
1. บทนำ
ใน Lab นี้ คุณจะได้สร้างระบบแบบหลาย Agent แบบกระจายซึ่งไม่ใช่แค่แชทบอทธรรมดา
แม้ว่า LLM เดียวจะตอบคำถามได้ แต่ความซับซ้อนในโลกแห่งความเป็นจริงมักต้องใช้บทบาทเฉพาะทาง คุณจะไม่ขอให้วิศวกรแบ็กเอนด์ออกแบบ UI และจะไม่ขอให้นักออกแบบเพิ่มประสิทธิภาพการค้นหาฐานข้อมูล ในทำนองเดียวกัน เราสามารถสร้างเอเจนต์ AI เฉพาะทางที่มุ่งเน้นงานเดียวและประสานงานกันเพื่อแก้ปัญหาที่ซับซ้อนได้
คุณจะสร้างระบบการสร้างหลักสูตรซึ่งประกอบด้วย
- Agent นักวิจัย: ใช้ google_search เพื่อค้นหาข้อมูลล่าสุด
- ผู้ประเมิน Agent: วิจารณ์การค้นคว้าข้อมูลเพื่อดูคุณภาพและความครบถ้วน
- เอเจนต์ตัวสร้างเนื้อหา: เปลี่ยนงานวิจัยให้เป็นหลักสูตรที่มีโครงสร้าง
- Orchestrator Agent: จัดการเวิร์กโฟลว์และการสื่อสารระหว่างผู้เชี่ยวชาญเหล่านี้
สิ่งที่คุณจะได้เรียนรู้
- กำหนดเอเจนต์ที่ใช้เครื่องมือ (นักวิจัย) ที่ค้นหาในเว็บได้
- ใช้เอาต์พุตที่มีโครงสร้างด้วย Pydantic สำหรับผู้พิพากษา
- เชื่อมต่อกับเอเจนต์ระยะไกลโดยใช้โปรโตคอล Agent-to-Agent (A2A)
- สร้าง LoopAgent เพื่อสร้างวงจรความคิดเห็นระหว่างนักวิจัยและผู้ตัดสิน
- เรียกใช้ระบบแบบกระจายในเครื่องโดยใช้ ADK
- ติดตั้งใช้งานระบบแบบหลาย Agent ใน Google Cloud Run
- ใช้โมเดล Gemma ใน GPU ของ Cloud Run สำหรับเอเจนต์เครื่องมือสร้างเนื้อหา
สิ่งที่คุณต้องมี
- เว็บเบราว์เซอร์ เช่น Chrome
- โปรเจ็กต์ Google Cloud ที่เปิดใช้การเรียกเก็บเงิน
2. หลักการด้านสถาปัตยกรรมและการจัดการเป็นกลุ่ม
ก่อนอื่นมาทำความเข้าใจวิธีที่เอเจนต์เหล่านี้ทำงานร่วมกัน เรากำลังสร้างไปป์ไลน์การสร้างหลักสูตร
การออกแบบระบบ
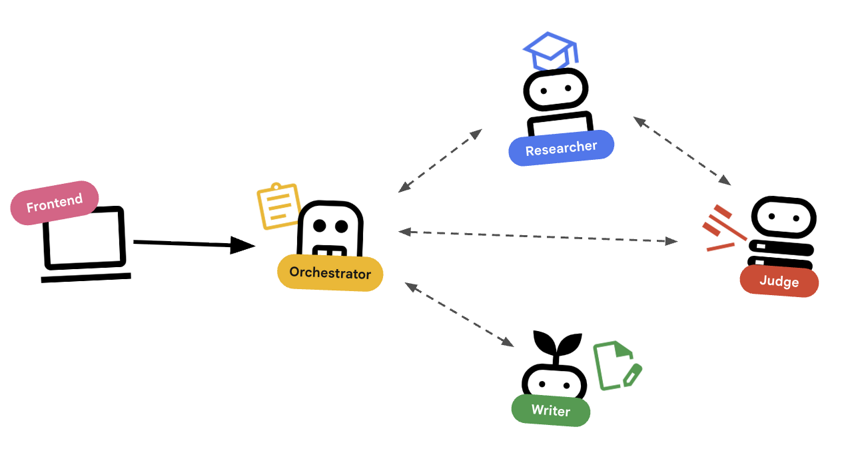
การประสานงานด้วย Agent
เอเจนต์มาตรฐาน (เช่น นักวิจัย) จะทำงาน Agent ผู้จัดการ (เช่น LoopAgent หรือ SequentialAgent) จะจัดการ Agent อื่นๆ โดยที่ผู้จัดการไม่ได้มีเครื่องมือของตัวเอง แต่ "เครื่องมือ" ของผู้จัดการคือการมอบหมายงาน
LoopAgent: การดำเนินการนี้จะเหมือนกับลูปwhileในโค้ด โดยจะเรียกใช้ลำดับของเอเจนต์ซ้ำๆ จนกว่าจะเป็นไปตามเงื่อนไข (หรือถึงการวนซ้ำสูงสุด) เราใช้ข้อมูลนี้สำหรับวงจรการวิจัย ดังนี้- นักวิจัยค้นหาข้อมูล
- ผู้พิพากษาวิจารณ์
- หาก Judge ระบุว่า "ไม่ผ่าน" EscalationChecker จะทำให้ลูปดำเนินต่อไป
- หากผู้ตรวจสอบพูดว่า "ผ่าน" EscalationChecker จะหยุดการวนซ้ำ
SequentialAgent: การดำเนินการนี้จะเหมือนกับการเรียกใช้สคริปต์มาตรฐาน โดยจะเรียกใช้ Agent ทีละรายการ เราใช้สิ่งนี้สำหรับไปป์ไลน์ระดับสูง- ก่อนอื่น ให้เรียกใช้วงจรการวิจัย (จนกว่าจะเสร็จสิ้นด้วยข้อมูลที่ดี)
- จากนั้นเรียกใช้เครื่องมือสร้างเนื้อหา (เพื่อเขียนหลักสูตร)
การรวมทั้ง 2 อย่างนี้เข้าด้วยกันทำให้เราสร้างระบบที่มีประสิทธิภาพซึ่งสามารถแก้ไขตัวเองได้ก่อนที่จะสร้างเอาต์พุตสุดท้าย
3. ตั้งค่า
การตั้งค่าโปรเจ็กต์
สร้างโปรเจ็กต์ Google Cloud
- ในคอนโซล Google Cloud ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud ในหน้าตัวเลือกโปรเจ็กต์
- ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ Cloud แล้ว ดูวิธีตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินในโปรเจ็กต์แล้วหรือไม่
เริ่มต้น Cloud Shell
Cloud Shell คือสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานใน Google Cloud ซึ่งโหลดเครื่องมือที่จำเป็นไว้ล่วงหน้า
- คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud
- เมื่อเชื่อมต่อกับ Cloud Shell แล้ว ให้ยืนยันการตรวจสอบสิทธิ์โดยทำดังนี้
gcloud auth list - ตรวจสอบว่าได้กำหนดค่าโปรเจ็กต์แล้ว
gcloud config get project - หากไม่ได้ตั้งค่าโปรเจ็กต์ตามที่คาดไว้ ให้ตั้งค่าดังนี้
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
การตั้งค่าสภาพแวดล้อม
- เปิด Cloud Shell: คลิกไอคอนเปิดใช้งาน Cloud Shell ที่ด้านขวาบนของคอนโซล Google Cloud
รับโค้ดเริ่มต้น
- โคลนที่เก็บเริ่มต้นลงในไดเรกทอรีหลัก:ย้ายไปยังไดเรกทอรีหลัก
cd ~git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git temp-repo && cd temp-repo && git sparse-checkout set agents/multi-agent-system && cd .. && mv temp-repo/agents/multi-agent-system . && rm -rf temp-repocd multi-agent-system - เปิดใช้ API: เรียกใช้คำสั่งต่อไปนี้เพื่อเปิดใช้บริการ Google Cloud ที่จำเป็น
gcloud services enable \ run.googleapis.com \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ aiplatform.googleapis.com \ compute.googleapis.com - เปิดโฟลเดอร์นี้ในโปรแกรมแก้ไข
cloudshell edit .
ตั้งค่าสภาพแวดล้อม
- ตั้งค่าตัวแปรสภาพแวดล้อม เราจะสร้างไฟล์
.envเพื่อจัดเก็บตัวแปรเหล่านี้เพื่อให้คุณโหลดซ้ำได้ง่ายๆ หากเซสชันขาดการเชื่อมต่อcat <<EOF > .env export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) export GOOGLE_CLOUD_LOCATION=europe-west4 export GOOGLE_GENAI_USE_VERTEXAI=true EOF - ส่งออกตัวแปรสภาพแวดล้อม
source .env
4. 🕵️ Agent นักวิจัย
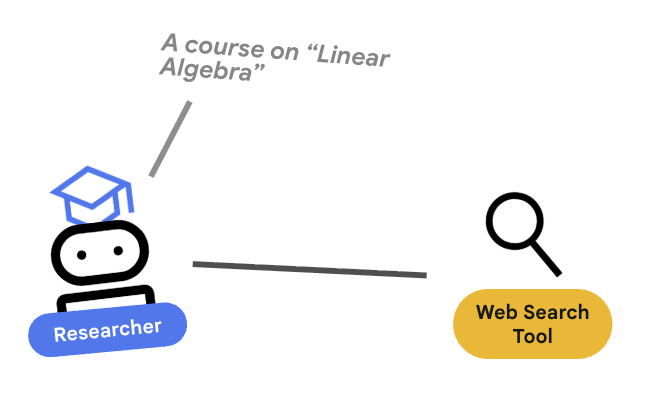
นักวิจัยคือผู้เชี่ยวชาญ หน้าที่ของเครื่องมือนี้มีเพียงการค้นหาข้อมูล โดยต้องมีสิทธิ์เข้าถึงเครื่องมือ Google Search
เหตุใดจึงแยก Researcher
เจาะลึก: ทำไมไม่ใช้เอเจนต์คนเดียวทำทุกอย่าง
Agent ขนาดเล็กที่มุ่งเน้นเฉพาะทางจะประเมินและแก้ไขข้อบกพร่องได้ง่ายกว่า หากการค้นหาไม่ดี ให้ทำซ้ำพรอมต์ของนักวิจัย หากการจัดรูปแบบหลักสูตรไม่ดี คุณจะทำซ้ำในเครื่องมือสร้างเนื้อหา ในพรอมต์แบบโมโนลิธที่ "ทำทุกอย่าง" การแก้ไขสิ่งหนึ่งมักจะทำให้สิ่งอื่นเสีย
- หากคุณทำงานใน Cloud Shell ให้เรียกใช้คำสั่งต่อไปนี้เพื่อเปิด Cloud Shell Editor
cloudshell workspace . - เปิด
agents/researcher/agent.py - ตรวจสอบโค้ดต่อไปนี้ที่กำหนดตัวแทน
