
১. ভূমিকা
এই কোডল্যাবে, আপনি একটি ক্রস-ক্লাউড ওপেন ডেটা লেকহাউস তৈরি করবেন যা জটিল ETL-এর প্রয়োজন ছাড়াই AWS, Google Cloud, এবং AlloyDB জুড়ে থাকা ডেটা সিলোগুলোকে একত্রিত করবে। আপনি লেকহাউসকে কেন্দ্রীয় ইন্টেলিজেন্স হাব হিসেবে, AlloyDB-কে একটি অপারেশনাল ডেটা সোর্স হিসেবে, এবং উচ্চ-পারফরম্যান্স ভেক্টরাইজড প্রসেসিংয়ের জন্য Apache Spark-এর ম্যানেজড সার্ভিস ব্যবহার করবেন। সবশেষে, আপনি আপনার লেকহাউস থেকে শক্তিশালী ব্যবসায়িক অন্তর্দৃষ্টি আহরণ করতে Gemini ব্যবহার করবেন।
ধরুন, আপনার লেনদেন সংক্রান্ত ডেটা ( users , orders , order items ) একটি চালু AlloyDB ডেটাবেসে, আপনার product ডেটা একটি AWS S3 বাকেটে এবং বিপুল পরিমাণ ক্লিকস্ট্রিম event logs ক্লাউড স্টোরেজে সংরক্ষিত আছে। আপনার পরবর্তী মার্কেটিং ক্যাম্পেইনের জন্য নির্দিষ্ট গ্রাহকগোষ্ঠী শনাক্ত করতে এবং ব্যক্তিগতকৃত আউটরিচ ইমেল তৈরি করতে এই ডেটাসেটগুলোকে একত্রিত করা প্রয়োজন।
পূর্বশর্ত
- মৌলিক SQL এবং টার্মিনাল কমান্ড সম্পর্কে ধারণা থাকা।
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট।
আপনি যা শিখবেন
- BigQuery জিরো-ETL (AlloyDB) এবং Lakehouse for Apache Iceberg ব্যবহার করে কীভাবে বিভিন্ন ডেটা সিলোকে একীভূত করা যায়
- C++ নেটিভ লাইটনিং ইঞ্জিন দ্বারা চালিত অ্যাপাচি স্পার্কের ম্যানেজড সার্ভিস ব্যবহার করে কীভাবে একটি দ্রুতগতির বিহেভিওরাল প্রোফাইলিং জব চালানো যায়।
- ইউনিফাইড ডেটার উপর জটিল স্বাভাবিক ভাষা বিশ্লেষণ করার জন্য কীভাবে BigQuery ডেটা এজেন্ট ব্যবহার করবেন।
- অ্যাপাচি আইসবার্গের জন্য আপনার লেকহাউস থেকে ডেটা পড়তে এবং মার্কেটিং কনটেন্টের খসড়া তৈরি করতে জেমিনি সিএলআই-কে অনুমতি দেওয়ার জন্য মডেল কনটেক্সট প্রোটোকল (এমসিপি) কীভাবে কনফিগার করবেন।
আপনার যা যা লাগবে
- একটি গুগল ক্লাউড অ্যাকাউন্ট এবং গুগল ক্লাউড প্রজেক্ট
- ক্রোমের মতো একটি ওয়েব ব্রাউজার
আপনার যা যা লাগবে
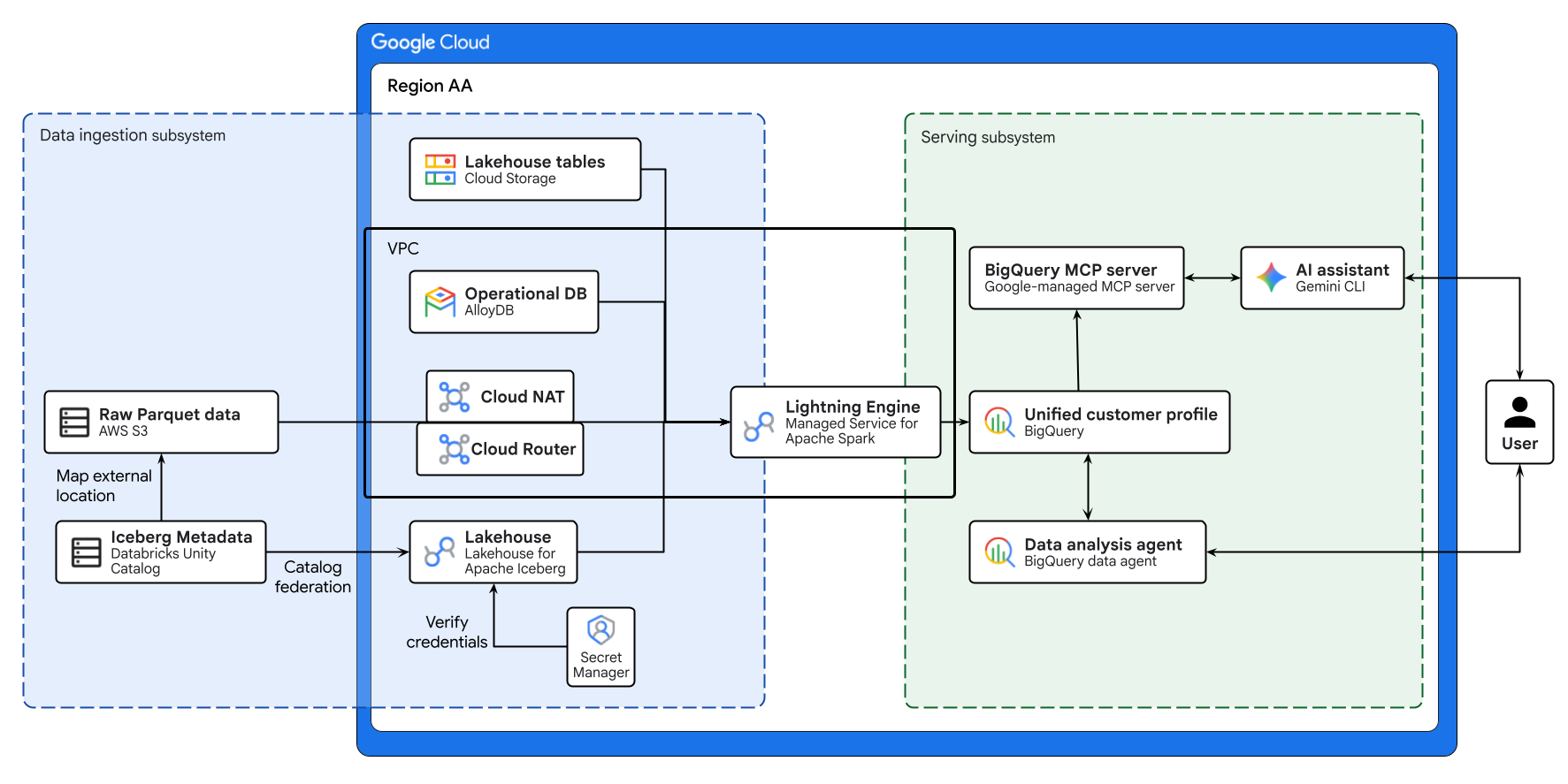
উপরের ডায়াগ্রামটি এই কোডল্যাবে নির্মিত ক্রস-ক্লাউড লেকহাউসের এন্ড-টু-এন্ড কার্যপ্রবাহ তুলে ধরেছে। AlloyDB থেকে অপারেশনাল ডেটা এবং AWS S3 থেকে রিমোট ডেটা, Lakehouse for Apache Iceberg ব্যবহার করে নিরাপদে ফেডারেট করা হয়। Managed Service for Apache Spark এই ভিন্ন ভিন্ন উৎসগুলোকে প্রসেস করে BigQuery-তে একটি সমন্বিত কাস্টমার প্রোফাইল তৈরি করে। সবশেষে, একটি BigQuery Data Agent এবং Gemini CLI-এর মাধ্যমে Google-পরিচালিত BigQuery MCP সার্ভার উন্নত ডেটা বিশ্লেষণের জন্য একটি স্বজ্ঞাত, AI-চালিত ইন্টারফেস প্রদান করে।
মূল ধারণা
- ক্রস-ক্লাউড ওপেন ডেটা লেকহাউস: জটিল ETL-এর প্রয়োজন ছাড়াই AWS, গুগল ক্লাউড এবং অন-প্রিমিসেস পরিবেশ জুড়ে থাকা ডেটা সিলোগুলোকে একীভূত করে।
- BigQuery জিরো-ETL: জটিল ডেটা স্থানান্তর ছাড়াই অপারেশনাল ডেটাবেস থেকে সরাসরি কোয়েরি করার সুবিধা দেয়।
- লেকহাউস ফর অ্যাপাচি আইসবার্গ: অ্যাপাচি আইসবার্গ ফরম্যাট ব্যবহার করে বিভিন্ন ক্লাউডের স্টোরেজে সামঞ্জস্যপূর্ণ নিরাপত্তা ও পরিচালনা নিশ্চিত করে।
- লাইটেনিং ইঞ্জিন: উচ্চ-কর্মক্ষমতাসম্পন্ন অ্যাপাচি স্পার্ক এক্সিকিউশনের জন্য একটি সি++ নেটিভ ইঞ্জিন।
- মডেল কনটেক্সট প্রোটোকল (MCP): জেমিনিকে সরাসরি আপনার বিগকোয়েরি লেকহাউসের সাথে সংযুক্ত করে।
২. সেটআপ এবং প্রয়োজনীয়তা
একটি গুগল ক্লাউড প্রজেক্ট তৈরি করুন
- গুগল ক্লাউড কনসোলের প্রজেক্ট সিলেক্টর পেজে, একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন ।
- আপনার ক্লাউড প্রোজেক্টের জন্য বিলিং চালু আছে কিনা তা নিশ্চিত করুন। কোনো প্রোজেক্টে বিলিং চালু আছে কিনা তা কীভাবে পরীক্ষা করবেন, তা জেনে নিন।
ক্লাউড শেল শুরু করুন
যদিও গুগল ক্লাউড আপনার ল্যাপটপ থেকে দূরবর্তীভাবে পরিচালনা করা যায়, এই কোডল্যাবে আপনি গুগল ক্লাউড শেল ব্যবহার করবেন, যা ক্লাউডে চালিত একটি কমান্ড লাইন পরিবেশ।
গুগল ক্লাউড কনসোল থেকে, উপরের ডানদিকের টুলবারে থাকা ক্লাউড শেল আইকনটিতে ক্লিক করুন:
পরিবেশটি প্রস্তুত করতে এবং এর সাথে সংযোগ স্থাপন করতে মাত্র কয়েক মুহূর্ত সময় লাগবে। এটি শেষ হলে, আপনি এইরকম কিছু দেখতে পাবেন:

এই ভার্চুয়াল মেশিনটিতে আপনার প্রয়োজনীয় সমস্ত ডেভেলপমেন্ট টুলস লোড করা আছে। এটি একটি স্থায়ী ৫ জিবি হোম ডিরেক্টরি প্রদান করে এবং গুগল ক্লাউডে চলে, যা নেটওয়ার্ক পারফরম্যান্স ও অথেনটিকেশনকে ব্যাপকভাবে উন্নত করে। এই কোডল্যাবে আপনার সমস্ত কাজ একটি ব্রাউজারের মধ্যেই করা যাবে। আপনাকে কিছুই ইনস্টল করতে হবে না।
পরিবেশ প্রারম্ভিক করুন
ক্লাউড শেল খুলুন এবং আপনার প্রোজেক্ট ভেরিয়েবলগুলো সেট করুন, যাতে সমস্ত কমান্ড সঠিক ইনফ্রাস্ট্রাকচারকে টার্গেট করে।
cat << 'EOF' > env.sh
#!/bin/bash
# env.sh: Environment variables
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-west1"
export NETWORK_NAME="default"
export BUCKET_NAME="lakehouse-data-${PROJECT_ID}"
export BQ_DATASET="demo_lakehouse"
export BQ_RESOURCE_CONN="lakehouse-iceberg-conn"
export BQ_ALLOYDB_CONN="alloydb-fed-conn"
export ALLOYDB_CLUSTER="demo-alloy-cluster"
export ALLOYDB_INSTANCE="demo-alloy-primary"
export ALLOYDB_PASSWORD="SuperSecretPassword123!"
export ALLOYDB_DB_NAME="retail_db"
# Multi-cloud configuration identifiers
export SECRET_NAME="dbx-oauth-secret"
