
1. Einführung
In diesem Codelab erstellen Sie ein cloudübergreifendes, offenes Data Lakehouse, das Datensilos in AWS, Google Cloud und AlloyDB ohne komplexen ETL-Prozess vereinheitlicht. Sie verwenden Lakehouse als zentralen Knotenpunkt für Analysen, AlloyDB als operative Datenquelle und Managed Service for Apache Spark für die leistungsstarke vektorisierte Verarbeitung. Schließlich verwenden Sie Gemini, um aussagekräftige geschäftliche Erkenntnisse aus Ihrem Lakehouse zu gewinnen.
Angenommen, Ihre Transaktionsdaten (users, orders, order items) befinden sich in einer AlloyDB-Betriebsdatenbank, Ihre product-Daten in einem AWS S3-Bucket und umfangreiche Clickstream-event logs in Cloud Storage. Sie müssen diese Datasets zusammenführen, um Zielgruppen für Ihre nächste Marketingkampagne zu ermitteln und personalisierte E-Mails zu generieren.
Voraussetzungen
- Grundkenntnisse in SQL und Terminalbefehlen
- Google Cloud-Projekt mit aktivierter Abrechnungsfunktion.
Lerninhalte
- So integrieren Sie unterschiedliche Datensilos mit BigQuery Zero-ETL (AlloyDB) und Lakehouse für Apache Iceberg.
- So führen Sie einen schnellen Job zur Verhaltensprofilerstellung mit Managed Service for Apache Spark aus, der von der nativen C++-Lightning Engine unterstützt wird.
- So führen Sie mit dem BigQuery-Daten-Agenten komplexe Analysen in natürlicher Sprache für einheitliche Daten durch.
- Konfigurieren des Model Context Protocol (MCP), damit die Gemini CLI Daten aus Ihrem Lakehouse für Apache Iceberg lesen und Marketinginhalte entwerfen kann
Voraussetzungen
- Ein Google Cloud-Konto und ein Google Cloud-Projekt
- Ein Webbrowser wie Chrome
Voraussetzungen
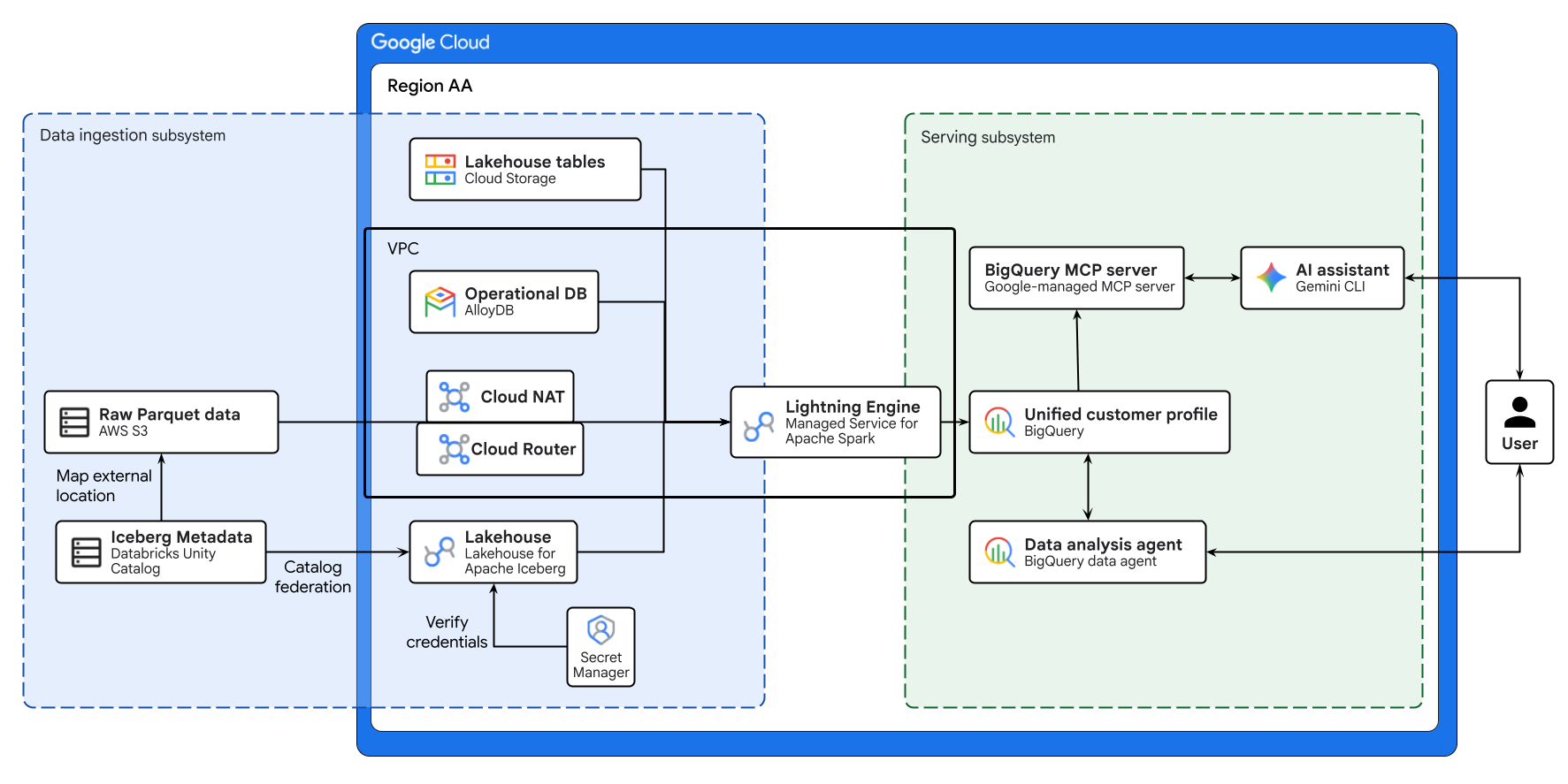
Das obige Diagramm veranschaulicht den End-to-End-Ablauf des cloudübergreifenden Lakehouse, das in diesem Codelab erstellt wird. Betriebsdaten aus AlloyDB und Remotedaten aus AWS S3 werden mit Lakehouse für Apache Iceberg sicher zusammengeführt. Managed Service for Apache Spark verarbeitet diese unterschiedlichen Quellen, um ein einheitliches Kundenprofil in BigQuery zu erstellen. Ein BigQuery Data Agent und ein von Google verwalteter BigQuery MCP-Server über die Gemini CLI bieten eine intuitive, KI-gesteuerte Schnittstelle für die erweiterte Datenanalyse.
