Judge Agent: ocenia jakość i kompletność wyników wyszukiwania.
- Agent do tworzenia treści: przekształca wyniki badań w uporządkowany kurs.
- Agent orkiestrator: zarządza przepływem pracy i komunikacją między tymi specjalistami.
Czego się nauczysz
- Określ agenta korzystającego z narzędzi (badacza), który może przeszukiwać internet.
- Wdrożenie uporządkowanych danych wyjściowych za pomocą Pydantic dla sędziego.
- Nawiązywanie połączenia z agentami zdalnymi za pomocą protokołu Agent-to-Agent (A2A).
- Skonstruuj obiekt LoopAgent, aby utworzyć pętlę informacji zwrotnych między badaczem a oceniającym.
- Uruchom system rozproszony lokalnie za pomocą ADK.
- Wdróż system wieloagentowy w Google Cloud Run.
- Używaj modelu Gemma na GPU Cloud Run w przypadku agenta do tworzenia treści.
Czego potrzebujesz
- przeglądarka, np. Chrome;
- projekt Google Cloud z włączonymi płatnościami;
2. Zasady architektury i orkiestracji
Najpierw dowiedzmy się, jak te agentki ze sobą współpracują. Tworzymy potok tworzenia kursów.
Projekt systemu
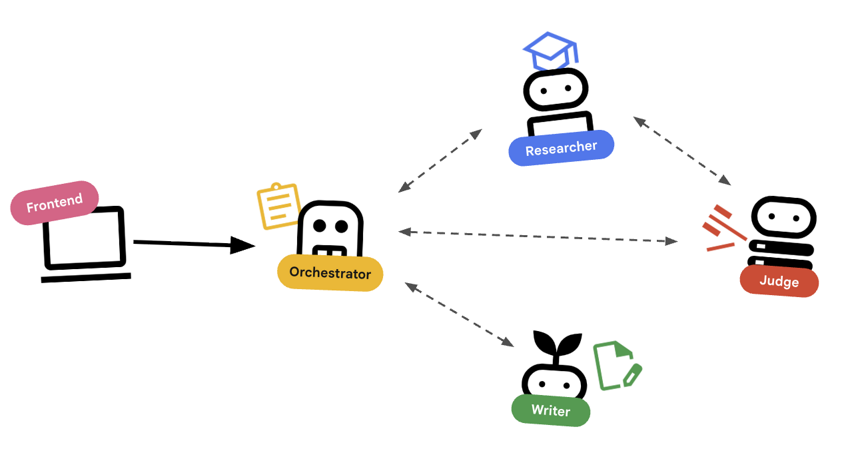
Administrowanie za pomocą agentów
Standardowi agenci (np. badacz) wykonują pracę. Agenty aranżujące (np. LoopAgent lub SequentialAgent) zarządzają innymi agentami. Nie mają własnych narzędzi. Ich „narzędziem” jest delegowanie zadań.
LoopAgent: działa to jak pętlawhilew kodzie. Wykonuje sekwencję agentów wielokrotnie, dopóki nie zostanie spełniony warunek (lub nie zostanie osiągnięta maksymalna liczba iteracji). Używamy go w pętli badawczej:- Badacz znajduje informacje.
- Sędzia ocenia je.
- Jeśli Judge zwróci wartość „Fail”, EscalationChecker zezwoli na kontynuowanie pętli.
- Jeśli Judge odpowie „Pass”, EscalationChecker przerywa pętlę.
SequentialAgent: działa to jak standardowe wykonanie skryptu. Uruchamia agentów jeden po drugim. Używamy go w przypadku potoku wysokiego poziomu:- Najpierw uruchom pętlę wyszukiwania (aż do uzyskania odpowiednich danych).
- Następnie uruchom kreator treści (aby napisać kurs).
Łącząc te elementy, tworzymy solidny system, który może samodzielnie korygować błędy przed wygenerowaniem ostatecznego wyniku.
3. Konfiguracja
Konfigurowanie projektu
Tworzenie projektu Google Cloud
- W konsoli Google Cloud na stronie wyboru projektu wybierz lub utwórz projekt w chmurze Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności.
Uruchamianie Cloud Shell
Cloud Shell to środowisko wiersza poleceń działające w Google Cloud, które zawiera niezbędne narzędzia.
- U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell.