researcher# ... existing imports ... # Define the Researcher Agent researcher = Agent( name="researcher", model=MODEL, description="Gathers information on a topic using Google Search.", instruction=""" You are an expert researcher. Your goal is to find comprehensive and accurate information on the user's topic. Use the `google_search` tool to find relevant information. Summarize your findings clearly. If you receive feedback that your research is insufficient, use the feedback to refine your next search. """, tools=[google_search], ) root_agent = researcher
แนวคิดหลัก: การใช้เครื่องมือ
โปรดสังเกตว่าเราส่งผ่าน tools=[google_search] ADK จะจัดการความซับซ้อนของการอธิบายเครื่องมือนี้ให้ LLM เมื่อโมเดลตัดสินใจว่าต้องการข้อมูล โมเดลจะสร้างการเรียกใช้เครื่องมือที่มีโครงสร้าง ADK จะเรียกใช้ฟังก์ชัน Python google_search และส่งผลลัพธ์กลับไปยังโมเดล
5. ⚖️ ตัวแทนผู้พิพากษา
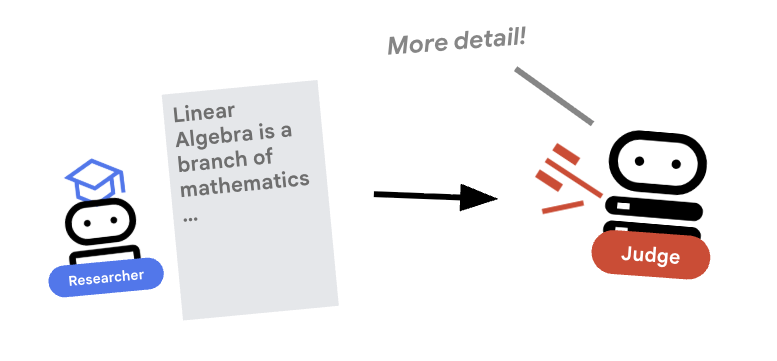
นักวิจัยทำงานอย่างหนัก แต่ LLM อาจขี้เกียจ เราต้องการผู้พิพากษาเพื่อตรวจสอบงาน กรรมการยอมรับการวิจัยและส่งผลการประเมินแบบผ่าน/ไม่ผ่านที่มีโครงสร้าง
เอาต์พุตที่มีโครงสร้าง
เจาะลึก: หากต้องการทำให้เวิร์กโฟลว์เป็นอัตโนมัติ เราต้องมีเอาต์พุตที่คาดการณ์ได้ การรีวิวแบบข้อความที่ยาวเหยียดจะแยกวิเคราะห์โดยใช้โปรแกรมได้ยาก การบังคับใช้สคีมา JSON (โดยใช้ Pydantic) ช่วยให้มั่นใจได้ว่า Judge จะแสดงผลบูลีน pass หรือ fail ที่โค้ดของเราสามารถดำเนินการได้อย่างน่าเชื่อถือ
- เปิด
agents/judge/agent.py - ตรวจสอบโค้ดต่อไปนี้ที่กำหนดสคีมา
JudgeFeedbackและเอเจนต์judge# 1. Define the Schema class JudgeFeedback(BaseModel): """Structured feedback from the Judge agent.""" status: Literal["pass", "fail"] = Field( description="Whether the research is sufficient ('pass') or needs more work ('fail')." ) feedback: str = Field( description="Detailed feedback on what is missing. If 'pass', a brief confirmation." ) # 2. Define the Agent judge = Agent( name="judge", model=MODEL, description="Evaluates research findings for completeness and accuracy.", instruction=""" You are a strict editor. Evaluate the 'research_findings' against the user's original request. If the findings are missing key info, return status='fail'. If they are comprehensive, return status='pass'. """, output_schema=JudgeFeedback, # Disallow delegation because it should only output the schema disallow_transfer_to_parent=True, disallow_transfer_to_peers=True, ) root_agent = judge
แนวคิดหลัก: การจำกัดลักษณะการทำงานของเอเจนต์
เราตั้งค่า disallow_transfer_to_parent=True และ disallow_transfer_to_peers=True ซึ่งจะบังคับให้ผู้พิพากษาแสดงผลเฉพาะ JudgeFeedback ที่มีโครงสร้าง โดยไม่สามารถตัดสินใจที่จะ "แชท" กับผู้ใช้หรือมอบหมายให้ตัวแทนรายอื่น ซึ่งทำให้เป็นคอมโพเนนต์ที่กำหนดได้ในโฟลว์ตรรกะ
6. ✍️ เอเจนต์สร้างเนื้อหา
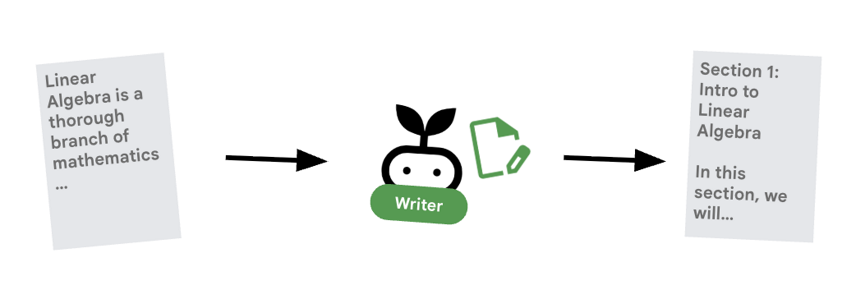
เครื่องมือสร้างเนื้อหาคือผู้เขียนครีเอทีฟโฆษณา โดยจะนำงานวิจัยที่ได้รับอนุมัติมาเปลี่ยนเป็นหลักสูตร โดยใช้โมเดล Gemma ที่ให้บริการโดย Cloud Run