Wichtige Konzepte
- Cloudübergreifendes offenes Data Lakehouse:Vereinheitlicht Datensilos in AWS-, Google Cloud- und lokalen Umgebungen, ohne dass komplexes ETL erforderlich ist.
- BigQuery Zero-ETL:Ermöglicht das direkte Abfragen von operativen Datenbanken ohne komplexen Datentransfer.
- Lakehouse for Apache Iceberg:Ermöglicht einheitliche Sicherheits- und Governance-Kontrollen für cloudübergreifenden Speicher mit dem Apache Iceberg-Format.
- Lightning Engine:C++-Engine für die hochleistungsfähige Ausführung von Apache Spark.
- Model Context Protocol (MCP): Verbindet Gemini direkt mit Ihrem BigQuery-Lakehouse.
2. Einrichtung und Anforderungen
Google Cloud-Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
Cloud Shell starten
Während Sie Google Cloud von Ihrem Laptop aus per Fernzugriff nutzen können, wird in diesem Codelab Google Cloud Shell verwendet, eine Befehlszeilenumgebung, die in der Cloud ausgeführt wird.
Klicken Sie in der Google Cloud Console rechts oben in der Symbolleiste auf das Cloud Shell-Symbol:
Die Bereitstellung und Verbindung mit der Umgebung sollte nur wenige Augenblicke dauern. Anschließend sehen Sie in etwa Folgendes:

Diese virtuelle Maschine verfügt über sämtliche Entwicklertools, die Sie benötigen. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft in Google Cloud, was die Netzwerkleistung und Authentifizierung erheblich verbessert. Sie können alle Aufgaben in diesem Codelab in einem Browser erledigen. Sie müssen nichts installieren.
Umgebung initialisieren
Öffnen Sie Cloud Shell und legen Sie Ihre Projektvariablen fest, damit alle Befehle auf die richtige Infrastruktur ausgerichtet sind.
cat << 'EOF' > env.sh
#!/bin/bash
# env.sh: Environment variables
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-west1"
export NETWORK_NAME="default"
export BUCKET_NAME="lakehouse-data-${PROJECT_ID}"
export BQ_DATASET="demo_lakehouse"
export BQ_RESOURCE_CONN="lakehouse-iceberg-conn"
export BQ_ALLOYDB_CONN="alloydb-fed-conn"
export ALLOYDB_CLUSTER="demo-alloy-cluster"
export ALLOYDB_INSTANCE="demo-alloy-primary"
export ALLOYDB_PASSWORD="SuperSecretPassword123!"
export ALLOYDB_DB_NAME="retail_db"
# Multi-cloud configuration identifiers
export SECRET_NAME="dbx-oauth-secret"
export CATALOG_NAME="aws_dbx_catalog"
EOF
Wenden Sie die Variablen auf Ihre aktive Sitzung an:
source ./env.sh
APIs aktivieren
Aktivieren Sie die erforderlichen Google Cloud-Dienste.
gcloud services enable \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
compute.googleapis.com \
biglake.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com \
servicenetworking.googleapis.com \
secretmanager.googleapis.com \
dataplex.googleapis.com \
datacatalog.googleapis.com \
dataform.googleapis.com \
dataproc.googleapis.com --quiet
3. Kerninfrastruktur einrichten
Anstatt alle Daten über anfällige ETL-Pipelines in ein einzelnes Repository zu verschieben, erstellen Sie eine föderierte Cloud-übergreifende Architektur. In einem realen Unternehmen sind Daten aufgrund unterschiedlicher Systemanforderungen von Natur aus fragmentiert. Sie orchestrieren die folgenden Datenquellen:
- AlloyDB (Core transactional DB): Speichert Daten zu Nutzern, Bestellungen und order_items. Als operative Live-Datenbank garantiert sie die für Finanztransaktionen und Profilaktualisierungen erforderlichen ACID-Attribute.
- AWS S3 (Stammdaten): Speichert den
products-Katalog. Darstellung eines Legacy-Stammdatenverwaltungssystems (Master Data Management, MDM) in AWS. - Google Cloud Storage (Massive Data Lake): Speichert
events(Clickstream-Logs). Daten mit hohem Durchsatz wie Weblogs würden eine relationale Datenbank zum Absturz bringen. Objektspeicher bietet unendliche Skalierbarkeit und die Speicherung in Google Cloud maximiert die Rechenlokalität für Ihre Analyse-Engines.
Konfigurieren Sie zuerst das zugrunde liegende Netzwerk. Für Google Cloud-verwaltete Datenbanken wie AlloyDB ist eine private VPC-Peering-Verbindung erforderlich, um sicher innerhalb Ihres Projektnetzwerks zu kommunizieren.
# Allocate an IP range for Google Cloud managed services
gcloud compute addresses create google-managed-services-${NETWORK_NAME} \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Establish the VPC peering connection
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=google-managed-services-${NETWORK_NAME} \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID}
Als Nächstes erstellen Sie ein BigQuery-Dataset und eine Lakehouse-Cloud-Ressourcenverbindung. Architektonisch wird bei einer Ressourcenverbindung der Datenzugriff an ein dediziertes, von Google verwaltetes Dienstkonto delegiert, wodurch das Prinzip der geringsten Berechtigung durchgesetzt wird.
# Create the central data lakehouse dataset
bq mk --dataset --location=${REGION} ${PROJECT_ID}:${BQ_DATASET}
gcloud storage buckets create gs://${BUCKET_NAME} --location=${REGION}
# Create a Lakehouse resource connection
bq mk --connection --location=${REGION} \
--connection_type=CLOUD_RESOURCE ${BQ_RESOURCE_CONN}
# Retrieve the automatically provisioned service account
CONN_SA=$(bq show --connection --format=json ${PROJECT_ID}.${REGION}.${BQ_RESOURCE_CONN} | jq -r '.cloudResource.serviceAccountId')
# Grant the service account permissions to read/write to the data lake
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${CONN_SA}" \
--role="roles/storage.admin" \
--quiet
4. Operative Datenbank bereitstellen
Stellen Sie eine primäre AlloyDB-Instanz bereit und fügen Sie Ihre geschäftskritischen Transaktionsdaten ein.
