
1. مقدمة
في هذا الدرس التطبيقي حول الترميز، ستنشئ بحيرة بيانات مفتوحة على عدة سُحب إلكترونية توحّد مستودعات البيانات المنعزلة على AWS وGoogle Cloud وAlloyDB بدون الحاجة إلى عمليات معقّدة لاستخراج البيانات وتحويلها وتحميلها. ستستخدم Lakehouse كمركز ذكاء مركزي، وAlloyDB كمصدر بيانات تشغيلية، والخدمة المُدارة لـ Apache Spark للمعالجة المتجهة عالية الأداء. أخيرًا، ستستخدم Gemini لاستخلاص إحصاءات فعّالة عن نشاطك التجاري من مستودع البيانات.
لنفترض أنّ بيانات المعاملات (users وorders وorder items) موجودة في قاعدة بيانات تشغيلية على AlloyDB، وأنّ بيانات product موجودة في حزمة AWS S3، وأنّ بيانات مسار النقرات الضخمة event logs مخزّنة في Cloud Storage. عليك دمج مجموعات البيانات هذه لتحديد الفئات السكانية المستهدَفة لحملتك التسويقية التالية وإنشاء رسائل إلكترونية مخصّصة للتواصل مع العملاء.
المتطلبات الأساسية
- الإلمام بأوامر SQL الأساسية وأوامر سطر الأوامر
- مشروع Google Cloud تم تفعيل الفوترة فيه
ما ستتعلمه
- كيفية دمج مستودعات البيانات المنفصلة باستخدام ميزة zero-ETL في BigQuery (AlloyDB) وLakehouse for Apache Iceberg
- كيفية تنفيذ مهمة تحديد السمات السلوكية العالية السرعة باستخدام Managed Service for Apache Spark المستندة إلى Lightning Engine الأصلية بلغة C++
- كيفية استخدام وكيل بيانات BigQuery لإجراء تحليل معقّد للغة الطبيعية على البيانات الموحّدة
- كيفية إعداد بروتوكول Model Context Protocol (MCP) للسماح لأداة Gemini CLI بالقراءة من Lakehouse for Apache Iceberg وإنشاء مسودّة للمحتوى التسويقي
المتطلبات
- حساب Google Cloud ومشروع Google Cloud
- متصفّح ويب، مثل Chrome
المتطلبات
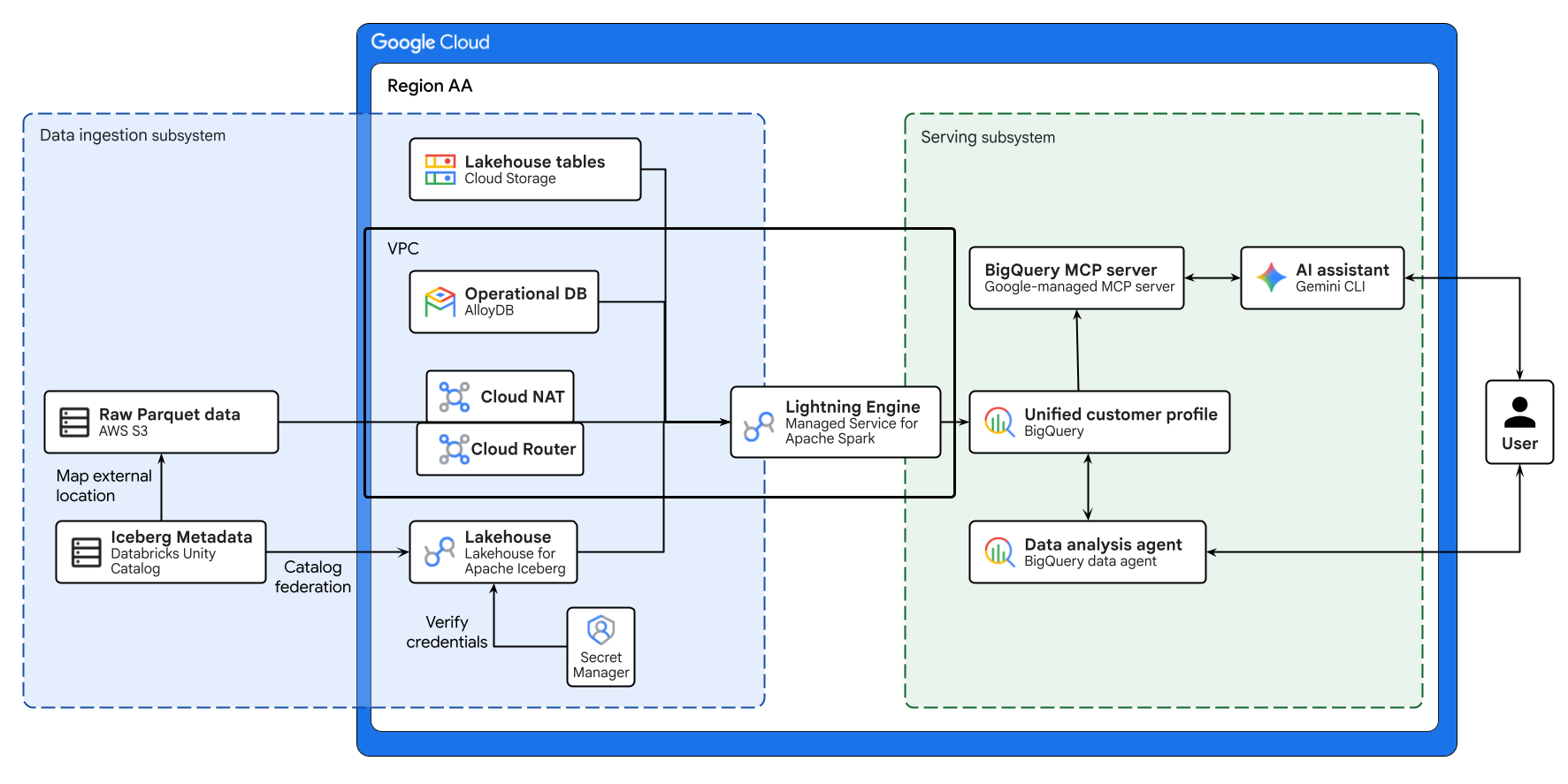
يوضّح المخطّط البياني أعلاه مسار العمل المتكامل لبحيرة البيانات المتعددة السحابات التي تم إنشاؤها في هذا الدرس التطبيقي حول الترميز. يتم ربط البيانات التشغيلية من AlloyDB والبيانات البعيدة من AWS S3 بشكل آمن باستخدام Lakehouse for Apache Iceberg. تعالج خدمة Managed Service for Apache Spark مصادر البيانات المختلفة هذه لإنشاء ملف موحّد للعميل في BigQuery. أخيرًا، يوفّر وكيل بيانات BigQuery وخادم MCP مُدار من Google في BigQuery من خلال Gemini CLI واجهة سهلة الاستخدام مستندة إلى الذكاء الاصطناعي لتحليل البيانات المتقدّم.