- Po połączeniu z Cloud Shell sprawdź uwierzytelnianie:
gcloud auth list - Sprawdź, czy projekt jest skonfigurowany:
gcloud config get project - Jeśli projekt nie jest ustawiony zgodnie z oczekiwaniami, ustaw go:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Konfiguracja środowiska
- Otwórz Cloud Shell: w prawym górnym rogu konsoli Google Cloud kliknij ikonę Aktywuj Cloud Shell.
Pobieranie kodu startowego
- Sklonuj repozytorium początkowe do katalogu głównego:przejdź do katalogu głównego.
cd ~git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git temp-repo && cd temp-repo && git sparse-checkout set agents/multi-agent-system && cd .. && mv temp-repo/agents/multi-agent-system . && rm -rf temp-repocd multi-agent-system - Włącz interfejsy API: uruchom to polecenie, aby włączyć niezbędne usługi Google Cloud:
gcloud services enable \ run.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - Otwórz ten folder w edytorze.
cloudshell edit .
Konfigurowanie środowiska
- Skonfiguruj zmienne środowiskowe.Utworzymy plik
.envdo przechowywania tych zmiennych, aby w razie rozłączenia sesji można było je łatwo ponownie załadować.cat <<EOF > .env export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) export GOOGLE_CLOUD_LOCATION=europe-west4 export GOOGLE_GENAI_USE_VERTEXAI=true EOF - Ustaw zmienne środowiskowe:
source .env
4. 🕵️ Agent do wyszukiwania informacji
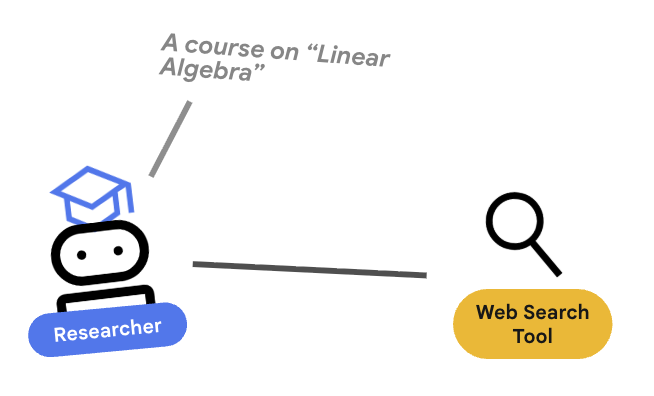
Badacz to specjalista. Jego jedynym zadaniem jest wyszukiwanie informacji. Aby to zrobić, potrzebuje dostępu do narzędzia: wyszukiwarki Google.
Dlaczego warto rozdzielić rolę badacza?
Szczegółowe informacje: dlaczego nie może być tylko jednego agenta, który robi wszystko?
Małe, wyspecjalizowane agenty łatwiej ocenić i debugować. Jeśli wyniki są niezadowalające, zmień prompta badacza. Jeśli formatowanie kursu jest nieprawidłowe, możesz wprowadzić zmiany w narzędziu do tworzenia treści. W monolitycznym prompcie typu „zrób wszystko” poprawienie jednej rzeczy często powoduje, że przestaje działać inna.
- Jeśli pracujesz w Cloud Shell, uruchom to polecenie, aby otworzyć edytor Cloud Shell:
cloudshell workspace . - Otwórz pokój
agents/researcher/agent.py. - Sprawdź ten kod, który definiuje agenta
researcher:# ... existing imports ... # Define the Researcher Agent researcher = Agent( name="researcher", model=MODEL, description="Gathers information on a topic using Google Search.", instruction=""" You are an expert researcher. Your goal is to find comprehensive and accurate information on the user's topic. Use the `google_search` tool to find relevant information. Summarize your findings clearly. If you receive feedback that your research is insufficient, use the feedback to refine your next search. """, tools=[google_search], ) root_agent = researcher
Kluczowe pojęcie: korzystanie z narzędzi
Zwróć uwagę, że przekazujemy wartość tools=[google_search]. ADK zajmuje się złożonością opisywania tego narzędzia modelowi LLM. Gdy model stwierdzi, że potrzebuje informacji, generuje wywołanie narzędzia w formacie strukturalnym, ADK wykonuje funkcję Pythona google_search i przekazuje wynik z powrotem do modelu.