# Create the AlloyDB cluster
gcloud alloydb clusters create ${ALLOYDB_CLUSTER} \
--region=${REGION} \
--password=${ALLOYDB_PASSWORD} \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Create the primary instance
gcloud alloydb instances create ${ALLOYDB_INSTANCE} \
--cluster=${ALLOYDB_CLUSTER} \
--region=${REGION} \
--instance-type=PRIMARY \
--cpu-count=2 \
--assign-inbound-public-ip=ASSIGN_IPV4 \
--database-flags=password.enforce_complexity=on
Sobald die Datenbank bereit ist, müssen Sie eine externe BigQuery-Verbindung zu AlloyDB erstellen. In dieser Verbindung werden die Datenbankanmeldedaten und der Endpunkt sicher gespeichert, sodass BigQuery die SQL-Ausführung direkt an die AlloyDB-Compute-Engine übertragen kann (Zero-ETL).
# Create the BigQuery to AlloyDB connection
bq mk --connection --location=${REGION} --project_id=${PROJECT_ID} \
--connector_configuration "{
\"connector_id\": \"google-alloydb\",
\"asset\": {
\"database\": \"${ALLOYDB_DB_NAME}\",
\"google_cloud_resource\": \"//alloydb.googleapis.com/projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE}\"
},
\"authentication\": {
\"username_password\": {
\"username\": \"postgres\",
\"password\": { \"plaintext\": \"${ALLOYDB_PASSWORD}\" }
}
}
}" ${BQ_ALLOYDB_CONN}
# Grant the BigQuery connection service agent permission to access AlloyDB
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
BQ_SERVICE_AGENT="service-${PROJECT_NUMBER}@gcp-sa-bigqueryconnection.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${BQ_SERVICE_AGENT}" \
--role="roles/alloydb.client" \
--quiet
Die transaktionalen Tabellen sicher in AlloyDB übertragen. Verwenden Sie den AlloyDB Auth-Proxy, um Ihre lokale Cloud Shell-Sitzung sicher mit der privaten AlloyDB-Instanz zu verbinden. So können Sie die Transaktionsdaten mit lokalen Befehlszeilentools übertragen.
# Extract full raw data to Cloud Storage using the BigQuery extract API
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.users" gs://${BUCKET_NAME}/tmp/users.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.orders" gs://${BUCKET_NAME}/tmp/orders.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.order_items" gs://${BUCKET_NAME}/tmp/order_items.csv
# Download the CSVs to the local Cloud Shell session
gcloud storage cp gs://${BUCKET_NAME}/tmp/users.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/orders.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/order_items.csv .
# Download and start the AlloyDB auth proxy
curl -sL "https://storage.googleapis.com/alloydb-auth-proxy/v1.13.11/alloydb-auth-proxy.linux.amd64" -o alloydb-auth-proxy && chmod +x alloydb-auth-proxy
./alloydb-auth-proxy projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE} --public-ip &
PROXY_PID=$!
sleep 15 # Wait for the proxy to fully initialize
# Create the database
export PGPASSWORD=${ALLOYDB_PASSWORD}
psql -h 127.0.0.1 -p 5432 -U postgres -c "CREATE DATABASE ${ALLOYDB_DB_NAME};" || true
# Load into AlloyDB mimicking the exact schema via heredoc
psql -h 127.0.0.1 -p 5432 -U postgres -d ${ALLOYDB_DB_NAME} << 'EOF'
CREATE TABLE IF NOT EXISTS users (id INT PRIMARY KEY, first_name VARCHAR(255), last_name VARCHAR(255), email VARCHAR(255), age INT, gender VARCHAR(50), state VARCHAR(100), street_address VARCHAR(255), postal_code VARCHAR(50), city VARCHAR(100), country VARCHAR(100), latitude FLOAT, longitude FLOAT, traffic_source VARCHAR(100), created_at TIMESTAMP, user_geom TEXT);
CREATE TABLE IF NOT EXISTS orders (order_id INT PRIMARY KEY, user_id INT, status VARCHAR(50), gender VARCHAR(50), created_at TIMESTAMP, returned_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, num_of_item INT);
CREATE TABLE IF NOT EXISTS order_items (id INT PRIMARY KEY, order_id INT, user_id INT, product_id INT, inventory_item_id INT, status VARCHAR(50), created_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, returned_at TIMESTAMP, sale_price FLOAT);
\copy users FROM 'users.csv' WITH (FORMAT csv, HEADER true)
\copy orders FROM 'orders.csv' WITH (FORMAT csv, HEADER true)
\copy order_items FROM 'order_items.csv' WITH (FORMAT csv, HEADER true)
EOF
# Clean up local temporary files and Cloud Storage artifacts
kill $PROXY_PID && rm -f users.csv orders.csv order_items.csv alloydb-auth-proxy
gcloud storage rm gs://${BUCKET_NAME}/tmp/*.csv
5. Masterdaten föderieren (AWS-Spoke)
Unser Produktkatalog mit Rohdaten zu Artikelmetadaten befindet sich nativ in AWS S3 als Apache Iceberg-Tabellen. Die Metadaten werden von einem Remote-Katalog verwaltet.
Anstatt anfällige ETL-Pipelines zu erstellen, um diese Daten in Google Cloud zu kopieren, verwenden Sie Lakehouse for Apache Iceberg (REST-Katalogföderation).
Mit diesem Zero-ETL-Ansatz können Lakehouse und Managed Service for Apache Spark die Iceberg-Metadaten und die zugrunde liegenden Parquet-Dateien dynamisch direkt aus Ihrer Remote-Umgebung ermitteln und lesen.
Wenn Sie ein aktives AWS-Konto und Databricks Unity Catalog konfiguriert haben, können Sie diese verwenden. Andernfalls können Sie Ihre Umgebung mit Google Cloud Storage simulieren. Wählen Sie eine der beiden Optionen aus.
Option A: Eigene AWS-Umgebung verwenden (nativ für Apache Iceberg)
Voraussetzung: Bei dieser Option wird davon ausgegangen, dass Sie bereits einen AWS S3-Bucket bereitgestellt, ihn als externen Speicherort im Databricks Unity Catalog verbunden, eine Iceberg-Tabelle zugeordnet und einen OAuth-Dienstprinzipal mit Lesezugriff generiert haben.