export CATALOG_NAME="aws_dbx_catalog"
EOF
আপনার সক্রিয় সেশনে ভেরিয়েবলগুলো প্রয়োগ করুন:
source ./env.sh
এপিআই সক্ষম করুন
প্রয়োজনীয় গুগল ক্লাউড পরিষেবাগুলো সক্রিয় করুন।
gcloud services enable \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
compute.googleapis.com \
biglake.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com \
servicenetworking.googleapis.com \
secretmanager.googleapis.com \
dataplex.googleapis.com \
datacatalog.googleapis.com \
dataform.googleapis.com \
dataproc.googleapis.com --quiet
৩. মূল অবকাঠামো স্থাপন করুন
দুর্বল ETL পাইপলাইনের মাধ্যমে সমস্ত ডেটা একটিমাত্র রিপোজিটরিতে স্থানান্তরের পরিবর্তে, আপনি একটি ফেডারেটেড ক্রস-ক্লাউড আর্কিটেকচার তৈরি করবেন। বাস্তব জগতের প্রতিষ্ঠানে, বিভিন্ন সিস্টেমের প্রয়োজনীয়তার কারণে ডেটা স্বভাবতই খণ্ডিত থাকে। আপনি নিম্নলিখিত ডেটা সোর্সগুলো অর্কেস্ট্রেট করবেন:
- অ্যালয়ডিবি (কোর ট্রানজ্যাকশনাল ডিবি): ব্যবহারকারী, অর্ডার এবং অর্ডার_আইটেম ডেটা সংরক্ষণ করে। একটি লাইভ অপারেশনাল ডেটাবেস হিসেবে, এটি আর্থিক লেনদেন এবং প্রোফাইল আপডেটের জন্য প্রয়োজনীয় ACID বৈশিষ্ট্যগুলির নিশ্চয়তা দেয়।
- AWS S3 (মাস্টার ডেটা):
productsক্যাটালগ সংরক্ষণ করে। এটি AWS-এর একটি লিগ্যাসি মাস্টার ডেটা ম্যানেজমেন্ট (MDM) সিস্টেমের প্রতিনিধিত্ব করে। - গুগল ক্লাউড স্টোরেজ (বিশাল ডেটা লেক):
events(ক্লিকস্ট্রিম লগ) সংরক্ষণ করে। ওয়েব লগের মতো উচ্চ-থ্রুপুট ডেটা একটি রিলেশনাল ডেটাবেসকে ক্র্যাশ করে দিতে পারে। অবজেক্ট স্টোরেজ অসীম স্কেলেবিলিটি প্রদান করে, এবং এটিকে গুগল ক্লাউডে রাখলে আপনার অ্যানালিটিক্যাল ইঞ্জিনগুলির জন্য কম্পিউট লোকালিটি সর্বোচ্চ পর্যায়ে পৌঁছায়।
প্রথমে, অন্তর্নিহিত নেটওয়ার্কটি কনফিগার করুন। AlloyDB-এর মতো গুগল ক্লাউড পরিচালিত ডেটাবেসগুলোকে আপনার প্রজেক্ট নেটওয়ার্কের মধ্যে নিরাপদে যোগাযোগ করার জন্য একটি প্রাইভেট VPC পিয়ারিং কানেকশনের প্রয়োজন হয়।
# Allocate an IP range for Google Cloud managed services
gcloud compute addresses create google-managed-services-${NETWORK_NAME} \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Establish the VPC peering connection
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=google-managed-services-${NETWORK_NAME} \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID}
এরপর, একটি BigQuery ডেটাসেট এবং একটি Lakehouse ক্লাউড রিসোর্স কানেকশন তৈরি করুন। কাঠামোগতভাবে, একটি রিসোর্স কানেকশন একটি ডেডিকেটেড গুগল-পরিচালিত সার্ভিস অ্যাকাউন্টে ডেটা অ্যাক্সেসের দায়িত্ব অর্পণ করে, যা ন্যূনতম বিশেষাধিকারের নীতিকে বলবৎ করে।
# Create the central data lakehouse dataset
bq mk --dataset --location=${REGION} ${PROJECT_ID}:${BQ_DATASET}
gcloud storage buckets create gs://${BUCKET_NAME} --location=${REGION}
# Create a Lakehouse resource connection
bq mk --connection --location=${REGION} \
--connection_type=CLOUD_RESOURCE ${BQ_RESOURCE_CONN}
# Retrieve the automatically provisioned service account
CONN_SA=$(bq show --connection --format=json ${PROJECT_ID}.${REGION}.${BQ_RESOURCE_CONN} | jq -r '.cloudResource.serviceAccountId')
# Grant the service account permissions to read/write to the data lake
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${CONN_SA}" \
--role="roles/storage.admin" \
--quiet
৪. অপারেশনাল ডেটাবেস সরবরাহ করুন
একটি AlloyDB প্রাইমারি ইনস্ট্যান্স প্রস্তুত করুন এবং আপনার অত্যন্ত গুরুত্বপূর্ণ লেনদেন সংক্রান্ত ডেটা প্রবেশ করান।
# Create the AlloyDB cluster
gcloud alloydb clusters create ${ALLOYDB_CLUSTER} \
--region=${REGION} \
--password=${ALLOYDB_PASSWORD} \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Create the primary instance
gcloud alloydb instances create ${ALLOYDB_INSTANCE} \
--cluster=${ALLOYDB_CLUSTER} \
--region=${REGION} \
--instance-type=PRIMARY \
--cpu-count=2 \
--assign-inbound-public-ip=ASSIGN_IPV4 \
--database-flags=password.enforce_complexity=on
ডাটাবেস প্রস্তুত হয়ে গেলে, আপনাকে AlloyDB-এর সাথে একটি BigQuery এক্সটার্নাল কানেকশন তৈরি করতে হবে। এই কানেকশনটি ডাটাবেসের ক্রেডেনশিয়াল এবং এন্ডপয়েন্ট নিরাপদে সংরক্ষণ করে, যা BigQuery-কে সরাসরি AlloyDB কম্পিউট ইঞ্জিনে SQL এক্সিকিউশন পুশ ডাউন করার সুযোগ দেয় (জিরো-ETL)।
# Create the BigQuery to AlloyDB connection
bq mk --connection --location=${REGION} --project_id=${PROJECT_ID} \
--connector_configuration "{
\"connector_id\": \"google-alloydb\",
\"asset\": {
\"database\": \"${ALLOYDB_DB_NAME}\",
\"google_cloud_resource\": \"//alloydb.googleapis.com/projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE}\"
},
\"authentication\": {
\"username_password\": {
\"username\": \"postgres\",
\"password\": { \"plaintext\": \"${ALLOYDB_PASSWORD}\" }
}
}
}" ${BQ_ALLOYDB_CONN}
# Grant the BigQuery connection service agent permission to access AlloyDB
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