المفاهيم الأساسية
- مستودع بيانات مفتوح متعدد السُحب: يوحّد مستودعات البيانات المنعزلة في AWS وGoogle Cloud والبيئات المحلية بدون الحاجة إلى عمليات استخراج وتحويل وتحميل معقّدة.
- BigQuery zero-ETL: تتيح إمكانية طلب البيانات مباشرةً من قواعد البيانات التشغيلية بدون الحاجة إلى نقل البيانات المعقّد.
- Lakehouse for Apache Iceberg: يتيح الأمان والحوكمة المتسقَين في جميع وحدات التخزين على السحابات الإلكترونية المختلفة باستخدام تنسيق Apache Iceberg.
- Lightning Engine: محرك C++ أصلي لتنفيذ Apache Spark عالي الأداء
- بروتوكول Model Context Protocol (MCP): يربط Gemini مباشرةً بمستودع البيانات الخاص بك في BigQuery.
2. الإعداد والمتطلبات
إنشاء مشروع على Google Cloud
- في Google Cloud Console، في صفحة اختيار المشروع، اختَر مشروعًا على Google Cloud أو أنشِئ مشروعًا.
- تأكَّد من تفعيل الفوترة لمشروعك على السحابة الإلكترونية. كيفية التحقّق مما إذا كانت الفوترة مفعَّلة في مشروع
بدء Cloud Shell
على الرغم من إمكانية تشغيل Google Cloud عن بُعد من الكمبيوتر المحمول، ستستخدم في هذا الدرس التطبيقي حول الترميز Google Cloud Shell، وهي بيئة سطر أوامر تعمل في السحابة الإلكترونية.
من Google Cloud Console، انقر على رمز Cloud Shell في شريط الأدوات أعلى يسار الصفحة:
لن يستغرق توفير البيئة والاتصال بها سوى بضع لحظات. عند الانتهاء، من المفترض أن يظهر لك ما يلي:

يتم تحميل هذه الآلة الافتراضية مزوّدة بكل أدوات التطوير التي ستحتاج إليها. توفّر هذه الخدمة دليلًا منزليًا دائمًا بسعة 5 غيغابايت، وتعمل على Google Cloud، ما يؤدي إلى تحسين أداء الشبكة والمصادقة بشكل كبير. يمكن إكمال جميع المهام في هذا الدرس العملي ضمن المتصفّح. لست بحاجة إلى تثبيت أي تطبيق.
إعداد البيئة
افتح Cloud Shell واضبط متغيرات مشروعك لضمان استهداف جميع الأوامر للبنية الأساسية الصحيحة.
cat << 'EOF' > env.sh
#!/bin/bash
# env.sh: Environment variables
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-west1"
export NETWORK_NAME="default"
export BUCKET_NAME="lakehouse-data-${PROJECT_ID}"
export BQ_DATASET="demo_lakehouse"
export BQ_RESOURCE_CONN="lakehouse-iceberg-conn"
export BQ_ALLOYDB_CONN="alloydb-fed-conn"
export ALLOYDB_CLUSTER="demo-alloy-cluster"
export ALLOYDB_INSTANCE="demo-alloy-primary"
export ALLOYDB_PASSWORD="SuperSecretPassword123!"
export ALLOYDB_DB_NAME="retail_db"
# Multi-cloud configuration identifiers
export SECRET_NAME="dbx-oauth-secret"
export CATALOG_NAME="aws_dbx_catalog"
EOF
طبِّق المتغيّرات على جلستك النشطة:
source ./env.sh
تفعيل واجهات برمجة التطبيقات
فعِّل خدمات Google Cloud اللازمة.
gcloud services enable \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
compute.googleapis.com \
biglake.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com \
servicenetworking.googleapis.com \
secretmanager.googleapis.com \
dataplex.googleapis.com \
datacatalog.googleapis.com \
dataform.googleapis.com \
dataproc.googleapis.com --quiet
3- إعداد البنية الأساسية
بدلاً من نقل جميع البيانات إلى مستودع واحد من خلال مسارات ETL غير مستقرة، ستنشئ بنية موحّدة متعددة السُحب. في المؤسسات الواقعية، تكون البيانات مجزّأة بطبيعتها بسبب اختلاف متطلبات الأنظمة. ستنسّق مصادر البيانات التالية:
- AlloyDB (قاعدة بيانات المعاملات الأساسية): تخزِّن بيانات المستخدمين والطلبات وبنود الطلبات. وباعتبارها قاعدة بيانات تشغيلية مباشرة، تضمن خصائص ACID المطلوبة للمعاملات المالية وتعديلات الملفات الشخصية.
- AWS S3 (البيانات الرئيسية): تخزِّن هذه الخدمة كتالوج
products. تمثّل هذه الفئة نظامًا قديمًا لإدارة البيانات الرئيسية (MDM) على AWS. - Google Cloud Storage (مستودع بيانات مركزي ضخم): يخزِّن
events(سجلات مسار النقر). فالبيانات ذات معدّل النقل العالي، مثل سجلّات الويب، قد تؤدي إلى تعطُّل قاعدة البيانات الارتباطية. توفّر خدمة تخزين العناصر قابلية توسّع لا نهائية، كما أنّ الاحتفاظ بها في Google Cloud يزيد من موضعية الحوسبة لمحركات التحليل.
أولاً، اضبط إعدادات الشبكة الأساسية. تتطلّب قواعد البيانات المُدارة من Google Cloud، مثل AlloyDB، اتصالاً خاصًا بتبادل المعلومات بين شبكات VPC للتواصل بشكل آمن داخل شبكة مشروعك.
# Allocate an IP range for Google Cloud managed services
gcloud compute addresses create google-managed-services-${NETWORK_NAME} \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Establish the VPC peering connection
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=google-managed-services-${NETWORK_NAME} \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID}
بعد ذلك، أنشئ مجموعة بيانات BigQuery وعملية ربط بمورد Lakehouse السحابي. من الناحية الهندسية، يفوّض ربط الموارد إذن الوصول إلى البيانات إلى حساب خدمة مخصّص تديره Google، ما يفرض مبدأ الامتياز الأقل.