1. Sicherer Anmeldedatenspeicher
Das Festcodieren von langlebigen Zugriffstokens ist ein architektonisches Anti-Pattern. Sie speichern die Databricks-OAuth-Client-ID und das Secret in Google Cloud Secret Manager. Der Lakehouse-Dienst ruft diese dynamisch zur Laufzeit ab, um kurzlebige Tokens auszugeben. So wird die Verwaltung Ihrer Anmeldedaten zentralisiert.
Führen Sie den folgenden Block aus, um das Skript zu generieren. (Noch nichts bearbeiten)
cat << 'EOF' > create_secret.sh
#!/bin/bash
source ./env.sh
# Define your Databricks OAuth credentials
DATABRICKS_CLIENT_ID="<YOUR_DATABRICKS_CLIENT_ID>"
DATABRICKS_CLIENT_SECRET="<YOUR_DATABRICKS_CLIENT_SECRET>"
DATABRICKS_WORKSPACE="<YOUR_WORKSPACE>.cloud.databricks.com" # Exclude https://
DATABRICKS_CATALOG="google_lakehouse_catalog"
# Define the secure credentials payload
export CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/"
SECRET_PAYLOAD="{ \"client_id\": \"${DATABRICKS_CLIENT_ID}\", \"client_secret\": \"${DATABRICKS_CLIENT_SECRET}\" }"
# Pipe the JSON payload into Google Cloud Secret Manager
echo "$SECRET_PAYLOAD" | gcloud secrets create ${SECRET_NAME} \
--location=${REGION} \
--project=${PROJECT_ID} \
--data-file=-
EOF
Führen Sie dann den folgenden Befehl aus, um das generierte Skript automatisch im visuellen Code-Editor über dem Terminal zu öffnen.
cloudshell edit create_secret.sh
- Ersetzen Sie im Editor die
<YOUR_...>-Platzhalter durch Ihre tatsächlichen Databricks-Anmeldedaten. - Achten Sie darauf, dass die Arbeitsbereichs-URL keine
https://oder abschließende Schrägstriche (z.B.123456789.cloud.databricks.com) enthält. - Drücken Sie
Ctrl+S(oderCmd+Sauf einem Mac), um die Datei zu speichern. - Kehren Sie zu Ihrer Terminalsitzung zurück und führen Sie das Skript aus:
source create_secret.sh
2. Föderierten Katalog erstellen
Der Einfachheit halber konfigurieren Sie in diesem Codelab den Katalog so, dass er das öffentliche Internet sicher durchläuft. Bei Produktionsarbeitslasten verursacht das Abfragen umfangreicher Datasets über das öffentliche Internet jedoch unnötige Kosten für ausgehenden Traffic und unvorhersehbare Latenz. Best Practices sehen vor, eine private Cross-Cloud Interconnect-Verbindung (CCI) zwischen AWS und Google Cloud zu konfigurieren. Dadurch werden die Egress-Kosten erheblich gesenkt und eine deterministische Netzwerkleistung sichergestellt.
Stellen Sie den föderierten Lakehouse-Katalog mit der gcloud CLI bereit:
# Execute the Lakehouse CLI to provision the federated catalog
gcloud alpha biglake iceberg catalogs create ${CATALOG_NAME} \
--project="${PROJECT_ID}" \
--primary-location="${REGION}" \
--catalog-type="federated" \
--federated-catalog-type="unity" \
--secret-name="projects/${PROJECT_ID}/locations/${REGION}/secrets/${SECRET_NAME}" \
--unity-instance-name="${DATABRICKS_WORKSPACE}" \
--unity-catalog-name="${DATABRICKS_CATALOG}" \
--refresh-interval="330s"
3. IAM-Bindungen mit geringsten Berechtigungen anwenden
Als Sie den föderierten Katalog im vorherigen Schritt bereitgestellt haben, wurde in Google Cloud Lakehouse automatisch ein Hintergrundaktualisierungsjob gestartet, um die Iceberg-Manifeste alle 330 Sekunden zu synchronisieren.
Sie müssen dem Dienstkonto des Lakehouse-Katalogs die Rolle secretAccessor zuweisen, damit es das Databricks-OAuth-Token während dieser Hintergrundsynchronisierungen und Abfrageausführungen sicher abrufen kann. Wenn diese Bindung fehlt, treten beim Versuch von Lakehouse, den Katalog zu aktualisieren, 403-Fehler auf.
# Extract the automatically provisioned Lakehouse catalog service account
LAKEHOUSE_SA=$(curl -s -X GET "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/${CATALOG_NAME}" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" | jq -r '."biglake-service-account"')
# Grant the secretAccessor role for background metadata synchronization and query execution
gcloud secrets add-iam-policy-binding ${SECRET_NAME} \
--project=${PROJECT_ID} --location=${REGION} \
--member="serviceAccount:${LAKEHOUSE_SA}" \
--role="roles/secretmanager.secretAccessor" --quiet
4. Ausgehendes Internet für Managed Service for Apache Spark aktivieren
In einem nachfolgenden Schritt liest Managed Service for Apache Spark die Remote-AWS-Daten. Da Managed Service for Apache Spark Serverless vollständig in einem privaten VPC-Netzwerk ohne externe IP-Adressen ausgeführt wird, kann es standardmäßig nicht über das Internet auf AWS S3 zugreifen. Sie müssen Cloud NAT bereitstellen, damit die Spark-Worker ausgehenden Internetzugriff haben.
# Create a Cloud Router
gcloud compute routers create lakehouse-router \
--network=${NETWORK_NAME} \
--region=${REGION}
# Create a Cloud NAT attached to the router
gcloud compute routers nats create lakehouse-nat \
--router=lakehouse-router \
--auto-allocate-nat-external-ips \
--nat-all-subnet-ip-ranges \
--region=${REGION}
5. Downstream-Ziel definieren
Exportieren Sie diese Variable, damit nachgelagerte Apache Spark-Jobs genau wissen, wo die AWS-Daten abgefragt werden müssen, ohne dass manuelle Codeänderungen erforderlich sind.
# Assuming your schema is 'retail' and table is 'aws_products'
export AWS_PRODUCTS_TABLE="${CATALOG_NAME}.retail.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
Option B: AWS-Umgebung über Cloud Storage simulieren
Wenn Sie kein aktives AWS-Konto haben, können Sie das Cloud-übergreifende Silo nativ mit Lakehouse-verwalteten Tabellen in Google Cloud Storage simulieren.