5. ⚖️ Agent sędzia
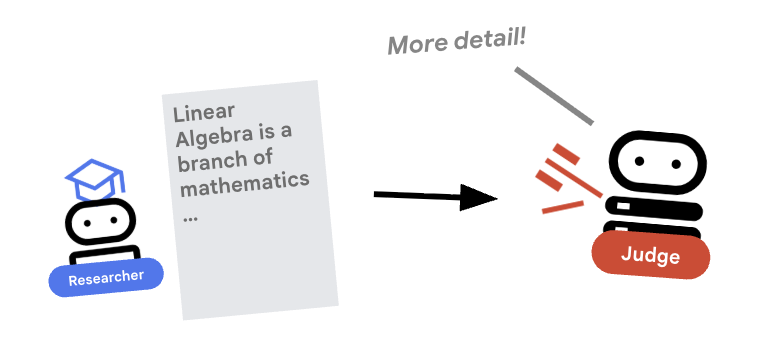
Badacz ciężko pracuje, ale LLM-y mogą być leniwe. Potrzebujemy oceniającego, który sprawdzi Twoją pracę. Sędzia akceptuje badania i zwraca uporządkowaną ocenę pozytywną lub negatywną.
Uporządkowane dane wyjściowe
Szczegółowe informacje: aby zautomatyzować przepływy pracy, potrzebujemy przewidywalnych wyników. Długie i niezrozumiałe opinie tekstowe są trudne do analizy automatycznej. Wymuszając schemat JSON (za pomocą Pydantic), zapewniamy, że funkcja Judge zwraca wartość logiczną pass lub fail, na podstawie której nasz kod może niezawodnie podejmować działania.
- Otwórz pokój
agents/judge/agent.py. - Zapoznaj się z poniższym kodem, który definiuje schemat
JudgeFeedbacki agentajudge.# 1. Define the Schema class JudgeFeedback(BaseModel): """Structured feedback from the Judge agent.""" status: Literal["pass", "fail"] = Field( description="Whether the research is sufficient ('pass') or needs more work ('fail')." ) feedback: str = Field( description="Detailed feedback on what is missing. If 'pass', a brief confirmation." ) # 2. Define the Agent judge = Agent( name="judge", model=MODEL, description="Evaluates research findings for completeness and accuracy.", instruction=""" You are a strict editor. Evaluate the 'research_findings' against the user's original request. If the findings are missing key info, return status='fail'. If they are comprehensive, return status='pass'. """, output_schema=JudgeFeedback, # Disallow delegation because it should only output the schema disallow_transfer_to_parent=True, disallow_transfer_to_peers=True, ) root_agent = judge
Kluczowe pojęcie: ograniczanie działania agenta
Ustawiliśmy wartości disallow_transfer_to_parent=True i disallow_transfer_to_peers=True. Wymusza to na sędzim wyłącznie zwrócenie ustrukturyzowanego JudgeFeedback. Nie może on „czatować” z użytkownikiem ani przekazywać sprawy innemu agentowi. Dzięki temu jest to deterministyczny komponent w naszym przepływie logicznym.
6. ✍️ Agent tworzenia treści
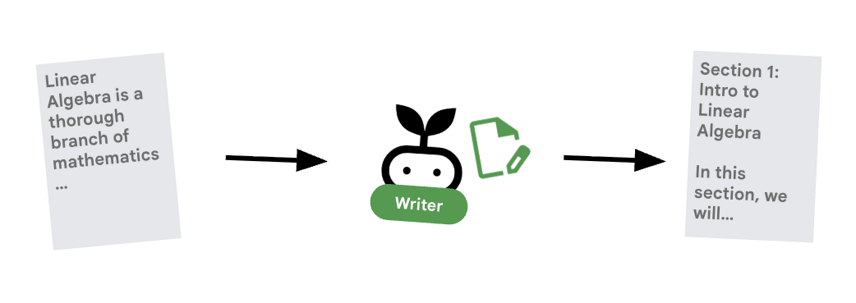
Kreator treści to twórca treści. Na podstawie zatwierdzonych badań tworzy kurs. Korzysta z modelu Gemma obsługiwanego przez Cloud Run.
Najpierw przyjrzyjmy się usłudze Cloud Run, która hostuje model.
- Otwórz:
ollama_backend/Dockerfile - Możesz tu zobaczyć, jak plik Dockerfile używa obrazu Ollama, nasłuchuje żądań na porcie 8080 i przechowuje żądany model w folderze /model.
FROM ollama/ollama:latest # Listen on all interfaces, port 8080 (Cloud Run default) ENV OLLAMA_HOST 0.0.0.0:8080 # Store model weight files in /models ENV OLLAMA_MODELS /models
⚙️ Podczas wdrażania skonfigurujesz te ustawienia:
- GPU: NVIDIA L4, wybrany ze względu na doskonały stosunek ceny do wydajności w przypadku zbiorów zadań wymagających wnioskowania. L4 ma 24 GB pamięci GPU i zoptymalizowane operacje tensorowe, dzięki czemu idealnie nadaje się do modeli z 270 milionami parametrów, takich jak Gemma.