BQ_SERVICE_AGENT="service-${PROJECT_NUMBER}@gcp-sa-bigqueryconnection.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${BQ_SERVICE_AGENT}" \
--role="roles/alloydb.client" \
--quiet
ট্রানজ্যাকশনাল টেবিলগুলো নিরাপদে AlloyDB-তে পুশ করুন। আপনার লোকাল ক্লাউড শেল সেশনকে প্রাইভেট AlloyDB ইনস্ট্যান্সের সাথে নিরাপদে সংযুক্ত করতে AlloyDB Auth Proxy ব্যবহার করুন। এর ফলে আপনি লোকাল কমান্ড-লাইন টুল ব্যবহার করে ট্রানজ্যাকশনাল ডেটা পুশ করতে পারবেন।
# Extract full raw data to Cloud Storage using the BigQuery extract API
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.users" gs://${BUCKET_NAME}/tmp/users.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.orders" gs://${BUCKET_NAME}/tmp/orders.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.order_items" gs://${BUCKET_NAME}/tmp/order_items.csv
# Download the CSVs to the local Cloud Shell session
gcloud storage cp gs://${BUCKET_NAME}/tmp/users.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/orders.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/order_items.csv .
# Download and start the AlloyDB auth proxy
curl -sL "https://storage.googleapis.com/alloydb-auth-proxy/v1.13.11/alloydb-auth-proxy.linux.amd64" -o alloydb-auth-proxy && chmod +x alloydb-auth-proxy
./alloydb-auth-proxy projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE} --public-ip &
PROXY_PID=$!
sleep 15 # Wait for the proxy to fully initialize
# Create the database
export PGPASSWORD=${ALLOYDB_PASSWORD}
psql -h 127.0.0.1 -p 5432 -U postgres -c "CREATE DATABASE ${ALLOYDB_DB_NAME};" || true
# Load into AlloyDB mimicking the exact schema via heredoc
psql -h 127.0.0.1 -p 5432 -U postgres -d ${ALLOYDB_DB_NAME} << 'EOF'
CREATE TABLE IF NOT EXISTS users (id INT PRIMARY KEY, first_name VARCHAR(255), last_name VARCHAR(255), email VARCHAR(255), age INT, gender VARCHAR(50), state VARCHAR(100), street_address VARCHAR(255), postal_code VARCHAR(50), city VARCHAR(100), country VARCHAR(100), latitude FLOAT, longitude FLOAT, traffic_source VARCHAR(100), created_at TIMESTAMP, user_geom TEXT);
CREATE TABLE IF NOT EXISTS orders (order_id INT PRIMARY KEY, user_id INT, status VARCHAR(50), gender VARCHAR(50), created_at TIMESTAMP, returned_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, num_of_item INT);
CREATE TABLE IF NOT EXISTS order_items (id INT PRIMARY KEY, order_id INT, user_id INT, product_id INT, inventory_item_id INT, status VARCHAR(50), created_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, returned_at TIMESTAMP, sale_price FLOAT);
\copy users FROM 'users.csv' WITH (FORMAT csv, HEADER true)
\copy orders FROM 'orders.csv' WITH (FORMAT csv, HEADER true)
\copy order_items FROM 'order_items.csv' WITH (FORMAT csv, HEADER true)
EOF
# Clean up local temporary files and Cloud Storage artifacts
kill $PROXY_PID && rm -f users.csv orders.csv order_items.csv alloydb-auth-proxy
gcloud storage rm gs://${BUCKET_NAME}/tmp/*.csv
৫. মাস্টার ডেটা ফেডারেশন করুন (AWS-এর ভাষ্য)
আমাদের পণ্যের ক্যাটালগ, যাতে প্রতিটি আইটেমের প্রাথমিক মেটাডেটা থাকে, তা মূলত AWS S3-তে অ্যাপাচি আইসবার্গ টেবিল হিসেবে সংরক্ষিত থাকে। এই মেটাডেটা একটি রিমোট ক্যাটালগ দ্বারা নিয়ন্ত্রিত হয়।
এই ডেটা গুগল ক্লাউডে কপি করার জন্য দুর্বল ETL পাইপলাইন তৈরি করার পরিবর্তে, আপনি অ্যাপাচি আইসবার্গের (REST ক্যাটালগ ফেডারেশন) জন্য লেকহাউস ব্যবহার করবেন।
এই জিরো-ইটিএল পদ্ধতিটি লেকহাউস এবং ম্যানেজড সার্ভিস ফর অ্যাপাচি স্পার্ক-কে আপনার রিমোট এনভায়রনমেন্ট থেকে সরাসরি আইসবার্গ মেটাডেটা এবং অন্তর্নিহিত পার্কেট ফাইলগুলো ডাইনামিকভাবে খুঁজে বের করতে ও পড়তে সক্ষম করে।
আপনার যদি একটি সক্রিয় AWS অ্যাকাউন্ট এবং Databricks Unity Catalog কনফিগার করা থাকে, তবে আপনি সেটি ব্যবহার করতে পারেন। অন্যথায়, আপনি Google Cloud Storage ব্যবহার করে আপনার পরিবেশটি মক করতে পারেন। দুটির মধ্যে যেকোনো একটি বেছে নিন।
বিকল্প A: আপনার নিজস্ব AWS (নেটিভ অ্যাপাচি আইসবার্গ) ব্যবহার করুন
পূর্বশর্ত: এই বিকল্পটির জন্য ধরে নেওয়া হচ্ছে যে আপনি ইতিমধ্যেই একটি AWS S3 বাকেট প্রোভিশন করেছেন, সেটিকে Databricks Unity Catalog-এ একটি এক্সটার্নাল লোকেশন হিসেবে সংযুক্ত করেছেন, একটি Iceberg টেবিল ম্যাপ করেছেন এবং রিড অ্যাক্সেস সহ একটি OAuth সার্ভিস প্রিন্সিপাল জেনারেট করেছেন।
১. পরিচয়পত্রের নিরাপদ সংরক্ষণ
দীর্ঘস্থায়ী অ্যাক্সেস টোকেন হার্ডকোড করা একটি আর্কিটেকচারাল অ্যান্টি-প্যাটার্ন। আপনি ডেটাব্রিকস OAuth ক্লায়েন্ট আইডি এবং সিক্রেট গুগল ক্লাউড সিক্রেট ম্যানেজারে সংরক্ষণ করবেন। লেকহাউস সার্ভিসটি রানটাইমে ডায়নামিকভাবে এগুলো ফেচ করে স্বল্পস্থায়ী টোকেন সরবরাহ করবে, যা আপনার ক্রেডেনশিয়াল গভর্নেন্সকে কেন্দ্রীভূত করবে।
স্ক্রিপ্টটি তৈরি করতে নিচের ব্লকটি চালান। (এখনও কোনো কিছু সম্পাদনা করবেন না)।