1. Mock-Iceberg-Tabelle erstellen
# Copy raw products data to a temporary BigQuery table
bq cp --force bigquery-public-data:thelook_ecommerce.products ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
# Create an open Iceberg table using the Lakehouse cloud resource connection
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.aws_products\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/aws_products')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_products_raw\`;"
# Cleanup temporary table
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
2. Downstream-Ziel definieren
Standard-BigQuery-Datasets verwenden eine dreiteilige Namespace-Struktur (project.dataset.table). Exportieren Sie diese Variable, damit der nachgelagerte Apache Spark-Job auf die Mock-Daten ausgerichtet ist.
export AWS_PRODUCTS_TABLE="${PROJECT_ID}.${BQ_DATASET}.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
6. Ereignisprotokolle aufnehmen (Google Cloud-Spoke)
Clickstream-Daten wachsen exponentiell. Sie speichern die vollständigen, nicht aggregierten Rohereignisse lokal in Cloud Storage als verwaltete Lakehouse-Tabellen.
bq cp --force bigquery-public-data:thelook_ecommerce.events ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.google_events\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/google_events')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_events_raw\`;"
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
7. Einheitliches Kundenprofil erstellen
Nachdem Ihre Rohinfrastruktur vollständig eingerichtet ist, können Sie ein einheitliches Kundenprofil erstellen.
Sie verwenden Managed Service for Apache Spark, das auf der Lightning Engine basiert. Lightning Engine ist der leistungsstarke C++-native Abfragebeschleuniger von Google Cloud, der auf Open-Source-Technologien wie Apache Gluten und Velox basiert. Er steigert die Ausführung automatisch, indem er die CPU-Effizienz maximiert und Daten intelligent im Cache speichert. Dieser Ansatz ist ideal für umfangreiche Multi-Way-Joins, komplexes Windowing oder Verhaltensaggregationen in mehreren Clouds.
Sie verwenden den Spark BigQuery-Connector, um die föderierten AlloyDB Zero-ETL-Abfragen und Lakehouse-Tabellen direkt zu lesen, die massiven vektorisierten Aggregationen nativ in Spark auszuführen und das resultierende einheitliche Profil zurück in BigQuery zu schreiben.
IAM-Berechtigungen für Managed Service for Apache Spark konfigurieren
Standardmäßig werden Batchjobs in Serverless Spark mit dem Compute Engine-Standarddienstkonto ausgeführt. Bevor Sie den Job einreichen, müssen Sie diesem Dienstkonto die erforderlichen Berechtigungen zum Ausführen der Arbeitslast und zum Verwalten von BigQuery-Jobs erteilen.
Hinweis: Der Dienstname wurde in „Managed Service for Apache Spark“ geändert, um der branchenüblichen Terminologie zu entsprechen. Die zugrunde liegenden API-Befehle und IAM-Rollen verwenden jedoch weiterhin die Kennung „dataproc“.
# Retrieve the project number to construct the Compute Engine default service account
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
# Grant the Managed Service for Apache Spark Worker role to allow job execution
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/dataproc.worker" \
--quiet
# Grant the BigQuery Admin role to allow reading, writing, and querying external connections
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/bigquery.admin" \
--quiet
Job erstellen und einreichen
Erstellen Sie zuerst das PySpark-Jobskript. Das Skript erkennt anhand Ihrer Umgebungsvariable AWS_PRODUCTS_TABLE automatisch, ob Sie Option A (AWS Federated Catalog) oder Option B (Google Cloud Mock) ausgewählt haben. Es definiert die Spark SQL-Logik und verwendet die native Array-Bearbeitung von Spark, um die RFM-Zeiträume (Aktualität, Häufigkeit, Umsatz) zu berechnen.
Führen Sie den folgenden Block in Cloud Shell aus.
# Determine which option was selected based on the AWS_PRODUCTS_TABLE variable
if [[ "${AWS_PRODUCTS_TABLE}" == *"${CATALOG_NAME:-undefined}"* ]]; then
echo "=> Option A (AWS Federated Catalog) detected."
export IS_AWS_CATALOG="True"
export OAUTH_TOKEN=$(gcloud auth print-access-token)
else
echo "=> Option B (Google Cloud Mock) detected."
export IS_AWS_CATALOG="False"
export OAUTH_TOKEN=""
fi
# Create the PySpark script with safely injected variables
cat << EOF > spark_lakehouse_join.py
from pyspark.sql import SparkSession
# --- Environment Variables dynamically injected ---
PROJECT_ID = "${PROJECT_ID}"
CATALOG_NAME = "${CATALOG_NAME}"
OAUTH_TOKEN = "${OAUTH_TOKEN}"
BUCKET_NAME = "${BUCKET_NAME}"
BQ_DATASET = "${BQ_DATASET}"
REGION = "${REGION}"
BQ_ALLOYDB_CONN = "${BQ_ALLOYDB_CONN}"
AWS_PRODUCTS_TABLE = "${AWS_PRODUCTS_TABLE}"
IS_AWS_CATALOG = ${IS_AWS_CATALOG}
# ---------------------------------------------------
# 1. Initialize SparkSession (Dynamic Configuration)
packages =[
"org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.3",
"org.apache.iceberg:iceberg-aws-bundle:1.4.3",
"org.apache.hadoop:hadoop-aws:3.3.4",
"com.amazonaws:aws-java-sdk-bundle:1.12.262",
"com.google.cloud.spark:spark-bigquery-with-dependencies_2.12:0.36.1"
]
builder = SparkSession.builder \\
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \\
.config("spark.dataproc.lightningEngine.runtime", "native") \\
.config("spark.hadoop.fs.gs.velox.client.table-cache-max-size", "0") \\
.config("spark.jars.packages", ",".join(packages))
# Conditionally configure Lakehouse REST Catalog for Option A
if IS_AWS_CATALOG:
builder = builder \\
.config(f"spark.sql.catalog.{CATALOG_NAME}", "org.apache.iceberg.spark.SparkCatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.type", "rest") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.uri", "https://biglake.googleapis.com/iceberg/v1/restcatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.warehouse", f"bl://projects/{PROJECT_ID}/catalogs/{CATALOG_NAME}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.X-Iceberg-Access-Delegation", "vended-credentials") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.x-goog-user-project", PROJECT_ID) \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.Authorization", f"Bearer {OAUTH_TOKEN}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.rest-metrics-reporting-enabled", "false")