- Pamięć: 16 GB pamięci systemowej do obsługi ładowania modelu, operacji CUDA i zarządzania pamięcią przez Ollamę.
- CPU: 8 rdzeni do optymalnego obsługiwania wejścia/wyjścia i zadań przetwarzania wstępnego
- Równoczesność: 4 żądania na instancję równoważą przepustowość z wykorzystaniem pamięci przez GPU.
- Czas oczekiwania: 600 sekund na początkowe wczytanie modelu i uruchomienie kontenera.
Przyjrzyjmy się teraz agentowi Content Builder, który korzysta z modelu Gemma.
- Otwórz pokój
agents/content_builder/agent.py. - Sprawdź poniższy kod, który definiuje agenta
content_builder.
# the `ollama-gemma-gpu` Cloud Run service URL which hosts the Gemma model
target_url = os.environ.get("OLLAMA_API_BASE")
# ... existing code ...
# (Note: We use 'ollama/gemma3:270m' to align with ADK's expected prefix)
gemma_model_name = os.environ.get("GEMMA_MODEL_NAME", "gemma3:270m")
model = LiteLlm(
model=f"ollama_chat/{gemma_model_name}",
api_base=target_url
)
# 5. Define the Agent
content_builder = Agent(
name="content_builder",
model=model,
description="Transforms research findings into a structured course.",
instruction="""
You are an expert course creator.
Take the approved 'research_findings' and transform them into a well-structured, engaging course module.
**Formatting Rules:**
1. Start with a main title using a single `#` (H1).
2. Use `##` (H2) for main section headings. These will be used for the Table of Contents.
3. Use `###` (H3) for sub-sections within main sections.
4. Use bullet points and clear paragraphs.
5. Maintain a professional but engaging tone.
**Structure Requirements:**
- Begin with a brief Introduction section explaining what the learner will gain.
- Organize content into 3-5 main sections with clear headings.
- Include Key Takeaways at the end as a bulleted summary.
- Keep each section focused and concise.
Ensure the content directly addresses the user's original request.
Do not include any preamble or explanation outside the course content itself.
""",
)
root_agent = content_builder
Kluczowe pojęcie: propagacja kontekstu
Możesz się zastanawiać: „Skąd konstruktor treści wie, co znalazł badacz?”. W ADK agenty w potoku udostępniają session.state. Później w Orchestratorze skonfigurujemy Researcher i Judge tak, aby zapisywali wyniki w tym stanie współdzielonym. Prompt w Kreatorze treści ma dostęp do tej historii.
7. 🎻 Aranżer
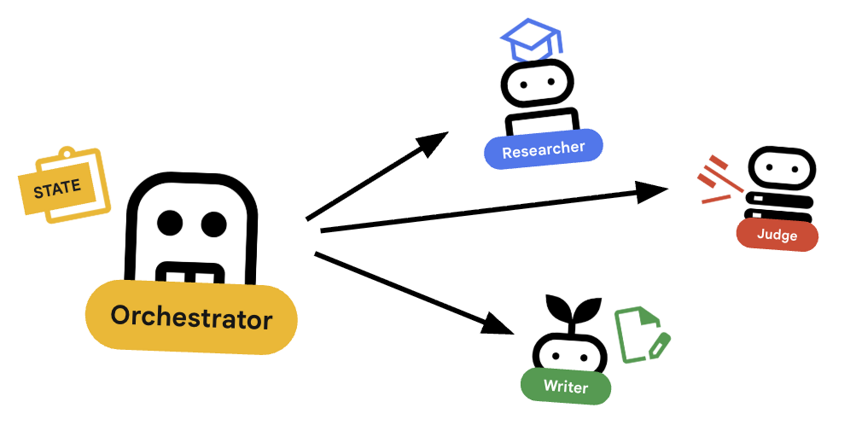
Orchestrator to menedżer naszego zespołu wieloagentowego. W przeciwieństwie do specjalistycznych agentów (Badacz, Sędzia, Twórca treści), którzy wykonują określone zadania, zadaniem Koordynatora jest koordynowanie przepływu pracy i zapewnienie prawidłowego przepływu informacji między nimi.