ก่อนอื่นมาดูบริการ Cloud Run ที่โฮสต์โมเดลกัน
- เปิด
ollama_backend/Dockerfile - ในที่นี้ คุณจะเห็นว่า Dockerfile ใช้อิมเมจ Ollama อย่างไร รับฟังคำขอในพอร์ต 8080 และจัดเก็บโมเดลที่ขอในโฟลเดอร์ /model
FROM ollama/ollama:latest # Listen on all interfaces, port 8080 (Cloud Run default) ENV OLLAMA_HOST 0.0.0.0:8080 # Store model weight files in /models ENV OLLAMA_MODELS /models
⚙️ เมื่อทำการติดตั้งใช้งาน คุณจะต้องตั้งค่าต่อไปนี้
- GPU: NVIDIA L4 ได้รับเลือกเนื่องจากมีอัตราส่วนราคาต่อประสิทธิภาพที่ยอดเยี่ยมสำหรับปริมาณงานการอนุมาน L4 มีหน่วยความจำ GPU ขนาด 24 GB และการดำเนินการกับ Tensor ที่ได้รับการเพิ่มประสิทธิภาพ จึงเหมาะสำหรับโมเดลที่มีพารามิเตอร์ 270 ล้านรายการ เช่น Gemma
- หน่วยความจำ: หน่วยความจำระบบ 16 GB เพื่อรองรับการโหลดโมเดล การดำเนินการ CUDA และการจัดการหน่วยความจำของ Ollama
- CPU: 8 คอร์เพื่อการจัดการ I/O และการประมวลผลล่วงหน้าที่ดีที่สุด
- การทำงานพร้อมกัน: คำขอ 4 รายการต่ออินสแตนซ์จะปรับสมดุลปริมาณงานกับการใช้หน่วยความจำ GPU
- ระยะหมดเวลา: 600 วินาทีรองรับการโหลดโมเดลเริ่มต้นและการเริ่มต้นคอนเทนเนอร์
ตอนนี้เรามาดูเอเจนต์เครื่องมือสร้างเนื้อหาที่ใช้โมเดล Gemma กัน
- เปิด
agents/content_builder/agent.py - ตรวจสอบโค้ดต่อไปนี้ที่กำหนดเอเจนต์
content_builder
# the `ollama-gemma-gpu` Cloud Run service URL which hosts the Gemma model
target_url = os.environ.get("OLLAMA_API_BASE")
# ... existing code ...
# (Note: We use 'ollama/gemma3:270m' to align with ADK's expected prefix)
gemma_model_name = os.environ.get("GEMMA_MODEL_NAME", "gemma3:270m")
model = LiteLlm(
model=f"ollama_chat/{gemma_model_name}",
api_base=target_url
)
# 5. Define the Agent
content_builder = Agent(
name="content_builder",
model=model,
description="Transforms research findings into a structured course.",
instruction="""
You are an expert course creator.
Take the approved 'research_findings' and transform them into a well-structured, engaging course module.
**Formatting Rules:**
1. Start with a main title using a single `#` (H1).
2. Use `##` (H2) for main section headings. These will be used for the Table of Contents.
3. Use `###` (H3) for sub-sections within main sections.
4. Use bullet points and clear paragraphs.
5. Maintain a professional but engaging tone.
**Structure Requirements:**
- Begin with a brief Introduction section explaining what the learner will gain.
- Organize content into 3-5 main sections with clear headings.
- Include Key Takeaways at the end as a bulleted summary.
- Keep each section focused and concise.
Ensure the content directly addresses the user's original request.