# Create the central data lakehouse dataset
bq mk --dataset --location=${REGION} ${PROJECT_ID}:${BQ_DATASET}
gcloud storage buckets create gs://${BUCKET_NAME} --location=${REGION}
# Create a Lakehouse resource connection
bq mk --connection --location=${REGION} \
--connection_type=CLOUD_RESOURCE ${BQ_RESOURCE_CONN}
# Retrieve the automatically provisioned service account
CONN_SA=$(bq show --connection --format=json ${PROJECT_ID}.${REGION}.${BQ_RESOURCE_CONN} | jq -r '.cloudResource.serviceAccountId')
# Grant the service account permissions to read/write to the data lake
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${CONN_SA}" \
--role="roles/storage.admin" \
--quiet
4. توفير قاعدة البيانات التشغيلية
توفير مثيل AlloyDB أساسي وإدخال بيانات المعاملات المهمة للغاية
# Create the AlloyDB cluster
gcloud alloydb clusters create ${ALLOYDB_CLUSTER} \
--region=${REGION} \
--password=${ALLOYDB_PASSWORD} \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Create the primary instance
gcloud alloydb instances create ${ALLOYDB_INSTANCE} \
--cluster=${ALLOYDB_CLUSTER} \
--region=${REGION} \
--instance-type=PRIMARY \
--cpu-count=2 \
--assign-inbound-public-ip=ASSIGN_IPV4 \
--database-flags=password.enforce_complexity=on
بعد أن تصبح قاعدة البيانات جاهزة، عليك إنشاء اتصال خارجي في BigQuery بـ AlloyDB. يخزّن هذا الربط بيانات اعتماد قاعدة البيانات ونقطة النهاية بشكل آمن، ما يسمح لـ BigQuery بتنفيذ طلبات SQL مباشرةً على محرّك الحوسبة في AlloyDB (بدون استخراج البيانات وتحويلها وتحميلها).
# Create the BigQuery to AlloyDB connection
bq mk --connection --location=${REGION} --project_id=${PROJECT_ID} \
--connector_configuration "{
\"connector_id\": \"google-alloydb\",
\"asset\": {
\"database\": \"${ALLOYDB_DB_NAME}\",
\"google_cloud_resource\": \"//alloydb.googleapis.com/projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE}\"
},
\"authentication\": {
\"username_password\": {
\"username\": \"postgres\",
\"password\": { \"plaintext\": \"${ALLOYDB_PASSWORD}\" }
}
}
}" ${BQ_ALLOYDB_CONN}
# Grant the BigQuery connection service agent permission to access AlloyDB
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
BQ_SERVICE_AGENT="service-${PROJECT_NUMBER}@gcp-sa-bigqueryconnection.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${BQ_SERVICE_AGENT}" \
--role="roles/alloydb.client" \
--quiet
يمكنك نقل جداول المعاملات بأمان إلى AlloyDB. استخدِم AlloyDB Auth Proxy لربط جلسة Cloud Shell المحلية بشكل آمن بمثيل AlloyDB الخاص. يتيح لك ذلك إرسال البيانات المتعلقة بالمعاملات باستخدام أدوات سطر الأوامر المحلية.
# Extract full raw data to Cloud Storage using the BigQuery extract API
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.users" gs://${BUCKET_NAME}/tmp/users.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.orders" gs://${BUCKET_NAME}/tmp/orders.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.order_items" gs://${BUCKET_NAME}/tmp/order_items.csv
# Download the CSVs to the local Cloud Shell session
gcloud storage cp gs://${BUCKET_NAME}/tmp/users.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/orders.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/order_items.csv .
# Download and start the AlloyDB auth proxy
curl -sL "https://storage.googleapis.com/alloydb-auth-proxy/v1.13.11/alloydb-auth-proxy.linux.amd64" -o alloydb-auth-proxy && chmod +x alloydb-auth-proxy
./alloydb-auth-proxy projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE} --public-ip &
PROXY_PID=$!
sleep 15 # Wait for the proxy to fully initialize
# Create the database
export PGPASSWORD=${ALLOYDB_PASSWORD}
psql -h 127.0.0.1 -p 5432 -U postgres -c "CREATE DATABASE ${ALLOYDB_DB_NAME};" || true
# Load into AlloyDB mimicking the exact schema via heredoc
psql -h 127.0.0.1 -p 5432 -U postgres -d ${ALLOYDB_DB_NAME} << 'EOF'
CREATE TABLE IF NOT EXISTS users (id INT PRIMARY KEY, first_name VARCHAR(255), last_name VARCHAR(255), email VARCHAR(255), age INT, gender VARCHAR(50), state VARCHAR(100), street_address VARCHAR(255), postal_code VARCHAR(50), city VARCHAR(100), country VARCHAR(100), latitude FLOAT, longitude FLOAT, traffic_source VARCHAR(100), created_at TIMESTAMP, user_geom TEXT);
CREATE TABLE IF NOT EXISTS orders (order_id INT PRIMARY KEY, user_id INT, status VARCHAR(50), gender VARCHAR(50), created_at TIMESTAMP, returned_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, num_of_item INT);
CREATE TABLE IF NOT EXISTS order_items (id INT PRIMARY KEY, order_id INT, user_id INT, product_id INT, inventory_item_id INT, status VARCHAR(50), created_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, returned_at TIMESTAMP, sale_price FLOAT);
\copy users FROM 'users.csv' WITH (FORMAT csv, HEADER true)
\copy orders FROM 'orders.csv' WITH (FORMAT csv, HEADER true)
\copy order_items FROM 'order_items.csv' WITH (FORMAT csv, HEADER true)
EOF
# Clean up local temporary files and Cloud Storage artifacts
kill $PROXY_PID && rm -f users.csv orders.csv order_items.csv alloydb-auth-proxy
gcloud storage rm gs://${BUCKET_NAME}/tmp/*.csv
5- تجميع البيانات الرئيسية (AWS spoke)
يتم تخزين كتالوج المنتجات، الذي يحتوي على البيانات الوصفية الأولية الخاصة بالمنتجات، بشكل أصلي على AWS S3 كجداول Apache Iceberg. تخضع بيانات التعريف لكتالوج بعيد.
بدلاً من إنشاء مسارات ETL غير مستقرة لنسخ هذه البيانات إلى Google Cloud، ستستخدم Lakehouse for Apache Iceberg (اتحاد كتالوج REST).
يتيح نهج zero-ETL لخدمتَي Lakehouse وManaged Service for Apache Spark إمكانية اكتشاف بيانات Iceberg الوصفية وملفات Parquet الأساسية وقراءتها بشكل ديناميكي مباشرةً من بيئتك البعيدة.
إذا كان لديك حساب نشط على AWS وتم إعداد Databricks Unity Catalog، يمكنك استخدام ذلك. في الحالات الأخرى، يمكنك محاكاة بيئتك باستخدام Google Cloud Storage. اختَر إمّا حملات التطبيقات أو نوع حملة آخر.
الخيار (أ): استخدام AWS الخاص بك (Apache Iceberg الأصلي)
المتطلبات الأساسية: يفترض هذا الخيار أنّك قد وفّرت حزمة AWS S3 وربطتها كموقع خارجي في Databricks Unity Catalog، وربطت جدول Iceberg، وأنشأت مدير خدمة OAuth لديه إذن الوصول للقراءة.