spark = builder.getOrCreate()
spark.conf.set("temporaryGcsBucket", BUCKET_NAME)
spark.conf.set("viewsEnabled", "true")
spark.conf.set("materializationDataset", BQ_DATASET)
# 2. Extract operational data via AlloyDB Zero-ETL
users_df = spark.read.format("bigquery").option("query", f"""SELECT id AS user_id, age, country FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT id, age, country FROM users")""").load()
orders_df = spark.read.format("bigquery").option("query", f"""SELECT user_id, order_id, CAST(created_at AS TIMESTAMP) AS order_date FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT user_id, order_id, created_at FROM orders WHERE status = 'Complete'")""").load()
items_df = spark.read.format("bigquery").option("query", f"""SELECT order_id, product_id, sale_price FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT order_id, product_id, sale_price FROM order_items")""").load()
# 3. Read AWS Products (Option A vs B) & Google Cloud Logs
if IS_AWS_CATALOG:
products_df = spark.table(AWS_PRODUCTS_TABLE)
else:
products_df = spark.read.format("bigquery").option("table", AWS_PRODUCTS_TABLE).load()
events_df = spark.read.format("bigquery").option("table", f"{PROJECT_ID}.{BQ_DATASET}.google_events").load()
# Register Temp Views
users_df.createOrReplaceTempView("live_user_profiles")
orders_df.createOrReplaceTempView("live_transactions")
items_df.createOrReplaceTempView("live_order_items")
products_df.createOrReplaceTempView("raw_aws_products")
events_df.createOrReplaceTempView("google_events")
# 4. Multi-cloud Distributed Join
unified_profile_df = spark.sql("""
WITH aws_master_catalog AS (
SELECT id AS product_id, category, brand
FROM raw_aws_products
),
google_behavioral_logs AS (
SELECT user_id,
COUNT(DISTINCT session_id) AS total_sessions,
COUNT(CASE WHEN event_type = 'cart' THEN 1 END) AS cart_adds
FROM google_events
WHERE user_id IS NOT NULL
GROUP BY user_id
),
user_purchases AS (
SELECT
t.user_id, t.order_date, t.order_id, oi.sale_price,
COALESCE(p.category, 'Unknown') AS category,
COALESCE(p.brand, 'Unknown') AS brand
FROM live_transactions t
JOIN live_order_items oi ON t.order_id = oi.order_id
LEFT JOIN aws_master_catalog p ON oi.product_id = p.product_id
),
rfm_base AS (
SELECT
user_id,
MAX(order_date) AS last_purchase_date,
COUNT(DISTINCT order_id) AS total_orders,
SUM(sale_price) AS lifetime_value
FROM user_purchases
GROUP BY user_id
),
ranked_items AS (
SELECT
user_id, category, brand, sale_price,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY sale_price DESC) as rn
FROM user_purchases
),
top_items AS (
SELECT
user_id,
COLLECT_LIST(NAMED_STRUCT('category', category, 'brand', brand, 'sale_price', sale_price)) AS top_preferences
FROM ranked_items
WHERE rn <= 3
GROUP BY user_id
)
SELECT
CURRENT_TIMESTAMP() AS snapshot_date,
u.user_id, u.age, u.country,
r.last_purchase_date,
COALESCE(r.total_orders, 0) AS total_orders,
COALESCE(ROUND(r.lifetime_value, 2), 0.0) AS lifetime_value,
COALESCE(b.total_sessions, 0) AS total_sessions,
COALESCE(b.cart_adds, 0) AS cart_adds,
t.top_preferences
FROM live_user_profiles u
LEFT JOIN rfm_base r ON u.user_id = r.user_id
LEFT JOIN top_items t ON u.user_id = t.user_id
LEFT JOIN google_behavioral_logs b ON u.user_id = b.user_id
""")
unified_profile_df.show()
# 5. Write back to BigQuery native partitioned table
(unified_profile_df.write
.format("bigquery")
.option("table", f"{PROJECT_ID}.{BQ_DATASET}.unified_customer_profile")
.option("partitionField", "snapshot_date")
.option("partitionType", "DAY")
.option("writeMethod", "direct")
.mode("overwrite")
.save())
EOF
Nachdem das Script vollständig zusammengestellt und die erforderlichen Konfigurationen dynamisch eingefügt wurden, senden Sie den Batchjob an Managed Apache Spark Serverless.
gcloud dataproc batches submit pyspark spark_lakehouse_join.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--subnet=${NETWORK_NAME} \
--deps-bucket=${BUCKET_NAME} \
--properties="dataproc.tier=premium,spark.dataproc.lightningEngine.runtime=native"
Jobausführung in der Console prüfen
Nachdem der Batchjob eingereicht wurde, können Sie prüfen, ob er die beschleunigte C++-Ausführungs-Engine verwendet:
- Rufen Sie in der Google Cloud Console Managed Service for Apache Spark > Serverless > Batches auf.
- Klicken Sie auf den Job, der gerade ausgeführt wird.
- Prüfen Sie im Bereich mit den Jobdetails, ob die Eigenschaft Tier auf
Premiumund „Engine“ aufLightning Enginefestgelegt ist.
8. Mit dem BigQuery-Daten-Agent analysieren
Nachdem Sie die fragmentierten cloudübergreifenden Daten zusammengeführt und die umfangreichen Verhaltensaggregationen mit Managed Service for Apache Spark ausgeführt haben, ist der nächste Schritt die Datenanalyse.
Sehen Sie sich zuerst das Schema der neu erstellten Tabelle mit dem einheitlichen Profil in der BigQuery-Benutzeroberfläche an, um die Datenstruktur zu verstehen, die Sie dem Agent zur Verfügung stellen:
- Rufen Sie in der Google Cloud Console BigQuery auf.
- Maximieren Sie im Bereich „Explorer“ auf der linken Seite Ihr Projekt und das Dataset
demo_lakehouse. - Klicken Sie auf die Tabelle
unified_customer_profile. - Wählen Sie im Hauptarbeitsbereich den Tab „Schema“ aus.
Prüfen Sie das Schema der neuen Tabelle. Die Spalte top_preferences ist ein REPEATED STRUCT (ein Array von Datensätzen mit category, brand und sale_price). Normalerweise erfordert das Abfragen verschachtelter Arrays komplexes SQL mit der Funktion UNNEST(), was für Business-Analysten eine Hürde sein kann. Wenn Sie einen BigQuery-Daten-Agent auf dieser bestimmten Tabelle basieren lassen, versteht der Agent das Schema automatisch und führt komplexe Google Standard-SQL-Vorgänge im Hintergrund aus.