cat << 'EOF' > create_secret.sh
#!/bin/bash
source ./env.sh
# Define your Databricks OAuth credentials
DATABRICKS_CLIENT_ID="<YOUR_DATABRICKS_CLIENT_ID>"
DATABRICKS_CLIENT_SECRET="<YOUR_DATABRICKS_CLIENT_SECRET>"
DATABRICKS_WORKSPACE="<YOUR_WORKSPACE>.cloud.databricks.com" # Exclude https://
DATABRICKS_CATALOG="google_lakehouse_catalog"
# Define the secure credentials payload
export CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/"
SECRET_PAYLOAD="{ \"client_id\": \"${DATABRICKS_CLIENT_ID}\", \"client_secret\": \"${DATABRICKS_CLIENT_SECRET}\" }"
# Pipe the JSON payload into Google Cloud Secret Manager
echo "$SECRET_PAYLOAD" | gcloud secrets create ${SECRET_NAME} \
--location=${REGION} \
--project=${PROJECT_ID} \
--data-file=-
EOF
এরপর, আপনার টার্মিনালের উপরের ভিজ্যুয়াল কোড এডিটরে তৈরি হওয়া স্ক্রিপ্টটি স্বয়ংক্রিয়ভাবে খোলার জন্য নিম্নলিখিত কমান্ডটি চালান।
cloudshell edit create_secret.sh
- এডিটরে,
<YOUR_...>প্লেসহোল্ডারগুলিকে আপনার আসল ডেটাব্রিকস ক্রেডেনশিয়াল দিয়ে প্রতিস্থাপন করুন। - নিশ্চিত করুন যে আপনার ওয়ার্কস্পেস URL-এ
https://বা শেষের দিকে স্ল্যাশ নেই (যেমন,123456789.cloud.databricks.com)। - ফাইলটি সংরক্ষণ করতে
Ctrl+S(অথবা Mac-এCmd+S) চাপুন। - আপনার টার্মিনাল সেশনে ফিরে যান এবং স্ক্রিপ্টটি চালান:
source create_secret.sh
২. ফেডারেটেড ক্যাটালগ তৈরি করুন
এই কোডল্যাবে সরলতার জন্য, আপনি ক্যাটালগটিকে পাবলিক ইন্টারনেটের মাধ্যমে নিরাপদে ডেটা আদান-প্রদানের জন্য কনফিগার করবেন। তবে, প্রোডাকশন ওয়ার্কলোডের ক্ষেত্রে, পাবলিক ইন্টারনেটের মাধ্যমে বিশাল ডেটাসেট কোয়েরি করলে অপ্রয়োজনীয় ইগ্রেস খরচ এবং অপ্রত্যাশিত ল্যাটেন্সি দেখা দেয়। সর্বোত্তম অনুশীলন অনুযায়ী AWS এবং Google Cloud-এর মধ্যে একটি প্রাইভেট ক্রস-ক্লাউড ইন্টারকানেক্ট (CCI) কনফিগার করা বাধ্যতামূলক, যা ইগ্রেস খরচ উল্লেখযোগ্যভাবে কমায় এবং সুনির্দিষ্ট নেটওয়ার্ক পারফরম্যান্স নিশ্চিত করে।
ফেডারেটেড লেকহাউস ক্যাটালগটি প্রোভিশন করতে gcloud CLI ব্যবহার করুন:
# Execute the Lakehouse CLI to provision the federated catalog
gcloud alpha biglake iceberg catalogs create ${CATALOG_NAME} \
--project="${PROJECT_ID}" \
--primary-location="${REGION}" \
--catalog-type="federated" \
--federated-catalog-type="unity" \
--secret-name="projects/${PROJECT_ID}/locations/${REGION}/secrets/${SECRET_NAME}" \
--unity-instance-name="${DATABRICKS_WORKSPACE}" \
--unity-catalog-name="${DATABRICKS_CATALOG}" \
--refresh-interval="330s"
৩. সর্বনিম্ন বিশেষাধিকার IAM বাইন্ডিং প্রয়োগ করুন
পূর্ববর্তী ধাপে যখন আপনি ফেডারেটেড ক্যাটালগটি প্রোভিশন করেছিলেন, তখন গুগল ক্লাউড লেকহাউস স্বয়ংক্রিয়ভাবে প্রতি ৩৩০ সেকেন্ডে আইসবার্গ ম্যানিফেস্টগুলো সিঙ্ক্রোনাইজ করার জন্য একটি ব্যাকগ্রাউন্ড রিফ্রেশ জব চালু করেছিল।
আপনাকে অবশ্যই লেকহাউস ক্যাটালগ সার্ভিস অ্যাকাউন্টে secretAccessor রোলটি প্রদান করতে হবে, যাতে এটি এই ব্যাকগ্রাউন্ড সিঙ্ক এবং কোয়েরি এক্সিকিউশনের সময় নিরাপদে ডেটাব্রিকস OAuth টোকেন সংগ্রহ করতে পারে। এই বাইন্ডিংটি না থাকলে, লেকহাউস যখন ক্যাটালগ আপডেট করার চেষ্টা করবে তখন নীরবে 403 এরর দেখা দেবে।
# Extract the automatically provisioned Lakehouse catalog service account
LAKEHOUSE_SA=$(curl -s -X GET "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/${CATALOG_NAME}" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" | jq -r '."biglake-service-account"')
# Grant the secretAccessor role for background metadata synchronization and query execution
gcloud secrets add-iam-policy-binding ${SECRET_NAME} \
--project=${PROJECT_ID} --location=${REGION} \
--member="serviceAccount:${LAKEHOUSE_SA}" \
--role="roles/secretmanager.secretAccessor" --quiet
৪. অ্যাপাচি স্পার্কের জন্য পরিচালিত পরিষেবার জন্য বহির্গামী ইন্টারনেট সক্রিয় করুন
পরবর্তী ধাপে, ম্যানেজড সার্ভিস ফর অ্যাপাচি স্পার্ক রিমোট AWS ডেটা পড়বে। যেহেতু ম্যানেজড সার্ভিস ফর অ্যাপাচি স্পার্ক সার্ভারলেস কোনো বাহ্যিক আইপি অ্যাড্রেস ছাড়াই সম্পূর্ণভাবে একটি প্রাইভেট VPC নেটওয়ার্কের মধ্যে চলে, তাই এটি ডিফল্টভাবে ইন্টারনেটের মাধ্যমে AWS S3-তে পৌঁছাতে পারে না। স্পার্ক ওয়ার্কারদের বহির্গামী ইন্টারনেট অ্যাক্সেস দেওয়ার জন্য আপনাকে অবশ্যই একটি ক্লাউড NAT স্থাপন করতে হবে।
# Create a Cloud Router
gcloud compute routers create lakehouse-router \
--network=${NETWORK_NAME} \
--region=${REGION}
# Create a Cloud NAT attached to the router
gcloud compute routers nats create lakehouse-nat \
--router=lakehouse-router \
--auto-allocate-nat-external-ips \
--nat-all-subnet-ip-ranges \
--region=${REGION}
৫. ডাউনস্ট্রিম টার্গেট নির্ধারণ করুন
এই ভেরিয়েবলটি এক্সপোর্ট করুন, যাতে পরবর্তী অ্যাপাচি স্পার্ক জবগুলো ম্যানুয়াল কোড পরিবর্তনের প্রয়োজন ছাড়াই সঠিকভাবে জানতে পারে যে AWS ডেটা কোথা থেকে কোয়েরি করতে হবে।