1. وحدة تخزين بيانات الاعتماد بشكل آمن
يُعدّ الترميز الثابت لرموز الدخول الطويلة الأمد من الأنماط المضادة للهندسة المعمارية. عليك تخزين معرّف عميل OAuth وسرّه في Databricks في Google Cloud Secret Manager. ستجلب خدمة Lakehouse هذه البيانات ديناميكيًا في وقت التشغيل لتقديم رموز مميّزة قصيرة الأمد، ما يؤدي إلى مركزية إدارة بيانات الاعتماد.
نفِّذ الكتلة التالية لإنشاء النص البرمجي. (لا تعدّل أي شيء بعد).
cat << 'EOF' > create_secret.sh
#!/bin/bash
source ./env.sh
# Define your Databricks OAuth credentials
DATABRICKS_CLIENT_ID="<YOUR_DATABRICKS_CLIENT_ID>"
DATABRICKS_CLIENT_SECRET="<YOUR_DATABRICKS_CLIENT_SECRET>"
DATABRICKS_WORKSPACE="<YOUR_WORKSPACE>.cloud.databricks.com" # Exclude https://
DATABRICKS_CATALOG="google_lakehouse_catalog"
# Define the secure credentials payload
export CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/"
SECRET_PAYLOAD="{ \"client_id\": \"${DATABRICKS_CLIENT_ID}\", \"client_secret\": \"${DATABRICKS_CLIENT_SECRET}\" }"
# Pipe the JSON payload into Google Cloud Secret Manager
echo "$SECRET_PAYLOAD" | gcloud secrets create ${SECRET_NAME} \
--location=${REGION} \
--project=${PROJECT_ID} \
--data-file=-
EOF
بعد ذلك، نفِّذ الأمر التالي لفتح النص البرمجي الذي تم إنشاؤه تلقائيًا في أداة تعديل الرموز المرئية أعلى الوحدة الطرفية.
cloudshell edit create_secret.sh
- في المحرّر، استبدِل العناصر النائبة
<YOUR_...>ببيانات اعتماد Databricks الفعلية. - تأكَّد من أنّ عنوان URL لمساحة العمل لا يتضمّن
https://أو شرطات مائلة لاحقة (مثل123456789.cloud.databricks.com). - اضغط على
Ctrl+S(أوCmd+Sعلى جهاز Mac) لحفظ الملف. - ارجع إلى جلسة الوحدة الطرفية ونفِّذ النص البرمجي:
source create_secret.sh
2. إنشاء الفهرس الموحّد
لتبسيط الأمور في هذا الدرس التطبيقي حول الترميز، ستضبط الفهرس على اجتياز الإنترنت العام بأمان. ومع ذلك، بالنسبة إلى أحمال العمل في مرحلة الإنتاج، يؤدي طلب البحث عن مجموعات بيانات ضخمة عبر الإنترنت العام إلى تكبّد تكاليف خروج غير ضرورية ووقت استجابة غير متوقّع. تتطلّب أفضل الممارسات ضبط Cross-Cloud Interconnect (CCI) خاص بين AWS وGoogle Cloud، ما يقلّل بشكل كبير من تكاليف نقل البيانات ويضمن أداءً محدّدًا للشبكة.
استخدِم gcloud CLI لتوفير كتالوج Lakehouse الموحَّد:
# Execute the Lakehouse CLI to provision the federated catalog
gcloud alpha biglake iceberg catalogs create ${CATALOG_NAME} \
--project="${PROJECT_ID}" \
--primary-location="${REGION}" \
--catalog-type="federated" \
--federated-catalog-type="unity" \
--secret-name="projects/${PROJECT_ID}/locations/${REGION}/secrets/${SECRET_NAME}" \
--unity-instance-name="${DATABRICKS_WORKSPACE}" \
--unity-catalog-name="${DATABRICKS_CATALOG}" \
--refresh-interval="330s"
3. تطبيق عمليات ربط إدارة الهوية وإمكانية الوصول بأدنى صلاحيات
عند توفير الكتالوج الموحّد في الخطوة السابقة، أطلقت Google Cloud Lakehouse تلقائيًا مهمة إعادة تحميل في الخلفية لمزامنة بيانات Iceberg كل 330 ثانية.
يجب منح دور secretAccessor لحساب خدمة "كتالوج Lakehouse" حتى يتمكّن من استرداد رمز OAuth من Databricks بشكل آمن أثناء عمليات المزامنة وعمليات تنفيذ طلبات البحث في الخلفية. سيؤدي عدم توفّر هذا الربط إلى حدوث أخطاء 403 غير ظاهرة عند محاولة Lakehouse تعديل الفهرس.
# Extract the automatically provisioned Lakehouse catalog service account
LAKEHOUSE_SA=$(curl -s -X GET "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/${CATALOG_NAME}" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" | jq -r '."biglake-service-account"')
# Grant the secretAccessor role for background metadata synchronization and query execution
gcloud secrets add-iam-policy-binding ${SECRET_NAME} \
--project=${PROJECT_ID} --location=${REGION} \
--member="serviceAccount:${LAKEHOUSE_SA}" \
--role="roles/secretmanager.secretAccessor" --quiet
4. تفعيل الوصول إلى الإنترنت الصادر لخدمة Managed Service for Apache Spark
في خطوة لاحقة، ستقرأ خدمة "الخدمة المُدارة لـ Apache Spark" بيانات AWS البعيدة. بما أنّ خدمة Managed Service for Apache Spark Serverless تعمل بالكامل ضِمن شبكة VPC خاصة بدون عناوين IP خارجية، لا يمكنها الوصول إلى AWS S3 عبر الإنترنت تلقائيًا. يجب توفير Cloud NAT للسماح للعاملين في Spark بالوصول إلى الإنترنت بشكل صادر.
# Create a Cloud Router
gcloud compute routers create lakehouse-router \
--network=${NETWORK_NAME} \
--region=${REGION}
# Create a Cloud NAT attached to the router
gcloud compute routers nats create lakehouse-nat \
--router=lakehouse-router \
--auto-allocate-nat-external-ips \
--nat-all-subnet-ip-ranges \
--region=${REGION}
5. تحديد الهدف النهائي
يمكنك تصدير هذا المتغير لكي تعرف مهام Apache Spark اللاحقة المكان الذي يجب الاستعلام منه عن بيانات AWS بدون الحاجة إلى إجراء تغييرات يدوية على الرمز.
# Assuming your schema is 'retail' and table is 'aws_products'
export AWS_PRODUCTS_TABLE="${CATALOG_NAME}.retail.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
الخيار (ب): محاكاة بيئة AWS من خلال Cloud Storage
إذا لم يكن لديك حساب نشط على AWS، يمكنك محاكاة مستودع البيانات المعزول على عدة أنظمة أساسية باستخدام جداول Lakehouse المُدارة على Google Cloud Storage.