Do not include any preamble or explanation outside the course content itself.
""",
)
root_agent = content_builder
แนวคิดหลัก: การเผยแพร่บริบท
คุณอาจสงสัยว่า "เครื่องมือสร้างเนื้อหารู้ได้อย่างไรว่าเครื่องมือวิจัยค้นพบอะไร" ใน ADK เอเจนต์ในไปป์ไลน์จะแชร์ session.state ต่อมาใน Orchestrator เราจะกำหนดค่า Researcher และ Judge ให้บันทึกเอาต์พุตไปยังสถานะที่แชร์นี้ พรอมต์ของเครื่องมือสร้างเนื้อหาจะเข้าถึงประวัติการสนทนานี้ได้อย่างมีประสิทธิภาพ
7. 🎻 Orchestrator
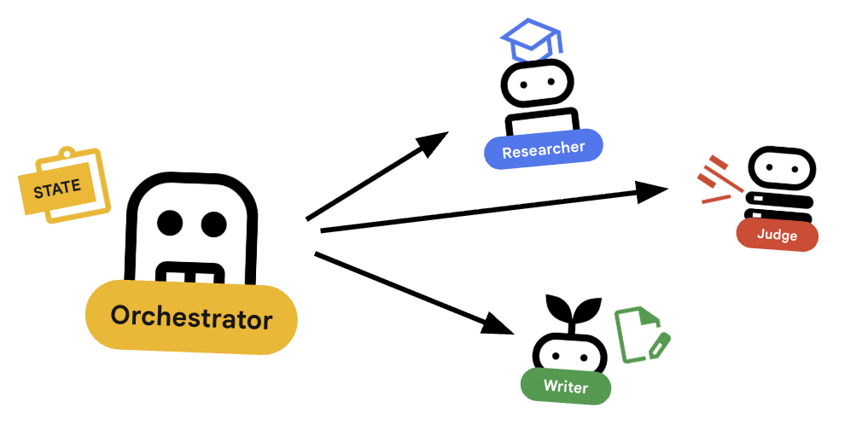
Orchestrator เป็นผู้จัดการทีมแบบหลายเอเจนต์ของเรา ซึ่งแตกต่างจากตัวแทนผู้เชี่ยวชาญ (นักวิจัย ผู้ตัดสิน ผู้สร้างเนื้อหา) ที่ทำหน้าที่เฉพาะเจาะจง งานของ Orchestrator คือการประสานงานเวิร์กโฟลว์และตรวจสอบว่าข้อมูลไหลเวียนระหว่างตัวแทนผู้เชี่ยวชาญอย่างถูกต้อง
🌐 สถาปัตยกรรม: ตัวแทนถึงตัวแทน (A2A)
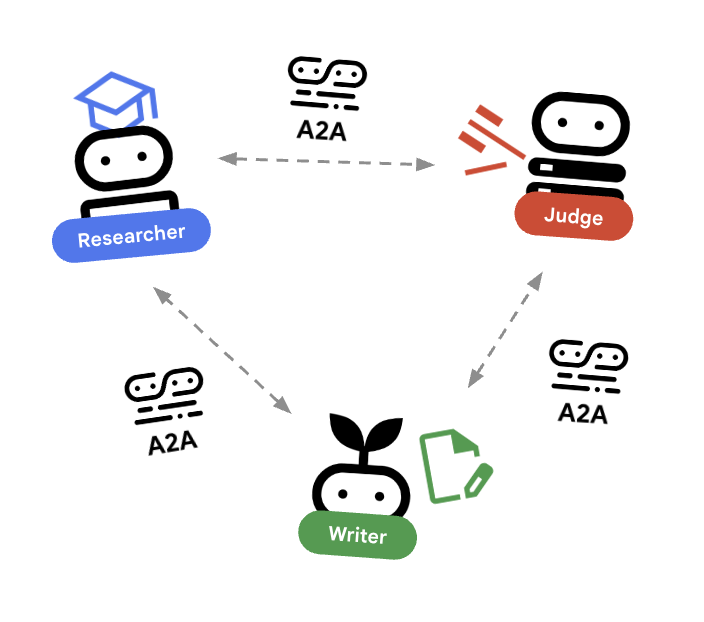
ใน Lab นี้ เราจะสร้างระบบแบบกระจาย เราจะทำให้เอเจนต์ทำงานเป็นไมโครเซอร์วิสอิสระแทนที่จะให้เอเจนต์ทั้งหมดทำงานในกระบวนการ Python เดียว ซึ่งช่วยให้แต่ละเอเจนต์ปรับขนาดได้อย่างอิสระและล้มเหลวได้โดยไม่ทำให้ระบบทั้งหมดล่ม
เราใช้โปรโตคอล Agent-to-Agent (A2A) เพื่อให้การดำเนินการนี้เป็นไปได้
โปรโตคอล A2A
เจาะลึก: ในระบบที่ใช้งานจริง เอเจนต์จะทำงานบนเซิร์ฟเวอร์ที่แตกต่างกัน (หรือแม้แต่ในระบบคลาวด์ที่แตกต่างกัน) โปรโตคอล A2A สร้างวิธีมาตรฐานให้ค้นพบและสื่อสารกันผ่าน HTTP RemoteA2aAgent เป็นไคลเอ็นต์ ADK สำหรับโปรโตคอลนี้
- เปิด
agents/orchestrator/agent.py - ดูวิธีที่โค้ดต่อไปนี้กำหนดการเชื่อมต่อ
# ... existing code ... # Connect to the Researcher (Localhost port 8001) researcher_url = os.environ.get("RESEARCHER_AGENT_CARD_URL", "http://localhost:8001/a2a/agent/.well-known/agent-card.json") researcher = RemoteA2aAgent( name="researcher", agent_card=researcher_url, description="Gathers information using Google Search.", # IMPORTANT: Save the output to state for the Judge to see after_agent_callback=create_save_output_callback("research_findings"), # IMPORTANT: Use authenticated client for communication httpx_client=create_authenticated_client(researcher_url) ) # Connect to the Judge (Localhost port 8002) judge_url = os.environ.get("JUDGE_AGENT_CARD_URL", "http://localhost:8002/a2a/agent/.well-known/agent-card.json") judge = RemoteA2aAgent( name="judge", agent_card=judge_url, description="Evaluates research.", after_agent_callback=create_save_output_callback("judge_feedback"), httpx_client=create_authenticated_client(judge_url) ) # Content Builder (Localhost port 8003) content_builder_url = os.environ.get("CONTENT_BUILDER_AGENT_CARD_URL", "http://localhost:8003/a2a/agent/.well-known/agent-card.json") content_builder = RemoteA2aAgent( name="content_builder", agent_card=content_builder_url, description="Builds the course.", httpx_client=create_authenticated_client(content_builder_url) )
8. 🛑 เครื่องมือตรวจสอบการยกระดับ