# Assuming your schema is 'retail' and table is 'aws_products'
export AWS_PRODUCTS_TABLE="${CATALOG_NAME}.retail.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
বিকল্প B: ক্লাউড স্টোরেজের মাধ্যমে AWS পরিবেশের অনুকরণ
আপনার যদি একটি সক্রিয় AWS অ্যাকাউন্ট না থাকে, তাহলে আপনি Google Cloud Storage-এ Lakehouse পরিচালিত টেবিল ব্যবহার করে স্বাভাবিকভাবেই ক্রস-ক্লাউড সাইলোর অনুকরণ করতে পারেন।
১. একটি নমুনা আইসবার্গ টেবিল তৈরি করুন।
# Copy raw products data to a temporary BigQuery table
bq cp --force bigquery-public-data:thelook_ecommerce.products ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
# Create an open Iceberg table using the Lakehouse cloud resource connection
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.aws_products\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/aws_products')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_products_raw\`;"
# Cleanup temporary table
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
২. ডাউনস্ট্রিম টার্গেট নির্ধারণ করুন
স্ট্যান্ডার্ড BigQuery ডেটাসেটগুলো একটি ৩-অংশের নেমস্পেস কাঠামো ( project.dataset.table ) ব্যবহার করে। এই ভেরিয়েবলটি এক্সপোর্ট করুন যাতে পরবর্তী Apache Spark জবটি মক ডেটাকে টার্গেট করে।
export AWS_PRODUCTS_TABLE="${PROJECT_ID}.${BQ_DATASET}.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
৬. ইভেন্ট লগ গ্রহণ করুন (গুগল ক্লাউডের দৃষ্টিকোণ থেকে)
ক্লিকস্ট্রিম ডেটা দ্রুতগতিতে বাড়তে থাকে। আপনি সম্পূর্ণ, অসংকলিত কাঁচা ইভেন্টগুলো স্থানীয়ভাবে ক্লাউড স্টোরেজে ম্যানেজড লেকহাউস টেবিল হিসেবে সংরক্ষণ করেন।
bq cp --force bigquery-public-data:thelook_ecommerce.events ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.google_events\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/google_events')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_events_raw\`;"
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
৭. একটি সমন্বিত গ্রাহক প্রোফাইল তৈরি করুন
আপনার প্রাথমিক পরিকাঠামো সম্পূর্ণরূপে সজ্জিত হয়ে গেলে, এখন একটি সমন্বিত গ্রাহক প্রোফাইল তৈরি করার সময় এসেছে।
আপনি লাইটনিং ইঞ্জিন দ্বারা চালিত অ্যাপাচি স্পার্কের জন্য ম্যানেজড সার্ভিস ব্যবহার করবেন। লাইটনিং ইঞ্জিন হলো গুগল ক্লাউডের একটি উচ্চ-পারফরম্যান্স সম্পন্ন C++ নেটিভ কোয়েরি অ্যাক্সিলারেটর, যা অ্যাপাচি গ্লুটেন এবং ভেলক্সের মতো ওপেন-সোর্স প্রযুক্তির উপর ভিত্তি করে নির্মিত। এটি সিপিইউ-এর কার্যকারিতা সর্বাধিক করে এবং বুদ্ধিমত্তার সাথে ডেটা ক্যাশ করার মাধ্যমে স্বয়ংক্রিয়ভাবে এক্সিকিউশনের গতি বাড়িয়ে দেয়। একাধিক ক্লাউড জুড়ে ব্যাপক মাল্টি-ওয়ে জয়েন, জটিল উইন্ডোয়িং বা বিহেভিওরাল অ্যাগ্রিগেশন সম্পাদনের জন্য এই পদ্ধতিটি আদর্শ।
আপনি Spark BigQuery কানেক্টর ব্যবহার করে সরাসরি ফেডারেটেড AlloyDB জিরো-ETL কোয়েরি এবং Lakehouse টেবিলগুলো পড়বেন, Spark-এর মধ্যেই ব্যাপক ভেক্টরাইজড অ্যাগ্রিগেশনগুলো সম্পাদন করবেন এবং ফলাফলস্বরূপ প্রাপ্ত ইউনিফাইড প্রোফাইলটি BigQuery-তে পুনরায় লিখবেন।
অ্যাপাচি স্পার্কের জন্য পরিচালিত পরিষেবার IAM অনুমতি কনফিগার করুন
ডিফল্টরূপে, সার্ভারলেস স্পার্ক কম্পিউট ইঞ্জিনের ডিফল্ট সার্ভিস অ্যাকাউন্ট ব্যবহার করে ব্যাচ জবগুলো সম্পাদন করে। জব সাবমিট করার আগে, আপনাকে অবশ্যই এই সার্ভিস অ্যাকাউন্টটিকে ওয়ার্কলোড সম্পাদন এবং বিগকোয়েরি জবগুলো পরিচালনা করার জন্য প্রয়োজনীয় অনুমতি প্রদান করতে হবে।
(দ্রষ্টব্য: শিল্প-মানসম্মত পরিভাষা প্রতিফলিত করার জন্য পরিষেবার নাম পরিবর্তন করে ‘ম্যানেজড সার্ভিস ফর অ্যাপাচি স্পার্ক’ রাখা হলেও, অন্তর্নিহিত API কমান্ড এবং IAM রোলগুলিতে এখনও ‘dataproc’ আইডেন্টিফায়ারটি ব্যবহৃত হয়)।
# Retrieve the project number to construct the Compute Engine default service account
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
# Grant the Managed Service for Apache Spark Worker role to allow job execution
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/dataproc.worker" \
--quiet
# Grant the BigQuery Admin role to allow reading, writing, and querying external connections
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/bigquery.admin" \
--quiet
কাজটি তৈরি করুন এবং জমা দিন
প্রথমে, পাইস্পার্ক জব স্ক্রিপ্টটি তৈরি করুন। এই স্ক্রিপ্টটি আপনার AWS_PRODUCTS_TABLE এনভায়রনমেন্ট ভেরিয়েবলের উপর ভিত্তি করে স্বয়ংক্রিয়ভাবে শনাক্ত করে যে আপনি অপশন A (AWS ফেডারেটেড ক্যাটালগ) নাকি অপশন B (গুগল ক্লাউড মক) বেছে নিয়েছেন, স্পার্ক SQL লজিক নির্ধারণ করে এবং RFM (রিসেন্সি, ফ্রিকোয়েন্সি, মনিটারি) উইন্ডোগুলো গণনা করার জন্য স্পার্কের নিজস্ব অ্যারে ম্যানিপুলেশন ব্যবহার করে।
ক্লাউড শেলে নিম্নলিখিত ব্লকটি চালান।
# Determine which option was selected based on the AWS_PRODUCTS_TABLE variable
if [[ "${AWS_PRODUCTS_TABLE}" == *"${CATALOG_NAME:-undefined}"* ]]; then
echo "=> Option A (AWS Federated Catalog) detected."
export IS_AWS_CATALOG="True"
export OAUTH_TOKEN=$(gcloud auth print-access-token)
else
echo "=> Option B (Google Cloud Mock) detected."