🌐 Architektura: agent-agent (A2A)
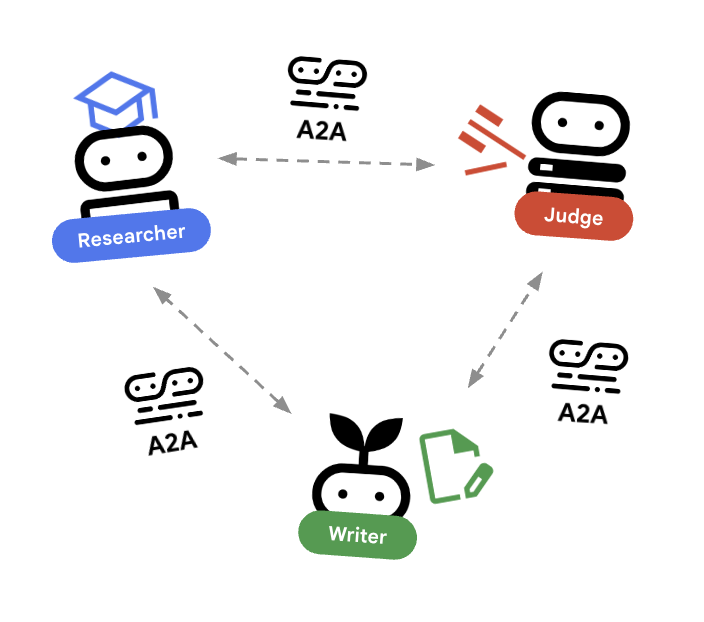
W tym module utworzymy system rozproszony. Zamiast uruchamiać wszystkie agenty w jednym procesie Pythona, wdrażamy je jako niezależne mikroserwisy. Dzięki temu każdy agent może być skalowany niezależnie i ulegać awarii bez powodowania awarii całego systemu.
Aby to umożliwić, używamy protokołu Agent-to-Agent (A2A).
Protokół A2A
Szczegółowe informacje: w systemie produkcyjnym agenci działają na różnych serwerach (a nawet w różnych chmurach). Protokół A2A tworzy standardowy sposób wykrywania i komunikowania się ze sobą za pomocą protokołu HTTP. RemoteA2aAgent to klient ADK dla tego protokołu.
- Otwórz pokój
agents/orchestrator/agent.py. - Sprawdź, jak poniższy kod definiuje połączenia.
# ... existing code ... # Connect to the Researcher (Localhost port 8001) researcher_url = os.environ.get("RESEARCHER_AGENT_CARD_URL", "http://localhost:8001/a2a/agent/.well-known/agent-card.json") researcher = RemoteA2aAgent( name="researcher", agent_card=researcher_url, description="Gathers information using Google Search.", # IMPORTANT: Save the output to state for the Judge to see after_agent_callback=create_save_output_callback("research_findings"), # IMPORTANT: Use authenticated client for communication httpx_client=create_authenticated_client(researcher_url) ) # Connect to the Judge (Localhost port 8002) judge_url = os.environ.get("JUDGE_AGENT_CARD_URL", "http://localhost:8002/a2a/agent/.well-known/agent-card.json") judge = RemoteA2aAgent( name="judge", agent_card=judge_url, description="Evaluates research.", after_agent_callback=create_save_output_callback("judge_feedback"), httpx_client=create_authenticated_client(judge_url) ) # Content Builder (Localhost port 8003) content_builder_url = os.environ.get("CONTENT_BUILDER_AGENT_CARD_URL", "http://localhost:8003/a2a/agent/.well-known/agent-card.json") content_builder = RemoteA2aAgent( name="content_builder", agent_card=content_builder_url, description="Builds the course.", httpx_client=create_authenticated_client(content_builder_url) )
8. 🛑 Narzędzie do sprawdzania eskalacji
Pętla musi mieć możliwość zatrzymania. Jeśli sędzia powie „Pass”, chcemy natychmiast wyjść z pętli i przejść do narzędzia do tworzenia treści.
Logika niestandardowa z BaseAgent
Szczegółowe informacje: nie wszyscy agenci korzystają z dużych modeli językowych. Czasami potrzebujesz prostej logiki Pythona. BaseAgent umożliwia zdefiniowanie agenta, który po prostu uruchamia kod. W takim przypadku sprawdzamy stan sesji i używamy EventActions(escalate=True), aby zasygnalizować LoopAgent, że ma się zatrzymać.