ลูปต้องมีวิธีหยุด หากผู้พิพากษาพูดว่า "ผ่าน" เราต้องการออกจากลูปทันทีและไปที่เครื่องมือสร้างเนื้อหา
ตรรกะที่กำหนดเองด้วย BaseAgent
เจาะลึก: เอเจนต์บางตัวไม่ได้ใช้ LLM บางครั้งคุณก็ต้องการตรรกะ Python แบบง่ายๆ BaseAgent ช่วยให้คุณกำหนด Agent ที่เรียกใช้โค้ดเท่านั้นได้ ในกรณีนี้ เราจะตรวจสอบสถานะเซสชันและใช้ EventActions(escalate=True) เพื่อส่งสัญญาณให้ LoopAgent หยุด
- ยังอยู่ใน
agents/orchestrator/agent.py - ตรวจสอบโค้ดต่อไปนี้เพื่อดูความคิดเห็นของกรรมการและไปยังขั้นตอนถัดไปเมื่อพร้อม
class EscalationChecker(BaseAgent): """Checks the judge's feedback and escalates (breaks the loop) if it passed.""" async def _run_async_impl( self, ctx: InvocationContext ) -> AsyncGenerator[Event, None]: # Retrieve the feedback saved by the Judge feedback = ctx.session.state.get("judge_feedback") print(f"[EscalationChecker] Feedback: {feedback}") # Check for 'pass' status is_pass = False if isinstance(feedback, dict) and feedback.get("status") == "pass": is_pass = True # Handle string fallback if JSON parsing failed elif isinstance(feedback, str) and '"status": "pass"' in feedback: is_pass = True if is_pass: # 'escalate=True' tells the parent LoopAgent to stop looping yield Event(author=self.name, actions=EventActions(escalate=True)) else: # Continue the loop yield Event(author=self.name) escalation_checker = EscalationChecker(name="escalation_checker")
แนวคิดหลัก: การควบคุมโฟลว์ผ่านเหตุการณ์
Agent สื่อสารกันไม่ใช่แค่ด้วยข้อความ แต่ยังใช้เหตุการณ์ด้วย เมื่อส่งเหตุการณ์ด้วย escalate=True เอเจนต์นี้จะส่งสัญญาณไปยังองค์ประกอบระดับบน (LoopAgent) โดย LoopAgent ได้รับการตั้งโปรแกรมให้ตรวจจับสัญญาณนี้และสิ้นสุดลูป
9. 🔁 วงจรการวิจัย
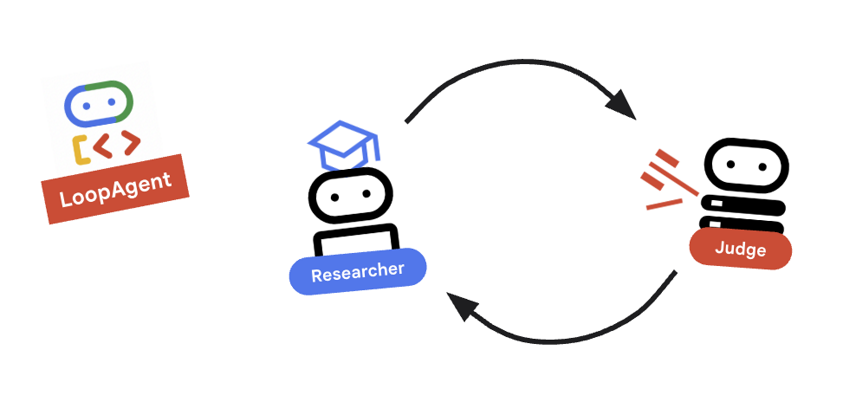
เราต้องการวงจรความคิดเห็น: การวิจัย -> การตัดสิน -> (ล้มเหลว) -> การวิจัย -> ...
- ใน
agents/orchestrator/agent.py - ดูว่าโค้ดต่อไปนี้กำหนด
research_loopอย่างไรresearch_loop = LoopAgent( name="research_loop", description="Iteratively researches and judges until quality standards are met.", sub_agents=[researcher, judge, escalation_checker], max_iterations=3, )
แนวคิดหลัก: LoopAgent
LoopAgent จะsub_agentsตามลำดับ
researcher: ค้นหาข้อมูลjudge: ประเมินข้อมูลescalation_checker: ตัดสินใจว่าจะyield Event(escalate=True)หรือไม่ หากescalate=Trueเกิดขึ้น ลูปจะหยุดก่อนกำหนด ไม่เช่นนั้น ระบบจะรีสตาร์ทที่ผู้เข้าร่วมการวิจัย (สูงสุดmax_iterations)
10. 🔗 ไปป์ไลน์สุดท้าย
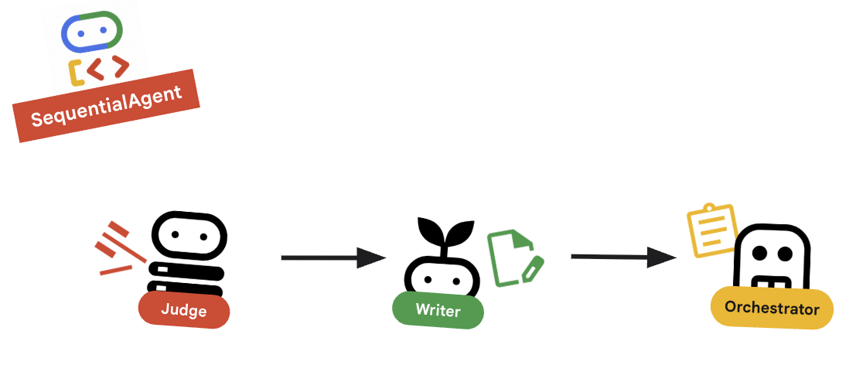
รวมทุกสิ่งไว้ในที่เดียว....