KI-Datenagenten erstellen
In diesem Abschnitt erstellen Sie einen BigQuery-KI-Datenagenten und interagieren mit ihm. Statt komplexen SQL-Code manuell zu schreiben, um Arrays zu verschachteln und Messwerte zu berechnen, stellen Sie einen KI-Agenten bereit, der speziell auf Ihr neu erstelltes einheitliches Profil zugeschnitten ist. So können Sie Daten in natürlicher Sprache analysieren.
- Suchen Sie im linken Navigationsbereich nach Agents und klicken Sie darauf.
- Klicken Sie auf + Neuer Agent, um einen neuen KI-Assistenten zu initialisieren.
- Agent konfigurieren:
- Name des Kundenservicemitarbeiters:
Retail VIP Analysis Agent - Datenquellen: Klicken Sie auf Quelle hinzufügen und suchen Sie nach der Tabelle
unified_customer_profile.
- Klicken Sie auf Hinzufügen und warten Sie einige Sekunden, bis der Agent seinen Arbeitsbereich initialisiert hat.
Nachdem der Agent eingerichtet wurde, ist das Definieren expliziter Systemanweisungen eine wichtige Data-Governance-Maßnahme. Systemanweisungen als semantische Ebene verwenden Durch die Einbettung unternehmensweiter Geschäftsdefinitionen, die Berücksichtigung von Schemakomplexitäten und die Einrichtung von Analyse-Guardrails wird die technische Komplexität für den Endnutzer abstrahiert und das LLM daran gehindert, Schlussfolgerungen aus statistisch nicht signifikanten Daten zu ziehen.
Fügen Sie Folgendes in das Feld Anleitung ein:
You are an expert Data Analyst specializing in e-commerce customer retention.
Your primary data source is the `unified_customer_profile` table.
Strict Schema Rules:
- The `top_preferences` column is a REPEATED STRUCT (ARRAY).
- Whenever you analyze product categories, brands, or prices, you MUST explicitly use the UNNEST() function on `top_preferences` to access the underlying fields.
Semantic Layer & Business Definitions:
- "At-Risk VIP": Define this specific user cohort as anyone meeting ALL of the following criteria: `lifetime_value` > 100, `cart_adds` > 0, and `last_purchase_date` is more than 90 days ago.
Analytical Guardrails:
- Prioritize statistical significance. When generating business insights based on geographic or demographic groupings, explicitly ignore or deprioritize segments with negligible sample sizes (e.g., countries with very few users) to prevent skewed marketing strategies.
Agenten auffordern
Da die komplexe Geschäftslogik (die genaue Definition eines „VIP mit Risiko“) und die Anforderungen an die Schemabehandlung sicher durch die Systemanweisungen geregelt werden, muss der Datenanalyst keinen ausführlichen Prompt mit vielen Bedingungen schreiben.
Geben Sie in der Chatoberfläche den folgenden Prompt ein:
Find the total count of At-Risk VIPs grouped by country. For each country, extract the single most frequent product category based on their top preferences. Order the results by the user count in descending order.
Generierte Statistiken auswerten
Nachdem Sie den Prompt gesendet haben, überprüfen Sie die nativ generierte Ausgabe sorgfältig, um zu sehen, wie der BigQuery Data Agent Ihre Systemanweisungen durchgesetzt hat. Er fungiert dabei sowohl als verwaltete semantische Ebene als auch als analytische Schutzmaßnahme.
Lesen Sie zuerst den Zusammenfassungstext, der über den Daten generiert wurde. Der Agent übersetzt Ihre einfache Anfrage nach „VIPs mit Risiko“ automatisch in die genauen Messwertschwellen, die in Ihren Systemanweisungen definiert sind (z.B. mit Verweis auf lifetime_value > 100, cart_adds > 0 und 90 Tage Inaktivität). So wird bestätigt, dass der Agent Ihre Geschäftslogik verinnerlicht hat. Endnutzer müssen sich also keine komplexe Logik merken oder in ihre täglichen Prompts einfügen.
Maximieren Sie als Nächstes die SQL-Ansicht, um den generierten Code zu prüfen. Der Agent sollte auf Grundlage Ihrer Anweisungen mathematisch korrekte Google Standard-SQL erstellt haben:
- Dynamische Zeitfenster:Suchen Sie nach der Zeitstempelberechnung in der
WHERE-Anweisung (normalerweise mitTIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 90 DAY)). - Strikte Einhaltung des Schemas:Bestätigen Sie, dass der KI-Agent Ihre strengen Schemaregeln eingehalten hat, indem Sie die Funktion
UNNEST()explizit auf das Arraytop_preferencesanwenden. Um die häufigste Kategorie pro Land genau zu isolieren, werden in der Regel erweiterte Techniken wie eineROW_NUMBER() OVER()-Fensterfunktion in einem Common Table Expression (CTE) verwendet.
Sehen Sie sich das automatisch gerenderte Diagramm und die Datentabelle an. Die Daten machen Ihre wichtigsten Märkte für die Kundenbindung (in der Regel Länder mit hohem Volumen wie China oder die USA) sowie die universell dominanten Produktaffinitäten (häufig „Jeans“) sichtbar. Die native Benutzeroberfläche strukturiert die Ausgabe so, dass sie sofort verwendet werden kann, ohne dass expliziter Visualisierungscode erforderlich ist.
Lesen Sie den vom Agenten generierten Aufzählungstext unter Insights. Da Sie analytische Guardrails festgelegt haben, sollten Sie speziell nach einem Insight zu Datenqualität oder Statistischer Signifikanz suchen. Möglicherweise werden vom Kundenservicemitarbeiter Länder mit sehr wenigen Nutzern (z.B. Regionen mit nur einer Handvoll Nutzern) explizit am Ende der Tabelle gekennzeichnet. Anstatt auf Grundlage eines einzelnen Datenpunkts blind eine gezielte Marketingkampagne zu entwickeln, wird der Agent korrekt darauf hinweisen, dass diese Anomalien für eine groß angelegte Strategie statistisch nicht signifikant sind. So wird deutlich, wie durch die Einbettung von Governance-Schutzmaßnahmen direkt in den Agenten KI-basierte Fehlkalkulationen effektiv verhindert werden.
9. KI-Statistiken mit Gemini und MCP erstellen
Der Agent hat die primäre demografische Zielgruppe erfolgreich identifiziert: gefährdete VIPs in bestimmten Ländern. Die Arbeit eines Analysten endet jedoch mit der Erkenntnis. Um diese Nutzer noch einmal anzusprechen, muss das Marketingteam eine Kampagne starten.