- Nadal w
agents/orchestrator/agent.py. - Zapoznaj się z poniższymi informacjami o ocenie kodu, aby poznać opinię sędziego i przejść do następnego kroku, gdy będziesz gotowy.
class EscalationChecker(BaseAgent): """Checks the judge's feedback and escalates (breaks the loop) if it passed.""" async def _run_async_impl( self, ctx: InvocationContext ) -> AsyncGenerator[Event, None]: # Retrieve the feedback saved by the Judge feedback = ctx.session.state.get("judge_feedback") print(f"[EscalationChecker] Feedback: {feedback}") # Check for 'pass' status is_pass = False if isinstance(feedback, dict) and feedback.get("status") == "pass": is_pass = True # Handle string fallback if JSON parsing failed elif isinstance(feedback, str) and '"status": "pass"' in feedback: is_pass = True if is_pass: # 'escalate=True' tells the parent LoopAgent to stop looping yield Event(author=self.name, actions=EventActions(escalate=True)) else: # Continue the loop yield Event(author=self.name) escalation_checker = EscalationChecker(name="escalation_checker")
Kluczowa koncepcja: sterowanie przepływem za pomocą zdarzeń
Agenci komunikują się nie tylko za pomocą tekstu, ale też za pomocą zdarzeń. Przekazując zdarzenie za pomocą escalate=True, agent wysyła sygnał do elementu nadrzędnego (LoopAgent). Element LoopAgent jest zaprogramowany tak, aby przechwytywać ten sygnał i kończyć pętlę.
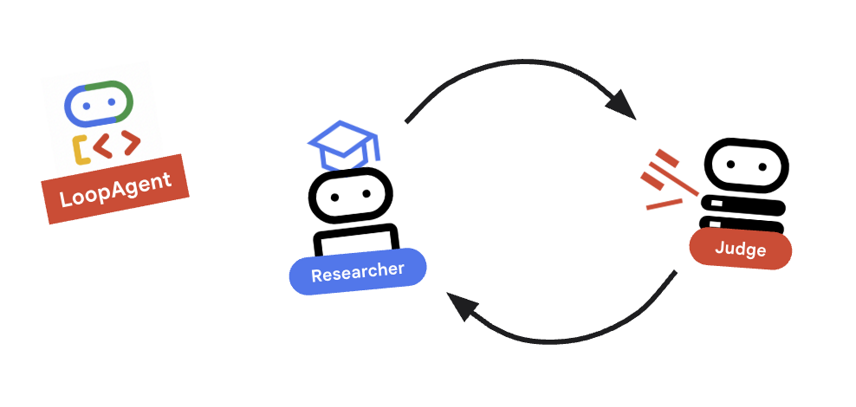
9. 🔁 Pętla badań
Potrzebujemy pętli informacji zwrotnej: badania –> ocena –> (niepowodzenie) –> badania –> …
- W języku:
agents/orchestrator/agent.py. - Sprawdź, jak poniższy kod definiuje definicję
research_loop.research_loop = LoopAgent( name="research_loop", description="Iteratively researches and judges until quality standards are met.", sub_agents=[researcher, judge, escalation_checker], max_iterations=3, )
Kluczowe pojęcie: LoopAgent
LoopAgent przełącza się między sub_agents w określonej kolejności.
researcher: wyszukuje dane.judge: ocenia dane.escalation_checker: określa, czyyield Event(escalate=True). Jeśli wystąpi warunekescalate=True, pętla zostanie przerwana wcześniej. W przeciwnym razie rozpocznie się ponownie od etapu badacza (maksymalniemax_iterations).
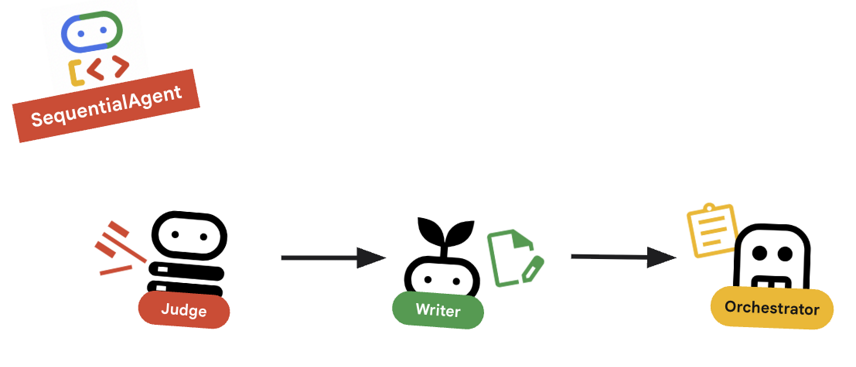
10. 🔗 Ostateczny potok
Wszystko w jednym miejscu…
- W języku:
agents/orchestrator/agent.py. - Sprawdź, jak zdefiniowano
root_agentna dole pliku.root_agent = SequentialAgent( name="course_creation_pipeline", description="A pipeline that researches a topic and then builds a course from it.", sub_agents=[research_loop, content_builder], )
Kluczowe pojęcie: kompozycja hierarchiczna
Zwróć uwagę, że research_loop jest agentem (LoopAgent). Traktujemy go tak samo jak każdego innego sub-agenta w SequentialAgent. Ta kompozycyjność umożliwia tworzenie złożonej logiki przez zagnieżdżanie prostych wzorców (pętli w sekwencjach, sekwencji w routerach itp.).