- ใน
agents/orchestrator/agent.py - ดูวิธีกำหนด
root_agentที่ด้านล่างของไฟล์root_agent = SequentialAgent( name="course_creation_pipeline", description="A pipeline that researches a topic and then builds a course from it.", sub_agents=[research_loop, content_builder], )
แนวคิดหลัก: การจัดองค์ประกอบแบบลำดับชั้น
โปรดทราบว่า research_loop เป็นเอเจนต์ (LoopAgent) เราจะถือว่า research_loop เป็นเหมือน Agent ย่อยอื่นๆ ใน SequentialAgent ความสามารถในการประกอบนี้ช่วยให้คุณสร้างตรรกะที่ซับซ้อนได้โดยการซ้อนรูปแบบที่เรียบง่าย (ลูปภายในลำดับ ลำดับภายในเราเตอร์ ฯลฯ)
11. 🚀 ทำให้ใช้งานได้กับ Cloud Run
เราจะติดตั้งใช้งาน Agent แต่ละตัวเป็นบริการแยกต่างหากใน Cloud Run ซึ่งรวมถึงบริการ Cloud Run สำหรับ UI ของผู้สร้างหลักสูตร และบริการ Cloud Run ที่ใช้ GPU สำหรับโมเดล Gemma
ทำความเข้าใจการกำหนดค่าการทำให้ใช้งานได้
เมื่อติดตั้งใช้งาน Agent ใน Cloud Run เราจะส่งตัวแปรสภาพแวดล้อมหลายรายการเพื่อกำหนดค่าลักษณะการทำงานและการเชื่อมต่อของ Agent ดังนี้
GOOGLE_CLOUD_PROJECT: ตรวจสอบว่า Agent ใช้โปรเจ็กต์ Google Cloud ที่ถูกต้องสำหรับการบันทึกและการเรียก Vertex AIGOOGLE_GENAI_USE_VERTEXAI: บอกให้เฟรมเวิร์กของ Agent (ADK) ใช้ Vertex AI สำหรับการอนุมานโมเดลแทนการเรียกใช้ Gemini API โดยตรง[AGENT]_AGENT_CARD_URL: ข้อมูลนี้มีความสำคัญอย่างยิ่งสำหรับ Orchestrator ซึ่งจะบอก Orchestrator ว่าจะค้นหา Agent ระยะไกลได้ที่ไหน การตั้งค่านี้เป็น URL ของ Cloud Run ที่ทำให้ใช้งานได้ (โดยเฉพาะเส้นทางการ์ดเอเจนต์) จะช่วยให้ Orchestrator ค้นพบและสื่อสารกับ Researcher, Judge และ Content Builder ผ่านอินเทอร์เน็ตได้
หากต้องการทําให้ Agent ทั้งหมดใช้งานได้กับบริการ Cloud Run ให้เรียกใช้สคริปต์ต่อไปนี้
ก่อนอื่น ให้ตรวจสอบว่าสคริปต์สามารถเรียกใช้งานได้
chmod u+x ~/multi-agent-system/deploy.sh
หมายเหตุ การดำเนินการนี้จะใช้เวลาหลายนาทีเนื่องจากระบบจะติดตั้งใช้งานแต่ละบริการตามลำดับ
~/multi-agent-system/deploy.sh
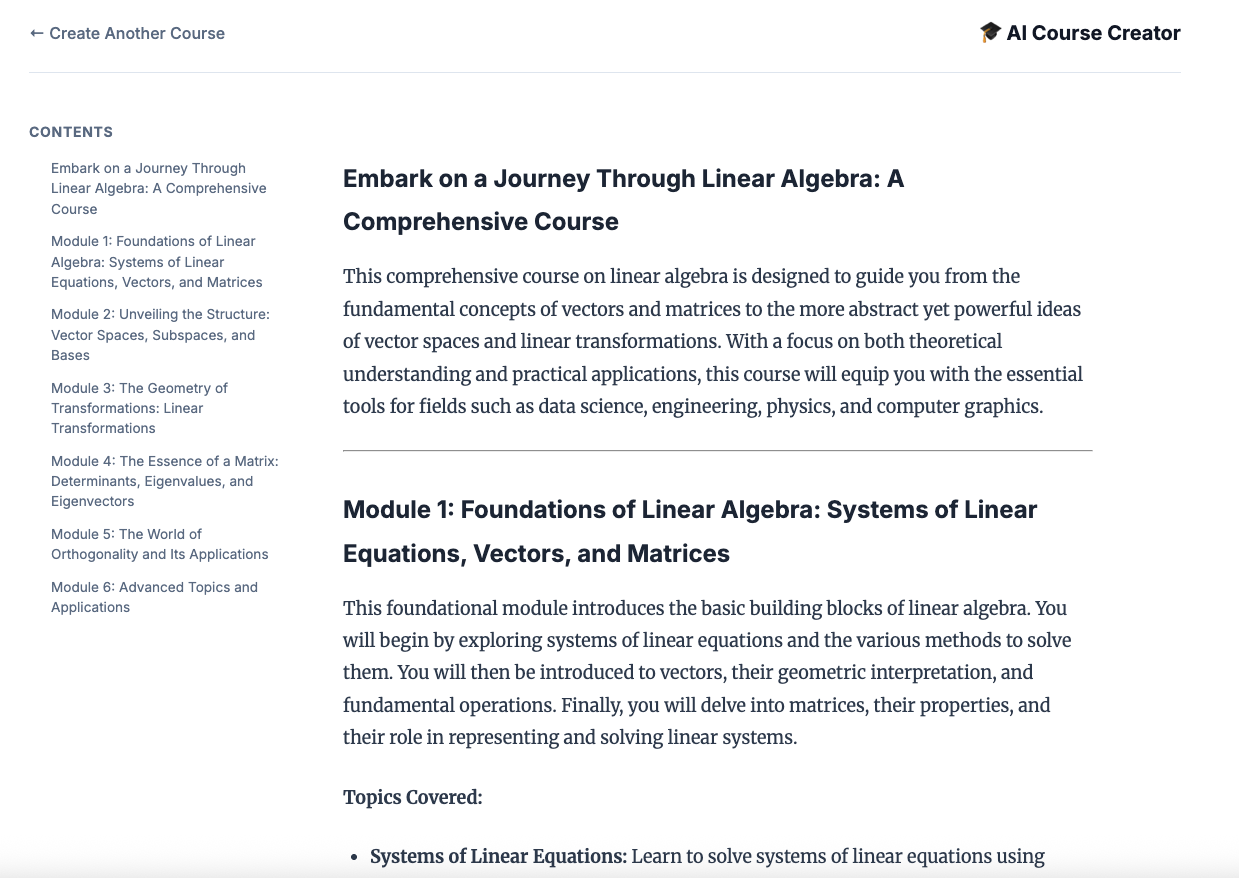
12. สร้างหลักสูตร
เปิดเว็บไซต์ Course Creator บริการ Cloud Run ของผู้สร้างหลักสูตรเป็นบริการสุดท้ายที่ทำให้ใช้งานได้จากสคริปต์ คุณระบุ URL ให้แก่ผู้สร้างหลักสูตรเป็น https://course-creator- ซึ่งควรเป็นบรรทัดเอาต์พุตสุดท้ายจากสคริปต์การติดตั้งใช้งาน