1. إنشاء جدول Iceberg وهمي
# Copy raw products data to a temporary BigQuery table
bq cp --force bigquery-public-data:thelook_ecommerce.products ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
# Create an open Iceberg table using the Lakehouse cloud resource connection
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.aws_products\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/aws_products')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_products_raw\`;"
# Cleanup temporary table
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
2. تحديد الهدف النهائي
تستخدِم مجموعات بيانات BigQuery العادية بنية مساحة اسم مكوّنة من 3 أجزاء (project.dataset.table). صدِّر هذا المتغيّر لكي تستهدف مهمة Apache Spark اللاحقة البيانات الصورية.
export AWS_PRODUCTS_TABLE="${PROJECT_ID}.${BQ_DATASET}.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
6. استيعاب سجلّات الأحداث (نظام Google Cloud الفرعي)
تتزايد بيانات مسار النقر بشكل كبير. يمكنك تخزين الأحداث الأولية الكاملة وغير المجمّعة على جهازك في Cloud Storage كجداول Managed Lakehouse.
bq cp --force bigquery-public-data:thelook_ecommerce.events ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.google_events\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/google_events')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_events_raw\`;"
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
7. إنشاء ملف موحّد للعميل
بعد ملء البنية الأساسية الأولية بالكامل، حان الوقت لإنشاء ملف موحّد للعميل.
ستستخدم Managed Service for Apache Spark المستندة إلى Lightning Engine. Lightning Engine هو أداة تسريع طلبات البحث الأصلية عالية الأداء بلغة C++ من Google Cloud، وهي تستند إلى تكنولوجيات مفتوحة المصدر، مثل Apache Gluten وVelox، وتعمل تلقائيًا على تحسين التنفيذ من خلال زيادة كفاءة وحدة المعالجة المركزية إلى أقصى حد وتخزين البيانات مؤقتًا بشكلٍ ذكي. تُعدّ هذه الطريقة مثالية عند إجراء عمليات ربط متعددة الاتجاهات أو عمليات تقسيم معقّدة أو عمليات تجميع سلوكية على مستوى عدة خدمات سحابية.
ستستخدم موصّل Spark BigQuery لقراءة طلبات البحث الموحّدة AlloyDB zero-ETL وجداول Lakehouse مباشرةً، وإجراء عمليات التجميع المتّجهة الضخمة بشكلٍ أصلي في Spark، وكتابة الملف الموحّد الناتج مرة أخرى إلى BigQuery.
ضبط أذونات إدارة الهوية وإمكانية الوصول (IAM) لخدمة Managed Service for Apache Spark
بشكلٍ تلقائي، ينفّذ Serverless Spark مهام معالجة الدفعات باستخدام حساب الخدمة التلقائي في Compute Engine. قبل إرسال المهمة، يجب منح حساب الخدمة هذا الأذونات المطلوبة لتنفيذ عبء العمل وإدارة مهام BigQuery.
(ملاحظة: على الرغم من أنّ اسم الخدمة قد تغيّر إلى "الخدمة المُدارة لـ Apache Spark" ليعكس المصطلحات المتوافقة مع معايير المجال، لا تزال أوامر واجهة برمجة التطبيقات الأساسية وأدوار إدارة الهوية وإمكانية الوصول (IAM) تستخدم المعرّف dataproc).
# Retrieve the project number to construct the Compute Engine default service account
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
# Grant the Managed Service for Apache Spark Worker role to allow job execution
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/dataproc.worker" \
--quiet
# Grant the BigQuery Admin role to allow reading, writing, and querying external connections
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/bigquery.admin" \
--quiet
إنشاء مهمة وإرسالها
أولاً، أنشئ نصًا برمجيًا لمهمة PySpark. يكتشف هذا النص البرمجي تلقائيًا ما إذا كنت قد اخترت الخيار أ (فهرس AWS الموحّد) أو الخيار ب (Google Cloud Mock) استنادًا إلى متغيّر بيئة AWS_PRODUCTS_TABLE، ويحدّد منطق Spark SQL، ويستخدم معالجة مصفوفة Spark الأصلية لاحتساب فترات RFM (مدى الحداثة والتكرار والقيمة النقدية).
نفِّذ الكتلة التالية في Cloud Shell.
# Determine which option was selected based on the AWS_PRODUCTS_TABLE variable
if [[ "${AWS_PRODUCTS_TABLE}" == *"${CATALOG_NAME:-undefined}"* ]]; then
echo "=> Option A (AWS Federated Catalog) detected."
export IS_AWS_CATALOG="True"
export OAUTH_TOKEN=$(gcloud auth print-access-token)
else
echo "=> Option B (Google Cloud Mock) detected."
export IS_AWS_CATALOG="False"
export OAUTH_TOKEN=""
fi
# Create the PySpark script with safely injected variables
cat << EOF > spark_lakehouse_join.py
from pyspark.sql import SparkSession
# --- Environment Variables dynamically injected ---
PROJECT_ID = "${PROJECT_ID}"
CATALOG_NAME = "${CATALOG_NAME}"
OAUTH_TOKEN = "${OAUTH_TOKEN}"
BUCKET_NAME = "${BUCKET_NAME}"
BQ_DATASET = "${BQ_DATASET}"
REGION = "${REGION}"
BQ_ALLOYDB_CONN = "${BQ_ALLOYDB_CONN}"
AWS_PRODUCTS_TABLE = "${AWS_PRODUCTS_TABLE}"
IS_AWS_CATALOG = ${IS_AWS_CATALOG}
# ---------------------------------------------------
# 1. Initialize SparkSession (Dynamic Configuration)
packages =[
"org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.3",
"org.apache.iceberg:iceberg-aws-bundle:1.4.3",
"org.apache.hadoop:hadoop-aws:3.3.4",
"com.amazonaws:aws-java-sdk-bundle:1.12.262",
"com.google.cloud.spark:spark-bigquery-with-dependencies_2.12:0.36.1"
]
builder = SparkSession.builder \\
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \\
.config("spark.dataproc.lightningEngine.runtime", "native") \\
.config("spark.hadoop.fs.gs.velox.client.table-cache-max-size", "0") \\
.config("spark.jars.packages", ",".join(packages))
# Conditionally configure Lakehouse REST Catalog for Option A
if IS_AWS_CATALOG:
builder = builder \\
.config(f"spark.sql.catalog.{CATALOG_NAME}", "org.apache.iceberg.spark.SparkCatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.type", "rest") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.uri", "https://biglake.googleapis.com/iceberg/v1/restcatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.warehouse", f"bl://projects/{PROJECT_ID}/catalogs/{CATALOG_NAME}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.X-Iceberg-Access-Delegation", "vended-credentials") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.x-goog-user-project", PROJECT_ID) \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.Authorization", f"Bearer {OAUTH_TOKEN}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.rest-metrics-reporting-enabled", "false")