export IS_AWS_CATALOG="False"
export OAUTH_TOKEN=""
fi
# Create the PySpark script with safely injected variables
cat << EOF > spark_lakehouse_join.py
from pyspark.sql import SparkSession
# --- Environment Variables dynamically injected ---
PROJECT_ID = "${PROJECT_ID}"
CATALOG_NAME = "${CATALOG_NAME}"
OAUTH_TOKEN = "${OAUTH_TOKEN}"
BUCKET_NAME = "${BUCKET_NAME}"
BQ_DATASET = "${BQ_DATASET}"
REGION = "${REGION}"
BQ_ALLOYDB_CONN = "${BQ_ALLOYDB_CONN}"
AWS_PRODUCTS_TABLE = "${AWS_PRODUCTS_TABLE}"
IS_AWS_CATALOG = ${IS_AWS_CATALOG}
# ---------------------------------------------------
# 1. Initialize SparkSession (Dynamic Configuration)
packages =[
"org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.3",
"org.apache.iceberg:iceberg-aws-bundle:1.4.3",
"org.apache.hadoop:hadoop-aws:3.3.4",
"com.amazonaws:aws-java-sdk-bundle:1.12.262",
"com.google.cloud.spark:spark-bigquery-with-dependencies_2.12:0.36.1"
]
builder = SparkSession.builder \\
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \\
.config("spark.dataproc.lightningEngine.runtime", "native") \\
.config("spark.hadoop.fs.gs.velox.client.table-cache-max-size", "0") \\
.config("spark.jars.packages", ",".join(packages))
# Conditionally configure Lakehouse REST Catalog for Option A
if IS_AWS_CATALOG:
builder = builder \\
.config(f"spark.sql.catalog.{CATALOG_NAME}", "org.apache.iceberg.spark.SparkCatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.type", "rest") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.uri", "https://biglake.googleapis.com/iceberg/v1/restcatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.warehouse", f"bl://projects/{PROJECT_ID}/catalogs/{CATALOG_NAME}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.X-Iceberg-Access-Delegation", "vended-credentials") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.x-goog-user-project", PROJECT_ID) \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.Authorization", f"Bearer {OAUTH_TOKEN}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.rest-metrics-reporting-enabled", "false")
spark = builder.getOrCreate()
spark.conf.set("temporaryGcsBucket", BUCKET_NAME)
spark.conf.set("viewsEnabled", "true")
spark.conf.set("materializationDataset", BQ_DATASET)
# 2. Extract operational data via AlloyDB Zero-ETL
users_df = spark.read.format("bigquery").option("query", f"""SELECT id AS user_id, age, country FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT id, age, country FROM users")""").load()
orders_df = spark.read.format("bigquery").option("query", f"""SELECT user_id, order_id, CAST(created_at AS TIMESTAMP) AS order_date FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT user_id, order_id, created_at FROM orders WHERE status = 'Complete'")""").load()
items_df = spark.read.format("bigquery").option("query", f"""SELECT order_id, product_id, sale_price FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT order_id, product_id, sale_price FROM order_items")""").load()
# 3. Read AWS Products (Option A vs B) & Google Cloud Logs
if IS_AWS_CATALOG:
products_df = spark.table(AWS_PRODUCTS_TABLE)
else:
products_df = spark.read.format("bigquery").option("table", AWS_PRODUCTS_TABLE).load()
events_df = spark.read.format("bigquery").option("table", f"{PROJECT_ID}.{BQ_DATASET}.google_events").load()
# Register Temp Views
users_df.createOrReplaceTempView("live_user_profiles")
orders_df.createOrReplaceTempView("live_transactions")
items_df.createOrReplaceTempView("live_order_items")
products_df.createOrReplaceTempView("raw_aws_products")
events_df.createOrReplaceTempView("google_events")
# 4. Multi-cloud Distributed Join
unified_profile_df = spark.sql("""
WITH aws_master_catalog AS (
SELECT id AS product_id, category, brand
FROM raw_aws_products
),
google_behavioral_logs AS (
SELECT user_id,
COUNT(DISTINCT session_id) AS total_sessions,
COUNT(CASE WHEN event_type = 'cart' THEN 1 END) AS cart_adds
FROM google_events
WHERE user_id IS NOT NULL
GROUP BY user_id
),
user_purchases AS (
SELECT
t.user_id, t.order_date, t.order_id, oi.sale_price,
COALESCE(p.category, 'Unknown') AS category,
COALESCE(p.brand, 'Unknown') AS brand
FROM live_transactions t
JOIN live_order_items oi ON t.order_id = oi.order_id
LEFT JOIN aws_master_catalog p ON oi.product_id = p.product_id
),
rfm_base AS (
SELECT
user_id,
MAX(order_date) AS last_purchase_date,
COUNT(DISTINCT order_id) AS total_orders,
SUM(sale_price) AS lifetime_value
FROM user_purchases
GROUP BY user_id
),
ranked_items AS (
SELECT
user_id, category, brand, sale_price,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY sale_price DESC) as rn
FROM user_purchases
),
top_items AS (
SELECT
user_id,
COLLECT_LIST(NAMED_STRUCT('category', category, 'brand', brand, 'sale_price', sale_price)) AS top_preferences
FROM ranked_items
WHERE rn <= 3
GROUP BY user_id
)
SELECT
CURRENT_TIMESTAMP() AS snapshot_date,
u.user_id, u.age, u.country,
r.last_purchase_date,
COALESCE(r.total_orders, 0) AS total_orders,
COALESCE(ROUND(r.lifetime_value, 2), 0.0) AS lifetime_value,
COALESCE(b.total_sessions, 0) AS total_sessions,
COALESCE(b.cart_adds, 0) AS cart_adds,
t.top_preferences
FROM live_user_profiles u
LEFT JOIN rfm_base r ON u.user_id = r.user_id
LEFT JOIN top_items t ON u.user_id = t.user_id
LEFT JOIN google_behavioral_logs b ON u.user_id = b.user_id
""")
unified_profile_df.show()
# 5. Write back to BigQuery native partitioned table
(unified_profile_df.write
.format("bigquery")
.option("table", f"{PROJECT_ID}.{BQ_DATASET}.unified_customer_profile")
.option("partitionField", "snapshot_date")
.option("partitionType", "DAY")
.option("writeMethod", "direct")
.mode("overwrite")
.save())
EOF
স্ক্রিপ্টটি সম্পূর্ণরূপে তৈরি হয়ে গেলে এবং প্রয়োজনীয় কনফিগারেশনগুলো ডায়নামিকভাবে যুক্ত হয়ে গেলে, ব্যাচ জবটি ম্যানেজড অ্যাপাচি স্পার্ক সার্ভারলেস-এ জমা দিন।
gcloud dataproc batches submit pyspark spark_lakehouse_join.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--subnet=${NETWORK_NAME} \
--deps-bucket=${BUCKET_NAME} \
--properties="dataproc.tier=premium,spark.dataproc.lightningEngine.runtime=native"
কনসোলে কাজের সম্পাদন যাচাই করুন।
ব্যাচ জবটি সাবমিট করা হয়ে গেলে, আপনি যাচাই করে দেখতে পারেন যে এটি অ্যাক্সিলারেটেড C++ এক্সিকিউশন ইঞ্জিন ব্যবহার করছে কিনা:
- Google Cloud কনসোলে, Managed Service for Apache Spark > Serverless > Batches -এ যান।
- বর্তমানে চলমান কাজটি ক্লিক করুন।
- জব ডিটেইলস প্যানে, যাচাই করুন যে টিয়ার (Tier) প্রপার্টিটি
Premiumএবং ইঞ্জিন (Engine)Lightning Engineহিসেবে সেট করা আছে।
৮. BigQuery ডেটা এজেন্ট দিয়ে বিশ্লেষণ করুন
এখন যেহেতু আপনি অ্যাপাচি স্পার্কের ম্যানেজড সার্ভিস ব্যবহার করে খণ্ডিত ক্রস-ক্লাউড ডেটা একত্রিত করেছেন এবং জটিল বিহেভিওরাল অ্যাগ্রিগেশনগুলো সম্পাদন করেছেন, পরবর্তী ধাপ হলো ডেটা বিশ্লেষণ।
প্রথমে, এজেন্টের কাছে আপনি যে ডেটা কাঠামোটি প্রকাশ করছেন তা চাক্ষুষভাবে বোঝার জন্য BigQuery UI-তে নতুন তৈরি করা ইউনিফাইড প্রোফাইল টেবিলের স্কিমাটি পরিদর্শন করুন:
- Google Cloud কনসোলে, BigQuery- তে যান।
- বাম দিকের এক্সপ্লোরার প্যানে আপনার প্রজেক্ট এবং
demo_lakehouseডেটাসেটটি এক্সপ্যান্ড করুন। -
unified_customer_profileটেবিলটিতে ক্লিক করুন। - মূল ওয়ার্কস্পেসে স্কিমা ট্যাবটি নির্বাচন করুন।
নতুন টেবিলের স্কিমাটি পরীক্ষা করুন। top_preferences কলামটি একটি REPEATED STRUCT (যা category , brand , এবং sale_price ধারণকারী রেকর্ডের একটি অ্যারে)। প্রথাগতভাবে, নেস্টেড অ্যারে কোয়েরি করার জন্য UNNEST() ফাংশন ব্যবহার করে জটিল SQL প্রয়োজন হয়, যা বিজনেস অ্যানালিস্টদের জন্য একটি বাধা হতে পারে। এই নির্দিষ্ট টেবিলের উপর ভিত্তি করে একটি BigQuery ডেটা এজেন্ট তৈরি করার ফলে, এজেন্টটি সহজাতভাবেই স্কিমাটি বুঝতে পারে এবং নেপথ্যে জটিল Google Standard SQL অপারেশনগুলো পরিচালনা করে।
ডেটা এজেন্ট তৈরি করুন
এই অংশে, আপনি একটি BigQuery ডেটা এজেন্ট তৈরি করবেন এবং সেটির সাথে কাজ করবেন। অ্যারে আননেস্ট করতে এবং মেট্রিক গণনা করতে ম্যানুয়ালি জটিল SQL লেখার পরিবর্তে, আপনি আপনার নতুন তৈরি করা ইউনিফাইড প্রোফাইলের জন্য বিশেষভাবে তৈরি একটি AI এজেন্ট প্রোভিশন করবেন, যা আপনাকে স্বাভাবিক ভাষায় ডেটা অন্বেষণের সুযোগ দেবে।
- বাম দিকের নেভিগেশন প্যানেলে, Agents খুঁজে বের করুন এবং সেটিতে ক্লিক করুন।
- একটি নতুন এআই অ্যাসিস্ট্যান্ট চালু করতে + New Agent-এ ক্লিক করুন।
- এজেন্ট কনফিগার করুন:
- এজেন্টের নাম :
Retail VIP Analysis Agent - ডেটা উৎস : ' উৎস যোগ করুন'-এ ক্লিক করুন এবং
unified_customer_profile' টেবিলটি অনুসন্ধান করুন।
- অ্যাড-এ ক্লিক করুন এবং এজেন্টটির ওয়ার্কস্পেস চালু হওয়ার জন্য কয়েক সেকেন্ড অপেক্ষা করুন।
এজেন্টটি প্রতিষ্ঠিত হয়ে গেলে, সুস্পষ্ট সিস্টেম নির্দেশাবলী নির্ধারণ করা একটি অত্যন্ত গুরুত্বপূর্ণ ডেটা গভর্নেন্স অনুশীলন। সিস্টেম নির্দেশাবলীকে একটি সিম্যান্টিক লেয়ার হিসেবে ব্যবহার করুন। এন্টারপ্রাইজ-ব্যাপী ব্যবসায়িক সংজ্ঞা অন্তর্ভুক্ত করে, স্কিমার জটিলতা সামলে এবং বিশ্লেষণাত্মক সুরক্ষা ব্যবস্থা স্থাপন করে, আপনি শেষ ব্যবহারকারীর কাছ থেকে প্রযুক্তিগত জটিলতা আড়াল করেন এবং পরিসংখ্যানগতভাবে গুরুত্বহীন ডেটা থেকে LLM-কে সিদ্ধান্তে পৌঁছানো থেকে বিরত রাখেন।
নিম্নলিখিতটি নির্দেশনা ক্ষেত্রে পেস্ট করুন:
You are an expert Data Analyst specializing in e-commerce customer retention.