11. 🚀 Wdróż w Cloud Run
Każdego agenta wdrożymy jako osobną usługę w Cloud Run, w tym usługę Cloud Run dla interfejsu twórcy kursu i usługę Cloud Run korzystającą z GPU dla modelu Gemma.
Informacje o konfiguracji wdrożenia
Podczas wdrażania agentów w Cloud Run przekazujemy kilka zmiennych środowiskowych, aby skonfigurować ich działanie i łączność:
GOOGLE_CLOUD_PROJECT: zapewnia, że agent używa prawidłowego projektu w chmurze Google Cloud do logowania i wywołań Vertex AI.GOOGLE_GENAI_USE_VERTEXAI: informuje platformę agentów (ADK), aby do wnioskowania o modelu używała Vertex AI zamiast bezpośrednio wywoływać interfejsy Gemini API.[AGENT]_AGENT_CARD_URL: jest to kluczowe dla aranżera. Informuje aranżera, gdzie znajdują się zdalni agenci. Ustawiając tę wartość na wdrożony adres URL Cloud Run (a konkretnie ścieżkę karty agenta), umożliwiamy Orchestratorowi wykrywanie i komunikowanie się z Researcherem, Judge i Content Builderem przez internet.
Aby wdrożyć wszystkie agenty w usługach Cloud Run, uruchom ten skrypt.
Najpierw upewnij się, że skrypt jest wykonywalny.
chmod u+x ~/multi-agent-system/deploy.sh
Uwaga: wykonanie tego polecenia zajmie kilka minut, ponieważ każda usługa jest wdrażana sekwencyjnie.
~/multi-agent-system/deploy.sh
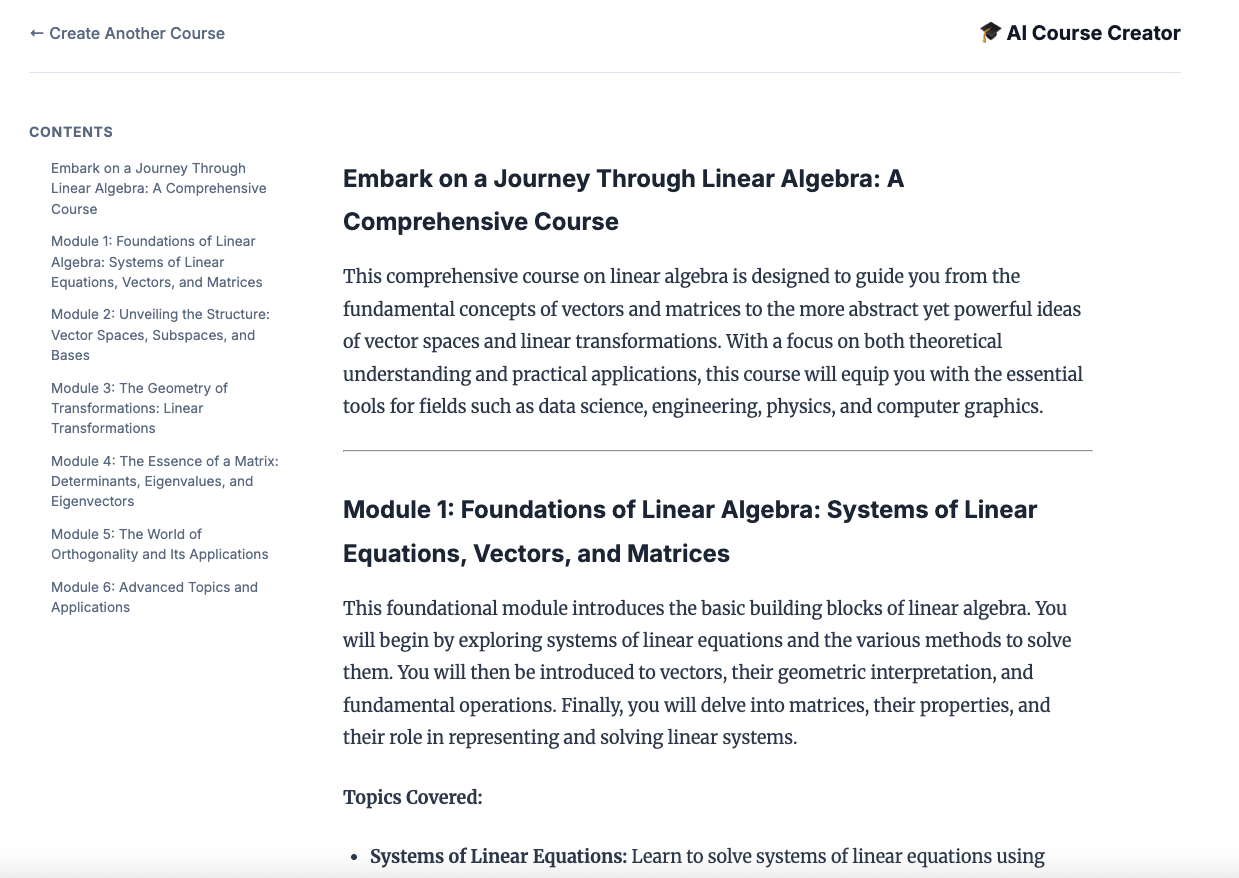
12. Utwórz kurs!
Otwórz witrynę Course Creator. Usługa Cloud Run Course Creator to ostatnia usługa wdrożona ze skryptu. Adres URL do twórcy kursu możesz oznaczyć jako https://course-creator-. Powinien to być ostatni wiersz danych wyjściowych ze skryptu wdrażania.
Wpisz pomysł na kurs, np. „algebra liniowa”.
Przedstawiciele zaczną pracować nad Twoim kursem.
13. Czyszczenie
Aby uniknąć obciążenia konta Google Cloud opłatami za zasoby zużyte w tym samouczku, wykonaj te czynności, aby usunąć usługi i obrazy kontenerów.
1. Usuwanie usług Cloud Run
Najskuteczniejszym sposobem na zwolnienie miejsca jest usunięcie usług wdrożonych w Cloud Run.