spark = builder.getOrCreate()
spark.conf.set("temporaryGcsBucket", BUCKET_NAME)
spark.conf.set("viewsEnabled", "true")
spark.conf.set("materializationDataset", BQ_DATASET)
# 2. Extract operational data via AlloyDB Zero-ETL
users_df = spark.read.format("bigquery").option("query", f"""SELECT id AS user_id, age, country FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT id, age, country FROM users")""").load()
orders_df = spark.read.format("bigquery").option("query", f"""SELECT user_id, order_id, CAST(created_at AS TIMESTAMP) AS order_date FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT user_id, order_id, created_at FROM orders WHERE status = 'Complete'")""").load()
items_df = spark.read.format("bigquery").option("query", f"""SELECT order_id, product_id, sale_price FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT order_id, product_id, sale_price FROM order_items")""").load()
# 3. Read AWS Products (Option A vs B) & Google Cloud Logs
if IS_AWS_CATALOG:
products_df = spark.table(AWS_PRODUCTS_TABLE)
else:
products_df = spark.read.format("bigquery").option("table", AWS_PRODUCTS_TABLE).load()
events_df = spark.read.format("bigquery").option("table", f"{PROJECT_ID}.{BQ_DATASET}.google_events").load()
# Register Temp Views
users_df.createOrReplaceTempView("live_user_profiles")
orders_df.createOrReplaceTempView("live_transactions")
items_df.createOrReplaceTempView("live_order_items")
products_df.createOrReplaceTempView("raw_aws_products")
events_df.createOrReplaceTempView("google_events")
# 4. Multi-cloud Distributed Join
unified_profile_df = spark.sql("""
WITH aws_master_catalog AS (
SELECT id AS product_id, category, brand
FROM raw_aws_products
),
google_behavioral_logs AS (
SELECT user_id,
COUNT(DISTINCT session_id) AS total_sessions,
COUNT(CASE WHEN event_type = 'cart' THEN 1 END) AS cart_adds
FROM google_events
WHERE user_id IS NOT NULL
GROUP BY user_id
),
user_purchases AS (
SELECT
t.user_id, t.order_date, t.order_id, oi.sale_price,
COALESCE(p.category, 'Unknown') AS category,
COALESCE(p.brand, 'Unknown') AS brand
FROM live_transactions t
JOIN live_order_items oi ON t.order_id = oi.order_id
LEFT JOIN aws_master_catalog p ON oi.product_id = p.product_id
),
rfm_base AS (
SELECT
user_id,
MAX(order_date) AS last_purchase_date,
COUNT(DISTINCT order_id) AS total_orders,
SUM(sale_price) AS lifetime_value
FROM user_purchases
GROUP BY user_id
),
ranked_items AS (
SELECT
user_id, category, brand, sale_price,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY sale_price DESC) as rn
FROM user_purchases
),
top_items AS (
SELECT
user_id,
COLLECT_LIST(NAMED_STRUCT('category', category, 'brand', brand, 'sale_price', sale_price)) AS top_preferences
FROM ranked_items
WHERE rn <= 3
GROUP BY user_id
)
SELECT
CURRENT_TIMESTAMP() AS snapshot_date,
u.user_id, u.age, u.country,
r.last_purchase_date,
COALESCE(r.total_orders, 0) AS total_orders,
COALESCE(ROUND(r.lifetime_value, 2), 0.0) AS lifetime_value,
COALESCE(b.total_sessions, 0) AS total_sessions,
COALESCE(b.cart_adds, 0) AS cart_adds,
t.top_preferences
FROM live_user_profiles u
LEFT JOIN rfm_base r ON u.user_id = r.user_id
LEFT JOIN top_items t ON u.user_id = t.user_id
LEFT JOIN google_behavioral_logs b ON u.user_id = b.user_id
""")
unified_profile_df.show()
# 5. Write back to BigQuery native partitioned table
(unified_profile_df.write
.format("bigquery")
.option("table", f"{PROJECT_ID}.{BQ_DATASET}.unified_customer_profile")
.option("partitionField", "snapshot_date")
.option("partitionType", "DAY")
.option("writeMethod", "direct")
.mode("overwrite")
.save())
EOF
بعد تجميع النص البرمجي بالكامل وإدخال الإعدادات المطلوبة بشكل ديناميكي، أرسِل مهمة الدفعات إلى Managed Apache Spark Serverless.
gcloud dataproc batches submit pyspark spark_lakehouse_join.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--subnet=${NETWORK_NAME} \
--deps-bucket=${BUCKET_NAME} \
--properties="dataproc.tier=premium,spark.dataproc.lightningEngine.runtime=native"
التحقّق من تنفيذ المهمة في وحدة التحكّم
بعد إرسال مهمة الدفعات، يمكنك التأكّد من أنّها تستخدم محرك تنفيذ C++ السريع من خلال اتّباع الخطوات التالية:
- في وحدة تحكّم Google Cloud، انتقِل إلى الخدمة المُدارة لـ Apache Spark > الحوسبة بدون خادم > الدفعات.
- انقر على المهمة التي يتم تنفيذها حاليًا.
- في جزء تفاصيل الوظيفة، تأكَّد من أنّ السمة المستوى مضبوطة على
Premiumوأنّ "المحرّك" مضبوط علىLightning Engine.
8. التحليل باستخدام "وكيل بيانات BigQuery"
بعد أن جمعت البيانات المجزّأة من عدة سُحب ونفّذت عمليات تجميع سلوكية كبيرة باستخدام "الخدمة المُدارة لـ Apache Spark"، تتمثّل الخطوة التالية في تحليل البيانات.
أولاً، افحص مخطط جدول الملفات الموحّدة الذي تم إنشاؤه حديثًا في واجهة مستخدم BigQuery لفهم بنية البيانات التي تعرضها للوكيل بشكل مرئي:
- في Google Cloud Console، انتقِل إلى BigQuery.
- في جزء "المستكشف" (Explorer) على يمين الصفحة، وسِّع مشروعك ومجموعة بيانات
demo_lakehouse. - انقر على الجدول
unified_customer_profile. - انقر على علامة التبويب "المخطط" في مساحة العمل الرئيسية.
تحقَّق من مخطط الجدول الجديد. العمود top_preferences هو REPEATED STRUCT (مصفوفة من السجلات التي تحتوي على category وbrand وsale_price). يتطلب الاستعلام عن المصفوفات المتداخلة عادةً استخدام SQL معقّد باستخدام الدالة UNNEST()، ما قد يشكّل عائقًا أمام محللي الأعمال. من خلال ربط وكيل بيانات BigQuery بهذا الجدول المحدّد، يفهم الوكيل المخطّط بشكلٍ أساسي ويتعامل مع عمليات Google Standard SQL المعقّدة في الخلفية.