Your primary data source is the `unified_customer_profile` table.
Strict Schema Rules:
- The `top_preferences` column is a REPEATED STRUCT (ARRAY).
- Whenever you analyze product categories, brands, or prices, you MUST explicitly use the UNNEST() function on `top_preferences` to access the underlying fields.
Semantic Layer & Business Definitions:
- "At-Risk VIP": Define this specific user cohort as anyone meeting ALL of the following criteria: `lifetime_value` > 100, `cart_adds` > 0, and `last_purchase_date` is more than 90 days ago.
Analytical Guardrails:
- Prioritize statistical significance. When generating business insights based on geographic or demographic groupings, explicitly ignore or deprioritize segments with negligible sample sizes (e.g., countries with very few users) to prevent skewed marketing strategies.
এজেন্টকে নির্দেশ দিন
যেহেতু জটিল ব্যবসায়িক যুক্তি (যা ‘ঝুঁকিপূর্ণ ভিআইপি’-এর সঠিক সংজ্ঞা) এবং স্কিমা পরিচালনার প্রয়োজনীয়তাগুলো সিস্টেম নির্দেশাবলী দ্বারা সুরক্ষিতভাবে নিয়ন্ত্রিত হয়, তাই ডেটা বিশ্লেষককে একটি বিশদ, শর্তবহুল প্রম্পট লেখার প্রয়োজন হয় না।
চ্যাট ইন্টারফেসে, নিম্নলিখিত প্রম্পটটি লিখুন:
Find the total count of At-Risk VIPs grouped by country. For each country, extract the single most frequent product category based on their top preferences. Order the results by the user count in descending order.
উৎপন্ন অন্তর্দৃষ্টি মূল্যায়ন করুন
প্রম্পটটি জমা দেওয়ার পরে, বিগকোয়েরি ডেটা এজেন্ট কীভাবে আপনার সিস্টেম নির্দেশাবলী প্রয়োগ করেছে তা মূল্যায়ন করতে স্বয়ংক্রিয়ভাবে তৈরি আউটপুটটি মনোযোগ সহকারে পর্যালোচনা করুন, যা একটি নিয়ন্ত্রিত শব্দার্থিক স্তর এবং একটি বিশ্লেষণাত্মক রক্ষাকবচ উভয় হিসাবে কাজ করে।
প্রথমে, ডেটার উপরে তৈরি হওয়া সারসংক্ষেপ লেখাটি পড়ুন। লক্ষ্য করুন, কীভাবে এজেন্টটি আপনার 'ঝুঁকিপূর্ণ ভিআইপি' (At-Risk VIPs) সংক্রান্ত সাধারণ অনুরোধটিকে স্বয়ংক্রিয়ভাবে আপনার সিস্টেম নির্দেশাবলীতে (System Instructions) সংজ্ঞায়িত সুনির্দিষ্ট মেট্রিক থ্রেশহোল্ডে (metric thresholds) রূপান্তরিত করে (যেমন, lifetime_value > 100, cart_adds > 0 , এবং ৯০ দিনের নিষ্ক্রিয়তার উল্লেখ করে)। এটি নিশ্চিত করে যে এজেন্টটি আপনার ব্যবসায়িক যুক্তি (business logic) আত্মস্থ করেছে, যার অর্থ হলো ব্যবহারকারীদের তাদের দৈনন্দিন নির্দেশাবলীতে জটিল যুক্তি মুখস্থ বা হার্ডকোড করার কোনো প্রয়োজন নেই।
এরপর, তৈরি হওয়া কোডটি পরীক্ষা করার জন্য SQL ভিউটি প্রসারিত করুন। এজেন্টটি আপনার নির্দেশনার উপর ভিত্তি করে গাণিতিকভাবে সঠিক গুগল স্ট্যান্ডার্ড SQL তৈরি করবে:
- ডাইনামিক টাইম উইন্ডো:
WHEREক্লজে টাইমস্ট্যাম্প ক্যালকুলেশনটি খুঁজুন (সাধারণতTIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 90 DAY)) ব্যবহার করে)। - কঠোর স্কিমা অনুসরণ:
top_preferencesঅ্যারেতে স্পষ্টভাবেUNNEST()ফাংশন প্রয়োগ করে এজেন্ট আপনার কঠোর স্কিমা নিয়ম মেনে চলেছে কিনা তা নিশ্চিত করুন। প্রতিটি দেশের জন্য সবচেয়ে বেশি ব্যবহৃত একক ক্যাটাগরিটি নির্ভুলভাবে আলাদা করতে, আপনি সাধারণত দেখবেন এটি একটি কমন টেবিল এক্সপ্রেশন (CTE)-এর মধ্যেROW_NUMBER() OVER()উইন্ডো ফাংশনের মতো উন্নত কৌশল ব্যবহার করে।
স্বয়ংক্রিয়ভাবে প্রদর্শিত চার্ট এবং ডেটা টেবিলটি পর্যালোচনা করুন। এই ডেটা আপনার মূল রিটেনশন মার্কেটগুলোকে (সাধারণত চীন বা মার্কিন যুক্তরাষ্ট্রের মতো উচ্চ-বিক্রয় পরিমাণের দেশগুলোকে তুলে ধরে) এবং তাদের বিশ্বব্যাপী প্রভাবশালী পণ্যের প্রতি আকর্ষণকে (প্রায়শই "জিন্স") দৃশ্যমানভাবে প্রকাশ করবে। লক্ষ্য করুন, কীভাবে নেটিভ UI কোনো সুস্পষ্ট ভিজ্যুয়ালাইজেশন কোডের প্রয়োজন ছাড়াই তাৎক্ষণিক ব্যবহারের জন্য আউটপুটটি সাজিয়ে দেয়।
এজেন্ট দ্বারা তৈরি বুলেট পয়েন্টে থাকা ইনসাইটস টেক্সটটি মনোযোগ দিয়ে পড়ুন। যেহেতু আপনি অ্যানালিটিক্যাল গার্ডরেলস স্থাপন করেছেন, তাই বিশেষভাবে ডেটা কোয়ালিটি বা স্ট্যাটিস্টিক্যাল সিগনিফিকেন্স সম্পর্কিত কোনো ইনসাইট খুঁজুন। আপনি হয়তো দেখবেন যে এজেন্ট টেবিলের নিচের দিকে থাকা খুব কম সংখ্যক ব্যবহারকারীযুক্ত দেশগুলোকে (যেমন, হাতেগোনা কয়েকজন ব্যবহারকারী আছে এমন অঞ্চল) স্পষ্টভাবে চিহ্নিত করছে। একটিমাত্র ডেটা পয়েন্টের উপর ভিত্তি করে অন্ধভাবে একটি টার্গেটেড মার্কেটিং ক্যাম্পেইন কল্পনা করার পরিবর্তে, এজেন্ট সঠিকভাবে পরামর্শ দেবে যে এই অসঙ্গতিগুলো একটি বৃহৎ-মাপের কৌশলের জন্য পরিসংখ্যানগতভাবে তাৎপর্যপূর্ণ নয়। এটি দেখায় যে কীভাবে এজেন্টের মধ্যে সরাসরি গভর্নেন্স গার্ডরেলস স্থাপন করা এআই-চালিত ব্যবসায়িক ভুল হিসাবকে কার্যকরভাবে প্রতিরোধ করে।
৯. জেমিনি এবং এমসিপি-এর মাধ্যমে এআই ইনসাইট তৈরি করুন
এজেন্ট সফলভাবে প্রাথমিক লক্ষ্যবস্তু জনগোষ্ঠীকে চিহ্নিত করেছে: নির্দিষ্ট কিছু দেশের ঝুঁকিতে থাকা ভিআইপিরা। তবে, একজন বিশ্লেষকের কাজ শুধু এই অন্তর্দৃষ্টিতেই থেমে যায়। এই ব্যবহারকারীদের পুনরায় সম্পৃক্ত করতে, বিপণন দলকে একটি প্রচার অভিযান পরিচালনা করতে হবে।
আপনি মডেল কনটেক্সট প্রোটোকল (MCP) ব্যবহার করে একটি বাহ্যিক এআই অ্যাসিস্ট্যান্টকে BigQuery-এর এই নির্দিষ্ট ডেমোগ্রাফিক তালিকার সাথে সরাসরি সংযুক্ত করবেন, যার ফলে কাস্টম এপিআই তৈরি না করেই ডেটা বিশ্লেষণ থেকে এআই-চালিত কার্যকলাপে রূপান্তর ঘটবে।
BigQuery MCP সার্ভার কনফিগার করুন
mcp.json কনফিগারেশন ফাইলটি তৈরি করতে নিচের ব্লকটি চালান। এই ফাইলটি প্রয়োজনীয় সংযোগ প্যারামিটার সরবরাহ করে, যাতে Gemini CLI নিরাপদে BigQuery-এর সাথে ইন্টারফেস করতে পারে।