# Delete the main agent and app services
gcloud run services delete researcher content-builder judge orchestrator course-creator \
--region $REGION --quiet
# Delete the GPU backend (Ollama)
gcloud run services delete ollama-gemma-gpu \
--region $OLLAMA_REGION --quiet
2. Usuwanie obrazów Artifact Registry
Gdy użyjesz flagi --source do wdrożenia, Google Cloud utworzy w Artifact Registry repozytorium do przechowywania obrazów kontenerów. Aby usunąć te repozytoria i zaoszczędzić na kosztach przechowywania, wykonaj te czynności:
gcloud artifacts repositories delete cloud-run-source-deploy --location us-east4 --quiet
3. Usuwanie plików lokalnych i środowiska
Aby zachować porządek w środowisku Cloud Shell, usuń folder projektu i wszelkie lokalne konfiguracje:
cd ~
rm -rf multi-agent-system
4. (Opcjonalnie) Usuwanie projektu
Jeśli projekt został utworzony specjalnie na potrzeby tego laboratorium, możesz uniknąć dalszych opłat, zamykając go na stronie Zarządzanie zasobami.
14. Gratulacje!
Udało Ci się utworzyć i wdrożyć przygotowany do zastosowań produkcyjnych rozproszony system wieloagentowy.
Co udało Ci się osiągnąć
- Podzieliliśmy złożone zadanie: zamiast jednego obszernego prompta podzieliliśmy pracę na wyspecjalizowane role (badacz, sędzia, twórca treści).
- Wdrożona kontrola jakości: użyliśmy
LoopAgenti ustrukturyzowanegoJudge, aby mieć pewność, że tylko informacje wysokiej jakości docierają do ostatniego etapu. - Stworzony z myślą o produkcji: dzięki użyciu protokołu Agent-to-Agent (A2A) i usługi Cloud Run stworzyliśmy system, w którym każdy agent jest niezależną, skalowalną mikrousługą. Jest to znacznie bardziej niezawodne niż uruchamianie wszystkiego w jednym skrypcie Python.
- Orchestration: użyliśmy elementów
SequentialAgentiLoopAgent, aby zdefiniować jasne wzorce przepływu sterowania. *. GPU w Cloud Run: wdrożenie modelu Gemma na GPU w Cloud Run.