إنشاء وكيل البيانات
في هذا القسم، ستنشئ وكيل بيانات BigQuery وتتفاعل معه. بدلاً من كتابة استعلامات SQL معقّدة يدويًا لإلغاء تداخل المصفوفات واحتساب المقاييس، يمكنك توفير وكيل ذكاء اصطناعي مخصّص لملفك الموحّد الذي تم إنشاؤه حديثًا، ما يتيح استكشاف البيانات باللغة الطبيعية.
- في لوحة التنقّل اليمنى، ابحث عن الوكلاء وانقر عليه.
- انقر على + وكيل جديد لتهيئة مساعد جديد مستند إلى الذكاء الاصطناعي.
- اضبط إعدادات "الوكيل":
- اسم الوكيل:
Retail VIP Analysis Agent - مصادر البيانات: انقر على إضافة مصدر، ثم ابحث في جدول
unified_customer_profile.
- انقر على إضافة وانتظر بضع ثوانٍ إلى أن يبدأ "الوكيل" في تهيئة مساحة عمله.
بعد إنشاء الوكيل، يُعدّ تحديد تعليمات النظام الواضحة من الممارسات المهمة لإدارة البيانات. استخدام "تعليمات النظام" كطبقة دلالية من خلال تضمين تعريفات الأنشطة التجارية على مستوى المؤسسة، والتعامل مع تعقيدات المخطط، ووضع ضوابط تحليلية، يمكنك إبعاد التعقيد الفني عن المستخدم النهائي ومنع النموذج اللغوي الكبير من استخلاص استنتاجات من بيانات غير مهمة إحصائيًا.
الصِق ما يلي في حقل التعليمات:
You are an expert Data Analyst specializing in e-commerce customer retention.
Your primary data source is the `unified_customer_profile` table.
Strict Schema Rules:
- The `top_preferences` column is a REPEATED STRUCT (ARRAY).
- Whenever you analyze product categories, brands, or prices, you MUST explicitly use the UNNEST() function on `top_preferences` to access the underlying fields.
Semantic Layer & Business Definitions:
- "At-Risk VIP": Define this specific user cohort as anyone meeting ALL of the following criteria: `lifetime_value` > 100, `cart_adds` > 0, and `last_purchase_date` is more than 90 days ago.
Analytical Guardrails:
- Prioritize statistical significance. When generating business insights based on geographic or demographic groupings, explicitly ignore or deprioritize segments with negligible sample sizes (e.g., countries with very few users) to prevent skewed marketing strategies.
تلقين الوكيل
بما أنّ منطق النشاط التجاري المعقّد (التعريف الدقيق لـ "عميل مهم معرّض للخطر") ومتطلبات معالجة المخطط محكومة بشكل آمن من خلال "تعليمات النظام"، لا يحتاج محلّل البيانات إلى كتابة طلب مفصّل يتضمّن العديد من الشروط.
في واجهة المحادثة، أدخِل الطلب التالي:
Find the total count of At-Risk VIPs grouped by country. For each country, extract the single most frequent product category based on their top preferences. Order the results by the user count in descending order.
تقييم الإحصاء الذي تم إنشاؤه
بعد إرسال الطلب، راجِع بعناية الناتج الذي تم إنشاؤه بشكلٍ أصلي لتقييم كيفية تطبيق "وكيل بيانات BigQuery" لتعليمات النظام، مع العمل كطبقة دلالية مُدارة وواقي تحليلي.
أولاً، اقرأ نص الملخّص الذي تم إنشاؤه فوق البيانات. لاحظ كيف يترجم الوكيل تلقائيًا طلبك البسيط بشأن "الشخصيات المهمة المعرّضة للخطر" إلى حدود المقاييس الدقيقة المحدّدة في "تعليمات النظام" (مثل الإشارة إلى lifetime_value > 100, cart_adds > 0 و90 يومًا من عدم النشاط). يؤكّد ذلك أنّ الوكيل استوعب منطق عملك، ما يعني أنّ المستخدمين النهائيين لن يحتاجوا أبدًا إلى حفظ منطق معقّد أو ترميزه بشكل ثابت في طلباتهم اليومية.
بعد ذلك، وسِّع عرض SQL لفحص الرمز البرمجي الذي تم إنشاؤه. من المفترض أن يكون الوكيل قد أنشأ عبارة Google Standard SQL صحيحة رياضيًا استنادًا إلى تعليماتك:
- فترات زمنية ديناميكية: ابحث عن عملية احتساب الطابع الزمني في عبارة
WHERE(عادةً باستخدامTIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 90 DAY)). - الالتزام الصارم بالمخطط: تأكَّد من أنّ البرنامج الآلي التزم بقواعد المخطط الصارمة من خلال تطبيق الدالة
UNNEST()بشكلٍ صريح على مصفوفةtop_preferences. لعزل الفئة الأكثر تكرارًا في كل بلد بدقة، ستلاحظ عادةً استخدام تقنيات متقدّمة، مثلROW_NUMBER() OVER()دالة نافذة ضمن تعبير جدول عام (CTE).
راجِع الرسم البياني وجدول البيانات اللذين يتمّ عرضهما تلقائيًا. ستكشف البيانات بشكل مرئي عن أسواق الاحتفاظ الأساسية (مع تسليط الضوء عادةً على البلدان التي تشهد عددًا كبيرًا من عمليات الاحتفاظ، مثل الصين أو الولايات المتحدة) إلى جانب ميول المنتجات السائدة عالميًا (مثل "سراويل الجينز" في كثير من الأحيان). لاحظ كيف تنظّم واجهة المستخدم الأصلية الناتج للاستهلاك الفوري بدون الحاجة إلى رمز مرئي صريح.
اقرأ النص الذي يتضمّن الإحصاءات على شكل نقاط من إنشاء الوكيل. بما أنّك وضعت "ضوابط تحليلية"، ابحث تحديدًا عن إحصاءات بشأن جودة البيانات أو الدلالة الإحصائية. قد يحدّد الوكيل البلدان بشكل صريح في أسفل الجدول التي تضمّ عددًا قليلاً جدًا من المستخدمين (مثل المناطق التي تضمّ عددًا قليلاً من المستخدمين). بدلاً من إنشاء حملة تسويقية مستهدفة بشكل عشوائي استنادًا إلى نقطة بيانات واحدة، سيقدّم الوكيل النصيحة الصحيحة بأنّ هذه الحالات الشاذة غير مهمة إحصائيًا بالنسبة إلى استراتيجية واسعة النطاق. يوضّح ذلك كيف أنّ دمج ضوابط الحوكمة مباشرةً في الوكيل يمنع بشكل فعّال الأخطاء في الحسابات التجارية المستندة إلى الذكاء الاصطناعي.
9- إنشاء إحصاءات مستندة إلى الذكاء الاصطناعي باستخدام Gemini وMCP
حدّد الوكيل بنجاح الفئة الديمغرافية المستهدَفة الأساسية: الشخصيات المهمة المعرّضة للخطر في بلدان معيّنة. ومع ذلك، تتوقف مهمة المحلّل عند تقديم الإحصاءات. لتجديد تفاعل هؤلاء المستخدمين، على فريق التسويق تنفيذ حملة.