mkdir -p ~/.gemini
cat << EOF > ~/.gemini/settings.json
{
"mcpServers": {
"bigquery": {
"httpUrl": "https://bigquery.googleapis.com/mcp",
"authProviderType": "google_credentials",
"oauth": {
"scopes": [
"https://www.googleapis.com/auth/bigquery"
]
}
}
}
}
EOF
একটি মার্কেটিং ইমেল তৈরি করুন
আপনার টার্মিনাল থেকে Gemini CLI টুলটি চালু করুন এবং আপনার BigQuery লেকহাউস পড়ার অনুমতি দেওয়ার জন্য স্পষ্টভাবে MCP কনফিগারেশন ফ্ল্যাগটি পাস করুন।
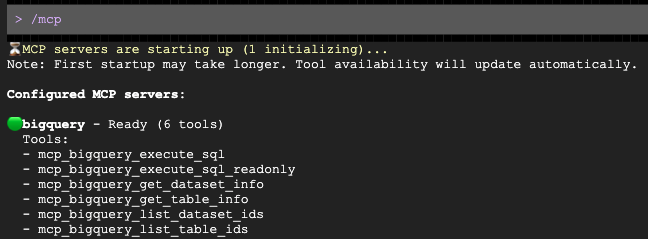
Gemini CLI চালান।
source env.sh
gemini
প্রম্পটটি খুললে, আপনার লক্ষ্যযুক্ত জনগোষ্ঠীর জন্য একটি ব্যক্তিগতকৃত প্রচারপত্র তৈরি করতে বলুন:
Analyze the demo_lakehouse.unified_customer_profile table in BigQuery. Find exactly one 'country and age group' target demographic that has a high average order value (sale_price >= $80) but a relatively low total revenue compared to others. Then, draft a highly engaging, premium VIP promotional email tailored to this specific demographic. Use $PROJECT_ID to get the current project id.
জেমিনি স্বয়ংক্রিয়ভাবে এমসিপি সার্ভারের মাধ্যমে বিগকোয়েরি-তে তথ্য অনুসন্ধান করে জনসংখ্যাতাত্ত্বিক পরিচয় শনাক্ত করবে এবং আপনার জন্য ইমেলের খসড়া তৈরি করে দেবে!
১০. আপনার পরিবেশ পরিষ্কার করা
আপনার গুগল ক্লাউড অ্যাকাউন্টে চলমান চার্জ এড়াতে এবং ভবিষ্যতের রানের জন্য আপনার প্রজেক্টটি পরিষ্কারভাবে রিসেট করতে, এই কোডল্যাবের সময় তৈরি করা রিসোর্সগুলি আপনাকে অবশ্যই মুছে ফেলতে হবে।
cleanup.sh স্ক্রিপ্টটি তৈরি করতে নিম্নলিখিত ব্লকটি চালান। এই স্ক্রিপ্টটি একটি স্বয়ংক্রিয় টিয়ারডাউন প্রক্রিয়া হিসেবে কাজ করে, যা পরবর্তী বিলিং প্রতিরোধ করার জন্য AlloyDB ক্লাস্টার ও ইনস্ট্যান্স, BigQuery ডেটাসেট এবং আপনার ক্লাউড স্টোরেজ বাকেট স্থায়ীভাবে মুছে ফেলে।
cat << 'EOF' > cleanup.sh
#!/bin/bash
source ./env.sh
echo "=> Deleting BigQuery Dataset (${BQ_DATASET})..."
bq rm -r -f -d ${PROJECT_ID}:${BQ_DATASET} || true
echo "=> Deleting Lakehouse resource connection (${BQ_RESOURCE_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_RESOURCE_CONN} || true
echo "=> Deleting AlloyDB connection (${BQ_ALLOYDB_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_ALLOYDB_CONN} || true
echo "=> Deleting AlloyDB Instance (${ALLOYDB_INSTANCE}) - This takes a few minutes..."
gcloud alloydb instances delete ${ALLOYDB_INSTANCE} --cluster=${ALLOYDB_CLUSTER} --region=${REGION} --quiet || true
echo "=> Deleting AlloyDB Cluster (${ALLOYDB_CLUSTER})..."
gcloud alloydb clusters delete ${ALLOYDB_CLUSTER} --region=${REGION} --force --quiet || true
echo "=> Deleting Cloud Storage bucket (${BUCKET_NAME})..."
gcloud storage rm -r gs://${BUCKET_NAME} || true
echo "=> Deleting Lakehouse Federated Catalog (if created in Option A)..."
curl -s -X DELETE "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/aws_dbx_catalog" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" || true
echo "=> Deleting Secret Manager Regional Secret (if created in Option A)..."
CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/" \
gcloud secrets delete dbx-oauth-secret --location=${REGION} --project=${PROJECT_ID} --quiet || true
echo "=> Deleting Cloud NAT and Router (if created in Option A)..."
gcloud compute routers nats delete lakehouse-nat --router=lakehouse-router --region=${REGION} --quiet || true
gcloud compute routers delete lakehouse-router --region=${REGION} --quiet || true
echo "=> Deleting Service Networking VPC Peering..."
gcloud compute networks peerings delete servicenetworking-googleapis-com \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID} --quiet || true
echo "=> Deleting Allocated IP Range for Managed Services..."
gcloud compute addresses delete google-managed-services-${NETWORK_NAME} \
--global \
--project=${PROJECT_ID} --quiet || true
echo "=> Removing local temporary files..."
rm -f spark_lakehouse_join.py users.csv orders.csv order_items.csv alloydb-auth-proxy env.sh cleanup.sh ~/.gemini/settings.json
echo "============================================="
echo " TEARDOWN COMPLETED."
echo "============================================="
EOF
আপনার রিসোর্সগুলি নিরাপদে মুছে ফেলার জন্য ক্লিনআপ স্ক্রিপ্টটি চালান:
bash cleanup.sh
১১. অভিনন্দন!
আপনি সফলভাবে একটি ক্রস-ক্লাউড ওপেন ডেটা লেকহাউস তৈরি করেছেন এবং তাতে কোয়েরি চালিয়েছেন।
আপনি শিখেছেন:
- BigQuery Zero-ETL এবং Google Cloud Lakehouse ব্যবহার করে কীভাবে বিভিন্ন উৎস থেকে ডেটা একত্রিত করা যায়
- অ্যাপাচি স্পার্কের ব্যাপক ভেক্টরাইজড জয়েনগুলোর জন্য ম্যানেজড সার্ভিসে কীভাবে C++ নেটিভ লাইটনিং ইঞ্জিনকে কাজে লাগানো যায়
- স্বাভাবিক ভাষা অনুসন্ধানের জন্য BigQuery ডেটা এজেন্ট কীভাবে ব্যবহার করবেন
- মডেল কনটেক্সট প্রোটোকল (MCP) এবং জেমিনি ব্যবহার করে কীভাবে আপনার ডেটা জেমিনির সাথে সংযুক্ত করবেন।
এরপর কী?
- লেকহাউস ডকুমেন্টেশন অন্বেষণ করুন
- AlloyDB জিরো-ইটিএল থেকে BigQuery সম্পর্কে আরও জানুন
- লাইটনিং ইঞ্জিন সম্পর্কে পড়ুন