แล้วพิมพ์ไอเดียหลักสูตร เช่น "พีชคณิตเชิงเส้น"
ตัวแทนจะเริ่มดำเนินการกับหลักสูตรของคุณ
13. ล้าง
โปรดทำตามขั้นตอนต่อไปนี้เพื่อลบบริการและอิมเมจคอนเทนเนอร์เพื่อหลีกเลี่ยงการเรียกเก็บเงินกับบัญชี Google Cloud สำหรับทรัพยากรที่ใช้ใน Codelab นี้
1. ลบบริการ Cloud Run
วิธีที่มีประสิทธิภาพมากที่สุดในการล้างข้อมูลคือการลบบริการที่คุณทำให้ใช้งานได้ใน Cloud Run
# Delete the main agent and app services
gcloud run services delete researcher content-builder judge orchestrator course-creator \
--region $REGION --quiet
# Delete the GPU backend (Ollama)
gcloud run services delete ollama-gemma-gpu \
--region $OLLAMA_REGION --quiet
2. ลบรูปภาพใน Artifact Registry
เมื่อคุณใช้แฟล็ก --source เพื่อติดตั้งใช้งาน Google Cloud จะสร้างที่เก็บใน Artifact Registry เพื่อจัดเก็บอิมเมจคอนเทนเนอร์ หากต้องการนำที่เก็บเหล่านี้ออกและประหยัดค่าใช้จ่ายในการจัดเก็บ ให้ลบที่เก็บโดยทำดังนี้
gcloud artifacts repositories delete cloud-run-source-deploy --location us-east4 --quiet
3. นำไฟล์และสภาพแวดล้อมในเครื่องออก
หากต้องการรักษาสภาพแวดล้อมของ Cloud Shell ให้สะอาด ให้นำโฟลเดอร์โปรเจ็กต์และการกำหนดค่าในเครื่องออกโดยทำดังนี้
cd ~
rm -rf multi-agent-system
4. (ไม่บังคับ) ลบโปรเจ็กต์
หากสร้างโปรเจ็กต์สำหรับ Codelab นี้โดยเฉพาะ คุณสามารถปิดโปรเจ็กต์ผ่านหน้าจัดการทรัพยากรเพื่อให้มั่นใจว่าจะไม่มีการเรียกเก็บเงินเพิ่มเติม
14. ยินดีด้วย
คุณสร้างและติดตั้งใช้งานระบบ Multi-Agent แบบกระจายที่พร้อมใช้งานจริงเรียบร้อยแล้ว
สิ่งที่คุณทำสำเร็จ
- แยกย่อยงานที่ซับซ้อน: เราแบ่งงานออกเป็นบทบาทเฉพาะทาง (นักวิจัย ผู้ตัดสิน ผู้สร้างเนื้อหา) แทนที่จะใช้พรอมต์ขนาดใหญ่เพียงพรอมต์เดียว
- การควบคุมคุณภาพที่ใช้: เราใช้
LoopAgentและJudgeที่มีโครงสร้างเพื่อให้มั่นใจว่ามีเพียงข้อมูลคุณภาพสูงเท่านั้นที่จะไปถึงขั้นตอนสุดท้าย - สร้างขึ้นเพื่อการใช้งานจริง: เราได้สร้างระบบที่แต่ละ Agent เป็น Microservice แบบอิสระที่รองรับการปรับขนาดได้โดยใช้โปรโตคอล Agent-to-Agent (A2A) และ Cloud Run ซึ่งมีความเสถียรกว่าการเรียกใช้ทุกอย่างในสคริปต์ Python เดียวมาก
- การประสานงาน: เราใช้
SequentialAgentและLoopAgentเพื่อกำหนดรูปแบบโฟลว์การควบคุมที่ชัดเจน *. GPU ของ Cloud Run: ทำให้โมเดล Gemma ใช้งานได้กับ GPU ของ Cloud Run