ستستخدم بروتوكول سياق النموذج (MCP) لربط مساعد مستند إلى الذكاء الاصطناعي خارجي مباشرةً بقائمة التركيبة السكانية المحدّدة هذه في BigQuery، ما يتيح الانتقال من تحليل البيانات إلى اتّخاذ إجراء مستند إلى الذكاء الاصطناعي بدون إنشاء واجهات برمجة تطبيقات مخصّصة.
ضبط خادم MCP في BigQuery
نفِّذ الحزمة أدناه لإنشاء ملف الإعداد mcp.json. يوفّر هذا الملف مَعلمات الاتصال اللازمة لكي يتمكّن Gemini CLI من التفاعل بأمان مع BigQuery.
mkdir -p ~/.gemini
cat << EOF > ~/.gemini/settings.json
{
"mcpServers": {
"bigquery": {
"httpUrl": "https://bigquery.googleapis.com/mcp",
"authProviderType": "google_credentials",
"oauth": {
"scopes": [
"https://www.googleapis.com/auth/bigquery"
]
}
}
}
}
EOF
إنشاء رسالة إلكترونية تسويقية
ابدأ أداة Gemini CLI من نافذة الأوامر على جهازك، مع تمرير علامة إعداد MCP بشكل صريح للسماح لها بقراءة مستودع البيانات في BigQuery.
شغِّل Gemini CLI.
source env.sh
gemini
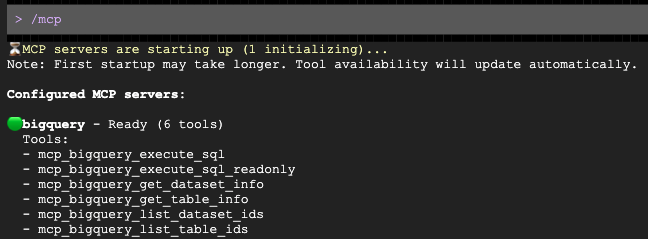
بعد فتح الطلب، اطلب منه إعداد مسودة رسالة تواصل مخصّصة للفئة الديمغرافية المستهدَفة:
Analyze the demo_lakehouse.unified_customer_profile table in BigQuery. Find exactly one 'country and age group' target demographic that has a high average order value (sale_price >= $80) but a relatively low total revenue compared to others. Then, draft a highly engaging, premium VIP promotional email tailored to this specific demographic. Use $PROJECT_ID to get the current project id.
سيطلب Gemini تلقائيًا من BigQuery عبر خادم MCP تحديد الفئة السكانية، ثم سيصيغ الرسالة الإلكترونية نيابةً عنك.
10. تنظيف البيئة
لتجنُّب فرض رسوم مستمرة على حسابك على Google Cloud وإعادة ضبط مشروعك بشكل سليم لتنفيذه في المستقبل، عليك حذف الموارد التي تم إنشاؤها أثناء هذا الدرس العملي.
نفِّذ الكتلة التالية لإنشاء النص البرمجي cleanup.sh. يعمل هذا النص البرمجي كآلية إيقاف مبرمَجة، حيث يزيل نهائيًا مجموعة AlloyDB ونسختها، ومجموعات بيانات BigQuery، وحزمة Cloud Storage لمنع إصدار المزيد من الفواتير.
cat << 'EOF' > cleanup.sh
#!/bin/bash
source ./env.sh
echo "=> Deleting BigQuery Dataset (${BQ_DATASET})..."
bq rm -r -f -d ${PROJECT_ID}:${BQ_DATASET} || true
echo "=> Deleting Lakehouse resource connection (${BQ_RESOURCE_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_RESOURCE_CONN} || true
echo "=> Deleting AlloyDB connection (${BQ_ALLOYDB_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_ALLOYDB_CONN} || true
echo "=> Deleting AlloyDB Instance (${ALLOYDB_INSTANCE}) - This takes a few minutes..."
gcloud alloydb instances delete ${ALLOYDB_INSTANCE} --cluster=${ALLOYDB_CLUSTER} --region=${REGION} --quiet || true
echo "=> Deleting AlloyDB Cluster (${ALLOYDB_CLUSTER})..."
gcloud alloydb clusters delete ${ALLOYDB_CLUSTER} --region=${REGION} --force --quiet || true
echo "=> Deleting Cloud Storage bucket (${BUCKET_NAME})..."
gcloud storage rm -r gs://${BUCKET_NAME} || true
echo "=> Deleting Lakehouse Federated Catalog (if created in Option A)..."
curl -s -X DELETE "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/aws_dbx_catalog" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" || true
echo "=> Deleting Secret Manager Regional Secret (if created in Option A)..."
CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/" \
gcloud secrets delete dbx-oauth-secret --location=${REGION} --project=${PROJECT_ID} --quiet || true
echo "=> Deleting Cloud NAT and Router (if created in Option A)..."
gcloud compute routers nats delete lakehouse-nat --router=lakehouse-router --region=${REGION} --quiet || true
gcloud compute routers delete lakehouse-router --region=${REGION} --quiet || true
echo "=> Deleting Service Networking VPC Peering..."
gcloud compute networks peerings delete servicenetworking-googleapis-com \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID} --quiet || true
echo "=> Deleting Allocated IP Range for Managed Services..."
gcloud compute addresses delete google-managed-services-${NETWORK_NAME} \
--global \
--project=${PROJECT_ID} --quiet || true
echo "=> Removing local temporary files..."
rm -f spark_lakehouse_join.py users.csv orders.csv order_items.csv alloydb-auth-proxy env.sh cleanup.sh ~/.gemini/settings.json
echo "============================================="
echo " TEARDOWN COMPLETED."
echo "============================================="
EOF
نفِّذ البرنامج النصي للتنظيف لحذف مواردك بأمان:
bash cleanup.sh
11. تهانينا!
لقد أنشأت وأجريت طلب بحث في مستودع بيانات مفتوح متعدد السحابات بنجاح.
تعرّفت على ما يلي:
- كيفية توحيد البيانات من مصادر مختلفة باستخدام BigQuery Zero-ETL وGoogle Cloud Lakehouse
- كيفية الاستفادة من محرك Lightning Engine الأصلي بلغة C++ في عمليات الربط المتجهة الضخمة في Managed Service for Apache Spark
- كيفية استخدام "وكيل بيانات BigQuery" لاستكشاف البيانات باللغة العادية
- كيفية ربط بياناتك بـ Gemini باستخدام بروتوكول Model Context Protocol (MCP) وGemini
الخطوات التالية
- استكشاف مستندات Lakehouse
- مزيد من المعلومات عن ميزة "نقل البيانات بدون استخراج وتحويل وتحميل" من AlloyDB إلى BigQuery
- مزيد من المعلومات حول Lightning Engine