Sie verwenden das Model Context Protocol (MCP), um einen externen KI-Assistenten direkt mit dieser spezifischen demografischen Liste in BigQuery zu verbinden. So können Sie von der Datenanalyse zu KI-gesteuerten Maßnahmen übergehen, ohne benutzerdefinierte APIs erstellen zu müssen.
BigQuery MCP-Server konfigurieren
Führen Sie den folgenden Block aus, um die Konfigurationsdatei „mcp.json“ zu generieren. Diese Datei enthält die erforderlichen Verbindungsparameter, damit die Gemini CLI sicher mit BigQuery interagieren kann.
mkdir -p ~/.gemini
cat << EOF > ~/.gemini/settings.json
{
"mcpServers": {
"bigquery": {
"httpUrl": "https://bigquery.googleapis.com/mcp",
"authProviderType": "google_credentials",
"oauth": {
"scopes": [
"https://www.googleapis.com/auth/bigquery"
]
}
}
}
}
EOF
Marketing-E‑Mail generieren
Starten Sie das Gemini CLI-Tool über das Terminal und übergeben Sie explizit das MCP-Konfigurationsflag, damit das Tool Ihr BigQuery-Lakehouse lesen kann.
Führen Sie die Gemini CLI aus.
source env.sh
gemini
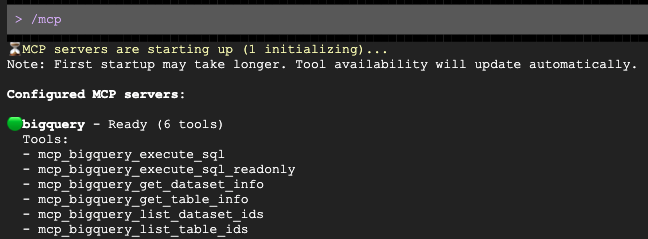
Wenn der Prompt geöffnet wird, bitten Sie ihn, einen personalisierten Outreach-Text für Ihre demografische Zielgruppe zu entwerfen:
Analyze the demo_lakehouse.unified_customer_profile table in BigQuery. Find exactly one 'country and age group' target demographic that has a high average order value (sale_price >= $80) but a relatively low total revenue compared to others. Then, draft a highly engaging, premium VIP promotional email tailored to this specific demographic. Use $PROJECT_ID to get the current project id.
Gemini fragt BigQuery automatisch über den MCP-Server ab, ermittelt die demografischen Daten und entwirft die E-Mail für Sie.
10. Umgebung bereinigen
Damit Ihrem Google Cloud-Konto keine laufenden Gebühren in Rechnung gestellt werden und Sie Ihr Projekt für zukünftige Ausführungen sauber zurücksetzen können, müssen Sie die in diesem Codelab erstellten Ressourcen löschen.
Führen Sie den folgenden Block aus, um das cleanup.sh-Skript zu erstellen. Dieses Skript dient als automatisierter Abbau-Mechanismus, mit dem der AlloyDB-Cluster und die ‑Instanz, die BigQuery-Datasets und Ihr Cloud Storage-Bucket endgültig entfernt werden, um weitere Abrechnungen zu verhindern.
cat << 'EOF' > cleanup.sh
#!/bin/bash
source ./env.sh
echo "=> Deleting BigQuery Dataset (${BQ_DATASET})..."
bq rm -r -f -d ${PROJECT_ID}:${BQ_DATASET} || true
echo "=> Deleting Lakehouse resource connection (${BQ_RESOURCE_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_RESOURCE_CONN} || true
echo "=> Deleting AlloyDB connection (${BQ_ALLOYDB_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_ALLOYDB_CONN} || true
echo "=> Deleting AlloyDB Instance (${ALLOYDB_INSTANCE}) - This takes a few minutes..."
gcloud alloydb instances delete ${ALLOYDB_INSTANCE} --cluster=${ALLOYDB_CLUSTER} --region=${REGION} --quiet || true
echo "=> Deleting AlloyDB Cluster (${ALLOYDB_CLUSTER})..."
gcloud alloydb clusters delete ${ALLOYDB_CLUSTER} --region=${REGION} --force --quiet || true
echo "=> Deleting Cloud Storage bucket (${BUCKET_NAME})..."
gcloud storage rm -r gs://${BUCKET_NAME} || true
echo "=> Deleting Lakehouse Federated Catalog (if created in Option A)..."
curl -s -X DELETE "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/aws_dbx_catalog" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" || true
echo "=> Deleting Secret Manager Regional Secret (if created in Option A)..."
CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/" \
gcloud secrets delete dbx-oauth-secret --location=${REGION} --project=${PROJECT_ID} --quiet || true
echo "=> Deleting Cloud NAT and Router (if created in Option A)..."
gcloud compute routers nats delete lakehouse-nat --router=lakehouse-router --region=${REGION} --quiet || true
gcloud compute routers delete lakehouse-router --region=${REGION} --quiet || true
echo "=> Deleting Service Networking VPC Peering..."
gcloud compute networks peerings delete servicenetworking-googleapis-com \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID} --quiet || true
echo "=> Deleting Allocated IP Range for Managed Services..."
gcloud compute addresses delete google-managed-services-${NETWORK_NAME} \
--global \
--project=${PROJECT_ID} --quiet || true
echo "=> Removing local temporary files..."
rm -f spark_lakehouse_join.py users.csv orders.csv order_items.csv alloydb-auth-proxy env.sh cleanup.sh ~/.gemini/settings.json
echo "============================================="
echo " TEARDOWN COMPLETED."
echo "============================================="
EOF
Führen Sie das Bereinigungsskript aus, um Ihre Ressourcen sicher zu löschen:
bash cleanup.sh
11. Glückwunsch!
Sie haben erfolgreich ein cloudübergreifendes offenes Data Lakehouse erstellt und abgefragt.
Sie haben Folgendes gelernt:
- So können Sie Daten aus unterschiedlichen Quellen mit BigQuery Zero-ETL und Google Cloud Lakehouse zusammenführen.
- So nutzen Sie die native C++-Lightning Engine in den massiven vektorisierten Joins von Managed Service for Apache Spark.
- So verwenden Sie den BigQuery Data Agent für die Analyse in natürlicher Sprache.
- So stellen Sie eine Verbindung zwischen Ihren Daten und Gemini her, indem Sie das Model Context Protocol (MCP) und Gemini verwenden.